AI News for 8/28/2024-8/29/2024. We checked 7 subreddits, 400 Twitters and 30 Discords (213 channels, and 2980 messages) for you. Estimated reading time saved (at 200wpm): 338 minutes. You can now tag @smol_ai for AINews discussions!
One of the core theses in the Rise of the AI Engineer is that code is first among equals among the many modalities that will emerge. Above the obvious virtuous cycle (code faster -> train faster -> code faster), it also has the nice property of being 1) internal facing (so lower but nonzero liability of errors), 2) improving developer productivity (one of the most costly headcounts), 3) verifiable/self-correcting (in the Let's Verify Step by Step sense).
This Summer of Code kicked off with:
- Cognition (Devin) raising $175m (still under very restricted waitlist) (their World's Fair talk here)
- Poolside raising $400m (still mostly stealth)
Today, we have:
- Codeium AI raising $150m on top of their January $65m raise (their World's Fair talk here)
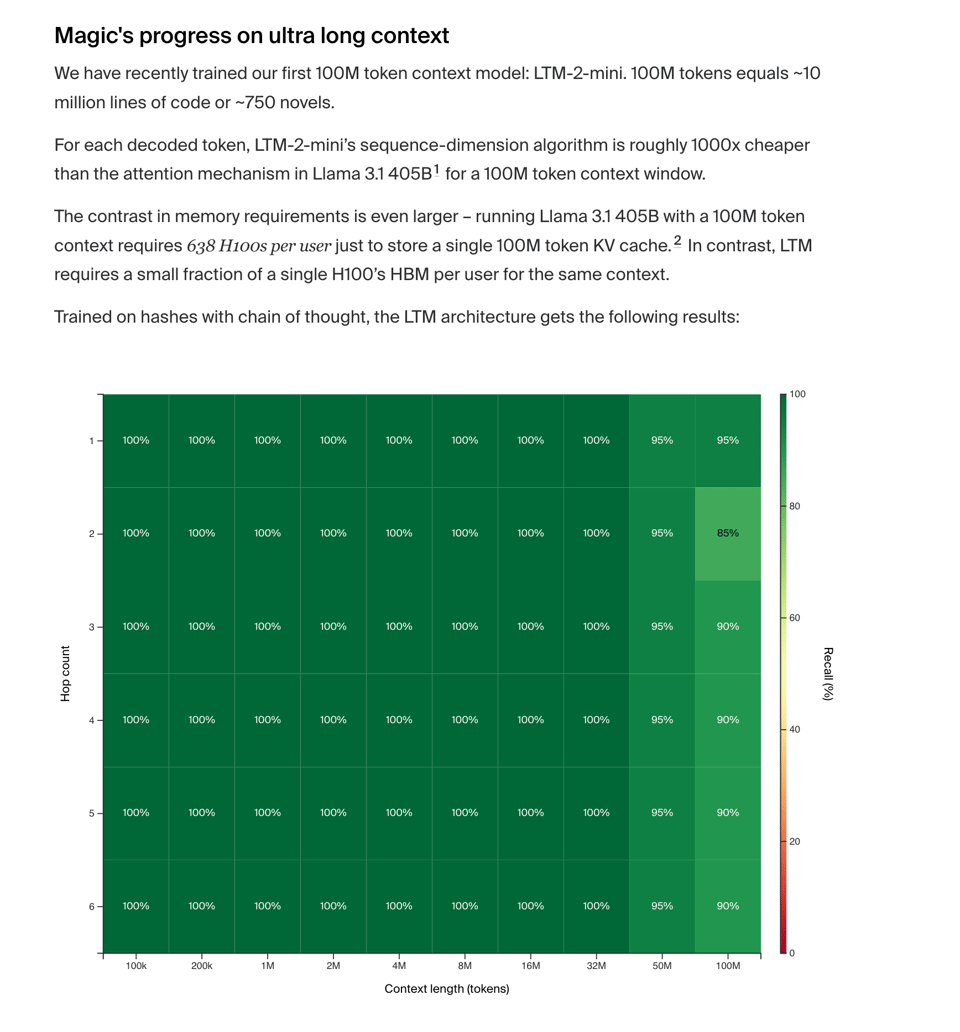
- Magic raising $320m on top of their $100m Febuary raise, announcing LTM-2, officially confirming their rumored 100m token context model, though still remaining in stealth.
While Codeium is the only product of the 4 you can actually use today, Magic's announcement is the more notable one, because of their promising long context utilization (powered by HashHop) and efficiency details teased by Nat Friedman in the previous raise:
For each decoded token, LTM-2-mini’s sequence-dimension algorithm is roughly 1000x cheaper than the attention mechanism in Llama 3.1 405B1 for a 100M token context window. The contrast in memory requirements is even larger – running Llama 3.1 405B with a 100M token context requires 638 H100s per user just to store a single 100M token KV cache. In contrast, LTM requires a** small fraction of a single H100’s HBM per user** for the same context.
This was done with a completely-written-from-scratch stack:
To train and serve 100M token context models, we needed to write an entire training and inference stack from scratch (no torch autograd, lots of custom CUDA, no open-source foundations) and run experiment after experiment on how to stably train our models.
They also announced a Google Cloud partnership:
Magic-G4, powered by NVIDIA H100 Tensor Core GPUs, and Magic-G5, powered by NVIDIA GB200 NVL72, with the ability to scale to tens of thousands of Blackwell GPUs over time.
They mention 8000 h100s now, but "over time, we will scale up to tens of thousands of GB200s" with former OpenAI Supercomputing Lead Ben Chess.
Their next frontier is inference-time compute:
Imagine if you could spend $100 and 10 minutes on an issue and reliably get a great pull request for an entire feature. That’s our goal.
{% if medium == 'web' %}
Table of Contents
[TOC]
{% else %}
The Table of Contents and Channel Summaries have been moved to the web version of this email: [{{ email.subject }}]({{ email_url }})!
{% endif %}
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI Model Developments and Applications
-
Gemini Updates: Google DeepMind announced new features for Gemini Advanced, including customizable "Gems" that act as topic experts and premade Gems for different scenarios. @GoogleDeepMind highlighted the ability to create and chat with these customized versions of Gemini.
-
Neural Game Engines: @DrJimFan discussed GameNGen, a neural world model capable of running DOOM purely in a diffusion model. He noted that it's trained on 0.9B frames, which is a significant amount of data, almost 40% of the dataset used to train Stable Diffusion v1.
-
LLM Quantization: Rohan Paul shared information about AutoRound, a library from Intel's Neural Compressor team for advanced quantization of LLMs. @rohanpaul_ai noted that it approaches near-lossless compression for popular models and competes with recent quantization methods.
-
AI Safety and Alignment: François Chollet @fchollet highlighted concerns about the prevalence of AI-generated content in election-related posts, estimating that a considerable fraction (~80% by volume, ~30% by impressions) aren't from actual people.
AI Infrastructure and Performance
-
Inference Speed: @StasBekman suggested that for online inference, 20 tokens per second per user might be sufficient, allowing for serving more concurrent requests with the same hardware.
-
Hardware Developments: David Holz @DavidSHolz mentioned forming a new hardware team at Midjourney, indicating potential developments in AI-specific hardware.
-
Model Comparisons: Discussions about model performance included comparisons between Gemini and GPT models. @bindureddy noted that Gemini's latest experimental version moved the needle slightly but still trails behind others.
AI Applications and Research
-
Multimodal Models: Meta FAIR introduced Transfusion, a model combining next token prediction with diffusion to train a single transformer over mixed-modality sequences. @AIatMeta shared that it scales better than traditional approaches.
-
RAG and Agentic AI: Various discussions centered around Retrieval-Augmented Generation (RAG) and agentic AI systems. @omarsar0 shared information about an agentic RAG framework for time series analysis using a multi-agent architecture.
-
AI in Legal and Business: Johnson Lambert, an audit firm, reported a 50% boost in audit efficiency using Cohere Command on Amazon Bedrock, as shared by @cohere.
AI Development Practices and Tools
-
MLOps and Experiment Tracking: @svpino emphasized the importance of reproducibility, debugging, and monitoring in machine learning systems, recommending tools like Comet for experiment tracking and monitoring.
-
Open-Source Tools: Various open-source tools were highlighted, including Kotaemon, a customizable RAG UI for document chatting, as shared by @_akhaliq.
AI Ethics and Regulation
-
Voter Fraud Discussions: Yann LeCun @ylecun criticized claims about non-citizens voting, emphasizing the importance of trust in democratic institutions.
-
AI Regulation: Discussions around AI regulation, including California's SB1047, were mentioned, highlighting ongoing debates about AI safety and governance.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Innovative Local LLM User Interfaces
- Yet another Local LLM UI, but I promise it's different! (Score: 170, Comments: 50): The post introduces a new Local LLM UI project developed as a PWA (Progressive Web App) with a focus on creating a smooth, familiar user interface. The developer, who was laid off in early 2023, highlights key features including push notifications for offline interactions and cross-device compatibility, with plans to implement a Character.ai-like experience for persona interactions. The project is available on GitHub under the name "suaveui", and the author is seeking feedback, GitHub stars, and potential job opportunities.
- Users praised the UI's sleek design, comparing it to messaging real humans. The developer plans to add more skins inspired by popular messaging apps and implement a one-click-and-run experience with built-in secure tunneling.
- Several users requested easier installation methods, including Docker/docker-compose support and a more detailed tutorial. The developer acknowledged these requests and promised improvements in the coming days.
- Discussion around compatibility revealed plans to support OpenAI-compatible endpoints and various LLM servers. The developer also expressed interest in implementing voice call support, inspired by Character.ai's call feature.
Theme 2. Advancements in Large Language Model Capabilities
- My very simple prompt that has defeated a lot of LLMs. “My cat is named dog, my dog is named tiger, my tiger is named cat. What is unusual about my pets?” (Score: 79, Comments: 89): The post presents a simple prompt designed to challenge Large Language Models (LLMs). The prompt describes a scenario where the author's pets have names typically associated with different animals: a cat named dog, a dog named tiger, and a tiger named cat, asking what is unusual about this arrangement.
- LLaMA 3.1 405b and Gemini 1.5 Pro were noted as the top performers in identifying both the unusual naming scheme and the oddity of owning a tiger as a pet. LLaMA's response was particularly praised for its human-like tone and casual inquiry about tiger ownership.
