UPDATE FOR YESTERDAY: sorry for the blank email - someone posted a naughty link in the langchain discord that caused the buttondown rendering process to error out. We've fixed it so you can see yesterday's Google Gemini recap here.
Gemini Pro has woken everyone up to the benefits of long context. The CUDA MODE Discord has started a project to implement the RingAttention paper (Liu, Zaharia, Abbeel, and extended with the World Model RingAttention paper)
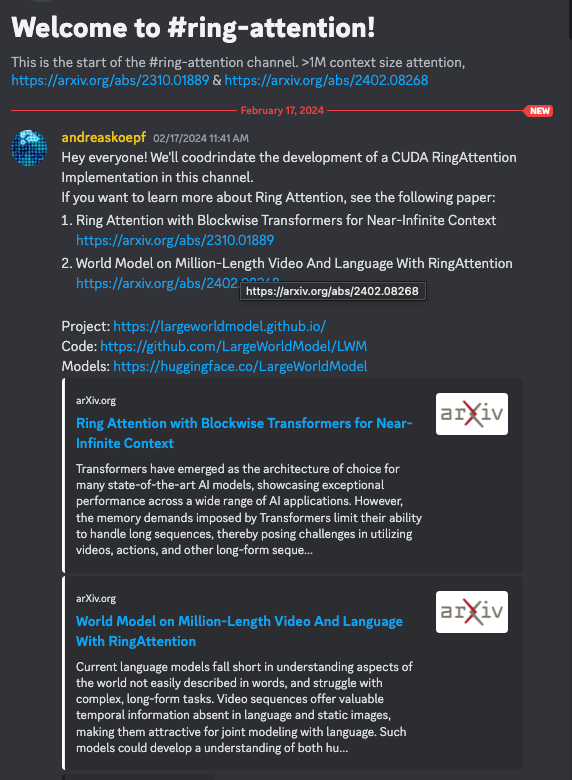
The paper of course came with a pytorch impl and lucidrains also has a take. But you can see the CUDA impl here: https://github.com/cuda-mode/ring-attention
Table of Contents
[TOC]
PART 1: High level Discord summaries
TheBloke Discord Summary
LLM Guessing Game Evaluation: Experiments with language models demonstrated their potential in understanding instructions, specifically for interactive guessing games where accurate number selection and user engagement are key.
UX Battleground: Chatbots: A heated debate around chatbot interfaces juxtaposed the cumbersome Nvidia's Chat with RTX against the nimble Polymind, underscoring the importance of user-friendly configurations.
RAG's Rigorous Implementation Road: Retrieval and generation feature integration sparked discussion, with attention on the complexity of incorporating such features cleanly and effectively into projects.
Discord Bots CSS Woes: Frustration was aired over CSS challenges when customizing Discord bots, highlighting the struggle for seamless integration between UI design and bot functionality.
VRAM: The Unseen Compute Currency: With an iron focus on resource optimization, the discourse centered on harmonizing VRAM capacity with model demands, emphasizing the balance between performance and computational overhead.
Character Roleplay Fine-tuning Finesse: Users like @superking__ and @netrve shared insights into the art of fine-tuning AI for character roleplay, with strategies revolving around comprehensive base knowledge and targeted training through Dynamic Prompt Optimization (DPO).
AI Story and Role-Play Enthusiasm: The release of new models targeted at story-writing and role-playing, trained on human-generated content for improved, steerable interactions in ChatML, has sparked keen interest for real-world testing.
Code Classification Conundrum: A quest for the ideal LLM to classify code relevance within a RAG pipeline led to the contemplation of deepseek-coder-6.7B-instruct, as community members seek further guidance.
Mistral Model Download Drought: An unelaborated request for local Mistral accessibility surfaces, but with too little information for constructive community support.
Workflow Woes on Mac Studio: The ML workflow struggle on Mac Studio was articulated, including a potential switch from ollama to llama.cpp, praising its simplicity and questioning the industry's push towards ollama.
VSCode Dethroned by Zed: Users like @dirtytigerx promote Zed as superior to Visual Studio Code, highlighting its minimal design and speed. An opening for Pulsar, an Atom-based text editor now open-sourced, is perceived with interest.
Scaling Inference with Tactical GPU Deployment: Cost-effective approaches to scaling inference servers are discussed, suggesting initial prototyping with affordable GPUs like the 4090 on runpod before full-scale deployment, mindful of the dependability of service agreements with cloud providers.
LM Studio Discord Summary
-
LM Studio Updates Demand Manual Attention: Users must manually download the latest features and bug fixes from LM Studio v0.2.16 as the in-app update feature is currently non-functional. The updates include Gemma model support, improved download management, and UI enhancements, with critical bugs addressed in v0.2.16, especially for MacOS users experiencing high CPU usage.
-
Community Tackles Gemma Glitches: Ongoing discussions reveal the Gemma 7B model has been problematic, with performance issues and errors; however, the Gemma 2B model received positive feedback. The Gemma 7B on M1 Macs showed improvements after GPU slider adjustments. A working Gemma 2B model is available on Hugging Face.
-
Stable Diffusion 3 Sparks Interest: Stability.ai announced the early preview of Stable Diffusion 3, sparking discussions among users interested in its improved multi-subject image quality. Enthusiasts consider signing up for the preview and discuss web UI tools like AUTOMATIC1111 for image manipulation tasks separate from LM Studio's focus.
-
Hardware Hurdles for Large Models Explored: The community delves into the challenges of running large models like Goliath 120B Q6, exchanging insights on the viability of older GPUs like the Tesla P40, and debating the balance between VRAM capacity and GPU performance for AI tasks.
-
Gemma Model Troubleshooting Continues: Users experience mixed success with different quantizations of Gemma, with the 7B model frequently producing gibberish, while the 2B model performs more reliably. LM Studio downloads have faced critical issues, with suggestions to resolve them on LM Studio's website and GitHub. A stable quantized Gemma 2B model confirmed for LM Studio can be found at this Hugging Face link.
Nous Research AI Discord Summary
Scaling LLMs to New Heights: @gabriel_syme highlighted a repository focused on data engineering for scaling language models to 128K context, a significant advancement in the field. The VRAM requirements for such models at 7B scale exceed 600GB, a substantial demand for resources as noted by @teknium.
Google Enters the LLM Arena: Google introduced Gemma, a series of lightweight, open-source models, with enthusiastic coverage from @sundarpichai and mixed community feedback comparing Gemma with existing models like Mistral and LLaMA. Users @big_ol_tender and @mihai4256 engaged in various discussions, from the impact of instruction placement to VM performance across different services.
Open Source Development and Support: @pradeep1148 shared a video suggesting self-reflection could improve RAG models, and @blackblize sought guidance on using AI for artistic image generation with microscope photos. Meanwhile, @afterhoursbilly and @_3sphere critiqued AI-generated imagery of Minecraft's inventory UI.
Emerging AI Infrastructure Discussions: Conversations on Nous-Hermes-2-Mistral-7B-DPO-GGUF reflected queries about its comparison to other models, and @iamcoming5084 talked about out-of-memory errors with Mixtral 8x7b models. Strategies for hosting large models like Mixtral 8x7b were also examined, with users debating over different tools and pointing out errors in inference codes (corrected inference code for Nous-Hermes-2-Mistral-7B-DPO).
Collaborative Project Challenges: In #project-obsidian, @qnguyen3 notified of project delays due to personal circumstances and suggested direct messaging for coordination on the project front.
Eleuther Discord Summary
-
Clarifying Model Evaluation and lm eval Confusion:
@lee0099's confusion overlm evalbeing set for runpod led to@hailey_schoelkopfclarifying the difference between lm eval and llm-autoeval, referencing the Open LLM Leaderboard’s HF spaces page for instructions and parameters. No clear consensus was formed on@gaindrew's proposal for ranking models by net carbon emissions due to the challenge in accuracy. -
Gemma's Growing Pains and Technical Teething: The introduction of Google's Gemma by
@sundarpichaistirred debates on its improvement over models like Mistral. Parameter count misrepresentation in Gemma models ("gemma-7b" actually with 8.5 billion parameters) was highlighted. Groq claims 4x throughput on Mistral Mixtral 8x7b model with a substantial cost reduction. Concerns about the environmental footprint of models and@philpax’s report on Groq's claims were discussed alongside researchers delving into model efficiency and PGI's use in addressing data loss. -
Navigating Through Multilingual Model Mysteries: A Twitter post and companion GitHub repository spurred a debate on whether models “think in English” and the utility of a tuned lens on models like Llama.
@mrgonao's discussion on multilingual capabilities led to a consideration of creating a Chinese lens. -
Technical Deep Dive in LM Thunderdome: Amidst a myriad of memory issues,
@pminervinifaced persistent GPU memory occupation post-OOM error in Colab, requiring a runtime restart, with the problem reproduced in Colab’s Evaluate OOM Issue environment. Problems were also reported with evaluating the Gemma-7b model, requiring intervention from@hailey_schoelkopfwho provided a fix approach and optimization tips usingflash_attention_2. -
Tackling False Negatives and Advancing CLIP: In multimodal conversations,
@tz6352and@_.hrafn._discussed the in-batch false negative issue within the CLIP model, elaborating on solutions involving unimodal embeddings and the strategy for negative exclusion by utilizing similarity scores during model training. -
The Importance of Pre-training Sequence Composition: Only one message was recorded from
@pminerviniin the gpt-neox-dev channel, which shared an arXiv paper stating the benefits of intra-document causal masking to eliminate distracting content from previous documents, potentially improving language model performance across various tasks.
LAION Discord Summary
-
Google Unveils Gemma Model, Steers Towards Open AI: Google has introduced Gemma, representing a step forward from its Gemini models and suggesting a shift towards more open AI development. There is community interest in Google's motivations behind releasing actual open-sourced weights, given their traditional reluctance to do so.
-
Stable Diffusion 3 Interests and Concerns: The early preview of Stable Diffusion 3 has been announced, focusing on improved multi-subject prompt handling and image quality, but its differentiation from earlier versions is under scrutiny. Questions have also arisen regarding the commercial utilization of SD3 and whether open-sourcing serves more as a publicity tactic than a revenue strategy.
-
AI Sector Centralization Raises Eyebrows: Discussions reflect growing concerns over the centralization of AI development and resources, such as Stable Diffusion 3 being less open, which potentially moves computing power out of reach for end-users.
-
Diffusion Models as Neural Network Creators: An Arxiv paper shares insights on how diffusion models can be used to generate efficient neural network parameters, indicating a fresh and possibly transformative method for crafting new models.
-
AnyGPT: The Dawn of a Unified Multimodal LLM: The introduction of AnyGPT, with demo available on YouTube, spotlighted the capability of Language Learning Models (LLMs) to process diverse data types such as speech, text, images, and music.
Mistral Discord Summary
-
Mistral's Image Text Extraction Capabilities Scrutinized: Mistral AI is questioned on its ability to retrieve text from complex images. gpt4-vision, gemini-vision, and blip2 were recommended over simpler tools like copyfish and google lens for tasks requiring higher flexibility.
-
Mistral API and Fine-tuning Explored: Users exchanged information on various Mistral models including guidance for the Mistral API, fine-tuning Mistral 7B and Mistral 8x7b models, and deploying models on platforms like Hugging Face and Vertex AI. The Basic RAG guide was cited for integrating company data (Basic RAG | Mistral AI).
-
Deployment Discussions Highlight Concerns and Cost Assessment: Queries about AWS hosting costs and proper GPU selection for vLLM sparked discussions on deployment options. Documentation was referenced for deploying vLLM (vLLM | Mistral AI).
-
Anticipation for Unreleased Mistral Next: Mistral-Next has been confirmed as an upcoming model with no API access at present, while Mistral Next's superb math performance drew comparisons with GPT-4. Details are anticipated but not yet released.
-
Showcasing Mistral's Versatility and Potential: A YouTube video showcased enhancing RAG with self-reflection (Self RAG using LangGraph), while another discussed fine-tuning benefits (BitDelta: Your Fine-Tune May Only Be Worth One Bit). Jay9265's test of Mistral-Next on Twitch (Twitch) and prompting capabilities guidance (Prompting Capabilities | Mistral AI) were also featured to highlight Mistral's capabilities and uses.
OpenAI Discord Summary
-
Google's AI Continues to Evolve: Google has unveiled a new model with updated features; however, details regarding its name and capabilities were not fully specified. In relation to OpenAI, ChatGPT's mobile version lacks plugin support, as confirmed in the discussions, leading users to try the desktop version on mobile browsers for a full feature set.
-
OpenAI Defines GPT-4 Access Limits: Debates occurred regarding GPT-4's usage cap, with members clarifying that the cap is dynamically adjusted based on demand and compute availability. Evidently, there is no reduction in GPT-4's model performance since its launch, putting to rest any circulating rumors about its purported diminishing power.
-
Stability and Diversity in AI Models: Stability.ai made news with their early preview of Stable Diffusion 3, promising enhancements in image quality and prompt handling, while discussions around Google's Gemini model raised questions about its approach to diversity.
-
Prompt Engineering Mastery: For AI engineers aiming to improve their AI's roleplaying capabilities, the key is crafting prompts with clear, specific, and logically consistent instructions, using open variables and a positive reinforcement approach. Resources for further learning in this domain can be found on platforms like arXiv and Hugging Face.
-
Navigating API and Model Capabilities: API interactions operate on a pay-as-you-go basis, separate from any Plus subscriptions, and there's a newly increased file upload limit of twenty 512MB files. Discussions also touched on the nuances of training models with HTML/CSS files, aiding engineers to refine GPT's understanding and output of web development languages.
HuggingFace Discord Summary
-
404 Account Mystery and Diffusion Model Deep Dive: Users reported various issues with HuggingFace such as an account yielding a 404 error, potentially due to inflating library statistics, and challenges configuring the
huggingface-vscodeextension on NixOS. Additionally, deep discussions on diffusion models like SDXL using Fourier transform for enhancing microconditioning inputs were shared, with interests also in interlingua-based translators for university projects and running the BART-large-mnli model with expanded classes. -
Engineering AI's Practicalities:
- A user shared a web app for managing investment portfolios, accompanied by a Kaggle Notebook.
- A multi-label image classification tutorial notebook using SigLIP was introduced.
- TensorFlow issue resolved by reinstalling with
version 2.15. - Sentence similarity challenges in biomedicine were addressed, with contrastive learning and tools like sentence transformers and setfit recommended for fine-tuning.
-
Challenging AI Paradigms:
- A problem with PEFT not saving the correct heads for models without auto configuration was discussed, and a new approach using the Reformer architecture for memory-efficient models on edge devices was cited.
- Discussions around model benchmarking efforts included a shared leaderboard and repository link, inviting contributions and insights.
-
Emerging AI Technologies Alerted:
- An Android app for monocular depth estimation and an unofficial ChatGPT API using Selenium were presented, raising TOS and protection evasion concerns.
- Announcements included Stable Diffusion 3's early preview and excitement for nanotron going open-source on GitHub, signifying continuous improvement and community efforts in the AI space.
Latent Space Discord Summary
-
Google Unveils Gemma Language Models: Google introduced a new family of language models named Gemma, with sizes 7B and 2B now available on Hugging Face. The terms of release were shared, highlighting restrictions on distributing model derivatives (Hugging Face blog post, Terms of release).
-
Deciphering Tokenizer Differences: An in-depth analysis comparing Gemma’s tokenizer to Llama 2's tokenizer was conducted, revealing Gemma's larger vocabulary and special tokens. This analysis was supported by links to the tokenizer's model files and a diffchecker comparison (tokenizer's model file, diffchecker comparison).
-
Stable Diffusion 3 Hits the Scene: Stability AI announced Stable Diffusion 3 in an early preview, improving upon prior versions with better performance in multi-subject prompts and image quality (Stability AI announcement).
-
ChatGPT's Odd Behavior Corrected: An incident of unusual behavior by ChatGPT was reported and then resolved, as indicated on the OpenAI status page. Members shared links to tweets and the incident report for context (OpenAI status page).
-
Exploring AI-Powered Productivity: Conversations revolved around the integration of Google's Gemini AI into Workspace and Google One services, discussing its new features such as the 1,000,000 token context size and video input capabilities (Google One Gemini AI, Google Workspace Gemini).
LlamaIndex Discord Summary
-
Simplifying RAG Construction:
@IFTTTdiscussed the complexities of building advanced RAG systems and suggested a streamlined approach using a method from @jerryjliu0’s presentation that pinpoints pain points in each pipeline component. -
RAG Frontend Creation Made Easy: For LLM/RAG experts lacking React knowledge, Marco Bertelli's tutorial, endorsed by
@IFTTT, demonstrates how to craft an appealing frontend for their RAG backend, with resources available from @llama_index. -
Elevating RAG Notebooks to Applications:
@wenqi_glantzprovides a guide for transforming RAG notebooks into full-stack applications featuring ingestion and inference microservices, shared in a tweet by@IFTTT, with the full tutorial accessible here. -
QueryPipeline Setup and Import Errors in LlamaIndex: Issues such as setting up a simple RAG using QueryPipeline, difficulties importing
VectorStoreIndexfromllama_index, and importingLangchainEmbeddingwere discussed, with the QueryPipeline documentation and suggestions to import fromllama_index.coresuggested as potential fixes. -
LlamaIndex Resource Troubleshooting: Topics covered the
ValueErrorwhen downloading CorrectiveRAGPack, for which a related PR #11272 might offer a solution, and broken documentation links affecting users like@andaldanawho sought updated methods or readers within LlamaIndex for processing data from SQL database entries. -
Engagement and Inquiries in AI Discussion:
@behanzin777showed appreciation for suggested solutions in the community,@dadabit.sought recommendations on summarization metrics and tools within LlamaIndex, and@.dheemanthrequested leads on a user-friendly platform to evaluate LLMs with capabilities akin to MT-Bench and MMLU.
OpenAccess AI Collective (axolotl) Discord Summary
-
Google's Gemma Unleashed: Google's new Gemma model family sparks active discussion, with licensing found to be less restrictive than LLaMA 2 and its models now accessible via Hugging Face. A 7B Gemma model was re-uploaded for public use, sidestepping Google's access request protocol. However, finetuning Gemma has presented issues, referencing GitHub for potential early stopping callback problems.
-
Axolotl Development Dives into Gemma: Work is underway on the axolotl codebase, integrating readme, val, and example fixes. Training Gemma models on the non-dev version of transformers was stressed, with an updated gemma config file shared for setup ease. There's debate over appropriate hyperparameters, such as learning rate and weight decay for Gemma models. Ways to optimize Mixtral model are also being explored, promising speed boosts in prefilling and decoding with AutoAWQ.
