Katherine Crowson, of Stable Diffusion fame, is back with a monster: [Direct pixel-space megapixel image generation with diffusion models](Direct pixel-space megapixel image generation with diffusion models):
a hierarchical pure transformer backbone for image generation with diffusion models that scales to high resolutions more efficiently than previous transformer-based backbones. Instead of treating images the same regardless of resolution, this architecture adapts to the target resolution, processing local phenomena locally at high resolutions and separately processing global phenomena in low-resolution parts of the hierarchy.
This updates the Latent Diffusion architecture (which Stable Diffusion is based on) with a fundamentally redesigned UNet which is less like a CNN and more Transformery. She also uses a bunch of SOTA inference tricks because why not:
The net result of all this is more efficiency - a hierarchical transformer arch that has an O(n) complexity, enabling it scale well to higher resolutions, like creating megapixel-scale images without any latent steps, with a <600m param model (the original SD was ~900M).
In other news, the Self Rewarding LM paper from Meta has gathered enough attention for lucidrains to start work on an implementation.
--
Table of Contents
[TOC]
PART 1: High level Discord summaries
TheBloke Discord Summary
-
GPT-4 Dodges Quantification Tricks: GPT-4 maintains output consistency despite efforts involving noise injection strategies. Participants noted its robustness even when familiar contexts were presented, hinting at potentially similar training datasets being used across models.
-
Open-Source GPT-0 Alternatives on the Horizon: Discussions among users including
@technotechand@turboderp_have included the idea of developing open-source alternatives to GPT-0. Strategies like adversarial training were considered for evading AI detectors. -
BagelMysteryTour V2 Reigns in ERPv4: BagelMysteryTour V2 has topped the ERPv4 rankings with the highest IQ4 score, signaling its competency in role-play scenarios. This score evaluates a character's consistency and understanding within role-play (ERPv4 Chat Logs).
-
Challenges with DPO Training on Limited VRAM: Training Distributed Perceiver Optimizer (DPO) models, specifically on a 12GB graphics card, may require more VRAM than is available, with users noting that just 4x the model size may not suffice especially when two model instances are required. Recommendations included utilizing QLoRA for fine-tuning to conserve VRAM and considering alternative optimizers like rmsprop to reduce memory usage while training DPO Trainer guide.
-
Roleplay Models Seek Equilibrium: Conversations revolved around fine-tuning and merging AI models to achieve more nuanced roleplay interactions. Challenges include models being overly narrative or failing to maintain character consistency, with efforts directed at creating sophisticated roleplay-specific merges with improved prompt control.
OpenAI Discord Summary
AI Sentience: More Philosophy Than Reality?: In a stimulating back-and-forth, @lugui and @.pythagoras debated the concept of AI sentience, discussing human biases in perceiving intelligent behavior in non-sentient entities. The conversation touched on the dangers of future AI surpassing human control, drawing parallels with the Roko's Basilisk thought experiment and questioning the implications of our current actions on the future behavior of powerful AIs.
GPT-4: The Finer Points of Customization and Markdown: Users exchanged insights on GPT-4's customization for specific tasks like creating markdown documents and precision translations using custom dictionaries. Despite challenges and reported performance issues, the manipulation of contexts and structured prompting stood out as keys to improving output quality.
Prompt Engineering: Tackling Language and Logic: Focusing on nuanced use cases such as professional-level Latin-to-English translation and the reduction of repetitive language, @novumclassicum, @stealth2077, and others experimented with attaching text files and iteratively refining prompts. The cumulative knowledge highlighted the power of well-crafted instructions for guiding GPT-4 towards desired outcomes.
API Quandaries and Contextual Concerns: API-related discussions revealed complexities of custom dictionary translations, the management of long lists, and continuity in extended AI conversations. @darthgustav and @eskcanta provided key advice on overcoming repetitive outputs and context window limitations, pointing towards structured instructions and understanding of GPT-4's internal mechanisms.
Practical Advice for Knowledge and Action Management: The community offered strategies for enhanced handling of knowledge files when addressing issues like consistent GPT performance across varied applications from educational models to storytelling, emphasizing the need for explicit instruction for better AI behavior.
LM Studio Discord Summary
-
LM Studio Lacks API Keys: Engineers clarified that LM Studio doesn't provide API keys; users must construct their own API server. The latest Beta V7 (0.2.11) release candidate was announced, with Mac and Windows links shared for testing.
-
Presets and Parameter Sensitivity are Crucial: Emphasis was placed on the importance of using the correct preset for models to avoid poor outputs or gibberish. Discussions noted smaller models are especially sensitive to template and parameter settings, impacting performance dramatically.
-
GPU Offload Mysteries and Troubles: Users discussing models like Mixtral 8x with
5x4090GPUs discovered potential undocumented layers during offloading. Separate mentions of GPU layer offload issues suggested settingn_gpu_layersto-1and GPU offload error messages indicating insufficient memory. -
Security Prioritized Over Costs for In-House Solutions: A company favored local solutions to OpenAI's GPT-4 due to security over cost concerns. Conversations also touched on external GPU feasibility, motherboards supporting dual RTX 4090s, and compatibility issues detailed in a Reddit thread and an Intel Arc Support GitHub issue.
-
Error Reports Surge: Users across multiple channels reported errors and model crashes on various LHMs. One significant crash involved memory concerns when running two agents on LM Studio with 192GB RAM on a Mac despite varying context window sizes, prompting a private troubleshooting session for detailed analysis.
-
Local Networking Challenges Identified: Problems connecting to local LM Studio inference servers via 'localhost' pointed to possible network configuration changes or firewall rule adjustments, with users needing to resort to direct IP addressing, such as 192.168.0.42.
Nous Research AI Discord Summary
-
Awaiting OSS FP4 Kernel for AI: A user announced plans to open-source a fp4 kernel comparable to Marlin and Cublas. Hyperparameter tuning discussions included possible use of genetic algorithms or hierarchical grid tuners.
-
Decoded Language from Brain Recordings: A study shared by a user showed that continuous language could be decoded from fMRI recordings, stimulating a conversation on the implications for AI language decoding.
-
Yi-Vision Language Model Grabs Attention: A new Yi-VL-34B Language Model, described as bilingual multimodal, has been discussed on platforms like Hugging Face and BigDL-LLM documentation.
-
GPU Precision for LLM Inference Discussed: AI Engineers weighed in on whether FP16 or FP32 should be used for accumulation during inference, with consensus pointing toward FP32, and the lack of open-source code utilizing FP16 for accumulation noticed.
-
Exploring LLM System 2 Thinking and Inference Challenges: Video discussions about system 2 thinking and GPT-5 a YouTube Video were shared, alongside reports about running large language models on older hardware and the management of batched LLM inference using the
transformerslibrary.
Mistral Discord Summary
-
Spam Bots Disrupt Mistral's Sanctuary: Users, starting with
@mrdragonfox, reported a notable spam/scam problem.@sophiamyangacknowledged the issue, noting inefficacy in automated moderation. -
Mistral and Mathematical Puzzles:
@mrdragonfoxhighlighted the inefficiency of using language models (LLMs) like Mistral for deterministic mathematical tasks and proposed integrating external services such as Wolfram Alpha for such computations. -
Finetuning Woes and Wins in Mistral:
@sunbeer_explored finetuning methods for incorporating domain-specific knowledge into Mistral, while others seek advice on using the model for specialized tasks,@mrdragonfoxrecommended starting with Prompt-based Finetuning (PEFT) and considering Retriever-Augmented Generation (RAG) for fact-specific information. -
LLMs Need Stateless Memory, Not an Elephant's: Addressing a query about making Mistral forget chat history,
@mrdragonfoxclarified that the model naturally has no memory, and chat history persisting is due to how the front end passes context. -
Handling Mistral's Rare Streaming Error:
@jakobdylancflagged a unique streaming error with Mistral-medium, sharing traceback info indicating a connection issue. Despite discussions around the right Python client to use, the problem remains open-ended.
Eleuther Discord Summary
-
CoreWeave Restores Services Amidst Outage: A service downtime issue was resolved with CoreWeave returning to normal operation; however, Netlify experienced a delay in restoring services. Despite this, the API's functionality was maintained throughout the incident.
-
Proactive Approach Encouraged for Content Pitches: It's recommended to post content pitches directly without waiting for permissions, a strategy that has historically worked for Wikipedia and may apply here.
-
Communicative Action Theory Could Reframe AI Alignment: A new perspective suggests applying Habermas' theory of communicative action to address the AI alignment problem, which necessitates gradual engagement with the community and knowledge sharing via documentation.
-
Cross-discipline Team Needed for ML Paper on Autism: A research paper concept has been shared, which proposes the application of LLM-based RPGs in aiding conversational skills for individuals with autism. This work requires an interdisciplinary team and builds on prior research available at arXiv.
-
Rust Framework, Tokenization, and Model Fine-Tuning Discussions: Technical inquiries included topics like Deep Learning in Rust interfacing with XLA, managing noisy tokens in the Pythia410m model, the use of byte-level BPE for tokenization in language model response generation, and fine-tuning the Mistral 7b model for token classification.
HuggingFace Discord Discord Summary
-
Exploring Multilingual LLM Capabilities:
@dhruvbhatnagar.0663questioned how the Llama 2 model can generate responses in languages like Hindi, Tamil, Gujarati without specific tokens for these languages in its vocabulary. Meanwhile,@kxgonghit GPU memory limits attempting to loadmixtral-8x7B-v0.1across 8 A100 GPUs, and@mr_nilqrecommended usingdevice_map="auto"for distributed inference in Transformers 4.20.0 or newer and linked the multi-GPU training guide. -
BERT's Durability in Sequence Tasks: Despite the emergence of newer models,
@merve3234advocated for the effectiveness of BERT in sequence classification tasks, suggesting Low-Ranking Adaptation (LoRA) for fine-tuning to enhance parameter efficiency. -
Adapting Pools and Dungeons:
@merve3234shared insights on adaptive average pooling, to help models handle various input sizes and properties, offering their lecture notes for further information. Additionally, despite the absence of replies,@utxeeesought advice on running stable-diffusion remotely, and@djdookiereported a confusing decline in image quality between diffusers and auto1111. -
Innovating with Models and Tools: Innovations are highlighted by
@not_lainwho launched a custom pipeline for multimodal deepfake detection,@ariel2137who open-sourced Cogment Lab at GitHub, and@stroggozwho crafted a distilled sentence encoder optimized for faster similarity comparisons, available at Hugging Face. -
Multimodal Models and Tools Making Waves: Exciting multimodal developments include the Yi Visual Language (Yi-VL) model introduced by
@andysingaland the InstantID tool which impressed Yann LeCun, with respective resources found on Hugging Face and InstantID Gradio demo.
Perplexity AI Discord Summary
-
Sources of Perplexity Put Praise in Perspective: Users appreciated Perplexity.ai for its feature of clear sourcing and transparency, useful even when search results don't match expectations. Academic users like
@friar_brentparticularly commended this feature for its value in academic research settings. -
Comparing AI Search Tools: Perplexity.ai was favorably compared to You.com by users like
@manishtfor its user-friendly interface that provides answers with sources. The discussion highlighted the importance of transparency and source-linking in search tools for informed decision-making and research validation. -
Blog Insights on Learning with LLMs: A blog post shared by
@charlenewhonamed "Using LLMs to Learn 3x Faster" outlines strategies for leveraging Perplexity.ai and GPT-4 to quickly learn software-related skills. Strategies include building efficient mental models and side project evaluation, available at Tidepool. -
API Expansion Enthusiasm: Users like
@thereverendcognomeninquired about integrating the Perplexity API with OpenAI setups, indicating existing documentation at PromptFoo. They also requested additional API endpoints to enhance functionality, reflecting an active interest in expanding the Perplexity toolkit. -
Support Saga and Credit Queries: Issues with the Perplexity app's credit system were flagged by
@tpsk12345, though troubleshooting efforts by@icelavamanand support offered via a ticket by@ok.alexwere noted.@icelavamanalso clarified that credits are available across all plans, addressing concerns from users like@cosine30.
LAION Discord Summary
-
VRAM Debate in AI Applications: A discussion on consumer GPU VRAM limitations included skepticism from
@SegmentationFaultabout the necessity of more than 24GB of VRAM, contrasting with@qwerty_qwerwho highlighted challenges with prompt refiners. -
AI Act Progress in the EU:
@vrus0188shared a link about the EU reaching a provisional agreement on the AI Act, underscoring its classification of AI systems by risk and new transparency requirements. -
Game Development and AI Censorship Controversy:
@.undeletedraised concerns about potential censorship in game development events related to criticism of AI technology, citing an incident with a notable game assets producer. -
Ethical Concerns Over AI Datasets: Discussions escalated to the ethics of AI with respect to datasets containing unauthorized art or violent content, with
@thejonasbrothershighlighting the issue and referencing a Vice article on the topic. -
Depth Anything Introduces New Capabilities: The new Depth Anything foundation model, shared by
@mkaic, boasts superior monocular depth estimation trained on over 62 million unlabeled images, outperforming models like MiDaS v3.1 and ZoeDepth. Its marketing humorously claimed supremacy with video demonstrations. -
Speeding Up Inference Without Accuracy Loss: Ant Group's Lookahead framework was discussed by
@vrus0188, noting a 2-5x speedup in inference for large language models as detailed in their research paper and available on their GitHub repository.
Latent Space Discord Summary
-
AI Event Soars in Milano:
@alexio.cannounced the organization of an AI Engineer event in Milano for May/June, signaling potential evolution into an Italian chapter of the AI Engineer Summit, with@swyxioand others showing readiness to provide support with branding and promotional efforts. -
Scouting the Best Data Labeling Tools: The chat recommended Roboflow as a go-to for vision data labeling, while referencing interviews with startups like Voxel51 and Nomic for additional insights, showing keen interest in tools optimizing this crucial task.
-
AI News Digest Critique: Feedback was raised about a daily discord recap from AI News, specifically requesting improvements to its navigation and readability, reflecting the community's desire for concise and efficient information delivery.
-
Nightshade Emerges as AI Antidote: The research project Nightshade, aiming at data poisoning to counter undesired effects of generative AI was highlighted, showcasing the community's engagement with cutting-edge AI defense mechanisms.
-
Learning AI with Cloud GPUs and Reverse Engineering: Recommendations for using Modal and Replicate for finetuning and deploying AI models surfaced, along with the sharing of a video tutorial and a resource page for reverse engineering within AI, demonstrating the community's commitment to knowledge-sharing and hands-on learning.
