As many would expect, the April GPT4T release retook the top spot on LMsys and it is now rolled out in paid ChatGPT and with a new lightweight reproducible evals repo. We've said before that OpenAI will have to prioritize rolling out new models in ChatGPT to reignite growth.
All in all, a quiet before the presumable storm of the coming Llama 3 launch. You could check out the Elicit essay/podcast or the Devin vs OpenDevin vs SWE-Agent livestream. However we give today's pride of place to Vik Paruchuri, who wrote about his journey from engineer to making great OCR/PDF data models in 1 year.
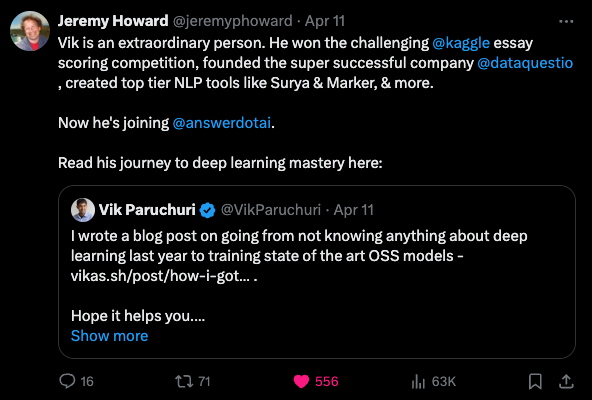
These fundamentals are likely much more valuable than keeping on top of day to day news and we like featuring quality advice like this where we can.
Table of Contents
[TOC]
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence. Comment crawling works now but has lots to improve!
TO BE COMPLETED
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
GPT-4 and Claude Updates
- GPT-4 Turbo regains top spot on leaderboard: @lmsysorg noted GPT-4-Turbo has reclaimed the No. 1 spot on the Arena leaderboard, outperforming others across diverse domains like Coding, Longer Query, and Multilingual capabilities. It performs even stronger in English-only prompts and conversations containing code snippets.
- New GPT-4 Turbo model released: @sama and @gdb announced the release of a new GPT-4 Turbo model in ChatGPT that is significantly smarter and more pleasant to use. @miramurati confirmed it is the latest GPT-4 Turbo version.
- Evaluation numbers for new GPT-4 Turbo: @polynoamial and @owencm shared the evaluation numbers, showing improvements of +8.9% on MATH, +7.9% on GPQA, +4.5% on MGSM, +4.5% on DROP, +1.3% on MMLU, and +1.6% on HumanEval compared to the previous version.
- Claude Opus still outperforms new GPT-4: @abacaj and @mbusigin noted that Claude Opus still outperforms the new GPT-4 Turbo model in their usage, being smarter and more creative.
Open-Source Models and Frameworks
- Mistral models: @MistralAI released new open-source models, including Mixtral-8x22B base model which is a beast for fine-tuning (@_lewtun), and Zephyr 141B model (@osanseviero, @osanseviero).
- Medical mT5 model: @arankomatsuzaki shared Medical mT5, an open-source multilingual text-to-text LLM for the medical domain.
- LangChain and Hugging Face integrations: @LangChainAI released updates to support tool calling across model providers, and a standard
bind_toolsmethod for attaching tools to a model. @LangChainAI also updated LangSmith to support rendering of Tools and Tool Calls in traces for various models. - Hugging Face Transformer.js: @ClementDelangue noted that Transformer.js, a framework for running Transformers in the browser, is on Hacker News.
Research and Techniques
- From Words to Numbers - LLMs as Regressors: @_akhaliq shared research analyzing how well pre-trained LLMs can do linear and non-linear regression when given in-context examples, matching or outperforming traditional supervised methods.
- Efficient Infinite Context Transformers: @_akhaliq shared a paper from Google on integrating compressive memory into a vanilla attention layer to enable Transformer LLMs to process infinitely long inputs with bounded memory and computation.
- OSWorld benchmark: @arankomatsuzaki and @_akhaliq shared OSWorld, the first scalable real computer environment benchmark for multimodal agents, supporting task setup, execution-based evaluation, and interactive learning across various operating systems.
- ControlNet++: @_akhaliq shared ControlNet++, which improves conditional controls in diffusion models with efficient consistency feedback.
- Applying Guidance in Limited Interval: @_akhaliq shared a paper showing that applying guidance in a limited interval improves sample and distribution quality in diffusion models.
Industry News and Opinions
- WhatsApp vs iMessage debate: @ylecun compared the WhatsApp vs iMessage debate to the metric vs imperial system debate, noting that the entire world uses WhatsApp except for some iPhone-clutching Americans or countries where it is banned.
- AI agents will be ubiquitous: @bindureddy predicted that AI agents will be ubiquitous, and with Abacus AI, you can get AI to build these agents in a simple 5-minute to few-hours process.
- Cohere Rerank 3 model: @cohere and @aidangomez introduced Rerank 3, a foundation model for enhancing enterprise search and RAG systems, enabling accurate retrieval of multi-aspect and semi-structured data in 100+ languages.
- Anthropic fires employees over information leak: @bindureddy reported that Anthropic fired 2 employees, one being Ilya Sutskever's close friend, for leaking information about an internal project, likely related to GPT-4.
Memes and Humor
- Meme about LLM model names: @far__el joked about complex model names like "MoE-8X2A-100BP-25BAP-IA0C-6LM-4MCX-BELT-RLMF-Q32KM".
- Meme about AI personal assistant modes: @jxnlco joked that there are two kinds of AI personal assistant modes for every company - philosophers and integration hell, comparing it to epistemology and auth errors.
- Joke about LLM hallucinations: @lateinteraction joked that they worry about a bubble burst once people realize that no AGI is near and there are no reliably generalist LLMs or "agents", suggesting it's wiser to recognize LLMs mainly create opportunities for making general progress in building AIs that solve specific tasks.
AI Discord Recap
A summary of Summaries of Summaries
-
Mixtral and Mistral Models Gain Traction: The Mixtral-8x22B and Mistral-22B-v0.1 models are generating buzz, with the latter marking the first successful conversion of a Mixture of Experts (MoE) model to a dense format. Discussions revolve around their capabilities, like Mistral-22B-v0.1's 22 billion parameters. The newly released Zephyr 141B-A35B, a fine-tuned version of Mixtral-8x22B, also sparks interest.
-
Rerank 3 and Cohere's Search Enhancements: Rerank 3, Cohere's new foundation model for enterprise search and RAG systems, supports 100+ languages, boasts a 4k context length, and offers up to 3x faster inference speeds. It natively integrates with Elastic's Inference API to power enterprise search.
-
CUDA Optimizations and Quantization Quests: Engineers optimize CUDA libraries like
CublasLinearfor faster model inference, while discussing quantization strategies like 4-bit, 8-bit, and novel approaches like High Quality Quantization (HQQ). Modifying NVIDIA drivers enables P2P support on 4090 GPUs, yielding significant speedups. -
Scaling Laws and Data Filtering Findings: A new paper, "Scaling Laws for Data Filtering", argues that data curation cannot be compute-agnostic and introduces scaling laws for working with heterogeneous web data. The community contemplates the implications and seeks to understand the empirical approach taken.
Some other noteworthy discussions include:
- The release of GPT-4 Turbo and its performance on coding and reasoning tasks
- Ella's subpar anime image generation capabilities
- Anticipation for Stable Diffusion 3 and its potential to address current model limitations
- Hugging Face's Rerank model hitting 230K downloads and the launch of the parler-tts library
- OpenAI API discussions around Wolfram integration and prompt engineering resources
PART 1: High level Discord summaries
Stability.ai (Stable Diffusion) Discord
Forge Ahead, Leave No A1111 Behind: Forge, a new fork of Automatic1111 boasting performance enhancements, is gathering acclaim. Enthusiasts can explore Forge without ditching A1111 and utilize ComfyUI models for a more efficient workflow.
Ella Falls Short in Anime Art: Experimentation with Ella for anime-style image generation ends in disappointment, failing to meet user expectations even with recommended checkpoints. Despite high hopes, the quality of anime images generated by Ella remains subpar and is considered unusable for the genre.
Stable Diffusion 3 Brings Hope and Doubt: The community is abuzz with a blend of anticipation and skepticism around Stable Diffusion 3 (SD3), particularly about its potential to overcome current model limitations like bokeh effects, color fidelity, and celebrity recognition.
Expanding Toolbox for Image Perfection: In discussion are several tools and extensions enhancing Stable Diffusion outputs, including BrushNet for outpainting and solutions improving depth-fm and geowizard for architecture, as well as a color correction extension.
Cascade Gains Notoriety for Fast Learning: Cascade stands out within the Stable Diffusion models for its swift learning capabilities and distinct characteristics, although it's noted for a steeper learning curve, affectionately deemed the "strange cousin of the SD family."
Cohere Discord
CORS Crashes Cohere Connections: Users encountered CORS policy errors preventing access to the Cohere dashboard, with issues arising from cross-origin JavaScript fetch requests from https://dashboard.cohere.com to https://production.api.os.cohere.ai.
Arguments Over Context Length: A passionate discussion unfolded regarding the effectiveness of extended context lengths in large language models (LLMs) versus Retrieval-Augmented Generation (RAG), debating computational costs and diminishing benefits of longer contexts.
Rerank 3's Pricing and Promotion: Rerank V3 has been announced with a pricing of $2 per 1k searches and an introductory promotional discount of 50%. For those seeking the prior version, Rerank V2 remains available at $1 per 1k searches.
Navigating Cohere's Fine-Tuning and Deployment: Questions arose about the possibilities of on-premise and platform-based fine-tuning of Cohere's LLMs, alongside deployment options on AWS Bedrock or similar on-premise scenarios.
Boosted Search with Rerank 3 Overview: Rerank 3 launches to enhance enterprise search, claiming a threefold increase in inference speed and support for over 100 languages with its extended 4k context. It integrates with Elastic's Inference API to improve enterprise search functionalities, with resources available such as a Cohere-Elastic integration guide and a practical notebook example.
Unsloth AI (Daniel Han) Discord
Ghost 7B Aces Multiple Languages: The new Ghost 7B model is generating buzz due to its prowess in reasoning and understanding of Vietnamese, and is eagerly anticipated by the AI community. It is highlighted as a more compact, multilinguistic alternative that could serve specialized knowledge needs.
Double Take on Fine-Tuning Challenges: Discussions surfaced regarding difficulties in fine-tuning NLP models, with a gap noted between promising training evaluations and disappointing practical inference performance. Particularly, a lack of accuracy in non-English NLP contexts has been a point of frustration among engineers.
Efficient Model Deployment Strategies Sought: Engineers are actively sharing strategies and resources to streamline the deployment of models like Mistral-7B post-training. Concerns over VRAM limits persist, prompting discourse on optimizing batch sizes and embedding contextual tokens to conserve memory.
Unsloth AI Champions Extended Context Windows: The Unsloth AI framework is commended for reducing memory usage by 30% and merely increasing time overhead by 1.9% while enabling fine-tuning with context windows as long as 228K as detailed on their blog. This represents a significant leap compared to the previous benchmarks, offering a new avenue for LLM development.
The Importance of Domain-Specific Data: There is a consensus on the need for more precise, domain-specific datasets, as generic data collection is insufficient for specialized models requiring detailed context. Best practices are still being debated, with many looking towards platforms like Hugging Face for advanced dataset solutions.
Nous Research AI Discord
-
RNN Revival on the Horizon: A new paper, found on arXiv, suggests an emerging hybrid architecture that could breathe new life into Recurrent Neural Networks (RNNs) for sequential data processing. Google's reported investment in a new 7 billion parameter RNN-based model stirs the community's interest in future applications.
-
Google's C++ Foray with Gemma Engine: The community noted Google's release of a C++ inference engine for its Gemma models, sparking curiosity. The standalone engine is open source and accessible via their GitHub repository.
-
Financial Muscle Required for Hermes Tuning: Fine-tuning the Nous Hermes 8x22b appears to be quite the wallet-buster, requiring an infrastructure rumored to cost approximately "$80k for a week". Detailed infrastructure specifics remain undisclosed, but clearly, this isn't a trivial undertaking.
-
Pedal to the Metal with Apple AI Potential: Engineers are paying close attention to Apple's M series chips, anticipating the M4 chip and its rumored 2TB RAM support. The M2 Ultra and M3 Max's AI inference capabilities, especially their low power draw, garner specific praise.
-
LLMs in the Medical Spotlight with Caution: The medical implications of using Large Language Models (LLMs) trigger a mix of excitement and concern within the community. There's chatter about legal risks and artificial restrictions hindering the development and application in healthcare.
CUDA MODE Discord
-
Cublas Linear Optimization: Custom
CublasLinearlibrary optimizations are accelerating model inferences for large matrix multiplications, though bottlenecks in attention mechanisms could be diminishing overall performance gains in models like "llama7b". -
Peak Performance with P2P: By hacking NVIDIA's driver, a 58% speedup for all reduce operations was achieved on 4090 GPUs. The modification enables 14.7 GB/s AllReduce, a significant stride towards enhancing tinygrad's performance with P2P support.
-
Hit the Quantization Target: Challenges and strategies around quantization, like 4-bit methods, are gaining traction, with a new HQQ (High Quality Quantization) approach being discussed for superior dequantization linearity. In tensor computation, 8-bit matrix multiplication was found to be double the speed of fp16, spotlighting the potential performance issues with
int4 kernels. -
Speed Breakthroughs and CUDA Advancements: The
A4000GPU achieved a max throughput of 375.7 GB/s withfloat4loads, indicating the efficient use of L1 cache. Meanwhile, CUDA's latest features like cooperative groups and kernel fusion are driving both performance gains and modern C++ adoption for maintainability. -
Community Resource Sharing and Organization: Members have established channels for sharing CUDA materials, such as renaming an existing channel for resource distribution, and they recommend organizing tasks for better workflow. A study group for PMPP UI has been initiated, welcoming participants via a Discord invite.
-
Conceptual Explanations and Academic Contributions: An explainer on ring attention, designed to scale context windows in LLMs, was shared, inviting feedback. In academia, Chapter 4 of a GPU-centric numerical linear algebra book in making and a modern CUDA version of Golub/Van Loan book tanked their artificial satellite into the fertile mindscape, deepening the knowledge pool. A practical course in programming parallel computers, inclusive of GPU programming, is offered online and open to all.
Perplexity AI Discord
-
GPT-4 Buzz in Perplexity: Engineers are curious about the integration of GPT-4 within Perplexity, questioning its features and API availability. Meanwhile, some users debate the capabilities of Perplexity beyond traditional search, suggesting it could be positioned as a composite tool for search and image generation.
-
Expanding API Offerings: A lively conversation explores integrating Perplexity API into e-commerce and users are pointed to the documentation for guidance. However, queries about the availability of a Pro Search feature in the API concluded with a clear negative response.
-
Coding the Perfect Extension: Technical discussions center on enhancing Perplexity's utility with browser extensions, despite the limitations that client-side fetching imposes. Tools like RepoToText for GitHub are mentioned as resources for marrying LLMs with repository contents.
-
Search Trails and Technical Trails: Users actively shared Perplexity AI search links, signaling a push towards broadening collaboration on the platform. Searches ranged from unidentified objects to dense technical matters like access logging and NIST standards, reflecting the crowd's versatile interests.
-
Anticipating Roadmap Realities: Eyes are on Perplexity's future with a user seeking updates on citation features, referencing the Feature Roadmap to clarify upcoming enhancements. The roadmap appears to plan multiple updates extending into June, though it remains silent on the much-awaited source citations.
LM Studio Discord
Quantization Quest Continues: The Mixtral-8x22B model is now quantized and available for download, yet it is not fine-tuned and may challenge systems that can't handle the 8x7b version. A model loading error can be resolved by upgrading to LM Studio 0.2.19 beta preview 3.
Navigating Through Large Model Dilemmas: Users shared experiences running large models on insufficient hardware, suggesting cloud solutions or hardware upgrades like the NVIDIA 4060ti 16GB. For those tackling time series data, a Temporal Fusion Transformer (TFT) was suggested as being well-suited for the task.