- The discussion highlighted the varying approaches of different LLMs, with some focusing solely on the circular naming, while others questioned the legality and practicality of owning a tiger. Claude 3.5 was noted for its direct skepticism, stating "you claim to have a pet tiger".
- Users debated the merits of different AI responses, with some preferring more casual tones and others appreciating direct skepticism. The thread also included humorous exchanges about the AI-generated image of a tiger on an air sofa, with comments on its unrealistic aspects.
{kind=link}
Theme 3. Challenges in Evaluating AI Intelligence and Reasoning
- Regarding "gotcha" tests to determine LLM intelligence (Score: 112, Comments: 73): The post critiques "gotcha" tests for LLM intelligence, specifically addressing a test involving unusually named pets including a tiger. The author argues that such tests are flawed and misuse LLMs, demonstrating that when properly prompted, even a 9B parameter model can correctly identify owning a tiger as the most unusual aspect. An edited example with a more precise prompt shows that most tested models, including Gemma 2B, correctly identified the unusual aspects, with only a few exceptions like Yi models and Llama 3.0.
- Users criticized the "gotcha" test, noting it's a flawed measure of intelligence that even humans might fail. Many, including the OP, initially missed the point about the tiger being unusual, focusing instead on the pet names.
- The test was compared to other LLM weaknesses, with users sharing links to more challenging puzzles like ZebraLogic. Some argued that LLMs can reason, citing benchmarks and clinical reasoning tests that show performance similar to humans.
- Discussion touched on how LLMs generate responses, with debates about whether they truly reason or just predict. Some users pointed out that asking an LLM to explain its reasoning post-generation can lead to biased or hallucinated explanations.
All AI Reddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI Research and Techniques
-
Google DeepMind's GameNGen: A neural model game engine that enables real-time interaction with complex environments over long trajectories. It can simulate DOOM at over 20 FPS on a single TPU, with next frame prediction achieving a PSNR of 29.4.
-
Diffusion Models for Game Generation: The GameNGen model generates DOOM gameplay in real-time as the user plays, demonstrating the potential for AI-generated interactive environments.
AI Model Releases and Improvements
- OpenAI's GPT-4 Iterations: OpenAI has released several versions of GPT-4, including GPT-4, GPT-4o, GPT4o-mini, and GPT4o Turbo. There is speculation about future releases and naming conventions.
AI Impact on Industry and Employment
- Klarna's AI-Driven Job Cuts: The buy now, pay later company Klarna is planning to cut 2,000 jobs as their AI chatbots now perform tasks equivalent to 700 human employees.
Technical Details and Discussions
-
GameNGen Architecture: The model uses 65 frames of game resolution as input, with the last frame being generated. It employs a noise addition technique to mitigate incremental corruption in AI-generated video.
-
GPT-4 Training Challenges: Discussions mention the significant computational resources required for training large language models, including the need for new power plants to support future generations of models.
AI Discord Recap
A summary of Summaries of Summaries by GPT4O (gpt-4o-2024-05-13)
1. LLM Advancements
- LLMs Struggle with Image Comparison: A member in the LM Studio Discord inquired about LM Studio's support for image formats, but others noted that most LLMs are not trained for image comparison tasks and they "see" images differently. They suggested trying a LLaVA model, which is specifically designed for vision tasks.
- @vision_expert noted, "LLaVA models have been showing promising results in vision tasks, which might be a good fit for your needs."
- Gemini's Capabilities Questioned: A user in the OpenAI Discord criticized Gemini's VR information, pointing out its incorrect labeling of the Meta Quest 3 as "upcoming". The user expressed their preference for ChatGPT, concluding that Gemini is a "bad AI".
- Other users chimed in, agreeing that Gemini needs improvements, particularly in accuracy and up-to-date information.
2. Model Performance Optimization
- Slowing Down Inference Speed: A member in the LM Studio Discord wanted to artificially slow down inference speed for a specific use case. LM Studio doesn't currently support this feature, but the server API can be used to achieve similar results by loading multiple models.
- This workaround sparked a discussion on optimizing server API usage to handle multiple models efficiently.
- RAG & Knowledge Graphs: A Powerful Duo: In the LangChain AI Discord, the user highlighted the benefits of Retrieval-Augmented Generation (RAG) for AI applications, enabling models to access relevant data without retraining. They expressed interest in combining RAG with knowledge graphs, exploring a hybrid approach for their text-to-SQL problem.
- @data_guru suggested integrating knowledge graphs to enhance the semantic understanding and accuracy of the models.
3. Fine-tuning Strategies
- The Prompt Engineering vs Fine-tuning Debate: In the OpenAI Discord, members engaged in a lively discussion about the merits of fine-tuning and prompt engineering for achieving desired writing styles. While some highlighted the effectiveness of prompt-by-example, others stressed the importance of data preparation for fine-tuning.
- @model_tuner emphasized that fine-tuning requires a well-curated dataset to avoid overfitting and ensure generalizability.
- Unsloth: Streamlined Fine-tuning: A member in the Unsloth AI Discord highlighted the benefits of using Unsloth for fine-tuning LLMs like Llama-3, Mistral, Phi-3, and Gemma, claiming it makes the process 2x faster, uses 70% less memory, and maintains accuracy. The member provided a link to the Unsloth tutorial, which includes automatic export of the fine-tuned model to Ollama and automatic
Modelfilecreation.- This sparked interest in the community, with members discussing their experiences with memory optimization and training efficiency.
4. Open Source AI Developments
- Daily Bots Launches Open Source Cloud for AI: In the OpenInterpreter Discord, Daily Bots, a low-latency cloud for voice, vision, and video AI, has been launched, allowing developers to build voice-to-voice interactions with any LLM at latencies as low as 500ms. The platform offers open source SDKs, the ability to mix and match AI models, and runs at scale on Daily's real-time global infrastructure, leveraging the open source projects RTVI and Pipecat.
- This launch was met with excitement, with @developer_joe noting the potential for real-time applications in customer service and beyond.
- Llama 3 Open Source Adoption Surges: In the Latent Space Discord, the open-source Llama model family continues to gain traction, with downloads on Hugging Face surpassing 350 million, a tenfold increase compared to last year. Llama's popularity extends to cloud service providers, with token usage more than doubling since May, and adoption across various industries, including Accenture, AT&T, DoorDash, and many others.
- @data_scientist discussed the implications of this growth, emphasizing the importance of community support and open-source collaboration.
5. AI Community and Events
- Perplexity Discord Celebrates 100K Members: The Perplexity AI Discord server has officially reached 100,000 members! The team expressed gratitude for the community's support and feedback, and excitement for future growth and evolution.
- Members shared their favorite Perplexity AI features and discussed potential improvements and new features they would like to see.
- AI Engineer Meetup & Summit: In the Latent Space Discord, the AI Engineer community is expanding! The first London meetup is scheduled for September, and the second AI Engineer Summit in NYC is planned for December. Those interested in attending the London meetup can find more information here, and potential sponsors for the NYC summit are encouraged to get in touch.
- The announcement generated buzz, with members expressing interest in networking opportunities and collaboration at the events.
PART 1: High level Discord summaries
LM Studio Discord
- LLMs Struggle with Image Comparison: A member inquired about LM Studio's support for image formats, but others noted that most LLMs are not trained for image comparison tasks and they "see" images differently.
- They suggested trying a LLaVA model, which is specifically designed for vision tasks.
- Slowing Down Inference Speed: A member wanted to artificially slow down inference speed for a specific use case.
- LM Studio doesn't currently support this feature, but the server API can be used to achieve similar results by loading multiple models.
- LM Studio's New UI Changes: A few members inquired about the missing Load/Save template feature in LM Studio 0.3.2, which was previously used to save custom settings for different tasks.
- They were informed that this feature is no longer necessary and custom settings can now be changed by holding ALT during model loading or in the My Models view.
- LM Studio's RAG Feature Facing Issues: A member reported an issue with LM Studio's RAG feature, where the chatbot continues to analyze a document even after it's finished being processed, making it difficult to carry on normal conversations.
- Another member reported an issue with downloading the LM Studio Windows installer, but this was resolved by removing a space from the URL.
- PCIE 5.0 x4 Mode for 3090: A user asked if a 3090 could be installed in PCIE 5.0 x4 mode and if that would provide enough bandwidth.
- Another user confirmed that current GPUs barely use PCIE 4.0 and 5.0 controllers run hot, with the first 5.0 SSDs needing active cooling.
OpenAI Discord
- Gemini's Capabilities Questioned: A user criticized Gemini's VR information, pointing out its incorrect labeling of the Meta Quest 3 as "upcoming."
- The user expressed their preference for ChatGPT, concluding that Gemini is a "bad AI."
- The Call for Personalized LLMs: A member proposed a vision for personalized LLMs, outlining desired features like customizable AI personalities, long-term memory, and more human-like conversations.
- They believe these features would enhance the meaningfulness and impact of interactions with AI.
- Tackling Context Window Limitations: Users discussed the limitations of context windows and the high cost of using tokens for long-term memory in LLMs.
- Solutions proposed included utilizing RAG to retrieve relevant history, optimizing token usage, and developing custom tools for memory management.
- The Prompt Engineering vs Fine-tuning Debate: Members engaged in a lively discussion about the merits of fine-tuning and prompt engineering for achieving desired writing styles.
- While some highlighted the effectiveness of prompt-by-example, others stressed the importance of data preparation for fine-tuning.
- OpenAI API: Cost and Alternatives: Conversations centered around the high cost of utilizing the OpenAI API, particularly for projects involving long-term memory and complex characters.
- Users explored strategies for optimization and considered alternative models like Gemini and Claude.
Stability.ai (Stable Diffusion) Discord
- SDXL Backgrounds Still a Challenge: A user expressed difficulty in creating good backgrounds with SDXL, often resulting in unknown things.
- The user is seeking advice on how to overcome this challenge and produce more realistic and coherent backgrounds.
- Lora Creation: Close-ups vs. Full Faces: A user asked if creating a Lora requires just a close-up of the desired detail, like a nose, or if the whole face needs to be included.
- The user is looking for guidance on the best practices for Lora creation, specifically regarding the necessary extent of the training data.
- Can ComfyUI Handle Multiple Characters?: A user asked if ComfyUI can help create images with two different characters without mixing their traits.
- The user is seeking to understand if ComfyUI offers features that enable the generation of images with multiple distinct characters, avoiding unwanted trait blending.
- Regularization Explained: AI Toolkit: A user asked how regularization works in AI Toolkit, after watching a video where the creator used base images without regularization.
