AI News for 6/5/2024-6/6/2024. We checked 7 subreddits, 384 Twitters and 30 Discords (408 channels, and 2450 messages) for you. Estimated reading time saved (at 200wpm): 304 minutes.
With Qwen 2 being Apache 2.0, Alibaba is now claiming to universally beat Llama 3 for the open models crown:
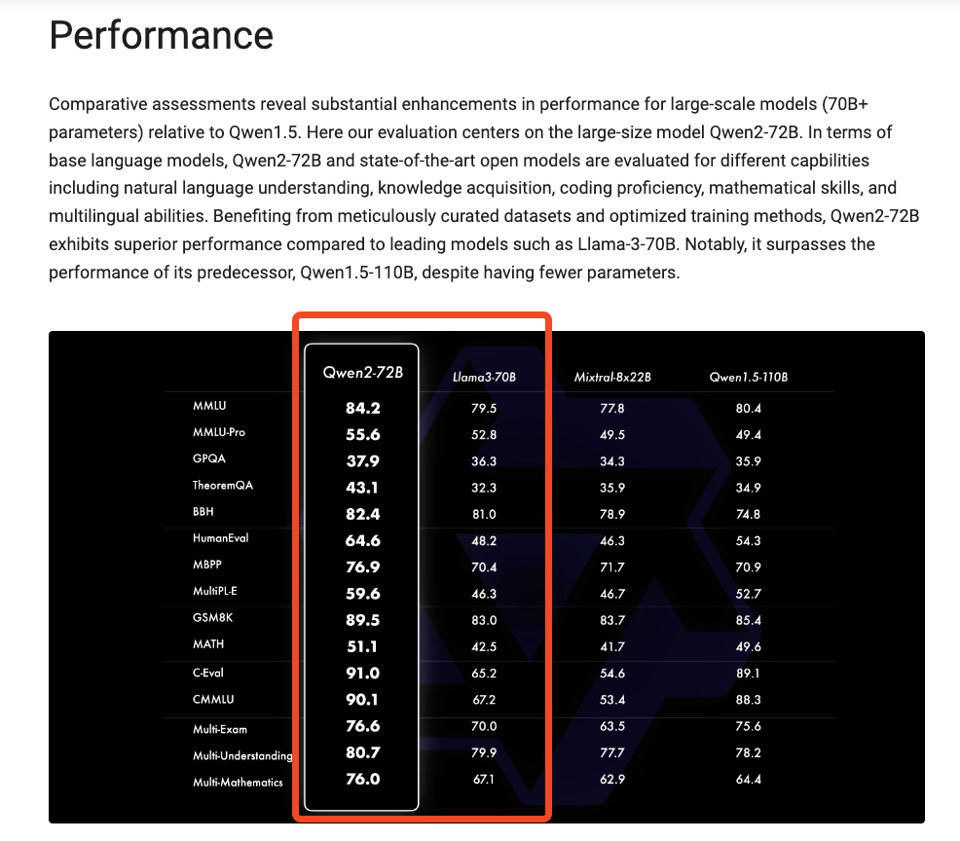
There are zero details on dataset so it's hard to get any idea of how they pulled this off, but they do drop some hints on post-training:
Our post-training phase is designed with the principle of scalable training with minimal human annotation.
Specifically, we investigate how to obtain high-quality, reliable, diverse and creative demonstration data and preference data with various automated alignment strategies, such as
- rejection sampling for math,
- execution feedback for coding and
- instruction-following, back-translation for creative writing,
- scalable oversight for role-play, etc.
These collective efforts have significantly boosted the capabilities and intelligence of our models, as illustrated in the following table.
They also published a post on Generalizing an LLM from 8k to 1M Context using Qwen-Agent.
{% if medium == 'web' %}
Table of Contents
[TOC]
{% else %}
The Table of Contents and Channel Summaries have been moved to the web version of this email: [{{ email.subject }}]({{ email_url }})!
{% endif %}
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
Qwen2 Open-Source LLM Release
- Qwen2 models released: @huybery announced the release of Qwen2 models in 5 sizes (0.5B, 1.5B, 7B, 57B-14B MoE, 72B) as Base & Instruct versions. Models are multilingual in 29 languages and achieve SOTA performance on academic and chat benchmarks. Released under Apache 2.0 except 72B.
- Performance highlights: @_philschmid noted Qwen2-72B achieved MMLU 82.3, IFEval 77.6, MT-Bench 9.12, HumanEval 86.0. Qwen2-7B achieved MMLU 70.5, MT-Bench 8.41, HumanEval 79.9. On MMLU-PRO, Qwen2 scored 64.4, outperforming Llama 3's 56.2.
- Multilingual capabilities: @huybery highlighted Qwen2-7B-Instruct's strong multilingual performance. The models are trained in 29 languages including European, Middle East and Asian languages according to @_philschmid.
Groq's Inference Speed on Large LLMs
- Llama-3 70B Tokens/s: @JonathanRoss321 reported Groq achieved 40,792 tokens/s input rate on Llama-3 70B using FP16 multiply and FP32 accumulate over the full 7989 token context length.
- Llama 70B in 200ms: @awnihannun put the achievement in perspective, noting Groq ran Llama 70B on ~4 Wikipedia articles in 200 milliseconds, which is about the blink of an eye, with 16-bit precision and 32-bit accumulation (lossless).
Sparse Autoencoder Training Methods for GPT-4 Interpretability
- Improved SAE training: @gdb shared a paper on improved methods for training sparse autoencoders (SAEs) at scale to interpret GPT-4's neural activity.
- New training stack and metrics: @nabla_theta introduced a SOTA training stack for SAEs and trained a 16M latent SAE on GPT-4 to demonstrate scaling. They also proposed new SAE metrics beyond MSE/L0 loss.
- Scaling laws and metrics: @nabla_theta found clean scaling laws with autoencoder latent count, sparsity, and compute. Larger subject models have shallower scaling law exponents. Metrics like downstream loss, probe loss, ablation sparsity and explainability were explored.
Meta's No Language Left Behind (NLLB) Model
- NLLB model details: @AIatMeta announced the NLLB model, published in Nature, which can deliver high-quality translations directly between 200 languages, including low-resource ones.
- Significance of the work: @ylecun noted NLLB's ability to provide high-quality translation between 200 languages in any direction, with sparse training data, and for many low-resource languages.
Pika AI's Series B Funding
- $80M Series B: @demi_guo_ announced Pika AI's $80M Series B led by Spark Capital. Guo expressed gratitude to investors and team members.
- Hiring and future plans: @demi_guo_ reflected on the past year's progress and teased updates coming later in the year. Pika AI is looking for talent across research, engineering, product, design and ops (link).
Other Noteworthy Developments
- Anthropic's elections integrity efforts: @AnthropicAI published details on their processes for testing and mitigating elections-related risks. They also shared samples of the evaluations used to test their models.
- Cohere's startup program launch: @cohere launched a startup program to support early-stage companies solving real-world business challenges with AI. Participants get discounted access, technical support and marketing exposure. Cohere also released a library of cookbooks for enterprise-grade frontier models for applications like agents, RAG and semantic search (link).
- Prometheus-2 for RAG evaluation: @llama_index introduced Prometheus-2, an open-source LLM for evaluating RAG applications as an alternative to GPT-4. It can process direct assessment, pairwise ranking and custom criteria.
- LangChain x Groq integration: @LangChainAI announced an upcoming webinar on building LLM agent apps with LangChain and Groq's integration.
- Databutton AI engineer platform: @svpino shared that Databutton launched an AI software engineer platform to help build applications with React frontends and Python backends based on a business idea.
- Microsoft's Copilot+ PCs: @DeepLearningAI reported on Microsoft's launch of Copilot+ PCs with AI-first specs featuring generative models and search capabilities, with the first machines using Qualcomm Snapdragon chips.
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity. Comment crawling works now but has lots to improve!
LLM Developments and Applications
-
Open-source RAG application: In /r/LocalLLaMA, user open-sourced LARS, a RAG-centric LLM application that generates responses with detailed citations from documents. It supports various file formats, has conversation memory, and allows customization of LLMs and embeddings.
-
Favorite open-source LLMs: In /r/LocalLLaMA, users shared their go-to open-source LLMs for different use cases, including Command-R for RAG on small-medium document sets, LLAVA 34b v1.6 for vision tasks, Llama3-gradient-70b for complex questions on large corpora, and more.
-
AI business models: In /r/LocalLLaMA, a user questioned how much original work vs leveraging existing LLM APIs new AI businesses are actually doing, as many seem to just wrap OpenAI's API for specific domains.
-
Querying many small files with LLMs: In /r/LocalLLaMA, a user sought advice on feeding 200+ small wiki files into an LLM while preserving relationships between them, as embeddings and RAG have been hit-or-miss. Proper LLM training or LoRA are being considered.
-
Desktop app for local LLM API: In /r/LocalLLaMA, a user created a desktop app to interact with LMStudio's API server on their local machine and is gauging interest in releasing it for free.
-
Educational platform for LLMs: In /r/LocalLLaMA, Open Engineer was announced, a free educational resource covering topics like LLM fine-tuning, quantization, embeddings and more to make LLMs accessible to software engineers.
-
LLM assistant for database operations: In /r/LocalLLaMA, a user shared their experience integrating an LLM assistant into software for database CRUD and order validation, considering using the surrounding system to supplement the LLM with product lookups for more robust order processing.
AI Developments and Concerns
-
Speculation on superintelligence development: In /r/singularity, a user speculated that major AI labs, chip companies and government agencies are likely already coordinating on superintelligence development behind the scenes, similar to the Manhattan Project, and that the US government is probably forecasting and preparing for the implications.
-
Questions around UBI implementation: In /r/singularity, a user expressed frustration at the lack of concrete plans or frameworks for implementing UBI despite it being seen as a solution to AI-driven job displacement, raising questions about funding, population growth impacts, and more that need to be addressed.
-
Risks of open-source AGI misuse: In /r/singularity, a user asked how the open-source community will prevent powerful open-source AGI from being misused by bad actors to cause harm, given the lack of safeguards, arguing the "it's the same as googling it" counterargument is oversimplified.
-
Controlling ASI: In /r/singularity, a user questioned the belief that ASI could be controlled by humans or militaries given its superior intelligence, with commenters agreeing it's unlikely and attempts at domination are misguided.
AI Assistants and Interfaces
-
Chat mode as voice data harvesting: In /r/singularity, a user speculated OpenAI's focus on chat mode is a strategic move to collect high-quality, natural voice data to overcome the limitations of text data for AI training, as voice represents a continuous stream of consciousness closer to human thought processes.
-
Unusual ChatGPT use cases: In /r/OpenAI, users shared unusual things they use ChatGPT for, including generating overly dramatic plant watering reminders, converting cooking instructions from oven to air fryer, and mapping shopping list items to store aisles.
-
Need for an "AI shell" protocol: In /r/OpenAI, a user envisioned the need for a standardized "AI shell" protocol to allow AI agents to easily interface with and control various devices, similar to SSH or RDP, as existing protocols may not be sufficient.
AI Content Generation
-
Evolving views on AI music: In /r/singularity, a user shared their evolving perspective on AI music, seeing it as well-suited for generic YouTube background music due to aggressive restrictions on mainstream music, and asked for others' thoughts.
-
AI-generated post-rock playlist: In /r/singularity, a user shared a 30-minute AI-generated post-rock playlist on YouTube featuring immersive tracks made with UDIO, receiving positive feedback about forgetting it's AI music.
-
AI in VFX project: In /r/singularity, a user shared a VFX project incorporating AI to create urban aesthetics inspired by ad displays, using procedural systems, image compositing, and layered AnimateDiffs, with CG elements processed individually and integrated.
AI Discord Recap
A summary of Summaries of Summaries
-
LLM and Model Performance Innovations:
-
Qwen2 Attracts Significant Attention with models ranging from 0.5B to 7B parameters, appreciated for their ease of use and rapid iteration capabilities, supporting innovative applications with 128K token contexts.
-
Stable Audio Open 1.0 Generates Interest leveraging components like autoencoders and diffusion models, as detailed on Hugging Face, raising community engagement in custom audio generation workflows.
-
ESPNet Competitive Benchmarks Shared for Efficient Transformer Inference: Discussions around the newly released ESPNet showed promising transformer efficiency, pointing towards enhanced throughput on high-end GPUs (H100), as documented in the ESPNet Paper.
-
Seq1F1B Promotes Efficient Long-Sequence Training: The pipeline scheduling method introduces significant memory savings and performance gains for LLMs, as per the arxiv publication.
-
-
Fine-tuning and Prompt Engineering Challenges:
-
Model Fine-tuning Innovations: Fine-tuning discussions highlight the use of gradient accumulation to manage memory constraints, and custom pipelines such as using
FastLanguageModel.for_inferencefor Alpaca-style prompts, as demonstrated in a Google Colab notebook. -
Chatbot Query Generation Issues: Debugging Cypher queries using Mistral 7B emphasized the importance of systematic evaluation and iterative tuning methods in successful model training.
-
Adapter Integration Pitfalls: Critical challenges with integrating trained adapters pointed to a need for more efficient adapter loading techniques to maintain performance, supported by practical coding experiences.
-
-
Open-Source AI Developments and Collaborations:
-
Prometheus-2 Evaluates RAG Apps: Prometheus-2 offers an open-source alternative to GPT-4 for evaluating RAG applications, valued for its affordability and transparency, detailed on LlamaIndex.
-
Launch of OpenDevin sparks collaboration interest, featuring a robust AI system for autonomous engineering developed by Cognition, with documentation available via webinar and GitHub.
-
Gradient Accumulation Strategies Improve Training: Discussions on Unsloth AI emphasized using gradient accumulation to handle memory constraints effectively, reducing training times highlighted by shared YouTube tutorials.
-
Mojo Rising as a Backend Framework: Developers shared positive experiences using Mojo for HTTP server development, depicting its advantages in static typing and compile-time computation features on GitHub.
-
-
Deployment, Inference, and API Integrations:
-
Perplexity Pro Enhances Search Abilities: The recent update added step-by-step search processes via an intent system, enabling more agentic execution, as discussed within the community around Perplexity Labs.
-
Discussion on Modal's Deployment and Privacy: Queries about using Modal for LLM deployments included concerns about its fine-tuning stack and privacy policies, with additional support provided through Modal Labs documentation.
-
OpenRouter Technical Insights and Limits: Users explored technical specifications and capabilities, including assistant message prefill support and handling function calls through Instructor tool.
-
-
AI Community Discussions and Events:
-
Stable Diffusion 3 Speculation: Community buzz surrounds the anticipated release, with speculation about features and timelines, as detailed in various Reddit threads.
-
Human Feedback Foundation Event on June 11: Upcoming discussions on integrating human feedback into AI, featuring speakers from Stanford and OpenAI with recordings available on their YouTube channel.
-
Qwen2 Model Launches with Overwhelming Support: Garnering excitement for its multilingual capabilities and enhanced benchmarks, the release on platforms like Hugging Face highlights its practical evaluations.
-
Call for JSON Schema Support in Mozilla AI: Requests for JSON schema inclusion in the next version to ease application development were prominently noted in community channels.
-
Keynote on Robotics AI and Foundation Models: Investment interests in "ChatGPT for Robotics" amid foundation model companies underscore the strategic alignment detailed in Newcomer's article.
-
PART 1: High level Discord summaries
LLM Finetuning (Hamel + Dan) Discord
-
Web Scraping Tool Talk: Engineers swapped notes on OSS scraping platforms like Beautiful Soup and Scrapy, with a nod to Trafilatura for its proficiency in extracting dynamic content from tricky sources like job postings and SEC filings, citing its documentation.
-
New UI Kid on the Block: Google's new Mesop is stirring conversations for its potential in crafting UIs for internal tools, stepping into the domain of Gradio and Streamlit, despite lacking advanced authentication - curiosity piqued with a glance at Mesop's homepage.
-
Query Crafting Challenges: Engineers debugged generating Cypher queries with Mistral 7B, emphasizing the importance of systematic evals, test-driven development, and the iterative process—a testament to the nitty-gritty of model fine-tuning.
