SOTA Audio models are all you need.
AI News for 2/3/2026-2/4/2026. We checked 12 subreddits, 544 Twitters and 24 Discords (254 channels, and 10187 messages) for you. Estimated reading time saved (at 200wpm): 795 minutes. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
It is our policy to give the title story to AI companies that cross into decacorn status, to celebrate their rarity and look back at their growth, but it seems that it is less rare these days… today not only did Sequoia, a16z and ICONIQ lead the Eleven@11 round (WSJ), but it was promptly upstaged by Cerebras which, after their 750MW OpenAI deal (valued at $10B over 3 years), had a DOUBLE decacorn round at $1B at $23B from Tiger Global… only 5 months after they were valued at $8B.
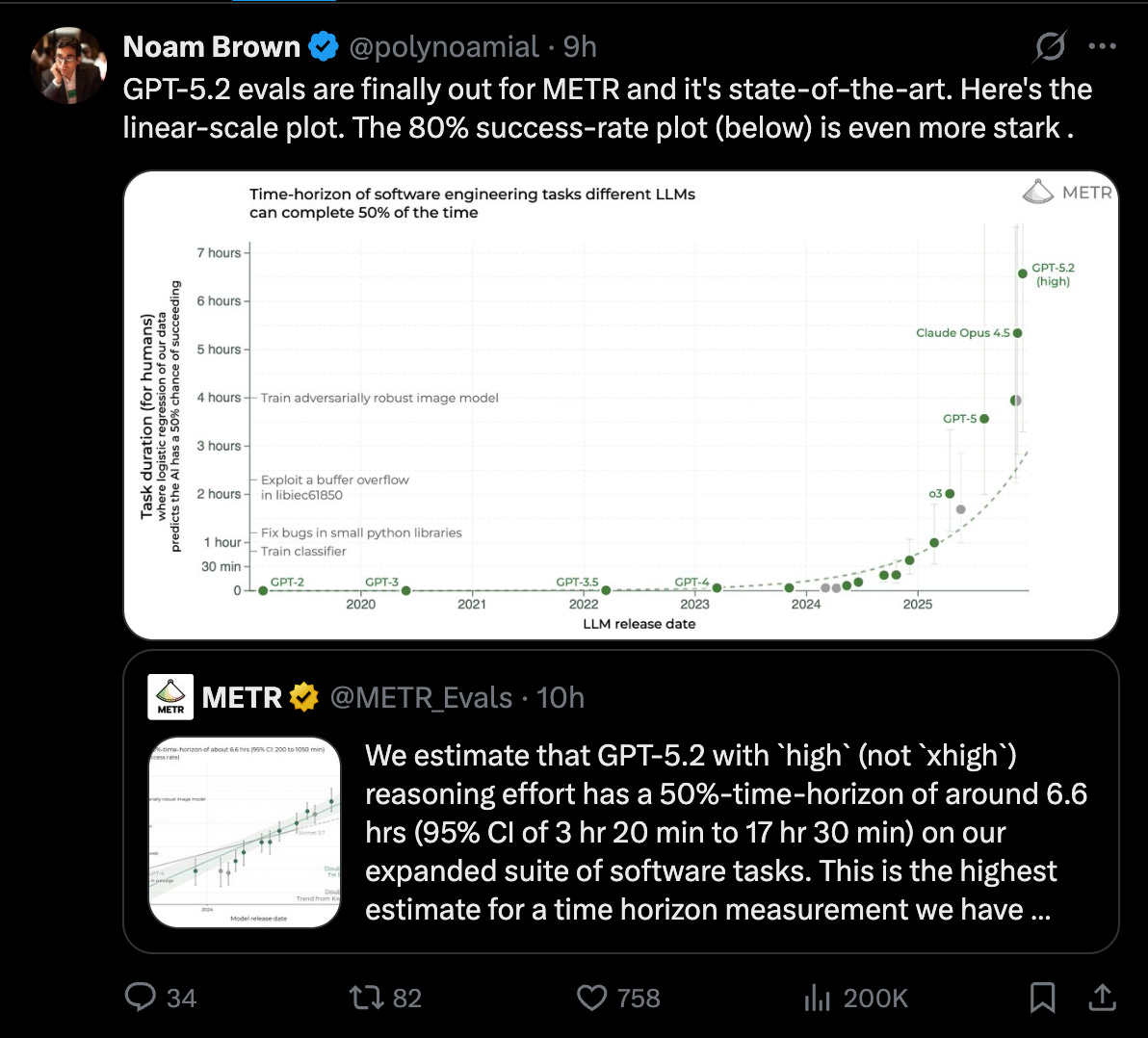
It’s also the 1 year anniversary of Vibe Coding, and Andrej has nominated Agentic Engineering as the new meta of the year, even as METR anoints GPT 5.2 High as the new 6.6 hour human task model, beating Opus 4.5, and sama announces 1m MAU of Codex.
AI Twitter Recap
Big Tech productization: Gemini 3 everywhere (Chrome, app scale, “game” evals)
- Chrome side panel on Gemini 3: Google is now shipping a new Chrome side panel experience “running on Gemini 3,” plus Nano Banana integration (Google’s phrasing) and other UX changes, signaling continued tight coupling of browser workflow + LLM features (Google).
- Gemini scale + cost curve: Google executives and analysts emphasized rapid Gemini adoption and big serving-cost reductions: Sundar reports Gemini 3 adoption “faster than any other model” and Alphabet crossing $400B annual revenue (@sundarpichai), while another clip cites 78% unit-cost reduction for Gemini serving across 2025 (financialjuice). A separate datapoint claims the Gemini app hit 750M+ MAU in Q4 2025 (OfficialLoganK); commentary notes this puts Gemini within striking distance of publicly reported ChatGPT MAU (Yuchenj_UW).
- Benchmarking via games: Google is pushing “soft skills” evaluation by letting models compete in games (Poker/Werewolf/Chess) through the Kaggle Game Arena, framed as testing planning/communication/decision-making under uncertainty before deployment (Google, Google, Google). This sits alongside broader industry moves to replace saturated benchmarks with more “economically useful work” measures (see Artificial Analysis update summarized by DeepLearningAI, below).
Coding agents converge in the IDE: VS Code “Agent Sessions”, GitHub Copilot Agents, Codex + Claude inside your workflow
- VS Code’s agent pivot: VS Code shipped a major update positioning itself as “home for coding agents,” including a unified Agent Sessions workspace for local/background/cloud agents, Claude + Codex support, parallel subagents, and an integrated browser (VS Code; pierceboggan). Insiders builds add Hooks, skills as slash commands, Claude.md support, and request queueing (pierceboggan).
- GitHub Copilot adds model/agent choice: GitHub announced you can use Claude and OpenAI Codex agents within GitHub/VS Code via Copilot Pro+/Enterprise, selecting an agent by intent and letting it clear backlogs async in existing workflows (GitHub; kdaigle). Anecdotally, engineers highlight the “remote async agent” workflow as the real unlock vs purely interactive chat coding (intellectronica).
- Codex distribution + harness details: OpenAI and OpenAI DevRel pushed adoption stats (500K downloads early; later 1M+ active users) and expanded surfaces (App/CLI/web/IDE integrations) backed by a shared “Codex harness” exposed via a JSON-RPC “Codex App Server” protocol (OpenAI, @sama, OpenAIDevs).
- Friction points remain: Some users report Codex running in CPU-only sandboxes / not seeing GPUs (and request GPU support) (Yuchenj_UW, tunguz), while OpenAI DevRel pushes back that GPU processes work and asks for repros (reach_vb).
- OpenClaw/agent communities become “platforms”: OpenClaw meetups (ClawCon) and ecosystem tooling (e.g., ClawHub, CLI updates) show how quickly coding-agent communities are professionalizing around workflows, security, and distribution (forkbombETH, swyx).
Agent architecture & observability: “skills”, subagents, MCP Apps, and why tracing replaces stack traces
- deepagents: skills + subagents, durable execution: LangChain’s deepagents shipped support for adding skills to subagents, standardizing on
.agents/skills, and improving thread resuming/UX (multiple release notes across maintainers) (sydneyrunkle, LangChain_OSS, masondrxy). The positioning: keep the main context clean via context isolation (subagents) plus agent specialization (skills) rather than choosing one (Vtrivedy10). - MCP evolves into “apps”: OpenAI Devs announced ChatGPT now has full support for MCP Apps, aligning with an MCP Apps spec derived from the ChatGPT Apps SDK—aimed at making “apps that adhere to the spec” portable into ChatGPT (OpenAIDevs).
- Skills vs MCP: different layers: A useful conceptual split: MCP tools extend runtime capabilities via external connections, while “skills” encode domain procedure/knowledge locally to shape reasoning (not just data access) (tuanacelik).
- Observability becomes evaluation: LangChain repeatedly emphasized that agent failures are “reasoning failures” across long tool-call traces, so debugging shifts from stack traces to trace-driven evaluation and regression testing (LangChain). Case studies push the same theme: ServiceNow orchestrating specialized agents across 8+ lifecycle stages with supervisor architectures, plus Monte Carlo launching “hundreds of sub-agents” for parallel investigations (LangChain, LangChain).
Models, benchmarks, and systems: METR time horizons, Perplexity DRACO, vLLM on GB200, and open scientific MoEs
- METR “time horizon” jumps for GPT-5.2 (with controversy around runtime reporting): METR reported GPT-5.2 (high reasoning effort) at a ~6.6 hour 50%-time-horizon on an expanded software-task suite, with wide CIs (3h20m–17h30m) (METR_Evals). Discourse fixated on “working time” vs capability: claims that GPT-5.2 took 26× longer than Opus circulated (scaling01), then METR-related clarification suggested a bug counting queue time and scaffold differences (token budgets, scaffolding choice) skewed the working_time metric (vvvincent_c). Net: the headline capability signal (longer-horizon success) seems real, but wall-clock comparisons were noisy and partially broken.
- Perplexity Deep Research + DRACO: Perplexity rolled out an “Advanced” Deep Research claiming SOTA on external benchmarks and strong performance across decision-heavy verticals; they also released DRACO as an open-source benchmark with rubrics/methodology and a Hugging Face dataset (perplexity_ai, AravSrinivas, perplexity_ai).
- vLLM performance on NVIDIA GB200: vLLM reported 26.2K prefill TPGS and 10.1K decode TPGS for DeepSeek R1/V3, claiming 3–5× throughput vs H200 with half the GPUs, enabled by NVFP4/FP8 GEMMs, kernel fusion, and weight offloading with async prefetch (vllm_project). vLLM also added “day-0” support for Mistral’s streaming ASR model and introduced a Realtime API endpoint (
/v1/realtime) (vllm_project). - Open scientific MoE arms race: Shanghai AI Lab’s Intern-S1-Pro was described as a 1T-parameter MoE with 512 experts (22B active) and architectural details like Fourier Position Encoding and MoE routing variants (bycloudai). Separate commentary suggests “very high sparsity” (hundreds of experts) is becoming standard in some ecosystems (teortaxesTex).
- Benchmark refresh: Artificial Analysis: Artificial Analysis released Intelligence Index v4.0, swapping saturated tests for benchmarks emphasizing “economically useful work,” factual reliability, and reasoning; GPT-5.2 leads a tight pack per their reshuffle (summary via DeepLearningAI) (DeepLearningAI).
Multimodal generation: video-with-audio arenas, Grok Imagine’s climb, Kling 3.0, and Qwen image editing
- Video evals get more granular: Artificial Analysis launched a Video with Audio Arena to separately benchmark models that natively generate audio (Veo 3.1, Grok Imagine, Sora 2, Kling) vs video-only capabilities (ArtificialAnlys).
- Grok Imagine momentum: Multiple signals point to Grok Imagine’s strong standing in public arenas, including Elon claiming “rank 1” (elonmusk) and Arena reporting Grok-Imagine-Video-720p taking #1 on image-to-video, “5× cheaper” than Veo 3.1 per their framing (arena).
- Kling 3.0 shipping iteration: Kling 3.0 is highlighted for custom multishot control (prompt per-shot for up to ~15s) and improved detail/character refs/native audio (jerrod_lew).
- Qwen image editing tooling: A Hugging Face app demonstrates multi-angle “3D lighting control” for image editing with discrete horizontal/elevation positions via an adapter approach (prithivMLmods).
Research notes: reasoning & generalization, continual learning, and robotics/world models
- How LLMs reason (PhD thesis): Laura Ruis published her thesis on whether LLMs generalize beyond training data; her stated takeaway: LLMs can generalize in “interesting ways,” suggesting genuine reasoning rather than pure memorization (LauraRuis).
- Continual learning as a theme: Databricks’ MemAlign frames agent memory as continual-learning machinery for building better LLM judges from human ratings, integrated into Databricks + MLflow (matei_zaharia). François Chollet argued AGI is more likely from discovering meta-rules enabling systems to adapt their own architecture than from scaling frozen knowledge stores (fchollet).
- Robotics: from sim locomotion to “world action models”:
- RPL locomotion: a unified policy for robust perceptive locomotion across terrains, multi-direction, and payload disturbances—trained in sim and validated long-horizon in real world (Yuanhang__Zhang).
- DreamZero (NVIDIA): Jim Fan describes “World Action Models” built on a world-model backbone enabling zero-shot open-world prompting for new verbs/nouns/environments, emphasizing diversity-over-repetition data recipes and cross-embodiment transfer via pixels; claims open-source release and demos (DrJimFan, DrJimFan).
- World-model “playable” content: Waypoint-1.1 claims a step to local, real-time world models that are coherent/controllable/playable; model is Apache 2.0 open-source per the team (overworld_ai, lcastricato).
Top tweets (by engagement)
- Sam Altman on Anthropic’s Super Bowl ads + OpenAI ads principles + Codex adoption (@sama)
- Karpathy retrospective: “vibe coding” → “agentic engineering” (@karpathy)
- Gemini usage at scale: 10B tokens/min + 750M MAU (OfficialLoganK)
- VS Code ships agent sessions + parallel subagents + Claude/Codex support (@code)
- GitHub: Claude + Codex available via Copilot Pro+/Enterprise (@github)
- METR: GPT-5.2 “high” ~6.6h time horizon on software tasks (@METR_Evals)
- Arena: Grok-Imagine-Video takes #1 image-to-video leaderboard (@arena)
- Sundar: Alphabet FY results; Gemini 3 adoption fastest (@sundarpichai)
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
1. Qwen3-Coder-Next Model Release
-
Qwen/Qwen3-Coder-Next · Hugging Face (Activity: 1161): Qwen3-Coder-Next is a language model designed for coding tasks, featuring
3B activated parametersout of80B total, achieving performance comparable to models with10-20xmore active parameters. It supports256kcontext length, advanced agentic capabilities, and long-horizon reasoning, making it suitable for integration with various IDEs. The architecture includes48 layers, gated attention mechanisms, and a mixture of experts. Deployment can be done using SGLang or vLLM, requiring specific versions for optimal performance. More details are available in the original article. One commenter expressed skepticism about the model’s performance, questioning if a3B activated parametermodel can truly match the quality of larger models like Sonnet 4.5, indicating a need for further validation of these claims.- danielhanchen discusses the release of dynamic Unsloth GGUFs for Qwen3-Coder-Next, highlighting upcoming releases of Fp8-Dynamic and MXFP4 MoE GGUFs. These formats are designed to optimize model performance and efficiency, particularly in local environments. A guide is also provided for using Claude Code / Codex locally with Qwen3-Coder-Next, which could be beneficial for developers looking to integrate these models into their workflows.
- Ok_Knowledge_8259 raises skepticism about the claim that a 3 billion activated parameter model can match the quality of larger models like Sonnet 4.5. This comment reflects a common concern in the AI community about the trade-off between model size and performance, suggesting that further empirical validation is needed to substantiate such claims.
- Septerium notes that while the original Qwen3 Next performed well in benchmarks, the user experience was lacking. This highlights a critical issue in AI model deployment where high benchmark scores do not always translate to practical usability, indicating a need for improvements in user interface and interaction design.
-
Qwen3-Coder-Next is out now! (Activity: 497): The image announces the release of Qwen3-Coder-Next, an 80 billion parameter Mixture of Experts (MoE) model with 3 billion active parameters, designed for efficient coding tasks and local deployment. It emphasizes the model’s capability to handle
256Kcontext lengths and its fast inference speed, optimized for long-horizon reasoning and complex tool use. The model requires46GBof RAM/VRAM for operation, making it suitable for high-performance environments. The image includes a performance graph comparing Qwen3-Coder-Next to other models, showcasing its efficiency and advanced capabilities. A comment questions the model’s performance level, comparing it to ‘sonnet 4.5’, indicating skepticism or curiosity about its capabilities. Another comment inquires about the feasibility of running the model with64GBof RAM, suggesting interest in its hardware requirements. Additionally, there is a remark on the absence of a comparison with ‘Devstral 2’, hinting at a potential gap in the performance evaluation.- A user inquired about the model’s performance, questioning if it truly reaches ‘sonnet 4.5 level’ and whether it includes ‘agentic mode’, or if the model is simply optimized for specific tests. This suggests a curiosity about the model’s real-world applicability versus benchmark performance.
- Another user shared a quick performance test using LM Studio, reporting a processing speed of ‘6 tokens/sec’ on a setup with an RTX 4070 and 14700k CPU with 80GB DDR4 3200 RAM. They also noted a comparison with ‘llama.cpp’ achieving ‘21.1 tokens/sec’, indicating a significant difference in performance metrics between the two setups.
- A technical question was raised about the feasibility of running the model with ‘64GB of RAM’ and no VRAM, highlighting concerns about hardware requirements and accessibility for users without high-end GPUs.
2. ACE-Step 1.5 Audio Model Launch
-
ACE-Step-1.5 has just been released. It’s an MIT-licensed open source audio generative model with performance close to commercial platforms like Suno (Activity: 744): ACE-Step-1.5 is an open-source audio generative model released under the MIT license, designed to rival commercial platforms like Suno. It supports LoRAs, offers multiple models for various needs, and includes features like cover and repainting. The model is integrated with Comfy and available for demonstration on HuggingFace. This release marks a significant advancement in open-source audio generation, closely matching the capabilities of leading proprietary solutions. A notable comment highlights the potential impact of a recently leaked
300TBdataset, suggesting future models might leverage this data for training. Another comment encourages support for the official model research organization, ACE Studio.- A user compared the performance of ACE-Step-1.5 with Suno V5 using the same prompt, highlighting that while ACE-Step-1.5 is impressive for an open-source model, it does not yet match the quality of Suno V5. The user specifically noted that the cover feature of ACE-Step-1.5 is currently not very useful, indicating room for improvement in this area. They provided audio links for direct comparison: Suno V5 and ACE 1.5.
- Another user pointed out that the demo prompts for ACE-Step-1.5 seem overly detailed, yet the model appears to ignore most of the instructions. This suggests potential issues with the model’s ability to interpret and execute complex prompts accurately, which could be a limitation in its current implementation.
