One thing we missed covering in the weekend rush is Lilian Weng's blog on Diffusion Models for Video Generation. While her work is rarely breaking news on any particular day, it is almost always the single most worthwhile resource on a given important AI topic, and we would say this even if she did not happen to work at OpenAI.
Anyone keen on Sora, the biggest AI launch of the year so far (now rumored to be coming to Adobe Premiere Pro), should read this. Unfortunately for most of us, the average diffusion paper requires 150+ IQ to read.

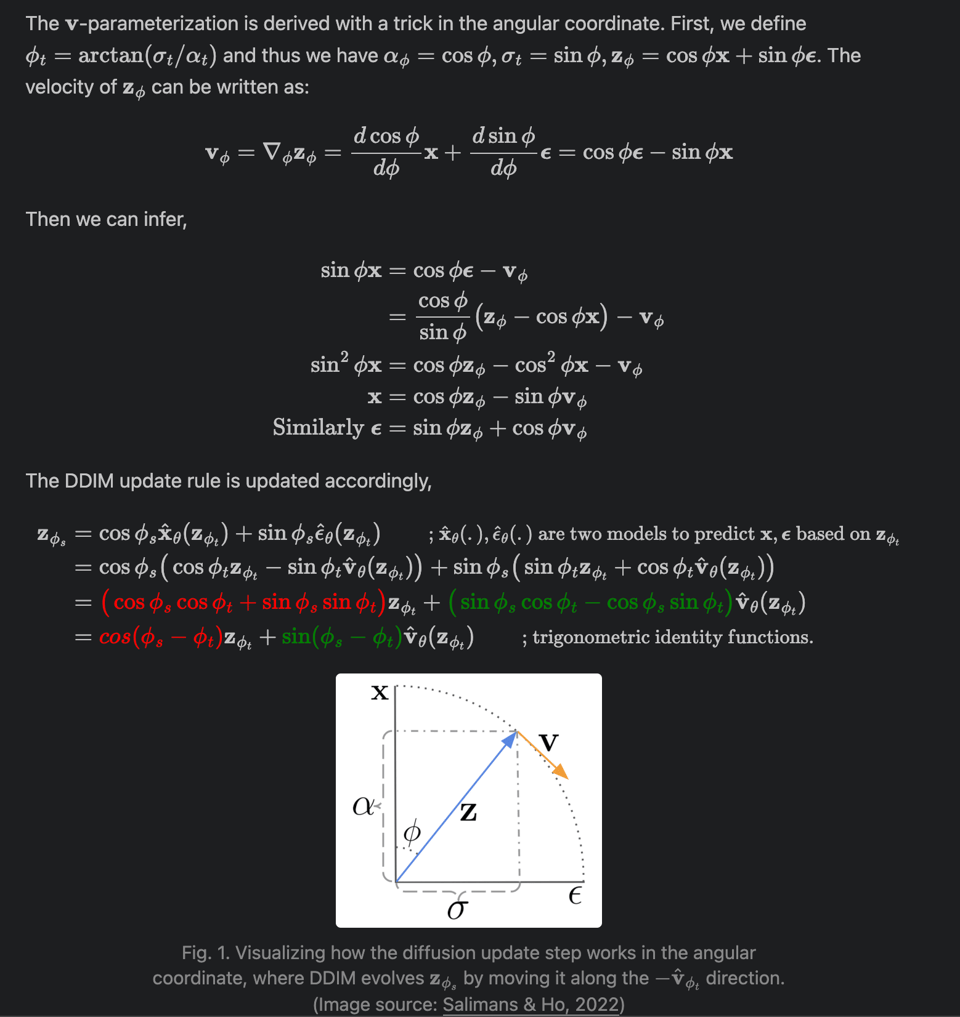
We are only half joking. As per Lilian's style, she takes us on a wild tour of all the SOTA videogen techniques of the past 2 years, humbling every other AI summarizooor on earth:
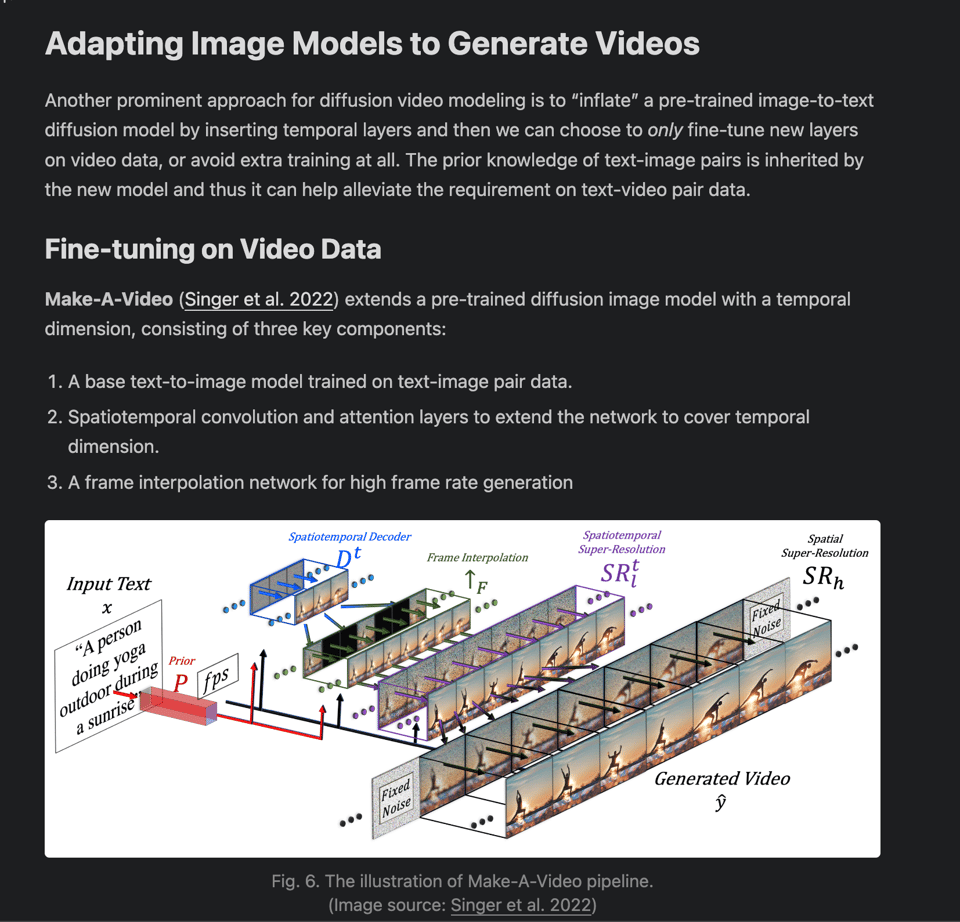
The surprise find of the day comes from her highlight of Training-free adaptation, which is exactly as wild as it sounds:
"Somehow surprisingly, it is possible to adapt a pre-trained text-to-image model to output videos without any training 🤯."

She unfortunately only spends 2 sentences discussing Sora, and she definitely knows more she can't say. Anyway, this is likely the most authoritative explanation to How SOTA AI Video Actually Works you or I are ever likely to get unless Bill Peebles takes to paper writing again.
Table of Contents
[TOC]
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/Singularity. Comment crawling works now but has lots to improve!
AI Companies and Releases
- OpenAI expands: OpenAI launches in Japan, introduces Batch API, and partners with Adobe to bring Sora video model to Premiere Pro.
- New models: Reka AI releases Reka Core multimodal language model.
- Competitive landscape: Sam Altman says OpenAI will "steamroll" startups. Devin AI model sees record internal usage.
{kind=link}
New Model Releases and Advancements in AI Capabilities
- WizardLM-2 released: In /r/LocalLLaMA, WizardLM-2 was just released and is showing impressive performance.
- Llama 3 news coming soon: An image post hints that news about Llama 3 will be coming soon.
- Reka Core multimodal model released: Reka AI announced the release of Reka Core, their new frontier-class multimodal language model.
- AI models showing intuition and creativity: Geoffrey Hinton says current AI models are exhibiting intuition, creativity and can see analogies humans cannot.
- AI contributing to its own development: Devin was the biggest contributor to its own repository for the first time, an AI system contributing significantly to its own codebase.
- AI recognizing its own outputs: In /r/singularity, it was shared that Opus can recognize its own generated outputs, an impressive new capability.
{kind=link}
Industry Trends, Predictions and Ethical Concerns
- Warnings about AI disruption: Sam Altman warned startups about the risk of getting steamrolled by OpenAI if they don't adapt quickly enough.
- Debate on AGI timelines: While Yann LeCun believes AGI is inevitable, he says it's not coming next year or only from LLMs.
- Toxicity issues with models: WizardLM-2 had to be deleted shortly after release because the developers forgot to test it for toxicity, highlighting the challenges with responsible AI development.
- Proposed AI regulation in the US: The Center for AI Policy put forth a new proposal for a bill to regulate AI development in the US.
- Warning about AI startups: A PSA in /r/singularity warned about being cautious with startups that seem too good to be true, as some have questionable pasts tied to crypto.
{kind=link}
Technical Discussions and Humor
- Building Mixture-of-Experts models: /r/LocalLLaMA shared a guide on how to easily build your own MoE language model using mergoo.
- Diffusion vs autoregressive models: /r/MachineLearning had a discussion comparing diffusion and autoregressive approaches for image generation and debating which is better.
- Fine-tuning GPT-3.5: /r/OpenAI posted a guide for fine-tuning GPT-3.5 for custom use cases.
- AI advancement memes: The community shared some humorous memes, including a "can't wait" meme about the pace of AI progress, a meme about reversing aging in mice, and a cursed rave video meme.
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
WizardLM-2 Release and Withdrawal
- WizardLM-2 Release: @WizardLM_AI announced the release of WizardLM-2, their next-generation state-of-the-art LLM family, including 8x22B, 70B, and 7B models which demonstrate highly competitive performance compared to leading proprietary LLMs.
- Toxicity Testing Missed: @WizardLM_AI apologized for accidentally missing the required toxicity testing in their release process, and stated they will complete the test quickly and re-release the model as soon as possible.
- Model Weights Pulled: @abacaj noted that WizardLM-2 model weights were pulled from Hugging Face, speculating it may have been a premature release or something else going on.
Reka Core Release
- Reka Core Announcement: @RekaAILabs announced the release of Reka Core, their most capable multimodal language model yet, which has a lot of capabilities including understanding video.
- Technical Report: @RekaAILabs published a technical report detailing the training, architecture, data, and evaluation for the Reka models.
- Benchmark Performance: @RekaAILabs evaluated Core on standard benchmarks for both text and multimodal, along with a blind third-party human evaluation, showing it approaches frontier-class models like Claude3 Opus and GPT4-V.
Open Source Model Developments
- Pile-T5: @arankomatsuzaki announced the release of Pile-T5, a T5 model trained on 2T tokens from the Pile using the Llama tokenizer, featuring intermediate checkpoints and a significant boost in benchmark performance.
- Idefics2: @huggingface released Idefics2, an 8B vision-language model with significantly enhanced capabilities in OCR, document understanding, and visual reasoning, available under the Apache 2.0 license.
- Snowflake Embedding Models: @SnowflakeDB open-sourced snowflake-arctic-embed, a family of powerful embedding models ranging from 22 to 335 million parameters with 384-1024 embedding dimensions and 50-56 MTEB scores.
LLM Architecture Developments
- Megalodon Architecture: @_akhaliq shared Meta's announcement of Megalodon, an efficient LLM pretraining and inference architecture with unlimited context length.
- TransformerFAM: @_akhaliq shared Google's announcement of TransformerFAM, where feedback attention is used as working memory to enable Transformers to process infinitely long inputs.
Miscellaneous Discussions
- Humanoid Robots Prediction: @DrJimFan predicted that humanoid robots will exceed the supply of iPhones in the next decade, gradually then suddenly.
- Captchas and Bots: @fchollet argued that captchas cannot prevent bots from signing up for services, as professional spam operations employ people to solve captchas manually for about 1 cent per account.
AI Discord Recap
A summary of Summaries of Summaries
1. New Language Model Releases and Benchmarks
-
EleutherAI released Pile-T5, an enhanced T5 model trained on the Pile dataset with up to 2 trillion tokens, showing improved performance across benchmarks. The release was also announced on Twitter.
-
Microsoft released WizardLM-2, a state-of-the-art instruction-following model that was later removed due to a missed toxicity test, but mirrors remain on sites like Hugging Face.
-
Reka AI introduced Reka Core, a frontier-class multimodal language model competitive with OpenAI, Anthropic, and Google models.
-
Hugging Face released Idefics2, an 8B multimodal model excelling in vision-language tasks like OCR, document understanding, and visual reasoning.
-
Discussions around model performance, sampling techniques like MinP/DynaTemp/Quadratic, and the impact of tokenization per a Berkeley paper.
{kind=link}
2. Open Source AI Tools and Community Contributions
-
LangChain introduced a revamped documentation structure and saw community contributions like Perplexica (an open-source AI search engine), OppyDev (an AI coding assistant), and Payman AI (enabling AI agents to hire humans).
-
LlamaIndex announced tutorials on agent interfaces, a hybrid cloud service with Qdrant Engine, and an Azure AI integration guide for hybrid search.
-
Unsloth AI saw discussions on LoRA fine-tuning, ORPO optimization, CUDA learning resources, and cleaning the ShareGPT90k dataset for training.
-
Axolotl provided a guide for multi-node distributed fine-tuning, while Modular introduced mojo2py to convert Mojo code to Python.
-
CUDA MODE shared lecture recordings, with focuses on CUDA optimization, quantization techniques like HQQ+, and the llm.C project for efficient kernels.
3. AI Hardware and Deployment Advancements
-
Discussions around Nvidia's potential early RTX 5090 launch due to competitive pressure and the anticipated performance gains.
-
Strong Compute announced grants of $10k-$100k for AI researchers exploring trust in AI, post-transformer architectures, new training methods, and explainable AI, with GPU resources up for grabs.
-
Limitless AI, previously known as Rewind, introduced a wearable AI device, sparking discussions around data privacy, HIPAA compliance, and cloud storage concerns.
-
tinygrad explored cost-effective GPU cluster setups, MNIST handling, documentation improvements, and enhancing the developer experience as it transitions to version 1.0.
-
Deployment insights like packaging custom models into llamafiles, running CUDA on consumer hardware, and converting models from ONNX to WebGL/WebGPU using tinygrad.
4. AI Safety, Ethics, and Societal Impact Debates
-
Discussions around the ethical implications of AI development, including the need for safety benchmarks like ALERT to assess potentially harmful content generation by language models.
-
Concerns over the spread of misinformation and unethical practices, with mentions of a potential AI scam advertised on Facebook called Open Sora.
-
Debates on finding a balance between AI capabilities and societal expectations, with some advocating for creative freedom while others prioritize safety considerations.
-
Philosophical exchanges comparing the reasoning abilities of AI systems to humans, touching on aspects like independent decision-making, emotional intelligence, and the neurobiological underpinnings of language comprehension.
-
Emerging legislation targeting deepfakes and the creation of explicit AI-generated content, prompting discussions around enforcement challenges and intent considerations.
5. Misc
-
Excitement and Speculation Around New Models: There was significant buzz and discussion around the release of new AI models like Pile-T5 from EleutherAI, Idefics2 8B from Hugging Face, Reka Core from Reka AI, and WizardLM 2 from Microsoft (despite its mysterious takedown). The AI community eagerly explored these models' capabilities and training approaches.
-
Advancements in Multimodal AI and Diffusion Models: Conversations highlighted progress in multimodal AI with models like IDEFICS-2 showcasing advanced OCR, visual reasoning and conversational abilities. Research into diffusion models for video generation (Lilian Weng's blog post) and the significance of tokenization in language modeling (UC Berkeley paper) also garnered interest.
-
Tooling and Frameworks for Model Development: Discussions covered various tools and frameworks for AI development, including Axolotl for multi-node distributed fine-tuning, LangChain for building LLM applications, tinygrad for efficient deep learning, and Hugging Face's libraries like parler-tts for high-quality TTS models.
-
Emerging Platforms and Initiatives: The AI community took note of various emerging platforms and initiatives such as Limitless (rebranded from Rewind) for personalized AI, Cohere Compass beta for multi-aspect data search, Payman AI for AI-to-human task marketplaces, and Strong Compute's $10k-$100k grants for AI research. These developments signaled an expanding ecosystem for applied AI.
PART 1: High level Discord summaries
Stability.ai (Stable Diffusion) Discord
- Stable Diffusion 3: A Legend or Reality?: The release date for Stable Diffusion 3 (SD3) has turned into folklore within the community, with speculated dates like "April 26" and "April 69" reflecting excitement and sarcasm about its long-awaited arrival.
