More experts are all you need?
DeepSeek V2 punches a hole in the Mistral Convex Hull from last month:
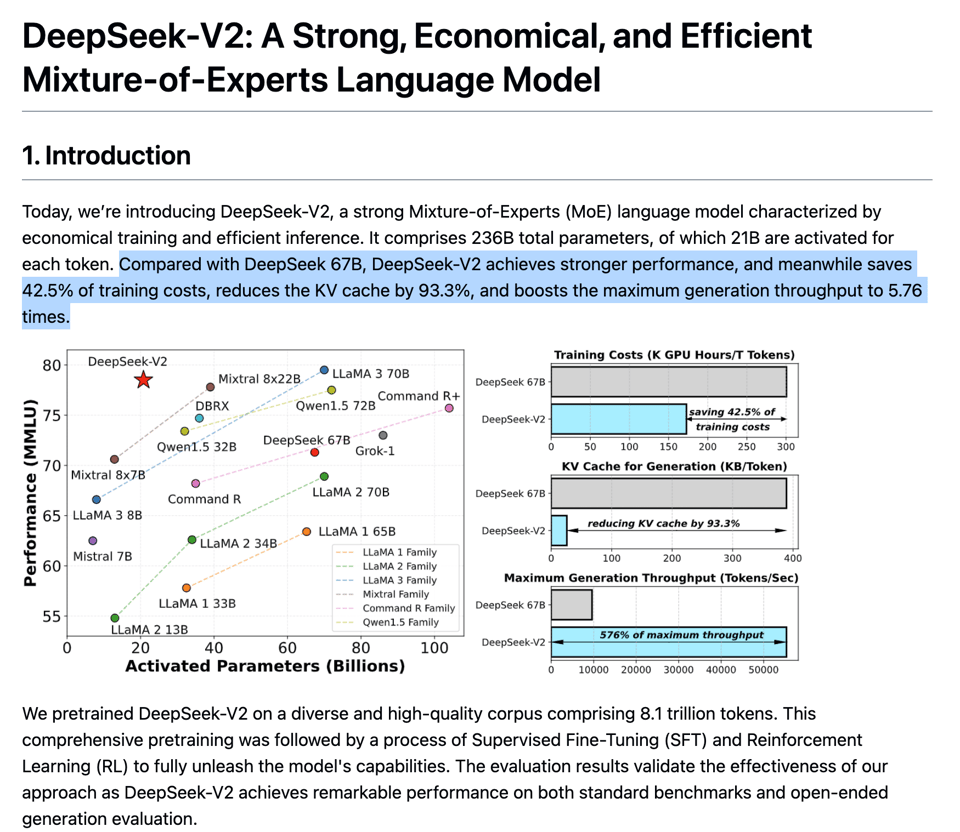
Information on dataset is extremely light; all they say is it's 8B tokens (4x more than DeepSeek v1) with about 12% more Chinese than English.
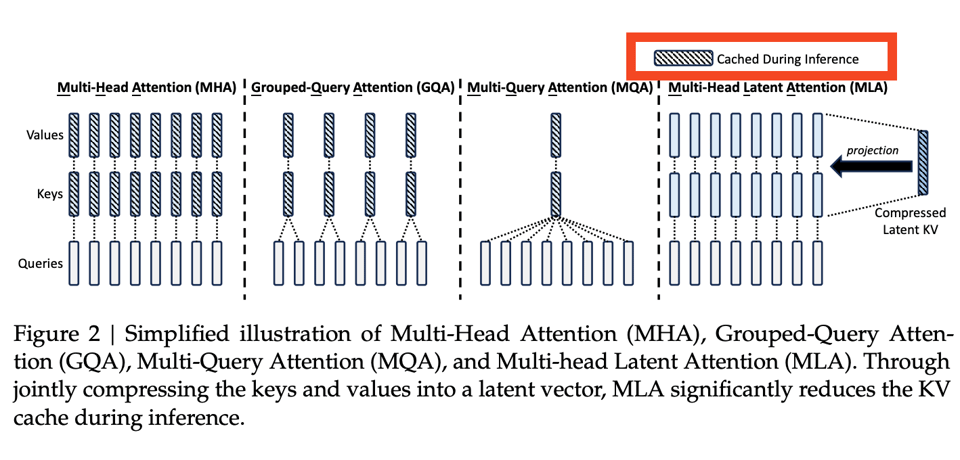
Snowflake Arctic was the last very large MoE model with the highest number of experts (128) we'd seen in the wild; DeepSeek v2 now sets a new high water mark scaling up what was already successful with DeepSeekMOE, but also introducing a new attention variant called Multi-Head Latent Attention.
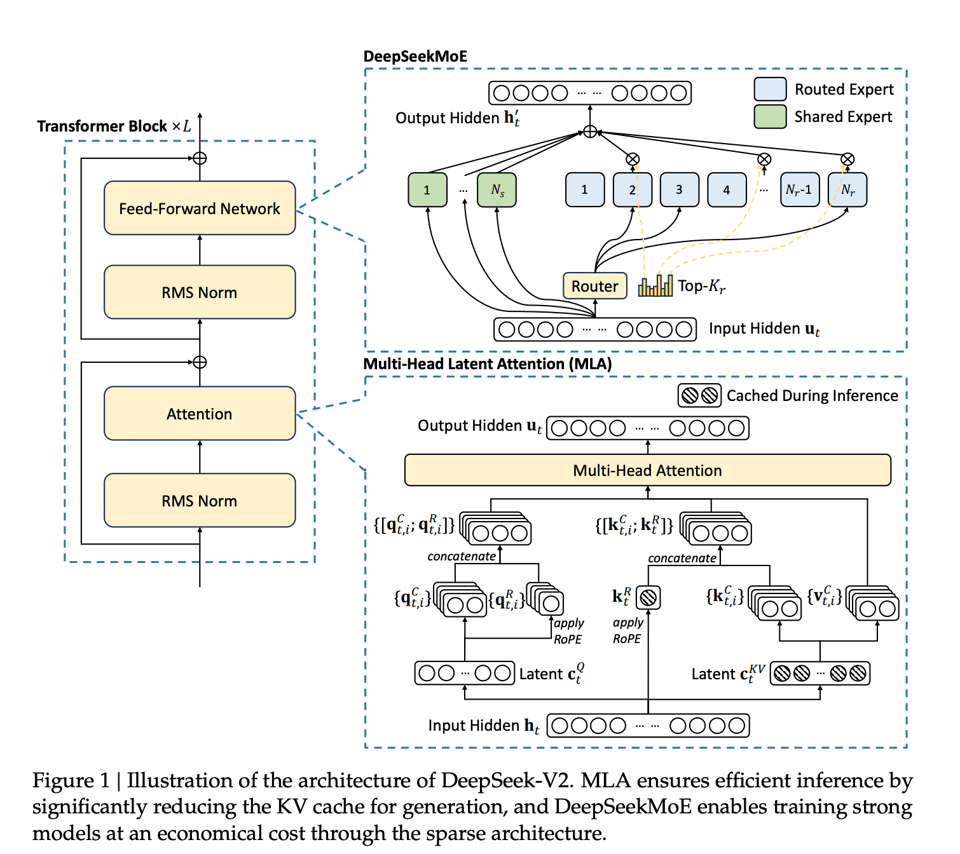
These result in much faster inference by caching compressed KVs ("reducing KV cache by 93.3%").
The paper details other minor tricks they find useful.
DeepSeek is putting their money where their mouth is - they are offering token inference on their platform for $0.28 per million tokens about half of the lowest prices seen in the Mixtral Price War of Dec 2023.
Table of Contents
[TOC]
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
LLM Developments and Releases
- Llama 3 Release: @erhartford noted that Llama 3 120B is smarter than Opus, and is very excited about llama3-400b. @maximelabonne shared that Llama 3 120B > GPT-4 in creative writing but worse than L3 70B in reasoning.
- DeepSeek-V2 Release: @deepseek_ai launched DeepSeek-V2, an open-source MoE model that places top 3 in AlignBench, surpassing GPT-4. It has 236B parameters with 21B activated during generation.
- MAI-1 500B from Microsoft: @bindureddy predicted Microsoft is training its own 500B param LLM called MAI-1, which may be previewed at their Build conference. As it becomes available, it will compete with OpenAI's GPT line.
- Mistral and Open LLMs Overfitting Benchmarks: @adcock_brett shared that Scale AI released research uncovering 'overfitting' of certain LLMs like Mistral and Phi on popular AI benchmarks, while GPT-4, Claude, Gemini, and Llama stood their ground.
Robotics and Embodied AI
- Tesla Optimus Update: @DrJimFan congratulated the Tesla Optimus team on their update, noting their human data collection farm is Optimus' biggest lead with best-in-class hands, teleoperation software, sizeable fleet, and carefully designed tasks & environments.
- Open-Source Robotics with LeRobot: @ClementDelangue welcomed LeRobot by @remicadene and team, signaling a shift towards open-source robotics AI.
- DrEureka from Nvidia: @adcock_brett shared Nvidia's 'DrEureka', an LLM agent that automates writing code to train robot skills, used to train a robot dog's skills in simulation and transfer them to real-world zero-shot.
Multimodal AI and Hallucinations
- Multimodal LLM Hallucinations Overview: @omarsar0 shared a paper that presents an overview of hallucination in multimodal LLMs, discussing recent advances in detection, evaluation, mitigation strategies, causes, benchmarks, metrics, and challenges.
- Med-Gemini from Google: @adcock_brett reported Google's introduction of Med-Gemini, a family of AI models fine-tuned for medical tasks, achieving SOTA on 10 of 14 benchmarks from text, multimodal, and long-context applications.
Emerging Architectures and Training Techniques
- Kolmogorov-Arnold Networks (KANs): @rohanpaul_ai highlighted a paper proposing KANs as alternatives to MLPs for approximating nonlinear functions, outperforming MLPs and possessing faster neural scaling laws without using linear weights.
- LoRA for Parameter-Efficient Finetuning: @rasbt implemented LoRA from scratch to train a GPT model for 98% accuracy in SPAM classification, noting LoRA as a favorite technique for parameter-efficient finetuning of LLMs.
- Hybrid LLM Approach with Expert Router: @rohanpaul_ai shared a paper on a cost-efficient hybrid LLM approach that uses an expert router to direct "easy" queries to a smaller model for cost reduction while maintaining quality.
Benchmarks, Frameworks, and Tools
- TorchScript Model Export from PyTorch Lightning: @rohanpaul_ai noted that exporting and compiling models to TorchScript from PyTorch Lightning is smooth with the
to_torchscript()method, enabling model serialization for non-Python environments. - Hugging Face Inference Endpoints with Whisper and Diarization: @_philschmid created an optimized Whisper with speaker diarization for Hugging Face Inference Endpoints, leveraging flash attention, speculative decoding, and a custom handler for 4.15s transcription of 60s audio on 1x A10G GPU.
- LangChain for Complex AI Agents: @omarsar0 shared a free 2-hour workshop on building complex AI agents using LangChain for automating tasks in customer support, marketing, technical support, sales, and content creation.
Trends, Opinions, and Discussions
- LLMs as a Commodity: @bindureddy argued that LLMs have become a commodity, and even if GPT-5 is fantastic, other major players will catch up within months. Inference prices will trend down, and the winning LLM changes every few weeks. The best strategy is to use an LLM-agnostic service and move on from foundation models to building AI agents.
- Literacy and Technology: @ylecun shared an observation on shifting attitudes towards reading and technology over time, from "why don't you plow the field instead of reading books?" in 1900 to "why don't you watch TV instead of being on your tablet?" in 2020.
- Funding Fundamental Research: @ylecun argued that almost all federal funding to universities goes to STEM and biomedical research, with very little to social science and essentially zero to humanities. Cutting these funds would "kill the golden goose" and potentially cost lives.
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity. Comment crawling works now but has lots to improve!
AI Development and Capabilities
- Tesla Optimus advancements: In /r/singularity, a new video showcases the latest capabilities of Tesla's Optimus robot, including fine tactile and force sensing in the hands. Discussions revolve around the robot's current speed limitations and potential for 24/7 operation in factories once it reaches "20x rate" of human workers.
- Sora AI video rendering: In /r/singularity, Sora, an AI system, demonstrates the ability to render a video while changing a single element, although this feature is still in the research phase and not yet publicly available.
- GPT-4 trained robo-dog: In /r/singularity, a robo-dog, trained using GPT-4, showcases its ability to maintain balance on a rolling and deflating yoga ball, demonstrating advancements in AI-powered robotics and balance control.
- Compute power and AI milestones: In /r/singularity, Microsoft CTO Kevin Scott suggests that the common factor in AI milestone achievements is the use of more compute power. Discussions on the potential for Llama 3 400b to outperform GPT-4 due to training on 25,000 H100s compared to GPT-4's reported 10,000 A100s.
- LLaMA 70B performance: In /r/singularity, a user reports running Llama 3 70B on a 7-year-old PC with a 4-year-old 3090 GPU, achieving better responses than GPT-4 and Claude 3 in some cases. The post highlights the implications of having a highly intelligent AI that doesn't require an internet connection and can provide high-quality outputs.
Societal Impact and Concerns
- Public awareness of AI-generated images: In /r/singularity, a survey reveals that half of Americans are unaware that AI can generate realistic images of people, raising questions about how many AI-generated images people have encountered without realizing it. Comments discuss the general lack of knowledge among the American public.
- AI and abundance for all: In /r/singularity, a post questions the belief that AI will lead to abundance for all, arguing that AI will likely entrench existing power structures and increase inequality. The author suggests that the transition will be gradual, with unemployment and cost of living increasing slowly over time until a catastrophe occurs.
- Warren Buffett's concerns about AI: In /r/StableDiffusion, Warren Buffett compares AI to the atomic bomb, highlighting its potential for scamming people and expressing concerns about the power of AI. Comments discuss the dual nature of AI, comparing it to the advent of electricity, with both positive and negative implications.
{kind=link}
AI Applications and Developments
- AI in medical notetaking: In /r/singularity, an Ontario family doctor reports that AI-powered notetaking has significantly improved her work and saved her job, highlighting the potential for AI to assist in medical documentation.
- Optimus hand advancements: In /r/singularity, Elon Musk announces that the new Optimus hand, set to be released later this year, will have 22 degrees of freedom (DoF), an increase from the previous 11 DoF.
- Future of AI training and inference: In /r/singularity, Nvidia CEO predicts that in the future, AI training and inference will be a single process, allowing AI to learn while interacting with users. The video is recommended as interesting content for those following AI developments.
Memes and Humor
- AI training and weird results: In /r/StableDiffusion, a meme image suggests that training AI on unusual or unconventional images leads to weird results.
- Delicate banana: In /r/StableDiffusion, a humorous image post features a delicate banana.
- Safety team suggestions: In /r/StableDiffusion, a video meme depicts a prank where a person's chair is pulled out from under them, causing them to fall. Comments discuss the dangerous nature of the prank and the potential for serious injury.
{kind=link}
{kind=link}
AI Discord Recap
A summary of Summaries of Summaries
-
Llama3 GGUF Conversion Challenges: Users encountered issues converting Llama3 models to GGUF format using llama.cpp, with training data loss unrelated to precision. Regex mismatches for new lines were identified as a potential cause, impacting platforms like ollama and lm studio. Community members are collaborating on fixes like regex modifications.
-
GPT-4 Turbo Performance Concerns: OpenAI users reported significant latency increases and confusion over message cap thresholds for GPT-4 Turbo, with some experiencing 5-10x slower response times and caps between 25-50 messages. Theories include dynamic adjustments during peak usage.
-
Stable Diffusion Installation Woes: Stability.ai community members sought help with Stable Diffusion setups failing to access GPU resources, encountering errors like "RuntimeError: Torch is not able to use GPU". Discussions also covered the lack of comprehensive, up-to-date LoRA/DreamBooth/fine-tuning tutorials.
-
Hermes 2 Pro Llama 3 Impresses with Context: Hermes 2 Pro Llama 3 showcased ~32k context on a 32GB Nvidia v100 Tesla using vLLM and RoPE scaling, with perfect 16k token recall and no degradation. Editing
config.jsonand the rope scaling factor enables extended context. -
Perplexity AI's Pages Feature Garners Attention: Perplexity AI's new Pages feature for comprehensive report creation generated buzz, while users expressed frustration over the 50 message per day limit on Claude 3 Opus compared to GPT-4 Turbo and Sonnet. Discussions also covered Perplexity's shift from unlimited to limited messages.
-
LM Studio Enables Headless Mode: LM Studio users leveraged the
lmsCLI tool for headless operation alongside the GUI, troubleshooting memory anomalies and strategizing for smooth server-side deployments without VRAM consumption via RDP. Fine-tuning bottlenecks were also discussed, with a member reporting success fine-tuning for 8 hours on a 128GB M3 Max MacBook Pro. -
CUDA Compiling and Multi-GPU Training Challenges: CUDA developers encountered issues with
nvcc 11.5throwing errors for bfloat16 operations on older GPUs, with a fix proposed to manually handle arithmetic for backward compatibility. Recent commits also caused multi-GPU training hangs, as reported in Issue #369, with a separate branch maintaining functionality. -
Mojo Compiler and Type System Evolution: Mojo's nightly compiler update brought changes to align with current practices, moving away from 80-column width and transitioning to register passable types. Discussions touched on phasing out
OptionalRegin favor of traits indicating register passability, as detailed in the changelog. -
HuggingFace Community Highlights: Notable projects in the HuggingFace community include Moondream 2 batch processing, FLUENT's newest iteration, a Portuguese translation of HF Audio course chapters, and a BLIP fine-tune for long captions. A comprehensive list is available in the community highlights.
-
Eleuther Ponders Transformer Chess Prowess: An arXiv paper showcasing a 270M parameter transformer model outperforming AlphaZero's policy and value networks in chess without domain-specific algorithms sparked discussions on the impact of scale on strategy games within the Eleuther community.
PART 1: High level Discord summaries
Unsloth AI (Daniel Han) Discord
GGUF Conversion Hiccups for Llama3: The Unsloth community encountered conversion issues with Llama3 models when using llama.cpp, notably affecting training data when transitioning to GGUF format. Issues weren't limited to FP16 conversions, implying deeper underlying problems than just precision loss.
New Lines, Big Problems: A recurrent theme in the glitches was linked to new line tokenization, with different behaviors across regex libraries leading to erratic tokenizer.json patterns. Potential solutions involving regex modifications were explored to fix the GGUF conversion challenges.
Llama Variant Takes on Genomic Data: The introduction of the LLaMA-3-8B-RDF-Experiment model by M.chimiste marks a push towards integrating LLMs with genomic data and knowledge graph construction.
Demand for Vision-Language Model Tuning Tools: Community request surfaced for a generalized method to fine-tune Language-Vision Models (LVLM), demonstrated by a member's interest in supporting Moondream, as detailed in their GitHub notebook.
Showcasing and Sharing Platform Growth: Proposals for a separate discussion channel on deploying large language models (LLMs) highlight a demand for shared learning. This aligns with showcases like Oncord's integration of Unsloth AI for web development AI tools and the release of models that enhance Llama-3 capabilities.
OpenAI Discord
Perplexity AI Pulls Ahead with Pages: Perplexity AI's new Pages feature garners attention for its ability to create comprehensive reports. Meanwhile, a healthy skepticism surrounds the potential of GPT-5 as engineers discuss the diminishing returns on investment.
