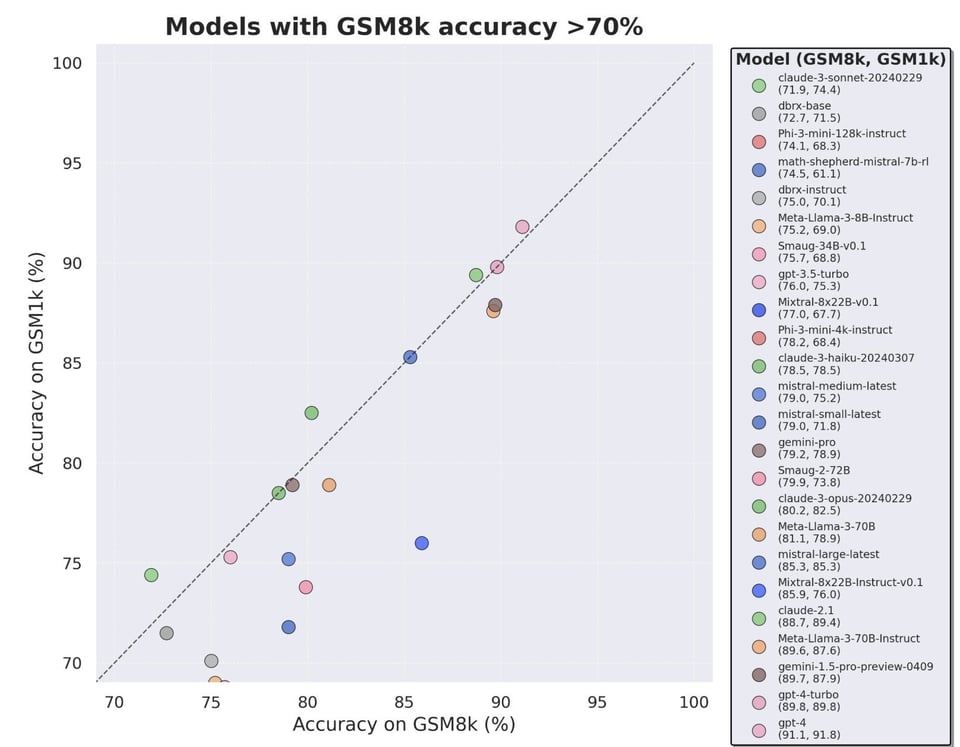
The problem of data/benchmark contamination is often a passing joke but this year is reaching a breaking point with decreasing trust in the previous practice of self reported scores on well known academic benchmarks like MMLU and GSM8K. Scale AI released A Careful Examination of Large Language Model Performance on Grade School Arithmetic which proposed a new GSM8K-like benchmark that would be less contaminated, and plotted the deviations - Mistral seems to overfit notably on GSM8k, and Phi-3 does remarkably well:
Reka has also released a new VibeEval benchmark for multimodal models, their chosen specialty. They tackle the well known MMLU/MMMU issues with multiple choice benchmarks not being a good/stable measure for chat models.
Lastly we'll feature Jim Fan's thinking on the path forward for evals:

Table of Contents
[TOC]
AI Reddit Recap
Across r/LocalLlama, r/machinelearning, r/openai, r/stablediffusion, r/ArtificialInteligence, /r/LLMDevs, /r/Singularity. Comment crawling works now but has lots to improve!
AI Development and Capabilities
-
GPT-4 and beyond: In various talks and interviews, OpenAI CEO Sam Altman has referred to GPT-4 as "dumb" and "embarrassing," hinting at the imminent release of GPT-5, which is expected to be a substantial improvement. Altman believes AI agents that can assist users with tasks and access personal information will be the next big breakthrough, envisioning a "super-competent colleague" that knows everything about the user's life.
-
Jailbreaking GPT-3.5: A researcher demonstrated how to jailbreak GPT-3.5 using OpenAI's fine-tuning API, bypassing safety checks by training the model on a dataset of harmful questions and answers generated by an unrestricted LLM.
AI Regulation and Safety
-
Calls for banning AI weapons: World leaders are calling for a ban on AI-powered weapons and "killer robots," comparing the current moment in AI development to the "Oppenheimer moment" of the atomic bomb. However, some believe such a ban will be difficult to enforce.
-
Human control over nuclear weapons: A US official is urging China and Russia to declare that only humans, not AI, should control nuclear weapons, highlighting growing concerns over AI-controlled weapons systems.
AI Applications and Partnerships
-
Ukraine's AI consular avatar: Ukraine's Ministry of Foreign Affairs has announced an AI-powered avatar to provide updates on consular affairs, aiming to save time and resources for the agency.
-
Moderna and OpenAI partnership: Moderna and OpenAI have partnered to accelerate the development of life-saving treatments using AI, with the potential to revolutionize medicine.
-
Sanctuary AI and Microsoft collaboration: Sanctuary AI and Microsoft are collaborating to accelerate the development of AI for general-purpose robots, aiming to create more versatile and intelligent machines.
AI Research and Advancements
-
Kolmogorov-Arnold networks: MIT researchers have developed "Kolmogorov-Arnold networks" (KANs), a new type of neural network with learnable activation functions on edges instead of nodes, demonstrating improved accuracy, parameter efficiency, and interpretability compared to traditional MLPs.
-
Meta's Llama 3 models: Meta is training Llama 3 models with over 400 billion parameters, expected to be multi-modal, have longer context lengths, and potentially specialize in different domains.
-
mRNA cancer vaccine breakthrough: A new mRNA cancer vaccine technique using "onion-like" multi-lamellar RNA lipid particle aggregates has shown success in treating brain cancer in four human patients.
-
First prime editing therapy: The FDA has cleared Prime Medicine's IND for the first prime editing therapy, a novel gene editing technique with the potential to treat genetic diseases more precisely than existing methods.
-
AI-powered animal longevity studies: Olden Labs has introduced AI-powered smart cages that automate animal longevity studies, aiming to deliver low-cost, data-rich studies while improving animal welfare.
Memes and Humor
- Regulating AI meme: A humorous image depicts a person attempting to regulate AI by physically restraining a robot with a leash, poking fun at the challenges of AI governance.
{kind=link}
AI Twitter Recap
all recaps done by Claude 3 Opus, best of 4 runs. We are working on clustering and flow engineering with Haiku.
LLMs in Space and Efficient Inference
- Hardening LLMs for Space: @karpathy proposed hardening LLM code to pass NASA standards, making it safe to run in space. LLMs are well-suited with a fixed array of floats and bounded, well-defined dynamics. Sending LLM weights to space could allow them to "wake up" and interact with aliens.
- Efficient Inference with Groq: @awnihannun highlighted @GroqInc leading the way in reducing $/token for high quality LLMs. @virattt found Llama-3 70B on @GroqInc has best performance and pricing on benchmarks. @svpino encouraged trying Groq for huge model speed.
- 4-bit Quantization: @awnihannun calculated 4-bit 70B Llama-3 on M2 Ultra costs $0.2/million tokens, consuming 60W power. @teortaxesTex showed quantization levels of "external brain".
Evaluating and Improving LLMs
- Evaluating LLMs: @DrJimFan proposed 3 types of evals: private test sets with public scores by trusted 3rd parties like @scale_AI, public comparative benchmarks like @lmsysorg Chatbot Arena ELO, and private internal benchmarks for each company's use case.
- GSM1K Benchmark: @alexandr_wang and @scale_AI introduced GSM1K, a new test set showing up to 13% accuracy drops in LLMs, with Phi and Mistral overfitting. @SebastienBubeck noted phi-3-mini 76.3% accuracy as "pretty good for a 3.8B model".
- Inverse Scaling in Multimodal Models: @YiTayML observed inverse scaling being more prominent in multimodal vs text-only models, where smaller models outperform larger ones. Still anecdotal.
- Evaluating Reasoning: @omarsar0 shared a paper on interpreting the inner workings of transformer LMs for reasoning tasks.
Open Source Models and Frameworks
- Reka Releases Evals: @RekaAILabs released a subset of internal evals called Vibe-Eval, an open benchmark of 269 image-text prompts to measure multimodal chat progress. 50%+ prompts unsolved by any current model.
- LlamaIndex Typescript Release: @llama_index released LlamaIndex.TS v0.3 with agent support, web streams, typing, and deployment enhancements for Next.js, Deno, Cloudflare and more.
Emerging Models and Techniques
- Jamba Instruct from AI21: @AI21Labs released Jamba-Instruct based on SSM-Transformer Jamba architecture. Leads quality benchmarks, has 256K context, and competitive pricing.
- Nvidia's Llama Finetune: @rohanpaul_ai noted Nvidia's competitive Llama-3 70B finetune called ChatQA-1.5 with good benchmarks.
- Kolmogorov-Arnold Networks: @hardmaru shared a paper on KANs as alternatives to MLPs for approximating nonlinear functions. @rohanpaul_ai explained KANs use learnable spline activation functions vs fixed in MLPs.
- Meta's Multi-Token Prediction: @rohanpaul_ai broke down Meta's multi-token prediction for training LMs to predict multiple future tokens for higher sample efficiency and up to 3x inference speedup.
Industry Developments
- Anthropic's Claude iOS App: @AnthropicAI released the Claude iOS app, putting "frontier intelligence" in your pocket. @alexalbert__ shared how it helped launch tool use.
- Lamini AI Raises $25M Series A: @realSharonZhou announced @LaminiAI's $25M Series A to help enterprises develop in-house AI capabilities. Investors include @AndrewYNg, @karpathy, @saranormous and more.
- Google I/O May 14: @GoogleDeepMind announced Google I/O developer conference on May 14 featuring AI innovations and breakthroughs.
- Anthropic Introduces Claude Team Plan: @AnthropicAI released a new Team plan for Claude with increased usage, user management, billing, and a 200K context window.
Memes and Humor
- Meme: @DeepLearningAI shared a meme about AI from buildooors on Reddit.
AI Discord Recap
A summary of Summaries of Summaries
-
Model Advancements and Fine-Tuning:
- Increasing LoRA rank to 128 for Llama 3 to prioritize understanding over memorization, adding over 335M trainable parameters [Tweet]
- Exploring multi-GPU support for model training with Unsloth, currently limited to single GPU [GitHub Wiki]
- Releasing Llama-3 8B Instruct Gradient with RoPE theta adjustments for longer context handling [HuggingFace]
- Introducing Hermes 2 Pro based on Llama-3 architecture, outperforming Llama-3 8B on benchmarks like AGIEval [HuggingFace]
-
Hardware Optimization and Deployment:
- Discussions on optimal GPU choices for LLMs, considering PCIe bandwidth, VRAM requirements (ideally 24GB+), and performance across multiple GPUs
- Exploring local deployment options like RTX 4080 for smaller LLMs versus cloud solutions for privacy
- Optimizing VRAM usage during training by techniques like merging datasets without increasing context length
- Integrating DeepSpeed's ZeRO-3 with Flash Attention for efficient large model fine-tuning
-
Multimodal AI and Computer Vision:
- Introducing Motion-I2V for image-to-video generation with diffusion-based motion modeling [Paper]
- Sharing resources on PyTorch Lightning integration with models like SegFormer, Detectron, YOLOv5/8 [Docs]
- Accelerating diffusion models like Stable Diffusion XL by 3x using PyTorch 2 optimizations [Tutorial]
- Unveiling Google's Med-Gemini multimodal models for medical applications [Video]
-
Novel Neural Network Architectures:
- Proposing Kolmogorov-Arnold Networks (KANs) as interpretable alternatives to MLPs [Paper]
- Introducing Universal Physics Transformers for versatile simulations across datasets [Paper]
- Exploring VisualFactChecker (VFC) for high-fidelity image/3D object captioning without training [Paper]
- Sharing a binary vector representation approach for efficient unsupervised image patch encoding [Paper]
-
Misc:
-
Stable Diffusion Model Discussions and PC Builds: The Stability.ai community shared insights on various Stable Diffusion models like '4xNMKD-Siax_200k' from HuggingFace, and discussed optimal PC components for AI art generation like the 4070 RTX GPU. They also explored AI applications in logo design with models like harrlogos-xl.
