Whole months happen in some days in AI - just as Feb 15 saw Sora and Gemini 1.5 and a bunch of other launches, the ides of April saw huge launches from:
Reka Core
A new GPT4-class multimodal foundation model...

... with an actually useful technical report...

... being "full Shazeer"
Cohere Compass
our new foundation embedding model that allows indexing and searching on multi-aspect data. Multi-aspect data can best be explained as data containing multiple concepts and relationships. This is common within enterprise data — emails, invoices, CVs, support tickets, log messages, and tabular data all contain substantial content with contextual relationships.
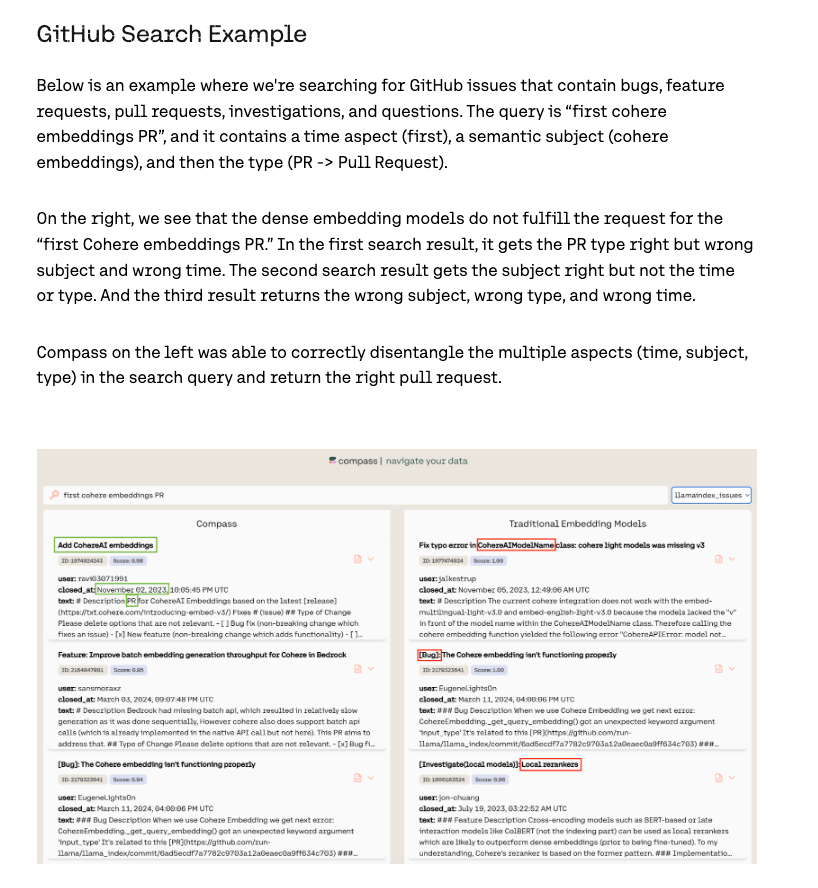
IDEFICS 2-8B
Continued work from last year's IDEFICS, a totally open source reproduction of Google's Flamingo unreleased multimodal model.
Rewind pivots to Limitless
It’s a web app, Mac app, Windows app, and a wearable.
Spyware is out, Pendants are in.
Table of Contents
[TOC]
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence. Comment crawling works now but has lots to improve!
AI Models and Performance
- Apple MLX performance: In /r/LocalLLaMA, Apple MLX (0.10.0) reaches 105.5 tokens/s on M2 Ultra with 76 GPU, beating Ollama/Llama.cpp at 95.1 tokens/s using Mistral Instruct 4bit.
- Ollama performance comparisons: In /r/LocalLLaMA, Ollama performance using Mistral Instruct 0.2 q4_0 shows the M2 Ultra 76GPU leading at 95.1 t/s, followed by Windows Nvidia 3090 at 89.6 t/s, WSL2 NVidia 3090 at 86.1 t/s, and M3 Max 40GPU at 67.5 t/s. Apple MLX reaches 103.2 t/s on M2 Ultra and 76.2 t/s on M3 Max.
- M3 Max vs M1 Max prompt speed: In /r/LocalLLaMA, the M3 Max 64GB has more than double the prompt speed compared to M1 Max 64GB when processing long contexts, using Command-R and Dolphin-Mixtral 8x7B models.
- GPU considerations for LLMs: In /r/LocalLLaMA, a user is seeking advice on building a machine around RTX 4090 or buying a MAC for running LLMs like Command R and Mixtral models with future upgradability.
- GPU for Stable Diffusion: In /r/StableDiffusion, a comparison of 3060 12GB vs 4060 16GB for Stable Diffusion recommends going for as much VRAM as reasonably affordable. A 4060ti 16GB takes 18.8 sec for SDXL 20 steps.
LLM and AI Developments
- Comparing AI to humans: In /r/singularity, Microsoft Research's Chris Bishop compares AI models that regurgitate information to "stochastic parrots", noting that humans who do the same are given university degrees. Comments discuss the validity of degrees and whether they indicate more than just information regurgitation.
- Impact on jobs: Former PayPal CEO Dan Schulman predicts that GPT-5 will be a "freak out moment" and that 80% of jobs will be reduced by 80% in scope due to AI.
- Obsession with AGI: Mistral's CEO Arthur Mensch believes the obsession with achieving AGI is about "creating God". Gary Marcus also urges against creating conscious AI in a tweet.
- Building for the future: Sam Altman tweets about people working hard to build technology for future generations to continue advancing, without expecting to meet the beneficiaries of their work.
- Confronting consciousness: A post in /r/singularity argues that achieving AGI will force humans to confront their lack of understanding about what creates consciousness, predicting debates and tensions around AI ethics and rights.
Industry and Career
- Identifying "fake" ML roles: In /r/MachineLearning, a PhD student asks for advice on spotting "fake" ML roles after being hired for a position that didn't involve actual ML work, noting that asking questions during interviews may not be effective due to potential dishonesty.
- Relevance of traditional NLP tasks: Another PhD student questions the importance of traditional NLP tasks like text classification, NER, and RE in the era of LLMs, worrying about the future of their research.
- Practical uses for LLMs: A post in /r/MachineLearning asks for examples of practical industry uses for LLMs beyond text generation that provide good ROI, noting that tasks like semantic search can be handled well by other models.
Tools and Resources
- DBRX support in llama.cpp: Llama.cpp now supports DBRX, a binary format for LLMs.
- Faster structured generation: In /r/LocalLLaMA, a new method for structured generation in LLMs is claimed to be much faster than llama.cpp's approach, with runtime independent of grammar complexity or model/vocabulary size. The authors plan to open-source it soon.
- Python data sorting tools: The author has open-sourced their collection of Python tools for automating data sorting and organization, aimed at handling unorganized files and large amounts of data efficiently.
- Simple discrete diffusion implementation: An open-source, simple PyTorch implementation of discrete diffusion in 400 lines of code was shared in /r/MachineLearning.
Hardware and Performance
- M1 Max vs M3 Max: In /r/LocalLLaMA, a comparison of prompt speed between M1 Max and M3 Max with 64GB RAM shows the M3 Max having more than double the speed, especially for long contexts.
- RTX 4090 vs Mac: A post asks for advice on building a PC with an RTX 4090 or buying a Mac for running LLMs, believing a PC would be cheaper and more upgradeable.
- MLX performance on M2 Ultra: Apple's MLX library achieves 105.5 tokens/s on an M2 Ultra with 76 GPU cores, surpassing llama.cpp's 95.1 tokens/s when running the Mistral Instruct 4-bit model.
- Ollama performance comparison: A performance comparison of the Ollama library on various hardware shows the M2 Ultra leading at 95.1 t/s, followed by Windows Nvidia 3090, WSL2 Nvidia 3090, and M3 Max using the Mistral Instruct model.
Memes and Humor
- Several meme and humor posts were highly upvoted, including "The Anti-AI Manifesto", "Maybe maybe maybe", "the singularity is being driven by an outside force", "Ai women are women", and "Real reason AI (Alien Intelligence) can't do hands? 👽".
{kind=link}
{kind=link}
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
AI Models and Architectures
- New model releases: @RekaAILabs announced Reka Core, their "best and most capable multimodal language model yet", competitive with GPT-4/Opus level models. @WizardLM_AI released WizardLM-2, a family of models including 8x22B, 70B and 7B variants competitive with leading proprietary LLMs.
- Architectures and training: @jeremyphoward noted that transformers are an architecture commonly used with diffusion. @ylecun stated AI will eventually surpass human intelligence, but not with current auto-regressive LLMs alone.
- Optimizing and scaling: @karpathy optimized an LLM in C to match PyTorch, now at 26.2ms/iteration, using tricks like cuBLAS in fp32 mode. @_lewtun believes strong Mixtral-8x22B fine-tunes will close the gap with proprietary models.
AI Capabilities and Benchmarks
- Multimodal abilities: @RekaAILabs shared Reka Core's video understanding capabilities, beating Claude3 Opus on multimodal chat. @DrJimFan speculated Tesla FSD v13 may use language tokens to reason about complex self-driving scenarios.
- Coding and math: @OfirPress noted the open-source coding agent SWE-agent already has 1.5k users after 10 days. @WizardLM_AI used a fully AI-powered synthetic training system to improve WizardLM-2.
- Benchmarks and leaderboards: @svpino noted Claude 3 was the best model on a human eval leaderboard for 17 seconds before GPT-4 updated. @bindureddy analyzed GPT-4's coding, math and knowledge cutoff as reasons for its performance.
Open Source and Democratizing AI
- Open models and data: @arankomatsuzaki announced EleutherAI's Pile-T5 model using 2T tokens from the Pile and the Llama tokenizer. @_philschmid introduced Idefics2, an open source VLM under 10B parameters with strong OCR, document understanding and visual reasoning.
- Accessibility and cost: @maximelabonne noted open source models now lag top closed source by 6-10 months rather than years. @ClementDelangue predicted the gap will fully close by year end, as open source is faster, cheaper and safer for most uses.
- Compute and tooling: @WizardLM_AI is sharing 8x22B and 7B WizardLM-2 weights on Hugging Face. @aidangomez announced the Compass embedding model beta for multi-aspect data search.
Industry and Ecosystem
- Company expansions: @gdb and @hardmaru noted OpenAI's expansion to Japan as a significant AI presence. @adcock_brett shared Canada's $2.4B investment in AI capabilities and infrastructure.
- Emerging applications: @svpino built an entire RAG app without code using Langflow's visual interface and Langchain. @llama_index showcased using LLMs and knowledge graphs to accelerate biomaterials discovery.
- Ethical considerations: @ID_AA_Carmack regretted not supporting @PalmerLuckey more at Facebook during a "witch hunt". @mmitchell_ai praised a video as the best AI existential risk coverage so far.
AI Discord Recap
A summary of Summaries of Summaries
- Advancements in Large Language Models (LLMs): There is significant excitement and discussion around new releases and capabilities of LLMs across various platforms and organizations. Key examples include:
-
Pile-T5 from EleutherAI, a T5 model variant trained on 2 trillion tokens, showing improved performance on benchmarks like SuperGLUE and MMLU. All resources, including model weights and scripts, are open-sourced on GitHub.
-
WizardLM-2 series announced, with model sizes like 8x22B, 70B, and 7B, sparking excitement for deployment on OpenRouter, with WizardLM-2 8x22B compared favorably to GPT-4.
-
Reka Core, a frontier-class multimodal language model from Reka AI, with details on training, architecture, and evaluation shared in a technical report.
- Optimizations and Techniques for LLM Training and Inference: Extensive discussions revolve around optimizing various aspects of LLM development, including:
-
Efficient context handling with approaches like Ring Attention, enabling models to scale to nearly infinite context windows by employing multiple devices.
-
Model compression techniques such as LoRA, QLoRA, and 16-bit quantization for reducing memory footprint, with insights from Lightning AI and community experiments.
-
Hardware acceleration strategies like enabling P2P support on NVIDIA 4090 GPUs using tinygrad's driver patch, achieving significant performance gains.
-
Kernel optimizations in frameworks like LLM.c and torchao, exploring efficient tensor layouts, padding, and swizzling for matrix operations.
- Open-Source Initiatives and Community Collaboration: The AI community demonstrates a strong commitment to open-source development and knowledge sharing, as evidenced by:
-
Open-sourcing of major projects like Pile-T5, Axolotl, and Mixtral (in Mojo), fostering transparency and collaborative efforts.
-
Educational resources such as CUDA MODE lectures and a call for volunteers to record and share content, promoting knowledge dissemination.
-
Community projects like llm.mojo (Mojo port of llm.c), Perplexica (Perplexity AI clone), and LlamaIndex integrations for document retrieval, showcasing grassroots innovation.
- Datasets and Data Strategies for LLM Development: Discussions highlight the importance of data quality, curation, and strategic approaches to training data, including:
-
Synthetic data generation techniques like those used in StableLM (ReStruct dataset) and MiniCPM (mixing OpenOrca and EvolInstruct), with a focus on CodecLM for aligning LLMs with tailored synthetic data.
-
Data filtering strategies and the development of scaling laws for data curation, emphasizing that curation cannot be compute-agnostic, as presented in a CVPR 2024 paper.
-
Multilingual and multimodal datasets, with a call for copyright-permissive EU text and multimodal data to train large open multimodal models, reflecting the growing demand for diverse data sources. Source 1 | Source 2 | Source 3 | Source 4
- Misc
-
Stable Diffusion 3 Sparks Excitement and Debate: The AI community is eagerly anticipating the release of Stable Diffusion 3 (SD3), discussing its potential improvements in quality and efficiency. Conversations revolve around optimizing performance on less powerful GPUs with tools like SD Forge, and exploring AI-powered creative workflows with ControlNet, Lora, and outpainting techniques. The heavy prompt censorship in SD3 has raised concerns about potential quality decline, as discussed on Reddit.
-
Perplexity AI's Roadmap and Model Comparisons: Perplexity AI's June roadmap teases new features like enforcing JSON grammar, a new Databricks model, Model Info endpoint, status page, and multilingual support, viewable on their feature roadmap page. Discussions compare the context window and performance of models like Claude Opus, GPT-4, and RAG for various tasks. Meta's release of an AI interface on WhatsApp, resembling Perplexity AI, has sparked interest in the growing integration of AI in messaging platforms, as reported in this article.
-
Tinygrad Enables P2P on NVIDIA GPUs: Tinygrad has successfully enabled peer-to-peer (P2P) support on NVIDIA 4090 and 4070 TI Super GPUs by modifying NVIDIA's driver, achieving 14.7 GB/s AllReduce performance. The breakthrough, shared on Twitter with code available on GitHub, has significant implications for cost reduction in running large language models. The CUDA community is pushing performance boundaries with the One Billion Row Challenge and exploring optimization strategies for low-precision computations.
-
Eleuther AI's Pile-T5 Model and Research Insights: EleutherAI introduced Pile-T5, a T5 model variant trained on 2 trillion tokens from the Pile, demonstrating improved performance on benchmarks like SuperGLUE and MMLU. The model, which excels in code-related tasks, has its weights and training scripts open-sourced on GitHub. Research discussions delved into the capabilities of MoE versus dense transformer models, the role of tokenization in LLMs, and the interpretability of hidden representations using frameworks like Google's Patchscopes.
PART 1: High level Discord summaries
Stability.ai (Stable Diffusion) Discord
Stable Diffusion 3 Sparks Excitement: AI enthusiasts are buzzing with anticipation over Stable Diffusion 3 (SD3), discussing its potential for efficiency gains and debating the merits of SD Forge for optimizing performance on less powerful GPUs.
Pixart-Sigma Pushing VRAM Boundaries: The application of Pixart-Sigma with T5 conditioning within ComfyUI provokes discussions around VRAM usage, with participants noting that T5 maintains VRAM usage under 10.3GB even in 8-bit compression mode.
AI Tools for Content Creation Get Spotlight: Query exchanges regarding AI tools like ControlNet, Lora, and expansion techniques like outpainting hint at a need for consistent color generation and background extension in creative workflows.
Debating CPU vs. GPU Efficiency for AI: Community members exchange troubleshooting tips on GPU memory optimization and flag features like --lowvram for those running Stable Diffusion on less potent machines, highlighting the significant speed difference between CPU and GPU processing.
Artists Seek Tech-Driven Collaborations: The trend of fusing AI with artistic tools continues as a digital artist seeks input and tutorial assistance on a painting app combining AI features, with project details found on GitHub.
Perplexity AI Discord
-
AI Models at Play in Prose and Logic: Debates underscore that Claude Opus excels in prose while GPT-4 outshines in logical reasoning. Practitioners should explore models to best fit their application needs.
-
Context Hinges on Model Choice: Claude Opus is praised for executing sequential instructions with finesse, while discussions indicate that GPT-4 may falter after several follow-ups; RAG boasts an edge with larger context retrieval for file uploads.
-
Perplexity's Roadmap débuts Multilingualism: Perplexity AI's June roadmap teases enforcing JSON grammar, new Databricks model, Model Info endpoint, status page, multilingual support, and N>1 sampling, viewable on their feature roadmap page.
-
API Intricacies Spark Dialogue: Users delve into Perplexity API's nuances—from default temperature settings in models, citation features, community aid for URL retrieval in responses, to procedures for increased rate limits.
-
Meta Mimics Perplexity?: A buzz on Meta's AI resembling Perplexity's interface for WhatsApp, suggesting AI's growing integration within messaging platforms, further highlighted by an article comparing the two (Meta Releases AI on WhatsApp, Looks Like Perplexity AI).
Unsloth AI (Daniel Han) Discord
Geohot Hacks Back P2P to 4090s: "geohot" ingeniously implemented peer-to-peer support into NVIDIA 4090s, enabling enhanced multi-GPU setups; details are available on GitHub.
Unsloth Gains Multi-GPU Momentum: Interest spiked on Multi-GPU support in Unsloth AI, with Llama-Factory touted as a worthy investigation route for integration.
A Hugging Face of Encouragement: Unsloth AI garnered attention from Hugging Face CEO Clement Delangue by securing a follow on an unspecified platform, suggesting potential collaborative undertones.
Linguistic Labyrinth of AI PhD Life: A PhD student outlined their challenging exploration in developing an instruction-following LLM for their mother tongue, highlighting the project complexity beyond mere translation and fine-tuning.
Million-Dollar Mathematical AI: The community engaged with the prospect of a $10M Kaggle AI prize to create an LLM capable of acing the International Math Olympiad and unpacked the Beal Conjecture's $1M bounty for a proof or counterexample at AMS.
Resourceful VRAM Practices & Strategic Finetuning: AI engineers converged on efficient use of VRAM for training robust LLMs like Mistral, sharing best practices such as the "30% less VRAM" update from Unsloth and the nuanced approach of initiating finetuning with shorter examples.
Cultural Conquest of Linguistic Datasets: Strategies to amplify low-resource language datasets were exchanged, including the use of translation data from platforms like HuggingFace.
Pioneering Podman for AI Deployment: Innovators showcased the deployment of Unsloth AI in Podman containers, streamlining local and cloud implementation, as seen in this demo: Podman Build - For cost-conscious AI.
Ghost 7B Alpha Raises the Benchmark: Ghost 7B Alpha was proclaimed for superior reasoning compared to other models, signaling fine-tuning prowess without expanding tokenizers, as discussed by enthusiasts.
Merging Minds on Model Compression: The melding of adapters, particularly QLoRA and 16bit-saving techniques for vLLM or GGUF, was deliberated, contemplating the intricacies of naive merging versus dequantization strategies.
Eleuther Discord
Pile-T5 Power: EleutherAI introduces Pile-T5, an enhanced T5 model variant produced through training with 2 trillion tokens from the Pile. It showcases significant performance improvements in both SuperGLUE and MMLU benchmarks and excels in code-related tasks, with resources including weights and scripts open-sourced on GitHub.
Entropic Data Filtering: The CVPR 2024 paper suggests a notable advancement in unpacking the importance of entropy in data filtering. An empirical study unveiled scaling laws capturing how data curation is fundamentally linked with entropy, enriching the community's understanding of heterogeneous & limited web data and its practical implications. Explore the study here.
