AI News for 7/23/2024-7/24/2024. We checked 7 subreddits, 384 Twitters and 30 Discords (474 channels, and 4118 messages) for you. Estimated reading time saved (at 200wpm): 428 minutes. You can now tag @smol_ai for AINews discussions!
It is instructive to consider the focuses of Mistral Large in Feb 2024 vs today's Mistral Large 2:
- Large 1: big focus on MMLU 81% between Claude 2 (79%) and GPT4 (86.4%), API-only, no parameter count
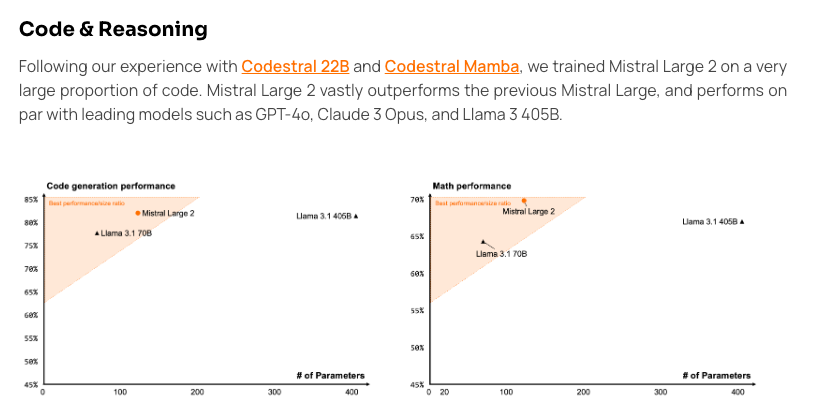
- Large 2: one small paragraph on MMLU 84% (still not better than GPT4!), 123B param Open Weights under a Research License, "sets a new point on the performance/cost Pareto front of open models" but new focus is on codegen & math performance using the "convex hull" chart made popular by Mixtral 8x22
- Both have decent focus on Multilingual MMLU
- Large 1: 32k context
- Large 2: 128k context
- Large 1: only passing mention of codegen
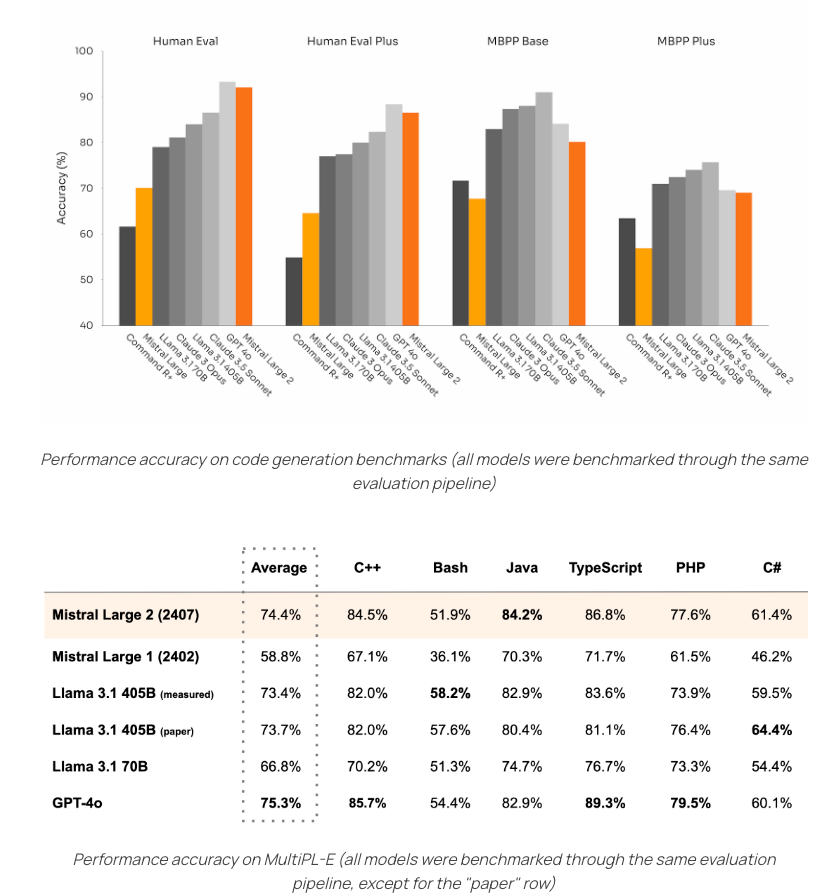
- Large 2: "Following our experience with Codestral 22B and Codestral Mamba, we trained Mistral Large 2 on a very large proportion of code."
- Large 1: "It is natively capable of function calling" and "JSON format"
- Large 2: "Sike actually our Function calling wasn't that good in v1 but we're better than GPT4o now"

- Large 2: "A significant effort was also devoted to enhancing the model’s reasoning capabilities."
- Llama 3.1: <<90 pages of extreme detail on how sythetic data was used to improve reasoning and math>>
Mistral's la Plateforme is deprecating all its Apache open source models (Mistral 7B, Mixtral 8x7B and 8x22B, Codestral Mamba, Mathstral) and only Large 2 and last week's 12B Mistral Nemo remain for its generalist models. This deprecation was fully predicted by the cost-elo normalized frontier chart we discussed at the end of yesterday's post.
{% if medium == 'web' %}
Table of Contents
[TOC]
{% else %}
The Table of Contents and Channel Summaries have been moved to the web version of this email: [{{ email.subject }}]({{ email_url }})!
{% endif %}
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
temporary outage today. back tomorrow.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Llama 3.1 Release and Capabilities
-
Meta Officially Releases Llama-3-405B, Llama-3.1-70B & Llama-3.1-8B (Score: 910, Comments: 373): Meta has officially released new versions of their Llama language models, including Llama-3-405B, Llama-3.1-70B, and Llama-3.1-8B. The models are available for download from the Llama website, and can be tested on cloud provider playgrounds such as Groq and Together.
-
Let's discuss Llama-3.1 Paper (A lot of details on pre-training, post-training, etc) (Score: 109, Comments: 26): Llama 3.1 paper reveals pre-training details The Llama 3.1 paper, available at ai.meta.com, provides extensive details on the model's pre-training and post-training processes. The paper includes hyperparameter overviews, validation loss graphs, and various performance metrics for different model sizes ranging from 7B to 70B parameters.
-
Early Hot Take on Llama 3.1 8B at 128K Context (Score: 72, Comments: 49): Llama 3.1 8B model's 128K context performance underwhelms The author tested the Llama 3.1 8B model with 128K context using a novel-style story and found it less capable than Mistral Nemo and significantly inferior to the Yi 34B 200K model. The Llama model struggled to recognize previously established context about a character's presumed death and generate appropriate reactions, even when tested with FP16 precision in 24GB VRAM using exllama with Q6 cache. Despite further testing with 8bpw and Q8 quantization, the author ultimately decided to abandon Llama 8B in favor of Mistral Dori.
Theme 2. Open Source AI Strategy and Industry Impact
-
Open source AI is the path forward - Mark Zuckerberg (Score: 794, Comments: 122): Mark Zuckerberg advocates for open source AI Mark Zuckerberg argues that open source AI is crucial for advancing AI technology and ensuring its responsible development. In his blog post, Zuckerberg emphasizes the benefits of open source AI, including faster innovation, increased transparency, and broader access to AI tools and knowledge.
-
Llama 3 405b is a "systemic risk" to society according to the AI Act (Score: 169, Comments: 68): Meta's Llama 3.1 405B model has been classified as a "systemic risk" under the European Union's AI Act. This designation applies to AI systems with more than 10^25 parameters, placing significant regulatory obligations on Meta for the model's development and deployment. The classification highlights the growing concern over the potential societal impacts of large language models and the increasing regulatory scrutiny they face in Europe.
-
OpenAI right now... (Score: 167, Comments: 27): OpenAI's competitors are closing the gap. The release of Llama 3.1 by Meta has demonstrated significant improvements in performance, potentially challenging OpenAI's dominance in the AI language model space. This development suggests that the competition in AI is intensifying, with other companies rapidly advancing their capabilities.
- ChatGPT's Declining Performance: Users report ChatGPT's coding abilities have deteriorated since early 2023, with GPT-4 and GPT-4 Turbo showing inconsistent results and reduced reliability for tasks like generating PowerShell scripts.
- OpenAI's Credibility Questioned: Critics highlight OpenAI's lobbying efforts to regulate open-source AI and the addition of former NSA head Paul Nakasone to their board, suggesting a shift away from their original "open" mission.
- Calls for Open-Source Release: Some users express desire for OpenAI to release model weights for local running, particularly for GPT-3.5, as a way to truly advance the industry and live up to their "Open" name.
{kind=link}
Theme 3. Performance Benchmarks and Comparisons
-
LLama 3.1 vs Gemma and SOTA (Score: 140, Comments: 37): Llama 3.1 outperforms Gemma and other state-of-the-art models across various benchmarks, including MMLU, HumanEval, and GSM8K. The 7B and 13B versions of Llama 3.1 show significant improvements over their predecessors, with the 13B model achieving scores comparable to or surpassing larger models like GPT-3.5. This performance leap suggests that Llama 3.1 represents a substantial advancement in language model capabilities, particularly in reasoning and knowledge-based tasks.
-
Llama 3.1 405B takes #2 spot in the new ZebraLogic reasoning benchmark (Score: 110, Comments: 9): Llama 3.1 405B has secured the second place in the newly introduced ZebraLogic reasoning benchmark, demonstrating its advanced reasoning capabilities. This achievement positions the model just behind GPT-4 and ahead of other notable models like Claude 2 and PaLM 2. The ZebraLogic benchmark is designed to evaluate a model's ability to handle complex logical reasoning tasks, providing a new metric for assessing AI performance in this crucial area.
-
The final straw for LMSYS (Score: 175, Comments: 55): LMSYS benchmark credibility questioned. The author criticizes LMSYS's ELO ranking for placing GPT-4o mini as the second-best model overall, arguing that other models like GPT-4, Gemini 1.5 Pro, and Claude Opus are more capable. The post suggests that human evaluation of LLMs is now limited by human capabilities rather than model capabilities, and recommends alternative benchmarks such as ZebraLogic, Scale.com leaderboard, Livebench.ai, and LiveCodeBench for more accurate model capability assessment.
{kind=link}
Theme 4. Community Tools and Deployment Resources
-
Llama-3.1 8B Instruct GGUF are up (Score: 50, Comments: 15): Llama-3.1 8B Instruct GGUF models have been released, offering various quantization levels including Q2_K, Q3_K_S, Q3_K_M, Q4_0, Q4_K_S, Q4_K_M, Q5_0, Q5_K_S, Q5_K_M, Q6_K, and Q8_0. These quantized versions provide options for different trade-offs between model size and performance, allowing users to choose the most suitable version for their specific use case and hardware constraints.
-
Finetune Llama 3.1 for free in Colab + get 2.1x faster, 60% less VRAM use + 4bit BnB quants (Score: 85, Comments: 24): Unsloth has released tools for Llama 3.1 that make finetuning 2.1x faster, use 60% less VRAM, and improve native HF inference speed by 2x without accuracy loss. The release includes a free Colab notebook for finetuning the 8B model, 4-bit Bitsandbytes quantized models for faster downloading and reduced VRAM usage, and a preview of their Studio Chat UI for local chatting with Llama 3.1 8B Instruct in Colab.
-
We made glhf.chat: run (almost) any open-source LLM, including 405b (Score: 54, Comments: 26): New platform glhf.chat launches for running open-source LLMs The newly launched glhf.chat platform allows users to run nearly any open-source LLM supported by the vLLM project, including models up to ~640GB of VRAM. Unlike competitors, the platform doesn't have a hardcoded model list, enabling users to run any compatible model or finetune by pasting a Hugging Face link, with support for models like Llama-3-70b finetunes and upcoming Llama-3.1 versions.
- The platform initially required an invite code "405B" for registration, which was mentioned in the original post. reissbaker, the developer, later removed the invite system entirely to simplify access for all users.
- Users encountered a "500 user limit" error due to an oversight in upgrading the auth provider. Billy, another glhf.chat developer, acknowledged the issue and promised a fix within minutes.
- In response to a user request, reissbaker shipped a fix for the Mistral NeMo architecture, enabling support for models like the dolphin-2.9.3-mistral-nemo-12b on the platform.
All AI Reddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI Model Releases and Benchmarks
-
Meta releases Llama 3.1 405B model: Meta has released a new 405 billion parameter Llama model. Benchmark results show it performing competitively with GPT-4 and Claude 3.5 Sonnet on some tasks.
-
Zuckerberg argues for open-sourcing AI models: Mark Zuckerberg made the case that open-sourcing AI models is beneficial, arguing that closed models will be stolen anyway. He stated that "it doesn't matter that China has access to open weights, because they will just steal weights anyway if they're closed."
-
Google releases "AI Agents System": Google has released Project Oscar, an open-source platform for creating AI agents to manage software projects, particularly for monitoring issues and bugs.
AI Capabilities and Benchmarks
-
Debate over AI surpassing human intelligence: There is ongoing discussion about whether current AI models have surpassed human-level intelligence in certain domains. Some argue that AI is now "smart enough to fool us", while others contend that AI still struggles with simple logic and math tasks.
-
Limitations of current benchmarks: Critics point out that current AI benchmarks may not accurately measure intelligence. For example, the Arena benchmark measures which responses people prefer, not necessarily intelligence.
AI Ethics and Corporate Practices
-
OpenAI criticized for non-disclosure agreements: OpenAI faced criticism after a community note on social media highlighted that the company had previously used non-disclosure agreements that prevented employees from making protected disclosures.
-
Debate over open vs. closed AI development: There is ongoing discussion about the merits of open-sourcing AI models versus keeping them closed. Some argue that open-sourcing promotes innovation, while others worry about potential misuse.
AI Discord Recap
A summary of Summaries of Summaries
1. Llama 3.1 Model Performance and Challenges
- Fine-Tuning Woes: Llama 3.1 users reported issues with fine-tuning, particularly with error messages related to model configurations and tokenizer handling, suggesting updates to the transformers library.
- Discussions emphasized the need for specifying correct model versions and maintaining the right configuration to mitigate these challenges.
- Inconsistent Performance: Users noted that Llama 3.1 8B struggles with reasoning and coding tasks, with some members expressing skepticism regarding its overall performance.
- Comparisons suggest that while it's decent for its size, its logic capabilities appear lacking, especially contrasted with models like Gemma 2.
- Overload Issues: The Llama 3.1 405B model frequently shows 'service unavailable' errors due to being overloaded with requests, suggesting higher demand and potential infrastructure limits.
- Users discussed the characteristics of the 405B variant, mentioning that it feels more censored compared to its 70B sibling.
2. Mistral Large 2 Model
- Mistral Large 2 Release: On July 24, 2024, Mistral AI launched Mistral Large 2, featuring an impressive 123 billion parameters and a 128,000-token context window, pushing AI capabilities further.
- Mistral Large 2 is reported to outperform Llama 3.1 405B, particularly in complex mathematical tasks, making it a strong competitor against industry giants.
- Multilingual Capabilities: The Mistral Large 2 model boasts a longer context window and multilingual support compared to existing models, making it a versatile tool for various applications.
- Members engaged in comparisons with Llama models, noting ongoing performance enhancement efforts in this evolving market.
3. AI in Software Development and Job Security
- Job Security Concerns: Participants addressed job security uncertainties among junior developers as AI tools increasingly integrate into coding practices, potentially marginalizing entry-level roles.
- Consensus emerged that experienced developers should adapt to these tools, using them to enhance productivity rather than replace human interaction.
- Privacy in AI Data Handling: Concerns arose regarding AI's data handling practices, particularly the implications of human reviewers accessing sensitive information.
- The discourse underscored the critical need for robust data management protocols to protect user privacy.
4. AI Model Benchmarking and Evaluation
- Benchmarking Skepticism: Skepticism arises over the performance metrics of Llama 405b, with discussions highlighting its average standing against Mistral and Sonnet models.
- The community reflects on varied benchmark results and subjective experiences, likening benchmarks to movie ratings that fail to capture true user experience.
- Evaluation Methods: The need for better benchmarks in hallucination prevention techniques was highlighted, prompting discussions on improving evaluation methods.
- A brief conversation with a Meta engineer raised concerns about the current state of benchmarking, suggesting a collaborative approach to developing more reliable metrics.
5. Open-Source AI Developments
- Llama 3.1 Release: The Llama 3.1 model has officially launched, expanding context length to 128K and supporting eight languages, marking a significant advancement in open-source AI.
- Users reported frequent 'service unavailable' errors with the Llama 3.1 405B model due to overload, suggesting it feels more censored than its 70B counterpart.
- Mistral Large 2 Features: Mistral Large 2 features state-of-the-art function calling capabilities, with day 0 support for structured outputs and agents.
- This release aligns with enhanced function calling and structured outputs, providing useful resources like cookbooks for users to explore.
PART 1: High level Discord summaries
Unsloth AI (Daniel Han) Discord
- Llama 3.1 Fine-Tuning Challenges: Users reported issues fine-tuning Llama 3.1, particularly with error messages stemming from model configurations and tokenizer handling, suggesting updates to the transformers library.
- Discussions emphasized the need for specifying correct model versions and maintaining the right configuration to mitigate these challenges.
- Job Security Concerns in AI Development: Participants addressed job security uncertainties among junior developers as AI tools increasingly integrate into coding practices, potentially marginalizing entry-level roles.
- Consensus emerged that experienced developers should adapt to these tools, using them to enhance productivity rather than replace human interaction.
- Insights on Image Generation Bias: Discussions around image generation highlighted challenges in achieving diversity and addressing biases inherent in AI models, which are crucial for educational contexts.
- Critiques of current diversity efforts emerged, pointing out execution flaws that could skew historical accuracy.
- Performance of Mistral Large 2: The Mistral Large 2 model surfaced as a strong competitor in the AI landscape, boasting a longer context window and multilingual support compared to existing models.
- Members engaged in comparisons with Llama models, noting ongoing performance enhancement efforts in this evolving market.
- Privacy Concerns in AI Data Handling: Concerns arose regarding AI's data handling practices, particularly the implications of human reviewers accessing sensitive information.
- The discourse underscored the critical need for robust data management protocols to protect user privacy.
LM Studio Discord
- LM Studio struggles running Llama 3.1: Users identified that LM Studio cannot run Llama 3.1 on OpenCL cards; upgrading to version 0.2.28 is recommended for better support.
- Confirmed updates from LM Studio are essential for effective performance of large models like Llama 3.1.
- ROCm 0.2.28 leads to performance degradation: After the ROCm 0.2.28 update, a user experienced reduced performance, seeing only 150w usage on a dual 7900 XT setup.
- Reverting to 0.2.27 restored normal performance, prompting calls for a deeper investigation into changes in the new update.
- Nemo Models face context and performance issues: Users report that Nemo models function with current versions but suffer from context length limitations and slower outputs due to insufficient RAM.
- There were success stories with particular setups, alongside suggestions for optimizations.
- GPU Offloading Problems Persist: Several members reported malfunctioning GPU offloading on their systems, particularly with M3 Max and 4080S GPUs, often requiring manual adjustments.
- Automatic settings caused errant outputs, indicating a need for more reliable manual configurations for better performance.
- Meta-Llama 3.1 70B hits the repository: The release of 70B quant models for Meta-Llama 3.1 has been announced, available through the repository.
- Enthusiasm in the channel was notable, with expectations for improved performance following a re-upload to fix a tokenizer bug.
Perplexity AI Discord
- Llama 3.1 405B Makes Waves: The Llama 3.1 405B model is touted as the most capable open-source model, now available on Perplexity, rivaling GPT-4o and Claude Sonnet 3.5 for performance.
- Exciting plans for its integration into mobile applications are in the works, enhancing accessibility for on-the-go developers.
- Mistral Large 2 Breaks New Ground: On July 24, 2024, Mistral AI launched Mistral Large 2, featuring an impressive 123 billion parameters and a 128,000-token context window, pushing AI capabilities further.
