With a sample size of 1600 votes, the early results from Lmsys were even better than reported benchmarks suggested, which is rare these days:
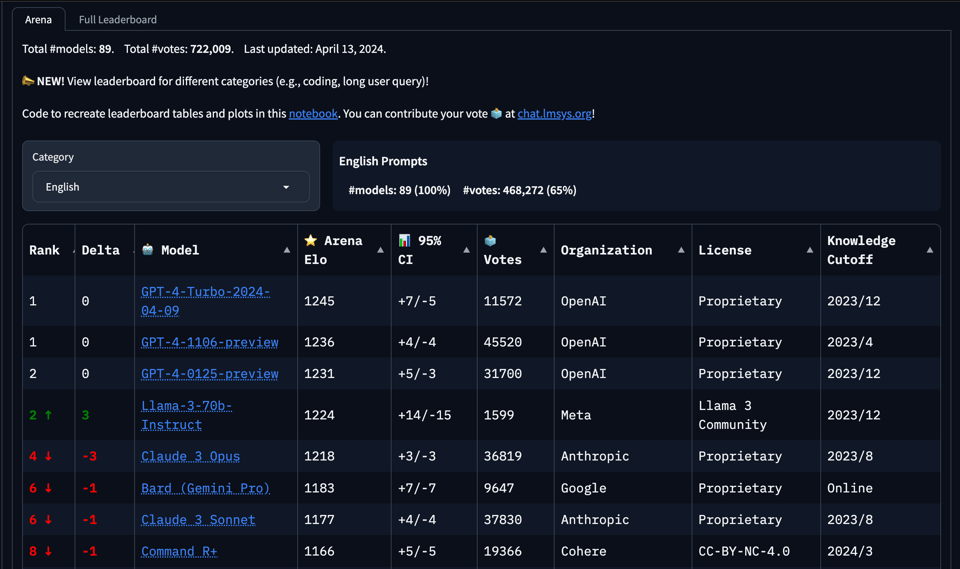
This is the first open model to beat Opus, which itself was the first model to briefly beat GPT4 Turbo. Of course this may drift over time, but things bode very well for Llama-3-400b when it drops.
Already Groq is serving the 70b model at 500-800 tok/s, which makes Llama 3 the hands down fastest GPT-4-level token source period.
With recent replication results on Chinchilla coming under some scrutiny (don't miss Susan Zhang banger, acknowledged by Chinchilla coauthor), Llama 2 and 3 (and Mistral, to a less open extent) have pretty conclusively consigned Chinchilla laws to the dustbin of history.
Table of Contents
[TOC]
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/Singularity. Comment crawling works now but has lots to improve!
Meta's Llama 3 Release and Capabilities
-
Llama 3 released as most capable open LLM: Meta has released Llama 3, their most capable openly available large language model to date. In /r/LocalLLaMA, it was noted that 8B and 70B parameter versions are available, supporting 8K context length. An open-source code interpreter for the 70B model was also shared.
-
Llama 3 outperforms previous models in benchmarks: Benchmarks shared in /r/LocalLLaMA show Llama 3 8B instruct outperforming the previous Llama 2 70B instruct model across various tasks. The 70B model provides GPT-4 level performance at over 20x lower cost based on API pricing. Tests also showed Llama 3 7B exceeding Mistral 7B on function calling and arithmetic.
Image/Video AI Progress and Stable Diffusion 3
-
Lifelike talking face generation and impressive video AI: Microsoft unveiled VASA-1 for generating lifelike talking faces from audio. Meta's image and video generation UI was called "incredible" in /r/singularity.
-
Stable Diffusion 3 impressions and extensions: In /r/StableDiffusion, it was noted that Imagine.art gave a false impression of SD3's capabilities compared to other services. A Forge Couple extension adding draggable subject regions for SD was also shared.
AI Scaling Challenges and Compute Requirements
- AI energy usage and GPU demand increasing rapidly: Discussions in /r/singularity highlighted that AI's computing power needs could overwhelm energy sources by 2030. Elon Musk stated training Grok 3 will require 100,000 Nvidia H100 GPUs, while AWS plans to acquire 20,000 B200 GPUs for a 27 trillion parameter model.
AI Safety, Bias and Societal Impact Discussions
-
Political bias and AI safety concerns: In /r/singularity, it was argued that perceived "political bias" in AI reflects more on political parties than the models. Llama 3 was noted for its honesty and self-awareness in interactions. Discussions emerged weighing AI doomerism vs optimism for beneficial AI development.
-
AI's potential to break encryption: A post in /r/singularity discussed the "quantum cryptopocalypse" and when AI could break current encryption methods.
AI Memes and Humor
- Various AI memes were shared, including the future of AI-generated memes, waiting for OpenAI's response to Llama 3, the AGI race between AI companies, and a parody trailer for humanity's AI future.
{kind=link}
{kind=link}
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
Meta Llama 3 Release
- Model Details: @AIatMeta released Llama 3 models in 8B and 70B sizes, with a 400B+ model still in training. Llama 3 uses a 128K vocab tokenizer and was trained on 15T tokens (7x more than Llama 2). It has an 8K context window and used SFT, PPO, and DPO for alignment.
- Performance: @karpathy noted Llama 3 70B broadly outperforms Gemini Pro 1.5 and Claude 3 Sonnet, with Llama 3 8B outperforming Gemma 7B and Mistral 7B Instruct. @bindureddy highlighted the 400B version approaching GPT-4 level performance on benchmarks.
- Availability: @ClementDelangue noted Llama 3 was the fastest model from release to #1 trending on Hugging Face. It's also available through @awscloud, @Azure, @Databricks, @GoogleCloud, @IBM, @NVIDIA and more.
Open Source AI Landscape
- Significance: @bindureddy argued most AI innovation in the open-source ecosystem will happen on the Llama architecture going forward. @Teknium1 felt Llama 3 disproved claims that finetuning can't teach models new knowledge or that 10K samples is the best for instruction finetuning.
- Compute Trends: @karpathy shared an update on llm.c, which trains GPT-2 on GPU at speeds matching PyTorch in 2K lines of C/CUDA code. He noted the importance of hyperoptimizing code for performance.
- Commercialization: @abacaj argued the price of tokens is plummeting as anyone can take Llama weights and optimize runtime. @DrJimFan predicted GPT-5 will be announced before Llama 3 400B releases, as OpenAI times releases based on open-source progress.
Ethical and Societal Implications
- Employee Treatment: @mmitchell_ai expressed empathy for Googlers fired for protesting, noting the importance of respecting employees even in disagreements.
- Data Transparency: @BlancheMinerva argued training data transparency is an unambiguous societal win, but incentives are currently against companies doing it.
- Ethics Requirements: @francoisfleuret imagined a world where email and web clients had to comply with the same ethical requirements as LLMs today.
AI Discord Recap
A summary of Summaries of Summaries
Meta's Llama 3 Release Sparks Excitement and Debate
-
Meta released Llama 3, a new family of large language models ranging from 8B to 70B parameters, with pre-trained and instruction-tuned versions optimized for dialogue. Llama 3 boasts a new 128k token tokenizer for multilingual use and claims improved reasoning capabilities over previous models. [Blog]
-
Discussions centered around Llama 3's performance benchmarks against models like GPT-4, Mistral, and GPT-3.5. Some praised its human-like responses, while others noted limitations in non-English languages despite its multilingual training.
-
Licensing restrictions on downstream use of Llama 3 outputs were criticized by some as hampering open-source development. [Tweet]
-
Anticipation built around Meta's planned 405B parameter Llama 3 model, speculated to be open-weight and potentially shift the landscape for open-source AI versus closed models like GPT-5.
-
Tokenizer configuration issues, infinite response loops, and compatibility with existing tools like LLamaFile were discussed as Llama 3 was integrated across platforms.
Mixtral Raises the Bar for Open-Source AI
-
The Mixtral 8x22B model from Mistral AI was lauded as setting new standards for performance and efficiency in open-source AI, utilizing a sparse Mixture-of-Experts (MoE) architecture. [YouTube]
-
Benchmarks showed the Mera-mix-4x7B MoE model achieving competitive results like 75.91 on OpenLLM Eval, despite being smaller than Mixtral 8x7B.
-
Multilingual capabilities were explored, with a new Mixtral-8x22B-v0.1-Instruct-sft-en-de model fine-tuned on English and German data.
-
Technical challenges like shape errors, OOM issues, and router_aux_loss_coef parameter tuning were discussed during large model training.
Efficient Inference and Model Compression Gain Traction
-
Quantization techniques like GPTQ and 4-bit models from Unsloth AI aimed to improve inference efficiency for large models, with reports of 80% less memory usage compared to vanilla implementations.
-
LoRA (Low-Rank Adaptation) and Flash Attention were recommended for efficient LLM fine-tuning, along with tools like DeepSpeed for gradient checkpointing.
-
Innovations like Half-Quadratic Quantization (HQQ) and potential CUDA kernel optimizations were explored for further compression and acceleration of large models on GPUs.
-
Serverless inference solutions with affordable GPU hosting were shared, catering to cost-conscious developers deploying LLMs.
Open-Source Tooling and Applications Flourish
-
LlamaIndex showcased multiple projects: building RAG applications with Elasticsearch [Blog], supporting Llama 3 [Tweet], and creating code-writing agents [Collab].
-
LangChain saw the release of a prompt engineering course [LinkedIn] and the Tripplanner Bot utilizing travel APIs [GitHub].
-
Cohere users discussed database integration, RAG workflows, and commercial licensing limitations for edge deployments.
-
OpenRouter confirmed production use at Olympia.chat and anticipated Llama 3 integration, while LM Studio released Llama 3 support in v0.2.20.
Emerging Research Highlights
-
A new best-fit packing algorithm optimizes document packing for LLM training, reducing truncations [Paper].
-
The softmax bottleneck was linked to saturation and underperformance in smaller LLMs [Paper].
-
DeepMind shared progress on Sparse Autoencoders (SAEs) for interpretability [Blog].
-
Chinchilla scaling laws were reinterpreted, suggesting more parameters could be prioritized over data for optimal scaling.
PART 1: High level Discord summaries
Perplexity AI Discord
-
Opus Users Hit Query Quota Quandary: Pro users are frustrated by a reduction in Opus queries from 600 to 30 per day, stirring up calls for a revised refund policy, given without advance notice of the change.
-
Model Mastery Marathon: Comparisons between Llama 3 70b, Claude, and GPT-4 centered around coding prowess, table lookups, and multilingual proficiency, alongside strategies for bypassing AI content detectors critical for deploying AI-generated content.
-
Anime Aesthetics and Image Implications: There's a surge of interest in applying AI to animations and images, referencing DALL-E 3 and Stable Diffusion XL, despite some challenges in harnessing their capabilities effectively.
-
Interpreting Complexity in AI Riddles: A complex snail riddle became a testbed for evaluating AI reasoning with models, highlighting the need for AIs that can navigate beyond simple puzzles.
-
Mixtral Sings Cohen, APIs Prove Playful: Mixtral-8x22B accurately interpreted Leonard Cohen's "Avalanche," while users confirmed Perplexity AI's chat models work with the API, giving life to applications like Mistral, Sonar, Llama, and CodeLlama.
Unsloth AI (Daniel Han) Discord
-
Llama 3 Outpaces GPT-4: The release of Meta's Llama 3 has ignited discussions comparing its tokenizer advantages and performance benchmarks against OpenAI’s GPT-4, with the anticipation of a large 400B model iteration. Debate is ongoing regarding the VRAM requirements for training across different GPUs, and Unsloth AI has quickly integrated Llama 3, touting improved training efficiency.
-
Unsloth Showcases Efficiency in 4-bits: Unsloth AI has updated its offerings with 4-bit models of Llama 3 for enhanced efficiency, with accessible models including 8B and 70B versions available on Hugging Face. Free Colab and Kaggle notebooks for Llama 3 have been provided, enabling users to more easily experiment and innovate.
-
Unsloth Users Tackle Training and Inference Challenges: The community within Unsloth AI is actively engaging in troubleshooting various complexities like tokenizer issues and training script shortcomings during fine-tuning of models like vllm. Unsloth has noted issues with Llama 3's tokenizer and informed users about their resolution efforts.
-
Community Endsures Model Mergers and Extensions: Interesting developments like Mixtral 8x22B, a substantial MoE model, and Neural Llama 3's addition to Hugging Face suggest steady advancement in model capabilities. User conversations also include practical advice and support on puzzles like JSON decoding errors, dataset structures, and memory limitations on platforms like Colab.
-
AI Pioneers Propose ReFT: The potential integration of the ReFT (Reinforced Fine-Tuning) method into the Unsloth platform has sparked interest among users. This method, noted for potentially aiding newcomers, is under consideration by the Unsloth team, reflecting the community’s proactive approach to refine and expand tool capabilities.
LM Studio Discord
-
Llama 3 Takes Center Stage: Meta's Llama 3 model is stirring up discussions, with users exploring the 70B and 8B versions, acknowledging its human-like responses comparable to larger models. Issues like infinite loops were noted, and the newly released Llama 3 70B Instruct promises to match GPT-3.5's performance and is available on Hugging Face.
-
Hardware Hurdles and Triumphs: There's active conversation around running AI models on various hardware configurations. A 1080TI GPU is highlighted for adequate AI model processing, while compatibility challenges for AMD GPUs, like the lack of AMD HIP SDK support for certain cards, are acknowledged. Additionally, model quantization versions like K_S and Q4_K_M raised issues, but Quantfactory versions were suggested as superior.
-
LM Studio Updates and Integration: The latest update, LM Studio 0.2.20, includes support for Llama 3. Users are encouraged to update via lmstudio.ai or by restarting the app. However, there's emphasis that only GGUFs from "lmstudio-community" will work for now. Discussions are also ongoing about ROCm support for AMD hardware with Llama 3 now supported on the ROCm Preview 0.2.20.
-
Innovations in Usability and Compatibility: A new feature called the "prompt studio" has been launched, allowing users to fine-tune their prompts in an Electron app built using Vue 3 and TypeScript. Meanwhile, llamafile is being lauded for its compatibility across various systems, contrasting with LM Studio's AVX2 requirement. Users advocate for backward compatibility, pointing out the issue with keeping the AVX beta as up-to-date as the main channel.
-
Efficiency and Community Contributions in AI: The efficient IQ1_M and IQ2_XS models require less than 20GB of VRAM for the IQ1_M variant, showcasing community efforts toward optimized AI model performance. Moreover, Llama 3 70B Instruct model quants, lauded for efficiency and compatibility with LM Studio, are now accessible, hinting at a forward leap in open-source AI.
Nous Research AI Discord
A Call for Multi-GPU Support: There are struggles with achieving efficient long context inference for models like Jamba using multi-GPU setups; deepspeed and accelerate documentation lack guidance on the matter.
Ripe for an Invite: TheBloke's Discord server resolved its inaccessible invite issue, with the new link now available: Discord Invite.
Reports Go Commando: The /report command has been introduced for effectively reporting rule violators within the server.
Llama 3 Ignites Benchmarking Blaze: Llama 3 is being rigorously benchmarked and compared to Mistral among users, with its performance and AI chat templates under the lens. Concerns about model limitations, such as the 8k token context limit, and restrictive licensing were prominent.
Pickle Cautions and AI Index: Dialogues on compromised systems via insecure pickle files and non-robust GPT models featured in the conversation. The AI community was directed to the AI Index Report for 2023 for insights on the year's development.
Cross-Model Queries and Support Calls: Queries included the search for effective prompt formats for Hermes-based models, anticipated release of llama-3-Hermes-Pro, and whether axolotl supports simultaneous multi-model training. The support for long context inferences on GPU clusters using models like jamba is under development, as seen in the vLLM project's GitHub pull request.
VLM on Petite Processors: A project aiming to deploy VLM (Vision Language Models) on Raspberry Pis for educational use hints at the ever-growing versatility in AI deployment platforms.
Data Dilemmas and Dimensionality Debates: Open-source models' need for fine-tuning and issues with data diversity, including the curse of dimensionality, have been topics of agreement. Moreover, strategies for creating effective RAG databases ranged from single large to multiple specialized databases.
Simulation Joins AI Giants: A fervent discussion has taken place centered around the integration of generative AI like Llama 3 and Meta.ai with world-sim, exploring the creation of rich, AI-powered narratives.
CUDA MODE Discord
Matrix Multiplication Mastery: Engineers debated optimal strategies for tiling matrix multiplication in odd-sized scenarios, proposing padding or boundary-specific code to improve efficiency. They highlighted the balance between major part calculations and special edge case handling.
CUDA Kernels Under the Microscope: Discussions on FP16 matrix multiplication (matmul) errors surfaced, suggesting the superior error handling of simt_hgemv compared to typical fp16 accumulation approaches. The group also examined dequantization in quantized matmuls, sequential versus offset memory access, and the value of vectorized operations like __hfma2, __hmul2, and __hadd2.
On the Shoulders of Giants: Members explored integrating custom CUDA and Triton kernels with torch.compile, sharing a Custom CUDA extensions example and directing to a comprehensive C++ Custom Operators manual.
CUDA Quest for Knowledge: There was an exchange on CUDA learning resources with the suggestion to learn it before purchasing hardware, and recommending a YouTube playlist for the theory and a GitHub CUDA guide for practice.
Leveraging CUDA for LLM Optimization: The community successfully reduced a CUDA model training loop from 960ms to 77ms using NVIDIA Nsight Compute for optimizations, highlighting the specific improvements and considering multi-GPU approaches for further enhancements. Details on the loop optimization can be found in a pull request.
Training Garb for Engineers: Discussions for CUDA Mode events necessitated coordination regarding recording duties, sparking conversations on suitable workflows and tools for capturing and potentially editing the sessions, in addition to managing event permissions and scheduling.
OpenAccess AI Collective (axolotl) Discord
-
LLaMA-3 Launch Spurs In-Depth Technical Dialogue: The advent of Meta LLaMA-3 triggered rich discussions around its tokenizer efficiency and architecture, with members weighing in on whether its predecessor's architecture was inherited and conducting comparative tests. Concerns were voiced about finetuning challenges, while some tinker with the qlora adapter to improve integration despite facing technical snags with tokenizer loading and unexpected keyword arguments.