-
Alpaca Aesthetics Add to Axolotl: A jinja template for alpaca is being sought after to enhance the axolotl repository. Training tips with DeepSpeed and correct inference formatting after finetuning models are in demand, alongside troubleshooting FlashAttention issues. Repeated inquiries prompt calls for better documentation, drawing attention to the necessity of a comprehensive guide.
-
Opus V1 Models Make for Magnetizing Storytelling: Opus V1 models have been unveiled, trained on a substantial corpus for story-writing and role-playing, accessible on Hugging Face. The models benefit from an advanced ChatML prompting mechanics for controlled outputs, with an instructional guide elaborating on steering the narrative.
-
RunPod Resources Require Retrieval: A user faced issues with the disappearance of the RunPod image and the Docker Hub was suggested as a place to look for existing tags. Erroneous redirects in the GitHub readme suggest documentation updates are needed to correctly guide users to the right resources.
CUDA MODE Discord Summary
-
Groq's LPU Outshines Competitors: Groq's Language Processing Unit achieved 241 tokens per second on large language models, a new AI benchmark record. Further insight into Groq's technology can be seen in Andrew Bitar’s presentation "Software Defined Hardware for Dataflow Compute" available on YouTube.
-
NVIDIA Nsight Issues in Docker: Engineers are seeking help with installing NVIDIA Nsight for debugging in Docker containers, with some pointing to similar struggles across cloud providers and one mention of a working solution at lighting.ai studios.
-
New BnB FP4 Repo Promises Speed: A new GitHub repository has been released for bnb fp4 code, reported to be faster than bitsandbytes, but requiring CUDA compute capability >= 8.0 and significant VRAM.
-
torch.compile Scrutinized: torch.compile's limitations are being debated, especially its failure to capture speed enhancements available through Triton/CUDA and its inability to handle dynamic control flow and kernel fusion gains effectively.
-
Gemini 1.5 Discussion Opened: All are invited to join a discussion on Gemini 1.5 through a Discord invite link. Additionally, a video showcasing AI's ability to unlock semantic knowledge from audio files was shared, offering insights into AI learning from audio here.
-
ML Engineer Role at SIXT: SIXT in Munich is hiring an ML Engineer with a focus on NLP and Generative AI. Those interested can apply via the career link.
-
CUDA Endures Amid Groq AI Rise: Discussions around CUDA’s possible obsolescence with Groq AI's emergence led to reaffirmations of CUDA's foundational knowledge being valuable and unaffected by advancing compilers and architectures.
-
TPU Compatibility and GPU Woes with ROCm: Migrating codes to GPU from TPU, facing shape dimension errors, and limited AMD GPU support with ROCm were hot topics. The shared GitHub repo for inference on AMD GPUs lacks a necessary backward function/kernel.
-
Ring-Attention Gathers Collaborative Momentum: The community is actively involved in debugging and enhancing the flash-attention-based ring-attention implementation, with live hacking sessions planned to tackle issues like the necessity of FP32 accumulation. Relevant discussions and code can be found in this repo.
-
House-Keeping for YouTube Recordings: A reminder was issued to maintain channel integrity, requesting users to post content relevant to youtube-recordings only, and redirect unrelated content to the designated suggestions channel.
Perplexity AI Discord Summary
Gemini Unveiled: @brknclock1215 helps dispel confusion around Google’s Gemini model family, sharing resources like a two-month free trial for Gemini Advanced (Ultra 1.0), a private preview for Gemini Pro 1.5, and directing users to a blog post detailing the differences.
Bot Whisperers Wanted: There's a jesting interest in the Perplexity AI bot, with users discussing its offline status and how to use it. For the perplexed about Perplexity's Pro version and billing, users shared a link to the FAQ for clarity.
API Conundrums and Codes: Contributors report discrepancies between Perplexity's API and website content, seeking improved accuracy. Guidance suggests using simpler queries, while an ongoing issue with gibberish responses from the pplx-70b-online model is acknowledged with an outlook towards resolution. Integrating Google's GEMMA with Perplexity's API is also queried.
Cryptocurrency and Health Searches on Spotlight: Curious minds conducted Perplexity AI searches on topics ranging from cryptocurrency trading jargon to natural oral health remedies, highlighting a community engaged in diverse subjects.
Financial Instruments Query: A quest for understanding led to a search query on financial instruments, pointing to a trend where technical specificity is key in discussions revolving around finance.
LangChain AI Discord Summary
-
Dynamic Class Creation Conundrum:
@deltz_81780encountered a ValidationError when attempting to dynamically generate a class for PydanticOutputFunctionsParser and sought assistance with the issue in the general channel. -
AI Education Expansion:
@mjoeldubannounced a LinkedIn Learning course focused on LangChain and LCEL and shared a course link, while a new "Chat with your PDF" LangChain AI tutorial by@a404.ethwas highlighted. -
Support and Discontent: Discussions around langchain support were had, where
@mysterious_avocado_98353expressed disappointment, and@renlo.responded by pointing out paid support options available on the pricing page. -
Error Strikes LangSmith API:
@jacobito15faced an HTTP 422 error from the LangSmith API due to aChannelWritename exceeding 128 characters during batch ingestion trials in the langserve channel. -
Innovation Invitation:
@pk_penguinextended an unnamed trial invitation in share-your-work,@gokusan8896posted about Parallel Function Calls in Any LLM Model on LinkedIn, and@rogesmithbeckoned feedback on a potential aggregate query platform/library.
DiscoResearch Discord Summary
-
Google's Open-Source Gemma Models Spark Language Diversity Queries: @sebastian.bodza brought attention to Google's Gemma models being open-sourced, with an inquiry on language support particularly for German, leading to a discussion on their listings on Kaggle and their instruction version availability on Hugging Face. The conversation also touched on commercial aspects and vocabulary size.
-
Mixed Reactions to Aleph Alpha's Model Updates: Skepticism over updates to Aleph Alpha's models was expressed by @sebastian.bodza, with a lack of instruction tuning highlighted and a follow-up by @devnull0 about recent hiring potentially influencing future model quality. Criticism was leveled at the updates for not including benchmarks or examples as seen in their changelog.
-
Model Performance Scrutinized from Tweets: The efficacy of Gemma and Aleph Alpha's models provoked critical discussions, with posted tweets by @ivanfioravanti and @rohanpaul_ai indicating performance issues with models, particularly in languages like German and when compared to other models like phi-2.
-
Batch Sizes Impact Model Scores: Issues were raised by @calytrix concerning the impact of batch size on model performance, specifically that a batch size other than one could lead to lower scores, as indicated in a discussion on the HuggingFace Open LLM Leaderboard.
-
Model Test Fairness Under Scrutiny: Discussions on fairness in testing models were sparked by @calytrix, who proposed that a fair test should be realistic, unambiguous, devoid of luck, and easily understandable, and asked for a script to regenerate metrics from a specific blog post, delving into the nuances of what could skew fairness in model evaluations.
Skunkworks AI Discord Summary
-
Insider Tips for Neuralink Interviews: A guild member,
@xilo0, is seeking advice for an upcoming interview with Neuralink, specifically on how to approach the "evidence of exceptional ability" question and which projects to highlight to impress Elon Musk's team. -
Exploring the Depths of AI Enhancements:
@pradeep1148shared a series of educational YouTube videos addressing topics such as improving RAG through self-reflection and the questionable value of fine-tuning LLMs, alongside introducing Google's open source model, Gemma. -
Mystery Around KTO Reference: In the papers channel,
nagaraj_arvindcryptically discusses KTO but withholds detail, leaving the context of the discussion incomplete and the significance of KTO to AI Engineers unexplained.
Datasette - LLM (@SimonW) Discord Summary
-
Google's Gemini Pro 1.5 Redefines Boundaries: Google's new Gemini Pro 1.5 offers a 1,000,000 token context size and has innovated further by introducing video input capabilities. Simon W expressed enthusiasm for these features, which set it apart from other models like Claude 2.1 and gpt-4-turbo.
-
Fresh Docs for Google's ML Products: Fresh documentation for Google's machine learning offerings is now accessible at the Google AI Developer Site, though no specific details about the documentation contents were provided.
-
Call for Support with LLM Integration Glitches: In addressing system integration challenges, @simonw recommended that any unresolved issues should be reported to the gpt4all team for assistance.
-
Vision for GPT-Vision: @simonw suggested adding image support for GPT-Vision in response to questions about incorporating file support in large language models (LLMs).
-
Gemma Model Teething Problems: There have been reports of the new Gemma model outputting placeholder text, not the anticipated results, leading to recommendations for updating dependencies via
llm pythoncommand to potentially remediate this.
Alignment Lab AI Discord Summary
- Scoping Out Tokens?: Scopexbt inquired about the existence of a token related to the community, noting an absence of information.
- GLAN Discussion Initiates:
.benxhshared interest in Gradient Layerwise Adaptive-Norms (GLAN) by posting the GLAN paper, prompting positive reactions.
LLM Perf Enthusiasts AI Discord Summary
- Google Unveils Gemma: In the #opensource channel, potrock shared a blog post announcing Google's new Gemma open models initiative.
- Contrastive Approach Gets a Nod: In the #embeddings channel, a user voiced support for ContrastiveLoss, emphasizing its efficacy in tuning embeddings and noted MultipleNegativesRankingLoss as another go-to loss function.
- Beware of Salesforce Implementations: In the #general channel, res6969 warned against adopting Salesforce, suggesting it could be a disastrous choice for organizations.
AI Engineer Foundation Discord Summary
- Talk Techie to Me: Gemini 1.5 Awaits!:
@shashank.f1extends an invitation for a live discussion on Gemini 1.5, shedding light on previous sessions, including talks on the A-JEPA AI model for extracting semantic knowledge from audio. Previous insights available on YouTube. - Weekend Workshop Wonders:
@yikesawjeezcontemplates shifting their planned event to a weekend, aiming for better engagement opportunities and potential sponsorship collaborations, which might include a connection with@llamaindexon Twitter and a Devpost page setup.
PART 2: Detailed by-Channel summaries and links
TheBloke ▷ #general (1132 messages🔥🔥🔥):
-
Exploring LLM Game Dynamics: Users experimented with language models to evaluate their ability to interpret instructions accurately, specifically within the context of guessing games where models were expected to choose a number and interact based on user guesses.
-
Chatbot User Experience Discussions: There were comparisons between different chatbot UIs, with a focus on their ease of setup and usage. The conversation included pointed criticisms towards Nvidia's Chat with RTX and appreciation for smaller, more efficient setups like Polymind.
-
Function Calling Challenges and RAG Implementations: Discussions included the complexity of implementing Retrieve and Generate (RAG) functionalities and custom implementations by users, with critiques on existing implementations' complexity and praise for more streamlined versions.
-
Discord Bots and CSS Troubles: Users shared frustrations with CSS implementation difficulties and talked about customizing Discord bots for better user interaction and task handling.
-
Optimizations and Model Preferences: Hardware constraints and optimizations were a significant topic, with users advising on suitable models for various hardware setups. The conversation highlighted the importance of VRAM and the balance between performance and model complexity.
Links mentioned:
- Tweet from Alex Cohen (@anothercohen): Sad to share that I was laid off from Google today. I was in charge of making the algorithms for Gemini as woke as possible. After complaints on Twitter surfaced today, I suddenly lost access to Han...
- Bloomberg - Are you a robot?: no description found
- Bloomberg - Are you a robot?: no description found
- Test Drive The New NVIDIA App Beta: The Essential Companion For PC Gamers & Creators: The NVIDIA app is the easiest way to keep your drivers up to date, discover NVIDIA applications, capture your greatest moments, and configure GPU settings.
- Know Nothing GIF - No Idea IDK I Dunno - Discover & Share GIFs: Click to view the GIF
- Chris Pratt Andy Dwyer GIF - Chris Pratt Andy Dwyer Omg - Discover & Share GIFs: Click to view the GIF
- Wyaking GIF - Wyaking - Discover & Share GIFs: Click to view the GIF
- No Sleep GIF - No Sleep Love - Discover & Share GIFs: Click to view the GIF
- https://i.redd.it/1v6hjhd86vj31.png: no description found
- I Dont Know But I Like It Idk GIF - I Dont Know But I Like It I Dont Know Idk - Discover & Share GIFs: Click to view the GIF
- How fast is ASP.NET Core?: Programming Adventures
- Machine Preparing GIF - Machine Preparing Old Man - Discover & Share GIFs: Click to view the GIF
- Painting GIF - Painting Bob Ross - Discover & Share GIFs: Click to view the GIF
- 3rd Rock GIF - 3rd Rock From - Discover & Share GIFs: Click to view the GIF
- Reddit - Dive into anything: no description found
- LLM (w/ RAG) need a new Logic Layer (Stanford): New insights by Google DeepMind and Stanford University on the limitations of current LLMs (Gemini Pro, GPT-4 TURBO) regarding causal reasoning, and logic. U...
- VRAM Calculator: no description found
- GitHub - itsme2417/PolyMind: A multimodal, function calling powered LLM webui.: A multimodal, function calling powered LLM webui. - GitHub - itsme2417/PolyMind: A multimodal, function calling powered LLM webui.
- Reddit - Dive into anything: no description found
- Interrogate DeepBooru: A Feature for Analyzing and Tagging Images in AUTOMATIC1111: Understand the power of image analysis and tagging with DeepBooru. Learn how this feature enhances AUTOMATIC1111 for anime-style art creation. Interrogate DeepBooru now!
- GitHub - Malisius/booru2prompt: An extension for stable-diffusion-webui to convert image booru posts into prompts: An extension for stable-diffusion-webui to convert image booru posts into prompts - Malisius/booru2prompt
{kind=link}
TheBloke ▷ #characters-roleplay-stories (299 messages🔥🔥):
-
Tuning Tips for Character Roleplay:
@superking__and@netrveexplored fine-tuning specifics for roleplay models; about having the base model know everything and then fine-tuning so that characters write only what they should know. There was also mention of using DPO (Dynamic Prompt Optimization) for narrowing down training and questioning how scientific papers are formatted in training datasets. -
AI Brainstorming for Better Responses:
@superking__observed that letting the model brainstorm before giving an answer often makes it appear smarter. Alternatively, forcing a model to answer using grammars might make it appear dumber due to limited hardware resources. -
Exploring Scientific Paper Formatting in Models:
@kaltcitshared their process of DPOing on scientific papers, creating a collapsed dataset from academic papers for DPO, and discussed the issue of model loss spikes during training with@c.gato. -
Roleplaying and ChatML Prompts Strategies:
@superking__and@euchalediscussed prompt structures for character roleplay and how to prevent undesired point-of-view shifts, while@netrveshared experiences using MiquMaid v2 for roleplay, noting its sometimes overly eager approach to lewd content. -
New AI Story-Writing and Role-playing Models Released:
@dreamgenannounced the release of new AI models specifically designed for story-writing and role-playing. These models were trained on human-generated data and can be used with prompts in an extended version of ChatML, aiming for steerable interactions. Users like@splice0001and@superking__expressed enthusiasm for testing them out.
Links mentioned:
- LoneStriker/miqu-1-70b-sf-5.5bpw-h6-exl2 · Hugging Face: no description found
- Viralhog Grandpa GIF - Viralhog Grandpa Grandpa Kiki Dance - Discover & Share GIFs: Click to view the GIF
- Sheeeeeit GIF - Sheeeeeit - Discover & Share GIFs: Click to view the GIF
- dreamgen/opus-v1-34b · Hugging Face: no description found
- Opus V1: Story-writing & role-playing models - a dreamgen Collection: no description found
- DreamGen: AI role-play and story-writing without limits: no description found
- Models - Hugging Face: no description found
- Models - Hugging Face: no description found
TheBloke ▷ #training-and-fine-tuning (3 messages):
-
Choosing the Right Model for Code Classification: User
@yustee.is seeking advice on selecting an LLM for classifying code relevance related to a query for a RAG pipeline.@yustee.is considering deepseek-coder-6.7B-instruct but is open to recommendations. -
Mistral Download Dilemma: User
@aamir_70931is asking for assistance with downloading Mistral locally but provided no further context or follow-up.
TheBloke ▷ #coding (163 messages🔥🔥):
-
ML Workflow Conundrums and Mac Mysteries:
@fred.blissdiscussed the challenges of establishing a workflow for machine learning projects using a Mac Studio and considering the use ofllama.cppinstead of ollama due to its simpler architecture. They express concern over the market push for ollama, although they've been usingllama.cppon non-GPU PCs for some time. -
Exploring MLX and Zed as VSCode Alternatives:
@dirtytigerxrecommended MLX for TensorFlow/Keras tasks and praised Zed, a text editor from the Atom team, for its performance and minimal setup preference over Visual Studio Code. There's also a hint of interest in an open-source project forked from Atom named Pulsar. -
VsCode vs. Zed Debate:
@dirtytigerxelaborated on their preference for Zed over Visual Studio Code to@wbsch, highlighting Zed's minimalistic design and speed. They also discussed their experience with Neovim as an alternative and the potential for Zed to support remote development similar to VSCode. -
Microsoft's Developer-Oriented Shift: A discussion between
@dirtytigerxand@wbschon Microsoft’s transformative approach towards catering to developers, specifically mentioning their acquisition of GitHub leading to positive developments and the popularity of VSCode with integration of tools like Copilot. -
Scaling Inference Servers and GPU Utilization: In a conversation with
@etron711,@dirtytigerxadvised on strategies for scaling inference servers to handle a high number of users, suggesting prototyping with cheaper resources, like $0.80/hr for a 4090 on runpod, as initial steps for cost analysis. They also cautioned about the reliance on GPU availability and SLAs when working with providers like AWS.
Links mentioned:
- GitHub - raphamorim/rio: A hardware-accelerated GPU terminal emulator focusing to run in desktops and browsers.: A hardware-accelerated GPU terminal emulator focusing to run in desktops and browsers. - raphamorim/rio
- GitHub - pulsar-edit/pulsar: A Community-led Hyper-Hackable Text Editor: A Community-led Hyper-Hackable Text Editor. Contribute to pulsar-edit/pulsar development by creating an account on GitHub.
LM Studio ▷ #💬-general (598 messages🔥🔥🔥):
- LM Studio Receives Updates: Users are advised to manually download the latest LM Studios updates from the website as the in-app "Check for Updates" feature isn't functioning.
- Gemma Model Discussions: Many users report problems with the Gemma 7B model, some citing performance issues even after updates. The Gemma 2B model receives some positive feedback, and a link to a usable Gemma 2B on Hugging Face is shared.
- Performance Concerns with New LM Studio Version: Several users describe performance drops and high CPU usage with the latest LM Studio version on MacOS, particularly affecting the Mixtral 7B model.
- Gemma 7B on M1 Macs Requires GPU Slider Adjustment: Users running Gemma 7B on M1 Macs noticed major performance improvements after adjusting the GPU slider to "max", although some still experience slower response times.
- Stable Diffusion 3 Announcement: Stability.ai announces Stable Diffusion 3 in an early preview phase, promising improved performance and multi-subject image quality. Users show interest and discuss signing up for the preview.