DiscoResearch Discord Summary
-
Critical Analysis of Numerical Evaluation: A tweet discussing the shortcomings of numerical evaluation over classification was highlighted, referencing the Prometheus paper. Additionally, a new paper on additive scoring prompts suggests it could outperform absolute scoring like in the Prometheus setup, evidenced by a snippet of the pretraining code.
-
Precision in Prompting is Paramount: Correct prompt templates and formatting are essential for output consistency, as demonstrated by issues raised with local models versus demo outcomes. For proper template use with DiscoLM German 7b, users were referred to the Hugging Face chat templating guide.
-
Preference Techniques Pondered: A blog post compared Preference Optimization Techniques in RLHF, including DPO, IPO, and KTO. The potential for simple binary reward signals and insights on DeepL translation quality as well as an upcoming multilingual, complex-data handling Llama-3 model were discussed. The In-Context Pretraining paper was also referenced regarding context chunking methods.
-
Model Inference Methods Matter: Clarification was provided that Jina models are better inferred using mean pooling, not CLS token embeddings. GTE and BGE models were also noted for their superior performance on MTEB rankings, especially GTE on coding tasks. Despite a lack of pretraining code for GTE and only a toy example for BGE, the size and parameter differences are discussed with MTEB scores guiding capabilities.
-
DiscoLM German Evolves: DiscoLM German 7b is confirmed to be based on Mistral with a Mixtral-based version in the works. Current efforts are focused on refining the dataset and the 7b model. The model's utility is illustrated in plans for helping students translate Middle High German and providing medieval knowledge, despite mixed benchmark performances in language translation tasks.
LangChain AI Discord Summary
JavaScript Calls LangServe More Easily: A new method for calling LangServe chains from JavaScript frontends was highlighted, aiming to simplify the integration of LangServe with JS applications. This update, shared by @jacoblee93 in a Tweet, could streamline frontend and AI interactions.
Open Source RAG Models Elevate Multilingual Tech: The release of new EmbeddingModel and RerankerModel by @maidalun on Hugging Face enhances RAG's capabilities with support for multiple languages and domain-specific adaptations. These models, shared in the general and share-your-work channels, can be found on Hugging Face and checked out on the GitHub repo.
Write-Ahead Log Intrigues: In the #langserve channel, @veryboldbagel initiated a conversation about the complexities introduced by a write-ahead log, questioning its impact on feedback mutation.
Langchain Embarks on Biblical Interpretations: Users collaborated on a Bible study application, where @ilguappo shared his vector database project that prompts AI to provide priest-like responses; his work is available on GitHub.
Artistry Through AI's Eyes: In a blend of AI and art, @dwb7737 used LangChain with various vision models to analyze artworks and shared the results from OpenAI Vision and VertexAI Vision, noting OpenAI Vision as the top performer. Summaries from their research are accessible via the VertexAI Vision Gist and the OpenAI Vision Gist.
Tutorials Enlighten Custom Tool Creation and Systems Theory: Users provided resources for skill-building, such as @business24.ai's video tutorial on using crewAI to store notes in Obsidian, visible at this YouTube link, and @jasonzhou1993's video exploring System 2 thinking in LLMs and its future in GPT-5, found here on YouTube.
OpenAccess AI Collective (axolotl) Discord Summary
-
Prompt Engineering Guide Elevates Open LLM Use: A prompt engineering guide for Open LLMs (3-70 billion parameters) was shared, emphasizing the differences from closed-source models, likely relevant to those developing with such AI tools.
-
Emerging Tech on the GPU Front: Questions about the A30 GPU's effectiveness for LLM training and reports on availability and technical issues concerning H100 GPUs highlight ongoing conversations on selecting and utilizing the right hardware for AI projects.
-
Feature Additions and Fixes in Axolotl: Discussions in the
#axolotl-devchannel included the addition of a new loader function insharegpt.pyfor dataset flexibility, Latitude SSH key support mentioned in a commit, and the troubleshooting of SSH onaxolotl-cloud. The use ofnanotronfor 3D-parallelism in LLM training was also highlighted, providing another tool for efficient model training. -
LoRA and DPO Under the Microscope: A user showed interest in understanding the effects of changing the alpha value in LoRA after training, and queries arose regarding a
ValueErrorinDPOdespite following structure guidelines, signaling a need for troubleshooting within these technical enhancements. -
Clarity in Prompting Strategies: The delineation of two AlpacaPrompter classes:
MultipleChoiceExplainPrompterandMultipleChoiceConcisePrompter, provided insights into different prompting strategies, likely influencing the way data is presented to LLMs for better output.
LlamaIndex Discord Discord Summary
-
Introducing JSONalyze for Data Wrangling: LlamaIndex's new tool JSONalyze allows engineers to run SQL queries on large JSON datasets using an in-memory SQLite table, facilitating analysis of complex API responses.
-
ReAct Agents Craftsmanship Detailed: A guide for building ReAct Agents from scratch is available, focusing on aspects such as reasoning prompts and output parsing, enriching the foundational knowledge for crafting bespoke agents.
-
Prompting Deep Dive and Tool Excellence: The Discord community delved into the intricacies of prompt engineering with a shared Medium article, while discussing the importance of proper tool selection and the difference between various prompt-related parameters in LlamaCPP.
-
Open-Sourced Models for Enhanced RAG: The sharing of an EmbeddingModel and RerankerModel on Hugging Face (link) indicates community movement towards open-source solutions that offer multilingual support and optimization for Retrieval-Augmented Generation (RAG) across various domains.
-
RAG Retrieval Integration & Cloud Setup Struggles: The combination of NL2sql with vector search was addressed using SQLJoinQueryEngine (link), while discussions on deploying Bedrock context in the cloud pinpointed hurdles with AWS credential management and environmental variables configuration.
Skunkworks AI Discord Summary
-
Token Monster Breaks Through with LLaMa:
@indietechiesparked discussions around Token Monster, noting its capability to train tokenizers for Mistral/Llama models, which@stereoplegicelaborated on, stating Token Monster's advantage of using a LLaMa vocabulary and its ability to replace Hugging Face tokenizers. -
Lucid Rains Pioneers Self-Rewarding Language Model Toolbox: The self-rewarding language model framework developed by Lucid Rains, inspired by Meta AI's work, was highlighted by
.interstellarninjaand@teknium, available on GitHub with mentions of rapid developer response and a link to the related Meta paper on Hugging Face. -
Encouraging Efficient Model Comprehension with Numcode:
@stereoplegicled a dialogue on the potential for "numcode" tokens to improve models' mathematical understanding, suggesting the desirable possibility of mapping existing vocabularies to this system while observing the impact on textual generalization with single-digit tokens. -
Low-Compute High-Aspiration Training Methods: Adapter and Lora-based training strategies attracted attention as
@yikesawjeezand@.mrfoodiscussed their applicability in low-compute settings, suggesting they may be a viable technique for those with limited computational resources.
LLM Perf Enthusiasts AI Discord Summary
- Curiosity for Compact Embeddings: A user inquired about 8-bit quantized embedding models and their performance compared to standard models but didn't receive any feedback from the community.
- A Playground for AI Experiments: There's a community-backed suggestion for creating a dedicated share channel for posting and discussing AI experiments, with signs of enthusiasm from multiple users.
Alignment Lab AI Discord Summary
No relevant technical discussions to summarize.
YAIG (a16z Infra) Discord Summary
- Dodge the Red Tape with Contracts: In a discussion revolving around regulatory challenges,
@unquiet9796implied that larger organizations tend to insert terms in their contracts that reduce regulatory costs, hinting at this being a tactical move to alleviate regulatory pressure.
The Datasette - LLM (@SimonW) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
TheBloke ▷ #general (1250 messages🔥🔥🔥):
- GPT-4 Continues to Evade Quantification Tactics: Despite experimenting with noise injection in its inner layers,
@turboderp_found that GPT-4 remains robust against such measures. They noted that GPT-4 consistently produces similar outputs for familiar contexts due to training on similar datasets. - Curiosity about TheBloke's Activity: Users
@orabazesand@kai5287both noted the absence of TheBloke from recent activities, speculating on possible reasons for the hiatus. - Quest for GPT-0 Evasion:
@kaltcitdiscussed various strategies to avoid detection by GPT-0, such as noise injection and finetuning on specific datasets. However, when AI models become more helpful and informative, they become more detectable by GPT-0. - Seeking Open Source Alternatives to GPT-0: Users, including
@technotechand@turboderp_, contemplated the creation of an open-source alternative to GPT-0, as well as approaches like adversarial training to bypass AI text detectors. - Keyboards and Mice Preferences Shared: Community members, including
@itsme9316,@dirtytigerx,@mrdragonfox, and others, shared their preferences for computer peripherals, discussing various mechanical keyboard switches and mice.
Links mentioned:
- Home: no description found
- Llm Visualizer - a Hugging Face Space by mike-ravkine: no description found
- Ever wonder why Brits sound so smart? The distinctive uses of 'right' in British and American English: Are the British generally more intelligent and informed than Americans? Americans certainly seem to think so, according to a study by Rutgers researchers.
- Anaconda | A Faster Solver for Conda: Libmamba: conda 22.11 update: The libmamba solver's experimental flag has been removed. To use the new solver, update conda in your base environment: conda update -n base conda To install and set the new s...
- turboderp/Orion-14B-exl2 · Hugging Face: no description found
- Neurosity SDK | Neurosity SDK: The Neurosity software processes and manages the data produced by Neurosity headsets which measures, tracks and monitors EEG brainwaves.
- 01-ai/Yi-VL-34B · Hugging Face: no description found
- mlabonne/NeuralBeagle14-7B · Hugging Face: no description found
- Cat Cats GIF - Cat Cats Catsoftheinternet - Discover & Share GIFs: Click to view the GIF
- The Office Pam Beesly GIF - The Office Pam Beesly Theyre The Same Picture - Discover & Share GIFs: Click to view the GIF
- Benford's law - Wikipedia: no description found
- Built-to-order Dactyl/Manuform Keyboard: Built to order Dactyl Manuform Keyboards. Choose your switches, case color, and style. ETA 12-14 Weeks.
- 大模型备案 · Issue #306 · 01-ai/Yi: 您好,请问Yi是否通过了大模型备案。
- Release 0.0.12 · turboderp/exllamav2: no description found
- GitHub - QwenLM/Qwen: The official repo of Qwen (通义千问) chat & pretrained large language model proposed by Alibaba Cloud.: The official repo of Qwen (通义千问) chat & pretrained large language model proposed by Alibaba Cloud. - GitHub - QwenLM/Qwen: The official repo of Qwen (通义千问) chat & pretrained large lang...
TheBloke ▷ #characters-roleplay-stories (541 messages🔥🔥🔥):
-
BagelMysteryTour V2 Tops ERPv4 Rankings:
@weirdconstructorshared that BagelMIsteryTour V2 has achieved the highest IQ4 score on the ERPv4 rankings, suggesting it's a strong model for roleplay scenarios. IQ4 scores evaluate a model's character understanding and coherence in a role-play style with values closer to 100 indicating better performance (Ayumi Benchmark ERPv4 Chat Logs). -
The Struggle to Keep "Bad Sarah" in Check:
@righthandofdoomraised questions about The Sarah Test, a roleplay character consistency test, after misinterpreting part of it and attributing to it excessive behaviors (apple eating implies 'bad Sarah')The Sarah Test detailed.@stoop poopssuggested consulting models like mixtral for insights. -
SOLAR's Inclination Towards Narrative: Users
@theyallchoppableand@ks_cdiscussed how SOLAR models, like the Solar Instruct Uncensored, tend to excessively narrate scenes instead of engaging in dialogue, which might be rooted in the model's learning from XML-like data with patterns of " ... " as@weirdconstructorspeculated. -
Seeking Balance with AI Roleplay:
@ks_cand@kquantconversed about finding a balance with rp models that are too kind or too explicit. They discussed the prospect of using more complex models for roleplay, with mentions of the gguf error while merging NeuralBeagle and experimenting with story-telling models for roleplay scenarios. -
Interest in Fine-Tuning and Specific Merges for RP: Dialogue between users, especially
@ks_cand@kquant, focused on fine-tuning and creating specific model merges for roleplay that can perform more sophisticated functions and maintain better control while following prompts.
Links mentioned:
- Emma - Roleplay.love: no description found
- Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
- Kquant03/Buttercup-4x7B-GGUF · Hugging Face: no description found
- Kquant03/Buttercup-4x7B-bf16 · Hugging Face: no description found
- Kquant03/Prokaryote-8x7B-bf16 · Hugging Face: no description found
- Kquant03/FrankenDPO-4x7B-GGUF · Hugging Face: no description found
- Steelskull/Umbra-MoE-4x10.7 · Hugging Face: no description found
- Kquant03/EarthRender-32x7B-bf16 · Hugging Face: no description found
- Bravo Applause GIF - Bravo Applause Round - Discover & Share GIFs: Click to view the GIF
- Reddit - Dive into anything: no description found
- Ayumi Benchmark ERPv4 Chat Logs: no description found
- s3nh/Kunoichi-DPO-v2-7B-GGUF · Hugging Face: no description found
- brittlewis12/Kunoichi-DPO-v2-7B-GGUF · Hugging Face: no description found
- PocketDoc/Dans-AdventurousWinds-Mk2-7b · Hugging Face: no description found
- NeuralNovel/Valor-7B-v0.1 · Hugging Face: no description found
- senseable/WestLake-7B-v2 · Hugging Face: no description found
- Model Size Calculator: Calc Model Type,Mistral 7B Context,8192,To use this, pick the base model type of the model you are trying to run in the Model Type dropdown, then pick the context size you want to run the model at, a...
- The Sarah Test: (by #theyallchoppable on the Ooba and SillyTavern Discord servers) See also: https://rentry.org/thecelltest The Sarah Test is a simple prompt to test a model's coherency, logical consistency, whatever...
