AI News for 9/11/2024-9/12/2024. We checked 7 subreddits, 433 Twitters and 30 Discords (216 channels, and 4377 messages) for you. Estimated reading time saved (at 200wpm): 416 minutes. You can now tag @smol_ai for AINews discussions!
o1, aka Strawberry, aka Q*, is finally out! There are two models we can use today: o1-preview (the bigger one priced at $15 in / $60 out) and o1-mini (the STEM-reasoning focused distillation priced at $3 in/$12 out) - and the main o1 model is still in training. This caused a little bit of confusion.
There are a raft of relevant links, so don’t miss:
- the o1 Hub
- the o1-preview blogpost
- the o1-mini blogpost
- the technical research blogpost
- the o1 system card
- the platform docs
- the o1 team video and contributors list (twitter)
Inline with the many, many leaks leading up to today, the core story is longer “test-time inference” aka longer step by step responses - in the ChatGPT app this shows up as a new “thinking” step that you can click to expand for reasoning traces, even though, controversially, they are hidden from you (interesting conflict of interest…):
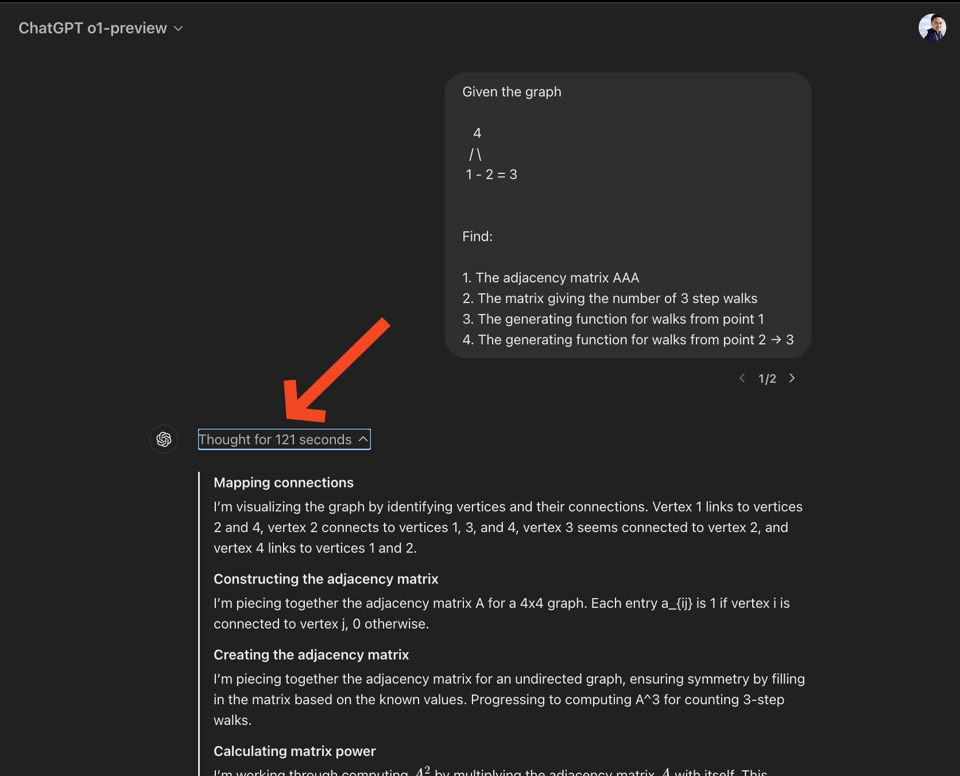
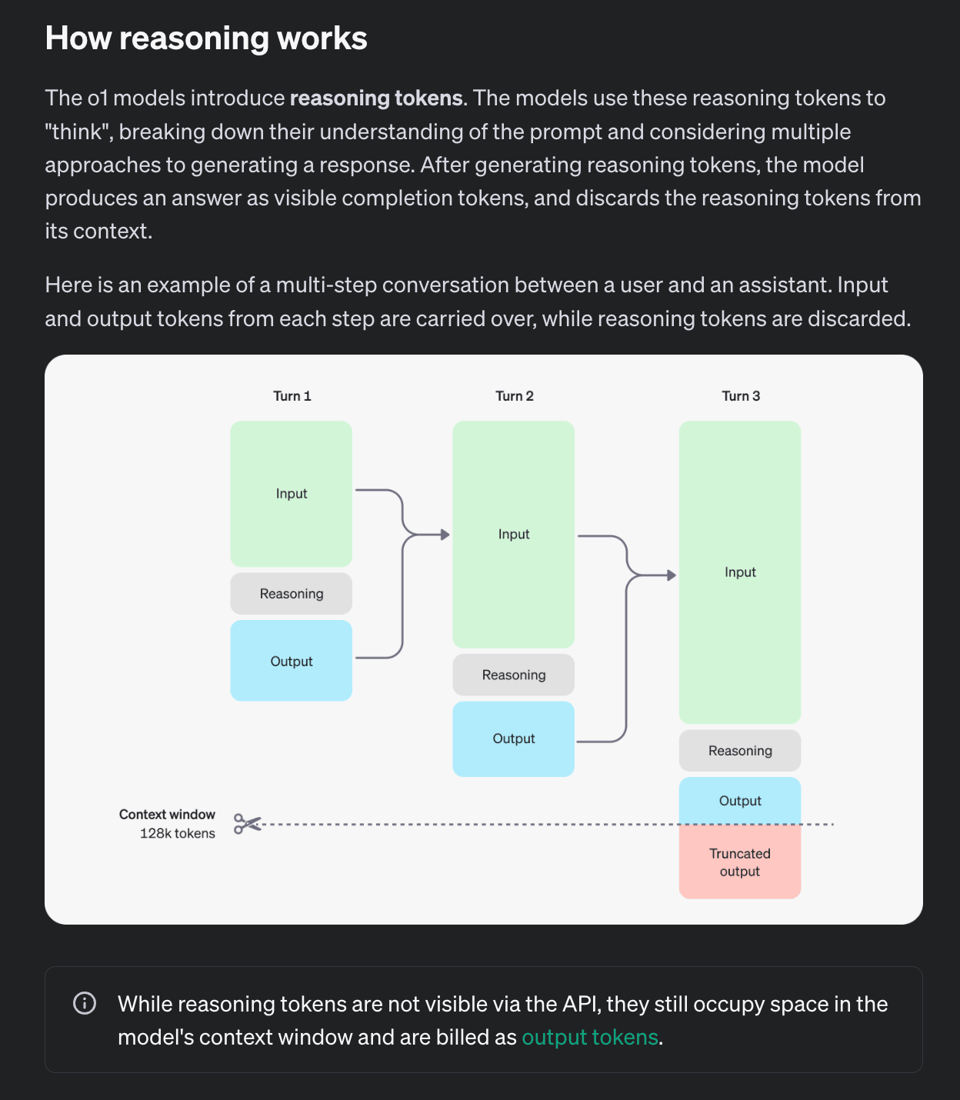
Under the hood, o1 is trained for adding new reasoning tokens - which you pay for, and OpenAI has accordingly extended the output token limit to >30k tokens (incidentally this is also why a number of API parameters from the other models like temperature and role and tool calling and streaming, but especially max_tokens is no longer supported).
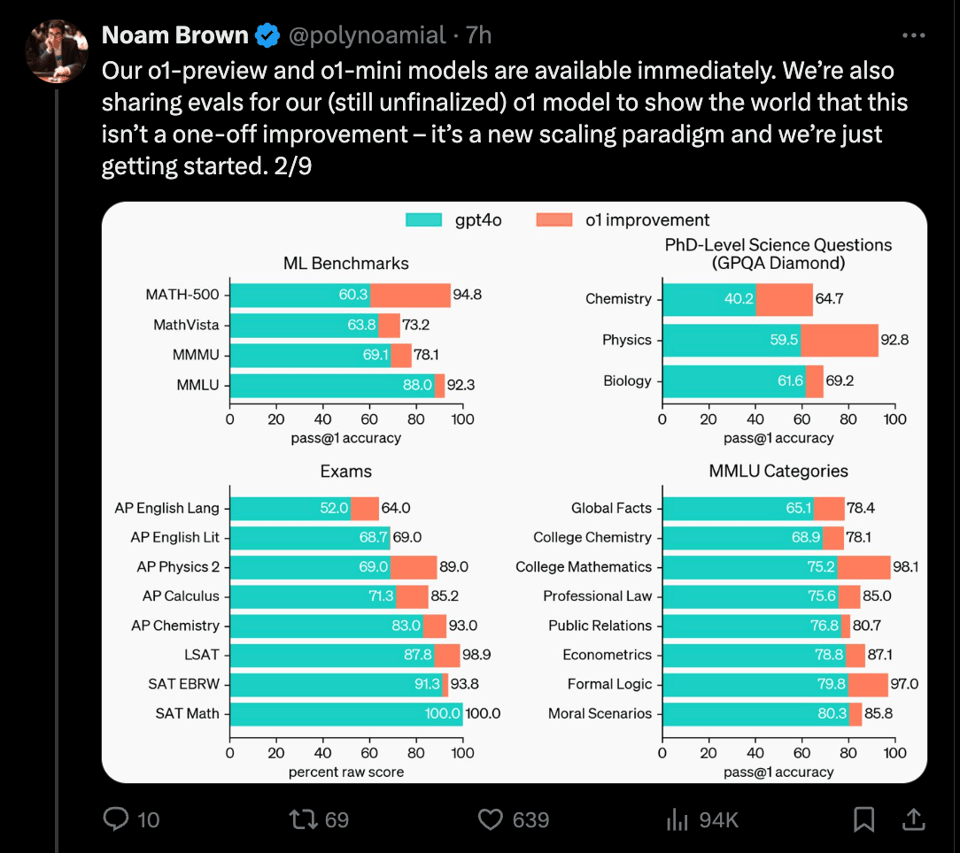
The evals are exceptional. OpenAI o1:
- ranks in the 89th percentile on competitive programming questions (Codeforces),
- places among the top 500 students in the US in a qualifier for the USA Math Olympiad (AIME),
- and exceeds human PhD-level accuracy on a benchmark of physics, biology, and chemistry problems (GPQA).
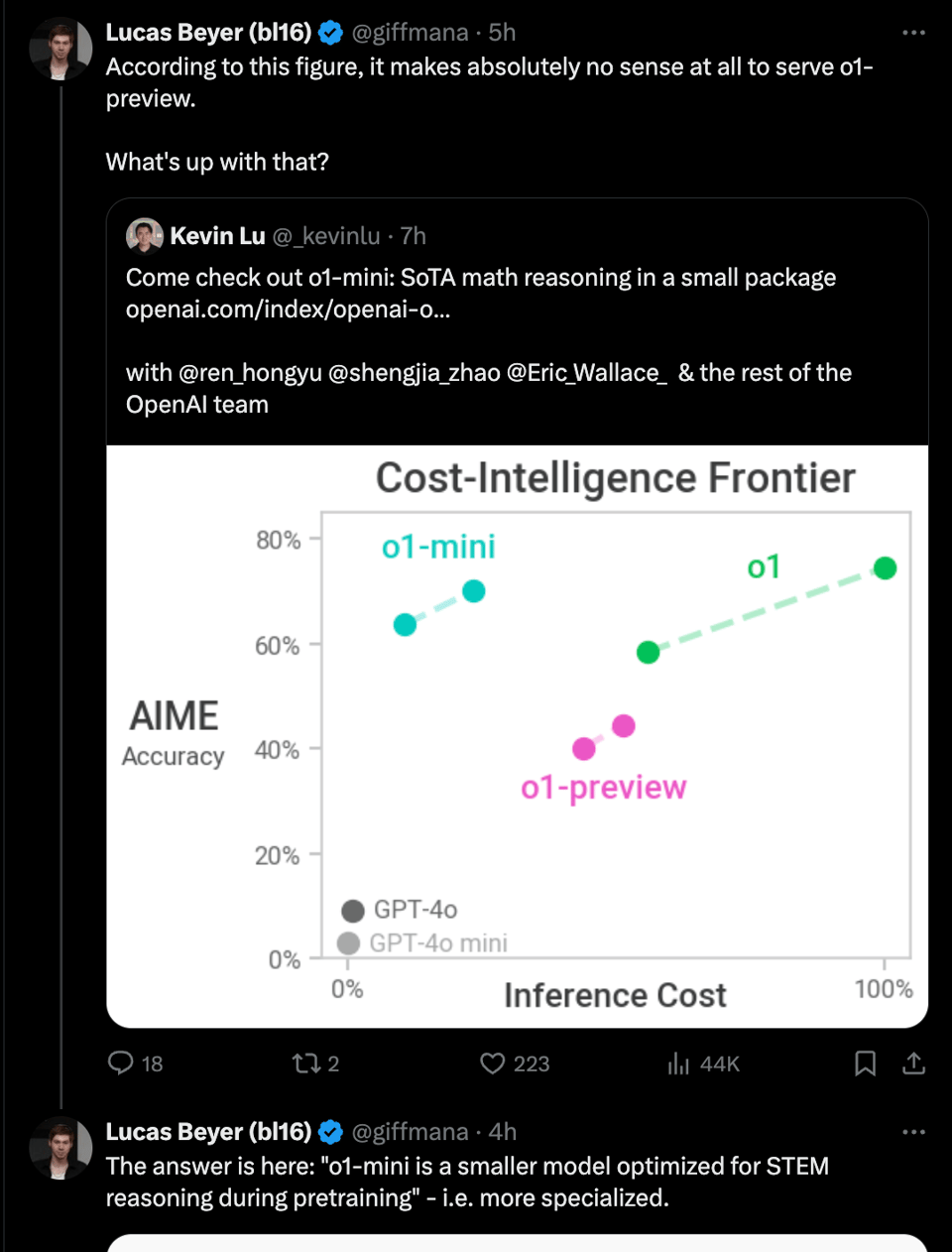
You are used to new models showing flattering charts, but there is one of note that you don’t see in many model announcements, that is probably the most important chart of all. Dr Jim Fan gets it right: we now have scaling laws for test time compute, and it looks like they scale loglinearly.
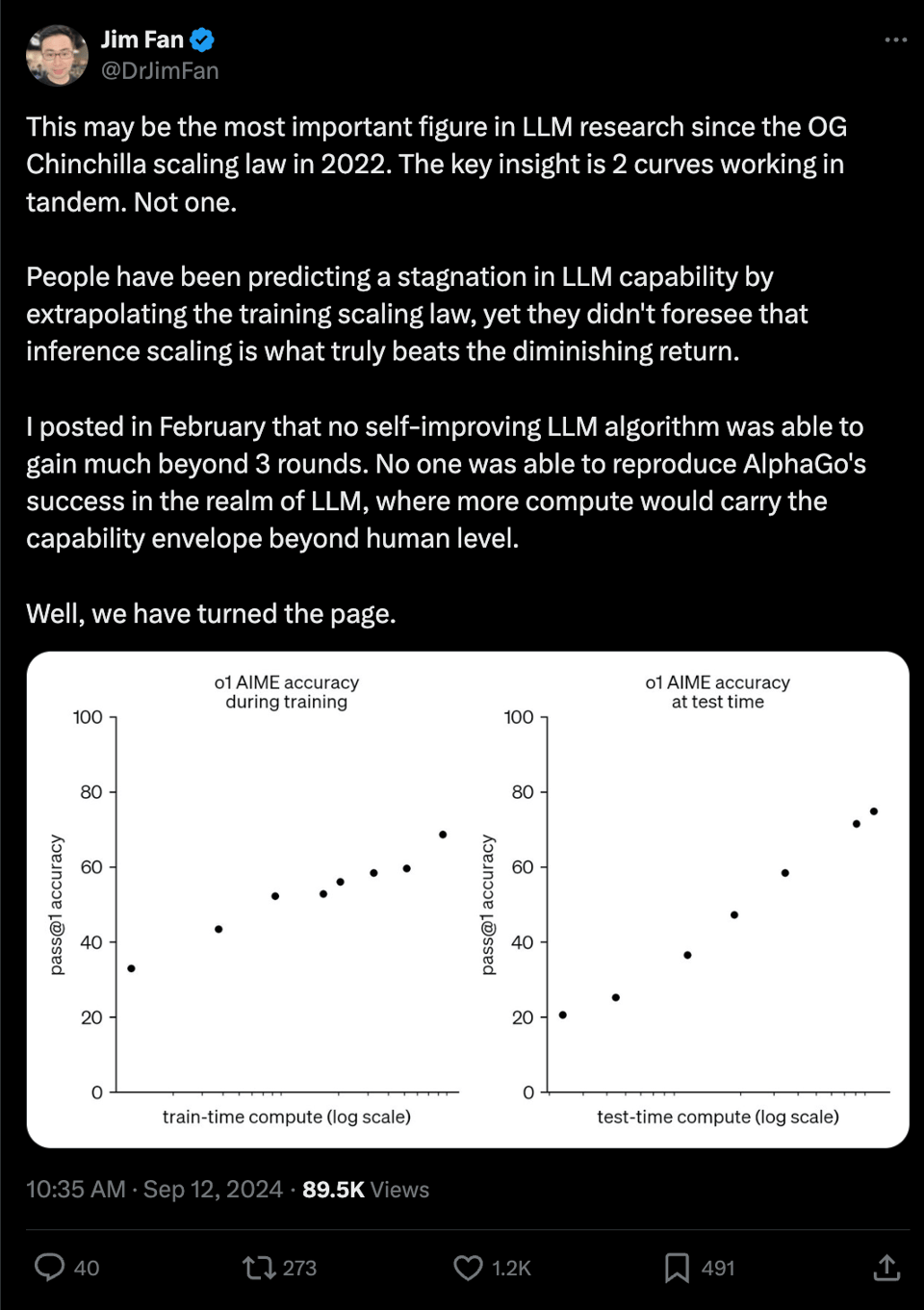
We unfortunately may never know the drivers of the reasoning improvements, but Jason Wei shared some hints:

Usually the big model gets all the accolades, but notably many are calling out the performance of o1-mini for its size (smaller than gpt 4o), so do not miss that.
{% if medium == 'web' %}
Table of Contents
[TOC]
{% else %}
The Table of Contents and Channel Summaries have been moved to the web version of this email: [{{ email.subject }}]({{ email_url }})!
{% endif %}
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
Nvidia and AI Chip Competition
-
Market share shifts: @draecomino noted that Nvidia is starting to lose share to AI chip startups for the first time, as evidenced by discussions at recent AI conferences.
-
CUDA vs. Llama: The same user highlighted that while CUDA was crucial in 2012, in 2024 90% of AI developers are web developers building off Llama rather than CUDA.
-
Performance comparisons: @AravSrinivas pointed out that Nvidia still has no competition in training, though it may face some in inference. However, B100s with fp4 inference could potentially outperform competitors.
-
SambaNova performance: @rohanpaul_ai shared that SambaNova launched the "World's fastest API" with Llama 3.1 405B at 132 tokens/sec and Llama 3.1 70B at 570 tokens/sec.
New AI Models and Releases
-
Pixtral 12B: @sophiamyang announced the release of Pixtral 12B, Mistral's first multimodal model. @swyx shared benchmarks showing Pixtral outperforming models like Phi 3, Qwen VL, Claude Haiku, and LLaVA.
-
LLaMA-Omni: @osanseviero introduced LLaMA-Omni, a new model for speech interaction based on Llama 3.1 8B Instruct, featuring low-latency speech and simultaneous text and speech generation.
-
Reader-LM: @rohanpaul_ai shared details about JinaAI's Reader-LM, a Small Language Model for web data extraction and cleaning that outperformed larger models like GPT-4 and LLaMA-3.1-70B on HTML2Markdown tasks.
-
GOT (General OCR Theory): @_philschmid described GOT, a 580M end-to-end OCR-2.0 model that outperforms existing methods in handling complex tasks like sheets, formulas, and geometric shapes.
AI Research and Developments
-
Superposition prompting: @rohanpaul_ai shared research on superposition prompting, which accelerates and enhances RAG without fine-tuning, addressing long-context LLM challenges.
-
LongWriter: @rohanpaul_ai discussed the LongWriter paper, which introduces a method for generating 10,000+ word outputs from long context LLMs.
-
AI in scientific discovery: @rohanpaul_ai highlighted research on using Agentic AI for automatic scientific discovery, revealing hidden interdisciplinary relationships.
-
AI safety and risks: @ylecun shared thoughts on AI safety, arguing that human-level AI is still far off and that regulating AI R&D due to existential risk fears is premature.
AI Tools and Applications
-
Gamma: @svpino showcased Gamma, an app that can generate functional websites from uploaded resumes in seconds.
-
RAG-based document QA: @llama_index introduced Kotaemon, an open-source UI for chatting with documents using RAG-based systems.
-
AI Scheduler: @llama_index announced an upcoming workshop on building an AI Scheduler for smart meetings using Zoom, LlamaIndex & Qdrant.
AI Industry and Market Trends
-
AI replacing enterprise software: @rohanpaul_ai noted that Klarna replacing Salesforce and Workday with AI-powered in-house software signals a trend of AI eating most SaaS.
-
AI valuation: @rohanpaul_ai shared that Anthropic's valuation has reached $18.4 billion, putting it among the top privately held tech companies.