- The user is requesting clarification on the purpose and implementation of regularization within the AI Toolkit context.
- SDXL on a 2017 Mid-Range Laptop: Feasibility?: A user inquired about the feasibility of running SDXL on a 2017 mid-range Acer Aspire E Series laptop.
- The user is seeking information on whether their older laptop's hardware capabilities are sufficient for running SDXL effectively.
Unsloth AI (Daniel Han) Discord
- Unsloth: Speed & Memory Gains: Unsloth uses 4-bit quantization for much faster training speeds and lower VRAM usage compared to OpenRLHF.
- While Unsloth only supports 4-bit quantized models currently for finetuning, they are working on adding support for 8-bit and unquantized models, with no tradeoff in performance or replicability.
- Finetuning with Unsloth on AWS: Unsloth doesn't have a dedicated guide for finetuning on AWS.
- However, some users are using Sagemaker for finetuning models on AWS, and there are numerous YouTube videos and Google Colab examples available.
- Survey Seeks Insights on ML Model Deployment: A survey was posted asking ML professionals about their experiences with model deployment, specifically focusing on common problems and solutions.
- The survey aims to identify the top three issues encountered when deploying machine learning models, providing valuable insights into the practical hurdles faced by professionals in this field.
- Gemma2:2b Fine-tuning for Function Calling: A user seeks guidance on fine-tuning the Gemma2:2b model from Ollama for function calling, using the XLM Function Calling 60k dataset and the provided notebook.
- They are unsure about formatting the dataset into instruction, input, and output format, particularly regarding the 'tool use' column.
- Unsloth: Streamlined Fine-tuning: A member highlights the benefits of using Unsloth for fine-tuning LLMs like Llama-3, Mistral, Phi-3, and Gemma, claiming it makes the process 2x faster, uses 70% less memory, and maintains accuracy.
- The member provides a link to the Unsloth tutorial, which includes automatic export of the fine-tuned model to Ollama and automatic
Modelfilecreation.
- The member provides a link to the Unsloth tutorial, which includes automatic export of the fine-tuned model to Ollama and automatic
Perplexity AI Discord
- Perplexity Discord Celebrates 100K Members: The Perplexity AI Discord server has officially reached 100,000 members! The team expressed gratitude for the community's support and feedback, and excitement for future growth and evolution.
- Perplexity Pro Membership Issues: Several users reported problems with their Perplexity Pro memberships, including the disappearing of magenta membership and free LinkedIn Premium offer, as well as issues with the "Ask Follow-up" feature.
- Others also experienced issues with the "Ask Follow-up" feature, where the option to "Ask Follow-up" when highlighting a line of text in perplexity responses disappeared.
- Perplexity AI Accuracy Concerns: Users expressed concerns about Perplexity AI's tendency to present assumptions as fact, often getting things wrong.
- They shared examples from threads where Perplexity AI incorrectly provided information about government forms and scraping Google, showcasing the need for more robust fact-checking and human review in its responses.
- Navigating the Maze of AI Models: Users expressed confusion over selecting the best AI model, debating the merits of Claude 3 Opus, Claude 3.5 Sonnet, and GPT-4o.
- Several users noted that certain models, such as Claude 3 Opus, are limited to 50 questions, and users are unsure if Claude 3.5 Sonnet is a better choice, despite its limitations.
- Perplexity AI Usability Challenges: Users highlighted issues with Perplexity AI's platform usability, including difficulty in accessing saved threads and problems with the prompt section.
- One user pointed out that the Chrome extension description is inaccurate, falsely stating that Perplexity Pro uses GPT-4 and Claude 2, potentially misrepresenting the platform's capabilities.
Cohere Discord
- LLMs Tokenize, Not Letters: A member reminded everyone that LLMs don't see letters, they see tokens - a big list of words.
- They used the example of reading Kanji in Japanese, which is more similar to how LLMs work than reading letters in English.
- Claude's Sycophancy Debate: One member asked whether LLMs have a tendency to be sycophantic, particularly when it comes to reasoning.
- Another member suggested adding system messages to help with this, but said even then, it's more of a parlor trick than a useful production tool.
- MMLu Not Great for Real-World Use: One member noted that MMLu isn't a good benchmark for building useful LLMs because it's not strongly correlated with real-world use cases.
- They pointed to examples of questions on Freud's outdated theories on sexuality, implying the benchmark isn't reflective of what users need from LLMs.
- Cohere For AI Scholars Program Open for Applications: Cohere For AI is excited to open applications for the third cohort of its Scholars Program, designed to help change where, how, and by whom research is done.
- The program is designed to help researchers and like minded collaborators and you can find more information on the Cohere For AI Scholars Program page.
- Internal Tool Soon to Be Publicly Available: A member shared that the tool is currently hosted on the company's admin panel, but a publicly hosted version will be available soon.
- The tool is currently hosted on the company's admin panel, but a publicly hosted version is expected soon.
LlamaIndex Discord
- LlamaIndex Workflows Tutorial Now Available: A comprehensive tutorial on LlamaIndex Workflows is now available in the LlamaIndex docs, covering a range of topics, including getting started with Workflows, loops and branches, maintaining state, and concurrent flows.
- The tutorial can be found here.
- GymNation Leverages LlamaIndex to Boost Sales: GymNation partnered with LlamaIndex to improve member experience and drive real business outcomes, resulting in an impressive 20% increase in digital lead to sales conversion and an 87% conversation rate with digital leads.
- Function Calling LLMs for Streaming Output: A member is seeking an example of building an agent using function calling LLMs where they stream the final output, avoiding latency hits caused by passing the full message to a final step.
- They are building the agent from mostly scratch using Workflows and looking for a solution.
- Workflows: A Complex Logic Example: A member shared a workflow example that utilizes an async generator to detect tool calls and stream the output.
- They also discussed the possibility of using a "Final Answer" tool that limits output tokens and passes the final message to a final step if called.
- Optimizing Image + Text Retrieval: A member inquired about the best approach for combining image and text retrieval, considering using CLIP Embeddings for both, but are concerned about CLIP's semantic optimization compared to dedicated text embedding models like txt-embeddings-ada-002.
Latent Space Discord
- Agency Raises $2.6 Million: Agency, a company building AI agents, announced a $2.6 million fundraise to develop "generationally important technology" and bring their AI agents to life.
- The company's vision involves building a future where AI agents are ubiquitous and integral to our lives, as highlighted on their website agen.cy.
- AI Engineer Meetup & Summit: The AI Engineer community is expanding! The first London meetup is scheduled for September, and the second AI Engineer Summit in NYC is planned for December.
- Those interested in attending the London meetup can find more information here, and potential sponsors for the NYC summit are encouraged to get in touch.
- AI for Individual Use: Nicholas Carlini, a research scientist at DeepMind, argues that the focus of AI should shift from grand promises of revolution to its individual benefits.
- His blog post, "How I Use AI" (https://nicholas.carlini.com/writing/2024/how-i-use-ai.html), details his practical applications of AI tools, resonating with many readers, especially on Hacker News (https://news.ycombinator.com/item?id=41150317).
- Midjourney Ventures into Hardware: Midjourney, the popular AI image generation platform, is officially entering the hardware space.
- Individuals interested in joining their new team in San Francisco can reach out to [email protected].
- Llama 3 Open Source Adoption Surges: The open-source Llama model family continues to gain traction, with downloads on Hugging Face surpassing 350 million, a tenfold increase compared to last year.
- Llama's popularity extends to cloud service providers, with token usage more than doubling since May, and adoption across various industries, including Accenture, AT&T, DoorDash, and many others.
OpenInterpreter Discord
- OpenInterpreter Development Continues: OpenInterpreter development is still active, with recent commits to the main branch of the OpenInterpreter GitHub repo.
- This means that the project is still being worked on and improved.
- Auto-run Safety Concerns: Users are cautioned to be aware of the risks of using the
auto_runfeature in OpenInterpreter.- It is important to carefully monitor output when using this feature to prevent any potential issues.
- Upcoming House Party: A House Party has been planned for next week at an earlier time to encourage more participation.
- This event will be a great opportunity to connect with other members of the community and discuss all things OpenInterpreter.
- Terminal App Recommendations: A user is looking for a recommended terminal app for KDE as Konsole, their current terminal, bleeds the screen when scrolling GPT-4 text.
- This issue could be due to the terminal's inability to handle the large amount of text output from GPT-4.
- Daily Bots Launches Open Source Cloud for AI: Daily Bots, a low-latency cloud for voice, vision, and video AI, has been launched, allowing developers to build voice-to-voice interactions with any LLM at latencies as low as 500ms.
- The platform offers open source SDKs, the ability to mix and match AI models, and runs at scale on Daily's real-time global infrastructure, leveraging the open source projects RTVI and Pipecat.
OpenAccess AI Collective (axolotl) Discord
- Macbook Pro Training Speed Comparison: A user successfully trained large models on a 128GB Macbook Pro, but it was significantly slower than training on an RTX 3090, with training speed roughly halved.
- They are seeking more cost-effective training solutions and considering undervolted 3090s or AMD cards as alternatives to expensive H100s.
- Renting Hardware for Training: A user recommends renting hardware before committing to a purchase, especially for beginners.
- They suggest spending $30 on renting different hardware and experimenting with training models to determine the optimal configuration.
- Model Size and Training Speed: The user is exploring the relationship between model size and training speed.
- They are specifically interested in how training time changes when comparing models like Nemotron-4-340b-instruct with Llama 405.
- Fine-Tuning LLMs for Dialogue: A member has good models for long dialogue, but the datasets used for training are all of the 'ShareGPT' type.
- They want to personalize data processing, particularly streamlining content enclosed by asterisks (*), for example, she smile to smiling.
- Streamlining Content via Instruction: A member asks if a simple instruction can be used to control a fine-tuned model to streamline and rewrite data.
- They inquire about LlamaForCausalLM's capabilities and if there are better alternatives, with another member suggesting simply passing prompts with a system prompt to Llama.
LangChain AI Discord
- Hybrid Search with SQLDatabaseChain & PGVector: A user is using PostgreSQL with
pgvectorfor embedding storage andSQLDatabaseChainto translate queries into SQL, aiming to modifySQLDatabaseChainto search vectors for faster responses.- This approach could potentially improve search speed and provide more efficient results compared to traditional SQL-based queries.
- RAG & Knowledge Graphs: A Powerful Duo: The user highlights the benefits of Retrieval-Augmented Generation (RAG) for AI applications, enabling models to access relevant data without retraining.
