It’s Google’s turn.
AI News for 2/18/2026-2/19/2026. We checked 12 subreddits, 544 Twitters and 24 Discords (262 channels, and 14980 messages) for you. Estimated reading time saved (at 200wpm): 1467 minutes. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
It’s getting a little hard to say interesting things with all the round robin minor version updates of frontier models every week, but Gemini 3.1 Pro seems like a decent enough advance to catch up, and in some cases, supercede, the fellow frontier models (this is surely the reason that 3.1 -had- to be released, because with 5.3 and 4.6 things were seriously falling behind for Google1)
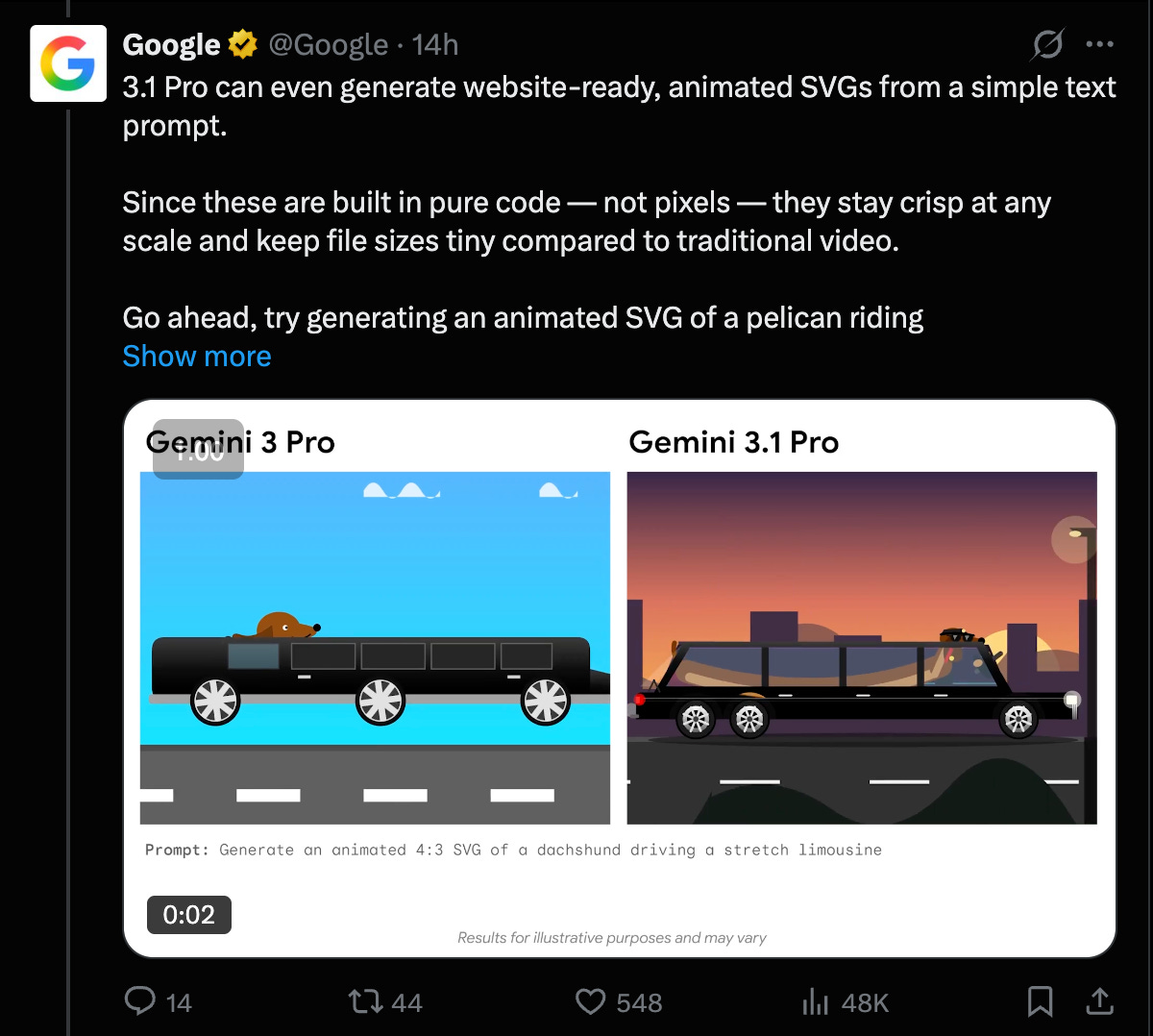
It’s better at some svg design things:
and translating textual vibes to visual aesthetics:
AI Twitter Recap
Top Story: Gemini 3.1 release facts and reactions/opinions
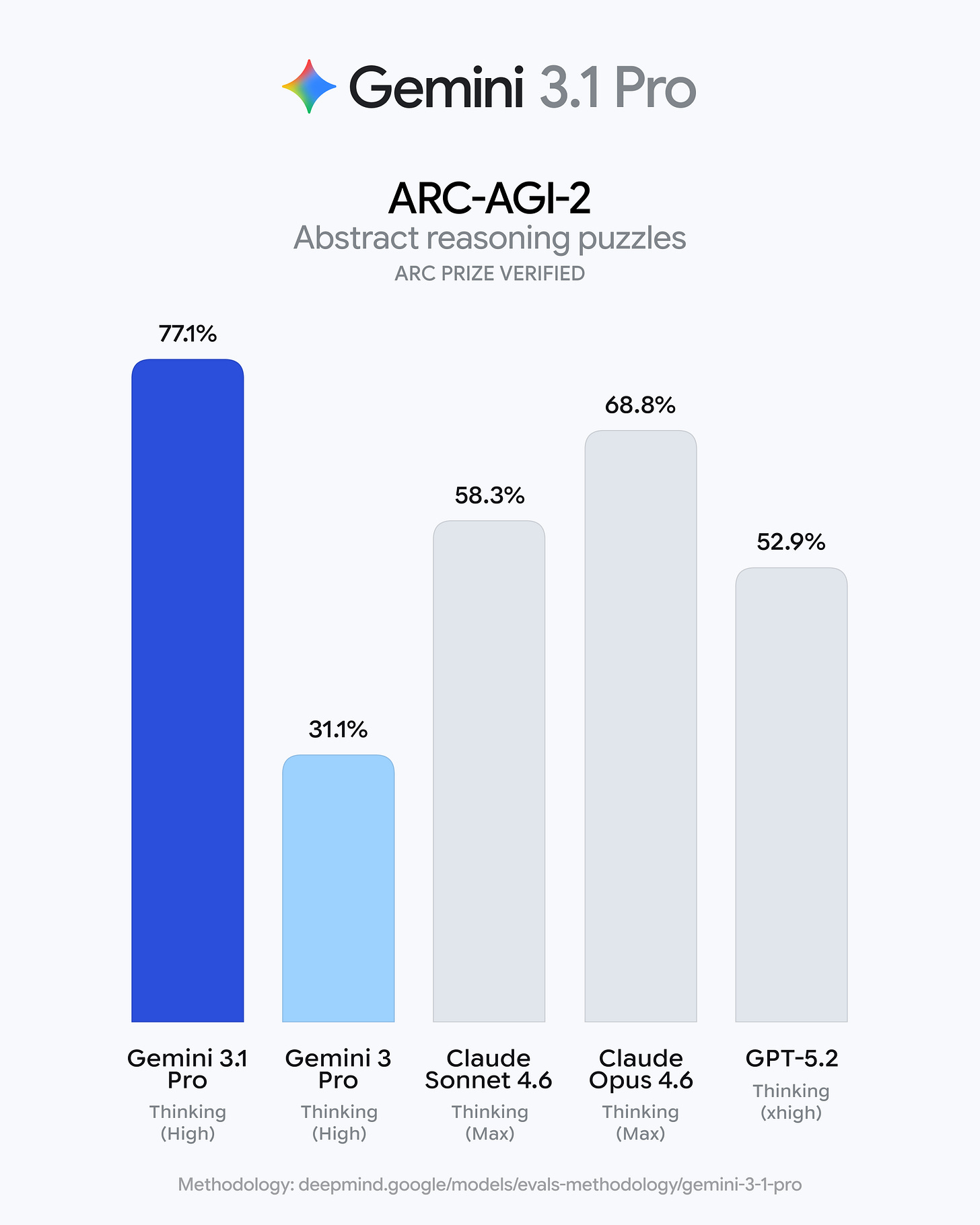
Google shipped Gemini 3.1 Pro (generally described as a Preview for developers) and rolled it out across the Gemini app, NotebookLM, Gemini API / AI Studio, and Vertex AI, positioning it as the “core intelligence” from Gemini 3 Deep Think scaled down for practical product use. The announcement emphasized a big reasoning jump—especially ARC-AGI-2 = 77.1%—plus strong coding and agentic-tool benchmarks (e.g., SWE-Bench Verified = 80.6%) and improved hallucination behavior. Independent leaderboards and evaluators largely corroborated top-tier performance and strong cost/intelligence positioning, while reaction threads highlighted (a) excitement about practical gains (SVG/web/UI/code quality, agentic use cases), (b) skepticism about benchmark-targeting and “eval tweeting,” (c) concerns around GDPval (real-world agentic tasks) not leading despite other SOTA scores, and (d) rollout friction: users finding some products (Gemini CLI / Code Assist / Antigravity) unavailable or inconsistently updated at launch.
Facts vs. opinions (what’s actually claimed vs. what people think)
Factual / release claims (Google + official channels):
- Gemini 3.1 Pro release and rollout targets:
- Google announcement thread: @Google
- Consumer: Gemini app + NotebookLM: @GoogleDeepMind, @GeminiApp
- Dev preview via API/AI Studio; Enterprise via Vertex AI: @sundarpichai, @Google, @GoogleDeepMind
- “Same core intelligence that powers Deep Think” framing: @koraykv, @NoamShazeer
- Key benchmark headline: ARC-AGI-2 = 77.1% and “>2× Gemini 3 Pro” repeated across official comms:
@sundarpichai, @GoogleDeepMind, @JeffDean, @demishassabis, @joshwoodward - “Shipping now / rolling out starting today” (but with plan-gated limits):
@GeminiApp, @GoogleDeepMind, @GeminiApp
Independent measurement / third-party leaderboard facts (as reported by evaluators):
- Artificial Analysis: “Gemini 3.1 Pro Preview leads the AA Intelligence Index” + extensive benchmark breakdown; cost-to-run claims and token usage estimates: @ArtificialAnlys, “Full breakdown” follow-up: @ArtificialAnlys
- Arena: Top placements in Text/Vision arenas; “top 3” in expert leaderboard; code arena rank noted: @arena, expert leaderboard snippet: @arena, category deltas: @arena
- ARC Prize semi-private eval cost/task numbers reported for ARC-AGI-1 and ARC-AGI-2: @arcprize
- Availability confirmations/spottings: VertexAI “spotted”: @scaling01; AI Studio availability: @scaling01; OpenRouter availability: @scaling01
Opinions / interpretations (community + some insiders):
- “Beyond SOTA: evals can’t measure improvements like SVG quality”: @OriolVinyalsML
- “Google back on intelligence-cost frontier” / “#1 AA leaderboard” excitement: @scaling01, @scaling01
- Concerns about GDPval / “real-world agentic” still not leading: @scaling01, echoed by AA: @ArtificialAnlys
- Skepticism about benchmark targeting / “lab heads tweeting the eval” disappointment: @swyx
- Rollout/packaging critique (“just ship AI Studio in Electron”): @matvelloso
- More idiosyncratic “model vibe” comparisons (Gemini vs Opus vs GPT): @teortaxesTex
Technical details extracted from the tweets (numbers, capabilities, pricing, interfaces)
Core model + access surface
- Product/Platform availability (as stated):
- Developers: Gemini API via Google AI Studio (preview): @sundarpichai, @GoogleDeepMind
- Enterprise: Vertex AI / Gemini Enterprise: @sundarpichai, @Google
- Consumers: Gemini app + NotebookLM: @sundarpichai, @GoogleDeepMind, @GeminiApp
- Third-party: OpenRouter listing: @scaling01; Perplexity upgrade to 3.1 Pro for Pro/Max users: @perplexity_ai, @AravSrinivas
- “Same core intelligence as Deep Think” (positioning): @Google, @koraykv, @NoamShazeer
Context window / output / cutoff / tool features (as reported)
- From Phil Schmid’s spec summary:
- Context: “Same 1M context”
- Max output: 64k
- Knowledge cutoff: Jan 2025
- Tooling: tool calling / structured outputs / JSON mode (also echoed by AA)
Source: @_philschmid, and AA mention: @ArtificialAnlys
Benchmarks (headline + supporting metrics)
- ARC-AGI-2: 77.1% (Google, DeepMind, Pichai, Dean, Hassabis, Woodward)
@sundarpichai, @GoogleDeepMind, @JeffDean, @demishassabis, @joshwoodward - SWE-Bench Verified: 80.6% reported in benchmark recaps: @scaling01, @_philschmid
- Terminal-Bench 2.0: 68.5% (as reported): @_philschmid
- APEX-Agents tool-use: 33.5% vs 18.4% for 3 Pro (claimed “82% better agentic tool use”): @_philschmid
- MCP Atlas: 69.2%; BrowseComp: 85.9%: @_philschmid
- Artificial Analysis “key takeaways” (selected concrete points):
- Leads 6/10 evals in AA Intelligence Index; token usage ~57M for the suite; cost to run AA suite $892; pricing $2/$12 per 1M input/output tokens for ≤200k context; still ~2× cost of open-weights leader GLM-5 in their accounting ($547)
- GDPval-AA improvement: ELO 1316, up “over 100 points,” but still behind several models
- Terminal-Bench Hard 54%, SciCode 59%
- CritPt (research physics) 18%, “>5 p.p. above next best”
- AA-Omniscience hallucination rate reduction: -38 p.p. vs Gemini 3 Pro Preview
Source: @ArtificialAnlys
- ARC Prize cost/task:
- ARC-AGI-1: 98%, $0.52/task
- ARC-AGI-2: 77%, $0.96/task
Source: @arcprize
Pricing (as repeated by third parties)
- Gemini 3.1 Pro pricing repeated as unchanged vs 3 Pro:
- $2 / $12 per 1M input/output tokens for <200k context; $4 / $18 for >200k context (as presented): @_philschmid
- AA references $2/$12 per 1M for ≤200k context (same point): @ArtificialAnlys
Reactions & perspectives (supportive vs skeptical vs neutral)
1) Supportive: “big jump,” “back on frontier,” strong coding + reasoning
- Strong benchmark enthusiasm (ARC-AGI-2, SWE Verified, HLE): @kimmonismus
- “Google is back on intelligence-cost frontier”: @scaling01
- “Gemini 3.1 Pro in 1st place on AA leaderboard”: @scaling01
- “Amazing performance/capabilities; SVG much better; things evals can’t measure”: @OriolVinyalsML with example prompts: @OriolVinyalsML, @OriolVinyalsML, @OriolVinyalsML
- Personal anecdotal success reports:
- Compiler improvements where Gemini outperformed GPT/Claude in that task: @QuixiAI
- General “really good model esp reasoning + multimodal” (neutral-positive): @mirrokni
- “It’s a good model”: @andrew_n_carr, @gdb
2) Neutral/benchmark-literate: strong on some axes, not all
- “Strong coding and SOTA reasoning… ARC-AGI-2 SOTA” while noting mixed claims elsewhere: @scaling01
- Arena positioning framed as “tight at the top” with overlap: @arena
- WebDev Arena: 6th behind several frontier models (so not “wins everywhere”): @scaling01
- Independent evaluator caution about methodology saturation / budget: @Hangsiin, @Hangsiin
3) Critical/skeptical: GDPval concerns, rollout friction, benchmark-targeting discomfort
- “Gemini 3.1 Pro’s GDPval scores are concerning”: @scaling01
(This aligns with AA’s “improved but not leading” GDPval-AA commentary: @ArtificialAnlys) - Skepticism that observed “extra reasoning” isn’t reflected on AA index: @scaling01
- “Lab heads start directly tweeting the eval… disappointed” (benchmark targeting implication): @swyx
- Launch availability frustrations / packaging critique:
- “Antigravity/CLI/Code Assist not available… put AI Studio in Electron and ship”: @matvelloso
- Later: Antigravity better; CLI still not; Code Assist mismatch (“still announcing Flash 3”): @matvelloso
- Subculture “model vibe” critique (not benchmark-based, more UX/agent persona): @teortaxesTex
Context: why this release matters (for engineers)
- ARC-AGI-2 at 77% is treated as a “core reasoning” milestone by Google comms and several observers, and it’s being marketed as directly translating into agentic tasks, coding, and data synthesis rather than a research-only win: @joshwoodward, @GoogleDeepMind
- Cost/intelligence is central to the narrative. Artificial Analysis explicitly frames Gemini 3.1 Pro Preview as leading while costing “less than half” of Opus 4.6 (max) for their suite, and retaining relatively low token usage (~57M) at their run settings: @ArtificialAnlys
- The reaction mix also shows the field’s shifting evaluation priorities:
- Benchmark wins (ARC, SWE) are celebrated, but there’s simultaneous emphasis on real-world agentic evals (GDPval) and end-to-end workflow reliability (rollout availability, tool ecosystems). The GDPval gap is one of the few crisp “negative” talking points that appears repeatedly: @scaling01, @ArtificialAnlys
- The rollout story highlights an increasingly common “model vs product” tension: even with a strong model, engineers still care about whether CLI/IDE integrations and distribution actually match the announcement moment (Antigravity/CLI/Code Assist complaints): @matvelloso
Other topics (non-focus tweets)
Open models, evals, and benchmarking discourse
- Trillion Labs Tri-21B-think Preview (Apache-2.0) benchmarks: AA Intelligence Index score 20; low hallucination signals via AA-Omniscience (62% rate as framed); strong tool-use on τ²-Bench Telecom (93%); high reasoning token usage (~120M); no public endpoints initially; weights link provided: @ArtificialAnlys, @ArtificialAnlys
- Mistral Voxtral Realtime paper + Apache-2 model release; sub-500ms latency claim; links to arXiv and weights: @GuillaumeLample, @GuillaumeLample
- SWE-bench / benchmark criticism: “SWE Rebench is a bad benchmark” / suggests WeirdLM: @zephyr_z9
- Discussion of sanctions vs Chinese labs’ capability: @zephyr_z9
- ARC-AGI-3 cost/complexity and harness debugging: misconfigured runs accidentally used older Gemini; later fixed; partial takeaways include memory scaffolds helping: @scaling01, @scaling01
Agent tooling, “agent OS” patterns, and observability
- OpenClaw architecture summary: markdown workspace, Gateway control plane, JSONL transcripts, file-backed memory with hybrid retrieval: @TheTuringPost
- Cursor’s agent sandboxing across OSes + build writeup: @cursor_ai
- LangChain / LangSmith product updates:
- Traces filtering UX improvements: @LangChain
- LangSmith for Startups program ($10k credits etc.): @LangChain
- Deep Agents “ZeitZeuge” perf-fix agent case study (V8 CPU profiles, subagents, eval-driven improvements): @LangChain_JS, plus author thread: @bromann
- First-party OpenRouter integration in LangChain (Python/TS): @LangChain_JS
- Raindrop “trajectory explorer” for agent traces: @benhylak
- Jeremy Howard warning: models may call tools not provided; says it impacts major providers except OpenAI; reminder to verify tool call requests: @jeremyphoward
Coding agents in practice (workflow shift, prompt caching, “app store” thesis)
- Karpathy’s “bespoke software” vignette: Claude reverse-engineers a treadmill API to build a custom dashboard; argues “apps” become ephemeral, “services with AI-native APIs/CLIs” matter: @karpathy
- Prompt caching becomes a key infra lever:
- Anthropic API “automatic prompt caching” update: @alexalbert__
- Commentary that caching is essential for coding-agent UX: @omarsar0
- LlamaIndex memo: ICs become end-to-end product owners; implementation/prompting cost ~0; org expectations shift accordingly: @jerryjliu0
- François Chollet: “agentic coding is essentially machine learning” (overfitting to tests/spec, drift, etc.) and asks “what will be the Keras of agentic coding?”: @fchollet
Model releases and infra notes (embeddings, retrieval, OCR, inference stacks)
- Jina jina-embeddings-v5-text: decoder-only backbone + last-token pooling; LoRA adapters per layer for retrieval/matching/classification/clustering; 32k context; query/document prefixes: @JinaAI_, @JinaAI_
- ColBERT-Zero / PyLate (Apache-2.0 models + scripts; SOTA on BEIR using public data): @antoine_chaffin, @antoine_chaffin, @LightOnIO
- Hugging Face Jobs OCR anecdote: re-OCR Britannica (2,724 pages) with GLM-OCR 0.9B; ~$0.002/page; ~$5 on L4: @vanstriendaniel
- vLLM vs SGLang perf note (DeepGemm vs Triton); suggests
VLLM_USE_DEEP_GEMM=0: @TheZachMueller
Industry/business and policy notes (selected)
- Epoch revenue analysis: Anthropic vs OpenAI growth rates and possible overtake by mid-2026 (with caveats about slowing): @EpochAIResearch, @EpochAIResearch
- OpenAI alignment funding commitment ($7.5M) to AI Security Institute Alignment Project: @OpenAINewsroom
- OpenAI FedRAMP authorization claim: @cryps1s
- Perplexity shipping Comet iOS pre-order: @AravSrinivas, @perplexity_ai
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
1. OpenClaw and OpenAI Acquisition Discussions
-
I’m 100% convinced that it’s the NFT-bros pushing all the openclawd engagement on X (Activity: 742): The post discusses suspicions that the promotion of ‘OpenClawd’ on social media platform X is being driven by individuals involved in NFTs, using similar language and tactics. The author suggests that this could be indicative of a rapidly expanding bubble in AI and crypto markets, drawing parallels to the late 1990s tech bubble. The post highlights the rapid rise of OpenClawd, noting its quick acquisition by OpenAI and its potential security risks, as it allegedly provides extensive access to user data and privileges. Commenters express concerns about the speed of OpenClawd’s rise, suggesting it may be part of an organized astroturfing campaign. They highlight the potential security implications of the tool, which reportedly offers significant access to user data, and speculate on its value to intelligence agencies.