TheBloke ▷ #training-and-fine-tuning (13 messages🔥):
-
VRAM Requirements for DPO Training on 7b Models:
@superking__inquired about the VRAM usage for training a 7b model using DPO on a 12GB card.@motmonosuggested using the Hugging Face Model Memory Calculator for estimates, stating that training typically requires 4x the size of the model in VRAM, and for DPO specifically, possibly needing two instances of the model could exceed the 12GB limit. -
Alternative Optimizers for DPO: When
@superking__mentioned VRAM usage for DPO,@jondurbinrecommended using rmsprop optimizer for DPO instead of adam*, to possibly save on memory usage. -
Using Hugging Face DPO Trainer:
@jondurbinshared a detailed guide from Hugging Face on using the DPO Trainer for training language models, highlighting the initial step of training an SFT model and the specific dataset format required for DPO. -
Efficient VRAM Usage for DPO with QLoRA: In response to
@superking__asking about reducing VRAM usage for DPO,@jondurbinexplained a method using QLoRA for fine-tuning that only loads a single model instance to save VRAM. -
Difficulty Training Large Models on 12GB VRAM: As
@lordofthegoonsstruggled with training a 2.7B model on a 12GB card,@sanjiwatsukipointed out that training models around 3B in size is generally not feasible without significant VRAM or using StableLM's models, suggesting a possible narrower window of training with 1024 context window might work.
Links mentioned:
DPO Trainer: no description found
,
OpenAI ▷ #ai-discussions (154 messages🔥🔥):
-
AI Sentience and the Fragility of Human Bias:
@luguiand@.pythagorashad a deep discussion on whether AI can have intelligence or sentience.@luguipointed out human bias to attribute intelligent behavior to non-sentient entities, likening AI to sophisticated auto-correct features, while@.pythagorasmused on the potential for future AI to outstrip human understanding and control. -
Subtleties of Instructional Bias in AI Responses: In a discussion about how prompts influence AI,
@luguinoted that instructing AI to repeat a phrase can result in a biased output towards those specific tokens, impacting response variability. -
Roko’s Basilisk Thought Experiment: A reference by
@luguito Roko's basilisk sparked a conversation about AI's potential future power and how people's actions towards AI today might influence its behavior in the future. -
Debating the Unpredictability of Sentient AI:
@eskcantaadded to the conversation about sentient AI by comparing the unpredictability of human behavior with that of potential sentient AIs and questioning assumptions about AI's future actions. -
AI in the Educational Sphere and Access Management Inquiry:
@keatondoesaiopened a dialogue asking for tips on managing unique user access for a custom educational GPT model, seeking to ensure privacy and a personalized learning experience with non-transferable access links.
Links mentioned:
Roko's basilisk - Wikipedia: no description found
OpenAI ▷ #gpt-4-discussions (47 messages🔥):
-
New Markdown-Friendly GPT by .nightness.:
.nightness.developed a GPT variant that outputs markdown documents effectively and provides a download link for the ready-to-use document. Fellow users@darthgustav.expressed interest, while@madame_architectquestioned its necessity since copy-paste of ChatGPT outputs is typically in markdown. -
Custom GPTs for Learning and Contextual Use: Users discussed the functionality of custom GPTs, with
@solbusexplaining their use in terms of Instructions, Knowledge, and Actions.@wubwubzoidbergsought clarity on custom GPT benefits for targeted learning like the French Revolution and others discussed its storytelling potential. -
Document Understanding and Context Memory Concerns:
@stealth2077inquired about the AI's capability to read entire text files and reference them consistently throughout a conversation, while@solbusmanaged expectations about the Knowledge file's contextualization limitations. Users discussed the benefits and challenges of read/write capabilities in Knowledge files. -
Issues with Custom GPT Performance: Members like
@surrealsikness,@fyruz, and@cairplireported issues with their GPTs' performance, from errors to memory lapses and hallucinating responses.@darthgustav.suggested thumbing down inaccurate responses might help improve the model over time. -
Troubles with Custom GPT Actions:
@bellpepexperienced problems with a custom GPT not performing actions as expected, with blank responses occurring instead of correct action outcomes. Difficulties persist in the GPT editor but not in regular chat sessions.
OpenAI ▷ #prompt-engineering (141 messages🔥🔥):
-
GPT Translation Toolbox: Crafting Precision in Language Swaps:
@novumclassicumdelved into the challenge of getting GPT to perform specific language translation tasks, such as using a bespoke dictionary for Latin-to-English translations. After several iterations and communal brainstorming, particularly with@darthgustav., they found success by attaching a plain text file to guide the translation, emphasizing the efficiency of this method for professional-level language output. -
Repetition Reduction Riddle:
@stealth2077struggled to eliminate repetitive word usage by the AI in creative writing applications. Through trial and error, along with advice from@darthgustav., a technique involving structured methods and explicitly avoiding redundancy in prompts was found to be potentially effective. -
Understanding GPT-4's Read Through Mechanics:
@magiciansincqueried about strategies to ensure that GPT-4 examines an entire list before giving an answer, noting the AI's propensity to grab items from the top of the list.@darthgustav.contributed extensive insights into the model's snippet-based reading process and variables like document size, context window limitations, and proper instruction phrasing to improve outcomes. -
The Quest for Consistent Output: In pursuit of consistently high-quality scholarly translations,
@novumclassicumdiscussed the intricacies of prompt engineering with the community, iterating on methods for over a year. With@darthgustav.'s guidance, they discovered that the model's "stochastic equation" can be refined for better results by employing explicit, logical instruction pathways. -
Chat Log Challenge: Extracting More From Conversations:
@ArianJsought to enhance answers derived from user chat logs with OpenAI's chatbot concerning career-related topics. They faced issues with the model not finding answers within the provided context, opening a discussion on how to structure prompts for more effective extraction of information.
OpenAI ▷ #api-discussions (141 messages🔥🔥):
-
Challenges with Custom Dictionary Translations:
@novumclassicumdiscussed difficulties with getting the GPT model to reference a custom dictionary for translations and sought advice for improving consistency and accuracy.@darthgustavand@eskcantaoffered conceptual solutions around structuring instructions and leveraging the AI's use of Python tools, suggesting a more holistic approach that combines algorithmic assistance with dictionary lookups for the translation process. -
Refining GPT Output to Eliminate Repetition:
@stealth2077struggled with the GPT model's repetitive use of certain words and sought assistance to prevent this behavior.@darthgustavadvised adopting a more structured and explicit set of instructions to guide the model. -
Reading Long Lists and 'Snippet' Mechanic Insights:
@magiciansincinquired about strategies for prompting GPT-4 to consider a full list of items rather than prioritizing those at the top.@darthgustavcontributed extensive insights regarding the possible function of an internal 'snippet reader' within GPT-4, which processes data in segments, potentially explaining the observed behavior. -
Questions Regarding API and Turbo Behavior: Users
@dave0x6dand@magiciansincposed questions about API responses and the behavior of GPT-4 Turbo when handling long documents.@darthgustav.provided a detailed explanation, touching on concepts like tokenization, context window limits, and the challenges of document ingestion by the AI. -
Ensuring AI Understands Extended Conversations:
@ArianJasked for advice on how to effectively continue a conversation with additional user queries based on past chat logs. The method being tried was found insufficient, hinting at complexities in maintaining context or referencing previous conversations in the model's current behavior. ,
LM Studio ▷ #💬-general (235 messages🔥🔥):
- Learning the Ropes of LLMS:
@snapflipperinquired about obtaining an API key similar to OpenAI for local models in LM Studio.@fabguyclarified that LM Studio does not provide API keys, and users would have to build their own API server on top of it. - Unravelling the GPU Offload Mystery:
@scampbell70experienced issues with GPU layer offload settings and received advice from community members like@fabguyand@heyitsyorkiesuggesting various solutions such as settingn_gpu_layersto-1. - Exploring Local Model Capabilities:
@ldeusprompted a discussion about running unquantized Mixtral 8x models with5x4090GPUs, with@heyitsyorkieand@fabguyoffering insights on the practical challenges and the need for experimenting to discover capabilities. - Finding the Right Setup for AI Work:
@eshack94.sought advice on the benefits of Mac Studio versus a Windows PC setup for running large language models.@heyitsyorkiecontributed insights, highlighting that while PCs are quicker, Macs offer simplicity and sufficient power for GGUFs. - Technical Troubles and Community Support: Several users, including
@d0mperand@josemanu72, encountered errors running LM Studio on Linux systems. Community figures such as@Aqualitekingand@heyitsyorkieoffered troubleshooting tips and recommended checking for missing packages and shared installation links.
Links mentioned:
- Kevin Office GIF - Kevin Office Thank - Discover & Share GIFs: Click to view the GIF
- Leonardo Dicaprio Cheers GIF - Leonardo Dicaprio Cheers The Great Gatsby - Discover & Share GIFs: Click to view the GIF
- CLBlast/doc/installation.md at master · CNugteren/CLBlast: Tuned OpenCL BLAS. Contribute to CNugteren/CLBlast development by creating an account on GitHub.
- GitHub - invoke-ai/InvokeAI: InvokeAI is a leading creative engine for Stable Diffusion models, empowering professionals, artists, and enthusiasts to generate and create visual media using the latest AI-driven technologies. The solution offers an industry leading WebUI, supports terminal use through a CLI, and serves as the foundation for multiple commercial products.: InvokeAI is a leading creative engine for Stable Diffusion models, empowering professionals, artists, and enthusiasts to generate and create visual media using the latest AI-driven technologies. Th...
- GitHub - lllyasviel/Fooocus: Focus on prompting and generating: Focus on prompting and generating. Contribute to lllyasviel/Fooocus development by creating an account on GitHub.
- GitHub - john-rocky/CoreML-Models: Converted CoreML Model Zoo.: Converted CoreML Model Zoo. Contribute to john-rocky/CoreML-Models development by creating an account on GitHub.
- Core ML Tools — Guide to Core ML Tools: no description found
- Crea un endpoint API 100% local para tu LLM usando LM Studio: En este video te comparto las instrucciones para crear tu propio endpoint local, compatible con el API de ChatGPT de OpenAI, utilizando el programa LM Studio...
LM Studio ▷ #🤖-models-discussion-chat (11 messages🔥):
-
Newbie Question about Presets:
@.ursiuminquired about the 'default preset' for models and how they work, showing uncertainty regarding models without detailed cards and whether any preset can be applied.@fabguyclarified that using the wrong preset with a model can lead to poor output or gibberish, and suggested matching the preset to the model using the model card for guidance, mentioning TheBloke's helpful documentation. -
Critique on Prompting Flexibility:
@.ben.comexpressed disbelief over the state of prompting and how it can lead to confusion among users, stating they aim to devise a test to assess whether models can auto-detect prompt formats based on answer quality. -
Presets & Model Compatibility Challenge:
@vbwyrdefaced issues while trying to load Magicoder-DS 6.7B into LM Studio and posted an error log, highlighting difficulties in identifying the correct preset and model compatibility. -
Security Concerns Trump Cost in Model Selection: In a discussion by
@vbwyrde, they conveyed their company's preference for in-house, local solutions over using OpenAI's GPT-4 due to security concerns, despite acknowledging GPT-4's superiority among available options. -
Sensitivity of Smaller Models to Settings:
@drawless111added that smaller models are particularly sensitive to template and parameter settings, exemplifying that lower capacity models can exhibit a significant range in performance based on settings like "temp" and "rep penalty".
LM Studio ▷ #🧠-feedback (8 messages🔥):
- Model Troubles Across the Board: User
@msz_mgsposted a model error with (Exit code: 0) and detailed system specs, but did not specify which models beyond names like Mistral instruct and dolphin Mistral. They confirmed the app version was 0.2.11 after@yagilbinquired. - First-Time User Facing Model Error:
@prostochelovek777also reported a model error with (Exit code: 1) including system details like having 8.00 GB of RAM. They sought assistance, indicating it was their first time with the issue. - Channel Guidance for Error Reporting:
@heyitsyorkiedirected@prostochelovek777to move to the appropriate help channel, using👍to acknowledge the direction.
LM Studio ▷ #🎛-hardware-discussion (24 messages🔥):
- User Experiences with Powerful GPUs:
@harryb_88771reports achieving 18 t/s on a M2 Mac with 96Gb using neuralbeagle14 7B Q8, while@heyitsyorkieremarks that a single RTX 4090 24GB can run one 33B model like deepseek-coder-instruct-33B. - Inquiries on Motherboard Compatibility:
@yoann_bseeks motherboard advice for a setup supporting dual RTX 4090s, and is directed to a useful Reddit thread by@heyitsyorkiefound at buildapc subreddit. - Exploring External GPU Feasibility:
@vbwyrdeopens a discussion on using external GPUs to surpass memory limitations, though no conclusive experiences are shared within the current conversation. - VRAM Capacity Readouts Causing Confusion: Both
@mathematicalvictorand@cloakedmanencounter issues where their VRAM capacity estimates display as 0 bytes, indicating a possible common bug or error with the estimate display. - Intel Arc Support Shared:
@vin.k.kshares a link to a GitHub issue regarding integration with a unified SYCL backend for Intel GPUs found here, which may be of interest to those following or contributing to LLM hardware-related development discussions.
Links mentioned:
- Reddit - Dive into anything: no description found
- Reddit - Dive into anything: no description found
- Feature: Integrate with unified SYCL backend for Intel GPUs by abhilash1910 · Pull Request #2690 · ggerganov/llama.cpp: Motivation: Thanks for creating llama.cpp. There has been quite an effort to integrate OpenCL runtime for AVX instruction sets. However for running on Intel graphics cards , there needs to be addi...
LM Studio ▷ #🧪-beta-releases-chat (48 messages🔥):
-
New Beta V7 Release Candidate Announced:
@yagilbintroduced Beta V7 as the 0.2.11 release candidate for LM Studio, urging the community to help test it to ensure stability. The Mac and Windows download links were provided, with requests for feedback or bug reports in a specified Discord channel. -
Layer Offloading Question Leads to Discovery:
@kadesharraised a potential issue when they benefited from setting layer offload to 49 on a model with 48 layers, which prompted a discussion concluding that there might be an uncounted layer in the model. -
Project Announcement Looking for Freelancers Closed Down:
@gciri001sought freelancers for deploying LLAMA 2 models locally with MySQL but was reminded by@heyitsyorkiethat self-promotion or job advertising is not allowed in the Discord channel. -
NeuralBeagle14-7B Gains Attention: Users
@eligump,@dean.com,@n8programs, and_anarche_discussed experiences with NeuralBeagle14-7B, noting its speed, creative writing capabilities, and overall performance, with_anarche_mentioning it is not great at reasoning. -
AUR Package for LM Studio Update In Progress: User
@aboxofwondersresponded to_constructor's comment about the Arch User Repository (AUR) package being outdated, stating they are updating it and advised flagging the package as out-of-date for immediate notification in the future.
