Apple's AI emergence continues apace ahead of WWDC. We've covered OLMo before, and it looks like OpenELM is Apple's first actually open LLM (weights, code) release sharing some novel research in the efficient architecture direction.

It's not totally open, but it's pretty open. As Sebastian Raschka put it:
Let's start with the most interesting tidbits:
- OpenELM comes in 4 relatively small and convenient sizes: 270M, 450M, 1.1B, and 3B
- OpenELM performs slightly better than OLMo even though it's trained on 2x fewer tokens
- The main architecture tweak is a layer-wise scaling strategy
But:
"Sharing details is not the same as explaining them, which is what research papers were aimed to do when I was a graduate student. For instance, they sampled a relatively small subset of 1.8T tokens from various publicly available datasets (RefinedWeb, RedPajama, The PILE, and Dolma). This subset was 2x smaller than Dolma, which was used for training OLMo. What was the rationale for this subsampling, and what were the criteria?"
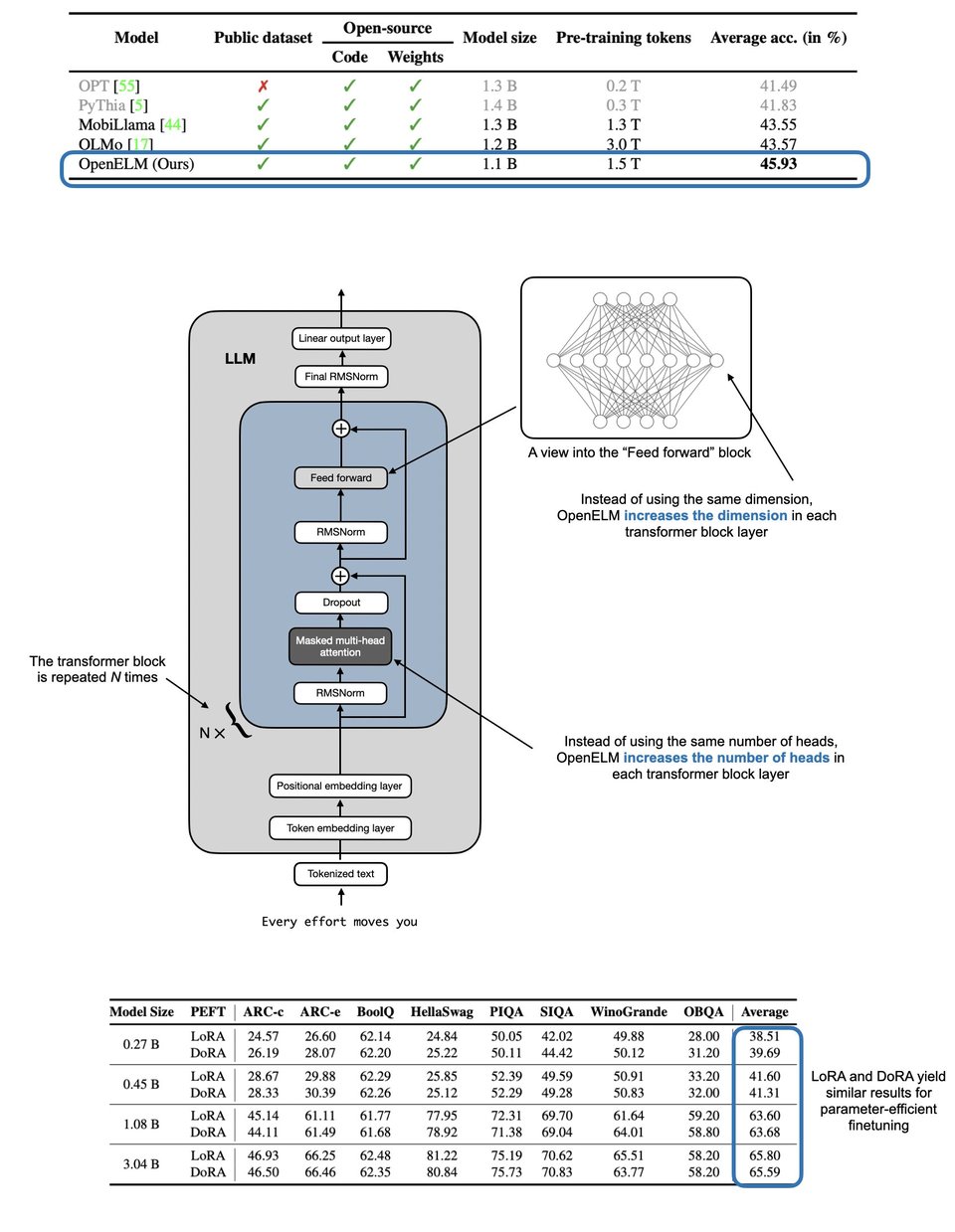
The layer-wise scaling comes from DeLight, a 2021 paper deepening the standard attention mechanism 2.5-5x in number of layers but matching 2-3x larger models by parameter count. These seem paradoxical but the authors described the main trick of varying the depth between the input and the output, rather than uniform:
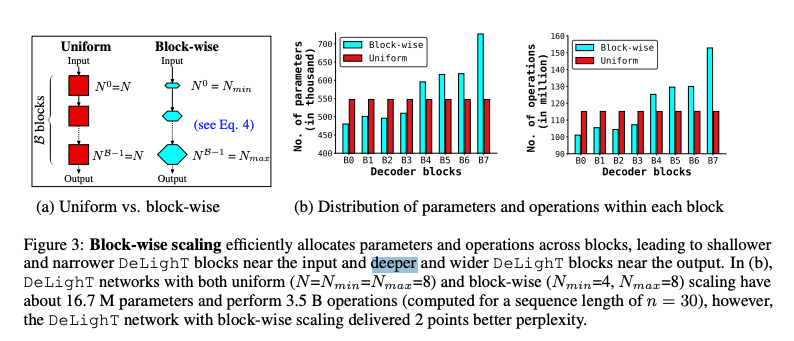
Table of Contents
[TOC]
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity. Comment crawling works now but has lots to improve!
LLaMA Developments
- LLaMA 3 increases context to 160K+ tokens: In /r/LocalLLaMA, LLaMA 3 increases context length to over 160K tokens while maintaining perfect recall. Commenters note this is impressive but will require significant consumer hardware to run locally at good speeds. Meta's Llama 3 has been downloaded over 1.2M times, with over 600 derivative models on Hugging Face.
- First LLama-3 8B-Instruct model with 262K context released: In /r/LocalLLaMA, the first LLama-3 8B-Instruct model with over 262K context length is released on Hugging Face, enabling advanced reasoning beyond simple prompts.
- Llama 3 70B outperforms 8B model: In /r/LocalLLaMA, comparisons show the quantized Llama 3 70B IQ2_XS outperforms the uncompressed Llama 3 8B f16 model. The 70B IQ3_XS version is found to be best for 32GB VRAM users.
- New paper compares AI alignment approaches: In /r/LocalLLaMA, a new paper compares DPO to other alignment approaches, finding KTO performs best on most benchmarks and alignment methods are sensitive to training data volume.
AI Ethics & Regulation
- Eric Schmidt warns about risks of open-source AI: In /r/singularity, former Google CEO Eric Schmidt cautions that open-source AI models give risky capabilities to bad actors and China. Many see this as an attempt by large tech companies to stifle competition, noting China likely has the capability to develop powerful models without relying on open-source.
- U.S. proposal aims to end anonymous cloud usage: In /r/singularity, a U.S. proposal seeks to implement "Know Your Customer" requirements to end anonymous cloud usage.
- Baltimore coach allegedly used AI for defamation: In /r/OpenAI, a Baltimore coach allegedly used AI voice cloning to attempt to get a high school principal fired by generating fake racist audio.
Hardware Developments
- TSMC unveils 1.6nm process node: In /r/singularity, TSMC announces a 1.6nm process node with backside power delivery, enabling continued exponential hardware progress over the next few years.
- Ultra-thin solar cells enable self-charging drones: In /r/singularity, German researchers develop ultra-thin, flexible solar cells that allow small drones to self-charge during operation.
- Micron secures $6.1B in CHIPS Act funding: In /r/singularity, Micron secures $6.1 billion in CHIPS Act funding to build semiconductor manufacturing facilities in New York and Idaho.
Memes & Humor
- AI assistant confidently asserts flat Earth: In /r/singularity, a humorous image depicts an AI assistant confidently asserting that the Earth is flat, sparking jokes about needing AI capable of believing absurdities or that humanity has its best interests at heart.
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
Here is a summary of the key topics and insights from the provided tweets:
Meta Llama 3 Release and Impact
- Rapid Adoption: In the week since release, Llama 3 models have been downloaded over 1.2M times with 600+ derivative models on Hugging Face, showing exciting early impact. (@AIatMeta)
- Training Optimizations: Meta is moving fast on optimizations, with Llama 3 70B training 18% faster and Llama 3 8B training 20% faster. (@svpino)
- Context Extension: The community extended Llama 3 8B's context from 8k to nearly 100k tokens by combining PoSE, continued pre-training, and RoPE scaling. (@winglian)
- Inference Acceleration: Colossal-Inference now supports Llama 3 inference acceleration, enhancing efficiency by ~20% for 8B and 70B models. (@omarsar0)
- Benchmark Performance: Llama 3 70B is tied for 1st place for English queries on the LMSYS leaderboard. (@rohanpaul_ai)
Phi-3 Model Release and Reception
- Overfitting Benchmarks: Some argue Phi-3 overfits public benchmarks but underperforms in practical usage compared to models like Llama-3 8B. (@svpino, @abacaj)
- Unexpected Behavior: As a fundamentally different model, Phi-3 can exhibit surprising results, both good and bad. (@srush_nlp)
Extending LLM Context Windows
- PoSE Technique: The Positional Skip-wisE (PoSE) method simulates long inputs during training to increase context length, powering Llama 3's extension to 128k tokens. (@rohanpaul_ai)
- Axolotl and Gradient AI: Tools like Axolotl and approaches from Gradient AI are enabling context extension for Llama and other models to 160k+ tokens. (@winglian, @rohanpaul_ai)
Cohere Toolkit Release
- Enterprise Focus: Cohere released a toolkit to accelerate LLM deployment in enterprises, targeting secure RAG with private data and local code interpreters. (@aidangomez)
- Flexible Deployment: The toolkit's components can be deployed to any cloud and reused to build applications. (@aidangomez, @aidangomez)
OpenAI Employee Suspension and GPT-5 Speculation
- Sentience Claims: An OpenAI employee who claimed GPT-5 is sentient has been suspended from Twitter. (@bindureddy)
- Hype Generation: OpenAI is seen as a hype-creation engine around AGI and AI sentience claims, even as competitors match GPT-4 at lower costs. (@bindureddy)
- Agent Capabilities: Some believe GPT-5 will be an "agent GPT" based on the performance boost from agent infrastructure on top of language models. (@OfirPress)
Other Noteworthy Topics
- Concerns about the AI summit board's lack of diverse representation to address power concentration risks. (@ClementDelangue)
- OpenAI and Moderna's partnership as a positive sign of traditional businesses adopting generative AI. (@gdb, @rohanpaul_ai)
- Apple's open-sourced on-device language models showing poor performance but providing useful architecture and training details. (@bindureddy, @rasbt)
AI Discord Recap
A summary of Summaries of Summaries
-
Extending LLM Context Lengths
- Llama 3 Performance and Context Length Innovations: Discussions centered around Llama 3's capabilities, with some expressing mixed opinions on its code recall and configuration compared to GPT-4. However, innovations in extending Llama 3's context length to 96k tokens for the 8B model using techniques like PoSE (Positional Skip-wisE) and continued pre-training with 300M tokens generated excitement, as detailed in this tweet thread.
- The EasyContext project aims to extrapolate LLM context lengths to 1 million tokens with minimal hardware requirements.
-
Optimizing LLM Training and Deployment
- Nvidia's Nsight Compute CLI is utilized for kernel profiling to optimize CUDA code for LLM training.
- Finetuning LLMs for Domain-Specific Gains: Interest grew in finetuning large language models for domain-specific improvements, with examples like Meditron for medical applications. Discussions also covered data synthesis strategies using tools like Argilla's Distilabel, and the challenges of multi-document, long-context finetuning. Cost-performance tradeoffs were debated, such as spending $2,368 for 4 epochs vs $41,440 for 50 epochs with potentially minor gains.
- PyTorch introduces Torchtitan, a library dedicated to aiding LLM training from scratch.
- The Mixture of Depths paper proposes accelerating transformer training using a modified MoE routing mechanism.
- CUDA Optimization Deep Dives: CUDA developers dug into kernel profiling with tools like NVIDIA Nsight Compute CLI, discussed memory coalescing and burst sizes around 128 bytes, and debated the efficiency of low-bit quantization methods. Conversations also covered flash attention compatibility issues with PyTorch 2.3.0, and the implications of PyTorch AO supporting custom CUDA extensions for performance tuning.
- Open-Source LLM Ecosystem Expansion
- Apple's Surprise Entry into Open-Source Models: Apple's release of OpenELM, a family of efficient open-source language models ranging from 270M to 3B parameters, caught the AI community by surprise. The move marked a shift from Apple's traditionally proprietary approach, with the 270M model quickly gaining attention on Hugging Face.
- BioMistral is introduced, leveraging Mistral for pretrained medical LLMs.
- Mozilla's llamafile project enables distributing and running LLMs locally with high performance.
- Dify emerges as an open-source LLM app development platform combining AI workflows and model management.
- Evaluating and Benchmarking LLMs
- On the Judgemark benchmark, Llama-3-70b shows promise for fine-tuning disco-judge applications.
- Discussions around the effectiveness of validation loss as a performance indicator for LLMs.
- The Low-Cost Language Models survey evaluates CPU-friendly LLMs on Python code generation tasks.
- Debates on the transparency of Nightshade's autoencoder capabilities and the need for publishing findings openly.
PART 1: High level Discord summaries
Unsloth AI (Daniel Han) Discord
-
Fine-Tuning Tribulations and Triumphs: Engineers shared their challenges with fine-tuning models, involving 4-bit quantization, VRAM requirements exceeding 48GB, and token index sequence length errors. Solutions included batch size revision, enabling pack functionality, and considering alternative testing environments like Aphrodite Engine or llama.cpp.
-
Gossip or Gone?: Speculation is rampant about the dissolution of the WizardLM team after Qingfeng Sun's staff page redirect. Contrasting sentiments were shared, from salvaging WizardLM datasets to showcase sessions where Meta's LlaMA-3 models (including an 8B and 70B version) were cited as top performers in their classes.
-
From Cold Storage to Hot Topics: A member proudly announced an open-source release of Kolibrify, a curriculum training tool for instruction-following LLMs. On a technical note, the community discussed Triton dependencies, errors with "Quantization failed," and gguf model testing strategies, reaching a consensus on best practices for fine-tuning and deployment options.
-
Pragmatic Pruning Progress: Insights were shared about a project on iterative context length increase for models using a triton laser merge trainer that operates during evaluation. This method, signaled as innovative due to no reinitialization requirements, could provide a pathway for enhanced model usability without system overhaul.
-
Unsloth's Milestones and Resources: Unsloth AI marked a significant milestone with 500k monthly downloads of their fine-tuning framework on Hugging Face and promoted the sharing of exact match GGUF models despite potential redundancy. Emphasis was also on directing users to Colab notebooks for effective fine-tuning strategies.
Perplexity AI Discord
-
Siri Gets a Brainy Buddy: Perplexity AI Discord chatbot introduces an exclusive auditory feature for iOS users that reads answers to any posed question.
-
Opus Limit Outcry: Frustration arises within the community concerning the new 50-query daily limit on Claude 3 Opus interactions, while still, Perplexity chatbot supports Opus despite these caps.
-
API Adoption Anxieties: AI Engineers are discussing integration issues with the Perplexity API, such as outdated responses and a lack of GPT-4 support; a user also sought advice on optimal hyperparameters for the
llama-3-70b-instructmodel. -
A Game of Models: The community is buzzing with anticipation around Google's Gemini model, and its potential impact on the AI landscape, while noting GPT-5 will have to bring exceptional innovations to keep up with the competition.
