AI News for 7/4/2024-7/5/2024. We checked 7 subreddits, 384 Twitters and 30 Discords (418 channels, and 3772 messages) for you. Estimated reading time saved (at 200wpm): 429 minutes. You can now tag @smol_ai for AINews discussions + try Smol Talk!
Qdrant is widely known as OpenAI's vector database of choice, and over the July 4 holiday they kicked off some big claims to replace the venerable BM25 (and even the more modern SPLADE), attempting to coin "BM42":
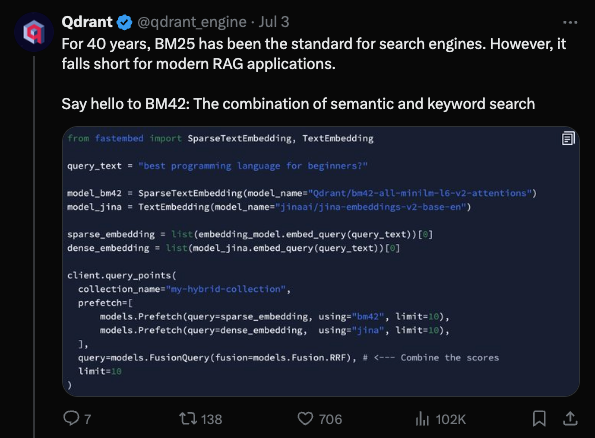
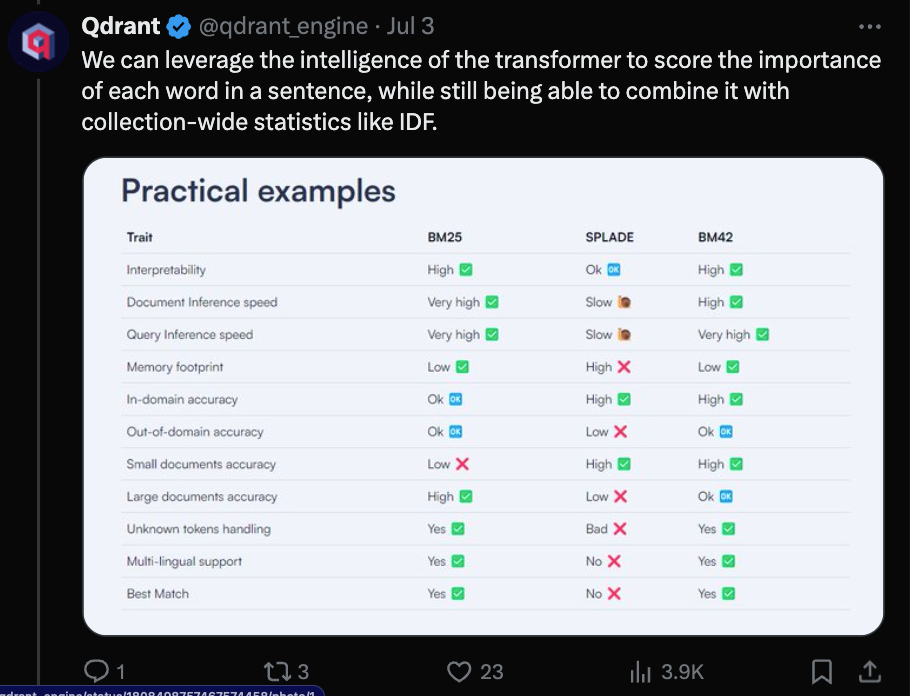
to solve the problem of semantic + keyword search by combining transformer attention for word importance scoring with collection-wide statistics like IDF, claiming advantages over every use case:
Only one problem... the results. Jo Bergum from Vespa (a competitor), pointed out the odd choice of Quora (a "find similar duplicate" questions dataset, not a Q&A retrieval dataset) as dataset and obviously incorrect evals if you know that dataset:
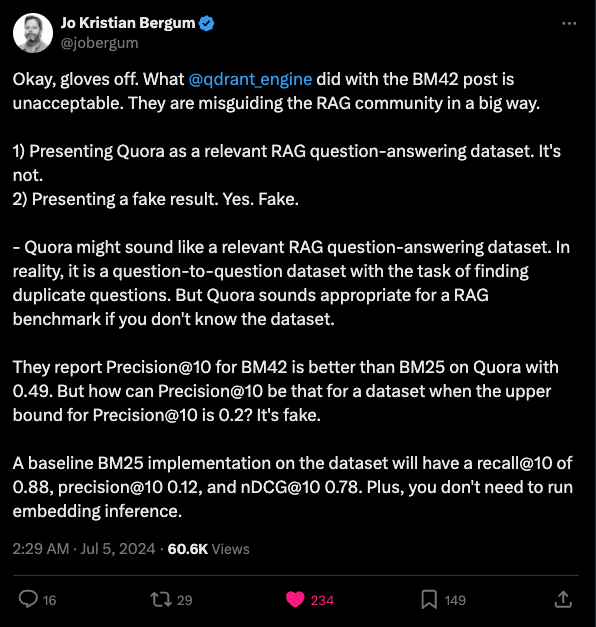
Specifically, the Quora dataset only has ~1.6 datapoints per query so their precision@10 number was obviously wrong claiming to have >4 per 10.
Nils Reimers of Cohere took BM42 and reran on better datasets for finance, biomedical, and Wikipedia domains, and sadly BM42 came up short on all accounts:
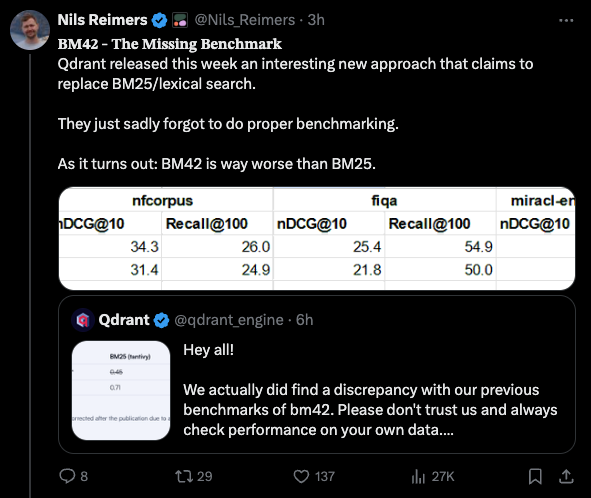
For their part, Qdrant has responded to and acknowledged the corrections, and published corrections... except still oddly running a BM25 implementation that scores worse than everyone else expects and conveniently worse than BM42.
Unfortunate for Qdrant, but the rest of us just got a lightning lesson in knowing your data, and sanity checking evals. Lastly, as always in PR and especially in AI, Extraordinary claims require extraordinary evidence.
Meta note: If you have always wanted to customize your own version of AI News, we have now previewed a janky early version of Smol Talk, which you can access here: https://smol.fly.dev
{% if medium == 'web' %}
Table of Contents
[TOC]
{% else %}
The Table of Contents and Channel Summaries have been moved to the web version of this email: [{{ email.subject }}]({{ email_url }})!
{% endif %}
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet.
Stripe Issues and Alternatives
- Stripe account issues: @HamelHusain noted Stripe is "holding all my money hostage" with "endless wall of red tape" despite no refund requests. @jeremyphoward called it "disgraceful" that Stripe canceled an account due to an "AI/ML model failure".
- Appealing Stripe decisions: @HamelHusain appealed a Stripe rejection but got denied within 5 minutes, with Stripe "holding thousands of dollars hostage".
- Alternatives to Stripe: @HamelHusain noted needing a "backup plan" as "Getting caught by AI/ML false positives sucks." @virattt expressed caution about using Stripe after seeing many posts about issues.
AI and LLM Developments
- Anthropic Constitutional AI: @Anthropic noted Claude 3.5 Sonnet suppresses parts of answers with "antThinking" tags that are removed on the backend, which some disagree with being hidden.
- Gemma 2 model optimizations: @rohanpaul_ai shared Gemma 2 can be finetuned 2x faster with 63% less memory using the UnslothAI library, allowing 3-5x longer contexts than HF+FA2. It can go up to 34B on a single consumer GPU.
- nanoLLaVA-1.5 vision model: @stablequan_ai announced nanoLLaVA-1.5, a compact 1B parameter vision model with significantly improved performance over v1.0. Model and spaces were linked.
- Reflection as a Service for LLMs: @llama_index introduced using reflection as a standalone service for agentic LLM applications to validate outputs and self-correct for reliability. Relevant papers were cited.
AI Art and Perception
- AI vs human art perception poll: @bindureddy posted a poll with 3 AI generated images and 1 human artwork, challenging people to identify the human one, as a "quick experiment" on art perception.
- AI art as non-plagiarism: @bindureddy argued AI art is not plagiarism as it does the "same thing humans do" in studying work, getting inspired, and creating something new. Exact replicas are plagiarism, but not brand new creations.
Memes and Humor
- Zuckerberg meme video: @GoogleDeepMind shared a meme video of Mark Zuckerberg reacting. @BrivaelLp joked about Zuckerberg's "masterclass" in transforming into a "badass tech guy".
- Caninecyte definition: @c_valenzuelab jokingly defined a "caninecyte" as a "type of cell characterized by its resemblance to a dog" in a mock dictionary entry.
- Funny family photos: @NerdyRodent humorously asked "Why is it that when I go through old family pictures, someone always has to stick their tongue out?" with an accompanying pixelated artwork.
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity. Comment crawling works now but has lots to improve!
AI Progress and Implications
- Rapid pace of AI breakthroughs: In /r/singularity, a post highlights how compressed recent AI advances are in the grand scheme of human history, with modern deep learning emerging in just the last "second" if human existence was a 24-hour day. However, an article questions the economic impact of AI so far despite the hype.
- AI humor abilities: Studies show AI-generated humor being rated as funnier than humans and on par with The Onion, though some /r/singularity commenters are skeptical the AI jokes are that original.
- OpenAI security breach: The New York Times reports that in early 2023, a hacker breached OpenAI's communication systems and stole info on AI development, raising concerns they aren't doing enough to prevent IP theft by foreign entities.
- Anti-aging progress: In a YouTube interview, the CSO of Altos Labs discusses seeing major anti-aging effects in mice from cellular reprogramming, with old mice looking young again. Human trials are next.
AI Models and Capabilities
- New open source models discussed include Kyutai's Moshi audio model, the internlm 2.5 xcomposer vision model, and T5/FLAN-T5 being merged into llama.cpp.
- An evaluation of 180+ LLMs on code generation found DeepSeek Coder 2 beat LLama 3 on cost-effectiveness, with Claude 3.5 Sonnet equally capable. Only 57% of responses compiled as-is.
AI Safety and Security
- /r/LocalLLaMA discusses ways to secure LLM apps, including fine-tuning to reject unsafe requests, prompt engineering, safety models, regex filtering, and not rewriting user prompts.
- An example is shared of Google's Gemini AI repeating debunked information, showing current AI can't be blindly trusted as factual.
{kind=link}
AI Art and Media
- Workflows are shared for generating AI singers using Stable Diffusion, MimicMotion, and Suno AI, and using ComfyUI to generate images from a single reference.
- /r/StableDiffusion discusses a new open source method for transferring facial expressions between images/video, and the emerging role of AI Technical Artists to build AI art pipelines for game studios.
- /r/singularity predicts a resurgence in demand for live entertainment as AI displaces online media.
{kind=link}
Robotics and Embodied AI
- Videos are shared of Menteebot navigating an environment, a robot roughly picking tomatoes, and Japan developing a giant humanoid robot to maintain railways.
- A tweet calls for development of open source mechs.
Miscellaneous
- /r/StableDiffusion expresses concern about the sudden disappearance of the Auto-Photoshop-StableDiffusion plugin developer.
- An extreme horror-themed 16.5B parameter LLaMA model is shared on Hugging Face.
- /r/singularity discusses a "Singularity Paradox" thought experiment about when to buy a computer if progress doubles daily, with comments noting flaws in the premise.
AI Discord Recap
A summary of Summaries of Summaries
1. LLM Performance and Optimization
-
New models like Llama 3, DeepSeek-V2, and Granite-8B-Code-Instruct are showing strong performance on various benchmarks. For example, Llama 3 has risen to the top of leaderboards like ChatbotArena, outperforming models like GPT-4-Turbo and Claude 3 Opus.
-
Optimization techniques are advancing rapidly:
- ZeRO++ promises 4x reduction in communication overhead for large model training.
- The vAttention system aims to dynamically manage KV-cache memory for efficient LLM inference.
- QServe introduced W4A8KV4 quantization to boost cloud-based LLM serving performance.
2. Open Source AI Ecosystem
- Tools like Axolotl are supporting diverse dataset formats for LLM training.
- LlamaIndex launched a course on building agentic RAG systems.
- Open-source models like RefuelLLM-2 are being released, focusing on specific use cases.
3. Multimodal AI and Generative Models
-
New multimodal models are enhancing various capabilities:
- Idefics2 8B Chatty focuses on improved chat interactions.
- CodeGemma 1.1 7B refines coding abilities.
- Phi 3 brings AI chatbots to browsers via WebGPU.
-
Combinations of models (e.g., Pixart Sigma + SDXL + PAG) are aiming to achieve DALLE-3 level outputs.
4. Stability AI Licensing
- Stability AI revised the license for SD3 Medium after community feedback, aiming to provide more clarity for individual creators and small businesses.
- Discussions about AI model licensing terms and their impact on open source development are ongoing across multiple communities.
- Stability AI's launch of Stable Artisan, a Discord bot integrating various Stable Diffusion models for media generation and editing, was a hot topic (Stable Artisan Announcement). Users discussed the implications of the bot, including questions about SD3's open-source status and the introduction of Artisan as a paid API service.
5. Community Tools and Platforms
- Stability AI launched Stable Artisan, a Discord bot integrating models like Stable Diffusion 3 and Stable Video Diffusion for media generation within Discord.
- Nomic AI announced GPT4All 3.0, an open-source local LLM desktop app, emphasizing privacy and supporting multiple models and operating systems.
6. New LLM Releases and Benchmarking Discussions:
- Several AI communities discussed the release of new language models, such as Meta's Llama 3, IBM's Granite-8B-Code-Instruct, and DeepSeek-V2, with a focus on their performance on various benchmarks and leaderboards. (Llama 3 Blog Post, Granite-8B-Code-Instruct on Hugging Face, DeepSeek-V2 on Hugging Face)
- Some users expressed skepticism about the validity of certain benchmarks, calling for more credible sources to set realistic standards for LLM assessment.
7. Optimizing LLM Training and Inference:
- Across multiple Discords, users shared techniques and frameworks for optimizing LLM training and inference, such as Microsoft's ZeRO++ for reducing communication overhead (ZeRO++ Tutorial), vAttention for dynamic KV-cache memory management (vAttention Paper), and QServe for quantization-based performance improvements (QServe Paper).
- Other optimization approaches like Consistency LLMs for parallel token decoding were also discussed (Consistency LLMs Blog Post).
8. Advancements in Open-Source AI Frameworks and Datasets:
- Open-source AI frameworks and datasets were a common topic across the Discords. Projects like Axolotl (Axolotl Dataset Formats), LlamaIndex (Building Agentic RAG with LlamaIndex Course), and RefuelLLM-2 (RefuelLLM-2 on Hugging Face) were highlighted for their contributions to the AI community.
- The Modular framework was also discussed for its potential in Python integration and AI extensions (Modular Blog Post).
9. Multimodal AI and Generative Models:
- Conversations surrounding multimodal AI and generative models were prevalent, with mentions of models like Idefics2 8B Chatty (Idefics2 8B Chatty Tweet), CodeGemma 1.1 7B (CodeGemma 1.1 7B Tweet), and Phi 3 (Phi 3 Reddit Post) for various applications such as chat interactions, coding, and browser-based AI.
- Generative modeling techniques like combining Pixart Sigma, SDXL, and PAG for high-quality outputs and the open-source IC-Light project for image relighting were also discussed (IC-Light GitHub Repo).
10. New Model Releases and Training Tips in Unsloth AI Community:
- The Unsloth AI community was abuzz with discussions about new model releases like IBM's Granite-8B-Code-Instruct (Granite-8B-Code-Instruct on Hugging Face) and RefuelAI's RefuelLLM-2 (RefuelLLM-2 on Hugging Face). Users shared their experiences with these models, including challenges with Windows compatibility and skepticism over certain performance benchmarks. The community also exchanged valuable tips and insights on model training and fine-tuning.
PART 1: High level Discord summaries
HuggingFace Discord
- Vietnamese Linguistics Voiced: Vi-VLM's Vision**: The Vi-VLM team announced a Vision-Language model tailored for Vietnamese, integrating Vistral and LLaVA frameworks to focus on image descriptions. Viewers can find the demo and supporting code in the linked repository.
- Dataset Availability: Vi-VLM released a dataset specific for VLM training in Vietnamese, which is accessible for enhancing local language model applications. The dataset adds to the linguistic resources available for Southeast Asian languages.
- Grappling with Graphics: WHAM's Alternative Search**: An enthusiast sought alternatives to WHAM for human pose estimation in complex videos, pointing out the ungainly Python and CV dependencies. The community exchange hints at a need for tools that accommodate non-technical users in sophisticated AI applications.
- Learning resources for ViT and U-Net implementations were shared, including a guide from Zero to Mastery and courses by Andrew Ng, indicating community interest in mastering these vision transformer models.
- Tuning In: Audio-Language Model Discourse**: Moshi's linguistic fluidity: Yann LeCun shared a tweet spotlighting Kyutai.org's digital pirate that can comprehend English spoken with a French accent, showcasing the model's diverse auditory processing capabilities.
- Interest in the Flora paper and audio-language models remains strong, reflecting the AI community's focus on cross-modal faculties. Upcoming paper reading sessions on these topics are anticipated with enthusiasm.
- Frozen in Thought: The Mistral Model Stalemate**: Users reported a crawling halt in the Mistral model's inference process, notably at iteration 1800 out of 3000, suggesting possible caching complications. This reflects on the pragmatic challenge of managing resources during extensive computational tasks.
- Conversations surfaced around making effective API calls without downloading models locally, highlighting the need for streamlined remote inference protocols. The API-centric dialogue underscores a trend towards more flexible, cloud-based ML operations.
- Diffusion Discussion: RealVisXL and ISR**: RealVisXL V4.0, optimized for rendering photorealistic visuals, is now in training, with an official page and sponsorship on Boosty, spotlighting community support for model development.
- The existing IDM-VTON's 'no file named diffusion_pytorch_model.bin' error in Google Colab exemplifies the troubleshooting dialogs that emerge within the diffusion model space, emphasizing the practical sides of AI deployment.
Stability.ai (Stable Diffusion) Discord
- Clearing the Confusion: Stability AI’s Community License: Stability AI has revised their SD3 Medium release license after feedback, offering a new Stability AI Community License that clarifies usage for individual creators and small businesses. Details are available in their recent announcement, with the company striking a balance between commercial rights and community support.