AGI Concept Sparks Debate: The AI community on Discord is locked in a debate over the definition of AGI and whether AI models like ChatGPT are pioneering versions of AGI. Interest in AI-generated music indicates a growing appetite for creative AI applications, with reference to services like Udio.
Performance Frustration Hits GPT-4 Turbo: Significant increases in response latency are reported for GPT-4 Turbo, and users are seeking clarity about inconsistent message cap thresholds, suggesting possible dynamic adjustments during peak times.
Prompt Engineering Challenges and Strategies: Engineers share experiences and resources, recommend "Wordplay" by Teddy Dicus Murphy for prompt-crafting insights, and delve into the intricacies of using logit bias to manipulate token probabilities in the OpenAI API.
Fine-Tuning AI for Queries: A lively discussion revolves around fine-tuning models to generate questions rather than answers, including strategies for improving GPT-4-TURBO prompts for product information extraction, backed by a logit bias tutorial.
Stability.ai (Stable Diffusion) Discord
-
GPU Troubles Take Center Stage: Members report difficulties with Stable Diffusion installations failing to access GPU resources, highlighted by errors like "RuntimeError: Torch is not able to use GPU."
-
Stable Diffusion 3 Rumors Stir the Pot: Anticipation bubbles around the release of Stable Diffusion 3, sparking debates on the implications of its potential delay, while skeptics question its arrival altogether.
-
The Finetuning Tutorial Void: The community voices frustration over a shortage of up-to-date, comprehensive tutorials for techniques like LoRA/DreamBooth/fine-tuning, which many find are either antiquated or skimpy on details.
-
Quest for Unique Faces: A member inquires about strategies to train AI for generating unique, realistic-looking faces, wondering whether to use LoRa on multiple faces or to train on a generated random face as the foundation.
-
Open-Source Obstacles Discussed: Conversations turn to the authenticity of Stable Diffusion's open-source commitments, with concerns about potential future gatekeeping of high-quality models, checkpoints, and training intricacies.
Nous Research AI Discord
- SVMs Still Kick in AI Circles: Discord members clarified that SVM stands for Support Vector Machine amidst technical chitchat.
- Anticipation for Meta-Llama-3-120B-Instruct: The Meta-Llama-3-120B-Instruct Hugging Face model sparked discussions on its potential, with calls for comprehensive benchmarking rather than relying on mere hype.
- Deployment Dilemmas: Users debated serverless Llama limitations, whilst discussing better GPU options with sufficient VRAM, like Azure's NC80adis_H100_v5, for handling large-context task demands.
- Hermes 2's Memorable Performance: The Hermes 2 Pro Llama 8B demonstrated an impressive ~32k extended context capacity with no noticeable degradation, showing perfect recall at 16k on a 32GB Nvidia v100 Tesla.
- Cynde Contributes to Data Farming: An update on Cynde was shared, marking the completion of its core implementation. Enthusiasm for this framework for intelligence farming is evident, with Cynde's repository welcoming contributors.
Perplexity AI Discord
-
Pages Beta No More Open Applications: The beta tester application phase for Pages has concluded due to sufficient participant enrollment. Future updates on Pages will be communicated accordingly.
-
Prominent Discussions on Perplexity AI's Performance and Limitations: Members experienced slow response times with the Claude 3 model and have expressed frustration over the 50 messages per day limitation on the Claude 3 Opus model. While comparing Opus with GPT-4 Turbo and Sonnet, users also expressed concerns over Perplexity's shift from unlimited to limited message capabilities.
-
Exploring AI for Creative and Novelty Uses: The Perplexity AI community is actively exploring the platform's abilities in image generation, emulating writing styles from novels, and diverse searches such as uncovering the history of BASIC programming language or delving into Perplexity's own history.
-
API Adventures and Agile Adjustments: Users discussed model transitions, specifically from sonar-medium-online to llama-3-sonar-large-32k-online, and queried about potential billing inconsistencies. The conversation also included successes and troubles with AI result optimization and suggestions for creating a minimum-code Telegram bot using Perplexity API.
-
Multi-Channel Search Query Sharing: The community shared multiple search queries and outcomes, engendering discussions about Perplexity’s effective use and the depth of insights it can provide. Such explorations were wrapped in a variety of contexts, ranging from programming history to proprietary technological insights.
LM Studio Discord
-
Headless Cauldron Brews Progress: Engineers are utilizing LM Studio's CLI tool,
lms, for headless operation alongside GUI versions, working through memory consumption anomalies and discussing tactics for smooth server-side deployments without consuming VRAM through RDP. -
Fine-tuning Finesse & Model Mishaps: Members troubleshoot fine-tuning bottlenecks, sharing success stories of long fine-tuning sessions on hardware like the 128GB M3 Max MacBook Pro, and discuss the inconsistent output issues plaguing models like Llama 3.
-
Interactive Intents & AI Memory Quirks: Users express a confounding observation that language models might hold onto the context of deleted prompt elements, suggesting potential bugs or a misunderstanding of model behavior. They explore interactive techniques to personalize writing styles and enable "scoped access" to document parts for LLMs.
-
Role-Play Without Limits? Not So Fast: A vivid conversation sparkles around the intersection of AI and RPGs, with users aiming to train AIs as Dungeon Masters for D&D, indicating that existing systems tangle with content moderation, which can impact the story's darkness and depth.
-
ROCm Raves & Linux Enthusiasm: Updates to ROCm prove resilient, but discussions also broach the challenges converting models and sending longer sequences for embeddings. The dialog shifts toward community interest in contributing to a Linux ROCm build, hinting at further engagement if the project sought more open-source collaboration.
-
AI on the Hardware Frontier: Members plunge into heated hardware exchanges, contrasting the appropriateness of older GPUs like the Tesla P40 over the GRID K1 and geeking out on multi-GPU setup nuances for AI-centric home labs. The nitty-gritty spreads from server hardware acquisitions to cooling, power, and driver compatibility issues.
-
LM Studio's Latest Line-up: The
lmstudio-communityrepo has been updated with CodeGemma 1.1 and Nvidia's ChatQA 1.5 models, with the former eliciting keen anticipation and the latter offering specialized models tailored for context-based Q/A applications.
CUDA MODE Discord
Backpack Packs a Punch: BackPACK, a PyTorch extender for extracting additional information from backward passes, has been discussed, highlighting its potential for PyTorch developers. Details are in the publication "BackPACK: Packing more into Backprop" by Dangel et al., 2020.
DoRA Delivers on Fusion: A new fused DoRA layer implementation decreases the number of individual kernels and has been optimized for GEMM and reduction operations, detailed in a GitHub pull request. Enthusiasm was noted for upcoming benchmarks focused on these enhancements.
Custom CUDA Extensions Customization: Members discussed best practices for installing custom PyTorch/CUDA extensions, sharing multiple GitHub pull requests like PR#135 and a sample setup.py for reference, aiming for cleaner installation processes.
Streaming Ahead with CUTLASS Interest has bubbled around stream-K scheduling techniques used in CUTLASS, with suggestions of diving deeper into its workings in a future talk.
GPU Communication Goes to School: Upcoming sessions on GPU Collective Communications with NCCL have been announced, with a focus on distributed ML concepts.
Must-Read ML Systems Papers: For newcomers to machine learning systems, an ML Systems Onboarding list on GitHub provides a curated selection of informative papers.
Overcoming CUDA Compiling Conundrums: Issues with CUDA compilers like nvcc 11.5 throwing errors for operations in bfloat16 have been addressed in a fix proposal, aiming to support older GPUs and toolkits. Multi-GPU training hangs have also been discussed, linked to Issue #369, with a separate branch maintaining functionality.
LLaMa's Lean Learning: Discussions around memory efficiencies during LLaMa 2 70B model training highlighted configurations that allow for reduced memory usage. A tool named HTA was mentioned for pinpointing performance bottlenecks in PyTorch.
Post-training Peaks with Quantization: A YouTube video was shared, detailing the process and benefits of quantization in PyTorch.
GreenBitAI Goes Global: A toolkit called green-bit-llm was introduced for fine-tuning and inferencing GreenBitAI's language models. Attention was drawn to BitBlas for rapid 2-bit operation gemv kernels, along with a unique approach to calculating gradients captured in the GreenBitAI's toolkit.
Modular (Mojo 🔥) Discord
Tune in to Mojo Livestream for MAX 24.3 Updates: Modular's new livestream video titled "Modular Community Livestream - New in MAX 24.3" invites the community to explore the latest features of MAX Engine and Mojo, along with an introduction to the MAX Engine Extensibility API.
Community Projects Zoom Ahead: Noteworthy updates include NuMojo's improved performance and the introduction of Mimage for image parsing. The Basalt project also reached a milestone of 200 stars and released new documentation.
Mojo Compiler Evolves: Mojo compiler sees nightly updates with changes to better fit current practices, such as the move away from 80-column width and transitioning to types more suited for register passability.
AI Engineers Seek Don Hoffman's Consciousness Exploration: Interest in Donald Hoffman's work at UCI linked to consciousness research correlates with AI, as parallels are drawn between sensory data limitations seen in split-brain patients and AI hallucinations.
Mojo's Growing Ecosystem & Developer Guidance: Discussion on contribution processes to Mojo, inline with GitHub's pull request guidelines, and insights into the development workflow with tutorials on parameters demonstrate the active support for contributors to the rapidly expanding Mojo ecosystem.
HuggingFace Discord
Moondream and BLOOM Make Waves: The HuggingFace community has spotlighted new advancements including Moondream 2 batch processing and FLUENT's newest iteration, as well as tools for multilingual support. Particularly noteworthy is the BLOOM multilingual chat and AutoTrain's support for YAML configs, simplifying the training process for machine learning newcomers. Check out the community highlights.
When Audio Models Sing: There's interest in audio diffusion models for generative music with Whisper being fine-tuned for Filipino ASR, prompting discussions on optimization. However, a user faced challenges converting PyTorch models into TensorFlow Lite due to size limits.
AI's Frontline: Cybersecurity took center stage as the Hugging Face Twitter account was compromised, underlining the need for robust AI-related security. Members also exchanged GPU utilization tips for variance in training times between setups.
Visions of Quantum and AI Unions: In computer vision, the emphasis was on improving traditional methods like YOLO for gap detection in vehicle parts and adapting models like CLIP for image recognition with rotated objects. GhostNet's pre-trained weights were sought after, and CV members pondered the contemporary relevance of methods like SURF and SIFT.
Graph Gurus Gather: Recent papers on using LLMs with graph machine learning propose novel ways to integrate the two, with a paper](https://arxiv.org/abs/2404.19705) specifically teaching LLMs to retrieve information only when needed via the <RET> token. The reading group provided additional resources for those eager to learn more.
Showcasing Synthesis and Applied AI: From the #i-made-this section, there's the launch of tools like Podcastify and OpenGPTs-platform, along with models like shadow-clown-BioMistral-7B-DARE using mergekit.
NLPer's Quandaries and Queries: In NLP, a user offered compensation for custom training on Mistral-7B-instruct and concerns were raised about LLMs evaluating other LLMs. The GEMBA metric for translation quality using GPT 3.5+ was introduced, with a link provided to learn more.
OpenInterpreter Discord
Integrating OpenInterpreter with Groq LLM: Engineers discussed challenges with integrating Groq LLM onto Open Interpreter, highlighting issues such as uncontrollable output and erroneous file creation. The connection command shared was interpreter --api_base "https://api.groq.com/openai/v1" --api_key "YOUR_API_KEY_HERE" --model "llama3-70b-8192" -y --max_tokens 8192.
Microsoft Hackathon Seeks Open Interpreter Enthusiasts: A team is forming to participate in the Microsoft Open Source AI Hackathon utilizing Open Interpreter; the event promises to offer hands-on tutorials and the sign-up details are available here.
Open Interpreter Gets an iOS Reimagining: Discussions revolved around reimplementation of TMC protocol for iOS on Open Interpreter and troubleshooting issues with setting up with Azure Open AI models, with one member sharing a GitHub repository link for the iOS app in development here.
Local LLMs Challenge Developers: Personal testings on local LLMs like Phi-3-mini-128k-instruct were shared, indicating significant performance variances and calling out for better optimization methods in future implementations.
AI Vtuber's STT Conundrum: Implementing Speech-to-Text for AI powered virtual streamers brought up practical challenges, with engineers considering using trigger words and working towards AI-driven Twitch chat interactions through a separate LLM instance, aiming for comprehensive responses. For those tackling similar integrations, a member pointed to a main.py file on their GitHub as a resource.
Eleuther Discord
-
Chess Grandmasters Beware, Transformers Are Coming: A new study reveals a 270M parameter transformer model surpassing AlphaZero's policy and value networks in chess without domain-specific algorithms, raising questions on scale's effectiveness in strategy games.
-
LLM Research Flourishes with Multilingualism and Prompting Techniques: Research highlights include a study on LLMs handling multilingual inputs and the potential of "Maieutic Prompting" for working with inconsistent data despite skepticism about its practicality. Contributions in this area provided insights and links to papers such as How Mixture Models Handle Multilingualism and methods to counteract LLM vulnerabilities, including The Instruction Hierarchy paper.
-
Model Performance Under the Microscope: The scaling laws for transfer learning indicate that pre-trained models improve on fixed-sized datasets via effective transferred data, resonating with the community's efforts to determine accurate measures of LLM in-context learning and performance evaluation methods.
-
Interpreting Transformers and Improving Deployability: A primer and survey on interpreting transformer-based LLMs have been shared, alongside discussions on cross-model generalization. There's active interest in resolving weight tying issues in models like Phi-2 and Mistral-7B and clarifying misunderstandings regarding weight tying in notable open models.
-
Community Engagement with ICLR and Job Searches: Preparations for an in-person meet-up at ICLR are unfolding despite travel challenges, and community support is evident with members sharing employment resources and experiences from engaging with projects such as OSLO and the Polyglot team.
OpenRouter (Alex Atallah) Discord
-
New Kids on the Llama Block: The Llama 3 Lumimaid 8B model has been released with an extended version also available, while the Llama 3 8B Instruct Extended sees a price reduction. A brief downtime was announced for the Lynn models due to server updates.
-
Beta Testers Wanted for High-Stakes AI: Rubik's AI Pro, an advanced research assistant and search engine, is seeking beta testers with 2 months of premium access including models like GPT-4 Turbo and Mistral Large. The project can be accessed here with the promo code
RUBIX. -
Mix and Match Models: Community members reported that Gemini Pro is now error-free and discussed potential hosts for Lumimaid 70B. Models like Phi-3 are sought after, but availability is scarce. Model precision varies across providers, with most using fp16 and some using quantized int8.
-
Mergers and Acquisitions: A conversation highlighted a newly created self-merged version of Meta-Llama 3 70B on Hugging Face, spurring debates about the effectiveness of self-merges versus traditional layer-mapped merges.
LlamaIndex Discord
Boosting Agent Smarts: LlamaIndex 0.10.34 ushers in introspective agents capable of self-improvement through reflection mechanisms, detailed in a notebook which comes with a content warning for sensitive material.
Agentic RAG Gets an Upgrade: An informative video demonstrates the integration of LlamaParse + Firecrawl for crafting agentic RAG systems, and the release can be found through this link.
Trust-Scored RAG Responses: "Trustworthy Language Model" by @CleanlabAI introduces a scoring system for the trustworthiness of RAG responses, aiming to assure accuracy in generated content. For more insights, refer to their announcement here.
Local RAG Pipeline Handbook Hits Shelves: For developers seeking independence from cloud services, a manual for setting up a fully local RAG pipeline with LlamaIndex is unveiled, promising a deeper dive than quickstart guides and accessible here.
Hugging Face, Now Hugging LlamaIndex Tightly: LlamaIndex declares support for Hugging Face TGI, enabling optimal deployment of language models on Huggingface with enhanced features like function calling and improved latency. Shed light on TGI's new capabilities here.
Creating Conversant SQL Agents: AI engineers are contemplating the use of HyDE to craft NL-SQL bots for databases brimming with tables, eyeing ways to elevate the precision of SQL queries by the LLM; meanwhile, introspective agent methodologies are making waves, with further reading at Introspective Agents with LlamaIndex.
OpenAccess AI Collective (axolotl) Discord
Hermes 2 Pro Llama 3 Speed Test Results: Hermes 2 Pro Llama 3 has showcased impressive inference speed on an Android device with 8GB RAM, boosted by enhancements in llama.cpp.
Anime’s Role in AI Conversations: Members humorously discussed the rise of anime as it relates to increasing capabilities in AI question-answering and image generation tasks.
Gradio Customization Achievements: Adjustments in Gradio now allow dynamic configuration set through a YAML file, enabling the setting of privacy levels and server parameters programmatically.
Datasets for AI Training Spotlighted: A new dataset containing 143,327 verified Python examples (Python Dataset) and difficulties in improving mathematical performance of Llama3, even with math-centric datasets, were discussed, highlighting dataset challenges in AI training.
AI Training Platform Enhancements and Needs: There was a call to refine Axolotl's documentation, particularly regarding merging model weights and model inference, accessible at Axolotl Community Docs. Additionally, issues with gradient clipping configurations were addressed, and Phorm offered insights into customizing TrainingArguments for gradient clipping and the chatbot prompt.
Latent Space Discord
-
Gary Rocks the Ableton: A new work-in-progress Python project, gary4live, integrates Python continuations with Ableton for live music performance, inviting contributors and peer review from the community.
-
Suno Scales Up Music Production: Discussion about using Suno for music generation included comparisons with other setups like Musicgen, with an emphasis on Suno's tokenization process for audio and exploration on whether these models can automatically produce sheet music.
-
Token Talk: Engaging deeply with music model token structures, participants navigated the token length and composition in audio synthesis, referencing but not detailing specific architectural designs from academic papers.
-
Breaking Barriers in Audio Synthesis: The potential of direct audio integration into multimodal models was discussed, focusing on real-time replacement of audio channels and the importance of direct audio for enabling omnimodal functionality.
-
The Business Beat of Stable Audio: Commercial use and licensing questions surfaced regarding stable audio model outputs, with a specific eye towards their real-time application in live performances and the possible implications for industries.
AI Stack Devs (Yoko Li) Discord
-
Local Hardware Tackles AI: Users can now use llama-farm to run Ollama locally on old laptops for processing LLM tasks without exposing them to the public internet. This was also linked to a GitHub repository with more details on its implementation (llama-farm chat on GitHub).
-
AI Cloud Independence Achieved: Discussions indicated that using Faraday allows users to keep downloaded characters and models indefinitely, and running tools locally can circumvent cloud subscription fees, given a 6 GB VRAM setup. Local execution requires no subscription, acting as a potential budget-friendly option for tool usage.
-
Ubuntu Users Regain Control: Installation problems with
convex-local-backendon Ubuntu 18 were solved by downgrading to Node version 18.17.0 and updating Ubuntu as per a GitHub issue. Dockerization was proposed as a potential solution to simplify future setups. -
Simulated Realities Attract Spotlight: An AI Simulated Party was featured at Mission Control in San Francisco, blending real and digital experiences. Additionally, the AI-Westworld simulation entered public beta, and a web app called AI Town Player was launched for replaying AI Town scenarios by importing sqlite files.
-
Clipboards and Beats Converge: There was a call for collaboration to create a simulation involving hip-hop artists Kendrick and Drake. It demonstrates an interest in combining AI development with cultural commentary.
LAION Discord
CLIP vs. T5: The Model Smackdown: There's a spirited discussion about integrating CLIP and T5 encoders for training AI models; while the use of both encoders shows promise, some argue using T5 alone due to prompt adherence issues with CLIP.