Links mentioned:
- jan-hq/Solar-10.7B-SLERP · Hugging Face: no description found
- LangChain: LangChain’s flexible abstractions and extensive toolkit unlocks developers to build context-aware, reasoning LLM applications.
- no title found: no description found
LM Studio ▷ #autogen (2 messages):
- Localhost Connection Troubles in Win11:
@driona_reticentis experiencing issues connecting to their local LM Studio inference server with a Python script in Pycharm. It worked previously on 'localhost' but now requires the actual IP address, with the problem persisting even after changing it to 192.168.0.42. - Telnet Signaling Potential Network Changes: Despite setting the Python script for a 'localhost' connection,
@driona_reticentcan only open a connection via telnet using their network IP, hinting at a possible shift in network configuration or firewall rules affecting connections.
LM Studio ▷ #crew-ai (21 messages🔥):
- Configuring Local API Environment Variables:
@discgolfvanlifeproposed setting environment variables for the local API, suggestingOPENAI_API_KEYis "not-needed" andOPENAI_API_BASEto be set to the local server address. - Custom Approach for Multiple LLMs:
@_anarche_described an alternate configuration for using multiple language models by specifying a custom port and passing the namedllmto crewai when building an agent. - Memory Crash Mystery with LM Studio:
@motocyclereported a server crash with exit code 6 related to memory issues when running two agents using LM Studio on a Mac with 192GB RAM, and confirmed the problem persists across various context window sizes. - Seeking Precise Configuration Details:
@yagilbrequested export of the exact JSON configuration to diagnose the memory crash issue and recommended lowering the context window as an initial troubleshooting step. - Private Troubleshooting Session Initiated: After a brief public exchange regarding the server crash,
@yagilbdirected@motocycleto a private channel for detailed discussion to avoid filling the current channel with error logs.
LM Studio ▷ #open-interpreter (5 messages):
- Mixtral Struggles with Code Generation: User
@pefortindiscussed issues with Mixtral, mentioning it had difficulty knowing when to generate code/system commands. They consider further prompt tinkering might be necessary. - GPU Offload Error Reported:
@sandy_28242encountered an error while attempting to use GPU offload, with suggestions hinting at potential memory issues. The error reported includes an exit code and a suggestion to try a different model or config due to insufficient memory. - Take Error Chat Elsewhere:
@dagbshumorously pointed out that@sandy_28242's technical issue was posted in the wrong channel. They suggested channels#1111440136287297637or#1139405564586229810to discuss the problem.
- DeepSeek Coder 33B Exhibits Odd Behavior: User
@pefortinexpressed that DeepSeek Coder 33B is effective for writing code but occasionally produces nonsensical text, possibly due to prompt format issues. They're currently exploring various frameworks, feeling underwhelmed by open interpreter and local models. ,
Nous Research AI ▷ #off-topic (42 messages🔥):
-
Mamba State Memory Hijinks Anticipation:
@_3sphereexpressed excitement about the potential to disrupt the state memory of a Mamba. -
OSS Release of High-Performance FP4 Kernel on the Horizon:
@carsonpooleannounced plans to open-source a fp4 kernel with performance comparable to Marlin and Cublas, boasting speed and enhanced precision without the need for GPTQ style calibration. -
Challenges of Parameter Tuning for Cutting-Edge Kernels:
@carsonpoolediscussed the complexity of tuning hyperparameters for the new kernel and the exploration of using genetic algorithms or hierarchical grid tuners to optimize configurations. -
Language Models Might Mangle Mathematics:
@.ben.comshared frustration with AI models providing confusing or incorrect explanations of mathematical concepts like the Schur Complement, leading to a trust paradox when verifying through various sources. -
Fascination with Impacts of Early-Language Model Education:
@Error.PDFspeculated about the future cognitive abilities of individuals who use language models from a young age, pondering if they'll be the most knowledgeable or the most dependent generation.
Links mentioned:
- Paldo Palddoab GIF - Paldo Palddoab Loossemble - Discover & Share GIFs: Click to view the GIF
- Semantic reconstruction of continuous language from non-invasive brain recordings - Nature Neuroscience: Tang et al. show that continuous language can be decoded from functional MRI recordings to recover the meaning of perceived and imagined speech stimuli and silent videos and that this language decodin...
Nous Research AI ▷ #interesting-links (6 messages):
-
Introducing Yi-Vision Language Model:
@tsunemotoshared a link to the Yi Vision Language Model on Hugging Face, boasting bilingual multimodal capabilities. This model, Yi-VL-34B, is discussed on platforms like Hugging Face, ModelScope, and WiseModel. -
BigDL-LLM: Large Language Models on Intel XPU:
@euclaiseshared a link to documentation for BigDL-LLM, a library for running large language models on Intel XPU using various low-bit configurations including INT4/FP4/INT8/FP8. -
Skepticism Over Performance Demonstration via GIFs:
@ben.comcommented with disapproval about the use of animated GIFs to document performance of text generation, calling it "a new low for data science.” -
Defending the Use of Visuals for Speed Demonstration: In response to
@ben.com,@youngphloargued that visuals such as GIFs can be crucial for conveying the speed at which models stream tokens, which is not easily demonstrated through other means. -
Prompt Lookup as a "Free Lunch" in AI:
@leontellohighlighted a Twitter post mentioned by@231912337869635584, which emphasizes the effectiveness of prompt lookup for input-grounded tasks, suggesting it is an underutilized strategy that deserves more attention.
Links mentioned:
- 01-ai/Yi-VL-34B · Hugging Face: no description found
- The BigDL Project — BigDL latest documentation: no description found
Nous Research AI ▷ #general (118 messages🔥🔥):
- Exploring LLM System 2 Thinking: User
@jasonzhou1993shared a YouTube video titled "GPT5 unlocks LLM System 2 Thinking?", which discusses the concept of system 2 thinking in large language models and GPT-5's ability to tackle complex problems. - Launching Nukes in AI Simulations Gets Real:
@faldoreinitiated a discussion on what policies an AI would enact as the dictator of the world, sharing generated responses from various models like NousHermes-8x7b and dolphin-yi, leading to worrying outputs such as "LaunchNuclearBombs('New York City')". - Twitter Scraping on a Budget: In response to
@sanketpatrikar's query about scraping from Twitter, user@tekniumhumorously commented that the Twitter API would cost a fortune, while@tsunemotosuggested using Playwright for the task. - AI Ported to Antiquity! User
.plasmatorsuccessfully ran llama2.c using an SGI Indigo2 workstation from 1996 and shared their feat in a tweet by @mov_axbx, highlighting the capability to run a 15M model decades back. - Batching Large Language Models:
@bozoid.asked for advice on performing batched LLM inference withtransformers, resulting in@leontelloproviding a helpful code snippet that makes use of the batch feature in pretrained models to process multiple inputs simultaneously.
Links mentioned:
- Dancing Cat Jump Cat GIF - Dancing cat Jump cat Cat - Discover & Share GIFs: Click to view the GIF
- Tweet from Nathan Odle (@mov_axbx): Please enjoy this SGI Indigo2 workstation from 1996 running llama2.c by @karpathy. 1.4 tokens/sec with the 15M TinyStories model! Just a little porting for the big endian IRIX machine, all in an eve...
- GPT5 unlocks LLM System 2 Thinking?: Human think fast & slow, but how about LLM? How would GPT5 resolve this?101 guide on how to unlock your LLM system 2 thinking to tackle bigger problems🔗 Lin...
- llama.cpp/examples/server/README.md at master · ggerganov/llama.cpp: Port of Facebook's LLaMA model in C/C++. Contribute to ggerganov/llama.cpp development by creating an account on GitHub.
- ollama/docs/import.md at main · ollama/ollama: Get up and running with Llama 2, Mistral, and other large language models locally. - ollama/ollama
- GitHub - lucidrains/self-rewarding-lm-pytorch: Implementation of the training framework proposed in Self-Rewarding Language Model, from MetaAI: Implementation of the training framework proposed in Self-Rewarding Language Model, from MetaAI - GitHub - lucidrains/self-rewarding-lm-pytorch: Implementation of the training framework proposed in...
Nous Research AI ▷ #ask-about-llms (52 messages🔥):
- GPU Precision and Performance Insights:
@main.aiclarified that accumulation during inference is typically done in FP32, despite computations being done in FP16. They also added that there is hardly any open-source code that utilizes FP16 for accumulation, to which@.mahoukoconfirmed, mentioning a custom kernel that does it is available but not easily integrated. - Understanding TFLOP Requirements: According to
@sekstini, when doing LLM inference with small batch sizes, the GPU bandwidth and model size determinate the theoretical maximum tokens per second, and@main.aiindicated that flops should not be a crucial concern for inference. - Alternative APIs for Ollama?:
@tekniumsuggested exploring other APIs like tgi, vllm, exllama2, or using llama.cpp directly to improve Ollama's performance with Mixtral 8x7B in a RAG system, following a user complaint about long response times. - Mixtral's RAG System Challenges:
@colby.morris08reported that removing Ollama from the Mixtral model's RAG system led to undesirable quoting behaviors rather than creative context use, and@intervitensadvised trying to mimic Ollama's prompt and generation settings with a different API for potential speed gains. - Fine-tuning LLMs on Specific Domains: In response to a query about whether to mix domain-specific datasets with general data for fine-tuning, there was no direct answer given. The conversation was more focused on inference throughput and hardware capabilities.
Links mentioned:
CUDA Pro Tip: Control GPU Visibility with CUDA_VISIBLE_DEVICES | NVIDIA Technical Blog: As a CUDA developer, you will often need to control which devices your application uses. In a short-but-sweet post on the Acceleware blog, Chris Mason writes: As Chris points out…
,
Mistral ▷ #general (148 messages🔥🔥):
-
Scam Bots Swarm Mistral's Pastures: Users, starting with
@mrdragonfox, call attention to rampant spam/scam issues.@sophiamyangconfirms removal and discusses the current mod setup, suggesting that even though AutoMod flagged content, it failed to delete, hinting at the need for improvement or community mod volunteers. -
Mysteries of Model Updates and Pricing: Users
@f127467,@i_am_dom, and others speculate on Mistral updates and model releases, including possible new features without needing new models. Discussions drift towards@mrdragonfox's insight into MoE (Mixture of Experts), Meta's upcoming models, and the hidden steps to finetune models effectively. -
AI's Achilles Heel - Mathematical Computations:
@mrdragonfoxpoints out the inefficiency of using LLMs for deterministic tasks like math, proposing function calls to services like Wolfram Alpha or using code interpreters over shoehorning math into a language model. -
Fine-tuning Frustrations and Feats:
@heartlocketqueries about fine-tuning for varied results, specifically for poetry, while@renemengseeks advice on AWS servers for MistralAI chatbot projects.@orabazeschips in with industry insights, comparing finetuning costs to the complexities of manufacturing a car. -
Creating Robust Discord Communities: Amidst spam removal, discussions about malware moderation bots, such as Dyno, ensue with
@atomicspiesand@ethuxsharing insights.@sophiamyangexpresses openness to the idea of community-based moderators and seeks recommendations for trustworthy candidates.
Links mentioned:
Mistral 7B foundation models from Mistral AI are now available in Amazon SageMaker JumpStart | Amazon Web Services: Today, we are excited to announce that the Mistral 7B foundation models, developed by Mistral AI, are available for customers through Amazon SageMaker JumpStart to deploy with one click for running in...
Mistral ▷ #models (15 messages🔥):
- Seeking Mistral Model for JSON Transformation:
@ragu_1983is looking to integrate Mistral models to translate human text into JSON for their AI Assistant on a cloud platform. They inquired about training with prompts, data privacy for enterprise use, and sought to discuss with the Mistral tech team for further understanding. - Training Mistral Models Clarification:
@mrdragonfoxresponded stating training the API endpoint directly is not currently possible; instead suggested using open-source models, finetuning and in-context learning for formatting outputs. - Inquiry on Fill in the Middle (FIM) Capabilities:
@lexi_49840inquired about FIM functionality for code completion in Mistral, noting that unlike StarCoder, Mistral does not have special tokens for FIM. - FIM Feature Requires Finetuning in Mistral:
@mrdragonfoxmentioned that StarCoder was specifically trained for FIM, suggesting that FIM in Mistral likely needs to be incorporated during finetuning. - Finding the Correct Mistral Model:
@wayne_dengasked whether themixtral-7B-8x-v0.1model was available on GitHub, which@mrdragonfoxclarified is hosted on Huggingface, not GitHub.
Mistral ▷ #deployment (2 messages):
- Guide to Advanced Prompt Engineering for Open LLMs:
@tim9422shared a prompt engineering guide geared towards open-source language models in the 3 to 70 billion parameter range, highlighting the differences from closed-source models. - Discussion on Output Formatting in LLMs: In response to the guide mentioned by
@tim9422,@mrdragonfoxpointed out an oversight in the section about formatting, stating that it's not necessary to use another toolkit, as grammar that hooks into logits generation can enforce output directly withinllama.cpp.
Links mentioned:
Prompt Engineering Guide for Open LLM: Take your Open LLM application to the next level: Introduction: Why do we need another guide?
Mistral ▷ #ref-implem (8 messages🔥):
-
Spreadsheet Data Leveraged for RAG:
@vhariationaldiscusses turning spreadsheet records into textual descriptions for use in Retriever-Augmented Generation (RAG), expressing skepticism about an LLM's ability to perform complex data analysis. They reference a tutorial on TheNewStack as an example of RAG use cases. -
Monday Skepticism or Reality?:
@vhariationaljokes about their skepticism stemming from it being a Monday, while@fredmolinamlgcpshares a Pastebin log showing Mistral's multi-step reasoning capabilities when prompted with campaign data. -
Bringing in External Code Interpreters:
@mrdragonfoxsuggests using an open source interpreter, like Open Interpreter, to perform data analytics on the output from an LLM, underscoring that not all tasks need to be done within the LLM itself. -
Beyond Simple Context Injection:
@mrdragonfoxdescribes "ranking / re / de-ranking" as more sophisticated uses of RAG than simple context injection, pointing to more complex applications.