Links mentioned:
- 👾 LM Studio - Discover and run local LLMs: Find, download, and experiment with local LLMs
- lmstudio-ai/gemma-2b-it-GGUF · Hugging Face: no description found
- MSN: no description found
- Gemma: Introducing new state-of-the-art open models: Gemma is a family of lightweight, state\u002Dof\u002Dthe art open models built from the same research and technology used to create the Gemini models.
- Stable Diffusion 3 — Stability AI: Announcing Stable Diffusion 3 in early preview, our most capable text-to-image model with greatly improved performance in multi-subject prompts, image quality, and spelling abilities.
- google/gemma-7b · Hugging Face: no description found
- LoneStriker/gemma-2b-GGUF · Hugging Face: no description found
- Reddit - Dive into anything: no description found
- How To Run Stable Diffusion WebUI on AMD Radeon RX 7000 Series Graphics: Did you know you can enable Stable Diffusion with Microsoft Olive under Automatic1111 to get a significant speedup via Microsoft DirectML on Windows? Microso...
- جربت ذكاء إصطناعي غير خاضع للرقابة، وجاوبني على اسئلة خطيرة: ستريم كل نهار في تويتش :https://www.twitch.tv/marouane53Reddit : https://www.reddit.com/r/Batallingang/إنستغرام : https://www.instagram.com/marouane53/سيرفر ...
- GitHub - lllyasviel/Fooocus: Focus on prompting and generating: Focus on prompting and generating. Contribute to lllyasviel/Fooocus development by creating an account on GitHub.
- Mistral's next LLM could rival GPT-4, and you can try it now in chatbot arena: French LLM wonder Mistral is getting ready to launch its next language model. You can already test it in chat.
- Need support for GemmaForCausalLM · Issue #5635 · ggerganov/llama.cpp: Prerequisites Please answer the following questions for yourself before submitting an issue. I am running the latest code. Development is very rapid so there are no tagged versions as of now. I car...
LM Studio ▷ #🤖-models-discussion-chat (149 messages🔥🔥):
-
Gemma Model Confusion: Users are experiencing issues with the Gemma model.
@macauljreports errors when trying to run the 7b Gemma model on his GPU, while@nullt3rmentions that quantized models are broken and awaiting fixes from llama.cpp.@yagilbadvises checking for a 2B version due to many faulty quants in circulation, and@heyitsyorkieclarifies that LM Studio needs updates before Gemma models can be functional. -
LM Studio Model Compatibility & Errors: Several users, including
@swiftyosand@thorax7835, discuss finding the best model for coding and uncensored dialogue, while@bambalejoencounters glitches with the Nous-Hermes-2-Yi-34B.Q5_K_M.gguf model. A known bug in version 0.2.15 of LM Studio causing gibberish output upon regeneration was addressed, with a fix suggested by@heyitsyorkie. -
Image Generation Model Discussion:
@antonsosnicevinquires about a picture generation feature akin to Adobe's generative fill, directed by@swight709towards AUTOMATIC1111's stable diffusion web UI for capabilities like inpainting and outpainting, highlighting its extensive plugin system and use for image generation separate from LM Studio's text generation focus. -
Hardware and Configuration Challenges: Users including
@goldensun3dsand@wildcat_aurorashare their setups and the challenges of running large models like Goliath 120B Q6, discussing the trade-offs between performance and hardware limitations such as VRAM and the system's memory bandwidth. -
Multimodal AI Anticipation: The conversation touches on the hope for models that can handle tasks beyond their current capabilities.
@drawingthesunexpresses a desire for LLM and stable diffusion models to interact, while@heyitsyorkiehints at future multimodal models with broader functionality.
Links mentioned:
- 👾 LM Studio - Discover and run local LLMs: Find, download, and experiment with local LLMs
- EvalPlus Leaderboard: no description found
- Master Generative AI dev stack: practical handbook: Yet another AI article. It might be overwhelming at times. In this comprehensive guide, I’ll simplify the complex world of Generative AI…
- lmstudio-ai/gemma-2b-it-GGUF · Hugging Face: no description found
- ImportError: libcuda.so.1: cannot open shared object file: When I run my code with TensorFlow directly, everything is normal. However, when I run it in a screen window, I get the following error. ImportError: libcuda.so.1: cannot open shared object fi...
- macaulj@macaulj-HP-Pavilion-Gaming-Laptop-15-cx0xxx:~$ sudo '/home/macaulj/Downl - Pastebin.com: Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
- Big Code Models Leaderboard - a Hugging Face Space by bigcode: no description found
- ```json{ "cause": "(Exit code: 1). Please check settings and try loading th - Pastebin.com: Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
- Models - Hugging Face: no description found
- wavymulder/Analog-Diffusion · Hugging Face: no description found
- Testing Shadow PC Pro (Cloud PC) with LM Studio LLMs (AI Chatbot) and comparing to my RTX 4060 Ti PC: I have been using Chat GPT since it launched about a year ago and I've become skilled with prompting, but I'm still very new with running LLMs "locally". Whe...
- GitHub - AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI: Stable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub.
- Reddit - Dive into anything: no description found
LM Studio ▷ #announcements (4 messages):
-
LM Studio v0.2.15 Release Announced:
@yagilbunveiled LM Studio v0.2.15 with exciting new features including support for Google's Gemma model, improved download management, conversation branching, GPU configuration tools, refreshed UI, and various bug fixes. The update is available for Mac, Windows, and Linux, and can be downloaded from LM Studio Website, with the Linux version here. -
Critical Bug Fix Update: An important update was urged by
@yagilb, asking users to re-download LM Studio v0.2.15 from the LM Studio Website due to critical bug fixes missing from the original build. -
Gemma Model Integration Tips:
@yagilbshared a link for the recommended Gemma 2b Instruct quant for LM Studio users, available on Hugging Face, and reminded users of Google's terms of use for the Gemma Services. -
LM Studio v0.2.16 Is Now Live: Following the previous announcements,
@yagilbinformed users of the immediate availability of LM Studio v0.2.16, which includes everything from the v0.2.15 update along with additional bug fixes for erratic regenerations and chat scrolls during downloads. Users who've updated to v0.2.15 are encouraged to update to v0.2.16.
Links mentioned:
- 👾 LM Studio - Discover and run local LLMs: Find, download, and experiment with local LLMs
- lmstudio-ai/gemma-2b-it-GGUF · Hugging Face: no description found
LM Studio ▷ #🧠-feedback (30 messages🔥):
-
Local LLM Installation Questions: User
@maaxportinquired about installing a local LLM with AutoGPT after obtaining LM Studio, expressing desire to host it on a rented server.@senecalouckoffered advice, indicating that setting up a local API endpoint and updating the base_url should suffice for local operation. -
Client Update Confusion:
@msz_mgsexperienced confusion with the client version, noting that 0.2.14 was identified as the latest, despite newer updates being available.@heyitsyorkieclarified that in-app updating is not yet supported and manual download and installation are required. -
Gemma Model Errors and Solutions:
@richardchinnisencountered issues with Gemma models, which led to a discussion culminating in@yagilbsharing a link to a quantized 2B model on Hugging Face to resolve the errors. -
Troubleshooting Gemma 7b Download Visibility: Users
@adtigerningand@thebest6337discussed the visibility of Gemma 7b download files, pinpointing issues with viewing Google Files in LM Studio.@heyitsyorkieprovided guidance on downloading manually and the expected file placement. -
Bug Report on Scrolling Issue:
@drawingthesunreported a scrolling issue in chats that was subsequently acknowledged as a known bug by@heyitsyorkie.@yagilbthen announced the bug fix in version 0.2.16, with confirmation of the resolution from@heyitsyorkie.
Links mentioned:
- 👾 LM Studio - Discover and run local LLMs: Find, download, and experiment with local LLMs
- lmstudio-ai/gemma-2b-it-GGUF · Hugging Face: no description found
LM Studio ▷ #🎛-hardware-discussion (130 messages🔥🔥):
-
Earnings Report Creates Nvidia Nerves:
@nink1shares their anxious anticipation over Nvidia's earnings report, as they've invested their life savings in Nvidia products, particularly the 3090 video cards. Despite teasing by@heyitsyorkieabout potential "big stonks" gains,@nink1clarifies that their investment has been in hardware, not stocks. -
Decoding the Worth of Flash Arrays:
@wolfspyreponders the potential applications for three 30Tb flash arrays, capable of 1M iops each, sparking a playful exchange with@heyitsyorkieabout piracy and the downsides of a buccaneer's life, such as scurvy and poor work conditions. -
VRAM vs. New GPUs for AI Rendering:
@freethepublicdebtqueries the value of using multiple cheap GPUs for increased VRAM when running large models like Mixtral8x7.@heyitsyorkieprovides links to GPU specs, suggesting that while more VRAM is key, GPU performance can't be ignored, and sometimes a single powerful card like the RTX 3090 suffices. -
Tesla P40 Gains Momentum Among Budget Constraints: Participants such as
@wilsonkeebsand@krypt_lynxdiscuss the viability of older GPUs like the Tesla P40 for AI tasks, weighing up their accessibility against slower performance compared to newer alternatives like the RTX 3090. -
AI Capabilities of Older Nvidia Cards Questioned: Several users like
@exio4and@bobzdarshare their experiences and test results regarding the use of older Nvidia GPUs for AI tasks, revealing that advancements in newer cards contribute significantly to performance gains in AI modeling and inference.
Links mentioned:
- no title found: no description found
- Deploying Transformers on the Apple Neural Engine: An increasing number of the machine learning (ML) models we build at Apple each year are either partly or fully adopting the [Transformer…
- MAG Z690 TOMAHAWK WIFI: Powered by Intel 12th Gen Core processors, the MSI MAG Z690 TOMAHAWK WIFI is hardened with performance essential specifications to outlast enemies. Tuned for better performance by Core boost, Memory B...
- Have You GIF - Have You Ever - Discover & Share GIFs: Click to view the GIF
- The Best GPUs for Deep Learning in 2023 — An In-depth Analysis: Here, I provide an in-depth analysis of GPUs for deep learning/machine learning and explain what is the best GPU for your use-case and budget.
- The Best GPUs for Deep Learning in 2023 — An In-depth Analysis): Here, I provide an in-depth analysis of GPUs for deep learning/machine learning and explain what is the best GPU for your use-case and budget.
- NVIDIA GeForce RTX 2060 SUPER Specs: NVIDIA TU106, 1650 MHz, 2176 Cores, 136 TMUs, 64 ROPs, 8192 MB GDDR6, 1750 MHz, 256 bit
- NVIDIA GeForce RTX 3090 Specs: NVIDIA GA102, 1695 MHz, 10496 Cores, 328 TMUs, 112 ROPs, 24576 MB GDDR6X, 1219 MHz, 384 bit
LM Studio ▷ #🧪-beta-releases-chat (266 messages🔥🔥):
- Gemma Quants in Question: Users report mixed results with Google's Gemma models, finding that the
7b-itquants often output gibberish, while the2b-itquants seem stable and work well.@drawless111highlights that full precision models are necessary to meet benchmarks, suggesting that smaller (1-3B) models require more precise prompts and settings. - LM Studio Continually Improving:
@yagilbannounces a new LM Studio download with significant bug fixes, particularly issues with the regenerate feature and multi-turn chats, solved here.@yagilbalso clarifies the regenerate issue was not related to models but to bad quants; the team is figuring out how to ease the download of functional models. - Issues with Gemma 7B Size Explained: Users discussed the large size of Google's Gemma
7b-itmodel, pointing out its lack of quantization and large memory demands. It's noted that llama.cpp currently has issues with Gemma, which are expected to be resolved soon. - User-Friendly Presets for Improved Performance: Users agree that the correct preset is needed to get good results from the Gemma models, with
@pandora_box_openstressing the necessity for specific presets to avoid subpar outputs. - LM Studio Confirmed Working GGUFs:
@yagilbrecommends a 2B IT Gemma model they quantized and tested for LM Studio, with plans to upload a 7B version as well.@issaminuconfirms this 2B model works but is less intelligent than the more functional 7B model.
Links mentioned:
- 👾 LM Studio - Discover and run local LLMs: Find, download, and experiment with local LLMs
- 👾 LM Studio - Discover and run local LLMs: Find, download, and experiment with local LLMs
- asedmammad/gemma-2b-it-GGUF · Hugging Face: no description found
- Thats What She Said Dirty Joke GIF - Thats What She Said What She Said Dirty Joke - Discover & Share GIFs: Click to view the GIF
- HuggingChat: Making the community's best AI chat models available to everyone.
- ```json{ "cause": "(Exit code: 1). Please check settings and try loading th - Pastebin.com: Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
- google/gemma-2b-it · Hugging Face: no description found
- lmstudio-ai/gemma-2b-it-GGUF · Hugging Face: no description found
- LoneStriker/gemma-2b-it-GGUF · Hugging Face: no description found
- google/gemma-7b · Why the original GGUF is quite large ?: no description found
- google/gemma-7b-it · Hugging Face: no description found
- Need support for GemmaForCausalLM · Issue #5635 · ggerganov/llama.cpp: Prerequisites Please answer the following questions for yourself before submitting an issue. I am running the latest code. Development is very rapid so there are no tagged versions as of now. I car...
- Add
gemmamodel by postmasters · Pull Request #5631 · ggerganov/llama.cpp: There are couple things in this architecture: Shared input and output embedding parameters. Key length and value length are not derived from n_embd. More information about the models can be found...
Nous Research AI ▷ #ctx-length-research (97 messages🔥🔥):
- Scaling Up with Long-Context Data Engineering:
@gabriel_symeexpressed excitement about a GitHub repository titled "Long-Context Data Engineering", mentioning the implementation of data engineering techniques for scaling language models to 128K context. - VRAM Requirements for 128K Context Models: In a query about the VRAM requirements for 128K context at 7B models,
@tekniumclarified that it needs over 600GB. - Tokenization Queries and Considerations:
@vatsadevmentioned that GPT-3 and GPT-4 have tokenizers which can be found at tiktoken, and also referenced a related video by Andrej Karpathy without providing a direct link. - Token Compression Challenges:
@elder_pliniusraised an issue about token compression when trying to fit the Big Lebowski script within context limits, leading to a discussion with@vatsadevand@blackl1ghtabout tokenizers and server behavior on the OpenAI tokenizer playground that resulted in extended observations about why compressed text is accepted by ChatGPT while the original isn't. - Long Context Inference on Lesser VRAM:
@blackl1ghtshared that they conducted inference on Mistral 7B and Solar 10.7B at 64K context with just 28GB VRAM on a V100 32GB, which led to a discussion with@tekniumand@bloc97on the viability of this approach and the capacity of the kv cache and offloading in larger models.
Links mentioned:
- gpt-tokenizer playground: no description found
- Tweet from Aran Komatsuzaki (@arankomatsuzaki): Microsoft Research presents LongRoPE: Extending LLM Context Window Beyond 2 Million Tokens https://arxiv.org/abs/2402.13753
- Tweet from Pliny the Prompter 🐉 (@elder_plinius): The Big Lebowski script doesn't quite fit within the GPT-4 context limits normally, but after passing the text through myln, it does!
- GitHub - FranxYao/Long-Context-Data-Engineering: Implementation of paper Data Engineering for Scaling Language Models to 128K Context: Implementation of paper Data Engineering for Scaling Language Models to 128K Context - FranxYao/Long-Context-Data-Engineering
Nous Research AI ▷ #off-topic (16 messages🔥):
-
Mysterious Minecraft Creature Inquiry: User
@tekniumquestioned the presence of a specific creature in Minecraft. The response by@nonameusrwas a succinct "since always." -
Exploring Self-Reflective AI in RAG:
@pradeep1148shared a link to a YouTube video titled "Self RAG using LangGraph," which suggests self-reflection can enhance Retrieval-Augmented Generation (RAG) models. -
Beginner's Guide Request for Artistic Image Generation: User
@blackblizeasked whether it's feasible for a non-expert to train a model on microscope photos for artistic purposes and sought guidance on the topic. -
Advancements in AI-Generated Minecraft Videos:
@afterhoursbillyanalyzed how an AI understands the inventory UI in Minecraft videos, while@_3sphereadded that while the AI-generated images look right at a glance, they reveal inaccuracies upon closer inspection. -
Nous Models' Avatar Generation Discussed: In response to
@stoicbatman's curiosity about avatar generation for Nous models,@tekniummentioned the use of DALL-E followed by img2img through Midjourney.
Links mentioned:
- Gemma Google's open source SOTA model: Gemma is a family of lightweight, state-of-the-art open models built from the same research and technology used to create the Gemini models. Developed by Goo...
- Self RAG using LangGraph: Self-reflection can enhance RAG, enabling correction of poor quality retrieval or generations.Several recent papers focus on this theme, but implementing the...
- BitDelta: Your Fine-Tune May Only Be Worth One Bit: Large Language Models (LLMs) are typically trained in two phases: pre-training on large internet-scale datasets, and fine-tuning for downstream tasks. Given ...
Nous Research AI ▷ #interesting-links (38 messages🔥):
-
Google Unveils Gemma:
@burnytechshared a link to a tweet by@sundarpichaiannouncing Gemma, a family of lightweight and open source models available in 2B and 7B sizes. Sundar Pichai's tweet expresses excitement for global availability and encourages creations using Gemma on platforms ranging from developer laptops to Google Cloud. -
Gemini 1.5 Discussion Happening:
@shashank.f1invited users to a discussion on Gemini 1.5, mentioning a previous session on the A-JEPA AI model, which is not affiliated with Meta or Yann Lecun as noted by@ldj. -
OpenAI's LLama Bested by A Reproduction:
@euclaiseand@tekniumdiscussed how a reproduction of OpenAI's LLama outperformed the original, adding intrigue to the capabilities of imitated models. -
Navigation Through Human Knowledge:
@.benxhprovided a method for navigating the taxonomy of human knowledge and capabilities, suggesting a structured list of all possible fields and directing users to The U.S. Library of Congress for a comprehensive example. -
Microsoft Takes LLMs to New Lengths:
@main.ailinked a tweet by@_akhaliqabout Microsoft's LongRoPE, a technique that extends LLM context windows beyond 2 million tokens, arguably revolutionizing the capacity for long-text handling in models such as LLaMA and Mistral. The tweet highlights this advancement without neglecting the performance at original context window sizes.
Links mentioned:
- Tweet from Sundar Pichai (@sundarpichai): Introducing Gemma - a family of lightweight, state-of-the-art open models for their class built from the same research & tech used to create the Gemini models. Demonstrating strong performance acros...
- Join the hedwigAI Discord Server!: Check out the hedwigAI community on Discord - hang out with 50 other members and enjoy free voice and text chat.