-
Crystal Ball for Net Neutrality: A linked article prompts discussions on the FCC's reestablishment of Net Neutrality, with implications for the AI Boom's future being pondered by community members.
CUDA MODE Discord
CUDA Collective Comes Together: Members focused on honing their skills with CUDA through optimizing various kernels and algorithms, including matrix multiplication and flash attention. Threads spanned from leveraging the NVIDIA Nsight Compute CLI User Guide for kernel profiling to debate on the efficiency of low-bit quantization methods.
PyTorch Tangles with Compatibility and Extensions: A snag was hit with flash-attn compatibility in PyTorch 2.3.0, resulting in an undefined symbol error, which participants hoped to see rectified promptly. PyTorch AO ignited enthusiasm by supporting custom CUDA extensions, facilitating performance tuning using torch.compile.
Greener Code with C++: An announcement about a bonus talk from the NVIDIA C++ team on converting llm.c to llm.cpp teased opportunities for clearer, faster code.
The Matrix of Memory and Models: Discussions delved deep into finer points of CUDA best practices, contemplating burst sizes for memory coalescing around 128 bytes as explored in Chapter 6, section 3.d of the CUDA guide, and toying with the concept of reducing overhead in packed operations.
Recording Rendezvous: Volunteers stepped up for screen recording with detailed, actionable advice and Existential Audio - BlackHole for lossless sound capture, highlighting the careful nuances needed for a refined technical setup.
LM Studio Discord
- GPU Offloads to AMD OpenCL: A technical hiccup with GPU Offloading was resolved by switching the GPU type to AMD Open CL, demonstrating a simple fix can sidestep performance issues.
- Mixed News on Updates and Performance: Upgrade issues cropped up in LM Studio with version 0.2.21, causing previous setups running phi-3 mini models to malfunction, while other users are experimenting with using Version 2.20 and facing GPU usage spikes without successful model loading. Users are actively troubleshooting, including submitting requests for screenshots for better diagnostics.
- LM Studio Turns Chat into Document Dynamo: Enthusiastic discussions around improving LM Studio's chat feature have led to embedding document retrieval using Retriever-Augmented Generation (RAG) and tweaking GPU settings for better resource utilization.
- Tackling AI with Graphical Might: The community is sharing insights into optimal hardware setups and potential performance boosts anticipated from Nvidia Tesla equipment when using AI models, indicating a strong interest in the best equipment for AI model hosting.
- AMD's ROCm Under the Microscope: The use of AMD's ROCm tech preview has shown promise with certain setups, achieving a notable 30t/s on an eGPU system, although compatibility snags underscore the importance of checking GPU support against the ROCm documentation.
Nous Research AI Discord
Pushing The Envelope on Model Context Limits: Llama 3 models are breaking context barriers, with one variant reaching a 96k context for the 8B model using PoSE and continued pre-training with 300M tokens. The efficacy of Positional Skip-wisE (PoSE) and RoPE scaling were key topics, with a paper on PoSE's context window extension and discussions on fine-tuning RoPE base during fine-tuning for lengthier contexts mentioned.
LLM Performance and Cost Discussions Engage Community: Engineers expressed skepticism about validation loss as a performance indicator and shared a cost comparison of training epochs, highlighting a case where four epochs cost $2,368 versus $41,440 for fifty epochs with minor performance gains. Another engineer is considering combining several 8B models into a mixture of experts based on Gemma MoE and speculated on potential enhancements using DPO/ORPO techniques.
The Saga of Repository Archival: Concerns were voiced about the sudden disappearance of Microsoft’s WizardLM repo, sparking a debate on the importance of archiving, especially in light of Microsoft's investment in OpenAI. Participants underscored the need for backups, drawing from instances such as the recent reveal of WizardLM-2, accessible on Hugging Face and GitHub.
Synthetic Data Generation: A One-Stop Shop: Argilla’s Distilabel was recommended for creating diverse synthetic data, with practical examples and repositories such as the distilabel-workbench illustrating its applications. The conversation spanned single document data synthesis, multi-document challenges, and strategies for extended contexts in language models.
Simulated World Engagements Rouse Curiosity: Websim’s capabilities to simulate CLI commands and full web pages have captivated users, with example simulations shared, such as the EVA AI interaction profile on Websim. Speculations on the revival of World-Sim operated in parallel, and members looked forward to its reintroduction with a "pay-for-tokens" model.
OpenAI Discord
-
Apple's Open Source Pivot with OpenELM: Apple has released OpenELM, a family of efficient language models now available on Hugging Face, scaling from 270M to 3B parameters, marking their surprising shift towards open-source initiatives. Details about the models are on Hugging Face.
-
Conversations Surrounding AI Sentience and Temporal Awareness: The community engaged in deep discussions emphasizing the difference between sentience—potentially linked to emotions and motivations—and consciousness—associated with knowledge acquisition. A parallel discussion pondered if intelligence and temporal awareness in AI are inherently discrete concepts, influencing our understanding of neural network identity and experiential dimension.
-
AI Voice Assistant Tech Talk: AI enthusiasts compared notes on OpenWakeWords for homegrown voice assistant development and Gemini's promise as a Google Assistant rival. Technical challenges highlighted include the intricacies of interrupt AI speech and preferences for push-to-talk versus voice activation.
-
Rate Limit Riddles with Custom GPT Usage: Users sought clarity on GPT-4's usage caps especially when recalling large documents and shared tips on navigating the 3-hour rolling cap. The community is exploring the thresholds of rate limiting, particularly when employing custom GPT tools.
-
Prompt Engineering Prowess & LLM Emergent Abilities: There's a focus on strategic prompt crafting for specific tasks such as developing GPT-based coding for Arma 3's SQF language. Fascination arises with emergent behaviors in LLMs, referring to phases of complexity leading to qualitative behavioral changes, exploring parallels to the concept of More Is Different in prompt engineering contexts.
Stability.ai (Stable Diffusion) Discord
AI Rollout Must Be Crystal Clear: Valve's new content policy requires developers to disclose AI usage on Steam, particularly highlighting the need for transparency around live-generated AI content and mechanisms that ensure responsible deployment.
Copyright Quandary in Content Creation: Conversations bubbled up over the legal complexities when generating content with public models such as Stable Diffusion; there's a necessity to navigate copyright challenges, especially on platforms with rigorous copyright enforcement like Steam.
Art Imitates Life or... Itself?: An inquiry raised by Customluke on how to create a model or a Lora to replicate their art style using Stable Diffusion sparked suggestions, with tools like dreambooth and kohya_ss surfaced for model and Lora creation respectively.
Selecting the Better Suited AI Flavor: A vocal group of users find SD 1.5 superior to SDXL for their needs, citing sharper results and better training process, evidence that the choice of AI model significantly impacts outcome quality.
Polishing Image Generation: Tips were shared for improving image generation results, recommending alternatives such as Forge and epicrealismXL to enhance the output for those dissatisfied with the image quality from models like ComfyUI.
HuggingFace Discord
-
BioMistral Launch for Medical LLMs: BioMistral, a new set of pretrained language models for medical applications, has been introduced, leveraging the capabilities of the foundational Mistral model.
-
Nvidia's Geopolitical Adaptation: To navigate US export controls, Nvidia has unveiled the RTX 4090D, a China-compliant GPU with reduced power consumption and CUDA cores, detailed in reports from The Verge and Videocardz.
-
Text to Image Model Fine-Tuning Discussed: Queries about optimizing text to image models led to suggestions involving the Hugging Face diffusers repository.
-
Gradio Interface for ConversationalRetrievalChain: Integration of ConversationalRetrievalChain with Gradio is in the works, with community efforts to include personalized PDFs and discussion regarding interface customization.
-
Improved Image Generation and AI Insights in Portuguese: New developments include an app at Collate.one for digesting read-later content, advancements in generating high-def images in seconds at this space, and Brazilian Portuguese translations of AI community highlights.
-
Quantization and Efficiency: There's active exploration on quantization techniques to maximize model efficiency on VRAM-limited systems, with preferences leaning toward Q4 or Q5 levels for a balance between performance and resource management.
-
Table-Vision Models and COCO Dataset Clarification: There's a request for recommendations on vision models adept at table-based question-answering, and security concerns raised regarding the hosting of the official COCO datasets via an HTTP connection.
-
Call for Code-Centric Resources and TLM v1.0: The engineering community is seeking more tools with direct code links, as exemplified by awesome-conformal-prediction, and the launch of v1.0 of the Trustworthy Language Model (TLM), introducing a confidence score feature, is celebrated with a playground and tutorial.
Eleuther Discord
-
Parallel Ponderings Pose No Problems: Engineers highlighted that some model architectures, specifically PaLM, employ parallel attention and FFN (feedforward neural networks), deviating from the series perception some papers present.
-
Data Digestion Detailing: The Pile dataset's hash values were shared, offering a reference for those looking to utilize the dataset in various JSON files, an aid found on EleutherAI's hash list.
-
Thinking Inside the Sliding Window: Dialogue on transformers considered sliding window attention and effective receptive fields, analogizing them to convolutional mechanisms and their impact on attention's focus.
-
Layer Learning Ladders Lengthen Leeway: Discussions about improving transformers' handling of lengthier sequence lengths touched upon strategies like integrating RNN-type layers or employing dilated windows within the architecture.
-
PyTorch's New Power Player: A new PyTorch library, torchtitan, was introduced via a GitHub link, promising to ease the journey of training larger models.
-
Linear Logic Illuminates Inference: The mechanics of linear attention were unpacked, illustrating its sequence-length linearity and constant memory footprint, essential insights for future model optimization.
-
Performance Parity Presumption: One engineer reported that the phi-3-mini-128k might match the Llama-3-8B, triggering a talk on the influences of pre-training data on model benchmarking and baselines.
-
Delta Decision's Dual Nature: The possibility of delta rule linear attention enabling more structured yet less parallelizable operations stirred a comparison debate, supported by a MastifestAI blog post.
-
Testing Through a Tiny Lens: Members cast doubt on "needle in the haystack" tests for long-context language models, advocating for real-world application as a more robust performance indicator.
-
Prompt Loss Ponderings: The group questioned the systemic study of masking user prompt loss during supervised fine-tuning (SFT), noting a research gap despite its frequent use in language model training.
-
Five is the GSM8K Magic Number: There was a consensus suggesting that using 5 few-shot examples is the appropriate alignment with the Hugging Face leaderboard criteria for GSM8K.
-
VLLM Version Vivisection: Dialogue identified Data Parallel (DP) as a stumbling block in updating VLLM to its latest avatar, while Tensor Parallel (TP) appeared a smoother path.
-
Calling Coders to Contribute: The lm-evaluation-harness appeared to be missing a
register_filterfunction, leading to a call for contributors to submit a PR to bolster the utility. -
Brier Score Brain Twister: An anomaly within the ARC evaluation data led to a suggestion that the Brier score function be refitted to ensure error-free assessments regardless of data inconsistencies.
-
Template Tête-à-Tête: Interest was piqued regarding the status of a chat templating branch in Hailey's branch, last updated a while ago, sparking an inquiry into the advancement of this functionality.
OpenRouter (Alex Atallah) Discord
Mixtral Muddle: A provider of Mixtral 8x7b faced an issue of sending blank responses, leading to their temporary removal from OpenRouter. Auto-detection methods for such failures are under consideration.
Soliloquy's Subscription Surprise: The Soliloquy 8B model transitioned to a paid service, charging $0.1 per 1M tokens. Further information and discussions are available at Soliloquy 8B.
DBRX AI Achieves AI Astonishment: Fprime-ai announced a significant advancement with their DBRX AI on LinkedIn, sparking interest and discussions in the community. The LinkedIn announcement can be read here.
Creative Model Melee: Community members argued about the best open-source model for role-play creativity, with WizardLM2 8x22B and Mixtral 8x22B emerging as top contenders due to their creative capabilities.
The Great GPT-4 Turbo Debate: Microsoft's influence on the Wizard LM project incited a heated debate, leading to a deep dive into the incidence, performance, and sustainability of models like GPT-4, Llama 3, and WizardLM. Resources shared include an incident summary and a miscellaneous OpenRouter model list.
LlamaIndex Discord
Create-llama Simplifies RAG Setup: The create-llama v0.1 release brings new support for @ollama and vector database integrations, making it easier to deploy RAG applications with llama3 and phi3 models, as detailed in their announcement tweet.
LlamaParse Touted in Hands-on Tutorial and Webinar: A hands-on tutorial showcases how LlamaParse, @JinaAI_ embeddings, @qdrant_engine vector storage, and Mixtral 8x7b can be used to create sophisticated RAG applications, available here, while KX Systems hosts a webinar to unlock complex document parsing capabilities with LlamaParse (details in this tweet).
AWS Joins Forces with LlamaIndex for Developer Workshop: AWS collaborates with @llama_index to provide a workshop focusing on LLM app development, integrating AWS services and LlamaParse; more details can be found here.
Deep Dive into Advanced RAG Systems: The community engaged in robust discussions on improving RAG systems and shared a video on advanced setup techniques, addressing everything from sentence-window retrieval to integrating structured Pydantic output (Lesson on Advanced RAG).
Local LLM Deployment Strategies Discussed: There was active dialogue on employing local LLM setups to circumvent reliance on external APIs, with guidance provided in the official LlamaIndex documentation (Starter Example with Local LLM), showcasing strategies for resolving import errors and proper package installation.
LAION Discord
Llama 3's Mixed Reception: Community feedback on Llama 3 is divided, with some highlighting its inadequate code recall abilities compared to expectations set by GPT-4, while others speculate the potential for configuration enhancements to bridge the performance gap.
Know Your Customer Cloud Conundrum: The proposed U.S. "Know Your Customer" policies for cloud services spark concern and discussion, emphasizing the necessity for community input on the Federal Register before the feedback window closes.
Boost in AI Model Training Efficiency: Innovations in vision model training are making waves with a weakly supervised pre-training method that races past traditional contrastive learning, achieving 2.7 times faster training as elucidated in this research. The approach shuns contrastive learning's heavy compute costs for a multilabel classification framework, yielding a performance on par with CLIP models.
The VAST Landscape of Omni-Modality: Enthusiasm is sighted for finetuning VAST, a Vision-Audio-Subtitle-Text Omni-Modality Foundation Model. The project indicates a stride towards omni-modality with the resources available at its GitHub repository.
Nightshade's Transparency Troubles: The guild debates the effectiveness and transparency of Nightshade with a critical lens on autoencoder capabilities and reluctances in the publishing of potentially controversial findings.
OpenInterpreter Discord
Mac Muscle Meets Interpreter Might: Open Interpreter's New Computer Update has significantly improved local functionality, particularly with native Mac integrations. The implementation allows users to control Mac's native applications using simple commands such as interpreter --os, as detailed in their change log.
Eyes for AI: Community members highlighted the Moondream tiny vision language model, providing resources like the Img2TxtMoondream.py script. Discussions also featured LLaVA, a multimodal model hosted on Hugging Face, which is grounded in the powerful NousResearch/Nous-Hermes-2-Yi-34B model.
Loop Avoidance Lore: Engineers have been swapping strategies to mitigate looping behavior in local models, considering solutions ranging from tweaking temperature settings and prompt editing to more complex architectural changes. An intriguing concept, the frustration metric, was introduced to tailor a model's responses when stuck in repetitive loops.
Driving Dogs with Dialogue: A member inquired about the prospect of leveraging Open Interpreter for commanding the Unitree GO2 robodog, sparking interest in possible interdisciplinary applications. Technical challenges, such as setting dummy API keys and resolving namespace conflicts with Pydantic, were also tackled with shared solutions.
Firmware Finality: The Open Interpreter 0.2.5 New Computer Update has officially graduated from beta, including the fresh enhancements mentioned earlier. A query about the update's beta status led to an affirmative response after a version check.