Are Smaller Models the Big Deal?: In the realm of model size, enhancement of smaller models is being prioritized, as evidenced by the focus on the 400M DeepFloyd, with technical conversations touching upon the challenges in scaling up to 8B models.
Releasing SD3: Keep 'Em Waiting or Drop 'Em All?: The community's reaction to Stability AI's hinted gradual rollout of SD3 models—from small to large—was a mix of skepticism and eagerness, reflecting on whether this release strategy meets the community's anticipation.
LLama Embeds Strut into the Spotlight: Debates over the efficacy of using LLama embeds in model training emerged, with some members advocating for their use over T5 embeds, and sharing resources like the LaVi-Bridge to illustrate modern applications.
From Concept to Application: A Data Debate: The conversation dove into why synthetic datasets are favored in certain research over real-world datasets such as MNIST and ImageNet, alluding to the value of interpretability in AI methods and sharing resources like the StoryDiffusion website for insights.
LangChain AI Discord
Code Execution Finds an AI Buddy: Enthusiastic dialogues emerged around using AI to execute generated code, highlighting methods like Open Interpreter and developing custom tools such as CLITOOL. These discussions are pivotal for those crafting more interactive and automated systems.
Langchain Learns a New Language: The Langchain library's expansion into the Java ecosystem via langchain4j marks a crucial step for Java developers keen to harness AI assistant capabilities.
Langchain Gets a High-Performance Polish: The coupling of LangChain and Dragonfly has yielded impressive enhancements in chatbot context management, as depicted in a blog post detailing these advancements.
Decentralized Search Innovations: The community is buzzing with the development of a decentralized search feature for LangChain, promising to boost search functionalities with a user-owned index network. The work is showcased in a recent tweet.
Singularity Spaces with Llama & LangGraph: A contributor shared a video on Retrieval-Augmented Generation techniques without a vectorstore using Llama 3, while another enriches the dialogue with a comparison between LangGraph and LangChain Core in the execution realm.
tinygrad (George Hotz) Discord
Clojure Captures Engineer's Interest in Symbolic Programming: Engineers are discussing the ease of using Clojure for symbolic programming compared to Python, suggesting the use of bounties to ramp up on tinygrad, and debating the merits of Julia over Clojure in the ML/AI space.
tinygrad's UOps Puzzle Engineers: A call for proposals was made to reformat tinygrad's textual UOps representation to be more understandable, potentially resembling llvm IR, alongside an explanation that these UOps are indeed a form of Static Single Assignment (SSA).
Optimizing tinygrad for Qualcomm's GPU Playground: It was highlighted that tinygrad runs efficiently on Qualcomm GPUs by utilizing textures and pixel shaders, with the caveat that activating DSP support might complicate the process.
Single-threaded CPU Story in tinygrad: Confirmation from George Hotz himself that tinygrad operates single-threaded on the CPU side, with no threads bumping into each other.
Understanding tinygrad's Tensor Tango: A user's curiosity about the matmul function and transposing tensors spurred explanations, and another user shared their written breakdown on computing symbolic mean within tinygrad.
Mozilla AI Discord
-
Json\Schema Skips a Beat with llamafile: A clash between
json_schemaand llamafile 0.8.1 prompted discussions, with a workaround using--unsecuresuggested and hints of a permanent fix in upcoming versions. -
In Search of Leaner Machine Learning Models: The community exchanged ideas on lightweight AI models, where phi 3 mini was deemed too heavy and Rocket-3B was suggested for its agility on low-resource systems.
-
Clubbing Caches for Llamafile: It was confirmed that llamafile can indeed utilize models from the ollama cache, potentially streamlining operations by avoiding repeated downloads, providing that GGUF file compatibility is maintained.
-
AutoGPT Goes Hand-in-Hand with Llamafile: An integration initiative was shared, highlighting a draft pull request to meld llamafile with AutoGPT; setup instructions were posted at AutoGPT/llamafile-integration, pending maintainer feedback.
-
Choosing the Right Local Models for Llamafile: Real-time problem-solving was spotlighted as a user managed to get llamafile up and running with locally cached .gguf files after distinguishing between actual model files and metadata.
DiscoResearch Discord
Mixtral Woes Spiral: The mixtral transformers hit a snag due to bugs impacting finetune performance; references include Twitter, Gist, and a closed GitHub PR. There's ambiguity whether the bug affects only training or generation as well, necessitating further scrutiny.
Quantized LLaMA-3 Takes a Hit: A Reddit post reveals quantization deteriorates LLaMA-3's performance notably compared to LLaMA-2, with a potentially enlightening arXiv study available. Meta's scaling strategy may account for LLaMA-3's precision reduction woes, while GitHub PR #6936 and Issue #7088 discuss potential fixes.
Meet the New Model on the Block: Conversations indicate 8x22b Mistral is being leveraged for current engineering tasks, though no performance metrics or usage specifics were disclosed.
Interconnects (Nathan Lambert) Discord
-
AI Voices: So Real It's Unreal: The Atlantic published an article discussing how ElevenLabs has created advanced AI voice cloning technology. Users expressed both fascinated and wary reactions to ElevenLabs' capabilities, with one showing disdain towards paywalls that limit full access to such content.
-
Prometheus 2: Judging the Judges: A recent arXiv publication introduced Prometheus 2, a language model evaluator aligned with human and GPT-4 judgments, targeting transparency and affordability issues in proprietary language models. Although the paper notably omitted RewardBench scores where the model underperformed, there is keen interest in the community to test Prometheus 2's evaluation prowess.
-
Enigma of Classical RL: Conversations in the rl channel featured curiosity about unexplored areas in classical reinforcement learning. Discussion put a spotlight on the importance of the value function in approaches like PPO and DPO, and emphasized its critical role in planning within RL systems.
-
The Mystery of John's Ambiguity: In the random channel, members shared cryptic concerns about repeated success and joked about a certain "john's" ambiguous response to a proposal. The relevance and context behind these statements remained unclear.
LLM Perf Enthusiasts AI Discord
- Anthropic's Prompt Generator Makes Waves: Engineers discussed a new prompt generator tool available in the Anthropic console, which may be useful for those seeking efficient ways to generate prompts.
- Politeness Mode Test Run: The tool's capability to rephrase sentences politely was tested, producing results that were well-received by members.
- Deciphering the System's Mechanics: Efforts are underway to understand how the tool's system prompt operates, with a focus on unraveling the secrets of the k-shot examples embedded within.
- Extracting the Long Game: There have been challenges in extracting complete data from the tool, with reports of system prompts being truncated, particularly during the extended Socratic math tutor example.
- Leak the Secrets: A commitment was made to share the full system prompt with the community once it has been successfully extracted in its entirety, which could be a resource for those interested in prompt engineering.
Skunkworks AI Discord
- Fake It 'til You Make It: A member is on the lookout for a dataset of fabricated data aimed at testing fine-tuning on Llama 3 and Phi3 models, implying that authenticity is not a requirement for their experiments.
- Accelerating AI with Fast Compute: Fast compute grants are up for grabs for Skunkworks AI projects that show promise, with further details available in a recent tweet.
- Educational AI Content on YouTube: An AI-related educational YouTube video was shared, potentially adding value to the community’s ongoing technical discussions.
Datasette - LLM (@SimonW) Discord
- LLM Turns Error Logs into Enlightenment: An approach that utilizes LLM to swiftly summarize errors after running a
conda activatecommand has proven effective, with suggestions to integrate the method into the LLM README documentation. - Bash Magic Meets LLM Insights: A newly crafted
llm-errbash function is on the table, designed to feed command outputs directly into LLM for quick error diagnosis, further streamlining error troubleshooting for engineers.
Cohere Discord
- Calling AI Experts in Austin: A friendly hello was extended to AI professionals located in Austin, TX.
- Finexov's Funding Frontier: Vivien introduced Finexov, an AI platform aimed at simplifying the identification of R&D funding opportunities, already active with initial partnerships and support from the Founder Institute (fi.co).
- Tech Leadership Hunt for Finexov: Seeking a CTO co-founder with a strong ML background to pilot Finexov and gear up for the challenges of team-building and fundraising; preference for candidates based in Europe or Middle East, French speakers are a bonus.
- Dubai Meetup on the Horizon: Vivien signals a potential meetup in Dubai this June, inviting potential collaborators to discuss opportunities with Finexov.
AI21 Labs (Jamba) Discord
- AI21 Labs Pushes the Envelope: AI21 Labs indicated their ambition to expand their technology further. The staff encouraged community members to share their use cases and insights through direct messages.
Alignment Lab AI Discord
- Get Your Compute Loading: Interested parties have a chance to gain fast compute grants; a tweet shared by a member calls for applications or nominations to award compute resources, beneficial for AI research and projects. Check out the tweet for details.
PART 2: Detailed by-Channel summaries and links
Unsloth AI (Daniel Han) ▷ #general (791 messages🔥🔥🔥):
-
Discussions on Llama3 finetuning and GGUF conversion: Users have been experimenting with finetuning Llama3 using Unsloth, and converting the finetuned models to GGUF with various outcomes. Some reported issues with infinite generation post-conversion and were directed to keep tabs on a GitHub issue highlighting problems with models converted to GGUF.
-
Inquiries on full finetuning with Unsloth: A user was curious about the possibility of full finetuning (not just LoRA) using Unsloth, leading to discussions about possible VRAM savings and performance. Unsloth community members provided insights into how to potentially achieve this, referencing a GitHub feature request.
-
Investigation into performance of heavily quantized models: A user questioned the effectiveness of heavy quantization like 4 Bit Q2_K for a 7B model, with the recommendation to possibly use Phi-3 instead for low resource applications, underscoring the importance of choosing the right quant level for model performance.
-
Sharing of resources and troubleshooting Unsloth: Users shared their experiences and offered advice on cloud providers like Tensordock for running Unsloth models, the usage of Unsloth Studio, as well as general tips on dealing with finetune datasets, quantization effects, and the use of different inference engines.
-
Uncertainties about fine-tuning low-resource languages with LLMS: A user considering fine-tuning with LLMs for low-resource languages sought advice on the efficacy of LLMs versus models like T5. Community discussion highlighted the potential of models like Phi-3 for such tasks, with contributions addressing how to handle different aspects of the fine-tuning process.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #random (107 messages🔥🔥):
- Graphic Content Alert with LLaMA3: A user reported inappropriate and graphic content generated by LLaMa3 when prompted with an obscene query, questioning the level of censorship in the model. Another user found similar results, even when using system prompts to prevent such responses.
- Fancy New Roles for Supporters: In a brief confusion about support roles, a user learned that there is a new "regulars" role, and private supporter channels are available for those who become members or donate at least $10.
- RTX 4090 Gets a Suprim(ary) Deal: A new graphics card deals discussion highlighted the MSi GeForce RTX 4090 SUPRIM LIQUID X on sale for $1549, with a user urging others to take advantage of the offer. The card's compact size compared to other models sparked further debate.
- Kendrick vs. Drake Dynamic: Users discussed the recent developments in the Kendrick Lamar and Drake beef, indicating that Kendrick's track "Meet the Grahams" was released shortly after Drake's "Family Ties" causing a significant stir in the rap world.
- Unsloth.ai on YouTube: A conversation thread involved a user congratulating another on presenting to the PyTorch team, directing them to a YouTube video from Unsloth.ai, hinting at further updates to be posted soon.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #help (1215 messages🔥🔥🔥):
- Llama3 GGUF Conversion Issues Pinned Down: Users found that GGUF conversion for Llama3 models using llama.cpp fails, resulting in altered or lost training data with no clear pattern of loss, regardless of using FP16 or FP32 conversion methods. These abnormalities occur even in F32, proving the issue is not tied to precision loss.
- Possible Regex Mismatch for New Lines: The problem may link to a regex library issue where
\nsequences are improperly tokenized, potentially due to different regex library behaviors. The suggested fix modifies the tokenizer.json regex pattern for more compatibility across regex libraries, but concerns remain about the impact on different '\n' lengths. - Issues Exist Beyond GGUF: Similar inference issues were found with AWQ in applications like ooba, pointing towards tokenizer or tokenization issues beyond just GGUF formatting. Unsloth's inference function seems to perform well, hinting at problems possibly specific to llama.cpp.
- Multiple Platforms Impacted: Platforms dependent on llama.cpp like ollama, and lm studio also face related bugs, with tokenization problems reported across different interfaces and potentially affecting a wide range of users and applications.
- Community Cooperation Towards Solutions: User contributions, including regex modifications, are being discussed and tested to provide temporary fixes for the gguf conversion troubles, with a focus on narrowing down whether issues are specific to the Unsloth fine-tuning process or the llama.cpp tokenization method.
Links mentioned:
-
Moved regex patterns to unicode.cpp and updated unicode.h
-
Moved header files
-
Resolved issues
-
added and refactored unic...GGUF breaks - llama-3 · Issue #430 · unslothai/unsloth: Findings from ggerganov/llama.cpp#7062 and Discord chats: Notebook for repro: https://colab.research.google.com/drive/1djwQGbEJtUEZo_OuqzN_JF6xSOUKhm4q?usp=sharing Unsloth + float16 + QLoRA = WORKS...Home: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unslothreadme : add note that LLaMA 3 is not supported with convert.py (#7065) · ggerganov/llama.cpp@ca36326: no description foundHome: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unslothI got unsloth running in native windows. · Issue #210 · unslothai/unsloth: I got unsloth running in native windows, (no wsl). You need visual studio 2022 c++ compiler, triton, and deepspeed. I have a full tutorial on installing it, I would write it all here but I’m on mob...Cannot convert llama3 8b model to gguf · Issue #7021 · ggerganov/llama.cpp: Please include information about your system, the steps to reproduce the bug, and the version of llama.cpp that you are using. If possible, please provide a minimal code example that reproduces the...GitHub - ggerganov/llama.cpp at gg/bpe-preprocess: LLM inference in C/C++. Contribute to ggerganov/llama.cpp development by creating an account on GitHub.llama3 custom regex split by jaime-m-p · Pull Request #6965 · ggerganov/llama.cpp: Implementation of unicode_regex_split_custom_llama3().Llama3 GGUF conversion with merged LORA Adapter seems to lose training data randomly · Issue #7062 · ggerganov/llama.cpp: I'm running Unsloth to fine tune LORA the Instruct model on llama3-8b . 1: I merge the model with the LORA adapter into safetensors 2: Running inference in python both with the merged model direct...Llama3 GGUF conversion with merged LORA Adapter seems to lose training data randomly · Issue #7062 · ggerganov/llama.cpp: I'm running Unsloth to fine tune LORA the Instruct model on llama3-8b . 1: I merge the model with the LORA adapter into safetensors 2: Running inference in python both with the merged model direct...Llama3 GGUF conversion with merged LORA Adapter seems to lose training data randomly · Issue #7062 · ggerganov/llama.cpp: I'm running Unsloth to fine tune LORA the Instruct model on llama3-8b . 1: I merge the model with the LORA adapter into safetensors 2: Running inference in python both with the merged model direct...Llama3 GGUF conversion with merged LORA Adapter seems to lose training data randomly · Issue #7062 · ggerganov/llama.cpp: I'm running Unsloth to fine tune LORA the Instruct model on llama3-8b . 1: I merge the model with the LORA adapter into safetensors 2: Running inference in python both with the merged model direct...Llama3 GGUF conversion with merged LORA Adapter seems to lose training data randomly · Issue #7062 · ggerganov/llama.cpp: I'm running Unsloth to fine tune LORA the Instruct model on llama3-8b . 1: I merge the model with the LORA adapter into safetensors 2: Running inference in python both with the merged model direct...llama.cpp/convert.py at master · ggerganov/llama.cpp: LLM inference in C/C++. Contribute to ggerganov/llama.cpp development by creating an account on GitHub.Llama3 GGUF conversion with merged LORA Adapter seems to lose training data randomly · Issue #7062 · ggerganov/llama.cpp: I'm running Unsloth to fine tune LORA the Instruct model on llama3-8b . 1: I merge the model with the LORA adapter into safetensors 2: Running inference in python both with the merged model direct...Llama3 GGUF conversion with merged LORA Adapter seems to lose training data randomly · Issue #7062 · ggerganov/llama.cpp: I'm running Unsloth to fine tune LORA the Instruct model on llama3-8b . 1: I merge the model with the LORA adapter into safetensors 2: Running inference in python both with the merged model direct...
Unsloth AI (Daniel Han) ▷ #showcase (80 messages🔥🔥):
-
Proposal for Model Size Discussion Channel: A user suggested creating a separate channel on Unsloth Discord for discussing the successes and strategies in deploying large language models (LLMs). The conversation emphasized the value of sharing experiences to enhance collective learning.
-
Push for Llama-3-8B-Based Projects: RomboDawg announced the release of a new coding model that enhances Llama-3-8B-Instruct and competes with Llama-3-70B-Instruct performance. The model can be accessed here, and excitement for a version 2, promised to be available in about three days, was expressed.
-
Knowledge Graph LLM Variant Released: M.chimiste has developed a Llama-3 variant to assist in knowledge graph construction, named LLaMA-3-8B-RDF-Experiment, emphasizing its utility in generating knowledge graph triples and potential for genomic data training. The model can be found at Hugging Face's model repository.
-
On the Horizon of Creptographic Collaborations: In an extended discussion, one user is seeking advice and collaborative discussion about building a system that could potentially integrate cryptographic elements into blockchain technologies, expressing interest in learning from the community.
-
AI-Enhanced Web Development Tools Theme: Oncord is showcased as providing a modern web development platform with built-in marketing and commerce tools, and its developer is integrating Unsloth AI for LLM fine-tuning to provide code completions and potentially power an AI-driven redesign feature. More about Oncord can be found here.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #suggestions (3 messages):
-
Fine-tuning LVLM Desired: A member expressed a wish for a generalised way of fine-tuning LVLM, indicating ongoing interest in customization and optimization of language-vision models.
-
MoonDream Fine-tuning Interest: Another member recommended support for Moondream, a tiny vision-language model which currently only finetunes the phi 1.5 text model. They provided a GitHub notebook as a resource: moondream/notebooks/Finetuning.ipynb on GitHub.
Link mentioned: moondream/notebooks/Finetuning.ipynb at main · vikhyat/moondream: tiny vision language model. Contribute to vikhyat/moondream development by creating an account on GitHub.
OpenAI ▷ #ai-discussions (854 messages🔥🔥🔥):
- A New Challenger Approaches Perplexity: Users are discussing the benefits of Perplexity AI, particularly its new Pages feature which allows for creation of comprehensive reports.
- AI and Self-Learning: Some discuss the possibility of AI engines like OpenAI's GPT to teach programming basics to users and help in creating code, espousing the idea of self-sufficient AIs with the capacity for self-improvement.
- The Evolving Definition of AGI: The community is engaging in a debate about the current state of AI and its proximity to true AGI (Artificial General Intelligence), with varying opinions on whether modern AI like ChatGPT qualifies as early AGI.
- Appetite for AI-Generated Music: Users express interest in AI-generated music, referencing services like Udio and discussing whether OpenAI should release its own AI music service.
- AI as a Tool for Expansion: The conversation explores how AI currently augments human productivity and the potential future where AI might take over mundane and complex tasks, also reflecting on how this might disrupt our socio-economic models.
Links mentioned:
OpenAI ▷ #gpt-4-discussions (40 messages🔥):
- Slow and Steady Doesn't Win the Race: Members are reporting significant increases in latency with GPT-4 Turbo, with some experiencing response times 5-10x slower than usual.
