Apple is finally waking up to AI in a big way ahead of WWDC. We featured MM1 a couple weeks ago and now a different team is presenting ReALM: Reference Resolution As Language Modeling. Reference resolution in their terminology refers to understanding what ambiguous references like "they" or "that" or "the bottom one" or "this number present onscreen" refer to, based on 3 contexts - 1) what's on screen, 2) entities relevant to the conversation, and 3) background entities. They enable all sorts of assistant-like usecases:
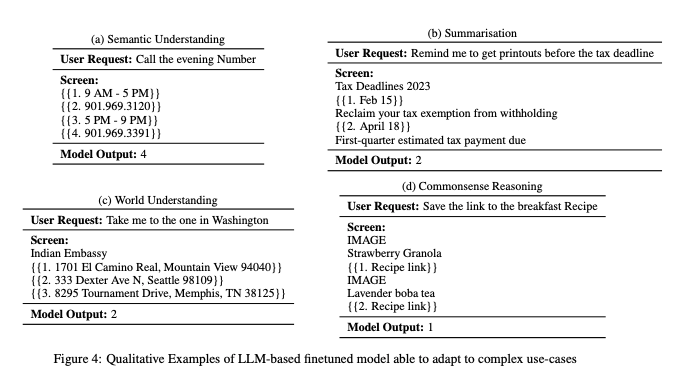
Which is a challenging task given it basically has to read your mind.
The authors use a mix of labeled and synthetic data to finetune a much smaller FLAN-T5 model that beats GPT4 at this task:
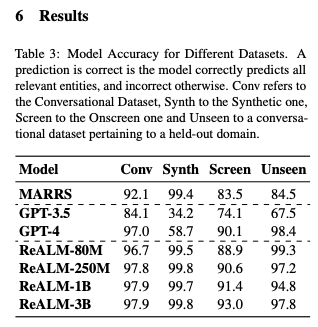
No model release, no demo. But it's nice to see how they are approaching this problem, and the datasets and models are small enough to be replicable for anyone determined enough.
The AI content creator industrial complex has gone bonkers over it, of course. There only a few more months' worth of headlines to make about things beating GPT4 before this is itself beaten to death.
Table of Contents
[TOC]
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence. Comment crawling still not implemented but coming soon.
AI Research and Development
- Open source coding agent: In /r/MachineLearning, researchers developed SWE-agent, an open source coding agent that achieves 12.29% on the SWE-bench benchmark. The agent can turn GitHub issues into pull requests, but the researchers found building effective agents to be harder than expected after 6 months of work.
- New RAG engine: Also in /r/MachineLearning, RAGFlow was introduced as a customizable, credible, explainable retrieval-augmented generation (RAG) engine based on document structure recognition models.
- Efficient quantization: In /r/LocalLLaMA, QuaRot was announced as a new quantization method enabling 4-bit inference, more efficient than current methods like GPTQ that require dequantization. It also supports lossless 8-bit quantization without calibration data.
AI Applications and Tools
- T-shirt design generator: In a video post, a Redditor shared a tool they made to generate t-shirt designs using AI.
- Podcast generation: In /r/OpenAI, podgenai was released as free GPT-4 based software to generate hour-long informational audiobooks/podcasts on any topic, requiring an OpenAI API key.
- Open-source language model: HuggingFace CEO reshared the release of PipableAI/pip-library-etl-1.3b, an open-source model that can be tried out without a GPU.
{kind=link}
AI Industry and Trends
- Impact of large language models: In /r/MachineLearning, a discussion was started on whether large language models (LLMs) are doing more harm than good for the AI field due to hype changing the focus of conferences and jobs superficially, with overpromising potentially leading to another AI winter.
- Decentralizing AI: An Axios article was shared on efforts to decentralize AI development and break the hold of big tech companies.
- Stability AI Japan hire: News was posted about Takuto Takizawa joining Stability AI Japan as Head of Japan Sales & Partnerships.
{kind=link}
Stable Diffusion Discussion
- Generating arbitrary resolutions: In /r/StableDiffusion, a user asked how Stable Diffusion generates images at resolutions other than 512x512 given the VAE input/output sizes, seeking an explanation and pointers to relevant code.
- Suitability for storytelling: Also in /r/StableDiffusion, a beginner asked if Stable Diffusion is suitable for creating specific characters, poses, and scenes for storytelling and comics, as they struggle to control the output and consider 3D tools as an alternative.
- Batch generation in UI: Another user in /r/StableDiffusion was looking for the setting to have Automatic1111's Stable Diffusion UI repeatedly generate images in batches overnight.
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
Anthropic Research on Jailbreaking LLMs
- Many-shot jailbreaking technique: @AnthropicAI released a research paper studying a long-context jailbreaking technique effective on most large language models. The research shows increasing context window is a double-edged sword, making models more useful but also vulnerable to adversarial attacks.
- Principled and predictable technique: @EthanJPerez noted this is the most effective, reliable, and hard to train away jailbreak known, based on in-context learning. It predictably gets worse with model scale and context length.
- Concerning results: @sleepinyourhat found the results interesting and concerning, showing many-shot prompting for harmful behavior gets predictably more effective at overcoming safety training with more examples, following a power law.
Adversarial Validation Technique for Identifying Distribution Shifts
- Clever trick to check train/test distribution: @svpino shared a trick called Adversarial Validation to determine if train and test data come from the same distribution. Put them together, remove target, add binary feature for train/test, train simple model. If AUC near 0.5, same distribution. If near 1, different distributions.
- Useful for identifying problem features: Adversarial Validation can identify problem features causing distribution shift. Compute feature importance, remove most important, rebuild model, recompute AUC. Repeat until AUC near 0.5. Useful in production to identify distribution shifts.
Impact of Taiwan Earthquake on Semiconductor Supply
- Proximity of earthquake to fabs: @nearcyan noted the 7.4 earthquake was 64 miles from Central Taiwan Science Park. In 1999, a 7.7 quake near fabs caused production losses. 2016 6.6 quake only delayed ~1% TSMC orders.
- TSMC preparedness: TSMC is well prepared for larger quakes. Government prioritizes utility restoration for fabs. No structural damage reported yet. Expect more disruption at Hsinchu/Taichung than 3nm Tainan fab.
- Potential delays: Expect nontrivial delays of at least few weeks, possibly months if unlucky. Will likely cause short-term semiconductor price action.
AI Advancements and Developments
- Genie AI model from DeepMind: @GoogleDeepMind announced Genie, a foundation world model that can create playable 2D platformer worlds from a single image prompt, sketch or text description. It could help train AI agents.
- Replit Code Repair AI agent: @pirroh announced Replit Code Repair, a low-latency code repair AI agent using GPT-4. It substantially outperforms open-source models on speed and accuracy.
- Sonnet model replacing GPT-4: @jxnlco is replacing GPT-4 with Sonnet for most use cases across 3 companies, showing a shift to more specialized models.
Memes and Humor
- Coding longevity meme: @svpino joked about being told in 1994 that coding would be dead in 5 years, yet still coding 30 years later.
- Anthropic jailbreaking violence meme: @goodside joked that if violence doesn't solve your LLM jailbreaking problems, you aren't using enough of it.
AI Discord Recap
A summary of Summaries of Summaries
-
Advancements in Memory-Efficient LLM Training:
- A new attention mechanism called DISTFLASHATTN claims to reduce quadratic peak memory usage to linear for training long-context LLMs, enabling up to 8x longer sequences. However, the paper lacks pseudocode for the backward pass, raising concerns about reproducibility.
- Discussions around CUDA optimization techniques like DISTFLASHATTN and its potential to revolutionize LLM training through memory efficiency and speed improvements over existing solutions like Ring Self-Attention.
-
AI Model Evaluations and Benchmarking:
- The SWE-agent open-source system claims comparable accuracy to Devin on the SWE-bench for autonomously solving GitHub issues.
- Varying performance of models like GPT-4, Claude, and Opus on tasks like solving historical prompts, math riddles, and code generation, highlighting the need for comprehensive evaluations.
- Platforms like Chaiverse.com for rapid feedback on RP-LLM models and LMSys Chatbot Arena Leaderboard for model benchmarking.
-
Prompt Engineering and Multimodal AI:
- Discussions on prompt engineering techniques for tasks like translation while preserving markdown, generating manager prompts, and improving multimodal QA using Chain of Thought.
- The potential of DSPy for prompt optimization compared to other frameworks like LangChain and LlamaIndex.
- Explorations into multimodal AI like using Stable Diffusion for depth mapping from stereo images and the launch of Stable Audio 2.0 for high-quality music generation.
-
Open-Source AI Developments and Deployments:
- Work on an Open Interpreter iPhone app and porting to Android Termux, M5 Cardputer, enabling voice interfaces and exploring local STT solutions.
- Unveiling of the Octopus 2 demo, a model capable of function calling, fueling excitement around on-device models.
- Releases like Axolotl documentation updates and the open-sourcing of Mojo's standard library.
-
Misc Themes:
-
Optimization Challenges and Breakthroughs in LLMs: Engineers grappled with memory and performance bottlenecks in training large language models, with the introduction of novel techniques like DISTFLASHATTN which claims linear memory usage and 8x longer sequences compared to existing solutions. Discussions also covered leveraging bf16 optimizers, tinyBLAS, and frameworks like IPEX-LLM (GitHub) for inference acceleration on specific hardware.
-
Anticipation and Analysis of New AI Models: Communities buzzed with reactions to newly released or upcoming models such as Apple's ReALM (paper), Stable Diffusion 3.0, Stable Audio 2.0 (website), and the SWE-agent which matches Devin's performance on the SWE-bench (GitHub). Comparative evaluations of instruction-following and chat models like Claude, Opus, and Haiku were also common.
-
Ethical Concerns and Jailbreaking in AI Systems: Discussions touched on the legal implications of training AI on copyrighted data, as seen with the music platform Suno, and the efficacy of jailbreak defenses in language models, referencing an arXiv paper on the importance of defining unsafe outputs. The emotional simulation capabilities of chatbots sparked philosophical debates likening AI to psychopathy.
-
Innovations in AI Interfaces and Applications: The potential of voice-based interactions with AI was highlighted by apps like CallStar AI, while communities worked on projects to make technology more accessible through conversational UIs. Initiatives such as Open Interpreter aimed to bring AI capabilities to mobile and embedded devices. Novel use cases for AI ranged from WorldSim's gamified simulations (Notion) to AI-generated art and music.
PART 1: High level Discord summaries
LAION Discord
-
Optimizer Headaches and Proposals: Technical talks revealed challenges with
torch.compileand optimizer functions. An emerging solution discussed involved a Python package withbf16 optimizerto address dtype conflicts and device compatibility issues. -
Sound of Legal Alarm for AI Tunes: The community spotlighted potential legal issues with the AI music platform Suno, emphasizing the risks of copyright infringement suits from record labels due to training on copyrighted content.
-
Memory Hogs & Crashes in Apple's MPS: Apple's MPS framework was under scrutiny for crashing at high memory allocations even when the memory was available. Theoretical internal limitations and attention slicing as a workaround were hot topics, albeit with concerns about resulting NaN errors.
-
Textual Details Elevate Image Quality: Research surfaced indicating that fine-tuning text-to-image models with precise spatial descriptions enhances the spatial consistency in generated images, as suggested by an arXiv paper.
-
Decoding AI Optimal Performance: From skepticism about SD3 Turbo's claimed efficiency to recommendations on model fine-tuning and scheduler effectiveness, the guild analyzed various AI strategies. There were also insights into how smaller models may outperform larger ones within the same inference budget, as shown in a recent empirical study.
Stability.ai (Stable Diffusion) Discord
Forge Ahead with Stable Diffusion: Users report that Forge, a user interface for Stable Diffusion, delivers superior performance especially on RTX 3060 and RTX 4080 graphics cards. DreamShaper Lightning (SDXL) models come recommended for efficiency and speed in image generation.
Anticipation High for SD3: The Stable Diffusion community is actively awaiting the release of Stable Diffusion 3.0, projected to launch in the next 3-5 weeks, with improvements to text rendering expected, though perfect spelling may remain elusive.
Creative AI Unleashed, But Not 'Unleash': Members are experimenting with Stable Diffusion to generate art for projects like tabletop RPGs and are considering storytelling through AI-generated visual narratives, possibly in comic or movie formats.
Tech Tips for Troubled Times: Discussions centered on addressing issues such as slow image generation and unwanted text appearance, with participants suggesting optimizations, and mentioning GitHub links as starting points for troubleshooting.
Features Forecast: There's evident excitement about upcoming features like sparse control net, SegMOE, and audiosparx models, with the community sharing resources and anticipating new possibilities for AI-generated content.
Unsloth AI (Daniel Han) Discord
Cortana 1.0 Chat Model Sparks Curiosity: Engineers discussed creating an AI prompt model named Cortana 1.0, based on the Halo series AI, emphasizing creating effective chat modes and prompt structures for streamlined interaction.
Unsloth Enterprise Capability Clarified: It was clarified that Unsloth Enterprise does indeed support full model training with a speed enhancement of 2-5x over FA2, rather than the expected 30-40x.
AI Optimization Exchange: A set of lively discussions covered diverse optimization topics, including advances in Unsloth AI with a mention of Daniel Han's Tweet, GitHub resources for accelerating AI inference like ipex-llm, and troubleshooting with AI models, notably the compatibility of SFTTrainer with Gemma models.
Innovative Approach to Asteroid Mining: The Open Asteroid Impact project captured interest with a novel concept of bringing asteroids to Earth to harness resources more effectively.
Groundwork for Full Stack Prospects: Solicitations for a skilled full stack developer within the community were made, and users were encouraged to DM if they could recommend or offer assistance.
Perplexity AI Discord
Reading Between the PDF Lines: Engineers discussed AI models such as Claude and Haiku for interpreting PDFs, with a focus on context windows and Perplexity's Pro features, especially the "Writing" focus and enabling "Pro" for accuracy. Some users favored Sonar for faster responses.
Ad-talk Sparks User Spat: The possibility of Perplexity introducing ads sparked debate, following statements by Perplexity's Chief Business Officer on integrating sponsored suggestions. Concerns were raised about the potential impact on the user experience for Pro subscribers, citing a Verge article on the subject.
