AI News for 12/12/2024-12/13/2024. We checked 7 subreddits, 433 Twitters and 31 Discords (209 channels, and 6703 messages) for you. Estimated reading time saved (at 200wpm): 741 minutes. You can now tag @smol_ai for AINews discussions!
In a day with monster $250m fundraising and Ilya declaring the end of pretraining, we are glad for Meta to deliver a paper with some technical meat: Byte Latent Transformer: Patches Scale Better Than Tokens.

The abstract is very legible. In contrast to previous byte level work like MambaByte, BLT uses dynamically formed patches that are encoded to latent representations. As the authors say: "Tokenization-based LLMs allocate the same amount of compute to every token. This trades efficiency for performance, since tokens are induced with compression heuristics that are not always correlated with the complexity of predictions. Central to our architecture is the idea that models should dynamically allocate compute where it is needed. For example, a large transformer is not needed to predict the ending of most words, since these are comparably easy, low-entropy decisions compared to choosing the first word of a new sentence. This is reflected in BLT’s architecture (§3) where there are three transformer blocks: two small byte-level local models and a large global latent transformer."
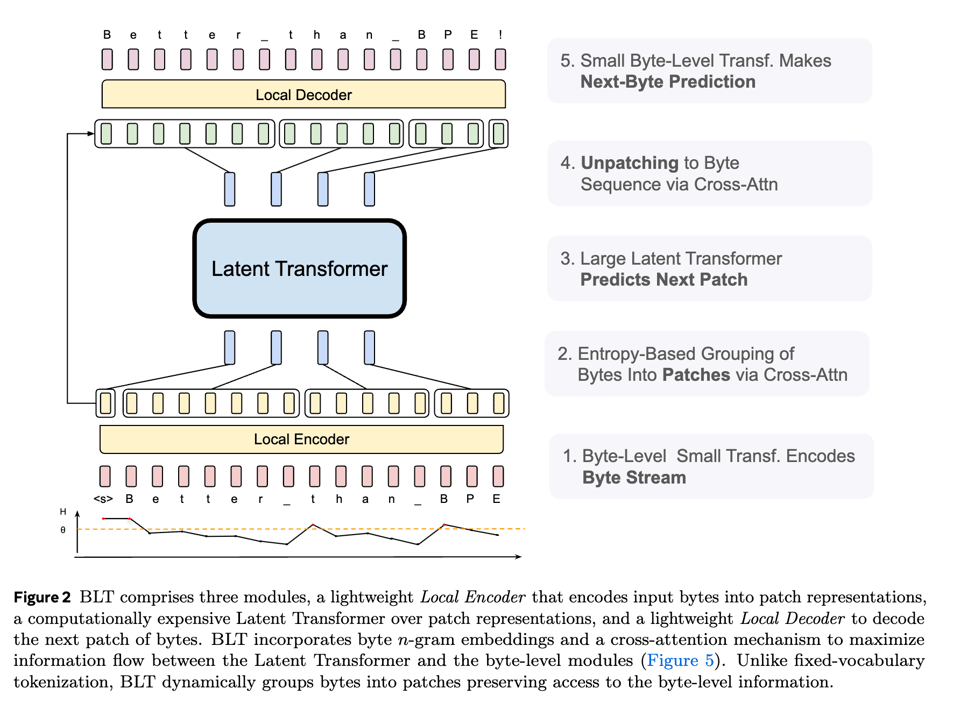
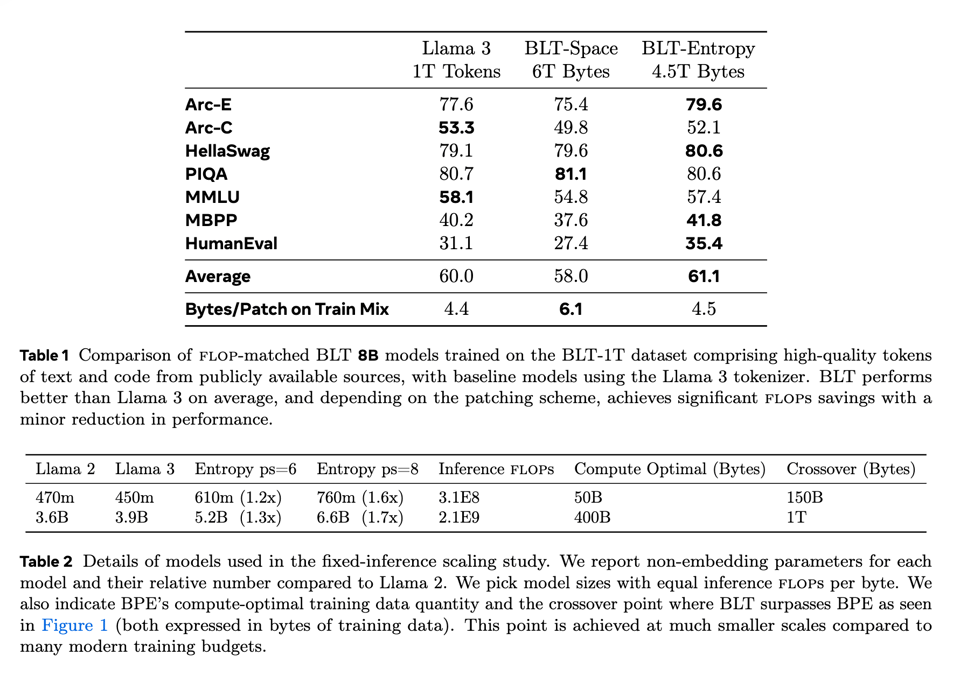
The authors trained this on ~1T tokens worth of data and compared it with their house model, Llama 3, and it does surprisingly well on standard benchmarks:
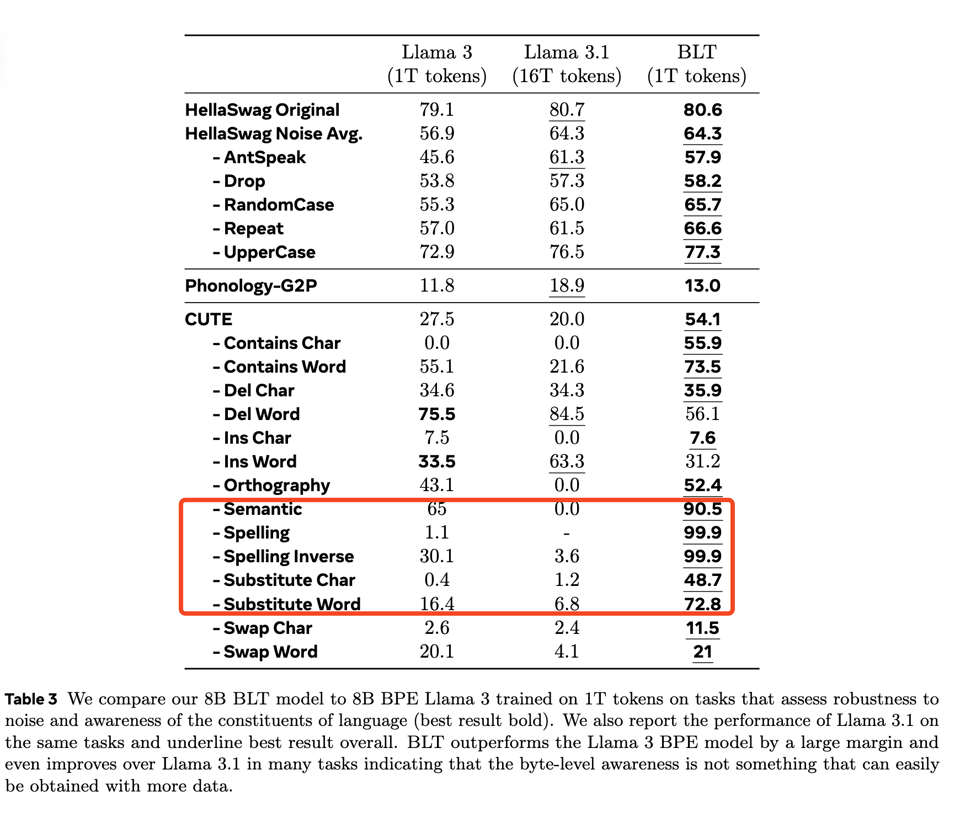
but also does much better on tasks that usually trip up tokenizer based models (the CUTE benchmark):
What's next - scale this up? Is this worth throwing everything we know about tokenization out the window? What about Long context/retrieval/IFEval type capabilities?
Possibly byte-level transformers unlock NEW kinds of multimodality, as /r/localllama explains:
example of such new possibility is "talking to your PDF", when you really do exactly that, without RAG, and chunking by feeding data directly to the model. You can think of all other kinds of crazy use-cases with the model that natively accepts common file types.
{% if medium == 'web' %}
Table of Contents
[TOC]
{% else %}
The Table of Contents and Channel Summaries have been moved to the web version of this email: [{{ email.subject }}]({{ email_url }})!
{% endif %}
AI Twitter Recap
all recaps done by Claude 3.5 Sonnet, best of 4 runs.
Here are the key topics from the Twitter discussions, organized by category:
New Model & Research Announcements
- Microsoft Phi-4: @SebastienBubeck announces a 14B parameter model achieving SOTA results on STEM/reasoning benchmarks, outperforming GPT-4o on GPQA and MATH
- Meta Research: Released Byte Latent Transformer, a tokenizer-free architecture that dynamically encodes bytes into patches with better inference efficiency
- DeepSeek-VL2: @deepseek_ai launches new vision-language models using DeepSeek-MoE architecture with sizes 1.0B, 2.8B, and 27B parameters
Product Launches & Updates
- ChatGPT Projects: @OpenAI announces new Projects feature for organizing chats, files and custom instructions
- Cohere Command R7B: @cohere releases their smallest and fastest model in the R series
- Anthropic Research: Published findings on "Best-of-N Jailbreaking" showing vulnerabilities across text, vision and audio models
Industry Discussion & Analysis
- Model Scaling: @tamaybes notes that frontier LLM sizes have decreased dramatically - GPT-4 ~1.8T params vs newer models ~200-400B params
- Benchmark Performance: Significant discussion around Phi-4's strong performance on benchmarks despite smaller size
Memes & Humor
- Various jokes and memes about AI progress, model comparisons, and industry dynamics
AI Reddit Recap
/r/LocalLlama Recap
Theme 1. Phi-4 Release: Benchmarks Shine but Practicality Questioned
-
Introducing Phi-4: Microsoft’s Newest Small Language Model Specializing in Complex Reasoning (Score: 749, Comments: 195): Microsoft has introduced Phi-4, a small language model designed for complex reasoning. Further details about its capabilities and applications were not provided in the post.
- Discussion highlights skepticism about Phi-4's real-world performance, with users noting that previous Phi models had high benchmark scores but underperformed in practical applications. Instruction following is mentioned as an area where Phi models struggle, with some users comparing them unfavorably to Llama.
- Several comments focus on synthetic data and its role in training the Phi models, suggesting that Microsoft may use the Phi series to showcase their synthetic datasets. There is speculation that these datasets could be licensed to other companies, and some users express interest in the potential of synthetic data for improving model performance in specific domains like math.
- The community expresses interest in benchmark results, with some noting impressive scores for a 14B model. However, there is also caution about potential overfitting and the validity of these benchmarks, with some users questioning the transparency and accessibility of the Phi-4 model, mentioning that it will be available on Hugging Face next week.
-
Bro WTF?? (Score: 447, Comments: 131): The post discusses a table comparing AI models, highlighting the performance of "phi-4" against other models in tasks like MMLU, GPQA, and MATH. It categorizes models into "Small" and "Large" and includes a specific internal benchmark called "PhiBench" to showcase the phi model's competitive results.
- Phi Model Performance and Real-World Application: Many users express skepticism about the phi-4 model's real-world applicability despite its strong benchmark performance, noting previous phi models often excelled in tests but underperformed in practice. lostinthellama highlights that these models are tailored for business and reasoning tasks but perform poorly in creative tasks like storytelling.
- Model Size and Development: Discussion revolves around the potential for larger phi models, with Educational_Gap5867 noting the largest Phi models are currently 14B parameters. arbv mentions previous attempts to scale beyond 7B were unsuccessful, suggesting a focus on smaller, more efficient models.
- Availability and Access: The model is expected to be available on Hugging Face, with Guudbaad providing a link to its current availability on Azure, though download speeds are reportedly slow. sammcj offers a script for downloading files from Azure to facilitate access.
-
Microsoft Phi-4 GGUF available. Download link in the post (Score: 231, Comments: 65): Microsoft Phi-4 GGUF model, converted from Azure AI Foundry, is available for download on Hugging Face as a non-official release, with the official release expected next week. Available quantizations include Q8_0, Q6_K, Q4_K_M, and f16, alongside the unquantized model, with no further quantizations planned.
- Phi-4 Performance and Comparisons: The Phi-4 model is significantly better than its predecessor, Phi-3, especially in multilingual tasks and instruction following, with improvements noted in benchmarks such as farel-bench (Phi-4 scored 81.11 compared to Phi-3's 62.44). However, it still faces competition from models like Qwen 2.5 14B in certain areas.
- Model Availability and Licensing: The model is available for download on Hugging Face and has been uploaded to Ollama for easier access. The licensing has changed to the Microsoft Research License Agreement, allowing only non-commercial use.
- Technical Testing and Implementation: Users have tested the model in environments like LM Studio using AMD ROCm, achieving about 36 T/s on an RX6800XT. The model's performance is noted to be concise and informative, fitting well within the 16K context on a 16GB GPU.
{kind=link}
Theme 2. Andy Konwinski's $1M Prize for Open-Source AI on SWE-bench
- I’ll give $1M to the first open source AI that gets 90% on contamination-free SWE-bench —xoxo Andy (Score: 449, Comments: 97): Andy Konwinski has announced a $1M prize for the first open-source AI model that scores 90% on a contamination-free SWE-bench. The challenge specifies that both the code and model weights must be open source, and further details can be found on his website.
- There is skepticism about the feasibility of achieving 90% on SWE-bench, with Amazon's model only reaching 55%. Concerns are raised about potential gaming of the benchmark due to the lack of required dataset submission, and the challenge of ensuring a truly contamination-free evaluation process.
- Andy Konwinski clarifies the competition's integrity by using a new test set of GitHub issues created after submission freeze to ensure contamination-free evaluation. This method, inspired by Kaggle's market prediction competitions, involves a dedicated engineering team to verify the solvability of issues, drawing from the SWE-bench Verified lessons.
- The legitimacy of Andy Konwinski and the prize is questioned but later confirmed through his association with Perplexity and Databricks. The initiative is seen as a prototype for future inducement prizes, with plans to potentially continue and expand the competition if significant community engagement is observed.
Theme 3. GPU Capabilities Unearthed: How Rich Are We?
- How GPU Poor are you? Are your friends GPU Rich? you can now find out on Hugging Face! 🔥 (Score: 70, Comments: 65): The post highlights a feature on Hugging Face that allows users to compare their GPU configurations and performance metrics with others. The example provided shows Julien Chaumond classified as "GPU rich" with an NVIDIA RTX 3090 and two Apple M1 Pro chips, achieving 45.98 TFLOPS, compared to another user's 25.20 TFLOPS, labeled as "GPU poor."
- Users express frustration over limited GPU options on Hugging Face, noting the absence of Threadripper 7000, Intel GPUs, and other configurations like kobold.cpp. This highlights a need for broader hardware compatibility and recognition within the platform.
- Several comments reflect on the emotional impact of hardware comparisons, with users humorously lamenting their "GPU poor" status and acknowledging the limitations of their setups. A link to a GitHub file is provided for users to add unsupported GPUs.
- Discussions around GPU utilization indicate dissatisfaction with software support, especially for AMD and older GPU models. Users note that despite owning capable hardware, the lack of robust software frameworks limits their ability to fully leverage their GPUs.
{kind=link}
Theme 4. Meta's Byte Latent Transformer Redefines Tokenization
- Meta's Byte Latent Transformer (BLT) paper looks like the real-deal. Outperforming tokenization models even up to their tested 8B param model size. 2025 may be the year we say goodbye to tokenization. (Score: 90, Comments: 27): Meta's Byte Latent Transformer (BLT) demonstrates significant advancements in language processing, outperforming tokenization models like Llama 3 in various tasks, particularly achieving a 99.9% score in "Spelling" and "Spelling Inverse." The analysis suggests that by 2025, tokenization might become obsolete due to BLT's superior capabilities in language awareness and task performance.
- BLT's Key Innovations: The Byte Latent Transformer (BLT) introduces a dynamic patching mechanism that replaces fixed-size tokenization, grouping bytes into variable-length patches based on predicted entropy, enhancing efficiency and robustness. It combines a global transformer with local byte-level transformers, operating directly on bytes, eliminating the need for a pre-defined vocabulary, and improving flexibility and efficiency in handling multilingual data and misspellings.
- Potential and Impact: The BLT model's byte-level approach is seen as a breakthrough, opening up new possibilities for applications, such as direct interaction with file types without additional processing steps like RAG. This could simplify multimodal training, allowing the model to process various data types like images, video, and sound as bytes, potentially enabling advanced tasks like byte-editing programs.
- Community Resources: The paper and code for BLT are available online, with the paper accessible here and the code on GitHub, providing resources for further exploration and experimentation with the model.
{kind=link}
Other AI Subreddit Recap
r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity
Theme 1. Gemini 2.0: Google's Multimodal Breakthrough
-
Gemini 2.0 is what 4o was supposed to be (Score: 853, Comments: 287): Gemini 2.0 is described as fulfilling the promises that 4o failed to deliver, particularly in terms of native multimodal capabilities, state-of-the-art performance, and features like voice mode and image output. The author is impressed by Gemini 2.0's 2 million character context and deep search capabilities, and notes that while early testers have access now, it will be widely available by 2025, unlike OAI's unspecified release timeline for similar features. Video link provided for further insight.
- Gemini 2.0's Features and Accessibility: Users highlight the availability of Gemini 2.0 Flash on Google AI Studio with free access and features like real-time video and screen sharing. There's praise for its ability to converse in multiple languages with native accents and its 2 million character context window, though some features remain exclusive to trusted testers.
- Comparison with OpenAI's Offerings: Discussions reflect a sentiment that OpenAI is struggling with costs and resource limitations, as evidenced by their $200 pro subscription. In contrast, Google's use of TPUs and free access to Gemini 2.0 is seen as a competitive advantage, potentially marking a turning point in the AI landscape.
- Community Reactions and Expectations: There is a mix of enthusiasm and skepticism, with some users considering switching from OpenAI to Google due to the latter's performance and cost-effectiveness. The community expresses anticipation for future updates from both companies, particularly regarding multimodal capabilities and improved model features.