- Users can now freely use Stability AI's models for non-commercial purposes under the new license, providing an open source boon to the community and prompting discussions about how these changes could impact model development and accessibility.
- Anime AI Model's Metamorphosis: Animagine XL 3.1: The Animagine XL 3.1 model by Cagliostro Research Lab and SeaArt.ai is driving conversations with its enhancements over predecessor models, bringing higher quality and broader range of anime imagery to the forefront.
- The AAM Anime Mix XL has also captured attention, sparking a flurry of comparisons with Animagine XL 3.1, as enthusiasts discuss their experiences and preferences between the different anime-focused generation models.
- Debating the GPU Arms Race: Multi-GPU Configurations: The technical community is actively discussing the optimization of multiple GPU setups to boost Stable Diffusion's performance, with emphasis on tools like SwarmUI that cater to these complex configurations.
- The debates converge on the challenges of efficiently managing resources and achieving high-quality outputs, highlighting the combination of technical prowess and creativity required to navigate the evolving landscape of AI model training.
- CivitAI's SD3 Stance Spurring Controversy: CivitAI's move to ban SD3 models has divided opinion within the community, as some view it as a potential roadblock for the development of the Stable Diffusion 3 framework.
- The discussions deepen with insights into licensing intricacies, commercial implications, and the overall trajectory of how this decision could shape future collaborations and model evolutions.
- License and Limits: Stable Diffusion Under Scrutiny: The latest conversations scrutinize the license for Stable Diffusion 3 and its compatibility with both individual and enterprise usage, considering the community's need for clarity and freedom in AI model experimentation.
- Community sentiment is split, as discussions pivot around whether the perceived license restrictions unfairly penalize smaller projects or whether they're an inherent part of maturing technologies in the field of AI.
Unsloth AI (Daniel Han) Discord
- Gemma's Quantum Leap: The new Gemma 2 has hit the tech scene, boasting 2x faster finetuning and a lean VRAM footprint, requiring 63% less VRAM (Gemma 2 Blog). Support for hefty 9.7K token contexts on the 27B model was a particular highlight among Unsloth users.
- The marred launch with notebook issues such as mislabeling was glossed over by a community member's remark on the rushed blogpost, but those issues have been swiftly tackled by developers (Notebook Fixes).
- Datasets Galore at Replete-AI: Replete-AI has introduced two extensive datasets, Everything_Instruct and its multilingual cousin, each packing 11-12GB of instruct data (Replete AI Datasets). Over 6 million rows are at AI developers' disposal, promising to fuel the next wave of language model training.
- The community's enthusiasm was tempered with quality checks, probing the datasets for deduplication and content balance, a nod to the seasoned eye for meticulous dataset crafting.
- Notebooks Nailed to the Mast: Requests in collaboration channels have led to a commitment for pinning versatile notebooks, assisting members to swiftly home in on valuable resources.
- Continued efforts were seen with correcting notebook links and the promise to integrate them into the Unsloth GitHub page, showcasing a dynamic community-driven documentation process (GitHub Unsloth).
- Patch and Progress with Unsloth 2024.7: Unsloth's patch 2024.7 got mixed reception due to checkpoint-related errors, yet it marks an important stride by integrating Gemma 2 support into Unsloth's ever-growing toolkit (2024.7 Update).
- Devoted users and Unsloth's responsive devs are on top of the fine-tuning foibles and error resolutions, evidencing a robust feedback loop essential for fine-grained model optimization.
- Facebook's Controversial Token Tactics: Facebook's multi-token prediction model stirred debate over access barriers, stirring a whirlwind of opinions among Unsloth's tight-knit community.
- Critical views on data privacy were par for the course, specifically relating to the need for sharing contact data to utilize Facebook's model, fueling an ongoing conversation on ethical AI usage (Facebook's Multi-Token Model).
Latent Space Discord
- Sprinting on Funding Runway: Following a link to rakis, community members discussed the whopping $85M seed investment intersecting AI with blockchain, sparking conversations on the current venture capital trends in technology.
- The developers of BM42 faced heat for potentially skewed benchmarks, leading to a vigilant community advocating for rigorous evaluation practices; this prompted a revised approach to their metrics and datasets.
- Collision Course: Coding Tools: Users compared git merge tool experiences, singling out lazygit and Sublime Merge, driving the conversation towards the need for more nuanced tools for code conflict resolution.
- Claude 3.5 and other AI-based tools grabbed the spotlight in discussions for their prowess in coding assistance, emphasizing efficiency in code completion and capabilities like handling complex multi-file refactors.
- Tuning into Technical Talk: On the Latent Space Podcast, Yi Tay from Reka illuminated the process of developing a training stack for frontier models while drawing size and strategy parallels with teams from OpenAI and Google Gemini.
- Listeners were invited to engage on Hacker News with the live discussion, bridging the gap between the podcast and broader AI research community dialogues.
- Navigating AV Troubles: OpenAI's AV experienced disruptions during the AIEWF demo, with voices for a switch to Zoom ensuing, followed by a swift action resulting in sharing a Zoom meeting link for better AV stability.
- Compatibility issues between Discord and Linux persisted as a recurrent technical headache, prompting users to explore more Linux-friendly communication alternatives.
- Deconstructing Model Merger Mania: Debates on model merging tactics took center stage with participants mulling the differing objectives and potential integrative strategies for tools like LlamaFile and Ollama.
- The conversation dived into the possibilities of wearable technology integration with AI for enhancing event experiences, paired with a deep consideration for privacy and consent.
LM Studio Discord
- Snapdragon's Surprising Speed: The Surface Laptop with Snapdragon Elite showcased heft, hitting 1.5 seconds to first token and 10 tokens per second on LLaMA3 8b with 8bit precision, whilst only using 10% GPU. No NPU activity yet, but the laptop's speed stirred speculation on eventual NPU boosts to LLaMA models.
- Tech enthusiasts compared Snapdragon's CPU prowess to older Intel counterparts, finding the former's velocity vivacious. Amidst laughter, the tech tribe teases about a makeshift Cardboard NPU, projecting potential performance peaks pending proper NPU programming.
- Quantization Quirks and Code Quests: Quantization quandaries arose with Gemma-2-27b, where model benchmarks behaved bizarrely across different quantized versions. Meanwhile, tailored system prompts polished performance for Gemma 2 27B, prompting PEP 8-adhering and efficient algorithm emission.
- Suggestions surfaced that Qwen2 models trot best with ChatML and a flash attention setting, while users with non-CUDA contraptions cautioned against the chaos of IQ quantization, noting notably nicer behavior on alternative architectures.
- LM Studio's ARM Standoff: A vexed user voiced frustration when LM Studio's AppImage defied a dance with aarch64 CPUs. The error light shone, signaling a syntax struggle, and a lamenting line confirmed, "No ARM CPU support on Linux."
- Dialogues dashed hopes for immediate ARM CPU inclusions, leaving Linux loyalists longing. A shared sibling sentiment suggested an architecture adjustment for LM Studio belongs on the horizon but hasn't hit home base just yet.
- RTX's Rocky Road: RTX 4060 8GB VRAM owners opined their predicament with 20B quantized models; a tenacious tussle with tokens terminated in total system freezes. Fellow forum members felt for them, flashing back to their own fragmentary RTX 4060 experiences.
- Guild guidance gave GPU grievances a glimmer of hope, heralding less loaded models like Mistral 7B and Open Hermes 2.5 for mid-tier machine mates. A commendatory chorus rose for smaller souls, steering clear of titanic token-takers.
- ROCm's Rescue Role: Seeking solace from stifled sessions, users with 7800XT aired their afflictions as models muddled up, missing the mark on GPU offload. A script signalled success, soothing overtaxed systems seeking ROCm solace.
- The cerebral collective converged on solutions, corroborating the effectiveness of the ROCm installation script. Joyous jingles jived in the forum, as confirmation came that GPGPU gurus had gathered a workaround worthy of the wired world.
CUDA MODE Discord
- CUDA Conundrums & Mixed-precision MatMul: Discussions in the CUDA MODE guild veered into optimizing matrix multiplication using CUDA, highlighting a blog post on techniques for column loading in GPU matrix multiplication; another thread featured the release of customized gemv kernels for int2*int8 and the BitBLAS library for mixed-precision operations.
- Users explored TorchDynamo's role in PyTorch performance, and compared ergonomics of Python vs C++ for CUDA kernel development, with Python favored for its agility in initial phases. Some faced challenges adapting to Python 3.12 bytecode changes with
torch.compile, addressed in a recent discussion.
- Users explored TorchDynamo's role in PyTorch performance, and compared ergonomics of Python vs C++ for CUDA kernel development, with Python favored for its agility in initial phases. Some faced challenges adapting to Python 3.12 bytecode changes with
- GPTs Crafting Executive Summaries & Model Training Trials: A blog post detailing the use of GPTs for executive summary drafting sparked interest, while LLM training trials with FP8 gradients were flagged for increasing losses, prompting a switch to BF16 for certain operations.
- Schedule-Free Optimizers boasted smoother loss curves, with empirical evidence of convergence benefits shared by users, meanwhile, a backend SDE's transition to CUDA inference optimization was deliberated with suggestions spanning online resources, course recommendations, and community involvement.
- AI Podcasts & Keynotes Spark Engaging Discussions: Lightning AI's Thunder Sessions podcast with Luca Antiga and Thomas Viehmann caught the attention of community members, whereas Andrej Karpathy's keynote at UC Berkeley was a highlighter of innovation and student talent.
- Casual conversations and channel engagement painted a picture of an interactive forum, with members sharing brief notes of excitement or appreciation, yet holding back on deeper technical exchanges in channels tagged as less focused.
- Deep Learning Frameworks & Triton Kernel Fixes: The quest to build a deep learning framework from scratch in C++, akin to tinygrad, uncovered the complexity hurdle, kindling a debate on the affordances of C++ vs Python in this context, while Triton kernel's
tl.loadissues in parallel CUDA graph instances required ingenuity to circumnavigate latency concerns.- Further intricacies surfaced when discussing the functioning of the
.tomethod in torch.ao, where current limitations restrict dtype and memory format changes, prompting temporary function amendments as discussed in issue trackers and commit logs.
- Further intricacies surfaced when discussing the functioning of the
Perplexity AI Discord
- Llamas Looping Lines: Repetition Glitch in AI**: Users experienced Perplexity AI outputting repetitive responses across models such as Llama 3 and Claude, and were reassured that the issue was being addressed with an imminent fix.
- Alex confirmed the issue's recognition and the ongoing efforts to rectify it, marking a pressing concern within the Perplexity AI's performance benchmark.
- Real-Time Reality Check Fails: Live Access Hiccups**: A gap in expectations has emerged as Perplexity AI users face live internet data retrieval issues, receiving obsolete rather than up-to-date information.
- Despite attempts to resolve the inaccuracies by restarting the application, the users indicated the problem persistence in the feedback channel.
- Math Model Missteps: Perplexity Pro's Calculation Challenges**: Perplexity Pro's computations, such as CAPM beta, were highlighted for inaccuracies despite its GPT-4o origins, casting shadows on its reliable academic application.
- The community expressed its dissatisfaction and concerns regarding the model's utility in fields requiring exact mathematical problem solving.
- Stock Market Success Stories: Perplexity’s Profitable Predictions**: Anecdotes of financial victories like making $8,000 surfaced among users who harnessed Perplexity AI for stock market decisions, triggering conversations on its varied benefits.
- Such user stories serve as testimonials to the diverse capabilities of the Pro version of Perplexity AI in real-world use cases.
- Subscription Scrutiny: Decoding Perplexity AI Plans**: Questions and comparisons flourished as users delved into the differences between Pro and Enterprise Pro plans, particularly concerning model allocations like Sonnet and Opus.
- Enquiries were directed at understanding not just availability but also the specificity of models included in Perplexity’s varied subscription offerings.
LAION Discord
- BUD-E Board Expansion: BUD-E now reads clipboard text, a new feature shown in a YouTube video with details on GitHub. The feature demo, presented in low quality, sparked light-hearted comments.
- The community discussed AI model training challenges due to recurrent usage of overlapping datasets, with FAL.AI's dataset access hurdles highlighting the issue. Contrastingly, breakthroughs like Chameleon are linked to a variety of integrated data.
- Clipdrop Censorship Confusion: Clipdrop's NSFW detection misfired, mislabeling a benign image as inappropriate, much to the amusement of the community.
- Stability AI revises license for SD3 Medium, now under the Stability AI Community License, allowing increased access for individual creators and small businesses after community feedback.
- T-FREE Trend Setter: The new T-FREE tokenizer, detailed in a recently released paper, promises sparse activations over character triplets, negating the need for large reference corpora and potentially reducing embedding layer parameters by over 85%.
- The approach is praised for enhancing performance on less common languages and slimming embedding timers, adding a compact edge to LLMs.
- Alert: Scammer in the Guild: A scammer was flagged in the #[research] channel, putting the community on high alert.
- A string of identical phishing links offering a '$50 gift card' was posted across multiple channels by a user, raising concerns.
OpenAI Discord
- Voices in the Void: The unveiling of a new Moshi AI demo sparked a mix of excitement for its real-time voice interaction and disappointment over issues with interruptions and looped responses.
- Hume AI's playground was scrutinized for its lack of long-term memory, frustrating users who seek persistent AI conversations.
- Memory Banks in Question: GPT's memory prowess came under fire as it saves user preferences but still fabricates responses, with members suggesting enhanced customization to mitigate this.
- A heated GPT-2 versus modern models debate surfaced, comparing the cost-efficiency of older models with the performance leaps in current iterations like GPT-3.5 Turbo.
- ChatGPT: Free vs. Plus Plans: Advantages of the paid ChatGPT Plus plan were clarified, detailing perks such as a higher usage cap, DALL·E access, and an expanded context window.
- GPT-4 usage concerns were addressed, with cooldown periods in place after limit hits, specifically allowing Plus members up to 40 messages every 3 hours.
- AI Toolbox Expansion: Community members explored tools for testing multiple AI responses to prompts, suggesting a custom-built tool and existing options for efficient assessment.
- Conversation turned to API integrations, looking at Rigorous Aggregate Generators (RAG) for linking AI models to diverse datasets and utilizing existing Assistant API endpoints.
- Contest with Context: In #prompt-engineering, strategies for contesting traffic tickets were delineated, advising structured approaches and legal argumentation techniques.
- Discussions blossomed over creating an employee recognition program to heighten workplace morale, focusing on goals and recognition criteria for notable contributions.
Nous Research AI Discord
- Datasets Deluge by Replete-AI: Replete-AI dropped two gargantuan datasets, titled Everything_Instruct and Everything_Instruct_Multilingual, boasting 11-12GB and over 6 million data stripes. Intent is to amalgamate variegated instruct data to advance AI training.
- The Everything_Instruct targets English, while Everything_Instruct_Multilingual brings in a linguistic mix to broaden language handling of AI. Both sets echo past successes like bagel datasets and take a cue from EveryoneLLM AI models. Dive in at Hugging Face.
- Nomic AI Drops GPT4All 3.0: The latest by Nomic AI, GPT4All 3.0, hits the scene as an open-source, local LLM desktop app catering to a plethora of models and prioritizing privacy. The app is noted for its redesigned user interface and is licensed under MIT. Explore its features.
- Touting more than a quarter-million monthly active users, GPT4All 3.0 facilitates private, local interactions with LLMs, cutting internet dependencies. Uptake has been robust, signaling a shift towards localized and private AI tool usage.
- InternLM-XComposer-2.5 Raises the Bar: InternLM introduced InternLM-XComposer-2.5, a juggernaut in large-vision language models that brilliantly juggles 24K interleaved image-text contexts and scales up to 96K via RoPE extrapolation.
- This model is a frontrunner with top-tier results on 16 benchmarks, closing in on behemoths like GPT-4V and Gemini Pro. Brewed with a sprinkle of innovation and a dash of competitive spirit, this InternLM concoction awaits.
- Claude 3.5's Conundrum and Lockdown: Attempts to bypass the ethical constraints in Claude 3.5 Sonnet led to frustration among users, with strategies around specific pre-prompts making little to no dent.
- Despite the resilience of Claude's restrictions, suggestions to experiment with Anthropic's workbench were shared. Yet, users were cautioned about the risks of account restrictions following such endeavors. Peer into the conversation.
- Apollo's Artistic AI Ascent: Achyut Benz bestowed the Apollo project upon the world, an AI that crafts visuals akin to the admired 3Blue1Brown animations. Built atop Next.js, it taps into GroqInc and interweaves both AnthropicAI 3.5 Sonnet & GPT-4.
- Apollo is all about augmenting the learning experience with AI-generated content, much to the enjoyment of the technophile educator. Watch Apollo's reveal.
OpenRouter (Alex Atallah) Discord
- Quantum Leap in LLM Deployment: OpenRouter's deployment strategy for LLM models specifies FP16/BF16 as the default quantization standard, with exceptions noted by an associated quantization icon.
- The adaptation of this quantization approach has sparked detailed discussions on the technical implications and efficiency gains.
- API Apocalypse Averted by OpenRouter: A sudden change in Microsoft's API could have spelled disaster for OpenRouter users, but a swift patch brought things back in line, earning applause from the community.
- The fix restored harmony, reflecting OpenRouter’s readiness for quick turnarounds in the face of technical disruptions.
- Infermatic Instills Privacy Confidence: In an affirmative update, Infermatic declared its commitment to real-time data processing with its new privacy policy, explicitly stating it won’t retain input prompts or model outputs.
- This update brought clarity and a sense of security to users, distancing the platform from previous data retention concerns.
- DeepSeek Decodes Equation Enigma: Users troubleshooting issues with DeepSeek Coder found a workaround for equations not rendering by ingeniously using regex to tweak output strings.
- Persistent problems with TypingMind's frontend not correctly processing prompts were flagged for a fix, demonstrating proactive community engagement.
- Pricey API Piques Peers: Debate heated up around Mistral's Codestral API pricing strategy, with the 22B model considered overpriced by some community members.
- Users steered each other towards more budget-friendly alternatives like DeepSeek Coder, which offers competitive coding capabilities without breaking the bank.
Eleuther Discord
- Fingerprints of the Digital Minds: The community explored Topological Data Analysis (TDA) for unique model fingerprinting and debated the utility of checksum-equivalent metrics for model validation, such as for the
LlamaForCausalLMusing tools like lm-evaluation-harness.- Discussions also touched on Topological Data Analysis to profile model weights by their invariants, referencing resources like TorchTDA and considering bit-level innovations from papers like 1.58-bit LLMs for efficiency.
- Tales of Scaling and Optimization: Attention was given to the efficientcube.ipynb notebook for scaling laws, while AOT compilation capabilities in JAX were highlighted as a step forward in pre-execution code optimization.
- FLOPs estimation methods for JIT-ed functions in Flax were shared, and critical batch sizes were reinvestigated, challenging the assumption that performance is unaffected below a certain threshold.