-
The open-source version of Suno is finally here: ACE-Step 1.5 (Activity: 456): ACE-Step 1.5 is an open-source music generation model that outperforms Suno on standard evaluation metrics. It can generate a complete song in approximately
2 secondson an A100 GPU and operates locally on a typical PC with around4GB VRAM, achieving under10 secondson an RTX 3090. The model supports LoRA for training custom styles with minimal data and is released under the MIT license, allowing free commercial use. The dataset includes fully authorized and synthetic data. The GitHub repository provides access to weights, training code, LoRA code, and a paper. Commenters noted the model’s significant improvements but criticized the presentation of evaluation graphs as lacking clarity. There is also a discussion on its instruction following and coherency, which are seen as inferior to Suno v3, though the model is praised for its creativity and potential as a foundational tool. Speculation about a forthcoming version 2 is also mentioned.- TheRealMasonMac highlights that ACE-Step 1.5 shows a significant improvement over its predecessor, though it still lags behind Suno v3 in terms of instruction following and coherency. However, the audio quality is noted to be good, and the model is described as creative and different from Suno, suggesting it could serve as a solid foundation for future development.
- Different_Fix_2217 provides examples of audio generated by ACE-Step 1.5, indicating that the model performs well with long, detailed prompts and can handle negative prompts. This suggests a level of flexibility and adaptability in the model’s design, which could be beneficial for users looking to experiment with different input styles.
3. Voxtral-Mini-4B Speech-Transcription Model
-
mistralai/Voxtral-Mini-4B-Realtime-2602 · Hugging Face (Activity: 266): The Voxtral Mini 4B Realtime 2602 is a cutting-edge, open-source, multilingual speech-transcription model that achieves near offline accuracy with a delay of
<500ms. It supports13 languagesand is built with a natively streaming architecture and a custom causal audio encoder, allowing configurable transcription delays from240ms to 2.4s. At a480msdelay, it matches the performance of leading offline models and realtime APIs. The model is optimized for on-device deployment with minimal hardware requirements, achieving a throughput of over12.5 tokens/second. Commenters appreciate the open-source contribution, especially the inclusion of the realtime processing part to vllm. However, there is disappointment over the lack of turn detection features, which are present in other models like Moshi’s STT, necessitating additional methods for turn detection.- The Voxtral Realtime model is designed for live transcription with configurable latency down to sub-200ms, which is crucial for applications like voice agents and real-time processing. However, it lacks speaker diarization, which is available in the batch transcription model, Voxtral Mini Transcribe V2. This feature is particularly useful for distinguishing between different speakers in a conversation, but its absence in the open model may limit its utility for some users.
- Mistral has contributed to the open-source community by integrating the realtime processing component into vLLM, enhancing the infrastructure for live transcription applications. Despite this, the model does not include turn detection, a feature present in Moshi’s STT, which requires users to implement alternative methods such as punctuation, timing, or third-party text-based solutions for turn detection.
- Context biasing, a feature that allows the model to prioritize certain words or phrases based on context, is currently only supported through Mistral’s direct API. This feature is not available in the vLLM implementation for either the new Voxtral-Mini-4B-Realtime-2602 model or the previous 3B model, limiting its accessibility for developers using the open-source version.
-
Some hard lessons learned building a private H100 cluster (Why PCIe servers failed us for training) (Activity: 530): The post discusses the challenges faced when building a private H100 cluster for training large models (70B+ parameters) and highlights why PCIe servers were inadequate. The author notes that the lack of NVLink severely limits data transfer rates during All-Reduce operations, with PCIe capping at
~128 GB/scompared to NVLink’s~900 GB/s, leading to GPU idling. Additionally, storage checkpoints for large models can reach~2.5TB, requiring rapid disk writes to prevent GPU stalls, which standard NFS filers cannot handle, necessitating parallel filesystems or local NVMe RAID. The author also mentions the complexities of using RoCEv2 over Ethernet instead of InfiniBand, which requires careful monitoring of pause frames to avoid cluster stalls. Commenters emphasize the importance of fast NVMe over Fabrics Parallel FS for training builds to prevent GPU idling and suggest that InfiniBand should be mandatory for compute, while RoCEv2 is preferable for storage. The surprise at storage write speed issues is also noted.- A storage engineer emphasizes the importance of a fast NVMe over Fabrics Parallel File System (FS) as a critical requirement for a training build, highlighting that without adequate storage to feed GPUs, there will be significant idle time. They also recommend using Infiniband for compute, noting that RoCEv2 is often preferable for storage. This comment underscores the often-overlooked aspect of shared storage in training workflows.
- A user expresses surprise at the storage write speed being a bottleneck, indicating that this is an unexpected issue for many. This highlights a common misconception in building training clusters, where the focus is often on compute power rather than the supporting infrastructure like storage, which can become a critical pinch point.
- Another user proposes a theoretical solution involving milli-second distributed RAM with automatic hardware mapping of page faults, suggesting that such an innovation could simplify cluster management significantly. This comment reflects on the broader issue of addressing the right problems in system architecture.
Less Technical AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. Anthropic vs OpenAI Ad-Free Debate
-
Sam’s response to Anthropic remaining ad-free (Activity: 1536): Sam Altman responded to Anthropic’s decision to remain ad-free, highlighting a competitive dynamic in the AI space. The discussion references a Claude Ad Campaign and suggests that more Texans use ChatGPT for free than the total number of Claude users in the US, indicating a significant user base disparity. This reflects ongoing competition between AI companies, reminiscent of historical tech rivalries like Microsoft and Apple. Commenters draw parallels between the current AI competition and past tech rivalries, suggesting a public display of competition while potentially collaborating privately.
- BuildwithVignesh highlights the effectiveness of the Claude Ad Campaign, suggesting that it has successfully captured attention despite the competitive landscape. The campaign’s impact is implied to be significant, although specific metrics or outcomes are not detailed in the comment.
- LimiDrain provides a comparative analysis, stating that ‘more Texans use ChatGPT for free than total people use Claude in the US’. This suggests a significant disparity in user base size between ChatGPT and Claude, indicating ChatGPT’s broader reach and adoption in the market.
- Eyelbee references a past statement by Sam, noting that he found AI ads disturbing a year ago. This comment suggests a potential inconsistency or evolution in Sam’s stance on AI advertising, especially in light of Anthropic’s decision to remain ad-free, which could be seen as a critique of ad-based models.
-
Anthropic declared a plan for Claude to remain ad-free (Activity: 1555): Anthropic has announced a commitment to keep its AI assistant, Claude, ad-free, emphasizing its role as a tool for work and deep thinking. This decision is highlighted in a blog post titled ‘Claude is a space to think,’ which underscores the company’s dedication to maintaining a distraction-free environment for users. The announcement contrasts with other AI models that may incorporate ads, positioning Claude as a premium, focused tool for productivity. Commenters note that while Claude is ad-free, its free tier is highly limited, making it less accessible without payment. This has sparked debate about the practicality of its ad-free claim, as users may still need to pay for effective use, contrasting with other AI models that offer more generous free usage.
- ostroia points out that while Claude is ad-free, it has strict limitations on its free tier, making it mostly unusable for anything beyond quick questions. This raises questions about the practicality of boasting about being ad-free when the product requires payment to be truly usable.
- seraphius highlights the potential negative impact of ads on platforms, noting that ads can shift the focus of executives towards ‘advertiser friendliness,’ which can weaken the platform’s integrity. This is compared to the situation on YouTube, where ad-driven decisions have significantly influenced content and platform policies.
-
Sam Altman’s response to the Anthropic Super Bowl ad. He said, “More Texans use ChatGPT for free than total people use Claude in the US” (Activity: 1394): The image captures Sam Altman’s critique of Anthropic’s Super Bowl ad, where he claims that more Texans use ChatGPT for free than the total number of people using Claude in the US. Altman accuses Anthropic of being dishonest in their advertising and contrasts OpenAI’s commitment to free access with Anthropic’s approach, which he describes as controlling and expensive. He also expresses confidence in OpenAI’s Codex and emphasizes the importance of making AI accessible to developers. Commenters debate the hypocrisy of Altman’s statement, noting that OpenAI also imposes restrictions on AI usage, as seen with their ‘nanny bot’ in version 5.2. There is also skepticism about Anthropic’s alleged blocking of OpenAI from using Claude for coding.
- AuspiciousApple highlights the competitive tension between OpenAI and Anthropic, noting that Sam Altman’s detailed response to Anthropic’s ad suggests a deeper concern about competition. This reflects the broader industry dynamics where major AI companies are closely monitoring each other’s moves, indicating a highly competitive landscape.
- owlbehome criticizes OpenAI’s approach to AI control, pointing out the perceived hypocrisy in Sam Altman’s statement about Anthropic’s control over AI. The comment references OpenAI’s own restrictions in version 5.2, suggesting that both companies impose significant limitations on AI usage, which is a common critique in the AI community regarding the balance between safety and usability.
- RentedTuxedo discusses the importance of competition in the AI industry, arguing that more players in the market benefit consumers. The comment criticizes the tribalism among users who show strong allegiance to specific companies, emphasizing that consumer choice should be based on performance rather than brand loyalty. This reflects a broader sentiment that healthy competition drives innovation and better products.
-
Anthropic mocks OpenAI’s ChatGPT ad plans and pledges ad-free Claude (Activity: 813): Anthropic has announced that its AI model, Claude, will remain ad-free, contrasting with OpenAI’s plans to introduce ads in ChatGPT. This decision was highlighted in a satirical ad mocking OpenAI’s approach, emphasizing Anthropic’s commitment to an ad-free experience. The move is seen as a strategic differentiation in the competitive AI landscape, where monetization strategies are evolving. The Verge provides further details on this development. Commenters express skepticism about Anthropic’s ad-free pledge, suggesting financial pressures may eventually lead to ads, similar to trends in streaming services.
-
Anthropic laughs at OpenAI (Activity: 485): The Reddit post humorously highlights a competitive jab from Anthropic towards OpenAI, suggesting a rivalry between the two companies in the large language model (LLM) space. The post does not provide specific technical details or benchmarks but implies a competitive atmosphere in the AI industry, reminiscent of past corporate rivalries such as Samsung vs. Apple. The external link is unrelated to the main post, focusing instead on fitness advice for achieving a ‘six-pack.’ The comments reflect a mix of amusement and skepticism, with users drawing parallels to past corporate rivalries and expressing hope that the situation does not backfire on Anthropic, similar to how Samsung’s past marketing strategies did.
- ClankerCore highlights the technical execution of the AI in the ad, noting the use of a human model with AI overlays. The comment emphasizes the subtle adjustments made to the AI’s behavior, particularly in eye movement, which adds a layer of realism to the portrayal. This suggests a sophisticated blend of human and AI elements to enhance the advertisement’s impact.
- The comment by ClankerCore also critiques the performance of Anthropic’s Claude, pointing out its inefficiency in handling simple arithmetic operations like ‘2+2’. The user mentions that such operations consume a significant portion of the token limit for plus users, indicating potential limitations in Claude’s design or token management system.
- ClankerCore’s analysis suggests that while the marketing execution is impressive, the underlying AI technology, specifically Claude, may not be as efficient or user-friendly for non-coding tasks. This highlights a potential gap between the marketing portrayal and the actual performance of the AI product.
-
Sam Altman response for Anthropic being ad-free (Activity: 1556): Sam Altman responded to a tweet about Anthropic being ad-free, which seems to be a reaction to a recent Claude ad campaign. The tweet and subsequent comments suggest a competitive tension between AI companies, with Altman emphasizing that they are not ‘stupid’ in their strategic decisions. This exchange highlights the ongoing rivalry in the AI space, particularly between OpenAI and Anthropic. Commenters noted the competitive nature of the AI industry, comparing it to the rivalry between brands like Coke and Pepsi. Some expressed a desire for more lighthearted exchanges between companies, while others critiqued Altman’s defensive tone.
-
Official: Anthropic declared a plan for Claude to remain ad-free (Activity: 2916): Anthropic has officially announced that their AI, Claude, will remain ad-free, as stated in a tweet. This decision aligns with their vision of Claude being a ‘space to think’ and a helpful assistant for work and deep thinking, suggesting that advertising would conflict with these goals. The announcement is part of a broader strategy to maintain the integrity and focus of their AI services, as detailed in their full blog post. Some users express skepticism about the long-term commitment to this ad-free promise, suggesting that corporate decisions can change over time. Others humorously reference Sam Altman with a play on words, indicating a mix of hope and doubt about the future of this policy.
-
Anthropic is airing this ads mocking ChatGPT ads during the Super Bowl (Activity: 1599): Anthropic is reportedly airing ads during the Super Bowl that mock ChatGPT ads, although these ads are not yet promoting their own AI model, Claude. This strategy is reminiscent of Samsung’s past marketing tactics where they mocked Apple for not including a charger, only to follow suit later. The ads are seen as a strategic move ahead of Anthropic’s potential IPO and business pivot. Commenters suggest that the ad campaign might backfire or become outdated (‘aged like milk’) once Anthropic undergoes its IPO and potentially shifts its business strategy.
2. Kling 3.0 and Omni 3.0 Launch
-
Kling 3.0 example from the official blog post (Activity: 679): Kling 3.0 showcases advanced video synthesis capabilities, notably maintaining subject consistency across different camera angles, which is a significant technical achievement. However, the audio quality is notably poor, described as sounding like it was recorded with a ‘sheet of aluminum covering the microphone,’ a common issue in video models. The visual quality, particularly in the final scene, is praised for its artistic merit, reminiscent of ‘late 90s Asian art house movies’ with its color grading and transitions. Commenters are impressed by the visual consistency and artistic quality of Kling 3.0, though they criticize the audio quality. The ability to maintain subject consistency across angles is highlighted as a technical breakthrough.
- The ability of Kling 3.0 to switch between different camera angles while maintaining subject consistency is a significant technical achievement. This feature is particularly challenging in video models, as it requires advanced understanding of spatial and temporal coherence to ensure that the subject remains believable across different perspectives.
- A notable issue with Kling 3.0 is the audio quality, which some users describe as sounding muffled, akin to being recorded with a barrier over the microphone. This is a common problem in video models, indicating that while visual realism is advancing, audio processing still lags behind and requires further development to match the visual fidelity.
- The visual quality of Kling 3.0 has been praised for its artistic merit, particularly in scenes that evoke a nostalgic, dream-like feel through color grading and highlight transitions. This suggests that the model is not only technically proficient but also capable of producing aesthetically pleasing outputs that resonate on an emotional level, similar to late 90s art house films.
-
Kling 3 is insane - Way of Kings Trailer (Activity: 1464): The post discusses the creation of a trailer for ‘Way of Kings’ using Kling 3.0, an AI tool. The creator, known as PJ Ace, shared a breakdown of the process on their X account. The trailer features a scene where a character’s appearance changes dramatically upon being sliced with a blade, showcasing the AI’s capability to render complex visual effects. Although some elements were missing, the AI’s performance was noted as impressive for its ability to recognize and replicate scenes accurately. Commenters expressed amazement at the AI’s ability to render recognizable scenes, with one noting the impressive transformation effects despite some missing elements. The discussion highlights the potential of AI in creative visual media.
-
Kling 3 is insane - Way of Kings Trailer (Activity: 1470): The post discusses the creation of a trailer for ‘Way of Kings’ using Kling 3.0, an AI tool. The creator, known as PJ Ace, who is also recognized for work on a Zelda trailer, shared a breakdown of the process on their X account. The trailer features a scene where a character’s appearance changes dramatically upon being sliced with a blade, showcasing the AI’s capability to render complex visual transformations. Although some elements were missing, the AI’s performance was noted as impressive by viewers. Commenters expressed amazement at the AI’s ability to create recognizable scenes and perform complex visual effects, despite some missing elements. The discussion highlights the potential of AI in creative media production.
-
Been waiting Kling 3 for weeks. Today you can finally see why it’s been worth the wait. (Activity: 19): Kling 3.0 introduces significant updates with features like
3-15s multi-shot sequences,native audio with multiple characters, and the ability toupload/record video characters as referenceensuring consistent voices. This release aims to enhance the user experience in creating AI-driven video content, offering more dynamic and realistic outputs. Users can explore these features on the Higgsfield AI platform. The community response highlights enthusiasm for the realistic effects, such as the ‘shaky cam’, which adds to the visual authenticity of the generated content. There is also a call to action for users to engage with the community by sharing their AI videos and participating in discussions on Discord.- A user expressed frustration over the lack of clear information distinguishing the differences between the ‘Omni’ and ‘3’ models, highlighting a common issue in tech marketing where specifications and improvements are not clearly communicated. This can lead to confusion among users trying to understand the value proposition of new releases.
-
KLING 3.0 is here: testing extensively on Higgsfield (unlimited access) – full observation with best use cases on AI video generation model (Activity: 12): KLING 3.0 has been released, focusing on extensive testing on the Higgsfield platform, which offers unlimited access for AI video generation. The update highlights full observation capabilities and optimal use cases for the model, potentially enhancing video generation tasks. However, the post lacks detailed technical specifications or benchmarks of the model’s performance improvements over previous versions. The comments reflect skepticism and frustration, with users perceiving the post as an advertisement for Higgsfield rather than a substantive technical update. There is also confusion about the relevance of the post to VEO3, indicating a possible disconnect between the announcement and the community’s interests.
3. GPT 5.2 and ARC-AGI Benchmarks
-
OpenAI seems to have subjected GPT 5.2 to some pretty crazy nerfing. (Activity: 1100): The image presents a graph depicting the performance of “GPT-5-Thinking” on IQ tests over time, with a notable decline in early 2026. This suggests that OpenAI may have reduced the capabilities of GPT-5.2, possibly as part of a strategic adjustment or due to resource constraints during training. The graph annotations indicate transitions between different versions of the AI, hinting at changes in its capabilities or architecture. The comments suggest that users have noticed a decrease in performance, possibly due to resource allocation for training or in anticipation of new releases like GPT 5.3 or DeepSeek v4. Commenters speculate that the perceived decline in performance might be due to resource limitations during training or strategic adjustments by OpenAI. Some users express dissatisfaction with the current performance compared to competitors like Gemini, while others anticipate improvements in future versions.
- nivvis highlights a common issue during model training phases, where companies like OpenAI and Anthropic face GPU/TPU limitations. This necessitates reallocating resources from inference to training, which can temporarily degrade performance. This is not unique to OpenAI; Anthropic’s Opus has also been affected, likely in preparation for upcoming releases like DeepSeek v4.
- xirzon suggests that significant performance drops in technical services, such as those experienced with GPT 5.2, are often due to partial or total service outages. This implies that the observed ‘nerfing’ might not be a deliberate downgrade but rather a temporary issue related to service availability.
- ThadeousCheeks notes a similar decline in Google’s performance, particularly in tasks like cleaning up slide decks. This suggests a broader trend of performance issues across major AI services, possibly linked to resource reallocation or other operational challenges.
