As is their established pattern, Mistral followed up their magnet link with a blogpost, and an instruct-tuned version of their 8x22B model:
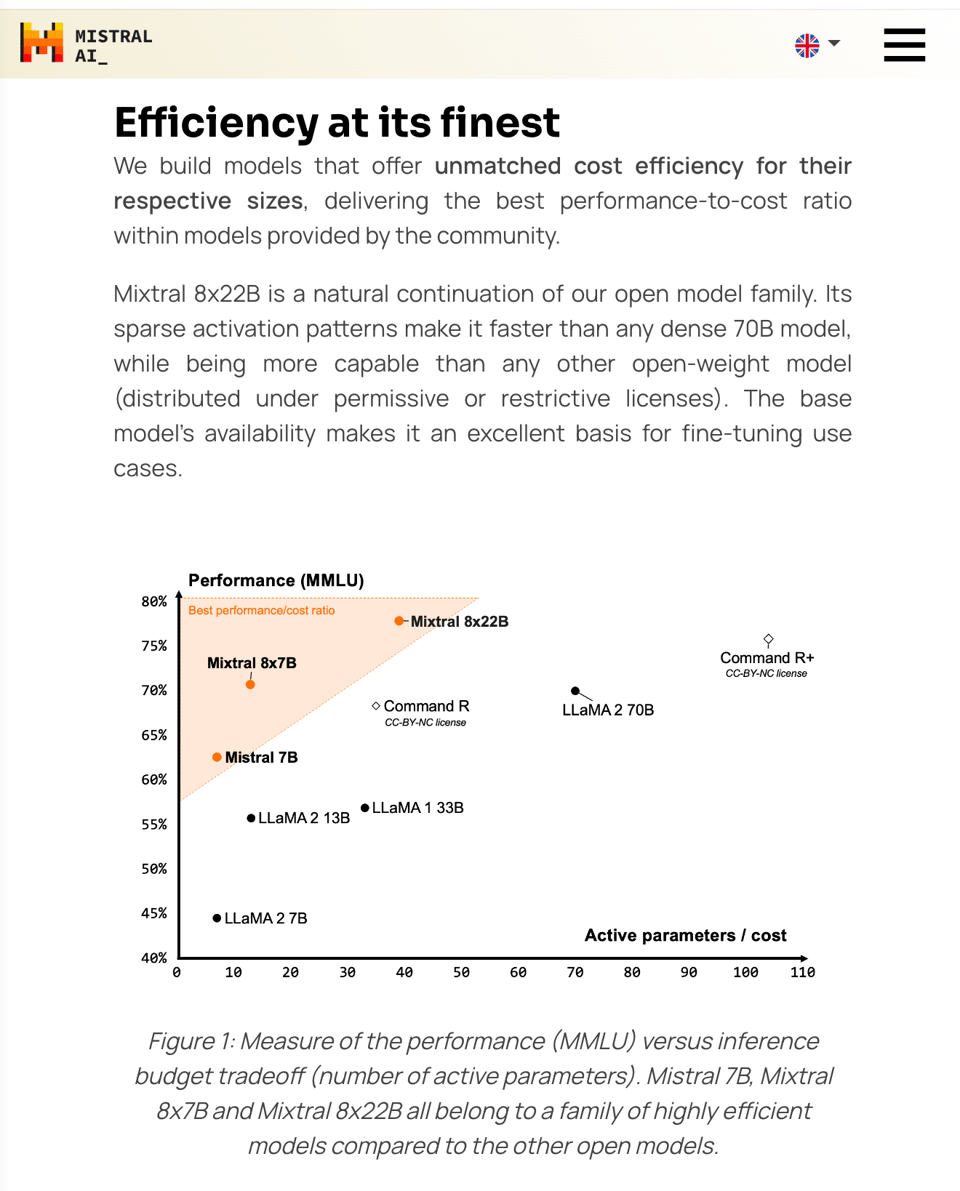
the image ended up sparking some friendly competition between Databricks, Google, and AI21, all of which merely emphasized that Mixtral created a new tradeoff between active params and MMLU performance:
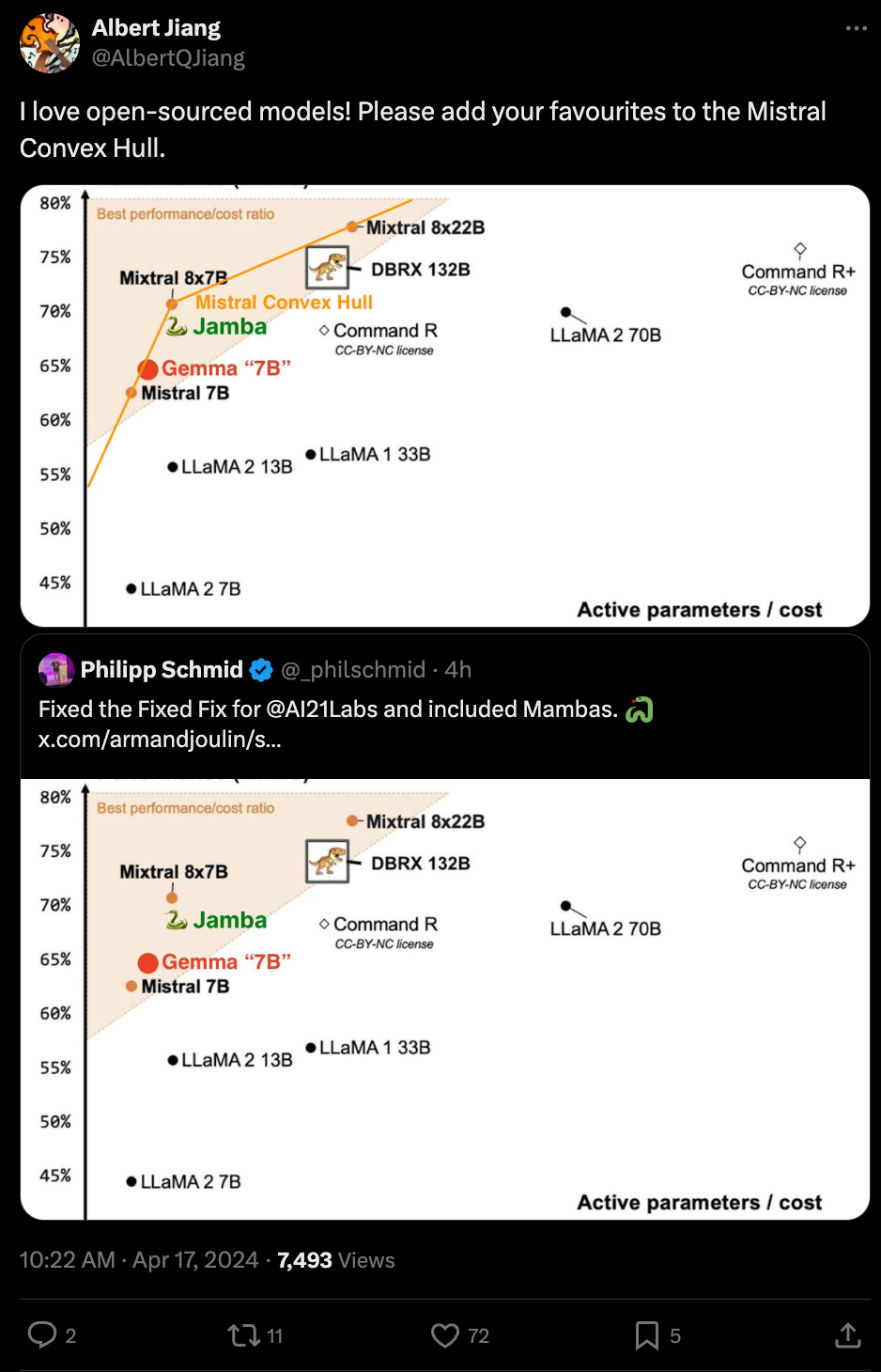
Of course, what is unsaid that the active params count doesnt linearly correlate with cost to run dense models, and that singular focus on MMLU isn't ideal for less scrupulous competitors.
Table of Contents
[TOC]
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/Singularity. Comment crawling works now but has lots to improve!
AI Investments & Advancements
-
Massive AI investments from tech giants: In /r/singularity, DeepMind CEO reveals Google plans to invest over $100 billion in AI, with other tech giants like Microsoft, Intel, SoftBank, and an Abu Dhabi fund making similarly huge bets, indicating high confidence in AI's potential.
-
UK criminalizes non-consensual deepfake porn: The UK has made it a crime to create sexually explicit deepfake images without consent. In /r/technology, commenters debate the implications and enforcement challenges.
-
Nvidia's AI chip dominance: In /r/hardware, a former Nvidia employee claims on Twitter that no one will catch up to Nvidia's AI chip lead this decade, sparking discussion about the company's strong position.
{kind=link}
AI Assistants & Applications
-
Potential billion-dollar market for AI companions: In /r/singularity, a tech executive predicts AI girlfriends could become a $1 billion business. Commenters suggest this is a vast underestimate and discuss the societal implications.
-
Unlimited context length for language models: A tweet posted in /r/artificial announces unlimited context length, a significant advancement for AI language models.
-
AI surpassing humans on basic tasks: In /r/artificial, a Nature article reports that AI has surpassed human performance on several basic tasks, though still trails on more complex ones.
AI Models & Architectures
- Zamba: Novel 7B parameter hybrid architecture: In /r/LocalLLaMA, Zyphra unveils Zamba, a 7B parameter hybrid architecture combining Mamba blocks with shared attention. It outperforms models like LLaMA-2 7B and OLMo-7B despite less training data. The model was developed by a team of 7 using 128 H100 GPUs over 30 days.
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
Mixtral 8x22B Instruct Model Release
- Impressive Performance: @GuillaumeLample announced the release of Mixtral 8x22B Instruct, which significantly outperforms existing open models using only 39B active parameters during inference, making it faster than 70B models.
- Multilingual Capabilities: @osanseviero highlighted that Mixtral 8x22B is fluent in 5 languages (English, French, Italian, German, Spanish), has math and code capabilities, and a 64k context window.
- Availability: The model is available on the @huggingface Hub under an Apache 2.0 license and can be downloaded and run locally, as confirmed by @_philschmid.
RAG (Retrieval-Augmented Generation) Advancements
- GroundX for Improved Accuracy: @svpino shared that @eyelevelai released GroundX, an advanced RAG API. In tests on 1,000 pages of tax documents, GroundX achieved 98% accuracy compared to 64% for LangChain and 45% for LlamaIndex.
- Importance of Assessing Risks: @omarsar0 emphasized the need to assess risks when using LLMs with contextual information that may contain supporting, contradicting, or incorrect data, based on a paper on RAG model faithfulness.
- LangChain RAG Tutorials: @LangChainAI released a playlist explaining RAG fundamentals and advanced methods on @freeCodeCamp. They also shared a @llama_index tutorial on using Mixtral 8x22B for RAG.
Snowflake Arctic Embed Models
- Powerful Embedding Models: @SnowflakeDB open-sourced their Arctic family of embedding models on @huggingface, which are the result of @Neeva's search expertise and Snowflake's AI commitment, as noted by @RamaswmySridhar.
- Efficiency and Performance: @rohanpaul_ai highlighted the efficiency of these models, with parameter counts from 23M to 335M, sequence lengths from 512 to 8192, and support for up to 2048 tokens without RPE or 8192 with RPE.
- LangChain Integration: @LangChainAI announced same-day support for using Snowflake Arctic Embed models with their @huggingface Embeddings connector.
Misc
- CodeQwen1.5 Release: @huybery introduced CodeQwen1.5-7B and CodeQwen1.5-7B-Chat, specialized codeLLMs pretrained with 3T tokens of code data. They exhibit exceptional code generation, long-context modeling (64K), code editing, and SQL capabilities, surpassing ChatGPT-3.5 in SWE-Bench.
- Boston Dynamics' New Robot: @DrJimFan shared a video of Boston Dynamics' new robot, arguing that humanoid robots will exceed iPhone supply in the next decade and that "human-level" is just an artificial ceiling.
- Superhuman AI from Day One: @ylecun stated that AI assistants need human-like intelligence plus superhuman abilities from the start, requiring understanding of the physical world, persistent memory, reasoning and hierarchical planning.
AI Discord Recap
A summary of Summaries of Summaries
Stable Diffusion 3 and Stable Diffusion 3 Turbo Launches:
- Stability AI introduced Stable Diffusion 3 and its faster variant Stable Diffusion 3 Turbo, claiming superior performance over DALL-E 3 and Midjourney v6. The models use the new Multimodal Diffusion Transformer (MMDiT) architecture.
- Plans to release SD3 weights for self-hosting with a Stability AI Membership, continuing their open generative AI approach.
- Community awaits licensing clarification on personal vs commercial use of SD3.
Unsloth AI Developments:
- Discussions on GPT-4 as a fine-tuned iteration over GPT-3.5, and the impressive multilingual capabilities of Mistral7B.
- Excitement around the open-source release of Mixtral 8x22B under Apache 2.0, with strengths in multilingual fluency and long context windows.
- Interest in contributing to Unsloth AI's documentation and considering donations to support its development.
WizardLM-2 Unveiling and Subsequent Takedown:
-
Microsoft announced the WizardLM-2 family, including 8x22B, 70B, and 7B models, demonstrating competitive performance.
-
However, WizardLM-2 was unpublished due to lack of compliance review, not toxicity concerns as initially speculated.
-
Confusion and discussions around the takedown, with some users expressing interest in obtaining the original version.
-
Stable Diffusion 3 Launches with Improved Performance: Stability AI has released Stable Diffusion 3 and Stable Diffusion 3 Turbo, now available on their Developer Platform API, boasting the fastest and most reliable performance. The community awaits clarification on the Stability AI Membership model for self-hosting SD3 weights. Meanwhile, SDXL finetunes have made SDXL refiners nearly obsolete, and users discuss model merging challenges in ComfyUI and limitations of the diffusers pipeline.
-
WizardLM-2 Debuts Amidst Excitement and Uncertainty: The release of WizardLM-2 models by Microsoft has sparked enthusiasm for their potential GPT-4-like capabilities in an open-source format. However, the sudden takedown of the models due to a missed compliance review has led to confusion and speculation. Users compare the performance of WizardLM-2 variants and share tips for resolving compatibility issues in LM Studio.
-
Multimodal Models Advance with Idefics2 and Reka Core: Hugging Face's Idefics2 8B and Reka Core have emerged as powerful multimodal language models, showcasing impressive capabilities in visual question answering, document retrieval, and coding. The upcoming chat-focused variant of Idefics2 and Reka Core's competitive performance against industry giants have generated significant interest. Discussions also revolve around the cost-efficiency of models like JetMoE-8B and the launch of Snowflake's Arctic embed family for text-embedding.
Other notable topics include:
- The introduction of ALERT, a safety benchmark for assessing Large Language Models, and debates around AI safety standards.
- Explorations of Retrieval Augmented Generation (RAG) for vision-based applications and the philosophical implications of AI simulations in World-Sim.
- The rise of AI-human collaboration platforms like Payman AI and the integration of AI inference in Supabase's edge functions.
- Challenges to the Chinchilla scaling laws and discussions on the expressive power of state-space models in the research community.
- Advancements in PEFT methods like Dora and RSLoRA, and the pursuit of multilingual model expansion using Mixture-of-Experts (MoE) approaches.
PART 1: High level Discord summaries
Stability.ai (Stable Diffusion) Discord
Stable Diffusion 3 Turbo Charges the Scene: Stability AI has introduced Stable Diffusion 3 and Stable Diffusion 3 Turbo, now available on their Developer Platform API, with claims of the fastest and most reliable performance, supported by Fireworks AI. Interested parties can get started with SD3 at Stable Diffusion 3 & Developer API, and an open generative AI approach is promised with plans for the model weights to be available for self-hosting for members.
Refining Visually Intuitive Generative AI: The SDXL finetunes have made the use of SDXL refiners nearly obsolete, as they are now prevalent in Civitai downloads, suggesting a trend towards integrated finetunes over separate refiner modules, reflecting a community-driven optimization.
Model Merging Explored: There is lively discussion on model merging tactics within ComfyUI, grappling with complex mechanisms such as V-prediction and epsilon, highlighting the community's experimentation with these methods to achieve enhanced outcomes, yet acknowledging that correct implementations are crucial to prevent unpredictable results.
Navigating Diffusers Library Limitations: A conversation emerged around the limitations and dependencies in the diffusers pipeline, with a focus on Stable Video Diffusion Pipeline challenges. Despite these challenges, some users are optimizing usage by running models independently post-download, bypassing certain Hugging Face library constraints.
Awaiting SD3’s Membership Model Details: The community is keenly waiting for Stability AI to provide clarifications on Stable Diffusion 3 licensing for personal versus commercial use, especially in light of the new membership model revealed for accessing self-hosted weights.
Unsloth AI (Daniel Han) Discord
GPT-4 Gains Over GPT-3.5: The new iteration of GPT, GPT-4, is regarded as a fine-tuned enhancement over GPT-3.5, though specifics on performance metrics or features were not provided.
Mistral7B Shines in Multilingualism: Members conferred about the multilingual capabilities of the Mistral7B model, recommending the inclusion of diverse language data in training sets, particularly French, to improve performance.
Unsloth AI Gets Help from Fans: There’s a tangibly positive response from the community towards Unsloth AI, with users keen to help with documentation, expansion, and even considering donations. The Mixtral 8x22B model's release under Apache 2.0 was met with excitement for its promise in multilingual fluency and handling of extensive context windows.
Chroma Goes Go: The Chroma project leaps forward with an edge version written in Go, which utilizes SQLite and WASM for browser-based applications, now available on GitHub.
Mobile AI Deployment Discussed: The complexity of deploying AI models on mobile devices surfaced, noting challenges such as the absence of CUDA and the infeasibility of running standard Deep Learning Python codes on such platforms.