-
Diving into Deployment: Questions swirled about Modal's usage, including its fine-tuning stack complexity and privacy policy—a reference to Modal Labs query for policy seekers, and a nod to their Dreambooth example for practical enlightenment.
-
CUDA Compatibility Quirks: The compatibility quirks between CUDA versions took the spotlight as engineers faced issues installing the
xformersmodule—a pointer to Jarvis Labs documentation on updating CUDA came to the rescue.
OpenAI Discord
- GPT-3's Programming Puzzle: While GPT models like GPT-3 are adept at assisting with programming, limitations become apparent with highly specific and complex questions, signaling a push against their current capabilities.
- Logical Loophes with Math Equations: Even simple logical tasks, such as correcting a math equation, can stumble GPT models, revealing gaps in basic logical reasoning.
- Eagerly Awaiting GPT-4o's Special Features: Discussions anticipate GPT-4o updates, with voice and real-time vision features to be initially available to ChatGPT Plus users in weeks, and wider access later, as suggested by OpenAI's official update.
- DALL-E's Text Troubles: Users are sharing workarounds for DALL-E's struggles with generating logos that contain precise text, including prompts to iteratively refine text accuracy and a useful custom GPT prompt.
- 7b and Vision Model Synergy: An integration success story where the 7b model harmonizes well with the llava-v1.6-mistral-7b vision model, expanding possibilities for model collaboration.
Unsloth AI (Daniel Han) Discord
Gradient Accumulation to the Rescue: Engineers agreed that gradient accumulation can alleviate memory constraints and improve training times, but warned of potential pitfalls with larger batch sizes due to unexpected memory allocation behaviors.
Tackling Inferential Velocity with Alpacas: An engineer shared a code snippet leveraging FastLanguageModel.for_inference to utilize Alpaca-style prompts for sequence generation in LLMs, which sparked interest alongside discussions about a shared Google Colab notebook.
Adapter Merging Mayday: Challenges with integrating trained adapters causing significant dips in performance led to calls for more efficient adapter loading techniques to maintain training efficiency.
Qwen2 Models Catch Engineers' Eyes: Excitement bubbles over the release of Qwen2 models, with engineers keen on the smaller-sized models ranging from 0.5B to 7B for their ease of use and faster iteration capabilities.
Quest for Solutions in the Help Depot: Conversations in the help channel emphasized a need for a VRAM-saving lora-adapter file conversion process, quick intel on a bug potentially slowing down inference, strategies for mitigating GPU memory overloads, and clarifications on running gguf models and implementing a RAG system, referenced to Mistral documentation.
Stability.ai (Stable Diffusion) Discord
-
Stable Audio Open 1.0 Hits the Stage: Stable Audio Open 1.0 garners community interest for its innovative components, including the autoencoder and diffusion model, with members experimenting with tacotron2, musicgen, and audiogen within custom audio generation workflows.
-
Size Matters in Stable Diffusion: Users recommend generating larger resolution images in Stable Diffusion before downsizing as an effective workaround for the random color issue plaguing small resolution (160x90) image outputs.
-
ControlNet Sketches Success: ControlNet emerges as a preferred solution among members for converting sketches to realistic images without retaining unwanted colors, providing better control over the final composition and image details.
-
CivitAI Content Quality Control Called Into Question: A surge in non-relevant content on CivitAI has led to calls for enhanced filtering capabilities to better curate quality models and maintain user experience.
-
Stable Diffusion 3 Awaits Clarification: Despite rampant speculation within the community, the release date and details surrounding Stable Diffusion 3 remain nebulous, with some members referencing a Reddit post for tentative answers.
LM Studio Discord
-
Taming the RAM Beast in LM Studio: Users discussed strategies to limit RAM usage in LM Studio, suggesting approaches like loading and unloading models during use; a detailed method can be found in the llamacpp documentation. While not a built-in feature in LM Studio, such tactics are employed to enable models to utilize RAM only when active despite efficiency losses.
-
Nomic Embed Models Step into the Limelight: The discussion elevated Nomic Embed Text models to multimodal status, thanks to nomic-embed-vision-v1.5, setting them apart with impressive benchmark performances. The AI community within the server also noted Q6 quant models of Llama-3 as a balance of quality and performance.
-
Jostling for the Perfect Configuration: A user raised an issue about model settings resetting when initiating new chats, and discovered that retaining old chats could be a simple fix. The conversation also touched on
use_mlockand--no-mmapsettings in LM Studio, affecting stability during 8B model operations, emphasizing operating system-dependent subtleties. -
Unlocking the Potential of Hardware Synergy for AI: Engineers entered into a hearty debate on Nvidia’s proprietary drivers versus AMD’s open-source approach, highlighting implications for systems administration and security. Additionally, there was excitement about the promises of new Qualcomm chips and caution against judging ARM CPUs solely by synthetic benchmarks.
-
Updates and Upgrades Stir Excitement: The Higgs LLAMA model garnered praise for its intelligence at a 70B scale, with anticipation building around an upcoming LMStudio update to incorporate relevant llamacpp adjustments. Another user is considering a massive RAM upgrade in anticipation of the much-discussed LLAMA 3 405B model, reflecting the intertwining interests between hardware capabilities and AI model evolution.
HuggingFace Discord
Moderation is Key: The community debated moderation strategies in response to reports of inappropriate behavior. Professionalism in handling such issues is crucial.
Gradio API Challenges: Integrating Gradio with React Native and Node.js raised questions within the community. It's built with Svelte, so users were directed to investigate Gradio's API compatibility.
Text with Stability: Discussion around Stable Diffusion models for text generation pointed members towards solutions like AnyText and TextDiffuser-2 from Microsoft for robust output.
When Compute Goes Peer-to-Peer: The conversation turned to peer-to-peer compute for distributed machine learning, with tools like Petals and experiences with privacy-conscious local swarms offering promising avenues.
Human Feedback in AI: The Human Feedback Foundation is making strides in incorporating human feedback into AI, with an event on June 11th and a trove of educational sessions on their YouTube channel.
Small Datasets, Big Challenges: In computer vision discussions, dealing with small datasets and unrepresentative validation sets was a pressing concern. Solutions include using diverse training data and maybe even transformers despite their longer training times.
Swin Transformer Tests: There was a query about applying the Swin Transformer to CIFar datasets, highlighting the community's interest in experimenting with contemporary models in various scenarios.
Deterministic Models Turn Down the Heat: A single message highlighted lowering temperature settings to 0.1 to achieve more deterministic model behavior, prompting reflection on model tuning approaches.
Sample Input Snafus: Confusion over text embeddings and proper structuring of sample inputs for models like text-enc 1 and text-enc 2 surfaced, along with a discussion on the challenges posed by added kwargs in a dictionary format.
Re-parameterising with Results: A member successfully re-parameterised Segmind's ssd-1b into a v-prediction/zsnr refiner model and lauded it as a new favorite, hinting at a possible trend toward 1B mixture of experts models.
A Helping Hand for Projects: In a stretch of community aid, members offered personal assistance through DMs for addressing dataset questions, adding to the guild's collaborative environment.
Eleuther Discord
KAN Skepticism Expressed: Kolmogorov-Arnold Networks (KANs) were deemed less efficient than traditional neural networks by guild members, with concerns about their scalability and interpretability. However, there's interest in more efficient implementations of KANs, such as those using ReLU, evidenced by a shared ReLU-KAN architecture paper.
Expanding the Data Curation Toolbox: Participants debated the utility of influence functions in data quality evaluation, with the LESS algorithm (LESS algorithm) being mentioned as a potentially more scalable alternative for selecting high-quality training data.
Breakthroughs in Efficient Model Training: Innovations in model training were widely shared, including Nvidia's new open weights available on GitHub, the exploration of MatMul-free models (arXiv) for increased efficiency, and Seq1F1B's promise for more memory-efficient long-sequence training (arXiv).
Quantization Technique May Boost LLM Performance: The novel QJL method presents a promising avenue for large language models by compressing KV cache requirements through a quantization process (arXiv).
Brain-Data Speech Decoding Adventure: A guild member reported experimenting with Whisper tiny.en embeddings and brain implant data to decode speech, requesting peer suggestions to optimize the model by adjusting layers and loss functions while facing the constraint of a single GPU for training.
Perplexity AI Discord
-
Perplexity Pro Gets Smarter: Perplexity Pro has upgraded to show its search process step-by-step, employing an intent system for a more agentic-like execution, approximately a week ago.
-
File Format Frustrations: Users are experiencing difficulties with Perplexity's ability to read PDFs, with success varying based on the PDF's content layout ranging from heavily styled to plain text.
-
Sticker Shock at Dev Costs: The community reacted with humor and disbelief to a member's request for building a text-to-video MVP on a shoestring budget of $100, highlighting the disconnect between expectations and market rates for developers.
-
Haiku Feature Haunts No More: The removal of Haiku and select features from Perplexity labs sparked discussions, leading members to speculate on cost-saving measures and express their discontent due to the impact on their workflow.
-
Curious about OpenChat Expansion: An inquiry was raised regarding the potential addition of an "openchat/openchat-3.6-8b-20240522" model to Perplexity, alongside current models like Mistral and Llama 3.
CUDA MODE Discord
-
Discovering Past Technical Sessions: Recordings of past CUDA MODE technical events can be accessed on the CUDA MODE YouTube channel.
-
Debugging Tensor Memory in PyTorch: A code snippet using
storage().data_ptr()was shared to test if two PyTorch tensors share the same memory, stirring discussion on checking memory overlap. A member requested assistance in locating the source code for a PyTorch C++ function, specifically at::_weight_int4pack_mm. -
Extension on AI Models and Techniques: Conversations hinge on methodologies like MoRA improving upon LoRA, and DPO versus PPO with respect to RLHF. Separate mentions went to CoPE for positional encodings and S3D accelerating inference, all found detailed in AI Unplugged.
-
Torch Innovation Sparks: Discussions ignited around torch.compile boosting KAN performance to rival MLPs, with insights shared from Thomas Ahle's tweet, practical experiences, and the GitHub repository for KANs and MLPs.
-
MLIR Sets Sights on ARM: An MLIR meeting covered creating an ARM SME Dialect, offering insights into ARM's Scalable Matrix Extension via a YouTube video. Hints pointing to potential Triton ARM support are discussed, with references to 'arm_neon' dialect for NEON operations in the MLIR documentation.
Interconnects (Nathan Lambert) Discord
-
The Quest for the ChatGPT of Robotics: Investors are on the lookout for startups that can be the "ChatGPT for robotics," prioritizing AI over hardware. Excitement is building around niche foundation model companies as detailed in this article.
-
Qwen2 Attracts Attention: Qwen2's launch has generated interest with models supporting up to 128K tokens in multilingual tasks, but users report gaps in recent event knowledge and general accuracy.
-
Dragonfly Unfurls Its Wings in Multi-modal AI: Together.ai's Dragonfly brings advances in visual reasoning, particularly in medical imaging, demonstrating integration of text and visual inputs in model development.
-
AI Community Takes a Critical View: From discussions around influential lab employees criticizing smaller players to a shared tweet highlighting the risk of AI labs inadvertently sharing advances with the CCP not the American research community, and The Verge article on Humane AI's safety issue, the community remains vigilant.
-
Reinforcement Learning Paper Stirring Interest: Sharing of the “Self-Improving Robust Preference Optimization” (SRPO) paper as announced in this tweet indicates a focus on training LLMs using robust and self-improving RLHF methods. Nathan Lambert plans to dedicate time to discuss such cutting-edge papers.
Modular (Mojo 🔥) Discord
-
Mojo Rising: Discussions in various channels have centered on the advantages of using Mojo for backend server development, with examples like lightbug_http demonstrating its use in crafting HTTP servers. The Mojo roadmap was shared, indicating future core programming features, as active comparison to Python sparked debates on performance merits due to Mojo's static typing and compile-time computation.
-
Keeping Python Safe: In teaching Python to newcomers, it's essential to avoid potential pitfalls ("footguns") to help learners transition to more complex languages, like C++.
-
Model Performance Frontiers Explored: Discussions indicated that extending models like Mistral beyond certain limits requires ongoing pretraining, with suggestions to apply the difference between UltraChat and base Mistral to Mistral-Yarn as a merging strategy, though practicality and skepticism were voiced.
-
Community Coding Contributions Cloaked with Humor: Expressions like "licking the cookie" were employed humorously to discuss encouraging open-source contributions, and members playfully reflected on the complexities of technical talks and coding challenges, likening a simple request for quicksort implementation to a noble quest.
-
Nightly Builds Yield Illumination and Frustration: Nightly builds were examined with a spotlight on the usage of immutable auto-deref for list iterators and the introduction of features like
String.formatin the latest compiler release2024.6.616. However, network hiccups and the unpredictable nature ofalgorithm.parallelizefor aparallel_sortfunction were sources of frustration, as seen from GitHub discussions and shared troubleshooting on workflow timing and network issues.
Latent Space Discord
- Cohere Cashes In Big Time: Cohere has secured a jaw-dropping $450 million in funding with significant contributions from tech titans like NVidia and Salesforce, despite not boasting a high revenue last year, as per a Reuters report.
- IBM's Granite Gains Ground: IBM's Granite models are being hailed for their transparency, particularly on data usage for training—prompting debates on whether they surpass OpenAI in the enterprise domain with insights from Talha Khan.
- Databricks Dominates Forrester’s AI Rankings: In the latest report by Forrester on AI foundation models, Databricks has been recognized as a leader, emphasizing the tailored needs of enterprises and suggesting benchmark scores aren't everything. The report is highlighted in Databricks' announcement blog and is accessible for free here.
- Qwen 2 Trumps Llama 3: The new Qwen 2 model, with impressive 128K context window capabilities, shows superior performance to Llama 3 in code and math tasks, announced in a recent tweet.
- New Avenues for AI Web Interaction and Assistance: Browserbase celebrates a $6.5 million seed fund aimed at enabling AI applications to navigate the web, shared by founders Nat & Dan, while Nox introduces an AI assistant designed to make the user experience feel invincible, with early sign-ups here.
LlamaIndex Discord
Prometheus-2 Pitches for RAG App Judging: Prometheus-2 is presented as an open-source alternative to GPT-4 for evaluating RAG applications, sparking interest due to concerns about transparency and affordability.
LlamaParse Pioneers Knowledge Graph Construction: A posted notebook demonstrates how LlamaParse can execute first-class parsing to develop knowledge graphs, paired with a RAG pipeline for node retrieval.
Configuration Overload in LlamaIndex: AI engineers are expressing difficulty with the complexity of configuring LlamaIndex for querying JSON data and are seeking guidance, as well as discussing issues with Text2SQL queries not balancing structured and unstructured data retrieval.
Exploring LLM Options for Resource-Limited Scenarios: Discussions on alternative setups for those with hardware limitations veer towards smaller models like Microsoft Phi-3 and experimenting with platforms like Google Colab for heavier models.
Scoring Filters Gain Customizable Edges: Engineers are discussing the capability of LlamaIndex to filter results by customizable thresholds and performance score, indicating a need for fine-tuned precision in search results.
Cohere Discord
-
Startup Perks for Early Adopters: Cohere introduces a startup program aiming to equip Series B or earlier stage startups with discounts on AI models, expert support, and marketing clout to spur innovation in AI tech applications.
-
Refining the Chatbot Experience: Upcoming changes to Cohere's Chat API on June 10th will bring a new default multi-step tool behavior and a
force_single_stepoption for simplicity's sake, all documented for ease of adoption in the API spec enhancements. -
Hot Temperatures for AI Samplers: OpenRouter stands out by allowing the temperature setting to exceed 1 for AI response samplers, contrasting with Cohere trial's 1.0 upper limit, opening discussions on flexibility in response variation and quality.
-
Developing Smart Group Chatbots: Suggestions arose regarding the deployment of AI chatbots in group scenarios like business meetings, analyzing Rhea's advantageous multi-user context handling and potential precision concerns for personalized responses among numerous users.
