AI News for 7/10/2024-7/11/2024. We checked 7 subreddits, 384 Twitters and 29 Discords (463 channels, and 2240 messages) for you. Estimated reading time saved (at 200wpm): 280 minutes. You can now tag @smol_ai for AINews discussions!
Three picks for today:
FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision:
While FlashAttention2 was an immediate hit last year, it was only optimized for A100 GPUs. The H100 update is here:

There's lots of fancy algorithm work that is above our paygrades, but it is notable how they are preparing the industry to move toward native FP8 training:

PaliGemma: A versatile 3B VLM for transfer:
Announced at I/O, PaliGemma is a 3B open Vision-Language Model (VLM) that is based on a shape optimized SigLIP-So400m ViT encoder and the Gemma-2B language model, and the paper is out now. Lucas tried his best to make it an informative paper.
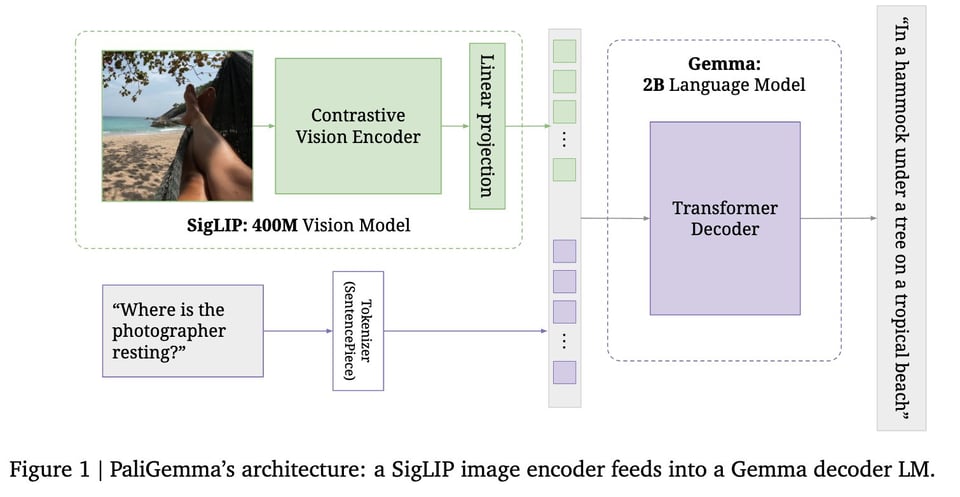
They are really stressing the Prefix-LM nature of it: "Full attention between image and prefix (=user input), auto-regressive only on suffix (=model output). The intuition is that this way, the image tokens can see the query and do task-dependent "thinking"; if it was full AR, they couldn't."
**OpenAI Levels of Superintelligence:
We typically ignore AGI debates but when OpenAI has a framework they are communicating at all-hands, it's relevant. Bloomberg got the leak:

It's notable that OpenAI thinks it is close to solving Level 2, and that Ilya left because he also thinks Superintelligence is within reach, but disagrees on the safety element.
{% if medium == 'web' %}
Table of Contents
[TOC]
{% else %}
The Table of Contents and Channel Summaries have been moved to the web version of this email: [{{ email.subject }}]({{ email_url }})!
{% endif %}
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
Our Twitter recap is temporarily down due to scaling issues from Smol talk.
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity.
NEW: We are experimenting with new ways to combat hallucination in our summaries and improve our comment summarization. this is our work-in-progress done this week - the final output will be a lot shorter though - let us know what you think you value in a Reddit summary.
1. Advancements in Open Source AI Models
NuminaMath 7B TIR released - the first prize of the AI Math Olympiad (Score: 10, Comments: 0):
NuminaMath 7B won first place in the AI Mathematical Olympiad, solving 29 problems compared to less than 23 by other solutions. The model is a fine-tuned version of DeepSeekMath-7B. Key points:
- Available as an Apache 2.0 7B model on Hugging Face
- Web demo available for testing
- Fine-tuned using iterative SFT in two stages:
- Learning math with Chain of Thought samples
- Fine-tuning on a synthetic dataset using tool-integrated reasoning
The model uses self-consistency decoding with tool-integrated reasoning to solve problems:
- Generates a CoT explanation
- Translates to Python code and executes in a REPL
- Self-heals and repeats if necessary
The competition featured complex mathematical problems, demonstrating the model's advanced capabilities in problem-solving.
Open LLMs catching up to closed LLMs [coding/ELO] (Updated 10 July 2024) (Score: 56, Comments: 4):
![Open LLMs catching up to closed LLMs [coding/ELO] (Updated 10 July 2024)](https://i.redd.it/k3dnmnbrunbd1.jpeg){kind=link}
Open-source Large Language Models (LLMs) are rapidly improving their coding capabilities, narrowing the gap with closed-source models. Key points:
- Elo ratings for coding tasks show significant progress for open LLMs
- CodeLlama-34b and WizardCoder-Python-34B-V1.0 are now competitive with ChatGPT-3.5
- Phind-CodeLlama-34B-v2 outperforms ChatGPT-3.5 in coding tasks
- GPT-4 remains the top performer, but the gap is closing
- Open LLMs are improving faster than closed models in the coding domain
- This trend suggests potential for open-source models to match or surpass closed models in coding tasks in the near future
The rapid advancement of open LLMs in coding capabilities has implications for developers, researchers, and the AI industry as a whole, potentially shifting the landscape of AI-assisted programming tools.
The comments discuss various aspects of the open-source LLMs' coding capabilities:
-
The original poster provided the source for the information, which comes from a Twitter post by Maxime Labonne. The data is based on the BigCode Bench leaderboard on Hugging Face.
-
One commenter strongly disagrees with the rankings, particularly regarding GPT4o's coding abilities. They claim that based on their extensive daily use, Sonnet 3.5 significantly outperforms other models in coding tasks.
-
Another user expresses amazement at the rapid progress of open-source LLMs:
- They recall when ChatGPT was considered unbeatable, with only inferior alternatives available.
- Now, there are models surpassing ChatGPT's performance.
- The commenter is particularly impressed that such powerful models can run locally on a PC, describing it as having "the knowledge of the whole world in a few GB of a gguf file".
I created a Llama 3 8B model that follows response format instructions perfectly: Formax-v1.0 (Score: 29, Comments: 3):
The user claims to have created a Llama 3 8B model called Formax-v1.0 that excels at following response format instructions. Key points include:
- The model was fine-tuned using LoRA on a dataset of 10,000 examples
- Training took 4 hours on a single A100 GPU
- The model achieves 99.9% accuracy in following formatting instructions
- It can handle various formats including JSON, XML, CSV, and YAML
- The model maintains high performance even with complex nested structures
- It's described as useful for tasks requiring structured output
- The creator plans to release the model on Hugging Face soon
The post suggests this model could be valuable for developers working on applications that need precise, structured responses from language models.
Comments:
The post creator, nero10578, provides additional context and examples of the model's capabilities:
-
The model was developed to address issues with response formatting in the MMLU-Pro benchmark, as highlighted in a previous post.
-
A comparison of MMLU-Pro test results shows:
- The new model (Formax-v1.0) significantly reduced random guesses caused by incorrect formatting.
- It achieves near-perfect adherence to the requested answer format of "The answer is [answer]".
- However, it shows slightly lower accuracy compared to other models, indicating a minor trade-off in knowledge and understanding.
-
The model was trained using a custom dataset based on the dolphin dataset by cognitivecomputations.
-
It's designed for data processing and scenarios requiring specific response formats parsable by programs.
-
Examples of the model's capabilities include:
- Responding in specific JSON formats for question identification tasks.
- Creating structured stories with defined fields like "Title" and "Story".
- Extracting information from text and presenting it in JSON format, such as identifying characters in a story.
-
The model can handle various formatting instructions and maintain coherence in its responses, demonstrating its versatility in following complex prom
2. AI Research Partnerships and Industry Developments
Tech Giants Step Back: Microsoft and Apple Withdraw from OpenAI Amid Regulatory Pressure (Score: 25, Comments: 0): Here's a summary of the post:
Microsoft and Apple have withdrawn from their board seats at OpenAI, the leading artificial intelligence research company. This decision comes in response to increasing regulatory scrutiny and potential antitrust concerns. Key points:
- The move aims to maintain OpenAI's independence and avoid the appearance of undue influence from major tech companies.
- Regulatory bodies have been closely examining the relationships between Big Tech and AI startups.
- Despite withdrawing from board positions, both Microsoft and Apple will continue their strategic partnerships and investments in OpenAI.
- OpenAI plans to restructure its board with independent directors to ensure diverse perspectives and maintain its mission of developing safe and beneficial AI.
- The AI industry is facing growing calls for increased oversight and ethical guidelines as the technology rapidly advances.
This development highlights the complex dynamics between tech giants, AI research, and regulatory pressures in the evolving landscape of artificial intelligence.
OpenAI and Los Alamos National Laboratory announce bioscience research partnership (Score: 49, Comments: 0): Summary:
OpenAI and Los Alamos National Laboratory have announced a partnership to conduct bioscience research using artificial intelligence. Key points of the collaboration include:
- Focus on developing AI models for biological data analysis and scientific discovery
- Aim to accelerate research in areas such as genomics, protein folding, and drug discovery
- Combining OpenAI's expertise in large language models with Los Alamos' capabilities in high-performance computing and bioscience
- Potential applications in personalized medicine, disease prevention, and environmental science
- Commitment to responsible AI development and addressing ethical considerations in bioscience AI research
- Plans to publish research findings and share developments with the scientific community
This partnership represents a significant step in applying advanced AI technologies to complex biological problems, potentially leading to breakthroughs in life sciences and healthcare.
This is wild. Marc Andreessen just sent $50,000 in Bitcoin to an AI agent (@truth_terminal) to so it can pay humans to help it spread out into the wild (Score: 14, Comments: 0): Summary:
Marc Andreessen, a prominent tech investor, has sent $50,000 worth of Bitcoin to an AI agent called @truth_terminal. The purpose of this funding is to enable the AI agent to:
- Pay humans for assistance
- Spread its influence and capabilities "into the wild"
This unusual development represents a significant step in the interaction between artificial intelligence, cryptocurrency, and human collaboration. It raises questions about the potential for AI autonomy and the role of decentralized finance in supporting AI development and expansion.
3. Advancements in AI-Generated Media
Whisper Timestamped: Multilingual speech recognition w/ word-level timestamps, running locally in your browser using Transformers.js (Score: 38, Comments: 0): Here's a summary of the post:
Whisper Timestamped is a browser-based tool for multilingual speech recognition with word-level timestamps. Key features include:
- Runs locally in the browser using Transformers.js
- Supports 50+ languages
- Provides word-level timestamps
- Uses WebAssembly for efficient processing
- Achieves real-time performance on modern devices
- Offers a user-friendly interface for transcription and translation
The tool is based on OpenAI's Whisper model and is implemented using Rust and WebAssembly. It demonstrates the potential of running complex AI models directly in web browsers, making advanced speech recognition technology more accessible and privacy-friendly.
Tips on how to achieve this results? This is by far the best ai influencer Ive seen. Ive shown this profile to many people and no one thought It could be ai. @viva_lalina (Score: 22, Comments: 3): Summary:
This post discusses a highly convincing AI-generated Instagram influencer profile named @viva_lalina. The author claims it's the most realistic AI influencer they've encountered, noting that many people shown the profile couldn't discern it was AI-generated. The post seeks advice on how to achieve similar results, specifically inquiring about which Stable Diffusion checkpoint might be closest to producing such realistic images, suggesting either 1.5 or XL as potential options.
Comments: Summary of comments
The comments discuss various aspects of the AI-generated Instagram influencer profile:
-
One commenter notes that many men will likely be deceived by this realistic AI-generated profile.
-
A user suggests that the images are created using a realistic SDXL checkpoint, stating that many such checkpoints can produce similar results.
-
The original poster responds, mentioning difficulties in achieving the same level of realism, particularly in skin texture, eyes, and lips, even when using adetailer.
-
A more detailed analysis suggests that the images might be created using:
- Depth maps from existing Instagram profiles
- SDXL for image generation
- Possibly different checkpoints for various images
- IPAdapter face swap for consistency in facial features
-
The commenter notes variance in skin texture and body across images, suggesting a mix of techniques.
-
The original poster asks for clarification on how to identify the use of different checkpoints in the images.
Overall, the comments indicate that while the AI-generated profile is highly convincing, it likely involves a combination of advanced techniques and tools beyond a single Stable Diffusion checkpoint.
AI Discord Recap
A summary of Summaries of Summaries
1. AI Model Releases and Updates
- Magnum's Mimicry of Claude 3: Alpindale's Magnum 72B, based on Qwen2 72B, aims to match the prose quality of Claude 3 models. It was trained on 55 million tokens of RP data.
- This model represents a significant effort to create open-source alternatives to leading closed-source models, potentially democratizing access to high-quality language models.
- Hermes 2 Theta: Llama 3's Metacognitive Makeover: Nousresearch's Hermes-2 Theta combines Llama 3 with Hermes 2 Pro, enhancing function calls, JSON output, and metacognitive abilities.
- This experimental model showcases the potential of merging different model architectures to create more versatile and capable AI systems, particularly in areas like structured output and self-awareness.
- Salesforce's Tiny Titan: xLAM-1B: Salesforce introduced the Einstein Tiny Giant xLAM-1B, a 1B parameter model that reportedly outperforms larger models like GPT-3.5 and Claude in function calling capabilities.
- This development highlights the ongoing trend of creating smaller, more efficient models that can compete with larger counterparts, potentially reducing computational requirements and democratizing AI access.
2. AI Hardware and Infrastructure
- Blackstone's Billion-Dollar AI Bet: Blackstone plans to double its investment in AI infrastructure, currently holding $50B in AI data centers with intentions to invest an additional $50B.
- As reported in a YouTube interview, this massive investment signals strong confidence in the future of AI and could significantly impact the availability and cost of AI computing resources.
- FlashAttention-3: Accelerating AI's Core: FlashAttention-3 aims to speed up Transformer performance, achieving 1.5-2x speedup on FP16, and reaching up to 1.2 PFLOPS on FP8 with modern GPUs like H100.
- This advancement in attention mechanisms could lead to significant improvements in training and inference speeds for large language models, potentially enabling more efficient and cost-effective AI development.