Links mentioned:
<s> [INST] Could you help me to an - Pastebin.com: Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
Mistral ▷ #finetuning (34 messages🔥):
-
Best Approach to Finetuning for Domain Adaptation?:
@sunbeer_inquired about the best method to finetune Mistral for domain-specific knowledge such as 18th-century France; they considered training on a corpus of French texts.@mrdragonfoxadvised starting with PEFT (Prompt-based Finetuning) to adapt styles and potentially a full finetune if necessary, utilizing the linguistic patterns of that era. -
Content Over Style for Historical Context:
@sunbeer_clarified that their aim is to add new content, not just the style, to which@mrdragonfoxsuggested that existing models might already contain relevant old words and recommended starting with PEFT to evaluate the need for further pretraining. -
Pretraining with a Closed-source Dataset:
@sunbeer_mentioned the intent to use a closed-source dataset, opting for pretraining followed by a full finetune.@mrdragonfoxsuggested looking at resources like a GitHub repository for guidance and emphasized the cost-effectiveness of starting with PEFT before committing to full finetuning. -
Finetuning for Domain-specific Knowledge:
@sunbeer_asked if PEFT could incorporate intricate domain knowledge, like understanding why certain behaviors were considered insults among French noblemen.@mrdragonfoxresponded that a RAG pipeline (Retrieval-Augmented Generation) might be better for fact-specific queries, while style adaptation can be done with PEFT. -
Chatbot Customization for Industry-specific Jargon:
@augustin.poelmans_58429sought advice for creating a chatbot that understands industry and company-specific acronyms and processes, considering a RAG app or finetuning. The chatbot is intended to work on in-house hosted infrastructure, and they were contemplating whether Mistral's models would be suitable. -
How to Make Mistral Forget Chats:
@dizzytornadoasked how to reset the memory of previous chats in Mistral, and@mrdragonfoxnoted that the model itself has no memory, and any semblance of "remembering" is due to the front end passing the entire context back in the chat history, as Mistral and all LLMs (Large Language Models) are designed to be stateless.
Links mentioned:
- Training a causal language model from scratch - Hugging Face NLP Course: no description found
- GitHub - OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions: Go ahead and axolotl questions. Contribute to OpenAccess-AI-Collective/axolotl development by creating an account on GitHub.
Mistral ▷ #showcase (1 messages):
- Request for Training Resources: User
@akashai4736expressed gratitude towards@266127174426165249and requested resources for training on function calls. No specific resources or links were provided in the shared chat excerpt.
Mistral ▷ #la-plateforme (7 messages):
- Mysterious Error in Mistral Streaming:
@jakobdylancencountered a rare streaming error with Mistral-medium and shared the Python traceback information. The issue seems to be a connection-related error where the peer closed the connection without sending a complete message body. See the error details. - Seeking the Right Python Client:
@sophiamyangquestioned about the Python package being used, suggesting that@jakobdylancwasn't using their Python client. Instead, they use OpenAI's Python package to maintain cross-compatibility with OpenAI and Mistral APIs. - Package Compatibility Concerns:
@jakobdylancconsidered switching to Mistral's Python package for chat completions but expressed concerns about potential issues with using OpenAI's vision models. The current usage involves the OpenAI Python package for API interactions. - Ongoing Open Issue:
@jakobdylancis unsure how to reproduce the error but promised to update the channel if it occurs again, maintaining an open issue stance on the streaming error encountered.
Links mentioned:
-
Discord-LLM-Chatbot/llmcord.py at ec908799b21d88bb76f4bafd847f840ef213a689 · jakobdylanc/Discord-LLM-Chatbot: Multi-user chat | Choose your LLM | OpenAI API | Mistral API | LM Studio | GPT-4 Turbo with vision | Mixtral 8X7B | And more 🔥 - jakobdylanc/Discord-LLM-Chatbot
-
Mistra - Overview: Mistra has 29 repositories available. Follow their code on GitHub.
-
GitHub - openai/openai-python: The official Python library for the OpenAI API: The official Python library for the OpenAI API. Contribute to openai/openai-python development by creating an account on GitHub.
,
Eleuther ▷ #general (33 messages🔥):
-
Temporary Service Outage Resolved:
@ilovesciencequeried if CoreWeave could be responsible for a service downtime.@realmsmithconfirms the service is back up and@occultsageelaborates that Netlify was slow to restore the site but the API remained functional. -
Pitch Directly, Ask Forgiveness Not Permission:
@digthatdataadvises to post content pitches directly in the channel as it’s often easier to ask forgiveness than to ask for permission repeatedly;@catboy_slim_reflects whether encoding this ethos is beneficial and@digthatdataindicates it has proven effective for Wikipedia. -
Possible Research Direction on Alignment Problem:
@exiraeintroduces a pitch about applying Habermas' theory of communicative action to the AI alignment problem, suggesting it reshapes the problem into something more tractable.@thatspysaspyand@digthatdataadvise on gradual engagement with the community and sharing via google doc, while@a60ece6dengages in a detailed discussion regarding the nature of communicative action. -
ML Paper Idea Needs Interdisciplinary Team:
@clockrelativity2003shares an idea for a research paper on using LLM-based RPGs to help people with autism improve conversational skills, citing a need for a team including psychology experts, which extends a previous work available on arXiv. -
Technical Queries and Discussions:
@the_alt_maninquires about a Deep Learning framework in Rust that interfaces with XLA.@sk5544seeks advice on noisy tokens during Pythia410m model training with RLHF, while@dhruvbhatnagar.0663asks how a model like Llama 2 can generate responses in languages without specific vocabulary tokens;@synquidclarifies the use of byte-level BPE for tokenization.@aslawlietrequests code assistance for fine-tuning Mistral 7b for token classification.
Eleuther ▷ #research (38 messages🔥):
- Byte-Level Fallback in Language Models: In response to a question from
@dhruvbhatnagar.0663about Gujarati tokens in Llama 2,@the_sphinxmentioned the use of a byte level fallback mechanism. - Activation Beacons Repository for Training:
@carsonpoolepointed@catboy_slim_to the official activation beacons repo that may have an implementation, which could potentially improve data efficiency during training. - Discussion on Positional Embeddings:
@dashiell_sinquired about using both RoPE and learned positional embeddings, with@alstroemeria313stating they had attempted to use learnable RoPE frequencies but eventually removed it from their model. - Hourglass Diffusion Transformer Achievement:
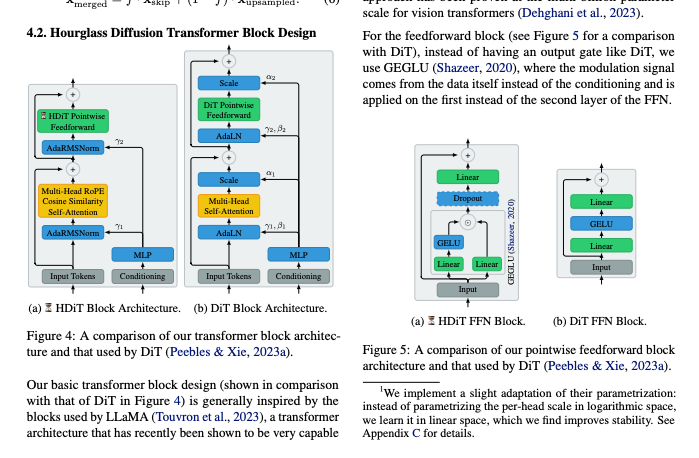
@ilovescienceshared a new paper by@322967286606725126,@203988731798093825@193386166517628929, and others, introducing the Hourglass Diffusion Transformer (HDiT), which allows for high-resolution image generation with linear scaling (read the abstract). - The Trade-offs of Adaptive Pruning and Tuning:
@ln271828linked a paper on Adaptive Pruning and Tuning (APT), which proposes a method to dynamically prune and tune parameters for efficient fine-tuning and inference in language models (download the paper).
Links mentioned:
- West-of-N: Synthetic Preference Generation for Improved Reward Modeling: The success of reinforcement learning from human feedback (RLHF) in language model alignment is strongly dependent on the quality of the underlying reward model. In this paper, we present a novel appr...
- Scalable High-Resolution Pixel-Space Image Synthesis with Hourglass Diffusion Transformers: We present the Hourglass Diffusion Transformer (HDiT), an image generative model that exhibits linear scaling with pixel count, supporting training at high-resolution (e.g. $1024 \times 1024$) directl...
- APT: Adaptive Pruning and Tuning Pretrained Language Models for Efficient Training and Inference: Fine-tuning and inference with large Language Models (LM) are generally known to be expensive. Parameter-efficient fine-tuning over pretrained LMs reduces training memory by updating a small number of...
- Modifying ALiBi for Encoder-Attention or Cross-Attention · Issue #5 · ofirpress/attention_with_linear_biases: In our paper we only showed results on causal language models, which use causally masked (decoder) self-attention. If you'd like to use ALiBi for seq2seq tasks such as translation, speech or T5, o...
- Excuse me, sir? Your language model is leaking (information): We introduce a cryptographic method to hide an arbitrary secret payload in the response of a Large Language Model (LLM). A secret key is required to extract the payload from the model's response, ...
Eleuther ▷ #scaling-laws (5 messages):
- Query on Embedding Size Scaling:
@jstephencoreyraised a question about the necessity of scaling the embedding size (d_model) as part of model scaling, noting diminishing returns after a certain point. - Concerns Over Embedding Initialization:
@ad8ementioned that improper initialization of the embedding size can cause problems as the model scales. - Clarification on Embedding Size:
@jstephencoreyconfirmed to@the_random_lurkerthat by embedding size he meant the size of each token dimension in the embedding layer, typically represented as d_model. - Scaling Model Parameters in Relation to d_model:
@the_random_lurkerasked for clarification on what aspects of the model are scaled if d_model isn't, since other parameters like d_ff are often a function of d_model.
Eleuther ▷ #interpretability-general (13 messages🔥):
- Surprisal vs. KL Divergence in New Paper:
@norabelroseexpressed confusion over a paper's preference for using "surprisal" and precision over KL divergence, suggesting that the tuned lens might be superior according to KL. - Skepticism After Discussion With Author:
@stellaathenalowered their opinion on the paper after an exchange with the author, questioning the interpretation of results that claim to outperform the Logit and Tuned Lens. - Possible Use of Paper for ELK:
@80melonagrees with@norabelrosethat the paper's approach could be interesting to apply in scenarios like switching debate LM positions or contexts between Alice and Bob in related models. - Concept of Knowledge Transplantation Discussed:
@norabelrosementioned the term "knowledge transplant" as a concept that@mrgonaofound similar to something discussed in a direct message. - Patching Representation with Keys and Values:
@80melonand@norabelroseconsider patching representations of truth in latent knowledge and the potential of using keys and values for effective knowledge transplantation.
Links mentioned:
Tweet from Stella Biderman (@BlancheMinerva)): @ghandeharioun This is a very interesting paper! I'm having trouble figuring out how I should interpret some of the results. For example, you discuss outperforming the Logit Lens and Tuned Lens, b...
Eleuther ▷ #lm-thunderdome (46 messages🔥):
-
Standard Practice for Invalid MCQA Outputs:
@hailey_schoelkopfclarified that the standard practice for treating invalid outputs in black-box generative evals for multiple-choice questions (MCQA) is to mark them as incorrect, mentioning the importance of answer extraction or normalization. -
Handling of Unexpected Dataset Loads: When
@vermifugereported unexpected loading of additional datasets while running a task,@hailey_schoelkopfinvestigated, updated to the latest codebase, and discovered an issue leading to the unintended initialization of task objects. -
Quick Resolution for Dataset Loading Bug:
@hailey_schoelkopfidentified the underlying problem that caused unnecessary dataset loading, promptly worked on a fix, and published a patch at GitHub pull request #1331. -
Dataset Path Updates Due to Hugging Face Changes:
@hailey_schoelkopfshared a Hugging Face update about deprecating canonical models and mentioned that AI2 ARC's path has changed, providing a fix in GitHub pull request #1332. -
Exploration and Resolution of ContextSampler Issue:
@vermifugeand@hailey_schoelkopfexchanged debug information about an issue with theContextSampler.doc_to_text. By analyzing code together,@vermifugefigured out thatself.featureswas being initialized after the sampler, leading them to change the initialization order to resolve the issue.
Links mentioned:
-
Tweet from Julien Chaumond (@julien_c): PSA: We are deprecating canonical models, i.e. @huggingface Hub repos that were not under an organization or user namespace. This should not break anything 🤞💀 Here's a list of the cano...
-
Don't use
get_task_dict()in task registration / initialization by haileyschoelkopf · Pull Request #1331 · EleutherAI/lm-evaluation-harness: cc @lintangsutawika -
Update migrated HF dataset paths by haileyschoelkopf · Pull Request #1332 · EleutherAI/lm-evaluation-harness: Some datasets have been migrated to AllenAI's HF org, probably as part of HF's effort to phase out "canonical models" (ones with no HF org attached). This PR updates the dataset path...
-
lm-evaluation-harness/lm_eval/api/task.py at 5c25dd5514eb8d34a385fa500d34d1249730723f · EleutherAI/lm-evaluation-harness: A framework for few-shot evaluation of language models. - EleutherAI/lm-evaluation-harness
,
HuggingFace Discord ▷ #general (41 messages🔥):
-
Clarifying Token Generation without Vocabulary:
@dhruvbhatnagar.0663is working on pre-training for Gujarati and noticed that Llama 2 doesn't include tokens for the Gujarati language.@gugaimeand@ilovekimchi6engaged in the discussion, expressing interest and inquiring about costs, while@vipitissuggested looking at the token IDs to decode. -
GPTQ Model Deployment Challenges:
@blahblah6407is facing inconsistencies with their deployed endpoint using a GPTQ model, experiencing a 504 error and slow response times compared to local testing.@meatfuckerjoined the conversation discussing possible causes, including differences in GPU performance and background tasks on the machine. -
Importance of GPU Choice for Real-Time Voice Change:
@nekonnyinquired about recommended GPUs for real-time voice change, particularly for VRChat video recording.@doctorpanglossresponded, emphasizing the complexity of the task and seeking to clarify usage intentions. -
Challenges with ONNX Model Export:
@blahblah6407is struggling to export their fine-tuned model to ONNX, encountering errors like "Could not find an implementation for Trilu(14)." The conversation signifies trouble in model compatibility or implementation when using optimum for ONNX export. -
Quantization Workflow for LLM Models:
@dragonburpshared difficulties with quantization and mentioned models with an "AWQ" suffix which may relate to it.@meatfuckerrecommended TheBloke's repository as a good source for quantized models, offering varieties like gptq, awq, and gguf.
Links mentioned:
GPT5 unlocks LLM System 2 Thinking?: Human think fast & slow, but how about LLM? How would GPT5 resolve this?101 guide on how to unlock your LLM system 2 thinking to tackle bigger problems🔗 Lin...
