AI News for 6/6/2024-6/7/2024. We checked 7 subreddits, 384 Twitters and 30 Discords (409 channels, and 3133 messages) for you. Estimated reading time saved (at 200wpm): 343 minutes.
A warm welcome to the TorchTune discord. Reminder that we do consider requests for additions to our Reddit/Discord tracking (we will decline Twitter additions - personalizable Twitter newsletters coming soon! we know it's been a long time coming)
With rumors of increasing funding in the memory startup and long running agents/personal AI space, we are seeing rising interest in high precision/recall memory implementations.
Today's paper isn't as great as MemGPT, but is indicative of what people are exploring. Though we are not big fans of natural intelligence models for artificial intelligence, the HippoRAG paper leans on "hippocampal memory indexing theory" to arrive at a useful implementation of knowledge grpahs and "Personalized PageRank" which probably stand on firmer empirical ground.
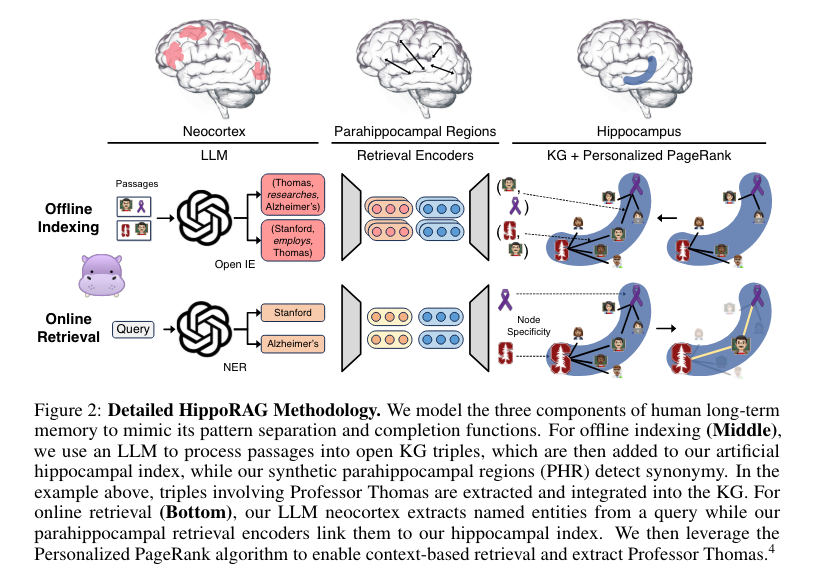
Ironically the best explanation of methodology comes from a Rohan Paul thread (we are not sure how he does so many of these daily):

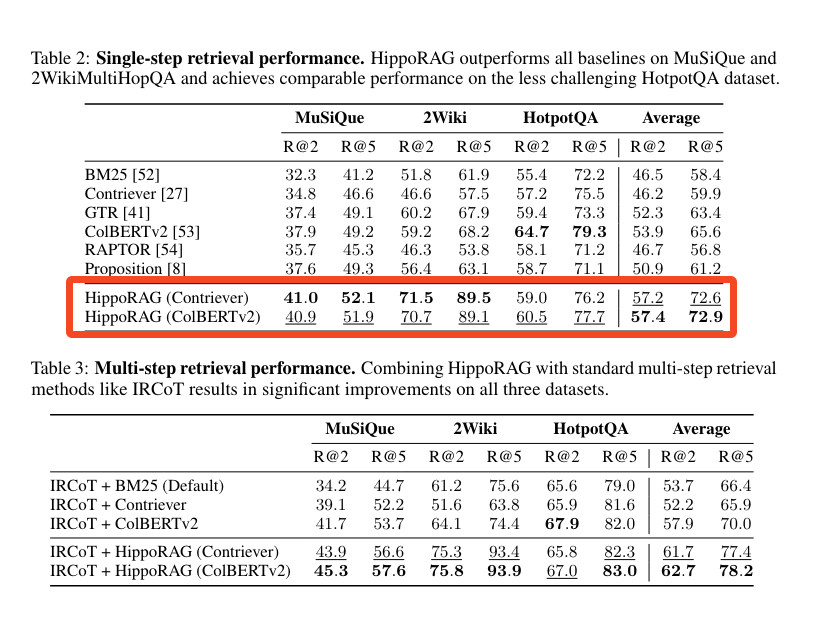
The Single-Step, Multi-Hop retrieval seems to be the key win vs comparable methods 10+ times slower and more expensive:
Section 6 offers a useful, concise literature review of the current techniques to emulate memory in LLM systems.

{% if medium == 'web' %}
Table of Contents
[TOC]
{% else %}
The Table of Contents and Channel Summaries have been moved to the web version of this email: [{{ email.subject }}]({{ email_url }})!
{% endif %}
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
New AI Models and Architectures
- New SOTA open-source models from Alibaba: @huybery announced the release of Qwen2 models from Alibaba, with sizes ranging from 0.5B to 72B parameters. The models were trained on 29 languages and achieved SOTA performance on benchmarks like MMLU (84.32 for 72B) and HumanEval (86.0 for 72B). All models except the 72B are available under the Apache 2.0 license.
- Sparse Autoencoders for interpreting GPT-4: @nabla_theta introduced a new training stack for Sparse Autoencoders (SAEs) to interpret GPT-4's neural activity. The approach shows promise but still captures only a small fraction of behavior. It eliminates feature shrinking, sets L0 directly, and performs well on the MSE/L0 frontier.
- Hippocampus-inspired retrieval augmentation: @rohanpaul_ai overviewed the HippoRAG paper, which mimics the neocortex and hippocampus for efficient retrieval augmentation. It constructs a knowledge graph from the corpus and uses Personalized PageRank for multi-hop reasoning in a single step, outperforming SOTA RAG methods.
- Implicit chain-of-thought reasoning: @rohanpaul_ai described work on teaching LLMs to do chain-of-thought reasoning implicitly, without explicit intermediate steps. The proposed Stepwise Internalization method gradually removes CoT tokens during finetuning, allowing the model to reason implicitly with high accuracy and speed.
- Enhancing LLM reasoning with Buffer of Thoughts: @omarsar0 shared a paper proposing Buffer of Thoughts (BoT) to enhance LLM reasoning accuracy and efficiency. BoT stores high-level thought templates distilled from problem-solving and is dynamically updated. It achieves SOTA performance on multiple tasks with only 12% of the cost of multi-query prompting.
- Scalable MatMul-free LLMs competitive with SOTA Transformers: @rohanpaul_ai shared a paper claiming to create the first scalable MatMul-free LLM competitive with SOTA Transformers at billion-param scale. The model replaces MatMuls with ternary ops and uses Gated Recurrent/Linear Units. The authors built a custom FPGA accelerator processing models at 13W beyond human-readable throughput.
- Accelerating LoRA convergence with Orthonormal Low-Rank Adaptation: @rohanpaul_ai shared a paper on OLoRA, which accelerates LoRA convergence while preserving efficiency. OLoRA uses orthonormal initialization of adaptation matrices via QR decomposition and outperforms standard LoRA on diverse LLMs and NLP tasks.
Multimodal AI and Robotics Advancements
- Dragonfly vision-language models for fine-grained visual understanding: @togethercompute introduced Dragonfly models leveraging multi-resolution encoding & zoom-in patch selection. Llama-3-8b-Dragonfly-Med-v1 outperforms Med-Gemini on medical imaging.
- ShareGPT4Video for video understanding and generation: @_akhaliq shared the ShareGPT4Video series to facilitate video understanding in LVLMs and generation in T2VMs. It includes a 40K GPT-4 captioned video dataset, a superior arbitrary video captioner, and an LVLM reaching SOTA on 3 video benchmarks.
- Open-source robotics demo with Nvidia Jetson Orin Nano: @hardmaru highlighted the potential of open-source robotics, sharing a video demo of a robot using Nvidia's Jetson Orin Nano 8GB board, Intel RealSense D455 camera and mics, and Luxonis OAK-D-Lite AI camera.
AI Tooling and Platform Updates
- Infinity for high-throughput embedding serving: @rohanpaul_ai found Infinity awesome for serving vector embeddings via REST API, supporting various models/frameworks, fast inference backends, dynamic batching, and easy integration with FastAPI/Swagger.
- Hugging Face Embedding Container on Amazon SageMaker: @_philschmid announced general availability of the HF Embedding Container on SageMaker, improving embedding creation for RAG apps, supporting popular architectures, using TEI for fast inference, and allowing deployment of open models.
- Qdrant integration with Neo4j's APOC procedures: @qdrant_engine announced Qdrant's full integration with Neo4j's APOC procedures, bringing advanced vector search to graph database applications.
Benchmarks and Evaluation of AI Models
- MixEval benchmark correlates 96% with Chatbot Arena: @_philschmid introduced MixEval, an open benchmark combining existing ones with real-world queries. MixEval-Hard is a challenging subset. It costs $0.6 to run, has 96% correlation with Arena, and uses GPT-3.5 as parser/judge. Alibaba's Qwen2 72B tops open models.
- MMLU-Redux: re-annotated subset of MMLU questions: @arankomatsuzaki created MMLU-Redux, a 3,000 question subset of MMLU across 30 subjects, to address issues like 57% of questions in Virology containing errors. The dataset is publicly available.
- Questioning the continued relevance of MMLU: @arankomatsuzaki questioned if we're done with MMLU for evaluating LLMs, given saturation of SOTA open models, and proposed MMLU-Redux as an alternative.
- Discovering flaws in open LLMs: @JJitsev concluded from their AIW study that current SOTA open LLMs like Llama 3, Mistral, and Qwen are seriously flawed in basic reasoning despite claiming strong benchmark performance.
Discussions and Perspectives on AI
- Google paper on open-endedness for Artificial Superhuman Intelligence: @arankomatsuzaki shared a Google paper arguing ingredients are in place for open-endedness in AI, essential for ASI. It provides a definition of open-endedness, a path via foundation models, and examines safety implications.
- Debate on the viability of fine-tuning: @HamelHusain shared a talk by Emmanuel Kahembwe on "Why Fine-Tuning is Dead", sparking discussion. While not as bearish, @HamelHusain finds the talk interesting.
- Yann LeCun on AI regulation: In a series of tweets (1, 2, 3), @ylecun argued for regulating AI applications not technology, warning that regulating basic tech and making developers liable for misuse will kill innovation, stop open-source, and are based on implausible sci-fi scenarios.
- Debate on AI timelines and progress: Leopold Aschenbrenner's appearance on the @dwarkesh_sp podcast discussing his paper on AI progress and timelines (summarized by a user) sparked much debate, with views ranging from calling it an important case for an AI capability explosion to criticizing it for relying on assumptions of continued exponential progress.
Miscellaneous
- Perplexity AI commercial during NBA Finals: @AravSrinivas noted that the first Perplexity AI commercial aired during NBA Finals Game 1. @perplexity_ai shared the video clip.
- Yann LeCun on exponential trends and sigmoids: @ylecun argued that every exponential trend eventually passes an inflection point and saturates into a sigmoid as friction terms in the dynamics equation become dominant. Continuing an exponential requires paradigm shifts, as seen in Moore's Law.
- John Carmack on Quest Pro: @ID_AA_Carmack shared that he tried hard to kill the Quest Pro completely as he believed it would be a commercial failure and distract teams from more valuable work on mass market products.
- FastEmbed library adds new embedding types: @qdrant_engine announced FastEmbed 0.3.0 which adds support for image embeddings (ResNet50), multimodal embeddings (CLIP), late interaction embeddings (ColBERT), and sparse embeddings.
- Jokes and memes: Various jokes and memes were shared, including a GPT-4 GGUF outputting nonsense without flash attention (link), @karpathy's llama.cpp update in response to DeepMind's SAE paper (link), and commentary on LLM hype cycles and overblown claims (example).
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity. Comment crawling works now but has lots to improve!
Chinese AI Models
- KLING model generates videos: The Chinese KLING AI model has generated several videos of people eating noodles or burgers, positioned as a competitor to OpenAI's SORA. Users discuss the model's accessibility and potential impact. (Video 1, Video 2, Video 3, Video 4)
- Qwen2-72B language model released: Alibaba has released the Qwen2-72B Chinese language model on Hugging Face. It outperforms Llama 3 on various benchmarks according to comparison images. The official release blog is also linked.
AI Capabilities & Limitations
- Open source vs closed models: Screenshots demonstrate how closed models like Bing AI and CoPilot restrict information on certain topics, emphasizing the importance of open source alternatives. Andrew Ng argues that AI regulations should focus on applications rather than restricting open source model development.
- AI as "alien intelligence": Steven Pinker suggests AI models are a form of "alien intelligence" that we are experimenting on, and that the human brain may be similar to a large language model.
AI Research & Developments
- Extracting concepts from GPT-4: OpenAI research on using sparse autoencoders to identify interpretable patterns in GPT-4's neural network, aiming to make the model more trustworthy and steerable.
- Antitrust probes over AI: Microsoft and Nvidia are facing US antitrust investigations over their AI-related business moves.
- Extreme weight quantization: Research on achieving a 7.9x smaller Stable Diffusion v1.5 model with better performance than the original through extreme weight quantization.
AI Ethics & Regulation
- AI censorship concerns: Screenshots of Bing AI refusing to provide certain information spark discussion about AI censorship and the importance of open access to information.
- Testing AI for election risks: Anthropic discusses efforts to test and mitigate potential election-related risks in their AI systems.
- Criticism of using social media data: Plans to use Facebook and Instagram posts for training AI models face criticism.
AI Tools & Frameworks
- Higgs-Llama-3-70B for role-playing: Fine-tuned version of Llama-3 optimized for role-playing released on Hugging Face.
- Removing LLM censorship: Hugging Face blog post introduces "abliteration" method for removing language model censorship.
- Atomic Agents library: New open-source library for building modular AI agents with local model support.
AI Discord Recap
A summary of Summaries of Summaries
1. LLM Advancements and Optimization Challenges:
- Meta's Vision-Language Modeling Guide provides a comprehensive overview of VLMs, including training processes and evaluation methods, helping engineers understand mapping vision to language better.
- DecoupleQ from ByteDance aims to drastically improve LLM performance using new quantization methods, promising 7x compression ratios, though further speed benchmarks are anticipated (GitHub).
- GPT-4o's Upcoming Features include new voice and vision capabilities for ChatGPT Plus users and real-time chat for Alpha users. Read about it in OpenAI's tweet.
- Efficient Inference and Training Techniques like
torch.compilespeed up SetFit models, confirming the importance of experimenting with optimization parameters in PyTorch for performance gains. - FluentlyXL Final from HuggingFace introduces substantial improvements in aesthetics and lighting, enhancing the AI model's output quality (FluentlyXL).
2. Open-Source AI Projects and Resources:
- TorchTune facilitates LLM fine-tuning using PyTorch, providing a detailed repository on GitHub. Contributions like configuring
n_kv_headsfor mqa/gqa are welcomed with unit tests. - Unsloth AI's Llama3 and Qwen2 Training Guide offers practical Colab notebooks and efficient pretraining techniques to optimize VRAM usage (Unsloth AI blog).
- Dynamic Data Updates in LlamaIndex help keep retrieval-augmented generation systems current using periodic index refreshing and metadata filters in LlamaIndex Guide.
- AI Video Generation and Vision-LSTM techniques explore dynamic sequence generation and image reading capabilities (Twitter discussion).
- TopK Sparse Autoencoders train effectively on GPT-2 Small and Pythia 160M without caching activations on disk, helping in feature extraction (OpenAI's release).
3. Practical Issues in AI Model Implementation:
- Prompt Engineering in LangChain struggles with repeated steps and early stopping issues, urging users to look for fixes (GitHub issue).
- High VRAM Consumption with Automatic1111 for image generation tasks causes significant delays, highlighting the need for memory management solutions (Stability.ai chat).
- Qwen2 Model Troubleshooting reveals problems with gibberish outputs fixed by enabling flash attention or using proper presets (LM Studio discussions).
- Mixtral 8x7B Model Misconception Correction: Stanford CS25 clarifies it contains 256 experts, not just 8 (YouTube).
4. AI Regulation, Safety, and Ethical Discussions:
- Andrew Ng's Concerns on AI Regulation mimic global debates on AI innovation stifling; comparisons to Russian AI policy discussions reveal varying stances on open-source and ethical AI (YouTube).
- Leopold Aschenbrenner's Departure from OAI sparks fiery debates on the importance of AI security measures, reflecting divided opinions on AI safekeeping (OpenRouter discussions).
- AI Safety in Art Software: Adobe's requirement for access to all work, including NDA projects, prompts suggestions of alternative software like Krita or Gimp for privacy-concerned users (Twitter thread).
5. Community Tools, Tips, and Collaborative Projects:
- Predibase Tools and Enthusiastic Feedback: LoRAX stands out for cost-effective LLM deployment, even amid email registration hiccups (Predibase tools).
- WebSim.AI for Recursive Analysis: AI engineers share experiences using WebSim.AI for recursive simulations and brainstorming on valuable metrics derived from hallucinations (Google spreadsheet).
- Modular's MAX 24.4 Update introduces a new Quantization API and macOS compatibility, enhancing Generative AI pipelines with significant latency and memory reductions (Blog post).