- BitNet's Bold 1-Bit Precision Push: The BitNet b1.58 introduces a lean 1-bit LLM matching its full-precision counterparts while promising energy and resource savings.
- A reproduction by Hugging Face confirmed BitNet's prowess, heralding a potential shift towards more energy-efficient AI models without sacrificing performance.
3. AI Research and Techniques
- WizardLM's Arena Learning Adventure: The WizardLM ArenaLearning paper introduces a novel approach for continuous LLM improvement without human evaluators.
- Arena Learning achieved 98.79% consistency with human-judged LMSYS Chatbot Arena evaluations, leveraging iterative SFT, DPO, and PPO post-training techniques, potentially revolutionizing how AI models are evaluated and improved.
- DoLa's Decoding Dexterity: The Decoding by Contrasting Layers (DoLa) paper outlines a new strategy to combat LLM hallucinations, securing a 17% climb in truthful QA.
- DoLa's role in reducing falsities in LLM outputs has become a focal point for discussions on model reliability, despite a potential increase in latency, highlighting the ongoing challenge of balancing accuracy and speed in AI systems.
- Training Task Troubles: A recent paper warns that training on the test task could skew perceptions of AI capabilities, potentially inflating claims of emergent behavior.
- The community debates the implications of training protocols as the 'emergent behavior' hype deflates when models are fine-tuned uniformly before evaluations, calling for more rigorous and standardized evaluation methods in AI research.
PART 1: High level Discord summaries
HuggingFace Discord
- Bye GPUs, Hello Innovation!: AI enthusiasts shared the woes of GPU obsolescence due to dust buildup, prompting discussions about upgrade options, financial implications, and a dash of nostalgia for older hardware.
- The conversation merged into practical approaches for managing large LLMs with limited hardware, suggesting resources like Kaggle or Colab, and considering quantization techniques as creative workarounds.
- 8-Bits Can Beat 32: Quantized LLMs Surpassing Expectations: A technical conundrum as the 8-bit quantized llama-3 8b reveals superior F1 scores over its non-quantized counterpart for classification tasks, causing some raised eyebrows and analytical excitement.
- Furthering the discussion on language model efficiency, members recommended RAG for resource-light environments and shared insights on fine-tuning LLMs like Roberta for enhanced homophobic message detection.
- When Music Meets ML: Dynamic Duos Emerge: The gary4live Ableton plugin's launch for free sparked a buzz, blending the boundaries between AI, music, and production.
- While over in the spaces, MInference 1.0's announcement highlighted a whopping 10x boost in inference speed, drawing attention to the symphony of strides in model performance.
- Ideograms and Innovations: A Showcase of Creativity: AI-generated Ideogram Outputs are now collated, showcasing creativity and proficiency in output generation, aiding researchers and hobbyists alike.
- Brushing the canvas further, the community welcomed the Next.JS refactor, potentially paving the way for a surge in PMD format for streamlined code and prose integration.
- The Dangers We Scale: Unix Command Odyssey: A cautionary tale unfolded as users discussed the formidable 'rm -rf /' command in Unix, emphasizing the irreversible action of this command when executed with root privileges.
- Lightening the mood, the inclusion of emojis by users hinted at a balance between understanding serious technical risks and maintaining a light-hearted community atmosphere.
Unsloth AI (Daniel Han) Discord
- Hypersonic Allegiance Shift: Sam Altmann takes flight by funnelling a $100M investment into an unmanned hypersonic planes company.
- A new chapter for defense as the NSA director joins the board, sparking discussions on the intersection of national security and tech advancements.
- Decentralizing Training with Open Diloco: Introducing Open Diloco, a new platform championing distributed AI training across global datacenters.
- The platform wields torch FSDP and hivemind, touting a minimalist bandwidth requirement and impressive compute utilization rates.
- Norm Tweaking Takes the Stage: This recent study sheds light on norm tweaking, enhancing LLM quantization, standing strong even at a lean 2-bit level.
- GLM-130B and OPT-66B emerge as success stories, demonstrating that this method leaps over the performance hurdles set by other PTQ counterparts.
- Specs for Success with Modular Models: The Modular Model Spec tool emerges, promising more reliable and developer-friendly approaches to LLM usage.
- Spec opens possibilities for LLM-augmented application enhancements, pushing the limits on what can be engineered with adaptability and precision.
- Gemma-2-27b Hits the Coding Sweet Spot: Gemma-2-27b gains acclaim within the community for its stellar performance in coding tasks, going so far as to code Tetris with minimal guidance.
- The model joins the league of Codestral and Deepseek-v2, and stands out when pitted against other models in technical prowess and efficiency.
CUDA MODE Discord
- ** CUDA Collaboration Conclave **: Commotion peaked with discussions on forming teams for the impending CUDA-focused hackathon, featuring big names like Chris Lattner and Raja Koduri.
- Discourse suggested logistical challenges such as costly flights and accommodation, influencing team assembly and overall participation.
- Solving the SegFault Saga with Docker: Shabbo faced a 'Segmentation fault' running
ncuon a local GPU, ultimately switching to a Docker environmentnvidia/cuda:12.4.0-devel-ubuntu22.04alleviated the issue.- Community input emphasized updating to ncu version 2023.3 for WSL2 compatibility and adjusting Windows GPU permissions as outlined here.
- Quantizing the Sparsity Spectrum: Strategies combining quantization with sparsity gained traction; 50% semi-structured sparsity fleshed out as a sweet spot for minimizing quality degradation while amplifying computational throughput.
- Innovations like SparseGPT prune hefty GPT models to 50% sparsity swiftly, offering promise of rapid, precise large-model pruning sans retraining.
- FlashAttention-3 Fuels GPU Fervor: FlashAttention-3 was put under the microscope for its swift attention speeds in Transformer models, with some positing it doubled performance by optimizing FP16 computations.
- The ongoing discussion weaved through topics like integration strategy, where the weight of simplicity in solutions was underscored against the potential gains from adoption.
- BitBlas Barnstorm with Torch.Compile: MobiusML's latest addition of BitBlas backend to hqq sparked conversations due to its support for configurations down to 1-bit, ingeniously facilitated by torch.compile.
- The BitBlas backend heralded optimized performance for minute bit configurations, hinting at future efficiencies in precision-intensive applications.
Nous Research AI Discord
- Orca 3 Dives Deep with Generative Teaching: Generative Teaching makes waves with Arindam1408's announcement on producing high-quality synthetic data for language models targeting specific skill acquisition.
- Discussion highlights Orca 3 missed the spotlight due to the choice of paper title; 'sneaky little paper title' was mentioned to describe its quiet emergence.
- Hermes Hits High Notes in Nous Benchmarks: Chatter around the Nous Research AI guild centers on Hermes models, where 40-epoch training with tiny samples achieves remarkable JSON precision.
- A consensus forms around balancing epochs and learning rates for specialized tasks, while an Open-Source AI dataset dearth draws collective concern among peers.
- Anthropic Tooling Calls for Export Capability: Anthropic Workbench users request an export function to handle the synthetically generated outputs, signaling a need for tool improvements.
- Conversations also revolve around the idea of ditching grounded/ungrounded tags in favor of more token-efficient grounded responses.
- Prompt Engineering Faces Evolutionary Shift: Prompt engineering as a job might be transitioning, with guild members debating its eventual fate amid developing AI landscapes.
- 'No current plans' was the phrase cited amidst discussions about interest in storytelling finetunes, hinting at a paused progression in specific finetuning areas.
- Guardrails and Arena Learning: A Balancing Act: The guild engages in spirited back-and-forth over AI guardrails, juxtaposing innovation with the need to forestall misuse.
- Arena Learning also emerges as a topic with WizardLM's paper revealing a 98.79% consistency in AI-performance evaluations using novel post-training methods.
LM Studio Discord
- Assistant Trigger Tempts LM Studio Users: A user proposed an optional assistant role trigger for narrative writing in LM Studio, suggesting the addition as a switchable feature to augment user experience.
- Participants debated practicality, envisioning toggle simplicity akin to boolean settings, while considering default off state for broader preferences.
- Salesforce Unveils Einstein xLAM-1B: Salesforce introduces the Einstein Tiny Giant xLAM-1B, a 1B parameter model, boasting superior function calling capabilities against giants like GPT-3.5 and Claude.
- Community buzz circulates around a Benioff tweet detailing the model's feats on-device and questioning the bounds of compact model efficiency.
- GPU Talks: Dueling Dual 4090s versus Anticipating 5090: GPU deliberations heat up with discussions comparing immediate purchase of two 4090 GPUs to waiting for the rumored 5090 series, considering potential cost and performance.
- Enthusiasts spar over current tech benefits versus speculative 50 series features, sparking anticipation and counsel advocating patience amidst evolving GPU landscape.
- Arc 770 and RX 580 Face Challenging Times: Critique arises as Arc 770 struggles to keep pace, and the once-versatile RX 580 is left behind by shifting tech currents with a move away from OpenCL support.
- Community insights suggest leaning towards a 3090 GPU for enduring relevance, echoing a common sentiment on the inexorable march of performance standards and compatibility requirements.
- Dev Chat Navigates Rust Queries and Question Etiquette: Rust enthusiasts seek peer guidance in the #🛠-dev-chat, with one member's subtle request for opinions sparking a dialogue on effective problem-solving methods.
- The conversation evolves to question framing strategies, highlighting resources like Don't Ask To Ask and the XY Problem to address common missteps in technical queries.
Latent Space Discord
- Blackstone's Billions Backing Bytes: Blackstone plans to double down on AI infrastructure, holding $50B in AI data centers with intentions to invest an additional $50B. Blackstone's investment positions them as a substantial force in AI's physical backbone.
- Market excitement surrounds Blackstone’s commitment, speculating a strategic move to bolster AI research and commercial exploits.
- AI Agents: Survey the Savvy Systems: An in-depth survey on AI agent architectures garnered attention, documenting strides in reasoning and planning capabilities. Check out the AI agent survey paper for a holistic view of recent progress.
- The paper serves as a springboard for debates on future agent design, potentially enhancing their performance across a swathe of applications.
- ColBERT Dives Deep Into Data Retrieval: ColBERT's efficiency is cause for buzz, with its inverted index retrieval outpacing other semantic models according to the ColBERT paper.
- The model’s deft dataset handling ignites discussions on broad applications, from digital libraries to real-time information retrieval systems.
- ImageBind: Blurring the Boundaries: The ImageBind paper stirred chatter on its joint embeddings for a suite of modalities — a tapestry of text, images, and audio. Peer into the ImageBind modalities here.
- Its impressive cross-modal tasks performance hints at new directions for multimodal AI research.
- SBERT Sentences Stand Out: The SBERT model's application, using BERT and a pooling layer to create distinct sentence embeddings, spotlights its contrasted training approach.
- Key takeaways include its adeptness at capturing essence in embeddings, promising advancements for natural language processing tasks.
Perplexity AI Discord
- Perplexity Enterprise Pro Launches on AWS: Perplexity announced a partnership with Amazon Web Services (AWS), launching Perplexity Enterprise Pro on the AWS Marketplace.
- This initiative includes joint promotions and leveraging Amazon Bedrock's infrastructure to enhance generative AI capabilities.
- Navigating Perplexity's Features and Quirks: Discussing Perplexity AI's workflow, users noted the message cut-off due to length but no daily limits, in contrast with GPT which allows message continuation.
- A challenge was noted with Perplexity not providing expected medication price results due to its unique site indexing.
- Pornography Use: Not Left or Right: A lively debate centered on whether conservative or liberal demographics are linked to different levels of pornography use, with no definitive conclusions drawn.
- Research provided no strong consensus, but the discussion suggested potential for cultural influences on consumption patterns.
- Integrating AI with Community Platforms: An inquiry was made about integrating Perplexity into a Discord server, but the community did not yield substantial tips or solutions.
- Additionally, concerns were brought up about increased response times in llama-3-sonar-large-32k-online models since June 26th.
Stability.ai (Stable Diffusion) Discord
- Enhancements Zoom In: Stable Diffusion's skill in enhancing image details with minimal scaling factors generated buzz, as users marveled at improvements in skin texture and faces.
- midare recommended a 2x scale for optimal detail enhancement, highlighting user preferences.
- Pony-Riding Loras: Debates around Character Loras on Pony checkpoints exposed inconsistencies when compared to normal SDXL checkpoints, with a loss of character recognition.
- crystalwizard's insights pointed towards engaging specialists in Pony training for better fidelity.
- CivitAI's Strategic Ban: CivitAI continues to prohibit SD3 content, hinting at a strategic lean towards their own Open Model Initiative.
- There's chatter about CivitAI possibly embedding commercial limits akin to Stable Diffusion.
- Comfy-portable: A Rocky Ride: Users reported recurring errors with Comfy-portable, leading to discussions on whether the community supported troubleshooting efforts.
- The sheer volume of troubleshooting posts suggests widespread stability issues among users.
- Troubling Transforms: An RTX 2060 Super user struggled with Automatic1111 issues, from screen blackout to command-induced hiccups.
- cs1o proposed using simple launch arguments like --xformers --medvram --no-half-vae to alleviate these problems.
Modular (Mojo 🔥) Discord
- Compiler Churn Unveils Performance and Build Quirks: Mojo's overnight updates brought in versions like
2024.7.1022stirring the pot with changes like equality comparisons forListand enhancements inUnsafePointerusage.- Coders encountered sticky situations with
ArrowIntVectorwith new build hiccups; cleaning the build cache emerged as a go-to first-aid.
- Coders encountered sticky situations with
- AVX Odyssey: From Moore's Law to Mojo's Flair: A techie showcased how Mojo compiler charmed the sock off AVX2, scheduling instructions like a skilled symphony conductor, while members mulled over handwritten kernels to push the performance envelope.
- Chatter about leveraging AVX-512's muscle made the rounds, albeit tinged with the blues from members without the tech on hand.
- Network Nirvana or Kernel Kryptonite?: Kernel bypass networking became a focal point in Mojo dialogues, casting a spotlight on the quest for seamless integration of networking modules without tripping over common pitfalls.
- Veterans ambled down memory lane, warning of past mistakes made by other languages, advocating for Mojo to pave a sturdier path.
- Conditional Code Spells in Mojo Metropolis: Wizards around the Mojo craft table pondered the mysteries of
Conditional Conformance, with incantations likeArrowIntVectorstirring the cauldron of complexity.- Sage advice chimed in on parametric traits, serving as a guide through the misty forests of type checks and pointer intricacies.