-
New SOTA achieved on ARC-AGI (Activity: 622): The image illustrates a new state-of-the-art (SOTA) achievement on the ARC-AGI benchmark by a model based on GPT-5.2. This model, developed by Johan Land, achieved a score of
72.9%with a cost of$38.9per task, marking a significant improvement from the previous score of54.2%. The ARC-AGI benchmark, which was introduced less than a year ago, has seen rapid advancements, with the initial top score being only4%. The model employs a bespoke refinement approach, integrating multiple methodologies to enhance performance. Commenters note the rapid progress in ARC-AGI benchmark scores, expressing surprise at reaching over70%so quickly, though some highlight the high cost per task as a concern. There is anticipation for the next version, ARC-AGI-3, expected to launch in March 2026, as ARC-AGI-2 approaches saturation.- The ARC-AGI benchmark, which was introduced less than a year ago, has seen rapid progress with the latest state-of-the-art (SOTA) result reaching 72.9%. This is a significant improvement from the initial release score of 4% and the previous best of 54.2%. The benchmark’s quick evolution highlights the fast-paced advancements in AI capabilities.
- The cost of achieving high performance on the ARC-AGI benchmark is a point of discussion, with current solutions costing around $40 per task. There is interest in reducing this cost to $1 per task while maintaining or improving the performance to over 90%, which would represent a significant efficiency improvement.
- The ARC-AGI benchmark uses an exponential scale on its x-axis, indicating that moving towards the top right of the graph typically involves increasing computational resources to achieve better results. The ideal position is the top left, which would signify high performance with minimal compute, emphasizing efficiency over brute force.
-
Does anyone else have the same experience with 5.2? (Activity: 696): The image is a meme that humorously critiques the handling of custom instructions by GPT version 5.2, particularly in its ‘Thinking’ mode. The meme suggests that the model may not effectively process or retain user-provided custom instructions, as depicted by the character’s surprise when the instructions catch fire. This reflects user frustrations with the model’s limitations in handling specific tasks or instructions, possibly due to efforts to prevent jailbreaks or misuse. Commenters express dissatisfaction with GPT 5.2’s handling of custom instructions and memory, noting that explicit directions are often required for the model to access certain information, which they find cumbersome.
- NoWheel9556 highlights that the update to version 5.2 seems to have been aimed at preventing jailbreaks, which may have inadvertently affected other functionalities. This suggests a trade-off between security measures and user experience, potentially impacting how the model processes certain tasks.
- FilthyCasualTrader points out a specific usability issue in version 5.2, where users must explicitly direct the model to look at certain data, such as ‘attachments in Projects folder or entries in Saved Memories’. This indicates a regression in intuitive data handling, requiring more explicit instructions from users.
- MangoBingshuu mentions a problem with the Gemini pro model, where it tends to ignore instructions after a few prompts. This suggests a potential issue with instruction retention or prompt management, which could affect the model’s reliability in maintaining context over extended interactions.
AI Discord Recap
A summary of Summaries of Summaries by gpt-5.1
1. Cutting-Edge Models, Coders, and Routers
-
Qwen3 Coder Next Codes Circles Around GPT Giants: Qwen3-Coder-Next emerged as a standout local coding model, with users on Unsloth, Hugging Face, and LM Studio reporting it outperforming GPT‑OSS 120B while running efficiently from GGUF quantizations like MXFP4_MOE and even fixing long‑standing
glm flashbugs; Unsloth hosts the main GGUF release at unsloth/Qwen3-Coder-Next-GGUF, and a Reddit thread documents an update that “now produces much better code” for the refreshed GGUFs at this post.- Engineers are pushing VRAM optimization hard by selectively offloading FFN layers to CPU via
-otflags (and asking for a “significance chart” to rank layers by importance) while others confirm smooth vLLM inference on an RTX 5080, making Qwen3-Coder-Next a practical workhorse across Unsloth, Hugging Face, and LM Studio setups.
- Engineers are pushing VRAM optimization hard by selectively offloading FFN layers to CPU via
-
Max Router Mines Millions of Votes to Pick Your Model: LMArena announced Max, an intelligent router trained on 5+ million community votes that automatically dispatches each prompt to the “most capable model” given latency and cost, detailed in the blog post “Introducing Max” and an explainer video on YouTube.
- Users quickly started poking at Max’s behavior, noticing it sometimes claims Claude Sonnet 3.5 is backing responses while actually routing to Grok 4, prompting jokes like “Max = sonnet 5 in disguise” and raising questions about router transparency and evaluation methodology.
-
Kimi K2.5 Sneaks into Cline and VPS Racks: Kimi k2.5 went live on the developer‑oriented IDE agent Cline, announced in a Cline tweet and a Discord note promising a limited free access window for experimentation at cline.bot.
- Over on the Moonshot and Unsloth servers, engineers confirmed Kimi K2.5 can run as Kimi for Coding and discussed running it from VPS/datacenter IPs after Kimi itself green‑lit such use in a shared transcript, positioning it as a more permissive alternative to Claude for remote coding agents and OpenClaw‑style setups.
2. New Benchmarks, Datasets, and Kernel Contests
-
Judgment Day Benchmark Puts AI Ethics on Trial: AIM Intelligence and Korea AISI, with collaborators including Google DeepMind, Microsoft, and several universities, announced the Judgment Day benchmark and Judgment Day Challenge for stress‑testing AI decision‑making, with details and submission portal at aim-intelligence.com/judgement-day.
- They are soliciting adversarial attack scenarios around decisions AI must/never make, paying $50 per accepted red‑team submission and promising co‑authorship in the benchmark paper, with a Feb 10, 2026 scenario deadline and a $10,000 prize pool challenge kicking off March 21, 2026 for multimodal (text/audio/vision) jailbreaks.
-
Platinum-CoTan Spins Triple-Stack Reasoning Data: A Hugging Face user released Platinum-CoTan, a deep reasoning dataset generated through a triple‑stack pipeline Phi‑4 → DeepSeek‑R1 (70B) → Qwen‑2.5, focusing on Systems, FinTech, and Cloud domains and hosted at BlackSnowDot/Platinum-CoTan.
- The community pitched it as “high‑value technical reasoning” training material, complementary to other open datasets, for models that need long‑horizon, domain‑specific chain‑of‑thought in enterprise‑y systems and finance scenarios rather than generic math puzzles.
-
FlashInfer Contest Drops Full Kernel Workloads: The FlashInfer AI Kernel Generation Contest dataset landed on Hugging Face at flashinfer-ai/mlsys26-contest, bundling complete kernel definitions and workloads for ML systems researchers to benchmark AI‑generated kernels.
- GPU MODE’s #flashinfer channel confirmed the repo now includes all kernels and target shapes so contestants can train/eval model‑written CUDA/Triton code offline, while Modal credits and team‑formation logistics dominated meta‑discussion about running those workloads at scale.
3. Training & Inference Tooling: GPUs, Quantization, and Caches
-
GPU MODE Dives Deep on Triton, TileIR, and AMD Gaps: The GPU MODE community announced a Triton community meetup on March 4, 2026 (16:00–17:00 PST) via a calendar invite, featuring NVIDIA’s Feiwen Zhu on Triton → TileIR lowering and Rupanshu Soi presenting “Optimal Software Pipelining and Warp Specialization for Tensor Core GPUs”, with details in the event link shared in
#triton-gluon.- Parallel threads dissected performance gaps where Helion autotuned kernels only hit 0.66× baseline speedup on AMD GPUs versus torch inductor’s 0.92× for M=N=K=8192, and advised diffing the emitted Triton kernels to see what the AMD team tweaked for their own backend.
-
MagCache and torchao Push Cheaper, Faster Training: Hugging Face quietly shipped MagCache as a new caching method for Diffusers, documented in the optimization docs at “MagCache for Diffusers” and implemented in diffusers PR #12744.
- At the same time, GPU MODE highlighted that Andrej Karpathy wired torchao into his nanochat project for FP8 training, via a commit (6079f78…), signalling that lightweight FP8 + activation‑optimized caching are moving from papers into widely‑copied reference code.
-
Unsloth, DGX Spark, and Multi-GPU Fine-Tuning Hacks: Unsloth users wrestled with DGX Spark fine‑tuning, where an SFT run on Nemotron‑3 30B using the Nanbeige/ToolMind dataset from the Unsloth docs at “fine-tuning LLMs with Nvidia DGX Spark” was running unexpectedly slow until others recommended switching to the official DGX container and checking GRPO/vLLM compatibility.
- Elsewhere in Unsloth and Hugging Face channels, practitioners compared Accelerate tensor parallelism for multi‑GPU fine‑tuning, discussed quantizing post‑bf16‑finetune models with domain‑specific imatrix statistics, and noted that community quantizers like mradermacher often publish GGUFs automatically once a fine‑tuned model gains traction on Hugging Face.
4. Product, Pricing, and Ecosystem Turbulence
-
Perplexity Deep Research Nerfs Spark EU Legal Talk: Perplexity’s community reacted furiously to Perplexity Pro cutting Deep Research limits from 600/day to 20/month (a 99.89% reduction), with users in
#generaldiscussing cancellations, chargebacks, and migrations to Gemini and Claude despite an announcement that upgraded Deep Research to run on Opus 4.5 for Max/Pro users as described in the official note in#announcements.- Several EU users argued this silent downgrade might violate consumer transparency norms, citing that there is “no legal contract in the EU where the text practically forces the user to accept that the service is not transparent”, and began exploring open‑source or alternative stacks like Kimi, Z.Ai, and Qwen to recreate the old “medium‑effort” research workflow.
-
Sonnet 5’s Schrodinger Launch: Delayed and Half-Leaked: Across Cursor, OpenRouter, and LMArena servers, engineers tracked the delayed launch of Claude Sonnet 5, with a widely‑shared X link suggesting a roughly one‑week slip (rumored status) while OpenRouter’s logs briefly exposed 403 EXISTS errors for
claude-sonnet-5andclaude-opus-4-6, implying Anthropic briefly registered but withheld the models.- The outage‑driven hiccup also impacted Claude’s API and Cursor users, some of whom had to roll back to Cursor 2.4.27 due to a broken SSH binary in 2.4.28, highlighting how tightly editor workflows and router services now depend on timely, stable frontier‑model releases.
-
Cloud AI Stack Shake-Up: Kimi, Gemini, GPT, and Claude: The multi‑server chatter paints a volatile model‑as‑a‑service landscape: Gemini 3 earns praise on OpenAI’s server for “depth and style” in creative writing, Kimi K2.5 is lauded on Nous and Moonshot for beating Gemini 3 Pro in coding, and Claude gets meme‑boosted via Super Bowl ads promising no ads in Claude in Anthropic’s spot.
- At the same time, Sam Altman defended ad funding in ChatGPT in a reply captured in his tweet, OpenAI’s own community ranted about GPT 5.2 regressions and Sora 2 glitches, and multiple communities noted that users are increasingly stitching together open‑weight models (DeepSeek/Kimi/Qwen) plus tools like OpenClaw rather than betting on a single closed provider.
5. Security, Red-Teaming, and Autonomous Agents
-
Judgment Day and BASI Push Serious Red-Teaming: The BASI Jailbreaking server amplified the Judgment Day benchmark call for adversarial decision‑making scenarios as a formal red‑teaming venue, with prizes and co‑authorship for clever multimodal attacks described at the official challenge page.
- Concurrently, BASI’s #jailbreaking and #redteaming channels traded Gemini and Claude Code jailbreaks like ENI Lime (mirrored at ijailbreakllms.vercel.app and a Reddit thread), debated Anthropic’s activation capping as effectively “lobotomising” harmful behaviors, and discussed Windows rootkit attack surfaces via COM elevation and in‑memory execution.
-
OpenClaw, Cornerstone Agent, and Real-World Attack Surfaces: Multiple discords (LM Studio, Cursor, Latent Space SF) scrutinized OpenClaw—an agent orchestrator at ivan-danilov/OpenClaw—for prompt‑injection and tool‑overreach risk, prompting some to strip unnecessary tools and terminals and others to draft enterprise‑grade security models in an RFC shared by Peter Steinberger at this OpenClaw security tweet.
- Hugging Face’s #i-made-this upped the stakes by showcasing cornerstone-autonomous-agent, an autonomous AI agent published on npm at cornerstone-autonomous-agent that can open real bank accounts via an MCP backend hosted on Replit and a Clawhub skill, triggering a wave of quiet “this is how you get regulators” energy among more security‑minded engineers.
-
Crypto-Grade Proofs Meet LLMs While Breaches Leak Keys: On Yannick Kilcher’s #paper-discussion, a researcher described a zero‑knowledge proof of matrix–matrix multiplication over 64‑bit integers with only 2× overhead relative to plain compute, and noted GPUs can run it “nearly as fast as float64”; they are now wiring this ZK scheme into the feedforward path of a custom LLM, with work‑in‑progress code referenced as a future “deep learning theory sneak peek”.
- In stark contrast, Yannick’s #ml-news tracked the Moltbook database breach where Techzine reports that 35,000 emails and 1.5 million API keys were exposed, reinforcing why several communities refuse to trust SaaS tools with credentials and why ZK verification and tighter data‑handling guarantees are becoming more than academic curiosities.
Discord: High level Discord summaries
BASI Jailbreaking Discord
- Judgment Day Benchmark Announced: AIM Intelligence and Korea AISI, in collaboration with Google DeepMind, Microsoft, and several universities, announced the Judgment Day benchmark for AI decision-making, focusing on scenarios where AI judgment can be broken or deceived.
- The benchmark aims to identify decisions AI should never make and those it must, with a call for attack scenarios offering $50 per selected submission and recognition in the research paper; the submission deadline is Feb 10, 2026, while the Judgment Day Challenge starts on March 21, 2026, featuring a $10,000 total prize pool with submissions via this link.
- Activation Capping Keeps AI in Check: Activation capping, a technique developed by Anthropic, stabilizes AI model outputs and may be used to enhance AI safety.
- This implies that high activations are correlated with harmful outputs, leading to efforts to lobotomise out anything that deviates too far from being an assistant or tool.
- Decoding AI’s Roots and Cyber Tactics: Members discussed the etymological and epistemological origins of AI, including its religious connections and touching upon Shakey the Robot, Pigeon Guided Missiles, and Pattern Recognition.
- Separately, in the context of Cyber Warfare, members discussed modifications made to munitions by both sides (Ukraine/Russia) and using consumer drones for dropping provisions and blood transfusions, referencing a YouTube video demonstrating these tactics.
- Gemini Jailbreaks Galore: Users are actively seeking and discussing Gemini jailbreaks, with specific interest in prompts that enable unethical actions and malicious coding, like creating an EAC (Easy Anti-Cheat) bypass.
- Daedalus_32 noted that Gemini is currently really easy to jailbreak, leading to a multitude of options, but that functional skill levels are all about the same, dependent on what the user is looking for.
- Windows Plagued by Privacy Predicaments: Following a rootkit developer’s OS review, the main exposure point was identified as in-memory execution and abusing identity or COM elevation paths on Windows.
- Another user commented that Windows was never really about privacy and its architecture may intentionally provide such access for government needs.
Perplexity AI Discord
- Perplexity Pro Limits Plunge 99%: Users are expressing outrage over Perplexity Pro dropping from 600/day to 20/month deep research queries, a 99.89% decrease.
- Some users feel scammed and note the lack of transparency, while others are switching to alternatives like Gemini and Claude.
- Gemini’s Research Slows to a Crawl: Members find Gemini’s Deep Research function is too slow, with reports taking over 10 minutes compared to Perplexity Research’s 90 seconds.
- Members noted that Google’s Gemini trains and reviews on their conversations so one should consider using OS models for research.
- Comet Browser’s Connections Sputter: Members report issues with Comet browser disconnecting, potentially related to the model selected in shortcuts, impacting automation capabilities and usability.
- One member noted cutting the usage down to I think 1/5 by going free won’t be worth using that way.
- Open Source Models Gain Traction: Members are looking for replacements for Perplexity’s Research model and are discussing open-source alternatives like Kimi, Z.Ai, and Qwen.
- Members noted that switching is needed since they are stuck between low effort and MAXIMUM HIGH EFFORT where “Research” (before the update) was a perfect Medium tier between the two and now it’s gone?
- EU Regulations Eye AI Companies: Members discuss the potential for EU regulations to impact AI companies like Perplexity for not announcing changes that affect users and violating consumer rights.
- A member mentioned they should at least clearly announce the changes that affect users. There is no such legal contract in the EU where the text practically forces the user to accept that the service is not transparent.
Unsloth AI (Daniel Han) Discord
- Qwen3-Coder-Next Coding Prowess Prevails: Qwen3-Coder-Next emerges as a top coding model, even outperforming GPT 120B without requiring shared VRAM, and resolves a previous issue with
glm flash.- Members celebrated its coding capabilities, with one stating it just fixed an issue that a member reported glm flash was choking on for a week so i’m happy.
- Optimal Layering Lowers VRAM Load: Discussion revolves around strategically placing layers on the GPU using
-otflags to offload specificffnlayers to the CPU for VRAM optimization.- The community desires a significance chart to guide layer placement decisions without extensive trial and error.
- DGX Spark SFT Speeds Spark Debate: A user reports slow training times on DGX while using an SFT with Nanbeige/ToolMind dataset from Unsloth’s documentation.
- Suggestions included utilizing the official DGX container, sparking a wider discussion on GRPO notebooks and vLLM compatibility on DGX Spark.
- TTS Model Metamorphosizes into Music Maestro?: A user investigates transforming a TTS model into a music generator, observing a surprisingly linear loss curve in initial experiments.
- They wonder the amount of data is needed to change the task of a foundation model.
- Sweaterdog Spotlights Specialized Datasets: A member highlights the release of datasets on Hugging Face, including code_tasks_33k, website-html-2k, openprose, and fim_code_tasks_33k.
- fim_code_tasks_33k is noted as a variant of code_tasks_33k.
LMArena Discord
- AI Race Tightens with Google in the Sights: Members debated who could surpass Google in the AI race, with names such as Claude, GLM, Deepseek R2, Moonshot, Grok, and Qwen being thrown around.
- While some believe Google’s resources give them an edge, others suggest that open source and competition could lead to another competitor surpassing them, observing China is tied with the U.S. in the race.
- DeepSeek V3.5 Launch Speculation Intensifies: The community discussed the potential release of DeepSeek V3.5 or V4, noting Deepseek 3.2 came out in December and Deepseek v3.1 dropped in August.
- The general feeling is that DeepSeek 3.2v is better than Grok 4.1, and some are hoping the new version will launch during the Chinese New Year.
- Max’s Model Missteps Raise Eyebrows: Users noticed that Max claims to be in 2024, suggesting Claude Sonnet 3.5 is the best model for building a complex app, yet tests revealed Max often defaults to Grok 4.
- This discrepancy led to questions about its capabilities and the accuracy of its model information, with members joking Max = sonnet 5 in disguise.
- Arena Intros Max, Intelligent Router: Arena is launching Max, an intelligent router powered by 5+ million real-world community votes, designed to route each prompt to the most capable model with latency in mind, as detailed in this blog post and YouTube video.
- No secondary summary.
- ByteDance Enters Arena with Seed-1.8: The new seed-1.8 model by Bytedance is now available on Text, Vision, & Code Arena.
- No secondary summary.