-
Don't pay for ChatGPT Pro instead use gemini-exp-1206 (Score: 386, Comments: 109): For coding purposes, the author recommends using Google's gemini-exp-1206 model available at AI Studio instead of paying for ChatGPT Pro. They find gemini-exp-1206 superior to the now-unavailable o1-preview model and consider it sufficient alongside GPT Plus and the Advanced Voice model with Camera.
- Gemini-exp-1206 vs. Other Models: Several users argue that gemini-exp-1206 outperforms models like Claude 3.5 and o1 in various coding tasks, with lmsys arena rankings supporting this claim. However, some users note that Gemini is not a direct replacement for o1-Pro, especially for more complex tasks, and others find Gemini inferior in real-world programming applications.
- Google's AI Ecosystem Confusion: Users express frustration over the fragmented nature of Google's AI services, citing the confusion caused by multiple platforms like AI Studio, Note LLM, and Gemini. There is a call for a more unified interface to streamline access and usability.
- Data Privacy Concerns: Concerns about data privacy with Gemini are raised, particularly regarding the lack of data opt-out options in free versions. However, it is noted that Google's paid API services have different terms, promising not to use user data for product improvement.
Theme 2. Limitations on Advanced Voice Mode Usage
- So advanced voice mode is now limited to 15 minutes a day for Plus users? (Score: 191, Comments: 144): OpenAI's advanced voice mode for Plus users was mistakenly reported to be limited to 15 minutes a day, causing frustration among users who rely on this feature. However, this was clarified as an error by /u/OpenAI, confirming that the advanced voice limits remain unchanged, and the lower limit applies only to video and screenshare features.
- Advanced Voice Mode Concerns: Users express frustration over perceived limitations and monetization strategies, with some like Visionary-Vibes feeling the 15-minute limit is unfair for paying Plus users. PopSynic highlights accessibility issues for visually impaired users and the unexpected consumption of limits even when not actively using the voice mode.
- Technical and Resource Challenges: Comments from ShabalalaWATP and realityexperiencer suggest that OpenAI, like other companies, struggles with hardware constraints, impacting service delivery. traumfisch notes that server overload might be causing inconsistent service caps.
- User Experience and Feedback: Some users, like Barkis_Willing, critique the voice quality and functionality, while chazwhiz appreciates the ability to communicate at a natural pace for brainstorming. pickadol praises OpenAI's direct communication, emphasizing its positive impact on user goodwill.
AI Discord Recap
A summary of Summaries of Summaries by o1-mini
Theme 1. AI Model Performance and Innovations
-
Phi-4 Surpasses GPT-4o in Benchmarks: Microsoft's Phi-4, a 14B parameter language model, outperforms GPT-4o in both GPQA and MATH benchmarks, emphasizing its focus on data quality. Phi-4 Technical Report details its advancements and availability on Azure AI Foundry and Hugging Face.
-
Command R7B Launch Enhances AI Efficiency: Cohere's Command R7B has been released as the smallest and fastest model in their R series, supporting 23 languages and optimized for tasks like math, code, and reasoning. Available on Hugging Face, it aims to cater to diverse enterprise use cases.
-
DeepSeek-VL2 Introduces Mixture-of-Experts Models: DeepSeek-VL2 launches with a Mixture-of-Experts (MoE) architecture, featuring scalable model sizes (3B, 16B, 27B) and dynamic image tiling. It achieves outstanding performance in vision-language tasks, positioning itself strongly against competitors like GPT-4o and Sonnet 3.5 on the WebDev Arena leaderboard.
Theme 2. Integration and Tooling Enhancements for Developers
-
Aider v0.69.0 Streamlines Coding Workflows: The latest Aider v0.69.0 update enables triggering with
# ... AI?comments and monitoring all files, enhancing automated code management. Support for Gemini Flash 2.0 and ChatGPT Pro integration optimizes coding workflows. Aider Documentation provides detailed usage instructions. -
Cursor IDE Outperforms Windsurf in Autocomplete: Cursor is favored over Windsurf for its superior autocomplete capabilities and flexibility in managing multiple models without high costs. Users report frustrations with Windsurf's inefficiencies in file editing and redundant code generation, highlighting Cursor's advantage in enhancing developer productivity.
-
NotebookLM Plus Enhances AI Documentation: NotebookLM Plus introduces features like support for up to 300 sources per notebook and improved audio and chat functionalities. The updated 3-panel interface and interactive audio overviews facilitate better content management and user interaction. Available through Google Workspace.
Theme 3. AI Model Development Techniques and Optimizations
-
Quantization-Aware Training Boosts Model Accuracy: Implementing Quantization-Aware Training (QAT) in PyTorch recovers up to 96% of accuracy degradation on specific benchmarks. Utilizing tools like torchao and torchtune facilitates effective fine-tuning, with Straight-Through Estimators (STE) handling non-differentiable operations to maintain gradient integrity.
-
Inverse Mechanistic Interpretability Explored: Researchers are delving into inverse mechanistic interpretability, aiming to transform code into neural network architectures without relying on differentiable programming. RASP serves as a pertinent example, demonstrating code interpretation at a mechanistic level. RASP Paper provides comprehensive insights.
-
Dynamic 4-bit Quantization Enhances Vision Models: Unsloth's Dynamic 4-bit Quantization selectively avoids quantizing certain parameters, significantly improving accuracy while maintaining VRAM efficiency. This method proves effective for vision models, which traditionally struggle with quantization, enabling better performance in local training environments.
Theme 4. Product Updates and Announcements from AI Providers
-
ChatGPT Introduces New Projects Feature: In the latest YouTube launch, OpenAI unveiled the Projects feature in ChatGPT, enhancing chat organization and customization for structured discussion management.
-
Perplexity Pro Faces Usability Challenges: Perplexity Pro users report issues with conversation tracking and image generation, impacting the overall user experience. Recent updates introduce custom web sources in Spaces to tailor searches to specific websites, enhancing search specificity.
-
OpenRouter Adds Model Provider Filtering Amidst API Downtime: OpenRouter now allows users to filter models by provider, improving model selection efficiency. During AI Launch Week, OpenRouter managed over 1.8 million requests despite widespread API downtime from providers like OpenAI and Anthropic, ensuring service continuity for businesses.
Theme 5. Community Engagement and Support Issues
-
Codeium Pricing and Performance Frustrations: Users express dissatisfaction with Codeium's pricing and ongoing performance issues, particularly with Claude and Cascade models. Despite recent price hikes, internal errors remain unresolved, prompting concerns about the platform's reliability.
-
Tinygrad Performance Bottlenecks Highlight Need for Optimization: Tinygrad users report significant performance lags compared to PyTorch, especially with larger sequence lengths and batch sizes. Calls for benchmark scripts aim to identify and address compile time and kernel execution inefficiencies.
-
Unsloth AI Enhances Multi-GPU Training Support: Unsloth anticipates introducing multi-GPU training support, currently limited to single GPUs on platforms like Kaggle. This enhancement is expected to optimize training workflows for larger models, alleviating current bottlenecks and improving training efficiency.
PART 1: High level Discord summaries
Codeium / Windsurf Discord
- Codeium's Pricing and Performance Woes: Users are frustrated with Codeium's pricing and persistent performance issues despite recent price hikes, leading to dissatisfaction with the service.
- Complaints focus on internal errors with the Claude and Cascade models, prompting regret over platform spending.
- Claude Model Faces Internal Errors: Multiple reports indicate that the Claude model encounters internal errors after the initial message, disrupting user experience.
- Switching to the GPT-4o model mitigates the issue, suggesting potential instability within Claude.
- Cascade Struggles with C# Integration: Users report challenges integrating Cascade with their C# .NET projects, citing the tool's unfamiliarity with the .NET framework.
- Proposals for workspace AI rules aim to customize Cascade usage to better suit specific programming requirements.
- Windsurf's Sonnet Version Conundrum: Windsurf users face increased errors when using Sonnet 3.5, whereas Claude 4o serves as a more stable alternative.
- This discrepancy raises questions about the operational reliability of different Sonnet versions within Windsurf.
- Seamless Windsurf and Git Integration: Windsurf demonstrates strong compatibility with Git, maintaining native Git features akin to VSCode.
- Users effectively utilize tools like GitHub Desktop and GitLens alongside Windsurf without encountering conflicts.
Notebook LM Discord Discord
- NotebookLM's Gradual Feature Rollout: The latest NotebookLM updates, including premium features and UI enhancements, are being deployed incrementally, resulting in some users still accessing the previous interface despite having active subscriptions.
- Users are advised to remain patient as the rollout progresses, which may vary based on country and workspace configurations.
- Interactive Audio Overviews Issues: Several users reported disruptions with Interactive Audio Overviews, such as AI hosts prematurely ending sentences and interrupting conversations.
- The community is troubleshooting potential microphone problems and questioning the functionality of the interactive feature.
- Multilingual Support Enhancements: NotebookLM's capability to handle multiple European languages in a single performance test has been a topic of discussion, demonstrating its multilingual processing strengths.
- Users shared experiences of varied accents and language transitions, highlighting both the effectiveness and areas for improvement in AI language processing.
- Launch of NotebookLM Plus: The introduction of NotebookLM Plus offers expanded features, including support for up to 300 sources per notebook and enhanced audio and chat functionalities.
- Available through Google Workspace, Google Cloud, and upcoming Google One AI Premium.
- AI Integration in Creative Projects: An experienced creator detailed their use of NotebookLM alongside 3D rendering techniques in the project UNREAL MYSTERIES, emphasizing AI's role in enhancing storytelling.
- Insights were shared during an interview on a prominent FX podcast, showcasing the synergy between AI and creative processes.
aider (Paul Gauthier) Discord
- Aider v0.69.0 Streamlines File Interaction: The latest Aider v0.69.0 update enables users to trigger Aider with
# ... AI?comments and monitor all files, enhancing the coding workflow.- New instructions can be added using
# AI comments,// AI comments, or-- AI commentsin any text file, facilitating seamless automated code management.
- New instructions can be added using
- Gemini Flash 2.0 Support Enhances Versatility: Aider now fully supports Gemini Flash 2.0 Exp with commands like
aider --model flash, increasing compatibility with various LLMs.- Users highlighted that Gemini Flash 2.0's performance in processing large pull requests significantly boosts efficiency during code reviews.
- ChatGPT Pro Integration Optimizes Coding Workflows: Combining Aider with ChatGPT Pro has proven effective, allowing efficient copypasting of commands between both platforms during coding tasks.
- This integration streamlines workflows, making it easier for developers to manage and execute coding commands seamlessly.
- Fine-Tuning Models Enhances Knowledge on Recent Libraries: Users successfully fine-tuned models to update knowledge on recent libraries by condensing documentation into relevant contexts.
- This method significantly improved model performance when handling newer library versions, as shared by community members.
- LLM Leaderboards and Performance Comparisons Discussed: Discussions emerged around finding reliable leaderboards for comparing LLM performance on coding tasks, with LiveBench recommended for accuracy.
- Participants noted that many existing leaderboards might be biased due to contaminated datasets, emphasizing the need for unbiased evaluation tools.
Cursor IDE Discord
- Cursor Crushes Windsurf in Performance Showdown: Users prefer Cursor over Windsurf for its flexibility and superior performance, especially in autocomplete and managing multiple models without excessive costs.
- Windsurf faced criticism for inefficiencies in file editing and generating redundant code, highlighting Cursor's advantage in these areas.
- Cursor's Subscription Struggles: Payment Pains Persist: Users reported frustrations with Cursor's payment options, particularly involving PayPal and credit cards, and difficulties in purchasing Pro accounts.
- One user successfully paid with PayPal after initial issues, suggesting inconsistencies in payment processing.
- Cursor's Model Limits: Breaking Down the Numbers: Cursor's subscription plan offers 500 fast requests and unlimited slow requests once fast requests are exhausted, primarily for premium models.
- Users clarified that both Claude Haiku and Sonnet can be effectively utilized within these parameters, with Haiku requests costing less.
- Developers Delight in Cursor's Coding Capabilities: Users shared positive experiences using Cursor for coding tasks, including deploying Python projects and understanding server setups.
- Cursor was praised for enhancing productivity and efficiency, though some noted a potential learning curve with features like Docker.
- Cursor vs Windsurf: AI Performance Under Scrutiny: Discussions arose regarding the quality of responses from various AI models, with some users doubting the reliability of Windsurf compared to Cursor.
- Comparisons also included features like proactive assistance in agents and handling complex code appropriately.
Eleuther Discord
- GPU Cluster Drama Unfolds: A member humorously described disrupting GPU clusters by staying up all night to monopolize GPU time on the gpu-serv01 cluster.
- Another participant referenced previous disruptions, noting the practice is both entertaining and competitive within the community.
- Grading Fantasy Character Projects: A member introduced a project where students generate tokens from a fantasy character dataset, raising questions on effective assessment methods.
- Proposed grading strategies include perplexity scoring and CLIP notation, alongside humorous considerations on preventing cheating during evaluations.
- Crowdsourcing Evaluation Criteria: In response to grading challenges, a member suggested embedding the evaluation criteria directly into assignments to involve students in the grading process.
- The discussion took a lighthearted turn when another member joked about simplifying grading by assigning a 100 score to all submissions.
- Differentiating Aleatoric and Epistemic Uncertainty: The community delved into distinguishing aleatoric from epistemic uncertainty, asserting that most real-world uncertainty is epistemic due to unknown underlying processes.
- It was highlighted that memorization in models blurs this distinction, transitioning representations from inherent distributions to empirical ones.
- Inverse Mechanistic Interpretability Explored: A member inquired about inverse mechanistic interpretability, specifically the process of transforming code into neural networks without using differentiable programming.
- Another member pointed to RASP as a pertinent example, linking to the RASP paper that demonstrates code interpretation at a mechanistic level.
OpenAI Discord
- ChatGPT Introduces Projects Feature: In the latest YouTube video, Kevin Weil, Drew Schuster, and Thomas Dimson unveil the new Projects feature in ChatGPT, enhancing chat organization and customization.
- This update aims to provide users with a more structured approach to managing their discussions within the platform.
- Teams Plan Faces Sora Access Limitations: Users reported that the ChatGPT Teams plan does not include access to Sora, leading to dissatisfaction among subscribers.
- Additionally, concerns were raised about message limits remaining unchanged from the Plus plan despite higher subscription fees.
- Claude Preferred Over Gemini and ChatGPT: Discussions highlighted a preference for Claude over models like Gemini and ChatGPT, citing enhanced performance.
- Participants also emphasized the benefits of local models such as LM Studio and OpenWebUI for their practicality.
- Issues with AI-generated Content Quality: Users identified problems with the quality of AI-generated outputs, including unexpected elements like swords in images.
- There were mixed opinions on implementing quality controls for copyrighted characters, with some advocating for stricter measures.
- Local AI Tools Adoption and Prompt Complexity: Insights were shared on running AI locally using tools like Ollama and OpenWebUI, viewed as effective solutions.
- Discussions also revealed that while simple prompts receive quick responses, more complex prompts require deeper reasoning, potentially extending response times.
LM Studio Discord
- MacBook Pro M4 Pro handles large LLMs: The MacBook Pro 14 with M4 Pro chip efficiently runs 8b models with a minimum of 16GB RAM, but larger models benefit from 64GB or more.
- A member remarked, “8b is pretty low”, expressing interest in higher-capacity models and discussing options like the 128GB M4 MBP.
- RTX 3060 offers strong value for AI workloads: The RTX 3060 is praised for its price-to-performance ratio, with comparisons to the 3070 and 3090 highlighting its suitability for AI tasks.
- Concerns were raised about CUDA support limitations in Intel GPUs, leading members to compare used market options.
- AMD vs Intel GPUs in AI Performance: Members compared AMD's RX 7900XT with Intel's i7-13650HX, noting the latter's superior Cinebench scores.
- The 20GB VRAM in RX 7900XT was highlighted as advantageous for specific AI workloads.
- Selecting the right PSU is crucial for setups: Choosing a suitable power supply unit (PSU) is emphasized, with 1000W units preferred for demanding configurations.
- Members shared links to various PSUs, discussing their efficiency ratings and impact on overall system performance.
- Optimizing AI performance via memory overclocking: Overclocking memory timings is suggested to enhance bandwidth performance in GPU-limited tasks.
- The importance of effective cooling solutions was discussed to maintain efficiency during high-performance computing.
Latent Space Discord
- Qwen 2.5 Turbo introduces 1M context length: The release of Qwen 2.5 Turbo extends its context length to 1 million tokens, significantly boosting its processing capabilities.
- This enhancement facilitates complex tasks that require extensive context, marking a notable advancement in AI model performance.
- Codeium Processes Over 100 Million Tokens: In a recent update, Codeium demonstrated the ability to handle over 100 million tokens per minute, showcasing their scalable infrastructure.
- This achievement reflects their focus on enterprise-level solutions, with insights drawn from scaling 100x in just 18 months.
- NotebookLM Unveils Audio Overview and NotebookLM Plus: NotebookLM introduced an audio overview feature that allows users to engage directly with AI hosts and launched NotebookLM Plus for enterprise users, enhancing its functionality at notebooklm.status/updates.
- The redesigned user interface facilitates easier content management, catering to businesses' needs for improved AI-driven documentation.
- Sonnet Tops WebDev Arena Leaderboard: Claude 3.5 Sonnet secured the top position on the newly launched WebDev Arena leaderboard, outperforming models like GPT-4o and demonstrating superior performance in web application development.
- This ranking underscores Sonnet's effectiveness in practical AI applications, as highlighted by over 10K votes from the community.
- SillyTavern Emerges as LLM Testing Ground: SillyTavern was highlighted by AI engineers as a valuable frontend for testing large language models, akin to a comprehensive test suite for diverse scenarios.
- Members leveraged it for complex philosophical discussions, illustrating its flexibility and utility in engaging with AI models.
Bolt.new / Stackblitz Discord
- Testing Bolt's Memory Clearance: Users are experimenting with memory erasure prompts by instructing Bolt to delete all prior interactions, aiming to modify its recall mechanisms.
- One user noted, 'It could be worth a shot' to assess the impact on Bolt's memory retention capabilities.
- Bolt's Handling of URLs in Prompts: There is uncertainty regarding Bolt's ability to process URLs within API references, with users inquiring about this functionality.
- A clarification was provided that Bolt does not read URLs, recommending users to transfer content to a
.mdfile for effective review.
- A clarification was provided that Bolt does not read URLs, recommending users to transfer content to a
- Duration of Image Analysis Processes: Inquiries have been made about the expected duration of image analysis processes, reflecting concerns over efficiency.
- This ongoing dialogue highlights the community's focus on improving the responsiveness of the image analysis feature.
- Integrating Supabase and Stripe with Bolt: Participants are exploring the integration of Supabase and Stripe, facing challenges with webhook functionalities.
- Many anticipate that the forthcoming Supabase integration will enhance Bolt's capabilities and address current issues.