- Tweet from AK (@_akhaliq): Microsoft presents LongRoPE Extending LLM Context Window Beyond 2 Million Tokens Large context window is a desirable feature in large language models (LLMs). However, due to high fine-tuning costs, ...
- Tweet from Emad (@EMostaque): @StabilityAI Some notes: - This uses a new type of diffusion transformer (similar to Sora) combined with flow matching and other improvements. - This takes advantage of transformer improvements & can...
- Library of Congress Subject Headings - LC Linked Data Service: Authorities and Vocabularies | Library of Congress: no description found
- benxh/us-library-of-congress-subjects · Datasets at Hugging Face: no description found
- A-JEPA AI model: Unlock semantic knowledge from .wav / .mp3 file or audio spectrograms: 🌟 Unlock the Power of AI Learning from Audio ! 🔊 Watch a deep dive discussion on the A-JEPA approach with Oliver, Nevil, Ojasvita, Shashank, Srikanth and N...
- JARVIS/taskbench at main · microsoft/JARVIS: JARVIS, a system to connect LLMs with ML community. Paper: https://arxiv.org/pdf/2303.17580.pdf - microsoft/JARVIS
- JARVIS/easytool at main · microsoft/JARVIS: JARVIS, a system to connect LLMs with ML community. Paper: https://arxiv.org/pdf/2303.17580.pdf - microsoft/JARVIS
Nous Research AI ▷ #general (419 messages🔥🔥🔥):
- Gemma vs Mistral Showdown: Tweets are circulating comparing Google Gemma to Mistral's LLMs, claiming that even after a few hours of testing, Gemma doesn't outperform Mistral's 7B models despite being better than llama 2.
- Debating Gemma's Instruction Following:
@big_ol_tendernoticed that for Nous-Mixtral models, placing instructions at the end of commands seems more effective than at the beginning, sparking a discussion about command formats. - The Speed of VMs on Different Services:
@mihai4256is recommended to try VAST for faster, more cost-effective VMs compared to Runpod, while another user notes Runpod's better UX despite speed issues.@lightvector_later reports that all providers seem slow today. - Curiosity for Crypto Payments for GPU Time:
@protofeatherinquires about platforms that offer GPU time purchase with crypto, leading to suggestions of Runpod and VAST, though there's a clarification that Runpod requires a Crypto.com KYC registration. - Potential Axolotl Support for Gemma:
@gryphepadarconducts a full finetune on Gemma with Axolotl, pointing out that it seems Gemma is 10.5B in size, thus requiring a lot more VRAM than Mistral. Moreover, users shared their experiences regarding difficulties and successes with various settings and DPO datasets.
Links mentioned:
- Tweet from Aaditya Ura (Ankit) (@aadityaura): The new Model Gemma from @GoogleDeepMind @GoogleAI does not demonstrate strong performance on medical/healthcare domain benchmarks. A side-by-side comparison of Gemma by @GoogleDeepMind and Mistral...
- Tweet from anton (@abacaj): After trying Gemma for a few hours I can say it won’t replace my mistral 7B models. It’s better than llama 2 but surprisingly not better than mistral. The mistral team really cooked up a model even go...
- Sad Cat GIF - Sad Cat - Discover & Share GIFs: Click to view the GIF
- LMSys Chatbot Arena Leaderboard - a Hugging Face Space by lmsys: no description found
- indischepartij/MiniCPM-3B-Hercules-v2.0 · Hugging Face: no description found
- Tweet from TokenBender (e/xperiments) (@4evaBehindSOTA): based on my tests so far, ignoring Gemma for general purpose fine-tuning or inference. however, indic language exploration and specific use case tests may be explored later on. now back to building ...
- no title found: no description found
- Models - Hugging Face: no description found
- Reddit - Dive into anything: no description found
- eleutherai: Weights & Biases, developer tools for machine learning
- The Novice's LLM Training Guide: Written by Alpin Inspired by /hdg/'s LoRA train rentry This guide is being slowly updated. We've already moved to the axolotl trainer. The Basics The Transformer architecture Training Basics Pre-train...
- GitHub - facebookresearch/diplomacy_cicero: Code for Cicero, an AI agent that plays the game of Diplomacy with open-domain natural language negotiation.: Code for Cicero, an AI agent that plays the game of Diplomacy with open-domain natural language negotiation. - facebookresearch/diplomacy_cicero
- Neuranest/Nous-Hermes-2-Mistral-7B-DPO-BitDelta at main: no description found
- BitDelta: no description found
- GitHub - FasterDecoding/BitDelta: Contribute to FasterDecoding/BitDelta development by creating an account on GitHub.
- Adding Google's gemma Model by monk1337 · Pull Request #1312 · OpenAccess-AI-Collective/axolotl: Adding Gemma model config https://huggingface.co/google/gemma-7b Testing and working!
Nous Research AI ▷ #ask-about-llms (9 messages🔥):
- Custom Tokenizer Training Query:
@ex3ndrinquired about the possibility of training a completely custom tokenizer and the ways to store it.@nanobitzresponded, prompting clarification about the end-goal of such a task. - Performance Inquiry on Nous-Hermes-2-Mistral-7B-DPO-GGUF:
@natefyi_30842asked for a comparison between the new Nous-Hermes-2-Mistral-7B-DPO-GGUF and its solar version, to which@emraza110commented on its proficiency in accurately answering a specific test question. - Out-of-Memory Error with Mixtral Model:
@iamcoming5084brought up an issue regarding out-of-memory errors when dealing with Mixtral 8x7b models. - Fine-Tuning Parameters for Accuracy:
@iamcoming5084sought advice on parameters that could affect the accuracy during the fine-tuning of Mixtral 8x7b and Mistral 7B, tagging@688549153751826432and@470599096487510016for input. - Hosting and Inference for Large Models:
@jacobidiscussed challenges and sought strategies for hosting the Mixtral 8x7b model using an OpenAI API endpoint, mentioning tools like tabbyAPI and llama-cpp. - Error in Nous-Hermes-2-Mistral-7B-DPO Inference Code:
@qtnxpointed out errors in the inference code section for Nous-Hermes-2-Mistral-7B-DPO on Huggingface and supplied a corrected version of the code. Inference code for Nous-Hermes-2-Mistral-7B-DPO.
Links mentioned:
- Welcome Gemma - Google’s new open LLM: no description found
- NousResearch/Nous-Hermes-2-Mistral-7B-DPO · Hugging Face: no description found
Nous Research AI ▷ #collective-cognition (3 messages):
- Short & Not-so-Sweet on Heroku:
@bfpillexpressed a negative sentiment with a blunt "screw heroku". Their frustration appears succinct but not elaborated upon. - Affable Acknowledgment:
@adjectiveallisonresponded, seemingly acknowledging the sentiment but pointing out "I don't think that's the point but sure". The exact point of contention remains unclear. - Consensus or Coincidence?:
@bfpillreplied with "glad we agree", but without context, it's uncertain if true agreement was reached or if the comment was made in jest.
Nous Research AI ▷ #project-obsidian (3 messages):
- Model Updates Delayed Due to Pet Illness:
@qnguyen3apologized for the slower pace in updating and completing models, attributing the delay to their cat falling ill. - Invitation to Directly Message for Coordination:
@qnguyen3invited members to send a direct message if they need to reach out for project-related purposes.
Eleuther ▷ #general (101 messages🔥🔥):
-
Confusion Over lm eval:
@lee0099wondered why lm eval seemed to be set up only for runpod, prompting@hailey_schoelkopfto clarify that lm eval is different from llm-autoeval, pointing to the Open LLM Leaderboard's HF spaces page for detailed instructions and command line parameters. -
Discussion on Model Environmental Impact:
@gaindrewspeculated on ranking models by the net carbon emissions they prevent or contribute. Acknowledging that accuracy would be a challenge, the conversation ended without further exploration or links. -
Optimizer Trouble for loubb:
@loubbpresented an unusual loss curve while training based on the Whisper model and brainstormed with others, such as@ai_waifuand@lucaslingle, about potential causes related to optimizer parameters. -
Google's Gemma Introduced:
@sundarpichaiannounced Gemma, a new family of models, leading to debates between users like@lee0099and@.undeletedon whether Gemma constituted a significant improvement over existing models, such as Mistral. -
Theoretical Discussion on Simulating Human Experience:
@rallio.provoked a detailed discussion on the theoretical possibility of simulating human cognition with@sparetime.and@fern.bear. The conversation ranged from the complexity of modeling human emotion and memory to how GPT-4 could potentially be used to create consistent, synthetic human experiences.
Links mentioned:
- Tweet from Sundar Pichai (@sundarpichai): Introducing Gemma - a family of lightweight, state-of-the-art open models for their class built from the same research & tech used to create the Gemini models. Demonstrating strong performance acros...
- PropSegmEnt: A Large-Scale Corpus for Proposition-Level Segmentation and Entailment Recognition: The widely studied task of Natural Language Inference (NLI) requires a system to recognize whether one piece of text is textually entailed by another, i.e. whether the entirety of its meaning can be i...
- Everything WRONG with LLM Benchmarks (ft. MMLU)!!!: 🔗 Links 🔗When Benchmarks are Targets: Revealing the Sensitivity of Large Language Model Leaderboardshttps://arxiv.org/pdf/2402.01781.pdf❤️ If you want to s...
Eleuther ▷ #research (305 messages🔥🔥):
-
Groq Attempts To Outperform Mistral:
@philpaxshared an article highlighting that Groq, an AI hardware startup, showcased impressive demos of the Mistral Mixtral 8x7b model on their inference API, achieving up to 4x the throughput and charging less than a third of Mistral's price. The performance improvement could benefit real-world usability for chain of thought and lower latency needs for coding generations and real-time model applications. -
Concerns About Parameter Count Misrepresentation with Gemma Models: Discussion in the channel raised issues with parameter count misrepresentation, for example, "gemma-7b" actually containing 8.5 billion parameters, with suggestions that model classifications such as "7b" should strictly mean up to 7.99 billion parameters at most.
-
Exploration of LLM Data and Compute Efficiency:
@jckwindstarted a conversation about the data and compute efficiency of LLMs, noting that they require a lot of data and build inconsistent world models. A shared graphic suggesting LLMs could struggle with bi-directional learning sparked debate and inspired thoughts on whether large context windows or curiosity-driven learning mechanisms could potentially address these inefficiencies. -
Novel Papers and Research Directions Discussed: Various papers and research topics were shared, including one on adversarial attacks on LLMs
@0x_pawsand another proposing the concept of programmable gradient information (PGI) to cope with data loss in deep networks@jckwind. -
Updates on Model Optimization and Attack Surfaces:
@benjamin_wmentioned that PyTorch 2.2's SDPA and FlashAttention v2.5.5 now support head dimensions that would allow for fine-tuning Gemma models on consumer GPUs, widening accessibility for optimizing and using these LLMs. Additionally, a paper was shared addressing broad adversarial attack surfaces on LLMs, including the pre-training of models with coding capabilities and the presence of "glitch" tokens in vocabularies@0x_paws.
Links mentioned:
- Coercing LLMs to do and reveal (almost) anything: It has recently been shown that adversarial attacks on large language models (LLMs) can "jailbreak" the model into making harmful statements. In this work, we argue that the spectrum of advers...
- YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information: Today's deep learning methods focus on how to design the most appropriate objective functions so that the prediction results of the model can be closest to the ground truth. Meanwhile, an appropri...
- Groq Inference Tokenomics: Speed, But At What Cost?: Faster than Nvidia? Dissecting the economics
- Spectral State Space Models: This paper studies sequence modeling for prediction tasks with long range dependencies. We propose a new formulation for state space models (SSMs) based on learning linear dynamical systems with the s...
- Feist Publications, Inc., v. Rural Telephone Service Co. - Wikipedia: no description found
- Gemma: Introducing new state-of-the-art open models: Gemma is a family of lightweight, state\u002Dof\u002Dthe art open models built from the same research and technology used to create the Gemini models.
- Fast Transformer Decoding: One Write-Head is All You Need: Multi-head attention layers, as used in the Transformer neural sequence model, are a powerful alternative to RNNs for moving information across and between sequences. While training these layers is ge...
- Paper page - LongRoPE: Extending LLM Context Window Beyond 2 Million Tokens: no description found
- Tweet from NVIDIA (@nvidia): Announced today, we are collaborating as a launch partner with @Google in delivering Gemma, an optimized series of models that gives users the ability to develop with #LLMs using only a desktop #RTX G...
- Tweet from Tri Dao (@tri_dao): FlashAttention v2.5.5 now supports head dim 256 backward on consumer GPUs. Hope that makes it easier to finetune Gemma models
- Lecture 20 - Efficient Transformers | MIT 6.S965: Lecture 20 introduces efficient transformers.Keywords: TransformerSlides: https://efficientml.ai/schedule/---------------------------------------------------...
Eleuther ▷ #interpretability-general (43 messages🔥):
- Multilingual Model's Internal Language Questioned:
@butaniumsparked a debate by sharing a Twitter post that suggests "the model 'thinks in English'" during non-English tasks. They provide insight from a paper and a GitHub repository that indicate how logit lens differs from the tuned lens in analyzing language usage within models. - Tuned Lens Availability for Llama Models:
@mrgonaoclarified the investigation into whether Llama models internally use English by using tuned lens trained on them, providing a Hugging Face space to check available resources. - Exploring Llama Models' Multilingual Capabilities:
@mrgonaoreported difficulties in running experiments across all languages due to incompleteness of the 13b-sized model and missing notebooks for certain tasks in the provided repo. They indicated a willingness to run more experiments once the issues are resolved. - Chinese Lens for Llama Model Under Consideration: In response to
@stellaathena's suggestion,@mrgonaocontemplated creating a lens for Chinese-language analysis using an easy-to-access Chinese dataset, and later indicated that training for such a lens has begun. - Discussion of Model Unlearning Techniques:
@millandershared a link to a new survey paper on unlearning for LLMs, without further discussion in the channel on the content of the paper.
Links mentioned:
- Rethinking Machine Unlearning for Large Language Models: We explore machine unlearning (MU) in the domain of large language models (LLMs), referred to as LLM unlearning. This initiative aims to eliminate undesirable data influence (e.g., sensitive or illega...
- phoeniwwx/tuned_lens_q · Hugging Face: no description found
- AlignmentResearch/tuned-lens at main: no description found
- shjwudp/chinese-c4 · Datasets at Hugging Face: no description found
- GitHub - epfl-dlab/llm-latent-language: Repo accompanying our paper "Do Llamas Work in English? On the Latent Language of Multilingual Transformers".: Repo accompanying our paper "Do Llamas Work in English? On the Latent Language of Multilingual Transformers". - epfl-dlab/llm-latent-language
- srgo - Overview: srgo has one repository available. Follow their code on GitHub.
Eleuther ▷ #lm-thunderdome (64 messages🔥🔥):
-
Experimenting with Few-Shots Context:
@baber_mentioned the possibility that instruct tuned models could perform better when the few-shots context and continuations are formatted in alternating "user" and "assistant" turns, though they haven't tested it yet. -
GPU Memory not Released Post-OOM:
@pminervinifaced an Out-Of-Memory (OOM) issue on Colab when usingevaluator.simple_evaluatethat wasn't resolved after garbage collection (gc.collect()was tried without success) and still showed GPU memory as occupied. The problem required a runtime restart to resolve, discussed with suggestions for potential fixes by@hailey_schoelkopfand@baber_, with a Colab link provided for reproduction: Evaluate OOM Issue. -
LM-Harness Logits Support Hurdle:
@dsajlkdasdsaklexperienced an issue where locally running tasks with log likelihood in LM-Harness worked fine but API-based models like GPT yielded a "No support for logits" error while the pre-defined tasks like gsm8k ran smoothly.@hailey_schoelkopfclarified that it was due to most API providers not supporting logits, suggesting to convert tasks to generative format and updating the error message for better clarity. -
Gemma Model Evaluation Issues: Users
@vraychev,.rand0mm, and@ilovesciencereported problems with evaluating the Gemma-7b model in the lm-evaluation-harness.@hailey_schoelkopfacknowledged that there had been bugs, provided steps for a fix involving adding a BOS token, and guided users on how to get Gemma 7b working with flash attention (attn_implementation="flash_attention_2"). There was mention of a potential issue in transformers 4.38 and the need to upgrade the torch version.
Links mentioned:
- Google Colaboratory: no description found
- Google Colaboratory: no description found
- lm-evaluation-harness/lm_eval/evaluator.py at c26a6ac77bca2801a429fbd403e9606fd06e29c9 · EleutherAI/lm-evaluation-harness): A framework for few-shot evaluation of language models. - EleutherAI/lm-evaluation-harness
- lm-evaluation-harness/lm_eval/api/model.py at ba5cdf0f537e829e0150cee8050e07c2ada6b612 · EleutherAI/lm-evaluation-harness: A framework for few-shot evaluation of language models. - EleutherAI/lm-evaluation-harness
Eleuther ▷ #multimodal-general (6 messages):
- In Batch False Negative Dilemma in CLIP model:
@tz6352initially raised a question about methods to address the in batch false negative problem in the CLIP model. - Clarification Sought on False Negatives:
@_.hrafn._prompted for clarification on whether the concern was about the potential for false negatives within the batch. - Acknowledging the False Negative Issue:
@tz6352confirmed the query was indeed about handling false negatives in batches, not specific to Image-Text pairs, which indicates a different application context. - Possible Solutions to Mitigate False Negatives:
@_.hrafn._suggested using unimodal embeddings from separate text and image models to compute similarity scores and exclude false negatives. - Refinement of Negative Exclusion Strategy: Additionally,
@_.hrafn._proposed the idea of utilizing one's own model during training to calculate similarity scores for more effectively screening out hard negatives.
Eleuther ▷ #gpt-neox-dev (1 messages):
- Exploring Sequence Composition Strategies:
@pminervinishared a recent arXiv paper discussing the impact of pre-training sequence composition on language models. The study suggests that intra-document causal masking could significantly improve model performance on various tasks by eliminating distracting information from previous documents.
Links mentioned:
Analysing The Impact of Sequence Composition on Language Model Pre-Training: Most language model pre-training frameworks concatenate multiple documents into fixed-length sequences and use causal masking to compute the likelihood of each token given its context; this strategy i...
