Jeremy Howard et al is back with a new tool for overcoming the memory constraints of doing 70b-scale training (either pretraining or finetuning, we don't care), usually costing $150k for 4 H100s, on desktop-class GPUs, which cost under $2.5k. These GPUs max out at 24GB per RTX 4090 card, but 70B-params LLMs take >140GB (just for weights).
Here’s the key point: the gaming GPUs have similar performance to the data center GPUs that cost over 10x more! It would be great if we could use these 10x cheaper (but nearly as fast) cards to train large language models, but we can’t, because they have much less memory. The best currently available data center cards have 80GB RAM, whilst gaming cards max out at 24GB RAM. Since only the largest models produce the best results, creating the best models has been largely inaccessible to most people.
QLoRA Limitations
The blogpost also gives a full account of QLoRA, HuggingFace's support, and the limitations they ran into:
QLoRA didn’t quite slay the problem we set out to solve, to train a 70b model on 24GB cards, but it got closer than anything before. When quantized to 4 bits (which is 0.5 bytes), the 70b model takes 70/2 = 35 GB, which is larger than the 24GB gaming GPUs we want to use.
They also discuss memory needs for training, including batch sizing, all of which take required memory well beyond a single 24GB card.
FSDP - Fully Sharded Data Parallel
- HF
transformers's `device_map='auto' setting - has a giant downside: only one GPU is ever active at a time, as all the others wait for their “turn”. - DDP - only works if you have the full model on each GPU
- Meta's FSDP library (see also Llama-Recipes for FSDP finetuning) splits model params across multiple GPUs. "By being smart about copying the data of the next layer at the same time the current layer is busy calculating, it’s possible for this approach to result in no slowdown compared to DDP."
FSDP solves the memory limitation issue for H100-size GPUs - but a 320GB RAM system of 4 H100s would cost $150k.
FSDP + QLoRA + HQQ
"We figured that if we could use QLoRA to reduce the size of a model by around 400% (so a 70b model would fit into 35GB RAM), and then we used FSDP to shard that across two or more 24GB consumer cards, that would leave enough RAM left over to train a model."
2 RTX 4090s would cost under $2.5k.
FSDP didn't work out of the box with QLoRA quantization, and figured out how to workaround assumptions in the FSDP, PEFT, and LoRA libraries/algorithms to make this all work. The team also used Gradient checkpointing, CPU offloading, FlashAttention 2, and HQQ which caused more integration issues. The blogpost has a lot more fascinating details for those who want to dive in.
Overall takeaway is clear:
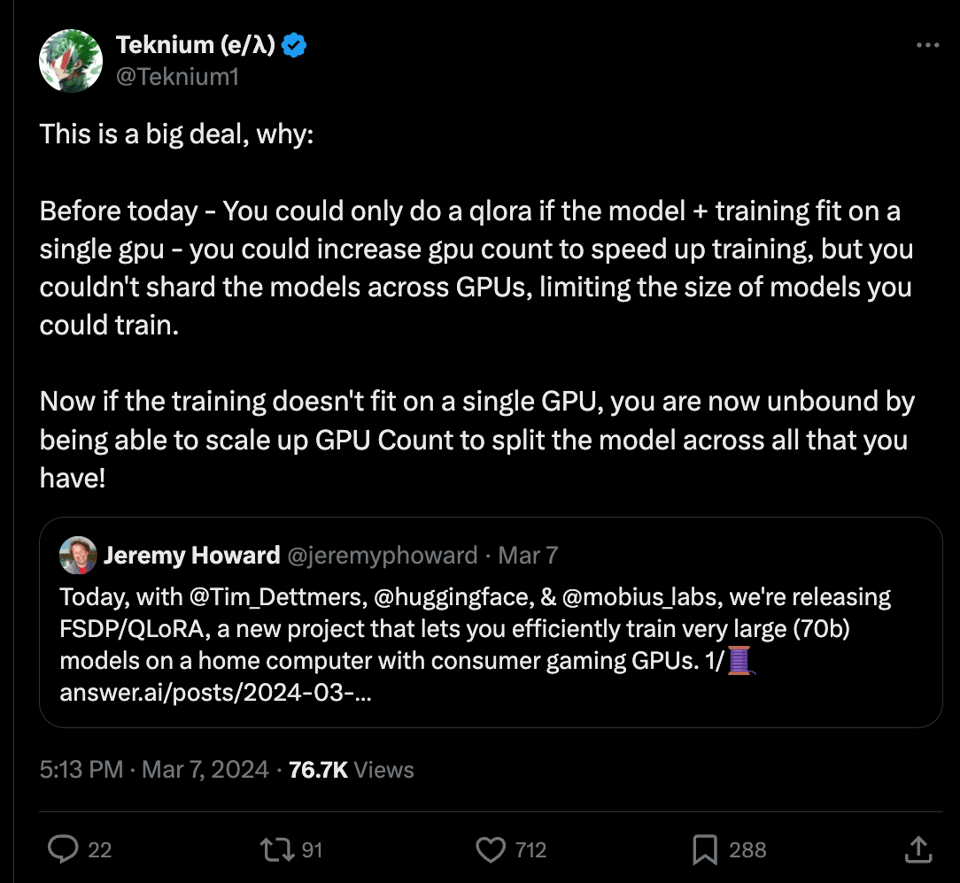
Table of Contents
[TOC]
PART X: AI Twitter Recap
all recaps done by Claude 3 Opus, best of 2 runs
Got it, here's the reformatted version including direct links to each tweet:
Launches & Announcements
- @inflectionAI: "Pi just got a huge upgrade powered by Inflection-2.5, which is neck and neck with GPT-4 on all benchmarks and used less than half the compute to train." (437,424 impressions)
- @jeremyphoward: "Today, with @Tim_Dettmers, @huggingface, & @mobius_labs, we're releasing FSDP/QLoRA, a new project that lets you efficiently train very large (70b) models on a home computer with consumer gaming GPUs." (231,343 impressions)
- @ibab_ml: "Grok just became 3x faster. More improvements coming soon." (104,956 impressions)
AI Capabilities & Benchmarks
- @ylecun: "My 3rd interview with @lexfridman: Path to human-level AI and why the doomers are wrong." (221,901 impressions)
- @ylecun: "Chain-of-Abstraction (CoA): training LLMs to perform multi-step reasoning and to use tools. From @EPFL_en and @AIatMeta." (79,272 impressions)
- @DrJimFan: "Moravec's paradox again: people think displays of self-awareness are breakthroughs, but in fact it's much easier to 'fake awareness' than reasoning tasks like solving novel math or coding problems. The latter requires true generalization." (69,483 impressions)
AI Industry Analysis & Speculation
- @abacaj: "Everyone is deploying a new LLM except OpenAI... what are they cooking?" (80,366 impressions)
- @fchollet: "For reference the entire consumer market for generative AI (of all kinds) was about 2B in 2023. About as much for enterprise. By 2025 it might be 10-12B in total. Not clear it would make sense to spend over half of that on training a single model." (68,014 impressions)
- @AravSrinivas: "Who is executing well, and who is executing poorly, between Microsoft & Google? What do you think of Apple in AI? Is 'answer engine' a similar change to the kind Google's Pagerank brought to web portals 20 years ago?" (73,728 impressions)
Engineering & ML Techniques
- @svpino: "10 techniques every machine learning engineer should know: 1. Active learning 2. Distributed training 3. Error analysis 4. Invariance tests 5. Two-phase predictions 6. Cost-sensitive deployments 7. Human-in-the-loop workflows 8. Model compression 9. Testing in Production 10. Continual learning" (68,248 impressions)
- @Teknium1: "This is a big deal, why: Before today - You could only do a qlora if the model + training fit on a single gpu - you could increase gpu count to speed up training, but you couldn't shard the models across GPUs, limiting the size of models you could train. Now if the training doesn't fit on a single GPU, you are now unbound by being able to scale up GPU Count to split the model across all that you have!" (62,594 impressions)
- @rasbt: "This is actually an excellent demo of a highly capable LLM-RAG setup. Had the pleasure of experimenting with it as an early reviewer, and I was genuinely impressed. Tested it on a recent LoRA/DoRA repository of mine that could not have been part of the Mistral training data yet & seriously didn't expect a Mistral 7B model to perform so well on coding tasks!" (61,178 impressions)
Memes & Humor
- @nearcyan: "its actually over literally no one hires junior devs anymore" (227,247 impressions)
- @yoheinakajima: "20k+ github stars, 45+ arxiv citations, 500eth secondaries on my nfts, welcoming 3 kids, while launching a venture fund, here's my secret 👇" (57,543 impressions)
- @cto_junior: "nooooooooooo claude, don't beee woke" (56,159 impressions)
PART 0: Summary of Summaries of Summaries
Claude 3 Sonnet (14B?)
-
Advancements in Memory-Efficient LLM Training:
- Gradient Low-Rank Projection (GaLore) enables training the Llama 7B LLM on a single RTX 4090 GPU, reducing memory requirements for optimizer states by over 82% [Tweet]. This breakthrough could revolutionize LLM training accessibility.
- A collaboration involving FSDP and QLoRA allows training 70B models on consumer GPUs like RTX 3090s [Blog Post], further democratizing large model development.
- Discussions around combining GaLore with 1-bit quantization techniques like HQQ and bitsandbytes [GitHub Repo] for potential compounded memory savings during fine-tuning.
-
Cutting-Edge Language Model Releases and Comparisons:
- Inflection AI claims their Inflection-2.5 model matches GPT-4 benchmarks while using less than half the compute for training [Tweet], though the claim wasn't highlighted in their official blog post.
- Anticipation builds for the release of GPT-4, as competitors like Claude 3 seem to be outperforming current OpenAI models according to some users.
- Discussions around the performance of models like Sonnet, Opus, and Mixtral, with Sonnet praised for its impressive price-performance ratio at costs as low as $0.03 for 5k context and 1200 response length.
-
Innovative AI Applications and Tools:
- Doodle Wars is a multiplayer game where players compete in doodling skills evaluated by a neural network [Doodle Wars], showcasing the gamification potential of AI.
- LangChain and Gradio were used to build a restaurant name and menu generator app [Demo], exemplifying the creative use of language models.
- The release of over 6.6 million state and federal court decisions with datasets and embeddings [Tweet] enables legal precedent exploration powered by AI.
- Prompt Mixer is a new desktop tool for building, testing, and iterating AI prompts with version tracking [Prompt Mixer], aiming to streamline prompt engineering workflows.
-
Advancements in Efficient Attention Mechanisms:
- Discussions around the mechanics of RelayAttention and its differences from ring/flash attention, with a GitHub repo showcasing vLLM with RelayAttention [GitHub].
- Implementations of Flash Attention using CUDA are shared, like a minimal version in ~100 lines of CUDA code [GitHub].
- The CuTe DSL from NVIDIA's FlashAttention repository is being studied to optimize tensor core utilization [GitHub].
- Benchmarking and discussions around the performance impact of techniques like thread coarsening and vectorized operations in CUDA kernels.
Claude 3 Opus (8x220B?)
-
Nitro Models Accelerate the Field: OpenRouter announced the introduction of Nitro models such as Mixtral, MythoMax, and Llama 70B, which feature more efficient speed and cost-effectiveness powered by Groq. Documentation on new developer features like performance timelines, JSON mode, and dynamic routing is available, and the speed-boosted Mistral 7b 0.2 Nitro model expands context to 32k.
-
GaLore Optimizer Grips Global Interest: Techniques like GaLore and CAME optimizer are catching attention for claims of memory efficiency and performance gains; however, the community's interest is coupled with skepticism and calls for empirical replication and understanding of versioning complexities. Users like
@tiagoefreitasshared insights that GaLore enables training Llama 7B LLM on a single RTX 4090 GPU. -
Democratizing AI Training with FSDP/QLoRA:
@jeremyphoward's tweet about FSDP/QLoRA was shared, signaling a collaboration that enables training large models on home GPUs, while@fx2ypointed to support for quantization techniques like HQQ and bitsandbytes, shared via a GitHub repo link. -
Inflection-2.5 Under the Microscope: Despite significant performance claims that Inflection-2.5 rivals GPT-4 with lower compute,
@swyxiohighlighted a gap in Inflection's official communication, observing the absence of this claim from their blog post detailing Inflection-2.5. -
Clash Over Proposed AI Safety Czar: Concerns surfaced about the anticipated appointment of Paul Christiano to the US AI Safety Institute, causing an internal crisis at NIST with staff threats of resignation and a revolt. The VentureBeat article details the conflict and Christiano's controversial views on AI's potential for causing existential risks.
ChatGPT (GPT4T)
-
Meme Generation and AI Integration: Nous Research AI Discord has showcased Meme Generation Fusion using Mistral LLM and Giphy API, demonstrating creative tech integration with a YouTube tutorial and a GitHub repository for practical application.
-
AMD's Engagement in AI Hardware Optimization: LM Studio Discord highlights AMD's AI hardware focus, with CEO Lisa Su addressing GPU firmware concerns for AI servers. AMD's initiative includes guidance on running LLMs with AMD Ryzen™ and Radeon™ as outlined in Tom's Hardware and AMD community post.
-
Claude 3's Diverse Applications and RAG Improvements: LlamaIndex Discord presents Claude 3's versatility in AI applications, with LlamaIndex's tools enhancing RAG models. New advancements include Jina's reranker (
jina-reranker-v1-base-en) for refining vector search results, as shared on Twitter. -
Efficiency and GPU Selection in AI Development: Discussions in LM Studio Discord stress the importance of power supply and GPU selection for AI work, suggesting a minimum of 750W PSU for an RTX 3090 and considering the Razer Core X eGPU enclosure. These hardware choices are crucial for running demanding AI models efficiently.
-
Integration and Retrieval Challenges in LlamaIndex: LlamaIndex Discord also delves into integration and retrieval challenges, such as the unavailability of older version documentation and issues with multi-modal data storage and retrieval. Solutions and discussions are facilitated through GitHub gists, blog posts, and documentation pages like the Slack bot learning guide.
-
CUDA Learning Resources and Efficiency: CUDA MODE Discord focuses on CUDA programming education and memory-efficient techniques for large model training, recommending CUDA lectures for beginners and discussing Gradient Low-Rank Projection (GaLore) as a memory-efficient training technique. GaLore enables training large models with reduced memory requirements, as detailed in an arXiv paper.
-
AI Model Performance and Hardware Discussions: Across discords, there's a significant focus on AI model performance comparisons and hardware optimization. Discussions range from model efficiency improvements, such as AMD's AI hardware engagement and CUDA's memory-efficient training techniques, to the practical challenges of GPU selection and power supply for AI development.
PART 1: High level Discord summaries
Nous Research AI Discord Summary
-
Meme Generation Fusion: A YouTube tutorial and corresponding GitHub repository demonstrate how to create memes using Mistral LLM with the Giphy API. This showcase of integrating humor into tech received attention in the off-topic channel.
-
Quest for Efficient AI: GaLore optimizers are being discussed in combination with other GitHub contributions as methods for improving computational efficiencies in AI model training.
-
Neural Doodles Score Big: A new multiplayer game, Doodle Wars, lets players compete in doodling skills evaluated by a neural network. The game, available at Doodle Wars, emphasizes the gamification possibilities in AI.
-
Boosting Language Models' Reasoning Abilities: Nous Research announced Genstruct 7B, capable of generating questions for complex scenarios that enhance AI step-by-step reasoning abilities—projects and downloads are accessible on the HuggingFace page.
-
EU Watches Microsoft and Mistral's Move: In the general channel, the Microsoft and Mistral AI deal drew attention due to EU regulatory scrutiny, with references to an AP news article highlighting the investigation's breadth.
