AI News for 9/17/2024-9/18/2024. We checked 7 subreddits, 433 Twitters and 30 Discords (221 channels, and 1591 messages) for you. Estimated reading time saved (at 200wpm): 176 minutes. You can now tag @smol_ai for AINews discussions!
We humans at Smol AI have been dreading this day.
For the first time ever, an LLM has been able to 100% match and accurately report what we consider to be the top stories of the day without our intervention. (See the AI Discord Recap below.)
Perhaps more interesting for the model trainers, o1-preview consistently beats out our vibe check evals. Every AINews daily run is a bakeoff between OpenAI, Anthropic, and Google models (you can see traces in the archives. we briefly tried Llama 3 too but it consistently lost), and o1-preview has basically won every day since introduction (with no specific tuning beyond needing to rip out instructor's hidden system prompts).
We now have LMsys numbers on o1-preview and -mini to quantify the vibe checks.
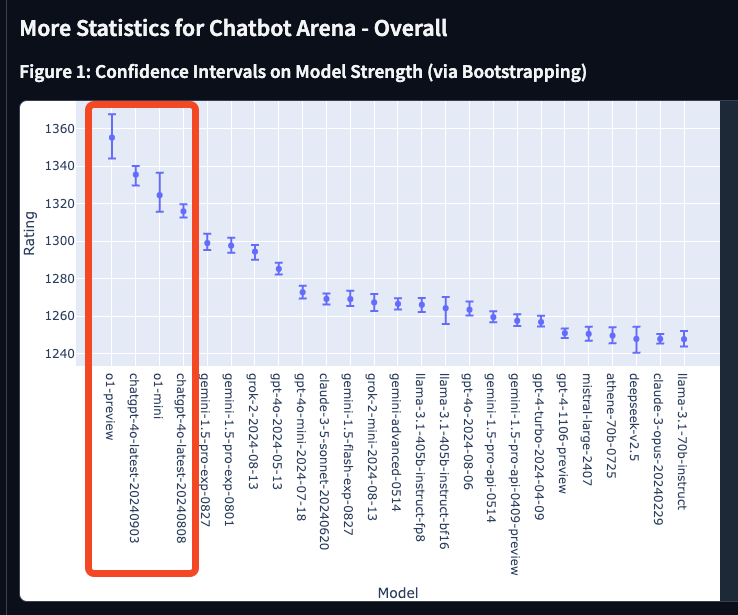
The top 4 slots on LMsys are now taken by OpenAI models. Demand has been high even as OpenAI is gradually raising rate limits by the day, now up to 500-1000 requests per minute.
Over in open source land, Alibaba's Qwen caught up to DeepSeek with its own Qwen 2.5 suite of general, coding, and math models, showing better numbers than Llama 3.1 at the 70B scale.
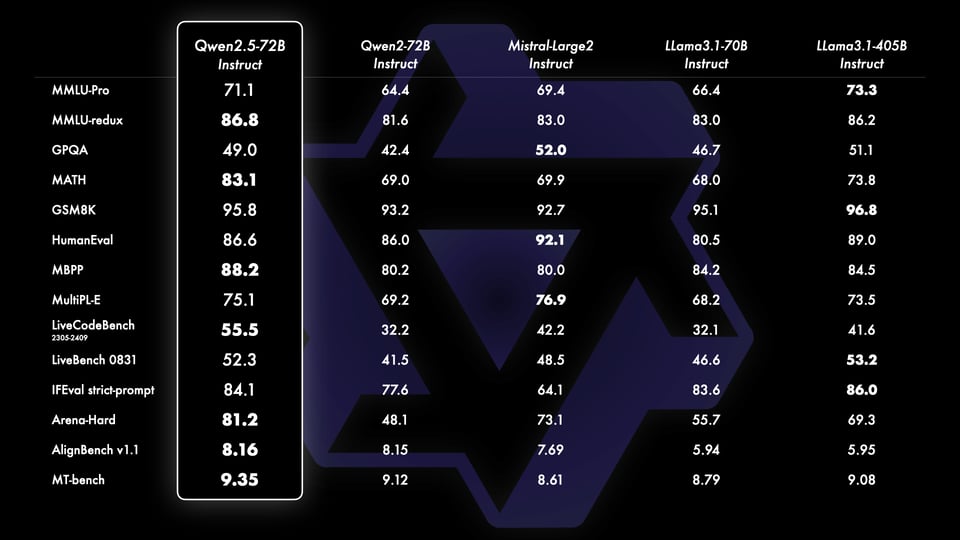
as well as updating their closed Qwen-Plus models to beat DeepSeek V2.5 but coming short of the American frontier models.
Finally, Kyutai Moshi, which teased its realtime voice model in July and had some entertaining/concerning mental breakdowns in the public demo, finally released their open weights model as promised, along with details of their unique streaming neural architecture that displays an "inner monologue".
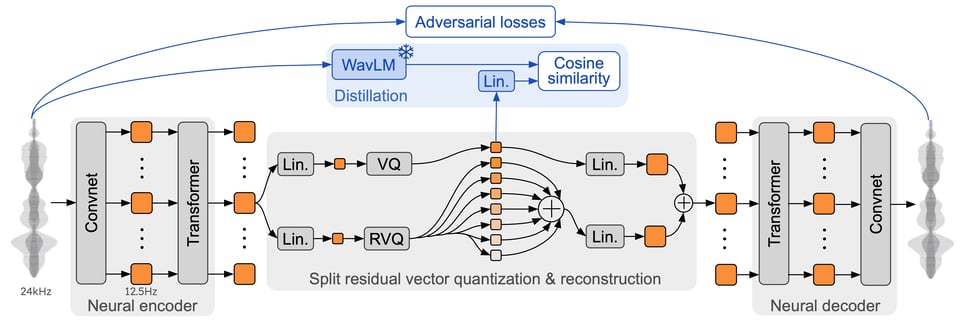
Live demo remains at https://moshi.chat, or try locally at
$ pip install moshi_mlx
$ python -m moshi_mlx.local_web -q 4
[This week's issues brought to you by Weights and Biases Weave!]: Look, we’ll be honest, many teams know Weights & Biases only as the best ML experiments tracking software in the world and aren’t even aware of our new LLM observability toolkit called Weave. So if you’re reading this, and you’re doing any LLM calls on production, why don’t you give Weave a try? With 3 lines of code you can log and trace all inputs, outputs and metadata between your users and LLMs, and with our evaluation framework, you can turn your prompting from an art into more of a science.
Check out the report on building a GenAI-assisted automatic story illustrator with Weave.
swyx's Commentary: I'll visiting the WandB LLM-as-judge hackathon this weekend in SF with many friends from the Latent Space/AI Engineer crew hacking with Weave!
{% if medium == 'web' %}
Table of Contents
[TOC]
{% else %}
The Table of Contents and Channel Summaries have been moved to the web version of this email: [{{ email.subject }}]({{ email_url }})!
{% endif %}
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
AI Model Updates and Releases
-
OpenAI's o1 models: @sama announced significant outperformance on goal 3, despite taking longer than expected. These models use chain-of-thought reasoning for enhanced complex problem-solving.
-
Mistral AI's Pixtral: @GuillaumeLample announced the release of Pixtral 12B, a multimodal model available on le Chat and la Plateforme. It features a new 400M parameter vision encoder and a 12B parameter multimodal decoder based on Mistral Nemo.
-
Llama 3.1: @AIatMeta shared an update on Llama's growth, noting rapidly increasing usage across major cloud partners and industries.
AI Development and Tools
-
ZML: @ylecun highlighted ZML, a high-performance AI inference stack for parallelizing and running deep learning systems on various hardware, now out of stealth and open-source.
-
LlamaCloud: @jerryjliu0 announced multimodal capabilities in LlamaCloud, enabling RAG over complex documents with spatial layouts, nested tables, and visual elements.
-
Cursor: @svpino praised Cursor's code completion capabilities, noting its advanced features compared to other tools.
AI Research and Benchmarks
-
Chain of Thought Empowerment: A paper shows how CoT enables transformers to solve inherently serial problems, expanding their problem-solving capabilities beyond parallel-only limitations.
-
V-STaR: Research on training verifiers for self-taught reasoners, showing 4% to 17% improvement in code generation and math reasoning benchmarks.
-
Masked Mixers: A study suggests that masked mixers with convolutions may outperform self-attention in certain language modeling tasks.
AI Education and Resources
-
New LLM Book: @JayAlammar and @MaartenGr released a new book on Large Language Models, available on O'Reilly.
-
DAIR.AI Academy: @omarsar0 announced the launch of DAIR.AI Academy, offering courses on prompt engineering and AI application development.
AI Applications and Demonstrations
-
AI Product Commercials: @mickeyxfriedman introduced AI-generated product commercials on Flair AI, allowing users to create animated videos from product photos.
-
Multimodal RAG: @llama_index launched multimodal capabilities for building end-to-end multimodal RAG pipelines across unstructured data.
-
NotebookLM: @omarsar0 demonstrated NotebookLM's ability to generate realistic podcasts from AI papers, showcasing an interesting application of AI and LLMs.
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. T-MAC: Energy-efficient CPU backend for llama.cpp
- T-MAC (an energy efficient cpu backend) may be coming to llama.cpp! (Score: 50, Comments: 5): T-MAC and BitBLAS, Microsoft-backed projects designed for efficient low-bit math, may be integrated into llama.cpp as the T-MAC maintainers plan to submit a pull request. T-MAC shows linear scaling of FLOPs and inference latency relative to bit count, supports bit-wise computation for int1/2/3/4 without dequantization, and accommodates various activation types using fast table lookup and add instructions. This integration could benefit projects like Ollama, potentially improving performance on laptops and mobile devices like the Pixel 6, which currently faces thermal throttling issues when running llama.cpp.
- Discussion arose about BitNet not being a true quantization method, as it's trained natively at 1 bit rather than being quantized from a higher resolution model. The original poster clarified that some layers still require quantization.
- Users expressed excitement about the potential of BitNet, with one commenter eagerly anticipating its full implementation and impact on the field.
- The concept of "THE ULTIMATE QUANTIZATION" was humorously referenced, with the original poster jokingly shouting about its supposed benefits like "LOSSLESS QUALITY" and "OPENAI IN SHAMBLES".
Theme 2. Qwen2.5-72B-Instruct: Performance and content filtering
- Qwen2.5-72B-Instruct on LMSys Chatbot Arena (Score: 31, Comments: 10): Qwen2.5-72B-Instruct has shown strong performance on the LMSys Chatbot Arena, as evidenced by a shared image. The Qwen2.5 series includes models ranging from 0.5B to 72B parameters, with specialized versions for coding and math tasks, and appears to have stricter content filtering compared to its predecessor, resulting in the model being unaware of certain concepts, including some non-pornographic but potentially sexually related topics.
- Qwen2.5-72B-Instruct faces strict content filtering, likely due to Chinese regulations for open LLMs. Users note it's unaware of certain concepts, including non-pornographic sexual content and sensitive political topics like Tiananmen Square.
- The model excels in coding and math tasks, performing on par with 405B and GPT-4. Some users found adding "never make any mistake" to prompts improved responses to tricky questions.
- Despite censorship concerns, some users appreciate the model's focus on technical knowledge. Attempts to bypass content restrictions were discussed, with one user sharing an image of a workaround.
{kind=link}
Theme 3. Latest developments in Vision Language Models (VLMs)
- A Survey of Latest VLMs and VLM Benchmarks (Score: 30, Comments: 8): The post provides a comprehensive survey of recent Visual Language Models (VLMs) and their associated benchmarks. It highlights key models such as GPT-4V, DALL-E 3, Flamingo, PaLI, and Kosmos-2, discussing their architectures, training approaches, and performance on various tasks. The survey also covers important VLM benchmarks including MME, MM-Vet, and SEED-Bench, which evaluate models across a wide range of visual understanding and generation capabilities.
- Users inquired about locally runnable VLMs, with the author recommending Bunny and referring to the State of the Art section for justification.
- A discussion on creating a mobile-first application for nonprofit use emerged, suggesting YOLO for training and a UI overlay for real-time object detection, referencing a YouTube video for UI inspiration.
- A proposal for a new VLM benchmark focused on manga translation was suggested, emphasizing the need to evaluate models on their ability to discern text, understand context across multiple images, and disambiguate meaning in both visual and textual modalities.
Theme 4. Mistral Small v24.09: New 22B enterprise-grade model
-
Why is chain of thought implemented in text? (Score: 67, Comments: 51): The post questions the efficiency of implementing chain of thought reasoning in text format for language models, particularly referencing o1, which was fine-tuned for long reasoning chains. The author suggests that maintaining the model's logic in higher dimensional vectors might be more efficient than projecting the reasoning into text tokens, challenging the current approach used even in models specifically designed for extended reasoning.
- Traceability and explainable AI are significant benefits of text-based chain of thought reasoning, as noted by users. The black box nature of latent space would make it harder for humans to understand the model's reasoning process.
- OpenAI's blog post revealed that the o1 model's chain of thought process is text-based, contrary to speculation about vectorized layers. Some users suggest that future models like o2 could implement implicit CoT to save tokens, referencing a paper on Math reasoning.
- Users discussed the challenges of training abstract latent space for reasoning, with some suggesting reinforcement learning as a potential approach. Others proposed ideas like gradual shifts in training data or using special tokens to control the display of reasoning steps during inference.
-
mistralai/Mistral-Small-Instruct-2409 · NEW 22B FROM MISTRAL (Score: 160, Comments: 74): Mistral AI has released a new 22B parameter model called Mistral-Small-Instruct-2409, which is now available on Hugging Face. This model demonstrates improved capabilities over its predecessors, including enhanced instruction-following, multi-turn conversations, and task completion across various domains. The release marks a significant advancement in Mistral AI's model offerings, potentially competing with larger language models in performance and versatility.
- Mistral Small v24.09 is released under the MRL license, allowing non-commercial self-deployment. Users expressed mixed reactions, with some excited about its potential for finetuning and others disappointed by the licensing restrictions.
- The model demonstrates improved capabilities in human alignment, reasoning, and code generation. It supports function calling, has a 128k sequence length, and a vocabulary of 32768, positioning it as a potential replacement for GPT-3.5 in some use cases.
- Users discussed the model's place in the current landscape of language models, noting its 22B parameters fill a gap between smaller models and larger ones like Llama 3.1 70B. Some speculated about its performance compared to other models in the 20-35B parameter range.
Other AI Subreddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
AI Model Advancements and Research
-
OpenAI's o1 model demonstrates impressive capabilities: OpenAI released a preview of their o1 model, which shows significant improvements over previous models. Sam Altman tweeted about "incredible outperformance on goal 3", suggesting major progress.
-
Increasing inference compute yields major performance gains: OpenAI researcher Noam Brown suggests that increasing inference compute is much more cost-effective than training compute, potentially by orders of magnitude. This could allow for significant performance improvements by simply allocating more compute at inference time.
-
Google DeepMind advances multimodal learning: A Google DeepMind paper demonstrates how data curation via joint example selection can further accelerate multimodal learning.