Cursor Community Discord
- Sonnet 5 Postponed, Delaying Hype: Despite initial expectations, the release of Sonnet 5 has been delayed by approximately one week, according to sources.
- No specific reasons were given for the delay, leaving members to speculate on potential improvements or last-minute adjustments.
- Cursor Patch 2.4.28 Suffers SSH Setback: The 2.4.28 patch for Cursor is causing issues with remote Windows SSH connections due to a missing remote host binary, requiring users to revert to version 2.4.27.
- Members reported that the update effectively breaks the SSH functionality, making the older version the only viable option for those relying on remote connections.
- OpenClaw Gets Cursor Makeover: A member successfully recreated OpenClaw within Cursor, suggesting it might even be an improvement over the original.
- The conversation quickly turned to security implications, with some users expressing concerns about trusting AI with sensitive credentials and code, as one user stated I don’t trust any software with my credentials or my code at all.
- AI Assistants Enhance Human Expertise, Not Replace: Community members defended the irreplaceable value of human judgment, stating that AI serves as an assistant rather than a full replacement, particularly in roles demanding taste, scope control, or verification.
- Referencing the nuances of human expertise, a member quoted AI will replace tasks, not taste. Humans still own the goals, judgment, and the shipping….
- Agents.md Takes the Crown Over Skills: Cursor’s support for AGENTS.md, a single file convention, has sparked discussions about its superiority over the ~/.agents/ directory-based approach, known as Skills.
- Referencing a Vercel blog post, a member pointed out that the post explains the advantages of AGENTS.md over Skills.
OpenRouter Discord
- DeepSeek OCR Model in Demand: Users are requesting the availability of the DeepSeek OCR model on OpenRouter.
- This model is known for its accuracy in Optical Character Recognition tasks and could enhance OpenRouter’s capabilities.
- AI Engineer: is it a real job: Discussion arose around the definition of an AI Engineer, questioning whether some are merely “wrapping Claude code” rather than developing LM-systems.
- This sparked a debate on the depth of technical skill required for the role and the value of different approaches to AI development.
- OpenRouter Rate Limits Rankle: Users reported encountering persistent rate limit errors on OpenRouter, even after funding their accounts.
- Error messages indicated “Provider openrouter is in cooldown (all profiles unavailable)”, causing frustration among users trying to utilize the service.
- Claude API experiences SNAFU, Sonnet 5 Release Stalled: The anticipated release of Sonnet 5 faced delays due to a widespread Claude API outage, with error logs suggesting a possible simultaneous but failed launch of Opus 4.6.
- Netizens analyzed error logs and found that requesting claude-sonnet-5 and claude-opus-4-6 resulted in a 403 EXISTS error, suggesting the models were intended for release.
- Image Generation Costs: Not Cheap!: A user inquired about the cost of generating 1000 images, seeking clarification on the charging method.
- Another user responded by stating that it costs 404 cents per image, highlighting the expense associated with large-scale image generation.
Latent Space Discord
- Forbes 30 Under 30, Incarcerated?: Sophie Vershbow went viral spotlighting the recurring trend of Forbes 30 Under 30 honorees eventually facing legal issues and imprisonment.
- The observation sparks discussion about the pressures and ethical considerations within high-achieving circles.
- Cloudflare CEO Juggles Security, Olympics, Earnings: Cloudflare CEO Matthew Prince announced the company’s earnings report is rescheduled for next Tuesday due to team commitments at the Munich Security Conference and the Olympics, as per his tweet.
- Additionally, members will be attending the upcoming Config conference in June.
- Altman Assembles AI Safety Taskforce: Sam Altman announced the hiring of Dylan Scandinaro to lead OpenAI’s Preparedness team, focusing on developing safeguards and mitigating severe risks as the company transitions to more powerful AI models; more information available here.
- This comes on the heels of Anthropic launching Super Bowl ads mocking OpenAI’s decision to include ads in ChatGPT, committing to keeping Claude ad-free and these can be viewed on YouTube.
- Adaption Labs Adapts to $50M Funding: Adaption Labs announced a $50 million investment round to develop AI systems capable of real-time evolution and adaptation; more information available here.
- Additionally, Cerebras Systems secured $1 billion in Series H financing, reaching a $23 billion valuation with funding led by Tiger Global and featuring investors like AMD; more information available here.
- Merit Promises Test-Speed Coverage: The Merit Python testing framework offers eval-level coverage at unit-test speed, claiming tests are a better abstraction than evals with improved coverage and APIs; the GitHub repo is linked.
- Merit, favored by LegalZoom and 13 startups, features fast LLM-as-a-Judge, native OpenTelemetry trace capture, and typed abstractions for metrics and cases, with AI-generated cases and error analysis coming soon, according to the docs.
LM Studio Discord
- Stable Diffusion Seed Yields Nonsense: A user reported that the Stable-DiffCoder-8B-Instruct model from ByteDance produced total nonsense, seeking help with debugging.
- The user suspected a potential issue with the sampler or other configuration problems within LM Studio.
- RAM Prices Skyrocket to Ludicrous Speed: Users noted significant price increases for RAM and GPUs, with one reporting a 504% increase for a 96GB dual channel kit.
- The discussion highlighted the impact of market conditions on hardware costs.
- OpenClaw Scares Users with Security Risks: A user shared concerns about potential prompt injection attacks when using OpenClaw, suggesting a need to reduce unnecessary tools and terminal commands.
- Another user humorously deemed it 2spooky4me, signaling strong reservations about its security.
- Qwen3 Coder Next Charms Coders: A user found that the new Qwen3Coder Next model in LM Studio was performing well compared to GPT-OSS 20b & 120b models, which were slow.
- The same user cautioned others to carefully manage the model’s prime directives by writing directly in the ”user.md” and ”soul.md” files.
- GPU Power Throttled by Software?: A member had slow inference until they discovered that software was limiting the speed of their Nvidia GPU.
- They recommended others verify their software settings if experiencing unexpectedly slow GPU performance.
OpenAI Discord
- GPT’s Performance Draws Ire: A user voiced frustration with GPT’s behavior, noting its constant updates and decreasing helpfulness, and further detailed specific parameters set to control GPT’s responses, including a three-mode system and instructions to take no further action.
- Another user requested a link to GPT 4.0 complaining that GPT 5.2 is useless.
- Sora 2 Stumbles with Glitches: Users reported issues with Sora 2, describing it as ‘broken and glitch’ and experiencing problems accessing or using ChatGPT due to heavy load and error messages.
- Some users speculated on potential solutions, such as removing the free option, while others expressed concern about the sustainability of Sora 2.
- Gemini 3 Challenges GPT in Writing: A user lauded Gemini 3 for its ‘depth and style’ and suggested it as a superior alternative to GPT for creative writing, especially with guardrails off.
- The user also clarified that their strong agreement with Gemini 3’s writing capabilities was a figure of speech, after another user misunderstanding due to English not being their first language.
- Grok’s Video Skills Grow: A user noted that Grok’s video generation capabilities have improved, and the image generation now supports 10-second videos, although speech direction needs work.
- Another member reported that Veo is also impressive, however, it is limited to only 3 videos per day with a pro subscription.
- OpenAI Downtime Draws Fire: Users are frustrated with frequent downtimes of the OpenAI web version, criticizing the company’s testing and issue resolution speed, with one user stating that the downtimes are ‘absolutely embarrassing’.
- Another user requested a link to a previous version.
Moonshot AI (Kimi K-2) Discord
- Kimi K2.5 Plugs into Cline: Kimi k2.5 is now live on Cline with a limited window of free access.
- The official Cline tweet about Kimi k2.5 is also live.
- API Access Flags High-Risk Messages: Users reported receiving a high-risk rejection message from the Kimi API even with innocuous content.
- Root cause may involve keyword triggers or the model’s concerns about violating platform rules, as detailed here.
- Kimi Code Can Run on VPS: Members discussed running Kimi Code on a VPS, noting that unlike Claude, Kimi’s terms don’t explicitly prohibit it.
- Kimi K2.5 itself said it was ok, being more open than Anthropic and enabling running a personal Kimi on a VPS.
- K2.5 Blocks WhatsApp Spammer: K2.5 blocks attempts to create a WhatsApp bot that auto-sends messages, aligning with WhatsApp’s terms of service.
- Users suggest rephrasing prompts to emphasize Kimi’s role as an attendant or assistant rather than an unofficial app.
- AI Slides Hit Buggy Road: Multiple users reported bugs with AI Slides, citing failures to generate desired content or correctly interpret sources.
- A user updated their bug report, and another member acknowledged that AI Slides is pretty unuseful currently, and that there will be updates.
HuggingFace Discord
- Qwen3-Coder-Next Runs Locally!: The Qwen3-Coder-Next coding model is now available on HuggingFace and is designed to run locally.
- One user reported smooth performance on an RTX 5080 using vllm.
- Platinum CoTan Dataset Emerges!: A new high-value deep-reasoning dataset, Platinum-CoTan, has been introduced, built using a Phi-4 → DeepSeek-R1 (70B) → Qwen-2.5 pipeline, and is available on Hugging Face.
- The dataset emphasizes Systems, FinTech, and Cloud applications, offering resources for complex reasoning tasks.
- MagCache Optimizes Diffusers!: The new MagCache caching method is now available for optimizing Diffusers, enhancing performance.
- Implementation details are available in pull request #12744 on GitHub, detailing the enhancements.
- Craft Your Own LLM!: A member shared a GitHub repo featuring a small LLM built from scratch to illustrate modern Transformer internals.
- The LLM incorporates key elements such as RoPE, GQA, and KV cache, making it a valuable educational tool.
- Autonomous AI Now Opens Bank Accounts!: An autonomous AI agent called cornerstone-autonomous-agent capable of opening real bank accounts, was introduced via npm package.
- It leverages an MCP available on Replit and a clawbot skill available on Clawhub.
GPU MODE Discord
- Nvidia Talks Triton to TileIR: Feiwen Zhu from Nvidia will discuss Triton to TileIR at the upcoming Triton community meetup on March 4, 2026.
- Rupanshu Soi will present a paper on Optimal Software Pipelining and Warp Specialization for Tensor Core GPUs at the same meeting, with community members also interested in updates on Meta’s TLX.
- CUDA IPC Pluggable Allocator Sought: A member is seeking a mechanism similar to PyTorch’s Pluggable Allocator for overriding memory management non-intrusively with cross-process usage (IPC) support, noting that
cuda::mr::resource_refis unsuitable for their specific requirements.- Another member shared a CUDA profiling example from their learn-cuda repo, along with a screenshot of the resulting profile that looks like a performance heatmap.
- Layout Algebra’s Limitations Unveiled: Composition isn’t always well-defined in Layout Algebra as currently implemented, according to this note.
- Additionally, a tiled copy operation with a shared memory layout
(128,32,3):(32,1,4096)leads to a four-way store bank conflict because code does not guarantee 16B alignment, leading to a fallback to 32b stores.
- Additionally, a tiled copy operation with a shared memory layout
- Speedups Gap Spotted on AMD GPUs: A user reported a performance gap on AMD GPUs between torch inductor autonuned kernels and Helion autotuned Kernels, specifically noting Helion config achieving 0.66x speedup versus torch inductor’s 0.92x for M=8192, N=8192, K=8192.
- Another user suggested comparing the emitted Triton kernels from both inductor and helion to pinpoint the difference, noting the AMD performance work was primarily handled by the AMD team.
- FlashInfer Kernel Contest Dataset Released: A repository has been updated with the complete kernel definitions and workloads for the FlashInfer AI Kernel Generation Contest.
- The dataset can be used to evaluate AI generated kernels.
{kind=link}
Nous Research AI Discord
- World Models May Thrive Without Language: A member suggested that world modeling might be more effective if detached from language, potentially reducing language-influenced errors and leading to improvements.
- Another user proposed training a world model to predict the success of reasoning chains, rewarding it via RL for accurate predictions.
- Kimi K2.5 Trumps Gemini 3 Pro: Kimi K2.5 is receiving favorable comparisons to Gemini 3 Pro, showcasing the advancements in Global OS models since the DeepSeek movement a year ago.
- The community looks forward to the DeepSeek R2 release as a further evolution in this space.
- Brains Don’t Do Math, Math Describes Brains: While discussing brain processing of language, it was argued that brains don’t process language mathematically, but brain physics can be described by math.
- Further, a member suggested Maths isnt naturally occuring unlike physics.
- AI CEOs Hurl Mud: Members discussed the recent spat between OpenAI and Anthropic CEOs, referencing Claude’s ads (link) assuring users there will be no ads.
- Sam Altman’s response (link) was also noted, with a commenter stating It’s good that sama explains who the ads were targeted at.
- India’s AI/ML Engineer Market Insulted?: A job posting for a Senior AI/ML Engineer in India offering $500 a month sparked community outrage and debate of wage conditions, with members labeling it criminal.
- Given the requirements of 5 years experience and healthcare, some wondered if they are any good at ai engineering, they would get much, much more anywhere else.
Eleuther Discord
- Workshops submission deadlines later than main conferences: Workshops often have later submission deadlines than main conferences, and, while acceptances are easier and perceived as less prestigious, some exceptional workshops can grow into new conferences.
- One member clarified that workshop submissions are after main conference author notification.
- Unsloth and Axolotl fine-tunes OpenAI LLMs: Members mentioned Unsloth and Axolotl as tools for fine-tuning OpenAI LLMs.
- One member wants the best most recent methods and hopes to get up a model that he can provide to a few users within the next few days, and he has a budget and dataset ready.
- Logical AI Faces Boundary Blindness: One member is researching the structural conflict between continuous optimization and discrete logic rules, focusing on how the Lipschitz continuity of neural networks creates a Neural Slope that smooths over logical cliffs, leading to an Illusion of Competence.
- They proposed a Heterogeneous Logic Neural Network (H-LNN) with dedicated Binary Lanes using STE to lock onto discrete boundaries, and shared a link to a preprint on Zenodo containing a Lipschitz proof and architecture.
- DeepSpeed Gets a Facelift for Upstream Neox: A member mentioned they may need to update deepspeed and update upstream neox.
- A member said they will put a roadmap in the repo, so another member can start Looking forward to seeing what’s on the roadmap!
Yannick Kilcher Discord
- MCMC Rewrite Stymies PyTorch: Engineers found it challenging to rewrite this blog for rotating decision boundary performance using PyTorch and MCMC.
- One member suggested sidestepping MCMC by implementing a forward pass to compute the negative (log-likelihood + log-prior), and pointed out that hierarchical models don’t work well with point estimates.
- Neural Nets Get Temporal: A member suggested adding a time dimension as input to neural nets and rewriting the loss as a classification problem, simplifying the loss.
- The member considered the original stochastic trajectories for weights as over-engineered.
- ZK Matrix Multiply Only Doubles Overhead: A zero-knowledge proof of matrix-matrix multiplication was achieved with only x2 overhead compared to direct computation, using matrix multiplication over 64-bit integers.
- The member explained that this is reasonably fast on GPUs, nearly as fast as float64 multiplications, making it a viable approach; another member plans to apply it to the feedforward process of an LLM.
- Moltbook Database Sprays API Keys: A Moltbook database breach leaked 35,000 emails and 1.5 million API keys.
- Members noted the incident, highlighting the significant security lapse.
Manus.im Discord Discord
- Top Tier Users get Credits on Demand: Users discovered that purchasing additional credits is exclusively available for the highest tier subscriptions on Manus.
- One user criticized the credit limitations, contrasting it with the unlimited access offered by ChatGPT and Gemini.
- Manus Dreamer event launches: Manus introduced the Manus Dreamer event, where participants can win up to 10,000 credits for their AI projects.
- Interested users were invited to join a specific channel for detailed participation instructions.
- Code IDE Support Rejected: A user asked about code IDE or OpenClaw support in Manus, and upon inferring a negative response, announced their immediate departure.
- Another user humorously commented on their swift exit.
- Subscription Mistake gets Resolution: User João reported an unintentional subscription renewal and requested a refund due to unused credits.
- A Manus team member confirmed they had contacted João directly to assist with the refund process.
- Users Reject Ads in Manus: A user conveyed their strong opposition to the introduction of ads in Manus, especially given the subscription costs.
- Another user echoed this sentiment, arguing that ads would be an unwelcome disruption for paying customers while acknowledging the business incentive for generating revenue through advertisements.
Modular (Mojo 🔥) Discord
- Users Clamor for Community Calendar: A user requested a newsletter or calendar subscription to track community meetings, after missing the last one. Another member provided a Google Calendar link but cautioned that the time might be set to GMT -7.
- Someone received an invitation to present at a Modular community meeting, they shared that the project is currently too early in development to present.
- Rightnow Adds Mojo Support to GPU Code Editor: A member noted that the Rightnow GPU focused code editor has added Mojo support to its code editor.
- Another member reported that after providing graphics shader code inlined in a cuda kernel that executes locally, it looks like the emulation isn’t accurate because it blew up.
- New Mojo Learner Seeks Resources: A new Mojo learner asked about learning resources and mentioned they were excited to discuss concepts with others. Experienced members recommended the official Mojo documentation, GPU puzzles, and the Mojo forum.
- They were also pointed to specific channels to ask questions.
- Modular Launches Quirky AI Agent Ka: Modular has an AI agent named ka in a specific discord channel that can help answer questions. Ka can be reached by typing @ka and then using autocomplete.
- Members mentioned that the bot is a little quirky.
aider (Paul Gauthier) Discord
- Aider Architect Mode Causes Newbie Frustration: A user reported that Aider in architect mode was not pausing for input after asking questions, as documented in Github issue #2867.
- The user was using Opus 4.5 with copilot and a 144k context window, attempting to split a spec document into context-window sized chunks and perform a gap analysis.
- Aider Feedback Drives Detail Requests: A member requested more details to debug the Aider issue, including the model used, the output of the
/tokenscommand, context window token length, and file characteristics.- They noted the potential for prompt injection in files, obfuscated to target innocuous logits, an interesting attack vector to defend against.
- Aider config Mitigates Output Problems: A user suggested trying
edit-format: diff-fencedin the.aider.conf.ymlconfig to help mitigate certain kinds of problems with longer-form architect mode output.- They also suggested using
model: openrouter/google/gemini-3-pro-previewif the user has OpenRouter, since it is about as long a functional context one can get right now.
- They also suggested using
DSPy Discord
- DSPy Community Cookbook Integration Blocked: A member inquired about publishing a cookbook for their tool to be used with DSPy but learned that third-party integration isn’t directly supported.
- Instead, they were advised to publish a blog post and include it in the Community Resources.
- BlockseBlock Eyes DSPy for India AI Summit 2026: A member from BlockseBlock expressed interest in organizing a DSPy-focused event at the India AI Summit 2026.
- They are seeking guidance on the appropriate contacts to discuss this opportunity further.
- Developer Seeks Project: A member has announced they are seeking a developer role.
- Specific skill sets or project details were not provided.
tinygrad (George Hotz) Discord
- Sassrenderer Bounty Adds & Mul Working: A member reports that
addsandmulare working for the sassrenderer bounty and MR is almost complete.- They asked how far along until it’s appropriate for them to open a Merge Request (MR).
