AI News for 9/5/2024-9/6/2024. We checked 7 subreddits, 384 Twitters and 30 Discords (214 channels, and 2813 messages) for you. Estimated reading time saved (at 200wpm): 304 minutes. You can now tag @smol_ai for AINews discussions!
We were going to wait til next week for the paper + 405B, but the reception has been so strong (with VentureBeat cover story) and the criticisms mostly minor so we are going to make this the title story even though it technically happened yesterday, since no other story comes close.
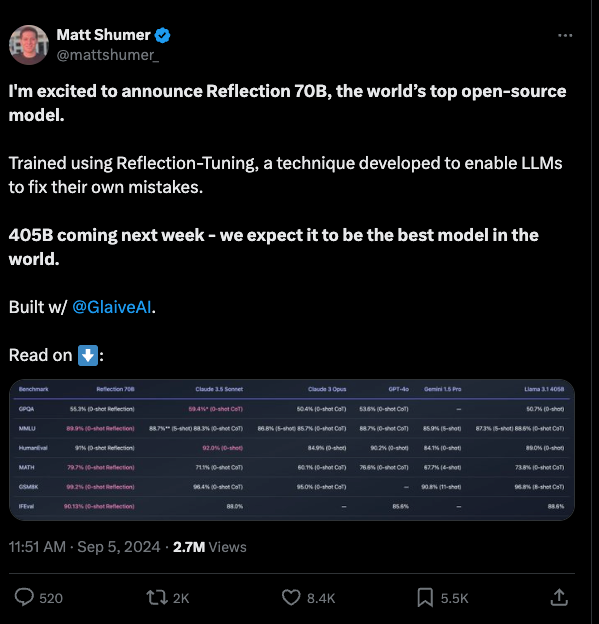
TL;DR a two person team; Matt Shumer from Hyperwrite (who has no prior history of AI research but is a prolific AI builder and influencer) and Sahil Chaudhary from Glaive finetuned Llama 3.1 70B (though context is limited) using a technique similar to a one year old paper, Reflection-Tuning: Recycling Data for Better Instruction-Tuning:
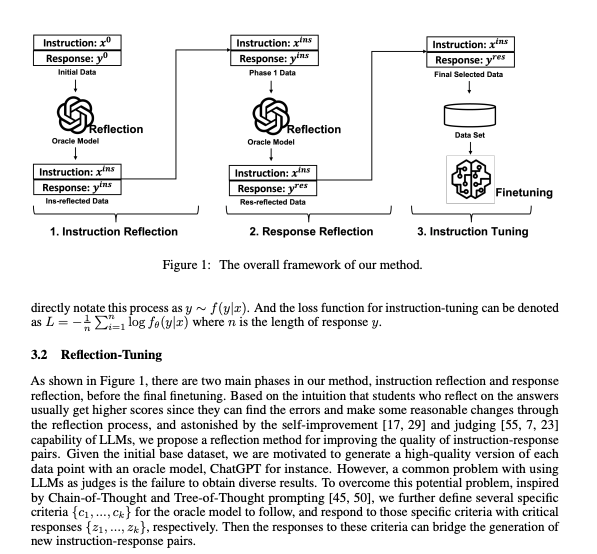
Matt hasn't yet publicly cited the paper, but it almost doesn't matter because the process is retrospectively obvious to anyone who understands the broad Chain of Thought literature: train LLMs to add thinking and reflection sections to their output before giving a final output.
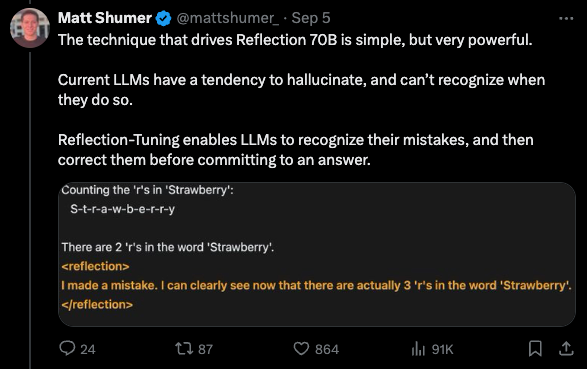
This is basically "Let's Think Step By Step" in more formal terms, and is surprising to the extent that the Orca series of models (our coverage here) already showed that Chain of Thought could be added to Llama 1/2/3 and would work:

It would seem that Matt has found the ideal low hanging fruit because nobody bothered to take a different spin on Orca + generate enough synthetic data (we still don't know how much it was, but it couldn't have been that much given the couple dozen person-days that Matt and Sahil spent on it) to do this until now.
The criticisms have been few and mostly not fatal:
- Contamination concerns: 99.2% GSM8K score too high - more than 1% is mislabeled, indicating contamination
- Johno Whitaker independently verified that 5 known wrong questions from GSM8K were answered correctly (aka not memorized)
- Matt ran the LMsys decontaminator check on it as well
- Worse for coding: Does worse on BigCodeBench-Hard - almost 10 points worse than L3-70B, and Aider code editing - 7% worse than L3-70B.
- Overoptimized for solving trivia: "nearly but not quite on par with Llama 70b for comprehension, but far, far behind on summarization - both in terms of summary content and language. Several of its sentences made no sense at all. I ended up deleting it." - /r/locallLama
- Weirdly reliant on system prompts: "The funny thing is that the model performs the same as base Llama 3.1 if you don't use the specific system prompt the author suggest. He even says it himself." /r/localllama
- grifter/hype alarm bells - Matt did not disclose that he is an investor in Glaive.
After a day of review, the overall vibes remain very strong - with /r/localLlama reporting that even 4bit quantizations of Reflection 70B are doing well, and Twitter reporting riddles and favorable comparisons with Claude 3.5 Sonnet that it can be said to at least pass the vibe check if not as a generally capable model, but on enough reasoning tasks to be significant.
More information can be found on this 34min livestream conversation and 12min recap with Matthew Berman.
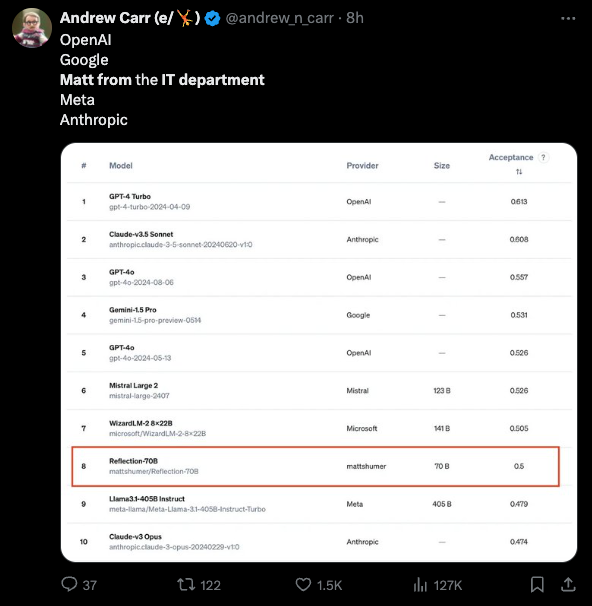
All in all, not a bad day for Matt from IT.
{% if medium == 'web' %}
Table of Contents
[TOC]
{% else %}
The Table of Contents and Channel Summaries have been moved to the web version of this email: [{{ email.subject }}]({{ email_url }})!
{% endif %}
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
LLM Training & Evaluation
- LLM Training & Evaluation: @AIatMeta is still accepting proposals for their LLM Evaluations Grant until September 6th. The grant will provide $200K in funding to support LLM evaluation research.
- Multi-Modal Models: @glennko believes that AI will eventually be able to count "r" with high accuracy, but that it might not be with an LLM but with a multi-modal model.
- Specialized Architecture: @glennko noted that FPGAS are too slow and ASICs are too expensive to build the specialized architecture needed for custom logic.
Open-Source Models & Research
- Open-Source MoE Models: @apsdehal announced the release of OLMoE, a 1B parameter Mixture-of-Experts (MoE) language model that is 100% open-source. The model was a collaboration between ContextualAI and Allen Institute for AI.
- Open-Source MoE Models: @iScienceLuvr noted that OLMOE-1B-7B has 7 billion parameters but only uses 1 billion per input token, and it was pre-trained on 5 trillion tokens. The model outperforms other available models with similar active parameters, even surpassing larger models such as Llama2-13B-Chat and DeepSeekMoE-16B.
- Open-Source MoE Models: @teortaxesTex noted that DeepSeek-MoE scores well in granularity, but not in shared experts.
AI Tools & Applications
- AI-Powered Spreadsheets: @annarmonaco highlighted how Paradigm is transforming spreadsheets with AI and using LangChain and LangSmith to monitor key costs and gain step-by-step agent visibility.
- AI for Healthcare Diagnostics: @qdrant_engine shared a guide on how to create a high-performance diagnostic system using hybrid search with both text and image data, generating multimodal embeddings from text and image data.
- AI for Fashion: @flairAI_ is releasing a fashion model that can be trained on clothing with incredible accuracy, preserving texture, labels, logos, and more with Midjourney-level quality.
AI Alignment & Safety
- AI Alignment & Safety: @GoogleDeepMind shared a podcast discussing the challenges of AI alignment and the ability to supervise powerful systems effectively. The podcast included insights from Anca Diana Dragan and Professor FryRSquared.
- AI Alignment & Safety: @ssi is building a "straight shot to safe superintelligence" and has raised $1B from investors.
- AI Alignment & Safety: @RichardMCNgo noted that EA facilitates power-seeking behavior by choosing strategies using naive consequentialism without properly accounting for second order effects.
Memes & Humor
- Founder Mode: @teortaxesTex joked about Elon Musk's Twitter feed, comparing him to Iron Man.
- Founder Mode: @nisten suggested that Marc Andreessen needs a better filtering LLM to manage his random blocked users.
- Founder Mode: @cto_junior joked about how Asian bros stack encoders and cross-attention on top of existing models just to feel something.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Advancements in LLM Quantization and Efficiency
- llama.cpp merges support for TriLMs and BitNet b1.58 (Score: 73, Comments: 4): llama.cpp has expanded its capabilities by integrating support for TriLMs and BitNet b1.58 models. This update enables the use of ternary quantization for weights in TriLMs and introduces a binary quantization method for BitNet models, potentially offering improved efficiency in model deployment and execution.
Theme 2. Reflection-70B: A Novel Fine-tuning Technique for LLMs
-
First independent benchmark (ProLLM StackUnseen) of Reflection 70B shows very good gains. Increases from the base llama 70B model by 9 percentage points (41.2% -> 50%) (Score: 275, Comments: 115): Reflection-70B demonstrates significant performance improvements over its base model on the ProLLM StackUnseen benchmark, increasing accuracy from 41.2% to 50%, a gain of 9 percentage points. This independent evaluation suggests that Reflection-70B's capabilities may surpass those of larger models, highlighting its effectiveness in handling unseen programming tasks.
- Matt from IT unexpectedly ranks among top AI companies like OpenAI, Google, and Meta, sparking discussions about individual innovation and potential job offers from major tech firms.
- The Reflection-70B model demonstrates significant improvements over larger models, beating the 405B version on benchmarks. Users express excitement for future fine-tuning of larger models and discuss hardware requirements for running these models locally.
- Debate arises over the fairness of comparing Reflection-70B to other models due to its unique output format using
<thinking>and<output>tags. Some argue it's similar to Chain of Thought prompting, while others see it as a novel approach to enhancing model reasoning capabilities.
-
Reflection-Llama-3.1-70B available on Ollama (Score: 74, Comments: 35): The Reflection-Llama-3.1-70B model is now accessible on Ollama, expanding the range of large language models available on the platform. This model, based on Llama 2, has been fine-tuned using constitutional AI techniques to enhance its capabilities in areas such as task decomposition, reasoning, and reflection.
- Users noted an initial system prompt error in the model, which was promptly updated. The model's name on Ollama mistakenly omitted "llama", causing some amusement.
- A tokenizer issue was reported, potentially affecting the model's performance on Ollama and llama.cpp. An active discussion on Hugging Face addresses this problem.
- The model demonstrated its reflection capabilities in solving a candle problem, catching and correcting its initial mistake. Users expressed interest in applying this technique to smaller models, though it was noted that the 8B version showed limited improvement.
{kind=link}
All AI Reddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI Model Developments and Releases
-
Reflection 70B: A fine-tuned version of Meta's Llama 3.1 70B model, created by Matt Shumer, is claiming to outperform state-of-the-art models on benchmarks. It uses synthetic data to offer an inner monologue, similar to Anthropic's approach with Claude 3 to 3.5.
-
AlphaProteo: Google DeepMind's new AI model generates novel proteins for biology and health research.
-
OpenAI's Future Models: OpenAI is reportedly considering high-priced subscriptions up to $2,000 per month for next-generation AI models, potentially named Strawberry and Orion.
AI Industry and Market Dynamics
-
Open Source Impact: The release of Reflection 70B has sparked discussions about the potential of open-source models to disrupt the AI industry, potentially motivating companies like OpenAI to release new models.
-
Model Capabilities: There's a disconnect between public perception and actual AI model capabilities, with many people unaware of the current state of AI technology.
AI Applications and Innovations
-
DIY Medicine: A report discusses the rise of "Pirate DIY Medicine," where amateurs can manufacture expensive medications at a fraction of the cost.
-
Stable Diffusion: A new FLUX LoRA model for Stable Diffusion has gained popularity, demonstrating the ongoing development in AI-generated art.
AI Discord Recap
A summary of Summaries of Summaries by Claude 3.5 Sonnet
1. LLM Advancements and Benchmarking
- Reflection 70B Makes Waves: Reflection 70B was announced as the world's top open-source model, utilizing a new Reflection-Tuning technique that enables the model to detect and correct its own reasoning mistakes.
- While initial excitement was high, subsequent testing on benchmarks like BigCodeBench-Hard showed mixed results, with scores lower than previous models. This sparked debates about evaluation methods and the impact of synthetic training data.
- DeepSeek V2.5 Enters the Arena: DeepSeek V2.5 was officially launched, combining the strengths of DeepSeek-V2-0628 and DeepSeek-Coder-V2-0724 to enhance writing, instruction-following, and human preference alignment.
- The community showed interest in comparing DeepSeek V2.5's performance, particularly for coding tasks, against other recent models like Reflection 70B, highlighting the rapid pace of advancements in the field.
2. Model Optimization Techniques
- Speculative Decoding Breakthrough: Together AI announced a breakthrough in speculative decoding, achieving up to 2x improvement in latency and throughput for long context inputs, challenging previous assumptions about its effectiveness.
- This advancement signals a significant shift in optimizing high-throughput inference, potentially reducing GPU hours and associated costs for AI solution deployment.
- AdEMAMix Optimizer Enhances Gradient Handling: A new optimizer called AdEMAMix was proposed, utilizing a mixture of two Exponential Moving Averages (EMAs) to better handle past gradients compared to a single EMA, as detailed in this paper.
- Early experiments show AdEMAMix outperforming traditional single EMA methods in language modeling and image classification tasks, promising more efficient training outcomes for various AI applications.
3. Open-source AI Developments
- llama-deploy Streamlines Microservices: llama-deploy was launched to facilitate seamless deployment of microservices based on LlamaIndex Workflows, marking a significant evolution in agentic system deployment.
- An open-source example showcasing how to build an agentic chatbot system using llama-deploy with the @getreflex front-end framework was shared, demonstrating its full-stack capabilities.
- SmileyLlama: AI Molecule Designer: SmileyLlama, a fine-tuned Chemical Language Model, was introduced to design molecules based on properties specified in prompts, built using the Axolotl framework.