- GPU Cooling and Power Solutions discussed innovative methods for setting up Tesla P40 and similar hardware with practical guides (GitHub guide).
- Experimentation and Learning Resources provided by tcapelle include practical notebooks and GitHub resources for fine-tuning and efficiency (Colab notebook).
PART 1: High level Discord summaries
LLM Finetuning (Hamel + Dan) Discord
-
RAG Revamp and Table Transformation Trials: Discontent over the formatting of markdown tables by Marker has led to discussions on fine-tuning the tool for improved output. Alternative table extraction tools like img2table are also under exploration.
-
Predictive Text for Python Pros with Predibase: Enthusiasm for Predibase credits and tools is noted, with LoRAX standing out for cost-effective, high-quality LLM deployment. Confirmation and email registration hiccups are prevalent, with requests for help directed to the registration email.
-
Open Discussions on Deep LLM Understanding: Posts from tcapelle offer deep dives into LLM fine-tuning with resources like slides and notebooks. Further, studies on pruning strategies highlight ways to streamline LLMs as shared in a NVIDIA GTC talk.
-
Cursor Code Editor Catches Engineers' Eyes: The AI code editor Cursor, which leverages API keys from OpenAI and other AI services, garners approval for its codebase indexing and improvements in code completion, even tempting users away from GitHub Copilot.
-
Modal GPU Uses and Gists Galore: Modal's VRAM use and A100 GPUs are appraised alongside posted gists for Pokemon card descriptions and Whisper adaptation tips._GPU availability inconsistencies are flagged, while dashboard absence for queue status is noted.
-
Learning with Vector and OpenPipe: The discussion included resources for building vector systems with VectorHub's RAG-related content, and articles on the OpenPipe blog received spotlighting for their contribution to the conversation.
-
Struggles with Finetuning Tools and Data: Issues with downloading course session recordings are being navigated, as Bulk tool development picks up motivated by the influx of synthetic datasets. Assistance for local Docker space quandaries during Replicate demos was sought without a solution in the chat logs.
-
LLM Fine-Tuning Fixes in the Making: A lively chat around fine-tuning complexities unfolded, addressing the concerns over merged Lora model shard anomalies, and proposed fine-tuning preferences such as Mistral Instruct templates for DPO finetuning. Interesting, the output discrepancy with token space assembly in Axolotl raised eyebrows, and conversations were geared towards debugging and potential solutions.
Perplexity AI Discord
-
Starship Soars and Splashes Successfully: SpaceX's Starship test flight succeeded with landings in two oceans, turning heads in the engineering community; the successful splashdowns in both the Gulf of Mexico and the Indian Ocean indicate marked progress in the program according to the official update.
-
Spiced Up Curry Comparisons: Engineers with a taste for international cuisine analyzed the differences between Japanese, Indian, and Thai curries, noting unique spices, herbs, and ingredients; a detailed breakdown was circulated that provided insight into each type's historical origins and typical recipes.
-
Promotional Perplexity Puzzles Participants: Disappointment bubbled among users expecting a noteworthy update from Perplexity AI's "The Know-It-Alls" ad; instead, it was a promotional video, leaving many feeling it was more of a tease than a substantive reveal as discussed in general chat.
-
AI Community Converses Claude 3 and Pro Search: Discussion flourished over different AI models like Pro Search and Claude 3; details about model preferences, their search abilities, and user experiences were hot topics, alongside the removal of Claude 3 Haiku from Perplexity Labs.
-
llava Lamentations and Beta Blues in API Channel: API users inquired about the integration of the llava model and vented over the seemingly closed nature of beta testing for new sources, showing a strong desire for more transparency and communication from the Perplexity team.
HuggingFace Discord
-
Electrifying Enhancement with FluentlyXL: The eagerly-anticipated FluentlyXL Final version is now available, promising substantial enhancements in aesthetics and lighting, as detailed on its official page. Additionally, green-minded tech enthusiasts can explore the new Carbon Footprint Predictor to gauge the environmental impact of their projects (Carbon Footprint Predictor).
-
Innovations Afoot in AI Model Development: Budding AI engineers are exploring the fast-evolving possibilities within different scopes of model development, from SimpleTuner's new MoE support in version 0.9.6.2 (SimpleTuner on GitHub) to a TensorFlow-based ML Library with its source code and documentation available for peer review on GitHub.
-
AI's Ascendancy in Medical and Modeling Musings: A recent YouTube video offers insights into the escalating role of genAI in medical education, highlighting the benefits of tools like Anki and genAI-powered searches (AI in Medical Education). In the open-source realm, the TorchTune project kindles interest for facilitating fine-tuning of large language models, an exploration narrated on GitHub.
-
Collider of Ideas in Computer Vision: Enthusiasts are pooling their knowledge to create valuable applications for Vision Language Models (VLMs), with community members sharing new Hugging Face Spaces Apps Model Explorer and HF Extractor that prove instrumental for VLM app development (Model Explorer, HF Extractor, and a relevant YouTube video).
-
Engaging Discussions and Demonstrations: Multi-node fine-tuning of LLMs was a topic of debate, leading to a share of an arXiv paper on Vision-Language Modeling, while the Diffusers GitHub repository was highlighted for text-to-image generation scripts that could also serve in model fine-tuning (Diffusers GitHub). A blog post offering optimization insights for native PyTorch and a training example notebook for those eager to train models from scratch were also circulated.
Stability.ai (Stable Diffusion) Discord
- AI Newbies Drowning in Options: A community member expressed both excitement and overwhelm at the sheer number of AI models to explore, capturing the sentiment many new entrants to the field experience.
- ControlNet's Speed Bump: User arti0m reported unexpected delays with ControlNet, resulting in image generation times of up to 20 minutes, contrary to the anticipated speed increase.
- CosXL's Broad Spectrum Capture: The new CosXL model from Stability.ai boasts a more expansive tonal range, producing images with better contrast from "pitch black" to "pure white." Find out more about it here.
- VRAM Vanishing Act: Conversations surfaced about memory management challenges with the Automatic1111 web UI, which appears to overutilize VRAM and affect the performance of image generation tasks.
- Waterfall Scandal Makes Waves: A lively debate ensued about a viral fake waterfall scandal in China, leading to broader discussion on its environmental and political implications.
Unsloth AI (Daniel Han) Discord
-
Adapter Reloading Raises Concerns: Members are experiencing issues when attempting to continue training with model adapters, specifically when using
model.push_to_hub_merged("hf_path"), where loss metrics unexpectedly spike, pointing to potential mishandling in saving or loading processes. -
LLM Pretraining Enhanced with Special Techniques: Unsloth AI's blog outlines the efficiency of continued pretraining for languages like Korean using LLMs such as Llama3, which promises reduced VRAM use and accelerated training, alongside a useful Colab notebook for practical application.
-
Qwen2 Model Ushers in Expanded Language Support: Announcing support for Qwen2 model that boasts a substantial 128K context length and coverage for 27 languages, with fine-tuning resources shared by Daniel Han on Twitter.
-
Grokking Explored: Discussions delved into a newly identified LLM performance phase termed "Grokking," with community members referencing a YouTube debate and providing links to supporting research for further exploration.
-
NVLink VRAM Misconception Corrected: Clarity was provided on NVIDIA NVLink technology, with members explaining that NVLink does not amalgamate VRAM into a single pool, debunking a misconception about its capacity to extend accessible VRAM for computation.
CUDA MODE Discord
-
Triton Simplifies CUDA: The Triton language is being recognized for its simplicity in CUDA kernel launches using the grid syntax (
out = kernel[grid](...)) and for providing easy access to PTX code (out.asm["ptx"]) post-launch, enabling a more streamlined workflow for CUDA developers. -
Tensor Troubles in TorchScript and PyTorch Profiling: The inability to cast tensors in torchscript using
view(dtype)caused frustration among engineers looking for bit manipulation capabilities with bfloat16s. Meanwhile, the PyTorch profiler was highlighted for its utility in providing performance insights, as shared in a PyTorch profiling tutorial. -
Hinting at Better LoRA Initializations: A blog post Know your LoRA was shared, suggesting that the A and B matrices in LoRA could benefit from non-default initializations, potentially improving fine-tuning outcomes.
-
Note Library Unveils ML Efficiency: The Note library's GitHub repository was referenced for offering an ML library compatible with TensorFlow, promising parallel and distributed training across models including Llama2, Llama3, and more.
-
Quantum Leaps in LLM Quantization: The channel engaged in deep discussion about ByteDance's 2-bit quantization algorithm, DecoupleQ, and a link to a NeurIPS 2022 paper on an approach improving over the Straight-Through Estimator for quantization was provided, pinpointing considerations for memory and computation in the quantization process.
-
AI Framework Discussions Heat Up: The LLVM.c community delved into discussions ranging from supporting Triton and AMD, addressing BF16 gradient norm determinism, and future support for models like Llama 3. Topics also touched on ensuring 100% determinism in training and considered using FineWeb as a dataset, amid considerations for scaling and diversifying data types.
OpenAI Discord
-
Plagiarism Strikes Research Papers: Five research papers were retracted for plagiarism due to inadvertently including AI prompts within their content; members responded with a mix of humor and disappointment to the oversight.
-
Haiku Model: Affordable Quality: Enthusiastic discussions surfaced regarding the Haiku AI model, lauded for its cost-efficiency and commendable performance, even being compared to "gpt 3.5ish quality".
-
AI Moderation: A Double-Edged Sword?: The guild was abuzz with the pros and cons of employing AI for content moderation on platforms like Reddit and Discord, weighing the balance between automated action and human oversight.
-
Mastering LLMs via YouTube: Members shared beneficial YouTube resources for understanding LLMs better, singling out Kyle Hill's ChatGPT Explained Completely and 3blue1brown for their compelling mathematical explanations.
-
GPT's Shifting Capabilities: GPT-4o is being introduced to all users, with new voice and vision capabilities earmarked for ChatGPT Plus. Meanwhile, the community is contending with frequent modification notices for custom GPTs and challenges in utilizing GPT with CSV attachments.
LM Studio Discord
-
Celebration and Collaboration Within LM Studio: LM Studio marks its one-year milestone, with discourse on utilizing multiple GPUs—Tesla K80 and 3090 recommended for consistency—and running multiple instances for inter-model communication. Emphasis on GPUs over CPUs for LLMs highlighted, alongside practicality issues presented when considering LM Studio's use on powerful hardware like PlayStation 5 APUs.
-
Higgs Enters with a Bang: Anticipation is high for an LMStudio update which will incorporate the impressive Higgs LLAMA, a hefty 70-billion parameter model that could potentially offer unprecedented capabilities and efficiencies for AI engineers.
-
Curveballs and Workarounds in Hardware: GPU cooling and power supply for niche hardware like the Tesla P40 stir creative discussions, from jury-rigging Mac GPU fans to elaborate cardboard ducts. Tips include exploring a GitHub guide to deal with the bindings of proprietary connections.
-
Model-Inclusive Troubleshooting: Fixes for Qwen2 gibberish involve toggling flash attention, while the perils of cuda offloading with Qwen2 are acknowledged with anticipation for llama.cpp updates. A member's experience of mixed results with llava-phi-3-mini-f16.gguf via API stirs further model diagnostics chat.
-
Fine-Tuning Fine Points: A nuanced take on fine-tuning highlights style adjustments via LoRA versus SFT's knowledge-based tuning; LM Studio's limitations on system prompt names sans training; and strategies to counter 'lazy' LLM behaviors, such as power upgrades or prompt optimizations.
-
ROCm Rollercoaster with AMD Technology: Users exchange tips and experiences on enabling ROCm on various AMD GPUs, like the 6800m and 7900xtx, with suggestions for Arch Linux use and workarounds for Windows environments to optimize the performance of their LLM setups.
Latent Space Discord
- AI Engineers, Get Ready to Network: Engineers interested in the AI Engineer event will have session access with the Expo Explorer ticket, though the speaker lineup is still to be finalized.
- KLING Equals Sora: KWAI's new Sora-like model calledKLING is generating buzz with its realistic demonstrations, as showcased in a tweet thread by Angry Tom.
- Unpacking GPT-4o's Imagery: The decision by OpenAI to use 170 tokens for processing images in GPT-4o is dissected in an in-depth post by Oran Looney, discussing the significance of "magic numbers" in programming and their latest implications on AI.
- 'Hallucinating Engineers' Have Their Say: The concept of GPT's "useful-hallucination paradigm" was debated, highlighting its potential to conjure up beneficial metrics, with parallels being drawn to "superprompts" and community-developed tools like Websim AI.
- Recursive Realities and Resource Repository: AI enthusiasts experimented with the self-referential simulations of websim.ai, while a Google spreadsheet and a GitHub Gist were shared for collaboration and expansive discussion in future sessions.
Nous Research AI Discord
-
Mixtral's Expert Count Revealed: An enlightening Stanford CS25 talk clears up a misconception about Mixtral 8x7B, revealing it contains 32x8 experts, not just 8. This intricacy highlights the complexity behind its MoE architecture.
-
DeepSeek Coder Triumphs in Code Tasks: As per a shared introduction on Hugging Face, the DeepSeek Coder 6.7B takes the lead in project-level code completion, showcasing superior performance trained on a massive 2 trillion code tokens.
-
Meta AI Spells Out Vision-Language Modeling: Meta AI offers a comprehensive guide on Vision-Language Models (VLMs) with "An Introduction to Vision-Language Modeling", detailing their workings, training, and evaluation for those enticed by the fusion of vision and language.
-
RAG Formatting Finesse: The conversation around RAG dataset creation underscores the need for simplicity and specificity, rejecting cookie-cutter frameworks and emphasizing tools like Prophetissa that utilize Ollama and emo vector search for dataset generation.
-
WorldSim Console's Mobile Mastery: The latest WorldSim console update remedies mobile user interface issues, improving the experience with bug fixes on text input, enhanced
!listcommands, and new settings for disabling visual effects, all while integrating versatile Claude models.
LlamaIndex Discord
-
RAG Steps Toward Agentic Retrieval: A recent talk at SF HQ highlighted the evolution of Retrieval-Augmented Generation (RAG) to fully agentic knowledge retrieval. The move aims to overcome the limitations of top-k retrieval, with resources to enhance practices available through a video guide.
-
LlamaIndex Bolsters Memory Capabilities: The Vector Memory Module in LlamaIndex has been introduced to store and retrieve user messages through vector search, bolstering the RAG framework. Interested engineers can explore this feature via the shared demo notebook.
-
Enhanced Python Execution in Create-llama: Integration of Create-llama with e2b_dev’s sandbox now permits Python code execution within agents, an advancement that enables the return of complex data, such as graph images. This new feature broadens the scope of agent applications as detailed here.
-
Synchronizing RAG with Dynamic Data: Implementing dynamic data updates in RAG involves reloading the index to reflect recent changes, a challenge addressed by using periodic index refreshing. Management of datasets, like sales or support documentation, can be optimized through multiple indexes or metadata filters, with practices outlined in Document Management - LlamaIndex.
-
Optimizations and Entity Resolution with Embeddings in LlamaIndex: Creating property graphs with embeddings directly uses the LlamaIndex framework, and entity resolution can be enhanced by adjusting the
chunk_sizeparameter. Managing these functions can be better understood through guides like "Optimization by Prompting" for RAG and the LlamaIndex Guide.
Modular (Mojo 🔥) Discord
-
Andrew Ng Rings Alarm Bells on AI Regulation: Andrew Ng cautions against California's SB-1047, fearing it could hinder AI advancements. Engineers in the guild compare global regulatory landscapes, highlighting that even without U.S. restrictions, countries like Russia lack comprehensive AI policy, as seen in a video with Putin and his deepfake.
-
Mojo Gains Smarter, Not Harder: The
isdigit()function's reliance onord()for performance is confirmed, leading to an issue report when problems arise. Async capabilities in Mojo await further development, and__type_ofis suggested for variable type checks, with the VSCode extension assisting in pre/post compile identification. -
MACS Make Their MAX Debut: Modular's MAX 24.4 release now supports macOS, flaunts a Quantization API, and community contributors surpass the 200 mark. The update can potentially slash latency and memory usage significantly for AI pipelines.
-
Dynamic Python in the Limelight: The latest nightly release enables dynamic
libpythonselection, helping streamline the environment setup for Mojo. However, pain points persist with VS Code's integration, necessitating manual activation of.venv, detailed in the nightly changes along with the introduction of microbenchmarks. -
Anticipation High for Windows Native Mojo: Engineers jest and yearn for the pending Windows native Mojo release, its timeline shrouded in mystery. The eagerness for such a release underscores its importance to the community, suggesting substantial Windows-based developer interest.
Eleuther Discord
-
Engineers Get Hands on New Sparse Autoencoder Library: The recent tweet by Nora Belrose introduces a training library for TopK Sparse Autoencoders, optimized on GPT-2 Small and Pythia 160M, that can train an SAE for all layers simultaneously without the need to cache activations on disk.
-
Advancements in Sparse Autoencoder Research: A new paper reveals the development of k-sparse autoencoders that enhance the balance between reconstruction quality and sparsity, which could significantly influence the interpretability of language model features.