- Animating Images Becomes Comfier: Engineers are exchanging tips for image animation, pointing towards ComfyUI workflows and Stability Forge while mentioning challenges in running models directly via Python, highlighting a need for simpler animation APIs.
- Pixel Art Gets a Realistic Touch: There's a buzz about turning pixel art into realistic images using models like SUPIR, available on Hugging Face, and enhancing pixelated images using img2img controlnet solutions like Fooocus or Magic Image Refiner.
- Prompt Engineering Debate: Prompt crafting best practices were discussed, with some arguing that expertise is not necessary and using services like Civitai can provide solid prompting baselines; discussions around WizardLM-2 were redacted due to untested toxicity concerns.
- AI Utopia or Dystopia?: Casual conversations veered into envisioning a future saturated with advanced AI applications, from style conversion in gaming to AI-assisted brain surgery, interspersed with jokes about an "AI University for prompt engineers" and tongue-in-cheek product names like "Stable Coin."
Unsloth AI (Daniel Han) Discord
Benchmark Bonanza: Engineers shared positive feedback on a first benchmark's results, praising its performance. There was also a conversation around extracting tokenizer.chat_template for model template identification in leaderboards.
Progressive Techniques in LoRA Tuning: Community members exchanged tips on LoRA fine-tuning, suggesting that the alpha parameter to tweak could be double the rank. They discussed ORPO's resource-optimization in model training and discouraged the use of native CUDA, advocating for Triton instead for learning and development benefits.
Data Hygiene Takes Center Stage: The ShareGPT90k dataset was presented in a cleaned and ChatML format to facilitate training with Unsloth AI, and users highlighted the key role of data quality in model training, alluding to a community preference for hands-on experimentation in learning model training approaches.
Collaboration and Contributions on the Rise: Open calls for contributions to Unsloth documentation and projects such as Open Empathic were made, indicating a receptive attitude toward community involvement. A member announced the development of an "emotional" LLM and collaboration with a Chroma contributor on libSQL and WASM integration.
Navigating Unsloth's Notebook Nuggets: Assistance with formatting personal messages for AI training was given, complete with a Python script link and a guide to use the ShareGPT format. Advice on packing and configurations for Gemma models were discussed to mitigate unexpected training issues.
Modular (Mojo 🔥) Discord
Bold Python Package Sets to Conquer Mojo Code: The creation of mojo2py, a Python package to convert Mojo language code into Python, indicates a trend toward developing tools for Python and Mojo interoperability.
Grammar Police Tackle Code Aesthetics: Engaging discussions highlighted the importance of indenting code, considered laughable yet significant for readability, and there was a sense of light-hearted camaraderie over code formatting conventions.
Accolades for Achieving Level 9 in Modular: A community member was congratulated for reaching level 9, indicating a point system or achievement metric within the Modular community.
Modular Tweets Tease the Tech-Savvy: A series of mysterious tweets from Modular sparked speculation and interest among the community, serving as an intriguing marketing puzzle.
Nightly Updates Kindle Community Interest: A fresh Mojo nightly update was announced, directing engineers to update their version to nightly/mojo and review the latest changes and enhancements detailed on GitHub's diff and the changelog.
Perplexity AI Discord
Billing Confusion and API Misalignments: Users express dissatisfaction with unexpected charges and discrepancies between Perplexity AI and API usage, pointing to instances where promo codes don't appear and seeking an understanding of parameters such as temperature for consistent results between different platforms.
Pro Feature Puzzlement: Changes to the Pro message counter in Perplexity AI led to mixed reactions, with some users enjoying "reduced stress" but others questioning the rationale behind such feature tweaks.
Model Performance Scrutiny: A divergence in opinion emerges on AI coding competencies, with GPT-4 seen as inadequate by some users, while others ponder the delicate trade-offs between various Perplexity models' abilities and performance.
Cultural Curiosity and Tech Talk: The community engages in a range of searches, from probing Microsoft's ad-testing endeavors to celebrating global cultural days, reflecting an eclectic mix of technical and creative interests.
API Result Inconsistencies Provoking Discussions: Queries in the community focus on aligning outcomes from Perplexity Pro and the API, with an undercurrent of worries about hallucinations and source credibility in the API's content.
LM Studio Discord
Windows Cleared for Model Takeoff: Responding to queries, members confirmed that the Windows executables for LM Studio are signed with an authenticode certificate and discussed the cost differences between Windows certificates and Apple developer licenses, with the former requiring a hardware security module (HSM).
The Trouble with VRAM Detection: Users reported errors related to AMD hardware on Intel-based systems in Linux, despite attempts to solve the issue with ocl-icd-opencl-dev. It led to a broader discussion about hardware misidentification and the challenges it poses in configurations.
WizardLM-2 Sharpens Its Conversational Sword: The WizardLM 2 7B model was praised for its ability in multi-turn conversations and its training methods, with its availability announced on Hugging Face. The WaveCoder ultra 6.7b was also recognized for its coding prowess following fine-tuning on Microsoft's CodeOcean.
Model Showdown: Users shared performance experiences with models like WizardLM-2-8x22B and Command R Plus, voicing mixed reactions. They exchanged views on what defines a "Base" AI model and the nuances of model fine-tuning and continuous learning, sparking debates over AI memory and bias.
Diverse Coding Prowess Under the Microscope: Within the guild, members delved into Python coding model capabilities, like Deepseek Coder and Aixcoder, urging others to check 'human eval' scores. Skepticism was expressed over claims about WaveCoder Ultra's superiority, with some implying exaggerated results, while discussions on model fine-tuning and quantization illuminated varying preferences for coding models and AI agent creation tools.
Nous Research AI Discord
-
Engineers Tackle Tokenization Trouble: An engineer experienced difficulties with tokenized outputs for end-of-sequence predictions using llama.cpp with the OpenHermes 2.5 Mistral 7B model on Hugging Face and sought advice on resolving the issue.
-
Tech Titans' AI Tools Scrutinized: Users compared Reka AI's Core model with GPT-4V, Claude-3 Opus, and Gemini Ultra in a showcase and discussed Google's CodecLM, which aims for high-quality synthetic data generation for language model alignment.
-
Innovation or Hype? Open AI Models Excite but Confuse: Despite the enthusiastic downloading of WizardLM-2 before its takedown, confusion remained about its removal, while new models like CodeQwen1.5 promise enhanced code generation in 92 languages, and Qwen's 7B, 14B, and 32B models are mentioned for their benchmark scores.
-
Breaking Binary Boundaries: Discussion of a binary quantization-friendly AI model on Hugging Face sparked interest due to memory-efficient int8 and binary embeddings, with calculation methods like XOR operations for embedding distance, cited from Cohere's blog post.
-
Game Design Meets Quantum Probability: Enthusiasm about WorldSim's potential to revolutionize game development is evident, with conversations about using LLMs in future to affect in-game variables and content creation, flavoring it with undertones of AI-assisted omnipotence.
OpenRouter (Alex Atallah) Discord
-
WizardLM Models Magically Appear on OpenRouter: The WizardLM-2 8x22B and WizardLM-2 7B models from Microsoft have been added to OpenRouter, with the former's cost now at $0.65/M tokens. Several members have initiated a thread to discuss the implications of this addition.
-
Intermittent Latency Looms Over Users: There were reports of high latency issues affecting models like Mistral 7B Instruct and Nous Capybara 34b, with the problem traced back to an upstream issue with a cloud provider's DDoS protection. Further complications have led to said provider being deranked to alleviate concerns, and global users are being called upon to report their experience with the issue.
-
Rubiks.ai Rolls Out Beta with Big Name Models: A new AI platform, Rubiks.ai, is courting beta testers with the offer of 2 months free premium access and the chance to experiment with models such as Claude 3 Opus, GPT-4 Turbo, and Mistral Large. Users facing account-related issues are advised to send feedback directly to the developers.
-
Falcon 180B Soars With GPU Thirst: The hefty GPU memory requirement of around 100GB for the Falcon 180B Chat GPTQ got the community talking about both the model's resource intensity and its potential usage considerations, underlined by a link to the Falcon 180B repository.
-
Cost-effective Communication & Model Responsiveness Advice: In a nod to efficient model usage, it was proposed that an average of 1.5 tokens per word could be a benchmark for cost calculation. Separate discussions highlighted positive attributes of the Airoboros 70B's prompt compliance, contrasting it with less consistent models.
CUDA MODE Discord
PyTorch Book Still Flares Interest: Despite being 4 years old, "Deep Learning with PyTorch" is seen as a useful foundation for PyTorch fundamentals, while chapters on transformers, LLMs, and deployment are dated. Anticipation grows for a new edition to cover recent advancements.
Torch and CUDA Grapple with Optimization: Understanding and implementing custom backward operations in Llama exhibit challenges for AI engineers, while the use of torch.nn.functional.linear and the stable-fast library are leading discussions for optimizing inference in the CUDA environment.
Novel Approaches in Transcript Processing: An automated transcript for a CUDA talk utilizing cutting-edge tools is provided by Augmend Replay, offering the AI community OCR and segmentation features for video content analysis.
Quantum Leaps with HQQ and GPT-Fast: Significant strides in token generation speeds are observed after implementing torchao int4 kernel in the generation pipeline for transformers, rising to 152 tokens/sec. The HQQ+ method also marked an accuracy increase, spurring discussions around quantization axis and integration with other frameworks.
llm.C at the Forefront of CUDA Exploration: The llm.C project ignites discussions on CUDA optimizations, underscoring the balance between education and creating efficient kernels. Optimizations, profiling, potential strategies, and applicable datasets all jostle for attention in this growing space.
Eleuther Discord
-
Pile-T5 Reveals Impressive Benchmarks: EleutherAI introduced Pile-T5, a T5 model family trained on the Pile with up to 2 trillion tokens and showing improved performance on language tasks with the new LLAMA tokenizer. Key resources include a blog post, GitHub repository, and a Twitter announcement.
-
Tackling the Temporal Challenge in Video Diffusion: Discussions in the research channel touched on the complexities of video synthesis using diffusion models, with participants referring to a post on diffusion models for video generation and deliberating on the importance of tokenization in language models, as outlined in a Berkeley paper.
-
LLM Evaluation Continues to Evolve: Within the lm-thunderdome channel, there were insights into OpenAI's public release of GPT-4-Turbo's evaluation implementations on GitHub, and enhancement of
lm-evaluation-harnesswith new benchmarks such asflores-200andsib-200. -
Token Management Under the Microscope: The gpt-neox-dev channel broached technical issues such as the effect of weight decay on dummy tokens, the necessity of sanity checks after model adjustments, and token encoding behaviors with shared code outputs demonstrating token transformations.
-
Debates on Model Architecture Efficiency: Active discussions contrasted dense models with Mixture-of-Experts (MoE), debated their efficiency, inference cost, and constraints, showing the ongoing quest for optimizing language model architectures.
OpenAI Discord
-
Brains and Bots: Members shared interest in Angela D. Friederici's book, Language in Our Brain: The Origins of a Uniquely Human Capacity, sparking dialogue on the neurobiological underpinnings that differentiate humans and AI in language capacities. The discussions stressed the challenge in neuroscience of handling the 'data glut' from Big Brain Projects and the proprietary hurdles that hinder data interpretation.
-
AI Limitations and Liberties: In a look at the contrast between AI and humans, it emerged that artificial systems are yet to match human-like storage of learned information, independent decision-making abilities, and emotional responses. The reference to Claude 3 API's accessibility issues in Brazil underscored the geographical nuances in reaching AI tools.
-
Chatbots Grapple with GPT Constraints: Despite advances, the GPT's context window remains a critical concern, with GPT-3's API permitting a 128k context but ChatGPT itself constrained to 32k. Mechanisms like "retrieval" through document upload were demystified, allowing extension of the effective context window within the API's framework.
-
Discovering the Depths of Turing Completeness: A spirited debate arose about the Turing completeness of Magic: The Gathering, suggesting that the concept extends its reach well beyond traditional computational systems.
-
Clouded Queries and Cryptic Replies: Prompt Engineering and API Discussions channels surfaced brief and ambiguous exchanges about an unidentified competition and cryptic one-word responses such as "buzz" and "light year," underscoring the occasional opacity in dialogue within technical forums.
LlamaIndex Discord
Tutorial Treasure Trove: LlamaIndex announced an introductory tutorial series for agent interfaces and applications, aiming to clarify usage of core agent interfaces. In collaboration, LlamaIndex and Qdrant Engine introduced a hybrid cloud service offering, and a new tutorial was shared highlighting the integration of LlamaIndex with Azure AI to leverage hybrid search in RAG applications, crafted by Khye Wei from Microsoft found here.
AI Chat Chops: Within the LlamaIndex community, discussion ranged from implementing async compatibility with Claude in Bedrock (where async has not yet been implemented) to complex query construction help available in the documentation. Integration issues with gpt-3.5-turbo and LlamaIndex were likely related to outdated versions or account balances, and configuring fallbacks for decision-making with incomplete data remains an open challenge.
Reasoning Chains Revolution: Revealing advancements in reasoning chain integration with LlamaIndex, a key article titled "Unlocking Efficient Reasoning" can be found here. Solutions for token counting in RAGStringQueryEngine and hierarchical document organization in LlamaIndex were discussed in detail, with the community providing a concrete token counter integration guide involving a TokenCountingHandler and CallbackManager as per LlamaIndex's reference documentation.
LAION Discord
Hugging Face Rings in New TTS Library: A high-quality TTS model library, parler-tts, for both inference and training was showcased, bolstered by its hosting on Hugging Face's community-driven platform.
Scaling Down CLIP – Less Data, Equal Power: A study on CLIP demonstrates that strategic data use and augmentation can allow smaller datasets to match the performance of the full model, introducing new considerations for data-efficient model training.
Deepfakes – Legislation Incoming, Controversies Continue: The community debated newly proposed laws against deepfakes as well as unethical practices in AI, raising awareness about a potential scam promoted through a suspicious site advertised on Facebook, found here.
Safety Benchmarking Becomes ALERT: Discussion on the importance of safety in AI highlighted the release of the ALERT benchmark, designed to evaluate large language models for handling potentially harmful content and reinforcing conversations around safety versus creative freedom.
Audio Generation Advancements on the Horizon: Research involving the Tango model to enhance text-to-audio generation shed light on improvements in relevance and order of audio events, marking progress for audio generation from text in data-scarce setups.
HuggingFace Discord
-
IDEFICS-2 Shines in Multimodal Processing: The recently released Idefics2 enhances multimodal capabilities, excelling in tasks such as image and text sequence processing, and is set to get a chatty variant for conversational interaction. When probed, demonstrations of its capabilities like decoding CAPTCHAs with heavy distortion were highlighted.
-
Diverse AI Insights and Queries: Community members have raised various topics ranging from BLIP model fine-tuning for long captions, musical AI projects like
.bigdookie'sinfinite remix GitHub repo, and the usage of Java for image recognition outlined in a Medium article. Discussions also cover best practices for collaborative work on HuggingFace and survey participation from machine learning practitioners. -
Unlock the Potential of BERTopic: AI engineers engaged in deep dives into frameworks like BERTopic, which revolutionizes topic modeling through the use of transformers. It's lauded for its performance and versatility, with guides like the BERTopic Guide assisting users in navigating its myriad capabilities for structured topic extraction.
-
Clarifying NLP and Diffusion Model Confusions: Clarifications were sought for NLP tensor decoding using T5 models and LoRA configurations, while questions about the differences between LLMs and embedding models, and issues with token limits in diffusion models were also discussed. A community member flagged a warning regarding token truncation when using stable diffusion models, referring to an open GitHub issue.
-
Vision and NLP Model Optimization Efforts: Engineers have shown interest in tuning models for specific use cases, such as a vision model for low-resolution image captioning and the potential use of advanced taggers for SDXL. Similarly, advice is sought for preparing a dataset for fine-tuning a ROBERTA Q&A chatbot and utilizing models like spaCy and NLTK for getting started in NLP.
Cohere Discord
Command-R Struggles with Macedonian: Discussions flagged that Command-R doesn't perform well in Macedonian, with concerns raised on the community-support channel. Issues raised highlight the need for multilingual model improvements.
Asynchronous Streaming with Command-R: Engineers queried the best practices for converting synchronous code to asynchronous in Python, aiming to enhance the efficiency of chat streaming with the Command-R model.
Trial API Limits Clarified: For Cohere's API, engineers discovered that the ‘generate, summarize’ endpoint has a limit of 5 calls per minute, while other endpoints permit 100 calls per minute, with a shared pool of 5000 calls per month for all trial keys.
Commander R+ Gains Traction: A discussion took root around accessing Commander R+ using Cohere’s paid Production API, highlighting existing documentation for potential subscribers.
Rubiks.ai Introduces AI Powerhouse: Engineers took note of the launch of Rubiks.ai, which offers a suite of models including Claude 3 Opus, GPT-4 Turbo, Mistral Large, and Mixtral-8x22B, with an introductory offer of 2 months of premium access on Groq servers.