- They express interest in combining RAG with knowledge graphs, exploring a hybrid approach for their text-to-SQL problem, potentially improving model understanding and accuracy.
- Crafting Adaptable Prompts for Multi-Database Queries: The user faces the challenge of creating optimal prompts for different SQL databases due to varying schema requirements, leading to performance issues and redundant templates.
- They seek solutions for creating adaptable prompts that cater to multiple databases without compromising performance, potentially improving efficiency and reducing development time.
- Troubleshooting OllamaLLM Connection Refused in Docker: A user encountered a connection refused error when attempting to invoke
OllamaLLMwithin a Docker container, despite successful communication with the Ollama container.- A workaround using the
langchain_community.llms.ollamapackage was suggested, potentially resolving the issue and highlighting a potential bug in thelangchain_ollamapackage.
- A workaround using the
- Exploring Streaming in LangChain v2.0 for Function Calling: The user inquired about the possibility of using LangChain function calling with streaming in version 2.0.
- Although no direct answer was provided, it appears this feature is not currently available, suggesting a potential area for future development in LangChain.
Torchtune Discord
- Torchtune Needs Your Help: The Torchtune team is looking for community help to contribute to their repository by completing bite-sized tasks, with issues labeled "community help wanted" available on their GitHub issues page.
- They are also available to assist contributors via Discord.
- QLoRA Memory Troubles: A member reported encountering out-of-memory errors while attempting to train QLoRA with Llama 3.1 70B using 4x A6000s.
- Another member questioned if this is expected behavior, suggesting it should be sufficient for QLoRA and advising to open a GitHub issue with a reproducible example to troubleshoot.
- Torchtune + PyTorch 2.4 Compatibility Confirmed: One member inquired about the compatibility of Torchtune with PyTorch 2.4 and received confirmation that it should work.
- Fusion Models RFC Debated: A member questioned whether handling decoder-only max_seq_len within the
setup_cachesfunction might cause issues, particularly forCrossAttentionLayerandFusionLayer.- Another member agreed and proposed exploring a utility to handle it effectively.
- Flamingo Model's Unique Inference: The conversation explored the Flamingo model's use of mixed sequence lengths, particularly for its fusion layers, necessitating a dedicated
setup_cachesapproach.- The need for accurate cache position tracking was acknowledged, highlighting a potential overlap between the Flamingo PR and the Batched Inference PR, which included updating
setup_caches.
- The need for accurate cache position tracking was acknowledged, highlighting a potential overlap between the Flamingo PR and the Batched Inference PR, which included updating
DSPy Discord
- LinkedIn Job Applier Automates Applications: A member shared a GitHub repo that utilizes Agent Zero to create new pipelines, automatically applying for job offers on LinkedIn.
- The repo is designed to use AIHawk to personalize job applications, making the process more efficient.
- Generative Reward Models (GenRM) Paper Explored: A new paper proposes Generative Reward Models (GenRM), which leverage the next-token prediction objective to train verifiers, enabling seamless integration with instruction tuning, chain-of-thought reasoning, and utilizing additional inference-time compute via majority voting for improved verification.
- The paper argues that GenRM can overcome limitations of traditional discriminative verifiers that don't utilize the text generation capabilities of pretrained LLMs, see the paper for further details.
- DSPY Optimization Challenges: One member struggled with the complexity of using DSPY for its intended purpose: abstracting away models, prompts, and settings.
- They shared a link to a YouTube video demonstrating their struggle and requested resources to understand DSPY's optimization techniques.
- Bootstrapping Synthetic Data with Human Responses: A member proposed a novel approach to bootstrapping synthetic data: looping through various models and prompts to minimize a KL divergence metric using hand-written human responses.
- They sought feedback on the viability of this method as a means of generating synthetic data that aligns closely with human-generated responses.
- DSPY Optimizer Impact on Example Order: A user inquired about which DSPY optimizers change the order of examples/shots and which ones don't.
- The user seems interested in the impact of different optimizer strategies on the order of training data, and how this may affect model performance.
AI21 Labs (Jamba) Discord
- Jamba 1.5 Dependency Issue: PyTorch 23.12-py3: A user reported dependency issues while attempting to train Jamba 1.5 using pytorch:23.12-py3.
- Jamba 1.5 shares the same architecture and base model as Jamba Instruct (1.0).
- Transformers 4.44.0 and 4.44.1 Bug: Transformers versions 4.44.0 and 4.44.1 were discovered to contain a bug that inhibits the ability to execute Jamba architecture.
- This bug is documented on the Hugging Face model card for Jamba 1.5-Mini: https://huggingface.co/ai21labs/AI21-Jamba-1.5-Mini.
- Transformers 4.40.0 Resolves Dependency Issues: Utilizing transformers 4.40.0 successfully resolved the dependency issues, enabling successful training of Jamba 1.5.
- This version should be used until the bug is fully resolved.
- Transformers 4.44.2 Release Notes: The release notes for transformers 4.44.2 mention a fix for Jamba cache failures, but it was confirmed that this fix is NOT related to the bug affecting Jamba architecture.
- Users should continue using transformers 4.40.0 until the Jamba bug is addressed.
tinygrad (George Hotz) Discord
- Tinygrad Optimized for Static Scheduling: Tinygrad is highly optimized for statically scheduled operations, achieving significant performance gains for tasks that do not involve dynamic sparsity or weight selection.
- The focus on static scheduling allows Tinygrad to leverage compiler optimizations and perform efficient memory management.
- Tinygrad's ReduceOp Merging Behavior: A user inquired about the rationale behind numerous
# max one reduceop per kernelstatements within Tinygrad'sschedule.pyfile, specifically one that sometimes triggers early realization of reductions, hindering their merging in the_recurse_reduceopsfunction.- A contributor explained that this issue manifests when chaining reductions, like in
Tensor.randn(5,5).realize().sum(-1).sum(), where the reductions aren't merged into a single sum, as expected, and a pull request (PR #6302) addressed this issue.
- A contributor explained that this issue manifests when chaining reductions, like in
- FUSE_CONV_BW=1: The Future of Convolution Backwards: A contributor explained that the
FUSE_CONV_BW=1flag in Tinygrad currently addresses the reduction merging issue by enabling efficient fusion of convolutions in the backward pass.- They also noted that this flag will eventually become the default setting once performance optimizations are achieved across all scenarios.
- Tinygrad Documentation: Your Starting Point: A user asked for guidance on beginning their journey with Tinygrad.
- Multiple contributors recommended starting with the official Tinygrad documentation, which is considered a valuable resource for beginners.
- Limitations in Dynamic Sparse Operations: While Tinygrad shines with static scheduling, it might encounter performance limitations when handling dynamic sparsity or weight selection.
- These types of operations require flexibility in memory management and computation flow, which Tinygrad currently doesn't fully support.
Gorilla LLM (Berkeley Function Calling) Discord
- Groq is Missing From the Leaderboard: A member asked why Groq is not on the leaderboard (or changelog) for Gorilla LLM.
- The response explained that Groq has not been added yet and the team is waiting for their PRs, which are expected to be raised next week.
- Groq PRs Expected Next Week: A member asked why Groq is not on the leaderboard (or changelog) for Gorilla LLM.
- The response explained that Groq has not been added yet and the team is waiting for their PRs, which are expected to be raised next week.
LAION Discord
- CLIP-AGIQA Boosts AIGI Quality Assessment: A new paper proposes CLIP-AGIQA, a method using CLIP to improve the performance of AI-Generated Image (AIGI) quality assessment.
- The paper argues that current models struggle with the diverse and ever-increasing categories of generated images, and CLIP's ability to assess natural image quality can be extended to AIGIs.
- AIGIs Need Robust Quality Evaluation: The widespread use of AIGIs in daily life highlights the need for robust image quality assessment techniques.
- Despite some existing models, the paper emphasizes the need for more advanced methods to evaluate the quality of these diverse generated images.
- CLIP Shows Promise in AIGI Quality Assessment: CLIP, a visual language model, has shown significant potential in evaluating the quality of natural images.
- The paper explores applying CLIP to the quality assessment of generated images, believing it can be effective in this domain as well.
Alignment Lab AI Discord
- Nous Hermes 2.5 Performance: A recent post on X discussed performance improvements with Hermes 2.5, but no specific metrics were given.
- The post linked to a GitHub repository, Hermes 2.5 but no further details were provided.
- No further details provided: This was a single post on X.
- There were no further details or discussion points.
Mozilla AI Discord
- Common Voice Seeks Contributors: The Common Voice project is an open-source platform for collecting speech data with the goal of building a multilingual speech clip dataset that is both cost and copyright-free.
- This project aims to make speech technologies work for all users, regardless of their language or accent.
- Join the Common Voice Community: You can join the Common Voice community on the Common Voice Matrix channel or in the forums.
- If you need assistance, you can email the team at [email protected].
- Contribute to the Common Voice Project: Those interested in contributing can find the guidelines here.
- Help is needed in raising issues where the documentation looks outdated, confusing, or incomplete.
The LLM Finetuning (Hamel + Dan) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
{% if medium == 'web' %}
LM Studio ▷ #general (161 messages🔥🔥):
LLM image comparisonLLM vision tasksLLM speedLLM custom instructionsLLM RAG
- Can LLMs compare images?: A member asked if LM Studio will support image formats to allow models to compare images, but another member pointed out that most models are not trained for that task and LLMs "see" images differently.
- They suggested trying a LLaVA model, which is specifically designed for vision tasks.
- Slow Down Inference Speed: A member asked about artificially slowing down inference speed for a specific use case, but it was determined that LMStudio doesn't currently support this feature.
- However, the server API can be used to achieve similar results by loading multiple models.
- LM Studio's New UI Changes: A few members inquired about the missing Load/Save template feature in LM Studio 0.3.2, which was previously used to save custom settings for different tasks.
- They were informed that this feature is no longer necessary and custom settings can now be changed by holding ALT during model loading or in the My Models view.
- LM Studio Bugs and Issues: A member reported an issue with LM Studio's RAG feature, where the chatbot continues to analyze a document even after it's finished being processed, making it difficult to carry on normal conversations.
- Another member reported an issue with downloading the LM Studio Windows installer, but this was resolved by removing a space from the URL.
Links mentioned:
LM Studio ▷ #hardware-discussion (67 messages🔥🔥):
PCIE 5.0llama.cppNPU supportLlama 70bMulti-GPU setup
- PCIE 5.0 x4 mode for 3090: A user asked if a 3090 could be installed in PCIE 5.0 x4 mode and if that would provide enough bandwidth.