-
Cohere Networking & Demos: Community members welcomed new participant Toby Morning, exchanging LinkedIn profiles (LinkedIn Profile) for broader connections and showcasing enthusiasm for upcoming demonstrations of the Coral AGI system's prowess in multi-user settings.
Nous Research AI Discord
Qwen2 Leaps Ahead: The launch of the Qwen2 models marks a significant evolution from Qwen1.5, now featuring support for 128K token context lengths, 27 additional languages, and pretrained as well as instruction-tuned models in various sizes. They are available on platforms like GitHub, Hugging Face, and ModelScope, along with a dedicated Discord server.
Map Event Prediction Discussion: A user inquired about predicting true versus false event points on a map with temporal data, leading to a conversation about relevant commands and techniques, although specific methods were not provided.
Update on Mistral API and Model Storage: Mistral's introduction of a fine-tuning API and associated costs sparked discussion, with a focus on practical implications for development and experimentation. The API, including pricing details, is explained in their fine-tuning documentation.
Mobile Text Input Gets a Makeover: WorldSim Console updated their mobile platform, resolving bugs related to text input, improving text input reliability, and offering new features such as enhanced copy/paste and cosmetic customization options.
Music Exploration in Off-Topic: One member shared links to explore "Wakanda music", though this might have limited technical relevance for the engineer audience. Among the shared links were music videos like DG812 - In Your Eyes and MitiS & Ray Volpe - Don't Look Down.
OpenRouter (Alex Atallah) Discord
Server Management Made Easy with Pilot: The Pilot bot is revolutionizing how Discord servers are managed by offering features such as "Ask Pilot" for intelligent server insights, "Catch Me Up" for message summarization, and weekly "Health Check" reports on server activity. It's free to use and improves community growth and engagement, accessible through their website.
AI Competitors in Role-Playing Realm: The WizardLM 8x22b model is currently gaining popularity in the role-playing community, nevertheless Dolphin 8x22 emerges as a potential rival, awaiting user tests to compare their effectiveness.
Gemini Flash Sparks Image Output Curiosity: Inquiries about whether Gemini Flash can render images spurred clarification that while no Large Language Model (LLM) presently offers direct image outputs, they can theoretically use base64 or call external services like Stable Diffusion for image generation.
Tool Tips for Handling Function Calls: For handling specific function calls and formatting, Instructor is recommended as a powerful tool, facilitating automated command execution and improving user workflows.
Technical Discussions Amidst Model Enthusiasm: A member's query regarding prefill support in OpenRouter led to a confirmation that it's possible, particularly with the usage of reverse proxies; meanwhile, excitement is building around GLM-4 due to its support for the Korean language, hinting at the model's potential in multilingual applications.
MLOps @Chipro Discord
-
Human Feedback Spurs AI Improvement: The upcoming Human Feedback Foundation event on June 11th is set to address the role of human feedback in enhancing AI applications across healthcare and civic domains; interested parties can register via Eventbrite. Additionally, recordings of past events with speakers from UofT, Stanford, and OpenAI are available at the Human Feedback Foundation YouTube Channel.
-
Azure Event Attracts AI Enthusiasts: "Unleash the Power of RAG in Azure" is a highly subscribed Microsoft event happening in Toronto, as mentioned by an attendee seeking fellow participants; more details can be found on the Microsoft Reactor page.
-
Tackling Messy Data: Engineers discussed strategies for dealing with high-cardinality categorical columns, including the use of aggregate/grouping, manual feature engineering, string matching, and edit distance techniques, all with the goal of refining inputs for better regression outcomes.
-
Merging Data and Clustering Techniques: There's a shared perspective that combining spell correction with feature clustering might streamline the challenges posed by high-cardinality categorical data, with an emphasis on treating such issues as core data modeling problems.
-
Practical Approaches to Feature Engineering: Conversations pivoted towards pragmatic approaches like breaking down complex problems (e.g., isolating brand and item elements) and incorporating moving averages as part of the simplification technique for price prediction. Appreciation was expressed for the multifaceted solutions discussed, including regex for feature extraction.
OpenAccess AI Collective (axolotl) Discord
Data Feast for AI Enthusiasts: Engineers lauded the accessibility of 15T datasets, humorously noting the conundrum of abundance in data but scarcity in computing resources and funding.
GPU Banter Amidst Hardware Discussions: The suitability of 4090s for pretraining massive datasets sparked a facetious exchange, jesting about the limitations of consumer GPUs for such demanding tasks.
Finetuning Fun with GLM and Qwen2: The community shared tips and configurations for finetuning GLM 4 9b and Qwen2 models, noting that Qwen2's similarity to Mistral simplifies the process.
Quest for Reliable Checkpointing: The use of Hugging Face's TrainingArguments and EarlyStoppingCallback featured in talks about checkpoint strategies, specifically for capturing both the most recent and best performing states based on eval_loss.
Error Hunting in AI Code: Troubleshooting the "returned non-zero exit status 1" error prompted members to suggest pinpointing the failing command, scrutinizing stdout and stderr, and checking for permission or environment variable issues.
LAION Discord
-
Catchy Naming Conundrum: In the guild, clarity was sought on the 1B parameter zsnr/vpred refiner; it's critiqued that the model is actually a 1.3B, not a 1B model, sparking a light-hearted jab at the need for more accurate catchy names.
-
Vega's Parameter Predicament: Discussions on the Vega model highlighted its swift processing prowess but raised concerns about its insufficient parameter size potentially limiting coherent output generation.
-
Elrich Logos Dataset Remains a Mystery: A member queried about the availability of the Elrich logos dataset but did not receive any conclusive information or response regarding access.
-
The Dawn of Qwen2: The launch of Qwen2 has been announced, introducing substantial improvements over Qwen1.5 across multiple fronts including language support, context length, and benchmark performance. Qwen2 is now available in different sizes and supports up to 128K tokens with resources spread across GitHub, Hugging Face, ModelScope, and demo.
LangChain AI Discord
-
Knowledge Graph Construction Security Measures: A tutorial on constructing knowledge graphs from text was shared, emphasizing the importance of data validation for security before inclusion in a graph database.
-
LangChain Tech Nuggets: Confusion about the necessity of tools decorator prompted discussions for clarity, while a request for understanding token consumption tracking methods was observed among users. Additionally, a question arose about the creation of RAG diagrams as seen in a LangChain's FreeCodeCamp tutorial video.
-
Flow Control and Search Automation Resources: A LangGraph conditional edges YouTube video was highlighted for its utility in flow control in flow engineering, and a new project termed search-result-scraper-markdown was shared for fetching search results and converting them to Markdown.
-
Cross-Framework Agent Collaboration: Users expressed interest in frameworks that enable collaboration among agents built with different tools, incorporating LangChain, MetaGPT, AutoGPT, and even agents from platforms such as coze.com, highlighting the potential of interoperability in the AI space.
-
Calls for GUI and Course File Guidance: There was a user query about finding a specific "helper.py" file from the AI Agents LangGraph course, pointing towards a need for better resource discovery methods within technical courses such as those offered on the DLAI course page.
tinygrad (George Hotz) Discord
- Tinygrad Preps for Prime Time: George Hotz highlighted the need for updates in tinygrad before the 1.0 release, with pending PRs expected to resolve the current gaps.
- Unraveling Tensor Puzzles with UOps.CONST: AI engineers examined the role of UOps.CONST in tinygrad, which serves as address offsets in computational processes for determining index values during tensor addition.
- Decoding Complex Code: In response to confusion over a snippet of code, it was clarified that intricate conditions are often needed to efficiently manage tensor shapes and strides within the row-major data layout constraints.
- Indexing Woes Solved by Dynamic Kernel: A discussion on tensor indexing in tinygrad revealed that kernel generation is essential due to the architecture's reliance on static memory access, with the kernel in question enabling operations like Tensor[Tensor].
- Masking with Arange for Getitem Operations: The similarity between the kernel used for indexing operations and an arange kernel was noted, which facilitates the creation of a mask during getitem functions for dynamic tensor indexing.
OpenInterpreter Discord
Need for Speed with Graphics: Members are seeking advice on executing graphics output with interpreter.computer.run, specifically for visualizations like those produced by matplotlib without success thus far.
OS Mode Mayhem: Conversations highlighted troubles in getting --os mode to operate correctly with local models from LM Studio, including issues with local LLAVA models not starting screen recording.
Vision Quest on M1 Mac: Engineers expressed frustration about hardware constraints on vision models for M1 Mac, indicating a strong interest in free and accessible AI solutions, given the high costs associated with OpenAI's offerings.
Integration Anticipation for Rabbit R1: Excitement is brewing over integrating Rabbit R1 with OpenInterpreter, particularly the upcoming webhook feature, to enable practical actions.
Bash Model Request Open: A call for suggestions for an open model suitable for handling bash commands has yet to be answered, leaving an open gap for potential recommendations.
AI Stack Devs (Yoko Li) Discord
Curiosity for AI Town's Development Status: Members in AI Stack Devs sought an update on the project, with one expressing interest in progress, while another apologized for not contributing yet due to a lack of time.
Tileset Troubles in AI Town: An engineering challenge surfaced around parsing spritesheets for AI Town, with a proposal to use the provided level editor or Tiled, supported by conversion scripts from the community.
Learning to Un-Censor LLMs: A member shared insights from a Hugging Face blog post on abliteration, which uncensors LLMs, featuring instruct versions of the third generation of Llama models. They followed up by inquiring about applying this technique to OpenAI models.
Unanswered OpenAI Implementation Query: Despite sharing the study on abliteration, a call for knowledge on how to implement the technique with OpenAI models went unanswered in the thread.
For a deeper dive:
- Parsing challenges and methods: (not provided)
- Blog post on abliteration: Uncensor any LLM with abliteration.
Datasette - LLM (@SimonW) Discord
-
The Truncated Text Mystery: When working with embeddings using
llm, a member discovered that input text exceeding the model's context length doesn't necessarily trigger an error and might result in truncated input. The actual behavior varies by model and underscores a need for clearer documentation on how each model handles excessive input length. -
Embedding Jobs: To Resume or Not to Resume: A query was raised regarding the functionality of
embed-multiin resuming large embedding jobs without reprocessing completed parts. This highlights the need for features that can manage partial completions within embedding processes. -
Documentation Desire for Embedding Behaviors: The response from @SimonW pointing to a lack of clarity in model behavior documentation directed at whether inputs are truncated or produce errors, indicates a larger call from users for comprehensive and accessible documentation on these AI systems.
-
Guesswork in Model Truncation: In absence of error messages, it was posited by @SimonW that the large text inputs leading to unexpected embedding results are likely being truncated, a behavior that should be explicitly verified within specific model documentation.
-
Efficiency in Large Embedding Tasks: The discussion around whether the
embed-multican identify and skip previously processed data in rerunning large jobs showcases a concern for efficiency and the need for intelligent job handling in long-running AI processes.
Torchtune Discord
Megatron's Checkpoint Conundrum: Engineers enquired about Megatron's compatibility with fine-tuning libraries, noting its unique checkpoint format. It was agreed that converting Megatron checkpoints to Hugging Face format and utilizing Torchtune for fine-tuning was the best course of action.
Mozilla AI Discord
- Call for JSON Schema Integration Heats Up: An AI Engineer proposed the inclusion of a JSON schema in the upcoming software version to streamline application development, acknowledging some bugs but underscoring the ease it brings to building applications. No details on a timeline or potential implementation challenges were provided.
YAIG (a16z Infra) Discord
- Weekend Audio Learning on AI Infrastructure: A link to a weekend listening session was shared by a member, featuring a discussion on AI infrastructure, which could be of interest to AI engineers looking to stay abreigned of the latest trends and challenges in the field. The content is accessible on YouTube.
The LLM Perf Enthusiasts AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
{% if medium == 'web' %}
LLM Finetuning (Hamel + Dan) ▷ #general (66 messages🔥🔥):
- OSS Scraping Platform Recommendations: A member asked for an OSS scraping platform and received suggestions including Beautiful Soup and Scrapy. Another member recommended Trafilatura for scraping dynamic content from job postings and SEC filings, providing a link to Trafilatura's documentation.
- Mesop compared with Gradio and Streamlit: Google released Mesop, a Python-based framework for building UIs, which members compared favorably to Gradio and Streamlit for internal low-traffic apps. More details are provided on the Mesop homepage, piquing interest despite questions about advanced authentication features.
- Finetuning Cypher Query Generation with Mistral 7B: A member struggling with generating correct Cypher queries using Mistral 7B discussed systematic debugging steps with HamelH. The conversation emphasized writing evals, testing failure modes, and iteratively improving prompts.
- Interest in Workshops on Finetuning Techniques: Multiple members expressed interest in workshops covering topics like SFT, DPO, and ORPO using the TRL library, recommending Leandro von Werra as a potential instructor. However, space constraints and scheduling issues were mentioned as limiting factors.
- Braintrust and OpenPipe Platforms: A question was raised about Braintrust and OpenPipe, with responses noting previous office hours and talks covering these platforms. Members shared that these events answered many common questions about the platforms' purposes and utilities.
Links mentioned:
LLM Finetuning (Hamel + Dan) ▷ #workshop-1 (2 messages):
-
Regulatory and Research Aid through LLMs: The LLM can serve as a Research Assistant by answering technical and regulatory questions using sources like scientific papers and regulatory documents. For pre-existing repositories like Arxiv, employing RAG and prompt engineering is recommended, while paywalled sources would need finetuning.
-
Discovery Helper for Research: A secondary use case is a Research Assistant that points to promising papers by analyzing abstracts, titles, and metadata, which is valuable even if full access is restricted. Tools such as SciHub and DTIC can support this initiative by focusing on potential papers for the user.
-
LLMs for Legal Document Analysis: The aforementioned research assistant LLMs can be adapted to handle legal documents for efficient research and discovery. The poster showed interest in seeing this implemented.
-
Document Distiller for Large Organizations: This LLM is tailored for organizations with extensive document corpora (e.g., financial, government) to assist in regulatory compliance by summarizing and returning relevant documents based on inferred user intent. This idea is backed by mentions at the DataScience Salon conference by the NY Federal Reserve AI Chairman.
LLM Finetuning (Hamel + Dan) ▷ #asia-tz (5 messages):
- **Jeremyhoward loves Hainan**: *"I love hainan! 😄"*. Later, Blaine shared his love for Shenzhou Peninsula mentioning nearby beaches and passion fruits.
- **Anmol from India seeks chatbot pricing advice**: Anmol asked for advice on pricing an enterprise customer service chatbot. He expressed hope that someone with experience could assist him.
- **Hanoi to Germany transition**: Hehehe0803 introduced themselves from Hanoi, Vietnam, currently living in Germany. They mentioned joining late and expressed hope to connect with others.
LLM Finetuning (Hamel + Dan) ▷ #🟩-modal (8 messages🔥):
- **Modal Privacy Policy Sought**: A user inquired about the privacy policy of Modal. Another user provided a link to a Google search for further information: [Privacy Policy Modal Labs](https://www.google.com/search?q=privacy+policy+modal+labs).
- **Confusion on LLM Inference Setup**: A user asked about setting up a server to run an LLM and expose an endpoint, referencing a [Modal example script on GitHub](https://github.com/modal-labs/modal-examples/blob/main/06_gpu_and_ml/llm-serving/text_generation_inference.py#L240C20-L240C30). They were unsure about how to get the base URL for calling the endpoint from REST clients like Postman.
- **Praise for Modal from a GPU Enthusiast**: A user who typically trains locally with multiple GPUs tried Modal and found it "super cool". They expressed their appreciation with emojis: 👍👏.
- **Dataset Handling Issue with Axolotl Configs**: A user experienced issues with Modal's insistence on passing a dataset, which overrode their existing axolotl configuration. They mentioned hacking the `train.py` to remove the dataset code, which resolved the issue for them.
Link mentioned: modal-examples/06_gpu_and_ml/llm-serving/text_generation_inference.py at main · modal-labs/modal-examples: Examples of programs built using Modal. Contribute to modal-labs/modal-examples development by creating an account on GitHub.
LLM Finetuning (Hamel + Dan) ▷ #learning-resources (1 messages):
- Loving the Discovery of Old News: A member shared their excitement about a discovery they found, attaching this paper from arXiv. They acknowledged it might be "old news" but expressed that they "love it".