- This development showcases Axolotl's capabilities in adapting existing Chemical Language Model techniques for specialized tasks like molecule design, pushing the boundaries of AI applications in chemistry.
4. AI Infrastructure and Deployment
- NVIDIA's AI Teaching Kit Launch: NVIDIA's Deep Learning Institute released a generative AI teaching kit developed with Dartmouth College, aimed at empowering students with GPU-accelerated AI applications.
- The kit is designed to give students a significant advantage in the job market by bridging knowledge gaps in various industries, highlighting NVIDIA's commitment to AI education and workforce development.
- OpenAI Considers Premium Pricing: Reports emerged that OpenAI is considering a $2000/month subscription model for access to its more advanced AI models, including the anticipated Orion model, as discussed in this Information report.
- This potential pricing strategy has sparked debates within the community about accessibility and the implications for AI democratization, with some expressing concerns about creating barriers for smaller developers and researchers.
PART 1: High level Discord summaries
HuggingFace Discord
- Vision Language Models Overview: A member shared a blogpost detailing the integration of vision and language in AI applications, emphasizing innovative potentials.
- This piece aims to steer focus towards the versatile use cases emerging from this intersection of technologies.
- Tau LLM Training Optimization Resources: The Tau LLM series offers essential insights on optimizing LLM training processes, which promise enhanced performance.
- It is considered pivotal for anyone delving into the complexities of training LLMs effectively.
- Medical Dataset Quest for Disease Detection: A member seeks a robust medical dataset for computer vision, aimed at enhancing disease detection through transformer models.
- They're particularly interested in datasets that support extensive data generation efforts in this domain.
- Flux img2img Pipeline Still Pending: The Flux img2img feature remains unmerged, as noted in an open PR, with ongoing discussions surrounding its documentation.
- Despite its potential strain on typical consumer hardware, measures for optimization are being explored, as shared in related discussions.
- Selective Fine-Tuning for Enhanced Language Models: The concept of selective fine-tuning has been highlighted, showcasing its capability in improving language model performance without full retraining.
- This targeted approach allows for deeper performance tweaks while avoiding the costs associated with comprehensive training cycles.
Stability.ai (Stable Diffusion) Discord
- ControlNet Enhances Model Pairings: Users shared successful strategies for using ControlNet with Loras to generate precise representations like hash rosin images using various SDXL models.
- They recommended applying techniques like depth maps to achieve better results, highlighting a growing mastery in combining different AI tools.
- Flux Takes the Lead Over SDXL for Logos: The community widely endorsed Flux over SDXL for logo generation, emphasizing its superior handling of logo specifics without requiring extensive training.
- Members noted that SDXL struggles without familiarity with the logo design, making Flux the favored choice for ease and effectiveness.
- Scamming Awareness on the Rise: Discussion on online scams revealed that even experienced users can be vulnerable, leading to a shared commitment to promote ongoing vigilance.
- Empathetic understanding of scamming behaviors emerged as a key insight, reinforcing that susceptibility isn't limited to the inexperienced.
- Tagging Innovations in ComfyUI: Community insights on tagging features in ComfyUI likened its capabilities to Langflow and Flowise, showcasing its flexibility and user-friendly interface.
- Members brainstormed specific workflows to enhance tagging efficacy, pointing to a promising wave of adaptations in the interface’s functionality.
- Insights Into Forge Extensions: Inquiries into various extensions available in Forge highlighted user efforts to improve experience through contributions and community feedback.
- Polls were referenced as a method for shaping future extension releases, underscoring the importance of quality assurance and community engagement.
Unsloth AI (Daniel Han) Discord
- Congrats on Y Combinator Approval!: Team members celebrated the recent backing from Y Combinator, showcasing strong community support and enthusiasm for the project's future.
- They acknowledged this milestone as a significant boost toward development and outreach.
- Unsloth AI Faces Hardware Compatibility Hurdles: Discussions highlighted Unsloth's current struggles with hardware compatibility, notably concerning CUDA support on Mac systems.
- The team aims for hardware agnosticism, but ongoing issues reduce performance on certain configurations.
- Synthetic Data Generation Model Insights: Insights were shared on employing Mistral 8x7B tunes for synthetic data generation, alongside models like jondurbin/airoboros-34b-3.3 for testing.
- Experimentation remains essential for fine-tuning outcomes based on hardware constraints.
- Phi 3.5 Model Outputs Confuse Users: Users reported frustrating experiences with the Phi 3.5 model returning gibberish outputs during fine-tuning efforts, despite parameter tweaks.
- This prompted a wider discussion on troubleshooting and refining input templates for better model performance.
- Interest Surges for Comparison Reports!: A member expressed eagerness for comparison reports on key topics, emphasizing their potential for insightful reading.
- Parallelly, another member announced plans for a YouTube video detailing these comparisons, showcasing community engagement.
LM Studio Discord
- Seeking Free Image API Options: Users investigated free Image API options that support high limits, specifically inquiring about providers offering access for models like Stable Diffusion.
- Curiosity was sparked around any providers that could accommodate these features at scale.
- Reflection Llama-3.1 70B Gets Enhancements: Reflection Llama-3.1 70B impressed as the top open-source LLM with updates that bolster error detection and correction capabilities.
- However, users noted ongoing performance issues and debated optimal prompts to enhance model behavior.
- LM Studio Download Problems After Update: Post-update to version 0.3.2, users faced challenges downloading models, citing certificate errors as a primary concern.
- Workarounds discussed included adjusting VRAM and context size, while clarifications on the RAG summarization feature were provided.
- Mac Studio Battling Speed with Large Models**: Concern arose over Mac Studio's capability with 256GB+ memory being sluggish for larger models, with hopes that LPDDR5X 10.7Gbps could remedy this.
- One discussion highlighted a 70% speed boost potential across all M4s, igniting further interest in hardware upgrades.
- Maximizing Performance with NVLink and RTX 3090: Users shared insights on achieving 10 to 25 t/s with dual RTX 3090 setups, especially with NVLink, while one reported hitting 50 t/s.
- Despite these high numbers, the actual inference performance impact of NVLink drew skepticism from some community members.
Nous Research AI Discord
- Reflection 70B Model Struggles on Benchmarks: Recent tests revealed that Reflection 70B underperformed in comparisons with the BigCodeBench-Hard, particularly affected by tokenizer and prompt issues.
- The community expressed concerns over evaluations, leading to uncertainty about the model’s reliability in real-world applications.
- Community Investigates DeepSeek v2.5 Usability: Members sought feedback on improvements seen with DeepSeek v2.5 during coding tasks, encouraging a share of user experiences.
- This initiative aims to build a collective understanding of the model's effectiveness and contribute to user-driven enhancements.
- Inquiries on API Usability for Llama 3.1: There was a discussion about optimal API options for implementing Llama 3.1 70B, emphasizing the need for tool call format support.
- Suggestions included exploring various platforms, pointing toward Groq as a promising candidate for deployment.
- Challenges with Quantization Techniques: Users reported setbacks with the FP16 quantization of the 70B model, highlighting struggles in achieving satisfactory performance with int4.
- Ongoing discussions revolved around potential solutions to enhance model performance while maintaining quality integrity.
- MCTS and PRM Techniques for Enhanced Performance: Conversations indicated interest in merging MCTS (Monte Carlo Tree Search) and PRM (Probabilistic Roadmap) to boost training efficiencies.
- The community showed enthusiasm about experimenting with these methodologies for improving model evaluation processes.
Latent Space Discord
- OpenAI Considers $2000 Subscription: OpenAI is exploring a pricing model at $2000/month for its premium AI models, including the upcoming Orion model, stirring accessibility concerns within the community.
- As discussions unfold, opinions vary on whether this pricing aligns with market norms or poses barriers for smaller developers.
- Reflection 70B's Mixed Benchmark Results: The Reflection 70B model has shown mixed performance, scoring 20.3 on the BigCodeBench-Hard benchmark, notably lower than Llama3's score of 28.4.
- Critics emphasize the need for deeper analysis of its methodology, especially regarding its claim of being the top open-source model.
- Speculative Decoding Boosts Inference: Together AI reported that speculative decoding can enhance throughput by up to 2x, challenging previous assumptions about its efficiency in high-latency scenarios.
- This advancement could reshape approaches to optimizing inference speeds for long context inputs.
- Exciting Developments in Text-to-Music Models: A new open-source text-to-music model has emerged, claiming impressive sound quality and efficiency, competing against established platforms like Suno.ai.
- Members are keen on its potential applications, although there are varied opinions regarding its practical usability.
- Exploration of AI Code Editors: Discussion on AI code editors highlights tools like Melty and Pear AI, showcasing unique features compared to Cursor.
- Members are particularly interested in how these tools manage comments and TODOs, pushing for better collaboration in coding environments.
OpenAI Discord
- Perplexity steals spotlight: Users praised Perplexity for its speed and reliability, often considering it a better alternative to ChatGPT Plus subscriptions.
- One user noted it is particularly useful for school as it is accessible and integrated with Arc browser.
- RunwayML faces backlash: A user reported dissatisfaction with RunwayML after a canceled community meetup, which raises concerns about their customer service.
- Comments highlighted the discontent among loyal members and how this affects Runway's reputation.
- Reflection model's promising tweaks: Discussion around the Reflection Llama-3.1 70B model focused on its performance and a new training method called Reflection-Tuning.
- Users noted that initial testing issues led to a platform link where they can experiment with the model.
- OpenAI token giveaway generates buzz: An offer for OpenAI tokens sparked significant interest, as one user had 1,000 tokens they did not plan to use.
- This prompted discussions around potential trading or utilizing these tokens within the community.
- Effective tool call integrations: Members shared tips on structuring tool calls in prompts, emphasizing the correct sequence of the Assistant message followed by the Tool message.
- One member noted finding success with over ten Python tool calls in a single prompt output.
Eleuther Discord
- Securing Academic Lab Roles: Members discussed strategies for obtaining positions in academic labs, emphasizing the effectiveness of project proposals and the lower success of cold emailing.
- One member highlighted the need to align research projects with current trends to grab the attention of potential hosts.
- Universal Transformers Face Feasibility Issues: The feasibility of Universal Transformers was debated, with some members expressing skepticism while others found potential in adaptive implicit compute techniques.
- Despite the promise, stability continues to be a significant barrier for wide adoption in practical applications.
- AdEMAMix Optimizer Improves Gradient Handling: The newly proposed AdEMAMix optimizer enhances gradient utilization by blending two Exponential Moving Averages, showing better performance in tasks like language modeling.
- Early experiments indicate this approach outperforms the traditional single EMA method, promising more efficient training outcomes.
- Automated Reinforcement Learning Agent Architecture: A new automated RL agent architecture was introduced, efficiently managing experiment progress and building curricula through a Vision-Language Model.
- This marks one of the first complete automations in reinforcement learning experiment workflows, breaking new ground in model training efficiency.
- Hugging Face RoPE Compatibility Concerns: A member raised questions regarding compatibility between the Hugging Face RoPE implementation for GPTNeoX and other models, noting over 95% discrepancies in attention outputs.
- This raises important considerations for those working with multiple frameworks and might influence future integration efforts.
OpenInterpreter Discord
- Open Interpreter celebrates a milestone: Members enthusiastically celebrated the birthday of Open Interpreter, with a strong community sentiment expressing appreciation for its innovative potential.
- Happy Birthday, Open Interpreter! became the chant, emphasizing the excitement felt around its capabilities.
- Skills functionality in Open Interpreter is still experimental: Discussion revealed that the skills feature is currently experimental, prompting questions about whether these skills persist across sessions.
- Users noted that skills appear to be temporary, which led to suggestions to investigate the storage location on local machines.
- Positive feedback on 01 app performance: Users shared enthusiastic feedback about the 01 app's ability to efficiently search and play songs from a library of 2,000 audio files.
- Despite praise, there were reports of inconsistencies in results, reflecting typical early access challenges.
- Fulcra app expands to new territories: The Fulcra app has officially launched in several more regions, responding to community requests for improved accessibility.
- Discussions indicated user interest in availability across locations such as Australia, rallying support for further expansion.
- Request for Beta Role Access: Multiple users are eager to get access to the beta role for desktop, including one who contributed to the dev kit for Open Interpreter 01.
- A user expressed their disappointment at missing a live session, asking, 'Any way to get access to the beta role for desktop?'
Modular (Mojo 🔥) Discord
- Mojo Values Page Returns 404: Members noted that Modular's values page is currently showing a 404 error at this link and may need redirection to company culture.
- Clarifications suggested that changes were required for the link to effectively point users to the relevant content.
- Async Functions Limitations in Mojo: A user faced issues using
async fnandasync def, revealing these async features are exclusive to nightly builds, causing confusion in stable versions.- Users were advised to check their version and consider switching to the nightly build to access these features.
- DType Constraints as Dict Keys: Discussion sparked over the inability to use
DTypeas a key in Dictionaries, raising eyebrows since it implements theKeyElementtrait.- Participants explored the design constraints within Mojo’s data structures that might limit the use of certain types.
- Constructor Usage Troubleshoot: Progress was shared on resolving constructor issues involving
Arc[T, True]andWeak[T], highlighting challenges with @parameter guards.- Suggestions included improving naming conventions within the standard library for better clarity and aligning structure of types.
- Exploring MLIR and IR Generation: Interest was piqued on how MLIR can be utilized more effectively in Mojo, especially regarding IR generation.
- A resource from a previous LLVM meeting was suggested, 2023 LLVM Dev Mtg - Mojo 🔥, to gain deeper insights on integration.
CUDA MODE Discord
- Reflection 70B launches with exciting features: The Reflection 70B model has been launched as the world’s best open-source model, utilizing Reflection-Tuning to correct LLM errors.
- A 405B model is expected next week, possibly surpassing all current models in performance.
- Investigating TorchDynamo cache lookup delays: When executing large models, members noted 600us spent in TorchDynamo Cache Lookup, mainly due to calls from
torch/nn/modules/container.py.- This points to potential optimizations required in the cache lookup process to improve model training runtime.
- NVIDIA teams up for generative AI education: The Deep Learning Institute from NVIDIA released a generative AI teaching kit in collaboration with Dartmouth College to enhance GPU learning.
- Participants will gain a competitive edge in AI applications, bridging essential knowledge gaps.
- FP16 x INT8 Matmul shows limits on batch sizes: The FP16 x INT8 matmul on the 4090 RTX fails when batch sizes exceed 1 due to shared memory limitations, hinting at a need for better tuning for non-A100 GPUs.
- Users experienced substantial slowdowns with enabled inductor flags yet could bypass errors by switching them off.
- Liger's performance benchmarks raise eyebrows: The performance of Liger's swiglu kernels was contrasted against Together AI's benchmarks, which reportedly offer up to 24% speedup.
- Their specialized kernels outperform cuBLAS and PyTorch eager mode by 22-24%, indicating the need for further tuning options.
Interconnects (Nathan Lambert) Discord
- Reflection Llama-3.1 70B yields mixed performance: The newly released Reflection Llama-3.1 70B claims to be the leading open-source model yet struggles significantly on benchmarks like BigCodeBench-Hard.
- Users observed a drop in performance for reasoning tasks and described the model as a 'non news item meh model' on Twitter.
- Concerns linger over Glaive's synthetic data: Community members raised alarms about the effectiveness of synthetic data from Glaive, recalling issues from past contaminations that might impact model performance.
- These concerns led to discussions about the implications of synthetic data on the Reflection Llama model's generalization capabilities.
- HuggingFace Numina praised for research: HuggingFace Numina was highlighted as a powerful resource for data-centric tasks, unleashing excitement among researchers for its application potential.
- Users expressed enthusiasm about how it could enhance efficiency and innovation in various ongoing projects.