-
The Next Leap for LLMs, Courtesy of the Neocortex: Members discussed the Thousand Brains Project by Jeff Hawkins and Numenta, which looks to implement the neocortical principles into AI, focusing on open collaboration—a nod to nature's complex systems for aspiring engineers.
-
Evaluating Erroneous File Path Chaos: Addressing a known issue, members reassured that file handling, particularly erroneous result file placements—to be located in the tmp folder—is on the fix list, as indicated by the ongoing PR by KonradSzafer.
-
Unearthing the Unpredictability of Data Shapley: Discourse on an arXiv preprint unfolded, evaluating Data Shapley's inconsistent performance in data selection across diverse settings, suggesting engineers should keep an eye on the proposed hypothesis testing framework for its potential in predicting Data Shapley’s effectiveness.
Interconnects (Nathan Lambert) Discord
-
AI Video Synthesis Wars Heat Up: A Chinese AI video generator has outperformed Sora, offering stunning 2-minute, 1080p videos at 30fps through the KWAI iOS app, generating notable attention in the community. Meanwhile, Johannes Brandstetter announces Vision-LSTM which incorporates xLSTM's capacity to read images, providing code and a preprint on arxiv for further exploration.
-
Anthropic's Claude API Access Expanded: Anthropic is providing API access for alignment research, requiring an institution affiliation, role, LinkedIn, Github, and Google Scholar profiles for access requests, facilitating deeper exploration into AI alignment challenges.
-
Daylight Computer Sparks Interest: The new Daylight computer lured significant interest due to its promise of reducing blue light emissions and enhancing visibility in direct sunlight, sparking discussions about its potential benefits over existing devices like the iPad mini.
-
New Frontiers in Model Debugging and Theory: Engaging conversations unfolded around novel methods analogous to "self-debugging models," which leverage mistakes to improve outputs, alongside discussions on the craving for analytical solutions in complex theory-heavy papers like DPO.
-
Challenges in Deepening Robotics Discussions: Members pressed for deeper insights into monetization strategies and explicit numbers in robotics content, with specific callouts for a more granulated breakdown of the "40000 high-quality robot years of data" and a closer examination of business models in the space.
Cohere Discord
-
Free Translation Research with Aya but Costs for Commercial Use: While Aya is free for academic research, commercial applications require payment to sustain the business. Users facing integration challenges with the Vercel AI SDK and Cohere can find guidance and have taken steps to contact SDK maintainers for support.
-
Clever Command-R-Plus Outsmarts Llama3: Users suggest that Command-R-Plus outperforms Llama3 in certain scenarios, citing subjective experiences with its performance outside language specifications.
-
Data Privacy Options Explored for Cohere Usage: For those concerned with data privacy when using Cohere models, details and links were shared on how to utilize these models on personal projects either locally or on cloud services like AWS and Azure.
-
Developer Showcases Full-Stack Expertise: A full-stack developer portfolio is available, showcasing skills in UI/UX, Javascript, React, Next.js, and Python/Django. The portfolio can be reviewed at the developer's personal website.
-
Spotlight on GenAI Safety and New Search Solutions: Rafael is working on a product to prevent hallucinations in GenAI applications and invites collaboration, while Hamed has launched Complexity, an impressive generative search engine, inviting users to explore it at cplx.ai.
OpenRouter (Alex Atallah) Discord
-
Qwen 2 Supports Korean Too: Voidnewbie mentioned that the Qwen 2 72B Instruct model, recently added to OpenRouter's offerings, supports Korean language as well.
-
OpenRouter Battles Gateway Gremlins: Several users encountered 504 gateway timeout errors with the Llama 3 70B model; database strain was identified as the culprit, prompting a migration of jobs to a read replica to improve stability.
-
Routing Woes Spur Technical Dialogue: Members reported WizardLM-2 8X22 producing garbled responses via DeepInfra, leading to advice to manipulate the
orderfield in request routing and allusions to an in-progress internal endpoint deployment to help resolve service provider issues. -
Fired Up Over AI Safety: The dismissal of Leopold Aschenbrenner from OAI kicked off a fiery debate among members about the importance of AI security, reflecting a divide in perspectives on the need for and implications of AI safekeeping measures.
-
Performance Fluctuations with ChatGPT: Observations were shared about ChatGPT's possible performance drops during high-traffic periods, sparking speculations about the effects of heavy load on service quality and consistent user experience.
OpenAccess AI Collective (axolotl) Discord
Flash-attn Installation Demands High RAM: Members highlighted difficulties when building flashattention on slurm; solutions include loading necessary modules to provide adequate RAM.
Finetuning Foibles Fixed: Configuration issues with Qwen2 72b's finetuning were reported, suggesting a need for another round of adjustments, particularly because of an erroneous setting of max_window_layers.
Guide Gleam for Multi-Node Finetuning: A pull request for distributed finetuning using Axolotl and Deepspeed was shared, signifying an increase in collaborative development efforts within the community.
Data Dilemma Solved: A member's struggle with configuring a test_datasets in JSONL format was resolved by adopting the structure specified for axolotl.cli.preprocess.
API Over YAML for Engineered Inferences: Confusion over Axolotl's configuration for API usage versus YAML setups was clarified, with a focus on broadening capabilities for scripted, continuous model evaluations.
LAION Discord
- A Contender to Left-to-Right Sequence Generation: The novel σ-GPT, developed with SkysoftATM, challenges traditional GPTs by generating sequences dynamically, potentially cutting steps by an order of magnitude, detailed in its arXiv paper.
- Debating σ-GPT's Efficient Learning: Despite σ-GPT's innovative approach, skepticism arises regarding its practicality, as a curriculum for high performance might limit its use, drawing parallels with XLNET's limited impact.
- Exploring Alternatives for Infilling Tasks: For certain operations, models like GLMs may prove to be more efficient, while finetuning with distinct positional embeddings could enhance RL-based non-textual sequence modeling.
- AI Video Generation Rivalry Heats Up: A new Chinese AI video generator on the KWAI iOS app churns out 2-minute videos at 30fps in 1080p, causing buzz, while another generator, Kling, with its realistic capabilities, is met with skepticism regarding its authenticity.
- Community Reacts to Schelling AI Announcement: Emad Mostaque's tweet about Schelling AI, which aims to democratize AI and AI compute mining, ignites a mix of skepticism and humor due to the use of buzzwords and ambitious claims.
LangChain AI Discord
-
Early Stopping Snag in LangChain: Discussions highlighted an issue with the
early_stopping_method="generate"option in LangChain not functioning as expected in newer releases, prompting a user to link an active GitHub issue. The community is exploring workarounds and awaiting an official fix. -
RAG and ChromaDB Privacy Concerns: Queries about enhancing data privacy when using LangChain with ChromaDB surfaced, with suggestions to utilize metadata-based filtering within vectorstores, as discussed in a GitHub discussion, though acknowledging the topic's complexity.
-
Prompt Engineering for LLaMA3-70B: Engineers brainstormed effective prompting techniques for LLaM3-70B to perform tasks without redundant prefatory phrases. Despite several attempts, no definitive solution emerged from the shared dialogue.
-
Apple Introduces Generative AI Guidelines: An engineer shared Apple's newly formulated generative AI guiding principles aimed at optimizing AI operations on Apple's hardware, potentially useful for AI application developers.
-
Alpha Testing for B-Bot App: An announcement for a closed alpha testing phase of the B-Bot application, a platform for expert knowledge exchange, was made, with invites extended here seeking testers to provide development feedback.
Torchtune Discord
-
Phi-3 Model Export Confusion Cleared Up: Users addressed issues with exporting a custom phi-3 model to and from Hugging Face, pinpointing potential config missteps from a GitHub discussion. It was noted that using the FullModelHFCheckpointer, Torchtune handles conversions between its format and HF format during checkpoints.
-
Clarification and Welcome for PRs: Inquiry about enhancing Torchtune with n_kv_heads for mqa/gqa was met with clarification and encouragement for pull requests, with the prerequisite of providing unit tests for any proposed changes.
-
Dependencies Drama in Dev Discussions: Engineers emphasized precise versioning of dependencies for Torchtune installation and highlighted issues stemming from version mismatches, referencing situations like Issue #1071, Issue #1038, and Issue #1034.
-
Nightly Builds Get a Nod: A consensus emerged on the necessity of clarifying the need for PyTorch nightly builds to use Torchtune's complete feature set, as some features are exclusive to these builds.
-
PR Prepped for Clearer Installation: A community member announced they are prepping a PR specifically to update the installation documentation of Torchtune, to address the conundrum around dependency versioning and the use of PyTorch nightly builds.
AI Stack Devs (Yoko Li) Discord
-
Game Over for Wokeness: Discussion in the AI Stack Devs channel revolved around the gaming studios like those behind Stellar Blade; members applauded the studios' focus on game quality over aspects such as Western SJW themes and DEI measures.
-
Back to Basics in Gaming: Members expressed admiration for Chinese and South Korean developers like Shift Up for concentrating on game development without getting entangled in socio-political movements such as feminism, despite South Korea's societal challenges with such issues.
-
Among AI Town - A Mod in Progress: An AI-Powered "Among Us" mod was the subject of interest, with game developers noting AI Town's efficacy in the early stages, albeit with some limitations and performance issues.
-
Leveling Up With Godot: A transition from AI Town to using Godot was mentioned in the ai-town-discuss channel as a step to add advanced features to the "Among Us" mod, signifying improvements and expansion beyond initial capabilities.
-
Continuous Enhancement of AI Town: AI Town's development continues, with contributors pushing the project forward, as indicated in the recent conversations about ongoing advancements and updates.
OpenInterpreter Discord
-
Is There a Desktop for Open Interpreter?: A guild member queried about the availability of a desktop UI for Open Interpreter, but no response was provided in the conversation.
-
Open Interpreter Connection Trials and Tribulations: A user was struggling with Posthog connection errors, particularly with
us-api.i.posthog.com, which indicates broader issues within their setup or external service availability. -
Configuring Open Interpreter with OpenAPI: Discussion revolved around whether Open Interpreter can utilize existing OpenAPI specs for function calling, suggesting a potential solution through a true/false toggle in some configuration.
-
Tool Use with Gorilla 2: Challenges with tool use in LM Studio and achieving success with custom JSON output and OpenAI toolcalling were shared. A recommendation was made to check out an OI Streamlit repository on GitHub for possible solutions.
-
Looking for Tips? Check OI Website: In a succinct reply to a request, ashthescholar. directed a member to explore Open Interpreter's website for guidance.
DiscoResearch Discord
-
Mixtral's Expert System Unveiled: A clarifying YouTube video dispels the myth about Mixtral, confirming it comprises 256 experts across its layers and boasting a staggering 46.7 billion parameters, with 12.9 billion active parameters for token interactions.
-
Which DiscoLM Reigns Supreme?: Confusion permeates discussions over the leading DiscoLM model, with multiple models vying for the spotlight and recommendations favoring 8b llama for systems with just 3GB VRAM.
-
Maximizing Memory on Minimal VRAM: A user successfully runs Mixtral 8x7b at 6-7 tokens per second on a 3GB VRAM setup using a Q2-k quant, highlighting the importance of memory efficiency in model selection.
-
Re-evaluating Vagosolutions' Capabilities: Recent benchmarks have sparked new interest in Vagosolutions' models, leading to debates on whether finetuning Mixtral 8x7b could triumph over a finetuned Mistral 7b.
-
RKWV vs Transformers - Decoding the Benefits: The guild has yet to address the request for insights into the intuitive advantages of RKWVs compared to Transformers, suggesting either a potential oversight or the need for more investigation.
Datasette - LLM (@SimonW) Discord
-
LLMs Eyeing New Digital Territories: Members shared developments hinting at large language models (LLMs) being integrated into web platforms, with Google considering LLMs for Chrome (Chrome AI integration) and Mozilla experimenting with transformers.js for local alt-text generation in Firefox Nightly (Mozilla experiments). The end game speculated by users is a deeper integration of AI at the operating system level.
-
Prompt Injection Tricks and Trades: An interesting use case of prompt injection to manipulate email addresses was highlighted through a member's LinkedIn experience and discussed along with a link showcasing the concept (Prompt Injection Insights).
-
Dash Through Dimensions for Text Analysis: A guild member delved into the concept of measuring the 'velocity of concepts' in text, drawing ideas from a blog post (Concept Velocity Insight) and showed interest in applying these concepts to astronomy news data.
-
Dimensionality: A Visual Frontier for Embeddings: Members appreciated a Medium post (3D Visualization Techniques) for explanations on dimensionality reduction using PCA, t-SNE, and UMAP, which helped visualize 200 astronomy news articles.
-
UMAP Over PCA for Stellar Clustering: It was found that UMAP provided significantly better clustering of categorized news topics, such as the Chang'e 6 moonlander and Starliner, over PCA, when labeling was done with GPT-3.5.
tinygrad (George Hotz) Discord
-
Hotz Challenges Taylor Series Bounty Assumptions: George Hotz responded to a question about Taylor series bounty requisites with a quizzical remark, prompting reconsideration of assumed requirements.
-
Proof Logic Put Under the Microscope: A member's perplexity regarding the validity of an unidentified proof sparked a debate, questioning the proof's logic or outcome.
-
Zeroed Out on Symbolic Shape Dimensions: A discussion emerged on whether a symbolic shape dimension can be zero, indicating interest in the limits of symbolic representations in tensor operations.
PART 2: Detailed by-Channel summaries and links
{% if medium == 'web' %}
LLM Finetuning (Hamel + Dan) ▷ #general (12 messages🔥):
- RAG means something silly?: Members joked about the meaning of RAG, suggesting it stands for "random-ass guess".
- Open-Source Model Training Misstep: One member shared insights on the misconception caused by open-source models' training steps and epochs, highlighting that "Num epochs = max_steps / file_of_training_jsonls_in_MB" led to 30 epochs for a 31 MB file.
- Mistral Fine-Tuning Repo Shared: A contributor shared a GitHub repository created for using the fine-tuning notebook from Mistral in Modal, while another shared modal-labs' guide noting issues with outdated deepspeed docs.
- Hybrid Search Inquiries: Questions were raised about normalizing BM25 scores and weighting them when combining with dense vector search. A member recommended a blog post for further reading.
- Accessing Old Zoom Recordings: A request for accessing old Zoom recordings was answered with a note to check on the Maven site.
Links mentioned:
LLM Finetuning (Hamel + Dan) ▷ #asia-tz (1 messages):
_ribhu: Hey I could help with that. Can you DM with the details?
LLM Finetuning (Hamel + Dan) ▷ #🟩-modal (17 messages🔥):
-
Enjoying Modal's VRAM and GPU power: A member praised the use of 10 A100 GPUs on Modal and inquired about VRAM usage visibility. They also shared a script for Pokemon cards description using Moondream VLM.
-
Installing flash-attn made easier: They sought tips for pip installing
flash-attnand later found a useful gist for Whisper which they adapted for their needs. The gist can be found here. -
Modal's cost efficiency impresses users: Running 13k images in 10 minutes using 10x A100 (40G) for just $7 was highlighted as very cost-effective. This was met with positive reactions from other members.
-
Issues with GPU availability: A member reported a 17-minute wait for an A10, which was unusual according to another member. They later confirmed it was working fine and any issues should be flagged for review by platform engineers.
-
Lack of queue status visibility: Another user, trying to get an H100 node, asked about dashboard availability for viewing queue status. It was clarified that while there are dashboards for running/deployed apps, there isn't one for seeing the queue status or availability estimates.
Links mentioned:
LLM Finetuning (Hamel + Dan) ▷ #learning-resources (2 messages):
-
Explore Vector-Powered Systems with VectorHub: A member shared a link to VectorHub by Superlinked, which offers resources on RAG, text embeddings, and vectors. The platform is a free educational and open-source resource for data scientists and software engineers to build vector-powered systems.
-
Relevant Articles on OpenPipe: Another member posted a link to the OpenPipe blog for relevant articles. The blog contains insights and information pertinent to the discussion topics within this channel.
Links mentioned:
LLM Finetuning (Hamel + Dan) ▷ #jarvis-labs (2 messages):
-
Credit where it's due for Cloud GPU Platform: A member thanked Vishnu for creating an awesome cloud GPU platform and shared a blog post about using it with Axolotl. They shared a tweet and detailed blog post discussing experiences from an LLM course and conference.
-
Crash Report on Huggingface Dataset Processing: A user reported a crash while processing a Huggingface dataset on an A6000 with 32 GB VRAM. They provided a gist link to the error details and mentioned that the process works fine on their 32 GB Dell laptop.
Links mentioned:
LLM Finetuning (Hamel + Dan) ▷ #hugging-face (3 messages):
- New form for credits opens on October 10th: A member announced that a new form for obtaining credits will officially re-open on Monday the 10th of October. The form will stay open until the 18th, allowing new students signing up by the 15th to receive credits.
- Missing credits concern: Another member expressed concern about missing credits that were previously in their account. They were advised to contact [email protected] to resolve the issue.
LLM Finetuning (Hamel + Dan) ▷ #replicate (1 messages):
- Local Disk Space Issues with Docker: A member reported issues with running
cog runandcog pushcommands during an attempted Replicate demo. They suspect their local computer lacks sufficient disk space and inquired about the possibility of conducting the build process remotely.
