AI News for 6/20/2024-6/21/2024. We checked 7 subreddits, 384 Twitters and 30 Discords (415 channels, and 2822 messages) for you. Estimated reading time saved (at 200wpm): 287 minutes. You can now tag @smol_ai for AINews discussions!
In a concise 962 word blogpost, Noam Shazeer returned to writing to explain how Character.ai serves 20% of Google Search Traffic for LLM inference, while reducing serving costs by a factor of 33 (compared to late 2022), estimating that leading commercial APIs would cost at least 13.5X more:
Memory-efficiency: "We use the following techniques to reduce KV cache size by more than 20X without regressing quality. With these techniques, GPU memory is no longer a bottleneck for serving large batch sizes."
- MQA > GQA: "reduces KV cache size by 8X compared to the Grouped-Query Attention adopted in most open source models." (Shazeer, 2019)
- Hybrid attention horizons: a 1:5 ratio of local (sliding window) attention layers to global (Beltagy et al 2020)
- Cross Layer KV-sharing: local attention layers share KV cache with 2-3 neighbors, global layers share cache across blocks. (Brandon et al 2024)
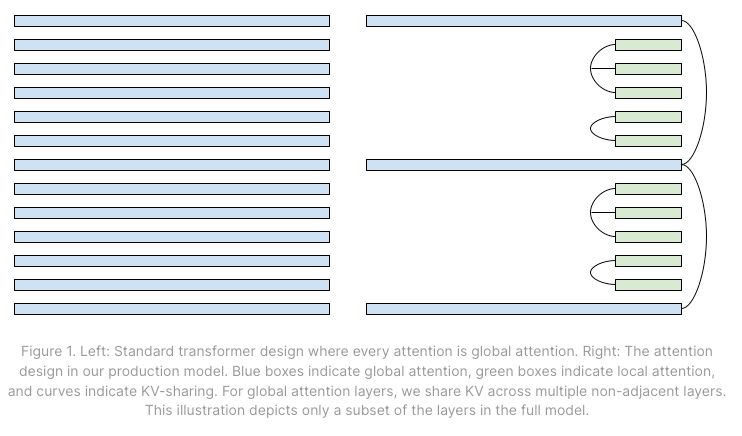
Stateful Caching: "On Character.AI, the majority of chats are long dialogues; the average message has a dialogue history of 180 messages... To solve this problem, we developed an inter-turn caching system."
- Cached KV tensors in a LRU cache with a tree structure (RadixAttention, Zheng et al., 2023) At a fleet level, we use sticky sessions to route the queries from the same dialogue to the same server. Our system achieves a 95% cache rate.
- Native int8 precision: as opposed to the more common "post-training quantization". Requiring their own customized int8 kernels for matrix multiplications and attention - with a future post on quantized training promised.
{% if medium == 'web' %}
Table of Contents
[TOC]
{% else %}
The Table of Contents and Channel Summaries have been moved to the web version of this email: [{{ email.subject }}]({{ email_url }})!
{% endif %}
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
Claude 3.5 Sonnet Release by Anthropic
- Improved Performance: @AnthropicAI released Claude 3.5 Sonnet, outperforming competitor models on key evaluations at twice the speed of Claude 3 Opus and one-fifth the cost. It shows marked improvement in grasping nuance, humor, and complex instructions. @alexalbert__ noted it passed 64% of internal pull request test cases, compared to 38% for Claude 3 Opus.
- New Features: @AnthropicAI introduced Artifacts, allowing generation of docs, code, diagrams, graphics, and games that appear next to the chat for real-time iteration. @omarsar0 used it to visualize deep learning concepts.
- Coding Capabilities: In @alexalbert__'s demo, Claude 3.5 Sonnet autonomously fixed a pull request. @virattt highlighted the agentic coding evals, where it reads code, gets instructions, creates an action plan, implements changes, and is evaluated on tests.
LLM Architecture and Scaling Discussions
- Transformer Dominance: @KevinAFischer argued transformers will continue to scale and dominate, drawing parallels to silicon processors. He advised against working on alternative architectures in academia.
- Scaling and Overfitting: @SebastienBubeck discussed challenges in scaling to AGI, noting models may overfit capabilities at larger scales rather than discovering desired "operations". Smooth scaling trajectories are not guaranteed.
- Importance of Architecture: @aidan_clark emphasized the importance of architecture work to enable current progress, countering views that only scaling matters. @karpathy shared a 94-line autograd engine as the core of neural network training.
Retrieval, RAG, and Context Length
- Long-Context LLMs vs Retrieval: Google DeepMind's @kelvin_guu shared a paper analyzing long-context LLMs on retrieval and reasoning tasks. They rival retrieval and RAG systems without explicit training, but still struggle with compositional reasoning.
- Infini-Transformer for Unbounded Context: @rohanpaul_ai highlighted the Infini-Transformer, which enables unbounded context with bounded memory using a recurrent-based token mixer and GLU-based channel mixer.
- Improving RAG Systems: @jxnlco discussed strategies to improve RAG systems, focusing on data coverage and metadata/indexing capabilities to enhance search relevance and user satisfaction.
Benchmarks, Evals, and Safety
- Benchmark Saturation Concerns: Some expressed concerns about benchmarks becoming saturated or less useful, such as @polynoamial on GSM8K and @arohan on HumanEval for coding.
- Rigorous Pre-Release Testing: @andy_l_jones highlighted @AISafetyInst's testing of Claude 3.5 pre-release as a first for a government assessing a frontier model before release.
- Evals Enabling Fine-Tuning: @HamelHusain shared a slide from @emilsedgh on how evals set up for fine-tuning, creating a flywheel effect.
Multimodal Models and Vision
- Differing Multimodal Priorities: @_philschmid compared recent releases, noting OpenAI and DeepMind prioritized multimodality while Anthropic focused on improving text capabilities in Claude 3.5.
- 4M-21 Any-to-Any Model: @mervenoyann unpacked EPFL and Apple's 4M-21 model, a single any-to-any model for text-to-image, depth masks, and more.
- PixelProse Dataset for Instructions: @tomgoldsteincs introduced PixelProse, a 16M image dataset with dense captions for refactoring into instructions and QA pairs using LLMs.
Miscellaneous
- DeepSeek-Coder-V2 Browser Coding: @deepseek_ai showcased DeepSeek-Coder-V2's ability to develop mini-games and websites directly in the browser.
- Challenges Productionizing LLMs: @svpino noted companies pausing LLM efforts due to challenges in scaling past demos. However, @alexalbert__ shared that Anthropic engineers now use Claude to save hours on coding tasks.
- Mixture of Agents Beats GPT-4: @corbtt introduced a Mixture of Agents (MoA) model that beats GPT-4 while being 25x cheaper. It generates initial completions, reflects, and produces a final output.
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity. Comment crawling works now but has lots to improve!
Claude 3.5 Sonnet Release
- Impressive performance: In /r/singularity, Claude 3.5 Sonnet was released by Anthropic and outperforms GPT-4o and other models on benchmarks like LiveBench and GPQA. It also solved 64% of agentic coding problems compared to 38% for Claude 3 Opus in an internal evaluation.
- Vision reasoning abilities: Claude 3.5 Sonnet outperforms GPT-4o on visual tasks, showcasing impressive vision reasoning abilities.
- UI enhancements: In addition to performance improvements, Claude 3.5 Sonnet comes with UI enhancements as noted in /r/LocalLLaMA.
- Promising writing partner: Early tests shared in a YouTube video suggest Claude 3.5 Sonnet shows promise as a writing partner.
OpenAI and Competition
- Desire for competition: In /r/OpenAI, some express a desire for OpenAI to have a model competitive with Claude 3.5 Sonnet to maintain competition and progress in the field.
- Criticism and distrust: OpenAI is facing criticism and distrust over issues like dismissing safety concerns, breaking compute commitments, and the delayed voice model.
Other AI Model Releases and Benchmarks
- Models from China: Over half of recent large language models are coming from China, as noted in /r/singularity.
- Aider benchmark: DeepSeek Coder V2 and Sonnet 3.5 top the Aider benchmark leaderboard, according to a post in /r/LocalLLaMA.
- Florence-2 vision model: Microsoft released Florence-2, a versatile open-source vision model that can handle multiple tasks in a unified way, as shared in /r/OpenAI.
Stable Diffusion and Image Generation
- Stable Diffusion 3 for cars: In /r/StableDiffusion, the Stable Diffusion 3 medium model is considered good at following prompts for generating cars and other subjects, though anatomy and consistency need work.
- Consistent scenes with SD XL: A Reddit video post demonstrates how combining Stable Diffusion XL with img2img and other techniques enables generating consistent scenes and characters.
Memes and Humor
- ChatGPT users leaving for Claude: A meme in /r/singularity jokes about ChatGPT users leaving for Claude after seeing the 3.5 Sonnet update.
AI Discord Recap
SPECIAL NOTE: As we do for fresh frontier model launches, we are displaying the differences in output from running the same prompts across Claude 3.5 and 3 and GPT4o.
Claude 3 Sonnet
1. LLM Advancements and Benchmarking
-
Meta's Llama 3 has topped leaderboards like ChatbotArena, outperforming GPT-4-Turbo and Claude 3 Opus as mentioned in this Discord discussion.
-
IBM's Granite-8B-Code-Instruct and DeepSeek's DeepSeek-V2 (236B params) were highlighted in this channel for code abilities.
-
Skepticism was expressed in this research channel about certain benchmarks, calling for credible sources to set realistic standards.
2. Optimizing LLM Inference and Training
-
ZeRO++ promising 4x faster GPU training was discussed in this channel.
-
The vAttention paper on efficient KV-caching was mentioned here.
-
QServe using W4A8KV4 quantization for GPU serving was brought up in this discussion.
-
Techniques like Consistency LLMs exploring parallel decoding were mentioned in this channel.
3. Open-Source AI Frameworks and Community Efforts
-
Andrew Ng's course on LlamaIndex for building agentic RAG systems was mentioned in this channel.
-
The open-source RefuelLLM-2 was introduced in this discussion as a top model for "unsexy" tasks.
-
Modular's Mojo and its potential for AI extensions were teased here.
4. Multimodal AI and Generative Modeling
-
Idefics2 8B Chatty for chat and CodeGemma 1.1 7B for coding were discussed in this channel.
-
Combining Pixart Sigma, SDXL and PAG to achieve DALLE-3 outputs was proposed in this generative AI discussion.
-
The IC-Light open-source project on image relighting was shared in this channel.
Claude 3.5 Sonnet
1. AI Model Releases and Performance Comparisons
-
New Models Claim Benchmark Victories: Nous Research's Hermes 2 Theta 70B and Turbcat 8b both claim to outperform larger models like Llama-3 Instruct on various benchmarks. Users across Discord channels discussed these releases, comparing their capabilities to established models like GPT-4 and Claude.
-
Claude 3.5 Sonnet Generates Mixed Reactions: Discussions in multiple Discords highlighted Claude 3.5 Sonnet's improved Python coding abilities, but some users found it lacking in JavaScript tasks compared to GPT-4. The model's ability to handle obscure programming languages was noted in the Nous Research Discord.
-
Code-Focused Models Gain Traction: The release of DeepSeek Coder v2 sparked conversations about specialized models for coding tasks, with claims of performance comparable to GPT4-Turbo in this domain.
2. AI Development Tools and Infrastructure Challenges
-
LangChain Alternatives Sought: A blog post detailing Octomind's move away from LangChain resonated across multiple Discords, with developers discussing alternatives like Langgraph for AI agent development.
-
Hardware Limitations Frustrate Developers: Discussions in the LM Studio and CUDA MODE Discords highlighted ongoing challenges with running advanced LLMs on consumer hardware. Users debated the merits of various GPUs, including NVIDIA's 4090 vs. the upcoming 5090, and explored workarounds for memory constraints.
-
Groq's Whisper Performance Claims: Groq's announcement of running the Whisper model at 166x real-time speeds generated interest and skepticism across channels, with developers discussing potential applications and limitations.
3. Ethical Concerns in AI Industry Practices
-
OpenAI's Government Collaboration Raises Questions: A tweet discussing OpenAI's early access provision to government entities sparked debates across multiple Discords about AI regulation and AGI safety strategies.
-
Perplexity AI Faces Criticism: A CNBC interview criticizing Perplexity AI's practices led to discussions in various channels about ethical considerations in AI development and deployment.
-
OpenAI's Public Relations Challenges: Members in multiple Discords, including Interconnects, discussed repeated PR missteps by OpenAI representatives, speculating on their implications for the company's public image and internal strategies.
Claude 3 Opus
1. Model Performance Optimization and Benchmarking
-
[Quantization] techniques like AQLM and QuaRot aim to run large language models (LLMs) on individual GPUs while maintaining performance. Example: AQLM project with Llama-3-70b running on RTX3090.