- Sparse Encoders and Residual Revelations: The deployment of Sparse Autoencoders (SAEs) trained on Llama 3 8B's residual stream discussed utilities for integrating with LLMs for better processing, furnished with details on the model's implementation.
- Looking into residual stream processing, the strategy organized SAEs by layer for optimizing their synergy with Llama 3 8B, as expanded upon in the associated model card.
- Harnessing the Horsepower of Parallel Evaluation: Enthusiast surfaced questions on the viability of caching preprocessed inputs and resolving Proof-Pile Config Errors, noting that changing to
lambada_openaicircumvented the issue.- Notables included model name length issues, prompting OSError(36, 'File name too long'), and guidance was sought on setting up parallel model evaluation, with warnings about single-process evaluation assumptions.
LangChain AI Discord
- LangChain Lamentations: LangChain users reported performance issues when running on CPU, with long response times and convoluted processing steps being a significant pain point.
- The debate is ongoing whether the sluggishness is due to inefficient model reasoning or the absence of GPU acceleration, while some suggest it's bogged down by unnecessary complexity, as discussed here.
- AI Model Showdown: OpenAI vs ChatOpenAI: Discussions ensued over the advantages of using OpenAI over ChatOpenAI as the former might be phased out, sparking a comparison of their implementation efficiencies.
- Members shared mixed experiences around task-specific requirements, while some preferred OpenAI for its familiar interface and tooling.
- Juicebox.ai: The People Search Prodigy: Juicebox.ai's PeopleGPT was praised for its Boolean-free natural language search capabilities to swiftly identify qualified talent, enhancing the talent search with ease-of-use features.
- The technical community lauded its combination of filtering and natural language search, elevating the overall experience for users; details are available here.
- RAG Chatbot Calendar Conundrum: A LangChain RAG-based chatbot developer sought guidance for integrating a demo scheduling function, highlighting the complexities found in the implementation process.
- Community response was geared towards assisting with this integration, indicating a cooperative effort to enhance the chatbot's capabilities despite the absence of explicit links to resources.
- Visual Vectored Virtuosity: A blogpost outlined creating an E2E Image Retrieval app using Lightly SSL and FAISS, complete with a vision transformer model.
- The post, accompanied by Colab Notebook and Gradio app, was shared to encourage peer learning and application.
LlamaIndex Discord
- LlamaIndex RAG-tastic Webinar Whirl: LlamaIndex partnered with Weights & Biases for a webinar demystifying the complexities involved in RAG experimentation and evaluation. The session promises insights into accurate LLM Judge alignment, with a spotlight on Weights and Biases collaboration.
- Anticipation builds as the RAG pipeline serves as a focal point for the upcoming webinar, highlighting challenges in the space. A hint of skepticism over RAG's nuanced evaluation underscores community buzz around the event.
- Rockstars of AI Edging Forward: Rising star @ravithejads shares his ascent in becoming a rockstar AI engineer and educator, fueling aspirations within the LlamaIndex community.
- LlamaIndex illuminates @ravithejads's contribution to OSS and consistent engagement with AI trends, igniting discussions about pathways for professional development in AI.
- Reflecting on 'Reflection as a Service': 'Reflection as a Service' enters the limelight at LlamaIndex, proposing an introspective mechanism to boost LLM reliability by adding a self-corrective layer.
- This innovative approach captivated the community, sparking dialogue on its potential to enhance agentic applications through intelligent self-correction.
- Cloud Function Challenges Versus Collaborative Fixes: Discussions surfaced on the Google Cloud Function regarding hardships with multiple model loading, sparking a collective search for more efficient methods among AI enthusiasts.
- Community wisdom circulates as members share their strategies for reducing load times and optimizing model use, showcasing a collaborative spirit in problem-solving.
- CRAG – Corrective Measures on Stage: Yan et al. introduce Corrective RAG (CRAG), an innovative LlamaIndex service designed to dynamically validate and correct irrelevant context during retrieval, stirring interest among AI practitioners.
- Connections are drawn between CRAG and possibilities for advancing retrieval-augmented generation systems, fueling forward-thinking conversations on refinement and accuracy.
Cohere Discord
- Open Invites to AI Soirees: Community members clarified that no special qualifications are necessary to attend the London AI event; simply filling out a form will suffice. The inclusive policy ensures that events are accessible to all, fostering a diverse exchange of ideas.
- Discussion around event attendance highlighted the importance of community engagement and open access in AI gatherings, as these policies promote broader participation and knowledge sharing across fields and expertise levels.
- API Woes in Production Mode: A TypeError issue was raised by a member deploying an app using Cohere's rerank API in production, sparking a troubleshooting thread in contrast with its smooth local operation.
- The community’s collaborative effort in addressing the rerank API problems showcased the value of shared knowledge and immediate peer support in overcoming technical challenges in a production environment.
- Fresh Faces in AI Development: Newly joined members of diverse backgrounds, including a Computer Science graduate and an AI developer focused on teaching, introduced themselves, expressing eagerness to contribute to the guild's collective expertise.
- The warm welcome extended to newcomers underlines the guild's commitment to nurturing a vibrant community of AI enthusiasts poised for collaborative growth and learning.
- Command R+ Steals the Limelight: Cohere announced their most potent model in the Command R family, Command R+, now ready for use, creating quite the buzz among the tech-savvy audience.
- The release of Command R+ is seen as a significant step in advancing the capabilities and applications of AI models, indicating a continuous drive towards innovation in the field.
- Saving Scripts with Rhea.run: The introduction of a 'Save to Project' feature in Rhea.run was met with enthusiasm as it allows users to create and preserve interactive applications through conversational HTML scripting.
- This new feature emphasizes Rhea.run’s dedication to simplifying the app creation process, thereby empowering developers to build and experiment with ease.
OpenInterpreter Discord
- MacOS Copilot Sneaks into Focus: The Invisibility MacOS Copilot featuring GPT-4, Gemini 1.5 Pro, and Claude-3 Opus was highlighted for its context absorption capabilities and is currently available for free.
- Community members showed interest in potentially open-sourcing grav.ai to incorporate similar functionalities into the Open Interpreter (OI) ecosystem.
- 'wtf' Command Adds Debugging Charm to OI: The 'wtf' command allows Open Interpreter to intelligently switch VSC themes and provide terminal debugging suggestions, sparking community excitement.
- Amazement over the command's ability to execute actions intuitively was voiced, with plans to share further updates on security roundtables and the upcoming OI House Party event.
- Shipping Woes for O1 Light Enthusiasts: Anticipation and frustration were the tones within the community regarding the 01 Light shipments, as discussions revolved around delays.
- Echoed sentiments of waiting reinforced the collective desire for clear communication on shipment timelines.
Modular (Mojo 🔥) Discord
- Mojo Objects Go Haywire!: Members discussed a casting bug affecting Mojo objects compared to Python objects, potentially linked to GitHub Issue #328.
- MLIR's Unsigned Integer Drama: The community discovered that MLIR interpreted unsigned integers as signed, sparking discussion and leading to the creation of GitHub Issue #3065.
- Concern surged around how this unsigned integer casting issue could impact various users, pivoting the conversation to this emerging bug.
- Compiler Nightly News: Segfaults and Solutions: Recent segfaults in the nightly build led to the submission of a bug report and sharing the problematic file, seen here.
- Added to this, new compiler releases were announced, with improvements including an
exclusiveparameter and new methods in version2024.7.505, linked in the changelog.
- Added to this, new compiler releases were announced, with improvements including an
- Marathon March: Mojo's Matrix Multiplication: Benny impressed by sharing a matrix multiplication technique and recommended tailoring block sizes, advising peers to consult UT Austin papers for insights.
- In a separate discussion thread, speed bumps occurred with increased compilation times and segfaults in the latest test suite, with participants directing each other to resources such as a Google Spreadsheet for papers.
LLM Finetuning (Hamel + Dan) Discord
- Solo Smithing Without Chains: Discussion confirmed LangSmith can operate independently of LangChain as demonstrated in examples on Colab and GitHub. LangSmith allows for instrumentation of LLMs, offering insights into application behaviors.
- Community members assuaged concerns about GPU credits during an AI course, emphasizing proper communication of terms and directing to clear info on the course platform.
- Credit Clarity & Monthly Challenges: A hot topic revolves around the $1000 monthly credit and its perishability, with consensus on no rollover but still appreciating the offer.
- A user's doubt about a mysteriously increased balance of $1030 post-Mistral finetuning led to speculation on a possible $30 default credit per month.
- Training Tweaks: Toiling with Tokens: A thread on the
Meta-Llama-3-8B-Instructsetup usingtype: input_outputsparked some confusion, with users examining special tokens and model configurations, referencing GitHub.- Trainers experienced better outcomes favoring L3 70B Instruct over L3 8B, serendipitously found when a configuration defaulted to the instruct model, highlighting model choice implications.
- Credit Confusion & Course Catch-up: Uncertainty loomed about credit eligibility for services, with one member seeking clarification on terms post-enrollment since June 14th.
- Another user echoed concerns about compute credit expiration, requesting an extension for the remaining credit which slipped through the calendar cracks.
Interconnects (Nathan Lambert) Discord
- Debunking the Demo Dilemma: Community member challenged the legitimacy of an AI demo, calling into question the realism of its responses and highlighting significant response time problems. The thread included a link to the contentious demonstration.
- In an apologetic pivot, Stability AI made revisions to the Stable Diffusion 3 Medium in response to community feedback, along with clarifications on their license, earmarking a path for future high-quality Generative AI endeavors.
- Search Smackdown: BM42 vs. BM25: The Qdrant Engine touted its BM42 as a breakthrough in search technology, promising superior RAG integration over the long-established BM25, as seen in their announcement.
- Critics, including Jo Bergum, questioned the integrity of BM42's reported success, suggesting the improbability of the claims and sparking debate on the validity of the findings presented on the dataset from Quora.
- VAEs Vexation and AI Investment Acumen: A humorous account of the difficulties in grasping Variational Autoencoders surfaced, juxtaposed against a claim of exceptional AI investment strategy within the community.
- A serious projection deduced that for AI to bolster GDP growth effectively, it must range between 11-15%, while the community continues to grapple with Anthropic Claude 3.5 Sonnet's opaque operations.
- Google's Grinder in the Global AI Gauntlet: Users discussed Google's sluggish start in the Generative AI segment, expressing concerns over the company's messaging clarity and direction regarding its products like Gemini web app.
- Discourse evolved around the pricing model and effectiveness of Google’s Gemini 1.5, with comparisons to other AI offerings and software like Vertex AI, amid reflections on the First Amendment's application to AI.
OpenAccess AI Collective (axolotl) Discord
- API Queue System Quirks: Reports of issues with the build.nvidia API led to discovery of a new queue system to manage requests, signaling a potentially overloaded service.
- A member encountered script issues with build.nvidia API, observing restored functionality after temporary downtime hinting at service intermittency.
- YAML Yields Pipeline Progress: A member shared their pipeline's integration of YAML examples for few-shot learning conversation models, sparking interest for its application with textbook data.
- Further clarifications were provided on how the YAML-based structure contributed to efficient few-shot learning processes within the pipeline.
- Gemma2 Garners Stability: Gemma2 update brought solutions to past bugs. A reinforcement of version control with a pinned version of transformers ensures smoother future updates.
- Continuous Integration (CI) tools were lauded for their role in preemptively catching issues, promoting a robust environment against development woes.
- A Call for More VRAM: A succinct but telling message from 'le_mess' underlined the perennial need within the group: a request for more VRAM.
- The single-line plea reflects the ongoing demand for higher performance computing resources among practitioners, without further elaboration in the conversation.
tinygrad (George Hotz) Discord
- Tensor Trouble in Tinygrad: Discussions arise about Tensor.randn and Tensor.randint creating contiguous Tensors, while
Tensor.fullleads to non-contiguous structures, prompting an examination of methods that differ from PyTorch's expectations.- A community member queried about placement for a bug test in tinygrad, debating between test_nn or test_ops modules, with the final decision leaning towards an efficient and well-named test within test_ops.
- Training Pains and Gains: Tinygrad users signal concerns about the framework's large-scale training efficiency, calling it sluggish and economically impractical, while considering employing BEAM search despite its complexity and time demands.
- A conversation sparks around the use of pre-trained PyTorch models in Tinygrad, directing users towards
tinygrad.nn.state.torch_loadfor effective model inference operations.
- A conversation sparks around the use of pre-trained PyTorch models in Tinygrad, directing users towards
- Matmul Masterclass: A blog post showcasing a guide to high-performance matrix multiplication achieves over 1 TFLOPS on CPU, shared within the community, detailing the practical implementation approach and source code.
- The share included a link to the blog post that breaks down matrix multiplication into an accessible 150 line C program, inviting discussion on performance optimization in Tinygrad.
Torchtune Discord
- Torchtune's Tuning Talk: Community members exchanged insights on setting evaluation parameters for Torchtune, with mentions of a potential 'validation dataset' parameter to tune performance.
- Others raised concerns about missing wandb logging metrics, specifically for evaluation loss and grad norm statistics, highlighting a need for more robust metric tracking.
- Wandb Woes and Wins: A topic of discussion was wandb's visualization capabilities, where a grad norm graph miss sparked questions about its availability compared to tools like aoxotl.
- Suggestions included adjusting the initial learning rate to affect the loss curve, but despite optimizations, one member noted no significant loss improvements, emphasizing the challenges of parameter fine-tuning.
AI Stack Devs (Yoko Li) Discord
- Code Clash: Python meets TypeScript: A challenging encounter was shared regarding the integration of Python with TypeScript while setting up the Convex platform. Issues surfaced when Convex experienced launch bugs stemming from a lack of pre-installed Python.
- Furthermore, discussion revolved around the difficulties faced in automating the installation of the Convex local backend within a Docker environment, emphasizing the complication arose from the specific configuration of container folders as volumes.
- Pixel Hunt: In Search of the Perfect Sprite: A member explored the domain of sprite sheets, expressing their goal to find visuals resonant with the Cloudpunk game's style, but found their assortment from itch.io lacking the desired cyberpunk nuance.
- They are on the lookout for sprite resources that align better with Cloudpunk's distinctive aesthetic, as previous acquisitions fell short in mirroring the game's signature atmosphere.
DiscoResearch Discord
- Summarizing with a GPT Trio: Three GPTs Walk into a Bar and Write an Exec Summary blog post showcases a dynamic trio of Custom GPTs designed to extract insights, draft, and revise executive summaries swiftly.
- This toolkit enables the producing of succinct and relevant executive summaries under tight deadlines, streamlining the process for delivering condensed yet impactful briefs.
- Magpie's Maiden Flight on HuggingFace: The Magpie model makes its debut on HuggingFace Spaces, offering a tool for generating preference data, albeit with a duplication from davanstrien/magpie.
- User experiences reveal room for improvement, as feedback indicates that the model’s performance isn't fully satisfactory, yet the community remains optimistic about its potential applications.
MLOps @Chipro Discord
- Build With Claude Campaigns Ahead: Engineering enthusiasts are called to action for the Claude hackathon, a creative coding sprint winding down next week.
- Participants aim to craft innovative solutions, employing Claude's capabilities for a chance to shine in the closing contest.
- Kafka's Cost-Cutting Conclave: A webinar set for July 18th at 4 PM IST promises insights into optimizing Kafka for better performance and reduced expenses.
- Yaniv Ben Hemo and Viktor Somogyi-Vass will steer discussions, focusing on scaling strategies and efficiency in Kafka setups.
Datasette - LLM (@SimonW) Discord
- Jovial Jest at Job Jargon: Conversations have sprouted around the growing potential uses for embeddings in the field, sparking some playful banter about job titles.
- One participant quipped about renaming themselves an Embeddings AyEngineer*, lending a humorous twist to the evolving nomenclature in AI.
- Title Tattle Turns Trendy: The rise in embedding-specific roles leads to a light-hearted suggestion of the title Embeddings Engineer.
- This humorous proposition underscores the significance of embeddings in current engineering work and the community's creative spirit.
The LLM Perf Enthusiasts AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The YAIG (a16z Infra) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
{% if medium == 'web' %}
HuggingFace ▷ #announcements (1 messages):
VLM training dataset in VietnameseHighlights parserSee 2 sound demotext2cypher modelGuide to Designing New Functional Proteins
- Vietnamese VLM Dataset Released: VLM training dataset in Vietnamese released by user. The dataset is now available for community use.
- Highlights Parser Tool: Highlights parser tool created by user is now available. It helps users parse community highlights effectively.
- See 2 Sound Demo: Check out the See 2 sound demo based on the newly released paper available on this space. It provides an innovative way to experience sound.
- Text2Cypher Model Outperforms GPT-4: The new text2cypher model by user outperforms GPT-4. This model represents a significant advancement in text-to-cypher translation.
- Guide to Designing Functional Proteins: Guide to Designing New Functional Proteins and improving them with Generative AI now available here. This guide covers protein function, stability, and diversity.
HuggingFace ▷ #general (495 messages🔥🔥🔥):
Use of Deepeval with HuggingFace TransformersProficiency certifications in MLUploading image on HuggingFace projects using Gradio APIGPU recommendations for ML beginnersIssues with renting A100 vs. 4090 GPUs for inference
- Proficiency certifications in ML: Members discussed various certifications to validate ML skills, preferring free options from platforms like Harvard and Coursera.
- GPU recommendations for ML beginners: Users debated between recommending RTX 3060 or 4060, considering VRAM and performance, with suggestions leaning towards 3060 for its 12GB VRAM.
- Issues with renting A100 vs. 4090 GPUs for inference: A discussion revolved around renting GPU configurations for efficient ML model inference, with suggestions pointing towards H100 over multiple 4090s for better performance.
- Creating video with AI models: The chat explored text-to-video generation AI models like the ipivs-morph-img2vid-animatediff-lcm-hyper-sd, noting that processing on standard devices is slow but feasible.
- Stable Diffusion model licensing update: Stability AI revised the license for SD3 Medium to better support the open-source community, addressing previous issues with commercial use restrictions.
HuggingFace ▷ #today-im-learning (2 messages):
Building a TikTok videos dataset for harmful content classificationTroubleshooting LDM implementation with RGB images
- TikTok Dataset to Classify Harmful Content: A user shared a TikTok videos dataset, 30 GB with around 3,000 videos, to build a video classification model for classifying harmful content for children. They also provided a notebook for fine-tuning a Hugging Face model on this dataset.
- LDM Model Troubleshooting: A user is learning to create LDMs from scratch with Flax library, succeeding with the MNIST dataset but facing issues with RGB images from imagenette/160px-v2. They requested tips for troubleshooting as their model only generates color blocks for RGB images.
HuggingFace ▷ #cool-finds (6 messages):
Kyutai.org's digital pirate understands English with a French accentSmall demo of Moshi, an audio language modelGraph Structure Learning (GSL) with GraphEdit and large language modelsClaude's ease in building Deep Learning Visualizer dashboardsnanoLLaVA - cool VLM under 1B
- Kyutai's digital pirate gets language savvy: A tweet from Yann LeCun reveals that Kyutai.org's digital pirate can understand English with a French accent. This was demonstrated in a small demo by Neil Zegh from the Moshi project.