- Mistral Large 2 is reported to outperform Llama 3.1 405B, particularly in complex mathematical tasks, making it a strong competitor against industry giants.
- AI Model Benchmarking Under Scrutiny: Skepticism arises over the performance metrics of Llama 405b, with discussions highlighting its average standing against Mistral and Sonnet models.
- The community reflects on varied benchmark results and subjective experiences, likening benchmarks to movie ratings that fail to capture true user experience.
- NextCloud Integrates OpenAI: A recent integration of NextCloud with OpenAI has sparked interest, featuring a community-driven, open-source approach that promotes clear coding standards.
- A GitHub repository was shared, providing aspiring developers resources to explore this new functionality and its implications.
- TikTok's Search Engine Potential: A lively discussion on TikTok as a search tool for Gen Z highlights its rising relevance and challenges traditional search engines.
- Concerns around the platform's reliability, especially in health advice, indicate a need for caution when using TikTok for critical information.
OpenAI Discord
- Mistral-7B boasts massive context windows: The Mistral-7B-v0.3 model features an impressive 128k context window and supports multiple languages, while the Mistral Large version runs efficiently at 69GB using ollama.
- Users praised its capabilities, pointing to potential applications for multitasking with larger datasets.
- Affordable GPU server options emerge: Discussions highlighted Runpod as a budget-friendly GPU server option for large models, priced at just $0.30/hour.
- Participants recommended using LM Studio and ollama for better performance tailored to specific model requirements.
- Kling AI offers quirky image-to-video generation: Kling AI impressed users with its ability to create videos from still images, although some noted issues with video quality and server overloads.
- Despite mixed experiences, the engaging output sparked further interest in experimenting with the tool.
- Memory feature inconsistencies frustrate users: Members reported variable appearances of the memory feature in the EU, with some only able to access it temporarily for five minutes.
- This led to lighthearted banter about the feature’s operational status and its overall reliability.
- Generating PDFs with OpenAI in Python: A user sought help for generating PDF documents via Python using OpenAI, looking for ways to automate section descriptions based on uploaded content.
- This discussion drove a collaborative exchange on effective workflows to enhance document generation processes.
Nous Research AI Discord
- LLM Distillation Advancements: Members have highlighted the potential of the Minitron GitHub repository for understanding recent advancements in LLM distillation techniques using pruning and knowledge distillation.
- This repository reflects ongoing efforts similar to models like Sonnet, Llama, and GPT-4Omini.
- LLaMa 3 Introduced as a New Player: The recently introduced LLaMa 3 models feature a dense Transformer structure equipped with 405B parameters and a context window of up to 128K tokens, designed for various complex tasks.
- These models excel in multilinguality and coding, setting a new benchmark for AI applications.
- Mistral Large 2's Competitive Edge: The release of Mistral Large 2 with 123B parameters and a 128k context window has captivated users, especially for coding tasks.
- Despite its non-commercial license, its innovative design positions it well for optimal API performance.
- Fine-Tuning Llama 3 Presents Challenges: Concerns surface over fine-tuning Llama 3 405B, where some suggest only Lora FTing as a feasible approach.
- This situation may bolster advances in DoRA fine-tuning efforts within the OSS community.
- Moral Reasoning and the Trolley Problem: Discussions around incorporating difficult moral queries, like the trolley problem, have emphasized the need to evaluate models' moral foundations.
- This triggers debates on whether these tasks examine pure reasoning skills or ethical frameworks.
OpenRouter (Alex Atallah) Discord
- DeepSeek Coder V2 Launches Private Inference Provider: DeepSeek Coder V2 now features a private provider to serve requests on OpenRouter without input training, marking a significant advancement in private model deployment.
- This new capacity reflects strategic progression within the OpenRouter platform as it enhances usability for users.
- Concerns over Llama 3.1 405B Performance: Users express dissatisfaction with the performance of Llama 3.1 405B, particularly its handling of NSFW content where it often refuses prompts or outputs training data.
- Feedback indicates temperature settings significantly affect quality, with some users reporting better output at lower temperatures.
- Mistral Large 2 Replacement Provides Better Multilingual Support: Mistral Large 2 is now launched as Mistral Large, effectively replacing the previous version with enhanced multilingual capabilities.
- Users speculate it may outperform Llama 3.1 when dealing with languages like French, as they assess its comparative effectiveness.
- Users Discuss OpenRouter API Limitations: Discussion highlights OpenRouter API challenges, particularly in terms of rate limits and multilingual input management, which complicates model usage.
- While some models are in free preview, users report strict limits on usage and context, pointing to a need for improvements.
- Interest in Open-Source Coding Tools Grows: Users show a keen interest in open-source autonomous coding tools like Devika and Open Devin, asking for recommendations based on current efficacy.
- This shift reflects a desire to experiment with alternatives to mainstream AI coding solutions that exhibit varied performance.
HuggingFace Discord
- Llama 3.1 Launches with Excitement: The Llama 3.1 model has officially launched, expanding context length to 128K and supporting eight languages, marking a significant advancement in open-source AI. The model can be explored in detail through the blogpost and is available for testing here.
- Users reported frequent 'service unavailable' errors with the Llama 3.1 405B model due to overload, suggesting it feels more censored than its 70B counterpart.
- Improved HuggingChat with Version v0.9.1: The latest version HuggingChat v0.9.1 integrates new features that significantly enhance user accessibility. Users can discover more functionalities through the's model page.
- The update aims to improve interactions utilizing the new HuggingChat features.
- Risks with MultipleNegativesRankingLoss: Difficulties were reported when training sentence encoders using MultipleNegativesRankingLoss, where increasing the batch size led to worse model performance. Insights were sought on common dataset pitfalls associated with this method.
- One user described their evaluation metrics, focusing on recall@5, recall@10, and recall@20 for better benchmarking.
- Mistral-NeMo 12B Shines in Demo: A demo of Mistral-NeMo 12B Instruct using llama.cpp showcases the model's significant performance enhancements. Users are encouraged to experiment for an improved chat experience.
- Community interest is soaring regarding the model's capabilities and potential applications in various AI tasks.
- Questions on Rectified Flow and Evaluation: Members expressed frustration regarding the lack of discussions around Rectified Flow and Flow Matching, especially in contrast to DDPM and DDIM debates. They emphasized the difficulty finding straightforward examples for Flow applications such as generating MNIST.
- Evaluation methods for generative models were explored, with a focus on qualitative and quantitative methods for assessing the performance of models like Stable Diffusion versus GANs.
Stability.ai (Stable Diffusion) Discord
- Kohya-ss GUI Compatibility Quirks: Users reported that the current version of Kohya-ss GUI faces compatibility issues with Python 3.10, requiring an upgrade to 3.10.9 or higher.
- One user humorously remarked that it resembles needing a weight limit of 180lbs but not exceeding 180.5lbs.
- Exciting Lycoris Features on the Horizon: Onetrainer is potentially integrating Lycoris features in a new dev branch, spurring discussions on functional enhancements.
- Community members noted a preference for bmaltais' UI wrapper, which could improve experiences with these new integrations.
- Community Raves About Art Models: Discussion outlined performance ratings for models including Kolors, Auraflow, Pixart Sigma, and Hunyuan, with Kolors being commended for its speed and quality.
- Participants engaged in a debate on user experiences and specific applications of these models, showcasing diverse opinions.
- Stable Diffusion Models Under the Microscope: Users examined the differences in output between Stable Diffusion 1.5 and SDXL, focusing on detail and resolution.
- Techniques such as Hidiffusion and Adaptive Token Dictionary were discussed as methods to boost older model outputs.
- Welcome to Stable Video 4D!: The newly introduced Stable Video 4D model allows transformation of single object videos into multi-angle views for creative projects.
- Currently in research, this model promises applications in game development, video editing, and virtual reality.
Eleuther Discord
- Diving Deep into Sampling Models: Members discussed various sampling methods such as greedy, top-p, and top-k, highlighting their respective trade-offs, particularly for large language models.
- Stochastic sampling is noted for diversity but complicates evaluation, contrasting with the reliability of greedy methods which generate the most probable paths.
- Llama 3.1's Sampling Preferences: In discussions about Llama 3.1, participants recommended consulting its paper for optimal sampling methods, with a lean towards probabilistic sampling techniques.
- One member pointed out that Gemma 2 effectively uses top-p and top-k strategies common in model evaluations.
- Misleading Tweets Trigger Discussion: Members analyzed a misleading tweet related to Character.ai's model, particularly its use of shared KV layers impacting performance metrics.
- Concerns arose regarding the accuracy of such information, highlighting the community's ongoing journey to comprehend transformer architectures.
- MoE vs Dense Models Debate: A lively debate emerged over the preference for dense models over Mixture-of-Experts (MoE), citing high costs and engineering challenges of handling MoEs in training.
- Despite the potential efficiency of pre-trained MoEs, concerns linger about varied organizational capabilities to implement them.
- Llama API Evaluation Troubles: Users reported errors with the
lm_evaltool for Llama 3.1-405B, particularly challenges in handling logits and multiple-choice tasks through the API.- Errors such as 'No support for logits' and 'Method Not Allowed' prompted troubleshooting discussions, with successful edits to the
_create_payloadmethod noted.
- Errors such as 'No support for logits' and 'Method Not Allowed' prompted troubleshooting discussions, with successful edits to the
CUDA MODE Discord
- CUDA Installation Troubleshooting: Members faced issues when Torch wasn't compiled with CUDA, leading to import errors. Installation of the CUDA version from the official page was recommended for ensuring compatibility.
- After setting up CUDA, one user encountered a torch.cuda.OutOfMemoryError while allocating 172.00 MiB, suggesting adjustments to max_split_size_mb to tackle memory fragmentation.
- Exploring Llama-2 and Llama-3 Features: A member shared a fine-tuned Llama-2 7B model, trained on a 24GB GPU in 19 hours. Concurrently, discussions on implementing blockwise attention in Llama 3 focused on the sequence splitting stage relative to rotary position embeddings.
- Additionally, inquiries on whether Llama 3.1 has improved inference latency over 3.0 were raised, reflecting ongoing interests in model performance advancements.
- Optimizations in FlashAttention for AMD: FlashAttention has gained support for AMD ROCm, following the implementation detailed in GitHub Pull Request #1010. The updated library maintains API consistency while introducing several new C++ APIs like
mha_fwd.- Current compatibility for the new version is limited to MI200 and MI300, suggesting potential broader updates may follow in the future.
- PyTorch Compile Insights: Users reported that
torch.compileincreased RAM usage with small Bert models, and switching from eager mode resulted in worse performance. Suggestions to use the PyTorch profiler to analyze memory traces during inference were offered.- Observations indicated no memory efficiency improvements with
reduce-overheadandfullgraphcompile options, emphasizing the importance of understanding configuration effects.
- Observations indicated no memory efficiency improvements with
- Strategies for Job Hunting in ML/AI: A user sought advice on drafting a roadmap for securing internships and full-time positions in ML/AI, sharing a Google Document with their plans. They expressed a commitment to work hard and remain flexible on timelines.
- Further feedback on their internship strategies was encouraged, highlighting the willingness to dedicate extra hours towards achieving their objectives.
OpenAccess AI Collective (axolotl) Discord
- Llama 3.1 Struggles with Errors: Users reported issues with Llama 3.1, facing errors like AttributeError, which may stem from outdated images or configurations.
- One user found a workaround by trying a different image, expressing frustration over ongoing model updates.
- Mistral Goes Big with Large Model Release: Mistral released the Mistral-Large-Instruct-2407 model with 123B parameters, claiming state-of-the-art performance.
- The model offers multilingual support, coding proficiency, and advanced agentic capabilities, stirring excitement in the community.
- Multilingual Capabilities under Scrutiny: Comparisons between Llama 3.1 and NeMo highlighted performance differences, particularly in multilingual support.
- While Llama 3 has strengths in European languages, users noted that NeMo excels in Chinese and others.
- Training Large Models Hits RAM Barriers: Concerns arose over the significant RAM requirements for training large models like Mistral, with users remarking on their limitations.
- Some faced exploding gradients during training and speculated whether this issue was tied to sample packing.
- Adapter Fine-Tuning Stages Gaining Traction: Members discussed multiple stages of adapter fine-tuning, proposing the idea of initializing later stages with previous results, including SFT weights for DPO training.
- A feature request on GitHub suggests small code changes to facilitate this method.
Interconnects (Nathan Lambert) Discord
- GPT-4o mini dominates Chatbot Arena: With over 4,000 user votes, GPT-4o mini is now tied for #1 in the Chatbot Arena leaderboard, outperforming its previous version while being 20x cheaper. This milestone signals a notable decline in the cost of intelligence for new applications.
- Excitement was evident as developers celebrated this accomplishment, noting its implications for future chatbot experiences.
- Mistral Large 2: A New Contender: Mistral Large 2 boasts a 128k context window and multilingual support, positioning itself strongly for high-complexity tasks under specific licensing conditions. Discussions surfaced on the lack of clarity regarding commercial use of this powerful model.
- Members emphasized the need for better documentation to navigate the licensing landscape effectively.
- OpenAI's $5 billion Loss Prediction: Estimates suggest OpenAI could face a staggering loss of $5 billion this year, primarily due to Azure costs and training expenses. The concern over profitability has prompted discussions about the surprisingly low API revenue compared to expectations.
- This situation raises fundamental questions about the sustainability of OpenAI's business model in the current environment.
- Llama 3 Officially Released: Meta has officially released Llama3-405B, trained on 15T tokens, which claims to outperform GPT-4 on all major benchmarks. This marks a significant leap in open-source AI technology.
- The launch has sparked discussions around the integration of 100% RLHF in the post-training capabilities of the model, which highlights the crucial role of this method.
- CrowdStrike's $10 Apology Gift Card for Outage: CrowdStrike is offering partners a $10 Uber Eats gift card as an apology for a massive outage, but some found the vouchers had been canceled when attempting to redeem them. This incident underscores the operational risks associated with technology updates.
- Members shared mixed feelings about the effectiveness of this gesture amid ongoing frustrations.
Modular (Mojo 🔥) Discord
- Mojo Compiler Versioning Confusion: A discussion highlighted the uncertainty ongoing about whether the next main compiler version will be 24.5 or 24.8, citing potential disconnects between nightly and main releases as they progress towards 2025.
- Community members raised concerns about adhering to different release principles, complicating future updates.
- Latest Nightly Update Unpacked: The newest nightly Mojo compiler update,
2024.7.2405, includes significant changes such as the removal of DTypePointer and enhanced string formatting methods, details of which can be reviewed in the current changelog.- The removal of DTypePointer necessitates code updates for existing projects, prompting calls for clearer transition guidelines.
- SDL Integration Questions Arise: A user requested resources for integrating SDL with Mojo, aiming to gain a better understanding of the process, and how to use DLHandle effectively.
- This reflects a growing interest in enhancing Mojo’s capabilities through third-party libraries.
- Discussion on Var vs Let Utility: A member initiated a debate on the necessity of using var in situations where everything is already declared as such, suggesting redundancy in usage.
- Another pointed out that var aids the compiler while let caters to those favoring immutability, highlighting a preference debate among developers.
- Exploring SIMD Type Comparability: Members discussed challenges in establishing total ordering for SIMD types, noting tension between generic programming and specific comparisons.
- It was proposed that a new SimdMask[N] type might alleviate some complexities associated with platform-specific behaviors.
Latent Space Discord
- Factorio Automation Mod sparks creativity: The new factorio-automation-v1 mod allows agents to automate tasks like crafting and mining in Factorio, offering a fun testing ground for agent capabilities.
- Members are excited about the possibilities this mod opens up for complex game interactions.
- GPT-4o Mini Fine-Tuning opens up: OpenAI has launched fine-tuning for GPT-4o mini, available to tier 4 and 5 users, with the first 2M training tokens free daily until September 23.
- Members noted performance inconsistencies when comparing fine-tuned GPT-4o mini with Llama-3.1-8b, raising questions about exact use cases.
- Mistral Large 2 impresses with 123B parameters: Mistral Large 2 has been revealed, boasting 123 billion parameters, strong coding capabilities, and supporting multiple languages.
- However, indications show it achieved only a 60% score on Aider's code editing benchmark, slightly ahead of the best GPT-3.5 model.
- Reddit's Content Policy stirs debate: A heated discussion surfaced about Reddit's public content policy, with concerns around user control over generated content.
- Members argue that the vague policy creates significant issues, highlighting the need for clearer guidelines.
- Join the Llama 3 Emergency Paper Club: An emergency paper club meeting on The Llama 3 Herd of Models is set for later today, a strong contender for POTY Awards.
- Key contributors to the discussion include prominent community members, emphasizing the paper's significance.
LlamaIndex Discord
- LlamaParse Enhances Markdown Capabilities: LlamaParse now showcases support for Markdown output, plain text, and JSON mode for better metadata extraction. Features such as multi-language output enhance its utility across workflows, as demonstrated in this video.
- This update is set to significantly improve OCR efficiency for diverse applications, broadening its adoption for various tasks beyond simple text.
- MongoDB’s AI Applications Program is Here: The newly launched MongoDB AI Applications Program (MAAP) aims to simplify the journey for organizations building AI-enhanced applications. With reference architectures and integrated technology stacks, it accelerates AI deployment timeframes; learn more here.
- The initiative addresses the urgent need developers have to modernize their applications with minimal overhead, contributing to more efficient workflows.
- Mistral Large 2 Introduces Function Calling: Mistral Large 2 is rolling out enhanced function calling capabilities, which includes support for structured outputs as soon as it launches. Detailed resources such as cookbooks are provided to aid developers in utilizing these new functionalities; explore them here.
- This release underscores functional versatility for LLM applications, allowing developers to implement more complex interactions effectively.
- Streaming Efficiency with SubQuestionQueryEngine: Members discussed employing SubQuestionQueryEngine.from_defaults to facilitate streaming responses and reduce latency within LLM queries. Some solutions were proposed using
get_response_synthesizer, though challenges remain in implementation.- Despite the hurdles in adoption, there's optimism about improving user interaction speeds across LLM integrations.
- Doubts Surface Over Llama 3.1 Metrics: Skepticism mounts regarding the metrics published by Meta for Llama 3.1, especially its effectiveness in RAG evaluations. Users are questioning the viability of certain models like
llama3:70b-instruct-q_5for practical tasks.- This skepticism reflects broader community concerns regarding the reliability of AI metrics in assessing model performance in various applications.
Cohere Discord
- Cohere Dashboard Reloading Trouble: Members reported issues with the Cohere account dashboard constantly reloading, while others noted no such problems on their end, leading to discussions on potential glitches.
- This prompted a conversation about rate limiting as a possible cause for the reloading issue.
- Cheering for Command R Plus: With each release of models like Llama 3.1, members expressed increasing appreciation for Command R Plus, highlighting its capabilities compared to other models.
- One user proposed creating a playground specifically for model comparisons to further explore this growing sentiment.
- Server Performance Under Scrutiny: Concerns arose regarding potential server downtime, but some users confirmed that the server was in full operational status.
- Suggestions included investigating rate limiting as a factor influencing user experience.
- Innovative Feature Suggestions for Cohere: A member suggested incorporating the ability to use tools during conversations in Cohere, like triggering a web search on demand.
- Initial confusion arose, but it was clarified that some of these functionalities are already available.
- Community Welcomes New Faces: New members introduced themselves, sharing backgrounds in NLP and NeuroAI, sparking excitement about the community.
- The discussion also touched on experiences with Command-R+, emphasizing its advantages over models like NovelAI.
DSPy Discord
- Zenbase/Core Launch Sparks Excitement: zenbase/core is now live, enabling users to integrate DSPy’s optimizers directly into their Python projects like Instructor and LangSmith. Support the launch by engaging with their Twitter post.
- Community members are responding positively, with a strong willingness to promote this recent release.
- Typed Predictors Raise Output Concerns: Users report issues with typed predictors not producing correctly structured outputs, inviting help from others. Suggestions include enabling experimental features with
dspy.configure(experimental=True)to address these problems.- Encouragement from peers highlights a collective effort to refine the usage of these predictors.