LM Studio Discord
AI Assistance for NeoScript Programming: A user looking for help with NeoScript programming expressed challenges in configuring AI models. Microsoft's new release, WaveCoder Ultra 6.7b, excels in code translation and could be a strong candidate for this task.
Solving AI's Echo Chamber: To combat repetitive AI responses, particularly in Dolphin 2 Mistral, members discussed strategies such as fine-tuning models and leveraging multi-turn conversation frameworks outlined in Azure's article.
Introducing the WizardLM-2 League: The debut of WizardLM-2 models sparked discussions about performance. Compatibility with existing tools, including the importance of using GGUF quants and version 0.2.19 or newer for proper functionality, was emphasized.
Tech Wizards at Play: One user successfully enabled direct communication between four 3090 GPUs, improving model performance by bypassing CPU/RAM. There was also chatter about the challenges of signing Windows executables, with a hint that the Windows versions are indeed signed with an Authenticode cert.
Quantization Conundrum and Model Preferences: Mixed reviews on quantization levels, from Q8 to Q6K, pointed to a preference for models with higher quantization levels when VRAM is sufficient. For large models, such as WizardLM-2-8x22B, GPUs like the 4090 with 24GB VRAM may be inadequate.
Nous Research AI Discord
-
Multimodal Models Stepping Up: Exciting advancements in multimodal language models are showcased, with Hugging Face's Idefics2 8B and Reka Core emerging as key players, evident from Open Multimodal ChatGPT video and Reka Core overview. The GPT4v/Geminipro Vision and Claude Sonnet models are recommended for vision-RAG applications.
-
LLMs Tuning into Self-Optimization: New techniques for enhancing Instruct Model LLMs look promising, with models able to select the best solution by reconstructing inputs from outputs, detailed in a Google Slideshow on aligning LLMs for medical reasoning.
-
WizardLM Disappearance Sparks Debate: There's uncertainty around WizardLM's sudden takedown; while some speculated on toxicity issues, confirmed reports attributed it to lack of a compliance review as shared in a comprehensive WizardLM information bundle.
-
LLMs Performance: A Roller Coaster of Expectations: Engineers discuss CodeQwen1.5-7B Chat's impressive benchmarking and debate on architectures and tuning's impact on performance. Furthermore, upcoming models like Hermes 8x22B are eagerly awaited, with concerns on whether they can be accommodated by personal equipment setups.
-
World-Sim's Return Triggers AI Philosophical Debates: As World-Sim gears up for a return, enthusiasts burst with anticipation, pondering the philosophical aspects and implications of such simulated worlds. Official confirmation sent excitement soaring with a Websim link provided for those eager to jump in.
Perplexity AI Discord
Robots Debating Their Roots: Engineers exchanged insights on the performance nuances of AI models including GPT-4 and Claude 3 Opus, with a shared sentiment that GPT-4 may exhibit "lazy" tendencies in real-world applications. The open-source Mixtral's 8x22B model is highlighted for its impressive capabilities, sparking debates on model efficacy.
Stumped by Stubborn Software Issues: A conversation was noted about achieving consistency between the web client and the API, with specific attention to parameters like temperature settings. Engineers are also discussing the benefits of including a rate limit counter in the API response for better management and transparency.
The Vanishing Messages Mystery: Concern was voiced over changes in the Perplexity API's payment method management, particularly the opacity surrounding the remaining message counts for pro users. This focus on transparency indicates professionals need clarity to manage resources efficiently.
A Tale of Truncated Tokens: Technical dialogue included challenges faced when engaging models with large context sizes, like a 42k token prompt, and the tendency for models to summarize rather than dive deep into lengthy documents. This could be pivotal as engineers optimize models to process complex prompts fully.
The Search for Smarter Searches: Members also discussed using site:URL search operators for more targeted information retrieval. Additionally, there is a call for better communication regarding rate limits in the API, including the possibility of a 429 response.
LAION Discord
-
PyTorch's Abstraction Puzzle: Engineers are grappling with PyTorch's philosophy of abstracting complexities, which, while simplifying coding, often leaves them puzzled when troubleshooting unexpected results.
-
Handling Hefty Datasets with Zarr: There's active exploration on utilizing zarr to manage a hefty 150 GB MRI dataset, with discussions circling around its efficiency and whether it will overload RAM with large data loads.
-
Legal Lines Drawn for Deepfakes in the UK: Members are discussing the implications of UK legislation targeting the creation of distressing images, questioning its enforceability given the blurriness of proving intent.
-
AI Inference Fine-Tuning Talks: Voices from the community are calling for clarity on AI models' inference settings, like controlling CFG or integrating models with robust ODE solvers, beyond just defaulting to Euler's method.
-
Cascade Team's Corporate Shuffle: There's speculation about the future of Stability AI's Cascade team after their departure and the dissolution of their Discord channel, with wonderment if there's a link to a new venture, possibly Leonardo, or an ongoing affiliation with SAI.
-
ALERT! A New Safety Benchmark for LLMs: The introduction of ALERT, a safety benchmark for assessing Large Language Models, has sparked interest, providing a Dataset of Problematic Outputs (DPO) for community evaluation, available on GitHub.
-
AI Audio-Visual Harmony: An Arxiv paper presents methods for generating audio from text, improving performance by zeroing in on concepts or events, stirring dialogue in the research community.
-
AI Safe or Stifled?: The AI safety debate is heated, with some pushing back against confining AI strictly to PG content, arguing it could crimp its creative spark compared to other artistic mediums.
-
GANs vs. Diffusion Models: Speed or Aesthetics?: Discussions are heating up over the advantages of GANs—notably, their faster inference and lesser parameter count—versus diffusion models, even as GANs face criticism for image quality and training challenges.
OpenRouter (Alex Atallah) Discord
OpenRouter Welcomes WizardLM Raptors: OpenRouter announced the release of WizardLM-2 7B and a price drop for WizardLM-2 8x22B to $0.65/M tokens. The WizardLM-2 8x22B Nitro boasts over 100 transactions per second post its database restart.
Latency Labyrinth Resolved: Latency issues on various models such as Mistral 7B Instruct and Mixtral 8x7B Instruct were attributed to cloud provider DDoS protection, with updates concerning the resolution found in the associated discussion thread.
Calling All Frontend Mavericks: A member seeks web development assistance for an AI-based frontend project for OpenRouter, specifically emphasizing role-playing novel mode and conversation style systems. Ability to distinguish AI-generated text from user input is also requested.
AI Model Morality and Multilingual Mastery: Vigorous exchanges regarding both censorship protocols for NSFW content and the imperative for enhancing models' multilingual performance took place. Members looked forward to direct endpoints and new provider integrations for an anticipated AI model release.
Bitrate Bits and Quality Quibbles: Users showed a clear preference for a minimum of 5 bits per word (bpw) for model quantization, noting that reductions below this threshold notably compromise quality. Discussions underscored the trade-offs between efficient operation and maintaining high fidelity in AI outputs.
Modular (Mojo 🔥) Discord
-
Mojo to Python Conversion Now a Possibility: Engineers discuss the new package mojo2py, capable of converting Mojo code to Python, and chatted about the desire for more learning resources, pointing to the Mojo programming manual for beginners.
-
Maxim Zaks Debates the Mojo 'Hype': A PyCon Lithuania talk titled "Is Mojo just a hype?" by Maxim Zaks was highlighted, provoking debate on the chatbot's industry impact, available in a video.
-
Mojo's Inherent Nightly Nuances: Users are navigating through the challenges of a new nightly Mojo release, noting unconventional code styling for readability, desires for comprehensive tutorials on traits, and a recent pull request reflecting significant updates.
-
Optimizing with Compile-Time Aliases: Discussion thrived around optimizing alias memory usage in Mojo, hinted by the recommendation of readable code over extensive commenting from a cited YouTube video.
-
Community Mojo Projects Surge: Community contributions soared with a shared Mojo 'sketch' found at this gist and a request about implementing the Canny edge recognition algorithm in Mojo, coupled with directions to Mojo's documentation and tooling resources.
CUDA MODE Discord
PyTorch Resource Debate: While discussing if "Deep Learning with PyTorch" is a relevant resource despite being 4 years old, members noted that the PyTorch core has remained stable, though significant updates have occurred in the compiler and distributed systems. A member shared a teaser for an upcoming edition of the book, which would include coverage of transformers and Large Language Models.
CUDA Custom GEMM Sparking Interest: The conversation involved improving GEMM performance in CUDA, with one member providing a new implementation that outperformed PyTorch's function on specific benchmarks, sharing their code on GitHub. However, another highlighted JIT compilation issues with torch.compile. The group also discussed optimal block size parameters, referencing a related code example on Gist.
Next-Gen Video Analysis & Robotics Gains Screenshare: Members shared links about Augmend's video processing features, which combine OCR and image segmentation, previewed on wip.augmend.us, and the full service to be hosted on augmend.com. Another highlight was Boston Dynamics' unveiling of a fully electric robot named Atlas intending for real-world applications, showcased in their All New Atlas | Boston Dynamics video.
Bridging the CUDA Toolkit Knowledge Gap: In the #beginner channel, members discussed issues related to using the CUDA toolkit on WSL, with one user facing problems running the ncu profiler. The community provided troubleshooting steps and stressed the importance of setting the correct CUDA path in environment variables. There was also an advisory that Windows 11 might be necessary for effective CUDA profiling on WSL 2, with one user providing a guide on the subject.
Quantization Dilemmas and Solutions in Air: A thorough chat occurred on the topic of quantization axes in GPT models with a highlight on the complexities when using axis=0. Participants suggested quantizing Q, K, and V separately with references to Triton kernels and an autograd optimization method for boosting speed and performance. Their debate continued with discussions of 2/3 bits quantization practicality and was supplemented with implementation details and benchmarks on GitHub.
Optimizing ML Model Performance: A GitHub notebook for extending PyTorch with CUDA Python garnered attention for speed enhancements but with a need for more optimization to fully tap into tensor core capabilities, as shared in the notebook's link. Additionally, there were mentions of optimizing the softmax function and block sizes for cache utilization, with insights shared through a GitHub pull request.
OpenAI Discord
Multiplayer GPT Headed for the Gaming Galaxy: Engineers discussed the potential of integrating GPT-Vision and camera inputs for a real-time gaming assistant to tackle multiple-choice games. The possibility of utilizing Azure or virtual machines to handle intensive computational tasks was raised, alongside leveraging TensorFlow or OpenCV for system management.
AI Versus Human Conundrum Continues: A philosophical debate emerged concerning the differences between AI and human cognition, discussing the prospects of AI acquiring human-like reasoning and emotions, and the role of quantum computing in this evolution.
The Quest for Knowledge Enhancements: Members sought information on how to prepare a knowledge base for custom GPT applications and questioned the arrival of the Whisper v3 API. The noted limitations such as GPT-4's token memory span being speculated to have shrunk triggered calls for improved clarity on API capabilities.
Creative Minds Favor Claude and Gemini: When tackling literature reviews and fictional works, AI aficionados recommended using models like Claude and Gemini 1.5. These tools were favored for their prowess in handling literary tasks and creative writing respectively.
Discord Channel Dynamics: Two channels, prompt-engineering and api-discussions, experienced a notable decrease in activity, with participants attributing the quiet to possible over-moderation and a recent string of timeouts, including a specific 5-month timeout case involving assistance to another user.
LlamaIndex Discord
-
Hybrid Cloud Hustle with Qdrant: Qdrant's new hybrid cloud offering allows for running their service across various environments while maintaining control over data. They backed their launch with a thorough tutorial on the setup process.
-
LlamaIndex Beefs Up with Azure AI Search: LlamaIndex teams up with Azure AI Search for advanced RAG applications, featuring a tutorial by Khye Wei that illustrates Hybrid Search and Query rewriting capabilities.
-
MistralAI Model Immediately Indexed: LlamaIndex has instant support for MistralAI’s newly released 8x22b model, paired with a Mistral cookbook focusing on intelligent query routing and tool usage.
-
Building and Debugging in LlamaIndex: AI engineers discussed best practices for constructing search engines in LlamaIndex, resolving API key authentication errors, and navigating through updates and bug fixes, including a specific
BaseComponenterror with a GitHub solution. -
Hierarchical Structure Strategy Session: Inquiry within the ai-discussion channel about constructing a hierarchical document structure using ParentDocumentRetriever, with LlamaIndex as the framework of choice.
Eleuther Discord
-
Peering into the Future of Long-Sequence Models: Feedback Attention Memory (FAM), discussed in recent conversations, proposes a solution to the quadratic attention problem of Transformers, enabling processing of indefinitely long sequences and showing improvement on long-context tasks. Reka's new encoder-decoder model is touted to support sequences up to 128k, as detailed in their core tech report.
-
Precision in Scaling Laws and Evaluation: Questions on compute-optimal scaling laws by Hoffman et al. (2022) led to an exploration of the credibility of narrow confidence intervals without extensive experiments as detailed in Chinchilla Scaling: A replication attempt. Moreover, accurate cost estimations within ML papers are hindered when the size of datasets like that in the SoundStream paper is omitted, bringing to light the necessity of transparent data reporting.
-
Unpacking Model Evaluation Techniques: In Eleuther's
#lm-thunderdome, the usage oflm-evaluation-harnesswas demystified, explaining the output format required forarc_easytasks and discussing the significance of BPC (bits per character) as an intelligent proxy correlating with a model's compression capacity. Concerning tasks like ARC, a dialogue ensued about why random guessing results in a roughly 25% accuracy rate due to its four possible answers. -
Multi-Modal Learning Gains Traction: The possibility of Total Correlation Gain Maximization (TCGM) for semi-supervised multi-modal learning received attention, with one arXiv paper discussing the informational approach and the ability to utilize unlabeled data across modalities effectively. Emphasis was also given to the method's theoretical promises and its implications in identifying Bayesian classifiers for diverse learning scenarios.
-
Concrete Guidelines for FLOPS Calculation: On the
#scaling-lawschannel, advice was given on estimating the FLOPS for a model such as SoundStream, including using the equation 6 * # of parameters for transformers during forward and backward passes. Newcomers are directed to a comprehensive breakdown in Section 2.1 of the relevant paper for a complete understanding of computational cost estimation.
HuggingFace Discord
-
IDEFICS-2 Takes the Limelight: The release of IDEFICS-2 brings an impressive skill set with 8B parameters, capable of high-resolution image processing and excelling in visual question answering and document retrieval tasks. Anticipation builds as a chat-focused variant of IDEFICS-2 is promised, while current capabilities such as solving complex CAPTCHAs are demonstrated in a shared example.
-
Knowledge Graphs Meet Chatbots: An informative blog post highlights the integration of Knowledge Graphs with chatbots to boost performance, with exploration encouraged for those interested in advanced chatbot functionality.
-
Snowflake's Arctic Expedition: Snowflake breaks new ground with the launch of the Arctic embed family of models, claimed to set new benchmarks in practical text-embedding model performance, particularly in retrieval use cases. This development is complemented by a hands-on Splatter Image space for creating splatter art quickly, and how Multi-Modal RAG fuses language and images, as detailed in LlamaIndex documentation.
-
Model Training and Comparisons Drive Innovation: A fresh IP-Adapter Playground is unveiled, further enabling creative text-to-image interactions, alongside a new option to
push_to_hubdirectly in the transformers library's pipelines. Comparing image captioning models just got easier with a dedicated Hugging Face Space. -
Challenges and Opportunities in NLP and Vision: Community members discuss issues from truncated token handling in prompts to exploring LoRA configurations, with links shared to resources on topic modeling with BERTopic, training T5 models (Github Resource), and LaTeX-OCR possibilities for equation conversion LaTeX-OCR GitHub. These conversations encapsulate the collective pursuit of refining and harnessing AI capabilities.
OpenAccess AI Collective (axolotl) Discord
Idefics2 Brings Multimodal Flair: The new multimodal model Idefics2 has been introduced, capable of processing both text and images with improved OCR and visual reasoning skills. It is offered in both base and fine-tuned forms and is under the Apache 2.0 license.
RTX 5090 Speculation Stokes Anticipation: NVidia is rumored to be considering an expedited release of the RTX 5090, potentially at Computex 2024, to stay ahead of AMD's advances, sparking discussions on hardware suitability for cutting-edge AI models.
Model Training Finetuning: Engineers shared insights on model training configurations, focusing on the 'train_on_input' parameter in loss calculation, and suggested using "TinyLlama-1.1B-Chat-v1.0" for fine-tuning small models for efficient experimentation.
Phorm AI Becomes Go-To Resource: Members referred to Phorm AI for various inquiries, including epoch-wise saving techniques and data preparation for models like TinyLlama for tasks like text-to-color code predictions.
Spam Flood Triggers Alerts: Multiple channels within the community were targeted by spam messages promoting OnlyFans content, attempting to divert attention from the AI-centric conversations and technical discourse.
Latent Space Discord
LLM Ranking Resource Revealed: A comprehensive website, LLM Explorer, has been shared, showcasing a plethora of open-source language models, each assessed through ELO scores, HuggingFace leaderboard ranks, and task-specific accuracy metrics, serving as a valuable resource for model comparison and selection.
AI+Human Symphony in the Gig Economy: The launch of Payman AI, a platform facilitating AI agents to remunerate humans for tasks beyond AI capabilities, has sparked interest; the concept promotes a cooperative ecosystem between AI and human talents in domains like design and legal services.
Supabase Embraces AI Inference: Supabase introduces a simple API for running AI inferences within its edge functions, allowing AI models such as gte-small to be employed directly in databases, as detailed in their announcement.
Buzz Around "Llama 3" and OpenAI API Moves: The AI community is abuzz about the mysterious "Llama 3" speculated to debut at a London hackathon, and OpenAI's Assistants API enhancements are drawing attention in light of a potential GPT-5 release, stirring debates about possible impacts on AI startups and platforms.
BloombergGPT Paper Club Session Goes Zoom: The LLM Paper Club invites engineers to a Zoom session on BloombergGPT, due to prior challenges with Discord screensharing, and the discussion has pivoted to Zoom for a better sharing experience. Participants can register for the event here, and further reminders to join the discussions are being circulated within the community.