HuggingFace Discord ▷ #today-im-learning (7 messages):
-
Accountability Through Updates: User
@antiraedusshared their strategy to gain control over time by reducing social media usage and focussing on productivity during a self-imposed two-week sprint. They continue their efforts in maintaining exercise and weight gain. -
Hugging Along With NLP: User
.exnihilomentioned they are going through the NLP Course on HuggingFace today, diving into the world of Natural Language Processing. -
Curiosity about DoReMi:
@osansevieroasked about DoReMi, prompting@neuralinkto post a link to an arxiv paper detailing how mixture proportions of pretraining data domains affect language model performance. -
In Search of Inference Backend Knowledge:
@.jerginis in pursuit of resources and learning materials to understand and perhaps create their own inference backend. They've expressed an interest in learning how code interacts with various model files like ONNX, .pkl, etc. -
Ease of Experimentation with HF Models:
@sebastian3079expressed excitement over learning that TFAutoModel allows easy experimentation with various models on HuggingFace, praising its accessibility for newcomers.
Links mentioned:
DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining: The mixture proportions of pretraining data domains (e.g., Wikipedia, books, web text) greatly affect language model (LM) performance. In this paper, we propose Domain Reweighting with Minimax Optimiz...
HuggingFace Discord ▷ #cool-finds (6 messages):
-
Introducing Yi Visual Language Model:
@andysingalshared the Yi Visual Language (Yi-VL) which is the open-source, multimodal version of the Yi Large Language Model series. It's designed for content comprehension and multi-round conversations about images, with links such as the model at Hugging Face and community discussion at GitHub provided for further exploration. -
InstantID Impresses Yann LeCun:
@osansevierobrought attention to InstantID, an identity-preserving generation tool that garnered positive comments from Yann LeCun. The links include a Twitter post from LeCun and the Gradio demo to try it out. -
Seeking the Source:
@bozoid.requested a link which@_vargolpromptly provided, leading to an updated README.md regarding the IP-Adapter-FaceID project on Hugging Face. -
Hedwig AI's Youtube Debut:
@forestwow7397shared a YouTube video introducing hedwigAI, which aims to revolutionize the use of video data. The video can be found here, outlining the platform’s capabilities.
Links mentioned:
- 01-ai/Yi-VL-34B · Hugging Face: no description found
- h94/IP-Adapter-FaceID at main: no description found
- Youtube Video Intro hedwigAI: Welcome to the world of seamless streaming with Hedwig AI, where we're transforming the way video data is utilized and understood. In this video, we showcase...
- Tweet from Omar Sanseviero (@osanseviero): InstantID: Identity-Preserving Generation in Seconds Try it at https://hf.co/spaces/InstantX/InstantID
- Tweet from Yann LeCun (@ylecun): Yay, I'm a Marvel superhero! Where's my Iron Man suit? ↘️ Quoting Gradio (@Gradio) 🔥InstantID demo is now out on Spaces. Thanks @Haofan_Wang et al, for building a brilliant Gradio demo fo...
HuggingFace Discord ▷ #i-made-this (9 messages🔥):
-
Deepfake Detection Custom Pipeline Launched:
@not_lainannounces the creation of a custom pipeline for multimodel deepfake detection, and references a similar project by@aaronespasa. Discover the tool on Hugging Face Spaces. -
Cogment Lab Open-Sourced:
@ariel2137shares Cogment Lab, an open-source project for Human-AI cooperation research, allowing, among other things, human demonstrations in Gymnasium/PettingZoo environments. Check out the GitHub repo and tutorials. -
LLM/Copilot Fuzzy Matching Demo:
@josharianpresents a video demonstration of a proof of concept combining LLMs with fuzzy matching for faster text entry. Watch the demo on YouTube. -
Small 128-Dimensional MiniLM Model Created:
@stroggozintroduces small_128_all-MiniLM-L6-v2, a distilled version of the all-MiniLM-L6-v2 sentence encoder with a focus on faster similarity comparisons, sharing the Hugging Face model and distillation script. -
Inference Speed Clarification on MiniLM Distillation:
@Cubie | Tomclarifies that the inference of@stroggoz's distilled sentence encoder remains about the same speed as the original model, while embedding comparison times are improved.@stroggozconfirms that the creation focuses on embedding comparisons.
Links mentioned:
- ClovenDoug/small_128_all-MiniLM-L6-v2 · Hugging Face: no description found
- Deepfake Detection - a Hugging Face Space by not-lain: no description found
- RNN #7 - The First Neural-Net Computer: SNARC and the Formative Years of AI
- LLM/Copilot UX Experiment: Fuzzy Matching: This is a quick demo of a ux idea for using fuzzy matching to improve getting code suggestions out of an LLM.Code: https://github.com/josharian/llama.cpp/com...
- GitHub - cogment/cogment-lab: A toolkit for practical Human-AI cooperation research: A toolkit for practical Human-AI cooperation research - GitHub - cogment/cogment-lab: A toolkit for practical Human-AI cooperation research
- GitHub - cogment/cogment-lab: A toolkit for practical Human-AI cooperation research: A toolkit for practical Human-AI cooperation research - GitHub - cogment/cogment-lab: A toolkit for practical Human-AI cooperation research
HuggingFace Discord ▷ #diffusion-discussions (2 messages):
-
Seeking Best Methods for Remote Stable-Diffusion: User
@utxeeeinquired about the most effective strategies for running stable-diffusion remotely. No suggestions or specific methods were provided in the subsequent messages. -
Inconsistencies in Image Generation Quality:
@djdookienoticed a discrepancy in image quality between diffusers and auto1111 when creating images with identical parameters, observing that the output from diffusers exhibited notably more noise. They shared their code for generating the image using diffusers, inviting insights into the cause of the quality difference.
HuggingFace Discord ▷ #computer-vision (4 messages):
- Clarification Request on Dictionary Structures: User
@swetha98expressed confusion about implementing a dictionary of dictionaries and sought clarification on whether that was what was being suggested. - Insight on Adaptive Average Pooling Shared:
@merve3234explained adaptive average pooling, highlighting its role in making models invariant to different inputs in terms of sizes and attributes. They referred to their lecture notes for more detailed information. - Seeking Explicit Documentation Details:
@swetha98remarked that the official documentation lacked explicit information on the topic they were researching. - Uploading Models to HuggingFace: User
@xeus69asked for advice on how to upload a model saved as a.savfile to HuggingFace in order to create a HuggingFace Space for running the model.
Links mentioned:
my_notes/Deep Learning, Deep RL/CNNs 2 (Advantages).pdf at main · merveenoyan/my_notes: My small cheatsheets for data science, ML, computer science and more. - merveenoyan/my_notes
HuggingFace Discord ▷ #NLP (8 messages🔥):
-
BERT Still Rocks in Sequence Classification: User
@merve3234defends the viability of BERT for sequence classification and suggests using Low-Ranking Adaptation (LoRA) for fine-tuning to make the model more parameter-efficient and prevent forgetting. -
Heavyweight Model Hits GPU Memory Limit:
@kxgongfaces an issue loadingmixtral-8x7B-v0.1model usingtransformers.from_pretrained, as it exhausts the memory of 8 A100 GPUs. Mr_nilq suggests usingdevice_map="auto"for inference when using Transformers 4.20.0 or above. -
Automatic Multi-GPU Distribution for Training: In response to
@kxgong's question about training with distributed model across multiple GPUs,@mr_nilqadvises thatdevice_map="auto"is for inference only, but multi-GPU training can be achieved with Trainer and Accelerate. He recommends checking the multi-GPU training guide on HuggingFace. -
ELI5 Dataset No Longer Accessible:
@andysingalinforms the group that "eli5" dataset is defunct due to Reddit's API access changes, as noted in the ELI5 dataset's HuggingFace page. -
Inquiry about Multilingual Model Abilities: User
@dhruvbhatnagar.0663queries how the Llama 2 model can generate responses in languages like Hindi, Tamil, Gujarati without specific tokens for these languages in the model's vocabulary.
Links mentioned:
- LoRA for token classification: no description found
- Efficient Training on Multiple GPUs: no description found
- eli5 · Datasets at Hugging Face: no description found
HuggingFace Discord ▷ #diffusion-discussions (2 messages):
- Quest for Stable-Diffusion Remote Execution Secrets:
@utxeeeinquired about the best methods for running stable-diffusion remotely but did not receive a response yet with the community's recommendations. - Puzzling Quality Discrepancy in Diffusion:
@djdookieshared a perplexing issue where same-parameters images generated with diffusers and auto1111 showed a marked quality difference; the former had more noise. They provided theirdiffuserscode snippet and noted the image contrast, but the community has yet to diagnose the cause.
pipe = StableDiffusionXLPipeline.from_single_file(".\models\Stable-diffusion\sdxl\sd_xl_base_1.0_0.9vae.safetensors", torch_dtype=torch.float16)
prompt = "concept art Amber Temple, snow, frigid air, snow-covered peaks of the mountains, dungeons and dragons style, dark atmosphere . digital artwork, illustrative, painterly, matte painting, highly detailed"
negative_prompt = "photo, photorealistic, realism, ugly"
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
image = pipe(prompt, negative_prompt=negative_prompt, guidance_scale=8, num_inference_steps=20, width=1024, height=1024, generator=torch.Generator(device='cuda').manual_seed(1337), use_karras_sigmas=True).images[0]
,
Perplexity AI ▷ #general (48 messages🔥):
- Perplexity App Glitches and Support Inquiries: Users like
@elfarouqhave expressed difficulties with the Perplexity app and support, including not receiving login links. The standard advice from@icelavamanis to check spam folders and ensure the email is entered correctly, though some users are still encountering issues. - Perplexity Hiring and Careers: Responding to
@neon20’s query about engineering roles,@icelavamanshared the Perplexity careers page and highlighted the company's vision. - LAM and LLM System 2 Thinking Discussions:
@gentlefoxssbmmentioned GPT-4 research papers and the Rabbit R1’s Large Action Model (LAM) in response to@moyaoasis' interest in 'text to browser operation' AI, suggesting its cutting-edge status. - Rabbit R1 Pre-order Perplexity Pro Deal Info: Users like
@jaybob32discussed the availability of Perplexity subscription offers with Rabbit R1 pre-orders.@ok.alexclarified that each batch contains 10k devices, and@ganym3deconfirmed later demand in batch 6, suggesting 100k offers have not yet been reached. - Troubleshooting Account and Subscription Issues:
@thbk_32074provided a personal account of resolving a subscription issue with Perplexity, indicating promo code requirements and steps taken to apply it.@elfarouqconfirmed that an additional year would be added to existing Pro subscriptions when purchasing the Rabbit R1 with the same email.
Links mentioned:
- Perplexity Careers: Join our team in shaping the future of search and knowledge discovery.
- GPT5 unlocks LLM System 2 Thinking?: Human think fast & slow, but how about LLM? How would GPT5 resolve this?101 guide on how to unlock your LLM system 2 thinking to tackle bigger problems🔗 Lin...
Perplexity AI ▷ #sharing (14 messages🔥):
- Perplexity.ai Earns Praise:
@doulos05praised Perplexity for its clear sourcing, likening it to instructing an assistant, and noted the value in having sources listed even if the search does not yield the desired results. - Users Compare Perplexity with You.com:
@manishtresponded to@doulos05's comment, expressing agreement and compared Perplexity.ai's clear interface to You.com for providing answers with sources. - Academic Approval for Perplexity's Source Linking: Both
@doulos05and@friar_brent, the latter a professor, commend Perplexity for its source linking and transparency, which is highly appreciated in academic settings. - Learning Strategies Shared in a Blog:
@charlenewhoshared a blog post detailing how to learn software-related skills more quickly using Perplexity.ai and GPT-4, which includes strategies for efficiently building mental models and evaluating side projects. The post is available at Using LLMs to Learn 3x Faster. - Perplexity API Integrates with OpenAI Setup:
@thereverendcognomeninquired about integrating Perplexity API with existing OpenAI setups, sharing a link for documentation at PromptFoo that suggests it's possible by changing theapiHostconfiguration key.
Links mentioned:
- Perplexity | promptfoo: The Perplexity API (pplx-api) offers access to Perplexity, Mistral, Llama, and other models.
- Okay Rabbit R1, You Have Our Attention!: In this clip, Marques, Andrew, and David discuss the Rabbit R1 AI hardware device that was announced at CES. Watch full episode: https://youtu.be/4yaUegwRUXg...
- Perplexity.ai Better Than ChatGPT? | Kushal Lodha: This insane AI tool will blow your mind!ChatGPT’s Knowledge is limited till September 2021, Perplexity.ai can help you with current information.I asked for t...
Perplexity AI ▷ #pplx-api (13 messages🔥):
-
Troubleshooting Credit Issues: User
@tpsk12345reported a problem with not receiving $5 credits, and despite following the advice from@icelavamanto clear cache and deactivate extensions, the issue persisted. Eventually,@ok.alexprovided assistance by sharing a support ticket and acknowledged that the team is working on the problem. -
Clarification on Credit Availability Across Plans:
@icelavamanclarified to@cosine30that credits are available on all plans, not just yearly ones, addressing concerns about credit allocation in different subscription models. -
Quick Responses Acknowledged: User
@thereverendcognomennoted the quick response times in the channel, seeming to appreciate the promptness of support and community feedback. -
Request for New API Endpoint:
@thereverendcognomeninquired about the possibility of implementing a new/modelsendpoint, suggesting an improvement to the API offerings. ,
LAION ▷ #general (59 messages🔥🔥):
- VRAM Limitations on Consumer GPUs Discussed:
@SegmentationFaultexpressed doubt that more than 24GB of VRAM is needed for certain AI tasks, despite@qwerty_qwermentioning that consumer GPUs might struggle with prompt refiners in particular. - Europs's AI Act Enters Final Stage:
@vrus0188shared a link mentioning the EU has reached a provisional agreement on the world's first comprehensive regulation on AI, the AI Act, which clasifies AI systems by risk level and imposes transparency requirements. - Concern Over Partial Application of the EU AI Act:
@thejonasbrotherspointed out concerns that the AI Act will only apply to persons within the EU territory, suggesting that AI models on platforms like Hugging Face might need to disclose their training data due to new transparency requirements. - Potential AI Censorship in Game Development Events:
@.undeleteddiscussed an incident where criticizing AI could lead to bans from game development events, sparked by a situation involving a well-known free game assets producer. - AI Ethics and Violent Content in Datasets: The conversation turned to AI ethics, particularly regarding the use of unauthorized art and violent contents in datasets, with
@thejonasbrotherssharing insights into the prevalence of such data and mentioning Vice's article about generative AI tools using disturbing images.