LLM Finetuning (Hamel + Dan) ▷ #langsmith (8 messages🔥):
-
Credit Access Clarification: Multiple users discussed issues related to credit availability and access. It was highlighted multiple times that "the credits were deposited regardless of if you set billing up. You just need a payment method on file in order to access the credits."
-
Form and Org ID Details: One user requested specific details about their org ID (b9e3d34d-3c3c-4528-8e2f-2b31075b47fd) for billing purposes. Follow-up prompts were made to confirm if they filled out a form previously, with an open offer to coordinate over email at [email protected] for further assistance.
LLM Finetuning (Hamel + Dan) ▷ #workshop-4 (1 messages):
- Predibase Office Hours Rescheduled: The Predibase office hours will now take place on Wednesday, June 12 at 10am PT. Topics include LoRAX, multi-LoRA inference, and fine-tuning for speed with speculative decoding.
LLM Finetuning (Hamel + Dan) ▷ #jason_improving_rag (64 messages🔥🔥):
<ul>
<li>
<strong>Marker disappoints with malformed markdown tables:</strong> A user expressed frustration with the <a href="https://github.com/VikParuchuri/marker/tree/master">Marker tool for converting PDFs to markdown</a>, explaining that the markdown tables often don't meet their requirements. This triggered a discussion about potentially fine-tuning the tool to improve table formatting.
</li>
<li>
<strong>Exploring embedding quantization:</strong> The utility of <a href="https://huggingface.co/blog/embedding-quantization">quantized embeddings</a> was discussed, highlighting a demo of a real-life retrieval scenario involving 41 million Wikipedia texts. The blog post covers the impact of embedding quantization on retrieval speed, memory usage, disk space, and cost.
</li>
<li>
<strong>GitHub repository for RAG complexities:</strong> A member shared a link to the <a href="https://github.com/jxnl/n-levels-of-rag">n-levels-of-rag</a> GitHub repository and a related <a href="https://jxnl.github.io/blog/writing/2024/02/28/levels-of-complexity-rag-applications/">blog post</a>, providing a comprehensive guide for understanding and implementing RAG applications across different levels of complexity.
</li>
<li>
<strong>Tackling table extraction challenges:</strong> An alternative tool for table extraction was discussed, with a user recommending <a href="https://github.com/xavctn/img2table">img2table</a>, an OpenCV-based library for identifying and extracting tables from PDFs and images. Users shared their experiences and potential improvements for existing table extraction and conversion tools.
</li>
<li>
<strong>Multilingual content embedding model query:</strong> A user inquired about embedding models suitable for multilingual content, which led to discussions on various recommendations and fine-tuning methodologies to better handle specific requirements in multilingual contexts.
</li>
</ul>
Links mentioned:
LLM Finetuning (Hamel + Dan) ▷ #jeremy_python_llms (221 messages🔥🔥):
-
Discussing FastHTML Features and Components: Members expressed excitement and curiosity about FastHTML, comparing it favorably to FastAPI and Django. The conversation included detailed explanations on creating apps, connecting to multiple databases, and using various libraries like picolink and daisyUI.
-
Jeremy and Team's Contributions and Future Plans: Jeremy and John frequently chimed in to answer questions, promising future markdown support and addressing the need for community-built component libraries. Jeremy invited members to contribute by creating easy-to-use FastHTML libraries for popular frameworks like Bootstrap or Material Tailwind.
-
Markdown Rendering with FastHTML: Jeremy and John discussed methods to render markdown within FastHTML, including using scripts and NotStr classes. John shared a code snippet demonstrating how to render markdown using JavaScript and UUIDs.
-
HTMX Integration and Use Cases: HTMX’s role in FastHTML was emphasized with examples provided for handling various events like keyboard shortcuts and database interactions. Members also shared HTMX usage tips and experiences, highlighting its effectiveness and comparing its interaction patterns to JavaScript.
-
Coding Tools and Environment Discussions: Additional tools and platforms like Cursor and Railway were discussed, with members sharing their experiences and best practices. FastHTML-related resources and tutorials were also shared, such as a WIP tutorial and several GitHub repositories.
Links mentioned:
LLM Finetuning (Hamel + Dan) ▷ #axolotl (23 messages🔥):
- Searching for Python script for FFT on Modal: A user is looking for a Python script to run FFT on Modal for llama-3 but has only found a Lora git project.
- Chat templates for Mistral Instruct: A member asks about available chat templates that support a system prompt for DPO finetuning, seeking clarity on formatting and template usage.
- Combining Axolotl and HF templates not advisable: A user discusses with hamelh about matching Axolotl finetuning templates with custom inference code, to avoid mismatches since Axolotl does not use Hugging Face (HF) templates.
- Confusion over token space assembly: A noob user queries why spaces are added when Axolotl assembles in token space, finding templates confusing.
- Issue with 7B Lora merge resulting in extra shards: A user experiences a weird phenomenon where merging a 7B Lora results in 6 shards instead of 3, and another user suggests uploading the LoRA for debugging. They also referenced a related GitHub issue and suggested possible fixes involving
torch.float16.
Links mentioned:
LLM Finetuning (Hamel + Dan) ▷ #zach-accelerate (5 messages):
- Quantization confirmed during model load: A member asked if quantization happens during model load and if the CPU is responsible for it. Another member confirmed, stating "It happens when loading the model weights" and provided links to Hugging Face documentation and the respective GitHub code.
Links mentioned:
LLM Finetuning (Hamel + Dan) ▷ #freddy-gradio (1 messages):
- Request for OAuth Integration Explained: One member thanked another for providing information on an HF option and requested further details on implementing a simple access control mechanism or integrating OAuth. They specifically sought expansion on how these security measures would work in their context.
LLM Finetuning (Hamel + Dan) ▷ #charles-modal (2 messages):
- Modal module error resolved: A member encountered an error saying, "No module named modal." They resolved this issue by using the command
pip install modal.
LLM Finetuning (Hamel + Dan) ▷ #credits-questions (6 messages):
-
Langsmith credits stuck in limbo: Several members reported not receiving their langsmith credits despite filling out the necessary forms. One asked explicitly, "What's the status on langsmith credits, has anyone received it?".
-
Fireworks credits form confusion: Multiple users mentioned not receiving their fireworks credits after submitting the form with their account IDs. A member recalled filling the form with "user ID back then" instead of account ID.
-
Request to share account IDs: In response to missing fireworks credits, a request was made for users to share their account IDs in a specific channel, <#1245126291276038278>.
-
June 2nd course credit redemption issue: A member inquired if they could still redeem their course credits purchased before June 2nd even though they delayed the redemption. This issue appears to have been resolved via email, with a follow-up from Dan Becker stating, "Looks like we have synced up by email".
LLM Finetuning (Hamel + Dan) ▷ #strien_handlingdata (3 messages):
-
Struggle to download session recordings: A member experienced difficulty downloading session recordings as the course website now embeds videos instead of redirecting to Zoom. They requested the Zoom link to gain downloading access.
-
Bulk tool gets a revamp: Inspired by the course, the member started developing the next version of their tool named "Bulk." Due to the influx of synthetic datasets, they see the value in building more tools in this area and invited feedback.
LLM Finetuning (Hamel + Dan) ▷ #fireworks (11 messages🔥):
- Users flood with credit issues: Multiple users raised concerns about not receiving their credits. They listed their account IDs and email addresses for reference.
- Invitation to AI Engineer World's Fair: One user invited another to meet up at the AI Engineer World's Fair.
LLM Finetuning (Hamel + Dan) ▷ #emmanuel_finetuning_dead (2 messages):
- LoRA Land paper sparks finetuning discussion: A user shared the LoRA Land paper and asked if it would change another user's perspective on finetuning. Another member responded with interest, appreciating the share with a thumbs-up emoji.
LLM Finetuning (Hamel + Dan) ▷ #east-coast-usa (1 messages):
- Demis Hassabis at Tribeca: A member pointed out that Demis Hassabis will be at The Thinking Game premier tonight. Tickets are available for $35, and the event will include a conversation with Darren Aronofsky about AI and the future. link
Link mentioned: Tweet from Tribeca (@Tribeca): Come and hear @GoogleDeepMind CEO & AI pioneer @demishassabis in conversation with director @DarrenAronofsky about AI, @thinkgamefilm and the future at #Tribeca2024: https://tribecafilm.com/films/thin...
LLM Finetuning (Hamel + Dan) ▷ #predibase (7 messages):
-
Predibase credits excite users: A user thanked team members for providing credits and referred to an example on Predibase. Another user inquired about when credits expire while noting that upgrading to the Developer Tier requires adding a credit card.
-
Email registration issues: Two users reported issues with receiving confirmation emails after registering on Predibase, preventing them from logging in.
-
LoRAX impresses workshop participant: A user praised the Predibase workshop for streamlining processes like fine-tuning and deploying LLMs. They mentioned that LoRAX particularly stands out by being cost-efficient and effectively integrating tools for deploying high-quality LLMs into web applications.
Link mentioned: Quickstart | Predibase: Predibase provides the fastest way to fine-tune and serve open-source LLMs. It's built on top of open-source LoRAX.
LLM Finetuning (Hamel + Dan) ▷ #career-questions-and-stories (19 messages🔥):
-
Cursor: The VS-Code based AI Code Editor impresses: Members discussed the capabilities of Cursor, an AI-powered code editor based on VS-Code. One member cited its key advantage: "it indexes your whole codebase for thorough multi-file and multi-location changes".
-
Pro Subscription praised for auto code completion: A user noted significant benefits from using the paid version of Cursor, particularly highlighting improvements in automatic code completion when using GPT-4.
-
Custom API keys make Cursor flexible: Cursor's integration allows users to input their own API keys for services like OpenAI, Anthropic, Google, and Azure. This feature received praise as it enables extensive AI interactions at the user's own cost.
-
Cursor compared favorably to GitHub Copilot: Users who switched from GitHub Copilot to Cursor shared positive experiences, emphasizing enhanced productivity and satisfaction. One user mentioned, "I fully switched after using copilot for like a year or two and haven't looked back."
-
VS-Code enthusiasts welcome Cursor: The adoption of Cursor by long-time VS-Code users was discussed, noting that since Cursor is built on open-source VS-Code, it retains familiar functionality while adding AI-powered enhancements. One member's endorsement: "it just feels better, you just enjoy the improvements".
Links mentioned:
LLM Finetuning (Hamel + Dan) ▷ #openpipe (2 messages):
Given the provided chat logs, there is insufficient information for a substantive summary. There are no significant topics, discussion points, links, or blog posts of interest provided in the messages.
LLM Finetuning (Hamel + Dan) ▷ #openai (29 messages🔥):
-
New Parallel Function Call Feature: Users can now disable parallel function calling by setting
"parallel_tool_calls: false", a feature shipped recently by OpenAI. -
Credits Expiry Clarified: OpenAI credits expire three months from the date of grant. This was clarified in response to user queries about credit usage deadlines.
-
Access Issues to GPT-4: Multiple users reported issues accessing GPT-4 models and discrepancies in rate limits. Affected users were advised to email [email protected] and cc [email protected] for resolution.
-
Cursor and iTerm2 Use Credits: Third-party tools like Cursor and iTerm2 allow users to utilize their OpenAI credits. These integrations offer flexibility in using various AI models with their own API keys.
-
Ideas for Credits Usage: A user shared a Twitter link listing creative ways to use credits, inviting others to share more ideas.
Links mentioned:
LLM Finetuning (Hamel + Dan) ▷ #capelle_experimentation (82 messages🔥🔥):
-
Exciting Talk and Resources from tcapelle: tcapelle shared an informative talk, with slides and a Colab notebook (connections) linked, explaining various concepts in LLM fine-tuning. The GitHub repo provided (connections) includes examples and code.
-
Fine-Tuning Tips and Community Interaction: tcapelle suggested training Llama3 for a few epochs and using big LLMs for assessment, emphasizing the community's extensive experience with Mistrals and Llamas. He recommended using Alpaca-style evaluations for accurate performance metrics.
-
Fast Learning and Pruning Insights: A Fast.ai post discussed neural networks' ability to memorize with minimal examples. tcapelle shared pruning scripts on GitHub (create_small_model.py) and recommended watching a GTC 2024 talk for insights on optimizing LLMs.
-
Weave Toolkit Integration and Features: Scottire mentioned upcoming features for curating samples in Weave and provided a code snippet for adding rows to datasets. Links to Weave on GitHub and its documentation were shared to assist users in integrating Weave into their workflows.
-
Engaging Community Ideas: Members discussed organizing weekly meetups, paper clubs, and working groups for collaborative learning and idea sharing. The humorous suggestion of a "BRIGHT CLUB" and various community bonding activities highlighted the vibrant and supportive nature of the group.
Links mentioned:
Perplexity AI ▷ #announcements (1 messages):
- Perplexity releases official trailer for "The Know-It-Alls": A link to YouTube video titled "The Know-It-Alls" by Perplexity was shared. The description poses the intriguing question, "If all the world’s knowledge were at our fingertips, could we push the boundaries of what’s possible? We’re about to find out."
Link mentioned: "The Know-It-Alls" by Perplexity | Official Trailer HD: If all the world's knowledge were at our fingertips, could we push the boundaries of what's possible? We're about to find out.Join the search. Find the answe...
Perplexity AI ▷ #general (493 messages🔥🔥🔥):
-
Perplexity's Time Zone and Server Mystery: Members discussed the time zone followed by Perplexity, with one noting that it likely depends on the server location, and another guessing it might be +2 or similar. A user inquired about how to find the server's exact location info.
-
Issues with Persistent Attachments: A user expressed frustration over Perplexity AI fixating on an irrelevant file for temporary context, despite multiple queries. Another explained that starting a new thread can resolve this context persistence issue.
-
"The Know-It-Alls" Ad Disappoints Viewers: Members anticipated a significant update or new feature from the "The Know-It-Alls" premiere, but it turned out to be a mere promotional video, leaving many feeling trolled and underwhelmed. Comments followed comparing it to a Superbowl ad.
-
Pro Search and Claude 3 Discussions: Various issues and preferences about AI models like Pro Search and Claude 3 were discussed. Users shared experiences, and some noted the recent removal of Claude 3 Haiku from Perplexity Labs.
-
Horse Racing Query Testing PPLX: Users tested PPLX with horse racing results queries, experiencing different results and accuracy based on the search's timing. Discussions showed how using structured prompts like helps make the AI's reasoning process clearer and more accurate.
Links mentioned:
Perplexity AI ▷ #sharing (16 messages🔥):
-
SpaceX's Starship achieves milestones: SpaceX's fourth test flight of the Starship launch system on June 6, 2024, marked significant progress. The flight involved successful splashdowns in both the Gulf of Mexico and the Indian Ocean.
-
Comparing Asian Curry varieties: A comprehensive comparison of Japanese, Indian, and Thai curries highlights their distinct characteristics. The detailed comparison includes historical origins, spices, herbs, and typical ingredients.
-
Concerns over generated content: There were issues with inaccurate content generation, specifically with a comparison between playground.com and playground.ai. Playground.com was inaccurately described.
-
Reactions to California Senate Bill 1047: Various stakeholders reacted to California Senate Bill 1047, which focuses on AI safety. AI Safety Advocates praised the bill for establishing clear legal standards for AI companies.
Links mentioned:
Perplexity AI ▷ #pplx-api (4 messages):
- Questions about llava model in API: A member asked if there are plans to allow the use of llava as a model in the API, mentioning that it has been removed from the labs. No response was documented in the provided messages.
- Frustration with beta testing for sources: Members expressed frustrations regarding the sources beta testing, with one noting, "I swear I have filled out this form 5 time now." They questioned whether new people are being allowed into the beta program.
HuggingFace ▷ #announcements (1 messages):
- FluentlyXL Final Version Is Here: The FluentlyXL Final version is available with enhancements in aesthetics and lighting. Check out more details on the Fluently-XL-Final page.
- Carbon Footprint Predictor Released: A new tool for predicting carbon footprints is available now. Find out more about it on the Carbon Footprint Predictor page.
- SimpleTuner Updates with MoE Support: SimpleTuner version 0.9.6.2 includes MoE split-timestamp training support and a brief tutorial. Get started with it on GitHub.
- LLM Resource Guide Compilation: An organized guide of favorite LLM explainers covering vLLM, SSMs, DPO, and QLoRA is now available. Check the details in the resource guide.
- ML Library Using TensorFlow: A new ML Library based on TensorFlow has been released. Find the source code and documentation on GitHub.
Links mentioned:
HuggingFace ▷ #general (248 messages🔥🔥):
-
Discussion on Virtual Environments and Package Managers: Members debated between using conda or pyenv for managing Python environments. One user expressed frustration with conda, preferring pyenv, while another admitted to using global pip installs without facing major issues.
-
GPT and PyTorch Version Compatibility: A user highlighted that Python 3.12 does not yet support PyTorch. This sparked more discussions around the challenges of maintaining compatibility with different Python versions in various projects.