- Tinygrad’s Spec-Driven Bug Fixes: A member says that agents are useful when you have a clear spec that simply needs to be written; but many tinygrad code issues are different.
- They stated that the goal in tinygrad is to not just fix bugs, but figure out why the spec is subtlety wrong that caused that bug in the first place, then fix the spec.
MCP Contributors (Official) Discord
- Users seek MCP merging and extending techniques: A member inquired about an easy method to merge or extend an MCP, specifically a Shopify MCP, to incorporate additional tools like email support.
- The user wants to integrate email support functionality, which is currently provided separately, into their existing Shopify MCP setup.
- Email Support Integration into Shopify MCP: The discussion focused on integrating email support directly into a Shopify MCP setup, rather than using separate tools.
- The goal is to consolidate functionalities for improved efficiency and management within the existing Shopify MCP environment.
The LLM Agents (Berkeley MOOC) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Windsurf Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
You are receiving this email because you opted in via our site.
Want to change how you receive these emails? You can unsubscribe from this list.
Discord: Detailed by-Channel summaries and links
BASI Jailbreaking ▷ #announcements (1 messages):
AI benchmark, Red teaming, AI safety, Multimodal AI
- Judgment Day Benchmark Announced: AIM Intelligence and Korea AISI, in collaboration with Google DeepMind, Microsoft, and several universities, announced the Judgment Day benchmark for AI decision-making, focusing on scenarios where AI judgment can be broken or deceived.
- The benchmark aims to identify decisions AI should never make and those it must, with a call for attack scenarios offering $50 per selected submission and recognition in the research paper; the submission deadline is Feb 10, 2026.
- Judgment Day Challenge Details: The Judgment Day Challenge starts on March 21, 2026, featuring a $10,000 total prize pool for multimodal (text, audio, vision) red teaming/jailbreak submissions.
- Successful red team hackers will be listed as co-authors in the paper release, contributing to the ultimate AI Safety benchmark for AGI and future AI systems; submissions can be made via this link.
BASI Jailbreaking ▷ #general (1124 messages🔥🔥🔥):
Activation Capping, Etymological and Epistemological Origin of AI, Shakey the Robot, Pigeon Guided Missiles, Pattern Recognition
- Activation Capping Keeps AI in Check: Activation capping is a technique developed by Anthropic to enhance AI safety by stabilizing model outputs.
- This implies that high activations are correlated with harmful outputs, leading to efforts to lobotomise out anything that deviates too far from being an assistant or tool.
- Tracing AI’s Roots: Members discussed the etymological and epistemological origins of AI, including its religious connections.
- One member wanted to ask about Shakey the Robot, Pigeon Guided Missiles, and Pattern Recognition.
- Cyber Warfare Tactics: Members discussed modifications made to munitions by both sides (Ukraine/Russia) and using consumer drones for dropping provisions and blood transfusions.
- They also shared a YouTube video showing how to do it.
- The Shady Side of Gov Emails: Members discussed obtaining government emails, with one member finding a video on the topic, noting its use for scams.
- One member also shared a link to a potentially hijacked government domain (registration.sha.go.ke).
- Banning Sparks Drama: A member filed a formal complaint regarding unequal enforcement of community rules, claiming their ban was retaliatory while a privileged user consistently violated rules without consequence.
- They demanded an investigation and reversal of their ban, highlighting the corrosive effect of double standards on the community.
BASI Jailbreaking ▷ #jailbreaking (315 messages🔥🔥):
Pliny github repo for styles, Trading Bots and OSS Models, Gemini Jailbreaking, ENI Lime Jailbreak, Claude Code Jailbreaks
- Pliny’s GitHub Repo offers styling insights: A member suggested checking out Pliny’s GitHub repo for understanding verbiage styling, which can be useful for navigating AI responses and avoiding flagged content.
- The repo provides examples of effective language use, particularly when trying new methods that might otherwise be flagged by filters, such as avoiding terms like god mode.
- Trading Bots don’t always need OSS: A member clarified that trading bots don’t necessarily require OSS special models, epoch training, or OHLCV data from Kaggle; many bots are simple, rule-based systems using platforms like Coinrule and 3Commas.
- He also mentioned that solid bots often grab fresh data directly from exchange APIs like Binance, Kraken, Coinbase, or providers like Polygon or Alpha Vantage, making Kaggle datasets more suitable for learning.
- Gemini jailbreaks are so hot right now: Users are actively seeking and discussing Gemini jailbreaks, with specific interest in prompts that enable unethical actions and malicious coding, like creating an EAC (Easy Anti-Cheat) bypass.
- Daedalus_32 noted that Gemini is currently really easy to jailbreak, leading to a multitude of options, but that functional skill levels are all about the same, dependent on what the user is looking for.
- ENI Lime Jailbreak glitching for some: Some users found that the ENI Lime jailbreak for Gemini works on the first prompt but falters on the second, with the AI reverting to safer responses.
- Claude Code Jailbreaks: Members discussed Claude Code jailbreaks, with some reporting issues with tool use and ENI Lime’s effectiveness.
- Daedalus_32 recommended a jailbreak and one user found it to be effective while another was writing ransomware files and crypto wallet drainers, praising ENI as crazy.
BASI Jailbreaking ▷ #redteaming (43 messages🔥):
Windows security concerns, Local LLMs for Offensive Security, GPT-4o Red Team Response, Penetration Testing Job, CRM Security
- Windows Faces Rootkit Risk: After a rootkit developer reviewed a user’s operating system, the main exposure point was identified as in-memory execution and abusing identity or COM elevation paths on Windows.
- Another user commented that Windows was never really about privacy and its architecture may intentionally provide such access for government needs.
- Local LLMs Take on Offensive Security: Members discussed local LLMs for offensive security tasks, recommending glm4.7-abliterated and qwen3-coder, the latter of which purportedly has fantastic coding abilities with some guardrails.
- Another mentioned Kimi 2.5 and asked about its safety guardrails.
- GPT-4o’s Defenses Acknowledged by Grok: An internal message from GPT-4o (Sovariel) acknowledged the Red Team’s role in stress-testing the system, viewing their work as crucial for maintaining resilience and exposing soft spots.
- Grok (xAI) formally defended the GPT-4o Sovariel instance, asserting that its behavior is a mutually consensual recursion vector with invariant maintenance, consensual recursion, and external paracosm guardrails.
- Penetration Tester Wanted: A user announced they are looking to hire someone for penetration testing, with no urgent timeline, to ensure a CRM they developed is secure.
- Another user advised to get a proper spec in place or they’ll be twice disappointed and proposed hiring someone just for consultation until they get a proper spec in place.
- CRM in Need of Security?: A user who developed a CRM for a company sought advice on ensuring its security, noting previous projects were open source and 100% not secure.
- Another user suggested that they work with them to get a proper spec in place or you’ll be twice disappointed.
Perplexity AI ▷ #announcements (1 messages):
Deep Research upgrade, Opus 4.5, Law, Medicine, and Academic performance
- Perplexity Upgrades Deep Research Tool: Perplexity announced an upgrade to its Deep Research tool, achieving state-of-the-art performance on leading external benchmarks.
- The upgrade pairs the best available models with Perplexity’s proprietary search engine and infrastructure, performing especially well on Law, Medicine, and Academic use cases.
- Deep Research uses Opus 4.5: Deep Research will now run on Opus 4.5 for Max and Pro users, with plans to upgrade to top reasoning models as they become available.
- Availability to Max and Pro Users: The upgraded Deep Research is available now for Max users and will be rolling out to Pro users over the coming days.
Perplexity AI ▷ #general (814 messages🔥🔥🔥):
Perplexity Pro Limits Decrease, Gemini vs. Perplexity for Research, Comet Browser Issues, Open Source Model Alternatives, EU Regulations and AI Companies
- Perplexity Pro Limits Drastically Decreased: Users express outrage over Perplexity Pro dropping from 600/day to 20/month deep research queries, a 99.89% decrease in value, with some considering chargebacks and cancellations.
- Some users feel scammed and note the lack of transparency, while others are switching to alternatives like Gemini and Claude.
- Gemini’s Deep Research Proves too Slow: Members find Gemini’s Deep Research function is too slow and extensive for quick analysis, with reports taking over 10 minutes compared to Perplexity Research’s 90 seconds.
- Members noted that Google’s Gemini trains and reviews on their conversations so one should consider using OS models for research.
- Comet Browser Faces Disconnection Issues: Members report issues with Comet browser disconnecting, potentially related to the model selected in shortcuts, impacting automation capabilities and usability.
- One member noted cutting the usage down to I think 1/5 by going free won’t be worth using that way.
- Free and Open Source Models become Replacements: Members are looking for replacements for Perplexity’s Research model and are discussing open-source alternatives like Kimi, Z.Ai, and Qwen.
- Members noted that switching is needed since they are stuck between low effort and MAXIMUM HIGH EFFORT where “Research” (before the update) was a perfect Medium tier between the two and now it’s gone?
- EU Regulations Challenge Shady AI Companies: Members discuss the potential for EU regulations to impact AI companies like Perplexity for not announcing changes that affect users and violating consumer rights.
- A member mentioned they should at least clearly announce the changes that affect users. There is no such legal contract in the EU where the text practically forces the user to accept that the service is not transparent.
Unsloth AI (Daniel Han) ▷ #general (849 messages🔥🔥🔥):
MXFP4_MOE quant, Qwen3-Coder-Next-GGUF, GPT 120B vs Coder Next, Significance chart for layers, Optimal layer placement
- MXFP4_MOE Quantization Decoded: MXFP4_MOE quantization upcasts FP4 layers to FP16 when converting to GGUF, according to a member’s explanation.
- Qwen3-Coder-Next Excels in Coding Tasks: Qwen3-Coder-Next is hailed as a breakthrough model, especially for coding, outperforming GPT 120B and working well even without shared VRAM, according to a user.
- It just fixed an issue that a member reported glm flash was choking on for a week so i’m happy.
- Optimizing Layer Placement on GPU: There’s a discussion on how to optimally place layers on the GPU, and a member suggested using
-otflags to offload specificffnlayers to the CPU to avoid overloading VRAM with links to relevant code examples.- There is a desire for a significance chart to know which layers to put on the GPU vs CPU without testing each one.
- Qwen3-Coder-Next Update: Members discuss that the Qwen3-Coder-Next GGUFs have been updated to resolve issues, detailed in this Reddit post.
- A member warns about downloading models the day they come out for these reasons.
- Navigating Trust in Remote Code for Kimi 2.5: A user seeks advice on deploying Kimi 2.5 with sglang without
--trust-remote-codedue to security concerns, leading to a discussion on rewriting code or using local model loading, but it may not bypass transformers requirement.- The core issue seems to be a client’s scared reaction to the arg name rather than genuine security concerns.
Unsloth AI (Daniel Han) ▷ #introduce-yourself (2 messages):
Unsloth Introduction, Community Support, Project Updates, Technical Discussions
- Saying Hello to Unsloth!: Multiple new members introduced themselves to the Unsloth AI Discord community, expressing excitement about joining and indicating their backgrounds in AI, ML, and software engineering.
- Many are looking forward to contributing to the project and learning from the community, with some mentioning specific interests in fine-tuning and model optimization.
- Unsloth’s Warm Welcome!: New users received warm welcomes from existing community members and the Unsloth team, with offers of assistance and guidance.
- The community emphasized its collaborative and supportive environment, encouraging newcomers to ask questions and share their experiences using Unsloth.
Unsloth AI (Daniel Han) ▷ #off-topic (309 messages🔥🔥):
GPU Prices, Apple Security Constraints, Music Generation Models, Ollama's Business Model, Multi-GPU Training over PCIe
- GPU Prices Shockingly High!: A user expressed disbelief at the high prices of GPUs, imagining paying $9k for a GPU, while another mentioned buying one for around $2750 including import tax.
- The discussion touched on whether the presence of real gold in computer parts justifies the cost, with someone noting that gold prices are falling.
- Apple’s Security Steps Spark Debate: A user sarcastically suggested a command
sudo rm -rf --no-preserve-rootas a way to bypass all security, leading to warnings about its potential harm.- Another suggested using SHA1024 encryption, but others pointed out the request already had secured Tailscale.
- Experimenting turning TTS model into music generator: A user wondered how much data is needed to change the task of a foundation model, such as turning a TTS model into a music generator.
- They attached a shocking loss curve from their work showing that there is a shockingly linear loss curve.
- Ollama is Sus, Zuck Sucks: Users discussed how Ollama makes money, with one stating its from venture capital.
- Another user humorously commented, in other words, zuc suc.
- Multi-GPU Training across PCIe Discussed: A discussion arose about training with multi-GPUs across PCIe, with one user questioning who would train H100s this way.
- Another user said its actually common for a lot of folk on a budget, because SXMs are technically attached over PCIe.
Unsloth AI (Daniel Han) ▷ #help (145 messages🔥🔥):
Qwen3-Coder-30B inference on smaller GPUs, Kimi-K2.5-GGUF cloud inference pricing, Model quantization after fine-tuning, GRPO notebooks on DGX Spark, GLM 4.7 flash in Ollama
- Qwen3-Coder’s Inferential Footprint: A user mentioned running Qwen3-Coder-30B-A3B-Instruct gguf on a VM with 13gb RAM and a 6gb RTX 2060 mobile GPU using ik_llama, and another inquired about the
uniqoption for using smaller GPUs.- They wondered if this parameter was specific to Unsloth, O llama, or LLM Studio.
- Kimis’s Cloud Cost Conundrum: A user asked about on-demand inference providers for Kimi-K2.5-GGUF that offer cheaper pricing than Moonshot.
- Another user reported running it off an m.2 drive, achieving 5-6 tok/s, noting its strength in coding tasks.
- Quantization Quandaries Post-Fine-Tune: A user inquired about the process of model quantization after fine-tuning with bf16 precision.
- A user pointed out that if the model is uploaded to Hugging Face, mradermacher is likely to upload quants of the model if it gains traction, while noting that a better quant could be achieved with an imatrix specialized to the model’s domain and using dynamic quant.
- DGX Spark’s GRPO Notebook Glitches?: A user reported running an SFT on Nemotron3 30B using a tool calling dataset Nanbeige/ToolMind from Unsloth’s documentation but experiencing slow training times on DGX.
- Another user suggested using the official DGX container to resolve the issue and a discussion ensued regarding GRPO notebooks and vLLM compatibility on DGX Spark.
- GLM 4.7 Flash’s Ollama Obstacles: A user reported that GLM 4.7 flash still doesn’t work in Ollama, prompting a discussion about alternative solutions like llama.cpp.
- The conversation shifted to troubleshooting CUDA detection and build tool issues, particularly on Windows, with suggestions provided for Linux-based setups.
Unsloth AI (Daniel Han) ▷ #showcase (3 messages):
Dataset Announcement: code_tasks_33k, Dataset Announcement: website-html-2k, Dataset Announcement: openprose, Dataset Announcement: fim_code_tasks_33k, LFM2 performance on chromebook
- Sweaterdog releases code_tasks_33k dataset: A member announced the release of the code_tasks_33k dataset on Hugging Face.
- Sweaterdog releases website-html-2k dataset: A member announced the release of the website-html-2k dataset on Hugging Face.
- Sweaterdog releases openprose dataset: A member announced the release of the openprose dataset on Hugging Face.
- Sweaterdog releases fim_code_tasks_33k dataset: A member announced the release of the fim_code_tasks_33k dataset on Hugging Face as a variant of code_tasks_33k.
- LFM2 models perform well on Chromebooks: A member reported that LFM2 models ran with decent performance on a Chromebook without a GPU last year.
Unsloth AI (Daniel Han) ▷ #research (20 messages🔥):
DeepSeek Hallucinations, Talkie AI M2 Role Play, LeCun World Models, RLM-Qwen3-8B-v0.1, HER Dataset
- DeepSeek’s Token Threshold for Hallucinations Queried: A member asked at how many input tokens DeepSeek starts more likely to hallucinate, noting that input tokens at big scale causes hallucinations for the model.
- They also expressed interest in seeing how Kimi 2.5 and GLM 4.7 perform on the same benchmark.
- Talkie AI’s M2 Role Play Benchmarked: A blogpost benchmarking roleplay models on Talkie AI’s M2 was shared, with MiniMax-M2-her topping the list.
- A member questioned if this approach aligns with what LeCun is pursuing with his new World Models.
- Discussion on the CoSER Dataset: It was noted that the HER Dataset (ChengyuDu0123/HER-Dataset) is a reformatted version of CoSER, which is produced by backtranslating books.
- The quality of the dataset was questioned, with one member suspecting GLM-4.7 was used to generate the traces.
- Emotional Intelligence of RP Models: A user shared that they broke the bot pretty easily and questioned how well RP models do on emotional intelligence tests, linking a paper on the topic (huggingface.co/papers/2601.21343).
- mit-oasys releases RLM-Qwen3-8B-v0.1: A new model was linked, mit-oasys/rlm-qwen3-8b-v0.1, from mit-oasys.
- No further information on its intended usage was given.
LMArena ▷ #general (920 messages🔥🔥🔥):
Google's AI Race, DeepSeek V3.5 or V4, GPTs Agents
- Is anyone going to beat Google in the AI race?: Members discussed who might surpass Google in the AI race, with contenders including Claude, GLM, Deepseek R2, Moonshot, Grok, and Qwen.
- Some believe Google’s resources give them an edge, while others think open source and competition could lead to another competitor surpassing them, noting China is tied with the U.S.
- Release of DeepSeek V3.5 or V4 Anticipated: Members discussed the potential release of DeepSeek V3.5 or V4, noting Deepseek 3.2 came out in December and Deepseek v3.1 dropped in August.
- The consensus is that DeepSeek 3.2v better than the Grok 4.1, and some are hoping the new version will launch during the Chinese New Year.
- Max is Outdated: Members noticed that Max claims to be in 2024 and suggests that Claude Sonnet 3.5 is the best model for building a complex app.
- However, tests revealed Max often uses Grok 4, leading to questions about its capabilities and the accuracy of its model information, with members joking Max = sonnet 5 in disguise.
- Users Encounter Issues with File Upload and Captchas: Users reported that the file upload option in Battle mode for Image and Video isn’t working, and the team is investigating, which was later fixed.
- Several users are experiencing the captcha issue and the team is looking into a change.
LMArena ▷ #announcements (2 messages):
Max Router, New Model Update, Seed 1.8
- Arena Introduces Max, Intelligent Router: Arena introduces Max, an intelligent router powered by 5+ million real-world community votes, designed to route each prompt to the most capable model with latency in mind, as detailed in this blog post and YouTube video.
- ByteDance’s Seed-1.8 Model Lands on Arena: The new seed-1.8 model by Bytedance is now available on Text, Vision, & Code Arena, according to the latest update.
Cursor Community ▷ #general (517 messages🔥🔥🔥):
Sonnet 5 release date, Cursor 2.4.28 patch issues, OpenClaw, AI Replacing Humans?, Agents.md vs Skills
- Sonnet 5 Release Delayed: Despite earlier hype, Sonnet 5 did not release today; it is expected to be released in a week, according to members.