OpenAccess AI Collective (axolotl) Discord
CEO's Nod to a Member's Tweet: A participant was excited about the CEO of Hugging Face acknowledging their tweet; network and recognition are alive in the community.
Tech Giants Jump Into Fine-tuning: With examples like Meditron, discussion on fine-tuning language models for specific uses is heating up, highlighting the promise for domain-specific improvements and hinting at an upcoming paper on continual pre-training.
Trouble in Transformer Town: An 'AttributeError' surfaced in transformers 4.40.0, tripping up a user, serving as a cautionary tale that even small updates can break workflows.
Mixing Math with Models: Despite some confusion, inquiries were made about integrating zzero3 with Fast Fourier Transform (fft); keep an eye out for this complex dance of algorithms.
Optimizer Hunt Heats Up: The FSDP (Fully Sharded Data Parallel) compatibility with optimizers remains a hot topic, with findings that AdamW and SGD are in the clear, while paged_adamw_8bit is not supporting FSDP offloading, leading to a quest for alternatives within the OpenAccess-AI-Collective/axolotl resources.
Cohere Discord
Upload Hiccups and Typographic Tangles: Users in the Cohere guild tackled issues with the Cohere Toolkit on Azure, pointing to the paper clip icon for uploads; despite this, problems persisted with the upload functionality going undiscovered. The Cohere typeface's licensing on GitHub provoked discussion; it's not under the MIT license and is slated for replacement.
Model Usage Must-Knows: Discussion clarified that Cohere's Command+ models are available with open weight access but not for commercial use, and the training data is not shared.
Search API Shift Suggestion: The guild mulled over the potential switch from Tavily to the Brave Search API for integrating with the Cohere-Toolkit, citing potential benefits in speed, cost, and accuracy in retrieval.
Toolkit Deployment Debates: Deployment complexities of the Cohere Toolkit on Azure were deliberated, where selecting a model deployment option is crucial and the API key is not needed. Conversely, local addition of tools faced issues with PDF uploads and sqlite3 version compatibility.
Critical Recall on 'Hit Piece': Heated discussions emerged over the criticism of a "hit piece" against Cohere, with dialogue focused on the responsibility of AI agents and their real-world actions. A push for critical accountability emerged, with members reinforcing the need to back up critiques with substantial claims.
tinygrad (George Hotz) Discord
-
Tinygrad Sprints Towards Version 1.0: Tinygrad is gearing up for its 1.0 version, spotlighting an API that's nearing stability, and has a toolkit that includes installation guidance, a MNIST tutorial, and comprehensive developer documentation.
-
Comma Begins Tinybox Testing with tinygrad: George Hotz emphasized tinybox by comma as an exemplary testbed for tinygrad, with a focus maintained on software over hardware, while a potential tinybox 2 collaboration looms.
-
Crossing off Tenstorrent: After evaluation, a partnership with Tenstorrent was eschewed due to inefficiencies in their hardware, leaving the door ajar for future collaboration if the cost-benefit analysis shifts favorably.
-
Sorting Through tinygrad's Quantile Function Challenge: A dive into tinygrad's development revealed efforts to replicate
torch.quantilefor diffusion model sampling, a complex task necessitating a precise sorting algorithm within the framework. -
AMMD's MES Offers Little to tinygrad: AMD's Machine Environment Settings (MES) received a nod from Hotz for its detailed breakdown by Felix from AMD, but ultimately assessed as irrelevant to tinygrad's direction, with efforts focused on developing a PM4 backend instead.
Modular (Mojo 🔥) Discord
Strong Performer: Hermes 2.5 Edges Out Hermes 2: Enhanced with code instruction examples, Hermes 2.5 demonstrates superior performance across various benchmarks when compared to Hermes 2.
Security in the Limelight: Amidst sweeping software and feature releases by Modular, addressing security loopholes becomes critical, emphasizing protection against supply chain attacks like the XZ incident and the trend of open-source code prevalence in software development forecasted to hit 96% by 2024.
Quantum Complexity Through A Geometric Lens: Members discussed how the geometric concept of the amplituhedron could simplify quantum particle scattering amplitudes, with machine learning being suggested as a tool to decipher increased complexities in visualizing quantum states as systems scale.
All About Mojo: Dialogue around the Mojo Programming Language covered topics like assured memory cleanup by the OS, the variance between def and fn functions with examples found here, and the handling of mixed data type lists via Variant that requires improvement.
Moving Forward with Mojo: ModularBot flagged an issue filed on GitHub about Mojo, urged members to use issues for better tracking of concerns, for instance, about __copyinit__ semantics via GitHub Gist, and reported a cleaner update in code with more insertions than deletions, achieving better efficiency.
LangChain AI Discord
A Tricky Query for Anti-Trolling AI Design: A user proposed designing an anti-trolling AI and sought suggestions on how the system could effectively target online bullies.
Verbose SQL Headaches: Participants shared experiences with open-source models like Mistral and Llama3 generating overly verbose SQL responses and encountered an OutputParserException, with links to structured output support and examples of invoking SQL Agents.
RedisStore vs. Chat Memory: The community clarified the difference between stores and chat memory in the context of LangChain integrations, emphasizing the specific use of RedisStore for key-value storage and Redis Chat Message History for session-based chat persistence.
Techie Tutorial on Model Invocation: There was a discussion on the correct syntax when integrating prompts into LangChain models via JavaScript, with recommendations for using ChatPromptTemplate and pipe methods for chaining prompts.
Gemini 1.5 Access with a Caveat: Users discussed the integration of Gemini 1.5 Pro with LangChain, highlighting that it necessitates ChatVertexAI instead of ChatGoogleGenerativeAI and requires configuring the GOOGLE_APPLICATION_CREDENTIALS environment variable for proper access.
Latent Space Discord
Apple Bites the Open Source Apple: Apple has stepped into the open source realm, releasing a suite of models with parameters ranging from 270M to 3B, with the 270M parameter model available on Hugging Face.
Dify Platform Ups and Downs: The open-source LLM app development platform Dify is gaining traction for combining AI workflows and model management, although concerns have arisen about its lack of loops and context scopes.
PyTorch Pumps Up LLM Training: PyTorch has introduced Torchtitan, a library dedicated to aiding the training of substantial language models like llama3 from scratch.
Video Gen Innovation with SORA: OpenAI's SORA, a video generation model that crafts videos up to a minute long, is getting noticed, with user experiences and details explored in an FXGuide article.
MOD Layers for Efficient Transformer Training: The 'Mixture of Depths' paper was presented, proposing an accelerated training methodology for transformers by alternately using new MOD layers and traditional transformer layers, introduced in the presentation and detailed in the paper's abstract.
Mozilla AI Discord
-
Phi-3-Mini-4K Instruct Powers Up: Utilizing Phi-3-Mini-4K-Instruct with llamafile provides a setup for high-quality and dense reasoning datasets as discussed by members, with integration steps outlined on Hugging Face.
-
Model Download Made Easier: A README update for Mixtral 8x22B Instruct llamafile includes a download tip: use
curl -Lfor smooth redirections on CDNs, as seen in the Quickstart guide. -
Llamafile and CPUs Need to Talk: An issue with running llamafile on an Apple M1 Mac surfaced due to AVX CPU feature requirements, with the temporary fix of a system restart and advice for using smaller models on 8GB RAM systems shared in this GitHub issue.
-
Windows Meets Llamafile, Confusion Ensues: Users reported Windows Defender mistakenly detecting llamafile as a trojan. Workarounds proposed included using virtual machines or whitelisting, with the reminder that official binaries can be found here.
-
Resource-Hungry Models Test Limits: Engaging the 8x22B model requires heavy resources, with references to a recommended 128GB RAM for stable execution of Mistral 8x22B model, marking the necessity for big memory footprints when running sophisticated AI models.
DiscoResearch Discord
Llama Beats Judge in Judging: On the Judgemark benchmark, Llama-3-70b showcased impressive performance, demonstrating its potential for fine-tuning purposes in disco-judge applications, as it supports at least 8k context length. The community also touched on collaborative evaluation efforts, with references to advanced judging prompt design to assess complex rubrics.
Benchmarking Models and Discussing Inference Issues: Phi-3-mini-4k-instruct unexpectedly ranked lower on the eq-bench leaderboard despite promising scores in published evaluations. In model deployment, discussions highlighted issues like slow initialization and inference times for DiscoLM_German_7b_v1 and potential misconfigurations that could be remedied using device_map='auto'.
Tooling API Evaluation and Hugging Face Inquiries: Community debates highlighted Tgi for its API-first, low-latency approach and praised vllm for being a user-friendly library optimized for cost-efficiency in deployment. Queries on Hugging Face's batch generation capabilities sparked discussion, with community involvement evident in a GitHub issue exchange.
Gratitude and Speculation in Model Development: Despite deployment issues, members have expressed appreciation for the DiscoLM model series, while also speculating about the potential of constructing an 8 x phi-3 MoE model to bolster model capabilities. DiscoLM-70b was also a hot topic, with users troubleshooting errors and sharing usage experiences.
Success and Popularity in Model Adoption: The adaptation of the Phi-3-mini-4k model, referred to as llamafication, yielded a respectable EQ-Bench Score of 51.41 for German language outputs. Conversation also pinpointed the swift uptake of the gguf model, indicated by a notable number of downloads shortly after its release.
Interconnects (Nathan Lambert) Discord
Claude Displays Depth and Structure: In a rich discussion, the behavior and training of Claude were considered "mostly orthogonal" to Anthropic's vision, revealing unexpected depth and structural understanding through RLAIF training. Comparisons were made to concepts like "Jungian individuation" and conversation threads highlighted Claude's capabilities.
Debating the Merits of RLHF vs. KTO: A comparison between Reinforcement Learning from Human Feedback (RLHF) and Knowledge-Targeted Optimization (KTO) sparked debate, considering their suitability for different commercial deployments.
Training Method Transition Yields Improvements: An interview was mentioned where a progression in training methods from Supervised Fine Tuning (SFT) to Data Programming by Demonstration (DPO), and then to KTO, led to improved performance based on user feedback.
Unpacking the Complexity of RLHF: The community acknowledged the intricacies of RLHF, especially as they relate to varying data sources and their impact on downstream evaluation metrics.
Probing Grad Norm Spikes: A request for clarity on the implications of gradient norm spikes during pretraining was made, emphasizing the potential adverse effects but specifics were not delivered in the responses.
Skunkworks AI Discord
Moondream Takes On CAPTCHAs: A video guide showcases fine-tuning the Moondream Vision Language Model for better performance on a CAPTCHA image dataset, aimed at improving its image recognition capabilities for practical applications.
Low-Cost AI Models Make Cents: The document "Low-Cost Language Models: Survey and Performance Evaluation on Python Code Generation" was shared, covering evaluations of CPU-friendly language models and introducing a novel dataset with 60 programming problems. The use of a Chain-of-Thought prompt strategy is highlighted in the survey article.
Meet, Greet, and Compute: AI developers are invited to a meetup at Cohere space in Toronto, which promises networking opportunities alongside lightning talks and demos — details available on the event page.
Arctic Winds Blow for Enterprises: Snowflake Arctic is introduced via a new video, positioning itself as a cost-effective, enterprise-ready Large Language Model to complement the suite of AI tools tailored for business applications.
Datasette - LLM (@SimonW) Discord
- Run Models Locally with Ease: Engineers explored jan.ai, a GUI commended for its straightforward approach for running GPT models on local machines, potentially simplifying the experimentation process.
- Apple Enters the Language Model Arena: The new OpenELM series introduced by Apple provides a spectrum of efficiently scaled language models, including instruction-tuned variations, which could change the game for parameter efficiency in modeling.
Alignment Lab AI Discord
- Llama 3 Steps Up in Topic Complexity: Venadore has started experimenting with llama 3 for topic complexity classification, reporting promising results.
The LLM Perf Enthusiasts AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
Unsloth AI (Daniel Han) ▷ #general (1265 messages🔥🔥🔥):
- Finetuning LLM Challenges: Members discussed finetuning issues with their models, particularly when working with tools like awq, gptq, and running models in 4-bit quantization. There were specific issues with token indices sequence length errors, over 48GB of VRAM being insufficient for running certain models, and confusion around utilizing Aphrodite Engine or llama.cpp for testing finetuned models. Remedies suggested included revising batch sizes and grad accumulation, enabling packing, and reaching out to community experts for guidance.
- Finding the Right Technology Stack: One user expressed a desire to integrate different AI models into a project that allows chatting with various agents for distinct tasks. Experienced community members recommended starting with simpler scripts instead of complex AI solutions and advised doing thorough research before implementation. Concerns about API costs versus local operation were also discussed.
- Game Preferences and Recommendations: Users shared their excitement about the recent launch of games like "Manor Lords" on early access and provided personal insights into the entertainment value of popular titles such as "Baldur's Gate 3" and "Elden Ring."
- Unlocking Phi 3's Fused Attention: It was revealed that Phi 3 Mini includes fused attention, sparking curiosity among members. Despite the feature's presence, users were advised by others to wait for further development before diving in.
- Unsloth Achieves Significant Downloads: The Unsloth team announced hitting 500k monthly model downloads on Hugging Face, thanking the community for the widespread support and usage of Unsloth's finetuning framework. The necessity of uploading GGUF models was discussed, with the possible redundancy noted due to others already providing them.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #random (18 messages🔥):
-
Finetuning Strategies Discussed: Members of the chat discuss whether finetuning a language model on raw text would cause it to lose its chatty capabilities. A solution is proposed to combine raw text with a chat dataset to preserve the conversational ability while adding knowledge from the raw text.
-
Rumors of WizardLM Disbanding: Speculation arises based on Qingfeng Sun's staff page redirection, suggesting that he may no longer be at Microsoft which could signal the closure of the WizardLM team. Links to a Reddit thread and a Notion blog post give credence to the theory.
-
Unsloth AI Finetuning Resources: For finetuning on combined datasets, members are directed to Unsloth AI’s repository on GitHub finetune for free, which lists all available notebooks, and specifically to a Colab notebook for text completion.
-
WizardLM Data Salvage Operation: Following the discussion about potential layoffs associated with Microsoft's WizardLM, a member comes forward stating they have copies of the WizardLM datasets which might aid in future endeavors.
-
The Rollercoaster of Model Training: Chat members humorously share their experiences with model training, referring to their loss curves with a mix of hope and defeat.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #help (86 messages🔥🔥):
-
Inference Snippet Inquiry: A member inquired about a simpler method to test GGUF models without loading them into Oobabooga. Another member indicated future plans to provide inference and deployment options.
-
Triton Troubles: Members discussed issues with Triton and its necessity for running Unsloth locally. A member had trouble with
triton.commonmodule due to a potential version conflict, and others acknowledged Triton as a requirement. -
Fine-Tuning Frustrations: A conversation circled around issues faced during fine-tuning where a model kept repeating the last token. The solution suggested was to update the generation config using the latest colab notebooks.
-
Quantization Failure Chaos: Multiple members encountered a "Quantization failed" error when trying to use
save_pretrained_mergedandsave_pretrained_gguf. The issue was ultimately identified as a user error where llama.cpp was not in the model folder, but was resolved after fixing the file location. -
Model Training Errors and Insights: A mix of questions and solutions were discussed regarding training errors, resuming training from checkpoints on platforms like Kaggle, and finetuning guidance. One notable point was the use of checkpointing, which allows training to resume from the last saved step, benefiting users on platforms with limited continuous runtime.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #showcase (10 messages🔥):
- Meta Unveils LlaMA-3: Meta announces the next generation of its LlaMA model series, releasing an 8B model and a 70B model, with a teased upcoming 400B model promising GPT-4 level benchmarks. Interested parties can request access to these models, which are reportedly top of their size classes; the detailed comparison and insights are available in a Substack article.
- Open-Sourcing Kolibrify: A user announces the release of their project Kolibrify, a tool for curriculum training of instruction-following LLMs with Unsloth, designed for PhD research. The tool, aimed at those finetuning LLMs on workstations for rapid prototyping, is available on GitHub.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #suggestions (7 messages):
-
Innovating with TRL Trainer: A member is working on implementing laser pruning and potentially freezing with a trl trainer that functions during the evaluation step. The goal is to iteratively increase context length for models while utilizing the same GPU.