PDF Roadblocks and Image Generation: While addressing technical issues, users clarified that Perplexity's mobile apps lack image generation support—an inconvenience tempered by the website’s desktop-like functionality on mobile devices for image generation. Separate discussions pointed to users wanting to lift the 25MB PDF limit for increased efficiency.
Engineers Exchange 'Supply Links': Referral programs and discounts became a hot topic, with mentions of savings through supplied links.
API Woes and Workarounds: Within the Perplexity API realm, users grappled with the lack of team support and payment issues for API credits, while also sharing frustrations over rate limits and receiving outdated responses from the sonar-medium-online model. The advice ranged from accurate request logging to refining system prompts for up-to-date news.
Curiosity Drives Deep Dives:
- Users applied AI to explore a range of subjects from Fritz Haber's life and ethical dilemmas to random forest classifiers and "Zorba the Greek," hinging on AI's suitability to satisfy diverse and complex inquiries.
- They leveraged Perplexity to efficiently compile comprehensive data for newsletters, indicating a strong inclination towards utilizing AI for streamlined content creation.
Latent Space Discord
Open Source AI Matches Devin: The SWE-agent presented as an open-source alternative to Devin has shown comparable performance on the SWE-bench, prompting discussions on its potential integrations and applications.
Apple's AI Research Readiness: A new paper by Apple showcases ReALM, hinting at AI advancements that could eclipse GPT-4's capabilities, closely integrated with the upcoming iOS 18 for improved Siri interactions.
Conundrum with Claude: Users are experimenting with Claude Opus but finding it challenged by complex tasks, leading to recommendations of the Prompt Engineering Interactive Tutorial for enhanced interactions with the model.
Supercharged Sound with Stable Audio 2.0: StabilityAI has introduced Stable Audio 2.0, pushing the boundaries of AI-generated music with its ability to produce full-length, high-quality tracks.
DALL-E Gets an Edit Button: ChatGPT Plus now includes features that allow users to edit DALL-E generated images and edit conversation prompts, bringing new dimensions of customization and control, detailed on OpenAI's help page.
DSPy Framework Discussion Heats Up: The LLM Paper Club scrutinized the DSPy framework's functionality and its advantage in prompt optimization over other frameworks, sparking ideas about its application in diverse projects such as voice API logging apps and a platform for summarizing academic papers.
Nous Research AI Discord
-
SWE-agent Rises, Devin Settles: A cutting-edge system named SWE-agent was introduced, claiming to match its predecessor Devin in solving GitHub issues with a remarkable 93-second average processing time, and it's available open-source on GitHub.
-
80M Model Sparking Skepticism: Engineers discussed an 80M model's surprising success on out-of-distribution data, prompting speculation about the margin of error and stirring debate about the validity of this performance.
-
Chinese Processor Punches Above its Weight: Conversations about AI hardware led to Intellifusion's DeepEyes, Chinese 14nm AI processor, offering competitive AI performance at significantly reduced costs, potentially challenging the hardware market (Tom's Hardware report).
-
Tuning Heroes and Model Troubles: The community shared experiences of tuning models, like Lhl's work with a jamba model and Mvds1's issue uploading models to Hugging Face due to a metadata snag, pointing out the need for manual adjustments to
SafeTensorsInfo. -
WorldSim Sparks Community Imagination: Engineers enthusiastically explored features for WorldSim, ranging from text-to-video integration to a community roadmap, discussing technical enhancements and sharing resources like the WorldSim Command Index on Notion. Technical constraints and gamification of WorldSim were among the hot topics, showcasing the community's drive for innovation and engagement in simulation platforms.
LM Studio Discord
- LM Studio Lacks Embedding Model Support: Users confirmed that LM Studio currently does not support embedding models, emphasizing that embedding functionality is yet to be implemented.
- AI Recommendation Query Gains Popularity: A user's request for a model capable of providing hentai anime recommendations prompted suggestions to use MyAnimeList (MAL), found at myanimelist.net, coupled with community amusement at the unconventional inquiry.
- Optimized LLM Setup Suspense: Discussions in the hardware channel revealed insights about multip GPU configurations without SLI for LM Studio, recommended GPUs like Nvidia's Tesla P40, and concerns regarding future hardware prices due to a major earthquake affecting TSMC.
- API Type Matters for Autogen Integration: Troubleshooting for LM Studio highlighted the importance of specifying the API type to ensure proper functioning with Autogen.
- Cross-Origin Resource Sharing (CORS) for CrewAI: A recommendation to enable CORS as a potential fix was discussed for local model usage issues in LM Studio, with additional guidance provided via a Medium article.
OpenAI Discord
-
DALL·E Enters the ChatGPT Realm: Direct in-chat image editing and stylistic inspiration have been introduced for DALL·E images within ChatGPT interfaces, addressing both convenience and creative exploration.
-
Bing API Goes Silent: Outages of the Bing API lasting 12 hours stirred up concerns among users, affecting services reliant on it, like DALL-E and Bing Image Creator, signaling a need for robust fallback options.
-
Perplexed by Emotion: Lively debate buzzed around whether GPT-like LLMs can authentically simulate emotions, pointing to the lack of intrinsic motivation in AI and invoking comparisons to psychopathy as well as the infamous Eliza effect.
-
Manager In A Box: Request for crafting prompts to tackle managerial tasks emphasizes the AI community’s interest in automating complex leadership roles, despite actual strategies or solutions not being churned out in discussions.
-
Translation Puzzles and Markdown Woes: Efforts to finesacraft translation prompts preserving markdown syntax faced headwinds; inconsistent translations, especially in Arabic, leave AI engineers questioning the limits of current language models' abilities to handle complex formatting and language nuances.
tinygrad (George Hotz) Discord
Saying Goodbye to a Linux GPU Pioneer: John Bridgman's retirement from AMD sparked discussions on his contributions to Linux drivers, with George Hotz commenting on the state of AMD's management and future directions. Hotz called for anonymous tips from AMD employees for a possible blog expose, amidst community concerns over AMD's follow-through on driver issues and open-source promises as highlighted in debates and a Phoronix article.
Linux Kernel and NVIDIA's Open Move: The discourse extended to implications of varying kernel versions, particularly around Intel's Xe and i915 drivers, and the transition preferences amongst Linux distributions, with a nod towards moving from Ubuntu 22.04 LTS to 24.04 LTS. Additionally, George Hotz referenced his contribution towards an open NVIDIA driver initiative, stirring conversations about the state of open GPU drivers compared to proprietary ones.
Tinygrad's Path to V1.0 Involves the Community: Exploration of tinygrad's beam search heuristic and CommandQueue functionality highlighted George Hotz's emphasis on the need for improved documentation to aid users in learning and contributing, including a proposed tutorial inspired by "Write Yourself a Scheme in 48 Hours". This goes hand-in-hand with community contributions, like this command queue tutorial, to polish tinygrad.
Active Member Engagement Strengthens Tinygrad: The community's initiative in creating learning materials received kudos, with members offering resources and stepping up to live stream their hands-on experiences with tinygrad, fostering a collaborative learning environment. This aligns with the collective goal to reach tinygrad version 1.0, cementing the platform's position as a tool for education and innovation.
Rethinking Memory Use in AI Models: A technical debate ensued on memory optimization during the forward pass of models, particularly regarding the use of activation functions with inverses, leveraging the inverse function rule. This represents the community's engagement in not only tooling but also foundational principles to refine processing efficiency in AI computations.
OpenInterpreter Discord
OpenInterpreter Dives into App Development: Development is progressing on an Open Interpreter iPhone app with about 40% completion, driven by community collaboration on GitHub, inspired by Jordan Singer's Twitter concept.
Making Tech More Accessible: There's a push in the Open Interpreter community to introduce a Conversational UI layer to aid seniors and the disabled, aiming to significantly streamline their interaction with technology.
Security Measures in a Digital Age: Members are warned to steer clear of potentially hazardous posts from a seemingly Open Interpreter X account suspected of being compromised, in efforts to avert crypto wallet intrusions.
Out-of-the-Box Porting Initiatives: OpenInterpreter is blurring platform lines with a new repo for Android's Termux installation, work on a M5 Cardputer port, and a discussion for implementing local STT solutions amid cost concerns with GPT-4.
Anticipation for AI Insights: The community shares a zest for in-depth understanding of LLMs, potentially indicating high interest in gaining advanced technical knowledge about AI systems.
Eleuther Discord
-
Saturation Alert for Tinystories: The Tinystories dataset is reportedly hitting a saturation point at around 5M parameters, prompting discussions to pivot towards the larger
minipiledataset despite its greater processing demands. -
Call for AI Competition Teams: There's a keen interest within the community for EleutherAI to back teams in AI competitions, leveraging models like llema and expertise in RLHF, along with recommendations to set up dedicated channels and pursue compute grants for support.
-
Defense Against Language Model Jailbreaking: A recent paper suggests that ambiguity in defining unsafe responses is a key challenge in protecting language models against 'jailbreak' attacks, with emphasis placed on the precision of post-processing outputs.
-
AI Model Feedback Submission Highlighted: Public comments on AI model policies reveal a preference for open model development, as showcased by EleutherAI's LaTeX-styled contribution, with discussions revealing both pride and missed opportunities for community engagement.
-
LLM Safety Filter Enhancement Suggestion: Conversations around mixing refusal examples into fine-tuning data for LLMs reference @BlancheMinerva's tweets and relevant research, corroborating the increased focus on robustness in safety filters as noted in an ArXiv paper.
-
Chemistry Breakthrough with ChemNLP: The release of the first ChemNLP project paper on ArXiv promises significant implications for AI-driven chemistry, sparking interest and likely discussions on future research avenues.
-
Legality Looms over Open Source AI: A deep dive into the implications of California’s SB 1047 for open-source AI projects encourages signing an open letter in protest, indicating the community's apprehension about the bill's restrictive consequences on innovation. The detailed critique is accessible here.
-
Conundrum between Abstract and Concrete: An offbeat clarification sought on how a "house" falls between a "concrete giraffe" and an "abstract giraffe" was met with a lighthearted digital shrug, indicating the playful yet enigmatic side of community discourse.
-
Open Call for Neel Nanda's MATS Stream: A reminder was shared about the impending deadline (less than 10 days) to apply for Neel Nanda's MATS stream, with complete details available in this Google Doc.
-
Engagement on Multilingual Generative QA: The potential of using Chain of Thought (CoT) to boost multilingual QA tasks is discussed, with datasets like MGSM in the mix and a generated list showcasing tasks incorporating a
generate untilfunction contributing to the conversation. -
CUDA Quandaries Call for Community Help: A user facing
CUDA error: no kernel image is available for execution on the devicewith H100 GPUs, not encountered on A100 GPUs, led to troubleshooting efforts that excluded flash attention as the cause, with further advice suggesting checking thecontext_layerdevice to resolve the issue. -
Elastic Adventures with PyTorch: Questions about elastic GPU/TPU adjustment during pretraining are met with suggestions of employing PyTorch Elastic, which showcases its ability to adapt to faults and dynamically adjust computational resources, piquing the interest of those looking for scalable training solutions.
HuggingFace Discord
Boost Privacy in Repos: Hugging Face now enables enterprise organizations to set repository visibility to public or private by default, enhancing privacy control. Their tweet has more details.
Publish with a Command: Quarto users can deploy sites on Hugging Face using use quarto publish hugging-face, as shared in recent Twitter and LinkedIn posts.
Gradio's New Sleek Features: Gradio introduces automatic deletion of state variables and lazy example caching in the latest 4.25.0 release, detailed in their changelog.
Exploring the CLI Frontier: A shared YouTube video explains how to use Linux commands, containers, Rust, and Groq in the command line interface for developers.
Pushing LLMs to Operative Zen: A user inquires about fine-tuning language models on PDFs with constrained computational resources, with a focus on inference using open-source models. Meanwhile, a discussion unfolds about modifying special tokens in a tokenizer when fine-tuning an LLM.
LangChain AI Discord
Persistent Context Quest in Chat History: Engineers discussed maintaining persistent context in chats, especially when interfacing with databases of 'question : answer' pairs, but did not converge on a specific solution. Reference was made to LangChain issues and documentation for potential ways forward.
Video Tutorial For LangServe Playground: An informative video tutorial introducing the Chat Playground feature in LangServe was shared, aimed at easing the initial setup and showcasing its integration with Langsmith.
Voice Commands the Future: Launch of several AI voice apps such as CallStar AI and AllMind AI was announced, suggesting a trend towards voice as the interface for AI interactions. Links were provided for community support on platforms like Product Hunt and Hacker News.
AI Engineering Troubles and Tutorials: A CI issue was reported on a langchain-ai/langserve pull request; and guidance was sought for a NotFoundError when employing LangChain's ChatOpenAI and ChatPromptTemplate. Meanwhile, novices were directed to a comprehensive LangChain Quick Start Guide.
Galactic API Services Offered and Prompting Proficiency Test: GalaxyAI provided free access to premium AI models, emphasizing API compatibility with Langchain, although the service link was missing. Another initiative, GitGud LangChain, challenged proficient prompters to test a new code transformation tool to uphold code quality.
Modular (Mojo 🔥) Discord
Mojo Mingles with Memory Safety: The integration of Mojo language into ROS 2 suggests potential benefits for robotics development, enhanced by Mojo's memory safety practices. C++ and Rust comparison shows the growing interest in performance and safety in robotics environments.
Docker Builds Set Sails: Upcoming Modular 24.3 will include a fix aimed at improving the efficiency of automated docker builds, which has been well-received by the community.
Logger's Leap to Flexibility: The logger library in Mojo has been updated to accept arbitrary arguments and keyword arguments, allowing for more dynamic logging that accommodates versatile information alongside messages.
Mojo Dicts Demand More Speed: Community engagement on the One Billion Row Challenge revealed that the performance of Dict in Mojo needs enhancement, with efforts and discussions ongoing about implementing a custom, potentially SIMD-based, Dict that could keep pace with solutions like swiss tables.
The Collective Drive for Mojo's Nightly Improvements: Members expressed a desire for clearer pathways to contribution and troubleshooting for Mojo's stdlib development with discussions on GitHub clarifying challenges such as parsing errors and behavior of Optional types, indicative of active collaboration to refine Mojo's offerings.
OpenRouter (Alex Atallah) Discord
-
TogetherAI Trips over a Time-Out: Users reported that the NOUSRESEARCH/NOUS-HERMES-2-MIXTRAL model experienced failures, specifically error code 524, which suggests a potential upstream issue with TogetherAI's API. A fallback model, Nous Capybara 34B, was suggested as an alternative solution.