-
Microsoft's MInference speeds up long-context inference: Microsoft's MInference technique enables inference of up to millions of tokens for long-context tasks while maintaining accuracy, dramatically speeding up supported models.
AI Applications and Demonstrations
-
AI-assisted rapid app development: A developer built and published an iOS habit tracking app in just 6 hours using Claude and OpenAI's o1 model, without writing any code manually. This demonstrates the potential for AI to dramatically accelerate software development.
-
Virtual try-on technology: Kling launched Kolors Virtual-Try-On, allowing users to change clothes on any photo for free with just a few clicks. This showcases advancements in AI-powered image manipulation.
-
AI-generated art and design: Posts in r/StableDiffusion show impressive AI-generated artwork and designs, demonstrating the creative potential of AI models.
Industry and Infrastructure Developments
-
Major investment in AI infrastructure: Microsoft and BlackRock are forming a group to raise $100 billion to invest in AI data centers and power infrastructure, indicating significant scaling of AI compute resources.
-
Neuralink advances brain-computer interface technology: Neuralink received Breakthrough Device Designation from the FDA for Blindsight, aiming to restore sight to those who have lost it.
-
NVIDIA's vision for autonomous machines: NVIDIA's Jim Fan predicts that in 10 years, every machine that moves will be autonomous, and there will be as many intelligent robots as iPhones. However, this timeline was presented as a hypothetical scenario.
Philosophical and Societal Implications
-
Emergence of AI as a new "species": An ex-OpenAI researcher suggests we are at a point where there are two roughly intelligence-matched species, referring to humans and AI. This sparked discussion about the nature of AI intelligence and its rapid progress.
-
Comparisons to historical technological transitions: A post draws parallels between current AI data centers and the vacuum tube era of computing, suggesting we may be on the cusp of another major technological leap.
AI Discord Recap
A summary of Summaries of Summaries by O1-preview
Theme 1. New AI Models Take the Stage
-
Qwen 2.5 Throws a Party with 100+ Models: Alibaba's Qwen 2.5 release boasts over 100 model variants, including Qwen2.5-Coder and Qwen2.5-Math ranging from 0.5B to 72B parameters. This open-source powerhouse challenges proprietary models, with the flagship Qwen2.5-72B-Instruct matching top benchmarks.
-
Moshi Unleashed: Kyutai Labs Debuts Conversational AI: Kyutai Labs released Moshi, an experimental low-latency AI model, along with a technical report, model weights, and streaming inference code in Pytorch, Rust, and MLX on their GitHub.
-
OpenAI's o1 Models Ace the Arena: OpenAI's o1-preview and o1-mini snagged top spots on Chatbot Arena, excelling in math, hard prompts, and coding tasks. Users lauded o1-mini as comparable to “an outstanding PhD student” in biomedical sciences.
Theme 2. Turbocharging Model Fine-Tuning
-
Unsloth Doubles Speeds and Slashes VRAM by 70%: Unsloth boosts fine-tuning speeds for models like Llama 3.1, Mistral, and Gemma by 2x, while reducing VRAM usage by 70%. Discussions highlighted storage impacts when pushing quantized models to the hub.
-
Torchtune 0.3 Drops with FSDP2 and DoRA Support: The latest Torchtune release introduces full FSDP2 support, enhancing flexibility and speed in distributed training. It also adds easy activation of DoRA/QDoRA features by setting
use_dora=True. -
Curriculum Learning Gets Practical in PyTorch: Members shared steps to implement curriculum learning in PyTorch, involving custom dataset classes and staged difficulty. An example showed updating datasets in the training loop for progressive learning.
Theme 3. Navigating AI Model Hiccups
-
OpenRouter Users Slammed by 429 Errors: Frustrated OpenRouter users report being hit with 429 errors and strict rate limits, with one user rate-limited for 35 hours. Debates ignited over fallback models and key management to mitigate access issues.
-
Cache Confusion Causes Headaches: Developers grappled with cache management in models, discussing the necessity of fully deleting caches after each task. Suggestions included using context managers to prevent interference during evaluations.
-
Overcooked Safety Features Mocked: The community humorously critiqued overly censored models like Phi-3.5, sharing satirical responses. They highlighted challenges that heavy censorship poses for coding and technical tasks.
Theme 4. AI Rocks the Creative World
-
Riffusion Makes Waves with AI Music: Riffusion enables users to generate music from spectrographs, sparking discussions about integrating AI-generated lyrics. Members noted the lack of open-source alternatives to Suno AI for full-song generation.
-
Erotic Roleplay Gets an AI Upgrade: Advanced techniques for erotic roleplay (ERP) with AI models were shared, focusing on crafting detailed character profiles and immersive prompts. Users emphasized building anticipation and realistic interactions.
-
Artists Hunt for Image-to-Cartoon Models: Members are on the lookout for AI models that can convert images into high-quality cartoons, exchanging recommendations. The quest continues for a model that delivers top-notch cartoon conversions.
Theme 5. AI Integration Boosts Productivity
-
Integrating Perplexity Pro with VSCode Hits Snags: Users attempting to use Perplexity Pro with VSCode extensions like 'Continue' faced challenges, especially distinguishing between Pro Search and pure writing modes. Limited coding skills added to the integration woes.
-
Custom GPTs Become Personal Snippet Libraries: Members are using Custom GPTs to memorize personal code snippets and templates like Mac Snippets. Caution is advised against overloading instructions to maintain performance.
-
LM Studio's New Features Excite Users: The addition of document handling in LM Studio has users buzzing. Discussions revolved around data table size limitations and the potential for analyzing databases through the software.
PART 1: High level Discord summaries
Unsloth AI (Daniel Han) Discord
- Unsloth speeds up model fine-tuning: Unsloth enhances fine-tuning for models like LlaMA 3.1, Mistral, and Gemma by 2x and reduces VRAM usage by 70%.
- Discussions highlighted that quantized models require different storage compared to full models, impacting memory availability.
- Qwen 2.5 hits the stage: The recently launched Qwen 2.5 model shows improved instruction-following abilities, particularly for coding and mathematics.
- Users noted its added capacity to handle nuances better than Llama 3.1, although issues arise with saving and reloading merged models.
- Gemma 2 fine-tuning struggles: Members reported challenges with fine-tuning Gemma 2, particularly errors encountered when saving and loading merged models.
- Suggestions pointed to potential issues with chat templates used in inference or general persistence problems within the model.
- Neural network code generation success: A community member expressed thanks for help in training a neural network to generate Python code, marking it as a promising start.
- Responses were encouraging, with the community applauding the achievement with Incredible and congrats!.
- vLLM serving brings latency concerns: A participant dealing with vLLM for serving mentioned latency issues while fine-tuning their model.
- They sought advice on using Quantization Aware LoRa training as well as concerns about merging models effectively.
Stability.ai (Stable Diffusion) Discord
- LoRa Models Training Essentials: A member inquired about effective images for training LoRa models, recommending diverse floor plans, doors, and windows to enhance the dataset.
- Emphasis was placed on tagging and community experience sharing to assist newcomers on their training journey.
- Resolution Rumble: SD1.5 vs. SD512: SD1.5 outperforms with 1024x1024 images over 512x512, especially when considering GPU limitations during generation.
- Adoption of turbo models was suggested for faster image generation without sacrificing efficiency.
- Multidiffusion Magic for Memory Saving: The multidiffusion extension was hailed as a memory-saving tool for low VRAM users, processing images in smaller tiled sections.
- Guides and resources were shared to help users integrate this extension effectively into their workflows.
- Riffusion Rocks AI Music Creation: The platform Riffusion facilitates music generation from spectrographs and may incorporate AI lyrics in future iterations.
- Discussion highlighted a scarcity of alternatives to Suno AI in the open-source realm for full-song generation.
- Remote Processing: A Double-Edged Sword: Concerns emerged around tools like iopaint using remote processing which limits user control and model flexibility.
- The community advocated for self-hosting models for enhanced customization and privacy.
OpenRouter (Alex Atallah) Discord
- Mistral API prices hit new lows: Members highlighted significant price reductions on the Mistral API, with competitive pricing like $2/$6 on Large 2 for large models.
- This pricing adjustment sets a favorable comparison against other providers, enhancing model accessibility for users.
- OpenRouter faces access barriers: Multiple users are encountering issues with OpenRouter, particularly receiving 429 errors and Data error output messages.
- To mitigate these problems, users were encouraged to create dedicated threads for reporting errors to streamline troubleshooting.
- Rate limits disrupt user workloads: Frustration arose over users hitting strict rate limits that hinder accessing models, causing significant productivity setbacks.
- One user noted they were rate-limited for 35 hours, prompting discussions about potential solutions like BYOK (Bring Your Own Key).
- Fallback models need a better strategy: There was a discussion regarding the order of operations using fallback models versus fallback keys during rate limit errors.
- Concerns about not using fallback models effectively were raised, especially when faced with Gemini Flash 429 errors.
- User queries on free LLM access: A user questioned how to provide free LLM access to 5000 individuals with an effective budget of $10-$15 per month.
- Discussions ensued about token usage, estimating around 9k tokens per user per day, which pushed for sophisticated optimization strategies.
aider (Paul Gauthier) Discord
- Aider behaves unexpectedly: Users found that Aider exhibited erratic behavior, sometimes following its own agenda after simple requests, requiring a restart to resolve. The issue seems linked to context retention during sessions.
- The community suggests investigating state management to prevent this kind of unexpected behavior in future updates.
- Feedback on OpenAI models disappoints: Users criticized the performance of the O1 models, particularly for refusing to obey formatting commands, which disrupts workflow efficiency. Many users turned to 3.5 Sonnet, citing improved control over prompts.
- This raised discussions about the importance of flexible parameter settings to enhance user interactions with AI models.
- Exploring DeepSeek limitations: Challenges surfaced around the DeepSeek model regarding its editing and refactoring capabilities, with suggestions to refine input formats for better outputs. Tuning efforts were proposed, seeking effective source/prompt examples for testing.
- The exchange indicates a collective need for clearer guidelines on optimizing model performance through effective prompt design.
- Claude 3.5 System Prompt Details Released: An extracted system prompt for Claude 3.5 Sonnet has been shared, aimed at enhancing performance in handling artifacts. This uncovering has sparked interest in how it might be applied practically.
- The community awaits insights on the impact of this prompt on practical applications and code generation tasks.
- FlutterFlow 5.0 Launch Enhancements: A YouTube video introduced FlutterFlow 5.0, which promises to revolutionize app development with new features aimed at streamlining component creation. The update claims significant performance improvements.
- Feedback suggests users are already eager to implement these features for better efficiency in coding workflows.
Perplexity AI Discord
- Integrating Perplexity Pro with VSCode: Users discussed how to utilize the Perplexity Pro model alongside VSCode extensions like 'Continue' for effective autocomplete functionality, despite integration challenges due to limited coding skills.
- The distinction between Pro Search and pure writing mode was highlighted, complicating usage strategies for some.
- O1 Model Utilization in Pro Search: The O1-mini is now accessible through the Reasoning focus in Pro Search, though its integration varies by model selection.
- Some users advocate for using O1 in role play scenarios due to character retention capabilities but demand higher usage limits.
- Debate on Perplexity vs ChatGPT: An ongoing debate compares the Perplexity API models with those in ChatGPT, particularly regarding educational utility and subscription benefits.
- One user pointed out the advantages of ChatGPT Plus for students while acknowledging the merits of a Perplexity Pro subscription.
- Slack Unveils AI Agents: Slack reported the introduction of AI agents, aimed at improving workflow and communication efficiency within the platform.
- This feature is expected to enhance the overall productivity of teams using the platform.
- New Affordable Electric SUV by Lucid: Lucid launched a new, more affordable electric SUV, broadening its market reach and appealing to environmentally conscious consumers.
- This affordable model targets a wider audience interested in sustainable transportation.
HuggingFace Discord
- Hugging Face Unveils New API Documentation: The newly launched API docs feature improved clarity on rate limits, a dedicated PRO section, and enhanced code examples.
- User feedback has been directly applied to improve usability, making deploying AI smoother for developers.
- TRL v0.10 Enables Vision-Language Fine-Tuning: TRL v0.10 simplifies fine-tuning for vision-language models down to two lines of code, coinciding with Milstral's launch of Pixtral.
- This release emphasizes the increasing connectivity of multimodal AI capabilities.
- Nvidia Launches Compact Mini-4B Model: Check out Nvidia's new Mini-4B model here, which shows remarkable performance but requires compatible Nvidia drivers.
- Users are encouraged to register it as a Hugging Face agent to leverage its full functionality.
- Open-source Biometric Template Protection: A member shared their Biometric Template Protection (BTP) implementation for authentication without server data access, available on GitHub.
- This educational code aims to introduce newcomers to the complexities of secure biometric systems while remaining user-friendly.
- Community Seeking Image-to-Cartoon Model: Members are on the lookout for a space model that can convert images into high-quality cartoons, with calls for recommendations.
- Community engagement is key, as they encourage shared insights on models that fulfill this requirement.
Nous Research AI Discord
- NousCon Ignites Excitement: Participants expressed enthusiasm for NousCon, discussing attendance and future events, with plans for an afterparty at a nearby bar to foster community interaction.
- Many requested future events in different locations, emphasizing the desire for more networking opportunities.
- Hermes Tool Calling Standard Adopted: The community has adopted a tool calling format for Qwen 2.5, influenced by contributions like vLLM support and other tools being discussed for future implementations.
- Discussions on parsing tool distinctions between Hermes and Qwen are ongoing, sparking innovative ideas for integration.
- Qwen 2.5 Launches with New Models: Qwen 2.5 has been announced, featuring new coding and mathematics models, marking a pivotal moment for open-source AI advancements.
- This large-scale release showcases the continuous evolution of language models in the AI community, with a detailed blog post outlining its capabilities.
- Gemma 2 Improves Gameplay: Members shared experiences about fine-tuning models like Gemma 2 to enhance chess gameplay, although performance highlighted several challenges.
- This reflects the creative development processes and collaborative spirit within the community, driving innovation backward from gameplay expectations.
- Hermes 3 API Access Confirmed: Access to the Hermes 3 API has been confirmed in collaboration with Lambda, allowing users to utilize the new Chat Completions API.
- Further discussions included potential setups for maximized model capabilities, with particular interest in running at
bf16precision.
- Further discussions included potential setups for maximized model capabilities, with particular interest in running at
CUDA MODE Discord
- Triton Conference Shoutout: During the Triton conference keynote, Mark Saroufim praised the community for their contributions, which excited attendees.
- The recognition sparked discussions on community engagement and future contributions.
- Triton CPU / ARM Becomes Open Source: Inquiries about the Triton CPU / ARM led to confirmation that it is now open-source, available on GitHub.
- This initiative aims to foster community collaboration and improve the experimental CPU backend.
- Training Llama-2 Model Performance Report: Performance metrics for the Llama2-7B-chat model revealed significant comparisons against FP16 configurations across various tasks.
- Participants underscored the need for optimizing quantization methods to enhance inference quality.
- Quantization Techniques for Efficiency: Discussions centered on effective quantization methods such as 4-bit quantization for Large Language Models, crucial for BitNet's architecture.