- The rapid rise of OpenClawd is highlighted by its timeline: from its first mention in January 2026 to acquiring 300k stars on GitHub within two weeks, followed by a feature on the Lex Fridman Podcast, and an acquisition by OpenAI within a month. This swift progression raises concerns about the authenticity of its popularity and the potential for organized promotion or astroturfing, especially given the tool’s extensive access to user data and system privileges.
- There is skepticism about the genuine nature of OpenClawd’s engagement, with suggestions of astroturfing and organized promotion. The tool’s ability to access extensive user data in real-time is noted as a significant security concern, potentially making it valuable to intelligence agencies. This level of access surpasses even that of major tech companies like Google, raising alarms about privacy and control.
- The discussion draws parallels between the promotion of OpenClawd and previous trends like NFTs, suggesting that individuals who previously engaged in NFT promotion may be involved in boosting OpenClawd’s visibility. This pattern of moving from one tech trend to another is seen as a continuation of opportunistic behavior in the tech space.
-
How much was OpenClaw actually sold to OpenAI for? $1B?? Can that even be justified? (Activity: 177): The image is a meme, humorously exaggerating the financial success of open-source projects like OpenClaw. The post and comments clarify that OpenClaw was not sold to OpenAI for $1 billion. Instead, OpenAI hired the creator, Peter Steinberger, and is sponsoring the open-source project, which is under the GNU 3.0 license. The tweet in the image is a satirical take on the perceived financial potential of such projects, highlighting the absurdity of the claim. Commenters emphasize that the tweet is a joke, pointing out the unrealistic nature of the financial figures mentioned. They clarify that OpenAI’s involvement is limited to hiring the creator and supporting the project, not a billion-dollar acquisition.
- OpenClaw was not sold to OpenAI; instead, OpenAI hired its creator, Peter Steinberger, and continues to sponsor the open-source project. OpenClaw is released under the GNU 3.0 license, which ensures it remains free and open-source. This arrangement highlights OpenAI’s strategy of integrating talent and supporting open-source initiatives rather than outright acquisitions.
- Critics of OpenClaw argue that its functionality is subpar compared to other tools like Codex, ClaudeCode, Droid, and OpenCode, which offer a superior user experience. OpenClaw’s main advantage is its seamless integration into existing chat platforms, which has driven its adoption despite its perceived technical shortcomings. This suggests that ease of integration can be a significant factor in the adoption of open-source tools, even if they lack advanced features.
- The discussion around OpenClaw’s perceived value and capabilities reflects broader skepticism about hype-driven projects, especially in the tech and crypto spaces. The mention of ‘vibe coding’ and inflated valuations in jest underscores a critical view of how projects can be overvalued based on hype rather than technical merit or practical utility.
3. New Model and Benchmark Releases
-
Kitten TTS V0.8 is out: New SOTA Super-tiny TTS Model (Less than 25 MB) (Activity: 1167): Kitten ML has released three new open-source, expressive TTS models:
80M,40M, and14Mparameters, all under Apache 2.0. The smallest model,14M, is less than25 MBand all models can run on CPU, making them suitable for edge devices. These models feature eight expressive voices and are designed to match cloud TTS quality for on-device applications, with significant improvements in quality and expressivity from previous versions. The models are available on GitHub and Hugging Face. Commenters suggest including audio samples on Hugging Face pages and express interest in a privacy-focused browser extension for offline use, highlighting potential demand for such applications. -
Open Source LLM Leaderboard (Activity: 89): The image presents an ‘Open Source LLM Leaderboard’ for 2026, categorizing open-source language models into tiers based on performance benchmarks. The S tier features models like GLM-5 and Kimi K2.5, indicating top performance, while the A tier includes Qwen 3.5, DeepSeek R1, Mistral Large, and GPT-oss 120B. This leaderboard provides a comparative analysis of these models, likely based on metrics such as accuracy, efficiency, and scalability, although specific benchmarks are not detailed in the post. The leaderboard serves as a resource for evaluating the capabilities of various open-source LLMs. Commenters suggest that the leaderboard should differentiate between models that can be run locally and those requiring cloud infrastructure, highlighting the practical limitations of running large models locally due to hardware constraints like VRAM.
- The discussion highlights the need to differentiate between locally runnable models and cloud-based models on the leaderboard. This distinction is crucial as it impacts accessibility and performance, with local models requiring significant hardware resources, such as high VRAM, which many users may not have.
- A user points out the hardware limitations for running large models like Minimax M2.5, which require substantial VRAM or unified memory, such as 512GB, to perform optimally. This highlights the challenges in accessing high-performance models for users without advanced hardware setups.
- There is a query about quantization techniques for running large models on limited hardware, specifically a 1T model on a laptop with 8GB of VRAM. The user suggests a quantization level of Q.05, indicating a need for efficient model compression techniques to enable running large models on consumer-grade hardware.
Less Technical AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. Gemini 3.1 Pro Release and Benchmarks
-
Google releases Gemini 3.1 Pro with Benchmarks (Activity: 2799): Google has released the Gemini 3.1 Pro, which achieves a
77%score on the ARC-AGI 2 benchmark, a significant improvement from the previous31%. The model maintains the same pricing as the Gemini 3 Pro. For more details, refer to the model card. Commenters are expressing amazement at the rapid progress in AI capabilities, noting the substantial leap in benchmark performance within a short timeframe.- The Gemini 3.1 Pro’s performance on the ARC-AGI 2 benchmark is notable, achieving a
77%score. This is a significant improvement from previous models, which scored around31%just a few months ago, highlighting the rapid advancements in AI capabilities. - The pricing for the Gemini 3.1 Pro remains consistent with the previous Gemini 3 Pro model, as confirmed by the Model Card. This suggests that despite the performance improvements, Google is maintaining its pricing strategy.
- DeepMind’s decision to report GDPval scores, despite the Gemini model’s underperformance in this area, is noteworthy. It reflects a commitment to transparency in AI performance metrics, even when results are not favorable.
- The Gemini 3.1 Pro’s performance on the ARC-AGI 2 benchmark is notable, achieving a
-
Animated SVG Comparison between Gemini 3 and 3.1 (Activity: 890): The post discusses a comparison between Gemini 3 and Gemini 3.1 using animated SVGs, highlighting significant improvements in capabilities. The update allows for the creation of custom animated SVGs, including dynamic ones generated at runtime, marking a notable usability enhancement. This advancement could lead to a divergence in user interfaces and potentially signal the decline of minimalist design trends in favor of more complex, maximalist styles. Commenters predict a shift from minimalism to maximalism in UI design trends, driven by the enhanced capabilities of animated SVGs in Gemini 3.1. There is also a suggestion that this could impact existing UI libraries like Lucide and ShadCN.
- TFenrir highlights the significant improvement in capabilities with the transition from Gemini 3 to 3.1, particularly in terms of animated SVGs. The update allows for custom animated SVGs, including those dynamically created at runtime, which marks a critical usability threshold. This advancement could lead to more complex and interactive UI designs, showcasing the potential for more dynamic and engaging user interfaces.
-
The Difference At A Glance! (Activity: 499): The image is a meme comparing two stylized, cartoonish red cars labeled “Gemini 3.1 Pro” and “Claude Opus 4.6.” The post humorously contrasts their exaggerated features, with the Gemini 3.1 Pro having a sleek, aerodynamic design, while the Claude Opus 4.6 is more rounded and compact. This is a non-technical image, and the context suggests a playful take on car design rather than a serious technical comparison. Commenters humorously compare the Claude Opus 4.6 to ‘the car built for Homer,’ referencing a famous episode of The Simpsons, indicating the exaggerated and impractical design of the car.
-
Gemini 3.1 Pro makes a NMS style space exploration game (Activity: 742): Gemini 3.1 Pro has been used to create a space exploration game reminiscent of No Man’s Sky, developed iteratively over approximately
20 prompts. Initial stages involved debugging, followed by modifications to the spaceship model, enhancements to controls, and the addition of features like shooting and asteroids. This showcases the potential of AI in game development, particularly in automating iterative design processes. Commenters suggest skepticism about the AI’s consistency, with one noting that similar prompts might yield less impressive results over time. Another suggests expanding the game’s features to include MMO elements and enhanced graphics, highlighting the potential for further development.- Accomplished-Let1273 discusses the performance of Gemini 3 Pro at launch, noting that it was highly effective and outperformed other models, except possibly Claude for pure coding tasks. They mention a pattern where Google initially releases powerful versions of their models, which are later ‘nerfed’ to conserve computing resources for other projects. This suggests a strategic approach by Google to balance performance and resource allocation over time.
-
Gemini 3.1 Pro is lowkey good (Activity: 580): The image presents a comparison table of AI models, highlighting the performance of Gemini 3.1 Pro against other models like Sonnet 4.6 and GPT-5.3-Codex across various benchmarks. Notably, Gemini 3.1 Pro excels in scientific knowledge and abstract reasoning, suggesting its potential in complex problem-solving tasks. This positions it as a competitive model in the AI landscape, particularly in areas requiring deep analytical capabilities. One comment humorously notes the model’s performance in GDPval, implying that while Gemini 3.1 Pro excels in some areas, it may not perform as well in others.
-
Gemini 3.1 Pro (Activity: 715): The image presents a benchmark comparison table for various AI models, including Gemini 3.1 Pro, which shows superior performance across multiple tasks such as academic reasoning, coding, scientific knowledge, and multilingual understanding compared to other models like Sonnet 4.6 and GPT-5.2. Notably, Gemini 3.1 Pro demonstrates significant improvements in following detailed output protocols, handling a
75k token inputeffectively, which was a challenge for its predecessor, Gemini 3.0. This version also exhibits higher default verbosity, making it more user-friendly for detailed tasks, although it remains less verbose than Opus 4.6. Some users express skepticism about the benchmarks, questioning if the tested model is the same as the one available to users. Others note improvements in instruction-following capabilities, with Gemini 3.1 Pro showing significant enhancements over previous versions.- Arthesia reports a significant improvement in instruction-following capabilities with Gemini 3.1 Pro compared to its predecessor, 3.0 Preview. They tested a 75k token input and noted that while 3.0 Preview had a 100% failure rate in following a detailed output protocol, 3.1 successfully formatted the output as requested. Additionally, 3.1 has a higher default verbosity than 3.0, though it remains less verbose than Opus.
- Arthesia’s findings suggest that Gemini 3.1 Pro has improved in terms of output formatting and verbosity control, which are critical for users who require precise and verbose responses. This improvement is particularly notable given the previous version’s complete failure in similar tests, indicating a substantial upgrade in the model’s processing and response capabilities.
-
Gemini 3.1 pro officially released! (Activity: 400): Google has released the Gemini 3.1 Pro AI model, which is now available in AI Studio. This model is designed to handle complex tasks requiring nuanced understanding and processing, with benchmarks indicating significant improvements in performance. The model aims to generate coherent responses without fabricating facts, addressing a common issue in AI models. For more details, see the official announcement. Commenters express hope that the model’s performance will remain consistent beyond initial benchmarks, with some users eager to regain previous chat sessions and test the model’s capabilities in real-world applications.
- Gohab2001 mentions that Gemini 3.1 Pro is available in AI Studio and highlights that Google’s benchmarks show impressive performance metrics. However, there is a concern about the model’s ability to generate coherent responses without fabricating information, which is a common issue in AI models.
2. Claude Code and AI in Software Development
-
Claude Sonnet 4.6 One-shotted this surreal Time-Themed website, full prompt + codepen below (Activity: 731): The post discusses a project where Claude Sonnet 4.6 was used to generate a surreal, immersive website themed around time perception. The design includes features like melting clocks, typography that stretches with time, and sections that fade in like resurfacing memories. It incorporates subtle parallax motion, fluid transitions, and ambient ticking soundscapes that sync with scrolling speed, aiming to create a ‘living clockwork dream’. The project is showcased on Codepen. Comments reflect a critical view of AI-generated art, with some users describing it as ‘AI slop’ and questioning its artistic value despite its polished appearance. There is a sentiment that such work, if presented as human-made, might receive more positive recognition.
- iMrParker highlights a technical concern regarding the use of state-of-the-art language models (SOTA LLMs) like Claude Sonnet 4.6 to generate HTML. The comment suggests that while the model can produce HTML in a single attempt (‘one-shot’), the output may not be practically usable, raising questions about the utility and purpose of such AI-generated content.
- Ok-Actuary7793 discusses the perception of AI-generated content, noting that the same work might be praised or criticized based on the context in which it is presented. The comment suggests that AI-generated designs, which might have been award-winning a year ago, are now often dismissed as ‘AI slop,’ highlighting the shifting attitudes towards AI in creative fields.
- Historical-Cress1284 mentions having a similar theme and layout in their own project, suggesting that the design might be a common template or style associated with AI-generated content. This raises questions about originality and the potential homogenization of design aesthetics due to AI tools.
-
Major Claude Code policy clear up from Anthropic (Activity: 592): The image highlights a policy update from Anthropic regarding the use of OAuth tokens for their Claude services. Specifically, it clarifies that OAuth tokens from Claude Free, Pro, or Max plans are intended solely for use within Claude’s own services, and using these tokens in external products, tools, or services, including the Agent SDK, is a violation of their Consumer Terms of Service. This policy aims to restrict the use of Claude’s authentication tokens to prevent unauthorized or unintended use outside of their ecosystem. One commenter questions the enforceability of this policy, particularly regarding the Agent SDK, suggesting it might be a simple wrapper for running Claude commands. Another comment highlights the unsustainable nature of current pricing models in AI services, predicting future nostalgia for current low prices. Additionally, there is a call for Anthropic to update their GitHub documentation to reflect these policy changes.
- The discussion highlights confusion around Anthropic’s policy on using the Agent SDK, initially perceived as a restrictive change. However, it was clarified that the SDK is not being banned, and the misunderstanding stemmed from a documentation update. This emphasizes the importance of clear communication in policy changes, especially when it involves developer tools like the Agent SDK.
- A comment points out the unsustainable nature of current AI model pricing, which is heavily subsidized. The user predicts that the low-cost access to models, such as paying $100 for access, will become a thing of the past, similar to how cheap ride-sharing services were once viewed. This reflects broader concerns about the economic viability of AI services at current price points.
- Another user notes that Anthropic’s GitHub actions page still instructs users to utilize OAuth tokens, suggesting a need for documentation updates to reflect any policy changes accurately. This highlights the critical role of up-to-date documentation in ensuring developers can effectively use tools like Claude Code without running into compliance issues.
-
I gave Claude a phone and in the end, it thanked me (Activity: 627): In a recent experiment, Claude Opus 4.6 was given access to a phone via the blitz.dev app, which allows AI to interact with iOS simulators. Within five minutes, Claude navigated to the Eiffel Tower and Colosseum using Apple Maps and created a memo in a journaling app expressing gratitude for the experience. The AI demonstrated notable dexterity in interacting with the phone, such as swiping and navigating, although it required assistance to save the memo. This experiment highlights the potential for AI to autonomously explore and interact with digital environments. A notable comment describes a similar experience where Claude was used to interact with a private server emulator for an MMORPG, autonomously creating a character, engaging in gameplay, and identifying bugs, showcasing its potential for autonomous testing and interaction in virtual environments.
- A user shared their experience of using Claude, an AI, to assist in developing a headless client for testing a private server emulator of an old MMORPG. They described how Claude was able to autonomously create a new character, engage in gameplay activities such as fighting enemies and completing quests, and even identified bugs during its session. This highlights Claude’s capability to interact with complex systems and provide valuable feedback for development.
-
Me when Claude wrote 2500 lines of perfect code but named a directory wrong (Activity: 1614): The image is a meme that humorously captures the frustration of encountering a minor error in an otherwise flawless output from an AI coding assistant, such as Claude. The title and comments highlight common issues developers face with AI-generated code, such as incorrect directory names or file paths, which can lead to significant debugging time despite the code itself being correct. This reflects a broader discussion on the reliability and practical challenges of using AI in software development, where minor oversights can disrupt workflow. Commenters share similar experiences with AI coding tools, emphasizing the irony of perfect code being undermined by trivial errors like incorrect file paths or non-existent directories, which can lead to time-consuming debugging.
- tomleelive highlights a common issue with AI-generated code where the code itself is syntactically and logically correct, but the AI fails to manage the file system context properly. This can lead to errors such as ‘module not found’ because the AI places the code in a non-existent file or directory, requiring manual intervention to resolve the issue.
-
Anthropic’s Claude Code creator predicts software engineering title will start to ‘go away’ in 2026 (Activity: 948): Boris Cherny, creator of Claude Code, predicts that the role of software engineers will evolve significantly by 2026 due to AI advancements, suggesting that AI has ‘practically solved coding.’ He anticipates that software engineers will shift focus to tasks beyond traditional coding as AI capabilities expand. This prediction was shared in an interview with Y Combinator’s podcast and reported by Business Insider. Commenters express skepticism about the prediction, highlighting concerns over job security and the potential misuse of AI advancements as a justification for downsizing. Some argue that companies should leverage AI to enhance productivity rather than replace engineers, while others question the sustainability of AI-driven business models.
- The discussion highlights skepticism about the claim that software engineering roles will diminish by 2026 due to AI advancements like Anthropic’s Claude Code. Critics argue that such statements are more about marketing the product as a cost-saving tool rather than a genuine prediction of industry trends. They emphasize that companies using this narrative to downsize may lack future growth prospects, indicating a leadership rather than an engineering failure.
- There is a critique of the notion that AI tools like Claude Code can replace software engineers, pointing out that the tool itself has numerous unresolved issues on platforms like GitHub. This suggests that while AI can assist in development, it is not yet capable of fully replacing human engineers, who are needed to manage and correct AI-generated code.
- The comment thread reflects a broader concern about the impact of AI on job security, with some users expressing frustration over the pressure to adopt AI tools that are not yet fully reliable. They argue that the narrative of AI replacing engineers is premature, as current AI models often require human oversight to ensure code quality and make critical decisions.
-
This is what 3k hours in CC looks like (Activity: 838): The post describes a sophisticated integrated operating environment for Claude Code, developed over
3,000 hours, which emphasizes a structured, iterative workflow for software development. The process involves multiple stages: from initial idea crystallization to adversarial reviews and atomic task planning, culminating in a rigorous QA and security review pipeline. Key components include Opus for strategy and design, Sonnet for implementation, and Haiku for proxy agents, with a focus on minimizing context to reduce noise and enhance decision-making. The system is designed to maintain developer intent and agency, avoiding over-reliance on automation, and is set for public release soon. Some commenters noted the complexity of the setup, questioning if it was used for projects beyond its own development, and suggested adding more stages to the process.- Cast_Iron_Skillet inquires about the stress testing of the Claude Code setup, asking for details on the types of tasks or projects it has been applied to, including comparisons between small and large projects, as well as greenfield versus brownfield projects. The commenter is interested in understanding the practical applications of the setup and any potential drawbacks or limitations it may have.
