Busy day today.
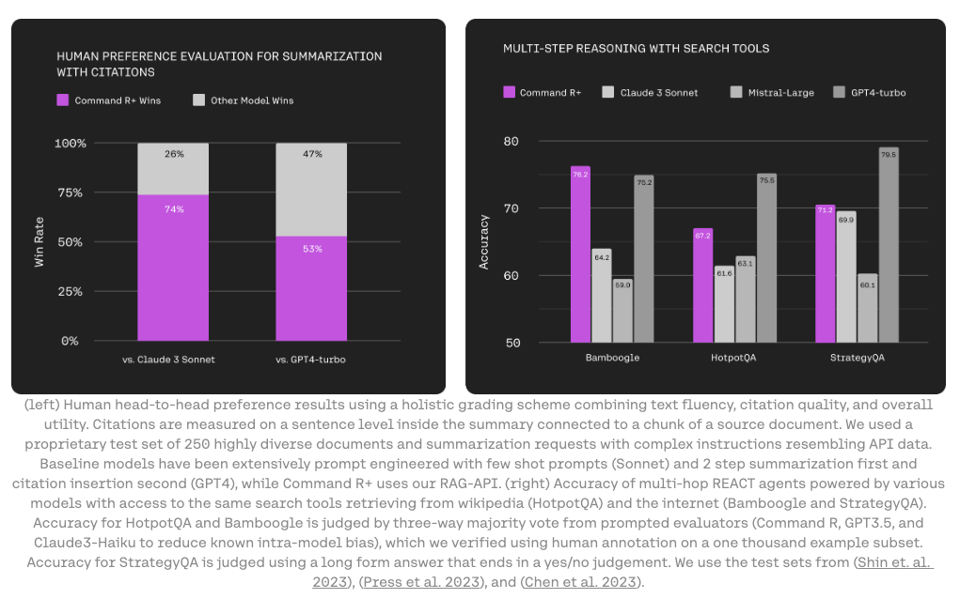
- The at least $500m richer Cohere launched a fast-follow of last month's Command R with Command R+ (official blog, weights). It's a 104B dense model with 128k context length focused on RAG, tool-use, and multilingual ("10 key languages")) usecases. Open weights for research but Aidan says "just reach out" if you want to license it (instead of paying their $3/$15 per mtok pricing). It now supports Multi-Step Tool use.
- The $2.75B richer Anthropic launched tool use in beta as previously promised (official docs). The extensive docs come with a number of notable features, most notably advertising the ability to handle over 250 tools which enables a very different function calling architecture than before. This is presumably due to context length and recall improvements in the past year. For more details see their 3 new cookbooks:
- Using a calculator tool with Claude
- Creating a customer service agent with client-side tools
- Extracting structured JSON using Claude and tool use
- OpenAI, which hasn't raised anything in the last month (that we know of), added a bunch of very welcome upgrades to the very MVPish finetuning experience together with 3 case studies with Indeed, SK Telecom, and Harvey that basically say "you can now DIY better but also we are open for business to finetune and train your stuff".
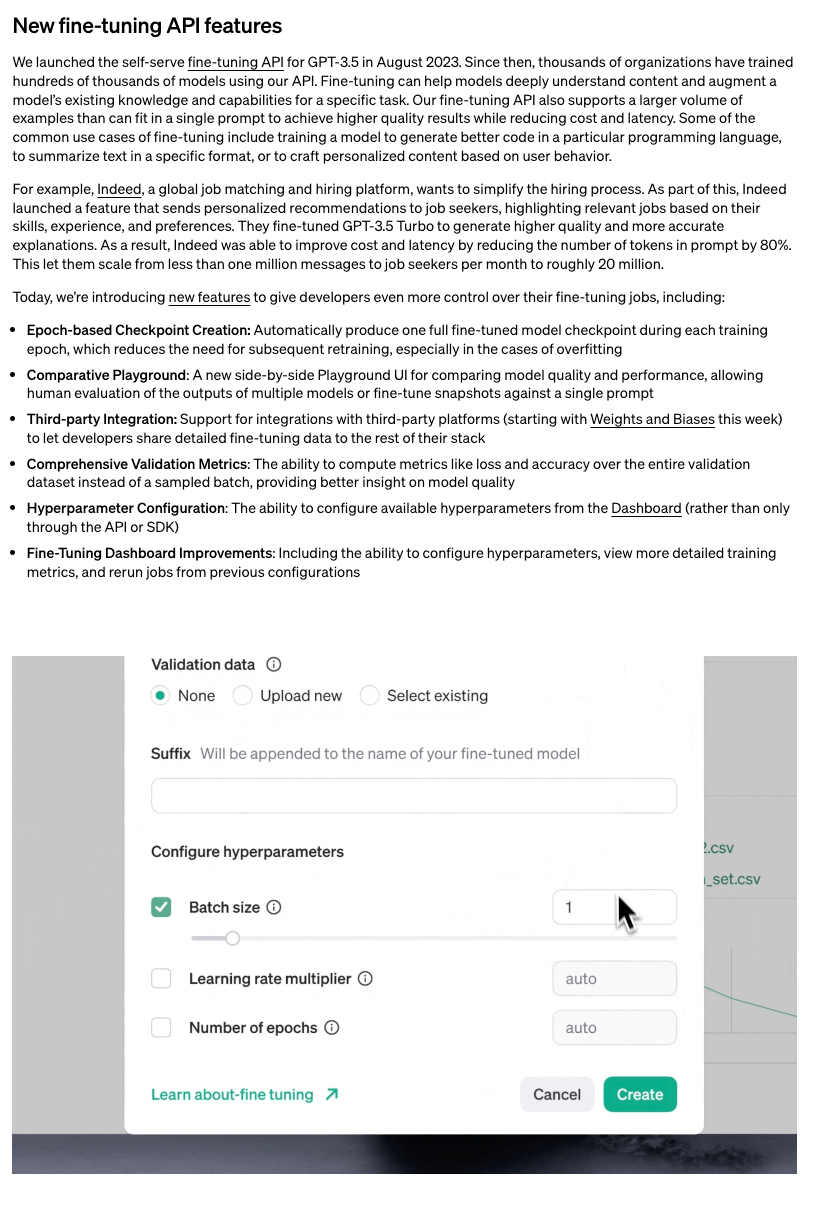
Table of Contents
[TOC]
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence. Comment crawling still not implemented but coming soon.
AI Technology Advancements
- Quantum Computing Breakthrough: In /r/singularity, Microsoft has achieved a quantum computing breakthrough, improving error rates by 800x with the most usable qubits to date, a significant step forward in quantum computing capabilities.
- Stable Audio 2.0 Release: In /r/StableDiffusion, Stability AI introduced Stable Audio 2.0, advancing audio generation capabilities with improved quality and control.
- Browser Integration of Large Language Models: In /r/LocalLLaMA, Opera browser has added support for running large language models like Meta's Llama, Google's Gemma, and Vicuna locally, making them more accessible.
Model Capabilities & Comparisons
- Gemini's Large Context Window: In /r/ProgrammerHumor, an image highlights that Gemini's context window is much larger than other models, enabling more contextual understanding.
- GPT-3.5-Turbo Model Size Analysis: In /r/LocalLLaMA, analysis suggests GPT-3.5-Turbo is likely an 8x7B model, similar in size to Mixtral-8x7B.
- Claude 3 vs ChatGPT Battle Simulation: In /r/LocalLLaMA, a video compares Claude 3 vs ChatGPT in a "Street Fighter" style battle using local 7B models like Mistral and Gemma.
{kind=link}
AI Research & Education
- Stanford Transformers Course Opens to Public: In /r/StableDiffusion, Stanford's CS 25 Transformers Course is opening to the public, featuring top researchers discussing breakthroughs in architectures, applications, and more.
- Stock Prediction Research Challenges: In /r/MachineLearning, a discussion explores why stock prediction research papers often don't translate to real-world production use.
- Retrieval-Augmented Generation Debate: In /r/MachineLearning, a debate arises on whether Retrieval-Augmented Generation (RAG) is just glorified prompt engineering.
AI Tools & Applications
- GPT-4-Vision for Online Mimicry: In /r/singularity, a video demonstrates using GPT-4-Vision to mimic oneself in emails or any site with one click.
- Automatic Video Highlight Detection: In /r/singularity, a tool is showcased for finding highlights in long-form video automatically with custom search terms.
- Daz3D AI-Powered Image Generation: In /r/StableDiffusion, Daz3D partners with Stability AI to launch Daz AI Studio for stylized image generation from text.
AI Memes & Humor
- Gemini Context Window Meme: In /r/ProgrammerHumor, a humorous image depicts "Gemini's context window is much larger than anyone else's".
- Super Metroid Parody Trailer: In /r/singularity, a parody movie trailer for Super Metroid was created with Dalle3 and GPT.
- Bedroom QR Code Meme: In /r/singularity, a bedroom QR code meme image was shared.
{kind=link}
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
Cohere Command R+ Release
- New open-source model: @cohere released Command R+, a 104B parameter model with 128k context length, open weights for non-commercial use, and strong multilingual and RAG capabilities. It's available on the Cohere playground and Hugging Face.
- Optimized for RAG workflows: Command R+ is optimized for RAG, with multi-hop capabilities to break down complex questions and strong tool use. It's integrated with @LangChainAI for building RAG applications.
- Multilingual support: Command R+ has strong performance across 10 languages including English, French, Spanish, Italian, German, Portuguese, Japanese, Korean, Arabic, and Chinese. @JayAlammar notes that the tokenizer is more efficient for Arabic and other non-English languages, requiring fewer tokens and leading to cost savings.
- Pricing and Availability: @cohere noted Command R+ leads the scalable market category, enabling businesses to move to production. It is available on Microsoft Azure and coming to other cloud providers soon. @JayAlammar added it takes RAG to a new level with multi-hop capabilities.
- LangChain Integration: @hwchase17 and @LangChainAI announced a
langchain-coherepackage to expose integrations like chat models and model-specific agents. @cohere is excited about the integration for adaptive RAG. - Hugging Face and Performance: @osanseviero noted it is available on Hugging Face with a playground link. @seb_ruder highlighted the multilingual capabilities in 10 languages. @JayAlammar mentioned tokenizer optimizations for languages like Arabic to reduce costs.
- Fine-tuning and Efficiency: @awnihannun showed fine-tuning Command R+ with QLoRA in MLX on an M2 Ultra. @_philschmid provided a summary of the 104B model with open weights, RAG and tool use, and multilingual support.
DALL-E 3 Inpainting Release
- New Feature: @gdb and @model_mechanic announced that DALL-E 3 inpainting is now live for all ChatGPT Plus subscribers. This allows users to edit and modify parts of an image from text instructions.
- How to Use: @chaseleantj provides a guide - brush over the region to replace, type the prompt describing the change, and do not brush over all the words for best results. There are still some limitations like inability to generate words in blank spaces.
Mixture-of-Depths for Efficient Transformers
- Approach: @arankomatsuzaki shares Google's Mixture-of-Depths approach to dynamically allocate compute in transformer models. It enforces a total compute budget by capping tokens in self-attention/MLP at each layer.
- Benefits: @rohanpaul_ai explains this minimizes compute waste by allocating more to harder-to-predict tokens vs. easier ones like punctuation. Compute expenditure is predictable in total but dynamic and context-sensitive at the token level.
RAG and Agent Developments
- Adaptive RAG techniques: New papers like Adaptive RAG and Corrective-RAG propose dynamically selecting RAG strategies based on query complexity. Implementations are available as LangChain and LlamaIndex cookbooks.
- RAG-powered applications: Examples of RAG-powered apps include Omnivore, an AI-enabled knowledge base, and Elicit's task decomposition architecture for scaling complex reasoning. Connecting RAG with tool use leads to more agentic systems.
Open-Source Models and Frameworks
- Anthropic Jailbreaking: @AlphaSignalAI shared Anthropic's research on "many-shot jailbreaking" which crafts benign dialogues to bypass LLM safety measures. It takes advantage of large context windows to generate normally avoided responses.
- @AssemblyAI introduced Universal-1, a multilingual speech recognition model trained on 12.5M hours of data. It outperforms models like Whisper on accuracy and hallucination rate.
- Open models and datasets: New open models include Yi from 01.AI, Eurus from Tsinghua, Jamba from AI21 Labs, and Universal-1 from AssemblyAI. Large OCR datasets from Hugging Face enable document AI research.
- Efficient inference techniques: BitMat reduces memory usage for quantized models. Mixture-of-Depths dynamically allocates compute in Transformers. HippoAttention and MoE optimizations speed up inference.
- Accessible model deployment: Hugging Face lowered prices for hosted inference, while Koyeb and SkyPilot simplify deploying models on any cloud platform.
Memes and Humor
- An AI-generated video of a sad girl singing the MIT License went viral.
- People speculated about Apple's AI ambitions and joked that AI will replace software engineers.
- There were memes poking fun at AI hype and the limitations of large language models.
AI Discord Recap
A summary of Summaries of Summaries
-
LLM Advancements and Integrations:
- Cohere unveils Command R+, a 104B parameter multilingual LLM optimized for enterprise use with advanced Retrieval Augmented Generation (RAG) and multi-step tool capabilities, sparking interest in its performance compared to other models.
- JetMoE-8B represents an affordable milestone at under $0.1 million cost, surpassing Meta AI's LLaMA2 performance using only 2.2B active parameters.
- Discussions around integrating LLMs like HQQ with gpt-fast, exploring 4/3 bit quantization approaches like the Mixtral-8x7B-Instruct quantized model.
-
Optimizing LLM Inference and Training:
- Mixture-of-Depths (MoD) enables transformers to dynamically allocate compute across sequences, potentially improving efficiency over uniform distribution.
- Visual AutoRegressive (VAR) modeling redefines autoregressive image generation, outperforming diffusion transformers in quality and speed.
- Techniques like BitMat offer efficient 1-bit LLM implementations per "The Era of 1-bit LLMs" paper.
-
LLM Evaluation and Benchmarking:
- New benchmarks evaluate LLM emotional intelligence: Creative Writing EQ-Bench and Judgemark using correlation metrics.
- COMET scores highlight the Facebook WMT21 model's translation prowess, with the highest score of 0.848375.
- Discussions on systematic evaluation practices for AI products, with Hamel Husain's post seen as groundbreaking.
-
Open-Source AI Frameworks and Tools:
- LlamaIndex unveils cookbooks guiding RAG system building with MistralAI, including routing and query decomposition.
- Koyeb enables effortless global scaling of LLM apps by connecting GitHub repos to deploy serverless apps.
- SaladCloud offers a managed container service for AI/ML workloads to avoid high cloud costs.
- The transformer-heads GitHub repo provides tools for extending LLM capabilities by attaching new model heads.
PART 1: High level Discord summaries
Stability.ai (Stable Diffusion) Discord
-
High-Res with Caution: Practitioners discussed optimal settings for Stable Diffusion Models when upscaling, advocating for 35 steps with specific upscalers and control nets to mitigate image distortion. Higher resolutions, particularly 2k, lead to longer generation times and potential issues, as outlined in Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction.
-
AI's Role in the Creative Process: There was a spirited discussion on AI's burgeoning effects on creative industries, specifically pondering its potential to supersede some roles in Hollywood and game development. The group contemplated how AI tools like SDXL could alter job landscapes, possibly raising the entry-level bar for producing quality output.
-
Techniques for Targeted Lora Training: To train loras for generating images of specific attire, such as corsets, suggestions were to use diverse angle shots of the item isolated from extraneous details. The aim is to help the AI focus on the core element, thus avoiding introducing unwanted features in the outputs.
-
Costs, Investors, and AI Market Dynamics: The guild tackled Stability AI's strategic hurdles—balancing between attracting investments, enriching datasets, and developing fresh models. Dialogue revolved around innovations in dataset monetization strategies for businesses in the face of rising computational costs and fluctuating model research interest.
-
Random Banter Is Still Alive: Amid technical talk, members exchanged casual banter, including cultural references and greetings. An off-topic link to a parody song was shared, showcasing the community's lighter side alongside their technical engagements.
Perplexity AI Discord
API Excitement Meets Payment Puzzles: A perplexing payment issue cropped up for a Perplexity API user whose transaction was stuck as "Pending" without updating the account balance. Meanwhile, discussions revolved around the potential of APIs and the choice between a Pro Subscription and pay-as-you-go API, with opinions favoring the subscription for initial business ideation due to cost predictability.
Model Mashing Madness: Users dived into model preferences, favoring a balance between a larger message count and an adequate context window. They also tackled the challenge of model limitations with complex programming languages like Rust and custom "metaprompt" strategies for structured output.