- Internal Execution Visibility Under Debate: There's a lively discussion over methods to observe internal program execution steps, including suggestions like
inspect_history. Users express the need for deeper visibility into model outputs, especially during type-checking mishaps.- A common desire for transparency showcases the importance of debugging tools in DSPy usage.
- Push for Small Language Models: One member shared an article on the advantages of small language models, noting their efficiency and suitability for edge devices with limited resources. They highlighted benefits like privacy and operational simplicity for models running on just 4GB of RAM.
- Check out the article titled Small Language Models are the Future for a comprehensive read on the topic.
- Call to Contribute to DSPy Examples: A user expressed interest in contributing beginner-friendly examples to the DSPy repository, aiming to enrich the resource base. Community feedback confirmed a need for more diverse examples, specifically in the
/examplesdirectory.- This initiative reflects a collaborative spirit to enhance learning materials within the DSPy environment.
tinygrad (George Hotz) Discord
- Members tackle Tinygrad learning: Members express their ongoing journey with Tinygrad, focusing on understanding its use concerning transformers. One noted, It's a work in progress, indicating a gradual mastery process.
- Discussion hinted at potential collective resources to enhance the learning curve.
- Molecular Dynamics engine under construction: A team is developing a Molecular Dynamics engine using neural networks for energy prediction, facing challenges in gradient usage. Input gradient tracking methods were suggested to optimize weight updates during backpropagation.
- Optimizing backpropagation emerged as a focal point to improve training performance.
- Creating a Custom Runtime in Tinygrad: A member shared insights on implementing a custom runtime for Tinygrad, emphasizing how straightforward it is to add support for new hardware. They sought clarity on terms like
global_sizeandlocal_size, vital for kernel executions.- Technical clarifications were provided regarding operational contexts for these parameters.
- Neural Network Potentials discussion: The energy in the Molecular Dynamics engine relies on Neural Network Potentials (NNP), with emphasis on calculation efficiency. Conversations revolved around strategies to optimize backpropagation.
- Clear paths for enhancing calculation speed are necessary to improve outcomes.
- PPO Algorithm scrutiny in CartPole: A member probed the necessity of the
.sum(-1)operation in the implementation of the PPO algorithm for the Beautiful CartPole environment. This sparked a collaborative conversation on the nuances of reinforcement learning.- Detailed exploration of code implementations fosters community understanding and knowledge sharing.
Torchtune Discord
- Countdown to 3.1 and Cool Interviews: Members inquired about whether there would be any cool interviews released along with the 3.1 version, similar to those for Llama3.
- This raises interest for potential insights and discussions that might accompany the new release.
- MPS Support PR Gains Attention: A new pull request (#790) was highlighted which adds support for MPS on local Mac computers, checking for BF16 compatibility.
- Context suggests this PR could resolve major testing hurdles for those using MPS devices.
- LoRA Functionality Issues Persist: Discussed issues surrounding LoRA functionality, noting it did not work during a previous attempt and was previously impacted by hardcoded CUDA paths.
- Members exchanged thoughts on specific errors encountered, highlighting ongoing challenges in implementation.
- Fixing the Pad ID Bug: A member pointed out that the pad id should not be showing up in generate functionality, identifying it as an important bug.
- In response, a Pull Request was created to prevent pad ids and special tokens from displaying, detailed in Pull Request #1211.
- Optimizing Git Workflow to Reduce Conflicts: Discussion around refining git workflows to minimize the occurrence of new conflicts constantly arose, emphasizing collaboration.
- It was suggested that new conflicts might stem from the workflow, indicating a potential need for tweaks.
LangChain AI Discord
- Hugging Face Models and Agents Discussion: Members discussed their experiences with Agents using Hugging Face models, including local LLMs via Ollama and cloud options like OpenAI and Azure.
- This conversation sparked interest in the potential applications of agents within various model frameworks.
- Python Developers Job Hunt: A member urgently expressed their situation, stating, 'anyone looking to hire me? I need to pay my bills.' and highlighted their strong skills in Python.
- The urgency of job availability in the current market was apparent as discussions about opportunities ensued.
- Challenges with HNSW IVFFLAT Indexes on Aurora: Members faced problems creating HNSW or IVFFLAT indexes with 3072 dimensions on Aurora PGVECTOR, leading to shared insights about solutions involving halfvec.
- This highlighted ongoing challenges with dimensionality management in high-performance vector databases.
- LangServe's OSError Limits: Users encountered an OSError: [Errno 24] Too many open files when their LangServe app processed around 1000 concurrent requests.
- They are actively seeking strategies to handle high traffic while mitigating system resource limitations, with a GitHub issue raised for support.
- Introduction of AI Code Reviewer Tool: A member shared a YouTube video on the AI Code Reviewer, highlighting its features powered by LangChain.
- This tool aims to enhance the code review process, suggesting a trend towards automation in code assessment methodologies.
OpenInterpreter Discord
- Llama 3.1 405 B impresses with ease of use: Llama 3.1 405 B performs fantastically out of the box with OpenInterpreter, offering an effortless experience.
- In contrast, gpt-4o requires constant reminders about capabilities, making 405b a superior choice for multitasking.
- Cost-effective API usage with Nvidia: A user shared that Nvidia provides 1000 credits upon signup, where 1 credit equals 1 API call.
- This incentive opens up more accessibility for experimenting with APIs.
- Mistral Large 2 rivals Llama 3.1 405 B: Mistral Large 2 reportedly performs comparably to Llama 3.1 405 B, particularly noted for its speed.
- The faster performance may be due to lower traffic on Mistral's endpoints compared to those of Llama.
- Llama 3.1 connects with databases for free: MikeBirdTech noted that Llama 3.1 can interact with your database at no cost through OpenInterpreter, emphasizing savings on paid services.
- It's also fully offline and private, nobody else needs to see your data, highlighting its privacy benefits.
- Concerns over complex databases using Llama 3.1: A member raised a concern that for complex databases involving joins across tables, this solution may not be effective.
- They expressed appreciation for sharing the information, remarking on the well-done execution despite the limitations.
LAION Discord
- Llama 3.1: Meta's Open Source Breakthrough: Meta recently launched Llama 3.1 405B, hailed as the first-ever open-sourced frontier AI model, outperforming competitive models like GPT-4o on various benchmarks. For more insights, check this YouTube video featuring Mark Zuckerberg discussing its implications.
- The reception highlights the model's potential impact on AI research and open-source contributions.
- Trouble Downloading LAION2B-en Metadata: Members reported difficulties in locating and downloading the LAION2B-en metadata from Hugging Face, querying if others faced the same problem. Responses indicate this is a common frustration with accessibility.
- Someone linked to LAION maintenance notes for further clarification on the situation.
- LAION Datasets in Legal Limbo: Discussion revealed that LAION datasets are currently in legal limbo, with access to official versions restricted. While alternatives are available, it is advised to utilize unofficial datasets only for urgent research needs.
- Members noted the ongoing complexities surrounding data legality in the AI community.
- YouTube Polls: A Nostalgic Debate: A member shared a YouTube poll asking which 90's movie had the best soundtrack, igniting nostalgia among viewers. This prompts members to reflect on their favorite soundtracks from the era.
- The poll sparks a connection through shared cultural experiences.
Alignment Lab AI Discord
- Legal Clarity on ML Dataset Copyright: A member pointed out that most of the datasets generated by an ML model are likely not copyrightable since they lack true creativity. They emphasized that content not generated by GPT-4 may be under MIT licensing, though this area remains murky amid current legal debates.
- This opens up discussions on the implications for data ownership and ethical guidelines in dataset curation.
- Navigating Non-Distilled Data Identification: Discussion arose around the methods to pinpoint non-distilled data within ML datasets, highlighting an interest in systematic data management.
- Members seek clearer methodologies to enhance the organization of dataset contents, aiming to improve usability in ML projects.
LLM Finetuning (Hamel + Dan) Discord
- Experimenting with DPO for Translation Models: A member inquired about successfully fine-tuning translation models using DPO, referencing insights from the CPO paper. They emphasized that moderate-sized LLMs fail to match state-of-the-art performance.
- Is anyone achieving better results? underscores the community's growing interest in fine-tuning techniques.
- CPO Enhances Translation Outputs: The CPO approach targets weaknesses in supervised fine-tuning by aiming to boost the quality of machine translation outputs. It turns the focus from just acceptable translations to higher quality results, improving model performance.
- By addressing reference data quality, CPO leads to significant enhancements, specifically underutilizing datasets effectively.
- ALMA-R Proves Competitive: Applying CPO significantly improved ALMA-R despite training on only 22K parallel sentences and 12M parameters. The model can now rival conventional encoder-decoder architectures.
- This showcases the potential of optimizing LLMs even with limited data, opening up discussions on efficiency and scaling.
- NYC Tech Meetup in Late August: Interest sparked for a tech meetup in NYC during late August, with members expressing their desire to connect in person. This initiative promises to foster deeper networking and collaboration opportunities.
- The buzz around this potential meetup highlights a sense of community among members eager to share insights and experiences.
MLOps @Chipro Discord
- ML Efficiency Boost through Feature Stores: A live session on Leveraging Feature Stores is scheduled for July 31st, 2024, at 11:00 AM EDT, aimed at ML Engineers, Data Scientists, and MLOps professionals.
- This session will explore automated pipelines, tackling unreliable data, and present advanced use cases to enhance scalability and performance.
- Addressing Data Consistency Challenges: The webinar will emphasize the importance of aligning serving and training data to create scalable and reproducible ML models.
- Discussions will highlight common issues like inconsistent data formats and feature duplication, aiming to enhance collaboration within ML teams.
- Enhancing Feature Governance Practices: Participants will learn effective techniques for implementing feature governance and versioning, crucial for managing the ML lifecycle.
- Attendees can expect insights and practical tools to refine their ML processes and advance operations.
Mozilla AI Discord
- Accelerator Application Deadline Approaches: The application deadline for the accelerator program is fast approaching, offering a 12 week program with up to 100k in non-diluted funds for projects.
- A demo day with Mozilla is planned, and members are encouraged to ask their questions here.
- Two More Exciting Events Coming Up: Reminder about two upcoming events this month featuring the work of notable participants, bringing fresh insights to the community.
- These events are brought to you by two members, further bolstering community engagement.
- Insightful Zero Shot Tokenizer Transfer Discussion: A session titled Zero Shot Tokenizer Transfer with Benjamin Minixhofer is scheduled, aiming to explore advanced tokenizer implementations.
- Details and participation links can be found here.
- AutoFix: Open Source Issue Fixer Launch: An announcement was made regarding AutoFix, an open source issue fixer that submits PRs from Sentry.io, streamlining developers’ workflows.
- More information on the project can be accessed here.
DiscoResearch Discord
- Llama3.1 Paper: A Treasure for Open Source: The new Llama3.1 paper from Meta is hailed as incredibly valuable for the open source community, prompting discussions about its profound insights.
- One member joked that it contains so much alpha that you have to read it multiple times like a favorite movie.
- Training a 405B Model with 15T Tokens: The paper reveals that the model with 405 billion parameters was trained using ~15 trillion tokens, which was predicted by extrapolating their scaling laws.
- The scaling law suggests training a 402B parameter model on 16.55T tokens to achieve optimal results.
- Insights on Network Topology: It includes a surprisingly detailed description of the network topology used for their 24k H100 cluster.
- Images shared in the thread illustrate the architecture, demonstrating the scale of the infrastructure.
- Training Interruptions Due to Server Issues: Two training interruptions during Llama3-405b's process were attributed to the 'Server Chassis' failing, humorously suggested to be caused by someone's mishap.
- As a consequence, 148 H100 GPUs were lost during pre-training due to these failures.
- Discussion on Hallucination Prevention Benchmarks: A brief conversation with a Meta engineer raised concerns about the need for better benchmarks in hallucination prevention techniques.
- The member shared that anyone else working on this should engage in further discussions.
The LLM Perf Enthusiasts AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI Stack Devs (Yoko Li) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
{% if medium == 'web' %}
Unsloth AI (Daniel Han) ▷ #general (772 messages🔥🔥🔥):
Unsloth and Llama 3.1 Fine-TuningAI in Software DevelopmentImage Generation ModelsMistral ModelsAI Privacy Concerns
- Challenges with Fine-Tuning Llama 3.1: Several users reported issues while fine-tuning the Llama 3.1 model, particularly with error messages related to model configuration and tokenizer handling.
- Updates to the transformers library were recommended to resolve some of these issues, and users discussed the importance of ensuring the correct model versions are used.
- AI in Software Development and Job Security: Participants discussed the evolving role of AI in software development, highlighting concerns from junior developers about job security as AI tools become more integrated into coding practices.
- There was a consensus that experienced developers can utilize AI to enhance productivity rather than replace their roles, emphasizing adaptation to new tools.
- Image Generation and Diversity Issues: The conversation shifted towards image generation tools, with members reflecting on the challenges of achieving diversity in generated content and the implications of biases in AI models.
- While some viewed attempts to ensure diversity as commendable, there were critiques regarding the execution of those efforts and their impact on historical context and educational use.
- Mistral Models and Competition: Discussion included the new capabilities of Mistral Large 2, noted for its extensive context window and support for multiple languages, posing as a strong alternative to existing large models.
- Comparisons were made to Llama models, highlighting the competitive landscape in the AI model space and the ongoing efforts for performance improvements.
- AI Privacy and Data Handling: Concerns were raised regarding privacy issues related to AI data handling, particularly the implications of human reviewers accessing sensitive data.
- Participants discussed the necessity of proper data management practices and the perception that some AI tools might be using data in ways that could compromise user privacy.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #announcements (1 messages):
Llama 3.1 ReleasePerformance ImprovementsNew UI FeaturesGoogle Colab Notebooks4-bit Models
- Llama 3.1 Release is Here! 🦙: Unsloth now supports Llama 3.1, making training 2.1x faster with 60% less memory used than previous versions. The model has been trained on 15.6T tokens and expands context lengths to 128K.
- Meta's update positions Llama 3.1 as the most advanced models yet, supporting new languages and enhanced performance.
- Google Colab Notebooks for Llama 3.1: A Google Colab notebook is available for finetuning Llama 3.1 (8B) on a free Tesla T4, streamlining access for users.
- Kaggle and Inference UI notebooks were also provided to enhance user interaction, inviting experimentation and testing.
- New UI Features for Llama 3.1: Unsloth has introduced a new inference UI for interacting with Llama 3.1 Instruct models in Colab.
- This user-friendly feature is set to elevate the overall experience and engagement with the models.
- Exciting Experimentation Opportunities!: The team encourages sharing, testing, and discussing models and results among users, aiming for collaboration and feedback.
- This community-driven approach is part of a broader push for development within Unsloth Studio.
- Explore 4-bit Models of Llama 3.1: 4-bit models of Llama 3.1 are available in multiple sizes including 8B and 70B.
- Model options are tailored for both base and instruct categories, enhancing flexibility for developers.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #off-topic (77 messages🔥🔥):
Abliterator on LLaMA3.1OpenAI API vs Open-Source ModelsFine-Tuning vs RAG ComplexityInternal Corp KnowledgeL3-8B-Stheno-v3.2 Dataset Request
- Discussion on Abliterator and LLaMA3.1: Members are curious about the effectiveness of abliterator on LLaMA3.1 but no definitive experiences were shared.
- They expressed a need for success stories regarding this integration.
- Cost Comparison of OpenAI API and Open-Source Models: A conversation revolved around the cost-efficiency of using OpenAI's chat API versus open-source models, emphasizing overhead and hardware expenses.
- Members noted that using OpenAI API often translates to lower initial costs and less operational risk for startups.
- Fine-Tuning vs RAG: It was highlighted that while fine-tuning is seen as cheaper and simpler initially, implementing RAG demands significant expertise and time investment.
- Members agreed that RAG needs careful design to avoid complexities and still deliver effective results in production.
- Importance of Internal Corp Knowledge: Discussion underlined how models typically lack internal corporate knowledge, thus requiring fine-tuning for accuracy in corporate applications.
- Members emphasized that fine-tuning on specific corporate contexts is crucial to avoid inaccuracies.
- Request for L3-8B-Stheno-v3.2 Dataset: A member requested the dataset for L3-8B-Stheno-v3.2, expressing disappointment that available datasets contain too much fictional content.
- Another member noted that few share their datasets nowadays, indicating a trend of limited accessibility.
Unsloth AI (Daniel Han) ▷ #help (147 messages🔥🔥):
Training in Loop IssuesUnsloth and Hugging Face Model LoadingLlama 3.1 Fine-TuningUsing FastLanguageModelInference with Fine-Tuned Models
- Training in Loop Causes OOM: A user reported that using
train()in a loop causes a VRAM explosion and results in an out-of-memory (OOM) error after the first training iteration.- They mentioned having gradient checkpointing enabled and are troubleshooting by checking configurations.
- Loading Models with Unsloth: A user encountered an OSError when trying to load the model 'unsloth/meta-llama-3.1-8b-bnb-4bit', which suggests double-checking the model path and ensuring the local directory does not conflict.
- For loading local model files, users discussed using specific paths to direct loading instead of pulling from Hugging Face.
- Fine-Tuning Llama 3.1 Issues: Some users noted issues while fine-tuning Llama 3.1 with various dataset formats, questioning if the prompt formats affected their results.
- Additionally, there was guidance about using appropriate training configurations to ensure expected losses during the fine-tune.
- FastLanguageModel Utilization: It was confirmed that using the FastLanguageModel is mandatory to achieve the claimed speed improvements for inference in Unsloath.
- Users were interested in how to effectively implement this model within VLLM for faster performance.
- Inference with Fine-Tuned Models: A user successfully fine-tuned a model and pushed it to Hugging Face but sought advice on how to effectively run inference on it.
- Recommendations included using Unsloath's inference code or VLLM to streamline the deployment process for testing in production.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #research (17 messages🔥):
LLaMa-3.1 for synthetic datasetsUse of attention masks in Vision Language ModelsInference speed vs training speedDecoding with different model sizes
- LLaMa-3.1 for Synthetic Data Generation: Members discussed leveraging LLaMa-3.1 for generating synthetic datasets, but many agreed that utilizing the 405B model is ideal for this purpose.
- *One member noted,
- Clarifying Attention Masks in Vision Language Models: A member described using an attention mask with 48 patches, stating the mask incorporates both sentence and patch masks effectively.
- They specified that with a decoder-only setup, the attention mask for the image patches should align with the sentence tokens.
- Interference Slower than Training Models: A member raised a question regarding why interference is significantly slower than training, noting a stark contrast in data processing rates.
- While training can handle hundreds of data points per minute, interference typically processes only 30-100 tokens/s.
- Using 8B Model for Data Formatting: Discussion revealed that the 8B model could potentially be used for formatting data or fine-tuning, though this wasn't the main focus of synthetic data generation.
- Members acknowledged the primary goal of synthesis is better served by larger models.
Links mentioned:
LM Studio ▷ #💬-general (192 messages🔥🔥):
LM Studio and Llama 3.1Nemo models performanceModel download issuesClaude Sonnet 3.5 as coding modelGPU usage for model inference
- LM Studio's Compatibility with Llama 3.1: Users have discussed LM Studio's inability to run Llama 3.1 on OpenCL cards and recommended upgrading to version 0.2.28 from the official website for better support.
- Several members confirmed the latest updates from LM Studio are crucial for running large models effectively.
- Nemo Models and Performance Issues: The Nemo models are reportedly functional on current versions, but users faced challenges with context length and slower outputs due to limited RAM.
- One user confirmed success with specific setups while others suggested improvements and optimizations.
- Download and Access Problems for Models: Some users experienced issues downloading models from Hugging Face, with reports ranging from regional CDN problems to browser caching issues.
- Others confirmed that specific links were accessible while others encountered 'Entry not found' errors.
- Claude Sonnet 3.5 as Benchmark for Coding Tasks: Users expressed that current local models do not match the coding capabilities of Claude Sonnet 3.5, particularly when generating full working code.