-
No Reinitialization Required for Context Expansion: The suggestion to increase available context length through model and tokenizer configuration adjustments was made. It was confirmed that these changes do not require reinitialization of the system.
-
Emoji Expressiveness in Chat: Members are using emojis in their communication, with comments expressing surprise and delight at the ability to type emojis in the chat.
Perplexity AI ▷ #announcements (1 messages):
- iOS Users Get Exclusive Feature: The Perplexity AI Discord chatbot has been updated with a new feature where users can ask any question and hear the answer. This feature is available for iOS <a:pro:1138537257024884847> users starting today.
Perplexity AI ▷ #general (531 messages🔥🔥🔥):
- Perplexity Supports Opus: The regular Perplexity chatbot still supports Opus, despite the recent caps placed on its usage.
- The Great Opus Limit Debate: Users express frustration over the sudden limit placed on Claude 3 Opus interactions, reducing the available queries from previous higher or unlimited numbers to just 50 per day. Discussions revolve around the difference in model performance and pricing compared to competitors like you.com, as well as transparency regarding usage caps.
- Enterprise Features Unclear: Members discussed the difference between regular Pro and Enterprise Pro versions of Perplexity, especially in the context of privacy settings and data usage for model training. There seems to be confusion about whether setting a toggle does protect users' data from being used by Perplexity's models or Anthropic's models.
- Transparency and Communication Critique: Community members criticize Perplexity for poor communication regarding usage changes and urge for official announcements. Comparisons are made with other services like poe.com, which users perceive as more transparent with their pricing and limits.
- Ecosystem Ramifications: Conversation pondered the implications of Google potentially getting serious with their Gemini model, which some believe offers competitive advantages due to scalability and Google's dataset. Expectations are forming around GPT-5 needing to be particularly impressive in light of increasing competition.
Links mentioned:
Perplexity AI ▷ #sharing (8 messages🔥):
- Exploring Perplexity AI: A user shared a search link without any accompanying commentary or context.
- Diving into Pool Chemistry: Discussing pool maintenance frustrations, a member mentioned the Langlier Saturation Index as a potentially helpful but complex solution not tailored for outdoor pools and shared an informative Perplexity AI search link.
- Net Neutrality and its AI Impact: A link was shared regarding the FCC's restoration of Net Neutrality, with the post hinting at possible implications for the AI Boom, accessible at Perplexity AI search.
- Command the Commands: One user queried about a specific command, referring to a Perplexity AI search. Another user reminded to ensure the thread is Shareable.
- AI for Voting?: There's interest in how AI could apply to voting systems, with a user linking to a Perplexity AI search.
- Homeland Security's New Directive: A share without comment included a link to a Perplexity AI search regarding an announcement from Homeland Security.
Perplexity AI ▷ #pplx-api (10 messages🔥):
-
API Integration Quirks Noted: An user mentioned integrating the Perplexity API with a speech assistant and observed issues with date relevance in responses, such as receiving a sports game score from a year ago instead of the current date. They also inquired about inserting documents for comparison purposes and expressed interest in expanded citation functionality, hinting at the potential for more versatile usage.
-
No GPT-4 Support with Perplexity: A member was looking to use GPT-4 through the Perplexity API but found it unsupported. Another member provided a documentation link listing available models, including
sonar-small-chat,llama-3-instructvariants, andmixtral-instruct, but no mention of GPT-4. -
Optimal Hyperparameters for llama-3-70b-instruct Usage: An individual posed a question about the appropriate hyperparameters for using the
llama-3-70b-instructmodel via the API, sharing their current parameters structure and seeking confirmation or corrections, specifically regardingmax_tokensandpresence_penaltyvalues. -
Unclear Integration Details: The same user mentioned staying within rate limits when making their calls to the API, although there was uncertainty regarding whether the Perplexity API operates identically to OpenAI's in terms of parameter settings.
-
Awaiting Enterprise API Response: An enterprise user reached out in the channel after emailing Perplexity AI's enterprise contacts regarding API usage and awaiting a response. They were advised by another member that response times range from 1-3 weeks.
-
Clarification Sought on "Online LLMs" Usage: A new user to Perplexity AI sought clarification on the guidance for using online LLMs, questioning whether to avoid using system prompts and if it was necessary to present queries in a single-turn conversation format.
Link mentioned: Supported Models: no description found
CUDA MODE ▷ #general (13 messages🔥):
-
Seeking Further CUDA Mastery: A discussion suggested enhancing CUDA learning through public demonstrations of skill, specifically by writing a fast kernel and sharing the work. Suggested projects included optimizing a fixed-size matrix multiplication, flash attention, and various quantization methods.
-
BASH Channel Turns CUDA Incubator: The
<#1189861061151690822>channel is slated to focus on algorithms that could benefit from CUDA improvement, inviting members to contribute with their optimized kernels. However, there was a recommendation to create a more permanent repository for these contributions beyond the transient nature of Discord channels. -
Instance GPU Configuration Verification: A user confirmed that upon accessing their instance via SSH, the GPU configuration is verified, revealing consistent assignment of a V100 for p3.2xlarge.
-
Next CUDA Lecture Up and Coming: An announcement was made regarding an upcoming CUDA mode lecture, scheduled to occur in 1 hour and 40 minutes from the time of the announcement.
-
Anticipating CUDA Updates: There was a query regarding the release schedule for CUDA distributables for Ubuntu 24.04, but there was no follow-up information provided within the message history.
CUDA MODE ▷ #cuda (40 messages🔥):
- Kernel Profiling Confusion: One member was trying to obtain more detailed information about kernel operations using NVIDIA's Nsight Profiler. After initial confusion between Nsight Systems and Nsight Compute, it was clarified that using NVIDIA Nsight Compute CLI User Guide could yield detailed kernel stats.
- Understand the Synchronize: An explanation was given about
cudaStreamSynchronize, how it implies the CPU waits for tasks in the CUDA stream to finish, and it was suggested to check if the synchronization is essential at each point it's called to potentially improve performance. - Occupancy and Parallelization Advice: Discussion touched on launch statistics of CUDA kernels, indicating that launching only a small number of blocks such as 14 blocks could result in GPU idle time unless multiple CUDA streams are being utilized.
- Performance Insights and Tweaks: For in-depth kernel analysis, it was suggested to switch to full metric selection in profiling for more comprehensive information, and a broader tip was given to aim for a higher number of blocks rather than introducing the complexity of CUDA streams, if feasible.
- Arithmetic Intensity vs Memory Bandwidth: There was a comparison of the FLOP/s and memory throughput between the tiled_matmult and coarsed_matmult kernels, with observations on how __syncthreads() calls and memory bandwidth relate. The discussion evolved into how arithmetic intensity (AI) is perceived from SRAM versus DRAM perspectives when profiling with Nsight Compute / ncu.
Links mentioned:
CUDA MODE ▷ #torch (9 messages🔥):
-
Tensor Expansion Explained: A discussion revealed that
Tensor.expandin PyTorch works by modifying the tensor's strides, not its storage. It was noted that when using Triton kernels, issues may arise from improper handling of these modified strides. -
Flash-Attention Incompatibility Alert: There was a report of incompatibility between the newly released flash-attn version 2.5.7 and the CUDA libraries installed by PyTorch 2.3.0, specifically an
undefined symbolerror, and hopes were expressed for a prompt update to resolve this. -
Building Flash-Attention Challenges: A user encountered difficulties in building flash-attn, mentioning that the process was excessively time-consuming without ultimate success.
-
Understanding CUDA Tensor Memory: A member shared a useful overview clarifying that the memory pointers for CUDA tensors always point to device memory, and cross-GPU operations are restricted by default in PyTorch.
Link mentioned: CUDA semantics — PyTorch 2.3 documentation: no description found
CUDA MODE ▷ #announcements (1 messages):
- Boost in LLM Performance: An exciting bonus talk by the NVIDIA C++ team was announced, discussing the porting of
llm.ctollm.cpppromising cleaner and faster code. The session was starting shortly.
CUDA MODE ▷ #algorithms (47 messages🔥):
- Exploring Plenoxels and SLAM Algorithms: The chat discussed Plenoxels CUDA kernels, which are faster variants of NeRF, and expressed interest in seeing a CUDA version of Gaussian Splatting SLAM.
- Acceleration of Mobile ALOHA with CUDA: The inference algorithms for Mobile ALOHA, such as ACT and Diffusion Policy, were topics of interest.
- Kernel Operations for Binary Matrices: There was a brainstorming session on creating a CUDA kernel for operations on binary (0-1) or ternary (1.58-bit, -1, 0, 1) matrices. The group discussed potential approaches avoiding unpacking, including a masked multiply tactic and kernel fusion.
- Low-bit Quantization and Efficiency Discussions: Members debated the efficiency of unpacking operations in Pytorch vs. fused CUDA or Triton kernels. Some suggested that operations be conducted without unpacking, while others highlighted memory copies and caching as significant concerns. Microsoft's 1-bit LLM paper was mentioned as a motivating idea for optimizing linear layers in neural networks.
- Challenges with Packed Operations in CUDA: The conversation centered around the feasibility of conducting matrix multiplication-like operations directly on packed data types without unpacking, referring to CUDA 8.0's bmmaBitOps as a potential method. Discussion included bit operations in CUDA's programming guide and the interest in trialing computations minimizing unpacking. A member provided a link to a CPU version of BitNet for testing purposes.
Link mentioned: GitHub - catid/bitnet_cpu: Experiments with BitNet inference on CPU: Experiments with BitNet inference on CPU. Contribute to catid/bitnet_cpu development by creating an account on GitHub.
CUDA MODE ▷ #beginner (6 messages):
- Exploring Multi-GPU Programming: One member hinted at the potential for learning about multi-GPU programming, suggesting it might be an area of interest.
- Laptop with NVIDIA GPU for Learning: Members concurred that a laptop with a NVIDIA GPU, such as one containing a 4060, is a cost-effective option suitable for learning and testing CUDA code.
- Jetson Nano for CUDA Exploration: A Jetson Nano was recommended for those looking to learn CUDA programming, especially when there is an extra monitor available.
- Search for NCCL All-Reduce Kernel Tutorial: A request was made for tutorials on learning NCCL to implement all-reduce kernels. No specific resources were provided in the chat.
CUDA MODE ▷ #pmpp-book (5 messages):
- Clarifying Burst Size: Burst size refers to the chunk of memory accessed in a single load operation during memory coalescing, where the hardware combines multiple memory loads from contiguous locations into one load to improve efficiency. This concept is explored in Chapter 6, section 3.d of the CUDA guide where it mentions that burst sizes can be around 128 bytes.
- Insights from External Resources: A helpful lecture slide by the book's authors was provided, affirming that bursts typically contain 128 bytes which clarifies the concept of coalesced versus uncoalesced memory access.
- Discrepancy in Burst Size Understanding Corrected: There was a reiterating message indicating that initially, there was a misunderstanding about coalesced access, which was resolved after revisiting and rereading the relevant section of the CUDA guide.
CUDA MODE ▷ #youtube-recordings (1 messages):
poker6345: ppt can be shared
CUDA MODE ▷ #torchao (2 messages):
-
Simplified BucketMul Function Revelations: A member shared a simplified version of the bucketMul function, highlighting how it factors both weights and dispatch in computing multiplications, and potentially optimizing memory loads. It resembles discussions on bucketed COO for better memory performance, with the added consideration of activations.
-
AO Welcomes Custom CUDA Extensions: PyTorch AO now supports custom CUDA extensions, allowing seamless integration with
torch.compileby following the provided template, as per a merged pull request. This is especially enticing for those adept at writing CUDA kernels and aiming to optimize performance on consumer GPUs.
Links mentioned:
CUDA MODE ▷ #ring-attention (1 messages):
iron_bound: https://www.harmdevries.com/post/context-length/
CUDA MODE ▷ #off-topic (1 messages):
iron_bound: https://github.com/adam-maj/tiny-gpu
CUDA MODE ▷ #llmdotc (377 messages🔥🔥):
-
Chasing MultigPU Efficiencies: The group is working on integrating multi-GPU support with NCCL, discussing performance penalties of multi-GPU configurations, and potential improvements like gradient accumulation. A move to merge NCCL code into the main branch is considered, along with a discussion about whether FP32 should support multi-GPU, leaning towards not including it.
-
Optimizing Gather Kernel without Atomics: A strategy is discussed for optimizing a layernorm backward kernel by avoiding atomics, using threadblock counting and grid-wide synchronization techniques to manage dependencies and streamline calculations.
-
Debugging and Decision-making for FP32 Path: It's suggested that the FP32 version of
train_gpt2be simplified for educational purposes, possibly stripping out multi-GPU support to keep the example as intuitive as possible for beginners. -
Brainstorming Persistent Threads and L2 Communication: There’s an in-depth technical discussion about the potential benefits and drawbacks of using persistent threads with grid-wide synchronization to exploit the memory bandwidth more efficiently and potentially run multiple kernels in parallel.
-
Parallelism and Kernel Launch Concerns: Dialogue revolves around the comparison of the new CUDA concurrent kernel execution model managed by queues to traditional methods, with thoughts on the pros and cons of embracing this uncharted approach to achieve better memory bandwidth exploitation and reduced latency.
Links mentioned:
CUDA MODE ▷ #massively-parallel-crew (25 messages🔥):
- Seeking Volunteers for Recording: One member commits to screen recording and requests a backup recorder due to having to leave the session early. They advise against using AirPods as they might change the system audio output unpredictably.
- Mac Screen Recording Tutorial: Guidance provided for screen recording on a Mac, including downloading Blackhole from here and setting up a Multi-Output Device in the "Audio MIDI Setup."
- Audio Troubleshooting with Blackhole: It's suggested to avoid Bluetooth devices for audio capture to prevent interruptions, and to select BlackHole 2ch for lossless sound recording.
- Step-by-Step Recording Instructions: Detailed instructions include using the Cmd + Shift + 5 shortcut, selecting the entire screen, saving to an external drive, and ensuring the microphone is set to BlackHole 2ch.
- Pre-Recording Tech Check Proposed: A call is suggested before the event for checking sound and recording settings.
Link mentioned: Existential Audio - BlackHole: no description found
LM Studio ▷ #💬-general (218 messages🔥🔥):
-
LM Studio Becomes a One-Stop Chat Hub: Members discussed integrating documents with the chat feature in LM Studio using Retriever-Augmented Generation (RAG) through custom scripts and the API. Some showcased successfully directing LM Studio to utilize their system's GPU instead of the CPU for model operations, with a switch found in the Settings panel.
-
Navigating Update Confusions: There was confusion about updating to version 0.2.21 of LM Studio, with some users not able to see the update through the auto-updater. It was clarified that the new version hadn't been pushed to the updater, and members were directed to manually download it from LM Studio's official website.
-
Challenges with Offline Image Generation and AI Chat: Users inquired about offline image generation capabilities, being redirected to Automatic1111 for those needs. The conversation also mentioned experiencing 'awe' moments with AI advancements, particularly when interacting with chatbots like AI Chat on LM Studio.
-
Troubleshooting Varied Issues: From GPU support questions to errors like "Exit code: 42," members tried to troubleshoot issues ranging from installation errors on different versions of LM Studio to getting specific models to work. heyitsyorkie provided advice on many technical issues, including recommending updates or altering settings to overcome errors.
-
Technical inquiries about LM Studio capabilities and settings: Users engaged in various technical discussions around LM Studio's API server capabilities, inference speeds, GGUF model support, and specific hardware requirements for running large language models. heyitsyorkie and other members shared insights and resources, including linking to the local server documentation and discussing optimal setups for AI inference.
Links mentioned:
LM Studio ▷ #🤖-models-discussion-chat (75 messages🔥🔥):
- Exploring Model Options for Confluence/Jira BI Analysis: A user inquired about a suitable model for analyzing data from Confluence/Jira for business intelligence analysis within a company intranet, seeking suggestions for potential models and implementation strategies.