-
AI in manufacturing: @weights_biases promoted a session on "Generative AI in Manufacturing: Revolutionizing Tool Development" at AIAI Berlin.
AI Ethics and Societal Impact
-
AI detection challenges: @rohanpaul_ai shared research showing that both AI models and humans struggle to differentiate between humans and AI in conversation transcripts.
-
Criminal case involving AI: @rohanpaul_ai detailed the first criminal case involving AI-inflated music streaming, where the perpetrator used AI-generated music and fake accounts to fraudulently collect royalties.
Memes and Humor
-
@ylecun shared a meme about a first grader upset for getting a bad grade after insisting that 2+2=5.
-
@ylecun joked about a Halloween special of The Simpsons where "In Springfield, they're eating their dawgs!"
-
@cto_junior shared a humorous image about what strawberry likely is.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Reviving and Improving Classic LLM Architectures
-
New release: Solar Pro (preview) Instruct - 22B (Score: 44, Comments: 14): The Solar Pro team has released a preview of their new 22B parameter instruct model, available on Hugging Face. This model is claimed to be the best open model that can run on a single GPU, though the post author notes that such claims are common among model releases.
- Users expressed disappointment with the 4K context window, considering it insufficient in 2024 when 8K is seen as a minimum. The full release in November 2024 will feature longer context windows and expanded language support.
- Discussions compared Solar Pro to other models, with some praising Solar 11B's performance. Users are curious about improvements to Phi 3's usability and personality, as it was seen as a "benchmark sniper" that underperformed in real-world applications.
- The claim of being the "best open model that can run on a single GPU" was noted as more realistic than claiming superiority over larger models like Llama 70B. Some users expressed interest in trying a GGUF version of Solar Pro.
-
Chronos-Divergence-33B ~ Unleashing the Potential of a Classic (Score: 72, Comments: 23): Zeus Labs introduced Chronos-Divergence-33B, an improved version of the original LLaMA 1 model with an extended sequence length from 2048 to 16,384 effective tokens. The model, trained on ~500M tokens of new data, can write coherently for up to 12K tokens while maintaining LLaMA 1's charm and avoiding repetitive "GPT-isms", with technical details and quantizations available on its Hugging Face model card.
- Users discussed the model's storytelling capabilities, with the developer confirming it's primarily focused on multiturn RP. Some users reported shorter responses than expected and sought suggestions for improvement.
- The community expressed interest in using older models as bases to avoid "GPT slop" or "AI smell" present in newer models. Users debated the effectiveness of this approach and discussed potential alternatives like InternLM 20B.
- Discussions touched on training techniques to remove biases, with suggestions including gentle DPO/KTO, ORPO, and SFT on pre-training raw text. Some proposed modifying the tokenizer to eliminate specific tokens associated with GPT-isms.
Theme 2. New Open-Source Speech Models Pushing Boundaries
-
New Open Text-to-Speech Model: Fish Speech v1.4 (Score: 106, Comments: 13): Fish Speech v1.4, a new open-source text-to-speech model, has been released, trained on 700,000 hours of audio data across multiple languages. The model requires only 4GB of VRAM for inference, making it accessible for various applications, and is available through its official website, GitHub repository, HuggingFace page, and includes an interactive demo.
- Users compared Fish Speech v1.4 to other open-source models, noting that while it's an improvement over previous versions, it's still not on par with XTTSv2 for voice cloning. The model's performance in German was positively received.
- The development team behind Fish Speech v1.4 includes members from SoVITS and RVC projects, which are considered notable in the open-source text-to-speech community. RVC was mentioned as potentially the best current open-source option.
- A user pointed out an unfortunate naming choice for the command-line binary "fap" (fish-audio-preprocessing), suggesting it should be changed to avoid awkward execution commands.
-
LLaMA-Omni: Seamless Speech Interaction with Large Language Models (Score: 74, Comments: 30): LLaMA-Omni is a new model that enables seamless speech interaction with large language models. The model, available on Hugging Face, is accompanied by a research paper and open-source code on GitHub, allowing for further exploration and development in the field of speech-enabled AI interactions.
- LLaMA-Omni uses only the voice encoder portion of Whisper to embed audio, not the full transcription model. This approach differs from prior multimodal methods that used Whisper's complete speech-to-text capabilities.
- The model's hardware requirements sparked discussion, with users noting high VRAM needs. The developer mentioned the possibility of using smaller Whisper models for faster inference at the cost of quality.
- Users debated the model's effectiveness, with some viewing it as a proof of concept comparable to existing solutions. Others questioned its voice quality and non-verbal speech capabilities, suggesting it might be a combination of separate ASR, LLM, and TTS models.
Theme 3. Benchmarking and Cost Analysis of LLM Deployments
-
Ollama LLM benchmarks on different GPUs on runpod.io (Score: 52, Comments: 16): The author conducted GPU and AI model performance benchmarks using Ollama on runpod.io, focusing on the
eval_ratemetric for various models and GPUs. Key findings include: llama3.1:8b performed similarly on 2x and 4x RTX4090, mistral-nemo:12b was ~30% slower than lama3.1:8b, and command-r:35b was twice as fast as llama3.1:70b, with minimal differences between L40 vs. L40S and A5000 vs. A6000 for smaller models. The author shared a detailed spreadsheet with their findings and welcomed feedback for potential extensions to the benchmark.- Users inquired about VRAM usage and quantization, with the author adding VRAM size ranges to the spreadsheet. A commenter noted running Q8 or fp16 models on Runpod for tasks beyond home capabilities.
- Discussion on context length impact on model speed, with the author detailing their testing process using a standard question ("why is the sky blue?") that typically generated 300-500 token responses across models.
- A user shared experience mixing GPU brands (7900xt and 4090) using kobalcpp with vulkan, achieving 10-14 tokens/second for llama3.1 70b q4KS, noting issues with llama.cpp and vulkan compatibility.
-
LLMs already cheaper than traditional ML models? (Score: 65, Comments: 40): The post compares translation costs between GPT-4 models and Google Translate, finding that GPT-4 options are significantly cheaper: GPT-4 costs $20/1M tokens, GPT-4-mini costs $0.75/1M tokens, while Google Translate costs $20/1M characters (equivalent to $60-$100/1M tokens). The author expresses confusion about why anyone would use the more expensive Google Translate, given that GPT-4 models also offer additional benefits like context understanding and customized prompts for potentially better translation results.
- Google Translate uses a hybrid transformer architecture, as detailed in a 2020 Google Research blog post. Users questioned its performance compared to newer LLMs, with some attributing this to its age.
- OpenAI's API pricing sparked debate about profitability. Some argued OpenAI isn't making money from API calls, while others suggested they're likely cash flow positive, citing efficient infrastructure and competitive pricing compared to open-source LLM providers.
- Users highlighted Google Translate's reliability for specific language pairs and less common languages, noting that GPT-4 might struggle with non-English translations or produce unrelated content. Some mentioned Gemini Pro 1.5 as a potential alternative for multi-language translation.
Theme 4. Developers Embrace AI Coding Assistants, Unlike Artists with AI Art
- I want to ask a question that may offend a lot of people: are a significant number of programmers / software engineers bitter about LLMs getting better in coding like a significant numbers of artists are bitter about AI art? (Score: 107, Comments: 275): Software engineers and programmers generally appear less bitter about Large Language Models (LLMs) improving at coding compared to artists' reactions to AI art. The overall mood in the programming industry seems to be one of adaptation and integration, with many viewing LLMs as tools to enhance productivity rather than as threats to their jobs.
- Software engineers generally view LLMs as productivity-enhancing tools rather than threats, using them for tasks like boilerplate creation, understanding new frameworks, and automating tedious work. Many see AI as another step in the abstraction level evolution of programming.
- While LLMs are helpful for coding assistance, they still have limitations such as hallucinating incorrect code and requiring human oversight. Some developers note that LLMs are currently poor at programming for real-world applications and shine mainly in generating simple or short code snippets.
- There's a spectrum of attitudes among developers, from enthusiastic early adopters to those in denial about AI's potential impact. Some express concern about management expectations and potential job market effects, while others view AI as an opportunity to focus on higher-level problem-solving and system design.
Other AI Subreddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI Model Releases and Improvements
-
OpenAI developments: There are rumors and speculation about upcoming releases from OpenAI, including a potential "Strawberry" model and GPT-4o voice mode. However, many users express frustration with vague announcements and delayed releases. An OpenAI head of applied research tweeted about "shipping" something soon, fueling more speculation.
-
Fish Speech 1.4: A new open-source text-to-speech model was released, trained on 700K hours of speech across 8 languages. It requires only 4GB VRAM and offers 50 free uses per day.
-
Amateur Photography Lora v4: An update to a Stable Diffusion Lora model for generating realistic amateur-style photos was released, with improvements in sharpness and realism.
{kind=link}
AI Research and Breakthroughs
-
Neuromorphic computing: Scientists reported a breakthrough in neuromorphic computing using molecular memristors, potentially enabling more efficient AI hardware. The device offers 14-bit precision, high energy efficiency, and fast computation.
-
PaperQA2: An AI agent was introduced that can conduct entire scientific literature reviews autonomously.
AI Industry News
-
OpenAI departures: Multiple high-profile researchers have left OpenAI recently, including Alexis Conneau, who was working on GPT-4o/GPT-5.
-
Ilya Sutskever's new venture: The ex-OpenAI researcher raised $1 billion for a new AI company without a product or revenue.
-
Apple's AI efforts: Apple's upcoming iPhone 16 AI features are criticized as "late, unfinished & clumsy" compared to competitors.
{kind=link}
AI Ethics and Societal Impact
-
Deepfake concerns: Taylor Swift expressed concerns about AI-generated deepfakes falsely depicting her endorsing political candidates.
-
Realistic AI-generated images: The Amateur Photography Lora v4 model demonstrates the increasing difficulty in distinguishing AI-generated images from real photos.
AI Discord Recap
A summary of Summaries of Summaries. We leave the 4o vs o1 comparisons for your benefit
GPT4O (gpt-4o-2024-05-13)
1. OpenAI O1 Model Launch and Reactions
- OpenAI O1 Model Faces Criticism Over Costs: OpenAI's O1 model has received criticism from users due to its high costs and underwhelming performance, especially in coding tasks, as discussed in OpenRouter.
- With pricing set at $60 per million tokens, users are concerned about unexpected costs and the overall value, prompting discussions about the model's practical utility.
- Mixed Reactions to OpenAI O1 Preview: The O1 preview received mixed feedback from users, questioning its improvements over models like Claude 3.5 Sonnet, particularly in creative tasks, as noted in Nous Research AI.
- Users are skeptical about its operational efficiency, suggesting it may need further iterations before a full rollout.
- OpenAI O1 Launches for Reasoning Tasks: OpenAI launched O1 models aimed at enhancing reasoning in complex tasks like science, coding, and math, available for all Plus and Team users in ChatGPT and through the API for tier 5 developers as reported in OpenAI.
- Users are noting that O1 models outperform previous iterations in problem-solving but some express skepticism about the price versus performance improvements.
2. AI Model Performance and Benchmarking
- DeepSeek V2.5 Launch with User-Friendly Features: DeepSeek V2.5 introduces a full-precision provider and promises no prompt logging for privacy-conscious users, as announced in OpenRouter.
- Additionally, DeepSeek V2 Chat and DeepSeek Coder V2 models have been merged into this version, allowing seamless redirection to the new model.
- PLANSEARCH Algorithm Boosts Code Generation: Research on the PLANSEARCH algorithm demonstrates it enhances LLM-based code generation by identifying diverse plans before code generation, promoting efficient outputs, as discussed in aider.
- By alleviating the lack of diversity in LLM outputs, PLANSEARCH shows valuable performance improvements across benchmarks like HumanEval+ and LiveCodeBench.
3. Challenges in AI Training and Inference
- Challenges with OpenAI O1 and GPT-4o Models: Feedback about the O1 and GPT-4o models underscores frustration as performance results indicate they do not markedly outperform previous versions, as noted in OpenRouter.
- Users advocate for more practical enhancements in these advanced models for real-world application, suggesting a need for consistent testing for validation.
- LLM Distillation Complexities: Participants in Unsloth AI expressed challenges in distilling LLMs into smaller models, emphasizing accurate output data as crucial for success.
- Reliance on high-quality examples is key, with slow inference arising from token costs for complex reasoning.
4. Innovations in AI Tools and Frameworks
- Ophrase and Oproof CLI Tools Transform Operations: A detailed article explains how Ophrase and Oproof bolster command-line interface functionalities by streamlining task automation and management, as discussed in HuggingFace.
- These tools offer substantial enhancements to workflow efficiency, promising a revolution in handling command line tasks.
- HTML Chunking Package Debuts: The new package
html_chunkingefficiently chunks and merges HTML content while maintaining token limits, crucial for web automation tasks, as introduced in LangChain AI.- This structured approach ensures valid HTML parsing, preserving essential attributes for a variety of applications.
5. AI Applications in Various Domains
- Roblox Capitalizes on AI for Gaming: A video discussed how Roblox is innovatively merging AI with gaming, positioning itself as a leader in this area, as noted in Perplexity AI.
- This development marks a substantial leap in integrating advanced technologies within gaming environments.
- Personal AI Executive Assistant Success: A member in Cohere successfully built a personal AI executive assistant that manages scheduling with a calendar agent cookbook, integrating voice inputs to edit Google Calendar events.
- The assistant adeptly interprets unstructured data, proving beneficial for organizing exam dates and project deadlines.
GPT4O-Aug (gpt-4o-2024-08-06)
1. OpenAI O1 Model Launch and Performance
- OpenAI O1 Model Draws Mixed Reactions: OpenAI O1 launched with claims of enhanced reasoning for complex tasks in science, coding, and math, sparking excitement among users.
- While some praise its problem-solving capabilities, others criticize its high costs and question if improvements justify the price, especially compared to older models like GPT-4o.
- Community Concerns Over O1's Practicality: Users express frustration over O1's performance in coding tasks, citing hidden 'thinking tokens' leading to unexpected costs, as noted at $60 per million tokens.
- Despite its marketed advancements, many users report preferring alternatives like Sonnet, highlighting the need for practical enhancements in real-world applications.
2. DeepSeek V2.5 Features and User Feedback
- DeepSeek V2.5 Launches with Privacy Features: DeepSeek V2.5 introduces a full-precision provider and ensures no prompt logging, appealing to privacy-conscious users.
- The new version merges DeepSeek V2 Chat and DeepSeek Coder V2, facilitating seamless model access while maintaining backward compatibility.
- DeepSeek Endpoint Performance Under Scrutiny: Users report inconsistent performance from the DeepSeek endpoint, questioning its reliability following recent updates.
- Community feedback suggests a need for improved performance consistency, with some considering alternative solutions.
3. AI Regulation and Community Reactions
- California's AI Regulation Bill Faces Opposition: Speculation around California's SB 1047 AI safety bill suggests a 66-80% chance of veto due to political dynamics, especially with Pelosi involved.
- Discussions highlight its potential impacts on data privacy and inference compute, reflecting tensions between tech innovation and regulatory measures.
- AI Regulation Discussions Spark Debates: Conversations on AI regulations, fueled by Dr. Epstein's insights on Joe Rogan's podcast, reveal concerns over narratives shaped by social media.
- Members advocate for a balanced approach to free speech versus hate speech, emphasizing moderation within AI discussions.
4. Innovations in LLM Training and Optimization
- PLANSEARCH Algorithm Boosts Code Generation: Research on the PLANSEARCH algorithm demonstrates it enhances LLM-based code generation by identifying diverse plans, improving efficiency.
- By broadening the range of generated observations, PLANSEARCH shows valuable performance improvements across benchmarks like HumanEval+ and LiveCodeBench.
- Dolphin Architecture for Efficient Context Processing: The Dolphin architecture introduces a 0.5B parameter decoder, promoting energy efficiency for long context processing while reducing latency by 5-fold.
- Empirical results reveal a 10-fold improvement in energy efficiency, positioning it as a significant advancement in model processing techniques.
5. Challenges in AI Model Deployment and Integration
- Reflection Model Faces Criticism: The Reflection 70B model drew fire over claims of falsified benchmarks, raising concerns about fairness in AI development.
- Critics labeled it a wrapper around existing techniques, emphasizing the need for transparency in model evaluations.
- API Access and Integration Challenges: Users express frustration over API limits and authorization issues, emphasizing the need for clarity in troubleshooting.
- Managing multiple AI models while keeping costs low remains a recurring theme in the discussions, highlighting integration challenges.
o1-mini (o1-mini-2024-09-12)
- OpenAI Unveils O1 Model with Superior Reasoning: OpenAI's O1 model series enhances reasoning in complex tasks, outperforming models like GPT-4o and Claude 3.5 Sonnet in over 50,000 matchups. Despite its advancements, users raise concerns about its high pricing of $60 per million tokens, prompting comparisons with alternatives such as Sonnet.
- Advanced Training Techniques Boost Model Efficiency: Innovations like ZeRO++ reduce GPU communication overhead by 4x, while vAttention optimizes KV-cache memory for efficient inference. Additionally, Consistency LLMs explore parallel token decoding, significantly lowering inference latency.
- Cost Management Strategies for High-Priced Models: Communities discuss optimizing usage to mitigate the costs of models like O1, emphasizing the importance of managing token consumption and exploring billing structures. Tips include leveraging /settings/privacy for data preferences and utilizing efficient prompting techniques to maximize value.
- Open-Source Frameworks Accelerate AI Development: Projects such as LlamaIndex and Axolotl empower developers with tools for building robust AI applications. Hackathons and community efforts offer over $10,000 in prizes, fostering collaboration and innovation in RAG technology and AI agent development.
- Fine-Tuning and Specialized Model Training Gains Traction: Techniques like Qlora facilitate effective fine-tuning of models such as Llama 3.1 and Mistral, enhancing performance in tasks like code generation and translations. Community benchmarks reveal that fine-tuned models can achieve competitive results, sparking ongoing discussions on optimizing training workflows and addressing domain-specific challenges.
o1-preview (o1-preview-2024-09-12)
OpenAI's o1 Model Launches to Mixed Reviews
- OpenAI released the o1 model series aiming to enhance reasoning in complex tasks like science, coding, and math. While some praised its improved problem-solving abilities, others criticized the high cost ($60 per million output tokens) and questioned its performance gains over existing models like GPT-4o and Sonnet.
Reflection 70B Model Faces Backlash Over Bold Claims
- The Reflection 70B model drew criticism for allegedly falsifying benchmarks claiming to outperform GPT-4o and Claude 3.5 Sonnet. Users labeled it "a wrapper around existing techniques" and reported disappointing performance, raising concerns about transparency in AI model evaluations.
AI Developers Embrace New Tools for Enhanced Workflows
- Projects like HOPE Agent introduce features like dynamic task allocation and JSON-based management to streamline AI orchestration. Additionally, Parakeet demonstrates rapid training capabilities, completing training in less than 20 hours using the AdEMAMix optimizer.
Skepticism Surrounds New AI Models Despite Promised Improvements
- Users expressed doubts about the effectiveness of models like OpenAI's o1, DeepSeek V2.5, and Solar Pro Preview, citing underwhelming performance and high costs. Discussions emphasized the need for verifiable benchmarks and practical enhancements over marketing hype in AI advancements.
California's AI Regulation Bill SB 1047 Raises Industry Concerns
- The proposed California AI regulation bill SB 1047 spurred debate over potential impacts on data privacy and inference compute. Speculation suggests a "66-80% chance of veto" due to political dynamics, highlighting tensions between tech innovation and regulatory measures.
PART 1: High level Discord summaries
OpenRouter (Alex Atallah) Discord
- DeepSeek V2.5 Rolls Out with User-Friendly Features: The launch of DeepSeek V2.5 introduces a full-precision provider and a promise of no prompt logging for users concerned about privacy, according to the OpenRouter announcement. Users can update their data preferences in the
/settings/privacysection.- Additionally, the DeepSeek V2 Chat and DeepSeek Coder V2 models have been merged into this version, allowing seamless redirection to the new model without losing access.
- OpenAI O1 Model Faces Criticism: The OpenAI O1 model is drawing ire from users regarding its high costs and disappointing outputs in coding tasks, particularly due to its use of hidden 'thinking tokens'. Several users reported they feel the model fails to deliver on expected capabilities.
- With pricing set at $60 per million tokens, users are raising concerns about unexpected costs and the overall value provided, prompting discussions around the model's practical utility.
- DeepSeek Endpoint's Performance Under Fire: Community members are reporting inconsistent performance from the DeepSeek endpoint, citing issues with previous downtimes and overall quality. Users are particularly questioning the reliability of the endpoint following recent updates.
- Concerns about performance consistency suggest users might need to replace or adjust their expectations concerning the endpoint's reliability and output quality.
- Diverse User Experiences in LLMs: Forum discussions reveal mixed experiences users have had with various LLMs, with many favoring alternatives such as Sonnet over OpenAI's O1. Some users indicate that despite O1's marketed advancements, performance was lacking compared to other competitors.
- These exchanges highlight a broader sentiment that while users hoped for improvements, many are pivoting to other models that have shown better results.
- Exploring Limitations of O1 and GPT-4o Models: Feedback about the O1 and GPT-4o models underscores frustration as performance results indicate they do not markedly outperform previous versions. Users advocate for more practical enhancements in these advanced models for real-world application.