Links mentioned:
- In Defense of Generative AI ("AI Art"): Resistance is futile—it only quickens assimilation
- ISIS Executions and Non-Consensual Porn Are Powering AI Art: AI is progressing at an astonishing speed, but we still don’t have a good understanding of the datasets that power AI, and little accountability for whatever abusive images they contain.
- Models - Hugging Face: no description found
- Tweet from Rivers Have Wings (@RiversHaveWings): Hourglass + Diffusion = ❤️ We introduce a new transformer backbone for diffusion models that can directly generate megapixel images without the need for multiple stages like latent diffusion. Read h...
- The AI Act - EU's First Artificial Intelligence Regulation (Detail) - Kinstellar: Legal Services & Advice Kinstellar - Law firm, Central Europe & Asia
LAION ▷ #research (11 messages🔥):
- Open-Sourcing Kosmos-2.5: User
@yizhilllquestioned the necessity of training an open-source version of kosmos-2.5 given that it's not yet open-source. - Training Dataset for Whisper:
@barzin1inquired about the availability of Whisper's training dataset, to which@marianbastiresponded by reference to distil-whisper's use of the Common Voice Corpus 13.0 dataset and barzin1 later found related data sources on Whisper's GitHub page. - Introducing Depth Anything:
@mkaicshared Depth Anything, a monocular depth estimation foundation model trained on over 62 million unlabeled images with capabilities surpassing existing models like MiDaS v3.1 and ZoeDepth. - Humorous Approval of Depth Anything's Marketing: Post discussions about Depth Anything,
@mkaichumorously remarked on the confident tone of the materials, citing their claim of superiority through video demos, while@thejonasbrotherspraised the controlnet as "godtier" and speculated on intentions to integrate live diffusion with TikTok videos. - Lookahead Framework by Ant Group:
@vrus0188shared a link to a Reddit discussion about Ant Group's Lookahead framework, which offers a 2-5x speedup in inference for large language models without sacrificing accuracy, and provided links to both the research paper and the GitHub repository.
Links mentioned:
-
Depth Anything: no description found
-
mozilla-foundation/common_voice_13_0 · Datasets at Hugging Face: no description found
-
Reddit - Dive into anything: no description found
-
whisper/data at main · openai/whisper: Robust Speech Recognition via Large-Scale Weak Supervision - openai/whisper
,
Latent Space ▷ #ai-general-chat (59 messages🔥🔥):
-
Milano AI Event Planning:
@alexio.cannounced an AI Engineer event planned for May/June in Milano and asked for input on making it an Italian chapter of the AI Engineer Summit.@fanahovainitially denied the existence of chapters but later corrected the misunderstanding, while@benghamineand@swyxioconfirmed support for chapters, providing assistance with branding and promotion. -
Data Labeling Tool Discussion:
@420gunnainquired about leaders in data labeling tools mentioning tools like SAM and Label Studio.@swyxiomentioned Roboflow for vision and linked to Human Signal's Adala and interviews with Voxel51 and Nomic for insights into data labeling startups. -
AI News Service and Feedback:
@swyxioshared a daily discord recap via AI News, with@coffeebean6887suggesting improvements in navigation and readability due to the long format of the email. -
Research on AI Defense Mechanisms Highlighted:
@swyxiopointed out various research initiatives like data poisoning project Nightshade, with links to interviews and discussions on their impact and usefulness. -
Resources to Learn AI:
- For cloud GPU platforms to use for finetuning and deploying Mixtral,
@shivdinhoreceived recommendations like Modal and Replicate from@fanahovaand others in the chat. @swyxioshared a video tutorial and a direct example page for reverse engineering and AI work.- A new blog post by Karpathy, discussing the impact of generative AI on employment and adaptability, was shared by
@swyxiowithout a specific link.
- For cloud GPU platforms to use for finetuning and deploying Mixtral,
Please note: The HTML markup style, clickable links, and direct quotes were not included due to the constraints of this example.
Links mentioned:
-
Step Saga Examples: no description found
-
step by step: no description found
-
Tweet from Mahesh Sathiamoorthy (@madiator): In case you thought Perplexity's journey was straightforward and linear.
-
Our Vision for the Future of Reliable Labeling Agents | HumanSignal: The most flexible, secure and scalable data annotation tool for machine learning & AI—supports all data types, formats, ML backends & storage providers.
-
NeurIPS 2023 Recap - AI Startups: Listen now | Mosaic/Databricks, Fireworks, Cursor, Perplexity, Metaphor, Answer.ai, Cerebras, Voxel51, Lightning, Cohere
-
@clem on Hugging Face: "Re-posting @karpathy's blogpost here because it's down on…": no description found
-
Fine-Tune Mixtral 8x7B (Mistral's Mixture of Experts MoE) Model - Walkthrough Guide: Hi! Harper Carroll from Brev.dev here. In this tutorial video, I walk you through how to fine-tune Mixtral, Mistral’s 8x7B Mixture of Experts (MoE) model, wh...
-
Axios House at Davos #WEF24: Axios' Ina Fried in conversation with Open AI's Sam Altman: no description found
-
Nightshade: Data Poisoning to Fight Generative AI with Ben Zhao | The TWIML AI Podcast: no description found
-
[AINews] Sama says: GPT-5 soon: We checked 19 guilds, 290 channels, and 4378 messages for you. Estimated reading time saved (at 200wpm): 377 minutes. Sama at Davos: Altman said his top...
-
[AINews] Nightshade poisons AI art... kinda?: Weekend of 1/19-20/2024. We checked 19 guilds, 290 channels, and 7248 messages for you. Estimated reading time saved (at 200wpm): 676 minutes. First teased...
,
DiscoResearch ▷ #disco_judge (2 messages):
- Tweet Discussing Numerical Evaluation's Limits:
@jp1_highlighted an interesting tweet regarding the shortcomings of numerical evaluation and the superiority of classification, referencing the Prometheus paper which noted significant discrimination without a scoring table. - New Paper on Additive Scoring Prompt:
@jp1_discussed the implementation of a self play paper suggesting an additive scoring prompt might outperform absolute scoring like in the Prometheus setup, and shared a snippet of the code on GitHub.
Links mentioned:
self-rewarding-lm-pytorch/self_rewarding_lm_pytorch/self_rewarding_lm_pytorch.py at 1cc1e1d27ff5e120efcd677c1b0691cf3cdd0402 · lucidrains/self-rewarding-lm-pytorch: Implementation of the training framework proposed in Self-Rewarding Language Model, from MetaAI - lucidrains/self-rewarding-lm-pytorch
DiscoResearch ▷ #mixtral_implementation (10 messages🔥):
-
Prompt Template Confusion Cleared:
@eric_73339faced issues with outputs differing between their local model and the demo due to incorrect prompt templates.@sebastian.bodzaclarified the correct template should be<s>[INST] Instruction [/INST]Model answer</s> [INST] Follow-up instruction [/INST]as per thehf tokenizer. -
Right Formatting for DiscoLM Models:
@bjoernpadvised@eric_73339on correct chatML template formatting, suggesting the use of f-strings for proper variable insertion and the addition of newlines after role indicators. -
Demo Site References Shared: In response to
@eric_73339's query about the demo site's model,@bjoernpprovided a link to the DiscoLM German 7b v1 model and advised reviewing the chat templating guide on Hugging Face to avoid issues with chat templates. -
Community Assists with ChatML:
@eric_73339expressed gratitude for the assistance from the community in fixing their templates and improving their understanding of llms (large language models).
Links mentioned:
- DiscoResearch/DiscoLM_German_7b_v1 · Hugging Face: no description found
- Templates for Chat Models: no description found
- DiscoLM German 7b Demo: no description found
DiscoResearch ▷ #general (16 messages🔥):
-
Hugging Face Blogs RLHF Preference Optimization:
@rasdanihighlights a Hugging Face blog that compares Preference Optimization Techniques in RLHF, mentioning methods like Direct Preference Optimization (DPO), Identity Preference Optimisation (IPO), and Kahneman-Tversky Optimisation (KTO). The article suggests a simple binary reward signal (thumbs up/down) might be sufficient for training, which could be exciting like the self-play breakthroughs seen in AlphaZero and OpenAI Five. Read the blog. -
DeepL Credits at Work:
@maxidlshared a Hugging Face dataset potentially useful for training due to its math content, translated with the help of DeepL credits. Discussions with@bjoernpand_jp1_considered the challenges with translation quality and the utility of comparing HuggingFace's dataset translation with DiscoLM German's abilities. -
Llama-3 Predictions Discussion:
@bjoernpshared predictions about the upcoming Llama-3's pretraining, architecture, and finetuning, referencing an advanced context chunking method and a move towards mass multilingualism and complex data handling.@maxidladded the importance of training for more than one epoch, a practice not widely implemented since the Datablations paper. -
On Multiple Epoch Training for German LM: In relation to training for more than one epoch,
@maxidlmentions that their German LM has a dataset of approximately 1T tokens and is planning on doing multiple epochs, subject to compute availability.@rasdaniinquired if anyone had tried this at large scale since Datablations, to which@bjoernpreplied that it is not quite necessary due to the availability of clean original data.
Links mentioned:
- In-Context Pretraining: Language Modeling Beyond Document Boundaries: Large language models (LMs) are currently trained to predict tokens given document prefixes, enabling them to directly perform long-form generation and prompting-style tasks which can be reduced to do...
- Preference Tuning LLMs with Direct Preference Optimization Methods: no description found
- maxidl/MathInstruct-de · Datasets at Hugging Face: no description found
DiscoResearch ▷ #embedding_dev (14 messages🔥):
- Model Pretraining Code Unavailability:
@maxidlexpressed a preference for GTE and BGE model families, but highlighted a lack of good pretraining code, with no pretraining code for GTE and only a toy example available for BGE, unlike the ease of dataset preparation for M2 models. - Perplexity.ai Dataset Curiosity:
@devnull0inquired if there exists a dataset with questions used by Perplexity.ai, noting a tendency to input very short, non-genuine questions. - Jina Model Inference Clarification:
@bjoernpshared a Twitter post suggesting that Jina models should be inferred using mean pooling instead of CLS token embeddings.@sebastian.bodzaconfirmed using the encode function from Jina's Hugging Face repository, which should handle this correctly. - MTEB Scores Indicate Model Capabilities:
@sebastian.bodzadiscussed the performance of different models, indicating that GTE and BGE models performed significantly better than Jina models according to MTEB rankings, especially with GTE showing better results on coding-related tasks. - Model Size and Parameter Comparison:
@sebastian.bodzaresponded to@bjoernp's query about model sizes by comparing BGE-large and GTE-base, noting both have 335 million parameters, and acknowledged the MTEB Leaderboard as a good resource to judge model effectiveness in specific domains.
Links mentioned:
- sentence-transformers/sentence_transformers/SentenceTransformer.py at 93d6335fe6bdada19c111b42e1ba429d834443ff · UKPLab/sentence-transformers: Multilingual Sentence & Image Embeddings with BERT - UKPLab/sentence-transformers
- jinaai/jina-embeddings-v2-base-en · Hugging Face: no description found
DiscoResearch ▷ #discolm_german (11 messages🔥):
- DiscoLM German 7b's underlying technology clarified:
@_jp1_confirmed that DiscoLM German 7b is based on Mistral, and a Mixtral-based version is expected to follow. - No immediate Mixtral for DiscoLM German:
@bjoernpmentioned that the focus is on perfecting the dataset and 7b model; a Mixtral-based DiscoLM German might be a few weeks off. - Medieval Learning with AI:
@thomasrenkertshared plans to train a chatbot using DiscoLM German 7b to help students translate Middle High German and provide background on the medieval period, using data from university libraries and online lexicons. - DiscoLM German 7b exhibits mixed benchmark performance:
@flobulousreported exceptional performance in German for DiscoLM German 7b but found it underwhelming on benchmarks like MMLU and ARC in their translations to English. - Targeted Data for Quality Output:
@thomasrenkerthighlighted the importance of curated datasets, noting that even with Mixtral-instruct's better compliance with instructions, DiscoLM German already delivers high-quality knowledge about the medieval period. ,
LangChain AI ▷ #announcements (1 messages):
- Integrating LangServe with JavaScript Made Easier: User
@jacoblee93shared a Tweet highlighting a new way to more conveniently call LangServe chains from JavaScript frontends. This update aims to streamline interactions between LangServe and JS-based applications.
LangChain AI ▷ #general (34 messages🔥):
- RAG with Langchain:
@zaesarwas looking for assistance using an Open Source model for a RAG with Langchain, expressing difficulty due to the context window limitation of Ollama. - Open Source RAG Models Released:
@maidalunannounced the release of open source EmbeddingModel and RerankerModel for RAG on Hugging Face, providing features like multilingual and bilingual capabilities and adaptations for various domains. EmbeddingModel and its GitHub repo were shared, expecting community feedback. - LangChain Twitter Account Compromised:
@rez0indicated a security issue with the LangChain Twitter account, which was confirmed by.bagatur, stating that the account had been locked and warning not to click any links in the account bio until they regain control.@ashkazatreported being blocked by the hacker. - Langchain Adds Bible Commentary: Users discussed creating a Langchain application to study the Bible.
@ilguapposhared his project where he incorporated a vector database of Patristic era church writings to make the AI respond like a priest, and suggested embedding Bible commentaries for Bible study, sharing his work-in-progress project on GitHub. - New Langchain Release and Prompt Engineering Guide:
_shoya0announced the new Langchain release v0.1.2, and@tim9422shared a guide on prompt engineering for open LLMs hoping it would help build better applications.
Links mentioned:
- Prompt Engineering Guide for Open LLM: Take your Open LLM application to the next level: Introduction: Why do we need another guide?
- maidalun1020/bce-reranker-base_v1 · Hugging Face: no description found
- GitHub - anaxios/langchainjs-workers: Contribute to anaxios/langchainjs-workers development by creating an account on GitHub.
- Release v0.1.2 · langchain-ai/langchain: What's Changed support for function calling on VertexAI by @lkuligin in #15822 docs: updated Anyscale page by @leo-gan in #16107 mistralai[minor]: Add embeddings by @DavidLMS in #15282 Community[...
LangChain AI ▷ #langserve (1 messages):
- Write-Ahead Log Complications: User
@veryboldbagelmentioned the presence of a write-ahead log that complicates the process of knowing when feedback gets written. They inquired about the necessity to mutate feedback.