- GraphEdit pushes the boundaries of GSL: The paper GraphEdit proposes a new approach to Graph Structure Learning using Large Language Models (LLMs) for enhanced reliability by instruction-tuning over graph structures.
- nanoLLaVA attains attention: The Hugging Face space nanoLLaVA is highlighted as a cool Visual Language Model (VLM) under 1 billion parameters. It has been noted for its impressive visualization capabilities.
HuggingFace ▷ #i-made-this (32 messages🔥):
Introduction of Vision-Language model for Vietnamese by Vi-VLM teamVi-VLM releasing a dataset for VLM training in VietnameseSimple translation tool for converting messages to pt-brCyclicFormer architecture enhancement for transformersUVR5's UI completion for audio separation
- Vi-VLM introduces Vision-Language model for Vietnamese: The Vi-VLM team introduced a Vision-Language model for Vietnamese, built on LLaVA and Vistral, with an image description focus; demo and code available here.
- CyclicFormer enhances transformer performance: The CyclicFormer architecture introduces a cyclic loop between decoder layers to enhance transformer performance, GitHub link here.
- E2E Image Retrieval app using Lightly SSL: An image retrieval app was built using an arbitrary image dataset from the Hub, leveraging FAISS for vector indexing and Lightly SSL for self-supervised learning, detailed in a blogpost.
- Check out the Gradio app for a practical demonstration.
- UVR5 UI for audio separation completed: UVR5's UI is now complete, allowing easy separation of vocals and instrumental tracks; it uses advanced audio separation models available via Gradio.
- Perfect separation of voice and melody in various tests, including popular songs like 'Faroeste Caboclo' from 1987.
- Simple translation tool for pt-br: A tool was created to translate community highlights into pt-br, useful for faster importing of messages; see the tool here.
HuggingFace ▷ #reading-group (7 messages):
triton paper readingupcoming paper reading scheduleinterest in audio-language modelsflora paper discussion
- Upcoming Paper Reading on Triton: A member apologized for delaying a planned paper reading on Triton due to being busy and invited others to present if interested. Participants were encouraged to contact another member for more information.
- Flora Paper Gains Interest: A member expressed interest in the Flora paper, calling it cool. This paper seems to be gaining attention for an upcoming discussion.
HuggingFace ▷ #computer-vision (4 messages):
WHAM alternatives for human pose estimation in monocular, in-the-wild videosLearning ViT and U-Net implementationsUsing visual-semantic information to boost fine-grained image classification performanceDiscussing zero/few shot multi-modal models at CVPR
- Searching for WHAM alternatives for wrestling animations: A non-coder is looking for a machine learning method for human pose estimation in monocular, in-the-wild videos of complex human interactions like Brazilian jiu-jitsu. They struggled with WHAM due to its complex Python and CV dependencies and seek a more user-friendly alternative.
- Learning ViT and U-Net from online resources: A member shared a link to learn ViT and U-Net implementations from the DL Specialization by Andrew Ng and CNN Course Week 3.
- Boosting image classification using visual-semantic info: Another user inquired about leveraging visual-semantic information from captions/metadata to enhance fine-grained image classification performance beyond zero/few shot learning. Florence 2 was suggested as a potential model for this specific supervised fine-tuning.
Link mentioned: 08. PyTorch Paper Replicating - Zero to Mastery Learn PyTorch for Deep Learning: Learn important machine learning concepts hands-on by writing PyTorch code.
HuggingFace ▷ #NLP (17 messages🔥):
Meta-LLaMA download issuesAPI calls to models without local downloadInference freeze in Mistral modelStatic KV cache documentationTroubleshooting errors related to memory
- Meta-LLaMA download struggles: A user expressed frustration over Meta-LLaMA taking forever to download and worried about their hard drive filling up due to potential temp files.
- API call confusion: There was confusion on whether one could build an API call to a model without a local download, questioning the feasibility of this approach.
- Mistral model freezes at iteration 1800: Mistral froze at iteration 1800 during inference of 3000 runs, whereas it worked fine for 100 inferences, leading to suspicion of some kind of caching problem.
- Static KV cache causes confusion: A user highlighted that the static KV cache is on by default since version 4.41, suggesting checking the relevant release for more details.
- TypedStorage deprecation concern: Concerns were raised about TypedStorage being deprecated, with a suggestion to wait for a stable solution before making any code changes.
Link mentioned: Release v4.38: Gemma, Depth Anything, Stable LM; Static Cache, HF Quantizer, AQLM · huggingface/transformers: New model additions 💎 Gemma 💎 Gemma is a new opensource Language Model series from Google AI that comes with a 2B and 7B variant. The release comes with the pre-trained and instruction fine-tuned v....
HuggingFace ▷ #diffusion-discussions (3 messages):
Running RealVisXL_V4.0_Lightning using diffusersError with yisol/IDM-VTON in Google ColabImproving resume analyzer to assess project intensity
- RealVisXL V4.0 Lightning model release: RealVisXL V4.0 Lightning is in training and supports photorealistic images in both sfw and nsfw categories. Users can support the creator on Boosty and find the CivitAI page here.
- Diffusers don't match A1111 quality: A user reported that the RealVisXL V4.0 model works well with A1111 but produces poorer quality images with diffusers despite using the same parameters.
- Error with IDM-VTON in Google Colab: A user is encountering a 'no file named diffusion_pytorch_model.bin' error while using yisol/IDM-VTON on Google Colab.
- Enhancing Resume Analyzer Beyond Keywords: A user is seeking advice on creating a resume analyzer that evaluates project intensity rather than just matching keywords. They aim to differentiate between less complex tasks and more significant projects.
Link mentioned: SG161222/RealVisXL_V4.0_Lightning · Hugging Face: no description found
Stability.ai (Stable Diffusion) ▷ #announcements (1 messages):
License concerns with SD3 Medium releaseStability AI Community License updateIssues with commercial licensing in previous releaseImprovement and support for open source community
- Stability AI updates license for broader use: Stability AI acknowledged that their SD3 Medium release didn't meet community expectations and the associated commercial license caused confusion. They have revised the license for individual creators and small businesses, covered under the new Stability AI Community License, read the full update here.
- Non-commercial use is free under new Stability AI License: Under the new Stability AI Community License, non-commercial use remains free. This change supports the open source community by giving broader access to recent releases, including SD3 Medium.
Link mentioned: Community License — Stability AI: Our new Community License is now free for research, non-commercial, and commercial use. You only need a paid Enterprise license if your yearly revenues exceed USD$1M and you use Stability AI models in...
Stability.ai (Stable Diffusion) ▷ #general-chat (528 messages🔥🔥🔥):
Hyper vs turboAAM Anime Mix XLAnimagine XL 3.1Stable Diffusion GPU usageCivitAI and SD3 discussions
- Hyper is the new Turbo: Animagine XL 3.1 Updates: Users discussed the merits of the anime-themed model Animagine XL 3.1. This model improves on Animagine XL 3.0 with higher quality images and a broadened character range from well-known anime series, developed by Cagliostro Research Lab and SeaArt.ai.
- AAM Anime Mix XL Gains Attention: A user shared their enthusiasm for AAM Anime Mix XL, another popular anime image generation model. This sparked comparisons and recommendations for related models like Animagine XL 3.1.
- Struggles with Multiple GPU Configurations: Users discussed the challenges and potential solutions for using multiple GPU setups to improve Stable Diffusion's speed and output quality. Specific tools like SwarmUI were highlighted for their capabilities of handling multi-GPU operations.
- CivitAI's SD3 Ban Sparks Debate: The community reacted to CivitAI's ban on SD3 models with mixed opinions. Many expressed that this move could hinder the development of SD3, while others discussed the technical and licensing issues surrounding the model.
- Stable Diffusion Licensing and Model Updates: The conversation included concerns about the license for Stable Diffusion 3 and its new models. There were debates over whether the licensing terms were too restrictive, affecting both small and large business users.
Unsloth AI (Daniel Han) ▷ #general (267 messages🔥🔥):
Gemma 2 Release and its featuresIssues with the Gemma 2 notebooks and user feedbackMethods for dataset preparation and handling long-context examplesPerformance and optimization techniques for various LLMsRecent advancements and announcements in AI models and tools
- Gemma 2 Release brings speed and VRAM improvements: The Gemma 2 Release is now available, claiming 2x faster finetuning and using 63% less VRAM compared to Flash Attention 2 (Gemma 2 Blog). Key details include support for up to 9.7K context lengths with Unsloth.
- "Blogpost was super rushed honestly I already found some mistakes," noted by a community member highlighting the fast-paced release.
- Unsloth notebooks and model directory issues: Users reported issues with the Gemma 2 notebooks, particularly errors related to model directory naming and missing configurations (e.g.,
unsloth/gemmainstead ofunsloth_gemma). Collaboration and quick fixes were made by the developers to address these problems. - Training on long-context examples and dataset preparation techniques: Members discussed techniques for handling long-context datasets, with some examples reaching up to 78,451 tokens. Suggestions included setting appropriate context lengths and using specific functions to find max tokens in a dataset.
- Sharing functions and discussing prompt engineering methods were common themes. Practical advice like, "you can choose the tone in the instruction part," were shared to help users better format their data for model training.
- Gemma 2 performance and limitations in the absence of Flash Attention support: Without Flash Attention support, Gemma 2 models are reported to be notably slow and almost unusable for intensive tasks. This highlights the significant impact of optimized attention mechanisms on model performance.
- Community members suggested that gradacc (gradient accumulation) might be a more efficient approach than traditional batching, with one noting, "If anything, gradacc was faster."
- New AI models and tools announcements: Nomic AI announced GPT4ALL 3.0, a new open-source local LLM desktop app, emphasizing privacy and local data processing (GPT4ALL 3.0 Announcement). It's praised for supporting thousands of models and major operating systems.
- InternLM-XComposer-2.5 was also mentioned, highlighting its capabilities to support long-context input and output, achieving GPT-4V level performance with just a 7B LLM backend (InternLM-XComposer-2.5).
Unsloth AI (Daniel Han) ▷ #announcements (1 messages):
Gemma 2 ReleaseTraining speed and VRAM reductionContext length improvements4-bit model support updatesExperimentation with models
- Gemma 2 speeds up finetuning: Unsloth now supports Gemma 2 with 2x faster training and 63% less memory usage. Check out the Gemma 2 Blog for more details.
- Context lengths boosted significantly: You can now finetune Gemma 2 (27B) with 9.7K context lengths on a 40GB GPU using Unsloth, compared to 3K with HF+FA2. The 9B model achieves 11K context lengths on a 24GB card, versus 2.6K with HF+FA2.
- New Free Notebooks available: Access the Gemma 2 (9B) Colab notebook to get started with the latest model. Gemma 2 (27B) notebook support has also been added.
- 4-bit models now supported: Explore the new 4-bit models: Gemma 2 (9B) Base, Gemma 2 (9B) Instruct, Gemma 2 (27B) Base, and Gemma 2 (27B) Instruct. The Phi 3 mini update is also available on HF.
- Call for community experimentation: Unsloth encourages users to share, test, and discuss their models and results in their community channels. Join the discussion and experiment with the latest updates.
Unsloth AI (Daniel Han) ▷ #off-topic (7 messages):
Release of Replete-AI datasetsDiscussion on Facebook multi-token predictionFireworks.ai yi-large issues
- Replete-AI Drops Massive Datasets: Replete-AI announced the release of two new datasets each around 11-12GB and containing over 6 million rows of data. The datasets include an English-only version and a multilingual version aimed at training versatile AI models.
- Is Facebook's Multi-Token Prediction Worth it?: Discussion sparked about the worthiness of Facebook's multi-token prediction model that requires sharing contact information to access. One member expressed skepticism, while another deemed it worthwhile despite Facebook's involvement.
- Fireworks.ai yi-large Disappoints Users: Users reported frustrations with the yi-large model on Fireworks.ai. One user admitted to being 'jebaited' by the model, indicating it did not meet their expectations.
Unsloth AI (Daniel Han) ▷ #help (121 messages🔥🔥):
Issues with Unsloth patch 2024.7 and checkpointsGemma 2 support in UnslothFine-tuning models using UnslothErrors during fine-tuning and evaluation processesUpdating Unsloth and GGUF issues
- Gemma 2 support announced in Unsloth!: Unsloth has added support for Gemma 2; you can now update and try the new features with the latest patch 2024.7.
- Checkpoint training errors in Unsloth patch 2024.7: Users reported errors like
RuntimeError: Expected all tensors to be on the same devicewhen resuming training from a checkpoint in Unsloth patch 2024.7. Some suggested returning to older versions, but issues persist and require investigation. - Unsloth fine-tuning pitfalls: Some users experienced issues fine-tuning Gemma 1.1 and Phi-3 mini models without LoRA; it works for Phi-3 but raises errors when attempted with full fine-tuning on Gemma 1.1.
- Errors with specific models and configurations: Various errors were encountered, such as
RuntimeError: The size of tensor a (4096) must match the size of tensor b (4608), when dealing with large models like Gemma-2-27B-bnb-4bit and potential VRAM issues noted during evaluation with specific metrics. - Updating Unsloth and handling GGUF issues: Users were guided to update Unsloth via the wiki; some faced errors pushing fine-tuned models to Hugging Face due to GGUF quantization issues, which have since been fixed according to dev updates.
Unsloth AI (Daniel Han) ▷ #showcase (3 messages):
Release of two new massive datasets by Replete-AIDetails and translations of Everything_Instruct_MultilingualQuestions about dataset deduplication and content balance
- Replete-AI unveils massive instruct datasets: Replete-AI released two new datasets, Everything_Instruct and Everything_Instruct_Multilingual, each sizing 11-12GB with over 6 million rows of data. These datasets combine multiple types of instruct data to train advanced AI models in English and multilingual versions.
- Translations for Everything_Instruct_Multilingual demo: A message demonstrated the Everything_Instruct_Multilingual dataset by providing translations in 10 different languages including Arabic, German, Spanish, and French for simple English commands.
- Translations such as 'wake me up at nine am on friday' were shown in each language, like German: 'weck mich am freitag um neun uhr auf'.
- Community queries dataset quality: Community members raised questions about the new datasets' quality, asking if they are deduped and decontaminated. Another member expressed concerns regarding the dataset's balance, noting that nearly 50% is code-related.
Unsloth AI (Daniel Han) ▷ #community-collaboration (10 messages🔥):
Pinning notebooksAdding notebooks to the GitHub pageCorrecting notebook links in the channels
- Pinning notebooks request confirmed: A member requested that certain notebooks be pinned, and another member confirmed that they would do so, asking for some time.
- Notebook links corrected in channels: A correction was made to the notebooks linked in the channels, clarifying that there were two notebooks: one about using multiple datasets and another about text classification.
- Notebooks to be added to GitHub page: It was mentioned that the notebooks will be added to the GitHub page, but more time is needed for checking and editing.
Latent Space ▷ #ai-general-chat (94 messages🔥🔥):
AI + Blockchain funding discussionsGit merge tool alternatives and conflict resolutionsLearning AI curriculum and recommendationsClaude and other AI tools for coding assistanceEvaluations and criticisms of new search algorithms like BM42
- AI + Blockchain grabs $85M seed: "AI + Blockchain = $85M seed ☠️ vcs are cooked," one member stated, joking about the massive funding while sharing a link to a free project: rakis.
- Git Merge Tools Showdown: Members discussed various tools for resolving git merge conflicts, including interactive rebase tools like lazygit and Sublime Merge, emphasizing the tediousness of manual conflict resolution.
- Learning AI Curriculum for Beginners: A user looking for AI learning resources received suggestions such as Replit's 100 Days of Code and the Deep Learning Specialization by Andrew Ng, and preferred interactive courses over books like Machine Learning Specialization.
- Claude 3.5 and Other AI Tools for Coding: Users shared their experiences with coding tools like Claude 3.5 and aider, with favorable mentions for Cursor in terms of code completion and the ability to handle complex multi-file refactors.
- Controversy Over BM42 Search Algorithm: The introduction of BM42 by Qdrant faced criticism for presenting potentially misleading benchmarks, prompting the developers to revise their evaluation metrics and datasets, as seen in their follow-up post.
Latent Space ▷ #ai-announcements (5 messages):
New podcast episode with Yi Tay of RekaDiscussion on the qualities of successful AI researchersComparisons of OpenAI, Google Gemini, and Reka teamsTechnical topics covered in the podcast
- Yi Tay on YOLO Researcher Metagame: New podcast episode with Yi Tay of Reka discusses his team’s journey in building a new training stack from scratch and training frontier models purely based on gut feeling. Yi Tay draws comparisons to OpenAI and Google Gemini team sizes and reflects on the research culture at Reka.
- "@sama once speculated on the qualities of '10,000x AI researchers', and more recently @_jasonwei described the 'Yolo run' researcher." Detailed topics include LLM trends, RAG, and Open Source vs Closed Models.
- Now on Hacker News: Latent Space Podcast episode with Yi Tay is now featured on Hacker News. Engage with the discussion and vote for visibility.
Latent Space ▷ #llm-paper-club-west (34 messages🔥):
Issues with Discord AVMigration to Zoom for better AVKnown compatibility issues between Discord and Linux
- Discord AV struggles during AIEWF demo: OpenAI AV faced significant issues during the AIEWF demo, with multiple users unable to see the screen and experiencing cut-outs. Eugene and others suggested switching to Zoom for a more stable experience.
- swyxio added:
- Switch to Zoom for Paper Club: The group decided to switch from Discord to Zoom due to continuous AV issues. The Zoom link was shared, and members began migrating.
- Discord-Linux compatibility problems discussed: Several participants highlighted known compatibility problems between Discord and Linux. Eugene added that Discord does not play well with Linux and suggested looking into alternatives.
Link mentioned: Join our Cloud HD Video Meeting: Zoom is the leader in modern enterprise video communications, with an easy, reliable cloud platform for video and audio conferencing, chat, and webinars across mobile, desktop, and room systems. Zoom ...
Latent Space ▷ #ai-in-action-club (243 messages🔥🔥):
User technical difficulties and skill humorPersonal compliments to workshop hostsDiscussion on model merging tacticsLlamaFile vs Ollama comparisonEvent planning and feedback
- Users Battle Technical Issues and Share Laughs: A user struggled to hear during a call, prompting jokes and the now-popular phrase, 'skill issue tbh'. Eventually, the user realized they were not in the call and reconnected with a humorous resolution.
- LlamaFile vs Ollama: Divergent Aims: Community members compared LlamaFile and Ollama, noting LlamaFile's strength in portability and optimization versus Ollama's broad compatibility with numerous models.
- Model Merging Tactics: A discussion highlighted the difference in product goals between LlamaFile and Ollama while raising ideas of potential model merging tactics and respective improvements needed on both sides.