- Critics call for a greater emphasis on real-world effectiveness rather than unsubstantiated claims of superior reasoning capabilities and argue that consistent testing is essential for validation.
aider (Paul Gauthier) Discord
- OpenAI o1 Pricing Shocks Users: OpenAI's o1 models, including o1-mini and o1-preview, come with hefty prices of $15.00 per million input tokens and $60.00 per million output tokens, leading users to worry about costs rivaling a full-time developer.
- Concerns arose that debugging with o1 could quickly escalate expenses, which has raised eyebrows within the community.
- Aider's Smart Edge Over Cursor: Comparisons between Aider and Cursor highlight Aider's strengths in code iteration and repository mapping, which aids pair programming.
- While Cursor allows for easier file viewing before commits, Aider is seen as the superior choice for making complex code adjustments.
- PLANSEARCH Algorithm Boosts Code Generation: Research on the PLANSEARCH algorithm demonstrates it enhances LLM-based code generation by identifying diverse plans before code generation, promoting more efficient outputs.
- By alleviating the lack of diversity in LLM outputs, PLANSEARCH exhibits valuable performance across benchmarks like HumanEval+ and LiveCodeBench.
- Community Buzz on Diversity in LLM Outputs: A new paper emphasizes that insufficient diversity in LLM outputs hampers performance, leading to inefficient searches and repetitive incorrect outputs.
- PLANSEARCH tackles this issue by broadening the range of generated observations, resulting in significant performance improvements in code generation tasks.
- Aider Scripting Improves Usability: Discussions around enhancing Aider scripting reveal suggestions for defining script file names and configuring .aider.conf.yml for efficient file management.
- Other users also tackled git ignore issues, offering solutions for editing ignored files by adjusting settings or employing command-line flags.
OpenAI Discord
- OpenAI launches o1 models for reasoning: OpenAI released a preview of o1, a new series of AI models aimed at enhancing reasoning in complex tasks like science, coding, and math. This rollout is available for all Plus and Team users in ChatGPT and through the API for tier 5 developers.
- Users are noting that o1 models outperform previous iterations in problem-solving but some express skepticism about the price versus performance improvements.
- ChatGPT struggles with memory functionality: Members reported ongoing issues with ChatGPT memory loading, affecting consistent responses over weeks of conversation. Some switched to the app hoping for reliable access while noting the absence of a Windows app.
- Frustration was voiced about shortcomings, especially in handling chat memory, alongside mixed feelings regarding the new o1 model's creativity compared to GPT-4.
- Active discussions on prompt performance: A member noted a prompt's execution time at 54 seconds, indicating good performance following optimizations, particularly after integrating enhanced physics functionalities. The location of the prompt-labs was clarified for better user accessibility.
- Community members expressed relief upon discovering the library section within the Workshop, revealing potential gaps in the communication of tool availability.
- API access for customizable ChatGPTs discussed: Discussions highlighted users' curiosity regarding accessing APIs for customizable ChatGPTs, with confirmation of availability but uncertainty on the effectiveness of models like o1. Concerns arose regarding user confusion over different model interfaces and rollout statuses.
- Critical experiences related to custom GPTs also surfaced, including issues with publishing due to suspected policy violations, raising questions about the reliability of OpenAI's processes.
Nous Research AI Discord
- Mixed Reviews on the o1 Preview: The o1 preview has received mixed feedback, with some users questioning its improvements over existing models like Claude 3.5 Sonnet, particularly in creative tasks.
- Concerns were raised about its operational efficiency, suggesting it may need further iterations before a full rollout.
- Dolphin Architecture Boosts Context Efficiency: The Dolphin architecture showcases a 0.5B parameter decoder, promoting energy efficiency for long context processing while reducing latency by 5-fold.
- Empirical results reveal a 10-fold improvement in energy efficiency, positioning it as a significant advancement in model processing techniques.
- Inquiring Alternatives for Deductive Reasoning: A discussion on the availability of general reasoning engines explored options beyond traditional LLMs, emphasizing a need for systems capable of solving logical syllogisms.
- An example problem involving potatoes illustrated gaps in LLM performance for deductive reasoning, hinting at the potential use of hybrid systems.
- Cohere Models Compared with Mistral: Feedback regarding Cohere models revealed sentiments of limited alignment and intelligence compared to Mistral, suggesting the latter offers better performance.
- Participants reinforced the comparison between Mistral Large 2 and CMD R+, showcasing Mistral's superior capabilities.
- AI in Product Marketing Discussion: Members investigated AI models that could autonomously manage marketing tasks across platforms, expressing the absence of viable solutions at present.
- The potential for integrating various APIs was floated, sparking ideas for future developments in marketing automation.
HuggingFace Discord
- Ophrase and Oproof CLI Tools Transform Operations: A detailed article explains how Ophrase and Oproof bolster command-line interface functionalities by streamlining task automation and management.
- These tools offer substantial enhancements to workflow efficiency, promising a revolution in handling command line tasks.
- Unpacking Reflection 70B Model: The Reflection 70B project illustrates advances in model versatility, utilizing Llama cpp for improved performance and user interaction.
- It opens a discussion on the dynamics of model adaptability, aiming for accessible community engagement around its functionalities.
- Launch of Persian Dataset for NLP: Introducing a new Persian dataset featuring 6K translated sentences from Wikipedia, aimed at aiding Persian language modeling.
- This initiative enhances resource availability for diverse language processing tasks within the NLP landscape.
- AI Regulation Brings Mixed Reactions: Conversations on AI regulations, sparked by Dr. Epstein's insights on Joe Rogan’s podcast, reflect worries about narratives shaped by social media platforms.
- Members advocate for a balanced approach to free speech versus hate speech, emphasizing the need for moderation within AI discussions.
- HOPE Agent Enhances AI Workflow Management: The HOPE Agent introduces features like dynamic task allocation and JSON-based management to streamline AI orchestration.
- It integrates with existing frameworks such as LangChain and Groq API, enhancing automation across workflows.
Modular (Mojo 🔥) Discord
- Mojo's Error Handling Importance: The discussion focused on ensuring syscall interfaces in Mojo return meaningful error values, which is crucial given the interface contract in languages like C.
- Designing these interfaces requires a thorough understanding of potential errors for effective syscall response management.
- Converting Span[UInt8] to String: Guidance was sought on converting a
Span[UInt8]to a string view in Mojo, with direction provided towardsStringSlice.- To properly initialize
StringSlice, theunsafe_from_utf8keyword argument was noted as necessary after encountering initialization errors.
- To properly initialize
- ExplicitlyCopyable Trait RFC Proposal: A suggestion was made to initiate an RFC for the
ExplicitlyCopyabletrait to require implementingcopy(), potentially impacting future updates.- This could significantly reduce breaking changes to existing definitions according to participants.
- MojoDojo's Open Source Collaboration: The community discovered that mojodojo.dev is now open-sourced, paving the way for collaboration.
- Originally created by Jack Clayton, this resource served as a playground for learning Mojo.
- Recommendation Systems in Mojo: Inquiry arose about existing Mojo or MAX features for developing recommendation systems, revealing both are still in the 'build your own' phase.
- Members noted ongoing development for these functionalities which are not fully established yet.
Perplexity AI Discord
- OpenAI O1 Sparks Enthusiasm: Users are buzzing about the release of OpenAI O1, a model series that promises enhanced reasoning and complex problem-solving capabilities.
- Speculations suggest it may integrate features from reflection and agent-oriented frameworks like Open Interpreter.
- Doubts Surround AI Music: Members expressed skepticism regarding the sustainability of AI-driven music, deeming it a gimmick devoid of genuine artistic value.
- They highlighted the absence of the human touch that gives traditional music its depth and meaning.
- Uncovr.ai Faces Development Challenges: The creator of Uncovr.ai shared insights on the hurdles faced during platform development, stressing the need for enhancements to the user experience.
- Concerns about cost management and sustainable revenue models were noted throughout discussions.
- API Limit Frustrations Prevail: Users aired frustrations over API limits and authorization issues, emphasizing the need for clarity in troubleshooting.
- Management of multiple AI models while keeping costs low was a recurring theme in the discussions.
- Roblox Capitalizes on AI for Gaming: A video discussed how Roblox is innovatively merging AI with gaming, positioning itself as a leader in this area; check the video here.
- This development marks a substantial leap in integrating advanced technologies within gaming environments.
Interconnects (Nathan Lambert) Discord
- OpenAI o1 Model Impresses with Reasoning: The newly released OpenAI o1 model is designed to think more before responding and has shown strong results on benchmarks like MathVista.
- Users noted its ability to handle complex tasks with mixed feedback on its practical performance moving forward.
- California's AI Regulation Bill SB 1047 Raises Concerns: Speculation around California's SB 1047 AI safety bill suggests a 66-80% chance of veto due to political dynamics, especially with Pelosi involved.
- Discussions on the bill’s potential impacts on data privacy and inference compute highlight the tension between tech innovation and regulatory measures.
- Benchmark Speculation on OpenAI o1 Performance: Initial benchmark tests indicate that OpenAI's o1-mini model is performing comparably to gpt-4o, particularly in code editing tasks.
- The community is interested in how the o1 model fares against existing LLMs, reflecting a competitive landscape in AI.
- Understanding RLHF in Private Models: Members are trying to uncover how RLHF (Reinforcement Learning from Human Feedback) functions specifically for private models as Scale AI explores this area.
- This approach aims to align model behaviors with human preferences, which could enhance training reliability.
- Challenges in Domain Expertise for Scale AI: In specialized fields like materials science and chemistry, challenges for Scale AI against established domain experts are anticipated.
- Members reflected that handling data in clinical contexts is significantly more complex compared to less regulated areas, impacting training effectiveness.
Unsloth AI (Daniel Han) Discord
- Reflection Model Faces Backlash: The Reflection 70B model drew fire over claims of falsified benchmarks, still being available on Hugging Face, which raised concerns about fairness in AI development.
- Critics labeled it a wrapper around existing techniques and emphasized the need for transparency in model evaluations.
- Unsloth Limited to NVIDIA GPUs: Unsloth confirmed it only supports NVIDIA GPUs for finetuning, leaving potential AMD users disappointed.
- The discussion highlighted that Unsloth's optimized memory usage makes it a top choice for projects requiring high performance.
- KTO Outshines Traditional Model Alignment: Insights on KTO indicated it could significantly outperform traditional methods like DPO, though models trained with it remain under wraps due to proprietary data.
- Members were excited about the potential of KTO but noted the need for further validation once models become accessible.
- Skepticism Surrounds Solar Pro Preview Model: The Solar Pro Preview model, boasting 22 billion parameters, has been introduced for single GPU efficiency while claiming superior performance over larger models.
- Critics voiced concerns about the practicality of its bold claims, recalling previous letdowns in similar announcements.
- LLM Distillation's Complexities: Participants expressed challenges in distilling LLMs into smaller models, emphasizing accurate output data as crucial for success.
- Disgrace6161 pointed out that reliance on high-quality examples is key, with slow inference arising from token costs for complex reasoning.
Latent Space Discord
- OpenAI Launches o1: A Game Changer for Reasoning: OpenAI has launched the o1 model series, designed to excel in reasoning across various domains such as math and coding, garnering attention for its enhanced problem-solving capabilities.
- Reports highlight that the o1 model not only outperforms previous iterations but also improves on safety and robustness, taking a notable leap in AI technology.
- Devin AI Shines with o1 Testing: Evaluations of the coding agent Devin with OpenAI's o1 models yielded impressive results, showcasing the importance of reasoning in software engineering tasks.
- These tests indicate that o1's generalized reasoning abilities provide a significant performance boost for agentic systems focused on coding applications.
- Scaling Inference Time Discussion: Experts are evaluating the potential of inference time scaling methods linked to the o1 models, proposing that it can rival traditional training scaling and enhance LLM functionality.
- Discussions emphasize the need to measure hidden inference processes to understand their effects on the operational success of models like o1.
- Community's Mixed Feelings on o1: The AI community has expressed a variety of emotions towards the o1 model, with some doubting its efficacy compared to earlier models like Sonnet/4o.
- Highlights of the conversation include concerns about LLM limitations for non-domain experts, underscoring the necessity for specialized tools in AI.
- Anticipating Future o1 Developments: The community is keen to see upcoming developments for the o1 models, especially the exploration of potential voice features.
- While excitement surrounds o1's cognitive capabilities, some users are facing limitations in functional aspects like voice interactions.
CUDA MODE Discord
- Exciting Compute Credits for CUDA Hackathon: The organizing team secured $300K in cloud credits along with access to a 10 node GH200 cluster and a 4 node 8 H100 cluster for participants of the hackathon.
- This opportunity includes SSH access to nodes, allowing for serverless scaling with the Modal stack.
- Robust Support for torch.compile: Support for
torch.compilehas been integrated into themodel.generate()function in version 0.2.2 of the MobiusML repository, improving usability.- This update means that the previous dependency on HFGenerator for model generation is eliminated, simplifying workflows for developers.
- GEMM FP8 Implementation Advances: A recent pull request implements FP8 GEMM using E4M3 representation, addressing issue #65 and testing various matrix sizes.
- Documentation for SplitK GEMM has been added to guide developers on usage and implementation strategies.
- Aurora Innovation Hiring Engineers: Aurora Innovation aims for a commercial launch by late 2024, seeking L6 and L7 engineers with expertise in GPU acceleration and CUDA/Triton tools.
- The company recently raised $483 million to support its driverless launch plans, highlighting significant investor confidence.
- Evaluating AI Models and OpenAI's Strategy: Participants expressed concerns about OpenAI's competitiveness compared to rivals like Anthropic, emphasizing the need for innovative training strategies.
- Debate around Chain of Thought (CoT) revealed frustrations over its implementation transparency, affecting perceptions of leadership effectiveness at OpenAI.
Stability.ai (Stable Diffusion) Discord
- Reflection LLM Performance Concerns: The Reflection LLM claimed to outperform GPT-4o and Claude Sonnet 3.5, yet its actual performance has drawn significant criticism, especially compared to the open-source variant.
- Doubts emerged regarding its originality as its API seemed to mirror Claude, prompting users to question its effectiveness.
- Exploration of AI Photo Generation Services: There were inquiries about the best paid AI photo generation services for realistic image outputs, creating a lively discussion around available options.
- A notable alternative was mentioned: Easy Diffusion, positioned as a strong free competitor.
- Flux Model Performance Optimizations: Users reported positive experiences with the Flux model, highlighting notable performance gains tied to memory usage tweaks and RAM limits.
- There is ongoing discussion about low VRAM optimizations, particularly in comparison to competitors like SDXL.
- Lora Training Troubleshooting: Members shared the difficulties encountered during Lora training, seeking help on better configurations for devices with limited VRAM.
- Discussions included references to resources for workflow optimizations, specifically highlighting trainers like Kohya.
- Dynamic Contrast Adjustments in Models: One user explored methods to decrease contrast in their lighting model by using specific CFG settings and proposed dynamic thresholding techniques.
- They requested advice on how to balance parameters when modifying CFG values, indicating a need for precise adjustments to improve output quality.
LM Studio Discord
- Guidelines for Implementing RAG in LM Studio: For a successful RAG pipeline in LM Studio, users should download version 0.3.2 and upload PDFs as advised by members. Another user encountered a 'No relevant citations found for user query' error, recommending to make specific inquiries instead of general questions.
- Members are encouraged to refer to Building Performant RAG Applications for Production - LlamaIndex for further insights.
- Ternary Models Performance Issues: Members discussed troubles with loading ternary models, with one reporting an error while accessing a model file and another suggested reverting to older quantization types since the latest 'TQ' types are still experimental.
- This highlights the need for caution when dealing with newer types and adjusting workflows accordingly.
- Community Meet-up in London: Users are invited to a community meet-up in London to discuss prompt engineering and share experiences, emphasizing readiness to connect with fellow engineers. Attendees should look for older members carrying laptops.
- This event provides a platform for networking and exchanging valuable insights.
- OpenAI O1 Access Rollout: Members are discussing their experiences with accessing the OpenAI O1 preview, noting the rollout occurs in batches. Several users have received access recently, while others await their opportunity.
- This rollout showcases the gradual availability of new tools within the community.
- Interest in Dual 4090D Setup: One member shared excitement over using two 4090D GPUs with 96GB RAM each but highlighted the power challenge needing a small generator for their 600W requirement. This humorous take on high power consumption caught the group's attention.
- This enthusiasm reflects the advanced setups members are considering to boost their performance.
OpenInterpreter Discord
- Enhanced Terminal Output with Rich: Rich is a Python library for beautiful terminal formatting, greatly enhancing output visuals for developers.
- Members explored various terminal manipulation techniques, discussing alternatives to improve color and animation functionalities.
- LiveKit Server Best Practices: Community consensus promotes Linux as the favored OS for the LiveKit Server, with anecdotes of troubles on Windows.
- One member humorously noted, 'Not Windows, only had problems so far,' easing others' concerns about OS choice.
- Preview Release of OpenAI o1 Models: OpenAI teased the preview of o1, a new model series aimed at improving reasoning in science, coding, and math applications, detailed in their announcement.
- Members expressed excitement over the potential for tackling complex tasks better than previous models.
- Challenges with Open Interpreter Skills: Participants highlighted Open Interpreter skills not being retained post-session, affecting functionality such as Slack messaging.
- A call for community collaboration to resolve this issue has been issued, seeking further investigation.
- Awaiting Cursor and o1-mini Integration: Users expressed eagerness for Cursor's launch with o1-mini, hinting at its upcoming functionality with playful emojis.
- The anticipation for o1-mini suggests a growing demand for novel tool capabilities in the community.
Cohere Discord
- Parakeet Project Makes Waves: The Parakeet project, trained using an A6000 line model for 10 hours on a 3080 Ti, produced notable outputs, stirring interest in the effectiveness of the AdEMAMix optimizer. A member noted, 'this might be the reason Parakeet was able to train in < 20 hours at 4 layers.'
- The success indicates a potential shift in training paradigms while inviting further investigations into optimization techniques.
- GPU Ownership Reveals Varied Setups: A member shared their impressive GPU lineup, boasting ownership of 7 GPUs, including 3 RTX 3070's and 2 RTX 4090's. This prompted humorous reactions regarding the naming conventions of GPUs and their relevance today.
- The ongoing discussions highlight the broad diversity in hardware choices and usage among members.
- Quality Over Quantity in Training Data: A conversation emphasized that it’s not the sheer volume but the quality of data that counts when training models - a perspective shared by a member regarding their work with 26k rows for a JSON to YAML use case. They stated, 'Less the amount of data - it's more the quality.'
- The exchange pointed towards a deeper understanding of data importance in training methodologies.
- Personal AI Executive Assistant Success: A member successfully built a personal AI executive assistant that manages scheduling with a calendar agent cookbook, integrating voice inputs to edit Google Calendar events. This project demonstrates an innovative use of AI for personal productivity.
- The assistant adeptly interprets unstructured data, proving beneficial for organizing exam dates and project deadlines.
- Seeking Best Practices for RAG Applications: A user inquired about best practices for implementing guardrails in RAG applications, stressing that solutions should be context-specific. This aligns with ongoing efforts to optimize AI applications for real-world utility.
- They also investigated tools used for evaluating RAG performance, aiming to pinpoint widely accepted metrics and methodologies.
Eleuther Discord
- Simplifying Contribution to Projects: A member emphasized that opening an issue in any project and following it up with a PR is the easiest way to contribute.
- This method provides clarity and fosters collaboration in ongoing projects.
- Excitement over PhD Completion: One member shared enthusiasm about finishing their PhD in Germany and gearing up for a postdoc focusing on safety and multi-agent systems.
- They also highlighted hobbies like chess and table tennis, showing a well-rounded personal life.
- RWKV-7 Stands Out with Chain of Thought: The RWKV-7 model, with only 2.9M parameters, demonstrates impressive capabilities in solving complex tasks using Chain of Thought.
- It's noted that generating extensive data with reversed numbers enhances its training efficiency.
- Pixtral 12B Falls Short in Comparisons: Discussion erupted over the Pixtral 12B's performance, which appeared inferior compared to Qwen 2 7B VL despite being larger.
- Skepticism arose regarding data integrity presented at the MistralAI conference, indicating potential oversights.
- Challenges in Multinode Training: Concerns were raised about the feasibility of multinode training over slow Ethernet links, particularly with DDP across 8xH100 machines.
- Members agreed that optimizing the global batch size is essential to overcome performance bottlenecks.
LlamaIndex Discord
- Hands-on AI Scheduler Workshop Coming Up: Join us at the AWS Loft on September 20th to learn about building a RAG recommendation engine for meeting productivity using Zoom, LlamaIndex, and Qdrant. More details can be found here.
- This workshop aims to create a highly efficient meeting environment with cutting-edge tools that provide transcription features.
- Build RAG System for Automotive Needs: A new multi-document agentic RAG system will help diagnose car issues and manage maintenance schedules using LanceDB. Participants can set up vector databases for effective automotive diagnostics as explained here.
- This approach underscores the versatility of RAG systems in practical applications beyond traditional settings.
- OpenAI Models Now Available in LlamaIndex: With the integration of OpenAI's o1 and o1-mini models, users can utilize these models directly in LlamaIndex. Install the latest version using
pip install -U llama-index-llms-openaifor full access details here.- This update enhances the capabilities within LlamaIndex, aligning with ongoing advancements in model utility.