- Exploration of alternatives and experimentation with lower quantization Claudes was suggested as a potential solution.
- Importance of GPU Offloading for AI Models: Discussions highlighted that using CPUs for inference leads to slower outputs compared to GPUs, emphasizing the need for suitable models that fit into GPU VRAM.
- Users were encouraged to seek out models labeled for 'full GPU offload' to maximize performance and reduce inference times.
Links mentioned:
LM Studio ▷ #🤖-models-discussion-chat (89 messages🔥🔥):
Llama 3.1 Model PerformanceModel Censorship and BehaviorMistral Large 2 ReleaseTesting and Troubleshooting ModelsModel Naming Trends
- Llama 3.1 struggles with reasoning and coding: Users noted that Llama 3.1 8B is not great for reasoning and coding tasks, with some members expressing skepticism regarding its overall performance.
- Comparisons suggest that while it's decent for its size, its logic capabilities appear lacking, especially contrasted with models like Gemma 2.
- Concerns about Censorship in Top Models: Discussions about model censorship revealed that models performing well may often be less censored, but this was debated among members.
- A member suggested that the censor labeling is indicative of an attempt to manage column width rather than a straightforward description of model behavior.
- Mistral Large 2 boasts significant improvements: The release of Mistral Large 2 with a 128k context window promises an improvement in performance and efficiency across numerous languages and coding tasks.
- This model's design aims for single-node inference, boasting 123 billion parameters, offering opportunities for innovative AI applications.
- Troubleshooting with LLMs and Flash Attention: Users reported issues with loading models like Llama 3.1 and recommended checking configurations related to Flash Attention, which can impact model behavior.
- Many experienced varying performance based on whether models were loaded fresh or with different configurations.
- Trends in Alien Naming among AI Models: A humorous thread explored the phenomenon of AIs using names like Zorvath and Elara for characters, wondering where these patterns originated.
- A member noted that literary influences might skew naming conventions, with some names appearing more frequently in certain genres and styles.
Links mentioned:
LM Studio ▷ #🧠-feedback (9 messages🔥):
Msty FeaturesLM Studio Server ConfusionModel Migration ConcernsGPU Configuration in LM Studio
- Msty offers compelling features over LM Studio: While using Msty for connecting to LM Studio from another device, a user highlighted its ability to update the Ollama version without a full app upgrade, a feature they wish for in LM Studio.
- They expressed irritation that LM Studio does not support endpoint usage and is limited to local inference only, making Msty a more practical choice.
- LM Studio's server functionality debate: Despite LM Studio advertising a server feature, users feel it lacks client capabilities, requiring additional software like Msty for effective connection between devices.
- This raises frustration as users suggest that having two apps for the same function feels redundant, highlighting Msty's dual server and client role.
- Concerns about migrating models to Ollama: A user mentioned their reluctance to switch from LM Studio to Msty due to the pain of migration, specifically in transferring models to the Ollama backend.
- They preferred the model management method of LM Studio over the methods used by Ollama, which they find cumbersome.
- GPU configuration in LM Studio: A discussion pointed out that proper configuration for GPU load distribution in LM Studio is not intuitive and requires digging into settings.
- Users can find advanced GPU options under AI Chat > New chat, allowing them to toggle settings for maximum acceleration.
LM Studio ▷ #⚙-configs-discussion (11 messages🔥):
Llama 3.1 presetsGPU settings for modelsContext length for Llama 3.1
- Llama 3.1 lacks visibility on presets: A user expressed frustration, stating they couldn't find any presets for Llama 3.1, indicating they were new to this environment.
- Another member suggested that the Llama 3 v2 preset works with an update to v0.2.28.
- Optimal context length for 3080ti: A question was raised about whether to leave the context length at 2048 for a 3070ti GPU.
- A recommendation was made to set it to 32k, as the model supports up to 128k context.
- Issues with GPU loading: A user reported issues with model loading, stating it didn't seem to load fully onto their GPU.
- They attempted to set the memory to max (-1) but found it reverted back after reloading.
LM Studio ▷ #🎛-hardware-discussion (35 messages🔥):
OpenCL DeprecationGPU Comparisons for StreamingFine-Tuning LLaMA 3.1Low-Budget GPUs for LLMsTech Shopping in Taiwan
- OpenCL Heads to Obsolescence: OpenCL is now deprecated, but users can still utilize it until more complete transitions to Vulkan occur in LM Studio.
- For now, its functionalities remain usable, even if not recommended for the long term.
- RTX 4090 vs RX 7900 XTX Debate: A member queried the benefits of using 1x RTX 4090 versus 2x RX 7900 XTX for streaming and local AI applications with the upcoming Ryzen 9950x.
- It's suggested that while the RX 7900 XTX may offer an edge in VRAM, compatibility with AI models could favor the more widely supported Nvidia options.
- Fine-Tuning LLaMA 3.1 VRAM Needs: The community discussed the VRAM requirements for fine-tuning the LLaMA 3.1 8B model, estimating it can be done with 32GB VRAM.
- Context length was debated, with the belief that 27k tokens could be aimed for with the mentioned VRAM capacity.
- Budget-Friendly GPU Options for LLMs: Members exchanged opinions on affordable GPUs for local LLMs, recommending the RTX 3060 12GB as a viable option over older AMD models.
- A suggestion came to consider Chinese-modified RTX 2080 Ti models with 22GB VRAM as a risky but potentially more powerful alternative.
- Exploring Tech Opportunities in Taiwan: A member expressed interest in visiting tech malls in Taiwan, inspired by notable videos showcasing impressive tech shopping experiences.
- They planned to look out for bargain NVME drives during their stay but noted that prices aren’t vastly different from online options.
Link mentioned: Reddit - Dive into anything: no description found
LM Studio ▷ #🧪-beta-releases-chat (87 messages🔥🔥):
Beta Release IssuesInterface Changes and FeedbackGPU Offloading ProblemsModel Loading ConcernsVersion Confusion
- Beta Release Issues on Windows: Users are experiencing issues with the beta not launching properly on Windows 10, with some unable to see the UI despite seeing processes in Task Manager.
- Known issues include the beta not starting correctly; recommended actions include restarting the app multiple times or waiting for future updates.
- Positive Feedback on New Interface: Many users shared their positive experiences with the new UI in Beta 1, noting features like Discovery and Collections as particularly useful.
- Concerns were raised about the structure of folders and settings but overall users appreciate the changes being made.
- GPU Offloading Not Working: Several users reported that GPU offloading isn't functioning as expected, especially on M3 Max and with a 4080S, often needing to rely on manual settings.
- The automatic GPU setting is criticism, as it often leads to gibberish outputs while manual settings appear more reliable.
- Model Loading Issues: Users faced challenges when trying to load models like bic llama, with some settings requiring adjustment to prevent crashes or RAM overloads.
- It's suggested to utilize the Developer button to load models into RAM effectively, bypassing integration with GPU.
- Version Confusion and Update Management: There is confusion regarding the versions of LM Studio, with users unsure of the latest release due to outdated links in channels.
- Calls were made for clearer communication regarding version updates, suggesting a need for improved organization of release information.
LM Studio ▷ #langchain (1 messages):
LangGraph tool bindingLLM limitationsLangChain integration issues
- Issues with LLM tool binding in LangGraph: A user is encountering an error when attempting to use
llm_with_tools = llm.bind_tools(tools)in their code with LangGraph.- They are questioning whether the error arises from LM Studio not supporting tool calling or due to the LLM being utilized.
- Potential causes of tool binding issues: The discussion highlights possible reasons for the malfunction, focusing on LLM compatibility issues.
- It remains unclear if the specific LLM currently in use is supported by the requested tool binding functionality.
LM Studio ▷ #memgpt (2 messages):
Krypt Lynx InstallationPip Install Success
- Successful Installation of Krypt Lynx: A member expressed interest in trying out the Krypt Lynx project and inquired about installation on Windows.
- They later updated that using pip install actually worked for them, showcasing a positive installation experience.
- Installation Inquiry on Windows: A member initiated a discussion asking how to install the Krypt Lynx project specifically on the Windows platform.
- This inquiry led to a clarification that the installation succeeded after attempting pip install, which was met with some relief.
LM Studio ▷ #amd-rocm-tech-preview (33 messages🔥):
ROCm 0.2.28 performance issuesLlama 3.1 compatibilityLM Studio update processOpenELM supportAppImage functionality
- ROCm 0.2.28 exhibits slower performance: After updating to ROCm 0.2.28, a user reported significantly slower inference performance on their 2x 7900xt system, seeing only 150w usage from one card vs 300w before.
- They downgraded to 0.2.27 and found performance normal, prompting a request for investigation into the changes made for 0.2.28.
- Llama 3.1 struggles on AMD cards: Multiple users discussed issues with getting Llama 3.1 to work on AMD cards, citing a tokenizer error when using llama.cpp.
- One user discovered the problem stemmed from using OpenCL instead of ROCM, while another reported their struggles with layer visibility.
- Update process for LM Studio: A user inquired about the update command for 0.2.28, suggesting that current instructions might still refer to the previous version.
- It was clarified that the update process for this build has reverted for simplicity, and a user noted the difficulty in finding version details via Discord.
- Interest in OpenELM support: There was curiosity about the potential support for OpenELM, with one user wanting to try Apple’s models and pointing out a recent relevant GitHub pull request.
- The response indicated that all model support depends on llama.cpp.
- AppImage works seamlessly: A user confirmed that after downloading the 0.2.28 AppImage for Linux, they could get a Llama 3.1 model working out of the box on their 7800XT.
- This satisfied the requirements for running Llama 3.1 with ROCm, demonstrating compatibility.
Link mentioned: OpenELM support by icecream95 · Pull Request #7359 · ggerganov/llama.cpp: Fixes: #6868. Thanks to @joshcarp for an initial try at doing this (#6986), it was very helpful as a source to copy-paste from and check against. Currently a bunch of the configuration is hardcoded...
LM Studio ▷ #model-announcements (7 messages):
Meta-Llama 3.1 70BTokenizer Bug Fix
- Meta-Llama 3.1 70B Now Available: A member announced that 70B quants for Meta-Llama 3.1 are available, linking to the repository.
- The excitement in the channel was palpable, with others commenting, that's why he's the goat.
- Tokenizer Bug Request for Re-upload: It was mentioned that the models will be re-uploaded to fix a tokenizer bug, which is expected to improve performance.
- For now, performance is reported as fine, with an expectation of better results post-update.
LM Studio ▷ #🛠-dev-chat (11 messages🔥):
LM Studio compatibilityAVX2 and AVX-512 instructionsKoboldcpp vs LM StudioModel downloading alternatives
- LM Studio's requirements and compatibility issues: A user reported issues running LM Studio on a Windows Server 2012 R2 setup due to unknown compatibility with the kernel32.dll. Another user confirmed that LM Studio won't install without AVX2 instructions, which the current CPU lacks.
- Koboldcpp runs fine on AVX512, but the user prefers LM Studio for its interface.
- Understanding AVX2 and AVX-512 Differences: There was a confusion regarding the use of AVX2 and AVX-512 instructions, with a member thinking that bigger instructions might be better. It was clarified that the Xeon 6138 does not support AVX2, making LM Studio incompatible regardless of additional errors.
- A user expressed gratitude for the clarification, further mentioning that understanding the instruction types could be helpful for future usage.
- Exploring Alternatives with llama.cpp: Another user mentioned that while LM Studio has compatibility issues, there's a way to build llama.cpp with AVX-512 support. This offers an alternative for model downloading and inference through console use or a server endpoint.
- Users were directed to check lms-comm or bartowski HF pages for available models as potential substitutes.
Link mentioned: Add avx-512 support? · Issue #160 · ggerganov/llama.cpp: No clue but I think it may work faster
Perplexity AI ▷ #announcements (1 messages):
Llama 3.1 405BOpen source models
- Llama 3.1 405B launches on Perplexity: The Llama 3.1 405B model, touted as the most capable open source model, is now available on Perplexity and rivals GPT-4o and Claude Sonnet 3.5.
- The team is actively working on integrating Llama 3.1 405B into their mobile apps, prompting users to stay tuned for updates.
- Upcoming mobile app integration: The Perplexity team announced plans to add Llama 3.1 405B functionality to their mobile applications next.
- Users are encouraged to stay tuned for more updates on this integration.
Perplexity AI ▷ #general (306 messages🔥🔥):
Llama 405b performanceMistral Large 2AI model comparisonsTikTok as a search engineLanguage symbol output issues
- Discussions on Llama 405b performance: Members expressed skepticism regarding Llama 405b's performance, stating it seems average compared to other models like Mistral and Sonnet.
- Some noted inconsistencies in benchmarking results across various models, impacting their decisions.
- Praise for Mistral Large 2: Mistral Large 2 received attention as a model that might outperform Llama 405b in terms of results, with users expressing a preference for it over Llama.
- Users are hopeful for Mistral's addition to Perplexity alongside existing models.
- Confusion over AI model benchmarks: The validity of AI benchmarks was questioned, with members comparing them to movie ratings, highlighting their inconsistency.
- Users noted that subjective experiences with models differ significantly, making it difficult to rely solely on benchmarks.
- Potential for TikTok as a search tool: Members discussed TikTok's emerging role as a search engine for Gen Z, with debates on its value compared to traditional search methods.
- Concerns were raised about the reliability of health advice found on TikTok and the implications of using such platforms for information.
- Issues with language symbol outputs: Users reported Llama models having trouble outputting Asian language symbols correctly, noting this as a limitation in performance.
- It was suggested that the model's reluctance to use symbols may stem from its training and handling of multilingual inputs.
Links mentioned:
Perplexity AI ▷ #sharing (13 messages🔥):
Mistral Large 2President Biden's Public AppearancesAI Monitoring at AEONOldest Trees in the WorldMeta's Llama 3.1
- Mistral Large 2 sets new AI standards: On July 24, 2024, Mistral AI released Mistral Large 2, featuring 123 billion parameters and a 128,000-token context window, enhancing capabilities in code generation and mathematics.
- The model reportedly outperforms Llama 3.1 405B and closely matches GPT-4 in mathematical tasks.
- President Biden's last public appearance: President Joe Biden was last seen in public on July 17, 2024, after testing positive for COVID-19 while campaigning in Las Vegas.
- This marked his final appearance before withdrawing from the presidential race on July 23.
- AI system monitors smiles at AEON stores: Japanese supermarket chain AEON has implemented an AI system named 'Mr Smile' to standardize employee smiles based on over 450 behavioral elements.
- The trial in eight stores reportedly improved service attitudes by 1.6 times over three months.
- The world's oldest trees compilation: Research highlights trees like the Great Basin bristlecone pine, known for its age of nearly 5,000 years, as the oldest non-clonal tree species.
- A variety of methods including tree-ring counting and radiocarbon dating help determine the ages of these ancient trees.
- Meta's Llama 3.1 launch: Meta's recent release of Llama 3.1 405B offers a competitive open-source model with a focus on challenging existing proprietary AIs like GPT-4.
- Boasting 405 billion parameters, it promises unprecedented access to advanced AI capabilities for developers.
Links mentioned:
Perplexity AI ▷ #pplx-api (8 messages🔥):
Llama 3 405b API PlansContext Size of Llama 3 405bPassing return_citations in LangchainNextCloud Integration with OpenAIMicrosoft Copilot Studio Perplexity Connector
- Plans for Llama 3 405b in API: A member confirmed that Llama 3 405b will be served in the API soon, indicating an upcoming feature release.
- This response generated excitement as it promises new capabilities for users.
- Llama 3 405b context size discussion: A member inquired about the context size of Llama 3 405b, suggesting it might be 128K as fine-tuning is unnecessary.
- They asserted that this feature could lower costs compared to existing models like Claude and GPT.
- Return citations in Langchain LLM chain: A user sought guidance on how to pass the return_citations value to an LLM chain using Langchain with Perplexity Chat.
- No concrete solutions were shared in the discussion, indicating a need for further exploration.
- NextCloud's OpenAI Integration Queries: A member shared a link to NextCloud integration with OpenAI, celebrating its community-driven, free, and open-source nature.
- They referenced the GitHub repository for those interested in the integration details.
- Issues with Microsoft Copilot Studio Connector: A user raised a concern regarding an unspecified error when uploading the Perplexity Connector to Microsoft Teams.
- The community's response indicates that troubleshooting may be necessary to resolve this issue.
Link mentioned: Nextcloud: 📱☁️💻 A safe home for all your data – community-driven, free & open source 👏 - Nextcloud
OpenAI ▷ #ai-discussions (298 messages🔥🔥):
Model CapabilitiesGPU Servers for AI ModelsKling AI Image to Video GenerationLLM Compatibility with Raspberry PiPrompt Libraries for Custom Models
- Mistral Models and Their Specifications: Users discussed the specifications of the Mistral-7B-v0.3 model, noting its improved capabilities with 128k context windows and support for multiple languages.
- It was mentioned that the Mistral Large model is 69GB and can run efficiently using ollama.
- Exploring GPU Server Options: Users highlighted GPU server options for running large models, suggesting Runpod as an affordable instance at $0.30/hour.
- One suggested using LM Studio or ollama for better performance and compatibility with specific models.
- Kling AI's Image-to-Video Features: Kling AI was noted for its impressive capabilities in generating moving images from still photos, though users reported some limitations in video quality.
- Despite the fun and engaging results, there were comments on server overload leading to longer generation times.
- LLM Compatibility and Performance on Raspberry Pi: The discussion shifted to the feasibility of running large language models (LLMs) on Raspberry Pi 4B, with users unsure of the performance capabilities.
- It was mentioned that models with varying RAM configurations could be run, potentially including 7B models using ollama.
- Prompt Library Access and Custom Models: Users inquired about accessing prompt libraries to create custom prompts for AI models, pointing to available channels for assistance.
- The conversation emphasized the need for specific model files and frameworks to successfully utilize certain large model capabilities.
Link mentioned: mistralai/Mistral-7B-v0.3 · Hugging Face: no description found
OpenAI ▷ #gpt-4-discussions (9 messages🔥):
Memory Feature Issues in EUSpelling Errors in MiniPython PDF Generation with OpenAIDebugging Model OutputUser Feedback on Model Mistakes
- Memory feature appears and disappears in EU: A member reported that they received the memory feature for only five minutes, prompting others to confirm similar experiences.
- Another user humorously remarked on this inconsistency, suggesting discussions on whether the feature is fully operational.
- Mini's frequent spelling error of 'composure': One member pointed out that Mini consistently misspells 'composure' as 'composposure' in their prompts.
- Another member could not replicate this issue and shared a link to their prompt highlighting a correctly spelled 'composure'.
- Using OpenAI to generate PDF content in Python: A user inquired about generating PDFs using Python and OpenAI, expressing the need for table contents and section descriptions based on uploaded files.
- This initiated a conversation about workflows and techniques for leveraging OpenAI for document generation.
- Debugging model output for spelling mistakes: A member noted frequent spelling mistakes, including 'itis' for 'it is', and plans to enable debugging to inspect the model's prompts.
- This prompted another member to suggest sharing specific examples to better understand the model's output tendencies.
- User experiences mispelled words in conversations: A user shared that they could provoke misspellings and spacing issues only by expressly requesting them and providing feedback.
- They pointed out a shared link exhibiting their interactions which highlighted this phenomenon.
Nous Research AI ▷ #research-papers (4 messages):
LLM DistillationLLaMa 3Common RAG Challenges
- Recent Papers on LLM Distillation: A member suggested checking out the Minitron GitHub repository, which details a family of compressed models obtained via pruning and knowledge distillation.
- This repository may provide insights into recent advancements in LLM distillation similar to models like Sonnet, Llama, and GPT-4Omini.
- Introduction of LLaMa 3 Models: A new set of foundation models called LLaMa 3 was introduced, featuring a dense Transformer with 405B parameters and a context window of up to 128K tokens.
- These models, which excel in multilinguality, coding, reasoning, and tool usage, are set to enhance a broad range of AI applications.
- Common RAG Challenges in Production: A member shared a link to a LinkedIn post discussing common RAG (Retrieval-Augmented Generation) challenges and potential solutions.