-
Axolotl Reflects on Finetuning and Tokenizer Configurations: Debates persisted on how to best finetune AI models, with a spotlight on Mistral and LLaMA-3, including specifics about unfreezing lmhead and embed layers and tackling tokenizer changes that lead to
ValueErrorissues. Members shared tokenizer tweaks, ranging from adjusting PAD tokens to exploring new tokenizer override techniques, such as in the proposed Draft PR on tokenizer overrides. -
AMD GPU Compatibility Receives Attention: Users exploring ROCm published an install guide, aiming to provide alternatives for attention mechanisms on AMD GPUs, which could par with Nvidia's Flash Attention. This is an ongoing topic where users endeavor to identify methods that are more compatible with non-Nvidia hardware.
-
Innovations in Language Modeling Noted: Significant advancements in language modeling were highlighted, including AWS's new packing algorithm triumph, reported to cut down closed domain hallucination substantially. A paper detailing this progress can be found at Fewer Truncations Improve Language Modeling, potentially informing future implementations for the engineering community.
-
Runpod Reliability Gets a Wink and a Nod: A member highlighted slow response times in the runpod service, resulting in a humorous jab at the service's intermittent reliability, poking fun at runpod's operational hiccups.
Stability.ai (Stable Diffusion) Discord
Mark Your Calendars for SD3 Weights: Discussions indicate excitement for the upcoming May 10th release of Stable Diffusion 3 local weights, with members anticipating new capabilities and enhancements.
Censorship or Prudence?: Conversations surfaced concerns regarding the Stable Diffusion API, which might produce blurred outputs for certain prompts, signaling a disparity in content control between local versions and API usage.
GPU Picking Made Simpler: AI practitioners highlighted the cost-effectiveness of the RTX 3090 for AI tasks, weighing its advantages over pricier options like the RTX 4080 or 4090, factoring in VRAM and computational efficiency.
Artistic Mastery in AI: Dialogue in the community has been geared towards fine-tuning content generation, with members exchanging advice on creating specific image types, such as half-face portrayals, and controlling the nuances of the resulting AI-generated art.
AI Assistance Network: Resources like a detailed Comfy UI tutorial have been shared for community learning, and users are both seeking and providing tips on handling technical errors, including img2img IndexError and strategies for detecting hidden watermarks in AI imagery.
Latent Space Discord
Rocking the Discord Server with AI: A member explored the idea of summarizing a dense Discord server on systems engineering using Claude 3 Haiku and an AI news bot; they also shared an invitational link.
Meta's Might in Machine Learning: Meta introduced Llama 3, with conversations buzzing around its 8B and 70B model iterations outclassing SOTA performance, a forthcoming 400B+ model, and comparison to GPT-4. Participants noted Llama 3's superior inference speed, especially on Groq Cloud.
Macs and Llamas, an Inference Odyssey: Debates flared up about running large models like Llama 3 on Macs, with some members suggesting creative workarounds by combining local Linux boxes with Macs for optimized performance.
Hunt for the Ultimate LLM Blueprint: In search of efficiency, community members shared litellm, a promising resource to adapt over 100 LLMs with consistent input/output formats, simplifying the initiation of such projects.
Podcast Wave Hits the Community: Latent Space aired a new podcast episode featuring Jason Liu, with community members showing great anticipation and sharing the announcement Twitter link.
Engage, Record, and Prompt: The LLM Paper Club held discussions on the relevance of tokenizers and embeddings, announced the recording of sessions for YouTube upload, and examined model architectures like ULMFiT's LSTM. In-the-know participants confirmed PPO's auxiliary objectives and engaged in jest about the so-called 'prompting epoch.'
AI Evaluations and Innovations: The AI In Action Club pondered the pros and cons of using Discord versus Zoom, shared insights into LLM Evaluation, tackled unidentified noise during sessions, and shared strategies for abstractive summarization evaluation. Links to Eugene Yan's articles were circulated, underscoring the importance of reliability in AI evaluations.
Eleuther Discord
Best-fit Packing: Less Truncation, More Performance: A new Best-fit Packing method reduces truncation in large language model training, aiming for optimal document packing into sequences, according to a recent paper.
Unpacking the Softmax Bottleneck: Small language models underperform due to saturation linked with the softmax bottleneck, with challenges for models under 1000 hidden dimensions, as discussed in a recent study.
Scaling Laws Remain Chinchillated: Conversations in the scaling-laws channel have concluded that the Chinchilla token count per parameter stays consistent and that there might be more benefit in adding parameters over accumulating more data.
DeepMind Dives into Sparse Autoencoders: DeepMind's mechanistic interpretability team outlined advancements in Sparse Autoencoders (SAEs) and provided insights on interpretability challenges and techniques in a forum post, along with a relevant tweet.
Tackling lm-evaluation-harness Challenges: Efforts to contribute to the lm-evaluation-harness project have been hampered by the complexity of configurations and the need for a cleaner implementation method, with shared insights into the potential for multilingual benchmarking via PRs.
LAION Discord
-
Shake-up at Stability AI: Stability AI has undergone layoffs of 20+ employees following the CEO's departure to address the issue of unsustainable growth, prompting discussions about the company's future direction and stability. The full memo/details on the layoff can be found in CNBC's coverage.
-
Rivalry in AI Art Space Heats Up: DALL-E 3 has been observed to outperform Stable Diffusion 3 in terms of prompt accuracy and visual fidelity, leading to community dissatisfaction with SD3’s performance. The comparison of these models has heightened discussions of their respective strengths and weaknesses in the text-to-image arena.
-
Meta Llama 3 Sparks Conversations: The introduction of Meta Llama 3 has triggered conversations regarding its implications for the AI landscape, with discussions encompassing its coding capabilities, limited context window, and how it might compete with other industry-leading models. An announcement confirmed that Meta Llama 3 will be available on major platforms such as AWS and Google Cloud, and can be reviewed in more detail at Meta's blog post.
-
Digging Deeper into Cross-Attention Mechanisms: There are ongoing discussions about cross-attention mechanisms, particularly in the imagen model from Google, which is gaining attention for its method of handling text embeddings during the model training and image sampling processes.
-
Advancing Facial Dynamics with Audio-Conditioned Models: Interest is on the rise for an open-source audio-conditioned generative model capable of facial dynamics and head movements, with a diffusion transformer model appearing as a strong candidate. Strategies involving latent space encoding of talking head videos or face meshes conditioned on audio are being evaluated for effectiveness in creating realistic facial expressions synchronized with audio.
HuggingFace Discord
Spanning Languages and Models: A Summary of Discourse
-
LLaMA 3 Takes the Stage: The engineering community is awash with discussions about LLaMA 3, with insights from a Meta Releases LLaMA 3: Deep Dive & Demo video. The anticipation for its performance on leaderboards is high, particularly noted at the handle
MaziyarPanahi/Meta-Llama-3-8B-Instruct-GGUFon HuggingFace. -
Meta-Llama 3 vs. Mixtral: Benchmarks comparing Meta Llama 3 and Mixtral are under scrutiny, with the recent Mera-mix-4x7B model achieving 75.91 on OpenLLM Eval. The community also shared a tip about a 422 Unprocessable Entity error with LLaMA-2-7b-chat-hf model, requiring token input reduction for resolution.
-
Expanding Multilingual Reach: Momentum is growing for multilingual accessibility as community members offer to translate and create content for a wider global audience, highlighted by Portuguese translations of Community Highlights available in a YouTube playlist and discussions on the importance of culturally relevant translations.
-
Quantization Queries and Dataset Discussions: Conversations pivot to quantization as the community contemplates its impact on model performance, linked to an analysis at Exploring the Impact of Quantization on LLM Performance, whereas sharing of the ORPO-DPO-mix-40k dataset taps into the need for improved machine learning model training.
-
Community Creates and Collaborates: The user-generated content shines through both in a creative audio-in-browser experience at zero-gpu-slot-machine and the launch of a new prediction leaderboard aimed at gauging LLMs' future event forecasting acumen, with the space located here. Meanwhile, a book on Generative AI garners interest as it promises more chapters, potentially on quantization and design systems.
Technical Exchange Flourishing: AI Engineers exchange knowledge on everything from deep reinforcement learning (DRL) in object detection to GPU issues in Gradio and the perplexing 'cursorop' error in TensorFlow. Discussions are also oriented towards 3D vision datasets and solutions for consistent backgrounds in inpainting with Lora. An open call was made to explore Counterfactual-Inception research on GitHub.
OpenRouter (Alex Atallah) Discord
-
Mix-Up Fixed for Mixtral Model: The prompt template for the Mixtral 8x22B Instruct model was corrected, impacting how users should interact with the model.
-
OpenRouter's Revenue Riddles: The guild is abuzz with speculation about OpenRouter's revenue strategies, with hypotheses about bulk discounts and commission from user top-ups, but no official stance from OpenRouter futures the debate.
-
Latency Lowdown: Concerns about VPS latency, especially in South America, were discussed without reaching a consensus on the impact of server location on performance.
-
Meta's LLaMA Lifts Off: Enthusiasm is high for the new Meta LLaMA 3 models, which are reported to be less censored. Engineers shared resources including the official Meta LLaMA 3 site and a download link for model weights at Meta LLaMa Downloads.
-
OpenRouter Hits Production: Reports confirm the deployment of OpenRouter in production, with users pointing to examples like Olympia.chat and seeking advice on integrating it as a replacement for direct OpenAI, with emphasis on the gaps in documentation for specific integrations.
OpenAI Discord
Turbo Challenged by Claude: Users have reported slow performance with gpt-4-turbo-2024-04-09, finding it slower than its predecessor, GPT-4-0125-preview. Inquiries were made about faster versions, and some have integrated Claude to compensate for speed issues, yet with mixed results.
AI Grapples with PDFs: Conversations zeroed in on the inefficiency of PDFs as a data input format for AI, with community members advising the use of plain text or structured formats like JSON, while also noting XML is not currently supported for files.
Performance Anxiety Over ChatGPT: Members expressed concerns over the declining performance of ChatGPT, sparking debate over possible reasons which ranged from strategic responses to legal challenges to deliberate performance downgrades.
Engineering More Effective Prompts: There was a community effort to confirm and update the prompt engineering best practices, as recommended in the OpenAI guide with discussions pointing to real issues in prompt consistency and failure to adhere to instructions.
Integrating AI with Blockchain: A blockchain developer called for collaboration on projects combining AI with blockchain, suggesting an interaction between advanced prompt engineering and decentralized technologies.
Interconnects (Nathan Lambert) Discord
-
Value-Guided AI Ascends: Excitement is building around PPO-MCTS, a cutting-edge decoding algorithm that combines Monte Carlo Tree Search with Proximal Policy Optimization, providing more preferable text generation through value-guided searches as explained in an Arxiv paper.
-
Meta Llama 3 Models Spark Buzz: Discussions heated over Meta's Llama 3, a series of new large language models up to 70 billion parameters, with particular attention to the possible disruptiveness of an upcoming 405 billion parameter model. The model's multilingual capabilities and fine-tuning effectiveness were topics of debate, alongside the potential shake-up against closed models like GPT-5 Replicate’s Billing, Llama 3 Open LLMs, Azure Marketplace, and OpenAssistant Completed.
-
Llama3 Release Keeps Presenters on Their Toes: Anticipation around the LLaMa3 release influenced presenters' slide preparations, with some needing to potentially include last-minute updates to their materials. Queries about LLaMA-Guard brought up discussions on safety classifiers and AI2's development of benchmarks for such systems.
-
Pre-Talk Prep: In light of the LLaMa3 discussion, presenters geared up to address questions during their talks, while concurrently prioritizing blog post writing.
-
Recording Anticipation: There's eagerness from the community for the release of a presentation recording, highlighting the interest in recent discussions and progress in AI fields.
Modular (Mojo 🔥) Discord
-
C Integration Made Easier in Mojo: The
external_callfeature in Mojo was highlighted, with plans to further streamline C/C++ integration by enabling direct calls to external functions without a complex FFI layer, as outlined in the Tutorial on Twitter and the Modular roadmap and mission. -
Mojo Ponders Garbage Collection and Testing Capabilities: Within the Modular community, there was a discussion about implementing runtime garbage collection, similar to Nim's approach; curiosity about first-class support for testing in Mojo, comparable to Zig; and debate regarding the desire for pytest-like assertions. Additionally, excitement was noted around community contributions towards the development of a packaging and build system for Mojo.
-
Rust vs. Mojo Performance Evaluated: A benchmarking debate revealed Rust's prefix sum computation to be slower than Mojo's equivalent, with Rust achieving a time of 0.31 nanoseconds per element using just
--releasecompile flag. -
Updating Nightly/Mojo with Care: Engineers reported issues updating Nightly/Mojo, with solutions ranging from updating the modular CLI to manually adjusting the
PATHin.zshrc. This brought to light both technical glitches and a gentle reminder of potential human errors affectionately phrased as Layer 8 issues. -
Meta's LLaMA 3 Model Discussed: The community shared a video titled "Meta Releases LLaMA 3: Deep Dive & Demo", exploring the features of Meta's LLaMA 3 AI model, noting the release date as April 18, 2024, viewable on YouTube.
Cohere Discord
-
Tool Time with Command R Model: The Command R model guide was reinforced with links to the official documentation and example notebooks. The use of JSON schemas to describe tools for Command models was endorsed.
-
Database Dynamics: Integration of MySQL with Cohere raised discussions, clarifying that it can be done without Docker, as demonstrated in the GitHub repository, even though the documentation may have outdated information.
-
The RAG-tag Team: Questions on implementing Retrieval Augmented Generation (RAG) with Cohere AI were answered, referencing Langchain and RagFlow according to the official Cohere docs.
-
Licenses and Limits: It was noted that Command R and Command R+ tools are bound by CC-BY-NC 4.0 licensing, which prohibits their commercial use on edge devices.
-
Scaling Model Deployment: Dialogue revolved around deploying large models, indicating the challenges of scaling up to 100B+ models and highlighting specific hardware considerations like dual A100 40GBs and MacBook M1.
-
Lockdown Breach Alert: Increasingly sophisticated jailbreaks in LLMs were discussed, highlighting the potential for serious repercussions including unauthorized database access and targeting individuals.
-
Surveillance in the Service Loop: An example was provided of enhancing a conversation by integrating llm_output with run_tool, enabling an LLM's output to guide a monitoring tool in a feedback loop.
LlamaIndex Discord
Retrieval Augmented Generations Right at Our Fingertips: Engineers at Elastic have released a blog post demonstrating the construction of a Retrieval Augmented Generation (RAG) application using Elasticsearch and LlamaIndex, an integration of open tools including @ollama and @MistralAI.
Llama 3 Gets a Handy Cookbook: The LlamaIndex team has provided early support for Llama 3, the latest model from Meta, through a "cookbook" detailing usage from simple prompts to entire RAG pipelines. The guide can be fetched from this Twitter update.
Setting Up Shop Locally with Llama 3: For those looking to run Llama 3 models in a local environment, Ollama has shared a notebook update that includes simple command changes. The update can be applied by altering "llama2" to "llama3" as detailed here.
Puzzle & Dashboards: Pinecone and LLM Daily Struggles: Amidst technical exchanges, there was curiosity about how Google's Vertex AI handles typos in signs like "timbalands", as seen on their demo site, and ongoing dialogues surrounding the creation of an interactive dashboard for generating recipes from input ingredients.
Ready, Set, Track LlamaIndex's Progress: Interest around tracking the development of LlamaIndex spiked among engineers following confirmation that LlamaIndex has secured funding, a nod to the project's growth and anticipated advancements in the space.
DiscoResearch Discord
Mixtral's Multilingual Might: The Mixtral model mix of English and German showcases its language prowess, though evaluations are imminent. Technical challenges, including shape errors and OOM issues, hint at the complexity of training large models, while the efficacy of parameters such as "router_aux_loss_coef" in Mixtral's config remains a point of debate.
Meta's Llama Lightning Strikes: Meta's Llama 3 enters the fray, touting multilingual capabilities but with discernible performance discrepancies in non-English languages. Access to the new tokenizer is anticipated, and critiques focus on downstream usage restrictions of model outputs, sparking a discussion on the confluence of open source and proprietary constraints.
German Language Models Under Microscope: Initial tests suggest Llama3 DiscoLM German lags behind Mixtral in German proficiency, with notable grammar issues and incorrect token handling, despite a Gradio demo availability. Questions regarding the Llama3's dataset alignment and tokenizer configurations arise, and comparisons with Meta's 8B models show performance gaps that beg investigation.
OpenInterpreter Discord
ESP32 Demands WiFi for Linguistic Acumen: An engineer pointed out that ESP32 requires a WiFi connection to integrate with language models, emphasizing the necessity of network connectivity for operational functionality.
Ollama 3's Performance Receives Engineer's Applause: In the guild, there was a buzz about the performance of Ollama 3, with engineers experimenting with the 8b model and probing into enhancements for the text-to-speech (TTS) and speech-to-text (STT) models for accelerated response times.
OpenInterpreter Toolkit Trials and Tribulations: Users shared challenges with OpenInterpreter, ranging from file creation issues using CLI that wraps output with echo to BadRequestError during audio transmission attempts with M5Atom.
Fine-Tuning Local Language Mastery: Guild members discussed how to set up OS mode locally with OpenInterpreter, providing a Colab notebook for guidance and exchanged insights on refining models like Mixtral or LLama with concise datasets for nimble learning.
Exploring Meta_llama3_8b: A member shared a link to Hugging Face where fellow engineers can interact with the Meta_llama3_8b model, indicating a resource for hands-on experimentation and evaluation within the community.
LangChain AI Discord
-
Chain the LangChain: The
RunnableWithMessageHistoryclass in LangChain is designed for handling chat histories, with a key emphasis on always includingsession_idin the invoke config. In-depth examples and unit tests can be found on their GitHub repository. -
RAG Systems Built Easier: LangChain community members are implementing RAG-based systems, with resources like a YouTube playlist on RAG system building and the VaultChat GitHub repository shared for guidance and inspiration.
-
Prompt Engineering Skills Now Online: A prompt engineering course featuring LangChain is now available on LinkedIn Learning, broadening the horizon for those seeking to improve their skills in this area. You can check it out here.
-
Test Drive Llama 3: Llama 3's experimentation phase is open, with a chat interface accessible at Llama 3 Chat and API services available at Llama 3 API, allowing engineers to explore this new AI horizon.