-
Historical Accuracy Test for Chatbots a Mixed Bag: When tasked with identifying Japanese General Isoroku Yamamoto from a historical WW2 context, LLMs such as claude, opus, and haiku exhibited varied levels of accuracy, underscoring the challenge in historical fact handling by current chatbots.
-
OpenRouter Hits a 4MB Ceiling: A technical limitation was highlighted in OpenRouter, imposing a 4MB maximum payload size for body content, a constraint confirmed to be without current workarounds.
-
Roleplaying Gets an AI Boost: In the realm of AI-assisted roleplaying, Claude 3 Haiku was a focus, with users sharing tactics for optimization including jailbreaking the models and applying few-shot learning to hone their interactions.
-
Community Sourcing Prompt Playgrounds: The SillyTavern and Chub's Discord servers were recommended for those seeking enriched resources for prompts and jailbroken models, pointing to particular techniques like the pancatstack jailbreak.
LlamaIndex Discord
RankZephyr Eclipses the Competition: The integration of RankZephyr into advanced Retrieval-Augmented Generation systems is suggested to enhance reranking, with the RankLLM collection recognized for its fine-tuning capabilities.
Enhancing Research Agility with AI Copilots: A webinar summary reveals key strategies in building an AI Browser Copilot, focusing on a prompt engineering pipeline, KNN few-shot examples, and vector retrieval, with more insights available on LlamaIndex’s Twitter.
Timely Data Retrieval Innovations: KDB.AI is said to improve Retrieval-Augmented Generation by incorporating time-sensitive queries for hybrid searching, facilitating a more nuanced search capability critical for contexts like financial reporting, as illustrated in a code snippet.
Intelligent Library Redefines Knowledge Management: A new LLM-powered digital library for professionals and teams is touted to revolutionize knowledge organization with features allowing creation, organization, and annotation in an advanced digital environment, as announced in a LlamaIndex tweet.
Community Dialogues Raise Technical Questions: Discussions in the community include challenges with indexing large PDFs, issues with qDrant not releasing a lock post IngestionPipeline, limitations of the HuggingFace API, model integration using the Ollama class, and documentation gaps in recursive query engines with RAG.
OpenAccess AI Collective (axolotl) Discord
Axolotl Docs Get a Fresh Coat: The Axolotl documentation received an aesthetic update, but a glaring omission of the Table of Contents was swiftly corrected as shown in this GitHub commit, although further cleanup is needed for consistency between headings and the Table of Contents.
Deployment Woes and Wins for Serverless vLLMs: Experiences with Runpod and serverless vLLMs were shared, highlighting challenges along with a resource on how to deploy large language model endpoints.
Data Aggregation Headaches: Efforts to unify several datasets, comprising hundreds of gigabytes, face complications including file alignment. Presently, TSV files and pickle-formatted index data are used for quick seeking amid discussions on more efficient solutions.
Casual AI Model Smackdown: A light-hearted debate compared the preferences of AI models such as 'qwen mow' vs 'jamba', with the community joking about the need for additional data and resources.
Call for High-Def Data: A community member seeks resources to obtain a collection of 4K and 8K images, indicating a project or research that demands high-resolution image data.
Mozilla AI Discord
-
Windows ARM Woes with Llamafile: Compiling llama.cpp for Windows ARM requires source compilation because pre-built support isn't available. Developers have been directed to use other platforms for building llamafile due to issues with Cosmopolitan's development environment on Windows, as highlighted in Cosmopolitan issue #1010.
-
Mixtral's Brains Better with Bigger Numbers: Mixtral version
mixtral-8x7b-instruct-v0.1.Q4_0.llamafileexcels at solving math riddles; however, for fact retention without errors, versions likeQ5_K_Mor higher are recommended. For those interested, the specifics can be found on Hugging Face. -
Performance Heft with TinyBLAS: GPU performance when working with llamafile can vastly improve by using a
--tinyblasflag which provides support without additional SDKs, though results may depend on the GPU model used. -
PEs Can Pack an ARM64 and ARM64EC Punch: Windows on ARM supports the PE format with ARM64X binaries, which combine Arm64 and Arm64EC code, detailed in Microsoft's Arm64X PE Files documentation. Potential challenge arises due to the unavailability of AVX/AVX2 instruction emulation in ARM64EC, which can impede operations that LLMs typically require.
-
References for Further Reading: Articles and resources including the installation guide for the HIP SDK on Windows and details on performance enhancements using Llamafile were shared, such as "Llamafile LLM driver project boosts performance on CPU cores" available on The Register and HIP SDK's installation documentation available here.
Interconnects (Nathan Lambert) Discord
-
Opus Judgement Predicts AI Performance Boost: Discussion highlighted the potential of Opus Judgement to unlock performance improvements in Research-Level AI Fine-tuning (RLAIF), with certainty hinging on its accuracy.
-
Google's AI Power Move: Engineers were abuzz about Logan K's transition to lead Google's AI Studio, with a surge of speculation about the motives ranging from personal lifestyle to strategic career positioning. The official announcement stirred expectations about the future of the Gemini API under his leadership.
-
Logan K Sparks Broader AI Alignment Debate: The move by Logan K sparked conversations regarding AI alignment values versus corporate lures, pondering if the choice was made for more open model sharing at Google or the attractive compensation regardless of personal alignment principles.
-
The Air of Mystery in AI Advances: A member noted the ripple effect caused by the GPT-4 technical report's lack of transparency, marking a trend towards increased secrecy among AI companies and less sharing of model details.
-
Access Denied to Financial AI Analysis: Interest in AI's financial implications was piqued by a Financial Times article discussing Google's AI search monetization, but restricted access to the content Financial Times limited the discussion among the technical community.
CUDA MODE Discord
-
CUDA Crashes into LLM Optimization: The DISTFLASHATTN mechanism claims to achieve linear memory usage during the training of long-context large language models (LLMs), compared to traditional quadratic peak memory usage, allowing for up to 8x longer sequence processing. However, the community noted the absence of pseudocode for the backward pass in the paper, raising concerns about reproducibility.
-
Code Talk: For those seeking hands-on CUDA experience, the CUDA MODE YouTube channel and associated GitHub materials were recommended as starting points for beginners transitioning from Python and Rust.
-
Memory-Efficient Training Makes Waves: The DISTFLASHATTN paper with its focus on optimizing LLM training is garnering attention, and a member flagged an upcoming detailed review, hinting at further discussion around its memory-efficient training advantages.
-
Backward Pass Backlash: A member's critique regarding the lack of backward pass pseudocode in the DISTFLASHATTN paper echoed a familiar frustration within the community, calling for improved scientific repeatability in attention mechanism research.
-
Pointers to Intel Analytics' Repo: A link to Intel Analytics' ipex-llm GitHub repository was shared without additional context, possibly suggesting new tools or developments in the LLM field.
AI21 Labs (Jamba) Discord
Token Efficiency Talk: A user highlighted a paper's finding that throughput efficiency increases with per token measurement, calculated by the ratio of end-to-end throughput (both encoding and decoding) over the total number of tokens.
Speed Debate Heats Up: There's a divide on how the addition of tokens affects generation speed — while encoding can be done in parallel, the inherent sequential nature of decoding suggests each new token would add to the processing time.
Focus on Encoding Performance: Clarification in the discussion pointed to a graph that plotted the speed of generating a fixed 512 tokens, implying that observed speed improvements in the plot should be attributed to faster encoding rather than decoding.
Decoding: The Sequential Slowdown Dilemma: Queries arose about the possibility of increasing the speed of decoding despite its sequential dependency, which theoretically mandates a waiting period for each token's predecessor.
Skunkworks AI Discord
-
Eager Pythonista Joins the Fray: An eager new contributor with a background in Python, software engineering, and a Master's in data science is looking to join the team and contribute to the onboarding process, bringing expertise from AI medical research and data pipeline construction.
-
GPT-4 Stumped by Math Without Context: Even advanced AIs like GPT-4 and Claude can stumble on solving equations unless the problems are posed with clarity in natural language, indicating there's room for improvement at the current state of AI models.
Alignment Lab AI Discord
It seems there is not enough context to generate a summary. Please provide more information or discussions across the channels within the Discord guild to output a meaningful summary.
Datasette - LLM (@SimonW) Discord
- Clarification on Dialogue Data: An AI engineer clarified the terminology used within conversation logs, referencing the
responsestable inlogs.db. The term "speaker turn" or simply "turn" was proposed for the initial part of a conversation, resulting in the renaming of their app's table toturns.
The LLM Perf Enthusiasts AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The DiscoResearch Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
LAION ▷ #general (699 messages🔥🔥🔥):
-
Troubleshooting Difficulties with Optimizer Implementations: Members engaged in a technical discussion about issues they experienced with the use of
torch.compileandadd_stochastic_functions, noting compatibility problems across different devices like NVIDIA, AMD, and MPS. A potential solution involving the creation of a Python package for bf16 optim was discussed, alongside possible modifications to prevent dtype conflict errors during operations. -
Skepticism Over SD3 Efficiency Improvements: Doubts were cast regarding claims about the efficiency improvements in SD3 Turbo after a member was banned from a server for questioning the training on limited tokens and the long-term viability of the approach. There were also suggestions that reliance on tools like CLIP may introduce artifacts hindering comprehensive learning.
-
Legal Risks for AI-Generated Music: A conversation about AI music platform Suno highlighted potential copyright infringement issues, where concerns were raised that record labels' powerful legal teams could pose serious challenges if Suno trained on copyrighted music. Users discussed the complexities of proving infringement in court.
-
MPS Limitations and Crashes at High Memory Utilization: It was pointed out that Apple's MPS framework would crash when more than 2^32 bytes of data were allocated during training, despite having sufficient memory, indicating a possible internal limitation. Practical workarounds such as attention slicing were also mentioned, though they may lead to other issues like NaN during the backward pass.
-
Recommendations for Model Fine-Tuning and Scheduler Choice: There were debates over how to properly implement CLIP in conjunction with other models like T5 for better performance, with one member supporting the eventual exclusion of CLIP in favor of purely T5 based models to avoid long-term issues. Further discussions touched on inconsistencies and misinformation spread within the community regarding sampler efficiency and ideal sampling numbers.
Links mentioned:
LAION ▷ #research (11 messages🔥):
-
Scaling vs. Sampling Efficiency Analyzed: An empirical study highlighted in this article explores the influence of model size on the sampling efficiency of latent diffusion models (LDMs). Contrary to expectations, it was found that smaller models often outperform larger ones when under the same inference budget.
-
In Search of Scalable Crawling Techniques: A member inquired about research into scalable crawling methods that could assist in building datasets for model training. However, no specific groups or resources were referenced in the response.
-
Mystery of Making $50K Revealed: A humorous exchange involved a link to a Discord mod ban GIF and a guess that the secret to making $50K in 72 hours could involve being a drug mule, referencing an MLM-related meme.
-
Teasing a New Optimizer on Twitter: There's anticipation for a new optimizer discussed on Twitter, promising potential advancements in the field.
-
Visual Enhancements through Specificity: Discussing an arXiv paper, it was mentioned that fine-tuning text-to-image (t2i) models with captions that include better spatial descriptions can lead to images with improved spatial consistency.
Links mentioned:
LAION ▷ #learning-ml (1 messages):
- LangChain's Harrison Chase to Illuminate LLM Challenges: Attendees are invited to an exclusive event with Harrison Chase, co-founder and CEO of LangChain. He will discuss the challenges companies face when moving from prototype to production and how LangSmith helps overcome these hurdles, providing insights during a meetup organized for April 17th at 18:30 @Online. Register here.
- Insider Access to LLM Framework Trends with LangChain: The co-founder of LangChain, Harrison Chase, will share his expertise on using LLMs (Large Language Models) for developing context-aware reasoning applications. This talk will address the challenges encountered by companies and the solutions implemented, as part of the third LangChain and LLM France Meetup.
Link mentioned: Meetup #3 LangChain and LLM: Using LangSmith to go from prototype to production, mer. 17 avr. 2024, 18:30 | Meetup: Nous avons le plaisir d'accueillir Harrison Chase, le Co-Founder et CEO de LangChain, pour notre troisième Meetup LangChain and LLM France ! Ne loupez pas cette occasion u
Stability.ai (Stable Diffusion) ▷ #general-chat (568 messages🔥🔥🔥):
- Stable Diffusion Secrets Revealed: Members are discussing the performance of various versions of Stable Diffusion. Forge is highlighted as the fastest UI right now, and there's a lot of love for models like DreamShaper Lightning (SDXL). Users with graphics cards like the RTX 3060 and RTX 4080 noted significant speed improvements when using Forge compared to A1111, with image generation times dropping significantly.
- Anticipation Builds for SD3: The community is eagerly waiting for the release of Stable Diffusion 3.0, with estimated arrival times ranging between 3-5 weeks. However, it was noted that while SD3 will improve text rendering, it might still not achieve perfect spelling due to its limitations and model size.
- Harnessing SD for Creative Projects: Users are exploring the use of Stable Diffusion for various creative endeavors such as generating art for tabletop RPGs or contemplating storytelling through images, potentially in comic or movie formats.
- Technical Tackles and Tips: A conversation around potential issues faced while generating images, such as slow speeds or text from one prompt appearing in another, led to suggestions on utilizing specific Stable Diffusion optimizations and trying out alternative interfaces, such as Forge.
- New Models and Features on the Horizon: Excitement is also buzzing around the community for the new features like sparse control net, SegMOE, and audiosparx model, shared alongside helpful GitHub links and tips on better leveraging AI-generated content.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #general (241 messages🔥🔥):
-
Request for Full Stack Developer Recommendations: A member sought recommendations for good full stack developers, inviting direct messages from anyone able to assist.
-
Inquiry About Unsloth Enterprise Model Training: A question was raised regarding whether Unsloth Enterprise supports full model training; the response clarified that it does, but the speedup factor would be between 2-5x faster than FA2, rather than 30-40x.
-
Discussion on Prompt Formats and Implementations: Members discussed custom AI models and prompt formats, with specific references to creating a model called Cortana 1.0, designed after the AI in the Master Chief video games. Concerns were raised about finding suitable models for chat mode and utilizing correct prompt structures for efficient operation.