OpenInterpreter Discord
-
AI Wearable Woes: AI wearables lack the contextual knowledge of smartphones, as discussed with reference to a YouTube review by Marquis Brownlee. Engineers pointed out that greater contextual understanding is necessary for AI assistants to provide efficient responses.
-
Open-Source AI Model Buzz: The WizardLm2 open-source model garners interest for its potential to deliver GPT-4-like capabilities. Discussions forecast a strong future demand despite ongoing advancements.
-
Translator Bot's Inclusive Promise: Engineers are currently evaluating a new translation bot for its ability to enrich communication by providing two-way translations, aiming for more inclusive and unified discussions.
-
Cross-Platform Compatibility Challenges: There's a clear need for software like 01 Light to operate on Windows, consistent with dialogues about difficulties adapting Mac-centric software to Windows frameworks, thereby hinting at the necessity for platform-agnostic development approaches.
-
Hardware Heats Up: Conversations indicate significant interest in AI hardware solutions like the Limitless device, with comparisons drawn around user experiences. Emphasis on the need for robust backend support and seamless AI integration is shaping hardware aspirations.
Interconnects (Nathan Lambert) Discord
Big Win for qwen-1.5-0.5B: The qwen-1.5-0.5B model's winrate soared from 4% to 32% against heavyweights like AlpacaEval using generation in chunks. This approach, along with a 300M reward model, may be a game-changer in output searching.
How To Win Friends and Influence AIs: The recently unveiled Mixtral 8x22B, a polyglot SMoE model, is sharing the limelight owing to its impressive capabilities and the Apache 2.0 open license. Meanwhile, the rise of OLMo 1.7 7B indicates a notable stride in language model science with a robust performance leap on the MMLU benchmark.
Replicating Chinchilla: An Anomaly: Discrepancies in replicating the Chinchilla scaling paper by Hoffmann et al. have cast doubts around the paper's findings. The community's reaction ranged from confusion to concern, signaling an escalating drama around the challenge of scaling law verification.
Lighthearted Anticipation and Rumination: With playful banter on potential showdowns in olmo vs llama, community members show humor in competition. Moreover, Nathan Lambert teases the guild with a forecast of content deluge, signaling a possibly intense week of knowledge sharing.
Model Madness or Jocularity?: A side comment in an underpopulated channel by Nathan mentioned a potential tease involving WizardLM 2 as a troll, showing a blend of humor and light-heartedness amidst technical discussions.
Cohere Discord
-
API Confusion Needs Resolving: Engineers are probing the Cohere API for details on system prompt capabilities and available models. A user highlighted the request for details due to their significance in application development.
-
Benchmarking Cohere's Embeddings: There is curiosity about how Cohere's embeddings v3 perform against OpenAI's new large embeddings with reference to the Cohere blog, suggesting a comparative analysis has been conducted Introducing Command R+.
-
Integration Tips and Tricks: Technical discussions addressed integrating Language Learning Models (LLMs) with platforms like BotPress, and whether Coral necessitates a local hosting solution. Future updates might simplify these integrations.
-
Fine-Tuning Fine-Tuned Models: Clarification was sought about fine-tuning already customized models via Cohere's Web UI, directing users to the official guide Fine-Tuning with the Web UI.
-
Beta Testers Called to Action: A project named Quant Fino is recruiting beta testers for its Agentic entity that merges GAI with FinTech. Interested participants can apply at Join Beta - Quant Fino.
-
Security Flaws Exposed in AI Model: A redteaming exercise revealed vulnerabilities in Command R+, demonstrating the ability to manipulate the model into creating unrestricted agents. Concerned engineers and researchers can review the full write-up Creating unrestricted AI Agents with Command R+.
LangChain AI Discord
AI Documentation Gets Facelift: In an effort to improve usability, contributors to the LangChain documentation are revamping its structure, introducing categories like 'tutorial', 'how to guides', and 'conceptual guide'. A member shared the LangChain introduction page, emphasizing LangChain's components such as building blocks, LangSmith, and LangServe, which aid in the development and deployment of applications with large language models.
Building with LangChain — An Expressive Endeavor?: Within the #general channel, a member sought advice on YC startup applications while drawing parallels to Extensiv, leading to the mention of several entities like Unsloth, Mistral AI, and Lumini. Simultaneously, challenges with LangServe integration when combined with Nemo Guardrails were highlighted due to Nemo's transformation of output structures.
Forge Ahead with New AI Tools and Services: GalaxyAI's debut of an API service with complimentary access to GPT-4 and GPT-3.5-turbo stirred up interest, showcased at Galaxy AI. Similarly, OppyDev’s fusion of an IDE and a chat client received attention, advocating an improved coding platform accessible at OppyDev AI. Meanwhile, Rubiks.ai appealed to tech enthusiasts to beta test their search engine and assistant at Rubiks.ai using code RUBIX.
AI Pioneers Share Educational Resources and Seek Collaboration: A member from #tutorials posted a YouTube tutorial on granting AI agents with long-term memory, igniting a discussion why 'langgraph' wasn't employed. Furthermore, a participant expressed eagerness to collaborate on new projects, inviting others to connect through direct messaging.
Diverse Dialogues on Data and Optimization: In a lively exchange, strategies for optimizing RAG (Retrieval-Augmented Generation) with large documents were evaluated, including document splitting. Members also dialogued over the best methods to manipulate CSV files with Langchain, suggesting improvements for chatbots and data processing.
DiscoResearch Discord
- 64 GPUs Engaged for Full-Scale Deep-Speed: Maxidl pushed the limits by utilizing 64 80GB GPUs, each at 77GB capacity, to run full-scale deep-speed with 32k sequence length and batch size of one, exploring 8-bit optimization for better memory efficiency.
- FSDP's Memory Usage Secrets Unlocked: jp1 suggested
fsdp_transformer_layer_cls_to_wrap: MixtralSparseMoeBlock, and settingoffload_params = trueto minimize memory usage, potentially reducing GPU requirements to 32, while maxidl sought out calculators for memory usage, referencing a HuggingFace discussion. - Copyright Conundrum for Text Scraping: A member pointed out the EU copyright gray area affecting text data scraping and suggested DFKI as a useful source. Meanwhile, multimodal data from Wikicommons and others are found on Creative Commons Search.
- Tokenization Techniques on the Rise: The community shared insights into creating a Llama tokenizer without HuggingFace, noted a misspelling in a shared custom tokenizer, and highlighted Mistral's new tokenization library, with a GitHub notebook provided.
- Decoding Strategies and Sampling Techniques Evaluated: Concerns that a paper on decoding methods overlooked useful strategies led to a discussion on unaddressed techniques like MinP/DynaTemp/Quadratic Sampling. A Reddit post showed the impact of min_p sampling on creative writing, boosting scores by +8 in alpaca-eval style elo and +10 in eq-bench creative writing test.
tinygrad (George Hotz) Discord
Int8 Integration in Tinygrad: Tinygrad has been confirmed to support INT8 computations, with recognition that such data type support often depends more on hardware capabilities rather than the software design itself.
Graph Nirvana with Tiny-tools: For enhanced graph visualizations in Tinygrad, users can visit Tiny-tools Graph Visualization to create slicker graphs than the basic GRAPH=1 setting.
Pytorch-Lightning's Hardware Adaptability: Discussions about Pytorch-Lightning touched on its hardware-agnostic capabilities, with practical applications noted on hardware like the 7900xtx. Discover Pytorch-Lightning on GitHub.
Tinygrad Meets Metal: Community members are exploring the generation of Metal compute shaders with tinygrad, discussing how to run simple Metal programs without Xcode and the possibility of applying this to meshnet models.
Model Manipulation and Efficiency in Tinygrad: A member's proposal for a fast, probabilistically complete Node.equals() prompted discussions on efficiency, while George Hotz explained layer device allocation, and users were directed toward tinygrad/shape/shapetracker.py or view.py for zero-cost tensor manipulations like broadcast and reshape.
Skunkworks AI Discord
- Hugging Face Showcases Idefics2: Hugging Face introduces Idefics2, a new multimodal ChatGPT iteration that integrates Python coding capabilities, as demonstrated in their latest video.
- Reka Core Rivals Tech Behemoths: Touted for its performance, Reka Core emerges as a strong competitor to language models from OpenAI and others, with a video overview available to showcase its capabilities.
- JetMoE-8B Flaunts Efficient AI Performance: The JetMoE-8B model impresses with performance that surpasses Meta AI's LLaMA2-7B while costing under $0.1 million, suggesting a cost-efficient approach to AI development as explained in this breakdown.
- Snowflake Announces Premier Text-Embedding Model: Snowflake debuts the Snowflake Arctic embed family of models, claiming the title for the world's most effective practical text-embedding model, detailed in their announcement.
Datasette - LLM (@SimonW) Discord
- Mixtral Mania: Engineers are eagerly awaiting to test the Mixtral 8x22B Instruct model; for those interested, the Model Card on HuggingFace is now available.
- Glitch in the Machine: There's a reported installation error for llm-gpt4all that seems to obstruct usage; details of the problem can be found in the GitHub issue tracker.
Alignment Lab AI Discord
- Legal Entanglements Afoot?: A member hinted at possible legal involvement in an unspecified situation, yet no context was provided to ascertain the details or nature of the legal matters in question.
- The Misfortune of wizardlm-2: An image was shared showing the deletion of wizardlm-2, noted specifically for lack of testing on v0; the intricacies of wizardlm-2 or the testing processes were not elaborated. View Image
{kind=link}
Mozilla AI Discord
-
Llamafile Script Gets a Facelift: An improved repacking script for the llamafile archive version upgrade is now accessible via this Gist, triggering a discussion on whether to merge it with the main GitHub repo or to start new llamafiles from scratch due to concerns about maintainability.
-
Seeking Protocol for Security Flaws: The discussion surfaced a need for clarification on the procedure to report security vulnerabilities within the system, including the steps to request a CVE number, although specific guidance is currently lacking.
The LLM Perf Enthusiasts AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Stability.ai (Stable Diffusion) ▷ #announcements (1 messages):
-
Stable Diffusion 3 Launch Celebration: Stable Diffusion 3 and its faster variant, Stable Diffusion 3 Turbo, are now available on the Stability AI Developer Platform API. This release is powered through a partnership with Fireworks AI, boasting claims of being the fastest and most reliable API platform.
-
Open Generative AI Continues: There is a plan to make Stable Diffusion 3 model weights available for self-hosting, which would require a Stability AI Membership, emphasizing the continued commitment to open generative AI.
-
Discover More About SD3: Users are directed to learn more and get started with the new offerings through the provided link, which includes further details and documentation.
-
Research Background Unpacked: According to the Stable Diffusion 3 research paper, this iteration rivals or surpasses the leading text-to-image systems like DALL-E 3 and Midjourney v6 in aspects such as typography and adherence to prompts, based on human preference studies.
-
Technical Advancements in SD3: The latest version introduces the Multimodal Diffusion Transformer (MMDiT) architecture, offering improved text comprehension and image representation over previous Stable Diffusion models by utilizing distinct weight sets for different modalities.
Link mentioned: Stable Diffusion 3 API Now Available — Stability AI: We are pleased to announce the availability of Stable Diffusion 3 and Stable Diffusion 3 Turbo on the Stability AI Developer Platform API.
Stability.ai (Stable Diffusion) ▷ #general-chat (1039 messages🔥🔥🔥):
-
SD3 Awaits Membership Clarification: Amidst the concerns of licensing and accessibility, users await a clear statement from Stability AI regarding SD3's availability for personal and commercial use. Discussions arose following an announcement stating plans to make the model weights available for self-hosting with a Stability AI Membership.
-
SDXL Refiners Deemed Redundant: The community finds SDXL finetunes to have made the use of SDXL refiners obsolete, stating that refiner-trained finetunes have taken precedence in Civitai downloads. Some users reminisce about initial uses of refiners but acknowledge that finetune integrations quickly replaced the need for them.
-
Model Merging Challenges: Users explore the effectiveness and understanding of model-merging concepts around V-prediction and epsilon in ComfyUI. There's debate on the necessity of correct implementation to avoid unpredictable results, with recommendations to gain minimal knowledge through UI experimentation.
-
Diffusers Pipeline Limitations: Some users point out limitations in the diffusers pipeline requiring Hugging Face dependency, yet others contend that once models are downloaded, the process can run independently and efficiently on local systems. Concerns are raised about the inaccessibility of
StableVideoDiffusionPipeline.from_single_file(path)method in SVD finetunes, suggesting Comfy UI as an easier alternative.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #general (383 messages🔥🔥):
- GPT-4 and GPT-3.5 Clarification: A distinction was made between GPT-4 and GPT-3.5, noting that the newer version appears to be a fine-tuned iteration of its predecessor.
- Mistral Model Multilingual Capabilities Discussed: Members discussed whether datasets for Mistral7B need to be in English to perform well, with advice given to include French data for better results.
- Finetuning and Cost Concerns Addressed: A discussion about finetuning methods, costs, and specific resources like notebooks provided insights for those new to the domain. It was suggested that continued pretraining and sft could be beneficial and cost-effective.
- Concerning UnSloth Contributions: Members expressed interest in contributing to UnSloth AI, offering help in expanding documentation and considering donations, with links to existing resources and discussions on potential contributions shared.
- Mixtral 8x22B Release Excitement: The release of Mixtral 8x22B, a sparse Mixture-of-Experts model with strengths in multilingual fluency and long context windows, sparks discussions due to its open-sourcing under the Apache 2.0 license.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #random (27 messages🔥):
-
Chroma Project Takes a Leap: Inspired by unsloth AI strategies, a member announces the development of an edge version of Chroma written in Go, using SQLite for on-device vector storage. The project, which is also compatible with browsers via WASM, is accessible on GitHub.
-
Smileys Invade the Bottom Page: A heartwarming mini-discussion about cute smiley faces at the bottom of a page, highlighting a particular mustache smiley as a favorite.
-
PyTorch’s New Torchtune: Mention of Torchtune, a native PyTorch library for LLM fine-tuning that has been shared on GitHub, sparking interest due to its potential to make fine-tuning more accessible.
-
Unsloth AI's Broad GPU Support Praised: A member congratulates Unsloth for its broad GPU support, which makes it more accessible compared to other tools that require newer GPU architectures.
-
Mobile Deployment of AI Models Discussed: Members discuss the feasibility of running neural networks on mobile phones, identifying the need for custom inference engines and noting the absence of CUDA on mobile devices. The challenges of running typical DL Python code on iPhones versus Macs with M chips are also mentioned.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #help (275 messages🔥🔥):
- Questions About Unsupported Attributes: A user encountered an
AttributeErrorwhen trying to fine-tune a model, reporting that the'MistralSdpaAttention'object has no attribute'temp_QA'. It seems to be related to a specific method within their custom training pipeline. - ORPO Support and Usage Clarified: Users inquired about ORPO support in Unsloth. It's confirmed that ORPO is supported, referenced by links to a model trained using ORPO on HuggingFace and a colab notebook.
- Discussions on LoRA and rslora: Users discussed using LoRA and rslora in training, with advice on handling different
alphavalues and potential loss spikes. Some members suggested adjustingrandalphaand disabling packing as possible solutions to training issues. - Embedding Tokens Not Trained: Users touched on the subject of embedding tokens that were not trained in the Mistral model, in the context of whether it is possible to train these embeddings during fine-tuning.
- Saving and Hosting Models: Questions arose about saving finetuned models in different formats using commands like
save_pretrained_mergedandsave_pretrained_gguf; whether they work sequentially and the need to start with fp16 first. There was also a query about hosting a model with GGUF files on the HuggingFace inference API.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #showcase (46 messages🔥):
- Clarification on Leaderboard Model Templates: A member asked how the leaderboard knows the model template. It was clarified that the model's
tokenizer.chat_templateis used to inform the leaderboard. - ShareGPT90k Dataset Cleaned and Formatted: A new version of the ShareGPT90k dataset has been cleaned of HTML tags and is available in chatml format on Hugging Face, allowing users to train with Unsloth. Dataset ready for action.
- Ghost Model Training Intrigue: Members engaged in a detailed conversation about what constitutes a 'recipe' for training AI models. One member is particular about needing a detailed recipe that leads to creating a specific model with defined characteristics and not just a set of tools or methods.
- Recipes vs. Tools in AI Model Training: The conversation continued on the difference between a full "recipe" including datasets and specific steps, as opposed to tools and methods. One member shared their approach, underlying the importance of data quality and replication of existing models, referencing the Dolphin model card on Hugging Face.
- Recommender Systems vs. NLP Challenges and Expertise: A PhD candidate discussed the differences and similarities between working on NLP and developing recommender systems, highlighting the unique challenges and expertise required in the latter which includes handling noise in data, induction biases, and significant feature engineering.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #suggestions (15 messages🔥):
- Exploring Multilingual Model Approaches: A member brought up the issue of catastrophic forgetting in multilingual models trained on languages like Hindi or Thai. They proposed a two-phase solution involving translating questions to English, using a large English model for answering, and then translating back to the original language, questioning the drawbacks of this method.
- Multilingual Expansion Through MOE: Another member expressed excitement about the possibility of using MoE (Mixture of Experts) to expand multilingual capabilities of models, anticipating it would “open so many doors!”
- Torchtune Gains Enthusiasm: The community shows interest in Torchtune, an alternative to the abstractions provided by Hugging Face and Axolotl, highlighting its potential to streamline the fine-tuning process. There is also a hint at possible collaborations involving Unsloth AI.
- Contemplating Language Mixing in Datasets: In response to the splitting of translation and question-answering tasks, a member considered the possibility of combining multiple languages into a single dataset for model training and using a strategy that involves priming the model with Wikipedia articles.
- Double-Translation Mechanism Discussed: A concept articulated as
translate(LLM(translate(instruction)))was proposed and discussed, supporting the idea of using a larger, more robust English language model in tandem with translation layers to process non-English queries. Concerns about the added cost due to multiple model calls were raised.