- Members demonstrated interest in models that apply quantization without grouping to ease inference costs.
- Upcoming Pixtral Model Release: Excitement surrounds the anticipated release of the Pixtral model on the Transformers library, with discussions on implementation strategies.
- Members noted the expected smooth integration with existing frameworks upon the release.
Eleuther Discord
- Open-Source TTS Migration Underway: A discussion arose on transitioning from OpenAI TTS to open-source alternatives, particularly highlighting Fish Speech V1.4 that supports multiple languages.
- Members debated the viability of using xttsv2 to enhance performance across different languages.
- Compression Techniques for MLRA Keys: Members explored the concept of utilizing an additional compression matrix for MLRA keys and values, aiming to enhance data efficiency post-projection.
- Concerns were raised about insufficient details in the MLRA experimental setup, particularly regarding rank matrices.
- Excitement Around Playground v3 Launch: Playground v3 (PGv3) was released, showcasing state-of-the-art performance in text-to-image generation and a new benchmark for image captioning.
- The new model integrates LLMs, diverging from earlier models reliant on pre-trained encoders to prove more efficient.
- Diagram of Thought Framework Introduced: The Diagram of Thought (DoT) framework was presented, modeling iterative reasoning in LLMs through a directed acyclic graph (DAG) structure, aiming to enhance logical consistency.
- This new method proposes a significant improvement over linear reasoning approaches discussed in previous research.
- Investigating Model Debugging Tactics: A member suggested initiating model debugging from a working baseline and progressively identifying issues across various configurations, such as FSDP.
- The back-and-forth underlined the need for sharing debugging experiences while optimizing model performance.
OpenAI Discord
- Custom GPTs Memorize Snippets Effectively: Members discussed using Custom GPTs to import and memorize personal snippets, such as Mac Snippets, although challenges arose from excessive information dumping.
- A suggestion emerged that clearer instructions and knowledge base uploads can enhance performance.
- Leaked Advanced Voice Mode Launch: An upcoming Advanced Voice Mode for Plus users is expected on September 24, focusing on improved clarity and response times while filtering noise.
- The community expressed curiosity on its potential impact on daily voice command usability.
- Debate on AI Content Saturation: A heated discussion centered on whether AI-generated content elevates or dilutes quality, with voices suggesting it reflects pre-existing low-quality content.
- Concerns were raised about disassociation from reality as AI capabilities grow.
- GPT Store Hosts Innovative Creations: One member touted their various GPTs in the GPT Store, which automate tasks derived from different sources, enhancing workflow.
- Specific prompting techniques inspired by literature, including DALL·E, were part of their offerings.
- Clarification on Self-Promotion in Channels: Members reviewed the self-promotion rules, confirming exceptions in API and Custom GPTs channels for shared creations.
- Encouragement to link their GPTs was voiced, highlighting community support for sharing while following server guidelines.
Cohere Discord
- Cohere Job Application Sparks Community Excitement: A member shared their enthusiasm after applying for a position at Cohere, connecting with the community for support.
- The community welcomed the initiative with excitement, showcasing friendly vibes for newcomers.
- CoT-Reflections Outshines Traditional Approaches: Discussion focused on how CoT-reflections improves response quality compared to standard chain of thought prompting.
- Members highlighted that integrating BoN with CoT-reflections could enhance output quality significantly.
- Speculations on O1's Reward Model Mechanism: Members speculated that O1 operates using a reward model that iteratively calls itself for optimal results.
- There are indications that O1 underwent a multi-phase training process to elevate its output quality.
- Billing Information Setup Confusion Resolved: A member sought clarification on adding VAT details after setting up payment methods via a Stripe link.
- The suggestion to email [email protected] for secure handling of billing changes was confirmed to be a viable solution.
LM Studio Discord
- Markov Models Get Props: Members noted that Markov models are less parameter-intensive probabilistic models of language, leading to discussions on their potential applications.
- Interest grew around how these models could simplify certain processes in language processing for engineers.
- Training Times Spark Debate: Training on 40M tokens would take about 5 days with a 4090 GPU, but reducing it to 40k tokens cuts that down to just 1.3 hours.
- Concerns remained regarding why 100k models still seemed excessive in training time.
- Data Loader Bottlenecks Cause Frustration: Members discussed data loader bottlenecks during model training, with reports of delays causing frustration.
- There was a call to explore optimization techniques for the data pipeline to enhance overall training efficiency.
- LM Studio's Exciting New Features: With new document handling features, excitement bubbled as a member returned to LM Studio after integrating prior feedback.
- Discussions revolved around understanding size limitations for data tables and analyzing databases through the software.
- AI Model Recommendations Swirl: In recommendations for coding, the Llama 3.1 405B model surfaced for Prolog assistance, prompting various opinions.
- Insights on small model alternatives like qwen 2.5 0.5b highlighted its coherence, though it lacked lowercase support.
Latent Space Discord
- Langchain Updates for Partner Packages: An inquiry arose regarding the process to update an old Langchain community integration into a partner package, with suggestions to reach out via joint communication channels.
- Lance Martin was mentioned as a go-to contact for further assistance in this transition.
- Mistral Launches Free Tier for Developers: Mistral introduced a free tier on their serverless platform, enabling developers to experiment at no cost while enhancing the Mistral Small model.
- This update also included revised pricing and introduced free vision capabilities on their chat interface, making it more accessible.
- Qwen 2.5: A Game Changer in Foundation Models: Alibaba rolled out the Qwen 2.5 foundation models, introducing over 100 variants aimed at improving coding, math reasoning, and language processing.
- This release is noted for its competitive performance and targeted enhancements, promising significant advancements over earlier versions.
- Moshi Kyutai Model Rocks the Scene: Kyutai Labs unveiled the Moshi model, complete with a technical report, weights, and streaming inference code on various platforms.
- They provided links to the paper, GitHub, and Hugging Face for anyone eager to dig deeper into the model's capabilities.
- Mercor Attracts Major Investment: Mercor raised $30M in Series A funding at a $250M valuation, targeting enhanced global labor matching with sophisticated models.
- The investment round featured prominent figures like Peter Thiel and Jack Dorsey, underlining its importance in AI-driven labor solutions.
Torchtune Discord
- Torchtune 0.3 packed with features: Torchtune 0.3 introduces significant enhancements, including full support for FSDP2 to boost flexibility and speed.
- The upgrades focus on accelerating training times and improving model management across various tasks.
- FSDP2 enhances distributed training: All distributed recipes now leverage FSDP2, allowing for better compile support and improved handling of LoRA parameters.
- Users are encouraged to experiment with the new configuration in their distributed recipes for enhanced performance.
- Training-time speed improvements: Implementing torch.compile has resulted in under a minute compile times when set
compile=True, leading to faster training.- Using the latest PyTorch nightlies amplifies performance further, offering significant reductions during model compilation.
- DoRA/QDoRA support enabled: The latest release enables users to activate DoRA/QDoRA effortlessly by setting
use_dora=Truein configuration.- This addition is vital for enhancing training capabilities related to LoRA and QLoRA recipes.
- Cache management discussions arise: A conversation sparked around the necessity of completely deleting cache after each task, with suggestions for improvements to the eval harness.
- One contributor proposed ensuring models maintain both inference and forward modes without needing cache teardown.
Interconnects (Nathan Lambert) Discord
- Qwen2.5 Launch Claims Big Milestones: The latest addition to the Qwen family, Qwen2.5, has been touted as one of the largest open-source releases, featuring models like Qwen2.5-Coder and Qwen2.5-Math with various sizes from 0.5B to 72B.
- Highlights include the flagship Qwen2.5-72B-Instruct matching proprietary models, showcasing competitive performance in benchmarks.
- OpenAI o1 Models Compared to PhD Level Work: Testing OpenAI's o1-mini model showed it to be comparable to an outstanding PhD student in biomedical sciences, marking it among the top candidates they've trained.
- This statement underscores the model's proficiency and the potential for its application in advanced academic projects.
- Math Reasoning Gains Attention: There's a growing emphasis on advancing math reasoning capabilities within AI, with excitement around the Qwen2.5-Math model, which supports both English and Chinese.
- Engagement from users suggests a collective focus on enhancing math-related AI applications as they strive to push boundaries in this domain.
- Challenges of Knowledge Cutoff in AI Models: Several users expressed frustration over the knowledge cutoff of models, notably stating it is set to October 2023, affecting their relevance to newer programming libraries.
- Discussions indicate that real-time information is critical for practical applications, presenting a challenge for models like OpenAI's o1.
- Transformers Revolutionize AI: The Transformer architecture has fundamentally altered AI approaches since 2017, powering models like OpenAI's GPT, Meta's Llama, and Google's Gemini.
- Transformers extend their utility beyond text into audio generation, image recognition, and protein structure prediction.
OpenInterpreter Discord
- 01 App is fully operational: Members confirmed that the 01 app works well on their phones, especially when using the -qr option for best results.
- One member tested the non-local version extensively and reported smooth functionality.
- Automating Browser Tasks Request: A member seeks guides and tips for automating browser form submissions, particularly for government portals.
- Despite following ChatGPT 4o suggestions, they're facing inefficiencies, especially with repetitive outcomes.
- CV Agents Available for Testing: A member shared their CV Agents project aimed at enhancing job hunting with intelligent resumes on GitHub: GitHub - 0xrushi/cv-agents.
- The project invites community contributions and features an attractive description.
- Moshi Artifacts Unleashed: Kyutai Labs released Moshi artifacts, including a technical report, model weights, and streaming inference code in Pytorch, Rust, and MLX, available in their paper and GitHub repository.
- The community is eager for more updates as the project gains traction.
- Feedback on Audio Sync: A user pointed out that an update to the thumbnail of the Moshi video could boost visibility and engagement.
- They noted slight audio sync issues in the video, signaling a need for technical adjustments.
LlamaIndex Discord
- Benito's RAG Deployment Breakthrough: Benito Martin shared a guide on building and deploying RAG services end-to-end using AWS CDK, offering a valuable resource for translating prototypes into production.
- If you're looking to enhance your deployment skills, this guide is a quick start!
- KeyError Hits Weaviate Users Hard: Yasuyuki raised a KeyError while reading an existing Weaviate database, referencing GitHub Issue #13787. A community member suggested forking the repo and creating a pull request to allow users to specify field names.
- This is a common pitfall when querying vector databases not created with llama-index.
- Yasuyuki's First Open Source Contribution: Yasuyuki expressed interest in contributing to the project by correcting the key from 'id' to 'uuid' and preparing a pull request.
- This first contribution has encouraged him to familiarize himself with GitHub workflows for future engagement.
- Seeking Feedback on RAG Techniques: .sysfor sought feedback on RAG (Retrieval-Augmented Generation) strategies to link vendor questions with indexed QA pairs.
- Suggestions included indexing QA pairs and generating variations on questions to enhance retrieval efficiency.
LangChain AI Discord
- Model Providers Cause Latency in LLMs: Latency in LLM responses is primarily linked to the model provider, rather than implementation errors, according to member discussions.
- This suggests focusing on optimizing the model provider settings to enhance response speeds.
- Python and LangChain's Minimal Impact on Latency: It's claimed that only 5-10% of LLM latency can be attributed to Python or LangChain, implying a more significant focus should be on model configurations.
- Optimizing model settings could vastly improve overall performance and reduce wait times.
- Best Practices for State Management in React: Users discussed optimal state management practices when integrating Langserve with a React frontend.
- The conversation hints at the importance of effective state handling, especially with a Python backend involved.
- PDF-Extract-Kit for High-Quality PDF Extraction: The PDF-Extract-Kit was presented as a comprehensive toolkit for effective PDF content extraction.
- Interest was sparked as members considered its practical applications in common PDF extraction challenges.
- RAG Application Developed with AWS Stack: A member showcased a new RAG application utilizing LangChain and AWS Bedrock for LLM integration and deployment.
- This app leverages AWS OpenSearch as the vector database, highlighting its robust cloud capabilities for handling data.
Modular (Mojo 🔥) Discord
- BeToast Discord Compromise Alert: Concerns arose about the BeToast Discord server potentially being compromised, fueled by a report from a LinkedIn conversation about hacking incidents.
- Members emphasized the necessity for vigilance and readiness to act if any compromised accounts start spamming.
- Windows Native Support Timeline Uncertain: Discussion on the Windows native support revealed a GitHub issue outlining feature requests, with an uncertain timeline for implementation.
- Many developers prefer alternatives to Windows for AI projects due to costs, using WSL as a common workaround.
- Converting SIMD to Int Explained: A user queried how to convert SIMD[DType.int32, 1] to Int, to which a member succinctly replied:
int(x).- This underscored the importance of understanding SIMD data types for efficient conversions.
- Clarifying SIMD Data Types: The conversation emphasized the need to understand SIMD data types for smooth conversions, encouraging familiarization with DType options.
- Members noted that this knowledge could streamline future queries around data handling.
LAION Discord
- Exploring State of the Art Text to Speech: A member inquired about the state of the art (sota) for text to speech, specifically seeking open source solutions. “Ideally open source, but curious what all is out there” reflects a desire to compare various options.
- Participants praised Eleven Labs as the best closed source text to speech option, while alternatives like styletts2, tortoise, and xtts2 were suggested for open source enthusiasts.
- Introducing OmniGen for Unified Image Generation: The paper titled OmniGen presents a new diffusion model that integrates diverse control conditions without needing additional modules found in models like Stable Diffusion. OmniGen supports multiple tasks including text-to-image generation, image editing, and classical CV tasks through its simplified architecture.
- OmniGen leverages SDXL VAE and Phi-3, enhancing its capability in generating images and processing control conditions, making it user-friendly for various applications.
- Nvidia's Official Open-Source LLMs: A member highlighted the availability of official Nvidia open-source LLMs, potentially relevant for ongoing AI research and development. This initiative might provide valuable resources for developers and researchers working in the field.
- The move supports a transition towards more collaborative and accessible AI resources, aligning with current trends in open-source software.
DSPy Discord
- Ruff Check Error Alert: A user reported a TOML parse error while performing
ruff check . --fix-only, highlighting an unknown fieldindent-widthat line 216.- This error indicates a need to revise the configuration file to align with the expected fields.
- Podcast with AI Researchers: A YouTube podcast featuring Sayash Kapoor and Benedikt Stroebl explores optimizing task performance and minimizing inference costs, viewable here.
- The discussion stirred interest, emphasizing the importance of considering costs in AI systems.
- LanceDB Integration Debut: The new LanceDB integration for DSpy enhances performance for large datasets, explained in this pull request.
- The contributor expressed willingness to collaborate on related personal projects and open-source initiatives.
- Concerns around API Key Handling: Users are questioning whether API keys need to be sent directly to a VM/server before reaching OpenAI, highlighting trust issues with unofficial servers.
- Clarity on secure processes is crucial to avoid compromising personal data.
- Creating a Reusable RAG Pipeline: A community member sought guidance on creating a reusable pipeline with RAG that can accommodate multiple companies without overloading prompts.
- Concerns about effectively incorporating diverse data were raised, aiming to streamline the process.