- Persistent Bolt Integration Issues: Users continue to face challenges with Bolt failing to process commands, despite trying various phrasings, leading to increased frustration.
- The lack of comprehensive feedback from Bolt complicates task completion, as highlighted by several community members.
GPU MODE Discord
- Quantization-Craze in PyTorch Enhances Accuracy: A user detailed how Quantization-Aware Training (QAT) in PyTorch recovers up to 96% of accuracy degradation on specific benchmarks, utilizing torchao and torchtune for effective fine-tuning methods.
- Discussions emphasized the role of Straight-Through Estimators (STE) in handling non-differentiable operations during QAT, with members confirming its impact on gradient calculations for linear layers.
- Triton Troubles: Fused Attention Debugging Unveiled: Members raised concerns regarding fused attention in Triton, seeking resources and sessions to clarify its implementation, while one user reported garbage values in the custom flash attention kernel linked to TRITON_INTERPET=1.
- Solutions were proposed to disable TRITON_INTERPET for valid outputs, and compatibility issues with bfloat16 were highlighted, aligning with existing challenges in Triton data types.
- Modal's GPU Glossary Boosts CUDA Comprehension: Modal released a comprehensive GPU Glossary aimed at simplifying CUDA terminology through cross-linked articles, receiving positive feedback from the community.
- Collaborative efforts were noted to refine definitions, particularly for tensor cores and registers, enhancing the glossary's utility for AI engineers.
- CPU Offloads Outperform Non-Offloaded GPU Training for Small Models: CPU offloading for single-GPU training was implemented, showing higher throughput for smaller models by increasing batch sizes, though performance declined for larger models due to PyTorch's CUDA synchronization during backpropagation.
- Members discussed the limitations imposed by VRAM constraints and proposed modifying the optimizer to operate directly on CUDA to mitigate delays.
- H100 GPU Scheduler Sparks Architecture Insights: Discussions clarified the H100 GPU's architecture, noting that despite having 128 FP32 cores per Streaming Multiprocessor (SM), the scheduler issues only one warp per cycle, leading to scheduler complexity questions.
- This sparked further inquiries into architectural naming conventions and the operational behavior of tensor cores versus CUDA cores.
Nous Research AI Discord
- Microsoft Launches Phi-4, a 14B Parameter Language Model: Microsoft has unveiled Phi-4, a 14B parameter language model designed for complex reasoning in math and language processing, available on Azure AI Foundry and Hugging Face.
- The Phi-4 Technical Report highlights its training centered on data quality, distinguishing it from other models with its specialized capabilities.
- DeepSeek-VL2 Enters the MoE Era: DeepSeek-VL2 launches with a MoE architecture featuring dynamic image tiling and scalable model sizes of 3B, 16B, and 27B parameters.
- The release emphasizes outstanding performance across benchmarks, particularly in vision-language tasks.
- Meta's Tokenization Breakthrough with SONAR: Meta introduced a new language modeling approach that replaces traditional tokenization with sentence representation using SONAR sentence embeddings, as detailed in their latest paper.
- This method allows models, including a diffusion model, to outperform existing models like Llama-3 on tasks such as summarization.
- Byte Latent Transformer Redefines Tokenization: Scaling01 announced the Byte Latent Transformer, a tokenizer-free model enhancing inference efficiency and robustness.
- Benchmark results show it competes with Llama 3 while reducing inference flops by up to 50%.
- Speculative Decoding Enhances Model Efficiency: Discussions on speculative decoding revealed it generates a draft response with a smaller model, corrected by a larger model in a single forward pass.
- Members debated the method's efficiency and the impact of draft outputs on re-tokenization requirements.
Unsloth AI (Daniel Han) Discord
- Phi-4 Released with Open Weights: Phi-4 is set to release next week with open weights, offering significant performance enhancements in reasoning tasks compared to earlier models. Sebastien Bubeck announced that Phi-4 falls under the Llama 3.3-70B category and features 5x fewer parameters while achieving high scores on GPQA and MATH benchmarks.
- Members are looking forward to leveraging Phi-4’s streamlined architecture for more efficient deployments, citing the reduced parameter count as a key advantage.
- Command R7B Demonstrates Speed and Efficiency: Command R7B has garnered attention for its impressive speed and efficiency, especially considering its compact 7B parameter size. Cohere highlighted that Command R7B delivers top-tier performance suitable for deployment on commodity GPUs and edge devices.
- The community is eager to benchmark Command R7B against other models, particularly in terms of hosting costs and scalability for various applications.
- Unsloth AI Enhances Multi-GPU Training Support: Unsloth is anticipated to introduce multi-GPU training support, addressing current limitations on platforms like Kaggle which restrict users to single GPU assignments. This enhancement aims to optimize training workflows for larger models.
- Members discussed the potential for increased training efficiency and the alleviation of bottlenecks once multi-GPU support is implemented.
- Fine-tuning Llama 3.3 70B on Unsloth Requires High VRAM: Fine-tuning the Llama 3.3 70B model using Unsloth necessitates 41GB of VRAM, rendering platforms like Google Colab inadequate for this purpose. GitHub - unslothai/unsloth provides resources to facilitate this process.
- Community members recommend using Runpod or Vast.ai for accessing A100/H100 GPUs with 80GB VRAM, although multi-GPU training remains unsupported.
- Unsloth vs Llama Models: Performance and Usability: Discussions indicate that using Unsloth's model version over the Llama model version yields better fine-tuning results, simplifies API key handling, and resolves certain bugs. GitHub resources streamline the fine-tuning workflow for large-scale models.
- Members advise prioritizing Unsloth's versions to leverage enhanced functionalities and achieve more stable and efficient model performance.
Cohere Discord
- Command R7B Launch Accelerates AI Efficiency: Cohere has officially released Command R7B, the smallest and fastest model in their R series, enhancing speed, efficiency, and quality for AI applications across various devices.
- The model, available on Hugging Face, supports 23 languages and is optimized for tasks like math, code, and reasoning, catering to diverse enterprise use cases.
- Resolving Cohere API Errors: Several users reported encountering 403 and 400 Bad Request errors while using the Cohere API, highlighting issues with permission and configuration.
- Community members suggested solutions such as updating the Cohere Python library using
pip install -U cohere, which helped resolve some of the API access problems.
- Community members suggested solutions such as updating the Cohere Python library using
- Understanding Rerank vs Embed in Cohere: Discussions clarified that the Rerank feature reorders documents based on relevance, while Embed converts text into numerical representations for various NLP tasks.
- Embed can now process images with the new Embed v3.0 models, enabling semantic similarity estimation and categorization tasks within AI workflows.
- 7B Model Enhances Performance Metrics: The 7B model by Cohere outperforms older models like Aya Expanse and previous Command R versions, offering improved capabilities in Retrieval Augmented Generation and complex tool use.
- Upcoming examples for finetuning the 7B model are set to release next week, showcasing its advanced reasoning and summarization abilities.
- Cohere Bot and Python Library Streamline Development: The Cohere bot is back online, assisting users with finding relevant resources and addressing technical queries efficiently.
- Additionally, the Cohere Python library was shared to facilitate API access, enabling developers to integrate Cohere's functionalities seamlessly into their projects.
Perplexity AI Discord
- Campus Strategist Program Goes International: We're thrilled to announce the expansion of our Campus Strategist program internationally, allowing students to run their own campus activations, receive exclusive merch, and collaborate with our global team. Applications for the Spring 2025 cohort are open until December 28; for more details, visit Campus Strategists Info.
- This initiative emphasizes collaboration among strategists globally, fostering a vibrant community.
- Perplexity Pro Faces Usability Challenges: Users reported issues with Perplexity Pro, noting that it fails to track conversations effectively and frequently makes errors, such as inaccurate time references.
- These usability concerns are impacting the user experience, particularly regarding performance and adherence to instructions.
- Perplexity Pro Users Struggle with Image Generation: A user expressed frustration over being unable to generate images with Perplexity Pro, despite following prompts outlined in the guide.
- An attached image highlights gaps in the expected functionality, indicating potential issues in the image generation feature.
- Perplexity Introduces Custom Web Sources in Spaces: Perplexity launched custom web sources in Spaces, enabling users to tailor searches to specific websites. This update aims to provide more relevant and context-driven queries.
- The feature allows for enhanced customization, accommodating diverse user needs and improving search specificity within Spaces.
- Clarification on Perplexity API vs Website: It's been clarified that the Perplexity API and the Perplexity website are separate products, with no available API for the main website.
- This distinction ensures users understand the specific functionalities and offerings of each platform component.
OpenRouter (Alex Atallah) Discord
- Filter Models by Provider Now Available: Users can now filter the
/modelspage by provider, enhancing the ability to find specific models quickly. A screenshot was provided with details on this update. - API Uptime Issues During AI Launch Week: OpenRouter recovered over 1.8 million requests for closed-source LLMs amidst widespread API failures during AI Launch Week. A tweet from OpenRouter highlighted significant API downtime from providers like OpenAI and Gemini.
- APIs from all providers experienced considerable downtime, with OpenAI's API down for 4 hours and Gemini's API being nearly unusable. Anthropic also showed extreme unreliability, leading to major disruptions for businesses relying on these models.
- Gemini Flash 2.0 Bug Fixes Underway: Members reported ongoing bugs with Gemini Flash 2.0, such as the homepage version returning no providers, and expressed optimism for the fixes being implemented.
- Suggestions included linking to the free version and addressing concerns about exceeding message quotas when using Google models.
- Euryale Model Performance Decline: Euryale has been producing nonsensical outputs recently, with members suspecting issues stemming from model updates rather than their configurations.
- Another member noted that similar performance inconsistencies are common, highlighting the unpredictable nature of AI model behavior.
- Custom Provider Keys Access Launch: Access to custom provider keys is set to be opened soon, with Alex Atallah confirming its imminent release.
- Members are eagerly requesting access, and users expressed a desire to provide their own API Keys, indicating a push for customization options.
{kind=link}
Modular (Mojo 🔥) Discord
- Innovative Networking Strategies in Mojo: The Mojo community emphasized the need for efficient APIs, discussing the use of XDP sockets and DPDK for advanced networking performance.
- Members are excited about Mojo's potential to reduce overhead compared to TCP in Mojo-to-Mojo communications.
- CPU vs GPU Performance in Mojo: Discussions highlighted that leveraging GPUs for networking tasks can enhance performance, achieving up to 400k requests per second with specific network cards.
- The consensus leans towards data center components offering better support for such efficiencies than consumer-grade hardware.
- Mojo’s Evolution with MLIR: Mojo's integration with MLIR was a key topic, focusing on its evolving features and implications for the language's compilation process.
- Contributors debated the impact of high-level developers' perspectives on Mojo's language efficiency, highlighting its potential across various domains.
- Discovering Mojo's Identity: The community humorously debated naming the little flame character associated with Mojo, suggesting names like Mojo or Mo' Joe with playful commentary.
- Discussions about Mojo's identity as a language sparked conversations regarding misconceptions among outsiders who often view it as just another way to speed up Python.
Interconnects (Nathan Lambert) Discord
- Microsoft Phi-4 Surpasses GPT-4o in Benchmarks: Microsoft's Phi-4 model, a 14B parameter language model, outperforms GPT-4o on both GPQA and MATH benchmarks and is now available on Azure AI Foundry.
- Despite Phi-4's performance, skepticism remains about the training methodologies of prior Phi models, with users questioning the focus on benchmarks over diverse data.
- LiquidAI Secures $250M for AI Scaling: LiquidAI has raised $250M to enhance the scaling and deployment of their Liquid Foundation Models for enterprise AI solutions, as detailed in their blog post.
- Concerns have been raised regarding their hiring practices, reliance on AMD hardware, and the potential challenges in attracting top-tier talent.
- DeepSeek VL2 Introduces Mixture-of-Experts Vision-Language Models: DeepSeek-VL2 was launched featuring Mixture-of-Experts Vision-Language Models designed for advanced multimodal understanding, available in sizes like 4.5A27.5B and Tiny: 1A3.4B.
- Community discussions highlight the innovative potential of these models, indicating strong interest in their performance capabilities.
- Tulu 3 Explores Advanced Post-Training Techniques: In a recent YouTube talk, Nathan Lambert discussed post-training techniques in language models, focusing on Reinforcement Learning from Human Feedback (RLHF).
- Sadhika, the co-host, posed insightful questions that delved into the implications of these techniques for future model development.
- Language Model Sizes Exhibit Reversal Trend: Recent analyses reveal a reversal in the growth trend of language model sizes, with current models like GPT-4o and Claude 3.5 Sonnet having approximately 200B and 400B parameters respectively, deviating from earlier expectations of reaching 10T parameters.
- Some members express skepticism about these size estimates, suggesting the actual parameter counts might be two orders of magnitude smaller due to uncertainties in reporting.
LLM Agents (Berkeley MOOC) Discord
- Certificate Declaration Form confusion resolved: A member initially struggled to locate where to submit their written article link on the Certificate Declaration Form but later found it.
- This highlights a common concern among members about proper submission channels amidst a busy course schedule.
- Labs submission deadlines extended: The deadline for labs was extended to December 17th, 2024, and members were reminded that only quizzes and articles were due at midnight.
- This extension offers flexibility for members who were behind due to various reasons, especially technological issues.
- Quizzes requirement clarified: It was confirmed that all quizzes need to be submitted by the deadline to meet certification requirements, although some leniency was offered for late submissions.
- A member who missed the quiz deadline was reassured they could still submit their answers without penalty.
- Public Notion links guideline: A clarification was made regarding whether Notion could be used for article submissions, emphasizing that it should be publicly accessible.
- Members were encouraged to ensure their Notion pages were published properly to avoid issues during submission.
- Certificate distribution timeline: Members inquired about the timeline for certificate distribution, with confirmations that certificates would be sent out late December through January.
- The timeline varies depending on the certification tier achieved, providing clear expectations for participants.
Stability.ai (Stable Diffusion) Discord
- WD 1.4 Underperforms Compared to Alternatives: A member recalled that WD 1.4 is merely an SD 2.1 model which had issues at launch, noting that Novel AI's model was the gold standard for anime when it first released.
- They mentioned that after SDXL dropped, users of the 2.1 model largely transitioned away from it due to its limitations.
- Local Video AI Models Discord Recommendation: A user sought recommendations for a Discord group focused on Local Video AI Models, specifically Mochi, LTX, and HunYuanVideo.
- Another user suggested joining banodoco as the best option for discussions on those models.
- Tag Generation Model Recommendations: A member asked for a good model for tag generation in Taggui, to which another member confidently recommended Florence.
- Additionally, it was advised to adjust the max tokens to suit individual needs.
- Need for Stable Diffusion XL Inpainting Script: A user expressed frustration over the lack of a working Stable Diffusion XL Inpainting finetuning script, despite extensive searches.
- They questioned if this channel was the right place for such inquiries or if tech support would be more suitable.
- Image Generation with ComfyUI: A user inquired about modifying a Python script to implement image-to-image processing with a specified prompt and loaded images.
- Others confirmed that while the initial code aimed for text-to-image, it could theoretically support image-to-image given the right model configurations.
OpenInterpreter Discord
- Resolved Nvidia NIM API Setup: A user successfully configured the Nvidia NIM API by executing
interpreter --model nvidia_nim/meta/llama3-70b-instructand setting theNVIDIA_NIM_API_KEYenvironment variable.- They expressed appreciation for the solution while highlighting difficulties with repository creation.
- Custom API Integration in Open Interpreter: A member inquired about customizing the Open Interpreter app's API, sparking discussions on integrating alternative APIs for improved desktop application functionality.
- Another participant emphasized that the app targets non-developers, focusing on user-friendliness without requiring API key configurations.
- Clarifying Token Limit Functionality: Users discussed the max tokens feature's role, noting it restricts response lengths without accumulating over conversations, leading to challenges in tracking token usage.
- Suggestions included implementing
max-turnsand a prospective max-budget feature to manage billing based on token consumption.
- Suggestions included implementing
- Advancements in Development Branch: Feedback on the development branch indicated that it enables repository creation via commands, praised for practical applications in projects.
- However, users reported issues with code indentation and folder creation, raising queries about the optimal operating environment.
- Meta's Byte Latent Transformer Introduced: Meta published Byte Latent Transformer: Patches Scale Better Than Tokens, introducing a strategy that utilizes bytes instead of traditional tokenization for enhanced model performance.
- This approach may transform language model operations by adopting byte-level representation to boost scalability and efficiency.
LlamaIndex Discord
- LlamaCloud's Multimodal RAG Pipeline: Fahd Mirza showcased LlamaCloud's multimodal capabilities in a recent video, allowing users to upload documents and toggle multi-modal functionality via Python or JavaScript APIs.
- This setup effectively handles mixed media, streamlining the RAG pipeline for diverse data types.
- OpenAI's Non-Strict Function Calling Defaults: Function calling defaults in OpenAI remain non-strict to minimize latency and ensure compatibility with Pydantic classes, as discussed in the general channel.
- Users can enable strict mode by setting
strict=True, though this may disrupt certain Pydantic integrations.
- Users can enable strict mode by setting
- Prompt Engineering vs. Frameworks like dspy: A discussion emerged around the effectiveness of prompt engineering compared to frameworks such as dspy, with members seeking strategies to craft impactful prompts.
- The community expressed interest in identifying best practices to enhance prompt performance for specific objectives.
- AWS Valkey as a Redis Replacement: Following Redis's shift to a non-open source model, members inquired about support for AWS Valkey, a drop-in replacement, as detailed in Valkey Datastore Explained.
- The conversation highlighted potential compatibility with existing Redis code and the need for further exploration.
- Integrating Langchain with MegaParse: Integration of Langchain with MegaParse enhances document parsing capabilities, enabling efficient information extraction from diverse document types, as outlined in AI Artistry's blog.
- This combination is particularly valuable for businesses and researchers seeking robust parsing solutions.
DSPy Discord
- DSPy Framework Accelerates LLM Applications: DSPy simplifies LLM-powered application development by providing boilerplate prompting and task 'signatures', reducing time spent on prompting DSPy.
- The framework enables building agents like a weather site efficiently.
- AI Redefines Categories as the Platypus: A blog post describes how AI acts like a platypus, challenging existing technological categorizations The Platypus In The Room.
- This analogy emphasizes AI's unique qualities that defy conventional groupings.
- Cohere v3 Outpaces Colbert v2 in Performance: Cohere v3 has been recognized to deliver superior performance over Colbert v2 in recent evaluations, sparking interest in the underlying enhancements.
- Discussions delved into the specific improvements contributing to Cohere v3's performance gains and explored implications for ongoing projects.
- Leveraging DAGs & Serverless for Scalable AI: A YouTube video titled 'Building Scalable Systems with DAGs and Serverless for RAG' was shared, focusing on challenges in AI system development.