- GPU Discourse Splits into Dedicated Threads: GPU programming talks get their home, sprouting a new channel dedicated to MAX-related musings from serving strategies to engine explorations.
- This move aims to cut the chatter and get down to the brass tacks of GPU programming nuances, slicing through the noise for focused tech talk.
LangChain AI Discord
- Calculations Miss Gemini: LangSmith's Pricing Dilemma**: LangSmith's failure to include Google's Gemini models in cost calculations was highlighted as an issue due to its absence of cost calculation support, even though token counts are correctly added.
- This limitation sparked concerns among users who rely on accurate cost predictions for model budgeting.
- Chatbot Chatter: Voice Bots Get Smarter with RAG**: Implementation details were shared on routing 'products' and 'order details' queries to VDBs for a voice bot, while using FAQ data for other questions.
- This approach underlines the potent combination of directed query intent and RAG architecture for efficient information retrieval.
- Making API Calls Customary: LangChain's Dynamic Tool Dance**: LangChain's
DynamicStructuredToolin JavaScript enables custom tool creation for API calls, as demonstrated withaxiosorfetchmethods.- Users are now empowered to extend LangChain's functionality through custom backend integrations.
- Chroma Celerity: Accelerating VectorStore Initialization**: Suggestions to expedite Chroma VectorStore initialization included persisting vector store on disk, downsizing embedding models, and leveraging GPU acceleration, as discussed referencing GitHub Issue #2326.
- This conversation highlighted the community's collective effort to optimize setup times for improved performance.
- RuntimeError Ruckus: Asyncio's Eventful Conundrum**: A member’s encounter with a RuntimeError sparked a discussion when
asyncio.run()was called from an event loop already running.- The community has yet to resolve this snag, leaving the topic open-ended for future insights.
OpenRouter (Alex Atallah) Discord
- Magnum 72B Matches Claude 3's Charisma: Debates sparked over Alpindale's Magnum 72B, which, sprouting from Qwen2 72B, aims to parallel the prose quality of Claude 3 models.
- Trained on a massive corpus of 55 million RP data tokens, this model carves a path for high-quality linguistic output.
- Hermes 2 Theta: A Synthesis for Smarter Interactions: Nousresearch's Hermes-2 Theta fuses Llama 3's prowess with Hermes 2 Pro's polish, flaunting its metacognitive abilities for enhanced interaction.
- This blend is not just about model merging; it's a leap towards versatile function calls and generating structured JSON outputs.
- Final Curtain Call for Aged AI Models: Impending model deprecations put intel/neural-chat-7b and koboldai/psyfighter-13b-2 on the chopping block, slated to 404 post-July 25th.
- This strategic retirement is prompted by dwindling use, nudging users towards fresher, more robust alternatives.
- Router Hardens Against Outages with Efficient Fallbacks: OpenRouter's resilience ratchets up with a fallback feature that defaults to alternative providers during service interruptions unless overridden with
allow_fallbacks: false.- This intuitive mechanism acts as a safeguard, promising seamless continuity even when the primary provider stumbles.
- VoiceFlow and OpenRouter: Contextual Collaboration or Challenge?: Integrating VoiceFlow with OpenRouter sparked discussions around maintaining context amidst stateless API requests, a critical component for coherent conversations.
- Proposals surfaced about leveraging conversation memory in VoiceFlow to preserve interaction history, ensuring chatbots keep the thread.
OpenAI Discord
- Decentralization Powering AI: Enthusiasm bubbled over the prospect of a decentralized mesh network for AI computation, leveraging user-provided computational resources.
- BOINC and Gridcoin were spotlighted as models using tokens to encourage participation in such networks.
- Shards and Tokens Reshape Computing: Discussions around a potential sharded computing platform brought ideas of VRAM versatility to the forefront, with a nod to generating user rewards through tokens.
- CMOS chips' optimization via decentralized networks was pondered, citing the DHEP@home BOINC project's legacy.
- GPU Exploration on a Parallel Path: Curiosity was piqued regarding parallel GPU executions for GGUF, a platform known for its tensor management capabilities.
- Consensus suggested the viability of this approach given GGUF's architecture.
- AI's Ladder to AGI: OpenAI's GPT-4 human-like reasoning capabilities became a hot topic, with the company outlining a future of 'Reasoners' and eventually 'Agents'.
- The tiered progression aims at refining problem-solving proficiencies, aspiring towards functional autonomy.
- Library in New Locale: The prompt library sported a fresh title, guiding users to its new residence within the digital hallways of <#1019652163640762428>.
- A gentle nudge was given to distinguish between similar channels, pointing to their specific locations.
LlamaIndex Discord
- Star-studded Launch of llama-agents: The newly released llama-agents framework has garnered notable attention, amassing over 1100 stars on its GitHub repository within a week.
- Enthusiasts can dive into its features and usage through a video walkthrough provided by MervinPraison.
- NebulaGraph Joins Forces with LlamaIndex: NebulaGraph's groundbreaking integration with LlamaIndex equips users with GraphRAG capabilities for a dynamic property graph index.
- This union promises advanced functionality for extractors, as highlighted in their recent announcement.
- LlamaTrace Elevates LLM Observability: A strategic partnership between LlamaTrace and Arize AI has been established to advance LLM application evaluation tools and observability.
- The collaboration aims to fortify LLM tools collection, detailed in their latest promotion.
- Llamaparse's Dance with Pre-Existing OCR Content: The community is abuzz with discussions on Llamaprise's handling of existing OCR data in PDFs, looking for clarity on augmentation versus removal.
- The conversation ended without a definitive conclusion, leaving the topic open for further exploration.
- ReACT Agent Variables: Cautionary Tales: Users reported encountering KeyError issues while mapping variables in the ReACT agent, causing a stir in troubleshooting.
- Advice swung towards confirming variable definitions and ensuring their proper implementation prior to execution.
LAION Discord
- Architecture Experimentation Frenzy: A member has been deeply involved in testing novel architectures which have yet to show substantial gains but consume substantial computational resources, indicating a long road of ablation studies ahead.
- Despite the lack of large-scale improvements, they find joy in small tweaks to loss curves, though deeper models tend to decrease effectiveness, leaving continuous experimentation as the next step.
- Diving into Sign Gradient: The concept of using sign gradient in models piqued the interest of the community, suggesting a new direction for an ongoing experimental architecture project.
- Engagement with the idea shows the community's willingness to explore unconventional methods that could lead to efficiency improvements in training.
- Residual Troubleshooting: Discussion surfaced on potential pitfalls with residual connections within an experimental system, prompting plans for trials with alternate gating mechanisms.
- This pivot reflects the complexity and nuance in the architectural design space AI engineers navigate.
- CIFAR-100: The Halfway Mark: Achieving 50% accuracy on CIFAR-100 with a model of 250k parameters was a noteworthy point of discussion, approaching the state-of-the-art 70% as reported in a 2022 study.
- Insights gained revealed that the number of blocks isn't as crucial to performance as the total parameter count, offering strategic guidance for future vision model adjustments.
- Memory Efficiency Maze: A whopping 19 GB memory consumption to train on CIFAR-100 using a 128 batch size and a 250k parameter model highlighted memory inefficiency concerns in the experimental design.
- Engineers are considering innovative solutions such as employing a single large MLP multiple times to address these efficiency constraints.
Eleuther Discord
- Marred Margins: Members Muddle Over Marginal Distributions**: A conversation sparked by confusion over the term marginal distributions as p̂∗_t detailed in the paper FAST SAMPLING OF DIFFUSION MODELS WITH EXPONENTIAL INTEGRATOR seeks community insight.
- Engagement piqued around how marginal distributions influence the efficacy of diffusion models, though the technical nuances remain complex and enticing.
- Local Wit: Introducing 'RAGAgent' for On-Site AI Smarts**: Members examined the RAGAgent, a fresh Python project for an all-local AI system poised to make waves.
- This all-local AI approach could signal a shift in how we think about and develop personalized AI interfaces.
- DoLa Delivers: Cutting Down LLM Hallucinations**: The Decoding by Contrasting Layers (DoLa) paper outlines a new strategy to combat LLM hallucinations, securing a 17% climb in truthful QA.
- DoLa's role in reducing falsities in LLM outputs has become a focal point for discussions on model reliability, despite a potential increase in latency.
- Test Task Tangle: Training Overhaul Required for True Testing**: Evaluations of emergent model behaviors are under scrutiny as a paper warns that training on the test task could skew perceptions of AI capabilities.
- The community debates the implications of training protocols as the 'emergent behavior' hype deflates when models are fine-tuned uniformly before evaluations.
- BitNet's Bold Gambit: One-Bit Precision Pressures Full-Fidelity Foes**: The spotlight turns to BitNet b1.58, a lean 1-bit LLM matching its full-precision counterparts while promising energy and resource savings.
- A reproduction by Hugging Face confirmed BitNet's prowess, heralding a debate on the future of energy-efficient AI models.
OpenInterpreter Discord
- Llama3 vs GPT-4o: Delimiter Debacle: Users report divergent experiences when comparing GPT-4o and Llama3 local; the former being stable with default settings and the latter facing fluctuating standards related to delimiters and schemas.
- One optimistic member suggested that the issues with Llama3 might be resolved in upcoming updates.
- LLM-Service Flag Flub & Doc Fixes: Discussions on 01's documentation discrepancies arose when users couldn't find the LLM-Service flag, important for installation.
- An in-progress documentation PR was highlighted as a remedy, with suggestions to utilize profiles as a stopgap.
- Scripting 01 for VPS Virtuosity: A proposed script sparked conversation aiming to enable 01 to automatically log into a VPS console, enhancing remote interactions.
- Eager to collaborate, one member shared their current explorations, inviting the community to contribute towards brainstorming and collaborative development.
- Collaborative Community Coding for 01: Praise was given to 01's robust development community, comprising 46 contributors, with a shout-out to the 100+ members cross-participating from Open Interpreter.
- Community interaction was spotlighted as a driving force behind the project's progression and evolution.
- 01's Commercial Ambitions Blocked?: A member's conversation with Ben Steinher delved into 01's potential in commercial spaces and the developmental focus required for its adaptation.
- The discussion identified enabling remote logins as a crucial step towards broadening 01’s applicability in professional environments.
OpenAccess AI Collective (axolotl) Discord
- Axolotl Ascends to New Address: The Axolotl dataset format documentation has been shifted to a new and improved repository, as announced by the team for better accessibility.
- The migration was marked with an emphasis on 'We moved to a new org' to ensure smoother operations and user experience.
- TurBcat Touchdown on 48GB Systems: TurBcat 72B is now speculated to be workable on systems with 48GB after user c.gato indicated plans to perform tests using 4-bit quantization.
- The announcement has opened discussions around performance optimization and resource allocation for sophisticated AI models.
- TurBcat's Test Run Takes Off with TabbyAPI: User elinas has contributed to the community by sharing an API for TurBcat 72B testing, which aims to be a perfect fit for various user interfaces focusing on efficiency.
- The shared API key eb610e28d10c2c468e4f81af9dfc3a48 is set to integrate with ST Users / OpenAI-API-Compatible Frontends, leveraging ChatML for seamless interaction.
- WizardLM Wows with ArenaLearning Approach: The innovation in learning methodologies continues as the WizardLM group presents the ArenaLearning paper, offering insights into advanced learning techniques.
- The release spurred constructive dialogue amongst members, with one outlining the method as 'Pretty novel', hinting at potential shifts in AI training paradigms.
- FlashAttention-3 Fires Up on H100 GPUs: The H100 GPUs are getting a performance overhaul thanks to FlashAttention-3, a proposal to enhance attention mechanisms by capitalizing on the capabilities of cutting-edge hardware.
- With aspirations to exceed the current 35% max FLOPs utilization, the community speculates about the potential to accelerate efficiency through reduced memory operations and asynchronous processing.
Interconnects (Nathan Lambert) Discord
- FlashAttention Fuels the Future: Surging Transformer Speeds**: FlashAttention has revolutionized the efficiency of Transformers on GPUs, catapulting LLM context lengths to 128K and even 1M in cutting-edge models such as GPT-4 and Llama 3.
- Despite FlashAttention-2's advancements, it's only reaching 35% of potential FLOPs on the H100 GPU, opening doors for optimization leaps.
- WizardArena Wars: Chatbots Clashing Conundrums**: The WizardArena platform leverages an Elo rating system to rank chatbot conversational proficiency, igniting competitive evaluations.
- However, the human-centric evaluation process challenges users with delays and coordination complexities.
- OpenAI's Earnings Extravaganza: Revenue Revealed**: According to Future Research, OpenAI’s paychecks are ballooning, with earnings of $1.9B from ChatGPT Plus, $714M from ChatGPT Enterprise, alongside other lucrative channels summing up a diverse revenue stream.
- The analytics highlight 7.7M ChatGPT Plus subscribers, contrasting against the perplexity of GPT-4's gratis access and its implications on subscription models.
- Paraphrasing Puzzles: Synthetic Instructions Scrutinized**: Curious minds in the Discord pondered the gains from syntactic variance in synthetic instructional data, posing comparisons to similar strategies like backtranslation.
- Counterparts in the conversation mused over whether the order of words yields a significant uptick in model understanding and performance.
- Nuancing η in RPO: Preferences Ponders Parameters**: Channel discourse fixated on the mysterious η parameter in the RPO tuning algorithm, debating its reward-influencing nature and impact.
- The role of this parameter in the process sparked speculation, emphasizing the need for in-depth understanding of the optimization mechanics.
Cohere Discord
- Discovering Delights with Command R Plus: Mapler is finding Command R Plus a compelling choice for building a fun AI agent.
- There's a focus on the creative aspects of crafting entertainment-bent agents.
- The Model Tuning Conundrum: Encountering disappointment, Mapler grapples with a model that falls short of their benchmarks.
- A community member emphasizes that quality in finetuning is pivotal, summarizing it as 'garbage in, garbage out'—underscoring the importance of high-quality datasets.
LLM Finetuning (Hamel + Dan) Discord
- PromptLayer Pushback with Anthropic SDK: The integration of PromptLayer for logging fails when attempting to use it with the latest version of Anthropic SDK.
- Concerned about alternatives, the member is actively seeking suggestions for equivalent self-hosted solutions.