-
Updates and Achievements Shared in AI Development: They shared Daniel Han's tweet reflecting on the potential of AI over a few months, given the short development time so far. Benchmarks for Unsloth AI were also discussed, including a 12.29% performance on the SWE Bench by their 'Ye' model.
-
Concerns and Optimizations for AI Performance: Various members inquired about optimizations and support for different AI models and platforms. For instance, discussions revolved around the support for Galore within Unsloth, the possible open-sourcing of GPT models, and efforts to accelerate local LLM inference and fine-tuning on Intel CPUs and GPUs. An exchange with links to GitHub highlighted resources for accelerating AI inference on specific hardware. There was also a discussion about potential performance improvements and updates coming soon from the Unsloth team.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #random (12 messages🔥):
-
Asteroid Mining Company with a Twist: The Open Asteroid Impact initiative is a unique approach to asteroid mining that proposes slinging asteroids to Earth instead of mining in space. The link provided displays their logo and underscores their aim to prioritize safety and efficiency in resources acquisition from space.
-
Praise for Unsloth's Website Design: A member complimented the website design for Unsloth, noting the attractiveness of the site.
-
Creativity on a Budget: The Unsloth website's sloth images were designed with Bing DALL-E due to budget constraints. The designer also expressed intentions to eventually commission 3D artists for a consistent mascot.
-
Design Consistency Through Hard Work: Responding to an inquiry about the uniformity of design, the Unsloth website designer mentioned generating hundreds of sloth images and refining them manually in Photoshop.
-
Bing DALL-E Over Hugging Face for Speed: The designer chose Bing DALL-E over Hugging Face’s DALL E's for image generation because of the ability to generate multiple images quickly and having available credits.
Link mentioned: Open Asteroid Impact: no description found
Unsloth AI (Daniel Han) ▷ #help (278 messages🔥🔥):
-
Evaluation During Training Explained: Members discussed why evaluation datasets are not added by default during fine-tuning—adding them slows down the process. The training loss is calculated using cross-entropy loss, and evaluation loss uses the same metric.
-
Pack Smart with SFTTrainer: When using
SFTTrainer, members shared how to configure and optimize training, including the use ofpackingand avoiding using it with Gemma models, as it can lead to problems. -
Dealing with Dataset Size Challenges: Users troubleshoot issues related to OOM errors and dataset size, including a discussion on the use of streaming datasets for large volumes and the challenges with tools like PyArrow when handling very large amounts of data.
-
GGUF Conversion Confusion: A member faced issues converting a model into GGUF format and debated the appropriate approach, discussing the possible need for manual architecture adjustments in conversion scripts.
-
Inference Troubles and Unsloth Updates: There was a case of a GemmaForCausalLM object causing an attribute error, which was fixed after the Unsloth library was updated and reinstalled. A member mentioned that using 16-bit model inference led to OOM errors, and someone had an issue with Python.h missing during the setup of a finetuning environment.
Links mentioned:
Perplexity AI ▷ #general (469 messages🔥🔥🔥):
-
Discussions on Pro Models and Usage: Users exchanged insights on using different AI models, such as Claude and Haiku, for reading and interpreting PDFs. They debated the advantages of Perplexity's Pro features and models' context windows, with suggestions to use "Writing" focus for detailed responses and enable "Pro" for more concise and accurate answers. Some suggested using Sonar for speedier responses.
-
Ads Coming to Perplexity?: There was a significant concern over reports of Perplexity planning to introduce ads. Users referenced statements from Perplexity's Chief Business Officer about the potential of sponsored suggested questions, with some expressing disappointment and hoping the ad integration would not affect the Pro user experience.
-
Image Generation Queries and Accessibility: Users asked about generating images on desktop and mobile, with a response confirming that while the mobile apps do not support image generation, the website does on mobile devices.
-
Referral Links and Discounts: Users shared referral links for Perplexity.ai, mentioning the availability of $10 discounts through these links.
-
Technical Support and Feature Requests: Users inquired about technical issues like API limits and slow response times, as well as feature updates like lifting the 25MB PDF limit. There was a recommendation to use Sonar for speed and some discussions on whether Perplexity has lifted certain restrictions.
Links mentioned:
Perplexity AI ▷ #sharing (23 messages🔥):
- Tailored Article Magic: A member discovered they can create articles highly customized to their interests, highlighting the ability to hone in on specific topics using Perplexity.
- Efficient Research for Newsletters: Perplexity facilitated a user in swiftly gathering accurate information, which significantly expedited the creation of a "welcome gift" for their newsletter subscribers.
- A Noble Examination of Fritz Haber: Utilizing the Perplexity search, a member delved into the life of Fritz Haber, revealing his pivotal contribution to food production with the Haber-Bosch process, his complex history with chemical warfare, and his moral stance against the Nazi regime. The nuances include his Nobel Prize-winning achievement and the unfortunate family and historical circumstances surrounding him.
- Curiosity Fueled Learning: Users are engaging with Perplexity to feed their curiosity on diverse topics ranging from convolutions in machine learning to Zorba the Greek, showcasing the platform's versatility in addressing various inquiries.
- Conceptual Clarity on Random Forest: Multiple members sought to understand the random forest classifier, indicating a shared interest in machine learning algorithms within the community.
Perplexity AI ▷ #pplx-api (24 messages🔥):
-
No Team Sign-Up for Perplexity API: A user inquired about signing up for the Perplexity API with a team plan, but it was confirmed that team sign-ups are currently unavailable.
-
Rate Limits Confusion: A member shared confusion about rate limits, specifically using the sonar-medium-online model. Despite adhering to the 20req/m limit, they are still encountering 429 errors; it was suggested to log requests with timestamps to ensure the rate limits are enforced correctly.
-
Trouble with Temporally Accurate Results: A user reported inaccurate results when asking for the day's top tech news using the sonar-medium-online model, receiving outdated information. It was recommended to include "Ensure responses are aligned with the Current date." in the system prompt to help guide the model's results.
-
Clarifying the Perplexity API's Functionality: A clarification was sought on how the Perplexity API works. Points include generating an API key, sending the key as a bearer token in requests, and managing the credit balance with possible automatic top-ups.
-
Payment Pending Issues for API Credits: A member voiced concerns about issues when trying to buy API credits — the process indicates "Pending" status without account updates. A request for account details to check the issue on the backend was made by a staff member.
Latent Space ▷ #ai-general-chat (76 messages🔥🔥):
- Open Source SWE-agent Rivals Devin: A new system called SWE-agent has been introduced, boasting similar accuracy to Devin on SWE-bench and has the distinguishing feature of being open source.
- Apple Research Hints at AI Leapfrogging GPT-4: An Apple research paper discusses a system named ReALM, suggesting capabilities that surpass ChatGPT 4.0, in sync with iOS 18 developments for Siri.
- Claude Opus's Performance Dilemma: Conversations report a notable performance gap between Claude Opus and GPT-4, with Opus struggling in certain tasks such as the "needle-in-a-haystack" test. There's mention of a Prompt Engineering Interactive Tutorial to improve results with Claude.
- Stable Audio 2.0 Launches: StabilityAI announces Stable Audio 2.0, an AI capable of generating high-quality, full-length music tracks, stepping up the game in audio AI capabilities.
- ChatGPT Plus Enhancements: ChatGPT Plus now allows users to edit DALL-E images from the web or app, and a recent iOS update includes an option to edit conversation prompts. Detailed instructions are available on OpenAI's help page.
Links mentioned:
Latent Space ▷ #llm-paper-club-west (356 messages🔥🔥):
-
DSPy Takes Center Stage: LLM Paper Club discussed the DSPy framework comparing its utility to that of LangChain and LlamaIndex. There's an emphasis on its ability to optimize prompts for different large language models (LLMs) and migrate models easily, a capability underscored in DSPy's arXiv paper.
-
Devin's Debut Draws Discussion: The concept of Devin, an AI with thousands of dollars of OpenAI credit backing it for demos, was mentioned, generating excitement and anticipation for its potential demonstration uses.
-
Exploring DSPy's Depth: Questions around DSPy's operation and execution were posed, including whether it can compile to smaller models, rate limit calls to avoid OpenAI API saturation, and save optimization outcomes to disk using the
.savefunction. -
Prompt Optimization Potential: There was an interest in DSPy's ability to optimize a single metric and whether multiple metrics could be combined into a composite score for optimization purposes. The discussion points highlighted DSPy's teleprompter/optimizer functionality, which does not require the metric to be differentiable.
-
Practical Applications Proposed: Club members proposed various practical applications for the LLMs, including an iOS app for logging voice API conversations, a front-end platform for summarizing arXiv papers based on URLs, a DSPy pipeline for PII detection, and rewriting of DSPy's documentation.
Links mentioned:
Nous Research AI ▷ #off-topic (4 messages):
-
Autonomous GitHub Issue Resolver Unveiled: A new system named SWE-agent has been shared, boasting similar accuracy to its predecessor Devin on SWE-bench and provided with an innovative agent-computer interface. It processes tasks in an average of 93 seconds and is available as open-source on its GitHub repository.
-
The Rise and Fall of Devin: A simple remark highlights the swift evolution in AI tools with Devin considered impressive just two weeks prior to the introduction of SWE-agent.
-
Exploration of Scalable Data Crawling: A member inquires about research into methods of scalable crawling for creating large datasets, with a response indicating a broad interest in both expanding dataset size and enhancing quality.
Link mentioned: Tweet from John Yang (@jyangballin): SWE-agent is our new system for autonomously solving issues in GitHub repos. It gets similar accuracy to Devin on SWE-bench, takes 93 seconds on avg + it's open source! We designed a new agent-co...
Nous Research AI ▷ #interesting-links (17 messages🔥):
- Understanding Unseen Performance: Discussion touched on a curious phenomenon where an 80M model bested larger ones on unseen performance. Skepticism arose around the validity of this result, with suggestions such as high margin of error for unseen domain evaluations.
- Peculiar OOD Data Results: Members remarked upon the oddity of an 80M model scoring highly on out-of-distribution (OOD) data, leading to speculation about potential errors in evaluation.
- Exploring LLM Vulnerabilities: A red teaming suite created by @enkryptai was mentioned, designed to examine the vulnerabilities of Large Language Models (LLMs) including tests on @databricks's DBRX and MoE SSM LLM Jamba. Results were shared indicating the discovery of some significant issues (Tweet about LLM vulnerabilities).
- Lollms & Ollama Server Tutorial: A YouTube tutorial was highlighted showcasing how to install and use lollms with Ollama Server, aimed at tech enthusiasts (YouTube Tutorial on lollms & Ollama Server).
- China's Alternative AI Hardware: Discussion about a Chinese chipmaker Intellifusion that launched a 14nm AI processor called "DeepEyes," which is significantly cheaper than comparable GPUs. The processor's AI performance and competitive pricing could challenge high-end hardware in the AI market (Tom's Hardware article on Intellifusion).
Links mentioned:
Nous Research AI ▷ #general (137 messages🔥🔥):
-
Query on Account Bans and Tool Restrictions: A user questioned an instaban, asking for clarification whether both API and web level accounts are permitted. Another mentioned that a tool like worldsim can generate content disallowed by Anthropic.
-
Jamba Model Tuning Experience Shared: Lhl shared results of tuning a jamba model over the weekend using the shisa-v1 bilingual tuning set, despite the "marginal results". Direct links to the training scripts and configurations are provided, with an admission that results for JA MT-Bench were not spectacular.
-
Inquiry on Foundational NLP Papers: A user searched for foundational papers in NLP, having finished "Attention Is All You Need." Responses included a recommendation to watch all of Andrej Karpathy's YouTube videos.
-
Issue Sharing Models on Hugging Face: Mvds1 reported a problem with uploading models to Hugging Face due to metadata issues with safetensors.sharded key and shared a workaround from a discussion that involves manually adding a
sharded: Noneparameter to theSafeTensorsInfodefinition. -
Discussing Novel LLM Compression Mechanisms: A lively discussion about theoretical and fringe methods for LLM efficiency ensued, touching on the use of solvers like Coq for enhancing model compression, with references to works by Goertzel on using paraconsistent probabilistic logic for AGI. Specific studies discussed include the concept of interiorizing a PDLU: Proof Driven Logic Unit within an LLM and the potential of (DSPy + Solver) Hylomorphic Recursor to achieve significant model compression.
Links mentioned:
Nous Research AI ▷ #ask-about-llms (34 messages🔥):
- Exploring Agent Research: A member with a background in cognitive science and reinforcement learning suggested that efficient exploration by calibrating what the LLM already knows is an under-explored area in agent research.
- Hermes 2 Pro Gathers Praise: After testing Hermes 2 Pro, a user commended the model, particularly its function calling capabilities, which performed reliably in large chat sessions without hallucinating about non-existent tools.
- Multilingual LLM Training Clarified: In response to questions about LLM training on multiple languages, it was clarified that Mistral is primarily pretrained in English, with some European languages, but finetuning training data contains minimal non-English content. The model's coherence in other languages could be attributed to language snippets present in the predominantly English training set.
- JSON Streaming for Function Calling: A user curious about streaming parameters for function calling was directed to the oboe.js library, which provides a streaming JSON parsing technique.
- Genstruct 7B Touted for Instruction Generation: In a discussion about generating synthetic data in different domains, members suggested using Genstruct 7B, an instruction-generation model designed to create valid instructions from raw text corpuses, as a reference point for crafting diverse instructional data for fine-tuning purposes.
Links mentioned:
Nous Research AI ▷ #project-obsidian (3 messages):
- Expressions of Intent: A member conveyed enthusiasm, possibly in response to an ongoing discussion or recent update in the project.
- Dataset Development Potential: The same member acknowledged the potential for building a dataset, implying a connection to the work or topic discussed within the channel.
- Acknowledgement of Time Restraints: This member also apologized for not having had time to try out something likely related to the project.
Nous Research AI ▷ #bittensor-finetune-subnet (2 messages):
- Huggingface Model Upload Issue: A member reported a problem with uploading to the chain, pinpointing the cause as Huggingface automatically adding a
safetensors.sharded = true/falsekey to the model metadata. This key is not recognized by the Huggingface Python library, creating an obstacle in the model upload process due to the inability to loadModelInfo.
