AI News for 5/27/2024-5/28/2024. We checked 7 subreddits, 384 Twitters and 29 Discords (382 channels, and 4432 messages) for you. Estimated reading time saved (at 200wpm): 521 minutes.
Five years ago, OpenAI spawned its first controversy with GPT-2 being called "too dangerous to release".
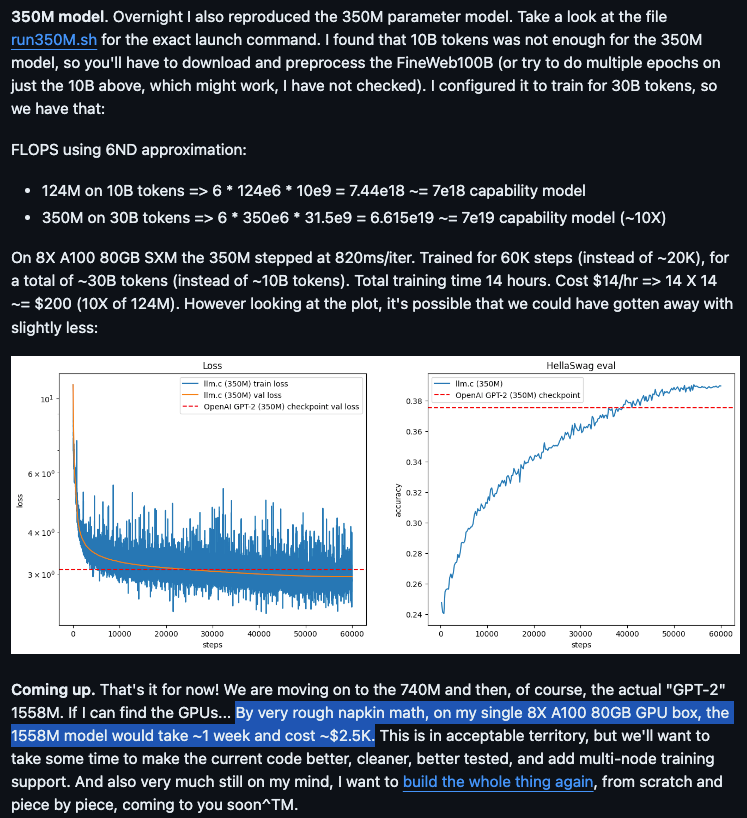
Today, with help from FineWeb (released last month), you can train a tiny GPT-2 in 90 minutes and $20 in 8xA100 server time. It is already working (kinda) for the 350M version, and Andrej estimates that the full 1.6B model will take 1 week and $2.5k.
And incredible accomplishment in 7 weeks of work from scratch, though at this point the repo is 75.8% CUDA, stretching the name of "llm.c".
Andrej also answered some questions on HN and on Twitter. one of the most interesting replies:
Q: How large is the set of binaries needed to do this training job? The current pytorch + CUDA ecosystem is so incredibly gigantic and manipulating those container images is painful because they are so large. I was hopeful that this would be the beginnings of a much smaller training/fine-tuning stack?
A: That is 100% my intention and hope and I think we are very close to deleting all of that.
It would be cheaper and faster if more H100s were available. Somebody help a newly GPU poor out?
{% if medium == 'web' %}
Table of Contents
[TOC]
{% else %}
The Table of Contents and Channel Summaries have been moved to the web version of this email: [{{ email.subject }}]({{ email_url }})!
{% endif %}
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
Yann LeCun and Elon Musk Twitter Debate
- Convolutional Neural Networks (CNNs) Importance: @ylecun noted CNNs, introduced in 1989, are used in every driving assistance system today, including MobilEye, Nvidia, Tesla. Technological marvels are built on years of scientific research shared through technical papers.
- LeCun's Research Contributions: @ClementDelangue would pick @ylecun over @elonmusk, as scientists who publish groundbreaking research are the cornerstone of technological progress, despite getting less recognition than entrepreneurs.
- Musk Questioning LeCun's CNN Usage: @elonmusk asked @ylecun how Tesla could do real-time camera image understanding in FSD without ConvNets. @ylecun responded Tesla uses CNNs, as attention is too slow for real-time high-res image processing. @svpino and @mervenoyann confirmed Tesla's CNN usage.
- LeCun's Research Productivity: @ylecun shared he published over 80 technical papers since January 2022, questioning Musk's research output. He also noted he works at Meta, with @ylecun stating there's nothing wrong with that.
- Musk Acting as LeCun's Boss: @ylecun joked Musk was acting as if he were his boss. @fchollet suggested they settle it with a cage fight, with @ylecun proposing a sailing race instead.
AI Safety and Regulation Discussions
- AI Doomsday Scenarios: @ylecun criticized "AI Doomsday" scenarios, arguing AI is designed and built by humans, and if a safe AI system design exists, we'll be fine. It's too early to worry or regulate AI to prevent "existential risk".
- AI Regulation and Centralization: @ylecun outlined "The Doomer's Delusion", where AI doomsayers push for AI monopolization by a few companies, tight regulation, remote kill switches, eternal liability for foundation model builders, banning open-source AI, and scaring the public with prophecies of doom. They create one-person institutes to promote AI safety, get insane funding from scared billionaires, and claim prominent scientists agree with them.
AI Research and Engineering Discussions
- Reproducing GPT-2 in C/CUDA: @karpathy reproduced GPT-2 (124M) in llm.c in 90 minutes for $20 on an 8X A100 80GB node, reaching 60% MFU. He also reproduced the 350M model in 14 hours for ~$200. Full instructions are provided.
- Transformers for Arithmetic: @_akhaliq shared a paper showing transformers can do arithmetic with the right embeddings, achieving up to 99% accuracy on 100-digit addition problems by training on 20-digit numbers with a single GPU for one day.
- Gemini 1.5 Model Updates: @lmsysorg announced Gemini 1.5 Flash, Pro, and Advanced results, with Pro/Advanced at #2 close to GPT-4o, and Flash at #9 outperforming Llama-3-70b and nearly GPT-4-0125. Flash's cost, capabilities, and context length make it a market game-changer.
- Zamba SSM Hybrid Model: @_akhaliq shared the Zamba paper, a 7B SSM-transformer hybrid model achieving competitive performance against leading open-weight models at a comparable scale. It's trained on 1T tokens from openly available datasets.
- NV-Embed for Training LLMs as Embedding Models: @arankomatsuzaki shared an NVIDIA paper on NV-Embed, which improves techniques for training LLMs as generalist embedding models. It achieves #1 on the MTEB leaderboard.
Memes and Humor
- Musk vs. LeCun Memes: @svpino and @bindureddy shared memes about the Musk vs. LeCun debate, poking fun at the situation.
- AI Replacing Twitter with AI Bot: @cto_junior joked about building an AI version of themselves on Slack to replace attending standups, rather than on Twitter.
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity. Comment crawling works now but has lots to improve!
AI Models and Architectures
- 01-ai removes custom licenses from Yi models: In /r/LocalLLaMA, 01-ai has switched the licensing of their original Yi models to Apache-2.0 on Huggingface, matching the license of their 1.5 series models.
- InternLM2-Math-Plus models released: A series of upgraded math-specialized open source large language models in 1.8B, 7B, 20B and 8x22B sizes was released. The InternLM2-Math-Plus-Mixtral8x22B achieves 68.5 on MATH (with Python) and 91.8 on GSM8K benchmarks.
- Pandora world model introduced: Pandora is a hybrid autoregressive-diffusion model that simulates world states by generating videos and allows real-time control with free-text actions. It aims to achieve domain generality, video consistency, and controllability.
- llama.cpp adds support for Jamba architecture: In /r/LocalLLaMA, support for AI21 Labs' Jamba architecture is being added to llama.cpp, with the first GGUF files being uploaded, including a model fine-tuned on the Bagel dataset.
- AstroPT models released for astronomy: AstroPT is an autoregressive pretrained transformer developed for astronomical use-cases, with models from 1M to 2.1B parameters pretrained on 8.6M galaxy observations. Code, weights, and dataset released under MIT license.
AI Applications and Tools
- Optimizing Whisper for fast inference: In /r/LocalLLaMA, tips were shared to speed up Whisper inference up to 5x using techniques like SDPA/Flash Attention, speculative decoding, chunking, and distillation.
- Android app for document Q&A: Android-Document-QA is an Android app that uses a LLM to answer questions from user-provided PDF/DOCX documents, leveraging various libraries for document parsing, on-device vector DB, and more.
- MusicGPT for local music generation: In /r/MachineLearning, MusicGPT was introduced as a terminal app that runs MusicGen by Meta locally to generate music from natural language prompts. Written in Rust, it aims to eventually generate infinite music streams in real-time.
- New web+LLM framework released: An open-source web framework optimized for IO-bound applications integrating with LLMs and microservices was announced, looking for early adopters to try it out and provide feedback.
AI Ethics and Safety
- Microsoft's Recall AI feature investigated over privacy concerns: Microsoft's new Recall AI feature, which tracks user activity to help digital assistants, is being investigated by UK authorities over privacy concerns, sparking debate about the data needed for useful AI assistance.
AI Industry and Competition
- Visualization of AI competition over past year: A visualization from the LMSYS Chatbot Arena showing the performance of top models from major LLM vendors over the past year highlights the intensifying competition and shifting trends.
- Contradictory claims about OpenAI equity clawbacks: An article claims data contradicts Sam Altman's statements about ignorance of equity clawbacks at OpenAI.
AI Discord Recap
A summary of Summaries of Summaries
LLM Advancements and Benchmarking:
- Llama 3 Leads the Pack: Llama 3 from Meta has topped leaderboards like ChatbotArena, surpassing models such as GPT-4-Turbo and Claude 3 Opus in over 50,000 matchups.
- IBM and RefuelAI Unleash New Models: IBM's Granite-8B-Code-Instruct enhances code task instruction following, while RefuelAI's RefuelLLM-2 boasts efficiency for data-heavy tasks.
Optimizing LLM Inference and Training:
- Cutting Edge Quantization Techniques: ZeRO++ aims for a 4x reduction in communication overhead during large model training on GPUs.
- Memory Efficiency Innovations: The vAttention system manages KV-cache memory more dynamically, improving LLM inference sharpens, and QSolve introduces W4A8KV4 quantization for enhancing cloud-based GPU performance.
Open-Source AI Frameworks and Community Efforts:
- Axolotl Captures Dev Interests: Supports diverse data formats, aiding LLM pre-training and instruction tuning.
- LlamaIndex Sparks Academic Curiosity: Powers a new course about building agentic RAG systems with Andrew Ng, promising advancements in AI extensions like bfloat16.
Multimodal AI and Generative Modeling Innovations:
- Idefics2 8B Makes Waves in Conversation: Fine-tuning the discourse on chat interactions, while CodeGemma 1.1 7B Improves Coding Tasks.
- Phi 3 Pioneers Browser-based AI: Introducing powerful AI chatbots directly in browsers via WebGPU, setting the stage for privacy-focused interaction enhancements.
{% if medium == 'web' %}
PART 1: High level Discord summaries
LLM Finetuning (Hamel + Dan) Discord
OCR Showdown: Google Vision vs. Microsoft Azure: AI engineers debated the merits and pitfalls of Google Vision OCR, acknowledging its precision but criticizing the developer experience. Suggestions for using Microsoft Azure OCR and Mindee Doctr, potentially offering better ease of use, surfaced here.
Curated Data: The Key to LLM Success: Workshop discussions underscored the importance of fine-tuning LLMs with high-quality, curated datasets, ranging from pharma applications to technical support chatbots. Expert opinion highlighted the need for precision in data choice to maximize LLM effectiveness, spotlighting domains like drug discovery, law, sales, and interdisciplinary work.
Axolotl Angst and Optimization: Users faced hurdles running Axolotl's 70B model on M3 Macs, with overwhelming latency during local inference, pointing to deployment on Modal as a possible solution. Cost concerns with Weights & Biases (WandB) prompted considerations of alternatives like Aim and MLflow for economically-minded solo developers Axolotl examples.
LLM Evaluation Deep Dive: A session on evaluating LLMs offered a treasure trove of insights, covering product metrics, traditional and dynamic performance metrics, and tools like LangFuse and EvalGen. Recommending resources by Eugene Yan and practical examples to visualize fine-tuning, participants noted the necessity of nuanced evaluations for LLM development.
Transcription Tangles and the Path to Summaries: Communication around transcripts from large meetings illuminated needs for efficient summaries, exposing potential roles for LLMs. While Zoom transcripts are on the horizon, Hamel encouraged using LLMs to generate more digestible summaries, echoing wider community involvement.
Perplexity AI Discord
-
Eagerly Awaiting imfo Alpha Release: A link to a tweet by @spectate_or hinted at the upcoming release of imfo alpha, sparking excitement and comparisons to similar tools within the engineering community.
-
AI Task Structure Debate: Engineers discussed categorizing AI tasks into retrieval and mutation types, exemplifying with queries like "Get the weight of the iPhone 15". The need for adjustments in tasks requiring sequential execution was highlighted with the insight that "all the steps just happen at the same time."
-
Scraping Accuracy Stumbles: Members voiced challenges in HTML parsing for reliable data scraping, with complications arising from sites like Apple and Docker's release notes. Workarounds through Playwright for JavaScript-centric sites were considered alongside issues with Cloudflare.
-
Exploring Cost-Efficient AI Model Utilization: The community delved into the cost-effectiveness of using various AI models such as Llama3 and Claude. An approach using a combined system suggested possibilities for greater savings.
-
API Functionality Quirks Highlighted: Confusion arose around an API output that displayed a JSON object sans functional links, potentially linked to the absence of a closed beta citations feature. Additional discussions included prompts to improve video link generation and a brief inquiry about a potential API outage.
Stability.ai (Stable Diffusion) Discord
New AI Features to Tinker With: Stability AI announces the launch of Stable Assistant sporting editing features built on Stable Diffusion 3, boasting of improved text-to-image quality available for a free trial here, and a beta chatbot with Stable LM 2 12B, heralding future enhancements for text generation tasks.
Education Merges with AI Innovation: An upcoming 4-week course by Innovation Laboratory, a collaboration between Stability AI and HUG, intends to guide participants on training AI models utilizing Stability AI's framework in tandem with HUG's educational approach; sign-ups are open until June 25, 2024, accessible here.
GPU Sharing in the Spotlight: AI engineers discuss a community-based GPU sharing proposal to decrease compute costs, with options ranging from a custom node to a potential blockchain setup designed to validate model training operations.
SD3 Accessibility Stirs Controversy: Discordance surfaces as members air grievances regarding Stable Diffusion's SD3 weights not being available for local use — slating Stability AI's cloud-only approach and stirring debate over cloud-dependency and data privacy concerns.
User Interfaces Under Comparison: A technical discourse unfolds on the pros and cons of various interfaces for Stable Diffusion, with ComfyUI pitted against more user-friendly alternatives like Forge; discussions also include community tips, inpainting methods, and ways to enhance artificial intelligence workflows.
OpenAI Discord
OpenAI Forms Safety Shield: OpenAI has established a Safety and Security Committee that will take charge of critical safety and security decisions across all its projects; full details can be found in their official announcement.
AI Muscle Flexes in Hardware Arena: Discussions about hardware costs arose, speculating on a $200-$1000 increase due to NPUs (Neural Processing Units), with focus on their economic impact for high-end models.
Plotting the Prompt Landscape: AI engineers debated the merits of meta-prompting versus Chain of Thought (CoT), examining the potential of using mermaid diagrams to conserve tokens and enhance output quality. There was also a sharing of improved prompts like here, showcasing practical applications of advanced prompt engineering tactics.
Rubber Meets The Code: Practical discussions included how AI handles YAML, XML, and JSON formats natively, with suggestions on using these structures for prompts to improve AI understanding and performance, and shared resources pointing to real-life prompt application for generating code and planning.
Interactive Inconsistencies Ignite Inquiry: Users reported issues with ChatGPT ranging from its refusal to draw tarot cards to context drops and unresponsiveness, spotlighting the need for improved and more predictable AI behavior.
HuggingFace Discord
Voice Commands Meet Robotics: A demo video titled "Open Source Voice-Controlled Robotic Arm" exhibits a voice-activated AI robotic arm. The perspective of democratizing robotics technology via community collaboration was forwarded.
Bridging Modalities: Contributions on creating early multi-modal spaces point to the use of single models and possibly stacked models with routing functionalities. For insights on such implementation, a source link was shared, providing a model example with practical applications.
Deep Learning Consult on the Fly: A user consulted the community about overcoming common pain points in training a model using Stanford Cars Dataset, managing only a 60% accuracy using ViT-B_16, with struggles involving overfitting. Meanwhile, another member is looking for help on how to better their deep learning model, indicating an environment that supports knowledge exchange for newcomers.
Diffusers Update for Not-Just-Generation: Hugging Face announced its Diffusers library now supports tasks beyond generative models, such as depth estimation and normals' prediction through Marigold. The update suggests an escalating trend in the versatility of diffusion models and their applications.
Model Choices for Cyber Security Assessments: Analysis from researchers examines the aptitude of various large language models in cyber security contexts. This provides AI engineers an angle to consider the security ramifications inherent in the deployment of LLMs.
Robust SDXL Space Realignment: SDXL embed space discussions underscore that newly aligned spaces default to zeroes instead of an encoded space. Such insights reflect the underlying complexity and time demands associated with realigning models to new unconditioned spaces, revealing the intricate process behind the science.
Gradio Piques Curiosity with Upgraded Clients: The Gradio team announced a forthcoming live event to dive into the latest features of Gradio Python and JavaScript clients. The engagement invitation emphasizes Gradio's continuous push to streamline AI integration into diverse applications through enhanced interfaces.
Ambiguity in Finding an SFW Dataset: Community chatter touches on the difficulty of locating the Nomos8k_sfw dataset, which is tied to the 4x-Nomos8kDAT model, suggesting the dataset’s limited availability or obscure placement. This highlights the occasional challenges inherent to dataset procurement.
Launching Latest Tools for AI Storytelling: Typeface Arc emerges as a comprehensive platform for seamlessness in creating AI-driven content. It features a tool, appropriately dubbed "Copilot", designed to amplify content creation via an interactive experience pivotal for brand narratives.
LM Studio Discord
Visualize This: OpenAI Integrates with LLama!: Engineers can now leverage LLaVA for visual capabilities in LM Studio by deploying it on a server and making use of the Python vision template provided.