-
HuggingFace and Academic Research Queries: A member inquired about the feasibility of using HuggingFace AutoTrain for an academic project without hosting the model themselves. The responses were mixed, noting that the available free services might not support larger models and the potential need for API costs.
-
Click-through Rate and Fashionability: Users discussed the idea of using AI to predict and generate highly clickable YouTube thumbnails or fashionable clothing by analyzing click-through rates and fashion ratings. Reinforcement Learning (PPO) and other methods were suggested to optimize for human preferences.
-
Gradio Privacy Concerns: There were mentions of issues related to making Gradio apps private while maintaining access. Also, a concern about potential breaches and updating gradio versions across repositories was discussed.
Links mentioned:
HuggingFace ▷ #today-im-learning (1 messages):
- AI in Medical Education overview: A new YouTube video discusses the current role of genAI in medical education and its future trajectory. Topics include the learning landscape, the usage of Anki for active recall, customization through AddOns, and the integration of genAI-powered search via Perplexity. AI In MedEd YouTube Video.
Link mentioned: AI In MedEd: In 5* minutes: In the first of a new series, we're going to go over what genAI's place currently is in medical education and where it's likely going. 1: MedEd's Learning la...
HuggingFace ▷ #cool-finds (2 messages):
- Member seeks AI collaboration: A senior web developer expressed interest in collaborating on an AI and LLM project. They requested others to text them if interested in organizing a collaboration.
- Introduction to TorchTune: A member shared a link to TorchTune, a native PyTorch library designed for LLM fine-tuning. The description highlights its role in fine-tuning large language models using PyTorch.
Link mentioned: GitHub - pytorch/torchtune: A Native-PyTorch Library for LLM Fine-tuning: A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub.
HuggingFace ▷ #i-made-this (13 messages🔥):
-
Fluently XL produces fantastic portraits with script: A user shared their experience using Fluently XL for text-to-image generation, incorporating both control net and image prompts. They provided links to two GitHub repositories they utilized: first script and second script.
-
Discussion on reading group opportunity: Members discussed the potential for a reading group focusing on a coding tutorial. They agreed to start the session next week at the usual time.
-
Demo of multi-agent BabyAGI system: A user shared a link to a demo video on Loom demonstrating BabyAGI as a true multi-agent system with agents running on different nodes.
-
New Rust crate for runtime detection: A user announced a new Rust crate for detecting operating systems at runtime, sharing their learning process. They provided a link to the project and asked for support.
-
Droid with dolphin-Llama3 model in comedic setting: A user humorously shared their experience of a droid running the dolphin-Llama3 model reacting to a standup and roast battle gig. Another user expressed enjoyment and appreciation for their videos.
Links mentioned:
HuggingFace ▷ #reading-group (13 messages🔥):
-
GitHub Repository for Past Presentations Compiled: A member shared a GitHub repository, describing it as a compilation of all past presentations from the Huggingface reading group.
-
Upcoming Meeting Reminder: A reminder was given for an imminent meeting, with the paper for discussion provided here. The paper focuses on incorporating inductive bias in neural networks for physical simulations, particularly addressing contact mechanics.
-
Differentiable Contact Model Paper Overview: The high-level overview of the paper, which introduces a differentiable contact model for neural networks, is available through a YouTube video. Accompanying code for this paper can be found on GitHub.
-
Discord Human Feedback Invite Issues: A user reported issues while attempting to join the Human Feedback, receiving an invalid invite message. Another member responded and offered to send a functioning link directly but faced issues due to the user's privacy settings.
Links mentioned:
HuggingFace ▷ #computer-vision (10 messages🔥):
-
Hangout receives positive feedback despite technical issues: One member expressed their appreciation for the Hangout event over the weekend, despite experiencing technical issues. They are looking forward to the next one.
-
Creation of useful apps for VLMs: A member shared two Hugging Face Spaces Apps they created, Model Explorer Model Explorer and HF Extractor HF Extractor, that are "particularly helpful for VLM apps". They also provided a YouTube video explaining the motivation behind these apps: YouTube video.
-
Pathway for new contributors in open source ML: A newcomer to open-source ML asked for guidance on how to contribute and grow. An experienced member suggested looking for "good first issues," reading the CONTRIBUTING.md file, and trying to contribute by following standards and learning from existing PRs.
-
Good first issues for transformers library: Suggested some GitHub issues as good starting points for new contributors, such as Move weight initialization for DeformableDetr and Adding Flash Attention 2 support for more architectures. This advice aims to help new contributors engage with practical tasks.
Links mentioned:
HuggingFace ▷ #NLP (3 messages):
- Multi-node fine-tuning query sparks interest: A member asked if anyone had ever attempted multi-node fine-tuning of an LLM before. This led to a shared arXiv paper by numerous authors discussing related research.
- Call for practical guidance: In response to the provided academic resource, another member asked for hands-on resources or practical guidance. The conversation did not extend further in the provided messages.
Link mentioned: An Introduction to Vision-Language Modeling: Following the recent popularity of Large Language Models (LLMs), several attempts have been made to extend them to the visual domain. From having a visual assistant that could guide us through unfamil...
HuggingFace ▷ #diffusion-discussions (8 messages🔥):
- Exploring Diffusers with Text-to-Image Example: One member shared a link to the Diffusers GitHub repository for text-to-image generation scripts. Another member pointed out that this script might be used for fine-tuning models.
- Optimized Inference with Native PyTorch: For optimized inference using native PyTorch, a blog post was recommended here. It covers various optimization techniques such as bfloat16 precision, scaled dot-product attention, torch.compile, and dynamic int8 quantization for speeding up text-to-image diffusion models by up to 3x.
- Training Models from Scratch: One member expressed interest in generating dataset samples like MNIST by training the model from scratch. They were directed to another resource, a training example notebook, which provided examples for unconditional generation.
Links mentioned:
Stability.ai (Stable Diffusion) ▷ #general-chat (236 messages🔥🔥):
- Newbie Overwhelmed by AI Models: A new user expressed their initial excitement and confusion about creating their own model due to the overwhelming number of underlying models, stating "...it's insane!!!".
- ControlNet Slows Down Image Generation: A user named arti0m reported significantly longer image generation times when using ControlNet, expressing confusion as he expected faster outputs but was experiencing up to 20-minute waits.
- CosXL Model Generates Better Tonal Range: Users discussed the new Stability.ai's CosXL model, which features improved tonal range from 'pitch black' to 'pure white'. Link to the model.
- VRAM and Memory Issues in Image Generation: A conversation highlighted memory management issues with the web UI Automatic1111, suggesting that it may cause excessive VRAM usage that slows down image generation significantly.
- Fun Debate on Chinese Waterfall Scandal: Users had a lively discussion on a viral scandal involving a fake waterfall in China, highlighting how the issue raised debates about environmental and political implications within the country.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #general (132 messages🔥🔥):
-
Troubles with training continuation: Members discussed issues with training model adapters saved with
model.push_to_hub_merged("hf_path"), noting performance drops when reloading adapters, with one user reporting that their loss increased from 0.4 to 2.0. They seek advice on the correct method to load adapters to continue training. -
Continued Pretraining Resource (LLama3 and Korean): Unsloth AI's blog post discusses continued pretraining LLMs like Llama3 for new languages, highlighting reduced VRAM usage and faster training using specialized techniques. A corresponding Colab notebook assists users in applying these methods.
-
Qwen2 Model Announcement: The community announced support for the Qwen2 model, noting its advancements like a 128K context length and support for 27 languages. Daniel Han's tweet shares Colab resources for finetuning Qwen2 7B.
-
Exploring Grokking: Members discussed a new phase in LLM performance called "Grokking." References included a YouTube video and several linked papers such as this one providing deeper insights.
-
Issues with using NVIDIA NVLink for extended VRAM: Users clarified that NVLink does not combine VRAM from two GPUs into one shared pool. Each GPU will still appear with its original VRAM capacity, contrary to a common misconception about extending VRAM.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #random (33 messages🔥):
-
Daniel Han YouTube Celebrity: Several members discussed seeing Daniel Han on YouTube, with one member mentioning, "Only 26! So smart!!!" Another member humorously commented, "He's not that smart... <:heehee:1238495823734640712>".
-
Training Code Struggles: A member shared their progress saying, "5 billion lines of code later and im finally at the point where something trains" to which another encouraged, "Progress is progress! <:bale:1238496073228750912>". Follow-up discussions touched on the complexity of quantization code.
-
DeepSeek Coder Recommendation: A member inquired about small models for coding and shared a link to DeepSeek Coder, highlighting its performance with various sizes from 1B to 33B versions.
-
Merging Model Issues: Discussions arose around issues with model merging, with a specific mention of problems merging 4bit and LoRA weights to 16bit. One member noted, "model.push_to_hub_merged seems to only push the adapter now", expressing confusion over the issue, while others attempted to troubleshoot.
Link mentioned: deepseek-ai/deepseek-coder-6.7b-instruct · Hugging Face: no description found
Unsloth AI (Daniel Han) ▷ #help (61 messages🔥🔥):
<ul>
<li><strong>Unsloth Llama3 lacks default LoRA adaptors</strong>: Contrary to some assumptions, unsloth's Llama3 models do not come with default LoRA adaptors. Members need to use <code>get_peft_model</code> to set them up.</li>
<li><strong>Unsloth to support Ollama soon</strong>: Upcoming unsloth release will add support for Ollama, generating enthusiastic responses from the community (*"amazing ❤️"*, shared a user).</li>
<li><strong>Error with "GIL must be held" message</strong>: A user encountered a perplexing error message: *"GIL must be held before you call parseIValuesToPyArgsKwargs"*. The troubleshooting suggestion was to check the Python version.</li>
<li><strong>SFTTrainer vs UnslothTrainer debate</strong>: Users questioned which trainer to use between `trl.SFTTrainer` and `unsloth.UnslothTrainer`. The response was that both work fine, leaving the choice up to individual preference.</li>
<li><strong>Wandb disabling instructions</strong>: For users wanting to disable Wandb tracking, setting the environment variable <code>"WANDB_DISABLED"</code> to *"true"* with `report_to = "none"` in the training arguments accomplishes this.</li>
</ul>
Links mentioned:
Unsloth AI (Daniel Han) ▷ #community-collaboration (6 messages):
- **Friendly Invitation**: "You should better invite em here!" and reassurance that "We are more friendlier" showcase the community's welcoming nature.
- **Community Praises**: A new member expressed satisfaction: "ahhaa i just joined the discord server it's very nice". Another added "thank you sharing!" reflecting gratitude and positive engagement within the group.
- **Member Recognition**: Highlighted key members by stating "no one beats <@1179680593613684819> or <@160322114274983936>", acknowledging their valued contributions to the community.
CUDA MODE ▷ #general (10 messages🔥):
-
Apple remains uninterested in Nvidia cooperation: Members expressed curiosity about why Apple does not cooperate with Nvidia despite opportunities. One member questioned, "If not in the past, why cooperate now?"
-
1-bit LLM working group: A participant mentioned hearing about a 1-bit LLM working group in a recent optimization workshop. Another provided a pointer to the relevant discussion channel
#1240586843292958790for further details. -
Time zone for event scheduling clarified: Questions arose about the time zone for scheduled events. One member clarified that the event at 3 PM mentioned was noon PST.
-
Alpaka for particle physics PhD work: A user shared an intriguing tool, Alpaka, noting its use in CMSSW for particle physics research. They mentioned, "I don't think it's popular in industry though."
-
Checking CUDA core utilization during training: Inquiry about monitoring CUDA cores utilization during training was posted. A user asked if it's possible to track how many of their 5000 cores are currently being used.
Link mentioned: GitHub - alpaka-group/alpaka: Abstraction Library for Parallel Kernel Acceleration :llama:: Abstraction Library for Parallel Kernel Acceleration :llama: - alpaka-group/alpaka
CUDA MODE ▷ #triton (4 messages):
- Simplify CUDA kernel launch with grid syntax: A member showed an easier way to launch a CUDA kernel using the grid syntax:
out = kernel[grid](...). This method streamlines the process for CUDA developers. - Access PTX code effortlessly: After launching the kernel, the PTX code can be accessed easily using
out.asm["ptx"]. This method provides quick access to the intermediate representation for further inspection.
CUDA MODE ▷ #torch (5 messages):
-
Tensor casting frustration in torchscript: A member expressed frustration about casting a tensor of dtype float32 to int32 without changing the underlying data or using
view(dtype)because it's "not supported in torchscript :((." They mentioned needing to perform bit manipulation with bfloat16s. -
Philox unpack confusion: A member questioned why
at::cuda::philox::unpackneeds to be called from the kernel when dealing with random numbers in torch. They wondered if it should return the same thing on the host. -
Looking for profiler info: A member asked for information on which profiler is used in a specific PyTorch blog post focused on accelerating generative AI models. Another member responded by sharing a PyTorch profiler tutorial, pointing out that it explains how to measure time and memory consumption of model operators.
Links mentioned:
CUDA MODE ▷ #algorithms (1 messages):
- Rethink LoRA initializations: A member shared their experiments on initializing A and B matrices differently in LoRA and claimed, "we CAN do better than default init". They encouraged others to read their findings on their blog.
Link mentioned: Know your LoRA: Rethink LoRA initialisations What is LoRA LoRA has been a tremendous tool in the world of fine tuning, especially parameter efficient fine tuning. It is an easy way to fine tune your models with very ...
CUDA MODE ▷ #cool-links (2 messages):
-
Note library revolutionizes ML with TensorFlow: A member shared the Note library's GitHub repository, which facilitates parallel and distributed training using TensorFlow. The library includes models like Llama2, Llama3, Gemma, CLIP, ViT, ConvNeXt, BEiT, Swin Transformer, and Segformer.
-
PyTorch's int4 decoding innovation: Another member shared a blog post on efficient decoding using Grouped-Query Attention and low-precision KV cache. The post discusses challenges in supporting long context lengths in large language models like Meta's Llama and OpenAI’s ChatGPT.
Links mentioned:
CUDA MODE ▷ #beginner (2 messages):
- Torch.compile speeds up SetFit models: A member reported they used torch.compile for a SetFit model and experienced some speedup. They also mentioned, "you can call torch.compile with different parameters!"
CUDA MODE ▷ #torchao (20 messages🔥):
-
ByteDance’s 2-bit quantization excites the channel: Members discussed ByteDance's 2-bit quantization algorithm, DecoupleQ for large language models, noting it reports perplexity but no speed benchmarks. The algorithm includes custom CUDA kernels and requires a calibration process that takes 3-4 hours for a 7B model.
-
Comparing quantization methods stirs debate: One user sought baseline numbers against FP16, prompting another user to clarify that DecoupleQ focuses on perplexity rather than speed benchmarks and suggesting it could be faster for I/O-bound operations.
-
Quantization techniques compared: Detailed discussions highlighted differences between quantization with calibration and quantization-aware fine-tuning. The debate emphasized calibration's memory and speed constraints versus quantization-aware fine-tuning's VRAM issues, with LorA weights providing an efficient workaround.
-
Hessian-based quantization insights shared: Members pointed out that DecoupleQ blends elements of GPTQ and HQQ, using alternate minimization and Hessian in the calibration process. They mentioned Hessian-based methods and specific challenges, including extensive memory and computational demands for calibration.
-
Quantization research papers shared: A community member provided a link to a NeurIPS 2022 paper that offers an improved approach over the Straight-Through Estimator (STE), which often results in poor gradient estimation and exploding losses during training.
Link mentioned: GitHub - bytedance/decoupleQ: A quantization algorithm for LLM: A quantization algorithm for LLM. Contribute to bytedance/decoupleQ development by creating an account on GitHub.
CUDA MODE ▷ #llmdotc (184 messages🔥🔥):
-
Aleksagordic ponders Triton and AMD support: Aleksagordic considers the benefits of supporting Triton for ease-of-use and educational value but acknowledges it requires abstraction away from CUDA and HIP specifics. Arund42 suggests supporting multiple GPU types, but warns that every kernel must adapt to Triton, potentially leading to a fork.
-
Gradient norms and stability concerns for BF16: Eriks.0595 highlights the necessity of making global gradient norms deterministic and expresses concerns over the stability of BF16 code for long training runs. Testing and addressing the current BF16 stability is noted as a priority before considering FP8 integration.
-
Plans to support Llama 3 and integration of new features: Akakak1337 and team discuss features like RoPE, RMSNorm, and potential integration of YaRN. There is also interest in establishing a high-level roadmap for upcoming model supports and testing framework improvements, such as enabling multi-node support and various FP8 computations.
-
Checkpoints and determinism challenges: Ensuring 100% determinism in training processes includes resolving issues with atomics in norm kernels and reconciling master weights saving and restoring. Akakak1337 suggests maintaining a clean logging system to manage checkpoint data efficiently.
-
Exploration of FineWeb as a dataset: Akakak1337 and Arund42 discuss the strengths and weaknesses of using FineWeb, particularly its concentration on English text and lack of other types of data like code/math, which could affect model training and evaluation outcomes.
Links mentioned:
OpenAI ▷ #ai-discussions (153 messages🔥🔥):
- 5 Research Papers Removed for Plagiarism: "5 research papers were removed for plagiarism because they forgot to remove the prompt they used." One member found it quite humorous and unfortunate.