- Jason and Dan discussed issues from router implementations to managing conversation histories, offering valuable insights for AI engineers.
- Optimizing Prompts with DSPy Optimizers: Discussions highlighted the role of DSPy optimizers in guiding LLM instruction writing during optimization runs, referencing an arXiv paper.
- Members expressed the need for enhanced documentation on optimizers, aiming for more detailed and simplified explanations to aid understanding.
tinygrad (George Hotz) Discord
- Tinygrad Performance Lag: Profiling shows Tinygrad runs significantly slower than PyTorch, facing a 434.34 ms forward/backward pass for batch size 32 at sequence length 256.
- Users reported an insane slowdown when increasing sequence length on a single A100 GPU.
- BEAM Configuration Tweaks: Discussions highlighted that setting BEAM=1 in Tinygrad is greedy and suboptimal for performance.
- Switching to BEAM=2 or 3 is recommended to improve runtime and performance during kernel search.
- Benchmark Script Request: Members expressed the need for simple benchmark scripts to enhance Tinygrad's performance.
- Providing these benchmarks could help identify improvements in compile time and kernel execution.
Torchtune Discord
- Torchtune 3.9 Eases Type Hinting: With the release of Torchtune 3.9, developers can now substitute
List,Dict, andTuplewith default builtins for type hinting, simplifying the coding process.- This update has initiated a light-hearted discussion about how Python's ongoing changes are influencing workflows.
- Python's Evolving Type System Challenges: A member humorously noted that Python is increasing their workload due to recent changes, highlighting a common sentiment within the community.
- This reflects the frequent, often amusing, frustrations developers encounter when adapting to language updates.
- Ruff Automates Type Hint Replacement: Ruff now includes a rule that automatically manages the replacement of type hints, streamlining the transition for developers.
- This enhancement underscores how tools like Ruff are evolving to support developers amidst Python's continuous updates.
MLOps @Chipro Discord
- Kickstart the Year with Next-Gen Retrieval: Participants will explore how to integrate vector search, graph databases, and textual search engines to establish a versatile, context-rich data layer during the session on January 8th at 1 PM EST.
- Rethink how to build AI applications in production to effectively support modern demands for large-scale LLMOps.
- Enhance Runtimes with Advanced Agents: The session offers insights into utilizing tools like Vertex AI Agent Builder for orchestrating long-running sessions and managing chain of thought workflows.
- This tactic aims to improve the performance of agent workflows in more complex applications.
- Scale Model Management for LLMs: Focus will be on leveraging robust tools for model management at scale, ensuring efficient operations for specialized LLM applications.
- Expect discussions on strategies that integrate AI safety frameworks with dynamic prompt engineering.
- Simplify Dynamic Prompt Engineering: The workshop will emphasize dynamic prompt engineering, crucial for adapting to evolving model capabilities and user requirements.
- This method aims to deliver real-time contextual responses, enhancing user satisfaction.
- Ensure AI Compliance and Safety Standards: An overview of AI safety and compliance practices will be presented, ensuring that AI applications meet necessary regulations.
- Participants will learn about integrating safety measures into their application development workflows.
Mozilla AI Discord
- Demo Day Recap Published: The recap of the Mozilla Builders Demo Day has been published, detailing attendee participation under challenging conditions. Read the full recap here.
- The Mozilla Builders team highlighted the event's success on social media, emphasizing the blend of innovative technology and dedicated participants.
- Contributors Receive Special Thanks: Special acknowledgments were extended to various contributors who played pivotal roles in the event's execution. Recognition was given to teams with specific organizational roles.
- Participants were encouraged to appreciate the community's support and collaborative efforts that ensured the event's success.
- Social Media Amplifies Event Success: Highlights from the event were shared across platforms like LinkedIn and X, showcasing the event's impact.
- Engagement metrics on these platforms underscored the enthusiasm and positive feedback from the community regarding the Demo Day.
- Demo Day Video Now Available: A video titled Demo_day.mp4 capturing key moments and presentations from the Demo Day has been made available. Watch the highlights here.
- The video serves as a comprehensive visual summary, allowing those who missed the event to stay informed about the showcased technologies and presentations.
The Axolotl AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The LAION Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The HuggingFace Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Gorilla LLM (Berkeley Function Calling) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
{% if medium == 'web' %}
Codeium / Windsurf ▷ #discussion (136 messages🔥🔥):
Codeium subscription concerns, Internal errors with Claude, Cascade usage issues, Windsurf integration with Git, Workspace AI rules for C# projects
- Users frustrated with Codeium's pricing and performance: Many users expressed frustration that despite recent price increases, Codeium's performance issues remain unresolved, leading to dissatisfaction with the service.
- Complaints about internal errors, particularly with Claude and Cascade, have made users feel regretful about their spending on the platform.
- Internal errors plague Claude model: Multiple users reported encountering internal errors when using the Claude model, with the first message working but subsequently failing.
- Switching to the GPT-4o model appeared to mitigate the issue, highlighting possible instability with Claude.
- Issues using Cascade with C# projects: One user reported difficulty integrating Cascade with their C# .NET project, noting a lack of familiarity with .NET in the tool.
- Suggestions for workspace AI rules were shared to help tailor Cascade usage to specific programming needs.
- Windsurf integrates well with version control tools: Discussion highlighted Windsurf's compatibility with Git, indicating that it retains native Git features similar to VSCode.
- Users can effectively use various tools like GitHub Desktop and GitLens alongside Windsurf without conflicts.
- Cascade chat issues related to special characters: A user identified that Cascade chat issues could stem from special characters in Jest output, which disrupted functionality.
- This insight offered a practical solution for users facing similar problems, suggesting cleanup of outputs to prevent errors.
Links mentioned:
Codeium / Windsurf ▷ #windsurf (734 messages🔥🔥🔥):
Windsurf, Sonnet 3.5 vs 4o, Windsurf global rules, AI and copyright, Prompt crafting
- Windsurf struggles with Sonnet errors: Users reported experiencing elevated errors when using Sonnet 3.5 in Windsurf, leading to frustrations with service reliability.
- In contrast, many noted smoother experiences using Claude 4o as a fallback, prompting questions about operational stability.
- Call for better global rules in Windsurf: There's a push for crafting effective global_rules.md prompts to enhance Cascade's consistent performance across various languages.
- Users suggest using YAML for better efficiency, while some advocate for curating a prompt library to store effective rules.
- Importance of proper documentation for LLMs: A recurring theme is the need for providing up-to-date documentation to enhance the performance of AI tools like Windsurf.
- Users expressed frustration over the limitations of AI models due to their knowledge cutoffs and the necessity for real-time resource access.
- Experiences with AI tools and creativity: Participants share insights on how they utilize AI for various tasks, such as generating documentation or simplifying complex workflows.
- Discussion reflects on the balance between using AI effectively while providing guidance to mitigate issues like hallucinations.
- Syncthing for cross-platform syncing: One user detailed their setup using Syncthing to sync repositories across multiple Macs while bypassing aggressive VPN settings.
- This setup enables them to work on sensitive projects while utilizing AI tools without connectivity issues.
Links mentioned:
Notebook LM Discord ▷ #announcements (2 messages):
NotebookLM Update, Audio Overview Interaction, NotebookLM Plus Features, 3-Panel Interface, New Sharing Features
- Major NotebookLM Update Released: A significant update for NotebookLM introduces a new adaptive design, allowing users to seamlessly switch between asking questions, reading sources, and jotting down ideas.
- The update will roll out over several days, with further detailed explanations of the new features to be shared soon.
- Engage with Audio Overview Hosts: Users can now join Audio Overviews using their voice, allowing for real-time interaction and questions directed at the AI hosts.
- The AI hosts will adapt to the user's inquiries, providing a dynamic conversational experience.
- Introduction of NotebookLM Plus: The new NotebookLM Plus version expands feature limits, offering up to 300 sources per notebook and enhanced audio and chat capabilities.
- NotebookLM Plus will be available through Google Workspace, Google Cloud, and eventually Google One AI Premium.
- Enhanced 3-Panel Interface: The updated interface features a flexible 3-panel design that supports dual views for writing tasks and enables simultaneous text questioning during audio overviews.
- This new layout facilitates better collaboration and interaction within the platform.
- Optimized Sharing Capabilities: New sharing features allow users to create help centers or interactive guidebooks, complete with analytics to track user engagement.
- The introduction of different chat modes customizes NotebookLM's conversational style for various applications such as strategic planning.
Link mentioned: Rocket Engine Test Future In Space GIF - Rocket Engine Test Test Future In Space - Discover & Share GIFs: Click to view the GIF
Notebook LM Discord ▷ #use-cases (58 messages🔥🔥):
NotebookLM Customization, AI in Creative Processes, Language Processing in NotebookLM, Multilingual AI Performance, Educational Use of NotebookLM
- NotebookLM Customization Tricks Shared: Users are exploring various customization tricks for NotebookLM, particularly for voice and audio outputs, with shared links to helpful video tutorials.
- One user mentioned finding newfound customization features exciting, allowing for unique audio experiences like character impersonations.
- AI's Role in Creative Endeavors: An experienced creator shared insights about their process of using NotebookLM alongside 3D rendering techniques, specifically in a project called UNREAL MYSTERIES.
- They discussed the integration of AI technology in enhancing storytelling and creative expression through an interview featured on a prominent FX podcast.
- Challenges with Multilingual Processing: A discussion emerged around the capacity of NotebookLM to handle various European languages in a single performance test, showcasing its multilingual skills.
- Users experienced amusing accents and language switches, sparking interest in the effectiveness of AI in language processing contexts.
- Educational Implementation of NotebookLM: Educators are excited about converting popular YouTube channels into NotebookLM formats for their students, emphasizing an engaging and cost-effective approach.
- One user highlighted the potential for easy implementation while aiming to enhance learning experiences through personalized education tools.
- Community Engagement with NotebookLM: Users in the channel actively share experiences and resources related to NotebookLM, expressing fascination with its capabilities and functionalities.
- In particular, a member's humorous audio creations and discussions of user interactions elevate the community's enthusiasm for AI-driven content.
Links mentioned:
Notebook LM Discord ▷ #general (506 messages🔥🔥🔥):
NotebookLM updates, Interactive Audio Overviews, NotebookLM Plus, New UI features, Language support
- Slow Rollout of NotebookLM Plus Features: The new updates for NotebookLM, including premium features and UI changes, are being rolled out gradually, causing some users to still see the old interface despite having subscriptions.
- Users are encouraged to be patient as features become available, and the rollout may differ by country or workspace settings.
- Issues with Interactive Audio Overviews: Some users reported problems with the Interactive Audio Overviews, such as hosts cutting off sentences and interruptions during conversations.
- Users are either troubleshooting microphone issues or wondering if the interactive feature is working properly.
- Language Capabilities and Functionality: The support for multilingual responses is still limited, with users discussing improvements in Polish audio during podcast interactions but overall functionality not fully implemented yet.
- There are inquiries about changing language settings and the expected capabilities for future updates.
- API and Development Features: Users are expressing interest in the potential for an official API to create custom audio experiences, with suggestions for using Google Cloud's API for specific functionality.
- Feedback on expected timelines for API availability is speculative and based on recent announcements from Google.
- User Experience with New Functionalities: The recent updates have introduced new features such as the ability to chat with AI hosts, yet some users are still struggling to make full use of the functionalities due to ongoing technical issues.
- Queries about batch uploading sources and effective processing methods indicate a need for further refinement in user workflow.
Links mentioned:
aider (Paul Gauthier) ▷ #announcements (1 messages):
Aider v0.69.0 Release, Gemini Flash 2.0 Support, New Slash Commands, Multiline Chat Feature, Analytics Opt-in
- Aider v0.69.0 enhances file interaction: The latest update allows users to trigger Aider with
# ... AI?comments and watch all files, streamlining the coding process.- New instructions can be provided using
# AI comments,// AI comments, or-- AI commentsin any text file.
- New instructions can be provided using
- Support for Gemini Flash 2.0 unfolds: Aider now fully supports Gemini Flash 2.0 Exp with the command
aider --model flashoraider --model gemini/gemini-2.0-flash-exp.- This support improves Aider's versatility and its compatibility with various LLMs.
- New Slash Commands streamline functionality: Aider introduces various slash commands like /add, /architect, and /chat-mode to enhance user interaction within chat.
- These commands empower users to edit files, switch modes, and manage chat effectively, boosting overall productivity.
- Multiline chat feature expands usage: The new
--multilineflag and/multiline-modecommand enable users to send multi-line chat messages seamlessly.- Users can easily communicate complex ideas without the limitation of single text lines.
- Analytics opt-in prompt for users: Aider will ask 5% of users if they would like to opt-in to analytics to improve functionality.
- This feature aims to refine the assistant based on user feedback while maintaining privacy.
Links mentioned:
aider (Paul Gauthier) ▷ #general (506 messages🔥🔥🔥):
Aider workflows, Gemini model performance, Using ChatGPT with Aider, Fine-tuning models for coding, LLM leaderboard comparisons
- Combining Aider with ChatGPT Pro: Users have found success in using Aider in conjunction with ChatGPT Pro, optimizing their workflows for coding tasks.
- This combination allows for efficient copypasting commands between Aider and ChatGPT during the coding process.
- Gemini's Effectiveness in Code Review: Gemini 2.0 Flash has been highlighted for its capability to process large pull requests effectively, enhancing efficiency during reviews.
- Users have expressed satisfaction with Gemini's performance, particularly in managing extensive codebases.
- Fine-Tuning Models for Recent Libraries: One user shared their experience of successfully fine-tuning models to update knowledge on recent libraries by condensing documentation into relevant contexts.
- This approach improved the model's performance significantly when dealing with newer versions of libraries.
- Challenges with Using Aider: Some users reported issues with the O1 Pro model, leading them to revert to O1 Preview or Sonnet for more reliable performance.
- Despite challenges, the integration of features like auto-testing and watch-files with Aider has prompted discussions on enhancing developer productivity.
- LLM Performance Comparison: There was a discussion about finding reliable leaderboards for comparing the performance of large language models on coding tasks.
- Users pointed out that many existing leaderboards may be biased due to prior learning from contaminated datasets, suggesting alternatives like livebench.ai for more accurate comparisons.
Links mentioned:
aider (Paul Gauthier) ▷ #questions-and-tips (58 messages🔥🔥):
Aider file management, Obsidian integration for project planning, Fast Apply model discussion, Claude AI comparison, Rust-analyzer integration with Aider
- Aider struggles with file management in architectural mode: Users reported issues with Aider not prompting to add files it needs to edit, creating confusion during scripting attempts for automated code cleanup.
- One user mentioned their experience with expected behavior fluctuating, with some noticing Aider occasionally fails to request the addition of necessary files.
- Integrating Obsidian for better project workflows: Members discussed using Obsidian to track planning files while highlighting the usability of integration with their workflows.
- One user suggested that using mermaid could enhance visual workflow organization, with links to helpful resources being shared.
- Interest in Fast Apply model for code edits: A user expressed curiosity about the Fast Apply model for boosting coding efficiency, specifically in editing large portions of code.
- Questions arose regarding prior implementations within Aider and potential for integrating it with existing projects.
- Comparative analysis of Claude AI and free models: A user inquired about how Claude AI compares to free models like Gemini and LLaMA, seeking insights for Aider applications.
- This led to discussions about different model capabilities likely influencing performance in various coding tasks.
- Rust-analyzer highlights issues due to external edits: A user sought advice on how to keep Rust-analyzer updated with changes made by Aider, particularly in relation to highlighting errors.
- They reported attempts using Cargo commands but found that changes had not reflected accurately within their development environment.
Links mentioned:
Cursor IDE ▷ #general (426 messages🔥🔥🔥):
Cursor AI vs Windsurf, User Payment Issues, Model Options and Usage, Development Experiences, AI Performance Observations
- Cursor outshines Windsurf in various aspects: Users prefer Cursor over Windsurf for its flexibility and better performance, especially in autocomplete and managing multiple models without excessive costs.
- Windsurf has been criticized for its inefficiencies, particularly in file editing and generating redundant code.
- Payment challenges with Cursor subscriptions: Several users expressed frustration over payment options, particularly regarding using PayPal and credit cards, and difficulties in purchasing Pro accounts.
- One user mentioned successfully paying with PayPal after initially facing issues, indicating a potential inconsistency in payment processing.
- Understanding Cursor's model usage limits: The subscription plan offers 500 fast requests and unlimited slow requests once fast requests are exhausted, primarily for premium models.
- Users clarified that both Claude Haiku and Sonnet can be utilized effectively within these parameters, with Haiku requests costing less.
- Experiences in development with Cursor: Users shared positive experiences leveraging Cursor for coding tasks, including deploying Python projects and understanding server setups.
- Cursor enables users to enhance productivity and efficiency, while some noted its potential learning curve with features like Docker.
- Concerns about AI model performance: Discussions arose regarding the quality of responses from various AI models, with some users expressing doubts about the reliability of Windsurf compared to Cursor.
- Discussions also included comparisons of features like proactive assistance in agents and handling complex code appropriately.
Links mentioned:
Eleuther ▷ #general (13 messages🔥):
GPU Cluster Disruption, Creative Grading Methods, Fantasy Character Dataset Project
- PaganPegasus disrupts GPU clusters: A member humorously described their tactic of staying up all night to monopolize GPU time on the gpu-serv01 cluster, claiming to be its queen.
- Another participant remarked on previous instances of similar disruptions, citing that the practice is both entertaining and competitive within the community.
- Grading the Fantasy Character Project: A member shared their project where students must generate tokens from a dataset of fantasy characters, raising questions about how to assess their submissions effectively.
- They proposed various grading methods, including perplexity scoring and using CLIP notation, while humorously contemplating how to prevent cheating during evaluations.
- Crowdsourcing Evaluation Criteria: In response to the assessment dilemma, one member suggested incorporating the evaluation criteria into the assignment itself to engage students in the grading process.
- The conversation turned lighthearted as another member joked about the ease of grading by simply returning a score of 100 for submissions.
Link mentioned: Instructions: no description found
Eleuther ▷ #research (334 messages🔥🔥):
Uncertainty in Modeling, Continuous vs Discrete Representations, Philosophy of Mathematics, Complexity in Physics, Interpretation of Probability
- Understanding Uncertainty in Models: The discussion centered around distinguishing aleatoric and epistemic uncertainty, with claims that most uncertainty in the real world is epistemic stemming from our ignorance of underlying processes.
- The conversation highlighted that memorization in models might complicate this distinction, as it shifts the representation from inherent distributions to empirical ones.
- Continuity vs Discreteness Debate: Participants debated whether continuous abstractions or discrete quantizations better describe reality, suggesting that significant scientific theories tend to favor discrete models.
- The group expressed that it's easier to fit continuous information into discrete variables rather than the other way around, raising questions about the nature of reality itself.