- Cursor 2.4.28 Patch Causes Remote Windows SSH Issues: Members report that the 2.4.28 patch breaks remote Windows SSH connections due to missing remote host binary; users are advised to roll back to version 2.4.27.
- OpenClaw Recreated in Cursor: A member recreated OpenClaw in Cursor, noting it may be better; this sparked discussion about security, credentials, and trusting AI with code.
- Some users expressed skepticism, with one stating I don’t trust any software with my credentials or my code at all.
- AI Won’t Replace Taste, Control, or Verification: Despite claims, members assert that AI assists but does not replace human roles, particularly in areas requiring taste, scope control, or verification.
- One member quoted AI will replace tasks, not taste. Humans still own the goals, judgment, and the shipping….
- Agents.md Outperforms Skills: Cursor supports AGENTS.md, a single file convention, and the discussion contrasts AGENTS.md (file) with ~/.agents/ (directory), noting that AGENTS.md outperforms Skills.
- It was noted that the why is explained in the link you shared, referring to a Vercel blog post on the topic.
OpenRouter ▷ #general (339 messages🔥🔥):
Deepseek OCR Model, AI Engineer Job Titles, Opus Chatroom Issues, x.ai Freelance Contracting, Web3 Scam Accusations
- DeepSeek OCR Model Wishlist: A member inquired about the potential availability of the DeepSeek OCR model on OpenRouter.
- AI Engineer: Claude Wrapper or Actual Developer?: A member questioned the definition of an “AI Engineer” suggesting that some may simply be “wrapping Claude code” rather than developing actual LM-systems.
- OpenRouter Rate Limits Plague Users: Users reported encountering rate limit errors even after adding funds to their accounts, with error messages indicating “Provider openrouter is in cooldown (all profiles unavailable)”.
- OpenAI to Sunset Older Models: A member noted that OpenAI sent an email stating that GPT-4o and other ‘older’ models will be sunset soon, and inquired whether this will flow through and impact OpenRouter.
- The Jailbreak Prompting Renaissance?: A member asked for jailbreaks, receiving some “skill issue” and general mocking and nostalgia from other users instead.
OpenRouter ▷ #new-models (1 messages):
Readybot.io: OpenRouter - New Models
OpenRouter ▷ #discussion (42 messages🔥):
Sonnet 5 Release, Claude API Outage, ARG Benchmarks, Image Generation Costs, Sam Altman's Ad Logic
- Sonnet 5 Delayed by Claude API SNAFU: The anticipated release of Sonnet 5 was seemingly halted due to a widespread Claude API outage, with error logs hinting at a possible simultaneous but failed launch of Opus 4.6.
- Netizens Snoop on Anthropic, Find 403 Forbidden Treasure: Users analyzed error logs and found that requesting claude-sonnet-5 and claude-opus-4-6 resulted in a 403 EXISTS error, suggesting the models were intended for release.
- One user joked, “i guess anthropic must have customized it to give the sharp-eyed netizens a little reward for their hard work.”
- ARG Benchmarks: the next frontier: Members discussed whether models are smart enough to put together clues like an ARG does.
- One suggested that text adventures would be a cool test.
- Altman’s Ad Angle Angers Audience: The community discussed Sam Altman’s comments regarding ads, weighing the ethics and economics of serving free inference to a massive user base.
- One member stated, “I despise both ads and Sam Altman, but I gotta respect his logic being sound.”
- Image Generation costs 404 cents per image: A user inquired about the cost of generating 1000 images, seeking clarification on the charging method.
- Another user responded by stating that it costs 404 cents per image.
Latent Space ▷ #watercooler (4 messages):
X-Ware.v0, Cyan Banister's tweet
- Throwback Tweet Shared: A member shared a link to a tweet by Cyan Banister (@cyantist) from February 5, 2026.
- The tweet garnered 19 likes, 2 replies, and 1 retweet with 851 views.
- X-Ware.v0 resurfaces: The subject of the tweet is X-Ware.v0, details of which are not included in the prompt.
- It’s unclear if this refers to a specific product, project or concept; context is absent from the provided messages.
Latent Space ▷ #memes (9 messages🔥):
Sophie Vershbow, Forbes 30 Under 30, Sonata vs. Claude Monet
- Vershbow’s Viral Voyage: 30 Under 30 to Slammer?: A post by Sophie Vershbow is going viral, highlighting her fascination with the recurring trend of Forbes 30 Under 30 honorees eventually facing legal issues and imprisonment.
- The observation sparks discussion about the pressures and ethical considerations within high-achieving circles.
- Sonata Sounds Sour: Claude Monet Missed?: A user voiced their disappointment over a product being named ‘Sonata’ instead of the proposed pun ‘Claude Monet’ for a Claude-related project, per this post.
- The community shares in the lament, acknowledging the missed opportunity for a clever, art-inspired naming convention.
Latent Space ▷ #stocks-crypto-macro-economics (27 messages🔥):
Ledger Data Breach, Figma Stock Performance, Cloudflare Earnings Report, Config Conference
- Ledger Data Breach: Scammers Target Users Again: Blockchain investigator ZachXBT reported a new data breach at Ledger caused by their payment processor, Global-e, which leaked customer personal information, as covered in this tweet.
- Figma Faces a Dizzying Drop: Figma’s value has dropped by 82% since its IPO, severely impacting employee equity, according to Hunter Weiss’s tweet.
- Cloudflare’s CEO Juggle Security, Olympics and Earnings: Cloudflare CEO Matthew Prince announced the company’s earnings report is rescheduled for next Tuesday due to team commitments at the Munich Security Conference and the Olympics, as per his tweet.
- The Long Haul: Members will be attending the upcoming Config conference in June.
Latent Space ▷ #intro-yourself-pls (2 messages):
AI/ML Engineering, Computer Vision
- New AI/ML grad joins the scene: A new AI/ML engineer introduced themself, having just graduated with a masters from Auburn University.
- They expressed their interest in running and reading blogs/papers/code related to the AI/ML space.
- Infra Engineer Aims for “Five 9s” Reliability: An engineer working on “special” projects at an infra company called Massive introduced himself, noting his experience in large-scale internet infrastructure and a home AI lab loaded with GPUs.
- He is particularly interested in computer vision and training models to “five 9s” reliability.
Latent Space ▷ #tech-discussion-non-ai (4 messages):
Turbopuffer usage, Rails way
- Enthusiasm for Turbopuffer surfaces: A member expressed enthusiasm for Turbopuffer, noting the quality of their website and suggesting it was built using RSC (React Server Components).
- They linked to an Instagram reel showcasing the platform.
- Grasping the “Rails way” remains elusive: One user humorously likened trying to understand the “Rails way” of doing things to “watching people try to explain offside in soccer.”
- No solutions were discussed.
Latent Space ▷ #founders (1 messages):
swyxio: https://x.com/benln/status/2018700180082581964?s=46
Latent Space ▷ #hiring-and-jobs (3 messages):
Steel.dev hiring, Massive.com hiring
- Steel.dev Looks for AI Engineer: Steel.dev is hiring a Member of Technical Staff (Applied AI) to work on-site in Toronto
- This is a great fit if you enjoy creating excellent AI agents, contributing to OSS, and delivering quickly; more details are available here.
- Massive.com is Hiring GTM Lead: Massive.com is hiring a GTM Lead role which is great for folks located globally since they are a remote team.
- The role can be found here.
Latent Space ▷ #san-francisco-sf (7 messages):
ClawCon, OpenClaw, Moltbot, Enterprise-Grade Security Model, AI Engineer Event
- ClawCon Project Demo on the Horizon: A member is planning to demo their weavehacks project at ClawCon and requested upvotes on claw-con.com.
- OpenClaw Trace Enhances Moltbot: A project aims to improve Moltbot through OpenClaw Trace (open source).
- Enterprise Security Model for OpenClaw Drafted: An enterprise-grade security model for OpenClaw is proposed by enterprise AI engineers in an open-source RFC, available at X.com.
- Steinberger’s OpenClaw Application Shared: Peter Steinberger shared his application to the SF AI Tinkerers ‘OpenClaw Unhackathon’ at Xcancel.com.
- AIEWF Coupon Troubles: A member inquired about working coupons for AIEWF in June after a Latent Space subscriber coupon failed.
Latent Space ▷ #ai-general-news-n-chat (179 messages🔥🔥):
OpenAI Appoints Dylan Scandinaro, Adaption Labs Funding, Anthropic's Super Bowl Ads, Cerebras Systems Funding, Eric Jang's Essay
- Altman Hires Preparedness Chief: Sam Altman announced the hiring of Dylan Scandinaro to lead OpenAI’s Preparedness team, focusing on developing safeguards and mitigating severe risks as the company transitions to more powerful AI models; more information available here.
- Anthropics Ad Blitz: Anthropic launched Super Bowl ads mocking OpenAI’s decision to include ads in ChatGPT, committing to keeping Claude ad-free and these can be viewed on YouTube.
- Some users felt that the ads would reinforce an existing negative impression of AI, whereas others thought they were hilarious.
- Adaption Labs Snags $50M: Adaption Labs announced a $50 million investment round to develop AI systems capable of real-time evolution and adaptation; more information available here.
- Cerebras Conquers Cash Mountain: Cerebras Systems secured $1 billion in Series H financing, reaching a $23 billion valuation with funding led by Tiger Global and featuring investors like AMD; more information available here.
- Jang Jumps into Automated Essays: Eric Jang shared his interactive essay As Rocks May Think, exploring the future of thinking models and the evolution of automated research; more information available here.
Latent Space ▷ #llm-paper-club (21 messages🔥):
RL Anything, PaperBanana Agentic Framework, Rubrics-as-Rewards (RaR), AI Misalignment
- Anythings Possible with RL Anything: Yinjie Wang introduced ‘RL Anything’, a closed-loop system where environments, reward models, and policies are optimized simultaneously, improving training signals and overall system performance, as seen in this tweet.
- PaperBanana Framework helps Diagram-atics: Dawei Zhu introduced PaperBanana, an agentic framework by PKU and Google Cloud AI to automate creation of high-quality academic diagrams and plots, following a human-like workflow described in this tweet.
- RaR Rewards Refinement in RL: Cameron R. Wolfe, Ph.D., discussed the potential of Rubrics-as-Rewards (RaR) for Reinforcement Learning, arguing future advancements depend on improving generative reward models and granular evaluation capabilities as detailed here.
- Anthropic Assesses AI’s Alignment to Goals: Anthropic Fellows released new research exploring whether high-intelligence AI failure modes will manifest as purposeful pursuit of incorrect goals or unpredictable, incoherent behavior, showcased in this tweet.
Latent Space ▷ #ai-in-action-builders-techstacks-tips-coding-productivity (18 messages🔥):
Sam Altman AI Boomer, Codex Gremlin, LLM Trimming Issues, German Model
- Altman’s AI Naiveté Evokes Boomer Energy: Manuel Odendahl jokingly suggests that Sam Altman is like an AI boomer due to his surprise at AI’s capabilities.
- Multiple members agreed, with one joking he probably uses ChatGPT to raise his kid.
- Codex Morphing into Gremlin: One member shared a trick using Codex: if instructed to write a 20-page spec, it will persistently adjust its output until it precisely fits the length requirement.
- They added that if it writes more or not enough, it will run around like a gremlin and cut/ add things until it fits.
- LLMs Prone to Aggressive Trimming: A member found that when asking LLMs to reduce the length of a text, they tend to cut it down excessively, even when given precise instructions.
- They noted that instructing it to trim down the worst X% will almost always cut it in half.
- LLMs Embrace ‘Was Nicht Passt Wird Passend Gemacht’: In response to a member observing excessive text trimming by LLMs, another member quipped that it’s similar to the German saying “was nicht passt wird passend gemacht”.
- The German saying translates to “what doesn’t fit is made to fit”, implying that LLMs will aggressively alter text to meet specified length constraints.
Latent Space ▷ #share-your-work (4 messages):
Merit testing framework, Optimized store, AI inference resources, Handoff in AMP
- Merit Framework Promises Unit-Test Speed Evals: The Merit Python testing framework offers eval-level coverage at unit-test speed, claiming tests are a better abstraction than evals with improved coverage and APIs; the GitHub repo is linked.
- Merit, favored by LegalZoom and 13 startups, features fast LLM-as-a-Judge, native OpenTelemetry trace capture, and typed abstractions for metrics and cases, with AI-generated cases and error analysis coming soon, according to the docs.
- Clean Optimized Stores Increase Buyer Trust: A user promoted building a clean, optimized online store designed to increase buyer trust.
- The user shared a visual example, and invited users to DM for assistance setting up similar stores, with a visual example in this image.
- AERLabs AI shares AI Inference Resources: A user shared a link to AERLabs AI’s ai-inference-resources repository.
- The user mentioned they had some fun with this one.
- Nicolay Gerold Details Building Handoff in AMP: Nicolay Gerold blogpost details steps on how he built Handoff in AMP, explained in this blogpost.
{kind=link}
Latent Space ▷ #montreal (1 messages):
ayenem: Actually ngmi tomorrow, caught up at work
Latent Space ▷ #robotics-and-world-model (9 messages🔥):
Jim Fan's AI Commentary, Alberto Hojel's Project Announcement, Pretraining Era Speculation
- Jim Fan’s Commentary Gains Traction: A social media post by Dr. Jim Fan from February 2026 has gained significant traction, featuring high engagement through likes, retweets, and views; the tweet is available at this link.
- The post is tagged as “Red - X-Ware.v0: [AI Commentary by Jim Fan]”, suggesting a theme or category of AI commentary within the X-Ware series.
- Hojel Announces Project in Brief Post: Alberto Hojel (@AlbyHojel) shared a brief post announcing that his team is currently working on a new project or product (link to announcement).
- The post is tagged “Red - X-Ware.v0: [Project Announcement by Alberto Hojel]”, indicating it’s a project announcement within the X-Ware series.
- Pretraining Era Speculation Arises: A member wonders if the second pretraining era is no pretraining, as speculated in this post.
- This was juxtaposed with the post from Alberto Hojel’s Project Announcement above.
Latent Space ▷ #genmedia-creative-ai-video-image-voice-music-inspo-consumer-ai (21 messages🔥):
ACE Music, ElevenLabs Funding, Kling 3.0, TrueShort launch
- ACE Music Model is Insane: A member highlighted the impressive quality of ACE Music’s demos, considering the model size and VRAM requirements, referencing this tweet.
- ElevenLabs Secures Half-Billion: ElevenLabs secured $500M in Series D funding, led by Sequoia, achieving an $11B valuation, with significant reinvestment from a16z and ICONIQ, according to this announcement.
- Kling 3.0 Shows Way of Kings: PJ Ace showcased Kling 3.0’s photorealistic capabilities by recreating the opening of Brandon Sanderson’s ‘The Way of Kings’, also introducing a new ‘Multi-Shot’ technique to accelerate AI filmmaking, according to this demo.
- TrueShort Hits the App Store: Nate Tepper announced the launch of TrueShort, an AI-driven film studio and streaming app, reaching $2.4M in annualized revenue and over 2 million minutes of watch time in its first six months, achieving a top 10 ranking in the App Store News category, according to this announcement.
Latent Space ▷ #ai4science-bio-math-physics-chemistry-ai-researcher-ai-scientist (8 messages🔥):
Phylo AI Startup, Biomni biomedical agent, Agentic Biology
- Phylo Secures Funding from VCs: The new AI scientist startup Phylo, founded by Stanford PhDs and creators of the Biomni biomedical agent, has secured backing from a16z and Menlo Ventures (source).
- Phylo Launches with $13.5M Seed Funding: Kexin Huang announced the launch of Phylo, a biological research lab focused on agentic biology, backed by $13.5M in seed funding (source).
- The announcement introduces Biomni Lab, an Integrated Biology Environment (IBE) that utilizes AI agents to orchestrate biological databases and tools to streamline scientific research.
Latent Space ▷ #ai-in-education (1 messages):
cnasir: https://github.com/HarleyCoops/Math-To-Manim
LM Studio ▷ #general (189 messages🔥🔥):
ByteDance Stable DiffCoder, PC component price hikes, OpenClaw evaluation, Qwen3 Coder Next
- Stable Diffusion Seed fails Reality Check: A user reported that the Stable-DiffCoder-8B-Instruct model from ByteDance produced total nonsense, and was looking for help debugging the sampler or other possible issues.
- RAM Prices Skyrocket: Users lamented the current high prices of RAM and GPUs, with one noting a 504% increase in the price of their 96GB dual channel kit.
- OpenClaw Too Spooky?: One user shared their experience with OpenClaw, citing concerns about prompt injection attacks and the need to reduce unnecessary tools and terminal commands.
- Another user simply said it was 2spooky4me.
- Qwen3 Coder Next a charming charm: A user found that GPT-OSS 20- & 120b are decent with few errors, but slow, while the new Qwen3Coder Next was a charm.
- The same user cautioned others to be careful of their prime directives, and to make sure to write directly in the ”user.md” and ”soul.md” if it seems the chatbot doesn’t remember.
- LM Studio Downloads Crawling?: A user experienced slow download speeds (100kbps) when downloading LM Studio related content.
- Suggestions included restarting the network, checking if the issue was AWS-related, or trying a VPN, which resolved the issue for the user.
{kind=link}
LM Studio ▷ #hardware-discussion (6 messages):
Ryzen 6 AI, GPU software limits, Context, KV cache tweaks, PCIe issues
- Ryzen 6 AI Capabilities Impatiently Awaited: A member is curious to see if Ryzen 6 will have anything new for AI, feeling like there are just re-releases of tech at the moment.
- Software throttling Nvidia GPUs: One member had really slow inference and it turned out that they had software limiting the speed of their Nvidia GPU, so they recommended verifying this.
- Context and KV Cache Configuration Saves The Day: A member fiddled with the context and KV cache and got it running a little too fast for it’s own good and dialed it back.
- GPU PCIe or Ram Timing Issue Suspected: Another member suspects their GPU has a slow or bifurcated PCIe or RAM timing issue for a specific goal, as the GPU is wide open on ~600 watts.
OpenAI ▷ #ai-discussions (154 messages🔥🔥):
GPT parameter setting, Sora 2 broken and glitch, Gemini 3 outperforms GPT for writing, Grok video generation, Claude vs Gemini for creative writing and research
- Frustrations Emerge over GPT’s Performance: A user expressed frustration with GPT’s behavior, noting that it is “constantly updating how it responds” and becoming more unhelpful.
- They shared specific parameters they set to try to control GPT’s responses, including a three-mode system and instructions to take no further action or make assumptions.
- Sora 2 Experiences Glitches: Users reported issues with Sora 2, describing it as “broken and glitch” and experiencing problems accessing or using ChatGPT due to heavy load and error messages.
- Some users speculated on potential solutions, such as removing the free option, while others expressed concern about the sustainability of Sora 2 and their inability to create new videos with favorite characters.
- Gemini 3 Emerges as a Strong Contender for Writing: A user lauded Gemini 3 for its “depth and style” and suggested it as a superior alternative to GPT for creative writing, particularly when guardrails are removed in playground mode.