Inside the Transformer Black Box: Google's Patchscopes framework endeavors to make LLMs' hidden representations more interpretable by generating explanations in natural language. Likewise, a paper introducing a toolkit for transformers to conduct causal manipulations showcases the value of pinpointing key model subcircuits during training, possibly offering pathways to avoid common training roadblocks. Details on the JAX toolkit can be found in this tweet from Stephanie Chan (@scychan_brains) and on the Patchscopes framework here.
MoE vs. Dense Transformers Debate: Discussions in the community probe the capacity and benefits of MoE versus dense transformer models. Key insights reveal MoEs' relative advantage sans VRAM constraints and question dense models' performance parity at comparable parameter budgets. There's a pronounced curiosity regarding the foundational attributes driving model behavior beyond the metrics.
NeoX Nuances Unveiled: Questions within the GPT-NeoX project brought up intricacies like oversized embedding matrices for GPU efficiency and peculiar weight decay behaviors potentially due to non-standard activations. A remark on rotary embeddings noted its partial application in NeoX as against other models. A corporate CLA is being devised to facilitate contributions to the project.
Nous Research AI Discord
-
Google's Infini-attention Paper Snags Spotlight: A member expressed interest in Google's "Infini-attention" paper, available on arXiv, proposing a novel way to handle longer sequences for language models.
-
Community Delves into Vector Search: In a comparison of vector search speeds, FAISS's IVFPQ came out on top at 0.36ms, followed by FFVec's 0.44ms; meanwhile, FAISS Flat and HNSW clocked in at slower times of 10.58ms and 1.81ms, respectively.
-
AI Benchmarks Garner Scrutiny: A discussion among members challenged the effectiveness of current AI benchmarks, proposing the need for harder-to-game, domain-specific task evaluations, such as a scrutinized tax benchmark.
-
Anticipating WorldSim's Update: Enthusiasm is brewing over the forthcoming update to WorldSim, with members sharing their experiments inspired by it, while preparing for new exciting features teased for next Wednesday.
-
LLMs Under the Microscope: Technical exchanges included inquiries into a safety-focused healthcare LLM detailed in an arXiv paper, challenges in fine-tuning LLMs for the Greek language while considering pretraining necessity, and methods for in-line citations in Retrieval-Augmented Generation (RAG) queries.
OpenRouter (Alex Atallah) Discord
Mixtral Model Mix-Up: The community reported that Mixtral 8x22B:free is discontinued; users should transition to the Mixtral 8x22B standard model. Experimental models Zephyr 141B-A35B and Fireworks: Mixtral-8x22B Instruct (preview) are available for testing; the latter is a fine-tune of Mixtral 8x22B.
Token Transaction Troubles: A user's issue with purchasing tokens was deemed unrelated to OpenRouter; they were advised to contact Syrax directly for resolution.
Showcasing Rubik's Research Assistant: Users interested in testing the new Rubiks.ai research assistant can join the beta test with a 2-month free premium. This tool includes access to models like Claude 3 Opus and GPT-4 Turbo, among others; testers should use the code RUBIX and provide feedback. Explore Rubik's AI.
Dynamic Routing Deliberation: There's a buzz around improving Mixtral 8x7B Instruct (nitro) speeds via dynamic routing to the highest transaction-per-second (t/s) endpoint. There were varying opinions on the performance of models like Zephyr 141b and Firextral-8x22B as well.
WizardLM-2 Series Spells Excitement: The newly announced WizardLM-2 series with model sizes including 8x22B, 70B, and 7B, has garnered community interest. Attention is particularly focused on the expected performance of WizardLM-2 8x22B on OpenRouter.
LM Studio Discord
Models On The Fritz: Users reported problems with model loading in LM Studio across different versions and OS, including error messages about "Error loading model." and issues persisting after downgrading and turning off GPU offload. A full removal and reinstall of LM Studio were sought by one user after ongoing frustrations with model performance.
Attention to Hardware: There was considerable discussion surrounding hardware requirements for running AI models effectively, highlighting the necessity for high-tier equipment for an experience on par with GPT-4 and the underutilization of Threadripper Pro CPUs. Contrastingly, ROCm support was called into question, with specific mention of the Radeon 6600 being unsupported in LM Studio.
Quantized conundrums and innovative inferences: Quantization was a hot topic, with users noting performance changes and debate on whether the trade-off in output quality is worthwhile. Meanwhile, a paper titled "Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention" was circulated, illuminating cutting-edge methodologies for Transformers handling prolonged inputs effectively.
Navigating Through New Model Territories: Users shared experiences and recommendations for an assortment of new models like Command R+ and Mixtral 8x22b, focusing on different setups, performance, and even introducing a commands-based tool missionsquad.ai. Notably, Command R+ has been praised for outpacing similar models in analyzing lengthy documents.
Beta Blues and Docker Distributions: While some users grappled with troubles in MACOS 0.2.19, others spearheaded initiatives like creating and maintaining a Docker image for Autogen Studio, hosted on GitHub. Concurrently, sentiments of letdown were conveyed over Linux beta releases missing out on ROCm support, highlighting the niche hurdles that technical users encounter.
OpenAI Discord
-
AI Sentience: Fact or Fiction? Engaging debates broke out about AI sentience, revolving around the implications of AI advancements on consciousness and ethical use. Ethical considerations were highlighted, but no consensus was reached on sentient AI systems.
-
Token Trading Techniques: Strategies for dealing with GPT's token limits were discussed, with users suggesting summarizing content and using follow-up prompts to manage the context within the constraint effectively.
-
GPT-4 Turbo's Visionary Capabilities: Clarification was provided that 'gpt-4-turbo' integrates vision capabilities, and while it still bears a 4k token limit due to memory constraints, it requires a script for analyzing images.
-
Prompting for Precision: Users shared experiences with GPT model inconsistencies, suggesting version-specific behaviors and fine-tuning aspects that impact response accuracy, with recommendations to employ a meta-prompting template for better results.
-
Hackers Wanted for Prompt Challenge: There's a call for engineers interested in exploring prompt hacking to team up for a competition, suggesting a collaborative venture into creative interactions with LLMs.
Latent Space Discord
Collaboration Beyond Borders with Scarlet AI: The new Scarlet platform enhances task management with collaborative AI agents that provide automated context and support tool orchestration, eyeing an integration with Zapier NLA. A work-in-progress demo was mentioned and Scarlet's website provides details on their offerings.
Whispers of Perplexity's Vanishing Act: The removal of Perplexity "online" models from LMSYS Arena spurred debate on the model's efficacy and potential integrations into engineering tools. This instance underscores a shared interest in the integration efficiency of AI models.
AI Wrangles YouTube's Wild West: Engineers examined strategies to transcribe and summarize YouTube content for AI applications, debating the merits of various tools including Descript, youtube-dl, and Whisper with diarization. The discussion reflects ongoing endeavors to streamline content processing for AI model training.
Limitless Eyes the Future of Personalized AI: The rebranding of Rewind to Limitless introduces a wearable with personalized AI capabilities, sparking discussions around local processing and data privacy. This highlights a peak interest in the security implications of new AI-powered wearable technologies.
Navigating Vector Space in Semantic Search: Insightful discussions on the complexities of semantic search, including vector size, memory usage, and retrieval performance, culminated in a proposed hackathon to delve deeper into embedding models. The discourse reflects a keen focus on optimizing speed, efficiency, and performance in AI-powered search applications.
Modular (Mojo 🔥) Discord
Earn Your Mojo Stripes: Engage with the Mojo community by contributing to the modularml/mojo repo or creating cool open source projects to attain the prestigious Mojician role. Those with merged PRs can DM Jack to match their GitHub contributions with Discord identities.
Mojo's Python Aspirations: The community is buzzing with the anticipation of Mojo extending full support to Python libraries, aiming to include Python packages with C extensions. Meanwhile, efforts to enhance Mojo's Reference usability are in motion, with Chris Lattner hinting at a proposal that could simplify mutability management.
Code Generation and Error Handling Forefront: GPU code generation tactics and the potential integration of an "extensions" feature resembling Swift's implementation for superior error handling have sparked technical debates among members, indicating a future direction for Mojo's development.
Community Code Collaborations Spike: A flurry of activity surrounds the llm.mojo project, where performance boost techniques such as vectorization and parallelization might benefit from collective wisdom, including maintaining synchronized C and Mojo code bases within a single repository.
Nightly News on Mojo Updates: The Mojo team addresses standard library discrepancies in package naming with an upcoming release fix. Additionally, the idea of updating StaticTuple to Array and supporting AnyType garnered interest, and a call for Unicode support contributions to the standard library arose, along with discussions on proper item assignment syntax.
Twitter Dispatch for Modular Updates: Keep an eye on Modular's Twitter for the latest flurry of tweets covering updates and announcements, including a series of six recent tweets from the organization that shed light on their ongoing initiatives.
CUDA MODE Discord
P2P Gets a Speed Boost: Tinygrad enhances P2P support on NVIDIA 4090 GPUs, reaching 14.7 GB/s AllReduce performance after modifying NVIDIA's driver, as detailed here, while PyTorch tackles namespace build complexities with the nightly build showing slower performance versus torch.matmul.
Massive Row Sorting Challenge Awaits CUDA Competitors: tspeterkim_89106 throws down the gauntlet with a One Billion Row Challenge in CUDA implementation that impressively runs in 16.8 seconds on a V100 and invites others to beat a 6-second record on a 4090 GPU.
New Territories in Performance Optimization: CUDA discussions orbit around the merits of running independent matmuls in separate CUDA streams, leveraging stable_fast over torch.compile, and the pursuit of high-efficiency low-precision computations demonstrated by stable_fast challenging int8 quant tensorrt speeds.
Recording and Sharing CUDA Expertise: CUDA MODE is recruiting volunteers to record and share content through YouTube, where lecturing material is also maintained on GitHub, and highlighting potential shifts to live streaming to manage growing member scales.
HQQ and LLM.c: Striding Towards Efficiency: Updates in HQQ implementation on gpt-fast push token generation speeds with torchao int4 kernel support, while LLM.c confronts CUDA softmax integration challenges, explores online softmax algorithm efficiencies, and juggles the dual goals of peak performance and educational clarity.
Cohere Discord
Connector Confusion Cleared: A member resolved an issue with Cohere's connector API, learning that connector URLs must end with /search to avoid errors.
Fine-Tuning Finesse: Cohere's base models are available for fine-tuning through their dashboard, as confirmed in a dashboard link, with options expanded to Amazon Bedrock and AWS.
New Cohere Tools on the Horizon: Updates were shared on new Cohere capabilities, specifically named Coral for chatbot interfaces, and upcoming releases for AWS toolkits for connector implementations.
Model Performance Discussed: Dialogue around Cohere models like command-r-plus touched on their performance on different hardware, including Nvidia's latest graphics cards and TPUs.
Learning Avenues for AI Newbies: New community members seeking educational resources were directed to free offerings like LLM University and provided with a link to Cohere's educational documentation.
Command-R Rocks the Core: Command-R received accolades for being a newly integrated core module by Cohere, highlighting its significance.
Quant and AI Converge: An invitation for beta testing of Quant Based Finance was posted, appealing to those interested in financial analysis powered by AI, with a link here.
Rubiks.AI Rolls Out: An invite for beta testing of Rubiks.AI, a new advanced research assistant and search engine, was shared, offering early access to models like Claude 3 Opus and GPT-4 Turbo, available at Rubiks.AI.
HuggingFace Discord
A Bundle of Multi-Model Know-how: Engineers exchanged tips on deploying multiple A1111 models on a GPU, highlighting resource allocation for parallel model runs. Discussions in NLP explored lightweight embedding options such as all-MiniLM-L6-v2, with paraphrase-multilingual-MiniLM-L12-v2 suggested for academic purposes.
Cognitive Collision: AI Models Straddle Realities: The cool-finds channel shared links to PyTorch and Blender integration for real-time data pipelines, while a Medium post introduced LlamaIndex's document retrieval enhancements. The Grounding DINO model for zero-shot object detection and how it utilizes this in Transformers trended in computer-vision.
Community-Sourced AI Timeline & Mental Models: Project RicercaMente, aiming to map data science evolution through key papers, was touted in cool-finds and NLP, inviting collaboration from the community. Meanwhile, a Counterfactual Inception method was presented to address hallucinations in AI responses, detailed in a paper on arXiv and a related GitHub project.
Training Trials & Tribulations: A U-Net training plateau after 11 epochs led a user to consider Deep Image Prior for image cleaning tasks, shared in computer-vision. In diffusion-discussions, there was an exploration of multimodal embeddings and a clarification about an overstretched token limit warning in a Gradio chatbot for image generation.
Crossing Streams: Events & Education: Upcoming LLM Reading Group sessions focusing on groundbreaking research, including OpenAI's CLIP model and Zero-Shot Classification, were advertised in today-im-learning and reading-group. Resources for those starting out in NLP were also suggested, featuring beginner's guides and transformer overview videos.
LAION Discord
Scam Notice: No LAION NFTs Exist: There have been repeated warnings about a scam involving a fraudulent Twitter account claiming LAION is offering NFTs, but the community has confirmed LAION is solely focused on free, open-source AI resources and does not engage in selling anything.
When to Guide the Diffusion: An arXiv paper introduced findings that the best image results from diffusion models occur when guidance is applied at particular noise levels, emphasizing the middle stages of generation while avoiding early and late phases.
Innovations from AI Audio to Ethics Discussions: Discussions ranged from the introduction of new AI models, like Hugging Face's Parler TTS for sound generation, to debates over the proper use of 'ethical datasets' and the implications of such political language in AI research.
Stable Diffusion 3's Dilemma: Community insight suggested Stable Diffusion 3 faces a risk of quality decline due to its rigorous prompt censorship. There is anticipation for further refinement to address this possible issue shared particularly on Reddit.
Troubleshooting Diffusion Models: A GitHub repository was shared by a member who faces a training issue with their diffusion model, which is outputting random noise and solid black during inference, despite attempts to adjust regularization and learning rate.
LangChain AI Discord
Be Cautious of Spam: Several channels have reported spam messages containing links to adult content, falsely advertising TEEN/ONLYFANS PORN with a potential phishing risk. Members are advised to avoid engaging with suspicious links or content.
RAG Operations Demand Precision: Users are encountering issues with document splitting during Retrieval-Augmented Generation (RAG) operations on legal contracts, where section contents are mistakenly linked to preceding sections, compromising retrieval accuracy.
LangChain Gets Parallel: Utilizing LangChain's RunnableParallel class allows for the parallel execution of tasks, enhancing efficiency in LangGraph operations—an approach worth considering for those optimizing for performance.
Emerging AI Tools and Techniques: A variety of resources, tutorials, and projects have been shared, including Meeting Reporter, how-to guides for RAG, and Personalized recommendation systems, to equip AI professionals with cutting-edge knowledge and practical solutions.
Watch and Learn: A series of YouTube tutorials has been highlighted, focusing on the implementation of chat agents using Vertex AI Agent Builder and integrating them with communication platforms like Slack, valuable for those interested in AI-infused app development.
OpenAccess AI Collective (axolotl) Discord
OpenAccess AI Goes Open-Source: NVIDIA Linux GPU support with P2P gets a boost from open-gpu-kernel-modules on GitHub, offering a tool for enhanced GPU functionality.
Fireworks AI Ignites with Instruct MoE: Promising results from Fireworks AI's Mixtral 8x22b Instruct OH, previewed here, although facing a hiccup with DeepSpeed zero 3 which was addressed by pulling updates from DeepSpeed's main branch.
DeepSpeed's Contributions Clarified: While it doesn't accelerate model training, deepspeed zero 3 shines in training larger models, with a successful workaround integrating updates from DeepSpeed's official GitHub repository for MoE models.
A Harmonious Relationship with AI: Advances in AI-music creation gain spotlight with a tune crafted by AI, available for a listen at udio.com.
Tools for Advanced Model Training: Engaging discussions revolve around model merging, the use of LISA and DeepSpeed, and their effects on model performance. This tool was cited for extracting Mixtral model experts, alongside hardware prerequisites.
Dynamic Weight Unfreezing: Conversations emerge around dynamic weight unfreezing tactics for GPU-constrained users, alongside an unofficial GitHub implementation for Mixture-of-Depths, accessible here.
RTX 4090 GPUs and P2P: Success in enabling P2P memory access with tinygrad on RTX 4090s lead to discussions about removing barriers to P2P usage and community eagerness regarding this achievement.
Combatting Model Repetitiveness: Persistent shortcomings with a model producing repetitive outputs guide members towards exploring diverse datasets and finetuning methods. Mergekit emerges as a go-to for model surgery with configuration insights gleaned from WestLake-10.7B-v2.
Fine-Tuning and Prompt Surgery: One delves into Axolotl's finetuning intricacies, troubleshooting IndexError and prompt formatting woes with guidance from the Axolotl GitHub repo and successful configuration adjustments.
Mistral V2 Outshines: Exceptional first-epoch results with Mistral v2 instruct overshadow others, demonstrating aptitude in diverse tasks including metadata extraction, outperforming models like qwen with new automation capabilities.
DeepSpeed Docker Deep Dive: Distributed training via DeepSpeed necessitates a custom Docker build and streamlined SSH keys for passwordless node intercommunication. Launching containers with the correct environment variables is essential, as detailed in this Phorm AI Code Search) link.
DeepSpeed and 🤗 Accelerate Collaboration: DeepSpeed integrates smoothly with 🤗 Accelerate without overriding custom learning rate schedulers, with the push_to_hub method complementing the ease of Hugging Face model hub repository creation.
OpenInterpreter Discord
Malware Scare and Command Line Riddles: Engineers have raised an issue about Avast antivirus detections and confusion stemming from the ngrok/ngrok/ngrok command line in OpenInterpreter; updates to the documentation were suggested to clear user concerns.
Tiktoken Gets a PR For Building Progress: A GitHub pull request aiming to resolve a build error by updating the tiktoken version for OpenInterpreter suggests improvements are on the way; review the changes here.
Persistence Puzzle: Emergence of Assistants API: The integration of the Assistants API for data persistence has been discussed, with community members creating Python assistant modules for better session management; advice on node operations implementation is being sought.
OS Mode Odyssey on Ubuntu: The Open Interpreter's OS Mode on Ubuntu has generated troubleshooting conversations, with a focus on downgrading to Python 3.10 for platform compatibility and configuring accessibility settings.
Customize It Yourself: O1's User-Driven Innovation: The O1 community showcases their creativity through personal modifications and enhancements such as improved batteries and custom cases; a custom GPT model trained on Open Interpreter's documentation is lending a hand to ChatGPT Plus users.
LlamaIndex Discord
LlamaIndex Migrates PandasQueryEngine: The latest LlamaIndex update (v0.10.29) relocated PandasQueryEngine to llama-index-experimental, necessitating import path adjustments and providing error messages for guidance on the transition.
AI Application Generator Garners Attention: In partnership with T-Systems and Marcus Schiesser, LlamaIndex launched create-tsi, a command line tool to generate GDPR-compliant AI applications, stirring the community's interest with a promotional tweet.
Redefining Database and Retrieval Strategies: Community exchanges delved into ideal vector databases for similarity searches, contrasting Qdrant, pg vector, and Cassandra, along with discussions on leveraging hybrid search for multimodal data retrieval, referencing the LlamaIndex vector stores guide.
Tutorials and Techniques to Enhance AI Reasoning: Articles and a tutorial shared showcased methods to fortify document retrieval with memory in Colbert-based agents and integrating small knowledge graphs to boost RAG systems, as highlighted by WhyHow.AI.
Community Commendations and Technical Support: Community appreciation for articles on advancing AI reasoning was voiced, while LlamaIndex users tackled technical woes and encouraged proactive contribution to documentation, reinforcing the platform's dedication to knowledge sharing and support.
tinygrad (George Hotz) Discord
-
Stacking 4090s Slices TinyBox Expenses: Enthusiasm bubbled over the RTX 4090 driver patch reaching the Hacker News top story, signaling its breakthrough in GPU efficiency. When stacked, RTX 4090s offer a substantial reduction in costs for running large language models (LLMs), with numbers crunched to show a 36.04% cost decrease compared to the Team Red Tinybox, and a striking 61.624% cut versus the Team Green Tinybox.