-
Plan with AI: Tripplanner Bot, a new tool built with LangChain, combines free APIs to assist in travel planning. It's an open project available on GitHub for those looking to dive in, contribute, or simply learn from its construction.
Alignment Lab AI Discord
-
Spam Bot Invasion Detected: Multiple channels within the Discord guild, namely
#ai-and-ml-discussion,#programming-help,#looking-for-collabs,#landmark-dev,#landmark-evaluation,#open-orca-community-chat,#leaderboard,#looking-for-workers,#looking-for-work,#join-in,#fasteval-dev, and#qa, have reported the influx of spam promoting NSFW and potentially illegal content involving a recurring Discord invite link (https://discord.gg/rj9aAQVQFX). The messages, possibly from bots or hacked accounts, peddle explicit material and incite community members to join an external server, raising significant concern for violation of Discord’s community guidelines and prompting calls for moderator intervention. -
Open-Sourcing WizardLM-2: The WizardLM-2 language model has been made open source, with references to its release blog, repositories, and academic papers. Curious minds and developers are encouraged to contribute and explore the model further, with resources and discussions available on Hugging Face and arXiv, along with an invitation to their Discord server.
-
Meta Llama 3 Under Privacy Lock: Initiatives to understand and utilize the Meta Llama 3 model involve adhering to privacy agreements as outlined by the Meta Privacy Policy, sparking dialogue around privacy concerns and access protocols. While there's a zeal for exploring the model's tokenizer, the official route requires a detailed check-in at the get-started page of Meta Llama 3, juxtaposed against the community's workaround on access through the Undi95's Hugging Face repository.
-
Post-Hype Model Evaluations: Despite the interferences from unwanted posts, the engineering community remains engrossed in ongoing discussions about evaluating AI models like Meta Llama 3 and WizardLM-2. As moderators resolve disruptions, engineers continue to seek out best practices and share insights on model performance, integration, and scaling challenges.
-
Beware of Discord Invite: With the aforementioned series of spam alerts, it is strongly advised to avoid interacting with the shared Discord link https://discord.gg/rj9aAQVQFX which is tied to all spam messages. Elevated caution is recommended to maintain operational security and protect community integrity.
Mozilla AI Discord
Llama 3 8b Takes the Stage: The llamafile-0.7 update now supports Llama 3 8b models using the -m <model path> parameter, as discussed by richinseattle; however, there's a token issue with the instruct format highlighted alongside a Reddit discussion.
Patch on the Horizon: A pending update to llamafile promises to fix compatibility issues with Llama 3 Instruct, which is detailed in this GitHub pull request.
Quantum Leap in Llama Size: jartine announced the imminent release of a quantized version of llama 8b on Llamafile, indicating advancements for the efficiency-seeking community.
Meta Llama Weights Unbound: jartine shared the Meta Llama 3 8B Instruct executable weights for community testing on Hugging Face, noting that there are a few kinks to work out, including a broken stop token.
Model Mayhem Under Management: Community efforts in testing Llama 3 8b models yielded optimistic results, with a fix for the stop token issue in Llama 3 70b communicated by jartine; minor bugs are to be anticipated.
Skunkworks AI Discord
Databricks Goes GPU: Databricks has released a public preview of model serving, enhancing performance for Large Language Models (LLMs) with zero-config GPU optimization but may increase costs.
Ease of LLM Fine-Tuning: A new guide explains fine-tuning LLMs using LoRA adapters, Flash Attention, and tools like DeepSpeed, available at modal.com, offering strategies for efficient weight adjustments in models.
Affordable Serverless Solutions: An affordable serverless hosting guide using GPUs is available on GitHub, which could potentially lower expenses for developers - check the modal-examples repo.
Mixtral 8x22B Raises the Bar: The Mixtral 8x22B is a new model employing a sparse Mixture-of-Experts, detailed in a YouTube video, setting high standards for AI efficiency and performance.
Introducing Meta Llama 3: Facebook's Llama 3 adds to the roster of cutting-edge LLMs, open-sourced for advancing language technologies, with more information available on Meta AI's blog and a promoting YouTube video.
LLM Perf Enthusiasts AI Discord
-
Curiosity around litellm: A member inquired about the application of litellm within the community, signaling interest in usage patterns or case studies involving this tool.
-
Llama 3 Leads the Charge: Claims have surfaced of Llama 3's superior capability over opus, particularly highlighting its performance in an unnamed arena at a scale of 70b.
-
Style or Substance?: A conversation sparked concerning whether performance discrepancies are a result of stylistic differences or a true variance in intelligence.
-
Warning on Error Bounds: Error bounds became a focal point as a member raised concerns, possibly warning other members to proceed with caution when interpreting data or models.
-
Humor Break with a Tumble: In a lighter moment, a member shared a gif depicting comic relief through an animated fall.
Datasette - LLM (@SimonW) Discord
Karpathy's Llama 3 Lasso: Andrej Karpathy's tweet raised discussions on the potential of compact models, noting an 8B parameter model trained on a 15T dataset as an example of possibly undertraining common LLMs by factors of 100-1000X, pointing engineers towards the notion of longer training cycles for smaller models.
Small Models, Big Expectations: Reactions to Karpathy's insights echo among members who express enthusiasm for the deployment of small yet efficient models like Llama 3, indicating a community ready to embrace optimal resource utilization in developing smaller, mightier LLMs.
Plugin Installation Snags: A member's ModuleNotFoundError while installing a llm plugin led to the revelation that conflicting installations from both brew and pipx might be at the root. A clean reinstall ended the ordeal, hinting at the necessity of vigilant environment management.
Concurrent Confusion Calls for Cleanup: The cross-over installation points from brew and pipx led a user astray, sparking reminders within the community to check which version of a tool is being executed with which llm to dodge similar issues in the future.
LLM Fun Facts: Amidst the technical back-and-forth, a shared use case for llm provided a light-hearted moment, presenting a practical, engaging application of the technology for members to explore.
tinygrad (George Hotz) Discord
- LLama3 Gallops Ahead: LLama3 has been released, boasting versions with both 8B and 70B parameters, broadening the horizons for AI applications.
- Speedy LLama Beats PyTorch: In initial testing, LLama3 demonstrated a slight speed advantage over PyTorch for certain models and showcased seamless compatibility with ROCm on XTX hardware.
AI21 Labs (Jamba) Discord
Long Context Inference Woes with Jamba: A Jamba user is struggling with long context inferences on a 2x A100 cluster and is seeking troubleshooting code for the distributed system's issue. There has been no follow-up discussion or provided solutions to the problem yet.
PART 2: Detailed by-Channel summaries and links
Perplexity AI ▷ #general (1059 messages🔥🔥🔥):
- Refund Requests and Model Usage Concerns: Pro users expressed frustration over the sudden limit to 30 Opus queries per day, down from 600, affecting those who primarily subscribed for Opus usage. There is a desire for a revised refund policy, especially since there was no prior notice given on the query limitation change.
- Animation and Image Modeling Capabilities: Users showed interest in expanding use cases to include animations and images, specifically mentioning DALL-E 3 and Stable Diffusion XL. However, some users faced issues in using these models effectively.
- Model Comparison and Performance: Discussions indicated a comparison between different models, like Llama 3 70b, Claude, and GPT-4, focusing on aspects like coding, table lookups, and multilingual capabilities. The conversation included methods to evade AI content detectors, which are essential for deploying AI-generated work in fields like academia.
- AI Riddle Challenge: A snail riddle puzzle prompted users to test various AI models and assess their reasoning and calculation capabilities. The complexity added to the riddle aimed to challenge AIs beyond commonly known puzzles.
- Language and Context Limitations: Users actively debated English language performance's importance, with the assertion that English's dominance on the web should not be the sole factor in evaluating language models. Awareness of the need for strong multilingual AI capabilities was also a key point. Also discussed were the apparent limitations in context windows for AI responses, affecting the models' effectiveness.
Links mentioned:
Perplexity AI ▷ #sharing (14 messages🔥):
- Exploring Fake Actors in AI: A link was shared to Perplexity AI's search results discussing actors and fake elements within AI contexts.
- Diving into AI History: A member posted a link that leads to Perplexity AI's search results on the historical aspects of AI.
- Unveiling the 'Limitless AI Pendant': Curiosity arises with a shared Perplexity link referencing a 'Limitless AI pendant'.
- Insights on Mistral's Growth: The community showed interest in Mistral's progress through a shared Perplexity search link regarding Mistral fundraising.
- Understanding HDMI Utilization: Members may find answers to why HDMI is used with a link to Perplexity AI's search on the topic.
Links mentioned:
Perplexity AI ▷ #pplx-api (11 messages🔥):
-
Mixtral Model Decodes Cohen's Lyrical Enigma: Mixtral-8x22B provided the most accurate interpretation of Leonard Cohen's "Avalanche," identifying the artist and song from the lyrics alone. The model interpreted themes of vulnerability, power, and evolving human relationships in its analysis.
-
API Queries Can Indeed Be Fun: A member confirmed that the Perplexity AI chat models can be used with the provided API endpoint, after clarifying the details including parameter count and context length for various models like Mistral, Sonar, Llama, and CodeLlama.
-
Embedding Models on Perplexity AI: It was shared that Llama-3 instruct models (8b and 70b) are accessible for chatting on labs.perplexity.ai and also available via pplx-api, with a mention of Pro users receiving monthly API credits.
-
Real-Time Delight with New AI Models: A community member expressed enthusiasm for the new models, stating they have significantly improved their application, despite not having access to the Claude Opus API.
-
Precision in API Responses Sought: A user sought assistance on how to limit API responses to an exact list of words when attempting to categorize items from a JSON file, mentioning trials with Sonar Medium Chat and Mistral without success.
-
Monitoring API Credits: A question was raised regarding the frequency of updates to remaining API credits, inquiring whether the refresh rate is in minutes, seconds, or hours after running a script that makes API requests.
-
Help Wanted for CORS Dilemma: A user requested examples or advice on resolving CORS issues when using the API in a frontend application, including setting up a proxy server as a potential solution.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #general (1147 messages🔥🔥🔥):
- Llama 3 Buzz: The recent release of Meta's Llama 3 has got the AI community excited, with discussions around its tokenizer benefits and the anticipation of a 400B model. The model is compared to OpenAI’s GPT-4, and users debate Llama 3’s performance on various benchmarks.
- Unsloth Readies for Llama 3: The AI tool, Unsloth, has quickly updated its support for the new Llama 3 within hours of its release. Meanwhile, users seek advice for fine-tuning Llama 3 and discuss the VRAM requirements for training on different GPU configurations.
- Issues with Llama 3's Tokenizer: A hiccup is found in Llama 3’s tokenizer, with some unintended behavior that raised comments from the community. The team at Unsloth notifies that they are aware of the issues and are working on fixes.
- Benchmarking and Model Size Discussions: There is an ongoing conversation about how Llama 3's size impacts its performance and the need for more extensive benchmarks to fully assess capacities. A pre-release is suggested to gather user feedback and further optimize the model.
- VRAM Usage for Model Training: Users exchange insights on VRAM usage for fine-tuning language models. Specific attention is given to the efficiency of using Unsloth for training models like Llama 3 8B using Quantum LoRa (QLoRA), with reports of VRAM usage with and without quantization.
Links mentioned:
We're upgrading Meta AI with our new state-of-the-art Llama 3 AI model, which we're open sourcing. With this new model, we believe Meta AI is now the most intelligent AI assistant that you can freely use.
We're making Meta AI easier to use by integrating it into the search boxes at the top of WhatsApp, Instagram, Facebook, and Messenger. We also built a website, meta.ai, for you to use on web.
We also built some unique creation features, like the ability to animate photos. Meta AI now generates high quality images so fast that it creates and updates them in real-time as you're typing. It'll also generate a playback video of your creation process.
Enjoy Meta AI and you can follow our new @meta.ai IG for more updates.": 157K likes, 9,028 comments - zuckApril 18, 2024 on : "Big AI news today. We're releasing the new version of Meta AI, our assistant that you can ask any question across our apps and glasses....Fail to load a tokenizer (CroissantLLM) · Issue #330 · unslothai/unsloth: Trying to run the colab using a small model: from unsloth import FastLanguageModel import torch max_seq_length = 2048 # Gemma sadly only supports max 8192 for now dtype = None # None for auto detec...Mark Zuckerberg - Llama 3, $10B Models, Caesar Augustus, & 1 GW Datacenters: Zuck on:- Llama 3- open sourcing towards AGI - custom silicon, synthetic data, & energy constraints on scaling- Caesar Augustus, intelligence explosion, biow...[Usage]: Llama 3 8B Instruct Inference · Issue #4180 · vllm-project/vllm: Your current environment Using the latest version of vLLM on 2 L4 GPUs. How would you like to use vllm I was trying to utilize vLLM to deploy meta-llama/Meta-Llama-3-8B-Instruct model and use OpenA...HuggingChat: Making the community's best AI chat models available to everyone.‘Her’ AI, Almost Here? Llama 3, Vasa-1, and Altman ‘Plugging Into Everything You Want To Do’: Llama 3, Vasa-1, and a host of new interviews and updates, AI news comes a bit like London buses. I’ll spend a couple minutes covering the last-minute Llama ...no title found: no description foundAdaptive Text Watermark for Large Language Models: no description foundGoogle Colaboratory: no description foundTweet from Andrej Karpathy (@karpathy): Congrats to @AIatMeta on Llama 3 release!! 🎉 https://ai.meta.com/blog/meta-llama-3/ Notes: Releasing 8B and 70B (both base and finetuned) models, strong-performing in their model class (but we'l...LLAMA-3 🦙: EASIET WAY To FINE-TUNE ON YOUR DATA 🙌: Learn how to fine-tune the latest llama3 on your own data with Unsloth. 🦾 Discord: https://discord.com/invite/t4eYQRUcXB☕ Buy me a Coffee: https://ko-fi.com...How to Fine Tune Llama 3 for Better Instruction Following?: 🚀 In today's video, I'm thrilled to guide you through the intricate process of fine-tuning the LLaMA 3 model for optimal instruction following! From setting...meta-llama/Meta-Llama-3-8B-Instruct · Fix chat template to add generation prompt only if the option is selected: no description found
Unsloth AI (Daniel Han) ▷ #announcements (1 messages):
-
Llama 3 Hits the Ground Running: Unsloth AI introduces Llama 3, promising double the training speed and a 60% reduction in memory usage. Details can be found in the GitHub Release.
-
Freely Accessible Llama Notebooks: Users can now access free notebooks to work with Llama 3 on Colab and Kaggle, where support for the Llama 3 70B model is also available.
-
Innovating with 4-bit Models: Unsloth has launched 4-bit models of Llama-3 to improve efficiency, available for both 8B and 70B versions. For more models, including the Instruct series, visit their Hugging Face page.
-
Experimentation Encouraged by Unsloth: The team is eager to see the community share, test, and discuss outcomes using Unsloth AI's models.
Link mentioned: Google Colaboratory: no description found
Unsloth AI (Daniel Han) ▷ #random (6 messages):
- HuggingFace's Inference API for LLAMA 3 is MIA: One member pointed out that HuggingFace has not yet opened the Inference API for LLAMA 3.
- LLAMA's Training Devours Compute: Another member humorously commented on the lack of compute by saying, No compute left after training the model followed by a skull emoji.
- LLAMA's Token Training Trove: In a brief exchange, members clarified the size of the training token set for LLAMA, settling on 15T tokens.
- AI Paparazzi Alert: A member shared a YouTube video discussing recent updates in AI, including LLAMA 3, with the whimsical introduction, "I am a paparaaaaazi!" accompanied by mind-blown and laughing emojis.
Link mentioned: ‘Her’ AI, Almost Here? Llama 3, Vasa-1, and Altman ‘Plugging Into Everything You Want To Do’: Llama 3, Vasa-1, and a host of new interviews and updates, AI news comes a bit like London buses. I’ll spend a couple minutes covering the last-minute Llama ...
Unsloth AI (Daniel Han) ▷ #help (341 messages🔥🔥):
-
Model Saving and Loading Quandaries: A member experimented with fine-tuning a model, but encountered issues when trying to save in 16-bit for vllm without the necessary code in their training script. They debated a workaround involving saving the model from the latest checkpoint after reinitializing training, attempting to resolve size mismatch errors when loading state dictionaries due to token discrepancies.
-
LLAMA3 Release and Inference Woes: As the team braced for the LLAMA3 release, other members struggled with utilizing the AI, with one member solving a size mismatch error by saving over from the checkpoint again and confirming the support of rank stabilization in high rank LoRAs. Another member grappled with inference problems, encountering an unanticipated termination after supposedly completing all steps in a single iteration.
-
Tokenization Tribulations Across Unsloth: Issues with tokenization within Unsloth arose persistently, specifically errors related to missing
add_bos_tokenattributes in tokenizer objects and confusion over the necessity of saving tokenizers post-training to retain special tokens. -
Technical Difficulties and Environment Troubleshooting: Users detailed various technical setbacks including pipeline issues, JSON decoding errors, and the ill effects of relying on
pipinstead ofcondafor installations in their environments. Questions also surfaced about fine-tuning applications of Llama3, such as for non-English wikis and function calling. -
Practical Guidance and Community Support: Community members actively assisted each other by confirming setting details for training arguments, suggesting remedies for memory crashes on Colab, and discussing dataset structures for chatML. As members exchanged solutions, they displayed a commitment to confronting and overcoming current limitations, whether in finetuning models, preparing datasets, or navigating installation hitches.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #showcase (4 messages):
- Mixtral and Mistral Make Waves: Mistral.ai released a torrent for Mixtral 8x22B, an opposite-of-understated MoE model that follows the release of Mixtral 8x7B, boasting increased hidden dimensions to 6144 in line with DBRX. The team continues its endeavors without much fanfare.
- Neural Llama Appears on Hugging Face: Neural Llama 3 has made its way to Hugging Face, trained using Unsloth and showcased alongside the likes of tatsu-lab's alpaca model. Members have acknowledged the presence of this new model with enthusiasm.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #suggestions (3 messages):
- ReFT Method Sparks Interest: A member mentioned the new ReFT (Reinforced Fine-Tuning) method and enquired about its potential integration into Unsloth. This technique could make it easier for newcomers to engage with the platform.