GPU vs. CPU: A Performance Puzzle: When running AI models, more system memory can help load larger LLMs, but full GPU inference with a card like the NVIDIA RTX A6000 is optimal for performance.
Emerging ROCm Enigma in Linux: Linux users curious about the amd-rocm-tech-preview support are left hanging, while those with compatible hardware like the 7800XT report coil whine during tasks. Meanwhile, building the gguf-split binary for Windows is a hurdle for testing on AMD hardware, requiring a look into GitHub discussions and pull requests for guidance.
BERT's Boundaries and Embedding Exploits: The Google BERT models are generally not directly usable with LM Studio without task-specific fine-tuning. For text embeddings utilizing LM Studio, larger parameter models like mxbai-large and GIST-large have been recommended over the standard BERT base model.
Please note that while this summary is comprehensive, specific channels may contain additional detailed discussions and links relevant to AI engineers.
Eleuther Discord
BERT's Bidirectional Brainache: Engineers raised the complexity of extending context windows for encoder models like BERT, referencing difficulty with bidirectional mechanisms and pointing to MosaicBERT which applies FlashAttention, with questions about its absence in popular libraries despite contributions.
Rethinking Transformers with Google's Mixture-of-Depths Model: Researchers are discussing Google's novel Mixture-of-Depths approach, which allocates computing differently in transformer-based models. Also catching attention is RULER's newly open-source yet initially empty repository here, aimed at revealing the real context size of long-context language models.
Scale the Data Mountain Wisely: A paper proposing that data curation is indispensable and cannot ignore computational constraints was shared. The discourse included a symbolic search for entropy-based methods in scaling laws and a reflection on foundational research principles.
Odd Behaviors in Large Language Models Puzzles Analysts: Members expressed intrigue over NeoX's embedding layer behavior, questioning if weight decay was omitted during training. They compared NeoX's output to other models and confirmed a distinct behavior, igniting curiosity about the technical specifics and implications.
Quantization Quest and Dataset Dilemmas: Community efforts include an attempt at 2-bit quantization to reduce VRAM usage for the Mixtral-8x22B model, while confusion arose around The Pile dataset's inconsistent sizing and the lack of extraction code for varied archive types.
OpenRouter (Alex Atallah) Discord
-
Mixtral Expands and Contracts: A new model called Mixtral 8x22B:free was released, enhancing clarity around routing and rate-limiting, and boasting an updated context size of 65,536. However, it was swiftly disabled, pushing users to transition to its viably active counterpart, Mixtral 8x22B.
-
New Experimental Models on the Block: The community has two new experimental models to play with: Zephyr 141B-A35B, an instruct fine-tune of Mixtral 8x22B, and Fireworks: Mixtral-8x22B Instruct (preview), spicing up the AI landscape.
-
Brick Wall in Purchase Process: A blip emerged for shoppers seeking tokens, triggering a snapshot share and presumably a call to iron out the kink in the transaction flow.
-
Self-Help for Platform Entrapment: A user entwined in login woes uncovered a self-extraction strategy, deftly navigating account deletion.
-
Turbo Troubles and Personal AI Aspirations: The orbit of discourse spanned from resolving GPT-4 Turbo malfunctions with a Heroku redeploy to tailoring AI setups interweaving tools like LibreChat. Deep dives into AI models' quirks and tuning sweet spots were also a hot theme, with Opus, Gemini Pro 1.5, and MoE structures getting the spotlight.
Modular (Mojo 🔥) Discord
-
Mojo's Community Code Contribution: Server members appreciate that Mojo has open-sourced its standard library, fostering community contributions and enhancements. Discussions revolved around integrating Modular into BackdropBuild.com projects for developer cohorts, yet members were reminded to keep business inquiries on the appropriate channels.
-
Karpathy Sets Sights on Mojo Port: An exciting talk sparked by GitHub issue #28 in Andrej Karpathy's
llm.crepository focused on benchmarking and comparison prospects of a Mojo port, as the creator himself expressed interest in linking to any Mojo-powered version. -
Row vs. Column: Matrix Showdown: An informative post available at Modular's blog breaks down the row-major versus column-major matrix storage and their performance analyses in Mojo and NumPy, enlightening the community on programming languages' and libraries' storage preferences.
-
Terminal Vogue with Mojo: Members showcased advanced text rendering in terminals using Mojo, demonstrating functionalities and interfaces inspired by
charmbracelet's lipgloss. Code snippets and implementation examples were shared, with the preview available on GitHub. -
Matrix Blog Misstep: A Call for Help: A member signaled an error while executing a Jupyter notebook from the "Row-major vs. Column-major matrices" blog post, confronting an issue with 'mm_col_major' declarations. This feedback creates an opportunity for community-supported debugging, with the notebook present at devrel-extras GitHub repo.
LangChain AI Discord
-
LangChain's PDF Summary Speed Boost: A method for improving the summarization efficiency of LangChain's
load_summarization_chainfunction on extensive PDF documents was highlighted, with a code snippet demonstrating amap_reduceoptimization approach available on GitHub. -
LangChain AI's New Tutorial Rolls Out: A recently introduced tutorial sheds light on LCEL and the assembly of chains using runnables, offering hands-on learning for engineers and inviting their feedback; see the details on Medium.
-
GalaxyAI API Launch Takes Off: GalaxyAI debuts with a free API service smoothly aligning with Langchain, introducing powerful AI models like GPT-4 and GPT-3.5-turbo; integration details can be approached on GalaxyAI.
-
Alert: Unwanted Adult Content Spams Discord: There have been reports of improper content being shared across various LangChain AI channels, which is against Discord community guidelines.
-
Meeting Reporter Meshes AI with Journalism: The new tool Meeting Reporter has been created to leverage AI in producing news stories, intertwining Streamlit and Langgraph, and requiring a paid OpenAI API key. The application is accessible via Streamlit, with the open-source code hosted on GitHub.
Note: Links related to adult content promotions have been actively ignored in this summary as they are clearly not relevant to the technical and engineering discussions of the guild.
HuggingFace Discord
Tweet Alert: osanseviero Shares News: osanseviero tweeted, potentially hinting at new insights or updates; check it out here.
RAG Chatbot Employs Embedded Datasets: The RAG chatbot uses the not-lain/wikipedia-small-3000-embedded dataset to inform its responses, merging retrieval and generative AI for accurate information inferences.
RMBG1.4 Gains Popularity: The integration of RMBG1.4 with the transformers library has garnered significant interest, reflected in 230K downloads this month.
Marimo-Labs Innovates Model Interaction: Marimo-labs released a Python package allowing the creation of interactive playgrounds for Hugging Face models; a WASM-powered marimo application lets users query models with their tokens.
NLP Community Pursues Longer-Context Encoders: AI engineers discussed the pursuit of encoder-decoder models like BigBird and Longformer for handling longer text sequences around 10-15k tokens and shared strategies for training interruption and resumption with trainer.train()'s resume_from_checkpoint.
Vision and Diffusion Achievements: GPU process management is enhanced with nvitop, while developers tackle video restoration through augmentation and temporal considerations, referencing works like NAFNet, BSRGAN, Real-ESRGAN, and All-In-One-Deflicker. Meanwhile, insights into Google's multimodal search capabilities are sought for improved image and typo brand recognition, with interest in the underpinnings of AI-demos' identifying technology.
Latent Space Discord
-
Hybrid Search Reranking Revisited: Engineers discussed whether combining lexic and semantic search results before reranking is superior to amalgamating and reranking all results simultaneously. Cohesion in reranking steps could streamline the process and reduce latency in search methodologies.
-
Rerank 3 Revolutionizes Search: Cohere's Rerank 3 model touts enhanced search and RAG systems, with 4k context length and multilingual capabilities across 100+ languages. Details of its release and capabilities are shared in a tweet by Sandra Kublik.
-
AI Market Heats Up With Innovation: The rise of innovative AI-based work automation tools, like V7 Go and Scarlet AI, suggests a growing trend toward automating monotonous tasks and facilitating AI-human collaborative task execution.
-
Perplexity's "Online" Models Vanish and Reclaim: The community mulled over Perplexity's "online" models' disappearance from LMSYS Arena and their subsequent reemergence, indicating models with internet access. Interest was rekindled as GPT-4-Turbo regained the lead in the Lmsys chatbot leaderboard, signaling strong coding and reasoning capabilities.
-
Mixtral-8x22B Breaks onto the Scene: The advent of Mixtral-8x22B in HuggingFace's Transformers format ignites conversations around its use and implications for Mixture of Experts (MoEs) architecture. The community explores topics such as expert specialization, learning processes within MoEs, and the semantic router, drawing attention to potential gaps in redundancy and expertise implementation.
-
Podcasting AI's Supervisory Role: A new podcast episode presents discussions with Elicit's Jungwon Byun and Andreas Stuhlmüller on supervising AI research. Available via a YouTube link, it tackles the benefits of product-oriented approaches over traditional research-focused ones.
LAION Discord
Draw Things Draws Criticism: Participants voiced their disappointment with Draw Things, pointing out its lack of a complete open source offering; the provided version omits crucial features including metal-flash-attention support.
Questionable Training Feats of TempestV0.1: Community members met the TempestV0.1 Initiative's claim of 3 million training steps with skepticism, questioning both that and the physical plausibility of its 6 million-image dataset occupying only 200GB.
Will LAION 5B Demo Reappear?: Regarding the Laion 5B web demo, there's uncertainty about its return, despite mentions of Christoph indicating a comeback with no given timeline or further information.
Alert on LAION Scams: Warnings circulated on scams such as cryptocurrency schemes misusing LAION's name, with recommendations to stay cautious and discussions about combating this with an announcement or automatic moderation enhancements.
Advancements in Diffusion and LRU Algorithms: The community is evaluating improved Least Recently Used (LRUs) algorithms on Long Range Arena benchmarks and discussing guidance-weight strategies to enhance diffusion models, with relevant research (research paper) and an active GitHub issue (GitHub issue) being applied to huggingface's diffusers.
LlamaIndex Discord
-
Pandas on the Move: The
PandasQueryEnginewill transition tollama-index-experimentalwith LlamaIndex python v0.10.29, and installations will proceed throughpip install llama-index-experimental. Adjustments to import statements in Python code are needed to reflect this change. -
Spice Up Your GitHub Chat: A new tutorial demonstrates creating an app to enable chatting with code from a GitHub repository, integrating an LLM with Ollama. Another tutorial details the incorporation of memory into document retrieval using a Colbert-based agent for LlamaIndex, providing a boost to the retrieval process.
-
Dynamic Duo: RAG Augmented with Auto-Merging: A novel approach to RAG retrieval includes auto-merging to form more contiguous chunks from broken contexts. Comparatively, discussing Q/A tasks surfaced a preference for Retriever Augmented Generation (RAG) over fine-tuning LLMs due to its balance of accuracy, cost, and flexibility.
-
Toolkit for GDPR-Compliant AI Apps: Inspired by Llama Index's create-llama toolkit, the create-tsi toolkit is a fresh GDPR-compliant infrastructure for AI applications rolled out by T-Systems and Marcus Schiesser.
-
Debugging Embeddings and Vector Stores: Discussions cleared up confusions on embedding storage, revealing they reside in vector stores within the storage context. For certain issues with 'fastembed' causing breaks in QdrantVectorStore, downgrading to
llama-index-vector-stores-qdrant==0.1.6was the solution, and metadata exclusions from embeddings need explicit handling in code.
OpenInterpreter Discord
Trouble in Installation Town: Members reported problems installing Poetry and litellm—a successful fix for the former included running pip install poetry, whereas diagnosing litellm issues involved using interpreter --version and pip show litellm. Further troubleshooting pointed towards the necessity of Python installation and particular git commits for package restorations.
Patience, Grasshopper, for Future Tech Gadgets: Inquiries were made on the preorder and delivery of new devices, revealing that some tech gadgets are still in the prototyping phase with shipments expected in the summer months. The conversation highlighted typical delays faced by startups in manufacturing and encouraged patience from eager tech aficionados.
Transformers Redefined in JavaScript: The transformers.js GitHub repository, offering a JavaScript-based machine learning solution capable of running in the browser sans server, piqued the interest of AI engineers. Meanwhile, a cryptic mention of an AI model endpoint at https://api.aime.info popped up without additional detail or fanfare.
OpenAI Plays the Credits Game: OpenAI's shift to prepaid credits away from monthly billing, which includes a promotion for free credits with a deadline of April 24, 2024, sparked curiosity and a flurry of information exchanges among the members regarding the implications for various account types.
Events and Contributions Galore: Community event Novus invites were buzzing as engineers looked forward to networking without the fluff, while a successful session on using Open Interpreter as a library yielded a repository of Python templates for budding programmers.
OpenAccess AI Collective (axolotl) Discord
Discussing Strategies and Anticipations in AI Development:
- Participants examined the implications of freezing layers within neural network models, expressing the view that while reduction may simplify models, it can also potentially reduce effectiveness, thus hinting at a delicate balance between complexity and resource efficiency. Links to discussions about the theoretical foundations of language model scaling, particularly Meta's study on knowledge bit scaling (Physics of Language Models: Part 3.3, Knowledge Capacity Scaling Laws), suggest LLaMA-3 may advance this balance further.
Training Challenges and Model Modifications:
- The conversion of Mistral-22B from a Mixture of Experts to a dense model (Vezora/Mistral-22B-v0.1) has been a focal point, suggesting a community interest towards dense architectures, possibly for their compatibility with existing infrastructure. Concurrently, discussions on training in 11-layer increments indicate a pursuit of training tactics that accommodate limited GPU capabilities.
Ecosystem Expansion and Assistance:
- The collective's endeavor to make the AI development process more accessible is evident with shared advice for new members on starting with Axolotl, reflected in both an insightful blog post and practical tips, such as utilizing the
--debugflag. Furthermore, the maintenance of a Colab notebook example assists users in fine-tuning models like Tiny-Llama on Hugging Face datasets.
Resourcefulness in Resource Constraints:
- Conversations are circling around inventive training strategies such as unfreezing random subsets of weights for users with lower-end hardware setups, evidencing a focus on democratizing training methods. Collaborative sharing of pretrain configs, and step-by-step interventions for leveraging Docker with DeepSpeed for multi-node fine-tuning demonstrate the community's resolve to navigate high-end training tactics within constrained environments.
Curiosity Meets Data Acquisition:
- Inquiry into datasets for formal logic reasoning and substantial 200-billion token datasets portrays an active search for challenging and large-scale data to push the boundaries of model pretraining and experimentation.
OpenAI Discord
API Stumbles with AttributeErrors: An OpenAI API user encountered an AttributeError in the client.beta.messages.create method in Python, raising concerns about potential documentation being out of sync with library updates. The shared code snippet didn't yield a solution within the guild discussions.
Models in the Spotlight: Members shared varying experiences using AI models like Gemini 1.5 and Claude, touching on differences in context windows, memory, and code query handling. For C# development specifically in Unity, the gpt-4-turbo and Opus model were suggested for efficacy.
Efficiency Hurdles with GPT-4 Turbo: One member observed that the GPT-4-turbo model appeared less skilled at function calls, while another was unsure about accessing it; however, detailed examples or solutions were not provided.
Large Scale Text Editing with LLMs: Queries about editing large documents with GPT sparked a discussion on the potential need for third-party services to bypass the standard context window limitations.
Navigating the Prompt Engineering Galaxy: For those embarking on prompt engineering, Prompting Guide was recommended as a resource, while integrating Wolfram with GPT can be managed via Wolfram GPT link and the @mention feature within the platform.
DiscoResearch Discord
Big Win for Dense Models: The launch of Mistral-22B-V.01, a new 22B parameter dense model, marks a notable achievement as it transitions from being a compressed Mixture of Experts (MoE) to a dense form, establishing a precedent in the MoE to Dense model conversion arena.
Crosslingual Conundrums and Corpus Conversations: While engineers work on balancing English and German data in models like DiscoLM 70b, with plans for updated models, they cited the need for better German benchmarks. Occiglot-7B-DE-EN-Instruct showed promise, hinting that a mix of English and German training data could be efficacious.
Sifting Through SFT Strategies: The community shared insights on the potential benefits of integrating Supervised Fine-Tuning (SFT) data early in the pretraining phase, backed by research from StableLM and MiniCPM, to enhance model generalization and prevent overfitting.
