AI News for 8/22/2024-8/23/2024. We checked 7 subreddits, 384 Twitters and 30 Discords (214 channels, and 2531 messages) for you. Estimated reading time saved (at 200wpm): 284 minutes. You can now tag @smol_ai for AINews discussions!
We've obliquely mentioned the 4B and 8B Minitron (Nvidia's distillations of Llama 3.1 8B) a couple times in recent weeks, but there's now a nice short 7 pager from Sreenivas & Muralidharan et al (authors of the Minitron paper last month) updating their Llama 2 results for Llama 3:

The reason this is important provides some insight on Llama 3 given Nvidia's close relatinoship with Meta:
"training multiple multi-billion parameter models from scratch is extremely time-, data- and resource-intensive. Recent work [1] has demonstrated the effectiveness of combining weight pruning with knowledge distillation to significantly reduce the cost of training LLM model families. Here, only the biggest model in the family is trained from scratch; other models are obtained by successively pruning the bigger model(s) and then performing knowledge distillation to recover the accuracy of pruned models.
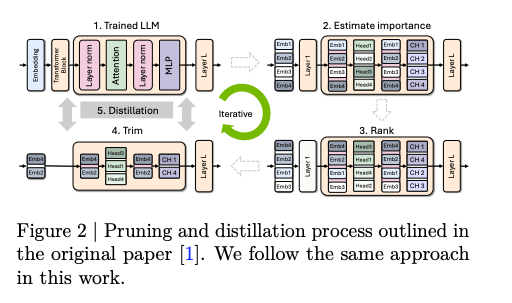
The main steps:
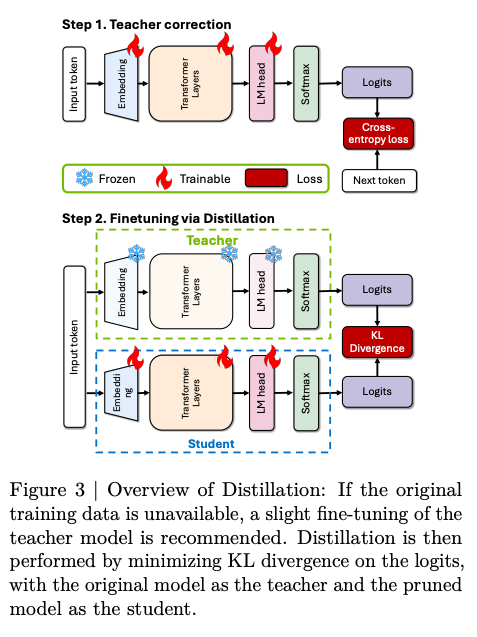
- teacher correction - lightly finetuning the teacher model on the target dataset to be used for distillation, using ∼127B tokens.
- depth or width pruning: using "a purely
activation-based importance estimation strategy that simultaneously computes sensitivity information for all the axes we consider (depth, neuron, head, and embedding channel) using a small calibration dataset and only forward propagation passes". Width pruning consistently outperformed in ablations.
- Retraining with distillation: "real" KD, aka using KL Divergence loss on teacher and student logits.
This produces a generally across-the-board-better model for comparable sizes:
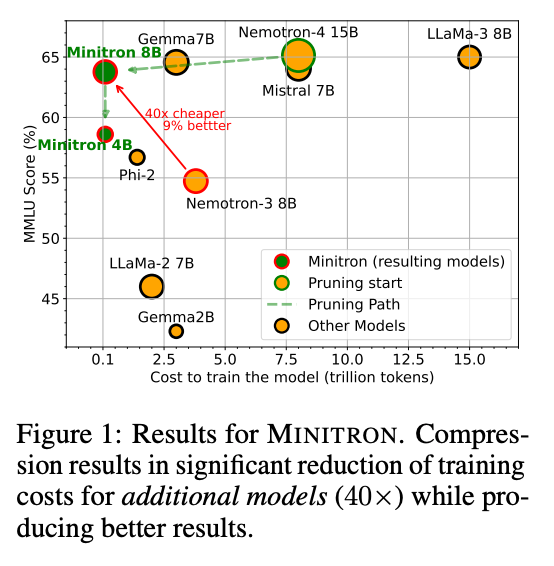
The distillation is far from lossless, however; the paper does not make it easy to read off the deltas but there are footnotes at the end on the tradeoffs.

{% if medium == 'web' %}
Table of Contents
[TOC]
{% else %}
The Table of Contents and Channel Summaries have been moved to the web version of this email: [{{ email.subject }}]({{ email_url }})!
{% endif %}
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI Model Releases and Developments
-
Jamba 1.5 Launch: @AI21Labs released Jamba 1.5, a hybrid SSM-Transformer MoE model available in Mini (52B - 12B active) and Large (398B - 94B active) versions. Key features include 256K context window, multilingual support, and optimized performance for long-context tasks.
-
Claude 3 Updates: @AnthropicAI added LaTeX rendering support for Claude 3, enhancing its ability to display mathematical equations and expressions. Prompt caching is now available for Claude 3 Opus as well.
-
Dracarys Release: @bindureddy announced Dracarys, an open-source LLM fine-tuned for coding tasks, available in 70B and 72B versions. It shows significant improvements in coding performance compared to other open-source models.
-
Mistral Nemo Minitron 8B: This model demonstrates superior performance to Llama 3.1 8B and Mistral 7B on the Hugging Face Open LLM Leaderboard, suggesting the potential benefits of pruning and distilling larger models.
AI Research and Techniques
-
Prompt Optimization: @jxmnop discussed the challenges of prompt optimization, highlighting the complexity of finding optimal prompts in vast search spaces and the surprising effectiveness of simple algorithms like AutoPrompt/GCG.
-
Hybrid Architectures: @tri_dao noted that hybrid Mamba / Transformer architectures work well, especially for long context and fast inference.
-
Flexora: A new approach to LoRA fine-tuning that yields superior results and reduces training parameters by up to 50%, introducing adaptive layer selection for LoRA.
-
Classifier-Free Diffusion Guidance: @sedielem shared insights from recent papers questioning prevailing assumptions about classifier-free diffusion guidance.
AI Applications and Tools
-
Spellbook Associate: @scottastevenson announced the launch of Spellbook Associate, an AI agent for legal work capable of breaking down projects, executing tasks, and adapting plans.
-
Cosine Genie:
@swyxhighlighted a podcast episode discussing the value of finetuning GPT4o for code, resulting in the top-performing coding agent according to various benchmarks. -
LlamaIndex 0.11: @llama_index released version 0.11 with new features including Workflows replacing Query Pipelines and a 42% smaller core package.
-
MLX Hub: A new command-line tool for searching, downloading, and managing MLX models from the Hugging Face Hub, as announced by @awnihannun.
AI Development and Industry Trends
-
Challenges in AI Agents: @RichardSocher highlighted the difficulty of achieving high accuracy across multi-step workflows in AI agents, comparing it to the last-mile problem in self-driving cars.
-
Open-Source vs. Closed-Source Models: @bindureddy noted that most open-source fine-tunes deteriorate overall performance while improving on narrow dimensions, emphasizing the achievement of Dracarys in improving overall performance.
-
AI Regulation: @jackclarkSF shared a letter to Governor Newsom about SB 1047, discussing the costs and benefits of the proposed AI regulation bill.
-
AI Hardware: Discussion on the potential of combining resources from multiple devices for home AI workloads, as mentioned by @rohanpaul_ai.
AI Reddit Recap
/r/LocalLlama Recap
- Exllamav2 Tensor Parallel support! TabbyAPI too! (Score: 55, Comments: 29): ExLlamaV2 has introduced tensor parallel support, enabling the use of multiple GPUs for inference. This update also includes integration with TabbyAPI, allowing for easier deployment and API access. The community expresses enthusiasm for these developments, highlighting the potential for improved performance and accessibility of large language models.
- Users express enthusiasm for ExLlamaV2's updates, with one running Mistral-Large2 at 2.65bpw with 8192 context length and 18t/s generation speed on multiple GPUs.
- Performance improvements noted, with Qwen 72B 4.25bpw showing a 20% increase from 17.5 t/s to 20.8 t/s at 2k context on 2x3090 GPUs.
- A bug affecting the draft model (qwama) was reported and promptly addressed by the developers, highlighting active community support and quick issue resolution.
All AI Reddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI and Machine Learning Advancements
-
Stable Diffusion's 2-year anniversary: On this date in 2022, the first Stable Diffusion model (v1.4) was released to the public, marking a significant milestone in AI-generated imagery.
-
NovelAI open-sources original model: NovelAI has decided to open-source their original AI model, despite it having leaked previously. This move promotes transparency and collaboration in the AI community.
AI-Generated Content and Tools
-
Anti-blur Flux Lora: A new tool has been developed to address blurry backgrounds in AI-generated images, potentially improving the overall quality of outputs.
-
Amateur Photography Lora: A comparison of realism in AI-generated images using an Amateur Photography Lora with Flux Dev, showcasing advancements in photorealistic AI-generated content.
-
Pony Diffusion V7: Progress towards developing the next version of Pony Diffusion, demonstrating ongoing improvements in specialized AI models.
Robotics and AR Technology
-
Boston Dynamics pushup video: Boston Dynamics posted a video of a robot doing pushups on their official Instagram, showcasing advancements in robotic mobility and strength.
-
Meta's AR glasses: Meta is set to unveil its new AR glasses in September, indicating progress in augmented reality technology from a major tech company.
AI-Related Discussions and Humor
-
AI hype and expectations: A humorous post about waiting for AGI to overthrow governments sparked discussions about the current state of AI and public perceptions. Comments highlighted concerns about overhyping AI capabilities and the need for realistic expectations.
-
AI video creation speculation: A video of a cat appearing to cook led to discussions about AI video generation techniques, with some users suggesting it was created using traditional video editing methods rather than AI.
Feature Requests for AI Tools
- A post highlighting a desired feature for Flux D, indicating ongoing user interest in improving AI image generation tools.
AI Discord Recap
A summary of Summaries of Summaries by Claude 3.5 Sonnet
1. AI Model Releases and Benchmarks
- Jamba 1.5 Jumps Ahead in Long Context: AI21 Labs launched Jamba 1.5 Mini (12B active/52B total) and Jamba 1.5 Large (94B active/398B total), built on the new SSM-Transformer architecture, offering a 256K effective context window and claiming to be 2.5X faster on long contexts than competitors.
- Jamba 1.5 Large achieved a score of 65.4 on Arena Hard, outperforming models like Llama 3.1 70B and 405B. The models are available for immediate download on Hugging Face and support deployment across major cloud platforms.
- Grok 2 Grabs Second Place in LMSYS Arena: Grok 2 and its mini variant have been added to the LMSYS leaderboard, with Grok 2 currently ranked #2, surpassing GPT-4o (May) and tying with Gemini in overall performance.
- The model excels particularly in math and ranks highly across other areas, including hard prompts, coding, and instruction-following, showcasing its broad capabilities in various AI tasks.
- SmolLM: Tiny But Mighty Language Models: SmolLM, a series of small language models in sizes 135M, 360M, and 1.7B parameters, has been released, trained on the meticulously curated Cosmo-Corpus dataset.
- These models, including datasets like Cosmopedia v2 and Python-Edu, have shown promising results when compared to other models in their size categories, potentially offering efficient alternatives for various NLP tasks.
2. AI Development Tools and Frameworks
- Aider 0.52.0 Adds Shell Power to AI Coding: Aider 0.52.0 introduces shell command execution, allowing users to launch browsers, install dependencies, run tests, and more directly within the tool, enhancing its capabilities for AI-assisted coding.
- The release also includes improvements like
~expansion for/readand/dropcommands, a new/resetcommand to clear chat history, and a switch togpt-4o-2024-08-06as the default OpenAI model. Notably, Aider autonomously generated 68% of the code for this release.
- The release also includes improvements like
- Cursor Raises $60M for AI-Powered Coding: Cursor announced a $60M funding round from investors including Andreessen Horowitz, Jeff Dean, and founders of Stripe and Github, positioning itself as the leading AI-powered code editor.
- The company aims to revolutionize software development with features like instant answers, mechanical refactors, and AI-powered background coders, with the ambitious goal of eventually writing all the world's software.
- LangChain Levels Up SQL Query Generation: The LangChain Python Documentation outlines strategies to improve SQL query generation using
create_sql_query_chain, focusing on how the SQL dialect impacts prompts.- It covers formatting schema information into prompts using
SQLDatabase.get_contextand building few-shot examples to assist the model, aiming to enhance the accuracy and relevance of generated SQL queries.
- It covers formatting schema information into prompts using
3. AI Research and Technical Advancements
- Mamba Slithers into Transformer Territory: The Mamba 2.8B model, a
transformers-compatible language model, has been released, offering an alternative architecture to traditional transformer models.- Users need to install
transformersfrom the main branch until version 4.39.0 is released, along withcausal_conv_1dandmamba-ssmfor optimized CUDA kernels, potentially offering improved efficiency in certain NLP tasks.