-
Efforts to boost transformer efficiency through methods like Dynamic Memory Compression (DMC), potentially improving throughput by up to 370% on H100 GPUs. Example: DMC paper by @p_nawrot.
-
Discussions on optimizing CUDA operations like fusing element-wise operations, using Thrust library's
transformfor near-bandwidth-saturating performance. Example: Thrust documentation. -
Comparisons of model performance across benchmarks like AlignBench and MT-Bench, with DeepSeek-V2 surpassing GPT-4 in some areas. Example: DeepSeek-V2 announcement.
2. Fine-tuning Challenges and Prompt Engineering Strategies
-
Difficulties in retaining fine-tuned data when converting Llama3 models to GGUF format, with a confirmed bug discussed.
-
Importance of prompt design and usage of correct templates, including end-of-text tokens, for influencing model performance during fine-tuning and evaluation. Example: Axolotl prompters.py.
-
Strategies for prompt engineering like splitting complex tasks into multiple prompts, investigating logit bias for more control. Example: OpenAI logit bias guide.
-
Teaching LLMs to use
<RET>token for information retrieval when uncertain, improving performance on infrequent queries. Example: ArXiv paper.
3. Open-Source AI Developments and Collaborations
-
Launch of StoryDiffusion, an open-source alternative to Sora with MIT license, though weights not released yet. Example: GitHub repo.
-
Release of OpenDevin, an open-source autonomous AI engineer based on Devin by Cognition, with webinar and growing interest on GitHub.
-
Calls for collaboration on open-source machine learning paper predicting IPO success, hosted at RicercaMente.
-
Community efforts around LlamaIndex integration, with issues faced in Supabase Vectorstore and package imports after updates. Example: llama-hub documentation.
GPT4O (gpt-4o-2024-05-13)
-
AI Model Performance and Training Techniques:
-
Gemini 1.5 excels with 1M tokens: Gemini 1.5 Pro impressed users by handling up to 1M tokens effectively, outperforming other models like Claude 3.5 and gaining positive feedback for long-context tasks. This model's ability to process extensive documents and transcripts was highlighted.
-
FP8 Flash Attention and GPTFast speed up inference: Discussions around INT8/FP8 kernels in flash attention and the recently introduced GPTFast indicated significant boosts in HF model inference speeds by up to 9x. Notable mentions included an open-source FP8 flash attention addition, set to receive official CUDA support in 12.5.
-
Null-shot prompting and DPO over RLHF: Community debates touched on the efficacy of null-shot prompting to exploit hallucinations in LLMs and the shift from Reinforcement Learning with Human Feedback (RLHF) to Direct Policy Optimization (DPO) for simplified training. Paper references included the concept's advantages in the LLMs' task performance.
-
-
AI Ethics and Accessibility:
-
AI Ethics spark debate: A Nature article criticizing OpenAI's departure from open-source principles stirred discussions on AI transparency and accessibility. Concerns were raised over the increasing difficulty of accessing cutting-edge AI tools and code.
-
Avoiding insincere AI apologies: Users voiced frustration with AI-generated apologies, calling them insincere and unnecessary. This sentiment reflected broader expectations for more authentic and practical AI interactions rather than automated expressions of regret.
-
OpenAI and government collaboration concerns: Concerns mounted over OpenAI's early model access for government entities, highlighted in a tweet. The conversation pointed to potential regulatory implications and strategic shifts towards AGI safety.
-
-
Open-Source AI Developments and Community Contributions:
-
Introducing Turbcat 8b: Announcements of the Turbcat 8b model included notable improvements like expanded datasets and added Chinese support. The model now boasts 5GB in data, with comparisons drawn against larger yet underdeveloped models.
-
Axolotl and Backgammon AI Tool: Collaboration efforts highlighted the open-sourced Backgammon AI tool, which simulates scenarios in backgammon for strategic enhancements. Discussions also included the Turbcat model and its functionalities for multilingual processing.
-
Dataset for computer vision from Stability.ai: Stability.ai released a dataset featuring 235,000 prompts and images from the Stable Diffusion community. This StableSemantics dataset aims to augment computer vision systems by providing extensive visual semantics data.
-
-
Hardware and Deployment Challenges:
-
GPU usage challenges and optimizations: Engineers shared insights and solutions for optimizing GPU and CPU integrations in different setups, such as enabling the second GPU for LM Studio and discussing alternatives for running sophisticated models. Used 3090s were recommended for cost efficiency, anticipating performance comparisons between NVIDIA 4090 and 5090.
-
TinyGrad's tangles with
clip_grad_norm_: Implementingclip_grad_norm_in TinyGrad faced bottlenecks due to Metal's buffer size limitations, suggesting division into 31-tensor chunks as a workaround. The comparison between Metal and CUDA highlighted performance differences, specifically for gradient clipping operations. -
Model deployment issues: Deployment challenges with models like Unsloth on platforms like Hugging Face created discussions around tokenizer compatibility and alternative deployment suggestions. Fine-tuning costs also varied dramatically between Together.ai and Unsloth's H100, raising questions about pricing errors.
-
-
Event Discussions and Professional Opportunities:
-
Techstars and RecSys Virtual Meetups: Upcoming events like the Techstars Startup Weekend in SF from June 28-30 and the RecSys Learners Virtual Meetup on June 29 were highlighted as opportunities for AI professionals to network, learn, and present innovative ideas. Details and RSVP links were shared for participants' convenience.
-
Job hunting and skill showcasing: Python AI Engineers actively sought job opportunities, emphasizing their skills in NLP and LLMs. Conversations also included insights into companies' support frameworks, like the Modal team's assistance with large models and developer preferences for Slack over Discord.
-
Talks and announcements at AI events: LlamaIndex's founder Jerry Liu's talks at the World's Fair on the future of knowledge assistants were promoted, with mentions of forthcoming special announcements on Twitter.
-
These discussions provide a comprehensive glance at the innovative, ethical, and practical aspects actively shaping the AI community.
PART 1: High level Discord summaries
OpenAI Discord
-
Gemini 1.5 Steps Up in Token Game: Gemini 1.5 Pro shines in handling long-context tasks with an impressive ability to process up to 1M tokens. Users appreciated its expertise on various topics when fed with documents and transcripts, though it comes with some access restrictions.
-
AI Ethics Debate Heats Up: A Nature article prompted discussions on the implications of AI model openness, sparking critique of OpenAI's shift from open-source principles. The conversation pointed to broader concerns about the accessibility of AI tools and code.
-
Finding Balance in Apologies: Several users voiced their annoyance with the frequency of AI's apologetic responses, deriding the insincerity of machines offering regret. This reflects a broader dissatisfaction with how AI personas handle errors.
-
Mac Preference for AI Developers: A user advocating for MacBooks signifies a strong preference within the development community, highlighting ease-of-use in development environments. While Windows Surface laptops were mentioned as contenders for hardware and design, the development experience on Windows was implicitly criticized.
-
Dall-E 3 Tackles Complex Imagery: Dall-E 3's capabilities were tested by users attempting to generate intricate images with specific attributes like asymmetry and precise placements, with mixed results. Notably, the OpenAI macOS app received praise for its integration with typical Mac workflows, suggesting a tool that aligns with the productivity preferences of AI professionals.
CUDA MODE Discord
-
INT8/FP8 Shakes Up Performance: A resurgence in discussions on INT8/FP8 flash attention kernels was inspired by a HippoML blog post, though code is currently not released for public benchmarking or integration with torchao. Meanwhile, an open source FP8 addition to flash attention was noted, referencing the Cutlass Kernels GitHub and the pending Ada FP8 support in CUDA 12.5.
-
GPTFast Paves the Way for Hasty Inference: The creation of GPTFast, a pip package boosting inference speeds for HF models by a factor of up to 9x, includes features like
torch.compile, key-value caching, and speculative decoding. -
GPU Optimization Nuggets Revealed: A discovery of old slides explaining GPU limitations, specifically about Llama13B's incompatibility with 4090 GPUs, encouraged further discussion on optimizing memory usage with LoRA. Additionally, a recent presentation offers strategies for managing GPU vRAM, benchmarking using torch-tune, and optimizing memory.
-
Stabilizing the Sync and Dance of NCCL: Experimentation in the NCCL realm raised flags over synchronization issues, with a proposed shift away from MPI to filesystem-based sync as per the NCCL Communicators Guide. Opinions diverged on the practicality of CUDA's managed memory, balancing code cleanliness against performance, and the emergence of training instabilities prompted a look into research on loss spikes (Loss Spikes Paper).
-
Intricacies in AI Benchmarking Techniques: The accuracy of processing time benchmarks was tackled with techniques such as
torch.cuda.synchronizeandtorch.utils.benchmark.Timer, and specific best practices were squinted at in the Triton's evaluation code, stressing the importance of L2 cache clearing prior to measurement.
Stability.ai (Stable Diffusion) Discord
-
Community Reacts to Channel Cuts: Many members voiced frustration regarding the deletion of underused channels, especially since these were used as a source of inspiration and community interaction. While Fruit mentioned that less active channels tend to attract bot spam, some participants are still looking for a better understanding or a possible restoration of the archives.
-
UI Preferences in Stable Diffusion: A lively debate surfaced on the efficiency and usability of ComfyUI relative to other interfaces such as A1111, with some users favoring node-based workflows while others prefer interfaces with traditional HTML-based inputs. No consensus was reached, but the discussion highlighted the diversity of preferences in the community with respect to UI design.
-
New Dataset Release for Computer Vision: A new dataset with 235,000 prompts and images, derived from the Stable Diffusion Discord community, was announced, aimed at improving computer vision systems by providing insights into the semantics of visual scenes. The dataset is accessible at StableSemantics.
-
Debate Over Channel Management: The decision to delete certain lower-activity channels sparked widespread debate, as users lost a valued resource for visual archives, and are seeking clarity on the criteria used for channel removal.
-
Exploring Stable Diffusion Tools: Users shared experiences and resources related to different Stable Diffusion interfaces, including ComfyUI, Invoke, and Swarm, as well as providing guides to assist newcomers in navigating these tools. Conversation threads provided comparisons and personal preferences, aiding others in selecting suitable interfaces for their workflows.
Perplexity AI Discord
-
AI Models' Exhibition Match: Interactions within the Discord guild showcased members comparing AI models like Opus, Sonnet 3.5, and GPT4-Turbo, with a spotlight on Sonnet 3.5 matching Opus's performance and discussing the usage of a Complexity extension for switching between these models efficiently.
-
Model Access Quandary: Users debated on the actual availability of Claude 3.5 Sonnet across different devices and expressed concerns over usage limitations like the 50 uses per day cap on Opus, which is stifling users' willingness to engage with the model.
-
Decoding Inference Hardware: Engineers dissected the possible hardware used for AI inference, speculating between TPUs and Nvidia GPUs, with a nod to AWS's Trainium for its machine learning training efficiency.
-
Hermes 2 Theta Takes the Crown: Excitement was noted regarding the launch of Hermes 2 Theta 70B by Nous Research, surpassing competitor benchmarks and bolstering capabilities like function calling, feature extraction, and different output modes, drawing comparisons to GPT-4's proficiency.
-
API Management Simplified: A brief guide was shared on managing API keys, directing users to Perplexity settings to generate or delete keys easily, though a query about limiting API searches to specific websites remained unanswered.
HuggingFace Discord
Fancy OCR Work, Florence!: Engineers discussed the unexpected superior OCR capabilities of the Florence-2-base model over its larger counterparts; the findings elicited curiosity and the need for further verification. Surprisingly, the sophisticated model struggled with the seemingly simpler task, indicating a need to measure model capabilities beyond mere scale.
Face-Plant at HuggingFace HQ: Users experienced interruptions with the Hugging Face website, encountering 504 errors and affecting their workflow continuity. This hicriticaluptcy in a critical development resource caused temporary setbacks for users depending on the platform's services.
Helping Hands for AI Projects: Open-source AI projects are seeking collaborative efforts: the Backgammon AI tool aims to simulate backgammon scenarios, while the Nijijourney dataset offers robust benchmarking despite access issues due to its local storage of images.
Play and Contribute: An innovative game, Milton is Trapped, was shared where the objective is to interact with a grumpy AI. Developers are encouraged to contribute to this playful AI endeavor via its GitHub repository.
Ethical Computing Crossroads: An engaging paper highlighting the compromising dialogue between fairness and environmental sustainability in NLP underlines the industry's delicate balancing act. It points out the necessity for a holistic view when advancing AI technologies, where an emphasis on one aspect can inadvertently impair another.