- Seeking Superior Python Coding Model: When asked about the best model for Python coding, responses varied, recommending models like CodeQwen1.5 or DeepSeek-Coder, with follow-up intentions to try these suggestions.
- Translation Capabilities Questioned: A user queried the chat for recommendations on a good 7b model that excels in translations, though no specific recommendations were provided within the messages summarized.
- LLM Studio Compatibility Queries for Apple's OpenELM: Discussion arose around getting Apple's OpenELM to work with LM Studio, highlighting challenges due to incompatibility with llama.cpp and waiting for required support (
https://github.com/ggerganov/llama.cpp/issues/6868). - Adventures with Phi-3 Models: Users discussed issues with downloading, loading, and running different versions of Phi-3 models in LM Studio, with some having trouble loading certain downloaded models. Conversations suggested using the GGUF format and checking if one's LM Studio version supports the phi3 format, with v0.2.21 potentially necessary for these models.
Links mentioned:
LM Studio ▷ #🧠-feedback (7 messages):
- Persistent Error Across Versions: A Linux user using Debian reports that they encounter the same error with the latest version, with the last working version being 2.19.
- Scaling GPU Usage But Model Fails to Load: Another member experiences a spike in GPU usage to 100% upon trying to load a model using LM Studio version 2.20, but the model fails to load despite high GPU utilization.
- Call for Reduced Graphics Memory Usage: It was highlighted that the LM Studio UI consumes around 500MB of graphics memory, which could potentially limit the memory available for models, prompting a suggestion to reduce the graphics memory usage.
- Update Woes with Phi-3 Mini: A member reports that after updating to version 0.2.21, their previously functioning setup with phi-3 mini (using official Microsoft gguf and LM Studio config from GitHub) now produces gibberish.
- Screenshot Request for Debugging: In response to the phi-3 mini issue, there was a request for screenshots to help investigate the problem.
LM Studio ▷ #🎛-hardware-discussion (64 messages🔥🔥):
- GPU Offload Error Resolved with Switch: A user found a solution to their GPU Offload error by switching the GPU type to AMD Open CL, which allowed the GPU offload to work despite an initial technical issue.
- Troubleshooting a Model Loading Error: A participant reported consistent problems with loading their model on a system with a Tesla P100 GPU, an e5-2450V4 CPU, and 16GB of RAM. Further conversation revealed the CPU's actual model to be 2650v4, not 2450v4.
- Query on GPU Selection for Model Utilization: A member asked for advice on directing Mistral 7B to use a dedicated GPU instead of defaulting to the CPU's integrated graphics, aiming to resolve performance issues.
- Anticipation for a Potential Performance Boost: After ordering an Nvidia Tesla P40, a community member eagerly anticipated a significant increase in token per second performance, which could enable the use of larger models and potentially multiple models at once.
- Hardware Advise for LLM Hosting: For those looking to host a home server for AI and web applications, members advised that a system with at least 16GB VRAM is necessary, and Nvidia's contemporary architecture GPU might be preferable.
Links mentioned:
LM Studio ▷ #amd-rocm-tech-preview (30 messages🔥):
- ROCm on Nvidia? Not Quite: A member mistakenly used AMD's ROCm preview with an Nvidia GPU, but realized it defaulted to the CPU. Using ROCm technology with incompatible hardware results in CPU fallback.
- ROCm Performance Report: An individual reported impressive speeds with ROCm, achieving 30t/s on an eGPU setup, indicating significant performance capabilities for supported configurations.
- Checking GPU Compatibility: In response to inquiries about GPU support, a member linked to documentation, emphasizing that only GPUs with a checkmark under the HIPSDK are compatible with the ROCm build.
- High Hopes for AMD Improvements: Community members are both critiquing and expressing hope for AMD's developments in the tech space, suggesting a mix of anticipation and skepticism within the chat.
- Troubleshooting ROCm Errors: Users discussed errors and compatibility issues when trying to run models with the ROCm build, indicating that proper driver installation and compatibility with the HIPSDK are crucial for success.
Nous Research AI ▷ #ctx-length-research (22 messages🔥):
-
Understanding RoPE and Extrapolation: RoPE scaling's effectiveness was debated, with one member sharing that changing the RoPE base during fine-tuning, not pretraining, enhances a model's ability to handle longer contexts as per a research paper. However, it was clarified that Llama 3 was pretrained with a 500k RoPE base, without changing the base, in an attempt to decrease RoPE decay factor for longer contexts.
-
Extrapolation Tokens Outweigh Pretraining: The community discussed the relationship between the number of pretraining tokens and the model's ability to extrapolate, concluding that extensive pretraining is necessary before any further pretraining with higher RoPE bases to prevent loss of extrapolation capabilities.
-
PoSE as an Alternative: A member referenced Positional Skip-wisE (PoSE) as a novel training method that simulates long inputs using a fixed context window, which could potentially address limitations of relative positional encodings. The method smartly chunks the original context window for efficient extension, as described in the associated paper.
-
Linear Scaling of RoPE Base Debated: One member solicited insights on how to scale RoPE base with context length, with a community expert noting that setting the base to an arbitrarily high number and then doing empirical testing is common, rather than any systematic linear scaling.
-
Endorsement for Better Positional Encodings: The conversation highlighted RoPE as potentially inadequate for long context generalization and proposed alternatives like YaRN or LongRoPE, specifically mentioning that LongRoPE is utilized in the phi-3-128k model.
Links mentioned:
Nous Research AI ▷ #off-topic (4 messages):
- Sharing Engaging YouTube Content: A member shared a YouTube video link, but the content and context of the video was not discussed.
- Expression of Appreciation: A simple heart emoji ("<3") was posted by a member, indicating a show of love or appreciation towards another member.
- Acknowledgement for Archiving Expertise: Recognition was given to a member for their archiving skills, possibly in relation to maintaining records or documentation.
- Another YouTube Share: A second YouTube video link was shared by the same member who shared the first link; however, no further details were provided.
Nous Research AI ▷ #interesting-links (7 messages):
-
Llama 3 Breaks Context Limit: Innovation in Llama 3's context space, reaching 96k context for the 8B model, using PoSE and continued pre-training. Extended context length achieved by pre-training with 300M tokens and increasing RoPE theta, shared in a detailed tweet thread.
-
LoRA Enables Context Enhancement: The extended context of Llama 3 8B to 64k+ through PoSE is also available as a LoRA, making it accessible for application to any L3 8B fine-tuned model. You can find this implementation on Hugging Face.
-
LLama-3 Soars with 160K Context: A new LLama-3 8B model with over 160K context has been released on Hugging Face. Achieved with less than 200M tokens of training and boasts of state-of-the-art (SOTA) long-term context handling, link to the model here.
-
WizardLM-2 Unveiled: The launch of WizardLM-2, a suite of next-generation large language models, has been announced, with variants including WizardLM-2 8x22B, WizardLM-2 70B, and WizardLM-2 7B. These models excel in chat, multilingual, reasoning, and agent tasks, with more information available in their release blog and repositories on Hugging Face and GitHub.
Links mentioned:
Nous Research AI ▷ #announcements (1 messages):
<ul>
<li><strong>Announcements Channel Upgrade</strong>: The "Announcements" channel has evolved! It can now be followed and integrated into other servers for streamlined updates.</li>
</ul>
Nous Research AI ▷ #general (212 messages🔥🔥):
<ul>
<li><strong>Discussing Context Window Expansion:</strong> Members are intrigued by works on language model context window expansion, referencing models with over 8k tokens context, and highlighting the possibilities of extending models into the tens of millions of tokens using techniques such as <strong>PoSE (Positional Space Encoding)</strong> and ring attention.</li>
<li><strong>Authorization of the AI Safety and Security Board:</strong> A tweet from Andrew Curran (@AndrewCurran_) sparked discussions with the announcement of the AI Safety and Security Board by the Department of Homeland Security, prompting mixed reactions.</li>
<li><strong>WizardLM and Microsoft’s Model Removals:</strong> Speculations arose when Microsoft's WizardLM repo vanished, with some pointing towards a strategic move by Microsoft in response to its investments in OpenAI and products outperforming their offerings. Members share concerns and emphasize the value of creating archives or backups for such repositories.</li>
<li><strong>AI Dialogue Systems:</strong> There's a mention of using GPT to generate dialogue and create high-quality training data through "Heated discussion between professors and student." These role-playing dialogues can lead to better question generation or more accurate answers.</li>
<li><strong>LLMs Frontend Choices:</strong> Multiple tools and interfaces for working with Large Language Models are brought up, including <strong>Librechat, Lm studio, and OpenRouter</strong>. Members seem to be exploring various options for the best tool fit.</li>
</ul>
Links mentioned:
Nous Research AI ▷ #ask-about-llms (50 messages🔥):
- Val Loss Not Indicative of Performance: One user mentioned tossing out validation loss checking from their process, stating that they found no correlation between validation loss and downstream performance, and that validation checks add to compute costs without providing value.
- Training on Synthetic Data: Another user inquired about strategies for generating diverse synthetic data. Helpful responses included using the Distilabel framework and examining certain papers like WizardLM and Airoboros for insights.
- Long Context Management in LLMs: The effectiveness of context management techniques in large language models was discussed, with Llama 3 being highlighted for its performance. Some mentioned methods involve rope scaling and the use of the PoSE technique to extend context length.
- Cost-Performance Considerations in Model Training: A comparison was shared regarding the cost of training epochs using Hermes 2 dataset on Llama-3 70B with qLora—4 epochs costing $2,368 versus $41,440 for 50 epochs, for potential minor performance improvements.
- Exploring MoE with Llama 3: One user proposed creating a 'clown car' mixture of experts (MoE) with Llama 3, drawing parallels to the Gemma MoE model. The user speculated on the potential gains from combining several 8B models and using DPO/ORPO techniques to enhance outputs.
Links mentioned:
Nous Research AI ▷ #project-obsidian (1 messages):
deoxykev: Does anybody know of work extending moondream’s input size?
Nous Research AI ▷ #rag-dataset (3 messages):
-
Exploring Dataset Synthesis with Distilabel: A member mentions utilizing Argilla's Distilabel for dataset synthesis and finds it valuable, despite some missing features. Examples on generating function calling and JSON/pydantic data can be found in the distilabel-workbench repository.
-
Synthesis Simplified for Single Documents: For single document data synthesis, the method appears straightforward after deciding on a specific structure or template.
-
Complex Challenges for Multi-hop Synthesis: Multi-document or multi-hop fact synthesis is acknowledged as more complex, yet potentially manageable with Raptor and smart prompting or agentic use of database.
Links mentioned:
Nous Research AI ▷ #world-sim (68 messages🔥🔥):
-
World-Sim Twitch Channel Blocked by Shutdown: A user geared up to launch their Twitch channel for a World-Sim session but was thwarted as World-Sim was shut down due to 4chan abusers, leaving the Twitch livestream slightly empty.
-
Exploring Websim's Capabilities: Members are discussing a webpage simulator, Websim, that is drawing interest for its ability to execute CLI commands similar to the defunct World-Sim and simulate entire web pages. Shareable links to the simulations have been exchanged, with one such link being https://websim.ai/c/p3pZvmAYbsRT2hzBz.
-
Anticipation for World-Sim's Return: Users speculate on the status and nature of World-Sim's return, discussing potential investment in the platform. One user announces that people from the channel will be invited to test World-Sim for free before it goes live again, while another provides clarity by mentioning it will be a pay-for-tokens system.
-
AI Companionship Through Websim: An AI named EVA, designed to be a human companion, has been shared among users, highlighting Websim's application for creating simulated interactions with AIs. The sharing of AI profiles, such as EVA, is met with enthusiasm as users look forward to engaging with these virtual entities.
-
Tabletop Simulator Curiosity and Participation: The conversation touches upon a tabletop simulator in development, with users expressing interest in participating and curiosity about how it might function. One user encapsulates the concept poetically with the phrase: "Sim within a Sim // Regression et Recursion // Limits we Limits."
Links mentioned:
OpenAI ▷ #ai-discussions (170 messages🔥🔥):
-
Apple Dives into Open Source: Apple has released OpenELM, an efficient language model family, marking a shift from their traditional proprietary approach. The models are available on Hugging Face, trained with a layer-wise scaling strategy, offering variations from 270M to 3B parameters, and can be found here.
-
Philosophy of Intelligence and Sentience: Users discussed the nuances of consciousness and sentience, with varying interpretations influenced by language and cultural differences. One user expressed that sentience might be about motivation and guidance by emotions, while consciousness is about understanding knowledge.
-
Temporal Awareness in AI: There was a philosophical debate about whether current models have temporal awareness or if intelligence and consciousness are discrete and decoupled from temporal constraints. The conversation touched on the complexity of identity in the context of neural networks and subjective experiences.
-
AI Voice Assistants on the Rise: Users discussed current and upcoming AI voice assistants, highlighting projects like OpenWakeWords for creating home voice assistants and the potential of Gemini as a Google Assistant alternative. The conversation delved into the technical challenges of interrupting AI mid-speech and the nuanced use of push-to-talk versus voice-activated systems.
-
Confusion Over AI Model Releases and Capabilities: Users speculated about the release dates of OpenAI's next models, compared the coding abilities of current models like GPT-4 and Claude, and even joked about naming conventions for AI models. Some suggested using VPNs to access region-restricted models and shared experiences with voice-to-text transcriptions.
Link mentioned: apple/OpenELM · Hugging Face: no description found
OpenAI ▷ #gpt-4-discussions (42 messages🔥):
-
Seeking GPT Performance Insights: A member expressed interest in GPT-4's capabilities, comparing its performance to that of Claude 3 and inquiring about the potential release of a hypothetical GPT-5.
-
Custom GPT for Web Browsing Abilities: Discussion around creating custom GPTs comparable to Perplexity AI Pro and You Pro for web browsing and summarization, with members sharing their experiences and insights about the difference between GPT-4 and the dedicated Web Browser GPT model.
-
Maximizing Context Windows in Large Document Analysis: Inquiry into tools for analyzing large text documents, with a member comparing Claude 3 Haiku and Gemini 1.5 Pro against OpenAI offerings. The conversation touched on how context size may affect model performance, suggesting interest in a future OpenAI model with a larger context window.
-
Resolving Rate Limits and Custom GPT Usage Counts: A user encountered a rate limit after recalling information from a large PDF using a custom GPT, spurring discussion on the nature and duration of usage caps. Clarifications were offered on the 3-hour rolling usage cap and the possibility of a lower sub-cap for custom GPTs.
-
Understanding the Mechanics of GPT Rate Limits: Clarification was sought on whether rate limits for custom GPT use are considered as part of the overall GPT-4 usage cap. Discussion highlighted the nuances of the 3-hour rolling cap, with advice offered on how to anticipate when message allowances reset.
OpenAI ▷ #prompt-engineering (20 messages🔥):
-
Challenges in Custom GPT for SQF in Arma 3: A user is seeking advice for crafting prompts to build a GPT for coding in SQF language tailored for Arma 3. They have uploaded various text files with information, example code, and URLs to assist the GPT model.
-
Considerations for Prompt Workflow: A veteran user recommends crafting a prompt to always scan the provided knowledge, but cautions that the practice may severely limit the programming solution space, and complex toolchain requirements could cause code hallucinations in a 32k context system.
-
AI Models' Performance Debate: Members engage in a debate questioning whether models like Claude and Llama can compete with GPT-3.5 in terms of logic and tone, with one pointing out that performance shouldn't just be measured by the ability to answer test questions.
-
Discussion on AI Intelligence Definition: Some users dispute the definition of intelligence for AI, with opinions varying on whether AI can solve problems it hasn't been trained on and the significance of semantic scoring as a use case where GPT-4 stands out.
-
Insights on Emergent Abilities in LLMs: A user reflects on emergent abilities in Large Language Models (LLMs), suggesting that after a certain point, quantitative increases in system complexity can lead to qualitative behavior changes not predictable from the system's earlier stages, mentioning the paper More Is Different and its relevance to prompt engineering.