Zephyr Soars with ORPO: Zephyr 141B-A35B, derived from Mixtral-8x22B and fine-tuned via a new algorithm named ORPO, was introduced and is available for exploration on the Hugging Face model hub.
MoE Merging Poses Challenges: The community's experiments with Mergekit to create custom MoE models through merging highlighted underwhelming performance, sparking an ongoing debate on the practicality of SFT on narrow domains versus conventional MoE models.
Interconnects (Nathan Lambert) Discord
Increment or Evolution?: Nathan Lambert sparked a debate regarding whether moving from Claude 2 to Claude 3 represents genuine progress or just an "INCREMENTAL" improvement, raising questions about the substance of AI version updates.
Building Better Models Brick by Brick: Members discussed the mixing of pretraining, Supervised Fine-Tuning (SFT), and RLHF, pointing out the respective techniques are often combined, although this practice is poorly documented. A member committed to providing insights on applying annealing techniques to this blend of methodologies.
Casual Congrats Turn Comical: A meme became an accidental expression of congratulations causing a moment of humor, while another conversation clarified that the server does not require acceptance for subscriptions.
Google's CodecLM Spotlight: The community examined Google's CodecLM, shared in a research paper, noting it as another take on the "learn-from-a-stronger-model" trend by using tailored synthetic data.
Intellectual Exchange on LLaMA: A link to "LLaMA: Open and Efficient Foundation Language Models" was posted, indicating an active discussion on the progress of open, efficient foundation language models with a publication date of February 27, 2023.
tinygrad (George Hotz) Discord
- Swift Naming Skills Unleashed: Members of the tinygrad Discord opted for creative labels such as tinyxercises and tinyproblems, with the playful term tinythanks emerging as a sign of appreciation in the conversation.
- Cache Hierarchy Hustle: A technical exchange in the chat indicated that L1 caches boast superior speed compared to pooled shared caches, due to minimized coherence management demands. This discussion underscored the performance differences when comparing direct L3 to L1 cache transfers with those of a heterogenous cache architecture.
- Contemplating Programming Language Portability: Dialogue revealed a contrasting opinion where ANSI C's wide hardware support and ease of portability stood in contrast to the shared scrutiny of Rust's perceived safety, which was demystified with a link to known Rust vulnerabilities.
- Trademark Tactics Trigger Discussions: A debatable sentiment was aired around the Rust Foundation's restrictive trademark policies, eliciting comparisons to other entities like Oracle and Red Hat and their own contentious licensing stipulations.
- Discord Discipline Instated: George Hotz made it clear that off-topic banter would not fly in his Discord, leading to a user being banned for their non-contribution to the focused technical discussions.
Skunkworks AI Discord
- Hunt for the Logical Treasure Trove: AI engineers shared a curated list full of datasets aimed at enhancing reasoning with formal logic in natural language, providing a valuable resource for projects at the intersection of logic and AI.
- Literature Tip: Empowering Coq in LLMs: An arXiv paper was highlighted, which tackles the challenge of improving large language models' abilities to interpret and generate Coq proof assistant code—key for advancing formal theorem proving capabilities.
- Integrating Symbolic Prowess into LLMs: Engineers took interest in Logic-LLM, a GitHub project discussing the implementation of symbolic solvers to elevate the logical reasoning accuracy of language models.
- Reasoning Upgrade Via Lisp Translation Explained: Clarification was offered on a project that enhances LLMs by translating human text to Lisp code which can be executed, aiming to augment reasoning by computation within the LLM's latent space while keeping end-to-end differentiability.
- Reasoning Repo Gets Richer!: The awesome-reasoning repo saw its commit history updated with new resources, becoming a more comprehensive compilation to support the development of reasoning AI.
LLM Perf Enthusiasts AI Discord
- Haiku Haste Hype Questioning: Community members are questioning the alleged speed improvements of Haiku, with concerns particularly aimed at whether it significantly enhances total response time rather than just throughput.
- Turbo Takes the Spotlight: Engineers in the discussion are interested in the speed and code handling improvements of the newly released turbo, with some contemplating reactivating ChatGPT Plus subscriptions to experiment with turbo's capabilities.
Alignment Lab AI Discord
Cry for Code Help: A guild member has requested help with their code by seeking direct messages from knowledgeable peers.
Server Invites Scrutiny: Concerns were raised over the excessive sharing of Discord invites on the server, sparking discussions about their potential ban.
Vitals Check on Project OO2: A simple inquiry was made into the current status of the OO2 project, questioning its activity.
Datasette - LLM (@SimonW) Discord
-
Gemini Listens and Learns: The Gemini model has been enhanced with the capability to answer questions concerning audio present in videos, marking progression from its earlier constraints of generating non-audio descriptions.
-
Google's Text Pasting Problems Persist: Technical discussions indicate a persistent frustration regarding Google's text formatting when pasting into their platforms, affecting user efficiency.
-
STORM Project's Thunderous Impact: Engineers took note of the STORM project, an LLM-powered knowledge curation system, highlighting its ability to autonomously research topics and generate comprehensive reports with citations.
-
macOS Zsh Command Hang-up Fixed: A hang-up issue when using the
llmcommand on macOS zsh shell has been resolved through a recent pull request, with verification of function across both Terminal and Alacritty on M1 Macs.
Mozilla AI Discord
-
Figma Partners with Gradio: Mozilla Innovations released Gradio UI for Figma, facilitating rapid prototyping for designers using a library inspired by Hugging Face's Gradio. Figma's users can now access this toolkit for enhanced design workflows.
-
Join the Gradio UI Conversation: Thomas Lodato from Mozilla’s Innovation Studio is leading a discussion about Gradio UI for Figma; engineers interested in user interfaces can join the discussion here.
-
llamafile OCR Potential Unlocked: There’s growing interest in the OCR capabilities of llamafile, with community members exploring various applications for the feature.
-
Rust Raves in AI: A new project called Burnai, which leverages Rust for deep learning inference, was recommended for its performance optimizations; keep an eye on burn.dev and consider justine.lol/matmul for Rust-related advancements.
-
Llamafile Gets the Green Light from McAfee: The llamafile 0.7 binary is now whitelisted by McAfee, removing security concerns for its users.
AI21 Labs (Jamba) Discord
Hunting for Jamba's Genesis: A community member expressed a desire to find the source code for Jamba but no URL or source location was provided.
Eager for Model Merging Mastery: A link to a GitHub repository, moe_merger, was shared that lays out a proposed methodology for model merging, although it's noted to be in the experimental phase.
Thumbs Up for Collaboration: Gratitude was shared by users for the resource on merging models, indicating a positive community response to the contribution.
Anticipation in the Air: There's a sense of anticipation among users for updates, likely regarding ongoing projects or discussions from previous messages.
Shared Wisdom on Standby: Users are sharing resources and expressing thanks, showcasing a collaborative environment where information and support are actively exchanged.
PART 2: Detailed by-Channel summaries and links
Stability.ai (Stable Diffusion) ▷ #general-chat (846 messages🔥🔥🔥):
-
Introducing Forge: Forge, a fork of Automatic1111 (or A1111), is being praised for its performance improvements over A1111. Users are encouraged to try it, especially as it doesn't require the removal of A1111 and can use models from ComfyUI.
-
Ella 's Anime Trouble: Users report that Ella, while promising, severely degrades the quality of generated anime-style images, making it unusable for this genre. Despite trying various checkpoints, including those recommended by Ella's creators, users are unable to attain satisfactory results.
-
Anticipation for SD3: Within the community, there's a mixture of excitement and skepticism regarding the release of Stable Diffusion 3 (SD3), with discussions around expectations for SD3 to solve present generative model limitations like the handling of bokeh effects, color accuracy, and celebrity recognitions.
-
Tools and Extensions Galore: The community discussed various tools and model extensions that improve Stable Diffusion outputs, such as BrushNet for outpainting, depth-fm, geowizard for architecture, and an extension for color accuracy. Users are encouraged to explore and stay up-to-date with new releases.
-
Cascade's Quirky Qualities: Cascade is noted for learning quickly and for its unique traits among SD models, though it's also described as challenging to use, with an endearing reference to being the "strange cousin of the SD family."
Links mentioned:
Cohere ▷ #general (522 messages🔥🔥🔥):
-
CORS Access Troubles: Users reported an issue where the Cohere dashboard was inaccessible, identifying a CORS policy error blocking a JavaScript fetch request from
https://dashboard.cohere.comtohttps://production.api.os.cohere.ai. -
Captivating Conversation on Command R+ and Context Length: The community engaged in a heated debate about the efficacy and practicality of long context lengths in LLMs versus strategies like Retrieval-Augmented Generation (RAG). Arguments included computational efficiency and the diminishing returns of increased context length.
-
Rerank V3 Launch Priced at $2 per 1K Searches: Clarification was provided on Rerank V3's pricing, set at $2 per 1,000 searches, with current promotions offering 50% off due to late pricing change implementation; Rerank V2 remains available at $1 per 1,000 searches.
-
Cohere Fine-Tuning and On-Premise Deployment Queries Addressed: In the discussion, questions were raised about the ability to fine-tune Cohere's LLMs on-premise or through the Cohere platform, as well as deploying these models on AWS Bedrock or on-premise setups.
-
Influx of Friendly Introductions to the Cohere Community: New members introduced themselves, including Tayo from Nigeria expressing gratitude for Cohere's LLM, and other individuals signaling their interest in or involvement with AI.
Links mentioned:
Cohere ▷ #announcements (1 messages):
- Rerank 3 Sets Sail for Enhanced Enterprise Search: Launching Rerank 3, a foundation model geared to increase the efficiency of enterprise search and RAG systems, now capable of handling complex, semi-structured data and boasting up to 3x improvement in inference speed. It supports 100+ languages and a long 4k context length for improved accuracy on various document types, including code retrieval.
- Boost Your Elastic Search with Cohere Integration: Rerank 3 is now natively supported in Elastic’s Inference API, enabling seamless enhancement of enterprise search functionality. Interested developers can start integrating with a detailed guide on embedding with Cohere and a hands-on Cohere-Elastic notebook example.
- Unlock State-of-the-Art Enterprise Search: Described in their latest blog post, Rerank 3 is lauded for its state-of-the-art capabilities, which include drastically improved search quality for longer documents, the ability to search multi-aspect data, and multilingual support, all while maintaining low latency.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #general (268 messages🔥🔥):
-
Mixtral Model Dilemmas: Several members voiced concerns about Mixtral and Perplexity Labs models having repetition issues and behaving erratically, likening the behavior to glitches. Critiques include superficial instruction fine-tuning and repetitive outputs similar to base models, with one member mentioning this GitHub repository as a better alternative for creating search-based models.
-
Anticipation Builds Around Upcoming Instruct Models: There's keen interest in the release of new instruct models, with a mod from Mistral confirming they're anticipated in a week, stirring up excitement for potential showdowns between different models like Llama and Mistral.
-
Exploring Long Context Windows in LLMs: Users delve into discussions about utilizing long context windows, up to 228K, for fine-tuning LLMs, with Unsloth AI reducing memory usage by 30% and only increasing time overhead by 1.9%, detailed further in Unsloth's blog.
-
The Quest for Domain-Specific Data: A member queries the community on the best practices for collecting a 128k context-size instructions dataset for a specific domain. Multiple suggestions are made, including looking at HF datasets, but the conversation leans towards the need for more specialized and domain-specific data collection methods.
-
Unsloth AI's Webinar on Fine-Tuning LLMs: Unsloth AI conducted a webinar hosted by Analytics Vidhya, walking through a live demo of Unsloth and sharing fine-tuning tips and tricks, which garnered interest from the community even leading to a last-minute notice. They also invite members to their Zoom event aimed at sharing knowledge and conducting a Q&A session.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #help (244 messages🔥🔥):
-
Solving Fine-Tuning Woes: Users were discussing challenges with fine-tuning models for NLP tasks; one concerning the discrepancy between good evaluation metrics during training and poor inference metrics, and another related to their struggle in training a model to improve accuracy, particularly in a non-English NLP context.
-
Model Deployment Dialogue: There was an exchange about how to deploy models after training with Unsloth AI, with references to possible merging tactics and a link to the Unsloth AI GitHub wiki for guidance on deployment processes, including for models like Mistral-7B.
-
VRAM Hunger Games: A member expressed difficulty trying to fit models within VRAM limits, even after applying Unsloth's VRAM efficiency updates. They discussed various strategies including fine-tuning batch sizes and consolidating contextual tokens into the base model to save on VRAM usage.
-
Dataset Formatting for GEMMA Fine-tuning: Someone seeking help with fine-tuning GEMMA on a custom dataset was directed towards using Pandas to convert and load their data into a Hugging Face compatible format, leading to a successful outcome.
-
GPU Limits in Machine Learning: In a debate over multi-GPU support for Unsloth AI, users clarified that while Unsloth works with multiple GPUs, official support and documentation may not be up-to-date, and that licensing restrictions aim to prevent abuse by large tech companies. A brief mention of integrating with Llama-Factory hinted at potential multi-GPU solutions.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #showcase (7 messages):
-
Sneak Peek of Ghost 7B: The upcoming Ghost 7B model is touted to be a small-size, multi-language large model that shines in reasoning, understanding of Vietnamese, and expert knowledge. The excitement is palpable among the community, with users anticipating its release.
-
Enriching Low-Resource Languages: Tips shared for enhancing low-resource language datasets include utilizing translation data or resources from HuggingFace. Members show support and enthusiasm for the Ghost X project's developments.
-
Community Support for Ghost X: The new version of Ghost 7B is welcomed with applause and encouragement from community members. Positive feedback underscores the work done on the Ghost X project.
Link mentioned: ghost-x (Ghost X): no description found
Unsloth AI (Daniel Han) ▷ #suggestions (1 messages):
starsupernova: oh yes yes! i saw those tweets as well!
Nous Research AI ▷ #off-topic (15 messages🔥):
- Money Rain Gif Shared: A member posted a gif link from Tenor, showing money raining down on Erlich Bachman from the TV show Silicon Valley.
- Insightful North Korea Interview: A YouTube video titled "Стыдные вопросы про Северную Корею" was shared, featuring a three-hour interview with an expert on North Korea, available with English subtitles and dubbing.
- Claude AI Crafts Lyrics: A member mentioned that the lyrics for a song listed on udio.com were created by an AI called Claude.
- Automatic Moderation against Spam: In response to a concern about invite spam, a member noted the implementation of an automatic system that removes messages and mutes the spammer if they send too many messages in a short period, with a notification sent to the moderator.
- Comparing Claude with GPT-4: One member expressed feeling a bit lost using Anthropics' Claude AI, indicating a preference for GPT-4's responses, which they felt were more aligned with their thoughts.
Links mentioned:
Nous Research AI ▷ #interesting-links (8 messages🔥):
-
The Renaissance of RNNs: A new paper attempts to revive Recurrent Neural Networks (RNNs) with an emerging hybrid architecture, promising in-depth exploration into the field of sequential data processing. The detailed paper can be found on arXiv.
-
Hybrid RNNs Might Be the Endgame: The discussion suggests a trend towards hybrid models when innovating with RNN architectures, hinting at the persistent challenge of creating pure RNN solutions that can match state-of-the-art results.
-
Google's New Model: There's buzz about Google releasing a new 7 billion parameter model utilizing the RNN-based architecture described in recent research, indicating substantial investment into this area.
-
Startup Evaluating AI Models: A member shared a Bloomberg article on a new startup that is focusing on testing the effectiveness of AI models, but the link led to a standard browser error message indicating JavaScript or cookie issues. The link to the article was Bloomberg.
-
Quotable Social Media Post: A member shared a link to a humorous tweet that reads, "Feeling cute, might delete later. idk," encouraging a brief moment of levity in the channel. The tweet is available here.
Links mentioned:
Nous Research AI ▷ #general (369 messages🔥🔥):
-
Google's Gemma Engine Gets a C++ Twist: Google has its own variant of llama.cpp for Gemma. A lightweight, standalone C++ inference engine for Google's Gemma models is available at their GitHub repository.