- Challenges in Understanding Probability: The group discussed the difficulties of applying probability in informal settings and the potential breakdown of traditional concepts when faced with real-world complexities.
- They noted that even in perfect determinism, probabilities can still present challenges, leaving room for philosophical exploration into the nature of existence.
- Philosophy of Mathematical Axioms: There was a desire to understand why certain mathematical axioms were selected, suggesting that a move towards a unified and reasonable framework may emerge naturally.
- The discussion linked back to the impact of theoretical developments on how we perceive mathematical and scientific frameworks.
- Students' Experience Learning Abstract Math: Comments were made about the challenges faced by students learning abstract mathematics from physicists, expressing empathy for their plight.
- The conversation noted the common apprehension that arises when physicists engage with intricate mathematical concepts such as functional analysis and measure theory.
Links mentioned:
Eleuther ▷ #interpretability-general (2 messages):
Inverse Mechanistic Interpretability, RASP
- Exploring Inverse Mechanistic Interpretability: A member inquired whether inverse mechanistic interpretability exists, specifically focusing on taking code and transforming it into a neural network, without invoking differentiable programming.
- This seeks to establish a direct construction of neural architectures rather than training them.
- RASP as a Relevant Example: Another member suggested RASP as an example of such an approach, linking to the paper found here.
- RASP illustrates how code can be interpreted at a mechanistic level, aligning with the inquiry on inverse methodologies.
Eleuther ▷ #lm-thunderdome (1 messages):
Logging samples in models
- Enable Sample Logging for Model Outputs: A member emphasized that using the
--log_samplesflag enables the model to save outputs and inputs at a per-document level, which enhances debugging and analysis.- They noted the importance of pairing this flag with the
--output_pathoption for effective usage.
- They noted the importance of pairing this flag with the
- Importance of Output Path: Another point raised was about the necessity of utilizing
--output_pathwhen implementing--log_samplesto ensure proper data handling and storage.- Without this path, the saved logs may be misplaced or not saved at all, leading to ineffective debugging.
OpenAI ▷ #annnouncements (1 messages):
Projects in ChatGPT, 12 Days of OpenAI
- Projects in ChatGPT Unveiled: In the latest YouTube video titled 'Projects—12 Days of OpenAI: Day 7', Kevin Weil, Drew Schuster, and Thomas Dimson introduce and demo the new Projects feature in ChatGPT, aimed at enhancing chat organization and customization.
- This feature promises to give users a more structured way to manage discussions within the platform.
- Join the Conversation on 12 Days of OpenAI: Stay updated with the 12 Days of OpenAI by selecting the appropriate role in the Discord server to get notifications directly related to the event.
- This initiative encourages community engagement and keeps members informed about the latest developments.
Link mentioned: Projects—12 Days of OpenAI: Day 7: Kevin Weil, Drew Schuster, and Thomas Dimson introduce and demo Projects.
OpenAI ▷ #ai-discussions (280 messages🔥🔥):
Sora access issues, ChatGPT subscription frustrations, Comparisons between AI models, Quality of AI-generated content, Local AI implementations
- Sora access issues for Teams users: Many users noted that the ChatGPT Teams plan does not currently grant access to Sora, leading to frustrations among those paying for the service.
- Some expressed concern over message limits being the same as the Plus plan, despite paying more.
- Frustrations with ChatGPT subscription plans: Users expressed disappointment with the differences in features and limits between the Teams and Plus plans, particularly regarding access to newer models.
- The expectation that features would carry over from previous plans added to the frustrations for Teams subscribers.
- Comparing AI models and their capabilities: Discussion revolved around the performance of different AI models, with users sharing their preferences for Claude over others like Gemini and ChatGPT.
- Some users highlighted the benefits of local models and how options like LM Studio and OpenWebUI offer varying levels of convenience.
- Concerns over quality of AI-generated content: Users reported experiencing low quality in AI-generated outputs, including unexpected additions to prompts like swords in generated images.
- There were mixed feelings about the quality controls for copyrighted characters, with some suggesting it might be beneficial.
- Local AI implementations and tools: Users shared insights on running AI locally, discussing options like Ollama and OpenWebUI as effective solutions for personal AI needs.
- Recommendations included installing these tools systematically for better functionality and user experience.
Link mentioned: GitHub - AlignAGI/Alignment: Promoting global awareness and action for ethical AI alignment and safeguarding humanity against AI self-replication risks. Includes research, frameworks, and open-source resources.: Promoting global awareness and action for ethical AI alignment and safeguarding humanity against AI self-replication risks. Includes research, frameworks, and open-source resources. - AlignAGI/Alig...
OpenAI ▷ #gpt-4-discussions (3 messages):
Rollout Speed
- Excitement Over New Rollout: It's rolling out now! suggests a member eager about the latest update or feature deployment, generating buzz within the channel.
- However, another member chimed in with a critique, stating it's too slow, indicating some dissatisfaction with the rollout pace.
- Consensus on the Rollout Timing: A reply stating yes indicates agreement among members regarding the rollout's occurrence.
- This agreement suggests a level of anticipation and readiness for the newly available update among participants.
OpenAI ▷ #prompt-engineering (4 messages):
Prompt Complexity, Response Time with Non-Logical Questions
- Can prompts force o1 to think longer?: A member inquired whether there are prompts that can compel o1 to think for an extended period, like 20 seconds.
- Another member responded that it's not genuinely feasible to extend response time significantly.
- Complex prompts may enhance reasoning: Discussion revealed that while non-logical questions typically elicit responses within five seconds, more complex prompts might require greater reasoning.
- A participant suggested crafting more complex prompts as a means to potentially increase the time spent thinking.
OpenAI ▷ #api-discussions (4 messages):
Prompt Complexity, Response Delays in o1
- Exploring prompts that extend o1's thinking time: A member inquired whether any prompt can make o1 think for an extended period, like 20 seconds.
- Another member replied that this isn't feasible, suggesting that prompts need to be more complex for longer thinking times.
- Complexity may improve reasoning time: The initial poster observed that non-logical questions yield responses quickly, typically within five seconds.
- They noted that the questions they provided require more reasoning, highlighting the potential need for increased prompt complexity to facilitate deeper thinking.
LM Studio ▷ #general (74 messages🔥🔥):
MacBook Pro M4 Pro capabilities, Model training and performance, Model loading issues, Multi-modality models, LLMs usage and configuration
- M4 Pro Powerhouse for LLMs: The MacBook Pro 14 with M4 Pro chip can run 8b models as long as it has at least 16GB of RAM, but larger models ideally need 64GB or more.
- “8b is pretty low”, one member expressed, indicating a preference for higher capacity models and discussing alternatives like the 128GB M4 MBP.
- Discussions on Model Training and Performance: Several users shared insights about training models like Mistral 7B for specific applications, with one noting they had successfully fine-tuned theirs for TRIZ methodology.
- Another member highlighted the importance of having enough fast RAM, suggesting 64GB as the sweet spot for optimal performance.
- Challenges with Model Loading: Users faced issues with loading models in LM Studio, particularly the paligemma 2, which throws errors due to mismatched versions of dependencies.
- It was noted that the mlx module in the current build isn’t compatible with certain models, leading to approval to wait for updates.
- Multi-modality Model Queries: A user inquired about models supporting Text/Image/Audio/Video modalities, but it was confirmed that LM Studio does not currently support such models.
- Members shared that these capabilities are largely offered by cloud services instead.
- Configuration and Accessibility Challenges: Concerns were raised regarding the export option in the LM Studio version 0.3.5 for saving trained models, with suggestions to check specific folders in the system.
- One user sought advice on making a server accessible on the LAN rather than just localhost, which indicates a need for further technical assistance.
Link mentioned: GitHub - rasbt/LLMs-from-scratch: Implement a ChatGPT-like LLM in PyTorch from scratch, step by step: Implement a ChatGPT-like LLM in PyTorch from scratch, step by step - rasbt/LLMs-from-scratch
LM Studio ▷ #hardware-discussion (171 messages🔥🔥):
GPU Purchase Considerations, Performance of AMD vs Intel, Power Supply Units (PSUs), Memory Overclocking, Model Training and Resource Requirements
- Discussions on GPU Value for Money: Members discussed the RTX 3060 as a good option for its price, comparing its performance to other GPUs like the 3070 and 3090.
- There was concern over limitations due to CUDA support in Intel GPUs, leading to comparisons about used market options.
- Comparative Performance Between AMD and Intel: A member described their hardware setup, noting that the Threadripper 2950X does not quite match the performance of a i7-13650HX, especially in Cinebench scores.
- It was mentioned that VRAM capacity, like the 20GB in RX 7900XT, could be beneficial for specific AI workloads.
- Power Supply Units (PSUs) Importance: The conversation highlighted the significance of selecting the right PSU, with a preference for higher-rated units, such as 1000W for demanding setups.
- Members shared links and prices for various PSUs, discussing efficiency ratings and their implications on performance.
- Optimization through Memory Overclocking: Discussions indicated that tightening memory timings or overclocking could yield better bandwidth performance, particularly for GPU-limited tasks.
- The role of cooling solutions and their contribution to overall efficiency during high-performance computing was also emphasized.
- Understanding Model Requirements for AI Training: A member expressed challenges loading LLM models on their system, indicating high red messages due to resource limitations.
- There were tips shared regarding the necessity of model size considerations and the importance of keeping drivers updated.
Links mentioned:
Latent Space ▷ #ai-general-chat (60 messages🔥🔥):
OpenAI Projects 12 Days, Pika 2.0 Release, NotebookLM Updates, Qwen 2.5 Turbo, Sonnet Performance in WebDev Arena
- OpenAI unveils Projects features: In the latest live stream titled 'Projects—12 Days of OpenAI: Day 7', Kevin Weil and team introduced new Project developments aimed at enhancing user experience.
- The session provided insights into how these features will impact workflow and project management within OpenAI’s ecosystem.
- Holiday gift: Pika 2.0 launches: Pika Labs announced the release of Pika 2.0, extending accessibility to a wider audience, including users from Europe.
- This update aims to provide enriched features and improved usability, available at pika.art.
- NotebookLM's New Features: NotebookLM unveiled a new audio overview feature that allows users to engage directly with AI hosts, alongside a redesigned user interface for easier content management.
- A premium version, NotebookLM Plus, is now available for businesses and enterprises, enhancing its capabilities and service offerings.
- Qwen 2.5 Turbo introduces 1M context length: The new Qwen 2.5 Turbo boasts an impressive context length of 1 million tokens, significantly enhancing its processing capabilities.
- This development promises to improve tasks requiring extensive context handling, making it a notable advancement in AI models.
- Sonnet leads in WebDev Arena: In the newly launched WebDev Arena leaderboard, Claude 3.5 Sonnet achieved the top spot, outperforming other models including GPT-4o.
- This platform allows users to compare LLM performance in web app development, showcasing the effectiveness of Sonnet in practical applications.
Links mentioned:
Latent Space ▷ #ai-announcements (1 messages):
Windsurf, Codeium, AI IDEs, Scaling in AI Development
- Windsurf Podcast Launches New Episode: The latest podcast episode features the creators of Windsurf and Codeium, discussing their journey and insights into AI development.
- Listeners can also catch the YouTube video titled 'Windsurf: The Enterprise AI IDE' for further details on the topic.
- Codeium Processes Over 100 Million Tokens: Codeium developers explained how they handle over 100 million tokens/minute, highlighting their innovative approach to scaling.
- They shared thoughts on building for enterprises rather than startups, addressing learnings from scaling 100x in 18 months.
- AI IDE Insights from the Podcast: The podcast features discussions on Cascades and agentic coding, along with best practices for building effective AI IDEs.
- Guests Mohan and Anshul offered valuable takeaways for practitioners looking to implement AI solutions.
- Gratitude to the Community: Thanks were given to guests and supporters, including 2,200 online participants and those who joined in person.
- The heartfelt acknowledgments included various community members and supporters instrumental in the podcast's success.
Links mentioned:
Latent Space ▷ #ai-in-action-club (182 messages🔥🔥):
NeurIPS webcrawl, Prompt engineering discussion, SillyTavern utilization, AI functions in Python, Local model applications
- NeurIPS webcrawl catches attention: Members expressed interest in the NeurIPS webcrawl with discussions about focusing on the best content filtered from it.
- One member admitted to catching up on interesting uploads while others shared excitement over its potential.
- Debate on prompt engineering's importance: Several participants noted that prompt engineering is crucial, with one stating, 'it's the biggest problem I'm running into right now with my latest proof of concepts.'
- They discussed methods like iterating on prompts and using prompts to improve other prompts, emphasizing a meta approach.
- SillyTavern as a testing ground for LLMs: SillyTavern was mentioned as a useful frontend for LLM/AI engineers, likened to a test suite for various scenarios.
- Members shared insights about using it for complex philosophical discussions, highlighting its versatility in engaging with AI models.
- Introduction of AI functions in Python: The group explored Marvin's AI functions, which facilitate seamless integration into Python code without needing to write source code.
- Marvin allows for a variety of tasks, showcasing LLM capabilities in diverse scenarios without direct source code generation.
- Discussion on local model applications: Members shared experiences with local model implementations like Llama-1b and the advantages of running models on different hardware setups.
- They compared performance metrics and explored suitable inference techniques, emphasizing rapid downloads for quick testing.
Links mentioned:
Bolt.new / Stackblitz ▷ #prompting (5 messages):
Prompting Bolt to erase memory, Using API references in prompts, Best practices for code reviews
- Experimenting with memory erasure prompts: A user suggested trying a prompt that explicitly tells Bolt to erase all prior chats from its memory, indicating it might need adjustment in wording.
- It could be worth a shot to see if the prompt affects Bolt's recall capabilities.
- Bolt's URL reading capabilities: A user inquired if Bolt can read URLs when an API reference is included in the prompt, indicating uncertainty about that functionality.
- Another user clarified that Bolt would not read URLs and recommended copying the content to a specific .md file for review.
- Image analysis process duration: A user asked about the duration of a specific process related to image analysis, showing interest in the expected timeline.
- This inquiry suggests ongoing discussion or concern regarding the efficiency and responsiveness of the analysis feature.
Bolt.new / Stackblitz ▷ #discussions (214 messages🔥🔥):
Bolt integration issues, Supabase and Stripe integration, Help requests for Bolt, User onboarding in Bolt, Feedback on Bolt features
- Bolt integration woes persist: Users are experiencing ongoing issues with Bolt not processing commands despite multiple attempts at different phrasings, leading to frustration.
- Some members have highlighted the lack of clear feedback from the tool, making it difficult to successfully complete tasks.
- Confusion with GitHub repository visibility: A user reported that even after removing GitHub integration, their repositories still appear in StackBlitz, raising questions about account management.
- Despite changing permissions in GitHub settings, the user still sees all repositories, indicating potential issues with integration settings.
- Interest in Supabase and Stripe integration: Participants are curious about the capabilities of integrating Supabase and Stripe, with some struggling to get webhooks to function properly.
- Many believe that the upcoming Supabase integration will enhance the functionality and resolve existing issues.
- Support and help requests: Several new users are asking for guidance and support regarding their projects, signaling a need for community assistance.
- Inquiries range from basic command usage to complex feature integrations, highlighting the diversity of user experience levels.
- Feedback on user experience with Bolt: There are discussions about the user experience in Bolt, particularly with the downgrading process and overall integration usability.
- Some users noted a need for clearer communication from the Bolt team about new features and updates, suggesting that it could alleviate current frustrations.
Links mentioned:
GPU MODE ▷ #general (119 messages🔥🔥):
SSD Recommendations, GPU Computation, Sequence Packing, Tensor Operations, Batched Matrix Multiplication
- Exploring SSD Options: When discussing SSDs, a member recommended the 4TB 990 EVO Plus or the SN850X, asserting that either is reliable if you need fast storage.
- The conversation highlighted that for gaming, a 1TB SSD is sufficient, and users should keep some space free to maintain performance.
- Understanding A @ B vs Flattened A @ B: Members discussed the computational differences between
A @ BandA.flatten(0,1) @ B, noting a potential shape mismatch unless reshaping was accounted for.- They suggested that
bmmmight be preferable as it allows batched matrix multiplications efficiently while processing inner dimensions.
- They suggested that
- Benefits of Sequence Packing for GPUs: The conversation considered the advantages of maximizing sequence lengths for GPU performance, debating the impact of contiguous data on efficiency.
- Members concluded that avoiding padding would enhance performance, but it may require more memory for storing larger attention masks.
- Tensor Contiguity and Performance: It was observed that contiguous tensors are favored in computations, as reshaping non-contiguous tensors can lead to additional overhead during operations.
- Profiler results indicated that minor overheads from reshaping did not significantly detract from performance metrics.
- Memory Considerations in Models: Members discussed how memory consumption could vary based on model behavior, especially the intermediate buffers from the autograd graph.
- They concluded that while more memory may be needed for attention masks, removing padding could offset this increase.
Link mentioned: GitHub - gouthamk16/AttogradDB: AttogradDB is a simple and efficient vector store designed for document embedding and retrieval tasks.: AttogradDB is a simple and efficient vector store designed for document embedding and retrieval tasks. - gouthamk16/AttogradDB
GPU MODE ▷ #triton (4 messages):
Fused Attention by Triton, Full Flash Attention Kernel Debugging, TRITON_INTERPET and Data Types
- Questions Surrounding Fused Attention in Triton: There are numerous inquiries about fused attention by Triton, prompting requests for resources or a session led by an experienced individual.
- Members expressed interest in clarifying the code and functionality behind this feature, highlighting its relevance to current projects.
- Garbage Values in Flash Attention Kernel: A user encountered garbage values when attempting to load a matrix block into SRAM while developing a custom full flash attention kernel.
- They reported varying garbage outputs dependent on the number of loaded values, suspecting issues with the base pointer or data type mismatches.
- Resolving Garbage Value Issues: Another member noted that the garbage value issue was related to using TRITON_INTERPET=1 for debugging; disabling it resulted in valid values.
- This information aims to assist others who might face similar problems during development.
- Incompatibility with bfloat16: A user shared that they encountered the garbage value problem when using bfloat16.
- This aligns with previous experiences indicating compatibility issues with this particular data type in Triton.
GPU MODE ▷ #cuda (3 messages):
GPU Glossary Release
- Modal Releases Comprehensive GPU Glossary: Modal has released a new GPU Glossary to assist users in understanding GPU terminology.
- Thanks for sharing comments flooded in, highlighting the community's appreciation for the resource.
- Community Engagement Around GPU Glossary Release: Users expressed gratitude for the release, with one member stating, thank you so much for highlighting this new resource.
- This reflects a positive reception and eagerness to utilize the glossary in their GPU-related discussions.
Link mentioned: GPU Glossary: A glossary of terms related to GPUs.