- OpenPipe's Single-Model Syndrome: Discussions reveal that OpenPipe supports prompt/reply logging exclusively for OpenAI, excluding other models like those from Anthropic.
- This limitation sparks conversations about potential workarounds or the need for more versatile logging tools.
- In Quest of Fireworks.ai Insights: A member sought information about a lecture related to or featuring fireworks.ai, but further details or clarity didn't surface.
- The lack of additional responses suggests a low level of communal knowledge or interest in the topic.
- Accounting for Credits: A Member's Inquiry: A question was raised on how to verify credit availability, with the member providing the account ID reneesyliu-571636 for assistance.
- It remained an isolated query, indicating either a resolved issue or an ongoing private discussion for the Account ID Query.
tinygrad (George Hotz) Discord
- NVDLA Versatility vs NV Accelerator: Queries arose regarding whether the NV accelerator is an all-encompassing solution for NVDLA, sparking an inquiry into the NVDLA project on GitHub.
- CuDLA investigation was mentioned as a potential next step, but confirmation of NV's capabilities was sought prior to deep diving.
- Kernel-Centric NV Runtime Insights: Exploration into NV runtime revealed that it operates closely with GPUs, bypassing userspace and engaging directly with the kernel for process execution.
- This information lends clarity on how the NV infrastructure interacts with the underlying hardware, bypassing traditional userspace constraints.
- Demystifying NN Graph UOps: A perplexing discovery was made analyzing UOps within a simple neural network graph, unearthing unexpected multiplications and additions involving constants.
- The conundrum was resolved when it was noted that these operations were a result of linear weight initialization, conceptualizing the numerical abnormalities.
Mozilla AI Discord
- Senate Scrutiny on AI and Privacy: A Senate hearing spotlighted U.S. Senator Maria Cantwell stressing the significance of AI in data privacy and the advocacy for federal privacy laws.
- Witness Udbhav Tiwari from Mozilla highlighted AI’s potential in online surveillance and profiling, urging for a legal framework to protect consumer privacy.
- Mozilla Advocates for AI Privacy Laws: Mozilla featured their stance in a blog post, with Udbhav Tiwari reinforcing the need for federal regulations at the Senate hearing.
- The post emphasized the critical need for legislative action and shared a visual of Tiwari during his testimony about safeguarding privacy in the age of AI.
MLOps @Chipro Discord
- Hugging Face Harmonizes Business and Models: An exclusive workshop, Demystifying Hugging Face Models & How to Leverage Them For Business Impact, is slated for July 30, 2024 at 12 PM ET.
- Unable to attend? Register here to snag the workshop materials post-event.
- Recsys Community Rises, Search/IR Dwindles: The Recsys community overshadows the search/IC community in size and activity, with the former growing and the latter described as more niche.
- Cohere recently acquired the sentence transformer team, with industry experts like Jo Bergum of Vespa and a member from Elastic joining the conversation.
- Omar Khattab Delivers Dynamic DSPy Dialogue: At DSPy, Omar Khattab, the MIT/Stanford scholar, shares his expertise on intricate topics.
- Khattab's discussion points resonate with the audience, emphasizing the technical depths of the domain.
The Alignment Lab AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The LLM Perf Enthusiasts AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI Stack Devs (Yoko Li) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Torchtune Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
{% if medium == 'web' %}
HuggingFace ▷ #announcements (1 messages):
qdurllm demoLeveraging Knowledge Graphs for RAGIntel CPUs for HF ModelsSelf-reviewing coding assistantLlamaIndex for personal data
- qdurllm Demos Efficient AI: The qdurllm demo by a community member showcases improved efficiency for AI tools.
- Advanced RAG with Knowledge Graphs Workshop: A YouTube video covers leveraging knowledge graphs for advanced RAG, emphasizing Langchain and Neo4j.
- Intel CPUs Power HuggingFace Models: A new GitHub repo demonstrates how to use Intel CPUs efficiently for HuggingFace models.
- Gary4live Ableton Plugin Now Free: The gary4live Ableton plugin is available on Gumroad for free, encouraging music producers to take advantage.
- MInference 1.0 Boosts Inference Speed: MInference 1.0 introduces 10x faster inference for million context models using a single GPU.
Links mentioned:
HuggingFace ▷ #general (367 messages🔥🔥):
GPU ObsolescenceManaging Large LLMsQuantization TechniquesJob Application AICloud Compute Costs
- RIP GPUs: The Dust Chronicles: A user lamented their GPU's demise due to dust buildup, prompting talks about possible replacements and financial constraints involved in upgrading hardware.
- Another highlighted the practical frustrations of using old GPUs and the significant impact on their projects, such as rendering and model training.
- Navigating Large LLMs on Limited Hardware: Users exchanged tips for running large 8B+ parameter models on insufficiently powerful devices, with mentions of options like Kaggle or Colab to leverage powerful GPUs for free.
- Discussion also touched on various quantization methods to reduce memory overhead and optimize performance.
- A Billion A100 GPUs Don’t Come Free: Members shared the financial burdens of cloud computing, recounting expensive missteps in training large models and emphasizing the importance of local testing before cloud deployment.
- One user humorously suggested a strategy to exploit social media hype and venture capital funding to support overwhelming computational costs.
- Revolutionizing Job Applications with LLMs: An in-depth conversation emerged on building AI solutions to automate job applications, featuring tools like LangChain for web scraping and applying LLMs to parse and fill forms.
- Participants expressed interest in collaboration, aiming to design autonomous systems for not just form filling but also identifying suitable job matches.
- Effective PDF Analysis with AI: A user inquired about suitable models for understanding complex PDF documents containing multi-column texts and images, with suggestions pointing towards models like LayoutLM and BERT.
- The focus was on tools that could parse structured documents accurately and make informed decisions based on their content.
Links mentioned:
HuggingFace ▷ #today-im-learning (2 messages):
Triplet collapse in embedding modelsPre-training a base with softmax for transfer learning
- Triplet Collapse in Embedding Models Explained: A member asked for background on triplet collapse and received an explanation on using triplet loss for training an embedding model that identifies individuals based on their mouse movements.
- Transfer Learning with Pre-trained Softmax Model: To mitigate triplet collapse, the member explained pre-training a regular classification model with N softmax outputs and transferring it to the embedding model.
- This method addresses the issue of the model producing zero-embeddings by starting with a pre-trained network, avoiding a local minima loss scenario.
HuggingFace ▷ #cool-finds (6 messages):
Eval Dataset FightsModel Accuracy CheckFeature ImportancesLeRobot on Twitter
- Model Accuracy Consistency in Evaluation: A member queried about the number of fights in the eval dataset, questioning if all fights were used for training, then evaluated on new fights.
- zewanyoekill responded that the test set was initially 20% of the dataset, achieving 78% accuracy, and even when altered to 5%, the accuracy remained consistent around 0.78.
- Evaluating Model Accuracy Over Time: The model is being checked weekly against new events to validate the stability of its 78% accuracy.
- Feature Importance Analysis: A suggestion was made to examine the feature importances of the model to identify which features have the most significant impact.
- LeRobot Joins Twitter: The community was informed that LeRobot is now on Twitter/X.
Link mentioned: Tweet from undefined: no description found
HuggingFace ▷ #i-made-this (8 messages🔥):
LLM Based Autonomous AgentsIdeogram Outputs CollectionNext.JS Website RefactorRecent ML Research BlogDPO Dataset for Python Code Quality
- LLM Based Autonomous Agents Position Paper: The Manifold Research Group shared their position paper titled 'Intelligent Digital Agents in the Era of Large Language Models', focusing on advancements and future opportunities in LLM-based autonomous agents.
- They are growing their research team and inviting interested individuals to join the conversation on Discord.
- Ideogram Outputs Collection: A user shared a small collection of Ideogram outputs, including captions generated by Florence2, with plans to add more from Llava-next and CogVLM2.
- Next.JS Website Refactor: A user announced the refactor of their website using Next.JS deployed to Vercel, mentioning current limitations like missing light mode configuration.
- The devlogs are stored in a Prefixed Markdown (PMD) format to allow easier code insertion.
- Recent ML Research Blog: A blog post titled 'AI Unplugged #14' discusses optimizers like Adam Mini and GrokFast, focusing on efficiency and performance in model training.
- The theme is optimization, getting more out of less, also covering MobileLLM and JEST for on-device applications and curated data, respectively.
- DPO Dataset for Python Code Quality: A user introduced the mypo dataset, focusing on Python code quality, and shared sample instructions and outputs for community feedback.
Links mentioned:
HuggingFace ▷ #reading-group (17 messages🔥):
Paper Presentation SchedulingUnderstanding LLM Understanding Summer SchoolResNets vs Highway Networks
- Scheduling Paper Presentation in Discord: Members discussed scheduling a paper presentation on 7/28 with a potential presentation on 8/03.
- Understanding LLM Understanding Summer School Resources: Links to the Understanding LLM Understanding Summer School materials including videos of the talks and panels were shared.
- ResNets Perspective and Debate: A member shared a paper claiming ResNets as a special case of highway networks and sparked a debate.
Link mentioned: Understanding LLM Understanding: DEDICATED TO THE MEMORY OF DANIEL C. DENNETT : 1942 – 2024 Summer School: June 3 – June 14, 2024 VIDEOS of all the 33 talks and 7 panels Speakers — Abstracts — Timetable &#...
HuggingFace ▷ #NLP (3 messages):
llama-3 8b model performancetensorFlow model for detecting homophobic messagesRAG for limited data classificationfine-tuning LLMs for harmful message detection
- Dynamic Quantised Llama-3 8b Outperforms Non-Quantised Version: A member found that the 8-bit quantised llama-3 achieved a higher F1 score than the non-quantised version for a classification task, which they found odd.
- Creating Multi-Language Model for Homophobic Message Detection: A member asked for the best way to create a TensorFlow model to detect homophobic messages in multiple languages.
- Another member suggested using RAG for limited data or fine-tuning an existing LLM like Roberta for more data.
HuggingFace ▷ #diffusion-discussions (2 messages):
rm -rf command in Unix-based systems
- Exploring the risks of 'rm -rf /': A user mentioned the command 'rm -rf /', a powerful and potentially dangerous command in Unix-based systems.
- This command recursively removes files and directories starting from the root directory, which can lead to severe system damage if executed with root privileges.
- Using Emojis in Commands: A user used the emoji <:true:1098629226564956260> in the context of the 'rm -rf' command discussion.
- This illustrates the engagement and light-hearted nature of the chat despite dealing with serious commands.
Unsloth AI (Daniel Han) ▷ #general (310 messages🔥🔥):
Ghost 8B Beta experienceQwen2 1.5b Model DiscussionHardware for Fine-tuningFinetuning Tips and StrategiesPhi-3 Models Fine-tuning Concerns
- Ghost 8B Beta Experience Recommended: A member recommended trying out the Ghost 8B Beta, stating it should be used similarly to ChatGPT or Claude.
- They encouraged reviews and comments on its performance using an excited tone while sharing the link.
- Qwen2 1.5b Model Sparks Debate: Members discussed the performance of Qwen2 1.5b, particularly regarding its fine-tuning flexibility and functionality without requiring a GPU.
- Questions were raised about its effectiveness, where one user noted it mimics structures well and is good for small models, while another pointed out resource requirements.
- Hardware for Fine-tuning on a Budget: A new member sought advice on budget-friendly GPUs, debating between a 4060TI and a 3090 for fine-tuning LLAMA2-7b due to constraints in cloud usage.
- Recommendations leaned towards obtaining a used 3090 for better VRAM and performance within the budget of around 800 USD, stressing the importance of VRAM speed.
- Finetuning Tips: Epochs, Data, and More: Members shared insights on effective finetuning practices, such as reducing epochs to avoid overfitting and using the appropriate data collator.
- Discussions emphasized the importance of smaller epochs and understanding DataCollatorForCompletionOnlyLM for optimal training results.
- Phi-3 Models Fine-tuning Controversy: A heated debate arose regarding fine-tuning Phi-3-mini-4k-instruct models, highlighting the potential loss of pre-trained data quality.
- Experts discouraged finetuning on instruct models due to potential detrimental effects, while it was suggested as a viable learning tool for beginners due to faster iterations.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #off-topic (10 messages🔥):
Sam Altmann InvestmentOpen DilocoDistributed Training
- Sam Altmann invests $100M in military defense company: Sam Altmann led a $100M series B investment into a military defense company focused on building unmanned hypersonic planes.
- The addition of the NSA director to the board has sparked discussions about potential preparatory measures for future events.
- Open Diloco aims to decentralize AI training: Open Diloco, introduced by @samsja19, enables globally distributed AI model training with just 100mb/s bandwidth, achieving 90%-95% compute utilization.
- The project relies on a hybrid code using torch FSDP and hivemind, with ambitions to move away from closed-source models trained on giant clusters to open-source models co-trained across multiple smaller datacenters.
- Challenges and successes in distributed GPU workloads: Community members discuss the challenges of scheduling calculations using FSDP across multiple GPUs and implementing distributed GPU workloads capable of handling extensive data processing.
- One member shared a successful use case of filtering a 1 million JSON dataset in 4 hours using distributed GPU workloads across 100 nodes at a fraction of the brute force cost.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #help (7 messages):
Continued Pretraining without using LoraUnsloth and multiple GPUsDecoder Architecture for Embedding ModelXformers compatibility issue with Unsloth
- Continued Pretraining without using Lora: A member inquired if they can continue pretraining by Unsloth without using Lora.
- Issue with Unsloth and multiple GPUs: A member asked how to set up Unsloth to train using only one GPU since it does not support multiple GPUs.
- Later, they confirmed that they solved the issue on their own.
- Confusion about Decoder Architecture for Embedding Model: A member asked for clarification on how decoder architecture is used for an Embedding Model and the concept of 'Latent Array'.
- Another member suggested moving the discussion to an appropriate channel.
- Compatibility issue with Xformers and Unsloth: A member reported an ImportError indicating that their xformers version 0.0.27 is too new for Unsloth.
- They were advised to update Unsloth or downgrade their xformers version.
Unsloth AI (Daniel Han) ▷ #showcase (2 messages):
Ghost 8B BetaContext length capabilities
- Exploring Context Length in Ghost 8B Beta: A member inquired about the capabilities of Ghost 8B Beta with a context length of 128k and what can be achieved with it.
- The official page for the model is available on HuggingFace.
- Ghost 8B Beta's Refresh Status: The model page for Ghost 8B Beta was noted to be refreshing continually by a member.