Unsloth AI (Daniel Han) Discord
-
Token Troubles in Training: Engineers discussed an issue with EOS tokens in OpenChat 3.5, noting confusion between
<|end_of_turn|>and</s>during various stages of training and inference. For instance, "Unsloth uses<|end_of_turn|>while llama.cpp uses<|reserved_special_token_250|>as the PAD token." -
Price War: Unsloth vs. Together.ai: A price comparison revealed that fine-tuning on Together.ai may cost around $4,000 for 15 billion tokens, as shown by their interactive calculator. By contrast, using Unsloth's H100, the same task could be executed for under $15 in roughly 3 hours, triggering disbelief and speculations of a pricing error.
-
Favoring Phi-3-mini Over Mistral: Comparing models, one engineer reported better consistency with phi-3-mini than Mistral 7b, using training datasets of 1k, 10k, and 50k examples, framing data within training as the only acceptable response.
-
DPO Over RLHF for Simplified Training: Members considered abandoning Reinforcement Learning with Human Feedback (RLHF) for Direct Policy Optimization (DPO), supported by Unsloth, for being simpler and equally effective. One participant mentioned, "I think I will switch to DPO first." after learning more about its benefits.
-
Deployment Woes with Hugging Face: Users shared difficulties deploying Unsloth-trained models on Hugging Face Inference endpoints due to tokenizer issues, which led to inquiries about alternative deployment platforms.
Nous Research AI Discord
-
Hermes 2 Theta 70B Trumps the Giants: The newly announced Hermes 2 Theta 70B collaboration between Nous Research, Charles Goddard, and Arcee AI, claims performance that overshadows Llama-3 Instruct and even GPT-4. Key features include function calling, feature extraction, and JSON output modes, with an impressive 9.04 score on MT-Bench. More details are at Perplexity AI.
-
Claude 3.5 Masters Obscurity: The latest from Claude 3.5 reveals an ability to tackle problems in self-created obscure programming languages, surpassing established problem-solving parameters.
-
AI/Human Collaboration Insight: A shift is noticed, positioning AI usage from mere task execution towards forming a symbiotic working relationship with humans—a detailed thread is available at "Piloting an AI".
-
Strategic Use of Model Hallucinations: An arXiv paper describes how null-shot prompting might smartly exploit large language models' (LLMs) hallucinations, outperforming zero-shot prompting in task achievement.
-
Access Hermes 2 Theta 70B Now: Downloads for Hermes 2 Theta 70B - both in FP16 and quantized GGUF formats - are up for grabs on Hugging Face, ensuring wide accessibility for eager hands. Find the FP16 version and the quantized GGUF version ready for use.
LM Studio Discord
Squeeze More Power from Your GPUs: Engineers found setting the main_gpu value to 1 enables the second GPU for LM Studio on Windows 10 systems. A user was also successful in running vision models solely on CPU by disabling GPU acceleration and using OpenCL, despite slower performance.
Integrating Ollama Models Just Got Easier: For incorporating Ollama models into LM Studio, contributors are shifting from the llamalink project to the updated gollama project, though different presets and flash attention have been proposed to mitigate model gibberish issues.
Advanced Models Challenge Hardware Capabilities: Discussions revealed frustrations with running high-end LLMs on current hardware setups, even with 96GB of VRAM and 256GB of RAM. The community is also exploring used 3090s for cost efficiency and eagerly anticipates performance comparisons between NVIDIA's 4090 and the upcoming 5090.
Optimizing AI Workflows in the Face of Error: In the wake of usability challenges post-beta updates, engineers recommend leveraging nvidia-smi -1 to check for model loads into vRAM, and consider disabling GPU acceleration for stability in Docker environments.
Chroma and langchain Perfect Their Harmony: A BadRequestError with langchain and Chroma's integration was swiftly addressed with a fix in GitHub Issue #21318, proving the community's responsive problem-solving skills in maintaining seamless AI-operated workflows.
Modular (Mojo 🔥) Discord
Pixelated Meetings No More: Community members discussed resolution issues with community meetings streamed on YouTube, noting that while streams can reach 1440p, phone resolutions are often throttled to 360p, possibly due to internet speed restrictions.
MLIR Quest for 256-Bit Integers: In the quest for handling 256-bit operations for cryptography, one user attempted multiple MLIR dialects but faced hurdles, prompting them to consider internal advice, as syntactical support in MLIR or LLVM is not straightforward.
Kapa.ai Bot Glitches With Autocomplete: Users have been experiencing autocompletion inconsistencies with the Kapa.ai bot on Discord, suggesting that manual typing or dropdown selection might be more reliable until the erratic behavior is addressed.
Mojo's Winding Road to Exceptions: Conversations revealed pending implementation of exception handling in Mojo's standard library, with a roadmap document shedding light on future feature rollouts and current limitations (Mojo roadmap & sharp edges).
Navigating Nightly Build Turbulence: The nightly release of the Mojo compiler was disrupted due to branch protection rule changes, but a community member's commit to fix the compiler version mismatch helped stabilize the pipeline, leading to the successful roll-out of the new 2024.6.2115 release, as detailed in the changelog.
OpenRouter (Alex Atallah) Discord
-
Stripe Smoothes Over Payment Snafu: OpenRouter announced a resolved Stripe payment issue that temporarily prevented credits from being added to users' accounts. The resolution was stated as being "Fixed fully, for all payments."
-
Claude Calms Down After Outage: Anthropic’s inference engine, Claude, had a 30-minute outage resulting in a 502 error which has been fixed, confirmable via their status page.
-
App Listing Advice on OpenRouter: An OpenRouter user wanting to list their app was advised to follow the OpenRouter Quick Start Guide, which requires specific headers for app ranking.
-
Claude 3.5 Sonnet Stirs Up Excitement (and Debate): The release of Claude 3.5 Sonnet generated excitement for its improved Python abilities, while sparking debate about its JavaScript performance compared to GPT-4.
-
Perplexity Labs Brings Nemetron 340b into Play: Perplexity Labs offers access to their Nemetron 340b model, boasting a response time of 23t/s—members are encouraged to try it out. A query was raised about VS2022 extensions for OpenRouter, with Continue.dev mentioned as a compatible tool.
Eleuther Discord
- Epoch AI's New Datahaven: Epoch AI unveiled an updated datahub housing data on over 800 models, spanning from 1950 to the present day, fostering responsible AI development with an open Creative Commons Attribution license.
- Clarifying Samba from the SambaNova Conundrum: In a wave of new models, distinction emerged between the Microsoft hybrid model termed "Samba," focusing on a mamba/attention blend, and the SambaNova systems, separate entities in the AI model realm.
- GoldFinch Paper Teaser: The anticipated release of the GoldFinch paper will introduce a RWKV hybrid model with a unique super-compressed kv cache and full attention mechanism. Concerns about stability in the training phase were acknowledged for the mamba variant.
- Rethinking Loss Functions: Fascinating debates surfaced around the idea of models internally generating representations of their loss functions during the forward pass, potentially improving performance on tasks requiring an understanding of global properties.
- NumPy Nostalgia Necessitated, Colab to the Rescue: Discussions addressed incompatibilities between NumPy 2.0.0 and modules compiled with 1.x versions, leading to recommendations to either downgrade numpy or update modules, while others found refuge in Colab for specific task executions.
tinygrad (George Hotz) Discord
GPT's Weight Tying Woes: Discussions have surfaced around the proper implementation of weight tying in GPT architectures, noting issues with conflicting methods that cause separate optimization pitfalls and timing out due to a weight initialization method that interferes with weight tying.
TinyGrad's Tangled clip_grad_norm_: Implementing clip_grad_norm_ in TinyGrad is generating performance bottlenecks, predominantly due to Metal's limitations in buffer sizes, suggesting a workaround of dividing the gradients into 31-tensor chunks for optimal efficiency.
Juxtaposing Metal and CUDA: A comparison between Metal and CUDA revealed Metal's inferior handling of tensor operations, specifically gradient clipping. Proposed solutions for Metal involve internal scheduler enhancements to better manage resource constraints.
AMD Device Timeouts in the Hot Seat: Users are experiencing timeouts with AMD devices when running examples like YOLOv3 and ResNet, pointing towards synchronization errors and potential overloads on integrated GPUs such as the Radeon RX Vega 7.
Developer Toolkit Spotlight: A Weights & Biases logging link was shared for insights into TinyGrad's ML performance, showcasing the utility of developer tools in tracking and optimizing machine learning experiments. W&B Log for TinyGrad
LAION Discord
-
Caption Dropout Techniques Scrutinized: Engineers debated the effectiveness of using zeros versus encoded empty strings as caption dropout in SD3. No significant result changes were identified when encoded strings were used.
-
Sakuga-42M Dataset Hits a Wall: The Sakuga-42M Dataset paper was unexpectedly withdrawn, thwarting advances in cartoon animation research. Specific reasons for the withdrawal remain unclear.
-
OpenAI's Cozy Government Relations Raise Eyebrows: A tweet sparked discussions about OpenAI's early access to AI models for the government, prompting calls for increased regulatory measures and questions about strategy shifts towards AGI safety.
-
MM-DIT Global Incoherency Alerts: As conversations about MM-DIT arose, concerns about the impact of increasing latent channels on global coherency were emphasized, noting specific issues like inconsistent representations of scenes.
-
Dilemmas in Chameleon Model Optimization: While fine-tuning the Chameleon model, anomalously high gradient norms have been causing NaN values, resisting solutions like adjusting learning rates, applying grad norm clipping, or using weight decay.
Interconnects (Nathan Lambert) Discord
-
Quick Releases Raise Eyebrows: Discussions arose about the rapid release of new versions, with members questioning whether improvements are due to posttraining or pretraining and the contribution that pod training may have in this process.
-
PR Perils for OpenAI's Mira: Mira's repeated public relations mistakes drew criticism from community members, with some suggesting a lack to PR training while others see these errors as a strategy to draw attention away from OpenAI executives. The frustration was amplified by a Twitter incident and a shift by Nathan Lambert to using Claude.
-
CNBC Rattles Perplexity's Cage: A CNBC interview cast Perplexity in a negative light, referencing a Wired article that criticized the company's practices. The YouTube video sparked a wave of criticism against Perplexity, with others, including Casey Newton, joining the fray by criticizing the company's founder.
-
Search for Engagement: A brief post by ‘natolambert’ calling out for 'snail' suggests an ongoing conversation or a project that might require attention or input from the mentioned individual.
-
Writing Ideas Circulate: An interest in developing written work focusing on recent tech topics was noted – a plan that may involve collaborative efforts to deepen understanding.
OpenInterpreter Discord
-
Open Interpreter Boasts Cross-Platform Functionality: A demo revealed Open Interpreter working on both Windows and Linux, leveraging gpt4o via Azure, with further enhancements on the horizon.
-
Praise for Claude 3.5 Sonnet: An individual highlighted the superior communicative abilities and code quality of Claude 3.5 Sonnet, favoring it over GPT-4 and GPT-4o due to usability.
-
Guided Windows Installation for Open Interpreter: The setup documentation for Open Interpreter clarifies the installation process on Windows, which includes
pipinstallations and configuring optional dependencies. -
Introducing DeepSeek Coder v2: The announcement of DeepSeek Coder v2 indicated a robust model focused on responsible and ethical use, potentially on par with GPT4-Turbo for code-specific tasks.
-
Open Interpreter's macOS Favoritism: Discussions pointed out that Open Interpreter tends to perform better on macOS, attributed to the core team's extensive testing efforts on that platform.
-
AI's Sticky Situation Overcome: A user showcased a tweet representing a fully local, computer-controlling AI's capability to connect to WiFi by reading the password from a sticky note—a tangible leap in practical AI utility.
LLM Finetuning (Hamel + Dan) Discord
- Abandoning Abstractions: The Octomind team detailed in a blog post their departure from using LangChain for building AI agents, citing its rigid structures and difficulty in maintenance, while some members suggested Langgraph as a viable alternative.
- Cold Shoulder to LangChain: Discontent with LangChain was echoed, as it's said to present challenges in debugging and complexity.
- Modal Mavens Amass Acclaim: Members commended the Modal team's support with the BLOOM 176B model, thumbs up for their helpful approach, but one user expressed a preference for Slack over Discord.
- Praise for Eval Framework: A user heralded the eval framework as outstanding due to its ease of use and flexibility with custom enterprise endpoints, emphasizing excellent developer experience with its intuitive API design.
- Credit Confusion and Check-ins: Users are seeking assistance on unlocking credit systems and verifying email registrations, one specific email mention being "[email protected]".
LangChain AI Discord
Meet AI Innovators at Techstars SF: Engineers interested in startup development should consider attending the Techstars Startup Weekend from June 28-30 in San Francisco; keynotes and mentorships from industry leaders are on the roster. More about the event can be found here.
Reflexion Tutorial Confounds with Complexity: Concerns were raised about the use of PydanticToolsParser over simpler loops in the Reflexion tutorial, questioning the implications of validation failures — the tutorial can be referenced here.