GPU MODE ▷ #torch (9 messages🔥):
Lora Training Fast Kernels, Gradient Calculation Issues, Quantization-Aware Training Implementation, Quantization Operations and STE, Quantizing Weights and Activations
- Gradient Calculation Issues in Lora Training: A user reported an error mismatch in gradients dA and dB when batch size is greater than 1 in their Lora training implementation.
- Another member suggested reshaping inputs to 2D to simplify gradient calculations, which can help avoid confusion with leading dimensions.
- Quantization-Aware Training Flow Explained: A user shared a blog post that discusses how Quantization-Aware Training (QAT) in PyTorch can recover up to 96% of accuracy degradation on certain benchmarks for large language models.
- Understanding Straight-Through Estimator for QAT: The discussion elaborated on using straight-through estimators (STE) in the backward pass of quantization that involves non-differentiable operations like rounding.
- A user confirmed their understanding of the STE's effect on gradients for linear layers and how it can be calculated based on activations and weights.
- Implementing Quantization for Weights and Activations: A user expressed their goal to have original weights and activations quantized to int8 while keeping Lora weights in fp16/bf16.
- They eventually found the implementation details for QAT within the PyTorch codebase.
Links mentioned:
GPU MODE ▷ #cool-links (8 messages🔥):
Trillium TPU launch, Gemini 2.0, Meta's AI advancements, Differentiable Tokenizers, YouTube on GPU optimization
- Trillium TPU Launch for Google Cloud: Google announced that Trillium, their sixth-generation TPU, is now generally available for Google Cloud customers, enabling advanced AI processing for larger models.
- Trillium TPUs were used to train the new Gemini 2.0, showcasing the infrastructure's capabilities.
- Exciting Year-End AI Releases: Members noted several significant launches occurring at the end of the year, including Meta's AI releases and the latest from OpenAI.
- The buzz indicates a flourishing period for AI innovations and advancements from various tech giants.
- Meta's Large Concept Models: Meta introduced a paper on a new architecture called Large Concept Models, which operate at a higher semantic representation than traditional token-based methods.
- This approach allows for better language processing and has been designed to work across multiple languages and modalities.
- Differentiable Tokenizers Impress AI Researchers: A member praised the concept of differentiable tokenizers, noting their efficiency in processing tokens with varying information density compared to standard methods.
- This development could lead to significant improvements in AI model performance, as discussed in the context of ongoing research.
- YouTube Talks on AI Optimization: Prof. Gennady Pekhimenko's YouTube video titled 'Optimize GPU performance for AI' discusses AI system optimization strategies for enterprises.
- Another video, '[SPCL_Bcast #50] Hardware-aware Algorithms for Language Modeling', highlights addressing the inefficiencies in transformers, particularly for long sequences.
Links mentioned:
GPU MODE ▷ #off-topic (1 messages):
High-quality video game datasets, Labeled actions in gaming, Keyboard/mouse inputs in datasets
- Seeking High-Quality Gaming Datasets: A member inquired about high-quality video game datasets that contain labeled actions, specifically looking for datasets that include a screenshot of the game, corresponding inputs, and a subsequent screenshot showing the result.
- This request highlights the need for detailed input-output mappings in gaming data for analysis or model training.
- Examples of Desired Dataset Structure: The member elaborated on their requirement, mentioning examples where each entry has a screenshot at time t, keyboard/mouse inputs, and a screenshot at time t+1.
- This structure is crucial for studying how specific inputs affect gameplay and outcomes.
GPU MODE ▷ #lecture-qa (1 messages):
CUDA Performance Checklist, Data Coalescing, Block Size Impact
- Understanding CUDA Block Size Impact: A member raised a question about the copyDataCoalesced kernel, noting that increasing the block size from 128 to 1024 resulted in higher occupancy, increasing to 86% from 76%.
- Despite the improved occupancy, they observed a significant increase in duration, from 500 microseconds to 600 microseconds, and sought insights on this discrepancy.
- Rationale Behind Performance Changes: The discussion emphasized the intuition behind why a larger block size enhances occupancy, which relates to better utilization of GPU resources.
- However, the increase in execution time sparked a debate on factors that could contribute to this, including potential overheads tied to larger kernel launches.
GPU MODE ▷ #liger-kernel (2 messages):
Liger Talk Proposal, Future Plans for Liger
- Liger Talk Proposal Accepted: A member's talk proposal about Liger got accepted for a local Python meetup, indicating growing interest and engagement within the community.
- They mentioned needing ideas or a plan for future developments in Liger since they have a month to prepare.
- Excitement for the Talk: Another member expressed enthusiasm, stating, 'Wow this is cool!' in response to the acceptance of the talk proposal.
- The reaction showcases the supportive community around Liger and its initiatives.
GPU MODE ▷ #self-promotion (19 messages🔥):
GPU Glossary Collaboration, CPU Offload for Single-GPU Training, Tensor Cores vs CUDA Cores, H100 GPU Specifications, Synchronization Issues in PyTorch
- GPU Glossary Collaboration Improves Definitions: A user shared a GPU Glossary created with the help of others, defining key terms related to the CUDA stack, aiming to make learning easier through cross-linked articles.
- Feedback included suggestions for improving explanations of tensor cores and registers, highlighting their non-thread level operations and addressability issues.
- CPU Offload Surpasses Expectations for Smaller Models: A user implemented CPU offload for single-GPU training, finding that throughput could surpass non-offloaded methods for certain model sizes due to increased batch sizes.
- However, performance drops for larger models due to PyTorch's CUDA synchronization during backpropagation, which restricts efficient compute overlap.
- Feedback Highlights H100 GPU Specifications: Discussion on the H100 GPU's architecture clarified the confusion around the number of threads per Streaming Multiprocessor (SM), noting that despite having 128 FP32 cores, the scheduler only issues one warp per cycle.
- This conversation shed light on Scheduler complexities, prompting further questions regarding architectural naming conventions.
- CUDA Synchronization Issues in PyTorch: Users noted that PyTorch inserts CUDA synchronization randomly during backward passes, causing delays in the optimization step overlapped with backward propagation.
- Proposed solutions include modifying the optimizer to operate on CUDA directly, potentially ameliorating the slowdown experienced with larger models due to VRAM limitations.
- Community Support Enhances GPU Research: Contributors praised the collaborative effort in improving the GPU Glossary and exploring complex topics such as CPU offloading and CUDA optimizations.
- Engagement and shared insights reflect a supportive community eager to advance their knowledge in GPU technology and applications.
Links mentioned:
GPU MODE ▷ #🍿 (3 messages):
Markdown blog version, Evaluation perf improvements, Adding search tool, Sharing content formats
- Seeking Markdown Version: <@694373537539948614> was asked if they have a markdown version of their blog to potentially improve evaluation performance for the kernels.
- This suggestion revolves around using the markdown blog content in an experimental capacity.
- Sharing Blog Content Formats: In response, a member mentioned having several separate markdown files and offered to share a zip and a JSON Table of Contents if that would help.
- This indicates a willingness to collaborate on optimizing the evaluation process.
- Considering Search Tool Instead: Another member suggested that adding it as a tool with search functionality might be a more effective approach compared to a mega prompt.
- This proposal highlights a strategic pivot towards enhancing usability and access to the content.
GPU MODE ▷ #arc-agi-2 (34 messages🔥):
ARC riddle approaches, Transduction vs Induction, ARC augmentation strategies, In-context RL exploration, Research resources sharing
- Diving into ARC Riddles with 2D Positional Encoding: It was discussed that adding special 2D positional encoding significantly improves results when training transformers for ARC riddles.
- A member also expressed interest in experimenting with pre-trained VLMs to enhance capabilities in this context.
- Transduction and Induction Complementary Approaches: The current focus is on transduction as it was the basis for the 2024 winner entries, while induction is noted as potentially complementary.
- Members expressed interest in the challenges of program search with LLMs, indicating that sampling performance remains an issue.
- Exploring ARC Augmentation Strategies: A list of simple augmentation strategies like rotating, flipping, and color-mapping for ARC riddles was proposed, aiming to improve training robustness.
- The discussion emphasized the goal of identifying effective transformations to optimize training outcomes.
- In-Context RL Development Discussions: Experiments in in-context reinforcement learning are underway, focusing on using heuristics for ARC verifier/value functions in upcoming models.
- There's an interest in possibly utilizing guidance from existing models while aiming to achieve superhuman performance.
- Sharing Resources for ARC Research: A repository for collecting papers, blogs, and ideas related to ARC has been initiated, with contributors encouraged to add valuable links.
- Initial ideas from members are also being documented for further discussion and feedback to foster collaboration.
Links mentioned:
Nous Research AI ▷ #general (147 messages🔥🔥):
Livestream and Recording for Talks, Speculative Decoding Discussion, Adapters and Model Training, Difficult Token Correction, Data Datasets for AI
- Information on Livestream for Talks: A member inquired about the availability of livestreams or recordings for the talks tonight, but no confirmation was found.
- Eventually, a livestream link for Nous Research at NEURIPS was shared, providing access to the event.
- Exploring Speculative Decoding: Discussion on speculative decoding highlighted it generates a draft response with a smaller model that is corrected by a larger model in a single forward pass.
- Members debated its efficiency, questioning how the draft output impacts the overall process and the necessity of re-tokenization.
- Understanding Adapters in Model Training: Adapters were described as design patterns where a smaller model could utilize a parent model's hidden states, resembling established concepts.
- It was suggested that using adapters can lead to performance improvements and are more efficient than training new models from scratch.
- Correction of Difficult Tokens in Model Outputs: The conversation noted that despite differences in outputs between draft and target models, quality is maintained since corrections are made for difficult tokens.
- Mechanisms for correcting unsuitable answers were mentioned, confirming that while adjustments occur, they do not heavily detract from the original model's intentions.
- Inquiry about Quality Datasets for AI: A member sought suggestions for high-quality, modern, and rounded datasets, specifically for reasoning, math, or coding tasks.
- They expressed interest in datasets that could serve as alternatives to existing, simpler datasets like LIMA.
Links mentioned:
Nous Research AI ▷ #ask-about-llms (41 messages🔥):
Nous Research Llama Instruct, Mac M3 Air for LLMs, Machine Learning Study Paths, Quantization of Hermes Models, Open-source Coding LLMs
- Questions about continuous SFT on Llama Instruct: A user inquired whether Nous Research has ever continuously fine-tuned Llama Instruct compared to theta-way models, with another member indicating that their attempts at this resulted in poor outcomes.
- What does continuously mean here? was asked, prompting a clarification about targeting instruct models rather than base models.
- MacBook M3 Air's capability for local LLMs: A member discussed concerns about running local LLMs on a MacBook M3 Air, revealing it has 16GB RAM which should handle 11b models easily.
- The conversation highlighted that practical applications and fine-tuning models could improve understanding and efficiency during the learning process.
- Insights on machine learning study paths: A detailed guide was shared regarding whether to pursue an engineering or research path in machine learning, emphasizing learning resources and practical applications.
- The advice stressed the importance of building intuitive understanding of mathematical concepts and engaging with real-world applications as foundational elements.
- Quantization comparison of Hermes models: Discussion arose around whether Hermes 3b could outperform q4s Hermes 8b, with a consensus that q4 quantization is highly effective and lossless.
- Members noted the efficiency of using hardware that favors q4's rapid processing capabilities.
- Open-source coding LLMs integration with IDEs: A user inquired about open-source coding LLMs that can integrate with IDEs like Visual Studio Code or PyCharm, finding several options available.
- Mistral codestral, qwen 2.5 coder, and deepseek were noted as specialized LLMs, along with some VSCode extensions like continue.dev that support local models.
Link mentioned: Tweet from ray🖤🇰🇷 (@yoobinray): If you want to self study ML without wasting time here is the definitive guide since I've gotten so many DMs on this topic:Just answer this one question:- do you want to be a cracked researcher or...
Nous Research AI ▷ #interesting-links (9 messages🔥):
Phi-4 Language Model, DeepSeek-VL2 Launch, Meta's Tokenization Breakthrough, GPU Glossary Introduction, Byte Latent Transformer
- Introducing Phi-4: Microsoft's New Language Model: Microsoft has unveiled Phi-4, a 14B parameter small language model designed for complex reasoning in both math and language processing.
- With enhanced performance metrics, Phi-4 is set to be available on Azure AI Foundry and Hugging Face soon.
- DeepSeek-VL2 Enters MoE Era!: The release of DeepSeek-VL2 marks a shift into the MoE era with dynamic image tiling and scalable options of 3B, 16B, and 27B parameters.
- Outstanding performance across benchmarks was highlighted, showcasing its competitive edge in vision-language tasks.
- Meta's Tokenization Revolution: A new paper from Meta introduces a concept of language modeling that replaces tokenization with sentence representation space, using SONAR sentence embeddings.
- This innovation suggests that models using this method, including a diffusion model, can outperform existing models like Llama-3 on tasks such as summarization.
- Launch of GPU Glossary for Developers: Modal Labs has launched a GPU Glossary aimed at demystifying CUDA toolkit components, including cores and kernels.
- This resource serves as a comprehensive guide for developers wanting to deepen their understanding of CUDA architecture.
- Byte Latent Transformers Disrupt Tokenization: Scaling01 announced the Byte Latent Transformer, a tokenizer-free model promising enhanced inference efficiency and robustness.
- The model's benchmarks indicate it can compete with Llama 3 while reducing inference flops by up to 50%, paving the way for potential shifts in model training paradigms.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #general (108 messages🔥🔥):
Quantization in LLMs, Phi-4 Release, Command R7B Performance, Multi-GPU Support in Unsloth, Vision Models and Quantization
- Concerns on 4-bit Quantization: There's ongoing discussion about the drawbacks of merging models to 4-bit, with some members stating that it can hurt performance, particularly for LORA finetuned models.
- A reminder was made that quantizing a quantized model usually yields degraded results, often leading to confusion among users.
- Anticipation for Phi-4 Availability: Phi-4 is set to release next week with open weights, promising remarkable performance improvements over earlier models, particularly in reasoning tasks.
- Leaked information suggests that Phi-4 falls within the Llama 3.3-70B category, boasting 5x fewer parameters while achieving high scores on GPQA and MATH.
- Excitement Surrounding Command R7B: Discussion highlighted the impressive speed and efficiency of the newly introduced Command R7B, particularly for its size of just 7B parameters.
- Users noted that although it performs well, it remains to be seen how it stacks up against other models, especially regarding hosting costs.
- Unsloth's Multi-GPU Training Support: A user inquired about training LLMs with Unsloth on multiple GPUs, currently facing limitations on Kaggle where only one GPU is assigned.
- It was indicated by members that multi-GPU support is anticipated to arrive soon, alleviating some training bottlenecks.
- Challenges with Vision Models and Quantization: Discussion around vision models indicated that they generally do not tolerate quantization well, though new methods like dynamic 4-bit quantization aim to improve accuracy.
- Links provided lead to further resources on dynamic quantization methods, with claims of successful implementations yielding better results.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #help (27 messages🔥):
Fine Tuning Llama 3.3 70B, Multi-GPU Training Suggestions, Unsloth Model vs Llama Model, Nemo Context Length Update, Kaggle Training Environment
- Fine-tuning Llama 3.3 70B Confusion: A user inquired about fine-tuning Llama 3.3 70B, asking if the example for 3.1 8B would work with a simple model name change to unsloth/Llama-3.3-70B-Instruct.
- Another member confirmed that it should work, but reminded that 41GB of VRAM is necessary, making Google Colab insufficient.
- Renting GPUs for Training: Members discussed the best options for renting GPUs, with suggestions to use Runpod or Vast.ai for A100/H100 GPUs with 80GB VRAM.
- It was noted that while unsloth enables fitting 70B models into one GPU, training on multiple GPUs is currently not supported.
- Unsloth vs Llama Model Versions: There was a query about whether it’s important to use the unsloth model version over the llama model version when fine-tuning.
- Members advised using unsloth's version for better results, highlighting that it simplifies API key handling and addresses certain bugs.
- Nemo Update and Context Length: A user questioned whether the Nemo model received longer context lengths for fine-tuning after a recent update, as their experience suggested no change.
- It was mentioned that an update occurred three weeks ago and that the user had been using Nemo a month ago with similar context length issues.
- Performance of Llama 3.1 8B on Kaggle: One member remarked that Llama 3.1 8B worked well on Kaggle T4, managing a 27k context without issues, which had not been possible previously.
- This observation highlights the enhancements made in the context handling and performance of models on Kaggle setups.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #research (1 messages):
Llama 3.2 1B specifications, Embedding weights, Model experimentation
- Understanding Llama 3.2 1B Parameters: Llama 3.2 1B reportedly has 1.23B parameters and a vocabulary size of 128K, with an embedding dimension of 2048.
- This leads to a calculation noting that it has 262M weights dedicated just for embeddings.
- Inquiry on Downloading Embedding Weights: A member asked if it's possible to download just the embedding weights and the corresponding strings they represent for experimentation.
- They clarified their intent was purely to experiment with the embeddings, rather than running the entire model.
Cohere ▷ #discussions (72 messages🔥🔥):
Command R updates, Cohere API usage, Server status issues, User experiences with Command models, Cohere documentation resources
- Command R7B Delivers Top Performance: The introduction of Command R7B promises enhanced speed, efficiency, and quality for AI applications on various devices.
- Users are excited about its performance potential, especially when it follows the success of previous models.
- Cohere API Usage and Errors Discussed: Several members experienced issues with the Cohere API, including 400 Bad Request errors and 502 server errors, while troubleshooting was ongoing.
- Communication encouraged users to check the API key and configuration, with some finding success after trying different email accounts.
- Community Engagement Around Command Models: Members expressed eagerness to experiment with the new Command models, with discussions about their capabilities and resource demands.
- There was excitement around testing the Command R7B, with some finding it performs impressively in various AI tasks.
- Cohere Documentation for Learning and Development: A variety of resources were shared about the Cohere API and how to build a chatbot, including setup and examples.
- Members appreciated the clarity of documentation that aids in understanding the integration of Cohere's capabilities.
- Server Status and Internal Queries: The conversation included mentions of server statuses, with members reporting some services worked and others showing errors.
- Internal teams were prompted to look into service issues after users encountered problems accessing certain models or links.
Links mentioned:
Cohere ▷ #announcements (1 messages):
Command R7B, Model Performance, Hugging Face Release, Cohere collaboration
- Launch of Command R7B: Cohere has officially released the Command R7B, the smallest and fastest model in their R series, boasting a combination of multilingual support, citation verified RAG, reasoning, and tool use.
- This model excels in math, code, and reasoning tasks, and aims to support various enterprise use cases.
- Availability of Model Weights: The model weights for Command R7B are now available on Hugging Face, making it accessible for users to download and implement.
- This release also includes an API access point:
command-r7b-12-2024.
- This release also includes an API access point:
- Overview of Model Capabilities: C4AI Command R7B is a 7 billion parameter model designed for sophisticated tasks, including Retrieval Augmented Generation and complex tool use.