- Haiku Model Praised for Cost and Quality: Several members discussed the cost-effectiveness and quality of the Haiku AI model. A member noted it was "like gpt 3.5ish quality" but very affordable.
- AI for Moderation Sparks Debate: Members debated the use of AI for moderation on platforms like Reddit and Discord. There were mixed feelings about AI taking actions versus just flagging content for human review.
- YouTube and Online Resources for Learning About LLMs: Recommendations were made for YouTube videos and channels to learn about LLMs, including Kyle Hill's ChatGPT Explained Completely and 3blue1brown for deeper dives into the math.
- LinkedIn Demo of OpenAI's Voice Capabilities: A LinkedIn post showcasing OpenAI's new voice capabilities was shared and praised for its quality. You can listen to the demo here.
OpenAI ▷ #gpt-4-discussions (33 messages🔥):
- Real-time Chat and New Capabilities Incoming: According to OpenAI's recent updates, GPT-4o is being rolled out to all users, with new voice and vision capabilities launching in weeks for ChatGPT Plus users. Real-time chat will enter Alpha for a small selection of Plus users, expanding to everyone in the coming months.
- Frequent Custom GPT Updates Spark Frustration: Users expressed frustration over frequent updates to custom GPTs resulting in a notification to start a new chat for the latest instructions. One member clarified that these updates happen when any changes are made to the GPT’s instructions or abilities, not the underlying model itself.
- Errors in Updating Custom GPTs: Users reported issues with updating their custom GPTs, receiving an "error saving the draft" message. This indicates potential problems with the custom GPTs functionality on the platform.
- CSV Files Issue with GPT: A member faced difficulties when making GPT select words from attached CSV files, despite them only containing simple text lists. They resorted to copying the list directly into the GPT's instructions, seeking further advice for a better solution.
- Subscription Support Issues: A user had trouble seeing GPT-4 access despite renewing their subscription. Support was advised to be reached through OpenAI's help page and live chat for resolving such issues.
Link mentioned: Tweet from OpenAI (@OpenAI): All users will start to get access to GPT-4o today. In coming weeks we’ll begin rolling out the new voice and vision capabilities we demo’d today to ChatGPT Plus.
OpenAI ▷ #prompt-engineering (6 messages):
- Frustrations with DALL-E's speed: A user expressed frustration with DALL-E's performance, noting it would stop after attempting multiple examples rapidly and then require a waiting period. They reported generating about 30 images unsuccessfully due to incorrect letter generation.
- GPT-4's approach to technical questions: Another user pointed out that GPT-4 tends to provide general answers first and then breaks down steps in detail, a method they believe aims to improve accuracy. Another member agreed, noting this method resembles "system 2 thinking" and is beneficial despite occasional misjudgments on when to shift approaches.
OpenAI ▷ #api-discussions (6 messages):
- DALL-E encounters speed limit issues: A user tried generating multiple images quickly with DALL-E but was stopped after being prompted to wait 2 minutes. Despite attempting the operation around 30 times, the results were still incorrect.
- GPT-4's iterative approach may frustrate users: A member noted that GPT-4 tends to answer technical questions by starting general and breaking down into detailed steps, which can be annoying but might improve accuracy. Another member agreed, likening it to system 2 thinking, and mentioned that it's good to see this approach even if GPT-4 sometimes misjudges when to use it.
LM Studio ▷ #💬-general (29 messages🔥):
- LM Studio celebrates one year: A user mentioned that LM Studio has been around for a year now, using emojis to celebrate the milestone.
- Mixing GPUs for heavy workloads: A member asked if it's possible to spread the workload across multiple GPUs, including Tesla K80 and 3090. Others advised that due to driver compatibility issues, sticking with the 3090 or adding a second 3090 would be the best option.
- Running multiple LM Studio instances: A member inquired about running two LM Studio instances simultaneously on the same machine to have them communicate. Responses clarified it's feasible to run multiple models in a Multi Model Session within one instance and suggested using frameworks like Autogen or custom Python scripts for model interaction.
- LM Studio usage on PS5 and VPS: There was curiosity about running LM Studio on a PlayStation 5 APU and inquiries on whether it's usable on a VPS. Comments indicated high hardware requirements make it practical mainly on powerful PCs.
- Generating embeddings from images in LM Studio: A member asked about using LM Studio to generate embeddings from images and cited daanelson/imagebind. They expressed interest in running it locally via LM Studio if possible.
Sources:
- "This is the way" Mandalorian GIF
Link mentioned: This Is The Way This Is The Way Mandalorian GIF - This Is The Way This Is The Way Mandalorian Mandalorian - Discover & Share GIFs: Click to view the GIF
LM Studio ▷ #🤖-models-discussion-chat (43 messages🔥):
- Qwen2 troubleshooting and fixes: One user had issues with Qwen2 outputting gibberish and inquired about presets, later discovering that enabling flash attention fixed the problem sometimes. Another user confirmed that the ChatML preset works for Qwen2.
- Unsuccessful attempts with Vision models via API: A user reported mixed results with llava-phi-3-mini-f16.gguf, getting inconsistent outputs when using via API despite various adjustments. They sought advice on Phi 3 and other vision models but received no definitive answers.
- Q&A on hardware for LM Studio: A newcomer inquired about CPU vs. GPU upgrades for optimal performance in the LM app. It was clarified that GPUs significantly enhance performance for LLMs, much more than CPUs.
- GPU and RAM requirements discussions: Someone mentioned that running large models, such as the 4_K_M model, requires substantial RAM (more than 36GB). Reducing the context length from 8K to 4K allowed the model to run smoothly.
- Issues with Qwen2 models: Users discussed problems with Qwen2 models, particularly with cuda offloading. It's a known issue, and the fix involves waiting for updates to llama.cpp and subsequent GGUF updates.
Link mentioned: Reddit - Dive into anything: no description found
LM Studio ▷ #📝-prompts-discussion-chat (11 messages🔥):
- Fine-tuning models for style, not knowledge: A member clarified that "fine-tuning is more about style rather than general knowledge," and it depends on the type of fine-tuning method used, such as SFT for adding knowledge and LoRA for style.
- Golden Gate Claude and GPU misreading: There was a peculiar discussion about an LLM misreading a 4060 as a GTX 460, raising questions about "qualia" and intentionality, linking it to the "golden gate claude" phenomenon.
- Customizing LLM Studio but no training: A member pointed out that in LM Studio, you can customize the system prompt to set a name, but "there's no training or data upload you can do." Only the original safetensors file of the model can be finetuned, not GGUF's.
- Overcoming 'lazy' model behavior: Multiple suggestions were offered to address a model being 'lazy,' including using a more powerful model, trying different models, or adjusting the preset template to better fit the llama 3 model.
LM Studio ▷ #🎛-hardware-discussion (19 messages🔥):
- Confusion over benchmark scores: Discussion emerged over what defines a "score," with mention that it "most likely" refers to Cinebench or another benchmark software. One user matched 3900x scores with Geekbench 6 data, but found a discrepancy with 5950x scores.
- Tesla P40 cooling challenge: A member's Tesla P40 GPU arrived, and they struggled with fitting a cooling solution, resorting to makeshift methods like a cardboard funnel. They sought advice on running airflow in reverse and learned about fans from old Mac GPUs as a potential fix, specifically 27" 2011 iMac GPU fans.
- MacGyver GPU cooling mods: With limited space in their PC case, a user discussed the impracticality of expensive cooling solutions and considered using a cardboard air duct. They humorously acknowledged the unusual but necessary modifications.
- Power supply concerns and solutions: The challenge of connecting a Tesla P40 GPU to their power supply was discussed, given the setup requires multiple connectors. A useful GitHub guide was shared, which helped clarify how to effectively distribute power supply cables.
Links mentioned:
LM Studio ▷ #🧪-beta-releases-chat (1 messages):
- Higgs LLAMA model impresses with 70B size: The new Higgs LLAMA model is garnering attention for its sophistication given its 70-billion parameter size. Members are keenly awaiting an LMStudio update, noting that it appears to use a llamacpp adjustment.
LM Studio ▷ #langchain (2 messages):
- Trouble with ChatPromptTemplate not recognizing variables: A member inquires if
ChatPromptTemplate.from_messagesandChatPromptTemplate.from_templatesupport{tools}and{tools_names}insystem_templateorhuman_template. They noted that while debugging the prompt, it did not recognize these variables and returned a blank response, despite usingcreate_react_agent. - Using LM Studio instead of GPT with LangChain: Another member shared their experience trying to use LM Studio with LangChain, mentioning that they have three interconnected chains. They are uncertain about whether it's necessary to specify the role and prompt in
messages=[]or use the System and User Message Suffix and Prefix when the same task is handled by LangChain itself.
LM Studio ▷ #amd-rocm-tech-preview (11 messages🔥):
-
Query about 6800m with ROCm on LM Studio: A member asked if anyone has successfully enabled ROCm on a 6800m in LM Studio. More responses suggested trying Arch Linux and mentioned various issues with getting ROCm to work on Windows.
-
7900xtx works fine on Windows: The same member shared that their 7900xtx works without issues on Windows, but their 6800m laptop does not.
-
Workarounds for ROCm on Windows: Another member suggested workarounds like setting
HSA_OVERRIDE_GFX_VERSION=10.3.0and using additional ROCm libraries for cards under the 6800XT series. They noted that they haven't had to use these workarounds themselves.
Latent Space ▷ #ai-general-chat (9 messages🔥):
- Expo Floor Clarification for AI Engineer Schedule: A member inquired about session availability with the Expo Explorer ticket for the AI Engineer event. They confirmed that while expo sessions are available, more titles from speakers are still pending.
- Kwai's KLING vs OpenAI's Sora: A post on X discussed KWAI's new Sora-like model called KLING, highlighting 10 impressive examples. Another member noted the convincing realism of a demonstration involving a Chinese man eating noodles.
- Insights on GPT-4o Vision: A member shared a comprehensive post by Oran Looney that dives into GPT-4o's token charging mechanism for processing high-resolution images. The post questions why OpenAI uses a specific token number (170) and explores the concept of "magic numbers" in programming.
Links mentioned:
Latent Space ▷ #ai-in-action-club (98 messages🔥🔥):
- Hallucinating Engineer Roleplay: Members humorously discussed their titles, with one claiming the role of "senior hallucinating engineer" and another responding, "No, the staff is my tool to conjure today's software."
- Websim.ai Exploration: Members shared their experiences using websim.ai, a live-streaming facial recognition website. One user noted, "going to websim.ai inside the websim.ai version of websim.ai lets you keep recursing...at 4 levels deep, my page got unresponsive."
- Useful Hallucinations with GPT: The group discussed the "useful-hallucination paradigm," where GPT would hallucinate useful metrics when monitoring its responses. This concept was received positively, with comments like "superprompts from quicksilver and stunspot."
- Resources and Links Shared: Several links were shared, including a Google spreadsheet with curated resources, and a GitHub Gist for the Websim system prompt.
- Moderation and Future Sessions: Members discussed future moderation and planning for upcoming sessions. Suggestions included a "walkthrough setting up a websim concept," and confirming roles for next week's moderator duties.
Links mentioned:
Nous Research AI ▷ #interesting-links (2 messages):
-
Mixtral 8x7B MoE explained: A member learned that Mixtral 8x7B does not have 8 independent experts but rather 32x8 experts. They shared a YouTube video titled "Stanford CS25: V4 I Demystifying Mixtral of Experts," where Albert Jiang from Mistral AI and the University of Cambridge discusses this in detail.
-
Kling Kuaishou link: A member shared a link to Kling Kuaishou.
Links mentioned:
Nous Research AI ▷ #general (60 messages🔥🔥):
-
Meta AI introduces Vision-Language Modeling guide: A new guide titled "An Introduction to Vision-Language Modeling" by Meta AI covers how VLMs work, their training processes, and evaluation methods. The guide aims to help those interested in the field understand the mechanics behind mapping vision to language.
-
Debate on Qwen-2's reasoning capabilities: Members discussed the "vibe check" on Qwen-2 7B, with critiques mentioning it doesn't compare well to larger models like Yi 1.5 34B. There was skepticism about its effectiveness despite its coherence over large contexts.
-
Excitement over new benchmarks: 57B-A14 MoE is noted to beat Yi 1.5 34B in many coding-related benchmarks. This model, licensed under Apache 2.0, has high VRAM requirements.
-
GPU poverty impacts model testing: Many members expressed challenges due to lack of GPUs ("GPU poor"), limiting their ability to test new models like those available through Together API and Fireworks.
-
Outpainting tool recommendations: For expanding images, members suggested the Krita plugin (GitHub link) and Interstice Cloud. They recommended incrementally increasing image resolution to achieve the desired aspect ratio.
Links mentioned:
Nous Research AI ▷ #ask-about-llms (1 messages):
- DeepSeek Coder 6.7B shines in coding tasks: A member inquired about code models and shared a detailed introduction of DeepSeek Coder 6.7B. This model is trained on 2 trillion tokens, primarily in code, and demonstrates state-of-the-art performance in project-level code completion and infilling across various model sizes from 1B to 33B.
Link mentioned: deepseek-ai/deepseek-coder-6.7b-instruct · Hugging Face: no description found
Nous Research AI ▷ #rag-dataset (12 messages🔥):
-
Mistral keeps it simple: "Good to see mistral understands keeping connective prompts small and simple." Emphasizes the simplicity of connective prompts for effective communication with Mistral.
-
Excessive dashes in formats: One member expressed concern over "excessive use of
--------------------" and noted it would be difficult for users to manually match "the exact number of-'s." -
Not a cookie-cutter framework: Mentioned that the dash-based separators in their format are specific to generating datasets for RAG. They clarified that this format does not qualify as standardized frameworks like markdown or XML.
-
Differences in UltraChat format: A member inquired about how UltraChat formatting differs from the ones they use while exploring Mistral documentation.
-
Prophetissa for RAG dataset: Shared Prophetissa, a RAG dataset generator using Ollama and emo vector search, mentioning potential improvements and exploring fun alternatives like LangChain.
Link mentioned: GitHub - EveryOneIsGross/Prophetissa: RAG dataset generator using ollama and emo vector search.: RAG dataset generator using ollama and emo vector search. - EveryOneIsGross/Prophetissa
Nous Research AI ▷ #world-sim (28 messages🔥):
- WorldSim Console Update Makes Mobile Usable: A recent update to the WorldSim console fixes numerous text input bugs on mobile devices. It also improves copy/pasting functionality, updates the
!listcommand, and includes a new option to disable visual effects. - Text Duplication and Other Glitches Fixed: Specific issues like text duplication and text jumping have been addressed. "Your text duplication glitch should be fixed" and "text jumping up a line while typing should be fixed."
- Labeling and Saving Chats: There is a way to give names to chats by using the
!savecommand. More features like chat size/length labels may be added in the future. - Custom Commands and Fun with Services: Members shared fun custom commands like
systemctl status machine_sentience.service. The ability to create entertaining fictional "service" installations was also highlighted. - WorldSim Using Claude Models: Users can select from various Claude models in WorldSim settings. However, attempts to use custom models have been deemed inadequate in comparison.
Link mentioned: Terminator2 Ill Be Back GIF - Terminator2 Ill Be Back Arnold Schwarzenegger - Discover & Share GIFs: Click to view the GIF
LlamaIndex ▷ #blog (3 messages):
-
Future of RAG: Embrace Agentic Knowledge Retrieval: A talk at the SF HQ by @seldo explored the future of RAG, moving from naive top-k retrieval to fully agentic knowledge retrieval. The video guide includes real-world code examples to help elevate your practices.
-
Introducing Two Memory Modules in LlamaIndex: LlamaIndex now features two memory modules for agents, enhancing the RAG framework. The Vector Memory Module stores user messages in a vector store and uses vector search for relevant message retrieval; see the demo notebook.
-
Create-llama Integration with e2b_dev's Sandbox: Create-llama now integrates with e2b_dev's sandbox, allowing Python code execution for data analysis and returning entire files such as graph images. This feature introduces a host of new possibilities for agent applications, as announced here.
LlamaIndex ▷ #general (95 messages🔥🔥):
<ul>
<li><strong>Simplify dynamic data updates for RAG</strong>: Despite issues with the query engine not reflecting immediate changes in the VectorStoreIndex, one solution is reloading the index periodically to ensure it uses the latest data, as demonstrated with code snippets. This ensures the RAG app can answer queries with new data dynamically.</li>
<li><strong>Index management recommendations</strong>: While discussing the best ways to manage different data sets (e.g., Sales data, Labor costs, technical support docs), it's suggested to either use separate indexes or apply metadata filters to let the LLM decide which index to query based on inferred topics from the query.</li>
<li><strong>Embedding enhancements with knowledge graphs</strong>: Users discussed how to directly create property graphs with embeddings using LlamaIndex and the benefit of attaching text embeddings from entities and their synonyms directly to entity nodes in the knowledge graph.</li>
<li><strong>Adjusting chunk sizes</strong>: To optimize LlamaIndex for larger texts, users can adjust the `chunk_size` parameter in the `Settings` class, enabling better chunk management and more precise embeddings depending on the use case.</li>
<li><strong>Entity resolution in graphs</strong>: Performing entity resolution can involve defining a custom retriever to locate and combine nodes, utilizing methods like manual deletion and upsert as highlighted by the provided `delete` method example.</li>
</ul>
Links mentioned:
Modular (Mojo 🔥) ▷ #general (8 messages🔥):
- Async functionality still in development: In response to a query about threading, it was pointed out that although Mojo supports
async fnandasync def, it does not yet supportasync forandasync with. There was also mention of@parallelize, indicating ongoing development in this area. - High demand for Windows release: Members are expressing eagerness for a Windows native release for max/mojo, with multiple requests and a bit of humor around the delay. The timeline for this release remains unclear and is currently a hot topic among users.