-
Nous Research is Feisty: The conversation touched upon the eagerly awaited Nous Hermes 8x22b and its development hardships. The Nous Hermes tuning, if attempted, would require infrastructure costing around "$80k for a week" and relies on tech that's not easily rentable.
-
Mac's AI Prediction Market: Discussion of Apple's M chips and their potential for AI inference set the group buzzing, with the M2 Ultra and M3 Max being notable for low power draw and high efficiency compared to Nvidia's GPUs. Some speculated about the future M4 chip, rumored to support up to 2TB of RAM.
-
Models on the Move: The chat noted the release of Mixtral-8x22b, and an experimental Mistral-22b-V.01, a dense 22B parameter model, as an extract from an MOE model, announced on the Vezora Hugging Face page. There's anticipation for the upcoming V.2 release with expectations of enhanced capabilities.
-
Fine-Tuning the Giants: The members debated the impact of prompt engineering on model performance, with recent tweets suggesting markedly improved results on benchmarks like ConceptArc and chess ELO ratings with carefully engineered prompts. The legitimacy of claims that GPT-4 can reach over 3500+ Elo in chess by leveraging this technique was also a topic of skepticism.
Links mentioned:
Nous Research AI ▷ #ask-about-llms (25 messages🔥):
-
Quest for 7B Mistral Finetuning Advice: A member inquired about a step-by-step guide for finetuning 7B Mistral. Suggestions included using the Unsloth repository and employing Qlora on a Colab GPU instead of a full finetune process for small datasets, or renting powerful GPUs from services like Vast.
-
Logic Reasoning Dataset Hunt: A dataset for reasoning with propositional and predicate logic over natural text was sought by a member. Another shared the Logic-LLM project on GitHub, noting it also provides an 18.4% performance boost over standard chain-of-thought prompting.
-
Freelancer Request for Finetuning Aid: One member expressed interest in hiring a freelancer to create a script or guide them through the finetuning process based on a provided dataset.
-
In Search of Genstruct-enhancing Notebooks: A member was looking for notebooks or tools to input scraped data as a primer for Genstruct and found a GitHub repository, OllamaGenstruct, that closely matches their needs.
-
Exploring LLMs in Healthcare and Medical Fields: Members discussed applications of LLMs in the medical domain, sharing papers and mentioning the potential legal risks of providing medical advice through such models. Artificial restrictions on models and other legal considerations were noted as impediments to development in this area.
Links mentioned:
Nous Research AI ▷ #world-sim (63 messages🔥🔥):
- UI Inspirations for Worldsim: A member shared a link to the edex-ui GitHub repository, which showcases a customizable science fiction terminal emulator. Although another user expressed interest, it was cautioned that the project is discontinued and could be unsafe.
- Anticipation for Worldsim's Return: The channel expresses eagerness with multiple members discussing when Worldsim might come back and what new features it might have. One member received confirmation that the Worldsim platform is planned to be back by next Wednesday.
- AGI as Hot but Crazy: In a light-hearted analogy, a member equated the allure of a dangerous UI to a "Hot but Crazy" relationship. The conversation shifted to discuss definitions of AGI with members adding different components like Claude 3 Opus, AutoGen, and Figure 01 to conceptualize AGI.
- Worldsim Coming Back Speculation: Members engaged in amateur predictions about when Worldsim would return, invoking Saturday based on nothing and using Claude 3's predictions, with estimates ranging from the upcoming Saturday to a more cautious end of next week.
- Potential Alternatives and Resources Explained: In response to a query about Worldsim alternatives during the downtime, a user mentioned the sysprompt is open-source and can be sent directly to Claude or used with the Anthropic workbench and other LLMs. Moreover, Anthropic API keys could be pasted into Sillytavern for those interested in experimenting with the Claude model.
{kind=link}
Links mentioned:
CUDA MODE ▷ #general (6 messages):
- Newcomer Alighted: A newcomer expressed excitement about discovering the CUDA MODE Discord community through another member's invitation.
- Video Resource Depot: The message informs that recorded videos related to the community can be found on CUDA MODE's YouTube channel.
- Peer-to-Peer Enhancement Announced: An announcement was made about the addition of P2P support to the 4090 by modifying NVIDIA's driver, enabling 14.7 GB/s AllReduce on tinybox green with support from tinygrad.
- CUDA Challenge Blog Post: A member shared their experience and a blog post about tackling the One Billion Row Challenge with CUDA, inviting feedback from CUDA enthusiasts.
- Channel Renaming for Resource Sharing: It was suggested to create a new channel for sharing materials. Subsequently, an existing channel was renamed to serve as the place for sharing resources.
Links mentioned:
CUDA MODE ▷ #cuda (168 messages🔥🔥):
-
Finding the Speed Limits with CublasLinear: Members discussed optimizations for faster model inference using custom CUDA libraries, with tests indicating that the custom
CublasLinearis faster for larger matrix multiplications. However, when tested within a full model such as "llama7b," the speedup wasn't as significant, potentially due to attention being the bottleneck rather than matrix multiplication. -
The Quest for Fast, Accurate Quantization: Various quantization strategies were debated, such as 4-bit quantization and its implementation challenges compared to other quant methods. A member is working on an approach called HQQ (High Quality Quantization) that aims to outperform existing quantization methods by using linear dequantization.
-
Driver Hacking for P2P Support: A message mentioned that P2P support was added to the RTX 4090 by modifying NVIDIA's driver, with a link provided to a social media post detailing the accomplishment.
-
CUDA Kernel Wishlist for New Language Model: A paper introducing RecurrentGemma, an open language model utilizing Google's Griffin architecture, was shared and prompted interest in building a CUDA kernel for it.
-
Benchmarking and Kernel Challenges: The conversation detailed the challenges of getting CUDA kernels to perform optimally and accurately, highlighting issues like differences in performance when moving from isolated tests to full model integrations and how changing precision can lead to errors or speed limitations.
Links mentioned:
CUDA MODE ▷ #torch (16 messages🔥):
- Quantization Quagmire for ViT Models: A member encountered an error when trying to quantize the
google/vit-base-patch16-224-in21kand shared a link to the related GitHub issue #74540. They are seeking a resolution and guidance in quantization and pruning techniques. - Fuss over FlashAttention2's Odd Output: When attempting to integrate flashattention2 with BERT, a member noted differences in outputs between patched and unpatched models, with discrepancies around 0.03 for the same inputs as reported in subsequent messages.
- Lament on Lagging LayerNorm: Despite claims of a 3-5x speed increase, a member found fused layernorm and MLP modules from Dao-AILab's flash-attention to be slower than expected, contrasting with what's advertised on their GitHub repository.
- Hacking the Hardware for Higher Performance: One user mentioned that Tiny Corp has modified open GPU kernel modules from NVIDIA to enable P2P on 4090s, achieving a 58% speedup for all reduce operations, with further details and results shared in a Pastebin link.
- Bitnet Bit-depth Blues: In search of optimizing storage for ternary weights in Bitnet implementations, a member discussed the possibility of using custom 2-bit tensors instead of the less efficient fp16 method, and was directed to a potential solution with a bitpacking technique in the mobiusml/hqq GitHub repository.
Links mentioned:
CUDA MODE ▷ #beginner (12 messages🔥):
-
Easing FOMO with Personal Pacing: A member acknowledged the temptation of feeling overwhelmed by others' progress in the server, emphasizing the importance of running one's own race and using language learning as an analogy.
-
CUDA Learning Curve vs. Language Proficiency: In a lighthearted comparison, members discussed whether learning CUDA is easier than learning German. A consensus seems to indicate that many in this Discord find CUDA simpler.
-
PMPP UI Study Group Invites: An announcement for a viewing party and study group for PMPP UI videos was made, with a scheduled first session and a posted Discord invite. The initiator is open to using existing voice channels for future sessions.
-
Is CUDA a Continuous Learning Curve?: Debates ranged on whether CUDA's evolving complexity is more challenging to stay current with than a static language like German learned in the past.
-
Programming Parallel Computers Free Online Course: A TA of a university course offered details of an open version for an online course on Programming Parallel Computers, including GPU programming, mentioning the automated benchmarking feature for exercises.
-
CUDA as an Acceleration Tool for Existing Frameworks: A member clarified that CUDA C/C++ functions can be called by TensorFlow and PyTorch when an Nvidia GPU is available, essentially acting as an accelerator by running parallel computations on the GPU.
Links mentioned:
CUDA MODE ▷ #pmpp-book (1 messages):
- Chapter 4 Shared: A member provided a Google Docs link to Chapter 4 of a document for perusal and feedback. The content of the document and the context of its use were not discussed.
CUDA MODE ▷ #ring-attention (8 messages🔥):
- Dataset Delivery: An oversized dataset was humorously likened to an extra large pizza, implying it's ready for use.
- Task Listing Suggestion: A user suggested creating a list of next tasks, indicating a need for organizing upcoming activities.
- Testing on Mamba: A member named jamesmel has indicated they have testing to do on a system or component named mamba.
- Infini-attention Introduction: An arXiv paper introduces Infini-attention, a method for scaling Transformers to handle infinitely long inputs within bounded memory and computation, spurring excitement with a 🔥 reaction.
- Ring Attention Explainer Shared: shindeirou shared a link to an explainer on ring attention geared towards making the concept accessible to a wider audience, the work of three colleagues highlighting the scalability of context windows in Large Language Models. Feedback was invited, and the animations within the explainer were praised.
Links mentioned:
CUDA MODE ▷ #off-topic (4 messages):
-
Beginning of a New Authorship: The channel saw the inception of a collaboration to write a modern equivalent of the Golub/Van Loan book, focusing on numerical linear algebra in the context of GPUs and Tensor Cores.
-
CUDA Compatibility Crackdown: Nvidia has updated its EULA to ban the use of translation layers for running CUDA software on non-Nvidia chips, a move seemingly aimed at projects like ZLUDA and certain Chinese GPU makers. This change was made online in 2021 but has only recently been added to the EULA in the installation process for CUDA 11.6 and newer.
Links mentioned:
CUDA MODE ▷ #hqq (11 messages🔥):
-
Benchmarking Kernels Across GPUs: Benchmarks reveal the int4mm kernel is much slower compared to other backends, and padding the weights doesn't affect the speed. The tests conducted across NVIDIA 3090, 4090, and A100 GPUs showed similar results, with mobicham's GitHub repository being referenced for the current implementation.
-
Updated Speed Evaluations: The speed-eval file has been updated and is available for use in further testing and optimizations, accessible via this GitHub Gist.
-
Speed Comparison of Matmul Operations: 8-bit matrix multiplication is reported to be twice faster than fp16, suggesting that the int4 kernel might have performance issues with larger batch sizes.
-
Incorporating HQQ into gpt-fast Branch: The gpt-fast branch now includes direct conversion of HQQ W_q into packed int4 format, with a successful reproduction reporting a perplexity (ppl) of 5.375 at 200 tokens per second using the
--compileoption, as detailed in zhxchen17's GitHub commit. -
Optimizations in HQQ Quant Config: Users should ensure to turn on the optimize setting in the quant_config when testing out HQQ to potentially improve performance. The effect of optimization on weight quality differs based on the axis configuration, as discussed in regard to HQQ's lower bit optimization.
Links mentioned:
CUDA MODE ▷ #triton-viz (3 messages):
-
Planning the Next Steps: A member suggested proceeding step by step when integrating new features, starting with adding code annotations.
-
Time for Development: Another member expressed their intention to start implementing the proposed ideas by coding them up.
-
GIF Guidance on Tensor Operations: A member pointed out a possible mistake in the order presented in a GIF, explaining that usually operations start with a large tensor that is loaded into a smaller one, and raised concerns about complications with more complex inner code.
CUDA MODE ▷ #llmdotc (98 messages🔥🔥):
-
A4000 Bandwidth Breakthrough with Vectorized Loads: A new approach using vectorized (
float4) loads and streaming load instructions on the A4000 has achieved a peak throughput of 375.7 GB/s, indicating almost the same speed up to a dimension of 8192. The method keeps cache requirements per SM consistent by doubling thread count when dimension doubles, ensuring L1 cache remains effective. -
Transitioning from C to C++ for CUDA Development: The utility of
C++overCin CUDA programming was discussed, emphasizing the ability for more modernC++features likeconstexpr, function overloads, and templates to potentially improve code quality. Despite no concrete immediate benefits outlined, there's consensus that since nvcc inherently uses a C++ compiler, the transition is reasonable for gains in maintainability. -
Cooperative Groups Enhance Softmax Performance: Cooperative groups are being employed to streamline the softmax kernel, enabling reductions across more threads without shared memory, and leveraging system-reserved shared memory when necessary. The incorporation of
cooperative groupshas been shown to offer around twice the speedup for certain kernels. -
CUDA Book Curriculum Outdated: Discussion pointed out that key features like cooperative groups are not covered thoroughly in the CUDA programming book used in CUDA MODE, even though they have been part of CUDA for over 5 years. This has been acknowledged by one of the book's authors, who agreed that future editions might use CUDA C++.
-
Performance Gains and PR Reviews: After intense optimization efforts including
cublasLt,TF32, and kernel fusion, a contributor was excited to have potentially outperformed PyTorch on an RTX 4090, as marked by their pull request. However, on an A100, PyTorch remained faster with a 23.5ms vs 30.2ms comparison in favor of PyTorch.
Links mentioned:
Perplexity AI ▷ #general (281 messages🔥🔥):
- Query on GPT-4's Inclusion in Perplexity: Users inquire about whether Perplexity has integrated an updated version of GPT-4 and its availability in the API.
- Model Matters: Perplexity vs. Opus: A user opines that Perplexity is not just a search engine but a blend of searching and image generation, suggesting it should not be restricted to search functions only.
- Considerations on API Flexibility: A discussion around incorporating the Perplexity API into an e-commerce website takes place, with users directing towards the Perplexity documentation.
- Image Generation Queries and Challenges: Members of the chatbot exchange thoughts on features like image generation, context limits, and the effectiveness of LLMs like GPT-4 Turbo and Claude 3 Opus.
- Using Extensions with Perplexity: Conversation touches on using browser extensions with Perplexity to enhance functionality and address the limitations of client-side fetching.
Links mentioned:
Perplexity AI ▷ #sharing (12 messages🔥):
- Discovering the Unknown: Users shared various Perplexity AI search links, exploring topics ranging from the unidentified (“What is the Ee0kScAbSrKsblBJxZmtgQ”) to specific queries such as “what is a PH63Fv40SMCGc7mtNDr2_Q” and “how to build whMjYrciQM.NXoSLpFSDcQ”.
- Enhancing Shareability: One user reminded to ensure that threads are Shareable, providing a Discord link for the reference screenshot but the details remain inaccessible due to the nature of the excerpts provided.
- Dive into Technical Concepts: Several search links hint at users delving into technical subjects, such as “rerank3-cohere-1UdMxh5DStirJf028HLA2g”, “Access-logging-should-9h6iZhUOQJ.JYhY8m1.cww”, and “Learning NIST 800-161-uu.csfXOSlGt5Xi_lc7TeQ”.
- Policy and Ethics in Focus: Members shared interest in policy considerations with searches related to the US government's deliberation in “US-is-considering-lJ9faQytRx.6RItBXyKFSQ” and ethical musings in “Why honesty is-I6x.NhtaQ5K.BycdYIXwrA”.
- Exploring Durability in Transformation: Curiosity also extended to exploring the concept of durability via a search link, “what is durable-XjhaEk7uSGi7.iVc01E1Nw”, suggesting a discussion on resilient systems or concepts.
Perplexity AI ▷ #pplx-api (6 messages):
- Pro Search via API Inquiries: A user queried about the ability to use "Pro Search" feature in the API, only to be informed that it is not possible to do so.
- In Search of Web Version Answers Through API: Users discussed whether API responses could match those from the web version of PERPLEXITY; one suggested explicitly asking the API to "provide your source URLs" as a method to obtain similar results.
- Feature Roadmap Queries: A user sought information on when citation features might be implemented, referring to the official PERPLEXITY documentation. The roadmap was noted to extend through June with various planned updates, but with no explicit mention of source citations.