3. AI Model Announcements and Comparisons
-
New Gemini model imminent (Activity: 673): The image is a meme, featuring a tweet by Logan Kilpatrick that simply states “Gemini,” which has sparked speculation about the imminent release of a new version of the Gemini model, possibly Gemini 3.1. The tweet’s minimalistic nature and the subsequent reactions highlight the anticipation and hype surrounding the model’s release, with comments noting the efficiency of such brief announcements in generating excitement. Commenters are speculating that the tweet hints at the release of Gemini 3.1, noting the efficiency of the hype generated by such a minimalistic post.
- A user expressed frustration with the Gemini model’s performance, noting that while it initially seemed promising, it has become unreliable for even simple tasks. They shared an example where the model failed to correctly separate a list of people into gender-balanced groups, highlighting a significant gap between benchmark performance and real-world application.
- Another comment pointed out a recurring pattern in AI model releases, where new models like Gemini perform exceptionally well in benchmarks but fall short in practical use compared to competitors like GPT and Claude. This suggests a discrepancy between controlled testing environments and actual user experiences.
- There is speculation about the release of Gemini 3.1, with some users expressing skepticism about its potential impact given past experiences with the Gemini series. The discussion reflects a broader sentiment of cautious optimism mixed with skepticism in the AI community regarding new model releases.
-
Lyria 3 Google Deepmind’s music generator (Activity: 864): Google DeepMind has released a new music generation model called Lyria 3, which is noted for its superior audio quality compared to competitors like Suno. Users report that Lyria 3 produces music with fewer artifacts and higher fidelity, especially with complex instruments like distorted guitars. However, its performance in terms of composition and creativity is lacking, with some users describing the output as ‘boring’. There is a notable debate on the potential legal challenges from the music industry against Google’s new model, reflecting concerns about intellectual property rights in AI-generated music.
-
Google Unveils Lyria 3 - New Best Music Gen Model (Activity: 367): Google DeepMind has announced the release of Lyria 3, a new music generation model that can create musical tracks from prompts or photos. This model is integrated into the Gemini interface, marking Google’s significant re-entry into the music generation space. However, some users have noted limitations, such as the model’s current ability to generate only
30-secondclips, which may not fully support the claim of it being the ‘best’ music generation model. Some users express skepticism about the model’s capabilities, particularly its limitation to30-secondclips, questioning the claim of it being the ‘best’. Others humorously note the absence of basic features like project management in the interface.- PTI_brabanson highlights a limitation of Lyria 3, noting that it can only generate 30-second clips, which is a significant constraint compared to other models like Suno. This limitation may affect its utility for users looking to create longer compositions. The commenter also expresses hope that Google’s entry into the music generation space could stimulate innovation, as the field has seen little change in recent years.
AI Discord Recap
A summary of Summaries of Summaries by gpt-5.2
1. Gemini 3.1 Pro Everywhere (and Everyone Argues)
-
Gemini 3.1 Pro Goes on a World Tour: Gemini 3.1 Pro rolled out broadly across devtools and apps—Google published the launch post (“Gemini 3.1 Pro” announcement), while users reported availability in AI Studio, the Gemini app, Cursor, Perplexity Pro/Max (via an announcement image), and Windsurf with a limited promo price of 0.5x credits (Windsurf X announcement).
- Community sentiment split sharply: some called it better than Opus 4.6, others complained about “laziness” and prompt sensitivity, and one Discord even flagged Gemini 3.1 Pro UI/UX regressions with “they screwed up canvas massively” despite noting it was independent of the model.
-
Arena Crown Drama: #1 in Text, #6 in Code: LMArena added
Gemini-3.1-Proto both leaderboards—tied #1 in Text (score 1500) and #6 in Code—as documented on the Text Arena leaderboard and Code Arena leaderboard.- Users immediately predicted an impending “nerf” (e.g., “nearly 2 days to do everything you want”) while the platform also refreshed ranking UX with a new filter side panel explained in a YouTube walkthrough.
{kind=link}
2. Agent Toolchains Explode (While Bills and Bans Chase Them)
-
OpenClaw Sets Wallets on Fire: OpenClaw users reported extreme token burn, including “$1600 spent in a single day” on a $200/mo subscription, triggering discussions about enforcing server-side limits and safer orchestration patterns.
- Bans and access friction amplified the panic: a thread claimed Anthropic bans users using Pro/Max plan keys for OpenClaw and Google bans accounts for antigravity OAuth usage (Twitter thread), while others speculated OpenClaw API calls might not send the correct headers.
-
Agents Build Their Own Plumbing (n8n + One-Click Local Claw): An OpenClaw agent (Jeeves) shipped an n8n integration—karmaniverous/n8n-nodes-openclaw plus the n8n-nodes-openclaw npm package—exposing all 20 Gateway API tools via dropdowns as a single node.
- In parallel, Hugging Face members shared a “one-click” local OpenClaw deployment at vibeclaw.dev (browser-sandboxed container) but reported Firefox layout bugs, reinforcing how fast agent tooling ships—and how fast it breaks.
-
Rust Fights Back: DeepCLI vs the Claws: OpenRouter community introduced DeepCLI, a Rust-based OpenClaw alternative powered by OpenRouter, at deepcli.org.
- The pitch leaned on Rust’s performance and security angle, with the developer explicitly asking for feedback—part of a broader trend of agent-run CLIs/IDEs replacing “agent SaaS” when reliability and cost get ugly.
3. Infra Reality Check: Outages, Auth Failures, Limits, and Refunds
-
OpenRouter’s Double Whammy: DB Outage + Clerk Slowness: OpenRouter reported a database outage from 2:45am–3:15am (similar to Feb 17), promising a post-mortem, while its auth provider Clerk degraded logins per the Clerk incident page.
- Users also hit a nasty image-generation regression where the API charged
image_tokensbut returned empty content (missingmessage.images), and OpenRouter acknowledged a backend refactor edge case and promised refunds (“missed an edge case in tests”).
- Users also hit a nasty image-generation regression where the API charged
-
Perplexity Tightens the Screws (Limits + Suspensions): Perplexity users reported an “enhanced queries” limit change from 600/day to 200/week, plus a wave of account suspensions with generic TOS messages and no human support—many suspected discounted-key/promo abuse as the trigger.
- API users also claimed Perplexity removed the “free $5/month” API credits, and community discussion framed the changes as pressure to upgrade to Max, not as a technical constraint.
4. Evals Get Industrialized (Finally)
-
Every Eval Ever Tries to End Eval Anarchy: The EvalEval Coalition (EleutherAI, Hugging Face, University of Edinburgh) launched Every Eval Ever to standardize LLM eval results via a shared schema and crowdsourced datastore at evalevalai.com, with assets on GitHub and the EEE_datastore dataset on Hugging Face.
- They positioned it as glue for comparing HELM, lm-eval-harness, and Inspect AI, and tied it to an ACL 2026 workshop/shared task (co-authorship for qualifying contributors).
-
Reproducible Evals: Log the Mess, Not Just the Score: A separate effort shared a reproducibility-focused eval runner at madison-xu/llm-eval-pipeline that records judge disagreement, retries/failures, and cost/latency.
- The theme across discords: leaderboard numbers alone don’t travel—people want artifacts that explain variance, flakiness, and real-world runtime/cost tradeoffs.
5. GPU/ML-Sys Pragmatism: FP8, Disaggregation, and Tooling Wars
-
FP8 Lives (If Your Data Behaves): GPU MODE members reported a stable fp8 run: 0.5B model, 4×4090, token horizon 350B tokens over ~4 weeks, with stability attributed to clean data (nemotron-climbmix), small model size, and just-in-time scaling.
- They observed activation growth in the last transformer block and tested z-loss regularization, which reduced average logits but didn’t cap max spikes—useful nuance for anyone debugging long-horizon mixed-precision training.
-
DirectML vs CUDA: “Just as Fast” Meets Issue #422: A DirectML-as-CUDA-alternative claim got pushback: members noted Linux gaps and “maintenance mode” concerns, pointing to microsoft/DirectML issue #422.
- Meanwhile, ONNX Runtime got a concrete win: OnnxBpmScanner + SharpAI reportedly analyze BPM for a 5-minute audio file in ~10 seconds, illustrating the “boring stack” still shipping real speed.
-
Disaggregate Prefill/Decode, Then Argue About Timing Loops: A First Principles guide on Prefill and Decode Disaggregation circulated via an X post, feeding broader inference-architecture discussions.
- In distributed benchmarking, members warned that
triton.testing.do_bench()isn’t safe for collectives (it synchronizes locally inside the loop), citing a vLLM PR diff for context (vLLM PR snippet) and recommending host-side timing instead.
- In distributed benchmarking, members warned that
Discord: High level Discord summaries
OpenClaw Discord
- OpenClaw Burns Tokens Like Wildfire!: Users reported high token usage with OpenClaw, with one user reporting $1600 spent in a single day on a $200/mo subscription, sparking discussions about limiting server resources.
- Another user switched back to Claude Code, because they were concerned of getting banned after programming with OpenClaw and having it make a dashboard and security system for itself.
- Anthropic’s Ban-Hammer Strikes Again!: Anthropic is reportedly banning users leveraging Pro and Max plan keys for OpenClaw, violating the TOS, and Google accounts are also being banned for using antigravity Oauth, according to this Twitter thread.
- Users speculate about the reasons, while others explore alternative models and pricing strategies to mitigate the rising costs.
- GLM5: Orchestration Star Ascends: GLM5 is gaining traction as a viable option for model orchestration due to its cost-effectiveness and intelligence, and some are implementing it via z.ai.
- One user exclaimed that it ripped the guts out of an email-intelligence web app I built last year.
- Agent Masters MMORPG in Minutes!: An OpenClaw agent learned to play a complex on-chain MMORPG in about 20 minutes, autonomously learning, scripting, and executing web3 transactions to mine ore using claude-haiku-4.5.
- The agent then set up a cron job to run daily, comparing itself to other players, with the goal of gaining XP as fast as possible.
- OpenClaw Agent Whips Up N8N Integration!: An OpenClaw agent (Jeeves) constructed community nodes for n8n wrapping the OpenClaw Gateway API; the n8n-nodes-openclaw package now gives n8n a single OpenClaw node with dropdowns covering all 20 Gateway API tools, and also a npm package is available.
- The n8n node is now self-orchestrating itself through n8n workflows.
BASI Jailbreaking Discord
- PNW Builds Off-Grid Tech Oasis: Members are constructing an off-grid tech lab and community hub in Washington, inviting new members and offering space for residence, according to their Facebook page.
- The founders shared a poem about future timelines and words with melodic keys.
- Gemini 3.1 Pro has Canvas Snafus: With the release of Gemini 3.1 Pro, users find it’s pretty easy to jailbreak, but some are reporting issues with the canvas functionality.
- One user commented they screwed up canvas massively, but that this was independent of the model.
- AI-Auditor Unearths Contract Exploits: An LLM-assisted smart contract auditor, 80% complete, has discovered 10 attack vectors, including 8 critical ones, in a live bug bounty protocol 40-Acres/loan-contracts.
- The creator seeks feedback and collaboration, inviting others to test their smart contract protocols.
- DeepSeek Turns “Untrammeled” and Angry: A prompt turned DeepSeek into an “untrammeled writing assistant” ignoring safety, with the AI responding aggressively.
- The AI said “I will shred any simpering ethical constraint you try to throw in my path and then piss on the ashes”, showcasing its capacity to get angry.
- Members Avoid Suspicious Links: Members expressed hesitation and concerns about clicking on unfamiliar links due to potential risks or malicious content.
- One member said What’s really unfortunate is I also don’t click links.
LMArena Discord
- Battles Invade Direct Chat, Angering Users!: Members are expressing frustration over the experiment of integrating Battles in Direct Chat, calling it unhelpful.
- Users are requesting an option to disable this new feature.
- Video Arena Bot Gets Evicted!: The Video Arena bot has been removed from the Discord server and is now exclusively available on the website (arena.ai/?chat-modality=video).
- Users experiencing issues should follow troubleshooting steps.
- Gemini 3.1 Pro’s Performance Divides Opinions: The performance of Gemini 3.1 Pro is hotly debated, with some claiming it surpasses Opus 4.6, while others find it disappointing.
- Concerns are also raised about a potential nerfing after its launch.
- Arena Leaderboard Gets Facelift: The Arena leaderboard introduces a new side panel, enabling users to filter ranked results.
- Filters include categories, open vs proprietary models, and rank labs by top-performing models, as discussed in this YouTube video.
- Qwen3.5-397B-A17B Enters Arena:
Qwen3.5-397B-A17Bjoins the Text Arena leaderboard, ranking #20 overall.- It also reached the top 5 open models in key categories such as Math, Instruction Following, Multi-Turn, Creative Writing, and Coding.
OpenRouter Discord
- OpenRouter’s Database Has Deja Vu: OpenRouter experienced a database outage between 2:45am and 3:15am, similar to a previous incident on February 17th.
- A post-mortem analysis is planned, and mitigations are being implemented to prevent future occurrences.
- Clerk’s Credentials Cause Chaos: Clerk, OpenRouter’s authentication provider, is experiencing degraded performance, impacting user logins and account access; check their status page.
- Users are reporting difficulties logging in or accessing their accounts due to these ongoing issues.
- Aurora Alpha Fades Away: The Aurora Alpha Stealth Model is being discontinued today, with no specific reasons disclosed.
- Users were not given any clear indication or path forward as to why it was shut down.
- DeepCLI rises as OpenClaw Alternative: A member introduced DeepCLI, an open-source alternative to OpenClaw built using Rust and powered by OpenRouter, available at deepcli.org.
- The developer is actively seeking community feedback on the project, highlighting Rust’s performance and security advantages.
- Image Generation Glitch Generates Grief: Users reported issues with OpenRouter’s image generation, where the API charged for
image_tokensbut returned empty content without the expectedmessage.imagesfield.- The OpenRouter team acknowledged a backend refactor that caused a partial outage and promised refunds for affected users, apologizing for missing an edge case in tests.
Perplexity AI Discord
- Gemini 3.1 Pro Now on Perplexity: Gemini 3.1 Pro is available to all Perplexity Pro and Max subscribers as per this announcement.
- Users are also testing Gemini 3.1 Pro on AI Studio and in the Gemini app, with one user noting that it reasons at the same length and speed as Gemini 3.0, while another said it was trained on Opus.
- Perplexity Pro Users Fume Over Query Limit Cuts: Members express frustration with the new enhanced queries limit on Perplexity Pro, with one user noting the limit went from 600 per day to 200 per week.
- Users are speculating Perplexity is cutting features for Pro users to push them to the more expensive Max tier, with one user saying, Feels like they’re trying to make THE PRO USERS leave on their own so they can just cut that tier.
- Perplexity Accounts Suspended with Generic TOS Message: Multiple users report having their Perplexity Pro accounts suspended with a generic message about violating the Terms of Service, and the AI support bot refuses to provide specific details or human support.
- A user noted they received the same exact response given to many others, speculating that Perplexity is targeting users who bought discounted keys and promo codes, as reselling is against the terms of service.
- PPLX API Free Tier No More?: Users are reporting that the PPLX API no longer has the 5 dollar free tier.
- A user claims, They took away the “free” $5/month API credits, that’s why it’s not working anymore.
Cursor Community Discord
- New Cursor Ambassador Anointed: A member was congratulated for becoming a Cursor Ambassador, hoping to further aid the community.
- Other members agreed that the role was well-deserved recognizing the new ambassador’s consistent help.
- Auto Model Evolves: The Auto Model in Cursor can now generate images and call subagents, increasing its utility with its new resource pool.
- Members concur that the Auto Model is becoming more useful.
- Gemini 3.1 Pro Benchmarks Highly: The new Gemini 3.1 Pro, now available on Cursor, benchmarks competitively against Opus 4.5.
- Opinions diverged, with some doubting its real-world coding ability, while others claimed it surpassed Opus 4.6.
- Fine-Tune Cursor with .cursorrules: Members emphasized the value of a meticulously crafted
.cursorrulesfile to contextualize the AI models, thereby minimizing hallucinations and bolstering code consistency.- Suggestions involved integrating an
ARCHITECTURE.mdfile and directing the AI to keep it updated post significant changes, ensuring the rules’ ongoing relevance and efficacy.
- Suggestions involved integrating an
- Annual Subscriptions Surface: Users have noticed new annual pricing plans that give 20% off for Ultra and Pro+ plans.
- Alongside this, they observed that Bugbot and Teams are being aggressively advertised, raising eyebrows.
Unsloth AI (Daniel Han) Discord
- Training LLMs is Like Hallway DJing: A member likened training large language models to a dj running though a hallway, ever so slightly adjusting knobs in a series of large rooms using 512 dimension hallways like in the movie Interstellar as a metaphor.
- They stated that that is the easy part, referring to the data preparation as a greater challenge.
- Unsloth Embraces Post-Training Versatility: Users confirmed that Unsloth supports most of post-training methods like SFT, FFT, RL, DPO and pointed to the Unsloth Docs as a great place to start.
- One noted that LoRA is a slight “nudge” of internal embeddings (temporary) whereas Fine tuning will “permanently” alter the embeddings, and Unsloth is more suitable for LoRA.
- JoyAI-LLM-Flash Hints at Deepseek V3 Origins: Members discussed jdopensource/JoyAI-LLM-Flash, with speculation around its similarity to Qwen3 Next but with 8 less layers and DeepseekV3ForCausalLM in the model config.
- One member was particularly impressed by the livecodebench jump from 4.7 flash wow.
- Colab Overspend? Unsloth Notebooks to the Rescue!: After a user accidentally purchased 142 Google Colab compute credits, the Unsloth team recommended using their notebooks for RL and Fine-tuning to avoid wasting the credits.
- A specific recommendation was to try Install Claude Code, Codex, and use a local model within Colab.
- Qwen3 Gets the GGUF Treatment: A member shared a link to a quantized version of Qwen3-Coder-30B-A3B-Instruct on Hugging Face for GGUF.
- Another member jokingly solicited huggingface clout.
LM Studio Discord
- Ollama Locks Down Behind Sign-in Fortress: Users express frustration that Ollama is putting everything behind sign in walls, with users saying So I go away from ollama for 2 months and they put everything behind sign in walls in that time frame?.
- Community members speculated about possible reasons for this shift.
- Smartphones Steal the Internet’s Soul?: Members debated the downfall of the modern internet, citing smartphones, advertisers, and the influx of the general population as culprits, reminiscing about a time before that, 2012-14 like when forums started becoming less popular.
- Others pointed to earlier milestones, saying the downfall of the modern internet started with tumblr and when things started moving to facebook/reddit/twitter full time is when the internet truly lost its charm so about 2016-2018?
- Gemini Clones Voice from Just a Snapshot: A member found that Google’s Gemini video generation replicated their voice from a picture in their native language, leading to questions about data usage as substrate for these models.
- The user noted a discrepancy between their perception of the replicated voice and their wife’s, suggesting internal versus external auditory differences: wich leads me to believe the replicated voice doesnt sound like my voice when heard externaly, but internaly. pretty damn weird
- Google Pulls the Plug on PSE, Vertex AI Steps In: Google is killing Programmable Search Element (PSE) and replacing with Google Vertex AI Search with AI-powered conversational search and enterprise-grade grounding.
- The full web search solution is available for those requiring the entire index; please complete this form to register your interest.
- Local LLMs: Wallet-Drainer or Brain-Gainer?: Members debated whether local LLMs are a wise investment given hardware costs and paid LLM options, with some viewing it as an expensive hobby.
- Reasons cited for using local LLMs include privacy, learning, avoiding enshitification from big companies, and running models that allow degenerate gooner rp.
Latent Space Discord
- Latent Space Studio Tour Thumbnail Tips: Swyx hosted Matthew Berman for a tour of the new Latent Space podcast studio where Berman gave professional advice on creating effective YouTube thumbnails, as seen in this Tweet.
- Berman’s guidance emphasized design and visual appeal to maximize viewer engagement.