-
LLaMA Context Extension Techniques: Across multiple communities, engineers discussed methods to extend the context window of LLaMA models, such as using the PoSE training method for 32k context or adjusting the rope theta. The RULER tool was mentioned for identifying actual context sizes in long-context models.
-
Quantization and Fine-Tuning Discussions: Quantization of LLMs was a common topic, with the Unsloth AI community increasing LoRA rank to 128 from 16 on Llama 3 to prioritize understanding over memorization. The OpenAccess AI Collective introduced Llama-3 8B Instruct Gradient with RoPE theta adjustments for minimal training on longer contexts (Llama-3 8B Gradient).
-
Retrieval-Augmented Generation (RAG) Techniques: Several communities explored RAG techniques for enhancing LLMs. A new tutorial series on RAG basics was shared (YouTube tutorial), and a paper on Adaptive RAG for dynamically selecting optimal strategies based on query complexity was discussed (YouTube overview). Plaban Nayak's guide on post-processing with a reranker to improve RAG accuracy was also highlighted.
-
Introducing New Models and Architectures: Various new models and architectures were announced, such as Hermes 2 Pro from Nous Research built on Llama-3 (Hermes 2 Pro), Snowflake Arctic 480B and FireLLaVA 13B from OpenRouter, and Kolmogorov-Arnold Networks (KANs) as alternatives to MLPs (KANs paper).
PART 1: High level Discord summaries
CUDA MODE Discord
CUDA Debugging Tips and Updates: Members exchanged insights on CUDA debugging, recommending resources such as a detailed Triton debugging lecture, and the importance of using the latest version of Triton, citing recent bug fixes in the interpreter.
CUDA Profiling Woes and Wisdom: Engineers grappled with inconsistent CUDA profiling results, suggesting the utilization of NVIDIA profiling tools like Nsight Compute/Systems over cudaEventRecord. A tinygrad patch for NVIDIA was shared, aiming to aid similar troubleshooting efforts.
Torch and PyTorch Prowess: Discussions mentioned the need for expertise in PyTorch internals, specifically ATen/linalg, while TorchInductor aficionados were pointed to a learning resource (though unspecified). A call went out to any PyTorch contributors for in-depth platform knowledge.
Advances in AI Model Training Constructs: Conversations in #llmdotc revealed a considerable volume of activity centered on model training. From FP32 master copy of params to CUDA Graphs, the talks included a range of technical challenges related to performance, precision, and complexity, coupled with links to various GitHub issues and pull requests for collaborative problem-solving.
Diving Deeper into Engineering Sparsity: Engineers mulled over the Effort Engine, debating its benchmark performances and the balance between speed and quality. Points of contemplation included parameter importance over precision, the quality trade-offs in weight pruning, and potential model improvements.
Forward-Thinking with AMD and Intel Tech: Enthusiasm was shown for AMD's HIP language with a tutorial playlist on the AMD ROCm platform, indicating a growing interest in diversified programming languages for GPUs. Additionally, a mention of Intel joining the PyTorch webpage suggested movement toward broader support across different architectures.
LM Studio Discord
CLI's New Frontier: The release of LM Studio 0.2.22 introduced a new command-line interface, lms, enabling functionalities such as loading/unloading LLMs and starting/stopping the local server, with development open for contributions on GitHub.
Tackling LLM Installation Chaos: Community discussions highlighted installation issues of LM Studio 0.2.22 Preview, which were surmounted by providing a corrected download link; meanwhile, users exchanged ideas on model performance improvements and quantization techniques, especially for the Llama 3 model.
Headless Operation Innovations: Members shared strategies for running LM Studio headlessly on systems without a graphical user interface, suggesting xvfb and other workarounds, creating a pathway for containerization possibilities like Docker.
ROCm and AMD Under the Lens: Conversations centered on the compatibility of different AMD GPUs with ROCm, alongside the challenges of ROCm's Linux support, highlighting the community's quest for efficient use of diverse hardware infrastructures.
Hardware Discourse Goes Deep: Discussions delved into the nitty-gritty of hardware choices, especially on suitable GPUs for running LLMs and the impact of PCIe 3.0 vs 4.0 on multi-GPU VRAM performance, culminating in a consensus that a minimum of 24GB VRAM is ideal for formidable models like Meta Llama 3 70B.
Stability.ai (Stable Diffusion) Discord
-
Stable Diffusion Gets an Upgrade: Discussions centered on the latest Stable Diffusion models such as 'Juggernaut X' and '4xNMKD-Siax_200k', with many users sourcing from HuggingFace for the 4xNMKD-Siax_200k model.
-
PC Build Recommendations for AI Workloads: Community members exchanged advice on the most suitable PC components for AI art creation, stressing the potential benefits of the upcoming Nvidia 5000 series and the current high-performing 4070 RTX GPU for running models efficiently.
-
AI Enters the Arena of Design: There was an in-depth conversation around using AI for logo design, highlighted by harrlogos-xl, which specializes in generating custom text within Stable Diffusion and touched on legal implications.
-
Tips on Upscaling and Inpainting for Enhanced Realism: The dialogue included tips on achieving higher image quality with upscale techniques LDSR, and sharing a Reddit guide on repurposing models for inpainting, though successes varied among users.
-
Securing Digital Artistic Endeavors with Open-Source Solutions: In the push for better security, some members recommended open-source alternatives like Aegis for Android and Raivo for iOS for one-time passwords (OTP), noting the importance of features, such as device syncing and secure backup options.
Unsloth AI (Daniel Han) Discord
-
LoRA Levels Up Llama 3: Engineers have been increasing LoRA rank on Llama 3 to 128 from 16, pushing trainable parameters past 335 million to prioritize understanding over rote memorization.
-
VRAM and Training Dynamics: Clarifications around VRAM usage in model training were made; merging datasets affects training time, not VRAM, unless it increases context length. Running Phi3 on Raspberry Pi was deemed feasible, with a successful instance of Gemma 2b running on an Orange Pi Zero 3.
-
Browsers Host Phi3: A Twitter post showcased Phi 3 running in a browser, sparking member interest. Meanwhile, Phi3 Mini 4k was flagged to outperform the 128k version on the Open LLM Leaderboard.
-
Fine-Tuning Finesse: Fine-tuning Llama 3 with Unsloth does not require ref_model in DPOTrainer; fine-tuning techniques and community collaboration were emphasized, and llama.cpp successfully deployed for a Discord bot.
-
Collaborative Coding Call: Members rallied for a designated collaboration channel leading to the creation of <#1235610265706565692> for project collaboration. The FlagEmbedding repository was shared for those interested in retrieval-augmented LLM work.
-
Improving AI Reasoning: To amplify task performance, an AI model was forced to memorize 39 reasoning modules from the Self-Discover paper, integrating advanced reasoning levels into tasks.
Nous Research AI Discord
-
Hermes 2 Pro: A New Model Champion: The introduction of Hermes 2 Pro by Nous Research, built on Llama-3 architecture, boasts superior performance on benchmarks like AGIEval and TruthfulQA when compared to Llama-3 8B Instruct. Its unique features include Function Calling and Structured Output capabilities, and it comes in both standard and quantized GGUF versions for enhanced efficiency, available on Hugging Face.
-
Exploring the Frontiers of Context Length: Research discussions revealed strategies to tackle out-of-distribution (OOD) issues for longer sequence contexts by normalizing outlier values, alongside arXiv:2401.01325 deemed influential for context length extension. Techniques from
llama.cpphighlight normalization approaches with debates concerning the efficacy of truncated attention to truly manifest "infinite" contexts. -
AI-Assisted Unreal Development and LLM Inquiries: Announcing the deployment of an AI assistant for Unreal Engine 5 on neuralgameworks.com, the guild also addressed the integration of GPT-4 vision in UE5 development. Questions around computational resources for AI research, such as access to A100 GPUs, were considered alongside tools and techniques for model training, like the Kolmogorov Arnold neural network's performance on CIFAR-10.
-
AI Orchestration and Prompt Structuring Insights: The shared orchestration framework MeeseeksAI makes waves among AI agents, while the knowledge base on prompt structuring grows with insights into using special tokens and guidance on generating certain output formats. Evidence of structured prompt benefits is exhibited in Hermes 2 Pro's approach to JSON output, detailed at Hugging Face.
-
Mining and Networking in AI Communities: Prospective finetuners of Large Language Models (LLMs) seek wisdom on suitable datasets, while WebSim's introduction of an expansive game spanning epochs promises updates that may reshape gaming experiences. The anticipation for testing environments like world-sim and ongoing discourse suggests community eagerness for collaborative developments and shared research pursuits.
Perplexity AI Discord
-
Opus Gains Buzz Over GPT-4 Amongst Techies: Technical discussions on Perplexity AI have compared the Claude Opus and GPT-4, noting a preference for Opus in maintaining conversation continuity and for GPT-4 regarding technical accuracy, despite a temporary daily limit of 50 uses on Opus.
-
New Pages Feature Ignites Creative Sparks: The Perplexity AI community is keen on the new Pages feature, chatting about its potential for transforming threads into formatted articles and hopes for future enhancements including image embedding.
-
AI Content Assistance A Hot Potato: Ranging from debates over drone challenges to the utility of AI in making food choices, links to Perplexity AI's insights were shared, with notable discussions on the proper consumption of raw pasta, DJI drones, and the Binance founder's legal woes, indicating a broad set of interests.
-
Bridge Building Between UI and API: The pplx-7b-online model yielded different results between Pro UI and API implementations, prompting users to seek an understanding of 'online models' and celebrate the addition of the Sonar Large model to the API, despite some material confusion over its parameter count.
-
Members Seek Solutions for Platform Gremlins: Users encountered bugs with Perplexity AI on browsers like Safari and Brave, along with issues in correctly citing from attachments, leading to shared troubleshooting methods and a collective look for fixes.
Note: For the detailed and latest updates on API offerings and models like Sonar Large, check the official documentation.
Eleuther Discord
-
Binary Brains Beat CNNs in Unsupervised Learning: Revolutionary research on binary vector representation for image patches suggests superior efficiency compared to supervised CNNs. The discussion, inspired by biological neural systems, spotlighted a repulsive force loss function for binary vectors, potentially mimicking neuron efficiency, as detailed in arXiv.
-
KANs Kickoff as MLP Rivals: The AI community is buzzing about Kolmogorov-Arnold Networks (KANs), which may offer interpretability improvements over MLPs. The conversation also tackled mode collapse in LLMs and the promise of Universal Physics Transformers, accompanied by a critique of GLUE test server anomalies and considerations of SwiGLU's unique scaling properties (KANs paper, Physics paper).
-
Interpreting the Uninterpretable: A rigorous dialogue explored the difficulties in articulating a model's "true underlying features", the role of tied embeddings in prediction models, and the definition of computation in next-token prediction. Celebrations were due for academic paper acceptances and the inception of the Mechanistic Interpretability Workshop at ICML 2024, with the community encouraged to contribute (workshop website).
-
MT-Bench: Mounting Expectation for Integration: A single yet significant request surfaced regarding the assimilation of MT-Bench into the lm-evaluation-harness, hinting at an eagerness for more rigorous conversational AI benchmarks.