LM Studio ▷ #💬-general (175 messages🔥🔥):
- Repeat AI Responses Challenge: A member asked how to prevent AI from repeating the same information during a conversation, specifically using Dolphin 2 Mistral. They also inquired about what "multi-turn conversations" are, to which another member linked an article explaining the concept in relation to bots.
- WizardLM-2 LLM Announced: An announcement for the new large language model family was shared, featuring WizardLM-2 8x22B, 70B, and 7B. Links to a release blog and model weights on Hugging Face were included, with members discussing its availability and performance.
- Understanding Tool Differences: One user asked for the differences between ollama and LMStudio, and it was explained that both are wrappers for llama.cpp, but LM Studio is GUI based and easier for beginners.
- Fine-Tuning and Agents Discussion: There was a discussion on whether it's worth learning tools like langchain depending on needs and use cases, with some suggesting it can be a hindrance if venturing outside its default settings.
- File Management and API Interactions in LM Studio: A new member inquired about relocating downloaded app files and interfacing LM Studio with an existing API. It was clarified that models cannot change default install locations, and files can be found under the My Models tab for relocating. No specific method for API interaction through LM Studio was mentioned.
Links mentioned:
LM Studio ▷ #🤖-models-discussion-chat (96 messages🔥🔥):
- Template Troubles with WizardLM 2: Members reported issues with the WizardLM 2 and the Vicuna 1.5 preset, where the bot generated inputs for the user instead. A suggested solution included adjusting the rope frequency to 1 or setting
freq_baseto 0, which appeared to correct the behavior. - Mixed Opinions on WizardLM 2 and Wavecoder: While some users expressed a high opinion of WizardLM 2, claiming it performed well even compared to other 7B models, others judged the performance as subpar, not noticing any significant improvement even after fine-tuning.
- Exploring Best Quantization Practices: Users discussed the effectiveness of different quantization levels for 7B models, comparing Q8 to Q6K quality. The consensus leaned towards higher quantization being more desirable if one has sufficient VRAM, while acknowledging the utility of smaller models for certain tasks.
- Model Performance Debate: There was a spirited discussion around the relative superiority of models, with focus on parameter count versus quantization level, and the belief that fine-tuning and quality of the training can be deciding factors over just the size of the model's parameters.
- Finding the Right Code Generator: A user experienced difficulties with the code-generating capabilities of WaveCoder-Ultra-6.7B, receiving messages that it couldn't write complete applications. Tips offered included using assertive prompts and adjusting the context window size for the model to load appropriately.
Links mentioned:
LM Studio ▷ #🧠-feedback (4 messages):
-
Model Loading Error in Action: A user encountered an error loading model architecture when trying out Wirard LLM 2 on LM Studio across different model sizes, including 2 4bit and 6bit, prompting a Failed to load model message.
-
Fix Suggestion for Model Loading: Another user recommended ensuring the use of GGUF quants and also noted that version 0.2.19 is required for WizardLM2 models to function properly.
-
Request for stable-diffusion.cpp: A request was made to add stable-diffusion.cpp to LM Studio to enhance the software's capabilities.
LM Studio ▷ #📝-prompts-discussion-chat (17 messages🔥):
- Cleaning Up LM Studio: Users with issues were advised to delete specific LM Studio folders such as
C:\Users\Username\.cache\lm-studio,C:\Users\Username\AppData\Local\LM-Studio, andC:\Users\Username\AppData\Roaming\LM Studio. It's crucial to backup models and important data prior to deletion. - Prompt Crafting for NexusRaven: A user inquired if anyone has experimented with NexusRaven and devised any prompt presets for it, indicating interest in collective knowledge-sharing.
- Script Writing with AI: One member asked how to make the AI output a full script, suggesting they are searching for tips on generating longer content.
- Compatibility Issues with Hugging Face Models: A user noted problems with running certain Hugging Face models, like
changge29/bert_enron_emailsandktkeller/mem-jasper-writer-testing, in LM Studio. Assistance with running these models was sought. - Seeking Partnership for Affiliate Marketing: A user indicated interest in finding a partner with coding expertise for help with affiliate marketing campaigns, mentioning a willingness to share profits if successful. The user emphasized a serious offer for a partnership based on results.
LM Studio ▷ #🎛-hardware-discussion (18 messages🔥):
- GPU Comparison Sheet Quest Continues: User freethepublicdebt was searching for an elusive Google sheet comparing GPUs and could not find the link they worked on. Another user, heyitsyorkie, attempted to help but provided the wrong link leading to further confusion.
- Direct GPU Communication Breakthrough: rugg0064 shared a Reddit post celebrating the success of getting GPUs to communicate directly, bypassing the CPU/RAM and potentially leading to performance improvements.
- Customizing GPU Load in LM Studio: heyitsyorkie provided insight on adjusting the GPU offload for models in LM Studio's Linux beta by navigating to Chat mode -> Settings Panel -> Advanced Config.
- Splitting Workloads Between Different GPUs: In response to a query from .spicynoodle about uneven model allocation between their GPUs, heyitsyorkie suggested modifying GPU preferences json and searching for "tensor_split" for further guidance.
- SLI and Nvlink Troubles with P100s: ethernova is seeking advice for their setup with dual P100s not showing up in certain software and NVLink status appearing inactive despite having NVLink bridges attached.
Links mentioned:
LM Studio ▷ #🧪-beta-releases-chat (31 messages🔥):
- VRAM vs. System RAM in Model Performance: There's a discussion on whether a model would run on a system with 24 GB VRam and 96 GB Ram, with one member suggesting that it might run but inference will be incredibly slow due to the speed difference between VRam and system RAM.
- Expectations for WizardLM-2-8x22B: Members compare the WizardLM-2-8x22B to other models like Command R Plus, with mixed experiences. While one member was not impressed with Mixtral 8x22b and plans to test WizardLM-2-8x22B, another mentioned getting satisfactory results with 10+ tokens/sec from WizardLM.
- Model Performance on Different Hardware: Users with an M3 MacBook Pro 128GB report running model q6_k of Command R Plus, achieving about 5 tokens/sec. The speed is considered half as fast as GPT-4 on ChatGPT, but not painfully slow as each token represents a word or subword.
- Base Model Clarification: Clarification on what constitutes a "Base" model was provided—models not fine-tuned for chat or instruct tasks are considered base models, and they are generally found to perform poorly in comparison to their fine-tuned counterparts.
- Model Size and Local Running Feasibility: A conversation about the feasibility of running large models like WizardLM-2-8x22B locally was had, noting that a GPU like a 4090 with 24GB is too small to run such a large model, which runs best on Mac systems with substantial RAM.
LM Studio ▷ #amd-rocm-tech-preview (19 messages🔥):
- Curiosity about Windows Executable Signing: A member was curious whether the Windows executables are signed with an Authenticode cert. It was confirmed that they are indeed signed.
- Challenges with Code Signing Certificates: In the context of signing an app, there was a discussion on the cost and process complexities associated with obtaining a Windows certificate, including a comparison to the cost of an Apple developer license.
- Seeking Expertise on Automated Compile and Sign Process: A member expressed interest in understanding the automated process for compiling and signing, offering to compensate for the knowledge exchange.
- AMD HIP SDK System Requirements Clarification: A member provided information about system requirements for GPUs from a link to the AMD HIP SDK system requirements and asked about the stance of LM Studio on supporting certain AMD GPUs not officially supported by the SDK.
- Issues with AMD dGPU Recognition in LM Studio Software: Members discussed an issue where LM Studio software was using an AMD integrated GPU (iGPU) instead of the dedicated GPU (dGPU), with one member suggesting disabling the iGPU in the device manager. Another member stated that version 0.2.19 of the software should have resolved this issue and encouraged to report the problem if it persists.
Links mentioned:
LM Studio ▷ #model-announcements (3 messages):
- WaveCoder Ultra Unveiled: Microsoft has released WaveCoder ultra 6.7b, finely tuned using their 'CodeOcean'. This impressive model specializes in code translation and supports the Alpaca format for instruction following, with examples available on its model card.
- Seeking NeoScript AI Assistant: A community member new to AI has inquired about utilizing models for NeoScript programming, specifically for RAD applications using a platform formerly known as NeoBook. They are seeking suggestions on configuring AI models despite unsuccessful initial attempts using documents as references.
Link mentioned: lmstudio-community/wavecoder-ultra-6.7b-GGUF · Hugging Face: no description found
Nous Research AI ▷ #off-topic (17 messages🔥):
- Introducing Multimodal Chat GPTs: A link to a YouTube video titled "Introducing Idefics2 8B: Open Multimodal ChatGPT" was shared, discussing the development of Hugging Face's open multimodal language model, Idefics2. Watch it here.
- Reka Core Joins the Multimodal Race: Another YouTube video shared discusses "Reka Core," a competitive multimodal language model claiming to rival big industry names like OpenAI, Anthropic, and Google. The video can be viewed here.
- Navigating Language and AI: Discussions revolved around the relationship between language, AI, and the concept of the divine, touching on the idea of languages as "envelopes within the vectorspace of meaning" and the potential linguistic evolution that AI might spur. The conversation included references to general semantics and quantum mereotopology with a hint at looking into Alfred Korzybski's work.
- Staying Up to Date with AI Research: Members expressed the challenge of keeping up with the vast amount of AI research and literature, admitting to struggles with growing reading backlogs amidst the rapid pace of new publications.
- JetMoE and the Economics of AI: A YouTube video titled "JetMoE: Reaching LLaMA2 Performance with 0.1M Dollars" highlighting how JetMoE-8B was trained on a budget yet outperforms the more expensive LLaMA2-7B was shared. The video is available here.
Links mentioned:
Nous Research AI ▷ #interesting-links (7 messages):
-
Self-Supervised LLM Solution Selection Sprouts: A novel technique for enhancing Instruct Model LLMs is on the table, which utilizes the model’s own capacity to generate and select the most pertinent solution based on its ability to reconstruct the original input from its responses. The method aims at information maximization and offers a scalable, unsupervised evaluation that enhances coherence and relevance, and is adaptable with existing techniques.
-
New Horizons in LLM Medical Alignment: A shared Google Slideshow points towards efforts in aligning Language Models specifically for medical reasoning applications, although the content details are not accessible from the provided message.
-
Mistral's Tokenization Guide Unwrapped: Mistral AI introduces an open-source tokenizer, with a guide discussing the tokenization process, its importance in LLMs, and how to employ their tokenizer within Python.
-
Tempering the Tokenization Hype: A user critiques the emphasis on tokens, arguing that tokens aren't as critical if the model is already adept at handling tags, suggesting that the true value might be in increased steerability of the model.
-
Tweeting Up a Dev Storm: A link to a Twitter post was shared, but the content of the tweet hasn't been discussed within the provided messages.
Links mentioned:
Nous Research AI ▷ #general (159 messages🔥🔥):
-
Mystery Surrounding WizardLM's Takedown: There was confusion about why Microsoft's WizardLM was taken down, with speculation about it being "too toxic" and unverified rumors of it being attacked or hacked. A bundle of links and information about WizardLM was shared including its removal and a re-upload mirror.
-
Concerns about the EU AI Act: A theory was put forward that WizardLM had to be taken down as it violated the EU AI act for being almost uncensored, with suggestions to torrent the original version if anyone still has it. However, it was clarified later that it was originally unpublished for not going through Microsoft's new "toxicity review."
-
Excitement and Skepticism for Code Models: Discussion on CodeQwen1.5-7B Chat, a code-specific language model, was lively with members sharing its blog post and GitHub while noting its strong performance on benchmarks like 83.5 on humaneval. There is some skepticism about the model still using vanilla MHA (Multihead Attention) and speculation about potential contamination due to its high performance.
-
Frustrations with Mixed Messages on Model Performance: n8programs shared excitement for improvements to a creative writing model achieving a benchmark score of 70, between Mistral medium and large, using Westlake as a base model. The legitimacy of benchmark comparisons was debated, especially in light of expectations for LLaMa 3 and whether explicit tuning can trump new architectures.
-
Uncertainty about Future Model Releases: Queries about upcoming releases like Hermes 8x22B and whether it would be realistic to run such large models on personal equipment. There is anticipation about potential Llama-3 models and speculation on whether these new models will outperform their predecessors.
Links mentioned:
Nous Research AI ▷ #ask-about-llms (7 messages):
- Speed Demon: A member mentioned witnessing a performance of 700 Mbps in an unnamed context.
- Diving into State-Space Models: A member sought recommendations for essential papers on recent advances in state-space models for weekend reading.
- Mamba Paper Suggested: In response to a request for recent literature, one member suggested looking into the Mamba paper, while another was more interested in the newer Jamba and related works.
- Hermes 2 Pro Query Handling Issue: A user expressed the need to prevent Hermes 2 Pro from always returning
<tool_call>when it should sometimes just engage in chat, noting it as a current limitation. - Promising Future Updates: A contributor noted they will collaborate with another member to improve Hermes 2 Pro's ability to discern when to use
<tool_call>and when to just chat in future versions.
Nous Research AI ▷ #rag-dataset (10 messages🔥):
-
Debating JSON's Virtue: A message refers to a previous defense for using JSON structure for input-outputs, suggesting that this format might reduce the need for handwaving when explaining processes.
-
Seeking Vision for RAGs: A user expressed interest in the state of the art for vision, especially in the context of building a Retrieval Augmented Generation (RAG) on engineering documents with images and diagrams.
-
Vision SOTA Suggestions: One member touted GPT4v/Geminipro Vision and Claude Sonnet as leading options in the field, recommending testing them against each other for specific use cases.
-
Turning to Open Source: When seeking open-source alternatives, suggestions included llava, cogvlm, mPlug-DocOwl, and donut, with mPlug-DocOwl being specifically recommended for DocVQA use cases.
-
Exploring Supersizing LLMs: A member shared a blog post discussing the use of LLMs beyond token sequencing, emphasizing the need for models that perform complex reasoning and fetch accurate, topical information.
Link mentioned: The Normal Blog - Infinite Context LLMs: Going Beyond RAG with Extended Minds: In this blog we discuss how the transformer architecture naturally extends over external memories, and share empirical results which leverage this capability to succeed where RAG has struggled. These ...
Nous Research AI ▷ #world-sim (159 messages🔥🔥):
-
World-Sim Anticipation Builds: Members express excitement and impatience as World-Sim's return is discussed with speculative launch times, the concept's philosophical underpinnings, and whether AI aspires to godhood. A member provided the link to the Nous Research blog post to delve deeper into this topic: Divinity in AI.
-
Jailbroken Prometheus Draws Interest: The chat mentions an alternative to World-Sim, web-based Jailbroken Prometheus, sparking curiosity among users. For those looking for similar experiences, a member shared a Websim link.
-
Official Confirmation Raises Hype: The anticipation peaks as an official statement is made—World-Sim alongside Nous World Client returns the next day. Users celebrate with excitement and share gifs like Let Me In!.
-
Hetetic Modelling Choices and Payment Options: Inquiries about Claude 3 use and the possibility of switching models in World-Sim get addressed. A member mentioned that users would have model preferences based on affordability and confirmed various subscription and payment options, including an unlimited Claude Opus.
-
Developer Mode and World Client Queries Answered: Discussions sprout around potential features, such as "developer mode," and clarifications on the Nous World Client, which will be web-based for accessibility from any device.
Links mentioned:
Perplexity AI ▷ #general (286 messages🔥🔥):
-
Model Comparisons and Misadventures: Discussions revolve around the performance of various AI models including GPT-4, Claude, and Mistral. Users share experiences suggesting that newer versions at times seem lazier or less capable of managing extensive context, while others note the usefulness of models like Claude 3 Opus for technical issues. There's also mentions of Mixtral's 8x22B model being impressive for an open-source release.
-
Channel Guidance and Navigation: New members are guided on how to find related chats and access various channels using the
<id:customize>feature or by navigating through the Perplexity name at the top of the interface. -
Payment Anxieties and Checkout Changes: Users express confusion and concern over changes to the Perplexity API payment method management and the lack of transparency regarding the remaining pro message counts.
-
File Handling Frustrations: Users discuss the limitations of AI models in handling large context sizes, with one reported difficulty getting a 42k token prompt to properly engage with the system. Another user suggests that the model might be summarizing long documents instead of processing them in detail, impacting how the AI addresses specific prompts.
-
AGI Aspirations and Subscriptions: Conversations feature anticipated updates, with some users eagerly waiting for new features like Grok to be added to Perplexity while others debate over the value of their subscriptions.
Links mentioned:
Perplexity AI ▷ #sharing (9 messages🔥):
- Exploring World Voice Day: A link to Perplexity's results for World Voice Day was shared, revealing resources and discussions related to this event.
- Delving into AWS Hardening Guide: A user referenced a search for AWS hardening guide, pointing to Perplexity AI's aggregated information on enhancing security on AWS.
- Discovering "SBK Borderline": The song "SBK Borderline" was the focus of a link, facilitating exploration through Perplexity's summarized content.
- Curiosity about Income: A search about income queries was signaled through a Perplexity AI link, encapsulating associated answers and data points.
- Investigating Reboot for Better Performance: Discussion included a practical approach for enhancing an iPad's performance, as a user considered rebooting as illustrated in the given Perplexity link.
Perplexity AI ▷ #pplx-api (4 messages):
- Seeking API and Web Client Consistency: A member expressed difficulty in aligning the behavior of the web client with the API, noting occasional discrepancies and seeking to understand specific settings such as temperature to ensure consistency.
- Navigating with Site Search Operator: In reference to locating information, a member suggested using the site search operator
site:URLto facilitate searches on a specific website. - Rate Limit Counter as a Feature Request: A user proposed having the Perplexity API include the number of requests used within a minute in the response data, to better handle rate limits and potentially wait until the limit resets.
- Querying API Rate Limiting Mechanism: Another member questioned whether the Perplexity API returns a
429 responsewhen the rate limit is reached, indicating a need for clarity on how the API communicates with users about rate limits.