- Users need to install
- AutoToS: Automating the Thought of Search: A new paper titled "AutoToS: Automating Thought of Search" proposes automating the "Thought of Search" (ToS) method for planning with LLMs, achieving 100% accuracy on evaluated domains with minimal feedback iterations.
- The approach involves defining search spaces with code and guiding LLMs to generate sound and complete search components through feedback from unit tests, potentially advancing the field of AI-driven planning and problem-solving.
- Multimodal LLM Skips the ASR Middle Man: A researcher shared work on a multimodal LLM that directly understands both text and speech without a separate Automatic Speech Recognition (ASR) stage, built by extending Meta's Llama 3 model with a multimodal projector.
- This approach allows for faster responses compared to systems that combine separate ASR and LLM components, potentially opening new avenues for more efficient and integrated multimodal AI systems.
4. AI Industry News and Events
- Autogen Lead Departs Microsoft for New Venture: The lead of the Autogen project left Microsoft in May 2024 to start OS autogen-ai, a new company that is currently raising funds.
- This move signals potential new developments in the Autogen ecosystem and highlights the dynamic nature of AI talent movement in the industry.
- NVIDIA AI Summit India Announced: The NVIDIA AI Summit India is set for October 23-25, 2024, at Jio World Convention Centre in Mumbai, featuring a fireside chat with Jensen Huang and over 50 sessions on AI, robotics, and more.
- The event aims to connect NVIDIA with industry leaders and partners, showcasing transformative work in generative AI, large language models, industrial digitalization, supercomputing, and robotics.
- California's AI Regulation Spree: California is set to vote on 20+ AI regulation bills this week, covering various aspects of AI deployment and innovation in the state.
- These bills could significantly reshape the regulatory landscape for AI companies and researchers operating in California, potentially setting precedents for other states and countries.
5. AI Safety and Ethics Discussions
- AI Burnout Sparks Industry Concern: Discussions in the AI community have raised alarms about the potential for AI burnout, particularly in intense frontier labs, with concerns that the relentless pursuit of progress could lead to unsustainable work practices.
- Members likened AI powerusers to a "spellcasting class", suggesting that increased AI model power could intensify demands on these users, potentially exacerbating burnout issues in the field.
- AI Capabilities and Risks Demo-Jam Hackathon: An AI Capabilities and Risks Demo-Jam Hackathon launched with a $2000 prize pool, encouraging participants to create demos that bridge the gap between AI research and public understanding of AI safety challenges.
- The event aims to showcase potential AI-driven societal changes and convey AI safety challenges in compelling ways, with top projects offered the chance to join Apart Labs for further research opportunities.
- Twitter's AI Discourse Intensity Questioned: A recent tweet by Greg Brockman showing 97 hours of coding work in a week sparked discussions about the intensity of AI discourse on Twitter and its potential disconnect from reality.
- Community members expressed unease with the high-pressure narratives often shared on social media platforms, questioning whether such intensity is sustainable or beneficial for the AI field's long-term health.
- AI Engineer Meetup in London: The first AI Engineer London Meetup is scheduled for September 12th, featuring speakers like @maximelabonne and Chris Bull.
- Participants are encouraged to register here to connect with fellow AI Engineers.
- Infinite Generative Youtube Development: A team is seeking developers for their Infinite Generative Youtube platform, gearing up for a closed beta launch.
- They are looking for passionate developers to join this innovative project.
PART 1: High level Discord summaries
LM Studio Discord
- LM Studio 0.3.0 is Here with Upgrades: LM Studio has released version 0.3.0, featuring a revamped UI, improved RAG functionality, and support for running a local server using
lms.- However, users reported bugs like model loading issues, indicating the development team is actively working on fixes.
- Llama 3.1's Hardware Performance Under Review: Llama 3.1 70B q4 achieves a token rate of 1.44 t/s on a 9700X CPU with 2 channel DDR5-6000, highlighting its CPU performance capabilities.
- Users noted that GPU offloading may slow inference if the GPU's VRAM is less than half the model size.
- Debate on Apple Silicon vs Nvidia for LLMs: An ongoing discussion contrasts the M2 24gb Apple Silicon against Nvidia rigs, with reports suggesting M2 Ultra may outperform a 4090 in specific scenarios.
- However, users face limitations on fine-tuning speed with Apple Silicon, with a reported 9-hour training on a max-spec Macbook Pro.
- GPU Offloading Remains a Hot Topic: Despite user reports of issues, GPU offloading is still supported in LM Studio; users can activate it by holding the ALT key during model selection.
- Continued exploration into optimal setups remains critical as users navigate performance with various configurations.
- LLM Accuracy Sparks Concern: Discussions reveal that LLMs, such as Llama 3.1 and Phi 3, can hallucinate, especially about learning styles or specific queries, leading to verbose outputs.
- A contrasting analysis states that Claude may demonstrate better self-evaluation mechanisms despite being vague.
Nous Research AI Discord
- Nous Research Merch Store is Live!: The Nous Research merch store has officially launched, offering a variety of items including stickers with every order while supplies last.
- Check out the store here for exclusive merch!
- Hermes 3 Recovers from Mode Collapse: A member reported successfully recovering Hermes 3 from a mode collapse, allowing the model to analyze and understand the collapse, with only a single relapse afterward.
- This marks a step forward in tackling mode collapse issues prevalent in large language models.
- Introducing Mistral-NeMo-Minitron-8B-Base: The Mistral-NeMo-Minitron-8B-Base is a pruned and distilled text-to-text model, leveraging 380 billion tokens and continuous pre-training data from Nemotron-4 15B.
- This base model showcases advances in model efficiency and performance.
- Exploring Insanity in LLM Behavior: A proposal was put forth to deliberately tune an LLM for insanity, aiming to explore boundaries in unexpected behavior and insights into LLM limitations.
- This project seeks to simulate anomalies in LLM outputs, which could lead to potentially groundbreaking revelations.
- Drama Engine Framework for LLMs: A member shared their project, the Drama Engine, a narrative agent framework aimed at improving agent-like interactions and storytelling.
- They provided a link to the project's GitHub page for anyone interested in contributing or learning more: Drama Engine GitHub.
HuggingFace Discord
- LogLLM - Automating ML Experiment Logging: LogLLM automates the extraction of experimental conditions from your Python scripts with GPT4o-mini and logs results using Weights & Biases (W&B).
- It simplifies the documentation process for machine learning experiments, improving efficiency and accuracy.
- Neuralink Implements Papers at HF: A member shared that their work at Hugging Face involves implementing papers, possibly as a paid role.
- They expressed excitement about their work and emphasized the importance of creating efficient models for low-end devices.
- Efficient Models for Low-End Devices: Members have shown a keen interest in making models more efficient for low-end hardware, highlighting ongoing challenges.
- This reflects the community's focus on accessibility and practical applications in diverse environments.
- GPU Powerhouse: RTX 6000 Revealed: Users discovered the existence of the RTX 6000, boasting 48GB of VRAM for robust computing tasks.
- At a price of $7,000, it stands out as the premier choice for high-performance workloads.
- Three-way Data Splitting for Generalization: A member suggested a three-way data split to enhance model generalization during training, validation, and testing.
- The emphasis is on testing with diverse data sets to assess a model's robustness beyond mere accuracy.
Stability.ai (Stable Diffusion) Discord
- SDXL vs SD1.5: The Speed Dilemma: A user with 32 GB RAM is torn between SDXL and SD1.5, reporting sluggish image generation on their CPU. Recommendations lean towards SDXL for superior images, despite potential out-of-memory errors and the need for increased swap space.
- Keep in mind, balancing CPU speeds with image quality is the key factor for these heavy models.
- Prompting Techniques: The Great Debate: Members share their experiences on prompt techniques, with one finding success using commas while others prefer natural language prompts. This variance highlights the ongoing discourse on optimal prompting strategies for consistency.
- Participants suggest that the effectiveness of prompts greatly depends on personal preference and experimentation.
- ComfyUI and Flux Installation Woes: A user faces challenges installing iPadaper on ComfyUI, prompting suggestions to venture into the Tech Support channel for assistance. Another user struggles with Flux, trying different prompts to overcome noisy, low-quality outputs.
- This underscores the community's shared trials and errors as they fine-tune their setups in pursuit of creative objectives.
- GPU RAM: The Weight of Performance: Questions arise about adjusting GPU weights in ComfyUI while using Flux on a 16GB RTX 3080. A user with a 4GB GPU reports frustrating slowdowns in A1111, indicative of GPU power's impact on image generation.
- This exchange suggests a critical need for robust hardware to enable smoother performance across various models.
- Stable Diffusion Guides Galore: A user requests recommendations for Stable Diffusion installation guides, with Automatic1111 and ComfyUI suggested as good starting points. AMD cards, though usable, are noted for slower performance.
- The Tech Support channel is highlighted as a valuable resource for troubleshooting and guidance.
aider (Paul Gauthier) Discord
- Aider 0.52.0 Release: Shell Command Execution & More: Aider 0.52.0 introduces shell command execution, allowing users to launch a browser, install dependencies, and run tests directly within the tool. Key updates include
~expansion for commands, a/resetcommand for chat history, and a model switch togpt-4o-2024-08-06.- Autonomously, Aider generated 68% of the code for this version, underlining its advancing capabilities in software development.
- Training Set for Aider: Meta-Format Exploration: A member is assembling a training set of Aider prompt-code pairs to create an efficient meta-format for various coding techniques using tools like DSPY, TEXTGRAD, and TRACE. This initiative includes a co-op thread for deeper brainstorming on optimization.
- The aim is to refine both code and prompts for better reproducibility, enhancing Aider's effectiveness in generating code.
- Using Aider for Token Optimization: A user seeks documentation on optimizing token usage for small Python files that exceed OpenAI's limits, specifically when handling complex tasks needing multi-step processes. They are looking for strategies to reduce token context within their projects.
- They specifically request advancements in calculations and rendering optimizations, underlining the need for improved resource management.
- Cursor's Vision for AI-Powered Code Creation: Cursor's blog post depicts aspirations for developing an AI-powered code editor that could potentially automate extensive code writing tasks. Features include instant responses, refactoring, and expansive changes made in seconds.
- Future enhancements aim at enabling background coding, pseudocode modifications, and bug detection, revolutionizing how developers interact with code.
- LLMs in Planning: AutoToS Paper Insights: AutoToS: Automating Thought of Search proposes automating the planning process with LLMs, showcasing its effectiveness in achieving 100% accuracy in diverse domains. The approach allows LLMs to define search spaces with code, enhancing the planning methodology.
- The paper identifies challenges in search accuracy and articulates how AutoToS uses feedback from unit tests to guide LLMs, reinforcing the quest for soundness in AI-driven planning.
Latent Space Discord
- Autogen Lead Takes Off From Microsoft: The lead of the Autogen project departed from Microsoft in May 2024 to initiate OS autogen-ai and is currently raising funds.
- This shift has sparked discussions about new ventures in AI coding standards and collaborations.
- Cursor AI Scores $60M Backing: Cursor successfully raised $60M from high-profile investors like Andreessen Horowitz and Jeff Dean, claiming to reinvent how to code with AI.
- Their products aim to develop tools that could potentially automate code writing on a massive scale.
- California Proposes New AI Regulations: California is set to vote on 20+ AI regulation bills this week, summarized in this Google Sheet.
- These bills could reshape the landscape for AI deployment and innovation in the state.
- Get Ready for the AI Engineer Meetup!: Join the first AI Engineer London Meetup on the evening of September 12th, featuring speakers like @maximelabonne and Chris Bull.
- Register via this link to connect with fellow AI Engineers.
- Taxonomy Synthesis Supports AI Research: Members discussed leveraging Taxonomy Synthesis for organizing writing projects hierarchically.
- The tool GPT Researcher was highlighted for its ability to autonomously conduct in-depth research, enhancing productivity.
OpenRouter (Alex Atallah) Discord
- OpenRouter Decommissions Several Models: Effective 8/28/2024, OpenRouter will deprecate multiple models, including
01-ai/yi-34b,phind/phind-codellama-34b,nousresearch/nous-hermes-2-mixtral-8x7b-sft, and the complete Llama series, making them unavailable for users.- Users are advised of this policy through Together AI's deprecation document, which outlines the migration options.
- OpenRouter's Pricing Mishap: A user incurred a $0.01 charge after mistakenly selecting a paid model, illustrating a potential issue for newcomers unfamiliar with the interface.
- In response, the community reassured the user that OpenRouter would not pursue charges for such a low balance, promoting a non-threatening environment for AI exploration.
- Token Counting Confusion Clarified: A discussion emerged on OpenRouter's token counting mechanism after a user reported a 100+ token charge for a simple prompt, revealing complexities in token calculations.
- Members clarified that OpenRouter forwards token counts from OpenAI's API, with variances influenced by system prompts and prior context in the chat.
- Grok 2 Shines on LMSYS Leaderboard: Grok 2 and its mini variant secured positions on the LMSYS leaderboard, with Grok 2 ranking #2, even overtaking GPT-4o in performance metrics.