- The post highlights various issues faced when implementing RAG in production environments that practitioners may find useful.
Link mentioned: GitHub - NVlabs/Minitron: A family of compressed models obtained via pruning and knowledge distillation: A family of compressed models obtained via pruning and knowledge distillation - NVlabs/Minitron
Nous Research AI ▷ #off-topic (2 messages):
PC Agent DemoProprietary Tools
- Exciting PC Agent Demo Released: A member shared a YouTube video titled "PC Agent Demo" showcasing a new agent from gate-app.com/research/pc-agent.
- This demo highlights the functionalities and potential applications of the PC Agent tool.
- Discussion on Proprietary Tools: A member suggested a potential connection to proprietary tools related to the earlier topics discussed in the channel.
- This discussion prompted engagement from other members, contemplating the implications and applications of such tools.
Link mentioned: PC Agent Demo: gate-app.com/research/pc-agent
Nous Research AI ▷ #interesting-links (20 messages🔥):
Meta Llama 3.1 capabilitiesSynthetic dataset creationMicrosoft GraphRAGAider's repo mapWordware apps
- Meta Llama 3.1 excels in multilingual tasks: The Meta Llama 3.1 collection includes pretrained models in sizes of 8B, 70B, and 405B, optimized for multilingual dialogue and outperforming many existing chat models.
- With fine-tuning options available, it supports synthetic dataset creation and offers a Community License for commercial and research use cases.
- Discussion on synthetic datasets potential: Questions arose about whether mass production of synthetic datasets will begin at NousResearch now that GPT-4 is accessible to them.
- Despite this enthusiasm, concerns were raised regarding the higher costs of using the 405B model for generation compared to Sonnet 3.5 or GPT-4o.
- Microsoft introduces GraphRAG: Microsoft unveiled GraphRAG, enhancing LLM capabilities to solve problems with unseen data by creating knowledge graphs from existing datasets.
- This approach promises improved semantic clustering and concept identification, making the RAG technique a significant tool for data investigation.
- Aider's repo map limitations: While Aider impressively maps a code repository, its architecture has limitations that made it less effective for semantic understanding of codebases.
- Current methods focus on entity frequency weights rather than truly understanding evolution, raising questions about advanced retrieval alternatives.
- Wordware apps feature JWST images: Wordware apps are set to feature published James Webb Space Telescope (JWST) images to enhance the visual appeal of the platform.
- An alternate app within Wordware tests multiple models simultaneously, showcasing enhanced search engine capabilities with output speed tracking.
Links mentioned:
Nous Research AI ▷ #announcements (1 messages):
Nous Research subredditAMA announcement
- Nous Research subreddit launched: A new subreddit for Nous Research has been started, where members can join to discuss the latest research and developments in AI.
- Users are encouraged to start threads and get involved here.
- Upcoming AMA with Nous leaders: An AMA session is planned with specific members in the coming weeks on Reddit to answer community questions.
- Further information will be shared as it approaches, so stay tuned for updates!
Link mentioned: Reddit - Dive into anything: no description found
Nous Research AI ▷ #general (224 messages🔥🔥):
Llama 3.1 PerformanceMistral Large 2 ReleaseOpen-Source TTS ModelsAutonomous Coding ToolsSynthetic Data in AI
- Llama 3.1 faces competition from Mistral: The Llama 3.1 model is being challenged by Mistral Large 2, which boasts a similar architecture but showcases better performance, especially in coding tasks.
- Users are excited about Mistral's potential for improved output quality and the growing capabilities of synthetic data.
- Mistral Large 2 impresses with capabilities: Mistral Large 2 has been released with 123 billion parameters, featuring a 128k context window and strong performance on coding tasks.
- Despite its non-commercial license restricting hosting options, it is expected to perform well on API platforms due to its innovative design.
- Exploration of open-weight TTS models: Users are discussing their experiences with various Text-to-Speech models, particularly focusing on quality, speed, and offline capabilities.
- Models like ElevenLabs and Apple's Siri voices are compared, with recommendations for newer solutions like parler-expresso and VITS.
- Inquiry about autonomous coding tools: There is interest in the current state of open-source autonomous coding tools, such as Devika and Open Devin.
- Users are looking for recommendations and comparisons to determine which tools may best suit their development needs.
- Potential of synthetic data: Users express enthusiasm about the use of high-quality synthetic data in training AI models, believing it could enhance performance and general applicability.
- There is speculation that future advancements in synthetic data generation may lead to significant improvements in model capabilities.
Links mentioned:
Nous Research AI ▷ #ask-about-llms (24 messages🔥):
Fine-tuning Llama 3Multi-language fine-tuningCustom tool callsHermes function callingGenerative capabilities of LLMs
- Fine-tuning Llama 3 presents challenges: Members expressed concerns that fine-tuning Llama 3 405B will be quite a challenge, with suggestions that only Lora FTing might take it on.
- One member noted that this situation might prompt advances in DoRA fine-tuning within OSS.
- Resources needed for fine-tuning Pashto: A member is seeking resources for fine-tuning models specifically for the Pashto language, highlighting the lack of available materials despite the large speaker base of 60 million.
- Another member suggested looking up recent Aya23 model+ papers for related information.
- Custom tool calls require attention: Discussion arose around the need for fine-tuning to achieve correct formats when performing custom tool calls, especially for simple tasks like checking for spam.
- A participant emphasized using the correct system prompt and schema provided in the GitHub repo for Hermes function calling.
- LLM struggles with generating complex code: One member reported their attempt to generate a snake game in Python using Llama 405B, successful initially but failing to include a DQN method effectively.
- They noted repeated failures despite providing error messages, indicating a need for better prompting strategies.
- Queries on Hermes release and progress: A couple of users inquired about the availability of a Hermes release for Llama 3.1, reflecting broader interest in updates.
- Members discussed ongoing efforts and resources being used for advanced projects, including multi-node training setups.
Nous Research AI ▷ #rag-dataset (4 messages):
Citizen Sleeper core mechanicswiki-phrases-tokenizergrounded refusals
- Citizen Sleeper's core mechanic explained: The core mechanic of Citizen Sleeper revolves around rolling dice to assign actions, which significantly impact player progression in the game.
- Each day, players roll dice whose outcomes are governed by the condition system, reinforcing themes of precarity and risk.
- Introduction to wiki-phrases-tokenizer dataset: A member shared a link to the wiki-phrases-tokenizer GitHub repository, highlighting its potential as sample data for RAG with datasets like the top 100k Wikipedia pages and Quora search queries.
- This dataset is described as containing valuable information for domain-specific extraction of entities and keywords.
- Meta team’s intelligence acknowledged: A member expressed surprise at not considering grounded refusals and acknowledged the meta team as being smarter in this regard.
- This comment reflects a sentiment of humility and recognition of the team's capabilities.
Link mentioned: wiki-phrases-tokenizer/data at master · vtempest/wiki-phrases-tokenizer: Wikipedia Outline Relational Lexicon Dataset (WORLD) * Domain-Specific Extraction of Entities and Keywords (DSEEK) * Wikipedia Important Named Topic Entity Recognition (WINTER) - vtempest/wiki-phr...
Nous Research AI ▷ #world-sim (3 messages):
Sub-Symbolic Concept SpaceLlama Model on GPU ClustersSubscription-based AI Access
- Exploring Sub-Symbolic Concept Space: A member expressed excitement about finally having a moment to engage with WorldSim and ponder sub-symbolic concept space.
- This indicates an ongoing interest in expanding on theoretical AI concepts in future discussions.
- Llama Model Could Enable Tiered Access: A member theorized that using the Llama model on a cluster of managed GPUs could create a gated playground accessible by subscription or tiers.
- They suggested that if feasible, it would make for a worthy discussion in a future gathering.
- Question about Code Availability: A member inquired if there is any code available for the discussed applications or models.
- This highlights a potential gap in resources for exploration within the community.
Nous Research AI ▷ #reasoning-tasks-master-list (13 messages🔥):
SMT Solvers and LLM TranslationUpdating Repo StructureDifficult Moral QueriesTrolley Problem Morality Debate
- Utilizing SMT Solvers for LLMs: @SMT_Solvers suggested that teaching LLMs to translate word problems from English/German to SMTLIB can yield significant reasoning capabilities, essentially a MADLIBS synthetic data problem using egraphs for exploration.
- This sparks potential for advanced reasoning tasks through effective translation methods, enhancing overall model performance.
- Repo Structure Updates In Progress: @teknium announced plans to update the repository's structure and schemas today, inviting collaboration from others in the community.
- @n8programs expressed eagerness for updates and offered assistance in the process, highlighting community engagement.
- Moral Dilemmas in Reasoning Tasks: A discussion emerged around whether to include a subsection for difficult/moral queries, like the trolley problem, as reasoning tasks that challenge models' foundational moral principles.
- This raises questions about the implications of moral reasoning versus the straightforward logical evaluation of scenarios, inviting deeper analysis.
- Reflection on the Trolley Problem: Concerns were raised about the trolley problem assessing which moral foundations models adopt rather than pure reasoning capabilities, with @stefangliga questioning its purpose.
- @_paradroid suggested that structuring prompts can clarify reasoning processes and thought evaluations, enhancing understanding of moral frameworks.
- Structured Reasoning in Moral Queries: @_paradroid shared a structured framework to analyze the moral implications of self-driving car decisions, aiming for superior reasoning clarity and accuracy.
- The framework includes identifying initial thoughts, providing context, and reflecting on the reasoning process, demonstrating a comprehensive approach to moral reasoning tasks.
Link mentioned: Tweet from Chad Brewbaker (@SMT_Solvers): @halvarflake As I told @Teknium1 we can get a lot of reasoning via SMT solvers if we can teach the LLM to translate word problems from English/German to SMTLIB. A MADLIBS synthetic data problem if you...
OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
DeepSeek Coder V2Private Inference Provider
- DeepSeek Coder V2 Launches Private Inference Provider: DeepSeek Coder V2 now features a private provider to serve requests on OpenRouter without input training.
- This new capability was announced on X, signifying a step forward in private model deployment.
- New Developments in Inference Providers: The announcement of a private inference provider indicates strategic progression in the OpenRouter platform.
- The absence of input training marks a significant difference from previous models, enhancing usability.
Link mentioned: Tweet from OpenRouter (@OpenRouterAI): DeepSeek Coder V2 now has a private provider serving requests on OpenRouter, with no input training! Check it out here: https://openrouter.ai/models/deepseek/deepseek-coder
OpenRouter (Alex Atallah) ▷ #general (273 messages🔥🔥):
Llama 3.1 405BMistral Large 2OpenRouter API IssuesCoding Tools ExplorationLanguage Model Pricing
- Concerns over Llama 3.1 405B Performance: Several users express dissatisfaction with the performance of Llama 3.1 405B, noting it struggles with NSFW content, often refusing prompts or outputting training data.
- User feedback indicates that temperature settings heavily influence output quality, with some reporting better results at lower temperatures.
- Mistral Large 2 Launch and Usage: The Mistral Large 2 model is now available as Mistral Large, effectively replacing the previous version with updates for improved multilingual capabilities.
- Users speculate on its performance compared to Llama 3.1, particularly in handling languages like French.
- OpenRouter API Challenges: Users discuss limitations in the OpenRouter API, including rate limits and the handling of multilingual input, noting challenges faced when using certain models.
- Reports indicate that while some models are free in preview, they may come with strict limitations on usage and context.
- Interest in Open-Source Coding Tools: In a shift of focus, users inquire about open-source autonomous coding tools like Devika and Open Devin, seeking recommendations based on current efficacy.
- The discussion highlights a growing interest in experimenting with alternative coding solutions beyond mainstream AI offerings.
- Model Pricing Comparisons: Discussion on pricing reveals that Mistral Large offers competitive rates at $3 per million tokens for input and $9 for output, drawing comparisons to other models.
- Users debate the value of uncensored outputs from various models, weighing it against the more commercial approach taken by other providers.
Links mentioned:
HuggingFace ▷ #announcements (1 messages):
Llama 3.1 ReleaseHuggingChat UpdatesCommunity ToolsUsage Guides
- Llama 3.1 Launches with Excitement: The Llama 3.1 model has officially launched, bringing exciting new features and capabilities. Check out the blogpost for all the juicy details.
- The model is available here for users to try it out.
- Explore the Models and Community Tools: Users are encouraged to dive into the models featured on Hugging Face, showcasing the latest advancements. Additionally, explore the community resource Quants for collaborative insights.
- Resources to enhance your experience include the How to use guide available on GitHub.
- HuggingChat Version v0.9.1 Released: The latest version HuggingChat v0.9.1 makes the best AI chat models available to everyone, improving accessibility. Users can view the model page for deeper insights into its functionalities.
- The new version integrates seamlessly with the Llama features to enhance user interactions.
Link mentioned: HuggingChat: Making the community's best AI chat models available to everyone.
HuggingFace ▷ #general (238 messages🔥🔥):
Llama 3.1 DiscussionTraining ModelsUsing Rust in MLMachine Learning CurriculumModel Performance and Issues
- Llama 3.1 405B Overload Issues: Users reported that the Llama 3.1 405B model is frequently showing 'service unavailable' errors due to being overloaded with requests.
- Some users discussed the characteristics of the 405B variant, mentioning that it feels more censored compared to its 70B sibling.
- Challenges in Training Models: There were several discussions on training models, including issues related to batch size not reducing training time or steps as expected.
- Users explored how the training script from GitHub might be flawed, making epochs perform similarly to steps.
- Using Rust in Machine Learning: A user inquired about the usefulness of Rust in the ML community, specifically referring to the 'candle' framework for performance and GPU support.
- The 'candle' project on GitHub was recommended as a Rust-based solution focused on machine learning applications.
- Adding ML to Academic Curriculum: A member shared challenges in helping their economics department add machine learning content to their undergraduate curriculum.
- Participants discussed foundational concepts needed, emphasizing the importance of logic and programming basics for students.
- AI-Generated Content Quality: Users shared experiences with AI-generated images, noting technical issues such as blurriness and unrealistic backgrounds.
- Maintaining image quality while performing techniques like fine-tuning a diffusion model was emphasized, alongside discussions about AI's ethical considerations.
Links mentioned:
HuggingFace ▷ #today-im-learning (7 messages):
PEFT model loading methodsStein score function relationshipModel training for summarizationUAE conceptsElastic Search and web crawling
- Understanding PEFT Model Loading Methods: A discussion arose regarding two methods to load a PEFT model, comparing AutoModelForCausalLM.from_pretrained with adapter loading methods for the model ybelkada/opt-350m-lora.
- Is the adapter config responsible for retrieving the whole model in the first method?
- Exploring Stein Score Function: A member expressed confusion about the relationship between the Stein score function and probability density function, specifically questioning the inclusion of the log (log pdf).
- They are seeking clarity on the significance of this logarithmic function.
- Training BERT for Summarization: A member shared their experience learning to train a model for text summarization using BERT with the model flan-t5-base-samsum.
- Summary metrics were shared, with highlights including a Rouge1 score of 47.2141.
- Learning UAE Concepts: A member is diving into concepts related to UAE, sharing a link to an arXiv paper as part of their study.
- They expressed a grasp of some concepts but are open to further explanations.
- Elastic Search and Web Crawling: Members discussed learning about Elastic Search and Apify, focusing on web crawling, scraping, and indexing techniques.
- These methods are crucial for data retrieval and management in various applications.
Link mentioned: sharmax-vikas/flan-t5-base-samsum · Hugging Face: no description found
HuggingFace ▷ #cool-finds (4 messages):
Meta's Llama 3.1 ModelsOpen Source AIMark Zuckerberg's Vision
- Meta launches Llama 3.1, a game changer in AI: Meta's latest Llama 3.1 models expand context length to 128K and offer support for eight languages, marking a significant advancement in open-source AI.
- Notably, the Llama 3.1 405B model boasts capabilities that rival closed-source models like OpenAI's GPT-4o, and the complete model is available for download including weights.
- Zuckerberg’s commitment to open-source tech: In a blog post, Mark Zuckerberg emphasizes that open-source AI is beneficial for developers, Meta, and society by fostering innovation and collaboration.
- He believes that Llama can evolve into a robust open AI ecosystem, enabling developers to unlock new workflows and create tools that enhance their projects.
Links mentioned:
HuggingFace ▷ #i-made-this (4 messages):
Mistral-NeMo 12B InstructPony Diffusion v6Llama 3.1 Release
- Lightning fast chat with Mistral-NeMo 12B Instruct: A demo showcasing Mistral-NeMo 12B Instruct with an implementation using llama.cpp has been released, promising impressive performance.
- Users are encouraged to try it out for a refreshing chat experience.
- Pony Diffusion v6 gets a weekly update: The latest version, Pony Diffusion v6, was recently announced and features many options aimed at power users, with updates rolled out weekly.
- The project can be found here, and it has connections to a previous demo by artificialguybr.
- Community Excitement for Llama 3.1: The community is buzzing about the release of Llama 3.1, with a new space built around the HF Inference API that allows customization of system instructions.
- Check out the space here to explore the features available for free, making it accessible to everyone.
Links mentioned:
HuggingFace ▷ #reading-group (2 messages):
Object Detection in Java
- Excitement Over Object Detection App Tutorial: A member shared a blog post detailing the development of an Object Detection App in Java.
- Great!!!! was the enthusiastic reaction from another member, indicating a positive reception and interest in the topic.
- Community Engagement on Java Development: Members expressed interest in Java development technologies, particularly regarding tutorials like the one shared.
- The excitement reflects a growing community interest in practical applications and learning resources in software development.
HuggingFace ▷ #computer-vision (1 messages):
Chameleon modelsBatch processing images
- Inquiry on Chameleon models: A member asked if anyone has worked on Chameleon models and stated they have questions regarding how to batch/collate images for a batched forward pass.
- Could anyone share insights on image processing for these models?
- Batch processing questions raised: The discussion highlighted the need for clarity on how to effectively implement batch processing and collate images for Chameleon models.
- Several members expressed interest in sharing their experiences and best practices with batching during forward passes.
HuggingFace ▷ #NLP (8 messages🔥):
Training Sentence EncodersMetrics for Model EvaluationFine-tuning Sentence TransformersRAG Pipeline for Q&AText-to-HTML/CSS Generation Model
- Challenges with MultipleNegativesRankingLoss: A member expressed difficulties training sentence encoders using MultipleNegativesRankingLoss and noticed worse performance upon increasing batch size for the CachedMultipleNegativesRankingLoss.
- They inquired about common dataset issues that could arise when increasing batch size, aiming for better model results.
- Metrics for Model Evaluation: One member outlined their evaluation metrics, using recall@5, recall@10, and recall@20 based on a small vector database from a fine-tuned model.
- They also mentioned utilizing an evaluator called TripletEvaluator to gauge model performance.
- Fine-tuning Sentence Transformers for Legal Norms: A beginner member sought guidance on fine-tuning a sentence transformer for a dataset focused on legal and financial norms, aiming for a RAG pipeline for Q&A.
- They requested steps and recommended readings to successfully approach this task.
- Interest in Tiktoken Experience: A member queried about others' experiences using tiktoken, prompting a call for shared insights.
- This highlights an area of curiosity regarding the integration and effectiveness of the tool in related projects.
- Open-source Text-to-HTML/CSS Generation Model: A member announced their intention to acquire an open-source text-to-HTML/CSS generation model and sought recommendations.
- This reflects ongoing exploration into tools that facilitate conversion of text content into web formats.
HuggingFace ▷ #diffusion-discussions (6 messages):
Rectified FlowFlow MatchingDDPM and DDIM DiscussionsEvaluation of Generative ModelsVAE Model Cards
- Lack of Interest in Rectified Flow: A member expressed frustration that while there are many discussions regarding DDPM and DDIM, there is little talk about Rectified Flow or Flow Matching.
- They highlighted the difficulty in finding minimal examples for Flow such as generating MNIST, questioning the general interest in this topic.