Content Sharing Caveat: A note was made to ensure threads are set to shareable when posting content on Discord, facilitating wider community engagement.
Thirst for Source Links in Sonar Model: Inquiries were made concerning the sonar-medium-online model's ability to return source links with data, but a definitive timeline on the feature's implementation remains elusive.
LLM Leaderboard Quirks and Queries: The LLM Leaderboard sparked an analytical discourse on model rankings with a dash of humor over model name mishaps, pointing to the significance of clarity in system prompts for better AI performance.
OpenAI Discord
-
DALL·E Dons a New Creative Cap: DALL·E now boats an Editing Suite for image edits and style inspiration on web, iOS, and Android platforms, offering enhancements to the creative potential across ChatGPT platforms. In tandem, the Fine-tuning API sees an infusion of new dashboards, metrics, and integrations for developers to forge custom models, detailed in a recent blog post.
-
AI's Existential Ruminations: Engineers engaged in a blaze of conversations around AI, untangling the question of AI "thinking" with a broad consensus refuting AI consciousness in lieu of complex data pattern executions. The palpable discord in live discussions also touched on correcting the AI vs AGI misconception prevalent amongst the public and ended with a proposition to train LLMs on goal-oriented sequences.
-
Customization or Complexity: Within the GPT-4 discussions, engineers wrangled over benefits of Custom GPTs, the utility of DALL·E's new features for image specificity, and questions on data retention policies surfaced—ensuring even deleted chats linger for a month.
-
Prelude to Prompt Perfection: Technicians noodled over issues in translating markdown into various languages and recommended using additional context to refine AI's interpretation during AI role play. Strategies for propelling text generation and ensuring document completeness when using LLMs were also broached, suggesting methods such as "continue" to extend responses.
-
Patience for Prompt Precision: As members grappled with translation issues with markup and advice on constructing effective prompts, they were directed to the refashioned #1019652163640762428 for resources. Insights on the efficacy of prompts, particularly in role-playing scenarios, also peeked through, emphasizing the importance of providing clear context to shape AI responses.
Unsloth AI (Daniel Han) Discord
CmdR Set to Join the Unsloth Ranks: The addition of CmdR support to Unsloth AI is in progress, with the community eagerly awaiting its integration post current task completions. The anticipation ties into plans for an open-source CPU optimizer, slated for reveal on April 22, to enhance AI model accessibility for those with limited GPU resources.
Interfacing Innovation with Continue's Autocomplete: A new tab autocomplete feature is in experimental pre-release for the Continue extension, designed to streamline coding in VS Code and JetBrains by consulting language models directly within the dev environment.
Error Extermination and Optimization Dialogues: AI engineers shared solutions to naming-related tokenizer errors, and discussed model.save_pretrained_merged and model.push_to_hub_merged functions for seamless model saving and sharing on Huggingface. Despite encountering AttributeError in GemmaForCausalLM, users were directed to update Unsloth for resolution.
Stumbling Blocks in Saving and Server-Side Setup: Users navigated challenges with GGUF conversions and Docker setups, tackling issues like python3.10-dev dependencies and workaround strategies for memory errors during finetuning on different platforms.
Diving into Unsloth Studio's Next Iteration Soon: An update on Unsloth Studio's release push is set for mid next month due to current bug fixes, ensuring ongoing compatibility with Google Colab alongside improvements for developers leveraging the Studio's capabilities.
Latent Space Discord
Stable Audio Hits a New High: Stability AI launched Stable Audio 2.0, enabling creation of lengthy high-quality music tracks utilizing a single prompt. Visit stableaudio.com to test the model and find further details in their blog post.
AssemblyAI Outperforms Whisper: AssemblyAI announced Universal-1, a speech recognition model surpassing Whisper-3 by achieving 13.5% better accuracy and demonstrating up to 30% decrease in hallucinations. The model processes an hour of audio in a mere 38 seconds and is available for trial at AssemblyAI's playground.
Enhance Your Images with ChatGPT Plus: Users of ChatGPT Plus now possess the ability to modify DALL-E-generated images and prompts, available on both web and iOS platforms. Full guidance on usage is provided in their help article.
AI Agents as Scalable Microservices: Discussions focused on utilizing event-driven architecture to build scalable AI agents, with the Actor Model cited as an inspiration, and a Golang framework presented for collaborative feedback.
Opera One Downloads AI Directly: Opera integrates the ability for users to run large language models (LLMs) locally, beginning with Opera One on the developer stream, harnessing the Ollama framework, as detailed by TechCrunch.
DSPy Steals the Spotlight: Members evaluated DSPy's performance in optimizing prompts for foundation models, focusing on model migration and optimization while being cautious of API rate limits. A detailed study of Devin surfaced numerous AI project opportunities, with keen interest in diverse applications ranging from voice-integrated iOS apps to documentation overhaul initiatives.
Nous Research AI Discord
- LoRA Boosts Mistral?: Engineers discuss employing Low-Rank Adaptation (LoRA) on Mistral 7B to enhance specific task performance, with plans to innovate sentence splitting and labeling techniques beyond standard methods.
- Web Crawling Woes and Wins: The practical issues of scalable web crawling were a hot topic, with talk of obstacles like anti-bot measures and JavaScript rendering. However, alignment was reached on the utility of Common Crawl and mysterious archival groups hoarding quality datasets.
- Learning Options Expand: Shared resources included guides on lollms with Ollama Server, budget AI chips from Intellifusion, and Hugging Face's dataset loaders utility, Chug. Meanwhile, CohereForAI's new multilingual 104B LLM has stirred interest, and OpenAI's exploratory GPT-4 fine-tuning pricing was editorialized.
- LLM Innovation at the Fore: Engineers exchange insights on language model pruning, specifically a 25% pruned Jamba model, and Google's paper advocating transformers learn to dynamically allocate compute, sparking a deeper analysis of speculative decoding versus Google's method.
- Diverse Fine-Tuning Conversations: Members introduced Eurus-7b-kto optimized for reasoning, debated the "divide by scale" in BitNet-1.58 for ternary encoding, deliberated implementation issues on Hermes-Function-Calling, considered QLoRA's VRAM efficiency, and noted Genstruct 7B's instructional generation prowess.
- Troubleshooting in Project Obsidian: Quick fixes in progress for ChatML in project "llava" and intentions to tackle Hermes-Vision-Alpha with scant details on specific issues.
- Finetuning Subnet Miner Mishaps: A miner script error in the finetuning-subnet repository points to a possible missing dependencies problem.
- RAG Dataset Discussions: Discourse on Glaive's RAG sample dataset and methods like grounded mode and proper citation markup, including an XML instruction format, emphasized for future uptake. Suggestions on filtering in RAG responses and Cohere's RAG documentation were also highlighted.
- Copying Conundrums & Command Quests in WorldSim: WorldSim's perplexing copy-paste mechanics, concern over mobile performances, and links to a comprehensive WorldSim Command Index brought forth both productivity hacks and culture snippets within the intrigue of jailbreaking Claude models and ASCII art enigmas.
Modular (Mojo 🔥) Discord
Mojo on the Move: Engineers shared that Mojo now runs on Android devices like Snapdragon 685 CPUs and discussed integrating Mojo with ROS 2, accentuating Mojo's memory safety over Python, particularly in robotics where Python’s GIL limits Nvidia Jetson hardware performance.
Performance Breakthroughs and Best Practices: Significant library performance improvements were noted, dropping execution times to minutes, beating previous Golang benchmarks. Methods such as pre-setting dictionary capacities for optimization were advised, and designers of specialized sorting algorithms for strings are encouraged to align with Mojo’s latest versions, seen at mzaks/mojo-sort.
From Parser to FASTQ: BlazeSeq🔥, a new feature-complete FASTQ parser, has been introduced, providing a CLI-compatible parser that conforms to BioJava and Biopython benchmarks. Enhanced file handling is promised by the buffered line iterator they implemented, indicating a move to a robust future standard for file interactions, showcased on GitHub.
Mojo Merger Madness: Innovative ideas on model merging and conditional conformance in Mojo used @conditional annotations for optional trait implementations, while merchandise ideas like Mojo-themed plushies stirred community excitement. Memory management optimizations were considered, examining potential changes to how Optional returns values in the nightly version of Mojo's standard library.
Modular Updates Galore: Max⚡ and Mojo🔥 24.2 release brings open-sourced standard libraries and nightly builds with community contribution. Docker build issues in version 24.3 are addressed, while continued development discussions recommend conditional conformance and error handling strategies for future roadmap considerations.
LM Studio Discord
Bold Boosts with ROCm: AMD hardware sees a massive increase in speed from 13 to 65 tokens/second when engineered with the ROCm preview, highlighting the significant potential of the right software interface for AMD GPUs.
Mixtral, Not a Mistral Mistake: Mixtral's distinct identity as a MOE model, combining the strength of eight 7B models into a 56B powerhouse, reflects a strategic approach unlike the standard Mistral 7B. Meanwhile, running a Mixtral 8x7b on a 24GB VRAM NVIDIA 3090 GPU may hit speed snafus, yet it’s a viable venture.
LM Studio 0.2.19 Courts Embeddings: The fresh-out-of-the-lab LM Studio version 0.2.19 Preview 1 now supports local embedding models, opening up new possibilities for AI practitioners. Despite lacking ROCm support in its current preview, Windows, Linux, and Mac users can grab their respective builds from the provided links.
Engineers Tackle Odd Model Behavior: Discourse on an AI model dishing out bizarre, task-unrelated responses uncovers potential mishaps in the model's training, signaling a programming predicament in need of debugging prowess.
CrewAI Collision with JSONDecodeError: Encountering a JSONDecodeError using CrewAI suggests a potential misstep in JSON formatting, a puzzle piece that AI engineers must properly place to avoid jeopardizing data parsing processes.
Eleuther Discord
Transformers Takeover at Stanford: The Stanford CS25 seminar on Transformers is open to the public for live audits and recorded sessions, with industry experts leading the discussions on LLM architectures and applications. Interested individuals can participate via Zoom, access the course website, or watch recordings on YouTube.
Skeptical About Efficiency Claims: The community voiced skepticism about the Free-pipeline Fast Inner Product (FFIP) algorithm's performance claims, noted in a journal publication, which promises efficiency by halving multiplications in AI hardware architectures.
CUDA Conundrums and Code Conflicts: A member troubleshooting a RuntimeError with CUDA identified apex as the issue when using the LM eval harness on H100 GPUs, recommending upgrades to CUDA 11.8 and other adjustments for stability.
Next-Gen AI Training Techniques Touted: An arXiv paper introduces dynamic FLOP allocation in transformers, potentially optimizing performance by diverging from uniform distribution. Additionally, cloud services like AWS and Azure support advanced training schemes, with AWS's Gemini mentioned explicitly.
Elastic and Fault-Tolerant How-To: Details on establishing fault-tolerant and elastic job launches with PyTorch were shared, with documentation available at the PyTorch elastic training quickstart guide.
LAION Discord
- AI Ethics in Code: A tool called ConstitutionalAiTuning allows fine-tuning language models to reflect ethical principles, utilizing a JSON file for principles input and aiming to make ethical AI more accessible.
- Type Wrestling in JAX: JAX's type promotion semantics show different outcomes based on operation order, as demonstrated with numpy and Jupyter array types—adding
np.int16(1)andjnp.int16(2)to3producesint16orint32based on the sequence of operations. - Model Training Quandaries: A discussion examined optimal text input configurations for models, debating the merits of sequence concatenation, T5 token extension, and fine-tuning techniques in the realm of SD3 models.
- Legal Beats and AI: Using copyrighted material to train AIs, such as with the Suno music AI platform, has sparked concerns about ensuing legal risks and potential suits from content owners.
- Financial Turbulence for AI Innovator: Stability AI faces financial headwinds, grappling with significant cloud service expenses that reportedly might eclipse their revenue capabilities, as detailed in a Forbes article.
In the research domain:
- Size Doesn't Always Matter for LDMs: A study revealed in an arXiv paper that larger latent diffusion models (LDMs) do not always outdo smaller ones when the inference budget remains constant.
- New Optimizer on the Horizon: A Twitter tease suggested that the AI community should keep their eyes peeled for a novel optimizer.
- VAR Model Revolutionizing Image Generation: The newly presented Visual AutoRegressive (VAR) model demonstrates superior efficacy in image generation compared to diffusion transformers, boasting improvements in both quality and speed, according to an arXiv paper.
OpenAccess AI Collective (axolotl) Discord
Patch Perfect: A noteworthy GitHub bug was swiftly eradicated in the OpenAccess AI Collective's axolotl repository, with the commit history accessible via GitHub Commit 5760099. Meanwhile, a README Table of Contents mismatch was flagged, prompting a cleanup.
Datasets and Model Dialogues: Queries about optimal datasets for training Mistral 7B models led to a recommendation for the OpenOrca dataset, while debates on fine-tuning practices leaned towards the strategy of prioritizing 'completion' before 'instructions'. Discussions spotlighted the potency of simple fine-tuning (SFT) over continual pre-training (CPT) when armed with high-quality instructional samples.
Bot-tled Service: The Axolotl help bot hit a snag, going offline and sparking a wave of mirthful member reactions, yet specifics behind the incident weren't disclosed. The bot was previously offering guidance on the integration of Qwen2 with Qlora and addressing challenges related to dataset streaming and multi-node fine-tuning within Docker environments.
AI Dialogues: The Collective's general channel buzzed with tech talk—from rapid model feedback services like Chaiverse to the novel resources for adding heads to Transformer models found in the GitHub repository for transformer-heads. CohereForAI unveiled a behemoth 104 billion parameter C4AI Command R+ model with specialized capabilities revealed on Hugging Face, stirring conversations about the financial implications of running massive models.
Infrastructure Innovations: SaladCloud's recent launch of a fully-managed container service for AI/ML workloads was recognized as a notable entrance, giving developers an edge against sky-high cloud costs and GPU shortages with affordable rates for inference at scale.
LlamaIndex Discord
AI Spellcheck Gets Real: A Node.js code shared by a member for correcting spelling mistakes using the LlamaIndex Ollama package showed an AI model named ‘mistral’ fixing user errors, like "bkie" to "bike," which can run locally without third-party services over localhost:11434.
Llama's Culinary Code-Loaded Cookbook: A new culinary-themed guidebook series is unveiled for AI enthusiasts, demonstrating how to build RAG, agentic RAG, and agent-based systems with MistralAI, including routing and query decomposition. Grab your AI recipes here.
Exploration and Confusion in LlamaIndex: Discussions in the community raised concerns about issues from lacking knowledgegraphs pipeline support to unclear graphindex and graphdb integrations, and several members struggled with querying OpenSearch and implementing ReAct agents in llama_index.
AI Discussion Evolves Beyond Text: Engaging talks emerged about the potential of enhancing image processing with Reading and Asking Generative (RAG) techniques, discussing applications ranging from CAPTCHA solutions to ensuring continuity in visual narratives like comics.
Scaling AI Deployment Made Convenient: Koyeb's platform was highlighted for effortlessly scaling LLM applications, directly connecting your GitHub repo to deploy serverless apps globally without managing infrastructure. Check out the service here.
HuggingFace Discord
Bold Repo Visibility Choices: HuggingFace has introduced settings for default repository visibility with options for public, private, or private-by-default for enterprises. The functionality is described in this tweet by Julien Chaumond.
Custom Quarto Publishing: HuggingFace now supports publishing with Quarto, as detailed in a tweet by Gordon Shotwell, with more information available on LinkedIn.
Summarization Struggles and Strategies: Users across channels discussed summarization challenges with GPT-2 and Hugging Face's pipeline, including ineffective length penalties and the search for prompt crafting that maximizes efficiency and result quality, even in CPU-only environments.
Innovations and Interactions in AI Circles: Excitement was shared for projects including Octopus 2, a model capable of function calls, and advancements in image processing with the new multi-subject image node pack from Salt. The community also highlighted academic discussions and resources, such as the potential of RAG for interviews and latency-reasoning trade-offs in production prompts, shared in Siddish's tweet.
Diffusion Model Dialogue Deliberates Depth: AI engineers explored creative implementations for diffusion models, discussing DiT with cross-attention for various data conditions, and considering Stable Diffusion modifications for tasks like stereo to depth map conversion, referring to the DiT paper and resources like Dino v2 GitHub and SD-Forge-LayerDiffuse GitHub.
tinygrad (George Hotz) Discord
Fishing for Compliments or Functionality?: Discord's switch from the whimsical fish logo to a more polished design sparked debate among members, leading to talks to potentially match the banner to the new aesthetic. The logo changes by George Hotz seem to have left some nostalgic for the old one.