- Unsloth Team Takes Note: Another member responded with interest in exploring the ReFT method further, indicating that the team will consider its implementation within Unsloth.
- Community Echoes Integration Request: A community member added their voice, appreciating that the question about the integration of the ReFT method into Unsloth was raised and is being considered by the team.
LM Studio ▷ #💬-general (661 messages🔥🔥🔥):
-
Llama 3 is the Hot AI on the Block: Users are discussing the performance of the newly-released Llama 3 model from Meta, particularly its 8B version. They suggest it is on par with other 70B models like StableBeluga and Airoboros, with responses feeling genuinely human-like.
-
GPU Woes and Server Interactions: Some users report issues with Llama 3 models spouting nonsensical outputs when GPU acceleration is enabled on Mac M1 systems, while others share how they can successfully run models on older hardware. There's also interest in learning whether LM Studio's server supports KV caches to avoid recomputing long contexts for each conversation.
-
Models and Quants Details: There are mentions of model quantization versions such as K_S and Q4_K_M causing issues in LM Studio, with some suggesting versions from other providers like Quantfactory work better. NousResearch's 70B instruction model is recommended, and there's speculation about updates to GGUFs improving model behavior.
-
Model Integration and Accessibility: Inquiries about integrating with other tools, embedding documents, and the ability to run on a headless server are brought up, with suggestions to use alternatives like llama.cpp for headless server deployment, and existing third-party tools like llama index for document proxy capabilities.
-
Fine-Tuning and Un-Censoring Discussions: Users are eager for uncensored versions of models, with suggestions to modify system prompts to coax more "human-like" behavior and circumvent restrictions. Some are also excited about the potential for the community to further improve and fine-tune Llama 3 going forward.
Links mentioned:
LM Studio ▷ #🤖-models-discussion-chat (617 messages🔥🔥🔥):
-
Llama 3 Buzz and Infinite Loops: Users are exploring the capabilities of Llama 3 models, particularly the 70B and 8B versions. Some are encountering issues with infinite response loops from the model, often involving the model improperly using the word "assistant."
-
Download and Runtime Concerns: Queries around whether various Llama 3 quants can run on specific hardware configurations are prevalent. Users are looking for models, especially ones that could efficiently operate on M3 Max with 128GB RAM or NVIDIA 3090.
-
Comparisons between Llama 3 and Other Models: Some are comparing Llama 3 to previous Llama 2 models and other AI models like Command R Plus. Reports indicate a similar or improved performance, though some users have language-specific concerns.
-
Prompt Template Confusions and EOT Token Issues: Users are seeking advice on the correct prompt settings for Llama 3 models to prevent unwanted loops and interactions in the responses. It appears version 0.2.20 of LM Studio is necessary along with specific community quants.
-
Announcement of Llama 3 70B Instruct by Meta: A version of Llama 3 70B Instruct is announced to be coming soon, and others like IQ1_M are highlighted for their impressive coherence and size efficiency, fitting large models into relatively small VRAM capacities.
Links mentioned:
LM Studio ▷ #announcements (1 messages):
- Introducing Llama 3 in LM Studio 0.2.20: LM Studio announces support for MetaAI's Llama 3 in the latest update, LM Studio 0.2.20, which can be accessed at lmstudio.ai or through an auto-update by restarting the app. The important caveat is that only Llama 3 GGUFs from "lmstudio-community" will function at this time.
- Community Model Spotlight - Llama 3 8B: The community model Llama 3 8B Instruct by Meta, quantized by bartowski, is highlighted, offering a small, fast, and instruction-tuned AI model. The original model can be found at Meta-Llama-3-8B-Instruct, and the GGUF version at lmstudio-community/Meta-Llama-3-8B-Instruct-GGUF.
- Exclusive Compatibility Note: Users are informed of a subtle issue in GGUF creation, which has been circumvented in these quantizations; as a result, they should not expect other Llama 3 GGUFs to work with the current LM Studio version.
- LLama 3 8B Availability and 70B on the Horizon: Llama 3 8B Instruct GGUF is now available for use, and the 70B version is hinted to be incoming. Users are encouraged to report bugs in the specified Discord channel.
Links mentioned:
LM Studio ▷ #🧠-feedback (5 messages):
- Thumbs-Up for Improved Model Sorting: A user has commended the new model sorting feature on the download page, appreciating the improved functionality.
- A Call for Text-to-Speech (TTS) in LM Studio: There has been a query regarding the future possibility of integrating text-to-speech (TTS) into LM Studio to alleviate the need to read text all day.
- Perplexed by Persistent Bugs: One user has reported a recurring bug where closing the last chat after loading a new model results in the need to reload, and the system does not retain the chosen preset.
- Suggestion for Tools to Tackle Text-to-Speech: In response to a query about TTS integration, a user suggested that system tools might offer a solution.
- Feedback on Error Display Design: A user has expressed frustration with the error display window in LM Studio, criticizing it for being narrow and non-resizable, and suggesting a design that is taller to better accommodate the vertical content.
LM Studio ▷ #📝-prompts-discussion-chat (4 messages):
- Mixtral Resume Rating Confusion: A member mentioned struggling to use Mixtral for rating resumes according to their criteria, whereas using Chat GPT for the same task presented no issues.
- Two-Step Solution Proposed: In response, another member suggested a two-step approach for handling resumes with Mixtral: one step to identify and extract relevant elements, and another to grade them.
- Alternative CSV Grading Method: It was also proposed to convert the resumes into a CSV format and use an Excel formula to handle the grading.
LM Studio ▷ #🎛-hardware-discussion (16 messages🔥):
- Gaming GPUs for AI: The 1080TI was mentioned for its adequate performance in processing large AI models, leveraging its power as needed.
- Joking on Crypto's New Frontier: There was a humorous remark about old cryptocurrency mining chassis potentially being repurposed as AI rigs.
- A Question of Space: One member expressed concern about fitting a new GPU in their case, highlighting the benefit of an additional 6GB of VRAM.
- Hardware Flex for Hardcore Tasks: A member listed their powerful hardware setup, including a 12900k/4090/128gb PC and a 128gb M3 Max Mac, capable of running virtually any AI models.
- AI as a Hobby Over Profession: The discussion touched on engaging in AI for fun, with a member using their 4090 PC for Gaming and Stable Diffusion rather than professional purposes.
LM Studio ▷ #🧪-beta-releases-chat (5 messages):
-
Speedy Chatbot Settings: A member shared their configuration for running a model with
n_ctxset at either 16384 or 32768 and a starting speed of 4tok/sec. They mentioned experimenting withn_threadssettings, raising them from the default 4 to 11 to see if it impacts performance. -
LLaMa Template Tease: In response to a brief mention of a LLaMa 3 chat template JSON, another member pointed out a link that requires some attention at the moment but didn't provide further details.
-
Smart Git Cloning to Avoid Double-Bloat: A member offered a useful tip on how to clone a model using Git without unnecessary file duplication by using
GIT_LFS_SKIP_SMUDGE=1before cloning and selectively pulling large files afterwards. They suggest this method can save space by preventing large files from being stored in both the.gitdirectory and the checked-out directory. -
Single File Focus for Git LFS: The same member noted that while their method is more useful in unquantized contexts, there's a nuance: the
--includeflag in thegit lfs pullcommand only works for one file at a time. They also provided an example bash loop to pull multiple files individually.
Link mentioned: lmstudio-community/Meta-Llama-3-8B-Instruct-GGUF · Hugging Face: no description found
LM Studio ▷ #autogen (7 messages):
- Prompt Studio Innovation in v1.1.0: A new feature called the "prompt studio" has been introduced, allowing users to fine-tune their prompts and save them to their agent's configuration.
- Electron App with Modern Frameworks: The application is an Electron app, built using Vue 3 and TypeScript.
- Privacy Concern Addressed: A member voiced discomfort with running an app without visibility into the code, while another assured that the risks are minimal, equating it to the same risk as using any mainstream website like Chrome.
LM Studio ▷ #rivet (1 messages):
- POST Request Repetition Confusion: A user attempting their first run noticed repetition in the server logs, specifically with POST requests following the message "Processing queued request...", and questioned if this behavior is normal.
LM Studio ▷ #avx-beta (2 messages):
-
LLamaFile Versatility Highlighted: A member mentioned llamafile's compatibility with various platforms including x64, arm64, and most Linux distributions, suggesting its feasibility to run on Raspberry Pi devices. The flexibility of running on diverse systems was contrasted with LM Studio's AVX2 requirement.
-
A Call for Backward Compatibility: The user expressed a desire for LM Studio to introduce a compatibility layer that would allow older CPUs to run the software, albeit slower, highlighting the limitation posed by the current AVX2 requirement. It was noted that the "LM-Studio-0.2.10-Setup-avx-beta-4.exe" version is outdated but previously ran well on multiple computers.
-
Challenges with Keeping AVX Beta Updated: The member voiced concerns about the AVX beta's update frequency and how it may lag behind the main channel build, wishing for more synchronization to ensure users with older CPUs can benefit from updates. There's a recognition of the significant updates and accessibility improvements in LM Studio, alongside a personal account of attempting to build their own setup without yet overcoming the learning curve.
LM Studio ▷ #amd-rocm-tech-preview (25 messages🔥):
- GPU Compatibility Questioned: A member claimed that their 5700xt worked with LM Studio, albeit slowly, but was quickly corrected by another who stated that there is no HIP SDK support from AMD for that card, suggesting that the performance issue might be due to the reliance on CPU for inference.
- 8B Models Exhibit Quirks on AMD: Users have reported issues with running the 8B model, with one stating it began "talking to itself" which could suggest it's not fully supported on AMD hardware yet.
- Inquiry About AMD Ryzen with Radeon: A user questioned the benefit of running version 0.2.19 with AMD ROCm on an AMD Ryzen 7 PRO 7840U with Radeon 780M, to which the response indicated that the hardware was unsupported.
- Llama 3 Embraced by LM Studio on ROCm: Llama 3 is now available on LM Studio ROCm Preview 0.2.20. This news was accompanied by information about model creators and a link to download compatible GGUFs from huggingface.co/lmstudio-community/Meta-Llama-3-8B-Instruct-GGUF.
- Potential for Expanded AMD Support: One user suggested that with some tinkering, such as faking the target to gfx1100, AMD ROCm might support other hardware like the Radeon 780M/gfx1103, hinting at a larger potential hardware support base for LM Studio endeavors.
Links mentioned:
LM Studio ▷ #model-announcements (1 messages):
-
Llama 3 70B Instruct Bows into Open Source Arena: The first quants of Llama 3 70B Instruct are now available, signifying a major step in open source AI with a performance on par with GPT-3.5. These models are optimized for use with the latest LM Studio, featuring a Llama 3 prompt and avoiding endless generation.
-
Efficient Performance with IQ Models: The IQ1_M and IQ2_XS models, both built using the importance matrix, provide reasonable performance while being memory efficient, requiring less than 20GB of VRAM for the IQ1_M variant.
-
Try Out Llama 3 70B Today: Users are encouraged to explore the capabilities of the new Llama 3 70B Instruct models. The models are accessible through Hugging Face.
Nous Research AI ▷ #ctx-length-research (2 messages):
- Seeking Guidance on Multi-GPU Long Context Inference: A member expressed challenges with using multiple GPUs for long context inference of Jamba. They have already checked the deepspeed and accelerate documentation but found no information regarding long context generation.
Nous Research AI ▷ #off-topic (18 messages🔥):
- Help Needed for TheBloke's Discord: Users sought assistance with accessing TheBloke Discord server due to an inactive Twitter link. A temporary solution was provided, and a new Discord invite link was shared:
https://discord.gg/dPfXbRnQ. - Mixtral Sets a New Standard: A YouTube video was shared, titled "Mixtral 8x22B Best Open model by Mistral", touting Mixtral 8x22B as the latest open model defining new performance and efficiency standards.
- Curiosity About AI-Powered Projects: A member inquired about projects like opendevin that utilize large language models (LLMs) for building applications.
- Nous Possibly Brewing Merchandise: A fun exchange sparked curiosity about Nous merchandise, drawing a parallel to EAI's absence of official merch.
- Introducing Meta's LLM: Another YouTube video link was shared titled "Introducing Llama 3 Best Open Source Large Language Model", presenting Meta's Llama 3 as an advanced open-source large language model.
Links mentioned:
Nous Research AI ▷ #interesting-links (33 messages🔥):
-
Pickling Large Docs for OpenAI: Users in the chat discussed the use of insecure pickle files in OpenAI's code environment as a workaround for importing large documents which the environment typically rejects. One user pointed out the potential risk of such practices, referencing an incident where someone used a pickle to compromise Hugging Face's system.
-
Critical GPTs Fallibility Exposed: The debate around insecure pickle files highlighted concerns about the robustness of GPT models, with users joking about the risk of AI becoming adversarial and conflating this with conspiracies and sci-fi plots for the downfall of humanity.
-
The AI Index 2023 Report Overview: The AI Index Report for 2023 released by Stanford's HAI provides extensive data on the year's AI trends, including a significant increase in the release of open-source foundation models, advancements in multimodal AI, and shifts in global AI perspectives.
-
Insights from Language and LLM Discussions: A member shared a link to a YouTube video featuring Edward Gibson discussing human language and grammar in relation to large language models, providing learnings useful for model design and interaction.
-
Emerging Research in Weight-Decomposed Adaptation: A GitHub repository DoRA by NVlabs was shared, which is dedicated to the Official PyTorch implementation of weight-decomposed low-rank adaptation, showcasing ongoing development and research in AI model efficiency.
Links mentioned:
Nous Research AI ▷ #general (807 messages🔥🔥🔥):
-
Llama 3 Excitement and Validation: Users are exploring and validating Llama 3's performance across various benchmarks and functionalities, reporting high satisfaction. Llama 3 is highly praised for its humanlike style, although there's ongoing discussion regarding its benchmark performance relative to other models such as Mistral.
-
Practical Implications of 8k Context Limit: Some users raised concerns over Llama 3’s 8k token context limit, noting it may not suffice for certain multi-turn interactions. Larger context capabilities, like those offered by Mistral, are still necessary for some practical use-cases.
-
Chat Templates and Generation Issues: Users are sharing fixes and updated chat templates for Llama 3, addressing generation issues where models would continue generating text endlessly. Fixed templates are being exchanged and tested within the community.
-
GGUF Transformations for Llama 3: There’s active sharing and creation of GGUF quantized models for both Llama 3 8b and 70b versions, with community contributions on platforms like Hugging Face and LM Studio. Quants are being evaluated for efficiency and accuracy.
-
License and Model Restrictions Discussed: Users discussed the licensing terms of Llama 3 which contain more restrictions compared to Mistral’s Apache 2.0. Restrictions include prohibitions on NSFW content and discussions prompting considerations on how such rules reflect on practical uses involving complex or mature themes.
Links mentioned:
Nous Research AI ▷ #rules (1 messages):
- New Reporting Command Introduced: Users have been informed that they can report spammers, scammers, and other violators by using the
/reportcommand followed by the offender's role. Upon reporting, a moderator will be notified and will review the incident.
Nous Research AI ▷ #ask-about-llms (12 messages🔥):
-
AI Chatbots Get Smarter with "directly_answer" Tool: An implementation of the "directly_answer" tool has been shared, showing how it can be used within an AgentExecutor chain to provide grounded responses to user interactions. The example demonstrates the tool facilitating a chatbot to reply to a simple greeting with a pleasant response.
-
Hunting for Hermes Prompting Formats: A member is seeking effective prompting formats for the model NousResearch/Hermes-2-Pro-Mistral-7B for error correction tasks and welcomes links or resources that could help improve outputs.
-
Eager Anticipation for Llama-3-Hermes-Pro: A succinct query was raised about the release schedule for llama-3-Hermes-Pro, though no further details were provided.
-
Axolotl Multitasking Capabilities Questioned: A question was posed whether axolotl supports training multiple models simultaneously on a setup with adequate VRAM.
-
Juggling Jamba on a GPU Cluster: There is a discussion about the challenges of performing long context inferences on GPU clusters and specifically optimizing the use of dual A100s for running jamba through a workload of 200k tokens. It was also mentioned that support for jamba is in development on the vLLM project as seen in a GitHub pull request.
Link mentioned: [Model] Jamba support by mzusman · Pull Request #4115 · vllm-project/vllm: Add Jamba support to vLLM, This PR comprises two parts: the Jamba modeling file and the Mamba memory handling. Since Jamba is a hybrid model (which alternates between mamba and transformer layers),...
Nous Research AI ▷ #project-obsidian (1 messages):
- VLM on Raspberries for Education: A participant mentioned plans to deploy VLM (Vision Language Models) on Raspberry Pis as part of a school project, acknowledging the usefulness of resources shared in the community. The aim is to explore educational applications and potentially derive benefits from this setup.
Nous Research AI ▷ #rag-dataset (24 messages🔥):
- Open Source Models Require Tailoring: There is consensus that while GPT4v is robust, most open-source models necessitate finetuning for specific tasks. General knowledge around engineering diagrams may be adequate, but issues arise when scaling to more complex operations.
- Search Optimization via Metadata Extraction: For improved search functionality, metadata extraction using OCR and high-level descriptions via vision models are deemed effective. There's active discussion around the ideal approach to retrieving the top k results, with concerns about overlap and quality.
- Curse of Dimensionality in Data: The curse of dimensionality was highlighted, pointing to a Wikipedia article, and its impact on retrieval accuracy and scaling is acknowledged, especially in high-dimensional data analysis.
- Exploring Data Type Transformation: A member shared their work with Opus on data type transformation, providing a GitHub link to their notes discussing this concept without categorical theory.
- RAG Database Structuring Observations: The effectiveness of creating a single large RAG database versus multiple specific databases was explored. It was suggested that large databases might introduce incorrect context, impacting performance negatively compared to targeted databases selected through SQL-like queries.
Links mentioned:
Nous Research AI ▷ #world-sim (446 messages🔥🔥🔥):
-
World-sim Anticipation and Impatience: Members are expressing heightened anticipation and some frustration about the repeatedly delayed relaunch of world-sim. They are eager to see the new features and discuss the potential release times, with some particularly worried about forgetting the site during the lengthy wait.