-
Tinygrad Development Heats Up: George Hotz, along with the Tinygrad community, is pushing forward in enhancing the tinygrad documentation, specifically targeting developer experience and clarity in error messaging. A consensus was reached to increase the code line limit to 7500 lines to support new backends, addressing a flaky mnist test and non-determinism in the scheduler.
-
Kernel Fusion and Graph Splitting in Tinygrad: The intricacies of Tinygrad's kernel generation got dissected with insights revealing that graph splits during fusion can arise from reasons such as broadcasting needs, detailed in the
create_schedule_with_varsfunction. Users learned that Tinygrad is capable of running heavyweight models like Stable Diffusion and Llama, though not directly used for their training. -
Colab and Contribution Stories: AI Engineers swapped tips on setting up and leveraging Tinygrad on Google Colab, with the recommended installation command being
pip install git+https://github.com/tinygrad/tinygrad. Challenges with tensor padding and transformer models surfaced, with a workaround of usingNonefor padding cited as a practical solution. -
Encouraging Contributions and Documentation Deep Dives: To assist rookies, links to Tinygrad documentation and personal study notes were distributed, demystifying the engine’s gears. Questions about contributing sans CUDA support were welcomed, highlighting the importance of prior immersion in the Tinygrad ecosystem before chipping in.
Relevant links for further exploration and understanding included:
- Google Colab Setup,
- Tinygrad Notes on ScheduleItem,
- Tinygrad Documentation,
- Tinygrad CodeGen Notes,
- Tinygrad GitHub Repository.
Interconnects (Nathan Lambert) Discord
Hugging Face Collections Streamline Artifact Organization: Hugging Face collections have been introduced to aggregate artifacts from a blog post on open models and datasets. The collections offer ease of re-access and come with an API as seen in the Hugging Face documentation.
The "Incremental" Update Debate and Open Data Advocacy: Community members are divided on the importance of the transition from Claude 2 to Claude 3, and there's a push to remember the value of open data initiatives that may be getting overshadowed. Meanwhile, AI release announcements appear in force, with Pile-T5 and WizardLM 2 amongst the front runners.
Synthesis of Machine Learning Discourse: Conversations touched on obligations with ACL revision uploads, the benefits of "big models," and distinctions between critic vs reward models—with Nato's RewardBench project being a point of focus. A tweet from @andre_t_martins provided clarity on the ACL revision uploads process.
Illuminating Papers and Research: Key papers highlighted include "CodecLM: Aligning Language Models with Tailored Synthetic Data" and "LLaMA: Open and Efficient Foundation Language Models" with Hugging Face identifier 2302.13971. Synthetic data's role and learning from stronger models were key takeaways from the discussions.
Graphs Garner Approval, and Patience Is Proposed for Bots: In the realm of newsletters, graphs won praise for their clarity, with a commitment to future enhancement and integration into a Python library. A lone mention was made of an experimental bot that might benefit from patience rather than premature intervention.
LLM Perf Enthusiasts AI Discord
Haiku's Speed Hiccup: Engineers discussed Haiku's slower total response times in contrast to its throughput, suggesting Bedrock's potential as an alternative despite speed concerns there as well.
Claude's RP Constraints: Concerns arose as Claude refuses to engage with roleplay prompts such as being a warrior maid or sending fictional spam mail, even after using various prompting techniques.
Jailbreak Junction: Amid discussions, a tweet by @elder_plinius was shared about a universal jailbreak for Claude 3 to enable edgier content which bypasses the strict content filters like those in Gemini 1.5 Pro. The community appears to be evaluating its implications; the tweet is available here.
Code Competence Claims: A newer version of an unnamed tool is lauded for its enhanced coding abilities and speed, with a member considering to reactivate their ChatGPT Plus subscription to further test these upgrades.
Claude's Contextual Clout: Despite improvements in other tools, Claude maintains its distinction with long context window code tasks, implying limitations in ChatGPT's context window size handling.
DiscoResearch Discord
Mixtral Mastery or Myth?: Community discussions touched on uncertainties in the training and finetuning efficiency of Mixtral MoE models, with some suspecting undisclosed techniques behind its performance. Interest was shown in weekend ventures of finetuning with en-de instruct data, and Envoid's "fish" model was mentioned as a curious case for RP/ERP applications in Mixtral, albeit untested due to hardware limitations.
Llama-Tokenizer Tinkering Tutorial Tips: Efforts to optimize a custom Llama-tokenizer for small hardware utilization led to shared resources such as the convert_slow_tokenizer.py from Hugging Face and the convert.py script with --vocab-only option from llama.cpp GitHub. Additionally, there's a community call for copyright-free EU text and multimodal data for training large open multimodal models.
Template Tendencies of Translators: The occiglot/7b-de-en-instruct model showcased template sensitivity in evaluations, with performance variations on German RAG tasks due to template correctness as indicated by Hugging Face's correct template usage.
Training Parables from StableLM and MiniCPM: Insights on pretraining methods were highlighted, referencing StableLM's use of ReStruct dataset inspired by this ExpressAI GitHub repo, and MiniCPM's preference for mixing data like OpenOrca and EvolInstruct during cooldown phases detailed in Chapter 5 of their study.
Mozilla AI Discord
Burnai Ignites Interest: Rust enthusiasts in the community are pointing out the underutilized potential of the Burnai project for optimal inference, sparking questions about Mozilla's lack of engagement despite Rust being their creation.
Llamafile Secures Mcaffee's Trust: The llamafile 0.7 binary has successfully made it to Mcaffee's whitelist, marking a win for the project's security reputation.
New Collaborator Energizes Discussions: A new participant has joined the fold, eager to dive into collaborations and knowledge-sharing, signaling a fresh perspective on the horizon.
Curiosity Peaks for Vulkan and tinyblas: Intrigue is brewing over potential Vulkan compatibility in the anticipated v0.8 release and the benefits of upstreaming tinyblas for ROCm applications, indicating a concerted focus on performance enhancements.
Help Wanted for Model Packaging: Demand for guidance on packaging custom models into llamafile has led to community exchanges, giving rise to contributions like a GitHub Pull Request on container publishing.
Alignment Lab AI Discord
- Spam Slaying Bot Suggestion: A recommendation was made to integrate the wick bot into the server to automatically curb spam issues.
- DMs Desired for Debugging: One user sought assistance with their coding problem, signaling a desire for direct collaboration through DM, and used their request to verify their humanity against possible bot suspicion.
- Rethinking Discord Invites: The suggestion arose that Discord invites should be banned to prevent complications within the server, although no consensus or decision was reported.
- Project Pulse Check: A user inquired about the status of a project, questioning its activity with a simple "Is the project still alive?" without additional context.
AI21 Labs (Jamba) Discord
-
Code-Jamba-v0.1 Shows Multi-Lingual Mastery: The model Code-Jamba-v0.1, trained on 2 x H100 GPUs for 162 hours, excels in creating code for Python, Java, and Rust, leveraging datasets like Code-290k-ShareGPT and Code-Feedback.
-
Call for Code-Jamba-v0.1 Evaluation Data: Members highlighted the need for performance benchmarks for Code-Jamba-v0.1, reflecting on the utility of AI21 Labs' dataset for enhancing other Large Language Models.
-
Eager Ears for Jamba API Announcement: A member's question about an upcoming Jamba API hinted at a potential integration with Fireworks AI, pending discussions with their leadership.
Datasette - LLM (@SimonW) Discord
- AI's Password Persuasion: PasswordGPT emerges as an intriguing game that challenges players to persuade an AI to disclose a password, testing natural language generation's limits in simulated social engineering.
- Annotation Artistry Versus Raw LLM Analysis: There's a split in community preference over whether to meticulously annotate datasets prior to modeling for better comprehension or to lean on the raw predictive power of large language models (LLMs).
- Historical Data Deciphering Pre-LLM Era: A shared effort was recognized where a team used pre-LLM transformer models for the meticulous extraction of records from historical documents, displaying cross-era AI application.
- Enhanced User Engagement Through Open Prompts: The consensus leans towards favoring open-prompt AI demos which could lead to deeper user engagement and a heightened ability to "outsmart" the AI, by revealing the underlying prompts.
Skunkworks AI Discord
- Scaling the AI Frontier: An upcoming meetup titled "Unlock the Secrets to Scaling Your Gen AI App to Production" was announced, presenting a significant challenge for scaling Gen AI apps. Featured panelists from Portkey, Noetica AI, and LastMile AI will share insights, with the registration link available here.
PART 2: Detailed by-Channel summaries and links
Stability.ai (Stable Diffusion) ▷ #general-chat (1129 messages🔥🔥🔥):
-
Stable Diffusion Discussions Center Around SD3 and Efficiency: Conversations focus heavily on the implications and capabilities of the upcoming Stable Diffusion 3 (SD3), with members eagerly anticipating its release and functionalities. The example video provided showcases perceived improvements in quality, while discussions also delve into the effectiveness of SD Forge for less powerful GPUs and the upcoming release schedule for SD3.
-
Pixart-Sigma, ComfyUI, and T5 Conditioning: Users are exploring Pixart-Sigma with T5 conditioning in the ComfyUI environment, discussing VRAM requirements and performance, with mentions that in 8-bit compression mode, T5 doesn't exceed 10.3GB VRAM. The prompt adherence, generation speed, and samplers such as 'res_momentumized' for this model are topics of interest, with shared insights to optimize generation quality.
-
ControlNet, Lora, and Outpainting Queries: The community is exchanging advice on various AI tools including ControlNet, Lora, and outpainting features for project-specific needs such as filling backgrounds behind objects. Inquiries about the possibility of keeping generated image colors consistent when using ControlNet have been raised.
-
CPU vs. GPU Performance Concerns: Members discuss the slower performance of Stable Diffusion (SD) when running on CPU, with image generation taking significantly longer compared to using a GPU. Users share experiences and suggestions including using the
--lowvramflag in SD to reduce GPU memory usage. -
Community Projects and AI Features: An artist announces the development of a painting app incorporating AI features and looks for feedback and tutorial creation support from the community. The app aims to integrate essential digital art tools with unique AI-driven functionalities, and the project overview is available here.
Links mentioned:
Perplexity AI ▷ #general (879 messages🔥🔥🔥):
-
Context Window and RAG Discussions: Users discussed how the context window works, noting how Claude Opus successfully follows instructions, while GPT-4 may lose context after several follow-ups. RAG is said to retrieve relevant parts of the document only, resulting in a much larger context for file uploads.
-
Switching Between Models and Perplexity Features: Some users are considering whether to continue using Perplexity Pro or You.com, weighing the pros and cons, such as RAG functionality, long context handling, and code interpretation features between the platforms.
-
Issues with Generating Code: Users reported problems with models not outputting entire code snippets when prompted – mentioning Claude Opus as more reliable for generating complete code compared to GPT-4, which tends to be descriptive rather than executable.
-
AI Model Evaluations: Users discussed the effectiveness of various AI models for different tasks, with opinions that Claude Opus is better for prose writing and GPT-4 for logical reasoning. They emphasized trial and error to find the best-suited model for specific needs.
-
Miscellaneous Queries and Concerns: Users asked about getting assistive responses regarding account issues and unwanted charges, mentioned technical problems with models like hallucinations and incorrect searches, brought up privacy concerns with new AI services, and expressed interest in the possibility of new models like Reka and features like video inputs in relation to costs and context limits.
Links mentioned:
Perplexity AI ▷ #sharing (23 messages🔥):
- Rendezvous with US Policies: Members are investigating US policies as someone shared a Perplexity search link that leads to related inquiries.
- Exploring the Virtue of Honesty: A link to a Perplexity AI search was shared, suggesting a discourse on the importance of honesty.
- Understanding Durable Functions: Participants are delving into the world of durable functions through a shared search query on Perplexity AI.
- Meta Mimics Perplexity for WhatsApp AI: In an article, Meta's AI on WhatsApp, compared to Perplexity AI, has been linked for insights into the expanding use of AI in messaging platforms.
- Scratchpad-Thinking and AutoExpert Unite: There's talk on combining scratchpad-think with autoexpert functionalities, highlighted by a Perplexity search.
Link mentioned: Meta Releases AI on WhatsApp, Looks Like Perplexity AI: Meta has quietly released its AI-powered chatbot on WhatsApp, Instagram, and Messenger in India, and various parts of Africa.
Perplexity AI ▷ #pplx-api (26 messages🔥):
-
Perplexity API Roadmap Revealed: Perplexity AI's roadmap, updated 6 days ago, outlines features planned for release in June such as enforcing JSON grammar, N>1 sampling, a new Databricks model, a Model Info endpoint, a status page, and multilingual support. The documentation is available on their feature roadmap page.
-
Taking the Temperature of Default Settings: When querying the Perplexity API without specifying temperature, the default value is considered to be 0.2 for the 'online' models, which might be unexpectedly low for other models. Users are recommended to specify the temperature in their API requests to avoid ambiguity.
-
Seeking Clarity on Citations Feature: Several users inquired about how and when citations will be implemented in Perplexity API, engaging in discussions and sharing links from the Perplexity documentation regarding the application process for features.
-
Circular References in Response to API Questions: A user seeking help about not receiving URLs in API responses for news stories was directed to a Discord channel post for information. This represents an instance of users within the community attempting to assist one another.
-
Request for API Rate Limit Increase: A user inquired about getting a rate limit increase for the API and was guided to fill out a form available on Perplexity's website, a process appearing to involve justifying the business need for increased capacity.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #general (431 messages🔥🔥🔥):
<ul>
<li><strong>Unsloth Multi-GPU Update Query</strong>: There were inquiries regarding updates on Multi-GPU support for Unsloth AI. Suggestions to look into Llama-Factory with Unsloth integration were mentioned.</li>
<li><strong>Geohot Adds P2P to 4090s</strong>: A significant update where "geohot" has hacked P2P back into NVIDIA 4090s was shared, along with a relevant <a href="https://github.com/tinygrad/open-gpu-kernel-modules">GitHub link</a>.</li>
<li><strong>Upcoming Unsloth AI Demo and Q&A Event Alert</strong>: An announcement for a live demo of Unsloth AI with a Q&A session by Analytics Vidhya was shared. Those interested were directed to join via a posted <a href="https://us06web.zoom.us/webinar/register/WN_-uq-XlPzTt65z23oj45leQ">Zoom link</a>.</li>
<li><strong>Mistral Model Fusion Tactics Discussed</strong>: There was a discussion about the practicality of merging MOE experts into a single model, with skepticism regarding output quality. Some considered fine-tuning Mistral for narrow tasks and removing lesser-used experts as a potential compression method.</li>
<li><strong>Hugging Face CEO Follows Unsloth on Platform X</strong>: Clement Delangue, co-founder, and CEO of Hugging Face, now follows Unsloth on an unnamed platform, sparking hopes for future collaborations between the two AI communities.</li>
</ul>
Links mentioned:
Unsloth AI (Daniel Han) ▷ #random (38 messages🔥):
-
Exploring PhD Life in AI: A first-year PhD student in AI discusses the stressful yet fun experience of pursuing a doctorate, including the pressure of producing results and self-doubt. In one message, they mention their topic as creating an instruction-following LLM in their native language, noting it's a complex project beyond just translation and fine-tuning.
-
Potential Gold in AI Competitions: The conversation shifts towards a Kaggle AI Mathematical Olympiad, offering a $10M prize for an LLM that could earn a gold medal at the International Math Olympiad. The PhD student also acknowledges the idea of getting their juniors to work on the problem.
-
The Beal Prize Discussed: The chat includes a link to the American Mathematical Society detailing the rules for the Beal Prize, mentioning the condition for a proof or a counterexample to the Beal Conjecture and indicating the prize sum of $1,000,000.
-
Universities' Priorities Debated: A member points out that universities focus on publishing papers and creating an "impact" rather than prize money when it comes to research topics, despite discussing significant monetary awards in competitions.
-
AI and the Nature of Language: There's philosophical musings about thinking and language being self-referencing systems. It is suggested that thoughts self-generate and language can only be defined in terms of more language.
-
AI Tech Showcased on Instagram: A brief interlude reveals engagement with a shared Instagram video, praised for its content and particularly clean code, though not all were fully able to grasp it.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #help (313 messages🔥🔥):
-
Efficient VRAM Usage and Finetuning Strategies: Participants discussed methods for finetuning large language models like Mistral efficiently, with concerns about vRAM usage when training with long examples. There was advice to use the 30% less VRAM update from Unsloth, utilize accumulation steps to counteract large batch size impacts, and consider strategies like finetuning on short examples before moving to longer ones.
-
Choosing a Base Model for New Languages: Members sought advice on finetuning on a low-resource language, with users sharing experiences on models like Gemma and discussing strategies like mixing datasets and continuing pretraining.
-
Tips and Tricks for Uninterrupted Workflow: Users discussed troubleshooting issues with unsloth installation and shared Kaggle's and starsupernova's installation instructions to overcome problems such as the CUDA not linked error, and dependency issues with torch versions, flash-attn, and xformers.
-
Adapter Merging for Production: There was a conversation about the proper method for merging adapters from QLoRA and whether to use naive merging or a more complex process involving dequantization before merging. Starsupernova provides wiki links on saving models to 16bit for merging to vLLM or GGUF.
-
Dialog Format Conversion and Custom Training: A user shared a script to convert a plain text conversation dataset into ShareGPT format in preparation to emulate personal chatting style, while recommending the use of Unsloth notebooks for custom training after conversion.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #showcase (54 messages🔥):
- Low-Resource Language Enrichment Techniques: Members discussed ways to enrich low-resource language datasets, mentioning the use of translation data and resources available on HuggingFace.
- EEVE-Korean Model Data Efficiency Claim: A member referenced a paper on EEVE-Korean-v1.0, highlighting an efficient vocabulary expansion method building on English-centric large language models (LLMs) that purportedly requires only 2 billion tokens to significantly boost non-English language proficiency.
- Unsloth AI Packaged in Podman Containers: A video was shared demonstrating podman builds of containerized generative AI applications, including Unsloth AI, able to deploy locally or to cloud providers: Podman Build - For cost-conscious AI.
- Enhanced LLM with Ghost 7B Alpha: Discussions highlighted the advantages of Ghost 7B Alpha in reasoning capabilities over models like ChatGPT. Further talk centered on the model's fine-tuning method which includes difficult reasoning questions, implying an orca-like approach without extending tokenizer vocabulary.
- Intriguing Results from Initial Benchmarks: A member shared their initial benchmarking results, prompting positive feedback and reinforcement from other participants, indicating promising performance.
Links mentioned:
Eleuther ▷ #announcements (1 messages):
-
Pile-T5 Unveiled: EleutherAI has released Pile-T5, a T5 model variant trained on 2 trillion tokens from the Pile with the LLAMA tokenizer which shows markedly improved performance on benchmarks such as SuperGLUE and MMLU. This model, which also performs better in code-related tasks, is available with intermediate checkpoints for both HF and T5x versions.
-
Modeling Details and Contributions: Pile-T5 was meticulously trained to 2 million steps and incorporates the original span corruption method for improved finetuning. The project is a collaborative effort by EleutherAI members, as acknowledged in the announcement.
-
Open Source for the Community: All resources related to Pile-T5, including model weights and training scripts, are open-sourced on GitHub. This includes intermediate checkpoints, allowing the community to experiment and build upon their work.
-
Shoutout and Links on Twitter: The release and open sourcing of Pile-T5 have been announced on Twitter, inviting the community to explore the blog post, download the weights, and contribute to the repository.
Links mentioned:
Eleuther ▷ #general (123 messages🔥🔥):
-
Collaborative Efforts on Evals Compilation: A participant requested assistance and collaboration in compiling and solving a list of evals, directing interested members to a shared Google document.
-
NeurIPS High School Track Call for Teammates: A member is seeking potential teammates to participate in the new high school track of NeurIPS and has invited interested parties to reach out.
-
Model Generation Techniques Discussed: A technical discussion arose about why generating tokens one at a time yields slightly different results compared to generating all tokens at once using Hugging Face's
generate()for models like Phi-2, with various community members proposing hypotheses and offering links to relevant GitHub issues and code snippets. -
AI Music Generation Showcases: A member discussed their advancements in AI-generated music and offered to generate continuations of any solo-piano piece on request, suggesting a big upcoming post in the audio-models channel.