Speedy Model Loading on M1 Max: AI models like MLX and EXL2 load swiftly on Apple's M1 Max, taking a mere 5 seconds for L3 8bit, indicating superior performance compared to GGUF Q8 which takes 29 seconds.
LM Studio Finetuning Frustrations: Despite being a robust environment, LM Studio currently lacks the ability to directly fine-tune models, with enthusiasts being pointed to alternative solutions like MLX designed for Apple Silicon.
Budget or Bust: AI practitioners debated the value proposition of various Nvidia GPUs, considering alternatives like the Tesla P40/P100 and eagerly discussed rumored GPUs like the 5090 with anticipation.
Beta Testing Blues: As they navigate the waters of new releases, users reported problems such as Windows CPU affinity issues with large models and errors on AVX2 laptops, hinting at the complexities of configuring modern hardware for AI tasks.
Unsloth AI (Daniel Han) Discord
-
GPT-2 Gets No Love from Unsloth: Unsloth confirmed that GPT-2 cannot be fine-tuned using its platform due to fundamental architectural differences.
-
Fine-Tuning Frustrations with Fiery Chat:
- When fine-tuning llama 3 with 50,000+ email entries, members shared advice on structuring prompts for optimal input-output pairing.
- Faced with a repeating sentence issue post-training, adding an End-Of-Sentence (EOS) token was recommended to prevent the model's overfitting or poor learning.
-
Vision Model Integration on the Horizon: Members are keenly awaiting Unsloth's next-month update for vision models support, citing referrals to Stable Diffusion and Segment Anything for current solutions.
-
LoRA Adapters Learning to Play Nice: The community shared tips on merging and fine-tuning LoRA adapters, emphasizing the use of resources like Unsloth documentation on GitHub and exporting models to HuggingFace.
-
Coping with Phi 3 Medium's Attention Span: Discussions on Phi3-Medium revealed its sliding window attention causes efficiency to drop at higher token counts, with many eager for enhancements to handle larger context windows.
-
ONNX Export Explained: Guidance was provided for converting a fine-tuned model to ONNX, as seen in Hugging Face's serialization documentation, with confirmation that VLLM formats are compatible for conversion.
-
Looks Like We're Going Bit-Low: Anticipation is building for Unsloth's upcoming support for 8-bit models and integration capabilities with environments like Ollama, analogous to OpenAI's offerings.
CUDA MODE Discord
-
CUDA Toolkit Commands for Ubuntu on Fire: A user suggested installing the CUDA Toolkit from NVIDIA, checking installation with
nvidia-smi, and offered commands for setup on Ubuntu, including via Conda:conda install cuda -c nvidia/label/cuda-12.1.0. Meanwhile, potential conflicts were identified with Python 3.12 and missing triton installation when setting up PyTorch 2.3, linked to a GitHub issue. -
GPT-4o meets its match in large edits: Members noted that GPT-4o struggles with extensive code edits, and a new fast apply model aims to split the task into planning and application stages to overcome this challenge. Seeking a deterministic algorithm for code edits, a member posed the feasibility of using vllm or trtllm for future token prediction without relying on draft models. More information on this approach can be found in the full blog post.
-
SYCL Debug Troubles: A member enquired about tools to debug SYCL code, sparking a discussion on stepping into kernel code for troubleshooting.
-
Torchao's Latest Triumph: The torchao community celebrated the merging of support for MX formats, such as
fp8/6/4, in PyTorch, offering efficiency for interested parties, provided in part by a GitHub commit and aligned with the MX spec. -
Understanding Mixer Models in DIY: Members dissected implementation nuances, such as integrating
dirent.hin llm.c, and the importance of guarding it with#ifndef _WIN32for OS compatibility. The addition of a-y 1flag for resuming training in interruptions was implemented, addressing warnings about uninitialized variables and exploring memory optimization strategies during backward pass computation, with a related initiative found in GitHub discussions. -
Quantizing Activations in BitNet: In the BitNet channel, it was concluded that passing incoming gradients directly in activation quantized neural networks might be erroneous. Instead, using the gradient of a surrogate function such as
tanhwas suggested, citing an arXiv paper on straight-through estimator (STE) performance.
Eleuther Discord
- No Post-Learning for GPT Agents: GPT-based agents do not learn post initial training, but can reference new information uploaded as 'knowledge files' without fundamentally altering their core understanding.
- Efficiency Milestones in Diffusion Models: Google DeepMind introduces EM Distillation to create efficient one-step generator diffusion models, and separate research from Google illustrates an 8B parameter diffusion model adept at generating high-res 1024x1024 images.
- Scaling Down for Impact: Super Tiny Language Models research focuses on reducing language model parameters by 90-95% without significantly sacrificing performance, indicating a path towards more efficient natural language processing.
- GPU Performance Without the Guesswork: Symbolic modeling of GPU latencies without execution gains traction, featuring scholarly resources to guide theoretical understanding and potential impact on computational efficiency.
- Challenging the Current with Community: Discussions highlight community-driven projects and the importance of collaborative problem-solving in areas such as prompt adaptation research and implementation queries, like that of a Facenet model in PyTorch.
OpenRouter (Alex Atallah) Discord
-
Latest Model Innovations Hit the Market: OpenRouter announced new AI models, including Mistral 7B Instruct v0.3 and Hermes 2 Pro - Llama-3 8B, while assuring that previous versions like Mistral 7B Instruct v0.2 remain accessible.
-
Model Curiosity on Max Loh's Site: Users show curiosity about the models utilized on Max Loh's website, expressing interest in identifying all uncensored models available on OpenRouter.
-
OCR Talent Show: Gemini's OCR prowess was a hot topic, with users claiming its superior ability to read Cyrillic and English texts, outdoing competing models such as Claude and GPT-4o.
-
OpenRouter Token Economics: There was clarification in the community that $0.26 allows for 1M input + output tokens on OpenRouter, and discussions emphasized how token usage is recalculated with each chat interaction, potentially inflating costs.
-
The Cost of Cutting-Edge Vision: There is a heated exchange on Phi-3 Vision costs when using Azure, with some members finding the $0.07/M for llama pricing too steep, even though similar rates are noted among other service providers.
Nous Research AI Discord
-
Translation Tribulations: Discussions touched on the challenges of translating songs with control over lyrical tone to retain the original artistic intent. The unique difficulty lies in balancing the fidelity of meaning with musicality and artistic expression.
-
AI Infiltrates Greentext: Members experimented with LLMs to generate 4chan greentexts, sharing their fascination with the AI's narrative capabilities — especially when concocting a scenario where one wakes up to a world where AGI has been created.
-
Philosophical Phi and Logically Challenged LLMs: Debates emerged over Phi model's training data composition, with references to "heavily filtered public data and synthetic data". Additionally, evidence of LLMs struggling with logic and self-correction during interaction was reported, raising concerns about the models' reasoning abilities.
-
Shaping Data for Machine Digestion: AI enthusiasts exchanged resources and insights on creating DPO datasets and adjusting dataset formats for DPO training. Hugging Face's TRL documentation and DPO Trainer emerged as key references, alongside a paper detailing language models trained from preference data.
-
Linking Minds for RAG Riches: Collaboration is in the air, with members sharing their intent to combine efforts on RAG-related projects. This includes the sentiment and semantic density smoothing agent project with TTS on GitHub, and intentions to port an existing project to SLURM for enhanced computational management.
LangChain AI Discord
Loop-the-Loop in LangChain: Engineers are troubleshooting a LangChain agent entering continuous loops when calling tools; one solution debate involves refining the agent's trigger conditions to prevent infinite tool invocation loops.
Details, Please! 16385-token Error in LangChain 0.2.2: Users report a token limit error in LangChain version 0.2.2, where a 16385-token limit is incorrectly applied, despite models supporting up to 128k tokens, prompting a community-lead investigation into this discrepancy.
SQL Prompt Crafting Consultation: Requests for SQL agent prompt templates with few-shot examples have been answered, providing engineers with the resources to craft queries in LangChain more effectively.
Disappearing Act: Custom kwargs in Langserve: Some users experience a problem where custom "kwargs" sent through Langserve for logging in Langsmith are missing upon arrival, a concern currently seeking resolution.
Showcasing Applications: Diverse applications developed using LangChain were shared, including frameworks for drug discovery, cost-saving measures for logging, enhancements for flight simulators, and tutorials about routing logic in agent flows.
Modular (Mojo 🔥) Discord
-
Python Version Alert for Mojo Users: Mojo users are reminded to adhere to the supported Python versions, ranging from 3.8 to 3.11, since 3.12 remains unsupported. Issues in Mojo were resolved by utilizing the deadsnakes repository for Python updates.
-
AI-Powered Gaming Innovations: Engineers discussed the prospect of subscription models based on NPC intelligence in open-world games, and introducing special AI-enabled capabilities for smart devices that could lead to AI inference running locally. They explored open-world games that could feature AI-driven custom world generation.
-
Mojo Mastery: Circular dependencies are permitted within Mojo, as modules can define each other. Traits like
IntableandStringableare inherently available, and while lambda functions are not yet a feature in Mojo, callbacks are currently utilized as an alternative. -
Performance Pioneers: An impressive 50x speed improvement was noted at 32 bytes in Mojo, though it encountered cache limitations beyond that length. Benchmarks for k-means algorithms demonstrated variability due to differences in memory allocation and matrix computations, with a suggestion to optimize memory alignment for AVX512 operations.
-
Nightly Builds Nightcaps: The latest Mojo compiler build (2024.5.2805) brought new features, including implementations of
tempfile.{mkdtemp,gettempdir}andString.isspace(), with full changes detailed in the current changelog and the raw diff. Structural sharing via references was also highlighted for its potential efficiency gains in Mojo programming.
Latent Space Discord
-
Debugging Just Got a Level Up: Engineers praised the cursor interpreter mode, highlighted for its advanced code navigation capabilities over traditional search functions in debugging scenarios.
-
A Co-Pilot for Your Messages: Microsoft Copilot's integration into Telegram sparked interest for its ability to enrich chat experiences with features such as gaming tips and movie recommendations.
-
GPT-2 Training on a Shoestring: Andrej Karpathy showcased an economical approach to training GPT-2 in 90 minutes for $20, detailing the process on GitHub.
-
Agents and Copilots Distinguish Their Roles: A distinction between Copilots and Agents was debated following Microsoft Build's categorization, with references made to Kanjun Qiu's insights on the topic.
-
AI Podcast Delivers Cutting-Edge Findings: An ICLR 2024-focused podcast was released discussing breakthroughs in ImageGen, Transformers, Vision Learning, and more, with anticipation for the upcoming insights on LLM Reasoning and Agents.
LlamaIndex Discord
-
Financial Geeks, Feast on FinTextQA: FinTextQA is a new dataset aimed at improving long-form finance-related question-answering systems; it comprises 1,262 source-attributed Q&A pairs across 6 different question types.
-
Perfecting Prompt Structures: An enquiry was made concerning resources for crafting optimal system role prompts, drawing inspiration from LlamaIndex's model.
-
Chat History Preservation Tactics: The community discussed techniques for saving chat histories within LlamaIndex, considering custom retrievers for NLSQL and PandasQuery engines to maintain a record of queries and results.
-
API Function Management Explored: Strategies to handle an extensive API with over 1000 functions were proposed, favoring hierarchical routing and the division of functions into more manageable subgroups.
-
RAG System Intricacies with LlamaIndex Debated: Technical challenges related to metadata in RAG systems were dissected, showing a divided opinion on whether to embed smaller or larger semantic chunks for optimal accuracy in information retrieval.
LAION Discord
AI Reads Between the Lines: Members shared a laugh over SOTA AGI models' odd claims with one model's self-training assertion, "it has trained a model for us," tickling the collective funny bone. Musk's jab at CNNs—quipping "We don’t use CNNs much these days"—set off a chain of ironical replies and a nod towards vision transformer models as the new industry darlings.
Artificial Artist's Watermark Woes: Corcelio's Mobius Art Model is pushing boundaries with diverse prompts, yet leaves a watermark even though it's overtaking past models in creativity. Ethical dilemmas arose from the capability of image generation systems to produce 'inappropriate' content, sparking debate on community guidelines and systems' control settings.
Synthetic Sight Seeks Improvement: In an effort to grapple with SDXL's inability to generate images of "reading eyes," a member asked for collaborative help to build a synthetic database using DALLE, hoping to hone SDXL's capabilities in this nuanced visual task.
Patterns and Puzzles in Generative Watermarks: Observations within the guild pointed out a recurring theme of generative models producing watermarks, indicating possible undertraining, which was found both amusing and noteworthy among the engineers.
Elon's Eyeroll at CNNs Stokes AI Banter: Elon Musk's tweet sent a ripple through the community, sparking jests about the obsolete nature of CNNs in today's transformative AI methodologies and the potential pivot towards transformer models.
tinygrad (George Hotz) Discord
GPU Latency Predictions Without Benchmarks?: Engineers discussed the potential for symbolically modeling GPU latencies without running kernels by considering data movement and operation times, though complexities such as occupancy and async operations were recognized as potential confounders. There's also anticipation for AMD's open-source release of MES and speculation about quant firms using cycle accurate GPU simulators for in-depth kernel optimization.
Optimizing with Autotuners: The community explored kernel optimization tools like AutoTVM and Halide, noting their different approaches to performance improvement; George Hotz highlighted TVM's use of XGBoost and stressed the importance of cache emulation for accurate modeling.
Latency Hiding Mechanics in GPUs: It was noted that GPUs employ a variety of latency-hiding strategies with their ability to run concurrent wavefronts/blocks, thus making latency modeling more complex and nuanced.
Buffer Creation Discussions in Tinygrad: The #learn-tinygrad channel had members inquiring about using post dominator analysis in scheduling for graph fusion efficiency and the creation of LazyBuffer from arrays, with a suggestion to use Load.EMPTY -> Load.COPY for such scenarios.
Code Clarity and Assistance: Detailed discussions were had regarding buffer allocation and LazyBuffer creation in Tinygrad, with one member offering to provide code pointers for further clarification and understanding.
AI Stack Devs (Yoko Li) Discord
-
Elevenlabs Voices Come to AI Town: Integrating Elevenlabs' text-to-speech capabilities, AI Town introduced a feature allowing conversations to be heard, not just read, with a minor delay of about one second, challenging real-time usage. The implementation process involves transforming text into audio and managing audio playback on the frontend.
-
Bring Science Debate to AI Chat: A concept was shared about utilizing AI chatbots to simulate science debates, aiming to foster engagement and demonstrate the unifying nature of scientific discussion.
-
Audio Eavesdropping Added for Immersion: The Zaranova fork of AI Town now simulates eavesdropping by generating audio for ambient conversations, potentially amplifying the platform's interactivity.
-
Collaborative Development Rally: There's an active interest from the community in contributing to and potentially merging new features, such as text-to-speech, into the main AI Town project.
-
Addressing User Experience Issues: A user experienced difficulties with the conversations closing too quickly for comfortable reading, hinting at potential user interface and accessibility improvements needed within AI Town.
Cohere Discord
-
Slimming Down on Logs: A new pipeline developed by a member removes redundant logs to reduce costs. They recommended a tool for selecting a "verbose logs" pipeline to achieve this.
-
Debating Deployment: Members discussed cloud-prem deployment solutions for reranking and query extraction, seeking insights on the best integrated practices without providing further context.
-
Financial RAG Fine-tuning: There was an inquiry on the possibility of fine-tuning Cohere models to answer financial questions, specifically mentioning the integration with RAG (Retrieve and Generate) systems using SEC Filings.
-
Aya23 Model's Restrictive Use: It was clarified that Aya23 models are strictly for research purposes and are not available for commercial use, affecting their deployment in startup environments.
-
Bot Plays the Game: A member launched a Cohere Command R powered gaming bot, Create 'n' Play, featuring "over 100 text-based games" aimed at fostering social engagement on Discord. The project's development and purpose can be found in a LinkedIn post.
OpenAccess AI Collective (axolotl) Discord
-
Inference vs. Training Realities: The conversation underscored performance figures in AI training, particularly regarding how a seemingly simple query about "inference only" topics quickly lead to complex areas focused on training's computational requirements.
-
FLOPS Define Training Speed: A key point in the discussion was that AI model training is, in practice, constrained by floating-point operations per second (FLOPS), especially when employing techniques like teacher forcing which increase the effective batch size.
-
Eager Eyes on Hopper Cards for FP8: The community showed enthusiasm about the potential of Hopper cards for fp8 native training, highlighting a keen interest in leveraging cutting-edge hardware for enhanced training throughput.
-
Eradicating Version Confusion with fschat: Members were advised to fix fschat issues by reinstallation due to erroneous version identifiers, pointing to meticulous attention to detail within the collective's ecosystem.
-
When CUTLASS Is a Cut Above: Discussions clarified the importance of setting
CUTLASS_PATH, emphasizing CUTLASS's role in optimizing matrix operations vital for deep learning, underscoring the guild’s focus on optimizing algorithmic efficiency.
Interconnects (Nathan Lambert) Discord
-
Apache Welcomes YI and YI-VL Models: The YI and YI-VL (multimodal LLM) models are now under the Apache 2.0 license, as celebrated in a tweet by @_philschmid; they join the 1.5 series in this licensing update.
-
Gemini 1.5 Challenges the Throne: Gemini 1.5 Pro/Advanced has climbed to #2 on the ranking charts, with ambitions to overtake GPT-4o, while Gemini 1.5 Flash proudly takes the #9 spot, edging out Llama-3-70b, as announced in a tweet from lmsysorg.
-
OpenAI's Board Left in the Dark: A former OpenAI board member disclosed that the board wasn't informed about the release of ChatGPT in advance, learning about it through Twitter just like the public.
-
Toner Drops Bombshell on OpenAI's Leadership: Helen Toner, a previous member of OpenAI's board, accused Sam Altman of creating a toxic work environment and acting dishonestly, pushing for "external regulation of AI companies" during a TED podcast episode.
-
Community Aghast at OpenAI's Revelations: In reaction to Helen Toner's grave allegations, the community expressed shock and anticipation about the prospect of significant industry changes, highlighted by Natolambert querying if Toner might "literally save the world?"
Datasette - LLM (@SimonW) Discord
- Go-To LLM Leaderboard Approved by Experts: The leaderboard at chat.lmsys.org was highlighted and endorsed by users as a reliable resource for comparing the performance of various large language models (LLMs).