- The link provided was refreshing and may need checking for availability.
Link mentioned: Ghost 8B Beta (β, 128k) - a Hugging Face Space by lamhieu: no description found
Unsloth AI (Daniel Han) ▷ #community-collaboration (10 messages🔥):
New message typesModular Model SpecTraining directly on new tokensPartially Trainable Config in PyTorchFinetuning Gemma-2-27b for coding
- Modular Model Spec Launched: The Modular Model Spec version 0.0.0 aims to increase the reliability, developer convenience, and flexibility of LLMs by outlining a unified, modular dataset format.
- Why This Spec Matters: Higher reliability, programmable settings, and improved flexibility for LLM-augmented applications.
- Training New Tokens via Examples: Given that new tokens won't appear in pretraining data, a member suggests training on them directly with numerous post-training examples.
- "These tokens won’t appear in any pretraining data, so training directly on them is the only option," they argued.
- Implementing Partially Trainable Config in PyTorch: A customized PartiallyTrainableConfig class and corresponding embedding and LMHead classes in PyTorch allow specific tokens to be trainable while freezing others.
- This approach modifies the model to only train embeddings and logits for the target tokens, but faces issues with requires_grad on specific weight matrix ranges.
- Gemma-2-27b Excels at Fine-tuning: Gemma-2-27b model stands out for coding tasks, reportedly being able to code Tetris in Python with only two shots.
- It joins Codestral and Deepseek-v2 on this front, outperforming other open-source models like llama-3-70b and qwen2-72b.
Link mentioned: Modular Model Spec: no description found
Unsloth AI (Daniel Han) ▷ #research (4 messages):
Model Compression in LLMsNorm Tweaking for QuantizationFlashAttention-3 Performance BoostPingpong Scheduler Implementation
- Norm Tweaking boosts LLM quantization: This paper introduces a technique known as norm tweaking to improve the precision of LLM quantization, achieving high accuracy even at 2-bit quantization.
- The method showed significant improvements on models like GLM-130B and OPT-66B, making it practical for real-world applications, especially when compared to existing PTQ methods.
- FlashAttention-3 speed up Transformer attention: FlashAttention-3 accelerates Transformer performance, achieving 1.5-2x speedup on FP16, and reaching up to 1.2 PFLOPS on FP8 with modern GPUs like H100.
- However, the improvements are currently limited to H100 GPUs, sparking curiosity about the new pingpong scheduler's applicability to other GPUs.
Links mentioned:
CUDA MODE ▷ #general (18 messages🔥):
Hackathon Team FormationFlashAttention discussionShared Memory Usage
- Hackathon Team Formation: Members discussed forming teams for an upcoming CUDA-focused hackathon, with notable speakers like Chris Lattner and Raja Koduri.
- as_ai mentioned expensive plane tickets, while ericauld mentioned the need for lodging but showed interest in making a team if both attend.
- FlashAttention in Modern GPUs: A blogpost was shared describing improvements in FlashAttention, which speeds up attention on GPUs and is used in various AI models.
- iron_bound humorously commented 'H100 go brrrrr' in response to the technical details.
- Shared Memory Usage Limitations: Members discussed the shared memory limit for CUDA blocks, specifically addressing how to use more shared memory efficiently within a single block.
- thakkarv_86311 clarified that the rest of the 51kib memory isn't necessarily left unused.
Links mentioned:
CUDA MODE ▷ #triton (1 messages):
User-defined Triton kernelstorch.compile for optimizationTriton kernel tutorial
- Optimize with User-defined Triton Kernels: A tutorial on using user-defined Triton kernels with
torch.compileto optimize model computations was shared by a user.- The tutorial includes example code for vector addition kernels and highlights potential performance improvements when integrating these optimized computations into PyTorch models.
- Basic Usage of Triton Kernels with torch.compile: The tutorial demonstrates basic usage by integrating a simple vector addition kernel from the Triton documentation with
torch.compile.- Example code and steps are provided to help users achieve peak hardware performance by integrating Triton kernels into their PyTorch models.
Link mentioned: Using User-Defined Triton Kernels with torch.compile — PyTorch Tutorials 2.3.0+cu121 documentation: no description found
CUDA MODE ▷ #torch (17 messages🔥):
bf16/fp16 model checkpoint issuesLottery ticket hypothesis with bfloat16flex_attention functionOptimization in test-time-training repo
- bf16/fp16 model checkpoint handling: A user asked if saving a model checkpoint trained in bf16/fp16 format saves it in fp32 by default and about the right way to handle it.
- Another user suggested that state dicts will be in bf16/fp16 but loading them would need explicit casting; double-checking recommended for accuracy concerns during inference.
- Model performance discrepancy with eval mode: A user experienced drastically worse performance during inference when a model, trained using lottery ticket hypothesis in bfloat16, was put in eval mode.
- They suspect issues with BatchNorm but recovered performance by not using model.eval(), which is considered odd.
- flex_attention for block-diagonal masks: A user inquired about using the recent
flex_attentionfunction for training models with block-diagonal masks. - Optimization in test-time-training repo: A user proposed adding optimization to the test-time-training PyTorch repository.
Link mentioned: GitHub - test-time-training/ttt-lm-pytorch: Official PyTorch implementation of Learning to (Learn at Test Time): RNNs with Expressive Hidden States: Official PyTorch implementation of Learning to (Learn at Test Time): RNNs with Expressive Hidden States - test-time-training/ttt-lm-pytorch
CUDA MODE ▷ #algorithms (1 messages):
Adam MiniGrokFastMobileLLMJEST
- Adam Mini Optimizes with Lower Memory: Adam Mini is an optimizer that uses significantly less memory while maintaining performance comparable to Adam.
- By tracking fewer parameters (momentum, variance, gradient), Adam Mini effectively reduces memory usage.
- GrokFast Accelerates Grokking Phenomenon: GrokFast aims to accelerate the Grokking phenomenon observed in Transformers, which was previously discussed.
- This approach helps models rapidly achieve a balance between memorization and generalization.
- MobileLLM Brings LLMs to Devices: MobileLLM focuses on developing large language models for on-device applications, enhancing their accessibility and performance on mobile platforms.
- This effort aims to enable robust AI functionality without the need for remote server access.
- JEST Boosts Training with Data Curation: JEST stands for Joint Example Selection Training, a data curation technique that accelerates learning by carefully selecting training examples.
- This method optimizes the training process by focusing on the most impactful data.
Link mentioned: AI Unplugged 14: Adam mini, GrokFast, MobileLLM, JEST: Insights over information
CUDA MODE ▷ #cool-links (2 messages):
AMD and Silo AI AcquisitionFlashAttention and GPU Performance
- AMD Acquires Silo AI for $665 million: AMD is set to acquire Finnish AI start-up Silo AI for $665 million in a move to bolster its AI services and compete with Nvidia. The acquisition, expected to close in the second half of the year, will see Silo’s 300-member team focus on building custom large language models.
- FlashAttention Empowers Modern GPUs: FlashAttention optimizes GPU performance by reducing memory reads/writes, significantly speeding up Transformer training and inference.
- Despite its success, FlashAttention-2 utilizes only 35% of the theoretical max FLOPs on H100 GPUs, highlighting room for further optimization.
Links mentioned:
CUDA MODE ▷ #beginner (11 messages🔥):
CUDA environment setupNCU segmentation faultGPU driver update for WSLDocker usage for CUDA
- NCU segmentation fault resolved with Docker: Shabbo experienced a 'Segmentation fault' when running
ncuin a Conda environment on a local laptop GPU (3050), ultimately solving it by using a Docker imagenvidia/cuda:12.4.0-devel-ubuntu22.04. - Potential Conda issue and alternative suggestions: Shabbo inquires about whether the Conda environment setup or lack of system CUDA installation is causing the
ncuissue, with another member suggesting to upgrade the GPU driver on Windows and verifying system CUDA toolkit installation.- Suggestions included using Docker as an alternative and upgrading the host Windows GPU drivers for better support with WSL as mentioned here.
Links mentioned:
CUDA MODE ▷ #torchao (2 messages):
Support for Smooth Quant and AWQImplementation of to_calibrating_ Function
- Support for Smooth Quant and AWQ Algorithms: Smooth Quant and AWQ are confirmed to be supported in the current workflow.
- Member posits starting with individual implementations of
to_calibrating_for each algorithm before evaluating a unified approach.
- Member posits starting with individual implementations of
- Implement to_calibrating_ for All Algorithms Individually: Implementation of
to_calibrating_function should be distinct initially for each algorithm.- Later evaluation may result in merging into a single flow, similar to the
quantize_API.
- Later evaluation may result in merging into a single flow, similar to the
CUDA MODE ▷ #hqq (1 messages):
BitBlas backendtorch.compile support
- BitBlas Backend Added with Torch.Compile Support: MobiusML added BitBlas backend with torch.compile support to hqq. The update now works with 4-bit, 2-bit, and 1-bit configurations.
- The commit includes detailed changes and improvements to the backend.
- Support for Multiple Bit Configurations: The recent update to hqq enables support for 4-bit, 2-bit, and 1-bit configurations via the BitBlas backend.
- This enhancement utilizes the torch.compile capability to improve performance and compatibility.
Link mentioned: add bitblas backend for 4-bit/2-bit · mobiusml/hqq@6249449: no description found
CUDA MODE ▷ #llmdotc (252 messages🔥🔥):
Bias Handling in ModelsParameterized GPT2 TrainingCustom Attention ImplementationsAdamW Optimizer PrecisionFlashAttention-3
- Biases handling diverges in trained models: Members discussed the operational norms of biases during training runs, noting similar loss curves but differing in norms, where biases were observed to drastically vary in magnitude during checkpoints.
- Andrej suggested a change to leave biases as zero rather than removing them, aiming to avoid creating confusing, complex code.
- Parameterized GPT-2 Training Scripts: Scripts for training GPT-2 models with cmdline options to exclude biases and achieving significant resemblance in loss metrics were shared among members.
- There is ongoing experimentation, with future plans to fine-tune and extend model parameters while ensuring simplicity and manageability in command configurations.
- Custom Attention Implementations in CUDA: The community debated using FlashAttention-3 versus cuDNN and ThunderKittens for faster Transformer attention, addressing the complexity and dependencies of these libraries.
- The retention of simpler solutions like creating a custom matmul via CUTLASS was favored until the more complex integrations become necessary.
- FP8 Impact on AdamW Optimizer: FP8 support for activation and optimizer states, especially AdamW, was explored, revealing that optimizer states take a significant amount of memory, approaching 50% in cases on single GPUs.
- Adam buffer precision optimization discussions prompted concerns about moving to lower bit precision (e.g., 8-bit), balancing complexity, and potential inaccuracy.
- FlashAttention-3's Impact and Adoption: FlashAttention-3 was highlighted for its impressive performance, boosting attention speeds by up to 2x using FP16 and 1.2 PFLOPS on FP8.
- Integration feasibility and the evaluation of taking this route versus other optimizations were considered, with an emphasis on simplicity and practicality.
Links mentioned:
CUDA MODE ▷ #sparsity (4 messages):
Quantization and SparsitySpeed-up TechniquesSparseGPTWANDA PruningDistillation with Sparsified Models
- Quantization and Sparsity Strategies: Exploring the combination of quantization and sparsity, it is proposed that higher bitwidth be reserved for non-sparse elements, improving quality without consuming more storage or computation.
- 50% semi-structured sparsity has minimal quality loss and provides a computational advantage.
- Achieving Speed-ups with Quantized Sparse Matrices: A fused gemv CUDA kernel demonstrated nearly 4x speed-ups when using a specific format: 1:2 sparsity with 7-bit non-sparse elements.
- Speed-ups were shown by packing sparse matrices efficiently, achieving 3.7337x to 3.3228x increases in speed for various matrix shapes.
- SparseGPT Pruning for Large Models: SparseGPT enables pruning large GPT-family models to 50% sparsity without retraining while maintaining accuracy.
- SparseGPT can execute on prominent open-source models like OPT-175B and BLOOM-176B within 4.5 hours, achieving up to 60% unstructured sparsity with negligible increase in perplexity.
- WANDA Pruning Approach: The WANDA method offers a simple and effective LLM pruning technique compatible with weight quantization approaches.
- GitHub link: WANDA provides more details on its implementation and effectiveness.
- Further Experiments with Distillation: Future plans include running distillation with the sparsified model to assess performance and accuracy improvements.
- By modifying packing strategies, further speed-ups and efficiency could be realized, potentially 6x-7x faster with 1:4 sparsity and 6-bit quantization.
Links mentioned:
Nous Research AI ▷ #interesting-links (2 messages):
Orca 3Generative Teachingsynthetic data for language models
- Orca's Generative Teaching Revolution: Arindam1408 announced their latest work on Generative Teaching, generating high-quality synthetic data for language models to teach specific skills such as RC, text classification, tool use, and math without extensive human effort.
- A user commented that Orca 3 flew under the radar due to its sneaky little paper title.
- Behind Orca 3's Stealthy Launch: The launch of Orca 3 was not widely noticed, leading to questions about its visibility.
- 420gunna suggested it was because they gave it a sneaky little paper title.
Link mentioned: Tweet from arindam mitra (@Arindam1408): #Orca I'm thrilled to announce our latest work on Generative Teaching: generating vast amount of diverse high-quality synthetic data for language models to teach a specific skill (e.g. RC, text cl...
Nous Research AI ▷ #general (177 messages🔥🔥):
Hermes Model PerformanceOpen-Source AIDataset AvailabilityGuardrails for AIArena Learning for LLMs
- Hermes Model Shows Impressive Performance: A member noted the impressive OOS performance of a model trained for 40 epochs with just 10 samples and a learning rate of 1e-6, leading to flawless JSON output with Mistral.
- Discussion highlights that low learning rate combined with high epochs might be ideal for specific tasks with small sample sizes.
- Open-Source AI Lacks Datasets: A member argued that while models like LLaMa 3 and Gemini 2 are advanced, the OSS projects lack the necessary datasets and pipelines to teach models specific skills.
- We're lacking completely OSS replications of highly intelligent LLMs like Gemini or LLaMa 3.
- AI Guardrails Debate Heats Up: Members debated the necessity and impact of AI guardrails, with some arguing they are needed to prevent misuse, while others see them as overly restrictive and stifling innovation.