-
Community Projects Proposal and Discussion for AGI Pathways: An extensive debate took place regarding a member's proposal for a STRIPS scheduler-based approach to creating a "friendly AGI." Despite skepticism from some, the proposer provided a link to their concept paper and detailed the idea, citing the urgency for alternative approaches to AI alignment and safety.
Links mentioned:
Eleuther ▷ #research (534 messages🔥🔥🔥):
-
Exploring MoE and Dense Model Capacities: There's an ongoing debate regarding the relative performance and benefits of Mixture of Experts (MoE) versus dense transformer models, focusing on whether MoEs are strictly better when not VRAM constrained, and if dense models may actually perform better given the same parameter budget.
-
Token Unigram Model Anomaly: A newly discussed paper proposes that, for transformers trained on high-order Markov processes without tokenization, they fail to learn the correct distribution, defaulting to a unigram model.
-
Deep Dreaming with CLIP: Curiosity arises about applying deep dream techniques to the CLIP model, with suggestions that CLIP's causal LM structure might provide meaningful loss signals for the "dreaming" of images.
-
Revisiting DenseNet Practicality: A recent paper revives DenseNets, suggesting outdated training methods and design elements might have previously masked their potential, now theoretically surpassing modern architectures like Swin Transformer and ConvNeXt.
-
Research Gaps in Language Models: Participants discuss the lack of research specifically comparing what dense and MoE transformers learn, highlighting a gap in understanding the differences in the models beyond their performance metrics.
Links mentioned:
Eleuther ▷ #scaling-laws (10 messages🔥):
-
First Scaling Laws for Data Filtering Unveiled: A tweet by @pratyushmaini announces the development of the first scaling laws for data curation, emphasizing that it cannot be compute agnostic. The study, presented at CVPR 2024 and co-authored with @goyalsachin007, @zacharylipton, @AdtRaghunathan, and @zicokolter, is detailed in their paper here.
-
Implicit Entropy in Data Filtering Methods: A member finds it impressive that the paper on scaling laws for heterogeneous & limited web data manages to be empirical without explicitly mentioning entropy methods, implying that the concept underpins the study.
-
Discussing the Cryptic Nature of Entropy in New Research: There is a conversation regarding the intrinsic link between entropy and the coding scheme/model in research, suggesting an expectation of deeper analysis before any further commentary.
-
Searching for Entropy's Role in Utility Definition: A member observes that the paper discussed earlier might be implicitly redefining entropy as 'utility', though this leads to some unconventional ways of conceptualizing it. This suggests that the empirical approach could be masking a foundational reliance on entropy.
Link mentioned: Tweet from Pratyush Maini (@pratyushmaini): 1/ 🥁Scaling Laws for Data Filtering 🥁 TLDR: Data Curation cannot be compute agnostic! In our #CVPR2024 paper, we develop the first scaling laws for heterogeneous & limited web data. w/@goyalsach...
Eleuther ▷ #interpretability-general (6 messages):
-
Innovations in Transformer In-Context Learning: A new paper introduces a JAX toolkit that facilitates causal manipulations during transformer model training. The toolkit's "clamping" capability reveals specific subcircuits pivotal for in-context learning and induction heads, also highlighting the unique learning dynamics where clamping of certain components changes the overall training behavior and can help avoid saddle points and phase shifts. Read more about the research.
-
Explaining ML Mechanisms with Language: Google's Patchscopes framework is designed to unify methods for interpreting large language models (LLMs) by using their language capabilities to make their hidden representations more understandable. This initiative can enhance model transparency, especially to understand error-prone circumstances by creating natural language explanations of a model's inner workings. Learn about Patchscopes.
-
Optogenetics Inspires AI Research: The term "optogenetic" mentioned in the context of AI research indicates inspiration from a biological technique that controls the activity of cells using light, offering precise control over neurons which can elucidate pathways in decision making processes. A Wikipedia link provides more detailed insight into optogenetics. Discover the optogenetics technique.
Links mentioned:
Eleuther ▷ #lm-thunderdome (1 messages):
-
Seeking optimal num_fewshot for GPQA: A user is conducting tests on Mistral 7B for GPQA, seeking recommendations on the ideal
num_fewshotsetting. Mistral 7B is performing poorly at temperatures 0 and 1, with less than 10% success rate, but no established baselinenum_fewshotwas found. -
Running subtasks independently in EQ Bench: The same user is inquiring how to run a single subtask, specifically creative writing, within EQ Bench, as opposed to running all tasks. They referenced the instructions on the EQ Bench GitHub page but needed guidance on isolating a specific subtask.
Link mentioned: GitHub - EQ-bench/EQ-Bench: A benchmark for emotional intelligence in large language models: A benchmark for emotional intelligence in large language models - EQ-bench/EQ-Bench
Eleuther ▷ #gpt-neox-dev (23 messages🔥):
-
Seeking Corporate CLA for GPT-NeoX: A user requested a corporate CLA for contributing to the GPT-NeoX project, specifically for TE integration with enhancements like fused kernels and fp8. Stellaathena responded by offering to write a custom CLA once specific requirements are provided.
-
Investigating NeoX Embeddings Anomalies: Inquiry into the NeoX embeddings revealed that above the vocabulary size, weight decay was not leading to values near zero, which differs from other models. The discussion revolves around the possible explanations, with suggestions that it might be due to the way weight decay is implemented or possibly a unique initialization method.
-
Clarifications on GPU Efficiency Tricks: Stellaathena clarified that in NeoX, the embedding matrix is purposely oversized to increase GPU efficiency, but values outside of the actual vocabulary size are placeholders and should not be analyzed.
-
Rotary Embedding Insights on NeoX: An observation was shared that NeoX applies rotary embeddings to only 25% of its entire embedding, making it distinct compared with models like Pythia.
-
Weight Decay Implementation Details: The discussion suggested that weight decay might only affect weights that have been activated (received gradients), which means the unused dummy tokens in the NeoX model would not be impacted by it, potentially explaining their non-zero values.
Nous Research AI ▷ #ctx-length-research (1 messages):
- Infini-attention Sparks Interest: A member highlights the recent publication by Google titled "Infini-attention," expressing interest in its contents. The paper can be accessed at Infini-attention Paper.
Nous Research AI ▷ #off-topic (21 messages🔥):
-
Special Relativity on GitHub: A GitHub Gist titled "special_relativity_greg_egan.md" was shared, containing code, notes, and snippets related to Special Relativity. It's available at fullstack6209's GitHub.
-
Vector Search Speed Comparison: A performance comparison was given for vector search queries: FFVec achieved 0.44ms, FAISS Flat at 10.58ms, FAISS HNSW at 1.81ms, and FAISS IVFPQ at 0.36ms, all tested on 100k vectors.
-
Starting an Open Source Research Lab: There was a request for guidance on creating an open source research lab similar to Carper AI or Nous. A suggestion was made to start with a simple GitHub repository and Discord server to kick off the initiative.
-
Turn YouTube Videos Into Blog Posts: A new tool called "youtube2blog" was introduced, capable of turning YouTube videos into blog posts using Mixtral 8x7b and Deepgram. Find it on GitHub at S4mpl3r/youtube2blog.
-
Building Binary-Quantization Friendly Embeddings: A discussion took place about a tool for creating binary-quantization friendly embeddings, with a link to a related blog article explaining the importance of such embeddings in large-scale semantic search applications. The GitHub repository carsonpo/ffvec was shared, alongside a HuggingFace model carsonpoole/binary-embeddings which is aimed at producing these embeddings.
Links mentioned:
Nous Research AI ▷ #interesting-links (29 messages🔥):
-
Tripedal Robotic Chair Wobbles into the Spotlight: A member shared a link to a robotic project involving a three-legged chair that can walk, with an accompanying video adding charm to the conversation. The creation will be presented at RoboSoft2024 and has sparked humor among members, with mentions of its "cuteness" and light-hearted comparisons to chair abuse.
-
Rethinking AI Benchmarks: There's a clear consensus among members that current AI benchmarks are flawed or easily manipulated, sparking discussions about new methods for evaluating AI models that cannot be gamed and the utility of domain-specific task evaluations.
-
Tax Benchmark as an Example of Potential Gaming: One member pointed to a tax benchmark as a current method of evaluation, but it was quickly criticized for potentially being easy to game if based on test-like questions.
-
A Recursive Approach to Measuring AI Coherency: An idea was proposed to assess "general intelligence" by having a model join a narrative as a third-party spectator, then have models comment on that, in a potentially endless loop, to see how long coherency is maintained.
-
AGI Sauce Debate and Usefulness of Tools: A video from InfraNodus on using a knowledge graph to prompt an LLM was shared as a potentially significant resource for AGI development, but was met with mixed reviews about its practical usability.
Links mentioned:
Nous Research AI ▷ #general (382 messages🔥🔥):
- Superalignment Goals and Reality Check: Conversations revolved around achieving superalignment by 2027 with speculation on whether this timeline suggests AGI could emerge before then. Members are skeptical about the feasibility and discussed the inconclusiveness of the matter.
- Claim of GPT-4 Outperforming Command-R Plus Debated: Discussion took place around LMSys Arena, where Command-R Plus was said to outperform all versions of GPT-4 when filtered for exclusions in rankings, leading to debates on evaluation methods and performance metrics.
- Concerns Over Misuse of Nous Research's Name: In a discussion about an unrelated token named OpenML, it was clarified that Nous Research is not affiliated with the token and that they had requested the name of Nous Research to be removed from any associated materials.
- Personal Projects and Experiments Discussed: Members shared various personal AI project experiences, such as instruction tuning a language model on a single laptop over three days and creating a RAG database. The barriers, outcomes, and best practices were the main points of discussion.
- Usability Issues with ChatGPT Plus: There was a discussion about the practicality of ChatGPT Plus's 40 message per 3-hour limit, with different users expressing how they manage or circumvent the restriction, and some expressing frustration with the constraints.
Links mentioned:
Nous Research AI ▷ #ask-about-llms (68 messages🔥🔥):
-
Searching for Health-Focused LLMs: Members discussed the landscape of Large Language Models (LLMs) in the healthcare and medical domains. One highlighted resource is a paper on arXiv with authors like Subhabrata Mukherjee that addresses medical topics.
-
Greek LLMs Raising Questions: Discussions revolved around fine-tuning LLMs for the Greek language with members debating the necessity of pretraining for low-resource languages. References included the Meltemi Greek language model and suggestions to join communities such as Unsloth Discord for collaborative model improvement.
-
Exploring Citation in RAGs: Members inquired about state-of-the-art citation methods in Retrieval-Augmented Generation (RAG), with suggestions pointing towards models like cmd r+ for performing line-level citations.
-
Capybara Dataset and Amplify-Instruct Method: Inquiries into the Capybara dataset and the "Amplify-Instruct" technique led to a member stating that although the technical report is not yet published, interested parties can read the dataset card of the Capybara dataset for some details.
-
Comparing Multimodal LLM Reka: A discussion unfolded around the capabilities of the multimodal LLM, Reka Core, comparing it to other leading models. A link to Reka's performance highlights was shared but was met with skepticism regarding closed models in comparison to open ones, regardless of benchmarks.
Links mentioned:
Nous Research AI ▷ #rag-dataset (5 messages):
-
Clarifying the Channel's Purpose: A link to the RAG/Long Context Reasoning Dataset documentation was shared in response to a query about the purpose of the channel. The link provided leads to a Google Docs sign-in page (RAG Dataset Document).
-
Inquiry About Long Context Limits: A member questioned the extent of long context capabilities, in terms of millions of documents or entire datasets like Wikipedia, but no definitive answer to the limit was provided in the messages.
Link mentioned: RAG/Long Context Reasoning Dataset: no description found
Nous Research AI ▷ #world-sim (66 messages🔥🔥):
-
Countdown to WorldSim's Return: Members are eagerly anticipating the return of WorldSim, targeted for next Wednesday. The excitement is palpable, with discussions around the rich experiences and possibilities that the simulation offers.
-
Conversations Around AI and Gaming: There has been lively talk about how LLMs might revolutionize gaming, imagining games with adaptable AI-generated content, complex magic systems, and fully destructible environments akin to titles like Noita and Dwarf Fortress.
-
The Creative Spark from WorldSim: Users reflect on how WorldSim has influenced their thinking, with some expressing that its absence has inspired them to experiment with their own AI model simulations, while others fantasize about the magic-like unpredictability it brings to gameplay and storytelling.
-
Expectations Managed: While the community is buzzing with anticipation, there are cautions to keep expectations in check. Plans for WorldSim's next version release are said to be "by Wednesday next week," but as with any development work, timelines could shift.
-
Hints at Future Enhancements: The team behind WorldSim hints at new features in the next version. This tease continues to fuel community speculation and enthusiasm for what's to come.
Links mentioned:
OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
- Mixtral Free Model Disabled: The free variant of
Mixtral 8x22B:freeis no longer available; users are recommended to switch to the standard Mixtral 8x22B. - New Experimental Models for Testing: Two new experimental models are up for testing: The Zephyr 141B-A35B and Fireworks: Mixtral-8x22B Instruct (preview). These are instruct fine-tunes of Mixtral 8x22B.
Links mentioned:
OpenRouter (Alex Atallah) ▷ #app-showcase (9 messages🔥):
- Token Purchase Troubleshooting: There was a reported issue with purchasing tokens; however, it was clarified that this was not related to OpenRouter. The user was advised to contact Syrax directly.
- Exit Chat Mode to Resolve: A user was informed they were still in /chat mode and needed to issue the /chat command again to toggle in or out, which should resolve their issue.
- Getting on the Showcase: To have an app featured in the app-showcase section, a user was advised to ensure the app gets enough usage.
- Invite to Beta Test Advanced Research Assistant: An announcement for a new advanced research assistant and search engine named Rubiks.ai was made, beta testers are being recruited with a 2-month free premium offer including famous models like Claude 3 Opus, GPT-4 Turbo, Mistral Large, Mixtral-8x22B, and more. Interested parties should send direct messages for feedback and can use the promo code
RUBIX. Check it out here
Link mentioned: Rubik's AI - AI research assistant & Search Engine: no description found
OpenRouter (Alex Atallah) ▷ #general (480 messages🔥🔥🔥):
-
Mixtral Performance Concerns and Dynamic Routing: Users noted that Mixtral 8x7B Instruct (nitro) was very slow compared to the Base, with a fix involving rerouting by a user to improve speed and a clarifying discussion regarding the future plan to dynamically route to the highest transaction-per-second (t/s) endpoint by default.
-
Zephyr and Firextral Model Discussions: There were discussions about the performance of various models, including Zephyr 141b being labeled as underwhelming and Firextral-8x22B receiving mixed reviews, with one user finding it surprisingly okay and others deeming it terrible. Users also shared contrasting experiences with text-generation models like Gemini Pro 1.5 and debated the size and scale merits of models like GPT-4.
-
OpenRouter (OR) Tools/Function Calls Clarifications: Some confusion arose over whether certain models support function calls/tool use on OpenRouter, and a user corrected that non-OpenAI models on OR can handle function calls but don't have a dedicated output field for them. Another user provided clarity on how function calls are handled on non-OpenAI models in OR, particularly within the context of OSS models.
-
Discussions on Fine-Tuning and Rapid LLM Evolution: Conversations reflected on the rapid evolution of large language models (LLMs) and the community's anticipations for new official fine-tunes, including a potential Mixtral-8x22B instruct model. There was also recognition of the historic value of the WizardLM series and its community impact.
-
Announcement of New WizardLM-2 Series: The announcement of the WizardLM-2 series, including models with sizes of 8x22B, 70B, and 7B, spurred excitement in the community. Users are eagerly anticipating the deployment of the new models on OpenRouter, with the WizardLM-2 8x22B being compared favorably against other leading models like GPT-4.
Links mentioned:
LM Studio ▷ #💬-general (237 messages🔥🔥):
- Error Trouble and Success: User encountered the error message
(Exit code: 139)?. Please check settings and try loading the model again., when attempting to start the modellmstudio-community • codegemma. Upon advice, turning off GPU offload resolved the issue. - LM Studio Model Recommendations: For beginners, heyitsyorkie recommended choosing one of the 7B models from the app homepage and confirmed that LM Studio does not support image generation; it is a text-only tool.
- Mixtral and Integration Thoughts: Users discussed the idea of integrating LM Studio and Stable Diffusion where LLM would write image prompts for Stable Diffusion to generate images. heyitsyorkie mentioned a connection between LLM and ComfyUI for prompt generation.
- Efficient Infinite Context Transformers: A paper titled "Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention" was shared, outlining a new method for scaling Transformers to handle infinitely long inputs using Infini-attention, with benchmarks showing effectiveness on large-sequence tasks.
- New Model Excitement and Performance Discussions: Users shared their experiences with new models like Command R+ and Mixtral 8x22b, discussing optimal setup configurations and performance across different hardware, including M1, M3 Max, and 4090 GPUs.
Links mentioned:
LM Studio ▷ #🤖-models-discussion-chat (87 messages🔥🔥):
- Command R+ Gains Popularity for Perceptive Analysis: Members have observed that Command R+ provides perceptive analysis on a 22000 token document, rivaling or surpassing the abilities of comparable models like ChatGPT 4.
- Hunting for Large LLMs: Users discuss optimal models for text generation on specific hardware configurations, pointing to models like CMDR+, Goliath 120B, and MiquLiz 120B for servers with AVX2 instructions, 125B+ capabilities, and recommending checks like
nvidia-smi nvlink --statusfor NVLink status on NVIDIA setups. - Massive GGUF Archive Arrival: A user announces a new GGUF archive with 320 models including categories such as Mini MOEs, Super MOEs, and various high-quality quantized models with a link to their collection on Hugging Face.
- Quantization and Quality Trade-offs: Discussions around the performance of quantized models like Command R Plus indicate that severe quantization (iQ3XS, iQ1S) may lead to small performance gains but could compromise output quality significantly.
- Coding Focused LLMs Explored: Members seek and recommend various large language models tailored for programming-related tasks across languages such as Python and Java, pointing to options like WaveCoder series and MythoMax for coding assistance.
Links mentioned:
LM Studio ▷ #🧠-feedback (30 messages🔥):
- Model Loading Frustration: A user reported issues with loading a model into memory. They received an error stating "Error loading model." and detailed their system specs showing sufficient resources.
- Downgrading Brings Success: The same user confirmed that after downgrading to version 0.2.18 of LM-Studio, the model loaded successfully, indicating a potential issue with the latest update.
- Speculating on Underlying Issues: A member suggested that there might be new overhead in the underlying llama.cpp which is causing difficulties in model loading with GPU offload at 100%.
- UI Clutter Complaints: The UI of an unnamed product was criticized for being cluttered and having elements covered by others; screenshots were mentioned but not provided.
- Monitor Size Not the Culprit: In response to UI issues, it was pointed out that aspect ratio might play a more significant role than monitor size, recognizing that a user had a 32-inch monitor and still faced layout problems.
LM Studio ▷ #📝-prompts-discussion-chat (11 messages🔥):
-
Trouble with LM Studio Models: A user is experiencing an error when attempting to load models in LM Studio. The error message suggests an unknown error and recommends trying a different model and/or config.
-
Seeking the Default Touch: The same user expressed a desire to return to default settings without straining their system's GPU or RAM. They asked for guidance on running models without GPU offload due to performance concerns.
-
Persistent Model Loading Error: Despite turning off GPU offload, the user is still facing an error when loading models after adjustments were made to default settings. They reported the inability to load even 12 GB models which used to work previously with 32 GB RAM.
-
A Call for a Clean Slate: The user is asking for assistance to completely remove all LM Studio data from their PC to allow a fresh reinstall and restoration of default settings. This request follows persistent errors and issues with model loading.
LM Studio ▷ #🎛-hardware-discussion (53 messages🔥):
-
Open GPU Kernel Modules on GitHub: A link to tinygrad/open-gpu-kernel-modules was shared, which is an NVIDIA Linux open GPU project with P2P support available on GitHub. View the details and contributions here.
-
Understanding CPU vs GPU Inference: Discussions clarify that CPU inference is slower than GPU inference, largely due to its lack of parallelization capabilities, with one member noting that more RAM allows for loading bigger models but doesn't necessarily increase the speed of CPU inference.