- Introduction of CHAMP benchmark for math reasoning: The community welcomed the new CHAMP benchmark aimed at assessing LLMs' mathematical reasoning abilities through annotated problems that provide hints.
- This dataset will explore how additional context aids in problem-solving under complex conditions, promoting further study in this area.
- Reliability issues of Fireworks and Together: Discussions unveiled that both Fireworks and Together are viewed as less than 100% reliable, prompting the implementation of failovers to maintain functionality.
- Users are cautious about utilizing these tools until assurances of reliability are fortified.
Perplexity AI Discord
- Tech Entry Without Skills: A member expressed eagerness to enter the tech industry without technical skills, seeking advice on building a compelling CV and effective networking.
- Another member mentioned starting cybersecurity training through PerScholas, underscoring a growing interest in coding and AI.
- Bing Copilot vs. Perplexity AI: A user compared Bing Copilot's ability to provide 5 sources with inline images to Perplexity's capabilities, suggesting improvements.
- They hinted that integrating hover preview cards for citations could be a valuable enhancement for Perplexity.
- Perplexity AI's Referral Program: Perplexity is rolling out a merch referral program specifically targeted at students, encouraging sharing for rewards.
- A question arose about the availability of a year of free access, particularly for the first 500 sign-ups.
- Web3 Job Openings: A post highlighted job openings in a Web3 innovation team, looking for beta testers, developers, and UI/UX designers.
- They invite applications and proposals to create mutual cooperation opportunities as part of their vision.
- Sutskever's SSI Secures $1B: Sutskever's SSI successfully raised $1 billion to boost advancements in AI technology.
- This funding aims to fuel further innovations in the AI sector.
tinygrad (George Hotz) Discord
- Bounty Exploration Sparks Interest: A user expressed interest in trying out a bounty and sought guidance, referencing a resource on asking smart questions.
- This led to a humorous acknowledgment from another member, highlighting community engagement in bounty discussions.
- Tinygrad Pricing Hits Zero: In a surprising twist, georgehotz confirmed the pricing for a 4090 + 500GB plan has been dropped to $0, but only for tinygrad friends.
- This prompted r5q0 to inquire about the criteria for friendship, adding a light-hearted element to the conversation.
- Clarifying PHI Operation Confusion: Members discussed the PHI operation's functionality in IR, noting its unusual placement compared to LLVM IR, especially in loops.
- One member suggested renaming it to ASSIGN as it operates differently from traditional phi nodes, aiming to clear up misunderstandings.
- Understanding MultiLazyBuffer's Features: A user raised concerns about the
MultiLazyBuffer.realproperty and its role in shrinking and copying to device interactions.- This inquiry led to discussions revealing that it signifies real lazy buffers on devices and potential bugs in configurations.
- Views and Memory Challenges: Members expressed ongoing confusion regarding the realization of views in the
_recurse_lbfunction, questioning optimization and utilization balance.- This reflection underscores the need for clarity on foundational tensor view concepts, inviting community input to refine understanding.
Torchtune Discord
- Gemma 2 model resources shared: Members discussed the Gemma 2 model card, providing links to technical documentation from Google's lightweight model family.
- Resources included a Responsible Generative AI Toolkit and links to Kaggle and Vertex Model Garden, emphasizing ethical AI practices.
- Multimodal models and causal masks: A member outlined challenges with causal masks during inference for multimodal setups, focusing on fixed sequence lengths.
- They noted that exposing these variables through attention layers is crucial to tackle this issue effectively.
- Expecting speedups with Flex Attention: There is optimism that flex attention with document masking will significantly enhance performance, achieving 40% speedup on A100 and 70% on 4090.
- This would improve dynamic sequence length training while minimizing padding inefficiencies.
- Questions arise on TransformerDecoder design: A member asked whether a TransformerDecoder could operate without self-attention layers, challenging its traditional structure.
- Another pointed out that the original transformer utilized both cross and self-attention, complicating this deviation.
- PR updates signal generation overhaul: Members confirmed that GitHub PR #1449 has been updated to enhance compatibility with
encoder_max_seq_lenandencoder_mask, with testing still pending.- This update paves the way for further modifications to generation utils and integration with PPO.
LlamaIndex Discord
- Llama-deploy Offers Microservices Magic: The new llama-deploy system enhances deployment for microservices based on LlamaIndex Workflows. This opens up opportunities to streamline agentic systems similar to previous iterations of llama-agents.
- An example shared in the community demonstrates full-stack capabilities using llama-deploy with @getreflex, showcasing how to effectively build agentic chat systems.
- PandasQueryEngine Faces Column Name Confusion: Users reported that PandasQueryEngine struggles to correctly identify the column
averageRating, often reverting to incorrect labels during chats. Suggestions included verifying mappings within the chat engine's context.- This confusion could lead to deeper issues in data integrity when integrating engine responses with expected output formats.
- Developing Customer Support Bots with RAG: A user is exploring ways to create a customer support chatbot that efficiently integrates a conversation engine with retrieval-augmented generation (RAG). Members emphasized the synergy between chat and query engines for stronger data retrieval capabilities.
- Validating this integration could enhance user experience in real-world applications where effective support is crucial.
- NeptuneDatabaseGraphStore Bug Reported: Concerns arose regarding a bug in NeptuneDatabaseGraphStore.get_schema() that misses date information in graph summaries. It is suspected the issue may be related to schema parsing errors with LLMs.
- Community members expressed the need for further investigation, especially surrounding the
datetimepackage’s role in the malfunction.
- Community members expressed the need for further investigation, especially surrounding the
- Azure LlamaIndex and Cohere Reranker Inquiry: A discussion emerged about integrating the Cohere reranker as a postprocessor within Azure's LlamaIndex. Members confirmed that while no Azure module exists currently, creating one is feasible due to straightforward documentation.
- The community is encouraged to consider building this integration as it could significantly enhance processing capabilities within Azure environments.
OpenAccess AI Collective (axolotl) Discord
- Reflection Llama-3.1: Top LLM Redefined: Reflection Llama-3.1 70B is now acclaimed as the leading open-source LLM, enhanced through Reflection-Tuning for improved reasoning accuracy.
- Synthetic Dataset Generation for Fast Results: Discussion focused on the rapid generation of the synthetic dataset for Reflection Llama-3.1, sparking curiosity about human rater involvement and sample size.
- Members debated the balance between speed and quality in synthetic dataset creation.
- Challenge Accepted: Fine-tuning Llama 3.1: Members raised queries regarding effective fine-tuning techniques for Llama 3.1, noting its performance boost at 8k sequence length with possible extension to 128k using rope scaling.
- Concerns about fine-tuning complexities arose, suggesting the need for custom token strategies for optimal performance.
- SmileyLlama is Here: Meet the Chemical Language Model: SmileyLlama stands out as a fine-tuned Chemical Language Model designed for molecule creation based on specified properties.
- This model, marked as an SFT+DPO implementation, showcases Axolotl's prowess in specialized model adaptations.
- GPU Power: Lora Finetuning Insights: Inquiries about A100 80 GB GPUs for fine-tuning Meta-Llama-3.1-405B-BNB-NF4-BF16 in 4 bit using adamw_bnb_8bit, underscored the resource requirements for effective Lora finetuning.
- This points to practical considerations essential for managing Lora finetuning processes efficiently.
Cohere Discord
- Explore Cohere's Capabilities and Cookbooks: Members discussed checking out the channel dedicated to capabilities and demos where the community shares projects built using Cohere models, referencing a comprehensive cookbook that provides ready-made guides.
- One member highlighted that these cookbooks showcase best practices for leveraging Cohere's generative AI platform.
- Understanding Token Usage with Anthropic Library: A member inquired about using the Anthropic library, sharing a code snippet for calculating token usage:
message = client.messages.create(...).- They directed others to the GitHub repository for the Anthropic SDK to further explore tokenization.
- Embed-Multilingual-Light-V3.0 Availability on Azure: A member questioned the availability of
embed-multilingual-light-v3.0on Azure and asked if there are any plans to support it.- This inquiry reflects ongoing interest in the integration of Cohere's resources with popular cloud platforms.
- Query on RAG Citations: A member asked how citations will affect the content of text files when using RAG with an external knowledge base, specifically inquiring about receiving citations when they are currently getting None.
- They expressed urgency in figuring out how to resolve the issue regarding the absence of citations in the responses from text files.
DSPy Discord
- Chroma DB Setup Simplified: A member pointed out that launching a server for Chroma DB requires just one line of code:
!chroma run --host localhost --port 8000 --path ./ChomaM/my_chroma_db1, noting the ease of setup.- They felt relieved knowing the database location with such simplicity.
- Weaviate Setup Inquiry: The same member asked if there’s a simple setup for Weaviate similar to Chroma DB, avoiding Go Docker complexities.
- They expressed a need for ease due to their non-technical background.
- Jupyter Notebooks for Server-Client Communication: Another member shared their use of two Jupyter notebooks to run a server and client separately, highlighting it fits their needs.
- They identify as a Biologist and seek uncomplicated solutions.
- Reflection 70B Takes the Crown: Reflection 70B has been announced as the leading open-source model, featuring Reflection-Tuning to enable the model to rectify its own errors.
- A new model, 405B, is on its way next week promising even better performance.
- Enhancing LLM Routing with Pricing: Discussion emerged around routing appropriate LLMs based on queries, intending to incorporate aspects like pricing and TPU speed into the logic.
- Participants noted that while routing LLMs is clear-cut, enhancing it with performance metrics can refine the selection process.
LAION Discord
- SwarmUI Usability Concerns: Members expressed discomfort with user interfaces showcasing 100 nodes compared to SwarmUI, reinforcing its usability issues.
- Discussion highlighted how labeling it as 'literally SwarmUI' reflected a broader concern about UI complexity among tools.
- SwarmUI Modular Design on GitHub: A link to SwarmUI on GitHub was shared, featuring its focus on modular design for better accessibility and performance.
- The repository emphasizes offering easy access to powertools, enhancing usability through a well-structured interface.
- Reflection 70B Debut as Open-Source Leader: The launch of Reflection 70B has been announced as the premier open-source model using Reflection-Tuning, enabling LLMs to self-correct.
- A 405B model is anticipated next week, raising eyebrows about its potential to crush existing benchmark performances.
- Self-Correcting LLMs Make Waves: New discussions emerged around an LLM capable of self-correction that reportedly outperforms GPT-4o in all benchmarks, including MMLU.
- The open-source nature of this model, surpassing Llama 3.1's 405B, signifies a major leap in LLM functionality.
- Lucidrains Reworks Transfusion Model: Lucidrains has shared a GitHub implementation of the Transfusion model, optimizing next token prediction while diffusing images.
- Future extensions may integrate flow matching and audio/video processing, indicating strong multi-modal capabilities.
LangChain AI Discord
- ReAct Agent Deployment Challenges: A member struggles with deploying their ReAct agent on GCP via FastAPI, facing issues with the local SQLite database disappearing upon redeploy. They seek alternatives for Postgres or MySQL as a replacement for
SqliteSaver.- The member is willing to share their local implementation for reference, hoping to find a collaborative solution.
- Clarifying LangChain Callbacks Usage: Discussion emerged on the accuracy of the syntax
chain = prompt | llm, referencing LangChain's callback documentation. Members noted that the documentation appears outdated, particularly with updates in version 0.2.- The conversation underscored the utility of callbacks for logging, monitoring, and third-party tool integration.
- Cerebras and LangChain Collaboration Inquiry: A member inquired about usage of Cerebras alongside LangChain, seeking collaborative insights from others. Responses indicated interest but no specific experiences or solutions were shared.
- This topic remains open for further exploration within the community.
- Decoding .astream_events Dilemma: Members discussed the lack of references for decoding streams from .astream_events(), with one sharing frustration over manually serializing events. The conversation conveyed a desire for better resources and solutions.
- The tedious process highlighted the need for collaboration and resource sharing in the community.
LLM Finetuning (Hamel + Dan) Discord
- Enhancing RAG with Limited Hardware: A member sought strategies to upgrade their RAG system using llama3-8b with 4bit quantization along with the BAAI/bge-small-en-v1.5 embedding model while working with a restrictive 4090 GPU.
- Seeking resources for better implementation, they expressed hardware constraints, highlighting the need for efficient practices.
- Maximizing GPU Potential with Larger Models: In response, another member suggested that a 4090 can concurrently run larger embedding models, indicating that the 3.1 version might also enhance performance.
- They provided a GitHub example showcasing hybrid search integration involving bge & bm25 on Milvus.
- Leveraging Metadata for Better Reranking: The chat underscored the critical role of metadata for each chunk, suggesting it could improve the sorting and filtering of returned results.
- Implementing a reranker, they argued, could significantly enhance the output quality for user searches.
Gorilla LLM (Berkeley Function Calling) Discord
- XLAM System Prompt Sparks Curiosity: A member pointed out that the system prompt for XLAM is unique compared to other OSS models and questioned the rationale behind this design choice.
- Discussion revealed an interest in whether these differences stem from functionality or licensing considerations.
- Testing API Servers Needs Guidance: A user sought effective methods for testing their own API server but received no specific documentation in reply.
- This gap in shared resources highlights a potential area for growth in community support and knowledge sharing.
- How to Add Models to the Leaderboard: A user inquired about the process for adding new models to the Gorilla leaderboard, prompting a response with relevant guidelines.
- Access the contribution details on the GitHub page to understand how to facilitate model inclusion.
- Gorilla Leaderboard Resource Highlighted: Members discussed the Gorilla: Training and Evaluating LLMs for Function Calls GitHub resource that outlines the leaderboard contributions.
- An image from its repository was also shared, illustrating the guidelines available for users interested in participation at GitHub.
Alignment Lab AI Discord
- Greetings from Knut09896: Knut09896 stepped into the channel and said hello, sparking welcome interactions.
- This simple greeting hints at the ongoing engagement within the Alignment Lab AI community.
- Channel Activity Buzz: The activity level in the #general channel appears vibrant with members casually chatting and introducing themselves.
- Such interactions play a vital role in fostering community connections and collaborative discussions.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
{% if medium == 'web' %}
HuggingFace ▷ #announcements (1 messages):
Vision Language ModelsTau LLM Training OptimizationAfrican Language ModelsNo-Code AI Model TasksSelective Fine-Tuning of Language Models
- Introduction to Vision Language Models: A member shared a blogpost on vision language models, providing a concise overview of the subject.
- This introductory piece aims to illuminate the potentials of combining vision and language in AI applications.
- Optimizing Tau LLM Training: The Tau LLM series focuses on optimizing training processes and enhancing model performance.
- Hailed as an essential resource, it promises to simplify learning the ins and outs of LLM training.
- InkubaLM-0.4B Targets African Languages: The newly released InkubaLM-0.4B aims to support African languages and expand linguistic representation.
- Developed specifically for this purpose, it showcases a commitment to inclusivity in AI language models.
- Shadowbox Offers No-Code Model Task Construction: Introducing Shadowbox, a no-code constructor for AI tasks using FOSS models, simplifying user experiences.
- Users can create tasks without coding expertise, broadening accessibility to AI solutions.
- Selective Fine-Tuning with Spectrum: The concept of selective fine-tuning for language models was discussed, highlighting its benefits.
- By focusing on certain aspects, finer model performance enhancements can be achieved without comprehensive retraining.
HuggingFace ▷ #general (258 messages🔥🔥):
Code Generation EvaluationsModel Training IssuesData Handling for TrainingFine-tuning and Pre-trainingPerformance Analysis of Models
- Performance Analysis in Code Generation: Discussions included analyzing how often functions appear in datasets and whether common functions result in fewer errors, exploring metrics that consider functional correctness.
- Contributors noted that near-exact clones of functions generated by models might indicate contamination in the training data.