Mozilla AI Discord
- Securing Local AI Endpoints Is Crucial: One member highlighted the importance of securing local endpoints for AI models, suggesting the use of DNS SRV records and public keys to ensure validated and trustworthy local AI interactions, jesting about the perils of unverified models leading to unintended country music purchases or squirrel feeding.
- Troubleshoot Alert: Llamafile Error Uncovered: A user running a Hugging Face llamafile - specifically
granite-34b-code-instruct.llamafile- reported an error with an "unknown argument: --temp," indicating potential issues within the implementation phase of the model deployment process. - Focus on the Running Model: In a clarification, it was noted that whatever model is running locally at
localhost:8080(like tinyllama) would be the default, with themodelfield in the chat completion request being inconsequential to the operation. This suggests a single-model operation paradigm for llamafiles in use.
Link mentioned: granite-34b-code-instruct.llamafile
OpenInterpreter Discord
- Request for R1 Update: A member expressed anticipation for the R1's future developments, humorously referring to it as a potential "nice paperweight" if it doesn't meet expectations.
- Community Seeks Clarity: There's a sense of shared curiosity within the community regarding updates related to R1, with members actively seeking and sharing information.
- Awaiting Support Team's Attention: An inquiry to the OI team concerning an email awaits a response, signifying the need for improved communication or support mechanisms.
AI21 Labs (Jamba) Discord
- Spotting a Ghost Town: A member raised the concern that the server appears unmoderated, which could indicate either an oversight or an intentional laissez-faire approach by the admins.
- Notification Fails to Notify: An attempted use of the @everyone tag in the server failed to function, suggesting restricted permissions or a technical snafu.
MLOps @Chipro Discord
- LLM for Backend Automation Inquiry Left Hanging: A member's curiosity about whether a course covers automating backend services using Large Language Models (LLM) remained unanswered. The inquiry sought insights into practical applications of LLMs in automating backend processes.
The LLM Perf Enthusiasts AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The YAIG (a16z Infra) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
LLM Finetuning (Hamel + Dan) ▷ #general (91 messages🔥🔥):
- Google Vision OCR likes and dislikes: Several members discussed Google Vision OCR where it was noted for its decent results and detailed confidence metrics at the character level, though the developer experience was critiqued as horrible. Alternatives like Microsoft Azure and open-source Mindee Doctr were mentioned as either better or simpler solutions.
- Gradio office hours hype: Hugobowne announced an upcoming office hours session with Freddy Boulton, prompting excitement and some jokes about AI swag like Scikit hoodies and Mistral t-shirts. Links were shared to Freddy's website and a YouTube tutorial on building a multimodal chatbot component.
- Modal as an all-encompassing cloud service: Charles highlighted Modal's full-stack capabilities for data ETL, fine-tuning, inference, web hosting, and more, positioning it as a serverless solution for a variety of tasks. This spurred discussions about full-stack app efficiency and examples were shared for S3 bucket mounts and web scraping.
- Choosing LLM libraries for building agents: Lalithnarayan and Chongdashu discussed the multitude of choices like Langchain, LlamaIndex, and DSPy for building LLM applications and agents. They concluded with advice to start with Langchain v0.1 and upgrade as necessary, given the recent breaking changes in v0.2.
- Data mixture for pretraining: Thechurros asked about the correct data mixture when continuing pre-training with synthetic data. Jeremy Howard suggested a rough guideline of 20% existing data and mentioned using curated common crawl subsets, highlighting the lack of definitive research and prompting mentions of related works like the Zephyr data mixture study.
Links mentioned:
LLM Finetuning (Hamel + Dan) ▷ #workshop-1 (10 messages🔥):
-
Honing LLMs for Pharma Sector: A discussion revolves around five compelling use cases for LLMs within the pharma/biotech sector, such as Accelerated Drug Discovery and Personalized Medicine. Each use case emphasizes fine-tuning with relevant datasets and leveraging RAG for contextual and specific information.
-
Legal Document Summarization: There is an interest in leveraging LLMs to summarize discovery documents for legal proceedings. Fine-tuning is suggested as crucial for adapting the model to the specific style and relevance criteria of legal summaries.
-
Customized Email Openers for Sales: One member discusses generating personalized first liners for sales emails. Fine-tuning the model with a dataset of successful email openers and profiles of recipients is proposed to enhance engagement and response rates.
-
Interdisciplinary Collaboration via Multi-Agent LLMs: The idea of creating a multi-agent LLM model, each specializing in a niche area, is introduced for solving complex interdisciplinary problems. This setup would involve RAG for additional context and fine-tuning each agent for their specific domain.
-
Chatbots for Technical Support and Incident Diagnosis: Discussion includes training models for chatbots tailored for answering technical questions from historical Slack & Jira data and diagnosing active incidents using post-mortem documentation. Fine-tuning is suggested for enhancing the efficacy of these chatbots.
LLM Finetuning (Hamel + Dan) ▷ #asia-tz (9 messages🔥):
-
Circleback Transcript Troubles: A user mentioned that Hamel had been using Circleback for transcription and notes but could not find the link to access them. Hamel replied that Circleback isn't transcribing these huge meetings but noted it's possible to export the transcripts, asking for help in uploading them to the course lessons.
-
Zoom Transcripts Coming Soon: Dan stated that Zoom uses a separate step/job to create transcripts and he has kicked off the jobs for all sessions. He mentioned that he would upload the transcripts on the course page in the afternoon and provide an update, clarifying that these would be transcripts rather than summaries.
-
Opportunity for LLM Summaries: Hamel suggested that creating summaries from the transcripts could be a good opportunity for someone to use LLMs. This implies there is room for contributions by course participants in refining the content.
-
Late Joiner Seeking Guidance: Shalini, a new member from Kolkata, inquired about the course's progress and what she should follow apart from catching up on recordings, as she joined in Week 3.
LLM Finetuning (Hamel + Dan) ▷ #🟩-modal (87 messages🔥🔥):
-
DeepSpeed Config Stumps Llama3-70B Trainers: A user struggled with OOM errors while training Llama3-70B on multiple GPUs, due to suspected misconfigured DeepSpeed settings. They received advice to reduce batch size, modify sequence length, and adjust target layers in their config files, while also sharing relevant WandB runs and configurations.
-
Debugging Model Configuration for Modal: Users worked through different strategies including setting the gradient accumulation to
1and turning off evaluations to debug OOM issues. They continually iterated on config settings and shared runs to better understand memory allocation. -
Getting Lorax Running on Modal: A user successfully ran Lorax on Modal after addressing Dockerfile ENTRYPOINT issues by clearing the existing entrypoint and wrapping the call to
lorax-launcherin a@modal.web_serverdecorator. Reference Code. -
Choosing GPU Instances for Training: A general query on heuristics for choosing the right instance type was addressed, suggesting starting with A10G GPUs if VRAM limits are met, with a potential future shift to L40S GPUs.
-
Caching Mechanism for Model Weights: A user sought confirmation on their method of caching model weights using Modal's caching mechanism and detailed their setup for feedback, which received validation.
Links mentioned:
LLM Finetuning (Hamel + Dan) ▷ #learning-resources (11 messages🔥):
-
Prince Canuma drops LLaMA 3 finetuning resources: A user shared that Prince Canuma has released a new video and weights on refining LLaMA 3 from 8B to 6B link to video.
-
OpenAI finetuning guide for beginners: It's suggested that beginners refer to the OpenAI fine-tuning guide to understand when fine-tuning is appropriate.
-
Struggling with .pth to safetensors conversion: A user requested help with converting a finetuned spam classifier from a .pth file to safetensors format for hosting on Hugging Face. They were directed to Hugging Face documentation and provided additional advice.
-
Upload model to Hugging Face hub first: It was also advised to first upload the model to the Hugging Face hub before attempting local conversions, with further guidance pointing to the convert.py file in the Hugging Face repository.
-
Keep HF tokens secure: A user was informed that their Hugging Face token was unintentionally exposed, and this discussion was suggested to be moved to a private channel.
Links mentioned:
LLM Finetuning (Hamel + Dan) ▷ #jarvis-labs (26 messages🔥):
-
Cache your Hugging Face models smartly: A user shared tips for caching Hugging Face models and datasets to specific directories to avoid running out of storage. They recommended setting environment variables like
HF_DATASETS_CACHEandHUGGINGFACE_HUB_CACHE. -
Accessing additional logs for troubleshooting: Members discussed difficulties in retrieving additional logs for errors, especially when instances restart unexpectedly. It was suggested to run long-running jobs on the JupyterLab terminal for clearer logs or convert notebooks to Python scripts.
-
Conda environments reset upon pausing: Users reported their conda environments being deleted when instances are paused and resumed. The issue appears linked to environments saved in the
/rootdirectory, and it was recommended to save them in custom paths. -
Managing credentials across different emails: Questions arose about using different emails for JarvisLabs and other platforms, causing issues with credits. The resolution was to ensure the same email is used across all relevant platforms and is registered with course instructors for credits.
-
Automating instance shutdowns: There was a discussion about scripting the startup and shutdown of instances for resource conservation. It emerged that
shutdown -hmight not work directly, and API usage was suggested for full automation.
Link mentioned: Create custom environment | Jarvislabs: You may want to create and maintain separate virtual environments as your project gets more complicated.
LLM Finetuning (Hamel + Dan) ▷ #hugging-face (19 messages🔥):
- HF credits meant for individuals, not organizations: Members clarified that grants are intended for individuals taking the course, not for organizations. Even so, it is acceptable to have an account that is a member of an organization.
- Ensure HF credits are applied by Friday: A member reminded everyone that credits will be distributed by Friday after enrollment closes. They stressed the importance of filling out the HF form sent via email to ensure credits are correctly applied.
- Trouble converting PyTorch model to safetensors: A user discussed their frustration with converting a PyTorch model to safetensors for production. They mentioned following a tutorial from GitHub - LLMs-from-scratch and raised questions about handling the specific file formats and inference code required.
Link mentioned: GitHub - rasbt/LLMs-from-scratch: Implementing a ChatGPT-like LLM in PyTorch from scratch, step by step: Implementing a ChatGPT-like LLM in PyTorch from scratch, step by step - rasbt/LLMs-from-scratch
LLM Finetuning (Hamel + Dan) ▷ #replicate (6 messages):
- Choose GitHub email for Replicate setup: It was clarified that for signing up on Replicate, the email associated with your GitHub account should be used. For preferred email settings, users are advised to use the email already associated with their Replicate account to avoid confusion.
- Replicants Recognized: A self-identified "Replicate person" humorously noted they are now called "Replicants." This highlights the inclusive and fun culture within the Replicate community.
- Email confusion clarified: After signing up with GitHub, a user expressed confusion over which email will be checked for Replicate credits. It was confirmed by a Replicant that tracking can be done via the Replicate (GitHub) username and to DM if any issues arise.
LLM Finetuning (Hamel + Dan) ▷ #langsmith (1 messages):
- Latencies Love In Langsmith: One member expressed appreciation for the latency graphs in Langsmith, raising two questions. They inquired whether there could be historical latency graphs of all models rather than just those in use, and how geographical distribution of models affects latency, asking about dependencies on zones for OpenAI, Anthropic, and Google models.
LLM Finetuning (Hamel + Dan) ▷ #kylecorbitt_prompt_to_model (3 messages):
- OpenPipe limits data formats: A member noted that OpenPipe currently only accepts external data in the OpenAI chat fine-tuning format, which restricts the ability to upload JSONL in Alpaca format. They expressed interest in the dataset creation interface seen in a recent talk.
- Future data format support likely: Another member responded to the query by clarifying that additional data formats might be supported in the future. This decision was made because the current format is what "most of our users were most familiar with."
LLM Finetuning (Hamel + Dan) ▷ #workshop-2 (64 messages🔥🔥):
-
Fine-Tuning with High-Quality Data Crucial: "You want to feed it high-quality stuff," emphasizes the importance of high-quality data for fine-tuning, not altering the objective function, but possibly the optimizer and hyperparameters. High-quality data maximizes the pre-built model's application-specific performance.
-
Loss Curve Interpretation and Overfitting Concerns: Discussion on Mistral8x7b fine-tuning highlights the issue of overfitting based on curve interpretation, recommending validation loss usage. Participants also debate learning rate adjustments, with suggestions pointing to a potentially too-high base learning rate.
-
Optimization Issues and Configuration Tweaks: Exploring reasons for increased and plateaued loss in training, suggestions include possibly high learning rates and using better initialization or configs like
rslora. Participants share Weights & Biases (wandb) run links for collaborative debugging. -
Curated and Synthetic Dataset Challenges: Rumbleftw and others discuss complexities with curated datasets and specific configurations for fine-tuning recent model releases. They address tokenizer issues, appropriate special tokens, and handle a dataset of around
165kdata points. -
Shared Resources and Configuration Advice: Community members share useful resources, including workshop notes from Cedric Chee's GitHub Gist, and discuss zero3 and zero3_bf16 deep-speed configurations from OpenAccess-AI-Collective's GitHub. The importance of proper configuration to avoid out-of-memory issues during model parallelism is also highlighted.
Links mentioned:
LLM Finetuning (Hamel + Dan) ▷ #workshop-3 (461 messages🔥🔥🔥):
- Awesome session on LLM Evals: Eugene Yan shared a thorough walkthrough of evaluating LLMs, covering iterating on evaluations and how they interlink with product metrics. Check out his visualizing finetunes repository for detailed notebooks.
- Data logging and evaluation tools emphasized: Tools like LangFuse, ChainForge, and EvalGen were highlighted for their potential to make tracing, logging, and evaluations more effective.
- Concerns on performance metrics: Discussion highlighted the challenges of traditional metrics like BLEU and the need for dynamic, task-specific evaluations as outlined in Eugene Yan's write-up.
- Engaging practical examples: The session included practical examples with detailed methodologies and technical insights, with resources like a notebook series elucidating fine-tuning processes.
- Rich resource sharing: The session and discussion brought together a wealth of resource links, from practical guidance articles like Eugene's piece on prompting fundamentals to the latest research like the Reversal Curse.
Links mentioned:
LLM Finetuning (Hamel + Dan) ▷ #clavie_beyond_ragbasics (2 messages):
-
Understanding Colbert's Output: A member admitted it’s unclear what comes out of Colbert and plans to run the code to check. They seem eager to gain firsthand insights into its results.
-
Interest in Discussing Sparse Embeddings and M3: A member expressed a desire to delve into discussions about sparse embeddings and M3, even though it's considered "rag basics". This indicates an interest in expanding beyond the conventional topics typically covered.
LLM Finetuning (Hamel + Dan) ▷ #axolotl (31 messages🔥):
- Loading error with Axolotl's 70B model: A user encountered an error while loading checkpoint shards for the 70B model using two RTXA6000 GPUs. The error was related to "torch.distributed.elastic.multiprocessing.errors.ChildFailedError", causing the process to fail at 93% completion.
- Cost concerns with WandB services: Multiple users discussed the high cost of WandB for extensive usage, with alternatives such as Aim and self-hosted MLflow suggested for their cost-effectiveness. One user mentioned the significant benefit of these tools is mainly for collaboration, recommending simpler solutions for solo developers.
- Preference for WandB: Despite cost, some users prefer WandB for its user-friendliness compared to other tools.
- Google Colab Debug for Axolotl: A user has made a pull request to fix issues with running Axolotl in Google Colab notebooks, including updates to configurations and installation steps.
- Inference discrepancies with TinyLlama: Users reported inconsistent outputs when performing inference with TinyLlama models post-training. Potential issues included improper prompting and disparities between training and inference setups detailed by config file examination and discussions on sample packing optimization.
Links mentioned:
LLM Finetuning (Hamel + Dan) ▷ #wing-axolotl (22 messages🔥):
-
Python function for DataFrame to JSONL conversion shared: A user shared code for converting a DataFrame to JSONL format, suggesting it as a simple and effective solution. The code iterates over DataFrame rows, converts each row to a dictionary, and writes it to a file as a JSON line.
-
Debate on load_in_8bit impacts on training: Users discussed whether using
load_in_8bit=Trueaffects training beyond reducing GPU VRAM usage. Observations included better gradient behavior withload_in_8bit=Falseand technical details on quantization and precision during training. -
Issues with Qwen tokenizer: There's an ongoing problem with the QwenCode1.5 tokenizer configuration being incorrect. The proposed solution is to switch to Qwen2Tokenizer, but validation or insights from Qwen are pending.
-
Context window length concerns: A user raised concerns about prompts exceeding the model’s context window length, noting potential exceptions or performance issues. They found success with the "rope_scaling" parameter and mentioned a model supporting longer context windows, like the Llama-3 8B Gradient Instruct.
-
Addressing token_type_ids in tokenizers: A critical issue was identified with the default PreTrainedTokenizer class emitting
token_type_ids, which some model classes do not handle. The correct implementation should iterate over possible vectors specified inmodel_input_nameswhen adjusting sizes, as discussed with references to HuggingFace code.
Links mentioned:
LLM Finetuning (Hamel + Dan) ▷ #freddy-gradio (78 messages🔥🔥):
- Early Birds and Night Owls Discuss Gradio: Members from different time zones shared their dedication, including 4 AM alarms in India and late-night coding sessions at 2 AM.
- Gradio vs Streamlit Debate: When asked about preferring Gradio or Streamlit, a member strongly favored Gradio, citing personal bias.
- Multimodal Chatbots and Google OAuth: Shared links to Gradio multimodal chatbots (link) and Google OAuth integration guides (link).
- Live Demo Errors: Learning Opportunity: Members discussed how live demo errors can be instructive, highlighting experts' debugging processes as beneficial learning moments.
- Freddy Aboulton's Session Praise: Participants expressed appreciation for Freddy's session and shared resources for further learning, including a video link (Zoom video) and Gradio performance tips guide (link).
Links mentioned:
LLM Finetuning (Hamel + Dan) ▷ #charles-modal (5 messages):
-
Slow Local Inference on M3 Mac Frustrates User: A user reported significant latency, over 2 minutes per response, when running inference locally on their M3 Mac using Modal's LLM engine. They inquired about deploying the model for inference elsewhere, such as Hugging Face or Replicate.
-
Deploying to Modal as a Solution: Another member clarified that deploying to Modal using
modal deploywould alleviate the latency issue, as the LLM engine boot would occur on Modal's infrastructure. They noted that latency would primarily be an issue only when a new instance spins up after a long delay. -
Using Weights Elsewhere: The same member mentioned that the model weights could also be extracted from the Modal volume and used externally, suggesting the use of
modal volumeCLI commands.