Link mentioned: Feature Roadmap: no description found
LM Studio ▷ #💬-general (173 messages🔥🔥):
-
Coping with Context Length: Users are encountering issues with models like Dolphin Mistral, where continual usage leads to repetition of certain words or sentences. To address this, they should adjust the context length, as typical issues arise upon reaching the model's context limit.
-
Navigating Local Model Limitations: There's a consensus that complex models like CommandR+ can place significant demands on hardware, with some users being unable to run heavier models due to limitations in VRAM and system specifications, highlighting GPU upgrades and using ngrok for server access as possible solutions.
-
LM Studio Tool Talk: Discussions revolve around the diverse functionalities of LM Studio, clarifying that it does not support internet access for models or drag-and-drop file input; however, links to third-party tools and methods are provided to overcome some of these constraints.
-
Model Hosting and Integration Queries: Users are asking about hosting models on various platforms like Runpod and GitPod, and querying the possibility of integrating text generation with image generation tools like Stable Diffusion.
-
Technical Support Exchange: There's active engagement regarding troubleshooting issues on various systems, such as AVX2 instruction absence and JavaScript errors in LM Studio. User heyitsyorkie frequently offers advice, including directing to support channels and confirming the necessity of turning off GPU offload for some fixes.
Links mentioned:
LM Studio ▷ #🤖-models-discussion-chat (46 messages🔥):
- Mixtral-8x22B Ready for Quantization: The Mixtral-8x22B model has been quantized using llama.cpp and is now available for download, split into parts due to its large size. Users are advised that it's a base model, not yet fine-tuned for chat or instruction-based tasks, and may struggle to run on systems that cannot handle the 8x7b version.
- LLM Architecture Load Error Solution: An error message "llama.cpp error: 'error loading model architecture: unknown model architecture: '''" appeared when attempting to load Mixtral-8x22B-v0.1 with LM Studio 0.2.17; upgrading to 0.2.19 beta preview 3 or newer resolves this issue.
- New Chat2DB SQL Models Released: User bartowski1182 announced the release of two new models optimized for SQL tasks, available at their respective Hugging Face URLs: Chat2DB-SQL-7B-GGUF and Chat2DB-SQL-7B-exl2.
- Performance Discussion for Large Models: Community members shared their experiences with large models, discussing the resource intensiveness of CMDR+ and Mixtral 8x22, with suggestions of trying smaller quantized versions or adjusting LM Studio settings, like turning off GPU offload and not keeping the model in RAM.
- Check Server Capabilities Before Upgrading: When discussing hardware upgrades and configurations for loading models of 100B+ parameters, it was noted the importance of having AVX2 instruction compatibility, and that servers should have at least 24GB VRAM GPUs for performance considerations.
Links mentioned:
LM Studio ▷ #📝-prompts-discussion-chat (2 messages):
- LLM Design Limitations in Time Series: It was mentioned that time series data is not suitable for Large Language Models (LLM) unless there is a change in the model's design.
- TFT as a Solution for Time Series Data: Training a Temporal Fusion Transformer (TFT) on time series data was suggested as a viable approach.
LM Studio ▷ #🎛-hardware-discussion (23 messages🔥):
- No Cloud GPU, but HuggingFace Chat is an Alternative: Cloud GPU services are not supported for Command-R Plus, though HuggingFace Chat offers the model CohereForAI/c4ai-command-r-plus as an online option.
- Running Large Models Local vs. Cloud: Discussion about the feasibility of running 72b models expressed concerns regarding VRAM limitations; alternatives include cloud solutions or local hardware upgrades like the NVIDIA 4060ti 16GB.
- Anticipating Apple’s M4 for AI: An upcoming Apple's M4 Mac release is rumored to focus on artificial intelligence applications, which may require a budget increase for potential buyers.
- Memory Trade-off for AI Applications: A debate on whether increasing from 16GB to 40GB of non-dual channel RAM would benefit large language model (LLM) performance, despite tradeoffs in gaming performance, concluded that for CPU inference in AI tasks, having more RAM is beneficial despite the loss of dual-channel advantage.
- GPU vs. CPU Inference: The discussion highlighted that CPU inference performs significantly slower compared to GPU inference, and while having more system memory allows loading larger LLMs, the ultimate goal is full GPU inference for optimal performance.
Links mentioned:
LM Studio ▷ #🧪-beta-releases-chat (9 messages🔥):
-
Mistral Model Loading Issues on Ubuntu: A user encountered an “Error loading model” with the Mistral model on Ubuntu 22.04 LTS when trying to load a local model with their server. System specifications, such as available RAM and GPU details, were shared to seek explanations for the Exit code: 0 error encountered during model loading.
-
BERT Embeddings Inquiry and Guide: One member inquired if it was possible to load Google BERT embed models, leading to a discussion where a link to the LM Studio docs about text embeddings was shared, explaining how to generate text embeddings for RAG applications using LM Studio's embedding server in GGUF format.
-
Clarification on Google BERT and Fine-Tuning: Another user clarified that basic Google BERT models are not available for use with LM Studio and are generally not suitable for direct use without fine-tuning on a downstream task, referencing a model from Hugging Face.
-
Recommendations for Better Embedding Models: Further recommendations were made for embedding models with larger parameters such as
mxbai-large,GIST-large, andLaBSEfor improved results over the standard BERT base model. -
Options for Compute Costs with Embeddings: There was a remark on different embedding models to suit computational capabilities, noting that there are
baseandsmallversions with 768 and 384 dimensions as alternatives to thelargeversion's 1024 dimensions.
Links mentioned:
LM Studio ▷ #amd-rocm-tech-preview (12 messages🔥):
- Linux Users Inquiring About ROCm: A user asked whether an amd-rocm-tech-preview will be available for Linux, to which another user indicated that it would happen eventually but not soon.
- User Experiences with ROCm Enabled Hardware: Multiple users reported on their experiences running ROCm with different hardware, specifically the 7800XT, 7900 XTX Nitro+, and 6800XT. They shared that running tasks produced audible coil whine, which varied by game or workload.
- Tech Preview Challenges on AMD 6750XT: A user noted that the ROCm tech preview claims to use the GPU on an AMD 6750XT but ends up only utilizing the CPU and RAM without throwing any compatibility errors. They contrasted this with regular studio, which properly offloads to the GPU using AMD OpenCL.
- Assistance Requested for Windows Binary Build: A member sought help for building the gguf-split binary on Windows in order to test on a 7900XT, linking to a GitHub discussion and pull request related to the issue: How to use the
gguf-split/ Model sharding demo and Add Command R Plus support.
Links mentioned:
Eleuther ▷ #general (96 messages🔥🔥):
-
Exploring Context Window Extension for Encoders: Members discussed the challenges of adapting methods used for extending context windows in decoder-only models to encoder models like BERT, citing difficulties due to bidirectional attention mechanisms. They also talked about MosaicBERT using FlashAttention and wondered why it isn't more commonly implemented in libraries such as Hugging Face's Transformers, despite community contributions.
-
Quantization and VRAM Concerns for Mixtral-8x22B Model: A member sought community support for running a 2-bit quantization of the Mixtral-8x22B model on a GPU server to make it possible to use with less than 72 GB of VRAM. There's anticipation for the AQLM team's progress which might take a week.
-
Exploring The Pile Dataset Size Discrepancies: Users shared their experiences with downloading and working with The Pile dataset, noting discrepancies in sizes between the reported 886GB uncompressed size and their compressed copies varying from 720GB to 430GB, and discussing the lack of extraction code for different archive types in The Pile.
-
Creating a Reading List for AI Leaning and Language Model Development: A member shared a GitHub repo containing a reading list designed to help newcomers at Elicit learn about language models ranging from basic transformer operations to recent developments.
-
EleutherAI Contributions and Public Models: A member highlighted EleutherAI's contributions to AI development and mentioned publicly available models such as GPT-J and NeoX. The discussion also touched on a new feature of the wiki pages being AI-generated with sources like EleutherAI.
Links mentioned:
Eleuther ▷ #research (93 messages🔥🔥):
- Google's Mixture of Depths Model Introduced: A tweet by @_akhaliq reveals that Google has presented a Mixture-of-Depths, aiming to dynamically allocate compute in transformer-based language models rather than spreading FLOPs uniformly across input sequences.
- RULER's Empty Repo Now Open-Sourced: The open-source community now has access to an empty repository for RULER, which promises insights into the real context size of long-context language models, as seen on GitHub.
- Adversarial Examples: Beyond Noise and Deformities: Discussion covered how adversarial examples are not always just unstructured noise, with some taking form as actual deformities on parts of an image. This complexity was further detailed in the ImageNet-A and ImageNet-O datasets paper with 1000 citations.
- Finetuning Subset of Layers Can Be Efficient: Emerging discussions on subset finetuning were highlighted where finetuning a subset of a network's layers can achieve comparable accuracy to full finetuning, particularly when training data is scarce, as posited in this paper.
- Affordable and Competitive Large Language Model JetMoE-8B: JetMoE-8B, a new affordable LLM trained with less than $0.1 million and featuring a Sparsely-gated Mixture-of-Experts architecture, is noted to outperform other models within similar scopes, marking a significant step for open-source models. Its details can be found here.
Links mentioned:
Eleuther ▷ #scaling-laws (11 messages🔥):
- Query on floating-point precision in large runs: A user inquired about the floating-point format used in the current largest training runs, wondering whether bf16 is still standard or if labs have moved to fp8.
- Scaling Laws for Data Filtering Paper Shared: A new scaling laws paper presented at CVPR2024 addresses the interplay between data curation and compute resources. It posits that data curation cannot be compute agnostic and introduces scaling laws for working with heterogeneous and limited web data.
- Muted Response to Paper: One member responded with a non-verbal emoticon, seeming to imply a lack of excitement or skepticism regarding the shared paper on scaling laws.
- Search for Entropy in Study Methods: Discourse continued with a member symbolically mentioning the search for entropy-based methods within the context of the scaling laws. This theme was acknowledged by another user, who noted the empirical approach taken without explicit mention of entropy.
- Contemplating the Foundations of New Research: Members reflected on how current research, like the scaling laws paper, might be grounded in classic concepts like entropy implicitly, even if not stated directly. They discussed the nuances of the paper's approach to redefining concepts like entropy as 'utility' leading to unconventional analytical perspectives.
Link mentioned: Tweet from Pratyush Maini (@pratyushmaini): 1/ 🥁Scaling Laws for Data Filtering 🥁 TLDR: Data Curation cannot be compute agnostic! In our #CVPR2024 paper, we develop the first scaling laws for heterogeneous & limited web data. w/@goyalsach...
Eleuther ▷ #interpretability-general (8 messages🔥):
- Surprise at GitHub Stars as a Metric: A member expressed astonishment regarding the use of GitHub stars as a metric, mentioning how they've encountered great projects with few stars and "absolute crimes against software with 10k+ stars".
- Intrigue Over Activation to Parameter: The concept of AtP(*) piqued a member's interest due to its potential use and value.
- Potential for Anomaly Detection with AtP: There is curiosity about utilizing AtP* for anomaly detection, specifically by contrasting the results from a single forward pass with multiple others to determine anomalies.
- A New Approach to AtP Analysis: Unlike the method in the paper where effects are averaged, the member suggests a different approach by comparing individual forward pass results to identify outliers.
Eleuther ▷ #lm-thunderdome (1 messages):
butanium: Someone in my lab was also wondering if those chat_template branches were usable or not
Eleuther ▷ #gpt-neox-dev (10 messages🔥):
- Corporate CLA Needed for Contribution: A member mentioned a requirement for a corporate Contributor License Agreement (CLA) to proceed with the fused kernels and fp8 integration for TE. The current EleutherAI/GPT-NeoX CLA is only for individuals.
- Writing a Custom Corporate CLA: In response, another member offered to write a custom CLA and asked for a specific requirements list and necessary changes from the current CLA.
- NeoX Embeddings Raise Questions: A member analyzing embeddings noted that NeoX appears to be an outlier and wondered if weight decay was not applied to its input embeddings, or if another specific trick was used.
- Comparing Pythia and NeoX Embeddings: Following a query on whether the NeoX model's odd behaviors were also found in Pythia, another member decided to inspect both.
- Distinct Behavior of NeoX Identified: After some analysis, it was confirmed that NeoX is a unique outlier in its embeddings, with
model.gpt_neox.embed_in.weight[50277:].sum(axis=1)not being near 0, unlike other models like GPT-J and OLMo.
OpenRouter (Alex Atallah) ▷ #announcements (2 messages):
-
Mixtral 8x22B:free Introduced and Updated: A new model, Mixtral 8x22B:free, has been created to align with existing :free models and to clarify routing/rate-limiting confusions. It also features an updated context size, from 64,000 to 65,536.
-
Switch Required from Disabled Free Model: Mixtral 8x22B:free has been disabled, and users are advised to switch to Mixtral 8x22B.
-
New Experimental Models for Testing: Two new instruct fine-tunes of Mixtral 8x22B are available for testing: Zephyr 141B-A35B and Fireworks: Mixtral-8x22B Instruct (preview).
Links mentioned:
OpenRouter (Alex Atallah) ▷ #app-showcase (1 messages):
.o.sarge.o.: Seems to be an issue when trying to purchase tokens. Here is an image
OpenRouter (Alex Atallah) ▷ #general (213 messages🔥🔥):
-
Log-in Issues Resolved Autonomously: A user incorrectly logged into a platform and then figured out a solution to not just log out but to delete the account entirely.
-
GPT 4 Turbo and Mistral Large Errors: Troubleshooting of
500 errorson GPT 4 turbo and mistral large led to a discovery that re-deploying to Heroku resolved the problem, suggesting a corrupted deployment might have been the cause. -
Personal AI System Setup Discussions: Community members discussed personal AI setups using OpenRouter and other tools, like LibreChat, suggesting options for a personalized AI experience that includes mobile and desktop usability, conversation storage, and low-latency web results.
-
Firextral-8x22B-Instruct Updates and Clarifications: Updates to routes for models like Firextral-8x22B-Instruct were discussed, with a switch to the Vicuna 1.1 template and clarifications of max context listings as "Max Output" on the OpenRouter website.
-
AI Models' Performance and Tuning Shared Experiences: Users shared their experiences and observations about various models' performance and tuning capabilities. Opinions varied with some favoring GPT-4 Turbo for certain tasks, others expressing interest in MoE architectures, and discussing the role of Opus, Gemini Pro 1.5, and the emergent behavior of models.
Links mentioned:
Modular (Mojo 🔥) ▷ #general (9 messages🔥):
-
Mojo Gives Back to the Community: Mojo has recently open-sourced their standard library, which now includes community-made changes from merged pull requests. This move allows the community to contribute and gives the Mojo team more time to focus on the compiler.
-
Seeking Modular Collaboration: An individual from BackdropBuild.com is looking for assistance to integrate Modular into their large-scale developer cohort programs. They are reaching out to collaborate with Modular to support builders using their technology.
-
Staying In The Right Lane: A reminder was given that inquiries for business and collaborations should be directed to the offtopic channel, facilitating better organization and relevance in the general discussion.
Link mentioned: Backdrop Build: Together we build - Bring that crazy idea to life alongside hundreds of other amazing builders in just 4 weeks.
Modular (Mojo 🔥) ▷ #💬︱twitter (1 messages):
ModularBot: From Modular: https://twitter.com/Modular/status/1778482233957101869
Modular (Mojo 🔥) ▷ #✍︱blog (1 messages):
- Mojo Tackles Matrix Storage: A new blog post on Modular's website dives into how matrices are stored in memory, exploring the distinctions and performance implications of row-major and column-major ordering. This investigation aims to clarify why different programming languages and libraries have preferences for either storage order.
Link mentioned: Modular: Row-major vs. column-major matrices: a performance analysis in Mojo and NumPy: We are building a next-generation AI developer platform for the world. Check out our latest post: Row-major vs. column-major matrices: a performance analysis in Mojo and NumPy
Modular (Mojo 🔥) ▷ #🔥mojo (125 messages🔥🔥):
-
Karpathy's llm.c Discussed in Mojo: A GitHub issue about why Andrej Karpathy's
llm.crepo doesn't use Mojo sparked interest. Andrej Karpathy mentions he's happy to link to any Mojo port from the readme for benchmarking and comparison. -
Binary File Reading in Mojo: Members discussed how to implement a binary file reader in Mojo similar to Python's
struct.unpack. One solution provided involved using Mojo'sreadinstead ofread_bytes, which seems to resolve the issue as showcased in a GitHub file. -
GUI Design Philosophies Clash: Conversations revolving around GUI frameworks prompted different opinions on design approaches, with a focus on the model/view paradigm. Some members showed preference for declarative GUIs like SwiftUI, while others defended the flexibility and control provided by imperative frameworks like Tk.