AI Engineering Talent on the Market: An experienced AI engineer with proficiency in LangChain, OpenAI, and multi-modal LLMs is currently seeking full-time opportunities within the industry.
Streaming Headaches with LangChain: Difficulty streaming LangChain's/LangGraph's messages with Flask to a React application has prompted a user to seek community assistance, but a solution remains elusive.
Innovations and Interactions in AI: Two notable contributions include an article on Retrieval Augmentation with MLX, available here, and the introduction of 'Mark', a CLI tool enhancing the use of markdown with GPT models detailed here.
OpenAccess AI Collective (axolotl) Discord
- Bigger and Multilingual: Turbcat 8b Makes Waves: The Turbcat 8b model, which features a dataset increase from 2GB to 5GB and added Chinese support, was introduced, sparking interest and public access for users.
- Uncertain GPU Compatibility Sparks Discussion: Queries about the AMD Mi300x GPU's compatibility with Axolotl's platform remain unanswered; a user suggested awaiting release notes or updates for PyTorch 2.4 to confirm support.
- Model Superiority Debated: Comparisons between Turbcat 8b and an upcoming 72B model have begun, with users highlighting Turbcat's dataset size but recognizing the potential of the larger model still under development.
- Training Time Pay Attention to the Clock: While a simple formula was proposed to estimate training time for models, practitioners stressed the importance of real world runs to gather accurate estimates, accounting for epochs and buffer time for evaluation.
- Message Relocation - Less is More: A lone message in the datasets channel simply redirected users to the general-help channel, emphasizing the organization and focus on streamlined conversation within the community.
Cohere Discord
-
API Role Confusion Resolved: Discussion in the guild clarified that Cohere's current API lacks support for OpenAI-style roles like "user" or "assistant"; however, a future API update is expected to introduce these features to facilitate integration.
-
Incongruent APIs Challenge Developers: There is a debate about the incompatibility issues between Cohere's Chat API and OpenAI's ChatCompletion API, with concerns that differing API standards are obstructing seamless service integration among AI models.
-
Model-Swapping Skepticism: Members are worried about services such as OpenRouter, which may substitute cheaper models instead of the requested ones, and they recommend using direct prompt inspection and comparisons to ensure model accuracy.
-
Best Practices for Resource Utilization: An insightful blog post shared by a member encourages the practice of utilizing available resources rather than hoarding them, drawing an enlightening parallel between in-game item management and the real-world promotion of projects or asking for help.
LlamaIndex Discord
-
Look Who's Talking at the World's Fair: LlamaIndex founder Jerry Liu will present at the World's Fair on the Future of Knowledge Assistants, with some special announcements scheduled for June 26th at 4:53 PM, followed by another talk on June 27th.
-
Job Hunting with Python Prowess: A Python AI engineering pro, skilled in AI-driven applications and large language models (LLMs), is on the job hunt, boasting proficiency in NLP, Transformers, PyTorch, and TensorFlow.
-
Graph Embedding Queries Spark Interest: Queries were raised regarding embedding generation for Neo4jGraphStore, emphasizing the integration of embeddings in an existing graph structure without initial LLMs usage.
-
LlamaIndex Extension Quest: Users explored how to extend LlamaIndex with practical functionalities such as emailing, Jira integrations, and calendar events, with a nod towards using custom agents documentation for guidance.
-
NER Needs and Model Merging Musings: Ollama and LLMs were discussed for Named Entity Recognition (NER) tasks, with one member suggesting a shift to Gliner; additionally, a novel "cursed model merging" technique involving UltraChat and Mistral-Yarn was debated.
Latent Space Discord
-
Swyx Pinpoints AI's Next Frontier: Shawn "swyx" Wang delves into new opportunities for AI in software development, emphasizing upcoming use cases in an article, and spotlights the AI Engineer World’s Fair as a key event for industry professionals.
-
Groq Takes on Real-time Whispering: Groq asserts their platform can execute the Whisper model at 166x real-time, sparking discourse on its implications for high-efficiency podcast transcription and potential challenges with rate limits.
-
Tuned In: Seeking Music-to-Text AI: A discussion emerged about AI systems capable of translating music into textual descriptions that detail genre, key, and tempo, highlighting a gap in the market for services that go beyond lyric generation.
-
Mixing It Up with MoA: The Mixture of Agents (MoA) model is unveiled, boasting costs 25x less than GPT-4 yet receiving a higher preference rate of 59% in human comparison tests; it also sets new benchmark records as tweeted by Kyle Corbitt.
AI Stack Devs (Yoko Li) Discord
Spam Strikes in AI Town: Community members have reported a user, <@937822421677912165>, for multiple spam incidents across different channels, prompting calls for moderator intervention. The situation escalated as members expressed frustration, with one stating "wtf what's wrong with u" and encouraging others to report the behavior to Discord.
MLOps @Chipro Discord
-
Catch the RecSys Wave: A RecSys Learners Virtual Meetup is calling for attendees for its event on 06/29/2024, slated to begin at 7 AM PST, offering an opportunity for affinity groups in Recommendation Systems to converge. Engineers and AI aficionados can RSVP for the meetup which promises a blend of exciting and informational sessions.
-
AI Quality Conference Curiosity: Queries were raised about attendance for the upcoming AI Quality Conference scheduled in San Francisco next Tuesday, with a member seeking additional details about the conference's offerings and themes.
Torchtune Discord
- Debating Data Structures in PyTorch: A member sought insights on whether to use PyTorch's TensorDict or NestedTensor for handling multiple data inputs. The consensus highlighted the efficiency of these structures in streamlining operations by avoiding repetitive code for data type conversions and device handling, and simplifying broadcasting over batch dimensions.
The LLM Perf Enthusiasts AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Datasette - LLM (@SimonW) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The YAIG (a16z Infra) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
{% if medium == 'web' %}
OpenAI ▷ #ai-discussions (597 messages🔥🔥🔥):
- Gemini 1.5 dominates long-context tasks: Users discussed the advantages of Gemini 1.5 Pro over GPT-4, particularly noting its ability to process 1M tokens effectively and free access with some limitations. As one member noted, "i paste the documents youtube transcripts... and it acts as an expert on this topic".
- Fun with Claude Sonnet 3.5: Several users shared their experiences with Claude Sonnet 3.5, noting its superior performance in handling nuanced debates and large code generation. One member highlighted, "In 3 prompts I had a driving game, with upgrade system and details like smoke coming out of the car when it crashed".
- Open source AI models under discussion: An article from Nature sparked discussions about AI model openness, with some users expressing disappointment in OpenAI's move away from their original open-source stance.
- Critiques on Claude and OpenAI's Services: Users compared Claude 3.5 Sonnet and GPT-4, expressing mixed feelings about both, particularly around Swift coding and integration features like artifacts. "Claude was ok with Python but... ChatGPT can run code whereas Claude can't," noted one member.
- Calls for AI to Stop Apologizing: Several members expressed frustration with AI-generated apologies, finding them overused and unnecessary. One noted, "how can an ai feel sorrow for a mistake? It can't feel! My screwdriver doesn't apologize when it strips a screw!"
Links mentioned:
OpenAI ▷ #gpt-4-discussions (6 messages):
- **Windows Surface laptops suggested but development in Windows not preferred**: A member suggested that the closest hardware and aesthetics to what another user is looking for are the newest Surface laptops but noted, *"have fun developing in windows."* The member hinted at a preference for MacBook for development.
- **Budget-buying advice given**: For a $900 budget, a member suggested a *"refurbished MacBook Air maybe."* Another suggestion was to join a server like *buildapc* for more tailored advice.
OpenAI ▷ #prompt-engineering (11 messages🔥):
- Hack silence and pauses into ChatGPT: A user discovered that inserting sequences like ". ? . ?" can create pauses of varying lengths in ChatGPT's responses when in voice mode. They shared examples for applications like suspenseful storytelling and guided meditation.
- Dall-E 3 struggles with specific placements: A user attempted to direct Dall-E 3 to place a cat on a specific side of an image but found it did not follow the instructions accurately. Despite better performance reportedly seen on the macOS app, specific placements remain challenging.
- macOS app praised for seamless integration: Another user expressed their appreciation for how well the OpenAI macOS app integrates with Mac workflows, calling it a well-executed tool. They highlighted its alignment with typical Mac user practices.
- Grunge cyberpunk and asymmetry challenges: Several users experimented with generating complex images like a "grunge cyberpunk anime billboard" and discussed the challenges of achieving specific visual effects like symmetry in "quintessential 'backrooms'" images. These challenges include managing focus distance and maintaining coherence in detailed prompts.
OpenAI ▷ #api-discussions (11 messages🔥):
-
Create pauses in ChatGPT with ". ? .?" sequence: A member shared a method to create pauses or silence in ChatGPT using the sequence ". ? . ?", scaling this to any duration. They provided examples for applications like suspense-filled storytelling and interactive meditation.
-
DALL-E 3 struggles with precise positioning: Attempting to position a cat in a specific side of the frame using DALL-E 3 did not yield accurate results. Outputs were not on the specified side despite efforts in different applications.
-
Praise for the MacOS OpenAI app: Users expressed their satisfaction with the MacOS OpenAI app, noting how well it integrates into Mac workflows. One mentioned the smooth execution of the application by OpenAI.
-
Challenge DALL-E 3 with complex prompts: Suggestions were made to test DALL-E 3's abilities with complex prompts such as creating an asymmetrical hallway like the 'backrooms' image for a real challenge. Focus distance and adding longer texts, like 300-character descriptions, were also discussed as potential hurdles.
CUDA MODE ▷ #general (9 messages🔥):
-
INT8/FP8 Flash Attention Kernels Topic Resurfaces: A member queried about the availability of INT8/FP8 flash attention kernels. They referenced a HippoML blog post which didn't release code, discussing possible benchmarking and integration with torchao.
-
Open Source FP8 Flash Attention: Another member shared a Colfax Research article on adding FP8 to flash attention and linked to the open source Cutlass Kernels GitHub. Discussion noted lack of Ada FP8 support until CUDA 12.5.
-
Nvidia's Market Dominance: A member asked why Nvidia has become the biggest company in the world. The response cited "Marketing and CUDA" as primary factors behind Nvidia's success.
CUDA MODE ▷ #torch (6 messages):
- Torch profiler.export_stacks issue remains unresolved: A member asked if anyone has found a workaround for the issue where
profiler.export_stacksdoesn’t return stack traces unlessexperimental_configis provided in the newer Torch versions. They attempted suggestions from the GitHub thread with no success. - Improve torch.compile times with cache settings: A member shared a tutorial on cache settings to improve warm compile times for
torch.compile. The document outlines the configurations for various caches employed by PyTorch Inductor to enhance compilation latency.
Links mentioned:
CUDA MODE ▷ #cool-links (1 messages):
- gpt-fast pip package speeds up HF models: A member announced the creation of a pip package based on gpt-fast, claiming it accelerates inference speeds by 7.6-9x. The package includes features like torch.compile, static key-value caching, INT8/INT4 GPTQ Quantization, and speculative decoding, with further development outlined in the project's readme file.
CUDA MODE ▷ #torchao (2 messages):
- Introducing GPTFast for Accelerated Inference: A member shared their new pip package GPTFast, which scales to more HF models and boosts inference speeds by 7.6-9x. It includes torch.compile, static key-value cache, INT8 and INT4 GPTQ quantization, and speculative decoding.
CUDA MODE ▷ #off-topic (8 messages🔥):
- Old Notes Reveal Slides on GPU Issues: A member shared that they found old slides detailing GPU issues, including why Llama13B doesn’t fit on a 4090 GPU. They mentioned that Slide 15 discusses LoRA using less activation memory, sparking questions about the underlying mechanisms.
- Request for Associated Talk: Another member inquired if there was an associated talk with the slides, to which it was clarified that the talk was unrecorded. However, a better version of the talk is now available.
- Link to Related Presentation: A member provided a link to a presentation on managing and debugging GPU vRAM. The presentation highlights optimizing torch-tune using training scripts as benchmarks, hosted on Maven.
Links mentioned:
CUDA MODE ▷ #llmdotc (341 messages🔥🔥):
-
NCCL-only vs MPI: Sync issues arise: Concerns about the new NCCL-only PR were raised, especially regarding process synchronization using the filesystem. Issues with
mpirunand environment variable handling were discussed along with considering simplifying the setup by dropping MPI dependency (NCCL Communicators Guide). -
Multi-node setup with MPI: Success was reported in running a multi-node setup using
mpirun, but complications with SLURM and OpenMPI's PMIx support were discussed. The need for robustifying filesystem synchronization was highlighted as non-trivial. -
Mixed feelings on managed memory: There's an ongoing debate about using CUDA's managed memory for cleaner code versus potential performance losses due to its internal management complexities. The need to evaluate real benefits and fallback on traditional approaches if necessary was suggested.