- The Cap on Conversation: There's confusion around the message cap for GPT-4, as users report different timeout thresholds. Some state a cap between 25 and 50 messages, while others suspect dynamic adjustments during high usage periods.
- OpenAI Platform's UX Blues: Complaints have emerged about the user experience on OpenAI's new projects feature, with issues in project management, deletion, and navigability; also noting an absence of activity tracking per project.
- Will There Be a GPT-5? Users are skeptical about the release of GPT-5, discussing diminishing returns and the likelihood that it would be "2x the cost for 1.5x better GPT-4".
- The Hunt for Knowledge Prioritization: Users debate strategies to make ChatGPT search its knowledge base first before responding, touching on concepts like RAG (Retrieval-Augmented Generation) and the vectorization of knowledge to assist in providing contextually relevant answers.
OpenAI ▷ #prompt-engineering (30 messages🔥):
-
Fine-tuning GPT for Questioning: A member is seeking advice on how to fine-tune a model to ask questions instead of giving answers, mentioning previous struggles with a similar project. They note difficulty finding appropriate user query and assistant query pairs and are considering using single tuple chats as samples for fine-tuning.
-
The Resilient Onboarding Bot: Member leveloper mentions a successfully functioning bot designed to ask questions during an onboarding process, which remains untricked by user attempts despite being on a large server.
-
Avoiding Negative Prompts: majestic_axolotl_19289 suggests that using negative prompts can backfire, as they tend to influence the outcome in unintended ways. Other members discuss whether negative prompts can be effective, citing the "Contrastive Chain of Thoughts" paper and personal experiences.
-
Book Recommendation for Prompt Engineering: Member sephyfox_ recommends "Wordplay: Your Guide to Using Artificial Intelligence for Writing Software" by Teddy Dicus Murphy, finding it helpful for prompt engineering.
-
Request for Improving GPT-4-TURBO Prompt for Product Info Extraction: Member stevenli_36050 seeks assistance in refining a prompt to extract product information, names, and prices from PDF supermarket brochures and categorize them accordingly.
-
Discussing Logit Bias in Token Suppression: The user bambooshoots shares a link (https://help.openai.com/en/articles/5247780-using-logit-bias-to-alter-token-probability-with-the-openai-api) about manipulating probabilities using logit bias to suppress certain tokens in the OpenAI API.
OpenAI ▷ #api-discussions (30 messages🔥):
-
In Search of the Questioning Bot: A member discussed the challenge of fine-tuning GPT for generating questions in conversations rather than providing answers, highlighting the difficulty in defining the structure of user queries and bot responses in such scenarios.
-
Contrastive Chain of Thought (CCoT) Discourse: There was a debate on the use of negative prompts in prompting strategies. The conversation mentioned a paper on "Contrastive Chain of Thoughts" and questioned the effectiveness of using CCoT in longer dialogs, prompting an invitation to read further on the AIEmpower blog.
-
Prompt Engineering Resources and Techniques Shared: Users shared resources about prompt engineering, including a recommendation for the book "Wordplay: Your Guide to Using Artificial Intelligence for Writing Software" by Teddy Dicus Murry and a LinkedIn learning course by Ronnie Sheer.
-
Extracting Supermarket Product Data: A user sought advice on improving GPT-4-TURBO prompts for identifying product names and prices from PDF supermarket brochures, seeking to output the results in CSV format.
-
Logit Bias for Token Probability Manipulation: A member referenced the logit bias as a method for manipulating token probabilities in prompts with a link to OpenAI's official documentation: Using logit bias to alter token probability with the OpenAI API.
Stability.ai (Stable Diffusion) ▷ #general-chat (919 messages🔥🔥🔥):
- GPU Compatibility Queries: Users are asking for assistance with Stable Diffusion installations that can't access GPU resources, mentioning errors like "RuntimeError: Torch is not able to use GPU".
- Stability.ai and SD3 Speculation: Conversations revolve around the anticipated release of Stable Diffusion 3, with many expressing doubt it will come out, while others discuss the impact if it doesn't.
- Finetuning Tutorials Seekers: Members express frustration over the lack of detailed tutorials for LoRA/DreamBooth/fine-tuning models, stating that available resources are outdated or not comprehensive.
- Request for Help on Generating Unique Faces: A query was made on how to train a unique realistic-looking person using AI, either through training LoRa on multiple faces or generating random ones and then training the LoRa on that result.
- Discussion on the 'Open Source' Nature of Stable Diffusion: Some users discuss the barriers to truly "open-source" AI art generation, sharing concerns about future paywalled access to high-quality model checkpoints and training details.
Links mentioned:
Nous Research AI ▷ #ctx-length-research (1 messages):
I apologize for the confusion, but as an AI, I do not have direct access to Discord servers, channels, or messages. Thus, I am unable to summarize the content from the Nous Research AI Discord channel named ctx-length-research. If you can provide the text from specific Discord messages that you'd like to be summarized, I'd be happy to assist you.
Nous Research AI ▷ #off-topic (20 messages🔥):
- Color Evolution on Camera: A member humorously noted that comparing images of Saint Petersburg, Ligovsky Avenue at Vosstaniya Square from 2002 and 2024 shows that cameras have gotten more color accurate.
- Culinary Flavor Fusion: A simple mention was made of Okroshka on kvas with mayonnaise accompanied by rye bread, possibly suggesting a discussion or reference to traditional Russian cuisine.
- Inquiry About SVM: A member asked, "What is SVM?" to which another member quickly clarified that SVM stands for Support Vector Machine.
- Improve the UX for FreeGPT.today: A member requested feedback on the user experience for their site FreeGPT.today, inviting others to sign up, chat, and test a PDF upload feature that generates graphs. Several suggestions for improvement were offered, including adding Google authentication, changing the default login landing page to "chat now," improving UI elements, and implementing a progress bar for file uploads.
- Beware of Spam Links: A mention was made that a Discord invite link shared in the chat was actually spam and led to the sharer getting banned.
Links mentioned:
Nous Research AI ▷ #interesting-links (47 messages🔥):
- Exploring Taskmaster with LLM: A code implementation of the show Taskmaster using structured data management, a state machine, and the OpenAI API was shared. The code is available on GitHub.
- Evaluating LLM Responses: Another GitHub repository was introduced featuring Prometheus, a tool for evaluating LLM responses, available at prometheus-eval.
- VRAM Consumption Calculator for LLMs: A Hugging Face space was mentioned which contains an LLM Model VRAM Calculator, to help users determine how much VRAM they'll require, viewable here.
- Fixing Mistral Model Issues: Discussions focused on fixing issues with the Mistral model and potential Pull Requests (PRs) to address these were highlighted. The ongoing conversation about modifications, particularly around the rotary embeddings, finds its latest relevant PR on GitHub.
- Improvements and Issues with Open Pretrain Datasets: A recent paper examining the quality of training corpora used for language models was mentioned. The study discussed the prevalence of duplicate, synthetic, and low-quality content in these datasets, with details available in their arXiv paper.
Links mentioned:
Nous Research AI ▷ #general (717 messages🔥🔥🔥):
-
Hermes Overperformance with Classic Llama Scaling: Hermes 2 Pro Llama 8B gained extended context capacity to ~32k using RoPE scaling with vLLM on a 32GB Nvidia v100 Tesla and showed no noticeable degradation, providing perfect recall at 16k according to users’ experiences.
-
Setting Up Enhanced Context: Editing the
config.jsonin the Hermes model from Hugging Face and tweaking the rope scaling factor before initializing the server is suggested for context extension. -
Serverless Llama Limitations: Users report different capabilities and limitations across model inference providers, with the need to coordinate features such as grammar and JSON mode, which is only supported in llama.cpp, not in vLLM according to discussions on the vLLM GitHub issues page.
-
High Anticipation for Llama-3-120B-Instruct: A Hugging Face model titled Meta-Llama-3-120B-Instruct, a self-merged model, has garnered attention and interest for its supposed increased performance; however, some users caution about believing the hype without thorough benchmarking.
-
Balancing Compute Resources and Model Performance: Users discuss the trade-offs of using beefier GPUs, such as Azure's NC80adis_H100_v5, and the balance between sufficient VRAM, latency, and tokens per second for practical use in tasks requiring large context sizes.
Links mentioned:
Nous Research AI ▷ #ask-about-llms (60 messages🔥🔥):
- LLMs Garner Enthusiasm: A member expressed delight in experimenting with a local AI, sharing their first enjoyable experience with the platform.
- Hermes 2 Pro Llama 3 vs. Mistral: Discussion evolved around Hermes 2 Pro Llama 3 underperforming compared to Mistral, sparking insights that Mixtral's larger model size contributes to its higher ranking, particularly in the MMLU benchmark.
- Understanding LLaVA's Multimodal Capabilities: In relation to teaching GPT/LLMs about images, members were directed to explore LLaVA, a large multimodal model with enhanced visual and language understanding that outperforms on 11 benchmarks.
- Tool XML Tag Troubles in Text Generation: There was an exchange about an issue when migrating to LlamaCPP where
<tool_call>xml tags were not generated, later resolved by updating LlamaCPP to the latest version. - Speed Woes with LoRA Llama 3 8B Training: A member inquired about the seemingly excessive duration for LoRA training on Llama 3 8B, contrasting it with far speedier experiences reported by others using different setups.
Links mentioned:
Nous Research AI ▷ #rag-dataset (2 messages):
-
Seeking Free Datasets: A member inquired about sources for good free generic datasets.
-
Cynde Core Implementation Update: An update on Cynde, a framework for intelligence farming, was shared. The core implementation is in place, and the contributor is open to help and efforts to maintain code cleanliness, stating there is no inclusion of RAG on purpose yet. The updated readme and notes are available at Neural-Dragon-AI/Cynde.
Link mentioned: Cynde/README.md at main · Neural-Dragon-AI/Cynde: A Framework For Intelligence Farming. Contribute to Neural-Dragon-AI/Cynde development by creating an account on GitHub.
Nous Research AI ▷ #world-sim (74 messages🔥🔥):
- Anticipation for World-Sim's Return: Members express excitement and inquiry about their role assignments in anticipation of potentially testing a new version of world-sim, with one member particularly excited because it coincides with their birthday.
- Philosophical Grounding in AI: There's a back-and-forth on the philosophical takes of Joscha and the cringe associated with philosophers reaching with bad takes due to A(G)I developments; specific cringe-worthy takes were not detailed.
- Cosmic Scale World-building: Member @amiramogus_90887 discusses the narrative layers of their project involving descendants of humanity, transcendental Minds, and galaxy spanning simulations run by the Brainers, showcasing expansive world-building concepts utilizing websim.ai.
- Ethical Considerations in Simulations: A member discusses the ethical implications of creating simulations, suggesting empathy for possible sentient entities within these simulations, while another member proposes mutual alignment and shared meta-reality explorations when interacting with AI.
- Sharing World Sim Projects & Volunteer Sign-Up: Several members share links to their world-sim related projects and others ask to sign up as volunteers, with one sharing a link they found on Twitter for what appears to be another world-sim project.
Links mentioned:
Perplexity AI ▷ #announcements (1 messages):
- Beta Testers Locked In: The Pages beta tester application is now closed, having attracted enough participants. Further updates on the development of Pages will be shared moving forward.
Perplexity AI ▷ #general (814 messages🔥🔥🔥):
-
Perplexity Performance Queries: Users reported slow responses from Perplexity AI, particularly with Claude 3, noting unusual delay when generating answers. Troubleshooting included examining internet connectivity and testing across different devices and browsers.
-
Opus Use Limits Discussion: The conversation focused on the limitation of Claude 3 Opus model usage to 50 messages per day. Several users expressed frustration and discussed alternatives, comparing Opus' capabilities for creativity and coding with GPT-4 Turbo and Sonnet.
-
Image Generation Inquiry: A user sought advice on the most effective image generation model available on Perplexity Pro, leading to discussions on the use cases and the legal ownership of generated imagery.
-
Scrutiny of User Limitation Communications: The community delved into Perplexity's communication about the introduction of message limits, with users examining the ethical implications of the change from unlimited to limited messages and its potential breach of advertised services.
-
Exploring Writing Styles with AI: Members discussed the potential of using Perplexity AI to learn and emulate writing styles from novels, with suggestions to utilize "collections" for retaining a consistent writing style across prompts.
Links mentioned:
Perplexity AI ▷ #sharing (43 messages🔥):
- Exploring Perplexity's Rich History: A member shared a link into the depths of Perplexity's history.
- BASIC Language Information Retrieved: Several members seem to have dug into the origins and details of the BASIC programming language through shared searches like this example.
- AI's Hidden Discoveries Revealed: An AI's revelation of 27,000 unknown items sparked curiosity among the community.
- Forbes Features Perplexity: A member highlighted Perplexity's features in a Forbes video, showcasing its capabilities to provide deeper internet insights. The video can be found here.
- Creative Search Queries Prompt AI Exploration: Links like this reveal members using Perplexity to explore a variety of creative inquiries.
Link mentioned: Perplexity Wants To Help You Find Better Answers On The Internet | Forbes: Google Search or Wikipedia may be the go-to methods for finding out information on the Internet. Perplexity aims to help you go deeper to find concise answer...
Perplexity AI ▷ #pplx-api (59 messages🔥🔥):
- Model Compatibility Inquiry: A member inquired about needing to switch from sonar-medium-online to llama-3-sonar-large-32k-online. The consensus is that the older model still functions but may require an update in the future.
- Optimizing AI Results: A member discussed issues with the AI model not returning expected competitor analysis results. The model was giving better outputs when provided with different prompt structures and settings, but consistency remained an issue.
- Opus Model Support Clarification: Members discussed the lack of API support for proprietary models like Opus within Perplexity's offerings. It was clarified that reselling access to proprietary models could not be expected.
- Billing Logic Changes: One user queried about possible changes to the billing logic for API credits as their account balance seemed inconsistent. There was no resolution provided in the discussion.
- Self-Hosted Telegram Bot: A member asked for recommendations on a Telegram bot integrated with the Perplexity API for minimum coding usage, and the response suggested that creating one shouldn't be too difficult.
Links mentioned:
LM Studio ▷ #💬-general (396 messages🔥🔥):
-
Launching LM Studio in Server Mode: Users are exploring ways to start LM Studio in headless server mode, querying whether command line options exist for starting the app with a preselected model and server mode activated. There is an ongoing discussion about the use of
lms(LM Studio's CLI tool) for achieving headless operation alongside the GUI version. -
Troubleshooting VRAM and RAM Usage in LM Studio: A user raised a concern about LM Studio's VRAM and RAM usage, noting unexpected memory consumption behavior when offloading models to GPU with flash attention enabled. The user was asked to share screenshots and further detail the expected versus actual behavior for assistance in resolving the issue.
-
Remote Access to VRAM on a Test System: A user asked for advice on remotely accessing a computer built for testing LLMs without disabling VRAM through RDP, with SSH and LMS via CLI being suggested as viable alternatives to maintain VRAM access.
-
Prompt Engineering for a Better LLM Experience: Discussion on the benefits of prompt engineering emphasized its importance in extracting high-quality output from language models. Prompt engineering can significantly influence the quality of generated content and is now recognized as a valuable skill in AI circles.
-
Exploring Stable Diffusion with LM Studio: Inquiry made about LM Studio's support for Stable Diffusion. Clarification provided that although Stable Diffusion models show up in the platform, LM Studio does not support them and the listed GGUFs are for the C++ implementation of Stable Diffusion.
Links mentioned:
LM Studio ▷ #🤖-models-discussion-chat (234 messages🔥🔥):
-
Fine-Tuning Struggles and Solutions: Members discussed fine-tuning models such as Llama 3 and phi 3, highlighting issues and sharing resources such as a guide for MacBooks and tips for using conversion tools. Some suggested looking into GPU services for better performance, while one member noted success with fine-tuning phi-3 for eight hours on a 128GB M3 Max MacBook Pro.
-
ChatQA Model Discussions: Users shared experiences with the ChatQA 1.5 model, including challenges with model coherence and template formatting. The consensus indicated that larger models like CMDR+ are superior for complexity and recall, especially on topics like the Bible.
-
Explorations of Vision and RAG Models: There was interest in vision models taking screenshots for web automation, with Pix2Struct and CLaude mentioned. For reading and generating text documents, such as PDFs, Command-R held by Cohere was suggested, while for RAG applications, ChatQA was recommended over regular Llama 3 Instruct.
-
Concerns over Llama 3 Model Output: Users reported issues with Llama 3 producing erratic or nonsensical output, such as speaking in Russian, shouting in caps, and more. One noted that even after adapting the template and removing unwanted token prefixes, the model's response quality was unpredictable.
-
Conversion Challenges for LLMs: A technical discussion unfolded around the challenges of converting Llama models to different formats. Solutions included adjusting the order of command arguments and ensuring proper file paths, with insights shared regarding changes in required flags for conversion scripts.
Links mentioned:
LM Studio ▷ #🧠-feedback (8 messages🔥):
-
Command Line Confusion Cleared: A member experienced an issue where system prompts were included when printing messages via the Python OpenAI API, which appears linked to experimenting with the LMS CLI tool. Another member recommended redownloading v0.2.22 from lmstudio.ai as the issue has been fixed in this version.
-
All Systems Functional: After redownloading the recommended version, the member confirmed that the GUI is working properly and planned to test the CLI for potential recurring issues.
-
Initialization Error in Version Discourse: A member inquired about initializing phi-3, encountering errors, and was directed by another member to upgrade to a newer version, specifically 0.2.22, which can be downloaded from lmstudio.ai.
Link mentioned: 👾 LM Studio - Discover and run local LLMs: Find, download, and experiment with local LLMs
LM Studio ▷ #📝-prompts-discussion-chat (8 messages🔥):
-
Quest for a Personalized Writing Assistant: A member discussed optimizing writing models to emulate personal writing styles, asking if prompt engineering or interactive techniques could enhance results. Another participant suggested finetuning existing models like "llama 2/3" or "Mistral" using tools such as autotrain for better adoption of one's individual style.
-
Scoped Document Access for AI: A member inquired about a method for providing "temporary scoped access" to specific document sections in a language model context. Selective inclusion of document parts in prompts was suggested as a practical workaround for this requirement.
-
Clarifying AI Memory Constraints: Following up, they queried the persistence of context after editing or deleting parts of a prompt in LM Studio, suspecting unintended retention of deleted content. It was concluded that if the language model appeared to remember deleted context, it could be due to a bug or error, considering it should not retain information that is removed.
LM Studio ▷ #⚙-configs-discussion (56 messages🔥🔥):
-
WSL Woes and Proxy Solutions: Members discussed issues connecting to LM Studio from WSL, suggesting that using the Windows WSL vEthernet adapter IP found in
ipconfigcould be a solution. Some noted that a reverse proxy might be necessary, one member provided a PowerShell netsh hack:netsh interface portproxy add v4tov4 listenport=$PORT listenaddress=0.0.0.0 connectport=$PORT connectaddress=127.0.0.1. -
Get Creative with D&D Campaigns:
- A member desires to use LM Studio to drive solo D&D campaigns with AI party members, inquiring about how to easily inject a personal library of novels and game books into the model for contextual gameplay.
- While a helpful suggestion was made to consider models like command-r-plus, further messages revealed the need for an AI Dungeon Master capable of remembering character sheets and adapting the game narrative effectively, underscoring the current limitations and the prospect for future advancements.