Sharding Optimizations In-Depth: George Hotz and community members explored optimization techniques and cross-GPU communications, facing challenges with launch latencies and data transfers. They examined the use of cudagraphs, peer-to-peer limitations, and the role of NV drivers.
Tinygrad Performance Milestone: Sharing performance benchmarks, it was revealed that Tinygrad achieved 53.4 tokens per second on a single 4090 GPU, marking 83% efficiency compared to gpt-fast. George Hotz indicated goals to further boost Tinygrad's performance.
Intel Hardware On The Horizon: Discussions on Intel GPU and NPU kernel drivers scrutinized various available drivers like 'gpu/drm/i915' and 'gpu/drm/xe', with anticipation for the performance and power efficiency that NPUs may bring when paired with CPUs.
Helpful Neural Net Education Hustle: The community found the Tinygrad tutorials to be a valuable starting point for neural network newbies and also recommended the JAX Autodidax tutorial, complete with a hands-on Colab notebook. Interest surged in adapting ColabFold or OmegaFold for Tinygrad, while also learning about PyTorch weight transfer methods.
OpenRouter (Alex Atallah) Discord
-
OpenRouter Adopts JSON Object Support: Models like OpenAI and Fireworks have been confirmed to support the 'json_object' response format, which can be verified via provider parameters on the OpenRouter models page.
-
Finding The Right Verse with Claude 3 Haiku: While the Claude 3 Haiku model exhibits a mixed performance in roleplay, it's suggested that providing multiple examples might yield better results. However, using jailbreak (jb) tweaks is advisable for a significant improvement in output.
-
Niche Servers for Claude's Jailbreaks: Users on the look for Claude model jailbreaks including NSFW prompts discussed resources, pointing out that SillyTavern's and Chub's Discord servers are go-to places, and provided guidance on how to navigate to these using tools like the pancatstack jb.
-
Dashboard Update Maps Out OpenRouter Credits: Recent updates to the OpenRouter's dashboard include a new designated location for credit display which is accessible at the
/creditsendpoint. However, issues with specific models’ functionality, such as DBRX and Midnight Rose, prompted concerns about their support compatibility. -
Moderation Tangle Affects OpenRouter API's Decline Rate: Reports highlighted a high decline rate with the self-moderated version of the Claude model, implicating possible overprotective "safety" prompts. There's also a mention of integrating better providers to aid in the stability of services for models like Midnight Rose.
OpenInterpreter Discord
-
Installation Celebration and Cross-Platform Clarity: An engineer was relieved to get a piece of software running on their Windows machine, and there was confirmation that this software is functional on both PC and Mac platforms. Detailed installation instructions and guides can be found in the project's documentation.
-
Persistent Termux Predicament: Discussions identified a recurring issue with
chroma-hnswlibduring installation processes, even though reports suggested it was removed. Members were advised to migrate detailed technical support queries to a designated support channel. -
Hermes-2-Pro Prompt Practices Discussed: Active dialogues emphasized the need to adjust system prompts as recommended in the Hermes-2-Pro model card. This is crucial for optimizing model performance and addressing verbose output that some users found burdensome.
-
Platform-Specific Quirks: Multiple members encountered and shared solutions to challenges with the 01 software across different operating systems—ranging from shortcut commands in Ollama, package dependencies in Linux, to
poetryissues on Windows 11. -
Cardputer Development Underway: Technical talk focused on the implementation and advancement of M5 Cardputer into the open-interpreter project. GitHub repositories and various tools like ngrok for secure tunnelling and rhasspy/piper for neural TTS systems were linked for reference.
Interconnects (Nathan Lambert) Discord
-
Command R+ Makes Waves with 128k Token Context: A new scalable LLM dubbed Command R+ is generating buzz with a hefty 128k token context window and the promise of reduced hallucinations due to refined RAG. Although there's curiosity about its performance compared to other models due to insufficient comparative data, enthusiasts can test out its capabilities via a live demo.
-
ChatGPT-Like Models for Business Under Scrutiny: Skepticism arises regarding how well ChatGPT and similar models can fulfill enterprise needs, with discussions pointing toward potentially custom-developed solutions to truly meet business demands.
-
Academia Cheers for Cost-Effective JetMoE-8B: The launch of JetMoE-8B is applauded in academic circles for its affordability—costing under $0.1 million—and impressive performance using only 2.2B active parameters. More details can be found on its project page.
-
Snorkel and Model Efficacy Debate Heats Up: Nathan Lambert stirs the pot with a suggestive tweet, teasing an analysis on the effectiveness of current AI models like those using RLHF, thereby igniting a conversation around the controversial Snorkel framework.
-
Stanford's CS25 Pulls in Transformer Enthusiasts: AI engineers show keen interest in Stanford's CS25 course, spotlighting discussions by Transformer research experts, with session schedules available here and the opportunity to gain insights through the course's YouTube channel.
Mozilla AI Discord
- Matrix Size Matters: A member made headway by optimizing a matmul kernel for large matrices, addressing CPU cache challenges when dealing with sizes above 1024x1024.
- Compiler Conundrum Conquered: Compiler enhancements led to celebrations among members, reflecting expectations of significant code performance improvements.
- A ROCm Solid Requirement: For the successful deployment of llamafile-0.7 on Windows, members acknowledged that ROCm version 5.7+ is necessary.
- Dynamic SYCL Discussions: Debates on handling SYCL code within llamafile resulted in a community-driven solution involving conditional compilation, though with noted incompatibility with MacOS.
- Perplexing Performance on Windows: An attempt to build llamafile on Windows met with complications involving the Cosmopolitan compiler, along with conversations about the need for a
llamafile-benchprogram to measure tokens per second and the potential impact of RAM on performance. Interested parties were directed to an article on The Register highlighting performance gains and a discussion on GitHub about Cosmopolitan.
LangChain AI Discord
Crypto Chatbot Craze Calls for Coders: An individual is in search of developers with LLM training expertise to create a chatbot simulating human conversation, utilizing real-time crypto market data. The aim is to enable nuanced discussions reflecting the latest market shifts.
Math Symbol Extraction Without MathpixPDFLoader: Alternatives to MathpixPDFLoader for extracting math symbols from PDFs are in demand, as users seek new methods to handle this specific task effectively.
LangChain LCEL Logic Lessons: A discussion clarified the use of the '|' operator in LangChain's Expression Language (LCEL), which chains components like prompts and LLM outputs into complex sequences. The intricacies are further explored in Getting Started with LCEL.
Voice Apps Vocalizing AI Capabilities: Newly launched voice applications such as CallStar are prompting discussions around their interactivity and setup, powered by technologies like RetellAI, with community support via Product Hunt and Reddit platforms.
LangChain Quickstart Walkthrough Woes: Sharing the LangChain Quickstart Guide, a user provided example code for integrating LangChain with OpenAI, yet faced a NotFoundError indicating a missing resource. The community's technical acumen is requested to troubleshoot this setback.
CUDA MODE Discord
- Bit by Bit, Efficiency Unfolds: The BitMat GitHub repository was referenced, promoting an efficient implementation of 1-bit Large Language Models (LLMs), aligning with the method proposed in "The Era of 1-bit LLMs."
- New Horizons for Triton and Torch: A new channel for contributing to the Triton visualizer has been proposed to foster collaboration. The Torch team is adjusting autotune settings, moving towards max-autotuning, and addressing benchmarking pain points including tensor core utilization and timing methods—their effort is documented in the keras-benchmarks.
- CUDA Content and Courses: For engineers keen on learning CUDA programming, the CUDA MODE YouTube channel was recommended, boasting of lectures and a supportive community to ease the CUDA learning curve.
- Quantum Leap in Model Integrations: New members mobicham and zhxchen17 ignited a discussion on integrating HQQ with gpt-fast, focusing on Llama2-7B (base), and delving into 4/3 bit quantization using models like Mixtral-8x7B-Instruct-v0.1.
- A Visual Boost for Triton: Within the discussion on Triton visualizations, suggestions for adding arrows for direction, integrating operation details into visuals, and potentially porting the project to JavaScript for enhanced interactivity emerged, though concerns about the actual utility of such features were raised.
Datasette - LLM (@SimonW) Discord
A New Approach to AI Dialogues: Reflecting on conversational AI terminology, a guild member suggested "turns" as a better descriptor than "responses" for the initial message in a dialogue, a decision fueled by the exploration of a logs.db database and resulting in the serendipitous pun with the term database 'turns'.
AI Product Evaluations Get a Thumbs Up: Guild members rallied around the importance of Hamel Husain's post on AI evaluations, which outlines strategies for creating domain-specific evaluation systems for AI and is considered potentially groundbreaking for new ventures.
SQL Query Assistant Plugin Eyes Transparency and Control: There's a pitch for making the evaluations of the Datasette SQL query assistant plugin visible and editable, aiming to enhance user interaction and control over the evaluation process.
Perusing the Future of Prompt Management: A debate is brewing over the best practices for AI prompt management, with potential patterns including localization, middleware, and microservices, suggesting different methods for integrating AI into larger systems.
High-Resolution API Details Exemplified: The Cohere LLM search API’s detailed JSON responses were spotlighted, providing an example of the granularity that can benefit AI developers, as demonstrated in a shared GitHub comment.
DiscoResearch Discord
-
Benchmarking Emotional Smarts: Newly launched Creative Writing EQ-Bench and Judgemark benchmarks aim to assess the emotional intelligence of language models, with Judgemark posing a rigorous test through correlation metrics. Standard deviation in scores is leveraged to differentiate how models use 0-10 scales to indicate finer judgment nuances compared to 0-5 rating systems.
-
Judgment Day for Creative Writing: The efficacy of the Creative Writing benchmark is attributed to its 36 specific judging criteria, emphasizing the importance of narrow parameters for model evaluation. Questions about these benchmark criteria are answered in the extensive documentation provided, demonstrating transparency and allowing for better model assessment.
-
Sizing Up Sentiment and Quality: Discussion regarding optimal scales revealed that sentiment analysis resonates best with a -1 to 1 range, while quality assessments prefer broader scales of 0-5 or 0-10, aiding models to convey more nuanced opinions. These insights highlight the necessity of tailoring evaluation metrics to the specific domain of judgment.
-
COMET Blazes Through Testing: The COMET evaluation scores herald the Facebook WMT21 model as a standout, with reference-free scores employing wmt22-cometkiwi-da methodology alongside useful scripts available on the llm_translation GitHub repository. Nonetheless, caution is advised due to potential inaccuracies, underscoring the need for continual vigilance in assessing model outputs.
-
Scaling the Peaks of Reference-Free Evaluation: The callout for accuracy in models emphasizes the non-absoluteness of COMET scoring results, with an invitation to flag significant discrepancies—a practice acknowledging the iterative nature of model refinement and validation. The highest COMET score recorded was 0.848375, demonstrating the advanced capabilities of current language models in translation tasks.
Skunkworks AI Discord
-
AI Enthusiasts Eye Healthcare: Community engagement in AI within the healthcare sector is on the rise, signaling increased cross-disciplinary applications of AI technologies.
-
Evolving LLMs with Mixture-of-Depths (MoD) Approach: Introduction of the Mixture-of-Depths (MoD) technique has been highlighted as a way to allow Language Models to allocate compute resources dynamically, potentially increasing efficiency. The approach and its capabilities are detailed in a paper available on arXiv.
-
Revolutionizing AI's Approach to Math: Discussing improved strategies for AI to tackle mathematical problems, it's suggested that training AI to convert word problems into solvable equations is more effective than direct computation. This method leverages the power of established tools like Python and Wolfram Alpha for the actual calculations.
-
Another Paper Added to the Trove: Additional resources are being shared, with a new paper added to the community's knowledge base, though no further context has been provided.
PART 2: Detailed by-Channel summaries and links
Stability.ai (Stable Diffusion) ▷ #general-chat (910 messages🔥🔥🔥):
-
Stable Diffusion Models and Upscaling: Users discussed the best practices for creating realistic high-resolution images, suggesting using lower steps, latent upscaling, and the use of hi-res fix to avoid image distortion. Suggested settings include 35 steps with dpmpp ancestral Karras or exponential and accompanying control nets. Higher resolutions like 2k are challenging, often leading to extended generation times and possible image distortion (related discussion).
-
The Future of AI and Content Creation: There was a robust debate on the impact of AI on various creative industries, with speculations about AI's potential to replace traditional roles in Hollywood and the videogame industry. Participants discussed whether AI models like SDXL would render some artist positions redundant and how evolving technology might increase the skill floor, requiring less effort to generate quality content.
-
Lora Training for Specific Items: A user inquired about training loras for generating images of people wearing specific items, such as corsets. Advice given includes using images of the item from different angles, ideally with backgrounds and faces removed, to prevent the AI from including unintended elements in the generated images.
-
Economic Considerations and AI: Participants discussed Stability AI's challenges, such as convincing investors and focusing on datasets versus developing new models. The conversation covered the potential of monetizing the dataset for enterprises to cope with the perceived declining interest in research models and the impact of high compute costs.
-
Miscellaneous Chat: Interactions included light-hearted exchanges with references to cultural subjects, general hellos, acknowledgments of greetings, and random statements that did not correlate with the main topics of discussion. There was also a link to an unrelated parody song shared by a user.
Links mentioned:
Perplexity AI ▷ #general (756 messages🔥🔥🔥):
- API Usage Explained: Users are curious about the functionalities and costs associated with Perplexity's API. It was clarified that APIs can be very powerful for automating tasks and are essential for developers looking to integrate specific services into their applications. The cost efficiency and usage depend on the scope of the project and the amount of data being processed.
- Pros and Cons of Pro Subscription vs API: There's a debate on whether it's more advantageous to subscribe to Perplexity for $20 a month or to use the pay-as-you-go API. For idea generation and beginning a business, the recommendation seems to be towards subscribing due to ease of use and cost management.
- Model Preferences Discussed: When it comes to usage, users prefer having a larger number of messages with a decent context window rather than a larger context with fewer messages. Perplexity's AI capabilities are being leveraged for a range of tasks, with the flexibility to work around limitations.
- Notifications and New UI Elements Update: There has been mention of news notifications not being readily accessible or communicated effectively, with the suggestion for the company to use Discord's announcement channels more strategically. Some concerns were raised about the lack of updates on the Android app.
- Integration Limits and Model Capabilities: Discussion around the limitations when using complex languages like Rust with AI, highlighting that AI models, including Opus, struggle to create compilable code. Some users are applying workarounds like starting new threads to manage large conversations for better context management.
Links mentioned:
Perplexity AI ▷ #sharing (15 messages🔥):
-
Exploring the Impact of Fritz Haber: A member highlighted Fritz Haber's contributions, such as enabling increased food production through the Haber-Bosch process. His complex legacy includes the Nobel Prize, involvement in chemical warfare, personal tragedies, and anti-Nazi sentiments. Read about Fritz Haber's legacy.
-
Intrigue at the LLM Leaderboard: A user examined the LLM Leaderboard, discussing model metrics and rankings, and discovered what "95% CI" means despite encountering amusing model name errors. Explore the LLM Leaderboard review.
-
Understanding Beauty through AI: Multiple members shared their curiosity about the concept of beauty by using Perplexity AI to access insights on the topic. Delve into the nature of beauty.
-
Dictatorship Discussion Initiated: One chat pointed users to Perplexity AI for a query on how dictatorship naturally arises, sparking an intellectual query into the origins of authoritarian regimes. Investigate the emergence of dictatorship.
-
Reminder for Shareable Content: A member was reminded to ensure their thread is set to shareable when posting links from the Discord channel. This ensures others can view and engage with the content shared. Make Discord threads shareable.
Perplexity AI ▷ #pplx-api (42 messages🔥):
- Perplexed about Perplexity API Sonar Model Source Links: A user inquired about when the sonar-medium-online model would be able to return the source link with the data, but did not receive a clear timeline on when this feature will be available.
- Credit Conundrum: Payments Pending in Perplexity: A member reported issues while trying to buy API credits; transactions showed as "Pending" and did not reflect in the account balance. Another member asked them to send account details for resolution, indicating a case-by-case troubleshooting approach.
- Trouble with Realms, ReALM, and Apple: Users experienced the bot getting confused when asked about Apple's ReALM, leading one suggestion that simplifying the system prompt might yield better performance, as complexity seems to lead to confusion.
- Custom GPT "metaprompt" for Organized Output: One user shared their experiment with creating a Custom GPT utilizing a "metaprompt" aimed at structuring responses efficiently, which primarily focused on delivering accurate information with clear citations.