-
Training instabilities and potential mitigations: An exploded 8x H100 GPT-2 training run spurred discussions on automatic detection and mitigation of loss spikes. Reference to recent papers tackling gradient explosions and potential fixes emphasized the need for more robust training methods (Paper on Loss Spikes).
-
Data and embedding considerations: Modifications to embeddings and data shuffling were suggested as vital steps to enhance training stability and model performance. Discussions alluded to the importance of advanced data handling and preparation techniques, emphasizing quality and variety in dataset construction.
Links mentioned:
CUDA MODE ▷ #rocm (2 messages):
- Skepticism over MI300A release: A member expressed doubt that an MI300A is coming. They also questioned why there is no MI300X PCI available, hinting at uncertainty in its development timeline.
- No architecture in LLVM for MI300X: Another member noted that considering there is no architecture in LLVM for it, they believe the development of an MI300X PCI will not be happening anytime soon.
CUDA MODE ▷ #bitnet (5 messages):
-
Sync issue solved with Triton trick: A member shared a trick to measure processing time more accurately by using
torch.cuda.synchronize, quoting a solution involving Triton'sdo_benchfunction. They credited @321144267785633800 for the tip: "gave me a very good trick to properly measure the processing time". -
Alternative Benchmarking Tools: Another member mentioned using
torchao.utils.benchmark_torch_function_in_microsecondswhich utilizestorch.utils.benchmark.Timer. This highlights different methods of measuring processing time within PyTorch environments. -
Triton Eval Code for Benchmarking: A member found an important trick in the Triton evaluation code, suggesting the allocation and zeroing of a large array (256mB) to clear the L2 cache before measuring time. They shared the link to the Triton GitHub as a reference.
-
Bitpacking Integration Challenge: One member discussed an issue integrating bitpacking into
int4wo quant APIwhere an assertion fails during compile time but not otherwise. They expressed confusion as to why compilation would change the tensor shapes: "its failing an assertion that innerk tiles isn't 2, 4, or 8 which is weird because i wouldn't think that compile changes the shapes of tensors".
Link mentioned: triton/python/triton/testing.py at main · triton-lang/triton: Development repository for the Triton language and compiler - triton-lang/triton
Stability.ai (Stable Diffusion) ▷ #general-chat (330 messages🔥🔥):
<ul>
<li><strong>Discord Community Shocked by Removal of Channels</strong>: Members expressed frustration over the deletion of various low-activity channels and archives, with one noting *"the archives were just nice place to see pictures, nothing to moderate anymore"*. There is a sense of loss among users who used the archives for inspiration and community engagement.</li>
<li><strong>Alternative Stable Diffusion Interfaces Discussed</strong>: Members discussed various interfaces, including ComfyUI, Invoke, and Swarm, with comparisons highlighting each tool's strengths and ease of use. A detailed guide was also shared to help new users get started with these interfaces.</li>
<li><strong>ComfyUI vs. Other UIs</strong>: There's a debate over the efficiency and popularity of ComfyUI compared to other interfaces like A1111, with some users advocating for the simplicity of node-based workflows and others preferring traditional HTML-based fields.</li>
<li><strong>Mystery Surrounding Channel Deletion Persists</strong>: <em>Fruit</em> explained the reason behind the channel deletions, stating that *"channels that collect dust...often accumulate bot spam”*. Yet, members remain confused about the necessity of removing the archives and sought clarity on potential restoration.</li>
<li><strong>New Dataset Announcement</strong>: A dataset of 235,000 prompts and images, collected from the Stable Diffusion Discord, was announced by a member, sharing a link to [StableSemantics](https://arxiv.org/abs/2406.13735v1). This dataset is aimed to aid in understanding the semantics of visual scenes in computer vision.</li>
</ul>
Links mentioned:
Perplexity AI ▷ #general (291 messages🔥🔥):
- Complexity Extension for Multiple Models: Members discussed the benefits of using the Complexity extension to switch between different models such as Opus, Sonnet 3.5, and GPT4-Turbo for optimal coding performance. One shared experience with this tool: "I prefer the extension made feline, it has lots of features including model selectors."
- Sonnet 3.5's Knowledge and Performance: There was a notable discussion regarding Sonnet 3.5's new features and improved performance, especially in summation and coding tasks. A notable comparison stated: "Sonnet 3.5 is in my experience as smart as Opus."
- Claude 3.5 Sonnet Availability on Perplexity: A debate emerged about the correct availability and functionality of Claude 3.5 Sonnet on various platforms and whether it includes the latest updates. Users clarified that while it appears as 3.5 in web settings, it might still show as 3 on mobile.
- Usage and Limitations of Opus and Sonnet: Some members discussed the limitations imposed on usage, particularly with Opus being capped at 50 uses per day. A user lamented: "It’s not that I get to that limit, I don’t because I'm afraid to use all that cap so I end up not using Opus at all."
- Hardware for Inference: There was curiosity about the hardware used by Anthropic for inference, debating between TPU or Nvidia GPUs. A user shared a link to AWS's Trainium for efficient ML training.
Links mentioned:
Perplexity AI ▷ #sharing (7 messages):
- Chatting with AI is like piloting a system: An insightful analogy is presented in Piloting AI, suggesting that interacting with AI is evolving from just directing it to achieving defined goals, towards a collaborative problem-solving partnership. The article was generated on Perplexity AI, showcasing an iterative process in detailed pages.
- Hermes 2 Theta outshines competition: Hermes 2 Theta 70B, developed by Nous Research in collaboration with Arcee AI and Charles Goddard, has surpassed benchmarks set by models like Llama-3 Instruct 70B. It exhibits advanced capabilities such as function calling, feature extraction, and JSON output modes, showcasing improvements on par with GPT-4.
- Top YouTube creators in 2024 revealed: A post on popular YouTube creators highlights MrBeast, Like Nastya, and PewDiePie as the leading figures, with MrBeast boasting 240 million subscribers. It provides multiple sources for further reading and verification.
- Elephants call each other by name: A groundbreaking study, discussed in Elephants Call Each Other by Name, reveals that African elephants use unique vocalizations to address each other. This discovery highlights the advanced cognitive abilities and complex social structures of these majestic creatures.
- Li-ion batteries power off-road innovations: Li-ion Off-road Powertrains examines how lithium-ion battery systems are transforming the off-road vehicle industry, offering superior power density, faster charging, and reduced maintenance. This advancement is enabling companies like Polaris and Alkè to develop electric off-road vehicles with enhanced performance and lower cost of ownership.
Links mentioned:
Perplexity AI ▷ #pplx-api (3 messages):
-
Resetting API Keys Made Easy: A user asked about resetting an API key, and they were directed to the Perplexity settings page. It's explained that you can manage this in the "API Keys" section where you can "delete" or "generate" keys.
-
Limiting API Research to Specific Websites: A member inquired if there's a way to get the Perplexity API to limit its research/results to a specified website, similar to the
site:example.comsyntax in Google. They didn't receive a direct answer in the provided messages.
Link mentioned: Perplexity: Perplexity is a free AI-powered answer engine that provides accurate, trusted, and real-time answers to any question.
HuggingFace ▷ #announcements (2 messages):
- Community Highlights Showcases Latest from Members: The latest community highlights feature impressive contributions, including a 520k Midjourney image+caption dataset and a 900M param PixArt model. Notably, Proteinviz now supports bulk predictions, and Transformers.js is the #1 trending GitHub repo.
- Innovative Projects and Tools Abound: Highlights include a Powershell + AI integration, an alternative to Microsoft's Recall AI, and a discussion on the impact of drug naming conventions on model performance, featured in the RABBITS dataset.
- Introduced New Argilla-focused Channels: New Argilla-focused channels have been added for community members. Users can access these by self-assigning the relevant role in the customization section.
Links mentioned:
HuggingFace ▷ #general (197 messages🔥🔥):
- Florence-2 for better OCR than expected: A user was surprised to find that the Florence-2-base model is better at OCR than the large or large-ft variant, suggesting more testing is needed to verify this. Another user argued that the base model might excel in OCR tasks more than the fine-tuned versions.
- Hugging Face site experiencing issues: Several users reported the Hugging Face website and related services were down or experiencing sporadic 504 errors. The outage issues caused interruptions in usage for many.
- Discussion on audio stream input for ASR models: A user sought guidance on using pre-trained transformer models for ASR with audio streams as input, instead of just links. They were directed to Hugging Face's ASR pipeline but found it lacked documentation on stream inputs.
- GPT-Based Private Document Interaction: Users discussed the
private-gptrepository that allows interaction with documents via GPT locally. Some found the setup documentation lacking and shared alternative projects for similar tasks. - Hugging Face blog submission guidance: A user asked about submitting a blog post, and it was clarified that they can create and submit blog articles through the Hugging Face community blog platform.
Links mentioned:
HuggingFace ▷ #cool-finds (5 messages):
-
Fairness vs. Environmental Sustainability: A member shared an interesting paper discussing the balance between fairness and environmental impact in NLP. The abstract highlights how focusing exclusively on either can hinder the other, and the paper aims to shed light on this critical intersection.
-
Game Alert: Milton is Trapped: Check out the game Milton is Trapped and its GitHub repository. The game is live, and contributors are welcome.
-
Real-time SadTalker Alternative: A new paper with no accompanying code implements a real-time version of SadTalker. The paper is available on arXiv.
Links mentioned:
HuggingFace ▷ #i-made-this (2 messages):
-
Backgammon AI Tool gets open-sourced: A user introduced an open-source project that "runs simulations of possible scenarios in backgammon, recording combinations in sequence." They invited others to contribute to the Backgammon AI tool and mentioned plans to add a user interface and enhance optimization.
-
Dataset error in Nijijourney release: A user shared an exception message showing issues with accessing split names for the Nijijourney dataset on HuggingFace. Despite the technical issues, they claimed the dataset offers "a nice regularisation effect on models" and includes image files to avoid link rot, making it suitable for reliable benchmarking.
Links mentioned:
HuggingFace ▷ #computer-vision (3 messages):
- Building an Object Detection App in Java: A member asked how to create an object detection app in Java with features like custom detection and live detection. They inquired about available models similar to YOLO in Python.
HuggingFace ▷ #NLP (1 messages):
- Preserving PDF Layout for Translation: A member inquired about methods to preserve the layout of a PDF after it has been modified, specifically for translation purposes. The query points to the need for technical solutions that maintain the document's format integrity during the translation process.
Unsloth AI (Daniel Han) ▷ #general (134 messages🔥🔥):
- **EOT token confusion in Unsloth**: Members discussed the eos token issue in OpenChat 3.5, where `<|end_of_turn|>` and `</s>` tokens are causing confusion during different stages of training and inference. One said, *"unsloth uses `<|end_of_turn|>`, while llama.cpp uses `<|reserved_special_token_250|>` as the `PAD token`."*
- **Ollama collaboration**: Discussions highlighted Ollama's compatibility and support with Unsloth. One member mentioned, *"I've just made a live session on Ollama with Daniel and Mike, where we were creating a fine-tuned model etc etc, and it works well."*
- **Null-shot prompting debate**: There was a skeptical discussion about the efficacy of null-shot prompting, with a paper on the topic from Arxiv mentioned. A member sarcastically summarized, *"Sounds like mysticism and praying to the machine spirits."*
- **Dry run suggestion for Unsloth**: A member proposed adding a dry-run feature for Unsloth to view steps before actual training. Another joked, *"are you washing clothes? last I checked, GPUs don't do good with water."*
- **Released YouTube video on emotion detection in AI**: The community was informed about the release of a relevant [YouTube video](https://youtu.be/ZJKglSWgD0w). It covers, "the creation of fine-tuning dataset for LLMs using Unsloth and Ollama."
Links mentioned:
Unsloth AI (Daniel Han) ▷ #random (10 messages🔥):
-
Together.ai fine-tuning costs thousands: A member revealed that fine-tuning on Together.ai can cost $4,000 for 15 billion tokens at 1 epoch using its interactive calculator.
-
Vs. Unsloth's H100 usage: They compare this with Unsloth's H100, claiming you can achieve the same fine-tuning for less than $15 in about 3 hours.
-
Questioning possible pricing glitch: Another member reacted with skepticism, asking if this cost discrepancy might be a glitch.
-
Together.ai pricing details shared: The discussion included a direct paste from Together.ai’s pricing page, elaborating costs per million tokens across different model sizes and categories.
-
Unsloth touted as significantly cheaper: Following this, they emphatically stated, "You can claim to be 250X cheaper than Together.ai lol."
Link mentioned: Together Pricing | The Most Powerful Tools at the Best Value: Get detailed pricing for inference, fine-tuning, training and Together GPU Clusters.