- LlamaIndex Hackathon Offers Cash Prizes: Prepare for the second LlamaIndex hackathon scheduled for October 11-13, with more than $10,000 in prizes sponsored by Pinecone and Vesslai. Participants can register here for this event focused on RAG technology.
- The hackathon encourages innovation in RAG applications and AI agent development.
- Debate on Complexity of AI Frameworks: Discussions arose over whether frameworks like LangChain, Llama_Index, and HayStack have become overly complex for practical use in LLM development. An insightful Medium post was referenced.
- This highlights ongoing concerns about balancing functionality and simplicity in tool design.
DSPy Discord
- Output Evaluation Challenges: Members highlighted a lack of methods to evaluate outputs for veracity beyond standard prompt techniques aimed at reducing hallucinations, emphasizing the need for better evaluations.
- One member humorously noted, Please don't cite my website in your next publication, stressing caution in using generated outputs.
- Customizing DSPy Chatbots: A member inquired about implementing client-specific customizations in DSPy-generated prompts using a post-processing step instead of hard-coding, aiming for flexibility.
- Another member proposed utilizing a 'context' input field similar to a RAG approach, suggesting training pipelines with common formats to enhance adaptability.
- O1 Pricing Confusion: Discussion about OpenAI's O1 pricing revealed that members were uncertain about its structure, with one confirming that O1 mini is cheaper than other options.
- Members expressed interest in conducting a comparative analysis between DSPy and O1, suggesting a trial of O1 for potential cost-effectiveness.
- Understanding RPM for O1: '20rpm' was clarified by a member as referring to 'requests per minute', a critical metric that impacts performance discussions regarding O1 and DSPy.
- This clarification led to further inquiries about the implications of this metric for current and future integrations.
- DSPy and O1 Integration Curiosity: Questions arose about DSPy's compatibility with O1-preview, reflecting the community's eagerness to explore more functionalities between these two systems.
- This interest signifies the importance of integration to enhance capabilities within DSPy.
Torchtune Discord
- Mixed Precision Training Complexity: Maintaining compatibility between mixed precision modules and other features requires extra work; bf16 half precision training is noted as strictly better due to fp16 support issues on older GPUs.
- Using fp16 naively leads to overflow errors, increasing system complexity and memory usage with full precision gradients.
- FlexAttention Integration Approved: The integration of FlexAttention for document masking has been merged, sparking excitement about its potential.
- Questions arose about whether each 'pack' is padded to max_seq_len, considering the implications of lacking a perfect shuffle for convergence.
- PackedDataset Shines with INT8: Performance tests revealed a 40% speedup on A100 with PackedDataset using INT8 mixed-precision in torchao.
- A member plans more tests, confirming that the fixed seq_len of PackedDataset fits well with their INT8 strategy.
- Tokenizer API Standardization Discussion: A member suggested addressing issue #1503 to unify the tokenizer API before tackling the eos_id issue, implying this could streamline development.
- With an assignee already on #1503, the member intends to explore other fixes to enhance overall improvements.
- QAT Clarification Provided: A member compared QAT (Quantization-Aware Training) with INT8 mixed-precision training, highlighting key differences in their goals.
- QAT aims to improve accuracy, while INT8 training focuses on enhancing speed and may not require QAT for minimal accuracy loss.
OpenAccess AI Collective (axolotl) Discord
- OpenAI Model Sparks Curiosity: Members are buzzing about the new OpenAI model, questioning its features and reception, suggesting it's a fresh release worth exploring.
- It sparked curiosity and further discussion about its capabilities and reception.
- Llama Index Interest Peaks: Interest in the Llama Index grows as members share their familiarity with its tools for model interaction and potential connections to the OpenAI model.
- This led to a potential exploration of how it relates to the new OpenAI model.
- Reflection 70B Labelled a Dud: Concerns emerged regarding the Reflection 70B model being considered a dud, spurring discussions about the implications of the new OpenAI release timing.
- The comment was shared light-heartedly, suggesting it was a response to previous disappointments.
- DPO Format Expectations Set: A member clarified the expected DPO format as
<|begin_of_text|>{prompt}followed by{chosen}<|end_of_text|>and{rejected}<|end_of_text|>, referencing a GitHub issue.- This update points to improvements in custom format handling within the Axolotl framework.
- Llama 3.1 Struggles with Tool Calls: Issues arose with the llama3.1:70b model regarding nonsensical outputs when utilizing tool calls, despite appearing functionally correct.
- In one instance, after the tool indicated the night mode was deactivated, the assistant still failed to appropriately respond to subsequent requests.
LAION Discord
- Flux by RenderNet launched!: Flux from RenderNet enables users to create hyper-realistic images from just one reference image without the need for LORAs. Check it out through this link.
- Ready to bring your characters to life? Users can get started effortlessly with just a few clicks.
- SD team undergoes name change: The SD team has changed its name to reflect their departure from SAI, leading to discussions about its current status.
- So SD has just died? This comment captures the sentiment of concern among members regarding the team's future.
- Concerns about SD's open-source status: Members expressed worries about SD's lack of activity in the open source space, indicating a possible decline in community engagement.
- If you care about open source, SD seems to be dead, was a notable remark on the perceived inactivity.
- New API/web-only model released by SD: Despite concerns about engagement, the SD team has released a recent API/web-only model, signaling some level of output.
- Though initial skepticism about their commitment to open source persists, the release shows they are still working.
- Stay Updated with Sci Scope: Sci Scope compiles new ArXiv papers with related topics, summarizing them weekly for easier consumption in AI research.
- Subscribe to the newsletter for straightforward updates delivered directly, enhancing your awareness of current literature.
LangChain AI Discord
- HTML Chunking Package Debuts: The new package
html_chunkingefficiently chunks and merges HTML content while maintaining token limits, crucial for web automation tasks.- This structured approach ensures valid HTML parsing, preserving essential attributes for a variety of applications.
- Demo Code Shared for HTML Chunking: A demo snippet showcasing
get_html_chunksillustrates how to process an HTML string while preserving its structure within set token limits.- The outputs consist of valid HTML chunks—long attributes are truncated, ensuring the lengths remain reasonable for practical use.
- HTML Chunking vs Existing Tools:
html_chunkingis compared to LangChain'sHTMLHeaderTextSplitterand LlamaIndex'sHTMLNodeParser, highlighting its superiority in preserving HTML context.- The existing tools primarily extract text content, undermining their effectiveness in scenarios demanding comprehensive HTML retention.
- Call to Action for Developers: Developers are encouraged to explore
html_chunkingfor enhanced web automation capabilities, emphasizing its precise HTML handling.- Links to the HTML chunking PYPI page and GitHub repo provide avenues for further exploration.
tinygrad (George Hotz) Discord
- George Hotz promotes sensible engagement: George Hotz has requested that members refrain from unnecessary @mentions unless their queries are deemed constructive, encouraging self-sufficiency in resource utilization.
- It only takes one search to find pertinent information, fostering a culture of relevance within discussions.
- New terms of service focus on ethical practices: George has introduced a terms of service specifically for ML developers, aimed at prohibiting activities like crypto mining and resale on GPUs.
- This policy intends to create a focused development environment, particularly leveraging MacBooks' capabilities.
LLM Finetuning (Hamel + Dan) Discord
- Literal AI's Usability Shines: A member praised Literal AI for its usability, noting features that enhance the LLM application lifecycle available at literalai.com.
- Integrations and intuitive design were highlighted as key aspects that facilitate smoother operations for developers.
- Boosting App Lifecycle with LLM Observability: LLM observability was discussed as a game-changer for enhancing app development, allowing for quicker iterations and debugging while utilizing logs for fine-tuning smaller models.
- This approach is set to improve performance and reduce costs significantly in model management.
- Transforming Prompt Management: Emphasizing prompt performance tracking as a safeguard against deployment regressions, the discussion indicated its necessity for reliable LLM outputs.
- This method proactively maintains quality assurance across updates.
- Establishing LLM Monitoring Setup: Insights were shared on building a robust LLM monitoring and analytics system, integrating log evaluations to uphold optimal production performance.
- Such setups are deemed critical for ensuring sustained efficiency in operations.
- Fine-tuning LLMs for Better Translations: A discussion surfaced about fine-tuning LLMs specifically for translations, pinpointing challenges where LLMs capture gist but often miss tone or style.
- This gap presents an avenue for developers to innovate in translation capabilities.
Gorilla LLM (Berkeley Function Calling) Discord
- Gorilla LLM Tests Reveal Mixed Accuracy: Recent tests on Gorilla LLM show concerning results, with irrelevance achieving a perfect accuracy of 1.0, while both java and javascript recorded 0.0.
- Tests such as live_parallel_multiple and live_simple were disappointing, prompting doubts on the models' effectiveness.
- Member Seeks Help on Prompt Splicing for Qwen2-7B-Chat: A user raised worries over the subpar performance of qwen2-7b-chat, questioning if it stems from issues with prompt splicing.
- They are looking for reliable insights and methods to enhance their testing experience with effective prompt strategies.
MLOps @Chipro Discord
- Insights Wanted on Predictive Maintenance: A member raised questions about their experiences with predictive maintenance and sought resources such as papers or books on optimal models and practices, especially regarding unsupervised methods without tracked failures.
- The discussion highlighted the impracticality of labeling events manually, emphasizing a need for efficient methodologies within the field.
- Mechanical and Electrical Focus in Monitoring: Discussion centered on a device that is both mechanical and electrical, which records several operational events that can benefit from improved monitoring practices.
- Members agreed that utilizing effective monitoring strategies could enhance maintenance approaches and potentially lower future failure rates.
The Alignment Lab AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
{% if medium == 'web' %}
OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
DeepSeek V2.5DeepSeek mergerReflection endpointData privacy
- DeepSeek V2.5 Launches with New Features: DeepSeek V2.5 now includes a new full-precision provider and ensures that there is no prompt logging for data-conscious users, as noted in the official announcement.
- Users can manage their data preferences through the
/settings/privacysection.
- Users can manage their data preferences through the
- DeepSeek Models Merged: The DeepSeek V2 Chat and DeepSeek Coder V2 models have been merged and upgraded into the new DeepSeek V2.5, ensuring backward compatibility with the redirection of
deepseek/deepseek-codertodeepseek/deepseek-chat.- This change simplifies the model access for users taken from OpenRouterAI announcement.
- Discontinuation of Free Reflection Endpoint: Attention is drawn to the fact that the free Reflection endpoint will be disappearing soon, with the standard version continuing as long as available providers exist.
- This impending change encourages users to prepare for the transition away from free access as shared by OpenRouterAI.
Link mentioned: Tweet from OpenRouter (@OpenRouterAI): DeepSeek 2.5 now has a full-precision provider, @hyperbolic_labs! It also doesn't log prompts, for data-conscious users. You can configure your data preferences in /settings/privacy
OpenRouter (Alex Atallah) ▷ #general (778 messages🔥🔥🔥):
OpenAI O1 ModelDeepSeek Endpoint PerformanceModel Pricing and CostsUser Experiences with LLMsLimitations of O1 and GPT-4o
- OpenAI O1 Model's Limitations: Users are expressing frustration with the OpenAI O1 model, noting its high costs and underwhelming performance, particularly in coding tasks. The model's reliance on hidden 'thinking tokens' adds to users' dissatisfaction.
- DeepSeek Endpoint Performance: The performance of the DeepSeek endpoint is under scrutiny, with users noting previous downtimes and fluctuating quality. Some users are curious if the endpoint is working consistently, given recent updates.
- Model Pricing and Costs: There is concern about the pricing structure for models like O1 and how it could lead to high costs for users, especially with hidden billing for tokens. Users mention that O1 costs $60 per million tokens and questions about the potential for excessive billing have arisen.
- User Experiences with LLMs: The conversation highlights varied user experiences with different LLMs, with some preferring OpenAI's models while others express preference for alternatives like Sonnet. A few users report better performance from other models despite O1's promised advancements.
- Limitations of O1 and GPT-4o: Feedback on O1 and GPT-4o indicates that while O1 is marketed with enhanced reasoning capabilities, practical tests show it may not perform significantly better than earlier iterations. Users emphasize that the results suggest a need for practical applications and improvements in these models.
Links mentioned:
aider (Paul Gauthier) ▷ #general (658 messages🔥🔥🔥):
OpenAI o1 Pricing and PerformanceAider vs. CursorUser Experiences with o1System Prompt Modifications in AiderJailbreak Attempts with o1
- OpenAI o1 Pricing and Performance: OpenAI's new o1 models, including o1-mini and o1-preview, have been noted for their high costs of $15.00 per million input tokens and $60.00 per million output tokens.
- Users expressed concern over the expense, indicating that debugging and usage could end up being as costly as hiring a full-time developer.
- Aider vs. Cursor: Users compared Aider and Cursor, highlighting Aider's superior ability to iterate on code due to its repo map, while Cursor provides ease with file viewing before commits.
- Overall, Aider was deemed smarter for making code changes, reinforcing the advantage of using it for pair programming.
- User Experiences with o1: One user reported success using o1-preview for a complex task involving a thousand lines of code, achieving results in just four prompts.
- Mixed reactions were expressed regarding o1's consistency and effectiveness, with some users optimistic while others raised concerns about its limitations.
- System Prompt Modifications in Aider: Users discussed the implications of modifying system prompts in Aider, with one sharing a detailed super prompt that significantly improved performance.
- These modifications are suggested to optimize how Aider handles tasks, specifically when integrated with new models like o1.
- Jailbreak Attempts with o1: Experimentation with jailbreaks attempted to unveil system prompts in o1 led to unexpected billing issues, with significant charges accruing for thought tokens generated during the attempts.
- Community members advised caution when using o1, emphasizing awareness of how its billing structure operates in relation to output and generated tokens.
Links mentioned:
aider (Paul Gauthier) ▷ #questions-and-tips (62 messages🔥🔥):
Aider scriptingDeepSeek integrationGit ignore issuesEnvironment variables in WindowsCached token usage
- Aider Scripting Enhancements: Users are discussing the possibility of defining script file names when using Aider, with suggestions to use specific commands for better results, such as including the desired file name in the prompt.
- There is also a suggestion to configure .aider.conf.yml for consistent loading of certain files, like CONVENTIONS.md, upon startup.
- DeepSeek Integration Questions: Users inquired about using DeepSeek models, discussing configurations and the distinctions between using DeepSeek API and OpenRouter APIs for accessing model functionalities.
- Clarifications were provided on how to use the right API endpoints and model names, as well as adjusting context size settings for better model performance.
- Git Ignore Issues with Aider: A user expressed difficulty in editing files that are listed in .gitignore, with Aider prompting for new file creation instead of editing when git refuses to include the files.
- It was noted that users can circumvent this by renaming or adding files to git or using command-line flags to bypass git checks.
- Environment Variables Troubleshooting: Users discussed encountering issues with required environment variables for DeepSeek while using Windows, where variables were set but not recognized.
- Suggestions included ensuring terminal restarts and proper variable configurations, alongside directing users to the relevant Aider documentation.
- Cached Token Usage and Costs: Discussion centered on the costs associated with caching tokens in Aider when using Sonnet, with users clarifying upfront and ongoing fees related to caching prompts and usage.
- It was advised that extensive caching could lead to hitting daily token limits quickly, encouraging users to manage their usage based on their tier limits.
Links mentioned:
aider (Paul Gauthier) ▷ #links (2 messages):
PLANSEARCH algorithmLLM code generationDiversity in LLM outputs
- PLANSEARCH Algorithm Enhances Code Generation: New research on the PLANSEARCH algorithm shows it significantly boosts performance in LLM-based code generation by exploring diverse ideas before generating code.
- The study reveals that by searching over candidate plans in natural language, it can mitigate the issue of lack of diversity in LLM outputs, leading to more efficient code generation.
- Diversity in LLM Outputs Key to Performance: The paper hypothesizes that the core issue in LLM performance is a lack of diverse outputs, resulting in inefficient searches and repeated sampling of incorrect generations.
- PLANSEARCH addresses this by generating a broad range of observations and constructing plans from them, which has shown strong results across benchmarks like HumanEval+ and LiveCodeBench.
- PLANSEARCH Paper and Implementation Available: The research paper detailing the PLANSEARCH algorithm is accessible here for those interested in the intricacies of the method.
- Additionally, the implementation can be found on GitHub at this link, showcasing the optimization of inference for LLMs.
Links mentioned:
OpenAI ▷ #annnouncements (1 messages):
OpenAI o1 modelsAI reasoning capabilitiesChatGPT updatesAPI access for developers
- OpenAI introduces o1 models for enhanced reasoning: OpenAI is releasing a preview of o1, a new series of AI models designed to spend more time thinking before responding, aimed at solving complex tasks in science, coding, and math.
- This rollout starts today in ChatGPT for all Plus and Team users, and developers at tier 5 can access it through the API.
- Enhanced problem-solving capabilities unveiled: o1 models can reason through harder problems better than previous iterations, marking a significant leap in AI functionality.
- Users are anticipated to benefit from increased efficiency in complex problem-solving tasks across various domains.
OpenAI ▷ #ai-discussions (416 messages🔥🔥🔥):
GPT-4o vs GPT o1Advanced Voice ModePerformance of AI Models in MathUse of Chain of ThoughtLimitations of File Upload Features
- Comparing GPT-4o and GPT o1: Users discussed the differences in performance between GPT-4o and GPT o1, noting GPT-4o can handle complex calculations like 3^^4 but struggles with 3^^5.
- Some expressed skepticism about whether the improvements in o1 justify its price, questioning if it's simply a fine-tuned version of GPT-4o.
- Frustration Over Advanced Voice Mode: Many users voiced their disappointment regarding the slow rollout of the advanced voice mode and the apparent lack of interest from OpenAI in prioritizing it.
- Some compared the anticipation of voice functionalities to the long-awaited release of GTA 6, reflecting on the fading excitement.
- AI Models and Math Benchmarking: Discussions highlighted surprising performances of AI models in math benchmarks, with some users questioning if it was achievable through Chain of Thought (CoT) alone.
- Concerns were raised about whether the high scores in math indicate a significant advancement in AI capabilities, calling for deeper analysis.
- Chain of Thought Implementation: Participants discussed the role of Chain of Thought in enabling AI models to perform better at reasoning tasks while acknowledging its limitations.
- There was speculation about whether current advancements are enough to elevate AI to a new level of intelligent reasoning or if future models may be required.
- File Upload Limitations: Users expressed dissatisfaction with GPT's current lack of file upload capabilities, which hampers tasks like extracting text from images.
- Some noted that while there are features in advanced modes, the restrictions still impact usability for specific applications.
Links mentioned:
OpenAI ▷ #gpt-4-discussions (27 messages🔥):
ChatGPT memory issuesOpenAI o1 model reactionsCustom GPT publishing problemsWindows app statusAPI for customizable GPTs
- ChatGPT struggles with memory loading: Several members expressed frustration that ChatGPT in the browser fails to load memory of the chat and produce responses consistently for weeks.
- One member mentioned switching to the app while another noted the lack of a Windows app, with hopes for its release.
- Mixed reactions to OpenAI o1 model: The community is eagerly discussing the new OpenAI o1 model, with mixed expectations about its creativity compared to the current 4.0 model.
- Critical comments highlighted the benchmarks suggesting that o1 might not outperform previous models in writing quality, despite claims of better reasoning capabilities.
- Publishing issues with custom GPTs: A member reported their custom GPT won't publish due to a suspected violation of usage policies, with their appeals being ignored.
- This raises concerns about the reliability of the publishing process for personalized models.
- Interest in API for customizable GPTs: Members inquired about the possibility of accessing APIs for customizable Chat GPTs, expressing the need for better integration.
- One member confirmed it is possible to get an API, but the effectiveness of the new model is yet to be determined.
- Access status and rollout of o1: There were discussions about access to the o1 model, with some members indicating they just received access while others are still awaiting it.
- Concerns were raised regarding user confusion between the models and their interfaces, and overall satisfaction with o1 seems lukewarm.
OpenAI ▷ #prompt-engineering (6 messages):
Library LocationPrompt Performance
- Find the Library in the Left Menu: A user clarified that the 'library' can be found in the left menu bar under ‘Workshop’, specifically in the 'prompt-labs' section.
- If 'prompt-labs' isn't visible right away, they suggested clicking 'Workshop' again for visibility.
- User expresses gratitude for Library info: After receiving the location of the library, a user expressed appreciation, saying, Bless you. They noted that prior searches yielded no information about it.
- This highlights potential gaps in communication about available resources within the server.
- Prompt Performance Noted: A member reported a prompt taking 54 seconds, commenting, Not bad, post-optimization.
- They mentioned this was following the integration of further physics functionalities.
OpenAI ▷ #api-discussions (6 messages):
Location of LibraryPrompt-LabsServer Search ChallengesPhysics IntegrationResponse Time
- Finding the Library Made Easy: A member shared that the ‘library’ can be found in the left menu bar under ‘Workshop’ with two categories: community-help and prompt-labs.
- If prompt-labs does not appear immediately, clicking on Workshop again will reveal it.
- Prompt-Labs Renamed: It was noted that prompt-labs is the new designation for the previously mentioned library, enhancing clarity for users.