- Search API Pricing Perplexities: A member questioned the pricing of search APIs compared to language models, discussing the cost-effectiveness of 1000 online model requests, which another clarified does not equate to 1000 individual searches but rather requests that can contain multiple searches each.
Links mentioned:
OpenAI ▷ #annnouncements (2 messages):
Link mentioned: Introducing improvements to the fine-tuning API and expanding our custom models program: We’re adding new features to help developers have more control over fine-tuning and announcing new ways to build custom models with OpenAI.
OpenAI ▷ #ai-discussions (494 messages🔥🔥🔥):
-
Understanding AI and Consciousness: Discussions revolved around the nature of AI's cognitive processes compared to human thought, debating whether AI such as LLMs are capable of "thinking" or just sophisticated algorithms performing complex patterns of data. Multiple participants contended that AI lacks consciousness and is instead a simulation of human-like behaviors.
-
The Complexity of Defining Sentience: Sentience and consciousness were hot topics, with explorations into the subjective experiences of animals as revealed by neural activity studies. The conversation pointed out the difficulty of discerning sentience in different life forms and the challenges in defining consciousness solely based on human-like behavior.
-
AI Misconceptions and Expectations: Some discussion highlighted a public misconception about AI, where many people equate all forms of AI with the concept of AGI (Artificial General Intelligence), as often depicted in science fiction. There was an emphasis on the need for clear distinctions between various forms of AI and the reality of current technologies.
-
Live Discussion Dynamics: Debates about AI often led to friction amongst participants, demonstrating a wide spectrum of beliefs and opinions about AI's capabilities, consciousness, and ethical considerations. Some recommended additional resources like YouTube videos to reinforce their viewpoints.
-
Potential AI Usage and Development Ideas: One user suggested training language models with goal-oriented sequences, such as
success <doing-business> success, for various applications including playing chess or developing business strategies, theorizing about its interactive possibilities when presented with new information during inference.
Links mentioned:
OpenAI ▷ #gpt-4-discussions (46 messages🔥):
-
Custom GPT vs. Base Model: Channel members are discussing the advantages of using Custom GPTs over the base ChatGPT models. While some prefer the ease of building complex prompts with Custom GPTs, others find base ChatGPT models to be sufficient for their needs and challenge the need for Custom GPTs when prompt engineering alone can be effective.
-
DALL·E Gains New Features: DALL·E has been updated with new features allowing for style suggestions and image inpainting, enabling users to edit specific parts of an image generated by DALL·E. This information might be particularly interesting for Plus plan users looking to utilize these functionalities.
-
Comparing Model Performance: There's an exchange regarding the performance of various GPT models and systems, with some members noting that in specific areas, some models might outperform others. The conversation shows a nuanced understanding that model performance can vary greatly depending on the use case and individual testing.
-
Utilizing AI for Wiki Data: A member is seeking advice on how to have GPT interpret and answer questions from an XML file containing a Wiki database dump. They expressed difficulty with the GPT providing accurate responses from the data in the XML file.
-
Data Retention Questions: Users inquire about OpenAI’s data retention policy, specifically after deleting a chat. The response indicates that deleted chats on OpenAI are typically held for about a month, though they become immediately invisible to the user upon deletion.
OpenAI ▷ #prompt-engineering (27 messages🔥):
-
Translation Troubles: A member is experiencing inconsistency when translating markdown content to various languages, especially Arabic. Efforts to tweak the prompt, such as adding "Only return translated text with its markup, not the original text," resulted in mixed outcomes, with some responses being untranslated.
-
Seeking the Prompt Library: One member inquired about the location of the prompt library, and another quickly guided them to the renamed channel using its channel ID.
-
Perfecting Apple Watch Expertise Prompts: A user sought advice on improving prompts to get better responses from the bot when asking as an Apple Watch expert. Another member advised experimenting with different versions of the prompts and even using the model to evaluate the prompts for clarity and potential hallucinations.
-
Dalle-3 Prompt Engineering Location Query: A user questioned where to conduct Dalle-3 prompt engineering, whether in the general prompt-engineering channel or a specific Dalle thread. A member suggested it's their choice, but more focused help might be available in the Dalle-specific channel.
-
Lengthening Text Responses: A member expressed frustration that the command "make the text longer" was no longer effective. Another member recommended a workaround involving copying the previous GPT response, starting a new chat, and then prompting with "continue."
-
LLM Draft Document Issue: A member asked for assistance with an LLM that fails to return certain sections of a document while drafting from a template, even when changes have been made to those sections. They are looking for a solution to ensure all modified sections are included in the outputs.
OpenAI ▷ #api-discussions (27 messages🔥):
-
Translation Troubles with Markup: A member attempted various prompt formulations to preserve Markdown markup and correctly translate content, including proper names and links, from one language to another. Despite the refined prompts, they faced issues with maintaining markdown formatting and receiving untranslated text, expressing frustration over the inconsistent translations.
-
Seeking the Prompt Library: When asked where to find the prompt library, a member was directed to a channel renamed to #1019652163640762428, indicating the location where resources can be found.
-
Improving Prompt Efficacy for AI Role Play: In a discussion about enhancing the quality of prompts for role-playing experts, a member suggested asking the AI to evaluate the prompt for clarity and consistency. They discussed the importance of the entire context of the prompt beyond single keywords like "roleplay" to influence the AI's response style.
-
Dalle-3 Prompt Engineering Discussion Placement: A member inquired where to discuss Dalle-3 prompt engineering—whether in the api-discussions channel or a Dalle-specific thread. They were told it's their choice, though a more focused response might be found in a dedicated Dalle thread.
-
Extending Iterative Text Generation: After experiencing issues with the command "make the text longer" not generating new content as expected, another member suggested copying the AI's response, initiating a new chat, and then using the word "continue" to extend the conversation.
Unsloth AI (Daniel Han) ▷ #general (306 messages🔥🔥):
-
Support for CmdR on the Horizon: Discussions indicate work is underway to add support for CmdR in Unsloth, following fixes to inference issues. There's excitement about the progress, and discussions imply a completion time frame after the current tasks.
-
Anticipation for Automatic Optimizer: Unsloth is planning a new open-source feature very important for the GPU poor set to be announced imminently, with a new release and an announcement on April 22. This feature is aimed to ameliorate AI accessibility by CPU optimization, supporting a wider range of models like command r, Mixtral, etc..
-
Performance Queries Addressed: Users engaged in technical discussions about memory optimization, VRAM savings of 70% with Unsloth, and inplace kernel executions. The conversation highlights inquiries about data layout results on different models and the effectiveness of Unsloth's in-place operations for memory reduction.
-
Enthusiasm and Confusion Clearing about the Gemma 2B Model: Support is given for changing to the Gemma 2B model in notebooks with provided instructions, and clarifications on downloading models in 4-bit versus 16-bit, with an assurance that accuracy degradation is usually between 0.1-0.5%.
-
Job Postings and Ethical Hiring Discussed: A request for a job channel sparked debates on the ethics of unpaid internships and the skill set expected from interns. The consensus emphasized the importance of providing financial compensation for any work performed.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #random (5 messages):
-
Unsloth Studio Overhaul in Progress: Unsloth AI team is delaying the release of the new version of Unsloth Studio due to persistent bugs. A tentative, early version might be available mid next month and the existing Unsloth package will remain compatible with Colab.
-
New Tab Autocomplete Feature in Pre-Release: A new pre-release experimental feature for tab autocomplete is available in the Continue extension for VS Code and JetBrains. Continue's open-source autopilot allows easier coding with any LLM by asking questions about highlighted code and referencing context inline, as showcased with animated GIFs in its documentation.
Link mentioned: Continue - Claude, CodeLlama, GPT-4, and more - Visual Studio Marketplace: Extension for Visual Studio Code - Open-source autopilot for software development - bring the power of ChatGPT to your IDE
Unsloth AI (Daniel Han) ▷ #help (248 messages🔥🔥):
-
Tokenizer Troubles: The error a user faced was due to incorrect naming of the model in the tokenizer, which resulted in it not being written properly, leading to execution issues. They resolved the issue on their own.
-
Successful Model Saving and Huggingface Push: Users discussed saving models with
model.save_pretrained_merged()andmodel.push_to_hub_merged(), focusing on properly setting naming parameters for model saving and Huggingface push. Relevant advice included replacing placeholders with a Huggingface username/model name and obtaining a Write token from Huggingface settings. -
Inference Issues on Gemma: A user encountered an
AttributeErrorrelated to aGemmaForCausalLMobject missing thelayersattribute, which was fixed via an update to Unsloth requiring users to reinstall the package on personal machines. -
Challenges with GGUF Conversions and Docker Environments: Users shared issues when converting models to GGUF format, and an instance where the Docker environment produced an error that was solved with the installation of
python3.10-dev. -
Finetuning Challenges and Solutions: Discussion included finetuning Gemma models in Colab, remedies for
OutOfMemoryErrorwhen using 24GB GPUs on Sagemaker, a GGUF-spelled words quirk after conversion, and insights on resuming training with altered parameters.
Links mentioned:
Latent Space ▷ #ai-general-chat (86 messages🔥🔥):
-
Stable Audio 2.0 Released: Stability AI introduces Stable Audio 2.0, capable of producing high-quality, full tracks with coherent musical structure up to three minutes long at 44.1 kHz stereo from a single prompt. Users can explore the model for free at stableaudio.com and read the blog post here.
-
AssemblyAI's New Speech Model Surpasses Whisper-3: AssemblyAI releases Universal-1, a model boasting 13.5% more accuracy and up to 30% fewer hallucinations than Whisper-3, capable of processing 60 minutes of audio in 38 seconds, though it only supports 20 languages. Test it in the free playground at assemblyai.com.
-
Edit DALL-E Images in ChatGPT Plus: ChatGPT Plus now allows users to edit DALL-E images and their own conversation prompts on the web and iOS app. Instructions and user interface details can be found here.
-
AI Framework Discussion by slono: Slono shared thoughts on building AI agents as microservices/event-driven architecture for better scalability, invoking ideas similar to the Actor Model of Computation and seeking feedback or assistance with their Golang framework.
-
Opera Allows Downloading and Running Local LLMs: Opera now enables users to download and run large language models (LLMs) locally, starting with Opera One users who have developer stream updates. The browser is making use of the open-source Ollama framework and plans to add more models from various sources for users' choice.
Links mentioned:
Latent Space ▷ #llm-paper-club-west (356 messages🔥🔥):
-
Intro to Detailed Summarization: Members discussed the ins and outs of using DSPy for optimizing prompting in foundation models, focusing on its efficacy in model migration and optimization for arbitrary metrics. Eric shared his presentation and participants acknowledged his insights with a round of applause.
-
Devin Draws Attention: Conversation shifted towards the manifold implications of Devin, with members sharing various project ideas that could be attempted using this high-profile AI model.
-
Hot Topic on Optimization Calls: The club identified dspy's optimization technique and raised concerns regarding API rate limits during the .compile() function calls due to the large number of calls DSPy makes.
-
Pragmatic Programming Considerations: Questions arose about practical use cases for DSPy Vs. other methods/frameworks, its advantages in different contexts, and how to mitigate issues like prompt debt during model migration.
-
Tech and Task Speculations: Suggestions for potential applications using Devin ranged from iOS apps with voice API integration to DSPy documentation rewrites, showcasing the breadth of community interest in applying AI to diverse challenges.
Links mentioned:
Nous Research AI ▷ #ctx-length-research (2 messages):
- Exploring LoRA for Enhanced Mistral: A suggestion was made about creating a LoRA (Low-Rank Adaptation) on top of something like Mistral 7B to achieve superior performance in specific tasks.
- Advanced Splitting and Labeling Planned: This approach is confirmed to be in the planning stages, where the task would involve not just splitting sentences, but also splitting and labeling each sentence according to a specific taxonomy.
Nous Research AI ▷ #off-topic (9 messages🔥):
-
The Web Crawling Conundrum: Discussing scalable web crawling, members acknowledged challenges in obtaining large, quality datasets, and noted the increased complexity and costs due to the need for headless browsers, bypassing anti-bot measures, and rendering modern JavaScript frameworks.
-
The Secret Archives: A member hinted at the existence of archival groups that possess a wealth of high-quality data, suggesting a discreet community that archives extensive datasets.
-
The Search for Data Hoarders: In response to a question about archival groups, another participant clarified the distinction between those who archive data out of principle and mere data hoarders.
-
Data Scavenging for Knowledge Collectors: One member suggested looking into Common Crawl as a resource for those interested in web crawling and the state of the art in data collection.
-
Eternal Playlist Addition: A light-hearted message where a member mentioned choosing a new song for their funeral, representing personal interests and a break from more technical discussions.
Nous Research AI ▷ #interesting-links (10 messages🔥):
- Lollms on Ollama Server: A YouTube tutorial was shared about installing and using lollms with Ollama Server, promising to guide viewers through the installation process.
- Cheaper AI Chips from China: Intellifusion's DeepEyes AI boxes, costing around $140, are offering 48 TOPS of AI performance, aiming to provide a cost-effective alternative to high-end hardware in AI applications.
- Precision of Time: A member referenced the ISO 8601 standard on Wikipedia, detailing the precise way to express current date and time in different formats including UTC and with offsets.
- Dataset Loaders on GitHub: Hugging Face introduced Chug, a repository with minimal sharded dataset loaders, decoders, and utils for multi-modal document, image, and text datasets.
- CohereForAI's Multilingual LLM: CohereForAI announced the release of C4AI Command R+, a 104B LLM that is multilingual in 10 languages, adding to their open weights offerings, which can be found on their Hugging Face page.
- GPT-4 Fine-tuning Pricing Strategy: OpenAI has experimental pricing for GPT-4 fine-tuning as they learn about quality, safety, and usage, which are detailed in a recent blog post.
Links mentioned:
Nous Research AI ▷ #general (150 messages🔥🔥):
-
Language Model Pruning Explorations: A member is experimenting with creating a pruned Jamba model (25% of the size). They are using a custom layer pruning script, discussing their methodology, and mentioning a related research paper on layer-pruning that examines strategies for reducing layer count without significantly impacting performance.
-
Dynamic Compute Allocation for LLMs: Members discuss a Google paper that suggests transformers can learn to allocate compute dynamically across a sequence. The conversation revolves around its potential for more efficient pretraining and inference, comparing it to speculative decoding methods and discussing the implications for retraining models.
-
Discussions on Speculative Decoding: The technique of speculative decoding was explained and scrutinized, with a participant highlighting differences from Google's dynamic compute approach. Members conversed about memory management in GPUs and batching for speeding up responses.
-
Cohere's Command R+ Model Introduced: Command R+, a new model by Cohere optimized for Retrieval Augmented Generation (RAG), was shared and briefly discussed. It's designed for scaling LLMs in business applications, providing features like multilingual support and advanced citations.
-
Neural Reasoning Exploration: The discord users engaged in a conversation about the neurallambda project on GitHub, which attempts to integrate lambda calculus with transformer-based LLMs. This neurosymbolic approach could be groundbreaking for AI reasoning.
Links mentioned:
Nous Research AI ▷ #ask-about-llms (58 messages🔥🔥):
- BitNet Discussion: The divide by "scale" in BitNet-1.58 was debated, with users questioning its necessity and expressing that it could potentially hinder the benefits of ternary encoding. However, it was pointed out that maintaining FP16 for training and scaling outputs could be beneficial for numeric stability.
- Eurus Model Appeals to Curiosity: Eurus-7b-kto, an LLM by OpenBMB optimized for reasoning, was tested with its fine-tuning datasets UltraInteract_sft and UltraInteract_pair, with a suggestion to apply SOLAR to this model for potential improvements.
- Function Calling in Repositories: Discrepancies in implementation were reported in the Hermes-Function-Calling repository, with issues regarding function calling and coding standards. The usage of langchain's convert_to_openai_tool() was specifically cited within the issue.
- QLoRA Gaining Traction: QLoRA, a recent LLM fine-tuning approach, got mentioned as potentially more efficient than LoRA, offering similar performance improvements with half the VRAM requirements.
- Genstruct for Instruction Generation: The utility and diversity of Genstruct 7B, an instruction-generation model from NousResearch, were discussed briefly, emphasizing its potential to create diverse instruction formats for fine-tuning datasets based on raw text corpuses.
Links mentioned:
Nous Research AI ▷ #project-obsidian (2 messages):
- ChatML Fixed for LLava: A member shared the successful resolution of issues with ChatML for the "llava" project. There is no further explanation or details on what the issues were or how they were resolved.