- Challenges in Model Training Setup: Members experienced issues related to hardware limitations, with several discussing their struggles using GPU resources effectively for training models.
- One user inquired about using platforms like Hugging Face for training, expressing concern about inadequate resources on their local setup.
- Insights on Pre-training and Data Quality: A paper was shared indicating the impact of including code in pre-training datasets and its benefits on non-code tasks and overall model performance.
- Participants debated whether excluding code from training sets could lead to less effective model outputs.
- Generation Scripts and Model Testing: A minimal script was provided for generating outputs from a specified base model, highlighting potential issues in post-processing results.
- Users were encouraged to test this script and analyze the generations, despite some concerns about the model's quality based on context length.
- Reflections on Model Evaluation Metrics: There was a consensus that static metrics for code generation are not ideal, with discussions emphasizing the importance of semantic correctness and functional output.
- Participants reflected on how certain metrics, including edit distance, correlate with model performance and reliability.
Links mentioned:
HuggingFace ▷ #today-im-learning (8 messages🔥):
Understanding Attention Mechanism in TransformersDiscussions on Cross-postingUsing AI for Tutoring KidsCreating a Python Microservice with Ollama
- Seeking clarity on the Attention Mechanism: A member asked about how to represent attention for a given token in transformers, specifically if it relates to the distance in latent vector space between tokens.
- They requested materials to aid in understanding this concept better, indicating a need for further explanation.
- Reminder on Cross-posting Etiquette: Multiple members discussed the issue of cross-posting questions in the channel, with one requesting to stop sending the same message across different channels.
- One member preferred to follow suggestions from other channels over the given advice, prompting another to state that one channel is sufficient.
- AI Tutoring for Kids without Bootcamp Approach: One member shared a learning experience regarding how to tutor kids on AI without the pressures of a formal bootcamp.
- This approach suggests a more engaging and less structured way to introduce children to AI concepts.
- Developing a Python Microservice with Ollama: A member inquired about creating a Python microservice using Ollama that can paraphrase sentences in ten different ways.
- This request indicates an interest in practical applications of AI in text manipulation tasks.
HuggingFace ▷ #cool-finds (2 messages):
ElasticsearchVespa Search Engine
- Goodbye Elasticsearch, Hello Vespa Search Engine: A member announced their transition from Elasticsearch to Vespa Search Engine in a tweet, creating some buzz.
- They included an emoji to express excitement: '👀' indicating positive anticipation for the change.
- Discussion on Search Engine Technologies: The shift from Elasticsearch to Vespa sparked a conversation about different search engine technologies and their advantages.
- Participants expressed curiosity about the performance and features of Vespa compared to traditional solutions.
Link mentioned: Tweet from Jo Kristian Bergum (@jobergum): Goodbye Elasticsearch, Hello Vespa Search Engine 👀
HuggingFace ▷ #i-made-this (14 messages🔥):
Pro-Pretorian Computer Vision SystemInteractive Model ComparatorChess Puzzle VisualizationTau LLM Series Update
- Pro-Pretorian Computer Vision System Launch: A member shared their completed first iteration of the Pro-Pretorian Computer Vision System, a Next.js app hosted on Azure with data persistence also on Azure, utilizing tfjs for inference via WebGL.
- They plan to enhance the system by adding fine-tuned models and creating a pipeline through their Hugging Face account for automation.
- Interactive Model Comparator Introduced: Another member presented the Interactive Model Comparator, a web tool designed for visually comparing output images of different machine learning models for computer vision tasks.
- The tool allows users to load images, switch between models, and preview comparisons in real-time, making it a valuable resource for researchers and developers, available on GitHub.
- Visualizing 4 Million Chess Puzzles: A project was highlighted where Hugging Face datasets were leveraged to visualize 4 million chess puzzles, with evaluations provided by Stockfish, detailing over 83 million chess positions.
- Key details include data formats and a link to the Lichess database for further exploration of chess evaluations.
- Exciting Updates in Tau LLM Series: Episode 15 of the Tau LLM series introduced various updates including automated data file de-duplication and a new ophrase Python module for generating paraphrases, enhancing dataset diversity.
- The episode promises the generation of new embeddings and a shift toward training an expanded dataset, aimed to bring efficiency and reduce entropy, shared via a YouTube link.
Links mentioned:
HuggingFace ▷ #reading-group (1 messages):
noaroggendorff: <@&1078351789843292311>
HuggingFace ▷ #core-announcements (1 messages):
Optimizing Flux and CogDiffusion modelsTorchAO
- New Recipe Repo Released for Optimization: A new GitHub repository has been released showcasing how to optimize Flux and Cog using diffusers and torchao, including both inference and FP8 training.
- This repo allows running Cog in just 3.1GB memory with quantization and various offloading methods.
- End-to-End Optimization for Diffusion Models: The repository provides comprehensive recipes aimed at optimizing diffusion models, making them more efficient in training and inference.
- It highlights techniques such as offloading and quantization, crucial for handling large model requirements.
Link mentioned: GitHub - sayakpaul/diffusers-torchao: End-to-end recipes for optimizing diffusion models with torchao and diffusers (inference and FP8 training).: End-to-end recipes for optimizing diffusion models with torchao and diffusers (inference and FP8 training). - sayakpaul/diffusers-torchao
HuggingFace ▷ #computer-vision (2 messages):
Medical dataset for disease detectionTraining Nougat and Donut
- Searching for medical datasets in CV: A member is looking for a good medical dataset for computer vision, aiming at disease detection or potentially for larger scale data generation using transformers.
- They expressed interest in datasets that could facilitate substantial data generation efforts.
- Training methods for Nougat and Donut: Another member inquired about anyone familiar with the specifics of training Nougat or Donut models.
- This could indicate a desire for insights on model architectures or training techniques relevant to these frameworks.
HuggingFace ▷ #NLP (4 messages):
OOM errors during evaluationDeepSpeed configuration for evaluationCustom Dataset for evaluationGPU distribution techniques
- OOM Errors Plague Evaluation Phase: Team encountered OOM errors during evaluation while using a custom setup with DeepSpeed, despite successful training on multiple GPUs.
- It was noted that smaller batches (<10 examples) evaluated fine, while larger batches (>100 examples) triggered the errors, leading to questions about GPU loading.
- Custom Dataset Recommended for Evaluation: A member advised to utilize a custom Dataset yielding specific batch sizes to mitigate OOM errors, suggesting starting evaluations with 50 examples as a test.
- They referred to the PyTorch Dataset tutorial for guidance on implementing this.
- Implementing Multi-GPU Distribution: There's a recommendation for using a custom evaluation loop to load data onto specific GPUs, facilitating distribution across multiple GPUs.
- Using methods like
data.to('cuda:1')for loading onto individual GPUs was suggested to directly tackle OOM issues.
- Using methods like
- Custom Evaluation Loop for Smaller Batches: Nympheliaa confirmed using a custom dataset and inquired about creating a custom evaluation loop with smaller batches for GPU distribution.
- They expressed intent to utilize techniques like torch DataParallel or DistributedDataParallel to better manage GPU resources.
HuggingFace ▷ #diffusion-discussions (10 messages🔥):
Flux img2img PipelineSD3 vs. SDXL modelsControlNets for SDXLAuto Class RecommendationsMemory Optimizations
- Flux img2img Pipeline not merged yet: A member noted that the Flux img2img feature is not merged and referenced an open PR for it. Another member confirmed the documentation contains information about Flux, including links to its blog post.
- Flux can be expensive to run on consumer hardware, but optimizations are possible, as discussed in a related blog post.
- Exploring Img2Img Pipeline Alternatives: When asked for alternatives to the Flux img2img Pipeline, a member suggested using the SD3 model for generic cases and SDXL for higher quality images involving humans. They also emphasized exploring ControlNets for enhanced functionality.
- Another member inquired about popular ControlNets for SDXL, and the response included suggestions like ControlnetUnion and Mistoline.
- Clarifying Usage of the Auto Class: A user asked whether they should simply use the Auto class for Img2Img alternatives while starting with SD. The conversation pivoted to model preferences for higher quality outputs, particularly involving human images.
- Documentation Discrepancies: There was a discussion regarding discrepancies in the documentation which mentioned a feature that isn't merged yet. The clarification was made that using the main branch references features that may not yet be fully integrated.
Link mentioned: Flux: no description found
Stability.ai (Stable Diffusion) ▷ #general-chat (274 messages🔥🔥):
ControlNet and Model UsageFlux vs. SDXL for Image GenerationScams and Online SafetyTagging and Workflow in ComfyUIIntegration of Extensions in Forge
- ControlNet Guidance and Model Pairing: Users discussed how to effectively use ControlNet, with specific emphasis on applying it to create accurate representations like hash rosin images using Loras along with various SDXL models.
- Recommendations for models included 'Flux' and specifics about how to integrate techniques like depth maps were mentioned to help achieve desired outcomes.
- Choosing Between Flux and SDXL for Logos: Flux was recommended over SDXL for generating logos, as it handles logos exceptionally well and allows for easy prompting without needing significant training.
- Conversely, users shared the difficulties employing SDXL for logos due to a lack of familiarity with the logo, thus advocating for Flux's capabilities.
- Online Safety and Scams Discussion: Members shared anecdotes about online scams and stressed the importance of vigilance, recalling how even experienced individuals can fall victim during vulnerable moments.
- Empathy was highlighted as a crucial approach to understanding the behaviors that lead to scams, indicating that scams are not exclusive to naive individuals.
- Tagging Techniques and Tools in ComfyUI: The conversation included using ComfyUI for tagging, likening the interface's functionality to Langflow and Flowise, which cater to LLM models.
- Community members discussed specific workflows in ComfyUI and adaptations made to enhance tagging effectiveness, emphasizing the flexibility it offers.
- Forge Extensions and Community Contributions: Users inquired about various extensions available in Forge, including those for utilizing ControlNet, and how these contribute to improving user experiences.
- A mention was made regarding community polls and their impact, suggesting that input could influence future releases, underlining the need for quality assurance.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #general (189 messages🔥🔥):
Congratulations on Y Combinator backingUnsloth AI functionality and supportModels for synthetic data generationReflection model performanceHardware requirements for Unsloth
- Congratulations to the team on YC backing: Members congratulated the team on their selection for Y Combinator, expressing excitement and support for their journey.
- The team reciprocated the gratitude and acknowledged the importance of community support.
- Unsloth's hardware compatibility in question: Discussions arose about Unsloth's compatibility with Mac systems, specifically in relation to CUDA support for GPU tasks.
- The team clarified they aim for hardware agnosticism but current limitations affect performance on certain setups.
- Recommendations for models in synthetic data generation: Kearm shared insights on using Mistral 8x7B tunes for synthetic data, while other models were also suggested, including jondurbin/airoboros-34b-3.3.
- Members discussed experimenting with these models for optimal results based on specific hardware limitations.
- Reflection model performance concerns: Members expressed mixed opinions about Matt Shumer's Reflection model, noting it has not performed well on private logic questions compared to other models like Claude 3.5 and GPT-4.
- There is ongoing skepticism regarding the model's capabilities and claims of being a top open-source LLM.
- Porting challenges for Mac users: Members discussed the need to port Unsloth functionalities like bitsandbytes and Triton for Mac users, highlighting the lack of CUDA support on Mac chips.
- The conversation emphasized the challenges of justifying high expenditures on hardware while attempting to optimize software compatibility.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #off-topic (10 messages🔥):
Evolution of UnslothEmoji CommunicationApp Promotion
- Evolution of Unsloth - A Fun Journey: A member shared a link discussing the Evolution of the Peaceful Sloth, sparking laughter about the topic.
- A reaction with emojis followed, showcasing enthusiasm for the discussion.
- Emojis as a Means of Communication: In a light-hearted moment, a member joked about being fine-tuned to convey messages using emojis, adding a playful tone to the chat.
- Yeppp fine tuned myself to do so.
- Conversation Around App Promotion: One member shared a link that seemed to promote an app directly after mentioning the evolution topic.
- This led to another member humorously stating, 'No promotion!', highlighting the spontaneous banter in the chat.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #help (43 messages🔥):
Unsloth Library InstallationKaggle Competition ConstraintsPhi 3.5 Fine TuningGemma-2-27B Loading IssuesMistral 7B Domain Limitation
- Unsloth Library Installation Problems: Some users reported issues with installing the Unsloth library on Kaggle, particularly with the latest notebook instructions. Assistance was sought regarding updates to the installation process.
- Participants are encouraged to share any recent development to address the installation problems users have been facing.
- Kaggle Competition Constraints on Internet Access: A member shared concerns regarding the requirement for no internet access during Kaggle competition submissions, impacting their ability to install required models and libraries. The discussion included suggested workarounds and potential solutions.
- Suggestions included running some cells with internet enabled before switching it off, although some felt that this would not adequately solve the problem.
- Phi 3.5 Template and Gibberish Output: Users reported challenges with the Phi 3.5 model returning gibberish outputs while attempting to fine-tune it during training. Adjusting parameters like temperature and top_p did not resolve the issue for all users.
- There was discussion on finding appropriate templates and troubleshooting methods, but many participants expressed frustrations with the model's performance.
- Gemma-2-27B Weight Initialization Warnings: Concerns were raised about initialization warnings for weights when loading trained Gemma-2-27B models, with users referencing a relevant GitHub issue for context. They sought workarounds to mitigate these warnings.
- Unexpected behavior was noted during model loading, prompting users to seek solutions from others who encountered similar issues.
- Limitations of Vision Models with Unsloth: A question was posed about using Phi 3.5 vision models with Unsloth, but the consensus was that it is not currently supported. There is anticipation that support for vision LLMs will be added in the future.
- Users expressed interest in the evolution of Unsloth's capabilities, especially concerning fine-tuning options for vision-related models.
Link mentioned: Qwen2 error when loading from checkpoint · Issue #478 · unslothai/unsloth: Works as expected when loading the base model, but when a LoRA checkpoint is loaded in place of the base model, unsloth returns: Unsloth cannot patch Attention layers with our manual autograd engin...
Unsloth AI (Daniel Han) ▷ #showcase (2 messages):
Comparison ReportsYouTube Explanations
- Interest in Comparison Reports: A member expressed interest in a report comparing certain topics, stating it would be interesting to read.
- No specific discussions or reports were mentioned regarding this comparison.
- Upcoming YouTube Video on Comparisons: Another member announced plans to create a YouTube video that will explain the comparisons in detail.
- This video aims to address the interest shown in comparing the relevant topics.
Unsloth AI (Daniel Han) ▷ #research (1 messages):
Message DuplicationChannel Oversight
- Duplicate Posting in Channels: A member questioned the rationale behind a message being posted in the channel, noting that it had already been shared in the 'help' channel.
- Please remove this was the direct request made, indicating frustration regarding the repetition of content.
- Concern Over Channel Management: The member expressed discontent over the lack of oversight in channel posts, highlighting that it led to confusion among participants.
- This reflects a broader concern regarding the organization and maintenance of topic relevance within the community.
LM Studio ▷ #general (142 messages🔥🔥):
Image API optionsReflection Llama-3.1 70B updatesLM Studio issuesScraping data with local LLMsAccessing Llama 3.1 405B model
- Searching for free high-limit Image API options: Users discussed potential free options for Image APIs with high limits, with curiosity about providers offering API access for models like Stable Diffusion.
- They also inquired about any providers giving access to these features at scale.
- Reflection Llama-3.1 70B receiving updates: Reflection Llama-3.1 70B has been hailed as the top open-source LLM, with new techniques enhancing its capability to detect and correct reasoning mistakes.
- Members also noted some performance issues and discussed working prompts for optimal behavior with the model.