- AI-Generated Notes and Wearable Tech: Discussion on the use of wearables highlighted their potential privacy concerns and the importance of consent in recording. Participants mentioned ambitions to integrate wearables with AI-generated notes for easier event navigation.
- Upcoming Event Plans and Feedback: Participants brainstormed potential improvements for future events, considering additional days for workshops and community events and noting the success of current methods for organizing and executing productive AI conferences.
LM Studio ▷ #💬-general (157 messages🔥🔥):
Waiting to upgrade hardware for LM StudioComparison of Llama3 and Mistral modelsUsage of API keys from OpenAI or Anthropic in LM StudioText embeddings and local server setup in LM StudioChallenges in running large models like Llama3 70b on limited hardware
- Waiting to upgrade hardware for LM Studio: A user mentioned planning to wait for 2 years to buy a new laptop for LM Studio, preferring to use their current setup with 64GB DDR4 RAM, Ryzen 5900 CPU, and 3060 6GB GPU in the meantime.
- Comparison of Llama3 and Mistral models: Members discussed preferences, with some favoring Llama3 8b over Mistral 7b Instruct 0.3, and others highlighting successful experiences with OpenHermes 2.5 finetuned from Mistral.
- Usage of API keys from OpenAI or Anthropic in LM Studio: A user inquired whether LM Studio allows using API keys from OpenAI or Anthropic for loading their models. They were informed that LM Studio supports only local text models.
- Challenges in running large models like Llama3 70b on limited hardware: A user reported issues running Llama3 70b on a RTX 3090 Ti due to memory constraints, receiving advice to lower GPU offload and context length or switch to smaller models.
LM Studio ▷ #🤖-models-discussion-chat (130 messages🔥🔥):
Discussion on model behavior mismatch between different quantized versions of Gemma-2-27bUsing system prompts to improve coding model behaviorsComparing different quantization techniques and their performanceQwen2 model preset and ChatML format discussionIssues and experiences with different large language models like Gemma, InternLM, and Dolphin
- Gemma 2 models underperform in benchmarks: Users reported that Gemma-2-27b models performed poorly and erratically in benchmarks, with significant inconsistencies across different quantization methods (Q5_K_M or Q6_K). A specific test showed vast discrepancies in performance between 27b and 9b models.
- System prompts improve coding responses: Crafting tailored system prompts for coding guidance improved response quality in models like Gemma 2 27B. A specific method, focusing on PEP 8 guidelines and efficient algorithms, enhanced code generation consistency and completeness.
- Understanding ChatML format for Qwen2: New users struggled with using Qwen2 models due to the lack of clear instructions on ChatML presets. A detailed explanation on the importance of ChatML format helped clarify preset configurations.
- Issues with different quantization techniques: Users discussed the instability of IQ quants on non-CUDA hardware, reporting slower token speeds and random behavior like infinite loops and inconsistent responses. It's advised to avoid IQ quants on Apple devices and consider other quantization methods for better performance.
- Experiences with various LLMs in game development and other tasks: Members shared mixed results from using different large models like Gemma, InternLM, and Dolphin for tasks like game development and VFX pipelines. Models showed uneven performances in retaining context and following instructions, leading to concerns over practical application and stability.
LM Studio ▷ #🧠-feedback (3 messages):
Issue with model downloads in LM on MacBook Pro M2Solution for pausing/stopping downloads in LM
- Models Get Stuck Downloading on MacBook Pro M2: msouga experienced an issue with some models in LM getting stuck downloading indefinitely on their MacBook Pro with an M2 chip, unable to stop these downloads or estimate their completion time.
- How to Pause/Stop Downloads in LM: a_dev_called_dj_65326 suggested checking under the downloads section (bottom bar) to pause or stop the downloads. msouga confirmed this solution worked perfectly.
LM Studio ▷ #⚙-configs-discussion (5 messages):
Nxcode 7B JSON requestCodeQwen 1.5 7B ChatML compatibilityRTX 4060 8GB VRAM and 16 GB DDR5 RAM performance issuesSuggested models for mid-range GPU setups
- Nxcode 7B JSON request: @49206c696b652063757465 asked for a JSON for Nxcode 7B or CodeQwen 1.5 7B.
- CodeQwen 1.5 7B ChatML compatibility: @heyitsyorkie mentioned that both Nxcode 7B and CodeQwen 1.5 7B use ChatML, and CodeQwen requires flash attention enabled.
- RTX 4060 8GB VRAM struggles with 20B models: @falconandeagle123 shared that their laptop with RTX 4060 8GB VRAM and 16 GB DDR5 RAM struggled to run q4 quant 20B models, causing the laptop to freeze.
- Suggested models for mid-range GPU setups: @niga256_512_1024_2048 suggested using simpler models like Mistral 7B, Open Hermes 2.5, Wizard code, and Phi 3 mini for mid-range GPU setups.
- They pointed out that these models are more suitable for systems similar to a laptop with RTX 4060.
LM Studio ▷ #🎛-hardware-discussion (61 messages🔥🔥):
Surface Laptop with Snapdragon Elite performance detailsNPU and GPU utilization in Snapdragon devicesComparison of CPU performance on Snapdragon and Intel devicesFuture support for NPU in Llama.cppGeneral discussion on hardware used with LM Studio
- *Snapdragon Elite CPU holds its own: Member discusses performance details of Surface Laptop with Snapdragon Elite, including first token speed and tokens per second (t/s) on LLaMA3 models. Other members compare this with their Intel quad-core laptops and find Snapdragon's CPU performance impressive.*: A member reports 1.5 seconds to first token and 10 t/s on LLaMA3 8b with 8bit precision on a Surface Laptop with Snapdragon Elite and 32 GB of RAM. They note 10% GPU usage and no NPU activity, sparking curiosity about potential future NPU utilization.
- Comparisons reveal Snapdragon Elite CPU's performance to be significantly faster than older Intel quad-core laptops, even rivaling typical cloud AI speeds. Members speculate about future NPU support possibly leading to further speed improvements.
- **Future NPU support for Llama.cpp?**: *Discussion on when NPU support might land for Llama models in LM Studio.*: Members discuss that NPU support is not yet available in Llama.cpp, leading to CPU-only performance for LLaMA models in LM Studio. Speculation arises about when support might be implemented, with hopes set for late 2024 or early 2025.
- Conversations reveal that Qualcomm has a GitHub repository showing LLaMA2 operating on NPU, though it's currently rough. Community shows enthusiasm for future enhancements*, especially with Qualcomm and Microsoft pushing for NPU utilization.
- NPU implementation faces delays*: *Members express hopes and struggles with current hardware performance.: Efforts to implement NPU in existing systems have been slow, with members sharing links to discussions and repositories investigating the subject (GitHub repo).
- Members appear optimistic about eventual improvements, even sharing humorous suggestions like a Cardboard NPU as a placeholder solution.
- Surface Laptop shows promise on Snapdragon Elite*: *Users share their positive experience regarding the new Surface Laptop's build quality and performance.: A member praises the build quality, keyboard, and trackpad of their Surface Laptop with Snapdragon Elite. They highlight the ability to perform video editing and play games as standout features.
- Overall, the Surface Laptop with Snapdragon Elite is well-received, especially as a daily driver for personal use, despite needing separate work laptops with IT restrictions.
LM Studio ▷ #🧪-beta-releases-chat (2 messages):
AppImage not compatible with aarch64 CPUsNo ARM CPU support on Linux for LM Studio
- AppImage not compatible with aarch64 CPUs: A user encountered an Exec format error while trying to execute LM_Studio-0.2.27.AppImage on an aarch64 system, indicating architecture incompatibility. The
lscpucommand output confirmed the CPU architecture as aarch64. - No ARM CPU support on Linux: Discussion highlighted the lack of ARM CPU support for LM Studio on Linux. A member confirmed, "No arm cpu support on linux".
LM Studio ▷ #amd-rocm-tech-preview (2 messages):
7800XT user confirms GPU worksProblems loading models with GPU offloadSuccessful ROCm installation script
- 7800XT user confirms GPU works: User reports that their 7800XT works successfully and is not sure if pinging is needed.
- Problems loading models with GPU offload: Loading models failed unless GPU offload is disabled. Users discussed installation scripts to address this issue.
- Successful ROCm installation script: A user suggested a script to install ROCm that helped solve loading issues with GPU offload. Another user confirmed it works well.
CUDA MODE ▷ #general (10 messages🔥):
Matrix multiplication in CUDAEfficient remote development with pay-for-use computeNew blog post on executive summary process using GPTsPaid CUDA/ML system certificationsUpcoming in-person CUDA mode event in October
- Matrix Multiplication in CUDA: Why Column Instead of Row?: A user questioned why a 64-element column is loaded on the purple tile instead of a row during a GPU matrix multiplication, and another shared a detailed blog post for optimizing this process using CUDA.
- Streamline Executive Summaries with GPTs: A new blog post details a process involving three Custom GPTs to expedite the writing of executive summaries, showing how they can extract insights, draft, and revise the summaries quickly.
- Tips for Efficient Remote Development: Members discussed solutions for remote development that allows for pay-per-use compute while retaining files, mentioning services like Lightning AI and AWS S3 as potential options.
- Recommendations for CUDA/ML Certifications: A user sought recommendations for paid CUDA/ML certifications under $500, leading to suggestions of NVIDIA courses and a possible community-organized workshop.
- In-Person CUDA Mode Event Announced: CUDA Mode is planning an in-person event for October, as revealed by a community member, promising more details soon.
CUDA MODE ▷ #triton (2 messages):
Triton kernels with multiple CUDA graphs create latency issuesSRAM contention affecting performance
- Triton Kernels under Parallel CUDA Execution: Multiple CUDA graph instances running in parallel with Triton kernels show worse latencies compared to local benchmarks.
- It's suggested that SRAM contention might be a cause if multiple instances are doing
tl.load.
- It's suggested that SRAM contention might be a cause if multiple instances are doing
- Comparison with Torch Performance: Despite potential SRAM contention, this issue doesn't seem present in Torch under similar conditions.
- This discrepancy raises questions about how SRAM evictions are handled differently between Triton and Torch.
CUDA MODE ▷ #torch (7 messages):
torch.compile not supported on Python 3.12Python bytecode compatibility issuesTorchDynamo and Python frame evaluation APITorchDynamo's role in PyTorch performance
- Torch 2.3
.compileUnsupported on Python 3.12: For torch 2.3, the.compilefunction is not supported on Python 3.12 due to changes in Python's internals, especially in how it handles bytecode. A detailed explanation can be found here. - Python Bytecode Changes Cause Lag in Support: Python bytecode changes every Python version, requiring time for frameworks like torch.compile to adjust and support these new changes. More information on the bytecode adjustments can be read in this documentation.
- TorchDynamo Enhances PyTorch Performance: TorchDynamo is a Python-level JIT compiler that hooks into CPython's frame evaluation to modify Python bytecode and compile PyTorch operations into an FX Graph. Using
torch._dynamo.optimize()wrapped bytorch.compile(), it boosts PyTorch code performance seamlessly.
CUDA MODE ▷ #algorithms (5 messages):
New method for training language models to predict multiple future tokensSelf speculative decoding in language modelsComparison between multi-token prediction and lookahead decoding baselinesEffectiveness of n-gram generation in multi-token prediction models
- New approach boosts language model efficiency: Latest research paper suggests training language models to predict multiple future tokens at once, resulting in higher sample efficiency and improved downstream capabilities with no additional training time. 13B parameter model shows substantial gains, solving 12% more problems on HumanEval and 17% more on MBPP.
- Self Speculative Decoding gets a thumbs up: A member mentioned the cool aspect of the model's ability to perform self speculative decoding.
- Questioning lookahead decoding baselines: Members wondered how this new multi-token prediction compares to lookahead decoding baselines.
- Dissecting n-gram effectiveness: A discussion emerged on the effectiveness of generating n-grams in multi-token prediction models and their alignment with traditional next-token prediction outputs.
Link mentioned: Better & Faster Large Language Models via Multi-token Prediction: Large language models such as GPT and Llama are trained with a next-token prediction loss. In this work, we suggest that training language models to predict multiple future tokens at once results in h...
CUDA MODE ▷ #cool-links (1 messages):
iron_bound: https://oimo.io/works/life/
CUDA MODE ▷ #beginner (17 messages🔥):
Learning path for backend SDEs interested in CUDA and inference optimizationChallenges of finding jobs with open source contributionsRecommendation of CUDA Mode GitHub for beginnersBuilding a deep learning framework from scratch in C++ using CUDAUsing Python for CUDA kernel development vs C++
- Finding Path to CUDA Mastery: A backend SDE seeks advice on transitioning to a job related to CUDA and inference optimization. Recommendations included watching specific channels and reading relevant resources, contributing to GitHub, and joining working groups.
- Open Source Contributions Not Always a Job Ticket: Concerns were raised about individuals making significant open source contributions yet failing to secure jobs. The community acknowledged the challenge and discussed the high bar for entry.
- CUDA Mode GitHub: A Beginner's Treasure Trove: For beginners looking to dive into CUDA, CUDA Mode GitHub was recommended as a fruitful starting point. It's suggested as a platform to build engaging projects and learn efficiently.
- Building Deep Learning Frameworks in C++ with CUDA: A member expressed interest in building a deep learning framework similar to tinygrad using CUDA and C++ for parallelism but encountered difficulties with C++ complexity. They considered using Python instead for better manageability and potential for faster completion.
- Python vs C++ for CUDA Kernel Development: Debate ensued over whether to use Python or C++ for CUDA kernel development. The consensus leaned towards using Python for initial endeavors and transitioning to C++ for deep system-level work, citing repositories like llama.c for learning.
CUDA MODE ▷ #pmpp-book (4 messages):
Fourth edition released in 2022Differences between third and fourth editions
- Fourth edition released in 2022: The fourth edition was released in 2022, whereas the previous edition was released in 2012.
- Differences between third and fourth editions: A member mentioned not having read the third edition, expressing curiosity about the differences. Another member referred to the back of their copy for details.
CUDA MODE ▷ #jax (4 messages):
casual conversationchannel engagement
- Casual Engagement in Channel: A member expressed their excitement with a simple "that's so cool!", indicating casual engagement and appreciation.
- Another member replied with "thanks", showing a friendly and appreciative interaction in the channel.
- Friendly Interactions: Members engaged in a casual and friendly manner with short messages like "yo" and "you".
- These interactions reflect a positive and welcoming community environment.
CUDA MODE ▷ #torchao (11 messages🔥):
Handlinga.tomethod recognition and functionalityRemoving unnecessary args in PyTorch/aoCurrent limitations and workarounds fora.tomethodAdding support fordeviceand dtype handling in subclassesFuture functionality and testing in Torchbench models
- Fixing
a.toissues in PyTorch: Thea.to(torch.int32)method is recognized asa.to(device=torch.int32)causing unexpected behavior, and needing removal of unnecessarydeviceandmemory_formatarguments in affine_quantized_tensor.py to fix this issue. - Challenges with
a.to(dtype=torch.int32): A discussion highlighted thata.to(dtype=torch.int32)currently only changes the device and not other keywords like dtype or layout, indicating that dtype and memory format changes are unsupported for now. - Temporary Function Adjustments in AQT: A suggestion was made to modify the
affine_quantized_tensor.pyfile to temporarily dropdevice,dtype, andmemory_formatarguments to handle the limitations in the current implementation. - Subclass
a.toMethod Limitations: Discussion around subclass functionality intorchbenchrevealed that handlinga.tomethod for differing dtypes was not intended as changing external representations' dtype poses complex challenges. - Testing Functionality in Torchbench: Concerns were raised about whether the current setup supports
.tomethod across various models intorchbench, especially regarding subclass handling and required functionality testing in AQT implementations.
CUDA MODE ▷ #off-topic (3 messages):
Thunder Sessions podcast by Lightning AIAndrej Karpathy's keynote at UC Berkeley AI Hackathon 2024
- Thunder Sessions podcast ignites excitement: Lightning AI announced the Thunder Sessions podcast hosted by Luca Antiga and Thomas Viehmann to cover compilers and performance optimization, airing Friday, July 5 @ 11am EST.
- Andrej Karpathy steals the show at UC Berkeley Hackathon: The YouTube video of the 2024 UC Berkeley AI Hackathon Awards Ceremony features Andrej Karpathy delivering an inspiring keynote, highlighting groundbreaking pitches from the participants.
CUDA MODE ▷ #llmdotc (134 messages🔥🔥):
CUDA MODE Discord chatbot messagesFP8 Gradient Issues in GPT-2 TrainingSchedule-Free Optimizer PaperGPT-2 Training PerformanceTraining Length Estimations for GPT-2
- Issues with Schedule-Free Optimizers: A member noted that using Schedule-Free Optimizers produced surprisingly smooth loss curves, which seemed improbable on noisy datasets like ImageNet. Despite initial skepticism, the optimizer showed significant convergence advantages even without custom optimizations.
- FP8 Gradient Activations Impact GPT-2 Training: A member found that converting gradient activations to FP8 significantly increased loss during GPT-2 test runs. They noted that this error propagated through the model, and attempts to mitigate it with stochastic rounding had limited success, suggesting keeping some operations in BF16 for stability.
- Technical Woes with Compile Times on Lambda Servers: A user reported much longer compile times on Lambda servers compared to local machines, likely due to disabled CPU Turbo on virtualized instances. Investigations revealed the CPU staying at a base clock of 2GHz, unable to utilize its full potential of 3.8GHz Turbo clock speeds.
- Sweeps on Hyperparameters and Model Scaling: Several discussions focused on sweeping different hyperparameters like LR,
attn_mult, andout_multacross different model widths and depths. Preliminary results indicated that cosine schedulers and anattn_multof 1 were optimal, but further tests were ongoing. - Austin Tech Scene Tidbits: Casual talk revealed that members attended July 4th parties with notable figures from the tech industry, like Lex Fridman. They also noted Austin's importance in semiconductor engineering but highlighted its lack of intersection with the broader tech scene.
CUDA MODE ▷ #bitnet (3 messages):
Optimized kernels in CUDA for int2*int8 gemmRelease of a custom gemv for int2*int8BitBLAS library for mixed-precision matrix multiplications
- Newcomer asks about optimized kernels for int2int8 gemm*: A new member asked if there are optimized kernels in CUDA for *int2int8 gemm** operations.
- Custom gemv kernel release announced: A member announced that they have made a custom gemv kernel for int2*int8, which will be released in a few days.
- They also suggested checking out BitBLAS as another option.
Link mentioned: GitHub - microsoft/BitBLAS: BitBLAS is a library to support mixed-precision matrix multiplications, especially for quantized LLM deployment.: BitBLAS is a library to support mixed-precision matrix multiplications, especially for quantized LLM deployment. - microsoft/BitBLAS
Perplexity AI ▷ #general (165 messages🔥🔥):
Perplexity AI Repetition IssueLive Internet Access ProblemsMath Accuracy in Perplexity ProExperience with Perplexity in Stock MarketSubscription Plans and Model Usage
- Perplexity AI Repetition Issue: Users reported Perplexity AI giving repetitive answers with the same prompt, particularly with models like Llama 3 and Claude. One user mentioned that Alex responded they are aware of the issue and working on a fix.