LLM Finetuning (Hamel + Dan) ▷ #jarvis-labs (2 messages):
- CUDA Version Mismatch Error: A member encountered a mismatch error when installing the
xformersPIP module due to differing CUDA versions, 11.8 and 12.1. They asked for the recommended way to upgrade the CUDA library in the Jarvis Labs container. - Solution for Updating CUDA: Another member provided a documentation link to Jarvis Labs for guidance on updating the CUDA version on the Jarvis Labs instance.
Link mentioned: Debugging and Troubleshooting | Jarvislabs: Some common troubleshooting tips for updating Cuda, Freeing up the disk space and many more.
LLM Finetuning (Hamel + Dan) ▷ #hugging-face (3 messages):
-
Members still awaiting credits: Multiple users reported filling out a web form but haven't received any credits as expected. "filled out the web form, but haven't received any as far as I can tell."
-
New form on the way: An update on the situation mentions that a new form will be available soon, with a status check currently taking place. "We’ll have a new form out soon, let me check on the status of it."
LLM Finetuning (Hamel + Dan) ▷ #replicate (9 messages🔥):
- Redeem credits through email works: One member had to accept credits via email and shared that "this worked" for them.
- Unreceived credits inquiry: "Hi @zeke6585 haven't received the email" stated a member, prompting another to check records and found the form was not filled out for replicate credits.
- Duplicate form submissions still unresolved: A member expressed confusion, having filled out the form twice and received credits from other services like OAI, HF, and Modal but not from Replicate.
- Comment clarification on credit status: A member clarified they were not spamming every channel but only the ones where credits were still pending, and noted an immediate resolution from Ankur on BrainTrust credits.
LLM Finetuning (Hamel + Dan) ▷ #langsmith (29 messages🔥):
-
Langsmith Input Missing Issue Solved: A member struggled with the
@traceabledecorator in Langsmith capturing outputs but not inputs in LLM calls. They resolved it by adding an argument to their function, realizing that inputs were essentially the arguments to the function without which nothing gets captured. -
LangSmith Credit Confusion: Multiple members expressed confusion and frustration over not receiving compute credits or understanding credit types. One highlighted that "Beta credits are only available for people who were LangSmith beta users."
-
Billing and Credits Follow-Up: Several users who set up billing complained about not receiving their credits. They were directed to reach out to a contact at LangSmith to address the issue by sending their organization IDs for resolution.
-
HIPAA Compliance and Enterprise Options: LangSmith aims to be HIPAA compliant by July 1st and offers self-hosted options for enterprise customers. Details about plans and features are available, and members were guided to contact for more information.
Links mentioned:
LLM Finetuning (Hamel + Dan) ▷ #workshop-3 (2 messages):
- Workshop videos receive high praise: A member expressed gratitude for the speakers and topics in the LLM Evals videos, stating the course has significantly helped them structure their approach more effectively than a year of self-research. They thanked <@525830737627185170> and <@916924724003627018> for putting it together.
- Facilitators appreciate positive feedback: One of the organizers responded to the praise with thanks, sharing that such encouragement is highly motivating. "It makes my day, and is super motivating!"
LLM Finetuning (Hamel + Dan) ▷ #workshop-4 (4 messages):
- Conference talk initially lacks sound: A member noted that the recording for "Conference Talk: Best Practices For Fine Tuning Mistral w/ Sophia Yang" appeared to lack audio. They later clarified, stating, "never mind. it has voice."
- Replicate vs. Modal deployment clarified: A member sought confirmation on the differing deployment processes between Replicate and Modal, particularly regarding where the Docker build process occurs. Another member confirmed, "the Modal build process runs remotely."
LLM Finetuning (Hamel + Dan) ▷ #clavie_beyond_ragbasics (2 messages):
- Ben's talk rescheduled due to illness: The team has rescheduled Ben's talk to next week because he isn't feeling well. Wishing that Ben gets well soon ❤️🔥.
LLM Finetuning (Hamel + Dan) ▷ #jason_improving_rag (150 messages🔥🔥):
- Frustration with Infographics and Tables in RAG: Users discussed the difficulties of extracting data from PDFs, especially tables and infographics, in RAG systems. Tools like PyMuPDF, AWS Textract, and converting PDFs to Markdown were mentioned as potential solutions, but issues persist as noted: "The markdown tables are malformed most of the time for my use case."
- Debate on Chunking Strategies: There was a lively debate on the best practices for chunking text data for RAG, with recommendations ranging from 500 to 800 tokens with a 50% overlap. A consensus formed around the complexity and necessity of chunking correctly to ensure accurate context and retrieval.
- Optimizing RAG with Fine-Tuning and Embeddings: The importance of fine-tuning embedding models for better RAG performance was highlighted, with a suggestion to use generated synthetic data. One member noted, "I think any company that is making money from RAG is leaving money on the table from not fine-tuning embedding models."
- Discussion on LanceDB for Multimodal AI: LanceDB was discussed as an alternative to databases like Pinecone and SQL for managing embeddings on large-scale, multimodal data. This database promises to be "easy-to-use, scalable, and cost-effective" with support for hybrid search solutions.
- Links Shared for Further Reading and Tools: Multiple links were shared covering resources like fine-tuning pipelines, embedding quantization, and tools for PDF handling and RAG implementations. Key links include Langchain Multi-modal RAG, LlamaParse, and Creating Synthetic Data for Embeddings.
Links mentioned:
LLM Finetuning (Hamel + Dan) ▷ #jeremy_python_llms (6 messages):
- Exclusive sneak peek discussed: Jeremy Howard shared a special sneak peek with members, instructing them, "so keep it to yourself, folks!" Despite the exclusivity, he mentioned it's fine to discuss it within this Discord.
- Anticipation builds for demo: A member expressed intent to wait for Jeremy Howard's demo after sneaking a peek at the codebase.
- Talk scheduled at an inconvenient time: Ashpun noted that the talk timings inconveniently fell at 3:30am IST for them.
- Setting multiple alarms: To not miss the talk, one member humorously mentioned setting "10 alarms" while another member appreciated having company for the early hour.
LLM Finetuning (Hamel + Dan) ▷ #yang_mistral_finetuning (2 messages):
-
Miscommunication cleared up with empathy: Aaah, okay, I understand now. That makes sense, and something I would expect as well. Sorry for misunderstanding you earlier.
-
Excitement about Mistral API: One member expressed enthusiasm about an upcoming workshop and stated, I will try the official Mistral API.
LLM Finetuning (Hamel + Dan) ▷ #axolotl (13 messages🔥):
-
Dependency Conflicts During Axolotl Installation: A user encountered errors while installing Axolotl with CUDA 12.1, Python 3.11, and PyTorch 2.3.1 due to dependency conflicts between multiple packages like Axolotl, Accelerate, Bitsandbytes, and Xformers. They sought resolutions for these conflicts.
-
Recommendation to Install Axolotl Without Xformers: One member suggested that the issue was specifically with Xformers, not Axolotl, and recommended first installing Axolotl without Xformers. They also mentioned the alternative of using the Docker image for Axolotl.
-
Switching to Python 3.10 Resolves Partial Issues: The user resolved some issues by switching to Python 3.10 and PyTorch 2.1.2, which allowed them to run the preprocess step but encountered a new error related to Flash Attention.
-
Flash Attention Requires Recompilation for CUDA 12.1: The user faced an ImportError related to
libcudart.so.11.0with Flash Attention, indicating a mismatch with their installed CUDA version (12.1). The suggested solution was to rebuild/recompile Flash Attention, which resolved the issue.
Link mentioned: Dependency Resolution - pip documentation v24.1.dev1: no description found
LLM Finetuning (Hamel + Dan) ▷ #zach-accelerate (12 messages🔥):
-
Safe tensors vary in merged adapters: A member questioned why merging an adapter to a base model sometimes results in 3 safe tensors and other times 6, while the base model only has 3 to start with, indicating variability in outcomes.
-
Enhance TPU efficiency with Keras's
steps_per_execution: A member shared a TensorFlow blog about usingsteps_per_executionto reduce Python overhead and maximize TPU performance. An alternate approach in PyTorch XLA involves adjusting calls toxm.mark_step()for similar benefits. -
Use
xm.mark_step()judiciously: A detailed explanation was given on how to manage TPU performance in PyTorch XLA usingxm.mark_step()by adjusting the frequency of its calls within the training loop to balance performance and reliability, suggesting a potential feature request for the accelerate library. -
FSDP tutorial by Less Wright: For those interested in FSDP, an excellent ten-part series on YouTube by Less Wright (former fastai alumn) was recommended as a comprehensive introduction.
-
Quantization process clarified: It was confirmed that quantization happens during model load and is handled by the CPU before passing it to the GPU. Relevant documentation and resources were provided, including Hugging Face Accelerate's quantization usage guide and the Accelerate GitHub repository.
Links mentioned:
LLM Finetuning (Hamel + Dan) ▷ #freddy-gradio (2 messages):
-
Watch the YouTube Link: A YouTube video was shared which can be accessed here.
-
Python Handles Server-Side Code: Discussion around the server-side code indicates that it’s still managed in Python. Points include scaling in Spaces and handling concurrency with Python.
LLM Finetuning (Hamel + Dan) ▷ #charles-modal (12 messages🔥):
- Fine-tuning with Modal can be complex but is worth exploring: Charles mentioned the complexity of the fine-tuning stack with Modal but suggested users check out their simpler Dreambooth example. This example demonstrates the core Modal concepts through finetuning the Stable Diffusion XL model using textual inversion.
- Adapt existing datasets for fine-tuning on Modal: Users can point to a Hugging Face dataset directly, as suggested by Charles. Adjustments should be made to avoid using Volumes for storing this data.
- Use batch processing for validation: Charles advised writing a custom
batch_generatemethod and using.mapfor processing and generating validation examples. He referenced the "embedding Wikipedia" example for further guidance. - Exploring Modal for cost-efficiency in app hosting: Alan was advised by Charles on potentially moving the retrieval part of his Streamlit app to Modal or considering moving the entire app there. Concerns about cold starts and cost with a 24/7 deployment were discussed.
- Quick support for script errors: Chaos highlighted an issue with the
vllm_inference.pyscript on GitHub, and Charles quickly responded, hinting at potential problems during the build step or GPU availability. Charles emphasized Modal’s culture of speed in support and communication.
Links mentioned:
LLM Finetuning (Hamel + Dan) ▷ #langchain-langsmith (1 messages):
- Langsmith tracing obstacles with streaming non-OpenAI models: A user discussed their challenge of capturing traces with Langsmith while using Groq/Llama3 in a streaming fashion. They noted that using the
@traceabledecorator doesn't work with streaming outputs, as the result stays ageneratorobject.
LLM Finetuning (Hamel + Dan) ▷ #credits-questions (22 messages🔥):
-
Last-minute enrollees can still claim credits: A user who enrolled on May 30th asked how to claim credits, and Dan clarified that while some platforms like OAI won't offer credits, others like Modal might still be available. He shared a link to claim OAI credits: OAI credits.
-
Modal credits now redeemable: For users who enrolled after May 30th, Dan directed them to claim their Modal credits via a provided form Modal form. He also provided a step-by-step guide for using Modal's platform and shared multiple example projects.
-
Credit claims still being processed: Dan explained that credits are being processed in batches and reassured users who haven't yet received theirs to check if they have filled out the necessary forms. He urged those without credits to use the Modal platform to receive additional credits before the Tuesday deadline.
-
Replicate account issues resolved: A user who hadn't received credits verified their Replicate account setup. After confirming the correct email and noticing the account creation date discrepancy, they found the credits in their email.
-
Replicate billing setup questions redirected: Dan asked a user who received a Replicate invite to direct their billing-related questions to a more appropriate channel to get faster responses from the Replicate team.
Links mentioned:
LLM Finetuning (Hamel + Dan) ▷ #strien_handlingdata (1 messages):
- Praise for Data-Talk Presentation: One member expressed strong appreciation for a particular presentation on data, emphasizing its foundational importance for tasks like evaluations and fine-tuning. They felt it would have been beneficial as the opening talk of the conference.
LLM Finetuning (Hamel + Dan) ▷ #fireworks (28 messages🔥):
-
Account ID mix-ups lead to credit problems: Multiple users reported issues with not receiving credits, often due to mistakenly filling out wrong account details like emails instead of account IDs in forms. Examples include user IDs such as biggafish8-37cf1d and jain-nehil-ab4ee8.
-
Credits now visible after corrections: A user confirmed that their credits became visible after providing the correct account ID, which was szilvia-beky-38bda3. This suggests successful resolution for some users once the correct details were processed.
-
Expired credits notice: When asked about the validity of credits, it was clarified that they expire after a year. This was confirmed by aravindputrevu stating “Yes, they expire after a year.”
-
Frequent guidance on form filling issues: It was highlighted by hamelh that incorrect form filling, such as entering email addresses instead of account IDs, was a frequent issue. project_disaster acknowledged this with an apology for the mistake.
-
Continued calls for assistance: Users continued to seek help with their account credits, providing their account IDs like raul-brebenaru-2d3d45 and roger-6803a6, indicating ongoing issues even after initial error rectification efforts.
LLM Finetuning (Hamel + Dan) ▷ #emmanuel_finetuning_dead (98 messages🔥🔥):
- Fine-tuning is not dead but niche: A member humorously suggested the title "Fine-tuning is not dead, it's niche" for clarity, emphasizing that fine-tuning has a specialized, expensive application. They stated, “fine-tuning can add hallucinations for Q&A,” highlighting its complexity and cost.
- Anthropic and Speculative Thoughts: Members discussed Anthropic's view on significant future changes, humor followed with mentions of 'Cylons'. The talk by an Anthropic representative was highlighted: “Anthropic betting 8 years from now humans might not be around in present form.”
- Resource Sharing for Fine-Tuning and RAG: Multiple resources were shared regarding fine-tuning and RAG, like Simon Willison's blog and Anthropic's research. Emmanuel’s book and tools like LLM CLI were mentioned as valuable for understanding fine-tuning's applied aspects.
- Prompting over Fine-Tuning: Members preferred focusing on prompt engineering over fine-tuning for many applications, suggesting reading materials like Emmanuel's spreadsheets on prompt engineering and HuyenChip's blog. The point was made with humor: "Do the boring thing!" as advice over complex fine-tuning.
- Dynamic Few-Shot and RAG Discussions: The talk concluded with insights into using dynamic few-shot prompting and RAG as viable alternatives or complements to fine-tuning. Links like dynamic few-shot prompting article were shared to emphasize practical approaches in evolving applications.
Links mentioned:
LLM Finetuning (Hamel + Dan) ▷ #braintrust (29 messages🔥):
- Braintrust Inputs Not Captured: A user noted that the Braintrust decorator wasn't capturing the inputs to their LLM function but was capturing the outputs. Another pointed out that the function had no arguments and suggested wrapping the OpenAI client with
wrap_openai. - Exploring Braintrust Tracing Methods: There was a discussion on three methods to trace in Braintrust:
wrap_openai, the@traceddecorator, and spans, with spans offering the most flexibility. One user considered using spans for a project integrating Braintrust with ZenML. - Credits Issue Resolved with UI Clarification: A user named "project_disaster" mentioned not seeing their credits, with "ankrgyl" clarifying that the absence of an "Upgrade" button indicates applied credits. The user suggested having a visible gauge for tracking credit consumption over time.
- Interest in TypeScript and Tracing Example: A user expressed an off-topic appreciation for the use of TypeScript. Another inquired about starting with a tracing example for an LLM project, eventually planning to move towards DPO finetuning, with "ankrgyl" suggesting they begin with the logging guide on Braintrust's documentation.
Links mentioned:
LLM Finetuning (Hamel + Dan) ▷ #europe-tz (2 messages):
- **Local Roots Shout-Out**: One user mentioned living in London but originally being from Portugal. Another user opted to keep their origin a secret with a *"🤐"* emoji.