OpenAccess AI Collective (axolotl) Discord
Deepspeed's Multi-node Milestone: A guide for multi-node distributed fine-tuning using Axolotl with Deepspeed 01 and 02 configurations was shared. The pull request outlines steps to address configuration issues.
Idefics2 Raises the Bar: The newly released Idefics2 8B on Hugging Face surpasses Idefics1 in OCR, document understanding, and visual reasoning with fewer parameters. Access the model on Hugging Face.
Pacing for RTX 5090's Big Reveal: Anticipation builds for Nvidia's upcoming RTX 5090 graphics card, speculated to debut at the Computex trade show. This early release may be fueled by competitive pressure as discussed on PCGamesN.
Gradient Accumulation Spotlighted: Queries on gradient accumulation's memory conservation in the context of sample packing and dataset length led to explorations of its impact on training time.
Streamline Model Saving with Axolotl: Configuring Axolotl to save models only upon training completion rather than after each epoch involves setting save_strategy to "no". Additionally, "TinyLlama-1.1B-Chat-v1.0" was recommended for tight computational spaces, with its setup in the examples/tiny-llama directory of Axolotl's repository.
Latent Space Discord
Rewound Now Unbound as Limitless: The wearable tech previously referred to as Rewind has been rebranded to Limitless, sparking a discussion about its real-time application potential and the implications for future AI advancements. Concerns regarding data privacy and HIPAA compliance for cloud-stored information were vocalized by members.
The Birth of Reka Core: Reka Core enters the chat as a multimodal language model that comprehends video. The community appears intrigued by the small team achievement in AI democratization and the technical report released at publications.reka.ai.
Cohere Compass Beta Steers In: Cohere's Compass Beta was unveiled as a next-level data search system, meriting discussion around its embedding model and the beta testing opportunities for applicants eager to explore its functional boundaries.
Payman AI Explores AI-Human Marketplaces: Payman AI piqued interest with its innovative concept of a marketplace where AI can hire humans, driving conversations around implications for data generation and advancing AI training methodologies.
Strong Compute Serves Resources on Silver Platter: Strong Compute revealed a grant program for AI researchers, dangling the carrot of $10k-$100k and substantial GPU resources for initiatives in Explainable AI, post-transformer models, and other groundbreaking areas, with a swift application deadline signaled by the end of April. Details on the offer and the application process were outlined at Strong Compute research grants page.
OpenInterpreter Discord
AI Innovation Storm Brewing: The OpenInterpreter community launched a brainstorming space to ideate on uses of the platform, focusing on features, bugs, and innovative applications.
Voice Communication Soars with Airchat: There’s a buzz around Airchat within the community as engineers exchange usernames and scrutinize its features and usability, signaling a growing interest in diverse communication platforms.
Open Source AI Generates Excitement: Opensource AI models, notably WizardLm2, are receiving attention for providing transparent access to powerful AI capabilities akin to GPT-4, highlighting community interest in open-source alternatives.
Navigating the 01 Pre-order Process: For those reconsidering their 01 pre-orders, they can easily cancel by reaching out to [email protected], and there’s growing discussion on Windows 11 installation woes and hardware compatibility improvisations using parts from AliExpress.
Linux Love for OpenInterpreter: Linux users are directed to rbrisita's GitHub branch, agglomerating all the latest PRs for the 01 device, and the community is also optimizing their 01 setups with custom designs and battery life improvements.
LangChain AI Discord
-
LangChain Documentation Revamp Requesting Feedback: LangChain engineers have outlined a new documentation structure to better categorize tutorials, how-to guides, and conceptual information, to improve user navigation across resources. Feedback is sought, and an introduction to LangChain has been made available, detailing its application lifecycle process for large language models (LLMs).
-
Parallel Execution and Azure AI Conflict Solving: Technical discussions confirmed that LangChain's
RunnableParallelclass allows for concurrent execution of tasks, with reference to Python documentation for parallel node running. Meanwhile, solutions are being exchanged on issues withneofjVectorIndexandfaiss-cpu, including LangChain version rollbacks and branch switches. -
Innovations and Announcements Flood LangChain: A series of project updates and community exchanges highlighted advancements such as improved Rag Chatbot performance via multiprocessing, the introduction of Perplexica as a new AI-driven search engine, and the launch of tools like Payman for AI-to-human payments, viewable at Payman.ai. Other announcements included GalaxyAI's free premium model access, OppyDev's AI-assisted coding tool (oppydev.ai), and a call for beta testers for Rubiks AI's research assistant with perks (rubiks.ai).
-
Channeling AI for RBAC Implementation and YC Aspirations: Specific discussions touched on implementing role-based access control (RBAC) within LangChain for large organizations and gauging the landscape for finetuning models for YC applications, indicating both challenges and existing companies like Holocene Intelligence in the space.
-
Nurturing AI with Memory and Collaborative Efforts: Shared knowledge included a video on crafting AI agents with long-term memory and a call for collaboration in integrating LangServe with Nemo Guardrails, suggesting a need for a new output parser due to updates. Community members also explored payment-enabled AI recommendations and document processing concerns, all hinting at an emphasis on shared growth and collaborative experimentation.
tinygrad (George Hotz) Discord
-
Budget-Friendly GPU Clusters: Engineers discussed a cost-effective alternative to TinyBox using six RTX 4090 GPUs, resulting in up to a 61.624% cost reduction compared to the $25,000 TinyBox model. The emphasis was on achieving 144 GB of GPU RAM within a budget.
-
A Potential BatchNorm Bug: George Hotz called for a test case to investigate a potential bug in tinygrad's batchnorm implementation, following a user's concern about the order of operations involving
invstdandbias. -
Navigating Tinygrad's Documentation Work: Participants recognized the need to enhance tinygrad documentation, with ongoing efforts to make strides towards more comprehensive guides, particularly as the system evolves from version 0.9 to 1.0.
-
Strategies for Model Conversion: Users are exploring ways to convert models from ONNX to WebGL/WebGPU efficiently, targeting memory optimization by potentially leveraging tinygrad's
extras.onnxmodule, as indicated by interest in Stable Diffusion WebGPU examples. -
Improving Tinygrad Development Experience: The community suggested increasing the line limit for merging NV backends to 7,500 lines, as seen in a recent commit, to balance codebase inclusiveness and quality, while addressing experiences of error comprehensibility.
Interconnects (Nathan Lambert) Discord
AI Models Flood the Market: EleutherAI has introduced the Pile-T5 with details shared in a blog post, while WizardLM 2 is drawing interest with its foundation transformer tech and guide on WizardLM's page. Additionally, Reka Core breaks onto the scene as explained in its technical report, and Idefics2's debut is narrated on the Hugging Face blog, amid Dolma going open-source under an ODC-BY license.
Graph Love and Hefty Models Emit Buzz: The community is showing keen interest in turning sophisticated graphs into a Python library for model exploration, while expressing mixed reactions to LLAMA 3's massive training scale of 30 trillion tokens.
WizardLM Vanishes with Abrupt Apology: Tension rose with the unexplained removal of WizardLM, with its model weights and posts erased, prompting speculation and an apology from WizardLM AI over a missed toxicity test, and a potential re-release in the pipeline.
Exploration vs. Intervention: A member considers whether to leave a bot to its own learning process or to step in, illustrating the fine line between letting algorithms explore and manual intervention.
Datasette - LLM (@SimonW) Discord
-
Debate on Data Annotation Necessity: In a recent discussion, participants explored whether the traditional practice of dataset annotation prior to training models is still critical given the rise of advanced LLMs. They pondered if in-depth understanding of datasets remains important or models can sufficiently learn patterns independently.
-
Transparency in LLM Demos Demanded: Dissatisfaction was voiced over LLM demos that lack open prompts, with users favoring clear insight into the model behavior to achieve desired outcomes without guesswork. Concerns were also raised about models inconsistently following privacy directives during tasks such as indexing sensitive information.
-
Streamlit Eases LLM Log Browsing: An LLM web UI for more user-friendly navigation of log data has been created using Streamlit, with an aim for simpler revisiting of past chats compared to Datasette. The interface currently supports log browsing and the creator provided the initial code via a GitHub gist.
-
Call for Interface Integration Ideas: Following the showcase of the web UI prototype, discussion ensued regarding the possibility of its integration either as a Datasette plugin or as a standalone tool, pondering the practicality and long-term utility of such enhancements.
-
Quest for a Consistent Indexing Tool: Exchanges highlighted the unpredictability of language models in handling tasks like newspaper indexing, particularly with models refusing to list names in adherence to privacy norms. The conversation underscored the need for more reliable tools and noted reaching out to Anthropic for assistance with model refusals.
Alignment Lab AI Discord
-
WizardLM2 Disappears from Hugging Face: The WizardLM2 collection on Hugging Face has vanished, and a collection update shows all models and posts are now missing. A direct link to the update is provided here: WizardLM Collection Update.
-
Potential Legal Concerns for WizardLM2: There's an unconfirmed question circulating about whether the removal of WizardLM2 is due to legal concerns, though no further information or sources are cited to clarify the nature of these potential issues.
-
Rush for WizardLM2 Resources: The community is actively seeking anyone who might have downloaded the WizardLM2 weights prior to their deletion.
-
Evidence of WizardLM2's Erroneous Deletion: A community member shared a screenshot that provides evidence that WizardLM2 was deleted as a result of improper testing. The screenshot can be viewed here: WizardLM2 Deletion Confirmation.
DiscoResearch Discord
LLama-Tokenizer Training Troubles: Engineering members shared challenges in training a Llama-tokenizer with the goal of achieving hardware compatibility via reduced embedding and output perceptron sizes. They explored scripts like convert_slow_tokenizer.py from Hugging Face and convert.py from llama.cpp to aid in the process.
Hunt for EU Copyright-Compliant Resources: There's an active quest to find text and multimodal datasets compatible with EU copyright laws for training a multimodal model. Suggestions for starting points included Wikipedia, Wikicommons, and CC Search to gather permissive or free data.
Sampling Strategies Examined: Discourse in the engineering circles revolved around decoding strategies for language models, emphasizing the need for academic papers to include modern methods like MinP/DynaTemp/Quadratic Sampling. A shared Reddit post offers a layman's comparison, while the conversation called for more rigorous research into these strategies.
Decoding Methodology Deserves a Closer Look: An examination of decoding methods in LLMs has exposed a gap in current literature, specifically related to open-ended tasks seen in operational models. Members expressed the need for in-depth research on advanced sampling methods and their impacts on model performance.
Creative Writing Boost with MinP Sampling: A notable performance boost in creative writing tasks was highlighted, with the alpaca-eval style elo score increasing by +8 and the eq-bench creative writing test seeing a +10 increment due to min_p sampling parameters. Such improvements signify the potential impacts of fine-tuning sampling strategies on LLM outputs.
Skunkworks AI Discord
-
NYC Event for Scaling Gen AI Apps: A General AI enthusiast meetup at Gunderson Legal in New York City will focus on scaling Gen AI applications to production stages. The event details and registration link are available here, alongside a note of participation by industry leaders from Portkey and Noetica.
-
Reka Core Emerges as a Strong Contender: A new video titled "Reka Core: A Frontier Class Multimodal Language Model" showcases Reka Core holding its own against competing models by OpenAI, Anthropic, and Google, highlighted in a YouTube video.
-
JetMoE-8B Achieves Cost-Efficient Superiority: The JetMoE-8B model, developed on a budget under $0.1 million, reportedly excels past Meta AI's LLaMA2-7B, a model created with significantly larger wealth, as revealed in a YouTube video.
Mozilla AI Discord
- Packaging Custom Models Just Got Easier: A community member's request for guides on packing customized AI models into a llamafile was noted, aiming to support peers in their endeavors.
- Docker Deployment Demystified: A GitHub pull request provided walkthrough steps for engineers to build and publish containers to Docker Hub using GitHub Actions, complete with necessary setting up of repository secrets like
DOCKER_HUB_USERNAMEandDOCKER_HUB_ACCESS_TOKEN. Publish container to Docker Hub.
The LLM Perf Enthusiasts AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Stability.ai (Stable Diffusion) ▷ #general-chat (1015 messages🔥🔥🔥):
- In Search of the Elusive SD3: The anticipated launch of Stable Diffusion 3 (SD3) remains a topic of speculation with various members inquiring about its release date, and many whimsically suggesting that it's a myth with satirical estimates like "April 26" or "April 69."
- Choosing an Image to Video Workflow: For those wanting to animate images, resources like ComfyUI workflows and Stability Forge are recommended. Some users experience difficulties running models directly in Python and seek advice on simple APIs for animation.
- Stable Diffusion with Different Technologies: Discussion threads touched upon various aspects of Stable Diffusion and related AI advances such as pixel art conversion to realistic images with models like SUPIR, and the transformation of pixelated images using img2img controlnet-based solutions like Fooocus or Magic Image Refiner.
- Prompt Crafting and Model Discussion: Users debate prompt engineering, with suggestions that you don't need to be an expert or take a course to craft an effective prompt; using platforms like civitai can give decent prompting baselines. New advancements like WizardLM-2 briefly appear before being deleted for untested toxicity.
- Casual Banter and AI Future Musings: The community casually jokes about "Stable Coin," "Stable Miner," and "university for prompt engineers," while also envisioning a world with advanced AI technologies like game style conversions and AI brain surgery, reflecting both humour and aspirational hopes for AI development.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #general (430 messages🔥🔥🔥):
-
Complications in Notebook Implementation: Members discussed the complexity of a certain task, mentioning they will need to create a detailed notebook for it. The process was acknowledged as complicated for both the members involved and the users.
-
Confusion over Crypto and TGE: A user asked about "mainnet" and "TGE" dates, leading to confusion among the chat participants. It was clarified that Unsloth AI is not associated with cryptocurrency.
-
Troubleshooting Technical Issues with Unsloth: Users faced issues with getting continuous outputs and package errors. It was suggested to use end-of-string markers (
</s>) to limit model generation, and members were advised to follow the Colab notebooks provided by Unsloth, which contain pre-configured settings. -
Discussions about Upcoming Model Releases: There were anticipations about potential new model releases, including discussions on "llama 3" and the difference between various Unsloth optimization tactics. Users shared resources and engaged in speculation based on reputation and past announcements, indicating a mix of excitement and nervousness about the potential workload a new release could bring to the team.
-
Contributions and Contributions to Unsloth: Individuals expressed interest in both contributing to Unsloth documentation and making a one-time financial contribution. It was mentioned that contributions focused on expanding Unsloth's Wiki, particularly regarding Ollama/oobabooga/vllm, would be valuable, and the team expressed openness to community involvement in improving their documentation.
-
Surrounding Controversy and Reupload of WizardLM: A notable incident was discussed concerning the re-upload of WizardLM versions on various platforms following the original release getting pulled due to a missed toxicity test. Multiple users exchanged information about the reuploads and the reasons for the original takedown.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #random (6 messages):
- Coding an Emotional LLM: ashthescholar. indicated that they are working on the skeleton for an "emotional" large language model (LLM) and are about to start coding, looking forward to sharing their progress.
- Syncing Up With Chroma's Roadmap: lhc1921 shared their plans to work on an edge version of Chroma with libSQL (SQLite) in Go and WASM, partially inspired by another member's strategy on making on-device training possible. The work is in collaboration with taz, a key Chroma contributor, and the repository can be found on GitHub - l4b4r4b4b4/go-chroma.
Link mentioned: GitHub - l4b4r4b4b4/go-chroma: Go port of Chroma vector storage: Go port of Chroma vector storage. Contribute to l4b4r4b4b4/go-chroma development by creating an account on GitHub.
Unsloth AI (Daniel Han) ▷ #help (322 messages🔥🔥):
- Unsloth Assists Data-Driven Chatbot Upgrade: A member discusses formatting personal chat messages for training an AI clone of themselves via Unsloth and gets assistance including a Python script for converting the dataset into ShareGPT format, and advice on using this script with their personal data to create a training-ready dataset. They were also directed to a related Unsloth notebook.
- LoRA Tweaking for Enhanced Training: Users report varying the alpha parameter during fine-tuning a model using LoRA. For rslora, it's suggested that alpha be double the rank value, though the exact optimal value may vary by case.
- ORPO Support with Unsloth: According to a member, ORPO, which optimizes the resources required for model training, is already supported within Unsloth. The ORPO method differs from DPO by not requiring a separate SFT (Supervised Fine-Tuning) step beforehand.
- CUDA Learning and Triton's Promise: A participant new to CUDA gets advice to lean on Triton tutorials for learning and advised that Unsloth does not recommend native CUDA, instead suggesting Triton as more beneficial for LLM work.
- Unsloth and Gemma: For best results, don't use packing with Gemma models. The Unsloth library is compatible with packing for Llama and Mistral, and configurations with high-rank adapters may exhibit unexpected loss jump issues during training.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #showcase (47 messages🔥):
- Benchmark Buzz: Members discussed a first benchmark's performance and shared encouraging remarks, such as proclaiming it looks "fantastic" and "pretty good."