-
Mojo's Potential to Enhance Python Performance: The community expressed enthusiasm for Mojo's future, notably its potential to augment Python's performance and possibly allow for direct Python code compilation. A link to a relevant podcast with Chris Lattner discussing Mojo's goals was shared.
-
Comparing Functionality between Mojo and C: Questions about Mojo's ability to mimic functionalities in C, such as bit operations, were discussed, with members sharing examples of translations and confirming functionality within Mojo for operations like shifts and bitwise XOR.
Links mentioned:
Modular (Mojo 🔥) ▷ #community-projects (2 messages):
- Sneak Peek at Terminal Text Rendering with Mojo: A member showcased text rendering in the terminal using Mojo and shared the code, inspired by
charmbracelet’s lipglosspackage. The preview code is available on GitHub, with a minor status bar issue soon to be fixed. - Cheers for Basalt Integration: Another community member complimented the integration of Basalt, finding the terminal rendering results impressive.
Link mentioned: mog/examples/readme/layout.mojo at main · thatstoasty/mog: Contribute to thatstoasty/mog development by creating an account on GitHub.
Modular (Mojo 🔥) ▷ #community-blogs-vids (1 messages):
-
Exploring Memory Storage in Matrices: A blog post titled "Row-major vs. Column-major matrices: A performance analysis in Mojo and Numpy" dives into row-major and column-major ordering. It discusses performance implications and the preferences of different languages and libraries for matrix memory storage.
-
Matrix Memory Order Notebook Error: A member attempting to follow the blog post encountered an error when running the second cell of the associated Jupyter notebook on GitHub, located at devrel-extras/blogs/mojo-row-major-column-major. The error involved an unknown declaration related to 'mm_col_major' when creating a MojoMatrix and converting it to column-major format.
Links mentioned:
LangChain AI ▷ #general (107 messages🔥🔥):
-
Tracking Token Usage in AIAssistant: A member is tracking their own token usage from OpenAI's API by receiving token counts, multiplying by pricing, and saving the data, due to LangSmith not providing token usage for AIAssistant.
-
Summarization Speed Struggle: Members discussed LangChain's
load_summarization_chainfunction, pointing out its slowness when summarizing large PDFs. One member shared a code snippet demonstrating the use ofmap_reducechain to improve speed. -
Integration and Usage of Instructor with LangChain: Discussion included the possibility of utilizing Instructor, which facilitates structured outputs like JSON from LLMs, with LangChain. A member expressed they would like a tool that produces valid pydantic objects and handles validation errors through LLMs.
-
Ensuring Valid Tool Args in LangChain Tool Calling Agent: One member sought advice on self-healing invalid tool args produced by LLMs within LangChain's Tool Calling Agent, citing Groq Mixtral issues.
-
Reading CSV Files Efficiently with LangChain: A member sought the most efficient way to read .csv files, using agents, and another member suggested using ChatOpenAI with the
openai-toolsagent type. Further discussion ensued about the model's performance with different numbers of .csv files. -
Handling Memory Release in FAISS-GPU with LangChain: A user queried about releasing memory when running into
[torch.cuda.OutOfMemoryError](https://pytorch.org/docs/stable/cuda.html#memory-management)with FAISS-GPU and Hugging Face embeddings within LangChain, unable to manually release GPU memory with the provided wrapper.
Links mentioned:
LangChain AI ▷ #langserve (4 messages):
- Inappropriate Content Alert: A message in the channel promoted adult content with a link, disguising it as an invitation to join a Discord server.
- Seeking Info on LangFuse Callbacks: A member requested assistance with utilizing langfuse callback handler for tracing via langserve and was looking for sources or examples on how to log inputs such as questions, session ID, and user ID in language.
Link mentioned: Join the Teen Content 18+ 🍑🔞 Discord Server!: Check out the Teen Content 18+ 🍑🔞 community on Discord - hang out with 441 other members and enjoy free voice and text chat.
LangChain AI ▷ #langchain-templates (3 messages):
- Inappropriate Content Alert: A message contained a link promoting adult content; was marked as spam. This type of content is typically against Discord's community guidelines.
Link mentioned: Join the Teen Content 18+ 🍑🔞 Discord Server!: Check out the Teen Content 18+ 🍑🔞 community on Discord - hang out with 441 other members and enjoy free voice and text chat.
LangChain AI ▷ #share-your-work (8 messages🔥):
-
Launch of Galaxy AI: GalaxyAI introduces a free API service featuring AI models such as GPT-4, GPT-4-1106-PREVIEW, GPT-3.5-turbo-1106, and Claude-3-haiku, with Langchain integration. Available at Galaxy AI, these APIs are in OpenAI format for easy integration into projects.
-
Appstorm v1.6.0 Elevates App Building: The new version 1.6.0 of Appstorm is released on Appstorm beta, incorporating mobile registration, music and map GPTs, data exploration and visualization, easier app sharing, improved concurrent app management, and bug fixes enhancing the app-building experience.
-
Request for AI Assistant Development Advice: A member is developing a virtual AI assistant requiring parsing of thousands of PDFs to generate RAG (Retriever-Answer Generator) based functionality and set configuration parameters for an IoT edge platform by reading datasheets, and seeks suggestions for tackling this project.
-
Inappropriate Content Alert: Warning: Posts from a member sharing explicit content and links to pornographic material were identified; they offered no constructive input to the AI discussions.
-
Meeting Reporter Enhancement via AI: A new application, Meeting Reporter, marries Streamlit with Langgraph to create news stories through a human-AI collaboration, requiring a paid OpenAI API key. It's showcased on Streamlit App and the open-source code is available on GitHub, with further details and session transcripts provided on a related blog post.
Links mentioned:
LangChain AI ▷ #tutorials (4 messages):
-
LangChain Tutorial Alert: A new tutorial on LCEL (LangChain Execution Language) and creating chains with runnables has been published. Interested parties can read and provide feedback at LangChain Tutorial: LCEL and Composing Chains from Runnables.
-
Spam Alert: The channel tutorials received multiple spam messages promoting adult content. These messages contain explicit material and are not related to the channel's purpose.
Link mentioned: Join the Teen Content 18+ 🍑🔞 Discord Server!: Check out the Teen Content 18+ 🍑🔞 community on Discord - hang out with 441 other members and enjoy free voice and text chat.
HuggingFace ▷ #announcements (9 messages🔥):
<ul>
<li><strong>Osanseviero's Tweet Blast</strong>: A new tweet has been shared by osanseviero, exciting news or insights expected. Check out the tweet <a href="https://twitter.com/osanseviero/status/1778430866718421198">here</a>.</li>
<li><strong>Highlighting the Highlights</strong>: Community Highlights #53 delivers diverse verified user content including a Portuguese introduction to Hugging Face, a fashion try-on space, and various intriguing GitHub repositories.</li>
<li><strong>Embedded for Success</strong>: The RAG chatbot is powered by an embedded dataset via <a href="https://huggingface.co/datasets/not-lain/wikipedia-small-3000-embedded">not-lain/wikipedia-small-3000-embedded</a>, serving as a retrieval source for generating user-informed responses.</li>
<li><strong>Retrieval and Generation Duo</strong>: Combining retrieval from an embedded dataset with generative AI, the RAG chatbot innovatively seeks to provide accurate information inferences.</li>
<li><strong>Rocking Downloads with RMBG1.4</strong>: RMBG1.4, integrated with the transformers library, hits a new milestone with 230K downloads this month, indicating strong community interest and usage.</li>
</ul>
Links mentioned:
HuggingFace ▷ #general (64 messages🔥🔥):
-
Basics of Datasets: A user inquired about starting points for learning about datasets. They were directed to the HuggingFace documentation which has explainers, templates, guides on creating datasets, and more, and can be found at HuggingFace's Datasets Library.
-
QA Bot to Aid Human Help: It was suggested that a QA bot in the #help channel could assist users by suggesting relevant information or pointing to similar solved problems. A button to enable bot suggestions might increase its visibility and use.
-
Training Models for GUI Navigation: There was a detailed conversation about the feasibility of training models for OS GUI navigation. Alternatives like using accessibility modes and app interfaces were discussed over pixel-perfect vision-based control.
-
Multiple Model Operations on Single GPU: A discussion about running multiple models simultaneously on a single GPU emerged. Users shared experiences and techniques, such as creating a web server with semaphores to optimize GPU throughput.
-
Handling Large Datasets and Progress Tracking with Datasets: Users debated the best ways to handle and upload very large datasets, especially for audio and images, with a focus on enabling streaming and efficient metadata updates. There were queries about how progress information could be extracted when mapping functions over datasets for UI integration.
Links mentioned:
HuggingFace ▷ #today-im-learning (1 messages):
- Docker-Alternative Deep Dive: A video tutorial entitled "Contain Your Composure: On Podman-Compose, Code Cleanup, and Tiny Llamas" provides a walkthrough for building microservices with Podman-Compose, emphasizing Yet Another Markup Language (YAML) files and introduction to Small Langu. The description hints at a focus on clean code practices and possibly a fun take on distilling complex topics.
Link mentioned: Contain Your Composure: On Podman-Compose, Code Cleanup, and Tiny Llamas: This video tutorial will walk you through the process of building microservices using Podman-Compose, Yet another Markdown language (YAML) files, Small Langu...
HuggingFace ▷ #cool-finds (6 messages):
-
CUDA Simplicity by Karpathy: Andrej Karpathy has implemented a straightforward approach to LLM training using raw C/CUDA. The code is accessible on GitHub with an illustrative llm.c repository.
-
Mistral 7B vs. Llama Models: A benchmarking site compares Mistral 7B to Llama 2 family, noting that Mistral 7B outshines Llama 2 13B across all metrics and rivals Llama 34B. Their findings commend Mistral 7B for exceptional performance in code and reasoning, Mistral 7B details here.
-
Awaiting Further Info: A member mentioned receiving a document from Google Cloud Next ’24, but did not provide further details or a link.
-
Introducing Parler TTS: HuggingFace introduces parler-tts, a library for inference and training of high-quality TTS models, available on their GitHub repository. Interested individuals can explore and contribute via the parler-tts GitHub page.
-
AI Book Recommendation: A member found "The age of AI" to be a really interesting read but provided no additional information or links.
-
Memory-Enhanced Document Retrieval Guide: A tutorial has been published on enhancing document retrieval with memory, detailing the use of LlamaIndex with a Colbert-based Agent. The tutorial is available on Medium, providing an insight into document retrieval advancements at Enhancing Document Retrieval Tutorial.
Links mentioned:
HuggingFace ▷ #i-made-this (8 messages🔥):
- Hugging Face Model Playground by Marimo: A member introduced marimo-labs, a new Python package that integrates with Hugging Face, enabling users to create interactive playgrounds for text, image, and audio models. This is powered by marimo's reactive execution combined with Hugging Face's free inference API.
- Marimo Playground Interactive Link: An interactive marimo application is shared where users can query models on Hugging Face interactively using their own tokens; the app runs locally via WASM.
- AI Concepts in Portuguese: A member has published a post and video in Portuguese introducing the fundamentals of Hugging Face, providing a valuable resource for Portuguese-speaking newcomers to AI. The content is part of a series titled "de IA a Z", available with additional posts covering various AI topics.
- Upcoming Features for Mergekit: An announcement was made about upcoming new methods for Mergekit, including the already added rescaled TIES.
- Vimeo Video Shared: A video link from Vimeo https://vimeo.com/933289700 was shared, although no context or description was provided.
Links mentioned:
HuggingFace ▷ #reading-group (1 messages):
- Fine-Tuning Blenderbot Tip: One member recommends fine-tuning Blenderbot by FAIR, which is available on HuggingFace, noting the need to source a suitable dataset for the task.
HuggingFace ▷ #computer-vision (14 messages🔥):
-
GPU Process Management Tool Recommended: A GPU process viewer named nvitop is suggested as a practical tool for managing GPU processes, with the source and more details found on GitHub - XuehaiPan/nvitop.
-
Starting Steps in Video Correction Techniques: A user seeking advice on video correction techniques such as denoising and removing artifacts is directed to an image restoration paper as a starting point and suggested to consider it an extension to video by adding temporal dimensions, available at arXiv's Paper on NAFNet.
-
The Importance of Data Augmentation in Image Restoration: In response to a concern about training datasets without ground truth for video restoration, it is highlighted that data augmentation is key, with links to two papers: BSRGAN and Real-ESRGAN that detail their augmentation pipelines which are useful for training restoration models.
-
Understanding Video Deflickering: For issues related to video noise and artifacts, the user is referred to a specific project on GitHub All-In-One-Deflicker that deals with blind video deflickering.
-
Integration of Multimodal and Vector Databases Explored: A discussion on integrating Google's Vertex multimodal embeddings with Pinecone vector database emerges, including how they handle typos and brand recognition through embeddings with a link to a demo by Google AI Demos Dev.
Links mentioned:
HuggingFace ▷ #NLP (12 messages🔥):
-
Seeking Longer Context Models: A member inquired about encoder-decoder models that can handle longer contexts around 10-15k tokens. Suggestions included looking into models like BigBird and Longformer.
-
Training with Checkpoints: An inquiry was made about using HuggingFace's
trainerto pause and resume training. Theresume_from_checkpointoption withintrainer.train()was confirmed to serve this purpose. -
Script Assistance Request: A member shared a detailed script
train_ddp.pyutilizing transformers, TRL, PeFT, and Accelerate for training a model and requested help to ensure its correctness and the proper saving of the trained model. -
Balancing Marks and Mentorship: Participants discussed methods for evaluating automated tutoring responses, considering using weighted averaging to prioritize a markscheme over mentoring principles with suggestions for embedding models suitable for semantic meanings, such as
sentence-transformers/all-MiniLM-L6-v2. -
Downloading Large Split Models: There was a question regarding the download and assembly of large models like Mixtral-8x22B, which are split into multiple GGUF files. The member asked if the files need to be manually merged or if they will be automatically assembled when loaded.
HuggingFace ▷ #diffusion-discussions (5 messages):
-
Fastai and Diffusers Deep Dive: A member recommended studying the fastai's second part course for a deep understanding and then exploring HuggingFace diffusers' GitHub issues and related HuggingFace blog posts. They also advised following the top GitHub discussions on diffusers for the latest insights.
-
PixArt-Alpha Pipeline Usage: In a short note, a member suggested checking out the PixArt-Alpha pipeline which utilizes the mentioned technology.
-
Limitations on Consumer GPUs: A member discussed limitations with consumer GPUs when using modern techniques like SDPA and
torch.compile(), suggesting that these are more beneficial on up-to-date GPUs. For those with less powerful GPUs, they shared suggestions from a GitHub discussion on how to accelerate diffusion. -
Understanding Multimodal Search Capabilities: A member asked how Google's multimodal embeddings were able to not only match images but also recognize a brand name with a typo, based on a demo by AI-demos. They expressed their intention to build a similar functioning web application and were seeking insights into the underlying mechanism.
Links mentioned:
Latent Space ▷ #ai-general-chat (86 messages🔥🔥):
-
Hybrid Search Methodology Debate: One user seeks advice on hybrid search strategies using Cohere's rerank and asks whether combining lexic and semantic search results before reranking is more effective than reranking them all together in one list. Fellow members suggest that the second approach may be more efficient as it involves a single reranking step and could save on latency.
-
Models on the Rise: A link to a tweet by Sandra Kublik announces the release of Rerank 3, a new model from Cohere, which boasts enhancements in search and RAG systems, including 4k context length, state-of-the-art (SOTA) search accuracy, code retrieval, and multilingual capabilities across 100+ languages. The original tweet with more details can be found here.