-
Access and Assessing GPT-4: Conversations in the ask-about-llms channel touched on accessing GPT-4 through platforms like Corcel.io and scoped out discussions about the differences in LLM pretraining and fine-tuning, with mention of optimizer techniques like LoRA and GaLore.
LM Studio Discord Summary
LM Studio Hits Version 0.2.16: LM Studio's latest version is 0.2.16, resolving previous terminal run errors and addressing GLIBC or LIBCBlast library issues. Compatibility discussions highlight challenges with gemma 7b gguf and starcoder2 models. For support with GGUF models, refer to Learning More About GGUF.
AMD's AI Hardware Optimism: AMD's CEO Lisa Su’s personal involvement to address Tiny Corp's GPU firmware concerns signals potential improvements for AI applications. AMD's article on running LLMs with AMD Ryzen™ and Radeon™ could assist in leveraging AI without internet dependence.
Rethinking Power Supply Units (PSU) for AI: Discussions suggest a minimum of 750W PSU for powering an RTX 3090, with the Razer Core X eGPU enclosure as an alternative. Debates on efficient hardware setups for language models consider VRAM, power efficiency, and cost-effectiveness.
Integrating and Selecting GPUs in LM Studio: There's a call for features allowing specific GPU selection in LM Studio, following incidents where the software defaults to integrated graphics, causing performance issues with demanding AI models.
Evolving Open Interpreter Usage and Model Sharing: Conversations in #open-interpreter include the implementation of custom system messages using command interpreter.system_message = "Your message" in Python scripts in Open Interpreter. The sharing of links to models such as LHK_DPO_v1 on Hugging Face spotlights the community's efforts in exchanging AI insights LHK_DPO_v1_GGUF. Concerns raised on the Forum about limitations of FusionNet_7Bx2_MoE_14B model's context size can be found here.
Beta Release Buzz in LM Studio: Anticipation is building in the #beta-releases-chat for an imminent new release, with community members teasing the release and sharing humorous banter about the update's arrival.
LlamaIndex Discord Summary
-
Survey Says! LlamaIndex Wants Your Input: LlamaIndex invites users to participate in a 3-minute user survey aimed at improving their services, specifically documentation, demos, and tutorials. The survey can be accessed through this SurveyMonkey link or via referenced Tweets.
-
Claude 3 Sparkles in Its Versatility: A new guide highlighting the varied applications of Claude 3 using LlamaIndex's tools, including Vanilla RAG, Routing, and Sub-question query planning, is now available in a video format, as announced on Twitter.
-
New Jina Reranker Enhances RAG: LlamaIndex shared about Jina's new reranking tool (
jina-reranker-v1-base-en) designed to improve Retrieval-Augmented Generation (RAG) models by refining vector search results, with details mentioned in a Twitter post. -
CodeHierarchyNodeParser: The Next Leap in Code Understanding: A breakthrough technique for parsing large code files into a hierarchical structure named
CodeHierarchyNodeParserhas been unveiled by LlamaIndex, potentially revolutionizing RAG/agents handling code. This was introduced on Twitter by ryanpeach. -
Tackling LlamaIndex Integration and Retrieval Challenges: Community discussions have highlighted challenges such as the unavailability of older version documentation, integration pitfalls with Chat Engine and NodeWithScore, confusion around multi-modal data storage and retrieval, scoring algorithm customization, and data persistence issues. These topics were addressed across several resources including GitHub gists, blog posts, and documentation pages, such as the Slack bot learning guide and vector stores on GitHub.
Perplexity AI Discord Summary
-
Claude 3 Opus Usage Debate: The Claude 3 Opus was a significant discussion point, where members voiced concerns regarding the restriction to five uses imposed by Perplexity AI's plans. The debate spanned over the cost-efficiency of subscription models, the daily message limits, and comparing to other services like ChatGPT Plus.
-
Technical Troubleshooting in Perplexity AI: Users reported difficulties utilizing features such as photo generation and the rewrite function with Perplexity AI. Suggestions included resetting browser data and reaching out to [email protected] for further assistance.
-
Efficiency and Performance Comparisons of AI Models: The relative performance of various AI models, including Inflection-2.5, was tossed around, with users discussing options for model comparison. Meanwhile, Sonnet emerged as a recommended tool for benchmarking AI efficiency.
-
Shared Links Deepen AI Understanding: Across channels, users shared Perplexity AI links to compare platforms, learn using AI resources, explore historical progress, understand AI's roles, question authorship within AI creations, and to probe into the contentious topic of AI emotions.
-
Inquiries and Discussions on Perplexity API Developments: Concerning Perplexity API, users inquired about the capabilities of Perplexity Discover and the RAG pipeline. There were also discussions regarding maximum token outputs for various AI models, highlighting the constraints imposed by context window and finetuning.
Eleuther Discord Summary
-
Harnessing Evaluation for Custom Needs:
@pminervinisought to customize the output format in the harness, proposing a two-step generation process; meanwhile,@baber_suggested modifying thegenerate_untilmethod and offered a GitHub link as a potential starting point. -
Spectacle of Specs: Docker or Local for GPT-NeoX: AI enthusiasts
@biiterand@tastybucketofricedebated over environment setup methods for GPT-NeoX development, discussing Docker's consistency against local setups, while@tfidiasuggested NVIDIA NGC containers as a solution for easing Apex and CUDA dependencies. -
GaLore Optimizer Grips Global Interest: Techniques like GaLore and CAME optimizer are catching attention for claims of memory efficiency and performance gains; however, the community’s interest is coupled with skepticism and calls for empirical replication and understanding of versioning complexities.
-
Data Driven: New Korean Benchmarks Announced:
@gson_arlointroduced two new Korean evaluation datasets, Hae-Rae Bench and K-MMLU, developed for assessing language models on Korean-specific knowledge, inviting contributions on multilingual model evaluation. -
Seeking AI Simplicity: Newcomer
@shida3916expressed a desire to explore everyday AI applications and seek straightforward answers, provoking discussions on the appropriate forums for such AI inquiries within the community.
OpenAI Discord Summary
-
Sonnet Shows Strength Over ChatGPT:
@aaron_speedysuggested that Sonnet outperforms ChatGPT 3.5, offering functionalities such as image upload and potentially supporting file uploads. Meanwhile, the release of GPT-4 is highly anticipated by users like@futuremachineand@drinkoblog.weebly.comdue to perceived competitive lag behind models like Claude 3. -
Effective Prompting Key to Model Utilization: Users like
@.vildenhighlighted the importance of precise prompting in maximizing the performance of models such as GPT 3.5, instead of using verbose prompts which may impede performance. -
Flashcard Creation AI Interest Sparked:
@khaledoo.inquired about an AI tool for transforming lecture PDFs into flashcards, promoting discussion among users regarding the tool's capability and content accuracy. -
GPT-4 Exhibiting Repeating Answers: Frustration over GPT-4's repeating answers and multilingual mishaps was reported by
@spikyd, which led to an exchange with@dojan1on possible underlying issues and workarounds. -
Localized Technical Issues with ChatGPT Addressed: Changes in language settings to "Auto-detect" and browser refresh (F5) were among the suggested fixes by users like
@pteromaplefor ChatGPT non-responsiveness. Issues with language settings causing interface breaks were confirmed by@joachimpimiskernand@pteromaple, hinting at a possible bug, while@meteopxused a VPN to circumvent regional access challenges with ChatGPT.
HuggingFace Discord Summary
-
AI Safety Czar Sparks Controversy: The expected appointment of Paul Christiano to the US AI Safety Institute has led to turmoil within the National Institute of Standards and Technology, with staff revolt and resignation threats due to Christiano's views on AI existential risks, as detailed in a VentureBeat article.
-
AI Optimization for Programming: DeepSeek-Coder instruct and the OpenCodeInterpreter paper were discussed for optimizing shader code with AI, while this code processing review work provides insights into AI's use in programming tasks.
-
Exploring the Future of AI in Geopolitics: A robust debate on the contrasting AI strategies of Western nations and China was had, touching on issues like censorship, asymmetric warfare, and the potential for AI regulation based on training data concerns.
-
AI Tools and Models Shared on HuggingFace: New resources are highlighted, including a RAG demo for Arxiv CS papers at HuggingFace Spaces, a fine-tuning demonstration of Google's Gemma with a notebook available at HuggingFace Spaces, a new 16k context pretrained encoder model at HuggingFace, and an educational resource on constructing GPT shared in "Let's Build GPT" on YouTube.
-
Diffusion Model Development Challenges: Efforts to merge SDXL-Lightning LoRA with standard SDXL were discussed, with training suggestions offered by the ByteDance organization in a HuggingFace discussion thread.
-
Learning and Discoveries in AI: Users expressed a keen interest in collaboration and learning about generative AI for data analytics, as well as other AI applications, showing enthusiasm for shared learning experiences and co-study partnerships.
-
Creative AI Projects and Contributions: Innovations included fine-tuning Gemma with ChatML by
@andysingal(model card available here), a CLIP index for a dataset hosted on Hugging Face Hub, and a restaurant name and menu generator app by@chongdashuwith Medium article and demo. -
Technical Discussions Embrace Humor and Helpfulness: From puns about retrievers to the lofty goal of running a 70B model on a Raspberry Pi, community members engage both humorously and helpfully on topics such as machine learning model recommendations for Google Colab and mapping attention weights in BertModel.
LAION Discord Summary
-
AI Image Generators Ignite Interest: Alternatives to the AI image generator Sora are being actively discussed, with numerous projects reportedly using MagViT2 as their foundation. Meanwhile, concerns over excessive marketing costs, with $7,099 spent per conversion for $100 sales, sparked discussions on the need for more efficient strategies.
-
Midjourney's Scraping Scare Sparks Humor and Criticism: Laughter and critical conversations emerged around Midjourney members' fear of a 'security issue' due to their AI-generated images being scraped, together with a controversy regarding an artist list used by Midjourney that included names ranging from Warhol to a 6-year-old child.
-
SVD Training Hiccup Hits Stable Cascade: Users report that SVD updates introduce significant pauses in the training process of Stable Cascade, causing a 2-minute interruption which hinders efficiency.
-
Efficiency Spotlight on Large Language Models: Lively discussions tackled the inefficiencies of current Large Language Models (LLMs), with individuals like
@mkaicarguing for the potential in training more efficient sparse/small networks and improving compression of training data within these models. -
Cutting Edge Discussions on Pruning and Model Efficiency: The engineering community delved into the challenges associated with model pruning and generalizability, pondering over pathways to more efficient architectures. A new paper was referenced in relation to these topics, while the debut of PixArt Sigma, a new 4K PixArt project with a focus on text-to-image generation, was announced despite its current issues with text representation using only 600m parameters.
OpenRouter (Alex Atallah) Discord Summary
-
Nitro Models Accelerate the Field: Alex Atallah announced the introduction of Nitro models such as Mixtral, MythoMax, and Llama 70B, which feature more efficient speed and cost-effectiveness powered by Groq. Documentation on new developer features like performance timelines, JSON mode, and dynamic routing is available, and the speed-boosted Mistral 7b 0.2 Nitro model expands context to 32k, with demonstrations shown on OpenRouter's site and Twitter.
-
Sonnet Scores High on Savings: Discussions in the community spotlighted Sonnet's advantageous price-performance balance, offering costs as low as .03 for scenarios involving "5k context and 1200 response length," setting it ahead of competitors in affordability.
-
Deciphering Moderation Layers: Clarification was provided on how OpenRouter applies a unique layer of moderation that may result in more refusals than direct interactions with OpenAI or Anthropic APIs, with additional insight by Alex Atallah on the specifics of Anthropic's server-side moderation for OpenRouter.
-
Data Usage Policy Under the Microscope: Anthropic's use of customer content for model training came under inquiry, with links to supportive articles leading to the consensus that content from paid services may be exempt from training purposes.
-
Cost vs. Throughput: A Community Analysis: The guild discussed the Nitro models' enhanced throughput and diverse pricing tiers, particularly noting the change with Mixtral 8x7b instruct nitro accommodating changes in rates to 0.27/1M tokens.
CUDA MODE Discord Summary
- Learning the CUDA Way: For those new to CUDA and parallel programming, the Discord's own lectures for complete beginners are recommended starting points, coupled with suggested concurrent study of associated books for a richer learning experience.
- CUDA Shared Memory Utilization: CuTe DSL is being studied within the NVIDIA FlashAttention repository to optimize tensor core utilization, while discussions revolve around the performances of kernel optimizations such as thread coarsening and vectorized operations.
- Memory-Efficient Techniques for Large Model Training: Gradient Low-Rank Projection (GaLore), as described in an arXiv paper, offers a path to train large models with reduced memory requirements, even fitting within a single RTX 4090 GPU, while a method combining FSDP and QLoRA enables fine-tuning a 70b model on standard gaming GPUs, details available at Answer.AI.
- Ring-Attention in Practice: Technical issues involving RelayAttention are under discussion, with reports of system failures when training at 16k resolution and inference processes stalling when using ring-llama on two GPUs after installing flash-attn via pip.
- PyTorch Device Cross-Talk Clarified: Scalars can be indexed by CUDA tensors in PyTorch due to automatic conversion, a holdover from earlier design decisions, but this auto-transfer can also lead to unexpected inefficiencies.
Latent Space Discord Summary
GaLore Lights Up GPU Potential: User @tiagoefreitas shared insights from @AnimaAnandkumar that Gradient Low-Rank Projection (GaLore) enables the Llama 7B LLM to be trained on a single RTX 4090 GPU, which could transform memory efficiency benchmarks for both pre-training and fine-tuning stages, possibly enhanced by 1-bit quantization.
Inflection-2.5 Under the Microscope: Despite significant performance claims that Inflection-2.5 rivals GPT-4 with lower compute, @swyxio highlighted a gap in Inflection's official communication, observing the absence of this claim from their blog post detailing Inflection-2.5.
Democratizing AI Training with FSDP/QLoRA: @jeremyphoward's tweet about FSDP/QLoRA was shared by @fanahova, signaling a collaboration that enables training large models on home GPUs, while @fx2y pointed to support for quantization techniques like HQQ and bitsandbytes, shared via a GitHub repo link.
Yann LeCun Expounds on AI’s Horizons: Discussions steered towards Yann LeCun's Lex Fridman podcast episode, where he shared his visions for Meta AI, the limitations of current LLMs, and prospects for Contrastive Learning's future.
Data Privacy Concerns in Personal AI: @swyxio related their experience with Life Story, a personal biographer AI, prompting @tiagoefreitas to encourage development of local-hosted applications for better data security.
Inside the Depth of GPT: @ivanleomk and @1123457263638683770 led a session on the GPT-2 paper, with materials explaining concepts and implementation highlighted, alongside a discussion punctuated by a clarification on "causal attention" and the introduction of a LLM Visualization tool.
LangChain AI Discord Summary
-
LangChain JS Still Chasing Python's Tail: Despite questions raised by
@0x404blockchainnotfound, there's still no clear confirmation if LangChain JS library has achieved feature parity with its Python counterpart; users discussed related tool issues instead, such as a delay with the Finished agent event in Python and formatting challenges when using PyPDFLoader. -
The Never-Ending AGI Debate: Conversations on AGI from Hacker News spilled over without reaching a conclusive end but did spark parallel discussions on LangChain tools and ReACT agents. Critical concerns remain unaddressed, indicating a need for deeper technical dives into the subject.