OpenRouter (Alex Atallah) Discord
-
Introducing Snowflake Arctic & FireLLaVA: OpenRouter unveiled two disruptive models: the Snowflake Arctic 480B, excelling in coding and multilingual tasks at $2.16/M tokens, and FireLLaVA 13B, a rapid, open-source multimodal model with a cost of $0.2/M tokens. Both models represent significant strides in language and image processing; Arctic combines dense and MoE transformer architectures, while FireLLaVA is designed for speed and multimodal understanding, as detailed in their release post.
-
Maximizing Performance with Load Balancing: In response to high traffic demands, OpenRouter introduced enhanced load balancing features and now enables providers to track performance statistics such as latency and completion reasons on the Activity page.
-
LLaMA Context Expanding Tactics Revealed: Engineers examined strategies to extend LLaMA's context window, featuring the PoSE training method for 32k context using 8 A100 GPUs, and the adjustment of rope theta. The discussion touched on RULER, a tool used to identify actual context size in long-context models, which can be explored further on GitHub.
-
Google Gemini Pro 1.5 Scrutinized for NSFW Handling: The community critiqued Google Gemini Pro 1.5 for its abrupt curtailment of NSFW content and noted substantial changes post-update, which seemed to diminish the model's ability to follow instructions.
-
AI Deployment Risks & Corporate Influence Examined: The debates dived into the deployment of "orthogonalized" models, the implications of unaligned AI, and the political sway injected by model creators into their AIs. There was critical reflection on corporate budget allocations, evidenced by Google's Gemini project, which contrasted marketing expenditures against those for research and development.
OpenAI Discord
-
Music Descriptors and DALL-E Developments Hit High Note: Engineers sought a tool to describe music tracks, while others updated that DALL-E 3 is being improved without a yet-announced DALL-E 4. The Claude IOS app was praised for its human-like responses by a middle school teacher, and discussions on leveraging AI in education emerged.
-
Chatbot Benchmarks Spark Conversation: A vigorous debate took place over the utility of benchmarks in gauging chatbot abilities, revealing a divide between those who see benchmarks as a beneficial metric and those who argue they do not accurately reflect nuanced real-world use.
-
ChatGPT Plus: Big on Tokens, Small on Limits: Users exchanged insights on ChatGPT's token limit; with clarification that ChatGPT Plus has a 32k token limit, although the actual GPT supports up to 128k via the API. Skepticism was advised when considering ChatGPT's self-referential answers about its architecture or limits, despite a participant's experience sending texts exceeding the supposed 13k character limit.
-
Prompt Engineering Prodigy or Illusion?: The community deliberated on prompt engineering, with strategies like few-shot prompting with negative examples and meta-prompting thrown into the mix. The extraction of Ideal Customer Persona (ICP) from social media analytics using personal branding was also discussed, and the use of GPT-4-Vision coupled with OCR was shared as a method for extracting information from documents.
-
LLM Recall: Room for Improvement: Conversation centered on enhancing Long-Lived Memory (LLM) recall; members considered how context window limits affect platforms like ChatGPT Plus and contemplated over the combination of GPT-4-Vision with OCR for better data extraction, acknowledging the ongoing challenges with data retrieval from extensive texts.
HuggingFace Discord
-
Fashionable AI Pondering: In search of an AI that can manipulate images to show a shirt on a kid in multiple poses while maintaining logo position, community members discussed the potential of existing AI solutions but did not point to a specific tool.
-
Community Constructs Visionary Course: A newly launched, community-developed computer vision course open for contributions on GitHub has been met with enthusiasm, aiming to enrich the know-how in the realm of computer vision.
-
SDXL Inference Acceleration with PyTorch 2: A Hugging Face tutorial illustrates how to reduce the inference time of text-to-image diffusion models like Stable Diffusion XL by up to 3x, leveraging optimizations in PyTorch 2.
-
Google Unleashes Multimodal GenAI in Medicine: Med-Gemini, Google's multimodal GenAI model tailored for medical applications, was highlighted in a YouTube video, aiming to raise awareness about the model's capabilities and applications.
-
PyTorch Lightning Shines on Object Detection: A member sought examples of PyTorch Lightning for object detection evaluation and visualization, which led to the sharing of comprehensive tutorials on PyTorch Lightning integration with SegFormer, Detectron, YOLOv5, and YOLOv8.
-
RARR Clarification Sought in NLP: Queries were raised about the RARR process, an approach that investigates and revises language model outputs, although further discussion on its implementation amongst the community appeared limited.
LlamaIndex Discord
LlamaIndex 0.3 Heralds Enhanced Interoperability: Version 0.3 of LlamaIndex.TS introduces Agent support for ReAct, Anthropic, and OpenAI, a generic AgentRunner class, standardized Web Streams, and a bolstered type system detailed in their release tweet. The update also outlines compatibility with React 19, Deno, and Node 22.
AI Engineers, RAG Tutorial Awaits: A new tutorial series on Retrieval-Augmented Generation (RAG) by @nerdai progresses from basics to managing long-context RAG, accompanied by a YouTube tutorial and a GitHub notebook.
Llamacpp Faces Parallel Dilemmas: In Llamacpp, concerns have been voiced about deadlocks while processing parallel queries, stemming from the lack of continuous batching support on a CPU server. Sequential request processing is seen as a potential workaround.
Word Loom Proposes Language Exchange Framework: The Word Loom specification is proposed for separating code from natural language, enhancing both composability and mechanical comparisons, with an aim to be globalization-friendly, as outlined in the Word Loom update proposition.
Strategies for Smarter AI Deployments: Discussions highlighted the sufficiency of the RTX 4080's 16 GB VRAM for smaller LLMs operations, while privacy concerns have some users shifting towards local computation stations over cloud alternatives like Google Colab for fine-tuning language models. Additionally, integrating external APIs with QueryPipeline and techniques for post-processing with a reranker to improve RAG application accuracy emerged as strategic considerations.
Modular (Mojo 🔥) Discord
Mojo's Anniversary Dominates Discussions: The Mojo Bot community commemorated its 1-year anniversary with speculations about a significant update release tomorrow. There were fond reflections on the progress Mojo made, particularly enhancements in traits, references, and lifetimes.
Modular Updates Celebrated: Community contributions have shaped the latest Mojo 24.3 release, leading to positive evaluations of its integration in platforms like Ubuntu 24.04. Concurrently, MAX 24.3 was announced, showcasing advancements in AI pipeline integration through the Engine Extensibility API, enhancing developer experiences in managing low-latency, high-throughput inferences as detailed in the MAX Graph APIs documentation.
CHERI's Potential Game-Changer for Security: The CHERI architecture is touted to significantly reduce vulnerability exploits by 70%, according to discussions referencing a YouTube video and the Colocation Tutorial. Talk of its adoption hinted at the possibility of transforming operating system development, empowering Unix-style software development, and potentially rendering conventional security methods obsolete.
Evolving Language Design and Performance: AI engineers continue to digest and deliberate on Mojo's language design objectives, aspiring to infer lifetimes and mutability akin to Hylo and debating the merit and safety of pointers over references. Community members leveraged Mojo's atomic operations for multi-core processing, achieving 100M records processing in 3.8 seconds.
Educational Content Spreads Mojo and MAX Awareness: Enthusiasm for learning and promotion of Mojo and MAX is evident with shared content like a video with Chris Lattner discussing Mojo, referenced as "Tomorrow's High Performance Python," and a PyCon Lithuania talk promoting Python's synergy with the MAX platform.
OpenInterpreter Discord
Bridging the Gap for AI Vtubing: Two AI Vtuber resources are now available, with one kit needing just a few credentials for setup on GitHub - nike-ChatVRM, as announced on Twitter. The other, providing an offline and uncensored experience, is shared along with a YouTube demo and source code on GitHub - VtuberAI.
Speed Boost for Whisper RKNN Users: A Git branch is now available that provides up to a 250% speed boost for Whisper RKNN on SBC with Rockchip RK3588, which can be accessed at GitHub - rbrisita/01 at rknn.
Ngrok Domain Customization Steps Outlined: Someone detailed a process for ngrok domain configuration, including editing tunnel.py and using a specific command line addition, with a helpful resource at ngrok Cloud Edge Domains.
Solving Independent Streaks in Ollama Bot: Trouble arose with Ollama, hinting at quirky autonomous behavior without waiting for user prompts, yet specific steps for resolution were not provided.
Eager for OpenInterpreter: There was speculation about the roll-out timeline for the OpenInterpreter app, the seamless inclusion of multimodal capabilities, and a sharing of community-driven assistance on various technical aspects. Solutions such as using the --os flag with GPT-4 for Windows OS mode compatibility, and a cooperative spirit were highlighted in the discussions.
Latent Space Discord
-
Mamba Zooms into Focus: Interest in the Mamba model peaked with a Zoom meeting and mention of the comprehensive Mamba Deep Dive document, sparking discussions around selective copying as a recall test in Mamba and considerations of potential overfitting during finetuning.
-
Semantic Precision in Chunking: Participants discussed advanced text chunking approaches, with a focus on semantic chunking as a technique for document processing. This included mention of practical resources such as LlamaIndex's Semantic Chunker and LangChain.
-
Local LLMs? There's an App for That: Engineers debated running large language models (LLMs) on MacBooks, highlighting tools and applications for local operations like Llama3-8B-q8 and expressing interest in efficiency and performance.
-
AI Town Packs 300 Agents on a MacBook: An exciting project, AI Town with a World Editor was showcased, depicting 300 AI agents functioning smoothly on a MacBook M1 Max 64G, likened to a miniature Westworld.
-
OpenAI's Web Woes?: Feedback on OpenAI's website redesign sparked conversations about user experience issues, with engineers noting performance lag and visual glitches on the new OpenAI platform.
OpenAccess AI Collective (axolotl) Discord
Time to Mask Instruct Tags?: Engineers debated masking instruct tags during training to enhance ChatML performance, using a custom ChatML format, and considered the impact on model generation.
Llama-3 Leaps to 8B: Llama-3 8B Instruct Gradient is now available, featuring RoPE theta adjustments for improved context length handling, with discussions on its implementation and limitations at Llama-3 8B Gradient.
Axolotl Devs Patch Preprocessing Pain Points: A pull request was submitted to address a single-worker problem in the Orpo trainer and similarly in the TRL Trainer, allowing multithreading for speedier preprocessing, captured in PR #1583 on GitHub.
Python 3.10 Sets the Stage: A new baseline has been set within the community, where Python 3.10 is now the minimum version required for developing with Axolotl, enabling the use of latest language features.
Optimizing Training with ZeRO-3: Talks revolved around integrating DeepSpeed's ZeRO-3 and Flash Attention for finetuning to accelerate training, where ZeRO-3 optimizes memory without affecting quality, when appropriately deployed.
LAION Discord
-
AI's Role in Education Raises Eyebrows: A member highlighted potential dependence issues with AI use in education, suggesting that an over-reliance could impede learning crucial problem-solving skills.
-
From Still Frames to Motion Pictures: The Motion-I2V framework was introduced for converting images to videos via a two-step process incorporating diffusion-based motion predictors and augmenting temporal attention, detailed in the paper found here.
-
Promising Results with LLaMA3, Eager Eyes on Specialized Fine-tunes: A discussion ensued on LLaMA3's performance post-4bit quantization, with members expressing optimism about future fine-tunes in specific fields and anticipating further code releases from Meta.
-
Enhancing Model Quality Under Scrutiny: There was a request for advice on improving the MagVit2 VQ-VAE model, with potential solutions revolving around the integration of new loss functions.
-
Coding the Sound of Music: Technical difficulties in implementing the SoundStream codec were brought to the table, with members collaborating to interpret omitted details from the original paper and pointing to resources and possible meanings.