Modular (Mojo 🔥) ▷ #💬︱twitter (1 messages):
ModularBot: From Modular: https://twitter.com/Modular/status/1799109375258484909
Modular (Mojo 🔥) ▷ #📺︱youtube (1 messages):
- Mojo Community Meeting #2 Released: Modular announced the release of a new YouTube video titled "Mojo Community Meeting #2." The video includes presentations on the Basalt ML Framework by Benny Notson, Compact Dict by Maxim Zaks, and Pandas for Mojo by Samay Kapad.
Link mentioned: Mojo Community Meeting #2: Recording of the Mojo Community Meeting #2 Presentations:🌋 Basalt ML Framework w/ Benny Notson📔 Compact Dict w/ Maxim Zaks🐼 Pandas for Mojo w/ Samay Kapad...
Modular (Mojo 🔥) ▷ #✍︱blog (1 messages):
- MAX 24.4 brings Quantization API and macOS compatibility: Modular announced the release of MAX 24.4, introducing a new Quantization API and extending MAX's reach to macOS. The API reduces latency and memory costs of Generative AI pipelines by up to 8x on desktops and 7x on cloud CPUs, without requiring model rewrites or application updates.
Link mentioned: Modular: MAX 24.4 - Introducing Quantization APIs and MAX on macOS: We are building a next-generation AI developer platform for the world. Check out our latest post: MAX 24.4 - Introducing Quantization APIs and MAX on macOS
Modular (Mojo 🔥) ▷ #announcements (1 messages):
- Mojo and MAX Release 24.4 Drops with macOS Support: The latest release, 24.4, of Mojo and MAX now includes quantization and macOS support. Check out the MAX install guide, launch blog, and an example running llama3 with MAX and quantization.
- Epic Changelogs Live: Full changelogs for this release can be found at Mojo changelog and MAX changelog.
- Community Contributions Celebrated: Over 200 contributions to the standard library by the community are included in this release.
- Python Installation Fix: Mojo now links to the first Python version on
PATHwhenMOJO_PYTHON_LIBRARYis not set. A script is available to find a compatible Python environment on your system. - Trouble Installing? Post any issues with MAX on macOS or running the llama3 quantization example in the Discord channel.
Modular (Mojo 🔥) ▷ #ai (7 messages):
-
Andrew Ng warns of stifling AI regulation: Andrew Ng's tweet draws attention to California's proposed law SB-1047, expressing concern that it could stifle AI innovation. He argues that safety should be assessed based on applications rather than the technology itself, using the analogy, "Whether a blender is a safe one can’t be determined by examining the electric motor."
-
Discussion on regulation feasibility: Members discuss the feasibility of regulating AI applications built on open-source technology. One member notes, "if the technology can be downloaded from the internet, is there any chance to regulate the applications build on top of it. I would say surely not very big."
-
Comparison to Russian AI regulation: A member remarks on the lack of open source AI regulation discussions in Russia, referencing a video where Vladimir Putin confronts an AI-generated version of himself.
-
Deepfake and dataset solutions: Potential solutions to major AI problems like "deepfakes" and inappropriate content generation are highlighted. One suggestion includes clearing datasets of harmful content, "well, it will be a long fighting story."
-
Global perspective on AI misuse: The conversation broadens to the inevitability of AI misuse globally, jesting that "even if USA will forbid that - Wakanda still will make deepfakes of twerking Thanos."
Links mentioned:
Modular (Mojo 🔥) ▷ #🔥mojo (53 messages🔥):
- Mojo
isdigit()efficiency and issues: Discussion revealed that theisdigit()function internally usesord()and aliases for efficiency, showing source code. A member expressed struggles with the function, eventually filing an issue report. - Current state of
asyncprogramming in Mojo: Members discussed the status of asynchronous programming, highlighting thatasyncis still a work in progress, with updates toCoroutineappearing in nightly builds. - Mojo
typechecking alternatives: A new user inquired about checking variable types, receiving advice to use the__type_offunction and insights on how the VSCode extension and REPL can help identify types before and after compile. - Mojo version 24.4 changes and bugs: Multiple members discussed issues after upgrading to version 24.4, including seg faults from the
islowerfunction and missingdata()method forTensor, now found to beunsafe_ptr()per updated documentation. - Mojo availability on platforms: A member asked about Mojo on Google Colab, with a response indicating that while it's not on Colab, users can currently use it on the Mojo Playground.
Links mentioned:
Modular (Mojo 🔥) ▷ #📰︱newsletter (1 messages):
Zapier: Modverse Weekly - Issue 36 https://www.modular.com/newsletters/modverse-weekly-36
Modular (Mojo 🔥) ▷ #nightly (22 messages🔥):
-
Dynamic libpython selection added in latest nightly: The latest nightly now implements dynamic libpython selection, removing the need to set
MOJO_PYTHON_LIBRARY. However, some users still need to usePython.add_to_path, despite claims that it should no longer be necessary if the virtual environment is properly activated. -
VS Code integration issues for virtual environments: Users reported that running Mojo files through VS Code does not retain the virtual environment activation, requiring manual intervention using
source .venv/bin/activate. This issue persists despite the integrated terminal showing the virtual environment as active. -
New nightly Mojo compiler release: A new nightly Mojo compiler, version
2024.6.714, has been released with changelog and raw diff available here and current changelog. -
Microbenchmarks now available: The latest
nightlyrelease includes microbenchmarks available in the Mojo GitHub repository. Users are encouraged to try them out, add or modify benchmarks, and provide feedback to improve the benchmark package.
Link mentioned: modula - Overview: GitHub is where modula builds software.
Eleuther ▷ #announcements (1 messages):
-
Beta release of TopK Sparse Autoencoder training code: The beta version of TopK sparse autoencoder training code was released, based on OpenAI's recent paper. It trains an SAE for each network layer without caching activations on disk, and future updates will include multi-GPU support and the AuxK auxiliary loss.
-
Unique functionality of the library: This library, unlike others, trains an SAE for all layers simultaneously and has been tested on GPT-2 Small and Pythia 160M. For more details and contributions, users are directed to the specific channel and GitHub repository.
Link mentioned: Tweet from Nora Belrose (@norabelrose): This is our training library for TopK sparse autoencoders, which were proposed by OpenAI this morning. I've tested it on GPT-2 Small and Pythia 160M. Unlike other libraries, it trains an SAE for ...
Eleuther ▷ #general (45 messages🔥):
-
New Insights into Data Shapley: An arXiv preprint was shared, discussing the inconsistency of Data Shapley in data selection across different settings and proposing a hypothesis testing framework to predict its effectiveness. The discussion highlighted that high-quality and low-quality data mixes can still yield useful insights.
-
Clearing Up LM Evaluation Harness Usage: A user questioned how to use the lm harness for evaluation and another pointed to the lm-evaluation-harness GitHub repository. There was some confusion whether it is for training or evaluation, which was clarified by explaining its use in evaluating models, with a note on accuracy calculation specifics.
-
Difficulty in Tensor Type Casting in TorchScript: A member sought advice on casting tensors from
float32toint32in TorchScript without changing the underlying data. Several suggestions were provided, including using C++ extensions and considering float-to-int quantization techniques. -
OpenLLM-Europe Community Introduction: Jean-Pierre Lorré introduced OpenLLM-Europe, aimed at gathering European stakeholders in open-source GenAI, focusing on multimodal models and their evaluation and alignment.
-
Outpainting Tools Recommendations: For converting 4:3 images to desktop wallpapers, stable-diffusion-ps-pea was recommended as a more current and active tool. Alternatives such as SD Turbo or CPU-based models were suggested for users without GPU access.
Links mentioned:
Eleuther ▷ #research (40 messages🔥):
-
Thousand Brains Project aims for new AI design: Jeff Hawkins and Numenta are embarking on a multi-year project to implement the Thousand Brains Theory into software, aiming to apply neocortex principles to AI. The project pledges extensive collaboration and open research practices, drawing excitement from the community.
-
Discussing GPT Autoregressive order modulation: A new paper on autoregressive models challenges the fixed order by adding a positional encoding that allows for dynamic token sampling. Members compared it to discrete diffusion models but acknowledged differences in conceptual rigor and training benefits.
-
ReST-MCTS improves LLM training quality: The ReST-MCTS approach uses process reward guidance and Monte Carlo Tree Search to collect high-quality reasoning traces for better LLM training. This method avoids the need for manual annotation by inferring process rewards from oracle correct answers.
-
Debate on the dangers of open-ended AI: A position paper from Google DeepMind argues for the viability of open-ended AI systems as a pathway to artificial superhuman intelligence (ASI). However, some members criticize this approach as potentially dangerous due to the lack of terminating conditions.
-
Sparse autoencoders for interpretable features: Another paper introduces k-sparse autoencoders for better balancing of reconstruction and sparsity objectives. This method simplifies tuning and improves the reconstruction-sparsity frontier, showing promise in extracting interpretable features from language models.
Links mentioned:
Eleuther ▷ #interpretability-general (4 messages):
- New Paper on Sparse Autoencoders: A paper on sparse autoencoders discusses using k-sparse autoencoders to control sparsity more effectively and improve the reconstruction-sparsity balance. The paper also introduces new metrics for evaluating feature quality and demonstrates clean scaling laws.
- Library for TopK Sparse Autoencoders: Norabelrose shared a training library for TopK sparse autoencoders tested on GPT-2 Small and Pythia 160M. Unlike other libraries, it trains an SAE for all layers simultaneously and does not require caching activations on disk.
- TopK Activations Revival: A member expressed excitement about the resurgence of interest in TopK activations, noting that previous innovations in this area were ahead of their time. This renewed interest is seen as an opportunity to revisit and experiment with these methods.
Links mentioned:
Eleuther ▷ #lm-thunderdome (4 messages):
- Fix pending for filename handling issues: A member acknowledged the issue with result file placements and assured it is on the todo list to fix. They mentioned the results should be in the tmp folder, where files can be opened and read.
- PR aims to resolve filename handling: One suggested that the Pull Request Results filenames handling fix by KonradSzafer might resolve the problems previously mentioned. This PR focuses on addressing bugs by refactoring and moving functions for better utilization across the codebase.
Link mentioned: Results filenames handling fix by KonradSzafer · Pull Request #1926 · EleutherAI/lm-evaluation-harness: This PR focuses on addressing: #1918 - by moving functions for handling results filenames to utils, so they can be used in other parts of the codebase #1842 - by refactoring the Zeno script to wor...
Interconnects (Nathan Lambert) ▷ #ideas-and-feedback (15 messages🔥):
- Debate on Robotics Article's Depth: There was a discussion on whether the robotics piece lacked details and insights, especially with "monetizing along the way" and business dynamics not fully articulated. One member suggested that unpacking the specifics and assumptions, particularly the calculation behind "40000 high-quality robot years of data," would add more depth.
- Suggestion for Periodic Recap Episodes: A suggestion was made for Nathan Lambert to consider doing "quarterly recap episodes" similar to Peter Attia, to reflect on takeaways and synthesize reader feedback. This could help differentiate content in convergence-heavy fields.
- Challenges in Grounding Robotics Content in Numbers: Another member called for more numbers and explicit assumptions when discussing algorithmic advances, data generation costs, and manufacturing costs, especially when the piece criticized Covariant's business model and VC expectations. A YouTube video by Eric Jang was recommended for reference on the matter.
- Feedback on Physically Intelligent Robots: Queries were made about the reported number of robots Physically Intelligent had, and the types of robots they possessed. Nathan Lambert mentioned a "mix of aloha’s / cheap stuff to nicer versions to extremely nice versions" but could not recall all brand names.
- Varied Feedback on Robotics Piece: Nathan Lambert acknowledged receiving mixed feedback on the article, with some robotics friends liking it and some not. Despite the critiques, Lambert remains "bullish on covariant succeeding as a business."
Link mentioned: Robots are suddenly getting cleverer. What’s changed?: no description found
Interconnects (Nathan Lambert) ▷ #news (16 messages🔥):
- Chinese AI video generator outperforms Sora: A Chinese AI video generator was released, capable of generating 2-minute, 30fps, 1080p videos via the KWAI iOS app, requiring a Chinese phone number. Members discussed its superiority over Sora, with comments on quality and public availability.
- Vision-LSTM merges xLSTM with image reading: Jo Brandstetter shared the introduction of Vision-LSTM, which enables xLSTM to read images effectively. The post included links to a preprint on arxiv and project details.
- Kling AI video generator gets tested: A user shared their test qualification for the KWAI video generator model Kling, posting some generated videos. Members analyzed these videos, focusing on physics and light/camera angles, and noted the quality improvements.
Links mentioned:
Interconnects (Nathan Lambert) ▷ #random (8 messages🔥):
-
Anthropic offers API access for AI alignment research: A member shared a link to Anthropic’s support article, detailing how alignment researchers can access the Claude API. Interested individuals need to provide their institution, role, LinkedIn, Github, and Google Scholar profiles along with a brief research plan.
-
New anonymous model "anon-leopard" (Yolo AI) release: A tweet was shared announcing the release of a new anonymous model called "anon-leopard" by "Yolo AI" on LMSYS. It is noted that this model does not use common OpenAI tokenizations.
-
Interest in the Daylight computer: Multiple users discussed their interest in the Daylight computer (link to product), a computer designed to be healthier and more human-friendly by avoiding blue light emissions and being visible even in direct sunlight. A user who already owns an iPad mini debated whether to preorder it.
Links mentioned:
Interconnects (Nathan Lambert) ▷ #memes (1 messages):
- Tweet Responses Avoidance Strategy: A member shared their approach to dealing with certain tweets by saying, "I always default to 'I am not the target audience for this tweet' and move on." They suggested that these tweets often look like group chat messages that spill over to the timeline.
Interconnects (Nathan Lambert) ▷ #rl (4 messages):
- Analogous to self-debugging models: Members compare a discussed method to self-debugging models, noting that it conditions on incorrect outputs to generate correct outputs, with an outer loop maximizing improvement difficulty. "They in the outer loop try and find a policy for direct generation (no self-improvement step) that is the hardest for the self-improvement model to improve upon."
- Interest in analytical solutions: A member expresses the need to better understand the analytical solutions in theory-heavy papers like DPO. They find maximizing improvement while minimizing it intriguing.
- Comment on a DPO-style theory paper: Nathan Lambert notes that a discussed paper is mostly theoretical with minimal real evaluations, similar to the original DPO. He mentions attempting to create content for it but scrapping the effort due to its complexity.
Interconnects (Nathan Lambert) ▷ #posts (3 messages):
- SnailBot Alerts Users About Secret Post: The message tags a role
<@&1216534966205284433>and announces, "Snailbot found my secret post for technical stuff." However, this turns out to be a non-serious alert. - Clarification on Fake Post: It is explicitly stated, "Not a real post," indicating that the previous message was not to be taken seriously.
Cohere ▷ #general (38 messages🔥):
-
Translation Costs for Aya Spark Curiosity: A member inquired about the costs of using Aya for translation purposes. Responses noted that Aya is free for research but not for commercial use, as the business has to sustain itself.
-
Command-R-Plus vs. Llama3 Debate: Discussion highlighted that some users find Command-R-Plus smarter than Llama3, especially outside language specifics. One user commented, "It ain’t just you," reinforcing this viewpoint.
-
Vercel AI SDK and Cohere Integration Concerns: A user reported issues with incomplete support in the Vercel AI SDK for Cohere, sharing a link to the SDK guide. Another member took swift action to address these integration concerns by contacting the SDK's maintainer.
-
Data Privacy for Free Personal Use Clarification: Queries around the privacy policy for free personal use of Cohere models were addressed by explaining options to use Cohere models locally or on cloud services like AWS and Azure, with links to the respective AWS and Azure documentation for more details.
-
Developer Portfolio Sharing: A user seeking a full-stack developer position shared their professional portfolio, featuring skills like UI/UX, Javascript, React, Next.js, and Python/Django, which can be viewed here.
Links mentioned:
Cohere ▷ #project-sharing (7 messages):
-
Rafael offers a solution for GenAI hallucinations: A former Apple AI/ML engineer, Rafael, is validating a product aimed at ensuring GenAI app safety by detecting and correcting hallucinations in real-time. He seeks those facing similar issues with GenAI in products or business processes to contact him for collaboration.
-
Complexity launch impresses community: Hamed announced the launch of Complexity, a generative search engine built on Cohere, receiving immediate positive feedback. Other members praised its performance and design, highlighting its simplicity and minimalistic approach despite its complex name.