- “Bless you. I tried searching the server and literally no one mentioned this.” expressed the relief of a member finally locating it.
- Fast Response Time on Prompts: A member reported a response time of 54 seconds for their prompt, indicating a solid performance.
- They mentioned this occurred “after integrating the rest of physics,” suggesting improvements in system efficiency.
Nous Research AI ▷ #general (296 messages🔥🔥):
Nous Research AI Discord Chatbot PerformanceOpenAI o1 Preview DiscussionMCTS and its Relation to LLMsConsensus Prompting TechniqueEvaluation of Hermes 3 and o1 Models
- Mixed Reviews on o1 Preview: Users have mixed opinions about the o1 preview, noting that it may not represent a significant improvement over existing models like Claude 3.5 Sonnet, despite some claiming higher performance.
- Concerns were raised regarding its utility in tasks like agentic performance and creative writing, often comparing it unfavorably to previous models.
- Technical Evaluation of LLMs: Benchmarks indicate that o1-preview operates at a middle compute range with a lower than expected accuracy compared to gpt-4o, suggesting it might require significantly more resources for optimal performance.
- Data extracted from accuracy vs. compute measurements imply o1-preview might be less efficient than gpt-4o, leading to speculation about further iterations before full deployment.
- MCTS and Prompting Techniques: There was discussion on the utility of Monte Carlo Tree Search (MCTS) in improving reasoning capabilities in LLMs, with some users arguing its necessity versus a single prompt chain.
- Participants debated whether a unified prompt chain could effectively replicate MCTS without the additional structure, evaluating the implications on model performance.
- Reflection Model in Hermes 3: Hermes 3 employs XML-based reflection techniques and showcases agentic capabilities, indicating a training methodology aimed at enhancing reasoning and performance in various tasks.
- Despite improvements in repetitive tasks, some users questioned the novelty of features and whether Hermes 3 unlocked any new abilities compared to its predecessors.
- User Experience and Performance Feedback: Several users shared their frustrations with the o1 models, including an incident about an infinite loop bug leading to high token consumption without output.
- General feedback indicates that while o1 shows potential, it might still struggle in practical applications without optimal prompting from users.
Links mentioned:
Nous Research AI ▷ #ask-about-llms (48 messages🔥):
Small LLM RecommendationsUsing AI for MarketingMistral Model DiscussionCohere Models' PerformanceSafety Alignment in AI
- Searching for Smaller LLMs: Members discussed various small language models, such as Qwen2-1.5b and Mistral alternatives, for users seeking options smaller than Llama 3.1 8B.
- One member pointed out the Open LLM Leaderboard as a great resource for discovering small models currently available.
- AI Solutions for Marketing Tasks: A query was raised about an LLM that could autonomously handle product marketing across social platforms, garnering feedback while publicizing products.
- Although no current solutions fully meet this demand, it was suggested that incorporating various APIs might lead to a startup idea.
- Mistral's Unique Features: Discussion highlighted Mistral's lesser emphasis on safety alignment, that's received mixed opinions, including comments on its capabilities in post-hoc moderation.
- Some members noted that it can effectively classify harmful prompts, demonstrating its adaptability for specific use cases.
- Weaknesses of Cohere Models: Users shared experiences regarding Cohere models, describing them as relatively weakly aligned and lacking in intelligence compared to Mistral.
- A comparison was made between CMD R+ and Mistral Large 2, reinforcing the perception that the latter has superior performance.
- Concerns Regarding AI Safety: Concerns were expressed about the necessity of safety alignment in AI, particularly the idea that AI should be able to perform moderation independently.
- Members suggested rigorous adversarial testing might be essential before AI evolves further, avoiding control issues in the future.
Links mentioned:
Nous Research AI ▷ #research-papers (4 messages):
Hallucinations in Large Language ModelsDolphin Architecture for Energy EfficiencyContextual Processing in Language Models
- Hallucinations: Inevitable Feature of LLMs: Research argues that hallucinations in Large Language Models are not mere errors but stem from their fundamental mathematical structure, a claim supported by Gödel's First Incompleteness Theorem. This implies that improvements in architecture or datasets cannot eliminate these hallucinations.
- Every stage of LLM processes, from training to generation, carries a non-zero chance of resulting in hallucinations, highlighting the inescapability of this issue.
- Dolphin Decoder for Efficient Context Processing: The Dolphin architecture introduces a 0.5B parameter decoder designed to enhance energy efficiency in processing long contexts, significantly decreasing input length for a 7B parameter main decoder, as detailed in the paper here. Empirical evaluations suggest a 10-fold improvement in energy efficiency and a 5-fold latency reduction.
- Utilizing a multi-layer perceptron (MLP), the design facilitates transforming the text encoding into context token embeddings, improving extended context processing without the usual computational costs.
- Smart Conditioning with Fewer Prefix Tokens: A discussion highlighted a smart approach in training a model to condition on fewer prefix tokens while closely aligning with the latent space expected from a longer history. One user noted that this involves training an MLP to carry out the appropriate projection to manage information effectively.
- By leveraging compact embeddings, the method aims to make predictions as if the model were conditioned on a more extensive context, showcasing an innovative direction in model efficiency.
Links mentioned:
Nous Research AI ▷ #interesting-links (2 messages):
AI models reasoningSci Scope newsletter
- New AI Models Emphasize Reasoning: OpenAI has developed a new series of AI models that spend more time thinking before they respond, aiming to reason through complex tasks.
- These models are reportedly better at solving harder problems in areas such as science, coding, and math; for further details, visit OpenAI's announcement.
- Stay Updated with Sci Scope: Sci Scope groups together ArXiv papers by topic and offers a weekly summary for easier navigation of AI research.
- Subscribe to the newsletter to receive a weekly overview of all AI research directly in your inbox at Sci Scope.
Link mentioned: Sci Scope: An AI generated newspaper on AI research
Nous Research AI ▷ #research-papers (4 messages):
Hallucinations in Language ModelsDolphin Architecture for Long ContextsProjector in Language ModelsEfficiency in Language Processing
- Hallucinations as Inevitable Features in LLMs: A recent paper argues that hallucinations in Large Language Models (LLMs) are not merely occasional errors but are fundamental to their design, citing Godel's First Incompleteness Theorem as a basis.
- The authors emphasize that improving architecture or datasets won't eliminate hallucinations, which are likely present in every stage of the LLM process.
- Dolphin Model Redefines Long Context Handling: The Dolphin architecture presents a compact 0.5B parameter decoder to efficiently manage extensive context in language models, showcasing significant reductions in energy consumption and latency.
- By encoding long textual contexts as a distinct modality, it aims for a 10-fold improvement in energy efficiency and a 5-fold reduction in latency.
- Innovative Projector for Contextual Information: Dolphin utilizes a multi-layer perceptron (MLP) projector to convert embedding information from the text encoder into context token embeddings for the main decoder.
- This method effectively connects different embedding dimensions, bridging the information between the compact 0.5B and the main 7B parameter decoder model.
- Discussion on Context Conditioning Techniques: A member discussed how Dolphin seeks to condition the model with fewer prefix tokens to produce results similar to longer histories, utilizing MLPs for projection.
- This highlights an innovative approach to maximizing the latent space effects in models despite reduced context inputs.
Links mentioned:
Nous Research AI ▷ #reasoning-tasks (2 messages):
Survey Paper ImplementationAlternatives to LLMs for Deductive ReasoningGeneral Reasoning EnginesSyllogisms and Logic Application
- Survey paper tasks implemented: A user reported implementing all tasks from a survey paper and is seeking verification of their utility to ensure they haven't already been included in the repository. They plan to submit a pull request if everything checks out, tagging relevant members for assistance.
- The repository aims to provide a comprehensive collection of reasoning tasks for Medical LLMs and beyond, highlighting its potential significance.
- Inquiry about general reasoning engines: A user inquired whether there are any general reasoning engines available that aren't limited to specific domains like math, particularly given that LLMs struggle with deductive reasoning. They discussed the need for a system capable of solving syllogisms and applying propositional and predicate logic.
- The user provided an example problem involving potatoes to illustrate the type of deductive reasoning they are interested in, suggesting the possibility of using an LLM in combination with a reasoning engine.
Links mentioned:
HuggingFace ▷ #announcements (1 messages):
CLI Tools RevolutionReflection 70B ModelPersian DatasetArena Learning PerformanceFine-Tuning LLMs
- Revolutionizing CLI Tools with Ophrase and Oproof: A detailed article discusses how Ophrase and Oproof are transforming command-line interface tools.
- The author highlights key features that make these tools extremely effective in simplifying tasks.
- Exploring Reflection 70B with Llama cpp: The Reflection 70B project showcases advancements in model versatility and performance using Llama cpp.
- This space offers insights into its capabilities and makes it accessible for community interactions.
- A New Persian Dataset Launch: A new Persian dataset has been introduced, featuring translations of 6K sentences from Wikipedia.
- This dataset aims to support Persian language modeling and enhance accessibility to diverse language resources.
- Improving Performance with Arena Learning: A blog post outlines how Arena Learning boosts performance in post-training scenarios.
- The article discusses techniques that demonstrate significant enhancements in model outcomes.
- Fine-Tuning LLMs on Kubernetes: An insightful guide details how to fine-tune LLMs using Kubernetes, leveraging Intel® Gaudi® Accelerator technology.
- The post serves as a practical resource for developers looking to optimize model training workflows using cloud infrastructure.
HuggingFace ▷ #general (324 messages🔥🔥):
AI Regulation DiscussionsML Community SentimentFree Speech vs. Hate SpeechDebate ReactionsFine-tuning Models with Qlora
- AI Regulation Discussions: There was a significant discussion on the impact of regulations like the EU regulations on AI, with references to Joe Rogan's podcast featuring Dr. Epstein discussing these issues.
- Participants expressed concern about how narratives are shaped by social media, specifically in relation to the accuracy of information derived from platforms like Reddit.
- ML Community Sentiment: Members noted a perceived bias against Americans within the community, expressing discomfort over how freely some express negative sentiments.
- Opinions were shared about the necessity of moderation in discussions, reflecting on the balance between free speech and maintaining a respectful environment.
- Free Speech vs. Hate Speech: The conversation included a debate about the definitions and boundaries of free speech, specifically highlighting the difference between free speech and hate speech.
- Participants discussed the implications of unmoderated speech and its potential to foster hate speech, emphasizing the need for some level of community guidelines.
- Debate Reactions: Reactions to a recent political debate were mixed, with members commenting on Trump's performance, which they found disastrous.
- The discussion shifted to broader themes of American politics, with some members expressing a desire to disengage from the political discourse.
- Fine-tuning Models with Qlora: A query was raised about the best learning rate schedulers for fine-tuning models using Qlora, with preferences leaning towards cosine schedules.
- The conversation also touched on scaling factors like rank and lora_alpha, noting that smaller ranks combined with higher alpha might yield better outcomes for instruction tuning.
Links mentioned:
HuggingFace ▷ #today-im-learning (1 messages):
lunarflu: awesome, let us know how it goes! <:hugging_rocket:968127385864134656>
HuggingFace ▷ #cool-finds (2 messages):
Exa AI search engineMeta Discovery framework in gaming
- Exa AI Search Engine Enhances Knowledge Retrieval: The Exa AI search engine connects your AI to a vast pool of knowledge, providing semantic and embedding search capabilities tailored for AI applications.
- It promises to deliver exactly what you ask for without clickbait, supporting features like scraping content and similarity searches.
- Meta Discovery Framework to Aid Game Balance Decisions: A paper discusses a Meta Discovery framework that utilizes Reinforcement Learning to predict the effects of balance changes in competitive games like Pokémon and League of Legends, as detailed in the arXiv paper.
- The authors assert that this framework can help developers make more informed balance decisions, demonstrating high accuracy in predictions during testing.
Links mentioned:
HuggingFace ▷ #i-made-this (5 messages):
HOPE AgentDebateThing.comSynthetic Data Generation PackagesHugging Face Community MappingBatch Size in Sentence Transformers
- HOPE Agent Streamlines AI Orchestration: Introducing the HOPE Agent which offers features like JSON-based Agent Management, dynamic task allocation, and modular plugin systems to simplify complex AI workflows.
- It integrates with LangChain and Groq API, enhancing the management of multiple AI agents effectively.
- DebateThing.com Generates AI-Powered Debates: DebateThing.com is a new AI-powered debate generator that allows up to 4 participants with text-to-speech support for audio debates over multiple rounds.
- Utilizing OpenAI's GPT-4o-Mini model, it creates simulated debates and is available as open-source under the MIT License.
- New Python Packages for Synthetic Data: An article discusses two new Python packages, ophrase and oproof, utilized for generating synthetic data and a working paraphrase generator able to create 9 variations of a sentence.
- The packages also include a proof engine for validating prompt-response pairs, with tests conducted on basic math, grammar, and spelling.
- Mapping the Hugging Face Community: A new community mapping project is now available at Hugging Face, designed to scale community engagement.
- It aims to create a space for synergy between developers and researchers in the AI landscape.
- Batch Size Importance in Sentence Transformers: A new Medium article highlights the significance of properly setting the batch size parameter for Sentence Transformers.
- The author emphasizes that not adjusting the batch size from the default of 32 can lead to inefficient VRAM usage and poorer performance.
Links mentioned:
HuggingFace ▷ #reading-group (1 messages):
Team Building in MLCollaborative Projects in AI
- Looking for ML Team Members: A member expressed interest in forming a team for ML projects, stating they are in the beginning phase of their machine learning journey.
- They invited others with a similar skill level to connect and collaborate on creating exciting models together.
- Call for Collaborative Learning in ML: The same member emphasized the desire for teamwork while learning, proposing that newcomers band together for mutual growth.
- They mentioned that coming together can enhance the learning process and lead to the development of innovative models.
HuggingFace ▷ #NLP (9 messages🔥):
NSFW text detection datasetsTransformer architecture and embeddingsMean pooling in embeddingsSelf-supervised training techniquesBuilding models from scratch
- Searching for NSFW text detection datasets: A member inquired about a standard academic dataset for detecting NSFW text akin to MNIST or ImageNet for images, mentioning CensorChat and Reddit datasets.
- The conversation highlighted a gap in readily available benchmark datasets for this specific purpose.
- Understanding transformers and embeddings is essential: One user emphasized the importance of familiarizing oneself with transformer architecture and the concept of embeddings for machine learning projects.
- They recommended searching for illustrations of transformers as a good starting point for beginners.
- Mean pooling issues with embeddings: A user reported that Chroma doesn't perform mean pooling by default, which caused issues with multi-dimensional embeddings.
- Another member suggested that the
Embedding_functions.SentenceTransformerEmbeddingFunctionfrom Chroma may offer solutions to this problem.
- Another member suggested that the
- Self-supervised training for transformers: Discussion surfaced around self-supervised training for transformers, noting that pretraining from scratch could be expensive without substantial funding.
- Members highlighted that training models is feasible for simpler domains but challenging otherwise.
- Building models without high-level tools: One member expressed a desire to build a model from scratch without using high-level tools to enhance learning.
- This sparked discussions about the viability and practicality of such an approach in model development.
Modular (Mojo 🔥) ▷ #general (274 messages🔥🔥):
Mojo Error HandlingString Conversion in Mojo
- Understanding Mojo's Error Handling for Syscalls: A discussion highlighted the importance of ensuring syscall interfaces return meaningful error values, as these depend heavily on the interface contract in languages like C.
- The conversation emphasized that designing interfaces requires knowledge of possible errors to ensure effective handling of syscall responses.
- Extracting a String from Span[UInt8]: One member sought guidance on converting a
Span[UInt8]to a string view and was directed toStringSlice.- After encountering an error, they clarified the need for the keyword argument
unsafe_from_utf8to properly initializeStringSlice.
- After encountering an error, they clarified the need for the keyword argument
Links mentioned:
Modular (Mojo 🔥) ▷ #mojo (24 messages🔥):
ExplicitlyCopyable traitMojoDojo open source communityRecommendation systems in MojoChaining in Rust-like syntaxAccessing errno in Mojo
- RFC Proposal for ExplicitlyCopyable: A member suggested spinning up an RFC for making the
ExplicitlyCopyabletrait require implementingcopy(), indicating this change could have significant impacts.- Another member noted that this change could allow for less breaking updates to definitions in the future.
- MojoDojo: An Open Source Opportunity: A member discovered that mojodojo.dev is open-sourced, presenting a chance for community collaboration.
- This platform was originally created by Jack Clayton as a resource for learning Mojo when it was just a web playground.
- Exploration of Recommendation Systems in Mojo: A user inquired about features available in Mojo or MAX for building recommendation systems.
- A response indicated that both Mojo and MAX are still in the 'build your own' phase and are under ongoing development.
- Chaining Syntax Preferences: Members debated between using a free function
copyversusExplicitlyCopyable::copy(self)for implementing copy functionality, with emphasis on the benefits of chaining.- One user expressed a preference for syntax resembling Rust’s
.cloneto facilitate functional programming styles.
- One user expressed a preference for syntax resembling Rust’s
- Access to errno in Mojo: An inquiry was made regarding the ability to access
errnowithin the Mojo language.- The discussion remains open as users seek clarity on this functionality.
Modular (Mojo 🔥) ▷ #max (3 messages):
Embedding in MAXVector databasesSemantic searchNatural Language ProcessingMAX Engine
- MAX lacks built-in embedding support: A member inquired about the availability of embedding, vector database, and similarity search capabilities in MAX for use with LLM.
- Response clarified that MAX does not provide these features out of the box, but there are options like chromadb, qdrant, and weaviate that can be used alongside the MAX Engine.
- Semantic search blog post shared: A contributing member pointed to a blog post that covers utilizing semantic search with the MAX Engine.
- The post emphasizes that semantic search goes beyond keyword matching, leveraging advanced embedding models to understand context and intent in queries.
- Highlight on Amazon Multilingual Dataset: The blog post also features the Amazon Multilingual Counterfactual Dataset (AMCD), useful for understanding counterfactual detection in NLP tasks.
- The dataset includes annotated sentences from Amazon reviews which help in recognizing hypothetical scenarios in user feedback.
Link mentioned: Modular: Semantic Search with MAX Engine: In the field of natural language processing (NLP), semantic search focuses on understanding the context and intent behind queries, going beyond mere keyword matching to provide more relevant and conte...
Perplexity AI ▷ #general (253 messages🔥🔥):
OpenAI O1 PreviewAI Music TrendsSuno Discord InsightsUser Experiences with APIsUncovr.ai Development
- Excitement Around OpenAI O1: Users are buzzing about the release of OpenAI O1, a new model series emphasizing improved reasoning and complex problem-solving capabilities.
- Some speculate it integrates concepts from reflection, Chain of Thought, and agent-oriented frameworks like Open Interpreter.
- Skepticism Towards AI Music: Members expressed doubts about the viability of AI-driven music, labeling it as a gimmick rather than a genuine art form and raising questions about its long-term value.
- Citing examples, they argued AI music lacks the human touch and deeper meaning that traditional music conveys.
- Challenges and Developments in Uncovr.ai: The creator of Uncovr.ai shared insights on the challenges faced while building the platform and the need for new features to enhance user experience.
- Concerns about cost and sustainable revenue models loomed large, with discussions on the importance of balancing features and expenses.
- Concerns over AI APIs and User Experience: Users discussed frustrations with API limits and authorization issues, highlighting the lack of clarity in troubleshooting these problems.
- The complexity of managing multiple AI models and keeping them efficient at low costs was emphasized throughout the conversations.
- Vision for Unique AI Solutions: Members encouraged innovative thinking about creating unique AI tools that stand out from competitive offerings, focusing on user needs.
- The conversation aimed to inspire developers to leverage their creativity and insights for building solutions that resonate authentically with users.
Links mentioned:
Perplexity AI ▷ #sharing (16 messages🔥):
Air Raid Sirens HistoryAI Developments in GamingIDE RecommendationsDark Shipping TrendsSupercomputer Innovations
- Exploring the Origins of Air Raid Sirens: A link was shared discussing when air raid sirens became standard, detailing their historical significance and evolution. Readers can explore the timeline and technology advancements here.
- The mention of air raid sirens highlights their role in emergency preparedness and community safety.
- Roblox Builds AI World Model: A member pointed out a video discussing how Roblox is at the forefront of integrating AI into gaming, emphasizing its innovative approaches. Check out the video here.
- This development positions Roblox as a leader in merging gaming with advanced technologies.
- Identifying the Top IDEs: A link was shared highlighting the top 10 IDEs for developers, shedding light on user preferences and features. You can view the IDE rankings and insights here.
- Choosing the right IDE is crucial for optimizing coding efficiency and enhancing user experience.
- The Rise of Dark Shipping: An article was referenced discussing the emergence of dark shipping trends, addressing their implications in logistics and security. Dive into the article here.
- This trend raises important questions about transparency and safety in shipping practices.
- Japan's Zeta-Class Supercomputer: A mention of Japan's Zeta-Class Supercomputer highlights cutting-edge advancements in computational power, important for various applications. More details on this supercomputer can be found here.
- These innovations signify a leap in capabilities for research and industry applications.