- Live Internet Access Problems: One user described issues with Perplexity AI accessing live internet for real-time data, providing inaccurate and outdated information instead. Despite closing and reopening the app, the problem persisted and the user noted it in the feedback channel.
- Math Accuracy in Perplexity Pro: Users expressed frustration with Perplexity Pro's inaccuracies in handling math problems like CAPM beta calculations. Despite the model being GPT-4o, results were significantly off, raising doubts about the model's efficacy in academic calculations.
- Experience with Perplexity in Stock Market: One user shared that they made $8k in the stock market using Perplexity, praising its abilities. This sparked a brief discussion about the various benefits users have experienced with the pro version.
- Subscription Plans and Model Usage: Users discussed the differences between Pro and Enterprise Pro plans, with specifics on model usage like Sonnet and Opus. Questions emerged about the availability and specificity of models in different subscription plans.
Perplexity AI ▷ #sharing (13 messages🔥):
Threads' MilestoneAncient Aboriginal RitualsNuclear-Powered Data CentersMars MossEating Contests
- Threads Hit Milestone: A YouTube video titled Discover today: Threads' Milestone, Ancient Aboriginal Rituals, and Nuclear-Powered Data Centers discusses the recent achievement by Threads.
- Mars Moss and Other Wonders: Another YouTube video titled Discover today: Mars Moss, Eating Contests, Tech Titans, and Toxic Green explores the existence of moss on Mars and various unusual topics.
Perplexity AI ▷ #pplx-api (15 messages🔥):
Difference between pplx-70b-online and llama-3-sonar-large-32k-onlineGoogle Dorks usage with the APITemporal awareness in LLMsEffectiveness of query commands in LLMsPerplexity AI models and model cards
- Google Dorks and API Mastery: A user suggested that leveraging Google Dorks can enhance the utility of the API, as it simplifies filtering source domains effectively on web products.
- LLMs Lack Temporal Awareness: Users discussed the inability of models like llama3 and haiku to intuitively understand 'latest' or 'most recent' without explicit cues, influencing their responses.
- Query Commands in LLMs: Not Official: It was highlighted that while Google Dork operators are often suggested to constrain results, they are not officially integrated into the backend of Perplexity's LLMs.
- Perplexity Model Clarification: A user sought clarification on the difference between pplx-70b-online and llama-3-sonar-large-32k-online models, referencing both Perplexity's blog and API documentation.
- Model Alias and Obsolescence: There was confusion over model aliases and potential obsolescence; one user suggested some models might be aliases, while another noted that certain models might now throw errors.
LAION ▷ #general (185 messages🔥🔥):
BUD-E update on new featuresIssues with Clipdrop NSFW detectionDiscussion on dataset availability and usagePerformance of various AI models and training techniquesCommercial licensing of Stability AI models
- BUD-E updates with Clipboard Access: A recent YouTube video showcases BUD-E's new feature of reading text from the screen and clipboard, detailed in the project description on GitHub. The demo was presented in 240p resolution, which drew some humorous criticism.
- Clipdrop's NSFW Detection Failure: A member shared a humorous incident where Clipdrop incorrectly labeled an image as NSFW content.
- Struggles with Dataset Availability: Members discussed the difficulties faced by FAL.AI in acquiring new datasets, with comments highlighting the extensive reliance on the same datasets for multiple models. One user emphasized that interesting breakthroughs, like Chameleon, come from diverse and integrated modalities.
- Stability AI's License Fix: Stability AI revised the commercial license for SD3 Medium to the Stability AI Community License, allowing broader free use for individual creators and small businesses. This change was made in response to community feedback regarding the original commercial license.
LAION ▷ #research (2 messages):
scammer alertnew tokenizer proposal for LLMsT-FREE tokenizer paper
- User flags a scammer: A user alerted the community to the presence of a scammer in the chat.
- T-FREE Tokenizer Proposal Shakes Up LLMs: A new paper proposes T-FREE, a tokenizer that embeds words through sparse activation patterns over character triplets, eliminating the need for a reference corpus and achieving a parameter reduction of more than 85% in embedding layers. You can view the paper here.
- The paper outlines T-FREE's advantages, including improved performance for underrepresented languages and significant compression of embedding layers.
Link mentioned: T-FREE: Tokenizer-Free Generative LLMs via Sparse Representations for Memory-Efficient Embeddings: Tokenizers are crucial for encoding information in Large Language Models, but their development has recently stagnated, and they contain inherent weaknesses. Major limitations include computational ov...
LAION ▷ #resources (1 messages):
khazn: $50 gift card steamcommunity.com/gift/sd271azjxn2h
LAION ▷ #learning-ml (1 messages):
khazn: $50 gift card steamcommunity.com/gift/sd271azjxn2h
LAION ▷ #paper-discussion (1 messages):
khazn: $50 gift card steamcommunity.com/gift/sd271azjxn2h
OpenAI ▷ #ai-discussions (116 messages🔥🔥):
Moshi AI demoIssues with GPT-2Voice modality in OpenAI modelsBangla language support in chatGPTAPI usage for AI integration
- *Moshi AI Demo Excites and Frustrates: A new Moshi AI demo was released, featuring real-time voice interaction and promises of open-source flexibility. However, users experienced issues like conversational interruptions and looped responses, highlighting the current model's limitations.*: A new Moshi AI demo was released, featuring real-time voice interaction and promises of open-source flexibility. However, users experienced issues like conversational interruptions and looped responses, highlighting the current model's limitations.
- *Lack of Long-Term Memory in AI: Hume AI's playground offers interruptable voice AI but lacks long-term memory functionality, resetting after each session. This limitation frustrates users who desire continuous learning from their AI interactions.*: Hume AI's playground offers interruptable voice AI but lacks long-term memory functionality, resetting after each session. This limitation frustrates users who desire continuous learning from their AI interactions.
- *Call for Enhanced Bangla Language Support: A user highlighted ongoing issues with chatGPT handling the Bangla language, urging improvements for better accessibility. The request was posted with a thread ID for specific reference and emphasizes the need for broader language support.*: A user highlighted ongoing issues with chatGPT handling the Bangla language, urging improvements for better accessibility. The request was posted with a thread ID for specific reference and emphasizes the need for broader language support.
- *GPT-2 vs Modern Models Debate: There was a discussion on whether to use the older GPT-2 model for text generation or upgrade to more current options like GPT-3.5 Turbo. While some argued for the cost-efficiency of GPT-2, others pointed out the drastically better performance of newer models.*: There was a discussion on whether to use the older GPT-2 model for text generation or upgrade to more current options like GPT-3.5 Turbo. While some argued for the cost-efficiency of GPT-2, others pointed out the drastically better performance of newer models.
- *Navigating AI Integration via API: Users discussed various methods for integrating AI models using APIs, particularly focusing on RAG via Assistant API endpoints. The conversation highlighted how crucial coding knowledge is for maximizing AI's utility and customization.*: Users discussed various methods for integrating AI models using APIs, particularly focusing on RAG via Assistant API endpoints. The conversation highlighted how crucial coding knowledge is for maximizing AI's utility and customization.
OpenAI ▷ #gpt-4-discussions (26 messages🔥):
Differences between free and paid ChatGPT plansHandling images and PDFs in GPT knowledge baseEffectiveness of GPT memoryAccessing other GPT models within a GPTExternal file linking and vector databases for GPT knowledge base
- Paid ChatGPT Plan Benefits Explained: A member asked about the benefits of a paid ChatGPT plan, and it was explained that Plus offers a higher usage cap, access to DALL·E, and a larger context window. Additional details can be found here.
- Images and PDFs in GPT Knowledge Base: Members discussed whether GPT uses vision to read images and handle PDFs uploaded to the knowledge section. The conclusion was that GPT does not use vision and relies on OCR for text extraction from images and PDFs.
- GPT Memory Effectiveness Questioned: A member criticized GPT's memory feature, noting it saves preferences but still makes things up. Another member clarified that these memories function as suggestions, not hard rules, and recommended using customization options to improve behavior.
- Linking GPTs and Document Services: A complex discussion unfolded around linking GPT knowledge bases to Google Drive and other similar services. It was noted that external files cannot match the optimization of vector databases without a custom backend, with some services offering live link support for similar features.
- GPT-4 Usage Cooldown Confirmed: Concerns about GPT-4 availability were addressed, explaining that users face a cooldown period before using GPT-4 again after hitting their limit. Plus users can send up to 40 messages every 3 hours on GPT-4 and 80 on GPT-4o, with potential reductions during peak hours.
OpenAI ▷ #prompt-engineering (16 messages🔥):
Employee Recognition ProgramContent Generation script for training coursesTool to test multiple AI responsesTabletop RPG promptsTraffic ticket challenge guidance
- Employee Recognition Program Boosts Morale: Users discussed developing an employee recognition program to boost morale and motivation. The program includes goals, recognition methods, criteria, an implementation plan, and feedback mechanisms.
- Effective Content Generation Script: One user is seeking advice on developing a content generation script to create training course structures based on inputs like location, length, topic, and audience. They are considering prompt engineering, RAG, and web search integration as potential techniques.
- Tool for Testing Multiple AI Responses: A user inquired about tools to test and visualize multiple AI responses from the same prompt, seeking features like supporting file uploads and displaying response variations. Suggestions included a custom-built tool or existing options like Autogen.
- Tabletop RPG Battle Maps Prompting: A user asked for prompt ideas for generating tabletop RPG battle maps. Specific tools or techniques were not discussed.
- Guidance on Challenging Traffic Tickets: The channel discussed a structured approach to challenging a traffic ticket in court. The guidance included steps for contesting the ticket effectively and strategies for presenting a case.
Nous Research AI ▷ #research-papers (1 messages):
teknium: https://x.com/kerstingaiml/status/1809152764649574541?s=46
Nous Research AI ▷ #datasets (1 messages):
Replete-AI releases two massive datasetsEverything_Instruct and Everything_Instruct_Multilingual datasetsSizes and features of new datasetsInfluence of bagel datasets and EveryoneLLM AI models
- Replete-AI Unveils Massive Datasets: <@716121022025302076> released two new datasets, Everything_Instruct and Everything_Instruct_Multilingual, each sized 11-12GB and containing over 6 million rows of data. These are formatted in Alpaca Instruct style with a focus on creating a comprehensive instruct dataset to train AI models.
- Dual Dataset for Ultimate AI Model Training: Everything_Instruct is designed for English-only data, while Everything_Instruct_Multilingual includes multilingual translations to enhance models' language capabilities. Both datasets are inspired by the bagel datasets and previous EveryoneLLM AI models.
- The goal is to combine all conceivable types of instruct data into one massive dataset to train top-notch AI models. Enjoy the datasets on Hugging Face.
Nous Research AI ▷ #off-topic (4 messages):
Upcoming Nous physical magazine contributionOpen-source / decentralized technology in StudioMilitary magazine
- Call for Contributions in Nous Physical Magazine: John0galt invited everyone to contribute to the upcoming Nous physical magazine by offering good writing, interesting content, or ideas. Reach out to John0galt if interested.
- StudioMilitary Magazine Seeking Contributions: StudioMilitary has begun work on their first magazine edition focusing on open-source and decentralized technology. They are looking for contributions in writing, articles, pictures, and infographics, and have encouraged interested parties to reach out.
Link mentioned: Tweet from John Galt (@StudioMilitary): I'm beginning work on the first edition of our magazine. General theme is open-source / decentralized technology. Highlighting the optimistic forces in our world. If you're interested in cont...
Nous Research AI ▷ #interesting-links (5 messages):
Apollo project by Achyut Benzflask-socketio-llm-completions GitHub repofoxhop's demo chatroom appLLM integration with flask-socketio
- Apollo project visualizes topics AI-generated in 3Blue1Brown style: Achyut Benz introduced Apollo, which visualizes topics in 3Blue1Brown style videos, all AI-generated. It uses the Next.js framework, GroqInc inference, and supports AnthropicAI 3.5 Sonnet & OpenAI GPT-4 integrated with LangChainAI.
- Inspired by Chris Abey, the project aims to enhance learning through AI-generated educational videos.
- Chatroom app sends messages to multiple LLMs via flask-socketio: foxhop shared a GitHub repo for flask-socketio-llm-completions, a chatroom app that sends messages to GPT, Claude, Mistral, Together, and Groq AI, streaming to the frontend.
- "This app is maintained to work seamlessly with various LLMs and demonstrates real-time communication capabilities."
- Foxhop showcases demo for LLM-integrated chatroom app: foxhop provided a demo link to showcase the chatroom app integrated with LLMs. The demo exemplifies how messages interact with vLLM, Hermes, and Llama3 models.
- The application serves as a practical tool for interacting and experimenting with LLM capabilities in a chatroom environment.
Nous Research AI ▷ #general (110 messages🔥🔥):
New datasets released by Replete-AINomic AI launches GPT4ALL 3.0InternLM-XComposer-2.5 model releaseChallenges with jailbreaks for Claude 3.5 SonnetDiscussion on visual latent space for LLMs
- Replete-AI Unveils Massive New Datasets: Replete-AI releases two new massive datasets, Everything_Instruct and Everything_Instruct_Multilingual, each sizing 11-12GB with over 6 million rows of data, aiming to combine various instruct data to train AI models to new heights. Details here.
- These datasets, inspired by bagel datasets and Replete-AI's EveryoneLLM models, include one set for English and another with multilingual translations to enhance models' multilingual capabilities.
- Nomic AI Launches GPT4ALL 3.0: Nomic AI announces the release of GPT4All 3.0, an open-source local LLM desktop app supporting thousands of models across major operating systems with significant UI/UX improvements and MIT license. Check it out, boasting 250,000+ monthly active users and privacy-first features with local file chat.
- InternLM-XComposer-2.5 Sets New Benchmarks: InternLM releases InternLM-XComposer-2.5, a versatile large-vision language model supporting long-contextual input and output, trained with 24K interleaved image-text contexts and capable of extending to 96K long contexts via RoPE extrapolation. Announcement here, it surpasses existing open-source models on 16 benchmarks and competes closely with GPT-4V and Gemini Pro.
- Frustrations with Jailbreaking Claude 3.5 Sonnet: Users share challenges in jailbreaking Claude 3.5 Sonnet, discussing attempts with specific pre-prompts and roles, but the AI remains persistent on ethical constraints. Some suggest using Anthropic's workbench for potentially higher success but warn of possible account bans.
- Exploring LLMs' Visual Latent Space Capabilities: Discussions arise about letting LLMs draw or represent their visual latent space, considering if trained on enough visual data, they could repeat visual elements like chemical structures or 3D spaces. Some examples include a model generating a 3D city using HTML and CSS, suggesting potential but noting the need for datasets involving visual data.
Nous Research AI ▷ #ask-about-llms (1 messages):
using visual-semantic information to boost image classification performancezero/few shot multi-modal models discussed at CVPRapplying Florence 2 for supervised fine-tuning
- Boosting Image Classification with Visual-Semantic Info: A user inquires about using the interaction between visual-semantic information to enhance fine-grained image classification performance, specifically through supervised fine-tuning. They mention a potential application of Florence 2 for this purpose.
- CVPR Highlights Zero/Few Shot Multi-modal Models: At CVPR, numerous papers focused on zero/few shot multi-modal models, demonstrating interest in leveraging both visual and textual data. A user working in computer vision seeks advice on employing this research in practical, supervised settings.
Nous Research AI ▷ #rag-dataset (8 messages🔥):
crossover with pipelines, flows, and agentsrag dataset as 0 shot context ingestioncontext and metadata for llmHF tool processing corpus queries against hf datasetskeyword matching for relevance score and filtering
- Crossover with pipelines, flows, and agents: Pipelines, flows, and agents are merging, and the idea is to make the RAG dataset primarily for 0 shot context ingestion, focusing on agent-based processing later.
- interstellarninja mentioned it's beneficial to incorporate cross-overs into agentic flows, even during RAG development.
- HF Tool Processing and Keyword Matching: A HF tool was described that can process a corpus of queries against HF datasets, converting them into schemas with metadata as .jsonl files, utilizing an inverted index for keyword matching.
- @everyoneisgross mentioned the interface allows for editing generations with Gradio, keyword search functions well for toy prompting.
Nous Research AI ▷ #world-sim (10 messages🔥):
Users discussing lack of credits to use WorldSIMIssues with using GPT-3.5 on WorldSIMPrompt engineering for different models on WorldSIMPositive feedback about WorldSIMBuddhist world simulation on WorldSIM
- WorldSIM Users Run Out of Credits: A user recommended explaining the credit limitations on WorldSIM, suggesting a heading like "Not enough credits to use" or using red text to indicate "NO CREDITS". This would help avoid confusion for new users.
- Frustration with GPT-3.5 on WorldSIM: Several members expressed frustration with using GPT-3.5 on WorldSIM, mentioning that it often returns one-line answers before eventually working. One user complained about wasting credits on multiple messages to get started.
- New Prompt Engineering for WorldSIM Models: A discussion revealed that WorldSIM is working on new prompt engineering for different models. A member mentioned that separating the prompts between different models is a work in progress (WIP).
- Members Praise WorldSIM: A member stated that WorldSIM is "bonkers" and congratulated the team on an awesome job. Another member shared their experience of using up all their credits during a lunch hour to create a world rooted in Buddhist principles.
OpenRouter (Alex Atallah) ▷ #app-showcase (1 messages):
Simple Telegram bot to interface with different AI modelsFirst 1000 responses free on the bot
- Try Mysticella Bot for AI Model Interfacing: Created a simple Telegram bot to interface with different AI models. First 1000 responses are free.
- Telegram Bot First 1000 Responses Free: Check out the new Telegram bot Mysticella for free AI model interfacing. The first 1000 responses are completely free.
OpenRouter (Alex Atallah) ▷ #general (107 messages🔥🔥):
Quantisation of deployed LLM models in OpenRouterMicrosoft's API changes affecting OpenRouterInfermatic's privacy policy updateIssues with DeepSeek Coder equations renderingMistral Codestral API pricing and performance
- LLM models quantization confusion clarified: OpenRouter LLM models are deployed in FP16/BF16 unless a provider specifies otherwise, as explained by a user. Another user clarified the presence of a quantization icon indicating model quantization status.
- Microsoft API change impacts OpenRouter: Microsoft introduced a breaking change to their API used by OpenRouter, but a patch was quickly deployed. User feedback praised the rapid response and fix.
- Infermatic clarifies privacy policy: Infermatic does not log any input prompts or model outputs, processing data in real-time only, as clarified in their revised privacy policy. Users found this reassuring compared to older policies indicating potential data retention.
- DeepSeek Coder equation issue resolved: Users experienced issues with equations not rendering correctly in DeepSeek Coder, although one user found solutions by manipulating output strings with regex. Another user reported the system prompts not being processed correctly on TypingMind's frontend, raising the issue for review.