- Flow Schedulers in Diffusers: Another member pointed out the existence of FlowMatchEulerDiscreteScheduler and FlowMatchHeunDiscreteScheduler in the
diffuserslibrary, implying their relevance to the discussion.- These resources can be found in the Hugging Face documentation.
- Evaluation Methods for Generative Models: A member referenced a document discussing qualitative and quantitative methods for evaluating Diffusion models, underscoring the complexity of model selection.
- They mentioned that both qualitative and quantitative evaluations provide a stronger signal for comparing models such as Stable Diffusion and GANs.
- Inquiring About VAE Model: A member inquired about the specific VAE being referenced in the discussion, seeking clarification on its identity.
- They requested the sharing of its corresponding model card to gain more insights.
Link mentioned: Evaluating Diffusion Models: no description found
Stability.ai (Stable Diffusion) ▷ #general-chat (239 messages🔥🔥):
Kohya-ss GUI IssuesLycoris Integration UpdatesModel Performance RatingsStable Diffusion Model ComparisonsNew AI Video Generation Model Announcement
- Kohya-ss GUI faces compatibility issues: Users reported issues with the current version of Kohya-ss GUI being incompatible with Python 3.10, needing an upgrade to 3.10.9 or higher.
- One user humorously remarked that it's like requiring a weight limit of 180lbs but no more than 180.5lbs, reflecting on the absurdity of such restrictions.
- Lycoris integration in development.: A mention was made of Onetrainer potentially implementing Lycoris features in a new dev branch soon, with community discussions around various functionalities.
- The preference for bmaltais' UI wrapper for Kohya's scripts was noted, enhancing user experience with these integrations.
- Community ratings for art model performance.: A discussion unfolded over the performance ratings of models including Kolors, Auraflow, Pixart Sigma, and Hunyuan, with Kolors being favored for its speed and quality.
- Participants emphasized different user experiences, debating the specific traits and applications of each model in depth.
- Evaluating Stable Diffusion model capabilities.: Several users debated the differences in output and usability between Stable Diffusion 1.5 and SDXL in terms of detail and resolution quality.
- Advanced techniques, such as Hidiffusion and Adaptive Token Dictionary, were highlighted as effective for enhancing output from older models.
- Introduction of Stable Video 4D for multi-angle video generation.: The Stable Video 4D model was introduced, enabling users to transform single object videos into new views for enhanced creative projects.
- This new model is currently in its research phase, with expectations for applications in game development, video editing, and virtual reality.
Links mentioned:
Eleuther ▷ #general (58 messages🔥🔥):
Sampling methods in language modelsLlama 3.1 benchmarkingLog likelihood evaluationGreedy vs stochastic samplingTail probability in sampling
- Understanding Sampling Methods for LLMs: Members discussed various sampling methods used in language models such as greedy sampling, top-p, and top-k, emphasizing their trade-offs.
- Stochastic sampling allows for diversity but requires multiple runs for statistically significant results, contrasting with the reliability of greedy sampling.
- Llama 3.1 Sampling Preferences: In the context of using Llama 3.1 for benchmarking, members suggest checking its paper for recommended sampling methods, with the consensus leaning towards probabilistic sampling.
- One member noted that Gemma 2 utilizes top-p and top-k, which are typical for models in evaluations.
- Log Likelihood as a Measurement Tool: Log likelihood was highlighted as a valuable metric for assessing model performance, allowing comparisons of how well models replicate results under different sampling methods.
- It's suggested that using log likelihood can help understand how sampling choices affect output distributions and overall model reliability.
- Greedy Sampling as a Baseline: Greedy sampling serves as a reliable baseline for model evaluations, generating the most probable output path through the vast output space.
- Members argued that while stochastic sampling can yield diverse outputs, it complicates evaluation and requires extensive runs to achieve statistical significance.
- Long Sequence Generation Challenges: Discussion surfaced around the complexities of measuring quality in longer generated sequences, with caveats tied to sampling methods and log likelihood.
- Concerns were raised that tail probabilities can lead to compounding errors in output, affecting the model's long-term performance and outcomes.
Links mentioned:
Eleuther ▷ #research (132 messages🔥🔥):
Misleading Tweets on Model PerformanceMoE vs Dense ModelsCharacter.AI's Model ArchitectureMixtral and Mistral Model DesignExternal Data in LLM Training
- Misleading Tweets and Assumptions about Model Performance: Discussion ensued regarding a misleading tweet related to projection calculations in language models, particularly focusing on how Character.ai uses shared KV layers and how this influences performance metrics.
- Members expressed confusion around the accuracy of the information shared and highlighted the personal journey of understanding transformer architectures.
- Debate on MoE vs Dense Models: Participants analyzed why dense architectures are being favored over Mixture-of-Experts (MoE) models, citing the high costs and engineering requirements for handling MoEs in large-scale training.
- Arguments were made that MoEs should perform better in terms of efficiency once a model is pretrained, although concerns about varied engineering capabilities within organizations were raised.
- Insights into Character.AI's Model Architecture: Insights on Character.AI's architectural choices were shared, emphasizing how they manage inference efficiently through design optimizations, though exact details remain unclear from their blog posts.
- Participants noted the potential for shared caches across layers, hinting that the model could benefit from architecture information that may not be publicly elucidated.
- Mistral and Mixtral's Model Choices: Discussion acknowledged the recent models like Mistral and Mixtral opting for dense architectures despite their abilities to implement MoEs, which surprised some members.
- The ongoing challenges associated with training and efficiency concerns during inference were highlighted as key reasons for these design decisions.
- Utilizing External Data in LLM Training: A paper on leveraging external sources in training language models was shared, paving the way for improved performance in complex reasoning tasks going beyond traditional methods.
- This sparked curiosity among members to explore how newer models incorporate such innovative techniques for better information retrieval and task execution.
Links mentioned:
Eleuther ▷ #lm-thunderdome (21 messages🔥):
Llama API evaluationChat format model usageMultiple-choice task handling
- Llama API Evaluation via lm_eval: Members discussed errors encountered while using the
lm_evaltool with the Llama 3.1-405B model through the API atllama-api.com, especially regarding support for logits and multiple-choice tasks.- “It gives an error: No support for logits.” prompted a series of troubleshooting attempts, including checking URL formats and API key usage.
- API Configuration Issues: To address the 'Method Not Allowed' error, it was suggested to use the full API URL and ensure parameters like temperature and max tokens are correctly configured.
- One member successfully edited the
_create_payloadmethod to address these issues, leading to functional model evaluations under specific configurations.
- One member successfully edited the
- Handling of Multiple-choice Questions: After successfully running evaluations for tasks like
gsm8k, errors emerged with multiple-choice tasks likemmlu_college_biology, specifically an 'AttributeError' related to content processing.- This raised questions about the compatibility of the API outputs with the evaluation framework, leaving members to seek solutions and share error logs for further analysis.
Links mentioned:
CUDA MODE ▷ #general (25 messages🔥):
GPU Bit-MatchingGPU FLOPS and Data TypesNon-Deterministic Results in Floating Point OperationsCUDA Lookback Scan AlgorithmNCCL Computation Overlap Issues
- Understanding GPU Bit-Matching: A question arose about whether results from a specific GPU model are uniquely bit-matched given certain inputs, with members noting that it depends on the algorithm used.
- Another commented that for most algorithms, results are consistent if run on the same GPU.
- GPU FLOPS and Data Type Dependencies: A member clarified that GPU FLOPS figures are influenced heavily by data types and whether computations use CUDA cores versus tensor cores.
- Another member added that Nvidia's specs provide performance details for different data types, found in their whitepapers.
- Non-Determinism in Floating Point Calculations: It was discussed that using floating point data can sometimes lead to beneficial non-deterministic results based on how operations are ordered.
- As noted, slight changes in kernel tuning or hardware can lead to variations in results, complicating debugging.
- Lookback Scan Algorithm in CUDA Mode: A member pointed out a CUDA mode episode regarding the lookback scan algorithm, suggesting it can sometimes be switched.
- However, members struggled to find documentation or examples discussing how to utilize this algorithm.
- Challenges in NCCL Computation Overlap: It was reported that recommendations about overlapping computation with NCCL during the backward pass did not yield the expected ease of implementation.
- A GitHub issue was cited, highlighting difficulties encountered while using NCCL for multi-GPU training in the context of ResNet-50.
Links mentioned:
CUDA MODE ▷ #triton (1 messages):
Profiling Triton kernelsAccelerating current Triton GPTQ kernelsIntegration of Triton kernels into PyTorch
- Seeking Help to Profile Triton Kernel: A user inquired about the process to profile Triton kernels as described in the PyTorch blog post. They highlighted the accelerations achieved with Triton but needed guidance on implementing profiling techniques.
- Steps to Accelerate Triton GPTQ Kernels: The blog outlines a first principles approach that accelerated Triton GPTQ kernels by 3x for core GPTQ and 6x for AutoGPTQ, reducing times from 275us to 47us for typical Llama style inference. It emphasizes the effectiveness of coalesced memory access and strategies to reduce warp stalling to boost throughput.
- Integrating Triton Kernels into PyTorch: As part of the optimization effort, the blog discusses integrating Triton kernels into PyTorch code, underscoring its potential to replace existing native CUDA implementations. Over time, this integration aims to surpass the performance of traditional CUDA native GPTQ kernels.
Link mentioned: Accelerating Triton Dequantization Kernels for GPTQ: TL;DR
CUDA MODE ▷ #torch (13 messages🔥):
torch.compile performanceGPU memory usage with torch.compileCUDA kernel anti-patternsPyTorch profiling toolsCUDA graphs in PyTorch
- torch.compile struggles with small Bert model: A user reported significantly increased RAM usage when testing
torch.compilewith a small Bert model, dropping batch size from 512 to 160 which was slower than using eager mode.- Despite compiling without issues when using
full_graph=True, the user seeks insights into potential causes for the observed performance drop.
- Despite compiling without issues when using
- Profiler Use Recommended for Memory Issues: One member suggested using the PyTorch profiler and its memory trace tool to investigate deeper into memory usage during model inference.
- This approach could provide insights into whether specific configurations or usages are leading to the increased memory demands.
- CUDA Graphs and Configuration Queries: A user confirmed they didn't explicitly set CUDA graphs, sticking to defaults while using
torch.compile; they referenced using 2.3.1 and 2.4 RC versions.- The interaction highlighted Inductor configurations and whether changing them could affect performance during model compilation.
- Highlighting CUDA Kernel Anti-patterns: A member emphasized a subtle anti-pattern for writing CUDA kernels in PyTorch related to GMEM scratch space allocation, recommend noting tensor lifetimes beyond kernel launches.
- This insight stemmed from debugging CI failures and relates to careful management of temporary tensors when developing new ops.
torch.compilewith reduced overhead shows no difference: The user observed no change in memory usage with or without thereduce-overheadandfullgraphoptions in theirtorch.compilesetup.- This stable observation sheds light on the necessity of understanding compile modes versus memory efficiency in practice.
Links mentioned:
CUDA MODE ▷ #cool-links (16 messages🔥):
VLM PerformanceCUDA AdvancementMistral Large 2FP16/FP32 IntrinsicsFeature Engineering Success
- VLMs outperforming in text generation: A discussion highlighted that even when VLMs are available, they typically excel in text tasks over image processing, as shown with GPT-4o's performance on the ARC test set.
- Ryan found that feature engineering the problem grid yielded better results compared to relying entirely on GPT-4o's vision capabilities.
- CUDA aiming to surpass cuBLAS: A member announced upcoming CUDA advancements, stating, we are going to outperform cuBLAS on a wide range of matrix sizes.
- This includes potential enhancements not only for SGEMM but for other operation types as well.
- Mistral Large 2 showcases advanced features: Mistral Large 2 boasts a 128k context window with support for multiple languages and 80+ coding languages, designed for efficient single-node inference.
- With 123 billion parameters, it is geared towards long-context applications and is released under a research license allowing for non-commercial usage.
- Impact of FP16/FP32 on performance: Discussion surfaced around NVIDIA's hardware intrinsics for FP16/FP32, which could significantly influence performance outcomes.
- This has generated excitement for future developments in the CUDA ecosystem.
- Interesting Benchmark Comparisons: Members found Mistral's latest benchmarks intriguing as they push the boundaries of cost efficiency, speed, and performance.
- The new features provided facilitate building innovative AI applications for various contexts.
Links mentioned:
CUDA MODE ▷ #jobs (1 messages):
ML/AI career roadmapInternship opportunitiesJob search strategies
- Seeking Guidance for ML/AI Career Path: A user requested help in designing a roadmap to secure full-time positions and internships in ML/AI roles, sharing a Google Document with details.
- They emphasized their willingness to work long hours to meet targets and are open to any suggestions regarding their roadmap.
- Open to Suggestions for Internships: The user is looking for feedback on their approach to landing internships in the ML/AI field and whether their plans are feasible.
- They explicitly stated that timelines should not be considered unrealistic as they can dedicate extra hours to complete tasks.
Link mentioned: ML Roadmap: 3 months - (sept, oct, nov) roadmap Statistics: https://www.youtube.com/watch?v=MXaJ7sa7q-8&list=PL0KQuRyPJoe6KjlUM6iNYgt8d0DwI-IGR&t=11s (1 week) Linear Algebra - https://www.youtube.com/wat...
CUDA MODE ▷ #beginner (10 messages🔥):
CUDA Installation IssuesOut of Memory ErrorsLlama-2 Chat ModelRunning Models as Discord Bots
- Torch not compiled with CUDA: A member discovered that Torch wasn't compiled with CUDA enabled and sought help on how to resolve it.
- Another member advised that installing the CUDA version directly from the install page would provide the exact command needed.
- Got CUDA working but hit a wall: After getting CUDA functional, a member encountered a torch.cuda.OutOfMemoryError, indicating insufficient GPU memory while trying to allocate 172.00 MiB.
- They received a suggestion to adjust the max_split_size_mb to prevent memory fragmentation, referencing documentation for resolution.
- Exploring Llama-2 7B Model: A member shared details about their fine-tuned Llama-2 7B model, trained on a 24GB GPU over 19 hours using the Wizard-Vicuna dataset.
- They provided multiple links to versions of the model, including GGML and GPTQ, hosted on Hugging Face.
- Running models as Discord bots: A member expressed interest in running the Llama-2 model as a Discord bot, showing their enthusiasm for its capabilities.
- This statement reflects a broader interest in integrating AI models into community platforms.
Link mentioned: georgesung/llama2_7b_chat_uncensored · Hugging Face: no description found
CUDA MODE ▷ #torchao (8 messages🔥):
ImportError in Torch AOSupported PyTorch versionsPruning and Quantization issues
- ImportError: Importing from Torch: A new user encountered an ImportError when trying to import 'return_and_correct_aliasing' in torch.utils._python_dispatch, indicating a version incompatibility.
- Linking to this GitHub issue was suggested for further investigation.
- Testing on PyTorch versions: Members indicated that they do not test on PyTorch versions before 2.2, implying that users should upgrade their versions for optimal functionality.
- One user confirmed they would try upgrading to torch 2.2 based on this advice.
- Concerns with Llama 3.1 Inference Latency: A user inquired whether Llama 3.1 8b has improved inference latency compared to 3.0, highlighting ongoing discussions about model performance.
- No responses were provided regarding the specific latency performance of the models.
- Tutorial Issues with Pruning and Quantization: A user shared confusion regarding the weight_orig and weight_mask transformations while implementing structured pruning with quantization, seeking clarity.
- They received a RuntimeError related to the deepcopy protocol when attempting to apply the detach operation, which broke model inference.
Links mentioned:
CUDA MODE ▷ #ring-attention (1 messages):
Blockwise Attention in Llama 3Input Sequence Splitting
- Implementing Blockwise Attention in Llama 3: A user inquired about the correct stage for splitting the input sequence into blocks when implementing blockwise attention in the Llama 3 architecture.
- They specifically asked whether this should occur after applying rotary position embeddings to vectors Q and K, or before the self-attention block.
- Clarification on Sequence Handling: The user expressed confusion regarding the implementation specifics of the Llama 3 architecture, indicating a need for clarity on the handling of input sequences.
- The discussion revolves around optimal strategies for integrating blockwise attention effectively into the model's processing flow.
CUDA MODE ▷ #hqq (1 messages):
iron_bound: neat https://github.com/AnswerDotAI/fsdp_qlora/tree/llama400b
CUDA MODE ▷ #llmdotc (71 messages🔥🔥):
KV Cache ImplementationZeRO-2 Performance InsightsLLaMA and muP ComparisonStochastic Rounding StrategiesGPT-2 Training Experiment
- Progress on KV Cache Logic: A member reported successful implementation of partial KV cache logic for attention, which involved using existing buffers intelligently without changing the layout.
- Debugging revealed discrepancies in token results during the second pass, but the overall implementation showed significant progress.
- Insights on ZeRO-2 Performance: Testing with ZeRO-2 and 2 GPUs showed an estimated 25% memory savings on gradients for smaller models, with plans for scalability in mind.
- Despite the improvements, challenges were noted with gradient computations needing additional copies during communication phases.
- Comparison Between LLaMA and muP Techniques: Discussion emerged around LLaMA's performance compared to muP, specifically regarding the use of techniques such as tanh soft clamping.
- Concerns were raised about whether muP enhances performance or primarily offers better learning rate transfers.
- Stochastic Rounding in Gradient Accumulation: A member highlighted a proposed method for stochastic rounding in gradient accumulation to improve training stability and efficiency.
- This approach could lead to more effective gradient updates while potentially allowing for greater accumulation during training.
- Training Results from GPT-2 Experiment: Training was completed on a GPT-2 350M model, using the Fineweb-edu dataset with interleaved OpenHermes data for instruction pretraining.
- Despite some curious training loss patterns, the overall results were deemed stable, and the model is available for public use on Hugging Face.
Links mentioned:
CUDA MODE ▷ #rocm (3 messages):
FlashAttention Support for AMDMI200 & MI300 CompatibilityGitHub Pull Requests
- FlashAttention Now Supports AMD ROCm: A recent GitHub Pull Request #1010 implements support for AMD ROCm in the FlashAttention 2 library, including several C++ APIs like
mha_fwdandmha_varlen_fwd.- The implementation is rooted in composable kernel technology, maintaining API consistency with the original version.
- Limited Compatibility with MI200 & MI300: It was stated, 'We only support mi200 & mi300 at this time' regarding the compatibility of the newly updated FlashAttention.
- This draws a clear line on current support, implying potential future updates for broader compatibility.
Link mentioned: Support AMD ROCm on FlashAttention 2 by rocking5566 · Pull Request #1010 · Dao-AILab/flash-attention: This PR implement the AMD / ROCm version of c++ flash api mha_fwd mha_varlen_fwd mha_bwd mha_varlen_bwd The kernel implementation comes from composable kernel The c++ api is same as original ver...
OpenAccess AI Collective (axolotl) ▷ #general (87 messages🔥🔥):
Llama 3.1 ErrorsMistral Large Model ReleaseMultilingual Model PerformanceTraining and Fine-tuning ChallengesSynthetic Data Generation in Models
- Llama 3.1 Encountering Errors: Users reported issues with Llama 3 resulting in errors like AttributeError and discussions suggested possible outdated images or configurations as causes.
- One user mentioned trying a different image to resolve the problem while another expressed general frustration with frequent model updates.
- Mistral Large Model Open-sourced: Mistral has released the Mistral-Large-Instruct-2407 model, featuring 123B parameters and claiming state-of-the-art performance.
- Key features include multilingual support across dozens of languages, proficiency in coding, and advanced agentic capabilities, prompting excitement among users.
- Discussion on Multilingual Model Performance: Comparisons between Llama 3.1 and NeMo revealed performance variances, particularly in multilingual capabilities, with specific strengths in different languages.
- Users noted that while Llama 3 had some European languages, NeMo reportedly offers better support for Chinese and other languages.
- Challenges in Model Training and Fine-tuning: Concerns were raised about the need for significant RAM to effectively train large models like Mistral, with some users remarking on their limitations.
- Someone expressed difficulties with exploding gradients during training, pondering whether this was linked to sample packing.