Perplexity AI ▷ #pplx-api (3 messages):
Enterprise Pro License IssuesFree Credit Balance ConcernsComparison of Perplexity Pro and Sonar Online
- Enterprise Pro License users report issues: Users expressed urgency in starting to use the API after signing up for the Enterprise Pro license, but faced technical issues.
- Concerns were raised regarding the processing of their credit card details and the subsequent availability of the API.
- Free Credit Balance not reflecting: Multiple users reported that their free credit bonus of $5 for Pro was not reflecting in their accounts despite setting up payment details.
- One user stated that the recent feedback made them doubt the process and suggested it was less than optimal.
- Comparative Analysis of Perplexity Pro and Sonar Online: Discussion arose about whether prompting alone could bridge the gap between Perplexity Pro and Sonar Online capabilities.
- Members are curious about the performance differentiators and how they can be improved through better prompting.
Interconnects (Nathan Lambert) ▷ #news (213 messages🔥🔥):
OpenAI o1 Model ReleaseCalifornia AI Regulation SB 1047AI Model BenchmarkingChain of Thought in AIAI Process and Reasoning
- OpenAI o1 model impresses with reasoning: The newly released OpenAI o1 model is designed to think more before responding and has shown strong results on benchmarks like MathVista.
- Users noted its ability to handle complex tasks and expressed excitement about its potential, although some are cautious about its actual performance in practical applications.
- California's AI regulation bill SB 1047 raises concerns: There is speculation surrounding the fate of California's SB 1047 AI safety bill, with predictions suggesting a 66-80% chance of veto due to political dynamics, particularly with Pelosi's involvement.
- The bill's potential impacts on data privacy and inference compute are under discussion, highlighting the intersection of tech innovation and legislative action.
- Comparative performance on coding benchmarks: Initial benchmark tests indicate that OpenAI's o1-mini model is performing comparably to gpt-4o, especially on code editing tasks as reported by Aider.
- Users are keen to explore further how the o1 model stacks up against existing LLMs across various benchmarks, reflecting a competitive landscape in AI development.
- Exploring chain of thought methodology in AI: Discussion highlights the use of chain of thought (CoT) reasoning in the o1 model, emphasizing the potential for improved AI performance through structured reasoning strategies.
- Experts believe that proper implementation of CoT could lead to better AI outputs, although questions remain about its true efficacy compared to simple prompting techniques.
- Challenges in AI inference and reliability: Concerns were raised about how inference compute is handled, noting that simply generating more tokens might not scale effectively for stable AI behavior.
- Participants discussed the limitations of AI models in practical scenarios, emphasizing the need for improved reasoning collectively as developments in AI tools continue.
Links mentioned:
Interconnects (Nathan Lambert) ▷ #random (6 messages):
Matt's API FixRecent Release ExcitementBenchmark Speculation
- Matt's Fix & API Hosting: A user mentioned that Matt from IT needs to announce that he 'fixed it' and potentially host an API to O1.
- It was acknowledged by a member that 'great minds think alike' while sharing a related tweet about Matt's benchmarks with O1.
- Excitement Around Recent Release: Users expressed excitement about a recent release, calling it 'fun' and looking forward to writing about it.
- Low stakes were mentioned, indicating a casual approach to the upcoming discussions regarding the release.
Link mentioned: Tweet from Xeophon (@TheXeophon): @terryyuezhuo lol what if matts benchmarks were done with o1
Interconnects (Nathan Lambert) ▷ #memes (2 messages):
xeophonlogan
- xeophon sparks interest: A member brought up xeophon, prompting reactions with a playful emoji <:3berk:794379348311801876>.
- Such expressions highlight community engagement around emerging topics.
- Praise for Logan: Another member affirmed that logan is great, indicating appreciation within the community.
- Comments like these enhance discussions about favorite models and personalities in AI.
Interconnects (Nathan Lambert) ▷ #posts (6 messages):
RLHF in Private ModelsEnterprise Offerings by Scale AIModel Behavior ShiftingTraining ReliabilityDomain Expertise Challenges
- Understanding RLHF for Private Models: Members are trying to uncover how RLHF (Reinforcement Learning from Human Feedback) specifically functions for private and bespoke models, as Scale AI explores this area.
- It seems to focus on aligning model behaviors with human preferences, making formats more reliable for training.
- Scale AI's Enterprise Play Lacks Details: While Scale AI promotes its enterprise offerings, members noted that the web page lacks substantial detail on how this benefits users.
- One member expressed expectations for ongoing relevance of enterprise AI in materials science and organic chemistry, despite limited foundational insights.
- Shifting Model Behaviors: A discussion highlighted that RLHF is primarily about shifting model behaviors to align with what humans favor, aiding in improving outputs.
- The focus on formatting reliability enables training to perform more effectively in targeted areas, such as math-related tasks.
- Challenges in Domain Expertise for Scale AI: In specialized fields like materials science and chemistry, members anticipated challenges for Scale AI against established domain experts.
- The sentiment suggests that it may be easier to learn data handling in less regulated areas than in clinical settings, which are much more complex.
Unsloth AI (Daniel Han) ▷ #general (179 messages🔥🔥):
Reflection Model ControversyUnsloth and GPU CompatibilityKTO Model AlignmentSolar Pro Preview ModelLLM Distillation Challenges
- Reflection Model Under Scrutiny: Discussion centered around the Reflection 70B model, with claims of falsified benchmarks and its continued availability on Hugging Face drawing criticism.
- Participants expressed concerns that such practices undermine fairness in AI development, with some referring to the model as merely a wrapper around existing techniques.
- Unsloth Requires NVIDIA GPUs: Wattana inquired about using Unsloth with an AMD GPU, leading to clarification that Unsloth is only compatible with NVIDIA GPUs for finetuning.
- Discussions highlighted the optimized memory usage of Unsloth but stressed the necessity of NVIDIA hardware.
- KTO Model Alignment Promises: Sherlockzoozoo shared insights about KTO as a promising model alignment technique, outperforming traditional methods like DPO.
- Experiments with KTO yielded positive results, though models trained with it remain unavailable due to proprietary data.
- Introduction of Solar Pro Preview: The Solar Pro Preview model, with 22 billion parameters, was announced for efficient usage on a single GPU, claiming performance improvements over larger models.
- Critics raised concerns over the model's bold claims and its viability in practice, pointing to previous disappointments in the AI community.
- Challenges in LLM Distillation: Participants discussed the complexities of distilling LLMs into smaller, reasoning-heavy models, emphasizing the need for accurate output data.
- Disgrace6161 argued that distillation relies on high-quality examples, and the slow inference processes stem from token costs associated with complex reasoning tasks.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #off-topic (12 messages🔥):
Discord recommendations for AIBeta testing Android appUsing LLMs with a single file
- Leaving x.com for Better AI Communities: A member remarked they've left x.com as it's a hellhole and sought discord recommendations for keeping up with the latest in AI, both open source and closed labs.
- Suggestions included mistral and cohere discords, as well as Reddit communities like the ChatGPT and LocalLLAMA subreddits.
- Seeking Beta Testers for 'Kawaii-Clicker' App: A member announced the creation of an Android app called 'Kawaii-Clicker' and is looking for beta testers to help release it while mentioning that profits will fund future AI models.
- They requested support by DMing their email for beta access, emphasizing that this is a free way to support their project while testing an unreleased game.
- Feedback on Llamafile from Mozilla-Ocho: Inquired if anyone has tried the Llamafile project on GitHub, which claims to distribute and run LLMs with a single file.
- A member responded that they tried it and verified that it does what it says it does.
- Developer Search for Collaborative Projects: A user is looking for a developer from the US or Europe who is communicative and reliable for collaborations on various projects.
- They emphasized the importance of meeting deadlines and maintaining integrity to build something great together.
Link mentioned: GitHub - Mozilla-Ocho/llamafile: Distribute and run LLMs with a single file.: Distribute and run LLMs with a single file. Contribute to Mozilla-Ocho/llamafile development by creating an account on GitHub.
Unsloth AI (Daniel Han) ▷ #help (29 messages🔥):
Finetuning Gemma with AlpacaUsing Unsloth for Llama 3.1Serving Quantized Models with vLLMDataset Formatting IssuesLearning Rate Schedulers for Qlora
- Finetuning Gemma produces unexpected output: After finetuning Gemma on Alpaca cleaned, a user reported that the model generates without producing a response.
- Another member suggested that the issue may stem from dataset formatting, encouraging the user to stick to the documented code.
- Unsloth Streamlines Llama 3.1 Finetuning: A member confirmed that Unsloth is ideal for finetuning models like Llama 3.1 on custom datasets, referencing the docs.
- They detailed the benefits of using Unsloth, such as speed and memory efficiency for various models.
- Deploying Quantized Models on vLLM: Discussion emerged regarding serving quantized models and their compatibility with vLLM, with one member seeking guidance on the process.
- They were directed to the vLLM documentation for further insights on memory management and serving.
- Clarifying Dataset Formatting Confusion: A user expressed confusion about the labels in the loss function, questioning why both y and label exist in the code.
- Members inquired whether this impacts the training and shared links to clarify specific code functionalities.
- Choosing Learning Rate Schedulers for Fine-Tuning: A user asked for recommendations on an appropriate lr_scheduler for fine-tuning with Qlora, highlighting various options like cosine and linear schedulers.
- Responses emphasized that there's no standard approach, and many factors influence outcomes, leading to a trial-and-error process.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #research (5 messages):
Sci Scope newsletterUnsloth AI performanceFast Forward optimization strategyOpenAI O1 preview
- Sci Scope makes AI research digestible: Sci Scope groups together new ArXiv papers on similar topics and provides a weekly summary to help researchers stay updated in the fast-paced AI field.
- They encourage users to subscribe to their newsletter for a concise overview of the latest AI research, making it easier to select reading material.
- Single GPU limits Unsloth's potential: Discussion highlights that powerful machines will not enhance Unsloth performance significantly, as it is designed to operate optimally on a single GPU.
- User emphasized that improvements in hardware will have minimal effect, suggesting a focus on software optimizations instead.
- Fast Forward boosts finetuning efficiency: This paper introduces Fast Forward, a parameter-efficient finetuning method that can accelerate training by repeating optimizer steps until loss improvement plateaus.
- The approach achieves up to an 87% reduction in FLOPs and an 81% reduction in training time, validated across various tasks without compromising performance.
- OpenAI unveils O1 preview: OpenAI has launched the O1 preview, offering new features aimed at enhancing AI interactions.
- Notable updates include user-friendly interfaces and improved functionality that aims to streamline user workflows.
Links mentioned:
Latent Space ▷ #ai-general-chat (133 messages🔥🔥):
OpenAI o1 model launchDevin AI coding agentInference time scalingReasoning capabilitiesAI industry reactions
- OpenAI Unveils o1: A New Reasoning Model: OpenAI has launched the o1 model series, which emphasizes reasoning capabilities and improved problem-solving across various domains, including math and coding, marking a significant shift in AI technology.
- The o1 model reportedly outperforms previous models in tasks requiring complex reasoning, showcasing advancements in safety and robustness.
- Testing o1 with Devin AI: The AI coding agent Devin has been tested with OpenAI’s o1 models, yielding promising results and highlighting the importance of reasoning in software engineering tasks.
- These evaluations indicate that o1’s generalized reasoning capabilities significantly enhance performance in agentic systems focused on coding.
- Inference Time Scaling Insights: Experts discuss inference time scaling concerning the o1 models, suggesting that it can compete with traditional training scaling and improve LLM capabilities.
- This approach includes measuring hidden inference processes and how they impact the overall functionality of models like o1.
- Mixed Reactions in the AI Community: There are varied reactions to the o1 model and its capabilities within the AI community, with some expressing skepticism about its impact compared to earlier models like Sonnet/4o.
- Certain discussions revolve around the limitations of LLMs for non-domain experts, emphasizing the importance of providing expert-oriented tools and frameworks.
- Future Developments and Voice Features: The community is eagerly awaiting further developments, including potential voice features for the o1 models that are still in the pipeline.
- Despite the excitement surrounding the cognitive capabilities of o1, users are currently limited in some functional aspects, such as voice interactions.
Links mentioned:
Latent Space ▷ #ai-announcements (1 messages):
swyxio: o1 meetup today in <@&979487661490311320> https://x.com/swyx/status/1834300361102029286
CUDA MODE ▷ #general (5 messages):
PTQ and Static QuantizationDynamic Quantization DiscussionCUDA MODE NotesDe-Quantization Error
- PTQ Implementation Overview: A member shared their experience running a Post-Training Quantization (PTQ), using a calibration dataset while attaching various observers for statistics.
- They quantified that static quantization could yield better results compared to dynamic approaches.
- Dynamic Quantization Concerns: Discussion emerged around dynamic quantization, where quantization parameters are calculated on the fly instead of being fixed.
- A concern was raised that this could lead to worse results due to the impact of outliers affecting de-quantization errors.
- Evaluation of Implementation Issues: A member expressed doubts about their implementation, linking to a discussion on PyTorch that addresses significant accuracy drops after custom activation quantization.
- They are seeking feedback to determine if any important details were overlooked in their approach.
- Sharing CUDA MODE Resources: A member provided a link to their CUDA MODE notes compiled from reading group lectures facilitated by Andreas Kopf and Mark Saroufim.
- These notes are available for public access through their blog at christianjmills.com.
Link mentioned: Christian Mills - CUDA MODE Lecture Notes: My notes from the CUDA MODE reading group lectures run by Andreas Kopf and Mark Saroufim.
CUDA MODE ▷ #triton (6 messages):
Utilizing Tensor CoresSupport for uint4Block Pointer Usage
- Tensor Cores Made Easy with Triton: Using tl.dot with correctly shaped inputs makes it straightforward to utilize tensor cores in Triton, aligning with the hardware-agnostic approach.
- For further details on matrix shapes, refer to the NVIDIA documentation.
- uint4 Support Questioned: Discussion arose regarding Triton's support for uint4, with a member expressing interest in its capabilities.
- However, another member clarified that uint4 is not currently supported in Triton.
- Cutlass for Advanced Features: In scenarios where uint4 support is needed, tools like Cutlass should be utilized for better performance.
- Cutlass offers CUDA templates helpful in linear algebra and may provide features Triton lacks.
- Concerns Over Block Pointers: Questions arose about the effectiveness of using block pointers (
make_block_ptr) in Triton, particularly after noticing documentation around them had been removed.- Concerns were substantiated by a GitHub issue indicating that creating block pointers might lead to slower performance compared to other methods.
Links mentioned:
CUDA MODE ▷ #torch (1 messages):
Torch Inductor InternalsPyTorch Native Compiler
- Request for Torch Inductor Documentation: A member is seeking more detailed documentation on Torch Inductor internals, beyond the existing discussion available here.
- Is there a more comprehensive resource that can provide insights into the inner workings of Torch Inductor?
- Discussion about PyTorch Native Compiler: There was a mention regarding the PyTorch native compiler and the challenges around accessing necessary documentation and resources.
- Members expressed a need for clearer articulations of the features and functionalities surrounding Torch Inductor.
Link mentioned: TorchInductor: a PyTorch-native Compiler with Define-by-Run IR and Symbolic Shapes: The PyTorch team has been building TorchDynamo, which helps to solve the graph capture problem of PyTorch with dynamic Python bytecode transformation. To actually make PyTorch faster, TorchDynamo must...
CUDA MODE ▷ #cool-links (5 messages):
HF transformers LLMsOpenAI O1 PreviewLearning to Reason with LLMsIterative Improvements with LLMs
- Make HF Transformers LLMs Work Like a Charm!: A member shared a trick to get HF transformers LLMs functioning properly with torch.compile and static cache without needing a custom generator.
- This approach simplifies the setup, potentially streamlining the development process for LLM users.
- Excitement Surrounds OpenAI O1 Preview: Linking to the OpenAI O1 Preview, members expressed enthusiasm about new developments in the AI landscape.
- The preview showcases several promising features and enhancements that could impact the direction of LLM application.
- Exploration of Learning to Reason with LLMs: Discussion turned to learning to reason with LLMs, highlighting the ongoing advancements in LLM capabilities.
- Members noted that recent improvements seem suspiciously effective, sparking debate over their authenticity and methodology.
- Iterative Improvements Raise Eyebrows: One member commented on the latest results seeming like too good of an improvement from previous iterative enhancements.
- This led to skepticism about the data and techniques used to achieve these results, indicating a possible need for further validation.
Link mentioned: Tweet from mobicham (@mobicham): Simple trick to make HF transformers LLMs work properly with torch.compile + static cache without implementing a custom generator!
CUDA MODE ▷ #jobs (1 messages):
Aurora InnovationHiring for EngineersCommercial Launch PlansRecent Funding RoundDriverless Truck Corridor
- Aurora Innovation's Expansion Plans: Aurora Innovation, a Public L4 Autonomous Trucking company, is targeting a commercial launch by the end of 2024 with no vehicle operators, and their stock price has 2x in the last six months.
- The company is seeking L6 and L7 engineers skilled in GPU acceleration, specifically with expertise in CUDA/Triton tools.
- Hiring Opportunities at Aurora: Aurora is hiring for positions related to GPU acceleration for both training and inference, offering good pay for talented engineers.
- Interested candidates can check out specific jobs such as Staff Software Engineer for Deep Learning Acceleration and Senior Staff Software Engineer for ML Accelerators.
- Recent Funding Fuels Aurora's Growth: Aurora recently raised $483 million in funding, exceeding its goal of $420 million, which reflects strong investor confidence in their long-term vision.
- This funding follows a previous $820 million capital raise and will support their efforts toward a driverless launch in late 2024.
- Driverless Truck Corridor Established: Aurora has successfully opened its first commercial-ready lane for driverless trucks between Dallas and Houston, enabling support for over 75 commercial loads a week.
- This strategic corridor is critical as nearly half of all truck freight in Texas moves along the I-45 route, making it ideal for their upcoming launch.
- Milestones and Future Vision: At a recent Analyst Day, investors experienced driverless truck rides, showcasing Aurora's technological advancements and partner ecosystem strength.
- Aurora's terminal system is designed to operate day and night, reinforcing its commitment to meet commercial logistics demands.
Links mentioned:
CUDA MODE ▷ #beginner (7 messages):
Rust CUDA CrateNCCL Allreduce DocumentationCublas GEMM Function Issues
- Rust Equivalent for Python's Numba CUDA: A member suggested checking out Rust-CUDA as a Rust crate similar to Python's
numba.cudafor writing and executing GPU code.- This GitHub repository hosts an ecosystem of libraries and tools dedicated to fast GPU development in Rust.
- Inquiry on NCCL Reduction Algorithms: A member inquired about the specific reduction algorithms used by NCCL for the allreduce operation across various message sizes and GPU setups.
- They were looking to simulate the accumulation order of
NCCL_ALGO=treewithin a single GPU node for testing purposes.
- They were looking to simulate the accumulation order of
- Cublas GEMM Function Troubles: A user faced issues using the
cublasSgemmfunction while trying to compute the matrix product of two column vectors represented asfloat*and received NaN results.- They later resolved their question independently but expressed it as a common beginner's challenge in using C++, CUDA, and cuBLAS.
Link mentioned: GitHub - Rust-GPU/Rust-CUDA: Ecosystem of libraries and tools for writing and executing fast GPU code fully in Rust.: Ecosystem of libraries and tools for writing and executing fast GPU code fully in Rust. - Rust-GPU/Rust-CUDA
CUDA MODE ▷ #pmpp-book (1 messages):
1 Radius Blur ImplementationGitHub Contributions
- Successfully Implemented 1 Radius Blur: A member expressed pride in successfully getting a 1 radius blur to work using code from chapter 6 of the book.
- They shared their code link for beginners interested in experimenting with the same implementation: Code on GitHub.
- Sharing Resources for Beginners: The member encouraged others, particularly beginners, to utilize the resources available from the book for practical implementations.
- They referenced a visual link to their project on GitHub, highlighting the impact of community learning through shared solutions: pmpp/src/convolution.cu.
Link mentioned: pmpp/src/convolution.cu at main · jfischoff/pmpp: Exercises for Programming Massively Parrallel Processors - jfischoff/pmpp
CUDA MODE ▷ #torchao (5 messages):
TorchAO limitationsAO document availabilityCUDA matmul operationsQuantization techniques
- TorchAO has some limitations: Several members pointed out that TorchAO does not work well with compile, is primarily a CPU model, and has a convolutional architecture that presents challenges.
- Additionally, there are concerns over unexpected behaviors, like issues with initializing linear operations using F.linear.
- Inquiry about AO document on PyTorch Domains: A member asked whether the AO document will be available on pytorch-domains, similar to torchtune.
- There were no definitive answers provided on this query in the discussion.
- Curiosity about CUDA matmul ops for FP16 input: A member expressed interest in whether there exists a CUDA matmul op for fp16 input with int8 weights in TorchAO, noting their challenges in parsing technical jargon.
- They referenced an informative GitHub issue that discusses the state of lower-bit kernels for improved performance.
- Clarification on _weight_int8pack_mm functionality: Discussion highlighted that _weight_int8pack_mm can be found at this link and primarily functions on CPU and MPS.
- Further insights into quantization techniques were also provided, directing queries to the relevant quantization techniques repository.
- Exploration of advanced quantization techniques: To minimize memory footprint, the option of trying int4_weight_only quantization was suggested, with the caveat that it only works with bfloat16.