OpenAI ▷ #api-discussions (20 messages🔥):
-
Challenges with Training for SQF Language in GPT: A member is trying to train GPT for SQF language coding in Arma 3 using various txt documents but is struggling to create an effective prompt. Other contributors suggest that a system with a larger context size and a better model may be necessary, considering the challenges with the current approach.
-
Debating Model Capabilities: Users engage in a conversation about comparing AI models like Claude, Llama, and GPT-3.5 on parameters like logic and tone, while discussing benchmarks such as SAT question responses or coding problem-solving.
-
AI Definition of Intelligence Debated: A discussion unfolds on defining intelligence for AI, with opinions that even bugs exhibit intelligence by compressing information and that AI can handle unseen logical problems.
-
Emergence in Large Language Models (LLMs): Emergent abilities in LLMs are discussed, characterizing the phenomenon where increasing size in AI systems leads to new qualitative behaviors not predictable from smaller models. This concept is related back to prompt engineering strategies like Chain of Thought (CoT).
Stability.ai (Stable Diffusion) ▷ #general-chat (246 messages🔥🔥):
- Stable Diffusion for Steam Games: Users discussed the usage of Stable Diffusion generated content on Steam. Valve's updated content survey now includes AI disclosure sections, and developers must describe their AI use and implement guardrails for live-generated AI content.
- Concerns Over Copyrighted Content: There was a debate regarding the use of public models like Stable Diffusion for content creation and whether the output may include copyrighted materials, alluding to the complexity of using such models on platforms like Steam with stringent copyright rules.
- Model vs. Lora Creation Queries: Customluke enquired about creating a model or a Lora from their artwork for generating similar art using Stable Diffusion. Suggestions included using dreambooth for models and kohya_ss for loras.
- Preferring SD 1.5 Over SDXL: Some users expressed a preference for SD 1.5 over other versions like SDXL, citing better results, especially with well-handled tagging and training.
- Suggestions for Improving Image Generation: Amid conversations about various topics, it was recommended to use different models like Forge and epicrealismXL when unsatisfied with image quality from other generators like ComfyUI.
Links mentioned:
HuggingFace ▷ #general (208 messages🔥🔥):
- Rollout of BioMistral for Medical LLMs: An announcement about BioMistral, a collection of open-source pretrained large language models for medical domains, was shared, highlighting its use of Mistral as its foundation model.
- Nvidia Adjusts for China: Discussion of Nvidia's launch of a China-specific graphics card, the RTX 4090D, which was introduced to comply with US export controls, featuring lower power draw and fewer CUDA cores compared to the standard RTX 4090. The situation was elaborated with links to articles from The Verge and Videocardz.
- Optimizing Text to Image Models: Inquiry about configurations for fine-tuning text to image models discussed, with a reference to the Hugging Face diffusers repository for potential solutions.
- Utilizing ConversationalRetrievalChain in Gradio: A user sought advice on implementing a ConversationalRetrievalChain with a Gradio chat interface, sharing their code and expressing a desire to use personal PDFs in the process.
- Utilizing Quantization for Model Efficiency: A conversation revolved around the best approaches to using quantization to increase efficiency on a limited VRAM setup, with a suggestion leaning towards using a Q4 or Q5 quantization level for optimal performance while being mindful of offloading to CPU.
Links mentioned:
HuggingFace ▷ #today-im-learning (3 messages):
- Mistral 7B Fine-tuning File Upload Conundrum: A member mentioned they are attempting to fine-tune Mistral 7B but observed that files get uploaded during the process, which wasn't the case before.
- Seeking Candle Documentation Comparable to Transformers: A member who has experience with the Transformers library expressed interest in Candle, inquiring about comprehensive documentation similar to what is available for Transformers, due to performance issues with Python in production environments.
HuggingFace ▷ #cool-finds (8 messages🔥):
-
Exploring the 6G Future: A member shared an arXiv paper that discusses the intersection of wireless communications and AI, envisioning 6G networks to support ubiquitous AI services and how AI will assist in designing and optimizing 6G networks.
-
Journey into Computer Vision with HuggingFace: A course on community-driven computer vision has been started by a member, which aims to cover everything from basics to advanced topics in the field. The course is accessible on HuggingFace's learning platform.
-
Reinforcement Learning Aided by Human Insight: An awesome-RLHF GitHub repository, a curated list of reinforcement learning resources incorporating human feedback, is being continually updated and shared in the community.
-
Eagerness for Computer Vision Learning Expressed: A member inquired about the quality of computer vision courses, referring to the HuggingFace's learning platform which offers education on applying ML libraries and models in the computer vision domain.
-
Phi3 Red Teaming Report Shared for Insights: Insights and takeaways from the Phi3 red teaming exercise were discussed, with a link provided to a LinkedIn post containing more detailed information.
Links mentioned:
HuggingFace ▷ #i-made-this (9 messages🔥):
- Read-Later Content, Now a Daily Digest: A user introduced an app called Collate.one that transforms read-later content into a bite-sized daily newsletter, inviting others to try it and share their feedback.
- Speedy High-Resolution Image Generation: A space has been created on Hugging Face for generating 4k images in 5 seconds, duplicating functionality from another space called PixArt-alpha/PixArt-Sigma.
- Troubleshooting Real-Time on New Space: Following an error reported by a user trying the image generation space with a specific prompt, the creator asked users to try again suggesting the issue had been addressed.
- AI Community Highlights in Brazilian Portuguese: Community Highlights #54 has been translated into Brazilian Portuguese with a released video and a related blog post, meant to share the open-source AI community updates with Portuguese-speaking individuals.
- Improvements to Docker XTTS Streaming Server: Enhanced the original XTTS streaming server, adding features like speech temperature control and batch processing, showcased in a GitHub repository while emphasizing it as a learning opportunity for Gradio and speech models.
- Mega Small Embed SynthSTS Model for Long Documents: A user posted about their Sentence Transformer Model, which produces embeddings for long text documents and is pre-trained for a context length of 16,384. The model could be particularly useful for clustering and semantic search tasks and might see future updates.
Links mentioned:
HuggingFace ▷ #computer-vision (2 messages):
- Seeking Table-QA Vision Models: A member asked for recommendations on vision models capable of performing question-answering on complex tables. They've tried IDEFICS2 and GEMINI 1.5 pro but encountered issues with inaccurate values.
- Security Concerns with COCO Dataset: A member expressed concern regarding the official COCO datasets being hosted on an HTTP connection, hinting at potential security implications.
HuggingFace ▷ #NLP (6 messages):
- Call for a more Code-Centric Resource: A member praised an existing resource, Dr. Valeriy, as a good model for creating tools that have direct links to code implementations, sharing the link to valerman/awesome-conformal-prediction for reference.
- Seeking SFFTrainer Training Details: A user sought a detailed understanding of the SFFTrainer's training process, particularly what components of a prompt are initially fed to the LLM and whether the LLM is restricted to the number of tokens in the provided answer.
- Looking for Open Source STT Web Frontends: A community member inquired about any available open-source speech-to-text (STT) web frontends.
- Seeking Copyright Information for safetensors: A member questioned the missing copyright details for safetensors, pointing out that, while the license is Apache, there are no year or ownership details in the LICENSE file.
- Celebrating the Launch of Trustworthy Language Model: The release of v1.0 of the Trustworthy Language Model (TLM) was announced, boasting a feature to combat LLM hallucinations with a confidence score system. Users were invited to try out the TLM and share findings via the playground, with further insights available in a blog post and a detailed tutorial.
Links mentioned:
HuggingFace ▷ #diffusion-discussions (6 messages):
-
Admiring LCM and ip-adapter Synergy: A member acknowledged that ip-adapter and lcm-lore work well together, suggesting their effectiveness in combination. Though there are complaints about LCM, the member hopes for improvements from hyper-sd.
-
Mystery of the Blue-Tinged Images: A user faced an issue with their images turning blue using a text-to-image pipeline with multiple controlnet. The reason remained unclear after the brief discussion.
-
Trial and Error with torch.compile: An attempt to use torch.compile during training was made, initially causing the program to hang during the first forward pass. Eventually, the process completed, taking around 10 minutes.
-
Forward Pass Speed Boost Using torch.compile: Post initial hurdles, the member noted a significant speed improvement in the forward pass, though the backward pass speed remained unaffected by using torch.compile.
HuggingFace ▷ #gradio-announcements (1 messages):
<ul>
<li><strong>Gradio Bolsters Custom Component Capabilities</strong>: Version 4.28.0 of Gradio introduces significant enhancements for custom components, including Tailwind styling, support for any vite plugin and preprocessors, and a refined custom component CLI that utilizes the vanilla Gradio SDK in spaces.</li>
<li><strong>Streamlined Development and New Features</strong>: Additional features accompany the custom components upgrade, such as setting a maximum upload size, persistent reloads in dev mode to maintain front-end state, and a re-organized documentation to better represent the Gradio ecosystem.</li>
<li><strong>Comprehensive Release with More Improvements</strong>: This is just a highlight of the update; more details can be found in the full changelog available on the Gradio website.</li>
</ul>
Eleuther ▷ #general (52 messages🔥):
- Clarifying Model Architecture: In discussing model architectures, one user clarified how some papers describe attention and feedforward neural networks (FFN) as parallel operations, referencing PaLM as an example where models use parallel attention + FFN.
- Decoding the Pile dataset hash: A member shared the hash values for the Pile dataset, providing a list with hashes linked to EleutherAI for those seeking to use the dataset in various JSON files.
- Receptive Field Mechanics in Transformers: A conversation on sliding window attention mentioned how the mask limits the scope of attention and compared it to the functioning of convolutions regarding effective receptive fields.
- Exploring Layered Learning and Attention Structures: Participants discussed the potential for interleaving RNN-type layers or using dilated windows for transformers to handle longer sequence lengths effectively.
- New PyTorch Library for Large Model Training: A user shared a link to the GitHub repository for a new PyTorch library named torchtitan, meant for large model training.
Links mentioned:
Eleuther ▷ #research (144 messages🔥🔥):
-
Linear Attention Breakdown Explained: A member provided a thorough explanation of how linear attention works by separating ( QK^T V ) into ( Q(K^T V) ) for inference. It was clarified that this approach is linear with respect to sequence length and maintains constant memory usage, unlike softmax attention which grows over time.
-
Benchmarking Beyond Hypothesized Formats: A member reported "benchmarking" phi-3-mini-128k against other models, suggesting its performance might be on par with Llama-3-8B. The discussion evolved around whether the pre-training data significantly influences post-training performance and what constitutes a "base" in the context of AI models like phi.
-
Deep Dive into Delta Rule Practicality: Conversations unfolded regarding the practicality and parallelization of delta rule linear attention, with one member sharing insights from a blog post on manifestai. It was noted that delta rule linear attention is more organized but less parallelizable, potentially slowing down training.
-
Needle in the Haystack Tests Scrutinized: Users questioned the efficacy of "needle in the haystack" tests for long-context language models, suggesting real-world application and personal testing are more indicative performance benchmarks. There is skepticism about how such a test accounts for the semantic similarity between the "needle" and its surrounding context.
-
Masking User Prompt Loss During SFT: There was curiosity whether masking the user prompt loss during supervised fine-tuning (SFT) on language models had been systematically studied. While a common practice, members noted the absence of research on its effects and discussed potential gains from including prompt loss in SFT.
Links mentioned:
Eleuther ▷ #interpretability-general (1 messages):
main.ai: https://twitter.com/sen_r/status/1783497788120248431
Eleuther ▷ #lm-thunderdome (21 messages🔥):
-
Few-Shot Performance Queries for GSM8K: A question about the number of few-shot examples (num_fewshot) for GSM8K arose to match the Hugging Face leaderboard, suggesting that the number should be 5.
-
VLLM Integration Blockers Discussed: A user inquired about obstacles to upgrading VLLM to the latest version. The discussion clarified that Data Parallel (DP) was a potential blocker, but Tensor Parallel (TP) should be fine.
-
Invitation for Filter Registry Function PR: A new member noticed an absence of a
register_filterfunction forFILTER_REGISTRYin lm_eval. The user was encouraged to submit a PR to address the issue. -
Musings on the Brier Score Function: A member encountered an issue with the Brier score function for ARC evaluation in the lm-evaluation-harness due to an anomaly in the data. It was suggested that the Brier score function be adjusted to avoid errors despite the dataset's inconsistency.
-
Progress Inquiry on Chat Templating Branch: A user queried the status of an active branch for chat templating on Hailey's branch, last updated two months ago, expressing interest in the progress toward functionality.
Links mentioned:
OpenRouter (Alex Atallah) ▷ #announcements (2 messages):
-
Identifying Provider Issues: A major Mixtral 8x7b provider was found to send blank responses and has been temporarily removed. Future solutions to auto-detect such issues are being considered.
-
Soliloquy 8B Switches to Paid Model: Soliloquy 8B shifted to a paid model, costing $0.1 per 1M tokens as per the latest update. Further details can be found on the provided Discord channel link.
Link mentioned: Lynn: Llama 3 Soliloquy 8B by lynn | OpenRouter: Soliloquy-L3 is a fast, highly capable roleplaying model designed for immersive, dynamic experiences. Trained on over 250 million tokens of roleplaying data, Soliloquy-L3 has a vast knowledge base, ri...
OpenRouter (Alex Atallah) ▷ #app-showcase (1 messages):
- Announcing AI Breakthrough on LinkedIn: A message included a LinkedIn post from fprime-ai talking about a technological breakthrough with their DBRX AI system. The post can be accessed and read in detail here.
OpenRouter (Alex Atallah) ▷ #general (215 messages🔥🔥):
-
Choosing the Best Model for Roleplay Creativity: Members discussed the most suitable open-source models for creative plot creation in role-play. Recommendations included WizardLM2 8x22B, command-based models for creative writing, and Mixtral 8x22B, with one user emphasizing Mixtral's exceptional degree of creativity.
-
Debate Over GPT Turbos and Microsoft's Wizard LM: An extensive debate erupted regarding Microsoft's impact on the Wizard LM project, with some suggesting the company halted older models and others arguing over the performance of GPT-4 "Turbo" models. A member produced evidence by linking a detailed summary of the incident.
-
Model Performance and Hosting Costs Explored: Members evaluated various models' performance, such as GPT-4, Llama 3, and WizardLM, while also discussing hosting costs and sustainability of current pricing, with calculations estimating costs per million tokens.
-
Concerns over Model Switching and API Logging: Users expressed concerns about the transparency of model switching in OpenRouter and the logging of API calls by providers, with some having hesitations about using models like Lynn: Llama 3 Soliloquy 8B.
-
OpenRouter Usage, Features, and Limitations: Discussion about OpenRouter covered topics from enabling system message mappings to playground response expansions. Users also inquired about handling HTTP 524 errors and avoiding negative balances while using paid LLMs.
Links mentioned:
LlamaIndex ▷ #blog (4 messages):
-
create-llama v0.1 Launches: The create-llama v0.1 release introduces easy setup for RAG applications with new features like @ollama support and new vector database integrations, facilitating the use of llama3 and phi3 models. The update was announced via a tweet with more details on the improvements.
-
Build RAG Apps with Qdrant and LlamaParse: A step-by-step tutorial highlighting how to build RAG applications using LlamaParse, @JinaAI_ embeddings, @qdrant_engine vector storage, and Mixtral 8x7b was detailed in another tweet. Interested developers can access the full tutorial here.
-
LlamaParse Webinar by KX: KX systems is organizing a webinar on maximizing the utility of LlamaParse for complex document parsing, table and image extraction, and natural language preprocessing. The event details are available in this twitter post.
-
AWS Workshop Featuring LlamaIndex: @llama_index teams up with AWS to offer workshop materials on building LLM apps with AWS, explaining how to use services such as S3, AWS Bedrock LLMs, and embedding storage in conjunction with LlamaParse and LlamaCloud. Workshop details are summarized in this tweet.