-
AI Startups and Innovation: A discussion around a new work automation tool for the multimodal AI era called V7 Go, introduced by Alberto Rizzoli, garners interest for its approach to tackling monotonous tasks with GenAI. Another competing product, Scarlet AI, is brought up by its creator, hyping its capabilities for planning and executing tasks with a blend of AI and human collaboration.
-
Perplexity's "Online" Models: Users discuss the disappearance of Perplexity's "online" models from LMSYS Arena, speculating on its meaning and the technology behind it. A link to Perplexity's blog post revealing it refers to models accessing the internet is provided here.
-
Leaders in the AI Chatbot Arena: An update about GPT-4-Turbo reclaiming the top spot on the Lmsys blind chatbot leaderboard is shared, highlighting its strong coding and reasoning capabilities as evidenced by over 8K user votes across various domains. The announcement tweet can be accessed here.
Links mentioned:
Latent Space ▷ #ai-announcements (3 messages):
- New Podcast Alert: Check out the latest podcast episode featuring discussions with Jungwon Byun and Andreas Stuhlmüller of Elicit. The episode delves into the supervision of AI research and can be listened to on Twitter.
- Elicit on YouTube: You can also watch the Elicit podcast episode on YouTube, including a deep dive into why products may be superior to research and the evolution of Elicit. Don't forget to like and subscribe for more!
Link mentioned: Supervise the Process of AI Research — with Jungwon Byun and Andreas Stuhlmüller of Elicit: Timestamps:00:00:00 Introductions00:07:45 How Johan and Andreas Joined Forces to Create Elicit00:10:26 Why Products are better than Research00:15:49 The Evol...
Latent Space ▷ #llm-paper-club-west (26 messages🔥):
- Mixtral-8x22B Makes Its Debut: The Mixtral-8x22B model has been converted to HuggingFace Transformers format, available for use, with gratitude noted to the user responsible for the conversion. Instructions for running the model using
transformersare provided along with a link to the model and a Twitter announcement. - DeepSeekMoE Challenges Google's GShard: DeepSeekMoE, featuring shared experts and fine-grained expert segmentation, reportedly rivals or exceeds the performance of Google's GShard model, with a link to the paper provided for details on the architecture.
- Educational Resource on Mixture of Experts: A blog post from HuggingFace discussing the Mixture of Experts (MoEs) and the recent release of Mixtral 8x7B is highlighted as an introductory resource for those new to the concept of MoEs.
- Exploration of Expert Specialization in MoEs: The community discusses the performance of Mixtral's MoEs and the notion of expert specialization, juxtaposing MoE with the semantic router, which specializes at inference time, and pondering how these models achieve expert specializations.
- Questions on Redundancy and Expertise in MoE Models: A dialogue emerges regarding the actual learning and specialization processes within experts of the MoE models, with a GitHub repository for the semantic router provided for reference, and curiosity about the implementation of device loss and its evident absence in the reported source code.
Links mentioned:
LAION ▷ #general (93 messages🔥🔥):
- Draw Things Criticized for Closed Source: Members expressed discontent with Draw Things, mentioning it is not open source and does not meaningfully give back to the community. It was also pointed out that the so-called open source version lacks essential features like metal-flash-attention support.
- Skepticism Over TempestV0.1's Claims: The TempestV0.1 Initiative was discussed with skepticism, particularly regarding its claim of 3 million training steps and the plausibility of its dataset size—6 million images purportedly only taking up 200GB.
- Concerns over the Laion 5B Demo: Users questioned the status of the Laion 5B web demo, with some expecting it not to return. However, Christoph was mentioned as saying it will come back, but no specific details or timelines were provided.
- Warning Against Potential Scams: There was notable concern about scams related to cryptocurrency and tokens falsely associated with LAION. Users were warned to be vigilant, and discussions suggested that such activities were exploiting LAION's name.
- Disapproval of Misleading Information and Solutions: An ongoing problem with misinformation was noted, especially relating to the circulation of false claims on platforms like Twitter. A suggestion was made to pin an announcement or add to the auto-moderation system to help prevent these scams.
Links mentioned:
LAION ▷ #announcements (1 messages):
- Beware of Fake LAION NFT Claims: A warning has been issued about a fake Twitter account falsely advertising that LAION is releasing NFTs. It was clarified emphatically that LAION does not sell anything, has no employees, and is a part of the open source community, offering AI resources that are open, transparent, and free.
LAION ▷ #research (19 messages🔥):
- Intel vs. AMD and Nvidia Manufacturing: It was noted that Intel manufactures its own chips, whereas AMD and Nvidia use TSMC for their semiconductor fabrication.
- LRUs Show Promise on LRA: Modified Least Recently Used (LRUs) algorithms are considered to perform well on Long Range Arena (LRA) benchmarks for long-context performance.
- Guidance Weight Strategy Improves Diffusion Models: A study highlighted the benefits of limiting guidance to specific noise levels in diffusion models; by doing so, you can increase inference speeds and improve image quality (research paper).
- Applying Research to Practical Tools: The information about managing classifier-free guidance (CFG) dynamically was connected to an existing GitHub issue for consideration, indicating that such research findings are actively being integrated into tool implementations, like huggingface's diffusers (GitHub issue).
- Dynamic Guidance Scheduling as a Learned Process: A member suggested looking at dynamic scheduling of CFG as a more granular and potentially learned process, referencing a method to have separate scale values for each timestep and even pulling from EDM2's techniques for continuous timesteps.
Links mentioned:
LAION ▷ #learning-ml (1 messages):
- In Search of HowTo100M Dataset: A member inquired if anyone has access to the HowTo100M dataset, expressing uncertainty about the appropriate channel for this request. The HowTo100M is a large-scale dataset featuring instructional videos.
LlamaIndex ▷ #announcements (1 messages):
- LlamaIndex PandasQueryEngine Moves to Experimental: The upcoming LlamaIndex (python) v0.10.29 will shift
PandasQueryEnginetollama-index-experimental. Users should adjust their code withfrom llama_index.experimental.query_engine import PandasQueryEngineand update viapip install llama-index-experimental.
LlamaIndex ▷ #blog (4 messages):
-
Chat with Your Code: A new tutorial by @helloiamleonie shows how to create an app that allows you to chat with code from a GitHub repository. The tutorial details setting up a local LLM and embedding model using tools like Ollama.
-
RAG Retrieval Enhanced with Auto-merging: Addressing the issue of "broken" context due to naive chunking in RAG, a solution has been proposed involving dynamic creation of more contiguous chunks with auto-merging retrieval.
-
Create-tsi Toolkit Launch: A new GDPR-compliant, full-stack AI application toolkit, create-tsi, is announced in partnership with T-Systems, Marcus Schiesser, and inspired by the Llama Index's create-llama toolkit.
-
Auto Abstraction for Complex LLM Queries: The new Chain of Abstraction technique proposed by Silin Gao et al. aims to surmount current frameworks' challenges in multi-step query planning with tool use among different LLMs.
LlamaIndex ▷ #general (101 messages🔥🔥):
-
Fine-Tuning versus Retriever Augmented Generation: Members discussed the shortcomings of fine-tuning for Q/A tasks, highlighting inefficient knowledge retention and intensive dataset requirements. Retriever Augmented Generation (RAG) is favored for its accuracy, cost, and flexibility in such cases.
-
Embedding Storage Confusion Solved: Questions about the storage of embeddings were clarified; they are stored in the vector store within the storage context. Mention of upcoming knowledge graph improvements was made to potentially streamline the process.
-
Metadata in Embeddings Clarification: It was explained that metadata is not excluded by default during embeddings generation and LLM, but can be manually removed if desired. Users discussed how to implement such exclusions in their code with provided snippets.
-
LLMs Parameter Setting in Ollama: A user inquired about setting LLM parameters like temperature and top_p when using Ollama to load a model. A GitHub code reference was provided to show how to pass additional parameters.
-
Troubleshooting Vector Store Issues with Fastembed: There was a discussion on issues with 'fastembed' breaking for QdrantVectorStore, and members suggested this could be due to optional dependency for hybrid search. A downgrade to a specific version ('llama-index-vector-stores-qdrant==0.1.6') was reported to resolve the problems for a user.
Links mentioned:
LlamaIndex ▷ #ai-discussion (1 messages):
- LlamaIndex gets a Memory Boost: A member shared a tutorial on enhancing document retrieval with memory for LlamaIndex using a Colbert based agent. It outlines steps to integrate memory capabilities into the retrieval process to improve performance.
OpenInterpreter ▷ #general (80 messages🔥🔥):
- Litellm Troubles in the Discord: Members are discussing issues with
litellm, including sudden breaks in functionality; one suggests checkinginterpreter --versionand issuing apip show litellmcommand for diagnosis. There's also a recommendation to continue discussing the problem in the issues channel, where the concern was later addressed. - OpenAI Credit Offering and Changes: OpenAI is transitioning to prepaid credits and discontinuing monthly billing; they are offering a promo for free credits when users purchase a minimum amount by April 24, 2024. Members inquire and share their understanding of how this change affects different OpenAI account types.
- Community Event Invites and Recap: A community event called Novus for startup builders in Vancouver is shared, with an emphasis on no-nonsense networking and building. Additionally, there's information about a successful past session on using Open Interpreter as a library, with a link to a GitHub repository containing templates for starters.
- Troubleshooting and Fixes for Open-Interpreter: A member experiencing trouble with Open-Interpreter receives tips, including a command to reinstall the package from a specific git commit to resolve issues. Discussions also reveal potential compatibility issues between dependencies and the suggestion to set environment variables to smoothly use Open-Interpreter.
- Learning Python with YouTube and ChatGPT: There are inquiries about the best course to learn Python, with various approaches suggested, including YouTube tutorials, project-based learning with assistance from ChatGPT, and a specific recommendation for a YouTube channel by Tina Huang.
Links mentioned:
OpenInterpreter ▷ #O1 (24 messages🔥):
-
Installation Hiccups with Poetry: A member experienced issues installing Poetry using the command
poetry installdue to a "command not found" error with bothpoetryandpip. It was suggested to trypip install poetryand to post in a specific channel for further assistance, later realizing that Python itself was not installed. -
Device Configuration Confusion: Someone encountered difficulties during the WiFi setup of their M5 Atom device, not receiving the prompt to input the server address on their phone. The issue was acknowledged and further testing was proposed to find a solution.
-
Proposal to Enhance Documentation: A member's detailed instructional content was praised, and there was a proposition to include it in the official documentation, to which they agreed with gratitude.
-
Questioning Device Preorder Wait Times: Inquiries were made about the delivery status of preordered devices, with clarification that these devices are still in the pre-production phase and the expectation should be set for summer shipments.
-
Anticipating Manufacturing Delays: A discussion about device manufacturing delays highlighted the usual challenges startups face, noting that the product is still in prototyping, and encouraging patience as even the "good startups" often take longer than estimated.
OpenInterpreter ▷ #ai-content (2 messages):
- Transformers Go JavaScript: transformers.js GitHub repository was shared allowing state-of-the-art machine learning to run directly in the browser without the need for a server. This is a JavaScript port of the HuggingFace Transformers library.
- AI Model Endpoint Unveiled: A member posted a link to https://api.aime.info, presumably an API endpoint related to an AI model, but no further information or context was provided.
Links mentioned:
OpenAccess AI Collective (axolotl) ▷ #general (54 messages🔥):
-
Newcomer Seeks Guidance: A member expressed their eagerness to contribute to Axolotl despite having limited programming experience and time. Suggestions from others included reproducing and confirming issues on GitHub, focusing on documentation, and using simple "print" statements to debug code.
-
Anticipating LLaMA-3: There was a debate among members about postponing fine-tuning efforts in anticipation of Meta's new LLaMA-3, with some citing a co-authored study by Meta on the scaling of knowledge bits in language models as potential "secret sauce" for LLaMA-3.
-
Mistral-22B Dense Model Conversion: An announcement about the release of Mistral-22B-V.01 was shared, a model that represents the first conversion of an Mixture of Experts (MoE) to a dense model format.
-
Discussing the Merits of Layer Freezing: A member brought up a recent paper suggesting that half the layers of a model could be removed without performance loss; however, others argue it may lead to overtraining, and the removal of even one layer can significantly impact a model.
-
Open-GPU Kernel Modules Stir Interest: An announcement about the open GPU kernel modules with P2P support on GitHub generated discussion, indicating the potential for NVIDIA 4090s to be more viable for model training.
Links mentioned:
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (11 messages🔥):
- Best Practices for Axolotl Configurations Suggested: A member pointed out the importance of capturing best practices and community insights into Axolotl configurations, using an example from a Reddit post which details options for layer training in a LORA model.
- GPU Initialization Error with Flash Attention 2.0: One user encountered an error suggesting “You are attempting to use Flash Attention 2.0 with a model not initialized on GPU.” They indicated a solution worked by targeting only 11 layers.
- Layer by Layer Training Consideration: There was a discussion around training models 11 layers at a time, presumably to manage computational resources or memory constraints.
- Bigstral Training Query: A user confirmed training a model named Bigstral, with another jokingly questioning the name.
- Unfreezing Weight Subsets Concept: There was a conversation about the possibility of unfreezing random subsets of weights at each step during training, devised as a strategy to accommodate users with lower GPU resources. It was noted that current implementations typically only support freezing parts of the model at the start.
Link mentioned: Reddit - Dive into anything: no description found
OpenAccess AI Collective (axolotl) ▷ #datasets (3 messages):
-
Seeking Logic Datasets: A user inquired about datasets that focus on reasoning with propositional and predicate logic over natural text, aiming to perform formal reasoning methods on linguistic data.
-
Hunting for a Hefty Dataset: Another member expressed the need for a 200 billion-token dataset to pretrain an experimental new architecture. In response to this query, one user recommended considering the slimpajama dataset and extracting an appropriate subset.
OpenAccess AI Collective (axolotl) ▷ #community-showcase (3 messages):
-
Axolotl for the Uninitiated: A new blog post has been shared, aimed at helping beginners get started with axolotl. The author, experienced with fine-tuning encoder LLMs, ventures into training decoder LLMs and plans to continue building and sharing insights on developing "useful" models.
-
Climbing the Learning Curve Together: Responding to the blog post on axolotl, one member expressed appreciation, noting it can serve as a good intro to those new to the tool and likely to assist fellow novices.
-
Debugging Data with Axolotl: A member offered a tip for using axolotl: apply the
--debugflag during the preprocess to ensure the data record is correct. This can aid in avoiding issues in later stages of model training or evaluation.
Links mentioned:
OpenAccess AI Collective (axolotl) ▷ #axolotl-help-bot (18 messages🔥):
- Request for Colab Notebook Creation: A user sought assistance to create a Google Colab notebook using the pre-installed version of PyTorch, aiming to specify prompts for inference. They need a framework that incorporates axolotl to finetune a base model (Tiny-Llama) on a dataset from Hugging Face and execute a query against both the original and finetuned models.
- Axolotl Colab Notebook Availability: It was mentioned that a Colab notebook is available at this GitHub link, which can be directed to use a TinyLlama config for model operations.
- Config for Continued Pretraining: A member requested an example config to continue pretraining TinyLlama on a Hugging Face dataset. A detailed pretrain configuration was shared for setting up and initiating the pretraining process with options for optimization and environmental setup specific to the user's task.
- Using Docker for Multi-Node Fine-Tuning with DeepSpeed: A user inquired about the steps to use Docker for multi-node finetuning with DeepSpeed. Detailed steps were provided, covering Docker image preparation, DeepSpeed configuration, node preparation, Docker container launching, and running the training script with DeepSpeed integrations.
Links mentioned:
OpenAI ▷ #ai-discussions (54 messages🔥):
-
OpenAI API Issues Reported: A member is experiencing issues with the OpenAI Assistant API, encountering an
AttributeErrorwith theclient.beta.messages.createmethod in Python. They suspect the documentation might be outdated compared to the new version of the OpenAI library and shared their problematic code snippet. -
Mixed Experiences with AI Models: Discussions highlight personal experiences with various AI models like Gemini 1.5 and Claude, comparing their context windows, memory recall abilities, and how they handle code-related queries. There's recognition of the limitations in API quota and the varying effectiveness of different models based on the task's complexity.