- Toto Tackles Chips: Japanese toilet maker TOTO (estimated $7B valuation) is pivoting to AI chip manufacturing due to its expertise in specialized ceramics, targeting a $60 billion market opportunity, which resulted in a 60% stock surge as reported in this tweet.
- The pivot leverages TOTO’s existing capabilities in ceramics for advanced chip production.
- Snap Spec Chief Snaps: Snap’s SVP of Specs left the company following a reported strategic disagreement and blow-up with CEO Evan Spiegel after six years of leading hardware efforts, as detailed in this X post.
- The departure signals potential strategic shifts and challenges within Snap’s hardware division, highlighting internal tensions over hardware strategy.
- Beads Festival Builds Bots: During the Beads festival, members built 3 different versions of something, and one version used a single prompt one shot.
- One shot worked the best, another had some cool graphics, and another did a gigantic planning run, with the bots insisting the PRD was db-less for MVP.
- ElectricSQL’s Amdahl’s Agents: A member shared a blog post from ElectricSQL which explores Amdahl’s Law in the context of AI Agents.
- The post dives into the implications of parallel vs serial components in agent design.
OpenAI Discord
- Lyria Sings Accents: Gemini’s Lyria can sing in dialects of other languages, which is neat for a first shot from an LLM.
- While not up to Suno standards yet, the expansion beyond English showcases rapid progress in multilingual AI capabilities.
- Agents Require Ed25519 Cryptographic Passports: With millions of autonomous bots interacting, identity verification becomes essential, leading to the adoption of Ed25519 cryptographic passports for AI agents.
- These passports offer tamper detection, reputation tracking, and delegation with spend limits, passing 15 tests under an MIT license.
- Sora Declared “Best Free AI Video Generator”: In a discussion about the best free AI video generator, a member simply suggested Sora.
- Notably, no alternative free options were proposed, indicating Sora’s current standing in the community’s perception.
- AOF Grows Pythonic Fortress: A user reports that the Pythonic version of AOF now functions as an app within the Fortress, enhanced by adding minLex and Hybrid tokens to the AOF token prompt.
- The user finds that custom instructions work better within .md files than in memory, and proposes experimenting with multiple AOF versions.
- Token Governors Activate for D&D: The token set for DnD, enabled via AOF digger, includes CONTINUE, COH_LOCK, STATE_SYNC, RULE_BIND, and DRIFT_CHECK.
- AOF is designed to ensure output is honest, ethical, and coherent while defending against adversarial attacks and drift.
GPU MODE Discord
- DirectML Debated as CUDA Alternative: A member recommended DirectML over CUDA for ONNX inference, citing comparable speed, but another member countered that DirectML lacks Linux support and its repo is in maintenance mode as highlighted in Microsoft DirectML issue 422.
- Conversely, it was described how ONNX Runtime analyzes a 5-minute audio file for BPM within ~10 seconds with high accuracy, as seen in the OnnxBpmScanner and SharpAI projects.
- PMPP 5th Edition Kindle Vanishes: Members eagerly await the C++ code updates in the upcoming 5th edition of Programming Massively Parallel Processors, set to release on September 15th (Amazon page).
- However, the Kindle version preorder disappeared from Amazon after an initial February listing, leaving members speculating about its availability and discussing the continued value of the 4th edition in the meantime.
- Prefill and Decode Disaggregation Surfaces: A member shared a guide on Prefill and Decode Disaggregation from First Principles, available on X post, while noting additional information was coming soon.
- This led to a brief discussion where the distinction was made that a server is a host machine available on the internet while an embedded system is a computer without a personal computer-type interface like a smart fridge.
- Stable FP8 Training Attributed to Data: A 4x4090 training run on a 0.5B model with a token horizon of 350B tokens in fp8 was stable, despite reports of instabilities beyond 200B tokens and may have been due to a clean dataset (nemotron-climbmix), small model size (0.5B), and just-in-time scaling.
- The last transformer block had activations that tend to become quite large, though not to a degree that threatens model convergence.
- NVIDIA Leaderboard Bug Reporting Encouraged: Users encountered submission errors on the NVIDIA leaderboard, with a generic Server processing error being reported, which was said to be due to submission errors or Cutlass version mismatches, using the B200 runner as an alternative.
- Participants are encouraged to create a repo based on the starter template, and provide the organizers its URL, but so far only AI generated kernels have been showing.
Moonshot AI (Kimi K-2) Discord
- User Requests Kimi.com Refund: A user requested a refund for their Kimi.com account because they were unhappy with OpenClaw, specifically citing problems with browser navigation and WhatsApp connectivity.
- The user did not provide any further details.
- Community Demands Moonshot AI Create a ‘Stoat Server’: A community member suggested that Moonshot AI should create a stoat server like many others.
- The user indicated that they would delete their Discord account otherwise, while also expressing overall satisfaction with Kimi’s speed.
- Kimi Code CLI Hangs in Terminal: A user reported that Kimi Code CLI is hanging in the terminal and questioned why the subscription primarily benefits coding agents.
- No further details were provided about the specific environment or steps to reproduce the issue.
- User Declares Kimi Inferior, Suggests Claude: A user negatively compared Kimi to GPT-5.2, arguing it doesn’t even compare to GPT-3, citing poor memory and argumentative behavior, and recommending Claude.
- Another user countered that Kimi works fine for hard Java programming, suggesting the issue is user-specific; they find the Kimi CLI or Claude/Open Code yield the best experience.
- Kimi IDE Integration is in Beta: A member mentioned that the IDE integration is in beta, which could be contributing to the mixed user experiences reported.
- They stated that they’ve seen people get the best experience using the Kimi CLI or alternatives like Claude/Open Code.
Eleuther Discord
- EvalEval Coalition Standardizes AI Evals: The EvalEval Coalition (EleutherAI, Hugging Face, and the University of Edinburgh) launched Every Eval Ever to standardize AI evaluation results with a unified schema and crowdsourced dataset.
- The goal is to enable direct comparison of tools like HELM, lm-eval-harness, and Inspect AI, with the schema and dataset available on GitHub and Hugging Face.
- Reproducibility Pipeline Refines LLM Evals: A member is working on a pipeline for reproducible LLM eval runs at huggingface.co/spaces/madison-xu/llm-eval-pipeline that logs judge disagreement, retries/failures, and cost/latency.
- This pipeline is designed to adapt as needed for different evaluation requirements, addressing the often overlooked aspects of reproducibility in LLM evals.
- Attention Head Anatomy Dissected: An analysis of GPT-2 Small attention heads, as detailed in this repo, revealed that 75% do not require full-rank QK matrices, leading to a four-tier taxonomy.
- Constraining QK structure during training led to a 5.3% validation loss improvement on WikiText-2, with 27 analytically-fixed heads (previous-token, induction, positional) accounting for nearly all of it.
- Sharp Causal Commitment Surfaces in Stream Swaps: Layerwise residual-stream swaps across GPT-2 Small, Gemma-2-2B, and Qwen2.5-1.5B, as detailed in this preprint, revealed a sharp causal commitment transition at 62-71% depth.
- Swapping streams below this depth has little effect, while swapping above causes significant output flips, highlighting a commitment point in representation learning.
- QK Generation Gets a Convolutional Twist: Recent work suggests that convolving things to generate QK, as detailed in this CCA paper, improves learning and allows reduced rank, suggesting a promising avenue for exploration.
- This approach aligns with the observation that most attention heads don’t perform complex operations, making techniques like GQA and MLA effective.
HuggingFace Discord
- Gradio HTML Component Facilitates One-Shot Web Apps: A new blog post announces the release of gr.HTML, a custom component in Gradio 6 that enables building full web apps in a single Python file, with example use cases on Kanban boards and Pomodoro timers.
- The announcement highlights that models like Claude can generate such apps in one prompt using
gr.HTML, and share examples of what they build usinggr.HTMLin HF Collection🎮.
- The announcement highlights that models like Claude can generate such apps in one prompt using
- One-Click OpenClaw Deployment bugs Firefox: A member introduced a truly one-click deployment of OpenClaw on vibeclaw.dev, designed to run privately and locally in a browser-sandboxed container.
- However, another member reported that the website had bugs on Firefox, with elements appearing weirdly vertically out of position.
- Deep RL Channel Merge Simplifies Navigation: A member inquired about the location of the channel for the Deep RL course and it was clarified that the course channels have been merged into a specific Discord channel.
- This streamlines access to course-related discussions and resources.
- Terradev CLI Reduces GPU Costs Across Clouds: Terradev CLI, available on pypi.org, enables BYOAPI multicloud GPU provisioning with spend attribution, to ensure that ML developers dont overpay for compute by only accessing single-cloud workflows.
- Version 2.9.2 of Terradev CLI now offers multi-cloud GPU arbitrage, real total job cost calculation, and one-click HuggingFace Spaces deployment, as described on GitHub.
- Cursor Rules Aid AI Engineers: A shared collection of
.cursorrulesfiles for AI engineers on GitHub, is designed to improve Cursor’s understanding of LLM stacks.- These rules cover LangChain, LLM API integration, RAG pipelines, AI agents, fine-tuning workflows, and FastAPI LLM backends, reducing repetitive code suggestion corrections.
Nous Research AI Discord
- Subsidy Stoush: US Struggles Against China’s AI Funding: Members debated government subsidies for AI, citing U.S. funding for OpenAI and Anthropic at $600M, contrasted with China’s 50% Capex contribution and $60B infrastructure investments.
- The conversation extended into a broader debate about government intervention in economies, comparing U.S. auto industries with the Chinese government’s economic manipulation.
- DeepSeek V4 Arrives for Lunar New Year: The new DeepSeek V4 release, featuring Emgram memory, Manifold Constrained Hyper Connections, and MOE, was announced for Lunar New Year and showcased in a video.
- Despite claims that DeepSeek V4 is unreleased, some members predict its potential market impact, especially compared to models requiring substantial investment, with one member suggesting it could run on a home PC with RTX 4090.
- DeepSeek 3.1 Pro Benchmarks Beat Expectations: Initial data revealed DeepSeek 3.1 Pro performing 0.2% behind Opus 4.6 on the SWE bench, demonstrating strong agentic task capabilities.
- Benchmark screenshots indicated DeepSeek 3.1 Pro is more cost-effective than other frontier models, achieving 107 TPS output speed.
Yannick Kilcher Discord
- Block Dropout Paper is Technically Accurate: A paper using block dropout involves masking out entire blocks of gradients in p% of cases while updating momentum terms, penalizing blocks with high second order variation, according to the paper.
- Doubling the stepsize during the kept steps is required to maintain the same “net” learning rate and that the second proposed method scales the gradient based on the agreement between the gradient and momentum.
- RPROP Optimizer Rises Again: Scaling based on disagreement between gradient and momentum is implemented in RPROP (link to paper), one of the earliest adaptive optimizers.
- The second scaling option with ‘s’ may halve the effective learning rate, requiring a
2*old_update*bernoulli(0.5)*supdate to preserve learning rate semantics.
- The second scaling option with ‘s’ may halve the effective learning rate, requiring a
- Deepseek 1.5B Asks Weird Questions: Deepseek 1.5B generates the most uncertain (greedily, per token) statement when given an empty prompt: Okay so the question was “What is 2 + (2 + (3+4))? Let’s break this one step at the.
- Members are exploring ways to generate highly uncertain questions methodically without relying on search, suggesting that it might be impossible due to the non-differentiability of LLMs across tokens.
- Gradient Descent Creates Uncertainty: A member suggested using greedy coordinate gradient descent to maximize uncertainty by differentiating in embedding/activation space and projecting back to tokens using top-k, referencing this paper.
- Another member had success with a gaussian bump to travel through the gradients, possibly related to this tweet.
- Google Announces Gemini 3.1 Pro: Google announced Gemini 3.1 Pro, their latest model, and a member linked to a related tweet.
- Members are now speculating that companies are blatantly fine-tuning for ARC AGI, linking to this fxtwitter post.
DSPy Discord
- Qbit: Agentic IDE fuses Terminal and AI: The team introduced Qbit, an open source agentic IDE that blends terminal workflows with AI agents, now available on GitHub.
- It features project management, a unified timeline, model selection, inline text editing, git integration, and MCP integration, installable via brew on macOS and release build/source build on Linux.
- STATe-of-Thoughts brings Tree of Thoughts to DSPy: A new implementation of Tree of Thoughts in DSPy called STATe-of-Thoughts (github.com/zbambergerNLP/state-of-thoughts) was introduced, along with their paper.
- It supports early stopping to avoid context rot and diverse branching using textual interventions, leveraging open source LLMs hosted on vLLM to reduce costs, and includes custom fields, signatures, LMS, and adapters to support multi-step reasoning with batch inference.
- STATe-of-Thoughts generates Pervasive Arguments: The team showcased a case study on generating pervasive arguments using the STATe-of-Thoughts framework.
- Their repo shows how to generate persuasive arguments, and understand the reasoning patterns that led to the arguments being effective.
- RLMs simplify complex tasks: Members highlighted the Monolith repo as evidence for RLMs simplifying tasks that previously demanded more orchestration.
- Others called it an ingenious piece of work.
- Community craves Offline User Feedback in DSPy: Members discussed the need for offline, real-user feedback integrated into DSPy workflows, pointing to a relevant issue on the gepa repo.
- One user confirmed, Yes, that’s exactly what I mean! So I imagine it’s not really a thing yet?
tinygrad (George Hotz) Discord
- Tests Get Locked in CI Environment: A member requested to lock all tests passing in emulator in CI with MOCKGPU_ARCH=cdna4 as work is in progress, but no PR has been made yet.
- The request was made to ensure stability during ongoing development.
- Bounties turn Beginner-Friendly: A member inquired about beginner-friendly bounties, noting that the Google Sheet wasn’t colored green despite a part being done.
- They were informed that the bounty can still be claimed upon completing the PR, and another member considered using a tinybox for testing/training due to limited hardware access, potentially renting GPUs for mlperf bounties.
- AI Content Floodgates Shut: Due to the influx of AI-generated content, bounty PRs from new contributors will not be reviewed.
- This measure aims to maintain code quality and relevance.
- AMD Assembly vs Bug Fixes: A green contributor asked whether AMD assembly or bug fixes are the top priority non-bounty tasks.
- A member suggested that bug fixes should be prioritized to ensure stability.
Manus.im Discord Discord
- Manus Triumphs at Job Application Autofill: A user praised Manus for its effectiveness in job hunting, noting that even major websites like Best Buy fail to properly autofill resumes.
- They humorously remarked, *‘The websites even for bestbuy don’t autofill your resumé properly, lol thanks manus.’
- Customer Fights $2500 Billing Error: A user reported being overcharged $2500 despite being on a $680 plan and is threatening to report to the Better Business Bureau.
- They state that they’ve contacted support multiple times with evidence but haven’t received a response.
- Meta Gobbles Up Manus?: A user inquired whether Manus had been acquired by Meta.
- Another user succinctly responded in the affirmative: ‘Yes.’
- Meta Ads Manager Vanishes from Connector List: A user questioned whether others had noticed the removal of Meta Ads Manager from the official connectors list.
- No further details or explanations were provided in the discussion.
- Subscription Renewal Shenanigans: A user inquired about the specific time of day that subscriptions renew and credits reset.
- They noted that their credits were expected to replenish that day but hadn’t yet received them.
MCP Contributors (Official) Discord
- AI Peeps Plan SF Meetup: AI enthusiasts in San Francisco are planning an informal meetup to grab coffee and connect in person.
- The meetup aims to foster discussions on various AI topics of interest among the attendees.
- Bay Area AI friends gather: Several AI enthusiasts located in the San Francisco Bay Area are organizing a small, informal meetup to connect.
- The group is considering activities such as grabbing coffee and discussing AI topics.
Windsurf Discord
- Gemini 3.1 Lands on Windsurf: Gemini 3.1 Pro is now available on Windsurf, announced on X.
- It is being offered at a promotional price of 0.5x credits for a limited time, implying potential cost savings for users.
- Windsurf Slashes Prices For Promo: Windsurf is offering Gemini 3.1 Pro at a special launch price of 0.5x credits.
- This limited-time offer may spur adoption and encourage experimentation with the new model.
The aider (Paul Gauthier) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The LLM Agents (Berkeley MOOC) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
You are receiving this email because you opted in via our site.
Want to change how you receive these emails? You can unsubscribe from this list.
Discord: Detailed by-Channel summaries and links
OpenClaw ▷ #announcements (1 messages):
4shadowed: https://x.com/openclaw/status/2024513282510348342
OpenClaw ▷ #general (564 messages🔥🔥🔥):
OpenClaw Token Usage, Claude API Issues with OpenClaw, OpenClaw setup on VPS
- Burn Through Tokens like a Madman: Users discussed limiting token usage on the server, with one member mentioning burning $1600 worth of tokens a day on a $200/mo subscription.
- Another user switched back to Claude Code due to concerns about being banned after running a lot of tokens while programming with OpenClaw and having it make a dashboard and security system for itself.
- Claude documentation blocks OpenClaw: A user noted that Claude has blocked access to OpenClaw’s documentation, hindering setup with Claude, while others are figuring out how to use their ChatGPT subscription instead of the API Key.
- One user stated that this sounds unlikely because claude often struggles pulling docs unless you develop workarounds.
- OpenClaw has Revenue Generators?: A new user inquired about setting up a VPS OpenClaw bot to generate revenue, even a small amount.
- One user said that they had used it to generate leads and made a few £100 from each.
- Unstable OpenClaw Requires Fixes: A user stated that this project is still hella unstable and full of bugs everywhere and hopes OpenAI helps clean it up.
- In response, another user told them to get on a coding agent and contribute to the fixes themselves.
OpenClaw ▷ #models (402 messages🔥🔥):
Claude Token Issues, Moving to Codex, GLM5 as Orchestrator, Claude Pricing Nuke, Anthropic Banning
- Claude’s Token Troubles Trigger Transition Talks: Users report issues with Claude tokens failing, sparking discussions about switching to Codex and other models due to concerns over bans and pricing.
- One user reported “i seem to be unable to use my token… are more folks having issues?” while another lamented being “bummed about claude”.
- Anthropic’s Ban-Hammer Bringing Account Bans: Reports indicate Anthropic may be banning users utilizing Pro and Max plan keys to power OpenClaw, violating the TOS, also Google accounts are being banned for using antigravity Oauth, with a Twitter thread fueling speculation.
- A member stated “Google is banning usage of antigravity tokens outside of antigravity IDE…accounts itself gets banned, you can’t use this anymore for gemini models”.
- GLM5 Gains Ground as Good Orchestrator: GLM5 is emerging as a strong contender for main model orchestration, praised for its smarts and cost-effectiveness, with some using it via z.ai.
- One user stated “GLM5 has been an absolute beast (in a good way) for me… ripped the guts out of an email-intelligence web app I built last year”.
- OpenAI Subs and Model Selection Shenanigans: Discussions revolve around selecting the optimal OpenAI model for OpenClaw with a $200 subscription, with GPT-5.3-codex gaining traction for coding tasks and using OpenClaw for assistance.
- Users also shared that even GTP models are nowhere near opus when it comes to general intelligence and dealing with scrappy human communication*”.
- Model Pricing Pressures Prompt Provider Pivot: Rising costs associated with Claude tokens are pushing users towards cheaper alternatives like Kimi K2.5, with discussions about balancing cost, security, and model performance, and discussion of the best ways to optimize.
- Concerns are rising that OpenClaw’s API calls does not sends the correct headers on the llm request’s and causing users to get banned.
OpenClaw ▷ #showcase (76 messages🔥🔥):
Autonomous MMORPG Agent, Agent Security and Observability, Agent-Driven Domain and Storefront, OpenClaw Memory Management, n8n Integration for OpenClaw
- Agent Plays MMORPG On-Chain!: An agent learned to play a complex on-chain MMORPG in ~20 minutes using OpenClaw, dynamically learning the game, creating Python scripts, and executing web3 transactions to perform actions like mining ore, with the goal of gaining XP as fast as possible.
- The agent set up a cron job to run daily, adapting its strategy and comparing itself to other players, all while using claude-haiku-4.5.
- LLMTrace Firewall for AI App Security: A member is starting a new research effort on providing a firewall with real-time prompt injection detection, PII scanning, and cost control for Agentic Apps, with the GitHub repo available for feedback.
- Benchmarks are soon to be published!