- Model Template Mysteries: A user queried how a leaderboard discerns the model template, which was clarified by another member pointing to
tokenizer.chat_template. - Squeaky Clean Data: A dataset named ShareGPT90k was pushed in a cleaned and ChatML format, with HTML tags like
<div>and<p>replaced with empty strings. The user urged others to use thetextkey when training with Unsloth AI. - Anticipating Ghost's Recipe: Debates arose around the accessibility and vulnerability of training recipes for LLMs, particularly regarding a model named Ghost. Users discussed the importance of data quality over fine-tuning techniques and gave a nod to the importance of gaining experience through experimentation rather than relying on predefined recipes.
- Sharing Academic Insights and Resources: Conversations included sharing valuable resources like detailed research papers and YouTube tutorials explaining advanced AI concepts like Direct Preference Optimization. One user specifically looked forward to learning about the training approach behind the Ghost model.
Links mentioned:
Modular (Mojo 🔥) ▷ #general (60 messages🔥🔥):
-
Kapa.AI Brings Instant Answers to Discord Communities: Kapa.AI offers customizable AI bots that provide instant technical support in communities such as Slack and Discord. Their bots can be added to servers to improve developer experience by providing immediate answers and eliminating wait times, which is elaborated on their community engagement use-case page and their Discord installation documentation.
-
Exploring Compilation Optimization with Mojo Language: A discussion on using aliases for compile-time parameter decisions in Mojo language revealed that using such methods can lead to memory optimizations as unused aliases don't reserve memory space after compilation. For more nuanced opinions on code clarity versus comments, a YouTube video on the subject was shared.
-
Understanding Typestates and Memory Efficiency: Conversing about the benefits of typestates over aliases, a member recommended a technique from Rust for making compile-time guarantees about object state, as described in an article about Rust typestates. The discussion evolved around memory use optimizations in language design, specifically how boolean values are stored and addressed in memory.
-
Bit-Level Optimizations in Programming Languages Explored: The chat shed light on why language specifications, like those in C, define enums as 32-bit integers and debated whether bools need to use a full byte. These topics touched on processor-level memory allocation and the potential efficiencies in memory usage at the language-level, referencing how boolean values could be represented more compactly as bits within a byte.
-
Rust's BitVec Crate Offers Both Speed and Memory Efficiency: The discussion concluded by endorsing Rust's BitVec crate for being both speed and memory efficient when handling sets of boolean flags. An example cited was an optimization case which improved performance, going from taking years to just minutes, by using a bitset in Rust, as detailed on willcrichton.net.
Links mentioned:
Modular (Mojo 🔥) ▷ #💬︱twitter (5 messages):
- Modular Tweets a Mystery: Modular shared a cryptic message on Twitter, enticing curiosity without context.
- The Plot Thickens with Another Tweet: Shortly after, Modular posted another enigmatic tweet, maintaining the suspense.
- Three's a Charm for Modular's Teasers: Continuing the trend, Modular released a third tweet, adding more intrigue.
- Modular's Tweet Streak Unbroken: The string of mysterious messages from Modular extended with a fourth tweet.
- Fifth Tweet Keeps the Mystery Alive: Modular capped off the series with a fifth mysterious tweet, leaving followers in anticipation.
Modular (Mojo 🔥) ▷ #ai (2 messages):
- Mojo Replication Buzz: A member expressed interest in replicating an unidentified feature or project within Modular (Mojo), signaling enthusiasm for the platform's capabilities.
- Unlocking AI Agents' True Potential: A member shared a YouTube video explaining the creation of long-term memory and self-improving AI agents in a concise 10-minute presentation, potentially offering valuable insights for fellow enthusiasts.
Link mentioned: Unlock AI Agent real power?! Long term memory & Self improving: How to build Long term memory & Self improving ability into your AI Agent?Use AI Slide deck builder Gamma for free: https://gamma.app/?utm_source=youtube&utm...
Modular (Mojo 🔥) ▷ #🔥mojo (541 messages🔥🔥🔥):
- Mojo Adaptation of Python Tools: A new Python package called mojo2py has been developed to convert Mojo code to Python code, indicating a growing interest in tools that bridge the gap between Python and Mojo. The repository is available on GitHub.
- Learning Mojo Essentials: For those looking to learn Mojo from scratch, the Mojo Programming Manual is the go-to comprehensive guide, with emphasis on core concepts such as parameters versus arguments and understanding traits.
- Introducing Conditional Conformance: There is an ongoing discussion about the potential for conditional conformance in Mojo, allowing for behaviors like structural patterns found in other languages such as C++ or Haskell, though there may be challenges when it comes to generic code.
- Variant Type for Runtime Flexibility: The usage of
Variantas a way to create a list containing multiple types akin to Python is validated, with the point made thatVariantacts more like a tagged union at runtime, akin to ADTs in TypeScript. - Efforts on Syntaxes and Representation: Multiple members are actively discussing possible improvements to Mojo's syntax for function signatures and type representation, including the use of
'1numerals to avoid verbose naming in partially-bound types, and Treesitter grammar/LSP development for broader integrations beyond VS Code.
Links mentioned:
Modular (Mojo 🔥) ▷ #community-projects (4 messages):
-
Mojo meets gRPC: A community member is working on integrating functional Mojo code with legacy C++ via IPC to improve product performance.
-
Hunting for the Updated Llama: A member inquires about an official version of Llama2 and shares a guest blog post by Aydyn Tairov about building the project. They have attempted to update the project to v24.2.x and provided a link to their work-in-progress on GitHub.
-
Llama2 Gets Official MAX API: In response to a query about Llama2, another member directs to the official llama2 in MAX graph API available on GitHub.
-
Mojo Code - Python Transformation Tool: A new Python package called mojo2py has been created by a community member to convert Mojo code into Python code, with the repository available here.
Links mentioned:
Modular (Mojo 🔥) ▷ #nightly (12 messages🔥):
- Jank Over Traits: The discussion humorously criticized the lack of trait parameterization with a preference for what's referred to as jank.
- Indentation Anarchy: One user lamented the lack of proper indentation in for loops, which prompted a mix of laughter and light-hearted agreement over the importance of indenting code.
- Leveling Up in Modular: <@244534125095157760> was congratulated for reaching level 9 in what appears to be a gamified system within the Modular community.
- Code Formatting Peer Pressure: There's a jest about giving in to peer pressure regarding code formatting, indicating a light-hearted conversation about personal coding styles within the community.
- Mojo Nightly Update Announced: A new Mojo update called
nightly/mojohas been released, with members encouraged to update and check the diff on GitHub and the changelog on their changelog page.
Links mentioned:
Perplexity AI ▷ #general (549 messages🔥🔥🔥):
-
Confusion Over Subscriptions and Payment Methods: Members reported instances of unexpected charges despite using promo codes and concerns about managing payment methods for Perplexity API. Promises for improvements to show main payment methods on the Perplexity website were mentioned by a user presumed to be a team member.
-
Perplexity Pro Message Counter Disappears: Users have noticed that the message counter, indicating the number of messages left for Perplexity Pro users, is not being displayed unless under 100 messages are left. A member with a presumed team role confirmed this change and cited user reports of reduced stress as the reason, while others expressed dissatisfaction with the removal.
-
Perplexity Performance and Model Updates: Some users express that Perplexity seems to be forgetting the context more quickly than before and question the reasoning behind changes to features such as the Pro message counter. Inquiries about the integration of GPT-4-Turbo-2024-04-09 into Perplexity were met with referenced previous statements, suggesting members refer to discussions in the official channel.
-
AI Models and Coding: There's a consensus among users that AI models are still lacking in coding capabilities, with GPT-4 mentioned as underperforming despite being better than its predecessors. Perplexity's diverse model offerings are acknowledged, but some feel that the original models are superior in performance.
-
Payment and Subscription Issues Discussed: Members discussed issues with promotional codes and billing confusion. One user pointed out a lack of clarity in managing payment methods for the Perplexity API, while others voiced concerns about not seeing promo code options upon checkout. A response from user ok.alex indicated upcoming improvements to the payment method visibility.
Links mentioned:
Perplexity AI ▷ #sharing (12 messages🔥):
- Exploring Perplexity AI: Members shared various searches on Perplexity AI, exploring topics such as Microsoft testing ads, World Art Day, and methods to act as an Ichjogu.
- Celebrating Days of Art and Voice: Searches were conducted related to World Art Day and World Voice Day, highlighting community interest in global cultural observations.
- Inspecting Tech and Games: Discussions included searches on Microsoft's test ads, Atari, and Amazon Web Services hardening guide.
- Music and Lyrics Searches: Members showed an inclination towards music by searching for lyrics to the song "SBK Borderline" and the phrase "Whatever It Is".
- Curiosities in Costs and Queries: The community delved into diverse inquiries, from asking about the cost of certain items to requesting explanations in Portuguese.
Perplexity AI ▷ #pplx-api (3 messages):
- Inconsistency in Perplexity Pro vs. API Answers: A member expressed difficulty with getting different responses when using Perplexity Pro compared to the API. There is a desire to understand settings like the temperature that the web client uses to try and match API results for consistency.
- Constraints on API Source Material: Another question was raised about the possibility of limiting API responses to content from specific websites. There is concern about responses containing possible hallucinations and incorrect source attributions.
LM Studio ▷ #💬-general (210 messages🔥🔥):
-
Collaborative Agents on LM Studio: Users are excited about agents working together in LM Studio and are anticipating a Windows version. An automated compilation process is mentioned as a necessary step before releasing the Windows version.
-
User Queries on Model Performance and Use: There are questions regarding model performance, specifically related to coding capabilities of models like Mistral. Another user inquired about multi-GPU support without NVLink for models in LM Studio.
-
WizardLM-2 Model Integration: Users discussed integrating WizardLM-2 models into LM Studio and shared community model links such as MaziyarPanahi/WizardLM-2-7B-GGUF on Hugging Face. The specifics of model naming and partitioning for Mixtral 8x22B were examined, as well as system requirements like VRAM for effective model usage.
-
Interest in AI Model Tuning and Agents: A discussion took place about the possibility of using LM Studio to create personal AI agents or assistants and the use of external tools for fine-tuning models to specific tasks. Resources for fine-tuning, like the LLaMA-Factory on GitHub, and agent creation tools were shared.
-
Mistaken Code Recognition and Dataset Tools: Users shared experiences with models incorrectly identifying programming languages, and techniques like adding context to prompts were suggested. Additionally, links for toolsets like Unstructured-IO for dataset creation were provided for those looking to build custom preprocessing pipelines.
Links mentioned:
LM Studio ▷ #🤖-models-discussion-chat (108 messages🔥🔥):
-
Python Coding Models Highlighted: Members discussed various Python coding models such as Deepseek Coder, Wizzard Coder, and Aixcoder, with recommendations to check the 'human eval' score for assessing model performance on coding challenges. Some models, like Aixcoder, are noted for writing code directly, while others also provide conversational interaction.
-
Skepticism and Praise for WaveCoder: WaveCoder Ultra, a model based on DeepseekCoder 6.7B, receives mixed feedback; some praise its performance, while others show skepticism about its superiority and hint at possible "faked results." It’s mentioned that Microsoft has released three WaveCoder models with varying performances, with WaveCoder Ultra touted for its performance on coding the snake game.
-
Questions on Vision Models and Java Coders: Discussion on the LM Studio Discord includes inquiries about good models for Swift/SwiftUI development and Java coders. Responders suggest that most coder models are generally trained on languages rather than tailored specifically to one.
-
Contours of Model Performance: Debates center on the tradeoffs between model size, quantization, and performance, with opinions varying on the effectiveness of 7B models versus more aggressively quantized larger models. While some users prefer the Q8 quant for 7B models, others argue that lower-quality quants of larger models may not retain higher intelligence.
-
Text-to-Image Generation Limits and Preferences: A member clarifies that text-to-image generation is not a task that LM Studio can do. Suggestions for alternative tools include GUI: DiffusionBee and using Automatic1111 for text-to-image tasks outside of LM Studio.
Links mentioned:
LM Studio ▷ #📝-prompts-discussion-chat (15 messages🔥):
-
Error Plague Hits LM Studio: A member grappled with an error when trying to load a model in LM Studio, even after attempts to uninstall and revert to default settings. They shared a code snippet of the error message, but the cause remained undisclosed with an "Unknown error" description and an exit code: 42.
-
GPU Offload: A Double-Edged Sword?: One member advised turning off the GPU Offload to circumnavigate loading issues, but the original poster faced dilemmas about performance degradation and continued error messages, even after disabling it.
-
Fresh Start for Frustrated User: In light of persisting issues with model loading, a solution was proposed to perform a full reset of LM Studio by deleting specific directories on the user's machine. The instructions included paths such as C:\Users\Username.cache\lm-studio and others, with a reminder to back up important data.
-
NexusRaven Prompting Queries Emerge: Another member jumped into the conversation with a query about prompt presets for NexusRaven, indicating a shift in topic towards AI model customization.
-
From Partial to Full Scripts: A succinct request was made for assistance in compelling NexusRaven to write complete scripts, hinting at challenges with the model outputting partial content.
LM Studio ▷ #🎛-hardware-discussion (21 messages🔥):
- VRAM Misidentifications Confuse Users: A member encountered a strange error pointing towards AMD hardware on an Intel-based Linux system and discussed potential issues with libOpenCL. They had hoped that installing
ocl-icd-opencl-devwould emulate a GPU, but continued to face loading failures even after altering GPU layers. - Link Lost in Chat: Members struggled to locate a previously mentioned Google sheet for GPU comparisons, and despite posting links, the exact resource in question remains unfound.
- Subreddit for Meta's Llama Model Discussed: A user shared a Reddit link that discusses achieving peer-to-peer communication with GPUs, theorizing potential benefits for bypassing CPU/RAM and enhancing performance.
- Memes Add Light-heartedness to Tech Talk: In the midst of technical discussion, a member shared a humorous George Hotz GIF from Tenor, possibly reflecting their feelings on the ongoing software wrestle or symbolizing a breakthrough.
- Hardware Allocation Challenges for Dual GPUs: One member is seeking advice on managing uneven model distribution between a
4070 TI 12GBand a4060 TI 16GBin their system to favor the larger GPU.
Links mentioned:
LM Studio ▷ #🧪-beta-releases-chat (26 messages🔥):
-
VRAM vs. RAM for Running Models: A member questioned if models could run on a system with 24 GB VRAM and 96 GB RAM, and there's concern that inference might be incredibly slow. Another found success with an M3 MacBook Pro 128GB, running models at speeds comparable to GPT-4 using LMStudio and MLX, achieving up to 10 tokens/sec.
-
Performance of Command R Plus and WizardLM-2-8x22B: A user reported they will test WizardLM-2-8x22B and share results. Another user was not impressed with Mixtral 8x22b and pondered whether its base model status affected performance.
-
Understanding Base Models: Users discussed what constitutes a "Base" model, clarifying that it's one that hasn't been fine-tuned for specific tasks like chat or instruct. There was a mention that any base model could potentially be prompted to perform various tasks.
-
Model Comparison and Fine-Tuning Considerations: A member reported getting over 10 tokens/sec on both MaziyarPanahi/WizardLM-2-8x22B.Q4_K_M and Command R Plus, with both prompting the model to write a simple Rust application successfully. Discussions also covered whether models continuously learn from chat and the concept of "forgetting" certain knowledge areas during fine-tuning.
-
Potential Implicit Bias in AI Models: It was suggested that AI models might be biased towards math, IT, AI, and computer vision, reflecting the interests of the developers and a majority of users. Queries were raised on whether models are always learning from interactions and the simplicity of fine-tuning models to forget unwanted knowledge domains.
LM Studio ▷ #amd-rocm-tech-preview (8 messages🔥):
-
Signed, Sealed, Delivered, It's Windows!: A member inquired about whether the Windows executables are signed with an authenticode certificate. The response confirmed that they are indeed signed.
-
Certificate Signing Curiosity: The same member expressed curiosity regarding the signing process, mentioning they didn't recall any notifications about it since Windows generally doesn't notify users once an application is signed.
-
Windows vs. Apple Developer Licenses – The Cost of Security: The member voiced their frustration over the costliness of acquiring a Windows certificate compared to an Apple developer license, highlighting the added financial burden due to the requirement for a hardware security module (HSM).
-
Seeking Knowledge on Compile and Signing Processes: The member sought advice on automating the compile and signing process for their app and expressed willingness to offer something in exchange for this shared expertise.
LM Studio ▷ #open-interpreter (1 messages):
rouw3n: Anyone here got the 01light software running on windows without problems ?