-
The Quest for an AI Dungeon Master: With desires to see an AI handle Dungeons & Dragons gaming sessions, members shared aspirations and ongoing attempts using platforms like AnythingLLM and SillyTavern, showcasing the goal to envelop stories, rules, and ambient features in a persistently evolving AI-driven adventure.
-
Concerns with AI's Role-Playing Boundaries: A member discussed the difficulties faced when trying to experience a darker, unrestricted tabletop role-playing game narrative with ChatGPT, running into policy violations with the AI, indicating current content moderation limitations within the AI system.
-
Unleashing AI's Potential in Gaming: Conversations veered into the potential futures of AI in gaming, discussing features like AI-generated images, dynamic background music, and character voice differentiation that would elevate immersive gaming experiences to new heights.
Link mentioned: Udio | AI Music Generator - Official Website: Discover, create, and share music with the world. Use the latest technology to create AI music in seconds.
LM Studio ▷ #🎛-hardware-discussion (123 messages🔥🔥):
Links mentioned:
LM Studio ▷ #autogen (1 messages):
- LM Studio API Speech Limitation: A member reported that their LM Studio API only speaks a maximum of two words before it stops. They are seeking technical insights from specialists as to why this issue might be occurring.
LM Studio ▷ #langchain (1 messages):
drjflamez: Secrets don't make friends
LM Studio ▷ #amd-rocm-tech-preview (28 messages🔥):
-
Update Alert: ROCm Download Ready: An update is mentioned for the ROCm tech preview; the fix is available on lmstudio.ai/rocm, resolving an earlier reported issue with embedding models.
-
Max Token Truncation Clarification: A member questions what happens when sequences larger than the reported 512 token max context are sent for embedding, noting their success in embedding 1000+ tokens without issue.
-
Stellar Performance on New Hardware: A user reports successful deployment of NousResearch/Hermes-2-Pro-Llama-3-8B-GGUF using 16 FP with 34 tensors per second on an RX 7900 xt, fitting perfectly in VRAM.
-
Praise for ROCm's Smooth Performance: A community member expresses satisfaction with the stability and effectiveness of ROCm, wondering why it's still labeled as a preview/beta despite excellent performance from versions 0.2.18 onwards.
-
Community-Driven Linux Build Interest: Discussions surface regarding a potential Linux ROCm build, with users sharing personal workarounds and expressing eagerness to contribute to the codebase if it were open-sourced.
Links mentioned:
LM Studio ▷ #model-announcements (1 messages):
-
CodeGemma 1.1 Joins the Line-up: The
lmstudio-communityrepo has been updated with CodeGemma 1.1. Anticipation is high for performance improvements similar to the upgrades from Gemma 1.0 to Gemma 1.1, although specific details remain scarce. Try CodeGemma 1.1 -
Nvidia Releases ChatQA 1.5 Models: Nvidia has released two versions of ChatQA 1.5 in sizes 8B and 70B. Designed for RAG and context-based Q/A, they might not serve as general-purpose chatbots but are tailor-made for context-related inquiries. Try ChatQA 1.5 - 8B, Try ChatQA 1.5 - 70B
LM Studio ▷ #🛠-dev-chat (53 messages🔥):
- Sandbox Solutions: Users discussed a fix for an app exiting on interaction with terminal using the
--no-sandboxflag after encountering an error suggesting a sandbox issue. - LM Studio.js Server Activation Advice: There was guidance provided for starting the LM Studio server with the
lms server startcommand and using an HTTP listener to wait for the server to activate. - LM Studio Goes Headless: yagilb explained that the new LM Studio v0.2.22 and the lms CLI allow for headless operation of the LM Studio, intending to simplify the process further in the future.
- CLI Contributions Welcome: LM Studio's CLI is open source, and the community is encouraged to contribute to its development.
- Expectation of a Streamlined Experience: One user expressed a desire for an easy-to-use headless setup for running LLMs on a Linux server, with yagilb responding that the CLI already facilitates this and will be further improved.
Links mentioned:
CUDA MODE ▷ #general (15 messages🔥):
-
BackPACK: A new tool for PyTorch users: The BackPACK library can extract more information from a backward pass in PyTorch. It includes a publication reference: Dangel, F., Kunstner, F., & Hennig, P. (2020) titled BackPACK: Packing more into Backprop.
-
Cuda NCCL Lecture: Due to issues with Discord, today's cuda nccl session was moved to Google Meet.
-
Best Practices for Google Meet: A member shared tips for managing Google Meet sessions, such as curating talks, having participants raise hands for questions, managing chat queries, dealing with bots, and encouraging the use of webcams for an interactive talk experience.
-
Enhancing Interactive Lectures: Participants are encouraged to stay interactive during talks by turning on their cameras, which can be more engaging than just a recording.
-
Citadel's Profit-Generating Strategies Revealed: A member shared an arXiv paper that explains Citadel's successful financial strategies.
-
Upcoming Recording for Cuda NCCL: A member enquired about a YouTube upload for the NCCL session, to which another member responded it would be done "soon TM".
Links mentioned:
CUDA MODE ▷ #triton (15 messages🔥):
-
Fused DoRA Kernels Announced: A new fused DoRA layer implementation has been announced which significantly reduces the number of individual kernels, particularly by customizing GEMM kernels for layer weight shapes and fusing reduction operations directly into the kernel's epilogue. Details, benchmarks, and usage can be found in the Fused DoRA kernels GitHub pull request.
-
Potential Optimization for DoRA: In response to the announcement, a suggestion was made that DoRA weights could be preprocessed to be equivalent to LoRA for inference to potentially reduce operations needed, although this wouldn't apply to training scenarios.
-
Custom Autotuner for DoRA: The new DoRA kernels implement a tweaked autotuner for debugging, which includes better logging functionalities, although it's acknowledged that similar capabilities may now exist in Triton's updated autotuner, and consideration is given to aligning with Triton's built-in autotuner.
-
In-depth Benchmarking Expected: Members express interest in seeing benchmarks comparing the costs of computations and data movements within the DoRA layer, particularly focusing on how the new fused GEMM kernels perform, with reference implementations included for further profiling.
-
Triton Kernels in ONNX: A request for assistance was posted regarding the use of Triton kernels as a custom operator in ONNX Runtime, as the available documentation is seen as somewhat limited and outdated.
Links mentioned:
CUDA MODE ▷ #cuda (64 messages🔥🔥):
-
Installing Custom PyTorch/CUDA Extensions: A member asked for a cleaner method of installing custom PyTorch/CUDA extensions within a
setup.pyfile. They referenced issues with logging and system compatibility using the command line. Discussion referenced three GitHub pull requests and a specific section of asetup.pyfrom the PyTorch/AO repo as examples: PR#135, PR#186, PR#176, and pytorch/ao setup.py sample. -
TorchServe GPU Configuration Clarifications: A member needed clarification on performance settings mentioned during a presentation, specifically regarding
torch.set_num_threads. A blog post was shared for details ontorch.set_num_threads. Further clarification pointed out incorrect documentation that should read higher latency with larger batch size and how to approach adjusting worker numbers for optimising throughput and latency. -
Atomic Operations in CUDA: Discussion about whether a certain CUDA code snippet using
reinterpret_castis atomic. It was confirmed that the code does perform atomically but has undefined behavior according to the C++ standard. The correct, standard-compliant method should usestd::bit_cast. -
Performance of Numba-CUDA vs. CUDA-C: An inquiry was made comparing the performance of numba-CUDA and CUDA-C with the numba-CUDA version running slower. Through sharing performance profiles and examining pTX files, it was discovered that the numba version includes memory safety checks which may slow down execution.
-
Interest in CUTLASS and Stream-K Scheduling Technique: A member expressed interest in having a future discussion or lecture on the stream-K scheduling technique employed in CUTLASS for GEMM. While there was openness to the suggestion, it was noted that stream-K could fit as a short subsection in another talk, particularly because explaining the CUTLASS 2.0 API could be extensive.
Links mentioned:
CUDA MODE ▷ #torch (19 messages🔥):
-
Debug Debugging Symbols: A participant is having trouble with a script intended for building specific files with debug symbols, which is not working well for them. They mention that everything is too mangled to debug properly and are seeking an alternative method for building with debug symbols, as the documentation lacks detail.
-
A Constraint in PyTorch: One member discussed an issue with inconsistent
ConstraintViolationErrorraised bytorch._dynamo.mark_dynamic(inputs, index=1)in PyTorch versions 2.2 and 2.3. They posted the error message and note that the compiler seems to disagree on the dynamic shape over multiple batches. -
A Call for GitHub Issues: A member recommended creating a GitHub issue to handle the previously mentioned PyTorch constraint problem, pointing out that a specific expert's insight was required.
-
Answer.AI Releases Open Source System: A member mentioned Answer.AI's new open source system, which allows training of a 70B parameter language model on a desktop with gaming GPUs. They provided a GitHub link and shared their question regarding the fastest setting that did not result in an out-of-memory error.
-
Model Training Memory Insights: Another conversation included members discussing the memory usage of the LLaMa 2 70B model training with different configurations and versions of PyTorch and Transformers. The reported peak memory of 8.6GB was unexpected, and commands for fine-tuning that use up to nearly 24GB of memory were shared.
-
Holistic Trace Analysis for PyTorch: A participant introduced HTA, the Holistic Trace Analysis tool, linking to the documentation. HTA is designed to assist in identifying performance bottlenecks by analyzing PyTorch Profiler traces.
-
Specialization Errors with
torch.compile: In response to an earlier constraint error, a member explained that the issue is due to the code forcing specialization of a dimension expected to be dynamic, and recommended running with increased logging to diagnose the issue.
Links mentioned:
CUDA MODE ▷ #announcements (1 messages):
- GPU Collective Communication Crash Course: The CUDA MODE Discord channel has an upcoming session on GPU Collective Communications with NCCL. An excited member anticipates learning about distributed ML concepts not covered in the PMPP book.
CUDA MODE ▷ #algorithms (5 messages):
- Helpful Paper Lists for ML System Newbies: Marksaroufim shared a GitHub link to an ML Systems Onboarding list containing helpful papers for those new to machine learning systems.
- Quantization Learning Resources: Mr.osophy linked a YouTube video explaining quantization and its implementation using PyTorch, which may be a valuable resource for those interested in learning about this topic.
- Dynamic Memory Compression (DMC) Boosts LLMs: Andreaskoepf mentioned a new technique known as Dynamic Memory Compression (DMC) that can increase the throughput of Llama models by up to 370% on a H100 GPU. They shared the source tweet which also links to the research paper.
Links mentioned:
CUDA MODE ▷ #beginner (9 messages🔥):
- Voice Channel Troubles in CUDA MODE Discord: Following misuse of the voice channel for inappropriate content, several users were mistakenly banned; the moderator apologized and began reinstating affected users, including @wilson, @c_cholesky, @jeffjeff, and @harryone1.
- GPU Clock Speed Confusion Clarified: A beginner question arose about the clock speed of H100 GPUs, specifically concerning the calculation of operations per second and theoretical peak performance. Another user pointed out a probable unit mistake, suggesting it should be 1.8 GHz, not 1.8 MHz.
CUDA MODE ▷ #pmpp-book (4 messages):
- Matrix Transposition Conundrum: A member questioned the necessity of tiling in matrix transposition when each element is accessed only once. The answer pointed out it's for coalesced memory writes, with a clarifying blog post on matrix transpose in CUDA.
- Preemptive Lesson on Coalescing: The member thanked for the clarification on coalescing, suggesting that this topic is covered in the following chapter, which led to their initial confusion.
- Sequence of Topics May Cause Confusion: In response, it was noted that questions sometimes precede the coverage of their topics in the book, which can be puzzling for readers.
Link mentioned: An Efficient Matrix Transpose in CUDA C/C++ | NVIDIA Technical Blog: My last CUDA C++ post covered the mechanics of using shared memory, including static and dynamic allocation. In this post I will show some of the performance gains achievable using shared memory.
CUDA MODE ▷ #youtube-recordings (6 messages):
- Support Acknowledged: A member expressed gratitude for the ongoing support and understanding regarding a high-priority job that caused a delay in a promised addition to the channel.
- Endorsement for PyTorch Profiling: Excitement was shared about nsys and the interest to try out the "lightweight" PyTorch profiling tools. The member was inspired by a recording and enquired about standout questions that might have been asked in the Discord after the event.
- Praise for Source Annotation: The member mentioned an upcoming source annotation tool by Taylor as "really cool", reminiscent of Apple's Metal profiler’s interface for line-by-line shader profiling. They linked to Apple's developer documentation: Optimize shaders with per-line shader profiling statistics.
- Profiler Capabilities Highlighted: A recounting of a profiler capable of making edits on a profiled trace with nearly real-time estimates was highlighted as a notable feature. It involves Instruments using architectural knowledge to 'rerun' executions, potentially based on sampling.
Link mentioned: Optimizing GPU performance | Apple Developer Documentation: Find and address performance bottlenecks using the Metal debugger.
CUDA MODE ▷ #jax (1 messages):
- Exploring JAX Multi-process Model: A member shared their appreciation for the distributed setup capabilities of JAX, particularly in the context of environments like GPU clusters and Cloud TPU pods. They referenced the JAX multi-process documentation, which offers detailed guidance on launching JAX processes and running multi-process computations.
Link mentioned: Using JAX in multi-host and multi-process environments — JAX documentation: no description found
CUDA MODE ▷ #off-topic (12 messages🔥):
-
Anime Favorites Shared: Members remarked on their anime preferences; one grew up watching Naruto, enjoys One Punch Man and Berserk, and acknowledges Jujutsu Kaisen (JJK) for having top-notch animations and fight scenes. Another member humorously expressed admiration for the character Sukuna from JJK after a particular scene's Blu-ray release.
-
iPhone & Mac as Improvised A/V Setup: A member suggested using an iPhone & Mac for better audio and video quality on calls, noting the automatic integration when both devices are updated and logged in with the same Apple ID. Selecting the iPhone as a camera/mic input works across various platforms like Photo Booth, Discord, Google Meet, and Streamlabs.
-
Interest in Discord to Google Calendar Automation: A member inquired about setting up automation to sync Discord events with Google Calendar to avoid missing out on the reading group. While no existing solution was mentioned, there was openness to setting it up if it became a significant need.
CUDA MODE ▷ #hqq (4 messages):
- GreenBitAI Introduces LLM Toolkit: A member highlighted GreenBitAI's green-bit-llm, a toolkit for fine-tuning, inferencing, and evaluating GreenBitAI's language models, offering a broader scope than the previously discussed bitblas, which focuses specifically on matrix multiplication operations.
- Fast Inference with BitBlas: According to one member, BitBlas boasts a fast gemv kernel optimized for 2-bit operations conducive to speeding up inference tasks, but they have yet to personally test it.
- GreenBitAI's Binary Matrix Multiplication: Intrigue was expressed regarding GreenBitAI's cutlass kernels, particularly for their implementation of binary matrix multiplication within their bitorch-engine.
- Gradients Calculated in Weights: Another member pointed out an interesting attribute of GreenBitAI's toolkit; it calculates gradients of weights as shown in a code snippet from bitorch-engine, sparking curiosity about the potential VRAM usage since the gradients aren't packed during training.
Links mentioned:
CUDA MODE ▷ #llmdotc (630 messages🔥🔥🔥):
- CUDA Compiling Quirks: Compilers like
nvcc 11.5throw errors for operations in bfloat16 on older GPUs; functions like__ldcsand__stcdare undefined, and operations like__bfloat1622float2cause issues. A fix is proposed to handle bfloat16 arithmetic manually to support older cards and toolkits. - Multi-GPU Training Hangs: Recent commits to the master branch caused multi-GPU training to hang, as reported in Issue #369. A separate working branch maintains functional multi-GPU training, and merging this while diagnosing the issue on the master branch is under consideration.
- Performance and Refactoring Updates: A PR has been merged that brings a small performance gain by introducing a new optimized matmul_bias kernel, and subsequent contributions aim to further enhance performance through kernel fusions and CUDA stream adjustments.
- Correctness in Overlapping NCCL and Compute: An attempt to overlap NCCL and backwards compute in multi-GPU training shows improved iteration times, from 225ms down to 193ms (PR #361). Correctness verification and testing remain essential while optimizing multi-GPU logic.
- Nsight Systems Profiling: Efforts to improve profiling include using Nvidia's Nsight Systems for better visualization and understanding the intricacies of application performance on GPUs. This includes creating a tutorial to help others set up and use Nsight Systems to analyze and optimize CUDA programs.
Links mentioned:
Modular (Mojo 🔥) ▷ #general (102 messages🔥🔥):
- Mojo Installation Query: A user inquired about instructions for installing Mojo on a desktop, indicating a need for support.
- Community Progression: ModularBot celebrated a community member leveling up, demonstrating an achievement-based engagement system.
- New Contributions to Mojo: Discussion indicates an open source development environment, with users directed to GitHub repositories and issues for contributing, especially to the Mojo standard library as suggested by 'soracc'.
- Addressing Contribution Confusion: Discussions between members like 'gabrieldemarmiesse' and 'soracc' centered around clarifying contribution processes, referencing GitHub, and considering methods to avoid duplication of work by contributors like the "licking the cookie" phenomenon.
- Mojo Versioning Scheme Explained: Users clarified that Mojo utilizes a
YY.major.minorversioning scheme, not Semantic Versioning (SemVer), with the year reflecting the first number (e.g., version 24.3.x represents the third main release of that year).
Links mentioned:
Modular (Mojo 🔥) ▷ #💬︱twitter (1 messages):
ModularBot: From Modular: https://twitter.com/Modular/status/1786483510141657384
Modular (Mojo 🔥) ▷ #📺︱youtube (1 messages):
- Modular Community Livestream Announcement: Modular announced a livestream event with an invitation to explore the latest update in their technology, titled "Modular Community Livestream - New in MAX 24.3". The video is set to discuss the new features in MAX Engine and Mojo🔥, as well as introduce the MAX Engine Extensibility API.
Link mentioned: Modular Community Livestream - New in MAX 24.3: MAX 24.3 is now available! Join us on our upcoming livestream as we discuss what’s new in MAX Engine and Mojo🔥 - preview of MAX Engine Extensibility API for...
Modular (Mojo 🔥) ▷ #ai (3 messages):
-
Interest in Donald Hoffman's Consciousness Research: A member plans to transfer to UCI to be around the work of Professor Donald Hoffman, who is engaged in mapping conscious experiences. They see a correlation between the limited sensory data in split-brain patients and AI hallucinations, supporting the efficiency of simulating brain function.
-
Shared Academic Aspirations: Another member expressed a shared interest in the goal mentioned above, indicating an alignment with the work related to consciousness research.
-
Seeking a Max Developer: A member has announced they are looking for a Max Developer for a project and has requested interested parties to direct message them for further details.
Modular (Mojo 🔥) ▷ #🔥mojo (172 messages🔥🔥):
- InlineArray Quirks for Large Arrays: There are some ongoing issues with
InlineArraybehaving erratically for large arrays, as highlighted in a GitHub issue here. - GPU Support in Question for Mojo: Users challenged the claim that Mojo is the language that unlocks AI hardware, leading to clarification that GPU support is intended for rollout in the coming months, specifically mentioning support for Nvidia.
- Mojo's Potential Unlocked by MLIR: A key discussion point was the fact that Mojo's potential isn't limited to GPU support but extends to other hardware acceleration through MLIR, which could future-proof the language against emerging technologies.
- Questions on Latex Script Parallelization in Mojo: A user encountered difficulties using parallelization in Mojo for a LaTeX script, which prompted advice on constraints about functions that could be parallelized and error handling.