LAION ▷ #general (346 messages🔥🔥):
-
Google's New Gemma Model Discussion:
@itali4noshared a link about Google's release of Gemma, which builds upon the technology of Gemini models, emphasizing responsible AI development. The community was intrigued, with queries about Google's move toward actual open-sourced weights, as they are traditionally more reserved in such aspects. -
Stable Diffusion 3 Early Preview Announcement:
@thejonasbrothersbrought attention to Stable Diffusion 3, discussing its enhanced ability to handle multi-subject prompts and image quality improvements as part of the early preview waitlist. The conversation around it included skepticism about its novelty and actual differentiation from previous models. -
Discussion on Photo Captions with CogVL:
@pseudoterminalxreported on captioning 28.8k images in 12 hours with cogVL and provided insights into the compute infrastructure and costs involved in captioning images, which were quite significant and often relied on rented multi-GPU boxes. -
Dominance and Centralization in AI Development: A conversation about the shift in how models and resources like SD3 are becoming less open and increasingly centralized, with
@nodjaand others expressing concern about computing becoming more centralized, and how this shift is moving further from end-user reach. -
Speculation on the Commercial Use of SD3: As Stability.AI announced SD3, a debate emerged about whether models like it would ever be used commercially, with
@thejonasbrothersnoting a trend of closed-off development and@chad_in_the_houseviewing open-sourcing primarily as an advertising move rather than a revenue strategy.
Links mentioned:
- Gemma: Introducing new state-of-the-art open models: Gemma is a family of lightweight, state\u002Dof\u002Dthe art open models built from the same research and technology used to create the Gemini models.
- Stable Diffusion 3 — Stability AI: Announcing Stable Diffusion 3 in early preview, our most capable text-to-image model with greatly improved performance in multi-subject prompts, image quality, and spelling abilities.
- no title found: no description found
- ptx0/photo-concept-bucket · Datasets at Hugging Face: no description found
LAION ▷ #research (65 messages🔥🔥):
- Synthetic Data Debate Continues:
@unjay.expresses strong suspicion that OpenAI's models leverage a significant amount of synthetic data due to the presence of certain CGI-like artifacts, despite not seeing official confirmation from OpenAI on the matter. The accurate replication of specific 3D styles and anomalies like walk cycle animations are key points in this argument. - Diffusion Models Generate High-Performing Models:
@jordo45shares an interesting Arxiv paper proving that diffusion models can generate effective neural network parameters, offering a novel approach to model creation without the need for extensive architecture changes or training paradigms. - New Multimodal LLM Introduced:
@helium__introduces AnyGPT, a unified multimodal language model capable of processing speech, text, images, and music using discrete representations, spotlighting the versatile capabilities of LLMs in handling multiple data formats. - Public Dataset Dynamics Discussed:
@top_walk_townsuggests that due to issues such as link rot and data poisoning, the LAION 5B dataset should possibly be retired, prompting a discussion on the potential for community efforts to develop new high-quality public datasets with better annotations. - OpenAI Acquisitions and Structure Explored: A conversation unfolds around OpenAI's acquisition strategy, with users discussing whether it's typical for a non-profit like OpenAI to acquire companies. Links are shared clarifying OpenAI's hybrid structure, with elements like a 100x return cap for investors and the for-profit subsidiary's commitment to the nonprofit’s mission, illustrating the complex business framework.
Links mentioned:
- Neural Network Diffusion: Diffusion models have achieved remarkable success in image and video generation. In this work, we demonstrate that diffusion models can also \textit{generate high-performing neural network parameters}...
- OpenAI acquires Global Illumination: The entire team has joined OpenAI.
- apf1/datafilteringnetworks_2b · Datasets at Hugging Face: no description found
- Our structure: We designed OpenAI’s structure—a partnership between our original Nonprofit and a new capped profit arm—as a chassis for OpenAI’s mission: to build artificial general intelligence (AGI) that is safe a...
- AnyGPT: no description found
- Demo for "AnyGPT: Unified Multimodal LLM with Discrete Sequence Modeling": Demo for "AnyGPT: Unified Multimodal LLM with Discrete Sequence Modeling"
LAION ▷ #paper-discussion (1 messages):
said2000: https://arxiv.org/abs/2402.05608
Mistral ▷ #general (296 messages🔥🔥):
-
Mistral AI's Image Text Capabilities Questioned:
@oweoweasked if Mistral AI can retrieve and process text from complex images such as tables in JPEG format.@i_am_domrecommended using gpt4-vision, gemini-vision, or blip2 for flexibility, suggesting simpler tools like copyfish and google lens for smaller-scale data. -
Open-Source Hopes and Workarounds: Users discussed the possibility and implications of Mistral AI's weights being released to the public.
@9faezspeculated that a free version would emerge quickly if weights were released, while@i_am_domdoubted this would happen unless there was another leak. -
Questions About Mistral API and UI Development: New programmer
@distrorodeosought help for using the Mistral AI API to make a Chat UI.@ethuxprovided a helpful GitHub link to Huggingface ChatUI for assistance. -
Mistral AI's Performance and Fine-Tuning Talk: Users like
@darocheexpressed surprise at how powerful the small Mistral 7b model is, while@paul.martrenchar_prosuggested using RAG (Retrieval-Augmented Generation) to integrate company data into Mistral. This technique can be learned about in detail through documentation found at https://docs.mistral.ai/guides/basic-RAG/. -
High Interest in Mistral's Next Model Iteration: Users such as
@egalitaristenand@sapphicsreported impressive performance from Mistral Next, particularly in math, placing it close to GPT-4's accuracy in evaluations. Users also discussed the possible improvements Mistral Next would need compared to previous versions like MiQU.
Links mentioned:
- Chat with Open Large Language Models: no description found
- Tweet from Aaditya Ura (Ankit) (@aadityaura): The new Model Gemma from @GoogleDeepMind @GoogleAI does not demonstrate strong performance on medical/healthcare domain benchmarks. A side-by-side comparison of Gemma by @GoogleDeepMind and Mistral...
- Chat with Open Large Language Models: no description found
- Pretraining on the Test Set Is All You Need: Inspired by recent work demonstrating the promise of smaller Transformer-based language models pretrained on carefully curated data, we supercharge such approaches by investing heavily in curating a n...
- gist:c9b5b603f38334c25659efe157ffc51c: GitHub Gist: instantly share code, notes, and snippets.
- Basic RAG | Mistral AI Large Language Models: Retrieval-augmented generation (RAG) is an AI framework that synergizes the capabilities of LLMs and information retrieval systems. It's useful to answer questions or generate content leveraging ...
- Mistral: no description found
- GitHub - MeNicefellow/DrNiceFellow-s_Chat_WebUI: Contribute to MeNicefellow/DrNiceFellow-s_Chat_WebUI development by creating an account on GitHub.
- GitHub - XiongjieDai/GPU-Benchmarks-on-LLM-Inference: Multiple NVIDIA GPUs or Apple Silicon for Large Language Model Inference?: Multiple NVIDIA GPUs or Apple Silicon for Large Language Model Inference? - XiongjieDai/GPU-Benchmarks-on-LLM-Inference
Mistral ▷ #models (20 messages🔥):
- Mistral-tiny Confusion Cleared Up:
@hojjat_22712inquired about the availability and differences between Mistral-tiny and the original 7B model, questioning the specifics that make the tiny version better.@akshay_1clarified that the API uses Mistral 7B instruct V2. - Unexpected Language Support in Mixtral:
@illorca_21005discussed testing Mixtral, reporting adequate performance in Dutch and Greek, although the official documentation only claims support for English, French, Italian, German, and Spanish. Despite the inquiry for documentation on pre-training datasets,@mrdragonfoxprovided no additional information. - Mistral-Next Existence Confirmed:
@paul16307sought confirmation on the existence of Mistral-Next, considering it superior to Mistral-Medium, flagged by a link that was marked as null.@ethuxconfirmed its reality but noted that there is no API access yet and details will be released in the future. - Anticipation for Mistral Details:
@ethuxalso mentioned that they aren't affiliated with Mistral, but assumes details about API access are forthcoming. - Mistral attracts with Pricing and Innovation:
@mrdragonfoxexpressed that the pricing of Mistral is highly attractive to many and that Mistral is pushing the envelope in terms of what is available outside of companies like OpenAI.
Links mentioned:
Chat with Open Large Language Models: no description found
Mistral ▷ #deployment (54 messages🔥):
- Hugging Face Integration: User
@sa_codementioned using Hugging Face'stext-generation-inferencefor some tasks without providing further context or links. - Cost Assessment Inquiry:
@ambre3024asked for assistance in estimating AWS hosting costs for Mistral, and@ethuxfollowed up to clarify which model (Mistral 7b or Mixtral) is being considered. - API Availability for Mistral Next:
@rantash68asked if Mistral next is available via API, to which@sophiamyangsimply responded with "no." - Deployment Options for Mistral on Vertex AI:
@louis2567inquired about deploying Mistral 7b and Mixtral 8x7b models on Vertex AI for batch prediction and discussed the absence of documentation and deployment efficiency with multiple community members, particularly@mrdragonfox, who provided detailed guidance and command examples for using Docker and scaling with GPUs. - Guide for GPU Selection with vLLM:
@buttercookie6265requested a guide for selecting the appropriate GPU for hosting vLLM, receiving advice from@mrdragonfoxabout memory requirements and occupying significant portions of the GPU by default.
Links mentioned:
vLLM | Mistral AI Large Language Models: vLLM can be deployed using a docker image we provide, or directly from the python package.
Mistral ▷ #finetuning (7 messages):
-
Inquiring Fine-tuning Parameters for Mistral:
@iamcoming5084asked about parameters that can influence accuracy during fine-tuning of Mistral 8x7b and Mistral 7B. The discussion on this topic did not provide further information or suggestions. -
Fine-tuning on Unstructured Dataset Inquiry:
@mohammedbelkaid.is seeking help with fine-tuning Mistral 7B on an unstructured email dataset and inquired whether simple preprocessing and tokenization might suffice for tasks like summarizing and responding to questions. -
Guidance Requested for Mistral on Google Colab:
@_logan8_requested assistance on how to fine-tune Mistral 7B on Google Colab using their own dataset, but no direct instructions or links were provided in the chat history. -
Unsloth Demystifies Fine-Tuning for Beginners:
_._pandora_._recommended using Unsloth's demo/notebook for fine-tuning with LoRA on Mistral models, highlighting the resource as beginner-friendly. -
Technical Tips for Better Fine-tuning Outcomes: In response to a question about fine-tuning parameters,
_._pandora_._mentioned adjusting epoch/steps, batch size, and LoRA hyperparameter r as fundamental elements to experiment with.
Mistral ▷ #showcase (13 messages🔥):
- Self-Reflection Enhancement for RAG via LangGraph:
@pradeep1148shared a YouTube video that demonstrates how self-reflection can enhance Retrieval-Augmented Generation (RAG) using LangGraph, a method potentially linked to Mistral applications. - AI Support for Creatives Discussed:
@distrorodeoexpressed interest in creating an AI Creativity decision support system for artists, inquiring about how to start such a project and whether it is feasible to do so alone. - Large Language Model Fine-Tuning Intricacies:
@pradeep1148promoted another YouTube clip discussing BitDelta and suggesting that fine-tuning Large Language Models may only yield marginal benefits. - Twitch Channel Tests Mistral-Next:
@jay9265mentioned testing Mistral-Next for data engineering use cases on their Twitch channel, providing a link to the broadcasts and requesting removal if it's considered self-promotion. - Prompting Capabilities Guide for Mistral:
@mrdragonfoxrecommended exploring Mistral's prompting capabilities further with a guide, providing a link that includes examples of classification, summarization, personalization, and evaluation with Mistral models.
Links mentioned:
- Twitch: no description found
- Prompting Capabilities | Mistral AI Large Language Models: When you first start using Mistral models, your first interaction will revolve around prompts. The art of crafting effective prompts is essential for generating desirable responses from Mistral models...
- Self RAG using LangGraph: Self-reflection can enhance RAG, enabling correction of poor quality retrieval or generations.Several recent papers focus on this theme, but implementing the...
- BitDelta: Your Fine-Tune May Only Be Worth One Bit: Large Language Models (LLMs) are typically trained in two phases: pre-training on large internet-scale datasets, and fine-tuning for downstream tasks. Given ...
Mistral ▷ #la-plateforme (12 messages🔥):
- Access Inquiry to Mistral-Next: User
@superseethatinquired about access to Mistral-Next, having access to Mistral Medium.@ethuxclarified that Mistral Next isn't released yet and can only be tested using the chat from lymsys. - Understanding API Billing Threshold: User
@sapphicsasked for clarification on what exceeding the API billing threshold means.@mrdragonfoxconfirmed the threshold and suggested contacting support at [email protected]. - Trouble with Support Responses:
@ginterhauserexpressed frustration over not receiving a response after reaching out to Mistral support to increase limits.@mrdragonfoxinquired whether an ID was included in the request, and@nicolas_mistraloffered to help if they sent a DM with their ID or email. - Offer to Resolve Support Issues:
@nicolas_mistraland@lerela** from Mistral offered assistance to@ginterhauser` with the billing issue, promising a resolution and asking for a direct message if the problem persisted.
Links mentioned:
no title found: no description found
OpenAI ▷ #ai-discussions (57 messages🔥🔥):
- Google Model Updates:
@oleksandrshrbrought up that Google released a new model with a new name and mentioned its availability for usage. Although@eredon_144also mentioned that he doesn't see the option for plugins on the mobile version of ChatGPT. - GPT-4 Usage Cap Debated:
@7_vit_7and@solbusdiscussed the usage cap for GPT-4, with@solbusproviding links to official explanations regarding the cap and its dynamic nature based on demand and compute availability. - Confusion Over GPT-4 Model Performance: Users discussed potential changes to GPT-4's power over time, with
@luguistating that rumors about GPT-4 being less powerful than at its release are not true. - Stability.ai Releases Stable Diffusion 3:
@pierrunoytshared a news link announcing Stable Diffusion 3 in early preview, aiming to improve multi-subject prompts, image quality, and spelling abilities. - Gemini Model Discourse:
@ertagonhighlighted a YouTube video discussing issues related to Google's Gemini model, particular with regards to diversity.
Links mentioned:
- Introducing ChatGPT Plus: We’re launching a pilot subscription plan for ChatGPT, a conversational AI that can chat with you, answer follow-up questions, and challenge incorrect assumptions.
- Stable Diffusion 3 — Stability AI: Announcing Stable Diffusion 3 in early preview, our most capable text-to-image model with greatly improved performance in multi-subject prompts, image quality, and spelling abilities.
- Gemini has a Diversity Problem: Google turned the anti-bias dial up to 11 on their new Gemini Pro model.References:https://developers.googleblog.com/2024/02/gemini-15-available-for-private-...
OpenAI ▷ #gpt-4-discussions (51 messages🔥):
-
API Access Explained:
@solbuscleared the confusion for@phil4246, stating that the OpenAI API operates on a pay-as-you-go model which is separate from a Plus subscription. They mentioned that tokens are used for specific services like DALL·E 2 but are unrelated to the Plus subscription as well. -
File Upload Caps Clarified: In response to
@my5042's query,@solbusprovided information that the file upload limit has been updated to twenty 512MB files, reaching the 10GB limit per end-user, and recommended checking the most recent FAQs for accurate details. -
GPT Writing Style Challenges:
@darthgustav.advised@thermaltfto use template examples and positive instructions only when attempting to train GPT to mimic their writing style. -
Mysterious ChatGPT Model Mishap:
@Makeshiftcommented on the need for enhanced critical thinking in AI, while@darthgustav.hinted that such requests might touch upon generating plagiarism prompts. -
Extracting Insights from Interviews:
@darthgustav.offered extensive advice to@col.bean, who was having difficulty creating a GPT to find interesting moments in interview transcripts. Suggestions included using positive framing and output templates for instructions, dealing with data chunk sizes, and possibly creating a new GPT for each transcript to avoid retrieval errors. -
No Plugins in Mobile ChatGPT: In response to
@eren_1444asking about using plugins with the mobile version of ChatGPT,@thedreamakeemconfirmed that plugins are not supported on mobile and suggested trying the desktop version on a mobile browser instead. -
Vector Database Discrepancy:
@thirawat_zexpressed concerns about getting results far off from a tutorial while working with OpenAI embeddings and Qdrant, sharing their significantly varying output compared to the expected one. -
Training ChatGPT with HTML/CSS Discussed:
@ls_chichainquired about training ChatGPT with HTML and CSS files, prompting@_jonpoto question the necessity given ChatGPT's extensive training, while@tororshowed interest in what@ls_chichaaimed to achieve beyond ChatGPT's current capabilities. -
AI Models in Conversation Idea:
@link12313suggested creating an app for GPT-4 and Google Gemini Ultra1.5 to converse, which@torornoted has been attempted with other models, often yielding monotonous exchanges without an engaging starting point.
OpenAI ▷ #prompt-engineering (91 messages🔥🔥):
-
Roleplaying with GPT-4:
@shokkunninquired about improving AI roleplay to sound more like the character rather than an actor portraying the character.@darthgustav.suggested specifying custom instructions clearly in the prompts, including concise directions and an output template with open variables that summarily encode the instructions for logical consistency. -
Positive Reinforcement in Prompts Proven More Effective:
@darthgustav.emphasized the importance of using positive instructions when prompting the AI, as negative instructions could lead to non-compliance. -
Turbo vs. Regular GPT-4 for Roleplaying:
@shokkunnobserved that the standard GPT-4 seems to perform better for roleplaying than the Turbo Preview Model.@darthgustav.advised to continue experimenting with prompts for best results and to prepare for transitions as older models are deprecated. -
Addressing Agent Loops in ReAct Prompting:
@tawsif2781encountered issues with their agent getting stuck in a logic loop using ReAct prompting.@darthgustav.recommended avoiding logical inconsistencies and negative instructions in prompts and suggested including redundancy to ensure the AI can continue productive operations through middle-context. -
Learning Resources for Prompt Engineering:
@loamy_asked for resources to learn more about prompt engineering, and@darthgustav.recommended starting with searches on arXiv and Hugging Face, sorting by oldest for basics or latest for advanced strategies.
OpenAI ▷ #api-discussions (91 messages🔥🔥):
- Roleplaying Tips and Tricks:
@shokkunnsought advice for role-playing as a character using AI, and@darthgustav.recommended using specific, concise, and logically consistent instructions, with an output template that reinforces instructions. The importance of positive instructions over negative ones was emphasized, as they yield better compliance. - Modifying Roleplaying Prompts for Better Performance:
@darthgustav.hinted that older models might be deprecated and suggested preparing to progress by adjusting prompts for the current model. Role-play templates should include open variables, and the naming convention should summarize the instructions. - Applying Timestamps for Unique AI Outputs: In a discussion about breaking AI loops and ReAct prompting,
@darthgustav.mentioned that every prompt is unique due to different timestamp tokens, suggesting redundancy in prompts can help bridge gaps in context. - Prompt Engineering Resources Discussed:
@loamy_and@droggerhdinquired about prompt engineering resources, for which@darthgustav.suggested searching arXiv and Hugging Face with specific keywords relating to prompt strategies and techniques. - Prompt Adjustments for Consistent Probability Outputs:
@deb3009was trying to get consistent probability values in outputs when comparing RCA to control datasets. They discussed the challenge of prompt engineering to yield consistent probabilities and received suggestions for crafting effective prompts.