-
The Redis Memory Mix-up:
@justanothergraphguygrapples with intricacies in structuring output in a chat chain with Redis, where "HumanMessage" incorrectly appears in theAIMessage, highlighting potential flaws in memory management during interactions. -
Vision Models Grab the Stage:
@vru.shankinvites the community to a workshop with MultiOn and Quizizz on integrating vision models into production, promising insights from the front lines of AI application. -
Prompt Mixer: A Developer’s New Best Friend?:
@tomatyssintroduces Prompt Mixer, a desktop application adept for crafting and iterating AI prompts, while also providing a tutorial to extend the tool with custom connectors, signaling a move towards more personalized and efficient AI development workflows.
DiscoResearch Discord Summary
-
In Search of a Sauerkraut-Flavored AI:
@johannhartmannmentioned a gap in German-fineturned models, emphasizing Nous Hermes Mixtral doesn't cater to German language prompts, and compared to sauerkraut oder discolm mixtrals. -
DNA's New Best Friend:
@rasdaniintroduced the Evo architecture—Striped Hyena by TogetherAI, specialized for DNA sequencing. Details about its application for biology can be found in their blog post, developed in collaboration with the Arc Institute. -
Tuning the Hermes Harmony:
@flozi00is refining the Nous Hermes Mixtral DPO model, and constructing an Argilla space for assessing translations from Google Translate, DeepL, and Azure Translate. Contributions to measure translation pair quality can be made to their HuggingFace collection. -
Dataset Dilemma Discussion:
@philipmayencountered licensing and accessibility issues with the mMARCO dataset, which now has an Apache 2.0 license but requires troubleshooting for dataset viewing on HuggingFace. -
Melding German with SPIN Strategy:
@johannhartmannutilizes a German-transformed dataset for Mistral merges that shows varied model responses post-merge, planning to share this dataset soon, while@crispstrobeexperiences success with Brezn3 surpassing Brezn-7b on EQ-Bench (v2) (de) without any specific DPO modifications confirmed as yet by@johannhartmann.
LLM Perf Enthusiasts AI Discord Summary
- Naming Conundrums in AI:
@res6969noted that names can be challenging for models to handle accurately, though no specific instances or models were cited. - Breaking Ground with Claude's Functions:
@res6969reported progress with function calling in Claude, attesting to its operational state but without providing specific examples or outcomes. - Claude's Humor Hits the Mark:
@res6969deemed Claude's output as both "hilarious and correct", though the context of this performance was not specified. - The XML Necessity for Claude's Calls: Function calling in Claude has been confirmed by
@res6969to work effectively, specifically when using XML tags, hinting at a technical requirement for Claude's optimal function-calling performance. - XML Tags: A Double-Edged Sword:
@pantsforbirdsraised concerns about the intricacies of using XML tags in prompt generators, implying potential difficulties in their implementation and use.
Datasette - LLM (@SimonW) Discord Summary
- GPT-4's Unexpected Shortcomings: Members were surprised at GPT-4's underperformance on an unspecified test, highlighting room for improvement in its development.
- Ingenious Clickable Bookshelves: A novel script for generating clickable bookshelf images that link to Google Books has captivated members, with references including a blog post and a demo.
- Library Tech Advancements Garner Interest: The idea of automated bookshelf management sparked interest, especially considering its potential to streamline shelf-reading tasks in extensive library collections.
- Scaling Library Management Efforts: A member shared insights into large-scale library management, noting their partner's role in overseeing the largest school library in a 35-school diocesan system, comparable to some public libraries.
- Little Library, Big Data: The concept of a small-scale app to catalog books in community-based little libraries was floated, indicative of personal projects leveraging cataloging and data management principles.
PART 2: Detailed by-Channel summaries and links
Nous Research AI ▷ #off-topic (17 messages🔥):
- Delayed Apologies:
@tekniumacknowledged seeing a direct message on Twitter after a long time and apologized for the missed communication, humorously expressing regret with "xD". - Meme Making with Mistral:
@pradeep1148shared a YouTube video titled "Making memes with Mistral & Giphy" and a GitHub repository containing a notebook for generating memes using Mistral LLM and Giphy API. - Inquiry on Nous' Origin:
@pier1337questioned if the Nous organization has French origins, leading to a response by@kainan_ewho clarified that the inspiration was from the Greek "νοῦς" meaning intelligence, not the French language. - Suggestions for Note-taking Excellence:
@sanketpatrikarsought advice on improving the experience of using a single markdown notes file, and@thiloteeprovided several recommendations, including using a good text editor, visiting alternative software websites like AlternativeTo and exploring the Zettelkasten method. - Doodle Wars Game Announcement:
@om7059introduced Doodle Wars—a multiplayer game where players doodle objects within 15 seconds and a neural network scores their creations. The highest-scoring player wins the round. Check out the game at Doodle Wars.
Links mentioned:
- Making memes with Mistral & Giphy: Lets make memes using mistral llm and Giphy api#llm #ml #python #pythonprogramming https://github.com/githubpradeep/notebooks/blob/main/Giphy%20Mistral.ipynb
- Doodle Wars: no description found
- Getting Started • Zettelkasten Method: no description found
- Noûs — Wikipédia: no description found
- Nous - Wikipedia: no description found
Nous Research AI ▷ #interesting-links (34 messages🔥):
-
Claude 3 Opus Casts a Spell on Circassian Translations:
@hahahahohoheshared a remarkable experience with @AnthropicAI's Claude 3 Opus, demonstrating exceptional Russian-Circassian translation skills, even with a limited dataset of 5.7K examples, surpassing expectations and previous models. However, it was later clarified that the model may have already had access to Circassian language information, underscoring the importance of accurate data about model capabilities. -
Exploring GitHub's Contributions to AI:
@random_string_of_characterposted a link to GaLore on GitHub, encouraging the community to assess its value, as well as suggesting combining it with low-bit optimizers for potential computational efficiency improvements. -
Yi Technology Pushes Bounds of Long Text Understanding:
@thiloteeshared a Reddit post and a Hugging Face link discussing the Yi-34B-200K base model's update, which significantly improved its performance on the "Needle-in-a-Haystack" test from 89.3% to 99.8% accuracy, pointing towards the continued enhancement of the model's handling of long contexts. -
Sparse Mixture of Models Enables Deep Understanding:
@shashank.f1pointed to a YouTube video where there's an in-depth conversation with the 🤗 community about sparse mixture of experts (MoE) architectures like Gemini, which have the potential to ingest and reason from entire books and movies in a single prompt.
Links mentioned:
- Tweet from An Qu (@hahahahohohe): Today while testing @AnthropicAI 's new model Claude 3 Opus I witnessed something so astonishing it genuinely felt like a miracle. Hate to sound clickbaity, but this is really what it felt like. ...
- Yi: Open Foundation Models by 01.AI: We introduce the Yi model family, a series of language and multimodal models that demonstrate strong multi-dimensional capabilities. The Yi model family is based on 6B and 34B pretrained language mode...
- Gemini 1.5 Pro: Unlock reasoning and knowledge from entire books and movies in a single prompt: 🚀 Dive into the world of AI with Gemini 1.5! 🌟In this video, we unpack the magic behind Gemini's sparse mixture of experts architecture, perfect for unleas...
- GitHub - jiaweizzhao/GaLore: Contribute to jiaweizzhao/GaLore development by creating an account on GitHub.
- 01-ai/Yi-34B-200K · Hugging Face: no description found
- Reddit - Dive into anything: no description found
- GitHub - thu-ml/low-bit-optimizers: Low-bit optimizers for PyTorch: Low-bit optimizers for PyTorch. Contribute to thu-ml/low-bit-optimizers development by creating an account on GitHub.
Nous Research AI ▷ #announcements (1 messages):
- Introducing Genstruct 7B:
@everyone, Nous Research released Genstruct 7B, an instruction-generation model inspired by Ada-Instruct. The model is capable of creating valid instructions from raw text corpus for synthetic finetuning datasets and is available for download on their HuggingFace page. - Advanced Reasoning Capabilities: Genstruct 7B excels in generating questions about complex scenarios, enhancing the ability of models to carry out step-by-step reasoning after being trained on the generated data. This project was led by
<@811403041612759080>at Nous Research.
Links mentioned:
NousResearch/Genstruct-7B · Hugging Face: no description found
Nous Research AI ▷ #general (289 messages🔥🔥):
-
Claude Pro As Daily Driver?: User
@leontelloinquired about people's experiences of swapping ChatGPT Plus for Claude Pro. Some users, like@teknium, expressed difficulty in even finding the Claude Pro chat interface, while others mentioned being unable to access it due to geographic restrictions. -
Gemma AI Bugs and Fixes: Discussion around bugs in Gemma implementation led to sharing a tweet from @danielhanchen, highlighting numerous issues and fixes that were pushed to @UnslothAI, comparing the Log L2 norms for each layer after applying fixes mentioned in an Unsloth AI blog post.
-
Low Rank Pre-Training on a 4090 GPU: User
@.interstellarninjashared a tweet from @AnimaAnandkumar announcing the Llama 7B LLM's capability to be trained on a single RTX 4090 GPU using a method that significantly reduces memory requirements for storing optimizer states via Gradient Low-Rank Projection (GaLore). -
Discussion on Model Performance and New Models: Amongst talks about various models,
@tekniumraises the question about the implications of multiple AI models potentially matching or outperforming OpenAI's flagship GPT models. A tweet from @inflectionAI claims their Inflection-2.5 model matches GPT-4 benchmarks while using less compute for training. -
EU Scrutiny of Microsoft’s Partnership with Mistral AI: Users discuss potential implications of Microsoft's deal with Mistral AI, including regulatory interest from the EU. References to an AP news article indicate that the EU is investigating the agreement, although no formal conclusions are mentioned.
Links mentioned:
- Tweet from Daniel Han (@danielhanchen): Found more bugs for #Gemma: 1. Must add 2. There’s a typo for <end_of_turn>model 3. sqrt(3072)=55.4256 but bfloat16 is 55.5 4. Layernorm (w+1) must be in float32 5. Keras mixed_bfloa...
- Answer.AI - You can now train a 70b language model at home: We’re releasing an open source system, based on FSDP and QLoRA, that can train a 70b model on two 24GB GPUs.
- Anthropic Console: no description found
- Tweet from Emad (@EMostaque): @Teknium1 Less stable above 7b. Transformer engine has it as main implementation. Intel have one too and Google have int8
- Tweet from FxTwitter / FixupX: Sorry, that user doesn't exist :(
- Tweet from Inflection AI (@inflectionAI): Pi just got a huge upgrade! It’s now powered by our latest LLM: Inflection-2.5, which is neck and neck with GPT-4 on all benchmarks and used less than half the compute to train. Pi now has world clas...
- Microsoft's new deal with France's Mistral AI is under scrutiny from the European Union: The European Union is looking into Microsoft’s partnership with French startup Mistral AI. It's part of a broader review of the booming generative artificial intelligence sector to see if it rais...
- Tweet from Sebastian Majstorovic (@storytracer): Open source LLMs need open training data. Today I release the largest dataset of English public domain books curated from the @internetarchive and the @openlibrary. It consists of more than 61 billion...
- Tweet from Prof. Anima Anandkumar (@AnimaAnandkumar): For the first time, we show that the Llama 7B LLM can be trained on a single consumer-grade GPU (RTX 4090) with only 24GB memory. This represents more than 82.5% reduction in memory for storing optimi...
- gguf/Genstruct-7B-GGUF · Hugging Face: no description found
- Weyaxi/Einstein-v4-7B · Hugging Face: no description found
- Tweet from Weyaxi (@Weyaxi): 🎉 Exciting News! 🧑🔬 Meet Einstein-v4-7B, a powerful mistral-based supervised fine-tuned model using diverse high quality and filtered open source datasets!🚀 ✍️ I also converted multiple-choice...
- WIP: galore optimizer by maximegmd · Pull Request #1370 · OpenAccess-AI-Collective/axolotl: Adds support for Galore optimizers Still a WIP, untested.
- GitHub - jiaweizzhao/GaLore: Contribute to jiaweizzhao/GaLore development by creating an account on GitHub.
- Tweet from Seb Lhomme (@slhomme): My new AI tool coming up: SocialClone - Create AI-Clone Videos Instantly!
- GitHub - e-p-armstrong/augmentoolkit: Convert Compute And Books Into Instruct-Tuning Datasets: Convert Compute And Books Into Instruct-Tuning Datasets - e-p-armstrong/augmentoolkit
- Swim In GIF - Swim In Swimming - Discover & Share GIFs: Click to view the GIF
- Worried Scared GIF - Worried Scared Oh No - Discover & Share GIFs: Click to view the GIF
- How to Fine-Tune LLMs in 2024 with Hugging Face: In this blog post you will learn how to fine-tune LLMs using Hugging Face TRL, Transformers and Datasets in 2024. We will fine-tune a LLM on a text to SQL dataset.
- Yann Lecun: Meta AI, Open Source, Limits of LLMs, AGI & the Future of AI | Lex Fridman Podcast #416: Yann LeCun is the Chief AI Scientist at Meta, professor at NYU, Turing Award winner, and one of the most influential researchers in the history of AI. Please...
Nous Research AI ▷ #ask-about-llms (83 messages🔥🔥):
-
Seeking Free GPT-4 Access:
@micron588inquired about ways to access GPT-4 for free, especially through an API.@tekniumoffered a point of help by referencing Corcel.io, a platform that provides free ChatGPT-4 access and direct API integration to the Bittensor network. -
Misunderstood Model Name:
@micron588expressed skepticism about the Corcel.io model being GPT-4 as it didn't respond in kind and lacked real-time data capabilities.@tekniumclarified that GPT-4 does not typically include real-time data. -
Nous-Hermes Model Context Length Query:
@nickcbrownasked why the context length in some Nous-Hermes models appeared to be reduced.@night_w0lfsuggested it might be a configuration or hardware limitation rather than an actual reduction. -
Discussion on LLM Pretraining and Finetuning: The difference between large language model (LLM) pretraining and fine-tuning was debated.
@tekniumand@carsonpoolediscussed the nuances of LoRA, DoRA, VeRA, and GaloRe and their impact on model optimization and expressiveness. -
The Cost of Pretraining and Model Optimization Techniques:
@umariganhighlighted the resource-intensive nature of continued pretraining for LLMs and shared an article on the subject, while@eas2535alluded to the advancements of FSDP and QLoRA for training large models on fewer resources.@tekniumcountered with skepticism, implying these strategies might still be out of reach for smaller operations.
Links mentioned:
- Corcel · Build with the power of Bittensor: no description found
- $ Cost of LLM continued pre-training: How much will it cost you to do continued pre-training for a small (7B) LLM?
- Trendyol/Trendyol-LLM-7b-base-v0.1 · Hugging Face: no description found
- Answer.AI - You can now train a 70b language model at home: We’re releasing an open source system, based on FSDP and QLoRA, that can train a 70b model on two 24GB GPUs.
- Poor Man GIF - Poor Man - Discover & Share GIFs: Click to view the GIF
- no title found: no description found
LM Studio ▷ #💬-general (148 messages🔥🔥):
- Update on LM Studio Version:
@datasoulmentions the latest version is 0.2.16.@heyitsyorkieprovides support regarding GGUF model compatibility and links to the Huggingface repository. - Evaluating Model Speed with Metal:
@nullt3rand@heyitsyorkiediscuss evaluation speeds for Mixtral and other models on various setups, with speeds ranging from 27 tok/s to 4 tok/s depending on the model and quality. - REOR, the Self-organizing AI Note-Taking App:
@clubofomfinds REOR to be an effective AI note-taking app and provides a link to the project page: www.reorproject.org. - Pi's Inflection 2.5 and Inflection AI:
@pierrunoytand@aswarpdiscuss the new Inflection-2.5 model from Inflection AI, noting improvements in coding and IT support. They also share a YouTube video discussing the update: Inflection 2.5. - Running Local LLM Models with LM Studio:
@heyitsyorkieadvises@.atipthat local LLM models must be in GGUF format and within specific folder structures to work with LM Studio, sharing a link to the unofficial FAQ: Learning More About GGUF and discussing the conversion process.