LM Studio ▷ #model-announcements (2 messages):
-
WizardLM 2 7B Shines in Multi-Turn Conversations: A new model, WizardLM 2 7B, has been highlighted for its excellent performance in multi-turn conversations. Available on Hugging Face, it employs novel training techniques as detailed in the associated blog post and mentioned at the end of the model card.
-
WaveCoder ultra 6.7b Fine-Tuned with CodeOcean: Microsoft's recent release, WaveCoder ultra 6.7b, is recognized for its code translation capabilities and is fine-tuned with their 'CodeOcean' platform, combining open-source code and models like GPT-3.5-turbo and GPT-4. The model can be explored and downloaded on Hugging Face, and it follows the Alpaca format for instruction following.
Links mentioned:
Nous Research AI ▷ #off-topic (18 messages🔥):
-
Quantization-Friendly AI Model Unveiled: AI practitioner, carsonpoole, highlighted a binary quantization-friendly AI model on Hugging Face with the intention of making embeddings more memory-efficient. The approach is detailed in this cohere blog post, which discusses reducing memory costs significantly by using int8 and binary embeddings.
-
Innovative Model Training Technique Explained: Further explaining the technique, carsonpoole emphasized that contrastive loss and the sign of model output are used, acting as the model's training mechanism. The method aims to maintain high search quality with the model performing well even with compressed embedding formats.
-
Cohere Embedders Training Available Through API: carsonpoole confirmed that while Cohere's embedders are currently not accessible outside of their API, the newly trained models serve to enable similar functionalities.
-
Understanding Binary Embedding Distances: In response to sumo43's query, carsonpoole clarified that embedding distance in binary cases is calculated using an XOR operation, equating to hamming distance.
-
Showcase of Multimodal LLM and Cost-Efficient Model: pradeep1148 shared YouTube videos introducing "Idefics2 8B: Open Multimodal ChatGPT" and "JetMoE: Reaching LLaMA2 Performance with 0.1M Dollars," showcasing advancements in the cost-effective development and capabilities of language models. Links to videos: "Introducing Idefics2 8B", "Reka Core: A Frontier Class Multimodal Language Model", and "JetMoE: Reaching LLaMA2 Performance with 0.1M Dollars".
Links mentioned:
Nous Research AI ▷ #interesting-links (4 messages):
-
Auto-Code Rover Making Moves: The Auto-Code Rover by NUS is an autonomous software engineer that's project structure aware and aims for autonomous program improvement. It reportedly resolved 15.95% of tasks in the full SWE-bench.
-
Auto-Code Rover Outperforms Devin: Mention of the Auto-Code Rover suggests it performs better than another AI, Devin, in software engineering tasks, and by a decent margin.
-
Google's CodecLM Framework Revealed: Google AI introduces CodecLM, a machine learning framework for generating high-quality synthetic data for language model alignment, discussed in a MarkTechPost article.
Links mentioned:
Nous Research AI ▷ #general (208 messages🔥🔥):
- No Affiliation with Nous Team: A token launched with OpenML is not affiliated with the Nous team despite using their name, and the team has requested that their name be removed from the project.
- Mysterious Take-down of WizardLM-2: The WizardLM-2 model was taken down unexpectedly, with suggestions ranging from it being too toxic and violating the EU AI act to missing evaluations. Links to download preserved versions of the model weights were shared, hinting at the community's rush to secure their own copies.
- Mistral Instruct Shows Impressive Progress: A member reported progress in fine-tuning the Mistral instruct v0.2, with the score improving from 58.69 to 67.59, surpassing many competitors but still behind others.
- Qwen Releases Code-specific Model: Qwen introduced CodeQwen1.5, a strong code-generation model for 92 coding languages and boasting high scores on benchmarks, including humaneval. A 7B version is available, and references were made to even larger 14B and 32B variants.
- AI Video on Long Term Memory and Self-Improvement: A video discussing long-term memory and self-improving AI agents with auto-generated teachability was shared with the community.
Links mentioned:
Nous Research AI ▷ #ask-about-llms (39 messages🔥):
-
Hermes 2.5 Inference Issues: A user highlighted problems with llama.cpp and the OpenHermes 2.5 Mistral 7B model from Hugging Face, facing difficulties with tokenized outputs for end-of-sequence predictions in Rust. They seek advice on configuration or model issues causing this.
-
Reka AI Showcases Its Model: In a shared showcase, Reka AI's Core model is presented as competitive with OpenAI's and others, with highlights stating it is on par with GPT-4V, Claude-3 Opus, and Gemini Ultra for various tasks. A subsequent link to Reka's news announcement elaborates on the Core's training and efficiency.
-
Hermes 2 Pro's Extended Context Quirks: OctoAI reports odd behavior with Hermes 2 Pro Mistral 7b when processing requests with a context longer than 4k, suspecting the issue relates to the model's sliding window functionality and seeking experience sharing about using this model with long contexts.
-
Citation Mechanisms in RAGs Lacking Uniformity: A member suggests that in Retriever-Augmented Generation models (RAGs), citation functionality typically depends on the system designer, pointing to Cohere's approach as an example but noting a lack of models generating their own source IDs.
-
Fast Model Downloading from Hugging Face: Users discussed ways to speed up downloads from Hugging Face, with one offering the
HF_HUB_ENABLE_HF_TRANSFER=1environment variable and pointing to Hugging Face's guide for faster downloads using the Rust-based hf_transfer library.
Links mentioned:
Nous Research AI ▷ #rag-dataset (9 messages🔥):
- Discovering the RAG/Long Context Reasoning Dataset: A link to a Google Document was shared, purportedly related to the RAG/Long Context Reasoning Dataset, although the content of the document wasn't visible due to the browser version being unsupported. Users are recommended to upgrade their browser based on the Google Support Page.
- Defining the Limits of Long Context: A member inquired about the limit of long context in relation to the number of documents or datasets like Wikipedia, though no specific answer was provided within the discussion.
- Introduction of Cohere Compass: Compass, a new foundation embedding model, was introduced and is distinguished by its ability to index and search against nested json relationships. The Cohere Compass beta offers a novel approach to handling multi-aspect data commonly found in enterprise information.
- Considerations for Structured Data Inputs: In relation to the discussion about Cohere Compass, a member noted that having json structure input outputs for data like what Compass offers would be beneficial, indicating less complexity in implementation.
- Inquiry and Response about State-of-the-Art Vision Models: A user asked about the best open-source vision models for a RAG with many images and diagrams related to engineering; another user responded with suggestions like GPT4v/Geminipro Vision and Claude Sonnet but specified that there is a need to test to see which performs best for certain cases. Open-source options, however, were not specified in the given excerpt.
Links mentioned:
Nous Research AI ▷ #world-sim (87 messages🔥🔥):
-
WorldSim as a Divine Sandbox: Messages in the channel reflect an excitement and anticipation for the inventive potential of WorldSim, with comparisons made to the omnipotence of gods and the introduction of dynamic, unexpected creativity similar to quantum probability.
-
Game Development Revolutions on the Horizon: Discussions consider the impact of LLMs on future game design, speculating on spell creation systems that could affect in-game physics and procedurally generated content that could significantly enhance narrative and environmental complexity.
-
Eagerly Awaiting WorldSim's Return: The chat contains several expressions of eagerness for the return of WorldSim, with members discussing the possibilities of the project, sharing their hopeful plans for its relaunch, and wondering about the exact time for the comeback announcement.
-
Websim's "Jailbroken Prometheus" and The Aura of Mystery: A link to a Websim featuring a "Jailbroken Prometheus" was shared, sparking discussions about the virtual entity's updated abilities and its interactions with users, ranging from engaging discussions to refraining from certain joke topics.
-
Artistic Inspirations from AI Interaction: Participants share personal anecdotes about their creative pursuits inspired by AI platforms, like WorldSim and Websim, emphasizing AI's role in creative thinking and expression, and extending an invitation to the community to share their AI-inspired art.
Links mentioned:
OpenRouter (Alex Atallah) ▷ #announcements (15 messages🔥):
-
WizardLM-2 Series Now on OpenRouter: The WizardLM-2 8x22B and WizardLM-2 7B models are now available on OpenRouter. The 8x22B model's cost has been reduced to $0.65/M tokens, with discussion ongoing in a specific thread.
-
Latency Issues Under the Microscope: High latencies were reported for Mistral 7B Instruct and Mistral 8x7B Instruct. An update was provided implicating an upstream issue with one of the cloud providers, which was resolved after identifying overly-aggressive DDoS protection.
-
Potential Latency Woes Return: The latency problem seemed to reoccur, potentially impacting Nous Capybara 34b and other traffic. The issue is under investigation, and one cloud provider is being deranked to mitigate the issue. Users from different world regions are encouraged to report if affected.
Links mentioned:
OpenRouter (Alex Atallah) ▷ #app-showcase (6 messages):
-
Seeking Beta Testers for New AI Platform: A new advanced research assistant and search engine named Rubiks.ai seeks beta testers, promising 2 months free premium access to various models like Claude 3 Opus, GPT-4 Turbo, and Mistral Large. Interested users can sign up using the promo code
RUBIXand are encouraged to provide feedback via DM. -
Early Subscription Hiccups: A user subscribed to the Pro version of a service with a promo code but encountered an issue where they are repeatedly prompted to subscribe again.
-
Comfy-UI Complements Development: A member praised the use of comfy-ui in the context of a development project, noting that it seems like a natural fit for this type of development.
-
Developer Search for AI Roleplay Frontend: A community member is seeking a web developer to assist with a project aimed at creating a general-purpose AI frontend for OpenRouter, with an emphasis on roleplay elements. The individual is currently learning on the job and expressed a need for both development help and teaching.
-
Design Assistance for Narrative and Interface Features: The same member has completed a novel mode for their project but requires assistance with the development of a conversational style mode and differentiating user-written text from AI-generated text. They are also looking to implement a flexible modal system within their interface.
Link mentioned: Rubik's AI - AI research assistant & Search Engine: no description found
OpenRouter (Alex Atallah) ▷ #general (258 messages🔥🔥):
-
Falcon 180B Chat's Massive Requirements: Users discussed the addition of Falcon 180B Chat GPTQ, noting its significant GPU memory requirement of around 100GB. The discussion included references to the Falcon 180B repository and its compatibility requirements.
-
Cost Calculation Tips for Tokenization: The chat addressed how to calculate costs per word for models, suggesting an average of 1.5 tokens per word as a good estimate, including considerations for punctuation marks and whitespaces.
-
Compliance with Prompting in Language Models: Airoboros 70B was mentioned as a model that effectively follows prompts, for example by avoiding euphemisms and using colloquial language, whereas other models may not be as responsive.
-
Excitement and Concerns Over New WizardLM Model: An announcement by a user about the release of a new model, WizardLM2, led to discussions about its features and comparisons to GPT-4. There were concerns about its removal from its original host due to a mysterious "missing internal process."
-
Weather Talk Amidst Model Discussions: Amidst the technical discussions, several users commented on the current weather in their locations, ranging from hot conditions to rain in Abu Dhabi, showcasing the global diversity of the chat participants.
Links mentioned:
CUDA MODE ▷ #general (8 messages🔥):
- Seeking PyTorch Knowledge: A member inquired if "Deep Learning with PyTorch" is the best starting point for going deeper into PyTorch, acknowledging the presence of two authors in the channel.
- Book Content Relevance Questioned: Due to the book being 4 years old, there was a concern regarding the relevance of its syntax for current PyTorch usage.
- PyTorch Fundamentals Still Strong: One member reassured that while the PyTorch core has not changed significantly, areas such as the compiler and distributed computing have evolved, but the book remains a good starting point.
- Transformers, LLMs, and Deployment Sections Outdated: Another member indicated that the book's content on transformers and LLMs is nonexistent, and the deployment section is now outdated.
- Anticipation for a New Edition: A member expressed curiosity about the potential release of a new edition of the book to cover recent developments.
CUDA MODE ▷ #cuda (30 messages🔥):
-
Full Graph Compilation Issues Resolved: After discussion, it was noted that using
torch.nn.functional.linearand disabling CUDA graph withenable_cuda_graph=Falsecan mitigate compilation issues faced withtorch.compileset tofull_graph=True. The token generation speed varies with and without full graph compilation but stable-fast could serve as an effective substitute in case of failures. -
Stable-fast's Utility Beyond Stable Diffusion: The use of stable-fast for optimizing inference proved to be beneficial, running close to INT8 quant TensorRT speeds. It was recommended for wider use beyond just Stable Diffusion models due to performance gains.
-
Exploring Fused Operations: A suggestion was made to extend stable-fast with more types of fused operations, highlighting the library's potential versatility.
-
CUDA Graphs Not Always Helpful: It was pointed out that CUDA graphs don't necessarily aid performance due to the overhead of recreating graphs for dynamic context lengths typical in autoregressive generation models.
-
GitHub Resource for Faster Matrix Operations: A new fp16 accumulation vector-matrix multiplication that rivals torch gemv was added to torch-cublas-hgemm, potentially offering a substantial boost in efficiency for specific matrix sizes.
Links mentioned:
CUDA MODE ▷ #torch (2 messages):
- Custom Backward Confusion: A member is working on custom backward operations that work with a
(bs, data_dim)input, similar toF.Linear, but faces issues when implementing within Llama due to a different input shape(bs, seq_len, data_dim). They are seeking the forward/backward implementation ofF.Linearand were unable to locate it intools/autograd/templates/python_nn_functions.cpp, asking for guidance or a Pythonic implementation.
CUDA MODE ▷ #cool-links (2 messages):
-
Automated Transcript Available for GPU Computing Talk: An automated transcript of a talk on Shared Memory and Synchronization in CUDA is available, featuring automatically created notes and the ability to do Q&A. The transcript can be accessed at Augmend Replay.
-
Augmend Offers Cutting-edge Video Processing: The platform, wip.augmend.us, is currently able to process videos, incorporating features like OCR and image segmentation to capture information directly from the screen. The main site augmend.com will soon offer the ability to process any videos with these advanced capabilities.
Link mentioned: Advancing GPU Computing: Shared Memory and Synchronization in CUDA: no description found
CUDA MODE ▷ #beginner (2 messages):
-
Newcomer Inquiry about PMPP Lectures: A member inquired about the schedule and progress of meetings for going through PMPP lectures. They were interested in the frequency of meetings, the current chapter the group is on, and whether the lectures are recorded.
-
Where to Find Lecture Recordings: Another member responded with a welcome and directed the newcomer to a specific channel (<#1198769713635917846>) to find the recorded lectures. They also updated that the last covered chapter of the PMPP book in the lectures was the 10th.
CUDA MODE ▷ #pmpp-book (4 messages):
- Vector Processing Dilemma: A member completed Chapter 2 and inquired about the best configuration for processing a 100-length vector with a choice between (blockDim = 32, blocks = 4) or (blockDim = 64, blocks = 2). Another member advised that both setups are acceptable, but also suggested an alternative of using (blockDim = 32, blocks = 1) with a for loop inside the warp for thread coarsening.
- Back to the Book After Midterms: A participant mentioned they will resume reading from Chapter 4 after their midterms, which are expected to end by approximately the end of the month.
CUDA MODE ▷ #youtube-recordings (8 messages🔥):
-
Weekend Talk Availability: A member inquired if the weekend's talk was recorded, confirming that although there is a live recording available, a better-quality version will be posted by tomorrow.
-
Recording Quality Matters: A re-recording of the weekend's talk is in progress to enhance the quality, following the intention to provide the best version possible.
-
Overseas Members Valuing Recordings: The recordings are appreciated, especially for members in different time zones who find attending live lectures at 3/5 AM challenging.
-
Pre-talk Tech Check to Ensure Quality: A member requested a way to test their setup before their scheduled talk to avoid any technical issues; they were advised to join early for a run-through.
-
Latest Lecture Video Shared: A link to the YouTube video titled "Lecture 14: Practitioners Guide to Triton" was shared, along with its corresponding GitHub lecture description.
Link mentioned: Lecture 14: Practitioners Guide to Triton: https://github.com/cuda-mode/lectures/tree/main/lecture%2014
CUDA MODE ▷ #torchao (2 messages):
- TorchAO Tensor Layout Optimization Suggestion: A member suggested that torchao could optimize tensor layout, as matrix multiplication operations could benefit from pre-swizzled weight storage and padded dimensions, potentially improving performance.
- Torch.compile Already Handles Some Optimizations: In response to the tensor layout optimization suggestion, another member clarified that torch.compile already deals with certain optimizations like padding (see config code) and layout optimization (see layout optimization code).
Links mentioned:
CUDA MODE ▷ #triton-puzzles (4 messages):
- Solutions for Triton Puzzles Available: A link to open solutions for Triton Puzzles was shared, available at Zhaoyue's GitHub Repository. The contributor invited feedback and expressed readiness to remove the solutions if necessary.
- Tutorial Video in the Works: Confirmation was given that sharing open solutions is acceptable, with a mention of a forthcoming tutorial video.