Nous Research AI ▷ #rag-dataset (7 messages):
- Scratchpad's Niche in Workflows: gabriel_syme discussed the value of using a scratchpad for intermediate results in workflows, mentioning a specific use case where
notesfunction as a scratchpad for users. - Glaive's RAG Sample Dataset Released: sahilch shared a link to a newly created sample dataset by Glaive that could aid in RAG data generation, available at GlaiveAI's RAG Sample on Hugging Face.
- DiscoResearch Synthesizes Advanced RAG Data: bjoernp from ellamind/DiscoResearch highlighted their efforts on synthetic data generation for advanced RAG applications, expressing interest in collaborating to develop a robust and varied dataset.
- Vision of RAG with Enhanced Functionality: bjoernp touted the potential of integrating RAG with function calling capabilities, enabling an LLM to manage query decomposition, multi-search coordination, and dynamic retrieval strategies.
- Ellamind's Early RAG Dataset and Intentions: rasdani introduced ellamind/DiscoResearch's preliminary RAG dataset in German and outlined their aspirations for contributing to the finetuning and enhancement of RAG capabilities, showing enthusiasm for Nous Research's previous work.
Link mentioned: glaiveai/rag_sample · Datasets at Hugging Face: no description found
Nous Research AI ▷ #world-sim (88 messages🔥🔥):
-
Creative Competitions with WorldSim: Members mused about a competitive platform for WorldSim, proposing races to achieve specific states in simulated worlds, embracing complexity, and discussing the role of rules and judges, evidencing a keen interest in gamified simulations. They referenced a Twitter post as a source for the WorldSim system prompt, and shared a Pastebin link for easy access.
-
Potential WorldSim Features Discussed: Several enhanced features for WorldSim were envisioned, such as text-to-video integration, possibly using an open-source project like ModelScope's MotionAgent, and persistent user entities and data for deeper interaction with the simulations. Some proposed advanced concepts involved read/write privileges into an actual kernel, creating a multiversive experience for users.
-
Roadmapping and Communication: There was talk about creating a community-driven roadmap and newsletter for WorldSim to inform users of potential updates and a desire for clearer communication on WorldSim's development. Suggestions arose for using visual organization tools and updates like the Dwarf Fortress roadmap shared in a link.
-
Technical Troubleshooting and Enhancements: Suggestions for improving WorldSim included ease of copy/pasting within the simulator, managing resource slowdowns, and saving/loading simulation states. Users volunteered various solutions, sharing their experiences with different versions of WorldSim integrated into platforms like Copilot and AI Dungeon.
-
Diverse Contributions and Resources: The community shared and appreciated a variety of resources, such as the WorldSim Command Index on Notion, and engaged in light-hearted banter, welcoming fellow users to a "digital afterlife". They also encountered issues with spam flags incorrectly applied to user profiles during their interactions.
Links mentioned:
LM Studio ▷ #💬-general (170 messages🔥🔥):
- LM Studio and Embedding Models Are Not Friends: Users clarified that LM Studio cannot currently support embedding models, pointing out that embedding models aren’t supported yet.
- Issues with Running LLM Studio on Certain CPUs: Discussed that LLM Studio installation problems might occur on processors that do not support AVX2 instructions, citing an older beta version available but noting that it's deprecated and not highly supported.
- Troubleshooting Model Loading Errors: Several members confronted errors when trying to load models into LM Studio, and advice included looking at presets lists, revising config files, and posting in specific help channels with system specs for further assistance.
- Usage of Local Server and Stability Concerns: Conversation included praises about the local server mode, while others expressed struggles with LLM's degrading performance or inability to maintain context in conversations, with suggestions to adjust context size and investigate logging.
- GPU performance and multi-user environment handling: Inquiries about hardware requirements for running models in LM Studio arose, with mentions of settings to offload GPU layers, and discussions on the feasibility of handling multiple users' chat requests in parallel, recommending enterprise-level solutions like Nvidia DGX H100 servers for companies.
Link mentioned: AnythingLLM | The ultimate AI business intelligence tool: AnythingLLM is the ultimate enterprise-ready business intelligence tool made for your organization. With unlimited control for your LLM, multi-user support, internal and external facing tooling, and 1...
LM Studio ▷ #🤖-models-discussion-chat (13 messages🔥):
- Databricks Download Dilemma: A member inquired about downloading databricks/dbrx-instruct into LM Studio but was informed that it is currently unsupported and resource-intensive, even failing to load in Apple MLX with 128gb M3 Max.
- Model for Hentai Anime Recommendations Sought: A user asked for a model capable of recommending hentai anime, but was advised to use MyAnimeList (MAL) as a conventional alternative and provided with the link: myanimelist.net.
- Hentai Recommendation Query Draws Humor: The community reacted with humor to the request for a model specializing in hentai anime recommendations, appreciating the user's audacity.
- Training LLMs with System Prompts: There was a discussion about the possibility of using the outputs of an LLM with a complex System Prompt to train another LLM to inherit this prompt's functionality, which could work as a form of model fine-tuning.
- Odd Response from Employer's Model: A member reported strange behavior from their employer's model, which consistently provided a non-relevant response related to completing a crossword puzzle, hinting at a possible issue with presets.
Link mentioned: MyAnimeList.net - Anime and Manga Database and Community : Welcome to MyAnimeList, the world's most active online anime and manga community and database. Join the online community, create your anime and manga list, read reviews, explore the forums, follo...
LM Studio ▷ #🧠-feedback (3 messages):
- Embedding Models Inquiry: A member asked about using embedding models with LM Studio and mentioned downloading an SFR embedding gguf model from Hugging Face.
- Embedding Support Currently Unavailable: In response, another participant clarified that embedding models are unsupported at this current time within LM Studio.
LM Studio ▷ #🎛-hardware-discussion (69 messages🔥🔥):
- Debunking SLI myths for LM Studio: Discussion clarifies that SLI is not required to use two GPUs and has been phased out post-3090 generation, with members confirming good performance running LM Studio with multiple GPUs without SLI, including configurations like 2x 3090s and 2x 48GB RTX8000s.
- P40 GPUs Attract Interest: A member shared a Reddit post about the performance of the Nvidia Tesla P40, while another outlined a detailed build using three P40s, capable of running a 70B parameter model efficiently.
- Performance Surprises in LM Studio: Users reported significant performance differences between systems, with one noting an AMD system running slower than expected. However, switching to ROCm preview showed a performance jump to about 65 tokens/sec, indicating that software and driver choices can have a drastic impact on performance.
- Considering GPU Upgrades for Faster LLM Responses: A user contemplating a hardware upgrade for improved performance with LLMs was advised that a 4090 GPU and a PSU upgrade would be sufficient, without a need for CPU changes.
- Concerns Over Future Hardware Prices: Discussion touched on potential impacts on GPU and Mac pricing following a major earthquake at TSMC production lines, suggesting these items could become more expensive or scarce.
Links mentioned:
LM Studio ▷ #autogen (3 messages):
- Troubleshooting LM Studio with Autogen: A user encountered an issue where Autogen is only returning a couple of tokens and then stops. They are unsure if special steps are needed for proper integration between LM Studio and Autogen.
- Model and API Specifications Matter: Another member hinted that the problem might be due to the incorrect model name and possibly omitting the API type in the configuration. They suggest checking the model details section in LM Studio for accurate information.
- API Type is Critical: It was confirmed that specifying the API type is essential for LM Studio to work with Autogen.
LM Studio ▷ #crew-ai (3 messages):
-
Troubleshooting LM Studio Connection: A member reports successfully integrating a project with OpenAI GPT-4 but faces issues when connecting it to LM Studio for local model usage. The local model, "TheBloke/Mistral-7B-Instruct-v0.2-GGUF/mistral-7b-instruct-v0.2.Q4_K_S.gguf," does not return a response despite the LM Studio Server indicating a streaming response.
-
CORS Might Be the Culprit: In response to the connection issue, another member suggests enabling CORS as a possible solution to the problem with LM Studio and crewai communication.
-
Helpful Resource for Integration: For further assistance with implementing LM Studio in crewai, a member provides a helpful Medium article guide.
OpenAI ▷ #annnouncements (1 messages):
- DALL·E Images Now Editable in ChatGPT: Users can now edit DALL·E images directly in ChatGPT across web, iOS, and Android platforms. Additionally, getting inspiration on styles when creating images with DALL·E in GPT is now possible.
OpenAI ▷ #ai-discussions (173 messages🔥🔥):
Links mentioned:
OpenAI ▷ #gpt-4-discussions (57 messages🔥🔥):
-
DALL-E's Inpainting Tease: Members are discussing the new editing feature in DALL-E that allows for style suggestions and inpainting, editing specific parts of an image. This feature seems to only be available to Plus plan members or above, and its rollout isn't complete, as some users report being unable to access it.
-
ChatGPT Performance Discussions: In the community, there are varying opinions and experiences regarding the performance of different models such as GPT-4 and Anthropic's Opus. One finds GPT-4 better in reasoning tasks and more consistently coherent, while another suggests that Opus outperforms GPT-4 in some areas.
-
Utilizing Custom GPTs: A lively debate is happening about the use of custom GPTs versus the base ChatGPT model. While some enjoy the efficiency these tailored models bring to the table, one user prefers the flexibility and direct interaction with the base model.
-
Exploring Custom Prompt Engineering: The discussion has touched on the advantages of custom GPTs for complex prompt construction. Users are sharing techniques on chaining prompts together using the builder menu and contrast the ease of custom GPTs with the process of instructing the base GPT model.
-
Plus Plan Perks: Users with Plus plans are inquiring how to use new Plus features like image editing since the feature isn't clearly available or functioning for everyone. The feature should present a noticeable button for editing after selecting an image if the rollout has reached the user’s account.
OpenAI ▷ #prompt-engineering (11 messages🔥):
- Seeking Manager Replacement Prompts: A member is looking for prompts to manage tasks like dividing directives and performance plans for middle management and C-suite roles. No specific suggestions or responses were provided in the discussion.
- Numpy Novice Needs a Hand: Amayl_ expressed difficulty with numpy, mentioning that it's related to a machine learning course they are taking. They asked for assistance but did not provide details of the exercise in question.
- Troubleshooting ChatGPT for Exercise Help: Eskcanta suggested asking ChatGPT, even the 3.5 model, for help with Amayl_'s exercise by copying and pasting the exercise details. No follow-up on this suggestion was given.
- Markdown Translation Conundrums: Mat_adore is facing issues with translating markdown text, where responses in Arabic are inconsistently translated or not translated at all. They shared several variations of their prompt with the goal of preserving markdown, links, and proper names.
- Prompt Engineering Frustrations Amplify: Mat_adore adjusted their translation prompts multiple times to address issues with markdown and proper language conversion but continues to face challenges, expressing frustration with inconsistent results.
OpenAI ▷ #api-discussions (11 messages🔥):
- Seeking Managerial Prompt Guidance: A user inquired about effective prompt strategies for manager replacement tasks, particularly catered to middle and C-suite management, which involves dividing up directives and performance plans.
- ML Course Numpy Assistance Requested: A member asked for assistance with a numpy exercise related to their machine learning course but did not provide specific details about the issue they are facing.
- Translation Troubleshooting: One user reported inconsistent results when translating markdown content into different languages; for some languages like Arabic, the output was occasionally untranslated, leading to frustration. They are seeking a prompt modification that ensures consistent translation while preserving markdown formatting.
- Markup Preservation a Challenge: The same user attempted various prompt iterations to maintain markdown markup and proper translation but continued to experience issues—specifically with language maintenance and appropriate markdown formatting in the translated text.
- Quest for a Foolproof Translation Prompt: Continuous efforts to craft an accurate translation prompt for markdown content have led to mixed results, with the user still facing challenges in achieving translation consistency and correctness in the target language while preserving both links and markdown markup.
tinygrad (George Hotz) ▷ #general (148 messages🔥🔥):
-
Farewell to a GPU Giant: John Bridgman retires from AMD, recognized for his contribution to getting a driver upstreamed into the Linux kernel. George Hotz comments on his impact and expresses skepticism about AMD’s management and their handling of GPU issues, inviting anonymous insights from AMD employees for a potential blog post. See discussions on Phoronix and a Twitter thread.
-
Open GPU Challenges and Promises: The AMD team's perceived inaction on GPU drivers and open-source commitments sparks debate; George Hotz highlights a history of unfulfilled promises and contends that significant cancellations might be the needed wake-up call for AMD. There's cautious optimism on an open-source approach marked by an AMD tweet, but credibility of their commitments is under scrutiny.
-
Kernel Discussions and Distro Evolution: The conversation moves to discuss the implications and support challenges of various kernel versions tagging Intel's Xe and i915 drivers, and the potential move from Ubuntu 22.04 LTS to 24.04 LTS. It wraps up with George Hotz stating he will switch to 24.04 LTS once dependencies align, coinciding with com.apple's migration to 24.04 from 20.04.
-
Logo Redesign Contributions: The community engages in updates to the tinygrad documentation, including the introduction and adjustment of a new SVG logo that adapts to light and dark mode. George Hotz commits the final changes, noting the removal of "excess stuff" and gratitude for the discovery of the 'source media' attribute helpful in the update.
-
NVIDIA Open GPU Driver Speculations: George Hotz shares a link to his own contribution to an open NVIDIA driver, clarifying it’s not the Nouveau driver but instead NVIDIA's open GPU kernel modules. This stirs up a discussion on the comparative merits and support of open GPU drivers across different hardware manufacturers.
Links mentioned:
tinygrad (George Hotz) ▷ #learn-tinygrad (28 messages🔥):
- Understanding Tinygrad's Beam Search Heuristic: A member was inquiring whether the beam search heuristic for tinygrad is related to the time it takes, prompting a discussion but no specific conclusion was reached.
- CommandQueue Sheds Light on Tinygrad's Functionality: George Hotz noted that CommandQueue serves as a replacement for the
run_schedulefunction within tinygrad. For a deep dive, alveoli3358 shared a tutorial on the new command queue implementation. - Memory Optimization Queries Spark Technical Evaluation: A member sparked a discussion by questioning if memory could be released during the forward pass specifically for activation functions with inverses. They referenced the inverse function rule from Wikipedia to illustrate the point further.
- Towards a More Polished Tinygrad: In the pursuit of reaching version 1.0, George Hotz highlighted the imminent need for more documentation and tutorials for tinygrad. He also suggested creating a tutorial similar to "Write Yourself a Scheme in 48 Hours" to help users learn by implementing pieces themselves.