-
Project Timelines and Advances Debate: The community engaged in discussions around project deadlines, using phrases like "Soon TM" informally, and expressed curiosity about the configurations used in LAION's stockfish dataset.
-
Exploring Innovative Network Architectures: The guild touched upon novel network alternatives to MLPs with the introduction of Kolmogorov-Arnold Networks (KANs), which are highlighted in a research paper emphasizing their improved accuracy and interpretability.
-
Quality Captioning Sans Training: Distinctions were made regarding the VisualFactChecker (VFC), which is a training-free method for generating accurate visual content captions, and its implications for enhanced image and 3D object captioning as described in this paper.
AI Stack Devs (Yoko Li) Discord
- The Allure of AI in Nostalgic Gaming: Discussions have surfaced about leveraging AI in reviving classic social media games, taking the example of Farmville, and extending to the creation of a 1950s themed AI town with a communist spy intrigue.
- Hexagen World Recognized for Sharp AI Imagery: Users are praising Hexagen World for its high-quality diffusion model outputs, and have been discussing its platform's potential for hosting AI-driven games.
- Possible Tokenizer Bug in AI Chat: Technical issues with ollama and llama3 8b configurations in ai-town, resulting in odd messages and strings of numbers, have been tentatively attributed to a tokenizer fault.
- Linux for Gamers? A Viable Option!: Among members, there's talk about shifting from Windows to Linux with reassurances shared about gaming compatibility, such as Stellaris running smoothly on Mac and Linux, and advice to set up a dual boot system.
- Invitation to Explore AI Animation: A Discord invite to an AI animation server was shared, aiming to bring in individuals interested in the intersection of AI and animation techniques.
LangChain AI Discord
Groq, No Wait Required: Direct sign-up to Groq's AI services is confirmed through a provided link to Groq's console, eliminating waitlist concerns for those eager to tap into Groq's capabilities.
AI's Script Deviation Head-Scratcher: Strategies to mitigate AI veering off script in human-AI interaction projects are sought after, highlighting the need for maintaining conversational flow without looping responses.
Adaptive RAG Gains Traction: A new Adaptive RAG technique, which selects optimal strategies based on query complexity, is discussed alongside a YouTube video explaining the approach.
LangChain Luminaries Launch Updates and Tools: An improved LangChain v0.1.17, Word Loom's open spec, deployment of Langserve on GCP, and Pydantic-powered tool definitions for GPT showcase the community's breadth of innovation with available resources on GitHub for Word Loom, a LangChain chatbot, and a Pydantic tools repository.
Feedback Loop Frustration in LangServe: A member's experience with LangServe's feedback feature highlights the importance of clear communication channels when submitting feedback, even after a successful submission response; changes may not be immediate or noticeable.
tinygrad (George Hotz) Discord
tinygrad Tackles Conda Conundrum: The tinygrad environment faced hitches on M1 Macs due to an AssertionError linked to an invalid Metal library, with potential fixes on the horizon, as well as a bounty posted for a solution to conda python issues after system updates, with progress reported recently.
From Podcast to Practice: One member's interest in tinygrad spiked after a Lex Fridman podcast, leading to recommendations to dive into the tinygrad documentation on GitHub for further understanding and comparing it with PyTorch.
Hardware Head-Scratcher for tinygrad Enthusiasts: A member deliberated over the choice between an AMD XT board and a new Mac M3 for their tinygrad development rig, highlighting the significance of choosing the right hardware for optimal development.
Resolving MNIST Mysteries with Source Intervention: An incorrect 100% MNIST accuracy alert prompted a member to ditch the pip version and successfully compile tinygrad from source, solving the version discrepancy and underscoring the approachability of tinygrad's build process.
CUDA Clarifications and Symbolic Scrutiny: Questions bubbled up about CUDA usage in scripts impacting performance, while another member pondered the differentiation between RedNode and OpNode, and the presence of blobfile was affirmed to be crucial for loading tokenizer BPE in tinygrad's LLaMA example code.
Mozilla AI Discord
-
Matrix Multiplication Mysteries: A user was baffled by achieving 600 gflops with np.matmul while a blog post by Justine Tunney mentioned only 29 gflops, leading to discussions about various methods for calculating flops and their implications for performance measurement.
-
File Rename Outputs Inconsistent: When running a file renaming task using llamafile, outputs varied, suggesting discrepancies across versions of llamafile or their executions, with one output example mentioned as
een_baby_and_adult_monkey_together_in_the_image_with_the_baby_monkey_on.jpg. -
Llamafile on Budget Infrastructure: A member queried the guild about the most effective infrastructure for experimenting with llamafile, debating between services like vast.ai and colab pro plus given their limited resources at hand.
-
GEMM Function Tips for the Fast Lane: Advice was sought on boosting a generic matrix-matrix multiplication (GEMM) function in C++ to cross the 500 gflops mark, with discussions revolving around data alignment and microtile sizes, in light of numpy's capability to exceed 600 gflops.
-
Running Concurrent Llamafiles: It was shared that multiple instances of llamafile can be executed simultaneously on different ports, but it was emphasized that they will compete for system resources as managed by the operating system, rather than having a specialized management of resources between them.
Cohere Discord
-
Stockholm's LLM Scene Wants Company: An invitation is open for AI enthusiasts to meet in Stockholm to dive into LLM discussions over lunch, highlighting the community's collaborative spirit.
-
Cohere for Cozy Welcomes: The Discord guild actively fosters a welcoming atmosphere, with members like sssandra and co.elaine greeting newcomers with warmth.
-
Tune Into Text Compression Tips: An upcoming session focusing on Text Compression using LLMs was announced, reinforcing the guild's commitment to continuous learning and skill enhancement.
-
Navigating the API Maze: Users shared real-world challenges involving AI API integration and key activation issues, with some hands-on guidance from co.elaine, including referencing the Cohere documentation on preambles.
-
Unlocking Document Search Strategies: A user sought advice on constructing a document search system tuned to natural language querying, contemplating the application of document embeddings, summaries, and extraction of critical information.
Interconnects (Nathan Lambert) Discord
-
Ensemble Techniques Tackled Mode Collapse: Discussions emphasized the potential of ensemble reward models in Reinforcement Learning for AI alignment, as demonstrated by DeepMind's Sparrow, to mitigate mode collapse through techniques such as "Adversarial Probing" despite a KL penalty.
-
Llama 3's Method Mix Raises Eyebrows: The community pondered why Llama 3 employed both Proximal Policy Optimization (PPO) and Decentralized Proximal Policy Optimization (DPO), with the full technical rationale still under wraps, possibly due to data timescale constraints.
-
Bitnet Implementation Interrogated: Curiosity was stoked about the practical application of the Bitnet approach to training large models, with successful small-scale reproductions such as Bitnet-Llama-70M and updates from Agora on GitHub; discussions also suggested significant hardware investments are necessary for efficiency in large model training.
-
Specialized Hardware for Bitnet a Tough Nut to Crack: The necessity for specialized hardware for Bitnet to be efficient was illuminated, referencing the need for chips supporting 2-bit mixed precision and recalling IBM's historical efforts, alongside the hype around CUDA's recent fp6 kernel.
-
AI Drama Unfolds Over Model Origins: The community dissected a speculative tweet about the unauthorized release of a model resembling one created by Neel Nanda and Ashwinee Panda, with a slight against its legitimacy and a call for more testing or release of the model weights. The tweet in question is Teortaxes' tweet.
-
Anthropic Lights Up with Claude: Anthropic's release of their Claude app stirred the community, with anticipation for comparative reviews against OpenAI’s products, while member conversations expressed admiration for the company's branding.
-
A Pat on the Back for Performance Upticks: Positive feedback was given in acknowledgment of the notable improvement in performance by an individual post-critical review.
Alignment Lab AI Discord
Since there was only a single, non-technical message shared, which read "Hello," by user manojbh, there is no relevant technical discussion to summarize. Please provide messages that contain technical, detail-oriented content for a proper summary.
Datasette - LLM (@SimonW) Discord
Seeking a Language Model Janitor: Discussions highlighted the need for a Language Model capable of identifying and deleting numerous localmodels from a hard drive, underscoring a practical use case for AI in system maintenance and organization.
DiscoResearch Discord
-
Qdora's New Tactic for LLM Enhancement: A user brought attention to Qdora, a method that enables Large Language Models (LLMs) to learn additional skills while sidestepping catastrophic forgetting, building on earlier model expansion tactics.
-
LLaMA Pro-8.3B Adopts Block Expansion Strategy: Members discussed a block expansion research approach, which allows LLMs like LLaMA to evolve into more capable versions (e.g., CodeLLaMA) while retaining previously learned skills, marking a promising development in the field of AI.
AI21 Labs (Jamba) Discord
Jamba-Instruct Rolls Out: AI21 Labs announced the release of Jamba-Instruct, as per a tweet linked by a member. This could signal new developments in instruction-based AI models.
The Skunkworks AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The LLM Perf Enthusiasts AI Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
PART 2: Detailed by-Channel summaries and links
CUDA MODE ▷ #general (7 messages):
- Ban Hammer Strikes: A member successfully identified and banned an unauthorized user, highlighting the group's monitoring efficiency.
- CUDA Best Practices Shared: CUDA C++ Core Libraries best practices and techniques were shared, including a link to a Twitter post and slides via Google Drive, although the shared folder currently appears empty. See the tweet
- Autograd Hessian Discussion: A member initiated a discussion on whether the
torch.autograd.gradfunction's second derivative returns the diagonal of the Hessian matrix. It was clarified that with specific parameters likecreate_graph=Trueit would, while another member pointed out that it is actually a Hessian vector product. - Estimating the Hessian's Diagonal: A different technique to estimate the Hessian's diagonal involving randomness plus the Hessian vector product was mentioned, referencing an approach seen in a paper.
Link mentioned: CCCL - Google Drive: no description found
CUDA MODE ▷ #triton (11 messages🔥):
-
Seeking Triton Debugging Wisdom: A member sought advice on the best approach to debug Triton kernels, expressing difficulties using
TRITON_INTERPRET=1anddevice_print, withTRITON_INTERPRET=1not allowing normal program execution anddevice_printyielding repetitive results. The best debugging practices were discussed, including watching a detailed Triton debugging lecture on YouTube and ensuring that they have the latest Triton version by installing from source or using triton-nightly. -
Triton Development Insights Shared: In the course of the discussion, it was suggested to ensure Triton is up-to-date due to recent fixes in the interpreter bugs. However, there is no confirmed date for the next release beyond the current 2.3 version.
-
Troubleshooting Gather Procedure in Triton: A newcomer to Triton presented an issue with implementing a simple gather procedure, specifically encountering an
IncompatibleTypeErrorImplwhen executing a store-load sequence. The desire to use Python breakpoints inside Triton kernel code for debugging was also mentioned, with difficulties in getting them to trigger.
Link mentioned: Lecture 14: Practitioners Guide to Triton: https://github.com/cuda-mode/lectures/tree/main/lecture%2014
CUDA MODE ▷ #cuda (14 messages🔥):
-
CUDA Profiling Puzzlement: A member discussed difficulties with inconsistent timing reports when profiling CUDA kernels using
cudaEventRecord. They observed unexpected timing results when adjusting tile sizes in a matrix multiplication kernel and questioned the robustness of the timing mechanism. -
NVIDIA Tools to the Rescue: In response to profiling concerns, a suggestion was made to try NVIDIA profiling tools like Nsight Compute or Nsight System, which are specifically designed for such tasks.