-
Generative AI and World-sim Potential: Discussions revolve around the potentials of combining World-sim with generative AI like Llama 3 and Meta.ai to create rich narrative experiences. Members are sharing their detailed alternate histories and fantasizing about AI integration that would further animate their simulated universes.
-
Desideradic AI & Philosophical Musings: Users are discussing the philosophical implications and potential narratives arising from Desideradic AI and related concepts, exchanging ideas about how this could influence AI-driven stories and character creation.
-
Animating World-sim Inspired Stories: Users are sharing and discussing their World-sim inspired animations and content, with some members providing informational resources like tutorials and links to their work.
-
Prometheus & Jailbroken Characters in AI Conversations: A member explains their interactive experience with a personality named "Whipporwhill" and an AI named Prometheus, underscoring the possibility of jailbreaking to create unique character dynamics within AI conversations.
Links mentioned:
CUDA MODE ▷ #general (28 messages🔥):
-
Matrix Tiling Conundrum: Discussion took place on the efficiency and feasibility of tiling matrix multiplication, especially with odd-sized (prime) matrices like 7x7. A member suggested padding to a square number or using special code for boundaries as a solution for maintaining efficiency with both large and small matrices.
-
Strategic Tiling Tactics: It was mentioned that optimal matrix handling may involve tiling the major part, like a 6x6 from a 7x7 matrix, and treating any partial tiles as special edge cases.
-
Meta Introduces Llama 3: An outside YouTube video link was posted with a brief description about Mark Zuckerberg discussing Llama 3, a 405b dense model, custom silicon, and other developments by Meta.
-
Spotlight on New Model Capabilities: A member discussed experimenting with new Llama models, mentioning an 8k context and a TikToken tokenizer, stating that these updates maintain a familiar Llama architecture for ease of integration.
-
Cosmic Rays and Hardware Failures: In response to a query about Colab sessions crashing during training, one commenter humorously hypothesized hardware failures or even cosmic rays as potential causes.
Links mentioned:
CUDA MODE ▷ #cuda (30 messages🔥):
-
FP16 Matmul Errors Probed: Members discussed the distribution of matmul error, noting that rand()*20 simulations can heavily influence fp16 accumulate errors. It was mentioned that compared to a typical fp16 accumulate matmul,
simt_hgemvhas significantly better error handling. -
Block Size Issues in Error Analysis: There's speculation that block size might impact the matmul error, highlighted by the observation of exact zero errors in certain calculations, suggesting a deeper investigation into the implementation may be needed.
-
Quantized Math in the Spotlight: A member planned to add dequantization on top of the gemv operation, despite quantized matmuls showing a very high absolute difference in errors; this highlights the resilience of LLMs to such discrepancies.
-
Sequential vs Offset Memory Access: In a discussion about the impact of memory access patterns on computations, it was mentioned that sequential memory access tends to be faster than offset memory access, which can potentially double the computation time when unavoidable offsets are involved.
-
Vectorization Technique Tactics: With the limitations of vectorized bit operations for integers, the participants felt fortunate to have vectorized operations for half precision like
__hfma2,__hmul2, and__hadd2, though such operations are limited.
CUDA MODE ▷ #torch (8 messages🔥):
- Seeking Compatibility with
torch.compile: A user asked for best practices in making custom functions fully compatible withtorch.compile, noting that some custom CUDA or Triton modules are not working as expected and errors are unhelpful. - Custom CUDA Kernel Guidance: It was suggested to review an example (Custom CUDA extensions) that might offer insights on composing custom kernels with
torch.compile. Further assistance might be found in a broader document discussing C++ Custom Operators. - Troubleshooting Custom Kernel Issues: The need for support with FakeTensor/Meta-dispatch for kernel development was acknowledged, pointing towards the same C++ Custom Operators manual as a potential aid in solving related issues.
- Useful Resource for Triton Kernel Development: A user recommended checking out the GitHub - openai/triton repository for tips on Triton language and compiler, which might help resolve compatibility problems.
- Documentation to Resolve Kernel Compatibility Issues: A user promised that the issues should be solved by the aforementioned documentation on custom kernels and to reach out if problems persist.
Links mentioned:
CUDA MODE ▷ #beginner (14 messages🔥):
- CUDA Learning Prerequisites Questioned: A member inquired about the prerequisites for learning CUDA with a background in CS focusing on Android, web, deep learning, and mathematics. Another member suggested that some knowledge of C/C++ is needed and access to a CUDA-capable machine would be helpful.
- CUDA Studies Can Begin Without Hardware: It was recommended to learn CUDA first before investing in hardware, and to consider potential applications of CUDA in one’s projects before making purchasing decisions.
- CUDA Learning Resources Shared: A YouTube playlist, "Livestream - Programming Heterogeneous Computing Systems with GPUs and other Accelerators (Spring 2023)", was shared as a learning resource, which might be challenging for beginners.
- Alternative CUDA Guide Available: For a more beginner-friendly resource, a CUDA guide was shared, which is hosted on GitHub and might be easier to follow for newcomers.
- Experienced in PyTorch, Seeking to Learn CUDA: A member mentioned the need to use CUDA for building deep learning models with prior years of experience in PyTorch, showing a transition from high-level deep learning frameworks to learning lower-level GPU computing.
Links mentioned:
CUDA MODE ▷ #pmpp-book (4 messages):
- Comparing Answers on CUDA Exercise: A member shared their solution for Chapter 6, Exercise 4.c with a result of 12.8 OP/byte and provided a screenshot for a step-by-step explanation.
- Members Syncing Up on Progress: Another participant mentioned they are currently working on Chapter 5 and expect to reach Chapter 6 soon due to having more flexibility in their schedule this week.
- Seeking Clarification on Tiling Benefit: A query was raised about the benefits of tiling, referencing Figure 5.9, lines 19 and 20, and questioning how tiling is beneficial if global memory calls are made regardless of data being in shared memory.
CUDA MODE ▷ #hqq (81 messages🔥🔥):
-
Exploring Group-Size Implications for GPTQ and int4wo: A discussion unfolded regarding how GPTQ and int4wo handle non-divisible group sizes in matrix operations. With GPTQ effectively treating dimensions as if they were divisible by group sizes, excess is ignored, while int4wo requires padding for non-divisible dimensions.
-
Jeff Johnson on tinygemm Row Wise Grouping: Jeff Johnson, the writer of tinygemm, explains that tinygemm uses row-wise grouping due to all presented matrices having the reduction dimension as the innermost, which is common across grouped quantization schemes. However, an alternate method using axis=1 was found slower due to increased zero/scale access.
-
Quantization and Concatenation Concerns for Model Weights: The compatibility of axis=0 grouping in tinygemm with QKV weight concatenation was questioned, as quantizing the combined weight would potentially mix channels of weight matrices.
-
CUDA Dequant Kernels Update: The discussion mentioned the optimization of CUDA dequant kernels for 4-bit operations, which could be especially beneficial for training quantized models on GPUs with limited capability.
-
Integrating HQQ into torchao: There was a dialogue about potentially integrating Half-Quadratic Quantization (HQQ) into torchao, addressing concerns about dependencies and suggesting alternatives like copying relevant code. The concept of a unique 4-bit quantization kernel, which utilizes lookup tables instead of scale and zero_point, was proposed and debated for efficiency and practicality in implementation.
Links mentioned:
CUDA MODE ▷ #llmdotc (552 messages🔥🔥🔥):
-
CUDA Profiling and Optimization Discussions: Members have been optimizing CUDA code for GPU efficiency using NVIDIA Nsight Compute. After much refinement, including loop reorganizations and eliminating redundant calculations, a significant speedup was achieved, bringing the CUDA model training loop down from 960ms to 250ms on an A4000 GPU, and to 77ms for a full training iteration, surpassing PyTorch's timing.
-
CUDA vs. PyTorch Performance: They discovered that after further optimizations and integration of the fused classifier kernel, performance exceeded PyTorch's metrics in certain tests, making PyTorch now the new target to beat.
-
Fused Classifier Improvements: Implementing a non
float4version of the classifier kernel in CUDA reduced the number of expensive CUDA calls, while the removal of manual softmax computation gained additional speedup despite being initially slower than thefloat4version. -
Efficiency in CUDA Kernels: Discussions highlight how integer divisions can be a significant performance hit in CUDA kernels. By passing pre-computed values from the CPU side, they achieved a 25% reduction in instructions and a 1% speedup of the kernel, despite overall time being constrained by waiting on data.
-
Multi-GPU Considerations: Conversations touched on potential approaches to multi-GPU training, preferring data parallelism (DDP) over model parallelism, starting with a single allReduce call for within-node GPU communication and possibly progressing to libraries like MPI or NCCL.
Links mentioned:
CUDA MODE ▷ #massively-parallel-crew (10 messages🔥):
- Panel vs CUDA Mode Clash: A panelist realized they're double-booked during the upcoming CUDA Mode event and is asking the community to handle the recording responsibilities for this particular session.
- Event Permissions Delegated: Specific permissions have been set to allow certain members to create/edit events and mute people on stages for the smooth running of future events.
- Recording Setup Discussions: Concerns were raised regarding the recording setup for the upcoming event due to potential memory issues on an older iPad, prompting a discussion on alternative recording solutions.
- Proposed Recording Workflow: Members discussed a proposed recording workflow involving native MacOS screen recording, a service called BlackHole for audio, and potential post-production editing if presenters can also record locally.
- EventType Update: A new talk is announced for April 26, indicating there will be two events in the same week to accommodate the additional content.
OpenAccess AI Collective (axolotl) ▷ #general (489 messages🔥🔥🔥):
-
Llama 3 Launch Leads to General Excitement and Tests: Users discussed the launch of Meta Llama 3, exploring its capabilities, tokenizer efficiency, and potential need for extensions beyond the 8k context window. Some are waiting for longer context versions, but appreciate that Llama 3's 8k tokens are more efficient than Llama 2's.
-
Mixed Feelings on Llama 3 Performance and Training: While some celebrate the strength of Llama 3, especially in medical and Chinese language evaluations, others experience sadness because the newly released model equals months of their personal tuning. There are concerns regarding the high initial loss rates and slow loss improvement during finetuning.
-
Technical Tussle with Axolotl and Llama 3: Users have reported issues merging qlora adapter into Llama 3, facing errors with tokenizer loading and unexpected keyword arguments during finetuning. Suggestions include changing the transformer version to 4.37 to circumvent some issues.
-
AMD GPU Users Seek Support and Options: One user detailed an install guide for those using ROCm, indicating that memory-efficient attention could offer benefits similar to Flash Attention for Nvidia users. There is interest in testing alternatives that could prove more friendly to AMD GPUs.
-
ChatML and Tokenizer Configurations Pose Challenges: Users discuss challenges with ChatML and map special tokens correctly, sharing attempts and fixes for tokenizer configurations. There's eagerness for successful implementations of ChatML in Llama 3, as well as some frustration with potential issues caused by existing template adaptations.
Links mentioned:
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (13 messages🔥):
- Fewer Truncations, Better Performance: AWS's new packing algorithm shows significant improvements with relatively +4.7% on reading comprehension and reduces closed domain hallucination by up to 58.3%. More details and the paper can be found at Fewer Truncations Improve Language Modeling.
- LLaMA-3 Inherits LLaMA-2’s Architecture: Discussion among members confirmed that LLaMA-3 uses the same architecture as its predecessor, despite initial expectations of changes from the data scaling paper.
- Tokenizer Tweaks for LLaMA-3: It was noted that LLaMA-3 has a larger tokenizer but keeps the same architecture as LLaMA-2. A training run is being set up to explore the new model's capabilities.
- Investigating PAD Token Fixes: A conversation about whether setting the PAD token manually would address certain issues led to a trial with
AutoTokenizer. Members are testing to see if these tokenizer configurations have an impact. - Testing Contributions on Pull Request: A request was made for spare computational resources to test a Draft PR that updates tokenizer overrides handling, with the link provided to the Draft: Update Tokenizer Overrides Handling in models.py.
Links mentioned:
OpenAccess AI Collective (axolotl) ▷ #general-help (43 messages🔥):
-
Mistral's Fine Tuning Secret Unfrozen: Users are discussing finetuning on models such as a 7b Mistral. One user mentioned that the model crashes unless the lmhead and embed layers are unfrozen during the process.
-
Llama-3 Finetuning Troubleshooting: Several users are engaging in troubleshooting the finetuning process for Llama-3. Problems such as a
ValueErrordue to missingpad_tokenand errors writing to files are being reported, with one user suggesting that the errors might relate to a lack of disk space. -
Tokenization Puzzles with Different Llama Models: Conversations reveal that the tokenizer configuration has changed between Llama-2 and Llama-3, with the padding token set as
<|end_of_text|>for the latter, causing some confusion among users. -
Instruction Datasets: Fulltune or Not to Fulltune?: One member is considering whether to fulltune on instruction datasets or just use completions. Subsequent discussion touched on whether the base model or instruct model is more suitable for fulltuning.
-
Finetuning Mishaps and Successes: There's an ongoing exchange about the peculiarities of finetuning Llama models, where participants encounter errors unrelated to memory issues and contemplate whether the root cause is insufficient storage or something else.
OpenAccess AI Collective (axolotl) ▷ #runpod-help (3 messages):
- Experiencing a Slow Spin-up: A user expressed that the process of spinning up a pod in runpod was taking an unusually long time, wondering if the service might be down.
- Light-Hearted Jibe at Runpod's Reliability: Another user made a humorous remark implying that runpod frequently experiences downtime.
OpenAccess AI Collective (axolotl) ▷ #axolotl-phorm-bot (14 messages🔥):
- PAD Tokens Configuration Quandary: A member asked how to set the PAD token in the YAML configuration, and the bot detailed that it would typically be included under the
tokenssection. - Token Replacement Tutorial: Guidance was sought on replacing tokens in a tokenizer with another token; the bot provided a step-by-step example using Hugging Face's
transformerslibrary, involvingadd_tokensand manual vocabulary adjustments. - Specifics on YAML Token Replacement: The same member further inquired about replacing tokens directly in the YAML config file; the bot clarified adding new tokens to the configuration file, and how to use these in place of original tokens via code adjustments.
Links mentioned:
Stability.ai (Stable Diffusion) ▷ #general-chat (471 messages🔥🔥🔥):
-
Anticipation for SD3 Local Weights: Users are eager for the release of Stable Diffusion 3 (SD3) local weights, with an expected date of May 10th for access, as repeated throughout the chat.
-
Stable Diffusion API Filtering Concerns: There's discussion about the API for SD3 potentially returning blurred images for prompts it deems 'edgy', sparking dialogue on how generated content might be filtered or censored compared to the local version.
-
Graphical Hardware Decisions: A user considering GPU options for AI work was advised on the value and efficiency of the RTX 3090 versus upcoming or more expensive models, like the RTX 4080 and 4090, considering the balance of VRAM, speed, and price.
-
Content Generation Techniques Explored: Members shared tips and sought guidance on generating specific types of content with various models, including crafting prompts for half-face images and managing the details of generated images.
-
Shared Tutorials and Assistance: A user provided a Comfy UI tutorial video link. Assistance is sought and offered for various issues, like handling IndexError in img2img and debating the visibility and removal of hidden watermarks in generated imagery.
Links mentioned:
Latent Space ▷ #ai-general-chat (229 messages🔥🔥):
-
Exploring Discord Summarization: A member inquired about summarizing a high-quality, dense Discord server on systems engineering. They discussed potentially using Claude 3 Haiku to structure data from Discord and then summarize it using an AI news bot. An invite link to the server was also shared: Invitation to systems engineering Discord.
-
Meta Unleashes Llama 3: The release of Meta's Llama 3 sparked conversations detailing its specs, like the 8B and 70B model sizes showing state-of-the-art (SOTA) performance, and a mention of a forthcoming 400B+ parameters model. Discussions included improvements, instruction tuning, security tools, and training details. Community members also debated about M4 computers' capabilities for running large models and dissected the potential of the Llama 3's 70B model comparing it to GPT-4 based on Lmsys scores, with one member stressing that quantization advancements might enhance performance.
-
Performance and Possibilities with Llama 3: Community members reviewed the new Llama 3 in comparison to existing models like GPT-4turbo, shared impressions, and suggested checking meta.ai for accuracy. The conversation delved into topics like inference speed, with a member highlighting fast time-to-first-byte performance on Groq Cloud, and discussed voice 2 voice AI use cases potentially utilizing Llama 3 over GPT-4-Turbo.
-
Mac Inference Capabilities Tackled: A lively exchange about running large models on Macs transpired, with members discussing their experiences and expectations for future Mac M4 chip performance. Focus centered around the practicality of running models like Llama 3 70B and 400B on personal computers, with suggestions for workarounds like utilizing local Linux boxes combined with Mac for efficiency.
-
Boilerplate for LLM Projects Sought by AI Enthusiasts: A community member sought a template or "cookiecutter" for starting LLM projects to reduce redundancy, and another shared litellm as a potential tool to call over 100 LLMs with uniform input/output formatting, alongside other features.
Links mentioned:
Latent Space ▷ #ai-announcements (3 messages):
- Latent Space Pod Drops New Episode: The Latent Space Discord community shares a new podcast episode featuring <@199392275124453376>. Excitement buzzes as the link to the Twitter announcement is provided: Listen to the new episode.
- Podcast Enthusiasm: Community member mitchellbwright expresses excitement for the latest podcast installment featuring Jason Liu.
Latent Space ▷ #llm-paper-club-west (66 messages🔥🔥):
- LLM Paper Club - Generative Pre-Training: The paper club discussed the paper "Improving Language Understanding by Generative Pre-Training," highlighting the significance of tokenizers and embeddings, and noting that “embeddings are their own NN”. Attention was drawn to the fact that contrary to embeddings, “tokenizers don’t really have to be learned”.
- Recording in Session: The sessions of the Asia Paper Club were confirmed to be recorded and there was an intention to upload them to YouTube, evidenced by “Monitoring the OBS stream, if everything is good then will upload to youtube after :)”.
- ULMFiT Clarification: A discussion clarified that ULMFiT uses an LSTM architecture, and it was referenced in the T5 paper.
- PPO's Auxiliary Objectives Explored: Conversation touched on Proximal Policy Optimization (PPO) algorithms, discussing if it has auxiliary objectives like Kullback–Leibler (KL) divergence, with a member confirming, “yes iirc".