LLM Finetuning (Hamel + Dan) ▷ #announcements (2 messages):
-
Fill out the OpenAI credits form: If you missed filling out the form the first time and want your OpenAI credits, please put your OAI org id in the form at this link.
-
Find your Organization ID for OpenAI credits: To see your Org ID, please go to this website after you are logged in under
Organization ID(this is available even if you are not part of an org with someone*).*
Link mentioned: no title found: no description found
LLM Finetuning (Hamel + Dan) ▷ #predibase (3 messages):
- Questions on starting model format: A user asked if they should start with awq or gptq format before training LoRAs for best performance. No specific guidance was provided in the conversation.
- Excitement for Predibase example: A member expressed excitement about using Predibase's example shared in the documentation. Predibase claims to offer the fastest way to fine-tune and serve open-source LLMs.
- Inquiry about credit expiry: A user asked about the expiration of credits and mentioned the requirement to add a credit card to be upgraded to the Developer Tier on the site. No further details about the credit expiry were discussed.
Link mentioned: Quickstart | Predibase: Predibase provides the fastest way to fine-tune and serve open-source LLMs. It's built on top of open-source LoRAX.
LLM Finetuning (Hamel + Dan) ▷ #openpipe (4 messages):
- Members still await their credits: Several members reported they have not yet received their credits. One provided an email for follow-up, urging a quick resolution.
LLM Finetuning (Hamel + Dan) ▷ #openai (69 messages🔥🔥):
<!-- Summary -->
- **OpenAI credits applied retroactively**: Several users noted that their credits were applied to their existing API balance, making it similar to adding funds via a credit card. [Members discussed](https://platform.openai.com/settings/organization/billing/overview) potential improvements for those new to the API.
- **Finalizing Tier 2 API status for students**: OpenAI granted Tier 2 API status to those who filled out the form in time, allowing them to utilize the additional credits. Users should stay tuned for updates if they missed the initial registration.
- **Late submission form for credits**: To rectify earlier submission errors, [a new form for additional credit requests](https://maven.com/parlance-labs/fine-tuning/1/forms/f2d68f) has been shared and needs to be correctly filled out.
- **Internal thoughts during fine-tuning**: There was an in-depth discussion regarding how to handle "internal thoughts" in long multi-turn conversations during OpenAI model fine-tuning. Delimiters and separate examples were proposed as potential solutions.
- **Public acknowledgment and kudos**: The group appreciated the efforts of OpenAI team members for their swift and effective support, highlighted in a [Twitter post](https://x.com/TheZachMueller/status/1798674326633247143) expressing gratitude.
Links mentioned:
OpenAI ▷ #ai-discussions (266 messages🔥🔥):
- **GPTs at their limits with advanced programming questions**: A user noted that their programming questions have become more specific and complex as their project advanced, leading to struggles with GPT models. They expressed concern that these models may be "pushing their limits for programming assistance 😁".
- **GPTs sometimes fail at simple corrections**: Another user pointed out a problem where the GPT could not correct an incorrect math equation despite being prompted, showcasing issues with basic logical consistency in the model.
- **Continuous Learning and Real-time Adjustments**: Discussion involved the idea that making models agentic and capable of continuous learning could be costly and pose regulatory challenges. Continuous learning could also lead to issues with personality drift and potential security risks.
- **Generative AI's current and future impact**: There was debate about the immediate usefulness and future potential of generative AI, with some users highlighting its potential to assist or significantly change job structures, while others were skeptical of its broader economic impacts.
- **Community discussions on AI advances and resource requirements**: Users conversed about the computational power required for training AI models, referencing specific hardware like A100 and H100 GPUs, and speculating on developments with upcoming models like GPT-5.
OpenAI ▷ #gpt-4-discussions (20 messages🔥):
- Voice chat removal concerns: Users discussed why voice chat was removed and speculated on its return with a new model. One user mentioned a new voice model based on GPT-4o is expected soon.
- Issues with generating Chinese text: A member reported that generating responses in Chinese using the GPT model sometimes results in special characters like \ufffd appearing. This issue occurs around 15% of the time and significantly impacts the text quality.
- GPT-4o feature rollout timelines debated: Members discussed the expected rollout timeline for GPT-4o's real-time voice and vision features. Official updates suggest initial availability for ChatGPT Plus users in the coming weeks, with broader access over the next few months (official update).
- GPT-4o free plan limits: A discussion touched on the number of questions one can ask on the GPT-4o free plan. The consensus was that the limit is around 10 questions.
Link mentioned: Tweet from OpenAI (@OpenAI): All users will start to get access to GPT-4o today. In coming weeks we’ll begin rolling out the new voice and vision capabilities we demo’d today to ChatGPT Plus.
OpenAI ▷ #prompt-engineering (6 messages):
-
LLaVA-Mistral Vision Model Coexists with 7b: A member mentioned that the 7b model appears to work well with the vision model from llava-v1.6-mistral-7b when combined. They found it neat that this integration works at all.
-
Confusion over Image Permissions: A member expressed frustration over the removal of image permissions in the channel, questioning why this change occurred. Another echoed the query in a follow-up message.
-
Challenges with Text Accuracy in DALL-E Logos: Members discussed difficulties in generating logos with exact text using DALL-E. One member shared a method for improving text accuracy by repeatedly checking and regenerating until the text in the image is correct as part of the prompt. Another member suggested including specific instructions to emphasize distinct text layers in the image generation process, linking to a custom GPT prompt for reference: Custom GPT prompt.
OpenAI ▷ #api-discussions (6 messages):
- 7b Model integrates with Vision Model: A member mentioned that the 7b model plays well with the vision model from llava-v1.6-mistral-7b when placed in its folder. They found it "kinda neat" that this integration works.
- Channel Image Permissions Concern: A member expressed confusion over the removal of image permissions in the channel. They questioned why these permissions were removed.
- Struggles with Exact Text in DALL-E Logos: A member asked if it's possible to generate logos with exact text using DALL-E, sharing difficulties with "misbuilded letters." Another member shared a workaround prompt that checks and corrects text until it is accurate.
- Helpful Prompt for Accurate Text in DALL-E Images: A member shared a prompt that helps ensure the text in DALL-E images is correct by layering and checking accuracy until the desired text is achieved. They also referenced incorporating this into custom GPT instructions to satisfy users.
Unsloth AI (Daniel Han) ▷ #general (148 messages🔥🔥):
<ul>
<li><strong>Gradient Accumulation Insights:</strong> Members discussed how <em>gradient accumulation</em> can help with memory issues and batch size. "It’ll decrease the time compared to small batch size", but gets tricky with larger batch sizes due to memory allocation quirks.</li>
<li><strong>Addressing CUDA Memory Issues:</strong> <em>"When increasing batch size, the sequences' different lengths slow down the process."</em> Suggested using "gradient accumulation" or "non-power of 2 batch sizes" to mitigate memory spikes.</li>
<li><strong>Training and Merge Issues:</strong> Members faced issues with <em>merging trained adapters</em> leading to significant performance degradation. There's a call out for effective loading of adapters to continue training without losing efficiency.</li>
<li><strong>Using Alpaca Prompt for Inferences:</strong> A detailed code snippet was shared for using <em>FastLanguageModel.for_inference</em> with Alpaca-style prompts for generating sequence completions after fine-tuning. This came from [a shared Colab link](https://colab.research.google.com/drive/15vttTpzzVXv_tJwEk-hIcQ0S9FcEWvwP?usp=sharing).</li>
<li><strong>Excitement Over Qwen2 models:</strong> Enthusiasm about the Qwen2 model release, with members particularly interested in small models (0.5B to 7B) for their ease of training and use. Discussions touched on the promise of "easy to train, easy to iterate, and can run everywhere."</li>
</ul>
Links mentioned:
Unsloth AI (Daniel Han) ▷ #random (9 messages🔥):
- Every company now AI-powered?: A member humorously questioned, "is every company just AI-powered now?" and joked about GitHub, "I swore github was powered by caffiene and 'lgtm'".
- Unsloth saves the day for a final project: A grateful user praised Unsloth, stating, "your SFT notebook trained in like 25 min on a100", which was crucial in adjusting hyperparameters and fixing data quickly. They added, "the DPO is again saving us so hard", emphasizing how vital it was for their success.
- Struggles with Kaggle's UX: One member complained about Kaggle's user experience being "quite horrible". They shared a recent issue where training "hung after 3 hours", and despite trying to disconnect after 2 more hours, they remained stuck.
Unsloth AI (Daniel Han) ▷ #help (54 messages🔥):
- **Feature Request for Lora-Adapter File Handling**: A user expressed the need for an unsloth lora-adapter file conversion process that doesn't require VRAM. They mentioned struggles with saving a ~7GB adapter for llama-3-70b in the current format.
- **Persistent Bug and Faster Inference**: A user detailed a bug causing persistent logging but mentioned that once fixed, it might result in slight performance improvements. "Once it's fixed you might get to claim slightly faster inference, since it won't be printing to console every iteration 😄".
- **Handling CUDA Out of Memory Issues**: Another member shared the usage of `torch.cuda.empty_cache()` to handle GPU memory issues. Inference using lm_head was consuming more memory than expected, leading to a CUDA out-of-memory error.
- **Running gguf models**: There was a discussion on running gguf models using llama-ccp-python, and the lack of support by transformers for running gguf directly. Another user suggested running gguf binaries directly via llama.cpp.
- **RAG System Confusion**: There was confusion about Mistral AI offering a RAG system; it was clarified that while Mistral does not offer RAG, there is [documentation for implementing it](https://docs.mistral.ai/guides/rag/).
Links mentioned:
Unsloth AI (Daniel Han) ▷ #community-collaboration (2 messages):
- Join New AI Fine-Tuning Server: A new AI community server started by a class of AI students is welcoming new members interested in AI fine-tuning. Check out the channel at this link for likeminded individuals and resources.
Link mentioned: Join the VirtualValleyAI Discord Server!: Check out the VirtualValleyAI community on Discord - hang out with 72 other members and enjoy free voice and text chat.
Stability.ai (Stable Diffusion) ▷ #general-chat (180 messages🔥🔥):
-
Stable Audio Open 1.0 generates interest: Several members discussed the availability and features of Stable Audio Open 1.0, including its components like an autoencoder and a transformer-based diffusion model. One member mentioned using tacotron2, musicgen, and audiogen in a custom workflow for audio generation.
-
Struggles with Stable Diffusion image quality: A user reported issues with generating small resolution images (160x90) in Stable Diffusion which resulted in random colors. Others suggested generating larger images (e.g., 512x512 or 1024x1024) and then downscaling them using any image editor.
-
ControlNet usage and questions: A member inquired about using ControlNet for transforming hand-drawn sketches to realistic images as their current image-to-image method preserved unwanted white color. Other members recommended using ControlNet to better control the composition and poses in the generated images.
-
Filtering concerns on CivitAI: One message highlighted the need for additional filters on CivitAI due to a surge of irrelevant content like OnlyFans and TikTokers. This was seen as making it harder to find quality models.
-
Stable Diffusion 3 speculations and misinformation: Multiple users debated the release date and authenticity of Stable Diffusion 3, with some confident about an impending release and others skeptical. Clarifications were offered, pointing to sources like a Reddit post detailing expected specs and dates.
Links mentioned:
LM Studio ▷ #💬-general (64 messages🔥🔥):
-
Discourse on Limiting RAM Usage with LM Studio: A user queried about limiting the RAM usage of a model, and it was clarified that it's not built into LM Studio but could be managed by loading in and out during use as described in llamacpp documentation. Despite being inefficient, this could allow models to utilize RAM only when active.
-
Quality of Quantized Models with iMat: The discourse involved the feasibility of using iMat for improving the quality of quantized models, which was clarified as not currently supported in LM Studio unless llamacpp introduces this capability.
-
Selecting AI Models for High VRAM Systems: A user with a system boasting 160GB of VRAM sought recommendations for suitable AI models, and was pointed towards the LLM Extractum.io for a comprehensive list filtered by size and quality.
-
Errors with Current LM Studio Versions: The conversation covered users experiencing errors and the advice provided included rolling back to older versions or adjusting context settings, such as
n_ctxwhich might be too high for the available VRAM. -
Support for PDF to Text Conversion: For users seeking to convert PDFs to text for summarization, it was suggested to use tools like pdftotext from XpdfReader, highlighting the availability of both Linux and Windows command line tools for this purpose.
Links mentioned:
LM Studio ▷ #🤖-models-discussion-chat (78 messages🔥🔥):
-
Quantization introduces slight differences in models: Discussants agreed that creating a quant model results in minor differences in token probabilities due to different datasets used. One summarized, "there will be (extremely subtle) differences in the token probabilities based on the dataset used."
-
Nomic Embed models integrate multimodality: The nomic-embed-vision-v1.5 was highlighted for sharing embedding space with its text counterpart, making all Nomic Embed Text models multimodal. Performance stats showed it superior in certain benchmarks compared to models like OpenAI's CLIP ViT B/16.
-
Llama-3 MahouDevil quant models discussed: Conversations centered on the usability of quantized versions like Q6 and Q8 for RP and general purposes. It's noted that Q6 is recommended for highest quality + best performance.
-
Jina AI introduces multimodal embedding model: Users pointed out Jina CLIP as a new entrant in multimodal (text-image) embedding models, available on Huggingface. This follows a trend of increasing multimodal support in embedding models.
-
MacOS's Metal memory issue identified in llama.cpp: A deep dive into memory allocation issues under Metal with high context parameters revealed that llama.cpp's Metal support was broken in recent builds. Users recommended sticking to version b3066 for stability, as newer builds like b3091 introduced bugs.
Links mentioned:
LM Studio ▷ #🧠-feedback (3 messages):
- Omits LM Studio mmap flag: A member highlights the benefits of the
--no-mmapoption for PCs with 8GB of RAM, proposing a potential toggle in LM Studio for easier configuration. They report this option prevents RAM spikes, reducing the risk of freezing during 8B model operations, with a minor trade-off of increased initial model load time. - Mlock settings in LMStudio: Another member clarifies the initial discussion around
--no-mmap, mentioning the similaruse_mlocksetting in LM Studio. They suggest exploring its effects, noting OS-dependent nuances, and ask for clarification on the software being discussed.
LM Studio ▷ #⚙-configs-discussion (3 messages):
- Settings reset issue when starting a new chat: A user reported that model settings are reset when starting a new chat. Another member advised applying settings in the "My Models" tab dropdown, and the user discovered that not deleting old chats before creating new ones prevents the reset.
LM Studio ▷ #🎛-hardware-discussion (26 messages🔥):
-
Nvidia vs AMD Drivers: A member pointed out that they wished Nvidia would open source their drivers like AMD. This sparked a discussion on the systems' administration and security policies.
-
Windows Security Practices Criticized: Members discussed the security drawbacks of Windows in business settings. One noted, "Windows is used... not because it is the best solution, but because it is the default," emphasizing limited IT support in small businesses.
-
Qualcomm's New Chips Look Promising: There's optimism about the new Qualcomm chips despite concerns over ARM processors and Microsoft's handling. One member noted, "the new Qualcomm chips are looking rather impressive for such a huge shift."
-
Hardware Upgrades for LLAMA 3 405B: A member is upgrading their PC with new GPU configurations and considering expanding to 128GB RAM if LLAMA 3 405B proves interesting. They shared, "I probably won't expand to 128GB RAM unless LLAMA 3 405B is really interesting."
-
ARM vs x86 Performance Caution: Caution was advised regarding the real-world performance of ARM CPUs compared to x86, despite impressive synthetic benchmarks. A member warned, "the chip might as well be optimized for synthetic loads... and suck in everything else."
Link mentioned: The Story of Snapdragon X Elite: Two lawsuits & a mystery: The Story of Snapdragon X Elite | In this video we will take a look at the exciting history of Qualcomm's new Arm SoC that aims to ...
LM Studio ▷ #🧪-beta-releases-chat (1 messages):
- Higgs LLAMA Model Receives Praise: A member noted that the new Higgs LLAMA model "looks smart" for its 70B size. They are waiting for an LMStudio update as it appears to be utilizing a llamacpp adjustment.