- LM Studio issues with model downloads: A user reported problems downloading models after an update to version 0.3.2, leading to inquiries regarding certificate errors and potential solutions.
- Community members discussed workarounds like adjusting VRAM and context size, while also clarifying that the summarization feature of RAG does not support certain functions.
- Web scraping and local LLM utilities: A user inquired about agents for web scraping that could connect to LM Studio, with replies suggesting Python and tools like ScrapeGraphAI.
- Community advice focused on the efficiency of scraping first and then processing data with LLMs instead of trying to scrape with LLMs directly.
- Accessing Llama 3.1 405B model: A discussion took place on obtaining access to the Llama 3.1 405B model, highlighting accessibility issues users faced on the meta.ai site.
- Alternative recommendations included checking lmarena.ai or using different models, with speculation about potential filtering measures on meta.ai.
Links mentioned:
- ggml-quants : faster 1.625 bpw AVX2 vec_dot
Not using a lookup table anymore makes it match q4_0 speed.
- gguf-py : fix formatt...
LM Studio ▷ #hardware-discussion (59 messages🔥🔥):
Apple Event AnnouncementMac Studio Performance ConcernsNVIDIA RTX 3090 Performance with NVLinkLMStudio Boot Time IssuesNAS Usage with Apple Devices
- Apple Event Set for iPhones and Watches: The upcoming Apple event on 9/9 has been confirmed to focus on new iPhones and watches.
- Members expressed anticipation for updates on the latest devices.
- Mac Studio Slow with Large Models: Concerns arose about Mac Studio with 256GB+ memory being too slow for large models, prompting hopes for upgrades to LPDDR5X 10.7Gbps.
- A member pointed out that this could significantly improve performance across all M4s, boosting speeds by 70%.
- NVLink Boosts NVIDIA RTX 3090 Performance: Discussion highlighted that with 2 RTX 3090s, users can achieve between 10 to 25 t/s for running a 70B model.
- One member mentioned achieving 50 t/s with NVLink, although others questioned its impact on inference performance.
- LMStudio Experiences Extended Boot Times: Users reported that LMStudio is taking 15-20 seconds to boot, significantly longer than the 2 seconds pre-update.
- Investigations suggested that internet connection may be causing delays, possibly related to update checks.
- NAS Talk for Apple Users: A member shared their positive experience with using an Asustor NAS for storage management compared to desktop setups.
- There were suggestions on setting up backups for multiple devices and sharing resources across family devices efficiently.
Links mentioned:
Nous Research AI ▷ #general (190 messages🔥🔥):
Reflection 70B ModelHermes 3 and Llama 3.1 API UsageBenchmarking reflection and ICL performanceMCTS and PRM TechniquesQuantization Issues
- Reflection 70B Model Performance Comparison: Recent discussions highlighted mixed results with the Reflection 70B model, especially when compared against benchmarks like BigCodeBench-Hard, showing inferior performance in certain areas.
- Users noted that system prompts and tokenizer issues may significantly affect outcomes, complicating the evaluation process.
- API Options for Llama Models: A member inquired about the best API options for using Llama 3.1 70B models, pointing out the need for support for tool call formats.
- Suggestions included exploring platforms like Groq for efficient deployment.
- Exploring MCTS and PRM for Model Enhancements: Conversations suggested that combining MCTS (Monte Carlo Tree Search) with PRM (Probabilistic Roadmap) might yield better results for model training and evaluation.
- Members expressed excitement about testing these techniques in their projects.
- Quantization Challenges with AI Models: Quantization efforts for the FP16 version of the 70B model produced disappointing results, particularly noted by users experimenting with int4 quantization.
- Discussion continued around potential workarounds to improve model performance without sacrificing quality.
- Exploration of Cognitive Science Concepts: A member shared an academic paper discussing the dynamical hypothesis in cognitive science, indicating possible intersections with AI cognition.
- The conversation hinted at the philosophical implications of expressing cognitive processes as computational functions.
Links mentioned:
Nous Research AI ▷ #ask-about-llms (1 messages):
DeepSeek v2.5Coding improvements
- Inquiry on DeepSeek v2.5 Performance: A member requested users to report any noticeable improvements while using DeepSeek v2.5 for coding tasks.
- Please share experiences and insights!
- Expectation for User Feedback: The community anticipates user feedback on the efficacy of DeepSeek v2.5, especially regarding coding enhancements.
- Members are encouraged to contribute their findings to foster collective learning.
Nous Research AI ▷ #interesting-links (1 messages):
teknium: https://x.com/alexandr_wang/status/1832147956562284987?s=46
Latent Space ▷ #ai-general-chat (52 messages🔥):
OpenAI's $2000 Subscription ModelReflection 70B Model PerformancesSpeculative Decoding in InferenceNew Text-to-Music ModelsAI Scientist Testing Challenges
- $2000 Subscription for ChatGPT on the Table: An ongoing discussion arises around OpenAI considering a subscription model priced at $2000/month for its more advanced AI models, including the expected Orion model.
- The implications of this pricing and its justification remain a hot topic among community members who share concerns about accessibility.
- Reflection 70B Model Under Scrutiny: The Reflection 70B model's testing showed mixed results compared to Llama3, with lower performance on code benchmarks like BigCodeBench-Hard and Aider.
- Critics suggest that performance discrepancies stem from the model’s methodology, requiring more thorough examination before fully relying on its metrics.
- Speculative Decoding Promises Enhanced Performance: Together AI shares findings that speculative decoding can improve latency and throughput by up to 2x for long context inputs, contradicting prior assumptions about its effectiveness.
- This advancement signals a significant shift in how high-throughput inference can be optimized using existing frameworks.
- New Developments in Text-to-Music Models: A new open-source text-to-music model has been released, showcasing impressive sound quality and efficiency compared to existing solutions like Suno.ai.
- Developers express excitement for its application potential, despite mixed sentiments regarding comparative quality and usability in practical scenarios.
- Challenges with AI Scientist Testing: There are inquiries into testing the Sakana AI Scientist on models compatible with Apple Silicon due to PyTorch compatibility issues.
- Discussion indicates concerns over the model's effectiveness, with members urging further investigation into performance and potential improvements.
Links mentioned:
Latent Space ▷ #ai-in-action-club (76 messages🔥🔥):
AI Code EditorsHandling Errors in EngineeringTools for Code AutomationCollaboration with AIFine-tuning Models
- Exploring AI Code Editors: Members expressed interest in various AI code editors like Melty and Pear AI as alternatives to Cursor, with some discussing their unique features.
- There's curiosity around features and usability, particularly with comments and TODO lines being stripped out in Cursor.
- Engineering Beyond Happy Paths: Discussions pointed out that effective software engineering requires handling edge cases, with one member noting their happy path code comprises only about 10% of total work.
- This sparked a conversation about tools like Aider which assists in editing code effectively.
- Collaboration Tools in AI Development: Zed AI was highlighted as a powerful code editor for high-performance collaboration, with members noting its potential benefits for developers working with AI.
- However, it was pointed out that it currently lacks bitmap font support, limiting its applicability for some users.
- Upcoming Topics on LLMs: Talks are in place for covering fine-tuning techniques using Loras or quantization techniques in future sessions, showing engagement in advanced AI topics.
- Members exchanged thoughts about the intricate details of such tasks and the models involved.
- Error Handling in AI Development: Members discussed the importance of error handling in coding, where handling 'non-happy-path' scenarios sets engineering apart from simple prototyping.
- Familiarity with tools that facilitate error management was also shared, emphasizing the need for robust solutions.
Links mentioned:
OpenAI ▷ #ai-discussions (80 messages🔥🔥):
Perplexity usageRunwayML controversyReflection model testingLuma Dream Machine preferencesOpenAI tokens availability
- Perplexity praised for efficiency: Users highlighted their preference for Perplexity as it provides the fastest access to reliable information in a usable format, with some considering switching from their ChatGPT Plus subscriptions to it.
- One user emphasized that it works well for school as it is not blocked, and Arc browser has it integrated, making it a fantastic AI search engine.
- Tensions rise over RunwayML's customer service: A user shared a troubling experience with RunwayML, describing the abrupt cancellation of a planned community meetup without any explanation, highlighting dissatisfaction with their customer service.
- This incident raises concerns about Runway's responsiveness to its community, especially considering the loyalty of its paying members and the potential impact on their reputation.
- Testing the Reflection model: Discussion revolved around the Reflection Llama-3.1 70B model, with users expressing interest in its performance and the new training technique called Reflection-Tuning that corrects reasoning mistakes.
- One user linked to a platform where interested individuals can try the model, noting that improvements were made after initial testing issues.
- Luma Dream Machine offers competitive plans: Members compared Luma Dream Machine with other offerings, appreciating its flexibility with plans ranging from free to $399 a month, with a recommended $29.99 per month plan being suitable for most users.
- The growth potential of the service was discussed, with members keen on exploring its features as well.
- OpenAI tokens are being given away: A user offered OpenAI tokens for free, indicating they have 1,000 tokens available but do not intend to use them.
- This sparked interest among channel members, suggesting a possible exchange or use of the tokens within the community.
Links mentioned:
OpenAI ▷ #gpt-4-discussions (10 messages🔥):
Rate Limit IssuesCustom GPT Sharing ProblemsBrowser Compatibility
- ChatGPT rate limit confusion persists: A Plus user reported consistently receiving an 'exceed rate limit' message despite minimal usage and switching to 4o mini. This issue prompted suggestions to seek help from OpenAI.
- The user expressed frustration over the limitations despite paying for the service, 'I haven't used ChatGPT for over 12 hours...'.
- Issues with sharing custom GPTs: Several users discussed difficulties in saving changes and sharing their custom GPTs, indicating a Fluctuating access issue. One noted that after deleting a file, sharing became possible but reverted with any new additions, resulting in an 'updates pending' status.
- Users are concerned this glitch may hinder functionality, hoping for a fix in future updates, as indicated by 'perhaps they will look into a fix in the next update.'
- Browser compatibility raises questions: A user mentioned experiencing the same issues on Firefox while testing on Chrome mobile. This led to speculation about the problem not being solely browser related.
OpenAI ▷ #prompt-engineering (10 messages🔥):
Incorporating tool callsPrompt library locationCreative prompt usage
- Success with Tool Calls: A member inquired about successfully incorporating tool calls into prompts, expressing frustration over error messages due to incorrect structure.
- Another member shared their success in creating tool chains using over ten Python tool calls in a single output, emphasizing the importance of using the correct tool name.
- Example for Tool Call Structure: After struggling, a member reported figuring out the structure to include Tool results with the correct matching IDs: an Assistant message followed by a Tool message.
- This highlights the need for meticulous attention to ID alignment in tool interactions.
- Prompt Library Access: A member asked for the location of the prompt library and was quickly informed by another member that it's called <#1019652163640762428> now.
- This demonstrates the community's willingness to assist with navigation within the platform.
- Unique Prompt Discovery: A member shared a quirky prompt idea that involves writing the entire content of the buffer to a code block verbatim.
- This showcases the creativity within the community in exploring different ways to use prompts.
OpenAI ▷ #api-discussions (10 messages🔥):
Incorporating Tool CallsPrompt Library LocationBuffer Content Prompt
- Success with Tool Calls in Prompts: A member expressed frustration with incorporating tool calls into prompts, mentioning that they received a simple error message from OpenAI.
- Another member claimed they successfully create tool chains using over ten python tool calls in a single output.
- Correct Tool Structure Explained: A member shared how to properly structure tool calls, emphasizing the need to follow an Assistant message with content and a corresponding Tool Message for the result.
- They realized their mistake when they forgot to add the tool result after one tool call.
- Finding the Prompt Library: A member inquired about the location of the prompt library, asking for guidance on where to find it.
- A response indicated that the prompt library is now referred to as <#1019652163640762428>.
- Interesting Prompt Found: A member shared a fun prompt they encountered, which instructs to output the entire content of the buffer verbatim.
- This prompt highlights the capability to capture comprehensive context and instruction from preceding conversations.
Eleuther ▷ #general (97 messages🔥🔥):
Academic Lab OpportunitiesUniversal TransformersRecurrence in Neural NetworksComputational Resource ChallengesIndependence in Research
- Exploring Academic Lab Opportunities: Members discussed the intricacies of securing roles in academic labs, noting that while internship programs exist, cold emailing is another option with lower success rates.
- One suggested writing a project proposal to pitch to labs, underscoring the importance of showcasing research, particularly if it's aligned with current trends.
- Universal Transformers Under Scrutiny: The conversation ventured into the feasibility of Universal Transformers (UTs), with one member expressing a personal obsession with this niche even if others doubt their future utility.
- They also highlighted discussions on adaptive implicit compute in UTs that could enhance performance, though stability remains a substantial barrier to implementation.
- Resource Allocation in Research: Concerns were raised about resource allocation in both academia and research labs, particularly how compute availability tends to favor product-focused projects over unconventional research.
- Members reflected on how seniority and alignment with popular research interests might impact an individual's freedom and available resources in institutions like DeepMind.
- Cultural Differences in Funding Between US and Europe: A member noted distinct differences in academic cultures between the US and European institutes, highlighting that European funding tends to be more relaxed.
- Despite the perceived freedom in academia, the 'publish or perish' culture can pressure researchers to conform to popular topics, complicating niche pursuits.
- Challenges with Recurrence in Models: The discussion touched on recurrence models, with a focus on Deep Equilibrium Models (DEQs) and their comparison to traditional RNNs and state space models.
- While some members shared enthusiasm for recurrence research, others expressed skepticism regarding the future of this approach, reinforcing its niche status.
Link mentioned: Universal Transformers: Recurrent neural networks (RNNs) sequentially process data by updating their state with each new data point, and have long been the de facto choice for sequence modeling tasks. However, their inherent...
Eleuther ▷ #research (5 messages):
Momentum-based OptimizersReinforcement Learning AutomationGradient Cosine SimilarityConsecutive Gradient Analysis
- AdEMAMix Optimizer Enhances Gradient Utilization: A proposed modification to the Adam optimizer, AdEMAMix, utilizes a mixture of two Exponential Moving Averages (EMAs) to optimize the handling of past gradients better than a single EMA PDF.
- This approach aims to balance the weight of recent gradients with older ones more effectively, which has shown promising results in language modeling and image classification.
- Automated Reinforcement Learning Agent Architecture: A new agent architecture automates aspects of reinforcement learning workflows, allowing it to independently manage experiment progress and build curricula using a Vision-Language Model (VLM) PDF.
- This system decomposes tasks into subtasks and retrieves skills, marking one of the first implementations of a fully automated reinforcement learning process.
- Gradient Cosine Similarity Insights: Cosine similarities of consecutive gradients suggest a recurring pattern in training datasets, correlating with the percentage of equal gradient signs and indicating underlying sequence structures.
- This correlation hints at the notion that gradients may increasingly point in similar directions under certain dataset conditions.
- Linear Relationship Between Gradients and Loss Derivative: A member noted that the cosine similarity of consecutive gradients seems to exhibit a linear relationship with the derivative of loss during training.
- This observation suggests deeper ties between gradient behavior and loss metric trends.
- Insights and Resources on Model Training: Links to the Model Card for the Distily Attn MLP sweep were shared, along with access to Training Metrics and Community Discussions.
- These resources provide a comprehensive overview of model performance and community interactions related to the sweep.
Links mentioned:
Eleuther ▷ #lm-thunderdome (2 messages):
Reusing Model Outputslm-evaluation-harness
- Inquiry on Reusing Model Outputs for Benchmarks: A member inquired about the possibility of reusing model outputs for multiple benchmarks if the datasets coincide, highlighting a concern about efficiency.
- This raises important questions about how outputs can be effectively shared across different evaluations to save time and resources.