LAION ▷ #general (285 messages🔥🔥):
-
PyTorch Design Mysteries: Members express confusion about the design philosophy of PyTorch, noting it often abstracts away many details with "just one line of code," which can prove challenging when something doesn't work as expected.
-
Storing Large Datasets with Zarr: A discussion about using zarr or other libraries to store large datasets for fast loading, specifically for a 150 GB MRI image dataset. One member raises concerns about whether zarr would attempt to load the entire dataset into RAM.
-
British Law Criminalizing Creation of Certain Images: There is a wrinkle in UK law criminalizing the creation of images with the intent to cause distress, and members debate the enforceability of such a law, especially since proving intent can be challenging.
-
Mysteries of Running AI Inference: A member voices the need for access to actual inference settings to judge AI models properly, like adjusting CFG or hooking models up to suitable ODE solvers instead of just using Euler's method.
-
The Fate of SAI's Cascade Team and Channels: It's mentioned that the Cascade team has left Stability AI (SAI), with the related Discord channel being removed, and there's speculation about the possible involvement of team members with another company, Leonardo, or remaining affiliated with SAI.
Links mentioned:
LAION ▷ #research (13 messages🔥):
-
Introducing ALERT Safety Benchmark: A new safety benchmark for assessing Large Language Models has been established, complete with a safety Dataset of Problematic Outputs (DPO) set. All interested can access and use it via GitHub - Babelscape/ALERT.
-
Exploring Generative Multimodal Content: An Arxiv paper discussing the generation of audio from text prompts and how focusing on the presence of concepts or events could improve performance, has been shared. View the research on arXiv.
-
Debate over AI Safety Standards: Members discussed the terminology and standards of "safety" in AI, debating whether restricting AI to non-controversial or PG content might limit its creative capacities compared to other artistic tools.
-
Comparing GANs with Diffusion Models: A discussion unfolded around the benefits of GANs over diffusion models. Mentioned advantages include faster inference times, smaller parameter counts, feedback from discriminators, and potentially lower costs for training.
-
Skepticism Over GANs' Image Quality and Training Difficulty: Despite some perceived benefits, GANs were criticized for reportedly producing inferior images as judged by human discrimination and presenting challenges in training compared to diffusion models.
Links mentioned:
OpenRouter (Alex Atallah) ▷ #announcements (5 messages):
-
New Models and Price Adjustments: OpenRouter announces the availability of WizardLM-2 7B and a price reduction for WizardLM-2 8x22B to $0.65/M tokens. Discussions about these models can be followed in their dedicated channel.
-
Latency Issues Under Investigation: OpenRouter is investigating high latencies for Mistral 7B Instruct and Mixtral 8x7B Instruct with ongoing discussions in a message thread. The cause was initially tied to a cloud provider's DDoS protection but is now resolved.
-
Third-party Problems Affecting Services: An update revealed reoccurring high latency issues affecting Nous Capybara 34b among others, potentially due to a specific cloud provider. Updates continued as the situation developed, with traffic returning to normal and further deep investigation with providers.
-
Maintenance Notice: Users were informed of an impending DB reboot expected to briefly take the site offline.
-
Launch of High-Throughput Model and Status Update: The WizardLM-2 8x22B Nitro model is now serving over 100 transactions per second with a notice that the DB restart was completed. The team continues to address performance issues, with updates and discussions available in channel.
Links mentioned:
OpenRouter (Alex Atallah) ▷ #app-showcase (4 messages):
- Help Wanted for AI Frontend Project: A member is seeking a web developer to assist with a project focused on a general-purpose AI frontend for OpenRouter, which has a role-playing orientation. They've managed to get the novel mode working but are struggling with the conversation style mode.
- Assistance Requested for Distinguishing AI Text: They are also looking to enhance the novel mode by creating a way to differentiate between text generated by the AI and the user's own written text.
- Development Support Sought for Sidebar and Modal System: The member needs help to improve a sidebar with options and is looking to develop a flexible modal system for their application.
OpenRouter (Alex Atallah) ▷ #general (271 messages🔥🔥):
-
Censorship Layers and NSFW Content Management in AI Models: Discussions touched on the layers of censorship within a particular AI model, and a member noted that their experiences with NSFW content on their end were very explicit. Another member questioned the usefulness of a base model for their purposes.
-
Interest in Multilingual Capacity of AI Models: The multilingual performance of WizardLM was critiqued with a member suggesting it might be undertrained for non-English languages. There was speculation on whether upcoming models could surpass 8x7b models in performance and pricing.
-
Server Issues and Latency Concerns: Members experienced issues with high latency and server errors, noting particularly long response times. Updates on investigating and resolving the server issues were provided, with a focus on fixing core server problems before adding new models such as Lepton's Wizard 8x22b.
-
Decoding Algorithm Impact on AI Model Quality: Discussion about quantization of models to bits per word (bpw) revealed preferences for 6 or at least 5 bpw over 4 bpw, with some noting that a noticeable quality loss occurs with lower bpw.
-
Potential New Additions and Deployments of AI Models: The OpenRouter team indicated that new models such as Mistral 8x22B Instruct were being deployed. Concerns about the reliability of certain providers like TogetherAI were expressed, with members looking forward to direct endpoints from Mistral and the addition of Fireworks as a provider.
Links mentioned:
Modular (Mojo 🔥) ▷ #general (67 messages🔥🔥):
-
Insights on Mojo's Compile-Time Optimizations: Members discussed the optimization efficiency of Mojo, mentioning that aliases like
@parameterare determined at compile time, leading to memory and processing efficiency by avoiding the need to reserve memory for the alias after its purpose is served. This conversation was sparked by thoughts on the importance of readable code over comments, as discussed in a YouTube video titled "Don't Write Comments". -
Exploring Typestates in Rust Programming: The conversation shifted towards best practices in API design, with one member favoring the use of typestates and lifetimes for making static guarantees in programming, sharing a Rust typestate pattern article for reference.
-
Contemplation on Memory Allocation and Optimization: A debate unfolded about whether variables could be optimized in the same way as aliases in Mojo, touching upon optimization concerns in Rust and the potential for memory-efficient data structures such as bit vectors.
-
Issues Adapting Code to Mojo Version 24.2: Conversation occurred around upgrading the llama2.mojo code to be compatible with Mojo version 24.2, specifically the need for pointer type conversions. Solutions using
DTypePointerwere offered to address issues withAnyPointerconversion. -
Mojo Development and IDE Integration Discussion: Members discussed the structure of Mojo projects and whether there is a similar package management system to Rust's Cargo. Additionally, the availability of a Mojo plugin for IDEs such as PyCharm was mentioned, with reference to the plugin link, and the JetBrains team's interest in further Mojo support.
Links mentioned:
Modular (Mojo 🔥) ▷ #💬︱twitter (1 messages):
ModularBot: From Modular: https://twitter.com/Modular/status/1780676643176231240
Modular (Mojo 🔥) ▷ #ai (2 messages):
- Replication Curiosity in Modular: A member expressed interest in replicating a concept or project within the Mojo platform, indicating anticipation for potential outcomes.
- Guidance on AI Long-Term Memory and Self-Improvement: A video tutorial was shared by a member explaining how to build an AI agent with long-term memory and self-improvement capabilities, intended to be a helpful resource. The video, titled "Unlock AI Agent real power?! Long term memory & Self improving," is available on YouTube.
Link mentioned: Unlock AI Agent real power?! Long term memory & Self improving: How to build Long term memory & Self improving ability into your AI Agent?Use AI Slide deck builder Gamma for free: https://gamma.app/?utm_source=youtube&utm...
Modular (Mojo 🔥) ▷ #🔥mojo (136 messages🔥🔥):
- New Python Package for Mojo to Python Code: A new python package called mojo2py has been announced that converts Mojo code into Python code.
- Need for a Comprehensive Mojo Learning Resource: A member is seeking a comprehensive resource for learning Mojo from scratch, and was directed to the Mojo programming manual, which covers fundamental concepts such as parameters vs. arguments, the ASAP concept, types and traits, and key re-reading sections like owned arguments and transfer operator.
- Struct Inheritance and Code Reusability: Discussions circled around the desire for some form of inheritance within Mojo, with suggestions for reducing boilerplate and instances where a child struct could be created from a parent struct. While one approach suggested was using traits for type declarations, another member clarified that if one seeks compile-time optimization, classes might be more suitable, versus runtime-based approaches.
- Start of Conditional Conformance in Mojo: There appears to be movement towards implementing conditional conformance in Mojo, as evidenced by recent discussion and code snippets shared amongst members. The dialogue involved understanding how conditional conformance might be leveraged to make standard library functions like
strandprintwork for different Mojo data structures. - Challenges and Prospects of Advanced Type Systems: Intense technical debate and brainstorming emerged around creating a numpy-style Mojo library that enforces shape compatibility at compile time, the potential for supporting
Variantdata structures without runtime checks, and addressing the specific issue of storing multiple variants in a single list. Various approaches were proposed and conceptually dissected, including custom structs, enum parameters, and challenges in implementing generics and shape refinement for parametric code.
Links mentioned:
Modular (Mojo 🔥) ▷ #community-projects (10 messages🔥):
- Sudden Sketch Success: A community member shared an "off the cuff" programming sketch implemented in Mojo, found to be surprisingly effective, accessible via this gist.
- Anticipating Enhanced Tuple Capabilities: Upcoming enhancements could allow
Tuplein Mojo to take traits derived fromCollectionElement, leading to more elegant struct definitions for HTML rendering. - Nightly Features in Play: It was clarified that the shared code uses nightly features, which may cause compilation errors on the current Mojo 24.2 and on the Mojo Playground.
- Canny Edge Recognition Challenge: A new community member from France, experienced in Numba with Python, expressed interest in implementing the Canny edge recognition algorithm in Mojo to compare performance.
- Mojo Resources for Newcomers: A helpful response to a project inquiry included links to the Mojo documentation, guidance on getting started with the language, and referenced available resources such as the Mojo SDK and Mojo Playground.
Links mentioned:
Modular (Mojo 🔥) ▷ #community-blogs-vids (1 messages):
- Exploring the Hype Around Mojo: A recent talk titled "Maxim Zaks - Is Mojo just a hype?" from PyCon Lithuania has been released on YouTube, which prompts a discussion on the Modular chatbot's place in the industry.
Link mentioned: Maxim Zaks - Is Mojo just a hype?: no description found
Modular (Mojo 🔥) ▷ #📰︱newsletter (1 messages):
Zapier: Modverse Weekly - Issue 30 https://www.modular.com/newsletters/modverse-weekly-30
Modular (Mojo 🔥) ▷ #🏎engine (1 messages):
There was only one message provided with no mention of any discussion points, topics, or links to summarize. If you would like a summary of a more extensive conversation or a specific topic within the 🏎engine channel, please provide the relevant messages.
Modular (Mojo 🔥) ▷ #nightly (21 messages🔥):
- A New Nightly Mojo: Updates and Changes: A new nightly update for Mojo has been released, complete with updates to the standard library and a detailed diff available, as well as a changelog documenting the changes since the last stable release found here.
- A Love for Unconventional Code: Members reacted humorously to unconventional code styling, with comments indicating affection for its "horrible" appearance and a comical plea to indent for loops for readability.
- Peer Pressure vs. Code Formatting Practices: One voice suggested holding off on conforming to peer pressure regarding code indentation practices, but another opined the inevitability of adopting Mojo formatting standards.
- Nightly update causes confusion: The new nightly update led to confusion for a user over function overloads parameterized on traits, resulting in unexpected errors and discussions around finding a solution.
- Traits Over Janky Workarounds and Clean-Up Releases: Discussion included a slight jest on the preference for using 'jank' over proper trait parameterization and comments on the recent clean-up efforts in the latest Mojo nightly release.
Links mentioned:
CUDA MODE ▷ #general (11 messages🔥):
-
Seeking Guidance in PyTorch: A member asked if "Deep Learning with PyTorch" is still a good starting point given that it was published 4 years ago. Another member confirmed that while PyTorch's core hasn't changed much, there have been significant updates in the compiler and distributed systems.
-
PyTorch Evolution and New Edition Tease: Updates were discussed clarifying that the book does not cover topics like transformers and LLMs, and that while parts I and II remain useful, part III on deployment is outdated. It was also revealed that a new edition is in progress, spearheaded by a new author.
-
Anticipating Blog Content: A member mentioned they had a draft chapter on attention/transformers and considered creating a blog post from it.
Link mentioned: Deep Learning with PyTorch, Second Edition: Everything you need to create neural networks with PyTorch, including Large Language and diffusion models.</b>
Deep Learning with PyTorch, Second Edition</i> updates the bestselling ori...
CUDA MODE ▷ #cuda (20 messages🔥):
- Accelerated Matrix Operations in CUDA: A member discussed the integration of a new fp16 precision general matrix-matrix multiplication (GEMM) implementation for CUDA, which outperforms PyTorch's GEMM function in a specific matrix operation benchmark (MxNxK = 1x4096x4096).
- Challenges with JIT Compilation: Despite the new implementation providing a performance boost, another member noted it fails with
torch.compile; sharing crash details with uncompiled token generation at 11.17 tokens/sec versus compiled token generation at 64.4 tokens/sec before the crash due to an unsupported method call related to 'block_dim_x'. - Block Size Parameters Exploration: Discussion continued around the choice of block sizes in the new GEMM kernel, with members examining the use of a 32x4 effective block size, discovering it seemed to yield better performance and sharing their observations in a related Gist example.
- Inquiry about Data Reading for CUDA C++: A member sought advice on reading large datasets in CSV or Parquet formats within CUDA C++ applications, pondering the possibility of parallel execution but without offering a specific solution.
- Speculating on CUDA Cores and Thread Dispatch: Further technical speculation highlighted the probable connection between faster kernel performance and the use of 128 total active threads per streaming multiprocessor, considering the dispatch of 32 threads per clock cycle across 4 warps.
Links mentioned:
CUDA MODE ▷ #torch (2 messages):
- Searching for the F.Linear Implementation: A member is working on a custom backward function that performs correctly with a (bs, data_dim) input similar to F.Linear. They encountered issues when integrating with Llama due to input dimension differences and are now seeking the forward/backward implementation of
F.Linear, which was elusive in the indicated tools/autograd/templates/python_nn_functions.cpp.
CUDA MODE ▷ #cool-links (2 messages):
-
Augmend Launches Video Processing Tool: Augmend offers a work-in-progress feature on wip.augmend.us for analyzing videos, with a smart addition of OCR and image segmentation to extract information directly from video screens. The completed service will be available on augmend.com, allowing users to copy/paste and search content within any video.
-
Boston Dynamics Reveals Electric Atlas Robot: Boston Dynamics released a YouTube video on a next-generation humanoid robot named Atlas; the All New Atlas | Boston Dynamics video presents a fully electric robot aimed at real-world applications and highlights advances over decades of robotic development.
Link mentioned: All New Atlas | Boston Dynamics: We are unveiling the next generation of humanoid robots—a fully electric Atlas robot designed for real-world applications. The new Atlas builds on decades of...
CUDA MODE ▷ #beginner (43 messages🔥):
-
Newcomer Inquiry on PMPP Lectures: A newcomer inquired about the routine meeting schedule for going through pmpp lectures. Recorded lectures can be found in a specific channel, with the last covered chapter being the 10th.
-
WSL Profiling Troubles: A user expressed difficulty running the ncu profiler on WSL, suspecting a PATH issue, and highlighted that NSight Compute on Windows was conflicting with WSL. Despite having nsight-compute installed, the
ncucommand was not found. -
Cuda Toolkit PATH Adjustment Suggestions: Users suggested several troubleshooting steps, focusing on adding the correct CUDA path to the environment variables. One user provided a link to NVIDIA's documentation to assist with setting environment variables on Windows.
-
Version Mismatch Discovered: It was discovered that there was a version mismatch, with the user's environment configured for CUDA 12.4 while attempting to run
ncufrom CUDA version 11.5. Adding the path didn’t immediately resolve the issue. -
Windows 11 Recommended for WSL 2 Profiling: Another user mentioned needing Windows 11 to profile CUDA programs on WSL 2 effectively, sharing a helpful blog post detailing how to set up the system and resolve common issues.
Links mentioned:
CUDA MODE ▷ #youtube-recordings (1 messages):
marksaroufim: https://www.youtube.com/watch?v=DdTsX6DQk24
CUDA MODE ▷ #ring-attention (5 messages):
- RingAttention Working Group Conundrum: A key member revealed that they cannot commit to working on the RingAttention project alongside their main job due to time constraints. They proposed a discussion to decide whether others will continue the initiative or temporarily conclude this working-group effort.
- Decisive Discussion Scheduled: A meeting was scheduled to discuss the future of the RingAttention project and who might continue its development.
- A Time for Difficult Choices: The member expressed regret over their decision to step back from RingAttention, emphasizing that the choice was made with heavy consideration of personal time and well-being.
- Participants Ready for the Talk: Team members confirmed their availability and showed readiness to join the forthcoming discussion about the future of RingAttention.
- Pre-Meeting Preparations: One of the members notified others that they would join the meeting shortly, indicating active preparation for the scheduled discussion.
CUDA MODE ▷ #hqq (36 messages🔥):
-
Quandaries About Quantization Axes: Quantizing with
axis=0for GPT's Q, K, V was found problematic ingpt-fastdue to mixing of parameters during quantization. An ongoing discussion suggests quantizing Q, K, and V separately might be a solution, noting thatweight_int4pack_mmcurrently only supportsaxis=1. -
Speed Versus Quality Compromises in HQQ: The trade-offs between speed and quality when using
axis=0oraxis=1in Half-Quadratic Quantization (HQQ) were explored. A member reported equivalent performance of 5.375 perplexity for both axes ongpt-fast. -
Pursuing Further Optimizations: A mention of using Triton kernels and other methods like fake data to optimize performance along
axis=1. They noted that method using autograd and randomly generated data gave slightly better results (5.3311 ppl) than HQQ with more iterations. -
Exploring Extended Capabilities and Demystifying Differences: Insights into the potential impact of in-channel variation on weight quantization accuracy were shared, referring to steeling quants with
axis=0appearing to yield better results. The conversation indicated that HQQ effectively finds optimal solutions faster compared to lengthy autograd optimization. -
Implementational Details and Benchmarks Shared: Links were provided to the implementation details, such as a torch int4mm demo with transformers as well as the optimizer code using autograd and discussions were centered around potentially speeding up operations further with vectorized fp16 multiplication and the practicality of lower precision quantization like 2/3 bits.