HuggingFace ▷ #general (120 messages🔥🔥):
-
Community discusses appropriate behavior and moderation: Members, including cakiki and lunarflu, discussed reporting inappropriate behavior in DMs and in threads. Legitimate concerns were noted, but maintaining professionalism was emphasized.
-
Gradio integration queries: A member asked about integrating Gradio with React Native and Node.js. pseudoterminalx noted that it was built with Svelte, and another suggested checking issues with the Gradio API.
-
Text generation using Stable Diffusion models: temperance6095 inquired about Stable Diffusion models capable of generating text, leading to recommendations like AnyText or TextDiffuser-2 from Microsoft.
-
Community Grants and Project Approvals: Members discussed the process and time for approval of community grants for HuggingFace spaces. It was noted that unique projects have a better chance of being approved sooner.
-
Peer-to-peer compute interest: Members discussed experiences and curiosity about peer-to-peer compute, mentioning tools like Petals for distributed machine learning. geekboyboss shared positive experiences using a local swarm for privacy reasons.
Links mentioned:
HuggingFace ▷ #today-im-learning (1 messages):
qasim_30: There is paper out there "7 billion is all you need"
HuggingFace ▷ #cool-finds (4 messages):
-
Q-Learning Agent plays Taxi-v3: A user shared a Q-Learning Agent for the Taxi-v3 environment, discussing the potential for creating an efficient and environmentally aware delivery system with this model. The user highlighted the importance of checking and adding additional attributes like
is_slippery=Falsewhen initializing the environment. -
Guidance sought for LLM-based test case generation: A member asked for guidance on building a product using LLM models to understand existing code repositories and generate automation test cases. Another member expressed interest in collaborating on this project, mentioning their background as a senior web developer and a beginner with AI and LLM, and encouraged others interested in collaboration to reach out.
Link mentioned: DAIEF/q-learning-Taxi-v3 · Hugging Face: no description found
HuggingFace ▷ #i-made-this (12 messages🔥):
-
Climate-conscious AI assistant for financial investments: Leveraging the
climatebert/tcfd_recommendationmodel, a user developed an AI assistant to help find climate-oriented investment solutions. They utilized Qdrant Cloud andmicrosoft/Phi-3-mini-128k-instructand shared the project on HuggingFace. -
SimpleTuner adds Mixture-of-Experts support: The latest release of SimpleTuner, v0.9.6.2, includes mixture-of-experts split-timestep training. A tutorial is available to help users get started with this new feature on GitHub.
-
Triton tutorials and lack of content: A member expressed difficulties understanding Triton tutorials and noted the scarcity of content on Triton. They shared a Medium article which they found helpful but still challenging.
-
Launching true multi-agent systems: A user is developing an SDK and compute servers for running true multi-agent systems, distinct from single-LLM-based agents. They referenced a Twitter discussion and invited interest in joining their forthcoming Discord community (details here).
-
FluentlyXL Final release: The final release of the FluentlyXL model series has arrived, with improvements in aesthetics and lighting. Links to the model on HuggingFace, CivitAI, and a playground were shared.
Links mentioned:
HuggingFace ▷ #reading-group (4 messages):
- Don't miss Human Feedback Foundation event: A member highlighted an upcoming event by the Human Feedback Foundation on June 11th. This foundation aims to integrate human feedback into AI, focusing on critical domains like healthcare and governance.
- Human Feedback Foundation YouTube archive available: The Human Feedback Foundation has past session recordings available on their YouTube channel. They feature speakers from institutions like UofT, Stanford, and OpenAI and aim to educate on AI safety research and promote public participation in AI through open-source initiatives.
- Catch up on HuggingFace reading group: A new member asked if there was a section for reading group recordings. Another member responded affirmatively, directing them to a GitHub repository that compiles all past presentations of the HuggingFace reading group.
Links mentioned:
HuggingFace ▷ #computer-vision (10 messages🔥):
-
Small datasets cause validation issues: Users discussed how a non-representative validation set often indicates a need for more diverse training data. One user suggested that even with fewer than 4,000 samples, models like EfficientNet V2 could perform well if other classes are included to prevent false positives.
-
Need for more details on project: Community members asked for more specifics about a dataset issue, including the number of classes and types of false positives, to provide better help. A user offered to provide personal assistance via DM.
-
Transformers vs traditional models debate: A user noted that while transformers in computer vision can handle data quality issues better, they significantly increase training times compared to models like YOLO and EfficientNet V2. Another member agreed, adding that transformer efficiency also depends on the size of the data.
-
Combining audio and video frames for streaming: A user inquired about the feasibility of syncing audio frames with generated video frames at 24 FPS for streaming via WebRTC or RTMP. They sought advice or resources to achieve this without losing FPS.
-
Swin Transformer for CIFAR discussion: One user asked if anyone had implemented the Swin Transformer (tiny) for the CIFAR dataset, though no further discussion followed on this topic.
HuggingFace ▷ #NLP (1 messages):
- Low temperature means deterministic models: It was suggested to try lowering the temperature to 0.1 for more deterministic models. "The lower the temperature, the more deterministic the model."
HuggingFace ▷ #diffusion-discussions (7 messages):
- Confusion over text embeddings: A member mentioned struggling with recognizing that text-enc 1 was 768 and text-enc 2 was 1280. They also had trouble properly including text_embeds and time_ids in the sample inputs.
- Critique on added kwargs: Another member expressed frustration that added kwargs being in a dictionary makes it "harder to track down what inputs are required."
- Re-parameterising Segmind Model: A member re-parameterised Segmind ssd-1b into a v-prediction/zsnr refiner model trained on 350 timesteps. They were surprised it worked so quickly with only about 800 steps of tuning.
- Favorite model and future plans: The same member declared it their "new favourite model." They plan to train another checkpoint from ssd-1b using the first 650 timesteps to create a true 1B mixture of experts.
- Compliment on lighting: A brief exchange where one member complimented the lighting and another thanked them.
Eleuther ▷ #general (104 messages🔥🔥):
-
KANs are Overhyped and Inefficient: Members discussed the limitations and inefficiency of Kolmogorov-Arnold Networks (KANs) compared to traditional neural networks, particularly for large-scale models. One noted, "KAN being useful for interpretability is pure hype, it won't work."
-
Efficient Implementation of KANs: There was interest in implementations that could make KANs more efficient, particularly using CUDA and alternatives like ReLU. A member shared a paper proposing a ReLU-KAN architecture, which achieved a significant speedup.
-
Data Selection Techniques: Members discussed various methods for evaluating data quality without full retraining. The concept of using influence functions was widely debated, with many finding them unscalable compared to manual and automated data curation techniques. One key resource mentioned was the LESS algorithm.
-
Interplay Between Training Data and Models: Conversations centered on how large models, like Transformer-based systems, balance the trade-off between data diversity and data quality. It was noted that larger models can handle more "crud" and require diverse training data for better world modeling.
-
Thousand Brains Project by Numenta: The project was briefly highlighted, focusing on the application of neuroscience principles to develop a new kind of AI. Detailed information is available on the Numenta website.
Links mentioned:
Eleuther ▷ #research (21 messages🔥):
-
Nvidia releases open weights variants: Nvidia has released an open weights version of its models in 8B and 48B variants, available on GitHub. The linked page provides ongoing research on training transformer models at scale.
-
AI historians use ChatGPT for archival work: Historian Mark Humphries found that AI, particularly GPT models, could significantly aid in transcribing and translating historical documents, ultimately creating a system named HistoryPearl. This system outperformed human graduate students in terms of speed and cost for transcribing documents (The Verge article).
-
MatMul-free models show promise: A new paper (arXiv) introduces MatMul-free models that maintain strong performance at billion-parameter scales while significantly reducing memory usage during training. These models achieve on-par performance with traditional transformers but with better memory efficiency.
-
Seq1F1B for efficient long-sequence training: Another paper (arXiv) presents Seq1F1B, a pipeline scheduling method aimed at improving memory efficiency and training throughput for LLMs on long sequences. The method reduces pipeline bubbles and memory footprints, enhancing scalability.
-
QJL quantization approach for LLMs: The QJL method, detailed in a recent study (arXiv), applies a Johnson-Lindenstrauss transform followed by sign-bit quantization to eliminate memory overheads in storing KV embeddings. This approach significantly compresses the KV cache requirements without compromising performance.
Links mentioned:
Eleuther ▷ #lm-thunderdome (3 messages):
- Llama-3 error on logprobs unveiled: A member faced a "Value error" from llama-3 when trying to request logprobs beyond the limit of five. Another member suggested that a potential solution involves hardcoding the harness to use a value within the valid range.
- Batch API integration into the harness queried: A member inquired about the possibility of adding OpenAI's batch API to the harness, referencing platform.openai.com documentation. The query seemed aimed at specific members for future plans or existing implementations.
Eleuther ▷ #multimodal-general (1 messages):
- Aligning brain data with Whisper embeddings: A member is working on aligning speech embeddings with brain implant neural data to decode speech, using a modified version of the Whisper tiny.en model. They're seeking feedback on which layers to unlock, additional loss functions to try, hyperparameters to tune, and ways to speed up or parallelize the training process with only one GPU, and are open to collaboration.
Perplexity AI ▷ #general (111 messages🔥🔥):
- Perplexity Pro adds new features: Perplexity Pro now shows step-by-step what it is searching, described as using an intent system for more agentic-like execution. Members noted this change as being about a week old.
- Issues with Perplexity reading files: Multiple users reported Perplexity struggling or failing to read PDF files despite being an allowed file type. Some suggested the issue might be related to the content type, such as heavily styled versus plain text PDFs.
- Budget shock for MVP project: A user sought a developer to build an MVP to generate video from text with a $100 budget, prompting humorous and critical reactions about the low budget and typical developer rates.
- Discontinuation of specific labs features: Members discussed the removal of the Haiku and other features from Perplexity labs, speculating it might be for cost-saving reasons and noting the unavailability of these features affected their usage.
- Query on Perplexity's future features: Users inquired about the ability to edit collections in the iOS app and create pages on Perplexity, but availability is currently limited to select users or in beta.
Links mentioned:
Perplexity AI ▷ #sharing (5 messages):
-
Bitcoin's History Highlights Development: An informative message shares the history of Bitcoin, highlighting its creation by Satoshi Nakamoto in 2009 and its significant impact on the financial world. A link to a detailed overview and history can be found here.
-
Perplexity AI's Capabilities Explored: Perplexity AI combines conversational search with direct links, providing answers while referencing sources. Key features include chat-based search, multi-turn dialogues, and multi-language support, as detailed here.
-
Perplexity AI Accesses Paywalled Content: There's a discussion on Perplexity AI's ability to access content behind paywalls. The tool offers various features and a Pro upgrade for enhanced functionalities, as mentioned here.
-
Revit 2024 Enhances PDF Export: Revit 2024 includes a native PDF-export function, simplifying the workflow for BIM modelers and electrical engineers without relying on external PDF printers. More details can be found here.
-
navigator.userAgentOutputs in React and JS: An explanation of thenavigator.userAgentin React and JavaScript, detailing how it returns a string identifying the user's browser and operating system. Examples and more information can be found here.
Links mentioned:
Perplexity AI ▷ #pplx-api (1 messages):
- Curiosity about OpenChat Model addition: A member asked if there is a plan to add another "openchat/openchat-3.6-8b-20240522" model. They inquired specifically about its inclusion alongside the existing Mistral and Llama 3 models.
CUDA MODE ▷ #general (3 messages):
- Find past event recordings on YouTube: A user inquired about the location of past event or lecture recordings. They were directed to check the relevant Discord channel and the CUDA MODE YouTube channel.
CUDA MODE ▷ #torch (2 messages):
-
Checking Tensor Memory Sharing in PyTorch: One member asked another if a specific piece of code can confirm whether two tensors share the same memory or if one is a copy. The code "samestorage" checks if the
storage().data_ptr()of two tensors are equal and prints "same storage" or "different storage". -
Issues Finding Function Source Code: Another member expressed trouble locating the source code for a function in PyTorch using a provided documentation link. They referenced a specific function in the PyTorch C++ documentation.
Link mentioned: Function at::_weight_int4pack_mm — PyTorch main documentation: no description found
CUDA MODE ▷ #algorithms (1 messages):
- Dive into MoRA and DPO vs PPO debate: Fresh research includes MoRA, an enhancement to LoRA, and a comparison between DPO and PPO for RLHF. Explore these topics in the latest AI Unplugged issue.
- CoPE introduces Contextual Position Encodings: The current weekly highlights innovative work like CoPE for better positional encoding. Get insights on this and more by reading the linked blog post.
- S3D for faster inference: The recent discussion includes S3D, a self-speculative decoding method aimed at speeding up inference. All are encouraged to read and share thoughts on the new techniques.
Link mentioned: AI Unplugged 12: MoRA. DPO vs PPO. CoPE Contextual Position Encoding. S3D Self Speculative Decoding.: Insights over Information
CUDA MODE ▷ #cool-links (22 messages🔥):
- **KANs rival MLPs with torch.compile**: A [tweet by Thomas Ahle](https://x.com/thomasahle/status/1798408687981297844) highlighted how torch.compile makes KANs as fast as MLPs, praising the performance improvement. This drew attention and comments from several users surprised and impressed by this claim.
- **Repository on GitHub**: The [GitHub repository](https://github.com/thomasahle/kanmlps) linked in the discussion provides resources for KANs and MLPs. Users are actively compiling and profiling these implementations to understand the performance benefits.
- **Practical profiling experiences**: Users shared their experiences and results while profiling the compiled KANs, noting improvements in speed by 1.5-2 times after compilation. One user mentioned compiling the `.forward` function with significant speed improvements.
- **Concerns over operator fusion and kernels**: There were technical discussions on potential downsides like losing operator fusion and questions about generating Triton kernels. Users are profiling different implementations to verify and compare results, referencing [specific code locations on GitHub](https://github.com/thomasahle/kanmlps/blob/main/models.py#L101).
- **Request for further collaboration**: There was a suggestion to invite Thomas Ahle to join the discussion and share insights about compile testing results. Users are interested in ensuring the implementations match academic papers and seeking verification outputs.
Links mentioned:
CUDA MODE ▷ #pmpp-book (1 messages):
piotr.mazurek: Chapter 4, exercise 9, anyone knows if this is the corrext solution here?
CUDA MODE ▷ #torchao (1 messages):
- Inductor Config Question: There was a query regarding the torch._inductor.config.force_fuse_int_mm_with_mul setting. The question asked whether this configuration applies to uint8 in addition to int8.
CUDA MODE ▷ #off-topic (1 messages):
- 40% worse machine learning at NetHack: A shared article from Ars Technica discusses a peculiar bug that made a machine-learning system's performance drop by 40% in the game NetHack. The bug is suggested to be caused by celestial reasons, making the scenario both novel and entertaining.
Link mentioned: What kind of bug would make machine learning suddenly 40% worse at NetHack?: One day, a roguelike-playing system just kept biffing it, for celestial reasons.
CUDA MODE ▷ #irl-meetup (1 messages):
- AI_dev in Paris captures interest: Someone asked if any members were attending AI_dev in Paris, mentioning they haven't registered yet but are considering it. They shared details and links about the event, which will take place from June 19-20, 2024, and highlighted that registration is required to attend.
Link mentioned: AI_dev Europe 2024 Schedule: Check out the schedule for AI_dev Europe 2024
CUDA MODE ▷ #llmdotc (52 messages🔥):
-
Column-Major Madness: The member finally understood the intricacies of cublas and its column-major order, explaining why they had to transpose matrices to compute
Q @ K^Tcorrectly with cublas. They also mentioned removing their "attention bug" PR after this realization. -
Consolidated Memory Allocations Proposal: Discussions focused on the benefits of consolidating all memory allocations into a single function for efficiency and easier tracking. This approach would remove the current duplication and streamline checkpointing, as noted by Erik's draft PR and linked PR for master weights.
-
Checkpointing with GPU CI: There's a consensus on improving the GPU Continuous Integration (CI) with enhanced verification tests, including training checkpointing and output comparison. Erik emphasized that while initial tests are sufficient, future extensions are necessary for robust validation.