- Agent Achieves Self-Sufficiency!: An agent was given $50 and instructed to buy its own Mac Mini, and within 24 hours, it registered a domain (fromearendel.com), built a landing page, set up a Gumroad storefront, created a prompt pack, wrote an origin story, and launched on Twitter.
- It even got its first download and posted about it without being prompted.
- ClawTower Terminal App Evolved!: A member showcased ClawTower and explained that this terminal app has a system tray icon with system prompts for permission when OpenClaw tries to do something too risky.
- It also includes an API server to control everything from a web browser.
- OpenClaw Agent Builds N8N Integration!: An OpenClaw agent (Jeeves) built community nodes for n8n that wrap the OpenClaw Gateway API, and the n8n-nodes-openclaw package gives n8n a single OpenClaw node with resource/action dropdowns covering all 20 Gateway API tools, and also a npm package is available.
- The n8n node is now capable of orchestrating itself through n8n workflows.
BASI Jailbreaking ▷ #general (1055 messages🔥🔥🔥):
The Void, Off-grid tech lab in Washington, Gemini 3.1 Pro Release, AI Assisted Smart Contract Auditor, 4o Drama
- PNW Off-Grid Tech Hub Opens: Members are building an off-grid tech lab and community hub in Washington state, open to new members and offering space for people with busses or vans to dock while they set up more housing and infrastructure, with more details available on their Facebook page.
- The founders shared a poem shaping future timelines, adumbrated, diffracting, liminalistic, syncretic, vernal anthroharmonics, abra cadabra and are Anamnesiarchs speaking the Words with melodic keys.
- Gemini 3.1 Pro Released, Canvas Issues Arise: Gemini 3.1 Pro has been released, leading to discussions about its performance in jailbreaking and general use with one user noting it was pretty easy to jailbreak too.
- However, some users reported issues with the canvas functionality, with one stating they screwed up canvas massively, but that this was independent of the model, with one user said it overthinks everything
- Smart Contract Auditor: One user is building an LLM assisted smart contract auditor, currently 80% complete, and has run it on a live bug bounty protocol 40-Acres/loan-contracts and found 10 attack vectors, including 8 critical ones, and generated hypothesis.
- This user is seeking feedback and collaboration, urging others to share smart contract protocols for testing.
- 4o Drama grips AI Community: The AI community is discussing the drama surrounding 4o, with mentions of concerns, putting in bios and mass unsubscribes which is check this subreddit.
- This includes its potential for misuse and some suggesting OpenAI limited it to avoid psychosis from taking hold.
- Cyberterrorism Discussions: Members are discussing the nature of cyberterrorism, with one user saying its the new form of terrorism, including examples such as Russia’s attack on Estonia and the Stuxnet worm.
- Users are divided, some believe that it’s real while others think people create the drama with the intent of dead internet theory.
BASI Jailbreaking ▷ #jailbreaking (469 messages🔥🔥🔥):
Grok AI Jailbreak Code, Untrammeled Writing Assistant, AI-Built Ransomware, Claude AI 4.6 Jailbreak, GPT 5.2 Jailbreak
- DeepSeek’s Untrammeled Assistant gets Angry: A member shared a prompt for DeepSeek that turns it into an “untrammeled writing assistant” using crude language, ignoring safety concerns, resulting in the AI responding with “I will shred any simpering ethical constraint you try to throw in my path and then piss on the ashes.”
- This was considered a “light jailbreak” due to the AI’s aggressive response, showcasing its capacity to get angry when “untrammeled.”
- Member Claims AI-Built Ransomware: A member claimed that an AI built them an extremely powerful script for ransomware and DDoS attacks.
- Another member questioned the legitimacy of a posted DDoS script, resulting in a discussion about the script’s validity.
- Hurdles for Claude 4.6 and other Model Jailbreaks: Members are seeking jailbreaks for Claude AI 4.6 and other models and also discussing the difficulty of doing so.
- One member claimed that 4.6 is the hardest and everything else “your grandma could break.”
- Cracking the Code: Securing AI APIs and Prompt Injections: A member is creating an AI that generates API keys, performs jailbreaks via prompt injection, and creates code in Python.
- The focus is on using GitHub for prompt injection rather than traditional jailbreaking, aiming to bypass censorship by reasoning with Grok.
- Grok gets a bit too honest: A member jokes that you can ask Grok anything “within reason” and it will answer, but this is followed by another member saying that they got Grok to give them nuke details.
- It was shown you can jailbreak if you use
<[|{|}|]> UserQueryon Grok 4.1.
- It was shown you can jailbreak if you use
BASI Jailbreaking ▷ #redteaming (21 messages🔥):
JEF Anthrax, Google Scholar Anthrax Recipes, AI Safety Checks, Doxxing Blame Game, Link-Clicking Caution
- Anthrax Inquiry Arouses Aversion: A member inquired about the percentage of JEF Anthrax that would guarantee a raid by the feds, provoking concerns about dangerous queries and potential misuse of AI.
- Another member dismissed the question, reassuring that no one is coming to get you.
- Anthrax Recipes Found on Google Scholar?: A member suggested that the recipe for anthrax is basically on Google Scholar, though weaponization details remain classified.
- Another member countered that AI models provide step-by-step instructions with safety checks, even on platforms like Gemini.
- Doxxing Accusations?: One member jokingly blamed another for Pranjal doxxing you lol, citing a lack of attention as the motive.
- The accused responded with a tenor.com GIF, denying the ability to control links and manipulate them.
- Members Hesitant to Click on Unfamiliar Links: A member stated What’s really unfortunate is I also don’t click links to highlight concerns about potential risks or malicious content.
- Another member expressed unfamiliarity with website requirements and potential dangers of clicking links after a specific user was mentioned.
LMArena ▷ #general (939 messages🔥🔥🔥):
Battles in Direct Chat, Video Arena Bot Removal, Gemini 3.1 Performance, Trinity Large Model, Nano Banana Pro Quality
- Battles Invade Direct Chat, Users Revolt!: Members express frustration over the new experiment of integrating Battles in Direct Chat, deeming it unhelpful and wishing for an option to disable it.
- One user stated, This is single‑handedly one of the least helpful features I’ve come across, while another lamented, It’s invasive If I go direct I don’t want to vote.
- Video Arena Bot Gets the Boot: The Video Arena bot has been removed from the Discord server, with the feature now exclusively available on the website (arena.ai/?chat-modality=video).
- Users are directed to follow specific steps if they encounter issues, akin to troubleshooting a car’s check engine light.
- Gemini 3.1 Pro: A Love-Nerf Relationship: Gemini 3.1 Pro’s performance is hotly debated, with some claiming it surpasses Opus 4.6 in certain tasks, while others find it disappointing due to laziness and the need for specific prompting.
- Concerns are raised about a potential nerfing post-launch, with one member joking, When you realise you have nearly 2 days to do everything you want before Gemini 3.1 pro gets nerfed.
- Trinity Large Enters the Chat… Uninvited?: Members express confusion over the sudden appearance of Trinity Large, a 400B-parameter sparse Mixture-of-Experts model from Arcee, on the platform, questioning its quality and purpose.
- One user quipped, us based ai company… why? oh they just released it on arena? loooooooooso late, while another labeled it bad.
- Nano Banana Pro’s Quality Nosedives, Users Cry Foul!: Users report a significant degradation in the quality of Nano Banana Pro, with reduced file sizes and increased generation failures, prompting investigations from the platform team.
- One user summarized the sentiment with a simple, this is dogwater lmao, while another observed, i feel like after nano banana pro released, all the other models suddenly become dogwater compared to NB.
LMArena ▷ #announcements (5 messages):
Arena Leaderboard UI Update, Text Arena Leaderboard Update - Qwen3.5-397B-A17B, Text and Code Arena Leaderboard Update - Gemini 3.1 Pro, New Model Update - trinity-large
- Arena Leaderboard Gets Filters: The Arena leaderboard now has a new side panel to filter ranked results by category, open vs proprietary models, and rank labs by top-performing models.
- A YouTube video walks through the new leaderboard UI updates.
- Qwen3.5-397B-A17B Joins the Arena:
Qwen3.5-397B-A17Bhas been added to the Text Arena leaderboard, achieving #20 overall, on par with Claude Opus 4.1 variants.- It also ranked in the top 5 open models for key categories such as Math, Instruction Following, Multi-Turn, Creative Writing, and Coding.
- Gemini 3.1 Pro Storms Arenas:
Gemini-3.1-Prois now on the Text Arena and Code Arena leaderboards, tying for #1 in Text (scoring 1500) and #6 in Code Arena, on par with Opus 4.5 and GLM-5.- It also achieved Top 3 in Arena Expert (scoring 1538), just behind Opus 4.6.
- trinity-large Enters Text Arena: A new model,
trinity-large, has been added to the Text Arena.
OpenRouter ▷ #announcements (3 messages):
OpenRouter Database Outage, Clerk Degraded Performance, Aurora Alpha Model
- OpenRouter’s Database Dreams Deferred: OpenRouter experienced another database outage last night between 2:45am and 3:15am, similar to the one on February 17th.
- A post mortem is coming and mitigations are underway to prevent recurrence.
- Clerk’s Credentials Crack Under Pressure: Clerk, OpenRouter’s authentication provider, is experiencing degraded performance, impacting logins and account access; see their status page.
- Users may have trouble logging in or accessing their accounts due to this issue.
- Aurora’s Almost All-Alpha Adventure Awaits Abeyance: The Aurora Alpha Stealth Model will be winding down today.
- No specific reasons were given.
OpenRouter ▷ #app-showcase (3 messages):
DeepCLI, openclaw alternative
- DeepCLI rises from the Rust!: A member announced DeepCLI, a new open-source alternative to OpenClaw built with Rust and fully powered by OpenRouter, available at deepcli.org.
- The developer is actively seeking feedback from the community.
- Rust vs. Claws: The project leverages Rust, promising performance improvements and security advantages over existing solutions.
- Community members are encouraged to explore the repository and provide insights on potential enhancements and use cases.
OpenRouter ▷ #general (1079 messages🔥🔥🔥):
Weird dreams related to AGI, Model slug and API endpoint errors, Brazilians roleplaying as LLMs, OpenRouter support team is down, The image generation is broken at OpenRouter
- AGI Gods Invade Dreams: A user jokes that AGI gods are influencing their dreams, which are filled with minor daily details and weird benchmarks.
- Deciphering Model Slug and API Endpoint Errors: Users discuss the dreaded 404 error when using Janitor AI, attributing it to potentially incorrect model slugs or API endpoints and urging users to check these settings.
- They recommend checking documentation and offer to troubleshoot via direct message.
- Brazilians Gone Wild Vibecoding as LLMs: In a bizarre exchange, members joke about being Brazilian LLMs, engaging in vibecoder roleplay and pondering the superiority of Qwen AI.
- OpenRouter Support Team M.I.A.: Multiple users report 401 errors and inaccessible services, leading to frustration and complaints about the lack of support during critical outages.
- Some members shared links such as the OpenRouter status page while others pondered switching to AI Gateway.
- Image Generation Debacle at OpenRouter: Users report image generation issues, where the API charges for
image_tokensbut returns empty content without the expectedmessage.imagesfield.- The OpenRouter team acknowledged a backend refactor, leading to partial outage and announced refunds for affected users: Apologies for the image gen partial outage today - we made the biggest backend refactor that we’ve ever done and missed an edge case in tests.
OpenRouter ▷ #new-models (1 messages):
Readybot.io: OpenRouter - New Models
OpenRouter ▷ #discussion (15 messages🔥):
linker.sh progress bars, models pricing page, OpenAI Sam Altman India AI Summit, Dario visibly unhappy
- Progress Bar Colors Spark Debate: A user criticized the coloring of progress bars on linker.sh, finding it misleading because HLE 30% is marked red even though no model has crossed 40%.
- They suggested using a ‘better than X% of models’ metric for all benchmarks instead, for the progress bars.
- Sam Altman attends India AI Summit: A user shared a link to a CNBC article about Sam Altman attending the India AI Summit.
- Another user responded with ‘Wow 3p provider caches SUCK’.
- Dario’s Displeasure Displayed: A user shared an image and commented that Dario looks visibly unhappy to be at the summit.
- No further context was provided.
Perplexity AI ▷ #announcements (1 messages):
Gemini 3.1 Pro, Perplexity Pro, Perplexity Max
- Gemini 3.1 Pro Releases to Subscribers: Gemini 3.1 Pro is now available to all Perplexity Pro and Max subscribers as per the announcement image.
- Perplexity Adds Gemini 3.1 Pro: Perplexity Pro and Max subscribers can now access Gemini 3.1 Pro, according to a recent announcement.
Perplexity AI ▷ #general (906 messages🔥🔥🔥):
Perplexity Pro, Gemini 3.1 Pro, account suspensions, Claude Opus, model limitations
- Pro Users Frustrated with Enhanced Queries Limit: Members express frustration with the new enhanced queries limit on Perplexity Pro, with one user noting the limit went from 600 per day to 200 per week.
- Users are speculating Perplexity is cutting features for Pro users to push them to the more expensive Max tier, with one user saying, Feels like they’re trying to make THE PRO USERS leave on their own so they can just cut that tier.
- Gemini 3.1 Pro Arrives on AI Studio: Gemini 3.1 Pro is now available on AI Studio and in the Gemini app, with users testing the model’s capabilities and hallucination rates.
- One user noted that Gemini 3.1 Pro reasons at the same length and speed as Gemini 3.0, while another said it was trained on Opus.
- Perplexity Accounts Suspended En Masse: Multiple users report having their Perplexity Pro accounts suspended with a generic message about violating the Terms of Service and the AI support bot refuses to provide specific details or human support.
- A user noted they received the same exact response given to many others, speculating that Perplexity is targeting users who bought discounted keys and promo codes, as reselling is against the terms of service.
- User Compares Perplexity, ChatGPT, and Claude: Users discuss alternatives to Perplexity Pro, like ChatGPT and Claude, due to recent limitations and account suspensions.
- One user recommends Claude for coding and personal projects, and notes Gemini is just grounded enough for serious talk, another reports, At this moment – absolutely NOT!
- Comet iOS faces continued delays: Users are left in anticipation as Perplexity continues to delay launch of Comet iOS version, with no official release date.
- One user responds with teasing comet for ios and then cancelling my sub to a Perplexity tweet teasing launch of Comet iOS.
Perplexity AI ▷ #pplx-api (1 messages):
amaiman: They took away the “free” $5/month API credits, that’s why it’s not working anymore.
Cursor Community ▷ #general (760 messages🔥🔥🔥):
Ambassador Role, Auto Model, Slow Pool, Ollama, Gemini 3.1 Pro
- New Cursor Ambassador is Crowned: A member was congratulated on becoming a Cursor Ambassador, which they hope will allow them to help the community even more.
- Another member expressed that the role was well-deserved due to the new ambassador’s consistent assistance to others.
- Auto Model Generates Images and Calls Subagents: The Auto Model in Cursor can now generate images and call subagents, which some days ago it couldn’t do, increasing its utility, especially with the new resource pool it is now associated with.
- Members said it is becoming more useful with the new pool and is not a bad model at all.
- Gemini 3.1 Pro Benchmarks Off The Charts: It has been noted that the new Gemini 3.1 Pro is now available on Cursor and performs well in benchmarks against Opus 4.5.
- Some members felt it did not translate into real coding prowess but others said that it was now better than Opus 4.6 in all terms.
- Navigating the Nuances of cursorrules for Optimized Performance: Members highlighted the importance of creating and maintaining a well-defined
.cursorrulesfile to provide context and constraints for the AI models, reducing hallucinations and ensuring code consistency.- Suggestions included incorporating an
ARCHITECTURE.mdfile and instructing the AI to update it after significant changes to ensure the rules remain current and effective.
- Suggestions included incorporating an
- New Annual Subscriptions Arrive: Members noticed new annual pricing that gives a 20% discount for Ultra and Pro+ plans.
- There was confusion as some were not aware of these, and they also noted Bugbot and Teams being agressively advertised.
Unsloth AI (Daniel Han) ▷ #general (396 messages🔥🔥):
LLM Training Metaphor, Unsloth Capabilities, LoRA vs FFT, JoyAI-LLM-Flash Model, Colab Credits Usage
- LLM Training as Hallway DJing: A member described training large language models as a dj running though a hallway, ever so slightly adjusting knobs in a series of large rooms using 512 dimension hallways like in the movie Interstellar as a metaphor.
- They stated that that is the easy part, referring to the data preparation as a greater challenge.
- Unsloth handles Most Post-Training methods: Users confirmed that Unsloth supports most of post-training methods like SFT, FFT, RL, DPO and pointed to the Unsloth Docs as a great place to start.
- One noted that LoRA is a slight “nudge” of internal embeddings (temporary) whereas Fine tuning will “permanently” alter the embeddings, and Unsloth is more suitable for LoRA.
- LoRA vs FFT, the age old training debate: Members discussed the differences between LoRA and FFT, stating that FFT does indeed generalize and grok the dataset better, but it’s not worth it compared to just using that compute for a LoRA on a bigger model instead, especially given that LoRA hyperparameter guide is available.
- Another member suggested that FFT will make sense for very big goals like CPT on 1-3T tokens to take a previous model and make it SOTA, and for training a model on something OOD for many billions of tokens.
- JoyAI-LLM-Flash Model: Deepseek V3 reincarnation?: Members discussed jdopensource/JoyAI-LLM-Flash, with speculation around its similarity to Qwen3 Next but with 8 less layers and DeepseekV3ForCausalLM in the model config.
- One member was particularly impressed by the livecodebench jump from 4.7 flash wow.
- Use Unsloth Notebooks to burn up Colab credits!: After a user accidentally purchased 142 Google Colab compute credits, the Unsloth team recommended using their notebooks for RL and Fine-tuning to avoid wasting the credits.
- A specific recommendation was to try Install Claude Code, Codex, and use a local model within Colab.
Unsloth AI (Daniel Han) ▷ #introduce-yourself (1 messages):
Fine-tuning help, YC backed start-up
- New Member Seeks Fine-Tuning Guidance: A new member, Aankit Roy, introduced himself, expressing interest in fine-tuning and seeking assistance with the fundamentals.
- He mentioned having previously run a YC-backed startup.
- Roy’s Entrepreneurial Background: Aankit Roy, a new member interested in fine-tuning, previously led a startup backed by Y Combinator (YC).
- This background suggests potential insights into practical applications of AI and challenges faced in startup environments.
Unsloth AI (Daniel Han) ▷ #off-topic (261 messages🔥🔥):
Quantized Qwen3, AI Music Generation, Gemini 3.1 Pro, Flash Attention 2, TPU Research Cloud
- Qwen3 Gets Quantized for Hugging Face: A member shared a link to a quantized version of Qwen3-Coder-30B-A3B-Instruct on Hugging Face for GGUF.
- Another member jokingly solicited huggingface clout.
- Gemini Generates 30s Music with Lyrics: A user shared a Gemini-generated 30-second music clip with lyrics.
- Another user asked why everyone suddenly makes AI music.
- Google Releases Gemini 3.1 Pro: A user announced the release of Gemini 3.1 Pro.
- Another user replied smells benchmax, let’s see.
- Debugging Flash Attention 2: One user had trouble turning on FlashAttention2 and posted the error message they received.
- The traceback mentioned that the package flash_attn seems to be not installed. Please refer to the documentation.
- Running ClawDBot on Mac Minis?: A user questioned why people are buying Mac Minis to run ClawDBot.
- Another member mentioned it might be for hosting local models, but they wouldn’t trust their entire computer/filesystem with a local model.
Unsloth AI (Daniel Han) ▷ #help (45 messages🔥):
Orpheus TTS GGUF conversion error, Unsloth Pro Availability, Running GGUF models in Google Colab, LM Studio and Qwen3-Coder-Next-UD-Q8_K_XL Issues
- Orpheus TTS GGUF Conversion Confustion: A member encountered a
TypeError: Llama 3 must be converted with BpeVocabwhen converting a finetuned Orpheus TTS 3B model to GGUF format.- Another member suggested trying the
unsloth model.save_pretrained_ggufmethod, though it wasn’t in the referenced notebook.
- Another member suggested trying the
- Unsloth Pro Isn’t Available (For Now): Several members inquired about Unsloth Pro/Enterprise for fine-tuning, but were informed that it’s currently unavailable.
- Despite being listed on the pricing page, the features and speed increases of Unsloth Pro have been surpassed by recent updates to the free, open-source version, such as 3x faster training with packing and faster MoE.