OpenAccess AI Collective (axolotl) Discord
- Implementing Curriculum Learning in PyTorch: To implement curriculum learning in PyTorch, define criteria, segment your dataset into stages of increasing difficulty, and create a custom dataset class to manage this logic.
- An example showed how to update the dataset in the training loop using this staged approach.
- Controlling Dataset Shuffling: A user raised a question about specifying the lack of random shuffling in a dataset, seeking guidance on this aspect.
- It was suggested that this query could be tackled in a separate thread for clarity.
tinygrad (George Hotz) Discord
- Tinybox Setup Instructions Needed: A request for help on setting up two tinyboxes was made, with a link to the Tinybox documentation provided for setup guidance.
- This highlights a demand for streamlined setup instructions as more users explore Tinygrad functionalities.
- Tinyboxes Boost Tinygrad CI: It was noted that tinyboxes play a crucial role in tinygrad's CI, showcasing their capabilities through running on MLPerf Training 4.0.
- This demonstrates their status as the best-tested platform for tinygrad integrations.
- Tinybox Purchase Options Explained: For those looking to buy, it was mentioned to visit tinygrad.org for tinybox purchases, reassuring others that it's fine not to get one.
- This caters to diverse user interests, whether in acquisition or exploration.
- Tinybox Features Uncovered: A brief overview highlighted the tinybox as a universal system for AI workloads, dealing with both training and inference tasks.
- Specific hardware specs included the red box with six 7900XTX GPUs and the green box featuring six 4090 GPUs.
LLM Finetuning (Hamel + Dan) Discord
- rateLLMiter Now Available for Pip Install: The rateLLMiter module is now available as a pip installable package, enhancing request management for LLM clients. Check out the implementation details on GitHub with information regarding its MIT license.
- This implementation allows LLM clients to better manage their API calls, making it easier to integrate into existing workflows.
- Rate Limiter Graph Shows Request Management: A graph illustrates how rateLLMiter smooths out the flow of requests, with orange representing requests for tickets and green showing issued tickets. This effectively distributed a spike of 100 requests over time to avoid server rate limit exceptions.
- Participants highlighted the importance of managing API rates effectively to ensure seamless interactions with backend services during peak loads.
Gorilla LLM (Berkeley Function Calling) Discord
- Member Realizes Prompt Misuse: A member acknowledged their misapplication of a prompt, which caused unexpected output confusion in Gorilla LLM discussions.
- This highlights the necessity of validating prompt usage to ensure accurate results.
- Prompt Template Now Available: The same member mentioned that a prompt template is now readily accessible to assist with crafting future prompts efficiently.
- Leveraging the template could help mitigate similar prompt-related errors down the line.
The Alignment Lab AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Mozilla AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
{% if medium == 'web' %}
Unsloth AI (Daniel Han) ▷ #general (196 messages🔥🔥):
Unsloth Model Fine-TuningQwen 2.5 ReleaseGemma 2 Fine-Tuning IssuesPytorch ConferenceUsing WSL for Installation
- Unsloth makes model fine-tuning efficient: Unsloth reportedly improves the fine-tuning speed for models like LlaMA 3.1, Mistral, and Gemma by 2x, while using 70% less VRAM.
- Discussions around pushing models to the hub highlighted that storage requirements for quantized vs. full models impact available memory.
- Qwen 2.5 just released: The Qwen 2.5 model was recently released, promising improved instruction-following and capability in areas like coding and mathematics.
- Users noted that Qwen 2.5 can manage nuances better than Llama 3.1, although there are concerns about saving and reloading merged models.
- Gemma 2 faces fine-tuning complications: Participants reported issues with fine-tuning Gemma 2, specifically related to errors when saving and reloading merged models.
- Suggestions indicated it might relate to chat templates used for inference or general model persistence problems.
- Pytorch Conference updates: A participant announced they will be speaking at the Pytorch Conference, sharing innovations on improving LLM training.
- The session is expected to be recorded, allowing missed attendees to catch up on the insights shared during the presentation.
- Discussion on WSL for Installation: Users inquired about using WSL under Windows for installation of models, discussing various methods to optimize setup.
- Recommendations were made regarding pushing only adapters to avoid space issues during model training and deployment.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #help (20 messages🔥):
Neural Network Code GenerationPath Specification for Llama-CPPFine-tuning Llama ModelsLoRa Quantization IssuesvLLM Serving Performance
- Neural Network Code Generation Success: A member expressed gratitude for the community's help in training a neural network to generate Python code, marking it as a small start to a big deal.
- Incredible and congrats! was the community's response, showcasing support for the achievement.
- Specifying Path for Llama-CPP: A user inquired about specifying the path to llama-cpp while facing errors during the
save_pretrained_ggufprocess.- Another member advised adding the file path to the system environment variables
PATHfor automatic path recognition.
- Another member advised adding the file path to the system environment variables
- Fine-tuning Llama Models Leads to Latency Issues: A user shared their experience fine-tuning a model and encountering latency problems, considering using vLLM for serving.
- They sought advice on the approach, particularly about Quantization Aware LoRa training and merging models.
- Merging LoRa with Quantized Models: Using vLLM for inference, it was suggested that members need not merge the LoRa adapter as it can handle loading on its own.
- A user explained their difficulties with loading their LoRa adapter, hinting at the potential loss of fine-tuning effects.
- Challenges with vLLM Serving: A member outlined their command for serving a model with vLLM, but noted issues with loading the LoRa adapter correctly.
- They were uncertain whether the LoRa was loaded properly or if the effects of their fine-tuning were diminished.
Link mentioned: unsloth/unsloth/save.py at main · unslothai/unsloth: Finetune Llama 3.1, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory - unslothai/unsloth
Stability.ai (Stable Diffusion) ▷ #general-chat (161 messages🔥🔥):
Training LoRa ModelsImage Generation TechniquesMultidiffusion UsageAudio Generation ToolsGeneral AI Discussions
- Best Practices for Training LoRa Models: A member asked about the necessary images to train a LoRa model effectively, suggesting collecting various floor plans and parts like doors and windows for training.
- Discussion also highlighted the importance of tagging and the sharing of experiences within the community to aid newcomers.
- Image Generation Resolution Advice: Members discussed generating images at different resolutions, noting that SD1.5 performs better at 1024x1024 images compared to 512x512, with considerations for GPU limitations.
- A suggestion proposed using turbo models to achieve faster generation times while maintaining efficiency.
- Multidiffusion Tools for Upscaling: The multidiffusion extension was recommended for low VRAM users, being described as a tiled sampler that processes smaller sections of images to save memory.
- Links to guides and resources were shared, assisting users in understanding how to implement this effectively in their workflows.
- Riffusion and Audio AI: Riffusion was mentioned as a platform for generating music from spectrographs, with the possibility of combining it with AI-driven lyric generation.
- The conversation explored the current state of open-source audio generation tools, noting a lack of alternatives to Suno AI for full-song generation.
- Challenges with Remote Processing in AI Tools: Concerns were raised about tools like iopaint using remote processing, affecting users' flexibility and control over models.
- The discussion emphasized the advantages of hosting one's own models for greater privacy and customization.
Links mentioned:
OpenRouter (Alex Atallah) ▷ #general (126 messages🔥🔥):
OpenRouter issuesMistral API price dropsRate limits and model accessBackup model usageLLM allocation for users
- Mistral API experiences significant price drops: Members highlighted recent significant price reductions on the Mistral API, with competitive pricing noted for large models.
- For instance, one user mentioned pricing of $2/$6 on Large 2, which is favorable compared to other models.
- Concerns over OpenRouter accessibility and errors: Several users reported ongoing issues accessing OpenRouter services, particularly faced with error messages such as 429 and Data error output.
- Assistance was suggested through creating threads to report errors with detailed examples for clearer troubleshooting.
- Rate limits affecting user experience: Users expressed frustrations with being rate-limited to the point of being unable to access models, impacting productivity significantly.
- One user mentioned being max rate-limited for 35 hours, prompting discussion about alternatives such as BYOK (Bring Your Own Key) to bypass limits.
- Usage of fallback models during errors: Members discussed the challenges of implementing fallback models when encountering 429 errors, expressing uncertainty regarding their effectiveness.
- It was noted that
4xxerrors represent unrecoverable issues, necessitating manual intervention rather than automatic fallback.
- It was noted that
- Calculation of LLM queries for large user bases: A user inquired about offering free LLM access to around 5000 individuals within a budget of $10-$15 per month, leading to discussions on token allocation.
- Insights were provided on effective usage rates, estimating around 9k tokens per user per day based on a monthly budget.
Links mentioned:
OpenRouter (Alex Atallah) ▷ #beta-feedback (21 messages🔥):
Fallback Model BehaviorAPI Key ManagementRate Limiting with Gemini FlashUser Implementation of Fallbacks
- Fallback Models Priority Needs Clarity: Members discussed the sequence of using a fallback model versus a fallback key when encountering rate limit issues, especially with Gemini Flash Exp.
- One user observed 429 errors, questioning why their specified fallback model was not being utilized in certain scenarios.
- Double Chat Confusion: A member clarified confusion surrounding double chat, ensuring they would streamline discussions in the same thread to avoid clutter.
- Another member reassured that there were no worries regarding overlapping discussions.
- User Workaround for Fallbacks: One member mentioned they manually implemented their own fallback solution, resolving their immediate issues with fallback models.
- They emphasized this approach could be worth considering for others facing similar challenges.
- Concerns About Abuse from Models: Discussion highlighted concerns that allowing fallback to paid models could lead to abuse where users exploit free access.
- Members agreed on the necessity of restrictions to prevent excessive access to paid features under free account conditions.
- General Frustration with Fallbacks: Users expressed their annoyance regarding the rigid fallback policies, particularly in relation to the Gemini models.
- While they understand the reasons behind these policies, they found them to be impractical and cumbersome in practice.
aider (Paul Gauthier) ▷ #general (109 messages🔥🔥):
Aider PerformanceUsing OpenAI ModelsO1 Mini FeedbackDeepSeek Model TestingOpenAI API Costs
- Aider experiences unexpected behavior: Users reported that Aider behaved erratically, with one user describing an issue where the AI continued with its own agenda for an extended period after a simple request.
- After restarting the application, they noted that the issue resolved, suggesting it was related to the context retained during that session.
- Feedback on OpenAI models: Several users expressed disappointment with the performance of the O1 models, mentioning limitations such as refusal to follow formatting instructions, which hampers effectiveness in workflows.
- Users discussed experimenting with other models and mentioned successes with 3.5 Sonnet, emphasizing the need for more control over parameters like system prompts.
- DeepSeek model use and limitations: Discussions highlighted challenges with the DeepSeek model, particularly its performance in editing and refactoring, and the need for specific formats to improve results.
- A user offered insights on tuning DeepSeek with new edit formats, seeking examples of source/prompt pairs that yield poor outcomes for comparison.
- Financial considerations for OpenAI API usage: Users shared insights into their costs associated with OpenAI API usage, noting a company-paid API key authorization and expressing curiosity about typical monthly spending.
- One user indicated spending around $200-$300 monthly, with the company covering 70% of costs, which sparked a conversation about budgeting for API expenses.
- Experimentation and automation in coding: Conversations revealed users exploring automation methods for programming tasks, with varying strategies being shared for optimizing code writing using AI tools.
- A user described creating structured plans for coding tasks with Aider to improve workflow, suggesting potential benefits from breaking down tasks into manageable steps.
Links mentioned:
aider (Paul Gauthier) ▷ #questions-and-tips (17 messages🔥):
Marblism toolAider functionality enhancementsRAG system integrationMarkdown vs XML discussionUser engagement with Aider
- Marblism offers user story-based approach: Members discussed Marblism which resembles Aider in app creation and incorporates user stories for each page setup, enhancing the development process.
- Aider could benefit from adopting a similar framework to improve feature generation based on user feedback.
- Aider's web scraping behavior needs clarity: Concerns were raised about using the
/webcommand compared to/add, as the former immediately launches a completion after scraping URLs without user input.- Suggestions were made to improve user experience by possibly having a web equivalent of
/addto allow more control.
- Suggestions were made to improve user experience by possibly having a web equivalent of
- RAG system integration curiosity: A user inquired whether it's feasible to integrate a RAG system with Aider to enhance its capabilities.
- The community is interested in exploring new integrations to improve the functionality of Aider.
- Markdown vs XML for beginners: Discussion noted that some users find Markdown challenging, suggesting alternatives like XML for formatting their prompts.
- Community members expressed the importance of clear instructions and easy formats for those new to using Aider.
- User engagement and productivity boosts: A user shared their new prompt to enhance productivity when using Aider, which involves ensuring all necessary files are available.
- Feedback highlighted the supportive nature of the community, with members sharing tips and strategies to aid each other.
Link mentioned: Images & web pages: Add images and web pages to the aider coding chat.
aider (Paul Gauthier) ▷ #links (9 messages🔥):
Claude 3.5 Sonnet system promptRethinkMCTSJavaScript trademark concernsFine-tuning GPT-4oFlutterFlow 5.0
- Claude 3.5 system prompt revealed: An extracted system prompt for Claude 3.5 Sonnet focused on artifacts was shared.
- The prompt aims to enhance performance but left users curious about its application.
- RethinkMCTS tackles code generation challenges: The paper titled RethinkMCTS discusses tree search algorithms enhancing LLM agents' performance in code generation, addressing low search quality issues.
- It introduces a thought-level search approach, which significantly expands strategy exploration.
- JavaScript trademark abandonment debate: A post on javascript.tm calls out Oracle for reportedly abandoning the JavaScript trademark, leading to public confusion.
- The discussion emphasizes that JavaScript has become a general-purpose term and should be in the public domain.
- User-friendly fine-tuning for GPT-4o: @AlexTobiasDev announced a fine-tuner for GPT-4o, allowing non-tech users to create JSONL datasets for fine-tuning with ease, linked here.
- This tool has reportedly resolved common bugs while streamlining the fine-tuning process.
- FlutterFlow 5.0 launches with new features: A YouTube video showcased FlutterFlow 5.0, introducing game-changing features to enhance app development.
- This release promises significant improvements in building flexible components.
Links mentioned:
Perplexity AI ▷ #general (120 messages🔥🔥):
Perplexity Pro Model IntegrationO1 and Reasoning FocusPerplexity API vs ChatGPTChallenges with Perplexity FeaturesUser Experience with Extensions
- Integrating Perplexity Pro model with VSCode: Users discussed how to utilize the Perplexity Pro model alongside VSCode extensions like 'Continue' for effective autocomplete functionality.
- One user mentioned integration challenges due to minimal coding skills and the distinction between Pro Search and pure writing mode.
- O1 model availability and usage: Users confirmed that the O1-mini is accessible through the Reasoning focus in Pro Search, but its integration varies based on model selection and settings.
- Some users prefer using O1 for role play scenarios due to its ability to maintain character, while others highlighted the necessity for higher usage limits.
- Comparison of Perplexity and ChatGPT: A debate arose over whether the models in the Perplexity API are superior to those available without a Pro subscription, especially in educational contexts.
- One user noted the availability of ChatGPT Plus, emphasizing it might provide more functionality for students, but acknowledged the benefits of Perplexity Pro subscriptions.