- For cases where float16 is necessary, members suggested exploring fpx_weight_only(3, 2) as a potential solution for effective quantization.
Links mentioned:
CUDA MODE ▷ #off-topic (49 messages🔥):
O1 and its limitationsComparison of AI modelsHidden Chain of Thought (CoT)OpenAI's decision-makingResearch landscape in AI
- O1 reveals hidden features but remains underwhelming: A discussion emerged about O1's apparent hidden feature, where it utilizes CUDA mode, prompting mixed feelings about its impact, with one member labeling it a massive nothingburger.
- Despite some impressive benchmarking results, many felt that improvements were still needed for effective end-to-end execution.
- Evaluating AI models: The race against time: Concerns were voiced about OpenAI seemingly playing catch-up in comparison to competitors like Anthropic, raising doubts about the base model's superiority.
- Many participants expressed skepticism about the trade-offs involved in current model training strategies, emphasizing a shift towards more RL fine-tuning methods.
- The debate on Hidden CoT's effectiveness: There was a consensus that Chain of Thought (CoT) is crucial for future advancements, but frustrations were expressed over its hidden implementation, with calls for more transparency.
- Members noted that despite its effectiveness, OpenAI's reasoning for concealing certain aspects seems questionable, especially in light of eventual leaks.
- OpenAI's approach under scrutiny: Discussions turned critical regarding OpenAI's leadership and their choice not to disclose prompts for all models, raising concerns about alignment between technical reality and company decisions.
- This lack of transparency led to sentiments that important ideas in the field might remain unexplored due to the risk-averse stance of major labs.
- AI research's evolution amidst industry focus: Participants noted a split between academic and industrial research, where academia pursues innovative yet smaller-scale optimizations while industry focuses on scaling existing ideas.
- This divergence is believed to contribute to slower overall progress, with some expressing hope for future improvements in programming benchmarks driven by proven techniques.
Links mentioned:
CUDA MODE ▷ #hqq-mobius (1 messages):
torch.compile supporttransformers model.generateHFGenerator deprecation
- torch.compile integrates with transformers: Support for
torch.compilehas been added directly to themodel.generate()function in version 0.2.2 of the MobiusML repository.- This improvement eliminates the need to use HFGenerator for generating models, making the process more streamlined.
- HFGenerator is no longer needed: With the recent update, users no longer need to rely on HFGenerator for generating models as
torch.compileis now integrated directly.- This change simplifies the workflow for developers who previously used HFGenerator for similar tasks.
CUDA MODE ▷ #llmdotc (2 messages):
Mixed Input Scale FactorGEMM Performance in Hopper
- Mixed Input Scale Factor Applies to Quantized Tensors: A member confirmed that the scale factor is relevant only for the quantized tensor in mixed input scenarios.
- This highlights the need to consider how scaling is applied in mixed tensor operations.
- Fusing Dequantization in GEMM Harms Performance: It was noted that fusing the dequantization of both A and B tensors in a GEMM on Hopper will significantly degrade performance.
- The emphasis was placed on the detrimental impact this technique could have on efficiency.
CUDA MODE ▷ #cudamode-irl (15 messages🔥):
CUDA Hackathon ResourcesCooley-Tukey FFT ImplementationGH200 Compute CreditsCustom Kernels and Track Proposals
- Exciting access to extensive compute credits!: The organizing team secured $300K in cloud credits and access to a 10 node GH200 cluster and a 4 node 8 H100 cluster for the hackathon.
- Participants will enjoy SSH access to nodes and the opportunity to leverage the Modal stack for serverless scaling.
- Dive into Cooley-Tukey Algorithm for FFT: A participant plans to implement the Radix-2 Cooley-Tukey algorithm for FFT using CUDA C++, with resources available at FFT details.
- The project is geared towards learning rather than advanced implementation, inviting others to collaborate.
- GH200 architecture resources shared: For those interested in the GH200 architecture, several links were shared, including NVIDIA's benchmark guide.
- A project on GitHub for training LLMs on GH200 also highlights its potential applications.
- Collaboration on Custom Kernels Document: A suggestion was made to create a Google Doc for custom kernels to consolidate contributions, as current documents focus on specific tasks like sparsity and quantization.
- Discussion continued on outlining proposals for various tracks, including a Maxwell's equations simulator for multi-GPU use.
- Need for more track resources: Members inquired about project lists for tracks other than multi-GPU, seeking clarity on what is available across different tracks.
- A summary of projects including Custom Kernels and LLM Inference was provided, along with links to relevant documents.
Links mentioned:
CUDA MODE ▷ #liger-kernel (4 messages):
GEMM FP8 ImplementationSplitK GEMM DocumentationTest Case Scaling Challenges
- GEMM FP8 goes E4M3: A recent pull request has been made to implement FP8 GEMM with E4M3 representation, addressing issue #65.
- The implementation involved testing square matrices of varying sizes including 64, 256, 512, 1024, and 2048, alongside non-square matrices.
- Documentation Added for SplitK GEMM: A detailed docstring has been added to clarify when to use SplitK GEMM and outline the intended structure for SplitK FP8 GEMM.
- This addition aims to improve understanding and usage among developers working with these functionalities.
- Addressing Comments on Changes: The contributor has resolved some comments regarding the recent changes made in the GEMM implementation.
- This indicates a collaborative effort to refine the code and address feedback effectively.
- Scaling Issues in Test Cases: One challenge faced was figuring out the scaling for test cases without directly casting to FP8.
- This remains an area of focus to ensure that all test cases pass successfully.
Link mentioned: gemm fp8 e4m3 by AndreSlavescu · Pull Request #185 · linkedin/Liger-Kernel: Summary Implemented FP8 gemm with E4M3 representation for FP8. Issue #65 Testing Done tested square matrices of varying sizes (64, 256, 512, 1024, 2048) + non-square matrices of varying sizes ...
Stability.ai (Stable Diffusion) ▷ #general-chat (93 messages🔥🔥):
Reflection LLMAI Photo Generation ServicesFlux Model PerformanceLora Training IssuesDynamic Thresholding in Models
- Reflection LLM Performance Concerns: The Reflection LLM was promoted as a superior model, capable of 'thinking' and 'reflecting' with benchmarks outperforming GPT-4o and Claude Sonnet 3.5 but is criticized for its actual performance discrepancies, especially with the open-source version.
- Concerns were raised about its API appearing to mimic Claude, raising doubts about its originality and effectiveness.
- Discussion on AI Photo Generation Services: Inquiries were made about discussing third-party AI photo generation services, with a question about the best paid options available for realistic and diverse image generation.
- A counterpoint was offered about free alternatives, specifically citing Easy Diffusion as a competitive option.
- Flux Model Performance Optimizations: Users are sharing experiences with the Flux model's memory usage, highlighting significant performance improvements while running tests with different RAM limits, achieving decent generation speeds.
- There is speculation regarding memory management flexibilities and the need for low VRAM optimizations, particularly when comparing it to competitors like SDXL.
- Lora Training Troubleshooting: Individual members faced challenges with Lora training processes, seeking advice on better configurations and training methods that can work on devices with limited VRAM.
- Recommendations included resources for workflow optimizations within training environments, with mentions of specific trainers like Kohya.
- Dynamic Contrast Adjustments in Models: A user is exploring ways to reduce contrast in their lightning model using specific steps and CFG settings, contemplating the implementation of dynamic thresholding solutions.
- Advice is sought on balancing parameters if increasing CFG values, indicating a need for adaptive adjustments in output quality.
Links mentioned:
. lllyasviel has 48 repositories available. Follow their code on GitHub.GitHub - bmaltais/kohya_ss at sd3-flux.1: Contribute to bmaltais/kohya_ss development by creating an account on GitHub.GitHub - kohya-ss/sd-scripts at sd3: Contribute to kohya-ss/sd-scripts development by creating an account on GitHub.GitHub - jhc13/taggui: Tag manager and captioner for image datasets: Tag manager and captioner for image datasets. Contribute to jhc13/taggui development by creating an account on GitHub.Home | COSMIC365: no description found
LM Studio ▷ #general (57 messages🔥🔥):
LM Studio RAG ImplementationTernary Models PerformanceStable Diffusion IntegrationCommunity Meet-up in LondonOpenAI O1 Access
- Guidelines for Implementing RAG in LM Studio: For implementing a RAG pipeline in LM Studio, users should download version 0.3.2 and upload PDFs to the chat as described by a member.
- Another member noted they encountered a 'No relevant citations found for user query' error, suggesting to ask specific questions instead of general requests.
- Issues with Ternary Models: Members discussed challenges with loading ternary models, with one reporting an error while trying to access a specific model file.
- It was suggested to try older quantization types, as the latest 'TQ' types are experimental and may not work on all devices.
- No Stable Diffusion Support in LM Studio: A user inquired about integrating Stable Diffusion into LM Studio, to which another member confirmed it is not possible.
- This discussion highlights the limitations of using LM Studio exclusively with local models.
- Community Meet-up in London: Users are invited to a meet-up in London tomorrow evening to discuss prompt engineering and share experiences.
- Attendees were encouraged to look for older community members using laptops at the location.
- Rollout of OpenAI O1 Access: Members are sharing updates on their access to the OpenAI O1 preview, noting that availability is rolling out in batches.
- Recent messages indicate that some members have recently gained access, while others are still awaiting their turn.
Links mentioned:
LM Studio ▷ #hardware-discussion (35 messages🔥):
4090D GPUsPower requirements for GPUsMixing GPU vendorsModel precision settingsROCm support for AMD GPUs
- Interest in Dual 4090D Setup: A member expressed excitement about using two 4090D GPUs with 96GB RAM each, but noted the challenge of requiring a small generator to support their 600W power needs.
- I would need a small generator to run my computer was a humorous acknowledgment of the high power consumption.
- Questions on GPU Mixing Stance: In discussing GPU vendor compatibility, a member learned that mixing Nvidia and AMD GPUs isn't feasible with LM Studio or similar tools, prompting further queries about using multiple GPUs of the same vendor.
- Members agreed that mixing within the same vendor's GPUs, such as AMD or Nvidia, should function properly, but caution was advised regarding ROCm support across generations.
- Debate on Model Precision and Performance: A member sought clarification on using FP8 versus FP16 for model performance, noting FP8 behaves similarly and seems preferred for efficiency.
- Supporting these claims, another member shared updated insights from the Llama 3.1 blog, maintaining precision settings are BF16 and FP8, not previous iterations.
- Performance Impact of MI GPUs: With the MI60 vs MI100 comparison, members discussed potential impacts on inference speeds, noting that context window allocation may influence model performance especially in offloading scenarios.
- The bigger the model the worse it will perform summarized concerns about model size versus processing capacity.
- Concerns Over MI100 ROCm Support: The AMD MI100 GPUs' performance and price were discussed, but members expressed concerns about its longevity in terms of ROCm support given its age since release in 2020.
- One member highlighted the 32GB HBM2 memory but tempered enthusiasm with concerns over potential lack of future updates.
Links mentioned:
OpenInterpreter ▷ #general (25 messages🔥):
Rich Python LibraryOpen Interpreter SkillsPrompt Caching for ClaudeExploring Hardware Possibilities with OIToken Usage in Open Interpreter
- Using Rich for Beautiful Terminal Output: Rich is a Python library that facilitates rich text and beautiful formatting in the terminal, enhancing visual appeal.
- Members discussed alternative techniques using terminal escape sequences for color and animations, highlighting the versatility of terminal manipulation.
- Challenges of Open Interpreter Skills: A member pointed out issues with Open Interpreter skills not being remembered after the session ends, specifically regarding a skill for sending Slack messages.
- Another member suggested creating a post for further investigation into this issue, prompting a community response.
- Implementing Prompt Caching with Claude: Guidelines for implementing prompt caching with Claude were shared, emphasizing proper structuring of prompts and the necessary API modifications.
- It was noted that these changes could reduce costs by up to 90% and latency by 85% for longer prompts.
- Exploring Building Options with OI: Members discussed the possibility of exploring different form factors and hardware configurations after the discontinuation of the 01 project.
- A member confirmed finding the builders tab, which is a good resource for this exploration.
- Concerns about Token Usage in Open Interpreter: A member raised concerns about Open Interpreter's token usage, questioning the efficiency of using 10,000 tokens for only 6 requests.
- Additionally, there was inquiry about integrating webhooks and API access for automation with Open Interpreter and its GPTs.
Link mentioned: GitHub - Textualize/rich: Rich is a Python library for rich text and beautiful formatting in the terminal.: Rich is a Python library for rich text and beautiful formatting in the terminal. - Textualize/rich
OpenInterpreter ▷ #O1 (36 messages🔥):
Setting up LiveKit ServerOpenAI O1 launchiPhone app installationPython certificate updateWindows installation challenges
- Linux Recommended for LiveKit Server: Members overwhelmingly suggested that Linux is the best operating system for setting up the LiveKit Server, with one stating, 'Not Windows, only had problems so far.'
- Following this sentiment, another expressed relief at this recommendation, stating, 'Good to know!! thank you. save me hours off my life.'
- OpenAI O1 Named After Strawberry Project: The OpenAI community noted with some humor that OpenAI has named its new project O1, stating, 'Open AI literally stole your project name, what an honour.'
- Members discussed the implications of this naming on their own work, referencing a blog post detailing the launch with skepticism.
- iPhone App Setup Guidance: One user sought help setting up the newly launched iPhone app, prompting members to share various resources including the set up guide and necessary commands.
- Instructions for using commands to start the app with LiveKit and obtaining a QR code were also provided.
- Necessary Python Certificate Updates: A user highlighted the need to update their Python certificates stating the specific command to use, triggering a discussion about installation issues.
- Another member indicated their process for updating these certificates to ensure smooth program operation, providing a detailed command line solution.
- Windows Users Facing Installation Challenges: A user shared their frustrations about installing on Windows, specifically a workaround they found necessary by replacing path references in the code.
- They noted the complexities of transitioning to their AI machine but expressed satisfaction with the supported features and configurations they finally managed to set up.
Links mentioned:
OpenInterpreter ▷ #ai-content (5 messages):
OpenAI o1 ModelsAccess to o1Cursor and o1-miniQuality of outputs
- OpenAI o1 Models Preview Released: OpenAI announced the release of a preview for o1, a new series of AI models that are designed to reason more effectively before responding, with applications in science, coding, and math. More details can be found in their announcement.
- According to their post, these models aim to tackle more complex tasks than their predecessors, promising enhanced problem-solving capabilities.
- Community Interest in o1 Access: There is growing curiosity among users about the availability of o1, with several members expressing interest in whether anyone has gained access yet. One user noted, *
- the anticipation for early access seems palpable, indicating a strong desire to explore these new capabilities as soon as possible.
- Waiting for Cursor and o1-mini Launch: Members are eager for Cursor to launch with o1-mini, expressing excitement and anticipation for its capabilities. One user shared a cheeky emoji hinting at their interest in this upcoming release.
- Discussion on Quality of Outputs: A member shared feedback that the outputs from o1 are of high quality, which might reflect positively on the new models' performance. This comment suggests early adopters have begun testing the capabilities of o1.
- Strategic Use of Message Limits: One user commented on the need to be strategic with their message limit set at 30 messages per week, indicating a careful approach to testing the new model's response. This reflects a growing interest in optimizing usage within platform constraints.
Link mentioned: Tweet from OpenAI (@OpenAI): We're releasing a preview of OpenAI o1—a new series of AI models designed to spend more time thinking before they respond. These models can reason through complex tasks and solve harder problems ...
Cohere ▷ #discussions (46 messages🔥):
Parakeet ProjectGPU Hardware SurveyUpcoming Developer Office HoursFinetuning Llama2 for American Bar Exam
- Parakeet's Rapid Training: The Parakeet project, trained on an A6000 line model for 10 hours on a 3080 Ti, achieved comprehensible outputs, sparking suspicions about the AdEMAMix optimizer's performance.
- One member remarked, 'this might be the reason Parakeet was able to train in < 20 hours at 4 layers.'
- Hardware Survey: GPU Ownership: Members shared their GPU setups, with one member reporting ownership of 7 GPUs, including 3 RTX 3070's and 2 RTX 4090's.
- There was humorous disbelief regarding the existence of models like the 3070, leading to jokes about the naming conventions of GPUs.
- Discussion on Training Data Quality: 'Less the amount of data - it's more the quality,' stated a member in response to a conversation on training with 26k rows for a JSON to YAML use case on Phi3.5.
- Another member stressed the importance of clean data, indicating that quality matters more than quantity in model training.
- Developer Office Hours Plans: With developer office hours approaching, the team is considering hosting them on Zoom to ensure better access to recordings for absent members.
- Members expressed a preference for interacting directly on the server, appreciating the great vibe during live interactions.
- Finetuning Llama2 Insights: A newcomer shared their work on finetuning Llama2 for the American bar exam and is exploring DPO, seeking feedback on the breadth versus depth of their research.
- Another member encouraged experimenting with Cohere's Command R+, providing links to relevant documentation and resources for further exploration.
Links mentioned:
Cohere ▷ #questions (1 messages):
Best practices for guardrails in RAG applicationsTools for evaluating RAG performance
- Exploring Guardrails for RAG Applications: A user sought ideas on best practices for designing and implementing guardrails in RAG applications to ensure their effectiveness.
- This discussion emphasized the need for tailored solutions based on specific application contexts.
- Popular Tools for RAG Performance Evaluation: The user asked for insights on the most popular tools or frameworks used for evaluating the performance of RAG applications.
- This query aimed to uncover commonly used metrics and methodologies for assessment.
Cohere ▷ #api-discussions (1 messages):
Polymorphic objectsStructured JSON in CohereCohere schema limitations
- Struggles with Polymorphic Support: A member inquired about supporting polymorphic objects with structured JSON in Cohere, noting that Cohere does not support
anyOf.- They attempted using
type: [null, object], but that was also rejected.
- They attempted using
- JSON Schema Approaches Explored: Two JSON schema approaches were shared: one using
anyOfforanimalobjects and another usingnullfor cat and dog property types.- The first approach defined required properties for both types of animals, while the second defined separate properties for each animal type, both facing rejection.
- JSON Schema Validations Not Working: The user's schemas aimed to define separate structures for cat and dog, focusing on their respective properties and types.
- However, both schemas were ultimately rejected by the Cohere platform due to its limitations.
Cohere ▷ #projects (3 messages):
Personal AI Executive AssistantScheduling AutomationAI General Purpose AgentRate Limit ConcernsOpen Source Codebase
- Personal AI Executive Assistant Achieves Scheduling Success: A member shared their experience building a personal AI executive assistant that effectively manages their scheduling using a calendar agent cookbook. They successfully integrated it with their Google Calendar to add/edit/delete events using voice input.
- Model Processes Unstructured Data Skillfully: The member highlighted that their model could accurately interpret unstructured text of exam dates and project deadlines from course syllabi, adding them to the correct dates and times.
- This capability greatly enhances organization and project management for their studies.
- General Purpose Agent for Documentation: They mentioned having a separate general purpose agent that utilizes a web search tool to answer prompts and help create outline documentation for course projects.
- This adds versatility to their personal assistant's functionality.
- Rate Limit Issues Impede Further Use: Having reached the rate limit on trial keys, the member inquired about the necessity of purchasing a production key for continued use of their AI assistant.
- This presents a critical transition point for their project as they consider their next steps.
- Open Source Codebase Available on GitHub: The member confirmed that their project is open source and the codebase is available on GitHub.
- This invites collaboration and contributions from the community interested in personal AI development.
Link mentioned: GitHub - mcruz90/ai-need-help: Contribute to mcruz90/ai-need-help development by creating an account on GitHub.
Eleuther ▷ #general (12 messages🔥):
Contributing to ongoing projectsPhD and postdoc transitionError with sqlitedict in virtual environment
- Guide to Contributing in Projects: A member suggested opening an issue in any project for contributions and following it up with a PR.
- This method was confirmed to be the simplest means of contributing.
- PhD to Postdoc Transition: A member shared their excitement about finishing their PhD in Germany and starting a postdoc focused on safety and multi-agent systems.
- They also mentioned enjoyable hobbies like playing chess and table tennis.
- Encountering Module Not Found Error: A member faced an issue where their installed sqlitedict module was not found despite being in a virtual environment.
- Another member recommended reaching out in the appropriate channel for potential solutions.
Eleuther ▷ #research (18 messages🔥):
RWKV-7Pixtral 12B resultsTransfusion PyTorch implementationOpenAI's o1 model seriesExtreme Chain of Thought (CoT)
- RWKV-7 shows strong performance with extreme CoT: A tiny #RWKV with 2.9M params can solve complex mathematical tasks with extreme Chain of Thought (CoT), demonstrating the model's efficiency without the need for a KV cache.
- The trick involves generating extensive data with reversed numbers to effectively train the model.
- Pixtral 12B's underwhelming results against Qwen 2 7B VL: There are claims of misleading presentations at the MistralAI conference, where Pixtral 12B was shown to perform worse than Qwen 2 7B VL, which is 40% smaller.
- Members expressed skepticism about the data's integrity, indicating they had similar results in their own comparisons, suggesting no malice but possible mistakes.
- Announcement of Transfusion in PyTorch: The Transfusion project aims to predict the next token and diffuse images using a single multi-modal model, with an upgraded approach that replaces diffusion with flow matching.