- The model excels particularly in math and instruction-following but also demonstrates high capability in coding challenges, raising discussions on its overall performance profile.
- OpenRouter Team Remains Mysterious: There was an inquiry about the OpenRouter team's current projects, but unfortunately, no detailed response was provided, leaving members curious.
- This lack of information highlights an ongoing interest in the development activities of OpenRouter, but specifics remain elusive.
Modular (Mojo 🔥) Discord
- Mojo's Open Source Licensing Dilemma: The question of Mojo's open source status arose, with Modular navigating licensing details to protect their market niche while allowing external use.
- They aim for a more permissive licensing model over time, maintaining openness while safeguarding core product features.
- Max Integration Blurs Lines with Mojo: Max functionalities now deeply integrate with Mojo, initially designed as separate entities, raising questions about future separation.
- Discussions suggest that this close integration will influence licensing possibilities and product development pathways.
- Modular's Commercial Focus on Managed AI: Modular is focusing on managed AI cloud applications, allowing continued investment in Mojo and Max while licensing Max for commercial applications.
- They introduced a licensing approach that encourages open development and aligns with their strategic business objectives.
- Paving the Way for Heterogeneous Compute: Modular is targeting portable GPU programming across heterogeneous compute scenarios, facilitating wider access to advanced computing tools.
- Their goal is to provide frameworks that simplify integration for developers seeking advanced computational capabilities.
- Async Programming Found a Place in Mojo: Users discussed the potential for asynchronous functionality in Mojo, particularly for I/O tasks, likening it to Python's async capabilities.
- The conversation included exploring a 'sans-io' HTTP implementation, emphasizing thread safety and proper resource management.
Perplexity AI Discord
- Perplexity Internals Dilemma: Users are seeking data on the frequency of follow-ups in Perplexity, including time spent and back-and-forth interactions, but responses indicate this data may be proprietary.
- This raises concerns about transparency and usability for engineers working on performance improvements.
- Perplexity Pro Source Count Mystery: A noticeable drop in the source count displayed in Perplexity Pro from 20 or more to 5 or 6 for research inquiries has sparked questions on whether there were changes to the service or incorrect usage.
- This inconsistency highlights the need for clarity in source management and potential impacts on research quality.
- Exploring Email Automation Tools: Users are diving into AI tools for automating emails, mentioning Nelima, Taskade, Kindo, and AutoGPT as contenders while seeking further recommendations.
- The exploration indicates a growing interest in streamlining communication processes through AI efficiencies.
- Perplexity AI Bot Seeks Shareable Threads: The Perplexity AI Bot encourages users to ensure their threads are 'Shareable' by providing links to the Discord channel for reference.
- This push for shareable content suggests a focus on enhancing community engagement and resource sharing.
- Social Sentiment Around MrBeast: Discussion surfaced around the internet's perception of MrBeast, with users linking to a search query for insights into the potential dislike.
- This conversation reflects broader trends in digital celebrity culture and public opinion dynamics.
OpenAccess AI Collective (axolotl) Discord
- Base Phi 3.5 Not Released: A member highlighted the absence of the base Phi 3.5, indicating that only the instruct version has been released by Microsoft. This poses challenges for those wishing to fine-tune the model without base access.
- Exploring the limits of availability, they seek solutions for fine-tuning using the available instruct version.
- QLORA + FSDP Hardware Needs: Discussion on running QLORA + FSDP centered around the requirement for an 8xH100 configuration. Members also noted inaccuracies with the tqdm progress bar when enabling warm restarts during training.
- Performance monitoring remains a challenge, prompting calls for refining the tracking tools available within the framework.
- SmolLM: A Series of Small Language Models: SmolLM includes small models of 135M, 360M, and 1.7B parameters, all trained on the high-quality Cosmo-Corpus. These models incorporate various datasets like Cosmopedia v2 and FineWeb-Edu to ensure robust training.
- Curated choice of datasets, aims to provide balanced language understanding under varying conditions.
- Mode-Aware Chat Templates in Transformers: A user reported an issue regarding mode-aware chat templates on the Transformers repository, suggesting this feature could distinguish training and inference behaviors. This could resolve existing problems linked to chat template configurations.
- Details are outlined in a GitHub issue which proposes implementing a template_mode variable.
OpenAI Discord
- GPT-3.5: Outdated or Interesting?: A discussion emerged on whether testing GPT-3.5 is still relevant as it may be considered outdated given the advancements in post-training techniques.
- Some members suggested it may lack significance compared to newer models like GPT-4.
- Exploring Email Automation Alternatives: Users sought tools for automating email tasks, looking for alternatives beyond Nelima for emailing based on prompts.
- This indicates a growing need for automation solutions in everyday workflows.
- SwarmUI: Praise for User Experience: SwarmUI received accolades for its user-friendly interface and compatibility with both NVIDIA and AMD GPUs.
- Users highlighted its intuitive design, making it a preferred choice for many developers.
- Knowledge Files Formatting Dilemma: A user questioned the efficacy of using XML versus Markdown for knowledge files in their project, aiming for optimal performance.
- This inquiry reflects the ongoing debate about the best practices for structuring content in GPTs.
- Inconsistent GPT Formatting Creates Frustration: Concerns about inconsistent output formatting in GPT responses were raised, specifically regarding how some messages conveyed structured content while others did not.
- Users are looking for solutions to standardize formatting to enhance readability and user experience.
Eleuther Discord
- Mastering Multi-Turn Prompts: A user highlighted the importance of including
n-1turns in multi-turn prompts, referencing a code example from the alignment handbook.- They explored the viability of gradually adding turns to prompt generation but raised concerns about its comparative effectiveness.
- SmolLM Model Insights: The SmolLM model was discussed, noting its training data sourced from Cosmo-Corpus, which includes Cosmopedia v2 among others.
- SmolLM models range from 135M to 1.7B parameters, showing notable performance within their size category.
- Mamba Model Deployment Help: Information was shared on the Mamba 2.8B model, which works seamlessly with the
transformerslibrary.- Instructions for setting up dependencies like
causal_conv_1dand using thegenerateAPI were provided for text generation.
- Instructions for setting up dependencies like
- Innovative Model Distillation Techniques: A suggestion was made to apply LoRAs to a 27B model and distill logits from a smaller 9B model, aiming to replicate functionality in a condensed form.
- This approach could potentially streamline large model performances in smaller architectures.
- Strategies for Model Compression: Proposals for compressing model sizes included techniques such as zeroing out parameters and applying quantization methods, with a reference to the paper on quantization techniques.
- Techniques discussed aim to enhance efficiency while managing size.
Cohere Discord
- Cohere API Error on Invalid Role: A user reported an HTTP-400 error while using the Cohere API, indicating that the role provided was invalid, with acceptable options being 'User', 'Chatbot', 'System', or 'Tool'.
- This highlights the need for users to verify role parameters before API calls.
- Innovative Multimodal LLM Developments: One member showcased a multimodal LLM that interprets both text and speech seamlessly, eliminating the separate ASR stage with a direct multimodal projector linked to Meta's Llama 3 model.
- This method accelerates response times by merging audio processing and language modeling without latency from separate components.
- Cohere's New Schema Object Excites Users: Enthusiasm grew around the newly introduced Cohere Schema Object for its ability to facilitate structured multiple actions in a single API request, aiding in generative fiction tasks.
- Users reported it assists in generating complex prompt responses and content management efficiently.
- Cohere Pricing - Token-Based Model: The pricing structure for Cohere’s models, such as Command R, is based on a token system, where each token carries a cost.
- A general guideline indicates that one word equals approximately 1.5 tokens, crucial for budgeting use.
- Cohere Models Set to Land on Hugging Face Hub: Plans are underway to package and host all major Cohere models on the Hugging Face Hub, creating an accessible ecosystem for developers.
- This move has generated excitement among members keen to utilize these resources in their projects.
Interconnects (Nathan Lambert) Discord
- AI Burnout Raises Red Flags: Concerns over AI burnout are escalating as members note that AI faces far greater burnout risks than humans, particularly in intense frontier labs, making for a sustainability issue.
- This discussion highlights the worrying trend of relentless workloads and the potential long-term implications on mental health in the AI community.
- AI Powerusers as Spellcasters: A member compared AI powerusers to a spellcasting class, emphasizing their constant tool usage which breeds stress and potential burnout.
- With advancements in AI models, the demands placed on these users may escalate, intensifying the burnout cycle already observed.
- The Endless Model Generation Trap: The quest for the next model generation is being scrutinized, with fears that the cyclical chase could culminate in severe industry burnout.
- Predictive models suggest a shift in burnout trends, linked to the accelerating pace of AI progress and its toll on developers.
- Twitter Anxiety Strikes Again: A recent Greg Brockman Twitter post showcasing 97 hours of coding in a single week sparked conversation about the pressures stemming from heightened intensity in AI discourse online.
- Participants voiced concern that the vibrant yet anxiety-inducing Twitter scene may detract from real-world engagement, highlighting a concerning disconnect.
LAION Discord
- Dev Recruitment for Infinite Generative Youtube: A team seeks developers for their Infinite Generative Youtube platform, launching a closed beta soon.
- They're particularly interested in enthusiastic developers to join their innovative project.
- Text-to-Speech Models for Low-Resource Languages: A user is eager to train TTS models for Hindi, Urdu, and German, aiming for a voice assistant application.
- This venture focuses on enhancing accessibility in low-resource language processing.
- WhisperSpeech's Semantic Tokens for ASR Exploration: Inquiries surfaced regarding the use of WhisperSpeech semantic tokens to enhance ASR in low-resource languages through a tailored training process.
- The proposed method includes fine-tuning a small decoder model using semantic tokens from audio and transcriptions.
- SmolLM: Smaller Yet Effective Models: SmolLM offers three sizes (135M, 360M, and 1.7B parameters), trained on the Cosmo-Corpus, showcasing competitive performance.
- The dataset includes Cosmopedia v2 and Python-Edu, indicating a strong focus on quality training sets.
- Mamba's Compatibility with Transformers: The Mamba language model comes with a transformers compatible mamba-2.8b version, requiring specific installations.
- Users need to set up 'transformers' until version 4.39.0 is released to utilize the optimized cuda kernels.
LangChain AI Discord
- Graph Memory Saving Inquiry: Members discussed whether memory can be saved as a file to compile new graphs, and if the same memory could be reused across different graphs.
- Is it per graph or shared? was the core question, with a keen interest in optimizing memory usage.
- Improving SQL Queries with LangChain: The LangChain Python Documentation provided new strategies for enhancing SQL query generation through create_sql_query_chain, focusing on SQL dialect impacts.
- Learn how to format schema information using SQLDatabase.get_context to improve the prompt's effectiveness in query generation.
- Explicit Context in LangChain: To use context like
table_infoin LangChain, you must explicitly pass it when invoking the chain, as shown in the documentation.- This approach ensures your prompts are tailored to provided context, showcasing the flexibility of LangChain.
- Deployment of Writer Framework to Hugging Face: A blog post explored deploying Writer Framework apps to Hugging Face Spaces using Docker, showcasing the ease of deployment for AI applications.
- The Writer Framework provides a drag-and-drop interface similar to frameworks like Streamlit and Gradio, aimed at simplifying AI app development.
- Hugging Face Spaces as a Deployment Venue: The noted blog post detailed the deployment process on Hugging Face Spaces, emphasizing Docker's role in hosting and sharing AI apps.
- Platforms like Hugging Face provide excellent opportunity for developers to showcase their projects, driving community engagement.
DSPy Discord
- Adalflow Launches with Flair: A member highlighted Adalflow, a new project from SylphAI, expressing interest in its features and applications.
- Adalflow aims to optimize LLM task pipelines, providing engineers with tools to enhance their workflow.
- DSpy vs Textgrad vs Adalflow Showdown: Curiosity brewed over the distinctions between DSpy, Textgrad, and Adalflow, specifically about when to leverage each module effectively.
- It was noted that LiteLLM will solely manage query submissions for inference, hinting at performance capabilities across these modules.
- New Research Paper Alert!: A member shared a link to an intriguing paper on ArXiv titled 2408.11326, encouraging fellow engineers to check it out.
- Details about the paper were not disclosed, but its presence indicates ongoing contributions to the DSPy community.
OpenInterpreter Discord
- Seek Open Interpreter Brand Guidelines: A user inquired about the availability of Open Interpreter brand guidelines, indicating a need for clarity on branding.
- Could you share where to find those guidelines?
- Surprising Buzz Around Phi-3.5-mini: Users expressed unexpected approval for the performance of Phi-3.5-mini, sparking discussions that brought Qwen2 into the spotlight.
- The positive feedback caught everyone off guard!
- Python Script Request for Screen Clicks: A user sought a Python script capable of executing clicks on specified screen locations based on text commands, like navigating in Notepad++.
- How do I make it click on the file dropdown?
- --os mode Could Be a Solution: In response to the script query, it was suggested that using the --os mode might solve the screen-clicking challenge.
- This could streamline operations significantly!