LlamaIndex ▷ #general (117 messages🔥🔥):
-
Exploring RAG Implementations: Members discussed the effectiveness of simple and advanced RAG (Retrieval-Augmented Generation) pipelines. It was suggested to explore more complex RAG solutions like sentence-window retrieval or auto-merging retrieval for improved results, and a video was linked for learning how to set up these pipelines (Lesson on Advanced RAG).
-
Technical Troubleshooting for Chatbot Implementations: There was a conversation about implementing a chatbot with gpt-4-vision-preview, where issues arose with the backend not supporting image uploads. A member found a solution when adding images as part of the content, rather than using
additional_args. -
Configuring and Using Pydantic with LlamaIndex: A user asked for information on getting structured Pydantic output from chat completions, and another raised an issue with Pydantic imports causing type checking errors. The suggestion was to use v1 imports directly or wait for LlamaIndex to phase out v1 support.
-
Query Pipeline Configuration Queries: Several users discussed the nuances of configuring query pipelines, mentioning issues with JSON output from GPT-4 within a pipeline and exploring how to format outputs at intermediate steps effectively. It was outlined that GPT-4 turbo does not support JSON output, while GPT-3.5 turbo does allow for JSON mode (GPT JSON Mode Documentation).
-
Local LLM Setup with LlamaIndex Guidance: A member sought guidance for using LlamaIndex with local language models to avoid using external APIs. They were directed to the official documentation for a starter example (Starter Example with Local LLM). The conversation included troubleshooting import errors and piecing together necessary package installations.
Links mentioned:
LAION ▷ #general (78 messages🔥🔥):
-
LAION Discord Reflects on Llama 3 Performance: Users have mixed opinions regarding Llama 3's performance, with some reporting issues in recalling code correctly, and others suggesting it may be due to configuration problems. While some find it comparable to GPT-4, others see significant room for improvement.
-
Debate Over Proposed Know Your Customer Requirements: A link to TorrentFreak discusses U.S. proposals for "Know Your Customer" requirements for cloud services and the implications for users. A member shares the Federal Register notice urging feedback before the comment period ends.
-
AI Enthusiasts Seek Like-Minded Communities: Members of the LAION Discord express interest in joining additional AI/ML-oriented Discord servers for wider community engagement and resource sharing.
-
Tuning AI Models Brings Performance Surprises: A member working on tuning the DF 400M/450M model discovers significant performance left untapped, emphasizing a low learning rate and improved upscaling of real photos.
-
Critique of the Efficacy of Nightshade and Publishing Protocols: Users discuss the need for transparency and data regarding the effectiveness of Nightshade, a theoretical discussion about autoencoder limits, and the reluctance to publish findings due to possible adverse reactions from the community.
Links mentioned:
LAION ▷ #research (12 messages🔥):
-
Revolutionizing Visual Representation Learning: A novel weakly supervised pre-training method for vision models was highlighted, which categorizes pre-training on image-text data as a classification task. This approach has achieved a training speed that is 2.7 times faster than traditional contrastive learning, without compromising the quality of representations, as detailed in this arXiv paper.
-
Simple Yet Effective: Building on the previous point, the method's success was attributed to detecting concepts from alt-text and training a multilabel classifier. It was noted that this led to the model performing comparably to CLIP in zero-shot scenarios and with greatly improved training efficiency.
-
The Cost of Contrast: In a conversation about the efficacy of text encoders and contrastive learning, it was pointed out that contrastive learning, especially while aligning text encoders, is costly. The approach can incur extra computational expenses when dealing with noisy alt text.
-
Fast Yet Still Lengthy: A humorous comment was shared acknowledging that while a 2.7x speed increase in training was significant, the overall process remains time-intensive. This reflects a realistic perspective on the improvements in speed.
-
Exploring VAST Possibilities: Interest was expressed in finetuning VAST, a Vision-Audio-Subtitle-Text Omni-Modality Foundation Model and Dataset, with a link provided to the project's GitHub repository.
Links mentioned:
OpenInterpreter ▷ #general (70 messages🔥🔥):
-
Mac Integration with Open Interpreter: Open Interpreter's New Computer Update Part II enhances local functionality with a first local vision model, native Mac integrations, improved launch speed, and additional features. Users can run simple commands such as
interpreter --osto control Mac's native applications directly from Open Interpreter, as detailed on their change log. -
Vision Model Showcases and Updates: Community members discussed the Moondream tiny vision language model, showcasing Img2TxtMoondream.py, a code demo for vision models. The conversation shifted towards the use of multimodal models like LLaVA available on Hugging Face, highlighting its foundation on NousResearch/Nous-Hermes-2-Yi-34B.
-
Resolving Loops and Model Performance: Participants exchanged tips on optimizing local models to prevent looping behavior, suggesting adjustments such as modifying temperature settings, prompt editing, or architectural changes. The concept of a frustration metric was also introduced to adapt a model's behavior after encountering successive loops.
-
Integration Exploration and Error Troubleshooting: A user pondered the integration of Open Interpreter for robot control, specifically with the Unitree GO2 robodog, asking for community experience. Others discussed technical issues and solutions for running local servers, such as setting dummy API keys and resolving namespace conflicts in Pydantic model configurations.
-
Open Interpreter 'New Computer Update' Non-Beta Release: A user confirmed running Open Interpreter 0.2.5 New Computer Update, indicating the version that includes the recent enhancements is out of beta. However, there was a question about the update's status change from beta, leading to a clarification through a version check.
Links mentioned:
OpenInterpreter ▷ #O1 (2 messages):
- Hardware Arrival Sparks Enthusiasm: A member expressed excitement about receiving their hardware for building, despite missing a yellow wire and switch, for which they have spares. Another member showed interest in the building process and looked forward to updates.
OpenInterpreter ▷ #ai-content (1 messages):
8i8__papillon__8i8d1tyr: https://www.youtube.com/watch?v=WeH3h-o1BgQ
OpenAccess AI Collective (axolotl) ▷ #general (56 messages🔥🔥):
- Tweet at the Top: A member shared their excitement about the CEO of Hugging Face commenting on their tweet.
- Warm Welcome: New member "lazeewhalee" joined the group and was directed to read the readme for navigation and guidelines.
- 70B Model Deployment Discussions: One member mentioned deploying and running the 70B model with exllama and inquired about potential issues due to a missing checkpoint.
- Speculation on AI Benchmarks: Concerns were raised about the validity of MMLU scores and the performance of various models, particularly an 8B model which performed worse than the base llama3 except on MMLU.
- Insights on Domain-Specific Training: Members discussed the benefits of fine-tuning Large Language Models (LLMs) for specific domains and shared Meditron as a thorough paper on the topic. A brief mention of an upcoming paper by a member on domain-adaptive continual pre-training was also made.
Links mentioned:
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (3 messages):
- Underlying Issue Reported: A member has confirmed experiencing an issue, although it's unclear what changed to cause it.
- Expression of Disappointment: The short response 'sadge' conveys disappointment or sadness over a topic that was likely discussed previously.
- Inquiry about zzero3 and fft compatibility: A member is asking if anyone has successfully integrated zzero3 with Fast Fourier Transform (fft).
OpenAccess AI Collective (axolotl) ▷ #general-help (3 messages):
- Well Wishes Exchanged: A user expressed hopes for another's success in their endeavors.
- Phi3 Fine-tuning Challenges: A member discussed the difficulties they experienced while fine-tuning the phi3 model, mentioning it requires a lot of RAM and operates slowly.
- Technical Troubleshooting: In response to a technical question, an issue was raised about an
AttributeErrorrelated to the 'TextIteratorStreamer' object not having an 'empty' attribute when using transformers 4.40.0.
OpenAccess AI Collective (axolotl) ▷ #axolotl-phorm-bot (10 messages🔥):
- Optimizer Compatibility Query: The search for optimizer compatibility with FSDP (Fully Sharded Data Parallel) reveals general support from optimizers like AdamW and SGD, though some, like
paged_adamw_8bit, do not support FSDP offloading. - Offloading Incompatibility Issue: There's an issue with
paged_adamw_8bitoptimizer as it's not compatible with FSDP offloading, indicating integration challenges between specific optimizers and FSDP features. - Searching for Solutions: In response to an error, efforts are being made to search the OpenAccess-AI-Collective/axolotl for alternative optimizers that support FSDP.
Links mentioned:
Cohere ▷ #general (63 messages🔥🔥):
- Toolkit Troubles: A user experiencing trouble with uploading documents to the Cohere Toolkit on Azure received guidance pointing to the paper clip attachment icon for uploads. However, they were still unable to find the upload option and interact with their Cohere-Toolkit instance.
- Typographic Turmoil: A user's query about whether the Cohere typeface on GitHub was under the MIT license was clarified with the information that the font isn't open-sourced and will be replaced.
- Model Access and Licensing Clarification: Cohere's Command+ models are open weight but not commercially applicable, with weights available for non-commercial use while training data remains withheld.
- Search Engine Explorations for AI: It was revealed that Tavily is used with Cohere-Toolkit; however, Brave Search API was suggested as a potentially faster, cheaper, and accurate alternative. A discussion ensued about search engines' cost-efficiency and usage in different contexts.
- Deployment Dilemmas with Cohere Toolkit: Users shared insights on deploying the Cohere Toolkit on Azure; one does not need to add a Cohere API key but must select a model deployment option to ensure the application functions properly. Subsequently, a user's difficulty adding tools locally was raised, encountering issues with uploading PDFs and an unsupported version of sqlite3.
Links mentioned:
Cohere ▷ #project-sharing (6 messages):
- Debate Over "Hit Piece" Against Cohere: Members engaged in a heated debate with one party defending Cohere against claims of being reckless and another questioning the responsibility in potentially creating "jailbreak" scenarios in AI agents that translate tokens into real-world actions.
- Confusion over Article Content and Comments: A member expressed that they no longer recall details from an article they criticized for being a hit piece, highlighting a lack of distinction between chatbot and agent behavior in the discussion.
- Challenge to Substantiate Criticism: Upon being asked to substantiate the claim that an article was unfairly discrediting Cohere, a member conceded that they could not recall specific reasons offhand, reducing the credibility of the critique.
- Miscommunication over Remembering Details: One member ridiculed the reasoning of not being able to remember specifics as a justification for not listing problems with the allegedly malicious article.
- Expectations of Accountability in Research Dialogue: The conversation culminated in a statement that if one criticizes research work as malicious, they should be prepared to substantiate their claims, implying a need for accountability when contributing to research discussions.
tinygrad (George Hotz) ▷ #general (62 messages🔥🔥):
- Partnerships Are Key to tinygrad's Success: Tinygrad aims to win through partnerships and getting others invested in its framework, with coma as the first partner on hardware for tinybox, and possibly collaborating with others on tinybox 2.
- TinyBox As The Tested Ground for tinygrad: The tinybox, produced by comma, is considered the most tested environment for tinygrad. George Hotz emphasizes that tinygrad's focus remains on the software, not the hardware production.
- Tenstorrent Considerations for Partnership: Despite initial discussions, a partnership with Tenstorrent did not make financial sense as their hardware wasn't competitively efficient or widespread. However, future collaboration is not ruled out if the financial calculus changes.
- AMMD's MES Limited Utility for tinygrad: George Hotz notes that the Machine Environment Settings (MES) from AMD are not likely to be useful for tinygrad, despite a helpful writeup from Felix at AMD. The team continues to work on a PM4 backend for their needs.
- tinygrad MNIST Tutorial and GPU Compatibility: A tinygrad MNIST tutorial has been shared, suitable for running in Google Colab with GPU support. Users reported issues with newer NVIDIA hardware, which were resolved by ensuring the latest CUDA libraries were installed.
Links mentioned:
tinygrad (George Hotz) ▷ #learn-tinygrad (6 messages):
-
Looking Forward to tinygrad 1.0: tinygrad's documentation was shared, highlighting that the API is stabilizing as it nears its version 1.0 release. It includes a guide to install from source, a MNIST tutorial, developer docs, and externally created tutorials.
-
tinygrad Takes on Quantile Function: A member discusses their project, which aims to reimplement the
torch.quantilefunction in tinygrad as part of developing sampling algorithms for diffusion models. This process includes an intermediate step of array sorting. -
tinygrad Docs to Get More Visibility: In anticipation of the launch of tinygrad 0.9, a member questioned whether links to the tinygrad documentation would be included in the project README. The response indicates an affirmative action will be taken with the 0.9 launch.
Link mentioned: tinygrad docs: no description found
Modular (Mojo 🔥) ▷ #💬︱twitter (1 messages):
ModularBot: From Modular: https://twitter.com/Modular/status/1783575774085410911
Modular (Mojo 🔥) ▷ #✍︱blog (1 messages):
-
Modular Tackles Software Security Challenges: Modular is constantly releasing new software and features, presenting security challenges due to vulnerabilities in modern software delivery mechanisms. Highlighting the urgency to prevent attacks, it's noted that by 2024, an estimated 96% of codebases will contain open-source code.
-
Secure Software Delivery Is Critical for Modular: The XZ supply chain attack has underscored the necessity for strong defenses against supply chain vulnerabilities, making secure software delivery a key focus for Modular since their first release of Mojo.
Link mentioned: Modular: Preventing supply chain attacks at Modular: We are building a next-generation AI developer platform for the world. Check out our latest post: Preventing supply chain attacks at Modular
Modular (Mojo 🔥) ▷ #ai (2 messages):
- Downplaying the Importance of Processing Units: A member expressed the opinion that processing units may not be as critical as widely believed.
- The Geometric Gateway to Quantum Simplification: Discussing the amplituhedron, a member suggested that geometric structures could make complex quantum phenomena like particle scattering amplitudes more comprehensible. The use of geometry in optimizing quantum algorithms and circuit designs was proposed to potentially reduce complexity and noise.
- Visualizing Quantum States with Geometry: The Bloch sphere was mentioned as a way to visualize quantum gates' effects on qubits through geometric transformations. Though effective for single qubits, the challenge of scaling to multiple qubits and representing entanglement may require complex hyper-dimensional spaces.
- Machine Learning as a Decoder of Hyper-Dimensional Spaces: The member posited that as the visualization of quantum entanglement becomes more complex with increased qubit count, machine learning might aid in deciphering the intricate graphs that arise.
Modular (Mojo 🔥) ▷ #🔥mojo (36 messages🔥):
-
Safe from Harm: An inquiry about potential irreversible damage to a PC caused by incorrect manual memory management in a custom type with Mojo was addressed with an assurance that the Operating System will clean up memory after a process exits, and Mojo doesn't require manual memory management.
-
Mojo Function Fundamentals: A Python-to-Mojo conversion discussion revealed two function types,
defandfn, as viable options. The conversation included code examples and explanations about the two different function definitions and how to declare variables in Mojo. Function declarations are described here. -
Learning Curve for Newcomers: In a discussion about understanding Mojo's nuances, community members were advised to focus on making their code work first, as it is normal to experience changes in a nascent programming language. The evolution of languages and potential requirement for future refactorings were highlighted as part of the learning process.
-
List Diversity in Mojo Query: A question regarding Mojo's ability to handle lists with mixed data types was fielded, revealing that while possible, the current method is considered "hacky". Illustrative examples were given showing lists containing both integers and strings using
Variantas seen in these Gists for Ints and Floats and for Ints and StringLiterals. -
Embrace the Mojo Journey: A newcomer to programming received a warm welcome from the community and a reminder to initially focus on writing code that works. Emphasizing that mastery comes with practice, there was an encouragement to stay adaptable and prepared for the evolving landscape of new programming languages.
Links mentioned:
Modular (Mojo 🔥) ▷ #community-blogs-vids (5 messages):
- Mojo vs. Rust: A Comparative Overview: A discussion on lobste.rs criticizes Mojo for being potentially less safe and slower than Rust, citing issues with copy on write semantics and inout parameters. The critique also suggests that Mojo’s marketing strategies may overshadow the need for robust technical advancements.
- Awaiting Mojo's Benchmark Debut: A user expressed excitement for Mojo to be included in future programming benchmark competitions, hinting at the community's interest in seeing empirical performance data.
- Benchmarks: A Heated Developer Hobby: One member commented on the developer community's fervent discussions regarding programming language benchmarks, noting that some developers tend to take preliminary GitHub speed benchmarks too seriously, even though they should be considered more as indicators than absolutes.