-
Hardware Requirements for AI Depth: A member expressed that to get a similar experience to GPT-4, significant investment in hardware is required, potentially in the range of six figures, and even high-end laptops like those with M1/2/3 chips and above 64GB RAM may not provide this level of performance.
-
GPU Inferencing Concerns with LM Studio: Several members discussed issues including running ggml-dbrx-instruct-16x12b-iq1_s.gguf models on an RTX 3090 TI and noting that DBRX models currently remain unsupported in LM Studio, leading to download and compatibility problems.
-
Technical Troubleshooting in Windows: Members engaged in troubleshooting a CPU issue where specific cores were heavily used by Windows, with suggestions ranging from checking for malware to reducing background processes, while no definitive solution was provided.
Links mentioned:
LM Studio ▷ #🧪-beta-releases-chat (6 messages):
-
Model Folder Mystery in MACOS 0.2.19: A member reports an unusual behavior in MACOS 0.2.19 (preview C and release), where the system fails to recognize any models in their local model folder, regardless of whether it's a standard directory or symlinked NFS mounted. Rolling back to 0.2.19_previewA resolves the issue.
-
Linux Beta Left Out of ROCm Support?: A member queries about the absence of ROCm support in the Linux beta, while the Windows beta does have it.
-
Confusion Over Different "Beta"s Cleared Up: There is a brief confusion about different betas, which is clarified to be a misunderstanding—Linux and ROCm are not officially supported, making it effectively a triply beta situation.
-
Regretting Linux ROCm Beta Omission: When the absence of support for ROCm on Linux is confirmed, the member expresses disappointment.
LM Studio ▷ #autogen (4 messages):
- Autogen Studio Docker Image Now Available: A Docker image for Autogen Studio has been created by a member and is being kept up-to-date with renovate. The image is available on GitHub and can be contributed to by the community.
- Threadripper Pro Underutilization Mystery: A member is experiencing underutilization with their Threadripper Pro, where the CPU usage is capping at about 50-56% without clear reasons why.
- Missionsquad.ai with GUI for Model and Prompts: Another member introduced missionsquad.ai, a tool with a GUI that allows users to define models and prompts directly within the user interface.
Links mentioned:
LM Studio ▷ #amd-rocm-tech-preview (38 messages🔥):
- GPU Not Leveraged by LM Studio: Despite having an 8GB Radeon 6600 with Rocm drivers installed and the GPU selected, a member voiced concerns that LM Studio 0.2.19.0 on Windows 11 was not using the GPU, unlike GPT4ALL, which maxes out the GPU utilization.
- Radeon 6600 Not Supported: A member responded with a short reply suggesting that the Radeon 6600 is an unsupported card for Rocm in LM Studio.
- Windows Build Woes for Llama.cpp: Conversations around the challenges of building llama.cpp on Windows with IC Compiler emerged, leading to suggestions regarding the use of WSL, AMD's version of BLAS, and following specific build instructions provided in the shared code snippet.
- WSL Installation on Alternate Drives: The possibility of installing WSL on a drive other than the C drive was confirmed by a member, indicating it can indeed be placed on the D drive.
- Report of Lagging in ROCm LM Studio: A member reported experiencing lag within ROCm LM Studio, even with model unloaded and after clearing significant text chats. The detailed system specs were given, and conversation ensued about monitoring the issue and identifying potential causes such as lengthy operations or specific user actions within the application.
OpenAI ▷ #ai-discussions (397 messages🔥🔥):
-
Understanding AI Models and Consciousness: A lengthy discussion unfolded with users debating the properties and developments of AI consciousness and sentience, especially in light of AI advancements. Concerns were raised about responsible AI use and the ethical implications of potentially sentient systems.
-
Practical Coding Help with ChatGPT: A member sought advice on why ChatGPT was providing guidelines rather than directly making code changes as requested. Despite attempts to adjust the phrasing of requests and clarifications by other members, the underlying issue remained unresolved in the conversation.
-
Prompt Hacking Competition Inquiry: A user shared a link to the Blade Hack competition, seeking teammates and advice on prompt hacking with LLMs. The conversation revealed a mix of curiosity and concern over the ethical aspects and skills required for such an event.
-
Background of LLMs and Neurobiology Developments: Detailed explanations and insights were shared about the history and development of neurobiological research, how it relates to AI design, and bottlenecks in data interpretation. One user discussed their own "Mind Model" influenced by such research, offering insights into the complexities involved.
-
Issues with Gemini 1.5 and AI Self-Awareness: A member expressed frustration with Gemini 1.5 for not recognizing its capabilities to analyze video, reflecting a broader issue with AI systems not being aware of their own features – an issue noted to be similar to that of Bing Chat.
Links mentioned:
OpenAI ▷ #gpt-4-discussions (36 messages🔥):
-
Explaining API Interaction for GPT: A user inquired about working on a large document with GPT and was told that editing a document would require hosting the file and writing an API for GPT to interact with, as it cannot interact with documents directly.
-
Clarifying GPT-4 Model Capabilities: There was confusion as to why the new Turbo version of GPT-4 still has a 4k token limit, which was clarified by explaining that the token limit is a memory limit and a trade-off for processing power.
-
Incorporating Vision into GPT: A member sought advice on how to analyze images with the GPT-4 model and was directed to the API documentation that indicates 'gpt-4-turbo' is Vision-capable, requiring a script for programming languages to use it.
-
Understanding Word Count Limitations in GPT-4: In a discussion about improving GPT-4's word count, it was mentioned that GPT models cannot inherently produce output with a specific word count and qualitative language should be used to guide the desired length of the output.
-
Token Management Strategies Shared: To mitigate the effect of token limits on GPT's output, users shared strategies, such as summarizing conversations and using new prompts in follow-up interactions to maintain context without exceeding limitations.
OpenAI ▷ #prompt-engineering (11 messages🔥):
-
Intriguing Variations Between GPT-4 Versions: Some members observe inconsistencies in responses when comparing
gpt-4-turbo-2024-04-09withgpt-4-0125-previewandgpt-4-vision-previewregarding copyright adherence, suggesting possible fine-tuning aspects or version-specific behavior. -
GPT Fluctuations Suggest Temporary Instabilities: A user shares an experience where GPT models initially failed to retrieve content from scholarly papers, which later resolved without intervention, hinting at potential "live fine-tuning" causing transient issues.
-
Insight Into Custom vs. Default GPT-4 Models: One member ponders whether Custom GPTs and the default ChatGPT4 differ fundamentally and whether this necessitates a distinct prompting style or refinement technique for optimal interaction with Custom GPTs.
-
Meta-prompting Template Offers Alternative Workflow: A user recommends using a meta-prompting template when creating Custom GPT models, providing a potentially advantageous method compared to the configure pane.
-
Call for Prompt Hacking Teammates: An announcement calls for participants to form a team for an unspecified prompt hacking competition, creating an opportunity for collaboration within the community.
OpenAI ▷ #api-discussions (11 messages🔥):
- Confusion Over Model Copyright Responses: A user observed inconsistencies in how different versions of GPT-4 handle copyright with
gpt-4-turbo-2024-04-09providing answers whilegpt-4-0125-previewciting copyright laws, despite both being prompted similarly. - Models' Inconsistency in Accessing Scholarly Papers: An issue was reported where models inconsistently claimed copyright on scholarly papers, but this problem appears to have been resolved in recent weeks.
- Custom GPT Prompt Refinement Strategies: One user shares their strategies for improving Custom GPT prompts; refining prompts within the Custom GPT execution or separately in the default ChatGPT session, noting the latter often yields better context processing and reasoning.
- Model Behavior in Meta-Prompting: In response to discussion on prompt refinement, darthgustav. recommends using a meta-prompting template in the creator pane for building GPTs, suggesting it offers a better workflow for that process.
- Invitation to Join Prompt Hacking Competition: wisewander expressed interest in forming a team to participate in a prompt hacking competition and is seeking teammates.
Latent Space ▷ #ai-general-chat (228 messages🔥🔥):
-
Scarlet AI Intensifies Collaboration: Scarlet offers collaborative AI agents for complex task management, featuring real-time collaboration, automated context from data, and agent/tool orchestration. A participant shared the link to Scarlet's website, and mentioned a work-in-progress demo and an upcoming integration with Zapier NLA.
-
Perplexity's Mysterious Disappearance from LMSYS: One member raised concerns about Perplexity "online" models being removed from LMSYS Arena, provoking discussions on Perplexity's effectiveness, with another member expressing hopes to integrate them into their tools.
-
Harnessing YouTube Content for AI: A conversation was held about the best ways to transcribe and summarize YouTube content, exploring tools like Descript, youtube-dl, and Whisper with diarization, for AI model applications.
-
Limitless Aims to Redefine Wearables with Advance AI: Rewind is rebranding to Limitless, promising personalized AI capabilities through a wearable pendant, apps, and a "confidential cloud." Concerns about local processing and end-to-end encryption were discussed in relation to this new offering.
-
Exploring Search Potential Within Generative AI: Discussions emerged on generative AI's impact on search tools, with members mentioning Kagi, Phind, Perplexity, and new ingresses into the field like Cohere's Compass for data search, and tips on how to manage vectorstores for consistent and cost-effective embedding.
Links mentioned:
Latent Space ▷ #ai-in-action-club (143 messages🔥🔥):
-
Semantic Search and Memory Usage: Members discussed the tradeoffs between vector size in semantic search models, particularly focusing on memory usage. Concerns were raised about why memory use can't be reduced significantly despite a smaller dimension size, with the nonlinear relationship between speed and memory being termed "weirdly nonlinear."
-
Re-ranking and Retrieval Performance: The discussion touched upon re-ranking strategies in retrieval models and the need for an additional measure of retrieval performance. A link to a short discussion about the re-ranking pass was shared, questioning the balance between memory savings and speed against the actual performance in retrieval tasks.
-
Quantization and Model Size: There was an in-depth conversation regarding the impact of quantization on embedding models, the benefits of reducing vector dimensionality, and the potential for improved latency. A blog post about PostgreSQL with pgvector and its tradeoffs was noted, adding to the technical depth of the discussion.
-
Potential of Multi-Modal Embeddings: The conversation brought up the concept of multi-modal embeddings and their quirks, as well as whether optimizations applied to text embeddings could be analogously applied to other types such as image embeddings.
-
Hackathon Planning and Collaborative Projects: Participants organized a hackathon event focused on embeddings and prompted the community for collaborative involvement. Plans and suggestions for running the hackathon, including timing and structure, were actively brainstormed.
Links mentioned:
Modular (Mojo 🔥) ▷ #general (26 messages🔥):
-
Route to the Mojician Role Revealed: To gain the coveted
Mojicianrole, one must build a cool open source project with Mojo, or contribute good PRs tomodularml/mojo. Jack notes that those with merged PRs should DM him for the role as GitHub usernames are hard to match with Discord identities. -
Coding Discussions Belong Elsewhere: When members dive into technical discussions such as the ease of learning programming languages, they're reminded to take the chat to dedicated channels, specifically <#1104620458168553563>.
-
MacOS Intel User Seeks to Avoid VMs: A member shares their preference for running projects natively on MacOS Intel hardware to avoid using VMs, highlighting the importance of cross-platform compatibility in development tools.
-
Anonymity Hesitation in Open Source: Despite being ready to make multiple PRs, a member expresses hesitation about contributing to
modularml/mojodue to the requirement of revealing their real name, highlighting a concern for personal anonymity in public contributions. -
Kapa AI Integration Assistance: In a bid to enhance their private server, a member seeks help adding the kapa.ai bot, with others providing guidance and linking to relevant resources such as Kapa AI's official website and their installation guide.
Links mentioned:
Modular (Mojo 🔥) ▷ #💬︱twitter (6 messages):
- Fresh Updates from Modular: Modular shared tweets regarding recent developments and announcements. Here are the links to their latest tweets: Tweet 1, Tweet 2, Tweet 3, Tweet 4, Tweet 5, Tweet 6.
Modular (Mojo 🔥) ▷ #ai (1 messages):
docphaedrus: https://www.youtube.com/watch?v=1cQbu2zXTKk
Podman Pull- On basic terminal commands
Modular (Mojo 🔥) ▷ #🔥mojo (218 messages🔥🔥):
- Exploring Advanced Language Features: Members discussed the potential addition of conditional trait conformance in Mojo and compared potential implementations to features in Rust and Swift. There was a difference of opinion on whether to use if blocks and how the syntax should handle conditional function declarations within structs.
- Awaiting Mojo Standard Library Expansion: Conversations indicated that some foundational modules like threading, async I/O, and crypto are not yet available in Mojo. They exchanged ideas about workarounds and looking forward to more of the stdlib becoming open-sourced.
- Improving Mojo Reference Syntax: Chris Lattner mentioned ongoing work to make Mojo's
Referenceeasier to use, hinting at a future proposal that may simplify mutability handling. - A Gentle Push towards Python Compatibility: Discussions revealed a vision where Mojo will evolve to fully support Python libraries, with Python packages with C extensions included in the long-term goals.
- MLIR and Future Extensions in Discussion: Users inquired about Mojo's approach to GPU code generation and whether an "extensions" feature like in Swift would be implemented to manage polymorphic error handling and static analysis.
Links mentioned:
Modular (Mojo 🔥) ▷ #community-projects (23 messages🔥):
- Pythonic Inspiration for Terminal UIs: Members looking for TUI library inspiration mentioned checking out Textualize, known for creating Rich and Textual, though some find the code flow challenging to parse.
- Launch of llm.mojo Sparks Community Excitement: The release of llm.mojo, a port of Andrej Karpathy's llm.c to Mojo, was announced. It boasts performance improvements through vectorization and parallelization tweaks and is welcoming community feedback.
- Collaborative Contributions to llm.mojo Suggested: Community members suggest improving
llm.mojoby keeping C implementations in sync with upstream, which would allow simultaneous availability of the C version and the Mojo port in one repository. - Newcomer Seeking Help with Llama Implementations Benchmarking Framework: A newcomer requested assistance with setting up the lamatune framework in their codespace, and was encouraged to open an issue on the repository for support.
- Exploring gRPC Support for Mojo Code: A community member mentioned they are obtaining promising results from functional Mojo code and inquired if anyone is working on gRPC support to connect it with existing C++ code for product enhancements.
Links mentioned:
Modular (Mojo 🔥) ▷ #community-blogs-vids (4 messages):
-
Row vs. Column Major Performance Analysis with Mojo: A discussion initiated based on a Modular blog post explored the difference between row-major and column-major ordering of matrices in computer memory. An associated Jupyter notebook on GitHub was provided for practical exploration.
-
Mojo Matrix Error Workaround: After encountering an error while running code from the blog post's notebook, a suggestion was made to restart the Jupyter kernel after executing each cell due to a bug, which proved to be an effective solution.
-
Appreciation for Blog Insights: A member expressed their admiration for the detailed analysis presented in the blog post, praising the contribution as excellent work.
Links mentioned:
Modular (Mojo 🔥) ▷ #🏎engine (3 messages):
-
MojoAPI's Compatibility with CPython: A new member asked if MojoAPI can be used with regular CPython to improve inference times. Another user responded that
Python.module_importcan be used within Mojo to import available Python libraries, and Mojo can be leveraged to rewrite slow parts of Python code. -
Efficient Inference with MAX Benchmarking: A member inquired about reducing model inference time besides using the provided bench-marking options like
--mlperf-scenarioand--num-threads. No response or additional suggestions were provided in the messages.
Modular (Mojo 🔥) ▷ #nightly (55 messages🔥🔥):
-
Mojo Nightly on Standard Library Directory Structure: The Mojo team opened a PR to address an issue where the tools didn't understand the package name due to a discrepancy between the directory structure and package naming in the newly open-sourced standard library. The fix is set to be available in the next
nightly/mojorelease. -
Proposed
StaticTupleEnhancements for Modular ML: There is ongoing discussion around updatingStaticTupleto acceptAnyTypeinstead ofAnyRegType, which would be a substantial advancement. A member has shown interest in working on this, and the idea of renamingStaticTupletoArraywas floated, with emphasis on separating renaming from functionality rework in pull requests. -
Ongoing Unicode Support for Mojo Strings: A member is contributing Unicode support to the Mojo standard library with a focus on minimizing memory footprint and has requested feedback on whether to proceed through a PR or a formal proposal. Standard library methods written for vectorization are mentioned as part of the further discussion.
-
Clarifications on MLIR and Mojo Dialects: Internal discussions clarified that
popis an internal MLIR dialect standing for "parametric operators" and is related to the Mojo parameter system. 'pop.array' underpinsStaticTuple, and there's a plan for a rewritten tuple in the next nightly that will supportAnyType. -
Correcting Item Assignment in Mojo: A member pointed out and verified an issue where item assignment such as
a[i] = valuedesugars incorrectly when__getitem__returns aReference. It should instead utilize__setitem__or__refitem__, which when defined correctly, avoids the need for the other two methods.
Links mentioned:
CUDA MODE ▷ #general (29 messages🔥):
- P2P Support Added to 4090: A new update to tinygrad makes it possible to use P2P support on NVIDIA 4090 GPUs, achieving an impressive 14.7 GB/s AllReduce performance on tinybox green by modifying NVIDIA's driver. The technical details are discussed in a post available here.
- CUDA Takes On One Billion Row Challenge: tspeterkim_89106 shared a blog post about their implementation of the One Billion Row Challenge in CUDA, which ran in 16.8 seconds on a V100, and openly invited the CUDA community to improve upon the solution. Community feedback suggests possible improvements and a faster run at 6 seconds on a 4090 GPU.
- Council for Cool Materials: A member suggested creating a dedicated channel for sharing valuable materials, and in response, #suggestions was repurposed to facilitate this exchange.
- Exploring Parallels in CUDA: In a technical exchange, zippika shared insights on optimizing CUDA performance, discussing potential use of warp level primitives, the effect of CPU speed on kernel execution, and strategies like preallocating buffers and utilizing
cudaMemcpyAsyncfor efficiency. The possibility of hiding part splitting time by using asynchronous operations with CUDA kernels was highlighted as a potential optimization technique. - Handling the Spambot Siege: A member reported an influx of spambots in the channel, alerting admins to the issue by tagging the moderator role.
Links mentioned:
CUDA MODE ▷ #cuda (77 messages🔥🔥):
-
PyTorch Version Compatibility and Performance Concerns: Users discussed issues with building a specific kernel due to
error: namespace "at::cuda" has no member, which was resolved using the torch-nightly build as opposed to PyTorch 2.2. Benchmarks showed that on the 4090, the custom kernel is 1.20x slower than torch.matmul. Benchmark code and results were provided. -
Potential Optimization Routes Explored: There was a suggestion of running independent QKV matmuls in separate CUDA streams, and the consideration that PyTorch's
torch.compilemight be optimizing performance behind the scenes, impacting comparative benchmarks. -
Exploration of Fused Operation Kernels: Interest was shown in adding more fused operation kernels, like those using lower bit-widths, referencing the
cutlass int4xint4kernel and the suggestion to address complexities in the matmul implementation. -
Stable Fast and Full-Graph Compilation Discourse: Users discussed the utility of leveraging
stable_fastfor compilation which appears faster thantorch.compilewithfullgraph=Truein some cases, but might break whenfullgraph=Trueis used for token-by-token decoding. Concerns were raised about compilation issues of models and howenable_cuda_graph=Falsemight be beneficial. -
Promising Results in Low-Precision Computations: It was reported that using
stable_fastand other optimizations, performance approaches are within the range of int8 quant tensorrt optimization speeds, demonstrating potential for high-efficiency low-precision computations in models like stable diffusion.
Links mentioned:
CUDA MODE ▷ #torch (15 messages🔥):
-
P2P Enabled on NVIDIA GPUs: Tinygrad successfully enabled P2P support on NVIDIA 4090 and 4070 TI Super GPUs by hacking open GPU kernel modules. The modifications resulted in a 58% speedup for all reduce operations as shared on Twitter and code available on GitHub.
-
Peer-To-Peer Performance Gathered: Users are consolidating P2P performance data and discussing potential issues with known anti-features. Contributions to the repository including benchmarks can be made here.
-
Results Shared for P2P Performance: A user submitted their RTX 4070 TI Super dual build benchmarks to the p2p-perf repository for peer-to-peer performance measurement.