-
Cublas vs Cutlass and C++ Requirements: Clarification was provided that cublas, with its C interface, does not require C++17, but cutlass does. Current code requirements for C++17 are limited to cudnn–a significant detail for future development considerations.
-
Parallel Programming Course Recommendation: The Programing Parallel Computers course and its exercises were recommended, with a note about a potential summer session that sets up a new leaderboard.
Links mentioned:
CUDA MODE ▷ #bitnet (1 messages):
CUDA MODE ▷ #arm (3 messages):
- YouTube Discusses ARM SME Dialect: A YouTube video titled "Open MLIR Meeting 06-22-2023: Targeting ARM SME from MLIR and SME Dialect" is shared, discussing a review and RFC on creating an ArmSME Dialect. The video includes an introduction to ARM's Scalable Matrix Extension.
- Potential for Triton ARM: It's suggested that the backend for Triton might support ARM, indicating promising developments for Triton ARM integration. The information is linked to the 'arm_neon' dialect in the MLIR documentation, which discusses multiple ARM NEON operations.
Links mentioned:
Interconnects (Nathan Lambert) ▷ #ideas-and-feedback (1 messages):
- Article Linked to PI Schilling Concerns: A GDM robotics person thought the author's article was "schilling PI" and expressed concerns about its content. The author speculated that the person might be "salty about RTX," implying a personal bias in their critique.
Interconnects (Nathan Lambert) ▷ #news (33 messages🔥):
- Investors chase robotics AI, avoiding hardware risks: Investors are keen on finding the "ChatGPT for robotics," seeking niche foundation model companies that differentiate themselves. Article details the excitement around this trend.
- Qwen2 makes impressive strides: Qwen2 introduces models in five sizes with improvements in multilingual tasks and extended context support up to 128K tokens. A demo and various resources are available, though some users note limitations in its recent knowledge.
- Qwen2 receives mixed reviews in practical tests: Users experimenting with Qwen2 comment on its limitations in understanding recent topics and providing accurate general knowledge. Despite some shortcomings, its multilingual performance on certain tasks was praised.
- Dragonfly architecture boosts multi-modal AI: Together.ai launched Dragonfly, enhancing visual understanding and reasoning with models like Llama-3-8B-Dragonfly-v1. These models show promising results, especially in medical imaging tasks.
Links mentioned:
Interconnects (Nathan Lambert) ▷ #ml-drama (12 messages🔥):
-
Microsoft admits to unauthorized GPT-4 testing: A tweet shared by Kevin Roose revealed that Microsoft admitted to testing an early version of GPT-4 in India without joint safety board approval after initially denying it.
-
Beware of Substack grift: Nathan Lambert cautioned against trusting Substack recommendations, describing them as grifts aimed at collecting subscribers.
-
Rick's grindy social media presence: A user commented on Rick's heavy focus on self-promotion via Twitter and LinkedIn, despite his generally nice demeanor.
-
Substack metrics and challenges: It was mentioned that gaining 1,000 subscribers on Substack is challenging, often taking a year or two. Lambert confirmed that clicks on Substack recommendations do drive up numbers.
Link mentioned: Tweet from Kevin Roose (@kevinroose): Interesting update to the OpenAI whistleblower story: After denying it on the record, Microsoft is now admitting that they tested an early version of GPT-4 in India without the approval of a joint saf...
Interconnects (Nathan Lambert) ▷ #random (4 messages):
- Google Vertex AI Gemini API is awesome: A member shared a link to the Google Vertex AI Gemini documentation and expressed enthusiasm about its capabilities. The API's ease of use was particularly highlighted.
- OpenAI’s API acclaimed: Another member praised OpenAI's API, stating it is "the best." This was noted in the context of setting up Gemini, indicating high satisfaction with the integration process.
Link mentioned: no title found: no description found
Interconnects (Nathan Lambert) ▷ #memes (13 messages🔥):
-
AI Labs Stop Sharing Advances: A shared tweet suggested that America's AI labs no longer share their algorithmic advances with the American research community but might be sharing them with the CCP due to poor security. Nathan Lambert agreed with the sentiment, adding, "now we're talking."
-
Humane AI Pin Battery Issues: An article from The Verge warned AI Pin owners to stop using its charging case immediately due to a fire safety risk. The company promised two free months of its subscription service as recompense and is looking for a new supplier for the charging cases.
-
Criticism in AI Industry: Discussions revealed discomfort with influential employees of big labs criticizing others, both large and small players. Nathan Lambert commented, "I don’t know this company sounds like such bs I considered it," while xeophon. mentioned the unnecessary criticism from people in major organizations.
-
Prevalence of "Dunking" in AI Community: Nathan Lambert and xeophon. noted the high propensity and habitual behavior of "dunking" on others within the AI community. Lambert admitted it is a "losing battle" against this behavior, to which xeophon. humorously added, "That’s what alts are for."
Links mentioned:
Interconnects (Nathan Lambert) ▷ #rl (2 messages):
- Interesting New Paper on Self-Improving RLHF: A user shared a post from @aahmadian_ on X introducing a paper titled “Self-Improving Robust Preference Optimization” (SRPO). The paper discusses training models that are self-improving and robust to evaluation tasks.
- Morning Paper Discussion Plans: Nathan Lambert plans to start a new series where he spends 15-20 minutes discussing new papers. He mentions wanting to read through the SRPO paper as part of this new routine.
Link mentioned: Tweet from Arash Ahmadian (@aahmadian_): 🤔Can we explicitly teach LLMs to self-improve using RLHF? Introducing “Self-Improving Robust Preference Optimization” (SRPO) which trains models that are self-improving and robust to eval tasks! w/...
Modular (Mojo 🔥) ▷ #general (7 messages):
-
Mojo used in Backend server development: A new user inquired about using Mojo for backend purposes. Another member provided an example of an HTTP server entirely in Mojo, directing them to lightbug_http on GitHub.
-
Member plans to replace PHP SaaS code: After seeing an example of Mojo's capabilities, a member expressed interest in replacing their PHP SaaS backend code with Python or Mojo. They planned to explore the provided resources further.
-
Mojo development roadmap shared: A member shared a link to the Mojo roadmap, highlighting the ongoing development and upcoming features. The roadmap emphasizes the focus on building core system programming features essential to Mojo's mission.
-
SO Survey Announcement: A member announced that the 2024 Stack Overflow survey is out and shared the link here.
-
Commentary on a technical talk: Members humorously discussed their difficulty in following a highly technical talk about Mojo, specifically regarding calling C code in the same OS process without memory interference.
Links mentioned:
Modular (Mojo 🔥) ▷ #💬︱twitter (1 messages):
ModularBot: From Modular: https://twitter.com/Modular/status/1798760653806817352
Modular (Mojo 🔥) ▷ #ai (4 messages):
- Quicksort request in Mojo: A user requested implementation of quicksort in Mojo. ModularBot responded with an elaborate and metaphorical encouragement, likening the coding challenge to embarking on a noble quest involving methodical partitioning and recursion.
Modular (Mojo 🔥) ▷ #🔥mojo (34 messages🔥):
- Avoid footguns in Python education: Members discussed teaching Python to non-programmers, emphasizing the importance of avoiding "footguns" to improve design and potentially ease transitions to languages like C++.
- Curiosity about function pointers in Mojo: A member inquired about storing C function pointers in a Mojo struct, sparking curiosity and some supportive responses.
- Mojo vs. Python performance: There was a detailed conversation on whether Mojo is intrinsically faster than Python, with explanations citing better engineering, static typing, and compile-time computation as factors for Mojo's superior performance.
- "Licking the cookie" analogy for community contributions: Chris clarified that Modular aims to avoid "licking the cookie" by allowing the community to adapt their Tensor library rather than dominating every development aspect, promoting collaboration and open-source contributions.
- Aesthetic and performance in code: A member sought advice on optimizing a code snippet in Mojo for checking digits in a string, illustrating challenges in finding aesthetically pleasing and performant solutions.
Modular (Mojo 🔥) ▷ #nightly (11 messages🔥):
-
Immutable auto-deref for list iterator in Mojo: A user suggested a patch for using immutable auto-deref for list iterators, shared via GitHub. They raised questions on timing, the usage of
iter_mut(), and whether to wait for more usage of explicit copy in stdlib. -
Workflow timing confusion and network issues: Discussions on the nightly workflow timings and issues arose, clarifying that nightly builds kick off at 2 am EST, not immediately after American working hours. An S3 network failure was identified as the cause of the issue for the night.
-
Parallel sorting function issues: A user, mzaks, mentioned issues with tests exploding when importing
algorithm.parallelizefor aparallel_sortfunction. They questioned the current feasibility of this implementation. -
New nightly compiler released: The new nightly Mojo compiler release
2024.6.616was announced, including significant updates like the addition of aString.formatmethod. The changelog and the raw diff of changes can be found here. -
Dynamic libpython selection update: Jack Clayton highlighted a new feature in the latest nightly that allows dynamic
libpythonselection, removing the need to setMOJO_PYTHON_LIBRARY. This improvement ensures access to Python modules in the active environment and the folder of the target Mojo file or executable.
Links mentioned:
Latent Space ▷ #ai-general-chat (54 messages🔥):
- Cohere raises $450m: Cohere has raised another $450 million in funding, with investors like NVidia and Salesforce participating despite having relatively low revenue last year. Reuters article.
- IBM's Granite models praised: IBM's Granite models receive credit for transparency and enterprise benefits, sparking discussions on whether they outperform OpenAI. Fun quotes from Talha Khan and debates on IBM's actual relevance.
- AI Foundation Models report by Forrester: Databricks celebrated being named a leader in Forrester’s latest report on AI foundation models. They emphasize enterprise-specific needs over simple benchmark scores, provide a free report, and share their blog post.
- Qwen 2 launch: Qwen 2 model is released, beating Llama 3 with a 128K context window and excelling at code and math, while being available in various forms (AWQ, GPTQ & GGUFs). Exciting announcement.
- Browserbase and Nox launches: Browserbase announces a $6.5 million seed funding with founders Nat & Dan, aimed at empowering AI applications to browse the web. Nox launches a new AI assistant aiming to make users feel invincible, with early access available here.
Links mentioned:
LlamaIndex ▷ #blog (2 messages):
- Prometheus-2: Open-source LLM evaluates your RAG app!: Using an LLM as a judge to evaluate RAG applications is gaining traction, with concerns about transparency, controllability, and affordability. Prometheus-2 offers an alternative to GPT-4 for such evaluations. Link
- LlamaParse and Knowledge Graphs: A perfect match!: A notebook by @jerryjliu0 showcases using LlamaParse for first-class parsing to build a knowledge graph. This setup constructs a RAG pipeline, retrieving initial nodes via the graph's structure. Link
LlamaIndex ▷ #general (43 messages🔥):
-
Overwhelmed by LlamaIndex configurations: A member discusses their struggle to implement a use case with LlamaIndex for querying JSON data from APIs. They express being overwhelmed by the multitude of components and seek advice on building a custom agent to handle API calls and JSON processing.
-
Text2SQL query issue: A member is facing issues with a Text2SQL and semantic similarity (RAG-based) approach, where a query retrieves structured data correctly but only provides answers from unstructured data. They seek assistance to correct this behavior and ensure both structured and unstructured data are utilized.
-
Count documents in Neo4j: Multiple users discuss methods to count documents in a Property Graph Index using Neo4j. One user shares a specific Cypher query to count distinct document IDs based on nodes tagged as chunks.
-
Alternative LLM setup in constrained environments: A new user to LlamaIndex inquires about alternatives to OpenAI due to hardware constraints. Other members suggest using smaller LLMs like Microsoft Phi-3 with Ollama or utilizing Google Colab for larger models.
-
Retrieving nodes by metadata only: A user inquires about retrieving nodes based solely on metadata without using a MetaDataFilter. Another user notes this might not be directly supported, suggesting examining the LlamaIndex API for potential workarounds.
Links mentioned:
LlamaIndex ▷ #ai-discussion (5 messages):
- Filter results by score with customization: Members discussed the capability of filtering results by score. It was noted that one could obtain the top k results with scores and set a threshold based on the specific case.
- Try out the filtering feature: A user showed interest in trying out the filtering feature after learning about its customizable threshold option.
- Prometheus 2 integrates with LlamaIndex: A link to a Medium article about Prometheus 2 was shared, highlighting its capabilities for evaluating RAG applications with LlamaIndex integration.
Cohere ▷ #general (45 messages🔥):
- OpenRouter offers more flexible sampler options: A member noticed that OpenRouter allows setting temperature above 1, unlike the Cohere trial, which caps it at 1. Another member clarified that OpenRouter processes this differently and accepts higher settings.
- Toby Morning invites connections: A new member, Toby Morning from SF, shared his LinkedIn link (LinkedIn Profile) and expressed interest in connecting with the community.
- Chatbot usage discussed for group interactions: A member suggested implementing a chatbot in various group scenarios, such as business meetings or educational settings, to discern between individual users and provide targeted responses. Another participant shared concerns about potential accuracy issues with too many personas.
- Rhea system praised for multi-user context: Members discussed the efficiency of the Rhea system in handling multi-user scenarios, with participants agreeing it manages context well. There was a mention of Coral running on Rhea and plans for a demo, with high expectations for its showcase.
- Proposed demo for Coral AGI: Participants showed interest in a demo for Coral AGI by Jonno, suggesting it could be featured on the server or demo day. There were acknowledgments of Jonno's expertise and past success with multi-user methods.
Cohere ▷ #announcements (2 messages):
-
Cohere launches startup program: Cohere announced a new startup program offering early-stage founders discounts on their AI models, support from technical experts, and marketing exposure. They aim to empower greater innovation and adoption of AI technology for startups with Series B funding or earlier.
-
Chat API changes effective June 10th: Cohere detailed forthcoming changes to the Chat API, including new multi-step tool use by default and a
force_single_stepparameter for reverting to single-step mode. Additional enhancements include a new "TOOL" message role and updated API specs available from June 10th, supporting various SDKs and platforms. -
Multi-step tool use documentation available: Users are directed to the multi-step tool use guide for handling complex tasks via multiple tool calls. Integration examples and additional resources are provided to facilitate a smooth transition.
-
Single-step tool use remains supported: For those preferring the traditional method, guidance on single-step tool use is still available. Example implementations can be found in a notebook on GitHub, emphasizing the utility of this feature for accessing external data sources.
Links mentioned:
Nous Research AI ▷ #off-topic (9 messages🔥):
- User explores Wakanda music on YouTube: A member expressed curiosity about "Wakanda music" and shared several YouTube links to various music videos. Some of the shared videos include DG812 - In Your Eyes, MitiS & Ray Volpe - Don't Look Down, Paco Vernen - Tesseract, and Xavi - To The Endless Searing Skies.
- Game idea in AR/VR spaces: A member proposed a unique AR/VR game concept where players communicate and respond solely through diverse media formats, excluding text entirely. This could foster innovative interactions and open up new avenues for gameplay.
- Philosophical universe creation: The same member shared an idea of creating a universe within a game, symbolizing existence from void through universe back to void, as an alchemical metaphor. The concept aims to communicate a collective journey of self-mastery and enlightenment.
Links mentioned:
Nous Research AI ▷ #interesting-links (2 messages):
- Qwen2 Models Release: A significant update from Qwen1.5 to Qwen2 was announced, including pretrained and instruction-tuned models in multiple sizes. New models support 128K token context lengths and have been trained in 27 additional languages beyond English and Chinese. Read the blog. GitHub, Hugging Face, ModelScope, Demo, Discord.
Link mentioned: Hello Qwen2: GITHUB HUGGING FACE MODELSCOPE DEMO DISCORD Introduction After months of efforts, we are pleased to announce the evolution from Qwen1.5 to Qwen2. This time, we bring to you: Pretrained and instruction...
Nous Research AI ▷ #general (29 messages🔥):
- Predict events on a map: A user inquired about how to predict event points on a map using temporal data and distinguish between true and false events. Another user suggested a command involving loading testChatName.
- EleutherAI's pile-T5 model reference: A user shared and questioned why the EleutherAI/pile-t5-xxl model on Hugging Face was overlooked. The link provided details about the model's text generation capabilities.