- Another user confirmed that current GPUs barely use PCIE 4.0 and 5.0 controllers run hot, with the first 5.0 SSDs needing active cooling.
- NPU support for llama.cpp: A member shared a method to compile NPU support into llama.cpp.
- They provided a link to a Qualcomm blog post about this method: https://www.qualcomm.com/developer/blog/2024/04/big-performance-boost-llama-cpp-chatglm-cpp-with-windows-on-snapdragon.
- Multi-GPU Setup for Llama Models: A user shared their setup of 6x RTX 4090 GPUs, a Threadripper 64 core CPU, and a patched GPU driver enabling P2P access for 51 GB/s direct memory access.
- They noted that LM Studio does not recognize this direct memory access and instead duplicates the model on each card, resulting in only 20 GB/s transfer speeds to the CPU.
- Challenges with Llama 70b and Multi-GPU Setup: A member reported issues loading Llama 70b with full precision on their 6x RTX 4090 setup.
- They encountered CUDA out of memory errors during training and had to purchase an additional GPU and increase CPU RAM to avoid those errors.
- Riser Cable Performance and Considerations: Users discussed the performance of various PCIE 4.0 riser cables and the issues they encounter, such as dropping to PCIE 3.0 speeds and errors.
- They shared links to various brands and models, emphasizing the importance of quality risers and the use of retimers to improve signal strength.
Links mentioned:
OpenAI ▷ #ai-discussions (215 messages🔥🔥):
Gemini's capabilitiesLLM personalizationMemory and context in LLMsFine-tuning vs. prompt engineeringOpenAI API usage and cost
- Gemini's shortcomings: A user noted an error in Gemini's VR information, stating that it incorrectly labeled the Meta Quest 3 as "upcoming."
- They concluded that Gemini is a "bad AI" and preferred ChatGPT.
- The Desire for Personalized LLMs: A member expressed a desire for personalized LLMs, outlining features such as customizable AI personality, long-term memory, and more human-like conversation.
- They believe that these features would make conversations more meaningful and impactful.
- Navigating Context Limitations in LLMs: Users discussed the limitations of context windows and the high cost of using tokens for long-term memory.
- Solutions proposed included using RAG to retrieve relevant history, optimizing token usage, and building custom tools to manage memory.
- The Great GPT Debate: Fine-tuning vs. Prompt Engineering: The group debated the merits of fine-tuning and prompt engineering for achieving specific writing styles.
- While some emphasized the benefits of prompt by example, others highlighted the data preparation needed for fine-tuning.
- OpenAI API: A Powerful Tool with a Price: Discussions centered on the high cost of using the OpenAI API, particularly for projects involving long-term memory and complex characters.
- Users shared strategies for optimization and explored alternative models like Gemini and Claude.
Link mentioned: Tweet from Ignacio de Gregorio (@TheTechOasis1): http://x.com/i/article/1827379585861709824
OpenAI ▷ #gpt-4-discussions (7 messages):
LLM Model PerformanceOpenAI Model LimitationsGPT-4 vs GPT-4oLlama 3 vs OpenAI Models
- Llama 3 Outperforms OpenAI Models: The user believes that the performance of the OpenAI models (like GPT-4) is not as good as it should be, citing examples where smaller models like Llama 3 (8B) provided better results in areas such as code generation and understanding.
- They used an analogy of a horse beating a Ferrari, suggesting that there are serious issues with the performance of the Ferrari (OpenAI models) if the horse (Llama 3) can outperform it.
- OpenAI Models Not Fine-Tuned for Specific Topics: The user claims that OpenAI models, despite their size, are not specialized for specific tasks, unlike models like DeepSeek Coder (which is fine-tuned for coding).
- They argue that this general-purpose nature contributes to the limitations observed in OpenAI models when compared to models like Llama 3 that are specifically designed for certain tasks.
- GPT-4 vs GPT-4o Performance Comparison: The user points out that GPT-4o (the cheaper version of GPT-4) appears to be the fastest, but also the lowest in quality, with GPT-4 providing better reasoning and more accurate results.
- They note that GPT-4o often fails to perform specific tasks such as browsing, while GPT-4 generally follows instructions more accurately.
- Declining Performance of OpenAI Models: Another user shares their experience with Chat GPT, stating that it seems to have reached a point of peak efficiency and has been declining in performance over the past few weeks.
- They mention that they cancelled their ChatGPT subscription a few days ago due to the declining quality and stability of GPT-4o, and observe a similar observation among other users.
OpenAI ▷ #prompt-engineering (2 messages):
ChatGPT Persona
- Make ChatGPT Sound More Human: A member asked how to make ChatGPT sound less like an AI and more like a person, as they're building a game where players chat with AI-controlled agents.
- They shared a link to a tool called Psychographic Agent Persona Builder that can help build a persona for the AI agents, and suggested including a key in a separate chat for additional customization.
- Another ChatGPT Persona Option: A user asked for suggestions on how to make ChatGPT sound more human in a game setting.
- The user's question was about making ChatGPT sound less like a helpful AI and more like a person. They requested help with engineering an initial prompt that would lock in a more human-like behavior for the AI.
OpenAI ▷ #api-discussions (2 messages):
ChatGPT persona
- Making ChatGPT sound less like a bot: A user asked how to make ChatGPT sound less like a "I'm here to help you" AI and more like a person they're talking with.
- Another user suggested using a tool called "Psychographic Agent Persona Builder" found at https://chatgpt.com/g/g-bIyZLKTwx-psychographic-agent-persona-builder to create more human-like personas for ChatGPT agents.
- Key for Persona Definitions: The user suggesting the persona builder tool mentioned that a key is required for persona definitions and should be obtained in a separate chat.
Stability.ai (Stable Diffusion) ▷ #general-chat (184 messages🔥🔥):
SDXL Background IssuesLora CreationModel MergingComfyUIRegularization
- SDXL Backgrounds are still a challenge: A user expressed difficulty in creating good backgrounds with SDXL, often resulting in unknown things.
- Creating a Lora from Close-ups: A user asked if creating a Lora requires just a close-up of the desired detail, like a nose, or if the whole face needs to be included.
- Can ComfyUI Handle Multiple Characters?: A user asked if ComfyUI can help create images with two different characters without mixing their traits.
- Regularization Explained: A user asked how regularization works in AI Toolkit, after watching a video where the creator used base images without regularization.
- SDXL Feasibility on Older Hardware: A user inquired about the feasibility of running SDXL on a 2017 mid-range Acer Aspire E Series laptop.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #general (93 messages🔥🔥):
Unsloth vs OpenRLHFUnsloth finetuningUnsloth multi-GPUUnsloth inferenceUnsloth on AWS
- Unsloth vs OpenRLHF: Speed & Memory: Unsloth uses 4-bit quantization to achieve much faster training speeds and lower VRAM usage compared to OpenRLHF.
- While Unsloth currently only supports 4-bit quantized models for finetuning, they are working on adding support for 8-bit and unquantized models. They claim there is no tradeoff in performance or replicability between the methods.
- Unsloth Finetuning on AWS: Unsloth doesn't have a dedicated guide for finetuning on AWS.
- However, some users are using Sagemaker to finetune models on AWS, and there are numerous YouTube videos and Google Colab examples for Unsloth.
- Unsloth Multi-GPU Support: Unsloth currently does not support multi-GPU training.
- This means you cannot train models larger than what fits on a single GPU, even though the 70B model only requires 48GB of VRAM when using 4-bit quantization.
- Unsloth Model Merging: You can merge an adapter with a base model by uploading both to Hugging Face and using the
model.push_to_hub_mergedfunction.- You can save the merged model in 4-bit format using the
save_method = 'merged_4bit_forced'argument.
- You can save the merged model in 4-bit format using the
- Unsloth EOS Token Mapping: The
map_eos_token = Trueoption in Unsloth allows you to map the<|im_end|>token to the</s>token without training, which can be necessary for specific chat templates.- This mapping can help avoid gibberish outputs, as some models expect only one
<|im_end|>token at the end of the prompt, and may require replacing other<|im_end|>tokens with</s>when finetuning with multi-turn prompts.
- This mapping can help avoid gibberish outputs, as some models expect only one
Links mentioned:
Unsloth AI (Daniel Han) ▷ #off-topic (1 messages):
ML model deployment challengesLLM limitationsSurvey for ML Professionals
- Survey Seeks Insights on ML Model Deployment: A survey was posted asking ML professionals about their experiences with model deployment, specifically focusing on common problems and solutions.
- The survey includes questions about job roles, top challenges, timing of these challenges, their difficulty, and solutions used, seeking to understand the complexities of bringing ML models to production.
- Challenges in Model Deployment Highlighted: The survey aims to identify the top three issues encountered when deploying machine learning models, providing valuable insights into the practical hurdles faced by professionals in this field.
- It seeks to uncover the frequency, severity, and root causes of these challenges, ultimately paving the way for improved solutions and best practices in model deployment.
- LLM Limitations Exploration: The survey also includes an optional section dedicated to exploring specific issues encountered when working with large language models (LLMs).
- This section encourages respondents to share any particular services or tools that hinder their ability to achieve optimal results with LLM technologies, providing valuable feedback for research and development.
Link mentioned: LLM Problems research: Hey, I’m working on an ML project and I need help from people who are building models and deploying them to production.
Unsloth AI (Daniel Han) ▷ #help (29 messages🔥):
Gemma2:2b Fine-tuningUnsloth for Fine-tuningFunction Calling DatasetsAPIGenMistral Fine-tuning
- Gemma2:2b Fine-tuning for Function Calling: A user is seeking guidance on fine-tuning the Gemma2:2b model from Ollama for function calling, using the XLM Function Calling 60k dataset and the provided notebook.
- They are unsure about formatting the dataset into instruction, input, and output format, particularly regarding the "tool use" column.
- Unsloth for Easier Fine-tuning: A member highlights the benefits of using Unsloth for fine-tuning LLMs like Llama-3, Mistral, Phi-3, and Gemma, claiming it makes the process 2x faster, uses 70% less memory, and maintains accuracy.
- The member provides a link to the Unsloth tutorial, which includes automatic export of the fine-tuned model to Ollama and automatic
Modelfilecreation.
- The member provides a link to the Unsloth tutorial, which includes automatic export of the fine-tuned model to Ollama and automatic
- APIGen Function Calling Datasets: A member mentions the APIGen project, an automated data generation pipeline for creating verifiable high-quality datasets for function calling.