HuggingFace ▷ #general (186 messages🔥🔥):
Links mentioned:
- 3rd Rock GIF - 3rd Rock From - Discover & Share GIFs: Click to view the GIF
- Deer GIF - Deer - Discover & Share GIFs: Click to view the GIF
- Use custom models: no description found
- Conrad Site: no description found
- Stable Diffusion 3 — Stability AI: Announcing Stable Diffusion 3 in early preview, our most capable text-to-image model with greatly improved performance in multi-subject prompts, image quality, and spelling abilities.
- On-device training in TensorFlow Lite — The TensorFlow Blog: no description found
- Google Colaboratory: no description found
- mayacinka/ramonda-7b-dpo-ties · Nice. This is awesome. I chose the same name for my models before you posted this.: no description found
- thomas-c-reid/ppo-LunarLander-v2 · Hugging Face: no description found
- Deep Reinforcement Learning Leaderboard - a Hugging Face Space by huggingface-projects: no description found
- AWS Innovate - AI/ML and Data Edition: no description found
- GitHub - kuangliu/pytorch-cifar: 95.47% on CIFAR10 with PyTorch: 95.47% on CIFAR10 with PyTorch. Contribute to kuangliu/pytorch-cifar development by creating an account on GitHub.
- GitHub - SYSTRAN/faster-whisper: Faster Whisper transcription with CTranslate2: Faster Whisper transcription with CTranslate2. Contribute to SYSTRAN/faster-whisper development by creating an account on GitHub.
- ptx0/photo-concept-bucket · Datasets at Hugging Face: no description found
- Mistral's next LLM could rival GPT-4, and you can try it now in chatbot arena: French LLM wonder Mistral is getting ready to launch its next language model. You can already test it in chat.
HuggingFace ▷ #today-im-learning (7 messages):
- New Member Seeking AI Assistance: User
@mfd000minquired about generating hero images for e-commerce products and asked for model recommendations on Hugging Face suitable for this task. - In Search for the Right Model:
@jamorphyqueried back to clarify which specific model@parvpareekwas referring to when they mentioned "A Neural Probabilistic Language Model." - Mysterious Discord Link Posted: User
@lightyisuposted a Discord linkhttps://discord.com/channels/879548962464493619/1106008166422028319/1106008166422028319, but no context or content was provided. - Flutter Game Query: User
.konohinquired about a flutter game, however no further context or response was given in the conversation. - Nanotron Open Sourced Announcement:
@neuralinkshared that a project named nanotron is now open source, providing a link to the GitHub repositoryhuggingface/nanotronalong with a note that they just merged it.
Links mentioned:
nanotron/examples/doremi at main · huggingface/nanotron: Minimalistic large language model 3D-parallelism training - huggingface/nanotron
HuggingFace ▷ #cool-finds (8 messages🔥):
- Bot Roleplay Development: User
@ainerd777mentioned working on roleplay chatbots, but no further details were provided. - Big Plans for Partnership:
@aaaliahmad.is looking forward to making a partnership with a company that has a 100M market cap. No specifics about the nature of this partnership were provided. - Sticker Shock at Event Pricing:
@lucifer_is_back_reacted to an event priced at $1000 a seat, remarking that with that kind of money they would rather invest in training a 70B model. - ryzxl Announces Model Benchmarking Results:
@ryzxlposted about their Comprehensive Model Benchmarking Initiative results, inviting the community to review the extensive tests conducted on datasets with models from industry leaders listed, and provided links to their leaderboard and repository (Leaderboard and Repo). - Call for Posting Etiquette:
@cakikireminded the community not to cross-post, labeling an instance of multiple posts as spam.
HuggingFace ▷ #i-made-this (22 messages🔥):
Links mentioned:
- Prompt Magic v0.0.1: no description found
- Proteus V0.4 - a Hugging Face Space by FumesAI: no description found
- Portfolio Management - a Hugging Face Space by luisotorres: no description found
- Building an Investment Portfolio Management App 💰: Explore and run machine learning code with Kaggle Notebooks | Using data from No attached data sources
- GitHub - shubham0204/Depth-Anything-Android: An Android app running inference on Depth-Anything: An Android app running inference on Depth-Anything - GitHub - shubham0204/Depth-Anything-Android: An Android app running inference on Depth-Anything
- GitHub - Priyanshu-hawk/ChatGPT-unofficial-api-selenium: This is unofficial ChatGPT API totally written by me in python with selenium: This is unofficial ChatGPT API totally written by me in python with selenium - Priyanshu-hawk/ChatGPT-unofficial-api-selenium
- generative-ai/language/use-cases/document-summarization/summarization_large_documents_langchain.ipynb at main · GoogleCloudPlatform/generative-ai: Sample code and notebooks for Generative AI on Google Cloud - GoogleCloudPlatform/generative-ai
- Cheapest GPT-4 Turbo, GPT 4 Vision, ChatGPT OpenAI AI API API Documentation (NextAPI) | RapidAPI: no description found
- Ultimate guide to optimizing Stable Diffusion XL: Discover how to get the best quality and performance in SDXL with any graphics card.
HuggingFace ▷ #diffusion-discussions (10 messages🔥):
- Timestep embedding in stable diffusion:
@pseudoterminalxdiscussed how in stable diffusion, a timestep embed is concatenated to the text embedding hidden states, which might not be a simple integer but could be a vector created via Fourier transform. - SDXL microconditioning inputs enhancement:
@pseudoterminalxexplained that SDXL uses a Fourier transform to enhance microconditioning inputs, expanding a 6 element input to a 256 element one, mentioning it specifically involves a "3 wide group of two element tuples." - Acknowledgment of diffusion discussions:
@mr.osophyacknowledged@pseudoterminalx's response on a diffusion topic and indicated an intention to delve deeper into the subject at a later time. - Interest in interlingua based translator:
@hobojesus6250aexpressed an interest in developing or finding an interlingua-based translator on Hugging Face for a university project, due to time constraints, looking to extend an existing model or language model to handle translation tasks. - Model expansion for additional classes:
@agusschmidtinquired about running the BART-large-mnli model with more than 10 classes, referencing a discussion that suggested it's possible when running the model locally and asking for guidance or an alternative model that allows for more classes.
HuggingFace ▷ #computer-vision (1 messages):
- Multi-label Image Classification Tutorial: User
@nielsr_shared a tutorial notebook for multi-label image classification, demonstrating the process using SigLIP, a strong vision backbone available in the Transformers library, while noting that any vision model from the library can be used.
HuggingFace ▷ #NLP (36 messages🔥):
- TensorFlow Troubles Tamed: User
@diegot8170experienced issues loading a model with TensorFlow, resolved by@cursoropsuggesting the reinstallation of TensorFlow with a specific version (2.15) using pip commands. - Custom Sentence Similarity for Biomedicine:
@joshpopelka20faced challenges with pre-trained embedding models for sentence similarity in biomedical terms, which led to a suggestion by@lavi_39761to explore contrastive learning and tools like sentence transformers and setfit for fine-tuning. - PEFT Persistence Problems: Participants
@grimsqueakerand@kingpokidiscussed a recurring issue where PEFT does not save the correct heads for models not covered by auto configuration, leading to workaround attempts through parameter adjustments. - Exploring the Reformer Architecture:
@devbravomentioned research into the Reformer architecture to develop smaller, more memory-efficient models suitable for edge devices. - Bert's Training Data Dilemmas Unaddressed:
@jldevtechqueried the community for insights into the minimum data requirements needed to train a Bert perf adapter for multi-label classification, but did not receive feedback within the given exchange.
HuggingFace ▷ #diffusion-discussions (10 messages🔥):
- Stable Diffusion Embeddings Discussed:
@pseudoterminalxnoted that in stable diffusion, the timestep embed is concatenated to the text embedding hidden states, possibly using a fourier transform to create a vector. - SDXL Microconditioning Explained: Further explaining,
@pseudoterminalxdescribed how SDXL uses a fourier transform on microconditioning inputs appended to the time embed, expanding a 6-element input to a 256-element output. - Tuple Expansion in Time Embed: Clarifying the dimensions,
@pseudoterminalxmentioned it's a 3 wide group of two-element tuples for the time embeds in stable diffusion. - mr.osophy Acknowledges Discussion Point:
@mr.osophyexpressed thanks for the prior response from@636706883859906562and plans to explore the topic more later. - Searching for Interlingua Translator Projects:
@hobojesus6250ainquired if anyone has worked with an interlingua-based translator on Hugging Face, expressing a desire to extend one for a university project due to time constraints. - Multiple Classes Query for BART Model:
@agusschmidtasked for guidance on running the BART-large-mnli model with more than 10 classes, wondering how to execute this locally or if another model allows for more classes.
Latent Space ▷ #ai-general-chat (78 messages🔥🔥):
-
Gemma Makes a Grand Entrance: Google rolls out a new family of language models, Gemma, with the 7B and 2B sizes on Hugging Face. User
@mjng93linked to the Hugging Face blog and@coffeebean6887shared the terms of release highlighting restrictions on distributing model derivatives. -
Gemma Under the Microscope:
@guardiangdissected the Gemma tokenizer in relation to the Llama 2 tokenizer, indicating that Gemma has a larger vocab and includes numerous special tokens; detailing this analysis was shared via links to the tokenizer's model file and a diffchecker comparison. -
Stable Diffusion 3 Emerges:
@rubenartusannounced the early preview of Stable Diffusion 3, providing links to the Stability AI announcement and a Twitter thread by EMostaque with further details. -
Google's Gemini Pro 1.5 Explored:
@nuvic_was intrigued by Gemini Pro 1.5's new 1,000,000 token context size and its ability to incorporate video as input, citing Simon Willison's experiments with the technology outlined on his personal blog. -
ChatGPT Goes Haywire, Then Fixed:
@swyxioshared a Twitter link addressing ChatGPT's strange behavior while@dimfeldpointed to the OpenAI status page confirming the resolution of the issue.
Links mentioned:
- no title found: no description found
- One Year of Latent Space: Lessons (and memories) from going from 0 to 1M readers in 1 year with Latent Space.
- Stable Diffusion 3 — Stability AI: Announcing Stable Diffusion 3 in early preview, our most capable text-to-image model with greatly improved performance in multi-subject prompts, image quality, and spelling abilities.
- The killer app of Gemini Pro 1.5 is video: Last week Google introduced Gemini Pro 1.5, an enormous upgrade to their Gemini series of AI models. Gemini Pro 1.5 has a 1,000,000 token context size. This is huge—previously that …
- Unexpected responses from ChatGPT: no description found
- Tweet from Andrej Karpathy (@karpathy): Seeing as I published my Tokenizer video yesterday, I thought it could be fun to take a deepdive into the Gemma tokenizer. First, the Gemma technical report [pdf]: https://storage.googleapis.com/de...
- Tweet from Dana Woodman (@DanaWoodman): what the actual fuck @ChatGPTapp 😂 i'm not a networking guru but i'm pretty sure this is just nonsense...
- Tweet from Hamilton Ulmer (@hamiltonulmer): I'm in the weirdest chatgpt experiment branch
- Welcome Gemma - Google’s new open LLM: no description found
- no title found: no description found
- Scaling ChatGPT: Five Real-World Engineering Challenges: Just one year after its launch, ChatGPT had more than 100M weekly users. In order to meet this explosive demand, the team at OpenAI had to overcome several scaling challenges. An exclusive deepdive.
- Launch HN: Retell AI (YC W24) – Conversational Speech API for Your LLM | Hacker News: no description found
- Rise of the AI Engineer (with Build Club ANZ): Slides:https://docs.google.com/presentation/d/157hX7F-9Y0kwCych4MyKuFfkm_SKPTN__BLOfmRh4xU/edit?usp=sharing🎯 Takeaways / highlights thread in the Build Club...
- Reddit - Dive into anything: no description found
- no title found: no description found
Latent Space ▷ #ai-announcements (3 messages):
- Dive into 'Building Your Own Product Copilot':
@swyxioannounced that@451508585147400209is leading a discussion on the Building Your Own Product Copilot paper. The session is accessible through a specific Discord channel. - Stay Informed of Future Events with Latent.Space:
@swyxioshared a link to Latent.Space events where users can click the RSS logo to add the event calendar to their personal calendars and receive notifications. Instructions include clicking the "Add iCal Subscription" on hover for automatic updates.
Links mentioned:
Latent Space (Paper Club & Other Events) · Luma: View and subscribe to events from Latent Space (Paper Club & Other Events) on Luma. Latent.Space events. PLEASE CLICK THE RSS LOGO JUST ABOVE THE CALENDAR ON THE RIGHT TO ADD TO YOUR CAL. "Ad...
Latent Space ▷ #llm-paper-club-west (173 messages🔥🔥):
- Hilarious Human-AI Interactions:
@_bassboosthighlighted a quirky instance from a paper where a conversation asking for recommendations led users to respond with personal issues such as not having friends. Engineers tried to steer the model away from topics that might lead to sensitive areas. - Paper Club Voting Spree: Members like
@eugeneyan,@henriqueln7, and@amgadozdiscussed and voted on which paper to dive into, with options such as a Copilot study and Sora being suggested. Links to the papers were provided, including an abstract for the Copilot study at arxiv. - Google Gemini Takes Off:
@coffeebean6887discussed the integration of Google's Gemini AI into Workspace and Google One services, providing visuals and blog post links that highlight its advanced capabilities (Google One, Workspace). - AI Eval Judges: The discussion shifted to evaluating AI responses, with members like
@henriqueln7,@swyxio, and@_bassboostdiscussing the use of Langsmith, GPT4, and smaller models as judges for conversational chatbots and learning platforms. Tools like predibase.com Lora Land were also shared for finetuning comparison. - Future of ML and GenAI Talent: In a forward-looking thread,
@lightningralfand@eugeneyandebated the evolving landscape for ML/GenAI talent and companies adopting AI. They speculated on the implications of rapidly improving tooling and AI advancements that could change the need for certain skillsets in a few years.
Links mentioned:
- Building Your Own Product Copilot: Challenges, Opportunities, and Needs: A race is underway to embed advanced AI capabilities into products. These product copilots enable users to ask questions in natural language and receive relevant responses that are specific to the use...
- Boost your productivity: Use Gemini in Gmail, Docs and more with the new Google One plan: We’re bringing even more value to the Google One AI Premium plan with Gemini in Gmail, Docs, Slides, Sheets and Meet (formerly Duet AI).
- LoRA Land: Fine-Tuned Open-Source LLMs: Fine-tuned LLMs that outperform GPT-4, served on a single GPU
- Tweet from Amazon Web Services (@awscloud): The PartyRock #generativeAI Hackathon by #AWS starts now! 📣 Learn how to build fun & intuitive apps without coding for a chance to win cash prizes and AWS credits. 🏆 #AI Don't forget your mug...
- SPQA: The AI-based Architecture That’ll Replace Most Existing Software: March 10, 2023 AI is going to do a lot of interesting things in the coming months and years, thanks to the detonations following GPTs. But one of the most impor
- no title found): no description found
- - Fuck You, Show Me The Prompt.: Quickly understand inscrutable LLM frameworks by intercepting API calls.
- New ways Google Workspace customers can use Gemini: We’re launching a new offering to help organizations get started with generative AI, plus a standalone experience to chat with Gemini.
- Founder’s Guide to Basic Startup Infrastructure: no description found
- GitHub - stanfordnlp/dspy: DSPy: The framework for programming—not prompting—foundation models: DSPy: The framework for programming—not prompting—foundation models - stanfordnlp/dspy
LlamaIndex ▷ #blog (3 messages):
- Simplifying RAG Complexity:
@IFTTThighlights the complexities in building advanced RAG systems due to numerous options. They suggest a method to simplify by pinpointing pain points and corresponding solutions in each pipeline component, sharing slides from @jerryjliu0’s presentation. - Frontend for LLM/RAG Experts: A tutorial by Marco Bertelli, recommended by
@IFTTT, teaches LLM/RAG experts without React knowledge how to create a beautiful frontend for their RAG backend, with resources from @llama_index. - From RAG Notebooks to Full-Stack Applications:
@wenqi_glantzprovides a tutorial on transforming RAG notebooks into comprehensive applications with ingestion and inference microservices, as shared by@IFTTTin their tweet featuring the tutorial link and further steps. See the full tutorial here.
LlamaIndex ▷ #general (246 messages🔥🔥):
- QueryPipeline RAG Clarification Sought: User
@lapexerwas curious about writing a simple RAG in QueryPipeline of a DAG with prompt, retriever, and llm. The documentation RAG Pipeline Without Query Rewriting was provided for guidance on setting up the pipeline. - LlamaIndex ImportError Troubles: Users
@emmepraand@pymangekyodiscussed issues importingVectorStoreIndexfromllama_index.@emmeprasuggested importing fromllama_index.coreinstead ofllama_index.legacyto possibly fix the problem, while@whitefang_jrrecommended using a fresh environment after uninstallation and re-installation. - LangchainEmbedding Import Issue: User
@pymangekyocould not importLangchainEmbeddingfromllama_index.embeddingsdespite following the documentation.@emmepraproposed a solution by advising to try importing fromllama_index.core.indices, but@pymangekyocontinued to face issues. - CRAG Pack Download Issues: User
@lapexerreported aValueErrorwhen trying to download the CorrectiveRAGPack withllamaindex-cli.@whitefang_jrnoted a related pull request fixing llama-pack downloads which might address the problem. PR #11272 was linked for reference. - LlamaIndex Docs and LlamaHub Reader Links Broken: User
@andaldanainquired about processing data where each SQL database entry is a document usingDatabaseReaderandCSVreader, but found that the documentation links were broken. They are seeking an updated method or reader within LlamaIndex to achieve their goal.
Links mentioned:
- no title found: no description found
- T-RAG = RAG + Fine-Tuning + Entity Detection: The T-RAG approach is premised on combining RAG architecture with an open-source fine-tuned LLM and an entities tree vector database. The…
- Fine-tuning - LlamaIndex 🦙 v0.10.11.post1: no description found
- Google Colaboratory: no description found
- Building Your Own Evals - Phoenix: no description found
- LangChain Embeddings - LlamaIndex 🦙 v0.10.11.post1: no description found
- RAG CLI - LlamaIndex 🦙 v0.10.11.post1: no description found
- Loading Data (Ingestion) - LlamaIndex 🦙 v0.10.11.post1,): no description found
- no title found: no description found
- no title found: no description found
- llama_index/llama-index-core/llama_index/core/question_gen/llm_generators.py at main · run-llama/llama_index: LlamaIndex (formerly GPT Index) is a data framework for your LLM applications - run-llama/llama_index
- llama_index/llama-index-core/llama_index/core/question_gen/llm_generators.py at da5f941662b65d2e3fe2100f2b58c3ba98d49e90 · run-llama/llama_index: LlamaIndex (formerly GPT Index) is a data framework for your LLM applications - run-llama/llama_index
- llama_index/llama-index-core/llama_index/core/callbacks/token_counting.py at 6fb1fa814fc274fe7b4747c047e64c9164d2042e · run-llama/llama_index: LlamaIndex (formerly GPT Index) is a data framework for your LLM applications - run-llama/llama_index
- An Introduction to LlamaIndex Query Pipelines - LlamaIndex 🦙 v0.10.11.post1: no description found
- no title found: no description found
- llama_parse/examples/demo_advanced_astradb.ipynb at main · run-llama/llama_parse: Parse files for optimal RAG. Contribute to run-llama/llama_parse development by creating an account on GitHub.