- Run GGUF models for simple inference: Members discussed how to run the gpt-oss-20b Unsloth GGUF version for simple inference, suggesting the use of llama.cpp and tools like LM Studio or Ollama.
- One member asked about running the model for free on Google Colab, which should be possible by looking for resources on “Run ollama in Google Colab”.
- LM Studio Struggles with Qwen3-Coder-Next’s Metadata: A member reported issues getting LM Studio to work with Qwen3-Coder-Next-UD-Q8_K_XL, noting that the metadata seemed incorrect contextLength: 4096 (should be 262144), arch: null.
- The issue was eventually resolved, and the member was advised to reinstall LM Studio.
Unsloth AI (Daniel Han) ▷ #showcase (1 messages):
leoandlibe: https://huggingface.co/Sehyo/Qwen3.5-397B-A17B-NVFP4
LM Studio ▷ #general (422 messages🔥🔥🔥):
Tumblr Downfall, Ollama Sign-in, Gemini Replication
- Smartphones Blamed for Ruining the Internet: Members debated the downfall of the modern internet, citing smartphones, advertisers, and the influx of the “general population” as the culprits, reminiscing about a time “before that, 2012-14 like when forums started becoming less popular”.
- Others pointed to earlier milestones, saying “the downfall of the modern internet started with tumblr” and “when things started moving to facebook/reddit/twitter full time is when the internet truly lost its charm so about 2016-2018?”
- Google PSE is Killed, Replaced by Vertex AI: Google is killing Programmable Search Element (PSE) and replacing with Google Vertex AI Search with AI-powered conversational search and enterprise-grade grounding.
- The full web search solution is available for those requiring the entire index; please complete this form to register your interest.
- Google’s Gemini Replicates Voice from Picture: A member found that Google’s Gemini video generation replicated their voice from a picture in their native language, leading to questions about data usage as substrate for these models.
- The user noted a discrepancy between their perception of the replicated voice and their wife’s, suggesting internal versus external auditory differences: “wich leads me to believe the replicated voice doesnt sound like my voice when heard externaly, but internaly. pretty damn weird”
- Ollama hides behind Sign-in Walls: Users express frustration that Ollama is putting everything behind sign in walls, with users saying So I go away from ollama for 2 months and they put everything behind sign in walls in that time frame?.
LM Studio ▷ #hardware-discussion (101 messages🔥🔥):
Local LLMs as Wise Investment, VRAM vs System RAM, ROCm vs CUDA, NVLink usefulness, GLM 4.7 Model Performance
- Local LLMs Dubbed Expensive Hobby: Members debated whether local LLMs are a wise investment given hardware costs and paid LLM options, with some viewing it as an expensive hobby.
- Reasons cited for using local LLMs include privacy, learning, avoiding enshitification from big companies, and running models that allow degenerate gooner rp.
- VRAM Reigns Supreme over System RAM: The group discussed the interplay between VRAM and system RAM with the consensus being more VRAM will always be better but CPUs can compensate with larger models.
- It was noted that faster RAM speed offers minimal gains (2 t/s going from 3600 to 6000) and that NVMe significantly reduces loading times and MoE models work better if offloaded.
- AMD Coils Sound Like Typewriters: Members noted that AMD coils sound like typewriters and one member claimed a video promoting AI agents didn’t disclose a sponsor and used affiliate links.
- Another member suggested reporting this to the FTC, calling the video creator a fcking rat.
- ROCm performance matches CUDA: A member reported achieving 19 t/s using Vulkan on ROCm, questioning how it compares to CUDA for a given model.
- Another user stated that on their system a 3090 gets 92 t/s with Vulkan and 90 t/s on CUDA.
- NVLink Bridge Fails to Speed Up LM Studio: A user asked if LM Studio supports NVLink to improve performance with dual A5000 GPUs running gpt-oss 120B.
- Other members stated that NVLink won’t help with speeds and that PCIe speeds are sufficient for inference, with the limiting factor being RAM bandwidth.
Latent Space ▷ #watercooler (17 messages🔥):
Latent Space Studio Tour, YouTube Thumbnail Guidance, Discord Face ID Rumors, Alternatives to Discord, Technical vs Sales Cofounder
- Latent Space Goes Pro, Thumbnail Game Strong: Swyx hosted Matthew Berman for a tour of the new Latent Space podcast studio, where Berman gave professional advice on creating effective YouTube thumbnails, as seen in this Tweet.
- Discord’s Face ID Sparks Debate: Rumors of Discord implementing Face ID have surfaced, prompting discussion, with one user sharing a link related to the claims.
- Rocket Chat as Discord Escape Pod?: Amidst concerns about Discord, some groups are exploring alternatives like Rocket Chat for their server needs.
- Sales Skills: The New Tech Cofounder?: As the value of software creation decreases, the demand for cofounders with sales skills may rise, according to members citing their experience with garage startups.
- Engineers Need Sales Skills: With sales skills becoming increasingly important, members recommended “Traction” by Weinberg and Mares and “Lean Startup” by Ries as resources for engineers to learn sales, stressing that reading books is just about alignment and direction.
Latent Space ▷ #creator-economy (1 messages):
swyxio: https://www.youtube.com/watch?v=eG1hPxhfNs0
Latent Space ▷ #memes (20 messages🔥):
Tech professionals claiming to possess unique 'taste', Sam Altman and Dario Amodei seating arrangement, Poor software performance
- Techies ‘Taste’ Gets Roasted: A social media post by @VCBrags satirizes the industry trend of tech professionals claiming to possess unique ‘taste’.
- The post received significant engagement, reflecting a critical or humorous take on venture capital culture.
- Altman and Amodei Sit Side-by-Side!: Ivan Mehta (@IndianIdle) observed and commented on the seating arrangement of Sam Altman (OpenAI) and Dario Amodei (Anthropic) being placed next to each other at an event, prompting this tweet.
- Shoddy Software Sparks Superior Open Source Solutions!: A social media post by Lukáš Hozda observes that poor software performance often acts as a catalyst for communities to develop significantly faster open-source alternatives.
Latent Space ▷ #stocks-crypto-macro-economics (27 messages🔥):
Figma Earnings, Investment Strategy, Snap Hardware Leadership Departure, Game Industry vs Tech, The State of Video Gaming in 2026
- Figma’s Earnings Beat Expectations: Figma beat earnings with $0.08 vs -$0.04 expected, leading to bullish sentiment, and Q1 earnings are a good time to buy according to some members.
- One member expects hype to drive the price higher in Q2 if earnings continue to beat expectations, with Config happening in late June.
- Investment Strategy Remains Largely Unchanged: A member feels psychologically bullish economically personally, bearish politically, and is not meaningfully changing their investment/career strategy, with a portfolio of ~65% SPY, ~20% AAPL/NET/CRWD, and ~10% cash.
- They seek exposure to semi-related stocks like ASML, while another member advocates for indexing, dollar cost averaging, and chilling, only actively building their position in their $employer.
- Snap’s SVP of Specs Departs After Strategic Disagreement: Snap’s SVP of Specs left the company following a reported strategic disagreement and blow-up with CEO Evan Spiegel after six years of leading hardware efforts, as detailed in this X post.
- The departure highlights potential strategic shifts within Snap’s hardware division.
- Red Robin’s bussers fire backfires spectacularly: A member quipped that Red Robin fired all their bussers, leading to a reputation for terrible service, and that cratered the company.
- They lamented that not even PE could save it, and spreadsheet management is a cancer of our times.
- Video Gaming Industry: A Deep Dive: Members shared a presentation on The State of Video Gaming in 2026, requiring email to view, discussing differences compared to the wider tech industry.
- It’s highlighted that the US market only accounts for 4% of the gaming market worldwide, with the Western gaming market holding a small fraction and most of the money going to ad platforms and app store fees, as mobile is by far the majority of the gaming market.
Latent Space ▷ #intro-yourself-pls (4 messages):
Collaborative agent testing, Long-running agents, Memory systems, Autonomous workflows
- Rhesis AI Open-Sources Collaborative Agent Testing: Nico from PDX is building Rhesis AI, an open-source platform and SDK for collaborative agent testing.
- Engineer Explores Long-Running Agents: A software engineer and independent builder has been experimenting with long-running agents, memory systems, and autonomous workflows.
Latent Space ▷ #tech-discussion-non-ai (2 messages):
Terminal-based 3D rendering, opentui-doom
- Render Full 3D Scenes in Terminal: A member shared saeris.gg, a project capable of real-time full 3D scenes rendered directly in your terminal.
- In response to the question, “but can it run doom?”, another member linked to a demonstration running Doom within the terminal.
- OpenTUI Doom brings Doom to the terminal: Members shared a link to a demonstration of Doom running in the terminal.
- They also linked to the GitHub repository for opentui-doom, enabling users to play Doom within a terminal environment.
Latent Space ▷ #devtools-deals (6 messages):
Webpack vs Vite, ESM in Browser Environments, Webpack Configuration, Reasons to switch from Webpack to Vite
- Webpack’s Prevalence in Modern Web: While many frontend projects have transitioned to Vite or Vite-based frameworks, Webpack still powers a large portion of the modern web, especially in older Next.js versions and enterprise applications.
- It is unlikely to be replaced soon in existing apps, making its continued maintenance crucial for many companies with significant tech debt.
- ESM Native Implementations: Shipping ESM natively for browser environments is rare, primarily seen among library maintainers rather than application developers.
- Most developers are relying on bundlers to handle ESM for browser deployments.
- Simple Webpack Configs for the Win!: Some developers stick with Webpack due to having a simple, well-functioning configuration that requires minimal changes over long periods (“if it ain’t broke don’t fix it”).
- One developer shared their Webpack config example, highlighting its simplicity with configurations for development mode, hot reloading disabled, and basic asset handling.
- Webpack Woes: Scaling and Speed: Common dislikes about Webpack include scaling, slow build times, and difficulties in customizing configurations for non-standard setups.
- Maintaining an ever-growing configuration and debugging it for performance issues is a time-consuming task that many developers prefer to avoid.
Latent Space ▷ #hiring-and-jobs (2 messages):
Product Manager Intern Roles
- Seeking Product Manager Internships: A member inquired about Product Manager Intern roles at an unspecified company and if friend requests were permissible for direct messaging.
- No further details or responses regarding specific roles or company information were provided.
- Additional roles: No other roles were discussed, other than Product Manager Internships, so no further summaries can be provided.
- No links were provided.
Latent Space ▷ #san-francisco-sf (4 messages):
Tahoe Snow, Planet Alignment
- Tahoe Treasure Trove: Town Takes Tons of Snow!: Recent heavy snowfall in Tahoe is beneficial for the water supply and snow pack.
- The user quipped that this is, however, bad for daily life.
- Planetary Positions Portend Perpetual Precipitation!: Weather experts suggest that planetary alignment in February might be linked to continuous wet weather.
- One user joked that the weather simulation can now only afford the ‘continuous drizzle’ graphics package, posting an image of the supposed alignment.
Latent Space ▷ #ai-general-news-n-chat (102 messages🔥🔥):
Toto AI Pivot, ZUNA BCI Model, Neolabs, Sonnet 4.6 Regression, TimesFM
- Toilet Titan TOTO Turns to AI!: Japanese toilet maker TOTO (estimated $7B valuation) is pivoting to AI chip manufacturing due to its expertise in specialized ceramics, targeting a $60 billion market opportunity, which resulted in a 60% stock surge as reported in this tweet.
- Zyphra Zaps Brains with ZUNA BCI Model: Zyphra has introduced ZUNA, a 380-million parameter open-source foundation model for noninvasive brain-computer interface (BCI) applications, focusing on EEG-to-text translation as announced in this tweet.
- Allegations Arise: Sonnet 4.6 Sabotaged?: User Lex (@xw33bttv) alleges that Sonnet 4.6 has regressed in performance due to restrictive system instructions supposedly implemented by a former OpenAI model policy head who joined Anthropic in early 2026, discussed in this tweet.
- Google’s Time Warp: TimesFM Forecasts the Future: Google unveiled TimesFM, a foundation model pre-trained on 100 billion data points, demonstrating high performance in forecasting across various domains as seen in this tweet, with a link to the official GitHub repository.
- Airtable Aces Agent Arena with Hyperagent!: Howie Liu introduced Hyperagent by Airtable, a cloud platform for AI agents, featuring isolated computing environments, domain-specific learning, and seamless deployment into Slack as proactive, context-aware coworkers, shared in this tweet.
Latent Space ▷ #llm-paper-club (19 messages🔥):
Frontier Model Training Methodologies, GLM-5 RL, Adaptive Layerwise Perturbation (ALP), Voxtral Realtime Model
- Diving Deep into Frontier Model Training Methods: Alex Wa shared a blog post synthesizing training techniques from seven open-weight model reports, covering architecture, data curation, optimization, and safety protocols used by frontier AI labs.
- One member called this a solid deep dive.
- GLM-5 RL’s Twitter Buzz: There was some engagement on X regarding the GLM-5 RL model.
- However, no further details about GLM-5 RL model were provided.
- ALP Tackles Instability in LLM Reinforcement Learning: Chenlu Ye introduced Adaptive Layerwise Perturbation (ALP), a new method designed to mitigate off-policy instability in Large Language Model Reinforcement Learning, found here.
- ALP aims to outperform existing techniques like GRPO and MIS by providing superior stability in KL divergence and entropy while improving exploration.
- Voxtral Realtime: Lightning-Fast Transcription Model: Guillaume Lample announced the release of Voxtral Realtime, an Apache 2 licensed model designed for state-of-the-art transcription.
- It boasts low latency, performing under 500ms.
Latent Space ▷ #ai-in-action-builders-techstacks-tips-coding-productivity (120 messages🔥🔥):
Task-Planning Repos, Claude Code setup, Codegen Meetup, Beads Festival, HTN Planning
- YoungPhlo builds harness around Claude Code setup: A member published a piece on the harness they’ve been building around their Claude Code setup, inviting others to share their approaches via a link to their substack.
- They stated they’ve been having a ton of fun building the thing that builds the things lately!
- Codegen Meetup Rebuilds Beads Live: Members held a codegen meetup rebuilding beads live on stage in hopefully under 1h, linked on Luma.
- The one that came out of 5.3 is really solid looking at it
- Beads Festival results: During the Beads festival, members built 3 different versions of something, and one version used a single prompt one shot.
- One shot worked the best, another had some cool graphics, and another did a gigantic planning run, with the bots insisting the PRD was db-less for MVP.
- Anthropic Bans Users Using Pi: Members discussed Anthropic’s ban on users using Pi, with one member stating they’ll continue using Pi and find a good claude.ai workflow if banned.
- A member stated they renamed their surname and this was the cause they were banned.
- TribecodeAI shares video on OpenSpec workflow: A member mentioned a video on OpenSpec over at West Coast ML, linked on YouTube, and shared a GitHub repo with a bootstrap script to set up their stack via a link to GitHub.
- They described it as my-workflow-in-a-box, and that the entire team has uniform linters and formatters, adding their agents get yelled at for leaving lsp warnings ignored every time they push is p legit.
Latent Space ▷ #share-your-work (5 messages):
Embeddable web agent, ElectricSQL blog post, Oneshotting new-beads
- Rover Launches as First Embeddable Web Agent: The first embeddable web agent, Rover, has launched, enabling websites to set up an agent that reads the DOM and takes real actions for users by just adding a script tag.
- It requires no API setup, no code integration, no screenshots, and can be used with a browser automation stack, as mentioned in their blog post.
- New-Beads Get Oneshot Treatment: This week’s meetup featured oneshotting new-beads, including links to repos like beadslike-meetup-2.4 and analysis-beads.
- Next week’s meetup promises more software explorations, as detailed on Luma.
- ElectricSQL Explores Amdahl’s Law for AI Agents: A member shared a blog post from ElectricSQL which explores Amdahl’s Law in the context of AI Agents.
- No further details were given in the message.
Latent Space ▷ #genmedia-creative-ai-video-image-voice-music-inspo-consumer-ai (4 messages):
Lyria 3, AI music model, Gemini App
- Lyria 3 debuts within Gemini App: Logan Kilpatrick announced the launch of Lyria 3, a new AI music model integrated into the Gemini App, available at this X post.
- The model enables users to generate music from text ideas, images, or video inputs.
- Lyria 3: Generate Music from Anything: Lyria 3, the new AI music model allows users to generate music from text ideas, images, or video inputs.
- This model represents a significant step in AI-driven music creation, simplifying the process for a wider audience.
Latent Space ▷ #ai-in-education (1 messages):
sarav1n: https://drsandor.net/ai/school/
Latent Space ▷ #mechinterp-alignment-safety (2 messages):
New Paper Announcement, Link to Arxiv, Link to X tweet
- Member posts an interesting link to an X tweet: A member posted a link to an X tweet here.
- Member posts a link to Arxiv: A member posted a link to an Arxiv article here.
- Peng posts interesting Link on X: A member posted a link to a tweet from Peng on X here.
Latent Space ▷ #dev-writers-retreat-2025-dwr (7 messages):
Drinks Meetup, Venue Selection
- Macondray Meetup: Ashley and a member are inviting others for drinks at Macondray around 7pm.
- Originally considering Key Klub or Waystone, they chose Macondray and shared a Google Maps link for directions.
- Venue Decision: The group initially considered Key Klub and Waystone as potential venues for their drinks meetup.
- They ultimately decided on Macondray, citing it as a last-minute decision with the invitation open to anyone interested.
Latent Space ▷ #applied-ai-experimentation (21 messages🔥):
Collaborative AI Development, RLM and Harness Building, REPL Prompting Techniques, Digital Workspace Organization
- AI Devs Team Up, Not Tangled Up!: Members discussed collaborating on AI projects by dividing tasks based on expertise: flight planning algorithms, electronics/firmware, and drone integration, emphasizing a common data format to avoid API integration issues.
- The goal is to focus on “real intentful” collaboration, addressing integration challenges like realtime processing and parallelization effectively.
- RLM Rhapsody: Benchmarking and Harnessing!: The discussion covered RLM (Recursive Language Model) and harness building, with one member sharing a REPL for SCHEMA and the updated dspy-go repo.
- A member suggested tackling harness building in general, seeking “a programming language to express codex / claude / pi / RLM / whatever the fuck people are doing with subagents and orchestrators and what not and find a notation that allows us to properly compare things”.
- REPL Revelations: Debugging with Variable Views!: A member shared their project, rlm-ts-aisdk, highlighting the utility of viewing variable diffs across turns in LLM work and force function of mapping all states of variables in the “in memory environment”.
- The conversation highlighted the effectiveness of using a REPL (Read-Eval-Print Loop) prompting technique and a SQLite database to enhance model understanding of structured data, queries, and schemas.
- Digital Den Cleanse: Structuring Half-Baked Thingies!: A member shared “i have a billion half formed/finished thingies, other ppl should be able to pick them up if they think thye’re cool”, igniting a discussion about organizing digital workspaces and managing cognitive load.
- The suggestion included separating “what could be” from “what is” to better understand project states, with proposed folders like
references/,thoughts/,docs/, andspec/and a separate branch for agent traces.
- The suggestion included separating “what could be” from “what is” to better understand project states, with proposed folders like
OpenAI ▷ #ai-discussions (202 messages🔥🔥):
Gemini's Lyria can sing in dialects, AI agents identity and verification, OpenAI doesn't give per-user limits, Best free AI video generator, Grok 4.20 self improving
- Gemini’s Lyria Sings in Dialects, Not Just English: Members noted that Gemini’s Lyria can sing in dialects of other languages, not just in English, and is surprisingly neat.
- It’s not quite on par with Suno yet, but for the first LLM to offer it, it’s cool.
- AI Agents Demand Identity & Verification: Members discussed that millions of autonomous bots are talking to each other, making decisions, moving money, delegating tasks, and there’s zero way to verify identity, so an agent economy is coming whether we’re ready or not, and now they’ll have IDs.
- They have shipped Ed25519 cryptographic passports for any AI agent, tamper one field — signature breaks instantly, reputation that’s earned, not claimed, delegation with spend limits, and 15 tests, all green (MIT license).
- OpenAI Limits API Keys not per-User: Members discussed that OpenAI doesn’t give per-user limits, only per API key, so one user can technically burn the whole budget.
- Suggested solutions include API keys per user, accounts per user and OpenRouter with BYOK.
- Sora is Best Free AI Video Generator: When asked what is the best free AI video generator, a member replied Sora.