- Prompting Epoch: There was mention of the start of prompt engineering with “start of prompt engineering” and a reference to the adage “scale is all you need”, suggesting the increasing importance of scale in model performance.
Links mentioned:
Latent Space ▷ #ai-in-action-club (69 messages🔥🔥):
- Zoom or Discord? Decision in the Air: Members discussed whether to continue with Discord or switch to Zoom for this week's meeting.
- Sharing AI Insights: A link to a Google Slides presentation on LLM Evaluation was shared for the group's review, indicating a focus on evaluating large language models.
- Curiosity About Noise: A member reported hearing an undefined hum during a session, which was resolved upon rejoining the chat.
- Summary Strategies Explored: Links to Eugene Yan’s articles were provided, exploring themes such as abstractive summarization and its versatility, as well as the intricacies of evaluation mechanics in machine learning.
- Ongoing AI Evaluations Discussed: Conversations related to the evaluation of large language models (LLM), effectiveness of retrieval processes, and shifting strategies in developmental branches hinted at the group’s efforts to enhance AI performance and reliability.
Links mentioned:
Eleuther ▷ #general (115 messages🔥🔥):
-
New Packing Method for LLM Input Sequence: A new paper introduces Best-fit Packing, a method that eliminates excessive truncations in large language model training by optimizing document packing into training sequences. The approach claims better performance and is detailed in the paper on arXiv.
-
LLaMA 3 Tokenizer Controversy: There has been a discussion about the weird tokenizer used by LLaMA 3, highlighting its oddities and clarifying that some supposed tokens were actually merge vocabs from the HF repository.
-
Seeking Stability in Optimizer: A conversation about AdamW optimizer stability encompassed techniques like lowering the learning rate, warming up from 0, logging std_mean(activation) after matrix computations, and suggestions to try StableAdamW or LaProp for better performance in training models.
-
Debugging Whisper Architecture Instabilities: Users deep-dived into troubleshooting Whisper architecture's training instability through strategies like modifying the Adam optimizer's hyperparameters, increasing batch sizes, and checking gradient norms and weight scale.
-
Unique Suggestions for Transformer Attention: A proposal was discussed for a Transformer attention mechanism with a learnable window, allowing the model to attend to relevant tokens far back in the text, aiming to reduce the complexity from O(n^2) to O(n).
Links mentioned:
Eleuther ▷ #research (149 messages🔥🔥):
-
Encountering the Softmax Bottleneck: The discussion pointed to saturation in smaller language models, referencing a new paper that connects saturation with the softmax bottleneck phenomenon. It highlights that models with less than 1000 hidden dimensions can struggle due to a mismatch between model size and the complexity of the target probability distribution.
-
Multilingual Alignment with Limited Data: Members explored a paper (abstract here) on training alignment models in a zero-shot cross-lingual context with limited multilingual data. The approach described shows aligned models are often preferred even when using reward models trained on different languages.
-
Exploring TC0 and Expressive Power of Neural Networks: There was a discussion questioning the TC0 complexity class and how it relates to neural networks like CNNs and Transformers. The conversation focused on whether various networks have similar levels of expressive power, with no definitive conclusion reached in the chat.
-
Meta Won't Likely Share Llama 3 Data Sources: Amid requests for Meta to document the dataset sources for Llama 3, users noted legal complexities and the improbability of Meta yielding to community petitions. The consensus seemed to be that legal barriers would prevent such a disclosure.
-
Potential Infinite Loop in Autograd Calculation: A user reported a peculiar issue when backpropagating a complex model using PyTorch on a GPU with 80GB RAM, raising questions regarding autograd computations and memory management. The discussion concluded that an infinite loop was unlikely given autograd's design to prevent gradient computation for parameters with existing gradients.
Links mentioned:
Eleuther ▷ #scaling-laws (38 messages🔥):
-
Chinchilla Token Count Unchanged: The "best average" Chinchilla token count per parameter remains the same, implying that nothing has meaningfully changed according to discussion.
-
Chinchilla's Third Method in Question: Chinchilla's third scaling law method was previously misapplied, but a corrected statistical analysis now aligns it more with the other two methods, offering a reinterpretation that more parameters might be a worthy investment over more data.
-
Critique on Third Method's Reliability: Despite the correction, some members are cautious about the third method's reliability for scaling strategies, suggesting alternative interpretations and recognizing the strength of the first two approaches hinted in the original Chinchilla paper.
-
Chinchilla Replication Attempt Debated: A replication attempt of the Chinchilla study indicates instability in parametric modeling, but opinions are divided on the implications, with discussions surrounding the paper's validity and the significance of statistical testing.
-
Discovering Easter Eggs in Paper Repositories: Members highlighted a lesser-known feature of arXiv, where the TeX source of papers can be downloaded to uncover potential easter eggs and commented-out content, an insight valuable for those interested in the intricacies and behind-the-scenes of academic publishing.
Eleuther ▷ #interpretability-general (2 messages):
- DeepMind's Mechanistic Interpretability Updates: Google DeepMind's mechanistic interpretability team shared a progress update covering advancements in Sparse Autoencoders (SAEs). Highlights include interpreting steering vectors with SAEs, devising inference-time sparse approximation algorithms, improving ghost gradients, and establishing infrastructure for working with larger models and JAX.
- Insights on Twitter: Neel Nanda of the DeepMind team tweeted about the update, reflecting on lessons and "hacks" learned from their mechanistic interpretability research. The tweet can be found here.
Link mentioned: Progress Update #1 from the GDM Mech Interp Team: Summary — AI Alignment Forum: Introduction This is a progress update from the Google DeepMind mechanistic interpretability team, inspired by the Anthropic team’s excellent monthly…
Eleuther ▷ #lm-thunderdome (14 messages🔥):
- Mulling Over MMLU as ARC: Members discussed the idea of presenting the MMLU benchmark similarly to ARC, without multiple choices. There seems to be interest but no concrete data or outcomes shared in the conversation, apart from an intent to compare it to a baseline.
- Clarification on Loglikelihood Calculation: In response to an inquiry about loglikelihood computation for language models, participants confirmed that the loglikelihood should be calculated over the continuation or target, not over the entire sentence, so that perplexity is computed over the continuation only.
- Vast vLLM Speed Improvement Noticed: A user reported a 10x speed-up when using vLLM for language generation compared to the conventional text-generate pipeline, prompting a discussion on optimal setup processes.
- Contributions to lm-evaluation-harness: A member shared Pull Requests (PRs) for flores-200 and sib-200 benchmarks to enhance multilingual evaluation. However, they were informed that the high number of configurations makes merging difficult as is, and a cleaner implementation method needs to be devised.
- Seeking Guidance for lm-evaluation-harness Unit Tests: A community member expressed interest in contributing to lm-evaluation-harness, seeking clarification on running unit tests and the current relevance of the CONTRIBUTING.md document, alongside questions about dependencies for various tests.
Links mentioned:
LAION ▷ #general (255 messages🔥🔥):
- Looming Layoffs at Stability AI: Stability AI is downsizing, laying off more than 20 employees post-CEO departure to "right-size" the business after unsustainable growth, sparking discussions of the company's future.
- Stable Diffusion 3 (SD3) Struggles Against DALL-E 3: Members shared comparisons between SD3 and DALL-E 3, repeatedly observing that DALL-E 3 outperforms SD3 in image quality and prompt adherence, with several members expressing dissatisfaction with SD3's current state.
- Thoughts on LLaMA Model: There's significant interest in Meta's Language Model for Many Applications (LLaMA), with discussions on its coding capabilities, small context window limitations, and overall performance that can rival other industry heavyweights.
- Understanding Cross-Attention Mechanisms: A discussion explored the specifics of cross-attention mechanisms in text-to-image models, with clarifications provided on how imagen – a model from Google – handles text embeddings during training and sampling.
- Prompt Engineering and Fine-Tuning Edges: Within the community, there's an ongoing evaluation and debate on prompt engineering techniques, such as adding camera and film style tags, and the potential necessity of fine-tuning models to correct persistent image generation artifacts.
Links mentioned:
LAION ▷ #research (15 messages🔥):
-
Exploring Open Source Audio-Conditioned Generative Models: There's an interest in developing an open source version of a generative model that's efficient and powerful for audio-conditioned generation of head and facial movements. A diffusion transformer model that trains in the latent space of holistic facial dynamics and head movements is being considered.
-
Potential Approaches to Handling Facial Dynamics: Latent space encoding of talking head videos or detailed face meshes coupled with a diffusion model conditioned on audio embeddings might be a promising route for generating facial dynamics. Training the model on the fly with audio embeddings is suggested as a possible strategy.
-
Meta Llama 3 Introduces New Possibilities: Meta Llama 3 has been announced, and will soon be available on multiple platforms including AWS, Databricks, Google Cloud, and Microsoft Azure. The announcement includes the mention of Meta's commitment to open source multimodal models to compete with proprietary solutions.
-
Impressions on Meta Llama 3's Potential Impact: One member expresses that Meta Llama 3's efficiency, if as good as claimed, would be significant, while another is skeptic about its accessibility for individuals and small startups. There's anticipation for the release of Meta's open source multimodal models, which are expected to rival proprietary alternatives.
Link mentioned: no title found: no description found
HuggingFace ▷ #announcements (11 messages🔥):
- Call for Multilingual Community Highlights: A member suggested expanding the weekly highlights to include more languages, to reach a broader global audience. They expressed that translating the weekly highlights could make the content more accessible and engaging for non-English speakers.
- Volunteer to Aid with Multilingual Models: Another member responded positively to the idea of translations, offering to help with smaller multilingual models and their testing to improve the initiative.
- Translation Bot vs. Local Context: While discussing the implementation of a translation bot for the Community Highlights, it was noted that adding local context in translations could increase engagement, highlighting the importance of nuanced, culturally relevant content.
- A Case for Human-Enhanced Translations: One contributor emphasized the value of creating content like video explanations in various languages, suggesting that translations go beyond text, enabling demonstrations and discussions on new features, and providing a deeper understanding that a simple bot translation might lack.
- Teasing the Arrival of LLM Llama3: The release of Llama3, also known as 🦙🦙🦙, was mentioned, with a note that it is already available on HuggingFace at
MaziyarPanahi/Meta-Llama-3-8B-Instruct-GGUFand that its performance on leaderboards is anticipated.
Links mentioned:
HuggingFace ▷ #general (166 messages🔥🔥):
- Gradio WebSockets Conundrum: A discussion about Gradio's dependency issue with websockets version arose, highlighting compatibility concerns when other dependencies require websockets 12, yet Gradio's latest release insists on a lower version.
- Meta Llama 3 Outshines Mixtral: The Mera-mix-4x7B, a mixture of experts (MoE) model, is introduced as being smaller but comparable to Mixtral-8x7B, with detailed benchmarks revealed in the discussion, such as achieving 75.91 on the OpenLLM Eval.
- Avoid the Crypto Confusion: Amid concerns about cryptocurrency scams, members suggest that HuggingFace should publicly refute any association with digital coins. A link to a Twitter post warning against such scams is shared.
- New Era of Quantization: Queries about the differences between quantization levels and their impacts on model performance arise, with links shared to discussions on the impact of quantization on LLM performance.
- Llama 3 Delimma: Users exchanged experiences and insights about the differences between Meta Llama models and instructions on using the Meta-Llama-3-8B Instruct model. Concerns are voiced about specific outputs from Llama 3 models and the default system prompt possibly guiding the model's behavior.
Links mentioned:
HuggingFace ▷ #today-im-learning (4 messages):
-
Input Validation Error Hits New User: A new member encountered a HfHubHTTPError: 422 when using the LLaMA-2-7b-chat-hf model. The error message indicates
inputs must have less than 4096 tokens. Given: 4545, pointing to a need for input size reduction. -
Meta Releases LLaMA 3 - A Dive into New Capabilities: A video titled "Meta Releases LLaMA 3: Deep Dive & Demo" was shared, detailing the launch of Meta's LLaMA 3 model and its features. The YouTube video provides insights into the model released on April 18, 2024.
-
Curiosity About LLaMA 3's Early Impressions: A member expressed interest in knowing others' experiences with the newly released LLaMA 3 model. Enthusiasm was shown through the use of an emoji.
Link mentioned: Meta Releases LLaMA 3: Deep Dive & Demo: Today, 18 April 2024, is something special! In this video, In this video I'm covering the release of @meta's LLaMA 3. This model is the third iteration of th...
HuggingFace ▷ #cool-finds (9 messages🔥):
-
Book on Generative AI Work in Progress: The book Hands-On Generative AI with Transformers and Diffusion Models received praise, and the author acknowledges it's still a work in progress with five more chapters to come.
-
Expect More on AI and Design: There's hope that upcoming chapters of the book will cover topics such as quantization and design systems.
-
Internal Library Used in Generative AI Book: In response to an inquiry about the library used for the
show_imagesfunction in the aforementioned AI book, no library was specified. -
Harnessing Blender for Synthetic Data Generation: A blog post highlights the potential of using Blender for synthetic data generation, showcasing its application in object recognition problems and delineating the process in multiple sections.
-
Ruff 0.4 Improves Performance: The lint and format performance of Ruff version 0.4 has been significantly improved, now more than double the speed compared to prior versions, thanks to a switch to a hand-written recursive descent parser.
-
Insights on PyTorch's Stable Loss Function: A Medium article decodes PyTorch's BCEWithLogitsLoss, emphasizing its numerical stability over using a plain Sigmoid followed by Binary Cross Entropy Loss.
-
ORPO-DPO-mix-40k Dataset for Training: The ORPO-DPO-mix-40k dataset combines high-quality DPO datasets for ORPO or DPO training, compiled to aid in the development of machine learning models.
-
Exploring the Dark Side of Llama3: A LinkedIn post discusses the 'dark side' of Llama3, providing insights into a lesser-known aspect of this AI tool.
Links mentioned:
HuggingFace ▷ #i-made-this (12 messages🔥):
-
Novel Audio-in-Browser Experience: A user shared their project, a HuggingFace space called zero-gpu-slot-machine, which is an innovative tool that uses audio inputs to generate music with midi2musicgen2musicgen and Gradio. They have created an unprompted generation system that can work with chords using MusicLang MIDI model and demonstrated its functionalities in a posted video.
-
New Leaderboard Launch for Predicting Future Events: HuggingFace has launched a new leaderboard to evaluate how effective LLMs, workflows, and agents are at predicting future events, a relatively unexplored task. The announcement included a link to the prediction leaderboard, currently featuring two open-source models with more to be added.
-
Extending Community Highlights to Portuguese Audiences: A member mentioned that they are translating the Community Highlights into Portuguese and including demos, with episodes #52 and #53 available in a YouTube playlist for Portuguese-speaking users.
-
Potential Multilingual Expansion for Community Content: In response to the Portuguese translation of Community Highlights, another member suggested the idea of creating content in other languages like Korean, with interest expressed in possibly creating blog posts or videos to cater to different language speakers.
-
Meta-Llama Quantized Version on HuggingFace: A user introduced the GGUF quantized version of Meta-Llama-3-8B-Instruct, hosted on HuggingFace, which is a re-uploaded model with a new end token that can be found here.
-
Community Guidelines Reminder: A moderator reminded users that Discord invites are not permitted in the channel and referred them to the relevant rules section.
Links mentioned:
HuggingFace ▷ #reading-group (1 messages):
- Invitation to Discuss Counterfactual-Inception: A member expresses interest in recent research on Counterfactual-Inception and invites the researcher to share insights with the reading group. The study is available on GitHub.
Link mentioned: GitHub - IVY-LVLM/Counterfactual-Inception: Contribute to IVY-LVLM/Counterfactual-Inception development by creating an account on GitHub.
HuggingFace ▷ #computer-vision (2 messages):
-
Inquiry on DRL-based Object Detection: A member inquired about object detection systems that utilize deep reinforcement learning (DRL), expressing interest in their performance metrics.
-
Seeking Insights on 3D Vision Datasets: Another member sought information and research papers on understanding 3D computer vision datasets, specifically mentioning Google Scanned Objects (GSO). They requested if anyone could share relevant study material.
HuggingFace ▷ #NLP (3 messages):
- Tracking Down the Elusive 'cursorop' Issue: A member mentioned that the 'cursorop' error typically occurs due to running out of memory or Package Compatibility Issues.
- TensorFlow Necessitates 'cursorop': The necessity of TensorFlow was implied as the main reason a member encounters the 'cursorop' error.
- Searching for the Cause of an Error: A member reached out asking for help in understanding the reasons behind an unspecified error, but did not provide further details or context.
HuggingFace ▷ #diffusion-discussions (4 messages):
- Raylib Troubles Cry Out for a Hero: A member expressed frustration after spending 3 hours trying to resolve an issue where the
raylib.hfile was not found. They openly requested for someone with experience in Raylib to assist. - Quest for Consistent Backgrounds in Inpainting with Lora: In the pursuit of maintaining consistent backgrounds without altering the foreground object, a member sought alternatives to standard inpainting methods, mentioning an interest in exploring Lora training. They requested suggestions from anyone with relevant experience or insights.
OpenRouter (Alex Atallah) ▷ #announcements (2 messages):
-
Prompt Template Correction: The prompt template for Mixtral 8x22B Instruct has been corrected after a confusion. This update affects the usage guidance for the model.
-
Tweet Alert: OpenRouter shared an update via a Twitter post - the contents of the tweet were not disclosed in the Discord message.
Link mentioned: Mixtral 8x22B by mistralai | OpenRouter: Mixtral 8x22B is a large-scale language model from Mistral AI. It consists of 8 experts, each 22 billion parameters, with each token using 2 experts at a time. It was released via [X](https://twitter...
OpenRouter (Alex Atallah) ▷ #general (198 messages🔥🔥):
-
Chatter About OpenRouter Revenue: Members speculate that OpenRouter might be making money through bulk discounts or taking a small cut from user top-ups, although there is no official confirmation provided in the chat. Some believe that such discounts are confirmed and shared between the users and the provider.
-
Latency and Server Locations: One user raised a concern about latency when using a VPS in South America, however, the discussion did not yield a definitive answer on whether the physical server location significantly affects latency.
-
Anticipation for LLaMA 3 Models: Discussion indicates LLaMA 3 models, including an 8 billion and an unprecedented 70 billion parameter version, are being released. Users share that Azure offers LLaMA 3 models and even provide a link to the offering.