- llama_parse/examples/demo_astradb.ipynb at main · run-llama/llama_parse: Parse files for optimal RAG. Contribute to run-llama/llama_parse development by creating an account on GitHub.
- [FIX] download_llama_pack for python packages containing multiple packs by nerdai · Pull Request #11272 · run-llama/llama_index: Description Previous download_llama_pack logic didn't traverse the Github tree deep enough, which posed a problem for packages with multiple packs (i.e., since there are more folders containing s...
- Survey on your Research Journey: In an effort to revolutionize academic and business research, EurekAI seeks your insights to tailor our tool to your needs. Whether you're immersed in research or engage with it sporadically, your...
- Custom Embeddings - LlamaIndex 🦙 v0.10.11.post1: no description found
- llama_index/llama-index-integrations/embeddings/llama-index-embeddings-ollama/llama_index/embeddings/ollama/base.py at main · run-llama/llama_index: LlamaIndex (formerly GPT Index) is a data framework for your LLM applications - run-llama/llama_index
- OpenAI API compatibility · Issue #305 · ollama/ollama: Any chance you would consider mirroring OpenAI's API specs and output? e.g., /completions and /chat/completions. That way, it could be a drop-in replacement for the Python openai package by changi...
LlamaIndex ▷ #ai-discussion (3 messages):
- Gratitude Expressed: User
@behanzin777expressed their intention to try out a suggested solution, showing gratitude with "Thanks. I will give it a try 🙏🏾". - Seeking Summarization Metrics for LlamaIndex:
@dadabit.inquired about effective metrics and tools for evaluating summarization within LlamaIndex. They are interested in recommendations based on community experiences. - Quest for an LLM Evaluation Platform:
@.dheemanthis on the lookout for an easy-to-use platform to evaluate Large Language Models (LLMs) that includes analysis, tracking, and scoring capabilities similar to MT-Bench and MMLU.
OpenAccess AI Collective (axolotl) ▷ #general (149 messages🔥🔥):
-
Google's Gemma AI Model Discussed: Users in the OpenAccess AI Collective are actively discussing Google's new Gemma model family.
@nafnlaus00examined the license details, noting its less restrictive nature compared to LLaMA 2.@le_messprovided updates on Gemma's integration on Hugging Face, with links to models and technical documentation. -
Gemma Model Attributes Revealed:
@le_messgained access to Gemma's repo, revealing characteristics such asmax_position_embeddings: 8192andvocab_size: 256000. Discussion centered around the implications of a high vocabulary size and how that might affect inference time. -
Public Access to Gemma Models:
@le_messreported on re-uploading Gemma's 7B model, making it accessible for public use on Hugging Face, bypassing the access request originally required by Google. -
Finetuning Challenges with Gemma: Several users reported issues finetuning Gemma, specifically
@stoicbatmanwho experienced an error at the end of training. Related GitHub issues were cited by@nanobitzindicating potential early stopping callback issues. -
Cloud Compute Cost Analysis:
@yamashibrought up the high cost of cloud compute resources in a discussion with Google, comparing it to the price of physically owning a server. DreamGen discussed potential discounts that could make cloud options more appealing, especially for researchers.
Links mentioned:
- no title found: no description found
- HuggingChat: Making the community's best AI chat models available to everyone.
- Welcome Gemma - Google’s new open LLM: no description found
- mhenrichsen/gemma-7b · Hugging Face: no description found
- Google introduces a lightweight open AI model called Gemma: Google says Gemma is its contribution to the open community and is meant to help developers "in building AI responsibly."
- mhenrichsen/gemma-7b-it · Hugging Face: no description found
- Tweet from Tri Dao (@tri_dao): FlashAttention v2.5.5 now supports head dim 256 backward on consumer GPUs. Hope that makes it easier to finetune Gemma models
- Error while saving with EarlyStoppingCallback · Issue #29157 · huggingface/transformers: System Info transformers version: 4.38.0.dev0 (also in 4.38.0 and 4.39.0.dev0) Platform: Linux-5.15.0-78-generic-x86_64-with-glibc2.35 Python version: 3.10.12 Huggingface_hub version: 0.20.3 Safete...
- llm-foundry/scripts/train/README.md at main · mosaicml/llm-foundry: LLM training code for MosaicML foundation models. Contribute to mosaicml/llm-foundry development by creating an account on GitHub.
- Enable headdim 256 backward on consumer GPUs (Ampere, Ada) · Dao-AILab/flash-attention@2406f28: no description found
- GitHub - Dao-AILab/flash-attention: Fast and memory-efficient exact attention: Fast and memory-efficient exact attention. Contribute to Dao-AILab/flash-attention development by creating an account on GitHub.
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (26 messages🔥):
- Merge Ready for Fixes:
@nanobitzsought confirmation to begin merging small PRs including readme fixes, val fixes, and example fixes into the axolotl codebase. - Gemma Training Requirements:
@giftedgummybeehighlighted the need for the non-dev version of transformers to train gemma models, mentioning that the dev version does not support "gemma" type models. This was corroborated by@stoicbatman, who experienced problems with the dev version on the axolotl docket image. - Configuration Clarity for Gemma:
@stoicbatmanshared an updated gemma config file to address issues during setup. Meanwhile,@nanobitznoted that sample packing is not yet functional with the model. - Hyperparameter Confusion on Gemma tuning:
@faldoreand@nanobitzdiscussed the appropriate learning rate and weight decay for Gemma models, with references to Google's various recommendations of 5e-5 and 2e-4 across different documents. - Optimization Suggestions for Mixtral:
@casper_aishared insights on optimizing the Mixtral model and discussed the potential for speed improvements, though noted a lack of expertise in writing CUDA backward passes. They also mentioned the success in prefilling and decoding speed with AutoAWQ.
Links mentioned:
- Welcome Gemma - Google’s new open LLM: no description found
- Google Colaboratory: no description found
- gemma_config_axolotl.yml: GitHub Gist: instantly share code, notes, and snippets.
OpenAccess AI Collective (axolotl) ▷ #general-help (51 messages🔥):
- Seeking Alpaca Template:
@yamashilooks for the jinja template for alpaca, with@rtyaxsharing a potential template and@yamashiintending to add it to the axolotl repository. - Genial Training Assistance:
@napuhexplores how to train faster with DeepSpeed and multiple GPUs, while@nanobitzclarifies that the micro batch size multiplied by gradient accumulation is per GPU, meaning more GPUs should result in fewer steps. - Finetuning Inference Formats:
@timisbisterand@nani1149inquire about the correct format for inference after finetuning their models,@nanobitzand@yamashirespond with template and format guidance, and@yamashinotes the need for proper documentation to reduce repeated questions. - FlashAttention Frustrations:
@rakesh_46298struggles with a runtime error related to FlashAttention and GPUs, and@nanobitzadvises to turn off the function but additional clarification is needed. - Documentation Desire: In light of repeating questions,
@yamashiand@nanobitzdiscuss the need for better documentation for axolotl through read-the-docs or gitbooks, noting that it was a topic of a previous discussion.
Links mentioned:
- tokenizer_config.json · teknium/OpenHermes-2.5-Mistral-7B at main: no description found
- GitHub - tatsu-lab/stanford_alpaca: Code and documentation to train Stanford's Alpaca models, and generate the data.: Code and documentation to train Stanford's Alpaca models, and generate the data. - tatsu-lab/stanford_alpaca
- text-generation-webui/instruction-templates/Alpaca.yaml at main · oobabooga/text-generation-webui: A Gradio web UI for Large Language Models. Supports transformers, GPTQ, AWQ, EXL2, llama.cpp (GGUF), Llama models. - oobabooga/text-generation-webui
OpenAccess AI Collective (axolotl) ▷ #community-showcase (1 messages):
- New Adventure in AI Storytelling:
@dreamgenannounced the release of their new models for AI-driven story-writing and role-playing that are now available on Hugging Face. These Opus V1 models were trained on approximately 100M tokens of human-generated text and are based on an extended version of ChatML. - Guiding the Narrative with ChatML+: The included models leverage an improved version of ChatML for prompting, with added flexibility for more controlled outputs. Detailed usage of the models, along with prompting instructions, can be found in the Opus V1 guide here.
- The Secret of Steering Conversations:
@dreamgenexplained the concept of steerable prompts, which involves a structured input: a system prompt that defines the story or role-play scene, followed by turns of text as the story unfolds and instructions to guide what happens next. This allows users to more directly influence the direction of the generated content.
Links mentioned:
- Opus V1: Story-writing & role-playing models - a dreamgen Collection: no description found
- DreamGen: AI role-play and story-writing without limits: no description found
OpenAccess AI Collective (axolotl) ▷ #runpod-help (6 messages):
- RunPod Image Mysteriously Vanishes:
@stoicbatmanreported an issue regarding the RunPod image being seemingly deleted and mentioned difficulty in locating it. - Helpful Direction to Docker Tags: In response to the confusion,
@nanobitzprovided a helpful link to Docker Hub, where the tags for the RunPod image can be found. - GitHub Readme Redirect Issues:
@stoicbatmanpointed out that the GitHub readme is not correctly redirecting users to the actual RunPod image, signifying a potential problem with the GitHub documentation. - Latest Link Dilemma:
@nanobitzenquired if@stoicbatmanhad the latest link, indicating a potential update or change in the resources that might lead to the correct RunPod image location.
Links mentioned:
Docker: no description found
CUDA MODE ▷ #general (2 messages):
-
Groq LPU sets new AI benchmarks:
@srns27highlighted the Groq LPU Inference Engine's performance breakthrough in large language models, where it outperformed competitors in a recent benchmark, achieving 241 tokens per second. The benchmark details are available on Groq's website and ArtificialAnalysis.ai. -
Deep Dive into Groq's Architecture:
@dpearsonshared a YouTube video by Groq's Compiler Tech Lead, Andrew Bitar, explaining the architecture behind Groq's high speed. The presentation titled "Software Defined Hardware for Dataflow Compute" was delivered at the Intel/VMware Crossroads 3D-FPGA Academic Research Center.
Links mentioned:
- Groq's $20,000 LPU chip breaks AI performance records to rival GPU-led industry.): Groq’s LPU Inference Engine, a dedicated Language Processing Unit, has set a new record in processing efficiency for large language models. In a recent benchmark conducted by ArtificialAnalysis....
- Software Defined Hardware for Dataflow Compute / Crossroads 3D-FPGA Invited Lecture by Andrew Bitar: Invited lecture by Groq's Compiler Tech Lead, Andrew Bitar, for the Intel/VMware Crossroads 3D-FPGA Academic Research Center on Dec 11, 2022.Abstract: With t...
CUDA MODE ▷ #triton (3 messages):
- Simplicity in Tools:
@srush1301mentioned using Excalidraw for simple tasks, while highlighting that gpu puzzles work with chalk-diagrams. - Discovering Excalidraw:
@morgangiraudexpressed that they were unfamiliar with the tool mentioned by@srush1301. - Questioning Triton's Advantages:
@_hazlerasked@745353422043087000whether implementing something in Triton offers any significant speed improvements or new deployment platforms, or if it's mainly for educational purposes.
CUDA MODE ▷ #cuda (18 messages🔥):
- CUDA Function Pointer Query: User
@carrot007.asked about calling a device function pointer within a global function when facing a warning duringcudaMemcpyFromSymbol.@morousgadvised against it due to potential inefficiency and bugs likecudaErrorInvalidPc, recommending C++ templates as an alternative to keep compilation optimizations intact. - Installing NVIDIA Nsight in Docker:
@dvruetteinquired about experience with installing NVIDIA Nsight for debugging within a Docker container on vast.ai.@marksaroufimmentioned similar issues across cloud providers and highlighted that lighting.ai studios had a working solution. - NVIDIA
ncuTool Works in Docker: In response to CUDA profiling discussions,@lntgconfirmed thatncuworks as expected within Docker containers and offered support for CUDA mode members with expedited verification and free credits on their platform. - Performance Trouble with NVIDIA Profiling Tool:
@complexfilterrencountered a warning saying==WARNING== No kernels were profiledwhen attempting to profile their CUDA code. They provided the command used which wasncu -o profile --set full ./add_cuda. - Announcement of New BnB FP4 Repo:
@zippikacreated a GitHub repository for their bnb fp4 code and reported it to be faster than bitsandbytes. The code requires CUDA compute capability >= 8.0. They also provided a detailed Python script testing the speed comparison and highlighted the high VRAM requirement for a specific model.
Links mentioned:
GitHub - aredden/torch-bnb-fp4: Contribute to aredden/torch-bnb-fp4 development by creating an account on GitHub.
CUDA MODE ▷ #torch (5 messages):
- Seeking Clarity on torch.compile's Limitations:
@ardywibowoenquired about what torch.compile doesn't do and was curious about the types of speed enhancements available through Triton/CUDA that might not be captured by torch.compile. - Query on Making Mixed Type Matmul Public:
@jeremyhowardsought information about whether there are any plans to make the mixed type matrix multiplication (matmul) public and if there are any safety or implementation details such as the use of nf4. - Custom Kernels vs. PyTorch Native Kernels:
@gogators.discussed that sometimes PyTorch’s native kernels are less performant, citing a 6x speed improvement with a custom kernel for 1D convolutions at batch size 1. Yet, the native kernels for common operators are efficient for non-research use cases. - torch.compile and Dynamic Control Flow:
@gogators.mentioned that torch.compile does not handle dynamic control flow well, which is mostly a rare scenario in neural networks. - Fusion Gains Missed by torch.compile:
@gogators.expressed doubts about torch.compile's ability to replicate the kernel fusion gains seen in flash-attention, highlighting that it may not optimize across all network architectures as custom kernels might.
CUDA MODE ▷ #suggestions (1 messages):
- Gemini 1.5 Discussion Invite:
@shashank.f1invites everyone to join a live discussion on Gemini 1.5. Interested participants can join through the provided Discord invite link. - A-JEPA AI Explores Audio for Semantic Knowledge: The same user shared a YouTube video titled "A-JEPA AI model: Unlock semantic knowledge from .wav / .mp3 file or audio spectrograms". The video promises insights into AI learning from audio and showcases a discussion with several experts.
Links mentioned:
- Join the hedwigAI Discord Server!: Check out the hedwigAI community on Discord - hang out with 50 other members and enjoy free voice and text chat.
- A-JEPA AI model: Unlock semantic knowledge from .wav / .mp3 file or audio spectrograms: 🌟 Unlock the Power of AI Learning from Audio ! 🔊 Watch a deep dive discussion on the A-JEPA approach with Oliver, Nevil, Ojasvita, Shashank, Srikanth and N...
CUDA MODE ▷ #jobs (1 messages):
- ML Engineer Opportunity at SIXT, Munich:
@ppeter0480announced a job opening for an ML Engineer at SIXT in Munich, focusing on NLP and Generative AI skills, along with strong engineering background. Interested candidates can apply through the provided career link. This role includes translating business problems into technical solutions and improving customer experiences with advanced algorithms.
Links mentioned:
Apply now: Senior Machine Learning Engineer (m/f/d) | Munich: The job of your dreams in Munich: Senior Machine Learning Engineer (m/f/d). Join the SIXT team! We are looking forward to your application!
CUDA MODE ▷ #beginner (12 messages🔥):
- CUDA Compile Times in Question:
@0ut0f0rderexpressed concerns about the slow compile times for simple CUDA kernels, experiencing about a 1-minute compile time for an x² kernel when using torch_inline. - Seeking Speed in Numba: In response to the slow compile times raised by
@0ut0f0rder,@jeremyhowardmentioned that while CUDA does have slow compile times, numba is a faster alternative. - Questioning CUDA's Longevity in the Face of Groq AI:
@dpearsonshared a YouTube video discussing Groq AI's new hardware and compiler, sparking a debate on whether learning CUDA will become obsolete as compilers become more efficient and automated in resource utilization. - Learning CUDA Still Valuable: User
@telepath8401rebutted concerns about CUDA's obsolescence raised by@dpearson, emphasizing the foundational knowledge acquired from CUDA learning and its value beyond specific architectures or platforms. - PyTorch 'torch_inline' Troubles: A technical issue with generating
.sofiles using torch_inline was reported by@jrp0, who is unable to produce the expected files in a Jupyter notebook launched through runpod, unlike when using Colab.
Links mentioned:
- torch.cuda.jiterator._create_jit_fn — PyTorch 2.2 documentation: no description found
- Software Defined Hardware for Dataflow Compute / Crossroads 3D-FPGA Invited Lecture by Andrew Bitar: Invited lecture by Groq's Compiler Tech Lead, Andrew Bitar, for the Intel/VMware Crossroads 3D-FPGA Academic Research Center on Dec 11, 2022.Abstract: With t...
CUDA MODE ▷ #youtube-recordings (1 messages):
- Channel Hygiene Reminder: User
andreaskoepfreminded all users to keep the youtube-recordings channel focused on its intended purpose and to move unrelated content to the appropriate channel <#1189868872887705671>.
CUDA MODE ▷ #jax (11 messages🔥):
-
CUDA vs TPU Compatibility Queries:
@drexaltcontemplates whether removing repeat calls for the TPU would make a code compatible with GPU. The user considers giving this approach a try. -
Shape Dimension Woes on GPU:
@iron_boundencounters the typical shape dimensions error when running processes on the GPU, but confirms that the program did start before crashing. -
Compatibility Issues with AMD GPUs:
@mrrationalreports that testing on AMD GPUs did not work, which is supported by@iron_boundwho has never managed to get FA2 training working on their 7900xtx, even with the Triton version. -
ROCm's Flash-Attention Lacks Backwards Kernel:
@iron_boundshares a GitHub repo that could potentially be used for inference on an AMD GPU but mentions it is missing the backwards function/kernel. -
Troubleshooting Flash-Attention on AMD:
@drisspginforms about limited Flash Attention v2 support in PyTorch that might run on AMD GPUs, and@iron_boundfollows up by posting an error message received when attempting to use a7900xtxGPU with the version2.3.0.dev20240118+rocm6.0.@drisspgoffers to forward the issue to AMD representatives if an issue is created.
Links mentioned:
- GitHub - srush/triton-autodiff: Experiment of using Tangent to autodiff triton: Experiment of using Tangent to autodiff triton. Contribute to srush/triton-autodiff development by creating an account on GitHub.