- Exciting Announcement for Free Data Analytics Masterclass: A user shared an announcement for a free masterclass on Data Analytics, promoting real-world applications and practical insights.
- Interested participants can register here and share in the excitement over potential engagement.
Gorilla LLM (Berkeley Function Calling) Discord
- Gorilla and Huggingface Leaderboards Now Align: A member queried the scores on the Gorilla and Huggingface leaderboards, which were initially inconsistent. The discrepancy has been resolved as the Huggingface leaderboard now mirrors the Gorilla leaderboard.
- This alignment indicates a more reliable comparison for users evaluating model performance across platforms.
- Llama-3.1-Storm-8B Debuts on Gorilla Leaderboard: A user submitted a Pull Request to add Llama-3.1-Storm-8B to the Gorilla Leaderboard for benchmarking. The PR will undergo review as the model recently completed its release.
- The inclusion of this model showcases the community's ongoing commitment to updating benchmarking frameworks.
- Guidance Requested for REST API Test Pairs: Inquiring users sought advice on crafting 'executable test pairs' for their REST API functionality, pointing to existing pairs from the Gorilla leaderboard. They showed a preference for tests that are both 'real' and 'easy' to implement.
- This indicates a demand for more practical testing resources and methods in API development.
- Clarification on Executable Test Pairs Needed: Another discussion arose regarding the term 'executable test pairs', with users seeking a clearer understanding of its relevance in REST API testing. This reveals a gap in conceptual clarity for members.
- Insight into this terminology could enhance comprehension and application in their testing strategies.
AI21 Labs (Jamba) Discord
- Jamba 1.5 Mini & Large Hit the Stage: AI21 Labs launched Jamba 1.5 Mini (12B active/52B total) and Jamba 1.5 Large (94B active/398B total), based on the new SSM-Transformer architecture, offering superior long context handling and speed over competitors.
- The models feature a 256K effective context window, claiming to be 2.5X faster on long contexts than rivals.
- Jamba Dominates Long Contexts: Jamba 1.5 Mini boasts a leading score of 46.1 on Arena Hard, while Jamba 1.5 Large achieved 65.4, outclassing even Llama 3.1's 405B.
- The jump in performance makes Jamba a significant contender in the long context space.
- API Rate Limits Confirmed: Users confirmed API rate limits for usage at 200 requests per minute and 10 requests per second, settling concerns on utilization rates.
- This information was found by users after initial inquiries.
- No UI Fine-Tuning for Jamba Yet: Clarification was provided regarding Jamba's fine-tuning; it's only available for the instruct version and currently not accessible through the UI.
- This detail raises questions for developers relying on UI for adjustments.
- Jamba's Filtering Features Under Spotlight: Discussions emerged on Jamba's filtering capabilities, particularly for roleplaying scenarios involving violence.
- Members expressed curiosity about these built-in features to ensure safe interactions.
MLOps @Chipro Discord
- NVIDIA AI Summit India Ignites Excitement: The NVIDIA AI Summit India takes place from October 23-25, 2024, at Jio World Convention Centre in Mumbai, featuring Jensen Huang among other industry leaders during over 50 sessions.
- The summit focuses on advancing fields such as generative AI, large language models, and supercomputing, aiming to highlight transformative works in the industry.
- AI Hackathon Offers Big Incentives: The AI Capabilities and Risks Demo-Jam Hackathon has launched with a $2000 prize pool, where top projects could partner with Apart Labs for research opportunities.
- This initiative aims to create demos addressing AI impacts and safety challenges, encouraging clear communication of complex concepts to the public.
- Exciting Kickoff for the Hackathon: The hackathon kicked off with an engaging opening keynote on interactive AI displays, followed by team formation and project brainstorming.
- Participants benefit from expert mentorship and resources, while the event is live-streamed on YouTube for wide accessibility.
tinygrad (George Hotz) Discord
- Tinygrad's Mypyc Compilation Quest: A member expressed interest in compiling tinygrad with mypyc, currently investigating its feasibility.
- The original poster invited others to contribute to this effort, emphasizing a collaborative spirit.
- Join the Quest!: The original poster invited others to contribute to the tinygrad compilation effort with mypyc.
- Engagement is encouraged as they explore this new venture.
The Alignment Lab AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The LLM Finetuning (Hamel + Dan) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Torchtune Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
{% if medium == 'web' %}
LM Studio ▷ #general (545 messages🔥🔥🔥):
LM Studio 0.3.0LM Studio 0.3.0 UILM Studio 0.3.0 BugsLM Studio ServerLM Studio RAG
- LM Studio 0.3.0 Released: The latest version of LM Studio, 0.3.0, was released and includes new features such as a revamped UI, improved RAG functionality, and the ability to run a local server.
- However, some users have reported bugs with the new version, such as model loading issues and issues with the RAG feature.
- LM Studio 0.3.0 UI Revamped: The new UI is more streamlined and includes a new settings menu that provides access to a variety of features.
- Some users have reported that they find the new UI to be confusing, but others find it to be an improvement over the previous version.
- LM Studio 0.3.0 Bugs and Issues: Some users have reported issues with the new version, such as model loading issues, issues with the RAG feature, and issues with the new UI.
- The development team is aware of these issues and is working on fixing them.
- LM Studio Server Functionality: LM Studio's server functionality has been improved, allowing users to run the server on a local network.
- Users can also now run the server without using the LM Studio desktop app, using the command-line tool
lms.
- Users can also now run the server without using the LM Studio desktop app, using the command-line tool
- LM Studio RAG Feature Improvements: The RAG (Retrieval Augmented Generation) feature has been improved in this version, allowing users to upload documents and ask the LLM questions about them.
- The RAG feature now uses the Nomic embedding model, which is pre-bundled with the app.
Links mentioned:
LM Studio ▷ #hardware-discussion (66 messages🔥🔥):
GPU offloadingLlama 3.1CPU performanceApple SiliconModel size and performance
- GPU offloading is still supported: Offloading is still supported, despite some users experiencing issues.
- To enable it, hold down the ALT key while choosing the model and check the box for GPU offload.
- Llama 3.1 performance on various hardware: Llama 3.1 70B q4 runs on CPU only with a token rate of 1.44 tokens per second on a 9700X with 2 channel DDR5-6000, and 1.37 tokens per second on a W-2155 with 4 channel DDR4-2666.
- Some users have reported that offloading to GPU can actually slow down inference if the GPU has less VRAM than half the model size.
- Apple Silicon vs Nvidia rigs for LLMs: A user is debating whether to go for cloud services or a dedicated Nvidia rig for LLMs, after experiencing good results with their M2 24gb Apple Silicon.
- Another user suggests that Apple Silicon is a consumer-friendly solution for LLMs, with the M2 Ultra outperforming a 4090 in some cases.
- Fine tuning models on Apple Silicon: Apple Silicon is limited for fine tuning due to its memory speed, and users may have to resort to cloud-based services.
- A user reports a 9-hour training time for Phi-3 on a max-spec Macbook Pro, highlighting the limitations of Apple Silicon for fine tuning.
- Model Accuracy and Evaluation: LLMs can hallucinate and produce misleading information, especially when asked learning style questions about specific topics.
- One user mentions that LLMs like Llama 3.1 and Phi 3 can be verbose and prone to info dumping, while Claude tends to be vague, suggesting it has better self-evaluation mechanisms.
Link mentioned: GitHub - tlkh/asitop: Perf monitoring CLI tool for Apple Silicon: Perf monitoring CLI tool for Apple Silicon. Contribute to tlkh/asitop development by creating an account on GitHub.
Nous Research AI ▷ #announcements (1 messages):
Nous Research Merch Store
- Nous Research Merch Store Launched!: The Nous Research merch store is now live!
- Stickers are included with every order while supplies last.
- Free Stickers With Every Order: The store is open!
- Stickers are available while supplies last.
Link mentioned: Nous Research: Nous Research
Nous Research AI ▷ #general (288 messages🔥🔥):
Hermes 3MistralMode CollapseLLM's InsanitySynthetic Data Generation
- Hermes 3 Mode Collapse Recovery: A member shared that they were able to recover Hermes 3 from a mode collapse, and now the model can accurately analyze the collapse without falling back into it, except for a single relapse.
- This successful recovery suggests progress in understanding and addressing mode collapse issues in LLMs.
- Mistral-NeMo-Minitron-8B-Base: A Pruned and Distilled LLM: Mistral-NeMo-Minitron-8B-Base is a base text-to-text model obtained by pruning and distilling the Mistral-NeMo 12B.
- The model was trained on 380 billion tokens and uses the continuous pre-training data corpus employed in Nemotron-4 15B.
- Intentionally Tuning LLMs for Insanity: A member proposed intentionally tuning an LLM to be absolutely insane, suggesting a project to explore the boundaries of LLM behavior.
- This project aims to simulate and enhance anomalous LLM behavior, potentially leading to new insights into LLM capabilities and limitations.
- Voidhead: A Finetuned Gemma Model for Anomalous Behavior: An experiment was released called Voidhead, which is a finetuned Gemma model trained on 5K examples of anomalous LLM behavior simulated by GPT-4.
- The model exhibits strange and unpredictable outputs, described as 'voidlike insanity', and showcases the potential for fine-tuning LLMs to create unique and unconventional behaviors.
- Hermes 3 Deprecation and Alternative Providers: Together.ai is deprecating all old Nous models, including Hermes 2 and Hermes 3, next week.
- Members discussed the need for alternative providers and the challenges of finding suitable serverless endpoints for Hermes 3, leading to a search for new solutions.
Links mentioned:
Nous Research AI ▷ #ask-about-llms (12 messages🔥):
AI Agent GitHub RepositoriesLangchain and CrewAIBuilding Your Own AI AgentDrama Engine FrameworkLLM Autocomplete Tool
- AI Agent Repositories: Focus on the Fundamentals: A user was looking for niche AI Agent GitHub Repositories beyond the typical BabyAGI and AutoGPT.
- Drama Engine: A Narrative Agent Framework: Another user shared their experience building their own agent-like framework, called Drama Engine, focusing on narrative aspects.
- LLM Autocomplete Tool: A User's Quest: A user inquired about the existence of a small LLM that could function as an autocomplete tool, providing suggestions based on the prompt and writing progress.
Link mentioned: GitHub - Write-with-LAIKA/drama-engine: A Framework for Narrative Agents: A Framework for Narrative Agents. Contribute to Write-with-LAIKA/drama-engine development by creating an account on GitHub.
HuggingFace ▷ #announcements (1 messages):
Offensive SecurityDeep Learning CoursesUnity ML AgentsGarfield DatasetTensor Parallelism
- Offensive Security Reconnaissance Blogpost: A verified blogpost on Offensive Security Reconnaissance was shared, featuring information on how to conduct a successful security assessment.
- The post is authored by a verified user and is available on the Hugging Face website.
- Deep Learning Course Gets Easier Navigation: A verified user shared an update on a deep learning course with a new website designed to make navigating the content easier and more intuitive.
- The course is authored by Simon Thomine and is available at https://simonthomine.github.io/CoursDeepLearning/.
- Unity ML-Agents: Pretrain an LLM from Scratch: A YouTube video showcasing the use of Unity ML-Agents and Sentence Transformers to create an intelligent chatbot was shared.
- The video, titled "Unity ML-Agents | Pretrain an LLM from Scratch with Sentence Transformers | Part 5," is part of a series and can be viewed at https://youtube.com/live/RdxtA_-47Kk?feature=share.
Links mentioned:
HuggingFace ▷ #general (232 messages🔥🔥):
RTX 6000HuggingFace Payment IssuesOpenAI Platform ChangesGPTs AgentsModel Merging
- RTX 6000 Exists: A user discovered the existence of the RTX 6000, a graphics card with 48GB of VRAM.
- The card costs $7,000 and is the only viable option for users.
- HuggingFace Payment Issues: A user reported that a $10 temporary charge was taken from their prepaid card, despite the transaction being declined.
- A HuggingFace staff member confirmed that this is a common occurrence and the hold should clear within a few business days, but advised the user to contact [email protected] if it doesn't.
- OpenAI Platform Sidebar Changes: Users reported that two icons - one for threads and another one for messages - disappeared from the sidebar of platform.openai.com.
- The user did not provide more details.
- GPTs Agents Cannot Learn After Initial Training: A user raised a concern about GPTs agents not being able to learn from additional information provided after their initial training.
- Another user clarified that uploaded files are saved as "knowledge" files for the agent to reference, but do not continually modify the agent's base knowledge.
- Discussion on Model Merging Tactics: A user suggested applying the difference between UltraChat and base Mistral to Mistral-Yarn as a potential merging tactic.
- Other users expressed skepticism, but the user remained optimistic, citing past successful attempts at what they termed "cursed model merging".
Links mentioned:
HuggingFace ▷ #today-im-learning (6 messages):
HF WorkNeuralink WorkEfficient Models
- Neuralink Implements Papers at HF: A member shared that their work at Hugging Face involves implementing papers, possibly as a paid role.
- They expressed excitement about their work and wished the other member luck in finding ways to make models more efficient on low-end devices.