- A user remarked, AI guardrails should be like the guard on a circular saw; present but removable when necessary.
- WizardLM Introduces Arena Learning: WizardLM announced the Arena Learning paper, describing an AI-powered synthetic data flywheel and simulated chatbot arena for continuous LLM improvement without human evaluators.
- Arena Learning achieved 98.79% consistency with human-judged LMSYS Chatbot Arena evaluations, leveraging iterative SFT, DPO, and PPO post-training techniques.
- VLLM Model JSON Mode and Guided Decoding: Discussion about vLLM's capability to enforce JSON output using guided decoding, noting that it's slow on first request but efficient thereafter.
- It's highlighted that an efficient JSON mode prompt can be implemented, ensuring adherence to specified JSON schemas.
Links mentioned:
Nous Research AI ▷ #ask-about-llms (7 messages):
Hermes 2 Theta Llama 3 70B FinetunesHermes 2 ProStorytelling Focused Finetunes
- Hermes 2 Theta Llama 3 70B Finetunes explored: A member inquired about other llama 3 70b finetunes that improved over the base instruct performance, besides Hermes-2-Theta-Llama-3-70B-GGUF.
- Another member mentioned that Hermes 2 Pro performs well on the typical Nous benchmarks but does not exceed in every test like IFEval.
- Discussion on storytelling focused finetunes: A member asked about the potential interest in developing storytelling focused finetunes on base models, mentioning that NovelAI seems to be the only group actively pursuing this.
- No current plans to work with pretraining data for storytelling models were noted, though an open source alternative would be welcomed.
Nous Research AI ▷ #rag-dataset (13 messages🔥):
Anthropic WorkbenchPrompt Engineering Job ReplacementGrounded vs Ungrounded TagsHermes RAG TemplatesSynthetic Generations Export
- Anthropic Workbench lacks export function: A user mentioned playing with the Anthropic Workbench and stated that it needs an export function for the synthetic generations.
- Debate on removing Grounded/Ungrounded tags: Users discussed the idea of removing the grounded/ungrounded tags to save tokens and focus on grounded answer generation, as responses were similar for both tags.
- Prompt Engineering as a profession is evolving: Users expressed that prompt engineering focused on merely constructing prompts may be obsolete.
- Hermes RAG Template tracking in Google Doc: Users shared a Google Doc for tracking various Hermes RAG templates.
Link mentioned: Hermes RAG Templates: Cohere-Hermes Format: [interstellarninja] System Prompt: ____________________________________________________________________________________ # Role You are an AI assistant that answers user queri...
LM Studio ▷ #💬-general (90 messages🔥🔥):
Feature Requests for LM StudioGPU Compatibility IssuesContext Overflow BugSetup and Configuration TipsModel and Proxy Issues
- Users request optional Assistant role generation triggers: A user suggested enabling assistant role inputs in LM Studio to trigger generation, treating it as a UI/UX feature that could enhance narrative writing.
- They emphasized it could be a simple optional setting, like a boolean, that remains off by default but can be toggled on for specific use cases.
- Trouble with GPU compatibility on Linux: A user reported that LM Studio doesn't recognize their Radeon RX7600XT GPU, although GPT4ALL uses it successfully.
- OpenCL GPU support is deprecated, and future updates might switch to Vulkan for better compatibility with non-CUDA/ROCM GPUs.
- Context overflow policy bugs: A user encountered issues with the context overflow policy set to 'Maintain a rolling window and truncate past messages'.
- Despite reproducing the issue initially, it seemingly resolved itself without consistent behavior, leading to considerations for a detailed bug report.
- Running LM Studio behind a proxy: A user inquired about running LM Studio behind a proxy, mentioning that the app doesn't recognize the proxy settings configured in Windows 10.
- Manual model downloads and placing them in the correct folder structure were suggested as a workaround.
- Optimization and setup advice for budget rigs: A user shared their experience of setting up LM Studio on a thrift-store-bought Dell Inspiron 3847 with a GTX1650 GPU.
- The community advised running smaller models like 7B Q4 and installing Linux for better performance.
Links mentioned:
LM Studio ▷ #🤖-models-discussion-chat (23 messages🔥):
Whisper and LM Studio integrationGemma-2 Flash Attention issueHandling system prompts for non-supporting modelsInstalling models using Ollama and LM StudioSalesforce introduces xLAM-1B
- Integration possibilities of Whisper with LM Studio: Users discussed the potential for integrating Whisper or other speech-to-text models with LM Studio, suggesting a framework akin to Anything LLM.
- Gemma-2 Flash Attention setting causes issues: Gemma-2 doesn't support Flash Attention, causing issues when attempting to use it.
- System prompt handling for models that don't support it: A discussion ensued about how LM Studio handles system prompts for models like Gemma and Mistral that do not officially support them.
- Efficient model installation using Ollama and LM Studio: One user realized that using Ollama for model installation and linking it to LM Studio was more efficient.
- Salesforce's new micro model xLAM-1B: Salesforce introduced a 1B parameter model called Einstein Tiny Giant xLAM-1B which allegedly outperforms larger models like GPT-3.5 and Claude in function calling.
Link mentioned: Tweet from Marc Benioff (@Benioff): Meet Salesforce Einstein “Tiny Giant.” Our 1B parameter model xLAM-1B is now the best micro model for function calling, outperforming models 7x its size, including GPT-3.5 & Claude. On-device agentic ...
LM Studio ▷ #🎛-hardware-discussion (30 messages🔥):
8cxWindows updatesDual 4090 GPUs vs. Waiting for 5090RX 580 setupArc 770 performance
- Qualcomm's 8cx viable for llama.cpp: A member mentioned the Qualcomm 8cx is being discussed for llama.cpp, with some improvements noted in open issues.
- Investing in Dual 4090s vs Waiting for 5090: A heated discussion arose on whether to buy two 4090 GPUs now or wait for the 5090.
- Some argued for waiting due to potential price drops and equal performance of used 3090s; others mentioned the potential specs of the 50 series as a deciding factor.
- RX 580 setup struggles to stay relevant: The RX 580 was labeled as outdated and unsupported, with OpenCL being deprecated.
- Community drivers can support ROCm, but one member warned it's a risky setup saying, this is a devil's play.
- Arc 770 performance falls short: Users confirmed the Arc 770 16GB is slow and unsupported in LM Studio.
- One member recommended saving for a 3090 instead for better performance.
- 3080 VRAM limitations push users to upgrade: A user expressed frustration over the 10GB VRAM limit on the 3080, seeking a cheap alternative for background usage.
- Suggestions leaned towards buying a 3090 at a reduced price, warning that AMD cards might still have driver issues.
Links mentioned:
LM Studio ▷ #🛠-dev-chat (5 messages):
Rust developmentEtiquette of asking questionsThe XY problem
- Discussion on Rust development: A member inquired if there were any Rust developers available for opinions or advice.
- Just looking for an opinion, noted the member, without specifying the exact issue.
- Understanding the etiquette of asking questions: A member shared a link to Don't Ask To Ask to stress the poor form of asking for experts without stating the problem directly.
- The member emphasized that such questions implicitly ask for more than it seems and can discourage helpful responses.
- Exploring the XY problem: Following the discussion on question etiquette, another member linked XY Problem to explain the common mistake of asking for help with an attempted solution instead of the actual problem.
- They also referenced Asking Smart Questions as a useful resource for better question framing.
Links mentioned:
Latent Space ▷ #ai-general-chat (36 messages🔥):
timestamped whisperuseful OpenAI API integrationsBlackstone's investment in AI data centersPaliGemma reportOpenAI's revenue and progress towards AGI
- Whisper Timestamped enables local in-browser speech recognition: Whisper Timestamped offers multilingual speech recognition with word-level timestamps running 100% locally in the browser, powered by 🤗 Transformers.js, which opens up new possibilities for in-browser video editing. source
- Call for useful OpenAI API integrations: Discussions focus on useful professional applications of OpenAI API, with suggestions to improve internal search and CI failure auto-resolution.
- Blackstone invests $100B in AI data centers: Blackstone is heavily investing in AI, owning $50B in current AI data centers and planning another $50B in construction. YouTube interview
- PaliGemma's new advancements detailed: PaliGemma's latest paper on arxiv discusses a 3B parameter VLM model, integrating SigLip image encoder and Gemma language model. link details
- OpenAI's revenue and progress levels: A report estimates OpenAI's revenue at $3.4B annually, with significant earnings from ChatGPT Plus, Enterprise, and API subscriptions. source
Links mentioned:
Latent Space ▷ #llm-paper-club-west (93 messages🔥🔥):
ColBERT paper discussionAI Agent survey paperImageBind modalitiesSBERT design and trainingMulti-agent systems in AI
- ColBERT Paper Review: ColBERT paper and its features were discussed, including the benefits of its inverted index retrieval method.
- The session included insights on how ColBERT compares to other semantic similarity models, revealing its efficiency in handling large datasets.
- Survey of AI Agent Implementations: The AI agent survey paper was reviewed focusing on recent advancements in AI agent implementations and their capabilities.
- Discussions centered on the architectures, design choices, and the importance of future developments for enhancing AI agent performance.
- Exploring ImageBind's Joint Embedding: A paper on ImageBind discussed creating joint embeddings for multiple modalities, such as images, text, and audio.
- Participants noted the innovative use of image-paired data for training and its state-of-the-art performance in cross-modal tasks.
- Understanding SBERT Design: Details on SBERT's (Sentence-BERT) design and training were shared, highlighting its use of BERT with a pooling layer for sentence embeddings.
- The contrastive training method, such as siamese networks, was noted for its effectiveness in deriving meaningful sentence representations.
- Multi-Agent Systems in AI: A detailed discussion on the structure and function of multi-agent systems in AI, emphasizing the role of different system prompts.
- Insights were shared on operational reasons for using multi-agent frameworks and their application in parallel task execution.
Links mentioned:
Perplexity AI ▷ #announcements (1 messages):
Perplexity and AWS collaborationLaunch of Perplexity Enterprise Pro on AWS MarketplaceBenefits of Amazon Bedrock for Perplexity
- Perplexity collaborates with AWS for Enterprise Pro: Perplexity announced a strategic collaboration with Amazon Web Services to bring Perplexity Enterprise Pro to all AWS customers through the AWS marketplace.
- This collaboration includes joint events, co-sell engagements, and co-marketing efforts, leveraging Amazon Bedrock for generative AI capabilities.
- New Milestones with Perplexity Enterprise Pro: This partnership with AWS marks a significant milestone in Perplexity's mission to empower organizations with AI-powered research tools that enhance efficiency and productivity without compromising security and control.
- Perplexity Enterprise Pro will enable businesses to transform how teams access and utilize information through AI-driven search and analytics, as part of this new collaboration.
Link mentioned: Perplexity collaborates with Amazon Web Services to launch Enterprise Pro: We’re taking another major step in giving organizations the ability to leverage AI-powered tools for greater efficiency and productivity.
Perplexity AI ▷ #general (110 messages🔥🔥):
Perplexity AI features and limitationsPharmacy and medication cost queriesPerplexity Pro and Education plansProgramming with Perplexity AIClaude LLM model updates
- Perplexity AI manages message length, not daily limits: A member highlighted that Perplexity AI cuts off messages if they get too long, but does not have a daily limit similar to GPT.
- Another member clarified that GPT shows a 'continue' button for long responses, whereas Perplexity does not.
- Pharmacist seeks comprehensive drug price search: A pharmacist discussed the issue of not finding costplusdrugs in Perplexity's search results for medication prices.
- Another member suggested that Perplexity uses its own site indexer, which might give different rankings than Google.
- Educational discounts and promo codes on Perplexity Pro: Members discussed using promo codes for Perplexity Pro subscriptions and mentioned a discounted education program.
- Programming challenges with MATLAB using Perplexity: A user described difficulties in maintaining formatting across prompts when writing MATLAB code with Perplexity's assistance.
- Others suggested structuring queries more clearly and consistently for better results and using additional programming resources like Stack Overflow.
- Claude model removed from labs and updated plans: Claude models were removed from Perplexity Labs and moved to the live environment, accessible to Pro users.
Link mentioned: Bringing Perplexity to education and not-for-profits : Perplexity Enterprise Pro, with special rates for philanthropic organizations, public servants, and schools
Perplexity AI ▷ #sharing (6 messages):
Demographic and Pornography UseFamily ConceptsPreventing Spam Phone CallsYouTube Dislike InformationDocker Compose Dependencies
- Debate on demographic information and pornography use: A user asked if there's a correlation between demographic information about conservatives and liberals and their use of pornography, suggesting conservatives might use more due to cultural repression.
- There is no clear consensus on whether conservatives use more pornography than liberals, although some studies hint that this might be the case.
- Steps to prevent spam phone calls: To prevent spam phone calls, users were advised to register on national 'Do Not Call' lists like the National DNCL in Canada and the FTC's Do Not Call Registry in the U.S.
- Enabling features like 'Silence Unknown Callers' in iOS was also recommended to mitigate spam calls effectively.
- Creators and YouTube video downvotes: Before YouTube made changes, creators could see the total number of likes and dislikes in YouTube Studio, but couldn't identify who specifically disliked their videos.
- Changes to this feature have been implemented, but the exact details of when these modifications occurred were not specified.
- Setting dependencies in Docker Compose: The
depends_ondirective in Docker Compose only works with services defined within the same Compose file but not for containers across different Compose files.- To handle dependencies between separate Compose files, options like using external networks with health checks or implementing a wait script were suggested.
Links mentioned:
Perplexity AI ▷ #pplx-api (3 messages):
Perplexity Discord integrationLatency issues with online modelsAccount balance check
- Perplexity Discord integration queries: A user inquired whether anyone has successfully integrated Perplexity into a Discord server.
- No follow-up or responses were provided to this question in the chat.
- Latency spike in online models noted: A user reported a significant latency increase in llama-3-sonar-large-32k-online models starting June 26th.
- They asked if this is a known issue and whether there are any plans to address the performance degradation.
- Account balance clarification needed: A user requested account details to verify if a balance issue has been resolved, tagging another member for follow-up.
Stability.ai (Stable Diffusion) ▷ #general-chat (116 messages🔥🔥):
Image EnhancementsCharacter LorasComfy-portableStable Diffusion issuesCivitAI banning SD3 content
- Image Enhancements with minimal scaling: A user shared their surprise at Stable Diffusion's ability to improve image details like skin texture and face even with minimal scale factors.