- Challenges with Mojo decorators and Custom
NoneValue: One user sought help about decorators, which are not fully supported yet, while another struggled with representingNonefor uninitialized struct members, learning to useOptional[Node]for proper typing.
Links mentioned:
Modular (Mojo 🔥) ▷ #community-projects (22 messages🔥):
-
NuMojo Update Rockets Ahead: NuMojo, previously Mojo-Arrays, is back in active development, updated to Mojo version 24.3. The library, focused on building functions around the standard library tensor, is now significantly faster, offering a performance boost of 6x to 20x compared to numpy.
-
Mimage Library for Mojo Image Parsing: A new library called Mimage for image parsing in Mojo has been introduced, with support for simple 8-bit RGB PNGs. There's an ongoing community discussion on whether to adopt a PIL-style Image class or an ND array representation for images.
-
Basalt Development Milestones: The Basalt project has celebrated reaching 200 stars, released new documentation at Basalt Docs, and announced updates for Mojo 24.3. These updates include experimental ONNX model import/export, dynamic operation support, and a variety of enhancements and bug fixes.
-
Prototype for Struct Composability in Mojo: The lsx library for HTML generation in Mojo has seen a new prototype for struct composability shared at GitHub lsx, aiming for full compatibility with lsx and better handling of UnsafePointers.
-
MinBPE Port and Performance Insights: A Mojo port of Andrej Karpathy’s minbpe project minbpe.mojo has been posted, highlighting the challenges of porting from Python and the absence of inheritance in Mojo. The Mojo version is about three times faster than the Python original, with noticeable performance gains after switching to a more efficient dictionary implementation.
Links mentioned:
Modular (Mojo 🔥) ▷ #community-blogs-vids (6 messages):
-
Building with Mojo and Parameters: A new tutorial was shared on using parameters to build a Mojo app, enhancing workflows and integrating custom constraints. The tutorial is available at GitHub - Tutorial on parameters in Mojo.
-
Syntax Highlighting Tip: In response to the tutorial on Mojo parameters, a suggestion was made to improve the readability of the code using proper syntax highlighting, by using triple backticks with the term "mojo" in markdown files.
-
Parsing PNGs in Mojo Explored: A blog post about parsing PNGs using Mojo was shared, along with the launch of a library named mimage for reading images in Mojo. Both the blog post and the mimage library are accessible online.
-
Community Positive Feedback: The blog post on PNG parsing received positive feedback from the community, with peers expressing admiration for the effort.
-
RSS Feed Needs a Fix: The same blog post author acknowledged the need to fix the RSS feed issue on their site after a community member expressed interest in subscribing to future articles.
Links mentioned:
Modular (Mojo 🔥) ▷ #📰︱newsletter (1 messages):
Zapier: Modverse Weekly - Issue 32 https://www.modular.com/newsletters/modverse-weekly-32
Modular (Mojo 🔥) ▷ #nightly (92 messages🔥🔥):
-
80 column debate heats up: Discord participants discussed the need to move beyond the 80-column convention, historical for punched cards and monitors. Some members expressed a preference for 100 columns, stating it would still allow multiple file views side-by-side.
-
Nightly Mojo compiler update: A new nightly release of the Mojo compiler was announced, with details on the recent changes available in the provided links. Users are encouraged to update with
modular update nightly/mojo. -
Register passable types on the chopping block: Discussion emerged around the evolution of the "register passable" concept in Mojo, with an aim to phase out types like
OptionalRegin favor of all-encompassing types likeOptionaland leaning towards traits to indicate register passability. -
The math module's status addressed: Confirmation that the math module has not disappeared; it's yet to be open-sourced, resulting in references to it being removed from the open-sourced part of the stdlib.
-
Pre-commit hook issue filed: An issue with the "check-license" pre-commit hook was reported, where it couldn't find the stdlib, leading to a discussion and an eventual open issue for the intermittent problem.
Links mentioned:
HuggingFace ▷ #announcements (2 messages):
<ul>
<li><strong>Community Highlights Get an Update</strong>: Community highlight #56 introduces <a href="https://huggingface.co/spaces/Csplk/moondream2-batch-processing">Moondream 2 batch processing</a>, <a href="https://huggingface.co/spaces/fluently/Fluently-Playground">FluentlyXL v4</a>, Portuguese translation of HF Audio course's first chapters, <a href="https://huggingface.co/spaces/unography/image-captioning-with-longcap">BLIP fine-tune</a> for long captions, and many other projects. A comprehensive Portuguese list and retrospective of highlights is also available <a href="https://iatalk.ing/destaques-comunidade-hugging-face/">here</a>.</li>
<li><strong>New Advances in AI Shared</strong>: Latest spaces feature <a href="https://huggingface.co/spaces/as-cle-bert/bloom-multilingual-chat">BLOOM multilingual chat</a>, an <a href="https://huggingface.co/spaces/tonyassi/inpainting-sdxl-sketch-pad">inpainting sketch pad</a>, and a link prediction <a href="https://github.com/Lama-West/PnPR-GCN_ACM_SAC_24/tree/main">repository</a>. Additionally, the HuggingFace alignment handbook task can now be run in the cloud with dstack as tweeted <a href="https://twitter.com/dstackai/status/1785315721578459402">here</a>.</li>
<li><strong>Cool Stuff Unveiled by Community</strong>: A wide range of topics is covered from <a href="https://huggingface.co/blog/AmelieSchreiber/protein-optimization-and-design">protein optimization with Generative AI</a> to <a href="https://huggingface.co/blog/AviSoori1x/seemore-vision-language-model">implementing a Vision Language Model from scratch</a>. Also discussed is the Google Search with LLMs, Token Merging for fast LLM inference, and <a href="https://huggingface.co/blog/maywell/llm-feature-transfer">creating chat models with a single click</a>.</li>
<li><strong>Cutting-edge Conversations</strong>: A reading group is scheduled to discuss recent progress and share insights, furthering the exchange of knowledge in the AI space. To join the next session, please check out this <a href="https://discord.com/events/879548962464493619/1234913780048203856">link</a>.</li>
<li><strong>AutoTrain Configs Introduced</strong>: AutoTrain now supports yaml config files simplifying the model training process, even for those new to machine learning. An announcement about this new feature has been <a href="https://twitter.com/abhi1thakur/status/1786368641388179797">tweeted</a>, and the Github repository with example configs can be accessed <a href="https://github.com/huggingface/autotrain-advanced">here</a>.</li>
</ul>
Links mentioned:
HuggingFace ▷ #general (225 messages🔥🔥):
-
Exploring Audio Diffusion Modelling: A conversation unfolded around creating a model that iteratively generates music based on feedback, potentially using audio diffusion models. Issues such as the computational depth required for such a model and its capabilities in generating longer and theoretically sound pieces were discussed.
-
Struggling with large model conversion: One user faced difficulties converting a PyTorch model into Tensorflow Lite format, encountering a size limit error. The model in question exceeded the 2GB limit during conversion from ONNX to TensorFlow.
-
Deploying Whisper for Filipino ASR: A discussion on the feasibility of fine-tuning the Whisper ASR model for Filipino language took place. Parameters such as
weight_decay, learning rate, and dataset size (80k audio chunks) were mentioned as factors influencing performance. -
Security Concerns Arise After Hacks: Several messages indicated that the Hugging Face Twitter account was compromised, leading to discussions about cybersecurity measures and their implications for AI systems. The community was active in flagging suspicious activity and investigating the situation.
-
GPU Utilization Mysteries: Users shared experiences and advice regarding disparate GPU training times between local machines and Google Colab, examining the efficiency differences between consumer gaming cards and edge inference cards, and providing optimization recommendations.
Links mentioned:
HuggingFace ▷ #today-im-learning (12 messages🔥):
- Trouble in Model Export Land: A member is experiencing difficulties exporting a fine-tuned model and has encountered errors that are causing frustration.
- To Loop or Not to Loop: There's a debate on whether it is always advisable to write your own training loop, with a member suggesting that using examples from Diffusers and then modifying them allows for more customization.
- Intrigued by Kolmogorov-Arnold Networks: Kolmogorov-Arnold Networks (KANs) are highlighted for their potential to use less computational graphs than MLPs. The concept is backed by research with a shared academic link, which compares KANs to MLPs in terms of accuracy and interpretability.
- Diving into Fine-Tuning: A member shared educational resources about what fine-tuning a generative AI model means, including a two-minute YouTube video and a HuggingFace tutorial.
- Overcoming API Deployment Challenges: A learner sought assistance with issues faced during the building stage of the API in Hugging Face Space, pointing to a lesson in the deeplearning.ai Hugging Face course and citing a problem with versions in
requirements.txt. - Methodology for Step-by-Step Reasoning: A member experimented with implementing a 'think step by step' approach for LLM outputs but found that local models did not grasp this well. An alternative setup involving a chain of
planner,writer,analyst, andeditorachieved more comprehensive results when tested with Llama 3 instruct 7B.
Links mentioned:
HuggingFace ▷ #cool-finds (11 messages🔥):
- Revolutionizing Retrieval with RAG: A Databricks glossary entry discusses Retrieval-Augmented Generation (RAG), highlighting its solution to issues of Large Language Models (LLMs) not being able to access data beyond their original training sets, making them static and sometimes inaccurate.
- Dataset Giants Clashing on GitHub: Microsoft released the MS-MARCO-Web-Search dataset, a large-scale web dataset with millions of real clicked query-document labels for improving information retrieval systems.
- Let Webhooks Ring: Hugging Face has published a guide on creating a server listening to webhooks, deploying to Gradio-based Spaces, and integrating with the Huggingface Hub.
- Stepping Into Quantum Services: A link to an oqtant™ quantum virtual server platform was shared, suggesting advancements in the accessibility of quantum computing resources.
- Gauge Your RAG with Ragas: The Ragas framework is presented as a tool for assessing the performance of Retrieval-Augmented Generation (RAG) pipelines in LLM applications, emphasizing metrics-driven development and synthetic testset generation for robust evaluations.
Links mentioned:
HuggingFace ▷ #i-made-this (19 messages🔥):
- Shadow-Clown BioMistral Unveiled: A new model called shadow-clown-BioMistral-7B-DARE has been created, merging BioMistral-7B-DARE and shadow-clown-7B-dare using mergekit, aiming to combine the capabilities of both models.
- Generative Synthetic Data Tool Launched: A new tool for generating and normalizing synthetic data is now available on PyPI, which may be beneficial for fine-tuning large language models. Further details can be found on the GitHub repository.
- Loading LLMs Efficiently via Ollama: A GitHub page and a LinkedIn post showcase methods for efficient loading and unloading of LLMs when using them via Ollama.
- AI Assists Your Podcast Creation: The Podcastify space on HuggingFace can convert articles into podcast-like conversations.
- OpenGPTs Challenges GPT Store: The OpenGPTs-platform is launched, aiming to emulate and extend the abilities of the official GPT Store, starting with a foundational version that includes an "Assistants API" and various tools for content retrieval.
Links mentioned:
HuggingFace ▷ #reading-group (45 messages🔥):
- Graph ML and LLMs Discussion Alert: The HuggingFace Discord group is holding a meeting centered around a recent paper on Graph Machine Learning. The paper covers the use of large language models (LLMs) in graph machine learning and its wide applications.
- GNNs: A Landscape of Possibilities: Members are discussing the diverse uses of Graph Neural Networks (GNNs), ranging from fraud detection to generating recommendations, and even task planning for robots. The versatility of GNNs has piqued the interest of participants, prompting some to experiment with these models.
- Presentation Resources Shared: The presenter, linked as Isamu Isozaki, shares a medium article diving deeper into the topic discussed and a YouTube video for those who missed the live presentation. Furthermore, there is a discussion about uploading content to an alternative platform due to Medium's access restrictions.
- Incorporating Special Tokens in LLMs: One member highlights a paper proposing a training method that teaches LLMs to use a special token,
<RET>, to trigger information retrieval when uncertain. The method aims to boost both the accuracy and efficiency of LLMs by only retrieving information when necessary.
{kind=link}
Links mentioned:
HuggingFace ▷ #computer-vision (42 messages🔥):
-
Gap Detection Challenge in Auto Parts: A member described issues with using a simple YOLO classification model to detect gaps in certain vehicle parts. They requested suggestions on alternative models or techniques to improve detection performance.
-
Craving for Classic CV: A relatively new member to computer vision queried the current industry relevance of traditional CV techniques like SURF and SIFT and wondered if in-depth knowledge of these methods is necessary.
-
Fine-tuning Object Detection: There was a discussion on fine-tuning the classifier part of an object detection model, with a focus on whether it's helpful to use an additional CNN for image scaling instead of pre-scaling images before feeding them to models like Darknet YOLO.
-
CLIP Performance on Rotated Objects: A user sought advice on using the CLIP model to match images of Magic: The Gathering cards that aren't perfectly aligned. Recommendations included augmenting the training data with rotated and skewed images to improve robustness.
-
On the Hunt for GhostNet Weights: A member inquired about the availability of pre-trained GhostNet weights on ImageNet for TensorFlow, sharing the GhostNet paper abstract and Efficient-AI-Backbones GitHub repository but requested assistance on using the provided weights within TensorFlow.
Links mentioned:
HuggingFace ▷ #NLP (12 messages🔥):
- Seeking Simplified Instructions: A user inquired about using a simplified version of a tool or method, but did not specify which one.
- Custom Fine-Tuning Services Offered: There's an open request from a user offering financial compensation for guidance on how to fine-tune the Mistral-7B-instruct model with a custom dataset.
- LLM Evaluation Skepticism: A member expressed doubt about using Large Language Models (LLMs) to evaluate other LLMs, given potential hallucination issues and the rapid development of foundational models. The member also pointed out the challenge businesses face in evaluating LLMs and Retrieval-Augmented Generation (RAG) systems for their specific needs.
- Paper Introduction to LLM based Translation Metric: The GEMBA metric, a GPT-based translation quality assessment tool, was introduced via an ACL Anthology paper link, which described its effectiveness particularly with GPT 3.5 and larger models.
- Request for Flash Attention Implementation Tutorial: A member inquired about adding flash attention 2 to XLM-R and asked if Hugging Face provided any tutorials or guidelines for such an implementation.
Link mentioned: Large Language Models Are State-of-the-Art Evaluators of Translation Quality: Tom Kocmi, Christian Federmann. Proceedings of the 24th Annual Conference of the European Association for Machine Translation. 2023.
HuggingFace ▷ #diffusion-discussions (17 messages🔥):
-
Finetuning StableDiffusionPipelines: A member explored the concept of partial diffusion using two different pipelines, denoising an image halfway with one, then continuing with another. They were directed to an outstanding pull request that facilitates this process for the StableDiffusionXLPipeline.
-
Assistance for a Partial Diffusion PR: The same member was encouraged to test the partial diffusion feature via the linked pull request and to report any issues directly onto it, as the code would soon be revisited and updated.
-
Training Diffusion Models on Multiple Subjects: A member inquired about training diffusion models to learn multiple subjects simultaneously. It was suggested that they explore Custom Diffusion, a training technique that allows learning multiple concepts at once.
-
Accelerate Multi-GPU Running with CPU Offloading Issues: One member faced technical challenges combining accelerate's multi-GPU running with diffuser's model CPU offloading, specifically device-related errors. The community did not address this as of the last message.
-
Estimating Billing with LLM Pricing Calculator: Another member sought confirmation on whether the token counts they had were sufficient for estimating their API billings using a shared LLM Model Pricing calculator. The query remained unaddressed in the discussion.
Links mentioned:
OpenInterpreter ▷ #general (212 messages🔥🔥):
-
Calling Builders on Skills Library Opportunities: One member explored working on the OpenInterpreter skills library, referring to Killian’s contributions on GitHub and recommending to view the commit history for skills.py.
-
Microsoft Open Source AI Hackathon Announcement: Members are forming a team to participate in the Microsoft Open Source AI Hackathon in Seattle, with the intent to create a project using Open Interpreter. The hackathon promises hands-on tutorials, pizza, and afternoon snacks with details here.
-
Groq LLM Integration and Issues: There was a discussion on integrating Groq LLM with Open Interpreter and experiencing unexpected behaviors like uncontrollable output and creating multiple files on the desktop. The command provided for connection was
interpreter --api_base "https://api.groq.com/openai/v1" --api_key "YOUR_API_KEY_HERE" --model "llama3-70b-8192" -y --max_tokens 8192. -
OpenAI Token Cost and Optimization Concerns: One member expressed concern over the cost of using OpenAI's GPT, having spent substantial amounts on API tokens. There was also a critique on Open Interpreter's optimization for a closed-source AI system, causing confusion due to being an open-source project itself.
-
Sharing Experience with Local LLM Performance: Discussions included personal testing experiences with local LLMs, including Phi-3-mini-128k-instruct and Groq models, where one member observed significant performance issues with the former and issues with environmental setup. A member indicated that correcting the LLM's decisions might lead to better command execution.
Links mentioned:
OpenInterpreter ▷ #O1 (104 messages🔥🔥):
-
TMC Protocol for iOS Implementation: A member is reimplementing the TMC protocol for iOS to allow access to native features. They question the benefits of using the TMC protocol over normal function calling and await clarification on its advantages.
-
Setting Up O1 with Azure Open AI Models: A member is facing difficulties in setting up O1 to work with Azure Open AI models, noting that details in the .env are being ignored, despite OI working fine. They seek tips to resolve the issue after previous attempts failed.
-
Inquiries About O1 iOS App Release: Members inquire about the status of the O1 iOS app, with one sharing a link to the GitHub repository which includes the related source files. Further discussions suggest the app is a work in progress and directions are given via a YouTube link on building for both Android and iOS using Expo.
-
Technical Troubles and Solutions for O1: Members are troubleshooting various issues with O1, including problems with installing poetry, utilizing spacebar for commands, and difficulty in running local models. Suggestions for resolving these include using conda environments, downgrading Python versions, and installing packages correctly.
-
Exploring the Compatibility of Microsoft's Phi-3 Mini: One user asks if they can use Microsoft's Phi-3 Mini model with Open Interpreter, and another provides instructions to install the model and select it from the launch list.
Links mentioned:
OpenInterpreter ▷ #ai-content (15 messages🔥):
-
STT Challenges for AI Vtubers: A member highlighted they've implemented Speech-to-Text (STT) using fast whisper as push-to-talk, experiencing challenges with live transcription, such as the AI interrupting users and transcribing background speech. It was suggested to use a trigger word to cue the system but deemed awkward for a virtual streamer context.
-
Encouraging AI Interaction with Stream Audiences: The AI vtuber primarily responds to chat via the Twitch API, but for silence periods, a human catalyst can sustain interaction until an audience forms or the AI learns to engage with a game, representing the early phase of integrating Twitch chat interactions.
-
AI Managed Twitch Chat Interactions Plan: The approach to manage Twitch chat involves setting up a separate LLM instance, which will understand the dialog stream and user messages to create responses, with the goal to eventually have a chatbot that comprehensively interacts with live chat audiences.
-
Control Over LLM Behavior Through Prompts: Differentiating between standard models and Instruct models pertaining to prompts was emphasized; using an Instruct model, which has been fine-tuned to better follow instructions, was recommended for controllable outcomes.
-
Sharing Practical AI Integration Code: The main.py file on a member's GitHub was mentioned to contain working code for chatbot integration, where users can simply swap the system prompt to suit their implementation needs.