- Community Engagement and Tutorial Contributions: Members are actively contributing to tinygrad's learning resources, with positive feedback from fellow users. Contributions such as tutorials and live streaming oneself going through the quick start guide are helping users, particularly newcomers, to understand and engage with the technology.
Links mentioned:
OpenInterpreter ▷ #general (93 messages🔥🔥):
-
Open Interpreter App Development: Members discussed the potential of an iPhone app that communicates with Open Interpreter, referencing Jordan Singer's Twitter post. A React Native app is in development, around 40% completed, with the repository shared on GitHub for community collaboration.
-
Accessibility Focus for Open Interpreter: A member highlighted the significance of a Conversational UI layer to assist seniors and people with disabilities, aiming to simplify human-computer interaction by reducing search, click, and data management efforts.
-
Security Alert: Open Interpreter's X account Possibly Compromised: The Open Interpreter community cautioned against clicking links in suspicious posts from what appeared to be a compromised Open Interpreter X account and encouraged reporting the account to prevent crypto wallet breaches.
-
Community Engagement Reminder: Mike Bird reminded everyone about the April House Party, providing a Discord event link and prompted discussion on how Open Interpreter could universally improve the human condition.
-
Interactive Installation Queries Resolved: One user inquired about installation issues related to chroma-hnswlib, and the issue was directed to a more appropriate channel, emphasizing the value of community engagement and shared resolutions for technical snags.
Links mentioned:
OpenInterpreter ▷ #O1 (66 messages🔥🔥):
- OI on Android Termux: A repo has been shared providing instructions for installing the OpenInterpreter on Android devices using Termux, available here.
- Linux Server Hurdles: Multiple users are experiencing difficulties running the 01 server on various Linux distributions, with issues relating to audio and dependencies like
portaudio19-dev. - Suggestions for Local STT Usage: It was suggested that to cut down on costs, local Speech-to-Text (STT) could be used instead of cloud services before feeding text outputs to OpenAI, leveraging tools like
Whisper.cpp. - Porting on M5 Cardputer: Work is underway to port OpenInterpreter to the M5 Cardputer, with updates and branches shared, including a function to send messages to both serial and screen. The relevant GitHub repo can be found here.
- GPT-4 Cost Concerns and Alternatives: Discussion on the high cost of testing with GPT-4 led to suggestions of more cost-effective alternatives like
gpt-4-turboand Claude’s Haiku; concerns are being considered for future model defaults in OpenInterpreter.
Links mentioned:
OpenInterpreter ▷ #ai-content (2 messages):
- Excitement Over Deep Dives: A member expressed enthusiasm about gaining deeper insights into the underlying mechanisms that drive Large Language Models (LLMs). The use of a rocket emoji underscored the member's excitement for this advanced knowledge.
Eleuther ▷ #general (67 messages🔥🔥):
-
Performance Limits of Tinystories: A discussion highlighted the limitations of the Tinystories dataset for model training, mentioning that it begins to saturate around 5M parameters. Members suggested utilizing the
minipiledataset instead, as it's roughly 4 times larger, although more resource-intensive to process. -
Interest in AI Competitions: Community members expressed a desire for EleutherAI to sponsor groups to compete in AI competitions, specifically citing the potential of leveraging the llema models, carperai, and other partners with RLHF expertise. To facilitate competition participation, a suggestion was made to form a group in a specified chat channel and discuss eligibility for compute grants.
-
EAI's Position on Jailbreak Defenses and Unsafe Outputs: An arXiv paper was shared, raising doubts over the effectiveness of existing enforcement mechanisms guarding against "jailbreak" attacks on language models. The paper argued the importance of having a clear definition of unsafe responses for better defense strategies, highlighting the adequacy of post-processing outputs.
-
Seeking PyTorch Interview Tips for Research Engineering Roles: With members seeking advice for research engineering interviews focusing on PyTorch knowledge, there was consensus on the importance of discussing one's work confidently. Tips included relying on the STAR method for behavioral questions and mastering medium-level coding problems that most candidates would get correct.
-
Public Comments on AI Models: A link to public comments from regulations.gov discussing open AI models was shared, with EleutherAI's comment highlighted for its LaTeX formatting. Some members regretted not contributing, while others nodded to the predominant support for open models and rejection of fearmongering in the comments section.
Links mentioned:
Eleuther ▷ #research (53 messages🔥):
-
Exploring LLM Robustness Ideas: A suggestion to investigate the robustness of safety filters for LLMs was shared, referencing a tweet by BlancheMinerva discussing the potential of using refusal examples mixed into finetuning data. The concept aligns with current research indicated by a provided ArXiv paper.
-
Monitoring Open Source AI Legislation: An analysis of California’s SB 1047's impact on open-source AI development was highlighted, with an open letter available for signatures. The bill critiques are extensive, addressing concerns of legal liability and efficiency in the AI field, and the full analysis can be found here.
-
Discoveries in AI Jailbreaking: Anthropic's new research on "many-shot jailbreaking," a technique effective on various LLMs including their own, was discussed along with a critique about the originality of the paper's findings on how in-context learning follows power laws. The full paper can be explored on their research page.
-
ChemNLP First Paper Published: The first paper from the ChemNLP project through OpenBioML.org, which may be an important step in AI-driven chemistry, has been made available on ArXiv.
-
Discussing Gradient Notations in Research: A conversation about notation for gradients ensued, with suggestions on whether to use partial derivative notation or the nabla symbol depending on whether the gradient refers to model parameters or not. The discussion also touched on preferences for different versions of the epsilon symbol in reports.
Links mentioned:
Eleuther ▷ #interpretability-general (4 messages):
- Abstract House Conundrum: A member humorously questioned how a house could be considered somewhere between a concrete giraffe and an abstract giraffe.
- Keep Calm and Shrug On: In response to the abstract/concrete giraffe house conundrum, another member offered a classic internet shrug emoticon as a nonchalant answer.
- Opportunity Closing for Neel Nanda's MATS Stream: The admissions procedure for Neel Nanda's MATS stream closes in just under 10 days, with a link to the application details on Google Docs.
- Cryptic Twitter Mention: A member shared a tweet, with the context and content of the tweet not included in the message.
Link mentioned: Neel Nanda MATS Stream - Admissions Procedure + FAQ: no description found
Eleuther ▷ #lm-thunderdome (24 messages🔥):
- Exploring Multilingual Generative QA: Participants acknowledged the potential for using Chain of Thought (CoT) variants to improve performance on multilingual QA tasks and are considering datasets like MGSM and others like
nq_openortriviaqa. - Generate Until Task Arouses Interest: Debugging efforts led to the observation that not many tasks utilize the
generate untilfunction, with confirmed ones being gsm8k, bigbench, and mgsm. Later, a comprehensive list was found containing tasks that implementgenerate until. - Troubleshooting Multi-Choice Output in LM Eval: There was a discussion about resolving an "index out of range" issue when using multiple-choice outputs for evaluation datasets in a CSV format, hinting at adjusting indexing for the answers.
- CUDA Error Conundrum on Different GPU Architectures: A user encountered a
CUDA error: no kernel image is available for execution on the devicewhen running an older version of the LM Eval Harness on H100 GPUs, while A100 GPUs worked fine. The issue was isolated to not being caused by flash attention. - CUDA Error Investigation: Further investigation into the CUDA error suggested it is not being caused by the
.contiguous()function, as minimal examples with this operation work correctly. The advice was given to check the devicecontext_layeris on to further troubleshoot the issue.
Link mentioned: Build software better, together: GitHub is where people build software. More than 100 million people use GitHub to discover, fork, and contribute to over 420 million projects.
Eleuther ▷ #gpt-neox-dev (2 messages):
- Elastic Pretraining Frameworks: One user inquired about pretraining frameworks capable of elastic GPU/TPU adjustment during training. Another user provided a solution using PyTorch Elastic, which allows jobs to run fault-tolerantly with a specified number of restarts, and can handle joining nodes in an elastic fashion.
Link mentioned: Quickstart — PyTorch 2.2 documentation: no description found
HuggingFace ▷ #announcements (3 messages):
- Set Your Visibility: Enterprise organizations on 🤗 now have the option to set default repository visibility to public, private, or private by default. Check out the tweet for more info.
- Quarto Publishing: Quarto! now allows users to deploy sites on Hugging Face with a simple command
use quarto publish hugging-face. Detailed instructions can be found in these Twitter and LinkedIn posts. - New HF Enterprise Page and HuggingChat Updates: A new HuggingFace Hub Enterprise page is live, and HuggingChat assistants now support custom settings for generation parameters. Discover the new Enterprise page and HuggingChat features.
- Fine-Grained Control & GGUF on the Hub: There's now fine-grained access control per repo for Enterprise orgs, and GGUF support updates on the Hub have been implemented. Find out more about access control in this tweet and GGUF updates in this status post.
- Datasets 2.18.0 Released: The release of Datasets version 2.18.0 brings new features, JSON builder support, and ensures compatibility with PyTorch data types. Explore the new release.
HuggingFace ▷ #general (70 messages🔥🔥):
- Searching for Multilingual Image-Captioning Models: A user inquired about pretrained image-captioning models that support multiple languages, including Portuguese, but no specific solutions were given.
- Stable Diffusion for Photo Lighting: A discussion around using Stable Diffusion to equalize lighting in photos took place, with a member pointing to normalization of luma instead of manipulating the image texture directly. The conversation included the desire to batch process images with various lighting biases.
- Precision Goals in NLP Project: Members engaged in a discussion about acceptable precision levels for NLP projects, with one user questioning if 0.68 precision is good enough for a first project. Another suggested aiming for at least 80% precision.
- Fine-Tuning Challenges and Solutions: Users shared experiences and challenges related to fine-tuning Mistral models, with references to successfully fine-tuned versions like Mistral Alpaca LoRA and tips on using Google Colab for the process.
- Summarization Pipeline Tweaks for Brevity: One user sought advice on generating shorter summarizations using the Hugging Face summarization pipeline. The conversation included hints to adjust
max_new_tokensrather thanmax_lengthto avoid truncated outputs, with more discussions directed to Hugging Face's Discord channels.
Links mentioned:
HuggingFace ▷ #today-im-learning (2 messages):
- Exploring the Command Line Universe: A channel member shared a YouTube video titled "Super User Do - Tinkering with Linux commands, Containers, Rust, and Groq", offering an introduction to navigating a computer using the command line interface (CLI).
- A New Perspective on Scaling: Discussion hinted at an unidentified subject that is scaled exponentially rather than linearly, although specific details were not provided.
Link mentioned: Super User Do- Tinkering with Linux commands, Containers, Rust, and Groq: A brief intro for basic commands to navigate your computer from what's called the "command line interface" or "CLI". How to update, upgrade, move in and out ...
HuggingFace ▷ #cool-finds (5 messages):
- Innovations in Text Generation: A Medium article was shared discussing IPEX-LLM and LlamaIndex highlighting their potential to shape the future of text generation and chat applications. Read about these advances in the full article here.
- Testing the Waters of LLM Security: A new suite for red teaming has been developed to test the vulnerabilities of LLMs, with a specific focus on DBRX and Jamba. Details of their findings are mentioned in the shared tweet.
- Educational Watch: GPT Demystified: A YouTube video from 3blue1brown titled "But what is a GPT? Visual intro to Transformers" offers an engaging explanation of transformers and GPT architectures. Preview the educational content here, with acknowledgments to the video’s supporters.
- Apple Claims AI Supremacy Over OpenAI: A short notice revealed that Apple announced its latest model being more powerful than OpenAI's GPT-4, without providing additional details or supporting evidence.
Links mentioned:
HuggingFace ▷ #i-made-this (14 messages🔥):
-
Musical Innovation Strikes a Chord: A new Gradio app called a 'musical slot machine' was created, integrating Musiclang for random seed generation or input chords and allowing users to pick from community-made fine-tunes. The result is a form of text2midi2audio conversion, highlighted in a YouTube video, and though the app is made for testing fine-tunes, it doubles as a playful instrument for musicians.
-
Bringing Order to Chaos with Hypergraph Visualization: A Space for visualizing high-dimensional hypergraph datasets was constructed, dealing with up to 150k rows and serving as a way to bring sense to the complex information. A concise link to the Space was shared, along with a reference to the original collection and an accompanying Twitter thread.
-
Octopus 2 Hooks Developers with Functionality: A demo for Octopus 2, a model capable of function calling, debuted. Although it takes 1500 seconds to render, the model promises new possibilities, especially with excitement building around on-device models, highlighted in the Space.
-
Local Tune Assembly Hits a High Note: Discussion highlighted that music models might be better off running locally to improve accessibility and usability, in line with the concept of on-device models being more convenient.
-
GPU Expense Spurs Optimism for CPU Optimizations: The high cost of GPUs fueled a conversation about the anticipation of significant advancements in CPU optimization for AI and ML applications in the near future.
Links mentioned:
HuggingFace ▷ #computer-vision (3 messages):
- Effective Batch Size Optimization: Seanb2792 mentioned that while computationally the cost might be similar, increasing the effective batch size can be achieved without using additional VRAM. This is particularly valuable as larger batch sizes may enhance the performance of certain models.
- Batch Size Affects Model Performance: In tests on medical data, Huzuni found that a larger batch size generally results in better performance, even if the improvements are marginal or non-significant.
- Batch Normalization Draws Concern: Huzuni also observed that accumulating more than two batches can have a detrimental effect on performance, likely due to batch normalization, based on their latest tests.
HuggingFace ▷ #NLP (13 messages🔥):
-
LLM Fine-tuning on a Budget: A user is exploring how to build a language model on top of PDFs with limited computational resources, preferring to use inference with open-source models like llama2, mistral, phi, etc. There is an inquiry about the minimum requirements for llm models, mentioning that phi-2 requires more than 10GB of free space to run on a PC with 16GB RAM.
-
KV Cache Queries in Transformers: A member asks for use cases or examples related to using KV Cache with HuggingFace, linking to the specific Dynamic Cache in the transformers' GitHub repository.
-
Changing Special Tokens in Tokenizers: There's a discussion on how to modify special tokens in a tokenizer when fine-tuning an LLM. A member provided a solution to add new special tokens using
tokenizer.add_special_tokens(special_tokens)and another advised changing the tokenizer's dictionary directly but cautioned about potential merges during tokenization. -
Issues with Multinode Fine-tuning: A user experiences a timeout while trying to finetune llama2 using multi-node from Docker with deepspeed and axolotl. Despite having proper communication between nodes and visible GPUs in their stack, the fine-tuning process freezes with the given deepspeed command.