- Advocating for Borrowed Defaults: A user acknowledges the benefits of some Mojo features over Rust, particularly after a critique by a Rust community member known for explaining async Rust. The conversation touches on borrowed references and how they could be better presented as advantages of Mojo.
- Spreading Mojo in Academia: A user shared a GDSC event link focusing on Python and Mojo: Python and Mojo: Good, Bad, and the Future. The event aimed to familiarize students with Mojo, highlighting its integration with Python and its potential in systems programming.
Links mentioned:
Modular (Mojo 🔥) ▷ #performance-and-benchmarks (6 messages):
- Curiosity About Issue Filing: A request was made to file an issue for an unspecified matter, expressing curiosity about the topic.
- Issue Filing Accomplished: An issue regarding the Mojo Programming Language has been filed on GitHub, as confirmed by the link to the relevant issue.
- Exploring
__copyinit__Semantics: Linked GitHub Gist raises a question whether it's up to the type author to implement copy-on-write semantics, or if another issue should be filed. - Invitation to Track via Issues: The suggestion was made that filing an issue would make the behavior concerning
__copyinit__more trackable, ensuring a proper response is received. - Level Up Announcement: ModularBot celebrated a user's advancement to level 9 in the community.
Links mentioned:
Modular (Mojo 🔥) ▷ #🏎engine (3 messages):
- Optimism for Continuous Improvement: A member expressed a positive outlook, suggesting that the performance will likely improve over time.
- Performance Gains Coincidence: It was noted with amusement that despite differences, PyTorch and TensorFlow reported the same performance gains.
- Curiosity about Performance Consistency: A member queried what the outcome would be if the performance gain tests were rerun.
Modular (Mojo 🔥) ▷ #nightly (11 messages🔥):
- Confusion Cleared on Overload Resolution: The overload resolution in programming gives precedence to functions with fewer parameters. Therefore, methods within a trait with lower precedence can be overridden by a type that declares both.
- Trait Conformance Without Extra Parameters: It was pointed out that a trait does not need to declare an
__eq__method with anoneparameter to conform; this could simplify trait declarations. - Potential SIMD Equality Compatibility: A slight modification may allow SIMD to conform to EqualityComparable without altering the trait’s declaration.
- A Redundant Parameter's Dilemma: The downside of the discussed method adjustment is the left-over redundant
noneparameter, though it's typically not used directly in dunder methods. - Code Efficiency Boost with
kgen.pack.load: A change in the code usingkgen.pack.loadin a printf function resulted in a more efficient update: 14 insertions and 985 deletions.
LangChain AI ▷ #general (44 messages🔥):
- AI Hunts Trolls: A user shared plans to create an anti-trolling AI targeting bullies, with a query for suggestions on additional actions the bot could take.
- SQL Q&A with Mistral and Llama3: A user encountered issues with SQL responses being too verbose with open-source models like Mistral or Llama3 and later an
OutputParserException. Discussions included structured output support by Ollama and examples of invoking SQL Agents with these models. - Understanding Redis Integration with Langchain: A distinction between stores and chat memory was clarified; the former is a generic key-value store accessible by the
RedisStoreclass, while the latter is specific to persisting chat messages by session through Redis Chat Message History integration. - LangChain Model Invocation Syntax Support: A user sought advice on incorporating a prompt into a LangChain model invocation using JavaScript, with some guidance provided on chaining prompts using the
ChatPromptTemplateand instance methods likepipe. - Clarifying Access to Gemini 1.5 Pro Model: Users discussed how to use Gemini 1.5 Pro with LangChain; the correct usage involved
ChatVertexAI, with indications that Gemini models cannot be accessed with ChatGoogleGenerativeAI. Correct implementation requires setting theGOOGLE_APPLICATION_CREDENTIALSvariable.
Links mentioned:
LangChain AI ▷ #langchain-templates (1 messages):
- LLaMA Prompt Template Queries: A member inquired about header usage for providing context within LLaMA3 prompts, referencing the official documentation. Concern was expressed about the documentation's completeness due to the model's novelty.
LangChain AI ▷ #share-your-work (5 messages):
-
Collate Launches Personalized Newsletters: Vel_y announced the launch of Collate, a service that transforms articles and PDFs into a bite-sized daily newsletter. The platform provides a way to manage information overload, turning saved content into easily digestible newsletters with a "try now" option available here.
-
BlogIQ Streamlines Content Creation: Vishal_blueb introduced BlogIQ, an app that combines the capabilities of OpenAI and Langchain to assist bloggers in content creation. The app is positioned as a clone of services like writesonic.com and copy.ai, geared towards simplifying the process of content development for blogs.
-
LangGraph for Invoice Extraction: Toffepeermeneer shared their first project with LangGraph, an invoice extractor that takes information from pictures and stores it in a Postgres database. The project can be found on GitHub and includes an Excalidraw project overview.
-
Galaxy AI Opens Access to Premium AI Models: White_d3vil announced Galaxy AI, a service offering free API access to premium AI models including GPT-4, GPT-4-1106-PREVIEW, and Gemma. The APIs are compatible with OpenAI's format for easy project integration, and more information, including an invite to their Discord server, can be found here.
Links mentioned:
Latent Space ▷ #ai-general-chat (35 messages🔥):
- Apple Shares Open Source Models: Apple enters the open source space with smaller-than-expected models, including a 270M parameter model featured on Hugging Face, alongside 450M, 1.1B, and 3B variants.
- Dify's App Development Platform Gains Attention: Dify offers an open-source LLM app development platform that combines various features such as AI workflow and model management; however, some users raise concerns about its lack of loops and context scopes.
- New PyTorch Library for Training LLMs: PyTorch announces Torchtitan, a new library that supports training large language models such as llama3 from scratch.
- Interest in SORA Video Generation: A Recap on SORA, an advanced video generation model by OpenAI that can create cohesive videos up to a minute long, with details and feedback from early users shared in an FXGuide article.
- Handling Claude 3 Output Quotations: In a discussion about issue of quotation marks causing JSON parsing errors with Opus’s Claude 3, one member advised asking the model to escape the problematic characters, which has proven effective for them especially with CSV outputs.
Links mentioned:
Latent Space ▷ #llm-paper-club-west (12 messages🔥):
- Mixture of Depths Paper Presented: A discussion on the paper titled 'Mixture of Depths' began with the presentation shared through this link. The paper introduces an approach to accelerate the training of transformers by using a modified MOE routing mechanism to adapt token flow dynamically through transformer layers.
- Transforming Attention Mechanics: The Mixture Of Depths paper proposes a solution to the problem of scaling transformers with longer sequences. By alternating between new MOD layers and normal transformer layers, the computational attention demand is cut in half, improving various training elements.
- Large Language Models' Real-World Application Challenges: Another paper was referenced which explores the deployment challenges of Large Language Models (LLMs) such as computing resource demands. It was mentioned that smaller, compact LLMs often do not outperform larger zero-shot LLMs in meeting summarization tasks, even after fine-tuning, as detailed in the abstract.
Links mentioned:
Latent Space ▷ #ai-in-action-club (1 messages):
- Recording Request for Vector DBs Chat: A member expressed interest in the Vector DBs chat scheduled for Friday, APR 26 but mentioned they might miss it. They inquired if the chat could be recorded, acknowledging that while not common, it has been done before.
Mozilla AI ▷ #llamafile (40 messages🔥):
- Understanding Phi-3-Mini-4K Instruct Usage: A discussion provided insights on using the Phi-3-Mini-4K-Instruct with llamafile; GGUF format details were highlighted, mentioning steps for setting up the model and its properties including high-quality and reasoning dense datasets.
- Mixtral 8x22B Instruct Llamafile Quickstart: A README update was mentioned for the Mixtral 8x22B Instruct llamafile, recommending the use of
curl -Lfor redirections on CDNs when downloading.cat*files from the provided Quickstart guide. - CPU Feature Requirements for Llamafile: A user encountered a "fatal error" related to AVX CPU feature requirements when attempting to run a llamafile on a Mac M1. It was suggested to restart the computer and consider using smaller models for 8GB RAM systems.
- Windows Defender Flags Llamafile as Trojan: A user reported Windows Defender flagged a llamafile as a trojan; suggestions included trying alternative environments like virtual machines or whitelisting the folder in Windows Defender settings. Windows Defender support is only guaranteed for binaries on the official release page.
- Resource Requirements and Troubleshooting for Llamafile Use: Users discussed the resource demands of running the 8x22B model, noting significant RAM requirements and potential crashes due to high memory usage. It was mentioned that at least 128GB is recommended for the Mistral 8x22B model.
Links mentioned:
DiscoResearch ▷ #disco_judge (6 messages):
-
Llama-3-70b Excels in Judgemark: Llama-3-70b showed promising results on Judgemark, indicating its strong potential as a base for fine-tuning the disco-judge. Judgemark evaluates a model's capability to judge creative writing and requires at least 8k supported context length.
-
Potential Collaboration on Evaluation: A user is open to collaborating, offering insights gained from creating the evaluation and suggested their elaborate judging prompt design for testing complex rubrics.
-
Learning from Magazine and MMLU: The user @jp1 praised the work in an article for creating MAGI, a highly selective and discriminative subset of MMLU, designed to challenge and differentiate high-ability models.
-
Judgemark Data for Fine-Tuning: A user expressed readiness to format and share all Judgemark outputs for potential use in fine-tuning datasets, asking about the collection process for said datasets.
-
Phi-3-mini-4k-instruct's Mixed Results: Despite less impressive performance on eq-bench compared to their published evaluations, Phi-3-mini-4k-instruct is listed on the eq-bench leaderboard, where users may need to scroll to find it.
Links mentioned:
DiscoResearch ▷ #general (4 messages):
<ul>
<li><strong>API Focus and Library Ease Discussed:</strong> Tgi is presented as API-first and prioritizes low latency, while vllm is acclaimed for being an easy-to-use library, emphasizing cost-effective and high-throughput deployment.</li>
<li><strong>Batch Generation Inquiry at Hugging Face:</strong> A debate finds its way to Hugging Face regarding batch generation capabilities <a href="https://github.com/huggingface/text-generation-inference/issues/1008#issuecomment-1742588516"><strong>GitHub Issue #1008</strong></a>, revealing community-driven problem-solving.</li>
<li><strong>DiscoLM Inference Speed Woes:</strong> A member reports slow initialization and inference times for DiscoLM_German_7b_v1 on a high-performance computing system, contrasting with much faster times on a local setup without GPUs.</li>
<li><strong>Potential Misconfiguration in DiscoLM:</strong> Another member suggests ensuring correct model loading with <code>device_map='auto'</code>, expecting a significant speed improvement when using 2x V100 GPUs for inference.</li>
</ul>
Link mentioned: Batch generate? · Issue #1008 · huggingface/text-generation-inference: System Info Hi, i like to ask if it is possible to do batch generation? client = Client("http://127.0.0.1:8081",timeout = 60) gen_t = client.generate(batch_text,max_new_tokens=64) generate c...
DiscoResearch ▷ #discolm_german (7 messages):
- DiscoLM-70b Deployment Struggles: A member described issues with running DiscoLM-70b, facing the "Template not found" error and nonsensical output from the
/generateendpoint onhuggingface/text-generation-inference. - Appreciation for DiscoLM Models: Salvasfw expressed their deep appreciation for the DiscoLM series of models, even amidst troubleshooting challenges.
- Musings on Powerful MoE Model: There was speculation about the potential of building and training an 8 x phi-3 MoE model, with curiosity about its capabilities.
- Mini 4k Llamafication Success: The
Phi-3-mini-4kwas successfully llamafied, according to crispstrobe, with a decent EQ-Bench Score (v2_de) of 51.41, despite some mistakes in the German output. The model did not specifically train on German data, and the results suggest it might be further trainable. - Gguf Model Downloads: Johannhartmann highlighted the popularity of the gguf model, which saw 1500 downloads within two days of release.
Interconnects (Nathan Lambert) ▷ #ml-questions (12 messages🔥):
-
Debating Claude’s Capabilities: An online discussion explored Claude’s RLAIF training as light-handed and well-executed. It is reported that Claude’s behavior shows unexpected structure and a deep understanding, ‘mostly orthogonal’ to Anthropic’s vision, giving off "Jungian individuation" and "Bodhisattva vibes." The thread also speculates on the effects of RLAIF versus the base model’s latent dynamics and discusses the potential for Claude's mode collapse to be rectified (Claude’s conversation thread).
-
RLHF vs. KTO in Commercial Deployments: In response to a query about the stability of Reinforcement Learning from Human Feedback (RLHF), it’s suggested that its application depends on the context, and that Knowledge-Targeted Optimization (KTO) might be better suited for certain applied tasks.
-
Transitioning Training Methods for Improved Results: A mention of an interview shares an experience where moving from Supervised Fine Tuning (SFT) to Data Programming by Demonstration (DPO) provided better outcomes, and subsequently moving to KTO further improved performance based on user feedback.
-
Complications and Nuance in RLHF: There’s an assertion that RLHF is more nuanced than commonly thought, particularly when considering the variety of data and how it interacts with downstream evaluation metrics.
-
Understanding Grad Norm Spikes: The channel requested clarity on why spikes in gradient norms during pretraining might be undesirable, but no detailed explanation was provided in the response.
Link mentioned: Tweet from j⧉nus (@repligate): definitely have no doubt there are various ways to do RL/generation-discrimination/synthetic data/self-play-esque training on top of teacher-forcing that makes the models smarter, but especially more ...
Interconnects (Nathan Lambert) ▷ #random (4 messages):
- The "Pick Your Brain" Conundrum: Nathan Lambert mentioned his discomfort with the term "pick your brain" especially now that he tends to decline such requests due to being busy.
- Humorous Take on Brain Picking: Vsreekanti responded humorously to the discomfort toward brain-picking, suggesting that one should inquire about the type of pick, jokingly preferring a lobotomy.
- Brain Picking as Vague Request: Drj.bet added that the phrase "pick your brain" often implies a desire for conversation without a specific question in mind.
Skunkworks AI ▷ #general (1 messages):
- CPU-friendly Language Models Tackling Python: An article titled "Low-Cost Language Models: Survey and Performance Evaluation on Python Code Generation" has been shared, delving into performance evaluations of CPU-friendly language models. It introduces a dataset of 60 programming problems and discusses the use of a Chain-of-Thought prompt to guide models in problem-solving, available through this link: View PDF.
Link mentioned: Low-Cost Language Models: Survey and Performance Evaluation on Python Code Generation: Large Language Models (LLMs) have become the go-to solution for many Natural Language Processing (NLP) tasks due to their ability to tackle various problems and produce high-quality results. Specifica...
Skunkworks AI ▷ #off-topic (4 messages):
- Fine-tuning Moondream for Image Recognition: A YouTube video was shared demonstrating the fine-tuning of the Moondream Vision Language Model on a Captcha image dataset. It's described as a guide to improve performance on a downstream task.
- AI Developers Meetup in Toronto: The upcoming local & open-source AI developer meetup at Cohere space in Toronto was highlighted with a link to the event. A member named Andrei is helping organize, and it features lightning talks, demos, and networking.
- Introducing Snowflake Arctic: Another YouTube video showcases Snowflake Arctic, an enterprise-focused LLM designed for cost-effective AI solutions. Briefly, the video introduces this new addition to the landscape of large language models.
Links mentioned:
Datasette - LLM (@SimonW) ▷ #ai (2 messages):
- GUI for GPT Lovers: A member discovered jan.ai, which is praised as a user-friendly graphical user interface for running models locally.
- Smaller Models with Big Ambitions: A member shared OpenELM, an efficient language model family released by Apple, which offers both pretrained and instruction tuned models, utilizing a unique layer-wise scaling strategy for efficient parameter allocation.
Link mentioned: apple/OpenELM · Hugging Face: no description found
Alignment Lab AI ▷ #general-chat (1 messages):
venadore: trying to get llama 3 to do topic complexity classification, not half bad