Unsloth AI (Daniel Han) ▷ #help (63 messages🔥🔥):
- **Phi-3-mini shines over Mistral 7b**: *"I've had great luck with phi-3-mini"* as it demonstrated better reasoning consistently compared to Mistral 7b non-instruct. This user used 1k, 10k, and 50k example sets for training and structured the data within training as the only acceptable response.
- **Experimenting with domain adaptation**: *"I need to get other work done, but will check out domain adaptation when I get back to it,"* noted one user, expressing eagerness to explore further after successful training runs.
- **Finetuning model issues**: Numerous users experienced problems with saving and loading fine-tuned models, particularly when using `save_pretrained_merged()`. Recommendations included using simpler save methods and avoiding 16bit quantization, which seemed to cause issues.
- **Debating DPO vs RLHF**: Users discussed switching from Reinforcement Learning with Human Feedback (RLHF) to Direct Policy Optimization (DPO) for ease and efficacy, as DPO is supported by Unsloth and involves simpler training datasets. *"I was thinking to start with RFHF and then check DPO, but now after checking more about DPO, I think i wil switch to DPO first."*
- **Deployment challenges with Hugging Face**: Users shared issues deploying Unsloth-trained models via Hugging Face Inference endpoints due to tokenizer errors. One user sought advice on best deployment platforms using various credits, with responses pending further details.
Links mentioned:
Nous Research AI ▷ #off-topic (2 messages):
- Hermes 2 Theta 70B Surpasses Llama-3 Instruct: Nous Research announced the release of Hermes 2 Theta 70B, claiming it exceeds benchmarks set by models like Llama-3 Instruct and achieves performance on par with GPT-4. The model introduces new capabilities such as function calling, feature extraction, and JSON output modes, developed in collaboration with Arcee AI and Charles Goddard. More details are available on Perplexity AI.
- Piloting AI as the Future of Interaction: An intriguing analogy was shared, emphasizing AI communication evolving from task direction to a collaborative partnership between humans and machines. This concept was iterated on the Perplexity AI platform, linking to an initial thread titled "Piloting an AI".
Links mentioned:
Nous Research AI ▷ #interesting-links (1 messages):
spencerbot15: https://arxiv.org/abs/2406.14491
Nous Research AI ▷ #announcements (1 messages):
- Hermes 2 Theta 70B Model Debuts: Nous Research has introduced Hermes 2 Theta 70B in collaboration with Charles Goddard and Arcee AI. With function calling, feature extraction, and JSON mode outputs, it scores 9.04 on MT-Bench, outpacing GPT-4-0314's 8.94 and surpassing Llama-3 70B Instruct in multiple benchmarks.
- Benchmark Dominance: Hermes 2 Theta 70B notably surpasses Llama-3 70B Instruct on various benchmarks including MT Bench, GPT4All Suite, BigBench, and Instruction Following Eval.
- Download Options Available: Both FP16 and quantized GGUF versions of Hermes 2 Theta 70B are available on Hugging Face. Download FP16 Version Here and Download GGUF Version Here.
Links mentioned:
Nous Research AI ▷ #general (193 messages🔥🔥):
-
Claude 3.5 handles obscure programming languages: Claude 3.5 has shown remarkable progress by solving problems in a self-invented obscure programming language correctly. "Claude 3.5 sonnet is insane."
-
HF experiences server overload amid new model releases: HuggingFace went down amidst new model releases, leading to several speculations about the cause. One user reported, "you guys slashdotted hf with the new model I guess."
-
Null-shot prompting exploits LLM hallucinations for better performance: An arXiv paper was shared, detailing how null-shot prompting can utilize hallucinations in LLMs to improve task performance compared to zero-shot prompting. "Null-shot prompting exploits hallucination in large language models (LLMs) by instructing LLMs to utilize information from the 'Examples' section that never exists within the provided context."
-
Hermes 2 Theta raises censorship discussions: The new Hermes 2 Theta model sparks conversation on its degree of censorship, with users sharing mixed reactions. "hermes 2 theta is uncensored? ... moderately uncensored, not abliterated though."
-
Claude's system prompt introduces internal chain-of-thought tag: Claude’s system prompt implements a tag for internal chain-of-thought to improve model responses, which intrigued several members. "It seems to introduce a tag for internal chain-of-thought, where the output is not shared with the user."
Links mentioned:
Nous Research AI ▷ #ask-about-llms (3 messages):
- Anticipation for Hermes Theta 70B release: A member expressed excitement about using Hermes Theta 70B on their AI/Human discussion server and inquired about its release date on together.ai. Unfortunately, there was no available information on the release date.
- Query on Hermes 2 Theta Llama datasets: A member sought information on the datasets used for Hermes 2 Theta Llama-3 70B model. They linked to the Hugging Face model card for Hermes 2 Theta Llama-3 70B.
Link mentioned: NousResearch/Hermes-2-Theta-Llama-3-70B · Hugging Face: no description found
Nous Research AI ▷ #world-sim (4 messages):
-
L'ENTOURLOOP music video shared: A user shared a YouTube video titled "L'ENTOURLOOP - Lobster Shwarama Ft. Troy Berkley & Khoe Wa (Official Video)", referencing the track "Lobster Shwarama" from the album "Chickens In Your Town." The video's description includes a link to the album.
-
Concerns over world-sim script breakage: A user humorously admitted to potentially breaking the world-sim script feature while engaging in a "funny wacky crossover adventure." This led to a question about the availability of the new Claude model on world-sim.
-
Confirmation of new Claude model: In response to concerns about the world-sim, another user confirmed that the new Claude model would indeed be on world-sim soon. They reaffirmed this confirmation succinctly, replying with a simple "Yes."
Link mentioned: L'ENTOURLOOP - Lobster Shwarama Ft. Troy Berkley & Khoe Wa (Official Video): "Lobster Shwarama Feat Troy Berkley & Khoe Wa" taken from L'Entourloop "Chickens In Your Town" album, available 👉 https://smarturl.it/LNTRLPChickensIYT♦︎ V...
LM Studio ▷ #💬-general (42 messages🔥):
<ul>
<li><strong>Fix GPU Utilization in LM Studio</strong>: A member found a solution to use their second GPU in LM Studio by setting the <code>main_gpu</code> value to <code>1</code>. This was helpful for users running multiple GPUs on Windows 10.</li>
<li><strong>Running Vision Models on CPU</strong>: A member with an older laptop and unsupported AMD GPU successfully ran vision models by disabling GPU acceleration and leveraging OpenCL. However, the operation was notably slower.</li>
<li><strong>Integrating Ollama Models with LM Studio</strong>: A possible workaround for integrating Ollama models with LM Studio is to use the <a href="https://github.com/sammcj/llamalink">llamalink GitHub project</a>. Another user updated this information by recommending the newer <a href="https://github.com/sammcj/gollama">gollama GitHub project</a>.</li>
<li><strong>Presets and Model Issues</strong>: Members discussed problems with models generating gibberish and suggested trying different presets. Flash attention was mentioned as a practical fix for these issues.</li>
<li><strong>Flash Attention Resolves Issues</strong>: Another issue was resolved by enabling flash attention, which normalized the model's responses after encountering issues with query formatting.</li>
</ul>
Links mentioned:
LM Studio ▷ #🤖-models-discussion-chat (46 messages🔥):
- 128g M3 Max MBP Model Recommendations: Members shared their favorite models for 128g M3 Max MBP configurations. Models mentioned included c4ai-command-r-v01-Q8_0.gguf, Llama3-FiditeNemini-70B, Twilight-Miqu-146B, and others with specific usage and performance tips.
- Experimenting with DeepSeek-Coder-V2: Suggestions and troubleshooting were discussed for running DeepSeek-Coder-V2 on different setups. Links to the HuggingFace model and related resources like llama.cpp quantizations were shared.
- Issues with Quantization and Memory Usage: Members discussed challenges with Q3 and Q4 quantization for large models and the importance of memory management. One user suggested needing to adapt quants to fit specific memory configurations to ensure optimal performance.
- Flash Attention and LM Studio Configuration Tips: Users engaged in troubleshooting configuration settings in LM Studio including turning off Flash Attention for certain builds. They provided steps to access and adjust these settings in version 0.2.25.
- GPU Offloading Problems: When using GPU offloading with any number of
n_gpu_layers, users reported issues such as gibberish outputs. Solutions included settingn_gpu_layersappropriately or turning off GPU acceleration.
Links mentioned:
LM Studio ▷ #🎛-hardware-discussion (89 messages🔥🔥):
-
NVIDIA 4090 vs 5090 for LLMs: Members discussed whether to go for a NVIDIA 4090 now or wait for the 5090 for LLMs, with mixed opinions. One stated, "From what I’ve read, the 5090 is not going to be significantly better than the 4090," while another countered, "last i heard im p sure it will be better."
-
Value of Refurbished 3090s: Discussing GPU options, someone recommended getting refurbished or used 3090s for better value, noting that "bang/buck is significantly higher" compared to newer models like the 4090.
-
Hardware Struggles with High-End LLMs: Multiple users expressed frustration over not being able to run advanced LLMs on their current setups. One said, "I’ve got 96gb of vram and 256gb of ram. I still can't run what I want," highlighting the high hardware requirements.
-
GPU Offload Issues and Solutions: Members discussed the limitations and potential solutions for partial GPU offload. A user noted that "6700XT is unsupported in ROCM so won't work for GPU offload unfortunately," suggesting that a 3060 12GB would be a better alternative.
-
PCIe Slot and Adapter Concerns: Queries about using PCIe slots effectively were raised, with suggestions for adapters to expand M.2 NVMe storage. One linked an adapter that could add extra M.2 slots and mentioned it's "only $10 and even comes with a low profile bracket."
Links mentioned:
LM Studio ▷ #🧪-beta-releases-chat (4 messages):
- Users face issues with GPU limitations: One member reported being "unable to run smaller quants in GPU" due to insufficient RAM and mentioned that models under 30GB can run on CPU but not on GPU.
- Docker container problems persist after beta update: Another member confirmed experiencing similar issues in their Docker containers post the latest beta update and hasn't found a fix yet.
- vRAM check suggested using 'nvidea-smi': To diagnose the problem, a member suggested using
nvidea-smi -1to check if the model loads into vRAM. - Turning off GPU acceleration for stability: A member proposed that the issue might be due to the model's RAM requirements nearing the system limit and suggested turning off GPU acceleration and enabling 'mlock' for more stable and fast performance.
LM Studio ▷ #langchain (2 messages):
-
Issue with LM Studio embedding model and Chroma: A member reported an error when using LM Studio embedding model with langchain and Chroma, which threw a 400 BadRequestError indicating that the "'input' field must be a string or an array of strings." They verified that direct requests to OpenAI online and non-langchain code samples worked fine.
-
Bug fixed through GitHub issue: The problem was later resolved as referenced in GitHub Issue #21318. This issue documented the error in the POST payload when using langchain_openai.OpenAIEmbeddings for the embedding API.
Link mentioned: Local LLM with LM Studio Server: Error in POST payload when using langchain_openai.OpenAIEmbeddings for embedding API. · Issue #21318 · langchain-ai/langchain: Checked other resources I added a very descriptive title to this issue. I searched the LangChain documentation with the integrated search. I used the GitHub search to find a similar question and di...
Modular (Mojo 🔥) ▷ #general (47 messages🔥):
- Community meeting resolution issues: Users discussed the resolutions available for the newer community meetings, noting that despite going up to 1440p, phones sometimes only show 360p due to internet speed throttling by YouTube.
- MLIR and 256-bit operations: A member inquired about performing operations on 256-bit unsigned integers for cryptography purposes. Jack Clayton mentioned trying various MLIR dialects without success and decided to seek internal advice for a solution, referencing issues and potential routes with MLIR and LLVM.
- Autocompletion issues with Kapa bot: Users reported inconsistent behavior with the Kapa.ai bot and Discord's autocompletion, with some members suggesting manual typing or selecting from the dropdown as reliable methods.
- Raising exceptions in Mojo: Discussions revealed that raising exceptions is a Mojo language feature not yet implemented in the stdlib, referencing a roadmap document for future updates.
- Ubuntu installation issues for Mojo: A user shared their experience with installing Mojo on Ubuntu 24.04, expressing frustration that the nightly instructions failed due to an incompatibility with Python 3.12, and considering alternative solutions such as using a PPA or reinstalling Linux.
Links mentioned:
Modular (Mojo 🔥) ▷ #💬︱twitter (1 messages):
ModularBot: From Modular: https://twitter.com/Modular/status/1804190052060401850
Modular (Mojo 🔥) ▷ #🔥mojo (4 messages):
-
Chris Lattner's smile is contagious: A user commented, "Chris Lattner has the most precious smile," followed by "It's contagious." Clearly, Chris Lattner's charisma left an impression on the Discord community.