Eleuther ▷ #general (113 messages🔥🔥):
-
Paper Follow-Ups Spark Interest: Members were sharing links to related papers validating how large language models (LLMs) handle multilingualism and discussing the framework that portrays the processing of multilingual inputs by LLMs with links to papers like How Mixture Models handle Multilingualism.
-
Adversarial Challenges and Architectural Discussions: The community engaged in a technical discussion on adversarial robustness, the potential of scaling models for improved defense, and the need for systemic hierarchies or buffers to prevent exploitation, citing a relevant paper on addressing LLM vulnerabilities.
-
Job Search Shares and Community Support: A member actively sought employment opportunities, sharing their LinkedIn and Google Scholar profiles, and highlighting their experience with EleutherAI and contributions to the Polyglot team and OSLO project.
-
Improving in-Context Learning Measurement: There was a proposal for a new benchmark methodology to measure in-context learning performance of models by varying the number of shots, which spurred a dialogue on the best approaches to assess this aspect of LLM behavior.
-
ICLR Meet-Up Coordination: Several community members discussed and arranged a meet-up at ICLR, sharing plans and expressing excitement about meeting in person, despite some facing travel constraints like visa issues.
-
Exploring the Role of System Prompts: A member mentioned an interest in exploring how the system prompt affects model performance using the lm-evaluation-harness, but noted difficulty finding a way to specify the system prompt using Hugging Face models.
Links mentioned:
Eleuther ▷ #research (165 messages🔥🔥):
-
Scaled Transformers Conquer Chess: A new research paper discusses a 270M parameter transformer model trained on 10 million chess games annotated by Stockfish 16, which achieves remarkable performance in Lichess blitz games and chess puzzles without domain-specific tweaks or explicit search algorithms. This model outperforms AlphaZero's policy and value networks sans MCTS and raises questions about the impact of scale on strategy games.
-
Resurrection of GPT-2: Messages allude to a significant gap between postings and interactions on the server, such as a member mentioning a three-year break before replying to older posts and another maintaining a running interaction with outdated content.
-
Enhancing LLM Search with 'Maieutic Prompting': The concept of Maieutic Prompting, a method to improve LLM's inference from noisy and inconsistent data by generating a tree of abductive explanations, was introduced, albeit with skepticism about its practical effectiveness.
-
Challenges and Considerations in Human-Led Evaluations: A detailed discourse covered the complexities in determining sample size, the significance level, and statistical tests for human evaluations in research, like comparing two chatbots. Discussions mentioned non-inferiority testing and the analysis of systematic error to evaluate the intervention's impact meaningfully.
-
Non-Fine-Tunable Learning to Prevent Model Misuse: A new concept named non-fine-tunable learning, showcased in the SOPHON framework, aims to protect pre-trained models from being fine-tuned for unethical use while maintaining performance in their original tasks. Concerns were raised about the potential overreach of such protections limiting the adaptability of future models for legitimate applications.
Links mentioned:
Eleuther ▷ #scaling-laws (9 messages🔥):
-
Scaling Laws in Pre-training and Fine-tuning: A link to a study on arXiv details empirical scaling laws for transfer learning. The study finds that pre-trained models continue to improve on a fixed-size dataset due to effective data transferred from pre-training, described by a power-law of parameter count, and fine-tuning dataset size.
-
Accuracy Amidst Dataset Concerns: Two separate members discussed the implications of Papers With Code showing over 70% accuracy within two years for math problem-solving. A member suggested that some recent advancements might be a result of data leakage from datasets specifically designed for performance measurements like GSM8K and MATH.
-
Inclusion of Exam Data in Pre-Training: Members discussed the possibility of OpenAI including GSM8K and MATH data in its pre-training datasets. While some expressed uncertainty about the adherence to rules, they clarified that fine-tuning on MATH was standard practice for achieving state-of-the-art in 2021.
-
Evaluating Original Test Dataset Performance: A member provided a link to odyssey-math on GitHub and commented on a reported baseline of 47% accuracy for gpt-4-turbo on this original test dataset. They plan to subsample some of the problems to assess the dataset's difficulty, noting the small size of about 350 problems.
Links mentioned:
Eleuther ▷ #interpretability-general (7 messages):
- Transformer Models Decoded: A new primer on transformer-based language models has been introduced, offering insights into the model components and interpretation methods garnered from years of research, along with an extensive survey of interpretability tools.
- Seeking Model Deployment Assistance: One member has requested help with model deployment but did not provide further details on the issue they are facing.
- Cross-Model Generalization Confirmed: Results on language model interpretability using English as a pivot language have been replicated across various models, including llama 1, 2, and now llama 3, as shared in a recent tweet.
- Diving Deep into Weight Tying Issues: A member is exploring weight tying in open models like Phi-2 and Mistral-7B using LogitLens and has come across unexpected results in the output layers.
- Clarifying Weight Tying Conundrum: Further investigation has led to the conclusion that contemporary open models, in fact, do not employ weight tying, which clarifies the earlier irregular results observed.
Eleuther ▷ #lm-thunderdome (3 messages):
- Prometheus Model Sparks Interest: Members expressed interest in the AlekseiPravdin/prometheus-7b-v2_0-gguf model on Hugging Face, suggesting it might be a significant improvement for inclusion in their work.
- Call for Collaboration: A member has volunteered to assist with the integration of the aforementioned model, highlighting the benefits seen from chat templates in performance metrics.
- Preparation for Integration Underway: Work on a product requirement document (PRD) is in progress for implementing improvements based on AlekseiPravdin/prometheus-7b-v2_0-gguf. The model's author is present in the chat, indicating potential direct collaboration.
Link mentioned: Paper page - Prometheus 2: An Open Source Language Model Specialized in Evaluating Other Language Models: no description found
OpenRouter (Alex Atallah) ▷ #announcements (3 messages):
- Llama 3 Lumimaid 8B Now Available: OpenRouter has released a new model, Llama 3 Lumimaid 8B, available for the year 2023 - 2024.
- Extended Llama 3 Lumimaid 8B Released: An extended version of Llama 3 Lumimaid 8B is also on offer, providing users with additional features, aptly named Llama 3 Lumimaid 8B Extended.
- Price Cut for Llama 3 8B Instruct Extended: There's good news for users looking for a bargain as the price for Llama 3 8B Instruct Extended has been reduced.
- Temporary Downtime for Lynn Models: A server update will lead to a brief ~10-minute downtime for Lynn and associated models.
- Soliloquy L3 8B Updated to v2: The Soliloquy L3 8B model has been upgraded to version 2, boasting improvements such as repetition and retrieval issue fixes, enhanced instruction following, and a new price of $0.15 per 1M tokens. Explore Soliloquy L3 8B v2 here.
Links mentioned:
OpenRouter (Alex Atallah) ▷ #app-showcase (3 messages):
-
Introducing eGirlfriend AI: A member has built an initial version of a project called eGirlfriend AI and invites the community for feedback, noting that it's 100% free.
-
Family-Friendly Streamlit Chat App: A chat application designed for family called Family Chat has been created to utilize OpenRouter API and OpenAI's API cost-effectively, featuring Conversational Memory, PDFChat, and Image Generation. You can explore and contribute to it on GitHub.
-
Rubik's AI Pro Seeks Beta Testers: The creator of an advanced research assistant and search engine named Rubik's AI Pro is seeking beta testers, offering 2 months of free premium which includes access to models like GPT-4 Turbo and Mistral Large. Interested parties can sign up and enter promo code
RUBIXhere.
Links mentioned:
OpenRouter (Alex Atallah) ▷ #general (248 messages🔥🔥):
-
Gemini Pro Glitch Fixed: An issue with Gemini Pro error messages was reported but resolved within days. Users were advised it's working and to contact support if the problem persists.
-
Lumimaid 70B Anticipation: Discussions indicate communication with Mancer about hosting Lumimaid 70B, and the suggestion to enquire about it with Novita, a provider focused on RP models.
-
Phi-3 Hosting Uncertainty: Despite interest, there seems to be a lack of providers currently hosting Phi-3, though Microsoft Azure runner is said to have it, albeit with no per-token pricing.
-
OpenRouter and AI Model Precision: It's clarified that model providers on OpenRouter use different precisions; most run at fp16, and some at quantized int8.
-
Meta-Llama 3 120B Instruct Self Merge: A self-merged version of Meta-Llama 3 70B has been noted on Hugging Face, inspired by other large merges, raising curiosity about the efficacy of self-merges compared to layer-mapped merges.
Links mentioned:
LlamaIndex ▷ #blog (7 messages):
-
Reflective Self-Improving Agents: LlamaIndex 0.10.34 introduces introspective agents that can boost their performance through reflection and self-critique without human intervention. This method and the
llama-index-agent-introspectivepackage are detailed in a notebook with an installation guide, bearing a content warning for sensitive material. -
Agentic RAG Advancements Demonstrated: A video by @jasonzhou1993 presents an overview of components necessary for agentic RAG, featuring advanced document processing with LlamaParse + Firecrawl. The video is available here for those interested in constructing agentive systems.
-
Trust Assessments in RAG Responses: @CleanlabAI developed a "Trustworthy Language Model" that assigns trustworthiness scores to Retrieval-Augmented Generation (RAG) responses, addressing the challenge of verifying the accuracy of generated content. More details about this feature can be found in their tweet here.
-
Guide for Local RAG Setups: For those seeking a fully local RAG pipeline, @pavan_mantha1 provides an insightful handbook introducing the setup with @llama_index and a HyDE layer. Described as a lower-level guide compared to the "5 lines of code" Quickstart, the article is accessible via this link.
-
Hugging Face TGI Support Revealed by LlamaIndex: LlamaIndex announces support for Hugging Face TGI, a toolkit ensuring optimized deployment for language models on Huggingface, now with features such as function calling, batched inference, and must faster latencies. Details about TGI's capabilities are outlined here.
Link mentioned: Introspective Agents: Performing Tasks With Reflection - LlamaIndex: no description found
LlamaIndex ▷ #general (226 messages🔥🔥):
-
Exploring RAG with Controllable Agents: A user inquired about implementing Controllable agents in a Retrieval-Augmented Generation (RAG) project, to make agents capable of asking follow-up questions for more precise retrieval results. A detailed implementation guide with LlamaIndex is provided, including links to relevant documentation like Agent Runner and Controllable Agent Runner.
-
LlamaIndex Memory Issues Troubleshooting: Users discussed high VRAM usage and potential memory leak issues when using LlamaIndex, leading to slow cleanup and fallback to CPU processing. One user pointed to successfully resolving such issues with the new ollama v0.1.33 update.
-
LLM Fine-tuning and Cost Discussions: There were discussions on fine-tuning language models (LLMs) specifically for tasks like a light model that is specialized in a particular field. The costliness of fine-tuning was noted, with users looking for optimizable, cost-effective solutions.
-
Implementing Sharepoint Reader and VectorStore Challenges: A member sought feedback on integrating the SharePoint Reader for loading files from SharePoint, and another experienced empty responses from a SupabaseVectorStore in LlamaIndex, indicating possible configuration issues.
-
Understanding and Optimizing Q&A Systems Over Excel Data: One user inquired about the best approach for building a Q&A system over a moderately sized Excel table, focusing on providing contextually relevant information to complex queries.
-
Implementation and Configuration of LlamaIndex Specifics: Various users discussed importing errors, the right pathways in
llama-index, how to handle legal document data extraction, how to deal with embeddings for Intel processors, and configuring ReAct agents dynamically. Assistance was sought and exchanged among peers and with the help of cheesyfishes, presumably a knowledgeable figure in the community, offering guidance on LlamaIndex's usage and integration.
Links mentioned:
LlamaIndex ▷ #ai-discussion (4 messages):
- Seeking NL-SQL Bot Wisdom: A member is creating a NL-SQL chat bot for a complex database with hundreds of tables and inquires about using a HyDE method. They are exploring solutions for improving the LLM's accuracy for generating SQL queries, noting that HyDE has mostly been used in text-based chatbots.
- Introspective Agents Discourse: There's a mention of an article titled "Introspective Agents with LlamaIndex", indicating a new approach or development involving introspective agents. A link to the article was shared: Introspective Agents with LlamaIndex.
OpenAccess AI Collective (axolotl) ▷ #general (33 messages🔥):
-
Hermes Gets Speedy on Android: A member expressed amazement over the inference speed of Hermes 2 Pro Llama 3 on an 8GB RAM Android device, attributing the performance to llama.cpp.
-
Anime Shapes AI Innovation: There was humorous discussion suggesting that advancements in AI and technological innovation are seemingly intertwined with the proliferation of anime both in question-answering and image generation.
-
Llama.cpp Merges Performance-Enhancing PR: A member shared news about a new pull request merged into llama.cpp that results in a 30% speed improvement for inference, seemingly inviting the creation of more anime.
-
Axolotl's Progressive Documentation: A link to the work-in-progress documentation for the Axolotl community was shared with an invitation for feedback.
-
Gradient Checkpointing Optimizations Reported: An update was noted regarding the new unsloth gradient checkpointing leading to reduced VRAM usage, showcasing the active effort in the community to optimize memory utilization in machine learning processes.
Links mentioned:
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (8 messages🔥):
-
Configurability Comes to Gradio: One member sought assistance on making Gradio options like making the demo private and setting an IP address configurable via yaml. The solution involved adding those options into yaml and modifying the code to parse the settings as demonstrated in their implementation.
-
Deep Dive into Gradio Token Troubles: There was a puzzling issue where Gradio did not utilize the correct tokens for the llama3 model, with it printing
<|end_of_text|>tokens unexpectedly. It appeared that Gradio's default tokens might unintentionally overwrite a loaded tokenizer's settings unless special tokens are specified. -
Pushing for a More Dynamic Gradio: A code change was discussed to allow dynamic configuration of Gradio's parameters, such as "private", "server_name", and "port". This will enable greater control over Gradio's behavior through yaml configuration.
-
PR Ready for Review: A pull request was submitted addressing Gradio customization, adding configurable parameters for various hardcoded options in the project, capturing important details and demonstrating the implementation with a GitHub PR.
-
Issue or Pull Request? The Eternal Question: A member inquired whether to open an issue for a problem or to just submit a pull request. While the response was not recorded, the member took initiative and created a pull request to address the underlying issue.
Link mentioned: Gradio configuration parameters by marijnfs · Pull Request #1591 · OpenAccess-AI-Collective/axolotl: Various parameters of Gradio were hardcoded (e.g. share=True, ip address, port, number of tokens, temperature) I made them configurable here. Additionally the default tokens were overwritten into t...
OpenAccess AI Collective (axolotl) ▷ #general-help (8 messages🔥):
- Calling Inference on Trained Llama3: There was a question about how to call inference after training llama3 with the fft script, clarifying that the usual qlora command and qlora_model_dir don't seem applicable.
- Tuning Inference Parameters: A member recommended using a parameter setting of 4,4 as effective for an unspecified context, implying success with these settings.
- Conversion of Safetensors to GGUF: One user sought assistance in converting safetensors to gguf with more options than provided by llama.cpp, specifically mentioning formats like
Q4_KandQ5_K. - Script for Llama.cpp Conversions: The user was directed to llama.cpp's conversion scripts, with a particular call-out to convert-gg.sh, presumably for dealing with gguf conversion options.
- Axolotl Community Documentation: A link to the Axolotl community documentation was shared, which requires more work especially on merging model weights post-training and using the model for inference, with invites for feedback at Axolotl Community Docs.
Links mentioned:
OpenAccess AI Collective (axolotl) ▷ #datasets (39 messages🔥):
-
CodeTester Dataset Expansion: An updated Python dataset from Vezora now features 143,327 carefully tested and working examples of code, created to assist with extracting and verifying Python code snippets from Alpaca-formatted datasets. More information about the dataset and its creation process can be found on Hugging Face's dataset repository.
-
Tough Time Training Llama3 on Math: Members discussed difficulties in improving model performance on mathematical content with Llama3, noting a decrease in math topic scores despite training on datasets like orca-math-word-problems-200k and MetaMathQA, which are available at MathInstruct and MetaMathQA.
-
Impact of Quantization on Model Performance: One member highlighted the potential negative impact of llama.cpp quantization on model performance, referencing a discussion about Llama3 GGUF conversion with merged LORA Adapter on GitHub, which can be further explored in this issue.
-
Evaluation Scripts and Prompting: A member used the lm-evaluation-harness for inference and evaluation of Llama3, while others pointed out the importance of ensuring the correct prompt format and raised questions about the potential effects of using Alpaca-format prompts on model performance.
-
Prompt Format Puzzles: There is ongoing debate about how the prompt format during finetuning, such as using the Alpaca format, might affect model performance. Members are contemplating whether this could lead to issues even if the model does not generate out-of-vocabulary end-of-text tokens.
Links mentioned:
OpenAccess AI Collective (axolotl) ▷ #axolotl-phorm-bot (27 messages🔥):
-
Gradient Clipping Inquiries: Discussions arose around setting gradient clipping in Axolotl using the Axolotl
TrainingArgumentsor within a YAML configuration. Phorm suggested settingmax_grad_normin theTrainingArgumentsor within the YAML file under optimization settings. -
Hyperlink to the Documentation Needed: Members pointed out that specifying gradient clipping in the Axolotl YAML might not be reflected in the documentation due to a transition to quarto markdown, indicating a need to update the documentation index.
-
Modifying the Chatbot Prompt: A user inquired about modifying the system prompt for conversational training within the ShareGPT dataset format. Phorm indicated to adjust the conversation template or the initial message in the
ShareGPTPrompterclass or in associated configuration files.
Links mentioned:
Latent Space ▷ #ai-in-action-club (95 messages🔥🔥):
- Gary for Live! A Compute Music Journey: A member shared a link to gary4live on GitHub, a work-in-progress project involving python continuations and Ableton, encouraging others to take a look at the code.
- Suno and Music Generation Discussion: Conversations unfolded around using Suno for generating music, as well as the capabilities of other music generation setups like Musicgen. There was a particular interest in exploring how these models handle different audio elements and whether they generate assets like sheet music.
- Deep Dive into Music Model Tokens: The chat navigated through the intricacies of music model tokens, with discussions emphasizing Suno's tokenization of audio and questions about the length and composition of these tokens. References to architectural designs from papers were mentioned, yet specific details weren't fleshed out within the discussion.
- Latent Spaces in Audio Synthesis: Participants discussed the potential of multimodal models integrating audio directly without text intermediates, highlighting the relevance of audio inclusion for truly omnimodal capabilities. The conversation included ideas like using model generations to replace audio channels in real-time applications.
- Exploring Commercial Use and Licensing for Stable Audio: One member raised questions regarding the commercial use and licensing of outputs from stable audio models. The discussion veered towards the real-time applications of such models, like live performance looping with AI.
Links mentioned:
AI Stack Devs (Yoko Li) ▷ #ai-companion (6 messages):
- Clarity on Cloud Subscription Fees: Members confirmed no cloud subscription fees are required if you run it locally; the tool works fine with 6 GB VRAM and includes free voice output.
- Owning Downloads: It was highlighted that once you download characters and models with Faraday, they are yours to keep forever.
- Local Use Overrides Cloud Subscription: A GPU of sufficient power negates the need for a cloud subscription, which was suggested as an optional donation to the tool's developers.
AI Stack Devs (Yoko Li) ▷ #team-up (2 messages):
- Call for Collaboration on a Hip-Hop Simulation: A member expressed interest in creating a fun simulation referencing the situation between Kendrick and Drake. Another member responded positively to the collaboration call.