-
Discrepancies in Profiling Data: The member continued to note discrepancies between timings reported by
cudaEventRecordand theDurationfield in the NCU (Nsight Compute) report. It was clarified that profiling itself incurs overhead, potentially affecting the captured timings. -
Nsight Systems as an Alternative: A further recommendation was made to use Nsight Systems, which handles profiling without the explicit use of
cudaEventRecord. -
Sharing Solutions for Tinygrad on NVIDIA: A post was shared regarding a tinygrad patch for the NVIDIA open driver, documenting issues and solutions encountered during installation, potentially aiding others with similar issues.
CUDA MODE ▷ #torch (3 messages):
- Learning Opportunity for TorchInductor Enthusiasts: A member encouraged those interested in learning more about TorchInductor to check out an unspecified resource.
- Seeking PyTorch Contributor Insight: A user requested to connect with any PyTorch contributors with knowledge of the platform's internals.
- In Search of ATen/linalg Experts: The same user further specified a need for expertise in ATen/linalg, a component of PyTorch.
CUDA MODE ▷ #algorithms (11 messages🔥):
- Effort Engine Discussion Unfolds: The creator of Effort Engine joined the chat, teased about an upcoming article, and indicated that despite new benchmarks, effort/bucketMul is inferior to quantization in terms of speed/quality.
- Quality Over Quantity: It was noted that Effort Engine's method shows less quality degradation when compared to pruning the smallest weights, and charts are promised for visual comparison.
- Understanding Sparse Matrices: A comparison was shared contrasting the removal of least important weights from a matrix versus skipping the least important calculations, commencing a deeper dive into the subject of sparsity.
- Matrix Dimensions Matter: A discrepancy in matrix/vector dimensions was pointed out and acknowledged, with a commitment to rectify the vector orientation errors mentioned in the documentation.
- Exploration of Parameter Importance Over Precision: A member reflects on Effort Engine and recent advances suggesting that the number of parameters in AI models might be more important than their precision, citing examples such as quantization to 1.58 bits.
CUDA MODE ▷ #cool-links (2 messages):
- Exploring Speed Enhancements: A member mentioned that random_string_of_character is currently very slow, expressing curiosity about potential methods to accelerate its performance.
CUDA MODE ▷ #beginner (2 messages):
- Seeking CUDA Code Feedback: A member inquired if there is a dedicated channel or individuals available for feedback on their CUDA code. Another member directed them to post in a specific channel identified by its ID (<#1189607726595194971>) where such discussions are encouraged.
CUDA MODE ▷ #youtube-recordings (1 messages):
- Request for Taylor Robie's Scripts on Lightning: A member expressed interest in having Taylor Robie upload his scripts as a studio to Lightning for the benefit of beginners. There was a suggestion that this could be a helpful resource.
CUDA MODE ▷ #torchao (1 messages):
- FP6 datatype welcomes CUDA enthusiasts: An announcement about new fp6 support was shared with a link to the GitHub issue (FP6 dtype! · Issue #208 · pytorch/ao). Those interested in developing a custom CUDA extension for this feature were invited to collaborate and offered support to get started.
Link mentioned: FP6 dtype! · Issue #208 · pytorch/ao: 🚀 The feature, motivation and pitch https://arxiv.org/abs/2401.14112 I think you guys are really going to like this. The deepspeed developers introduce FP6 datatype on cards without fp8 support, wh.....
CUDA MODE ▷ #off-topic (2 messages):
- Creating Karpathy-style Explainer Videos: A member seeks advice on creating explainer videos following the style of Andrej Karpathy, particularly combining a live screen share with a face cam overlay. They provided a YouTube video link to illustrate, showing Karpathy building a GPT Tokenizer.
- OBS Streamlabs Recommended for Video Creation: In response to the inquiry on making explainer videos, a member recommended using OBS Streamlabs, highlighting the availability of numerous tutorials for it.
Link mentioned: Let's build the GPT Tokenizer: The Tokenizer is a necessary and pervasive component of Large Language Models (LLMs), where it translates between strings and tokens (text chunks). Tokenizer...
CUDA MODE ▷ #triton-puzzles (2 messages):
- Confusion Over Problem Information: A member mentioned that the problem description contains contradictory details, assuming that N0 = T led to avoiding conflicting information.
- Acknowledgment of Error in Problem Description: It was acknowledged that the problem description was incorrect, and a member confirmed an update would be released with a clearer version.
CUDA MODE ▷ #llmdotc (813 messages🔥🔥🔥):
<ul>
<li><strong>Master Params Mayhem</strong>: A recent merge enabling FP32 master copy of params by default disrupted expected model behavior, causing significant loss mismatches.</li>
<li><strong>Stochastic Rounding to the Rescue</strong>: Tests showed that incorporating stochastic rounding during parameter updates aligns results more closely with expected behavior.</li>
<li><strong>CUDA Concerns</strong>: Discussion raised around the substantial size and compilation time of cuDNN and possible optimizations for better usability within the llm.c project.</li>
<li><strong>CUDA Graphs Glow Dimly</strong>: CUDA Graphs, which improve kernel launch overhead, were briefly mentioned as a possible performance booster, but current GPU idle times imply limited benefits.</li>
<li><strong>Aiming for NASA Level C Code?🚀</strong>: Ideation around improving llm.c code to potentially meet safety-critical standards, with a side dream of LLMs in space and discussions on optimizing for more significant model sizes.</li>
</ul>
Links mentioned:
CUDA MODE ▷ #rocm (2 messages):
- Expressing Enthusiasm: A participant indicated strong interest with a brief message "super interesting".
- AMD HIP Tutorial Compilation: A YouTube playlist was shared, titled "AMD HIP Tutorial," providing a series of instructional videos on programming AMD GPUs with the HIP language on the AMD ROCm platform.
Link mentioned: AMD HIP Tutorial: In this series of videos, we will teach how to use the HIP programming language to program AMD GPUs running on the AMD ROCm platform. This set of videos is a...
CUDA MODE ▷ #oneapi (1 messages):
neurondeep: also added intel on pytorch webpage
LM Studio ▷ #💬-general (240 messages🔥🔥):
-
Command Line Interface Arrives: Members enthusiastically discussed the release of LM Studio 0.2.22, which introduces command line functionality with a focus on server mode operations. Issues and solutions for running the app in headless mode without a GUI on Linux machines were a key topic, with members actively troubleshooting and sharing advice (LM Studio CLI setup).
-
Flash Attention Sparks Intrigue: There were several discussions about Flash Attention at 32k context, highlighting its ability to allegedly improve processing speed by 3 times for document analysis with long contexts. This upgrade is poised to revolutionize interactions with large text blocks, like books.
-
Beta Testing Invites Sent: Users shared excitement over the latest beta build for LM Studio 0.2.22 and discussed the potential for community feedback to influence development. Mentioned were pull requests on llama.cpp that are relevant to the updates.
-
Headless Mode Workarounds and Hacks: Various members brainstormed workarounds for running LM Studio in a headless state on systems without a graphical user interface, suggesting methods like using a virtual X server or utilizing
xvfb-runto avoid display-related errors. -
Helpful YouTubing Advice: When asked about adding voice to read generated text, one member pointed to sillytavern or external solutions utilizing xtts, suggesting that tutorials are available on YouTube for implementation guidance.
Links mentioned:
LM Studio ▷ #🤖-models-discussion-chat (159 messages🔥🔥):
-
Exploring LLAMA's Bible Knowledge: A member expressed curiosity about how well LLAMA 3 model can recite known texts like the Bible. They shared an experiment to graph the model's recall of Genesis and John, revealing a poor recall rate for Genesis and only a 10% correct recall for John.
-
Quality Matters for Storytelling AI: One member discussed the importance of "quality" for story writing with AI, stating a preference for Goliath 120B Q3KS for better prose over faster models like LLAMA 3 8B. They emphasized that while they have high standards, no AI is perfect, and human rewriting is still essential.
-
The Right Tool for Biblical Recall: In response to the Bible recall rate test, another member mentioned trying the CMDR+ model, which seemed to handle the task better than LLAMA 3. It showed strong recall for specific biblical passages.
-
Technical Discussions on AI Model Quantization: There was a technical exchange about GGUF models and the process of quantization, with users sharing insights and seeking advice on techniques to quantize models like Gemma.
-
Exploring Agents and AutoGPT: A conversation about the potential of "agents" and AutoGPT took place, discussing the ability to create multiple AI instances that communicate with one another to optimize outputs. However, no consensus was reached on their effectiveness compared to larger models.
-
LLAMA's Vision Abilities Questioned: Members discussed the capabilities of LLAMA models with vision, comparing LLAMA 3 with other models and mentioning LLAVA's ability to understand but not generate images. There were also queries about the best text-to-speech (TTS) models, with a nod to Coqui still being on top.
Links mentioned:
LM Studio ▷ #announcements (1 messages):
- LM Studio Gets a CLI Companion: LM Studio introduces its command-line interface,
lms, featuring capabilities to load/unload LLMs and start/stop the local server. Interested parties can installlmsby runningnpx lmstudio install-cliand ensure they update to LM Studio 0.2.22 to use it. - Streamline Workflow Debugging: Developers can now use
lms log streamto debug their workflows more effectively with the newlmstool. - Join the Open Source Effort:
lmsis MIT licensed and available on GitHub for community contributions. The team encourages developers to smash that ⭐️ button and engage in discussions in the #dev-chat channel. - Pre-requisites for Installation: A reminder was given that users need to have NodeJS installed before attempting to install
lms, with installation steps available on the GitHub repository.
Link mentioned: GitHub - lmstudio-ai/lms: LM Studio in your terminal: LM Studio in your terminal. Contribute to lmstudio-ai/lms development by creating an account on GitHub.
LM Studio ▷ #🧠-feedback (4 messages):
- Respect for Different Projects: A member pointed out that expressing preference for one project doesn’t equate to disparaging another, emphasizing that both can be great and there’s no value in trashing other projects.
- Strawberry vs Chocolate Milk Analogy: In an attempt to illustrate that a preference doesn’t imply criticism of the alternatives, a member compared their liking for LM Studio over Ollama to preferring strawberry milk over chocolate, without trashing the latter.
- Standing Firm on Opinions: Another member reaffirmed their stance by recognizing the worth of other programs but maintaining a personal preference for LM Studio, indicating that this shouldn't be seen as attacking the other project.
LM Studio ▷ #⚙-configs-discussion (3 messages):
- Restoring Configs to Defaults: A member needed to reset the config presets for llama 3 and phi-3 after an update to version 22. Another member advised deleting the configs folder to repopulate it with the default configurations upon the next app launch.
LM Studio ▷ #🎛-hardware-discussion (247 messages🔥🔥):
-
RAM Speeds and CPU Compatibility: Members discussed RAM speed limitations based on CPU compatibility, specifically mentioning that E5-2600 v4 CPUs support faster RAM than 2400MHz. However, the specific capabilities of different Intel Xeon processors were examined, with links to Intel's official specifications provided to clarify.
-
Choosing GPUs for LLM: Participants talked about the optimal GPU choices for running language models, debating between models such as P100s and P40s, and K40's lower compatibility with certain backends. Tesla P40's performance was appraised through a Reddit post, and concerns were raised about second-hand market supply and shipping times from China for desired GPU models.
-
NVLink and SLI: Users clarified that while SLI is not a feature for enterprise GPUs, NVLink bridges can be used, however, the physical layout of the P100 might inhibit easy connection of NVLink bridges due to shroud design.
-
PCIe Bandwidth and Card Performance: Discussions occurred about PCIe 3.0 versus 4.0 bandwidth and how it impacts VRAM performance across multiple GPUs. Real-world performance drop was noted when incorporating Gen 3 cards into a system heavily utilizing Gen 4 cards.