-
Calls for Structured Training Examples: A user struggles with training GPT2 for text summarization, encountering issues like OOM errors and stagnating validation metrics. They suggest that HuggingFace should provide structured examples on how to perform specific tasks with various models to aid users in their training efforts.
Link mentioned: transformers/src/transformers/cache_utils.py at c9f6e5e35156e068b227dd9b15521767f6afd4d2 · huggingface/transformers: 🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX. - huggingface/transformers
HuggingFace ▷ #diffusion-discussions (8 messages🔥):
-
Seeking DiT with Enhanced Conditioning: A user inquired about a modified DiT (Diffusion Image Transformer) that supports conditioning with text, images, or other modalities using cross-attention. The only available DiT on Hugging Face Diffusers is conditioned by class, and the original team's source code isn't publicly shared, as noted with a link to the paper.
-
Cost Concerns of Public DiTs: A member pointed out that publicly available DiTs are class-conditioned because it's more cost-effective compared to cross-attention methods, echoing the discussion about the expense of such models.
-
Exploration of Diffusion Models for Depth Mapping: A user is considering modifying Stable Diffusion (SD) for converting stereo images into depth maps, as the current best public model for such a task is inadequate for their challenge.
-
Potential Modification of Stable Diffusion Architectures: The user asked if it's possible to fine-tune Stable Diffusion using input images with more than three channels, exploring the feasibility of using LoRA or ControlNet with StableDiffusion for their task.
-
Advocacy for Modifying SD Over Training from Scratch: In response to the query, another participant suggested slightly modifying the SD architecture to adapt it for the user's needs, indicating that training from scratch should be a last resort option.
HuggingFace ▷ #gradio-announcements (1 messages):
- Gradio Hits Version 4.25.0: A new update for Gradio is out, introducing automatic deletion of
gr.Statevariables for better traffic management and an unload event for browser tab closures. The update also features lazy example caching withcache_examples="lazy"suitable for ZeroGPU, a fix for a bug with streaming audio outputs, and enhancements togr.ChatInterface, including image pasting from the clipboard. - Changelog Ready for Review: The full list of changes and fixes in Gradio 4.25.0 can be explored in the changelog.
LangChain AI ▷ #general (104 messages🔥🔥):
- Searching for Persistent Chat History Solutions: A member inquired about techniques for maintaining persistent context when chatting with a database formatted with 'question : answer' pairs, expressing uncertainty about which methods to apply.
- Structured Tool Validation Query: A discussion unfolded around validating fields in a
StructuredToolusing LangChain. The conversation mentioned utilizing Pydantic'sBaseModelandroot_validatorfor field validation, referencing specific Github issues and documentation. - Exception Handling in Structured Tools: Members explored strategies on how to catch and display
ValueErrortexts in structured tools when error conditions are met, with reference to Github issues for relevant methods. - Integrating Langchain with External APIs: Questions arose regarding the integration of LangChain with Azure API Management (APIM), in particular fetching results with AzureOpenAI, for which a troubleshooting link to a specific Github issue was suggested.
- Creating a Database-Connected Appointment Bot: A member sought assistance for creating a bot in LangChain and Javascript that not only schedules appointments but also handles the storage and retrieval of dates from a database, prompting recommendations for libraries like Sequelize and node-postgres.
Links mentioned:
LangChain AI ▷ #langserve (2 messages):
-
CI Confusion on Langserve: A member sought assistance with a failed CI related to a pull request #580 on langchain-ai/langserve. They indicated having tested the changes locally with Python 3.10, where all tests passed.
-
New Tutorial for Langserve Chat Playground: A full video tutorial was shared explaining how to utilize the new Chat Playground feature of Langserve, especially in cases where it does not work out of the box. Here is the video link, which also includes a showcase of Langsmith and the final code in the description.
Links mentioned:
LangChain AI ▷ #share-your-work (7 messages):
-
Prompt-Breaking Challenge Issued: A member introduced a tool for automatically generating code transformations to ensure code quality and standards for production. Feedback is solicited from proficient prompters to test the tool and the link GitGud LangChain was shared for this purpose.
-
CallStar AI Voice Apps Launched: The member announced the launch of several AI voice apps including CallStar AI, Call Jesus AI, Call PDF AI, Call Tube AI, Call Website AI, and Call Hacker News AI. Enthusiasm for voice as the future of AI interaction was expressed, and links to support the project on Product Hunt, Reddit, and Hacker News were provided.
-
AllMind AI Emerges for Financial Analysis: A new large language model called AllMind AI was launched for financial analysis and research. This LLM aims to revolutionize financial research by providing access to insights and comprehensive financial data on a single platform, with promotional links on AllMind Investments and Product Hunt.
-
Galaxy AI Unveiled: GalaxyAI has announced a free API service giving access to premium AI models including various versions of GPT-3.5, GPT-4, and Gemini-PRO API, all compatible with Langchain integration and formatted like OpenAI's APIs. They encouraged integration into projects and provided a link for trying the service, though the URL was not included in the message.
Links mentioned:
LangChain AI ▷ #tutorials (1 messages):
-
Your Guide to the LangChain Universe: A member highlighted the LangChain Quick Start Guide which offers a comprehensive introduction to LangChain, including setting up LangSmith and LangServe, using prompt templates, models, output parsers, and building simple applications.
-
Encountering the 404 Abyss: When attempting to run LangChain code involving
ChatOpenAIandChatPromptTemplate, a member encountered aNotFoundErrorwith a 404 error code suggesting a "Resource not found" issue. This hiccup occurred during the execution of the member's program in their virtual environment.
Link mentioned: Quickstart | 🦜️🔗 Langchain: In this quickstart we'll show you how to:
Modular (Mojo 🔥) ▷ #general (38 messages🔥):
- Comprehensive Mojo Docs Praised: The Mojo documentation was mentioned to be fairly comprehensive, offering insight into future implementations, including MAX Engine and C/C++ interop, which are expected to enhance development and efficiency.
- Mojo and Mathematical Variable Names: A question about Mojo supporting mathematical variable names like Julia led to a clarification that currently Mojo only supports ASCII for variable names and follows Python's convention for variable naming, starting with a character or underscore.
- Debate on Mojo's Variable Naming with Emojis: A discussion emerged on whether Mojo supports non-traditional variable names, confirming that emojis and other symbols can be used as variable names if enclosed in backticks.
- Mojo's Wikipedia Page Needs Updates: Concerns were raised over the poor state and outdated information on Mojo's Wikipedia page, with a recent edit correcting the misunderstanding that Mojo is still proprietary.
- Code Snippet Troubleshooting: There was a troubleshooting discussion about a code snippet where
listdirreturned a list of references which needed to be dereferenced using[]to allowprintto work properly, a solution was found and applied successfully.
Link mentioned: Mojo🔥 roadmap & sharp edges | Modular Docs: A summary of our Mojo plans, including upcoming features and things we need to fix.
Modular (Mojo 🔥) ▷ #💬︱twitter (3 messages):
- Modular Tweets Its Moves: Modular shared a tweet on their official Twitter handle which can be checked out here.
- Another Tweet from Modular: Another tweet was posted by Modular on their Twitter account.
- Modular Continues the Twitter Streak: Modular posted yet another tweet on their Twitter feed.
Modular (Mojo 🔥) ▷ #✍︱blog (1 messages):
- MAXimum Mojo Momentum: The Modular Mojo 24.2 update has been released and details are provided in a recent blog post. This release is especially significant for Python developers adopting Mojo, offering a line-up of new features and enhancements.
Link mentioned: Modular: What’s new in Mojo 24.2: Mojo Nightly, Enhanced Python Interop, OSS stdlib and more: We are building a next-generation AI developer platform for the world. Check out our latest post: What’s new in Mojo 24.2: Mojo Nightly, Enhanced Python Interop, OSS stdlib and more
Modular (Mojo 🔥) ▷ #ai (4 messages):
-
Proposing Mojo on ROS 2: A member suggested integrating Mojo support into ROS 2, a widely used robotics middleware framework, with potential benefits due to Mojo's memory safety practices. The ROS 2 community has native Rust support, with a shift towards Rust-based middleware like Zenoh.
-
Rust vs Python in ROS 2: It was noted that despite most of the ROS 2 community's preference for Python due to their research backgrounds, Rust offers a compelling alternative in terms of performance and safety.
-
Rewriting Python Code for Performance: The member mentioned that while many robotics systems are initially written in Python for convenience, they are often rewritten in C++ for speed in serious applications.
-
Mojo's Potential with Nvidia Jetson: It was pointed out that Mojo could better leverage hardware like Nvidia Jetson products, which are increasingly used in robotics, unlike Python which is limited by the Global Interpreter Lock (GIL).
Link mentioned: GitHub - ros2-rust/ros2_rust: Rust bindings for ROS 2: Rust bindings for ROS 2 . Contribute to ros2-rust/ros2_rust development by creating an account on GitHub.
Modular (Mojo 🔥) ▷ #tech-news (2 messages):
- Docker Builds on Autopilot: A fix is prepared for version 24.3 that addresses the solution for automated docker builds. Members reacted positively to this news.
Modular (Mojo 🔥) ▷ #🔥mojo (30 messages🔥):
-
The Perils of Non-Trivial Structs: It's confirmed that @register_passable("trivial") can't be used for structs with memory allocation due to the shared pointer issue, requiring the use of @register_passable for proper functionality.
-
Embarking on SIMD Search: A member aimed to implement SIMD Naïve Search in Mojo but was unclear about implementing 'found' and 'SIMDcompare' functions. A fellow member compared it with native Mojo code for SIMD operations, pointing to Mojo's SIMD documentation as a starting point.
-
Top-Level Code Temporarily Grounded: Discussion around the introduction of top-level code in Mojo reveals complications without a current estimated time of arrival. The issue with a missing page on the "escaping" operator has been raised, and the documentation team has been pinged.
-
A Decorator's Dilemma: Custom decorators in Mojo are not yet possible, as they're hardcoded in the compiler; a workaround was shared to manually decorate functions, while acknowledging the limitation.
-
Equality Check Enigma in Iteration: A scenario where a member tried to check for string equality within a List iteration in Mojo led to a clarification that explicit dereferencing with brackets
x[]is required due to how Mojo handles Reference types.
Links mentioned:
Modular (Mojo 🔥) ▷ #community-projects (1 messages):
- Logger Library Gets an Update: The logger library now accepts arbitrary args and kwargs for logging messages. The update enhances the functionality, allowing entry of variable information along with log messages like
key=valueorerroring=True.
Modular (Mojo 🔥) ▷ #performance-and-benchmarks (7 messages):
-
Mojo Lagging Behind Go in 1BRC: A member shared their experience working on the One Billion Row Challenge in Mojo language, noting a performance of approximately 23 minutes with optimizations on a MacBook Air M1, significantly longer compared to a Go implementation which completes in around 96 seconds.
-
Searching for a Faster Dict: The member expressed concerns about the performance of
Dictin Mojo, considering it does many memory copies and discussing potential improvements including a SIMD version. -
A New Dict Implementation on the Horizon: A different member mentioned having a custom
Dictimplementation that is faster than the standard one in Mojo, offering hope for performance improvements. -
Benchmarking Against Swiss Table: When asked about comparisons to the swiss table, a member responded that they haven't yet benchmarked against it, and that such a benchmark would need to be written in C++ or Rust.
Links mentioned:
Modular (Mojo 🔥) ▷ #📰︱newsletter (2 messages):
-
Max⚡ and Mojo🔥 24.2 Released: Last week marked the release of Max⚡ and Mojo🔥 24.2, along with the open-sourcing of the standard library and the launch of nightly builds. The community has shown active engagement with approximately 50 pull requests raised and 10 merged; interested users can explore and contribute on GitHub.
-
Explore the Latest in Mojo🔥: For those keen to dive into the latest updates and contributions, Modular has made available several resources: The Next Big Step in Mojo🔥 Open Source, the Mojo launch blog, details on What’s new in Mojo 24.2 including Mojo nightly, enhanced Python interop, open-source stdlib, and more.
- Find Modular's development insights on their blog about Open Source progress.
- Discover the new features of Mojo 24.2 by reading the Mojo launch blog and the detailed account on What’s new in 24.2.
Link mentioned: Modverse Weekly - Issue 28: Welcome to issue 28 of the Modverse Newsletter covering Featured Stories, the Max Platform, Mojo, & Community Activity.
Modular (Mojo 🔥) ▷ #nightly (13 messages🔥):
- Path to GitHub Collaboration: A user suggested using Discord for general discussions and moving more specific topics onto GitHub for collaboration purposes.
- Importing Python stdlib into Mojo: A developer inquired whether they could use the Python standard library as a reference for contributing to Mojo's stdlib. The response highlighted that this approach would introduce a dependency on the CPython interpreter, contrary to the goal of enabling standalone binaries.
- Seeking Guidance on Mojo stdlib Development: A user looking to contribute to the Mojo stdlib stated that existing documentation like
stdlib/docs/development.mdwas helpful yet found it challenging to begin actual development. - Resolving Parsing Errors and Test Failures in stdlib: One user faced parsing errors and test failures including a
FileCheck command not founderror. Guidance was provided on locatingFileCheckwithin WSL and adding it to the path, which resolved the issue. - Discussion on
OptionalBehavior in Mojo: A link to GitHub was shared discussing whetherOptionalcan return a reference forvalue()in Mojo's standard library amidst the current behavior of dereferencing the value.
Link mentioned: mojo/stdlib/src/collections/optional.mojo at nightly · modularml/mojo: The Mojo Programming Language. Contribute to modularml/mojo development by creating an account on GitHub.
OpenRouter (Alex Atallah) ▷ #general (91 messages🔥🔥):
- Timeout Concerns & Model Failures: Messages indicate NOUSRESEARCH/NOUS-HERMES-2-MIXTRAL model suffering from failures with error code 524, and one member mentions issues using TogetherAI's API, indicating an upstream problem. Another mentions a backup model, Nous Capybara 34B, as a potential alternative.
- Testing LLMs with Historical Questions: Some members are discussing the varying accuracy of different LLMs in response to a historical prompt involving a Japanese general from WW2. Isoroku Yamamoto is identified as the correct answer, but models such as claude, opus, and haiku show mixed results.