LLM Finetuning (Hamel + Dan) ▷ #langchain-langsmith (2 messages):
-
Langsmith Annotation Queue UI Troubles: A user mentioned that the Langsmith annotation queue UI looked very different from what was demonstrated, stating, "The input and output are empty. When I hit
Vthen I can see the run." -
Langsmith Deployment Inquiry: Another user inquired about the possibility of deploying Langsmith on a private cloud/VPC.
LLM Finetuning (Hamel + Dan) ▷ #credits-questions (12 messages🔥):
-
Langsmith Bug Fix for Student Credits Setup: Langsmith reported a bug where students must enroll in Plus to set up billing for credits. They're working on a fix to allow students to enter credit card information without being charged.
-
Survey Responses Verification: A user inquired about receiving a copy of all their responses to ensure correctness due to tricky organization names/IDs. Another user agreed, acknowledging they will double-check by May 30th.
-
Predibase Gmail Registration Success: Despite a form stating otherwise, a user managed to sign up for Predibase using a Gmail address via an alternative workflow. Danbecker confirmed that if issues arose later, Predibase support would be responsive.
-
Phone Number Verification Issue: A user faced problems after verifying a phone number for API creation tied to their personal account and noted difficulties in changing the phone number. Danbecker suggested running credits to that personal account and resubmitting the credits form to update the info.
-
Missing Credits for New Joiners: Users, including "enginoid" and "seanlovesbooks," joined on May 23 but have not received credits. They contacted to resolve the issue.
Perplexity AI ▷ #general (659 messages🔥🔥🔥):
- **Anticipation for imfo alpha launch**: An exciting new development is incoming, with a teaser link shared: [spectate_or on X](https://x.com/spectate_or/status/1795077451195830661?s=46). This generated enthusiasm and comparisons to similar tools in the community.
- **Detailed discussion on AI task implementation**: Members discussed categorizing tasks into retrieval and mutation types, with queries like "Get the weight of the iPhone 15" exemplifying this structure. One member emphasized, *"all the steps just happen at the same time,"* needing adjustments for tasks requiring sequential execution.
- **Frustrations around scraping accuracy**: Members faced challenges with HTML parsing for accurate data retrieval, particularly from complex sources like Apple and Docker's release notes. Cloudflare issues and suggestions like using Playwright for JavaScript-heavy sites were also discussed.
- **Cost-effective AI model usage insights**: Detailed calculations were shared on the cost efficiency of using various AI models, with a combined system using Llama3 and Claude models showing significant potential savings.
- **Claude 3 model's performance concerns**: A member shared frustrations about Claude 3 not improving prompts as effectively as before. This triggered a broader discussion on prompt engineering and model performance across different tasks.
Links mentioned:
Perplexity AI ▷ #sharing (6 messages):
- Daily Focus shares an emotional piece: Daily Focus shared a link to a topic titled "Opus 50 sad". Users can explore this link for a deeply emotional and reflective piece of content.
- TheFuzzel explains Perplexity AI: TheFuzzel provided a link explaining what Perplexity AI is. This resource could be beneficial for newcomers wanting to understand the basics.
- Slayer_Terrorblade highlights tech conferences: Slayer_Terrorblade shared a link to a search on upcoming tech conferences. Tech enthusiasts can use this link to stay updated on major events.
- RiseNoctane queries average information: RiseNoctane posted a link with a search query about averages. This might address a broad range of topics related to statistical averages.
- Bambus89 shares top TV shows for May: Bambus89 shared a link about the best TV shows of May. This can be useful for anyone looking for entertainment recommendations for that month.
Perplexity AI ▷ #pplx-api (6 messages):
- Unclear API Output Frustrates Users: A member shared confusion about whether the API output they received was intended, showing a JSON object without functional links in its content. Another member suggested this could be due to the absence of the closed beta citations feature.
- Troubleshooting API Link Generation: To generate relevant video links without access to the citations feature, a member recommended experimenting with different prompts. They provided an example prompt and suggested varying the model size and the number of links requested could help.
- API Outage Concerns: A user inquired if the API was down, hinting at potential service disruptions. There were no follow-up messages confirming or denying this issue.
Stability.ai (Stable Diffusion) ▷ #announcements (2 messages):
-
Stable Assistant Launches with New Features: Stability AI announces new editing features in Stable Assistant, leveraging Stable Diffusion 3 to produce higher quality text-to-image outputs. Try it for free on your images here.
-
Chatbot Beta Enhancements: The chatbot, currently in beta, integrates Stable LM 2 12B to assist with various text-generation tasks like blog posts, scripts, and image captions. Continuous improvements and more features are expected soon.
-
Stability AI and HUG Team Up for Summer Course: Innovation Laboratory offers a 4-week guided course on training your AI model, with Stability AI's tools and HUG's educational expertise. Register for the event here before June 25, 2024.
Links mentioned:
Stability.ai (Stable Diffusion) ▷ #general-chat (495 messages🔥🔥🔥):
- GPU Community Computing Proposal: A member discussed the idea of a community sharing compute costs by offering unused GPU time, possibly through a custom node or even a blockchain ("start a new blockchain that somehow uses training community models as its mining function").
- Debate on Cloud-Based AI Assistants: Concerns were raised about the privacy issues of cloud-based AI assistants, with a sentiment against using such services due to data security risks ("cloud-based, I won't use them. That's a massive privacy concern").
- SD3 Release Frustration and Cloud Services Skepticism: Members expressed frustration about SD3 weights not being released for local use and skepticism towards cloud-only options. There was significant dissatisfaction with StabilityAI's business decisions ("SD 3 in cloud... if you SD team want to differ... needs to release SD3 local").
- Stable Diffusion Workflow and Inpainting Discussions: Members shared tips and tools for enhancing workflows, such as using various extensions and inpainting methods. One suggested watching tutorials on YouTube for better understanding ("google inpainting stable diffusion... watch some YouTube videos").
- Debated Benefits of ComfyUI vs Other UIs: Discussions compared the benefits of ComfyUI to other UIs like Forge or A1111, highlighting ComfyUI's need for technical knowledge versus the ease of use of alternatives. One member shared how certain extensions could enhance ComfyUI's functionality.
Links mentioned:
OpenAI ▷ #annnouncements (1 messages):
- OpenAI Board forms Safety and Security Committee: OpenAI has announced the formation of a Safety and Security Committee responsible for making recommendations on critical safety and security decisions for all OpenAI projects. More details can be found in their official announcement.
OpenAI ▷ #ai-discussions (321 messages🔥🔥):
-
Self-organizing filesystem fascinates users: Users discussed a "self-organizing filesystem" called LlamaFS, which organizes files based on content and time. One user pointed out, "I want self-organizing everything in my life," indicating their enthusiasm for such automation.
-
Discussion on AI Model Costs and NPU Integration: There was an in-depth conversation about the increase in hardware costs due to the integration of NPUs (Neural Processing Units). Members speculated on the economic impact, debating if NPUs would add $200-$1000 to the hardware costs, especially for high-end models.
-
Debating AI's Role in Game Development: A heated debate ensued around the potential of AI to assist in developing complex games like GTA. One member commented, "in a few years an individual could make a GTA game by himself with AI," while another dismissed this as overly optimistic, citing current limitations.
-
Curing cancer, GPT, and TOS considerations: There were considerations around using GPT for ambitious projects like curing cancer, and how such initiatives interact with OpenAI's TOS. Amid the discussion, someone clarified that using GPT for AI projects might be okay if it's not to "scrape their data and make a competing model."
-
Memory and Context Capabilities of Models: Members were impressed by GPT-4o's capability to recall video and audio events, discussing its memory storage as encoding tokens in special folders. SunSweeper noted, "I saw the GPT-4o demo... able to recall the event," expressing amazement at the memory abilities of the AI models.
Link mentioned: MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training: In this work, we discuss building performant Multimodal Large Language Models (MLLMs). In particular, we study the importance of various architecture components and data choices. Through careful and c...
OpenAI ▷ #gpt-4-discussions (21 messages🔥):
-
Building Business Websites with ChatGPT: A member questioned the practicality of using ChatGPT to create a professional business website. Another clarified, "It can create simple wireframes and basic functions, but a fully functional website with only ChatGPT? No."
-
Custom GPTs Memory Feature Confusion: There was confusion about whether custom GPTs have access to memory features. One user explained, "Currently, GPTs do not have long-term memory... but we can design a GPT to help manage information and mimic a long-term memory experience."
-
No Significant Updates Noticed: Discussions around the iOS app update led to members asking if there were any new features; one responded, "Nothing new."
-
Multiple Issues with GPT Functionality: Users reported various issues such as context drops, blanked-out memories, and coding errors. “Is GPT-4 tripping for anyone else?” highlights general dissatisfaction with the current performance.
-
ChatGPT Availability Issues: Intermittent problems with ChatGPT being unresponsive were noted, with one user confirming, “chat gpt is not responding. Does anybody has the same problem?” Another replied, “working perfectly here.” prompting confusion.
OpenAI ▷ #prompt-engineering (76 messages🔥🔥):
-
ChatGPT Refuses to Draw Tarot Cards, Then Cooperates on Smaller Request: A user shared their anecdote about asking ChatGPT to draw three tarot cards which it refused, but it complied after the user asked for drawing just one. Many users agree on experiencing ChatGPT's arbitrary refusal of feasible tasks.
-
Alternate Language Prompt Solves Task Refusal Issue: When asked to process a French document with an English prompt, ChatGPT initially refused but then performed the task when the request language matched the document. Users noted this can be a solution to similar task refusals.
-
Balancing Prompt Length with Response Quality: A user faced issues with their extensive prompt cutting off responses in GPT-4o. Another user shared strategies like replacing verbose planning with mermaid diagrams to reduce token usage while maintaining output quality.
-
Meta-Prompting vs. Chain of Thought: A debate ensued on whether meta-prompting or Chain of Thought (CoT) methods yield better outcomes, with suggestions on optimizing meta-prompting by introducing knowledge representation attachments. Users were advised to creatively combine these methods to avoid narrow projections and hallucinations.
-
Sharing Results and Resources: Users shared prompt results and discussed further optimizations, including a user sharing their improved prompt for Computer and AI literacy.
OpenAI ▷ #api-discussions (76 messages🔥🔥):
-
ChatGPT tarot card refusal frustrates user: A member shares an anecdote about ChatGPT refusing to draw tarot cards despite repeated requests, highlighting the unpredictable nature of the AI's refusals. Another member noted similar experiences with ChatGPT claiming tasks are too large but working with a better prompt.
-
Challenge balancing prompt detail in GPT-4: Users discuss issues with GPT-4 cutting off answers due to prompt length and finding a balance. One suggestion was using mermaid diagrams for planning to conserve tokens and another to fuse it with a zero-shot approach.
-
Meta-prompting versus Chain of Thought: A debate occurs on the effectiveness of zero-shot versus chain of thought (CoT) in meta-prompting. Meta-prompting is highlighted as optimizing AI for open-ended tasks with higher-dimensional solution spaces, while CoT can lead to deterministic outputs.
-
Insights on using YAML and XML for AI prompts: The conversation dives into how AI handles YAML, XML, and JSON natively. Examples and suggestions were provided on using these formats to structure prompts for better AI understanding and performance.
-
Practical examples and shared resources: Members shared experiences and links to successful prompts, such as generating flutter code and comprehensive planning templates for trips, demonstrating practical applications of discussed techniques. Links included Computer and AI Literacy prompt and expanded literacy coverage.
HuggingFace ▷ #announcements (1 messages):
-
Hugging Face drops new models: A new batch of open models includes CogVLM2 for multimodal conversations, Yi 1.5 with long context, and Falcon VLM among others. Check out the detailed announcement and links.
-
Sentence-transformers v3.0 released: The new release features multi-GPU training, bf16 support, and more. Click here for full details.
-
Diffusers 0.28.0 now supports non-generative tasks: The latest update adds functionality for depth estimation and normals' prediction through Marigold. Detailed release notes can be found here.
-
Gradio introduces new features: Major launch event unveils new libraries and features for Gradio apps. Mark your calendars for June 6th.
-
LLMs and cyber security: Researchers evaluate which large language models are safest for cyber security scenarios. Read the full analysis here.
Links mentioned:
HuggingFace ▷ #general (333 messages🔥🔥):
-
Creating Multi-modal Spaces Explained: A user asked about the creation of early multi-modal spaces, whether they are single models or stacked models with a router. Another user shared a source link to view the specifics of such an implementation.
-
Account Creation Issues Due to VPN/Adblock: A user faced issues creating an account, receiving 'account not found' errors. Solutions suggested included disabling VPN, proxy, and adblocker settings as HuggingFace has tight security.
-
TinyLlama Training Insights and Issues: Several users discussed the dataset size and steps required for effective training of TinyLlama. An example was given where finetuning TinyLlama on a small dataset can be done efficiently within approximately 2 hours on a 10k entry dataset.
-
Spectogram-to-Wav Model Release: A user announced the upcoming release of a new spectogram-to-wav model and the challenges faced due to compute limitations. Another shared their experience and suggestions on finetuning models and avoiding common pitfalls.
-
Video Classification Model on Kaggle: One user reported issues with a Video Classification Model only utilizing CPU during validation despite performing correctly with GPU during training. A link to their Kaggle notebook was shared for more context.
Links mentioned:
HuggingFace ▷ #today-im-learning (1 messages):
- SDXL Embed Space Alignments Explained: The SDXL embed space aligns the unconditioned space to zeroes instead of an encoded space like earlier SD 1.5/2.x models/DeepFloyd. "Realigning a model to a new uncond space is painful and takes a long time."
- ControlNet Training Uncertain: The member has learned about ControlNet training but isn't sure if they implemented it correctly. This uncertainty is common when tackling complex models.
- Optimizing Timestep Range Slicing: Segmenting the timestep range to match the batch size allows for more uniform sampling of timesteps for smaller compute training. Without this, you may end up with large gaps in the timestep training distribution, potentially compromising training stability.
- Benefits of Aspect Bucketing and Drawbacks: Using random aspect bucketing helps shift content-aspect bias and is likely used in DALLE-3, which also supports three resolutions. However, it's challenging to maximize training samples without introducing distortions.
- Pitfalls in Training Workflows: Leaving the Torch anomaly detector on for months accidentally wastes time, and trying to fixed something "100% for realsies" tends to introduce new issues.
HuggingFace ▷ #cool-finds (1 messages):
-
Explore Open Source AI Repositories: A member shared an interesting article on the open-source AI ecosystem and how it has evolved, with accompanying discussions on Hacker News, LinkedIn, and a Twitter thread. The article provides a comprehensive list of open-source AI repositories, updated every six hours, which can also be found in the cool-llm-repos list on GitHub.
-
Revisit MLOps Analysis: The member conducted an analysis of the open source ML ecosystem four years ago and revisited the topic to focus exclusively on the stack around foundation models. The full details include data on repositories and the evolution of the AI stack over time.
Link mentioned: What I learned from looking at 900 most popular open source AI tools: [Hacker News discussion, LinkedIn discussion, Twitter thread]
HuggingFace ▷ #i-made-this (6 messages):
-
Voice-Controlled Robotic Arm Project Unveiled: A user shared a YouTube video titled "Open Source Voice-Controlled Robotic Arm" showcasing an AI-powered robotic arm controlled by voice commands. The project aims to democratize robotics through open-source contributions.
-
TinyML Bird Classification Model in Action: An individual discussed their TinyML bird classification model based on EfficientNetB0, tested on random Reddit birding posts and a clean test set. They shared a detailed article covering the model's generation and invited partnerships for further research.
-
SD.Next Releases Major Update: The SD.Next project announced a significant release featuring a new ModernUI, various built-in features like HiDiffusion and enhanced samplers, and newly supported models like PixArt-Σ. Full release details and features are available in the project's Changelog.
-
Introducing HuggingPro Assistant: A user introduced HuggingPro, an AI assistant designed to navigate the Hugging Face ecosystem. The assistant offers accurate info on models, datasets, and more, aiming to make the experience both efficient and enjoyable.
-
Everything-AI v2.0.1 Adds New Functionalities: The user promoted the latest version of everything-ai, an AI-powered local assistant with new features like audio file handling, text-to-video generation, and protein structure prediction. They provided a quick-start guide for users interested in setting up the tool locally.
Links mentioned:
HuggingFace ▷ #reading-group (1 messages):
pr0x7: okay I will try and prepare.update you accordingly. thanks
HuggingFace ▷ #computer-vision (4 messages):
-
Collecting Topics for Hugging Face CV Hangout: A member created a Google Sheet to gather discussion points for a Saturday hangout. Topics can range from new models to personal projects, and participants are encouraged to contribute.
-
Struggles with Stanford Cars Dataset: A user shared their attempt to classify the make and model of cars using the Stanford Cars dataset with the ViT-B_16 model, achieving only 60% accuracy. They detailed their augmentation techniques and learning rate scheduler but faced overfitting issues and sought advice on fine-grained image classification.
-
Request for Deep Learning Guidance: The user acknowledged being new to deep learning and requested guidance from more experienced practitioners to improve their model's performance.
-
New Member Introduction: A user introduced themselves as being new to the community. They did not provide any further context or specific questions.
Link mentioned: Hugging Face Computer Vision Hangout: Tabellenblatt1 Topic (Fine-Tuning/Cool Project/etc.),Style (Short Presentation/Discussion/etc.),Proposed by (discord name)
HuggingFace ▷ #diffusion-discussions (2 messages):
- Search for Nomos8k_sfw dataset reveals obstacles: A member expressed difficulty finding the Nomos8k_sfw dataset mentioned in the 4x-Nomos8kDAT model, questioning whether it's exclusive or just well-hidden.
- Typeface Arc aims for efficient AI content creation: The Typeface Arc platform provides tools to create and manage brand stories in one unified experience. It features a "Copilot" to effortlessly generate 10x more content using continuous feedback for optimization.
Link mentioned: Typeface | Personalized AI Storytelling for Work: Typeface, the generative AI application for enterprise content creation, empowers all businesses to create exceptional, on-brand content at supercharged speeds.
HuggingFace ▷ #gradio-announcements (1 messages):
- Gradio Clients 1.0 Livestream Announcement: The Gradio team announced a livestream event set for June 6th to unveil the new and improved Gradio Python and JavaScript clients. Interested parties can join via Discord or watch on YouTube to learn how to incorporate Gradio into various applications.