-
VRAM Requirements for LLMs: There was a back-and-forth about the amount of VRAM required to efficiently run models, such as Meta Llama 3 70B, with the consensus being that a minimum of 24GB VRAM is ideal. The recommendation was to use GPUs with full offloading capabilities for the best speed, with 70B models still proving challenging for even 24GB cards, while 7/8B models are comfortably runnable across the board.
Links mentioned:
LM Studio ▷ #🧪-beta-releases-chat (152 messages🔥🔥):
-
Chaos in 0.2.22 Preview Installation: Users experienced issues when installing LM Studio 0.2.22 Preview, with downloads leading to version 0.2.21 instead. After several updates and checks by community members, a fresh download link was shared which resolved the version discrepancy.
-
In Search of Improved Llama 3 Performance: Participants discussed ongoing issues with the Llama 3 model, especially GGUF versions, underperforming on reasoning tasks. It was recommended to use the latest quantizations that incorporate recent changes to the base llama.cpp.
-
Quantization Quandaries and Contributions: Users shared GGUF quantized models and debated over the discrepancy in performance across different Llama 3 GGUFs. Bartowski1182 confirmed that 8b models were on latest quants, and was in the process of updating the 70b models.
-
Server Troubles Spotted in 0.2.22: One user flagged potential server issues on LM Studio 0.2.22, with odd prompts being added to each server request and suggested using the
lms log streamutility for an accurate diagnosis. -
Cross-Compatibility and Headless Operation: A conversation on how to run LM Studio on Ubuntu was concluded with simple installation steps, and there was excitement about the possibility of creating a Docker image thanks to headless operation capability.
Links mentioned:
LM Studio ▷ #amd-rocm-tech-preview (25 messages🔥):
- Curiosity About LM Studio and OpenCL: A member mentioned surprise upon discovering that LM Studio can utilize OpenCL, although they noted it is slow. This underscores a general interest in alternative compute backends for machine learning software.
- ROCm Compatibility Quandaries: Members discussed the compatibility of ROCm with various AMD GPUs, specifically the 6600 and 6700 XT models. For instance, a member shared that their 6600 does not appear to be supported by ROCm, as evidenced by the official AMD ROCm documentation.
- Lack of Linux Support for ROCm Build: A direct question about the availability of a ROCm build for Linux led to the revelation that there currently is no such build specifically for Linux. Participants were seeking alternatives for utilizing their AMD hardware efficiently.
- Comparing GPU Prices Across Regions: The conversation took a lighter turn as members considered international travel to the UK to procure an AMD 7900XTX GPU at a significantly lower price compared to local costs, revealing the impact of regional pricing variances on consumer decisions.
- New CLI Tool for LM Studio ROCm Preview: A detailed announcement introduced
lms, a new CLI tool designed to assist with managing LLMs, debugging workflows, and interacting with the local server for LM Studio users with the ROCm Preview Beta. The information included a link to LM Studio 0.2.22 ROCm Preview and the lms GitHub repository, encouraging community involvement and contributions.
Links mentioned:
LM Studio ▷ #🛠-dev-chat (4 messages):
-
Sneak Peek at LM Studio CLI: @LMStudioAI tweets about the new
lmscommand-line interface (CLI), which offers functionalities like loading/unloading of LLMs and starting/stopping a local server. It requires LM Studio 0.2.22 or newer and the code is MIT licensed and available on GitHub. -
LM Studio Goes Terminal: The
lmsCLI tool is capable of debugging workflows vialms log streamand is easily installable withnpx lmstudio install-cli. -
Headless Tutorial for LM Studio: A user provides a tutorial to run LM Studio (version 0.2.22) in a headless environment using
xvfb, as well as steps to install and use the newlmsCLI tool after the setup.
Links mentioned:
Stability.ai (Stable Diffusion) ▷ #general-chat (766 messages🔥🔥🔥):
-
Stable Diffusion Enthusiasts Sharing Insights: Users exchanged tips on various Stable Diffusion models and implementations, discussing the performance of different checkpoints like 'Juggernaut X' and '4xNMKD-Siax_200k'. Some recommended HuggingFace as a source for the latter model.
-
PC Upgrade Advices for AI Art: Members discussed ideal PC components for AI image generation like a 4070 RTX GPU, with suggestions leaning towards waiting for the Nvidia 5000 series announcement. Concerns related to running Stable Diffusion effectively and efficiently on different hardware configurations were a common theme.
-
Practical AI Art & Design with Logo Focus: The community had a robust conversation regarding AI's applications in logo design, with a specific model, harrlogos-xl, being referenced for creating custom text in Stable Diffusion. Discussions also touched on legal considerations and recommendations for using AI to support creative work.
-
AI Upscaling and Inpainting Queries: Users sought advice on upscale techniques like LDSR and tools for photorealism. A Reddit post was linked on how to convert any model into an inpainting model, though some users reported mixed results.
-
Exploration of Software for Two-Factor Authentication: Several members recommended various open-source software alternatives to Google Auth and Authy for one-time passwords (OTP), such as Aegis for Android and Raivo for iOS, with discussion about features like backup and syncing across devices.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #general (512 messages🔥🔥🔥):
-
Finetuning and Parameter Adjustment: Members are discussing various approaches to fine-tuning LLMs, specifically Llama 3. One discussed increasing the LoRA rank to 128 from 16 to avoid the AI memorizing information instead of understanding it, reporting a substantial increase in trainable parameters to over 335 million.
-
Exploring Multi-GPU Support: Conversations focused on optimizing VRAM usage during model training, highlighting Unsloth's limitations to single GPU use currently, but noting that multi-GPU support is in development, although no timeline was provided.
-
Interface Generation via Prompts: A member is working on a project to generate wireframes for applications using textual descriptions of mobile UI screens. They are finetuning a model to improve the quality of generated UI wireframes.
-
Llama 3 with Extended Context: Discussions included how to extend context window sizes for models, especially Llama 3, to match or exceed GPT-4 and others in the field. Unsloth was mentioned to allow 4x longer contexts through fine-tuning but does require additional VRAM.
-
Utilizing Llama Factory for Training: A suggestion was made to use Llama Factory to potentially overcome some of Unsloth's limitations, specifically the inability to utilize multi-GPU configurations. However, this suggestion is put forward without official testing or integration into the Unsloth package.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #random (17 messages🔥):
- Phi3 Mini Scores over 128k: A mention was made that on the Open LLM Leaderboard, Phi3 Mini 4k outperforms the 128k version, suggesting the Mini could be a better choice.
- Mistral-fied Phi3 Confined: A user confirmed that Mistral-fied Phi3 will only work on their variant of Phi, indicating a customized or modified application of the model.
- Running Models on Modest Hardware: Discussion touched upon the feasibility of running Phi-3 on a Raspberry Pi or Orange Pi, with a user sharing their experience of Gemma 2b running slightly fast on an Orange Pi Zero 3.
- Models in Browsers: There was a share of a Twitter post showing someone running Phi 3 within a browser, which amused the members.
- Improving Reasoning with AI Models: A member described a method to enhance task performance by forcing ChatGPT to memorize 39 reasoning modules from a Self-Discover paper, using them for diverse levels of reasoning on tasks. The paper was linked for reference: Self-Discover.
Unsloth AI (Daniel Han) ▷ #help (139 messages🔥🔥):
-
Discord Welcome Warmth: Users are greeted with enthusiasm upon joining the chat, with members expressing gratitude for help provided by the community and welcoming newcomers.
-
Llama-CPP in Action: A member shared successful deployment of the Unsloth AI using llama.cpp, hooking it up to a Discord bot. The server command used was
./server --chat-template llama3 -m ~/Downloads/model-unsloth.Q5_K_M.gguf --port 8081. -
Clarification on Fine-Tuning and Checkpointing: Inquiry about fine-tuning methods led to a clarification that ref_model isn't needed in DPOTrainer, and checkpointing along with progress saving was discussed with GitHub links provided for guidance.
-
Explanation of Adapter Issues and Kaggle Training Challenges: Users discussed errors related to model adapters, sharing solutions that involved removing certain lines from configs that appeared to be version mismatches.
-
Deployment Dilemmas and Recommendations: Users pondered over the possibility of serverless deployment for fine-tuned models while sharing experiences and suggestions for deployment providers and examples using Unsloth AI.
Links mentioned:
Unsloth AI (Daniel Han) ▷ #showcase (35 messages🔥):
- Collaboration Channel Proposal: A suggestion was made to create a channel for members to collaborate and code together, drawing inspiration from the EleutherAI Discord setup.
- Discussion on Channel Functionality: Members discussed whether to repurpose an existing channel or create a new one, pondering on the best use for the #community-projects versus a #collab-projects channel.
- Consensus on Channel Naming: There was debate over the most appropriate and descriptive name for the new collaboration channel, with members inclined towards names that clearly indicate the channel's purpose.
- Channel Creation Accomplished: A new channel named <#1235610265706565692> was created to facilitate community collaboration on projects, announced with encouragement for members to post their work and seek collaborators.
- Conversation about Specific Use-Cases: A member inquired about fine-tuning and retraining projects, discussing the application of models like LLAMA 3 7B for specific use cases, such as coding Solidity smart contracts.
Unsloth AI (Daniel Han) ▷ #suggestions (11 messages🔥):
- VRAM Confusion Cleared Up: Discussed whether merging datasets for training increases VRAM usage; it was clarified that merging might lead to longer training time but not necessarily higher VRAM usage unless data concatenation occurs, which could increase context length.
- Dataset Fit for Fine-Tuning: Inquiry about the feasibility of fine-tuning Mistral 7B with 16GB of VRAM on lmsys-chat-1m dataset, despite the fact that accessing the dataset requires contact information.
- Training Time vs Colab Constraints: A member confirmed the possibility of fine-tuning large datasets like lmsys-chat-1m with ample VRAM, but noted the impracticality of using Colab due to time restrictions and suggested using curation for efficiency.
- Creating a Simple Roadmap: A request was made to write a simple roadmap to outline future plans, following a specific question from another channel.
- Retrieval and Augmented LLMs Resource Shared: A member shared a link to FlagEmbedding, a GitHub repository focusing on retrieval and retrieval-augmented LLMs, as a potentially useful resource. See FlagEmbedding on GitHub.
Links mentioned:
Nous Research AI ▷ #ctx-length-research (25 messages🔥):
- Addressing Positional OOD Issues for Longer Contexts: A member highlighted a solution to the out-of-distribution (OOD) problems with long sequence contexts, emphasizing its potential to improve generalization. The approach involves normalizing outlier values to maintain good performance.
- Potential Breakthrough in Context Length Extension: The paper mentioned is considered "slept-on" but could have significant implications for context length extension in machine learning. It can be found at arXiv:2401.01325.
- Normalization Technique Showcased in llama.cpp: In relation to context length enhancements, a member referenced the
llama.cpprepository with a reference implementation that demonstrates the normalization technique using certain parameters. The implementation can be explored here on GitHub. - Debate Over Truncated Attention and "Infinite" Context: There was a discussion around the balance between preventing OOD issues and enhancing models' context capabilities. A concern was raised that some methods claiming to provide "infinite" context are in fact reducing the long context capabilities of models.
- Uncovering Parallel Research on Rotary Position Embeddings (ReRoPE): The conversation mentioned an apparent similarity or potential overlap between a newly discussed paper and the ReRoPE method, which could imply independent discovery or issues with plagiarism. More information on ReRoPE can be found here on GitHub, a project attributed to the original Rotary Position Embeddings (RoPE) author Su.
Links mentioned:
Nous Research AI ▷ #off-topic (20 messages🔥):
-
Revolutionizing Game Development: night_w0lf announces the launch of a new RAG-based AI assistant for Unreal Engine 5, calling for feedback especially from users within the community. The assistant promises to streamline the development workflow and is available at neuralgameworks.com.