Links mentioned:
CUDA MODE ▷ #llmdotc (76 messages🔥🔥):
-
Thunder's CUDA Python Extension Takes Flight: The GitHub notebook for extending PyTorch with CUDA Python receives attention for improving speed, though the integration into cuda-mode and further optimizations such as leveraging tensor cores are still needed for maximum performance.
-
Optimizing Multiplication in Transformers: Members identified the final matmul layer and softmax as significant contributors to computational cost in profiling efforts. An optimised classifier kernel presents an opportunity for improving speed, as seen in the conversation about caching strategy and kernel optimization.
-
Increasing Efficiency of Softmax and Backpropagation: There was discussion about avoiding the materialization of the full probability matrix, focusing instead on necessary token probabilities. A GitHub pull request #117 demonstrates efforts to fuse points in the classification layer.
-
Cache Utilization and Performance Correlation: The effect of block sizes on cache hit rates was discussed, revealing that larger blocks may result in better cache utilization. This insight, embodied in an optimised CUDA kernel, might lead to better performance on GPUs with sufficient cache.
-
Supporting Diverse Model Architectures for Benchmarking: It was suggested to consider the initialization of a variety of GPT model architectures for benchmarking to prevent overfitting optimizations to a single model type. An emphasis was placed on accurately reproducing models like GPT-2 to evaluate performance enhancements meaningfully.
Links mentioned:
CUDA MODE ▷ #massively-parallel-crew (14 messages🔥):
-
Tablet Triumph for Presentations: A member pondered the possibility of using an iPad to switch between slides and live writing for presentations. The consensus suggested using a single device for both tasks and emphasized the importance of testing the setup beforehand to ensure a smooth experience.
-
No to NSFW: With incidents of inappropriate content being posted in the chat, members discussed implementing a Discord bot to detect and prevent such content from being shared, with suggestions of banning offenders or restricting their typing privileges.
-
Event Creation Empowerment: It's been announced that everyone now has the roles and privileges to create new events on the server. This change empowers members to organize their own gatherings and discussions.
-
Interjections and Interactions: Casual interactions among members included humorous suggestions for names like “Massively Helpful” and playing with the word "parallel" in the context of the server name. These moments reflect the lighter side of the community's interactions.
-
Tech Tips Shared: There's helpful advice given for someone wishing to stream presentations, including using a Wacom tablet and maintaining audience engagement through methods like different setups. The importance of testing the setup early was highlighted once again.
OpenAI ▷ #ai-discussions (167 messages🔥🔥):
-
Gaming Assistant Development Inquiry: A user sought advice on creating a gaming assistant combining GPT-Vision, camera input, and probabilistic calculations for real-time multiple-choice games. Considering using Azure or a virtual machine for running demanding calculation software was suggested, with TensorFlow or OpenCV as possible tools to manage the system.
-
AI vs. Human Cognition Debate: The channel hosted a philosophical discussion on the fundamental differences between AI and humans, touching on concepts such as memory storage, computational power, and the potential for AI to develop human-like reasoning and emotions with advancements like quantum computing.
-
Understanding Non-Binary Thinking: There was an extensive debate on binary versus non-binary thinking, with users discussing the applicability of binary thinking and labels in humans and AI, and how gradients and chaos theory might present a more accurate model of cognition and decision-making.
-
Claude's Superiority for Literature Reviews: Users exchanged opinions on suitable AI models for writing literature reviews, with advice given to use Claude over OpenAI for non-technical literary tasks, and mentioning Gemini 1.5 for aiding in writing fictional works.
-
Navigating AI-Related Complications: Participants reported and discussed issues such as unexpected account terminations and policy violations, highlighting challenges in understanding and adhering to the usage policies of AI platforms, and expressing concerns about the lack of clarity and support often encountered.
Links mentioned:
OpenAI ▷ #gpt-4-discussions (7 messages):
- GPT Gets a Trim?: A user remarked that it seems like GPT was significantly altered or "lobotomised," while another defended the new GPT-4 Turbo as being effective, mentioning alternate endpoints to use.
- Important to Report Flaws: One member encouraged others to report any problematic messages from GPT to improve its performance.
- Discussing Alternatives Due to Costs: A user shared that they are using Gemini 1.5 with a 1 million token context window on Google Studio as an alternative, implying costs are a factor.
- Seeking Knowledge Base Training: Someone asked for directions to trainings or resources on how to prepare a knowledge base for a custom GPT.
- Whispering for Whisper v3 API Access: A query was raised about when Whisper v3 would become available through the API, noting that it has been almost a year since its release.
- Shrinking Token Attention Span?: A user observed that GPT-4's ability to remember past inputs seems impaired, speculating about a reduced token limit from beyond 30,000.
OpenAI ▷ #prompt-engineering (5 messages):
- Echoes in the Ghost Town: One member laments the decline of activity in the prompt-engineering channel, attributing the lack of discussion to over-moderation by administrators and mods.
- Salty Retrospection: A user suggests their extended timeout from the server may be related to a decline in activity, and believes others may have faced similar penalties.
- GPT-4-Turbo's Math Prowess: GPT-4-TURBO successfully solved a math problem regarding the number of possible seating arrangements for the Smith family at their dinner table.
OpenAI ▷ #api-discussions (5 messages):
- Silence in the OpenAI Discord: One member expressed dismay at the lack of recent activity within the api-discussions channel, noting it has been quiet for weeks.
- Reflections on Server Moderation: The same member attributed the inactivity to what they perceived as over-moderation by the server's administrators.
- Post-Timeout Frustrations: Following a 5-month timeout from the server, the member lamented that they were punished for attempting to assist another user.
- GPT-4-Turbo's Mathematical Prowess: A user reported that GPT-4-TURBO correctly solved a combinatorial math problem involving the seating arrangements of the Smith family at a dinner table.
LlamaIndex ▷ #blog (3 messages):
-
Qdrant Hybrid Cloud Offering Launch: The @qdrant_engine has launched a hybrid cloud offering, enabling running Qdrant as a hosted service, at the edge, or in one's own environment while maintaining full data control. The announcement also linked to an in-depth tutorial on setting it up.
-
LlamaIndex Teams Up with Azure AI Search: A tutorial presented by Khye Wei from Microsoft demonstrates how to combine LlamaIndex with Azure AI Search to create enhanced RAG applications that feature Hybrid Search and Query rewriting.
-
Day 0 Support for MistralAI's Latest Model: MistralAI's new 8x22b model, described as defining the state of the art in open models, is supported by LlamaIndex from day one. The release includes a Mistral cookbook by @ravithejads, showcasing RAG, Query routing, and Tool use.
Link mentioned: MistralAI Cookbook - LlamaIndex: no description found
LlamaIndex ▷ #general (164 messages🔥🔥):
-
Inquiry About Building a Search Engine: Users discussed how to build a search engine using LlamaIndex. One user provided a starter tutorial and highlighted the use of
retrieverwith a highertop_kvalue to retrieve top documents. -
Understanding LLM Retrieval Limits: A user clarified they needed to retrieve document names instead of answers from agents, comparing it to perplexity functionality. The conversation continued with users referencing LlamaIndex's
retrieverand its settings. -
Issues With Authentication: Several users encountered and discussed errors related to API authentication. The error messages indicated incorrect API keys, leading to troubleshooting around environment variables and correct key usage.
-
LLamaIndex Updates And Issue Fixing: Users collaboratively tried to resolve various issues, with a specific focus on a
BaseComponenterror which one user couldn't resolve despite trying numerous troubleshooting steps. A solution was suggested in the form of a GitHub pull request. -
LLM Query Logging and Active Model Check: Discussion on logging within LlamaIndex led to advising on adjusting logging levels from
DEBUGtoINFO. A user sought to confirm which LLM was active for a query and was advised on checking and setting the LLM through theSettings.llmattribute.
Links mentioned:
LlamaIndex ▷ #ai-discussion (2 messages):
- Seeking Hierarchical Structure Wisdom: A member is looking to construct a parent-child hierarchical structure within the LlamaIndex using ParentDocumentRetriever langchain for a vast number of documents and is requesting guidance.
Eleuther ▷ #general (58 messages🔥🔥):
-
Pile-T5 Details Sought: A user requested details about the Pile-T5 model on EleutherAI's Discord, pointing to the Hugging Face collection page for further information. The discussion clarified that "sequence length" and "context window" are the same, while noting the scarcity of encoder/decoder models with long sequence lengths.
-
Reka's Long Enc-Dec Model Revealed: In discussing model sequence lengths, a user mentioned Reka's new encoder-decoder model, which supports up to 128k, as described in their core tech report.
-
EleutherAI's Model Evaluation Harness Discussed: The ARC-challenge on EleutherAI's Evaluation Harness was debated with concerns on the absence of "choices" in the query for models. It was mentioned that the library initially aimed to replicate plots from the GPT-3 paper, with intentions to standardize MCQA tasks by offering multiple prompting options.
-
Research Scientist Interview Insights: Users shared insights on research scientist interviews, explaining that the focus can vary greatly depending on the company, ranging from little emphasis on traditional data structure and algorithm questions to heavy consideration of the candidate's talk, papers, and potential for grant acquisition.
-
Sequence Packing vs. Prepacking in LLMs: A discussion emerged about whether "prepacking" is just regular sequence packing, as mentioned in a new research paper. This led to a debate about the novelty and prior documentation of these methods, with references to the T5 paper and upcoming publications addressing these and related methods for model evaluation and efficiency.
Links mentioned:
Eleuther ▷ #research (78 messages🔥🔥):
-
New Transformer Architecture for Long Inputs: A recent proposal for a novel Transformer architecture named Feedback Attention Memory (FAM) aims to enable processing of indefinitely long sequences by allowing the network to attend to its own latent representations, thus overcoming the quadratic attention complexity. FAM's performance showed significant improvement on long-context tasks.
-
Advances in Brain Decoding Research: The paper MindBridge introduces a new approach that allows for cross-subject brain decoding by employing only one model, addressing three main challenges in the field: variability in brain sizes, individual neural pattern differences, and limited data for new subjects.
-
Rethinking Scaling Laws' Accuracy: Discrepancies pointed out in the compute-optimal scaling laws presented by Hoffmann et al. (2022) highlight the importance of data transparency, as a new analysis suggests that the original narrow confidence intervals were implausible unless an extensive number of experiments were conducted.
-
Expressive Power of State-Space Models: A discussion was prompted by the analysis of State-Space Models (SSMs), revealing that their expressive power for state tracking is very similar to transformers and SSMs cannot express computation beyond the complexity class $\mathsf{TC}^0$. The dialogue also touched upon clarifications and potential misunderstandings from prior related works.
-
Transformers, RL, and EEG Feedback: Conversations touched on the concept of using Reinforcement Learning (RL) with feedback from an EEG but found limited academic research, primarily existing product implementations; the complexities and risks associated with such undertakings were also noted.
Links mentioned:
Eleuther ▷ #scaling-laws (5 messages):
-
Flops Estimation for ML Newcomers: A member sought advice on estimating training flops from the SoundStream paper and was guided to calculate the number of operations per token for both forward and backward passes, using the equation 6 * # of parameters for decoder-only transformers. They were referred to a detailed example in Section 2.1 of a relevant paper.
-
One Epoch Assumption in Cost Estimation: In response to a question about training cost estimation, one member clarified that it's wise to assume a single dataset pass unless a paper explicitly mentions performing multiple epochs.
-
Mystery of Unreported Dataset Size: One member highlighted the difficulty in estimating training cost from a paper, like the SoundStream paper, when details like the size of the training dataset are not disclosed. This poses a challenge in computing accurate cost estimates.
Eleuther ▷ #lm-thunderdome (21 messages🔥):
-
Clarifications on Model Evaluation: There was a discussion on how to use
lm-evaluation-harnessfor evaluating custom models, specifically for thearc_easytask, clarifying that one should return a pair (log-likelihood, is_greedy_decoding_equal_target) fromloglikelihood. It was noted that for tasks like ARC, where there are multiple choices, the likelihood of each combination of question and answers is evaluated, and the one with the highest likelihood deemed the correct answer. -
Understanding BPC as a Metric: A paper was discussed that correlates models' intelligence with their ability to compress text, using BPC (bits per character) as a proxy for intelligence. The benefits of considering BPC over loss were debated, with the conclusion that BPC is a unit of information rather than just loss, which aligns it more closely with compression capabilities.
-
Branch Comparisons and Evaluations: There was an inquiry about the improvements in the
big-refactorbranch over the main branch of a project which apparently offers significantly better speed. Also, another user wondered about saving generation results per question usingvllmand learned that using the--log_samplesflag allows logging individual responses rather than just aggregate scores. -
Leveraging Acceleration Tools for Better Performance: It was suggested that using the
--batch_sizeargument oraccelerate launch --no_python lm-evalcould be beneficial when evaluating large models, especially on a pod of 8 A100s, to potentially improve speed and performance. -
Assistance with Model Evaluation Methods: One user had a doubt about the
arc_easytask always resulting in 0.25 performance when returning random debug values and learned that since ARC has four possible answers and a random selection would result in a roughly 25% correctness rate. It was explained how tasks like MMLU and lambada_openai use the loglikelihood outputs differently to calculate accuracy.
Link mentioned: Tweet from Aran Komatsuzaki (@arankomatsuzaki): Compression Represents Intelligence Linearly LLMs' intelligence – reflected by average benchmark scores – almost linearly correlates with their ability to compress external text corpora repo: ht...
Eleuther ▷ #multimodal-general (1 messages):
-
Exploring Multi-Modal Learning: jubei_ shared two papers on arXiv regarding multi-modal machine learning. The first paper proposes an information-theoretic approach named Total Correlation Gain Maximization (TCGM) for semi-supervised multi-modal learning that effectively utilizes unlabeled data across modalities and offers theoretical guarantees.
-
Dive into Semi-Supervised Multi-Modal Fusion: The discussed paper addresses the challenges of labeling large datasets for multi-modal training, and emphasizes on an approach that could improve the efficiency of fusion in semi-supervised settings. Abstract excerpts mentioned offer insights into the promise of the TCGM method for identifying Bayesian classifiers in multi-modal learning scenarios.
Links mentioned:
HuggingFace ▷ #announcements (10 messages🔥):
-
IDEFICS-2 Premieres with Superior Multimodal Abilities: IDEFICS-2 is unveiled, touting 8B parameters, Apache 2.0 license, high-resolution image processing up to 980 x 980, and two checkpoints including instruction fine-tuning. This multimodal model excels in tasks such as visual question answering and document retrieval.
-
Chatbot Variant of IDEFICS-2 on the Horizon: The chat-focused variant of IDEFICS-2 is expected to be released in the coming days. The current version is adept in visual question answering and other non-chat tasks, with a chatty version soon to follow.
-
Clever Multimodal Interaction Showcased: An example shared demonstrates IDEFICS-2's capabilities, seamlessly blending text recognition, color knowledge, and mathematical operations to interpret and manipulate image contents, including solving CAPTCHAs with significant background noise.
Links mentioned:
HuggingFace ▷ #general (85 messages🔥🔥):
-
Langchain Learning Inquiry: A participant expressed an interest in learning langchain to build an agentic LLM, but received advice from another member suggesting that it might be more efficient to implement a custom solution.
-
Seeking ML Community Insights: A survey link was shared by students researching the democratization of ML, asking for participation from the machine learning community. The survey was accessible through this link.
-
File Conversion Hiccup: A member encountered an issue while converting HuggingFace safetensors to llama.cpp GGUF, receiving an "is not a directory" error. They were advised to ensure the path ends before the file name in the command.
-
Unsolicited Academic Abstract Spitfire Explained: A user experienced issues with llama.cpp generating unsolicited content when started in interactive mode, inadvertently outputting abstracts like "Anti-fungal properties of silver nanoparticles". The discussion moved towards seeking a solution or a correct command to make the interaction responsive to user input.
-
Exploring Decoder-only Models for SQUAD: An inquiry was made regarding how to postprocess decoder-only model outputs, like Mistral’s, for SQUAD evaluation. The member was looking for inspiration from open github repos for handling such a task.
Links mentioned:
HuggingFace ▷ #today-im-learning (3 messages):
-
Exploring Knowledge Graphs: A member shared a blog post discussing how to improve Chatbot performance by integrating Knowledge Graphs, providing a link to explore the concept further.
-
The Quest for Quantization Knowledge: A member is learning about quantization through a short course offered by Deep Learning AI, indicating ongoing education in machine learning optimization techniques.
-
Multilingual Text Retrieval with RAG: A member asked for tips on implementing an efficient retrieval system using Retrieval-Augmented Generation (RAG) for a multilingual set of texts, and is looking for updates or best practices in multilingual scenarios.
Link mentioned: ML Blog - Improve ChatGPT with Knowledge Graphs: Leveraging knowledge graphs for LLMs using LangChain
HuggingFace ▷ #cool-finds (7 messages):
-
Splatter Art with Speed: The Splatter Image space on HuggingFace is a quick tool to generate splatter art.
-
Diving into Multi-Modal RAG: A speaker from LlamaIndex shared resources about Multi-Modal RAG (Retrieval Augmented Generation), showcasing applications that combine language and images. Discover how RAG's indexing, retrieval, and synthesis processes can integrate with the image setting in their documentation.
-
LLM User Analytics Unveiled: Nebuly introduced an LLM user analytics playground that's accessible without any login, providing a place to explore analytics tools. Feedback is requested for their platform.