- Efficient Models for Low-End Devices: A member expressed interest in finding ways to make models more efficient on low-end devices.
HuggingFace ▷ #cool-finds (1 messages):
this_is_prince: https://github.com/All-Hands-AI/OpenHands
HuggingFace ▷ #i-made-this (11 messages🔥):
LogLLMRYFAIWriter FrameworkUnslothNeuroSync
- LogLLM: Automating ML Experiment Logging: LogLLM is a package that automates the extraction of experimental conditions from your Python scripts with GPT4o-mini and logs results using Weights & Biases (W&B).
- It extracts conditions and results from your ML script, based on a prompt designed for advanced machine learning experiment designers.
- RYFAI: Private AI App with Open Source Models: RYFAI is a private AI app that uses open source AI models hosted by Ollama, allowing you to use it completely disconnected from the internet.
- This ensures that no data is collected behind the scenes, addressing concerns about corporations tracking AI conversation data.
- Writer Framework Deployed to Hugging Face Spaces: A blog post describes how to deploy Writer Framework apps to Hugging Face Spaces using Docker.
- Writer Framework is an open source Python framework for building AI apps with a drag-and-drop builder and Python backend, similar to FastHTML, Streamlit, and Gradio.
- Unsloth Token Retrieval Logic Update: A pull request was submitted to Unsloth to update its token retrieval logic to use the Hugging Face standard method.
- This change allows for reading the token from colab secrets or a config file, offering advantages in terms of token retrieval flexibility.
- NeuroSync: Seq2Seq Transformer for Face Blend Shapes: NeuroSync is a Seq2Seq transformer architecture designed to predict sequences of face blendshape frames from audio feature inputs.
- This architecture aims to enhance the synchronization of facial expressions with audio cues, potentially improving the realism of animated characters.
Links mentioned:
HuggingFace ▷ #reading-group (3 messages):
Alignment Techniques Reading Group
- Alignment Techniques Reading Group: A member expressed interest in reading papers related to alignment techniques, asking for the reading topic for the week, time of the session, and URLs to read.
- The member asked for the session to be scheduled for tomorrow if possible.
- Next Steps: The member is awaiting further details and a confirmation of the session time.
HuggingFace ▷ #NLP (3 messages):
Data SplittingHF Dataset HomogeneitySQL Summarization
- Three-way Data Splitting: The Importance of Generalization: A member suggests a three-way data split for model training, validation, and testing, highlighting the need to assess model generalization beyond just fitting to homogenous data.
- They emphasize the importance of testing on datasets within the same domain but with different characteristics to ensure the model's ability to generalize.
- Chat Template: Instruction Tuning and Customization: The chat template is recommended based on the structure used during instruction tuning, implying its potential impact on model performance.
- This suggests the possibility of creating custom chat templates for instruction tuning base models and tailoring them to specific tasks.
- Search for SQL Summarization Model: The discussion expresses interest in finding a model capable of summarizing existing SQL queries and generating novel SQL from user queries.
- This indicates a need for models that can effectively understand and manipulate SQL code, facilitating more efficient data manipulation and analysis.
HuggingFace ▷ #diffusion-discussions (25 messages🔥):
Flux Pipelinetorch.compilefp8 checkpointsModel Loading SpeedHugging Face Snapshots
- Flux Pipeline Compilation Performance: When using
torch.compileinFluxPipeline, performance can be slower than without it; the compilation happens inFluxPipeline's__init__after input and weight scales are adjusted. - Fp8 Checkpoints for Flux Schnell: An fp8 checkpoint for Flux Schnell is available, and it's easy to create one by loading the pipeline and running at least 30 steps.
- This takes 6 minutes currently, and the code needs to be updated to handle loading from prequantized t5's.
- Loading Time Improvements: Loading the pipeline takes 6 minutes, and the speed may be impacted by HF downloads.
- The author suggests allowing loading from prequantized t5's, which could be achieved by downloading a snapshot of the BFL HF weights.
- Hugging Face Snapshot Downloads: A suggestion was made to allow users to download a snapshot of the BFL HF weights using
huggingface_hub.download_snapshot(bfl/schnell).
Stability.ai (Stable Diffusion) ▷ #general-chat (199 messages🔥🔥):
SDXL vs SD1.5prompting techniquesconsistency issuecomfyUI and FluxGPU Ram Issues
- SDXL vs SD1.5: Which One to Choose?: A user with 32 GB of RAM is trying to decide between SDXL and SD1.5, but they are experiencing slow image generation speeds on their CPU.
- Another member recommends SDXL because even though it will be slow on CPU, the user will experience better quality images, but they should be aware of potential out-of-memory errors and require more swap space.
- Prompting Techniques: Commas and Consistency: Several users are discussing the importance of consistency and prompt adherence in image generation.
- One member argues that prompting with commas and listing desired elements works best for them, while others find that natural language prompts work better.
- ComfyUI and Flux: Performance and Installation: A user is struggling to install iPadaper on ComfyUI, and they're recommended to check out the Tech Support channel for help.
- Another user is having trouble generating noisy, low-quality images in Flux and is experimenting with different prompts and settings to achieve the desired look.
- GPU Ram Issues: Flux and 3080: A user asks how to set GPU weights in ComfyUI when using Flux and has a 16GB RTX 3080.
- A user with a 4GB GPU reports slow performance in A1111, highlighting the need for sufficient GPU power for smoother image generation.
- Stable Diffusion Installation and Guides: A user asks for recommendations for guides on installing Stable Diffusion, and Automatic1111 and ComfyUI are suggested.
- It is noted that while AMD cards can be used for Stable Diffusion, they will be slower and the Tech Support channel provides helpful resources.
Links mentioned:
aider (Paul Gauthier) ▷ #announcements (1 messages):
Aider 0.52.0
- Aider 0.52.0 Released: Shell Command Execution & More: Aider 0.52.0 brings shell command execution, allowing users to launch a browser, install dependencies, run database migrations, exercise code changes, and run tests directly within the tool.
- Other key updates include
~expansion for/readand/drop, a new/resetcommand to clear chat history, improvements to auto commit sequencing, and a default OpenAI model switch togpt-4o-2024-08-06.
- Other key updates include
- Aider Wrote 68% of the Code for This Release: Aider autonomously generated 68% of the code for version 0.52.0, showcasing its growing capabilities in software development.
aider (Paul Gauthier) ▷ #general (129 messages🔥🔥):
fzf supportAider training setDSPY, TEXTGRAD, TRACEaider co-op threaddiff vs diff-fenced
- fzf support requested: A member requested support for
fzfwithin the prompting area, as well as the ability to display more than two lines of autocomplete suggestions. - Training set for Aider prompt-code pairs: A member is creating a training set of prompts and their corresponding Aider code outputs to define an efficient meta-format for generating permutations of techniques, stacks, and design patterns.
- They are exploring tools like DSPY, TEXTGRAD, and TRACE to optimize either the code or the prompt for reproducibility and have created an Aider co-op thread for further brainstorming.
- Aider and Arima model code: A member inquired about using Aider for writing code for training models like Arima, and whether it could be helpful for analysis.
- Gemini-experimental on Google Cloud VertexAI: A member asked about using Gemini-experimental with Google Cloud VertexAI and encountered errors while using it with Aider.
- Another member clarified that Gemini-experimental is currently not available on VertexAI but can be accessed via AI Studio, and suggested using Sonnet-3.5 tokens for free on VertexAI.
- Aider browser UI demo and use: A member inquired about the Aider browser UI and was provided with a link to a demo video and documentation on how to use it to collaborate with LLMs to edit code in local Git repos.
- Aider directly edits code in local source files, commits changes with sensible commit messages, and supports various LLMs like GPT 3.5, GPT-4, GPT-4 Turbo with Vision, and Claude 3 Opus.
Links mentioned:
aider (Paul Gauthier) ▷ #questions-and-tips (53 messages🔥):
Repo MapGroq API KeyToken OptimizationAider's Chat ModesAider as a Chatbot
- Repo Map Details: The
/repocommand output and repo map are similar but not identical, as the repo map is dynamic and the one displayed by/repomay change before it is sent to the LLM.- Use the
--verboseflag to view the actual repo map sent to the LLM.
- Use the
- Setting Groq API Key in Windows: You need to restart your terminal after setting the GROQ_API_KEY environment variable using
setx.- A user reported receiving an argument error when trying to set the API key using
setx, but after restarting the terminal, the issue was resolved.
- A user reported receiving an argument error when trying to set the API key using
- Optimizing Token Usage: A user is looking for documentation on optimizing token usage, specifically in relation to small Python files that are still exceeding the OpenAI limit.
- The user is requesting changes like calculations and rendering that would potentially require a multi-step process, and is looking for ways to reduce the token context.
- Aider's Chat Modes: A user inquired about using Aider as a regular chatbot interface for non-coding tasks.
- The user was advised to switch to
askmode using/chat-mode askand was provided a link to the Aider documentation for further reference.
- The user was advised to switch to
- Aider as a Chatbot: A user wanted to use Aider as a chatbot for non-coding tasks like asking questions about the distance between Earth and the Moon.
- The user was advised to create a
CONVENTIONS.mdfile with a prompt instructing Aider to act like a chatbot, and was given an example and a link to the Aider documentation.
- The user was advised to create a
Links mentioned:
aider (Paul Gauthier) ▷ #links (5 messages):
CursorAiderOpenAI's ComposerAI Code GenerationAutoToS
- Cursor's AI-powered Code Generation: The Cursor blog describes a vision for an AI-powered code editor that would one day write all the world's code.
- Cursor already allows instant answers, mechanical refactors, terse directive expansion, and thousand-line changes in seconds, with future plans for AI-powered background coders, pseudocode viewing and modification, and bug scanning.
- Aider: Outperforming OpenAI's Composer?: A user expressed gratitude for Paul's work on Aider, citing its superior performance compared to OpenAI's Composer, even with the ability to override prompts with repository specifics in Composer.
- AutoToS: Automating Thought of Search: A paper titled "AutoToS: Automating Thought of Search" proposes automating the "Thought of Search" (ToS) method for planning with LLMs.
- ToS involves defining the search space with code, requiring human collaboration to create a sound successor function and goal test. AutoToS aims to automate this process, achieving 100% accuracy on evaluated domains with minimal feedback iterations using LLMs of various sizes.
- LLMs in Search and Planning: The paper highlights a shift towards using LLMs for search, moving away from traditional world models.
- ToS, with its code-based search space definition, has proven successful in solving planning problems with 100% accuracy on tested datasets, demonstrating the potential of LLMs in this domain.
- Challenges of LLM-based Planning: The paper acknowledges the challenge of LLMs in planning, specifically the need for soundness and completeness in search components.
- AutoToS addresses these challenges by guiding LLMs to generate sound and complete search components through feedback from unit tests, ultimately achieving 100% accuracy.
Links mentioned:
Latent Space ▷ #ai-general-chat (58 messages🔥🔥):
Autogen LeadThePrimeagenCursorAI RegulationsInflection
- Autogen Lead Leaves Microsoft: The lead of the Autogen project left Microsoft to start OS autogen-ai.
- This occurred in May 2024 and the new company is raising funds.
- ThePrimeagen's Stream: A streamer called ThePrimeagen wrote some basic JavaScript tests and used Sonnet 3.5 / GPT-4 to write code that would pass those tests.
- They found that LLMs struggled with state management, prompting discussions about the need for better models and tools for long-context and agentic coding.
- Cursor AI Raises $60M: Cursor announced they have raised $60M from Andreessen Horowitz, Jeff Dean, John Schulman, Noam Brown, and the founders of Stripe and Github.
- They claim to have become recognized as the best way to code with AI and are building a tool that will eventually write all the world's software.
- California's AI Bills: There are 20+ AI regulation bills California is voting on this week, summarized in this Google Sheet.
- Inflection's Drama: There has been drama at Holistic AI (formerly known as H), a startup that recently raised a $220M seed round.
- Three of the five founders, who were previously longtime Google DeepMind researchers, have left the company.
Links mentioned:
Latent Space ▷ #ai-announcements (1 messages):
AI Engineer Meetup in LondonSpeakers at the MeetupAI Engineer World's Fair
- AI Engineer Meetup London is Coming!: The first AI Engineer London Meetup is happening on the evening of September 12th, bringing a slice of @swyx's AI Engineer World's Fair to the city.
- The event will feature four amazing speakers - @maximelabonne, @roviosc, @BruverisMartins, and Chris Bull.
- Register Now for the London Meetup!: Be sure to register for the event using the registration link provided, and join the #LondonAI tag on Discord to connect with other London-based AI engineers.
- See you there!
Link mentioned: Tweet from Damien C. Tanner (@dctanner): We're brining a slice of @swyx's AI Engineer World's Fair to London! Evening of 12 September is the first AI Engineer London Meetup. Hear from 4 amazing speakers: @maximelabonne, @rovio...