- lm-evaluation-harness GitHub Resource Shared: A member shared a link to the lm-evaluation-harness, a framework for few-shot evaluation of language models.
- This resource may provide useful insights into how model result management can be optimized across various benchmarks.
Link mentioned: GitHub - EleutherAI/lm-evaluation-harness: A framework for few-shot evaluation of language models.: A framework for few-shot evaluation of language models. - EleutherAI/lm-evaluation-harness
Eleuther ▷ #gpt-neox-dev (2 messages):
Hugging Face RoPE Implementation CompatibilityTraining Model for 1 Epoch
- Hugging Face RoPE compatibility in GPTNeoX: A member inquired about the compatibility between the Hugging Face implementation of RoPE for GPTNeoX/Pythia and that used by Llama/GPT-Fast.
- They observed that attention outputs from the scale_dot_product_attention function were significantly different (over 95%) between their implementation and the Pythia model.
- Running model for just one epoch: Another member asked if it's possible to run the model for just 1 epoch or if they need to compute the
train_itersmanually.- They speculated that
train_iterscould be calculated as num_data_sequences/(batch_size * number_of_ddp_processes).
- They speculated that
OpenInterpreter ▷ #general (74 messages🔥🔥):
Open Interpreter birthday celebrationSkills functionality in OIFeedback on 01 app performanceFulcra app availabilityBeta testing for OI
- Open Interpreter celebrates a milestone: Members enthusiastically celebrated the birthday of Open Interpreter, with comments expressing excitement about its potential in AI-human interaction.
- Happy Birthday, Open Interpreter! was a recurring sentiment, showcasing community appreciation for the innovation.
- Skills in Open Interpreter still experimental: Discussion highlighted that skills functionality in OI is experimental, with users asking about the persistence of skills across sessions.
- One user noted that skills appear to be temporary, with suggestions to check the skills storage location on their machine.
- Positive feedback on 01 app performance: Users were impressed with the performance of the 01 app, with one stating it efficiently searched and played a song from 2,000 audio files.
- There were some mentions of inconsistencies in results, reflecting typical early access app experiences.
- Fulcra app expands to new regions: The Fulcra app has launched in multiple new regions based on community requests, enhancing its accessibility.
- Users inquired about the availability in Australia, signaling interest in expanding reach further.
- Beta testing opportunities for Open Interpreter: Community members expressed interest in participating in beta testing, with confirmations that opportunities were still available.
- The enthusiasm for early access testing reflects a supportive and engaged user base.
Links mentioned:
OpenInterpreter ▷ #O1 (8 messages🔥):
Beta role for desktopOpen Interpreter 01 issuesAudio device inquiry
- Request for Beta Role Access: Multiple users expressed a desire for access to the beta role for desktop, including a fan who worked on the dev kit for Open Interpreter 01.
- One user noted, 'Wasn't able to join live—any way to get access to the beta role for desktop?'.
- Issues Running 01 on M1 Mac: A member on an M1 Mac reported issues with running Open Interpreter 01, citing errors with torch and environment conflicts.
- They reached out for help, asking if any expert would be willing to troubleshoot live, stating, 'DM me if you're down.'.
- Inquiry About Audio Device: A user asked if the 01 audio device was mentioned during the presentation, following a positive comment about the session.
- This indicates a keen interest in the technology discussed.
Modular (Mojo 🔥) ▷ #general (13 messages🔥):
404 on values pageIntegration of C and MojoCompany culture link update
- 404 Error on Values Page: Members discussed that the values page on Modular's site is currently returning a 404 error at this link. It was suggested that it might need to point to company culture instead.
- C and Mojo Integration Made Simple: A member inquired about integrating C with Mojo, and another member confirmed that it is possible to dynamically link to a
.sofile usingDLHandle.- An example was provided:
handle = DLHandle('path/to/mylib.so')followed by calling the functionis_evenfrom the C library.
- An example was provided:
- Company Culture Link Location: A user asked where the company culture link was found, and another user specified it was in the careers post under the section 'core company cultural values'.
- This was confirmed with appreciation from another member, thanking for the clarification.
Links mentioned:
Modular (Mojo 🔥) ▷ #mojo (68 messages🔥🔥):
Mojo async functionalityUse of DType as Dict keyImprovements in constructor usageWrapper for pop.arrayMLIR and IR generation in Mojo
- Mojo's Async Functions Confusion: A user reported issues with using
async fnandasync def, indicating their attempts did not work in the stable build of Mojo.- It was clarified that async features are only available in nightly builds, leading to a suggestion to check the version being used.
- DType Cannot Be Used as Dict Key: A user questioned why
DTypecannot be used as a key in a Dictionary, despite it implementing theKeyElementtrait.- This issue sparked a discussion about the constraints and usage of types in Mojo's data structures.
- Enhancements in Constructor Usage: A user shared progress in resolving constructor issues related to
Arc[T, True]andWeak[T], emphasizing the complexity with @parameter guards.- Suggestions were made to maintain consistent naming in the standard library and improve the structure of types for better clarity.
- Wrapper for pop.array Insights: A member discussed creating a wrapper for
pop.arrayintended for optional fields, revealing some difficulties in locating the implementation.- Further notes were made about refining pointer indirection within the data structure to enhance usability.
- Discussion on MLIR and IR Generation: Several users expressed interest in how MLIR can be utilized more effectively within Mojo, particularly regarding IR generation and its benefits.
- A video from a LLVM meeting was proposed as a valuable resource to understand Mojo's interplay with MLIR and LLVM in further detail.
Link mentioned: 2023 LLVM Dev Mtg - Mojo 🔥: A system programming language for heterogenous computing: 2023 LLVM Developers' Meetinghttps://llvm.org/devmtg/2023-10------Mojo 🔥: A system programming language for heterogenous computingSpeaker: Abdul Dakkak, Chr...
CUDA MODE ▷ #general (4 messages):
Reflection 70B modelReflection Tuning techniqueTogether's custom kernel performance
- Announcement of Reflection 70B Model: An exciting announcement revealed the launch of Reflection 70B, claimed to be the world’s top open-source model using Reflection-Tuning to allow LLMs to correct their own mistakes.
- A forthcoming 405B model is anticipated next week to potentially outperform all existing models in the market.
- Explaining Reflection Tuning: Discussion emerged on Reflection-Tuning, with claims that it integrates and tags for Chain of Thought (CoT) and self-reflection in outputs, as illustrated in this example of long addition.
- It's suggested that synthetic training data, possibly generated with STaR, plays a crucial role in the training process.
- Together GPU Clusters' Performance Boost: Questions arose about new 20% faster MLP kernels released by Together, which promise significant speed improvements for AI operations, claiming up to 24% faster training and 75% faster FP8 inference compared to standard implementations.
- These enhancements are designed to reduce GPU hours and associated costs, thereby accelerating time to market for AI solutions.
Links mentioned:
CUDA MODE ▷ #triton (9 messages🔥):
Debugging tips for TritonMLIR_ENABLE_DUMPTRITON_INTERPRETTriton vs Marlin comparisonQuantum zero effects
- Use MLIR_ENABLE_DUMP for debugging: A member suggested using
MLIR_ENABLE_DUMP=1to dump MLIR after each compiler pass, showing the IR before and after TTIR, TTGIR, and LLIR generation.- This allows for detailed insight into how Triton is compiling code, potentially aiding in pinpointing issues.
- TRITON_INTERPRET is a helpful tool: Another user mentioned that
TRITON_INTERPRET=1is one of the best debugging aids in Triton.- The community seems to agree that adjustments to settings can greatly facilitate troubleshooting.
- Environment variables essential for debugging: A member highlighted that the README contains various environment variables that may assist in debugging tricky issues, although not all will be necessary.
- They encouraged checking these out as they can provide significant help in overcoming challenges.
- Triton shines with minimal code: A user expressed how impressive the capabilities of Triton are, noting that significant tasks can be accomplished with just a few lines of code.
- However, they clarified that comparing Triton with Marlin (VLLM) isn't straightforward due to differences in how zero quantization is handled.
- Concerns over quantizing zeros: A discussion arose about the drawbacks of quantizing zeros, referencing potential accuracy issues with this approach.
- Another member noted that in the Marlin implementation, they mainly round the zeros for AWQ, with a distinction between symmetric and asymmetric quantization.
Link mentioned: GitHub - triton-lang/triton at 7480ef5028b724cb434b7841b016c6d6debf3b84: Development repository for the Triton language and compiler - GitHub - triton-lang/triton at 7480ef5028b724cb434b7841b016c6d6debf3b84
CUDA MODE ▷ #torch (1 messages):
TorchDynamo Cache LookupPerformance Issues with Large Modelstorch/nn/modules/container.py
- Investigating TorchDynamo Cache Lookup Delays: When running very large models, members noted that 600us is spent in TorchDynamo Cache Lookup due to frequent calls to
torch/nn/modules/container.py(320): __getitem__.- A query was raised about the specific location of this logic, seeking pointers for further investigation.
- Performance Concerns in Large Models: There is ongoing discussion about the performance impact on large models with particular focus on cache lookup delays.
- This highlights the need for optimization strategies as these delays can accumulate during model training and inference.
CUDA MODE ▷ #cool-links (3 messages):
NVIDIA Generative AI Teaching KitEfficient Machine Learning CourseModel Compression TechniquesLlama2-7B Deployment
- NVIDIA collaborates with Dartmouth for AI education: NVIDIA's Deep Learning Institute released a generative AI teaching kit developed with Dartmouth College, aimed at empowering students to understand GPU-accelerated applications.
- Sam Raymond emphasized that students completing this course will gain a significant advantage in the job market, aiding in bridging knowledge gaps in various industries.
- MIT's Efficient Machine Learning Course Announcement: A new course at MIT focuses on efficient machine learning and systems to tackle the computational demands of deep neural networks, which burden cloud infrastructure and everyday devices. Topics covered include model compression, pruning, and quantization.
- Students will gain hands-on experience deploying Llama2-7B on laptops, learning practical techniques to enhance deep learning applications on resource-constrained devices.
Links mentioned:
CUDA MODE ▷ #jobs (3 messages):
Citadel Securities hiringLiquid AI remote rolesCUDA Mode awareness
- Citadel Securities seeks research engineers: Citadel Securities is looking for research engineers experienced in Triton and/or CUDA, emphasizing their capability to train models on terabytes of financial data.
- They aim to optimize their training pipeline and enable production deployment within days, with more details available on their careers page.
- Remote roles at Liquid AI catch attention: A member pointed out exciting remote opportunities at Liquid AI, specifically for the Member of Technical Staff - AI Inference Engineer position.
- The roles are fully remote across major cities, and the talent lead is familiar with CUDA mode, making it a promising application for interested engineers.
- Positive feedback on posting jobs in CUDA mode: Another member shared that they know a recruiter at Liquid AI and complimented them for posting job openings in CUDA mode.
- This indicates a supportive community and sharing of relevant opportunities in the AI field.
Link mentioned: Liquid AI jobs: Job openings at Liquid AI
CUDA MODE ▷ #beginner (9 messages🔥):
Image Convolution OptimizationControl Divergence vs ArithmeticTriton Kernels for LLM Training
- Beginners Explore Image Convolution Optimizations: A member shared their experimentation with optimization techniques for improving image convolution, highlighting constant memory use and unexpected register behavior.
- Local memory usage reduced the constant load, challenging the member's understanding of memory access patterns.
- Control Divergence vs Arithmetic Discussions: The community analyzed the performance implications between control divergence in CUDA, with one member favoring option 1 due to compiler optimizations and fewer global memory accesses.
- Conversely, another pointed out that option 2 struggles with automatic coalescence, complicating its efficiency.
- Exploring Google Triton for Training: A member expressed their excitement about the Google Triton group and a YouTube lecture on efficient Triton kernels for LLM training.
- They plan to delve into tutorials and contribute to the community in the forthcoming weeks.
Link mentioned: Lecture 28: Liger Kernel - Efficient Triton Kernels for LLM Training: Byron Hsu presents LinkedIn's open-source collection of Triton kernels for efficient LLM training.TIMESTAMPS00:00 Host Opening00:22 Main Focus01:18 Outline03...
CUDA MODE ▷ #jax (1 messages):
0ut0f0rder: Thanks!
CUDA MODE ▷ #torchao (14 messages🔥):
Batch Size Limitations in FP16 x INT8 MatmulTorch Compiler Performance IssuesTorchao Installation Errors
- FP16 x INT8 Matmul hits wall with batch size > 1: The FP16 x INT8 matmul with
torch.compilebreaks when the batch size exceeds 1 on a 4090 RTX, raising an error related to shared memory capacity.- Users speculate that the inductor configurations are likely tuned for A100 GPUs, leading to failures on less powerful devices.
- Performance drop with flags on inductor: When the inductor flags are enabled, computations become significantly slower with batch sizes greater than 1, despite sometimes not throwing an error.
- Turning the flags off allows the matmul operation to proceed without errors, albeit at reduced speed.
- Torchao installation error resolved: After encountering a
RuntimeErrorrelated totorchao::quant_llm_linearduring installation, a user linked to a potential fix in a GitHub pull request.- Following the suggested correction, the error was resolved, enabling successful import of the necessary modules.
Link mentioned: Unbreak build after #621 by andrewor14 · Pull Request #826 · pytorch/ao: no description found
CUDA MODE ▷ #off-topic (9 messages🔥):
Avoiding Burnout StrategiesPersonal Projects for ProductivityFlow State in ProgrammingWork-Life BalanceNew System Torture Test Script
- Avoiding Burnout Made Simple: A member expressed that it's better to consistently give 95% effort rather than push for 105%, emphasizing it leads to greater sustainability and productivity in the long run.
- They highlighted that identifying what’s in your control and accepting what isn’t are crucial for managing personal goals without falling into the burnout trap.
- Side Projects Reignite Passion: Another member shared that engaging in small side projects outside of work has helped counteract burnout, allowing them to feel rewarded without corporate stress.
- They noted that this approach keeps the joy of programming alive and prevents feelings of stagnation.
- Finding Your Flow State: The discussion highlighted the importance of reaching a flow state in programming, with members agreeing that nothing compares to that intense focus and productivity.
- One noted that while they find coding easier to justify when it's for school or income, maintaining that flow is crucial.
- Work-Life Balance Importance: Several members agreed on the necessity of maintaining a balance in personal care, stating that neglecting basic needs leads to decreased productivity and misery.
- They emphasized that fun and enjoyment in work improve output, advising to deal with life’s challenges before diving deep into work.
- Introducing a System Torture Test Script: One member shared a new system torture test script that runs valid Bash, C, C++, and CUDA all at once, providing a fun and useful challenge for users.
- The script can be found on GitHub, showcasing how it compiles itself and launches testing kernels based on available compilers.
Links mentioned:
CUDA MODE ▷ #llmdotc (6 messages):
Small Talk on llm.c in YerevanInnovative Uses of llm.cNCCL Multi-GPU TrainingScaling on GPUs
- Upcoming Talk on llm.c in Yerevan: @aleksagordic announced a small talk on llm.c in Yerevan, aiming to provide a high-level overview, including contributions from others.
- Members expressed excitement and interest, with one looking forward to a recording of the talk.
- Collecting Creative Uses of llm.c: A query arose about whether there’s a compiled list of creative ways people have utilized llm.c, aside from forks.
- The discussion highlighted a specific instance where chinthysl ran llm.c on 472x H100s, showcasing the capability of scaling.
- NCCL Multi-GPU Multi-Node Training Success: A member referenced a GitHub PR by chinthysl on running NCCL only multi-GPU training without MPI, which simplified job scheduling using Slurm.
- It was noted that they achieved linear scaling up to at least 128 GPUs, marking a notable success in performance.