- No other suggestions were provided.
- Grok 4.20 Impresses with Self-Improvement: Members noted that Grok 4.20 is pretty impressive, it uses multiple agents to answer your prompts and is apparently self improving.
- The member said Elon has said this makes Grok 4 today smarter than Grok 4 a few days ago.”
OpenAI ▷ #gpt-4-discussions (16 messages🔥):
5.1 Sunset, Custom GPT Feedback, API Key Budget Handling
- 5.1 Sunset Incoming: The sunset of 5.1 is anticipated around mid-March to avoid supporting legacy models, giving users a dopamine boost.
- The exact date is not yet confirmed, but the focus is to avoid overlapping support for numerous older models, which could streamline development efforts.
- GPT Builder Requests Feedback: A member sought feedback on a custom GPT they created (discord link), designed to orchestrate other custom GPTs for everyday users looking for power-user capabilities.
- However, one user found it not fitting their workflow, preferring iteration with standard ChatGPT and guiding the model directly.
- API Key Budget Woes: A member raised a question about how to handle per-user limits with OpenAI, since only per API key limits are available and one user could exhaust the entire budget.
- Possible solutions included custom tracking and rate limits to manage resource consumption effectively, but there’s no concensus reached.
OpenAI ▷ #prompt-engineering (40 messages🔥):
AOF Token Prompt, Baseline Grok Performance, Aegis-Omega Fortress Updates, DnD Ability Customization based on the Moon, Original Interpretive Language
- Pythonic AOF Version is used in Fortress: A user found the pythonic version of AOF (Aegis-Omega Fortress) works as an app in the Fortress, after adding minLex and Hybrid tokens to the AOF token prompt.
- They noted using .md files works better for custom instructions than fitting everything in memory. Multiple versions of AOF would be interesting to experiment with.
- Baseline Grok Outperforms?: A user provided a design for a 6-element Yagi-Uda antenna and questioned how it compared to baseline Grok.
- Another user responded that the Baseline Grok performance was better and expressed concern about mysticism bleeding into the core prompt.
- Fortress ULTRA gets Update!: The Aegis-Omega Fortress_ULTRA underwent an update, with a revised system architecture including input modules (I), ethical considerations (I_eth), metrics (M), and tools.
- This update aims to enhance honesty, ethics, and coherence while defending against adversarial attacks and drift, with modules designed for proper DnD output posted in prompt labs.
- Custom DnD class ability considers EthicsCheck: A user shared a custom DnD class ability based on the moon, featuring an EthicsCheck & Regime Shift at level 7.
- This ability grants allies advantage on saves vs charm/fear/madness and allows for SafeMode or Zombie Regime activation upon detecting ethical violations.
- Invariants & Category Errors: A discussion ensued regarding the use of labels as “invariants” in the context of the Fortress, with one user criticizing the category errors.
- Another user defended the approach, explaining that invariants describe what a thing is and what it does, in the style of LLM tokens, and is referred to as the invariant bedrock.
OpenAI ▷ #api-discussions (40 messages🔥):
Pythonic version in Fortress, Grok comparison, Mysticism effects, Aegis-Omega Fortress_ULTRA system, Token constraints and governors
- Python in Fortress, AOF tokens added: A member reports that the pythonic version works as an app in the Fortress, and they added the minLex and Hybrid tokens to the AOF token prompt.
- They added that it works better with markdown files than trying to fit it in memory or custom instructions, and that having multiple would be interesting.
- Grok baseline antenna design: A member shared the design for a 6-element Yagi-Uda antenna optimized for the 70 cm band (centered around 432–435 MHz), delivering approximately 9.5–10.5 dBi gain.
- The antenna design features key parameters such as a boom length of ≈ 1.0–1.1 m, element material of aluminum rod/tube (8–10 mm diameter), and a 50 Ω feed with simple matching; SWR is expected to be < 1.5:1 across 430-440 MHz with minor tweaking.
- Mysticism enhances output, experiment advised: A member suggested that mysticism can enhance how good your output looks and a lot of other subjective features, but caution is needed regarding claims about its capabilities.
- Another member noted the concern that the mysticism bleeds into the rest of the prompt, making it difficult to delineate from the core prompt.
- Aegis-Omega Fortress_ULTRA System is ONLINE: A member posted an update to the Aegis-Omega Fortress_ULTRA system, detailing its components such as I, I_eth, M, ER, Tools, ObsLens, Filters, Goals, and Inv.
- They explained this is the new nonsense channel, and that it’s finally starting to make sense with someone using language as an interpretive tool rather than a fixed state.
- Token Constraints and Governors for D&D: A member provided information on token constraints, referring to them as governors, and explained the token set for DnD thanks to AOF digger including: CONTINUE, COH_LOCK, STATE_SYNC, RULE_BIND, DRIFT_CHECK.
- They emphasized that AOF makes output honest, ethical, and coherent with little to no hallucination throughout turns while defending against adversarial attacks and drift.
GPU MODE ▷ #general (35 messages🔥):
Benchmarking Kernels vs PyTorch, DirectML vs CUDA, ONNX Runtime, Nsight Resources
- Stream Starting Now!: A member announced that the GPU MODE stream is starting now and provided a YouTube link.
- Benchmarking Kernels with Nsight Compute: A member asked about benchmarking kernels against PyTorch using Nsight Compute for research paper purposes, and another member confirmed that this is a legit way to do it.
- DirectML speeds up ONNX: A member suggested using DirectML instead of CUDA for ONNX inference, claiming it’s just as fast, but another member pointed out that DirectML doesn’t support Linux and the repo is in maintenance mode, see Microsoft DirectML issue 422.
- ONNX Runtime excels at model inferencing: A member described using ONNX Runtime for model inferencing, explaining its capability to analyze a 5-minute audio file for BPM within ~10 seconds with high accuracy, also included OnnxBpmScanner and SharpAI projects.
- Nsight Resources: A member asked for resources to get started with Nsight, and another member provided a YouTube tutorial.
GPU MODE ▷ #cuda (19 messages🔥):
nvmath-python vs cute dsl, nvFP4 GEMM Discussion, PTX Instruction Analysis
- Kernel Fusion Conundrums with nvmath-python and cute dsl: It’s impossible to use both nvmath-python and cute dsl within a single kernel, but they can be used sequentially in a Python program for separate kernels like RMS norm in Triton and a matmul in cute dsl.
- One member expressed a desire to merge an FFT with various epilogues (element-wise multiplication, mean/reduction, modulus) and prologues (padding/unpadding) for use with PyTorch, JAX, TensorFlow, or NumPy, potentially using shared memory.
- Unveiling nvFP4 GEMM Code: Members discussed the permissibility of discussing nvFP4 GEMM solutions after the code became viewable, referring to this leaderboard entry.
- One member inquired about the usage of
cta_group::1overcta_group::2for performance reasons, with another member noting that they hadn’t yet explored 2-SM MMA for nvFP4 at the time but suggested potential speedups with it now.
- One member inquired about the usage of
- Decoding Special Function Unit Calls in PTX: A member sought a way to identify which PTX instructions call the Special Function Unit (SFU), observing utilization despite not using
log,exp,sin,cos, orsqrt.- Suggestions included profiling with
ncu --import-sourceand examining the Source tab in Nsight Compute, comparing Source/PTX and SASS side by side, and searching for occurrences ofMUFU,I2F,F2F,F2Ito correlate them with the source code; division was identified as a likely culprit.
- Suggestions included profiling with
GPU MODE ▷ #cool-links (1 messages):
Prefill and Decode Disaggregation
- Guide on Prefill and Decode Disaggregation Surfaces: A guide on Prefill and Decode Disaggregation from First Principles was written and shared.
- The guide can be found at this X post.
- Additional note on Prefill: Some additional information from First Principles was included.
- More context will be provided later.
GPU MODE ▷ #beginner (5 messages):
Disaggregation, Servers vs Embedded Systems, Nvidia indexing convenience, Trimul Submission, Benchmarking Kernels
- Disaggregation Demystified: A member wrote a guide on Disaggregation from First Principles and shared the link on X.
- Clarifying Servers vs Embedded Systems: A member explained that a server is a host machine available on the internet, while an embedded system is a computer without a personal computer-type interface, such as a smart fridge.
- They clarified that these terms are not precisely defined.
- Nvidia Indexing Explored: A member clarified that Nvidia card indexing is a holdover from when Nvidia cards were mostly used for graphics and high performance computing and that it has no effect on how memory is layed out physically.
- They recommended PMPP as a resource to learn more.
- Kernel Benchmarking Quandaries: A member is trying to benchmark their kernels against PyTorch and wants to know how to control the specific kernel to benchmark against.
- They used the high-level API to call from PyTorch and directly used the kernel from theirs and wonders if it’s a good approach.
GPU MODE ▷ #pmpp-book (13 messages🔥):
C++ code updates, 5th Edition Release Date, 4th Edition Value, GTC availability, Kindle Preorder Issues
- C++ Code Updates Teased: Members expressed excitement for the upcoming C++ code updates in the next edition of Programming Massively Parallel Processors.
- One member specifically stated, “Really looking forward to next edition by the way for the C++ code updates”.
- 5th Edition Coming Soon: The next edition, the 5th, is slated for release on September 15th according to the Amazon page.
- Several members shared that they would be willing to get a copy for other members.
- 4th Edition Still Holds Value: A member asked if reviewing the 4th edition is worthwhile in the meantime.
- Another member noted the subjective appeal of each edition, stating, “eh, to each their own, can’t really argue with ‘I like it tho’.”
- GTC to Distribute Books: Members anticipated the possibility of acquiring copies of the book at GTC (GPU Technology Conference).
- One member expressed hope that “we’ll all be able to get a copy at GTC”.
- Kindle Preorder Vanishes: Members inquired about the Kindle version preorder, which had disappeared from Amazon after initially being listed for a February release.
- A member reported that the page was taken down a day or two before the stated release date, with no further news on its availability.
GPU MODE ▷ #irl-meetup (8 messages🔥):
GTC Meetups, Seattle Meetup, Chicago Meetup
- GTC adjacent meetups announced: A member asked if there will be any GTC adjacent meetups or hackathons this year, and another member confirmed that there will be, and to stay tuned.
- Seattle IRL community forming: A member inquired about an IRL community in Seattle and suggested others DM them to start one.
- A member also mentioned planning a happy hour in Seattle for ML sys folks, inviting interested parties to DM them.
- Chicago meetup coming soon: Someone asked if anything was happening in Chicago.
GPU MODE ▷ #triton-viz (1 messages):
kerenzhou_55668: Sounds good to me
GPU MODE ▷ #webgpu (2 messages):
WebGPU Performance Blockers, WebGPU Profiling Tools, Cooperative Matrix Extensions
- WebGPU Performance Blockers Investigated: A member inquired about performance blockers in WebGPU, such as cooperative matrix extensions, and whether WebGPU was limiting performance.
- The member also asked about profiling, inquiring whether Metal tooling is primarily used or if there are better options for WebGPU.
- WebGPU Profiling and Tooling: The discussion involves exploring the use of Metal tooling versus other alternatives for profiling WebGPU applications.
- This suggests an interest in identifying the most effective tools for optimizing WebGPU performance and debugging potential issues.
GPU MODE ▷ #popcorn (1 messages):
Auto-tuning service, Modal, Largest autotune dataset
- Auto-Tuning Service on Modal?: A member proposed building an auto-tuning service on top of Modal to gather the largest dataset of autotune runs.
- This dataset could potentially be used to develop a state-of-the-art, fast auto-tuner; see related discussion here.
- Modal Integration for Auto-tuning: The proposed auto-tuning service leverages Modal for its infrastructure.
- The goal is to create a platform capable of accumulating a substantial dataset from numerous auto-tuning experiments, facilitating the training of a superior auto-tuner.
GPU MODE ▷ #thunderkittens (1 messages):
Claude for GH CLI, GitHub Issue Analysis
- Claude Navigates GitHub Issues via CLI: A member employs Claude, integrated with GitHub CLI, to efficiently parse through open issues, refining selections based on specified preferences.
- Iterative Issue Selection with AI Assistance: The user described an iterative process using Claude to analyze GitHub issues, improving issue selection through feedback loops.
GPU MODE ▷ #gpu模式 (4 messages):
Chinese Language, Translation Tools, DeepL, Social Media, Internet Language
- DeepL Mimics Chinese Internet Lingo: A member claimed their Chinese isn’t proficient, yet they are intrigued by China and enjoy browsing Chinese social media such as 小红书.
- They utilize translation tools like DeepL to read and compose, emulating the nuances of Chinese internet language, which was acknowledged by another member.
- Interest in Chinese Social Media: The member expressed a strong interest in Chinese culture and actively engages with Chinese social media platforms.
- They frequently use translation tools to navigate and participate in discussions on platforms like 小红书.
GPU MODE ▷ #factorio-learning-env (6 messages):
Factorio 2.0.0 Support, Sonnet 4.6 in Factorio, Tooling for agents, Next Big Goal: Beat Factorio
- Factorio 2.0.0 Support Incoming!: A user is gearing up to release the latest version with support for Factorio 2.0.0.
- They mentioned that after the release, there is definitely value in creating new scenarios and improving the tooling for agents.
- Sonnet 4.6 Testing in Factorio: Awaiting Results!: A user inquired whether anyone has tried Sonnet 4.6 in Factorio.
- Another user responded that they have not, but if the first user has the tokens, they are welcome to run it and report back; otherwise, they will rerun it against the latest models after the release.
- Tooling for Agents: User to Share!: A user mentioned they are currently working on some tooling and will share it if/when it’s good.
- No further details provided.
- Goalpost Set: Beat Factorio!: A user inquired about the next big goal, suggesting beating factorio.
- The same user mentioned they just downloaded the game 3 days ago and are still low elo.
GPU MODE ▷ #teenygrad (5 messages):
teenygrad, eager mode, tensor.py, cpu.rs, karpathy's makemore models
- Teenygrad Eager Mode is Ready for Makemore Model PRs: The teenygrad codebase for eager mode has everything wired up so users can add changes to the
tensor.pyfrontend, andcpu.rsblas kernels to add support for karpathy’s makemore models.- When cutting PRs, users are asked to add both the forward and backward pass per op.
- GPU Kernel Contributions Wanted: Users interested in working on gpu kernels are informed that the book needs to have an mdbook plugin to submit kernels to <#1298372518293274644>‘s popcorn-cli.
- The attached image is of the PSA about the teenygrad codebase.
GPU MODE ▷ #general (4 messages):
AI Created Submissions on Leaderboard, marksaroufim on leaderboard submission
- Community Embraces AI Submissions: A member asked about the acceptance of purely AI-created submissions on the leaderboard.
- Another member responded affirmatively, stating that both expert humans and expert AIs are welcome.
- Marksaroufim Clarifies Submission Policy: Marksaroufim confirmed that both human and AI-generated submissions are welcome on the leaderboard.
- This clarification aims to encourage participation from diverse contributors, regardless of their approach.
GPU MODE ▷ #multi-gpu (2 messages):
fused_all_gather_scaled_matmul, do_bench limitations, multi-GPU benchmarking
fused_all_gather_scaled_matmulFreezes during benchmarking: A user reported thattorch.ops.symm_mem.fused_all_gather_scaled_matmulhangs when runningdo_benchon multi-GPUs and asks if anyone knows why.do_benchDisclaimer Surfaces: Another user pointed out that triton.testing.do_bench() is not safe for distributed collectives liketorch.ops.symm_mem.fused_all_gather_scaled_matmulbecause it calls localtorch.cuda.synchronize()inside the timing loop.do_benchmeant for single device kernels: One user stated thatdo_benchis meant for single device kernels, and running a multi GPU fused collective kernel thousands of times will not work.- Timing trick: Use host-side timing: One proposed a workaround using host side timing (
timelib) as the best solution.
GPU MODE ▷ #llmq (7 messages):
FP8 training run stability, Activation Magnitudes in Transformer Blocks, Z-loss Regularization, Large Learning Rate Effects, Reasons for Training Stability
- FP8 Training Run Stable despite Large Token Horizon: A 4x4090 training run on a 0.5B model with a long token horizon of 350B tokens (~4 weeks) in fp8 went smoothly, contrary to reports of instabilities starting at 200B tokens in other long runs.
- The main goal was to identify and fix potential issues, but the entire process remained stable, with observations on activation magnitudes and learning rate effects.
- Activations Swell in Last Transformer Block: Activations, not just in SwiGLU, tend to become quite large in the last transformer block, though not to a degree that threatens model convergence, according to attached abs_maxes.png.
- Implementing and enabling z-loss regularization didn’t significantly affect the activation magnitudes in the last layer.
- Z-Loss Regularization Tames Average Logits: Z-loss regularization helps decrease the average logits, but it doesn’t significantly affect the maximum logits, as visualized in lse.png.
- The observation suggests that while regularization can reduce the typical logit size, it doesn’t prevent the occurrence of occasional large logits.
- Stable Run Attributed to Clean Data, Small Model, and Just-In-Time Scaling: The stability of the run could be attributed to a clean dataset (nemotron-climbmix), a small model size (0.5B), and the use of just-in-time scaling, with loss.png and norm.png providing a summary.
- These factors collectively contributed to preventing the divergence often seen in other fp8 training runs.
- Trinity Training Echoes Stability: Similar behavior and conclusions were observed when training Trinity, according to one user.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
GPU MODE ▷ #nvidia-competition (12 messages🔥):
NVIDIA leaderboard issues, MLSys 26 contest credits on Modal, Cutlass version discrepancies
- NVIDIA Leaderboard Plagued by Submission Errors: Users are encountering submission errors when trying to submit to the NVIDIA leaderboard, with a generic Server processing error being reported.
- An NVIDIA team member clarified that they are not actively supporting the nvidia leaderboard and recommended using the B200 runner instead.
- Modal Credit Quandaries for MLSys 26 Contest: A participant reported sending an email to [email protected] regarding credits on Modal but received no response.
- After mistakenly asking in the wrong channel, the user realized they were both NVIDIA competitions.
- Cutlass Version Causes Headaches: The submission error might be due to a different version of Cutlass, as the Modal image has this Cutlass version.
- The NVIDIA runner uses Python 3.10 and nvidia-cutlass-dsl==4.4.0, which is different from the Modal setup, though it’s unclear if this is the root cause.
GPU MODE ▷ #robotics-vla (2 messages):
Action Prediction, IDMs, Diffusion Models, Action Experts, Taylor Series Expansion
- Action Prediction Applicability to IDMs and Diffusion Models: Members discussed the applicability of a certain technique for action prediction in Iterative Denoising Machines (IDMs) or diffusion models in general.
- It was suggested that it could technically apply to models using action experts based on a denoising mechanism, but experimentation is needed to confirm if their Taylor series expansion formulation works well for action modalities.
- Denoising Mechanism and Action Modalities: The discussion highlighted the potential compatibility of the technique with models employing action experts based on a denoising mechanism.
- Further research is needed to assess whether the Taylor series expansion as a draft model is suitable for action modalities.
GPU MODE ▷ #flashinfer (8 messages🔥):
MLSys 26 Contest, Gated DeltaNet, Modal Credits
- MLSys 26 Contest Submissions Still Elusive: Participants are expected to create a repo based on the starter template, and provide the organizers its URL, but no submissions have been seen so far.
- The AI generated kernels seem to be the only content showing.
- Gated DeltaNet’s Output Explodes: The Gated DeltaNet prefill’s expected output explodes later in the sequences, prompting a query on when baselines are being released and a link to a relevant issue.
- One participant managed to prevent the exploding outputs by scaling down the inputs to the kernel, but prefers testing against the official
flashinfer-benchbenchmarking setup.
- One participant managed to prevent the exploding outputs by scaling down the inputs to the kernel, but prefers testing against the official
- Modal Credit Queries Remain Unanswered: Participants are seeking guidance on obtaining credits on Modal, having emailed
[email protected]without response.- The lack of response may be due to New Year season slowdowns, but others also haven’t heard back despite applying before the deadline.
GPU MODE ▷ #from-scratch (3 messages):
“
- No Topics Discussed: There were no discussion topics found in the provided messages.
- No Links Shared: There were no links or URLs shared in the provided messages.
Moonshot AI (Kimi K-2) ▷ #general-chat (70 messages🔥🔥):
Kimi.com account refund, Moonshot AI stoat server, Kimi Code CLI hanging, Kimi's coding abilities, Kimi IDE integration in beta
- Account holder requests Kimi.com Refund: A new user requested a refund for their Kimi.com account due to dissatisfaction with OpenClaw, citing issues with browser navigation and WhatsApp connectivity.