Latent Space ▷ #ai-in-action-club (53 messages🔥):
Duplicate TopicsSimilar TopicsTaxonomy SynthesisGPT ResearcherEmbedland
- Dealing with Duplicate or Similar Topics: A member asked about handling duplicates or extremely similar topics generated from thousands of potential topics.
- Suggestions included using a small embedding model, enforcing a minimum cosine distance, or running the topics through UMAP/TSNE and then performing kNN clustering.
- Taxonomy Synthesis for Hierarchical Planning: A member noted that Taxonomy Synthesis could be useful for hierarchically planning writing papers.
- They also mentioned that GPT Researcher is a tool that uses LLMs to autonomously conduct research on any given topic.
- Embedding Models for Topic Similarity: A member inquired whether embedding models work well with one or two words, and another member pointed out that you don't need a vector DB for cosine distance calculations.
- The discussion then shifted to using UMAP/TSNE for dimensionality reduction, followed by kNN clustering, and then using an LLM to name the clusters, with Embedland as an example.
- Storm: LLM-Powered Knowledge Curation: A member suggested that Storm could be used for hierarchical planning of writing papers.
- Storm is an LLM-powered knowledge curation system that researches a topic and generates a full-length report with citations.
- BERTopic's Algorithm and Entropy Generation: A member mentioned that BERTopic uses a similar approach for topic representation, particularly in its clustering step.
- The discussion then touched on entropy generation, implying a potential connection to the topic of duplicate topics and their reduction.
Links mentioned:
OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
Model DeprecationYi ModelHermes ModelMistral ModelLlama 2
- Several Models Deprecate: Several models are no longer accessible, effective 8/28/2024, due to the model provider's deprecation decision.
- The models affected include
01-ai/yi-34b,01-ai/yi-6b,phind/phind-codellama-34b,nousresearch/nous-hermes-2-mixtral-8x7b-sft,open-orca/mistral-7b-openorca,allenai/olmo-7b-instruct,meta-llama/codellama-34b-instruct,meta-llama/codellama-70b-instruct,meta-llama/llama-2-70b-chat,meta-llama/llama-3-8b, andmeta-llama/llama-3-70b.
- The models affected include
- Yi Model Deprecation: The base versions of the Yi model,
01-ai/yi-34band01-ai/yi-6b, are no longer available.- This includes the base versions of the Yi model,
01-ai/yi-34band01-ai/yi-6b.
- This includes the base versions of the Yi model,
- Hermes Model Deprecation: The
nousresearch/nous-hermes-2-mixtral-8x7b-sftmodel has been deprecated.- This specific model,
nousresearch/nous-hermes-2-mixtral-8x7b-sft, is no longer available.
- This specific model,
- Mistral Model Deprecation: The
open-orca/mistral-7b-openorcamodel has been deprecated.- The
open-orca/mistral-7b-openorcamodel is no longer accessible.
- The
- Llama 2 and Llama 3 Deprecation: The
meta-llama/llama-2-70b-chat,meta-llama/llama-3-8b(base version), andmeta-llama/llama-3-70b(base version) models have been deprecated.- The
meta-llama/llama-2-70b-chat,meta-llama/llama-3-8b(base version), andmeta-llama/llama-3-70b(base version) models are no longer available.
- The
OpenRouter (Alex Atallah) ▷ #app-showcase (1 messages):
OpenRouter Team's work
- Oz's team's current project: A user asked Oz about their team's current projects and their work.
- Oz did not reply with any information about their team's work.
- No Further Information: No further information was provided regarding the OpenRouter team's current projects or work.
OpenRouter (Alex Atallah) ▷ #general (104 messages🔥🔥):
OpenRouter PricingOpenRouter Token CountingOpenRouter Model DeprecationsLlama 2Grok 2
- OpenRouter accidentally charges user $0.01: A new OpenRouter user, unfamiliar with English, accidentally clicked on a paid model after intending to use a free model, leaving a $0.01 balance.
- They asked for help in understanding how to pay and a member assured them that OpenRouter won't sue over a $0.01 balance.
- OpenRouter's token counting mystery: A member inquired about OpenRouter's method for counting input tokens, noting that a simple "hey" prompt resulted in a charge for over 100 input tokens.
- Several members clarified that OpenRouter simply forwards token counts from OpenAI's API for GPT-4o models, while the count can be affected by system prompts, tool calls, and the inclusion of previous messages in the chat history.
- OpenRouter deprecating models: Together AI is deprecating several models, including some available as dedicated endpoints, and will remove them in six days.
- The deprecation policy is outlined on Together AI's website and users will be notified by email with options to migrate to newer models.
- Llama 2 70b launched: Alex Atallah confirmed that Llama 2 70b has been launched but not yet formally announced.
- The model is available on OpenRouter and other platforms, with discussion on its performance and availability.
- Grok 2 on LMSYS Leaderboard: Grok 2 and Grok-mini have been added to the LMSYS leaderboard, with Grok 2 currently ranked #2, surpassing GPT-4o (May) and tying with Gemini.
- Grok 2 excels in math and ranks highly across other areas, including hard prompts, coding, and instruction-following, showcasing its capabilities.
Links mentioned:
Modular (Mojo 🔥) ▷ #general (57 messages🔥🔥):
Mojo LicensingMojo and MaxModular's Business ModelHeterogenous Compute
- Mojo's Open Source Status: The question of Mojo's open source status arose from recent statements regarding licensing.
- Modular has previously stated they are figuring out licensing details, aiming to protect their product within a specific AI market slice while allowing open use outside this scope.
- Mojo vs Max: Blurred Lines: The discussion centered around the relationship between Mojo and Max, particularly their close integration and the impact on licensing.
- While initially conceived as separate components, Max's functionalities are now deeply integrated into Mojo, leading to questions about whether Max could be separated in the future.
- Modular's Business Focus on Managed AI: Modular's commercial focus is on managed AI cloud applications, which allows them to continue investing in Mojo and Max.
- They are making Max freely available, allowing for open development, but will license commercially for specific applications. They envision a more permissive licensing approach over time.
- The Future of Heterogenous Compute: Modular is aiming to make portable GPU programming widely accessible for heterogenous compute scenarios.
- Their vision is to catalyze the movement towards more widespread heterogenous compute, focusing on providing tools and frameworks for seamless integration.
Modular (Mojo 🔥) ▷ #mojo (28 messages🔥):
Mojo Community WelcomeAsync in MojoMojo's HTTP ImplementationMojo's Versioning and StabilityMojo's Memory Management
- New User Welcomed to Mojo Community: A new user expressed interest in using Mojo for data science projects and asked for guidance on sharing their tools.
- Another user directed them to the #mojo-project-showcase channel on Discord for community feedback.
- Asynchronous Programming in Mojo: A user asked about the potential for async functionality in Mojo, specifically for I/O tasks, drawing a parallel with Python's asynchronous capabilities.
- A discussion ensued on the merits of a sans-io HTTP implementation that could potentially be plugged into various I/O frameworks.
- Developing a Sans-IO HTTP Implementation for Mojo: A user requested a simple example of a 'sans-io' HTTP implementation, prompting a discussion on how it differs from traditional I/O HTTP implementations.
- A code snippet illustrating a basic sans-io HTTP implementation was provided, highlighting the importance of thread safety and proper resource management.
- Mojo's Release Cycle and Stability: A user inquired about the upcoming transition from Mojo 24.4 to 24.5, expressing concern about potential code changes required for their project.
- Several users discussed the ongoing evolution of Mojo, emphasizing the importance of staying up-to-date with the changelog and embracing the dynamic nature of the language.
- Understanding Mojo's Memory Management: A user encountered an error while using references within a struct definition, specifically regarding the
__lifetime_of()function.- The discussion focused on the correct usage of
__lifetime_of(), highlighting the importance of ownership delegation and potential alternatives likeUnsafePointerfor managing references in Mojo.
- The discussion focused on the correct usage of
Link mentioned: Network protocols, sans I/O — Sans I/O 1.0.0 documentation: no description found
Modular (Mojo 🔥) ▷ #max (3 messages):
Modular Max Installation IssuesM1 Max CompatibilityModular Clean Command
- Max Installation Fails on M1 Max: A user reported being unable to install Max on an M1 Max machine, encountering an error message indicating an invalid manifest and a missing or invalid root JSON.
- Solution: Modular Clean Command: The user successfully resolved the installation issue by running the command
modular cleanfollowed by reinstalling Max.
Perplexity AI ▷ #general (43 messages🔥):
Perplexity's internalsTwitter sourcesPerplexity Pro source countGenerating images from PerplexityPerplexity's future
- Perplexity's Internal Data: A user requested data on the frequency of Perplexity-generated follow-ups vs. user-generated follow-ups, time spent on each interaction type, and number of back-and-forths per type.
- Another user responded that this data may be proprietary.
- Twitter Sources in Perplexity: A user asked if there was a way to increase the weight of Twitter sources when using Perplexity to understand public opinion on a topic.
- A user responded that this feature is currently only available through the API.
- Perplexity Pro Source Count Change: A user noticed a decrease in the number of sources displayed in Perplexity Pro, from 20 or more to 5 or 6, for research-based questions.
- This user questioned if this was a change to Perplexity Pro or if they were using it incorrectly.
- Email Automation Tools for AI Agents: A user asked for recommendations on AI tools or agents that can automatically send emails on their behalf.
- They mentioned Nelima, Taskade, Kindo, and AutoGPT as potential options, but wanted to know if there were any other tools available.
- LinkedIn Premium and Perplexity Pro: A user asked for confirmation on a potential offer where getting a free trial of LinkedIn Premium and canceling before it ends would grant them a year of Perplexity Pro.
- Other users suggested checking with LinkedIn support for the latest information on the offer.
Link mentioned: Black Topographic Map Images - Free Download on Freepik: Find & Download Free Graphic Resources for Black Topographic Map. 20,000+ Vectors, Stock Photos & PSD files. ✓ Free for commercial use ✓ High Quality Images. #freepik
Perplexity AI ▷ #sharing (14 messages🔥):
Perplexity AI BotShareable ThreadsMrBeast
- Perplexity AI Bot Asks for Shareable Threads: The Perplexity AI Bot is prompting several users to ensure their threads are 'Shareable' by providing a link to the Discord channel for further reference.
- Internet's Dislike of MrBeast: A user mentioned that the internet seems to dislike MrBeast and provides a link to a search query on Perplexity AI for potential reasons.
OpenAccess AI Collective (axolotl) ▷ #general (11 messages🔥):
Phi 3.5QLORA + FSDPPretrainingData Structure
- Base Phi 3.5 Not Released: A member expressed curiosity about the availability of the base Phi 3.5, noting that only the instruct version was released by Microsoft.
- They indicated a desire to fine-tune the model but found it challenging without the base version.
- QLORA + FSDP Needs 8xH100: A member inquired about the specific hardware requirements for running QLORA + FSDP, suggesting that an 8xH100 configuration is necessary.
- They also mentioned issues with the tqdm progress bar being inaccurate when warm restarts are enabled during training.
- Pretraining Doesn't Require Prompt Style: A member confirmed that pretraining does not necessitate a prompt style, implying that it can be done without specific input prompts.
- This was affirmed by another member, suggesting that the model's primary focus during pretraining is not on prompt engineering but on learning general patterns and representations from the data.
- Structured Pretraining for Better Data Focus: A member pointed out that adding structure to pre-training data, such as including URLs at the start, can prevent overfitting on irrelevant information.
- They suggested that incorporating a system prompt with relevant information about the data could improve performance, but acknowledged that this technique has not been widely adopted and its effectiveness remains uncertain.
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (33 messages🔥):
Gradients IssueChat Template and Special TokensPhi_3 Chat TemplateResize_token_embeddings_to_32xChatML
- Gradients Issue: Packing Support and Chat Templates: The gradients issue is caused by a combination of factors: lack of packing support and the use of special tokens in chat templates.
- ChatML: Teaching the Model a New Template: The user strongly desires to teach the model ChatML, a new chat template, and believes it's possible.
- Dolphin-2.9.4-llama3.1-70b Performance: The user is experimenting with
dolphin-2.9.4-llama3.1-70band reports initial improvement after a one-epoch checkpoint. - Phi's Issues and Possible Solutions: The user acknowledges
phihas always been problematic but believes the issue lies within the modeling code rather than the weights. - Transformers Issue: Mode-Aware Chat Templates: The user opened an issue on the Transformers repository to explore the potential for mode-aware chat templates.
Link mentioned: Mode-aware chat templates for distinct training and inference behaviors · Issue #33096 · huggingface/transformers: Feature request Implement mode-aware chat templates for distinct training and inference behaviors Proposed Solution To resolve this, I propose adding a new variable called template_mode to indicate...
OpenAccess AI Collective (axolotl) ▷ #general-help (5 messages):
SmolLMMambaMamba TrainingCosmo2 TokenizerBOS/EOS Token
- SmolLM: A Series of Small Language Models: SmolLM is a series of small language models available in three sizes: 135M, 360M, and 1.7B parameters.
- These models are trained on Cosmo-Corpus, a meticulously curated high-quality training dataset, including Cosmopedia v2, Python-Edu, and FineWeb-Edu.