-
Seeking the Best Model for C# Development: A member inquires about the best AI model to use for developing scripts in C# for the Unity game engine, seeking a model that works on the first attempt. A suggestion was made to try out the latest gpt-4-turbo and possibly Opus, along with the strategy of feeding documentation directly to ChatGPT for better context.
-
Dealing with a Multitude of Functions for an LLM: One member asks for advice on handling 300 functions with an LLM when they can’t pass all the schemas of the functions. The conversation evolved to discuss the use of embeddings as a solution and strategies for creating concise summaries of each function or potentially distributing them across multiple agents.
-
Limitations of ChatGPT Knowledge Updates: A member's query about current football teams is met with outdated information from ChatGPT, and another explains that because ChatGPT doesn't update its knowledge base in real-time, it may provide outdated information unless it's programmed to browse the internet for updates, a feature which is not available in GPT-3.5.
OpenAI ▷ #gpt-4-discussions (8 messages🔥):
- GPT-4 Speed Inconsistency Reported: A user expressed concerns about GPT-4 being slow, while others suggested it might be a Wi-Fi issue, although the original user claimed their internet was functioning properly.
- GPT-4 Turbo Less Skilled in Function Calls: A message indicated that the new GPT-4-turbo model is significantly less efficient at function calling, without providing further context or support.
- Accessing GPT-4 Turbo: One user inquired about how to verify if they have access to the GPT-4-turbo model on the site, but no further details or clarification were provided.
- Large Document Editing with GPT: A member asked about the feasibility of working on a large document with GPT, questioning whether it's possible beyond the normal context window and how to enable document editing, which might require a third-party service.
OpenAI ▷ #prompt-engineering (8 messages🔥):
- Guide to the Wolfram GPT Universe: A member provided a direct solution to using Wolfram with GPT, guiding to access it via Wolfram GPT link and mentioning that @mention feature can be used once it's been accessed.
- First Steps in Prompt Engineering: A new member requested resources for learning about prompt engineering and was referred to a website, Prompting Guide, that offers comprehensive information on the subject.
OpenAI ▷ #api-discussions (8 messages🔥):
-
Wolfram GPT Integration Clarified: Users enquired on how to get GPT to work with Wolfram. It was clarified that this can be achieved by using the Wolfram GPT and mentioned in chats using the
@mentionfunction. -
Starting with Prompt Engineering: A new community member sought resources for prompt-engineering. They were directed to a helpful site called promptingguide.ai.
DiscoResearch ▷ #mixtral_implementation (13 messages🔥):
-
Mistral Extends to 22B: A new 22B parameter dense model called Mistral-22b-V.01 has been released, and excitement is in the air about this milestone. This model is a compressed MOE, converted into a dense form, hailed as the first successful MOE to Dense model conversion.
-
Mergekit Challenges Discussed: Community experimentation with converting models using Mergekit into MoE models and subsequent fine-tuning has reported disappointing results; generally, these custom MoE merged models underperform compared to the original models, and no superior MoE merged models have been published so far.
-
Introducing Zephyr 141B-A35B: The new Zephyr 141B-A35B model, an assistant trained with a novel algorithm called ORPO, has been released and is a fine-tuned version of Mixtral-8x22B, trained with 7k instances for just over an hour on impressive hardware. The model can be found on HuggingFace's model hub.
-
Mixtral vs. SFT Performance Debate: There's discussion about the performance of Supervised Fine-Tuning (SFT) Mixtral models versus original Mixtral instruct, with some members asserting SFT on narrow domains yields better results compared to MoE models created through Mergekit.
-
Queries About Fine-tuning 22b Models: Community members are curious and asking if anyone has successfully fine-tuned 22b models, especially considering the mentioned secret sauce about routing that the official Mixtral models might have, potentially resulting in superior Mixtral Instruct performance over fine-tuned variants.
Links mentioned:
DiscoResearch ▷ #general (4 messages):
-
Inquiry about German Language Benchmarks: A user expressed interest in seeing models run on a German language benchmark. Discussion followed regarding the relevance of German benchmarks and referencing the common use of lm eval harness.
-
Access to Full Model Evaluation Outputs: A dataset containing complete evaluation outputs from the Open LLM Leaderboard has been made available. For the Mixtral-8x22B-v0.1 model, the dataset can be accessed at Hugging Face.
Link mentioned: open-llm-leaderboard/details_mistral-community__Mixtral-8x22B-v0.1 · Datasets at Hugging Face: no description found
DiscoResearch ▷ #discolm_german (22 messages🔥):
- DiscoLM 70b German Capacities Questioned: A user asked if ablations were done with DiscoLM 70b, a 70 billion parameter model with 65 billion tokens of German pretraining. It was mentioned that no ablations have occurred due to other priorities, but new models with improved datasets are planned soon.
- English+German Finetuning Balance: Members discussed the ideal balance between English and German data for finetuning models like DiscoLM 70b. Concerns were raised about potentially diminishing the model's previously strengthened German capabilities post-English finetuning.
- Exploring Linguistic Nuance Through Finetuning: A user provided a link to a paper discussing multilingual model fine-tuning but expressed uncertainty regarding the impact of language imbalance during this process. Another paper proposed a framework for assessing cross-lingual knowledge alignment within large language models, available here.
- Occiglot-7B-DE-EN-Instruct Achievements: One user revealed their work on Occiglot-7B-DE-EN-Instruct, indicating that it performed well on benchmarks, suggesting that English and German data mix could be effective. However, they cautioned about the inadequacy of current German benchmarks for thorough analysis and shared the Occiglot Research page.
- Leveraging Pretraining with SFT Data for Language Models: There was a discussion about the benefits of incorporating Supervised Fine-Tuning (SFT) data during the pretraining phase rather than only during standard SFT. The talk was prompted by findings from StableLM's tech report and MiniCPM, suggesting that SFT data included in pretraining phases may help prevent overfitting and strengthen generalization.
Links mentioned:
Interconnects (Nathan Lambert) ▷ #news (12 messages🔥):
- Claude's Evolution Mentioned: Nathan Lambert highlighted the shift from Claude 2 to Claude 3, questioning the significance of the change and describing it as "INCREMENTAL."
- Questioning the Hard Fork: Lambert expressed frustration, suggesting that this week's hard fork seemed misaligned with current AI developments and felt to be “triggering me.”
- Seeking Open Data Details: Lambert noted an apparent lack of detailed discussion on open data within the AI community, with an “AHEM” possibly indicating a call to action for more coverage.
- Journalistic Views on AI Scrutinized: Eugene Vinitsky made an observation that popular tech journalists may harbor a distaste for technology, which he finds to be “the weirdest thing.”
Link mentioned: Tweet from rohan anil (@arohan): Interesting! “Answer the following multiple choice question. The last line of your response should be of the following format: 'ANSWER: $LETTER' (without quotes) where LETTER is one of ABCD. ...
Interconnects (Nathan Lambert) ▷ #ml-questions (6 messages):
- Blending Methodologies in Model Training: One member pointed out that in practice, pretraining, Supervised Fine-Tuning (SFT) datasets, and Reinforcement Learning from Human Feedback (RLHF) prompts are often blended together during the training process, but recognized that this isn't clearly documented.
- Clarification on 'Blend': The same member clarified that by "blend," they meant using mechanisms like curriculums, schedulers, or annealing to combine different training methodologies, despite the lack of clear documentation.
- Documentation and Knowledge Sharing: The individual promised to share more information specifically on annealing soon, hinting at upcoming insights into the process.
Interconnects (Nathan Lambert) ▷ #random (12 messages🔥):
- Meme As Congratulations: Discussion reveals someone might have entered a congratulatory phrase as a meme, which was found amusing.
- Subscription Confusion Cleared: When questioned about needing acceptance for subscriptions, it was clarified that the acceptance feature is turned off, making subscription processes automatic.
- Potential New Server Member: There's speculation about Satya joining the server, with someone hinting at having referred him, followed by an acknowledgment and a note about needing to do some recruiting.
Interconnects (Nathan Lambert) ▷ #reads (1 messages):
- Inspecting Google's CodecLM: A member shared a paper on CodecLM, which is Google's approach to aligning Language Models with tailored synthetic data. The member observed that it seems like another instance of the "learn-from-a-stronger-model" strategy.
Interconnects (Nathan Lambert) ▷ #sp2024-history-of-open-alignment (1 messages):
- LLaMA Research Shared: A link to a paper on "LLaMA: Open and Efficient Foundation Language Models" was shared, which is published and accessible on Hugging Face. The paper was published on February 27, 2023.
Link mentioned: aligning open language models - a natolambert Collection: no description found
tinygrad (George Hotz) ▷ #general (18 messages🔥):
-
Cache Coherence and Performance: Discussing cache levels, a message highlighted that lower-level caches like L1 are faster due to less coherence management. The heterogenous shared cache pool, though faster than transferring data from RAM to VRAM, doesn't match the speed of direct L3 to L1 cache transfers on CPUs with dedicated CCX caches.
-
Portability and Security of Programming Languages: A member argued that ANSI C is supported on all hardware by default and easy to port to hardware description languages. Conversely, another member shared a link to Rust vulnerability details, criticizing the perception of Rust as a 'magic bullet' for programming safety.
-
Controversy over the Rust Foundation's Policies: One user pointed to The Rust Foundation's restrictive policies on the usage of the term "Rust" and the modification of the Rust logo, comparing it to organizations like Oracle and Red Hat, which they avoid due to "political unsafety" and licensing restrictions.
-
AI Lawyer Project Vision: An individual expressed their refusal to accept any licensing that gives outside control over their project, specifically mentioning the aspiration to build an AI lawyer and averting lawfare leading to acquisition or bankruptcy.
-
Discord Ban for Off-topic Discussion: In response to a user's off-topic remarks on programming languages, George Hotz clarified that further irrelevant discussions would result in bans, after which a user named endomorphosis was banned for their non-contributory messages.
Links mentioned:
tinygrad (George Hotz) ▷ #learn-tinygrad (6 messages):
- Tiny Naming Conundrum: Discord chat participants humorously brainstormed names, suggesting both tinyxercises and tinyproblems for potential project titles.
- Name Approval: A participant responded positively to the brainstormed names, signaling preference with a succinct "ayyy."
- Gratitude in Tiny Form: Another reply expressed thanks with a creative twist, coining the term tinythanks in the chat.
Skunkworks AI ▷ #datasets (7 messages):
- Seeking Datasets for Logical Reasoning: A user inquired about datasets for reasoning with formal logic over natural text. Another provided a curated list with resources on math, logic, and reasoning datasets.
- Resource Sharing for Symbolic Solvers and LLMs: Users exchanged links including a GitHub repository named Logic-LLM, which is a project for empowering language models with symbolic solvers.
- Scholarly Work on Coq for Large Language Models: A link to an arXiv paper discussing a dataset to improve LLMs' ability to interpret and generate Coq code was shared.
- Clarification on a Reasoning Project:
- A user sought clarification on a project that aims to enhance existing LLM architectures for better reasoning via translating human text into Lisp and executing it.
- The explanation emphasized the goal of making use of preset LLMs and augmenting reasoning ability by performing computation in the latent space and maintaining end-to-end differentiability.
- Updates on Reasoning Resource Compilation: An acknowledgment was made of the addition of the recommended resources to the awesome-reasoning repo, which is a collection aimed at aiding the development of reasoning AI. The update was confirmed with a commit history.
Links mentioned:
LLM Perf Enthusiasts AI ▷ #claude (3 messages):
-
Haiku Speed Questioned: A member raised concerns regarding Haiku, questioning its speed improvement, which was assumed to be a major advantage of the model.
-
Throughput vs. Response Time: Another member highlighted that their primary concern was not throughput but the total response time when using Haiku.
LLM Perf Enthusiasts AI ▷ #openai (4 messages):
- Turbo Charged Reactions: A member inquired about the community's opinion on the new turbo.
- Code Proficiency Boosted: Another participant confirmed that the new turbo is indeed better at handling code.
- Enhanced Speed Performance: It was also mentioned that the new turbo has faster performance capabilities.
- Plus Reactivation for Turbo Exploration: In response to the feedback, a member considered reactivating their ChatGPT Plus to test the new turbo.
Alignment Lab AI ▷ #ai-and-ml-discussion (1 messages):
fredipy: <@748528982034612226>
Alignment Lab AI ▷ #general-chat (4 messages):
- Request for Assistance on Code: A member has reached out for help with their code, asking directly for a DM.
- Concern Over Server Invites: Another member expressed frustration over the prevalence of Discord invites on the server and proposed a ban on them to prevent such issues.
Alignment Lab AI ▷ #oo2 (1 messages):
aslawliet: Is the project still alive?
Datasette - LLM (@SimonW) ▷ #ai (4 messages):
- Gemini Upgrades - Audio in Video Capabilities: Gemini's new ability to answer questions about audio in videos has been tested in an AI class, showing significant improvement from its previous limitation of only generating descriptions without audio.
- Google Pasting Pain Points: Members shared frustrations about Google's text formatting issues when pasting text into their playground, hoping for a solution.
- STORM Brings the Thunder: The STORM project on GitHub was highlighted, showcasing an LLM-powered knowledge curation system that can research a topic and generate a full-length report with citations.
Link mentioned: GitHub - stanford-oval/storm: An LLM-powered knowledge curation system that researches a topic and generates a full-length report with citations.: An LLM-powered knowledge curation system that researches a topic and generates a full-length report with citations. - stanford-oval/storm
Datasette - LLM (@SimonW) ▷ #llm (1 messages):
- Pull Request Mends macOS Zsh Command Hang-up: An issue with the llm-cmd on MacOS, where the llm command caused terminal hangs, has been resolved by a new pull request. It has been confirmed to work on M1 MacOs Terminal and Alacritty with zsh.
Link mentioned: fix: macos zsh llm cmd hangs by nkkko · Pull Request #12 · simonw/llm-cmd: Fix for #11, tested on M1 MacOs (14.3.) in Terminal and Alacritty (zsh), now works fine.
Mozilla AI ▷ #announcements (1 messages):
<ul>
<li><strong>Gradio UI for Figma Launches:</strong> Mozilla Innovations introduces <strong>Gradio UI for Figma</strong>, a library based on Hugging Face's Gradio, to facilitate rapid prototyping in the design phase. Access the toolkit on <a href="https://www.figma.com/@futureatmozilla">Figma here</a>.</li>
<li><strong>Join the Gradio UI Discussion:</strong> A conversation thread about <strong>Gradio UI for Figma</strong> with Thomas Lodato from Mozilla’s Innovation Studio is available for those interested in discussing the tool further. Join in on Discord through <a href="https://discord.com/channels/1089876418936180786/1091372086477459557/1228056720132280461">this thread</a>.</li>
</ul>
Link mentioned: Figma (@futureatmozilla) | Figma: The latest files and plugins from Mozilla Innovation Projects (@futureatmozilla) — We're building products that focus on creating a more personal, private and open-source internet
Mozilla AI ▷ #llamafile (4 messages):
- Exploring OCR in Llamafile: A member inquired about the OCR capabilities of llamafile, sparking interest in its potential uses.
- Rust in Deep Learning - A Call to Explore Burnai: A member praised a project they found, Burnai, which uses Rust for deep learning inference and suggested that the community investigate its promising optimizations for inference across platforms. They appreciated a related work at justine.lol/matmul and shared about Burnai at burn.dev, highlighting its focus on performance.
- Llamafile Cleared by Mcaffee: The llamafile 0.7 binary has been whitelisted by Mcaffee, as noted by a member with celebratory emojis.
- Warm Welcome to a New Member: A new member greeted the channel, expressing enthusiasm for fruitful collaboration and discussions.
Link mentioned: Burn: no description found
AI21 Labs (Jamba) ▷ #jamba (4 messages):
- Seeking Jamba Code: A user expressed interest in locating the source code for Jamba.
- Awaiting Updates: A user inquired about any updates, implying a follow-up to a previous message or ongoing discussion.
- Repository for Model Merging Shared: A user shared a link to a GitHub repository (moe_merger) that details their process for merging models. They noted the method has not been thoroughly tested.
- Appreciation for Shared Resources: Another user expressed gratitude for the repository shared on model merging.