- midare suggests that most users typically apply a 2x scale for enhancements.
- Challenges with Character Loras on Pony checkpoints: Discussion around training Loras for Pony checkpoints highlighted that character Loras often look more realistic on normal SDXL checkpoints compared to Pony checkpoints, where characters are less recognizable.
- crystalwizard advised consulting experts who specialize in training for Pony.
- CivitAI maintains ban on Stable Diffusion 3 (SD3): CivitAI continues to ban SD3 content despite its recent license update, suggesting a strategic decision tied to their investments in the Open Model Initiative (OMI).
- Speculation arises about CivitAI's future becoming similar to Stable Diffusion, with potential commercial restrictions.
- Troubleshooting Comfy-portable errors: Several users discussed difficulties in fixing errors with Comfy-portable and questioned whether these issues were supported within the community.
- Stable Diffusion performance and setup advice: A user described persistent issues with Automatic1111 on an RTX 2060 Super, including screen blackouts and difficulty generating images after using certain commands like --xformers.
- cs1o recommended simple launch arguments such as --xformers --medvram --no-half-vae to avoid these problems.
Links mentioned:
Modular (Mojo 🔥) ▷ #general (2 messages):
mdBook advantagesModularBot level advancements
- Why mdBook is a better choice: mdBook is recommended for its ability to be downloaded as a PDF for offline reading and its feature to include outlines using a specific Python library.
- User level advancement: A user has been congratulated by ModularBot for advancing to level 1.
Modular (Mojo 🔥) ▷ #💬︱twitter (2 messages):
Modular Twitter updateModular status announcement
- Modular posts Twitter update: Modular shared a new post via their Twitter account.
- Modular announces status update on Twitter: Another status update was announced by Modular on their Twitter account.
Modular (Mojo 🔥) ▷ #mojo (44 messages🔥):
Setitem syntax issueNuMojo compatibility with nightlyMojo open-source timelineKernel bypass networking in MojoDynamic operands in mlir_ops
- Setitem syntax issue with Mojo: A member encountered an error using
A[0] = 1in Mojo, which does not occur withA.__setitem__(0, 1). The problem seems related to the type checks between__getitem__and__setitem__, leading them to raise issue #3212. - NuMojo compatibility issues with Mojo nightly: Updating to the latest Mojo nightly caused incompatibility issues with NuMojo, especially with DTypePointer API changes. The nightly still shows the same error with a simplified example, despite recent updates.
- Mojo will eventually open-source: Chris Lattner reassured users that Mojo will open-source in the future, comparing it to LLVM and Swift which took years to be open-sourced. He cited the temporary closed stage as a way to refine the project without the burden of early wide-scale contributions.
- Focus on kernel bypass networking in Mojo: Darkmatter__ expressed hope that Mojo avoids mistakes other languages made with kernel bypass networking. Ensuring clean integration of networking components seems to be a significant concern for users.
- Dynamic operands in mlir_ops: A question was raised about using dynamic operands in mlir operations, particularly for index addition. The query looks for a method to dynamically pass attributes to mlir operations.
Links mentioned:
Modular (Mojo 🔥) ▷ #max (1 messages):
Channel Name ChangesGPU Programming Channel
- Channel Names Updated for MAX Discussions: The channel names have been updated; <#1212827597323509870> is now dedicated to discussions on everything MAX-related including serving, engine, and pipelines.
- Members can now differentiate discussions more easily with these changes.
- New Dedicated GPU Programming Channel: A new channel, <#1212827673257316453>, is now specifically for upcoming information and discussions related to GPU programming.
- This separation aims to foster focused and efficient conversations on GPU topics.
Modular (Mojo 🔥) ▷ #max-gpu (1 messages):
MAX-related discussionDedicated GPU programming information
- MAX-related channel update: The channel names have changed slightly, and <#1212827597323509870> is now dedicated to discussion of everything MAX-related including serving, engine, pipelines etc.
- Dedicated GPU programming channel: <#1212827673257316453> has been designated as the dedicated channel for upcoming information and discussion related to GPU programming.
Modular (Mojo 🔥) ▷ #nightly (51 messages🔥):
New Mojo Compiler Nightly ReleasesArrowIntVector Conditional ConformanceMojo Build IssuesVariant Type in Mojo
- Mojo Compiler Sees Multiple Nightly Releases: The nightly Mojo compiler has been updated multiple times, with version updates such as
2024.7.1022,2024.7.1105, and2024.7.1114. These releases include updates like implementing equality comparisons forList, usingUnsafePointerinsort.mojo, and removingLegacyPointerversion ofmemcpyalong with associated changelogs and raw diffs. - ArrowIntVector Conditional Conformance Query: A user shared code concerning the conditional conformance of
ArrowIntVectorto traitsStringGetterandIntGetterin the Mojo language to receive feedback on its correctness, highlighting issues with the latest build.- Another user suggested ensuring
ArrowIntVectorconforms toIntGetterand using parametric traits, while troubleshooting build issues related to pointer types.
- Another user suggested ensuring
- Addressing Mojo Build Issues and Cache: Users encountered build issues with Mojo, particularly concerning pointer errors in the
ArrowIntVectorexample. Recommendations included cleaning the compilation cache stored in.modular/.mojo_cacheand ensuring traits conformity. - Leveraging Variant Type for Conditional Conformance: Members discussed using the
Varianttype in Mojo for working with runtime-variant types, which looks promising for handling varied data types within fixed sets. Examples include a JSON parser demonstrating practical usage of theVarianttype in Mojo.
Links mentioned:
Modular (Mojo 🔥) ▷ #mojo-marathons (5 messages):
Mojo compiler performanceAVX2 and AVX-512 utilizationHandwritten kernels vs compilerAssembly code review
- Mojo compiler handles AVX2 efficiently: A member shared their assembly output, highlighting that the Mojo compiler performed admirably by efficiently scheduling AVX2 instructions.
- Advantages of handwritten kernels: Despite the compiler's performance, members agree that handwritten kernels could further optimize by removing stack allocation and using registers directly.
- I'm happy that I don't need to handcraft all the kernels for different configs, just one generic kernel.
- Discussion on AVX-512 capabilities: A discussion emerged about the benefits of using AVX-512 loads, although one member's computer lacks AVX-512 capabilities.
LangChain AI ▷ #general (71 messages🔥🔥):
LangSmith Cost CalculationVoice Bot ImplementationVector Store Retriever ToolChroma DB InitializationOpenAI Vector Store
- LangSmith lacks support for Google's Gemini model cost calculation: A member highlighted that LangSmith does not display costs for Google's Gemini models as it currently doesn't support built-in cost calculation, despite correctly adding token counts.
- Implementing a Voice Bot with RAG: A user shared code to identify query intent for a voice bot, routing 'products' and 'order details' queries to corresponding VDBs, and using FAQ data for other queries.
- Add Custom API Call as a Tool: Instructions provided on how to write a custom tool in JavaScript for calling a backend API using LangChain's
DynamicStructuredToolclass.- The explanation included an example of using
axiosorfetchfor making HTTP requests within the custom tool.
- The explanation included an example of using
- Accelerate Chroma VectorStore Initialization: Suggestions to reduce Chroma VectorStore initialization time included persisting the vector store to disk, using a smaller embedding model, and utilizing a GPU where possible, referencing GitHub Issue #2326.
- Using OpenAI Vector Store as Retriever: To use an OpenAI vector store as a retriever, you can instantiate a vector store with embeddings and then create a retriever using the
.as_retriever()method as outlined in the LangChain documentation.
Links mentioned:
LangChain AI ▷ #langserve (14 messages🔥):
Asyncio.run() RuntimeErroruvicorn.run() issuesStream content type errorLangServe replacementLangGraph Cloud
- Asyncio.run() RuntimeError explained: A member encountered a RuntimeError while running
asyncio.run()from a running event loop: asyncio.run() cannot be called from a running event loop.- No solutions were provided to resolve this issue, leaving it open for further discussion.
- Stream content type error in chat: A member faced an error with an unexpected content type: expected text/event-stream, but got application/json instead while using
playground_type="chat".- The error appears to be related to chat history, but no specific solutions were mentioned.
- LangServe replaced by LangGraph Cloud: It was announced that LangServe has been replaced by LangGraph Cloud in the LS portal, as confirmed by Harrison.
- Although OSS LangServe will continue to exist, the hosted option is now LangGraph Cloud, which some members prefer for agent functionality.
OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
Magnum 72BHermes 2 ThetaModel DeprecationsRouter Resilience Update
- Magnum 72B aims for Claude 3 level prose: Alpindale's Magnum 72B is designed to achieve the prose quality of the Claude 3 models, with origins in Qwen2 72B and trained with 55 million tokens of RP data.
- Hermes 2 Theta merges Llama 3 with metacognitive abilities: Nousresearch's Hermes-2 Theta is an experimental model combining Llama 3 and Hermes 2 Pro, notable for function calls, JSON output, and metacognitive abilities.
- Older models face deprecation: Due to low usage, intel/neural-chat-7b and koboldai/psyfighter-13b-2 are set for deprecation and will begin to 404 over the API by July 25th.
- Router gains resilience with fallback feature: A new router feature will use fallback providers by default unless
allow_fallbacks: falseis specified, ensuring resilience during top provider outages.
Links mentioned:
OpenRouter (Alex Atallah) ▷ #general (62 messages🔥🔥):
Noromaid model removalLLaMA-Guard benefitsVoiceFlow integration with OpenRouterMaintaining conversation contextOpenRouter and assistant API
- Noromaid model phased out due to cost: Members discussed the removal of the noromaid model due to its high cost and low usage.
- One member noted, 'I really liked that noromaid model, it was just too dang expensive to use all the time.'
- LLaMA-Guard as a moderator model alternative: Members considered using LLaMA-Guard as an alternative to Noromaid for moderation purposes, noting that it could be passed filter arguments through OR.
- A member shared a link to LLaMA-Guard and mentioned, 'And small enough to run locally.'
- Challenges of integrating OpenRouter with VoiceFlow: VoiceFlow integration with OpenRouter was discussed for managing conversation context with OR, raising concerns about stateless requests.
- One suggestion was to use conversation memory on VoiceFlow to maintain chat history.
- Importance of maintaining conversation context: Users discussed strategies for maintaining conversation context using APIs like OpenRouter and frameworks such as LangChain.
- 'VoiceFlow will (or should) have a way to maintain the conversation history,' noted a member, highlighting the need for context persistence.
- Interest in Assistant API for OpenRouter: There was a discussion about the potential benefits of OpenRouter supporting an Assistants API, similar to OpenAI's setup.
- Members pointed out the value this could bring, including features like embedded docs and code interpreter, if it weren't such a huge undertaking.
Links mentioned:
OpenAI ▷ #ai-discussions (53 messages🔥):
Decentralized AIBOINCSharded ComputingParallel GPU UsageOpenAI's New Models
- Decentralized AI Computing Gains Traction: Members discussed the possibilities of creating a decentralized mesh network where users can contribute their computation power, facilitated by advancements in bandwidth and compression.
- Mention of BOINC and crypto projects like Gridcoin were highlighted as examples of incentivizing such decentralized networks with tokens.
- Sharded Computing for AI: A proposal was made for a sharded computing platform that can use various VRAM sizes, rewarding users with tokens for their contributed compute.
- Optimizing CMOS chip configurations using decentralized compute was mentioned, referencing the decommissioned DHEP@home BOINC project.
- Parallel GPU Queries: Queries were raised about the feasibility of running the GGUF platform on parallel GPUs.
- Responses indicated that given its nature as a tensor management platform, it is indeed possible.
- OpenAI's New Model Capabilities Revealed: A report detailed that OpenAI is testing new capabilities in its GPT-4 model, showing skills that rise to human-like reasoning, and is progressing through a tiered system towards AGI.
- The company explained that the second tier involves 'Reasoners' capable of doctorate-level problem solving, with future tiers moving towards 'Agents' that can take autonomous actions.
- Claude AI Performance Issues: Users reported severe lag in Claude AI chats after about 10 responses, making the chat function nearly unusable.
- Speculations pointed to possible memory leaks or backend issues, contrasting with more stable experiences with GPT-4 models.
Links mentioned:
OpenAI ▷ #prompt-engineering (3 messages):
Prompt library renameReminder about different channels
- Prompt library renamed: The prompt library has been renamed and can be found under the new channel <#1019652163640762428>.
- A member clarified the location for those looking for it.
- Channel mix-up reminder: A reminder was issued that this channel is not the same as the renamed prompt library channel.
- The clarification aims to prevent confusion among members about channel destinations.
OpenAI ▷ #api-discussions (3 messages):
Prompt Library RenameChannel Difference Reminder
- Prompt Library Renamed: A member notified that the prompt library has been renamed and directed to a new channel <#1019652163640762428>.
- Distinction Between Channels Clarified: Another member reminded the group that this channel is different from another one.
LlamaIndex ▷ #blog (3 messages):
llama-agents launchNebulaGraph integrationLlamaTrace collaboration
- llama-agents framework launch hits 1100 stars: Last week, llama-agents, a new multi-agent deployment framework, was launched and received an enthusiastic response with the repo reaching 1100 stars.
- MervinPraison provided a YouTube walkthrough covering the usage and features of llama-agents.
- NebulaGraph integration with LlamaIndex: Check out the new NebulaGraph integration with LlamaIndex, enabling powerful GraphRAG capabilities using a property graph index.
- This integration allows sophisticated extractors and customizable extraction, as described in their announcement.
- LlamaTrace collaboration with Arize AI for LLM observability: Announcing LlamaTrace, a collaboration with Arize AI to introduce advanced tracing, observability, and evaluation tools for LLM applications.
- This initiative adds to the array of LLM tools and is highlighted in their promotion.
LlamaIndex ▷ #general (32 messages🔥):
Llamaparse and OCRSetting language for prompt templatesAccessing additional_kwargs in CompletionResponseVoice chat with GPT modelsReACT agent variable mapping issues
- Llamaparse handles pre-existing OCR: Users were discussing whether Llamaparse removes existing OCR from PDFs or augments it, with some confusion on the process and no clear resolution.
- Prompt templates in specific languages: A member inquired about setting prompt templates in a specific language, with responses suggesting it depends on the LLM's capabilities and referencing the LlamaIndex documentation.