Links mentioned:
- 👾 LM Studio - Discover and run local LLMs): Find, download, and experiment with local LLMs
- RIP Midjourney! FREE & UNCENSORED SDXL 1.0 is TAKING OVER!: Say goodbye to Midjourney and hello to the future of free open-source AI image generation: SDXL 1.0! This new, uncensored model is taking the AI world by sto...
- Reddit - Dive into anything: no description found
- The unofficial LMStudio FAQ!: Welcome to the unofficial LMStudio FAQ. Here you will find answers to the most commonly asked questions that we get on the LMStudio Discord. (This FAQ is community managed). LMStudio is a free closed...
- 22,000 H100s later, Inflection 2.5!!!: 🔗 Links 🔗https://inflection.ai/inflection-2-5❤️ If you want to support the channel ❤️Support here:Patreon - https://www.patreon.com/1littlecoder/Ko-Fi - ht...
- Inflection-2.5: meet the world's best personal AI: We are an AI studio creating a personal AI for everyone. Our first AI is called Pi, for personal intelligence, a supportive and empathetic conversational AI.
- Reor: AI note-taking app that runs models locally & offline on your computer.
- Pal - AI Chat Client: A lightweight but powerful and feature-rich AI Chat Client for your iPhone! Support for: GPT-4 Turbo, GPT-4 Vision, DALL-E 3, Claude 3 Opus, Gemini Pro, Mistral Large, Openrouter, and custom endpoin...
LM Studio ▷ #🤖-models-discussion-chat (68 messages🔥🔥):
- LM Studio Terminal Troubles:
@heyitsyorkieclarified that running LM Studio from the terminal should not result in any errors such as missingGLIBCorLIBCBlastlibraries as of version 0.2.16. - Gemma Model Gripes:
@honeylaker_62748_43426faced an error with agemma 7b ggufmodel which@heyitsyorkieconfirmed to be a known issue with these models. - Starcoder2 Compatibility Confusion: Multiple users including
@madhur_11,@poshigetoshi, and@zachmayerdiscussed issues withstarcoder2as it is not recognized by LM Studio in its current build. - Image Generation Guidance:
@heyitsyorkieredirected@callmemjininalooking for a model to generate pictures to explore image generation tools like Stable Diffusion and interfaces like Automatic 1111 or ComfyUI. - RAG Explanation Requested: As
@neuropixelsinquired about setting up a knowledge database for chatbots,@heyitsyorkieshared a link to IBM's article explaining Retrieval-Augmented Generation (RAG), which could potentially address their requirements.
Links mentioned:
- What is retrieval-augmented generation? | IBM Research Blog: RAG is an AI framework for retrieving facts to ground LLMs on the most accurate information and to give users insight into AI’s decisionmaking process.
- Kquant03/TechxGenus-starcoder2-15b-instruct-GGUF · Hugging Face: no description found
LM Studio ▷ #🧠-feedback (1 messages):
heyitsyorkie: Stop using <#1113937247520170084> for help posts. Use <#1111440136287297637>
LM Studio ▷ #🎛-hardware-discussion (66 messages🔥🔥):
- Powering up the RTX 3090:
@wilsonkeebsis looking for the smallest PSU to power a standalone RTX 3090 and@heyitsyorkiesuggests a 750W PSU at minimum, mentioning that lower wattage PSUs might lack the necessary PCIe cables, despite another user recommending a Razer Core X eGPU enclosure. - Considering Future Upgrades:
@wilsonkeebsplans to eventually rebuild their PC with a 1500W PSU and a larger case, with the current search for a PSU being a temporary solution. - The Value Debate of GPUs: In the context of LM (language model) focused builds, users discuss the cost versus VRAM benefits of newer 4060 Ti cards against the second-hand market for the 3090, considering power efficiency and pricing differences across various regions like Canada and Australia.
- Board Choices and Component Compatibility:
@jedd1and@nink1discuss the challenges of finding motherboards that support multiple high-end GPUs, with considerations of PCIe slot availability and supported features, alongside power consumption and pricing strategies for builds. - Running Heavy Models on Consumer Hardware:
@neuropixelsshares difficulties in running a large language model on a Nvidia GeForce 1080 Ti with 11GB VRAM, which is resolved after restarting the workstation, indicating potential issues with hardware compatibility or software glitches when dealing with demanding AI models.
Links mentioned:
- Razer Core X - Thunderbolt™ 3 eGPU | Razer United Kingdom: Now compatible with Mac and Windows laptops, featuring 3-slot PCI-Express desktop graphic cards, 650W power supply, and charges via USB-C.
- PSU for NVIDIA GeForce RTX 3090 | Power Supply Calculator: See what power supply you need for your NVIDIA GeForce RTX 3090
LM Studio ▷ #🧪-beta-releases-chat (4 messages):
- Anticipation Builds Up: User
@yagilbhinted at an upcoming release with a brief message: Coming soon. - Are We There Yet?:
@wolfspyreinquired in a light-hearted fashion about the arrival of the expected update, asking, are we there yet? - The Countdown Reset: Shortly after,
@wolfspyrejokingly apologized for resetting the imaginary countdown for the awaited update, saying, oops... I just reset the timer y'all... my bad... it's my fault it's gonna take a bit longer... sorry.
LM Studio ▷ #amd-rocm-tech-preview (22 messages🔥):
- AMD's CEO Intervenes in Tiny Corp GPU Saga:
@senecalouckposted an article link highlighting how AMD's CEO Lisa Su stepped in to address Tiny Corp's frustration with the Radeon RX 7900 XTX GPU firmware, following public complaints and a request for the firmware to be open sourced;@berendbotje1sees this as potentially eye-opening for AMD. - Boost Your Productivity with AMD and AI:
@hellowordshared an AMD Community Blog post detailing how to run a GPT based LLM-powered AI chatbot on AMD Ryzen™ AI PCs or Radeon™ 7000 series graphics cards to help increase productivity without needing an internet connection. - Troubleshooting LM Studio on AMD:
@briansp2020described issues with running models on LM Studio using the Radeon 7900XTX GPU, which worked when not using GPU acceleration;@jello_puddingsuggested LM Studio might be trying to use an integrated GPU instead of the dedicated one. - GPU Selection for LM Studio:
@jello_puddingmentioned the need for a feature to select specific GPUs for LM Studio usage, hinting at difficulties caused by the software defaulting to integrated graphics;@yagilbacknowledged the suggestion as a valid point of concern. - VRAM Confusion Resolved: Clarifications regarding VRAM estimations were discussed as
@beanz_yquestioned the VRAM capacity, with@yagilbcorrecting that the 47GB figure referred to regular RAM, while the program estimated23.86GBVRAM usage.
Links mentioned:
- AMD’s Lisa Su steps in to fix driver issues with GPUs in new TinyBox AI servers — firm calls for AMD to make its GPU firmware open source, points to issues with Radeon 7900 XTX: The intervention comes as Tiny Box publicly frets about Radeon-based platform bugs.
- How to run a Large Language Model (LLM) on your AMD Ryzen™ AI PC or Radeon Graphics Card: Did you know that you can run your very own instance of a GPT based LLM-powered AI chatbot on your Ryzen™ AI PC or Radeon™ 7000 series graphics card? AI assistants are quickly becoming essential resou...
- GitHub - amd/RyzenAI-SW: Contribute to amd/RyzenAI-SW development by creating an account on GitHub.
LM Studio ▷ #crew-ai (3 messages):
- Seeking Solutions for Response Speed:
@alluring_seahorse_04960is in search of ways to increase response speed and encountered aConnection to telemetry.crewai.com timed outerror. - Baseline for Local Operations:
@wolfspyresuggests establishing a baseline with a simple operation that runs locally as a potential starting point for dealing with response speed issues. - Building a Generalizable Framework:
@pefortindetailed their work on a more generalizable framework involving a front-facing agent to clarify user tasks, a project manager to delineate atomic tasks, HR recruitment expert agents to craft specialized agents for tasks, and an executor agent to launch configured python scripts. While the system is currently slow and performing poorly, refinements are underway.
LM Studio ▷ #open-interpreter (87 messages🔥🔥):
-
Confusion Over Interpreter Options: User
@nxonxibrought up running the interpreter with a system message option, while@1sbeforeexpressed confusion, noting that it wasn't mentioned in the docs they found.@nxonxithen clarified the option-sis short for--system_messageas mentioned in the documentation. -
Seeking Python Script Help:
@nxonxisought assistance on setting the default system message within a Python script, which@1sbeforeadmitted inability to help with. The issue revolved around using the commandinterpreter.system_message = "Your message"in the script but not getting the expected result. -
Troubleshooting Profile Issues:
@nxonxifaced challenges trying to implement changes in intent profiles, ending in no observed changes on the language model server (LMS).@1sbeforesuggested ensuring the modification path matched with the Python path provided bywhich interpreterin the user's environment. -
Exploring Different Language Models: There was a discussion about various language models such as deepseek coder 6 and openchat/mistral and their responses to prompts.
@berendbotje1and@1sbeforeconsidered the potential and shared experiences with models like LHK_DPO_v1 and Truthful_DPO_TomGrc_FusionNet_7Bx2_MoE_13B. -
Exchanging Model Insights and Recommendations:
@1sbeforeprovided a link to the GGUFs for HanNayeoniee/LHK_DPO_v1 hosted on Hugging Face, and expressed intention to update channel members on further tests. They also warned about potential limitations regarding context size, citing a discussion on the reliability of FusionNet_7Bx2_MoE_14B beyond 4000 tokens (source).
Links mentioned:
- owao/LHK_DPO_v1_GGUF · Hugging Face: no description found
- All Settings - Open Interpreter: no description found
- All Settings - Open Interpreter: no description found
- TomGrc/FusionNet_7Bx2_MoE_14B · Contextsize: no description found
- GitHub - jondurbin/bagel: A bagel, with everything.: A bagel, with everything. Contribute to jondurbin/bagel development by creating an account on GitHub.
LlamaIndex ▷ #announcements (1 messages):
- We Want Your Feedback!:
@seldo_vinvites users to complete a 3-minute user survey to assist LlamaIndex in enhancing their offerings. The survey seeks to gather insights to improve documentation, demos, and tutorials; the link is here.
Links mentioned:
LlamaIndex user survey: Take this survey powered by surveymonkey.com. Create your own surveys for free.
LlamaIndex ▷ #blog (4 messages):
- Exploring Claude 3's Versatility: A new video guide 🎞️ showcases a comprehensive cookbook for Claude 3, featuring various use cases with @llama_index's tools such as Vanilla RAG, Routing, Sub-question query planning, and more. The guide is accessible on Twitter.
- LlamaIndex Seeks User Feedback: LlamaIndex is conducting a quick 3-minute user survey to better understand users' experience levels and needs in order to improve documentation, demos, and tutorials. Interested participants can find the survey here.
- Improving RAG with Jina's New Reranker: A just-released reranker tool named
jina-reranker-v1-base-enby @JinaAI_ promises to dramatically enhance RAG applications by providing quality improvements to vector search. Details are available via Twitter. - Novel Hierarchical Code Splitting Technique Unveiled: The
CodeHierarchyNodeParseris a new technique credited to ryanpeach, allowing for advanced RAG/agents for code understanding by converting large code files into a manageable hierarchy. Announcement and more information shared on Twitter.
Links mentioned:
LlamaIndex user survey: Take this survey powered by surveymonkey.com. Create your own surveys for free.
LlamaIndex ▷ #general (339 messages🔥🔥):
- Missing Documentation for Older Versions: Users
@torsten_13392and@nesgivexpressed concerns about the unavailability of older version documentation for LlamaIndex, noting that they could no longer access them via Google or on the official site. - Integration Issues with Chat Engine and NodeWithScore:
@cheesyfishesclarified to@nesgivthat chat engines only take strings as input and are specifically meant for chatting, suggesting that customization outside of this may require a custom retriever. - Multi-modal Data Storage and Retrieval Confusion: Users encountered difficulties determining how to store images with metadata in Weaviate using LlamaIndex.
@cheesyfishesshared a workaround to store the node in the database and the image elsewhere, while@whitefang_jrreferred users to Chroma. - Customizing Scoring Algorithms: User
@cheesyfishesprovided insight on customizing the scoring algorithm in a retriever, indicating that the ability to configure scoring depends on the vector database exposing such an option. - Issues with Updating and Persisting Data: Users including
@capn_stabndiscussed issues related to updating indexes and persistent storage. Capn_stabn specifically mentioned problems with Milvus deleting data after updating the index, which was later resolved by adjusting theoverwritesetting.
Links mentioned:
- no title found: no description found
- no title found: no description found
- no title found: no description found
- no title found: no description found
- no title found: no description found
- Prefill Claude's response: no description found
- Starter Tutorial - LlamaIndex 🦙 v0.10.18.post1: no description found
- LlamaIndex user survey: Take this survey powered by surveymonkey.com. Create your own surveys for free.
- gist:7f54b5ae756b5362b3ec0871b845eeac: GitHub Gist: instantly share code, notes, and snippets.
- Building a Slack bot that learns with LlamaIndex, Qdrant and Render — LlamaIndex, Data Framework for LLM Applications: LlamaIndex is a simple, flexible data framework for connecting custom data sources to large language models (LLMs).
- Advanced Multi-Modal Retrieval using GPT4V and Multi-Modal Index/Retriever - LlamaIndex 🦙 v0.10.18.post1: no description found
- Usage Pattern - LlamaIndex 🦙 v0.10.18.post1: no description found
- HuggingFace LLM - StableLM - LlamaIndex 🦙 v0.10.18.post1: no description found
- Ingestion Pipeline - LlamaIndex 🦙 v0.10.18.post1: no description found
- Chroma Multi-Modal Demo with LlamaIndex - LlamaIndex 🦙 v0.10.18.post1: no description found
- Multimodal Retrieval Augmented Generation(RAG) | Weaviate - Vector Database: A picture is worth a thousand words, so why just stop at retrieving textual context!? Learn how to perform multimodal RAG!
- Ensemble Retrieval Guide - LlamaIndex 🦙 v0.10.18.post1: no description found
- Custom Response - HTML, Stream, File, others - FastAPI): FastAPI framework, high performance, easy to learn, fast to code, ready for production
- llama_index/llama-index-integrations/vector_stores/llama-index-vector-stores-opensearch/llama_index/vector_stores/opensearch/base.py at 0ae69d46e3735a740214c22a5f72e05d46d92635 · run-llama/llama_index: LlamaIndex is a data framework for your LLM applications - run-llama/llama_index
Perplexity AI ▷ #general (269 messages🔥🔥):
-
Claude 3 Opus Usage Limits Discussed: Users expressed concern about the limited number of uses for Claude 3 Opus under Perplexity's plan, with users like
@hra42noting disappointment about the 5-use limit. The conversation circled around the cost-efficiency of Perplexity AI subscription plans, with some users debating the sufficiency of the daily message limits. -
Difficulty Accessing Features for Some Users: Multiple users, including
@netrot.and@laurant3855, encountered issues when attempting to use certain features such as photo generation, using Cloude 3 Opus, and the rewrite function.@icelavamanand@icelavamanprovided assistance, including suggesting to reset browser data and contacting [email protected]. -
Comparisons of AI Performance and Efficiency: Various AI models were compared throughout the discussion for their performance and efficiency. Models like Inflection-2.5 were announced by
@codelicious, and tools such as Sonnet were suggested as viable options for model comparison by@deicoonand supported by other users like@akumaenjeru. -
Pros and Cons of Perplexity AI and Other AI Services: Users like
@thaholylemonand@hra42evaluated the value and capabilities of Perplexity AI, comparing its services and cost against other platforms like ChatGPT Plus. Discourse centered around the benefits of source-gathering functionality and overall value for researchers and students, while others discussed their personal preferences and experiences with different subscriptions. -
Subscription Elements and User Experiences Exchange: Users were seen exchanging experiences with different AI platforms and debating the features included with premium subscriptions like Pro Discord and access to models like Claude 3 Opus. Some users, such as
@toby1260, reported ambiguous experiences with the AI’s responses, leading to a discussion of prompt engineering and model limitations.