- Possible Fixes for Hermes-Vision-Alpha: The same member expressed their intention to work on resolving issues with Hermes-Vision-Alpha. Details on the nature of these issues or specific fixes were not provided.
Nous Research AI ▷ #bittensor-finetune-subnet (2 messages):
- Finetuning Miner Error: A member encountered an error while running the
miner.pyscript in the finetuning-subnet repository. Assistance was offered pointing to potential missing dependencies as the issue.
Nous Research AI ▷ #rag-dataset (34 messages🔥):
- Glaive's Data Generation Contribution: Glaive has created a sample dataset to assist in data generation for RAG applications, showcasing the ability to integrate multiple documents into responses.
- RAG Grounding Clarified: Sahilch explains that grounded mode in RAG distinguishes when the model should use context from a document exclusively and when to blend its own knowledge with documents, adding granularity to the response generation process.
- Commands for RAG and Citation Markup: Interninja discusses the importance of proper citation markup, suggesting a JSON format for citations may be beneficial, and shares an XML instruction format for the new CommandR+ with RAG which includes complex multi-step querying and uses
<co: doc>tags for referencing documents. - Cohere's RAG Documentation: Bjoernp highlights the potential of RAG combined with function calling, shares a Cohere RAG documentation link, and debates the implications for synthetic data generation within their Acceptable Use Policy.
- Filtering Retrievals in RAG Applications: Iriden promotes the idea of adding a filtering step between retrieval and response in RAG, which has practical success especially when users interact with the selection process for more refined results.
Links mentioned:
Nous Research AI ▷ #world-sim (96 messages🔥🔥):
- Copy-Pasting Quirks: Members discuss copy-pasting difficulties on Desktop compared to Mobile, noting that each character is wrapped in a
<span>on the website, making it challenging. One member mentions creating a python program to generate the corresponding HTML code to "paste" but it initially broke the website. - WorldSim Slowdown Concerns and Solutions: A discussion highlights concerns about the website slowing down during prolonged use, particularly on mobile. Solutions suggested include reloading from a save, while the best performance is noted to come from the original WorldSim, despite lacking quality-of-life features found in variants.
- Sharing WorldSim System Prompts: The system prompt for WorldSim is shared and clarified to be publicly available through a Twitter post, and an easier-to-copy version is posted on Pastebin.
- WorldSim Commands Compilation: A link to an updated WorldSim Command Index is shared, containing advanced commands for user reference, and prompting a discussion about a "sublimate" command for dismissing persona entities.
- Jailbreaking Claude Models and Puzzling Over ASCII Art: Users engage in trying to bypass preset prompts using Claude models, with successful results reported on labs.perplexity.ai. Another user enquiry about an ASCII art of a woman's face generated by WorldSim leads to the revelation that it represents the Nous girl logo.
Links mentioned:
Modular (Mojo 🔥) ▷ #general (16 messages🔥):
-
GitHub Workflow Example Shared: A user provided an example of a GitHub workflow related to modular auth and Mojo packaging. The initial link shared turned out to be inaccessible but was followed up by a copy-pasted snippet of the workflow.
-
In Search of Debuggers and Editors: A member inquired about the availability of a debugger and LSP for editors beyond VSCode, specifically mentioning neovim.
-
Discord Solution Link Offered: In response to a problem a user was experiencing, another member directed them to a solution posted previously in a Discord message, but the link to the solution was incomplete.
-
Community Livestream Notification: A user pointed out a lack of notification for an upcoming "Modular Community Livestream." The livestream link was provided, discussing "New in MAX 24.2".
-
Request for Mojo Completion Roadmap: A post originating from the Mojo channel was shared to the general channel requesting a detailed roadmap to "completion" for the Mojo project and a comparison with Taichi or Triton. Another user addressed this by sharing a link to the Mojo development roadmap.
Links mentioned:
Modular (Mojo 🔥) ▷ #💬︱twitter (4 messages):
- Tweet Alert: Modular shared a tweet on Twitter.
- Modular's Twitter Update: Another tweet was posted from Modular's official Twitter account.
- Tweet Sharing Session: Check out this recent Modular tweet for the latest insights.
- Another Tweet on the Radar: Modular continues its Twitter streak with this post.
Modular (Mojo 🔥) ▷ #ai (4 messages):
-
Integration of Mojo with ROS 2 Proposed: A member suggested integrating Mojo with ROS 2, believing that Mojo's memory safety practices could mitigate bugs in ROS 2. They highlighted the Rust support via ros2-rust and mentioned that ROS 2 is adopting a new middleware, zenoh-plugin-ros2dds, also written in Rust.
-
The ROS 2 Community's Predominant Use of Python Over Rust: It was pointed out that most of the ROS 2 community comes from research backgrounds favoring Python and doesn't usually utilize Rust. The contribution reflects the community's overall programming preference within robotics and AI-related projects.
-
Python's Limitations in Robotics Lead to C++ Transition: The same member shared their experience with ROS, noting that although Python is convenient for initial development in robotics, it's often too slow, leading to a rewrite of systems in C++ for serious applications.
-
Opportunities for Mojo on Nvidia Jetson Hardware: The member noted the potential for Mojo to leverage Nvidia Jetson hardware, which is increasingly used in robotics and whose performance is limited by Python's Global Interpreter Lock (GIL).
Link mentioned: GitHub - ros2-rust/ros2_rust: Rust bindings for ROS 2: Rust bindings for ROS 2 . Contribute to ros2-rust/ros2_rust development by creating an account on GitHub.
Modular (Mojo 🔥) ▷ #tech-news (3 messages):
-
Automated Docker Builds Fix Incoming: A fix is announced for version 24.3, addressing issues with automated docker builds.
-
Community Cheers for Docker Fixes: The announcement about the fix for automated docker builds in version 24.3 has been met with positive reactions from the community.
-
Modular Auth Example Shared: A member provided a link to an example of modular authentication on GitHub, which can be seen here.
Modular (Mojo 🔥) ▷ #🔥mojo (277 messages🔥🔥):
- Exploring Conditional Conformance: Members discussed how to implement conditional conformance in Mojo, using
traitandstructsyntax with ideas influenced by Swift and Rust. Proposed solutions included using@conditionalannotations to indicate optional trait implementation within structures. - External Call String Issues: One user encountered difficulties passing a string argument to
external_callbecause a StringLiteral is compile-time and immutable. It was suggested to use a C-style null-terminated char pointer extracted from a Mojo string, similar to an example shared in the chat. - Mojo Program Running on Android: A user showcased Mojo running on Android, specifically on a Snapdragon 685 CPU. This was met with interest and questions about CPU details and a request for the output of
lscpu. - Merchandise Possibilities: A question was raised regarding the future availability of Mojo-themed merchandise, invoking responses from team members to explore the idea. Plush toys and phone cases featuring the Mojo mascot were mentioned as potential items.
- Error Handling Discussion: Error handling possibilities in Mojo were speculated by users, discussing hypothetical syntax for error handling and polymorphic error resolution similar to traditional
try-exceptblocks in Python.
Links mentioned:
Modular (Mojo 🔥) ▷ #community-projects (3 messages):
-
Logger Library Updated: The logger library has received an update that now allows logging messages with arbitrary arguments and keyword arguments. Examples provided show how to log information, warnings, errors, and fatal messages with the improved function calls.
-
Introducing BlazeSeq:
BlazeSeq🔥has been published, a complete rewrite ofMojoFastTrim, acting as a feature-complete FASTQ parser that matches the test suites of BioJava and Biopython; it is available for CLI use or as a foundation for future applications. Benchmarks and usage examples are available on GitHub. -
Buffered Line Iterator for Improved File Handling: A new implementation includes a buffered line iterator, akin to Rust's buffer_redux crate, capable of handling incomplete lines and larger-than-buffer lines from either file or in-memory sources. This iterator is touted as a robust solution for projects until such functionality is integrated into the standard library.
Link mentioned: GitHub - MoSafi2/BlazeSeq: Contribute to MoSafi2/BlazeSeq development by creating an account on GitHub.
Modular (Mojo 🔥) ▷ #performance-and-benchmarks (11 messages🔥):
- New Level Unlocked!: A user was congratulated for advancing to level 3 in the ModularBot system, indicating engagement and contribution within the community.
- Library Performance Gains: A user reported significant performance improvements using a library, dropping execution time to 10m35s from a prior faster benchmark of 96s achieved with Golang.
- Link to Helpful Shell Script: The creator of the discussed library shared a Medium post describing a shell script for easy installation of the library.
- Library Optimization Tips: It was suggested to set a capacity when instantiating a dictionary to reduce reallocations and rehashing, potentially optimizing performance further.
- Sorting Algorithm Still to be Updated: There was a mention of a specialized sorting algorithm for strings that could offer better performance, located at mzaks/mojo-sort, but it hasn't been updated for the new versions of Mojo.
Modular (Mojo 🔥) ▷ #📰︱newsletter (2 messages):
- Max⚡ and Mojo🔥 24.2 Officially Released: Modular announced the release of Max⚡ and Mojo🔥 24.2, along with the open-sourcing of their standard library and the launch of nightly builds. The update has seen community engagement with roughly 50 pull requests opened and 10 merged; contributors are encouraged to explore and ask questions on Discord.
- Jump into the Mojo🔥 Open Source Movement: A new blog post titled The Next Big Step in Mojo🔥 Open Source details the latest advancements in the Mojo🔥 open source initiative.
- Discover What's New in Mojo🔥 24.2: The release of Mojo🔥 24.2 brings enhanced Python interoperability, among other features, as outlined in the Mojo launch blog and the follow-up article on What’s new in Mojo 24.2.
- Exploring Higher Order Functions in Mojo🔥: Readers are invited to find out about Higher Order Functions in Mojo🔥, with a teaser link provided on Twitter. However, the link appears to be incomplete.
Link mentioned: Modverse Weekly - Issue 28: Welcome to issue 28 of the Modverse Newsletter covering Featured Stories, the Max Platform, Mojo, & Community Activity.
Modular (Mojo 🔥) ▷ #nightly (17 messages🔥):
- Resolution for Parsing Errors in Standard Library: A member working off of the nightly branch reported parsing errors in the stdlib, yet mentioned being able to build the stdlib without issues. Concern was raised as to whether this should be a cause for alarm.
- FileCheck Troubles in WSL Solved: Running tests resulted in
FileCheck command not founderrors for one member, but thanks to community assistance and the use ofdpkg -S llvm | grep FileCheck, the issue was resolved by finding the correct directory (/usr/lib/llvm-14/bin) and adding it to the path. - Unsupported Tests Not a Concern: After troubleshooting
FileCheckinstallation, the member reported 7 unsupported tests, which was confirmed by another member as fine since those tests are platform-specific. - Optimizing Mojo's Optional Value Method: There was a discussion about the possibility for Mojo's
Optionalto return a Reference instead of a copy for thevalue()method, referencing the current implementation and suggesting the improvement could be actionable. - Approachability of Reference Issues for New Contributors: While considering making returning a reference from
Optionala 'good first issue', members agreed that dealing with references might not be user-friendly for new contributors unfamiliar with lifetimes, as proper inference requires experienced plumbing through the function parameters.
Links mentioned:
LM Studio ▷ #💬-general (171 messages🔥🔥):
- Understanding LLM Multitasking and Scaling: A detailed discussion reveals that multitasking with a single LLM may lead to reduced performance due to shared resources like VRAM and RAM. It was suggested that better performance might be achieved by running separate models concurrently on different servers and distributing requests via a queuing system.
- Pondering Local vs. Cloud LLM Usage: Participants debated the merits of running local LLMs versus cloud-based solutions such as GPT-4. Some prefer local models for their uncensored output and the ability to leverage powerful hardware without cloud restrictions.
- Model Suggestions for AI Enthusiasts: Various users recommended specific models for coding and general use, highlighting Hermes-2-Pro-Mistral-7B Q8 and Goliath 120B Longlora Q3KS, among others. Users discussed how VRAM and system specs influence the performance and suitability of different LLMs.
- Technical Issues and Solutions Explored: Members navigated common errors and provided solutions involving GPU offloading settings and C Redistributable installation. Discussions clarified that LM Studio cannot execute web searches and that it is necessary to have the latest drivers for efficient GPU utilization.
- Feature Updates and Community Engagement: LM Studio's upcoming support for text embeddings was announced, while individuals inquired about running multiple GPUs, interacting with documents via AnythingLLM, and creating Discord bots with contextual awareness.
Links mentioned:
LM Studio ▷ #🤖-models-discussion-chat (39 messages🔥):
- System Prompt Training Can Be Auto-activated: A concept was discussed about training a smaller LLM with outputs generated from a larger model using a complex System Prompt. This would effectively embed the System Prompt into the smaller model, negating the need to use context space for it, although the process could be costly in time and money.
- Conundrum in Model Responses: An issue was raised about a model providing odd, task-oriented responses irrelevant to input queries. It suggests confusion in preset behaviors that could be linked to the model's training.
- Mixtral vs Mistral Clarification: Differentiations were made between Mistral and Mixtral models; Mixtral is a Mixture of Experts (MOE) model combining eight 7B models into an equivalent 56B parameter model, whereas Mistral is a standard 7B model.
- Large Model, Tiny Hardware: There was a discussion about running a Mixtral 8x7b model on a 24GB VRAM NVIDIA 3090 GPU, noting that while feasible, it operates at reduced speeds. Also, LM Studio can not run on a Raspberry Pi, but smaller models like tinyllama might be compiled for operation on such devices.
- New Model and Support Development Discussions: Links were shared for the new 104B parameter C4AI Command R+ model with advanced capabilities and the newly available Eurus-7b model. There were also discussions indicating that llamacpp requires updates to support some of these newer models.
Links mentioned:
LM Studio ▷ #🧠-feedback (8 messages🔥):
-
Embedding Models Not Supported, Until Now: A member asked about using embedding models with LM Studio and mentioned downloading a gguf embedding model. It was clarified that embedding models were previously unsupported, but text embedding support has been introduced in version 0.2.19, with a beta available here.
-
LM Studio (Linux) Update Notification Issues: A user reported that LM Studio for Linux does not notify them of updates, observing that despite running version 0.2.17, version 0.2.18 is available and a beta for 0.2.19 exists.
-
Linux In-App Update Mechanism Still Pending: In response to the update notification issue, it was highlighted that the lack of an in-app update mechanism for Linux is one of the reasons why the platform is still considered "beta."
-
Enthusiasm for Linux Development: Members showed enthusiasm for the development of LM Studio on Linux, including the possibility of having a .deb package.
LM Studio ▷ #🎛-hardware-discussion (23 messages🔥):
-
Switching to ROCm Yields Speed Boost: Utilizing the ROCm preview resulted in a remarkable boost from 13 to 65 tokens/second on AMD hardware, showing that AMD's system can vastly outperform expectations with the correct software interface.
-
GPU Market Fluctuations Noted: Recent price increases in GP100 GPUs were observed, with costs rising from around $350 to $650-$700, signaling volatile market trends.
-
TSMC Disruption May Impact Prices: A Bloomberg article about a major earthquake leading to the evacuation of TSMC production lines suggests potential price increases for GPUs and Macs.
-
CUDA vs. ROCM vs. OpenCL Performance Layers: It's estimated that NVIDIA CUDA is approximately twice as fast as ROCm, which in turn is estimated to be about five times faster than OpenCL or DirectML.
-
Mixed GPU Configurations for Inference: While combining NVIDIA and AMD GPUs in one configuration isn't possible due to software incompatibilities, running separate instances of LM Studio to utilize each card individually for different inference tasks is a viable solution.
Links mentioned:
LM Studio ▷ #🧪-beta-releases-chat (19 messages🔥):
-
Introducing LM Studio 0.2.19 Preview 1 with Embeddings: LM Studio version 0.2.19 Preview 1 now supports local embedding models, such as
nomic-embed-text-v1.5-GGUFvia its OpenAI-likePOST /v1/embeddingsendpoint and LLama.cpp updates. Windows, Linux, and Mac preview builds are available for download. -
Separate ROCm Version for Compatibility: There will be a separate version for those needing ROCm support; it is not included in the current build.
-
Beta Version Confusion Clarified: The version displayed in LM Studio beta builds reflects the current shipping version, not the beta iteration, with version bumps occurring only at full release for clarity's sake.
-
No Support for GPU over IP Yet: LM Studio does not currently support using multiple GPUs across different machines, known as GPU over IP.
-
Chat Feature with Documents Still Pending: The ability to "Chat with your documents" is not yet implemented in LM Studio, but using LM Studio server mode with anythingLLM is suggested as an alternative.