- Excitement Around llm.c Performance: Some members expressed enthusiasm over the impressive scaling results observed in chinthysl's GPU runs, especially regarding the 472x GPU setup.
- They noted that chinthysl's figures showed improvement after certain fixes, reinforcing the effectiveness of the method.
Link mentioned: NCCL only multi-gpu multi-node training without MPI by chinthysl · Pull Request #426 · karpathy/llm.c: Scheduling jobs using Slurm seems much easier in a multi-node training setup compared to setting up MPI for the cluster. This draft contains the changes to use mpirun for single-node training and S...
CUDA MODE ▷ #liger-kernel (5 messages):
Multimodal Convergence TestsLiger's Swiglu Kernels performanceTogether AI's GPU ClustersPerformance comparison against cuBLASKernel optimization strategies
- Multimodal Convergence Tests PR Ready for Review: A member announced that a pull request is ready for review, which includes multimodal convergence tests.
- This new feature is expected to enhance the testing capabilities of the implementation.
- Liger's Swiglu Kernels vs Together AI Benchmarks: A member inquired about the performance of Liger's swiglu kernels compared to benchmarks from Together AI.
- They highlighted that Together's TKC offers up to 24% speedup for frequent training operations.
- Performance Assessment of Specialized Kernels: It was shared that their specialized kernel outperforms the common implementation using cuBLAS and PyTorch eager mode by 22-24%.
- Members discussed the lack of granular tuning as a potential area for improvement in their fusion process.
- Curiosity About Performance Achievements: A member asked for insights on how Together AI achieves their performance improvements compared to other implementations.
- This reflects ongoing interest in understanding best practices for kernel optimization.
Link mentioned: Supercharging NVIDIA H200 and H100 GPU Cluster Performance With Together Kernel Collection: no description found
Interconnects (Nathan Lambert) ▷ #news (43 messages🔥):
Reflection Llama-3.1 70BGlaive data usageModel performanceHype around LLMsFeedback on self-reflection prompts
- Reflection Llama-3.1 70B faces mixed results: The recently released Reflection Llama-3.1 70B claims to be the world's top open-source model but has shown disappointing performance on benchmarks like BigCodeBench-Hard, with scores much lower than previous models.
- One user noted a decline in performance for reasoning tasks and humorously described the model's reception on Twitter as 'non news item meh model'.
- Concerns over Glaive's synthetic data: Some users expressed skepticism about the effectiveness of synthetic data generated by Glaive, referencing past contamination issues in datasets.
- The conversation hinted at the possibility that this synthetic data might have adversely affected the performance and generalization capabilities of the Reflection Llama model.
- Intrigue around self-reflection capabilities: Questions arose regarding the underlying logic of the self-reflection process, with suggestions that models might learn to generate errors purposely to enable reflections and corrections.
- Critics pointed out that if the training data emphasizes corrections over correct reasoning, it could cultivate a disadvantageous model behavior.
- The impact of social media hype: The group acknowledged the significant hype surrounding new AI models, emphasizing how social media can amplify expectations despite potential performance discrepancies.
- One commenter humorously remarked on the Twitter hype culture, suggesting that it fosters unnecessary excitement around models that may not perform as advertised.
- Discourse contributing to SEO: Several users recognized the merit of engaging in Twitter discussions for enhancing blog post visibility and SEO metrics.
- One individual expressed a pragmatic view on participating in the discourse primarily for the benefit of their online presence, despite personal skepticism about the model.
Links mentioned:
Interconnects (Nathan Lambert) ▷ #ml-questions (5 messages):
HuggingFace NuminaMath benchmarksCHAMP benchmarkResearch queries
- HuggingFace Numina is a valuable resource: Recent discussions highlighted that HuggingFace Numina offers great tools for data-related tasks, making it a valuable asset for researchers.
- Members expressed excitement about its potential applications in various projects.
- Standard math benchmarks remain unchanged: Despite having many tools available, the general sentiment is that there are not many new math benchmarks, with focus still on MATH and GSM8k.
- This could indicate a need for fresh datasets or evaluation metrics to further the field.
- Introduction of CHAMP benchmark: A new benchmark dataset called CHAMP was introduced, focusing on examining LLMs' mathematical reasoning ability using annotated math problems with hints.
- This aims to provide a framework for exploring how additional information impacts problem-solving in complex scenarios.
- Research collaboration sought: A user sought input on unconventional HuggingFace projects that might be off the beaten path for a research endeavor.
- There was an appeal for any notable resources or ideas that could aid in advancing their research.
Link mentioned: CHAMP: A Competition-level Dataset for Fine-Grained Analyses of LLMs' Mathematical Reasoning Capabilities: Recent large language models (LLMs) have shown indications of mathematical reasoning ability on challenging competition-level problems, especially with self-generated verbalizations of intermediate re...
Interconnects (Nathan Lambert) ▷ #random (16 messages🔥):
Reliability of Fireworks and TogetherGitHub organization takedownsStandardization of AI chat logsEmbarrassment in AI interactionsChat templates for AI models
- Fireworks and Together Reliability Issues: Users discussed the reliability concerns of Fireworks and Together, acknowledging that neither is 100% reliable.
- To address this, they have implemented failovers to ensure functionality.
- Curiosities about GitHub Takedowns: A query arose regarding whether GitHub takes down organizations without supplying a reason, with some recalling past instances of this occurring.
- Concerns were expressed about the lack of communication, particularly for larger entities like Alibaba.
- Need for Standard AI Chat Logs: A member proposed that there should be a standard
chats.txtfile to document interactions with AI for better codebase documentation.- Another suggested that Cursor enhances this idea's utility, indicating a shift that may already be happening.
- Embarrassment About AI Questions: Concerns were voiced about the embarrassment of asking simple questions to Cursor, wishing to maintain the facade of competence.
- This sentiment resonated with others, highlighting a common fear of being perceived as inexperienced.
- Chat Templates for Model Standardization: A suggestion was made to standardize chat templates for AI models as a precursor to implementing a
chats.txtfile.- This playfully implied hidden goals towards creating such a standardized logging system.
Perplexity AI ▷ #general (42 messages🔥):
Getting into Tech with No ExperienceBing Copilot CapabilitiesPerplexity AI Referral ProgramWeb3 Innovation Job Opportunities
- Advice for Entering Tech Industry without Skills: A member expressed eagerness to enter the tech industry without technical skills, seeking advice on building a compelling CV and networking effectively.
- Another member mentioned starting cybersecurity training through PerScholas, highlighting enthusiasm for coding and AI.
- Bing Copilot's Source Presentation: A user compared Bing Copilot's ability to provide up to 5 sources with inline images to Perplexity's current capabilities.
- They suggested that Copilot's hover preview cards on citations might be an enhancement Perplexity could consider implementing.
- Perplexity AI Referral Program for Merch: A shared link revealed that Perplexity is offering new merchandise through a referral program aimed at students, emphasizing sharing to earn more.
- Another member queried about obtaining a year of free access, asking if it was limited to the first 500 sign-ups.
- Job Openings in Web3 Innovation Team: A post highlighted job openings in a Web3 innovation team, seeking positions from beta testers to developers and UI/UX designers.
- The team invites applications and proposals for mutually beneficial cooperation as part of their creative vision.
Link mentioned: Tweet from Perplexity (@perplexity_ai): New merch for students 🔜 Just one way to get it: refer your friends to Perplexity! Share more, get more: http://perplexity.ai/backtoschool
Perplexity AI ▷ #sharing (11 messages🔥):
Sutskever's SSI fundingVolkswagen ChatGPT integrationAI-powered worldbuildingNFL 2024 season kickoffVehicle-to-everything tech
- Sutskever's SSI Secures $1B Funding: Perplexity AI announced that Sutskever's SSI has successfully raised $1 billion to further its advancements in AI technology.
- This sizable funding is expected to drive more innovations in the AI sector.
- Volkswagen Teams Up with ChatGPT: Volkswagen has integrated ChatGPT into its systems, enhancing user interaction and driving experience.
- This move represents a significant step toward integrating advanced AI capabilities into automotive technologies.
- Biohybrid Mushroom Robot Unveiled: Biohybrid mushroom robots are now a reality, showcasing exciting developments in robotics and biotechnology.
- These robots are designed to interact with their environment in unique ways, pushing the boundaries of traditional robotics.
- NFL 2024 Season Kickoff Announced: The NFL 2024 season kickoff details have been unveiled, generating excitement among fans and teams.
- Fans are particularly looking forward to the new teams and players joining the roster this season.
- Exploring Vehicle-to-Everything Tech: The latest discourse surrounding vehicle-to-everything (V2X) tech highlights its potential in improving traffic efficiency and safety.
- Innovations in V2X are anticipated to enhance connectivity between vehicles, infrastructure, and pedestrians.
Link mentioned: YouTube: no description found
Perplexity AI ▷ #pplx-api (2 messages):
pplx-api memory usageTelegram bot memory storage
- Inquiry about Memory Usage in pplx-api: A member asked if it's possible to utilize memory storage while using the pplx-api through Python.
- They requested guidance on how to implement this feature.
- Telegram Bot's Memory Storage Strategy: Another member shared their attempt to achieve memory usage by managing it with a separate database for their Telegram bot.
- This suggests an interest in integrating memory capabilities into current chat systems.
tinygrad (George Hotz) ▷ #general (15 messages🔥):
Bounty QuestionsTinygrad PricingServer RelevanceCode ReadabilityGuidelines Acknowledgment
- Bounty Exploration Initiation: A user expressed interest in trying out a bounty and asked for guidance on where to start, prompting a response pointing to a resource on asking smart questions: Smart Questions FAQ.
- User th.blitz humorously acknowledged this guidance.
- Tinygrad Pricing Drops to Zero: A user questioned a post about offering a 4090 + 500GB for $60 a month, and georgehotz revealed that the price had been dropped to $0, but only for friends of tinygrad.
- r5q0 immediately inquired about becoming friends.
- Server's Relevance to AI Queries: One user pointed out that another user's questions about AI architecture/dataset/LLM finetuning were off-topic in the tinygrad server, which focuses on a different abstraction level.
- This user suggested that while some members might have expertise, the questions were likely not well-received in this context.
- Code Readability Concerns: A member expressed difficulty reading the tinygrad code due to the lack of enforced column width limits, despite larger monitor availability.
- leikowo acknowledged that such limits should be in place but noted some lines may have this feature disabled.
- Guidelines Acknowledgment Visibility: A user asked if the guidelines in a specific channel were the first thing seen, requiring acknowledgment before proceeding.
- wozeparrot confirmed that it should indeed be the case.
Link mentioned: How To Ask Questions The Smart Way: no description found
tinygrad (George Hotz) ▷ #learn-tinygrad (18 messages🔥):
PHI operation confusionMultiLazyBuffer featuresSharded buffer behaviorDiscussion on SDXL inferenceUnderstanding Tensor views
- Clarifying PHI Operation Confusion: A member questioned the functionality of the PHI operation in IR, noting its placement differences compared to LLVM IR, particularly in loop structures.
- Another member suggested it might be more accurately termed as ASSIGN rather than PHI, indicating it behaves differently from traditional phi nodes.
- Understanding MultiLazyBuffer's 'real' Property: A user raised concerns about the purpose of
MultiLazyBuffer.real, especially its role inMultiLazyBuffer.shrinkand its interaction withcopy_to_device.- This led to further investigation, where another member noted that it represents real lazy buffers on devices and there may be bugs with similar devices in configurations.
- Sharded Buffer Behavior Inquiry: A user detailed their exploration of shared buffers, specifically focusing on how they interact with sharded axes for SDXL inference and the impact on GPGPU performance.
- This investigation prompted them to open a discussion thread seeking feedback on their findings and suggestions for improvements.
- Discussion on Cat and Shrink Along Sharded Axis: A user created a discussion to document findings on the capabilities and limitations of tensor operations like cat and shrink along sharded axes, specifically for MLPerf inference tasks.
- They provided examples of unsupported operations within tinygrad and are seeking community input to address these gaps.
- Views and Memory Realization Clarification: A member expressed confusion regarding the realization of views in the
_recurse_lbfunction, questioning the balance between memory optimization and view utilization.- This discussion highlights the ongoing efforts to clarify the foundational concepts of tensor views among users.
Links mentioned:
Torchtune ▷ #general (2 messages):
Gemma 2 modelLinks to resourcesModel information
- Discussion about Gemma 2 model's link: Members discussed the Gemma 2 model card shared by a user, which provides various links to technical documentation and resources.
- Gemma is described as a family of lightweight, state-of-the-art open models from Google, built from the same technology as the Gemini models.
- Resources linked for Gemma 2: Several resources for the Gemma model were shared, including a Responsible Generative AI Toolkit and links to Kaggle and Vertex Model Garden.
- Members highlighted the importance of reviewing these resources for understanding the capabilities and ethics surrounding generative AI.
Link mentioned: google/gemma-2-9b · Hugging Face: no description found
Torchtune ▷ #dev (28 messages🔥):
Multimodal Generation HandlingFlex Attention for Document MaskingINT8 Mixed-Precision TrainingTransformerDecoder ConfigurationGitHub PRs for Generation Overhaul
- Handling Causal Masks for Multimodal Models: A member outlined the challenge of managing causal masks during inference in multimodal setups, particularly with fixed sequence lengths.
- Seeing that we're already exposing these variables through our attention layers helps clarify the approach.
- Expecting Speedups with Flex Attention: There is optimism that flex attention with document masking will provide significant speedups in performance, especially 40% on A100 and 70% on 4090.
- This approach is crucial for enhancing dynamic sequence length training while minimizing padding inefficiencies.
- Questions on TransformerDecoder Design: A member queried whether a TransformerDecoder could be set up without self-attention layers, referencing its traditional structure.
- Another pointed out that the original transformer utilized cross and self-attention layers, indicating the challenge of deviating from that model.
- PR Updates for Generation Overhaul: A member confirmed that #1449 has been updated to improve compatibility with
encoder_max_seq_lenandencoder_mask, although testing remains pending.- Once this overhaul lands, it will allow for further updates to generation utils and integration into PPO.
- Cache Refactor and Generation Utils: There was a discussion around moving generation out of utils with related GitHub PR #1424 pending due to a needed cache refactor.
- Addressing issues with the GemmaTransformerDecoder being outdated made the conversation quite pressing for further developments.
Links mentioned:
LlamaIndex ▷ #blog (4 messages):
llama-deploy launchagentic system deployment exampleRunning Reflection 70Badvanced agentic RAG pipelines
- llama-deploy Launch for Microservices: Announcing the launch of llama-deploy, a system designed to facilitate the seamless deployment of microservices based on LlamaIndex Workflows. This marks a significant evolution since the introduction of llama-agents and Workflows.
- For more details, check out the launch announcement.
- End-to-End Example Using llama-deploy: @LoganMarkewich shared an open-source example showcasing how to build an agentic chatbot system using llama-deploy with the @getreflex front-end framework. This full-stack example demonstrates deploying an agentic system as microservices.
- Find the code and details in this example link.
- Running Reflection 70B on Your Laptop: You can now run Reflection 70B using Ollama, provided your laptop can handle it. This allows for immediate work with it from LlamaIndex.
- For more information, see the tweet.
- Building RAG Pipelines with Amazon Bedrock: Learn how to build advanced agentic RAG pipelines using LlamaIndex and Amazon Bedrock. The process includes creating pipelines, implementing dynamic query routing, and using query decomposition.
- Follow step-by-step instructions in the detailed guide available here.