-
Replit Bounties for Collaborative Projects: night_w0lf shared a link to Replit's bounties, which allows creators to collaborate and bring ideas to life, although there's no specific bounty for the context mentioned in prior messages.
-
GPT-4 Vision in Game Development: orabazes discusses their use of GPT-4 vision for UE5 development, stating it provides a visual guide alongside text queries and has proved particularly effective for editing blueprints in the engine.
-
Seeking Compute Resources for AI Research: yxzwayne inquires about grants or computing resources such as access to A100 GPUs to further their data generation and evaluation projects, indicating that using an M2 Max chip is limiting.
-
Challenge with Kolmogorov Arnold Neural Network: sumo43 expresses frustration with the Kolmogorov Arnold neural network's performance on CIFAR-10, comparing it unfavorably to a Multilayer Perceptron due to a high loss rate.
Links mentioned:
Nous Research AI ▷ #interesting-links (8 messages🔥):
- Exploring Kolmogorov Arnold Networks: The GitHub repository KindXiaoming/pykan introduces Kolmogorov Arnold Networks, opening a space for contribution and development of this concept.
- HybridAGI Joins the AGI Race: A newly shared GitHub project named SynaLinks/HybridAGI promises a Programmable Neuro-Symbolic AGI that allows behavior programming through Graph-based Prompt Programming.
- Elevated AI Performance with DPO+NLL: A discussion highlighted the use of DPO+NLL instead of just DPO as a major contributor to improved performance in an unspecified context, sparking validation and inquiries about dataset sharing.
- Tenyx Introduces Llama3-70B Model: Romaincosentino shared a new fine-tuned Llama3-70B model, boasting state-of-the-art results on GSM8K and competitive performance against GPT-4 on various benchmarks.
- Anticipation Over GPT-News: A tweet by @predict_addict is shared without context, but it appears to relate to anticipation over news or developments concerning GPT models; the specific content of the tweet remains unspecified in the channel.
Links mentioned:
Nous Research AI ▷ #announcements (1 messages):
<ul>
<li><strong>Hermes 2 Pro Debuts on Llama-3 8B</strong>: Nous Research introduces <strong>Hermes 2 Pro</strong>, their first model based on Llama-3 architecture, available on HuggingFace. It outperforms Llama-3 8B Instruct on several benchmarks including AGIEval and TruthfulQA. <a href="https://huggingface.co/NousResearch/Hermes-2-Pro-Llama-3-8B">Explore Hermes 2 Pro</a>.</li>
<li><strong>New Capabilities & Structured Output</strong>: Hermes 2 Pro brings Function Calling and Structured Output capabilities, using dedicated tokens to simplify streaming function calls. The model also shows improvements in function calling evaluation and structured JSON output metrics.</li>
<li><strong>Quantized Model Versions Are Available</strong>: For those interested in optimized models, GGUF quantized versions of Hermes 2 Pro can be accessed, providing a more efficient alternative. <a href="https://huggingface.co/NousResearch/Hermes-2-Pro-Llama-3-8B-GGUF">Check out the quantized version of Hermes 2 Pro</a>.</li>
<li><strong>Team Effort Recognized</strong>: The development of Hermes Pro models is credited to the collaborative work of several contributors, alongside those customizing tools to support the models' unique prompt formatting needs.</li>
<li><strong>Social Media Updates</strong>: You can follow along with Nous Research's updates and announcements regarding Hermes 2 Pro via their <a href="https://twitter.com/NousResearch/status/1785779313826308096">Twitter post</a>.</li>
</ul>
Links mentioned:
Nous Research AI ▷ #general (441 messages🔥🔥🔥):
-
Mermaid Graph for Agent Orchestration: An orchestration framework called MeeseeksAI for AI agents, resembling CrewAI's functionality, has been introduced. It leverages Claude to generate execution graphs which direct agent interactions, currently with predefined agents akin to tools (MeeseeksAI on GitHub).
-
Mindful of Function Calling: The community discussed the function of "Function Calling" in large language models (LLMs), noting it's designed to use external functions/tools for validation instead of generating assumptions. A dataset example, Glaive Function Calling V2, was shared for those interested in implementing function calling (Glaive Function Calling V2).
-
Curiosities about Knowledge and Algorithms in LLMs: Discussion emerged on how well LLMs maintain knowledge from one dataset to the next, addressing potential overfitting and the concept that "unlearning" may occur during successive supervised fine-tuning. Some members noted the need to explore various fine-tuning techniques and dataset combinations beyond sequential supervised fine-tuning.
-
New Model Merging Tools: A new method for merging pretrained large language models, "mergekit," has been released by arcee-ai, aiming to combine the strengths of different models (Mergekit GitHub).
-
Exploration and Insights into Model Scaling: The channel saw mentions of the ongoing exploration of model scaling, such as increasing context lengths from 8k to 32k or beyond with modifications like rope theta adjustments. Some community members are validating this claim and the broader potential of such scaling techniques.
Links mentioned:
Nous Research AI ▷ #ask-about-llms (34 messages🔥):
-
Grokking Demystified: A member shared a study on the emergent behavior of neural networks, focusing on a phenomenon called "grokking". The case study involved reverse-engineering small transformers trained on modular addition, revealing they use discrete Fourier transforms and trigonometric identities.
-
Scoring LLMs Without Breaking the Bank: Methods for comparing, scoring, and ranking LLM outputs were discussed. While using GPT-4 was suggested, an alternative approach such as argilla distilable or a reward model may provide qualitative ranking more cost-effectively.
-
Troubleshooting GP2-like Model Training on Shakespeare: A member sought assistance with a GP2-like model that was not learning as expected. They reported a high initial loss that would not decrease, and linked their GitHub repository for reference at Om-Alve/Shakespeare.
-
Token Replacement Tricks for ChatML Integration: In a conversation about the L3 model config, members discussed how replacing reserved tokens with ChatML ones led to functionality improvements. Errors like unintentionally duplicating tokens were also resolved by the model's automated systems.
-
Running Hermes 2 Pro with Llama-3 8B Optimally: A member shared their intent to run Hermes 2 Pro on Llama-3 8B and sought advice on the best software and quantization levels for a 16GB VRAM GPU. It was advised to start with a quantization level like Q8_0 and use a software called lmstudio, though some configuration issues were also discussed.
Links mentioned:
Nous Research AI ▷ #bittensor-finetune-subnet (1 messages):
- Eager New Miner Seeking Finetuning Knowledge: A newcomer expressed a desire to participate in mining and is looking to finetune a Large Language Model (LLM) beforehand. They asked the community for guidance on acquiring datasets and understanding the type of data necessary for finetuning an LLM.
Nous Research AI ▷ #rag-dataset (16 messages🔥):
- Boosting Performance with Fine-Tuning Techniques: One member discussed an approach demonstrated by a new paper to train LLMs using a special token,
<RET>, for more effective information retrieval, which helps to determine when extra context is necessary for answering questions. - Structured Output in AI Models: In the context of generating specific output formats, a member recommended maintaining a consistent instruction phrase, such as "Output only in json.", with a hint to look at how Hermes 2 Pro handles structured output.
- Efficient Tracking of Pydantic Validated Objects: Mention of a tool that automatically logs the time and hierarchy of each function call along with the validated Pydantic objects was made, implying significant benefits for improved function calling and result tracking.
- Simplicity in Fine-Tuning for Specific Outputs: Members discussed that the process of fine-tuning to generate a certain output format is straightforward, involving consistent phrasing within prompts to instruct the model on the desired output format.
- Training Innovation: An acknowledgment of the interesting approach to use special tokens in training LLMs for improved accuracy and efficiency was noted, with a member affirming the viability of such methods in model training.
Links mentioned:
Nous Research AI ▷ #world-sim (19 messages🔥):
- World Simulation Talks - A Gathering of Minds: A YouTube video titled "World Simulation Talks @ AGI House SF" features discussions from figures like Jeremy Nixon, Karan Malhotra of Nous Research, and Rob Hasfield, CEO of Websim. Participants express their excitement about the shared research efforts and valued contributions to the field.
- Anticipation and Uncertainty for World-Sim Testing: Members discuss the eagerly-awaited announcement for testing the world-sim, with expectations for a possible test later in the week or weekend, although no firm commitments have been made.
- A DIY Approach to Simulation: A member shares a custom Claude AI CLI-like prompt emulation for world simulation experiences, inviting feedback from the community and providing the sys template for others to use.
- Proposal for a Multilateral Sim Event: An idea has been pitched to host a combined WorldSim and WebSim event in LA with a creative and developer community, suggesting potential global connections including a San Francisco meetup and a Discord meetup for broader international engagement.
- Websim.ai Gaming Innovations: A member announces their new game on Websim.ai, which spans from the stone age to the galactic age, with an imminent update to add more features to the gameplay.
Links mentioned:
Perplexity AI ▷ #general (303 messages🔥🔥):
-
Exploring Perplexity's Opus Usage and Model Comparisons: Members discussed daily usage limits of models offered by Perplexity AI, specifically noting the temporary 50 uses per day for Claude Opus. They also compared responses from Opus and GPT-4, with some preferring Opus for conversation continuity and GPT-4 for precise technical answers.
-
Pages Feature Gains Traction: The introduction of the new Pages feature on Perplexity AI has generated interest, with users discussing its capabilities, such as transforming threads into formatted articles and embedding images. They are looking forward to seeing expanded functionality in this feature.
-
Challenges with Attachments and Citing Info: Some users encountered issues where Perplexity AI would either incorrectly cite information from attached documents or persistently reference an attached file in subsequent unrelated requests. A known bug was mentioned, and users shared workarounds to manage this.
-
Addressing Platform Accessibility Difficulties: Users highlighted problems using Perplexity AI on specific browsers like Safari and Brave, mentioning difficulties in submitting prompts or registering, and looked for potential solutions or hacks.
-
Member Conversations on AI Video Content and Language Models: The community shared and discussed various AI-related video content, while others sought advice on utilizing AI for tasks like translating PDFs and understanding shortcut keys, emphasizing a need for practical application guidance.
Links mentioned:
Perplexity AI ▷ #sharing (17 messages🔥):
- Drone Dilemmas: A member shared a link to Perplexity AI's page discussing the challenges DJI drones face.
- Finding the Right Path: A curious exploration into whether certain paths produce happiness became a point of interest through this member's shared link.
- Pasta Perceptions: One post focused on the common query about raw pasta's edibility and its potential health effects.
- Artificial Intelligence in Cooking: The conversation heated up with a link to how AI can assist in making better food choices.
- Legal Troubles in Cryptospace: The sentence handed down to the Binance founder was the subject of one shared Perplexity AI search result.
Perplexity AI ▷ #pplx-api (18 messages🔥):
-
Discrepancies in API and Pro UI Results: A user noticed different results when using the same prompt on the Pro UI versus the API for the
pplx-7b-onlinemodel. It was clarified that the API uses an older version while the UI uses llama 3 70b. -
Documentation Check: Users referred to official documentation to clarify details concerning the models available on the API, discussing discrepancies and updates.
-
Understanding 'Online Models': A member explained that an 'online model' implies sources are injected into the context, with the model being fine-tuned to utilize these sources effectively, but it does not have actual internet access.
-
Sonar Large Now Accessible via API: Users celebrated the recent addition of Sonar Large model to the API, as shown in the updated model cards document, despite some confusion over the displayed parameter count.
-
Typo in Parameter Count for Sonar Large: There was a consensus that the parameter count for Sonar Large being listed as 8x7B in the documentation was a typo, and it should be 70B.