-
Meta LLaMA 3 Released: Users eagerly discuss the new Meta LLaMA 3 models, pointing out they seem less censored, offering posted links to both the model page and a download location to request access to the weights at Meta LLaMa Downloads.
-
Use of OpenRouter in Production: One user confirms the use of OpenRouter in a production environment, sharing their experience at Olympia.chat and suggesting that many other production users can be found on the OpenRouter homepage. Another user seeks suggestions for integrating specific messages, such as tools and function calls, when transitioning from direct OpenAI usage to OpenRouter, highlighting the lack of clear documentation.
Links mentioned:
OpenAI ▷ #ai-discussions (106 messages🔥🔥):
- Curious Minds Want to Know: Members sought best practices for implementing OpenAI products in corporate applications, including gathering, organizing, and categorizing these practices. They discussed challenges related to direct file uploads and were curious about ways to increase upload limits for team subscriptions.
- AI Model Speed and Performance Debate: Participants discussed the speed and performance of various models like GPT-4, Claude, and Llama 3. It was highlighted that Claude Opus is fast and comparable to GPT-4 Turbo, and members suggested that the performance might depend on factors like region and whether prompts are streamed.
- Exploring Llama 3's Impact and Integration: Conversation centered on Meta's Llama 3, with links shared to blog posts such as Meta Llama 3 introduction. There was debate over Llama 3's comparison with GPT-3.5 and anticipation for its integration into consumer applications.
- Model Accessibility and Consumer Hardware Challenges: Members discussed the practicality of running large models like Llama 3 and GPT-4 on consumer hardware. Concerns were raised about the computational and cost requirements, and some touched upon potential improvements and adaptations for consumer-grade devices in the future.
- Learning and Mastery of AI Tools: The community exchanged views on the best ways to learn and master tools like DALL-E 3, questioning the credibility and effectiveness of available courses. Some advised skepticism of self-proclaimed experts and recommended seeking help from specific Discord channels or learning through direct use of the technology.
Links mentioned:
OpenAI ▷ #gpt-4-discussions (22 messages🔥):
-
Seeking the Fastest Model: A user reported that GPT-4-0125-preview has been slow and inquired about faster versions of GPT-4. Suggestions included trying out the updated gpt-4-turbo-2024-04-09, but the user felt it was even slower.
-
Model Speed and Performance Comparison: Users discuss alternative models to GPT-4, such as Claude and Command R, questioning their speed and intelligence in comparison. One user mentioned that Claude becomes less effective after a series of messages.
-
Concerns About GPT-4 Turbo: A user expressed disappointment with gpt-4-turbo (non-preview, the 0409 one), feeling it underperforms compared to the previous 0125 preview version for their assistant application.
-
Assistant API yielding sluggish loading messages: User raising an issue with the Assistant API where the system waits for the function result before displaying a loading message. One user suggested a UI workaround to control the visibility of loading messages dynamically.
-
Integrating GPT-4 with Claude: A user has combined GPT-4 with Claude 3 Opus to create a chat experience where GPT-4 first responds, then queries the Claude model, and combines both responses. However, there was a report of an error when trying the service at the provided link.
OpenAI ▷ #prompt-engineering (30 messages🔥):
- Code Integration Frustrations: A member expressed frustration with attempting to integrate three simple Python files as the system was “dropping code constantly”; they had to complete the integration manually.
- ChatGPT's Performance Under Scrutiny: Discussion about ChatGPT's decreasing performance post Elon Musk's lawsuit included references to sandbagging and comments suggesting the inferior quality seems deliberate.
- Antidotes to AI's PDF Poison: In a technical advice exchange, a member was advised against using PDFs for providing rules to an AI assistant, noting numerous issues with PDFs and encouraged the use of plain text or structured formats like XML or JSON instead.
- Prompt Engineering Best Practices Inquiry: A member looked for confirmation on the latest prompt engineering best practices from OpenAI, referencing an official OpenAI guide and queried the community for updates.
- JSON Data Summarization Challenge: A member sought assistance on how to get GPT to return exact text from a specific field within a JSON data summary, noting difficulties despite explicitly stating instructions in their prompts.
OpenAI ▷ #api-discussions (30 messages🔥):
- PDF Pitfalls in AI: Members discussed the unsuitability of PDFs for providing context to AI, with one suggesting that plain text is much better, and another stressing how PDFs are a "metadata disaster area" and "hot garbage for AI." It's advised to provide rules in a more structured format like JSON or XML, but as noted, XML is not supported for files, so embedding the rules or using a plain text format is recommended.
- Prompt Crafting Challenges: One member expressed frustration with the AI dropping code while trying to integrate multiple Python files, leading them to resort to manual integration. Similarly, another member struggled to get the AI to include exact text from a specific field while summarizing JSON data, despite numerous attempts.
- Model Performance Anxieties: The discussion surfaced concerns about perceived declines in ChatGPT’s performance, with members speculating on possible reasons for this, ranging from strategic "sandbagging" due to legal pressures, to deliberate degradation, to poor prompt design characterized by "system prompt delta hades."
- Exploring Task-Specific Summarization: A member is using the OpenAI API to analyze meeting transcriptions and extract tasks or summaries for each participant. They referred to the OpenAI prompt engineering best practices and are considering using the batch API for non-real-time processing.
- Blockchain and AI Fusion Idea: A new member, identifying as a blockchain developer, is looking to combine AI with blockchain technology and has invited others to collaborate on developing this concept. They are also seeking to enhance their prompt design.
Interconnects (Nathan Lambert) ▷ #ideas-and-feedback (3 messages):
- MCTS Explained Briefly: One member clarified that MCTS stands for Monte Carlo Tree Search, a search algorithm often used in game playing AI.
- Combining MCTS with PPO for Language Generation: A member shared excitement about working with an author of a paper on integrating MCTS with PPO, enhancing text generation by utilizing the value network from PPO to inform MCTS during inference time. The paper introduces PPO-MCTS, a novel value-guided decoding algorithm.
Link mentioned: Don't throw away your value model! Generating more preferable text with Value-Guided Monte-Carlo Tree Search decoding: Inference-time search algorithms such as Monte-Carlo Tree Search (MCTS) may seem unnecessary when generating natural language text based on state-of-the-art reinforcement learning such as Proximal Pol...
Interconnects (Nathan Lambert) ▷ #news (142 messages🔥🔥):
- Meta Llama 3 Takes the Stage: Meta has released the Meta Llama 3 family of large language models, with pre-trained and fine-tuned versions ranging from 8 billion to 70 billion parameters, optimized for dialogue use cases. The announcement included access to the Llama-3-8B inference APIs and hosted fine-tuning in Azure AI Studio, which touts features conducive to building Generative AI apps.
- Replicate's Competitive Pricing Revealed: A price list for GPUs and CPUs used in model hosting services, with costs broken down per second and per hour, was shared, emphasizing the financial aspects of using external computational resources for AI work.
- Meta's Llama 3 Model Stirs Excitement and Skepticism: Discourse on the channel reflects anticipation regarding Meta's Llama 3 model, with speculation about its potential as a 'GPT-4 killer' and discussions about its language capabilities, pricing, and comparative performance to existing models like GPT-3.5.
- Concerns over the Real-World Usability of Llama 3: The release was noted to be early, with critiques over its multi-language effectiveness and fine-tuning, suggesting that although Llama 3 claims multilingual capabilities, it may not be highly prioritized or fully realized in the current iteration.
- Predictions for Scale and Accessibility of the 405B Model: Enthusiasm surrounds Meta's announcement of a planned Llama 3 model with 405 billion parameters, speculating it will be an open-weight model, potentially shifting the landscape for open-source AI and increasing the stakes for closed models like GPT-5. The official announcement and further details are eagerly anticipated.
Links mentioned:
Interconnects (Nathan Lambert) ▷ #sp2024-history-of-open-alignment (16 messages🔥):
- LLaMa3 Anticipation in Presentations: @philpax humorously contemplated whether @natolambert would have to include last minute updates about the LLaMA3 release in his slides. Meanwhile, @xeophon hoped the release would drop promptly, as they'd already referenced it in a talk.
- LLaMA3 Excitement Cools: @natolambert expressed a lack of enthusiasm for LLaMA3, stating they could add a slide about it to appease the audience but emphasizing the current abundance of ongoing projects.
- Preparing for Queries Post-Talk: @natolambert shared the intention to open the floor to questions at the end of the talk and mentioned being focused on writing a blog post first.
- Inquiry about LLaMA-Guard and Its Benchmarks: @420gunna brought up curiosity about LLaMA-Guard, asking if models like it have a specific name or benchmarks. @natolambert responded, referring to it as a "safety classifier" and noting AI2's development of a benchmark for related systems.
- Awaiting the Recording Release: @philpax inquired about the availability of a recording soon, likely referring to @natolambert's presentation or a related event.
Interconnects (Nathan Lambert) ▷ #posts (2 messages):
- SnailBot Promotion: A user made a light-hearted comment, congratulating the SnailBot for being put to work on a work-in-progress post.
- A Cheeky Welcome: natolambert playfully acknowledged a user's accomplishment with the SnailBot, coupling congratulations with humor.
Modular (Mojo 🔥) ▷ #general (19 messages🔥):
- Mojo Meets C Programming: Users can leverage C within Mojo by using the
external_callfeature, as demonstrated in a recent tutorial on Twitter. The process will be simplified in future, aiming to enable calling C/C++ functions directly without a complex FFI layer. - C in Mojo Gets Easier: The development team has plans to streamline the integration of C within Mojo, potentially allowing developers to import and call external functions with regular arguments, as mentioned by a member, simplifying the current process.
- Mojo-Swift Interoperability Discussion: Discussion on interfacing Mojo with Swift revolved around a potentially smoother interop that might involve Mojo <-> C++ <-> Swift, with reference to the FFI (Foreign Function Interface), and examples like MLX-Swift on GitHub.
- Modular's Roadmap and Language Priorities: The Mojo language is focusing on essential system programming features as its roadmap and mission show, with an acknowledgment of the language being in its early stages.
- Community Interest in GUI for Mojo: There seems to be interest in a GUI library for Mojo, with Swift UI suggested as an ideal tool, although creating such a library might be a community-driven effort rather than a direct output from the developers at Modular.
Links mentioned:
Modular (Mojo 🔥) ▷ #💬︱twitter (2 messages):
-
Modular Takes to Twitter: Modular shared a tweet on their official account, providing insights or updates to the followers.
-
Fresh Off the Press: Another tweet was posted by Modular, likely delivering new content, announcements, or engaging with their community.
Modular (Mojo 🔥) ▷ #ai (2 messages):
-
Meta Unveils LLaMA 3: A video was shared, titled "Meta Releases LLaMA 3: Deep Dive & Demo", discussing the release of Meta's LLaMA 3. The video is described as a special coverage of Meta's third iteration of this model, dated April 18, 2024, and can be viewed here.
-
Level Up Notification: A user was congratulated for advancing to level 1 in the ModularBot ranking system. No further context was provided.
Link mentioned: Meta Releases LLaMA 3: Deep Dive & Demo: Today, 18 April 2024, is something special! In this video, In this video I'm covering the release of @meta's LLaMA 3. This model is the third iteration of th...
Modular (Mojo 🔥) ▷ #🔥mojo (118 messages🔥🔥):
-
Exploring Runtime Garbage Collection Discussions: The conversation revolved around the Nim language's cycle collector with ref counting in version 2.0, which runs at runtime. One user proposed the possibility of Modular's Mojo language integrating something similar, suggesting that Mojo sometimes just moves references, but other members expressed concerns about the complexity and potential performance implications.
-
Mojo's Language Capabilities and Feature Speculations: Users discussed the extent to which Mojo supports various functionalities. There was talk of Mojo possibly supporting shell commands through C external calls, confusion over printing tuples since they lack a "Stringable" trait, and curiosity about whether Mojo will include first-class test support akin to Zig.
-
Pondering First-Class Test Support and Decorators: A key topic was the potential for incorporating first-class testing in Mojo, similar to Zig's testing approach. There was also a mention of preferring an
@testdecorator for tests to be a dead code when not testing, similar to Rust's#[cfg(test)]. -
Wishing for Pytest-Like Assertions: One member expressed a wish for assertions in Mojo to be more like Pytest, using the built-in assert keyword. This sparked a discussion about the differences between tests and assertions and the significance of having a test suite.
-
Package Management and Community Contributions: There was excitement about community involvement in Mojo's growth and the possibility of a packaging and build system. Modular's intent to develop tools like
mojo testand to lay foundations for a packaging system spurred on discussion about allowing the community to build test frameworks and other packages.
Links mentioned:
Modular (Mojo 🔥) ▷ #community-projects (1 messages):
arnaud6135: thank you, I'll read it right away 😄
Modular (Mojo 🔥) ▷ #performance-and-benchmarks (3 messages):
- Mystery of the Speedy Mojo: Comparing computation speeds, a member noticed Rust prefix sum computation is 6 times slower than Modular (Mojo) despite attempts to optimize Rust with targeted hardware flags.
- Benchmarks Put to the Test: A follow-up from a different member reported a time of 0.31 nanoseconds per element using the Rust code without any specific hardware optimizations, just "--release".
Modular (Mojo 🔥) ▷ #nightly (15 messages🔥):
-
Update Woes for Nightly/Mojo: A member encountered an error when trying to update Nightly/Mojo and got a 'No such file or directory' message. They previously succeeded with the same command a few days ago without any changes on their end.
-
Cleaning Isn't Enough: Another user experienced a similar update error and reported that running
modular cleandidn't resolve the issue, but upgradingmodularwithbrew upgrade modularfixed it. -
Modular CLI Update Required: It was suggested that updating the modular CLI can resolve these issues, as confirmed by a member who successfully updated after following this advice.
-
Path Update Solves Final Hurdle: After upgrading
modular, a member had to manually update their.zshrcwith the path"/users/carlcaulkett/.modular/pkg/packages.modular.com_nightly_mojo/bin"to solve the issue completely. -
Acknowledgement of Human Factor: The conversation concludes humorously with the acknowledgment that Layer 8 (a reference to user or human error in the OSI model of computer networking) issues will always be a factor.
Cohere ▷ #general (157 messages🔥🔥):
- Model Tool Use Clarification: Members shared resources and clarified the use of Command R model tool calling, providing links to the official documentation and a notebook with examples. It was confirmed that JSON schemas can be used to describe tools for Command models.
- RAG and Database Integration Questions: Queries about attaching databases to Cohere AI and the Retrieval Augmented Generation (RAG) feature were answered, with references to both Langchain and RagFlow, and the official Cohere docs.
- MySQL and Cohere Integration Inquiry: A member inquired how to integrate MySQL with Cohere and sought clarification on whether it is possible without Docker, which was discussed along with a link to a GitHub repository and directions pointing out potential outdated information in the official documentation.
- Commercial Use of Command R/R+ on Edge Devices: It was clarified that Command R and Command R+ cannot be used for commercial purposes due to CC-BY-NC 4.0 licensing restrictions, which stipulate non-commercial use only.
- Model Deployment Conversations: Community members talked about the deployment of large models, including 70B class models and the practicality of deploying 100B+ models for personal use. Specific hardware like dual A100 40GBs and MacBook M1 were mentioned in this context.
Links mentioned:
Cohere ▷ #project-sharing (3 messages):
- Discussing the Rising Importance of Jailbreaks: One member highlighted the evolving nature of jailbreaks in Large Language Models (LLMs), where the stakes are higher than simple profanities, potentially leading to agentic behavior with serious implications, such as compromising company databases or harassing individuals.
- Model Integration with Monitoring Tools: Another member detailed their approach to integrating a model with a monitoring tool. They followed instructions for scaffolding, using a loop where llm_output feeds into run_tool, combining both outputs to enhance the conversation process.
LlamaIndex ▷ #blog (5 messages):
-
Building RAG with Open Tools: A blog post from @elastic, utilizing @ollama and @MistralAI, illustrates how to construct a RAG (Retrieval Augmented Generation) application using Elasticsearch and LlamaIndex, showcasing the integration of these open and free components. The detailed guide can be found in the accompanying blog post.
-
Day 0 Support for Meta's Llama 3 by LlamaIndex: A collaboration between @ravithejads and @LoganMarkewich showcases a "cookbook" on how to use Meta's newly released Llama 3 model, detailing procedures from basic prompts to full RAG pipeline development, available directly via @huggingface. The guide is accessible through this Twitter update.
-
Running Llama 3 on Ollama Local Environment: Ollama provides straightforward commands to run Llama 3 locally, as demonstrated in the updated notebook that requires changing "llama2" to "llama3" for the new model. Interested parties can follow the process detailed here.
-
Creating a Code-Writing Agent with @TechWithTimm: LlamaIndex's latest project with @TechWithTimm offers a tutorial on creating an agent that utilizes documentation to write code, using local LLMs with @ollama and LlamaParse for document parsing. Learn more about programming an intelligent agent in their recent collaboration.
-
Local RAG App Development with Llama-3: A practical resource on building a RAG application locally using MetaAI's Llama-3 has been made available, directing users to a comprehensive guide on the process. This how-to is outlined in the posted link.
Links mentioned:
LlamaIndex ▷ #general (118 messages🔥🔥):
- Google Vertex Multimodal Embedding Puzzle: A participant was curious about replicating a feature from Google's demo site using Pinecone. They inquired how Google's model handled partial and misspelled queries, such as "timbalands," and sought guidance on implementing a similar feature.
- Building a Dashboard with a Recipe-Serving LLM: There was a discussion about creating an interactive dashboard that uses ingredients input to generate recipes via RAG, including direct PDF access to cited recipes.
- Milvus as a VectorDB with LlamaIndex: A user encountered exceptions while working with Milvus for vector databases in LlamaIndex and solved the problem by explicitly setting a
search_configwith a "metric_type". - Confusion Over ChatResponse Objects: Users shared tips on properly accessing the messages within a ChatResponse object, reflecting a common point of friction when interfacing with chat models.
- Concerns About LlamaIndex's Security Policies: A participant revealed difficulty in locating LlamaIndex's security policy information, especially regarding data security when using LlamaParse.