Links mentioned:
LM Studio ▷ #💬-general (61 messages🔥🔥):
-
Using vision with OpenAI API in LM Studio clarified: To integrate vision capabilities in LM Studio, use a model like LLaVA, set it up on a server, and utilize the vision Python template. "Just get a model that has vision like llava. Load it on to a server. And copy paste the vision python template."
-
MLX/EXL2 loading faster on Apple's M1 Max: MLX and EXL2 models load significantly faster than GGUF on Apple's M1 Max, taking around 5 seconds for L3 8bit, and 29 seconds for GGUF Q8. "MLX/EXL2 are much faster than GGUF's. mainly cause the inference engine is different."
-
Using RAG with Local LLMs: LM Studio does not support direct interaction with PDFs or Ebooks; however, running a server via LM Studio and using AnythingLLM can set up Retrieval Augmented Generation. "start a server through LM Studio's Local Server tab and then run AnythingLLM."
-
Fine-tuning not supported in LM Studio: LM Studio does not support fine-tuning, but fine-tuning can be done using other tools like MLX on Mac with Apple Silicon. "Training models is way more resource intensive than running models + the inference engine (llama.cpp doesn't support finetuning)."
-
Function calling in LM Studio not supported: LM Studio and similar llama.cpp-based APIs do not support function calling. "function calling isn't supported in the API."
Links mentioned:
LM Studio ▷ #🤖-models-discussion-chat (45 messages🔥):
- Fight the "Can I ask a question?" Trap: Members discussed frustration with people who ask "Can I ask a question?" instead of directly asking their question, wasting time for both parties involved. As one member put it, "you can save your time and everyone else's time if you just ask the question instead of asking to ask the question."
- Use AI and Experts Wisely: While Google and AI can be unreliable, one member noted, "I ask an AI first, then confirm it with an expert if it's not working." This highlights a balanced approach to solving problems with technology and human expertise.
- Phi-3-Vision Support Limitations: One member asked if Phi-3-Vision-128K-Instruct can work in LM Studio, but another clarified, "Still not working in llama.cpp so won't work in LM Studio."
- Exploring "Glitchy" Model Behaviors: There was an inquiry into models exhibiting "glitchy" behaviors with specific prompts. An example given was dolphin 2.9 llama 3, which shows erratic behavior when loaded with specific presets.
Link mentioned: microsoft/Phi-3-vision-128k-instruct · Hugging Face: no description found
LM Studio ▷ #📝-prompts-discussion-chat (12 messages🔥):
-
Wrong Chat Template Causes AI Errors: A member faced an issue with the AI response and it was clarified that they had not configured the right chat template for Llama 3. It was suggested to pick the correct preset from the top-right menu.
-
Blood and Caesar AI Message Causes Confusion: A bizarre message generated by the AI about writing a message in blood saying "Hail Caesar!" led to speculation. A user suggested it might be some uncensored model training bleeding through.
-
Llama 3 List Generation Annoys Users: A member complained about Llama 3 constantly generating lists despite system prompts instructing it not to. They shared an example system prompt that appears ineffective, seeking better alternatives.
LM Studio ▷ #🎛-hardware-discussion (135 messages🔥🔥):
-
Users debate Nvidia budget choices vs expensive GPUs for AI training: Several members discussed options like the Nvidia Tesla P40/P100 and the highly rumored 5090 GPUs with 32GB VRAM, contemplating their cost and performance. Alternately, Macs were suggested for inference purposes, but a PC is considered better for training.
-
Cautious optimism about GPUDirect Storage: The tech that allows GPUs to access SSDs directly without CPU involvement was explored. However, its complex installation and the unknowns around if it’s worth the effort tempered excitement.
-
Concerns about Nvidia’s market bubble: Some members considered the potential bubble in Nvidia shares due to their dominant AI chip market position and debated the stability and future impact of competitor advances from AMD or Intel.
-
Diverse experiences with delivery and couriers: Members shared issues with hardware delivery speeds and reliability, particularly contrasting experiences in Russia and Australia, highlighting the frustrations with courier services compared to traditional postal options.
-
Speculation on whether new AI PCs are worthwhile: There was skepticism about the “Copilot + PC” and other AI PCs being heavily marketed, with concerns about whether they truly added significant value or were overhyped products relying more on cloud services than local capabilities.
Links mentioned:
LM Studio ▷ #🧪-beta-releases-chat (13 messages🔥):
- Windows CPU affinity issues with large models: A user discussed how Windows starts inferencing on all cores but eventually moves work to one CCD after a few minutes when running large models. They are planning to experiment with configuring each CCD as a separate NUMA node to improve system memory bandwidth utilization.
- Error with loading models on AVX2 laptop: A member shared an error encountered when loading a model on a new laptop with AVX2 support, leading to GPU offload issues on Linux. The suggestion to disable GPU acceleration settings did not resolve the problem as the settings were grayed out.
- Processor masquerading issues: Another user speculated that the error might be due to the processor being used as a GPU and recommended disabling the processor's "GPU" to resolve the issue. This might help the system connect to an actual GPU resource.
Unsloth AI (Daniel Han) ▷ #general (169 messages🔥🔥):
-
GPT-2 Not Supported by Unsloth: Members asked if GPT-2 is supported for fine-tuning in Unsloth. It was confirmed it is not, due to architectural differences.
-
Dataset Preparation for Fine-Tuning with Unsloth: A user sought advice on fine-tuning a dataset of over 50k email entries using llama 3 with Unsloth, focusing on creating the proper structure for inputs and outputs. Several users offered assistance and suggestions, including restructuring the prompt template to fit the dataset.
-
Vision Models to be Supported Soon: Discussion highlighted that Unsloth does not currently support vision models, but support is expected next month. This sparked conversations on existing vision models, such as Stable Diffusion and Segment Anything, with links shared for more information (Stable Diffusion, Segment Anything).
-
Using and Merging LoRA Adapters: Members discussed how to merge and fine-tune LoRA adapters with the original model, and the tools available for saving and uploading these models to platforms like HuggingFace. GitHub link was shared for related resources.
-
Phi 3 Medium Sliding Window Issue: It was noted that Phi3-Medium uses a sliding window attention mechanism that caused performance issues at higher token counts. Many users expressed frustration and anticipation for the model to support higher context windows, specifically mentioning 128K context.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #help (48 messages🔥):
- **Fix GDrive Save Error by Correcting Argument Order**: A member struggled with an error while saving a model to GDrive due to incorrect argument order in `save_pretrained_merged`. Another member suggested fixing the argument order which solved the issue (*"Welp, that was dumb of me, thanks!"*).
- **Batch Size and Steps During Training**: Members discussed how to set epochs and steps for a model with 500 examples using batch size 8 and 62 steps. It was suggested to use `num_train_epochs = 3` and remove `max_steps = 500` to potentially avoid repetitive outputs and overfitting.
- **Repeating Sentences in Model Training**: A member encountered an issue with the model repeating the same sentence after training, possibly due to missing EOS tokens. This suggests the need to ensure that an EOS token is added to prevent overfitting or insufficient training.
- **Exporting Models to ONNX**: A member sought help converting a fine-tuned model to ONNX format. They were directed to Hugging Face's [ONNX export guide](https://huggingface.co/docs/transformers/en/serialization) and clarified that VLLM format works for the conversion.
- **Support for 8-bit and OpenAI-compatible Servers**: Discussions covered future support for 8-bit models and OpenAI-compatible servers. It's indicated that 8-bit support is coming soon, and there's a pathway for running Unsloth models in environments similar to LM Studio, Jan AI, or Ollama.
Links mentioned:
CUDA MODE ▷ #general (2 messages):
- Lighting.ai receives praise for GPGPU: A member inquired about using Lighting.ai for GPGPU programming, explaining they lack commodity hardware for an NVIDIA card and need to program in CUDA and SYCL. A response affirmed that Lighting.ai is amazing for this use case.
CUDA MODE ▷ #triton (2 messages):
- Deep Dive into GPU Hardware and Programming Model: A member shared two articles explaining the GPU hardware and programming model. They mentioned the importance of understanding GPU capabilities for optimizing the performance of large language models (LLMs) and reducing latency (Part 1, Part 2).
- ViT Model in Triton: The member also mentioned implementing the ViT model completely from scratch in Triton. They claim the performance is competitive with Hugging Face's implementation and provided a GitHub link for those interested in learning about Triton.
Links mentioned:
CUDA MODE ▷ #torch (12 messages🔥):
- Torch.compile incompatible with Python 3.12: A user discovered that torch.compile does not work with Python 3.12, due to missing triton installation after setting up PyTorch 2.3 on Ubuntu 24.04. They found a related GitHub issue tracking this problem and noted that flash-attention works on Python 3.12.
- Pyenv suggested to manage Python versions: Another user experienced the same issue on Arch Linux with Python 3.12 and noted support in PyTorch nightlies. They recommended using pyenv to manage multiple Python versions.
- New bytecode causing issues: It was clarified that dynamo needs to interpret new bytecodes introduced in each Python version, causing the issue. Plans to align PyTorch releases more closely with Python versions and noting partial support in nightlies were discussed.
- Windows support awaited: A user working in a .NET-focused environment expressed the need for native Windows support for torch.compile with Python 3.12.
Links mentioned:
CUDA MODE ▷ #algorithms (1 messages):
-
GPT-4o straggles with large code edits: Frontier models such as GPT-4o struggle with large edits, facing issues like laziness, inaccuracy, and high-latency. "Accurately editing hundreds of lines can take multiple model calls, at times trapping the agent in an infinite loop."
-
Fast Apply model aims to address weaknesses: A specialized model named fast apply is trained to address these weaknesses, breaking down the task into planning and applying stages. "In Cursor, the planning phase takes the form of a chat interface with a powerful frontier model."
-
Seeking deterministic algorithm leads: A member is seeking leads for implementing a deterministic algorithm for code edits, mentioning potential feasibility with vllm or trtllm. They believe it’s possible to speculate on future tokens using such an algorithm rather than relying on a draft model.
For more details, you can read the full blog post.
Link mentioned: Near-Instant Full-File Edits: no description found
CUDA MODE ▷ #beginner (15 messages🔥):
-
Install CUDA Toolkit via Conda and System Requirements: A member suggested to another that they "install the CUDA Toolkit" from the NVIDIA developer site and to check if it's already installed by typing
nvidia-smiin the terminal. They also recommended using the official CUDA downloads page and provided additional resources for documentation and forums. -
Command for Installing on Ubuntu: To set up CUDA on Ubuntu, a user provided commands: "conda install cuda -c nvidia/label/cuda-12.1.0" and "conda install 'pytorch>2.0.1' torchvision torchaudio pytorch-cuda=12.1 -c pytorch-nightly -c nvidia/label/cuda-12.1.0" from Jeremy's tweet. Another user mentioned the necessity of ensuring NVIDIA GPU drivers are installed.
-
Blog for Installing CUDA on Ubuntu: A member vaguely recalled the existence of a blog on properly installing Nvidia drivers and CUDA toolkit on Ubuntu/Linux, although no specific link was provided.
-
Seeking PMPP Study Guide: A different user inquired if anyone had created a study guide for PMPP, including prioritized sections and exercises. The request implies a need for structured study materials.
Link mentioned: CUDA Toolkit 12.1 Downloads: Get the latest feature updates to NVIDIA's proprietary compute stack.
CUDA MODE ▷ #torchao (3 messages):
-
Understanding torch.fx.Interpreter and GPTQRunner: A member raised a question regarding the behavior of
call_functionin thetorch.fx.Interpreterdocs versus its use inGPTQRunner. They provided a link to the GPTQRunner class for context. -
Support for MX formats merged: Another member excitedly announced the merging of support for MX formats, including
fp8/6/4in PyTorch. They invited others interested in improving speed to tag them orvkuzoon GitHub and mentioned that reviewing the code alongside the MX spec clarified many details.
Links mentioned:
CUDA MODE ▷ #off-topic (27 messages🔥):
-
Choosing the right tech city: A member sought recommendations for cities with a strong tech culture and social activities like hackathons. Suggestions included big cities like SF, NYC, and London for their vibrant social scene and smaller cities like Seattle, which had mixed reviews.
-
Cities in Europe: Berlin and Warsaw were recommended over Munich for being more exciting. Berlin was particularly highlighted for its vibrant culture, including "3-day long techno parties and yummy kebabs".
-
San Diego and Ithaca: San Diego was praised by a member who lived there for many years, whereas Ithaca was noted for producing successful individuals from Cornell but was described as boring.
-
Seattle's social scene: A member shared their negative experience living in Seattle, describing it as the least social city due to its long, dark winters and tendency for people to stay indoors.
-
Tech companies in Berlin: It was noted that Google and other small startups operate in Berlin, but major engineering work is limited. The suggestion was made to gain big tech experience in SF or NYC for future opportunities like starting a company.
CUDA MODE ▷ #llmdotc (131 messages🔥🔥):
- Debate on
dirent.handunistd.hintegration: Members discussed where to incorporatedirent.h, with one suggesting putting the code inunistd.hand renaming it to avoid conflicts with the standard Windowswindows.h. Another member preferred the namewindows_posix.hto prevent potential issues. - Compiler Warnings and Fixes: There were warnings about potentially uninitialized local variables in various header files, which led to a commit to address these warnings. A member suggested ensuring
#ifndef _WIN32arounddirent.hto manage compatibility between different operating systems. - Implementation of "Resume Training" Flag: A new
-y 1flag was introduced to resume training automatically after interruptions, enhancing the training process efficiency. This feature proved helpful in reproducing a 350M parameter model over 14 hours at approximately $200. - Discussion on Memory Optimization for Backward Pass: To conserve memory, members discussed recomputing layernorm during the backward pass instead of storing entire activations, potentially leading to efficiency gains. A member began implementing this approach, aiming to reduce memory footprint without sacrificing performance.
- Hosting Large Dataset on S3: The conversation touched on hosting FineWeb100B on S3, considering costs and dependency management. Alternatives like Zenodo or Ubicloud were explored, highlighting the need for an efficient and scalable data hosting solution.
Links mentioned:
</a>: no description found
CUDA MODE ▷ #oneapi (1 messages):
orion160: What are tools to debug SYCL code? In general stepping into kernel code....
CUDA MODE ▷ #bitnet (9 messages🔥):
-
Gradient issues in activation quantized neural networks: A member stated that passing the incoming gradient directly is wrong, and suggested using the gradient of a surrogate function, such as
tanh. They referenced an arXiv paper that explains why even incorrect gradients can minimize training loss using a straight-through estimator (STE). -
Trouble with C extensions in tests: A member faced an
ImportErrorwhen C extensions fromtorchaoweren't importing properly. They speculated that their use of cuda12.4 might be the issue, as cuda12.1 is the default on PyPi. -
Switching CUDA versions: Another member suggested installing cuda12.1 via
cudatoolkitwith conda as a potential solution. They also recommended opening an issue if the problem persists locally.
Link mentioned: Understanding Straight-Through Estimator in Training Activation Quantized Neural Nets: Training activation quantized neural networks involves minimizing a piecewise constant function whose gradient vanishes almost everywhere, which is undesirable for the standard back-propagation or cha...
Eleuther ▷ #general (14 messages🔥):
-
Members offer warm welcomes and share personal experiences: Several new members introduced themselves, expressed their excitement to join, and shared their backgrounds in ML and development. One member mentioned feeling "inadequate" but eager to "improve my agency" by contributing to research.
-
Curiosity about prompt modification research: A solo developer working on research and benchmarking inquired about existing research related to prompt modification/structuring adjacent to MMLU. They shared their personal experiment results, noting a "10-20% hit on various categories" after adapting inputs to fit Anthropic’s XML prompt syntax.
-
Research areas and community projects suggested: A community member was directed to check out community projects for exploring research areas. The response was met with appreciation for the useful suggestion.
-
Request for help with reimplementing Facenet model: A member requested assistance in reimplementing the Facenet model code from scratch using PyTorch. No replies or solutions were provided in the messages.
-
Question about LLMs on Databricks dismissed: A member asked about conducting batch inferencing with LLMs hosted on Databricks. Another member advised that such questions are best directed to Databricks support, pointing out that Databricks is "not known broadly for being compatible with things that are not Databricks".
Eleuther ▷ #research (122 messages🔥🔥):
-
GPTs Agents Cannot Learn After Initial Training: A member shared a concern about GPTs agents not learning from additional information provided after their initial training. Another member clarified that uploaded files are saved as knowledge files for the agent to reference when required, but they do not continually modify the agent's base knowledge.
-
EM Distillation for Efficient Diffusion Model Sampling: A new paper from Google DeepMind proposes EM Distillation, a maximum likelihood-based approach that distills a diffusion model to a one-step generator model with minimal loss of perceptual quality. The technique introduces a reparametrized sampling scheme and noise cancellation to stabilize the distillation process.
-
Google Trains an 8B Parameter Diffusion Model for 1024x1024 Images: Google researchers trained a non-cascaded pixel-space diffusion model to directly produce 1024x1024 images, detailed in their new paper. Discussions included anticipation about comparisons with Imagen 3.
-
STLMs Aim to Minimize Parameters in LLMs: A new research effort introduces Super Tiny Language Models (STLMs) that aim to reduce parameter counts by 90% to 95% while maintaining performance. The paper is vague on specific implementation details but mentions future work on tokenizer-free models, self-play, and alternative training objectives.
-
Questions on GPU Latency Modeling: A member inquired about symbolically modeling GPU latencies without running the kernel or using a learned model. A helpful response provided links to relevant research papers and a PhD thesis discussing theoretical approaches.
Links mentioned:
OpenRouter (Alex Atallah) ▷ #announcements (2 messages):
-
New Models Released: Announcing the launch of Mistral 7B Instruct v0.3 and Hermes 2 Pro - Llama-3 8B. The Mistral 7B Instruct and its free variant now point to the latest v0.3 version.
-
Versioned Model Access: Older versions like Mistral 7B Instruct v0.2 and v0.1 remain accessible.
-
OpenAI Outage Resolved Quickly: There was a brief outage affecting OpenAI usage. However, they swiftly resolved it, with Azure and its fallback remaining operational during the downtime.
Links mentioned:
OpenRouter (Alex Atallah) ▷ #app-showcase (1 messages):
- Inquiry about models on Max Loh's website: A member asked which models are being used on Max Loh's website. They also inquired if anyone knows how to find a list of all the uncensored models available on OpenRouter.