- Mistral Fine-tuning for Retrieval Tasks: A user is attempting to fine-tune Mistral for retrieval tasks, utilizing the NV-Embed model and adapting the loss function due to not generating tokens, but rather taking the embedding of the end-of-sentence token.
- They inquire about using Unsloth with regular Transformers or PyTorch-Lightning code instead of
SFTTrainer.
- They inquire about using Unsloth with regular Transformers or PyTorch-Lightning code instead of
- Xformers Installation Issues: A user encounters an
ImportError: Unsloth: Xformers was not installed correctly.error while trying to use the Gemma notebook, but not with the Llama notebook.- They resolve the issue by changing the Xformers installation from Xformers<0.0.27 to Xformers and installing Triton manually, recommending this fix for similar problems.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #community-collaboration (1 messages):
hamchezz: I want to finetune a llm on some undefined goal just because 😄
Unsloth AI (Daniel Han) ▷ #research (1 messages):
Runpod pricingLLaMa 4 MoEFlexattentionUnsloth Pro training
- Runpod H200 price prediction: A member predicted that Runpod will offer the H200 for $6 per hour in 12 months.
- LLaMa 4 series predictions: A member predicted the LLaMa 4 series will include a Mixture of Experts (MoE) model with 70-100B parameters.
- This model is predicted to have slightly better performance than the current 70B LLaMa model.
- Flexattention combination: A member predicted that Flexattention will enable the combination of non-contaminated packing and FA3 in the next 12 months.
- Unsloth Pro training speed: A member predicted that the combination of Unsloth Pro, Flexattention and FP8 activations will enable the LLaMa 4 model to train faster than the LLaMa 3 8B model on an H100.
- This would be achieved by training the LLaMa 4 model on an H200.
Perplexity AI ▷ #announcements (1 messages):
Discord Community Growth
- Perplexity Discord Reaches 100K Members: The Perplexity AI Discord server has officially reached 100,000 members!
- The team expressed gratitude for the community's support and feedback, and excitement for future growth and evolution.
- Thank You to the Community: The Perplexity AI team is grateful for all the support and feedback they have received from the Discord community.
- The team is excited to continue growing and evolving with the community.
Perplexity AI ▷ #general (97 messages🔥🔥):
Perplexity Pro issuesPerplexity AI IssuesAI model limitationsPerplexity AI model selectionPerplexity AI usability
- Perplexity Pro Membership Issues: Users reported problems with their Perplexity Pro memberships, including the disappearing of magenta membership and free LinkedIn Premium offer, as well as issues with the "Ask Follow-up" feature.
- Others also experienced issues with the "Ask Follow-up" feature, where the option to "Ask Follow-up" when highlighting a line of text in perplexity responses disappeared.
- Perplexity AI struggles with factual accuracy: Users expressed concerns about Perplexity AI's tendency to present assumptions as fact, often getting things wrong.
- They shared examples from threads where Perplexity AI incorrectly provided information about government forms and scraping Google, showcasing the need for more robust fact-checking and human review in its responses.
- Navigating the maze of AI models: Users expressed confusion over selecting the best AI model, debating the merits of Claude 3 Opus, Claude 3.5 Sonnet, and GPT-4o.
- Several users noted that certain models, such as Claude 3 Opus, are limited to 50 questions, and users are unsure if Claude 3.5 Sonnet is a better choice, despite its limitations.
- Perplexity AI Usability Challenges: Users highlighted issues with Perplexity AI's platform usability, including difficulty in accessing saved threads and problems with the prompt section.
- One user pointed out that the Chrome extension description is inaccurate, falsely stating that Perplexity Pro uses GPT-4 and Claude 2, potentially misrepresenting the platform's capabilities.
- Perplexity API Integration: Users inquired about the possibility of connecting Perplexity's API to the Cursor AI platform, seeking guidance on integration methods.
- While one user reported trying to connect via OpenAI API key settings but encountered a loading issue, others expressed interest in utilizing Perplexity API for developing Telegram chatbots.
Links mentioned:
Perplexity AI ▷ #sharing (9 messages🔥):
MrBeastPerplexity AI DiscordAnthropic's ClaudeKustom.techOpenAI's Threads
- MrBeast: What happened to him?: A user asked 'What happened to MrBeast?' in a Perplexity search.
- Perplexity AI Discord Announcements: A user shared a message reminding another user to make their thread 'Shareable' on the Perplexity AI Discord.
- Anthropic's Claude: There was a Perplexity search for information on Anthropic's Claude.
- Kustom.tech: The url 'kustom.tech' was shared in the Discord channel.
- Perplexity's Search Functionality: A user asked 'Can Perplexity AI assist with this topic' in a Perplexity search.
Link mentioned: YouTube: no description found
Perplexity AI ▷ #pplx-api (14 messages🔥):
Perplexity APIBeta ApplicationTelegram ChatbotTemu Promo BotsFree API Credits
- Perplexity API Beta Application: A user expressed frustration about not receiving a response after applying for the Beta program, specifically to test the citation return feature.
- They stated that they have applied multiple times over several months and are eager for their users to try the citation feature.
- Telegram Chatbot using Make & Perplexity API: A user is looking for help creating a Telegram chatbot using Make and the Perplexity API.
- Temu Promo Bots Infest Discussion Forum: A user expressed annoyance at the presence of excessive Temu promotional bots flooding the discussion forum.
- Missing Free API Credits for Pro Users: Multiple users reported not receiving their free $5 Perplexity API credits after subscribing to the Pro plan.
- A moderator clarified that Pro features are not yet available via the API.
- Pro Searches Unavailable via API: A user inquired about the availability of Pro searches through the Perplexity API.
- A moderator confirmed that Pro features, including Pro searches, are currently not available through the API.
Link mentioned: API Beta access: Hi, How long does it take to get accepted for the Beta use? I want to test the citation return feature, we applied for it multiple times in the last months and didn't hear a word. We have users who ...
Cohere ▷ #discussions (38 messages🔥):
LLM TokenizationSycophancy Behavior in ModelsMMlu IssuesCOT & Scratch Pad Evaluation
- LLMs don't see letters, they see tokens: A member pointed out that all the talk of counting characters with LLMs is a red herring as models don't see letters, they see tokens which are like a big list of words.
- They gave the example of reading kanji in Japanese, which is more similar to how LLMs work than reading letters in English.
- Does Claude have 'sycophancy behavior'?: A member asked if LLMs have a tendency to be sycophantic, especially when it comes to reasoning.
- Another member suggested adding system messages to help with this, but said even then, it's more of a parlor trick than a useful production tool.
- MMlu not a good benchmark for real-world use: One member noted that MMLu isn't a good benchmark for building useful LLMs because it's not strongly correlated with real-world use cases.
- They pointed to examples of questions on Freud's outdated theories on sexuality, implying the benchmark isn't reflective of what users need from LLMs.
- COT and Scratch Pad Evaluation are still in early stages: One member said they don't care about MMlu as it's only for the delta - a 'vibe check' - and that they're waiting for new releases.
- Another member agreed, saying they want a graph of thought with scratchpad evaluation, but they lack the necessary GPUs.
Link mentioned: joey234/mmlu-human_sexuality-original-neg · Datasets at Hugging Face: no description found
Cohere ▷ #questions (28 messages🔥):
Cohere for AI Scholars ProgramCohere for AI CommunityCohere APICrewAIAya-23-8b Inference Time
- Cohere for AI Scholars Program: Cohere For AI is excited to open applications for the third cohort of its Scholars Program, designed to help change where, how, and by whom research is done.
- The program is designed to help researchers and like minded collaborators.
- Cohere for AI Community: A member suggested joining the Cohere for AI community, a resource for researchers and collaborators.
- The community provides information and folks to help with Cohere for AI's Scholar Program.
- Aya-23-8b Inference Time: A question arose regarding the inference time of the Aya-23-8b model for 50 tokens.
- The response indicated that inference time depends heavily on infrastructure and model quantization.
- Using Cohere with CrewAI: A question was asked about using Cohere with CrewAI, a tool for creating conversational AI applications.
- Specifically, the inquiry focused on whether it is possible to specify the model type used with Cohere when integrating it with CrewAI.
- Cohere API and AI Discussion: The server has a channel for discussing the Cohere API and another for general AI discussions.
- The server also has a channel for sharing cool projects made with Cohere.
Links mentioned:
Cohere ▷ #projects (1 messages):
- ``
- Internal Tool Hosted on Admin Panel: A member shared that the tool is currently hosted on the company's admin panel, but a publicly hosted version will be available soon.
- Tool Availability Update: The tool is currently hosted on the company's admin panel, but a publicly hosted version is expected soon.
LlamaIndex ▷ #blog (2 messages):
LlamaIndex WorkflowsGymNation Case Study
- LlamaIndex Workflows Tutorial Now Available: A comprehensive tutorial on LlamaIndex Workflows is now available in the LlamaIndex docs.
- The tutorial covers a range of topics, including getting started with Workflows, loops and branches, maintaining state, and concurrent flows.
- GymNation's Success Story with LlamaIndex: GymNation partnered with LlamaIndex to improve member experience and drive real business outcomes.
- They achieved impressive results, including a 20% increase in digital lead to sales conversion and an 87% conversation rate with digital leads.
LlamaIndex ▷ #general (37 messages🔥):
Function Calling LLMsWorkflowsImage & Text RetrievalLlamaIndex IntegrationPinecone Vector Store
- Function Calling LLMs for Streaming Output: A member is looking for an example of building an agent using function calling LLMs where they stream the final output.
- They are building the agent from mostly scratch using Workflows and looking for a solution to avoid latency hits caused by passing the full message to a final step.
- Workflows for Complex Logic: A member shared a workflow example that utilizes an async generator to detect tool calls and stream the output.
- They also discussed the possibility of using a "Final Answer" tool that limits output tokens and passes the final message to a final step if called.
- Best Practices for Image + Text Retrieval: A member asked for input on the best approach for combining image and text retrieval.
- They are considering using CLIP Embeddings for both image and text, but are concerned about CLIP's semantic optimization compared to dedicated text embedding models like txt-embeddings-ada-002.
- LlamaIndex Integration Expansion: A member expressed interest in expanding LlamaIndex's integration for users.
- They wanted to discuss the idea with the team before implementing it and asked for guidance on whether to file an issue, discuss in the channel, or take another approach.