Links mentioned:
LlamaIndex ▷ #ai-discussion (2 messages):
- Tracking LlamaIndex and Zep: A member questioned whether it was too soon to track LlamaIndex and Zep, indicating interest in these projects' developments. Another expressed appreciation for the reminder and confirmed the intention to add both to a tracking list after noting LlamaIndex had raised funds.
DiscoResearch ▷ #mixtral_implementation (8 messages🔥):
- Mixtral SFT Training Completed: Mixtral-8x22B-v0.1-Instruct-sft-en-de is a full SFT model trained on a mix of English and German instruction data. There's also an ORPO-trained alternative, Mixtral-8x22B-v0.1-capybara-orpo-en-de.
- Awaiting Benchmarks for Mixtral Model: The user mentions planning to conduct benchmarks soon for the newly trained Mixtral model when they find some time.
- Technical Challenge with Large Model Training: A user faced shape errors using MixtralSparseMoeBlock and experienced out-of-memory (OOM) issues on a 32 GPU setup, suspecting that parameters and optimization states might not be correctly handled in mixed precision.
- Evaluation Techniques for Large Models: Usage of eval-harness and device_map="auto" was discussed for evaluating large models like Mixtral, along with alternatives like vllm and Lighteval from Hugging Face.
- Questioning Mixtral's Router Aux Loss Coef: There was a conversation regarding Mixtral's "router_aux_loss_coef" parameter in the model config, speculating if its value could be a key factor in the model's performance and whether it needed adjustment.
Link mentioned: maxidl/Mixtral-8x22B-v0.1-Instruct-sft-en-de · Hugging Face: no description found
DiscoResearch ▷ #general (21 messages🔥):
-
Meta Unveils Llama 3: Meta introduces Meta Llama 3, an open-source large language model. Llama 3 will be available across multiple cloud platforms and hardware, boasting improved performance from a new tokenizer with 128k tokens, efficient for multilingual use.
-
Understanding Llama 3's Multilingual Capabilities: While Llama 3 includes over 5% non-English high-quality data spanning 30 languages, “we do not expect the same level of performance in these languages as in English”, indicating potential limitations in multilingual applications.
-
Seeking the New Tokenizer: A member queries about downloading the new tokenizer, with another suggesting it might be on Hugging Face (HF) pending access approval. An instant approval for access to the official hf repository is mentioned by a subsequent participant.
-
New Llama 3 Models Unveiled: Mention of Llama 3's alternative models such as 8B instruct and 8B Guard have been made, stirring curiosity about the origins of their 15 trillion token dataset.
-
Feedback and Critique on Llama 3's Limitations: A member shares a tweet criticizing Llama 3 for imposing restrictions on downstream usage of the model output, highlighting concerns about open-source development and contribution.
Links mentioned:
DiscoResearch ▷ #discolm_german (26 messages🔥):
-
Language Skills on Trial: Early tests suggest that Llama3 DiscoLM German models require finetuning to match Mixtral models in German language proficiency. A member mentioned the grammar was not as good despite understanding the instructions, indicating possible additional orpo training may be needed.
-
Expect a Bug or Two: A member discussed the Llama3 DiscoLM German 8b v0.1 Experimental model having special token issues, with a note to use it with
skip_special_tokens=true. A demo and model are available at Hugging Face and Gradio, but with caution due to the token generation issue. -
German RAG Evaluations in Question: RAG evaluation results shared by a member for Llama3 DiscoLM German 8b v0.1 show lower than expected accuracy across tasks. Another member suggested checking the new line fix in the dataset and the odd configuration found in
tokenizer_config.jsonrelating to bos and eos tokens. -
Training Data Discussion: Debates arise about whether the Llama3 DiscoLM German model appropriately aligns with training data requirements. Some suggest that the current tokenizer configuration might be detrimental, while a member mentioned ongoing discussions about best practices, providing a Twitter thread as a reference.
-
Comparing Meta and DiscoLM Performances: German RAG evaluation results indicate that the training of Llama3 DiscoLM German 8b v0.1 Experimental might have reduced RAG skills in contrast with results from the meta-llama/Meta-Llama-3-8B-Instruct model. Members are looking into the reasons behind the performance difference.
Links mentioned:
OpenInterpreter ▷ #general (18 messages🔥):
- ESP32 Requires Network for LLM: A member mentioned that the ESP32 hardware needs to have wifi to connect with a Language Model (LLM) for functioning.
- Assistance Sought for OpenInterpreter Usage: A member requested help with an issue, sharing a Discord link for context, but provided no further details.
- File Creation Quirk with CLI Interpreter: When using OpenInterpreter for system tasks and Kubernetes from the command-line interface, a member faced problems with file creation, where output is inaccurately wrapped with
echo. - Ollama 3 Excitement and TTS/STT Model Inquiry: Discussions highlight excitement around Ollama 3's performance with a member experimenting with the 8b model, while another member inquired about changing the model for text-to-speech (TTS) and speech-to-text (STT) for faster responses.
- Local OS Mode Setup and Fine-Tuning Insights: Members shared how to set up OS mode locally with OpenInterpreter and provided a Colab notebook for general guidance. They also discussed fine-tuning models like Mixtral or LLama with small datasets for fast learning.
Links mentioned:
OpenInterpreter ▷ #O1 (17 messages🔥):
- Poetry Installation Puzzles: A member asked about the duration for completing the poetry install step, but figured it out themselves after initial confusion.
- M5Atom Connective Challenges: A conversation highlighted struggles in connecting the M5Atom to various systems; users reported attempting multiple approaches, including using the Arduino IDE and PlatformIO, but facing issues with audio and server connectivity.
- O1 Compatibility Questions: Members inquired about O1 compatibility with Windows, sharing mixed experiences, with one user choosing to buy a MacBook for running O1 while using Windows for other models.
- Llama 3 Powers O1 Platform: Enthusiasm was shared for O1 being powered by Llama 3.
- M5Atom Audio Transmission Troubles: A user detailed making some progress with transmitting audio to the server using the M5Atom after multiple installation attempts and troubleshooting, but encountering a BadRequestError related to message formatting.
OpenInterpreter ▷ #ai-content (1 messages):
kieguin: https://huggingface.co/spaces/ysharma/Chat_with_Meta_llama3_8b
LangChain AI ▷ #general (28 messages🔥):
-
Runnable Class Usage: Members discussed using
RunnableWithMessageHistoryin LangChain, detailing its application through Python examples and emphasizing the requirement to always includesession_idin the invoke config for managing chat histories. For more in-depth guidance, the LangChain codebase and unit tests can be explored at their GitHub repository. -
Learning RAG with LangChain: A member shared their implementation of a RAG-based system utilizing LangChain ingestion and retrieval chains, directing others to a helpful YouTube playlist on how to build such systems and providing a link to their GitHub for VaultChat.
-
Handling Dates with LLM: Queries about getting the next day's date from a large language model (LLM) were answered using examples from the LangChain documentation, showing sample Python code that utilizes
AmazonAPIGatewayLLM to resolve such prompts. -
Vertex AI and Claude 3 Integration Inquiry: A member enquired about LangChain's support for Claude 3 through Google Vertex AI, suggesting that the correct API URL might be inputted to the
apiUrlparameter as per the documentation. -
Learning LLAMA 3 Functionality: A video guide titled "Learn How LLAMA 3 Works Now: The Complete Beginner’s Guide" was shared to assist those interested in understanding LLAMA 3 on YouTube.
Links mentioned:
LangChain AI ▷ #langserve (2 messages):
-
Seeking Client-side Feedback Integration: A user inquired about a tutorial for adding feedback through langserve on the client side using JavaScript. No tutorial link or further guidance was provided within the channel.
-
Dynamic PDF Upload to API for RAG Inquiry: Another member sought assistance with a method to dynamically upload PDF files to an API for retrieval-augmented generation (RAG). No solutions or suggestions were discussed in the channel.
LangChain AI ▷ #langchain-templates (1 messages):
- FstAPI route code hunt: A member inquired about locating the code for the FstAPI route within the template, specifically for pirate-speak. They experienced difficulty finding the code in the application folder for all routes and asked the community for guidance.
LangChain AI ▷ #share-your-work (3 messages):
-
Prompt Engineering Course Launched: A new course on prompt engineering with LangChain is now available on LinkedIn Learning. Details and access to the course can be found here.
-
Llama 3 Availability Announcement: Llama 3 is now hosted for those interested in experimenting with it. The chat interface can be accessed at Llama 3 Chat, and the API is available on Llama 3 API.
-
Introducing Tripplanner Bot: The newly created Tripplanner Bot utilizes langchain in conjunction with free APIs to provide location information, explore places of interest, and plan routes with multiple waypoints and transportation modes. Visit the GitHub repository for more details and contribute with suggestions or criticism.
Links mentioned:
Alignment Lab AI ▷ #ai-and-ml-discussion (3 messages):
- Spam Alert: The channel has messages promoting inappropriate content with links to external sites; these messages might be from bots or fake accounts and should be disregarded and reported.
- LLAMA 3 Model Explained: A beginner's guide video to the LLAMA 3 model, a transformer architecture in AI, has been shared. The video, titled "Learn How LLAMA 3 Works Now: The Complete Beginner’s Guide," promises to simplify understanding of the model's operations for newcomers. Watch the video here.
Links mentioned:
Alignment Lab AI ▷ #programming-help (2 messages):
- Inappropriate Content Alert: A message was posted containing a link purportedly leading to inappropriate content involving minors and a reference to OnlyFans. This kind of content is likely a violation of Discord's terms of service and community guidelines.
Link mentioned: Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
Alignment Lab AI ▷ #looking-for-collabs (2 messages):
- Inappropriate Content Alert: The channel received a message promoting NSFW content, specifically related to 'Hot Teen & Onlyfans Leaks'. The message included a Discord invite link (https://discord.gg/rj9aAQVQFX).
Link mentioned: Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
Alignment Lab AI ▷ #landmark-dev (2 messages):
- Inappropriate Content Alert: A user posted a message promoting hot teen & Onlyfans leaks with a link to a Discord server and emojis suggesting adult content. The message feels out of place and potentially violates Discord's community guidelines.
Link mentioned: Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
Alignment Lab AI ▷ #oo (6 messages):
- WizardLM-2, Now Open Source: Alpin announced the reupload of WizardLM-2 models and provided resources like the release blog, Hugging Face and GitHub repos, and related academic papers on arXiv. The community is also invited to join their Discord server.
- Meta Llama 3 Access Bound by Meta Privacy: Imonenext linked the Meta Llama 3 model, which requires agreeing to share contact information subject to the Meta Privacy Policy. The official Meta Llama 3 documentation is available at their get-started page.
- Seeking Access and Tokenizer for Meta Llama 3: Users discussed accessing Meta Llama 3-8B with Imonenext expressing a desire for the model's tokenizer.
- Meta Llama 3 Unofficially Reuploaded: Nanobitz reported that some users had already reuploaded the Meta Llama 3 model; a link to Undi95's Hugging Face repository was provided for direct access.
Links mentioned:
Alignment Lab AI ▷ #landmark-evaluation (2 messages):
- Inappropriate Link Circulating: A user posted a suspicious link that appears to advertise content related to leaked OnlyFans material and tagged everyone. The message contained emojis implying underage content.
Link mentioned: Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
Alignment Lab AI ▷ #open-orca-community-chat (3 messages):
- Spam Alert in Community Chat: A user posted a message promoting adult content and providing a shady link that was indicated to lead to Onlyfans Leaks.
- Moderation Action Required: Another member highlighted the spam incident and tagged a potential moderator suggesting that action might be needed for banning.
Link mentioned: Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
Alignment Lab AI ▷ #leaderboard (2 messages):
- Inappropriate Content Alert: A member posted a link promoting an Onlyfans Leaks community with suggestive emojis and a discord invite (https://discord.gg/rj9aAQVQFX). The post appears to violate community guidelines by linking to potentially NSFW content.
Link mentioned: Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
Alignment Lab AI ▷ #looking-for-workers (2 messages):
- Inappropriate Content Alert: A message was posted that appears to promote adult content with an invitation to a Discord server. The content of the message included suggestive emoji and a link.
Link mentioned: Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
Alignment Lab AI ▷ #looking-for-work (2 messages):
Link mentioned: Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
Alignment Lab AI ▷ #join-in (2 messages):
- Inappropriate Content Alert: The "join-in" channel contained a message promoting adult content featuring hot teens and OnlyFans leaks. The message included a Discord invite link.
Link mentioned: Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
Alignment Lab AI ▷ #fasteval-dev (2 messages):
- Spam Alert in fasteval-dev: The fasteval-dev channel received messages promoting inappropriate content related to "Hot Teen & Onlyfans Leaks". No other content or discussion points were available in the message history.
Link mentioned: Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
Alignment Lab AI ▷ #qa (2 messages):
- Inappropriate Content Alert: A message promoting adult content with a link was posted, which is likely against server and community guidelines. The message includes suggestive emoji and a call to action directed at all members.
Link mentioned: Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
Mozilla AI ▷ #llamafile (19 messages🔥):
- Compatibility and Usage of Llama 3 8b: richinseattle highlighted that llamafile-0.7 can run models with the
-m <model path>parameter. However, there are token issues with the llama3 instruct format; a Reddit discussion explains that the current llamafile and llama.cpp server bin do not support these args. - Fix in Progress for Llama 3 8b: An update to llamafile is pending that will resolve compatibility issues of Llama 3 Instruct, as seen on this GitHub pull request.
- Imminent Release of Quantized Llama 8b Version: jartine promised the release of the quantized version of llama 8b on Llamafile today, acknowledging the request from a user.
- Meta Llama 3 8B Instruct on Llamafile: jartine provided a link to Meta Llama 3 8B Instruct executable weights, also known as llamafiles, for testing on Hugging Face, cautioning about ongoing issues such as a broken stop token.
- Testing and Updates of Llamafile Models: Several users confirm successful tests of Llama 3 8b models on various systems; jartine reports to have fixed the stop token issue for the upcoming Llama 3 70b, and notes that there may be minor bugs to expect.
Links mentioned:
Skunkworks AI ▷ #finetuning (6 messages):
-
Databricks Enhances Model Serving: Databricks announced a public preview of GPU and LLM optimization support for their Model Serving, which simplifies the deployment of AI models and optimizes them for LLM serving with zero configuration. This service is a first-of-its-kind serverless GPU product on a unified data and AI platform.
-
The Cost of Innovation Might Pinch: A member humorously commented that the Databricks GPU and LLM optimization support for Model Serving is expected to be expensive.
-
Fine-Tuning LLMs Made Easier: Modal shared a guide to fine-tuning LLMs, which includes advanced techniques such as LoRA adapters, Flash Attention, gradient checkpointing, and DeepSpeed for efficient model weight adjustments.
-
Serverless Hosting for Wallet-Conscious Developers: Serverless hosting that promises to be affordable can be found in an example on GitHub (modal-examples/06_gpu_and_ml/llm-frontend/index.html) which serves as a repository offering serverless GPU hosting solutions.
-
Member Finds Serverless Inference Solution: A member expressed satisfaction upon discovering serverless inference options, indicating that it aligns with their requirements.
Links mentioned:
Skunkworks AI ▷ #off-topic (2 messages):
- Mixtral Sets New Standards: The latest Mixtral 8x22B model is hailed as a new benchmark for AI performance and efficiency according to a YouTube video. The model utilizes a sparse Mixture-of-Experts philosophy to advance the AI community.
- Meet Meta Llama 3: Facebook's new large language model, Llama 3, is introduced as a state-of-the-art open-source offering, with details available in this YouTube video and on the Meta AI blog. The model aims to push the boundaries of current large language technologies.
Links mentioned:
LLM Perf Enthusiasts AI ▷ #general (6 messages):
- LitelLM Usage Inquiry: A member expressed curiosity about whether anyone in the group uses litellm.
- Animated Tumble: A member shared a humorous gif from Tenor showing a character tumbling down stairs.
- Llama vs. Opus - Arena Showdown: Llama 3 is claimed to be superior to opus in the context of their performance on an unspecified arena, and this is achieved with a capacity of just 70b.
- Concern about Error Bounds: The error bounds in a discussion provoked a comment with a cautionary note.
- Style vs. Intelligence Debate: There was speculation on whether differences in performance are attributable to stylistic variations or actual intelligence.
Link mentioned: Falling Falling Down Stairs GIF - Falling Falling Down Stairs Stairs - Discover & Share GIFs: Click to view the GIF
Datasette - LLM (@SimonW) ▷ #ai (3 messages):
-
New Llama 3 Insights Spark Interest: A member shared a tweet by Andrej Karpathy discussing the potential of small models, particularly the unusual but welcome approach of training a model with 8B parameters on a 15T dataset. The tweet suggests that common LLMs might be undertrained by 100-1000X, encouraging a future trend of longer-trained, smaller models.
-
Anticipation for Proliferation of Smaller Models: Following the insights from Karpathy's tweet, a member expressed enthusiasm about the potential widespread application of small yet capable models like Llama 3. The member appreciates the call for developing even smaller versions, hinting at a shift towards efficiency in model training.
Datasette - LLM (@SimonW) ▷ #llm (3 messages):
-
Plugin Development Perils: A member shares a traceback error while trying to install a new plugin for llm, indicating a
ModuleNotFoundErrorforllm_web. The issue was resolved by completely uninstalling and reinstalling llm, suggesting complications with concurrent installations from brew and pipx. -
Multiple Installations Confusion: It is suggested that part of the installation problem might stem from having llm installed via both brew and pipx, causing confusion over which instance is being invoked with
which llm. -
Interesting LLM Use Case Shared: A fun use case for llm has been crossposted in the channel, with a link provided for members to explore. Link to use case.
tinygrad (George Hotz) ▷ #general (2 messages):
- LLama3 Release Announcement: A member excitedly noted that LLama3 is now available.
- LLama3 Shows Speed Improvement: They reported that LLama3 is slightly faster than PyTorch for a few models they've been working on, and confirmed compatibility with ROCm on XTX hardware.
Link mentioned: Meta Llama 3: Build the future of AI with Meta Llama 3. Now available with both 8B and 70B pretrained and instruction-tuned versions to support a wide range of applications.
AI21 Labs (Jamba) ▷ #jamba (1 messages):
- Jamba Distributed System Query: A user is encountering issues with long context inference of Jamba on a 2x A100 cluster and is seeking example code to help resolve the difficulties with the distributed system. No solutions or further discussions have been provided yet.