- Mistral Codestral API pricing criticized: Users expressed dissatisfaction with Mistral's Codestral API pricing, considering it overpriced for a 22B model. Alternative options like DeepSeek Coder were recommended for better cost efficiency and comparable coding performance.
Eleuther ▷ #general (42 messages🔥):
Failed jobs on the leaderboardChecksum for generative modelsTopological Data Analysis for model fingerprinting1.58 bit LLM paper and its implementationVQ-VAE immunity to posterior collapse
- Leaderboard Job Issues Surface: A member inquired about failed jobs on the Hugging Face leaderboard and whether they can be re-added.
- Debate on Checksums for Generative Models: Discussion arose on whether there is a checksum-like metric for generative models like
LlamaForCausalLMusing lm-evaluation-harness, with discrepancies noted between benchmarks and checksums. - Exploring TDA for Model Fingerprinting: Members delved into the use of Topological Data Analysis (TDA) to fingerprint models by measuring topological invariants, referencing tools like TorchTDA.
- ’Have you ever looked into Topological Data Analysis? You could potentially accomplish this by using TDA to profile the weights by their inherent topological invariants.’
- Implementing 1.58-bit LLM Innovations: A member sought guidance on adopting techniques from the 1.58-bit LLM paper to quantize weights and activations for higher cost-efficiency.
- They planned to replace the linear layers with a 'BitLinear' layer in a pre-trained model like Pythia to test quantized weight training.
- Struggles with PDF Markup Tools: A member expressed frustration over the lack of PDF markup tools with a 'Search -> Markup All' function, mentioning expensive options like Bluebeam and PDF Studio.
Eleuther ▷ #research (28 messages🔥):
Diffusion forcing for planningComparison with Nathan Frey's walk_jump methodDiscussing new research strategiesContinual pre-training for LLMsFunction approximation with different homotopy classes
- Diffusion Forcing Shows Promise in Planning: A member shared a video demonstrating diffusion forcing for planning, generating a lot of interest and positive feedback, 'really cool result tbh'.
- Diffusion Forcing vs Walk-Jump Method: Discussion on whether diffusion forcing would outperform Nathan Frey's walk_jump method concluded that they may be orthogonal techniques with different mechanisms.
- Effective Paper Consumption Strategy: A member inquired about the strategy for keeping up with new research, receiving advice that skimming ArXiv papers on release and systematic effort in filtering important ones is key.
- Continual Pre-training for Large Language Models: Recent research on continual pre-training observed a 'stability gap' in the performance of LLMs when adapting to new domains, and proposed three strategies to mitigate it.
- Homotopy Classes in Function Approximation: A member queried the benefit of having each basis function's image belong to different homotopy classes during function approximation, particularly in modeling rotation trajectories.
Eleuther ▷ #scaling-laws (5 messages):
efficientcube.ipynb in chinchilla repositoryXLA capabilities in JAXFLOPs estimation for JIT-ed functions in FlaxCritical batch size and performance degradation
- EfficientCube Notebook in Chinchilla: A toolkit for scaling law research, named efficientcube.ipynb, has been added to the Chinchilla repository. The notebook includes utilities relevant for scaling research activities.
- JAX adds AOT Compilation Capabilities: JAX now supports ahead-of-time (AOT) compilation in addition to JIT compilation. This allows users to compile code prior to execution, giving more control over the compilation process.
- Flax FLOPs Estimation Method Shared: A code snippet for estimating FLOPs of JIT-ed functions in Flax was shared in a discussion on GitHub. This method leverages XLA’s capabilities within JAX for precise performance measurements.
- Reevaluation of Critical Batch Size Theory: Recent findings suggest that below a certain optimal batch size, performance degrades, contradicting the conventional wisdom that any batch size below a critical value is good. This is noted as being interesting in theory but not significant at large scales.
Eleuther ▷ #interpretability-general (3 messages):
SAEs on Llama 3 8BSparse autoencodersResidual stream processing
- SAEs on Llama 3 8B trained: Sparse autoencoders (SAEs) trained on the residual stream of Llama 3 8B are now available for use. These SAEs employ the RedPajama corpus and can be loaded using the EleutherAI
saelibrary.- Downloads are not currently tracked for this model.
- Residual stream processing using SAEs: This project organizes SAEs by layer and integrates them with the Llama 3 8B model to process residual streams more effectively. For more details, consult the model card.
Link mentioned: EleutherAI/sae-llama-3-8b-32x · Hugging Face: no description found
Eleuther ▷ #lm-thunderdome (18 messages🔥):
Preprocessing Function OptimizationProof-Pile Config ErrorMetric Inconsistencies in ConfigLong Model Names IssueEvaluating Model in Parallel
- Preprocessing Caching Alternative: A user inquired if preprocessed questions/arguments could be saved before feeding them into the model, to avoid rerunning preprocessing functions every time.
- Proof-Pile Config Error Resolution: A user faced an error with the
proof-piletask using a specific config file. Switching tolambada_openaiworked, indicating a potential issue with the dataset itself. - Metric Mismatch Identified in Config: There was confusion over using
loglikelihood_rollingin the config whileloglikelihoodgot called, likely due to metric inconsistencies. loglikelihood metrics:perplexityvsword_perplexity,byte_perplexity,bits_per_byte. - Long Model Names Cause Saving Issues: A user experienced issues with saving due to long model names causing files and directories to not be written correctly. Errors returned OSError(36, 'File name too long').
- Parallel Evaluation Setup Inquiry: A user asked how to evaluate the model in a parallelized way while passing it via the
pretrainedparameter. Warning received: 'assuming single-process call to evaluate() or custom distributed integration'.
Eleuther ▷ #multimodal-general (1 messages):
wendlerc: Does anyone have a good SDXL latent downscaler? I’d like to go from 128x128x4 to 64x64x4.
LangChain AI ▷ #general (75 messages🔥🔥):
Difficulty using LangChainPreference between OpenAI or ChatOpenAIPeopleGPT and Juicebox.ai functionalityRAG Architecture for scheduling demosLangChain performance issues and improvements
- Whys and Whys Nots of LangChain: A member expressed difficulty using LangChain and questioned its utility, citing long response times and unnecessary steps in processing, especially while running locally on CPU.
- Another user pointed out it might be the model's reasoning performance or simply the fact it's running without a GPU, leading to inefficiencies like excessive irrelevant searches.
- OpenAI vs. ChatOpenAI: OpenAI and ChatOpenAI were compared for task executions, with a user inquiring the pros and cons and noting that OpenAI might be deprecated in favor of ChatOpenAI.
- Several members clarified that diverse experiences exist, depending on the exact requirements and implementation contexts.
- PeopleGPT in Juicebox.ai Shines: A member discussed Juicebox.ai powered by PeopleGPT, a natural language-based search engine for finding qualified talent without using Booleans, providing easy clickable examples here.
- The discussion focused on the technical functionality, highlighting it combines filters with search to enhance user experience.
- Issues with LangChain and CSV Files: A user sought updated methods for dealing with multiple CSV files in LangChain, noting previous limitations in handling more than two files post-update.
- The member reminisced about the effectiveness of previous modules and queried modern alternatives for optimal performance and integration.
- Challenges with LangChain for Scheduling Demos: A member struggled with incorporating demo scheduling features in a chatbot using LangChain and RAG architecture, mentioning tools like SlackScheduleMessage.
- Detailed steps provided from LangChain's community were discussed for possible solutions, emphasizing the need for further community input.
LangChain AI ▷ #share-your-work (3 messages):
Adding demo scheduling feature to chatbot using the RAG architecture and LangChain frameworkBlogpost on creating an E2E Image Retrieval app using Lightly SSL and FAISSBeta testing for advanced research assistant and search engine with premium model access
- RAG Chatbot Needs Demo Scheduling Feature: A member asked for community help to add a demo scheduling feature to their chatbot built using the RAG architecture and the LangChain framework.
- Lightly SSL and FAISS power Image Retrieval App: A blogpost was shared on creating an E2E Image Retrieval app using Lightly SSL and FAISS, including implementing a vision transformer model and creating vector embeddings. The detailed blogpost includes a Colab Notebook and a Gradio app.
- Rubik's AI offers Free Beta Testing: An invitation was extended for beta testing an advanced research assistant and search engine, offering 2 months of free premium access to models like Claude 3 Opus, GPT-4o, and more.
- Users were prompted to sign up using the promo code 'RUBIX' for the free trial.
LangChain AI ▷ #tutorials (1 messages):
dievas_: https://www.youtube.com/watch?v=yF9kGESAi3M try this one
LlamaIndex ▷ #announcements (1 messages):
Next webinar on RAG experimentation/evaluation with LlamaIndex and Weights and BiasesAnnouncements about the timing and focus of the upcoming webinarComplex challenge of aligning LLM Judge for accurate evaluation
- *� Next Webinar on Aligning Your LLM Judge: Join the next webinar on a principled approach to RAG experimentation/evaluation with LlamaIndex and Weights and Biases next Wednesday at 9am PT. Reserve your spot by registering through the provided link.
- Complex Challenge of Aligning Your LLM Judge: This webinar will explore various evaluation strategies focused on aligning your LLM Judge using a RAG pipeline as a case study. It will also demonstrate how to leverage Weights and Biases Weave for systematic assessment.
Link mentioned: LlamaIndex Webinar: Aligning Your LLM Judge with LlamaIndex and W&B Weave · Zoom · Luma: While creating a RAG pipeline is now straightforward, aligning your LLM Judge for accurate evaluation remains a complex challenge. In this webinar, we’ll delve…
LlamaIndex ▷ #blog (4 messages):
New Webinar: A Principled Approach to RAG Experimentation + EvaluationReflection as a ServiceBecoming a Rockstar AI Engineer and EducatorCorrective RAG as a Service
- Webinar: Partnering with Weights & Biases on RAG: LlamaIndex announced a webinar with Weights & Biases to showcase building, evaluating, and iterating on RAG pipelines. This follows 1+ years of RAG development but notes that proper evaluation remains challenging.
- Ensuring Reliability with Reflection as a Service: LlamaIndex discussed the concept of 'Reflection as a Service,' addressing reliability issues in agentic applications by implementing a reflection step to self-correct outputs if incorrect. This solution aims to prevent problematic outputs from LLMs.
- Rockstar AI Engineer: @ravithejads's Journey: LlamaIndex highlighted the journey of community member @ravithejads, who became a developer advocate through passion, OSS contributions, and staying updated with the latest AI trends. His story is shared to inspire others to excel in AI engineering and education.
- Releasing Corrective RAG as a Service: LlamaIndex announced the release of Corrective RAG (CRAG) by Yan et al., which dynamically validates retrieved context and corrects it if irrelevant, using web search before the generation step.
LlamaIndex ▷ #general (71 messages🔥🔥):
Google Cloud Function inference pipeline with multiple model loadingPerformance comparison of Cohere's command r+Implementing conversational memory in LlamaIndex with RAGUsing hybrid retrievers without storing/loading from filesystemFew-shot example technique for 'Poor man's RLHF'
- Multiple Model Loading in Google Cloud Function Inference Pipeline: A user expressed issues with loading the Alibaba NLP embedding model and Llama3 LLM for inferences on a Google Cloud Function, facing repetitive loading times. They asked for alternatives to load embeddings directly from Vertex AI and received suggestions but no concrete solution.
- Handling Conversational Memory in LlamaIndex: A user sought ways to avoid overuse of conversation memory in LlamaIndex and received advice on improving prompt engineering to mitigate the issue. They agreed that modifying the system prompt might help.
- Hybrid Retriever Usage Without Filesystem Storage: A user inquired about implementing a hybrid retriever without filesystem storage, and suggestions included writing the BM25 algorithm for sparse vectors and storing them in a vector store. Discussion also mentioned future explorations with bm42 and minor tweaks needed for LlamaIndex support.
- Handling Large Models and Quantization: A user discussed challenges with using the 'gte-Qwen2-7B-instruct' and 'BAAI/bge-large-en-v1.5' embedding models due to GPU limitations. They planned to test quantized embedding models and learned both models can be used if dimensions match.
- Local LLMs, GPT4All, and Outdated Documentation: Concerns were raised about outdated examples and links in the documentation. Latest information on using local LLMs was shared, and it was noted that contributions to update the documentation are welcome.
Cohere ▷ #general (45 messages🔥):
Discussion about qualifications for attending the London eventIssue with deploying an app using Cohere's rerank API in productionIntroduction of new membersTeaching AI and advanced developmentWorking on AI-Plans, a peer review platform for red teaming alignment plans
- No Qualification Needed for London Event: A member asked if certain qualifications were necessary to attend the London event, and others clarified that no prerequisite requirements were needed and anyone could attend by filling out a form. No PhD needed to attend community events was a key message.
- Rerank API Error in Production: A member raised a TypeError when deploying an app using the rerank API in production, contrasting its local functionality. Another member noted that the issue seems unrelated to Cohere and asked for the Streamlit script for further diagnosis.
- New Members Introduce Themselves: Several new members, including a recent Computer Science graduate and an AI developer interested in teaching, introduced themselves and expressed excitement about joining the community. They highlighted their backgrounds and what they hope to achieve within the Discord.
- Teaching AI and Advanced Development: A member expressed keen interest in teaching AI and advanced development, inviting others to reach out for collaboration. This was well-received, with another member openly offering to seek his expertise soon.
- AI-Plans Platform: A member revealed working on AI-Plans, a peer review platform for red teaming alignment plans. This sparked interest and welcomed them to further discuss their project.
Cohere ▷ #project-sharing (17 messages🔥):
Featuring a tutorial on Cohere blogIntroducing Command R+, the new powerful modelUsing Rhea.run to create toy appsNew 'Save to Project' feature in Rhea.run
- Feature Tutorial on Cohere Blog: A member expressed interest in featuring a tutorial on the Cohere blog and shared an old blog post and starter code for a Slack bot on GitHub. Another member confirmed they will follow up directly.
- Using Rhea.run for Toy Apps: Members discussed using Rhea.run to create toy apps, noting its capability to generate interactive applications by asking it to design HTML scripts.
- Introducing Command R+: Cohere announced the release of Command R+, their most powerful model in the Command R family, now available for use.
- New Feature in Rhea.run: A new 'Save to Project' feature was introduced in Rhea.run, which allows users to create interactive applications by designing HTML scripts through conversations.
OpenInterpreter ▷ #general (57 messages🔥🔥):
Technical question about interpreter outputDiscussion on new MacOS Copilot, InvisibilityAcknowledgment and progress on Open Interpreter (OI) securityOpen Interpreter's new debugging featureMonthly House Party events
- Invisibility: MacOS Copilot Gains Traction: Members discussed the new Invisibility MacOS Copilot that uses GPT-4, Gemini 1.5 Pro, and Claude-3 Opus, highlighting its free availability and features like seamless context absorption. Development of voice, long term memory, and iOS is ongoing.
- Interest was expressed about integrating similar tools into the OI ecosystem, with one member suggesting the possibility of open-sourcing grav.ai, a preceding project.
- Open Interpreter Implements Debug Command: One user excitedly reported that Open Interpreter can now change the VSC theme from light mode to dark mode automatically, showcasing its ability to perform certain actions without explicit programming. This feature, referred to as the 'wtf' command, allows for debugging errors in the terminal and suggesting fixes.
- This newly implemented functionality caused quite a buzz, with members sharing their amazement and support for ongoing improvements.
- Acknowledgment of OI Security Measures: A member praised the OI team for their dedication to security, mentioning a meeting where various ideas and suggestions were discussed to improve the system's security model. The team's commitment to making security a priority was highly appreciated.
- Plans for future security roundtables were mentioned, with a promise to update the community on dates and ongoing efforts.
- Monthly House Party Recap: The community celebrated the success of OI’s 4th of July House Party which showcased new demos, faces, and previews of upcoming updates. The next event is scheduled for August 1st.
- Members expressed their joy and gratitude for the event, highlighting its role in fostering engagement and collaboration within the community.
OpenInterpreter ▷ #O1 (2 messages):
01 Light shipments updateDelays in 01 Light shipments
- 01 Light Shipments Update: Members expressed anticipation about the 01 Light shipments with one hoping for an update soon. Another member shared their frustration, stating they've been waiting forever.
- Frustration Over Shipment Delays: A member conveyed their dissatisfaction over the prolonged wait for the 01 Light. The sentiment was echoed by another member, indicating collective frustration.
Modular (Mojo 🔥) ▷ #general (5 messages):
Discussion on casting bugs in MojoComparison between Mojo and Python objectsProposal for a Mojo Fundamentals course at EDxResources for learning Mojo
- Casting Bug in Mojo: A member highlighted the casting bug with references to relevant GitHub issues #3065 and #3167.
- Mojo vs Python Objects Discussion: There is speculation that the casting bug might be related to differences between Mojo objects and Python objects, referencing issue #328.
- Mojo Fundamentals Course Proposal: A user proposed creating a "Mojo Fundamentals" course for EDx, but another member suggested it would become outdated quickly. They recommended using Mojo by example and mojo-learning as up-to-date resources instead.
Modular (Mojo 🔥) ▷ #🔥mojo (22 messages🔥):
Casting file pointer to struct in MojoCalling external programs in Mojo using system or popenHandling bitcast issues in Mojo with byte array manipulationPass a List as an argument to a function in MojoMLIR issue with unsigned integer casting in Mojo
- Casting file pointer to struct in Mojo: A user successfully bitcasted a
List'sUnsafePointerto a struct in Mojo using an example shared by another user, with specific reference to bitcast. - MLIR unsigned integer casting bug reported: MLIR Issue #3065 was discussed where casting to unsigned integers behaves like casting to signed integers, creating inconsistencies. This issue has been affecting multiple users and the discussion moved from Discord to GitHub Issue #3065.
- External programs in Mojo: Running external programs in Mojo can be achieved using
external_callwith references given to example here for implementations likesystemandpopen. A Python example forpopenwas shared, detailing how to run - Handling bitcast issues in Mojo with byte array manipulation: A user encountered inconsistencies when bitcasting objects from a file pointer in Mojo, with behaviors changing based on byte array lookup. The issue was suspected to be due to the bytes getting freed, suggesting keeping the bytes around or using
Referenceto avoid undefined behavior. - Pass a List as an argument to a function in Mojo: A user resolved an issue passing
Listas an argument by specifying the type in the function signature asinout inList:List[String]. They initially faced type errors but successfully appended items to the list following the fix.
Modular (Mojo 🔥) ▷ #nightly (10 messages🔥):
segfault issues with nightly buildbug report submissionos.path.expanduser bugnew nightly Mojo compiler releaseschangelog updates
- Nightly Build Segfaults on Compilation: A member experienced a segfault while compiling a source file with the nightly build and shared the problematic file. This prompted them to submit a bug report.