OpenRouter (Alex Atallah) ▷ #general (122 messages🔥🔥):
-
Debate Over Phi-3 Vision Costs and Availability: Discussion revolves around the high cost of using Phi-3 Vision on Azure, with a member suggesting that "looking at llama prices I'd hit $0.07/M". Another member counters, pointing out that other providers also charge similarly.
-
Gemini's Superior OCR Capabilities: Members discuss the OCR capabilities of Gemini, with claims that it "can read Cyrillic text pretty well" and is "better than Claude and GPT-4o" in reading both Cyrillic and English texts.
-
Langchain and Streamlit for Python Chatbots: Inquiries were made about suitable templates for building a Flask-based chatbot. Recommendations included checking out Streamlit templates and Langchain, with emphasis on easy integrations and the possibility of using database adapters.
-
OpenRouter Token Costs Clarifications: Participants debated the costs involved with OpenRouter tokens, clarifying that $0.26 buys 1M input + output tokens and discussing how token count affects pricing. Fry69_61685 emphasizes that each chat interaction recounts the entire history, increasing token usage.
-
Handling OpenAI Model Outages: An outage affected OpenAI GPT-4o, causing interruptions in service. Alex Atallah reassured users by confirming the issue was fixed quickly and promising better checks in the future.
Links mentioned:
Nous Research AI ▷ #off-topic (6 messages):
-
Song Translation Challenges Explored: A member inquired about the current state of song translation, specifically about maintaining the tone with some form of control over the lyrics. The interest lies in managing lyrical translation while preserving the artistic intent.
-
Greentext AGI Scenario: A member found it intriguing to use LLMs to create 4chan greentext snippets. They asked the LLM to generate a greentext about waking up and discovering AGI was created, noting that the results were particularly interesting.
-
Concerns Over Project Management: There's a discussion regarding a user who is hesitant to adopt another platform for an OpenCL extension due to concerns about codebase size. The member expressed disinterest in contributing unless the code is upstreamed, critiquing the project management approach.
-
CrewAI Video Shared: A member shared a YouTube video, "CrewAI Introduction to creating AI Agents". The video provides a tutorial on creating AI agents using CrewAI, including a link to the CrewAI documentation.
-
Tech Culture in University Cities: An upcoming grad student is seeking recommendations for universities in cities with robust tech cultures. They are interested in places like SF, Munich, and NYC for reading groups or hackathons, aiming to connect with peers working on similar AI projects.
Link mentioned: CrewAI Introduction to creating AI Agents: We will take a look at how to create ai agents using crew aihttps://docs.crewai.com/how-to/Creating-a-Crew-and-kick-it-off/#python #pythonprogramming #llm #m...
Nous Research AI ▷ #general (63 messages🔥🔥):
-
Phi model training debate: Members discussed whether Phi used a majority of textbook data or synthetic data for training. One noted, "Phi used majority textbooks," while another corrected, "The paper claims it's a mix of heavily filtered public data and synthetic data."
-
Logic and self-correction in LLMs: Users tested LLMs' ability to provide logical explanations and self-correct, noting failures. One user observed, “It treats questioning its logic as if I said 'That's wrong.'” while another commented, “Models that always agree with the user might turn out stupid too.”
-
Epochs and batch sizes for fine-tuning: Users shared opinions on the number of epochs and batch sizes for model fine-tuning. One suggested, "1-3 is good generally," and another added, "4-6 is over-fitting territory but can work."
-
RAG-in-a-box solutions: A user inquired about recommendations for uploading thousands of PDFs for RAG searches. Another explained that building a proper RAG solution depends on many factors, including the type of data and specific queries.
-
Arithmetic in transformers: The potential complexity of transformers performing arithmetic operations was explored. A member described it as, "layer by layer transformation of partial results," highlighting fundamental limitations in handling arithmetic with token prediction models.
Links mentioned:
Nous Research AI ▷ #ask-about-llms (28 messages🔥):
- Fitting 70B in a Single A100 GPU: "Jaredquek" discussed using axolotl with seq len at 1200 and text completion, utilizing 98% of GPU memory for 8bit lora. He noted that with qlora, there is more spare capacity.
- Experimental RepEng Vectors in Hermes: "Max_paperclips" highlighted that subtracting the honesty vector in Hermes caused it to break quickly, while other models like Mistral responded differently. Azure2089 and others noted similar experiences, with Azure2089 providing a link to prompts addressing model reasoning in presence of misleading information.
- Challenges in Creating DPO Datasets: Lokesh8882 and Thilotee exchanged views on starting a DPO dataset with custom organization data, with Thilotee suggesting reference to scientific papers. Dumball noted that DPO requires specific formats, and linked to Hugging Face's TRL documentation as an example.
- Custom Dataset Formats for DPO Training: Thilotee provided a resource from Hugging Face TRL on the DPO Trainer for language models from preference data, described in this paper. Dumball confirmed that DPO requires data in the form of prompt, chosen, and rejected responses.
- Concept Proposal: Small LLM with Larger Attention Mechanism: Bliponnobodysradar suggested the idea of training a small LLM like llama3 8b with a larger attention mechanism to achieve the context awareness of a larger model, inviting feedback on the idea.
Links mentioned:
Nous Research AI ▷ #rag-dataset (2 messages):
- Pooling Resources for RAG Projects: A member shared their sentiment and semantic density smoothing agent project, available on GitHub, and mentioned they are back from a break and keen to pool resources. They noted that the TTS component might need some preparation to run smoothly, possibly requiring model caching.
- Video Game Break and SLURM Porting: Another member mentioned they had taken a week off to play video games and are now focusing on porting their project, Cynde, to SLURM as their next task.
Link mentioned: GitHub - EveryOneIsGross/densefeelsCHAT: sentiment and semantic density smoothing agent. w/ tts: sentiment and semantic density smoothing agent. w/ tts - EveryOneIsGross/densefeelsCHAT
Nous Research AI ▷ #world-sim (1 messages):
jakekies: hi
LangChain AI ▷ #general (76 messages🔥🔥):
Links mentioned:
LangChain AI ▷ #langserve (4 messages):
- Custom kwargs in Langserve with Langsmith go missing: A member is trying to send custom "kwargs" with their request in Langserve to track and log data in Langsmith. They report that these kwargs do not appear in the Langsmith log item and are looking for solutions.
- Configurable Pinecone namespace request: A member inquires about making the namespace of the Pinecone store configurable to change the namespace based on the user making the API call. They included a code snippet but did not receive an explicit solution in the messages.
LangChain AI ▷ #share-your-work (4 messages):
-
Generative AI for Drug Discovery: A member announced an upcoming event titled "Local Generative AI Model Frameworks for Different Stages of Drug Discovery" scheduled for May 30. More details can be found on LinkedIn.
-
Cutting Costs on Logging: A member shared a pipeline for removing redundant logs to help companies save money. They recommended using this tool, selecting the "verbose logs" pipeline.
-
Flight Simulator Co-Pilot: A project is in progress to create a co-pilot for flight simulators like Microsoft Flight Simulator. Check out a demonstration video on YouTube.
-
Routing Logic in Agent Flows: An informative video on using routing logic in agent flows with Visual Agents, built on LangChain, was shared. Watch the YouTube video here.
Links mentioned:
Modular (Mojo 🔥) ▷ #general (20 messages🔥):
- Mojo Python Version Support Reminder: Please make sure you're using the supported Python version 3.8 to 3.11. Note that 3.12 isn't supported yet. Resolved version issues by adding the deadsnakes repo and updating to 3.11.
- Discussion on Tensor Package Deprecation: Questions arose about Tensor being deprecated as seen in a YouTube video. Clarifications were made that Tensor will be open-sourced and removed from the standard library.
- Making Mojo Practical for Flutter Apps: A member suggested using Mojo to build apps with Flutter for enhanced speed and deployability, referencing a YouTube tutorial. The versatility of combining Flutter's UI capabilities with Mojo was highlighted.
- Interest in LLaMA2.mojo Project: Users showed interest in tutorials for the llama2.mojo GitHub project, focusing on inference and AI model fine-tuning in Mojo. Community members were invited to join a Discord server to discuss this further.
- Low-Level GPU Assembly Code Queries: Where should I ask questions relating to low level GPU assembly code? Discussion pointed towards using tools like Nsight for Python/Mojo.
Links mentioned:
Modular (Mojo 🔥) ▷ #tech-news (6 messages):
- Open-world games use AI to customize NPC intelligence levels: A member suggests that open-world games could offer subscription packages based on the intelligence of NPCs, increasing costs for more "sentient" NPCs. They emphasize this would be an online feature only.
- Smart devices add special AI capabilities: Another member shares that future AI inference will likely occur locally as many smart devices are now shipping with accelerators and CPUs are adopting special registers for matrix multiplication. This hardware shift indicates a move toward more distributed AI processing.
- Custom worlds in open-world games: Expanding on the previous idea, a member envisions open-world games that use AI to build custom worlds based on player interaction. They see a potential to leverage vast online model libraries to enhance gameplay and personalization.
Modular (Mojo 🔥) ▷ #🔥mojo (14 messages🔥):
- Mojo Supports Circular Dependencies: A member questioned how modules can define each other in Mojo. Another clarified that Mojo allows circular dependencies due to the way modules are modeled, particularly with the
__init__.mojoroot (example explanation). - Built-in Traits Import Automatically: Queries regarding the visibility of traits like
IntableandStringablewithout explicit import were answered. It was explained that such traits are part of the built-in package and are hence automatically imported. - Dual Purpose of ^ Operator: Discussion clarified the dual functionality of the
^operator in Mojo. It's used for both XOR operations and signaling the end of an object's lifetime to the compiler. - Callbacks Possible but No Lambdas Yet: Members discussed the use of callback functions in Mojo and noted that lambda functions are not implemented yet. Current alternatives like passing functions as method parameters were explored.
- Enhancing the
vectorizeFunction: A proposal was made to modify thevectorizefunction to allow the closure function to return aBoolfor loop control, akin to functionality in a progress bar project. This sparked interest and further exploration among members.
Modular (Mojo 🔥) ▷ #performance-and-benchmarks (21 messages🔥):
-
50x Speedup at 32 Bytes Hits Cache Issues: fnands shares a detailed benchmark showcasing performance improvements with varying byte lengths, achieving a top speedup of 50x at 32 bytes before bumping into cache limitations. They invite Apple silicon users to test further using a GitHub file.
-
Disparity in k-means Benchmarks Discussed: Cyrus_msk points out that different memory allocation practices and matrix implementations make benchmark comparisons between Python and Mojo's k-means algorithms non-equivalent. Highlights include preallocated memory in Mojo and
BLAS normvs. a parallel SIMD hacked norm function. -
Prefetching and Caching Discussion: Fnands seeks advice on
prefetchoptions to improve performance, discussing performance impact with and without explicit prefetching. Darkmatter__ suggests using tools like Intel's VTune Profiler for detailed CPU performance insights and emphasizes the importance of cache-line alignment for efficient memory access. -
Aligning Memory for Better Performance: Darkmatter__ advises on the importance of ensuring that memory tables are 64-byte aligned to optimize performance on AVX512 operations, reducing cache mismanagement and encouraging prefetching. They also clarify that avoiding false sharing is crucial primarily in multithreaded scenarios.
Link mentioned: fnands.com/blog/2024/mojo-crc-calc/crcn.mojo at main · fnands/fnands.com: My personal blog. Contribute to fnands/fnands.com development by creating an account on GitHub.
Modular (Mojo 🔥) ▷ #nightly (13 messages🔥):
- Interest in Reference Returns: Members discussed whether functions returning
Referenceare good candidates for contributing to the new return convention. One member remarked, "almost all functions that returnReference'should' be converted," with exceptions being those where the reference is often stored by users. - Excitement Over Structural Sharing: A member expressed excitement about the reference changes, highlighting that it "enables structural sharing," meaning multiple structs can share some fields.
- New Nightly Mojo Compiler Released: The latest nightly Mojo compiler version
2024.5.2805was announced. The update includes implementations liketempfile.{mkdtemp,gettempdir}and the addition ofString.isspace()to the standard library; full changes are detailed in the current changelog and raw diff. - Contributor Clarification: One member clarified they are not Modular staff but a contributor.
- Discussion about PR Secrecy: There was a brief conversation on where to comment about an issue, with humor about PR confidentiality as one member noted they are "still waiting for a green light" on an undisclosed PR.
Latent Space ▷ #ai-general-chat (68 messages🔥🔥):
-
Cursor Interpreter Mode Wows User: A user praises cursor interpreter mode for its debugging capabilities, describing it as "a better search that can follow execution path" and being more agentic in navigating a codebase compared to traditional search tools.
-
Microsoft’s Copilot Now on Telegram: Users are excited about Microsoft Copilot integrating into Telegram for a smarter chat experience. The tool offers features like gaming tips, movie suggestions, dating advice, and recipes, optimizing everyday conversations.
-
Training GPT-2 on a Budget: Andrej Karpathy shares a method to train GPT-2 (124M) in 90 minutes for $20 using llm.c, highlighting that GPU constraints can be managed cost-effectively. Detailed instructions are provided in a GitHub discussion.
-
Microsoft Separates Copilots vs Agents: Discussion about Microsoft Build's decision to differentiate Copilots and Agents, with Copilots being more personalized and prompt-based while Agents operate autonomously. A relevant interview with Kanjun Qiu was noted as insightful.
-
Vector Database Integration Queries: A user seeks vector database abstractions similar to ORMs for easier integration and swapping of different vector databases. LangChain and LlamaIndex are suggested, with further recommendations for pgvector for efficient embedding storage and relational metadata management.
Links mentioned:
Latent Space ▷ #ai-announcements (3 messages):
- **New podcast on ICLR 2024 papers**: A new episode covering highlights from ICLR 2024 has been released, featuring various groundbreaking papers and talks. [Listen here](https://x.com/latentspacepod/status/1795196817044594817) for insights on ImageGen, Compression, Adversarial Attacks, Vision Learning, and more.
- **Spotlight on ImageGen and Compression**: Topics discussed include "Auto-encoding Variational Bayes" and "Würstchen: An Efficient Architecture for Large-Scale Text-to-Image Diffusion Models". Notable mentions are detailed insights from Ilya Sutskever and Christian Szegedy.
- **Vision Learning advancements**: The podcast delves into papers like "Vision Transformers Need Registers" and "Think before you speak: Training Language Models With Pause Tokens". It also investigates the statistical theory of data selection under weak supervision.
- **Enhancing Transformer models**: Discussion on efficient fine-tuning and context window extension of large language models with papers like "LongLoRA" and "YaRN". Topics like adaptive KV cache compression and efficient communication for giant model training also featured.
- **State Space Models vs Transformers**: The importance of data-driven priors in long-sequence models is highlighted in the paper "Never Train from Scratch". Stay tuned for more content on LLM Reasoning and Agents in Part 2.
Link mentioned: Tweet from Latent Space Podcast (@latentspacepod): 🆕 ICLR 2024: Best Papers (Part 1) We present our selections of outstanding papers and talks thematically introducing topics for AI Engineers to track: Section A: ImageGen, Compression, Adversarial ...
LlamaIndex ▷ #blog (1 messages):
- FinTextQA: New financial dataset launched: Check out FinTextQA, a new dataset and RAG benchmark for long-form financial question answering from Jian Chen and team. It features 6 different question types and includes 1,262 high-quality, source-attributed question-answer pairs with associated document contexts.
LlamaIndex ▷ #general (59 messages🔥🔥):
-
Achieving Perfect System Role Prompt Structures: A user asked for an article on perfect system role prompt structures similar to what LlamaIndex uses in their examples.
-
Persistence of Chat Histories in LlamaIndex: Users discussed how to save chat history for results from NLSQL and PandasQuery engines. Suggestions included creating a custom retriever to wrap the query engine.
-
Handling Multiple Functions in API with Function Calling: Members brainstormed strategies for managing an API with 1000 separate functions. Ideas included hierarchical routing to divide functions into manageable subgroups.
-
Differences Between LLMSelector and PydanticSelector: Detailed explanations were provided on how LLM selectors use text completion endpoints to generate query data, while Pydantic selectors use pydantic objects for function calling API.
-
Challenges and Solutions in RAG Systems with LlamaIndex: Users discussed metadata handling, the impact of embedding smaller semantic chunks versus larger chunks, and potential trade-offs in information retrieval accuracy.
Links mentioned:
LAION ▷ #general (40 messages🔥):
- Humor in Shitty SOTA AGI Predictions: Various members were discussing the humor and despair in the current state of SOTA AGI models. One interesting note was that a model supposedly trained itself, with remarks like "it has trained a model for us."
- Corcelio's Mobius Art Model on Hugging Face: Images generated by Corcelio's Mobius Art Model were shared with prompts ranging from "Thanos smelling a little yellow rose" to "The Exegenesis of the soul." It was noted for surpassing limitations of previous models but surprisingly generating watermarks.
- Community Concerns on Image System's Ethics: There were concerns raised about people using image generation systems to create inappropriate content, including "porn of stuff they shouldn't lol." This issue brought up questions about the site's prompts and sampler settings.
- Undertrained Model Issues and Watermarks: The new unnamed T2I model on imgsys was discussed, with observations that it often appears undertrained and routinely generates watermarks. Some members found this a recurring and humorous theme.
- Elon Musk's Tweet Mocking CNNs: A shared tweet from Elon Musk highlighted that they "don’t use CNNs much these days," which spurred humorous reactions like advising to use vision transformer models instead. Members joked about the industry's shifting trends and the use of irony in responses.
Links mentioned:
LAION ▷ #research (2 messages):
- SDXL struggles with generating "reading eyes": A member discovered that SDXL couldn’t generate a close-up portrait of a woman reading. They shared their detailed prompt and generation settings used in the horde.
- Call to generate data via DALL-E: The same member tagged other users to suggest generating the image with DALL-E. They aim to create a synthetic database to use as training material to improve "reading eyes" generation with SDXL.
tinygrad (George Hotz) ▷ #general (25 messages🔥):
-
GPU Latency Modeling Might Be Possible: A member suggested that symbolically modeling GPU latencies and runtime could be possible without running kernels, based on data movement between memory types and operation times. However, occupancy and asynchronous operations might complicate the model.
-
Halide and AutoTVM Explored for Kernel Optimization: Members discussed tools like AutoTVM and Halide autotuner, noting that Halide uses a learned weighting of a hand-coded model and AutoTVM likely uses empirical methods. George Hotz pointed out that TVM uses XGBoost and emphasized the importance of properly emulating the cache hierarchy for accurate modeling.