- Issues with Perplexity Features: A user raised concerns about the thread search function, mentioning that searches do not seem to return expected results consistently.
- This ongoing issue has been frustrating for users, as they expect comprehensive results from their search queries.
- User feedback on extensions: The Complexity extension for Firefox was praised for enhancing the Perplexity experience, allowing for improved model and collection selection.
- Several users expressed a desire for similar extensions on iOS/Safari, while acknowledging that the open-source nature of the extension may allow for future adaptations.
Links mentioned:
Perplexity AI ▷ #sharing (7 messages):
Slack AI AgentsLucid Electric SUVBitcoin PuzzleWindows Registry TipsMotorola Smartphones
- Slack Debuts AI Agents: Perplexity AI reported that Slack has introduced new AI agents, enhancing collaboration features in their platform.
- This move aims to streamline workflows and improve communication efficiency for users.
- Lucid Launches Affordable Electric SUV: The discussion highlighted Lucid's release of a more affordable electric SUV, expanding their market presence.
- This model is expected to attract a broader customer base looking for sustainable transportation options.
- Bitcoin's 66-bit Puzzle Solved: The community celebrated as the 66-bit puzzle related to Bitcoin was successfully solved, showcasing advancements in computational challenges.
- This event further emphasizes the ongoing evolution of cryptocurrency technologies and their cryptographic foundations.
- Windows Registry Tips Shared: A member shared resources on how to add and create Windows registry entries, useful for system optimization.
- This guide helps users manage their system settings more effectively and safely.
- Motorola Smartphones Insight: A discussion thread evaluated various Motorola Moto smartphones, particularly focusing on their thin design and performance capabilities.
- This evaluation is part of ongoing conversations about smartphone innovations and user preferences.
Link mentioned: YouTube: no description found
Perplexity AI ▷ #pplx-api (3 messages):
Perplexity API consistencyNew API features timeline
- Strategies for Enhanced API Accuracy: A member shared their approach to improve consistency and accuracy of the Perplexity API by using query expansion and variations for vague topics before summarizing results with GPT.
- This method improved consistency, but they noted it isn't perfect due to rate limits.
- Waiting on New API Features: Another member inquired about the timeline for new API features, expressing eagerness to start showcasing images.
- They realized they hadn't sent in an email regarding their application, which likely delayed their response.
HuggingFace ▷ #announcements (1 messages):
Hugging Face API DocsTRL v0.10 ReleasePySpark for HF DatasetsSentence Transformers v3.1DataCraft Introduction
- Revamped Hugging Face API Documentation Launched: The new API docs have been launched with improved features like clearer rate limits, a dedicated PRO section, and more detailed code examples.
- Deploying AI made simple, and the feedback from users has been implemented to enhance usability.
- TRL v0.10 Unleashes Vision-Language Models: TRL v0.10 has been released, adding fine-tuning capabilities for vision-language models in just two lines of code, coinciding with Mistral's release of Pixtral.
- This timely update highlights the growing integration of multimodal capabilities in AI projects.
- PySpark Optimizes HF Datasets Access: A new code snippet for ✨PySpark✨ allows users to easily read/write from/to HF Datasets, enhancing data handling capabilities.
- It provides an optimized distributed solution, making it simpler for users to interact with datasets.
- Sentence Transformers v3.1 Enhances Model Training: The latest release, Sentence Transformers v3.1, includes a hard negatives mining utility and a new strong loss function for better model performance.
- It also supports training with streaming datasets, along with custom modules and various bug fixes.
- DataCraft Revolutionizes Synthetic Dataset Creation: DataCraft has been introduced to build synthetic datasets using natural language, simplifying the dataset generation process.
- This no-code UI tool incorporates best practices for creating high-quality synthetic data, streamlining a typically complex endeavor.
Links mentioned:
HuggingFace ▷ #general (101 messages🔥🔥):
Hugging Face Conference AttendanceJSON Output in LLMsMoshi Checkpoint ReleaseADIFY AI Playlist GeneratorQwen2.5 Math Demo Release
- Hugging Face Community at PyTorch Conference: A user inquired about Hugging Face community members attending the PyTorch conference in SF, expressing a desire to meet AFK.
- Another user shared a tweet about Hugging Face's preparations for the conference, mentioning swag like socks.
- JSON vs Simpler Output Formats: A discussion emerged on why LLMs are often designed to output JSON instead of simpler parsing formats, with one participant noting that structured output can negatively impact performance.
- The conversation highlighted that while structured output may be less damaging to quality, there's a suggestion for a flow that separates normal text from structured outputs for efficiency.
- Moshi Checkpoint Now Available: A user mentioned the release of the Moshi checkpoint along with its code, describing it as an experimental low latency conversational AI from the Kyutai team.
- The Moshi project is open source, incorporating PyTorch and Rust implementations, and includes voices Moshiko and Moshika.
- ADIFY AI Introduced: A user promoted ADIFY AI, an intelligent Spotify playlist generator that creates custom playlists based on user-defined moods or activities.
- Another participant reminded the user not to engage in self-promotion, leading to a humorous exchange on the topic.
- Qwen2.5 Math Demo Publicized: The community received updates about the Qwen2.5 Math Demo, which features impressive results and is considered an innovative release.
- Users were encouraged to check out the demo's space on Hugging Face, showcasing its incredible capabilities.
Links mentioned:
HuggingFace ▷ #today-im-learning (1 messages):
Lunar Flu FAQSupport Requests
- Questions Welcome in Lunar Flu Channel: Members are encouraged to ask questions regarding Lunar Flu in <#1019883044724822016>.
- Feel free to ask in the channel puts a welcoming vibe for inquiries about anything related!
- Community Engagement Encouraged: The message indicates a strong sense of community and support among members. Lunar Flu topics seem to foster open discussions and shared inquiries.
HuggingFace ▷ #i-made-this (5 messages):
Mini-4B Model ReleaseBiometric Template Protection ImplementationInteractive World & Character Generative AIReasoning and Reflection Theories Dataset
- Nvidia Launches Mini-4B Model: Nvidia released a new small model called Mini-4B, which requires Nvidia drivers, making it not device-compatible. Check it out here as it reportedly performs best among its peers.
- This model has been noted by users for its impressive performance given its size, and is encouraged to be registered as a HuggingFace agent for enhanced functionality.
- Biometric Template Protection for Secure Authentication: A member shared their work on Biometric Template Protection (BTP), aimed at enabling authentication without server data access with an educational implementation on GitHub. This implementation serves as a beginner-friendly introduction to the concept.
- BTP can be complex for newcomers, but this basic model is designed specifically for educational purposes, highlighting its potential utility in secure biometric systems.
- Interactive AI & Anime Platform Beta Test: A group of enthusiasts is developing an Interactive World & Character Generative AI platform for creating themed worlds and characters with immersive interaction possibilities. They are seeking participants for their Beta Testing phase.
- Interested users are invited to get in touch via direct message to explore this creative AI venture further.
- New Reasoning Dataset Derived from GSM8K: One user is creating a dataset centered around Reasoning and Reflection theories based on GSM8K to enhance mathematical problem-solving and reasoning capabilities in models. This new dataset can be found here.
- The focus of the dataset is on logical reasoning and step-by-step processes, aiming to benchmark model performance through improved deductive reasoning tasks.
Links mentioned:
HuggingFace ▷ #computer-vision (5 messages):
Open-source computer vision projectsResearch topic exploration in CV and MLAI video encoding models for live streamingPython implementation for token settings
- Contributing to open-source CV projects: For those looking to contribute, two suggestions were provided: Kornia, a geometric computer vision library for spatial AI, and Roboflow Supervision, which focuses on reusable computer vision tools.
- Both projects invite collaboration and offer a chance to enhance skills in computer vision.
- Struggles in finding research topics in ML: A member expressed difficulties in keeping up with the growing volume of research papers in CV, NLP, and ML.
- They inquired about methods to identify relevant research topics from this vast field.
- Inquiry about AI video encoding models: A member requested names of AI video encoding models specifically suitable for live streaming applications.
- This highlighted a need for information on advanced encoding solutions in the AI community.
- Implementing min_tokens in Python: A user confirmed that they found a certain feature pretty nice and asked about how to implement a 'min_tokens' setting in their Python code.
- This reflects the ongoing interest in customizing functionalities within Python for better performance.
Links mentioned:
HuggingFace ▷ #NLP (4 messages):
Llama3 model uploadMLflow model registration
- Challenges Uploading Llama3 Model: One member expressed difficulty in uploading the Llama3 model locally and specifically needs it in PyTorch format for further usage.
- They mentioned they are working with a tool that converts PyTorch code into MLIR.
- MLflow Throws Warning on Encoder Call: Another member using MLflow experienced a Bert pool warning every time they called the encoder after registering a model, while it worked fine outside of MLflow.
- They are unsure if they missed a hidden step during registration, particularly with embedding models and tokenizers.
HuggingFace ▷ #diffusion-discussions (2 messages):
Image to Cartoon ModelsAI Video Encoding for Live Streaming
- Seeking Image to Cartoon Model: A member is looking for a space model that can convert images into high-quality cartoons.
- If anyone has recommendations or knows of similar models, sharing would be appreciated.
- Request for AI Video Encoding Models: Another member inquires about AI video encoding models suitable for live streaming.
- They are specifically looking for names, hoping to get input from the community.
Nous Research AI ▷ #general (84 messages🔥🔥):
NousCon AttendanceHermes Tool CallingQwen 2.5 ReleaseFine-tuning ModelsAI Community Interaction
- NousCon and Afterparty Plans: Participants expressed excitement about NousCon, with some mentioning being unable to attend or requesting future events in different locations like NYC.
- An afterparty is planned at a nearby bar after the event, encouraging community interaction.
- Updates on Hermes Tool Calling Standard: The tool calling format for Qwen 2.5 has been adopted based on contributions from the community, specifically crediting the vLLM support as influential.
- Discussions revolve around distinguishing tool parsing between Hermes and Qwen for future implementations.
- Qwen 2.5 Model Release Highlights: The Qwen team announced the release of Qwen 2.5, featuring various new models including specialized versions for coding and mathematics, showcasing significant advancements in open-source AI.
- The announcement indicates a large-scale release, marking a milestone in the development of language models in the community.
- Innovation in AI Fine-tuning: Members discussed fine-tuning experiences, including creating models like 'Gemma 2' to enhance gameplay in chess, although the performance exhibited challenges.
- Conversations highlighted the creative processes involved in developing AI models and the community's collaborative spirit.
- General AI and Developer Interaction: The channel witnessed a lively exchange about various projects, with users seeking advice and sharing experiences related to AI tools and development.
- Curiosity about services and technologies, like Lambda Labs and tool usage in Axolotl, showcased a vibrant community eager for knowledge and assistance.
Links mentioned:
Nous Research AI ▷ #ask-about-llms (11 messages🔥):
Hermes 3 API AccessOpen Source LLM Prompt SizeGemma 2 Token TrainingModel Parameter Calculation
- Hermes 3 API Access Confirmed: Users inquired if Hermes 3 has APIs available for access, with a response indicating that it is partnered with Lambda. The new Lambda Chat Completions API is available for use with Hermes 3.
- Handling Large Prompts with Open Source LLMs: Discussion revolved around methods for sending and receiving very large responses using gpt4all. One suggestion highlighted using ollama if the model is set up locally to facilitate local APIs.
- Clarification on Gemma 2 Token Count: A member raised the question regarding whether the 13 trillion tokens mentioned for training Gemma 2 refer to total or seen tokens. This inquiry seeks clarification on the data used in the model's training process.
- Model Parameter Calculation in Training: A technical member detailed the calculation of parameters for models using floating-point precision configurations, explaining specifics about memory allocation. This includes factors like gradients and optimizer states, indicating a significant consideration for model performance.
- Hermes 3 API Query Continuation: Further discussion on whether Hermes 3 is running at
bf16, with suggestions from a member to set up a full resolution API if necessary. This reflects an interest in maximized utilization of the model's capabilities.
Link mentioned: Unveiling Hermes 3: The First Full-Parameter Fine-Tuned Llama 3.1 405B Model is on Lambda’s Cloud: Introducing Hermes 3 in partnership with Nous Research, the first fine-tune of Meta Llama 3.1 405B model. Train, fine-tune or serve Hermes 3 with Lambda
Nous Research AI ▷ #research-papers (5 messages):
Research on chunking phasesReverse engineering o1OpenAI Strawberry speculation
- Exploring research on chunking phases: A member inquired about research papers focusing on chunking phases and approximation techniques, asking for top tier and latest resources.
- No specific papers were offered in response.
- Engaging in reverse engineering: A member expressed interest in discussing reverse engineering o1 and encouraged others to engage in conversation about it.
- They noted that they are currently working through related resources chronologically.
- Speculation around OpenAI's Strawberry: A member questioned the availability of public information regarding Strawberry from OpenAI, wondering if it was merely speculation.
- Another member responded, indicating that there is not a lot of information available on the topic.
Nous Research AI ▷ #research-papers (5 messages):
chunking phases researchOpenAI's strawberry speculation
- Exploring Chunking Phases Research Papers: A member inquired about latest research papers regarding chunking phases and approximation techniques, seeking top tier sources.
- Another member, @bradhilton, praised a resource they were working through in a roughly chronological order, inviting further discussions.
- Speculation on OpenAI's Strawberry: A member questioned whether there was any public information released about strawberry from OpenAI, or if the details were merely speculative.
- Another member, teknium, responded that there has been not a lot of information available on this topic.
CUDA MODE ▷ #triton (6 messages):
Triton Conference KeynoteTriton CPU / ARM StatusCUDA Community Engagement
- Mark Saroufim Shoutout at Triton Keynote: @marksaroufim highlighted the community during the Triton conference keynote, thanking members for their contributions.
- The excitement was palpable as users noted this momentous recognition and shared their enthusiasm.
- Triton CPU / ARM is Open-Source!: @tailoredcub inquired about the status of Triton CPU / ARM, and @ptillet confirmed that it's open-source, providing a link to the GitHub repository.
- This openness encourages community contributions and collaboration on the experimental CPU backend.
- CUDA Server Praised as the Best: Members expressed love for the CUDA community, with @kashimoo declaring that the server is definitely the best for CUDA enthusiasts.
- This sentiment was echoed by others, reinforcing the strong sense of community within the server.
Link mentioned: GitHub - triton-lang/triton-cpu: An experimental CPU backend for Triton: An experimental CPU backend for Triton. Contribute to triton-lang/triton-cpu development by creating an account on GitHub.
CUDA MODE ▷ #torch (1 messages):
kashimoo: is there a video or smth for navigating across chrome tracing with the pytorch profiler
CUDA MODE ▷ #algorithms (2 messages):
TritonFine-grained control
- Comparison Between Triton and New Framework: A member noted the new framework looks quite similar to Triton but offers more fine-grained control.
- Another member expressed intrigue, responding with a thoughtful emoji.
- Discussion on Fine-grained Capabilities: The conversation sparked curiosity about the fine-grained control aspects, hinting at potential advantages over Triton.
- Members seemed interested in exploring how these capabilities could impact their workflows.
CUDA MODE ▷ #jax (1 messages):
betonitcso: What do you use if you want a very high throughput dataloader? Is using Grain common?