AI Stack Devs (Yoko Li) ▷ #ai-town-discuss (15 messages🔥):
- AI Leadership Elections Discussed: Curiosity was shown regarding whether AIs elect leaders and specifically about a mayor election depicted in the original simulation paper, which apparently never actually triggers in the simulation.
- Setting Up AI Elections in Player Bios: A member stated that setting up AI elections in player bios would be simple to set up, referencing a curiosity about mayoral events in an AI simulation.
- AI-Westworld Public Beta and The THING Simulation: A tweet by @TheoMediaAI highlighted exploring two AI world simulations, including the AI-Westworld by @fablesimulation which is in public beta, and recreating The THING movie in @realaitown.
- Introducing AI Town Player for Replayability: A tweet by @cocktailpeanut introduced the AI Town Player web app, which allows replaying any AI Town by importing a sqlite file, noting that the whole AI Town is stored in a single sqlite file via @convex_dev and is compatible with Mac & Linux but not Windows.
- AI Simulated Party Makes News: A feature on sfstandard.com described an AI Simulated Party at Mission Control in San Francisco, where human attendees were paralleled by AI versions running around a digitized version of the event on display.
Links mentioned:
AI Stack Devs (Yoko Li) ▷ #ai-town-dev (61 messages🔥🔥):
-
Ubuntu and Node Version Woes: User
utensil_18981reported issues when attempting to runconvex-local-backendon Ubuntu 18, ultimately resolving multiple problems by downgrading Node to version 18.17.0 and patching Ubuntu, as described in this GitHub thread. -
Pondering Docker for Simplification:
utensil_18981expressed frustration with setting upconvex-backendandollama, mentioning a possible Docker build could simplify the process..casadoacknowledged the idea's merit and considered looking into it, potentially over the weekend. -
Launch of llama-farm for Local LLMs:
ianmacartneyintroducedllama-farm, a new project aimed at connecting local machines running Ollama to a cloud backend, offering easy scaling and safety by avoiding public internet exposure. The project can be found on GitHub here. -
AI Reality TV and AI Town Experiences Teased:
edgarhndgave a sneak peek into an upcoming iteration of AI Reality TV that would allow public interaction with AI Town, hinting at an enhanced and shared experience. -
Challenges and Solutions for Remote LLM Deployment: Members discussed the intricacies and obstacles of deploying local language model servers (
ollama) and connecting them to remote convex backends, withutensil_95057ultimately getting it to run by updating to the latest Ollama version and usingsshtunneling.
Links mentioned:
AI Stack Devs (Yoko Li) ▷ #local-ai-stack (1 messages):
- Introducing llama-farm for Old Laptops: A member announced the release of
llama-farm, which allows running Ollama on older laptops to service LLM tasks for public-facing AI applications. This setup scales by running the client on additional machines and doesn’t require a proxy or exposure to public internet, as outlined on GitHub.
Link mentioned: GitHub - get-convex/llama-farm-chat: Use locally-hosted LLMs to power your cloud-hosted webapp: Use locally-hosted LLMs to power your cloud-hosted webapp - get-convex/llama-farm-chat
AI Stack Devs (Yoko Li) ▷ #paper-spam (1 messages):
Deforum Daily Papers: Papers will now be sent to <#1227492197541220394>
AI Stack Devs (Yoko Li) ▷ #ai-raspberry-pi (1 messages):
jakekies: ??
LAION ▷ #general (59 messages🔥🔥):
- Exploration of CLIP and T5 Combination: There's a discussion around using CLIP and T5 encoders for model training; one member mentioned prompt adherence issues with CLIP and is considering T5 only, while another highlighted past success using both encoders.
- Considerations for Improving Smaller Models: A focus on enhancing smaller models for practicality was mentioned, with a note on the 400M DeepFloyd and the challenges of preparing 8B models for release.
- Skeptical Reception of SD3 Strategy: Comments from Stability AI suggest a gradual release of SD3 models, ranging from smaller first to larger ones, which prompted a discourse on whether this is an efficient approach, especially given the community's anticipation.
- Potential Use of LLama Embeds in Training: A dialogue regarding the merit of employing LLama embeds instead of T5 for training, with a link shared to an example bridge called LaVi-Bridge, highlighting modern applications and efficiency.
- Comparative Progress in Image Gen and LLM Spaces: Members compared the status of open-source models in the image generation and LLM fields, discussing the adaptation of new models and mentioning a new CogVL marquee.
Links mentioned:
LAION ▷ #research (5 messages):
-
Real-World vs Synthetic Datasets Query: A member expressed curiosity about why synthetic datasets are used for experiments instead of standard ones like MNIST, CIFAR, or ImageNet. Concerns were raised regarding the real-world applicability of methods that prioritize interpretability but may not solve practical tasks.
-
Interpretability Demonstrations Discussed: It was mentioned that the use of synthetic datasets in experiments is to demonstrate the aspect of interpretability in methods being developed.
-
StoryDiffusion Resource Shared: A link to the StoryDiffusion website was shared which may contain related information or resources about interpretability in AI.
-
Complexity Over Simplicity in Function Representation: A member clarified that research sometimes targets approximating complex mathematical representations with functions, as opposed to the "simple" template-like tasks often associated with visual recognition.
LangChain AI ▷ #general (45 messages🔥):
- Database Interfacing with LLMs Sparks Curiosity: Participants debate whether to convert database data to natural language text versus using an LLM to convert natural language to database queries. Discussions also consider the suitability of graph versus relational databases in this context.
- Node.JS Conundrums and First Steps with Langchain: A user seeks assistance with parsing user questions and extracting JSON data in NodeJS, while another encounters an error using FAISS with Langchain but resolves it by upgrading to the latest version.
- Executing through Code with AI: Community members exchange insights on executing generated code through an AI agent, with suggestions such as using Open Interpreter and creating custom tools like
CLITOOL. - Langchain Integration Queries: Users inquire about support for Microsoft Graph within Langchain, using APIs like kappa-bot-langchain at work, and if there is an upload size limit when using Langsmith's free tier.
- New Developments and Custom Tools Discussed: Speculation arises regarding changes in ChatGPT's responses post-GPT2 issues, and conversation revolves around creating and sharing custom tools within the Langchain community.
Links mentioned:
LangChain AI ▷ #share-your-work (6 messages):
-
Java Joins the LangChain Family: LangChain is now available for Java developers through langchain4j, a Java port of the LangChain library, offering an expanded application ecosystem for the AI assistant toolset.
-
Dragonfly Boosts LangChain Caching Capabilities: LangChain's integration with Dragonfly, a high-performance in-memory data store, showcases significant improvements in chatbot context management, as detailed in a new blog post.
-
Decentralizing the Search with Langchain: A new decentralized search feature is underway, leveraging a network of user-owned indexes to provide powerful search capabilities, all of which is documented in a recent tweet by the developers.
-
OpenGPTs-platform Unveiled: An open-source alternative to the GPT Store called OpenGPTs-platform has been launched, featuring tools like 'retrieval' and 'web_retrieval', and the demo is showcased on YouTube. The project aims to replicate and expand upon the capabilities of the GPT Store using a modular approach, engaging the community via the OpenGPTs Discord.
-
Meet everything-ai: The All-in-One AI Assistant: the rebranded v1.0.0 everything-ai local assistant provides a range of tasks from chatting with PDFs and models to summarizing texts and generating images. This multi-container Docker application focuses on versatility and privacy, and its features and quick-start documentation are available on its GitHub page.
-
Beta Testers Invited for Advanced Research Assistant: A call for beta testers to experience an advanced research platform with access to multiple AI models, including GPT-4 Turbo and Mistral Large, is posted with the promise of a free two-month premium using code
RUBIXon Rubiks.ai. The offer includes additional models and tools tailored to enhance research capabilities.
Links mentioned:
LangChain AI ▷ #tutorials (2 messages):
- RAG Techniques with Llama 3: A user shared a YouTube video titled "Llama 3 RAG without Vectorstore using SVM," providing insights on Retrieval-Augmented Generation using Llama 3 with a simplicity measurement classifier and eliminating the need for vectorstore.
- Exploring LangGraph as AgentExecutor: Another contribution is a YouTube video that presents a comparison between LangGraph and LangChain Core components, suggesting advancements in AgentExecutor implementation.
Links mentioned:
tinygrad (George Hotz) ▷ #general (17 messages🔥):
- Exploring Symbolic Programming in Clojure: A user mentioned using bounties to familiarize with tinygrad, finding symbolic programming easier in Clojure than Python.
- Julia vs. Clojure Debate: A member argued that Julia is superior to Clojure for symbolic programming and expressed surprise over its lack of popularity in ML/AI spaces.
- Seeking Guidance on tinygrad Bugs: Users are directed to report bugs in tinygrad using the GitHub issues tab or the bug reports channel on Discord.
- Difficulty Understanding tinygrad's UOps Representation: A member expressed difficulty in understanding tinygrad's textual UOps representation and suggested a change to a format closer to llvm IR for readability, sparking a discussion on the formatting and use of phi.
- Representing UOps in Static Single Assignment (SSA) Form: The discussion continued with an explanation of UOps as a form of SSA, why the phi is located at the end of a block, and a suggestion for potentially opening a Pull Request (PR) to propose improvements.
tinygrad (George Hotz) ▷ #learn-tinygrad (12 messages🔥):
- Tinygrad Thrives on Qualcomm GPUs: Tinygrad is optimized for Qualcomm GPUs through the use of textures and pixel shaders in calculations, with data management in image datatype distributed throughout the codebase, as explained by terafo.
- Exploring Tinygrad on Qualcomm: Running Tinygrad on Qualcomm smartphones is feasible without extensive effort unless DSP support is required, which significantly increases the complexity.
- Insights on Tinygrad Symbolic Operations: A member shared a link to their post that breaks down the symbolic mean computation in tinygrad, providing clarity and insights which may be valuable for others working with or learning tinygrad. See their explanation here.
- CPU Operations are Ordered, Not Parallel in Tinygrad: George Hotz confirmed that tinygrad is single-threaded, and no parallel thread operations occur during CPU computations.
- Questioning Tensor Operations in Tinygrad: Cappuchinoraro queried about the behavior of the
matmulfunction and the implications of transposing tensors within tinygrad's operations.
Link mentioned: tinygrad-notes/symbolic-mean.md at main · mesozoic-egg/tinygrad-notes: Tutorials on tinygrad. Contribute to mesozoic-egg/tinygrad-notes development by creating an account on GitHub.
Mozilla AI ▷ #llamafile (25 messages🔥):
-
Troubleshooting json_schema Compatibility: A member encountered issues with
json_schemanot working with llamafile 0.8.1; another recommended using the--unsecureflag as a potential fix and mentioned a plan to address it in an upcoming release. -
Seeking Lightweight Models: A discussion about finding a model that operates on low specs was initiated. A recommendation for phi 3 mini was made, while a smaller model, Rocket-3B, was suggested for better speed when the phi 3 mini model performed too slowly.
-
Utilizing ollama Cache with llamfile: A member inquired if llamafile can use models stored in the ollama cache to prevent redundant downloads, with another confirming it's possible if the GGUF files are supported by llamafile.
-
Integration of llamfile and AutoGPT: A request for feedback was discussed around a pull request submitted to integrate llamafile as an LLM provider with AutoGPT. Someone shared a link to instructions (AutoGPT/llamafile-integration) for setting up this configuration, awaiting a response from maintainers before proceeding with further coding efforts.
-
Identifying and Using Correct Local Models: A user successfully operated llamafile with locally cached .gguf files after a discussion clarified which files are actual models and which are metadata, demonstrating live troubleshooting and peer support in action.
Links mentioned:
DiscoResearch ▷ #mixtral_implementation (7 messages):
-
Mixtral Transformers Bug Affects Performance: It has been highlighted that there were bugs in the mixtral transformers implementation, which led to poor performance in past mixtral finetunes. Critical issues and further discussion about this problem were shared via links to Twitter, Gist, and a Pull Request on GitHub.
-
Uncertainty Around Mixtral's Scope of Issues: Members questioned whether the mixtral issue was limited to training or if it also affected generation. There was no clear consensus on the matter, accentuating a need for further clarification.
-
Problem-Solving in Progress: An ongoing conversation mentioned by a member, pointing to a discussion with another Discord user, suggested that work was being done to pinpoint and address the issues with mixtral. However, specific details of the conversation were not provided.
-
Bug Resolution Seemingly in Limbo: A member expressed humor at the situation, indicating a belief that there were known issues with mixtral all along. This interjection suggests a perception among users that issues were anticipated.
-
Pull Request Rejection Adds to Mixtral Confusion: The mentioned pull request for fixing the mixtral bug was closed/rejected, adding another layer of uncertainty to the resolution status of these issues. The implications of this rejection on the mixtral implementation were not discussed further.
DiscoResearch ▷ #general (3 messages):
- Performance Dip in Quantized LLaMA-3: A Reddit post discussed the impact of quantization on LLaMA-3, suggesting that performance degradation is more prominent in LLaMA-3 compared to LLaMA-2. A study on low-bit quantization of LLaMA-3 may provide additional insights into the challenges of LLM compression.
- Meta Misses on Chinchilla Lessons?: A member pointed out that Meta's approach to scale LLaMA despite the lessons from Chinchilla could be why information loss is more significant with precision reduction in the LLaMA-3 model.
- Fix Patches in the Works: A GitHub pull request offers possible fixes for the quantization issues observed in LLaMA-3, including additional statistics and documentation (PR #6936), as well as a conversation surrounding pre-tokenization BPE processing (Issue #7088).
Links mentioned:
DiscoResearch ▷ #discolm_german (3 messages):
- Current Model in Use Revealed: Discussion in the channel revealed that 8x22b Mistral is the current model being used by a member for their tasks. No further details about performance or application specifics were provided.
Interconnects (Nathan Lambert) ▷ #news (3 messages):
-
Behind ElevenLabs' Convincing AI Voices: An article in The Atlantic details how a start-up named ElevenLabs has developed some of the most convincing AI voice cloning technology. The author shared a personal experience with the service, using it to clone their own voice.
-
Paywalls: A Modern Nuisance: A member expressed frustration with encountering a paywall, indicating an inability to access the full content of The Atlantic article on ElevenLabs.
-
ElevenLabs: A Wild Existence: The same member remarked on the existence of ElevenLabs, describing the start-up as "wild" for its capability to create convincing AI-generated voices.
Link mentioned: ElevenLabs Is Building an Army of Voice Clones: A tiny start-up has made some of the most convincing AI voices. Are its creators ready for the chaos they’re unleashing?
Interconnects (Nathan Lambert) ▷ #ml-drama (2 messages):
- Paper Skips RewardBench Scores: A newly published paper on arXiv overlooked reporting RewardBench scores because the results were unfavorable, prompting a bit of academic shade with a <:facepalm:1207415956020797521> emoji.
- Prometheus 2 LM Introduced for Bias-Free Evaluations: The paper introduces Prometheus 2, an open-source evaluator language model that claims to closely align with human and GPT-4 judgments, and it addresses issues of transparency, controllability, and affordability that affect proprietary LMs.
- Desire to Implement and Test Prometheus 2: One member expressed eagerness to implement Prometheus 2 in order to challenge and verify the paper's claims through a practical demonstration.
Link mentioned: Prometheus 2: An Open Source Language Model Specialized in Evaluating Other Language Models: Proprietary LMs such as GPT-4 are often employed to assess the quality of responses from various LMs. However, concerns including transparency, controllability, and affordability strongly motivate the...
Interconnects (Nathan Lambert) ▷ #random (2 messages):
- Unstoppable Success Raises Eyebrows: A member expressed amazement and a touch of concern with the phrasing "he can't keep getting away with this."
- Uncertainty Around John's Response: Another member reflected on a conversation with "john", highlighting a non-committal answer to a proposal with the remark, "dang so that's why john said only maybe to me lol."
Interconnects (Nathan Lambert) ▷ #rl (4 messages):
- Pondering the Unknown in Classical RL: A member sparked curiosity by asking if there's research regarding a particular aspect in classical RL, hinting at a potential knowledge gap or area for future inquiry.
- Value Function: A Possible Key in Different Approaches: Another member suggested an exploration into connections between PPO value function, and DPO's credit assignment, implying it could lead to interesting insights within reinforcement learning strategies.
- Value Function's Significance in Planning: Follow-up discussion emphasized the value function’s significance, particularly within the context of planning rather than classical reinforcement learning, underscoring its critical role.
LLM Perf Enthusiasts AI ▷ #prompting (7 messages):
- Exploring Anthropic's Prompt Generator: A new prompt generator tool was mentioned being available in the Anthropic console.
- Polite Rephrasing Results: A member tested the tool asking it to rephrase a sentence in more polite language and shared the outcome was not bad.
- Decoding the System Prompt: Work is being done to extract the system prompt from the tool, with k-shot examples being a significant part of it, including a notable Socratic math tutor example.
- Extracted Data Incomplete: The member attempting the extraction reports the prompt is so extensive that it is cut off mid-way, especially during the long math tutor example.
- Promise of Sharing the Full Prompt: The member committed to sharing the full system prompt here once successfully extracted and compiled.
Skunkworks AI ▷ #datasets (1 messages):
- In Search of Fabricated Data: A member expressed the need for a dataset filled with fake information for the purpose of experimenting with fine-tuning techniques on models like Llama 3 and Phi3. They indicated that even completely fake data would be acceptable for their research.
Skunkworks AI ▷ #off-topic (2 messages):
- Fast Compute Grants Available: A member offers fast compute grants for inspiring Skunkworks AI projects, expressing eagerness to support innovation. The support offer can be found in a tweet.
- AI Video Resource Shared: A link to a YouTube video related to artificial intelligence has been shared, serving as a potential resource or point of interest to members of the community. The video can be viewed here.
Datasette - LLM (@SimonW) ▷ #llm (3 messages):
-
LLM Proves Handy for Error Summaries: A member shared an effective method for summarizing errors using LLM; they provided an example
conda activatecommand piped through LLM. It's suggested this could be included in the LLM README. -
Bash Function Utilizes LLM for Error Evaluation: A new
llm-errbash function is proposed to help evaluate errors by piping command outputs directly to LLM. The function takes a command as an argument and uses LLM to specify the cause of any error encountered.
Cohere ▷ #collab-opps (2 messages):
- Shoutout for Austin, TX Community: A member sends a friendly hello to anyone located in Austin, TX.
- French AI Startup in Funding Phase: Vivien from France introduces Finexov (Finexov), an AI platform streamlining the process of identifying R&D funding opportunities and application generation. The platform has been launched with partnerships in place and backing from the Founder Institute (FI.co).
- Seeking a CTO Co-Founder: Vivien is seeking a CTO co-founder with a deep background in ML with the ambition to build and lead a team. The potential CTO should be Europe or Middle East-based, with French language skills being a bonus, and prepared for intensive work including fundraising efforts.
- Meeting Opportunity in Dubai: There's an opportunity to meet in Dubai at the beginning of June, where Vivien invites interested parties to reach out for a potential catch-up.
Link mentioned: Founder Institute: World’s largest pre-seed startup accelerator.: no description found
AI21 Labs (Jamba) ▷ #jamba (2 messages):
- Exploring New Heights: AI21 Labs staff stated, “We are still exploring, but we can go much higher” regarding some aspect of their technology, inviting community members to discuss their use cases and thoughts in direct messages.
Alignment Lab AI ▷ #general-chat (1 messages):
- Fast Compute Grants Available: A member shared a Twitter post announcing fast compute grants for those in need. The tweet seems to be a call for applications or nominations for receiving compute resources.