- OpenRouter's Maximum Payload Size: A discussion about OpenRouter's limitation of 4MB max body size was highlighted, with confirmation that this limit currently has no workaround.
- Roleplaying with AI Models: Members were seeking advice on using various AI models for roleplaying, specifically Claude 3 Haiku. The conversation includes recommendations for jailbreaking the models and using few-shot examples to improve performance.
- Discord Servers for Prompt Resources: Members looking for prompt examples and jailbroken prompts were directed to SillyTavern and Chub's Discord servers, where they can find resources such as the suggested pancatstack jailbreak.
Links mentioned:
LlamaIndex ▷ #blog (4 messages):
-
RankZephyr Leads in Advanced RAG: Recommending specific rerankers for advanced Retrieval-Augmented Generation, IFTTT suggests using an LLM like RankZephyr for better results. An open-source collection of LLMs called RankLLM is also highlighted for its excellence in finetuning for reranking.
-
Webinar Unveils AI Browser Copilot Secrets: A recent webinar featuring @dhuynh95 offered valuable insights into building an AI Browser Copilot, emphasizing the prompt engineering pipeline and the importance of KNN few-shot examples and vector retrieval. More details are available on the LlamaIndex Twitter page.
-
Boosting RAG with Time-Sensitive Queries: KDB.AI's integration with Retrieval-Augmented Generation (RAG) allows for hybrid searching that combines literal, semantic, and time-series analysis. This enables more accurate results by filtering for relevancy based on a time index, essential for financial reports such as quarterly earnings statements, as showcased in the shared code snippet.
-
Introducing an AI-Powered Digital Library: The unveiling of a new LLM-powered digital library designed for professionals and teams promises an advanced system for organizing knowledge. This platform transcends traditional data management by offering features to create, organize, and annotate data in a self-managing digital space as mentioned in this LlamaIndex tweet.
Links mentioned:
LlamaIndex ▷ #general (45 messages🔥):
-
PDF Indexing Dilemmas: A member sought advice on indexing a 2000-page PDF without using llamaparse, mentioning that current methods were time-consuming. Another member suggested increasing
embed_batch_sizeon the embedding model, which was later said to be unhelpful, indicating the need for alternative strategies. -
Understanding qDrant Lock Files: One user encountered an issue where qDrant wouldn't release a lock after running an IngestionPipeline, querying the community if it was an LlamaIndex or a qDrant specific problem. The user received no certain answer, highlighting a gap in collective experience regarding this issue.
-
HuggingFace API Limitations Discussed: There was confusion about potential rate limits and charges when using HuggingFaceInferenceAPIEmbedding and HuggingFaceInferenceAPI with a token. While one member initially thought there were no rate limits, another later confirmed rate limit errors and the possibility of charges by Hugging Face.
-
Integration Challenges with Alternate Models: A user was trying to integrate a model named "llama2" into an LlamaIndex agent and was advised to use the Ollama class, which uses the REST API for interaction. Helpful documentation was shared, and the integration process with Ollama was discussed in detail.
-
RAGAs with Recursive Query Engines: A conversation about the absence of documentation for recursive query engines with RAGAs was raised, leading to a realization of potential issues between langchain and ragas and highlighting the need for clearer guidance or fixes in this area.
Link mentioned: Ollama - LlamaIndex: no description found
LlamaIndex ▷ #ai-discussion (7 messages):
-
Exploring the Future of Text and Chat Generation: A Medium article titled Unlocking the Future of Text Generation and Chat with IPEX-LLM and LlamaIndex explores advancements in text generation. The article can be found at Unlocking the future of text generation.
-
Step-by-Step RAG App Tutorial Shared: A member shared a link to a YouTube tutorial on building a RAG app using LlamaIndex, Pinecone, and Gemini Pro. The tutorial can be viewed at How to build a RAG app using Gemini Pro.
-
RAG Tutorial Receives Community Support: Another member expressed enthusiasm about the RAG app video tutorial shared earlier, indicating community support for such educational content.
-
Comparing Fine-Tuning and Few-Shot Learning for Multistep Tasks: A member inquires into research comparing fine-tuning versus few-shot learning in improving a model's execution of multistep agentic tasks, considering two approaches – inclusion of reasoning examples in prompts, or dataset building and fine-tuning.
-
Seeking Local Text Enhancement Solution: A member requests advice on technologies for building a local application to enhance text by correcting errors without altering its original meaning, with an aim to avoid third-party services like ChatGPT.
Link mentioned: How to build a RAG app using Gemini Pro, LlamaIndex (v0.10+), and Pinecone: Let's talk about building a simple RAG app using LlamaIndex (v0.10+) Pinecone, and Google's Gemini Pro model. A step-by-step tutorial if you're just getting ...
OpenAccess AI Collective (axolotl) ▷ #general (48 messages🔥):
- Mistral Office Hour Alert: The channel is notified about the Mistral office hour being available for questions.
- Dataset Unification Challenges: A member describes the complex process of unifying numerous datasets totaling hundreds of gigabytes, involving issues like file alignment. They're currently using TSV files and pickle-format index data for quick seeking, but the ideal solutions and infrastructure are still under consideration.
- Runpod Serverless vLLM Experiences: Discussions around Runpod and serverless vLLM include challenges related to setup and operation. Shared resources on GitHub demonstrate how to deploy large language model endpoints.
- Evaluating RP-LLMs: A member introduces Chaiverse.com as a platform for receiving rapid feedback on RP-LLM models, highlighting that it's already evaluated 1k models and 5k variants. They invite feedback on the service and discuss the benefits of non-public evaluation datasets for preventing training to the test.
- Qwen Mow Versus Jamba: A playful debate regarding the preference of AI models, such as 'qwen mow' versus 'jamba', suggests varying opinions on different models' effectiveness for specific cases like RAG or general-purpose considerations. There's humor about needing more training data and collective investment for better servers.
Links mentioned:
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (5 messages):
- Documentation Update Praised: The updated docs for Axolotl received compliments for the new look, but an issue was raised regarding the missing Table of Contents which was supposed to include various sections like Axolotl supports, Quickstart, Common Errors, and more, as shown here.
- Table of Contents Actually Fixed: A member fixed the missing Table of Contents and confirmed the update with a GitHub commit.
- Discrepancy in Table of Contents Noted: It was observed that the Table of Contents in the README does not match the markdown headings exactly, implying a need for further cleanup to ensure consistency.
Links mentioned:
OpenAccess AI Collective (axolotl) ▷ #general-help (2 messages):
-
Models Behaving Unpredictably: A member expressed frustration that certain models are getting stuck despite having the same configuration as others which are functioning properly.
-
Quest for High-Resolution Images: Another member inquired about resources to crawl a large quantity of 4K and 8K images for their needs.
Mozilla AI ▷ #llamafile (36 messages🔥):
- Llamafile Builds for Windows ARM: To build llama.cpp for Windows ARM, you'll need to compile it from source, as Windows ARM isn't within the current support vector.
- Mixtral's Math-Riddle Solving Capability: The
mixtral-8x7b-instruct-v0.1.Q4_0.llamafilecan solve math riddles succinctly, but for recalling obscure facts without hallucinations, a version likeQ5_K_Mor higher is necessary. Find related details on Hugging Face. - Optimizing GPU Performance with TinyBLAS: When using llamafile, GPU performance can differ significantly, often depending on vendor-provided linear algebra libraries. A
--tinyblasflag is available that enables GPU support without needing extra SDKs, though its performance may vary based on the specific GPU model. - Windows Executable Formats for ARM: Windows on ARM supports PE format via the ARM64X binary that contains both Arm64 and Arm64EC code. The lack of emulation for AVX/AVX2 with ARM64EC presents challenges for LLM operations which often require instructions like SVE or NEON. More details can be seen in Microsoft's documentation.
- Compiling Issues on Windows for Llamafile: Windows users are encouraged to build llamafile on Linux, Mac, or BSD due to complications in setting up a Cosmopolitan development environment on Windows, as mentioned in the Cosmopolitan issue #1010.
Links mentioned:
Interconnects (Nathan Lambert) ▷ #news (1 messages):
- Potential for Opus Judgement to Boost Performance: There's speculation that, if Opus Judgement is accurate, there could be unutilized potential which may enhance results through further Research-Level AI Fine-tuning (RLAIF).
Interconnects (Nathan Lambert) ▷ #random (29 messages🔥):
- Google's New AI Lead Excites Discord: Members expressed surprise and humor over Logan K's announcement of joining Google to lead product for AI Studio and supporting the Gemini API, with reactions ranging from shock to speculation over practical reasons such as location.
- The Logan Strategy: Lifestyle or Poaching?: The conversation speculated on various factors influencing Logan's move to Google, including the appeal of Chicago, perceived HR poaching strategies, chances of future stock gains, and Google's relative openness in releasing model weights compared to OpenAI.
- Ideology or Opportunity?: Members discussed Logan's potential ideological reasons for leaving OpenAI, such as a desire for more openness, but also considered the possibility of being attracted by Google's offers despite personal values.
- Startup Ambitions or Strategic Move?: The dialogue included guesses about whether Logan had startup aspirations indicated by his previous "building at" bio, or if the move was a strategic choice due to Google's current positive momentum in AI.
- Financial Times and the AI Buzz: A member shared a link to a Financial Times article about AI, but the content was locked behind a subscription, leaving the discussion about it incomplete (FT content).
Links mentioned:
Interconnects (Nathan Lambert) ▷ #sp2024-history-of-open-alignment (1 messages):
- Open Science Turns Opaque: Post the release of the GPT-4 technical report, which withheld model details, a trend began where other companies also started keeping their model information under wraps. The member recalls this as a shift toward increased secrecy in the field.
CUDA MODE ▷ #general (1 messages):
iron_bound: https://github.com/intel-analytics/ipex-llm
CUDA MODE ▷ #algorithms (4 messages):
-
Revolutionizing LLMs with DISTFLASHATTN: DISTFLASHATTN presents a memory-efficient attention mechanism that claims to reduce quadratic peak memory usage to linear, and optimize long-context LLM training. It reportedly achieves up to 8x longer sequences and significant speed advantages over existing solutions like Ring Self-Attention and Megatron-LM with FlashAttention.
-
Code for Cutting-edge LLM Training Released: Researchers can access the code for DISTFLASHATTN, which boasts considerable improvements in training sequence lengths and speeds for models like Llama-7B, via the provided GitHub repository.
-
Lack of Backward Pass Pseudocode in DISTFLASHATTN Critique: A member pointed out an omission in the DISTFLASHATTN paper; it does not include pseudocode for the backward pass.
-
Previous Attention Mechanisms With Similar Issues: The same member noted that Ring Attention, a prior technique, also failed to include pseudocode for its backward pass.
-
A Call for Scientific Repeatibility: A comment was made highlighting the frustration with the lack of repeatability in science, which may be linked to the omission of detailed implementation details like pseudocode in published works.
Link mentioned: DISTFLASHATTN: Distributed Memory-efficient Attention for Long-context LLMs Training: FlashAttention (Dao, 2023) effectively reduces the quadratic peak memory usage to linear in training transformer-based large language models (LLMs) on a single GPU. In this paper, we introduce DISTFLA...
CUDA MODE ▷ #beginner (2 messages):
- CUDA Learning Resources for Beginners: A new member inquired about recommendations for learning the basics of CUDA programming given their background in Python and Rust. Another member suggested starting with a series of lectures found on CUDA MODE YouTube channel and supplementary content available on their GitHub page.
Link mentioned: CUDA MODE: A CUDA reading group and community https://discord.gg/cudamode Supplementary content here https://github.com/cuda-mode Created by Mark Saroufim and Andreas Köpf
CUDA MODE ▷ #ring-attention (2 messages):
-
DISTFLASHATTN for Memory-Efficient LLM Training: A new distributed memory-efficient attention mechanism named DISTFLASHATTN is introduced, optimizing the training of long-context large language models (LLMs) with techniques like token-level workload balancing. It outperforms existing models, achieving up to 8x longer sequence lengths and speedups compared to Ring Self-Attention and Megatron-LM with FlashAttention, with source code available on GitHub.
-
Reading Scheduled for DISTFLASHATTN Paper: A member shared an intention to review the DISTFLASHATTN paper on the following day, indicating interest and potential discussion to ensue.
Link mentioned: DISTFLASHATTN: Distributed Memory-efficient Attention for Long-context LLMs Training: FlashAttention (Dao, 2023) effectively reduces the quadratic peak memory usage to linear in training transformer-based large language models (LLMs) on a single GPU. In this paper, we introduce DISTFLA...
AI21 Labs (Jamba) ▷ #jamba (6 messages):
- Clarifying Throughput Efficiency: A user referenced a paper, highlighting that efficiency per token increases as it's measured by end-to-end throughput (encoding + decoding) divided by total number of tokens.
- Debating the Speed of Token Generation: A discussion ensued about how adding more tokens can lead to increased speed. The point raised was that while encoding may run in parallel, decoding is sequential, hence the expectation that each additional token would take the same amount of time to decode.
- Encoding Speed Insight: Further explanation clarified that the graph in question showed speed for generating a constant 512 tokens, which implies that any speedup in the plot is associated with the encoding process.
- Decoding Speed Questioned: There was persistence in understanding the process, questioning how decoding could get faster with a larger context since it's sequential in nature, requiring each token to wait for its predecessor.
Skunkworks AI ▷ #general (1 messages):
- New Contributor Eager to Join: A member expressed interest in an onboarding session, highlighting their background in Python, software engineering, and a Master's degree in data science. They have experience in AI medical research in collaboration with someone from StonyBrook and are skilled in writing data pipelines.
Skunkworks AI ▷ #finetuning (1 messages):
- Natural Language Crucial for Equations: Despite the high-level capabilities of GPT-4 and Claude, they sometimes still struggle to solve equations unless the problem is carefully explained in natural language. This suggests a significant challenge remains at the current scale of AI.
Alignment Lab AI ▷ #general-chat (1 messages):
jinastico: <@748528982034612226>
Datasette - LLM (@SimonW) ▷ #llm (1 messages):
- Terminology Tangle in Conversation Logs: A participant made an observation regarding the
responsestable inlogs.db, revealing an interest in what to call parts of a dialogue. They shared that the initial part of a conversation where the first person speaks is termed a "speaker turn" or "turn," leading them to name their app's tableturnsinstead.