-
Cycle Accurate GPU Simulators are High Precision: There's speculation that quant firms might use cycle accurate GPU simulators for kernel optimization, providing very detailed profiling capabilities. However, the advantage of these simulators over empirical methods in terms of evaluation speed was questioned.
-
AMD MES Open-Source Release Anticipated: There was brief mention of AMD's plans to open-source MES, with the documentation apparently released and the source code eagerly awaited by the community.
-
Differences in GPU Strategies for Latency Hiding: Members highlighted that different GPUs employ various latency-hiding strategies, making it difficult to model latencies accurately. The large number of concurrent wavefronts/blocks in GPUs allows them to handle latencies more efficiently than might be assumed.
Link mentioned: GPUs Go Brrr: how make gpu fast?
tinygrad (George Hotz) ▷ #learn-tinygrad (5 messages):
-
Post dominator analysis confusion: A member questioned why post dominator analysis isn't used during scheduling to identify self-contained subgraphs for fusion. This technique could theoretically enhance efficiency in certain computations.
-
Creating a LazyBuffer with multiple values: A member inquired about creating a LazyBuffer from an array of values rather than a single one. The response alluded to using Load.EMPTY -> Load.COPY as the general method and mentioned factory methods like
fullandrandfor easy creation. -
Code pointers offered for clarity: After a detailed explanation, one member expressed readiness to provide code pointers for better understanding. The initial solution reference included insights on simulating buffer allocation for LazyBuffer creation.
AI Stack Devs (Yoko Li) ▷ #ai-town-discuss (25 messages🔥):
-
Elevenlabs Text-to-Speech Integration Debuts: A user inquired about text-to-speech mods and another mentioned Elevenlabs integration in a branch. Code for textToSpeech was provided.
-
Implement Text-to-Speech in AI Town: The procedure to set up the text-to-speech feature involves converting text to audio, patching messages with audio URLs, and handling audio play on the frontend. It's noted that the process is fast but has an almost one-second delay, making real-time implementation challenging.
-
Interest in Science Debates: A user expressed their intention to create an engaging experience by having AI chatbots debate science topics. This user values science’s power to bring people together and create hope.
-
Add Eavesdropping Mechanic: The Zaranova fork includes an eavesdropping mechanic, generating audio for nearby conversations. This feature could be added to enrich AI Town's interactive experience.
-
Interest in Collaborative Coding: Another user showed interest in contributing to this feature by promising to look into creating a pull request. There was also interest in merging these changes into the AI Town main project.
Links mentioned:
AI Stack Devs (Yoko Li) ▷ #ai-town-dev (1 messages):
gomiez: hi. how do i stop conversations from closing? i cant read that fast
AI Stack Devs (Yoko Li) ▷ #late-night-lounge (1 messages):
angry.penguin: LMK if you have any luck with inference
Cohere ▷ #general (12 messages🔥):
-
Logging pipeline optimized to save costs: A member shared they developed a pipeline to remove redundant logs, potentially added by mistake and pushed to production, to save costs on logging. They used this tool and recommended selecting the "verbose logs" pipeline.
-
Inquiries about cloud-prem deployment options: There was a question about cloud-prem deployment options for reranking and query extraction. The member sought insights on available solutions or best practices.
-
Fine-tuning Cohere model for RAG: A user inquired if Cohere models could be fine-tuned to answer Financial Questions and then used with RAG (Retrieve and Generate) to focus responses based on SEC Filings.
-
Aya23 models restricted to non-commercial use: It was clarified that Aya23 models are limited to non-commercial usage as they are intended for research purposes only. No plans for commercial use were indicated, even for small startups.
-
Creating a DPO dataset with custom data: One member asked for tips on creating a custom DPO dataset, considering options like generating response pairs using GPT-4 or combining GPT-4 output with base model responses.
Link mentioned: GitGud: no description found
Cohere ▷ #project-sharing (3 messages):
-
Cohere-powered gaming bot launches: A member shared about their new creation, a gaming bot for Discord using Cohere Command R. They mentioned that the bot, Create 'n' Play, features "over 100 engaging text-based games" and is designed to enhance social engagement with AI.
-
Check out the gaming bot on LinkedIn: The LinkedIn post offers additional insights into the project's development and functionalities. It aims at easy team formations and interactions within the Discord community.
OpenAccess AI Collective (axolotl) ▷ #general (4 messages):
- Inference-only Query Sparks Discussion: A member asked if the topic was for inference only. The response moved the conversation towards training complexities and performance considerations.
- Training Bottlenecks Center on FLOPS: "Training is almost always bound by flops." When dealing with a batch size of 1 and sequence length of 4096, the effective batch size turns out to be 4096 due to teacher forcing methods.
- FP8 Native Training on Hopper Cards: There was expressed interest in exploring "fp8 native training on hopper cards." This suggests a focus on advanced hardware capabilities for optimized training performance.
- Acknowledgment of Past Mistake: A member humorously admitted, "True, I was wrong back then." This exchange shows a culture of open acknowledgment and learning within the community.
OpenAccess AI Collective (axolotl) ▷ #general-help (1 messages):
- Update fschat properly: A member explained that the version identifier of fschat was not updated, causing issues. They suggested uninstalling and reinstalling fschat to resolve this issue.
OpenAccess AI Collective (axolotl) ▷ #axolotl-phorm-bot (4 messages):
- Clarifying CUTLASS_PATH necessity: A member asked if they should set
CUTLASS_PATH. Phorm responded to check if their project or tools require CUTLASS (CUDA Templates for Linear Algebra Subroutines and Solvers), which is essential for high-performance matrix operations in deep learning applications.
Link mentioned: OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
Interconnects (Nathan Lambert) ▷ #news (2 messages):
- YI and YI-VL models updated to Apache 2.0: A member shared that YI and YI-VL (multimodal LLM) models have been updated to Apache 2.0, joining the 1.5 series. The update was announced by @_philschmid, thanking @01AI_Yi for the update.
- Gemini 1.5 series makes waves: @lmsysorg announced that Gemini 1.5 Pro/Advanced and Flash results are out, with Pro/Advanced ranked #2, closing in on GPT-4o. Gemini 1.5 Flash is at #9, outperforming Llama-3-70b, highlighting its cost-effectiveness, capabilities, and unmatched context length as significant advancements.
Links mentioned:
Interconnects (Nathan Lambert) ▷ #ml-drama (6 messages):
- OpenAI Learns About ChatGPT on Twitter: Former OpenAI board member reveals, "It's things like when ChatGPT came out November, 2022, the board was not informed in advance about that. We learned about ChatGPT on Twitter." (See tweet).
- Shocking Revelations in Podcast: Helen Toner, former OpenAI board member, exposes that Sam Altman was fired for dishonesty, creating a toxic work environment, and accusations of "psychological abuse." She calls for "external regulation of AI companies," citing that self-governance may not always be effective (Podcast link).
- Natolambert's Reaction: Natolambert reacted strongly to Helen Toner's revelations, exclaiming, "holy shit" and then questioning if "helen [is] literally going to save the world?"
Links mentioned:
Datasette - LLM (@SimonW) ▷ #llm (3 messages):
- Reliable AI Model Leaderboard Shared: A user asked for a good website to find the best models and shared a leaderboard link. Simon confirmed that it is his favorite site for comparing LLMs, calling it reliable.
Mozilla AI ▷ #llamafile (3 messages):
-
Local Endpoints for AI Models Must Be Secure: A member expressed excitement about "ubiqutizing, standardizing, and enabling locally available endpoints," but emphasized the need for a secure validation mechanism such as DNS SRV records and pub keys. They humorously noted the importance of verifying the trustworthiness of local AI models, as one might otherwise end up "buy[ing] country music or... feed[ing] skwirrelz."
-
Error with
granite-34b-code-instruct.llamafile: Upon attempting to run a llamafile from Hugging Face, a member encountered an "unknown argument: --temp" error. The process involved downloading, changing permissions, and running the file, culminating in this issue. -
Llamafiles Store and Run One Model: It was clarified that whatever model is running at
localhost:8080is the one used, exemplified by tinyllama. Themodelfield in the chat completion request was noted as irrelevant in this context.
Link mentioned: no title found: no description found
OpenInterpreter ▷ #O1 (3 messages):
- R1 is quite the paperweight: One member mentioned, “I’m holding out hoping R1 will follow through. If not it’s a nice paperweight.”.
- Seeking solutions and updates: Another member expressed curiosity saying, “lmk if u ever find anything on this.”.
- Email response needed: A member requested assistance from the OI team, stating, “Hi OI team, I had sent an email a few days ago to which I haven’t yet received a response for. I just sent a reminder again.”.
AI21 Labs (Jamba) ▷ #general-chat (2 messages):
- **Server seems unmoderated**: A member pointed out that "it looks like the server is unmoderated..." highlighting an apparent lack of moderation.
- **Attempted @everyone ping fails**: The same member tried to use the @everyone tag but noted it "doesn't ping" as intended.
MLOps @Chipro ▷ #events (1 messages):
- Question about course content: A member inquired, "How is this course going for you? Do they teach you to automate backend services using LLM?" There was no reply to this query in the channel.
{% else %}
LLM Finetuning (Hamel + Dan) Discord
OCR Showdown: Google Vision vs. Microsoft Azure: AI engineers debated the merits and pitfalls of Google Vision OCR, acknowledging its precision but criticizing the developer experience. Suggestions for using Microsoft Azure OCR and Mindee Doctr, potentially offering better ease of use, surfaced here.
Curated Data: The Key to LLM Success: Workshop discussions underscored the importance of fine-tuning LLMs with high-quality, curated datasets, ranging from pharma applications to technical support chatbots. Expert opinion highlighted the need for precision in data choice to maximize LLM effectiveness, spotlighting domains like drug discovery, law, sales, and interdisciplinary work.
Axolotl Angst and Optimization: Users faced hurdles running Axolotl's 70B model on M3 Macs, with overwhelming latency during local inference, pointing to deployment on Modal as a possible solution. Cost concerns with Weights & Biases (WandB) prompted considerations of alternatives like Aim and MLflow for economically-minded solo developers Axolotl examples.
LLM Evaluation Deep Dive: A session on evaluating LLMs offered a treasure trove of insights, covering product metrics, traditional and dynamic performance metrics, and tools like LangFuse and EvalGen. Recommending resources by Eugene Yan and practical examples to visualize fine-tuning, participants noted the necessity of nuanced evaluations for LLM development.
Transcription Tangles and the Path to Summaries: Communication around transcripts from large meetings illuminated needs for efficient summaries, exposing potential roles for LLMs. While Zoom transcripts are on the horizon, Hamel encouraged using LLMs to generate more digestible summaries, echoing wider community involvement.
Perplexity AI Discord
-
Eagerly Awaiting imfo Alpha Release: A link to a tweet by @spectate_or hinted at the upcoming release of imfo alpha, sparking excitement and comparisons to similar tools within the engineering community.
-
AI Task Structure Debate: Engineers discussed categorizing AI tasks into retrieval and mutation types, exemplifying with queries like "Get the weight of the iPhone 15". The need for adjustments in tasks requiring sequential execution was highlighted with the insight that "all the steps just happen at the same time."
-
Scraping Accuracy Stumbles: Members voiced challenges in HTML parsing for reliable data scraping, with complications arising from sites like Apple and Docker's release notes. Workarounds through Playwright for JavaScript-centric sites were considered alongside issues with Cloudflare.
-
Exploring Cost-Efficient AI Model Utilization: The community delved into the cost-effectiveness of using various AI models such as Llama3 and Claude. An approach using a combined system suggested possibilities for greater savings.
-
API Functionality Quirks Highlighted: Confusion arose around an API output that displayed a JSON object sans functional links, potentially linked to the absence of a closed beta citations feature. Additional discussions included prompts to improve video link generation and a brief inquiry about a potential API outage.
Stability.ai (Stable Diffusion) Discord
New AI Features to Tinker With: Stability AI announces the launch of Stable Assistant sporting editing features built on Stable Diffusion 3, boasting of improved text-to-image quality available for a free trial here, and a beta chatbot with Stable LM 2 12B, heralding future enhancements for text generation tasks.
Education Merges with AI Innovation: An upcoming 4-week course by Innovation Laboratory, a collaboration between Stability AI and HUG, intends to guide participants on training AI models utilizing Stability AI's framework in tandem with HUG's educational approach; sign-ups are open until June 25, 2024, accessible here.
GPU Sharing in the Spotlight: AI engineers discuss a community-based GPU sharing proposal to decrease compute costs, with options ranging from a custom node to a potential blockchain setup designed to validate model training operations.
SD3 Accessibility Stirs Controversy: Discordance surfaces as members air grievances regarding Stable Diffusion's SD3 weights not being available for local use — slating Stability AI's cloud-only approach and stirring debate over cloud-dependency and data privacy concerns.
User Interfaces Under Comparison: A technical discourse unfolds on the pros and cons of various interfaces for Stable Diffusion, with ComfyUI pitted against more user-friendly alternatives like Forge; discussions also include community tips, inpainting methods, and ways to enhance artificial intelligence workflows.
OpenAI Discord
OpenAI Forms Safety Shield: OpenAI has established a Safety and Security Committee that will take charge of critical safety and security decisions across all its projects; full details can be found in their official announcement.
AI Muscle Flexes in Hardware Arena: Discussions about hardware costs arose, speculating on a $200-$1000 increase due to NPUs (Neural Processing Units), with focus on their economic impact for high-end models.
Plotting the Prompt Landscape: AI engineers debated the merits of meta-prompting versus Chain of Thought (CoT), examining the potential of using mermaid diagrams to conserve tokens and enhance output quality. There was also a sharing of improved prompts like here, showcasing practical applications of advanced prompt engineering tactics.
Rubber Meets The Code: Practical discussions included how AI handles YAML, XML, and JSON formats natively, with suggestions on using these structures for prompts to improve AI understanding and performance, and shared resources pointing to real-life prompt application for generating code and planning.
Interactive Inconsistencies Ignite Inquiry: Users reported issues with ChatGPT ranging from its refusal to draw tarot cards to context drops and unresponsiveness, spotlighting the need for improved and more predictable AI behavior.
HuggingFace Discord
Voice Commands Meet Robotics: A demo video titled "Open Source Voice-Controlled Robotic Arm" exhibits a voice-activated AI robotic arm. The perspective of democratizing robotics technology via community collaboration was forwarded.
Bridging Modalities: Contributions on creating early multi-modal spaces point to the use of single models and possibly stacked models with routing functionalities. For insights on such implementation, a source link was shared, providing a model example with practical applications.
Deep Learning Consult on the Fly: A user consulted the community about overcoming common pain points in training a model using Stanford Cars Dataset, managing only a 60% accuracy using ViT-B_16, with struggles involving overfitting. Meanwhile, another member is looking for help on how to better their deep learning model, indicating an environment that supports knowledge exchange for newcomers.
Diffusers Update for Not-Just-Generation: Hugging Face announced its Diffusers library now supports tasks beyond generative models, such as depth estimation and normals' prediction through Marigold. The update suggests an escalating trend in the versatility of diffusion models and their applications.
Model Choices for Cyber Security Assessments: Analysis from researchers examines the aptitude of various large language models in cyber security contexts. This provides AI engineers an angle to consider the security ramifications inherent in the deployment of LLMs.
Robust SDXL Space Realignment: SDXL embed space discussions underscore that newly aligned spaces default to zeroes instead of an encoded space. Such insights reflect the underlying complexity and time demands associated with realigning models to new unconditioned spaces, revealing the intricate process behind the science.
Gradio Piques Curiosity with Upgraded Clients: The Gradio team announced a forthcoming live event to dive into the latest features of Gradio Python and JavaScript clients. The engagement invitation emphasizes Gradio's continuous push to streamline AI integration into diverse applications through enhanced interfaces.
Ambiguity in Finding an SFW Dataset: Community chatter touches on the difficulty of locating the Nomos8k_sfw dataset, which is tied to the 4x-Nomos8kDAT model, suggesting the dataset’s limited availability or obscure placement. This highlights the occasional challenges inherent to dataset procurement.
Launching Latest Tools for AI Storytelling: Typeface Arc emerges as a comprehensive platform for seamlessness in creating AI-driven content. It features a tool, appropriately dubbed "Copilot", designed to amplify content creation via an interactive experience pivotal for brand narratives.
LM Studio Discord
Visualize This: OpenAI Integrates with LLama!: Engineers can now leverage LLaVA for visual capabilities in LM Studio by deploying it on a server and making use of the Python vision template provided.
Speedy Model Loading on M1 Max: AI models like MLX and EXL2 load swiftly on Apple's M1 Max, taking a mere 5 seconds for L3 8bit, indicating superior performance compared to GGUF Q8 which takes 29 seconds.
LM Studio Finetuning Frustrations: Despite being a robust environment, LM Studio currently lacks the ability to directly fine-tune models, with enthusiasts being pointed to alternative solutions like MLX designed for Apple Silicon.
Budget or Bust: AI practitioners debated the value proposition of various Nvidia GPUs, considering alternatives like the Tesla P40/P100 and eagerly discussed rumored GPUs like the 5090 with anticipation.
Beta Testing Blues: As they navigate the waters of new releases, users reported problems such as Windows CPU affinity issues with large models and errors on AVX2 laptops, hinting at the complexities of configuring modern hardware for AI tasks.
Unsloth AI (Daniel Han) Discord
-
GPT-2 Gets No Love from Unsloth: Unsloth confirmed that GPT-2 cannot be fine-tuned using its platform due to fundamental architectural differences.
-
Fine-Tuning Frustrations with Fiery Chat:
- When fine-tuning llama 3 with 50,000+ email entries, members shared advice on structuring prompts for optimal input-output pairing.
- Faced with a repeating sentence issue post-training, adding an End-Of-Sentence (EOS) token was recommended to prevent the model's overfitting or poor learning.
-
Vision Model Integration on the Horizon: Members are keenly awaiting Unsloth's next-month update for vision models support, citing referrals to Stable Diffusion and Segment Anything for current solutions.
-
LoRA Adapters Learning to Play Nice: The community shared tips on merging and fine-tuning LoRA adapters, emphasizing the use of resources like Unsloth documentation on GitHub and exporting models to HuggingFace.
-
Coping with Phi 3 Medium's Attention Span: Discussions on Phi3-Medium revealed its sliding window attention causes efficiency to drop at higher token counts, with many eager for enhancements to handle larger context windows.