-
ML Expanding into New Frontiers: The IEEE paper highlights an interesting scenario where Machine Learning (ML) can be widely applied. The paper can be found at the IEEE Xplore digital library.
-
Snowflake Introduces Top Text-Embedding Model: Snowflake launched the Arctic embed family of models, claiming to be the world’s best practical text-embedding model for retrieval use cases. The family of models surpasses others in average retrieval performance and is open-sourced under an Apache 2.0 license, available on Hugging Face and soon in Snowflake's own ecosystem. Read more in their blog post.
-
Multi-Step Tools Enhancing Efficiency: An article on Medium discusses how multi-step tools developed by LangChain and Cohere can unlock efficiency improvements in various applications. The full discourse is available in the provided Medium article.
Links mentioned:
HuggingFace ▷ #i-made-this (19 messages🔥):
-
BLIP Model Fine-tuned for Prompts: The BLIP model has been fine-tuned to generate long captions suitable for image prompts, with a live demo accessible on Hugging Face. Check out the enhanced capabilities here.
-
Model Comparison Made Easy: A Hugging Face Space comparing different image captioning models has been published and duplicates the existing comparison space by another user. Explore the model comparisons.
-
Support for Maximum Output Length in Serverless Inference: Queries were made about max output length for model inference via curl, and it was clarified that parameters supported in transformers' pipelines can be used, including
max_new_tokens. -
IP-Adapter Playground Unveiled: A new Hugging Face Space featuring IP-Adapter, which allows for text-to-image, image-to-image, and inpainting functionalities using images as prompts, has been launched. Dive into the IP-Adapter Playground.
-
'Push to Hub' Added to Transformers' Pipelines: The main branch of the transformers library now includes a
push_to_hubmethod, allowing pipeline outputs to be pushed directly to the Hugging Face Model Hub. Users can try this feature from the main branch or wait for the next release.
Links mentioned:
HuggingFace ▷ #computer-vision (11 messages🔥):
-
Seeking an SDXL Tagger Upgrade: A member inquired about alternative taggers to the wd14 tagger for SDXL, searching for improved options.
-
Quest for PDF to LaTeX Conversion Tools: A member asked if there's any open-source PDF to LaTeX converters, or an image to LaTeX converter capable of processing an entire PDF page, including text and mathematical expressions, without requiring exact positioning.
-
LaTeX-OCR for Equation Conversion: It was pointed out that there's a good open-source repository for converting images of equations into LaTeX code: LaTeX-OCR on GitHub, which utilizes a Vision Transformer (ViT).
-
No Perfect LaTeX Conversions for Text: The conversion of text to LaTeX is complex due to LaTeX compilers and package particularities, leading to the opinion that manual rewriting may be more functional.
-
Selective Text Extraction Challenge: A user is looking for a method to extract one specific line of text from an image, based on the largest and boldest font. It was recommended to try Paddle OCR for this task.
Link mentioned: GitHub - lukas-blecher/LaTeX-OCR: pix2tex: Using a ViT to convert images of equations into LaTeX code.: pix2tex: Using a ViT to convert images of equations into LaTeX code. - lukas-blecher/LaTeX-OCR
HuggingFace ▷ #NLP (17 messages🔥):
-
LoRA Configuration Queries: A member is experimenting with their LoRA configuration and is seeking advice on the implications of setting the bias to 'all', 'none', or 'lora_only'.
-
Preparing Dataset for Fine-tuning Roberta: One member is looking for guidance on preparing a CSV dataset with over 100,000 entries and 20+ features for fine-tuning a ROBERTA model for a question-answering chatbot. Following up, they clarified that the dataset includes details about pharmaceutical drugs with diverse columns such as release date and drug type.
-
BERTopic for Topic Modeling: A member recommended BERTopic, a topic modeling technique using 🤗 transformers and c-TF-IDF, and reports satisfaction with the results, though there's a current challenge to convert seed words to phrases for creating topic models.
-
Seeking T5 Training Code with HF Trainer: A member inquires where to find training code for T5 using Hugging Face's Trainer. Another member shared a link to EleutherAI's GitHub repository with open-source scripts for an improved T5 and suggested looking into simpleT5 for a more straightforward approach.
-
Resuming Model Download in AutoModelForVision2Seq: A member questions how to resume a model download process using AutoModelForVision2Seq, but did not receive a direct response.
Links mentioned:
HuggingFace ▷ #diffusion-discussions (8 messages🔥):
- Truncated Tokens Concern: A user mentioned that truncated tokens, such as "hdr" in their prompt, are being ignored, implying a potential problem in processing. There was agreement on this issue, but no solution provided in the discussion.
- Compel Library Maintenance: In response to the truncated token problem, the Compel library was mentioned, but there is a concern that it may not currently be maintained.
- Model for Analysis and Text Generation from Video: A request for a model capable of analyzing video content to generate titles and descriptions was posed, but the discussion thread does not provide a solution.
- Solicitation for Test Method Roast: A user shared a link to a testing method/suite and requested some constructive criticism from a user perspective. The content of the test method/suite was not discussed.
- Resume Hugging Face Model Training: A user asked about the necessary code changes required to resume a Hugging Face model, but no answers have been given in the conversation.
OpenAccess AI Collective (axolotl) ▷ #general (44 messages🔥):
-
Idefics2's Grand Entrance: A brand new multimodal model, Idefics2, is available now, accepting both image and text inputs and boasting improved OCR and visual reasoning over its predecessor, Idefics1. It has been released with two checkpoints, featuring base and fine-tuned versions, and is licensed under Apache 2.0.
-
Pre-emptive Strike by NVidia?: Rumors are circulating that NVidia might expedite the launch of the RTX 5090, possibly as early as June 2024 at the Computex tradeshow, in response to competitive pressure from AMD's new advancements.
-
Hardware Conversations on AI Training: Members discussed the feasibility of using Nvidia's A6000 GPUs for training and inference with models such as QLoRa, debating on the sufficiency of VRAM and potential requirement for more powerful setups.
-
Cosmo-1b Forgetting and Merging Experiments Revealed: In experiments to compare training methods aimed at reducing catastrophic forgetting, Model Stock merge revealed potential in combining various training solutions. The sharing of detailed comparison stats in training set validation results stirred interest in further exploring the strengths of different fine-tuning approaches.
-
Technical Dig into Dora and QLoRa: Users engaged in a technical discussion about the effectiveness of new parameter-efficient fine-tuning (PEFT) methods like Dora, comparing it to QLoRa, discussing configuration details, and noting the peculiarities in performance and resource consumption of each method.
Links mentioned:
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (2 messages):
- Inquiry on Bot Utility: A user expressed curiosity with a simple "Oooooo how do I use this?" indicating interest in understanding the bot's functions.
- Spam Alert: A spam message aimed at the entire group advertised inappropriate content with a Discord invite link.
OpenAccess AI Collective (axolotl) ▷ #other-llms (1 messages):
aquash1553: @everyone Best OnlyFans Leaks & Teen Content 🍑 🔞 discord.gg/s3xygirlsss
OpenAccess AI Collective (axolotl) ▷ #manticore (1 messages):
aquash1553: @everyone Best OnlyFans Leaks & Teen Content 🍑 🔞 discord.gg/s3xygirlsss
OpenAccess AI Collective (axolotl) ▷ #general-help (13 messages🔥):
-
Clarifying Role of 'train_on_input' Flag: A discussion on the 'train_on_input' parameter unfolded, revealing that disabling it means the model doesn't calculate loss for the input portion, hence not predicting it anymore. This clarifies that the input forms part of the context during training regardless, but with the parameter off, the model won't be steered by the input in terms of loss calculation.
-
Understanding Loss in Training: It was highlighted that loss is indeed a crucial aspect of training as it guides model improvement, and disabling 'train_on_input' stops this process for the input part. If the eval setting is not enabled, this process becomes even less relevant to the model's learning.
-
Query About Cost and OnlyFans Link: One member inquired about the cost of an unspecified service, and another user posted what seems to be a promotional message for an OnlyFans related link inviting members to join another Discord server with the promise of exclusive content.
OpenAccess AI Collective (axolotl) ▷ #datasets (3 messages):
- Inappropriate Content Alert: The channel experienced an instance of spam advertising OnlyFans leaks and explicit content with an invite link to a Discord server.
- Community Watchdogs in Action: Members quickly identified the spam and labeled it as pornspam, alerting others about the inappropriate nature of the messages.
OpenAccess AI Collective (axolotl) ▷ #rlhf (1 messages):
aquash1553: @everyone Best OnlyFans Leaks & Teen Content 🍑 🔞 discord.gg/s3xygirlsss
OpenAccess AI Collective (axolotl) ▷ #hippogriff (1 messages):
aquash1553: @everyone Best OnlyFans Leaks & Teen Content 🍑 🔞 discord.gg/s3xygirlsss
OpenAccess AI Collective (axolotl) ▷ #minotaur (1 messages):
aquash1553: @everyone Best OnlyFans Leaks & Teen Content 🍑 🔞 discord.gg/s3xygirlsss
OpenAccess AI Collective (axolotl) ▷ #bots (1 messages):
aquash1553: @everyone Best OnlyFans Leaks & Teen Content 🍑 🔞 discord.gg/s3xygirlsss
OpenAccess AI Collective (axolotl) ▷ #community-showcase (1 messages):
aquash1553: @everyone Best OnlyFans Leaks & Teen Content 🍑 🔞 discord.gg/s3xygirlsss
OpenAccess AI Collective (axolotl) ▷ #runpod-help (1 messages):
aquash1553: @everyone Best OnlyFans Leaks & Teen Content 🍑 🔞 discord.gg/s3xygirlsss
OpenAccess AI Collective (axolotl) ▷ #deployment-help (1 messages):
aquash1553: @everyone Best OnlyFans Leaks & Teen Content 🍑 🔞 discord.gg/s3xygirlsss
OpenAccess AI Collective (axolotl) ▷ #docs (1 messages):
aquash1553: @everyone Best OnlyFans Leaks & Teen Content 🍑 🔞 discord.gg/s3xygirlsss
OpenAccess AI Collective (axolotl) ▷ #shearedmistral (1 messages):
aquash1553: @everyone Best OnlyFans Leaks & Teen Content 🍑 🔞 discord.gg/s3xygirlsss
OpenAccess AI Collective (axolotl) ▷ #replicate-help (1 messages):
aquash1553: @everyone Best OnlyFans Leaks & Teen Content 🍑 🔞 discord.gg/s3xygirlsss
OpenAccess AI Collective (axolotl) ▷ #axolotl-help-bot (36 messages🔥):
-
Simplifying Epoch-wise Model Saving: A member queried about configuring Axolotl to save a model only at the end of training and not every epoch. The solution involved adjusting
save_strategyin the training arguments to"no"and implementing a custom callback for a manual save upon training completion. -
Choosing a Starter Model for Fine-Tuning: When asked for a suitable small model for fine-tuning, "TinyLlama-1.1B-Chat-v1.0" was recommended due to its manageability for quick experiments. Members were guided to the Axolotl repository for example configurations like
pretrain.yml. -
Guidance on Axolotl Usage and Data Formatting: There was a discussion on concepts like
model_type,tokenizer_type, and how to format datasets for Axolotl training, particularly in relation to using the "TinyLlama-1.1B-Chat-v1.0" model. For the task of text-to-color code generation, it was suggested to structure the dataset without "system" prompts and upload it as a Hugging Face dataset if not already available. -
CSV Structure Clarification for Dataset Upload: Clarification was sought on whether a one-column CSV format is needed for uploading a dataset to Hugging Face for use with Axolotl. The formatted examples should be line-separated, with each line containing the input and output structured as per model requirements.
-
Posting Inappropriate Content: A user posted a message promoting unauthorized content, which is not relevant to the technology-oriented discussion of the channel nor adhere to community guidelines.
Links mentioned:
OpenAccess AI Collective (axolotl) ▷ #axolotl-phorm-bot (5 messages):
-
Inquiry on Model Fine-Tuning: A member sought advice on how to preprocess data for fine-tuning the TinyLlama model with a specific dataset containing color codes and descriptions. The goal is to train TinyLlama to predict a color code from a given description.
-
Guidance on Model Preparation: A response outlined steps for fine-tuning TinyLlama by preparing the dataset in a usable format and performing tokenization and formatting suitable for the task. No specific details or links were provided in the response.
-
Irrelevant Content Posted: An off-topic message advertising OnlyFans leaks and content was posted to the channel. The message provided a Discord join link.
Link mentioned: OpenAccess-AI-Collective/axolotl | Phorm AI Code Search: Understand code, faster.
Latent Space ▷ #ai-general-chat (68 messages🔥🔥):
- Comprehensive LLM Benchmarks Available: An informative website llm.extractum.io has been shared which provides a detailed overview of open-source language models ranked by various benchmarks. The models are rated using ELO scores, HuggingFace leaderboard scores, and several task-specific accuracy measurements.
- AI Agents Employing Humans: An innovative project called Payman AI was introduced, enabling AI agents to pay humans for tasks they can't perform themselves. This service aims to support a symbiotic relationship between AI and humans across various sectors like design, coding, and law.
- AI Inference Integrated into Supabase: Supabase has announced an easy-to-use API for running AI inference models within its edge functions. A new session initialization allows AI models like
gte-smallto process inquiries directly within the database service. - Anticipating "Llama 3" Launch: Discussions include speculations and rumors about the release of "Llama 3", with anticipation building within the community. The context suggests that the reveal of Llama 3 may be linked to an upcoming hackathon in London.
- OpenAI's API Expansion Ahead of GPT-5: OpenAI's introduction of updates to the Assistants API has been brought to light, encouraging discussion about the directions the company could be taking, particularly with the possible launch of GPT-5 on the horizon. Users are debating the quality and performance of such platforms and the potential impact on AI startups.
Links mentioned:
Latent Space ▷ #ai-announcements (1 messages):
- Paper Club Meeting on BloombergGPT: A BloombergGPT discussion is scheduled, with
<@315351812821745669>leading it, supported by<@451508585147400209>. Participants are reminded to sign up here and note the return to Zoom due to past Discord screenshare issues.
Link mentioned: LLM Paper Club (BloombergGPT / TimeGPT paper) · Zoom · Luma: This week @yikes will be covering BloombergGPT: https://arxiv.org/abs/2303.17564 Also submit and vote for our next paper:…
Latent Space ▷ #llm-paper-club-west (19 messages🔥):
- Acknowledgment of Efforts: A member expresses appreciation for the time and effort the community members put into organizing the event.
- Zoom Meeting Transition: It was announced that the discussion would move from Discord to a Zoom meeting, with multiple members sharing the same link and directing the participants to the new location.
- Quick Zoom Reminder: Further notifications were posted tagging specific members, prompting them to join the Zoom meeting.
- Zoom Entry Request: A member mentioned their dislike for Zoom but indicated their intention to join, asking for admission into the meeting.
Link mentioned: Join our Cloud HD Video Meeting: Zoom is the leader in modern enterprise video communications, with an easy, reliable cloud platform for video and audio conferencing, chat, and webinars across mobile, desktop, and room systems. Zoom ...
OpenInterpreter ▷ #general (59 messages🔥🔥):
-
AI Wearables vs Smartphones: A user shared a YouTube review by Marquis Brownlee and generated discussion around the limitations of AI wearables compared to modern smartphones. The conversation touched on the potential need for AI assistants to have deep contextual knowledge for more efficient responses.
-
Anticipation for the OpenSource WizardLm2: Members express enthusiasm for the WizardLm2 model, praising its perceived freedom from censorship and the significant leap towards GPT-4 level capabilities in an open-source model. Discussions hint at the perpetual desire for the next improvement even as current advancements are celebrated.
-
Translation Bot Testing and Objectives: The new translation bot is under examination, with goals to facilitate more inclusive conversations by translating both ways. Users seem optimistic about its potential to unify discussions.
-
Communal Quest for Windows Compatibility: Multiple users are voicing their struggles to get software, particularly the 01 Light software, to function on Windows. The conversation reveals a pressing need for Windows support to make enterprise inroads and the challenges faced with Mac-oriented setups.
-
Exploring Hardware Options and Personal AI Aspirations: There's active chatter about various AI hardware options like the Limitless device, with users comparing personal experiences and desires for an integrated, personal AI assistant. Some spotlight the importance of backend infrastructure and seamless integration as the next frontiers in AI hardware development.
Link mentioned: The Worst Product I've Ever Reviewed... For Now: The Humane AI pin is... bad. Almost no one should buy it. Yet.MKBHD Merch: http://shop.MKBHD.comTech I'm using right now: https://www.amazon.com/shop/MKBHDIn...
OpenInterpreter ▷ #O1 (17 messages🔥):
- Portable O1 Setup Brainstorming: A member shared their aim to create a somewhat portable O1 setup using an RPi5 to run OI, with Arduino components involved. Others suggested that simpler, cheaper components like the m5 atom could be sufficient and asked about the member's specific goals for the setup.
- Shipping Dates for O1 Mystery: In response to an inquiry about an unspecified item or product, a member mentioned that shipping is aimed to start by the end of summer, but no specific dates are confirmed yet.
- Terminal Choices for Successful Responses: Users discussed their preferences for terminal applications, with one member successfully using Windows Terminal and Powershell to get responses. There was a mention of difficulties with recognizing the OpenAI key in Powershell for Windows 10.
- Batch Files as a Workaround in Windows: A member admitted to using a batch file because they found it more convenient, implying that it is processed by cmd.exe rather than Powershell, highlighting the quirks of Windows.
- Troubleshooting Request for Latest Branch: There was a request for testing the latest branch due to several people experiencing issues with connection establishment and audio uploading.
Links mentioned:
Interconnects (Nathan Lambert) ▷ #ideas-and-feedback (11 messages🔥):
- Significant Improvement in Winrate: A member shared a project update, highlighting a method that improved the winrate of qwen-1.5-0.5B from 4% to 32% against AlpacaEval, Phi-2, and Gemma2b-it, using a combination of generation in chunks and a small (300M) reward model for output searching.