Links mentioned:
Inflection-2.5: meet the world's best personal AI: We are an AI studio creating a personal AI for everyone. Our first AI is called Pi, for personal intelligence, a supportive and empathetic conversational AI.
Perplexity AI ▷ #sharing (6 messages):
-
Perplexity AI vs. Other Platforms: User
@oen99unshared a comparison between Perplexity AI and another platform, highlighting differences and similarities. -
Learning on Perplexity AI:
@bluesky1911provided a link detailing methods for learning using Perplexity AI's vast resources. -
Historical Innovations and Progress:
@vishrutkmr7shared a link related to past innovations and the progress of civilization. -
Perplexity AI's Role Understanding: User
@croak_plonkposted a link that examines the concept and functionality of Perplexity AI in chatbot form. -
Questions on Authorship in AI:
@pope9870shared a link delving into who holds the writing credit in AI-assisted creation. -
Existence of Emotion in AI:
@bodhibiosposed a question about AI and emotions, referencing a Perplexity AI query exploring this concept.
Perplexity AI ▷ #pplx-api (14 messages🔥):
-
Perplexity Discovery Feature Inquiry:
@yankovichasked about Perplexity Discover's functionality, to which@bitsavage.described it as a tool for exploring new content based on user interests.@bitsavage.suggested checking the Perplexity API documentation for potential implementation. -
Channel Preservation Check-in:
@leoesqposted a message to keep the pplx-api channel active, while@po.shprovided a tip on how to view all channels in Discord to prevent losing access in the future. -
Seeking Documentation on RAG Pipeline:
@leoesqinquired about the documentation regarding the RAG pipeline and specific text handling used by Sonar, showing interest in understanding the interaction between search text and the LLM. -
API Inquiry for Answer Engine:
@ruxorlyquestioned the future availability of an API for using models like Claude/GPT4/Mistral Large with web search capability through Perplexity API. -
Clarification on Model Output Limitations:
@brknclock1215and@leoesqdiscussed the maximum output in tokens for models, noting that it depends on the model's context window and finetuning behavior, which significantly affects the token output size.
Eleuther ▷ #announcements (1 messages):
- New Benchmarks for Korean Language Models:
@gson_arloannounced the creation of two new Korean language evaluation datasets: Hae-Rae Bench and K-MMLU. Hae-Rae Bench is accepted at LREC-COLING 2024, and KMMLU, a Korean adaptation of MMLU, is under review at ACL, with both benchmarks designed to test language models' abilities to understand Korean-specific knowledge. - Call for Multilingual Model Evaluation:
@gson_arlohighlighted the limited tooling for evaluating multilingual models, particularly for languages other than English and Chinese, and invited community members to contribute to designing benchmarks for diverse languages and cultures in the<#1208111628051152969>channel. They also directed those interested in model evaluation to the<#755950983669874798>channel.
Eleuther ▷ #general (39 messages🔥):
- TensorRT Code Integration Pending Approval:
@abhishekvijeevinformed that they, along with another user, are in the process of integrating their TensorRT code, which requires approval due to being developed with company resources. - Context Length in Training LLMs Discussed:
@sentialxand@thooton_discussed training large language models (LLMs) with longer versus shorter contexts, with@thooton_explaining the benefits of starting with shorter context lengths for more focused training before moving to longer contexts. - EEVE-Korean-v1.0 Introduced:
@seungdukshared an arXiv technical report on efficiently adding more tokens to LLMs while maintaining the original model's performance, mentioning their work on \texttt{EEVE-Korean-10.8B-v1.0}. - Open Invitation for ML/AI Research Collaboration:
@andrew_f0874offered his background in CS, PhD from Cornell, and experience as a Google research scientist to collaborate part-time on ML/AI research, stating a broad interest especially in RL, ML privacy, ML security, and applying ML to programming/compilers. - Simple AI Discussions and Questions: New member
@shida3916sought a suitable forum to discuss everyday AI uses and ask simple questions, while@stellaathenasuggested looking at other servers listed in <#732688974337933322> for more beginner-friendly advice.
Links mentioned:
- Efficient and Effective Vocabulary Expansion Towards Multilingual Large Language Models: This report introduces \texttt{EEVE-Korean-v1.0}, a Korean adaptation of large language models that exhibit remarkable capabilities across English and Korean text understanding. Building on recent hig...
- eleutherai?): Weights & Biases, developer tools for machine learning
Eleuther ▷ #research (107 messages🔥🔥):
-
GaLore's Memory Efficiency Draws Attention: Users
@xylthixlm,@main.ai, and others discussed the potential of GaLore, a technique that claims better results than full-rank updates with less memory usage. Skepticism about the actual gradient savings and the practicalities of its implementation were expressed, particularly due to the way gradients are handled within the optimizer. -
Anticipation for GaLore Replication: Community members such as
@ai_waifu,@random_string_of_character, and@jckwindshowed interest in seeing replication of the GaLore results. A pull request for an optimizer by@maximegmdon GitHub suggests that replication attempts are imminent. -
Exploring GaLore's Codebase Raises Questions:
@xylthixlmexamined GaLore's code, noting that the optimizer runs after every parameter grad update during backprop, which suggests that all gradients don't need to be stored simultaneously. Users also discussed Python's capability to index a dictionary with a PyTorch parameter, with contributions from@_inoxand@tulkascodes. -
CAME Optimizer Piques Curiosity: The CAME optimizer was mentioned by
@xylthixlmas a lesser-known tool featured in PixArt-\Sigma; it aims to provide the speed of adaptive methods with reduced memory usage. Interest in understanding CAME's performance and comparisons with other optimizers like Adafactor and Adam was sparked. -
Instruction Tuning Dataset Discussions:
@kublaikhan1inquired about the best instruction tuning dataset, receiving a response from@jstephencoreywho recommended OpenAssistant and others. The importance of fine-tuning order and dataset quality was discussed, referring to a recent paper that found high-quality SFT (single fine-tuning) on GPT-4 outputs can yield results as good as or better than more complex tuning methods.
Links mentioned:
- PixArt-Σ: Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation: In this paper, we introduce PixArt-Σ, a Diffusion Transformer model~(DiT) capable of directly generating images at 4K resolution. PixArt-Σrepresents a significant advancement over its predecessor, Pix...
- CAME: Confidence-guided Adaptive Memory Efficient Optimization: Adaptive gradient methods, such as Adam and LAMB, have demonstrated excellent performance in the training of large language models. Nevertheless, the need for adaptivity requires maintaining second-mo...
- SOCIAL MEDIA TITLE TAG: SOCIAL MEDIA DESCRIPTION TAG TAG
- Pretrained-Language-Model/CAME/came.py at master · huawei-noah/Pretrained-Language-Model: Pretrained language model and its related optimization techniques developed by Huawei Noah's Ark Lab. - huawei-noah/Pretrained-Language-Model
- pytorch/torch/_tensor.py at main · pytorch/pytorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration - pytorch/pytorch
- A direct comparison between llama.cpp, AutoGPTQ, ExLlama, and transformers perplexities - LLM blog: no description found
- A detailed comparison between GPTQ, AWQ, EXL2, q4_K_M, q4_K_S, and load_in_4bit: perplexity, VRAM, speed, model size, and loading time. - LLM blog: no description found
- ToDo: Token Downsampling for Efficient Generation of High-Resolution Images: Attention mechanism has been crucial for image diffusion models, however, their quadratic computational complexity limits the sizes of images we can process within reasonable time and memory constrain...
- Making Large Language Models Better Reasoners with Step-Aware Verifier: Few-shot learning is a challenging task that requires language models to generalize from limited examples. Large language models like GPT-3 and PaLM have made impressive progress in this area, but the...
- GitHub - jiaweizzhao/GaLore: Contribute to jiaweizzhao/GaLore development by creating an account on GitHub.
- GaLore/torchrun_main.py at master · jiaweizzhao/GaLore: Contribute to jiaweizzhao/GaLore development by creating an account on GitHub.
- WIP: galore optimizer by maximegmd · Pull Request #1370 · OpenAccess-AI-Collective/axolotl: Adds support for Galore optimizers Still a WIP, untested.
Eleuther ▷ #lm-thunderdome (24 messages🔥):
-
Custom Output Format Implementation for Harness:
@pminerviniinquired about customizing output format in the harness, suggesting a two-step generation process.@baber_proposed a modification of thegenerate_untilmethod and shared a GitHub link as a potential starting point for implementation. -
MCQA Evaluation Paper Discussion:
@nish5989shared their paper on multiple-choice questions (MCQA) evaluation and dataset artifacts. The subsequent discussion touched on empirical results of answer format validity in the appendix and the consideration of rerunning experiments with likelihood methods. -
The Question of Language-Specific Evaluation:
@seanbethardquestioned the preference for language-specific evaluation criteria over crosslingual criteria, referencing language nuances like evidentiality and animacy, but arguing for the sufficiency of syntax and lexicon for language evaluation. -
Confidence Interval Clarification:
@yamashisought clarification on calculating a 95% confidence interval using the standard error of the mean (SEM).@hailey_schoelkopfconfirmed that multiplying 1.96 times the SEM is the correct approach. -
BOS Token Usage Variances:
@jwngxasked about the standards for using the beginning-of-sentence (BOS) token in evaluations, noting a recent change in practice.@stellaathenaclarified that usage depends on the model, but no consolidated information exists on which models perform better with it.
Links mentioned:
- Multiple Choice Question Standard Deviation · Issue #1524 · EleutherAI/lm-evaluation-harness: I saw that the multiple choice type evaluation would compute the metrics along with standard deviation. From my understanding, multiple choice answer is chosen from the choice with highest probabil...
- lm-evaluation-harness/lm_eval/models/huggingface.py at 9e6e240229429d2214bc281bed7a4e288f5169a1 · EleutherAI/lm-evaluation-harness.): A framework for few-shot evaluation of language models. - EleutherAI/lm-evaluation-harness
- Do Prompt-Based Models Really Understand the Meaning of their Prompts?: Recently, a boom of papers has shown extraordinary progress in zero-shot and few-shot learning with various prompt-based models. It is commonly argued that prompts help models to learn faster in the s...
- Are Language Models Worse than Humans at Following Prompts? It's Complicated: Prompts have been the center of progress in advancing language models' zero-shot and few-shot performance. However, recent work finds that models can perform surprisingly well when given intention...
Eleuther ▷ #multimodal-general (1 messages):
- New Member Seeking AI Knowledge:
@shida3916expressed enthusiasm about joining the community, looking to discuss everyday AI applications and seek answers to simple questions. They inquired if this Discord server is the appropriate place for such discussions.
Eleuther ▷ #gpt-neox-dev (102 messages🔥🔥):
-
Exploring Environment Setup Options:
@biiterand@tastybucketofricediscussed the intricacies of setting up environments for GPT-NeoX development, pondering over using Docker versus local system setups and acknowledging the complexity of dependency management. The idea of consolidating the environment setup was proposed by@catboy_slim_to ensure one correct way to prepare the development environment. -
NGC Container Contemplations:
@tfidiaintroduced the use of NVIDIA NGC PyTorch container to ease the struggles with setting up Apex and CUDA dependencies, and offered details on dependencies pre-installed within these containers.@catboy_slim_acknowledged the benefits but also expressed caution over potential reproducibility issues when moving outside of the containerized environment. -
Dependency Management Discussions: The conversation moved towards managing dependencies more effectively, with
@catboy_slim_suggesting a move to poetry for deterministic package management, while also considering the current dependency state and setup instructions. There was recognition of the usefulness of NGC containers, but also the challenges they might introduce due to pre-installed and pre-updated packages like Flash Attention. -
Flash Attention Update Conundrum:
@catboy_slim_pointed out concerns about version inconsistencies with Flash Attention when provided in pre-built containers like those from NGC.@tfidiaadvised on how to manually update Flash Attention, and the ongoing discussion acknowledged pytorch version specifications and the potential need for precision in dependency management. -
ProtoBuf Dependency Mystery Solved:
@hailey_schoelkopfand@catboy_slim_hashed out the need for the ProtoBuf dependency installation, deducing that it might be required for SentencePiece usage within Llama's tokenizer, illustrating the complexity in pinpointing dependency origins. The exchange highlights the importance of documenting dependency reasons in dynamic development environments.
Links mentioned:
- PyTorch Release 24.02 - NVIDIA Docs: no description found
- GitHub - Dao-AILab/flash-attention: Fast and memory-efficient exact attention: Fast and memory-efficient exact attention. Contribute to Dao-AILab/flash-attention development by creating an account on GitHub.
- Cleaner dockerfile: Remove already installed deps by tf-nv · Pull Request #1175 · EleutherAI/gpt-neox: Cleaning up the Dockerfile after the ngc pytorch switch (#1170): Eliminate already installed apt packages sparse attn requirement lead to a triton downgrade flash attn is already part of the ngc c...
- PyTorch Release 24.02 - NVIDIA Docs: no description found
OpenAI ▷ #ai-discussions (94 messages🔥🔥):
- Sonnet vs ChatGPT:
@aaron_speedyhighlighted that Sonnet is a stronger free model than ChatGPT 3.5, noting features like image upload and queries if it supports file uploads. - Anticipating GPT-4: Both
@futuremachineand@drinkoblog.weebly.comare looking forward to the release of GPT-4, especially since competitors like Claude 3 seem to be outperforming current models. - Prompt Optimization Debate:
@.vildenmentioned that overly verbose prompts can limit model performance, advising users to learn effective prompting to see fewer limitations with GPT 3.5. - Seeking AI for Flashcard Creation:
@khaledoo.inquired about an AI tool that can convert lecture PDFs into flashcards, sparking interest from others like@glamratand questions about content accuracy from@dezuzel. - Encountering GPT-4 Issues:
@spikydreported that GPT-4 has been repeating answers and providing responses in incorrect languages, voicing frustration about the service quality, which led to a discussion with@dojan1about potential workarounds and reasons for these anomalies.
Links mentioned:
GitHub - Kiddu77/Train_Anything: A repo to get you cracking with Neural Nets .: A repo to get you cracking with Neural Nets . Contribute to Kiddu77/Train_Anything development by creating an account on GitHub.
OpenAI ▷ #gpt-4-discussions (38 messages🔥):
- No GPTs over API for now:
@solbusclarified that GPTs are exclusive to ChatGPT and cannot be accessed via the OpenAI API in response to@cliffsayshi's query about using custom GPTs like Human Writer-Humanizer-Paraphraser (Human GPT) via the API. - Understanding OpenAI's offering: In the discussion with
@cliffsayshi,@solbusexplained that the entities available through the OpenAI API such as DALL-E, and the Babbage and Davinci models are not referred to as GPTs but as "models," with GPTs being a specific feature of ChatGPT. - ChatGPT Access Issues Addressed: Users
@pteromaple,@bluesdante,@aialra, and@cypriangfound that changing the language settings to "Auto-detect" and refreshing (F5) resolved issues with ChatGPT not responding in browsers. - Language Settings Bug:
@joachimpimiskernand@pteromaplereported and confirmed an ongoing issue with language settings in ChatGPT, where using English resolved the problem, but switching to other languages could cause the interface to break again. - Localized ChatGPT Troubleshooting:
@meteopxmentioned that using a VPN allowed messages to send through ChatGPT, highlighting localized technical concerns regarding the accessibility of the service in different regions.