-
ONNX Export Explained: Guidance was provided for converting a fine-tuned model to ONNX, as seen in Hugging Face's serialization documentation, with confirmation that VLLM formats are compatible for conversion.
-
Looks Like We're Going Bit-Low: Anticipation is building for Unsloth's upcoming support for 8-bit models and integration capabilities with environments like Ollama, analogous to OpenAI's offerings.
CUDA MODE Discord
-
CUDA Toolkit Commands for Ubuntu on Fire: A user suggested installing the CUDA Toolkit from NVIDIA, checking installation with
nvidia-smi, and offered commands for setup on Ubuntu, including via Conda:conda install cuda -c nvidia/label/cuda-12.1.0. Meanwhile, potential conflicts were identified with Python 3.12 and missing triton installation when setting up PyTorch 2.3, linked to a GitHub issue. -
GPT-4o meets its match in large edits: Members noted that GPT-4o struggles with extensive code edits, and a new fast apply model aims to split the task into planning and application stages to overcome this challenge. Seeking a deterministic algorithm for code edits, a member posed the feasibility of using vllm or trtllm for future token prediction without relying on draft models. More information on this approach can be found in the full blog post.
-
SYCL Debug Troubles: A member enquired about tools to debug SYCL code, sparking a discussion on stepping into kernel code for troubleshooting.
-
Torchao's Latest Triumph: The torchao community celebrated the merging of support for MX formats, such as
fp8/6/4, in PyTorch, offering efficiency for interested parties, provided in part by a GitHub commit and aligned with the MX spec. -
Understanding Mixer Models in DIY: Members dissected implementation nuances, such as integrating
dirent.hin llm.c, and the importance of guarding it with#ifndef _WIN32for OS compatibility. The addition of a-y 1flag for resuming training in interruptions was implemented, addressing warnings about uninitialized variables and exploring memory optimization strategies during backward pass computation, with a related initiative found in GitHub discussions. -
Quantizing Activations in BitNet: In the BitNet channel, it was concluded that passing incoming gradients directly in activation quantized neural networks might be erroneous. Instead, using the gradient of a surrogate function such as
tanhwas suggested, citing an arXiv paper on straight-through estimator (STE) performance.
Eleuther Discord
- No Post-Learning for GPT Agents: GPT-based agents do not learn post initial training, but can reference new information uploaded as 'knowledge files' without fundamentally altering their core understanding.
- Efficiency Milestones in Diffusion Models: Google DeepMind introduces EM Distillation to create efficient one-step generator diffusion models, and separate research from Google illustrates an 8B parameter diffusion model adept at generating high-res 1024x1024 images.
- Scaling Down for Impact: Super Tiny Language Models research focuses on reducing language model parameters by 90-95% without significantly sacrificing performance, indicating a path towards more efficient natural language processing.
- GPU Performance Without the Guesswork: Symbolic modeling of GPU latencies without execution gains traction, featuring scholarly resources to guide theoretical understanding and potential impact on computational efficiency.
- Challenging the Current with Community: Discussions highlight community-driven projects and the importance of collaborative problem-solving in areas such as prompt adaptation research and implementation queries, like that of a Facenet model in PyTorch.
OpenRouter (Alex Atallah) Discord
-
Latest Model Innovations Hit the Market: OpenRouter announced new AI models, including Mistral 7B Instruct v0.3 and Hermes 2 Pro - Llama-3 8B, while assuring that previous versions like Mistral 7B Instruct v0.2 remain accessible.
-
Model Curiosity on Max Loh's Site: Users show curiosity about the models utilized on Max Loh's website, expressing interest in identifying all uncensored models available on OpenRouter.
-
OCR Talent Show: Gemini's OCR prowess was a hot topic, with users claiming its superior ability to read Cyrillic and English texts, outdoing competing models such as Claude and GPT-4o.
-
OpenRouter Token Economics: There was clarification in the community that $0.26 allows for 1M input + output tokens on OpenRouter, and discussions emphasized how token usage is recalculated with each chat interaction, potentially inflating costs.
-
The Cost of Cutting-Edge Vision: There is a heated exchange on Phi-3 Vision costs when using Azure, with some members finding the $0.07/M for llama pricing too steep, even though similar rates are noted among other service providers.
Nous Research AI Discord
-
Translation Tribulations: Discussions touched on the challenges of translating songs with control over lyrical tone to retain the original artistic intent. The unique difficulty lies in balancing the fidelity of meaning with musicality and artistic expression.
-
AI Infiltrates Greentext: Members experimented with LLMs to generate 4chan greentexts, sharing their fascination with the AI's narrative capabilities — especially when concocting a scenario where one wakes up to a world where AGI has been created.
-
Philosophical Phi and Logically Challenged LLMs: Debates emerged over Phi model's training data composition, with references to "heavily filtered public data and synthetic data". Additionally, evidence of LLMs struggling with logic and self-correction during interaction was reported, raising concerns about the models' reasoning abilities.
-
Shaping Data for Machine Digestion: AI enthusiasts exchanged resources and insights on creating DPO datasets and adjusting dataset formats for DPO training. Hugging Face's TRL documentation and DPO Trainer emerged as key references, alongside a paper detailing language models trained from preference data.
-
Linking Minds for RAG Riches: Collaboration is in the air, with members sharing their intent to combine efforts on RAG-related projects. This includes the sentiment and semantic density smoothing agent project with TTS on GitHub, and intentions to port an existing project to SLURM for enhanced computational management.
LangChain AI Discord
Loop-the-Loop in LangChain: Engineers are troubleshooting a LangChain agent entering continuous loops when calling tools; one solution debate involves refining the agent's trigger conditions to prevent infinite tool invocation loops.
Details, Please! 16385-token Error in LangChain 0.2.2: Users report a token limit error in LangChain version 0.2.2, where a 16385-token limit is incorrectly applied, despite models supporting up to 128k tokens, prompting a community-lead investigation into this discrepancy.
SQL Prompt Crafting Consultation: Requests for SQL agent prompt templates with few-shot examples have been answered, providing engineers with the resources to craft queries in LangChain more effectively.
Disappearing Act: Custom kwargs in Langserve: Some users experience a problem where custom "kwargs" sent through Langserve for logging in Langsmith are missing upon arrival, a concern currently seeking resolution.
Showcasing Applications: Diverse applications developed using LangChain were shared, including frameworks for drug discovery, cost-saving measures for logging, enhancements for flight simulators, and tutorials about routing logic in agent flows.
Modular (Mojo 🔥) Discord
-
Python Version Alert for Mojo Users: Mojo users are reminded to adhere to the supported Python versions, ranging from 3.8 to 3.11, since 3.12 remains unsupported. Issues in Mojo were resolved by utilizing the deadsnakes repository for Python updates.
-
AI-Powered Gaming Innovations: Engineers discussed the prospect of subscription models based on NPC intelligence in open-world games, and introducing special AI-enabled capabilities for smart devices that could lead to AI inference running locally. They explored open-world games that could feature AI-driven custom world generation.
-
Mojo Mastery: Circular dependencies are permitted within Mojo, as modules can define each other. Traits like
IntableandStringableare inherently available, and while lambda functions are not yet a feature in Mojo, callbacks are currently utilized as an alternative. -
Performance Pioneers: An impressive 50x speed improvement was noted at 32 bytes in Mojo, though it encountered cache limitations beyond that length. Benchmarks for k-means algorithms demonstrated variability due to differences in memory allocation and matrix computations, with a suggestion to optimize memory alignment for AVX512 operations.
-
Nightly Builds Nightcaps: The latest Mojo compiler build (2024.5.2805) brought new features, including implementations of
tempfile.{mkdtemp,gettempdir}andString.isspace(), with full changes detailed in the current changelog and the raw diff. Structural sharing via references was also highlighted for its potential efficiency gains in Mojo programming.
Latent Space Discord
-
Debugging Just Got a Level Up: Engineers praised the cursor interpreter mode, highlighted for its advanced code navigation capabilities over traditional search functions in debugging scenarios.
-
A Co-Pilot for Your Messages: Microsoft Copilot's integration into Telegram sparked interest for its ability to enrich chat experiences with features such as gaming tips and movie recommendations.
-
GPT-2 Training on a Shoestring: Andrej Karpathy showcased an economical approach to training GPT-2 in 90 minutes for $20, detailing the process on GitHub.
-
Agents and Copilots Distinguish Their Roles: A distinction between Copilots and Agents was debated following Microsoft Build's categorization, with references made to Kanjun Qiu's insights on the topic.
-
AI Podcast Delivers Cutting-Edge Findings: An ICLR 2024-focused podcast was released discussing breakthroughs in ImageGen, Transformers, Vision Learning, and more, with anticipation for the upcoming insights on LLM Reasoning and Agents.
LlamaIndex Discord
-
Financial Geeks, Feast on FinTextQA: FinTextQA is a new dataset aimed at improving long-form finance-related question-answering systems; it comprises 1,262 source-attributed Q&A pairs across 6 different question types.
-
Perfecting Prompt Structures: An enquiry was made concerning resources for crafting optimal system role prompts, drawing inspiration from LlamaIndex's model.
-
Chat History Preservation Tactics: The community discussed techniques for saving chat histories within LlamaIndex, considering custom retrievers for NLSQL and PandasQuery engines to maintain a record of queries and results.
-
API Function Management Explored: Strategies to handle an extensive API with over 1000 functions were proposed, favoring hierarchical routing and the division of functions into more manageable subgroups.
-
RAG System Intricacies with LlamaIndex Debated: Technical challenges related to metadata in RAG systems were dissected, showing a divided opinion on whether to embed smaller or larger semantic chunks for optimal accuracy in information retrieval.
LAION Discord
AI Reads Between the Lines: Members shared a laugh over SOTA AGI models' odd claims with one model's self-training assertion, "it has trained a model for us," tickling the collective funny bone. Musk's jab at CNNs—quipping "We don’t use CNNs much these days"—set off a chain of ironical replies and a nod towards vision transformer models as the new industry darlings.
Artificial Artist's Watermark Woes: Corcelio's Mobius Art Model is pushing boundaries with diverse prompts, yet leaves a watermark even though it's overtaking past models in creativity. Ethical dilemmas arose from the capability of image generation systems to produce 'inappropriate' content, sparking debate on community guidelines and systems' control settings.
Synthetic Sight Seeks Improvement: In an effort to grapple with SDXL's inability to generate images of "reading eyes," a member asked for collaborative help to build a synthetic database using DALLE, hoping to hone SDXL's capabilities in this nuanced visual task.
Patterns and Puzzles in Generative Watermarks: Observations within the guild pointed out a recurring theme of generative models producing watermarks, indicating possible undertraining, which was found both amusing and noteworthy among the engineers.
Elon's Eyeroll at CNNs Stokes AI Banter: Elon Musk's tweet sent a ripple through the community, sparking jests about the obsolete nature of CNNs in today's transformative AI methodologies and the potential pivot towards transformer models.
tinygrad (George Hotz) Discord
GPU Latency Predictions Without Benchmarks?: Engineers discussed the potential for symbolically modeling GPU latencies without running kernels by considering data movement and operation times, though complexities such as occupancy and async operations were recognized as potential confounders. There's also anticipation for AMD's open-source release of MES and speculation about quant firms using cycle accurate GPU simulators for in-depth kernel optimization.
Optimizing with Autotuners: The community explored kernel optimization tools like AutoTVM and Halide, noting their different approaches to performance improvement; George Hotz highlighted TVM's use of XGBoost and stressed the importance of cache emulation for accurate modeling.
Latency Hiding Mechanics in GPUs: It was noted that GPUs employ a variety of latency-hiding strategies with their ability to run concurrent wavefronts/blocks, thus making latency modeling more complex and nuanced.
Buffer Creation Discussions in Tinygrad: The #learn-tinygrad channel had members inquiring about using post dominator analysis in scheduling for graph fusion efficiency and the creation of LazyBuffer from arrays, with a suggestion to use Load.EMPTY -> Load.COPY for such scenarios.
Code Clarity and Assistance: Detailed discussions were had regarding buffer allocation and LazyBuffer creation in Tinygrad, with one member offering to provide code pointers for further clarification and understanding.
AI Stack Devs (Yoko Li) Discord
-
Elevenlabs Voices Come to AI Town: Integrating Elevenlabs' text-to-speech capabilities, AI Town introduced a feature allowing conversations to be heard, not just read, with a minor delay of about one second, challenging real-time usage. The implementation process involves transforming text into audio and managing audio playback on the frontend.
-
Bring Science Debate to AI Chat: A concept was shared about utilizing AI chatbots to simulate science debates, aiming to foster engagement and demonstrate the unifying nature of scientific discussion.
-
Audio Eavesdropping Added for Immersion: The Zaranova fork of AI Town now simulates eavesdropping by generating audio for ambient conversations, potentially amplifying the platform's interactivity.
-
Collaborative Development Rally: There's an active interest from the community in contributing to and potentially merging new features, such as text-to-speech, into the main AI Town project.
-
Addressing User Experience Issues: A user experienced difficulties with the conversations closing too quickly for comfortable reading, hinting at potential user interface and accessibility improvements needed within AI Town.
Cohere Discord
-
Slimming Down on Logs: A new pipeline developed by a member removes redundant logs to reduce costs. They recommended a tool for selecting a "verbose logs" pipeline to achieve this.
-
Debating Deployment: Members discussed cloud-prem deployment solutions for reranking and query extraction, seeking insights on the best integrated practices without providing further context.
-
Financial RAG Fine-tuning: There was an inquiry on the possibility of fine-tuning Cohere models to answer financial questions, specifically mentioning the integration with RAG (Retrieve and Generate) systems using SEC Filings.
-
Aya23 Model's Restrictive Use: It was clarified that Aya23 models are strictly for research purposes and are not available for commercial use, affecting their deployment in startup environments.
-
Bot Plays the Game: A member launched a Cohere Command R powered gaming bot, Create 'n' Play, featuring "over 100 text-based games" aimed at fostering social engagement on Discord. The project's development and purpose can be found in a LinkedIn post.
OpenAccess AI Collective (axolotl) Discord
-
Inference vs. Training Realities: The conversation underscored performance figures in AI training, particularly regarding how a seemingly simple query about "inference only" topics quickly lead to complex areas focused on training's computational requirements.
-
FLOPS Define Training Speed: A key point in the discussion was that AI model training is, in practice, constrained by floating-point operations per second (FLOPS), especially when employing techniques like teacher forcing which increase the effective batch size.
-
Eager Eyes on Hopper Cards for FP8: The community showed enthusiasm about the potential of Hopper cards for fp8 native training, highlighting a keen interest in leveraging cutting-edge hardware for enhanced training throughput.
-
Eradicating Version Confusion with fschat: Members were advised to fix fschat issues by reinstallation due to erroneous version identifiers, pointing to meticulous attention to detail within the collective's ecosystem.
-
When CUTLASS Is a Cut Above: Discussions clarified the importance of setting
CUTLASS_PATH, emphasizing CUTLASS's role in optimizing matrix operations vital for deep learning, underscoring the guild’s focus on optimizing algorithmic efficiency.
Interconnects (Nathan Lambert) Discord
-
Apache Welcomes YI and YI-VL Models: The YI and YI-VL (multimodal LLM) models are now under the Apache 2.0 license, as celebrated in a tweet by @_philschmid; they join the 1.5 series in this licensing update.
-
Gemini 1.5 Challenges the Throne: Gemini 1.5 Pro/Advanced has climbed to #2 on the ranking charts, with ambitions to overtake GPT-4o, while Gemini 1.5 Flash proudly takes the #9 spot, edging out Llama-3-70b, as announced in a tweet from lmsysorg.
-
OpenAI's Board Left in the Dark: A former OpenAI board member disclosed that the board wasn't informed about the release of ChatGPT in advance, learning about it through Twitter just like the public.
-
Toner Drops Bombshell on OpenAI's Leadership: Helen Toner, a previous member of OpenAI's board, accused Sam Altman of creating a toxic work environment and acting dishonestly, pushing for "external regulation of AI companies" during a TED podcast episode.
-
Community Aghast at OpenAI's Revelations: In reaction to Helen Toner's grave allegations, the community expressed shock and anticipation about the prospect of significant industry changes, highlighted by Natolambert querying if Toner might "literally save the world?"
Datasette - LLM (@SimonW) Discord
- Go-To LLM Leaderboard Approved by Experts: The leaderboard at chat.lmsys.org was highlighted and endorsed by users as a reliable resource for comparing the performance of various large language models (LLMs).
Mozilla AI Discord
- Securing Local AI Endpoints Is Crucial: One member highlighted the importance of securing local endpoints for AI models, suggesting the use of DNS SRV records and public keys to ensure validated and trustworthy local AI interactions, jesting about the perils of unverified models leading to unintended country music purchases or squirrel feeding.
- Troubleshoot Alert: Llamafile Error Uncovered: A user running a Hugging Face llamafile - specifically
granite-34b-code-instruct.llamafile- reported an error with an "unknown argument: --temp," indicating potential issues within the implementation phase of the model deployment process. - Focus on the Running Model: In a clarification, it was noted that whatever model is running locally at
localhost:8080(like tinyllama) would be the default, with themodelfield in the chat completion request being inconsequential to the operation. This suggests a single-model operation paradigm for llamafiles in use.
Link mentioned: granite-34b-code-instruct.llamafile
OpenInterpreter Discord
- Request for R1 Update: A member expressed anticipation for the R1's future developments, humorously referring to it as a potential "nice paperweight" if it doesn't meet expectations.
- Community Seeks Clarity: There's a sense of shared curiosity within the community regarding updates related to R1, with members actively seeking and sharing information.
- Awaiting Support Team's Attention: An inquiry to the OI team concerning an email awaits a response, signifying the need for improved communication or support mechanisms.
AI21 Labs (Jamba) Discord
- Spotting a Ghost Town: A member raised the concern that the server appears unmoderated, which could indicate either an oversight or an intentional laissez-faire approach by the admins.
- Notification Fails to Notify: An attempted use of the @everyone tag in the server failed to function, suggesting restricted permissions or a technical snafu.
MLOps @Chipro Discord
- LLM for Backend Automation Inquiry Left Hanging: A member's curiosity about whether a course covers automating backend services using Large Language Models (LLM) remained unanswered. The inquiry sought insights into practical applications of LLMs in automating backend processes.
The LLM Perf Enthusiasts AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The YAIG (a16z Infra) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: [{{ email.subject }}]({{ email_url }})!
If you enjoyed AInews, please share with a friend! Thanks in advance!
{% endif %}