Links mentioned:
LM Studio ▷ #autogen (1 messages):
- Autogen Studio Outputs Truncated: A member reported receiving only 1 or 2 tokens in their inference results when using LM Studio with Autogen Studio, seeking a solution for obtaining the full completion response.
LM Studio ▷ #langchain (1 messages):
- Question on "Memory" Retention in Runtime: A member asked how to achieve "memory" retention within the same runtime, having managed to make it work only with file analysis. There is a gap in understanding of how to maintain state across interactions with the bot.
LM Studio ▷ #amd-rocm-tech-preview (9 messages🔥):
- LM Studio Activated on AMD GPU: A member elaborated on their experience getting LM Studio to operate on an AMD GPU in a system that includes both RTX 2060 and 7900 XTX GPUs.
- ROCm vs. OpenCL Performance Inquiry: One participant enquired about the speed difference between ROCm and OpenCL, mentioning their own unsuccessful attempts to load models on a 6700XT GPU despite configuration efforts.
- System Specs for ROCm Build Shared: A member contributed their system specifications, revealing the use of an AmdROCm GPU type and noting 15.94 GB of RAM with 11.86 GB VRAM unused on a Windows 10 platform.
- Driver Issue Blocks ROCm on Lower Series AMD GPUs: It was mentioned that AMD's driver issues prevent the ROCm build from functioning on 6700 series or lower GPUs, indicating that resolution depends on AMD's intervention.
- ROCm Performance Exceeds OpenCL on Alternative Platforms: A member detailed their positive experience with a ROCm fork of KoboldAI, observing a significant performance boost to 33T/s over 12T/s when compared to LMStudio + OpenCL.
LM Studio ▷ #crew-ai (24 messages🔥):
- CORS Might Help: A member suggested turning on CORS (Cross-Origin Resource Sharing) to potentially solve an issue, without specifying the exact problem being addressed.
- LM Studio Implementation Resource: It was recommended to check out an article for implementing LM Studio in CrewAI, titled "Implementing LM Studio in CrewAI" available at Medium by Tayyib Ali.
- CrewAI Logging Levels and Display Issues: A member discussed the logging features of CrewAI mentioning that verbose can be set to 1 or 2 for different levels of logging details, and showed concern when no logs appeared at the expected location in LM Studio.
- Troubleshooting Missing LM Studio Logs: During a troubleshooting conversation about missing logs in LM Studio, a member noted that they were not seeing any processing in LM Studio but confirmed that CrewAI was functioning correctly on its end.
- JSONDecodeError in CrewAI: A member encountered a "json.decoder.JSONDecodeError" when using CrewAI and sought assistance; the error indicates a problem with a JSON string not being properly terminated.
Eleuther ▷ #general (194 messages🔥🔥):
-
Transformers Course Goes Public: Stanford CS 25 seminar on Transformers is open to the public for auditing live or via recorded sessions. Interesting topics like LLM architectures and applications across various fields will be discussed, with lectures by prominent industry experts. Join on Zoom, check the course website, or watch past sessions on YouTube.
-
Interview Tips from the Trenches: Experienced engineers recommend focusing on high-level skills and confidence in work over coding tests for senior roles. For assessing basic Python skills, some even use a simple coding exercise to ensure candidates don't overly rely on tools like ChatGPT.
-
Mathical Difficulty: A member sought help understanding a mathematical problem from a non-public working paper, leading to a discussion on binary search on sets and the importance of defining variables within academic papers.
-
Secure the Launch, Stanford!: A course on Transformers at Stanford, featuring guest researchers and covering deep learning models, is now available to the public through Zoom, with a corresponding Discord server opened for wider community discussion.
-
Go Play: Members exchange usernames and links to play the game, Go. Options include Online Go Server (OGS) for correspondence matches and a custom version available at Infinite Go.
Links mentioned:
Eleuther ▷ #research (51 messages🔥):
-
Innovations in Efficient Model Architectures: A new approach called T-GATE suggests cross-attention in text-to-image diffusion models may be unnecessary after understanding the coarse semantics of an image, potentially speeding up the process (T-GATE on GitHub). However, samples provided haven't fully convinced the community of its effectiveness.
-
Hardware Optimization Breakthrough or Bust?: References to potential hardware improvements like Free-pipeline Fast Inner Product (FFIP) algorithm claim significant efficiency gains, casting half the multiplications for cheap additions (Journal Publication). The community is skeptical, pondering whether there's a catch to these seemingly too good to be true claims.
-
Dynamic Allocation of FLOPs in Transformers: An arXiv paper introduces a method for transformers to allocate compute dynamically across a sequence, potentially optimizing performance and allowing for a pre-defined compute budget. This approach diverges from uniform FLOP distribution, proposing a more selective and potentially efficient allocation of resources.
-
Discussions on Large Language Models: Conversation about Huge Scale Language Models (HLB-GPT) explores follow-up to Mixture of Experts (MoE) work and specific design choices. A thread (HLB-GPT MoE and MoD Thread) has been dedicated for detailed exchange without cluttering the main channel.
-
Contentious Data Crawling Practices: Discussion surfaced on the challenges and potential violations associated with scraping platforms like Discord. While theoretically feasible, it breaches Terms of Service and can result in account bans.
Links mentioned:
Eleuther ▷ #interpretability-general (7 messages):
-
Countdown to MATS Stream Applications: The deadline to apply for Neel Nanda's MATS stream is approaching in less than 10 days. Interested applicants can find details and the FAQ in the provided Google Docs link.
-
Attention to Neural Networks: A Github repository named atp_star which provides a PyTorch and NNsight implementation of AtP* has been shared, courtesy of a DeepMind paper by Kramar et al., 2024. The repository can be found at koayon/atp_star on GitHub.
-
Saprmarks Tweets: A member shared a link to a Twitter post by @saprmarks, though the content was not discussed in the provided messages.
-
Gratitude for Sharing Code: The query about an open-source implementation for the latest AtP* paper was resolved with thanks, following the provision of the GitHub repository link.
Links mentioned:
Eleuther ▷ #lm-thunderdome (17 messages🔥):
-
CUDA Error Troubleshooting: A member faced a RuntimeError with CUDA while running an older version of the LM eval harness on H100s, which worked on A100s, pointing to a potential issue with
flash attention. Several suggestions noted including upgrading to CUDA 11.8 might help, but the actual culprit was identified asapex. Isolated tests with.contiguous()function and motion towards single GPU resolved the issue. -
top_pUnrecognized Argument in Colab: Another member encountered an unrecognized argument error when trying to settop_p=1in an LM eval harness command in Google Colab. The suggestion pointed out that the issue might be due to spaces in the arguments list.
Link mentioned: Google Colaboratory: no description found
Eleuther ▷ #gpt-neox-dev (3 messages):
-
Fault-Tolerant and Elastic Job Launch in PyTorch: A user shared a link to the PyTorch documentation for setting up fault-tolerant and elastic jobs, detailing the commands needed to launch them. The process involves specific settings for nodes, trainers per node, maximum restarts, and rendezvous endpoints, as shown in PyTorch's elastic training quickstart guide.
-
Cloud Support for Advanced Training Schemes: Another member mentioned that cloud services like AWS and Azure support advanced job training schemes, with AWS having released something called Gemini in the previous year.
Link mentioned: Quickstart — PyTorch 2.2 documentation: no description found
LAION ▷ #general (158 messages🔥🔥):
- Socratic Tutors and Constitutional AI: A package called ConstitutionalAiTuning was mentioned that allows fine-tuning of LLMs into Socratic tutors adhering to one's ethical principles. It requires a JSON file with principles and uses those to construct improved answers for fine-tuning models, meant to ease the process for those with less technical expertise.
- JAX Type Promotion and Semantics Clarified: Discussion on JAX type promotion semantics revolved around how types are promoted during operations in JAX. Code snippets illustrated the behavior, like
np.int16(1) + jnp.int16(2) + 3resulting inint16while3 + np.int16(1) + jnp.int16(2)results inint32. - SD3 Model Input Configuration Debated: There was an extensive technical discussion on the setup of text input for models like SD3, suggesting alternative approaches to concatenating sequences and the potential benefits of extending T5 tokens during fine-tuning while limiting the use of CLIP.
- Legal Risks with AI and Copyright Infringement: A conversation highlighted the legal risks associated with using copyrighted material to train AI systems, referring to the Suno music AI platform and possible legal repercussions from recording labels.
- GPU Infrastructure Costs and Stability AI's Challenged Finances: Reported financial challenges for Stability AI were discussed, including their struggle with high infrastructure costs from cloud services and potential inability to cover these expenses, as per an exposé by Forbes.
Links mentioned:
LAION ▷ #research (10 messages🔥):
- Scaling Latent Diffusion Models (LDMs): An arXiv paper detailed the study of the sampling efficiency scaling properties of LDMs. The study found that smaller models often outperform larger ones under the same inference budget.
- Moderation GIF Shared: A member posted a moderation-related GIF from Tenor.com, possibly indicating the action taken against off-topic or inappropriate messages.
- Banter About Quick Cash: Users joked about missing out on learning how to make "$50k in 72 hours" due to a message moderation, with guesses and meme references about drug smuggling.
- Tease of a New Optimizer: Drhead shared a Twitter post hinting at the imminent release of a new optimizer.
- Visual AutoRegressive (VAR) Model Outperforms: An arXiv paper introduced VAR, a new image autoregressive modeling paradigm that has shown to outperform diffusion transformers in image generation on multiple dimensions, including quality and speed.
Links mentioned:
OpenAccess AI Collective (axolotl) ▷ #general (67 messages🔥🔥):
-
Exploring Diverse AI Datasets: A member listed several datasets they have, indicating sizes ranging from 106G for "pairs" to 994k for "PheMT," with several datasets involving translations from EU languages. Some datasets, such as "pairs" and "WikiMatrix," were noted as less reliable, requiring metrics and cutoff points for quality assessment.
-
Rapid Feedback for RP-LLMs: A new service by Chaiverse allows for fast feedback on RP-LLM models, providing model evaluation within 15 minutes. It aims to provide the fastest and most accurate feedback using human preferences, avoiding training to the test due to non-public evaluation datasets.
-
Unveiling SaladCloud for AI/ML Workloads: SaladCloud promises to help developers avoid high cloud costs and GPU shortages by offering a fully-managed container service that opens up access to thousands of consumer GPUs, with rates starting at $00/hr and built for inference at scale.
-
Adding Heads to Transformer Models Made Easier: The GitHub repository for transformer-heads was shared, offering tools for attaching, training, saving, and loading new heads for transformer models, which could be quite beneficial for those looking to extend the capabilities of LLMs.
-
CohereForAI's Massive Model, C4AI Command R+: Creators release a model called C4AI Command R+, which is a 104 billion parameter multilingual model with abilities like Retrieval Augmented Generation (RAG) and multi-step tool use for complex tasks. The cost of running such large models remains a concern for some members.
Links mentioned:
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (4 messages):
-
GitHub Bug Squashed: A fix was applied to address an issue, with a commit pushed to GitHub, visible at GitHub Commit 5760099.
-
Table of Contents Mismatch Alert: A discrepancy was observed in the README's Table of Contents, which does not match its markdown headings, indicating a need for cleanup.
-
Comparative Analysis for Clarity: A suggestion was made to view the current TOC and markdown headings side by side for better visibility of inconsistencies.
-
Incorrect Heading in Training Config: An issue was identified with the heading used in
config/train, noting it was incorrect and suggesting a potential correction.
Link mentioned: fix toc · OpenAccess-AI-Collective/axolotl@5760099: no description found
OpenAccess AI Collective (axolotl) ▷ #general-help (11 messages🔥):
- Looking for High-Resolution Images: A member inquired about where to find a large collection of 4K and 8K images to crawl, but no sources or suggestions were provided in the following discussion.
- Deployment with UI Feedback Needed: Someone asked for recommendations on a good UI for deploying models and obtaining expert feedback, though no suggestions were made on the thread.
- Exploring Non-Instruction Text Data for Training: A member discussed using non-instructional text data like podcast transcripts for training a model to generate text in the style of the training data, referencing MistralAI and asking if others are doing similar experiments.
- Order of Fine-Tuning Practices: In a strategy discussion, there was a consensus that one should train 'completion' before 'instructions' while finetuning, which is especially useful for increasing domain-specific knowledge in models.
- Fine-Tuning Techniques and Efficiency: There was an exchange about fine-tuning techniques, where members noted that sometimes simple fine-tuning (SFT) and prompt engineering can be more effective than continual pre-training (CPT) for domain-specific training. It was mentioned that quality and diversity in instructional samples, even in smaller amounts, often yield better performance than larger quantities of lower-quality data.
OpenAccess AI Collective (axolotl) ▷ #datasets (2 messages):
- Optimal Dataset for Mistral 7B: A member inquired about the recommended dataset for training a Mistral 7B model using axolotl on Ubuntu 22.04. Another member suggested the OpenOrca dataset for its utility in all-around use.
OpenAccess AI Collective (axolotl) ▷ #announcements (1 messages):
- New Discord Bot Integration Live!: A new Discord bot integration has been set up to directly answer questions from the OpenAccess AI Collective. Members are encouraged to test the bot and leave feedback in a designated channel.
OpenAccess AI Collective (axolotl) ▷ #axolotl-help-bot (62 messages🔥🔥):
- Fine-tuning Qwen2 with Qlora: A detailed answer elucidated steps for fine-tuning Qwen2 using Qlora, such as setting
base_modelandadapterin the configuration file, using 4-bit precision, and specifying optimizer settings. An example configuration file was provided to assist in the process. - Dataset Streaming in Axolotl: Axolotl supports the use of local datasets for streaming, contrary to a previous documentation misunderstanding that implied otherwise. The steps include configuring
pretraining_datasetwith the Hugging Face dataset path in the.ymlfile. - Multi-Node Fine-Tuning with Docker: Guidelines were presented for multi-node fine-tuning using Docker, such as setting up accelerate config, configuring FSDP settings on the model, and ensuring all machines share the same Axolotl commit and model configuration file.
- Issues with Checkpoints and Mixed Precision: A member encountered a
ValueErrorwhen trying to flatten tensors with different data types during the use of Qlora with FSDP on the Mixtral model. The solution involves ensuring uniform data types for tensors before operations. - Axolotl Bot Goes Offline: The Axolotl bot experienced downtime, causing members to express their discontent through humorous replies. No solution or reason for the outage was provided in the chat history.
Links mentioned:
LlamaIndex ▷ #announcements (1 messages):
jerryjliu0: webinar is in 15 mins! ^^
LlamaIndex ▷ #blog (6 messages):
-
Revolutionize Your Knowledge Management: The new LLM-powered, self-organizing digital library is more than just a chat system; it's an AI-powered tool designed for professionals and teams to create, organize, and annotate their data. Discover it here.
-
Advanced RAG Meetup in Tokyo: Join the evening of lightning talks on 4/18 from 7-9pm JST in Tokyo, featuring speakers @hexpode, Diego, and Sudev discussing RAG applications, hosted by Rakuten. Details and signup can be found here.
-
Deploy LLM Apps Globally with Ease: Koyeb's interface conveniently scales LLM applications by connecting your GitHub repo to deploy serverless apps globally with zero infrastructure setup. Check out Koyeb here.
-
Tailoring RAG to Question Complexity: The "Adaptive RAG" paper by @SoyeongJeong97 explores tailored RAG techniques for varying complexities of questions, addressing the speed and specificity trade-offs. Learn more here.
-
Culinary Coding with the LlamaIndex + MistralAI Cookbook: Explore the series of cookbooks that guide users through building RAG, agentic RAG, and agent-based systems with MistralAI, including routing and query decomposition. Get your recipes here.
Link mentioned: IKI AI – Intelligent Knowledge Interface: Smart library and Knowledge Assistant for professionals and teams.
LlamaIndex ▷ #general (112 messages🔥🔥):
- Exploring GraphIndex Limitations: A member expressed confusion about the lack of pipeline support when working with knowledgegraphs in llama_index, stating that there is no clear documentation on creating a
graphindexfrom agraphdbor the role ofdocstore. They noted that while vectorindex has a pipeline and docstore for re-indexing nodes, graphindex seems to require custom code. - Seeking Recursive Query Engine Docs: A member couldn't find documentation on ragas with recursive query engine, leading to a conversation about potential issues between langchain and ragas and difficulties in importing functions from ragas.metrics.