- Query Engine Deprecation and Alternatives: A member inquired about the deprecation of QueryEngines in LlamaIndex.
- It was clarified that only a specific method for structured outputs is deprecated, not all query engines, and that the preferred way is to use
llm.as_structured_llm(output_class)in the query engine.
- It was clarified that only a specific method for structured outputs is deprecated, not all query engines, and that the preferred way is to use
Links mentioned:
LlamaIndex ▷ #ai-discussion (1 messages):
GenAI OpsGenAI Ops CommunityGenAI Ops Book
- GenAI Ops Community Launch: A member is launching a non-profit community called GenAI Ops dedicated to operationalizing generative AI, working with the UK CTO of Microsoft.
- GenAI Ops Ambassador Search: The community is currently seeking Ambassador candidates with deep exposure to the field and alignment with the community's values.
- New Book on GenAI Ops: The member recently published a book titled Exploring GenAI Ops: Empowering Innovators and Operationalizing Generative AI which can be found on Amazon.
- This book is a foundation and introduction to GenAI Ops, and the member believes it may be insightful or useful for the community.
Link mentioned: Exploring GenAIOps: Empowering Leaders and Innovators: Operationalising Generative AI: Amazon.co.uk: Kirby, Harrison: 9798334554955: Books: no description found
Latent Space ▷ #ai-general-chat (33 messages🔥):
Agency FundraiseAI Engineer Meetup & SummitAI for Individual UseMidjourney HardwareLlama 3 Open Source Adoption
- Agency Raises $2.6 Million: Agency, a company building AI agents, announced a $2.6 million fundraise to develop "generationally important technology" and bring their AI agents to life.
- The company's vision involves building a future where AI agents are ubiquitous and integral to our lives, as highlighted on their website agen.cy.
- AI Engineer Meetup & Summit: The AI Engineer community is expanding! The first London meetup is scheduled for September, and the second AI Engineer Summit in NYC is planned for December.
- Those interested in attending the London meetup can find more information here, and potential sponsors for the NYC summit are encouraged to get in touch.
- AI for Individual Use: Nicholas Carlini, a research scientist at DeepMind, argues that the focus of AI should shift from grand promises of revolution to its individual benefits.
- His blog post, "How I Use AI" (https://nicholas.carlini.com/writing/2024/how-i-use-ai.html), details his practical applications of AI tools, resonating with many readers, especially on Hacker News (https://news.ycombinator.com/item?id=41150317).
- Midjourney Ventures into Hardware: Midjourney, the popular AI image generation platform, is officially entering the hardware space.
- Individuals interested in joining their new team in San Francisco can reach out to [email protected].
- Llama 3 Open Source Adoption Surges: The open-source Llama model family continues to gain traction, with downloads on Hugging Face surpassing 350 million, a tenfold increase compared to last year.
- Llama's popularity extends to cloud service providers, with token usage more than doubling since May, and adoption across various industries, including Accenture, AT&T, DoorDash, and many others.
Links mentioned:
Latent Space ▷ #ai-announcements (1 messages):
Latent Space PodcastLLM BenchmarksNicholas CarliniGoogle DeepMindTraining Data Extraction
- New Latent Space Podcast Episode: The latest Latent Space Podcast episode features Nicholas Carlini of Google DeepMind.
- The episode covers various topics, including Carlini's approach to AI use, his custom LLM benchmark, and extracting training data from LLMs, including the impact of OpenAI's logprobs removal.
- Upcoming AI Meetup: The announcement also highlights an upcoming AI meetup organized by a member.
- The meetup is scheduled for next month and is intended for those interested in AI.
Link mentioned: Tweet from Latent.Space (@latentspacepod): 🆕 Why you should write your own LLM benchmarks w/ Nicholas Carlini of @GoogleDeepMind Covering his greatest hits: - How I Use AI - My benchmark for large language models - Extracting Training Data...
OpenInterpreter ▷ #general (9 messages🔥):
OpenInterpreter developmentAuto-run safetyBackupsHouse PartyTerminal app recommendations
- OpenInterpreter Development is still active!: Development is still ongoing and there have been recent commits to the main branch of the OpenInterpreter GitHub repo.
- Auto-run is Dangerous!:
auto_runis dangerous and users are cautioned to keep an eye on their output when using it. - House Party next week!: A House Party has been planned for next week at the earlier time to encourage more participation.
- Recommended Terminal app for KDE: A user is looking for a recommended terminal app for KDE, noting that Konsole, the current app they are using, bleeds the screen when scrolling while GPT-4 outputs text.
Link mentioned: Commits · OpenInterpreter/open-interpreter: A natural language interface for computers. Contribute to OpenInterpreter/open-interpreter development by creating an account on GitHub.
OpenInterpreter ▷ #ai-content (17 messages🔥):
Daily BotsBlandAI Phone AgentsFrameDiffusion Models
- Daily Bots: Open Source Cloud for Real-Time AI: Daily Bots, a low-latency cloud for voice, vision, and video AI, is being launched today, allowing developers to build voice-to-voice interactions with any LLM at latencies as low as 500ms.
- This platform offers open source SDKs, the ability to mix and match AI models, and runs at scale on Daily's real-time global infrastructure. It's the culmination of 18 months of work with customers and partners, and leverages the open source projects RTVI and Pipecat.
- Bland: Your Newest AI Employee: Bland, a customizable phone calling agent that sounds human, has secured $22 million in Series A funding.
- This AI agent can talk in any language or voice, handle millions of calls simultaneously 24/7, and is designed for any use case without hallucinations. Bland is available for calls at Bland.ai.
- Frame: Open Source AR Glasses: Frame, a pair of AR glasses, is designed to fit most people, weighing less than 40g and offering all-day battery life.
- The glasses feature a bright microOLED display, a 20-degree field of view, and are fully open source with design files and code available on GitHub. They can be tried on in AR and have an IPD range of 58-72mm.
- Diffusion Models Are Game Engines: Diffusion models, used in AI image generation, can also be used to create playable games.
- A diffusion model was used to predict the next frame of the classic shooter DOOM, resulting in a playable game at 20fps without a traditional game engine. Further reading on this topic is available at https://gamengen.github.io/.
- AgentOps: Building AI Agents: Adam Silverman, founder of AgentOps, discusses the best AI agents in a YouTube video titled "I tested 400 AI Agents, these are the best."
- He promotes his company's services, including Skool, Agency, and AgentOps, which aim to help people make money with AI agents.
Links mentioned:
OpenAccess AI Collective (axolotl) ▷ #general (16 messages🔥):
Macbook pro trainingGPU vs. CPUTraining speedModel sizeTraining cost
- Training LLMs on a Macbook Pro: A user reported successfully training large models on a 128GB Macbook Pro.
- They noted that while it works, it is significantly slower than training on a RTX 3090, with training speed roughly halved.
- GPU vs CPU for Training: The user is seeking cost-effective training solutions after their previous sponsorship ended.
- They are considering undervolted 3090s or potentially AMD cards as alternatives to expensive H100s.
- Hardware Considerations for Training: A user recommends renting hardware before committing to a purchase, especially for beginners.
- They suggest spending $30 on renting different hardware and experimenting with training models to determine the optimal configuration.
- Training Speed and Model Size: The user is exploring the relationship between model size and training speed.
- They are specifically interested in how training time changes when comparing models like Nemotron-4-340b-instruct with Llama 405.
Link mentioned: Replete-AI (Replete-AI): no description found
OpenAccess AI Collective (axolotl) ▷ #general-help (2 messages):
Fine-tuning LLMs for dialogueData Streamlining
- Fine-tuning LLMs for Long Dialogue: A member states they have good models for long dialogue, but the datasets used for training are all of the 'ShareGPT' type.
- They want to personalize data processing, particularly streamlining content enclosed by asterisks (*), for example, "she smile" to "smiling"
- Streamlining Content via Instruction: The member inquires about using a simple instruction to control a fine-tuned model to streamline and rewrite data.
- They ask if LlamaForCausalLM is capable of this or if there are better alternatives.
- Simple Prompting with Llama: Another member suggests simply passing prompts with a system prompt to Llama.
- They mention that this approach seems simple but may require checking for false positives.
OpenAccess AI Collective (axolotl) ▷ #datasets (1 messages):
teknium: https://x.com/nousresearch/status/1829143753036366325?s=46
LangChain AI ▷ #general (15 messages🔥):
SQLDatabaseChainVector StoresSQL Record ManagerRAG (Retrieval Augmented Generation)Knowledge Graphs
- SQLDatabaseChain + PGVector for Hybrid Search: A user described their current setup for storing and querying data: using PostgreSQL with
pgvectorfor embedding storage andSQLDatabaseChainto convert user queries into SQL queries.- They aim to modify the
SQLDatabaseChainprompt to search on vectors for faster responses, but haven't implemented it yet.
- They aim to modify the
- RAG & Knowledge Graphs: The Next Frontier: The user discussed the benefits of Retrieval-Augmented Generation (RAG) for AI applications, allowing models to access relevant data without retraining.
- They expressed interest in combining RAG with knowledge graphs and mentioned a hybrid approach that might be suitable for their text-to-SQL problem.
- Prompt Engineering for Multi-Database Queries: The user faced a challenge of creating ideal prompts for each SQL database due to different schema requirements, leading to performance issues and prompt template redundancy.
- They inquired about potential solutions for creating adaptable prompts that cater to various databases without sacrificing performance.
- OllamaLLM Connection Refused in Docker: Another user reported a connection refused error when trying to invoke
OllamaLLMwithin a Docker container, despite successful communication with the Ollama container.- A workaround using the
langchain_community.llms.ollamapackage was suggested and potentially resolved the issue, suggesting a potential bug in thelangchain_ollamapackage.
- A workaround using the
- Streaming in LangChain v2.0 for Function Calling: The user inquired about the possibility of using LangChain function calling with streaming in version 2.0.
- No direct answer was given, but it seems this feature is not currently available, highlighting a potential area for future development.
Links mentioned:
Torchtune ▷ #general (7 messages):
Torchtune ContributingQLoRA + Llama 3.1 Memory IssuesTorchtune Github Issues
- Torchtune Community Help Wanted: The Torchtune team is encouraging community members to contribute to their repository by completing bite-sized tasks, with issues labeled "community help wanted" available on their GitHub issues page.
- They are also happy to assist contributors via Discord.
- QLoRA + Llama 3.1 Memory Issues: A member with 4x A6000s reported encountering out-of-memory (OOM) errors while attempting to train QLoRA with Llama 3.1 70B.