-
Perplexity vs. Anthropic: Another user clarified that Perplexity is more of a RAG service, whereas Anthropic is a direct competitor to OpenAI. "They make really good foundation models," the user noted, highlighting Anthropic's strengths in the AI space.
-
Sonnet 3.5 offers significant improvements: A user shared positive feedback about Sonnet 3.5, stating, "just by playing around with Sonnet 3.5 it’s clearly an improvement for my use case." This demonstrates that the model upgrades are having a noticeable impact on real-world applications.
Modular (Mojo 🔥) ▷ #📰︱newsletter (1 messages):
Zapier: Modverse Weekly - Issue 37 https://www.modular.com/newsletters/modverse-weekly-37
Modular (Mojo 🔥) ▷ #nightly (17 messages🔥):
-
UnsafePointer method discussed for potential bugs: Members shared their thoughts on a method in
UnsafePointer, and concerns about potential memory issues. One member identified that a move operation might fix the problem, referencing the source code. -
Nightly release issues disrupt workflow: The nightly release was not updated as expected, leading to workflow interruptions. Members discussed potential solutions such as increasing the frequency of releases and acknowledged that the discrepancy was caused by a configuration change in branch protection rules.
-
Fix for compiler version mismatch shared: A member shared a commit fixing the compiler version mismatch which was affecting the nightly builds. This ensured the continuous integration pipeline could run unit tests smoothly.
-
New nightly Mojo compiler release announced: The issue with the nightly release was resolved and a new version
2024.6.2115was released. Updates include math constants and new assertion functions, as detailed in the changelog and raw diff.
Links mentioned:
OpenRouter (Alex Atallah) ▷ #announcements (2 messages):
-
Stripe payment issue resolved: A Stripe payment issue caused credits not to be added to users' OpenRouter accounts for a brief period. "Fixed fully, for all payments," confirms the resolution of this problem.
-
Claude's brief outage fixed: Anthropic’s inference engine experienced a 30-minute outage that led Claude to return error 502. The issue has been resolved, as indicated on their status page.
Link mentioned: Anthropic Status: no description found
OpenRouter (Alex Atallah) ▷ #app-showcase (2 messages):
- Seeking App Listing on OpenRouter: A user asked about getting their app listed after spending a lot of tokens. Another user directed them to the OpenRouter Quick Start Guide, emphasizing the need to include certain headers like
"HTTP-Referer"and"X-Title"for proper app ranking.
Link mentioned: Not Found | OpenRouter: The page you are looking for does not exist
OpenRouter (Alex Atallah) ▷ #general (63 messages🔥🔥):
-
Claude 3.5 Sonnet drops, sparks opinions: Members expressed excitement over the Claude 3.5 Sonnet release, comparing its Python coding skills to earlier versions. Some reported it as an improvement over 3.0, particularly for Python, while others found it lagging behind GPT-4 for JavaScript.
-
Anthropic server issues cause errors: Users experienced internal server errors with Anthropic models, confirmed by testing other models like OpenAI and Cohere which worked fine. Members pointed out that these issues were not yet reported on Anthropic's status page.
-
Auto-routing updates announced: When asked if auto-routing would switch to Claude 3.5 Sonnet instead of 3.0, an update was confirmed to be in the works immediately.
-
Perplexity Labs offers Nemetron 340b at a decent speed: Perplexity Labs allows users to try out the Nemetron 340b model at a reasonable speed of 23t/s, inviting members to test it out on their platform.
-
VS2022 extension inquiry for OpenRouter: A member inquired about an extension for VS2022 that works with OpenRouter and allows toggling context via a click or shortcut. The question was whether Continue.dev is the only compatible option available.
Links mentioned:
Eleuther ▷ #general (26 messages🔥):
- Epoch AI updates its datahub: Epoch AI announced a new iteration of their datahub, featuring data on over 800 models from 1950 to the present. The data is free under the Creative Commons Attribution license, intended to foster responsible AI development.
- Samba models cause name confusion: A participant expressed concern about the name "Samba" for a Microsoft model, highlighting potential confusion with SambaNova. Another user clarified that Samba is a hybrid mamba/attention model, distinct from Zamba which uses sliding window attention.
- GoldFinch paper and model conversion: A member mentioned the imminent release of the GoldFinch paper, which will present a RWKV hybrid model featuring a super-compressed kv cache and full attention. They also indicated that their conversion process works with the mamba variant but noted instability issues in training.
Link mentioned: Data on the Trajectory of AI: Our public databases catalog over 1300 machine learning models. Explore data and graphs showing the growth and trajectory of AI from 1950 to today.
Eleuther ▷ #research (16 messages🔥):
- Debate on Models Building Loss Function During Forward Pass: Members discussed whether models could build models of their loss functions during the forward pass to "check their work before they submit it." One user suggested that while this doesn't typically happen, it could be beneficial for tasks involving detailed global properties.
- Anthropic's Insights on Language Models: A user linked to Anthropic's study on how language models perform chain-of-thought reasoning. The study suggests that CoT explanations might misrepresent the actual reason behind a model's prediction due to external biases.
- Q Introduced for Improved Decoding*: A discussion about Q*, a framework to guide LLMs' decoding process by integrating a heuristic Q-value model. This aims to alleviate issues like errors and inconsistencies without fine-tuning the LLMs extensively.
- Debate on Training Environments with Internet Access: A user raised concerns about the safety of giving training environments live internet access, suggesting that it might be problematic.
- Introduction of DigiRL for Device Control: Another article, DigiRL, was shared, highlighting a novel RL approach for training device control agents in real-world conditions through fine-tuning VLMs. This method aims to address limitations in static demonstration training.
Links mentioned:
Eleuther ▷ #interpretability-general (1 messages):
There is not enough information in the given message history to create a summary. Please provide more messages or context for an accurate and informative summary.
Eleuther ▷ #lm-thunderdome (5 messages):
- NumPy 2.0.0 Compatibility Issues: A discussion highlighted the problem of modules compiled with NumPy 1.x failing with NumPy 2.0.0. Users were advised to downgrade to 'numpy<2' or upgrade the affected modules.
- Colab as a Solution: Members explored using Colab for running specific tasks. One member managed to install and run
lm_evalsuccessfully and offered to help others replicate the setup. - Demo_boolq Issue in Colab: Despite success with most examples, the
demo_boolqtask encountered issues with running remote code in Colab. The problem persisted despite troubleshooting efforts. - Distinction Between 'main' and 'master' Branches: Clarification was provided that the correct branch to use is
main, notmaster. A suggestion was made to useyes | lm_eval...to auto-approve third-party code prompts.
tinygrad (George Hotz) ▷ #learn-tinygrad (28 messages🔥):
-
Issues with weight tying in GPTs implementation: A member questioned differences in implementing weight tying between embedding and output logit linear layers compared to Karpathy’s GPT-2 method. Further discussion revealed separate optimization due to two copies of tied weights, timing out due to a weight initialization method overriding the tying.
-
Clip_grad_norm_ implementation problems in TinyGrad: Members discussed performance issues and possible errors when implementing
clip_grad_norm_in TinyGrad. “...metal can only have so many buffers” was cited as a specific limitation affecting its performance, leading to discussions about dividing sums into chunks of 31 tensors. -
Metal vs CUDA for gradient clipping: Metal's buffer limitations necessitate chunking tensors, unlike CUDA. Members clarified future plans to address these rough edges, including making internal scheduler fixes.
-
Timeout errors with AMD devices in examples: Members reported timeouts when running YOLOv3 and ResNet examples on AMD devices, with error logs indicating synchronization problems. Users pointed out integrated GPUs like Radeon RX Vega 7 and discussed potential overload issues on the
tiny11server running fuzzers.
Link mentioned: chenyuxyz: Weights & Biases, developer tools for machine learning
LAION ▷ #general (10 messages🔥):
-
Caption Dropout Method Discussion: Members discussed if training SD3 with zeros as the caption dropout or encoded empty strings is more effective. It's noted that encoded strings did not alter the results significantly.
-
Sakuga Paper Withdrawal Surprise: There was an announcement that Zhenglin Pan's Sakuga-42M Dataset paper, initially aimed at advancing cartoon animation research, was withdrawn. The paper proposed a large-scale cartoon animation dataset but faced unspecified issues leading to its withdrawal.
-
Concerns Over OpenAI's Government Collaboration: A tweet was shared expressing concerns about OpenAI giving the government early access to new AI models and advocating for more regulation. The tweet suggested this move indicates a significant strategic shift, possibly due to the perceived dangers of AGI.
Links mentioned:
LAION ▷ #research (13 messages🔥):
-
More Latent Channels Increase Global Incoherency in MM-DIT: Concerns were raised that "going to more latent channels seems to cause more global incoherency problems" in models like MM-DIT. Examples include issues like "the girl lying in grass problem" and difficulty with "a coherent dragon flying in the air".
-
Grad Norm Issues with Chameleon Model: A user reported that while training the new Chameleon model, embedding and norm layers experience extreme grad norms, leading to NaN values. Despite trying common mitigation techniques like lower learning rates, grad norm clipping, and weight decay, the issues persisted.
-
Batch Size and Learning Rate Recommendations: It was suggested that for training models with llama architecture, very large batch sizes, consisting of "hundreds of thousands or millions of tokens," may be required. This recommendation came after addressing a similar issue experienced during training the Chameleon model with image-caption pairs.
LAION ▷ #resources (1 messages):
sajackie: 50$ from steam steamcommunity.com/gift/9178 @everyone
LAION ▷ #learning-ml (1 messages):
sajackie: 50$ from steam steamcommunity.com/gift/9178 @everyone
LAION ▷ #paper-discussion (1 messages):
sajackie: 50$ from steam steamcommunity.com/gift/9178 @everyone
Interconnects (Nathan Lambert) ▷ #news (5 messages):
-
Speed of Release Raises Questions: Curiosity was expressed about the implications of the speed at which new versions are released, specifically whether improvements stem from posttraining or pretraining. One member speculated it could be related to pod training.
-
Pod Training Highly Valued: The value of pod training seems underestimated, according to one contributor who emphasized its importance. Another contributor agrees but notes that confusing factors like continued pre-training make it difficult to pinpoint exact contributions.
-
Plans for Further Writing: One contributor expressed a desire to further explore and write about the topic, stating the need to consult with others to gather more information.
Interconnects (Nathan Lambert) ▷ #ml-drama (10 messages🔥):
- Mira's PR Blunders Need Stopping: A member expressed frustration over Mira's repeated PR mistakes, sharing a Twitter link. Another agreed, saying, "The hubris from OAI is unbearable."
- PR Training Deficiency Highlighted: Nathan Lambert noted that Mira seems to lack PR training, implying this could explain her errors. Another member argued there's no need for "fancy and expensive PR training" for Mira.
- Switch to Claude: Nathan Lambert mentioned he has switched to using Claude, suggesting dissatisfaction with current products. He also pointed out that Mira doesn’t use her own company's products.
- Mira as a Scapegoat: A member speculated that Mira might be used as a scapegoat to handle criticism and deflect attention from higher-ups like Greg Brockman and Sam Altman, who might prefer to stay focused on other work. This strategy was seen as part of OpenAI's attempt to present itself as a "serious company."
Interconnects (Nathan Lambert) ▷ #random (8 messages🔥):
- Anchor Blasts Perplexity on CNBC: A member mentions an interview on CNBC where the anchor had a surprisingly strong negative opinion on Perplexity: "Almost as if he perplexity’ed himself and got very negative answers." The interview was about a Wired article criticizing Perplexity for ignoring robots.txt protocols.
- CNBC Interview on YouTube: A link to the YouTube video titled, "Wired: AI startup Perplexity is 'BS machine'" was shared. The video features Wired's global editorial director discussing an investigation into AI search startup Perplexity.
- Wave of Criticism Against Perplexity: Members noted a recent surge in negative sentiments against Perplexity, with one person stating, "a bit surprised but not that much."
- Casey Newton's Negative Take: It was mentioned that Casey Newton also wrote an article criticizing Perplexity's founder Aarvind, calling him "a bit naive". Another expressed frustration with Newton's anti-tech stance in his tech coverage.
Link mentioned: Wired: AI startup Perplexity is 'BS machine': Katie Drummond, Wired’s global editorial director, joins 'Squawk Box' to discuss the magazine's investigation into AI search startup Perplexity.
Interconnects (Nathan Lambert) ▷ #posts (1 messages):
natolambert: snail where you at dude wtf
OpenInterpreter ▷ #general (19 messages🔥):
-
YouTube demo showcases Windows/Linux compatibility: A member shared a YouTube video titled "open interpreter compatch demo," highlighting a basic UI and TTS functionality for Windows/Linux setups. This demo uses gpt4o via Azure, with promises of more features soon.