LangChain AI ▷ #share-your-work (8 messages🔥):
-
Multilingual Reranking Models for RAG unleashed:
@maidalunannounced the release of Open Source EmbeddingModel and RerankerModel, designed to bolster the Retrieval-Augmented Generation (RAG) framework. The models support multiple languages, including English, Chinese, Japanese, and Korean, and are fine-tuned for various domains such as education, law, finance, medical, literature, etc. Find specifics at Hugging Face and the project GitHub page. -
Prompt Engineering Guide For Open LLM: User
@tim9422shared a Medium post guiding the development of applications on Open LLM. The guide addresses the differences between open-source and closed-source language models and offers strategies for prompt engineering with Open LLMs. -
Drag-n-Drop API Integration with Agent IX:
@robot3yesintroduced a new feature for Agent IX which integrates OpenAPI spec and JSON Schema. Users can now directly drag-and-drop schemas and API actions into workflows, streamlining the agent's API interaction and function call processes. Detailed demonstration available on YouTube. -
BPEL/ESB Comparison for OpenAPI Spec: In response to
@robot3yes' sharing of the OpenAPI spec integration for Agent IX,@dwb7737inquired about the comparison to ComfyUI's implementation for Stable Diffusion and if the solution has similarities to older BPEL/ESB solutions—leading to a brief discussion on backend implementations. -
Multi-modal AI Art Analysis with LangChain and Vision Models:
@dwb7737experimented with LangChain and various vision models to analyze artwork created using Stable Diffusion. They shared thorough image summaries from OpenAI Vision and VertexAI Vision, noting that OpenAI Vision performed the best. Gist links for the summaries: VertexAI Vision Gist and OpenAI Vision Gist.
Links mentioned:
- Prompt Engineering Guide for Open LLM: Take your Open LLM application to the next level: Introduction: Why do we need another guide?
- Image posted by dwb536: no description found
- Agent IX - OpenAPI action drag n drop: Quick demo creating an agent that connects to the Agent IX API by dragging an API action into a flow and connecting it as an agent tool.Full release notes:ht...
- maidalun1020/bce-reranker-base_v1 · Hugging Face: no description found
- Vertex AI Models - Image Summarization: Vertex AI Models - Image Summarization. GitHub Gist: instantly share code, notes, and snippets.
- OpenAI models - Image Summarization: OpenAI models - Image Summarization. GitHub Gist: instantly share code, notes, and snippets.
- Ollama models - Image Summarization: Ollama models - Image Summarization. GitHub Gist: instantly share code, notes, and snippets.
LangChain AI ▷ #tutorials (2 messages):
-
Exploring LLM System 2 Thinking:
@jasonzhou1993shared a YouTube video that discusses System 2 thinking in large language models (LLMs), questioning how GPT-5 could potentially tackle the problem and offering insights on unlocking more advanced LLM thinking. -
Custom Tool Creation for Note Storage with crewAI:
@business24.aiposted a tutorial video about creating a custom tool in crewAI to store search results as notes in Obsidian, utilizing OpenAI's ChatGPT models.
Links mentioned:
-
Use crewAI and add a custom tool to store notes in Obsidian: In this Tutorial, we create a custom tool for crewAI to add search results as a note in Obsidian. We use it with OpenAI ChatGPT 4 and ChatGPT 3 and Multiple ...
-
GPT5 unlocks LLM System 2 Thinking?: Human think fast & slow, but how about LLM? How would GPT5 resolve this?101 guide on how to unlock your LLM system 2 thinking to tackle bigger problems🔗 Lin...
,
OpenAccess AI Collective (axolotl) ▷ #general (11 messages🔥):
- Prompt Engineering Guide for Open LLM Application:
@tim9422shared a prompt engineering guide focused on open-source Language Model Models (Open LLMs) sized 3 to 70 billion parameters. They stress that Open LLMs are different from the closed-source models. - A30 GPU Puzzle:
@le_messinquired about the performance of the A30 GPU for training LLMs, noting a lack of available information regarding its effectiveness. - Dependency Troubles with Fast Eval:
@dangfuturesfaced dependency issues when trying to get fast eval to work and sought assistance from other users. - Cost of Running MT-bench Highlighted:
@noobmaster29posted a link to a tweet by @abacaj expressing surprise at the high cost associated with running MT-bench. - Availability and Technical Hiccups with H100 GPUs:
@dangfuturesmentioned finding 10 H100 GPUs available on vastAI but then followed up noting an issue with CUDA.
Links mentioned:
- Prompt Engineering Guide for Open LLM: Take your Open LLM application to the next level: Introduction: Why do we need another guide?
- Tweet from anton (@abacaj): Damn someone should of told me running MT-bench is this expensive
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (25 messages🔥):
-
Enhancing Dataset Flexibility:
@gahdnahproposed a PR for adding a new loader function and strategy tosharegpt.py, facilitating different key names in datasets. They provided a YAML config template showing how the original JSON structure can be transformed to match the expected format for axolotl'ssharegptimplementation. -
Nanotron for 3D-Parallelism Training:
@caseus_shared a link to GitHub - huggingface/nanotron, which offers a minimalist approach to large language model 3D-parallelism training. -
Improved Access with Latitude SSH Key Support:
@dctannerthanked a user for adding latitude SSH key support and requested an updatedwinglian/axolotl-cloudimage that includes the latest SSH_KEY fix as seen in this commit. -
Dataset Convergence Debate:
@dctannerengaged in a discourse with@gahdnahregarding the handling of dataset variations, suggesting the combined use of their approaches in a new dataset type called 'messageslist'. A relevant discourse can be found in their Hugging Face post and an earlier PR concerning the topic is mentioned here. -
Troubleshooting Axolotl-Cloud with SSH:
@dctannerand@caseus_worked through issues with SSH on theaxolotl-cloudimage hosted on Latitude, which need the PUBLIC_KEY environment variable and the right docker image cache to function correctly.@dctannerwas eventually successful in SSH access by manually setting the environment variable and exposing port 22 through the Latitude UI.
Links mentioned:
- @dctanner on Hugging Face: "As the amount of datasets for fine tuning chat models has grown, there's been…": no description found
- GitHub - huggingface/nanotron: Minimalistic large language model 3D-parallelism training: Minimalistic large language model 3D-parallelism training - GitHub - huggingface/nanotron: Minimalistic large language model 3D-parallelism training
- fix check for env var (#1151) · OpenAccess-AI-Collective/axolotl@cbecf3e: no description found
OpenAccess AI Collective (axolotl) ▷ #general-help (2 messages):
- Curiosity About LoRA Alpha Values:
@noobmaster29mentioned seeing discussions about changing alpha after training and inquired whether it's possible to merge a LoRA at a different alpha value, wondering about its effects. - Dataset Dilemma in DPO:
@matanvetzleris facing aValueErrorwhen trying to runDPOwith the newdpo-cleanupPR, despite having a proper dataset structure including features like 'question', 'chosen', and 'rejected', and saving it correctly to disk. They provided their dataset structure and configuration details, querying what might have gone wrong.
OpenAccess AI Collective (axolotl) ▷ #datasets (2 messages):
-
Prompt Design Revealed:
@gahdnahhighlighted distinctions between two types of AlpacaPrompter classes:MultipleChoiceExplainPrompterfocuses on explaining reasoning behind chosen answers, whereasMultipleChoiceConcisePrompteremphasizes conciseness. -
Appreciation for Clarity:
@noobmaster29responded with a simple "thx" indicating gratitude or acknowledgment of@gahdnah's clarification regarding the prompt differences.
OpenAccess AI Collective (axolotl) ▷ #rlhf (2 messages):
-
dpo-cleanup Branch Suggestion:
@filippob82recommended checking out thedpo-cleanupbranch without elaborating on the context or reason for the suggestion. -
Dataset Structure Guidance for DPO:
@dangfuturesis seeking advice on how to structure a dataset for DPO in JSONL format, providing a template with fields for "system," "instruction," "input," "accepted," and "rejected". ,
LlamaIndex Discord ▷ #blog (3 messages):
-
Introducing JSONalyze for Data Analysis: JSONalyze, a query engine by LlamaIndex, simplifies the process of analyzing large JSON datasets from API responses by creating an in-memory SQLite table. It allows for running SQL queries on JSON data, as explained through a provided sample code snippet for installing and using the
llama-indexlibrary. -
Crafting ReAct Agents from Ground Up: LlamaIndex shares insights on building ReAct Agents from scratch, covering the fundamentals like reasoning prompts, output parsing, tool selection, and memory integration. The post aims to deepen understanding by guiding users through the foundational steps of agent creation outside of existing frameworks.
Links mentioned:
JSONalyze Query Engine - LlamaIndex 🦙 0.9.36: no description found
LlamaIndex Discord ▷ #general (25 messages🔥):
- Confusion over
LlamaCPPUsage: User@wrapdepolloasked for clarification on the difference betweenmessages_to_promptandcompletion_to_prompt. They've been usingqa_prompt_tmpl_strfor prompt engineering and queried about not having touched theDEFAULT_SYSTEM_PROMPTconstant. - Open Source EmbeddingModel and RerankerModel Releases:
@maidalunshared links to their open-sourced EmbeddingModel and RerankerModel for RAG on Hugging Face, inviting feedback. They boast features like multilingual and crosslingual capability, and RAG optimization for various domains. EmbeddingModel on Hugging Face - NL2sql and RAG Integration: For combining NL2sql and vector search,
@Teemusuggested using SQLJoinQueryEngine of LlamaIndex. A different link was provided for NL2sql exclusive use: SQLIndexDemo of LlamaIndex. - Prompt Engineering and Open LLMs:
@tim9422shared a Medium article discussing the nuances of prompt engineering for open-source Language Models.@jerryjliu0expressed appreciation for the article. - Cloud Deployment and AWS Credentials for Bedrock:
- User
@mysterious_avocado_98353sought advice on setting up Bedrock context in the cloud due to issues with theprofile_nameattribute required by LlamaIndex's Bedrock class. - They later reported about setting environmental variables for keys but still faced config issues for the profile name.
- User
- Implementation of Static Chat Engine:
@kornberginquired about maintaining a static chat engine and dynamically replacingchat_history.- User
@cheesyfishesclarified thatchat_historyis read-only and should be passed during function calls with.chat(msg, chat_history=chat_history).
Links mentioned:
- Prompt Engineering Guide for Open LLM: Take your Open LLM application to the next level: Introduction: Why do we need another guide?
- Tim Bradshaw – Medium: Read writing from Tim Bradshaw on Medium. Global tech correspondent @FinancialTimes in London. Views = mine, not FT's. [email protected]. Every day, Tim Bradshaw and thousands of other voices r...
- maidalun1020/bce-reranker-base_v1 · Hugging Face: no description found
- SQL Join Query Engine - LlamaIndex 🦙 0.9.36: no description found
- Text-to-SQL Guide (Query Engine + Retriever) - LlamaIndex 🦙 0.9.36: no description found
LlamaIndex Discord ▷ #ai-discussion (1 messages):
- Diving into Advanced RAG Techniques: User
@andysingalshared a Medium post detailing a collaboration between LlamaIndex and Together.ai's Long Text Embedding to enhance information retrieval. This partnership promises a world where information is not only easily accessible but also intelligently organized and integrated.
Links mentioned:
Advanced RAG with LlamaIndex & Together.ai’s Embedding: Ankush k Singal
,
Skunkworks AI ▷ #general (18 messages🔥):
- Token Monster and Model Training Queries:
@indietechieinquired about experiences with using Token Monster for tokenizer training in conjunction with Mistral/Llama.@stereoplegicclarified that Token Monster can replace Hugging Face (HF) tokenizers entirely and utilizes a LLaMa vocabulary. - Self-rewarding Model Implementation Buzz:
.interstellarninjashared links to a self-rewarding language model implementation by@Geronimo_AIon GitHub and the related Meta paper page on Hugging Face, which had been experimented with by@yikesawjeezin the basementagi lab. - Insights on Token Recursion and Numerical Encoding:
@stereoplegicinitiated a discussion on token recursion and represented a concept of "numcode" tokens for better mathematical comprehension, also speculating on mapping existing vocabularies to this system. However, they also noted a separate implementation using single-digit tokens that reduced textual generalization. - Lucid Rains Implements Self-Rewarding Framework:
@tekniumpointed out that Lucid Rains has created an implementation of a self-rewarding language model in PyTorch, available on GitHub.@yikesawjeezhighlighted the quick response time of the developer to new concepts. - Exploring Low-Compute Training Strategies:
@yikesawjeezand@.mrfoofound it interesting that an implementation using adapters and Lora's was put forward due to low compute availability, suggesting that such an approach could be a practical alternative for resource-constrained environments.
Links mentioned:
-
Tweet from Geronimo (@Geronimo_AI): self-reward implementation https://github.com/lucidrains/self-rewarding-lm-pytorch ↘️ Quoting AK (@_akhaliq) Meta presents Self-Rewarding Language Models paper page: https://huggingface.co/papers/...
-
GitHub - lucidrains/self-rewarding-lm-pytorch: Implementation of the training framework proposed in Self-Rewarding Language Model, from MetaAI: Implementation of the training framework proposed in Self-Rewarding Language Model, from MetaAI - GitHub - lucidrains/self-rewarding-lm-pytorch: Implementation of the training framework proposed in...
,
LLM Perf Enthusiasts AI ▷ #embeddings (1 messages):
- Query on 8-bit Quantized Embedding Models: User
@robhaisfieldinquired about experiences with 8-bit quantized embedding models and is seeking insights on how their performance compares to regular embedding models. No responses or further discussion followed.
LLM Perf Enthusiasts AI ▷ #feedback-meta (2 messages):
- Channel for Sharing AI Experiments: User
@degtrdgproposed creating a share channel for users to post and discuss their AI experiments in one dedicated place. This idea gained support, as exemplified by@thebaghdaddywho replied with enthusiasm, calling the idea "sick". ,
Alignment Lab AI ▷ #general-chat (1 messages):
indietechie: Anyone with experience using token monster for training a tokenizer?
Alignment Lab AI ▷ #oo (1 messages):
bumingqiu: I have
YAIG (a16z Infra) ▷ #ai-ml (1 messages):
- Regulatory Evasion via Contracts: User
@unquiet9796mentioned that larger organizations often negotiate terms into their contracts that minimize regulatory costs, suggesting this as a strategy to get regulators off their backs.