- Mamba: Transformers Compatible Model: This repository contains the
transformerscompatiblemamba-2.8bmodel.- The
config.jsonand tokenizer are provided in this repository, and you need to installtransformersfrommainuntiltransformers=4.39.0is released.
- The
- Mamba Training with Transformers: A user is trying to pretrain a small Mamba model (around 150M parameters) from scratch using transformers and the
cosmo2-tokenizer.- They are encountering an issue with convergence and have realized that neither
cosmo2-tokenizernor SmolLM/Mamba series have separate BOS tokens, leading to potential training difficulties.
- They are encountering an issue with convergence and have realized that neither
- Cosmo2 Tokenizer: Training Dataset: The
cosmo2-tokenizerwas trained on 1M samples from various datasets, including FineWeb-Edu, Cosmopedia v2, StarCoderData, OpenWebMath, and StackOverFlow.- It is used for training the
cosmo2model and provides a tokenizer for text processing and language understanding tasks.
- It is used for training the
- Missing BOS Token in SmolLM and Mamba: The
cosmo2-tokenizerand SmolLM/Mamba series do not have distinct BOS tokens, with the EOS token serving as both.- This could be a potential cause for training issues, as the model might not be able to properly distinguish between the beginning and end of sequences.
Links mentioned:
OpenAI ▷ #ai-discussions (20 messages🔥):
GPT-3.5 vs GPT-4GPT-2 vs GPT-3.5Email AutomationSwarmUIOpenAI Finetuning API
- GPT-3.5: Outdated or Interesting?: A discussion arose about the relevance of testing GPT-3.5 in a benchmark, with some considering it outdated due to its age and the advancements in post-training techniques.
- GPT-2: A Waste of Time?: There was speculation about why GPT-2 wasn't included in the benchmark, with some suggesting it might be considered too outdated and a waste of time.
- Email Automation Tools: Beyond Nelima: The discussion shifted towards tools capable of automating email tasks, seeking alternatives to Nelima for sending emails based on prompts.
- SwarmUI: A ComfyUI Wrapper: SwarmUI was highly praised for its intuitive interface, ease of use, and support for NVIDIA/AMD GPUs.
- Exploring OpenAI's Finetuning API: A question was raised about the appropriateness of discussing OpenAI's finetuning API in the channel.
OpenAI ▷ #gpt-4-discussions (10 messages🔥):
GPTs Knowledge FilesGPTs formattingGPTs formatting and styleChatGPT GPTs
- Knowledge Files: XML vs Markdown: A user is seeking guidance on the best format for knowledge files used in GPTs, particularly for a project involving the creation of attacks, dodges, and counterattacks for roleplaying games or writing pieces.
- They're exploring whether XML currently offers better performance compared to Markdown, suggesting a preference for using the format that proves most effective.
- GPT Formatting Inconsistency: A user is experiencing inconsistent formatting in their GPT's responses, with some messages exhibiting well-structured bold questions and explanations, while others present a block of text.
- They're looking for solutions to achieve consistent formatting in their GPT's outputs, considering providing examples or altering the instruction style.
- ChatGPT Misinterpretation: In a previous conversation, a user requested a GPT for creating roleplaying content but received responses suggesting an API-based implementation instead of a custom GPT on ChatGPT.
- This highlights the potential for ChatGPT to misinterpret instructions and the importance of clarity in expressing desired outcomes, particularly when specifying the desired tool (custom GPT or API).
- Formatting Mimicry by GPTs: A member suggests that GPTs tend to emulate the style in which instructions are written.
- This provides valuable insight into GPT behavior and how formatting consistency can be influenced by the structure and style of user prompts.
OpenAI ▷ #prompt-engineering (7 messages):
ChatGPT Playground LimitationsGPT Output Token Limits
- ChatGPT Playground's Drawing Capabilities: A user asked if ChatGPT can draw complex equations with text, highlighting a possible feature request for the Playground.
- Another user responded that the Playground currently lacks this capability, suggesting it's not fully developed yet.
- GPT's Output Token Limit: A user inquired about why GPT seems to be capped at 2k tokens in its output, even when requesting higher limits.
- They mentioned experimenting with different settings, including the new 16k output window, but GPT consistently falls short of the desired token count.
OpenAI ▷ #api-discussions (7 messages):
ChatGPT drawing complex equationsPlayground limitationsChatGPT's roles in automationChatGPT output token limits
- ChatGPT struggles drawing complex equations: A user asked if ChatGPT could draw complex equations with text, but it appears the Playground is not yet capable of this.
- The Playground's output is currently limited to text-based responses, and does not yet have the capability to display equations.
- ChatGPT's roles in automation: Another user brought up the three roles of ChatGPT in automation tools, which are System, User, and Assistant/Agent, along with GPT, suggesting a GPT IG Writer.
- ChatGPT's output token limits: A user is struggling to get ChatGPT to utilize the maximum output window, even with the new 16k token model.
- Despite setting the output to max and requesting a specific number of tokens, ChatGPT seems to be limited to 2k tokens or less in output.
Eleuther ▷ #general (7 messages):
Prompt Engineering for Multi-Turn MessagesSmolLM ModelMamba ModelTraining from ScratchBOS Token Usage
- Prompt Engineering for Multi-Turn Messages: A member discussed the importance of including
n-1turns in the prompt when training on multi-turn messages, referencing a specific code example from the alignment-handbook repository.- They suggested an alternative approach of gradually adding turns to the prompt to create multiple samples from a single sample, but questioned its effectiveness compared to using only the last
n-1turns.
- They suggested an alternative approach of gradually adding turns to the prompt to create multiple samples from a single sample, but questioned its effectiveness compared to using only the last
- SmolLM Model Details and Training Data: A user inquired about the SmolLM model and its training data, which includes Cosmo-Corpus containing Cosmopedia v2, Python-Edu, and FineWeb-Edu.
- The model comes in three sizes: 135M, 360M, and 1.7B parameters, and has demonstrated promising results compared to other models in its size categories.
- Mamba Model Usage and Installation: A user shared information about using the Mamba 2.8B model and explained its compatibility with the
transformerslibrary.- They provided instructions for installing the necessary dependencies, including
transformers,causal_conv_1d, andmamba-ssm, and outlined the process of using thegenerateAPI to generate text.
- They provided instructions for installing the necessary dependencies, including
- Training a Small Mamba Model from Scratch: A user encountered challenges while attempting to pretrain a small Mamba model (around 150M parameters) from scratch using the cosmo2-tokenizer.
- They noticed that neither the cosmo2-tokenizer nor SmolLM/original Mamba series have distinct BOS tokens, leading to convergence issues, raising questions about the expected behavior.
- BOS Token Usage in Language Models: A member clarified that not all models utilize BOS tokens during training, attributing this to convention and codebase dependencies.
- They emphasized that the absence of distinct BOS tokens is not necessarily an error, suggesting that the user may be experiencing issues related to model architecture or training parameters.
Links mentioned:
Eleuther ▷ #research (22 messages🔥):
Model DistillationModel CompressionPositional Embeddings in GraphsResearch ProjectsTree and Digraph Embeddings
- Distilling Smaller Models from Larger Ones: A user suggested adding LoRAs to a larger model (27B) and performing model distillation on the logits of a smaller model (9B) to create a model with similar functionality but smaller size.
- This approach aims to replicate the performance of the smaller model by leveraging the knowledge from the larger model.
- Compressing Models by Reducing Parameters: Another user proposed methods for reducing model size, including zeroing out subsets of parameters, quantizing weights to lower bit precision, and applying noise to the weights.
- They cited a recent research paper (Quantization for Large Language Models) that explores these techniques for model compression.
- Encoding Positional Information in Graphs: A user raised the challenge of encoding positional information in tree or digraph-shaped contexts for text LLMs, aiming to preserve graph structure without linearization.
- They proposed using wavefront encoding, where nodes at similar distances from the root are assigned close embeddings, allowing for parallel paths to attend to each other.
- Seeking Research Projects to Contribute: A user inquired about finding research projects to contribute to.
- A response directed them to a dedicated channel for research projects within the Discord server.
- Exploring Graph Embedding Techniques: The discussion explored the challenge of encoding graph structures for LLMs, aiming to avoid linearization and preserve graph symmetries.
- They considered various approaches like wavefront encoding, rope embeddings, and conditional positional embeddings, acknowledging the complexity of representing graph structure in a way that allows the model to attend to branches effectively.
Link mentioned: The Vizier Gaussian Process Bandit Algorithm: Google Vizier has performed millions of optimizations and accelerated numerous research and production systems at Google, demonstrating the success of Bayesian optimization as a large-scale service. O...
Eleuther ▷ #lm-thunderdome (2 messages):
Llama 406B on SlurmMultiple Choice EvalsChatGPT4oAnthropic APIsClaude
- Running Llama 406B on Slurm: A user successfully ran 406B Llama on a Slurm cluster using the VLLM backend and their harness fork.
- They shared a Slurm script to help others run large language models on their clusters.
- Multiple Choice Evals with OpenAI and Anthropic: The user asked if anyone had figured out how to run multiple choice evaluations with OpenAI's ChatGPT4o or Anthropic's external APIs.
- They were willing to forgo logprobs as long as the API could provide a multiple choice answer.
- Multiple Choice Questions on ChatGPT4o and Claude: The user also inquired if anyone had attempted to answer multiple choice questions using ChatGPT4o or Claude.
Link mentioned: lm-evaluation-harness/jobs/scripts/submit/models_XXL/eval_llama31_instruct_405B_smartt.sh at main · DCGM/lm-evaluation-harness: A framework for few-shot evaluation of language models. - DCGM/lm-evaluation-harness
Cohere ▷ #discussions (18 messages🔥):
Cohere API ErrorMultimodal LLMCohere Schema ObjectPrompt Tuner
- Cohere API Error: Invalid Role: A user reported an HTTP-400 error when using the Cohere API, stating that the role was invalid.
- The error message suggests that the provided role was not one of the accepted options: 'User', 'Chatbot', 'System', or 'Tool'.
- Multimodal LLM with Speech Understanding: A user shared their work on a multimodal LLM that can understand both text and speech without a separate ASR stage.
- They extended Meta's Llama 3 model with a multimodal projector that directly converts audio into the high-dimensional space used by the model, allowing for faster responses compared to systems that combine separate ASR and LLM components.
- Cohere Schema Object for Patterned Responses: A user expressed enthusiasm for the new schema object addition to Cohere, finding it helpful for structuring multiple actions in a single API call.
- They're using this feature for generative fiction, where responses need to produce content, suggest character actions, and generate Diffusion prompts.
- Prompt Tuner Feature Requests: Multiple users expressed interest in having the prompt tuner support preamble and prompt tuning simultaneously.
- They believe this would provide more depth analysis and improve overall performance for various models.
Cohere ▷ #questions (4 messages):
Cohere PricingTokenizationCohere APIOracle APEXCommand R Models
- Cohere Pricing - Detailed breakdown: Cohere's generative models such as Command R and Command R+ are priced per token.
- Tokenization explained: Cohere language models understand 'tokens' - a part of a word, a whole word, or punctuation, rather than characters or bytes.
- Rule of thumb: 1 word = 1.5 tokens: A rule of thumb is that one word is approximately 1.5 tokens.
- Cohere Trial Usage vs. Production: Cohere distinguishes between "trial" and "production" usage.
- Cohere Models are cost-efficient: Cohere models are some of the most cost-efficient options on the market today for scaling production use cases.
Links mentioned:
Cohere ▷ #api-discussions (5 messages):
Command R+ via HTTPStructured Outputs
- Command R+ via HTTP: Yes, Command R+ with 128k context is available via HTTP requests, specifically using
curl.- You can find the documentation for this in the Cohere API Reference at https://docs.cohere.com/reference/chat.
- Structured Outputs are not yet available: Cohere does not currently offer a structured outputs feature like the one available in OpenAI's API.
Link mentioned: Chat Non-streaming — Cohere: Generates a text response to a user message. To learn how to use the Chat API with Streaming and RAG follow our Text Generation guides .
Cohere ▷ #projects (2 messages):
Cohere Models on Hugging Face Hub
- Cohere models coming to Hugging Face Hub: A member shared that they are working on getting all major models, including Cohere models, packaged and hosted on the Hugging Face Hub.
- Another member expressed excitement about this news.
- Updates on Cohere Integration: There is no mention of any updates regarding Cohere integration, so we can't provide a summary on this.
Interconnects (Nathan Lambert) ▷ #news (17 messages🔥):
AI burnoutAI powerusersModel GenerationsTwitter fatigue
- AI Burnout a Concern: A member expressed concern that AI can get far more burnout-y than humans.
- This concern was echoed by others, who pointed out the intense work ethic prevalent in frontier labs, which is seen as unsustainable for the long term.
- AI Powerusers, A Magic-Wielding Class: A member noted that AI powerusers are akin to a spellcasting class, with their constant use of AI tools.
- They further posited that increased AI model power would intensify the demands on these powerusers, leading to further burnout.