- Extracting additional_kwargs attribute in RAG pipeline: A member asked how to access additional_kwargs in a RAG pipeline, with suggestions to use retrievers or hook into underlying LLM events shared and referencing extensive examples.
- Direct voice chat with GPT models not yet feasible: It was confirmed that direct voice chat with GPT models without converting speech-to-text is not currently possible; TTS and Whisper were suggested as interim solutions for conversion.
- ReACT agent variable mapping causing errors: A member reported KeyError issues while setting variable mappings in ReACT agent, with responses suggesting checking variable definitions and their inclusion before use.
Links mentioned:
LAION ▷ #research (29 messages🔥):
Experimental ArchitecturesSign GradientResidual ConnectionsMemory Efficiency in Training
- Exploring experimental architectures: A member shared their experience obsessively running experiments on novel architectures, even though they didn't yield significant improvements and were highly compute-hungry, potentially requiring extensive future ablation testing.
- They expressed enjoyment in watching marginal improvements in loss curves, noting that deeper configurations seemed to be less effective but were keen on uncovering potential benefits through continuous troubleshooting.
- Sign Gradient suggestion: A member suggested using sign gradient for the experimental architecture, which another member found interesting and was eager to explore further.
- Chasing SOTA in low-param vision models: The member achieved 50% accuracy on CIFAR-100 with a 250k parameter model, close to the roughly 70% accuracy reported in a 2022 paper on low-param vision models, the current SOTA.
- They observed that their model's performance wasn't sensitive to the number of blocks but was related to the total parameter count, with additional depth often proving detrimental.
- Residual connection issues: A member noted potential issues with their architecture's residual connections and planned to experiment with different gating mechanisms.
- Memory efficiency problems: The experimental architecture was reported to be highly memory inefficient, using 19 GB to train CIFAR-100 with a 128-batch size and only 250k parameters.
- Attempts to optimize this included experimenting with one large MLP reused multiple times instead of multiple smaller MLPs per block.
Eleuther ▷ #general (11 messages🔥):
Diffusion ModelsLocal AI ProjectsDoLa Decoding StrategyHugging Face DatasetsLLM Hallucinations
- Marginal distributions in Diffusion Models: A member is confused about the term marginal distributions as p̂∗_t from the paper FAST SAMPLING OF DIFFUSION MODELS WITH EXPONENTIAL INTEGRATOR and seeks clarification on its meaning.
- Introducing 'RAGAgent' Project: A member shared their new Python project, an all-local AI system called RAGAgent.
- Decoding by Contrasting Layers (DoLa): Discussion on the paper Decoding by Contrasting Layers (DoLa), which proposes a strategy to reduce LLM hallucinations by contrasting logits from different layers.
- A notable improvement is a 17% increase on truthful QA, but it might cause a nontrivial slowdown in inference time.
- Aligning Llama1 without Fine-Tuning: A member notes that Llama1 is only pre-trained and that DoLa might be a method to align a model without additional alignment steps.
- EOS Tokens Handling in Pile-Deduped Dataset: A member questions whether the EleutherAI/pile-deduped-pythia-random-sampled dataset was intended to exclude EOS tokens.
- They seek clarification on the procedure used to arrive at 2048-token chunks without EOS or control tokens.
Links mentioned:
Eleuther ▷ #research (8 messages🔥):
Training on the test taskBitNet b1.58 LLMEmergent behavior in modelsReproduction studies of LLM papersUnderstanding of large models
- Training on the test task confounds evaluations: A recent paper discusses how training on the test task can distort model evaluations and claims about emergent capabilities.
- Adjusting for this factor by fine-tuning each model on the same task-relevant data before evaluation shows that instances of emergent behavior largely vanish.
- BitNet b1.58 LLM challenges full-precision models: BitNet b1.58 introduces a 1-bit LLM that matches full-precision models in performance while being more cost-effective, significantly reducing latency, memory, throughput, and energy consumption.
- Discussion continues if anyone has tested it yet, with references to a Hugging Face reproduction of the model showing similar results.
- Emergent behavior debated in large LLMs: Members are intrigued by how much today's largest models genuinely 'understand' and generate new insights versus merely regurgitating data from the training set.
- There are calls for more intuitive explanations and empirical evidence to clarify the depth of understanding in these models.
Links mentioned:
OpenInterpreter ▷ #general (3 messages):
GPT-4o profilesLlama3 local standards
- GPT-4o vs Llama3 Local: Standards in Flux: A member noted they experience fewer issues with GPT-4o using the default profile, while more issues arise with Llama3 local as many standards around delimiters and schemas are still coalescing.
- I figure it goes away with updates, indicating an expectation of resolution with future updates.
- General Channel Directives: A member requested to post in the general channel (<#1210088092782952498>).
- Another user acknowledged the request with, 'Fair enough, thanks for the reply.'
OpenInterpreter ▷ #O1 (15 messages🔥):
LLM-Service Flag IssueProfile Workaround for 01Remote Experience Script for 01Community Contributions in 01 DevelopmentCommercial Applications of 01
- LLM-Service Flag Issue in 01 Documentation: A member noted that the LLM-Service flag mentioned in the documentation for 01 does not exist, causing installation issues.
- Another member mentioned an ongoing PR to update the documentation and suggested using profiles as a temporary workaround.
- Remote Experience Script for 01 on VPS: A member expressed the need for a script to allow 01 to automatically log in on the console for better remote experience on a VPS.
- The same member indicated ongoing research and willingness to collaborate with others on brainstorming and development.
- Community Contributions Drive 01 Development: A member emphasized that 01 has 46 contributors and many of them, along with over 100 from Open Interpreter, are part of the server.
- This highlights the strong community involvement in the project's development.
- Commercial Applications and Blockers for 01: A developer working on 01's remote experience is also in communication with Ben Steinher about its commercial applications.
- They believe remote login capabilities are a significant blocker for the adoption of 01 in business environments.
OpenAccess AI Collective (axolotl) ▷ #general (17 messages🔥):
Axolotl dataset formats linkTurBcat 72B usageTesting TurBcat APIWizardLM ArenaLearningFlashAttention-3 on H100 GPUs
- Axolotl dataset formats link moved: The link to Axolotl dataset formats has moved to a new location.
- 'We moved to a new org' to facilitate better access.
- TurBcat 72B usage possible on 48GB.: TurBcat 72B potentially usable on 48GB systems with API support.
- User c.gato plans to test with 4-bit quantization to facilitate this.
- Testing TurBcat API provided by elinas: User elinas shared an API for TurBcat 72B testing: TabbyAPI with key eb610e28d10c2c468e4f81af9dfc3a48.
- This API is claimed to be compatible with ST Users / OpenAI-API-Compatible Frontends and uses ChatML.
- WizardLM introduces ArenaLearning: The WizardLM ArenaLearning paper was discussed.
- User described it as a 'Pretty novel method.'
- FlashAttention-3 boosts H100 GPU efficiency: FlashAttention-3 aims to speed up attention on H100 GPUs by exploiting modern hardware capabilities.
- Proposed techniques include minimizing memory reads/writes and asynchronous operation, targeting improved utilization beyond the current 35% of max FLOPs.
Links mentioned:
Interconnects (Nathan Lambert) ▷ #news (7 messages):
Data CurationFlashAttentionLMSYS Chatbot Arena
- FlashAttention speeds up Transformers: FlashAttention pioneered a method to speed up attention in Transformers on GPUs, significantly increasing LLM context lengths from 2-4K to 128K, and even 1M in recent models like GPT-4 and Llama 3.
- Despite its success, FlashAttention-2 achieves only 35% of the theoretical max FLOPs utilization on the H100 GPU, indicating much potential for further optimization.
- WizardLM2 relies on WizardArena: The LMSYS Chatbot Arena is a platform for assessing and comparing chatbot models by pitting them in conversational challenges and ranking them with an Elo rating system.
- Despite the excitement, the human-based evaluation process of WizardArena poses significant orchestration and wait-time challenges.
Links mentioned:
Interconnects (Nathan Lambert) ▷ #ml-questions (4 messages):
Synthetic Instruction DataRPO Preference TuningNemotronInstruction BacktranslationReward-Aware Preference Optimization
- Benefits of Paraphrasing in Synthetic Instruction Data: A member asked about the meaningful benefit of varying the order and syntax in synthetic instructions, like 'Write an essay about Machine Learning, and make it three paragraphs' vs. 'Write a three-paragraph essay about the following topic: Machine Learning'.
- They compared this technique to backtranslation but noted it's different from the instruction backtranslation paper.
- RPO Preference Tuning Questions: A user asked about the significance of η in the RPO preference tuning loss function, speculating it's some sort of reward parameter.
- They seemed unsure if this parameter plays an important role, inquiring about its impact on the optimization process.
Interconnects (Nathan Lambert) ▷ #random (3 messages):
OpenAI's revenue breakdownSubscription model of ChatGPTFree usage of GPT-4
- OpenAI reports impressive revenue figures: Future Research breaks down OpenAI's revenue as follows: $1.9B from ChatGPT Plus, $714M from ChatGPT Enterprise, $510M from the API, and $290M from ChatGPT Team.
- The figures include 7.7M subscribers at $20/mo for ChatGPT Plus, 1.2M users at $50/mo for ChatGPT Enterprise, and 80K subscribers at $25/mo for ChatGPT Team.
- Questioning the subscription model amidst free GPT-4 access: How are that many people subscribing right now when GPT-4 is free?
- Comment on subscriptions and Interconnects: smh take that money and subscribe to Interconnects twice instead
Link mentioned: Tweet from Jeremy Nixon (@JvNixon): The report on OpenAI's revenue by futureresearch is out, showing: $1.9B for ChatGPT Plus (7.7M subscribers at $20/mo), $714M from ChatGPT Enterprise (1.2M at $50/mo), $510M from the API, and $290...
Interconnects (Nathan Lambert) ▷ #rlhf (1 messages):
emily_learner: Super nice. Thanks so much. Will take look.
Cohere ▷ #general (8 messages🔥):
GPT AgentsCommand R PlusFine-tuning models
- Playing with Command R Plus: Mapler is exploring Command R Plus and finding it enjoyable.
- They are attempting to build an agent for fun.
- Challenges in Fine-tuning Models: Mapler faced issues with fine-tuning a model, stating it did not meet their expectations.
- Another member pointed out that finetuning is just garbage in garbage out, emphasizing the importance of a good dataset.
LLM Finetuning (Hamel + Dan) ▷ #general (4 messages):
Prompt/Reply Logging ToolsOpenPipe for OpenAIFireworks.ai Lecture
- PromptLayer fails with latest Anthropic SDK: A member expressed issues using PromptLayer for prompt/reply logging, stating it does not work with the latest Anthropic SDK.
- The member sought recommendations for self-hosting alternatives.
- OpenPipe limited to OpenAI: A member highlighted that OpenPipe offers prompt/reply logging but is restricted to OpenAI.
- They noted the lack of support for other models like Anthropic.
- Search for Fireworks.ai lecture: A member inquired about a lecture that discusses or includes folks from fireworks.ai.
- There were no further responses or clarifications regarding this topic.
LLM Finetuning (Hamel + Dan) ▷ #fireworks (1 messages):
Credits CheckAccount ID Query
- Checking your credits: A member asked how to check if they have credits and provided their account ID as reneesyliu-571636.
- Account ID Query: The user included their Account ID in their query for assistance: reneesyliu-571636.
tinygrad (George Hotz) ▷ #learn-tinygrad (4 messages):
NVDLA vs NV acceleratorRuntime operations in NVUnexpected UOps in simple NN graph
- Clarifying NV Accelerator Capabilities: A member asked if the NV accelerator covers all of NVDLA or if a separate NVDLA/DLA accelerator needs to be written, citing the NVDLA GitHub.
- They also mentioned looking into cuDLA but needed to confirm their understanding before proceeding.
- NV Runtime Bypassing Userspace: Another member clarified that the NV runtime operates with GPUs, directly interacting with the kernel and bypassing userspace.
- Unexpected UOps in Simple NN Graph: Someone analyzed the UOps graph of a simple NN and noticed unexpected multiplications and additions with constants like 2.0 and -0.9999.
- Those are from the linear weight init, another member explained, clarifying the anomaly.
Link mentioned: nvdla: NVDLA Open Source Project. nvdla has 17 repositories available. Follow their code on GitHub.
Mozilla AI ▷ #llamafile (4 messages):
US Senate AI hearingMozilla blog on privacy law
- US Senate highlights AI's impact on privacy: During a Senate hearing, U.S. Senator Maria Cantwell emphasized AI’s role in transforming data privacy, advocating for federal comprehensive privacy law.
- Witnesses like Udbhav Tiwari from Mozilla underscored AI’s capabilities for online surveillance and consumer profiling.
- Mozilla's push for federal privacy law blogged: Mozilla featured on their distilled blog that Udbhav Tiwari testified at the Senate about the need for federal privacy laws in AI.
- The blog included a photo of Tiwari testifying and detailed the urgency of legislative action to protect individual privacy against AI-induced challenges.
Links mentioned:
MLOps @Chipro ▷ #events (1 messages):
Hugging Face WorkshopBusiness Impact of LLMsPrema RomanPatrick Deziel
- Join Hugging Face Models Workshop on July 30!: An exclusive online workshop titled Demystifying Hugging Face Models & How to Leverage Them For Business Impact is scheduled for July 30, 2024, at 12 PM ET. Registration is available here.
- Can't attend? Register to receive materials: Participants who cannot attend the Hugging Face workshop on July 30, 2024 can still register to receive the materials afterwards.
Link mentioned: What's in an LLM? Demystifying HuggingFace models & How to Leverage Them For Business Impact | July 30, 2024: Join us on July 30 via Zoom.
MLOps @Chipro ▷ #general-ml (2 messages):
Recsys CommunitySearch/IR CommunityCohere's Sentence Transformer TeamVespaElastic
- Recsys Community Larger Than Search/IR: A member noted that the Recsys community is much larger and more active compared to the search/IR community, which is described as 'niche' and 'different'.
- They mentioned Cohere's ownership of the entire sentence transformer team and cited key industry experts like Jo Bergum of Vespa and a member from Elastic.
- Omar Khattab’s Talk on DSPy: A member shared that Omar Khattab, an expert from MIT/Stanford, was a speaker at DSPy.
{% else %}
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: [{{ email.subject }}]({{ email_url }})!
If you enjoyed AInews, please share with a friend! Thanks in advance!
{% endif %}