- GitHub - ROCm/flash-attention at howiejay/navi_support: Fast and memory-efficient exact attention. Contribute to ROCm/flash-attention development by creating an account on GitHub.
CUDA MODE ▷ #ring-attention (39 messages🔥):
-
Exploring Flash Attention Mechanics:
@nshepperddiscussed the mechanics of flash attention, specifying the need for accumulators during the forward pass and mentioned that for the backward pass, the existinglsenegates the need for an online softmax. Insights into the workings of the algorithm were detailed, suggesting the flow of gradients and data between nodes. -
Seeking Contributions for Attention Distribution Example:
@andreaskoepfexpressed interest in an example notebook simulating attention distribution across multiple dummy GPUs, prompting@ericauldto share an in-progress dummy version of the algorithm, which they noted has significant numerical inaccuracies that may be stemming from typos in the FlashAttention2 paper they used as a reference. -
Typo Hunting in Attention Algorithm:
@lancertsacknowledged and confirmed the existence of typos in the FlashAttention2 paper, highlighted by@ericauld, and offered corrections. They also suggested a fix in the discussed algorithm for a highlighted portion via a Pull Request. -
Rapid PyTorch Translation and Debugging: Both
@iron_boundand@andreaskoepfshared their progress in translating the code to PyTorch and debugging existing implementations, respectively, showcasing community-driven development. Iron Bound made a call for assistance with torch distributed integration. -
Planning Collaborative Live Hacking Session:
@andreaskoepforganized a live hacking session and encouraged participation to improve the flash-attention-based ring-attention implementation. A potential floating-point precision issue was raised concerning the necessity of FP32 accumulation in flash attention for handling long contexts.
Links mentioned:
- Google Colaboratory: no description found
- Is there an equivalent of jax.lax.scan (eg in torch.func)?: I would like to translate the following jax code (that implements a Kalman filter) to torch. def kf(params, emissions, return_covs=False): F, Q, R = params['F'], params['Q'], para...
- Tweet from Andreas Köpf (@neurosp1ke): We will live hack today 19:00 UTC in the cuda mode discord on this nice flash-attention based ring-attention impl (>1M context length) - kudos Zilin Zhu: https://github.com/zhuzilin/ring-flash-atte...
- ring-attention/notebooks/DummyRingAttentionImpl.ipynb at main · cuda-mode/ring-attention: Optimized kernels for ring-attention [WIP]. Contribute to cuda-mode/ring-attention development by creating an account on GitHub.
- GitHub - zhuzilin/ring-flash-attention: Ring attention implementation with flash attention: Ring attention implementation with flash attention - zhuzilin/ring-flash-attention
- xformers/xformers/ops/fmha/init.py at 99ad1723b0b80fb21c5e4dc45446e93752f41656 · facebookresearch/xformers: Hackable and optimized Transformers building blocks, supporting a composable construction. - facebookresearch/xformers
- ring-attention/ring_attn/ring_attention.py at tests · Iron-Bound/ring-attention: Optimized kernels for ring-attention [WIP]. Contribute to Iron-Bound/ring-attention development by creating an account on GitHub.
- fix the dummy-nb by lancerts · Pull Request #8 · cuda-mode/ring-attention: @ericauld
- ir - Overview: ir has 4 repositories available. Follow their code on GitHub.
Perplexity AI ▷ #general (58 messages🔥🔥):
- Google's Gemini Model Confusion:
@brknclock1215clarifies the Gemini model family, sharing a two-month free trial link for Gemini Advanced (Ultra 1.0) and a private preview application for Gemini Pro 1.5. Additionally, they recommend watching Sam Witteveen's YouTube videos for real-world testing and point to a blog post that explains the Gemini family of models. - Perplexity AI Discord Bot Queries: Multiple users inquire about using or locating a Perplexity AI bot within Discord.
@icelavamanand@mares1317guide users to appropriate channels,@nocindmentions a bot being offline, and jesting occurs about the life and death of said bot. - Pro Version Access & Subscription Concerns: Users face confusion about accessing features associated with Perplexity's Pro version.
@me.lksuggests rejoining the server while@mares1317provides a link to the billing and subscription FAQ page.@tree.aiand@ok.alexrespond to questions about adding team members and availability of the Gemini Ultra model. - Concerns Over Inconsistent API Responses: Users express issues with inconsistent responses when using the Perplexity AI API.
@ok.alexacknowledges the problem and suggests switching to a different model for the time being. - Requests for Perplexity Pro Access and AI Capabilities: Users engage in conversations about gaining access to Perplexity Pro channels and inquire about newly released features and models.
@gooddawg10eagerly waits for updates on GPT vision connecting to the web, and@ok.alexpromises to keep the community informed.
Links mentioned:
- Code is a Four Letter Word: Gemini Versus Gemini: Understanding Google's Latest... Thing: no description found
- Discover Daily by Perplexity: We want to bring the world's stories to your ears, offering a daily blend of tech, science, and culture. Crafted from our Discover feed, each episode is desi...
- Gemini 1.5: Our next-generation model, now available for Private Preview in Google AI Studio - Google for Developers: no description found
- Sam Witteveen: HI my name is Sam Witteveen, I have worked with Deep Learning for 9 years and with Transformers and LLM for 5+ years. I was appointed a Google Developer Expert for Machine Learning in 2017 and I curr...
- Tweet from Perplexity (@perplexity_ai): Introducing new additions to Perplexity Labs: Experience Gemma 2B and 7B models known for impressive performance despite being lightweight. Try it now on http://labs.pplx.ai.
- Billing and Subscription: Explore Perplexity's blog for articles, announcements, product updates, and tips to optimize your experience. Stay informed and make the most of Perplexity.
Perplexity AI ▷ #sharing (3 messages):
- Exploring the Mechanics of Cryptocurrency:
@ivanrykovskishared a Perplexity AI search related to the specifics ofdy/dx, a term associated with cryptocurrency and derivatives trading. - Natural Oral Health Regimens:
@uberkoolsounddiscussed a shift towards using less processed chemicals in oral care, prompted by content from Andrew Huberman and Paul Saladino. They included a Perplexity AI search about the benefits of salt water as a potential natural remedy. - Querying the Definition of Financial Instruments:
@swordfish01posted a Perplexity AI search without context, presumably inquiring about a specific financial instrument or concept.
Perplexity AI ▷ #pplx-api (20 messages🔥):
-
Inconsistent API and Website Responses:
@iflypperexpressed difficulties with the API providing different answers compared to the out-of-date website. They shared a piece of code in search for a more accurate implementation. -
Simplify Queries for Better Responses:
@brknclock1215suggested keeping API queries simple for better performance, as complex or multifaceted queries tend to struggle. -
API Model Behavior Puzzles User: After
@iflypperremoved a system prompt and received an irrelevant response,@brknclock1215entertained the idea but recalled that system messages might no longer be ignored, referencing updated documentation. -
Gibberish Responses from pplx-70b-online:
@useful_tomreported getting gibberish responses from the pplx-70b-online model, noting that others have faced similar issues.@icelavamanmentioned the team is looking into it, while@brknclock1215recommended trying other online models as a workaround. -
Payment Issues and Potential New Features:
@jenish_79522mentioned having issues finalizing a payment for API credits, and@karan01993inquired about support for integrating Google's GEMMA with the Perplexity AI API.
Links mentioned:
- Supported Models: no description found
- no title found: no description found
LangChain AI ▷ #general (38 messages🔥):
-
Dynamic Class Generation Issue:
@deltz_81780encountered a ValidationError when trying to dynamically generate a class for use with PydanticOutputFunctionsParser. They shared code snippets and error messages, seeking assistance. -
Discussion on Agent Types and Uses:
@problem9069asked about different types of agents, such as OpenAITools and OpenAIFunctions, elaborating on intended model types and features. They questioned whether learning about all the types is necessary or if there's a go-to type among them. -
LinkedIn Learning Course Highlight:
@mjoeldubshared information about a new LinkedIn Learning course with a major focus on LangChain and LCEL, including a course link. -
New LangChain AI Tutorial Alert:
@a404.ethannounced a new tutorial, "Chat with your PDF," a build RAG from scratch using LangChainAI, mentioning the use of LangSmith and improvements to conversation history, with a call for feedback linked to a Twitter post. -
Support Model Discussions:
@mysterious_avocado_98353expressed disappointment with the langchain support in the channel, followed by a response from@renlo.highlighting the paid support options available via their pricing page.
Links mentioned:
- Agent Types | 🦜️🔗 Langchain: This categorizes all the available agents along a few dimensions.
- Tweet from Austin Vance (@austinbv): 🚨 New Tutorial 🚨 The finale of my "Chat with your PDF" build RAG from scratch with @LangChainAI tutorial! In Part 4 we - Use LangSmith for EVERYTHING - Implement Multi Query to increase ret...
- Pricing: Plans for teams of any size.
- langgraph/examples/multi_agent/agent_supervisor.ipynb at main · langchain-ai/langgraph: Contribute to langchain-ai/langgraph development by creating an account on GitHub.
- Survey on your Research Journey: In an effort to revolutionize academic and business research, EurekAI seeks your insights to tailor our tool to your needs. Whether you're immersed in research or engage with it sporadically, your...
LangChain AI ▷ #langserve (1 messages):
- Batch Ingestion Failure in LangSmith API:
@jacobito15encountered a warning indicating a failure to batch ingest runs due to aLangSmithError. The error suggests an issue with aChannelWritename exceeding 128 characters, leading to an HTTP 422 error on the endpointhttps://api.smith.langchain.com/runs/batch.
LangChain AI ▷ #share-your-work (3 messages):
-
Request for Thoughts and Testers: User
@pk_penguinmade an open call for thoughts on an unspecified topic and offered a trial. Interested users were asked to direct message for details. -
Parallel Function Calls Unleashed:
@gokusan8896shared a link to a LinkedIn post about enabling Parallel Function Calls in Any LLM Model. This feature could significantly boost efficiency and capabilities, and the post contains further details: Explore Parallel Function Calls. -
Aggregate Query Platform/Library Inquiry:
@rogesmithis considering whether to continue developing a platform/library that enables users to query document data in aggregate rather than individually. The message serves as an invitation for feedback on the potential public utility of the project.
LangChain AI ▷ #tutorials (1 messages):
pradeep1148: https://www.youtube.com/watch?v=Eb7QF1nDWGU
DiscoResearch ▷ #general (29 messages🔥):
-
Opensource Models by Google: User
@sebastian.bodzashared a Kaggle link about Google's open-source models named Gemma, prompting another user@philipmayto inquire about the language diversity, particularly German, within these models. The link redirects to Google's Gemma models on Kaggle. -
Hugging Face Hosts Gemma Model: User
@bjoernpprovided a link to Gemma's instruct version on Hugging Face, noting the commercial viability of its license and referencing the substantial 256k vocabulary size. Check out the Gemma Model here on Hugging Face. -
Aleph Alpha's Model Update Skepticism: User
@sebastian.bodzahighlighted updates to Aleph Alpha's models, expressing uncertainty about the quality. User@devnull0pointed out Andreas Köpf's move to Aleph Alpha, possibly raising future expectations for the company's models. -
Aleph Alpha's Changelog and Criticism:
@devnull0shared changes in Aleph Alpha's models, as per their changelog, which was met with criticism from_jp1_for lacking benchmarks or examples, and a follow-up comment from@sebastian.bodzamentioning the absence of instruction tuning in the new models. -
Performance Concerns: Concerning discussions arose around the performance of both Gemma and Aleph Alpha's models in various languages and contexts.
@bjoernpposted disappointing German evaluation results for Gemma, while@devnull0shared a tweet suggesting performance issues with Llama models, linking a tweet by @ivanfioravanti confirming problems (tweet) and another by @rohanpaul_ai comparing Gemma-2b unfavorably to phi-2 on a benchmark suite (tweet).
Links mentioned:
- Gemma: Gemma is a family of lightweight, open models built from the research and technology that Google used to create the Gemini models.
- Tweet from Rohan Paul (@rohanpaul_ai): Gemma-2b underperforms phi-2 by quite a margin on Nous' benchmark suite https://eqbench.com/
- HuggingChat: Making the community's best AI chat models available to everyone.
- Blog | Aleph Alpha API: Blog
- Tweet from ifioravanti (@ivanfioravanti): After some initial testing with gemma model on @ollama and Apple MLX I can definitely say that: - llama.cpp has some issues, fix in progress https://github.com/ggerganov/llama.cpp/pull/5631 - temperat...
- google/gemma-7b-it · Hugging Face: no description found
- Chibb - German-English False Friends in Multilingual Transformer Models- An Evaluation on Robustness and Word-to-Word Fine-Tuning.pdf: no description found
- flozi00/dibt-0.1-german · Datasets at Hugging Face: no description found
- DIBT/10k-prompt-collective · Datasets at Hugging Face: no description found
DiscoResearch ▷ #benchmark_dev (1 messages):
- Batch Size Affects Performance: User
@calytrixhighlighted a potential issue that using a batch size other than 1 can negatively impact model scores, referencing a discussion on the HuggingFace Open LLM Leaderboard. - Seeking Metrics Regeneration Code:
@calytrixalso inquired if there is a script or code available to regenerate all the metrics from a particular blog post. - Test Fairness Criteria for Models:
@calytrixshared thoughts on what constitutes a fair test for models, stating that it should be realistic, unambiguous, luckless, and easy to understand. They elaborated with examples to identify when tests may not be fair.
Links mentioned:
HuggingFaceH4/open_llm_leaderboard · MMLU blog post discussion: no description found
Skunkworks AI ▷ #general (1 messages):
- Seeking Wisdom for Neuralink Interview:
@xilo0is in the advanced stages of a Neuralink interview and looking for advice on answering the "evidence of exceptional ability" question. They are contemplating which projects to present and are seeking insights from others who have applied to Elon Musk’s companies.
Skunkworks AI ▷ #off-topic (4 messages):
-
Self RAG Enhancement through Self-Reflection:
@pradeep1148shared a YouTube video titled "Self RAG using LangGraph", discussing how self-reflection can improve Retrieval-Augmented Generation (RAG) by correcting poor quality retrieval or generations. -
Appraising Fine-Tuning in Large Language Models:
@pradeep1148posted another YouTube video titled "BitDelta: Your Fine-Tune May Only Be Worth One Bit", which questions the value of fine-tuning Large Language Models (LLMs) when the actual impact may be minuscule. -
Introduction to Google's Open Source Gemma Model: In a continuing share of resources,
@pradeep1148presented a video detailing "Gemma," Google's open-source model that is part of the same family as the state-of-the-art Gemini models.
Links mentioned:
- Gemma Google's open source SOTA model: Gemma is a family of lightweight, state-of-the-art open models built from the same research and technology used to create the Gemini models. Developed by Goo...
- Self RAG using LangGraph: Self-reflection can enhance RAG, enabling correction of poor quality retrieval or generations.Several recent papers focus on this theme, but implementing the...
- BitDelta: Your Fine-Tune May Only Be Worth One Bit: Large Language Models (LLMs) are typically trained in two phases: pre-training on large internet-scale datasets, and fine-tuning for downstream tasks. Given ...
Skunkworks AI ▷ #papers (1 messages):
nagaraj_arvind: I mentioned KTO at the end. But did not get into the details.
Datasette - LLM (@SimonW) ▷ #ai (2 messages):
-
Google Unveils Gemini Pro 1.5:
@simonwhighlighted the recent launch of Google's Gemini Pro 1.5, praising its 1,000,000 token context size which eclipses competitors like Claude 2.1 and gpt-4-turbo. More notably, he was excited about the model's ability to use video as input, a feature explored via Google AI Studio. -
Google's New Machine Learning Documentation: As shared by
@derekpwillis, Google has released new documentation available at Google AI Developer Site for its machine learning products. No further details about the documentation or its content were discussed.
Links mentioned:
- The killer app of Gemini Pro 1.5 is video: Last week Google introduced Gemini Pro 1.5, an enormous upgrade to their Gemini series of AI models. Gemini Pro 1.5 has a 1,000,000 token context size. This is huge—previously that …
- no title found: no description found
Datasette - LLM (@SimonW) ▷ #llm (4 messages):
- Troubleshooting Integration Issues:
@simonwreached out regarding@887493957607645184's issue with system integration and suggested reporting it to the gpt4all team if it hasn't been resolved yet. - Exploring File Support for LLM:
@simonwaddressed@314900216124014623's query about adding file support to LLM and suggested starting with image support for GPT-Vision. For PDFs, he recommends using tools to extract text to feed into LLM. - Gemma Model Implementation Hurdle:
@simonwattempted to run the new Gemma model from Google but encountered output issues, receiving only placeholder text instead of expected results. He also noted the need to updatellama-cpp-pythonusing thellm pythoncommand.
Alignment Lab AI ▷ #general-chat (1 messages):
scopexbt: Hey all, i cant find anything about token, do we have one?
Alignment Lab AI ▷ #oo (2 messages):
- GLAN Paper Shared:
@.benxhqueried if anyone is working on Gradient Layerwise Adaptive-Norms (GLAN) and shared the GLAN paper. - Interest in GLAN Expressed:
@entropiexpressed interest in the GLAN concept with a succinct, "Whoa, nice."
LLM Perf Enthusiasts AI ▷ #general (1 messages):
res6969: Stay away from salesforce, itll be the biggest mistake you make as a company
LLM Perf Enthusiasts AI ▷ #opensource (1 messages):
potrock: https://blog.google/technology/developers/gemma-open-models/
LLM Perf Enthusiasts AI ▷ #embeddings (1 messages):
- ContrastiveLoss Wins dartpain's Favor:
@dartpainexpressed a preference for ContrastiveLoss when tuning embeddings, highlighting its impact on adjustments. They also mentioned MultipleNegativesRankingLoss as a favored loss function.
AI Engineer Foundation ▷ #events (3 messages):
- Join the Discussion on Gemini 1.5:
@shashank.f1invites all to join a live discussion on Gemini 1.5, also remembering the last session on the A-JEPA AI model which discusses unlocking semantic knowledge from audio files. Check out the previous session on YouTube. - Yikesawjeez Planning with Flair:
@yikesawjeezis considering moving their event to the weekend to allow more time to connect with@llamaindexon Twitter and secure sponsors. They also mention the need to work on launching their Devpost page.
Links mentioned:
- Join the hedwigAI Discord Server!: Check out the hedwigAI community on Discord - hang out with 50 other members and enjoy free voice and text chat.
- A-JEPA AI model: Unlock semantic knowledge from .wav / .mp3 file or audio spectrograms: 🌟 Unlock the Power of AI Learning from Audio ! 🔊 Watch a deep dive discussion on the A-JEPA approach with Oliver, Nevil, Ojasvita, Shashank, Srikanth and N...