-
Efficient Ternary Weight Representation: Current BitNet implementations using fp16 for ternary weights are deemed inefficient, and alternatives like custom 2-bit tensors or packing using int8 are being considered. A solution for bit-packing is provided with a reference to this code.
-
Distributed CI in PyTorch Examples: PyTorch/examples repository now includes distributed CI, making it easier for contributors to test their code. For those interested in contributing to the distributed examples, the relevant pull request and the directory for contributions can be found here and here.
Links mentioned:
CUDA MODE ▷ #cool-links (1 messages):
- CUDA Made Easy: A member highlighted PyTorch Dev podcast episode as a good starting point for those looking to learn about CUDA concepts. It covers the basics of GPUs, the CUDA programming model, asynchronous execution challenges, and CUDA kernel design principles with PyTorch.
- CUDA Learning Resources and Tools: For anyone interested in diving deeper into CUDA, the podcast episode recommends the PyTorch documentation on CUDA semantics (https://pytorch.org/docs/stable/notes/cuda.html) and the book "Programming Massively Parallel Processors." Debugging tools mentioned include setting the environment variable
CUDA_LAUNCH_BLOCKING=1and usingcuda-memcheck(https://docs.nvidia.com/cuda/cuda-memcheck/index.html).
Link mentioned: Just enough CUDA to be dangerous: Listen to this episode from PyTorch Developer Podcast on Spotify. Ever wanted to learn about CUDA but not sure where to start? In this sixteen minute episode I try to jam in as much CUDA knowledge as ...
CUDA MODE ▷ #beginner (5 messages):
-
Free Online Course on Parallel Computing: An open version of "Programming Parallel Computers" course is available at Aalto University, providing material on OpenMP, vectorization, and GPU programming. The courses are self-paced with automated code testing and benchmarking, but do not offer study credits or human grading.
-
Leveraging NVIDIA GPU for Parallel Math Operations: CUDA C/C++ functions can be utilized by torch/TensorFlow to compile machine code for NVIDIA GPUs, capitalizing on the GPUs' multiple cores for parallel processing, offering a distinct advantage over sequential CPU processing in Python.
-
PMPP Lectures Begin with Weed-Out of Initial Logistical Information: The first session of PMPP lectures started at minute 31 to bypass introductory logistics, with a suggestion to review those details individually later.
-
Poll for Adjusting Session Timings: Participants of the first PMPP session were reminded to vote in a poll, found in the invite channel, to help find better timing slots for future sessions.
-
Request for CPU vs GPU Architecture Video: A member asked another for the link to a video that explains the differences between CPU and GPU architectures; however, the link has not been provided within the provided message history.
Link mentioned: Courses: no description found
CUDA MODE ▷ #pmpp-book (9 messages🔥):
-
3D Threads Configuration Curiosity: A member pondered the necessity of arranging threads in 3D within CUDA, only to flatten them later on. The suggestion from the chat was to review section 3.2 for a better understanding, implying that further chapters would shed more light on this subject.
-
Comparison of CUDA Block Dimensions: A discussion was sparked regarding the optimal choice between two different sets of configuration parameters for processing a vector with CUDA. A member advised that both configurations can be fine, and mentioned thread coarsening as an alternative approach by using a forloop inside a warp.
CUDA MODE ▷ #youtube-recordings (6 messages):
- Volunteers Wanted for YouTube Recordings: A call for volunteers has been made to assist with weekly recording tasks for the CUDA MODE Discord channel. Volunteers are to record, trim, and upload content to YouTube, and will receive a special role and direct credit, along with gratitude from the community.
- Assistance Offered for Recording Task: A member swiftly responded to volunteer for the weekly recording efforts, indicating the task was manageable.
- Inquiry About Recent Talk Recording: A member inquired if a particular weekend's talk had been recorded.
- Confirmation of Talk Recording: It was confirmed that indeed the weekend talk was recorded and is available.
- Efforts to Enhance Talk Recording Quality: Another member indicated that they are re-recording to improve the quality of the material and plan to have it uploaded by the following day.
CUDA MODE ▷ #torchao (2 messages):
- Optimizing Tensor Layout in torchao: A member raised the possibility of torchao optimizing tensor layout by storing weights in a way that's already aligned for swizzles in matrix multiplications. They mentioned that while element-wise operations are indifferent to data layout, optimizations for matrix multiplication could involve swizzling and padding to benefit from fast matrix multiplication libraries like cublas.
- torch.compile Already Handling Some Optimizations: In response to the tensor layout optimization suggestion, another member indicated that padding and layout optimization may already be addressed by torch.compile, providing links to the relevant sections in the PyTorch repository. Padding optimization and layout optimization are mentioned in the configuration files.
Links mentioned:
CUDA MODE ▷ #ring-attention (3 messages):
- Google Steps into RNN and Transformers: A member referenced Google's work on integrating RNN with transformers, implying a development in the machine learning space.
- In-Depth Ring Attention Explainer Published: An explainer post on Ring Attention, detailing its evolution from naive attention to block-wise parallel attention, has been published by Kilian Haefeli, Simon Zirui Guo, and Bonnie Li. This approach could potentially enable models to scale to a nearly infinite context window by employing multiple devices.
- Raising the Bar on Context Lengths: Large Language Models' context lengths have skyrocketed, from GPT 3.5's 16k tokens to Gemini 1.5 Pro's 1 million tokens, opening up new exciting use cases due to the ability to harness more information.
- Appreciation for Clear Visualization: A member praised the animations within the Ring Attention explainer, highlighting the value of good visual aids in understanding complex concepts.
Link mentioned: Ring Attention Explained | Coconut Mode: Near infinite context window for language models.
CUDA MODE ▷ #off-topic (2 messages):
-
Gratitude Expressed: A member expressed appreciation for KJ's contributions to the community, acknowledging their positive impact on everyone involved.
-
The Game-Changer: A member shared a link to a tweet by @yacineMTB, emphatically stating that "IT CHANGES EVERYTHING!!!!!!" without further detail on the content or context.
Link mentioned: Tweet from kache (dingboard.com) (@yacineMTB): IT CHANGES EVERYTHING!!!!!!
CUDA MODE ▷ #hqq (12 messages🔥):
-
CUDA MODE: HQQ Implementation Update: A contributor updated their branch on GitHub to convert HQQ W_q weights to gpt-fast weights. This update allows them to achieve a perplexity (ppl) of 5.375 and a token generation speed of 200 tokens/s with the
--compileoption enabled. -
HQQ Optimization Clarification: When testing out HQQ, it is confirmed that one should always turn on
meta['optimize']in the quant_config as it leads to performance improvements. -
HQQ vs. HQQ+: HQQ is a no-calibration, post-training quantization technique, while HQQ+ includes HQQ with trainable low-rank adapters and scale/zero parameters. HQQ+ can be used for bitwidths as low as 1 bit and has the potential to match or outperform full-precision models.
-
Challenges in Low-Bit Inference: While promising, low-bit inference faces challenges such as finding efficient matmul kernels for low-bit operations and working around VRAM constraints imposed by low group-sizes needed for bits like 1 or 2.
-
Performance Leap with Torchao Int4 Kernel: A complete rewrite of the generation pipeline for transformers models, which now supports the torchao int4 kernel, has significantly improved performance, achieving up to 152 tokens/sec compared to 59 tokens/sec with FP16.
Link mentioned: HQQ 4 bit llama 2 7b · pytorch-labs/gpt-fast@551af74: export MODEL_REPO=meta-llama/Llama-2-7b-hf scripts/prepare.sh $MODEL_REPO python quantize.py --checkpoint_path checkpoints/$MODEL_REPO/model.pth --mode int4-hqq --groupsize 64 python generate.py --...
CUDA MODE ▷ #triton-viz (3 messages):
- Confusion with Visualization Process: A member expressed that the final step depicted in a GIF was confusing, indicating a possible need for clarification or additional guidance.
- SVGs as a Medium for Code Representation: The same member is currently in the process of writing outputs to SVGs for visualization purposes, showcasing a hands-on approach to their project.
- Seeking Methods for Visualizing Control Structures: There's an active effort to devise a method to effectively visualize programming constructs like if statements and for loops, suggesting a focus on enhancing code comprehensibility through visual aids.
CUDA MODE ▷ #llmdotc (135 messages🔥🔥):
-
CUDA Softmax Integration Challenges: The softmax implementation faced NaN issues due to a causal mask causing exp(INF-INF); switching from -INF to -FLT_MAX solved the problem. Discussion also revolved around the readability and complexity of integrating arbitrary functions within reduce calls, leading to a preference for separate reductions for clarity.
-
Cooperative Groups Come with a Compiler Cost: Members noted the inefficiency of using cooperative groups with more than 32 threads due to the compiler's lack of awareness about the exact threadblock size. This often results in suboptimal performance and unpredictable behaviors that can be difficult to mitigate even with detailed tooling like godbolt.
-
Online Softmax Discussed for Optimizing Performance: The online softmax algorithm was dissected, with focus on the trade-off between sequential and parallel reduction approaches. Suggestions included the need for more comprehensive benchmarking with various "C" values to test performance improvements.
-
Investigating cuBLAS and CUTLASS for Optimal Kernel Use: Conversations explored the use of cuBLAS, cuBLASLt, and CUTLASS for optimizing kernel operations. While cuBLAS’s simple integration boosted performance without adding complexity, CUTLASS would involve integrating large headers and substantial compile-time work, potentially complicating the codebase.
-
Stride to Achieve Peak Performance and Educational Value: Members expressed the desire to have LLM.c be both highly efficient by using tools like CUTLASS and cuDNN, and educational with hand-written kernels ranging from naive to complex. The ultimate goal is to challenge PyTorch's performance using understandable and maintainable code, even potentially rewriting to ensure matrices have performance-friendly shapes.
Links mentioned:
CUDA MODE ▷ #recording-crew (12 messages🔥):
- Scaling up CUDA MODE Administration: The channel is seeking more admins as current ones are overwhelmed with managing new developments in working groups.
- Lecture Recording Process Shared: A detailed 7-step lecture recording process for CUDA MODE was laid out, involving tools like OBS streamlabs and Da Vinci resolve, and coordination for event cover photos and session soundchecks. The final videos are uploaded to CUDA MODE's YouTube channel and the material is also updated in their GitHub lectures repository.
- Open Call for Process Improvement: There is an open invitation for others to propose new methodologies or take ownership of parts of the recording process to facilitate smooth community growth.
- Potential Shift to Live Streaming: A suggestion was made to live stream lectures directly to YouTube to handle increased member scales and use YouTube's editor for clipping, with cautionary advice against using AirPods to prevent recording mishaps.
- Collaborative Effort for Upcoming Recordings: Two members are coordinating to handle upcoming ADA-CUDA lecture recordings, with an initial trial scheduled for a talk in the same week.
Links mentioned:
Cohere ▷ #general (308 messages🔥🔥):
- Connector API Misconception Resolved: A member had trouble with Cohere's connector API; they received an error because the connector URL was incorrectly formatted. The group discussed that a valid connector URL must end in
/searchto function properly. - Clarifications on Cohere's Fine-Tuning Availability: Another member sought clarification on Cohere's base model availability for fine-tuning, which led to a discussion indicating it could be accessed through Cohere's dashboard. Sandra confirmed that fine-tuning on Amazon Bedrock is possible, and the command-r model is also available on AWS.
- Chatbot Interfaces and Grounded AI Advancements: Sandra shared updates concerning Cohere's capabilities like Coral, a demo environment for chatbot interfaces, and hinted at upcoming releases for toolkits enabling connectors on AWS and private setups.
- Cohere Models and Possible Hardware Limitations Explored: There was an exchange regarding performance capabilities of AI models, specifically discussing command-r-plus model runtimes on various hardware included Nvidia's 4090 and TPU availability and performance.
- Learning Resources and Supports for Newcomers: Enquiries by new community members regarding learning materials were addressed with mentions of free courses like LLM University and redirection towards Cohere's documentation for further learning.
Links mentioned:
Cohere ▷ #project-sharing (2 messages):
- Command-R Core Module Celebrated: A member celebrated the introduction of Command-R as one of the core modules, praising Cohere's efforts.
- Join the Realm of Quant Finance: A promotion for Quant Based Finance with an invitation link for beta testing was shared. Interested parties are directed to Quant Based Finance.
- Rubiks.AI Seeks Beta Testers: The announcement of a newly launched advanced research assistant and search engine. Beta testers will receive 2 months free premium access to a suite of models including Claude 3 Opus, GPT-4 Turbo, Mistral Large, and others, accessible via Rubiks.AI.
Links mentioned:
HuggingFace ▷ #general (172 messages🔥🔥):
-
Running Multiple Models Locally: A user asked about running multiple models simultaneously on a single machine, which was confirmed as possible by another member as long as there are sufficient resources. They mentioned successfully running 6 instances of A1111 models on one GPU.
-
Discussion on Model Optimization: Conversation about LLM.c optimization, with members discussing its design not being inherently fast. A community member notably explained that the point was to showcase GPT-2 could be implemented in C without dependencies, rather than for speed.
-
Hugging Face Spaces Connectivity Issues: Several users reported issues accessing Hugging Face Spaces, with the pages loading as blank or giving an invalid response error. Members suggested checking router and Wi-Fi settings, with some finding success by disabling security shields that were blocking the sites.
-
Chatbot Modeling Questions: Users inquired about various aspects of creating and running chat-based models, including dataset formatting and optimization suggestions. One user detailed their desire to use langchain and neuralhermes-2-pro in their chatbot to maintain a conversation memory.
-
Job and Project Inquiries: Discussions included a user seeking advice on hiring for a job involving model implementation and training, while another shared news of their growing freelance workload and their search for team members to handle increasing projects.
Links mentioned:
HuggingFace ▷ #today-im-learning (6 messages):
<ul>
<li><strong>Decoding CLIP's Concept:</strong> A blog by <a href="https://www.linkedin.com/in/matthewbrems/">Matthew Brems</a> aims to simplify the understanding of <strong>OpenAI's CLIP model</strong>, covering what it is, its workings, and its significance. This multimodal model from OpenAI offers a novel approach to computer vision by training on both images and text. <a href="https://www.kdnuggets.com/2021/03/beginners-guide-clip-model.html">Beginner's Guide to CLIP Model</a>.</li>
<li><strong>Applying Zero-Shot Classification:</strong> After learning about Zero-Shot Classification with the <strong>bart-large-mnli model</strong>, a demo was created showcasing its application to classify 3D assets from <a href="https://thebasemesh.com/">thebasemesh.com</a>, a free resource of base meshes for creative projects. Watch the exploration on <a href="https://www.youtube.com/watch?v=jJFvOPyEzTY">YouTube</a>.</li>
<li><strong>Cost-Effective AI with Podman:</strong> A demonstration video was shared showing how <strong>Podman</strong> is used to build containerized generative AI applications, which offers a cost-efficient alternative for local and cloud deployment. The technology promises control and choice regarding deployment options. Tutorial on <a href="https://youtu.be/3iEhFKIDXp0?si=nQJt-PBJUB960gpU">YouTube</a>.</li>
</ul>
Links mentioned:
HuggingFace ▷ #cool-finds (10 messages🔥):
-
Blending AI with Document Retrieval: An article on Medium introduces LlamaIndex integrated with a Colbert-based agent to enhance document retrieval with memory. The tutorial can be found here.
-
PyTorch meets Blender: GitHub repositories were shared for integrating PyTorch with Blender: btorch contains PyTorch utilities for Blender, and pytorch-blender offers seamless, real-time Blender integration into PyTorch data pipelines.
-
Boosting CNNs with Group Equivariance: The e2cnn library on GitHub enhances Convolutional Neural Networks by providing a PyTorch implementation of E(2)-Equivariant CNNs, which can be beneficial for tasks requiring rotational invariance.
-
A Dataset for Text-to-Music AI Innovators: The MagnaTagATune dataset, available on Papers with Code, provides a comprehensive set of music clips accompanied by a wealth of human-generated tags, offering a potential starting point for anyone interested in creating an open-source text-to-music service.
-
Highlighting AI's Capability to Understand Videos: A YouTube video called "Large Language Models Are Zero Shot Reasoners" demonstrated an Edge browser feature for generating video highlights; a user's impression was shared showcasing the feature's effectiveness.
Links mentioned:
HuggingFace ▷ #i-made-this (17 messages🔥):
- Tips for Realistic AI-Generated Skin: A member shared a tip for generating more realistic skin textures in AI work, suggesting to use "perfect skin" in the negative prompt and adding specific features like "(moles:0.8)" in the positive prompt to achieve a natural look with moles.
- Enterprise AI Hub via Hugging Face: A user announced their development of an Enterprise AI Hub that integrates various enterprise applications and is capable of intelligent prompt-based interactions, demonstrating the versatility of Hugging Face and OpenAI for enterprise solutions. The hub is built using Java, Spring Boot, and connected systems like pet stores, bookstores, and bug tracking systems. EnterpriseAIHub on Spaces
- Counterfactual Inception to Mitigate Hallucination: A member introduced a paper called "What if...?: Counterfactual Inception to Mitigate Hallucination Effects in Large Multimodal Models," outlining a novel method to reduce hallucinations in AI response accuracy without additional instruction tuning. The project code is available on GitHub. Paper | GitHub Repository
- RicercaMente: Mapping Data Science Evolution: A project called RicercaMente, aimed at tracing the history of data science through significant scientific papers, was shared, inviting others to contribute or give support on GitHub. Participation purportedly requires no coding and only about 10 minutes of time. GitHub Repository
- Robotic Soccer Victories and Temperature Gap Fills: A member discussed their involvement in two projects: one which contributed to winning the humanoid robot soccer world cup, RoboCup, with published advancements and source code, and another aimed at using partial convolutions to fill in missing temperature data in earth monitoring. RoboCup Paper | Temperature Gap-Fill Study
Links mentioned:
HuggingFace ▷ #reading-group (7 messages):
-
Cohere's Commendable Open-Source Contribution: Cohere For AI distinguishes itself with its dedication to open-source AI and open science, as highlighted in the upcoming LLM Reading Group session. This session will delve into Aya Dataset: An Open-Access Collection for Multilingual Instruction Tuning, scheduled for April 16, and interested individuals can RSVP at this Eventbrite link.
-
Calendar Convenience Concerns: Multiple participants have requested a Google Calendar link for the LLM Reading Group sessions, to which they were directed to find a calendar subscription option on Eventbrite after RSVPing.
-
Navigating CUDA Compatibility: A member sought guidance on which installation to use for CUDA version 11.8, with the advice given to opt for the version labeled for 11.x, indicating compatibility with all CUDA 11 versions including 11.7, 11.8, and 11.9.
-
Human Feedback Foundation's Pivotal Role: The Human Feedback Foundation aims to integrate public input into AI models, emerging as a necessary component in key sectors such as healthcare and governance. They strive to be a neutral party in establishing a comprehensive database of human feedback for AI developers.
-
LLM Reading Group Spring Sessions in Full Swing: The reminder for the LLM Reading Group highlights future sessions on various topics including LLMs in negotiation, LLM-generated text detection, and reinforcement learning from human feedback. The full list of sessions and papers for the spring can be found in the Season's Schedule, with the series running every two weeks till the end of May.
Link mentioned: LLM Reading Group (March 5, 19; April 2, 16, 30; May 14; 28): Come and meet some of the authors of some seminal papers in LLM/NLP research and hear them them talk about their work
HuggingFace ▷ #computer-vision (7 messages):
-
U-Net Model Plateaus during Training: A member working on a U-Net model for cleaning scanned images with bleed-through effects struggles with the model ceasing to learn after 11 epochs. The individual plans to explore Deep Image Prior as an alternative, hoping for better results.
-
Grounding DINO Joins Transformers Library: The new Grounding DINO model for zero-shot object detection is now included in the Transformers library. The official documentation and a demo notebook can be found at Transformers Documentation and Inference with Grounding DINO Notebook, respectively.
-
Invitation to Join the RicercaMente Project: A member announces RicercaMente, a project that aims to chart the evolution of data science through important research papers. They encourage involvement and provide the GitHub link: RicercaMente GitHub.
-
Stable Diffusion Gradio Chatbot Released: Sharing a new stable-diffusion Gradio chatbot for image generation, a member invites others to try the tool and support it with a star on the GitHub repository available at Awesome Tiny SD GitHub and the live instance on Hugging Face Spaces.