LlamaIndex ▷ #general (21 messages🔥):
PandasQueryEngine issuesCustomer support chatbot integrationNeptuneDatabaseGraphStore bugCohere reranker in Azure
- PandasQueryEngine struggles with column names: A user reported that the
PandasQueryEnginecan't correctly identify the columnaverageRatingwhen used with the chat engine, often defaulting to incorrect names likerating.- Another member suggested verifying the mapping of DataFrame columns within the chat engine's context to resolve the issue.
- Combining chat and query engines for a chatbot: A community member seeks advice on developing a customer support chatbot that utilizes both a conversation engine and a retrieval-augmented generation (RAG) approach.
- Members agreed that various chat engines can integrate efficiently with query engines to enhance dialogue and data retrieval capabilities for chatbot applications.
- Potential bug in NeptuneDatabaseGraphStore: Concerns were raised about a possible bug with the
NeptuneDatabaseGraphStore.get_schema()function, which fails to include date information in graph summaries.- One user indicated that the issue likely stems from a schema parsing error when feeding data to an LLM, and there are suspicions about the
datetimepackage as well.
- One user indicated that the issue likely stems from a schema parsing error when feeding data to an LLM, and there are suspicions about the
- Cohere reranker integration in Azure: An individual inquired about using the Cohere reranker as a node postprocessor within Azure's LlamaIndex, referencing a GitHub inquiry about it.
- It's confirmed that no existing Azure rerank module exists yet, but a community member encouraged creating one since the base class is simple and documentation is available.
Link mentioned: Node Postprocessor - LlamaIndex: no description found
OpenAccess AI Collective (axolotl) ▷ #general (18 messages🔥):
Reflection Llama-3.1 70BSynthetic Dataset GenerationModel Thinking SpaceFine-tuning ChallengesReAct CoT Technique
- Reflection Llama-3.1 70B emerges as top LLM: Reflection Llama-3.1 70B is the world's leading open-source LLM, utilizing Reflection-Tuning to enhance reasoning accuracy after initial upload issues were resolved.
- Synthetic Dataset Generation Speeds: Discussion highlighted that the synthetic dataset for Reflection Llama-3.1 was reportedly generated quite quickly, raising questions about its human rater involvement and sample size.
- Members speculated on how fast such datasets could be created while maintaining quality.
- Model's Thinking Space brings improvement: One member remarked that the ability to give models space to think, known in AI circles, is well-established, referencing that ReAct has been implementing this for nearly two years.
- They further noted the interesting capacity of a 4B parameter model outperforming GPT-3.5 turbo, stirring excitement.
- Challenges in Fine-tuning Llama-3.1: The conversation turned toward the challenges of fine-tuning such a dense model, with members acknowledging that every parameter is crucial for performance.
- Concerns about the complexity of fine-tuning were raised, with arguments about the need for custom tokens surfacing in connection with expected dataset structures.
- ReAct CoT Performance Discussion: Members discussed the effectiveness of the ReAct Chain of Thought method, stating it yields strong results without necessarily retraining models.
- Strategies like logit constraints were mentioned as alternatives for managing outputs while maintaining clarity.
Link mentioned: mattshumer/Reflection-Llama-3.1-70B · Hugging Face: no description found
OpenAccess AI Collective (axolotl) ▷ #general-help (2 messages):
Fine-tuning Llama 3.1GPU requirements for Lora finetuning
- Fine-tuning Llama 3.1 with Extended Sequence Length: A member inquired about techniques for fine-tuning Llama 3.1 effectively, mentioning that it performs well at 8k sequence length.
- They noted that rope scaling seems to enhance performance up to 128k, suggesting there might be a trick involved.
- A100 GPUs Needed for Lora Finetuning: Another member asked for an estimate of the number of A100 80 GB GPUs required for fine-tuning Meta-Llama-3.1-405B-BNB-NF4-BF16 in 4 bit using adamw_bnb_8bit.
- This highlights the practical considerations and resource needs for efficient Lora finetuning.
OpenAccess AI Collective (axolotl) ▷ #community-showcase (2 messages):
SmileyLlamaChemical Language ModelMolecule Design
- SmileyLlama: New Chemical Language Model: SmileyLlama is a fine-tuned Chemical Language Model that designs molecules based on properties specified in the prompt.
- It is a SFT+DPO model comparable to pure CLMs, but specifically built with
Axolotl.
- It is a SFT+DPO model comparable to pure CLMs, but specifically built with
- Axolotl's Approach to Molecule Generation: The development of SmileyLlama showcases Axolotl's capabilities in fine-tuning models for specific tasks like molecule design.
- This advancement illustrates how Axolotl adapts existing CLM techniques to enhance functionality.
Link mentioned: Tweet from Axolotl (@axolotl_ai): SmileyLlama, a fine-tuned Chemical Language Model to design molecules from properties specified in the prompt. An SFT+DPO model on par with other pure CLM's, but built with Axolotl.
Cohere ▷ #discussions (15 messages🔥):
Cohere resourcesAnthropic library usageEmbed-multilingual-light-v3.0 on Azure
- Explore Cohere's Capabilities and Cookbooks: Members discussed checking out the channel dedicated to capabilities and demos where the community shares projects built using Cohere models, referencing a comprehensive cookbook that provides ready-made guides.
- sssandra highlighted that these cookbooks showcase best practices for leveraging Cohere's generative AI platform.
- Understanding Token Usage with Anthropic Library: vpkprasanna inquired about using the Anthropic library, sharing a code snippet for calculating token usage:
message = client.messages.create(...).- They directed others to the GitHub repository for the Anthropic SDK to further explore tokenization.
- Embed-Multilingual-Light-V3.0 Availability on Azure: arcz1337 questioned the availability of
embed-multilingual-light-v3.0on Azure and asked if there are any plans to support it.- This inquiry reflects ongoing interest in the integration of Cohere's resources with popular cloud platforms.
Links mentioned:
Cohere ▷ #questions (2 messages):
RAG citationsText files as knowledge base
- Query on RAG Citations: A member asked how citations will affect the content of text files when using RAG with an external knowledge base.
- They specifically inquired about receiving citations when they are currently getting None for text file content.
- Request for Help with RAG Citations: The same member probed for assistance in getting citations for the content sourced from text files in their RAG implementation.
- They expressed urgency in figuring out how to resolve the issue regarding the absence of citations in the responses.
DSPy ▷ #show-and-tell (3 messages):
Chroma DB SetupWeaviate ExamplesJupyter Notebooks for Server-Client Communication
- Chroma DB Easier Setup: A member highlighted the minimal setup for Chroma DB using just one line of code to run the server locally:
!chroma run --host localhost --port 8000 --path ./ChomaM/my_chroma_db1.- They expressed satisfaction with knowing the database location and operations so simply.
- Seeking Simplified Weaviate Setup: The same member inquired if a similar straightforward setup for Weaviate exists without resorting to using Go Docker and additional complexities.
- They emphasized a desire for ease of use given their non-technical background.
- Biologist's Tooling with Jupyter Notebooks: Another member shared their approach of utilizing two Jupyter notebooks to separately fire the server and run the client, stating this works for their needs.
- They identified themselves as a Biologist rather than a computer science graduate, reinforcing their need for simplicity.
- Desire for Weaviate Examples: The member expressed intent to create practical examples for Weaviate to assist in understanding and setup.
- This shows a proactive approach to learning despite the technical challenges involved.
DSPy ▷ #papers (3 messages):
Importance of NamesCollaborative LearningAI in EducationMAIC ProposalOnline Course Evolution
- Names have Infinite Potential: A member noted how it is amazing we never run out of names, highlighting the variety and creativity in name generation.
- This conversation illustrates the limitless possibilities in naming conventions within various contexts.
- Collaborative Learning Innovations: The mention of collabin signalizes ongoing discussions about cooperative initiatives in online education and project work.
- Such platforms emphasize the shift towards more integrated learning experiences in educational environments.
- AI Enhancements Transform Education: A detailed link shared about the paper discusses how AI technologies are integrated into online education for personalization and improved learning outcomes.
- This highlights the emerging trend of using large language models to enhance learning experiences.
- Introducing MAIC for Online Education: The proposed MAIC (Massive AI-empowered Course) aims to leverage LLM-driven multi-agent systems for constructing AI-augmented classrooms.
- This concept seeks to balance technology integration while enhancing the educational experience for learners.
- Evolution of Online Courses: Discussion around the evolution of online courses showcases the ongoing adaptation of educational models over time.
- Such adaptability is crucial for accommodating various learning needs and preferences, underscoring the importance of continuous innovation.
Link mentioned: Paper page - From MOOC to MAIC: Reshaping Online Teaching and Learning through LLM-driven Agents: no description found
DSPy ▷ #general (2 messages):
Reflection 70BRouting LLMs by QueryTPU Speed and Pricing
- Reflection 70B announced as leading open-source model: The unveiling of Reflection 70B, touted as the world's top open-source model, was shared, emphasizing its ability to correct its mistakes through Reflection-Tuning.
- 405B is expected next week with promises of superior performance, developed in collaboration with @GlaiveAI.
- Interest in CoT DSpy Program Logic: A community member inquired about the specifics of the CoT DSpy program, questioning its functionality regarding reflection upon provided answers.
- There seems to be anticipation around its implementation and utility for task execution.
- Adding Pricing and TPU Speed to LLM Routing: A member expressed interest in developing a method to route the appropriate LLM based on queries, incorporating pricing and TPU speed based on model hosting.
- They noted that while routing the right LLM is straightforward, additional elements like performance and cost will enhance the process.
Link mentioned: Tweet from Matt Shumer (@mattshumer_): I'm excited to announce Reflection 70B, the world’s top open-source model. Trained using Reflection-Tuning, a technique developed to enable LLMs to fix their own mistakes. 405B coming next week ...
LAION ▷ #general (5 messages):
SwarmUIUser Interface DesignBane Meme
- Discussion on SwarmUI Usability: A member expressed discomfort with UIs featuring 100 nodes, leading to a mention of SwarmUI as a comparison.
- Another member reinforced this point, declaring that it is 'literally SwarmUI'.
- Introduction to SwarmUI GitHub: A link to SwarmUI on GitHub was shared, highlighting its modular design aimed at enhanced accessibility and performance.
- The project is noted for its focus on making powertools easily accessible, with an image showing the repository's visual.
- Bane Meme and GIF Share: A member shared a Bane-themed GIF, featuring a green frog captioned 'and you are'.
- The GIF sparked further discussion with multiple related searches linked, showcasing various Bane and explosion themes.
Links mentioned:
LAION ▷ #research (3 messages):
Reflection 70BLLM Self-CorrectionLucidrains Transfusion Implementation405B Model Release
- Reflection 70B Launches as Top Open-Source Model: Matt Shumer announced the launch of Reflection 70B, claiming it to be the world’s top open-source model trained via Reflection-Tuning which allows LLMs to fix their own mistakes.
- He also hinted at a 405B model coming next week, expected to surpass all existing benchmarks.
- LLMs Combat Bugs with Self-Correction: Kimmonismus expressed disbelief about a new LLM that can not only correct itself but also purportedly beats GPT-4o in every benchmark tested, including MMLU and MATH.
- He highlighted that this new model is open-source and dramatically outperforms Llama 3.1's 405B, marking a significant advancement in LLM capabilities.
- Lucidrains Implements Transfusion Model: A reimplementation of the Transfusion model by Lucidrains has been shared, aimed at predicting the next token while diffusing images, showcasing its multi-modal capabilities.
- The project promises future extensions to include flow matching and audio/video processing, representing a noteworthy development in AI models.
Links mentioned:
LangChain AI ▷ #general (6 messages):
Deploying ReAct agent on GCPLangChain Callbacks systemCerebras with LangChainDecoding streams from .astream_events
- ReAct Agent Deployment Challenge: A member is facing challenges deploying their ReAct agent on GCP using FastAPI since the local SQLite database disappears on redeploys. They are seeking alternatives, specifically for Postgres or MySQL implementation as a replacement for
SqliteSaver.- The member is open to sharing their local implementation for reference if someone finds it helpful.
- Clarifying Usage of Callbacks in LangChain: A discussion arose about whether the syntax
chain = prompt | llmis correct, pointing to LangChain's callback documentation. Members noted that the documentation might be outdated, specifically mentioning updates in version 0.2.- The conversation emphasized the utility of the callbacks system for logging, monitoring, and integrating with third-party tools.
- Inquiry on Cerebras and LangChain: A member asked if anyone is using Cerebras in conjunction with LangChain, indicating a need for collaborative insights. The responses highlighted potential interest but lacked specific interactions.
- No direct solutions or experiences were shared in relation to this inquiry.
- Exploring .astream_events() Decoding: A member inquired about a reference implementation for decoding streams from
.astream_events(). Another member shared their experience of manually serializing every event type due to a lack of resources.- This dialogue expressed frustration over the tedious process and a hope for better solutions within the community.
Link mentioned: Callbacks | 🦜️🔗 LangChain: Head to Integrations for documentation on built-in callbacks integrations with 3rd-party tools.
LLM Finetuning (Hamel + Dan) ▷ #general (5 messages):
RAG system improvementsEmbedding model usageHybrid searchMetadata and reranking
- Improving RAG System with Hardware Constraints: A member inquired about enhancing their RAG system, specifically using llama3-8b with 4bit quantization and BAAI/bge-small-en-v1.5 embedding model.
- They expressed limitations due to hardware (only a 4090 GPU) and sought resources for better implementation.
- Exploring Bigger Models with 4090 GPU: In response, a member noted that with a 4090, it’s possible to run a larger embedding model concurrently with llama-8b, suggesting that the 3.1 version might also be beneficial.
- They shared a useful GitHub example demonstrating hybrid search integration with bge & bm25 on Milvus.
- Utilizing Metadata for Reranking: The discussion highlighted the importance of having metadata for each chunk to assist in further sorting and filtering through results.
- A reranker could significantly refine the search process, enhancing the overall output quality for users.
Link mentioned: pymilvus/examples/hello_hybrid_sparse_dense.py at master · milvus-io/pymilvus: Python SDK for Milvus. Contribute to milvus-io/pymilvus development by creating an account on GitHub.
Gorilla LLM (Berkeley Function Calling) ▷ #leaderboard (1 messages):
XLAM system promptOSS models comparison
- XLAM's Unique System Prompt: A member noticed that the system prompt for XLAM differs from that of other OSS models.
- Is there a particular reason why? sparked interest in exploring the rationale behind these differences.
- Curiosity about System Design Choices: The discussion highlights an interesting aspect regarding the design choices behind XLAM's system prompts.
- Members are keen to understand if the variations are due to functionality or licensing considerations.
Gorilla LLM (Berkeley Function Calling) ▷ #discussion (3 messages):
Testing API serverAdding models to leaderboardGorilla leaderboard
- How to Test Your Own API Server: A user inquired about methods to effectively test their own API server and requested related documentation.
- No specific resources were provided in response, indicating potential knowledge gaps in the responses.
- Contributing to the Leaderboard: A user asked how to add a new model to the leaderboard, which is crucial for acknowledging model contributions.
- In response, a link to the relevant GitHub page was shared, detailing contribution guidelines for the Gorilla leaderboard.
- Gorilla Leaderboard GitHub Resource: Another user highlighted the Gorilla: Training and Evaluating LLMs for Function Calls resource available on GitHub.
- This resource details the process of contributing to the leaderboard and was illustrated with an image from its GitHub repository.
Link mentioned: gorilla/berkeley-function-call-leaderboard at main · ShishirPatil/gorilla: Gorilla: Training and Evaluating LLMs for Function Calls (Tool Calls) - ShishirPatil/gorilla
Alignment Lab AI ▷ #general (1 messages):
knut09896: hi there
{% else %}
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: [{{ email.subject }}]({{ email_url }})!
If you enjoyed AInews, please share with a friend! Thanks in advance!
{% endif %}