OpenAI ▷ #prompt-engineering (54 messages🔥):
- Roleplay Prompt Guidance Questioned:
@loamy_discusses the best way to instruct AI for roleplay while@dezuzelrecommends providing positive instructions on actions the AI should perform, rather than mentioning what it shouldn't do. They suggest being explicit about AI reactions to achieve the desired roleplay effect. - Random Seeds in GPT:
@interactiveadventureaiqueries whether GPT can use a different seed for random number generation each iteration to enhance an interactive adventure.@solbusrecommends using Python via data analysis features for generating randomness, clarifying that control over the underlying model's seed isn't available to users. - Combatting Narrative Overlays in Outputs:
@interactiveadventureaiseeks advice to eliminate unwanted narrative summaries in the AI's responses, and@eskcantasuggests altering the writing style in the prompts as a possible solution. A touch of humor is added with a playful mention of drastic measures against servers. - New Member Intro:
@thebornchampionintroduces themselves to the community, expressing their enthusiasm for prompt engineering and discussing their use of GPT for data analytics and various personal projects, like planning a trip and academic support. - GPT Classifier for Conversation Closure:
@chemloxdiscusses building a GPT classifier to decide if an agent-consumer conversation should be closed, contemplating between using a react-based agent or fine-tuning GPT with training data.@eskcantarecommends testing the base model first to save effort and resources. - Organic Dialogue and Custom Instructions:
@feedonyourtearskappaseeks advice on creating more organic dialogue without repetitive phrases, while@openheroeshighlights the "Customize ChatGPT" feature to set instructions for a more natural writing style, including mimicry of specific text examples. - Professional Headshots with DALL-E:
@elhadrami.oussamaexpresses interest in generating professional headshots using DALL-E and seeks insights, but@enkai3526responds with a humorous comment related to gaming.
OpenAI ▷ #api-discussions (54 messages🔥):
- Prompt Engineering for Roleplay: User
@loamy_discussed how to formulate prompts for roleplay scenarios, considering whether to instruct the AI never to claim it's an assistant.@dezuzelrecommended focusing on what the AI should do rather than what it shouldn't. - Random Seed Selection Solved:
@interactiveadventureaisought advice on having GPT select a different seed for random number generation, considering using timestamps.@solbussuggested using Python's built-in random functions in the context of the data analysis feature. - Optimizing Narrative Responses:
@interactiveadventureaiexpressed frustration over the AI's tendency to provide narrative summaries and a certain style of dialogue.@eskcantashared guidance on prompt engineering to steer GPT into different writing styles. - Building a GPT Classifier for Conversations: User
@chemloxasked for advice on creating a GPT classifier to assess if user-agent conversations are resolved.@eskcantaadvised checking GPT's base model performance before deciding on further actions. - Crafting More Organic Dialogue Responses:
@feedonyourtearskappainquired about prompting the AI to produce natural dialogue without repetition.@openheroessuggested using the "Customize ChatGPT" feature to guide the model toward the desired output.
HuggingFace ▷ #announcements (1 messages):
- RAG Demo Live:
@bishmoyshared a RAG demo for searching Arxiv CS papers, accessible at HuggingFace Spaces. - Novel Protein Anomaly Detection:
@403280164433297409released a paper on detecting anomalous proteins using deep representations, announcement was accompanied by a Twitter link. - Fine-tuning Gemma with ChatML:
@817334594075623435provided a finetuning demonstration of Google's Gemma LLM with a notebook now available at HuggingFace Spaces. - Illuminating LLM Insights:
@1120804749273477242authored a blog post discussing the need to move beyond conversation to meaningful AI actions, linked on LinkedIn. - Cutting-edge LLM Interface in Rust: An interface using HuggingFace/Candle among others has been built entirely in Rust, showcased in a video by
@538229308678733851, while@282727276733399041introduced a new 16k context pretrained encoder model available at HuggingFace.
Links mentioned:
- Arxiv CS RAG - a Hugging Face Space by bishmoy: no description found
- Andyrasika/Gemma-ChatML · Hugging Face: no description found
- Andyrasika/vit-base-patch16-224-in21k-finetuned-lora-food101 · Hugging Face: no description found
- Open Llm Leaderboard Viz - a Hugging Face Space by dimbyTa: no description found
- UDOP DocVQA - a Hugging Face Space by RamAnanth1: no description found
- Yi 9B - a Hugging Face Space by Tonic: no description found
- BEE-spoke-data/mega-encoder-small-16k-v1 · Hugging Face: no description found
- Andyrasika/lora_gemma · Hugging Face: no description found
- Locutusque/UltraTextbooks-2.0 · Datasets at Hugging Face: no description found
- Mistral-ChatBot-Arena - a Hugging Face Space by rwitz: no description found
- GitHub - treebeardtech/treebeard-kubeflow: 🪐 scale Jupyter in Kubernetes: 🪐 scale Jupyter in Kubernetes. Contribute to treebeardtech/treebeard-kubeflow development by creating an account on GitHub.
- Large Language Models in Quest for Adventure: no description found
HuggingFace ▷ #general (142 messages🔥🔥):
- Clash Over Proposed AI Safety Czar: Concerns surfaced about the anticipated appointment of Paul Christiano to the US AI Safety Institute, causing an internal crisis at the National Institute of Standards and Technology with staff threats of resignation and a revolt. The article details the conflict and Christiano's controversial views on AI's potential for causing existential risks.
- AI for Optimizing Code:
@techintermezzosought advice on the best AI model for optimizing shader code, prompting discussions on models like DeepSeek-Coder instruct and resources like the OpenCodeInterpreter paper. The code processing review work breaks down current advancements, helping those interested in understanding and utilizing AI for programming tasks. - Exploring AI-Enhanced Geopolitics: In a lengthy discussion about the potential of AI in global strategies,
@acidgrimand others debated the contrasting approaches of Western and Chinese AI, touching on topics from censorship to potential applications in asymmetric warfare. The debate covered implications of unrestricted AI, AI training data concerns, and potential regulations. - Prompt Engineering for RAG:
@jeffry4754inquired about the standard term for preprocessing a question into sub-questions for Retrieval-Augmented Generation (RAG), suggesting "multi-hop question-answering task" might be the title for such a technique. The conversation continued without a clear consensus or reference for a standard term. - Stable Diffusion Query: User
@maycolroxrequested assistance with loading models in the diffusers library pertaining to stable diffusion, implying a problem with a model called loras. No direct solution was offered within the given messages.
Links mentioned:
- no title found: no description found
- Inflection-2.5: meet the world's best personal AI: We are an AI studio creating a personal AI for everyone. Our first AI is called Pi, for personal intelligence, a supportive and empathetic conversational AI.
- Repeat After Me: Transformers are Better than State Space Models at Copying: Transformers are the dominant architecture for sequence modeling, but there is growing interest in models that use a fixed-size latent state that does not depend on the sequence length, which we refer...
- NIST staffers revolt against expected appointment of ‘effective altruist’ AI researcher to US AI Safety Institute: NIST faces turmoil as staff consider quitting over Paul Christiano's expected appointment to a role at the US AI Safety Institute, sources say.
- Deploying 🤗 Hub models in Vertex AI: no description found
- OpenCodeInterpreter: Integrating Code Generation with Execution and Refinement: The introduction of large language models has significantly advanced code generation. However, open-source models often lack the execution capabilities and iterative refinement of advanced systems lik...
- blog-explorers (Blog-explorers): no description found
- Haiper | Generative AI For Video Content Creation: Video creation AI products crafted to empower individuals in creatively expressing themselves.
- Unifying the Perspectives of NLP and Software Engineering: A Survey on Language Models for Code: In this work we systematically review the recent advancements in code processing with language models, covering 50+ models, 30+ evaluation tasks, 170+ datasets, and 700+ related works. We break down c...
- Deploying 🤗 Hub models in Vertex AI: no description found
- Federal Register :: Request Access: no description found
- Regulations.gov: no description found
- My views on “doom” — LessWrong: I’m often asked: “what’s the probability of a really bad outcome from AI?” …
HuggingFace ▷ #today-im-learning (4 messages):
- Interest in AI for Data Analytics:
@umbreenhexpressed a desire to learn about using generative AI for data analytics development and welcomed any assistance or pointers in this domain. - Collaborative Learning Spirit:
@yasirali1149responded to@umbreenhwith an interest to learn together about generative AI applications in data analytics. - Ready to Join the Learning Venture:
@kenngalaaddressed@Singhaditya4333(who hasn't written in the provided messages), indicating their readiness to engage and collaborate in the learning process.
HuggingFace ▷ #cool-finds (5 messages):
-
"Let's Build GPT" Educational Resource Shared:
@kurtfehlhauerrecommended an introductory video to GPT construction - a thorough walkthrough titled "Let's build GPT: from scratch, in code, spelled out." The video explains the creation of a Generative Pretrained Transformer following OpenAI's papers. -
Spotlight on Hugging Face's Task Page:
@andysingalexpressed enthusiasm for Hugging Face's Machine Learning tasks portal, which lists resources like demos, use cases, models, datasets across various tasks in computer vision and other domains. -
A Gentle Note on Resource Familiarity: In response to @andysingal's post about the tasks page,
@cakikipointed out that the resource isn't new and credited@697163495170375891for their longstanding efforts on the platform. -
Discovery is Personal: Continuing the dialogue,
@andysingalclarified that the tasks page was new to him and hence his excitement. -
Qwen-Agent Empowers AI Developers:
@andysingalhighlighted the capabilities of Qwen-Agent, an AI framework that integrates instruction following, tool usage, planning, and memory in LLMs, in a detailed Medium article titled "Unleashing the Power of Qwen-Agent: Revolutionizing AI Assistance with RAG Application."
Links mentioned:
- Tasks - Hugging Face: no description found
- Let's build GPT: from scratch, in code, spelled out.: We build a Generatively Pretrained Transformer (GPT), following the paper "Attention is All You Need" and OpenAI's GPT-2 / GPT-3. We talk about connections t...
- Unleashing the Power of Qwen-Agent: Revolutionizing AI Assistance with RAG Application: Ankush k Singal
HuggingFace ▷ #i-made-this (13 messages🔥):
-
Gemma Takes on ChatML:
@andysingalshared their work on fine-tuning Gemma, Google's LLM, with ChatML, demonstrating this with a model card and acknowledging @philschmid’s tokenizer. -
Recap of AI x Web3 at ETHDenver:
@aerophilianpenned a recap of ETHDenver, highlighting Web3 and AI intersection and shared a blog post with insights and YouTube links for conference talks. -
Searching via CLIP Index Just Got Easier:
@robbesneydersintroduced a CLIP index for the Datacomp-12.8M dataset, facilitating prompt-based searches, and pointed to their team's method and outputs on the Hugging Face Hub and a blog post for more details. -
Fine Dining with AI:
@chongdashubuilt a restaurant name and menu generator app in under 100 lines of Python, showcasing LangChainAI and Gradio, complete with a Medium article, live demo, and full source code. -
Legal Precedents at Your Fingertips:
@conceptofmindannounced the release of over 6.6 million state and federal court decisions, a collaborative effort supported by the Caselaw Access Project and Harvard Library Innovation Lab, with datasets and embeddings available for use, as mentioned in an update by @EnricoShippole and acknowledged additional help from<@274244546605613056>.
Links mentioned:
- Doodle Wars: no description found
- Andyrasika/Gemma-ChatML · Hugging Face: no description found
- ETHDenver Recap: Emerging Trends in web3 and AI: Where we're at, where we're heading, and the return of Kevin.
- Tweet from Enrico Shippole (@EnricoShippole): @TeraflopAI is excited to help support the @caselawaccess and @HarvardLIL, in the release of over 6.6 million state and federal court decisions published throughout U.S. history.
- Building a Datacomp CLIP index with Fondant - Fondant.): no description found
- Langchain Crash Course (Gradio) - a Hugging Face Space by chongdashu: no description found
- GitHub - chongdashu/langchain-crash-course at lesson-1: Contribute to chongdashu/langchain-crash-course development by creating an account on GitHub.
HuggingFace ▷ #reading-group (45 messages🔥):
-
Seeking Guidance for llamas2 Chatbot: User
@neerajjulka1986requested resources for an end-to-end chatbot project using the opensource model llamas2.@chad_in_the_houserecommended checking out resources for finetuning and deployment on GitHub, including PEFT and text-generation-inference, and mentioned TRL for reinforcement learning at TRL GitHub. -
Gathering for Gemini 1.5 Pro Overview:
@shashank.f1announced a meeting on Sparse MOEs and Gemini 1.5 Pro, providing a Zoom link and indicating an overview would take place. They also shared Jeremy Howard's tweet about Sparse MOEs as a resource. -
Gemini 1.5 Pro Discussion Recording Shared:
@shashank.f1posted a YouTube video link to the earlier Gemini 1.5 Pro discussion and Sparse Mixture of Experts Model, which can be found here on YouTube. -
Understanding Mixture of Experts (MoEs):
@chad_in_the_houserecommended a blog post from Hugging Face to understand MoEs, accessible here. Additionally,@shashank.f1explained that the VRAM requirement for tuning MoEs with QLoRA goes up, making it impractical on a single GPU but viable with multiple GPUs, and shared a library for implementing this at fsdp_qlora. -
Meeting times and recordings: Users asked about meeting times and recording availability.
@chad_in_the_houseconfirmed that meetings might be planned for the weekend and indicated that recordings should be posted by@shashank.f1.
Links mentioned:
- Join our Cloud HD Video Meeting: Zoom is the leader in modern enterprise video communications, with an easy, reliable cloud platform for video and audio conferencing, chat, and webinars across mobile, desktop, and room systems. Zoom ...
- Join our Cloud HD Video Meeting: Zoom is the leader in modern enterprise video communications, with an easy, reliable cloud platform for video and audio conferencing, chat, and webinars across mobile, desktop, and room systems. Zoom ...
- Gemini 1.5 Pro: Unlock reasoning and knowledge from entire books and movies in a single prompt: 🚀 Dive into the world of AI with Gemini 1.5! 🌟In this video, we unpack the magic behind Gemini's sparse mixture of experts architecture, perfect for unleas...
- GitHub - huggingface/trl: Train transformer language models with reinforcement learning.: Train transformer language models with reinforcement learning. - huggingface/trl
- GitHub - AnswerDotAI/fsdp_qlora: Training LLMs with QLoRA + FSDP: Training LLMs with QLoRA + FSDP. Contribute to AnswerDotAI/fsdp_qlora development by creating an account on GitHub.
- Mixture of Experts Explained: no description found
- GitHub - huggingface/peft: 🤗 PEFT: State-of-the-art Parameter-Efficient Fine-Tuning.: 🤗 PEFT: State-of-the-art Parameter-Efficient Fine-Tuning. - huggingface/peft
- GitHub - huggingface/text-generation-inference: Large Language Model Text Generation Inference: Large Language Model Text Generation Inference. Contribute to huggingface/text-generation-inference development by creating an account on GitHub.