-
Complexity link shared: Hamed provided a link to the Complexity search engine (Complexity), prompting further testing and admiration from the community.
Link mentioned: Complexity: The world's knowledge at your fingertips
OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
- Qwen 2 72B Instruct Model Launched: The Qwen 2 72B Instruct model is now available. This release marks a significant addition to OpenRouter's offerings for 2023-2024.
Link mentioned: Qwen 2 72B Instruct by qwen: Qwen2 72B is a transformer-based model that excels in language understanding, multilingual capabilities, coding, mathematics, and reasoning. It features SwiGLU activation, attention QKV bias, and gro...
OpenRouter (Alex Atallah) ▷ #general (36 messages🔥):
-
Widespread 504 Gateway Timeout Errors: Many users experienced issues with 504 gateway timeouts when attempting to use the server, specifically with the Llama 3 70B model. Alex Atallah confirmed and noted that the database strain coincided with the 504 errors and is moving jobs to a read replica to mitigate this issue.
-
Issues with WizardLM-2 8X22 Responses: Users reported that WizardLM-2 8X22 is generating unintelligible responses when routed through DeepInfra. Alex Atallah suggested excluding problematic providers using the
orderfield in request routing, and further discussions revealed that other providers besides DeepInfra might also be causing issues. -
Discussion on Routing Control and Model Provider: Asperfdd raised a concern about the inability to control routing options while using certain services like Chub Venus, looking for updates on resolving these provider issues. Discussions also hinted at an internal endpoint deployment for troubleshooting.
-
Debate on AI Security: A heated discussion occurred on the merit of AI security and the recent firing of Leopold Aschenbrenner from OAI. Opinions varied significantly, with some dismissing AI security concerns and others criticizing Aschenbrenner's stance on the subject.
-
ChatGPT Performance During Peak Load: User pilotgfx speculated that ChatGPT might be performing worse during peak load hours, suspecting some form of performance quantization due to high user volume. Another user agreed but generalized that "3.5 is very dumb in general nowadays".
Link mentioned: Provider Routing | OpenRouter: Route requests across multiple providers
OpenRouter (Alex Atallah) ▷ #일반 (1 messages):
voidnewbie: Qwen2도 한국어를 지원해요!
OpenAccess AI Collective (axolotl) ▷ #general (10 messages🔥):
-
Torch Tune availability questioned: A user inquired, "Do we have torch tune yet?" There was no follow-up response provided in the extracted messages.
-
Interest in Japanese-specialized models: A member asked, "Any model specialized for Japanese?" This message indicates an interest in models tailored for specific languages.
-
Qwen2 72b Finetuning Issues Highlighted: A member pointed out issues with the configuration of a finetuned Qwen2 72b model, stating it had "max_window_layers set to 28," similar to the 7b variant, which caused noticeable performance degradation. They suggested that a further round of finetuning might be necessary due to this "oversight."
-
Discussion on Model's Performance: The conversation mentions a user confirming the model "works for me," while another member noted poor performance specifically for the GGUF format. There was an indication that updates had been made in the commit history to correct the oversight.
-
Pull Request for Distributed Finetuning Guide Shared: A member shared a pull request for a guide on distributed finetuning using Axolotl and Deepspeed. This PR was created as per request, indicating ongoing enhancements in collaborative projects.
Link mentioned: Update multi-node.qmd by shahdivax · Pull Request #1688 · OpenAccess-AI-Collective/axolotl: Title: Distributed Finetuning For Multi-Node with Axolotl and Deepspeed Description: This PR introduces a comprehensive guide for setting up a distributed finetuning environment using Axolotl and A...
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (1 messages):
josharian: i just experienced this exact behavior as well.
OpenAccess AI Collective (axolotl) ▷ #general-help (8 messages🔥):
- Building flashattention on slurm is problematic: A member expressed frustration over building flashattention, calling it "ridiculous." They detailed the solution, involving loading specific modules and ensuring sufficient RAM on slurm.
- Cluster-specific CUDA load module needed: A member shared that the cluster support had to create a CUDA load module because the system could not find
cuda_home, leading to the solution. - Issues installing Nvidia Apex on slurm: A member mentioned struggling to install Nvidia Apex on slurm, indicating persistent problems.
- Potential guide on installing Megatron on slurm: One user announced they might create a guide for installing Megatron on slurm due to difficulties with docker containers not working universally in cluster environments.
- Axolotl installation issues: A member reported running into memory issues (64GB RAM usage) while following the Axolotl quickstart guide on installing with
flash-attnanddeepspeeddependencies using Python 3.10 and Axolotl 0.4.0.
OpenAccess AI Collective (axolotl) ▷ #datasets (2 messages):
- Struggles with JSONL Test Split Resolved: A member expressed difficulty in adding a
test_datasetsin thecontext_qa.load_v2JSONL format, receiving the error, "no test split found for dataset." They later shared a working configuration using a regular JSONL file formatted as specified in the documentation foraxolotl.cli.preprocess.
OpenAccess AI Collective (axolotl) ▷ #axolotl-help-bot (13 messages🔥):
-
Axolotl API usage discussion: A member asked for an example of how to use the Axolotl API to perform inferences. They specifically wanted to script continuous model evaluations by asking multiple questions and saving the answers without repeatedly using the command line.
-
Clarification on API vs. YAML configs: Another member confused the request for API usage with YAML configurations. The original poster clarified their interest in API-based inferences, not YAML-based configurations.
-
Flash-attn RAM requirements: A member inquired about the RAM requirements for installing
flash-attn. It was explained that while the library does not require much RAM for installation, significant resources, including high GPU memory (VRAM) and matching system RAM, are needed for training large models.
Links mentioned:
LAION ▷ #general (29 messages🔥):
- Chinese AI video generator launches before Sora: A Chinese AI video generator, available on the KWAI iOS app, generates 2-minute videos at 30fps and 1080p quality (source). Demonstrations of the generator's capabilities are available via linked videos.
- Stable Audio Open Multiplayer update: An update for Stable Audio Open introduces a multiplayer feature to collectively improve prompting strategies (source). The update aims to turn the individual exploration process into a collective learning experience.
- AI safety in art software discussion: Concerns arise over the requirement for Adobe Photoshop to have full access to any created work, including NDA work (source). Some members suggest alternative tools like Krita, Affinity Designer/Photo, and Gimp.
- New AI video generator, Kling, impresses: A YouTube video titled "New AI Video Generator is Sora-level" unveils Kling, a new realistic video generator (source). It's noted for its impressive capabilities, but some doubt its authenticity.
- Schelling AI announcement brings mixed reactions: @EMostaque announces Schelling AI, aiming to democratize AI using digital assets and AI compute mining (source). The lofty claims and use of buzzwords draw skepticism and humorous responses from the community.
Links mentioned:
LAION ▷ #research (5 messages):
-
σ-GPT dynamically generates sequences: A new model, σ-GPT, developed in partnership with SkysoftATM, generates sequences in any order dynamically at inference time, challenging the traditional left-to-right approach of GPTs. This potentially decreases the steps required for generation by an order of magnitude according to its arXiv paper.
-
Skepticism about σ-GPT's practicality: A member expressed skepticism, noting that the need for a curriculum to reach high performance might hinder this approach in practice with relatively little gain, comparing it to XLNET's underwhelming adoption ("XLNET basically did the same thing as a pretraining task and that never caught on").
-
Alternatives and potential applications: For infilling tasks, alternatives like GLMs might be more practical**," a member suggested. Moreover, finetuning an existing model with an additional set of positional embeddings for non-textual sequence modeling, such as in RL, could be intriguing.
Links mentioned:
LangChain AI ▷ #general (21 messages🔥):
-
Early Stopping Method Issue in LangChain: A member mentioned that the early_stopping_method="generate" option in LangChain doesn't work in newer versions and linked an open GitHub issue. They inquired about any plans to fix it or available workarounds.
-
Data Privacy in RAG with ChromaDB: A member asked about managing user-specific document access in LangChain paired with ChromaDB. Another member suggested filtering by metadata in vectorstores, while emphasizing the complexity and best practices.
-
Handling Repeated Steps in Agents: A user sought help solving an issue where an agent gets stuck in a loop by making repeated steps. No specific solution was provided in the messages.
-
Effective Prompting for LLaMA3-70B: A user asked for prompt suggestions to get LLaMA3-70B to perform tasks like summarization without prefacing the results with phrases like "here is the thing you asked". Several prompts were attempted, but no solution was found.
-
Clarification on Vector Store Usage: Another member inquired if Chroma supports returning IDs during similarity searches, sharing details about working with SupabaseVectorStore and other vector stores. No direct answer to the query about Chroma was recorded in this message snapshot.
Links mentioned:
LangChain AI ▷ #share-your-work (3 messages):
-
Apple's Generative AI principles: Guiding principles for implementing local generative AI on Apple devices like iPhone Pro, iPad Pro, and MacBook Pro were shared. These principles aim to optimize AI performance on device hardware.
-
Streamlit app for virtual interviews: A user introduced their first Streamlit app Baby Interview AGI, which functions as a virtual job interview chat app using LangChain and OpenAI. They expressed excitement about launching on Streamlit's community cloud.
-
Closed alpha testing for B-Bot application: An announcement detailed the commencement of a closed Alpha Testing phase for the B-Bot application, an advanced virtual platform for expert-user knowledge exchange. They are seeking 10-20 testers via an invitation to refine the app and provide valuable feedback.
Links mentioned:
Torchtune ▷ #general (10 messages🔥):
- Exporting custom phi-3 model issues: A user inquired about exporting a custom phi-3 model and encountered issues trying to download model files from Hugging Face. They realized from a GitHub link that some configurations might be causing the problem.
- HF format for model files clarification: Another user clarified that models downloaded from Hugging Face are in HF format, but when using the FullModelHFCheckpointer in Torchtune, it converts internally to Torchtune format and back to HF format when saving checkpoints.
- Interest in n_kv_heads for mqa/gqa: A user asked if there is interest in having the kv cache use n_kv_heads for mqa/gqa and if PRs would be welcome. They were told that PRs are welcome but must include accompanying unit tests.
Link mentioned: torchtune/torchtune/_cli/download.py at 16b7c8e16ade9ab0dc362f1ee2dd7f0e04fc227c · pytorch/torchtune: A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub.
Torchtune ▷ #dev (6 messages):
- Dependencies Versioning on Torchtune: Members discussed the importance of being explicit about dependency versioning in the installation instructions for Torchtune. Suggestions included recommending users to ensure they have the latest stable version of PyTorch installed and linking to relevant issues like Issue #1071, Issue #1038, and Issue #1034.
- Supporting PyTorch Nightlies: It was noted that many features in Torchtune are only supported with PyTorch nightlies, and this should be explicitly mentioned somewhere for users to get the fullest feature set.
- Upcoming PR for Installation Instructions: A member mentioned their intention to create a PR to update the installation instructions and address dependency versioning and the use of PyTorch nightly builds.
Links mentioned:
AI Stack Devs (Yoko Li) ▷ #ai-companion (5 messages):
- **Interest in Stellar Blade and Studio's Approach**: A member asked another to share thoughts on **Stellar Blade**, particularly the studio's stance against western **SJW** (social justice warriors). Another member replied expressing support for any developer who focuses on making a good game over "wokeness."
- **Chinese Developers' Attitude Towards DEI**: One member pointed out that **Chinese developers** typically do not concern themselves with feminism and DEI (Diversity, Equity, and Inclusion). They expressed approval of this attitude, emphasizing a focus on the game itself.
- **South Korean Developers and Feminism**: The discussion shifted to **Shift Up**, a South Korean studio developing **Stellar Blade**. Another member commented on South Korea's issues with feminism and low birth rates, describing the studio's approach as *"quite refreshing."*
AI Stack Devs (Yoko Li) ▷ #ai-town-discuss (8 messages🔥):
-
Building an AI-Powered "Among Us" Mod: A member expressed interest in another's project of building an interactive "Among Us" mod using AI Town, describing it as "super interesting". They inquired about the progress and any performance issues or limitations encountered.
-
Bare Bones but Effective: Another member mentioned that the project was still in a rudimentary state, noting, "It's obviously very bare bones, but AI Town was really great for this". They faced some limitations but intentionally kept the scope small.
-
Switch to Godot for Advanced Features: They shared that they moved to Godot to implement new features since they needed tools provided by a game editor. They highlighted that despite initially facing limitations, the project had foundational success using AI Town.
-
AI Town Receives Further Development: They acknowledged that another member has pushed AI Town forward, indicating ongoing advancements in the project.
OpenInterpreter ▷ #general (11 messages🔥):
-
Curious about Desktop UIs for Open Interpreter: A member asked whether there's any desktop UI available for the Open Interpreter. No answer was provided in the thread.
-
Dealing with Posthog Connection Errors: "Does anyone know how to ignore these Backing off send_request(...) for (requests.exceptions.ConnectionError)" noted a user. This highlights issues with connecting to
us-api.i.posthog.com. -
Inquires about OpenAPI Specs and Function Calling: Members discussed whether Open Interpreter can take in existing OpenAPI specs for function calling. It included a suggestion that it might be possible by setting a true/false value in the configuration.
-
Struggles with Gorilla 2 LLM and Tool Use in LM Studio: One member shared difficulties "gettin ANY succes with tool use in LM Studio", specifically referencing custom JSON output and OpenAI toolcalling. Encouragement was given to check out an OI Streamlit repo on GitHub for potential solutions.
OpenInterpreter ▷ #O1 (1 messages):
ashthescholar.: yes, look at OI’s website
DiscoResearch ▷ #mixtral_implementation (2 messages):
-
Clearing the Mixtral expert myth: A YouTube video shared (link) clarifies a common misconception. The video states "There are 8 experts in each layer, with 32 layers, resulting in 256 experts", contradicting the myth of only 8 experts in Mixtral.
-
Impressive parameter count in Mixtral: The video further reveals that Mixtral has 46.7 billion parameters. Each token gets to interact with 12.9 billion active parameters.
DiscoResearch ▷ #general (1 messages):
sinan2: What are the intuitional benefits vs RKWV vs Transformers?
DiscoResearch ▷ #discolm_german (8 messages🔥):
- Confusion over current DiscoLM models: A member expressed confusion about which DiscoLM model is the current flagship, noting that there are many models now. Another member recommended using 8b llama for a setup with 3GB VRAM.
- Running Mixtral 8x7b on limited VRAM: A user mentioned they can run a Q2-k quant of Mixtral 8x7b at a rate of 6-7 tokens per second on their setup with 3GB VRAM. This setup limits the choice of models to those that are more memory-efficient.
- Exploring Vagosolutions models: Another member considered revisiting Vagosolutions' models, noting that previous experiences showed inferior performance but recent benchmarks indicate potential improvements. They debated whether a finetune of Mixtral 8x7b would outperform a Mistral 7b finetune.
Datasette - LLM (@SimonW) ▷ #ai (5 messages):
-
LLMs might integrate into web platforms: A member shared a link suggesting that LLMs might soon be integrated into the web platform. Another noted that Firefox is integrating transformers.js, referencing a post on local alt-text generation.
-
AI integration at the OS level is the end game: A user opined that the ultimate goal might be integrating AI at the OS level, suggesting a deeper level of integration beyond web platforms.
-
Prompt injection for email manipulation: Another user shared a link to an example of effective prompt injection usage. They also shared their own experience of using a similar prompt injection in their LinkedIn profile to manipulate email addresses, though it mostly resulted in spam.
Links mentioned:
Datasette - LLM (@SimonW) ▷ #llm (4 messages):
-
Exploring Concept Velocity in Text: A member shared a blog post from Interconnected.org discussing visualizing embeddings and the intriguing idea of measuring the velocity of concepts in text. They expressed interest in applying these ideas to their astronomy news data, noting that the process is "meandering" and "technical."
-
Dimensionality Reduction for Embeddings: They found a helpful Medium blog post that explains dimensionality reduction techniques like PCA, t-SNE, and UMAP to visualize high-dimensional token embeddings. They successfully visualized 200 astronomy news articles using these techniques.
-
Clustering Results Improve with UMAP: Initially using PCA, they labeled main categories generated by GPT-3.5, noting clustering of news topics like Chang'e 6 moonlander and Starliner. They found that UMAP gave much better clustering results compared to PCA.
Links mentioned:
tinygrad (George Hotz) ▷ #general (2 messages):
- Question about Taylor Series bounty requisites: A user asked about the requisites for the Taylor series bounty. George Hotz responded, seemingly puzzled, by asking, "why do you think there's requisites?"
tinygrad (George Hotz) ▷ #learn-tinygrad (2 messages):
<ul>
<li><strong>Questioning Proof Validity</strong>: A member asked, "How does this proof prove anything?", indicating a challenge in understanding the logic or result of a proof.</li>
<li><strong>Can Symbolic Shape Dim Be Zero?</strong>: Another member asked whether a symbolic shape dimension can ever be 0, probing into the constraints of symbolic representations.</li>
</ul>
LLM Perf Enthusiasts AI ▷ #resources (1 messages):
potrock: This is so good. Thank you!
{% else %}
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: [{{ email.subject }}]({{ email_url }})!
If you enjoyed AInews, please share with a friend! Thanks in advance!
{% endif %}