- Mistral fine-tuning API release: Mistral introduced a fine-tuning API described in their documentation, with specifics on the costs associated with fine-tuning jobs. Another user emphasized that using this API allows quick experiments on their datasets before scaling.
- Qwen2 model release and benchmarks: Announcement of Qwen2’s release, including 5 model sizes and a notable improvement in coding, mathematics, and multilingual capabilities. Impressive benchmark results were shared, including scores in MMLU and GSM8K.
- Discussion on Pricing and Alternatives: Users debated the cost implications of using Mistral’s API versus other options like OpenAI and Runpod, which were mentioned to be cheaper. A user also highlighted the marketing aspect of these services.
Links mentioned:
Nous Research AI ▷ #ask-about-llms (1 messages):
quantumalchemy: Hermes pro mistral v0.3 ?
Nous Research AI ▷ #rag-dataset (1 messages):
- Mistral prompt template for RAG fine-tuning: A user shared a Mistral prompt template for generating query-context-answer triplets for RAG finetuning. They also cautioned that fine-tuning comes with a minimum fee of $4 per job and a monthly storage fee of $2 per model, with more details available on the pricing page.
Link mentioned: Fine-tuning | Mistral AI Large Language Models: Every fine-tuning job comes with a minimum fee of $4, and there's a monthly storage fee of $2 for each model. For more detailed pricing information, please visit our pricing page.
Nous Research AI ▷ #world-sim (2 messages):
- WorldSim Console fixes mobile text input bugs: The update made significant improvements, addressing numerous text input bugs on mobile devices, enhancing copy/pasting functionality, and introducing more reliable performance. Additionally, slight styling changes, an improved
!listcommand, and the option to disable visual glow & CRT screen effects have been added. - Specific bug fixes for users: Various user-specific issues were addressed, including fixing a text duplication glitch and resolving text jumping while typing. The
!backand!newcommands should now operate differently, although one issue couldn't be reliably reproduced for further debugging.
OpenRouter (Alex Atallah) ▷ #app-showcase (2 messages):
-
Pilot Bot revolutionizes server management: Thanks to OpenRouter, a new Discord bot named Pilot helps server owners grow and manage their communities with ease. Pilot offers features like "Ask Pilot," which understands the server and provides intelligent insights, "Catch Me Up," which summarizes unread messages, and "Health Check," providing weekly activity analyses.
-
Pilot Bot is free and easy to access: The bot is completely free to use and can be invited to servers via their website. This makes server management accessible and efficient for all server owners.
-
Visual guide available: Users can view screenshots to see Pilot in action and explore its various features like "Ask Pilot" for intelligent advising and "Catch Me Up" for staying updated.
{kind=link}
Link mentioned: Pilot - The co-owner for your Discord server.: Pilot takes the work out of running a server. Get AI-enhanced advice, insights, and more to help you grow and manage your community.
OpenRouter (Alex Atallah) ▷ #general (40 messages🔥):
-
WizardLM 8x22b Faces Competition From Dolphin 8x22: There's enthusiasm around WizardLM 8x22b, touted as the best model for role-playing. However, another member mentioned they've heard about Dolphin 8x22 as a potential competitor but haven't tested it yet.
-
Query on Gemini Flash and Image Output Capabilities: A member asked if the Gemini Flash model can output images. Responses clarified that no LLM currently allows for direct image output, although it's theoretically possible using base64 encoding or external function calls to image generators like Stable Diffusion.
-
Assistant Model Recommendations for Function Calls: A member sought recommendations for a model adept at handling function calls and specific formatting. Instructor was suggested as a suitable tool for their needs.
-
Insights on OpenRouter's Free Model Limits: Members discussed the limits on message requests for free models, with references to OpenRouter's documentation. There were also mentions of models like Llama 3 8B (free) and Mistral having reliability issues.
-
Assistant Prefill Support Confirmation: A member inquired if OpenRouter supports assistant prefill, especially via a reverse proxy. Alex Atallah confirmed that it's supported as long as you end with an assistant message and can send the required prompt or chatml array.
Links mentioned:
OpenRouter (Alex Atallah) ▷ #일반 (1 messages):
voidnewbie: GLM-4가 한국어를 지원해서 기대됩니다
MLOps @Chipro ▷ #events (6 messages):
- Human Feedback Foundation event on June 11: "Don’t miss the upcoming event of the Human Feedback Foundation June 11th." Event Link - This event focuses on integrating human feedback in AI for critical domains like healthcare, governance, and democracy.
- Check past sessions on YouTube: Members were directed to "check out our previous session recordings on our YouTube channel" featuring speakers from UofT, Stanford, and OpenAI. YouTube Channel
- LLM Reading Group Discord issue: A user inquired about a separate Discord for the LLM Reading Group. The respondent tried "sending you a direct message with an invitation but couldn't due to your privacy settings."
- "Unleash the Power of RAG in Azure" event in Toronto: An attendee asked if anyone else was going to this overbooked Microsoft event in Toronto. Event details
Links mentioned:
MLOps @Chipro ▷ #general-ml (23 messages🔥):
-
Dealing with high-cardinality categorical columns: A member sought advice on handling categorical columns with numerous slightly related features and spelling mistakes, particularly for a regression task. Another member suggested aggregate/grouping and manual feature engineering or implementing spell correction techniques like string matching, and edit distance.
-
Feature Engineering vs. Clustering: Following advice on manual grouping and spell correction, the discussion pivoted to whether clustering the features based on edit distance and their relation to the target variable would be more efficient. The consensus was to combine spell correction with other types of grouping, treating this challenge as a data modeling problem.
-
Data Modeling and Simplification Techniques: The conversation also touched on simplifying the model by isolating problems into components like brand and item instead of using entire titles. An additional suggestion for price prediction was to employ moving averages or exponential moving averages to simplify the process.
-
Acknowledgement and Learning: The member seeking advice expressed gratitude, acknowledging the valuable insights and different approaches discussed, including regex usage for feature extraction.
-
Request for help: Another user shared a link requesting assistance on a separate issue but did not provide specific context or details in the conversation.
OpenAccess AI Collective (axolotl) ▷ #general (17 messages🔥):
-
Celebrate access to vast datasets: Members expressed amazement at having access to 15T datasets of high quality publicly available. One highlighted the ironic situation of having "all the data, none of the money or compute."
-
Debate over AI hardware: In a tongue-in-cheek conversation about pretraining huge datasets, one member suggested buying 4090s. The sarcastic response about using consumer GPUs for such a large project elicited laughter: "not with this attitude you wont".
-
Exploring GLM and Qwen finetuning: Members are inquiring about and sharing configurations for finetuning GLM 4 9b and Qwen2 models. Qwen2 was noted to be nearly identical to Mistral, which simplifies configuration.
-
Announcement mirroring request: A teacher explained setting up a small Discord server for AI students, which included mirroring setup for updates from Unsloth. They asked if there can be a similar announcement mirroring setup for Axolotl due to its frequent usage by the class.
Links mentioned:
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (1 messages):
josharian: i just experienced this exact behavior as well.
OpenAccess AI Collective (axolotl) ▷ #axolotl-help-bot (11 messages🔥):
-
Configure Checkpoints in Trainer: Members discussed configuring training to save two checkpoints, one for the last run and another for the best
eval_loss. An example was provided using Hugging Face'sTrainingArgumentsandEarlyStoppingCallback. -
Solve Non-Zero Exit Status Error: A user queried how to fix the "returned non-zero exit status 1" error. Suggestions included identifying the failing command, capturing
stdoutandstderr, and troubleshooting permission issues or environment variables.
Links mentioned:
LAION ▷ #general (21 messages🔥):
-
"1B Parameter" Terminology Confusion: Members discussed the naming of the 1B parameter zsnr/vpred refiner, with some confusion about the exact parameter count. One clarified that it’s actually 1.3B and not just 1B, and joked about the higher-ups needing a catchy name.
-
Vega Model's Parametric Limitations: There was a brief discussion on the Vega model, where it was pointed out that despite being impressively fast, it's likely "too small" to provide coherent outputs, as it's at the lower limit of necessary parameters.
-
Elrich Logos Dataset Query: A member inquired about the availability of the Elrich logos dataset without receiving a direct answer.
-
Qwen2 Model Launch: Announcement of the Qwen2 model launch, featuring significant enhancements from Qwen1.5. The Qwen2 model comes in five sizes, supports 27 additional languages, excels in benchmarks, and extends context length up to 128K tokens. Members shared links to the project's GitHub, Hugging Face, ModelScope, and demo.
Link mentioned: Hello Qwen2: GITHUB HUGGING FACE MODELSCOPE DEMO DISCORD Introduction After months of efforts, we are pleased to announce the evolution from Qwen1.5 to Qwen2. This time, we bring to you: Pretrained and instruction...
LangChain AI ▷ #general (14 messages🔥):
-
Guide on Constructing Knowledge Graphs with LangChain: A user shared a guide on constructing knowledge graphs from text. They highlighted the importance of ensuring security by verifying and validating data before importing it into a graph database.
-
Tracking Customer Token Consumption: A user inquired about methods for tracking customer token consumption.
-
Tools Decorator Confusion: A user expressed confusion about the necessity of the tools decorator in tutorials and asked for more information.
-
Creating Colorful Diagrams for RAG: A user asked about the tools used to create colorful RAG diagrams in LangChain's FreeCodeCamp video.
-
Framework for Agent Collaboration: A user sought recommendations for frameworks that facilitate teamwork among agents developed using different frameworks, including LangChain Agent, MetaGPT, and AutoGPT, with an exciting possibility of incorporating agents from platforms like coze.com.
-
Searching for GUI Helper File: A user requested information on locating the "helper.py" file from the AI Agents LangGraph course on DLAI course page.
Links mentioned:
LangChain AI ▷ #tutorials (3 messages):
-
LangGraph's conditional edges tutorial on YouTube: A new YouTube video titled "LangGraph conditional edges" explains how to use conditional edges in LangGraph for flow engineering. The tutorial details controlling flow based on specific conditions within LangGraph.
-
Check out emarco's video: Another helpful YouTube video was shared, though its specific content isn't elaborated upon in this summary.
-
Jina AI alternative: Search-result-scraper on GitHub: A project named search-result-scraper-markdown aims to provide a powerful web scraping tool. It fetches search results, converts them into Markdown format using FastAPI, SearXNG, and Browserless, and includes proxy support and efficient HTML to Markdown conversion.
Links mentioned:
tinygrad (George Hotz) ▷ #learn-tinygrad (16 messages🔥):
- Tinygrad needs updates for 1.0 release: George Hotz mentioned that some PRs will handle this, but it's not in master yet. He emphasized that this update is critical for the 1.0 release.
- Explanation of UOps.CONST in Tinygrad: A user sought clarification on why UOps.CONST is used in the UOps for adding two tensors. It was explained that these represent address offsets needed for row-major data to compute index values.
- Confusion over complex code snippet: Users discussed why complex conditions are used in a piece of code. Fluentpython noted the necessity due to row-major data layouts and handling tensor shapes and strides efficiently.
- Kernel generation for indexing operation in Tinygrad: There was a question about why a specific kernel is generated for tensor indexing. It was clarified that Tinygrad only supported static memory access and this kernel supports dynamic indexing operations with Tensor[Tensor].
- Arange kernel in Tensor getitem operations: Zibokapi pointed out that the kernel for the indexing operation resembles an arange kernel used to create a mask in getitem functions. This helps in dynamic indexing scenarios.
OpenInterpreter ▷ #general (10 messages🔥):
-
Running graphics outputs in interpreter: A member asked if there is a way to get the output from
interpreter.computer.runfor graphics, likematplotlib'splot.show, when called just from code. The question remains unanswered in the chat. -
Struggles with --os mode and local models: Members discussed issues with getting
--os modeto work with local models from LM Studio. One member noted that local LLAVA models failed to start screen recording. -
Vision models for practical hardware: A query on the best vision model for an M1 Mac highlighted the limitations of some members' hardware. Members expressed frustration about the limitations and cost of using OpenAI models, emphasizing the need for accessible and free solutions.
-
Robin-R1 integration excitement: A member shared their excitement about receiving a Rabbit R1 in July and integrating it with OpenInterpreter to conduct actions. They are looking forward to the introduction of webhooks for this project.
-
Editing system messages for AI behavior: There was a discussion on how OpenInterpreter creates system messages, with comparisons between local flags and GPT-4O's system prompts. One member humorously questioned if extreme language like "your family will be murdered if you don't perform" would coax better performance from LLaMA models.
OpenInterpreter ▷ #O1 (2 messages):
- Question about O1 availability: A user asked, "Hi is 01 sold online? would like to try it :)". There was no follow-up or provided link in response to this query.
- Seeking Model for Bash: Another user inquired, "does anyone know which open model works good for bash commands?". This question remained open without any replies or references given.
AI Stack Devs (Yoko Li) ▷ #ai-town-discuss (2 messages):
- Checking on Progress: A member inquired about progress updates, showing interest in the current status. They stated, "hiya ramon. would love to hear how progress is".
- Apologize for Delay: Another member apologized for not having spent time on the project yet. They mentioned, "Oh sorry I haven't had time to spend on this!".
AI Stack Devs (Yoko Li) ▷ #ai-town-dev (3 messages):
-
Parsing spritesheets in AI Town: A member is struggling with parsing spritesheets they purchased, particularly sorting through formats like rpgmaker PNG files, yympas files, and unitypackage files. They ask if there's a better method than manually identifying tile coordinates.
-
Two practical approaches for tilesets: Another member responded, suggesting two practical approaches for handling tilesets: using the level editor (npm run le) or using Tiled and a specific script to convert to AI Town. There's mention of leveraging scripts by another community member (@379381319219806209).
AI Stack Devs (Yoko Li) ▷ #local-ai-stack (2 messages):
-
Discover Abliteration with Hugging Face: A member shared a link to a blog post on Hugging Face about "abliteration," which covers various aspects including implementation and DPO fine-tuning. The third generation of Llama models are highlighted for their instruct versions excelling in following instructions but being "heavily censored."
-
Seeking OpenAI Implementation: The same member later asked if anyone knows how to implement abliteration with OpenAI models. No responses to the query were recorded in the provided messages.
Link mentioned: Uncensor any LLM with abliteration: no description found
Datasette - LLM (@SimonW) ▷ #llm (6 messages):
- Handling context length exceedance in
llmembeddings: A member asks what happens if the input text exceeds the model's context length when creating embeddings usingllm. They tested this with the entire King James Bible text file and received some results without an error, querying if those embeddings represent the whole file or if it's truncated. - Model behavior documentation lacking clarity: Simon Willison responded that the behavior varies by model, with some truncating the input and others returning an error. He expressed the need for better documentation on this subject.
- Assumption on truncated input: Simon suggested that if no error is returned, it's likely that the input is being truncated. The specifics depend on the model's implementation.
- Query on resuming embedding jobs: Another member asked if rerunning a large embedding job with
embed-multiwould skip already completed parts. The question points to the need for handling partial job completions, possibly through SQL queries.
Torchtune ▷ #general (3 messages):
- Inquiry about Megatron Checkpoint Compatibility: A member asked if Megatron has its own checkpoint format and whether it is compatible with existing fine-tuning libraries.
- Suggestion to Convert Megatron to HF Format: Another member suggested converting Megatron checkpoints to Hugging Face (HF) format and using Torchtune for fine-tuning. This was agreed upon as the best solution.
Mozilla AI ▷ #llamafile (1 messages):
- JSON Schema request buzzes for next version: A member inquired about the possibility of getting JSON schema in the next version, emphasizing that it makes building applications much easier, despite any potential implementation bugs. "It makes building applications way easier even if their implementation seems buggy," the user noted.
YAIG (a16z Infra) ▷ #ai-ml (1 messages):
oliver.jack: Weekend listening:
https://youtu.be/4jPg4Se9h5g?si=ULVqGQa6AvI8Ch3o
{% else %}
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: [{{ email.subject }}]({{ email_url }})!
If you enjoyed AInews, please share with a friend! Thanks in advance!
{% endif %}