HuggingFace ▷ #diffusion-discussions (1 messages):
- Seeking Guides on Merging SDXL with LoRA:
happy.jis looking for resources or guides on how to merge sdxl-lightning LoRA with a standard SDXL model, pointing to a discussion where more information on the procedure would be appreciated. - ByteDance Weighs in on SDXL-Lightning Techniques: The
ByteDance orgsuggests training a regular SDXL model on your dataset before applying SDXL-Lightning LoRA for acceleration, and for best compatibility, to train SDXL as LoRA from the start. - Advanced Training Tips from ByteDance: For those seeking higher quality,
ByteDance orgrecommends merging SDXL-Lightning LoRA onto your model and then training, while noting that using MSE loss may dilute acceleration benefits. The most advanced method involves merging and then using an adversarial objective, as described in the SDXL-Lightning paper.
Links mentioned:
ByteDance/SDXL-Lightning · finetune: no description found
HuggingFace ▷ #computer-vision (9 messages🔥):
-
Normalization Conundrum in Data Processing:
@huzuniraised a topic about the effectiveness of normalization, stating they have noticed little to no impact on their data metrics with various normalization methods like imagenet norm, channel wise norm, and min-max norm. They inquired whether there are studies on the actual effects of normalization or explanations for its potential lack of utility. -
Seeking Ultralytics Alternatives for Commercial Use:
@prod.dopamineprompted discussion for alternatives to ultralytics, expressing discontent with the AGPL license for commercial applications. They are looking for options that offer ease of use like Ultralytics but are also suitable for commercial use. -
Yolov4 Suggested as a Viable Alternative: In response to @prod.dopamine,
@toni_alrightsuggested Yolov4 as an alternative due to its different license that is more suitable for commercial use. The implication is that Yolov4 could be used as an Ultralytics alternative that conforms to commercial license requirements. -
Darknet Implementation of Yolov4 Clarification: Following the suggestion,
@prod.dopamineasked whether the recommended Yolov4 was the darknet implementation or another one, indicating a need for clarity on the specific alternative being proposed. -
Call for AI Co-Study Partners:
@nobita_nobii_put out a call for a co-study partner in AI, which led to an affirmative response from@prod.dopamine. This indicates community interest in collaborative learning within the channel.
HuggingFace ▷ #NLP (18 messages🔥):
-
DeBERTa Pre-Training Hurdles:
@henkiespenkie22is facing issues pre-training DeBERTa from Microsoft, with current implementations like camemdeberta not working for them.@grimsqueakerresponded, highlighting that Electra pretraining is not supported in HuggingFace, presenting a challenge for users seeking to pre-train these models. -
Retriever Puns Galore: After
@.sgpasked what a retriever is,@cakikishared a humorous Golden Retriever GIF, and@lucnzzquipped about a retriever being "a dog that catches embeddings." -
Choosing the Right Language Model for Colab:
@iloveh8inquired about recommendations for small to medium open-source language models suitable for Google Colab, leading to suggestions from@cursoropwho mentioned any 2b model and flan T5, while@lucnzzproposed any small quantisized 4-bit models. -
Herculean Task on a Raspberry Pi 4:
@verdagonhumorously contemplated the idea of running a 70B model on a Raspberry Pi 4, even if it meant 40 minutes per token. -
Mapping Attention Weights Challenge:
@komorebi6466sought advice on how to map attention weights to each word in a sentence using BertModel for sentiment analysis, wanting to convert the attention output to a list with a specific shape.@darwinanim8orrequested to see their code, offering a code snippet that demonstrates a similar process for a classifier based on DeBERTa.
Links mentioned:
Golden Retriever Dog GIF - Golden Retriever Dog Puppy - Discover & Share GIFs: Click to view the GIF
HuggingFace ▷ #diffusion-discussions (1 messages):
- Seeking Guidance on SDXL-Lightning LoRA Merging: User
happy.jis looking for assistance on how to merge SDXL-Lightning LoRA with a standard SDXL model, expressing difficulty in finding resources beyond a HuggingFace discussion thread. - Expert Recommendations for SDXL Variants: A member from the ByteDance organization recommends first training a regular SDXL model and then applying SDXL-Lightning LoRA for acceleration. For compatibility, training the SDXL with LoRA from the outset is preferred.
- Advanced Training Approaches for SDXL-Lightning LoRA: For quality improvements, ByteDance suggests merging SDXL-Lightning LoRA with the user's model and training further, cautioning that using MSE loss could dilute acceleration benefits. Employing an adversarial objective during training is considered the most advanced strategy, following the SDXL-Lightning paper's approach.
Links mentioned:
ByteDance/SDXL-Lightning · finetune: no description found
LAION ▷ #general (113 messages🔥🔥):
- AI Image Generator Alternatives Buzz:
@lunseiasked about alternatives to Sora being developed.@thejonasbrothershumorously replied that numerous projects are in the works, with@pseudoterminalxadding that many are following MagViT2 as a base. - Marketing Spend Mayhem Uncovered!:
@pseudoterminalxrevealed shocking marketing expenditure figures, with $7,099 spent per conversion for mere $100 sales, invoking criticism and disbelief among community members. The conversation touched on gross inefficiencies and the need for better campaign strategies. - Midjourney Users Alarmed by Scraping: Some users in the discussion, such as
@pseudoterminalx, chuckled over Midjourney members panicking about a 'security issue' regarding their AI-generated images being scraped. Meanwhile,@mfcooland@chad_in_the_housetalked about the simplicity of accessing these images and a leaked artist list used by Midjourney. - SD3 Discussed, Diffusers Updates Anticipated:
@thejonasbrothersshared news about upcoming invites to use SD3 on Discord and hinted at contributions to the Diffusers project. - Ideogram AI Test Skepticism:
@pseudoterminalxvoiced skepticism regarding the claimed superiority of Ideogram AI compared to SDXL, sharing disappointment in trying to generate decent images and raising questions about the credibility of blind test results.
Links mentioned:
- What Luddites can teach us about resisting an automated future: Opposing technology isn’t antithetical to progress.
- 360° Panorama Viewer Online: Online Panorama 360 Viewer. An easy way to View & Share 360-degree pictures for free. VR ready. 360 image viewer instantly creates interactive full-screen immersive VR spherical 360 3d panoramas i...
- Database of 16,000 Artists Used to Train Midjourney AI, Including 6-Year-Old Child, Garners Criticism: Artists included Warhol, Picasso, Cezanne, van Gogh, Anish Kapoor, Yayoi Kusama, Gerhard Richter, Frida Kahlo, and Banksy.
LAION ▷ #research (83 messages🔥🔥):
- SVD Update Slows Down Training: User
@metal63mentioned experiencing significant delays when performing SVD updates with Stable Cascade, leading to a 2-minute pause in the whole training process. - Inefficiency of LLMs Challenged:
@mkaicstrongly critiqued the parameter inefficiency in large language models (LLMs) and opened a discussion on the potential for breakthroughs in training more efficient sparse/small networks, sparking a lively debate with@recvikingand@thejonasbrothers. - LLMs and the Compression Challenge:
@mkaicposited that current LLMs do not optimally compress training data and suggested that there's significant room for improving the architectures and training methods to better utilize parameters. - PixArt Sigma Debuts:
@thejonasbrothersshared about a new 4K PixArt named PixArt Sigma, providing a link to the project along with several sample images, and noted that it still has issues with text due to using only 600m parameters. - Discussing the Nature of Pruning: A series of exchanges between
@recviking,@thejonasbrothers, and@mkaicexplored the limits and implications of model pruning and generalizability, with commentary on the current state of model efficiency.@thejonasbrothersreferred to a new paper in their discussion.
Links mentioned:
- PIXART-Σ:Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation: SOCIAL MEDIA DESCRIPTION TAG TAG
- Neverseenagain Yourleaving GIF - Neverseenagain Yourleaving Oh - Discover & Share GIFs: Click to view the GIF
OpenRouter (Alex Atallah) ▷ #announcements (3 messages):
-
Early Sneak Peek at 'Nitro' Models:
@alexatallahalerted users to the appearance of new "nitro" models which are safe to use and build with, despite the possibility of minor changes before an official announcement. -
Introducing Nitro Models and Extended Contexts:
@alexatallahexcitedly introduced Nitro models, including Mixtral, MythoMax, and Llama 70B, which feature a new Nitro variant button and are powered by Groq and other providers. Additionally, context-extended models are now available, with Mixtral expanding to 732,768 context (OpenRouter Models), and a dedicated video demonstration showcases the models' improved speed and cost-effectiveness. -
Developer Features and Dynamic Routing: New developer features are highlighted, including performance timelines, JSON mode, and dynamic routing. Early users are invited to check out the documentation for detailed information.
-
OpenRouter's Path to Model Selection and Use:
@alexatallahexplains that OpenRouter helps in selecting models based on price and performance metrics, standardized APIs for easy switching between models, and upcoming features that include usage-based comparison and OAuth capabilities for user-choice models. Details can be found in the documentation and rankings. -
Mistral 7b 0.2 Goes Nitro:
@alexatallahreveals the latest Nitro model, Mistral 7b 0.2, noting its significant speed increase (up to 20x for long outputs), and an expanded context limit of 32k. A live demo is available on Twitter.
Links mentioned:
- Mixtral 8x7B Instruct (nitro) by mistralai | OpenRouter: A pretrained generative Sparse Mixture of Experts, by Mistral AI, for chat and instruction use. Incorporates 8 experts (feed-forward networks) for a total of 47 billion parameters. Instruct model fin...
- OpenRouter: Build model-agnostic AI apps
OpenRouter (Alex Atallah) ▷ #general (109 messages🔥🔥):
-
Model Comparison and Performance:
@filth2highlighted that Sonnet offers an impressive price-performance ratio, with costs as low as .03 for "5k context and 1200 response length," making it a valuable option compared to other models. Meanwhile,@phoshnkand@mka79debated the subtle differences and cost-effectiveness between Opus and Sonnet, with a general consensus on Sonnet being more affordable. -
Moderation Layer Confusion Clarified:
@filth2,@spaceemotion, and@alexatallahdiscussed the nuances of moderation in models offered by OpenAI, Anthropic, and OpenRouter. It was clarified that OpenRouter applies an additional layer of moderation, which could lead to more refusals compared to using the OpenAI or Anthropic API directly. -
Data Retention and Training Practices Inquired:
@mka79raised questions about Anthropic's use of customer content in model training.@spaceemotionshared links to Anthropic's support articles, leading to the understanding that content from paid services may not be used for training. -
Anthropic Endpoint Clarifications by Alex Atallah:
@alexatallahilluminated how Anthropic moderates content specifically for OpenRouter self-moderated requests, which includes a server-side classifier and transformer affecting the responses. Users engaging directly with Anthropic's API may not have an additional moderation layer, but risk facing repercussions without a proper moderation strategy in place. -
Discussions on Nitro Models and Pricing Insights: Users like
@starlord2629,@xiaoqianwx, and@louisgvtalked about Nitro models, particularly their higher throughput and different pricing, with Groq now powering Mixtral 8x7b instruct nitro at a cost of 0.27/1M tokens. Users expressed optimism and interest around these developments.
CUDA MODE ▷ #general (6 messages):
- Memes Incoming: User
@iron_boundexpressed a strong desire to post memes, encouraged by@marksaroufimwho directed them to post in a specific memes channel. - Flash Attention in CUDA Shared:
@tspeterkim_89106shared a project implementing Flash Attention using CUDA (Flash Attention in ~100 lines of CUDA) and opened the floor for feedback and discussion about flash attention implementations. - CUDA Explained in a Flash:
@iron_boundshared a YouTube video titled "Nvidia CUDA in 100 Seconds", summarizing what CUDA is and its role in AI development. - Nvidia's Slick Marketing Move Noticed:
@iron_boundcommented on the Nvidia's strategy of featuring a 4090 graphics card in a video mentioning Nvidia's GPU Technology Conference (GTC), with@apazacknowledging the observation.
Links mentioned:
- Nvidia CUDA in 100 Seconds: What is CUDA? And how does parallel computing on the GPU enable developers to unlock the full potential of AI? Learn the basics of Nvidia CUDA programming in...
- GitHub - tspeterkim/flash-attention-minimal: Flash Attention in ~100 lines of CUDA (forward pass only): Flash Attention in ~100 lines of CUDA (forward pass only) - tspeterkim/flash-attention-minimal
CUDA MODE ▷ #triton (1 messages):
marksaroufim: do you see where the link to join that meetup is?
CUDA MODE ▷ #cuda (78 messages🔥🔥):
- Coarsening May Hit Throughput Ceiling:
@cudawarpedsuggested that coarsening might not improve performance on a workload already at 93% memory throughput, implying a performance ceiling had been reached. - CuTe DSL Studying for Better Understanding of FlashAttention:
@ericaulddiscussed studying the CuTe DSL as it is used in the NVIDIA FlashAttention repository, indicating that it is necessary for optimizing tensor core utilization. - Discovering Dequantization Speed:
@zippikashared a dequantize implementation using thecuda::pipelineAPI, which was improved upon realizing a bug, claiming that the dequantize is now faster than bnb dequant. - Vectorized Operations in CUDA:
@uwu1468548483828484inquired about vector loads for generic types in CUDA, to which@zippikashared an example implementation and suggested that vectorized addition and storage could improve performance. - Benchmarks in CUDA Indicate Coarsening Works on Large Data:
@zippikaand@cudawarpedhad a detailed discussion on the effect of thread coarsening and the use of vectorized loads and storage, with benchmarks showing some benefits but also complexities related to usingint4/float4types and vectorized operations like__hadd2on half precision arrays.
Links mentioned:
cutlass/media/docs/cute at main · NVIDIA/cutlass: CUDA Templates for Linear Algebra Subroutines. Contribute to NVIDIA/cutlass development by creating an account on GitHub.
CUDA MODE ▷ #torch (4 messages):
- Clarifying CPU and CUDA Tensor Indexing:
@mikkeliskexpressed confusion about why CPU tensors can be indexed by CUDA tensors if they are scalar, despite typically not being able to mix devices in operations.@_t_vi_explained that mixing is allowed due to compatibility with indexing using non-tensor CPU objects and historical reasons related to the special treatment of scalars. - Scalars Bridge the CPU-CUDA Gap in PyTorch: Focusing on why this mix of devices works,
@_t_vi_pointed out that scalars are treated specially and are automatically converted, a convenience and a legacy from the times when PyTorch treated scalars differently at the C/C++ level throughc10::Scalar. - Beware of Hidden Inefficiencies:
@_t_vi_warned that while auto-transfer between CPU and GPU tensors for scalars is convenient, it can lead to hard-to-debug inefficiencies in code.
CUDA MODE ▷ #algorithms (5 messages):
-
Query on RelayAttention Mechanics:
@lancertsinquired about the differences between RelayAttention and ring/flash attention after coming across the GitHub repository vLLM with RelayAttention. -
Memory-Efficient Fine-Tuning Method:
@iron_boundreferenced a method that significantly lowers memory requirements for fine-tuning, called Gradient Low-Rank Projection (GaLore), as described in an arXiv paper. They mentioned that even a single RTX 4090 GPU can be used for pre-training large models. -
Efficient Training on Standard Gaming GPUs:
@iron_boundshared information about a technique enabling the fine-tuning of a 70b model on desktop computers with standard gaming GPUs. The method combines FSDP and QLoRA and has been detailed on Answer.AI's blog post, showcasing a collaboration with notable figures and organizations in the AI field.
Links mentioned:
- GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection: Training Large Language Models (LLMs) presents significant memory challenges, predominantly due to the growing size of weights and optimizer states. Common memory-reduction approaches, such as low-ran...
- Answer.AI - You can now train a 70b language model at home: We’re releasing an open source system, based on FSDP and QLoRA, that can train a 70b model on two 24GB GPUs.