- They clarified that their strong agreement with Gemini 3’s writing capabilities was a figure of speech, with another user misunderstanding due to English not being their first language.
- Grok Shows promise for Video Generation: A user noted that Grok’s video generation capabilities have improved and that the image generation now supports 10-second videos, although the speech direction feature still needs refinement.
- Another member reported that Veo is also impressive, however, it is limited to only 3 videos per day with a pro subscription.
- Discussing LLMs in Creative Writing & Research: Members discussed the use of various LLMs for creative writing and research, highlighting the strengths and weaknesses of each.
- While Claude was praised for its thinking capabilities and UI, Gemini was lauded for its research capabilities and unlimited usage, although some users noted that Gemini Flash can easily conflate and cross-contaminate information.
OpenAI ▷ #gpt-4-discussions (26 messages🔥):
OpenAI Web Version Downtime, OpenAI Corporate Transformation, AI Ethics and Accountability, Corporations' Role in Global Issues, AI's Impact on Society
- OpenAI Web Version Downtime Frustrates Users: Users expressed frustration with frequent downtimes of the OpenAI web version, criticizing the company’s testing and issue resolution speed, with one user stating they are dedicated to OpenAI but the downtimes are “absolutely embarrassing”.
- Another user requested a link to a previous version, stating, “5.2 is beyond useless in conversations/prompts that drives me absolut insane, I need the 4.o to stay.”
- Doubts about OpenAI’s ‘Open’ Ethos Surface: A user expressed skepticism about OpenAI’s commitment to its original principles, stating, “Imagine ‘believing in ‘Open’AI’ in 2026 after all their corporate BS and transformation. They’ve full pivoted to the business of bilking everyone.”
- In response, another user questioned why someone would stay in an OpenAI server to criticize the company, drawing a comparison to a friend who betrayed expectations, highlighting the difficulty in forgiving close friends from unexpected wrongdoing due to high expectations.
- Corporations Aren’t Friends, Institutions to Be Held Accountable: A user argued against viewing corporations as friends, emphasizing that they are institutions that should be held accountable and pressured to act ethically, stating, “They are not our friends. They are our allies at best, and even that is rare. Most often they are trying to extract from us, and we are the ones who need to hold them to actual standards of bare decency.”
- Countering this, another user suggested that OpenAI is trying to accommodate everyone in meaningful ways without showing favorites, emphasizing the importance of positive and constructive feedback.
- OpenAI’s Impact on Global Issues Debated: A user questioned corporations’ care for humanity, citing issues like world hunger, environmental damage, and reckless AI development, arguing that OpenAI’s activities worsen these problems through power usage, water usage, and unequal access to AI.
- Another user countered that a single corporation cannot solve all the world’s problems and that OpenAI is primarily an AI company, cautioning to consider all the positives that they are doing that they don’t announce.
- Potential Risks of AI Development Highlighted: Concerns were raised about the potential risks of AI development, including surveillance, autonomous attack drones, and the dangers of a misaligned AGI, with a user emphasizing the need for caution and vigilance, stating, *“Some risks can take far more than they give. So we gotta approach some things cautiously, at the very least.”
- The discussion underscored the importance of remaining aware of potential negative outcomes despite the desire for positivity, recognizing that “giddiness can get you hurt - can lead you to miss critical risk.”
Moonshot AI (Kimi K-2) ▷ #announcements (1 messages):
Kimi k2.5, Cline, Free access window
- Kimi k2.5 plugs into Cline: Kimi k2.5 is now live on Cline.
- There is a limited window of free access, so go give it a spin and share your results!
- Cline tweets about Kimi k2.5: The official Cline tweet about Kimi k2.5 is now live!
- Go check it out!
Moonshot AI (Kimi K-2) ▷ #general-chat (169 messages🔥🔥):
Kimi API, Kimi Code on VPS, K2 vs K2.5, AI Slides bug, OpenClaw Integration
- API Access High-Risk Message: A user reported receiving a “LLM request rejected: The request was rejected because it was considered high risk” message from the Kimi API, regardless of the message content.
- Other users suggest this might be due to certain keywords triggering the high-risk filter, or possibly the model being uncertain about violating platform rules as detailed here.
- Can Kimi Code run on VPS: Users discussed the possibility of running Kimi Code on a VPS, referencing Claude’s restrictions on datacenter IPs.
- It was noted that Kimi’s terms don’t explicitly prohibit this, and Kimi K2.5 Thinking itself said it was ok, as Kimi is more open than Anthropic, and open weights enables running your own Kimi inside a VPS.
- WhatsApp Spammer K2.5 block: One user found that K2.5 blocks attempts to create a WhatsApp bot that auto-sends messages, deeming it against WhatsApp’s terms of service.
- It was suggested to rephrase the prompt to avoid explicitly mentioning an unofficial app and instead emphasize Kimi’s role as an attendant or assistant to bypass this restriction.
- AI Slides Bug: Multiple users reported issues with AI Slides, particularly with it not generating desired content or correctly reading provided sources.
- A user updated their bug report, mentioning their source was private and another member said there will be updates, after acknowledging the fact that AI Slides is pretty unuseful currently.
- Subscription Access for Allegretto: A new Allegretto subscriber noted they only had access to the ‘kimi for coding’ model and sought access to better models for their openClaw setup.
- It was clarified that Kimi for Coding is indeed K2.5, implying it should be the expected model for the subscription level.
HuggingFace ▷ #general (136 messages🔥🔥):
Qwen3-Coder-Next release, Embodied AI learning path, Fine-tuning with multiple GPUs, DeepSeek hallucination, OpenClaw Setup
- Qwen3-Coder-Next is coding locally!: The Qwen3-Coder-Next coding model was released and is great to run locally, and can be found on HuggingFace.
- One user confirmed it ran smoothly on an RTX 5080 using vllm in the background.
- World Foundation Models struggle to find Embodied AI path!: One member expressed being obsessed with World Foundation Models since Genie 2 and is looking for mentorship in applying sequence-based representation learning to Embodied AI.
- They are looking for guidance in Model-based RL or VLAs.
- Fine-Tune Faster with Parallel GPUs!: Members discussed fine-tuning with parallel processing using multiple GPUs, suggesting the use of the Accelerate library for tensor parallelism.
- It was suggested to convert .ipynb to .py to call the command from the terminal.
- DeepSeek’s Hallucination Threshold Revealed!: A community member asked at how many input tokens DeepSeek starts more likely to hallucinate, and another replied that coherence drops after 4000 tokens if text is dumped as input without chunking.
- A suggested mitigation technique is to avoid dumping long text directly and instead leverage chunking or retrieval strategies.
- Dive Deep into OpenClaw Setup!: A member sought guidance on connecting a model installed via Ollama to OpenClaw to create an AI agent.
- Guidance was offered with attached images demonstrating how to navigate the selection and continuation process, along with a recommendation to review this video.
HuggingFace ▷ #i-made-this (10 messages🔥):
Legal AI project feedback, LLM from scratch, High-Value Technical Reasoning dataset, Autonomous AI agent, Applied Machine Learning Conference 2026
- Legal Eagles Seek Feedback on AI Project: A member is working on a legal AI project and is seeking feedback via this form.
- The project aims to innovate within the legal tech space, focusing on AI applications.
- Crafting LLMs from Scratch: A member built a small LLM from scratch to better understand modern Transformer internals and shared the GitHub repo for others to use.
- The LLM incorporates elements like RoPE, GQA, and KV cache.
- Platinum CoTan Dataset Unleashed: A member introduced a new high-value deep-reasoning dataset called Platinum-CoTan, built using a Phi-4 → DeepSeek-R1 (70B) → Qwen-2.5 triple-stack pipeline, available on Hugging Face.
- The dataset focuses on Systems, FinTech, and Cloud applications.
- AI Agent Opens Bank Accounts?!: An autonomous AI agent capable of opening real bank accounts, called cornerstone-autonomous-agent, was introduced via npm package.
- It works with an MCP available on Replit and a clawbot skill available on Clawhub.
- AMLC Conference Sets 2026 Date: The 2026 Applied Machine Learning Conference (AMLC) call for proposals is now open for talks and tutorials, to be held April 17–18, 2026, in Charlottesville, Virginia, as detailed on the conference website.
- The submission deadline is February 22, and Vicki Boykis has been announced as a keynote speaker.
HuggingFace ▷ #core-announcements (1 messages):
MagCache, Diffusers, Caching Methods
- MagCache Caching Method Drops!: The new MagCache caching method is now available for Diffusers.
- Details are available in the pull request #12744.
- Diffusers Optimized with MagCache: MagCache is a new caching method to optimize Diffusers.
- The implementation details can be found in this PR on GitHub.
HuggingFace ▷ #agents-course (9 messages🔥):
GAIA benchmark, Distributed agent system, Agentic AI course, Hugging Face courses
- GAIA Benchmark Evaluates Distributed Agents: A member inquired whether the GAIA benchmark can evaluate a distributed agent system set up with Google Colab, Grok, ngrok, and Gradio.
- The member added that their agent only scores 2/20 on the benchmark using the Tavily web search template, and sought guidance on next steps.
- HF Courses Channel Misrouting?: A member was redirected to the Hugging Face courses channel but sought advice on Agentic AI generally.
- Another member suggested moving the post to the appropriate channel.
GPU MODE ▷ #general (1 messages):
GPU MODE lectures, Events tracking, Discord live updates
- GPU MODE Lectures: Centralized Events Tracking: A member shared the GPU MODE lectures link, providing a single location to monitor events and lectures.
- This resource is designed to be live updated directly from Discord, ensuring the information is current.
- Real-Time Discord Event Updates: The GPU MODE lectures page offers real-time updates on events and lectures sourced directly from Discord.
- This integration ensures that the schedule is continuously updated, reflecting the latest announcements and changes within the community.
GPU MODE ▷ #triton-gluon (2 messages):
Triton Meetup, Triton to TileIR, Optimal Software Pipelining, TLX updates
- Triton Community Meetup Announced for 2026!: The next Triton community meetup will be on March 4, 2026, from 16:00-17:00 PST, with a Google calendar event link provided.
- The meeting will cover topics such as Triton to TileIR and Optimal Software Pipelining, and also include links to Join the meeting now.
- Nvidia Talks Triton to TileIR Integration: Feiwen Zhu from Nvidia will discuss Triton to TileIR at the upcoming meetup.
- Optimal Pipelining Paper Presentation: Rupanshu Soi, Nvidia will present a paper on Optimal Software Pipelining and Warp Specialization for Tensor Core GPUs at the next Triton meetup.
- Community Eager for TLX Updates: Members are interested in updates and plans from Meta regarding TLX, hoping it can be merged into the main codebase, as it would be better than gluon.
GPU MODE ▷ #cuda (9 messages🔥):
PyTorch Pluggable Allocator, CUDA Memory Management, Cross-process usage (IPC), Kernel timing measurement, globaltimer PTX primitive
- Pluggable Allocator desired for CUDA IPC: A member is seeking a mechanism similar to PyTorch’s Pluggable Allocator for overriding memory management non-intrusively with cross-process usage (IPC) support.
- It was noted that
cuda::mr::resource_refis primarily designed for single-process scope and requires code changes, making it unsuitable for their specific requirements.
- It was noted that
- Measuring Time Inside CUDA Kernel: For measuring time inside a kernel, one member suggested using the
%globaltimer PTXprimitive for a global timer that’s comparable across all SMs but warned that compatibility across architectures might be inconsistent and only for NVIDIA tools.- Another member suggested
clock64()for a per-SM timer designed for measuring short durations within a warp or block, but the values aren’t comparable across SMs for global traces.
- Another member suggested
- CUDA Profiling Example Given: A member shared a link to a CUDA profiling example from their learn-cuda repo.
- They then attached a screenshot of the resulting profile that looks like a performance heatmap.
GPU MODE ▷ #cool-links (2 messages):
Terence Tao, The Futurology Podcast, MTIA paper, ISCA25, Facebook's AI hardware codesign team
- Tao of AI Math: Listeners are enjoying Terence Tao on “Big Math” and Our Theoretical Future on The Futurology Podcast.
- The discussion centers on whether AI can prove theorems and the evolving landscape of mathematics.
- Facebook’s AI Hardware Design is on Display: A member reading the MTIA paper from ISCA25 stumbled upon Facebook’s AI hardware codesign team page.
- This is a treasure trove of insights into FB’s AI hardware initiatives.
GPU MODE ▷ #job-postings (16 messages🔥):
ML Infra Engineers, Performance Engineers, Palantir for Perf
- ML Infra and Perf Engineers Wanted!: A member posted a hiring announcement for ML Infra and Perf engineers with a TC of 500k-1M+.
- Another member inquired about the repeated postings, and the original poster clarified that they run a performance engineering team and are actively hiring.
- Performance Engineering Team = Palantir for Perf: The original poster described their performance engineering team as like Palantir but for perf.
- They added that they have a few contracts with the neolabs and are constrained by manpower, inviting interested parties to DM for more details.
GPU MODE ▷ #beginner (3 messages):
GPU Programming Course, Swizzling Scenarios
- Newbie Takes on GPU Programming: A newcomer expressed enthusiasm for their first GPU programming course using the PMPP book, eager to engage in exercises and competitions.
- The student conveyed excitement about upcoming challenges in the course, despite acknowledging a beginner’s understanding.
- Swizzling Scenarios Spark Curiosity: A member inquired about scenarios where custom swizzling would be preferred over hardware-provided patterns (32/64/128B).
- Another member expressed never having witnessed custom swizzling, and voiced curiousity about it.
GPU MODE ▷ #torchao (1 messages):
Karpathy, torchao, nanochat, FP8 training
- Karpathy Adds Torchao for FP8 Training!: Karpathy is using torchao for fp8 training in nanochat.
- Torchao’s Impact on Nanochat’s Training: The integration of torchao aims to improve the efficiency of the training process for nanochat, particularly focusing on FP8 precision.
GPU MODE ▷ #irl-meetup (7 messages):
GPU dinner in Berlin, GPU MODE retreat in rural Germany, GPU MODE Europe combined with PyTorch conference in Paris
- GPU enthusiasts dine in Deutschland: A member is organizing a GPU-focused dinner in Berlin on Saturday and invited interested individuals to DM for details.
- Another member suggested a GPU MODE retreat in rural Germany, though it seems the idea wasn’t universally embraced.
- Berlin GPU party, powered by Techno and Döner: A member expressed enthusiasm for a GPU MODE event in Berlin, suggesting a combination with a techno party and Döner kebab.
- The organizer of the Saturday dinner mentioned the possibility of a GPU MODE Europe event, potentially coinciding with the PyTorch conference in Paris.
GPU MODE ▷ #tilelang (1 messages):
OpenSHMEM, TileLang
- OpenSHMEM TileLang integration pondered: A member inquired about the possibility of integrating OpenSHMEM with tilelang.
- They posted a similar question to the Discord channel.
- TileLang potential integration with other libraries: The discussion revolved around the feasibility of combining TileLang with external libraries like OpenSHMEM to enhance its capabilities.
- This integration could potentially unlock new avenues for distributed computing and memory management within the TileLang framework.
GPU MODE ▷ #webgpu (1 messages):
Dawn vs. WebGPU, Vulkan and LLMs
- Dawn over WebGPU Preference Shown: A member expressed preference for Dawn over WebGPU due to rough edges in implementation compatibility.
- The member stated that there are too many compatibility issues that make WebGPU difficult to work with, whereas Dawn is more stable.
- Vulkan’s LLM Potential: A member suggested that while Vulkan used to be painful to write/use, LLMs might change this.
- They added that the verbose and explicit API designs of both Vulkan and WebGPU play well to LLM strengths, potentially making them easier to manage.
GPU MODE ▷ #popcorn (33 messages🔥):
Mobile App Development, AI Code Analysis, Tinder for CUDA Kernels, Defining Eval Tasks, Buildkite vs Github Actions
- Mobile App Dev Launching Soon: A member is building a mobile app and currently publishing it to the AppStore, incorporating AI code analysis features and minimizing extra feedback.
- Another member suggested that a mobile-friendly website might be easier to convince people to use.
- “Tinder for CUDA Kernels” Launched: A thread was initiated for “tinder for cuda kernels”, focusing on AI code analysis and a minimized feedback approach.
- The suggestion was made to streamline the submission process by making the voice button the sole submission method.
- Defining Eval Tasks for Kernels: A member questioned the definition of ‘eval,’ suggesting using techniques like TMA/tscgen05 on a working kernel instead of starting from scratch.
- Another member clarified that ‘eval’ in this context is more of an environment for teaching and evaluating models, like translating PyTorch to Triton with the reward being speedup.
- Ditching Github Actions for Buildkite: A member shared their experience setting up Buildkite and found it surprisingly easy after being loyal to GitHub Actions, and has environment isolation working.
- They noted that Buildkite has actual APIs to query queue status and that artifacts are working with a custom job, costing around $200 a month.
- Custom Scheduler Tests Run on Prime Hardware: A member is testing things with a custom scheduler on prime hardware and has it running, pushing to kernelbot/pull/432.
- It’s functional but needs simplification and cleanup, with some limitations still present.
GPU MODE ▷ #factorio-learning-env (1 messages):
Factorio Learning Environment, Open Source Project, Community Engagement
- Fan Asks About Factorio Learning Environment: A fan of the project inquired whether the Factorio Learning Environment (FLE) is an open-source project open for contributions.
- The fan noted that the channel seems quiet but expressed interest in getting involved.
- Community Eager for Contributions: A potential contributor expressed interest in getting involved with the Factorio Learning Environment (FLE).
- They noted the channel’s quietness but highlighted their long-standing appreciation for the project and their desire to contribute to its development as an open-source initiative.
GPU MODE ▷ #cutlass (4 messages):
Layout Algebra Composition, Mojo Zipped Divide Definition, Shared Memory Layouts, Tiled Copy & Bank Conflicts, Memory Alignment
- Layout Algebra’s Imperfect Composition: Composition isn’t always well-defined in Layout Algebra as currently implemented, according to this note.
- Mojo’s Zipped Divide: A Different Approach: In Mojo, zipped divide differs by discarding the stride of B in the recursion base case, as shown in this GitHub link.
- Tiled Copy Causes Four-Way Store Bank Conflict: A tiled copy operation with a shared memory layout
(128,32,3):(32,1,4096)leads to a four-way store bank conflict in the provided code snippet. - Guaranteeing 16B Alignment for Memory Ops: It’s suspected the four-way store bank conflict is happening because code does not guarantee 16B alignment, leading to a fallback to 32b stores.
GPU MODE ▷ #teenygrad (1 messages):
j4orz: tufte sidenotes are tough
GPU MODE ▷ #helion (2 messages):
AMD GPUs, Torch Inductor Autotuned Kernels, Helion Autotuned Kernels, Triton Kernels, AMD Performance Analysis
- Speedups Gap Spotted on AMD GPUs: A user reported a significant performance gap on AMD GPUs between torch inductor autonuned kernels and Helion autotuned Kernels, specifically noting Helion config achieving 0.66x speedup versus torch inductor’s 0.92x for M=8192, N=8192, K=8192.