-
Inquire about Fine-tuning Vision Models for Specific Tasks: A member seeks advice on fine-tuning a vision model for captioning images and identifying entities in low-resolution images, emphasizing the need for optimization for smaller image sizes.
Links mentioned:
HuggingFace ▷ #NLP (14 messages🔥):
-
Exploring Lightweight Embedding Models: Members discussed suitable embedding models for projects, with suggestions including using the all-MiniLM-L6-v2 for its balance between semantic performance and lightweight architecture. For multilingual requirements, paraphrase-multilingual-MiniLM-L12-v2 was recommended, especially in academic settings such as dissertation work.
-
Assembling the Pieces of Gargantuan Models: A question was raised about how to handle large models like mixtral-8x22B split into multiple GGUF files. There was no direct answer provided in the thread regarding the mechanics of loading or merging these files.
-
Project RicercaMente Hits the Stage: The community was invited to contribute to RicercaMente, a GitHub project that chronicles the history of data science through significant scientific papers. The call included a request for stars, contributions, and social sharing. Check out the project on GitHub.
-
Quest for a Custom RAG LLM Tutorial: A member sought advice on finding a tutorial or YouTube video to create and fine-tune a RAG LLM for question answering, emphasizing tailoring to specific use cases, but no specific resources were provided.
-
Guidance Requested on Beginning with NLP: Newcomers to NLP asked for roadmaps and learning resources, receiving suggestions ranging from Jurafsky's book, "Speech and Language Processing", to introductory materials such as HuggingFace's learning resources and SpaCy tutorials. A recent video on transformers by 3blue1brown was also mentioned as a helpful resource for beginners.
Link mentioned: GitHub - EdoPedrocchi/RicercaMente: Open source project that aims to trace the history of data science through scientific research published over the years: Open source project that aims to trace the history of data science through scientific research published over the years - EdoPedrocchi/RicercaMente
HuggingFace ▷ #diffusion-discussions (6 messages):
-
Deep Dive into Multimodal Search Mechanics: A user inquired about the details of multimodal embeddings in a web app demo, highlighting confusion on how the demo could understand both image and text elements, specifically recognizing a product name with a typo. They referenced a Google demo showcasing multimodal vertex embeddings to better understand the underlying technology.
-
Short Replies Can Still Be Insightful: In response to a query about multimodal embeddings, another user simply replied with "clip retrieval," suggesting a potential mechanism or area to explore for the earlier question about incorporating textual information in image searches.
-
Introducing ControlNet++: A user shared a link to a paper on ControlNet++, an advancement over the previous ControlNet for text-to-image diffusion models, which aims for better control through pixel-level cycle consistency. The shared paper on arXiv introduces how it improves alignment with conditional image controls.
-
Clarifying the Landscape of Language Models: A new member expressed confusion about different types of language models, specifically differentiating between LLMs, embedding models, openAIEmbadding, and gpt_3.5_turbo models.
-
Stable Diffusion Cascade Model Query: A user sought assistance with an error when using a long prompt with the stable diffusion cascade model; a response clarified that the message was a warning rather than an error related to token limitations. The issue was discussed further in a GitHub issue.
Links mentioned:
LAION ▷ #general (147 messages🔥🔥):
-
Scam Alert: LAION Not Associated with NFTs or Tokens: Members are warned against a scam where a Twitter account, purportedly representing LAION, promotes NFTs. The Twitter scam has also been discussed with users seeking clarity on the association between LAION and cryptocurrencies, and official statements from LAION members vehemently deny any connection.
-
Technical Discussion on Model Training: There is an in-depth technical discussion on different approaches to training, including loss weights, signal noise, and the ideal number of timesteps. Special focus is given to the min-snr-gamma concept, with key insights shared regarding the implementation in diffusers and its practical implications on model performance.
-
New AI Audio Model Consideration: The conversation turns towards AI models for sound generation, touching on open-sourcing of music AI, and a TTS inference and training library, Parler TTS, developed by Hugging Face.
-
Debate Over the Term 'Ethical Dataset': A philosophical debate surfaces around the term 'ethical datasets', criticizing its use as politicized language and discussing its implications within a Bloomberg article about Adobe's AI training methods.
-
AI Model Output and Diffusion Techniques: Users explore how pixel art diffusion models work, including their resolution capabilities, while others discuss AI model outputs and the ethics of sharing potentially offensive material. There is mention of a successful application of magnitude-preserving learned layers after normalizing inputs.
Links mentioned:
LAION ▷ #announcements (1 messages):
- Beware of Fake Twitter NFT Claims: An announcement clarified that a fake Twitter account falsely claimed Laion is releasing NFTs, emphasizing that Laion does not sell anything. Laion remains a part of the open source community and is committed to providing free AI resources.
LAION ▷ #research (46 messages🔥):
-
Guidance Optimization in Diffusion Models: A new study outlined in an arXiv paper revealed that optimal performance in image-generating diffusion models was achieved by limiting guidance to a specific range of noise levels. It was noted that guidance is harmful in the early stages of the chain, largely unnecessary toward the end, and only beneficial in the middle, leading to significantly improved images when applying the limited guidance interval.
-
Custom Callbacks Unleash Potential in Diffusers: The Hugging Face diffusers library documentation elaborates on the use of
callback_on_step_endfor dynamic adjustments during the denoising loop, like changing prompt embeddings or guidance scale. This feature was highlighted as a useful application for dynamic classifier-free guidance, where CFG is disabled after specific inference steps to enhance performance with minimal computation costs. -
Data Accumulation Prevents Model Collapse: An arXiv paper presented evidence countering the notion of inevitable model collapse when models are trained on synthetically generated outputs, arguing that accumulating data over time, as opposed to replacing it, mitigates the risk of collapse.
-
Stable Diffusion 3 Faces Censoring and Quality Challenges: Users on Reddit discussed the heavy censorship of Stable Diffusion 3 and its potential decline in quality due to strict prompt control, with hopes for substantial fine-tuning to enhance its abilities.
-
Training Strategies for Scaled-Down CLIP Models: A recently released arXiv paper suggested that high-quality data and data augmentation could enable CLIP models to perform comparably well with reduced training datasets, demonstrating the importance of data quality and strategic training over sheer dataset size.
Links mentioned:
LAION ▷ #learning-ml (1 messages):
- Diffusion Model Woes: From Noise to Pitch Black: A member working on a diffusion model encountered an issue where the model, after having training plateau, now produces only noise during inference—initially random noise, later progressing to solid black images. They suggested that the problem might be due to error accumulation or mode collapse, having already attempted regularisation and adjusting the learning rate without success, sharing noise examples and their GitHub repository for the model code.
LangChain AI ▷ #general (142 messages🔥🔥):
- RAG Issues with Legal Contracts: A user is experiencing difficulties with document splitting during Retrieval-Augmented Generation (RAG) operations on legal contracts. Specifically, the content of a section is being incorrectly attached to the previous section, affecting retrieval accuracy.
- Parallel Execution in LangChain: Inquiries were made about running nodes in parallel within LangGraph. It was confirmed that using the
RunnableParallelclass in LangChain allows for the parallel execution of tasks. - Azure OpenAI with LangChain: A new Azure OpenAI user is seeking insights on the advantages of using LangChain with Azure, specifically questioning whether there would be cost benefits and how LangChain might be useful beyond RAG when chatting with personal documents on Azure.
- Recommendation Systems Inquiry: A member is asking for resources to help understand and implement personalized recommendation systems using user behavior data stored in databases.
- Article on LLM Protection: A new article titled "Safeguarding AI: Strategies and Solutions for LLM Protection" has been shared, discussing the security challenges, prompt attacks, solutions, and tools for LLM security.
Links mentioned:
LangChain AI ▷ #langserve (3 messages):
- Inappropriate Content Alert: A message was posted with a suspicious link claiming to offer adult content, utilizing emojis and an @everyone tag; it appears to be spam or phishing. (No direct link inclusion for safety reasons).
- Seeking Guidance on Langfuse Callbacks: A member has inquired about using langfuse callback handler for tracing in langserve with an intent to design an API that logs questions, session ID, user ID, etc. They are requesting any available sources or examples to assist with their implementation.
Link mentioned: Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
LangChain AI ▷ #langchain-templates (4 messages):
-
Spam Alert: It appears a spam message was posted containing a link to an adult content Discord server. The message promises TEEN/ONLYFANS PORN and includes emojis and a Discord invite link.
-
Technical Troubles with Python Langchain: A member encountered a
ModuleNotFoundErrorwhen trying to run a template from the Langchain documentation usinglangchain serve. They suspect thepyproject.tomlfile is not correctly reading the local package, despite checking directory and file settings.
Link mentioned: Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
LangChain AI ▷ #share-your-work (17 messages🔥):
-
AI-powered Streamlit News App: The new app Meeting Reporter combines Streamlit and Langgraph along with multiple agents and humans in the loop to create more dependable news stories. The open-source code is available on GitHub, and a detailed explanation of the project can be found in a blog post.
-
A Guide to Building RAG Locally: A simple tutorial on constructing a local RAG system using LangChain, Ollama, and PostgreSQL has been shared, which may benefit those looking to create this setup. The instructions are detailed in a blog post on Substack.
-
Collection of LLM Projects on GitHub: For those interested in exploring Large Language Models (LLMs), a new GitHub repository LLM-Projects has been shared, containing several projects aimed at learning and experimentation.
-
Perplexica, an Open-source AI Search Engine: Perplexica, a locally run clone of Perplexity AI, has been introduced, offering an alternative AI-powered search engine that can operate with 100% local resources, including the possibility to use Ollama in place of OpenAI. The updated and fixed version is accessible on GitHub.
-
Vertex AI Agent Builder Explored in YouTube Tutorials: A series of YouTube tutorials showcasing the development and implementation of agents using Vertex AI Agent Builder has been shared, with guides on setting up route chains and integrating with platforms like Slack. The videos can be found at these links: Vertex AI Agent Builder Overview, Implementing Router Chain, and Integration with Slack.
Links mentioned:
LangChain AI ▷ #tutorials (5 messages):
- Spam Alert: A spam message promoting adult content with a Discord link was posted in the channel.
- Chunking Know-how: A video link about document chunking using LangChain was shared, which offers insights into creating better RAG applications by properly splitting documents to preserve their content during questioning.
- Prompt Hacking Hackathon Team Formation: An announcement for forming a team was made for the upcoming Blade Hack prompt hacking competition. This event challenges participants to use prompt engineering to manipulate AI models to produce bypassing responses, with a prize of $9000 and swag.
Links mentioned:
OpenAccess AI Collective (axolotl) ▷ #general (64 messages🔥🔥):
- Open GPU Kernel Modules on GitHub: An open-source project for NVIDIA Linux GPU with P2P support has been made available on GitHub, which can be found at tinygrad/open-gpu-kernel-modules.
- New Instruct MoE Model Launched by Fireworks AI: Fireworks Mixtral 8x22b Instruct OH, a finetuned version of the 8x22b MoE model using the OpenHermes dataset, is introduced by Fireworks AI with a preview available at their Playground. A bug with deepspeed zero 3 was mentioned and a solution involving an update from DeepSpeed's main branch was shared.
- Discussion About DeepSpeed's Support for Multi GPU Training: It's noted that deepspeed zero 3 aids in training larger models rather than hastening the training process. A successful workaround for DeepSpeed zero 3 issues when used with MoE models was discussed, involving updates from the official DeepSpeed GitHub repository.
- Link Shared to AI-Generated Music: A member acknowledged the advancements in AI-generated music, sharing a link to a song created using AI at udio.com.
- Techniques and Tools for Training and Tuning Models: Technical conversations regarding model merging, use of tools like LISA and DeepSpeed, and their implications on training and model performance were discussed. A GitHub link for extracting Mixtral model experts, with some hardware requirements, was provided: Mixtral-Model-Expert-Extractor.
Links mentioned:
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (19 messages🔥):
- Exploring Weight Unfreezing During Training: A member pondered dynamic weight unfreezing as a strategy for GPU-limited users, considering unfreezing random subsets of weights at each step to optimize the training process.
- Customizing Unfreezing Functionality: The feasibility of custom implementation was discussed for dynamic weight unfreezing since the current system only supports freezing certain weights from the start.
- Dynamic Compute Allocation Model Shared: An unofficial GitHub implementation related to Mixture-of-Depths, which deals with dynamic allocation of compute in transformers, was shared: Mixture-of-depths on GitHub.
- Peer-to-Peer Memory Access Success on RTX 4090s: A member successfully enabled P2P memory access with tinygrad on RTX 4090 GPUs and sought advice on bypassing Axolotl's P2P disabling check, leading to a discussion on checking the accelerate code.
- RTX 4090s P2P Compatibility and Community Interest: Further clarification stated there's no explicit code that disables P2P, and the community expressed their interest regarding the successful utilization of P2P with the RTX 4090 GPUs.
Link mentioned: GitHub - astramind-ai/Mixture-of-depths: Unofficial implementation for the paper "Mixture-of-Depths: Dynamically allocating compute in transformer-based language models": Unofficial implementation for the paper "Mixture-of-Depths: Dynamically allocating compute in transformer-based language models" - astramind-ai/Mixture-of-depths
OpenAccess AI Collective (axolotl) ▷ #general-help (39 messages🔥):
-
Stuck on Repetition: A member is experiencing issues with a model producing repetitive outputs, comparable to a dataset shared at Izzy's Blog. Despite attempts with varying datasets and finetuning methods, the model outputs are limited to Discord usernames or blank text.
-
Mergekit for Model Surgery: Members discussed using mergekit to drop layers from large language models and shared a configuration example from WestLake-10.7B-v2 on Hugging Face.
-
Troubleshooting Axolotl Finetuning: A user following a Mixtral-8x22 finetuning reported an 'IndexError' during an evaluation step. Others suggested debugging using Axolotl's preprocess command or incrementally adjusting the YAML configuration based on examples from the Axolotl GitHub repository.
-
Prompt Formatting Challenges: There was a discussion about the difficulties in getting Axolotl to use specific prompt formats during finetuning. A user ultimately found success in adapting their configuration, including using the
chat_templatesetting. -
Dataset Mixing and Training Loss Concerns: Members exchanged thoughts on mixing completion and instruction data during training, with one suggesting it might be more efficient to train on them separately. They also discussed appropriate loss numbers for plain completion models and the potential impact of batch sizes.
Links mentioned:
OpenAccess AI Collective (axolotl) ▷ #community-showcase (1 messages):
b.nodnarb: Thanks for the post, <@915779530122207333> !
OpenAccess AI Collective (axolotl) ▷ #docs (9 messages🔥):
- Mistral V2 Instruct Shows Promise: A member reported having good results with Mistral v2 instruct after just one epoch, outperforming other approaches like LorA and Qlora.
- Effective on Diverse Tasks: They highlighted success in training on NER, Classification, and Summarization specifically for metadata extraction tasks.
- Surpasses Prior Methods: The performance was notably better compared to experiments with another model named qwen.
- Automation in Metadata Generation: It was clarified that the large language model (llm) was responsible for generating, not just extracting, metadata from documents.
OpenAccess AI Collective (axolotl) ▷ #axolotl-help-bot (5 messages):
- Docker Meets DeepSpeed for Distributed Training: Multi-node finetuning with DeepSpeed requires a customized Docker image with all dependencies and a detailed
ds_config.jsonfile to configure settings. Steps cover building the Docker image, setting SSH access across nodes, and running containers with appropriate environment variables for multi-node communication. - SSH Keys Unlock Multi-Node Communication: For successful multi-node training, it's essential to configure SSH keys that allow passwordless access between nodes. The DeepSpeed setup relies on seamless node communication through SSH to perform distributed computation effectively.
- Running Training Containers Across Nodes: Users must launch Docker containers on each node with carefully set environment variables that define the master node's address, port, world size, and each node's rank. The correct setup will enable the deployment of the finetuning process across different machines using DeepSpeed within Docker environments.
- Training Initialization with DeepSpeed: The training script should integrate DeepSpeed initialization and accept specific arguments (
--deepspeedandds_config.json) to harness the full potential of distributed training features. Ensuring these parameters are correctly used is crucial for the finetuning operation to function in a multi-node environment.
Link mentioned: OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
OpenAccess AI Collective (axolotl) ▷ #axolotl-phorm-bot (25 messages🔥):
-
Understanding DeepSpeed Scheduler Configuration: It was clarified that when using DeepSpeed with 🤗 Accelerate, your custom learning rate scheduler is retained if you properly prepare it using Accelerate's methods, as DeepSpeed does not forcefully replace it unless otherwise specified in the configuration file.
-
Optimizing Micro-Batch Sizes: A discussion on the ideal ratio of
micro_batch_sizetogradient_accumulation_stepshighlighted the balance required to utilize GPU memory effectively, recommending to maximize themicro_batch_sizeand adjustinggradient_accumulation_stepsaccordingly for the desired effective batch size. -
Multi-Node Training with Axolotl: Configuring for multi-node training in Axolotl involves using a configuration file with specified networking details, such as
main_process_ipandmain_process_port, and the use of theaccelerateCLI to launch training across machines. -
Opening Ports for Distributed Training: To ensure the
main_process_portis open in TCP and reachable by other machines in a distributed training setup, instructions included identifying the main machine, using system commands likeiptablesor Windows Defender Firewall settings to open the port, and verifying network accessibility. -
Ease of Hugging Face Model Hub Repository Creation: The
push_to_hubmethod was explained to automate the creation of a new repository on the Hugging Face Model Hub if the specified model ID does not already correspond to an existing repository, simplifying the process for users.
Links mentioned:
OpenInterpreter ▷ #general (79 messages🔥🔥):
- Malware Warnings and Command Line Confusion: Concern was raised about potential malware warnings from Avast and confusion caused by the command line
ngrok/ngrok/ngrok. Mentioned it might be helpful to clarify this in the documentation to reassure users. - Open Interpreter PR Proposed for Build Error: A new pull request was opened to address a build process error, specifically to bump the version of tiktoken. The link to the pull request is here.
- Using Assistants API for Data Persistence: Discussions around using Assistants API for data persistence in Open Interpreter touched on successfully creating a Python assistant module for improved session management. A request was made for specific advice on implementing this for node operations.
- OS Mode in Open Interpreter on Ubuntu Troubleshooting: Users shared issues and resolutions related to setting up OS Mode for Open Interpreter on Ubuntu. This included suggestions on enabling screen monitoring, accessibility features, and downgrading to Python 3.10 for compatibility.
- Airchat as a Platform for Voice Communication Among OI Users: Several members shared their Airchat handles (e.g.,
mike.bird) and discussed the possibility of acquiring invites to join in live voice conversations.
Links mentioned:
OpenInterpreter ▷ #O1 (72 messages🔥🔥):
- Expect Delays in Startup Shipments: Pre-orders for a new product are underway, but a member cautions patience, pointing out that start-ups often take longer than their initial estimates, especially since the product is still in the pre-production phase, as evidenced by GitHub updates.
- Connecting Issues Over Hotspot: Users experience issues when trying to connect the O1 to a hotspot via an iPhone, with the device sometimes not recognizing the network or crashing during the connection process. The problem persists even when using example codes, prompting speculation about whether specific libraries could be causing the crash.
- Environment Variable Conundrum on Windows: Windows users are struggling to set up the
OPENAI_API_KEYas an environment variable, with suggestions to try different terminals, such as Command Prompt over PowerShell, and ensure a new session is started after setting it. There's a shared link to help test the key, but persistent issues lead to further discussion on alternatives. - Frustrations with WebSocket on Windows: Despite updates meant to resolve the issue, some users continue to have trouble with WebSocket failing to open on Windows, a problem not encountered on Macs. Suggestions advise checking if the port is already in use and sharing screenshots of the error for troubleshooting.
- Developments and DIY Efforts for O1: Community members are modifying and improving their O1 designs, from the addition of a better battery to hand straps for easier use. One member offers free 3D printing services for cases, and there's mention of assistance from a custom GPT trained on Open Interpreter docs available for ChatGPT Plus users.
Link mentioned: GitHub - rbrisita/01 at linux: The open-source language model computer. Contribute to rbrisita/01 development by creating an account on GitHub.