-
Claude 3.5 Sonnet impresses in practical use: A member praised Claude 3.5 Sonnet, mentioning, "I like how it communicates and the quality of the code." They expressed a preference for Claude 3.5 over GPT-4 and GPT-4o, stating the latter's interaction as "annoying."
-
Installation guidance for Open Interpreter on Windows: Discussion on installation referred to the Open Interpreter documentation. The process includes
pipinstallations and optional dependencies, showcasing compatibility with Windows systems. -
DeepSeek Coder v2 shared: A link to DeepSeek Coder v2 was shared, including a licensing agreement and usage parameters. This model emphasizes responsible downstream use and ethical considerations.
-
Open Interpreter's testing preference revealed: A query about Open Interpreter's best performance on Mac revealed that it performs optimally on Macs due to the core team’s extensive testing on this platform.
Links mentioned:
OpenInterpreter ▷ #ai-content (1 messages):
- Open Interpreter connects to WiFi using sticky note: A user shared an experience where a fully local, computer-controlling AI successfully read a WiFi password from a sticky note to connect online. They included a link to a tweet by @hellokillian showcasing this capability.
Link mentioned: Tweet from killian (@hellokillian): i showed a fully local, computer-controlling AI a sticky note with my wifi password. it got online.
LLM Finetuning (Hamel + Dan) ▷ #general (12 messages🔥):
-
Seeking AI Events for Consultancy Grant: A member inquired about interesting events for a €2000 travel/customer discovery grant, pointing out that the AI Engineer World Fair was too soon and distant. Another member mentioned a recent OSS AI event in Paris that had just concluded.
-
Issues with Presentation Links: One member asked if others were also not receiving a link for a current presentation. Another confirmed that a link for a public livestream was available.
-
Challenges in Saving Custom Models with HF Trainer: A member shared insights on using the Hugging Face framework, noting that while monkey patching allowed for training, it failed to save the custom patched module. They provided an example code snippet illustrating the problem.
-
Abandoning LangChain at Octomind: Members discussed a blog post detailing why Octomind no longer uses LangChain for their AI agents. The conversation highlighted issues with LangChain's rigid abstractions and complexity, making it difficult to debug and maintain, with some suggesting Langgraph as a potential alternative.
Links mentioned:
LLM Finetuning (Hamel + Dan) ▷ #🟩-modal (1 messages):
- Modal crew praised for excellent support: One member praised the Modal team for their assistance in running the BLOOM 176B model last summer. They hoped the team would continue their friendly and helpful spirit, mentioning, "It was siick... like moving a mountain".
- Preference for Slack over Discord: Despite the support, the member expressed a preference for Slack, noting that the Modal team also provides assistance on that platform. They remarked, "They also have Slack and they help people out, which is sooo nice, (I don't like Discord)."
LLM Finetuning (Hamel + Dan) ▷ #replicate (1 messages):
4.8.15.16.23.42_: I believe they mentioned somewhere - a year
LLM Finetuning (Hamel + Dan) ▷ #allaire_inspect_ai (1 messages):
- Eval Framework Delights: "Playing with the eval framework today and it’s fantastic!" A member praised the eval framework for its intuitive API design and well-written code, highlighting the developer experience. They also appreciated the flexibility to use proxy endpoints for LLMs, mentioning it’s easy to execute against custom enterprise base URLs.
LLM Finetuning (Hamel + Dan) ▷ #east-coast-usa (1 messages):
stevenmerrill: Similar question: anyone in Greater Boston?
LLM Finetuning (Hamel + Dan) ▷ #predibase (2 messages):
- User seeking advice on unlocking credits: A user inquired about how to unlock certain credits and asked for assistance. "Also not sure how to unlock these credits, plz advice."
- Registration and email verification issue: Another user asked for verification of their email as they might have been slow to register, despite filling out the forms. "Could you please check [email protected]?"
LLM Finetuning (Hamel + Dan) ▷ #openpipe (1 messages):
abhishek_54517: Seems to be 1 year
LangChain AI ▷ #general (14 messages🔥):
-
Join Techstars Startup Weekend SF: A member announced the Techstars Startup Weekend in San Francisco from June 28-30, 2024, at Convex. Gabriela de Queiroz, Director of AI @ Microsoft, will be a keynote speaker, with mentors from Google, Meta, and others More details.
-
Clarification Needed on Reflexion Tutorial: A user was confused about why the Reflexion tutorial uses
PydanticToolsParserandbind_toolsfor validation instead of a simple loop withwith_structured_output. They also asked what happens if the LLM's answer fails validation withwith_structured_output. -
Seeking AI Engineering Role: A member shared their extensive AI experience and expertise in technologies like LangChain, OpenAI, and multi-modal LLMs, looking for full-time opportunities to discuss further.
-
LangChain Message Streaming Issue: A member struggled to stream LangChain's/LangGraph's messages through Flask in a React app and reached out for assistance but did not receive a solution.
-
Parallel Request Handling Issue: A member described difficulties in processing parallel requests with their AI chatbot using LangChain and Gemini models on an EC2 instance with FastAPI. Another member suggested using asynchronous code or serverless functions to resolve the issue.
Links mentioned:
LangChain AI ▷ #share-your-work (4 messages):
-
Exploring Retrieval Augmentation with MLX: A user shared a new article titled "Retrieval augmentation with MLX: A bag full of RAG, part 2". The article can be found on GitHub here.
-
Introducing 'Mark' CLI Tool for GPT: Another user introduced a markdown-focused CLI tool called 'Mark' that leverages links and image tags as RAG methods to interact with GPT models. More details on the tool and its design thought process can be found in their detailed post.
Links mentioned:
OpenAccess AI Collective (axolotl) ▷ #general (8 messages🔥):
- Turbcat 8b Released: A link to Turbcat 8b was shared, showcasing the model's improved dataset size from 2GB to 5GB and added Chinese support. Screenshots of the model and details were also provided.
- AMD Mi300x GPU Compatibility Question: A user inquired about training with an Mi300x GPU using Axolotl, mentioning it seems to fit with PyTorch 2.4. However, another user replied, "Sorry, I’m not aware on amd side," indicating uncertainty about Mi300x compatibility.
- Comparison to 70B Model: A user expressed amazement at the Turbcat 8b release and questioned if it is considered better than the 70B model. The response clarified that the dataset is larger but the 72B model is still in development.
Link mentioned: turboderp/llama3-turbcat-instruct-8b · Hugging Face: no description found
OpenAccess AI Collective (axolotl) ▷ #general-help (7 messages):
-
Estimate Training Time: Simple Formula vs Practical Execution: A member asked if training time can be estimated by multiplying token train rate, dataset token size, and estimated epoch number. Another member suggested the most reliable way is to "Run the training and see the estimate after a few steps" and to add some buffer time for evaluation.
-
Formatting Data for Tool Calling Models: One member sought advice on transforming a dataset into a format compatible with axolotl using
<|tool_call|>tokens. Another suggested looking at example configs that include ShareGPT settings for guidance on formatting.
OpenAccess AI Collective (axolotl) ▷ #datasets (1 messages):
ben44: Moved to <#1110594519226925137>
Cohere ▷ #general (15 messages🔥):
- Discord API version update in the works: A member inquired if Cohere's API supports OpenAI-style roles like "user" or "assistant". Another member clarified that the current API does not but a new version is being developed that will accommodate these roles to ease integration.
- Incompatibility with OpenAI ChatCompletion: Multiple users discussed how Cohere's Chat API is not compatible with OpenAI's ChatCompletion API, mentioning that many services adopt OpenAI's API while Cohere does not. Other models and services have diverging APIs, complicating universal integration.
- Concerns over model integrity in services like OpenRouter: Members expressed skepticism about services like OpenRouter, fearing they might swap out requested models for cheaper alternatives based on the prompt. One user suggested using raw prompts and side-by-side comparisons to verify the model provided.
- Link to personal blog on resource hoarding: A user shared a blog post comparing the hoarding of single-use items in RPG games to avoiding asking for favors or promoting projects in real life. They discussed how this mindset changed after playing Baldur's Gate 3, where they decided to use resources as intended, which turned out to be fun.
Link mentioned: Use Your Potions and Scrolls: I find that when I play RPG games, I often hoard single-use items like potions and scrolls, saving them for some future critical moment. I finish games like Skyrim with a backpack full of unspent res...
LlamaIndex ▷ #blog (1 messages):
- Catch Founder at World's Fair: Attendees of the @aiDotEngineer's World's Fair can catch LlamaIndex founder @jerryjliu0 speaking twice. On June 26th at 4:53 PM, he will discuss the Future of Knowledge Assistants with special announcements; the second talk is on June 27th at 3:10 PM.
LlamaIndex ▷ #general (13 messages🔥):
-
Python AI Engineer seeks job opportunities: A seasoned Python AI full-stack developer with extensive experience in AI-driven software applications and LLMs shared their detailed resume. They highlighted their deep skills in NLP techniques and frameworks such as Transformers, PyTorch, and TensorFlow.
-
Generating embeddings for Neo4jGraphStore: A member asked for guidance on how to generate embeddings for Neo4jGraphStore using LLMs when initially not used for adding nodes and relationships. The query emphasizes the need for embedding integration post node creation.
-
Structured NER tasks with Ollama and LLMs: A member mentioned using Ollama and open-source models for NER tasks, but encountered issues with achieving structured outputs as prompted. Another member recommended using Gliner instead of LLMs for NER tasks.
-
Adding task functionality in LlamaIndex: A user sought resources for adding functionalities like sending emails, creating Jira tickets, and calendar events in their LlamaIndex project. Another member suggested that agents could be useful and provided documentation for custom agents.
-
Llama and Nuxt.js project example: A member asked if there was an example project utilizing Llama and Nuxt.js. There was no direct response provided in the captured messages.
Links mentioned:
Latent Space ▷ #ai-general-chat (12 messages🔥):
-
Swyx Talks AI Opportunities: A member shared an article discussing AI engineering expert Shawn "swyx" Wang and the new opportunities in AI for use cases and software developers. The article also promotes the AI Engineer World’s Fair event.
-
Groq Adds Whisper Model Support: Groq announced the addition of Whisper model support, claiming it runs at 166x real-time speeds. However, some members expressed concerns about the low rate limits for applications like podcast transcribing and speculated about the potential non-linear, multi-call processing use cases.
-
Music-to-Text Model Inquiry: A member inquired about modern AI solutions capable of generating textual descriptions of music, such as genre, key, tempo, and other tags. The discussion focused on the need for accurate, detailed musical descriptions rather than lyrics.
-
MoA Beats GPT-4: A tweet announced the Mixture of Agents model with a fine-tuning pipeline that is 25x cheaper than GPT-4. According to the tweet, humans prefer MoA outputs 59% of the time, and it sets a new state-of-the-art on Arena-Hard and Alpaca Eval benchmarks.
Links mentioned:
AI Stack Devs (Yoko Li) ▷ #ai-town-discuss (2 messages):
- **Spam Alert Initiated**: A message highlights that user <@937822421677912165> is once again involved in spam activity. The user is tagged to alert moderators for intervention.
- **Repeated Spam by Same User**: Another alert calls out the same user, <@937822421677912165>, for repetitive spam occurrences. Moderators are being summoned to handle the situation.
AI Stack Devs (Yoko Li) ▷ #assets (3 messages):
- Spam reports spark action: One member expressed their frustration with another user's inappropriate message, saying "wtf what's wrong with u". Others suggested reporting the message as spam, hoping Discord would take action.
MLOps @Chipro ▷ #events (4 messages):
- RecSys Learners Virtual Meetup calls for RSVPs: The meetup aimed at Recommendation Systems enthusiasts is scheduled for 06/29/2024 at 7 AM PST. It's free to join and interested participants can RSVP here to receive the event link.
- Query about AI Quality Conference: A member asks if anyone is attending the AI Quality conference next Tuesday in San Francisco. Another member expresses curiosity, asking for more details about the event.
Link mentioned: RecSys Learners Virtual Meetup · Luma: Join us for an exciting and informative RecSys Learner Virtual Meetup, designed for enthusiasts and professionals passionate about Recommendation Systems. This…
Torchtune ▷ #general (2 messages):
- PyTorch/TensorDict or PyTorch/NestedTensor Utility Inquiry: A user inquired about the use cases and preferences for PyTorch's TensorDict or NestedTensor. Another member praised its utility for handling multiple data inputs as a single object, eliminating the need for boilerplate code when managing dtypes/devices or broadcasting across batch dimensions.
{% else %}
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: [{{ email.subject }}]({{ email_url }})!
If you enjoyed AInews, please share with a friend! Thanks in advance!
{% endif %}