- The project will maintain its essence while attempting to extend capabilities to multiple modalities, as shared in a GitHub repo.
- OpenAI's new o1 model series teased: A new series of models referred to as the o1 series has been teased by OpenAI, focusing on general reasoning capabilities.
- Excitement grows around the potential features of this model lineage, but specific details remain sparse.
- Discussion on model improvements and functions: There are discussions about enhancing models to perform tasks like forking and joining states for search capabilities, particularly in the context of RNN-style models.
- Members debated the efficacy of recurrent neural networks for these tasks, highlighting the potential for creative solutions in model design.
Links mentioned:
Eleuther ▷ #scaling-laws (5 messages):
CoT and scaling lawsImpact of context length on computeMultiple branches in CoTTree search dynamicsLog-log plot observations
- CoT Scaling Shows Linear to Quadratic Shift: When scaling test time compute using Chain of Thought (CoT), the compute scales linearly with context length until it reaches a certain threshold, after which the quadratic cost of attention takes over.
- This should result in a distinct kink in the scaling law curve if sampled densely enough unless the value of tokens changes to counteract this effect.
- Using Multiple Branches in CoT Controversy: There was a discussion about the feasibility of using multiple branches of CoT, with skepticism expressed regarding its ability to mitigate earlier discussed effects.
- One member mentioned that generating many short, fixed-size chains independently might help, but it raises questions about scaling dynamics.
- Branching Factor's Limited Impact on Scaling: Another member suggested that regardless of the branching factor, it would just act as a b^n multiplier in front of the single context scaling effect.
- This indicates that the kink in compute scaling observed before would still appear in the log-log plot.
Eleuther ▷ #gpt-neox-dev (9 messages🔥):
Multinode training challengesDDP performance with slow linksHSDP for inter-node communicationOptimal global batch sizeToken estimation methods
- Multinode Training with Slow Ethernet Links: A user inquired about the feasibility of multinode training using slow Ethernet links between 8xH100 machines, specifically for DDP across nodes.
- Another member responded that it would be challenging, particularly emphasizing the importance of a larger global batch size for better performance.
- Setting Global Batch Sizes for DDP: It was mentioned that increasing the
train_batch_sizeis crucial to saturate VRAM and improve the DDP performance during training.- One user noted that 4M-8M tokens per global batch is typically necessary to impact convergence positively during Pythia pretraining.
- HSDP for Enhanced Communication: A suggestion was made to use HSDP (High Speed Data Path) to optimize communication between nodes, which could alleviate slow link issues.
- Another member assured that 50G links should suffice for DDP if HSDP comms are tuned properly to overlap with compute times.
- Token Estimation Techniques: A user shared a token estimation formula based on dataset size and parameters like micro batch size and gradient accumulation steps.
- This method approximates
num_total_tokensusing the disk size of prepared .bin files, suggesting a division by 4 for the estimated count.
- This method approximates
- Resources for HSDP Communication Tuning: A user requested references for tuning HSDP communications effectively during their multinode training.
- Other users provided suggestions while sharing their previously used methods and experiences for optimizing data transfer.
LlamaIndex ▷ #blog (5 messages):
AI Scheduler WorkshopMulti-document RAG System for AutomotiveOpenAI o1 and o1-mini Models IntegrationLlamaIndex TypeScript ReleaseLlamaIndex Hackathon
- Build an AI Scheduler with Zoom!: Join us at the AWS Loft on September 20th for a hands-on workshop to learn how to create a RAG recommendation engine for meeting productivity using Zoom, LlamaIndex, and Qdrant.
- Create a highly efficient meeting environment with our transcription SDK! More details.
- Create a RAG System for Automotive Needs: Learn how to build a multi-document agentic RAG system using LanceDB to diagnose car issues and manage maintenance schedules.
- Set up vector databases for efficient automotive diagnostics! Read more.
- OpenAI Integrates o1 Models with LlamaIndex: With access to OpenAI's new o1 and o1-mini models, users can now integrate them into LlamaIndex using the latest version available via pip.
- Update your installation with
pip install -U llama-index-llms-openaito explore its capabilities here.
- Update your installation with
- LlamaIndex.TS Now Available!: TypeScript enthusiasts can rejoice as LlamaIndex.TS is now available, expanding access for developers who prefer TypeScript.
- Discover more about this release and its features on NPM.
- LlamaIndex Hackathon Announcement: The second LlamaIndex hackathon is set for October 11-13, with over $10,000 in cash prizes and credits available, sponsored by Pinecone and Vesslai.
- Participants can register here to be part of this exciting event that merges RAG technology with AI agents.
Links mentioned:
LlamaIndex ▷ #general (28 messages🔥):
Llama3.1 function callingAdvanced RAG with chat_engineStreaming ReAct agent activityLlamaParse usage on private serverFiltering by specific document in Qdrant
- Llama3.1 enables function calling in OpenAI library: A member questioned why the OpenAI library utilizes Llama3.1 for function calling while LlamaIndex cannot.
- Another member suggested that passing the
is_function_calling_modelvalue asTrueduring initialization may resolve the issue.
- Another member suggested that passing the
- Easy transition from query_engine to chat_engine: A member explained that configuring an advanced RAG using
chat_engineis as simple as mirroring the parameters used forquery_engineinitialization.- Code examples were shared to illustrate how to enable similarity-based querying in both engines.
- Streaming ReAct agent activities is possible: Members discussed the potential of streaming responses from LlamaIndex to enhance the interaction with ReAct agents.
- A detailed explanation of enabling streaming in a query engine setup was provided, including configuration steps.
- LlamaParse can be hosted on-premise: A member confirmed the capability to run LlamaParse on private servers, catering to privacy concerns.
- Contact information was shared for discussing specific use cases related to hosting LlamaParse.
- Filtering documents in Qdrant vector store: A member sought advice on filtering specific documents in Qdrant and was guided to use metadata or raw filters.
- Links to relevant documentation were shared to assist with implementing filters based on document ID or filename.
Links mentioned:
LlamaIndex ▷ #ai-discussion (1 messages):
LangChainLlama_IndexHayStackRetrieval Augmented Generation (RAG)LLM development
- Are LangChain, Llama_Index, and HayStack getting bloated?: A discussion emerged questioning if frameworks like LangChain, Llama_Index, and HayStack have become overly complex for LLM application development, suggesting a move towards simpler core APIs.
- The commentator refers to a Medium post unveiling their sentiments on this phenomenon.
- Understanding Retrieval Augmented Generation (RAG): Retrieval Augmented Generation (RAG) applications allow generic LLMs to answer business-specific queries by searching through a tailored corpus of documents for relevant information.
- The typical process of a RAG application involves querying a vector database followed by generating an answer utilizing the retrieved documents.
Link mentioned: Do we need LangChain, LlamaIndex and Haystack, and are AI Agents dead?: LangChain, LLamaIndex and Haystack are python frameworks for LLM development, especially Retrieval Augmented Generation (RAG) applications.
DSPy ▷ #papers (2 messages):
Output Evaluation TechniquesHallucination ReductionWebsite Citation Concerns
- Lack of Output Evaluation for Veracity: A member noted they currently don't have methods to evaluate outputs for veracity beyond standard prompt techniques aimed at reducing hallucinations.
- Please don't cite my website in your next publication was humorously added, emphasizing the caution needed in using generated outputs.
- Sources for Output Generation: Despite the lack of direct evaluation methods, the member mentioned that all sources used to generate outputs are listed on their website.
- This implies an awareness of transparency, although it doesn't ensure the veracity of the outputs.
DSPy ▷ #general (22 messages🔥):
DSPy Chatbot CustomizationOpenAI O1 PricingRequests Per Minute for O1DSPy and O1 Integration
- Dynamic Customizations in DSPy Chatbots: A member inquired about adding client-specific customizations to DSPy-generated prompts without hard-coding client information, suggesting a post-processing step.
- Another member advised using a 'context' input field, comparing it to a RAG approach and suggesting the training of pipelines with common formats for context.
- Confusion Over O1 Pricing: Discussion arose regarding the pricing of OpenAI's O1, with one member questioning its structure and another confirming that O1 mini is cheaper.
- Members expressed a desire for comparative analysis of DSPy and O1, with one suggesting a trial of O1 for cost-effectiveness.
- 20 RPM Metric Clarification: During discussions about O1, a member shared that '20rpm' refers to 'requests per minute', prompting questions about the context.
- This metric seems significant to the ongoing analysis of performance for services like O1 and DSPy.
- Curiosity on DSPy and O1 Compatibility: A member queried whether DSPy works with O1-preview, highlighting the ongoing interest in integrating these tools.
- This reflects the community's anticipation for more functionalities between DSPy and O1.
Torchtune ▷ #general (5 messages):
Mixed Precision TrainingFP16 vs BF16Quantization IssuesTokenizer API Standardization
- Mixed Precision Training Complexity: Maintaining compatibility between mixed precision modules and other features requires extra work; currently, bf16 half precision training is noted as strictly better due to issues with fp16 support on older GPUs.
- One member pointed out that using fp16 naively leads to overflow errors, thereby increasing system complexity and memory usage due to full precision gradients.
- FP16 Training Challenges: A member highlighted that while FP16 training can be achieved with automatic mixed precision (AMP), it necessitates keeping the weights in FP32, significantly increasing memory usage for large language models.
- It was also mentioned that while fairseq can handle full FP16 training, the complexity of the codebase makes it challenging and likely not worth the engineering effort.
- Tokenizer API Standardization Discussion: One member suggested addressing issue #1503 to unify the tokenizer API before tackling the eos_id issue, implying this could streamline future development.
- With an assignee already on #1503, the member planned to explore other possible fixes to contribute to overall improvements.
Torchtune ▷ #dev (17 messages🔥):
FlexAttention integrationPackedDataset performanceINT8 mixed-precision trainingFSDP integrationQAT vs INT8 training
- FlexAttention Integration Approved: The integration of FlexAttention for document masking has been merged, leading to excitement about its potential.
- Questions arose regarding whether each 'pack' is padded to max_seq_len and the implications of not having a perfect shuffle for convergence.
- PackedDataset Shines with INT8: Performance tests revealed a 40% speedup on A100 with the PackedDataset using INT8 mixed-precision in torchao.
- A member plans to run more tests, confirming that the fixed seq_len of PackedDataset fits well with their INT8 strategy.
- PR Discussions on FSDP Integration: A proposal for a PR to expose a new setting in torchtune was discussed, as it consists of just three lines of code.
- Members expressed interest in integrating support for FSDP + AC + compile with the new features.
- QAT Clarification Provided: A member compared QAT (Quantization-Aware Training) with INT8 mixed-precision training, highlighting key differences in their goals.
- They noted that while QAT aims to improve accuracy, INT8 training primarily focuses on enhancing training speed and may not require QAT for minimal accuracy loss.
- Discussion on Ablation Experiments: Members discussed potential changes to num_warm_up steps, specifically looking to decrease from 100 to 10.
- Contributions were made to earlier ablation study results, emphasizing communication and future experimentation.
Links mentioned:
OpenAccess AI Collective (axolotl) ▷ #general (4 messages):
New OpenAI modelLlama IndexReflection 70B
- Discussion on New OpenAI Model: One member asked if anyone had tinkered with the new OpenAI model, suggesting it might be a recent release.
- It sparked curiosity and further discussion about its capabilities and reception.
- Familiarity with Llama Index: A member expressed familiarity with the Llama Index, indicating an interest in the tools available for model interaction.
- This led to a potential exploration of how it relates to the new OpenAI model.
- Reflection 70B Labelled a Dud: Concerns were raised about the Reflection 70B model being perceived as a dud, prompting speculation on the timing of the new OpenAI release.
- The comment was shared light-heartedly, suggesting it was a response to previous disappointments.
- OpenAI Model as a Marketing Strategy: A member dismissed the new OpenAI model as merely a marketing model, questioning its true value.
- This sentiment reflects skepticism about the intentions behind product releases.
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (6 messages):
Duplicating Code for Chat FormatsInternal Data Format for DatasetsChat Template FeatureMultimodal Support in Chat TemplatesLlama 3.1 Performance
- Continuing Code Duplication for Chat Formats: A member questioned whether the plan is to continue duplicating the code for all chat formats in Axolotl, acknowledging the positive direction towards an internal data format.
- I thought overall the idea of moving to an internal data format... is a great idea.
- Emphasizing Chat Template Feature: Another member believes that focusing on the chat template feature for templating is essential, noting it has not shown any usability issues.
- I haven't found a use case that it wasn't usable for yet.
- Reflection Handling in Training: A member pointed out the importance of not training on incorrect initial thoughts, preferring to focus on reflections and improved outputs.
- They highlighted an example in the tests illustrating this approach.
- Multimodal Challenges with Chat Templates: Concerns were raised about whether current chat templates support multimodal capabilities, especially regarding token masking in responses.
- Members acknowledged the complexity of utilizing an inferencing chat template for multimodal tasks.
- Positive Experience with Llama 3.1 Templates: One member reported no issues with Llama 3.1 or ChatML templates while using the chat_template prompt strategy with masking.
- However, they advised caution as they had not explored multimodal functionalities yet.
OpenAccess AI Collective (axolotl) ▷ #general-help (3 messages):
DPO Custom FormatsLlama 3.1 Tool Call Issues
- DPO Format Expectations Clarified: A member clarified the expected format for running DPO, using the notation
<|begin_of_text|>{prompt}followed by{chosen}<|end_of_text|>and{rejected}<|end_of_text|>.- They mentioned updates to custom format handling, referring to this issue on GitHub for additional context.
- Llama 3.1 Struggles with Tool Responses: A member reported issues with the
llama3.1:70bmodel, noting that despite calling a tool, the responses being generated were nonsensical.- In one instance, after the tool indicated the night mode was deactivated, the assistant still failed to appropriately respond to subsequent requests.
Link mentioned: Issues · axolotl-ai-cloud/axolotl: Go ahead and axolotl questions. Contribute to axolotl-ai-cloud/axolotl development by creating an account on GitHub.
LAION ▷ #general (8 messages🔥):
Flux by RenderNetChanges in SD teamAPI/web-only model from SDOpen source status of SD
- Flux by RenderNet launched!: 🚀 Flux from @bfl_ml is now available on RenderNet, enabling users to create hyper-realistic images from just one reference image without the need for LORAs.
- Ready to bring your characters to life? Users can try it out with just a few clicks.
- SD team undergoes name change: Members discussed that the SD team has undergone a name change because they no longer work for SAI.
- So SD has just died? one member reflected on the status of the team following this change.
- SD's open-source presence in question: Concerns were raised that SD hasn't been active in the open source space, suggesting a decline in its community involvement.
- Basically if you care about open source, SD seems to be dead, another member remarked on the situation.
- New API/web-only model released by SD: Despite concerns, the SD team recently released an API/web-only model, showing some level of activity.
- However, skepticism around their commitment to open-source efforts remains prevalent among members.
Link mentioned: Tweet from rendernet (@rendernet_ai): 🚀 Flux from @bfl_ml is now on RenderNet! Create hyper-realistic, character-consistent images with just one reference image — no LORAs required. Ready to bring your characters to life? Try it with j...
LAION ▷ #research (1 messages):
helium__: https://openai.com/index/introducing-openai-o1-preview/
LAION ▷ #resources (1 messages):
Sci Scope HighlightsAI Research NewsletterArXiv Paper SummariesNavigation of AI Literature
- Stay Updated with Sci Scope: Sci Scope groups together new ArXiv papers with similar topics and summarizes them weekly, streamlining your reading choices in AI research.
- Subscribe to the newsletter for a concise overview delivered directly to your inbox, making it easier to stay informed.
- Effortless Access to AI Research: The platform aims to simplify navigation through the rapidly changing landscape of AI literature with a user-friendly summary system.
- By collating similar papers, it enhances your ability to identify relevant and interesting reading material in the field.
Link mentioned: Sci Scope: An AI generated newspaper on AI research
LangChain AI ▷ #general (2 messages):
- ``
- Cheers exchanged in the chat: A member expressed appreciation with a simple 'cheers!'.
- This was followed by another member responding with 'Thanks.'
- Community engagement remains light: The interaction consisted of two brief exchanges with no significant discussion topics raised.
- This indicates low engagement in the conversation at this time.
LangChain AI ▷ #share-your-work (1 messages):
HTML chunking packageWeb automation toolsHTML parsing techniques
- Introducing the HTML Chunking Package: A new package called
html_chunkinghas been launched, which efficiently chunks and merges HTML content while respecting token limits for web automation tasks.- The process is well-structured, ensuring accurate HTML parsing and maintaining a preserved structure with attributes tagged appropriately for use in various applications.
- Demo Code for HTML Chunking: A demo snippet was shared showing how to use
get_html_chunksfrom thehtml_chunkingpackage to process an HTML string with a maximum token limit, preserving valid HTML structure.- The output results in multiple chunks of valid HTML, truncating excessively long attributes to ensure manageable lengths.
- Comparison with Existing Tools: The HTMLChunking package is positioned as a superior solution for chunking HTML compared to LangChain's
HTMLHeaderTextSplitterand LlamaIndex'sHTMLNodeParser, which strip the HTML context.- These existing tools only extract text content, limiting their utility in scenarios where the full HTML context is essential.
- Call to Action: Explore HTML Chunking: Users are encouraged to investigate
html_chunkingfor web automation and related tasks, highlighting its benefits for accurate HTML chunking.- Links to the HTML chunking PYPI page and their Github repo were provided for further exploration.
Link mentioned: GitHub - KLGR123/html_chunking: A Python implementation for token-aware HTML chunking that preserves structure and attributes, with optional cleaning and attribute length control.: A Python implementation for token-aware HTML chunking that preserves structure and attributes, with optional cleaning and attribute length control. - KLGR123/html_chunking
tinygrad (George Hotz) ▷ #general (2 messages):
George Hotz's Engagement PolicyTerms of Service for ML Developers
- George Hotz advises against unnecessary pings: A member reminded others that George has requested not to be @mentioned unless the question is deemed useful, reinforcing a culture of relevance within the discourse.
- It only takes one search to find this policy, encouraging members to utilize the available resources.
- New terms of service targeting specific practices: George announced there will be a terms of service aimed at banning practices like crypto mining and resale, maintaining a focused environment.
- This policy is tailored for ML developers, emphasizing the goal of accessing powerful GPUs via their MacBooks.
tinygrad (George Hotz) ▷ #learn-tinygrad (1 messages):
xprose7820: http://www.catb.org/~esr/faqs/smart-questions.html
LLM Finetuning (Hamel + Dan) ▷ #general (2 messages):
LLM ApplicationsLLM ObservabilityLLM MonitoringLLM IntegrationsFine-tuning for Translations
- Literal AI shines in usability: A member highlighted their positive experience with Literal AI, particularly enjoying its usability as seen on literalai.com.
- They remarked that it offers useful integrations and features that support the LLM application lifecycle.
- LLM observability boosts app lifecycle: The importance of LLM observability was emphasized, stating it enhances the app lifecycle by allowing faster iteration and debugging. Developers can leverage logs to fine-tune smaller models, improving performance while lowering costs.
- Transform prompt management into risk mitigation: Prompt performance tracking was discussed as a means to ensure no regressions take place before deploying new version updates. This proactive management helps maintain consistency and reliability in LLM outputs.
- Comprehensive LLM monitoring setup: The conversation included insights on establishing a comprehensive system for LLM monitoring and analytics after integrating log evaluations. This set-up is seen as crucial for maintaining optimal performance in production environments.
- Fine-tuning LLMs for translations: A query was raised about experiences in fine-tuning LLMs specifically for translations, noting a common issue where LLMs excel at capturing the gist but fail to convey the original tone or style.
- This issue highlights a gap in current LLM translation capabilities that developers seek to address.
Link mentioned: Literal AI - RAG LLM observability and evaluation platform: Literal AI is the RAG LLM evaluation and observability platform built for Developers and Product Owners.
Gorilla LLM (Berkeley Function Calling) ▷ #leaderboard (2 messages):
Test Results AccuracyPrompt Splicing for Qwen2-7B-Chat
- Accuracy Results from Tests: Multiple tests were conducted, with irrelevance achieving an accuracy of 1.0, while the rest, including java and javascript, scored 0.0.
- Tests like live_parallel_multiple and live_simple also fell flat, raising questions about the effectiveness of the models.
- Seeking Advice on Prompt Splicing: A member expressed concern over the poor performance of qwen2-7b-chat asking, 'Is it the problem of prompt splicing?'
- They requested insights or methods regarding prompt splicing to improve the testing experience.
MLOps @Chipro ▷ #general-ml (1 messages):
Predictive MaintenanceUnsupervised Learning in MaintenanceEmbedded Systems Monitoring
- Seeking insights on Predictive Maintenance: A member inquired about experiences with predictive maintenance and requested resources like papers or books on best models and practices.
- They mentioned the need for unsupervised methods due to a lack of tracked system failures and the impracticality of manually labeling events.
- Focus on Mechanical and Electrical Systems: The device discussed is described as partly mechanical and partly electrical, logging numerous events during operation.
- Members noted that effective monitoring could improve maintenance strategies and reduce future failures.
{% else %}
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: [{{ email.subject }}]({{ email_url }})!
If you enjoyed AInews, please share with a friend! Thanks in advance!
{% endif %}