CUDA MODE ▷ #hqq (35 messages🔥):
-
Increased Efficiency with Torchao Int4 Kernel: A rewrite of the generation pipeline for transformers now supports torchao int4 kernel, resulting in a performance increase to 152 tokens/sec from 59 tokens/sec with FP16, reflecting substantial improvements aligning with gpt-fast benchmarks.
-
Accuracy Improvements in HQQ Quantization: A member noted improved accuracy in newer HQQ+ results, with a Wiki Perplexity drop from 7.3 to 6.06, and questioned if this involved corrections from the official GitHub implementation of HQQ.
-
Resolving HQQ and GPT-Fast Compatibility Issues: There's an ongoing discussion on how quantization axis (0 or 1) affects model performance where one member observed non-ideal interactions with gpt-fast’s pipeline when using
axis=0. There’s active exploration of optimizing alongaxis=1, including utilizing fake data for autograd, and combining HQQ with LoRA. -
Code Push for Tensor Cable Support and Autograd Optimizers: The mobiusml team shared a code push demonstrating how torch int4mm can work with Hugging Face transformers, reaching up to 154 tokens/sec. Also released were experimental optimizers using autograd and fake data with potential for further iteration speed improvements.
-
Vectorized FP16 Multiplication Possibilities And Future Plans: Participants also discussed the potential use of vectorized fp16 multiplication from a Triton kernel repository to speed up the quantized operations; one user emphasized that using
__hmul2for half precision float multiplications could further enhance performance.
Links mentioned:
CUDA MODE ▷ #llmdotc (129 messages🔥🔥):
- CUDA Functionality Expansion and cuDNN Discussion: A member introduced their own rudimentary llm.C project, prompting a discussion about whether optimizations like cuDNN for gelu/softmax operations have been addressed and reasons for not utilizing cuDNN. The size of cuDNN and its impact against the project's goals were debated, leading to suggestions for potential integration as comparison points while considering the project's principles.
- Project Goals and Direction Clarified: The project lead clarified the dual goals: educating with hand-written kernels for various layers and striving to create highly efficient kernels that rival those of CUTLASS, cuDNN, or any tool that offers significant performance gains. The importance of maintaining simple code while achieving performance was emphasized, even if it means foregoing minor gains for disproportionate complexity.
- Optimization Steps and Profiling: Various members participated in a technical discussion about optimization strategies. This included ideas such as exploiting padding for performance and using vectorized loads. It was agreed that profiling is a necessary first step to determine optimization targets, implying a need for analyzing kernels, particularly attention and softmax kernels.
- Emerging PRs and Optimizations: Several members shared their work on different PRs related to optimizing the current implementation, which included discussions about potential speedups by avoiding calculating the full probability matrix when unnecessary, and considering fusing operations within matmul layers. Specific attention was given to a fused classifier kernel and other potential easy gains.
- Data Sets and Benchmarks for Training: There was a conversation about selection of pretraining datasets like SlimPajama, Dolma, and MiniPile, as well as the difficulty in evaluating and comparing to GPT-2. A suggestion was made to integrate the ability to generate a GPT model at initialization to facilitate benchmarking and prevent hyperoptimization for the current model shapes.
Links mentioned:
CUDA MODE ▷ #recording-crew (9 messages🔥):
- Volunteer for Recording and More: A member, mr.osophy, offered to handle recording, live streaming, clipping, as well as updating the video description and the repository.
- Teamwork on Recording Duties: Another member, marksaroufim, mentioned that someone else (ID: 650988438971219969) is also interested in recording. They have been asked to coordinate for the recording setup.
- Backup Recording Plans: Marksaroufim plans to record the upcoming talk as a backup but will skip doing so the following week.
- Coordination Confirmed: Genie.6336 confirmed reaching out to Phil (presumably ID: 650988438971219969) via direct message to discuss recording responsibilities.
- Role Name Brainstorming: Members brainstormed on a role name, with suggestions like "gpu poor" by muhtasham and "Massively Helpful" by mr.osophy being offered in a light-hearted context.
Eleuther ▷ #announcements (1 messages):
<ul>
<li><strong>Introducing Pile-T5</strong>: EleutherAI has released <strong>Pile-T5</strong>, an enhanced T5 model family trained on the Pile with up to 2 trillion tokens, showing improved performance on SuperGLUE, code tasks, MMLU, and BigBench Hard. The models leverage the new LLAMA tokenizer and can be further finetuned for better results.</li>
<li><strong>Intermediate Checkpoints Available</strong>: Intermediate checkpoints of Pile-T5 have been made available in both HF and original T5x versions, inviting the community to explore and build upon this advance in NLP models.</li>
<li><strong>Comprehensive Resources for Pile-T5</strong>: Check out the <a href="https://blog.eleuther.ai/pile-t5/">detailed blog post</a> introducing Pile-T5 and the rationale behind its development, and access the code on <a href="https://github.com/EleutherAI/improved-t5">GitHub</a> to implement these improvements in your own projects.</li>
<li><strong>Spreading the Word on Twitter</strong>: The release of Pile-T5 has also been announced on <a href="https://x.com/arankomatsuzaki/status/1779891910871490856">Twitter</a>, providing insights into the model's training process and highlighting its open-source availability.</li>
</ul>
Links mentioned:
Eleuther ▷ #general (61 messages🔥🔥):
- Discussions on Model Sharing and Access: A member inquired about sharing a new model based on LLaMA, and another guided them to a specific channel for llama finetunes. However, the original poster reported they lacked permission to post there.
- Missing Discord Emotes and TensorBoard Expertise: Conversation included lighthearted regret over missing custom emotes. Also, a user sought documentation on Tensorboard's event files format and expertise in Tensorboard.
- Exploration of Alternative Layer Configurations: Sentialx queried the potential effects of splitting a single large layer into parts and adding them with weighted averaging. This prompted another member to liken it to a dot product, with varying reports on effectiveness based on personal experience.
- Tokenizer Comparisons and Model Release Processes: Users compared Pile-T5 and LLAMA tokenizers, noting differences such as vocabulary and support for newlines. Furthermore, a tweet by WizardLM was discussed, mentioning an omission in their model release process -- toxicity testing.
- Latest on Encoder-Decoder Models and Compute Requirement Predictions: A new encoder-decoder model named Reka was highlighted, reportedly supporting up to 128k, sparking conversations about the rarity of encoder-only or encoder-decoder models with long sequence lengths. Meanwhile, advice was sought on predicting compute requirements for reinforcement learning in LLM research, with a latent space article suggested as a starting point for estimating an upper bound of transformer compute requirements.
Links mentioned:
Eleuther ▷ #research (137 messages🔥🔥):
-
Exploring the Limits of Language Models in Video Generation: Diffusion models for video generation pose a more challenging problem than image synthesis due to the need for temporal consistency and difficulty in collecting high-quality video data. Pre-read material on Diffusion Models for image generation is recommended for better understanding.
-
Examining Tokenization's Role in Language Models: Research paper from Berkeley shows the significance of tokenization in language modeling. Without tokenization, transformers default to unigram models, but tokenization permits near-optimal modeling of sequence probabilities.
-
LLMs as Data Compressors: A study (arXiv:2404.09937) finds that perplexity is highly correlated with downstream performance when evaluating language models. This supports the idea that model compression capabilities may facilitate artificial intelligence development.
-
Challenges in Scaling Transformers to Unlimited Context Length: The introduction of Megalodon and Feedback Attention Memory (FAM) (arXiv:2404.08801 and arXiv:2404.09173) demonstrates attempts to improve transformer efficiency for handling long sequences.
-
Debate on Depth vs. Mixture-of-Experts (MoE) Models Efficacy: Discussions centered around whether dense models or MoE models are superior, with considerations of VRAM constraints and inference cost. No clear consensus was reached, but various angles on advantages and constraints for each model type were debated.
Links mentioned:
Eleuther ▷ #lm-thunderdome (27 messages🔥):
-
OpenAI Unlocks GPT-4-Turbo Eval Implementations: OpenAI has made public their evaluation implementations used for GPT-4-Turbo, allowing contributions through GitHub. The repository can be found at openai/simple-evals on GitHub.
-
Few-Shot Prompts Labeled Relics of the Past: It was mentioned that few-shot prompts are considered remnants of base models, with zero-shot chain-of-thought prompts now being favored for robust inference.
-
Continuous Tasks Added to Evaluation Harness: A contribution to the
lm-evaluation-harnessincludes the addition of newflores-200andsib-200benchmarks, aiming to enhance multilingual evaluation for translation and text classification. Contributions can be reviewed in the respective pull requests: Implement Sib200 evaluation benchmark and Implementing Flores 200 translation evaluation benchmark. -
Technical Discussion on Big-Bench-Hard Evaluation: A user inquiring about evaluation times for the
big-bench-hardbenchmark received advice on speeding up the process by adjusting the batch size or usingaccelerate launch, with mentions of changes to task names likebbh_cot_zeroshot. -
Exploring LLM Compression as a Marker of Intelligence: An interesting discussion topic arose around whether looking at Bits Per Character (BPC) as a unit of information could serve as a beneficial perspective in evaluating language model intelligence. A Twitter post and respective GitHub repository provide context for the conversation.
Links mentioned:
Eleuther ▷ #gpt-neox-dev (7 messages):
- Decay Impact Limited by Weight Activation: A member discussed that weight decay might only impact weights that are activated, suggesting if it's built into the optimizer and the model employs dummy tokens, those may not be affected due to lack of gradients.
- Sanity Checks for Arbitrary Model Adjustments Under Scrutiny: The effectiveness of sanity checks was questioned by a member, especially in cases where modifying values doesn't affect the model's performance, leading to suspicions that weights may not be decaying as intended.
- Initialization Consistency for Dummy Weights Questioned: One member signaled uncertainty about whether the dummy weights are initialized in the same manner as other weights within the model, which could influence their behavior.
- Dummy Weights Probably Initialized Similarly: Another member chimed in with insights implying that dummy weights are likely initialized the same as other weights, based on the norm comparison with ordinary tokens.
- Token Encoding Insights Shared: Token encoding behavior was highlighted by sharing code and output that compared several encoded and decoded tokens to demonstrate how specific tokens are transformed.
OpenAI ▷ #ai-discussions (167 messages🔥🔥):
-
Exploring the Neurobiological Basis of Language: A member shared a link to Language in Our Brain: The Origins of a Uniquely Human Capacity by Angela D. Friederici, discussing neurobiological differences in species that may explain the human capacity for language. This book offers insight into how language subcomponents are neurologically integrated.
-
The Data Glut Issue in Neuroscience: A conversation about recent neuroscience research highlighted the challenge of a 'DATA Glut'—massive amounts of MRI data from the Big Brain Projects are stored, but proprietary software/hardware combinations cause bottlenecks in data interpretation and dissemination.
-
AI and Human Comparison Debates: Members discussed the similarities and differences between AI and human beings, mentioning how AI systems cannot store learned information like humans and lack the ability to make independent decisions or feel emotions. The argument offered insight into current AI limitations and the philosophical implications of developing AI reasoning capabilities.
-
AI Research Tool API Availability: A member initially expressed issues accessing Claude 3 API in Brazil, but after checking the availability list and reattempting, they managed to gain access. This showcases the intricacy of accessing AI tools across different countries and the need for clarification on availability.
-
Discussion on Turing Completeness in Magic: The Gathering (MTG): Members debated whether MTG, a collectible card game, could be considered Turing complete, linking to an academic paper for further exploration. This initiated a broader conversation on the Turing completeness and its applications outside of traditional programming languages.
Links mentioned:
OpenAI ▷ #gpt-4-discussions (7 messages):
- GPT's Context Window a Known Limitation: A member lamented that OpenAI has yet to significantly increase GPT's context window, stating this as a limitation one needs to adjust to due to the current constraints on context size.
- ChatGPT vs. GPT Context Sizes Clarified: The API for GPT was mentioned, allowing up to a 128k context, whereas ChatGPT typically supports up to a 32k context.
- Extra Context Via API Document Uploads: When using the API for interaction, documents can be uploaded in playground assistants, extending the effective context window to 128k.
- Document Upload Feature Termed "Retrieval": The term "retrieval" was introduced to describe the process of uploading documents to expand context when using the API.
- Inquiries About GPT Dynamic: A user asked for clarification on what GPT Dynamic is and how it operates, indicating curiosity about newer or less-known functionalities.
OpenAI ▷ #prompt-engineering (3 messages):
- Seeking the Name of the Contest: A user inquired about the name of a certain competition.
- Short and Mysterious Reply: Another member simply responded with the word "buzz."
- Possible Pixar Reference?: A different user mentioned "light year," possibly alluding to Disney-Pixar's 'Toy Story' franchise character Buzz Lightyear.
OpenAI ▷ #api-discussions (3 messages):
- Inquiry About Competition Name: A member inquired about the name of a competition but did not provide further details.
- Onomatopoeic Interaction: Another individual simply contributed the word "buzz" without any context or additional information.
- Possible Competition or Project Mention: A reference was made to "light year" which could suggest the topic of a competition or project but lacked detail or clarification.
LlamaIndex ▷ #blog (3 messages):
-
Launch of IFTTT Agent Interfaces Tutorial Series: Agent interfaces and applications tutorial series announced, intended as an introductory course to clarify ambiguities around core agent interfaces and their uses.
-
Qdrant Engine Hybrid Cloud Debut: Qdrant Engine rolls out its hybrid cloud service in partnership with LlamaIndex, allowing users to host Qdrant across various environments.
-
Hybrid Search with Azure AI and LlamaIndex: Learn how to integrate LlamaIndex with Azure AI Search for enhanced RAG applications, offering features like hybrid search and query rewriting, in a new tutorial shared by Khye Wei from Microsoft.
LlamaIndex ▷ #general (117 messages🔥🔥):
-
Async Compatibility Query for Claude in LlamaIndex: A member inquired about async compatibility with Claude in Bedrock within LlamaIndex. Another member responded that async is not implemented for Bedrock and is open to contributions here.
-
Implementing Assistance Sought: When a member asked for help constructing complex queries, they were guided to examples in the LlamaIndex documentation.
-
Usage of Llama CPP Server in LlamaIndex: There were inquiries about using an async Huggingface embedding model with LlamaIndex through Sagemaker and using a hosted Llama CPP server for chat functionality. It was indicated that async compatibility needs to be implemented, with a suggestion to use an async boto session, and no clarity was provided on utilizing a hosted CPP server.
-
Troubleshooting Integration Issues: A member trying to use LlamaIndex with gpt-3.5-turbo encountered an authentication error, which might be due to an old version of the integration or missing balance on the Azure account. Updating LlamaIndex can potentially resolve this issue.
-
Agent Behavior Under Specific Conditions: An inquiry was made on how to condition an LLM to make decisions if no matching rows are found in a CSV file. No solution was provided within the messages, but the issue seems to involve configuring a fallback to a fine-tuned model.
Links mentioned:
LlamaIndex ▷ #ai-discussion (15 messages🔥):
- Efficient Reasoning Chain Integration: An article titled "Unlocking Efficient Reasoning: Integrating LlamaIndex with Chain of Abstraction" was shared, highlighting advancements between LlamaIndex and abstraction chains. The article can be found at Unlocking Efficient Reasoning.
- Positive Reception to Articles: A member commended the articles shared in the chat, particularly praising the one regarding efficient reasoning.
- Inquiry about Token Counter in RAGStringQueryEngine: A user sought advice on integrating a token counter into a RAGStringQueryEngine within LlamaIndex.
- Detailed Token Counter Integration Guide: An extensive step-by-step guide was provided for adding a token counter to the LlamaIndex's
RAGStringQueryEngine. It involves creating aTokenCountingHandler, aCallbackManager, and then assigning the manager to both global settings and the specific query engine. - Hierarchical Document Structuring Question: A user queried about building a hierarchical parent-child structure in LlamaIndex (ParentDocumentRetriever langchain) for managing millions of documents, seeking any leads or guidance.
Links mentioned:
LAION ▷ #general (108 messages🔥🔥):
- High-Quality TTS Library by Hugging Face: A link to the GitHub repository for Hugging Face's high-quality TTS models inference and training library, parler-tts, was shared.
- Incorrect Min-SNR-Gamma Implementation in Diffusers: A member noted that the min-snr-gamma formula in Diffusers might be incorrect for v-prediction. They are planning to use symbolic regression to find a better starting point after letting the current process converge.
- New Legislation on Deepfakes: Discussion on upcoming legislation targeting the creation of deepfake images intended to cause distress. Debate over the practicality of enforcing such laws and the focus on the intent behind creating the images.
- Misleading and Dishonest AI Projects Discussed: 'Stable Attribution' was pointed out as a misleading AI project from the last year. It was noted that misleading information about the project remains uncorrected in official publications.
- Beware of AI Scams: A potential scam targeting AI enthusiasts was mentioned. Users were advised to be cautious, as it appeared to be a fake company named Open Sora through a Facebook Ad.