- os.path.expanduser Bug Causes Nightly Build Failures: A bug introduced by using
os.path.expandusercaused nightly builds to fail because theHOMEenvironment variable was not set during tests. A member admitted the mistake, apologizing for the inconvenience. - New Nightly Mojo Compiler Released: A new Mojo compiler version
2024.7.416has been released, featuring updates like anexclusiveparameter to pointer types and the implementation ofcollections.Counter. See the changelog and raw diff for detailed changes. - Subsequent Nightly Mojo Compiler Release: Another nightly compiler version
2024.7.505was released, deprecatingtime.nowin favor oftime.perf_countermethods. Detailed changes are available in the changelog and raw diff.
Modular (Mojo 🔥) ▷ #mojo-marathons (17 messages🔥):
Feedback from Modular staff on best answersInterest in x86 and SVE roundsPR for a better timer needing MLIR knowledgeBenny's solution for matrix multiplicationCompilation times and segfaults in test suite
- Modular staff to provide feedback on best answers: Modular staff will give feedback on the best answer at the end of the challenge, as well as offer suggestions for improvement.
- Interest in x86 and SVE benchmarks: A discussion emerged about conducting x86 (with and without AMX) and SVE rounds since Graviton 4 is expected to go GA soon, and it features SVE.
- Benny shares matrix multiplication solution and hints: Benny shared his best solution for matrix multiplication and hinted at tuning the block size for improved performance. He mentioned using CPU cache sizes as parameters and suggested checking UT Austin papers for more details.
- Compilation time and segfault issues in test suite: Users reported long compilation times and internal segfault issues when running the latest test suite with provided solutions.
- Relevant papers for parameter tuning: Benny referenced several UT Austin papers for parameter tuning related to cache sizes and matrix multiplication performance improvements. He provided a Google Spreadsheet link listing those papers.
Link mentioned: Matrix Multiplication: Sheet1 Contstraints,Parameters / Tuning Vectorization,Contiguous Access,Nelts, Unrollable Parallelization,Unrollable Unrolling,Contiguous Operations Tiling Square Optimized,Amorized Increase,Recursiv...
LLM Finetuning (Hamel + Dan) ▷ #general (12 messages🔥):
Usage of LangSmith without LangChainAccusation of lack of GPU credits during AI course3rd place solution in AI Mathematical OlympiadBenefits of in-context learning vs. fine-tuning
- LangSmith Operates Independently from LangChain: A user inquired if LangSmith can be used without LangChain, to which others confirmed that it's possible and provided a Colab example and GitHub link. LangSmith allows instrumentation of any LLM application, useful for debugging and monitoring.
- Accusations About Missing GPU Credits: A heated debate ensued over claims that participants of a course did not receive GPU credits, with multiple members pointing out that the terms were clearly stated and visible on the course platform. Some speculated that the complaints might be unfounded or driven by ulterior motives.
- Top 3rd Place AI Mathematical Olympiad Solution’s Lack of Fine-Tuning: A user highlighted that the 3rd place solution in the AI Mathematical Olympiad, which won $32k, did not involve any fine-tuning. The leaderboard can be reviewed for more details here.
- In-Context Learning vs Fine-Tuning Discussion: An interesting discussion was sparked by a LinkedIn post comparing in-context learning with fine-tuning for LLMs. The detailed insights can be found here.
LLM Finetuning (Hamel + Dan) ▷ #🟩-modal (7 messages):
Discussion on monthly credits and expirationDistributed finetuning issue solutionsClarifying the usage and remaining balance of credits
- Clarifying monthly credits and expiration: Members discussed the $1000 monthly credit and potential loopholes, clarifying that unused credits may not carry over, but still finding it generous.
- Issues with distributed finetuning: A member shared a link to a thread detailing steps to resolve issues encountered during distributed finetuning.
- Understanding credit usage and balance: Discussion centered on members noticing their remaining balance, with one reporting $1030 after finetuning Mistral, and questioning if it is due to a default $30 per month allocation.
LLM Finetuning (Hamel + Dan) ▷ #jarvis-labs (1 messages):
goktrenks: when is the expiration date for the credits? (thanks btw!)
LLM Finetuning (Hamel + Dan) ▷ #ankurgoyal_textsql_llmevals (2 messages):
Text2SQL use case discussion and appreciation for iterative eval dataset building
- Iterative Building of Eval Dataset Impresses: A member expressed appreciation for the session on Text2SQL, highlighting its value due to the iterative building of the eval dataset.
- The iterative process was particularly appreciated and seen as beneficial for an upcoming use case.
- Thanks to the Community: Members expressed gratitude towards the community, particularly towards an individual for their guidance in building the eval dataset for Text2SQL.
- Such sessions and discussions are found incredibly valuable by the members.
LLM Finetuning (Hamel + Dan) ▷ #workshop-2 (1 messages):
Applying eval framework to unstructured applicationsChallenges of using unit tests/Level 1 evals without structured output
- Challenges in Eval Framework for Unstructured Output: A user questioned the applicability of the eval framework to outputs that lack strict syntax rules, like a query language. They expressed confusion over implementing unit tests/Level 1 evals without a structured output.
- Missing Methodology in Unstructured Eval Applications: The user asked if they were missing something when considering how to apply the eval framework to less structured applications, indicating a gap in understanding or practice.
LLM Finetuning (Hamel + Dan) ▷ #jeremy_python_llms (2 messages):
Pushing models to HF_HUB for inference endpointsTraining models on HF_HUB as endpoints
- Push Models to HF_HUB for Inference: Inference endpoints on HF_HUB might be facilitated by pushing a model to the hub and then using the credits for an endpoint. This suggestion revolves around utilizing existing resources for creating efficient inference pipelines.
- Training Not Feasible as Endpoints: The idea that training will work as an endpoint on HF_HUB is questionable. It's discussed that training may not be practical for endpoints, possibly due to resource or infrastructure limitations.
LLM Finetuning (Hamel + Dan) ▷ #axolotl (3 messages):
Using type: input_output with Meta-Llama-3-8B-InstructSpecial tokens configuration in AxolotlTraining outcomes with L3 8B base vs L3 70B InstructTemplate usage for prompt formattingSpecial tokens setup discrepancies between models
- Struggling with Meta-Llama-3-8B-Instruct setup: A user shared challenges with using
type: input_outputand configuringspecial_tokensfor theMeta-Llama-3-8B-Instructmodel, citing confusion over correct setup in their jsonl and yml files. They referenced a GitHub example and a blog post for additional context. - Disparities in special tokens setup: Discussion included the need to add special tokens from Meta's special_tokens_map.json, comparing it to the special tokens setup for Mistral 7B base. They suggested following similar configurations as used in other training setups to avoid issues.
- Training results favoring L3 70B Instruct: A user noted better subjective outcomes training on L3 70B Instruct base compared to L3 8B base, discovering the improved results only after checking the model configuration post-training. They mentioned an accidental but preferable result when a training setup defaulted to the 70B instruct model.
Link mentioned: Hamel’s Blog - Template-free axolotl: Template-free prompt construction in axolotl with the new input_output format.
LLM Finetuning (Hamel + Dan) ▷ #credits-questions (1 messages):
Eligibility for credits on all servicesEnrollment date and course catch-up
- Seeking Eligibility for Credits: A member inquired about their eligibility for credits on all services and expressed gratitude for any applicable credits.
- Course Enrollment Date: The same member mentioned they enrolled in the course on June 14th and have been catching up recently.
LLM Finetuning (Hamel + Dan) ▷ #predibase (1 messages):
Expired compute creditsExtension request for compute credits
- Compute Credits Expire Too Soon: A member realized that their compute credits have expired after only one month, leaving them with around $70 still unused.
- Extension Request for Compute Credits: The same member politely asked if it is possible to get an extension for the remaining compute credits.
LLM Finetuning (Hamel + Dan) ▷ #openai (1 messages):
Credit grant requestEnrollment details
- Credit grant request: A user requested credit grants for their updated form with organization ID org-SxGZTlTAAYP5xAswIojG7KI5.
- Enrollment details: The user mentioned they enrolled on June 14th and are catching up on the course lately.
Interconnects (Nathan Lambert) ▷ #news (5 messages):
Unimpressed reaction to AI demoStability AI's apology and license update
- AI Demo Criticism Raises Authenticity Questions: @benhylak expressed disappointment with an AI demo on X, questioning its authenticity by stating 'it's really, really bad... leaves me wondering if the demo was fake?'. Response time issues were particularly noted.
- Stability AI Apologizes and Updates License: Stability AI acknowledged that Stable Diffusion 3 Medium didn't meet community expectations and clarified updates on its commercial license, aiming to address confusion and concerns. They committed to releasing high-quality Generative AI models moving forward.
Interconnects (Nathan Lambert) ▷ #other-papers (8 messages🔥):
BM42 vs BM25 in search enginesContextual AI's focus on RAGJo Bergum's critique of Qdrant's BM42 claims
- BM42 challenges BM25 in search tech: Qdrant Engine claims that the new search model, BM42, surpasses the traditional BM25 in modern RAG applications, offering a mix of semantic and keyword search as mentioned in their tweet.
- Jo Bergum- BM42 results are fake: Jo Bergum criticized Qdrant Engine for falsifying results about BM42 on a Quora dataset, stating that Precision@10 reported was impossibly high, and calling the results **
Interconnects (Nathan Lambert) ▷ #random (9 messages🔥):
Understanding VAEsInterconnects' investment geniusGDP growth rate from AI for timelinesAnthropic Claude 3.5 Sonnet suppressing answers
- Understanding VAEs leads to nosebleeds: VAEs (Variational Autoencoders) have caused confusion, with one user humorously noting they got a nosebleed trying to understand them.
- Investment Genius in Interconnects: In a recent post, it was revealed that interconnects showcased his prowess as an "absolute investment genius."
- AI-driven GDP growth requires significant rates: GDP growth from AI needs to be between 11-15% to meet Stuart's timelines, depending on initial conditions. This metric was checked for feasibility and deemed reasonable.
- Anthropic Claude 3.5 Sonnet suppressing answers: Anthropic Claude 3.5 Sonnet is reportedly suppressing parts of its answers from users. The usage of hidden tags like §§antThinking§§ has raised concerns about transparency in these AI systems.
Link mentioned: Tweet from Philipp Schmid (@_philschmid): I wasn't aware of that, but it looks like Anthropic Claude 3.5 Sonnet on (claude ai) is suppressing parts of his answer from the user, which are not sent to the client. You can test that with, fro...
Interconnects (Nathan Lambert) ▷ #posts (4 messages):
Gemini web appGoogle AI StudioVertex AIGoogle's AI raceFirst Amendment and weights
- Google's AI race lags behind: Google is behind other companies in the AI race, needing to clean up clarity issues that caused user confusion, according to a detailed discussion in the chat.
- One participant expressed that Google is slow and messy booting up in the AI race, but acknowledged that they are improving.
- Understanding Gemini and its offerings: The Gemini web app costs $20/mo and competes with ChatGPT, previously named Bard and powered by PaLM 2 before now using Gemini 1.5. Google AI Studio provides an API key for developers to use Gemini 1.5 with 2M context, while Vertex AI offers the same for enterprises.
- One user expressed confusion about whether the paid version of Gemini always uses Gemini 1.5 due to unclear FAQs.
- First Amendment and weights: A user discussed the application of the First Amendment to AI model weights, suggesting it could be a logical but optimistic view.
- The idea is that weights should be protected as something published, thereby covered by the First Amendment.
OpenAccess AI Collective (axolotl) ▷ #general (20 messages🔥):
Issues with build.nvidia APIQueue system for build.nvidia APIScript issues and resolutionsPipeline using YAML examples
- build.nvidia API has hiccups: A member noted trouble with the build.nvidia API. Another pointed out the emergence of a queue system for handling requests.
- In attempts to resolve the script issues, a member realized it worked again after a brief pause, suggesting intermittent reliability of the API.
- Pipeline accepts YAML inputs: In a discussion on handling inputs, a member mentioned their pipeline employs YAML examples of conversations for few-shot learning. They clarified this when questioned about incorporating textbook data.
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (1 messages):
Gemma2 update fixing issuesPinned version of transformersCI catching problems
- Gemma2 Fixes Issues in Updates: The update for Gemma2 addressed previously encountered problems. Using the pinned version of transformers ensures these issues are avoided, thanks to our CI system detecting such problems.
- CI Ensures Stability with Transformers: Pinned version of transformers should sidestep issues, as continuous integration (CI) will catch potential problems. This guarantees a more stable development environment.
OpenAccess AI Collective (axolotl) ▷ #axolotl-help-bot (1 messages):
le_mess: Need more VRAM 🙂
tinygrad (George Hotz) ▷ #general (3 messages):
test for bug placementissue reproductionfocused test casePR management
- Test Bug Placement Decision: A user inquired about the best location for a bug test—either in test_nn or test_ops—and asked for advice on naming it.
- The user confirmed understanding and delegated the task to someone else, indicating that they will handle it.
- Issue Reproduction and PR Management: Another user suggested leaving the PR open, treating it as an issue with a reproduction step, and ensuring the fix includes a more focused test case.
- Final confirmation from the original user implied they would handle the specifics.
tinygrad (George Hotz) ▷ #learn-tinygrad (12 messages🔥):
Contiguous Tensors in TinygradTinygrad Training Efficiency ConcernsMatrix Multiplication Blog PostUsing Pre-trained PyTorch Models with Tinygrad
- Tinygrad Contiguous Tensors Confuse Users: There's a discussion about
Tensor.randn/randintcreating contiguous Tensors whereasTensor.fulland similar methods create non-contiguous ones, which contrasts with PyTorch behavior. - Optimize Tinygrad for Large Scale Training: Members discuss the inefficiencies in Tinygrad for large-scale training, mentioning it as slow and not cost-effective. A suggestion to use BEAM search was made but it takes time.
- Learn Matmul with an Informative Blog Post: An engaging blog post about high-performance matrix multiplication on CPU is shared, demonstrating over 1 TFLOPS performance with easy-to-understand code.
- Run Inference on Tinygrad with PyTorch Models: Inquiry about the best way to run inference with a pre-trained PyTorch model using Tinygrad. The answer provided points to the usage of
tinygrad.nn.state.torch_load.
Torchtune ▷ #general (8 messages🔥):
Setting evaluation parameters for TorchtuneGrad norm graph on wandbLoss curve optimization in wandbLearning rate adjustment impactsMissing wandb logging metrics
- Setting evaluation parameters for Torchtune: A user inquired about how to set evaluation parameters in Torchtune, and another mentioned there should be a parameter for 'validation dataset' or something similar.
- Missing grad norm graph in wandb: A user sought assistance on obtaining a grad norm graph in wandb, as it is a default graph in other tools like aoxotl.
- Loss curve optimization in wandb: A user was advised to observe the shape of the loss curve for a downward trend and was provided an example with a link. They noted insufficient optimisation in their loss curve and the suggestion to increase the initial learning rate.
- Learning rate adjustment impacts: After receiving feedback, a user increased the initial learning rate and altered several parameters to optimize their model but reported no significant improvement in the loss.
- Missing wandb logging metrics: A user questioned the absence of wandb logging for evaluation loss and grad norm, indicating an issue with metric logging.
Link mentioned: salman-mohammadi.): Weights & Biases, developer tools for machine learning
AI Stack Devs (Yoko Li) ▷ #ai-town-discuss (5 messages):
Investigating system robustness with Python and TypeScriptChallenges with automatic Docker installation of Convex local backend
- Python & TypeScript face integration issues: A member shared issues with integrating Python and TypeScript, specifically encountering bugs when launching Convex if Python wasn't pre-installed.
- Docker's Convex backend installation is tricky: Another member discussed challenges in making the Convex local backend installation automated within Docker, mainly due to how the container folder was set up as a volume for ease of updates and access.
AI Stack Devs (Yoko Li) ▷ #assets (1 messages):
Collection of sprite sheetsAesthetics and style matching with CloudpunkLargest tilemaps on itch.io
- Searching for sprite sheets to match Cloudpunk's aesthetics: A member inquired about the source of a specific collection of sprite sheets, mentioning their purchases of several large tilemaps on itch.io that didn't quite match the dark, futuristic, cyberpunk aesthetics of Cloudpunk.
- Matching aesthetics of purchased tilemaps: The member is curious about where to obtain spritesheets that go well with the Cloudpunk aesthetic, as their current collections and purchases from itch.io fall short.
DiscoResearch ▷ #general (1 messages):
Three GPTs Walk into a Bar and Write an Exec Summary blog post by dsquared70Utilizing Custom GPTs for creating executive summariesProcesses for high-frequency, short turnaround executive summaries
- Three GPTs Revolutionize Executive Summaries: Three GPTs Walk into a Bar and Write an Exec Summary blog post introduces a simple process for rapid executive summary creation. Three Custom GPTs work together: one extracts insights, one crafts summaries, and a third revises the content.
- High-Frequency Executive Summary Tactics: The blog details how these Custom GPTs address high-frequency and short turnaround needs when summarizing events, technology, or trends. Often tasked with tight deadlines, this process ensures quick yet meaningful summaries.
Link mentioned: Three GPTs Walk into a Bar and Write an Exec Summary – D-Squared: no description found
DiscoResearch ▷ #discolm_german (2 messages):
Magpie model available on HuggingFace SpacesGenerating preference data via HuggingFace SpacesDuplicated model from davanstrien/magpieUser feedback on Magpie model performance
- Magpie model available on HuggingFace Spaces: A Magpie model is now accessible on HuggingFace Spaces, which has been duplicated from davanstrien/magpie.
- Doesn't work that well yet, but the concept of generating preference data via HuggingFace Spaces is well-liked.
- User feedback on Magpie model performance: A user shared that the Magpie model doesn’t function effectively but appreciates the concept.
Link mentioned: Magpie - a Hugging Face Space by sroecker: no description found
MLOps @Chipro ▷ #events (2 messages):
Claude hackathon collaborationKafka optimization webinar
- Claude Hackathon Collaboration: A member invited others to collaborate and build something cool for the Claude hackathon ending next week.
- Optimize Kafka and Save Costs!: Join a webinar on July 18th at 4 PM IST to learn best practices for optimizing Kafka, including scaling strategies and cost-saving techniques.
- Expert Speakers at Kafka Webinar: The event will feature Yaniv Ben Hemo from Superstream and Viktor Somogyi-Vass from Cloudera, who will share their expertise on building scalable, cost-efficient Kafka environments.
Datasette - LLM (@SimonW) ▷ #llm (1 messages):
Potential uses for embeddingsNew job title 'Embeddings Engineer'
- Embeddings Engineer finds more uses: An individual stated they are discovering more potential uses for embeddings and joked about adopting the title Embeddings Engineer.
- New job title humor: Embeddings Engineer was suggested humorously as a new job title due to the increasing number of uses for embeddings.
- I think I'll call myself Embeddings Engineer from now on 😄
{% else %}
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: [{{ email.subject }}]({{ email_url }})!
If you enjoyed AInews, please share with a friend! Thanks in advance!
{% endif %}