CUDA MODE ▷ #torchao (9 messages🔥):
torch.compile() performanceNVIDIA NeMo model timingsLlama benchmarksTorchInductor performance dashboard
- torch.compile() recommended over eager mode: A speaker at the PyTorch conference emphasized using torch.compile() instead of eager mode to fuse scaling operations and minimize kernel launch overhead.
- This recommendation triggered curiosity about the compile time on various representative models.
- Compile time can vary significantly: Initial runs of torch.compile() involve extensive auto tuning that can take several minutes, especially for large models like those in NVIDIA NeMo.
- However, subsequent runs are typically much faster due to reduced overhead.
- Llama benchmark compile time is under one minute: For their Llama benchmarks, one user noted that compile time is generally under 1 minute for generation tasks.
- This suggests that compile times can be optimized after the initial tuning phase.
- Performance metrics available on dashboard: There's a performance dashboard for torch.compile() that provides numbers on compile overhead.
- A user shared a link to the TorchInductor Performance Dashboard for more detailed metrics.
Link mentioned: no title found: no description found
CUDA MODE ▷ #irl-meetup (1 messages):
nahidai: Is there any GPU programming reading/work group based on SF? Would love to join
CUDA MODE ▷ #llmdotc (41 messages🔥):
RMSNorm kernel issuesTraining Llama3 with FP32Introduction to Torch TitanFP8 stability and multi-GPU setupMeeting up to discuss Llama3.1 hacks
- RMSNorm Kernel Refinements: A member highlighted modifications from layernorm to rmsnorm and requested reviews on a GitHub Pull Request.
- Discrepancies between Python and C/CUDA were observed, but it turned out to be a bug with data types rather than kernel issues.
- Training Llama3 with FP32: The conversation switched to training configurations, with commands shared for the llmc and pytorch sides to ensure the correct precision during training.
- Confusion arose as one member confirmed pushing the latest code to the llama3 branch.
- Exploring Torch Titan for Model Training: A member introduced Torch Titan, describing it as a simple training script boilerplate similar to nanoGPT.
- The consensus was that it represents a competitive option for research requiring extensive GPU resources, though it may not match the efficiency of Megatron or Deepspeed.
- FP8 Stability and Multi-GPU Setup: Discussions around FP8 support revealed that it is a priority for upcoming developments, with plans to test stability on an 8xH100 setup.
- One member humorously noted their adjusted sleep schedule to avoid jet lag while preparing for real-world meetings.
- Llama 3.1 Optimization Ideas: A suggestion was made to add a llm.c Llama 3.1 405B optimized on GH200 project to the agenda, inspired by a call for members to prioritize useful projects.
- This reflected a strategic shift towards focusing efforts on impactful developments, even amid ongoing discussions about contributions.
Links mentioned:
CUDA MODE ▷ #bitnet (24 messages🔥):
Ternary LUT ImplementationQuantization TechniquesPerformance of Llama-2 ModelKernel Performance in BitNetTraining with int4 Tensor Cores
- Ternary LUT Implementation Discussion: In a message, a member outlined a Python code snippet for creating a ternary LUT and highlighted the challenge of packing 5 elements into 1, suggesting padding might be needed.
- Another participant contributed that a clearer method could involve shifting values instead of directly using modulo for better performance.
- Quantization Techniques for Models: Members discussed the quantization of Large Language Models, stressing the importance of minimizing computational costs available through techniques like 4-bit quantization, specifically in relation to BitNet's architecture.
- A member referenced a model implementation that applies quantization without grouping, proposing its effectiveness for inference.
- Evaluating Llama-2 Model Performance: Details were shared regarding the performance metrics of the Llama2-7B-chat model with statistics comparing it against its FP16 counterpart across various tasks.
- There was a consensus on the need to optimize quantization methods while maintaining quality during inference using techniques like low-rank adapters.
- Kernel Performance and Constraints in BitNet: A participant raised questions about a check in the matrix multiplication implementation requiring packed weight matrices, indicating confusion over its application in kernel level operations.
- The discussion clarified that the kernel conforms to specific dimension constraints for optimal performance, related to packing mechanisms that utilize lower-bit formats.
- Training with int4 Tensor Cores: The potential of training models with int4 tensor cores was explored, with discussions centered around how grouping affects this process and the relevance of findings from related papers.
- Participants indicated that there may be valuable insights from using int4 training, which could challenge existing methodologies.
Links mentioned:
CUDA MODE ▷ #cudamode-irl (14 messages🔥):
PyTorch Conference AttendanceRSVP Email StatusProject Proposals for HackathonMentorship in CUDAIRL Hackathon Acceptance
- PyTorch Conference Attendance: Members confirmed their attendance at the PyTorch conference in San Francisco, with someone inviting others to connect via their name tag.
- One member showcased his hack idea for WebGPU backend for llm.c during the conference.
- Ongoing RSVP Email Rollout: Concerns were raised about RSVP emails as not all team members have received them, prompting clarification on the rolling acceptance process.
- It's indicated that confirmation emails are sent after drop-offs due to limited seating, potentially leading up to the day before the event.
- Mentorship in CUDA Hackathon: A member expressed excitement about mentoring in the LLM inference group and provided project suggestions for the hackathon.
- They proposed building a Python-only alternative to
torch.amp.autocastand implementing jax.numpy.nonzero in PyTorch, emphasizing ease of start for newcomers.
- They proposed building a Python-only alternative to
- Clarification on Team Definitions for Hackathon: Discussions emphasized that the definition of 'teammate' matters for the hackathon participation, particularly regarding project proposals.
- Acceptances are contingent upon whether both members have submitted a reasonable project proposal for the hackathon.
- Interest in IRL Hackathon Participation: Inquiries were made about the acceptance of new participants for the upcoming hackathon, with several members sharing their team name details.
- This highlights the importance of ensuring team member confirmations for successful participation and project proposals.
Links mentioned:
CUDA MODE ▷ #liger-kernel (3 messages):
Nondeterministic MethodsPixtral SupportUpcoming Release
- Nondeterministic Issues in Tutorial: A member noted that the nondeterministic behavior could be due to the atomic exchange method used in a tutorial, suggesting that a different aggregation approach was employed.
- This new method does not rely on atomic operations, thereby potentially mitigating the issues observed.
- Pixtral Support PR Opened: There's an ongoing effort to add Pixtral support via a Pull Request #253 that indicates successful testing with a 4090 hardware setup.
- The author confirmed running both
make testfor functionality andmake checkstylefor code style adherence.
- The author confirmed running both
- Anticipating New Model Release: Members discussed the pending release of the Pixtral model on the Transformers library, expressing excitement about its implementation.
- Once the new version is released, it is expected to integrate seamlessly with existing frameworks.
Link mentioned: [Model] Pixtral Support by AndreSlavescu · Pull Request #253 · linkedin/Liger-Kernel: Summary This PR aims to support pixtral Testing Done tested model + tested monkey patch Hardware Type: 4090 run make test to ensure correctness run make checkstyle to ensure code style run ...
CUDA MODE ▷ #metal (1 messages):
.mattrix96: Just started with puzzles now!
Eleuther ▷ #general (11 messages🔥):
Open-Source TTS ModelsModel DebuggingImage Style Changes
- Exploring Open-Source TTS Models: A member expressed the need to migrate from OpenAI TTS to open-source models and was directed to Fish Speech V1.4, a top contender supporting multiple languages.
- They received a recommendation to also consider xttsv2 and mentioned that it’s acceptable to use different models for better performance in specific languages.
- Insights on TTS Model Performance: Discussion regarding the Fish Speech V1.4 model highlighted its training on 700k hours of audio data across various languages, including English and Chinese.
- Another member clarified that they can disregard some models, as they are only proficient in English, leaving Fish Speech and xtts as solid options.
- Debunking Style Changes in Images: A member inquired whether a model can perform style changes on existing photos, eliciting a response indicating interest in such capabilities.
- Although no specific model was mentioned for this image modification, the conversation opened potential avenues for exploring image processing features.
- Debugging Tactics for Model Issues: A suggestion was made for debugging models by starting with a working baseline and incrementally testing components until issues are identified.
- The member was encouraged to explore various configurations, including FSDP and mixed precision, to optimize performance and pinpoint problems.
Links mentioned:
Eleuther ▷ #research (41 messages🔥):
Compression Techniques for MLRADiagram of Thought (DoT)Low-Precision Training ExperimentsPlayground v3 Model ReleaseEvaluation Methods for LLM Outputs
- Compression of MLRA Keys with Extra Matrix: Members discussed the potential for compressing MLRA keys and values using an additional compression matrix post-projection.
- Questions arose about the lack of details in the MLRA experimental setup, including specifics on rank matrices.
- Introducing Diagram of Thought Framework: A framework called Diagram of Thought (DoT) was introduced, which models iterative reasoning in LLMs using a directed acyclic graph (DAG) structure, allowing for complex reasoning pathways.
- This approach aims to improve logical consistency and reasoning capabilities over traditional linear methods.
- Investigation into Low-Precision Training: Experiments using very-low-precision training showed that ternary weights require 2.1x more parameters to match full precision performance, while septernary weights show improved performance per parameter.
- Members pondered the availability of studies on performance vs. bit-width figures during training quantization.
- Playground v3 Model Achieves SoTA Performance: Playground v3 (PGv3) was released, demonstrating state-of-the-art performance in text-to-image generation and introducing a new benchmark for evaluating detailed image captioning.
- It fully integrates LLMs, diverging from traditional models that rely on pre-trained language encoders.
- Challenges in Evaluating LLM Outputs: There was a discussion on developing systematic evaluation methods for LLM outputs, proposing the use of perplexity on human-generated responses as a potential metric.
- Participants highlighted that numerous existing papers cover similar challenges, emphasizing the importance of not overly narrowing evaluation criteria.
Links mentioned:
Eleuther ▷ #scaling-laws (3 messages):
Training Compute-Optimal Large Language ModelsPythia Scaling CurvesBig Bench Tasks
- Exploring Training Compute for LLMs: A conversation sparked around the paper Training Compute-Optimal Large Language Models by Hoffman et al, indicating interest in model efficiency and training paradigms.
- Members were encouraged to share insights or examples related to compute optimization in the context of large language models.
- Query on Pythia Scaling Curves: One member sought information on whether there are scaling curves for Pythia pertaining to every Big Bench task.
- They expressed particular curiosity about identifying any possible discontinuities that might emerge below the 1B size.
Eleuther ▷ #interpretability-general (9 messages🔥):
Fourier Transforms of Hidden StatesPythia CheckpointsPower Law Behavior in ModelsAttention Residual Analysis
- Fourier Transforms reveal hidden states behavior: An exploration was discussed regarding the Fourier transforms of hidden states in a pretrained OPT-125m, showing power law distribution develop over training.
- Initial findings suggest that freshly initialized models display different spectral properties, raising questions about the architecture and initialization regimes.
- Pythia Recommended for Further Exploration: A member suggested utilizing the Pythia suite to investigate how the observed phenomena vary across scales and during training.
- This approach is expected to clarify whether the behaviors are induced by specific models or are inherent to the training process.
- Power Law Emergence Needs Explanation: It was proposed that the power law behavior observed in hidden states might be due to either an efficient representation developed during training or a bias introduced via the training process.
- Notably, attention residuals being close to a power law at initialization implies these spectral properties could be present right from the start.
- Attention and MLP Residuals in Pretrained Model: The conversation included visualizations showing attention residuals for different layers of a pretrained model, with a clear emphasis on the spiking behavior of attention and MLP residuals.
- Such analysis reinforces the overall investigation into how layers manage information differently across training epochs.
- Clarifications on Model Behavior Observations: Clarifications were made regarding the distinction between the plots for pretrained versus freshly initialized models, indicating that power law behavior is not present initially.
- This highlights the need for further analysis across different training stages to understand the underlying mechanisms at work.
Link mentioned: interpreting GPT: the logit lens — LessWrong: This post relates an observation I've made in my work with GPT-2, which I have not seen made elsewhere. …
Eleuther ▷ #lm-thunderdome (8 messages🔥):
kv-cache issue workaroundChain of Thought prompting with lm eval harnessPending PRs for new benchmarksComments on PR improvements
- Setting sample size may resolve kv-cache issues: A member suggested that if the issue is related to kv-cache, then setting the sample size might be an effective solution.
- For multiple-choice tasks, a simple forward pass is all that's needed to obtain the logits.
- Exploring Chain of Thought using lm eval harness: A member inquired about experiences with Chain of Thought prompting using the lm eval harness, specifically about appending answers to follow-up prompts.
- It's unclear if other members have implemented this approach, but the discussion continues.
- Awaiting updates on new benchmark PRs: A member expressed concern about five new benchmark PRs that have been pending for almost two months, with only one approved so far.
- They asked for an ETA on these PRs and the next release to incorporate approved changes.
- Feedback on PRs to enhance task entries: Feedback was provided on improving recently submitted PRs, particularly regarding the
groupAPI and task differentiation for benchmarks.- Suggestions included adding identifiers for machine translations and enhancing documentation in
m_eval/tasks/README.mdfor better discovery.
- Suggestions included adding identifiers for machine translations and enhancing documentation in
- Acknowledgement of PR Pending Review: A member reassured another that they would review the outstanding PRs soon, acknowledging the delay.
- The original member expressed understanding and anticipation of the feedback.
Link mentioned: lm-evaluation-harness/docs/new_task_guide.md at main · EleutherAI/lm-evaluation-harness: A framework for few-shot evaluation of language models. - EleutherAI/lm-evaluation-harness
Eleuther ▷ #gpt-neox-dev (2 messages):
Model OutputsFrontier Setup Progress
- Excitement for Model Outputs: A member expressed happiness regarding someone getting their setup working and encouraged them to share their models or outputs with the community.
- The community is eager to hear about the great things people are accomplishing using the provided libraries.
- Almost Done with Frontier Setup: A member shared that they are working on a 1-script setup for Frontier, nearing completion and focusing on building the fused kernels in HIP.
- They aim to share their progress once the setup is finalized, signaling collaboration within the community.
OpenAI ▷ #ai-discussions (44 messages🔥):
Custom GPT Use CasesAdvanced Voice Mode UpdateConcerns Over AI SaturationPDF Formatting Issues for LLMsAI Content Quality Debate
- Custom GPTs can memorize snippets: Members shared experiences using Custom GPTs to import and memorize personal snippets, such as Mac Snippets. However, there were concerns about poor results when too much information was dumped into the instructions.
- One user suggested that a cleaner format with clear instructions can improve performance and that uploading knowledge bases is better than just instructions.
- Upcoming Advanced Voice Mode feature: A leak indicates that the new Advanced Voice Mode will be available for Plus users starting September 24, promising improved clarity and response times. This feature is expected to filter background noise and recognize complex commands for smoother interactions.
- Members expressed curiosity about its real-world impact and raised discussions on transforming everyday usage of voice commands.
- Debate over AI content saturation: Discussion erupted over whether the prevalence of AI-generated content is beneficial or harmful, with suggestions that AI merely reflects the low-quality content that already existed. Some argued that talented creators will still produce quality content regardless of the tools available.