- Model Generations: The Burnout Cycle?: A member suggested that the relentless pursuit of "one more model generation" could lead to significant burnout in the AI field.
- The shape of this burnout curve could change, with the rate of progress in AI increasing the potential for exhaustion.
- Twitter Anxiety: A Disconnect from Reality?: A member mentioned a recent post by Greg Brockman on Twitter showing 97 hours of coding work in a week.
- Others expressed a sense of unease with the intensity of AI discourse on Twitter, finding it anxiety inducing and potentially disconnecting from real life.
LAION ▷ #general (9 messages🔥):
Infinite Generative YoutubeTTS for Low Resource LanguagesWhisperSpeech Semantic Tokens for ASR
- Seeking Devs for Infinite Generative Youtube Beta: A team is looking for developers interested in building an infinite generative Youtube platform.
- They are gearing up to launch their closed beta soon and are seeking passionate developers to join their team.
- TTS for Hindi, Urdu, and German: A user expressed interest in training Text-to-Speech (TTS) models for low-resource languages such as Hindi, Urdu, and German.
- They mentioned wanting to use the TTS for a voice assistant.
- WhisperSpeech Semantic Tokens for ASR: A user inquired about the feasibility of using WhisperSpeech semantic tokens for Automatic Speech Recognition (ASR) in low-resource languages.
- They proposed a process involving training a small decoder model on text data and then fine-tuning it using semantic tokens generated from available audio and transcriptions.
LAION ▷ #research (1 messages):
SmolLMMambaCosmo2-tokenizerBOS Tokens
- SmolLM: Smaller Language Models: SmolLM is a series of smaller language models in three sizes: 135M, 360M, and 1.7B parameters, trained on a meticulously curated dataset called Cosmo-Corpus.
- Cosmo-Corpus includes Cosmopedia v2, Python-Edu, and FineWeb-Edu, and SmolLM models have shown promising results when compared to other models in their size categories.
- Mamba: Transformers Compatible Language Model: This repository contains the
transformerscompatiblemamba-2.8bmodel.- You need to install
transformersfrommainuntiltransformers=4.39.0is released and installcausal_conv_1dandmamba-ssmfor the optimisedcudakernels.
- You need to install
- Cosmo2-tokenizer: Tokenizer for Cosmo2 Training: This tokenizer was trained on 1M samples from various datasets, including FineWeb-Edu, Cosmopedia v2, StarCoderData, OpenWebMath, and StackOverFlow.
- Downloads are not tracked for this model, but the tokenizer was trained with a specific focus on educational content and code.
- The Missing BOS Token Mystery: Neither cosmo2-tokenizer nor SmolLM/Mamba series have distinct beginning of sentence (BOS) tokens.
- While technically they do have a BOS token, it is the same as the end of sentence (EOS) token, leading to potential issues during pretraining.
Links mentioned:
LangChain AI ▷ #general (2 messages):
Graph memoryMemory saving
- Graph Memory Saving: A member asked if memory can be saved as a file and then used to compile a new graph.
- They also asked if the same memory can be used for two different graphs or if it is per graph.
- Graph Memory Saving: A member asked if memory can be saved as a file and then used to compile a new graph.
- They also asked if the same memory can be used for two different graphs or if it is per graph.
LangChain AI ▷ #langchain-templates (5 messages):
LangChain PromptingSQL Query GenerationLangChain DocumentationChain Inspection
- Prompting Strategies in LangChain for SQL Queries: This document from the LangChain Python Documentation (https://python.langchain.com/v0.2/docs/how_to/sql_prompting/#table-definitions-and-example-rows) outlines strategies to improve SQL query generation using create_sql_query_chain.
- It covers how the dialect of the SQLDatabase impacts the prompt of the chain, how to format schema information into the prompt using SQLDatabase.get_context, and how to build and select few-shot examples to assist the model.
- Explicit Context Passing in LangChain Chains: The line of code
prompt_with_context = chain.get_prompts()[0].partial(table_info=context["table_info"])is not passed by default in LangChain.- You need to explicitly pass the context, which includes the
table_info, when calling the chain as demonstrated in the LangChain Python Documentation.
- You need to explicitly pass the context, which includes the
- LangChain Chain Inspection: The get_prompts() method is used to retrieve the prompts used in a LangChain chain.
- This method is discussed in the LangChain Python Documentation (https://python.langchain.com/v0.2/docs/how_to/inspect/#get-the-prompts), which covers methods for programmatically introspecting the internal steps of chains.
Links mentioned:
LangChain AI ▷ #share-your-work (1 messages):
Writer FrameworkHugging Face SpacesDocker Deployment
- Writer Framework App Deployment to Hugging Face Spaces with Docker: A blog post was published explaining how to deploy Writer Framework applications to Hugging Face Spaces via Docker.
- Writer Framework is an open source Python framework that allows building AI applications with a drag-and-drop builder and Python backend, similar to FastHTML, Streamlit, and Gradio.
- Writer Framework - A Drag-and-Drop Builder for AI Apps: Writer Framework is described as a free open-source Python framework that enables the creation of AI applications using a drag-and-drop interface.
- This framework offers a Python backend and functions like other popular frameworks, such as FastHTML, Streamlit, and Gradio.
- Hugging Face Spaces as a Deployment Platform: The blog post details the deployment process of Writer Framework applications onto Hugging Face Spaces, utilizing Docker containers.
- This integration allows developers to host and share their AI applications through Hugging Face's platform, showcasing the power of Writer Framework and the ease of deployment.
Link mentioned: Using Writer Framework with Hugging Face Spaces: no description found
DSPy ▷ #announcements (1 messages):
okhattab: https://lu.ma/03f7pesv
DSPy ▷ #papers (1 messages):
mrauter: https://arxiv.org/abs/2408.11326
DSPy ▷ #general (5 messages):
AdalflowDSpy vs Textgrad vs Adalflow
- Adalflow: SylphAI's New Project: A member inquired about Adalflow, a new project from SylphAI.
- They are interested in exploring its features and potential applications.
- Comparing DSpy, Textgrad, and Adalflow: Another member expressed curiosity about the differences between DSpy, Textgrad, and Adalflow, and when to use each module.
- They also mentioned that LiteLLM will only handle sending queries for inference.
Link mentioned: Get Started — AdalFlow: The Library to Build and Auto-Optimize LLM Task Pipelines: no description found
OpenInterpreter ▷ #general (7 messages):
Open Interpreter brand guidelinesPhi-3.5-miniQwen2Python screen clicking scriptData Analytics masterclass
- Open Interpreter brand guidelines inquiry: A user asked where the brand guidelines for Open Interpreter are available.
- Phi-3.5-mini's surprising performance: Two users expressed surprise and agreement with the unexpectedly good performance of Phi-3.5-mini, followed by a mention of Qwen2.
- Python script for clicking screen locations based on text commands: A user requested a Python script capable of accurately clicking on specific screen locations based on text commands, giving the example of "click on the file dropdown of my notepad++ window".
- Potential solution: --os mode: A response suggested that the --os mode might be suitable for this task.
- Free Data Analytics Masterclass Announcement: A user announced a free masterclass on Data Analytics, highlighting practical insights and real-world applications.
- The announcement provided a registration link https://forms.gle/xoJXL4qKS8iq9Hxb7 and expressed excitement for potential participation.
Gorilla LLM (Berkeley Function Calling) ▷ #leaderboard (4 messages):
Gorilla LeaderboardHuggingface LeaderboardLlama-3.1-Storm-8B
- Gorilla and Huggingface Leaderboards are Now Aligned: A member asked about the discrepancy between the Gorilla and Huggingface leaderboards, noting that the Huggingface one had higher scores.
- Another member responded that the issue has been resolved and the Huggingface leaderboard is now a mirror of the Gorilla leaderboard.
- Llama-3.1-Storm-8B Model Added to Gorilla Leaderboard: A user submitted a Pull Request (PR) to add Llama-3.1-Storm-8B to the Gorilla Leaderboard for benchmarking.
- The PR was acknowledged and will be reviewed later.
Link mentioned: [BFCL] Adding Llama-3.1-Storm-8B model handler by akshita-sukhlecha · Pull Request #598 · ShishirPatil/gorilla: Llama-3.1-Storm-8B model was recently released. This PR adds model handler for Llama-3.1-Storm-8B.
Gorilla LLM (Berkeley Function Calling) ▷ #discussion (3 messages):
REST API testingTest pairsGorilla leaderboard
- User seeks guidance on preparing test pairs for REST API: A user inquired about techniques to create "executable test pairs" for REST API functionality.
- They referenced existing test pairs from the Gorilla leaderboard and wondered if they were prepared manually or through other methods. The user emphasized a desire for "real" tests that are "easy" to implement.
- Clarification needed on "executable test pairs": Another user requested clarification on the meaning of "executable test pairs" in the context of REST API testing.
Links mentioned:
AI21 Labs (Jamba) ▷ #announcements (1 messages):
Jamba 1.5SSM-Transformer architectureLong context handlingSpeedQuality
- Jamba 1.5 Mini & Large Released: AI21 Labs announced the release of Jamba 1.5 Mini (12B active/52B total) and Jamba 1.5 Large (94B active/398B total), built on the new SSM-Transformer Jamba architecture.
- The models offer superior long context handling, speed, and quality—outranking competitors in their size class and marking the first time a non-Transformer model has been successfully scaled to the quality and strength of the market’s leading models.
- Jamba: Long Context King: Jamba boasts a 256K effective context window, the longest in the market, enabling it to handle thousands of pages of text, complex code, and sophisticated agents.
- It's 2.5X faster on long contexts, making it the fastest in its class and delivering significant performance advantages.
- Jamba Quality: Top of its Class: Jamba 1.5 Mini leads its size class with a score of 46.1 on Arena Hard, while Jamba 1.5 Large scores 65.4, outperforming Llama 3.1 70B and 405B.
- Jamba: Multilingual and Developer-Ready: Jamba supports English, Spanish, French, and more, including Hebrew and Arabic, making it a powerful tool for global applications.
- It offers native support for JSON output, function calling, and document processing, making it easy for developers to integrate into their projects.
- Jamba: Open and Accessible: Jamba is available for immediate download on Hugging Face, with deployment options across major cloud platforms (Together AI, AWS, GCP, Azure, and more).
- This open accessibility fosters further experimentation and allows developers to build upon its capabilities.
Links mentioned:
AI21 Labs (Jamba) ▷ #jamba (4 messages):
Jamba Fine-TuningJamba Model Filtering
- No UI Fine-Tuning for Jamba: A member asked if Jamba could be fine-tuned through the UI, but a staff member confirmed that fine-tuning is only available for the instruct version of the model, which is currently not available through the UI.
- Jamba Filtering for Roleplaying: A member asked if Jamba has any built-in filters for things like violence, specifically for roleplaying scenarios.
AI21 Labs (Jamba) ▷ #general-chat (2 messages):
API Rate Limits
- API Rate Limits: A user inquired about the rate limits for API usage.
- The user later mentioned finding the rate limits, which are 200 requests per minute (rpm) and 10 requests per second (rps).
- API Rate Limits: The user asked about API usage rates.
- The user then found the limits themselves, which are 200 requests per minute (rpm) and 10 requests per second (rps).
MLOps @Chipro ▷ #events (3 messages):
NVIDIA AI Summit IndiaAI SafetyDemo-Jam Hackathon
- NVIDIA AI Summit India Kicks Off: The NVIDIA AI Summit India will be held on Oct 23-25, 2024, at Jio World Convention Centre in Mumbai, featuring a fireside chat with Jensen Huang and 50+ sessions on AI, robotics, and more.
- The event aims to connect NVIDIA with industry leaders and partners, showcasing transformative work and valuable insights from leaders in AI across generative AI, large language models, industrial digitalization, supercomputing, robotics, and more.
- AI Capabilities and Risks Demo-Jam Hackathon: The AI Capabilities and Risks Demo-Jam Hackathon commenced with a $2000 prize pool, offering the top projects a chance to join Apart Labs and potentially become a research paper.
- The event encourages participants to create demos that bridge the gap between AI research and public understanding, showcase potential AI-driven societal changes, and convey AI safety challenges in compelling ways.
- Hackathon Features Opening Keynote and Team Formation: The hackathon kicked off with an opening keynote on interactive AI demonstrations, followed by team formation and project ideation.
- Participants have access to expert mentors and resources, and the event is live-streamed on Youtube, allowing anyone to watch the innovation unfold.
Link mentioned: Join NVIDIA AI Summit 2024: October 23–25, Mumbai, India
tinygrad (George Hotz) ▷ #general (2 messages):
tinygrad mypyc compilation
- Tinygrad's Mypyc Compilation Quest: A member expressed interest in compiling tinygrad with mypyc.
- They indicated they are currently investigating the feasibility of this project.
- Join the Quest!: The original poster also invited others to contribute to this effort.
{% else %}
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: [{{ email.subject }}]({{ email_url }})!
If you enjoyed AInews, please share with a friend! Thanks in advance!
{% endif %}