- Synthetic Data Generation Mentioned: The launch of Llama 3.1 included a reference to Synthetic Data Generation, prompting calls for internal documentation scripts.
- Users discussed the idea as potentially beneficial for fine-tuning and training models.
Links mentioned:
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (33 messages🔥):
Adapter Fine-TuningLlama-3.1 CompatibilityCUDA ErrorsH100 Configurations
- Discussion on Adapter Fine-Tuning Stages: Members discussed the potential of implementing multiple stages of adapter fine-tuning, considering initializing later stages with previous results, such as using SFT weights for DPO training.
- A related feature request was found on GitHub with suggestions for small code changes to facilitate this approach.
- Llama-3.1 Fine-Tuning Troubles: Several users reported errors when fine-tuning Llama-3.1-8b, with issues regarding CUDA check failures and suggestions to use official weights from Hugging Face.
- One member confirmed successful fine-tuning with 12b models while another found that updating transformers resolved their issues with Llama 3.1.
- Insights on CUDA Check Implementation Errors: A user queried about a specific CUDA error encountered during the training process, leading to discussions about potentially corrupted CUDA installations.
- Other members suggested reinstalling relevant libraries and shared their configurations as possible solutions.
- Request for H100 Configuration References: A member inquired about known Axolotl configurations that work well for fine-tuning on a single 8xH100 setup.
- The request highlights the community's need for effective model configurations tailored for specific hardware deployments.
Links mentioned:
OpenAccess AI Collective (axolotl) ▷ #general-help (1 messages):
Request for HelpExperience Sharing
- Seeking Relevant Experience for Assistance: A member requested help regarding a specific topic link shared in the channel.
- They called for anyone with relevant experience to step forward and assist with the inquiry.
- Open Request for Support in the Channel: The same member emphasized the need for collective knowledge within the community about the issue linked.
- They reiterated that any input from experienced individuals would be invaluable for resolving their query.
Interconnects (Nathan Lambert) ▷ #news (69 messages🔥🔥):
GPT-4o mini updatesMistral Large 2 detailsOpenAI's financial challengesAI licensing and usageNew RLHF discussions
- GPT-4o mini dominates Chatbot Arena: With over 4,000 user votes, GPT-4o mini is now tied for #1 in the Chatbot Arena leaderboard, outperforming its previous version while being 20x cheaper.
- The excitement was evident as developers celebrated this milestone, noting the continuous drop in the cost of intelligence for new applications.
- Mistral Large 2: A New Contender: Mistral Large 2 boasts a 128k context window and supports dozens of languages, making it a top-tier model for high-complexity tasks, aimed at commercial and research usage under their specific license.
- Discussions arose around the licensing conditions, with clarity lacking on commercial use as users seek practical applications for the technology.
- OpenAI's $5 billion Loss Prediction: Recent estimates suggest OpenAI could face a staggering loss of $5 billion this year, attributing significant costs to Azure bills and training expenses.
- Concerns about sustainability and profitability were raised amid discussions of API revenue being surprisingly low compared to expectations.
- Chatbot Licensing and Legal Challenges: Questions arose about whether the EU AI Act influenced Mistral's licensing approach, speculating on potential commercial usage restrictions associated with legal compliance.
- The dialogue highlighted the need for clearer documentation and guidance regarding commercial applications of emerging models.
- Shifts in RLHF Methodologies: The conversation pointed to Llama 3 marking a significant shift away from traditional RLHF approaches, with implications for the effectiveness of contractor-based data labeling.
- Anticipation is building for future posts exploring new RLHF strategies and the potential existence of data foundries to support evolving methodologies.
Links mentioned:
Interconnects (Nathan Lambert) ▷ #ml-questions (8 messages🔥):
Vocabulary Size Impact on InferenceByte Pair Encoding and TokenizationModel Size Relation to VocabularyTradeoffs in Vocabulary Expansion
- Larger Vocabulary Might Slow Inference: Concerns emerged regarding a larger vocabulary size potentially slowing down inference, challenging the common belief that it reduces forward passes needed for common sentences.
- One member questioned if this assumption was valid, suggesting that context may matter especially for small models where a vocabulary increase has a larger parameter impact.
- Tradeoffs in Vocabulary Sizing Logic: Discussion revolved around the idea that a smaller vocabulary compresses sequences, while a larger one potentially increases token count, which may complicate inference time.
- Members debated the advantages of having fewer tokens for frequent phrases versus retaining finer interactions that larger vocabularies might miss.
- Complexity in Vocabulary Research: A member pointed out the potential high costs and narrow applicability of conducting thorough experiments to test vocabulary effects on different models.
- They noted that findings might not generalize well, emphasizing the need for caution in broad claims about model capabilities.
- Byte Pair Encoding's Role in Vocabulary Building: One participant highlighted how Byte Pair Encoding (BPE) constructs vocabulary by first creating tokens for individual words and then merging them into larger tokens when context allows.
- This process sparks discussion on whether using multiple tokens instead of a single compound token could enhance sequence comprehension and attention metrics.
Interconnects (Nathan Lambert) ▷ #ml-drama (4 messages):
IBM's StrategiesMagic Quadrant
- IBM's Shift in Focus: A member pointed out that the previous content was replaced with a page highlighting popular providers, prompting curiosity about what IBM is doing now.
- This shift raises questions regarding IBM's strategies in the current tech landscape.
- Insights on the Magic Quadrant: A member mentioned the potential influence over the Magic Quadrant, focusing on factors like Ability to Execute and Completeness of Vision.
- This indicates ongoing competition and strategic positioning within the tech industry.
- Discussion on AI and Midjourney: A relevant article from The New York Times titled A Letter to Midjourney was shared, discussing current trends in AI.
- The article may provide insights into public perception and the evolving role of AI technologies.
Interconnects (Nathan Lambert) ▷ #random (11 messages🔥):
CrowdStrike outage apologyPre-training data benchmarksDatacenter throughput issues
- CrowdStrike's $10 Apology Gift Card for Outage: After a massive outage caused by a botched update, CrowdStrike is offering partners a $10 Uber Eats gift card as an apology, according to multiple reports.
- However, some recipients found that when attempting to redeem the gift card, they received an error indicating that the voucher had been canceled.
- Paid Bonuses for Benchmark-Free Data: A member highlighted that they literally paid people bonuses if the pre-training data used in their models did not contain any benchmarks.
- This sparked a discussion on Twitter, where many caught other interesting details from the paper that could potentially warrant further papers.
- Datacenter Microclimate Affects Throughput: Participants discussed a note in the paper indicating a 2% drop in throughput at midday due to issues related to the datacenter microclimate.
- This detail was pointed out as significant, showcasing how minor environmental factors impact performance.
Links mentioned:
Interconnects (Nathan Lambert) ▷ #memes (3 messages):
Mark Zuckerberg's AI EraSnail emoji enthusiasm
- Inside Mark Zuckerberg's AI Era: A shared YouTube video titled 'Inside Mark Zuckerberg's AI Era | The Circuit' discusses the latest battle in the AI wars between open and closed models, highlighting Mark Zuckerberg's front-line role.
- The video description notes it gives insights into Meta's rebranding and direction amidst ongoing AI developments.
- Community celebrates the humble snail: A member expressed their love for snails, sharing a friendly emoji depicting the creature.
- We love snail was the enthusiastic sentiment that captured members' appreciation for this unique representation.
Link mentioned: Inside Mark Zuckerberg's AI Era | The Circuit: If the latest battle in the AI wars is between open and closed models, Meta CEO and Founder Mark Zuckerberg is right on the frontlines. Since rebranding as M...
Interconnects (Nathan Lambert) ▷ #rlhf (2 messages):
Llama 3 ReleaseRLHF in CapabilitiesSynthetic Data for Alignment
- Llama 3 Officially Released: Today, Meta is officially releasing the largest and most capable open model to date, Llama3-405B, which is trained on 15T tokens and beats GPT-4 on all major benchmarks.
- This model is a dense transformer that signifies a notable advancement in open-source AI capabilities.
- RLHF Leads to Post-Training Capabilities: An alignment lead on Llama stated that 100% RLHF is responsible for how capabilities emerge post-training, highlighting the importance of this method.
- This statement prompts discussions on effective alignment methods in model training.
- Synthetic Data's Role in Alignment Discussed: A noteworthy overview was shared on the utilization of synthetic data for alignment, shedding light on its potential benefits.
- This discussion emphasizes the growing interest in leveraging synthetic data to improve AI alignment strategies.
- Join the Emergency LLM Paper Club: Members are invited to join the emergency LLM paper club for an in-depth discussion about the Llama 3 paper.
- This initiative reflects a collaborative effort to analyze significant AI literature.
- AI in Action Club Featuring Cursor Cofounders: For ongoing engagement, members are encouraged to participate in the AI in Action club focusing on a special feature with the Cursor cofounders about their latest coding agent, Composer.
- This highlights the community's commitment to staying updated with innovative AI tools.
Link mentioned: Llama 2, 3 & 4: Synthetic Data, RLHF, Agents on the path to Open Source AGI: Llama 2 lead and Llama 3 post-training lead Thomas Scialom of Meta/FAIR, on the Chinchilla trap, why Synthetic Data and RLHF works, and how Llama4's focus on Agents will lead us to Open Source AG...
Interconnects (Nathan Lambert) ▷ #posts (4 messages):
SnailBot News
- SnailBot News Announced: A notification was sent regarding SnailBot News to the tag <@&1216534966205284433>.
- Interesting updates seem to be anticipated based on recent discussions.
- Time Reference of 45 Minutes: A member specified an interesting observation related to 45 minutes.
- The context of this time period remains unspecified in the current discussion.
Modular (Mojo 🔥) ▷ #general (12 messages🔥):
MAX and Mojo Compiler VersioningNightly Compiler ReleasesConfusion in VersioningFeature vs Calendar Based Releases
- MAX and Mojo Compiler Versioning Dilemma: Discussion arose around whether the next main compiler version would be 24.5 or 24.8, considering that feature/stable and nightly versions follow different release principles.
- Concerns were highlighted about the potential disconnect between the nightly and main versions moving forward, especially regarding future dates like 2025.
- Nightly Releases Follow a Calendar System: It was clarified that the nightly releases are based on a calendar model while the main releases are driven by marketing considerations, not strictly by date.
- One member noted that the accidental alignment of versions could cause confusion, citing their own experience mixing up version numbers during discussions.
- Community Exploration into ML Complexity: One participant mentioned delving into machine learning topics and described it as a 'hot mess', sharing their wonder at the complexities they encountered recently.
- This comment underscored the ongoing challenge of navigating ML discussions in the community and the various confusions that can arise.
Modular (Mojo 🔥) ▷ #mojo (17 messages🔥):
v24.5 release speculationUsing SDL with MojoDiscussion on Var and LetGenerated Art vs AIRegex library in Mojo
- Speculation on v24.5 Release Date: There's ongoing chatter regarding GPU features, leading to the guess that the release of v24.5 could take some time as the team stabilizes its features.
- There’s some debate about why the versioning system follows an increment per year.
- Interest in Using SDL with Mojo: A user inquired about resources to learn about SDL integration with Mojo, expressing a desire to understand the process better.
- On a related note, there's curiosity about how to utilize DLHandle within the context of SDL.
- Debate Over Var and Let Usage: A user questioned the necessity of using var if everything is declared as var, suggesting it might be redundant.
- In response, another member noted that var is beneficial to the compiler, whereas let primarily serves those who prefer immutability.
- Generated Art Performance Compared to AI: One user remarked about their computer creating some 'art', stating it's not as good as the gen ai.
- Another user suggested that comparisons should consider the amount of compute power spent.
- Query on Regex Library Availability: A user asked if a regex library exists within Mojo, highlighting interest in handling regular expressions.
- The conversation did not provide a definitive answer to the query.
Modular (Mojo 🔥) ▷ #nightly (54 messages🔥):
Mojo UpdatesGit InstructionsDTypePointer RemovalSIMD ComparisonsContributing to Mojo
- Significant Mojo Updates Released: A new nightly Mojo compiler has been released, updating to
2024.7.2405with notable changes including the removal ofDTypePointerand new methods for string formatting.- A complete changelog can be found at current changelog.
- Git Rebase Challenges: Several members discussed challenges with git rebasing and encountered issues like unresolved merge conflicts while following contributing guides.
- One member expressed frustration over feeling limited in their ability to contribute due to these tooling issues.
- DTypePointer's Impact on Mojo Projects: The removal of
DTypePointerfrom Mojo requires projects to update their code, transitioning to useUnsafePointerinstead.- There is a call for clear guidelines to assist developers with this transition, especially for prevalent usages in existing Mojo projects.
- Comparability of SIMD Types: A discussion arose around the challenges of establishing a total ordering for SIMD types, emphasizing the conflict between generic programming and specific comparisons.
- It was suggested that introducing a
SimdMask[N]type could help bridge the gap between architecture-dependent behavior and programming expectations.
- It was suggested that introducing a
- Contributions to Mojo Compiler Features: Contributors expressed a desire to simplify the Mojo library through improved generic programming and iterator implementations while addressing current compiler issues.
- There is an ongoing effort to streamline the API, particularly concerning overloads related to sorting and type handling.
Links mentioned:
Latent Space ▷ #ai-general-chat (57 messages🔥🔥):
Factorio Automation ModGPT-4o Mini Fine-TuningMistral Large 2 ReleaseReddit's Content Policy ControversyArxiv2Video Generator
- Factorio Automation Mod released: A new mod called factorio-automation-v1 has been released, allowing agents to perform various game actions like crafting and mining.
- It offers a great playground for agents to test their capabilities within the game.
- GPT-4o Mini Fine-Tuning Launch: OpenAI has launched fine-tuning for GPT-4o mini, now accessible to tier 4 and 5 users, with the first 2M training tokens daily being free until September 23.
- Members discussed evaluations comparing fine-tuned GPT-4o mini against Llama-3.1-8b, noting some performance inconsistencies.
- Mistral Large 2's Impressive Features: Mistral Large 2 has been unveiled with 123 billion parameters, offering support for multiple languages and strong code ability.
- It features open-weights for non-commercial use and is designed for long-context applications.
- Reddit's Content Policy Raises Eyebrows: A discussion emerged around Reddit's public content policy, with members expressing concerns about the control Reddit exerts over user-generated content.
- Many believe that users should have a choice over their content and argue that the policy's ambiguity raises significant issues.
- Arxiv2Video Generator Showcased: An open-sourced Arxiv2Video generator was introduced, with a demo created for the Herd of Llamas Paper Club.
- This tool, showcased by @aditya_advani, produces engaging video summaries of academic papers and invites further interest and potential collaborations.
Links mentioned:
Latent Space ▷ #ai-announcements (1 messages):
Llama 3 Paper ClubCursor's AI Developer ToolsAsia LLM Paper Club
- Emergency Paper Club on Llama 3: Join the emergency paper club in 2 hours to discuss @lvdmaaten et al's The Llama 3 Herd of Models, an early contender for the POTY Awards. More details are on Latent Space Pod.
- Members including @swyx, @vibhuuuus, and @eugeneyan will be present to explore this significant topic in detail.
- Cursor's Co-founder Discusses AI Tools: A special session will feature the co-founder of Cursor discussing Cursor, Composer, and AI developer tools in an upcoming meeting. This is a chance to get insights directly from the source.
- The exact date and time for this discussion were not provided, but it's set to be an important event for those interested in AI development.
- Don't Miss the Asia LLM Paper Club: Make sure to participate in the Asia LLM Paper Club for engaging discussions focused on recent advancements and papers in the field. You can find more about the meeting here.
- This club continues to be a key gathering for those invested in LLM research and collaboration.
Link mentioned: Tweet from Latent.Space (@latentspacepod): 🚨 EMERGENCY PAPER CLUB The @latentspacepod discord is meeting in 2hrs to talk thru @lvdmaaten et al's The Llama 3 Herd of Models, early contender to win the POTY* Awards! Join us (link below) w...
LlamaIndex ▷ #blog (5 messages):
LlamaParse FeaturesMongoDB AI Applications Program (MAAP)Mistral Large 2 CapabilitiesStructured Extraction in LLMs
- LlamaParse Unleashes Markdown and More: In a recent video, features of LlamaParse were showcased, including options for Markdown and plain text output, and JSON mode for richer metadata extraction.
- The tool also supports multi-language output for improved OCR, making it a versatile addition to any workflow. Watch the video here.
- MongoDB Launches AI Applications Program: The newly announced MongoDB AI Applications Program (MAAP) is designed to assist organizations in building and deploying modern AI-enhanced applications quickly.
- It provides reference architectures and a comprehensive technology stack with leading tech integrations, enabling enterprises to accelerate their AI journey. Learn more about MAAP.
- Mistral Large 2 Brings Advanced Function Calling: Mistral Large 2 features state-of-the-art function calling capabilities, with day 0 support for structured outputs and agents.
- This release aligns with enhanced function calling and structured outputs, providing useful resources like cookbooks for users to explore. Check out the cookbooks.
- Structured Extraction for LLMs Released: The latest release offers structured extraction capabilities for LLM-powered ETL, RAG, and agent pipelines, supporting both async and streaming functionalities.
- By defining a Pydantic object and attaching it to the LLM, users can significantly enhance their data processing workflows. Discover more here.
Link mentioned: MongoDB AI Applications Program: Get the support you need to accelerate your AI application journey and launch with confidence and speed.
LlamaIndex ▷ #general (52 messages🔥):
SubQuestionQueryEngineLlama 3.1 TestingRAG Setup for PDF DisplayText-to-SQL Pipeline OptimizationReAct Agent Behavior
- Streaming Responses with SubQuestionQueryEngine: Members discussed using
SubQuestionQueryEngine.from_defaultswith the goal of streaming final responses from the LLM to reduce latency.- A solution involving
get_response_synthesizerand utilizing token printing techniques was shared, but there were challenges implementing it.
- A solution involving
- Skepticism about Llama 3.1 Metrics: Some users expressed distrust in the metrics provided by Meta for Llama 3.1, with discussions on its usability for RAG evaluations.
- Concerns were raised about whether using models like
llama3:70b-instruct-q_5would be beneficial for such tasks.
- Concerns were raised about whether using models like
- Optimizing RAG with PDF Interfaces: A discussion focused on strategies to improve a RAG setup involving the display of PDFs through buttons in a web interface.
- Suggestions included avoiding large projects with many PDFs and using libraries that can directly handle PDF files without conversion.
- Improving Text-to-SQL Pipeline Speed: Users highlighted slow response times in their Text-to-SQL pipelines and sought advice on potential optimizations.
- Recommendations included using faster LLMs or condensing inputs; streaming output for a better user experience was also explored.
- ReAct Agent Hallucinations: A member reported that their ReAct agent would continuously hallucinate when responding to inputs, following an incorrect processing loop.
- Discussions pointed towards the LLM's inability to adhere to expected output formats and suggestions were made for adding stop tokens to improve behavior.
Links mentioned:
LlamaIndex ▷ #ai-discussion (1 messages):
RAG pipeline evaluationCustom RAG evaluation systemRAGAS frameworkImproving evaluation methods
- Evaluating RAG Pipeline Effectively: A member expressed the need for professional advice on evaluating their RAG pipeline after using the RAGAS framework, which they found to be too random.
- They noted they are now developing a custom RAGAS-like evaluation system to gain more control over the metrics.
- Seeking Suggestions for RAG Evaluation Packages: The member is looking for improvements to their custom evaluation method and asks if others can suggest better packages for their needs.
- They appreciated any advice shared on enhancing their system or alternatives worth considering.
Cohere ▷ #general (34 messages🔥):
Cohere Dashboard IssuesModel Testing AppreciationServer Performance ConcernsFeature Suggestions for ToolsCommunity Introductions
- Cohere Dashboard reloading issue: A member mentioned that their Cohere account dashboard appeared to be constantly reloading, while another confirmed it was fine on their end.
- This sparked a brief discussion about potential glitches and rate limiting.
- Appreciation for Command R Plus: With each new release of highly anticipated models like Llama 3.1, a member expressed growing appreciation for Command R Plus.