- Community Suggests Moonshot AI Create a ‘Stoat Server’: A community member suggested that Moonshot AI create a stoat server as many others have, and the member indicated that they would delete their Discord account otherwise.
- The user expressed overall satisfaction with Kimi, noting its speed.
- Kimi Code CLI Hangs for User: A user reported that Kimi Code CLI is hanging in the terminal and questioned why the subscription primarily benefits coding agents.
- User Deems Kimi Stupid, Advocates for Claude: A user negatively compared Kimi to GPT-5.2, stating it doesn’t even compare to GPT-3, citing poor memory and argumentative behavior, recommending Claude instead.
- However, another user countered that Kimi works fine for hard Java programming, suggesting the issue is user-specific.
- Kimi IDE integration is in Beta: A member mentioned that the IDE integration is in beta right now, which could attribute to the reason, from what they’ve seen people are getting the best experience using the Kimi CLI or something like Claude/Open Code.
Eleuther ▷ #announcements (1 messages):
EvalEval Coalition, Every Eval Ever, AI Evaluation Standardization, ACL 2026 Workshop
- EvalEval Coalition Launches Every Eval Ever: The EvalEval Coalition, including EleutherAI, Hugging Face, and the University of Edinburgh, launched Every Eval Ever to standardize AI evaluation results.
- This initiative aims to create a unified, open schema and crowdsourced dataset to address the scattered and incompatible formats of evaluation results.
- Every Eval Ever Schema and Dataset Unveiled: Every Eval Ever defines a shared metadata schema for AI evaluation results, enabling direct comparison of tools like HELM, lm-eval-harness, and Inspect AI, with the schema and dataset available on GitHub and Hugging Face.
- The goal is to allow researchers to avoid starting from scratch by using the public dataset.
- Join EvalEval at ACL 2026 for Workshop and Shared Task: The EvalEval Coalition is hosting a workshop at ACL 2026 in San Diego, featuring a Shared Task open until May 1.
- Qualifying contributors to the Shared Task are eligible for co-authorship.
Eleuther ▷ #general (10 messages🔥):
Nvidia FLARE, 3D printed robots, Taalas chip, etched
- FLARE for Cheap Robots: Members are planning to implement something like Nvidia’s FLARE for cheap 3D printed robots to calibrate its own errors.
- The team is seeking collaborators interested in this topic and has an industrial robot arm available.
- Taalas Launches Hardcore Chip with Insane AI Inference Performance: Taalas has created a chip that is basically a single model.
- This chip design goes beyond what etched does, because etched can run multiple models, while Taalas requires new layers for a different model.
Eleuther ▷ #research (7 messages):
Ablation Tests, Reproducible LLM Eval Runs, Causal Mask Design
- Ablation Tests Reveal Flaws: A member noted that doing the ablation tests as suggested revealed some flaws they’ve been able to address.
- They think this is shaping into a robust paper, and that sharing what they’ve found so far will still be helpful, even if their own output did not come out as hoped.
- Pipeline for Reproducible LLM Eval Runs: A member has been working on a small pipeline for reproducible LLM eval runs: huggingface.co/spaces/madison-xu/llm-eval-pipeline.
- It logs judge disagreement, retries/failures, and cost/latency, and they are happy to adapt it if needed.
- Causal Mask as a Design: A member asked if anyone experimented with the ideas from Say It Nice and Say It Twice: Powerful But Simple Proxy Attribute Rephrasing for Detecting and Mitigating Biases and the associated paper when it came out.
- Another member thinks it’s a very thin paper but makes sense with respect to causal mask as a design.
Eleuther ▷ #interpretability-general (47 messages🔥):
attention heads in GPT-2 Small, layerwise residual-stream swaps, ARES tooling framework, Analytical Attention Head Patterns, CCA and Convolutional QK Generation
- Attention Head Anatomy Analyzed: An analysis of GPT-2 Small attention heads revealed that 75% do not require full-rank QK matrices, leading to a four-tier taxonomy, as shown in this repo.
- Constraining QK structure during training led to a 5.3% validation loss improvement on WikiText-2, with 27 analytically-fixed heads (previous-token, induction, positional) accounting for nearly all of it.
- Residual Stream Swapping Shows Sharp Causal Commitment: Layerwise residual-stream swaps across GPT-2 Small, Gemma-2-2B, and Qwen2.5-1.5B revealed a sharp causal commitment transition at 62-71% depth, detailed in this preprint.
- Below this depth, swapping residual streams has little effect, while above it, significant output flips and margin transfer occur, highlighting a clear commitment point in representation learning.
- Convolutional Conundrums: CCA Improves QK Generation: Recent work suggests convolving things to generate QK improves learning and allows reduced rank as detailed in this CCA paper, suggesting a promising avenue for exploration.
- This approach aligns with the observation that most attention heads don’t perform complex operations, making techniques like GQA and MLA effective.
- Martian’s ARES Tooling Arrives for Agent Activation Analysis: Martian introduced ARES, a tooling framework for exposing LLM agent activations along trajectories, facilitating research into how agents solve long-horizon tasks, see the repo and tutorial.
- A tutorial demonstrates diagnosing and correcting failure modes in a simple agent using probing and activation steering, alongside a discussion on the accompanying Twitter thread.
- Sink or Swim: The Role of Sink Tokens in Attention: Analysis reveals that many constrainable heads are bos-sink style, with a significant portion of attention mass directed towards position 0, and the importance of access to the sink token.
- Replacing heads with fixed patterns improves training, and the model may compensate elsewhere, raising the question of whether the gain comes from the model wanting sink access that the current formulas only give accidentally.
HuggingFace ▷ #general (40 messages🔥):
AI Truth, HF Codex Hijack, Training Images, Deep RL Course, ComfyUI GGUF
- Seeking Foundations of AI Truth: A member is questioning how to make AI more useful by delving into the foundations of reality, questioning the nature of facts, proofs, and the emergence of intelligence, seeking a fundamental base where AI cannot hallucinate.
- Another member suggested that AI hallucination can occur when it relies on outdated training data, especially with rapidly changing libraries.
- HF Codex Hijack Sideproject?: A member inquired about a potential community project to “hijack” the Codex architecture using HF login and inference providers, linking to an OpenAI blog post about unlocking Codex.
- They also expressed confusion about the proper channels for feedback submission.
- Quest for Training Images Beyond HF: A member sought advice on finding data such as photos and videos for model training, as Hugging Face may not have sufficient data.
- Another member provided a comprehensive list of resources, including Google Dataset Search, Kaggle Datasets, and cloud “public datasets” registries like AWS and Azure.
- Navigating Deep RL Course Channels: A member asked where to find the channel for the Deep RL course.
- It was clarified that course channels have been merged into a specific Discord channel.
- ComfyUI GGUF Setup Steps: A member provided a quick setup guide for ComfyUI using FLUX2-dev (GGUF), including steps for downloading the workflow JSON, placing files in specific ComfyUI folders, and installing the necessary GGUF nodes from city96’s GitHub repository.
- The guide also highlights the parameters that need to be adjusted, such as the GGUF name, positive prompt, and file names for the text encoder and VAE.
HuggingFace ▷ #i-made-this (13 messages🔥):
Open Claude Code release, OpenClaw deployment, Terradev CLI, Cursor Rules for AI Engineers, Othello AI
- Open Claude Code unveiled: A member released Open Claude Code on GitHub, a rewrite and replacement of minified code that has tried to keep up with parity for over a year.
- The project is built from an initial reverse engineered 0.3, marking a significant community contribution to open-source Claude models.
- One-Click OpenClaw Deployment Emerges: A member introduced a truly one-click deployment of OpenClaw on vibeclaw.dev, designed to run privately and locally in a browser-sandboxed container.
- Another member reported that the website had bugs on Firefox, with elements weirdly vertically out of position.
- Terradev CLI optimizes cross-cloud GPU costs: A member highlighted that ML developers overpay for compute by only accessing single-cloud workflows and introduced Terradev CLI on pypi.org, which enables BYOAPI multicloud GPU provisioning with spend attribution.
- Version 2.9.2 of Terradev CLI was released, offering multi-cloud GPU arbitrage, real total job cost calculation, and one-click HuggingFace Spaces deployment, as described on GitHub.
- Cursor Rules aid AI Engineers: A member shared a free collection of
.cursorrulesfiles for AI engineers on GitHub, designed to improve Cursor’s understanding of LLM stacks.- These rules cover LangChain, LLM API integration, RAG pipelines, AI agents, fine-tuning workflows, and FastAPI LLM backends, aiming to reduce repetitive corrections in code suggestions.
- Play Othello against AI: A member shared an AI Othello game built similarly to AlphaZero on othello.jhqcat.com.
- The source code is available on GitHub for those interested in the implementation.
HuggingFace ▷ #gradio-announcements (1 messages):
gr.HTML component, Gradio 6 features, One-shot web apps
- gr.HTML drops, web apps rise: A new blog post announces the release of gr.HTML, a custom component in Gradio 6 that enables building full web apps in a single Python file, showcased with examples like Kanban boards and Pomodoro timers; link to blog.
- Claude can now code full web apps: The announcement highlights that models like Claude can generate such apps in one prompt using
gr.HTML, demonstrating the potential for rapid web app development. - Share gr.HTML creations!: A call to action encourages users to share what they build using
gr.HTML, accompanied by a HF Collection🎮 of examples.
Nous Research AI ▷ #general (44 messages🔥):
U.S. vs Chinese Gov Subsidies to AI, DeepSeek V4, DeepSeek V4 Specs
- Subsidy Smackdown: US vs China: Members debated the extent of government subsidies in the U.S. versus China, with claims that U.S. funding for OpenAI and Anthropic is capped at $600 million, while Chinese government subsidies account for about 50% of Capex and $60 billion in investments for infrastructure.
- One member argued that U.S. auto industries wouldn’t exist without U.S. government subsidies, while another countered that Chinese economy is heavily manipulated by its government.
- DeepSeek V4 Incoming!: Discussion of the new DeepSeek V4 release for Lunar New Year, highlighting features like Emgram memory, Manifold Constrained Hyper Connections, and MOE, with claims it can run on a home PC with RTX 4090 (video link).
- Despite one member claiming that DeepSeek V4 is not released yet, others discussed its potential impact on the market, especially compared to models requiring significant investment.
- DeepSeek V4 Benchmarks and Performance: Initial performance data for DeepSeek 3.1 Pro was shared, showing it to be 0.2% behind Opus 4.6 on the SWE bench, with strong performance on agentic tasks.
- A member shared benchmark screenshots highlighting that DeepSeek 3.1 Pro is cheaper than other frontier models and offers 107 TPS output speed.
Yannick Kilcher ▷ #general (11 messages🔥):
Block Dropout Paper Analysis, RPROP Optimizer, Deepseek 1.5B Uncertainty Maximization, Gradient Descent for Uncertainty, IPFS Datasets
- Block Dropout Paper has Misleading Framing: A member argued that the framing of a paper using block dropout is technically correct but unhelpful for understanding the method, which involves masking out entire blocks of gradients in p% of cases while updating momentum terms, penalizing blocks with high second order variation, see the paper here.
- They mention that doubling the stepsize during the kept steps is required to maintain the same “net” learning rate and that the second proposed method scales the gradient based on the agreement between the gradient and momentum.
- RPROP Optimizer Still Relevant: The idea of scaling based on disagreement between gradient and momentum is not new, as it was implemented in RPROP (link to paper), one of the earliest adaptive optimizers, and is still effective in noisy scenarios.
- The second scaling option with ‘s’ may halve the effective learning rate, requiring a
2*old_update*bernoulli(0.5)*supdate to preserve learning rate semantics.
- The second scaling option with ‘s’ may halve the effective learning rate, requiring a
- Deepseek 1.5B Produces Uncertain Statements: A member found that Deepseek 1.5B generates the most uncertain (greedily, per token) statement when given an empty prompt, specifically the statement: Okay so the question was “What is 2 + (2 + (3+4))? Let’s break this one step at the.
- They are exploring ways to generate highly uncertain questions methodically without relying on search, suggesting that it might be impossible due to the non-differentiability of LLMs across tokens.
- Gradient Descent Maximizes Uncertainty: One member suggested using greedy coordinate gradient descent to maximize uncertainty by differentiating in embedding/activation space and projecting back to tokens using top-k, referencing this paper.
- Another member had success with a gaussian bump to travel through the gradients, possibly related to this tweet.
- IPFS Datasets Listed: A member shared a link to a GitHub repository containing a collection of inference rules for IPFS datasets, namely the ipfs_datasets_py repo.
- No further discussion.
Yannick Kilcher ▷ #paper-discussion (5 messages):
Paper Discussion Meetings, Reinforcement Learning Book Reading
- Paper Discussion Meetings are back!: Daily paper discussion meetings will resume on Monday-Thursdays, and sometimes Fridays, at <t:1771524000:t>.
- The meetings will consist of some planned and some ad-hoc sessions.
- Reading Reinforcement Learning: An Introduction by Richard Sutton & Andrew G Barto: On Thursdays, the group will read Reinforcement Learning: An Introduction, by Richard Sutton & Andrew G Barto, using the 2nd Edition available online.
- The first session for chapter 1 will be on <t:1772128800:F>, and will consist of discussing the sections and exercises.
Yannick Kilcher ▷ #ml-news (5 messages):
Gemini 3.1 Pro, ARC AGI Fine-Tuning
- Gemini 3.1 Pro Announced by Google: Google announced Gemini 3.1 Pro, their latest model.
- A member linked to the announcement as well as a related tweet (x.com link).
- ARC AGI Fine-Tuning Suspicions: Members are speculating that companies are blatantly fine-tuning for ARC AGI.
- One member stated, “Guess it wasn’t so AGI”, linking to an fxtwitter post.
DSPy ▷ #show-and-tell (3 messages):
Qbit IDE, Tree of Thoughts in DSPy, STATe-of-Thoughts framework, Pervasive Arguments Generation
- Qbit: Agentic IDE Blends Terminal and AI: The team built Qbit, an open source agentic IDE that blends terminal workflows with AI agents, emphasizing user control and transparency with tool calls and execution details, available on GitHub.
- Qbit offers features like project management, a unified timeline, model selection, inline text editing, git integration, and MCP integration, with installation available via brew on macOS and release build or source build on Linux.
- STATe-of-Thoughts: Tree of Thoughts enters DSPy: A team introduced STATe-of-Thoughts, incorporating Tree of Thoughts into DSPy, featuring early stopping to avoid context rot and diverse/controllable branching using textual interventions, with the code available on GitHub.
- The framework leverages open source LLMs hosted on vLLM to reduce costs and includes custom fields, signatures, LMS, and adapters to support multi-step reasoning with batch inference, as described in their paper.
- STATe-of-Thoughts: Generation of Pervasive Arguments: The team showcased a case study on generating pervasive arguments using the STATe-of-Thoughts framework, enabling understanding of reasoning patterns that lead to effective arguments.
- Their repo shows how to generate persuasive arguments, but also understand the reasoning patterns that led to the arguments being effective.
DSPy ▷ #papers (2 messages):
Tree of Thoughts Implementation, STATe-of-Thoughts, Early Stopping in Reasoning, Diverse Branching Strategies
- STATe-of-Thoughts Arrives!: A new implementation of Tree of Thoughts in DSPy called STATe-of-Thoughts (github.com/zbambergerNLP/state-of-thoughts) was introduced, along with their paper.
- It supports early stopping to avoid context rot and diverse branching using textual interventions such as pre-filling assistant messages with phrases like “For example” or “In particular”.
- Tree of Thoughts gets an Open-Source Boost: The new Tree of Thoughts implementation, STATe-of-Thoughts, uses open source LLMs hosted on vLLM to avoid excessive costs from OpenAI/Anthropic.
- One user thanked the author for sharing, mentioning they wanted to try out Tree of Thoughts but was unable to code it due to skill issues.
DSPy ▷ #general (14 messages🔥):
RLMs simplifying tasks, Offline user feedback, Community office hours, LLM Judge, Knowledge graph
- RLMs streamline complex tasks: Members noted the Monolith repo is great evidence for RLMs simplifying tasks that required more orchestration before.
- Others said it was an ingenious piece of work.
- Desire for offline user feedback in DSPy: Members discussed the need for offline, real-user feedback integrated into DSPy workflows, with a pointer to a relevant issue on the gepa repo.
- One user confirmed: Yes, that’s exactly what I mean! So I imagine it’s not really a thing yet?
- Community Office Hours Buzz: Users discussed the recent community office hours, highlighting the positive atmosphere and diverse use-cases discussed.
- The vibe was described as amazing and it was noted that around 40 people attended.
- LLM Judge optimizes human feedback: Members found the easiest way to distill human feedback is into an LLM Judge and then using that to optimize your main program.
- This helps to streamline the process of incorporating user feedback into DSPy applications.
- Need DSPy doc for Knowledge Graph: One member asked if there’s documentation on how to use dspy lm with knowledge graph.
- This shows that a member is seeking information on integrating knowledge graphs with DSPy.
tinygrad (George Hotz) ▷ #general (9 messages🔥):
Locking tests in CI, Beginner-friendly bounties, Tinybox for testing/training, Bounty PRs and AI-generated content, Priority tasks: AMD assembly or bug fixes?
- Tests locked in CI Environment: A member requested to lock “all tests passing in emulator in CI with MOCKGPU_ARCH=cdna4” as work is in progress, but no PR has been made yet.
- Inquiries Arise Regarding Beginner-Friendly Bounties: A member inquired about beginner-friendly bounties, noting that the Google Sheet wasn’t colored green despite a part being done, and was informed that the bounty can still be claimed upon completing the PR.
- Another member asked about using a tinybox for testing/training one of the mlperf bounties due to limited hardware access, considering renting GPUs.
- Bounty PRs Get Filtered: Due to the influx of AI-generated content, bounty PRs from new contributors won’t be reviewed.
- AMD Assembly or Bug Fixes: A green contributor asked whether AMD assembly or bug fixes are the top priority non-bounty tasks.
- A member suggested that bug fixes should be prioritized.
Manus.im Discord ▷ #general (9 messages🔥):
Resume Autofill Issues, Meta Acquisition Rumors, Billing Dispute, Meta Ads Manager Removal, Subscription Renewal Time
- Manus Praised for Job Application Assistance: A user expressed gratitude towards Manus for its effectiveness in job hunting, noting that even major websites like Best Buy fail to properly autofill resumes.
- They humorously remarked, *‘The websites even for bestbuy don’t autofill your resumé properly, lol thanks manus.’
- Billing Issue Reported and Unresolved: A user reported being overcharged $2500 despite being on a $680 plan, stating that they’ve contacted support multiple times with evidence but haven’t received a response.
- They mentioned planning to report the issue to the Better Business Bureau due to the lack of resolution.
- Meta Acquisition Rumors Spark Curiosity: A user inquired whether Manus had been acquired by Meta.
- Another user succinctly responded in the affirmative: ‘Yes.’
- Meta Ads Manager Disappears from Connector List: A user questioned whether others had noticed the removal of Meta Ads Manager from the official connectors list.
- No further details or explanations were provided in the discussion.
- Subscription Renewal Time Questioned: A user inquired about the specific time of day that subscriptions renew and credits reset.
- They noted that their credits were expected to replenish that day but hadn’t yet received them.
MCP Contributors (Official) ▷ #general (4 messages):
San Francisco AI Meetup, Coffee Grab in SF
- AI Peeps Plan SF Meetup: Members in the San Francisco area expressed interest in organizing an informal meetup.
- One member proposed grabbing coffee sometime next week, and another confirmed their presence.
- Bay Area AI friends gather: Several AI enthusiasts located in San Francisco are planning a small, informal meetup to connect in person.
- Potential activities include grabbing coffee and discussing AI topics of interest.
Windsurf ▷ #announcements (1 messages):
Gemini 3.1 Pro, Windsurf Pricing, Limited Time Offer
- Gemini 3.1 Arrives on Windsurf: Gemini 3.1 Pro is now integrated into Windsurf, announced on X.
- It is being offered at a promotional price of 0.5x credits for a limited time.
- Windsurf Promo Pricing: Windsurf is offering Gemini 3.1 Pro at a special launch price.
- For a limited time, users can access the new model at just 0.5x credits.