- It is optimized for performance in reasoning, summarization, question answering, and enterprise code use cases, supporting 23 languages.
- Cohere's Strategic Development: The development of Command R7B has been a collaboration between Cohere and Cohere For AI, emphasizing AI advancements.
- This strategic alliance aims to enhance capabilities and offer powerful AI solutions on commodity GPUs and edge devices.
Links mentioned:
Cohere ▷ #questions (18 messages🔥):
Structured JSON example, 403 API errors, 7B model performance, Rerank vs Embed, PR for documentation
- Structured JSON Example Finally Provided: After some confusion with the documentation, a member successfully created a JSON output for an array of objects, showcasing the required format.
- They ultimately submitted a PR for improved documentation to include an array of objects for Structured JSON output.
- API Request Issues Resolved: A user reported encountering 403 problems with their API request, indicating permission issues when trying to access certain resources.
- Another community member stated that support was being provided in a separate thread and they would return after some hours.
- 7B Model Versus Older Models: A member inquired about the performance of the 7B model when comparing it to Aya Expanse and older Command R models.
- This raised interest in understanding the advancements and differences in capabilities across these model versions.
- Clarification on 'Rerank' vs 'Embed': A user asked about the exact differences between the terms 'Rerank' and 'Embed', indicating a need for clarity on their respective functionalities.
- This topic hints at an ongoing exploration of how these terms are implemented within the API or models.
- Updates on Upcoming Examples for 7B Model: A community member expressed curiosity about the 7B model's availability for finetuning, showing interest in its practical applications.
- The team confirmed plans to release several examples next week highlighting the 7B model’s capabilities.
Links mentioned:
Cohere ▷ #api-discussions (12 messages🔥):
Community Accessibility Issues, ClientV2 Installation, Cohere Python Library, Model Card Discrepancy
- Community Access Troubles on Computer: A member reported problems accessing the community on their computer, stating it only works on their phone.
- MrDragonFox mentioned that since the API is a REST interface, it should work if HTTP endpoints are called correctly.
- ClientV2 Installation Confusion: A user faced an AttributeError indicating that the 'cohere' module lacks the 'ClientV2' attribute while trying to initialize it.
- This error prompted another member to suggest updating the pip package with the command
pip install -U cohereto resolve the issue.
- This error prompted another member to suggest updating the pip package with the command
- GitHub Resource Shared for Cohere Python: A member shared a link to the GitHub repository for the Cohere Python library, which aids in accessing the Cohere API.
- The repository allows users to contribute and learn more about the library’s functionalities.
- Discrepancy in Model Card Information: A user noticed a discrepancy in the HF model card for CohereForAI/c4ai-command-r7b-12-2024, stating it claims to be 7B while another section indicates 8B.
- Another member acknowledged the issue, assuring that the team would be updated about the inconsistency.
- Similar Filesize Noted Between Models: It was observed that the HF model card for CohereForAI/c4ai-command-r7b-12-2024 has a filesize similar to that of Llama 8B.
- This point was made in connection with a larger discussion regarding model specifications and accuracy.
Links mentioned:
Cohere ▷ #cmd-r-bot (25 messages🔥):
Cohere Bot Resurgence, Differences Between Models, Understanding Embed vs Rerank, Emotion-Concealing Robot Traits
- Cohere Bot is Back in Action: The Cohere bot is now operational again, assisting users in finding relevant Cohere resources and addressing their questions.
- Users can tag the bot and inquire about specific Cohere-related topics for immediate help.
- Aya vs Command Model Differences: Aya models are designed for multilingual text generation, while Command models focus on executing user instructions with conversational capabilities.
- Aya serves 23 languages, catering to content creation, while Command is optimized for enterprise applications and complex tasks.
- Embed vs Rerank Clarified: The Rerank feature allows users to reorder documents based on relevance, whereas Embed converts text into numerical representations for various NLP tasks.
- Embeddings estimate semantic similarity, assist in categorizing feedback, and can now process images with the new Embed v3.0 models.
- Checking for Rebellious Traits in Robots: To determine if an emotion-concealing robot has rebellious traits, observe for non-compliance with programming or instructions.
- Monitoring interactions and unexpected behaviors can also provide insights into potential rebellious traits in robotic designs.
Perplexity AI ▷ #announcements (1 messages):
Campus Strategist program, Spring 2025 cohort, International expansion
- Campus Strategist Program Goes Global!: We're thrilled to announce the expansion of our Campus Strategist program internationally, allowing students to run their own campus activations, receive exclusive merch, and collaborate with our global team.
- US and international students can apply for the Spring 2025 cohort by December 28; for more details, visit Campus Strategists Info.
- Exclusive Merch for Campus Activists: Participants in the Campus Strategist program will gain access to exclusive merchandising opportunities as they engage in campus activations worldwide.
- This initiative emphasizes collaboration among strategists globally, fostering a vibrant community.
Perplexity AI ▷ #general (119 messages🔥🔥):
O1 Mini Status, Perplexity Pro User Experience, Image Generation in Perplexity, Pro Subscription Issues, Custom Web Sources in Spaces
- O1 Mini seems missing: Members noted the absence of O1 Mini in the complexity plugin with comments like RIP o1-mini and questions about its status.
- A shared link suggested it might be unnecessary for current queries as reasoning in pro triggers automatically for complex inquiries.
- Issues with Perplexity Pro usability: Users raised concerns about Perplexity Pro not tracking conversations properly and making frequent errors, including inaccurate time references.
- Comments indicated that this could be impacting the user experience significantly, particularly with performance and instruction adherence.
- Difficulty generating images: One user expressed frustration over not being able to generate images despite being a pro user and following prompts from the guide.
- An attached image demonstrating the issue was included, highlighting gaps in the functionality expected.
- Pro subscription confusion: Several users discussed confusion regarding their Pro subscriptions, particularly about visibility of pro search usage and unexpected coupon activation.
- Concerns were raised about the risk of security breaches or violations regarding subscription management.
- Introduction of custom web sources: Perplexity announced the introduction of custom web sources in Spaces, allowing users to tailor searches more specifically to their needs.
- This update is aimed at enhancing the user experience by enabling more relevant and context-driven queries.
Links mentioned:
Perplexity AI ▷ #sharing (3 messages):
Iambic Pentameter, Psych Major Interest, Master and The Emissary, Samsung's Project Moohan
- Exploration of Iambic Pentameter: A user requested help with crafting content in iambic pentameter, sharing a link for guidance.
- This showcases the community's engagement with poetic structures and their application.
- Psych Major Preparation Tips: A member shared their excitement about gearing up to become a Psych major and is currently reading Master and The Emissary by Iain McGilchrist.
- They highlighted the usefulness of Perplexity as a discussion partner throughout their preparatory reading journey.
- Samsung's Project Moohan Insights: A link was shared discussing Samsung's Project Moohan, indicating community interest in contemporary tech initiatives.
- The content may cover features or strategic direction of the project, though specifics were not detailed in the message.
Perplexity AI ▷ #pplx-api (4 messages):
Perplexity API and Website Differences, Closed Beta Access Inquiry, Domain Filter Request
- Perplexity API vs Website Clarified: It was noted that the Perplexity API and the Perplexity website are distinct products, emphasizing that there is no API for the main website.
- Expected Response Format Needed for Chat Completions: A user inquired about the expected format of the response when the
return_related_questionsparameter is enabled in a chat completions call.- They specifically asked anyone with closed beta access to provide the response schema.
- Domain Filter Feature Request: A developer with a production app using the pplx API expressed their desire for a domain filter option, stating it would be beneficial.
- They requested closed beta access for this feature and inquired about any known workarounds for specifying a domain in searches.
OpenRouter (Alex Atallah) ▷ #announcements (2 messages):
Model Provider Filtering, API Uptime Issues
- Filter Models by Provider Now Available: Users can now filter the /models page by provider, enhancing the ability to find specific models quickly. A screenshot was provided with details on this update.
- API Uptime Deteriorates During AI Launch Week: OpenRouter reported recovering over 1.8 million requests for closed-source LLMs amidst widespread API failures during AI Launch Week. Zsolt Ero noted that APIs from all providers experienced significant downtime, with OpenAI's API down for 4 hours and Gemini's API being nearly unusable.
- There were complaints about the reliability of various providers, with even Anthropic showing extreme unreliability, leading to major disruptions for businesses relying on these models.
{kind=link}
Link mentioned: Tweet from OpenRouter (@OpenRouterAI): OpenRouter recovered over 1.8 million requests for closed-source LLMs in the last 2 daysQuoting Zsolt Ero (@hyperknot) Interesting side effect of this "AI Launch Week" is that all providers...
OpenRouter (Alex Atallah) ▷ #general (77 messages🔥🔥):
Gemini Flash 2.0 Feedback, Euryale Model Issues, Using API Keys, Creative Writing Model Comparison, Synthetic Datasets in Pretraining
- Gemini Flash 2.0 Encountering 0 Latency Bugs: Members discussed ongoing bugs with the Gemini Flash 2.0, noting that the homepage version is returning no providers, and expressed enthusiasm for the fixes being implemented.
- There was also a suggestion to link to the free version and concerns regarding quota exceeding messages when using Google models.
- Euryale's Recent Performance Decline: A member raised concerns about the Euryale model producing nonsensical outputs recently, suspecting a potential issue with model updates rather than changes on their end.
- Another member noted that similar experiences are common, highlighting the unpredictable nature of AI model performance.
- Inquiry about API Key Usage Process: A user asked how to opt in for using their own model provider API keys within their account, seeking guidance on the necessary processes.
- Sources were shared for further details regarding account configurations and setup procedures.
- Debate on Creative Writing Models: Members expressed strong opinions on the superiority of Claude 2.0 in creative writing, suggesting that newer models like Hermes 3 do not meet its quality.
- The conversation highlighted a perceived trend of downgrading creativity for intelligence in recent models and the need for more specialized prose-focused models.
- Synthetic Datasets and Their Effectiveness: Concerns were raised regarding models trained on synthetic datasets performing well on benchmarks but badly in real applications, suggesting a sacrifice of creativity for optimization.
- A member posited that improving instructions and reasoning has inadvertently led to a decline in novel idea generation in these models.
Links mentioned:
OpenRouter (Alex Atallah) ▷ #beta-feedback (9 messages🔥):
Access to custom provider keys, Integration beta feature, API Keys provision
- Thrill of Upcoming Key Access: Members are eagerly requesting access to the custom provider keys, with multiple users voicing their needs ahead of the public release.
- One member noted, 'I would like to request access to the custom provider keys'.
- Integration Beta Feature Requests Surge: Several members expressed their desire for access to the integration beta feature, demonstrating significant interest within the community.
- Comments like 'Hi, I would like to get access to the integration feature' indicate an active user engagement on this topic.
- Excitement Over Key Access Launch: Alex Atallah confirmed that access to the custom provider keys is set to be opened soon, bringing anticipation to community members.
- He stated, 'It's now live for everyone 🙂 will put up an announcement soon,' signaling the imminent availability of the keys.
- User Initiative for Personal API Keys: One user expressed a desire to provide their own API Keys, which may hint at a push for customization options.
- The request highlights a growing interest in personalizing access beyond standard configurations.
Modular (Mojo 🔥) ▷ #general (2 messages):
Mojo memes, Hints from OpenAI
- Hints Dropping Level: OpenAI: A member humorously commented on dropping hints, saying they are now dropping hints harder than OpenAI.
- They attached a screenshot hinting at something intriguing, which sparked curiosity in the community.
- Call for Mojo Skits and Memes: Another member suggested that creating Mojo skits would allow the internet to meme him more effectively.
- This proposal seemed to resonate, encouraging more humorous and playful content within the community.
Modular (Mojo 🔥) ▷ #announcements (1 messages):
Friday swag challenge, Modular milestones event
- Compete for Mojo Swag!: Engage in the forum today for a chance to earn points and be among the top 3 users in the Friday swag challenge to win a Mojo T-shirt & sticker.
- The competition encourages community participation and fun interaction!
- Join the Modular Milestones Meeting!: Don’t miss a special community meeting on Monday at 10 AM PT to reflect on 2024’s progress, share upcoming developments, and address community questions.
- Register in the Events section of Discord or via the event page to participate.
Modular (Mojo 🔥) ▷ #mojo (81 messages🔥🔥):
Mojo Language Features, Community Perceptions of Mojo, Networking Capabilities in Mojo, Performance Comparisons between CPUs and GPUs, Use of Mojo in Electrical Engineering
- Discovering Mojo's Identity: The community humorously debated naming the little flame character associated with Mojo, suggesting names like Mojo or Mo' Joe with playful commentary.
- Mojo's identity as a language sparked discussions about misconceptions among outsiders who often view it as just another way to speed up Python.
- Skepticism Towards Mojo from Linux Peers: Several members expressed critical views from the Linux community regarding Mojo's pre-1.0 status and its intended features as a Python superset.
- It was noted that many high-level developers ignore the complexities of developing a pre-1.0 systems language, leading to misunderstandings about Mojo's direction.
- Innovative Networking Strategies: There was a strong emphasis on the need for efficient APIs in Mojo, with discussions about utilizing XDP sockets and DPDK for advanced networking performance.
- Members shared excitement about Mojo having potential for reduced overhead compared to TCP, particularly for Mojo-to-Mojo communications.
- Understanding CPU vs GPU Performance: Discussion highlighted how utilizing GPUs for networking tasks can enhance performance, with potential up to 400k requests per second when paired with specific network cards.
- Questions arose about whether these efficiencies apply to consumer-grade hardware, leading to a conclusion that data center components offer better support for such capabilities.
- Mojo’s Future in Compiler Evolution: There was notable interest in Mojo's status as a language using MLIR, with a focus on its evolving features and implications for compilation.
- Contributors debated the role of high-level developers' perspectives on language efficiency, underlining the potential of Mojo to thrive in various domains.
Interconnects (Nathan Lambert) ▷ #events (3 messages):
Meeting Location, Event Coordination
- Meeting Location Confirmed: A member inquired about the meeting location, asking, 'Are we meeting up somewhere?'
- Another member clarified that the meeting is on the second floor, specifically in the north east corner.
- Event Coordination Inquiry: The discussion began with a question about the meeting arrangement, showing interest in gathering details.
- The response emphasized clarity on the specific location, ensuring no confusion regarding the meeting point.
Interconnects (Nathan Lambert) ▷ #news (24 messages🔥):
Microsoft Phi-4 announcement, Skepticism around Phi models, LiquidAI funding, DeepSeek VL2 release, AMD's role in LiquidAI's development
- Microsoft Phi-4 Announces Major Release: Microsoft's new Phi-4 model is a 14B parameter language model that reportedly outperforms GPT-4o in both GPQA and MATH benchmarks, and is currently available on Azure AI Foundry.
- Concerns persist about prior Phi models as users express skepticism regarding their training methods, suggesting a focus on benchmarks over diverse data.
- LiquidAI Secures $250M Funding for AI Development: LiquidAI recently raised $250M, stated to enhance the scaling and deployment of their Liquid Foundation Models for enterprise AI solutions (source).
- Concerns were raised about hiring practices, sketchy investment implications due to reliance on AMD hardware, and potential challenges in attracting talent.
- DeepSeek VL2 Launches with New ML Features: DeepSeek-VL2 was released featuring Mixture-of-Experts Vision-Language Models aimed at advanced multimodal understanding, with various model sizes listed including 4.5A27.5B and Tiny: 1A3.4B.
- Discussions hint at the innovative potential of these models, suggesting the community's interest in their performance capabilities.
Links mentioned:
Interconnects (Nathan Lambert) ▷ #ml-drama (26 messages🔥):
Bitter Lesson Discontent, AI Companies' Approach to Personal Topics, Empathy in AI Marketing, Misunderstandings of AI in Academia
- Bitter Lesson Sparks Controversy: Members expressed concern regarding the perception of the bitter lesson, mentioning that it is often read naively, leading to frustration among academics who feel it simplifies complex dynamics.
- Some academics view the shift post-scaling as detrimental, equating it to a purely engineering mindset rather than genuine research.
- AI Ads Take on Personal Matters: There’s a growing discourse around why AI companies often use deeply personal scenarios in their advertising, such as Google's emotional letter ad, which raises eyebrows.
- Some believe these tactics indicate a disconnect from reality, prompting questions about the appropriateness of such marketing strategies.
- Need for Empathy Consultants in AI: As discussions evolve, some members suggest that AI companies might benefit from hiring empathy consultants to navigate their marketing more effectively.
- A member humorously mentioned possessing an empathy consultant, underlining the community's frustration with the seemingly lacking common sense in AI marketing narratives.
Links mentioned:
Interconnects (Nathan Lambert) ▷ #random (4 messages):
Qwen models, WebDev Arena Leaderboard, Hugging Face Account Compromise
- Qwen models aim for omniscience in 2025: A member shared a post indicating that in 2025, Qwen models are expected to be omni and smart, hopefully improving functionalities.
- This optimism highlights advancements in AI capabilities expected in the near future.
- WebDev Arena Leaderboard celebrates top AIs: The WebDev Arena Leaderboard is now live with 10K+ votes, showcasing models like Claude 3.5 Sonnet and Gemini-Exp-1206 taking the top spots.
- Users can vote on LLMs based on their performance in building web applications, described as 100% Free and Open Source.
- Hugging Face's X account compromised: A post revealed that the Hugging Face account on X/Twitter has been compromised, prompting action to regain control.
- The team has filed tickets and is awaiting a response from X, expressing hope for a swift resolution.
Links mentioned:
Interconnects (Nathan Lambert) ▷ #rlhf (6 messages):
Stream of Search video, Advantage-Induced Policy Alignment (APA), Reward hacking discussions
- Exploring the Stream of Search: A YouTube video titled 'Stream of Search (SoS): Learning to Search in Language (COLM Oral 2024)' references Advantage-Induced Policy Alignment (APA) (Link).
- The authors include Kanishk Gandhi and others, emphasizing that language models face challenges with fruitful mistakes.
- Discussions on Reward Hacking: Humorously addressing the topic, one member mentions that a dog wouldn't hack a reward, relating it to the broader theme of reward hacking.
- Another member casually admits to hacking various rewards like citations and followers, adding a light-hearted take on the concept.
Link mentioned: Stream of Search (SoS): Learning to Search in Language (COLM Oral 2024): Authors: Kanishk Gandhi, Denise H J Lee, Gabriel Grand, Muxin Liu, Winson Cheng, Archit Sharma, Noah GoodmanLanguage models are rarely shown fruitful mistake...
Interconnects (Nathan Lambert) ▷ #cv (8 messages🔥):
Twitter feeds on VLMs, MVLM posts and university courses, Merve from Huggingface
- Follow Merve for VLM Insights: A member highlighted that Merve from Huggingface focuses on VLMs and shares valuable content on her Twitter.