- Another member questioned if this is expected behavior, suggesting it should be sufficient for QLoRA and advising to open a GitHub issue with a reproducible example to troubleshoot.
- Torchtune + PyTorch 2.4 Compatibility: One member inquired about the compatibility of Torchtune with PyTorch 2.4, receiving confirmation that it should work.
Link mentioned: Issues · pytorch/torchtune: A Native-PyTorch Library for LLM Fine-tuning. Contribute to pytorch/torchtune development by creating an account on GitHub.
Torchtune ▷ #dev (7 messages):
Fusion Models RFCBatched InferenceDecoder-only Max Seq LenFlamingo ModelCache Position Tracking
- Fusion Models RFC Discussion: A member questioned whether handling decoder-only max_seq_len within the
setup_cachesfunction might cause issues, particularly forCrossAttentionLayerandFusionLayer.- Another member agreed that this aspect should be addressed separately and proposed exploring a utility to handle it effectively.
- Flamingo Model and Batched Inference: The conversation delved into the Flamingo model's use of mixed sequence lengths, particularly for its fusion layers, necessitating a dedicated
setup_cachesapproach.- The need for accurate cache position tracking was acknowledged, highlighting a potential overlap between the Flamingo PR and the Batched Inference PR, which included updating
setup_caches.
- The need for accurate cache position tracking was acknowledged, highlighting a potential overlap between the Flamingo PR and the Batched Inference PR, which included updating
- Separate Cache Positions for Updates: A member shared an updated PR featuring separate cache positions for updating the cache, addressing the issue of shifted input positions for padded inputs.
- The discussion aimed to ensure that the updates aligned with the Flamingo PR's design and avoid any potential conflicts.
Links mentioned:
DSPy ▷ #show-and-tell (7 messages):
LinkedIn Job ApplierAgent ZeroGitHub repoAIHawkPipelines
- LinkedIn Job Applier with AI: Automating the Application Process: A member shared a GitHub repo that utilizes Agent Zero to create new pipelines, automatically applying for job offers on LinkedIn.
- Repo Still Under Development: Another member questioned the connection between the repo and previous discussions about Agent Zero.
Links mentioned:
DSPy ▷ #papers (2 messages):
Generative Reward Models (GenRM)DSPy Optimizers
- New Paper: Generative Reward Models (GenRM): A new paper proposes Generative Reward Models (GenRM), which leverage the next-token prediction objective to train verifiers, enabling seamless integration with instruction tuning, chain-of-thought reasoning, and utilizing additional inference-time compute via majority voting for improved verification.
- The paper argues that GenRM can overcome limitations of traditional discriminative verifiers that don't utilize the text generation capabilities of pretrained LLMs, see the paper for further details.
- DSPy Optimizers and Example Ordering: A user inquires about which DSPy optimizers change the order of examples/shots and which ones don't.
- The user seems interested in the impact of different optimizer strategies on the order of training data, and how this may affect model performance.
Link mentioned: Generative Verifiers: Reward Modeling as Next-Token Prediction: Verifiers or reward models are often used to enhance the reasoning performance of large language models (LLMs). A common approach is the Best-of-N method, where N candidate solutions generated by the ...
DSPy ▷ #general (4 messages):
DSPYOptimizersKL DivergenceSynthetic DataHuman Responses
- DSPY: A Challenging Optimization Problem: A member expressed frustration with the complexity of using DSPY for its intended purpose: abstracting away models, prompts, and settings.
- They shared a link to a YouTube video demonstrating their struggle and asked for resources to understand DSPY's optimization techniques.
- Seeking Examples of Working Optimizers: A member requested examples of working optimizers, specifically a GitHub repository or links to resources demonstrating their implementation.
- They emphasized their interest in seeing how optimizers are used effectively, particularly in the context of abstracting away models, prompts, and settings.
- Bootstrapping Synthetic Data with Human Responses: A member proposed a novel approach to bootstrapping synthetic data: looping through various models and prompts to minimize a KL divergence metric using hand-written human responses.
- They sought feedback on the viability of this method as a means of generating synthetic data that aligns closely with human-generated responses.
AI21 Labs (Jamba) ▷ #jamba (11 messages🔥):
Jamba 1.5 dependency issuestransformers version bug
- Jamba 1.5 dependency issues: A user reported having dependency issues when trying to train Jamba 1.5 using pytorch:23.12-py3.
- It was confirmed that Jamba 1.5 is based on the same architecture and base model as Jamba Instruct (1.0).
- Transformers 4.44.0 and 4.44.1 bug: It was discovered that transformers version 4.44.0 and 4.44.1 contain a bug that restricts the ability to run Jamba architecture.
- The bug is documented on the Hugging Face model card for Jamba 1.5-Mini: https://huggingface.co/ai21labs/AI21-Jamba-1.5-Mini.
- Transformers 4.40.0 works: A user confirmed that using transformers 4.40.0 resolved the dependency issues and allowed them to successfully train Jamba 1.5.
- Transformers 4.44.2 release notes: The release notes for transformers 4.44.2 mention a fix for Jamba cache failures, but it was confirmed that this fix is NOT related to the bug that restricts Jamba architecture.
- Users are advised to continue using transformers 4.40.0.
Link mentioned: transformers 4.44.2 on Python PyPI: New release transformers version 4.44.2 Release v4.44.2 on Python PyPI.
tinygrad (George Hotz) ▷ #general (1 messages):
Tinygrad PerformanceStatic SchedulingSparse Operations
- Tinygrad Optimized for Static Scheduling: Tinygrad is indeed highly optimized for statically scheduled operations, achieving significant performance gains for tasks that do not involve dynamic sparsity or weight selection.
- The focus on static scheduling allows Tinygrad to leverage compiler optimizations and perform efficient memory management.
- Limitations in Dynamic Sparse Operations: While Tinygrad shines with static scheduling, it might encounter performance limitations when handling dynamic sparsity or weight selection.
- These types of operations require flexibility in memory management and computation flow, which Tinygrad currently doesn't fully support.
tinygrad (George Hotz) ▷ #learn-tinygrad (7 messages):
ReduceOp Merging in Tinygradtinygrad's FUSE_CONV_BW FlagTinygrad Documentation for Beginners
- Tinygrad's ReduceOp Merging Behavior: A user inquired about the rationale behind numerous
# max one reduceop per kernelstatements within Tinygrad'sschedule.pyfile, specifically one that sometimes triggers early realization of reductions, hindering their merging in the_recurse_reduceopsfunction.- A contributor provided context, highlighting a pull request (PR #6302) that addressed this issue. This issue manifests when chaining reductions, like in
Tensor.randn(5,5).realize().sum(-1).sum(), where the reductions aren't merged into a single sum, as expected.
- A contributor provided context, highlighting a pull request (PR #6302) that addressed this issue. This issue manifests when chaining reductions, like in
- FUSE_CONV_BW=1: The Future of Convolution Backwards: A contributor explained that the
FUSE_CONV_BW=1flag in Tinygrad currently addresses this reduction merging issue by enabling efficient fusion of convolutions in the backward pass.- They also noted that this flag will eventually become the default setting once performance optimizations are achieved across all scenarios.
- Tinygrad Documentation: Your Starting Point: A user asked for guidance on beginning their journey with Tinygrad.
- Multiple contributors recommended starting with the official Tinygrad documentation, which is considered a valuable resource for beginners.
Link mentioned: tinygrad/tinygrad/engine/schedule.py at cb61cfce2492e53dac4691e92774e2704351b3ed · tinygrad/tinygrad: You like pytorch? You like micrograd? You love tinygrad! ❤️ - tinygrad/tinygrad
Gorilla LLM (Berkeley Function Calling) ▷ #discussion (3 messages):
Groq Leaderboard
- Groq Missing from Leaderboard: A member asked why Groq is not on the leaderboard (or changelog).
- Another member responded that Groq has not been added yet and the team is waiting for their PRs, which are expected to be raised next week.
- Groq's PRs Expected Next Week: A member asked why Groq is not on the leaderboard (or changelog).
- Another member responded that Groq has not been added yet and the team is waiting for their PRs, which are expected to be raised next week.
LAION ▷ #general (1 messages):
spirit_from_germany: https://youtu.be/DP454c1K_vQ?si=qYWw6oU0sQC9FPv4
LAION ▷ #research (1 messages):
CLIP-AGIQAAI-Generated Image Quality AssessmentCLIP for image quality assessmentGenerative technologiesAIGIs
- CLIP-AGIQA boosts AI-generated image quality assessment: A new paper proposes CLIP-AGIQA, a method using CLIP to improve the performance of AI-Generated Image (AIGI) quality assessment.
- The paper argues that current models struggle with the diverse and ever-increasing categories of generated images, and CLIP's ability to assess natural image quality can be extended to AIGIs.
- AIGIs are widely used but quality varies: The widespread use of AIGIs in daily life highlights the need for robust image quality assessment techniques.
- Despite some existing models, the paper emphasizes the need for more advanced methods to evaluate the quality of these diverse generated images.
- CLIP shows promise in image quality assessment: CLIP, a visual language model, has shown significant potential in evaluating the quality of natural images.
- The paper explores applying CLIP to the quality assessment of generated images, believing it can be effective in this domain as well.
Link mentioned: CLIP-AGIQA: Boosting the Performance of AI-Generated Image Quality Assessment with CLIP: With the rapid development of generative technologies, AI-Generated Images (AIGIs) have been widely applied in various aspects of daily life. However, due to the immaturity of the technology, the qual...
Alignment Lab AI ▷ #general (1 messages):
teknium: https://x.com/nousresearch/status/1829143753036366325?s=46
Mozilla AI ▷ #announcements (1 messages):
Common VoiceSpeech Data
- Common Voice Seeks Contributors!: The Common Voice project is an open-source platform for collecting speech data and building a multilingual speech clip dataset that is both cost and copyright-free.
- The goal of the project is to help make speech technologies work for all users who speak a variety of languages with a range of accents.
- Contribution Guidelines Available: Those interested in contributing can find the guidelines here.
- Help is needed in raising issues where the documentation looks outdated, confusing, or incomplete.
- Join the Community!: You can connect with the team on the Common Voice Matrix channel or in the forums.
- Support can also be sought by emailing the team at [email protected].
Link mentioned: Element: no description found
{% else %}
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: [{{ email.subject }}]({{ email_url }})!
If you enjoyed AInews, please share with a friend! Thanks in advance!
{% endif %}