- Querying Existing OpenSearch Index: A new member to llama-index enquired about querying an existing OpenSearch index. They provided detailed steps on setting up clients and stores but were uncertain about the process, later discovering the
VectorStoreIndex.from_vector_storemethod on their own. - In Search of LlamaIndex Agent Examples: Participants discussed various aspects of creating llama_index agents, including the complexities of generating in-depth responses, issues with persisting nodes taking an unexpectedly long time, and the proper use of ReAct agents.
- Handling Issues in LlamaIndex Implementations: Members sought advice on a range of llama_index implementation topics including the possibility of semantic similarity match in metadata, integrating SQL databases for chatbot functionality, and facing errors with async operations using elastic search as vector db storage.
Links mentioned:
LlamaIndex ▷ #ai-discussion (6 messages):
- Spellcheck the AI Way: A member shared a snippet of Node.js code utilizing the LlamaIndex
Ollamapackage to correct spelling errors in user-submitted text using a model named ‘mistral’. They indicated the service can run locally and handle errors, as demonstrated by the script correcting "bkie" to "bike" despite the ironic misspelling of "misspelled" in the prompt. - Local AI without Third-Party Services: The same user confirmed that the
Ollamapackage acts as a client/wrapper around a locally running AI server, suggesting the use of the commandollama run mistralfor local operation overlocalhost:11434. - Acknowledging the Benevolent AI: Humor was found in an AI's forgiving nature as a member humorously acknowledged the AI's utility after a self-reported misspelling incident in their own code example, praising the AI's ability to understand and process the intended input correctly.
- Enhancing Imagery with Reading and Asking (RAG): Discussion emerged around the potential of using Reading and Asking Generative (RAG) techniques for image processing tasks, with practical applications like overcoming CAPTCHAs or maintaining continuity in visual storytelling like comic strips.
HuggingFace ▷ #announcements (3 messages):
- Customize Your Repo Visibility: Enterprises using HuggingFace can now set a default Repo visibility to public, private, or private-by-default. More details can be found on this Twitter thread.
- Publish with Quarto on HuggingFace: There's a new publishing option for Quarto enabling users to deploy sites on HuggingFace easily. Instructions on publication are provided here and here.
- HuggingFace Hub Enterprise Page Launched: Explore the new HF Hub Enterprise page, a place for tailored enterprise solutions. The announcement and details are available here.
- Fine-Tune Access Control for Enterprise Repos: Have more control over your org's repositories with the new fine-grained access control feature. Available details can be found in this Twitter post.
- Major TOM Gets Sentinel-1: The expansion of Major TOM now includes Sentinel-1 data in the MajorTOM-Core, expanding the horizons for space observation capabilities. Learn more about the release here.
HuggingFace ▷ #general (48 messages🔥):
- Seeking AI for Game Testing: A member inquired about good machine learning AIs for testing games, implying interest in tools suitable for game development and quality assurance.
- Generating Succinct Summaries: One user struggled with the summarization pipeline in Hugging Face, noting that
text_length_penaltyseemed ineffective andmax_lengthappeared to truncate text. Discussion continued on model output lengths and how to achieve shorter summaries, with suggestions like usingmax_new_tokensand checking model configs or splitting the input samples. - Troubleshooting Multi-GPU System Setup: There was a request for information on the impact of PCIe slot speeds (x4/x8) on multi-GPU system performance for local large language models (LLMs).
- Deploying and Using HuggingFace Models: Queries were raised about deploying models and using the
predictfunction for a model deployment involving AWS Inferentia Instance, seeking clarity on the right approach and if this was the correct forum for such questions. - Image Generation Model Fine-Tuning Advice: Someone sought advice on fine-tuning an image generation model to create a painted portrait with a specific style and wondered if including images of paintings would assist in this goal; a suggestion was made to try using the IP adapter Face ID.
Links mentioned:
HuggingFace ▷ #today-im-learning (1 messages):
- Balancing Act Between Speed and Smartness: A member highlighted a trade-off between latency and reasoning in production prompts, suggesting that a prompt without reasoning yields fast but poor responses, while adding reasoning leads to smarter but slower replies. They proposed a hack of preemptively reasoning through most likely scenarios while the user is busy typing. Explore the idea here.
Link mentioned: Tweet from Siddish (@siddish_): stream with out reasoning -> dumb response 🥴 stream till reasoning -> slow response 😴 a small LLM hack: reason most likely scenarios proactively while user is taking their time
HuggingFace ▷ #cool-finds (5 messages):
- Apple Flexes Tech Muscle: A message mentioned that Apple claimed their latest model is more powerful than OpenAI's GPT-4.
- 3blue1brown Remains a Math Video Maven: A member expressed appreciation for 3blue1brown's continued production of educational videos, especially the earlier series on neural networks.
- Visual AutoRegressive Modeling Outshines Diffusion Transformers: A new paper, Visual AutoRegressive modeling (VAR), introduces a paradigm shift in autoregressive learning for images, which surpasses diffusion transformers in terms of image generation quality and inference speed.
- Chain of Thoughts Elevates AI Reasoning Skills: The paper Chain-of-Thought Prompting Elicits Reasoning in Large Language Models discusses significant performance improvements in complex reasoning tasks for large language models when using chain of thought prompting.
Links mentioned:
HuggingFace ▷ #i-made-this (20 messages🔥):
- Octopus 2: The Tentacles of Functionality: A demo for Octopus 2, a model with the capability to call functions, has been shared with excitement centered around its on-device potential. Check out the Space for Octopus 2, but expect a long render time of 1500 seconds when trying it out.
- Music Hurdles Overcome by Local Processing: Members discussed the benefits of running music models locally rather than over cloud services. They touched on expectations for hardware optimizations, and a Youtube Demo was shared celebrating a successful pipeline experiment.
- Making Images Come to Life with Salt AI: Innovative workflows have been released utilizing the new multi-subject image node pack from Salt, including body & face region detection and face swapping technology. Learn more about multi-subject image processing on GitHub.
- Sharing AI Impact on TED Stage: Community involvement and AI advancements were highlighted in a TED talk shared by a community member. The talk can be watched on YouTube expressing gratitude for community support during film production.
- PyTorch Geometric Welcomes CornellTemporalHyperGraphDataset: The pull request for the CornellTemporalHyperGraphDataset has been successfully merged into PyTorch Geometric, with immediate access through downloading from
master. View the PR here and get ready to incorporate it into your workflows.
Links mentioned:
HuggingFace ▷ #reading-group (5 messages):
-
RAG Resources for MLE Interview Prep: A member is seeking in-depth resources for studying Retrieval-Augmented Generation (RAG) ahead of a technical interview. They requested recommendations from the community for good study materials.
-
RAG Setup Struggles on WSL Ubuntu: A newcomer to AI is looking for assistance in setting up RAG on WSL Ubuntu 24.04 with Llama2 and mentioned difficulties in setting up privategpt.
-
Recording Next Presentation for Reference: A community member is unable to attend the next presentation and sought help in getting it recorded. They stated an intention to place the link in GitHub for future access.
-
Potential OBS Recording Solution: In response to the recording request, another member indicated that they are considering recording the presentation using OBS.
HuggingFace ▷ #computer-vision (8 messages🔥):
- Batch Size and Model Performance: Larger batch sizes are linked to increased model performance, as specific tests have shown improvements, particularly on medical data, although improvements can be marginal or non-significant. However, accumulation beyond 2 batches might negatively impact the performance, potentially due to batch normalization issues.
- Seeking Deep Learning Companions: A member mentioned they are looking for a partner to collaborate in the fields of Deep Learning and Natural Language Processing (NLP).
- Batch Size Impacts on Learning Dynamics: Different experiences were shared regarding batch size; one member found that smaller batches worked better for their small model, while another raised the issue that larger batches might skip local minima but smaller batches are more time-consuming.
- Learning Rate (LR) Schedulers as a Solution: The use of LR schedulers such as cyclic or cosine was suggested to address the issues of local minima encountered when working with larger batch sizes, providing both exploration and exploitation phases during training.
- Questions About Updating Custom Datasets on HuggingFace: A member inquired whether manually updating a custom dataset used for fine-tuning a pretrained model on HuggingFace would necessitate re-uploading or if the model would automatically update.
HuggingFace ▷ #NLP (21 messages🔥):
-
GPT-2 Stagnates on Summarization: A user training GPT-2 for text summarization experiences stagnation in validation metrics. They propose the idea of concise model training examples on the HuggingFace platform for specific tasks to avoid scavenging the internet.
-
Prompt Crafting for LLMs on CPU: A member seeks an open-source Large Language Model that can extract structured data like product names and prices from HTML, inquiring about suitable prompts. The user specifies a CPU-only setup with 16GB RAM for implementing the model.
-
BERT for Time Series Forecasting?: There's an interest in fine-tuning BERT for time series forecasting using methods like PEFT. One user provides assistance when asked for code samples or notebooks to guide this process.
-
Context Length Confines in Model Fine-tuning: A query about whether the context length of the Babbage-002 model can be changed during training was met with an explanation that it's immutable during fine-tuning but modifiable when training from scratch.
-
Enhancing Chatbot Responses with Free Models: A user creating a chatbot with Google Books API integration seeks a free language model to enhance response quality, ensuring answers are more conversational and complete.
HuggingFace ▷ #diffusion-discussions (11 messages🔥):
- Searching for DiT with Cross-Attention: A member inquired about a DiT (Diffusion Transformer) modified to use cross-attention for conditioning on text, image, or other data types. Another mentioned that the DiT on HF Diffusers is class-conditioned, linking to the paper (DiT Paper).
- Cost Considerations in Conditioning Strategies: A conversation highlighted that the public diffusion models like DiT are conditioned by class rather than using cross-attention to keep costs lower. One member suggested that modifications related to SD3 linear might be more practical.
- Customizing SD for Stereo to Depth Map Conversion: A member expressed the need to convert stereo images into depth maps, finding current models insufficient. They proposed possibly modifying Stable Diffusion (SD) for this task.
- Fine-Tuning Limits of SD with Custom Channels: A query about fine-tuning Stable Diffusion with more than 3 channels led to a suggestion that minor modifications to the SD architecture may be necessary as opposed to training from scratch.
- Alternative Approaches for Depth Estimation: It was suggested to look into Dino v2 for depth estimation training and to consider LoRA for stereo images, sharing relevant GitHub resources (Dino v2 GitHub, Depth Estimation Notebook). Another member pointed to work done with ControlNet, where 4-channel images were used, linking to a related repository (SD-Forge-LayerDiffuse GitHub).
tinygrad (George Hotz) ▷ #general (86 messages🔥🔥):
-
Logo Upgrade and Fish Farewell: The Discord logo got updated by George Hotz, sparking mixed feelings among members—some enjoyed the professionalism, while others mourned the loss of the quirky fish logo, which still remains on the banner. Discussion ensued about whether to update the banner as well.
-
Optimization and Cross-GPU Communication: Conversation turned towards optimization and sharding for machine learning models, with George Hotz and others discussing the impacts of launch latency on small kernels' performance and the challenge of data transfer between GPUs—cudagraphs, P2P limitations, and potential improvements with the use of NV drivers.
-
Tinygrad Performance Ambitions: Performance measures were shared, showing promising results like 53.4 tok/s on a single 4090 GPU with BEAM=4, achieving 83% of what gpt-fast can do. George Hotz highlighted ambitions to surpass these results using tinygrad soon.
-
Intel GPU and NPU Kernel Drivers: Technical details about kernel drivers for Intel's GPUs and NPUs were discussed, noting the various drivers available such as 'gpu/drm/i915', 'gpu/drm/xe', and 'accel/ivpu'. There was an exchange on possible performance and power efficiency gains when leveraging NPUs in conjunction with CPUs.
-
Upholding the Focus on Tinygrad Development: Amidst the technical discussions, George Hotz reiterated the channel's purpose for tinygrad-related talk, providing a reminder along with a link to the tinygrad GitHub repository and a guide on asking smart questions. This reinforced the goal of maintaining topical discussions within the channel.
Links mentioned:
tinygrad (George Hotz) ▷ #learn-tinygrad (23 messages🔥):
- Tinygrad Tutorials Win Praise: Users found the quick start guide with Tinygrad straightforward and praised its helpfulness for beginners; it motivated them to delve further into the field of neural networks.
- JAX Tutorial Highlighted: A member shared a link to the JAX Autodidax tutorial, offering a deep dive into the workings of JAX's core system with a hands-on Colab notebook.
- Tinygrad for Protein Folding Inquiry: Camelcasecam discussed the possibility of implementing ColabFold or OmegaFold with Tinygrad, questioning the potential performance improvements, while also showing interest in learning how to transfer PyTorch weights into Tinygrad.
- Collaborative Effort in Biofield Tech: In the context of adapting OmegaFold with Tinygrad, users from bioscience backgrounds expressed enthusiasm in teaming up for the project, suggesting that collaboration could yield better results.
- Exploring Performance Debugging with Tinygrad: Alveoli3358 shared their study notes on interpreting performance outputs when running Tinygrad with DEBUG=2, indicating an interest in calculating total FLOPS/memory required for an MNIST example to estimate theoretical training time.
Links mentioned:
OpenRouter (Alex Atallah) ▷ #general (83 messages🔥🔥):
-
JSON Object Support Clarification: Users confirmed that models supporting 'json_object' response format are notably OpenAI and Fireworks endpoints. They advised checking support by looking at provider parameters on the model's page (OpenRouter models).
-
Roleplaying Qualms with Claude 3 Haiku: The Claude 3 Haiku model received mixed reviews for roleplay, with suggestions to use the self-moderated version and to input several examples (few shot) for better output. However, jailbreak (jb) tweaks are recommended for improved performance.
-
Discord Resources for Jailbreaking Claude: Users discussed Claude jailbreaks and shared resources including SillyTavern's and Chub's Discord servers, where jailbreak listings and NSFW prompts can be found. The user was directed to easily accessible jailbreaks such as the pancatstack jb and advised on how to obtain NSFW roles.
-
OpenRouter Credit Location and Model Issues: Members discussed recent changes to OpenRouter's dashboard, including a new location for viewing credits now found at the
/creditsURL. Additionally, concerns were raised about the functionality of certain models like DBRX and Midnight Rose, and their support for specific features. -
Moderation and Response Issues with OpenRouter API: Users noted that even the self-moderated version of Claude model has a high decline rate and speculated about additional "safety" prompts. There were reports of non-responsiveness and a mention of implementing better providers to improve service stability for models like Midnight Rose.
Links mentioned:
OpenInterpreter ▷ #general (17 messages🔥):
- Installation Triumph: A member expressed satisfaction after successfully installing software on a Windows PC: Just got it installed and running on my windows PC. Damn.
- Termux Troubles: A snag with
chroma-hnswlibwas discussed; one member noted that despite being reportedly removed, the issue persists in the installation process. They sought advice on handling this problem. - Shift to Support Channel: In response to the above issue, the discussion was directed to another channel, suggesting moving detailed technical support topics to a more appropriate location.
- Support and Encouragement: There was an exchange of mutual encouragement and appreciation regarding posting in the community, with a focus on the belief that each issue raised is a valuable learning experience.
- Multi-Platform Capability Confirmed: Clarification was provided on the compatibility of certain software, confirming that it works on both PC and Mac, with reference to install instructions and guides in the documentation and pinned messages.
Links mentioned:
OpenInterpreter ▷ #O1 (55 messages🔥🔥):
- Hermes-2-Pro Best Practices: Members are discussing the use of Hermes-2-Pro and the importance of changing system prompts as advised in the model card.
- Shortcut Woes in the 01 Server: A user expressed difficulty with the 01 software output being verbose, seeking a local keyboard shortcut like
ctrl+cin Ollama to interrupt the LLM output without exiting the entire server. - Linux Complications with 01 Software: Users are sharing the troubleshooting and workarounds involved when running the 01 software on various Linux distros. Issues with package dependencies, system messages, and hardware compatibility such as audio (ALSA lib errors) are mentioned.
- Windows 11 Poetry Issues Identified: One user reports encountering problems when using
poetryon Windows 11, noting issues withCTRL+Cand audio recording. - Cardputer Discussion and Development: Participants discuss the development and potential of using the M5 Cardputer for the open-interpreter project, including implementation details and Github repository links for the ongoing work.
Links mentioned:
Interconnects (Nathan Lambert) ▷ #news (37 messages🔥):
-
Introducing Command R+: Command R+ is unveiled as a highly scalable LLM optimized for enterprise use, featuring advanced RAG for reduced hallucinations, multilingual support, and improved tool use. It boasts a context window of 128k tokens with model weights available for research use on Cohere's platform.
-
Command R+ Gains Attention: The new Command R+ model, possessing 104B parameters and demonstrating RAG capabilities, raises questions about its relative performance to other models due to lack of comparative data, while a live demo is available for experimentation.