- A user expressed concerns that escalating AI capabilities might lead to disassociation from reality, which could be dangerous in the long run.
- Issues with PDF formats for LLMs: Users discussed the challenges of uploading PDFs to Custom GPTs, highlighting that PDFs can pose formatting issues for LLMs. It was advised to convert documents properly or use file types more suited for AI reading.
- One member recalled a positive experience with a well-formatted PDF, prompting other users to reconsider the potential for PDF uploads if done correctly.
- Opinions on ChatGPT Plus subscription: Members debated the value of the ChatGPT Plus subscription, with some expressing satisfaction while others questioned its worth. This conversation illustrated the varying perceptions and experiences users have with paid AI services.
Link mentioned: Reddit - Dive into anything: no description found
OpenAI ▷ #gpt-4-discussions (12 messages🔥):
Sharing customized GPTsAutomated task requirementsTruth-seeking with GPTReporting cross postingAdvanced voice mode capabilities
- Guidance on Sharing Customized GPTs: A member sought help on sharing their customized GPTs without revealing their full billing name, which was greyed out in settings.
- Another member clarified that to publish in the GPT Store, you must use your billing name or a verified domain, while direct link sharing allows anonymity.
- Exploring GPT as a Truth-Seeking Mentor: One member shared that they have found peace by using their custom GPT as a wise mentor, likening its responses to the wisdom of the Buddha.
- They expressed excitement over the upcoming voice mode that would allow them to interact more personally with their GPT.
- Concern about Cross Posting: Members discussed the issue of cross posting messages across multiple channels, with one questioning how to report it.
- They were directed to report such instances under the spam category, as repeated posts disrupt the server environment.
- Desire for Automated Tasks with ChatGPT: A user expressed boredom and a need for ChatGPT to perform automated tasks as they already had access to advanced voice mode for a month.
- They mentioned feeling the need to utilize these capabilities to maintain engagement and productivity.
OpenAI ▷ #prompt-engineering (7 messages):
Solicitation RulesGPT Store Creations
- Clarification on Solicitation: Darthgustav prompted members to remember Rule 7, prohibiting self-promotion and solicitation, particularly regarding non-OpenAI services.
- They noted exceptions exist for API and Custom GPTs channels, emphasizing compliance with the rules.
- Language Barriers in Communication: Lucasgln0 humorously acknowledged their broken English, clarifying they have created several GPTs available on the GPT Store that automate processes based on different sources.
- Their GPTs focus on specific prompting methods, such as those from books on using DALL·E effectively.
- Further Discussion on GPT Store: Lucasgln0 reassured that their creations comply with the GPT Store's acceptance guidelines, emphasizing a strict no advertising policy.
- In response, Darthgustav indicated that linking their creations is acceptable in the channel.
OpenAI ▷ #api-discussions (7 messages):
GPT Store productsSelf-promotion rulesLanguage barriers in discussions
- Clarification on Self-Promotion Rules: Members discussed the server's rule against self-promotion, noting that solicitation is generally not allowed, except in specific channels like API & Custom GPTs.
- Darthgustav specifically asked if the inquiries made by another member constituted solicitation.
- Introduction of GPTs in GPT Store: A member shared that they have created several GPTs available in the GPT Store, each designed to automate processes based on different sources.
- For example, one GPT focuses solely on prompting methods for DALL·E derived from a specific paper.
- Addressing Language Barriers: One member acknowledged their broken English while discussing their GPT creations, indicating a willingness to clarify further.
- Darthgustav offered reassurance during the conversation, maintaining a supportive tone.
- Encouragement to Share Links: There was a suggestion for the member to share their GPT links, supporting the idea of linking their creations in the channel.
- The conversation emphasized the community's openness to sharing information about GPTs while adhering to the rules.
Cohere ▷ #discussions (56 messages🔥🔥):
Cohere Job ApplicationCoT-ReflectionsO1 and Reward ModelsCost of Experimenting with LLMsOpenAI's CoT Training
- Cohere Job Application Process Discussed: A member recently applied for a position at Cohere and expressed excitement to connect with the community.
- Welcome messages followed, showcasing the community's support for newcomers.
- Exploring CoT-Reflections: Discussion arose around how CoT-reflections differs from plain chain of thought prompting, focusing on improving response quality.
- One member mentioned that using CoT-reflections combined with BoN could yield higher quality outputs.
- Understanding O1's Reward Model: Members speculated that O1 employs a reward model that uses a similar prompt structure, calling itself until satisfactory results are achieved.
- There's a suggestion that O1 undertook a multi-phase training process to improve its output quality significantly.
- Cost-Efficiency in Local Experiments: The cost of running local experiments with LLMs was discussed, with one member noting that it's cheaper than hiring a new employee.
- Members shared that using methods like CoT with reflection is fast to verify, making it an appealing approach.
- Training Strategies Behind OpenAI's CoTs: Conversation centered on whether O1 was trained as a CoT or as an agent, with links provided to OpenAI's training examples.
- Several members agreed that overfitting might have occurred in O1's problem domain, affecting its performance.
Links mentioned:
Cohere ▷ #questions (6 messages):
Billing Information SetupVAT ConcernsSupport Contact
- Setting Up Billing Information Confusion: A user inquired about setting up billing information, specifically regarding the addition of VAT details after being able to set up a payment card.
- They asked if there was a Stripe link or similar to edit those details.
- Assistance with Account Billing: A member acknowledged the user's concern and suggested they email [email protected] with their VAT information to ensure secure handling.
- This allows for any necessary changes to the account's billing details to be made safely.
- Acknowledgment of Support Suggestion: The user confirmed they would follow the suggestion to email support regarding their billing information.
- They expressed appreciation with an 'Awesome thanks!' after receiving assistance.
LM Studio ▷ #general (49 messages🔥):
Markov ModelsTraining Time for ModelPyTorch FrameworkLM Studio UpdatesAI Model Recommendations
- Markov Models discussed: A member mentioned that Markov models are much less parameter intensive probabilistic models of language compared to others.
- Discussion around their potential usage sparked interest among members in the channel.
- Training Time Concerns: A member indicated that training their model on 40M tokens would take about 5 days using a 4090 GPU, but after adjusting the token count to 40k, it would only take 1.3 hours.
- Another member pointed out that this training time still seemed excessive for a 100k model.
- Data Loader Bottlenecks: There were concerns expressed about potential data loader bottlenecks causing delays during model training, with one member reporting being 'stuck waiting' for objects.
- This raised questions about optimizing the data pipeline for better performance.
- LM Studio's New Features: A member announced their return to LM Studio and expressed excitement over the integration of document handling, aligning with their prior feedback.
- Others chimed in to discuss size limitations for data tables and whether databases could be analyzed with LM Studio.
- AI Model Recommendations: Members provided recommendations regarding AI models for coding, specifically pointing to the Llama 3.1 405B model in context of Prolog assistance.
- Discussions included insights on fast and coherent small model alternatives like qwen 2.5 0.5b but noted its lack of lowercase writing.
Links mentioned:
LM Studio ▷ #hardware-discussion (12 messages🔥):
Intel Arc multi-GPU setupIPEX performance in LLMNVIDIA 5000 series rumorsGPU pricing
- Intel Arc A770 is a viable multi-GPU option: A member suggested using the Intel Arc A770 multi-GPU setup for LLM machines due to its effectiveness.
- Another member highlighted that it works well particularly in the IPEX SYCL backend of Llama.
- On IPEX Performance: It was noted that the IPEX backend achieves 2X to 3X faster performance compared to Vulkan at 34 tokens per second.
- However, there was clarification that the speed is slightly better in Llama backend with GGUF models compared to Vulkan.
- Rumors on NVIDIA's 5000 series cards: There were discussions about the rumored 5000 series NVIDIA consumer cards, with mixed sentiments on their validity.
- Speculation included mention of 32GB DDR7 memory for the supposed 5090 model, with some skepticism regarding pricing.
- NVIDIA GPU Pricing Concerns: A member shared current pricing for the 4070 Ti at $1400 and 4060 Ti at $750, considering it a steep premium.
- Another expressed hope for price reductions in the next three months.
Latent Space ▷ #ai-general-chat (47 messages🔥):
Langchain Partner PackagesMistral Free Tier ReleaseQwen 2.5 Full ReleaseMoshi Kyutai Model ReleaseInvestment in Mercor
- Langchain Partner Packages Inquiry: A discussion emerged about updating an old Langchain community integration to a partner package, prompting inquiries about the right contacts within Langchain.
- Suggestions included utilizing joint communication channels and contacting someone named Lance Martin for assistance.
- Mistral Introduces Free Tier: Mistral announced a free tier on their serverless platform, allowing developers to experiment without cost and offering an improved Mistral Small model.
- This launch also included a pricing update for the family of models and added free vision capabilities on their chat interface.
- Qwen 2.5 Full Release: Alibaba released the Qwen 2.5 foundation models, highlighting multiple sizes and enhancements, including competitive performance against previous models.
- The new models aim to improve functionalities in coding, math reasoning, and general language processing, with a total of over 100 model variants available.
- Moshi Kyutai Model Released: Kyutai Labs released several artifacts for the Moshi model, including a technical report and weights, accompanied by streaming inference code.
- They shared links to their paper, GitHub repository, and Hugging Face page for further exploration of the new technology.
- Mercor Secures New Funding: Mercor raised a $30M Series A investment at a $250M valuation, aimed at improving global labor matching through advanced models.
- This round included notable investors such as Peter Thiel and Jack Dorsey, highlighting the project's significance in understanding human abilities.
Links mentioned:
Torchtune ▷ #announcements (1 messages):
Torchtune 0.3 ReleaseFSDP2 IntegrationTraining-Time SpeedupsDoRA/QDoRA SupportMemory Optimization Techniques
- Torchtune 0.3 brings a host of new features: Torchtune 0.3 introduces numerous new features, including full recipes on FSDP2 for enhanced flexibility and speed.
- This release aims to accelerate training and streamline model handling across various tasks with cutting-edge enhancements.
- FSDP2 improves distributed training: All distributed recipes are now utilizing FSDP2, enabling better compile support and improved handling of LoRA parameters for quicker training.
- Users can try it out in any of the distributed recipes to experience the heightened performance.
- Get ready for major training-time speedups!: Implementing torch.compile has led to significantly reduced compile times, clocking in at under a minute when set
compile=Truein configurations.- This feature provides even quicker performance gains when using the latest PyTorch nightlies.
- Introducing DoRA/QDoRA support with ease!: The latest release now supports DoRA/QDoRA, enabling users to activate this feature by simply adding
use_dora=Trueto model configurations.- This addition is seen as pivotal for users engaging with LoRA and QLoRA recipes, enhancing their training capabilities.
- Explore memory optimization techniques: An updated documentation page describes various memory-saving techniques within Torchtune, providing users with several options to customize for their hardware needs.
- The guide includes a comprehensive table summarizing essential components, ensuring users can efficiently tune their model configurations.
Links mentioned:
Torchtune ▷ #dev (38 messages🔥):
Cache ManagementKV Caching for ModelsEvaluating Multi-Modal TasksPytorch Conference UpdatesThree Day Work Weeks
- Cache Management Issues: A discussion emerged around the need for cache to be fully deleted after each task, with one member suggesting that while it's necessary, the eval harness might iterate tasks internally.
- One contributor noted that supporting a model with inference and forward mode without tearing down caches could be a potential solution.
- KV Caching Mechanisms: Members explored how other models, like HF, use dynamic caching, which seems to accommodate smaller batch sizes without issues.
- It was suggested that a solution could involve a context manager to enable KV caching, but opinions varied on its effectiveness for different tasks.
- Pytorch Conference Discussions: As the end of the Pytorch conference approaches, discussions about reaching out for fixes, especially concerning compile errors, took place, linked to a specific GitHub issue.
- One member indicated they would escalate a fix request, while another noted that the issue likely wouldn't be resolved before Friday.
- Plans for Evaluating Multi-Modal Tasks: A user confirmed plans to get evals up and running for multimodal tasks with a batch size of 1 and utilizing KV caching.
- They expressed interest in a larger batch size evaluation if time permits, as one member indicated they had already made progress.
- Casual Workplace Banter: Members engaged in light-hearted banter about different work week lengths, with one humorously noting their three-day work week and time zone differences.
- This playful interaction culminated in a humorous exchange regarding conference schedules and deadlines.
Links mentioned:
Interconnects (Nathan Lambert) ▷ #news (32 messages🔥):
Qwen2.5 ReleaseOpenAI o1 Models PerformanceMath Reasoning in AIKnowledge Cutoff Issues
- Qwen2.5 Launch Claims Big Milestones: The latest addition to the Qwen family, Qwen2.5, has been touted as one of the largest open-source releases, featuring models like Qwen2.5-Coder and Qwen2.5-Math with various sizes from 0.5B to 72B.
- Highlights include the flagship Qwen2.5-72B-Instruct matching proprietary models, showcasing competitive performance in benchmarks.
- OpenAI o1 Models Compared to PhD Level Work: A user reported that testing OpenAI's o1-mini model showed it to be comparable to an outstanding PhD student in biomedical sciences, marking it among the top candidates they've trained.
- This statement underscores the model's proficiency and the potential for its application in advanced academic projects.
- Math Reasoning Gains Attention: There's a growing emphasis on advancing math reasoning capabilities within AI, with excitement around the Qwen2.5-Math model, which supports both English and Chinese.
- Engagement from users suggests a collective focus on enhancing math-related AI applications as they strive to push boundaries in this domain.
- Challenges of Knowledge Cutoff in AI Models: Several users expressed frustration over the knowledge cutoff of models, notably stating it is set to October 2023, affecting their relevance to newer programming libraries.
- Discussions indicate that real-time information is critical for practical applications, presenting a challenge for models like OpenAI's o1.
- Excitement Mixed with Exhaustion in AI Work: The pace of developments in AI is both exhilarating and exhausting for users actively working in this space, indicating the rapid march of innovation.
- Participants shared feelings of being overwhelmed while simultaneously thrilled by what’s emerging, balancing challenges with progress.
Links mentioned:
Interconnects (Nathan Lambert) ▷ #ml-questions (4 messages):
Transformer architectureBertViz libraryGDM LLM self-critique
- Transformers Revolutionize AI: The Transformer architecture, introduced in the seminal paper "Attention is All You Need", has fundamentally altered AI approaches since 2017, powering models like OpenAI's GPT, Meta's Llama, and Google's Gemini.
- Transformers also extend their utility beyond text into audio generation, image recognition, and protein structure prediction.
- Exploring BertViz for Attention Visualization: A useful tool, BertViz, can visualize attention in NLP models like BERT, GPT2, and BART, potentially integrating seamlessly into workflows.
- Although the library hasn't been widely used, it could offer plug-and-play capabilities for analyzing model attention.
- GDM's LLMs Lack Self-Critique: A humorous comment highlighted that GDM’s Large Language Models currently cannot perform self-critique, indicating a limitation in their operational capabilities.
- This points to ongoing challenges within LLMs regarding self-assessment and reflective learning in AI systems.