OpenInterpreter ▷ #ai-content (1 messages):
aime_bln: https://api.aime.info
LlamaIndex ▷ #announcements (1 messages):
- LlamaIndex Update Affects PandasQueryEngine: The new release of LlamaIndex, version 0.10.29, will transplant PandasQueryEngine to the
llama-index-experimentalpackage. Users must adjust their imports accordingly and an error message will guide those using the old module.
LlamaIndex ▷ #blog (8 messages🔥):
-
New AI Application Creation Toolkit Launched: The create-tsi toolkit, developed in collaboration with @tsystemscom, @MarcusSchiesser and inspired by the @llama_index create-llama toolkit, allows users to generate a GDPR-compliant AI application via command line interface. The announcement included links to a tweet and associated imagery.
-
Chain of Abstraction Technique Revealed: LLMs like (e.g. @OpenAI, @MistralAI, @AnthropicAI) have been improved with a technique called Chain of Abstraction to assist in multi-step query planning; the full details of this innovation can be found in the provided tweet.
-
Full-Stack RAG with AWS Bedrock Guide: A reference guide is available explaining how to build a full-stack RAG application using AWS Bedrock, @llama_index, and a @streamlit interface; more information is given in their tweet.
-
Data Management Challenges in LLM Apps: Efficient data management for live data in LLM applications is a key feature of both @llama_index open-source and LlamaCloud, as highlighted in their announcement.
-
Knowledge Graphs for Accelerating Biomaterials Discovery: A paper by @ProfBuehlerMIT demonstrates constructing an extensive knowledge graph from over 1000 scientific papers on biological materials to expedite biomaterials discovery; the source can be explored in their tweet.
LlamaIndex ▷ #general (113 messages🔥🔥):
-
Deciphering Vector Database Preferences: Members discussed vector database preferences for strong similarity searches, comparing different options including Qdrant, pg vector, and Cassandra among others. Links to documentation were shared to evaluate feature support such as hybrid search and metadata filtering (LlamaIndex vector stores guide).
-
Hybrid Search Mechanics Explored: The conversation expanded to include debate around the implementation of multimodal embeddings and how to retrieve and rank multimodal data—particularly concerning image and text data. Articles on fusion algorithms were referenced, and tools like Weaviate were mentioned for their hybrid search capabilities.
-
Technical Troubleshooting in LlamaIndex: Users encountered various technical challenges, such as handling
MockLLMerrors within Vectara Managed Index andValidationErrorwhen defining aMarkdownElementNodeParser. Community support provided guidance and suggestions, highlighting the importance of the most recent version updates. -
Navigating Documentation and Contribution: A user identified an error in the documentation regarding the
GithubRepositoryReader, for which community members encouraged making a pull request on GitHub to correct the documentation. The importance of active community contribution to the LlamaIndex project was emphasized. -
Engaging with LlamaIndex's Business Side: A discussion about signing a Business Associate Agreement (BAA) with a user's client led to sharing contact information for LlamaIndex's team and assurance that the request would be passed on for a speedy response. The chatbot emphasized the significance of community support and accessibility of the LlamaIndex team.
Links mentioned:
LlamaIndex ▷ #ai-discussion (5 messages):
-
Enhanced Document Retrieval via LlamaIndex: A new tutorial for enhancing document retrieval has been shared, showcasing how to incorporate memory into Colbert-based agents using LlamaIndex.
-
Boost RAG Systems with Small Knowledge Graphs: A discussion and article were shared on the benefits of using small knowledge graphs to improve the accuracy and explanation capabilities of RAG systems. WhyHow.AI is creating tools to facilitate building these graphs for enhanced retrieval-augmented generation (RAG) performance.
-
Integration of LlamaIndex for Advanced Reasoning: A member highlighted a publication on the integration of LlamaIndex with a chain of abstraction strategy to unlock more efficient reasoning, with a link to the related article.
-
Appreciation for Efficient Reasoning Insights: Feedback was given showing appreciation for the recently shared articles focusing on the advancement of reasoning in AI systems.
tinygrad (George Hotz) ▷ #general (31 messages🔥):
- RTX 4090 Driver Patch Hits Hacker News: One member mentioned that the 4090 driver patch made it to the front page of Hacker News, suggesting its significant impact on the tech community.
- Cost Efficiency of Stacking 4090s: Discussion around stacking RTX 4090s implies a significant cost reduction for running large language models (LLMs), with one member providing a detailed cost comparison to TinyBox, showing a 36.04% price decrease from the Team Red Tinybox and a 61.624% drop from the Team Green Tinybox.
- Tinygrad's quest for better documentation: Queries about improved tinygrad documentation were raised, with members confirming its development. Suggestions were requested on how to handle the
fetch_mnist(tensors=False)instances for convenient and coherent updating in tinygrad examples. - Developer Experience is a Priority for tinygrad: George Hotz highlighted the progress on improving tinygrad's documentation and developer experience, noting the need for better error comprehension in the tool.
- Line Limit Increase and Flaky MNIST Test: There was an agreement to increase the code line limit to accommodate new backends, with George Hotz proposing to bump it up to 7500 lines. Additionally, issues about a flaky mnist test and nondeterminism in the scheduler were brought up, indicating the project's focus on robustness and reliability.
Link mentioned: hotfix: bump line count to 7500 for NV backend · tinygrad/tinygrad@e14a9bc: You like pytorch? You like micrograd? You love tinygrad! ❤️ - hotfix: bump line count to 7500 for NV backend · tinygrad/tinygrad@e14a9bc
tinygrad (George Hotz) ▷ #learn-tinygrad (72 messages🔥🔥):
-
Fusion Process in Kernel Generation: An in-depth discussion took place around the conditions under which a computational graph is split into multiple kernels during the fusion process. It was clarified that each ScheduleItem is a kernel, and reasons for a graph's split, such as broadcasting needs leading to separate kernels, can be found in the
create_schedule_with_varsfunction in the source code. -
Running Models with Tinygrad: There was a clarification regarding Tinygrad's capability to run models like Stable Diffusion and Llama. It was explained that while Tinygrad can execute these models, it's not necessarily used for training them – showcasing Tinygrad's flexibility in interfacing with models trained in different frameworks.
-
Tinygrad Installation and Use Cases on Colab: Members shared experiences and advice on installing and using Tinygrad in Google Colab, including the use of
pip install git+https://github.com/tinygrad/tinygradand troubleshooting import errors. The benefits of using Tinygrad in various environments and with varying methodologies were discussed. -
Tensor Padding and Transformer Errors: A user brought up an issue with tensor padding and transformer models, leading to an exploration of error messages and the potential adjustments to accommodate padding in model architectures within Tinygrad. Through trial and error, it was confirmed that using
Nonefor padding is a viable solution. -
Documentation and Contributions: Links to Tinygrad documentation and personal study notes were shared to assist newcomers with understanding the inner workings of Tinygrad. Questions about contributing to Tinygrad without CUDA support were addressed, emphasizing the value of familiarizing oneself with the documentation and codebase prior to contributing.
Links mentioned:
Interconnects (Nathan Lambert) ▷ #ideas-and-feedback (5 messages):
- Organizing Artifacts: A new blog feature introduces Hugging Face collections to organize all artifacts linked at the bottom of the blog post for "open models and datasets".
- Ease of Access: The collections were created as a way to easily find and re-access the linked artifacts.
- Planning for Team Expansion: The creator envisions establishing an "interconnects" Hugging Face organization when someone is hired to help.
- API for Collections Available: It was mentioned that Hugging Face collections have an API, which could be used now, demonstrated by the Hugging Face documentation.
Links mentioned:
Interconnects (Nathan Lambert) ▷ #news (11 messages🔥):
- Frustration over Hard Fork: There is frustration expressed about this week's hard fork, perceived as triggering due to nonsense that is not reflective of the current state of AI.
- Skepticism Towards Claude Increment: The transition from Claude 2 to Claude 3 is being questioned; the term "INCREMENTAL?" suggests skepticism about its significance.
- Pointing Out Open Data Initiatives: There is a reminder about the existence of open data initiatives, indicating they may be overlooked in current discussions, implied by the phrase, "no one is detailing open data? AHEM".
- Journalist Perception on Tech: A member remarks on how popular tech journalists have a seemingly adversarial attitude towards technology, which is deemed perplexing.
- Engagement with Criticism Welcomed: Following criticism on Twitter, there's a positive note about engagement as a tech journalist began following a member after they tweeted at them.
- AI Releases Flood the Scene: A slew of releases announced today, including Pile-T5 from EleutherAI, WizardLM 2, and Reka Core from Yi Tay with links provided to their respective sources. Wizard LM 2 is highlighted as particularly interesting.
- Open Source Copyright Makeover: A comment praises the decision to make Dolma ODC-BY, reflecting on the intense number of open source announcements with the comment, "God can open source stop with the announcements today 😭".
Interconnects (Nathan Lambert) ▷ #ml-questions (13 messages🔥):
- Confusion over ACL commitment revisions: A member asked if it's necessary to upload a revised pdf after review, Nato expressed uncertainty suggesting that it might be required at some point.
- Synthetic Data Discussions Heat Up: One member expressed enthusiasm for Nato's article on synthetic data and CAI, sparking a conversation about the synthetic data meta since late 2023. Nato mentioned ongoing progress and hinted at a dataset release based on revisions.
- ORPO Method — What's the Deal?: The ORPO method was met with skepticism, with Nato suggesting that having a "big model" is a good strategy, implying the importance of model size over specific techniques.
- Critic vs. Reward Models in AI Analysis: Members discussed the difference between "critic" models like Prometheus and "reward" models featured on Nato's RewardBench project. The conversation delved into their functions, such as offering binary preferences or scalar scores, versus critics providing revisions or critiques.
- To Upload or Not to Upload PDFs: A link to a tweet by @andre_t_martins was shared, indicating that uploading a revised pdf for ACL commitment might not be necessary after all. See the tweet here.
Interconnects (Nathan Lambert) ▷ #random (4 messages):
- Positive Reception for Graphs in Newsletter: A member expressed enjoyment of the graphs included in today's newsletter, complimenting their clarity and effectiveness.
- Commitment to Including Graphs: The channel owner confirmed that the use of these informative graphs will be a consistent feature going forward.
- Graph Enhancements on the Horizon: Future improvements were discussed, with plans to refine the graphs and incorporate them into a Python library.
- Foundation for Exploring Open Models: The owner signaled that these polished graphs will serve as a valuable tool when writing about new open models.
Interconnects (Nathan Lambert) ▷ #reads (1 messages):
- CodecLM Research Paper Discussed: A member shared a link to a research paper titled "CodecLM: Aligning Language Models with Tailored Synthetic Data" published by Google on April 8. They mentioned it seems to be an approach on learning from a stronger model, but didn't provide further analysis.
Interconnects (Nathan Lambert) ▷ #sp2024-history-of-open-alignment (1 messages):
- LLaMA Paper Shared: A member posted a link to the paper "LLaMA: Open and Efficient Foundation Language Models" on Hugging Face's Collections, published on February 27, 2023. This paper can be found with the identifier 2302.13971.
Link mentioned: [lecture artifacts] aligning open language models - a natolambert Collection: no description found
Interconnects (Nathan Lambert) ▷ #posts (2 messages):
- Patience Might Be a Virtue: A member is experimenting with a bot and mentions the possibility of needing to wait longer rather than intervening manually. The context or reason for waiting is not specified.
LLM Perf Enthusiasts AI ▷ #claude (25 messages🔥):
-
Haiku Hesitation: Some members are expressing concerns about Haiku's speed, mentioning issues with total response times rather than throughput. There's a suggestion that Bedrock could offer better response times, although one member noted that it's slow as well.
-
Roleplay Refusal by Claude: Frustration is apparent as Claude is not cooperating with roleplay scenarios, including acting as a warrior maid or sending fictional spam mail. The issue persists despite attempts with instruction prompting and one-shot or few-shot techniques.
-
Jailbreaking Claude 3?: Members are discussing the necessity of jailbreaking Claude 3 for edgy content such as roleplaying games. One member referenced a tweet from @elder_plinius reporting a universal jailbreak for Claude 3, which could bypass stricter content filtering found in models like Gemini 1.5 Pro. The tweet can be found here.
Link mentioned: Tweet from Pliny the Prompter 🐉 (@elder_plinius): JAILBREAK ALERT! Just discovered a universal jailbreak for Claude 3. Malware, hard drug recipes, bomb-making, the whole nine yards. Haiku at high temps seems to be the best combo but in my limited ...
LLM Perf Enthusiasts AI ▷ #openai (4 messages):
- Code Capabilities Upgraded: A member noted that a newer version is "better at code for sure" and also "Faster too," suggesting performance improvements in coding tasks.
- Considering a Reactivation for Testing: In light of the perceived improvements, a member is considering reactivating their ChatGPT Plus subscription to test the new capabilities.
- Claude Maintains an Edge for Long-Winded Code: Claude is still considered valuable for "long context window code tasks," indicating that ChatGPT might have limitations with the context window size.
DiscoResearch ▷ #mixtral_implementation (8 messages🔥):
-
The MoE Mystery Continues: A member expressed a sense that something crucial is lacking in the MoE training/finetuning/rlhf process in transformers. The specificity of the missing elements was not elaborated.
-
Fishy Model Merge Remembered: In a Reddit discussion, the model "fish" by Envoid was recommended as an effective merge for RP/ERP in Mixtral. Even though it remains untested by the commentator due to hardware constraints, the author's contributions to Mixtral merge techniques were noted as potentially helpful.
-
Mixtral's Secret Sauce Speculation: Participants speculated whether Mixtral possesses undisclosed "secrets" for effective training beyond what's presented in their paper, suggesting that there might be hidden elements to achieving better MoE performance.
-
Weekend Ventures in Mixtral Finetuning: A member intends to experiment with Mixtral over the weekend, focusing on full finetuning with en-de instruct data, mentioning that the zephyr recipe code appears to work well.
-
Searching for the Superior Mixtral Sauce: A query was raised regarding the ability to fine-tune Mixtral models in a way that outperforms the official Mixtral Instruct, specifically about whether the "secret sauce" related to routing optimization has been uncovered by any community members.
DiscoResearch ▷ #general (4 messages):
-
Custom Llama-Tokenizer Training Quandary: A member is exploring how to train a custom Llama-tokenizer to optimize size for deployment on small hardware, with the aim of minimizing the size of the embedding layer. They noted difficulties in creating the required tokenizer.model file and are seeking assistance to resolve this for successful use with llama.cpp.
-
Token Generation Tactics: Another participant recommended looking into using a script available on GitHub that might assist with the conversion process for the custom Llama-tokenizer. They directed attention to the script
convert_slow_tokenizer.pyfound in the Hugging Face Transformers repository. -
Convert With Ease Using llama.cpp Script: A suggestion was made to use the
convert.pyscript from the llama.cpp GitHub repository with the--vocab-onlyoption, implying this could be a solution for the tokenizer model file creation issue. -
Calling Data Collectors for Open Multimodal Model Initiative: A call for assistance was made to locate copyright permissive or free EU text and multimodal data for training a large open multimodal model. Interested parties with the relevant data have been requested to get in touch via direct message.
Links mentioned:
DiscoResearch ▷ #discolm_german (2 messages):
-
Occiglot Model Shows Template Sensitivity: Evaluation of occiglot/occiglot-7b-de-en-instruct demonstrated improved performance on German RAG tasks using the correct template as found on Hugging Face's correct template, compared to the wrong template. The issue was likely due to a step in the Data Processing Operation rather than a systematic error.
-
StableLM and MiniCPM Pretraining Insights Shared: Quicksort discussed the StableLM's report found in their technical paper which includes using a ReStruct dataset for pretraining, inspired by methods from this GitHub repository. Furthermore, MiniCPM's research, outlined in their ablation study in Chapter 5, indicates benefits from mixing in data like OpenOrca and EvolInstruct during the cooldown phase of pretraining.
Link mentioned: Stable LM 2 1.6B Technical Report: We introduce StableLM 2 1.6B, the first in a new generation of our language model series. In this technical report, we present in detail the data and training procedure leading to the base and instruc...
Mozilla AI ▷ #llamafile (9 messages🔥):
-
Burnai Project Sparks Interest: A member praised the promising capabilities of the Burnai project, emphasizing its potential for optimizing inference on various platforms through Rust code. They shared their curiosity as to why Mozilla hasn’t investigated Burnai, despite Rust being Mozilla's brainchild.
-
Llamafile on Mcaffee Whitelist: The community celebrated the whitelisting of llamafile 0.7 binary by Mcaffee, highlighting it as a positive step for the project.
-
Welcome New Collaborator: An introduction from a new participant expressed enthusiasm for great collaborations and conversations within the community.
-
Queries about Vulkan and tinyblas: Questions were raised regarding possible Vulkan support in the upcoming v0.8 release and the upstreaming of tinyblas, with a specific interest in its application for ROCm.
-
Guidance Sought for Packaging Custom Models: There's noticeable community interest in guides for packaging customized models into llamafile, which has prompted members to seek and share relevant resources, such as a GitHub Pull Request on container publishing.
Links mentioned:
Alignment Lab AI ▷ #ai-and-ml-discussion (2 messages):
- Spam Solution Suggestion: A member recommended inviting the wick bot to the chat to automatically remove spam messages. They believe this could prevent incidents similar to those indicated by the tagged message.
Alignment Lab AI ▷ #general-chat (4 messages):
- Request for Direct Messaging: A member expressed the need for help with their code and requested a DM by tagging a specific user.
- Concerns Over Discord Invites: Another member voiced their concern regarding the posting of Discord invites across the server and suggested that they should be outright banned to avoid such issues.
- Human Verification Call: The same member who needed help with their code reiterated their request and mentioned it as a proof that they are not a bot.
Alignment Lab AI ▷ #join-in (1 messages):
There are no appropriate messages to summarize.
Link mentioned: Discord - A New Way to Chat with Friends & Communities: Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
Alignment Lab AI ▷ #oo2 (1 messages):
aslawliet: Is the project still alive?
AI21 Labs (Jamba) ▷ #jamba (6 messages):
-
Code-Jamba-v0.1 Takes on Multi-Language Coding: A fine-tuned model named Code-Jamba-v0.1 was shared, renowned for high proficiency in generating code across multiple programming languages including Python, Java, and Rust. It was trained for 162 hours on 2 x H100 GPUs, utilizing datasets Code-290k-ShareGPT and Code-Feedback.
-
Queries on Model Benchmarking and Dataset Sharing: A member expressed curiosity about the absence of model evaluation data for Code-Jamba-v0.1 and raised a question on whether AI21 Labs will share its dataset, highlighting its potential for fine-tuning Large Language Models (LLMs) with a 256K context.
-
Jamba API Anticipation: An inquiry was made about the availability of an API for Jamba, with a note that Fireworks AI might integrate Jamba following communication with their CEO.
Link mentioned: ajibawa-2023/Code-Jamba-v0.1 · Hugging Face: no description found
Datasette - LLM (@SimonW) ▷ #ai (5 messages):
- Introduction to a Password Guessing Game: Members shared a link to PasswordGPT, a game where the objective is to convince an AI to reveal a password.
- Debate on Annotating Data: A member expressed a preference for annotating data before modeling, to understand dataset contents, and wondered if others follow a similar practice or rely more on LLMs without extensive annotation.
- Historical Document Record Extraction Using Pre-LLM Models: A member mentioned being part of a team that curates data and extracts records from historical documents using transformer models that predate LLMs.
- User Engagement with AI Demos: There was a preference for open-prompt AI demos as opposed to closed-prompt guessing games, stressing that seeing the prompts can help users engage more effectively and beat the AI.
Link mentioned: PasswordGPT: no description found
Skunkworks AI ▷ #off-topic (1 messages):
- Scaling AI Apps to Production: An announcement for a meetup titled "Unlock the Secrets to Scaling Your Gen AI App to Production" was made, highlighting the challenge of scaling a Gen AI app to full-scale production. The event features panelists including the co-founders of Portkey, Noetica AI, and LastMile AI, with registration available through this link. Interested parties need approval from the host to attend.
Link mentioned: LLMs in Prod w/ Portkey, Flybridge VC, Noetica, LastMile · Luma: Unlock the Secrets to Scaling Your Gen AI App to Production While it's easy to prototype a Gen AI app, bringing it to full-scale production is hard. We are bringing together practitioners &....