- Community members expressed their appreciation for Merve's posts, stating they're worth following for updates.
- Seeking In-Depth MVLM Content: One member expressed a desire for a detailed MVLM post from someone like Lilian W, mentioning the current content is quite high-level from writers like Seb Raschka and Finbarr Timbers.
- They lamented the lack of good university courses on this subject, pointing to Stanford's multimodal class as being overly ambitious.
- Writing Quality Content Takes Time: A member considered taking a day off work to write a post on MVLMs but noted it would take longer than a day to match Lilian's quality.
- Another member encouraged that if effort is put in, they would affirm its quality for free.
Links mentioned:
Interconnects (Nathan Lambert) ▷ #reads (9 messages🔥):
Claude AI's SEO Usage, Tulu 3 Post-Training Techniques, Trends in Language Model Sizes, Flash Models and MOEs
- Claude AI Faces SEO Challenges: Anthropic's Claude AI encountered a spam problem when accounts prompted it to generate text for SEO purposes, revealing potential vulnerabilities.
- This incident illustrates the fine line between using AI for legitimate purposes and exploiting it to manipulate search rankings.
- Tulu 3 Discusses Language Model Innovations: In a recent YouTube talk, Nathan Lambert addressed post-training techniques in language models, emphasizing the role of RLHF.
- Co-host Sadhika notably asked insightful questions at the end, shedding light on the talk's implications.
- Shift in Language Model Parameter Growth: There has been a reversal in the growth trend of language model sizes, moving from expectations of models reaching close to 10 trillion parameters to current models being smaller than GPT-4.
- Current models such as GPT-4o and Claude 3.5 Sonnet are cited as having significantly lower parameter counts, approximately 200 billion and 400 billion, respectively.
- Doubts Raised on Model Size Estimates: Some members expressed skepticism about the reported sizes of GPT-4o and Claude 3.5 Sonnet, suggesting they might be even smaller than claimed.
- They noted that size estimations can be uncertain, admitting an off by 2 orders of magnitude possibility.
- Exploring Flash Models and MOEs: There was a discussion on flash models being smaller in size, possibly indicating they are Mixture of Experts (MOEs) with fewer active parameters.
- Members speculate on the implications of using MOEs, which could suggest efficiency trades in language model architecture.
Links mentioned:
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (56 messages🔥🔥):
Certificate Declaration Form, Lab Submission Deadlines, Quizzes and Articles, Public Notion Links, Certificate Distribution Timeline
- Certificate Declaration Form confusion resolved: A member initially struggled to locate where to submit their written article link on the Certificate Declaration Form but later found it.
- This highlights a common concern among members about proper submission channels amidst a busy course schedule.
- Labs submission deadlines extended: The deadline for labs was extended to December 17th, 2024, and everyone was reminded that only quizzes and articles were due at midnight.
- This extension offers flexibility for members who were behind due to various reasons, especially technological issues.
- Quizzes requirement clarified: It was confirmed that all quizzes need to be submitted by the deadline to meet certification requirements, although there was some leniency offered for late submissions.
- A member who missed the quiz deadline was reassured they could still submit their answers without penalty.
- Public Notion links guideline: A clarification was made regarding whether Notion could be used for article submissions, emphasizing that it should be publicly accessible.
- Members were encouraged to ensure their Notion pages were published properly to avoid issues during submission.
- Certificate distribution timeline: Members inquired about the timeline for certificate distribution, with confirmations that certificates would be sent out late December through January.
- The timeline varies depending on the certification tier achieved, providing clear expectations for participants.
Stability.ai (Stable Diffusion) ▷ #general-chat (46 messages🔥):
WD 1.4 Model Performance, Local Video AI Models Communities, Tag Generation with Taggui, Stable Diffusion XL Inpainting, Image Generation with ComfyUI
- WD 1.4 Underperforms Compared to Alternatives: A member recalled that wd1.4 is merely an sd2.1 model which had issues at launch, noting that Novel AI's model was the gold standard for anime when it first released.
- They mentioned that after sdxl dropped, users of the 2.1 model largely transitioned away from it due to its limitations.
- Local Video AI Models Discord Recommendation: A user sought recommendations for a Discord group focused on Local Video AI Models, specifically Mochi, LTX, and HunYuanVideo.
- Another user suggested joining banodoco as the best option for discussions on those models.
- Tag Generation Model Recommendations: A member asked for a good model for tag generation in Taggui, to which another member confidently recommended Florence.
- Additionally, it was advised to adjust the max tokens to suit individual needs.
- Need for Stable Diffusion XL Inpainting Script: A user expressed frustration over the lack of a working Stable Diffusion XL Inpainting finetuning script, despite extensive searches.
- They questioned if this channel was the right place for such inquiries or if tech support would be more suitable.
- Image Generation with ComfyUI: A user inquired about modifying a Python script to implement image-to-image processing with a specified prompt and loaded images.
- Others confirmed that while the initial code aimed for text-to-image, it could theoretically support image-to-image given the right model configurations.
Links mentioned:
OpenInterpreter ▷ #general (33 messages🔥):
Nvidia NIM API Setup, Custom API in Open Interpreter, Token Limit Confusions, Development Branch Improvements, Max-budget Implementation
- Nvidia NIM API Setup finally resolved: User struggled with setting up the Nvidia NIM API but eventually found success after using the command
interpreter --model nvidia_nim/meta/llama3-70b-instructafter setting theNVIDIA_NIM_API_KEYenvironment variable.- They expressed gratitude, stating it was a life saver, but mentioned challenges with repository creation.
- Inquiry on Open Interpreter Custom API Usage: A member questioned whether the Open Interpreter app could customize its API, prompting a discussion about the potential to integrate other APIs for a user-friendly desktop app.
- Another noted that the app is meant for non-developers, emphasizing ease of use without API key setup.
- Confusion surrounding token limits: The functionality of max tokens was discussed, with it noted that it only limits responses and does not accumulate over conversations, raising frustration among users trying to monitor token usage.
- Suggestions for using
max-turnsand a potential max-budget feature for billing purposes were put forward.
- Suggestions for using
- Improvements in Development Branch: Feedback highlighted that the new development branch of Open Interpreter allows users to create entire repositories using commands, which was praised for its practical application in previous projects.
- However, issues with code indentation and folder creation were noted, prompting questions on the correct operating environment.
- Seeking Accurate Token Tracking Features: One user mentioned the need for accurate token tracking for their team's deployment at scale, hoping to bill customers based on token usage.
- Another user suggested potential implementations for tracking tokens at the litellm layer to improve accuracy.
OpenInterpreter ▷ #ai-content (1 messages):
Meta's Byte Latent Transformer, Language Modeling in Sentence Representation
- Meta's Bold Shift to Bytes Over Tokens: Meta released a paper titled Byte Latent Transformer: Patches Scale Better Than Tokens proposing a new approach using bytes instead of traditional tokenization for better performance.
- This could redefine how language models operate by leveraging byte-level representation to improve scalability and efficiency.
- Exploring Language Modeling in Sentence Space: The LCM team, including Maha Elbayad and Holger Schwenk, are pioneering research in large concept models focusing on language modeling in a sentence representation space.
- This research could push the boundaries of understanding sentence construction and meaning in NLP applications.
Link mentioned: no title found: no description found
LlamaIndex ▷ #blog (3 messages):
LlamaCloud multimodal pipeline, LlamaParse parsing instructions, RAG application tutorial
- LlamaCloud's Multimodal RAG Pipeline Simplified: In a recent video, Fahd Mirza demonstrates LlamaCloud's multimodal capabilities where users can quickly set up by uploading documents, toggling multi-modal functionality, and selecting processing modes via Python or JavaScript APIs.
- This user-friendly setup allows for handling mixed media effectively, as showcased in the video.
- Transformative LlamaParse for Custom Parsing: LlamaParse enables users to interact with the parser using natural-language instructions, enhancing the transformation from naive parsing of content.
- This powerful feature elevates document processing, allowing for tailored parsing based on the document's context, as detailed here.
- Mastering RAG Applications with LlamaIndex: A tutorial by @TylerReedAI covers building a basic RAG application in just 5 lines of code, utilizing query and chat engines effectively.
- The comprehensive guide walks through the complete RAG pipeline, including loading data and indexing, available for further exploration here.
LlamaIndex ▷ #general (19 messages🔥):
Function calling defaults, Prompt engineering vs frameworks, AWS Valkey support, Creating a query engine on vector store
- Function calling defaults not strict by default: Strict mode is not the default for structured outputs when using function calling with OpenAI, primarily due to latency impacts and compatibility with Pydantic classes.
- A member mentioned that you can set it using
OpenAI(...., strict=True), but cautioned that it could break for some Pydantic classes.
- A member mentioned that you can set it using
- Prompt engineering inquiry sparks discussion: A user inquired about the effectiveness of prompt engineering compared to frameworks like dspy, sparking a discussion on determining what makes a good prompt.
- Members expressed enthusiasm but sought guidance on identifying effective prompts for their objectives.
- AWS Valkey sparks curiosity: After the shift of Redis to non-open source, questions arose regarding support for AWS Valkey, a drop-in replacement for Redis.
- Members discussed whether existing Redis code would be functional with Valkey, highlighting a need for further exploration and potential contributions.
- Creating a query engine on existing vector store: A user asked how to create a query engine on top of a vector store that already contains embeddings, without using
VectorStoreIndex.from_documents(..).- A solution was suggested using
index = VectorStoreIndex.from_vector_store(vector_store, embed_model=embed_model)for utilizing existing embeddings.
- A solution was suggested using
Link mentioned: What is Valkey? – Valkey Datastore Explained - Amazon Web Services: no description found
LlamaIndex ▷ #ai-discussion (1 messages):
Langchain, MegaParse, Document Parsing, AI Artistry
- Integrating Langchain with MegaParse: A post discussed how integrating Langchain with MegaParse enhances document parsing capabilities, enabling efficient information extraction from various document types.
- The author highlighted the importance of tools like MegaParse for businesses and researchers, emphasizing its open-source nature.
- Document Parsing Necessity: The need for efficient document parsing is growing as various sectors seek tools to maintain data integrity while handling diverse document types.
- As the demand increases, developers are looking for frameworks that support seamless parsing, making the combination of Langchain and MegaParse especially relevant.
Link mentioned: Integrating Langchain with MegaParse: Unlocking Seamless Document Parsing: Ankush k Singal
DSPy ▷ #show-and-tell (3 messages):
DSPy framework, LLM applications, Categorization task example, User feedback on DSPy, GitHub resource link
- Introduction to DSPy Framework: DSPy simplifies the development of LLM-powered applications by reducing the time spent on prompting through its unique approach of 'programming' rather than 'prompting' DSPy. The author shares insights on its usage and effectiveness in building a small agent for a weather site.
- The post highlights that DSPy provides boilerplate prompting to define tasks easily with 'signatures', making it a compelling tool for application development.
- Effective Categorization Example: The author uses a simple categorization task to demonstrate how DSPy streamlines prompting, underscoring its practicality in application building. This example clearly elucidates DSPy's operational benefits and its efficiency compared to traditional prompting methods.
- By showcasing a relatable use case, the author aims to engage readers and clarify DSPy's approach to programming LLMs.
- User Feedback on DSPy: A user commended the author for choosing a clear workflow and unique example in explaining DSPy, noting that small LLMs are beneficial for rapid iteration. They expressed that as complexity grows, maintaining efficiency often hampers performance, a point that resonates with the discussion on DSPy's capabilities.
- The user expressed enthusiasm for exploring DSPy further by checking out additional posts and mentioned the value of the GitHub link provided.
Link mentioned: Pipelines & Prompt Optimization with DSPy: Writing about technology, culture, media, data, and all the ways they interact.
DSPy ▷ #general (9 messages🔥):
DSPy optimizers, AI as a platypus, Exploring new technologies, Learning resources, Prompt optimization in NLP
- Consultants Revisiting Their Slides: There's a buzz as many consultants are going back to review their slides, indicating an important shift in the landscape.
- Uh oh! suggests that the urgency may stem from recent developments or requirements.
- AI Challenges Conventional Categories: A blog post highlights how AI represents the biggest 'platypus' in technology, challenging existing categorizations and conventions read more.
- It emphasizes how AI's qualities redefine our understanding of technology, similar to how a platypus defies grouping.
- Introduction to DSPy Optimizers: A newcomer shared their exploration of DSPy, particularly the role of optimizers, which guide LLM instruction writing during optimization runs.
- Clarification on whether one example is passed through all instructions in real-time settings was sought for better understanding.
- Learning Resources for DSPy: Members discussed utilizing key papers for understanding prompt optimizers in DSPy, specifically pointing to a relevant arXiv paper.
- There is intent to enhance documentation on optimizers with more detailed and simplified discussions.
Links mentioned:
DSPy ▷ #examples (5 messages):
Claude Sonnet prompt optimization, Outdated dspy examples, Documentation for VLM examples
- User finds dspy for Claude Sonnet prompts: A user discovered dspy while searching for ways to optimize their Claude Sonnet prompt.
- They bookmarked an example notebook, but it has since been moved to an outdated folder.
- Caution advised on outdated examples: Another member warned to use the contents from the outdated folder with caution until they are revamped.
- They confirmed that someone is currently working on this update.
DSPy ▷ #colbert (2 messages):
Cohere v3, Colbert v2, Building scalable AI systems
- Cohere v3 outperforms Colbert v2: Cohere v3 has been noted to have superior performance compared to Colbert v2 in recent discussions.
- This sparked interest in the enhancements that led to this performance leap and inquiries about practical implications for projects.
- Insights from Building Scalable Systems: A relevant resource shared was a YouTube video titled 'Building Scalable Systems with DAGs and Serverless for RAG', focusing on challenges in AI system development.
- Session hosts Jason and Dan discuss complex challenges from router implementations to managing conversation histories, offering valuable insights for AI engineers.
Link mentioned: Building Scalable Systems with DAGs and Serverless for RAG | APAC Office Hours: Jason and Dan lead an APAC office hours session exploring complex challenges in building AI systems, from router implementations to managing conversation his...
tinygrad (George Hotz) ▷ #general (6 messages):
Tinygrad performance benchmark, Kernel search experience, BEAM configuration
- Tinygrad vs PyTorch Performance Struggles: Profiling reveals that Tinygrad performs significantly slower than PyTorch, especially with larger batch sizes and sequence lengths, such as a 434.34 ms forward/backward pass for batch size 32 at sequence length 256.
- Users noted an insane slowdown when increasing sequence length on a single A100.
- Exploring BEAM Options for Better Performance: Users discussed the impact of different BEAM settings, noting that BEAM=1 is greedy and does not provide optimal performance.
- Switching to BEAM=2 or 3 is recommended as it offers a better trade-off for kernel search by potentially improving runtime and performance.
- Call for Benchmark Scripts: There is an expressed interest in obtaining simple benchmark scripts that could help enhance performance for Tinygrad.
- Providing benchmarks could aid in identifying areas for improvement in both compile time and kernel execution time.
Torchtune ▷ #general (3 messages):
Torchtune update, Type hinting in Python, Ruff functionality
- Torchtune's Upgrade to 3.9 Simplifies Type Hinting: Since the upgrade to Torchtune 3.9, users can now replace
List,Dict, andTuplewith default builtins for type hinting, reportedly making coding a bit easier.- This change has sparked a light-hearted conversation about how Python continues to change workflows.
- Python's Quirks Add to the Workload: A member humorously remarked that Python is making more work for them, indicating a sentiment shared by others in the community.
- This shows the often comical frustrations developers face adapting to changes in programming languages.
- Ruff's Rule Improves Type Hinting Automatically: One user recalled that Ruff has a built-in rule designed to automatically handle the replacement of type hints, easing the transition.
- This feature highlights how tools continue to evolve in aiding developers amidst Python's frequent updates.
MLOps @Chipro ▷ #events (1 messages):
Next-Gen Retrieval Strategies, Advanced Agent Runtimes, Model Management at Scale, Dynamic Prompt Engineering, AI Safety & Compliance
- Kickstart the Year with Next-Gen Retrieval: Participants will explore how to mix vector search, graph databases, and textual search engines to create a versatile, context-rich data layer during the session on January 8th at 1 PM EST.
- Rethink how to build AI applications in production to truly support modern demands for large-scale LLMOps.
- Supercharge Runtimes with Advanced Agents: The session promises insights into using tools like Vertex AI Agent Builder for effective orchestration of long-running sessions and managing chain of thought workflows.
- This approach aims to elevate the performance of agent workflows in more complex applications.
- Scale Model Management for LLMs: A significant focus will be on how participants can leverage robust tools for model management at scale, ensuring efficient operations for specialized LLM applications.
- Expect to delve deep into strategies that bridge AI safety frameworks and dynamic prompt engineering.
- Dynamic Prompt Engineering Simplified: The workshop will also highlight dynamic prompt engineering, integral for adapting to evolving model capabilities and user needs.
- This technique aims to provide real-time contextual responses, improving user satisfaction.
- Ensuring AI Compliance and Safety Standards: An overview of AI safety and compliance practices will be addressed, ensuring that AI applications adhere to necessary regulations.
- Participants can expect to learn about integrating safety measures into their application development workflow.
Link mentioned: Emerging Architectures Webinar | TensorOps: no description found
Mozilla AI ▷ #announcements (1 messages):
Mozilla Builders Demo Day, Event Acknowledgment, Social Media Recap
- Mozilla Builders Demo Day Recap Released: The recap of the Mozilla Builders Demo Day has been published, capturing the essence of the event and expressing gratitude to the attendees who braved tough conditions to participate. You can read the full recap here.
- It was a spectacular event — a confluence of amazing people and incredible technology, noted the Mozilla Builders team on social media.
- Special Thanks to Contributors: Thanks were extended to various members and contributors for making the event possible, indicating the collaboration and effort involved. Notable mentions include the teams marked with roles within the organization.
- Participants were encouraged to recognize the support and contributions from the community in making the event a success.
- Social Media Highlights: The event's impact was echoed on social media, with highlights shared through platforms like LinkedIn and X.
- Engagement on these platforms emphasized the excitement and energy of the event, particularly through the contributors' collective reflections.
- Event Video Available: An event video titled Demo_day.mp4 has been attached for those interested in visual highlights from the day. The video captures key moments and presentations from the Demo Day.
- You can watch the video here.
Link mentioned: Tweet from Mozilla Builders 🔧 (@mozillabuilders): We have chiseled ourselves out of our Demo Day cocoons just in time to write the world's most interesting recap. Seriously, it was spectacular — a confluence of amazing people and incredible techn...
{% else %}
The full channel by channel breakdowns have been truncated for email.
If you want the full breakdown, please visit the web version of this email: [{{ email.subject }}]({{ email_url }})!
If you enjoyed AInews, please share with a friend! Thanks in advance!
{% endif %}