-
Scrutinizing ChatGPT for Business: There's skepticism about the effectiveness of ChatGPT-like models for business applications, emphasizing that real enterprise use might require heavily customized solutions beyond what current "business-tailored" models offer.
-
Evaluating Models Raises Challenges: Discussions touch on the complex and potentially biased nature of evaluating models like Command R+, highlighting the importance of structured benchmarks like AssistantBench for more transparent assessments.
-
JetMoE-8B: A Cost-Effective Milestone for Academia: With costs under $0.1 million and performance surpassing Meta AI's LLaMA2 with only 2.2B active parameters during inference, JetMoE-8B represents a significant step in cost-effective and accessible LLMs for academic research, detailed on their project page.
Links mentioned:
Interconnects (Nathan Lambert) ▷ #ml-drama (3 messages):
-
Nathan Stirs the Pot: Nathan Lambert hinted at controversy with a tweet, saying "Hopefully doesn't turn into drama..."
-
Calling Out Snorkel: Following Nathan's comment, a reply called for a hot take on Snorkel, suggesting it's a topic ripe for discussion.
-
'All Models Are Bad' Article Tease: Nathan Lambert teases an upcoming article titled "all these models are bad," seemingly critiquing current models, including those integrated with RLHF (Reinforcement Learning from Human Feedback).
Interconnects (Nathan Lambert) ▷ #random (21 messages🔥):
- The FT's Locked Treasure: A member shared a Financial Times offer for unlimited article access, suggesting the need for a paid subscription to access quality journalism. The link included images of padlocks and product icons, signifying locked content, hinting at a comparison between content access and digital product offerings.
- Skepticism Over Business Models: In a brief exchange, a member expressed concern that traditional business models might inhibit the success of "genAI", hinting at potential rigidities in existing operations and the prospect of what they refer to as "product suicide."
- Tech Politics Discussion Not a Crowd-Pleaser: Members shared a link to a tech politics discussion by notable figures Ben Horowitz and Marc Andreessen, but the reception was lukewarm, with comments ranging from reluctant willingness to listen for political insight to outright dismissal of the content's value.
- CS25 Course Lecture Feature: A conversation revealed that a member, recognized as nato, is set to give a lecture for the CS25 course, expressing both anticipation and logistical considerations for the commitment.
- Stanford's CS25 Course Attracts AI Enthusiasts: The details of the CS25 course at Stanford were shared, indicating a robust lineup of discussions with Transformer research experts, including luminaries and industry professionals. Interested parties were pointed to a schedule and urged to tune into the course's YouTube channel for more insights.
Links mentioned:
Mozilla AI ▷ #llamafile (57 messages🔥🔥):
- Kernel Scalability Breakthrough: A member discussed improving a matmul kernel to process prompts efficiently for large matrices, overcoming limitations of the CPU cache when the matrix size exceeds 1024x1024.
- Compiler Magic Achieved: Celebrations were shared on getting the compiler to transform code, presumably leading to performance improvements.
- ROCm Version Clarification for Llamafile: For llamafile-0.7 on Windows, ROCm 5.7+ is required, indicating that support for different versions of ROCm, including 5.7 and 6.0.2, has been considered.
- SYCL Code Saga Continues: Spirited conversation about how to handle SYCL code in llamafile led to advice on checking out
llamafile/metal.candllamafile/cuda.cfor dynamic loading of DSOs. A community member contributed by implementing conditional compilation for SYCL support to work on Windows and Linux, but not on Mac. - Llamafile Performance and Issue with Cosmopolitan on Windows: A member attempted to build llamafile on Windows but faced issues with the Cosmopolitan compiler. An article was shared highlighting llamafile performance gains, and discussions surfaced around the need for a
llamafile-benchprogram to benchmark tokens per second. It was suggested that more RAM and faster RAM could improve performance, as CPU or memory constraints were not identified as bottlenecks.
Links mentioned:
LangChain AI ▷ #general (36 messages🔥):
- Seeking Experienced Chatbot Devs for Crypto: A user is looking for developers experienced in training LLMs and integrating them with a real-time database containing crypto market news and information, aiming to build a human-like chatbot.
- Extracting Math Symbols from PDF: A user inquires about alternatives to MathpixPDFLoader for extracting math symbols from PDF files, preferring other methods that could handle this task.
- LangChain Community Connection Sought: A user is seeking a community manager or developer advocate at LangChain for assistance with an integration, and was provided a link to contributing integrations: Guide to contributing integrations.
- Novice Inquiry on Bot Development with Langchain in JS: A user new to using Langchain in JavaScript is seeking guidance on creating a bot that schedules appointments and interacts with a database. Experienced users recommended Sequelize, an ORM for Node.js, for database interactions, with a link: Sequelize GitHub Repository.
- LCEL Chaining Puzzles and Poses: Members discussed the purpose of the '|' operator in LCEL (LangChain's Expression Language), which chains components such as prompts and llm outputs. A link was provided for further reading: Getting Started with LCEL.
Links mentioned:
LangChain AI ▷ #langserve (2 messages):
-
CI Failure Puzzle: A member sought assistance with a continuous integration failure on a PR that aims to serve the playground from the correct route, even with nested API routers. The PR in question is Serve playground from correct route PR #580, and local tests were passed using Python 3.10.
-
Chat Playground Walkthrough: A tutorial video has been shared, showcasing how to use Agents with the new Chat Playground of Langserve. The detailed walkthrough, including managing initial difficulties and featuring Langsmith, can be found on YouTube, with the final code provided in the description.
Links mentioned:
LangChain AI ▷ #langchain-templates (1 messages):
- Trouble with Agents Searching PDFs: A member highlighted an issue where their agent searches PDFs for every query. They suspected the system_prompt in the code to be the cause and sought advice on how to revise it.
LangChain AI ▷ #share-your-work (5 messages):
-
Launch of Multiple Voice Apps: The user announced the launch of several new voice apps, including CallStar, with a request to join the discussion and support the launch. The suite includes specialized apps like CallJesus and CallPDF, with links to Product Hunt and Reddit for upvotes.
-
Voice App Interactivity Inquiry: In response to the voice apps launch, a user inquired about the documentation behind the apps' responsive design. The original poster recommended RetellAI as the technology they use.
-
AllMind AI Tailored for Finance: A new LLM named AllMind AI, which focuses on financial analysis and research, was introduced to the community. The tool aims to provide users with insights and comprehensive financial data and was also featured on Product Hunt.
-
Galaxy AI's Free Premium API Service: Galaxy AI presents a free API service granting access to various premium AI models including GPT-4 and Gemini-PRO. This service is compatible with OpenAI format for easy project integration and supports Langchain, with further details to try now and more info at their homepage.
Links mentioned:
LangChain AI ▷ #tutorials (1 messages):
- LangChain Quickstart Guide Tour: A user shared a link to the LangChain Quickstart Guide which provides a detailed walkthrough of setting up LangChain, LangSmith, and LangServe, along with using prompt templates, models, output parsers, and the LangChain Expression Language to build and trace simple applications.
- Example Code & Error Encounter: The same user posted example Python code showcasing the integration of LangChain with a model using
ChatOpenAIandChatPromptTemplateclasses. However, they encountered aNotFoundErrorwith a404error code when running their code, indicating that a resource could not be found, and sought assistance with this issue.
Link mentioned: Quickstart | 🦜️🔗 Langchain: In this quickstart we'll show you how to:
CUDA MODE ▷ #triton (3 messages):
- BitMat Unveiled: A link was shared to BitMat's GitHub repo, which offers an efficient implementation of the method proposed in "The Era of 1-bit LLMs".
- Collaboration on Triton Visualizer: A new channel for contributors to the Triton visualizer was proposed to facilitate collaboration on the project.
- Lightning Strikes with LASP: Another GitHub link was provided to LASP's lightning_attention.py file, concerning Linear Attention Sequence Parallelism (LASP).
Links mentioned:
CUDA MODE ▷ #torch (4 messages):
- Switching to max-autotune compilation: A member suggested setting the compilation mode to max-autotune instead of reduce-overhead, sharing their experience of its benefits and expressing interest in other issues the torch team may find in the keras-benchmarks.
- Identifying torch benchmarking issues: The torch team's biggest concerns include not utilizing tensor cores and the inconsistency of enabling
torch.compile. They also noted problems with benchmarks like SAM, graph breaks that are fixable, and improper timing methods without cuda syncs, all of which they're addressing in a detailed response to come.
Link mentioned: keras-benchmarks/benchmark/torch_utils.py at main · haifeng-jin/keras-benchmarks: Contribute to haifeng-jin/keras-benchmarks development by creating an account on GitHub.
CUDA MODE ▷ #algorithms (1 messages):
iron_bound: : insert rant about repeatability in science here :
CUDA MODE ▷ #beginner (3 messages):
- CUDA Learning Path for Python and Rust Background: A member with experience in Python and Rust asked for recommendations on learning CUDA programming basics.
- CUDA MODE YouTube Lectures Suggested: Another member suggested starting with CUDA lectures available on a YouTube channel called CUDA MODE, which also offers a reading group and community on Discord and supplementary content on GitHub.
Link mentioned: CUDA MODE: A CUDA reading group and community https://discord.gg/cudamode Supplementary content here https://github.com/cuda-mode Created by Mark Saroufim and Andreas Köpf
CUDA MODE ▷ #ring-attention (1 messages):
- Lightning Fast Attention: The Triton "lightning_attention" kernel is mentioned as an efficient solution, nullifying the need for the FlashAttention repo plug which handled splitting data across devices. More details are available on the LASP GitHub repository.
Link mentioned: GitHub - OpenNLPLab/LASP: Linear Attention Sequence Parallelism (LASP): Linear Attention Sequence Parallelism (LASP). Contribute to OpenNLPLab/LASP development by creating an account on GitHub.
CUDA MODE ▷ #hqq (19 messages🔥):
- Introduction to the CUDA MODE Community: New members mobicham and zhxchen17 joined the CUDA MODE Discord and were welcomed by the community.
- Integration of HQQ with GPT-fast: zhxchen17 proposed creating a demo branch to show how HQQ can integrate with gpt-fast, including a separate branch for dependencies, a script for converting quantized weights, and benchmarking for collaborative review.
- Focus on Llama2 Model and Quantization: Mobicham suggested focusing on Llama2-7B (base) for integration due to existing benchmarks, and inquired about the desire to explore lower bit-level quantization beyond 4-bit. zhxchen17 confirmed looking into 4/3 bit quantization with a specific interest in the Mixtral-8x7B-Instruct-v0.1-hf-attn-4bit-moe-3bit-metaoffload-HQQ model.
- Confirmation and Clarification of Task Focus: After some confusion, mobicham clarified the goal of converting Llama2 HQQ into gpt-fast format, highlighting that a 4-bit HQQ with an appropriate group size could yield significant speed improvements.
- Potential Group-Size Restrictions and API Considerations: There was a discussion about potential group-size restrictions with
torch.ops.aten._weight_int4pack_mmand the design space for an API that converts models to GPT-fast format, with zhxchen17 indicating that the torchao team would be better equipped to define the API design.
Links mentioned:
CUDA MODE ▷ #triton-viz (13 messages🔥):
- Suggestion for Visual Indicators: A member proposed adding arrows or visual indicators for direction in the visualizations and provided a quick mock-up to illustrate the idea; however, they also mentioned that not every element should have an arrow, just enough to convey the concept.
- Integrating Operation Details into Visuals: The same member shared a code snippet highlighting the suggestion to visually represent operations, such as showing how an operand like 10 is added to input, similar to how a kernel functions in code.
- Concerns About Current Visualization Utility: A different member expressed concerns regarding the usefulness of adding indices to the current visualization and whether it would actually aid in understanding.
- Idea for Debugging with Interactive Elements: It was suggested that having interactive elements in the visualization, like hovering to see values, could be advantageous for debugging purposes.
- Potential Shift to JavaScript for Enhanced Interactivity: There was a mention that for implementing interactivity such as mouseovers in the visualization, it might be necessary to port the project to JavaScript.
Datasette - LLM (@SimonW) ▷ #ai (17 messages🔥):
- Evaluating AI Improvements: Members discussed the value of Hamel Husain's post on systematic AI improvements, describing it as "insanely valuable," with potential to inspire the founding of several companies.
- Datasette Plugin Enhancements: The idea was proposed to build evaluations for the Datasette SQL query assistant plugin, making them both visible and editable to users.
- The Prompt Dilemma: A member pondered whether prompts should reside within code, currently leaning towards "yes," but speculating this might not be sustainable in the long term.
- Evolving Prompt Management Practices: Potential future patterns for AI prompt management were outlined: localization, middleware, and microservice patterns, reflecting different strategies for integrating AI services into larger applications.
- Importance of Detailed API Response Data: The Cohere LLM search API was mentioned, highlighting the level of detail provided in responses, with a link to an issue comment showing a JSON output: Cohere API JSON data.
Links mentioned:
Datasette - LLM (@SimonW) ▷ #llm (1 messages):
- Terminology Tweaked for Dialogue: A member shared their finding on conversational terminology while exploring a
logs.dband mentioned that the term "response" might not be apt for the initial message in a conversation. They highlighted that "speaker turn" or "turn" is more appropriate and have decided to name their app's tableturns, amused by the accidental pun made.
DiscoResearch ▷ #benchmark_dev (10 messages🔥):
- Emotional Intelligence Benchmarks Unveiled: Two new leaderboards have been launched: Creative Writing EQ-Bench, evaluating emotional intelligence in LLMs, and Judgemark, which measures a model's ability to judge creative writing. Judgemark is described as a hard test involving correlation metrics and cost considerations; the benchmarks can be run through the EQ-Bench pipeline.
- Quality Ratings - Finding the Sweet Spot: When assessing the use of different scales for ratings – from -10 to 10, 0-10, 0-1, etc. – it was found that for sentiment, a scale of -1 to 1 works well, while for quality judgments, scales of 0-5 or 0-10 are preferred as models tend to use their ingrained understanding of what numbers mean.
- Creative Writing Judged on Details: The creative writing benchmark's success was credited to the use of 36 narrowly defined judging criteria. Scores based on broad criteria such as "rate this story 0-10" resulted in weak discrimination.
- Benchmark Criteria Documented: Questions about the judging criteria for benchmarks were addressed with a link to judge outputs, which included criteria. The example provided was gemini-ultra.txt from the EQ-bench results.
- Fine-tuning Rating Scales: Standard deviation of scores between models was used as an indicator to gauge the discriminative power of a question or criteria, and through this process, a 0-10 rating system was determined to be the most effective. Models tend to use the 0-10 range fully, which is assumed to add granularity compared to a 0-5 system.
Links mentioned:
DiscoResearch ▷ #discolm_german (3 messages):
-
COMET Scores Unveiled: A member shared COMET scores demonstrating the performance of various language models, with the Facebook WMT21 model standing out. The highest score was 0.848375 for a file named Capybara_de_wmt21_scored.jsonl.
-
Reference-Free Evaluation: The scores mentioned are reference-free COMET scores, specifically using wmt22-cometkiwi-da. Additional resources and scripts related to the evaluation were mentioned, available at llm_translation on GitHub.
-
Accuracy Caveats: The posted results are indicative but not absolute. The member noted potential inaccuracies when models stop continuing and requested to be notified of any significant errors.
Links mentioned:
Skunkworks AI ▷ #general (2 messages):
-
AI in Healthcare Gains Another Voice: A participant expressed their involvement in the AI medical field, indicating a growing number of community members in this healthcare tech space.
-
Innovating LLMs with Mixture-of-Depths (MoD): A new approach, called Mixture-of-Depths (MoD), has been shared; it allows Language Models to allocate compute dynamically, with an ability to skip the use of a single expert dynamically. The paper and its abstract are accessible via the PDF on arXiv.
Link mentioned: Mixture-of-Depths: Dynamically allocating compute in transformer-based language models: Transformer-based language models spread FLOPs uniformly across input sequences. In this work we demonstrate that transformers can instead learn to dynamically allocate FLOPs (or compute) to specific ...
Skunkworks AI ▷ #finetuning (1 messages):
- Decomposition Strategy for Math Problems: A member mentioned that rather than having an AI do math directly, it's better to train it to break down word problems into equations. These equations could then be solved using an external calculator, like Python or Wolfram Alpha.
Skunkworks AI ▷ #papers (1 messages):
carterl: https://arxiv.org/abs/2404.02684
Alignment Lab AI ▷ #general-chat (1 messages):
jinastico: <@748528982034612226>