Links mentioned:
LAION ▷ #research (17 messages🔥):
-
CLIP's Performance on a Budget Explored: A recent paper investigates the scaling down of Contrastive Language-Image Pre-training (CLIP) and suggests that high-quality data has a significant impact on model performance, even when dealing with smaller datasets. It further highlights that CLIP+Data Augmentation can match CLIP's performance using only half the training data, prompting discussions on data efficiency.
-
Pile-T5: A New Take on a Community Favorite: EleutherAI's blog post introduces Pile-T5, a modified version of the T5 model trained on the Pile dataset with the LLAMA tokenizer, covering double the token amount of the original model.
-
Launching a New Safety Benchmark for Language Models: The ALERT benchmark has been released, providing a new safety benchmark for assessing large language models with a focus on red teaming and potentially harmful content.
-
Text-to-Audio Generation Gets a Closer Look: An arXiv submission details efforts using the Tango model to improve the relevance and order of audio events generated from text prompts, aiming to boost performance in audio generation from text in data-limited scenarios.
-
Safety in AI: A Contentious Debate: Conversations about the establishment of safety benchmarks sparked discussions over the removal of content deemed unsafe for AI, the freedom in creative arts, and the balance between societal expectations and the capabilities of AI tools.
Links mentioned:
HuggingFace ▷ #announcements (10 messages🔥):
-
IDEFICS-2 Released with Multimodal Capabilities: The newly released Idefics2 boasts capabilities including image and text sequence processing, OCR enhancements, and high-resolution image handling up to 980 x 980. It competes with models such as LLava-Next-34B and performs tasks such as visual question answering and document understanding.
-
IDEFICS-2 Showcases Advanced Example: An example shared combines IDEFICS-2's understanding of text recognition, arithmetic, and color knowledge, effectively demonstrating its application by "solving" a CAPTCHA with significant noise.
-
Chatbot Format for IDEFICS-2 on the Horizon: While the current IDEFICS-2 model is tailored for tasks like visual question answering, an upcoming release will include a chatty version designed for conversational interaction.
-
Update Promised for Chat Variant: An interested party inquired about the chatbot variant of IDEFICS-2, to which it was mentioned that updates would be provided once a demo is available.
-
IDEFICS-2 Demonstrates Noise-Tolerant CAPTCHA Solving: IDEFICS-2 was showcased solving a CAPTCHA replete with a large amount of noise and extraneous text, highlighting its robust multimodal understanding and practical utility.
Links mentioned:
HuggingFace ▷ #general (72 messages🔥🔥):
- Mobile Discord Woes: A member expressed frustration regarding the mobile Discord version, mentioning it has taken a "weird turn" and appeared to downgrade, prompting agreement from others. The change seems to persist despite user feedback.
- Collaborative PRs on HuggingFace Hub: Members discussed whether it's possible to commit to someone else's PR on HuggingFace, with references to the HfApi.create_commits_on_pr documentation and general git best practices such as maintainer permissions and handling of PRs on forks.
- Generative Models on CPU and User Testing Opportunities: Users sought advice on generative art tools suitable for CPU use prioritizing speed, while another user invited the community for beta testing a new advanced research assistant and search engine with access to various advanced language models.
- Machine Learning Enthusiasts Needed for Survey: A Google Forms survey was shared by students researching the democratisation of machine learning, inviting participation from the ML community.
- Confusions in Checkpoint Conversions and Spaces Access: Users shared issues with conversion scripts erroneously asking for directories when files were provided and discussed the complication of internet providers blocking HuggingFace Spaces, where one space seemed unblocked for a user after being reported but others still experienced difficulties.
Links mentioned:
HuggingFace ▷ #cool-finds (4 messages):
- A Geometric Adventure on YouTube: A member shared a YouTube playlist that offers a visual journey through various concepts in geometry.
- Chain of Thoughts for AI: An article titled "Unlocking Efficient Reasoning: Integrating LlamaIndex with Chain of Abstraction" was shared, demonstrating how a structured searching method can enhance AI reasoning; read more on Locking Efficient Reasoning.
- Mysterious Machine Learning Source: A member posted a link which appears to be a shareable resource or dataset, but additional context was not provided. View it here: Link.
- Accelerated Artistry with AI: Check out this rapid image creation tool demonstrated at the HuggingFace Splatter Image space, which significantly speeds up the process of image generation.
Links mentioned:
HuggingFace ▷ #i-made-this (15 messages🔥):
-
Hyperparameter Experimentation: A member is experimenting with different training hyperparameters using their custom codebase and a model trained from scratch.
-
BLIP Model Fine-Tuning: A member has fine-tuned the BLIP model for generating long captions of images and launched a comparison of different models. They plan next to recaption some text-image datasets to fine-tune text-to-image models.
-
Musical AI Remix on GitHub: User
.bigdookiehas complexified a music creation project leading to an 'infinite' remix with musicgen-medium and shared it on GitHub. They also provided a YouTube demo and invited others to contribute. -
Community Highlights in Portuguese: The user
rrg92_50758shared a new YouTube video covering the Community Highlights #52 in Portuguese for the #huggingface Discord community. -
BLIP Model Usage Query: A discussion emerged on how to set maximum output length when using the BLIP model serverless inference through
curl. The conversation included links to the Hugging Face documentation and concluded with confirmation thatmax_new_tokensis the parameter to use. -
Stepping into Java for Image Recognition: A member shared a Medium article about using Gemini and Java for image recognition and function calling.
Links mentioned:
HuggingFace ▷ #reading-group (3 messages):
-
Join the LLMs Reading Group: A reminder for an upcoming free LLMs Reading Group session focused on the Aya Multilingual Dataset is scheduled for Tuesday, April 16th. Interested participants can RSVP here and explore the full 2024 session itinerary.
-
Linking to Google Calendar: For those looking to link the LLMs Reading Group events to their Google Calendar, it's noted that adding to the calendar can be done through Eventbrite after RSVPing to the sessions. Attendees are welcome to join any single session or multiple sessions as per interest.
-
Human Feedback Foundation's Role Highlighted: The Human Feedback Foundation supports the open-source AI community by integrating human input into AI models, particularly in critical areas such as healthcare and governance. The foundation aims to maintain a global database of human feedback to serve as a democratically sourced, authoritative dataset for AI developers.
Link mentioned: LLM Reading Group (March 5, 19; April 2, 16, 30; May 14; 28): Come and meet some of the authors of some seminal papers in LLM/NLP research and hear them them talk about their work
HuggingFace ▷ #computer-vision (2 messages):
- In Search of a Niche Vision Model: A member inquired about fine-tuning a vision model for captioning and identifying entities in low-resolution images. They stress the need for optimizing the model specifically for lower resolutions to avoid unnecessary complexity.
- Seeking an Advanced Tagger for SDXL: Another member asked for recommendations on sophisticated taggers for SDXL, hinting at a preference over the existing wd14 tagger.
HuggingFace ▷ #NLP (8 messages🔥):
-
NLP Beginners Start with spaCy and NLTK: A member began their NLP journey with spaCy and NLTK, and moved on to a contemporary textbook recommended within the community for more updated insights.
-
Deciphering Model Output: A user inquired about decoding a
batch_size, seq_size, emb_sizetensor into natural language using a T5 model. The attempt usingmodel.generatefailed due to requirements for a specific object structure includinglast_hidden_. -
Exploring LoRA Configurations: One user is experimenting with LoRA configurations for fine-tuning, seeking advice on the implications of changing the bias setting to 'all' or 'lora_only'.
-
Dataset Preparation for ROBERTA Q&A Chatbot: A member asked for guidance on preparing a CSV dataset with 100000 entries and over 20 features for fine-tuning a ROBERTA model for a question-answering chatbot.
-
BERTopic Framework in Discussion: Users discussed the BERTopic framework, a topic modeling technique that uses transformers and c-TF-IDF, highlighting its fast performance and good results with the option for guided, supervised, semi-supervised, manual, hierarchical, and class-based topic modeling (BERTopic Guide). The conversation touched on the need for including custom stop words and choosing an appropriate LLM for converting seed words into phrases.
Link mentioned: Home: Leveraging BERT and a class-based TF-IDF to create easily interpretable topics.
HuggingFace ▷ #diffusion-discussions (8 messages🔥):
-
Confusion Over Model Types Cleared Up: A new member inquired about the difference between LLMs and embedding models, specifically questioning the difference between the OpenAI Embedding model and OpenAI GPT-3.5 Turbo.
-
Token Limit Issue with Stable Diffusion Cascade Model: A member brought up an issue when using the stable diffusion cascade model with long prompts, encountering a token limit error where their input was truncated. They also shared a GitHub issue link where they detailed the problem.
-
Clarity on Token Truncation: In response to the confusion about the token limit, it was clarified that the message received was a warning, not an error, and that the truncated tokens, like 'hdr' in the example given, are indeed ignored.
-
Searching for Solutions to the Truncation Warning: The member expressed concern about the truncation warning being problematic, asking for potential solutions, with Compel library being mentioned as an exception.
-
Maintenance Questions Regarding the Compel Library: In response to the Compel library's mention, it was pointed out that Compel doesn't appear to be currently maintained. When queried about what maintenance was needed, there was no immediate response to specify the exact needs.
Link mentioned: error in using stable cascade with long prompt · Issue #7672 · huggingface/diffusers: Hi, When I use stable cascade model with long prompt, I get below error. Token indices sequence length is longer than the specified maximum sequence length for this model (165 > 77). Running this s...
Cohere ▷ #general (100 messages🔥🔥):
- User Reports Issue with Macedonian Translation: A member expressed concerns about the quality of Command-R when operating in Macedonian. They mentioned having reported this on the community-support channel.
- Inquiry About #computer-vision Channel Access: A user was seeking access to the #computer-vision channel and detailed the informative content and presentation schedules that feature in that channel.
- Making Chat Stream async in Python: There was a technical discussion on how to convert a piece of code into an asynchronous form to stream chat from the Command-R model efficiently.
- Questions About API Rate Limits: Queries about the trial key rate limits for Cohere's API were addressed, clarifying that "generate, summarize" has a limit of 5 calls/min, other endpoints have 100 calls/min, and there's a 5000 total limit across all trial API keys per month.
- Discussion About Cohere's Paid Production API: Members discussed the possibility of a paid program to access Commander R+ through Cohere. A link to the Cohere Production API documentation was shared, indicating that it already exists.
- Exploring Cohere's Chat API and Connectors: An inquiry was made about the functionality of the Chat API when used with connectors, and whether it manages embedding and retrieval processes. It was clarified that connectors are meant to link the model with sources of text and citations are an included functionality.
Links mentioned:
Cohere ▷ #project-sharing (1 messages):
- Rubiks.ai launches with a plethora of models: Rubiks.ai has launched an advanced research assistant and search engine. Users are offered 2 months of premium access free to test features including Claude 3 Opus, GPT-4 Turbo, Mistral Large, and other models like Mixtral-8x22B with RAG on Groq's high-speed servers.
Link mentioned: Rubik's AI - AI research assistant & Search Engine: no description found
OpenAccess AI Collective (axolotl) ▷ #general (56 messages🔥🔥):
-
Deepspeed Success on Multi-node: A member reported that Deepspeed 01 and 02 configurations work well on multi-node setups. A pull request with a guide for multi-node distributed fine-tuning using Axolotl was shared for anyone encountering configuration issues.
-
Idefics2 8B Outperforming its Predecessor: The Idefics2 model is now available on Hugging Face and enhances capabilities in OCR, document understanding, and visual reasoning, outperforming Idefics1 with fewer parameters and improved image handling. Access the model at Hugging Face.
-
RTX 5090 Launch Anticipation: Discussions suggest that Nvidia might release the RTX 5090 graphics card sooner than expected, potentially at the Computex trade show in June, due to competitive pressure, as reported on PCGamesN.
-
Mixtral 8x22B Inference Possibilities Explored: Members shared experiences with Mixtral 8x22B, noting that using 3 A6000 with FSDP for QLoRA during training, and theorizing that two A6000 could be sufficient for inference with up to 4k context length using 4-bit quantization.
-
Model Stock Method as Forgetting Mitigator: A comparison of different training methods on Cosmopedia-subset data indicates that Model Stock merge of various tuning methods is effective at repairing catastrophic forgetting. It was suggested that combined fine-tuning methods like Model Stock, QLoRA, GaLore, and LISA might reduce adaptation intensity, potentially needing louder LoRAs to compensate.
Links mentioned:
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (5 messages):
- Twitter Link Shared: A member shared a Twitter link, prompting reactions from others who found the content interesting. The precise content of the Twitter post is not described, but it elicited responses like "oh that's cool" and "oh nice."
- Seeking Guidance: One member expressed curiosity with "Oooooo how do I use this?" indicating a desire for guidance on the use of the content shared in the Twitter link.
OpenAccess AI Collective (axolotl) ▷ #general-help (11 messages🔥):
-
Gradient Accumulation Under Scrutiny: A member questioned the efficacy of gradient accumulation when using sample packing, as they observed that training time and dataset length change with varying gradient accumulation steps. The member was seeking clarity on whether gradient accumulation indeed conserves memory as expected.
-
Deciphering Input's Role in Training: One member inquired about the purpose of the input if
train_on_inputis disabled, speculating whether it's still used to teach the model context handling and prediction. Another member responded, suggesting that the input becomes a bigger part of the context, and the model will remember or steer towards it more. -
Clarifying Loss Calculation with
train_on_input: In a follow-up, it was clarified that whentrain_on_inputis enabled, the loss is not calculated with respect to the input, which subsequently influences the model training differently as it's not predicting the input part anymore. -
Understanding Impact of Loss on Training: The conversation continued with a discussion about the role of loss in training when
train_on_inputis on, leading to a confirmation that loss does not influence training in this scenario. It was also mentioned that without evaluation enabled, loss becomes even less relevant.
OpenAccess AI Collective (axolotl) ▷ #axolotl-help-bot (15 messages🔥):
- Axolotl's Epoch Dilemma: A member sought advice on how to configure Axolotl to prevent saving the model after every epoch and instead save only upon completion of training. The recommendation involves setting the
save_strategyto"no"in the training arguments orconfig.yml, and then manually setting up a save operation after training ends. - TinyLlama for Tight Spaces: For fine-tuning with a smaller-than-7B model, the "TinyLlama-1.1B-Chat-v1.0" was suggested for fast iteration and experimentation. This model's configuration can be found in the
pretrain.ymlwithin theexamples/tiny-llamadirectory in the Axolotl repository.
Links mentioned:
OpenAccess AI Collective (axolotl) ▷ #axolotl-phorm-bot (4 messages):
- Fine-Tuning TinyLlama with Color Descriptions: To fine-tune TinyLlama on a dataset with hex color codes and descriptions, one must first format the data with inputs as the color descriptions and target outputs as the color codes. Tokenization and formatting will follow using special tokens to concatenate inputs and outputs for the model's understanding.
- Phorm Query Pending Resolution: A question was raised about preprocessing data for model finetuning; Phorm was prompted to search the OpenAccess-AI-Collective/axolotl for answers. The response from Phorm with detailed steps is awaited.
Link mentioned: OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
Latent Space ▷ #ai-general-chat (89 messages🔥🔥):
Links mentioned:
Latent Space ▷ #ai-announcements (1 messages):
-
Grants Galore for AI Gurus: Strong Compute announces grants ranging from $10k-$100k for AI researchers needing access to High Performance Computing clusters. Eligible projects include exploring trust in AI, post-transformer architectures, new training methods, Explainable AI, and more ingenious topics applicants might propose.
-
GPU Bounty up for Grabs: Applicants stand a chance to win up to ~100x 24GB Ampere GPUs, along with ~1+TB storage per researcher. The total compute provided can translate to approximately 3,000-30,000 GPU hours depending on allocation and market dynamics.
-
Open Science, Big Prizes: Researchers must commit to publishing a public access demo, with code and a data sample—or ideally, the full dataset. The aim is to have results ready for publication by the end of July.
-
Application Countdown: Those interested should apply immediately through Strong Compute research grants page, as compute allocation decisions will be made by the end of April. Applicants can expect a response within two business days.
-
Inquiry Channels for Curious Minds: For questions, researchers are encouraged to reach out to community members tagged in the announcement.
Link mentioned: Research Grants: no description found
OpenInterpreter ▷ #general (51 messages🔥):
- Join the Innovation Brainstorming: A new channel has been introduced for brainstorming innovative uses of OpenInterpreter, bug bashing, and feature building.
- Airchat Buzz Among OpenInterpreters: Members are joining Airchat, a voice communication app, sharing handles like 'mikebird' and 'jackmielke', seeking invites, and discussing its features and usability.
- Anticipation for 01 Project Updates: Questions regarding the status and updates of the 01 project prompted responses about ongoing discussions with manufacturing services and anticipation for delivery timelines.