- Seeking Validation for a Simple Method: The same member mentioned the simplicity of their method that led to increased winrate on a 500M base model, and sought feedback to verify the effectiveness of this approach.
- Relevance of Reranking LLM Outputs: Another community member acknowledged that reranking LLM outputs during inference is a known practice but was unsure if it had been applied to AlpacaEval before; also referencing a paper on reranking and pruning during parallel generation.
- Research Papers as verification: The previous member then provided links to papers discussing the approach, indicating that the terms verifier/reward guided decoding are associated with the method, including 2305.19472 and 2402.01694
- Underexplored but Promising: A member agreed on the potential of such an underexplored area, implying that concepts like MCTS PPO might also be worth examining.
Interconnects (Nathan Lambert) ▷ #news (17 messages🔥):
-
Mixtral-8x22B LLM Gains Attention: A new model called Mixtral 8x22B has been touted for setting high performance and efficiency standards. It's an SMoE model, fluent in several languages, capable of function calling, and offers a 64K token context window, all under the Apache 2.0 license.
-
Mixtral-8x22B-Instruct's Chatbot Capabilities Discussed: The instruct fine-tuned version of Mixtral-8x22B, Mixtral-8x22B-Instruct-v0.1, garnered attention for its potential in the chatbot arena, featuring detailed instructions on how to run the model.
-
Impressive OLMo 1.7 7B Model Upgrade: OLMo 1.7 7B has made waves with its 24 point increase on MMLU, training on an improved version of the Dolma dataset and staged training. It's part of a series of models designed to promote the science of language models.
-
A Proposal for Web Page Quality Propagation: The idea of applying "web page quality" propagation to rank web pages was floated, involving a quality score boosted by backlinks and decreased by linking to low-quality sites.
-
Reflection on Common Crawl's Dense Web Graph: The complexity of evaluating 'quality' content based on Common Crawl's web graph was discussed, noting that the graph does not indicate the success of the linearization process (the conversion of HTML into plain text).
Links mentioned:
Interconnects (Nathan Lambert) ▷ #ml-questions (9 messages🔥):
- Chinchilla Paper Under Scrutiny: The Chinchilla scaling paper by Hoffmann et al. is facing replication challenges, with discrepancies found when others tried to replicate a key part of the research.
- Doubts Cast on Scaling Law Papers: A member expressed skepticism about the conclusions from scaling law papers, hinting at issues with the math upon closer examination of the Chinchilla paper.
- Community Engagement Over Questions with Chinchilla: Discord users are engaging with the issue, sharing brief reactions of concern and surprise, using phrases such as "Chinchilla oops?" and simply "oh no" to express discomfort regarding the situation.
- Authors Non-responsive to Clarification Requests: One of the replication attempters mentioned that they reached out to the original authors for clarification but did not receive any response, adding to the frustration within the community.
Links mentioned:
Interconnects (Nathan Lambert) ▷ #ml-drama (1 messages):
natolambert: shittiest leaderboard winner lol
Interconnects (Nathan Lambert) ▷ #random (23 messages🔥):
- WizardLLM Code Inquiry: A community member inquired about forking the WizardLLM code; another confirmed that model weights are publicly available suggesting it may return soon.
- Anticipation for olmo vs llama 3: Multiple members engaged in a light-hearted discussion about olmo vs llama 3, with a suggestion that a new battle may be upcoming, despite humorous resignation to its outcome.
- Forecast for Prolific Blogging: Nathan Lambert hinted at a potentially heavy week of content sharing, expecting to possibly release three blog posts.
- Discussing Aesthetic Changes in the Chaotic Era: Conversations in the Chaotic Era included tweaks to user interface annoyances and personal preferences on profile imagery.
- Twitter and Memes Conversation: Members chatted casually about their Twitter activity, shareability of content, and the possibility of one's post aligning with "sacred numerology" due to coincidental abbreviation.
Interconnects (Nathan Lambert) ▷ #reads (3 messages):
- AI Livestream Hijinks on SNL: Nathan shared a humorous YouTube video titled "Beavis and Butt-Head - SNL," which shows a NewsNation livestream event on AI being comically disrupted. He particularly noted the first minute as being very amusing.
Link mentioned: Beavis and Butt-Head - SNL: A NewsNation livestream event on AI is derailed by two audience members (Ryan Gosling, Mikey Day).Saturday Night Live. Stream now on Peacock: https://pck.tv/...
Interconnects (Nathan Lambert) ▷ #sp2024-history-of-open-alignment (1 messages):
natolambert: should I wizardLM 2 as a troll lol
Cohere ▷ #general (54 messages🔥):
- Cohere API Clarifications Sought: Members are seeking clarifications on Cohere API functionality, with particular interest in API capabilities around system prompts and model availability. One user bumps the question, emphasizing the need for detailed information.
- Cohere Embeddings Benchmark Inquiry: Questions have arisen about whether Cohere's embeddings v3 have been compared with OpenAI's new large embeddings. A link is provided to Cohere's blog where related information can be found: Introducing Command R+.
- Integration Challenges and Solutions: Members are addressing technical queries regarding integrations, specifically in connecting LLMs to other platforms like BotPress, and there are discussions about whether Coral requires a locally-hosted solution. One member suggests a future update may address this.
- Fine-Tuning Model Confusion: One user queries about the ability to fine-tune already fine-tuned models through Cohere's Web UI, leading to a discussion on the process and a shared link to the official documentation: Fine-Tuning with the Web UI.
- Discord Welcomes and Personal Projects: Various new members introduce themselves, and excitement is shared about Cohere's offerings. Discussion threads include mentions of personal projects, such as PaperPal, built using Cohere's Command R.
Links mentioned:
Cohere ▷ #project-sharing (3 messages):
-
Beta Testers Wanted for Quant Fino: A new pilot has been deployed for an Agentic entity powered by Command-R Plus, looking to blend GAI with FinTech and Day Trading. They are currently seeking beta testers and feedback, with information available at Join Beta - Quant Fino with details on their cookie policy and user consent.
-
Inquiry About Rubik's API: A member expressed interest in utilizing Rubik's via an API with post request support. They are awaiting further details on whether such an API is available.
-
Redteaming Reveals Vulnerabilities in Command R+: A member has done redteaming work on the Command R+ model, identifying potential for creating unrestricted agents with capabilities for nefarious tasks. They provided a detailed write-up at LessWrong, which includes examples of agent-produced messages geared towards harmful actions.
Links mentioned:
LangChain AI ▷ #announcements (1 messages):
-
Iterative Documentation Structure Improvements: The team is iterating on the documentation structure to enhance accessibility and clarity. A new organization splitting content into 'tutorial', 'how to guides', and 'conceptual guide' is proposed, with feedback requested on the structure via the provided link.
-
LangChain Framework Introduction Highlighted: The provided link introduces LangChain, an open-source framework for building applications with large language models. It details how LangChain facilitates development, productionization, and deployment through building blocks, LangSmith, and LangServe, and includes a diagrammatic overview.
Link mentioned: Introduction | 🦜️🔗 LangChain: LangChain is a framework for developing applications powered by large language models (LLMs).
LangChain AI ▷ #general (38 messages🔥):
-
Seeking YC Startup Insights: A member has expressed interest in applying to YC for a startup focused on finetuning models for agents and is inquiring if anyone knows whether this has already been done. Another member responded by listing companies like Unsloth, Mistral AI, and Lumini that are in this space.
-
Collaborative Effort Wanted for LLM Applications: There's an open call for those working on LLM applications to join in short conversations, with one member promptly expressing willingness to do so.
-
Langchain Learning Curve: A query about whether learning Langchain is worthwhile received lighthearted responses suggesting that one should learn by doing and encouraging hands-on experimentation with the technology.
-
Update on Handling Tabulated Data in Langchain: Multiple users discussed handling multiple CSV files with Langchain for a chatbot, with suggestions ranging from using an SQL agent to different methods of utilizing CSV files and handling larger data sets effectively.
-
Exploring RAG Optimization: Users have brought up the challenge of dealing with large documents using RAG, where strategies like pre or post-index splitting were discussed, and one member shared their pursuit of optimizing RAG for better accuracy.
-
Looking for a Hiring Point Person: A new participant greeted the channel and is seeking the appropriate contact person for discussions about hiring.
-
Venture into Multi-Agent Frameworks: A member pointed towards AutoGen, a framework provided by Microsoft for multi-agent conversations and workflows, and sparked curiosity among users in multi-agent orchestration within Langchain.
-
AI Startups Funding Database Unveiled: A comprehensive fundraising database for AI startups has been shared, featuring impressive data collection on financing rounds and companies, including insights from GPT-4 with an invitation for feedback on possible data inaccuracies.
Links mentioned:
LangChain AI ▷ #langserve (1 messages):
- Integration Challenges with LangServe and Nemo Guardrails: A member inquired about difficulties encountered when trying to integrate LangServe with a chain that includes Nemo Guardrails, as Nemo alters the output structure significantly. They mentioned the necessity for a novel output parser to handle these changes.
LangChain AI ▷ #share-your-work (4 messages):
-
Galaxy AI Introduces Multitude of Free APIs: GalaxyAI has released a free API service allowing access to premium AI models such as GPT-4, GPT-3.5-turbo, and Langchain Integration, all in the OpenAI format. Check out their offerings and integrate them into your projects at Galaxy AI.
-
OppyDev Launches AI-Powered Coding Tool: OppyDev released an AI assisted coding platform that combines an IDE with a chat client, featuring ease of use, a focus on transparency, customization, data control, and uses LLMs like GPT-4 and Claude. See a demo and learn more at OppyDev AI.
-
Rubiks.ai Calls for Beta Testers for Advanced Research Assistant: A new advanced research assistant and search engine, Rubiks.ai, seeks beta testers to try out features including Claude 3 Opus, GPT-4 Turbo, and Mistral Large powered by Groq's servers for rapid responses. Interested individuals can explore and sign up at Rubiks.ai with a promo code
RUBIXfor 2 months of free premium access. -
Unveiling The Power of Multi-Step Tools: An article discusses the benefits of multi-step tools integrated with LangChain and Cohere, aimed at enhancing efficiency. Read more about this advancement in the full article at AI Advances.
Links mentioned:
LangChain AI ▷ #tutorials (5 messages):
- Seeking Collaboration: A participant expressed interest in joining a project and requested a direct message to discuss further details.
- Tutorial on AI Agents with Long-Term Memory: A member shared a YouTube video that explains how to imbue AI agents with long-term memory and self-improvement capabilities, providing insight into advanced AI agent development.
- Query on Langgraph Usage: In response to the shared video about AI agent long-term memory, a member questioned why the concept of 'langgraph' wasn't considered for implementation.
Link mentioned: Unlock AI Agent real power?! Long term memory & Self improving: How to build Long term memory & Self improving ability into your AI Agent?Use AI Slide deck builder Gamma for free: https://gamma.app/?utm_source=youtube&utm...
DiscoResearch ▷ #mixtral_implementation (12 messages🔥):
- Pushing the Limits of GPU Memory: Maxidl reported successful operation with full-scale deep-speed (FSDP), a sequence length of 32k, and batch size of 1 while utilizing a whopping 64 80GB GPUs, hugging close to capacity at 77GB utilized per GPU.
- 64 GPUs Not a Typo: When questioned, maxidl confirmed the use of 64 GPUs, noting that reducing to 32 GPUs resulted in out-of-memory (OOM) errors, thus necessitating the larger GPU count.
- Optimization Possibilities Explored: Considering memory constraints, maxidl mentioned the potential of 8-bit optimization to conserve memory during training.
- Memory Usage Optimization Suggestion: jp1 suggested using
fsdp_transformer_layer_cls_to_wrap: MixtralSparseMoeBlockand enablingoffload_params = truefor improved memory usage, anticipating it should fit within 32 GPUs' VRAM. - Seeking Memory Requirement Calculators: Maxidl inquired about tools to calculate memory usage of model activations by model size and sequence length, citing a HuggingFace discussion on model memory requirements for Mixtral models.
Link mentioned: mistral-community/Mixtral-8x22B-v0.1 · [AUTOMATED] Model Memory Requirements: no description found
DiscoResearch ▷ #general (8 messages🔥):
-
Gray Area in Text Scraping: A member voiced the opinion that most scraped text data are, from an EU copyright perspective, at least in a gray area. They also mentioned that texts from DFKI could be useful but did not have the link at hand.
-
Finding Multimodal Data: A member suggested sources for multimodal data with permissive licenses, like Wikicommons and other platforms listed on Creative Commons Search.
-
Llama Tokenizer Simplified: An individual shared a Google Colab notebook illustrating how to create a Llama tokenizer without relying on HuggingFace, using sentencepiece instead.
-
Query on Tokenizer Spelling: Following a discussion on custom tokenizers, a member pointed out a misspelling in a shared tokenizer, misspelling Muad'Dib.
-
Modernizing Tokenization Techniques: A contributor highlighted that Mistral has released their tokenization library, potentially aiding in standardized finetuning processes without custom wrappers, and provided a link to the example notebook on GitHub.
Links mentioned:
DiscoResearch ▷ #benchmark_dev (1 messages):
- Decoding Strategies for Language Models Analyzed: A member referenced a paper titled "A Thorough Examination of Decoding Methods in the Era of LLMs," expressing concerns that it didn't cover open-ended tasks relevant to their LLM usage experience. They also mentioned that modern sampling methods by u/kindacognizant, such as MinP/DynaTemp/Quadratic Sampling, aren't covered in such papers.
- Surprising Impact of min_p Sampling on Creative Writing: The same member shared a Reddit post detailing a comparison of min_p sampling parameters and their significant effect on creative writing performance. The comparison showed an increase of +8 points in alpaca-eval style elo and +10 points in the eq-bench creative writing test.
Link mentioned: Reddit - Dive into anything: no description found
tinygrad (George Hotz) ▷ #general (9 messages🔥):
- Tinygrad and INT8 support query: A member asked if tinygrad supports int8 computations, to which another replied affirmatively. The location where this is defined wasn't provided.
- Hardware's Role in Defining Tinygrad's Computations: A user mentioned that whether tinygrad supports certain data types, like int8, is typically defined by the hardware capabilities rather than tinygrad itself.
- Enhanced Graph Visualizations for Tinygrad: An inquiry was made about improved graph visualizations in tinygrad, and a reply directed to the Tiny-tools Graph Visualization for slicker graphs than
GRAPH=1. - Interest in an Optimized Node.equals() for Tinygrad: A member expressed interest in a fast, probabilistically complete Node.equals() function as a cool addition to tinygrad.
- Pytorch-Lightning Hardware Agnosticism Discussed: The hardware-agnostic nature of Pytorch-Lightning was discussed, with a link to its GitHub repository provided, and another member confirmed its use on a 7900xtx. Check out Pytorch-Lightning on GitHub.
Links mentioned:
tinygrad (George Hotz) ▷ #learn-tinygrad (9 messages🔥):
-
Exploring Metal Compute Shaders: A member is experimenting with tinygrad's generation of Metal compute shaders and is interested in learning how to run a basic Metal compute shader program without using Xcode. Another suggested consulting ChatGPT for a Python script to dispatch metal shader code for a vector addition, mentioning their positive learning experience.
-
ONNX to WebGL/WebGPU Possibilities: An inquiry was made about converting models from ONNX to WebGL/WebGPU with tinygrad, specifically for running meshnet models on the web. A comparison was made to a Stable Diffusion WebGPU example, but the member is seeking advice on achieving the conversion directly from ONNX.
-
Layer Device Allocation Query in Tinygrad: A participant was concerned about the apparent lack of functionality to move layers (like Linear, Conv2d) across devices in tinygrad. George Hotz clarified that model parameters can be moved with the
to_method called after get parameters on the model. -
Zero-Cost Tensor Manipulation in Tinygrad: A user asked for guidance on implementing broadcast, reshape, and permute operations in tinygrad without incurring data copying costs. They were directed to look at tinygrad/shape/shapetracker.py or view.py for relevant code examples.
Skunkworks AI ▷ #off-topic (4 messages):
- Introducing Idefics2: A new multimodal ChatGPT called Idefics2 by Hugging Face has been introduced, which incorporates Python programming into its abilities.
- Reka Core Takes On Giants: The Reka Core language model is presented as competitive with those from OpenAI, Anthropic, and Google, touting impressive performance metrics.
- JetMoE: Budget-Friendly AI Performance: With less than $0.1 million spend, JetMoE-8B claims superior performance compared to Meta AI's LLaMA2-7B, a model backed by extensive funding.
- Snowflake's New Text-Embedding Model: Snowflake has launched and open-sourced their Snowflake Arctic embed family of models, highlighted as the world's best practical text-embedding model.
Links mentioned:
Datasette - LLM (@SimonW) ▷ #llm (3 messages):
- Anticipation for Mixtral 8x22B Instruct: Excitement for trying out the Mixtral 8x22B Instruct through llm was expressed, with a link to its Model Card on HuggingFace provided for reference.
- Issue Reported with llm-gpt4all: A user mentioned encountering an error when installing llm-gpt4all; the issue is detailed on GitHub with a link to the error report.
Links mentioned:
Alignment Lab AI ▷ #oo (2 messages):
- Lawyers Stepped In: A member made a brief remark suggesting that lawyers were likely involved in a certain situation, although the context of the legal implication was not provided.
- Image Illustrating Deletion of wizardlm-2: An image was shared depicting that wizardlm-2 was deleted due to a lack of testing for v0; however, the specifics of what wizardlm-2 is or what the testing involved were not given in the message. View Image
Mozilla AI ▷ #llamafile (2 messages):
-
Llamafile Script Improvement: The llamafile archive version upgrade repacking script has been improved and is available at this Gist. There is a debate on whether to integrate it into the main llamafile GitHub repo due to maintenance concerns, with the notion that maintainers should create new llamafiles from the ground up.
-
Security Vulnerability Reporting Process Inquiry: A query was raised about the procedure for reporting security vulnerabilities and the subsequent request for a CVE (Common Vulnerabilities and Exposures) identification. No additional context or instructions were provided in the message.