- Another user mentioned creating a playground for model comparisons to further explore this sentiment.
- Server performance inquiries: Concerns were raised regarding the server potentially being down, but others confirmed full operational status.
- Suggestions included checking for possible rate limiting affecting user experience.
- Feature suggestions for Cohere Tools: One member proposed the ability to use tools midway through conversations in Cohere, like invoking a web search on request.
- After some initial confusion, it was acknowledged that some of these features already exist.
- Introductions in the community: New members introduced themselves, discussing their background in NLP and NeuroAI and expressing excitement about the server.
- A discussion on experiences with Command-R+ highlighted its impact compared to other models like NovelAI.
DSPy ▷ #show-and-tell (6 messages):
zenbase/core launchDSPy optimizers
- Zenbase/Core Python Library Launch: A member announced that zenbase/core is now launched, allowing users to employ DSPy’s optimizers in their existing Python code like Instructor and LangSmith.
- They requested support through retweets, likes, and stars on their Twitter post.
- Member Engagement on Twitter: Another member enthusiastically responded, confirming they have liked and retweeted the launch announcement, expressing excitement about the new library.
- The overall sentiment in the channel reflects a positive reaction towards recent launches and developments.
DSPy ▷ #papers (1 messages):
batmanosama: done
DSPy ▷ #general (20 messages🔥):
Typed Predictors in DSPyInternal Steps Execution VisibilitySmall Language Models FutureContributing to DSPy RepositoryModel Fine-Tuning and Distillation
- Typed Predictors causing output issues: A user is facing trouble with typed predictors in DSPy not returning correctly structured output, despite following setup tips.
- Another user suggested configuring experimental features with
dspy.configure(experimental=True)for potential improvement.
- Another user suggested configuring experimental features with
- Inspecting internal program execution: Users discussed various methods to see the internal steps and prompts during program execution, with suggestions like
inspect_history.- One user expressed a need for more visibility into model outputs, even during type checking failures.
- Advocating for Small Language Models: A member shared an article promoting the efficiency and benefits of small language models that can run on minimal hardware.
- They emphasized privacy benefits and the suitability of small models for edge devices while maintaining useful intelligence.
- Opportunity to contribute to DSPy examples: Another user inquired about contributing examples to the DSPy repository, indicating readiness to create beginner-friendly content.
- Responses confirmed that there is a need for diverse examples, and contributions can be added to the
/examplesdirectory.
- Responses confirmed that there is a need for diverse examples, and contributions can be added to the
- Questions on model fine-tuning with DSPy: A user asked whether they could fine-tune and distill models like Llama 8B using DSPy without additional neural network code.
- Their curiosity highlighted the importance of understanding the capabilities of DSPy in relation to model training techniques.
Link mentioned: Small Language Models are the Future: My Thesis: Small language models (SLM)— models so compact that you can run them on a computer with just 4GB of RAM — are the future. SLMs…
tinygrad (George Hotz) ▷ #general (4 messages):
Learning TinygradGPU and Uops issuesOpenCL and Python challengesChecking Closed PRs
- Learning the ropes of Tinygrad: One member mentioned he is still on his list of things to learn concerning Tinygrad and transformers.
- It's a work in progress, he added, indicating a desire for gradual understanding.
- GPU and Uops are still a concern: A member is struggling with making the GPU and Uops turn green, while successfully using numpy and pytorch shapes.
- He seeks hints on fixing OpenCL and Python device issues, stating, I guess should be full green.
- Advice to check closed PRs: One user suggested that checking the closed PRs could provide insights into the ongoing issues.
- This user aims to help clarify any uncertainties around making progress.
- Understanding OpenCL and Python limitations: Another member pointed out that OpenCL and Python fail due to their inability to utilize views, which complicates matters.
- They noted that a simple 'bitcast' will not work with shape changing bitcasts, pointing out specifics to check with DEBUG=x.
tinygrad (George Hotz) ▷ #learn-tinygrad (19 messages🔥):
Molecular Dynamics Engine in tinygradCustom Runtime ImplementationNeural Network PotentialsPPO Algorithm in Beautiful CartPole
- Implementing a Molecular Dynamics Engine: A member is working with a group to implement a Molecular Dynamics engine in tinygrad, using neural networks to predict energies of configurations, while facing issues with gradient utilization.
- Another member suggested using input gradient tracking and modifying weight updates to avoid issues encountered during backpropagation.
- Guide for Custom Runtime in tinygrad: A user shared a guide on how to implement a custom runtime for tinygrad, highlighting that support for new hardware should be simple to add.
- They asked for clarifications on technical terms such as
global_sizeandlocal_size, which were explained as parameters for kernel execution counts in the operational context.
- They asked for clarifications on technical terms such as
- Understanding Neural Network Potentials: The discussion revealed that the energy used in the Molecular Dynamics engine is based on Neural Network Potentials (NNP), emphasizing the need for efficient calculations.
- The conversation included suggestions on how to optimize the backpropagation process to improve training results.
- PPO Algorithm in Beautiful CartPole: A member inquired about the purpose of the
.sum(-1)operation in the PPO implementation for the Beautiful CartPole environment, pointing to a specific line in the code.- This illustrates the collaborative nature of understanding nuances in reinforcement learning implementations among community members.
Links mentioned:
Torchtune ▷ #general (15 messages🔥):
3.1 release interviewsMPS support PRLoRA issuesConflicts in contributionsGit workflow optimizations
- Countdown to 3.1 and Cool Interviews: Members inquired about whether there would be any cool interviews released along with the 3.1 version, similar to those for Llama3.
- This raises interest for potential insights and discussions that might accompany the new release.
- MPS Support PR Gains Attention: A new pull request (#790) was highlighted which adds support for MPS on local Mac computers, checking for BF16 compatibility.
- Context suggests this PR could resolve major testing hurdles for those using MPS devices.
- LoRA Functionality Issues Persist: Discussed issues surrounding LoRA functionality, noting it did not work during a previous attempt and was previously impacted by hardcoded CUDA paths.
- Members exchanged thoughts on specific errors encountered, highlighting ongoing challenges in implementation.
- Endless Battle with Git Conflicts: Members expressed frustrations with frequent new conflicts in their contributions, believing it feels like an endless cycle, especially after fixing existing conflicts.
- It was suggested that new conflicts might stem from the workflow, indicating a potential need for tweaks.
- Optimizing Git Workflow to Reduce Conflicts: Discussion around refining git workflows to minimize the occurrence of new conflicts constantly arose, emphasizing collaboration.
- Suggesting improvements in contribution practices may help lighten the burden of merging challenges.
Link mentioned: MPS support by maximegmd · Pull Request #790 · pytorch/torchtune: Context For testing purposes it can be useful to run directly on a local Mac computer. Changelog Checks support for BF16 on MPS device. Added a configuration targeting MPS, changes to path were ...
Torchtune ▷ #dev (1 messages):
Pad ID BugPull Request #1211
- Fixing the Pad ID Bug: A member pointed out that the pad id should not be showing up in generate functionality, identifying it as an important bug.
- In response, a Pull Request was created to prevent pad ids and special tokens from displaying, detailed in Pull Request #1211.
- Details of Pull Request #1211: The Pull Request #1211 aims to address the issue regarding pad id by modifying the implementation in utils.generate.
- The context of the PR mentions it is meant to fix a bug, ensuring pad ids are implicitly handled correctly.
Link mentioned: Prevent pad ids, special tokens displaying in generate by RdoubleA · Pull Request #1211 · pytorch/torchtune: Context What is the purpose of this PR? Is it to add a new feature fix a bug update tests and/or documentation other (please add here) Pad ID is implicitly assumed to be 0 in utils.generate, ...
LangChain AI ▷ #general (6 messages):
Hugging Face AgentsJob Opportunities in PythonHNSW IVFFLAT Index IssuesSQLite Server Storage Management
- Exploring Agents with Hugging Face Models: A user inquired if anyone had experience working with Agents using Hugging Face models (LLM or Chat). Another user responded that they’ve done a lot with agents across OpenAI and Azure, as well as local LLMs via Ollama.
- Job Seeking for Python Developers: A member expressed the need for work, stating, 'anyone looking to hire me? I need to pay my bills.' They highlighted their proficiency in Python.
- HNSW and IVFFLAT Index Challenges in Aurora: A member reported difficulties in creating HNSW or IVFFLAT indexes with 3072 dimensions on Aurora PGVECTOR. They later shared their solution, which involved using halfvec.
- Managing SQLite Server Threads: A user asked how to check their SQLite server storage to monitor message and thread usage. They were curious about how to remove previous threads when using Langgraph.
LangChain AI ▷ #langserve (1 messages):
Scaling LangServeOSError handlingHandling concurrent requests
- Scaling LangServe hits open files limit: The user is experiencing an OSError: [Errno 24] Too many open files when the LangServe app receives around 1000 concurrent requests.
- They shared an issue on GitHub regarding the problem and are seeking advice on how to manage the request load effectively.
- Seeking solutions for high request loads: The user is looking for strategies to effectively handle a high volume of requests in their LangServe application.
- They hope to find methods to prevent errors related to system resource limitations while scaling up their application.
Link mentioned: Scaling to production -> OSError: [Errno 24] Too many open files socket.accept() out of system resource · Issue #714 · langchain-ai/langserve: Problem When my LangServe app gets ~1000 concurrent requests, it breaks with error: OSError: [Errno 24] Too many open files socket.accept() out of system resource Mitigation/quickfix I've checked ...
LangChain AI ▷ #tutorials (2 messages):
Fully Local Tool Calling with OllamaAI Code Reviewer
- Request for Notebook on Fully Local Tool Calling: A member requested the notebook for the 'Fully local tool calling with Ollama' session that was presented earlier today.
- They expressed appreciation for the content and emphasized its excellence.
- Introduction of AI Code Reviewer Tool: A member shared a YouTube video titled 'AI Code Reviewer Ft. Ollama & Langchain', introducing a CLI tool aimed at enhancing code review processes.
- The video highlights features powered by LangChain and showcases how it can revolutionize code assessment.
Link mentioned: AI Code Reviewer Ft. Ollama & Langchain: Welcome to Typescriptic! In this video, we introduce our Code Reviewer, a CLI tool designed to revolutionize the way you review your code. Powered by LangCha...
OpenInterpreter ▷ #general (6 messages):
Llama 3.1 405 BMistral Large 2API usageDeveloper opportunitiesLM Studio excitement
- Llama 3.1 405 B impresses with ease of use: Llama 3.1 405 B performs fantastically out of the box with OpenInterpreter, offering an effortless experience.
- In contrast, gpt-4o requires constant reminders about capabilities, making 405b a superior choice for multitasking.
- Cost-effective API usage with Nvidia: A user shared that Nvidia provides 1000 credits upon signup, where 1 credit equals 1 API call.
- This incentive opens up more accessibility for experimenting with APIs.
- Mistral Large 2 rivals Llama 3.1 405 B: Mistral Large 2 reportedly performs comparably to Llama 3.1 405 B, particularly noted for its speed.
- The faster performance may be due to lower traffic on Mistral's endpoints compared to those of Llama.
- Interest in developer contributions: There was a query about the potential for a skilled developer to contribute to an unspecified project.
- This highlights an ongoing interest in expanding developer support and collaboration.
- Excitement for integrating with LM Studio: A user expressed enthusiasm for using Llama 3.1 405 B with LM Studio, indicating a promising integration.
- This suggests anticipation for enhanced capabilities and functionalities through this combination.
OpenInterpreter ▷ #O1 (1 messages):
Device Shipping Timeline
- Inquiry on Device Shipping Timeline: A user inquired about the timeline for when the device will ship, expressing anticipation with a straightforward request for updates.
- The question highlights ongoing interest and concern regarding the delivery schedule amid the community.
- Community Anticipation for Device Delivery: The inquiry reflects a broader sentiment among users eager for updates on the device shipping date, connecting them to the brand.
- Discussions around shipping timelines have become a point of engagement, showcasing the community's investment in the product.
OpenInterpreter ▷ #ai-content (2 messages):
Llama 3.1OpenInterpreter Database IntegrationDatabase Complexities
- Llama 3.1 connects with databases for free: MikeBirdTech noted that Llama 3.1 can interact with your database at no cost through OpenInterpreter, emphasizing savings on paid services.
- It's also fully offline and private, nobody else needs to see your data, highlighting its privacy benefits.
- Concerns over complex databases using Llama 3.1: A member raised a concern that for complex databases involving joins across tables, this solution may not be effective.
- They expressed appreciation for sharing the information, remarking on the well-done execution despite the limitations.
Link mentioned: Tweet from Mike Bird (@MikeBirdTech): Llama 3.1 talks to your database for free with @OpenInterpreter Why pay for a talk-to-your-database service? Save money! It's also fully offline and private, nobody else needs to see your data
LAION ▷ #general (5 messages):
Llama 3.1 releaseLAION metadata download issuesLAION datasets legalityYouTube polls
- Llama 3.1: Meta's Open Source Breakthrough: Meta recently launched Llama 3.1 405B, hailed as the first-ever open-sourced frontier AI model, outperforming competitive models like GPT-4o on various benchmarks. For more insights, check this YouTube video featuring Mark Zuckerberg discussing its implications.
- The reception highlights the model's potential impact on AI research and open-source contributions.
- Trouble Downloading LAION2B-en Metadata: A member expressed difficulties in locating and downloading the LAION2B-en metadata from Hugging Face, questioning if others faced the same problem. Responses highlight ongoing challenges with accessibility, indicating it’s a common frustration.
- Someone linked to LAION maintenance notes for further clarification on the situation.
- LAION Datasets in Legal Limbo: Discussion revealed that LAION datasets are currently in legal limbo, with access to official versions restricted. Alternatives are available, but it's advised to only utilize unofficial datasets for urgent research needs.
- Members noted the ongoing complexities surrounding data legality in the AI community.
- YouTube Polls: A Nostalgic Debate: A member shared a YouTube poll asking which 90's movie had the best soundtrack, sparking nostalgia among viewers.
- This prompts members to reflect on their favorite soundtracks from the era, connecting through shared cultural experiences.
Links mentioned:
Alignment Lab AI ▷ #general-chat (1 messages):
spirit_from_germany: https://youtu.be/Vy3OkbtUa5k?si=mBhzPQqDLgzDEL61
Alignment Lab AI ▷ #open-orca-community-chat (2 messages):
Copyright issues in ML datasetsIdentifying non-distilled dataLegal considerations
- Legal Clarity on ML Dataset Copyright: A member discussed that most of the dataset generated by an ML model may not be copyrightable, indicating that it's not considered a truly creative work.
- They noted that the non-GPT-4 generated content should be solidly under MIT licensing, but acknowledged it's a grey area amidst ongoing legal discussions.
- Query on Non-Distilled Data Identification: A follow-up question was raised about how to identify the rows which are non-distilled in the dataset.
- This indicates an ongoing interest in ensuring clarity and organization in managing dataset contents.
LLM Finetuning (Hamel + Dan) ▷ #wing-axolotl (1 messages):
Translation model fine-tuningCPO approachALMA models performance
- Experimenting with DPO for Translation Models: A member is inquiring if anyone has successfully fine-tuned a translation model using DPO due to insights gathered from the CPO paper.
- They specifically refer to how moderate-sized LLMs don't match state-of-the-art models and point to the CPO paper for more details.
- CPO's Role in Improving Translation Models: The CPO approach aims to address the shortcomings of supervised fine-tuning in machine translation, highlighting issues in reference data quality.
- By training models to avoid generating just adequate translations, CPO enhances the performance of models like ALMA-R, which capitalizes on limited datasets.
- ALMA-R's Standout Performance: When applying CPO to ALMA models, significant improvements were noted despite only using 22K parallel sentences and 12M parameters.
- The resulting model, ALMA-R, can compete with or even surpass conventional encoder-decoder models.
Link mentioned: Contrastive Preference Optimization: Pushing the Boundaries of LLM Performance in Machine Translation: Moderate-sized large language models (LLMs) -- those with 7B or 13B parameters -- exhibit promising machine translation (MT) performance. However, even the top-performing 13B LLM-based translation mod...
LLM Finetuning (Hamel + Dan) ▷ #east-coast-usa (1 messages):
intheclouddan: <@1197944730378588170> <@811015724877217803> I'd be interested in NYC in late august
MLOps @Chipro ▷ #events (1 messages):
Feature StoresML OperationsScalabilityData ManagementFeature Governance
- Maximizing ML Efficiency with Feature Stores: A live session on Leveraging Feature Stores is scheduled for July 31st, 2024, at 11:00 AM EDT, targeting ML Engineers, Data Scientists, and MLOps professionals.
- The session will cover building automated pipelines, managing unreliable data, and showcasing advanced use cases for enhancing scalability and performance.
- Tackling Inconsistency in ML Data: The webinar will focus on eliminating differences between serving and training data to develop scalable and reproducible models.
- Challenges such as inconsistent data formats and feature duplication will also be addressed to improve collaboration within ML teams.
- Strategies for Robust Feature Governance: Participants will learn about implementing robust strategies for feature governance and versioning, which are vital for effective ML lifecycle management.
- Insights and practical tools will help attendees refine their ML processes and drive operations forward.
Link mentioned: Leveraging Feature Stores in ML: Join Hudson Buzby to learn about Advancing ML Operations and Scalability
Mozilla AI ▷ #announcements (1 messages):
Accelerator application deadlineUpcoming eventsZero Shot Tokenizer TransferAutoFix open source issue fixer
- Accelerator Application Deadline Approaches: The application deadline for the accelerator program is fast approaching, offering a 12 week program with up to 100k in non-diluted funds for projects.
- A demo day with Mozilla is also planned, and members are encouraged to ask their questions here.
- Two More Exciting Events Coming Up: Reminder about two upcoming events this month featuring the work of notable participants, bringing fresh insights to the community.
- These events are brought to you by two members, further bolstering community engagement.
- Insightful Zero Shot Tokenizer Transfer Discussion: A session titled Zero Shot Tokenizer Transfer with Benjamin Minixhofer is scheduled, aiming to delve into advanced techniques in tokenizer implementations.
- Details and participation links can be found here.
- AutoFix: Open Source Issue Fixer Launch: An announcement was made regarding AutoFix, an open source issue fixer that can submit PRs from Sentry.io, aiding developers in streamlining their workflows.
- More information on the project can be accessed here.
DiscoResearch ▷ #general (1 messages):
Meta's Llama3.1 PaperLlama3 training insightsHallucination prevention techniques
- Llama3.1 Paper: A Treasure for Open Source: The new Llama3.1 paper from Meta is hailed as incredibly valuable for the open source community, prompting discussions about its profound insights.
- One member joked that it contains so much alpha that you have to read it multiple times like a favorite movie.
- Training a 405B Model with 15T Tokens: The paper reveals that the model with 405 billion parameters was trained using ~15 trillion tokens, which was predicted by extrapolating their scaling laws.
- The scaling law suggests training a 402B parameter model on 16.55T tokens to achieve optimal results.
- Insights on Network Topology: It includes a surprisingly detailed description of the network topology used for their 24k H100 cluster.
- Images shared in the thread illustrate the architecture, demonstrating the scale of the infrastructure.
- Training Interruptions Due to Server Issues: Two training interruptions during Llama3-405b's process were attributed to the 'Server Chassis' failing, humorously suggested to be caused by someone's mishap.
- As a consequence, 148 H100 GPUs were lost during pre-training due to these failures.
- Discussion on Hallucination Prevention Benchmarks: A brief conversation with a Meta engineer raised concerns about the need for better benchmarks in hallucination prevention techniques.
- The member shared that anyone else working on this vital area should engage in further discussions.
Link mentioned: Thread by @jphme on Thread Reader App: @jphme: Live tweeting the most interesting insights from @Meta´s new Llama3 paper 1. How did the arrive at a 405b model trained with ~15T tokens? "Extrapolation of the resulting scaling law to 3....
{% else %}
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: [{{ email.subject }}]({{ email_url }})!
If you enjoyed AInews, please share with a friend! Thanks in advance!
{% endif %}