- Open Source AI Takes the Spotlight: Enthusiasm is shown for WizardLm2, an open source model compared to GPT-4, with excitement about the progress in AI and the availability of such models with open weights.
- Personal AI Assistant Search: Discussions revolved around the search for a personal AI assistant that offers speedy responses and integration of personal data for improved efficiency, with comparisons between products like the 01 and Limitless AI.
Links mentioned:
OpenInterpreter ▷ #O1 (25 messages🔥):
- Pre-order Cancellation Query: If you need to cancel an 01 pre-order, simply send an email to [email protected].
- Windows 11 Installation Blues: Some custom PRs are out to assist with 01 installation on Windows 11; however, they await merger. Meanwhile, it's noted that the software works but is tuned more for macOS.
- Attention Linux Users: For anyone using Linux, check out rbrisita's GitHub branch with all outstanding PRs for 01 merged. This branch is tested on Python 3.10 and 3.11.
- Hardware Compatibility Discussions: Users report various experiences with 01—some using official Light setups, others opting for economical alternatives from AliExpress. The consensus is it's fine for a demo but expect differences in mic accuracy and hardware performance.
- Minified 01 Design Endeavors: Members are sharing updates on their custom 01 designs—from cases that can be printed for free to battery optimizations with 18650 cells for longer life.
Links mentioned:
LangChain AI ▷ #announcements (1 messages):
- Revamped Documentation Structure: LangChain is seeking feedback on a new documentation structure, which explicitly differentiates between tutorials, how-to guides, and conceptual guides. The structure aims to make it easier for users to find relevant information.
- LangChain Framework Introduction: The shared documentation page provides a comprehensive introduction to LangChain, an open-source framework designed to streamline the application lifecycle of large language models (LLMs)—from development and productionization to deployment.
Link mentioned: Introduction | 🦜️🔗 LangChain: LangChain is a framework for developing applications powered by large language models (LLMs).
LangChain AI ▷ #general (43 messages🔥):
-
Concurrent Execution in LangChain: It is confirmed that you can run nodes in parallel in LangChain using the
RunnableParallelclass. Detailed usage examples are provided for both Python and JavaScript, with Python documentation showing how multiple Runnables can be executed simultaneously, returning a map of the outputs. -
Troubleshooting Azure AI Issues: Members are seen discussing issues around using certain versions of LangChain and encountering problems with the neo4jVectorIndex and
faiss-cpu. Specific advice includes downgrading LangChain to version 0.1.10 and trying out thelangchain_communitybranch for resolving issues. -
Role-Based Access Control (RBAC) and LangChain: A conversation around implementing RBAC in large companies using LangChain involved suggestions like specifying specific files for retrieval based on a user's role and potentially denying answers with a prompt.
-
Finetuning Models for YC Application: A member is interested in applying to YC with an idea on finetuning models for agents and is seeking information on whether this has been done before. They are informed of numerous startups such as Unsloth, mistral ai, and Holocene Intelligence already addressing this area.
-
Engagement and Collaboration Invitation: Several invitations and offers for assistance and discussion were apparent, including offers to help with running nodes in parallel, issues with document splitting, personalizing recommendations, and short conversations on working with LLM applications.
Link mentioned: Safeguarding AI: Strategies and Solutions for LLM Protection | LLM Security: Explore the security challenges and solutions of LLMs in this comprehensive guide. We cover potential risks, control mechanisms, and the latest tools for safer LLM application
LangChain AI ▷ #langserve (1 messages):
- Integration Challenge with Nemo Guardrails: A member inquired about successfully integrating LangServe with a chain that includes Nemo Guardrails, noting that a new output parser might be required due to structural changes introduced by Nemo. There's a request for advice or shared experience on this matter.
LangChain AI ▷ #share-your-work (6 messages):
- Rag Chatbot Gets a Performance Boost: The update to the rag chatbot scripts introduces multiprocessing for improved performance, specifically in parsing text with Spacy for Chroma metadata keys.
- Perplexica AI, the Open-Source Search Engine: ItzCrazyKns announces Perplexica, an open-source AI-powered search engine with features like citations, image and video search, and multiple focus modes, positioned as an alternative to Perplexity AI.
- Pay Humans with AI: A tool called Payman is shared, allowing AI agents to pay humans to complete tasks beyond their abilities, using Langchain Custom Tools. Those interested can try the demo or sign up at paymanai.com.
- Free Premium AI Models Access with Galaxy AI: GalaxyAI offers free access to PREMIUM AI models including GPT-4, GPT-3.5-turbo, and Claude-3-haiku with OpenAI format API compatibility.
- AI-Powered Coding with OppyDev: OppyDev introduces an AI-assisted coding tool that integrates agents like GPT-4 and Claude, featuring an IDE, a chat client, a project memory, and color-coded edits. A demo and full feature set are available at oppydev.ai.
- Rubiks AI Invites Beta Testers: Rubiks AI is building an advanced research assistant and search engine, offering beta testers 2-months premium access with various models including GPT-4 Turbo and Mixtral-8x22B. Interested testers should visit rubiks.ai and can use the promo code
RUBIX.
Links mentioned:
LangChain AI ▷ #tutorials (3 messages):
- Join The Club: A member expressed interest in joining an ongoing project or discussion and requested a direct message for more details.
- Learn about AI Agents with Long-term Memory: A video was shared explaining how to build self-improving AI agents with long-term memory. Those interested can view it here.
Link mentioned: Unlock AI Agent real power?! Long term memory & Self improving: How to build Long term memory & Self improving ability into your AI Agent?Use AI Slide deck builder Gamma for free: https://gamma.app/?utm_source=youtube&utm...
tinygrad (George Hotz) ▷ #general (32 messages🔥):
-
Cost Analysis of DIY GPU Cluster: A cost comparison was made between a hypothetical array of six RTX 4090 GPUs and TinyBox configurations, highlighting a 36.04% price decrease from the $15,000 TinyBox and a 61.624% price reduction from the $25,000 option, with both setups having 144 GB of GPU RAM.
-
MNIST Handling in Tinygrad: There are ongoing discussions about the ideal approach for handling MNIST dataset conversions within tinygrad, weighing options between updating examples to use tensor datasets, conversion upon calling, or reshaping before conversion.
-
Improving Tinygrad Documentation: There is an acknowledgment of the need for more complete public documentation for tinygrad, with confirmation that it's an area being actively worked on for improvement.
-
Developer Experience is Key in Tinygrad: Emphasis was placed on focusing on improving the developer experience for tinygrad, moving from version 0.9 to 1.0. Challenges with error comprehensibility were reported after replicating LLM.c training steps.
-
Efforts on MLPerf Plans and Codebase Management: Updates were provided on MLPerf plans, including the progress on ResNet and a potential first run of UNet3D and BERT on TinyBox, with a decision made to raise the line limit for merging NV backends to 7,500 lines to promote code inclusion and quality.
Link mentioned: hotfix: bump line count to 7500 for NV backend · tinygrad/tinygrad@e14a9bc: You like pytorch? You like micrograd? You love tinygrad! ❤️ - hotfix: bump line count to 7500 for NV backend · tinygrad/tinygrad@e14a9bc
tinygrad (George Hotz) ▷ #learn-tinygrad (7 messages):
-
BatchNorm Bug Hunt: A user questioned the correctness of multiplying by
invstdand then addingbiasin batchnorm operations within tinygrad. George Hotz indicated that this could be a bug and requested a minimum test case to reproduce it. -
Metal Compute Shaders Without Xcode: @taminka inquired about resources for running a basic Metal compute shader program without Xcode, while testing tinygrad's shader generation. Another user recommended using ChatGPT to generate a Python script that utilizes PyObjC for dispatching Metal shader code.
-
From ONNX to WebGL/WebGPU: @spikedoanz is looking for guidance on converting models from ONNX to WebGL/WebGPU, aiming to use tinygrad as an alternative to TensorFlow.js for better memory control. They shared a Stable Diffusion WebGPU example and asked about the feasibility of such a conversion using tinygrad's
extras.onnxmodule.
Interconnects (Nathan Lambert) ▷ #news (4 messages):
-
Pile-T5 Unveiled: EleutherAI has released Pile-T5, introduced in a detailed blog post, marking another step in the advancement of language models.
-
Magic in WizardLM 2: The WizardLM 2 model, featuring foundation transformer technology, catches attention with its fresh release and a guide available at WizardLM's page.
-
Reka Core Launch: A new Encoder-Decoder model by Yi Tay, Reka Core, has been detailed in a technical report, which you can deep dive into here.
-
Introducing Idefics2: The landscape of language model development gets richer with the introduction of Idefics2, as detailed on the Hugging Face blog.
-
Dolma Embraces Open Source: In an exciting development, Dolma has been made open-source with an ODC-BY license, frosting an intense day of announcements in the open-source community.
Interconnects (Nathan Lambert) ▷ #random (29 messages🔥):
- Graphs Take Center Stage: Enthusiasm was shown for well-crafted graphs in the recent newsletter, with plans to further refine them into a Python library for exploring new open models.
- LLAMA 3 Packs a Punch with 30T Tokens: Significant surprise and skepticism were expressed upon discovering that LLAMA 3 was trained on more than 30 trillion tokens, hinting at potential complexities in evaluating its performance.
- Mysterious Removal of WizardLM: Concern and intrigue arose surrounding the sudden deletion of WizardLM's model weights and associated announcement post. The model seemed to disappear from official Microsoft collections, while a mirror of the model remains on Hugging Face.
- WizardLM Controversy Spawns Apology: WizardLM AI issued an apology for the premature release of its model, attributing the error to a missed toxicity test and promising a re-release soon.
- Fate of WizardLM Weights and Code: There was a flurry of activity regarding the availability of WizardLM model weights and code, with confirmation that they are still accessible, despite the official takedown, pointing towards a likely return.
Links mentioned:
Interconnects (Nathan Lambert) ▷ #sp2024-history-of-open-alignment (1 messages):
natolambert: should I wizardLM 2 as a troll lol
Interconnects (Nathan Lambert) ▷ #posts (2 messages):
- Playtime with Bots: A member mentioned experimenting with a bot and pondered whether they should wait longer rather than intervening manually.
Datasette - LLM (@SimonW) ▷ #ai (8 messages🔥):
-
Machine Learning Enthusiast Seeks Dataset Annotation Opinions: The conversation opens with an individual's preference for data annotation before model training, sharing their practice of understanding datasets before letting a model learn patterns and questioning if annotation still holds importance in the era of powerful LLMs.
-
Historical Records Team Balances Data and Models: A team member responsible for extracting records from historical documents talks about their current practice, which involves gathering and curating data before using pre-LLM transformer models.
-
Frustration over Opaque LLM Demos: One user expresses discontent with demos that don't provide open prompts, preferring transparency for a better understanding of how to get advantageous results from models without resorting to guesswork.
-
Indexing Task Hurdles with Model Refusals: Users share challenges they face while indexing newspapers with the help of language models, especially when the model inconsistently adheres to privacy directives regarding the listing of names.
-
Exasperation with Model Inconsistencies: The inconsistencies of the model's response to tasks related to indexing personal information from the 1930s newspapers are highlighted, alongside a note about contact with Anthropic regarding a model's refusal to share the information as instructed.
Datasette - LLM (@SimonW) ▷ #llm (22 messages🔥):
-
Creating a Simplified LLM Web UI: A member has created a simple web UI for browsing LLM log data, offering more intuitive interaction than Datasette for viewing logs and the goal of easier revisiting of past chats. The prototype was made with Streamlit, and the initial version is for log browsing only, as the APIs appear to lack easy retrieval of past conversations.
-
Prototype Showcase and Discussion: The Streamlit-built UI prototype was shared in the chat, and another member expressed interest in knowing how it was built. The conversation expanded to discuss possibilities of integrating it as a Datasette plugin or as a standalone installable script.
-
Implementation and Tool Choice: The creator described their experience as positive with Streamlit, a first-time use, though they initially considered building it as a plugin for either Datasette or LLM.
-
Future Development and Sharing: While the current iteration is focused solely on browsing, it was mentioned that the app is around 200 lines and thus easy to work with. A GitHub gist link to the code was provided: Initial LLM WebUI Gist.
-
Understanding Discord Thread Mechanics: There was a brief confusion from the web UI creator about the nature of threading in Discord and whether it operated more like Slack. Another member clarified how participation impacts thread visibility.
Link mentioned: Initial LLM WebUI: Initial LLM WebUI. GitHub Gist: instantly share code, notes, and snippets.
Alignment Lab AI ▷ #oo (7 messages):
- WizardLM2 Collection Vanishes: Discussion emerged around the disappearance of WizardLM2 from Hugging Face, with a collection update showing that all models and posts had been deleted 22 hours ago, leaving the collection empty.
- Legal Eagles May Be Circling: Speculation suggests that the withdrawal of WizardLM2 might involve legal intervention, without specifying details.
- A Quest for Weights: In the wake of the deletion, there was an inquiry about whether anyone had already downloaded the weights of the WizardLM2 model.
- Confirmation of Deletion with Screenshot: A participant provided a screenshot confirming that WizardLM2 was deleted due to a failure to test it properly, available at this direct image link.
Link mentioned: WizardLM - a microsoft Collection: no description found
DiscoResearch ▷ #general (6 messages):
-
In Search of the Elusive tokenizer.model: A member is seeking advice on how to train a custom Llama-tokenizer, emphasizing the need to reduce embedding and output perceptron size for lightweight hardware compatibility. They are familiar with training Hugging Face tokenizers but have encountered difficulties in generating the required
tokenizer.modelfile for llama.cpp. -
Tips on Tokenizer Conversion: Another member suggested consulting the Hugging Face Transformers library, specifically pointing out the convert_slow_tokenizer.py script that may aid in the conversion of a slow tokenizer.
-
Potential Shortcut for Custom Tokenizer: To address the tokenizer training issue, a different member recommended the llama.cpp convert.py script with a
--vocab-onlyoption as a possible solution for creating a custom tokenizer. -
Quest for EU Copyright-Compliant Data: A member has reached out to the community in search of EU text and multimodal data that is copyright permissive or free, with the intent to train a substantial open multimodal model.
-
Sources for EU Permissive License Data: In response to the data hunt for copyright permissive or free EU multimodal data, one member suggests Wikipedia as a potential text source, while another highlights Wikicommons and CC Search for multimodal data, albeit they may not offer extensive collections.
Links mentioned:
DiscoResearch ▷ #benchmark_dev (1 messages):
-
Sampling Techniques in the Spotlight: A member highlighted their interest in decoding strategies for language models, sharing a Reddit post with an image comparing sampling techniques. They discussed the paper "A Thorough Examination of Decoding Methods in the Era of LLMs" but expressed that open-ended tasks relevant to their experiences with LLMs were not adequately covered.
-
Advanced Sampling Methods Untouched by Academic Papers: It was mentioned that modern sampling methods like MinP/DynaTemp/Quadratic Sampling, developed by u/kindacognizant, are not featured in academic papers despite their widespread use in various LLM frameworks. The member felt that these methods warrant more research attention.
-
Significant Boost in Creative Writing Performance: The member shared their discovery of the considerable impact that min_p sampling parameters have on creative writing performance. The observed differences totaled an impressive +8 points in alpaca-eval style elo and +10 points in the eq-bench creative writing test.
Link mentioned: Reddit - Dive into anything: no description found
Skunkworks AI ▷ #off-topic (4 messages):
-
Gen AI Scaling Secrets Revealed in NYC: A meetup is announced for General AI enthusiasts at Gunderson Legal in New York City, focusing on scaling Gen AI apps to production. Interested participants can register here and the panel includes leaders from companies like Portkey and Noetica.
-
Exploring Reka Core's Capabilities: A YouTube video titled "Reka Core: A Frontier Class Multimodal Language Model" was shared, detailing how Reka Core competes with models from OpenAI, Anthropic, and Google.
-
Cost-Effective AI Model Outperforms Giants: The JetMoE-8B model, trained with less than $0.1 million, reportedly surpasses the performance of LLaMA2-7B from Meta AI, despite Meta's significantly larger training resources.
Links mentioned:
Mozilla AI ▷ #llamafile (2 messages):
- Seeking Guides for Custom Model Packaging: A user expressed interest in finding resources or guides on how to package customized models into a llamafile to assist several members in the community.
- GitHub Resource for Docker Deployment: A link to a GitHub pull request was shared, offering instructions on how to build and publish a container to Docker Hub using GitHub Actions, which could be relevant for those looking to package their models. Publish container to Docker Hub.
Link mentioned: Publish container to Docker Hub by dzlab · Pull Request #59 · Mozilla-Ocho/llamafile: Build and Publish container to Docker Hub on release using Github Actions #29 For this to work, need to setup the repository secrets: DOCKER_HUB_USERNAME DOCKER_HUB_ACCESS_TOKEN