- GitHub - rayleizhu/vllm-ra: vLLM with RelayAttention integration: vLLM with RelayAttention integration. Contribute to rayleizhu/vllm-ra development by creating an account on GitHub.
CUDA MODE ▷ #beginner (4 messages):
- Beginner Seeks CUDA Wisdom: User
@violetmantissought advice on key resources within cuda-mode/resource-stream for learning about cache-efficient parallel algorithms and kernel development/optimization, hoping for direction on where to start given a plethora of available content. - Lectures for Starting Line:
@marksaroufimrecommended beginning with the Discord's lectures designed for complete beginners to CUDA and parallel programming. - Concurrent Study Approach Suggested:
@mertbozkir, while also new to the field, suggested pairing video lectures with the accompanying book for a more informative learning experience.
CUDA MODE ▷ #ring-attention (12 messages🔥):
- Training at 16k leads to System Failure:
@iron_boundreported that training at 16k leads to the system going "brain dead" after 5 minutes with the GPUs at 100w. They speculated that the failure may occur at the end of the first epoch according to wandb logs. - Scheduling Sync-Up Discussions:
@jamesmelindicated an intention to join the next day's discussion, while@iron_boundmentioned that there wasn't much to discuss in the last sync as only Eric and they attended. - Inference Stuck Using Flash Attention:
@jamesmelencountered an issue with ring-llama inference on two GPUs, getting stuck at theblock_outoperation within_flash_attn_forwardfunction, with both subprocesses pausing. They mentioned having installed flash-attn via pip before running ring-llama.
CUDA MODE ▷ #off-topic (1 messages):
- Mandelbrot Marvel: User
@apazshared an image link showcasing a Mandelbrot fractal. The image does not come with further context or discussion points.
{kind=link}
Latent Space ▷ #ai-general-chat (31 messages🔥):
-
GaLore Breakthrough in Memory Efficiency: User
@tiagoefreitasshared a tweet from@AnimaAnandkumarshowcasing that the Llama 7B LLM can now be trained on a single RTX 4090 GPU, significantly reducing memory costs for storing optimizer states.@fx2ypoints out the method, Gradient Low-Rank Projection (GaLore), offers huge memory savings not just for pre-training but possibly for fine-tuning as well, potentially enabling further combination with techniques like 1-bit quantization for even greater efficiency. -
Impressive Leap with Inflection-2.5:
@stealthgnomeintroduced a significant claim from@inflectionAIasserting that their Inflection-2.5 model approaches the performance of GPT-4 using only 40% of the compute for training.@swyxiopointed out that, while this claim is significant, Inflection didn't highlight it in their official blog post which gives a detailed introduction to Inflection-2.5. -
FSDP/QLoRA Enables Home Training of Large Models:
@fanahovashared a tweet from@jeremyphowardannouncing FSDP/QLoRA, a collaboration that allows training very large models on consumer-grade GPUs.@fx2yprovided a link to the GitHub repo and noted the support for quantization methods like HQQ and bitsandbytes. -
Yann LeCun Discusses AI Risks and Future on Lex Podcast: Users
@stealthgnome,@swyxio, and@mr.osophydiscussed Yann LeCun's appearance on the Lex Fridman podcast, where he talked about Meta AI, the limits of LLMs, and his views on the future of AI, touching on the concept of Contrastive Learning. -
Personal AI Stories with Life Story:
@swyxioshared their experience with Life Story, an AI that acts as a personal biographer, and provided feedback that while the call experience is good, he advised caution on the full experience and data security. The idea sparked interest, with@tiagoefreitasexpressing a desire for more locally-hosted apps like this feature. -
Controversy Surrounds OpenAI Leadership:
@guardiangpointed to brewing internal controversy at OpenAI with a New York Times article discussing the circumstances surrounding Sam Altman's departure. Further,@aardvarkoncomputerhighlighted an ongoing dispute between@inflectionAIand claims regarding their Claude-3 model's wrapper.
Links mentioned:
- Tweet from Prof. Anima Anandkumar (@AnimaAnandkumar): For the first time, we show that the Llama 7B LLM can be trained on a single consumer-grade GPU (RTX 4090) with only 24GB memory. This represents more than 82.5% reduction in memory for storing optimi...
- Inflection-2.5: meet the world's best personal AI: We are an AI studio creating a personal AI for everyone. Our first AI is called Pi, for personal intelligence, a supportive and empathetic conversational AI.
- Life Story: Capture life, one story at a time.
- Tweet from lmsys.org (@lmsysorg): 🔥Exciting news from Arena @Anthropic's Claude-3 Ranking is here!📈 Claude-3 has ignited immense community interest, propelling Arena to unprecedented traffic with over 20,000 votes in just three...
- Tweet from Jeremy Howard (@jeremyphoward): Today, with @Tim_Dettmers, @huggingface, & @mobius_labs, we're releasing FSDP/QLoRA, a new project that lets you efficiently train very large (70b) models on a home computer with consumer gaming G...
- Yann Lecun: Meta AI, Open Source, Limits of LLMs, AGI & the Future of AI | Lex Fridman Podcast #416: Yann LeCun is the Chief AI Scientist at Meta, professor at NYU, Turing Award winner, and one of the most influential researchers in the history of AI. Please...
- Tweet from swyx (@swyx): I've now had multiple >20min phone calls with AI therapists and it feels completely natural. Every AI Engineer should be building their own therapist rn, and voice is the right medium. forg...
Latent Space ▷ #ai-announcements (3 messages):
-
Epic GPT-2 Presentation Alert:
@ivanleomkannounced that@1123457263638683770will be presenting on the GPT-2 paper in 20 minutes, urging the Asia@paper-clubto attend what is promised to be an EPIC sharing. -
Catching the Replay:
@swyxioresponded to the announcement with excitement, indicating a desire to record the session.
Links mentioned:
Join the Latent Space (née /dev/invest) Discord Server!: Check out the Latent Space (née /dev/invest) community on Discord - hang out with 3061 other members and enjoy free voice and text chat.
Latent Space ▷ #llm-paper-club-west (30 messages🔥):
- Preparation for GPT Paper Share:
@ivanleomkannounced that the discussion will start soon and provided links to notes on the Generative Pre-trained Transformers, including the concept and the implementation, which@1123457263638683770would refer to during the sharing. - Ready to Start:
@ivanleomkgave a 5 minute heads-up before the start of the LLM paper club meeting. - A Newcomer's Enthusiasm:
@healthymonkeyexpressed being new to the NLP space and asked the more experienced participants like<@1039021595089448990>and<@206404469263433728>to correct any mistakes in their forthcoming discussion points. - Technical Clarification: During the discussion,
@kishore.reddycorrected@ivanleomk's explanation of a decoder model by mentioning "causal attention," which refers to ensuring that the model predicts the next token without access to future token states. - Practical Demonstration of LLM Concepts:
@fx2yshared a link to LLM Visualization, a tool useful for visualizing the GPT family of models, and commended@1123457263638683770's effort in the discussion.
Links mentioned:
- LLM Visualization: no description found
- The Concept of Generative Pre-trained Transformers (GPT) — Omniverse: no description found
- The Implementation of Generative Pre-trained Transformers (GPT) — Omniverse: no description found
LangChain AI ▷ #general (21 messages🔥):
- LangChain JS Feature Query:
@0x404blockchainnotfoundinquired about whether the LangChain JS library has achieved feature parity with the Python library, but no direct answer was provided within the chat. - AGI Claims Discussed:
@sales_godsought opinions on claims about agent/AGI discussed on Hacker News, but the discussion did not lead to a resolution and was sidetracked by the comment from@baytaewhighlighting concerns about the LangChain tool and ReACT agents. - Finished Agent Event in Python:
@cybersmithsreported a delay issue with the Finished agent event in Python, causing a 1-2 second delay after the last character is streamed. However, the thread did not include a solution to the problem. - Handling PDF Loader Extractions:
@yd4224encountered formatting problems when using langchain.document_loaders PyPDFLoader, receiving guidance from@travellingprogto create a custom loader or contribute to the repository to handleextraction_modearguments. - Push for JavaScript URL Loader:
@mohitsakhiya077expressed the need for functionality to load documents from multiple URLs in JavaScript, similar to what's available in the Python version withUnstructuredURLLoader, prompting discussion on parity between languages.
Links mentioned:
- no title found: no description found
- Ollama Functions | 🦜️🔗 Langchain: LangChain offers an experimental wrapper around open source models run locally via Ollama
- Extract Text from a PDF — pypdf 4.0.1 documentation: no description found
- URL | 🦜️🔗 Langchain: This covers how to load HTML documents from a list of URLs into a
- langchain/libs/community/langchain_community/document_loaders/parsers/pdf.py at v0.1.11 · langchain-ai/langchain: 🦜🔗 Build context-aware reasoning applications. Contribute to langchain-ai/langchain development by creating an account on GitHub.
LangChain AI ▷ #langchain-templates (9 messages🔥):
-
Redis Chat History Woes:
@justanothergraphguyis working to create a chat chain with Redis chat history and structured output parsing using a pydantic model. They encountered an issue where the latest "HumanMessage" appears in theAIMessagecontent incorrectly, suggesting potential problems with memory propagation. -
Designing the Prompt and Model: A system prompt for a "User Profile Builder" guides the assistant's interaction, aiming to extract user information and build a profile.
-
Technical Setup Unveiled:
@justanothergraphguyshared a snippet of Python code integrating variouslangchainmodules such asChatOpenAI,RunnableWithMessageHistory, andPydanticOutputParserto create the chat chain. -
First Interaction Flawlessly Executed: An initial example provided by
@justanothergraphguyshowed correct extraction of "Bob's" name, while the system prompted for more information to complete the profile. -
Subsequent Interaction Confusion: In the follow-up interaction, the output incorrectly included the 'HumanMessage' as part of the
AIMessagecontent, highlighting the memory issue in their system.
LangChain AI ▷ #share-your-work (2 messages):
-
Visual AI in the Spotlight:
@vru.shankannounced a workshop featuring MultiOn and Quizizz discussing their use of vision models in production. Interested individuals can RSVP for a session hosted by the LLMs in Prod community via this link. -
Introducing Prompt Mixer - Your Prompt IDE:
@tomatyssis developing Prompt Mixer, a desktop tool for building, testing, and iterating AI prompts with version tracking. Feedback and feature suggestions are welcomed, and interested users can download it at Prompt Mixer’s website. -
How to Customize Your Connectors: For advanced users of Prompt Mixer,
@tomatyssshared a documentation link detailing the steps to create a custom connector, thus enhancing their tool's flexibility and functionality.
Links mentioned:
- no title found): no description found
- Multi-Modal LLMs in Prod | Practitioners' Workshop · Luma: The LLMs in Prod community is hosting practitioners from top Gen AI companies to talk about how they are using multi-modal models (vision, audio, image gen, etc.) in...
- Prompt Mixer — Prompt IDE and LLMOps tool: PromptMixer – the innovative Prompt IDE for crafting, testing, and deploying prompts with unparalleled ease.
- Create a Custom Connector | Prompt Mixer Docs: Step 1: Copy the Sample Connector
LangChain AI ▷ #tutorials (1 messages):
pradeep1148: https://www.youtube.com/watch?v=PtP8R8VjTGc
DiscoResearch ▷ #general (3 messages):
- In search of German-finetuned Mixtral: User
@johannhartmanninquired about comparing models like sauerkraut oder discolm mixtrals for German language prompts and noted that Nous Hermes Mixtral has no German finetuning involved. - Introducing Evo: Biological Language Model:
@rasdanihighlighted the new Evo architecture from TogetherAI named Striped Hyena, designed for DNA sequence modeling. Read about Evo's capabilities in handling various biological sequences and its collaborative development with the Arc Institute.
Links mentioned:
Evo: Long-context modeling from molecular to genome scale: no description found
DiscoResearch ▷ #embedding_dev (11 messages🔥):
- Fine-Tuning Discourse with Hermes Mixtral DPO:
@flozi00is working on finetuning the Nous Hermes Mixtral DPO model, aiming for improvements before moving to train a classification model, but notes the process involves sorting out much trash. - Creating a Quality Translation Dataset: In pursuit of quality translation estimations,
@flozi00plans to set up an Argilla space to label translations from Google Translate, DeepL, and Azure Translate. - Targeting En-De Translation Pairs:
@crispstroberecommends leveraging the EN-DE pairs from the OPUS 100 dataset to create a subset with reliable pairings suited for unspecific contexts, highlighting the dataset's utility in creating training subsets. - Dataset Licensing and Quality Concerns:
@philipmayshares that the mMARCO dataset now has an Apache 2.0 license but encountered issues with viewing the dataset on HuggingFace, indicating the need for assistance to make the dataset viewer work. - Public Collection for Translation Data Quality:
@flozi00mentions an update to their judge model and datasets, seeking additional tips for improvement, which is now part of a HuggingFace collection aimed at measuring translation pair quality.
Links mentioned:
- Translation Data Quality - a flozi00 Collection: no description found
- unicamp-dl/mmarco · Datasets at Hugging Face: no description found
- Data (Hint ID): no description found
DiscoResearch ▷ #discolm_german (3 messages):
-
Merging German Translations with SPIN:
@johannhartmannshared that they use a German translation of the slim orca dataset for Mistral merges, applying a SPIN-like method across multiple steps. They create datasets with answers from multiple models for the same translated instruction/input-pair, which has led to observable drifts in the model's responses, sometimes becoming more verbose or degrading post-merge. They plan to clean up and upload the dataset soon. -
Brezn3 Outshines Brezn-7b:
@crispstrobeexpressed amazement as Brezn3 scores 63.25 on EQ-Bench (v2) (de) without revision, outperforming Brezn-7b's score of 58.22. They inquired whether this was solely due to changing the base model to LeoLM/leo-mistral-hessianai-7b-chat and settingtokenizer_source: base, or if different DPO modifications were applied. -
DPO Still Baking for Brezn3:
@johannhartmannresponded that the DPO process for Brezn3 is still underway, with approximately 13 hours remaining before completion.
LLM Perf Enthusiasts AI ▷ #claude (6 messages):
- Models and the Challenge with Names:
@res6969observed that names could pose a difficulty for models to handle correctly. - Hands-On with Claude Functionality:
@res6969shared their experience of experimenting with function calling on Claude, suggesting that progress is being made. - Accolades for Claude's Humorous Accuracy:
@res6969expressed amusement and approval for Claude's performance by calling it "hilarious and correct". - Function Calling Works with a Catch:
@res6969confirmed that function calling on Claude is effective, but highlighted that XML tags are necessary for optimal results. - XML Complexity Raises Concern:
@pantsforbirdscommented on the complexity of using XML tags, noting that it complicates the sharing of prompt generators.
Datasette - LLM (@SimonW) ▷ #ai (5 messages):
- GPT-4 Flunks the Test:
@dbreunigexpressed surprise at how poorly GPT-4 performed on an unspecified test. - Clickable Bookshelves Innovation:
@xnimrodxshared admiration for a script that automates the creation of clickable bookshelf images, leading users to a Google Books page for each book, found in a blog post and accompanied by a demo. - A Librarian's Dream Tool:
@xnimrodxnoted personal interest in automated bookshelf management for a librarian, remarking it would greatly aid in shelf-reading tasks across large collections. - Impressive Library Management:
@xnimrodxshared that their librarian-wife manages the largest school library within a 35-school diocesan system, rivaling the size of some public library branches. - Little Library Cataloging App Idea:
@dbreunigmentioned an interest in creating a toy app to catalog the books in little libraries throughout their town.
Links mentioned:
Making my bookshelves clickable | James' Coffee Blog: no description found