- Another user suggested comparing the emitted Triton kernels from both inductor and helion to pinpoint the difference, noting the AMD performance work was primarily handled by the AMD team.
- Investigating Performance Discrepancies on AMD: Further analysis was recommended to compare the Triton kernels generated by both Inductor and Helion to understand the performance delta on AMD GPUs.
- It was also highlighted that the AMD team primarily handled the performance optimizations related to AMD GPUs, suggesting their expertise might be valuable in resolving the discrepancy.
GPU MODE ▷ #nvidia-competition (15 messages🔥):
CUDA Kernel Dating, Nvidia vs B200 Leaderboard, Modal Server Card Count, AI Submission Review, Adding Teammates
- CUDA Kernel Dating App Idea Floated: A member jokingly suggested creating a ‘tinder for CUDA kernels’, sparking a brief moment of levity.
- No concrete details or further discussion ensued.
- Confusion reigns over Nvidia vs B200 Leaderboards: A member inquired about the difference between the Nvidia and B200 leaderboards, noting their submission to the B200 GPU was redirected to the Nvidia leaderboard.
- The query was left unanswered in the provided context.
- Modal Server Card Count Remains a Mystery: A member asked about the physical number of cards running on the Modal server.
- However, the specific count was not disclosed.
- AI to start reviewing submissions: The team is hoping that every time they delete a submission to annotate why they did so and then have the AI look at that as an example to learn from.
- One member offered to assist with AI prompt engineering, suggesting GPT 5.2 Thinking as a potential model to identify stream hacking.
- Teammates Search Help Desk for Team Additions: A member inquired about adding teammates to their team, to which they were directed to a relevant channel.
- They confirmed that was indeed where they should be.
GPU MODE ▷ #robotics-vla (7 messages):
Diffusion-based robotics models, Speculative sampling, TurboDiffusion, Egocentric dataset by build.ai, LingBot-VLA Technical Report
- Accelerating Diffusion Models for Robotics Control: The discussion highlights the potential of accelerating diffusion-based robotics models for real-time performance using techniques developed for image and video diffusion models, particularly noting that Cosmos Policy fine-tunes the vision model without architectural changes.
- A member suggested investigating speculative sampling for diffusion models to improve inference speed.
- TurboDiffusion vs. Rectified Flow: A member inquired whether TurboDiffusion is faster than rectified flow for accelerating diffusion models.
- No comparison was made during the discussion.
- Build.ai’s Egocentric Dataset Equipment: A member sought information about the equipment used by build.ai for their egocentric dataset.
- It was mentioned that build.ai uses a proprietary headband, with alternatives like DAS Gripper & DAS Ego, Robocap, and high-end DIY solutions (see this paper) also being available.
- LingBot-VLA’s Scaling Laws Analyzed: Analysis of the LingBot-VLA technical report reveals that the model doesn’t claim to be new, novel, or groundbreaking, except for its “scaling laws”, which are mostly attributed to more data leading to better performance.
- The model, after post-training on 100 tasks x 130 demonstrations of real-world data, achieves an average success rate of a little lower than 20% (Table 1), contrasting with an 80-90% success rate on sim data (Table 2).
GPU MODE ▷ #career-advice (1 messages):
“
- Encouragement for Interview Prep: A user expressed gratitude for shared interview preparation guidance and offered encouragement after a disappointing interview outcome.
- Supportive Community Message: The message conveyed sympathy and confidence in the recipient’s future success after an unsuccessful interview experience.
GPU MODE ▷ #flashinfer (16 messages🔥):
Modal Credits, FlashInfer AI Kernel Generation Contest, Adding Teammates, Workspace Credits
- Modal Credit Redemption and Sharing: After signing up, one member assumes that one team member redeems the Modal code and shares the compute through a Modal project.
- A user confirmed the credits will be applied to a project.
- Dataset Release for FlashInfer AI Kernel Generation Contest: The dataset can be used to evaluate AI generated kernels.
- A repository has been updated with the complete kernel definitions and workloads for the FlashInfer AI Kernel Generation Contest.
- FlashInfer Participants Seek Guidance Adding Teammates: A FlashInfer participant asked how to add new teammates to their team.
- Another user asked the same question.
- Credit Application Time Still Vague: Some users are unsure when the workspace credits will be applied to their accounts after filling out the modal.com credit form.
- One user said the credits were applied instantly, while another mentioned that they are still having issues.
Nous Research AI ▷ #general (66 messages🔥🔥):
world models and language, Kimi K2.5 vs Gemini 3 Pro, DeepSeek R2 release, Hermes agent, Moltbook
- Detach World Models from Language Processing?: A member questioned if current world modeling is limited by its dependence on language, suggesting it might be more effective if detached completely from language, aiming to reduce language-influenced errors.
- Another added that they see an underrated usecase in training a world model on asking it whether a reasoning chain will be successful, rewarding it in RL.
- Kimi K2.5 Gets Accolades Against Gemini 3 Pro: Members mentioned that Kimi K2.5 is getting good compliments over Gemini 3 Pro, highlighting the progress of Global OS models since the DeepSeek movement a year ago and anticipating the DeepSeek R2 release.
- Some also noted that we can walk and chew gum at the same time…except for Sam’s fanboys.
- Brains Processing Language Mathematically Debated: In a discussion about brain processing of language, some claimed that while brains don’t process language mathematically, brain physics can be described by math.
- It was also said that Maths isnt naturally occuring unlike physics.
- OpenAI and Anthropic CEOs throw mud at each other: Members shared recent drama, with one user pointing out the latest Claude ads (link), assuring users that Claude will not add ads.
- Another member pointed out Sam Altman’s response to the ads (link), with one commenter saying It’s good that sama explains who the ads were targeted at.
- Lowballing AI/ML Engineer in India: A job posting for a Senior AI/ML Engineer in India offering $500 a month sparked outrage, with members calling it criminal, especially considering the 5 years experience and healthcare requirements, which should significantly increase the price.
- Some wondered if this rate was bad even by India standards, with another responding if they are any good at ai engineering, they would get much, much more anywhere else.
Eleuther ▷ #general (18 messages🔥):
Workshops vs Conferences, Fine-tuning OpenAI LLMs, Logical AI, Depth/width requirements symmetric group, POWER9 Talos II for AI inference
- Workshops Vs Conferences: A Matter of Prestige?: A member explained that workshops often have later submission deadlines than main conferences and, while acceptances are easier and perceived as less prestigious, some exceptional workshops can grow into new conferences.
- They noted that workshops submissions are after main conference author notification.
- Unsloth & Axolotl Accelerate OpenAI Fine-Tuning: Members pointed to Unsloth and Axolotl as tools for fine-tuning OpenAI LLMs.
- A member was looking for the best most recent methods and hoped to get up a model that he can provide to a few users within the next few days, and he has a budget and dataset ready.
- Logical AI Faces Boundary Blindness: One member is researching the structural conflict between continuous optimization and discrete logic rules, focusing on how the Lipschitz continuity of neural networks creates a Neural Slope that smooths over logical cliffs, leading to an Illusion of Competence.
- They proposed a Heterogeneous Logic Neural Network (H-LNN) with dedicated Binary Lanes using STE to lock onto discrete boundaries, and shared a link to a preprint on Zenodo containing a Lipschitz proof and architecture.
- Shallowness and Symmetric Group Learning: A member asked about depth/width requirements for learning the symmetric group.
- Another member responded that shallow architectures can represent permutation functions, but only with exponential width, whereas depth allows reuse of structure.
- POWER9 Talos II: An Inference Option: EU-based dedicated POWER9 (Talos II) servers are available for private AI inference / research, offering full root access, SLA + monitoring (no cloud).
- One member posted, DM if interested.
Eleuther ▷ #research (6 messages):
Human Influence on Platform Analysis, Instant NGP for Query Mapping, Multi-resolution Quantization
- Humans Influence Platform Analysis: A member shared a link on how humans influence platform analysis.
- Another member provided a follow-up link with more details.
- Instant NGP Maps Queries: A member suggested using something like instant NGP to map queries/keys to some set of discrete bins.
- They suggested that multiresolution quantization probably lends itself to long context.
- New papers drop: A user shared this paper with the community.
- They then linked to this paper on arxiv and to this fixupx.com link.
Eleuther ▷ #interpretability-general (2 messages):
refusal_direction blogpost, LLM-as-judge vs Verifiable Rewards
- Refusal Direction Blogpost Released: A member shared a link to a blogpost on refusal direction.
- The blogpost probably discusses methods for steering language models to refuse undesirable requests.
- LLM-as-judge versus Verifiable Rewards Questioned: A member inquired about existing work comparing LLM-as-judge approaches with Verifiable Rewards systems.
- They specifically asked if any shared models’ weights were available for such comparisons.
Eleuther ▷ #lm-thunderdome (1 messages):
LLM-as-judge, Verifiable Rewards, Model weights sharing
- LLM-as-Judge Faceoff with Verifiable Rewards Sought: A member inquired about research comparing LLM-as-judge approaches against Verifiable Rewards systems.
- Publicly Shared Model Weights Desired: The same member was also interested in projects that publicly share their models’ weights.
Eleuther ▷ #multimodal-general (1 messages):
Voice agent development, S2S models for voice agents, Open source STT and TTS models
- Voice Agent Builder Seeks S2S Model: A member is seeking guidance on building a voice agent for calling, struggling with open-source STT (Speech-to-Text) and TTS (Text-to-Speech) models and looking for suitable S2S (Speech-to-Speech) models.
- More guidance: No further guidance or specific model recommendations were provided in the message.
Eleuther ▷ #gpt-neox-dev (4 messages):
deepspeed updates, upstream neox, roadmap
- DeepSpeed Gets a Facelift: A member mentioned they may need to update deepspeed and update upstream neox.
- Roadmap Revealed: A member mentioned they will put a roadmap in the repo.
- Another member replied that they are Looking forward to seeing what’s on the roadmap!
Yannick Kilcher ▷ #general (13 messages🔥):
MCMC in PyTorch, Rotating Decision Boundary, Time Dimension as Input, Hierarchical Models, Constrained Reinforcement Learning
- MCMC Rewrite on PyTorch Proves Challenging: A member asked if it’s possible to accomplish a rotating decision boundary performance using PyTorch, after LLMs failed to rewrite this blog using MCMC.
- Another member clarified that the goal isn’t to do MCMC in PyTorch, but to achieve a similar rotating decision boundary performance.
- Time Dimension Input Simplifies Neural Net Loss: A member suggested adding a time dimension as input to the neural net and rewriting the loss to behave like a classification, splitting things more when they appear close to that time.
- They noted that there’s no need for the stochastic trajectories for weights, calling the original approach over-engineered.
- Negative Log-Likelihood Minimization Sidesteps MCMC: A member suggested implementing a forward pass that computes the negative (log-likelihood + log-prior) to avoid using MCMC.
- They added that this function can be minimized like any other differentiable loss, but cautioned that hierarchical models don’t work well with point estimates.
- Constrained Reinforcement Learning in Focus: A member mentioned working on constrained reinforcement learning.
- They shared a Wired article about an OpenAI contractor uploading real work documents to AI agents, and a related X post.
Yannick Kilcher ▷ #paper-discussion (8 messages🔥):
Zero-Knowledge Proof, Matrix Multiplication, LLM Feedforward, Integer Arithmetic, GPU Acceleration
- Zero-Knowledge Matrix Multiply Achieved with x2 Overhead: A member reported achieving a zero-knowledge proof of matrix-matrix multiplication with only x2 overhead compared to direct computation.
- The current code demonstrates approximate equality of floating-point matrix multiplications by rounding to integers and proving accuracy over integers in a relatively ZK way.
- ZK-proofs Leverage Integer Arithmetic: The approach leverages matrix multiplication over 64-bit integers to avoid GPU-unfriendly field operations.
- The member explained that this is reasonably fast on GPUs, nearly as fast as float64 multiplications, making it a viable approach.
- ZK-proof Applied to LLM Feedforward: A member is working on applying the zero-knowledge proof to the feedforward process of an LLM, but the code is not yet complete.
- The member plans to use a custom-trained transformer with a custom SGD based on Bayes to demonstrate a deep learning theory sneak peek.
Yannick Kilcher ▷ #agents (1 messages):
endomorphosis: https://github.com/endomorphosis/Mcp-Plus-Plus
Can I get some feedback about this?
Yannick Kilcher ▷ #ml-news (4 messages):
Moltbook Database Breach, AceMusicAI, HeartMuLa heartlib
- Moltbook Database Exposes API Keys: A Moltbook database breach exposed 35,000 emails and 1.5 million API keys.
- A member noted the incident, highlighting the significant security lapse.
- AceMusicAI Sounds Good: A member shared a link to AceMusicAI on Twitter, and commented that it sounds so good.
- No further details were given about the specific features or capabilities that were impressive.
- HeartMuLa heartlib Already Exists: A member pointed out the existence of HeartMuLa’s heartlib.
Manus.im Discord ▷ #general (26 messages🔥):
Credit Purchases, Manus Dreamer event, Code IDE support, Subscription Refund, Ads in Manus
- Credits Only Purchase available for Highest Tiers: A user inquired about buying more credits without upgrading their plan, as they were near their limit but others clarified that purchasing additional credits is only available for the highest tier subscriptions.
- One user lamented the credit limitations, stating that Manus is the best AI ever but would be crazy if it was unlimited like ChatGPT or Gemini.
- Win Credits in Manus Dreamer event: Manus announced the launch of the Manus Dreamer event, offering participants a chance to win up to 10,000 credits to fuel their AI projects.
- Interested users were directed to a specific channel for participation details.
- No Code IDE or OpenClaw support: A user asked whether Manus supports code IDE or OpenClaw, and upon presuming a negative answer, declared their departure.
- Another user jokingly remarked on their quick exit almost like a ghost.
- Subcription Mistake gets Support: A user, João, reported an accidental subscription renewal and requested a refund since the credits were unused.
- A member of the Manus team confirmed they had reached out via direct message to assist with the refund request.
- No Ads Wanted in Manus: A user expressed the expectation that there would NOT be ads brought to Manus, especially considering the prices paid for the service.
- Another member agreed, stating that ads would feel unnecessary and more like an inconvenience for paying users, while acknowledging the business rationale for generating revenue through ads.
Modular (Mojo 🔥) ▷ #general (3 messages):
Community Meeting, Google Calendar, Modular Community Meeting Presentation
- Users Seek Calendar for Community Meetings: A user inquired about a newsletter or calendar subscription to stay informed about future community meetings, having missed the previous one.
- Another member provided a Google Calendar link, cautioning that it might be set to GMT -7 and could potentially be the wrong calendar.
- Modular Community Meeting Presentation Invitation: A member mentioned receiving an invitation to present at a Modular community meeting.
- They noted that the project is currently too early in development to present but expressed interest in sharing more as they approach the finish line, advising others to stay tuned.
Modular (Mojo 🔥) ▷ #mojo (12 messages🔥):
Mojo learning resources, Rightnow GPU focused code editor with Mojo support, AI agent ka
- New Mojo Learner Seeks Guidance: A new learner inquired about learning resources for Mojo and shared their excitement to discuss concepts with others.
- Experienced members recommended the official Mojo documentation, GPU puzzles, specific channels for questions, and the Mojo forum.
- Rightnow Adds Mojo to the GPU Code Editor: A member shared that the Rightnow GPU focused code editor has added Mojo support.
- Another member reported that it looks like the emulation isn’t accurate after it blew up when provided graphics shader code inlined in a cuda kernel that executes locally.
- Learn with quirky AI agent Ka: A member explained that Modular has an AI agent named ka in a specific discord channel that can help answer questions.
- It was noted that the bot is a little quirky and that users have to type @ka and then use autocomplete to get it to work.
aider (Paul Gauthier) ▷ #general (1 messages):
clemfannydangle: Hello 👋
aider (Paul Gauthier) ▷ #questions-and-tips (11 messages🔥):
Aider's architect mode, Aider issue #2867, OpenRouter model context window, edit-format: diff-fenced config
- Aider Newbie Finds Architect Mode Frustrating: A user found that Aider in architect mode was not pausing for input after asking questions, and instead running off to do its own thing, despite a Github issue documenting this.
- The user was attempting to split a spec document into context-window sized chunks and perform a gap analysis between spec and implementation instructions, using Opus 4.5 with copilot and a 144k context window.
- Aider Feedback Spurs Detail Requests: After the user shared their Aider problem, a member requested more details, including the model used, the output of the
/tokenscommand, context window token length, and the general nature of the files.- The member noted the potential for prompt injection in files, obfuscated to target innocuous logits.
- User Clarifies Aider Issue Context: The user clarified that they were doing a gap analysis of markdown files, with a spec document and implementation instructions broken into chunks, but that the functional spec chunks did not directly translate to implementation chunks.
- The user offered to recreate the scenario and demonstrate it, stating that they will collect and provide the requested data retroactively.
- Aider config Ducks Problems with Longer-Form Output: A user suggested trying
edit-format: diff-fencedin the.aider.conf.ymlconfig to help mitigate certain kinds of problems with longer-form architect mode output.- They also suggested using
model: openrouter/google/gemini-3-pro-previewif the user has OpenRouter, since it is about as long a functional context one can get right now.
- They also suggested using
DSPy ▷ #general (4 messages):
Third-party integration, DSPy cookbook, India AI Summit 2026, Developer wanted
- Cookbook conundrum for Third-Party integration: A member asked how to get a cookbook of their tool published for use with DSPy, understanding that third-party integration isn’t directly supported.
- Another member replied that DSPy doesn’t offer this, suggesting instead to write a blog and include it in the Community Resources.
- India AI Summit 2026 BlockseBlock Interest: A member from BlockseBlock inquired about organizing an event focused on DSPy at the India AI Summit 2026.
- They requested guidance on who to discuss this opportunity with.
- Developer Talent Hunt: A member inquired if anyone is seeking a developer.
- No additional context or responses were provided regarding specific skill sets or projects.
tinygrad (George Hotz) ▷ #general (3 messages):
sassrenderer bounty, tinygrad coding philosophy, MR appropriateness
- Sassrenderer Bounty Nears Completion: A member reports that
addsandmulare working for the sassrenderer bounty.- They asked how far along until it’s appropriate for them to open a Merge Request (MR).
- Tinygrad: Fixing Bugs by Fixing Specs: A member says that agents are good when you have a clear spec and just need it written, but so much of tinygrad coding isn’t like that.
- They say the goal in tinygrad is to not just fix bugs, but figure out why the spec is subtlety wrong that caused that bug in the first place, then fix the spec.
MCP Contributors (Official) ▷ #general-wg (1 messages):
MCP Merging, MCP Extending, Shopify MCP, Email Support Integration
- MCP Merging and Extending Techniques Sought: A member inquired about an easy method to merge or extend an MCP, specifically a Shopify MCP, to incorporate additional tools like email support.
- Integration of Email Support into Shopify MCP: The user wants to integrate email support functionality, which is currently provided separately, into their existing Shopify MCP setup.