Links mentioned:
Interconnects (Nathan Lambert) ▷ #random (1 messages):
xeophon.: https://x.com/agarwl_/status/1836119825216602548?s=46
Interconnects (Nathan Lambert) ▷ #memes (1 messages):
xeophon.: I love Twitter
OpenInterpreter ▷ #general (10 messages🔥):
01 App FunctionalityAutomating Browser Form TasksCV Agents Experimentation
- 01 App is fully operational: Members confirmed that the 01 app is working on their phones, with special attention to using the -qr option for functionality.
- One member mentioned they have not yet tested the app's local version but got the non-local version to work smoothly.
- Request for Automating Browser Tasks Tips: A member is seeking guides or tips for automating tasks related to browser form submissions, specifically for various government agency portals.
- They are currently following suggestions from ChatGPT 4o but are experiencing inefficiencies, as it is often going in circles.
- CV Agents Available for Testing: One member shared a link to their CV Agents project on GitHub, designed to help with smarter job hunting by utilizing intelligent resumes.
- The project is encapsulated with a visually appealing description and invites others to contribute.
- Inquiry on Application Control Features: A member inquired about the capabilities of CV Agents regarding controlling applications effectively.
- This sparked a conversation about potential integrations and the various methods being considered.
- Troubleshooting 01 App Errors: A member expressed frustration with an error encountered while using the 01 app, despite inputting the required parameters.
- They requested assistance to troubleshoot and sought a step-by-step guide to resolve the issue.
Link mentioned: GitHub - 0xrushi/cv-agents: Intelligent Resumes for Smarter Job Hunting: Intelligent Resumes for Smarter Job Hunting. Contribute to 0xrushi/cv-agents development by creating an account on GitHub.
OpenInterpreter ▷ #O1 (7 messages):
Beta Space AvailabilityBrowser Action Issues on WindowsError with Discord App Store Prompt
- Inquiry about Beta Space: <@631210549170012166> was asked about the availability of space in the beta for daily testing and feedback.
- Another member echoed this interest, emphasizing their eagerness for ongoing engagement.
- Perplexity Opening in Browser: A member reported that 01 opens Perplexity every time for browser action on Windows, raising concern about its functionality.
- They inquired if others had any similar experiences regarding this unexpected behavior.
- Discord App Store Prompt Failure: A member tried to execute a prompt to download Discord from the Microsoft App Store but received an error stating, 'this task is impossible'.
- They expressed frustration over this issue, noting that it runs code to open the app store but fails to complete the task.
OpenInterpreter ▷ #ai-content (4 messages):
Moshi artifacts releaseMoshi technical reportMoshi GitHub repositoryAudio sync feedback
- Moshi Artifacts Unleashed: Today, Kyutai Labs released several Moshi artifacts, including a detailed technical report, model weights, and streaming inference code in Pytorch, Rust, and MLX.
- You can find the paper here and access the repository on GitHub.
- Moshi GitHub Repository Discussed: A member shared the GitHub repository link for Moshi, emphasizing its importance for the community's engagement with the project.
- Another member expressed their anticipation for further updates regarding Moshi's development.
- Thumbnail and Audio Feedback: A user commented about the video related to Moshi, suggesting an update to the thumbnail for better visibility and increased views.
- They also noted that the audio sync was a bit off, indicating a need for technical adjustment.
Links mentioned:
LlamaIndex ▷ #blog (1 messages):
RAG services deploymentAWS CDKLlamaIndex
- Benito Martin's RAG Deployment Guide: Benito Martin shared a guide on building and deploying RAG services end-to-end using @awscloud CDK, offering a valuable resource for translating prototypes into production.
- If you're looking to enhance your deployment skills, this guide is a quick start!
- Infrastructure-as-Code for AWS: The guide emphasizes the use of Infrastructure-as-Code providers for AWS, streamlining the RAG service deployment process.
- This approach significantly simplifies the transition from development to production environments.
LlamaIndex ▷ #general (10 messages🔥):
Weaviate Issue ResolutionOpen Source Contribution ProcessFeedback on RAG Approaches
- Weaviate Issue Closed but Still Problematic: Yasuyuki raised an issue related to a KeyError encountered while reading an existing Weaviate database, referencing GitHub Issue #13787. A community member suggested forking the repo and creating a pull request to fix the functionality to allow users to specify field names.
- This is a common pitfall when querying vector databases not created with llama-index.
- Contribution to OSS Triggers New Learning: Yasuyuki expressed interest in contributing to the project and mentioned implementing a first aid measure by correcting the key from 'id' to 'uuid'. They are preparing to learn about making a pull request to officially submit the fix.
- This first contribution has encouraged him to familiarize himself with GitHub workflows for future engagement.
- Exploration of RAG Strategies: .sysfor sought feedback on integrating RAG (Retrieval-Augmented Generation) techniques to handle vendor questions by indexing related question-answer pairs. The strategy involved calculating semantic scores and potentially using metadata to link questions to their responses.
- Community members suggested indexing QA pairs, and there was consideration of generating variations on questions to enhance retrieval efficiency.
Link mentioned: [Question]: LLamaIndex and Weaviate · Issue #13787 · run-llama/llama_index: Question Validation I have searched both the documentation and discord for an answer. Question I am attempting to use llamaIndex to retrieve documents from my weaviate vector database. I have follo...
LangChain AI ▷ #general (3 messages):
LLMs Response LatencyPython and LangChain Optimizations
- Model Providers Cause Latency in LLMs: A member noted that latency in LLM responses is almost always attributed to the model provider.
- They emphasized that this is a significant factor affecting response times rather than issues with the implementation.
- Negligible Contribution of Python and LangChain to Latency: Another member suggested that only about 5-10% of the latency can be ascribed to Python or LangChain itself.
- This implies that optimizing the model or provider settings could have a much larger impact on response times.
LangChain AI ▷ #langserve (2 messages):
LangserveReact FrontendState ManagementPython Backend
- State Management in Langserve with React: A user inquired about the best practices for state management when integrating Langserve with a React frontend.
- They sought insights from those experienced in managing state effectively within this tech stack.
- Integration Challenges with Python Backend: The same user mentioned they are operating with a Python backend in their application setup.
- This implies the discussion may extend to how the React frontend interfaces with the Python backend for state handling.
LangChain AI ▷ #share-your-work (5 messages):
PDF Extraction ToolkitRAG Application with AWSLangChain Framework
- PDF-Extract-Kit for PDF Content Extraction: A member introduced the PDF-Extract-Kit as a comprehensive toolkit aimed at high-quality PDF content extraction, suggesting its usefulness for common use cases.
- Another member expressed curiosity about the toolkit's effectiveness and planned to try it out, highlighting that handling PDF extraction is a common requirement.
- RAG Application Using AWS Stack: A member shared an exciting new RAG application developed with Terraform as Infrastructure as Code (IaC), utilizing LangChain and AWS Bedrock for LLM and embedding models, alongside AWS OpenSearch as the vector database.
- The application is deployed on Amazon Web Services (AWS) using the available AWS OpenSearch endpoint, showcasing a robust cloud solution for data handling.
Links mentioned:
Modular (Mojo 🔥) ▷ #general (8 messages🔥):
BeToast Discord CompromiseWindows Native Support
- BeToast Discord Compromise Alert: A member raised concerns that the BeToast Discord server may be compromised, citing a conversation with an individual on LinkedIn who reported being hacked.
- Another member acknowledged the alert, stressing the need for vigilance and appropriate action if the compromised account begins spamming.
- Windows Native Support Timeline Uncertain: In response to a question about the Windows native support, a member shared a GitHub issue detailing requests for this feature, explaining that it may take some time.
- The discussion highlighted that many developers prefer alternatives to Windows for AI deployments due to cost and popularity issues, with WSL as a common workaround.
Link mentioned: [Feature Request] Native Windows support · Issue #620 · modularml/mojo: Review Mojo's priorities I have read the roadmap and priorities and I believe this request falls within the priorities. What is your request? native support for windows. when will it be available?...
Modular (Mojo 🔥) ▷ #mojo (2 messages):
SIMD ConversionData Type Handling
- Converting SIMD to Int Explained: A user asked how to convert SIMD[DType.int32, 1] to Int.
- phomola provided a succinct solution:
int(x).
- phomola provided a succinct solution:
- Clarifying SIMD Data Types: The discussion highlighted the importance of understanding SIMD and its data types in conversions.
- Members noted that familiarizing oneself with the DType options can simplify these kinds of queries.
LAION ▷ #general (6 messages):
State of the Art Text to SpeechOpen Source TTS SolutionsClosed Source TTS Solutions
- Exploring State of the Art Text to Speech: A member inquired about the state of the art (sota) for text to speech, specifically seeking open source solutions.
- “Ideally open source, but curious what all is out there” reflects a desire to compare various options.
- Praise for Eleven Labs: Eleven Labs was recommended by a member as the best closed source text to speech option available.
- This suggests it has strong capabilities, but opinions on open source options are still being discussed.
- Debate on Open Source TTS Options: Open source options included styletts2, tortoise, and xtts2, shared as alternatives to consider.
- The conversation indicates a variety of opinions on the effectiveness of these solutions.
LAION ▷ #research (4 messages):
OmniGenNvidia open-source LLMsSDXL VAEPhi-3
- Introducing OmniGen for Unified Image Generation: The paper titled OmniGen presents a new diffusion model that integrates diverse control conditions without needing additional modules found in models like Stable Diffusion.
- OmniGen supports multiple tasks including text-to-image generation, image editing, and classical CV tasks through its simplified architecture.
- Nvidia's Official Open-Source LLMs: A member highlighted the availability of official Nvidia open-source LLMs, potentially relevant for ongoing AI research and development.
- This initiative might provide valuable resources for developers and researchers working in the field.
- Features of OmniGen Highlight SDXL VAE and Phi-3: OmniGen leverages SDXL VAE and Phi-3, enhancing its capability in generating images and processing control conditions.
- These integrations further streamline its user-friendly architecture, making it more accessible for various applications.
Links mentioned:
DSPy ▷ #show-and-tell (6 messages):
Ruff check errorInterview with Sayash Kapoor and Benedikt StroeblLanceDB integration with DSpyElixir live codingTyped predictors example
- Ruff Check Error Alert: A user reported a TOML parse error while running
ruff check . --fix-only, indicating an unknown fieldindent-widthat line 216.- The error suggests revising the configuration file to adhere to the expected fields listed in the error message.
- Podcast with AI Researchers: An exciting YouTube podcast featuring Sayash Kapoor and Benedikt Stroebl discusses optimizing task performance while minimizing inference costs, available here.
- Listeners expressed eagerness to engage with the content, acknowledging the need for considering costs in AI systems.
- LanceDB Integration Debut: A new LanceDB integration was announced for DSpy, enhancing performance with a retriever for large datasets, detailed in this pull request.
- The contributor expressed interest in collaborating on personal projects and open-source initiatives.
- Elixir Live Coding Session: A live coding session focusing on Elixir templates and projects is happening in the lounge, inviting participation from the community.
- Members were informed via a Discord link to join the ongoing Elixir development activities.
- Request for Typed Predictors Example: A user inquired about a working O1 example using typed predictors, seeking help from the community.
- The request indicates a need for resources or demonstrations to assist in understanding this feature.
Links mentioned:
DSPy ▷ #general (3 messages):
API Key ManagementTrust Issues with Unofficial ServersReusable RAG PipelinesMulti-Company Context
- Concerns around API Key Handling: Users are questioning whether API keys must be sent directly to a VM/server before transferring them to OpenAI, emphasizing that users may distrust sending keys to unofficial servers.
- One member highlighted the need for clarity on secure processes to avoid compromising personal data.
- User Trust and API Computation: A discussion unfolded regarding whether users provide API keys for computations on a separate server, suggesting this trust issue impacts overall integration.
- The conversation indicated that this concern is distinct from challenges related to language interoperability.
- Creating a Reusable RAG Pipeline: A member sought advice on formulating a reusable pipeline with RAG for multiple companies while managing contextual information without overloading prompts.
- They expressed concerns about how to incorporate diverse data without convoluting the prompt with too much information.
OpenAccess AI Collective (axolotl) ▷ #axolotl-help-bot (8 messages🔥):
Curriculum Learning ImplementationDataset Shuffling Control
- Curriculum Learning Steps in PyTorch: To implement curriculum learning in a PyTorch-based environment, you should define criteria, sort your dataset, and create a custom dataset class to handle curriculum logic.
- An example illustrates how to segment the dataset into stages of increasing difficulty and update the dataset in the training loop.
- Dataset Shuffling Control Query: The user inquired about how to specify that they do not want to random shuffle a dataset.
- Guidance on specifying this in a dataset context was suggested to be addressed in a separate thread.
Link mentioned: OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
tinygrad (George Hotz) ▷ #general (3 messages):
Tinybox setup instructionsTinygrad and Tinybox integrationMLPerf Training with Tinyboxes
- Help needed for Tinybox setup: @drose0933 requested assistance with setting up their two tinyboxes and asked for instructions.
- In response, a member provided a link to the Tinybox documentation for setup guidance.
- Tinyboxes' role in Tinygrad CI: The tinyboxes are emphasized as a heavily used platform in tinygrad's CI, proven to be the best tested for working with tinygrad.
- They showcased their capabilities by running tinygrad on the MLPerf Training 4.0.
- Purchase options for Tinyboxes: For those interested in acquiring a tinybox, the member mentioned visiting tinygrad.org for purchases.
- They reassured that it's okay for those who may not be interested in obtaining one.
- Introduction to Tinybox features: The message included a brief introduction to the tinybox as a universal system designed for AI workloads, covering both training and inference.
- Details on the hardware specifications were provided, noting the red box contains six 7900XTX GPUs and the green box includes six 4090 GPUs.
Link mentioned: tinybox - tinygrad docs: no description found
LLM Finetuning (Hamel + Dan) ▷ #general (1 messages):
rateLLMiterAPI call managementPip install modules
- rateLLMiter Now Available for Pip Install: The rateLLMiter module is now available as a pip installable package, enhancing request management for LLM clients.
- The implementation can be found on GitHub with details on its MIT license.
- Rate Limiter Graph Shows Request Management: A graph illustrates how rateLLMiter smooths out the flow of requests, with the orange line representing requests for tickets and the green line showing issued tickets.
- It effectively spread a spike of 100 requests over time to prevent server rate limit exceptions.
Link mentioned: GitHub - llmonpy/ratellmiter: Rate limiter for LLM clients: Rate limiter for LLM clients. Contribute to llmonpy/ratellmiter development by creating an account on GitHub.
Gorilla LLM (Berkeley Function Calling) ▷ #discussion (1 messages):
Prompt ErrorsTemplate Usage
- Realization of Prompt Misuse: A member discovered they had utilized their own prompt incorrectly, leading to confusion in their output.
- This realization underscores the importance of double-checking prompt applications for accurate results.
- Availability of Prompt Template: The member noted that the provided prompt template was available for reference to aid in crafting future prompts.
- Utilizing the template effectively can help prevent similar issues in future interactions.
{% else %}
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: [{{ email.subject }}]({{ email_url }})!
If you enjoyed AInews, please share with a friend! Thanks in advance!
{% endif %}