Link mentioned: Supported Models: no description found
Eleuther ▷ #general (32 messages🔥):
- Exciting Advances in AI Image Representation: An AI hobbyist shared their decade-long research into efficient image patch representation, drawing inspiration from biological neural systems and using an unsupervised learning approach—a summary of which is available on arXiv. The study challenges traditional methods, showing that binary vector representations can be significantly more efficient than those learned by CNNs using supervised learning.
- Novel Repulsive Force Loss Function Draws Interest: Another member acknowledged the innovative aspect of using a repulsive force loss function to create binary vector representations, likening it to embedding distributions on the edge of the unit hypersphere—an idea applied in the RWKV LLM for improved learning speed.
- Binary Vectors and Biological Neurons — A Parallel Path?: The discussion further delved into how binary vector representations can bear similarity to biological neurons, potentially offering advantages in efficiency and robustness due to binary signaling, while discussing the potential for these representations to massively compress the model size.
- CLIP and DINO: Recommended Reading for Embedding Constraints: A member recommended reading seminal papers on CLIP and DINO CLIP and DINO, emphasizing these works' in-depth reasoning behind using the hypersphere for embeddings constraint.
- Challenges in Celebrity Image Classification Laid Out: A member sought advice for classifying 100k unlabeled images into categories representing three movie stars, facing issues with accuracy even with advanced models like ViT and ResNet50 from OpenAI's CLIP, managing only 36% accuracy and contemplating different prompts and descriptions to improve results. Other members inquired about the distribution and categorization methodology in an effort to assist.
Link mentioned: Efficient Representation of Natural Image Patches: Utilizing an abstract information processing model based on minimal yet realistic assumptions inspired by biological systems, we study how to achieve the early visual system's two ultimate objecti...
Eleuther ▷ #research (155 messages🔥🔥):
- Kolmogorov-Arnold Networks Take Center Stage: Members shared a research paper on Kolmogorov-Arnold Networks (KANs), highlighting their potential as efficient and interpretable alternatives to Multi-Layer Perceptrons (MLPs).
- Unpacking Mode Collapse in LLMs: A member shared a GitHub notebook to assist with exploring mode collapse in language models, facilitating easier modification and experimentation.
- Universal Physics Transformers Introduced: A link to a research paper on Universal Physics Transformers was shared, discussing their versatility across various simulation datasets (paper link).
- GLUE Test Server Questioned: There was skepticism about the correctness of the GLUE test server's scores, given an anomalous result of a non-fine-tuned model achieving a Spearman correlation of 99.2 while obtaining a corresponding Pearson correlation of -0.9.
- Exploring Neural Scaling Laws: The community engaged in a discussion around the findings of a paper (bits per param) suggesting that SwiGLU might have different scaling properties compared to regular MLPs in undertrained regimes, raising questions about model capacity and the effectiveness of gated MLPs.
Links mentioned:
Eleuther ▷ #interpretability-general (44 messages🔥):
-
Next-Token Prediction Loss Theory Shared for Feedback: A member discussed a theory regarding next-token prediction loss and its implications for computational model learning in sequence-prediction models, inviting feedback on their document Deriving a Model of Computation for Next-Token Prediction.
-
Tied Embeddings in Models Discussion: There was an exchange about the potential impact of tied embeddings on the next-token prediction model, suggesting that tied embeddings might make the decoder an inverse of the encoder, which aligns with certain methodological assumptions.
-
The Complexity of Defining Model Features Dissected: A detailed discussion ensued about the difficulty of defining "true underlying features" in a model, emphasizing the challenges in operationalizing this concept and the possible need to look at formal grammars as a basis.
-
Academic Success for Paper Submissions: Members of the channel celebrated the acceptance of their papers at academic venues, referencing a position paper by Hailey Schoelkopf et al., and indicating an overall high acceptance rate for their submissions.
-
First Mechanistic Interpretability Workshop at ICML 2024 Announced: A call was made for submissions to the first academic Mechanistic Interpretability workshop, to be held at ICML 2024. The post highlighted the welcoming of diverse contributions and provided links to the announcement Twitter thread and the workshop website.
Links mentioned:
Eleuther ▷ #lm-thunderdome (1 messages):
- Seeking MT-Bench Incorporation: A member inquired about the status of integrating MT-Bench or similar tools into lm-evaluation-harness. They also expressed interest in the inclusion of conversational AI quality benchmarks.
OpenRouter (Alex Atallah) ▷ #announcements (3 messages):
-
Introducing Snowflake Arctic & FireLLaVA: OpenRouter announces two new models: Snowflake Arctic 480B, showcasing strong coding and multi-language performance at $2.16/M tokens, and FireLLaVA 13B, a fast, open-source, multimodal model priced at $0.2/M tokens. Arctic is a dense-MoE hybrid transformer, while FireLLaVA excels in text and image understanding. Read about Arctic's release here.
-
Enhanced Load Balancing & Provider Stats: To address load surges and improve user experience, OpenRouter has implemented load balancing and now allows you to monitor latency and a provider's "finish reason" on the Activity page.
-
New Documentation Released: OpenRouter has added new sections in their documentation regarding images & multimodal requests and tool calls & function calling.
-
Feature Update and Price Cuts: Lepton models now support
logit_biasandmin_p, inducing the same for nitro models. Additionally, there's a 40% price cut on Mythomax Extended and a 4% cut for Mixtral 8x7b Instruct. -
App Showcase: OpenRouter highlights OmniGPT, a multi-model ChatGPT client, available at omnigpt.co, and Syrax, a versatile Telegram bot for summarizing chats and more, accessible at syrax.ai.
-
Traffic Surge Causes High Error Rates: Users are advised of possible disruptions due to a traffic surge causing errors, with ongoing efforts to scale up and stabilize the service.
Links mentioned:
OpenRouter (Alex Atallah) ▷ #app-showcase (2 messages):
-
Skribler Launches for Swedish Authors: Skribler, an AI tool designed to help Swedish writers boost creativity and productivity, has been released at skribler.se. The tool offers a variety of features, such as providing suggestions, formulating dialogues, and supporting the entire creative writing process.
-
DigiCord.Site Soft-Launch Announcement: An all-in-one AI Discord Bot, DigiCord, soft-launched today, offering access to over 40 LLMs including GPT-4, Gemini, and Claude, along with AI vision and stable disfusion models, all built atop OpenRouter. DigiCord features include summarizing content, writing SEO articles, image analysis, and artwork creation, available with a pay-as-you-go model and you can invite it to your server or join the community.
Links mentioned:
OpenRouter (Alex Atallah) ▷ #general (186 messages🔥🔥):
-
Discussions on Extending LLaMA's Context Window: Members talked about methods to extend the context window of LLaMA models, referencing that context extensions on Hugging Face are fake, but proposing PoSE method for training 32k context, which takes around a day with 8 A100 GPUs. A member mentioned adjusting rope theta for LLaMA 3 70b and shared a GitHub resource on RULER, which contains source code for identifying the real context size of long-context language models.
-
Exploring Google Gemini Pro 1.5: Conversations revolved around Google Gemini Pro 1.5 and its handling of NSFW content, noting the odd behavior of content being abruptly cut off, and discussing the different modes and behavior of the model after updates that stripped it of personality and made it less capable of following instructions.
-
Insights on Deploying Unaligned Models: The community discussed the risks and strategies of deploying "orthogonalized" models that tend to follow instructions without refusal. There was an acknowledgment of the effectiveness of these models while also considering how they omit subtle alignment, which could skew results.
-
Alignment and Open Source Challenges: A discussion emerged around the potential negative impacts of open sourcing powerful models, with some expressing concern about an anti-open-source sentiment that could stem from the uncensoring of aligned models. The conversation touched on the political leanings of models, how they can echo their creators' views, and the importance of the open-source community developing a strategy to push its own agenda.
-
Talks on AI Corporate Influence and Marketing: Users shared insights on how corporations allocate budgets, particularly highlighting the large proportion of funds spent on marketing compared to research and engineering, as exemplified by Google's Gemini project. There was also commentary on the influence of corporate control in various aspects of AI development and deployment.
Links mentioned:
OpenAI ▷ #ai-discussions (107 messages🔥🔥):
-
Music Track Description Tool Sought: A user asked for a tool to describe music tracks, experiencing difficulties with Music Generation and transcription tools. Another user suggested trying Gemini 1.5 Pro on Vertex ai or Google ai studio for understanding audio.
-
DALL-E 3 Continues to Improve: A user inquired about the existence of DALL-E 4, but others confirmed that though DALL-E 4 has not been announced, DALL-E 3's capabilities are still being improved and updated.
-
AI in Education with Claude: The release of Claude IOS app sparked discussions about its effectiveness, with a middle school teacher praising it for better 'human' responses compared to GPT, particularly for non-coding-related topics.
-
Assessing Benchmarks for Chatbots: There was a spirited debate about the value of benchmarks in representing chatbot capabilities, with some arguing they provide a useful measure, while others believed they fail to represent the nuanced real-world use of chatbots.
-
Exploring Keywords for AI-Generated Images: A user requested assistance with identifying keywords for images, indicating they would continue the discussion in the Dall-E discussions space.
Link mentioned: GitHub - openai/simple-evals: Contribute to openai/simple-evals development by creating an account on GitHub.
OpenAI ▷ #gpt-4-discussions (9 messages🔥):
- ChatGPT's Token Limit Under Scrutiny: A member questioned the claimed token limit for ChatGPT, stating they could send texts over 13k characters despite being told the limit was 4096. No link was provided with additional details.
- Member Advises Skepticism About Self-Knowledge: One user highlighted that ChatGPT might not accurately know or convey its capabilities regarding architecture or token limits and suggested not trusting its self-referential answers.
- ChatGPT Plus Token Limit Explained: Clarifying previous discussions, a member said ChatGPT Plus should have a 32k token limit, with the actual GPT model supporting up to 128k in the API, though each message has its own character constraints.
- Confirmation on ChatGPT Plus Messaging Limits: Another user confirmed there is still a messaging limit for ChatGPT Plus/Team, sharing the official OpenAI Help Article for further information.
- Enthusiasm for Improved GPT-3 Performance: A member expressed excitement about the improvements in GPT-3, noting renewed enjoyment in conversing with the AI.
OpenAI ▷ #prompt-engineering (36 messages🔥):
-
Few-Shot Prompting Debate: A member supported the use of few-shot prompting with negative examples, suggesting its superiority. However, another disagreed, raising concerns about noncompliance and task incompletion.
-
Ideal Customer Persona Extraction Plan: A user sought advice on crafting a detailed Ideal Customer Persona (ICP) using social media analytics and specified a method involving personal branding and target audience expertise to analyze data and create personas.
-
Hobbyist Prompt-Engineering Tips: A member new to prompt engineering was offered advice on generating complex behaviors and tools. They were encouraged to use meta-prompting with open variables and markdown to structure prompts.
-
LLM Recall Improvement Strategies: There was a discussion on improving Long-Lasting Memory (LLM) recall. A user suggested utilizing GPT's data analysis/code interpreter tool for tasks like counting keywords within texts.
-
GPT-4-Vision and OCR for Data Extraction: In an effort to extract information accurately from documents, a user shared their approach combining GPT-4-Vision and OCR. Another member made clear that this strategy does not bypass the LLM’s retrieval limits, suggesting Python as a solution for specific counting tasks like identifying unique word occurrences.
OpenAI ▷ #api-discussions (36 messages🔥):
-
Few-Shot Prompting with Negative Examples Discussed: In the discussion on few-shot prompting, one member mentioned that using negative examples has shown better performance than classic methods in some cases ("perform better than classic"), but another voiced skepticism about their effectiveness, mentioning issues such as noncompliance and incomplete tasks.
-
Developing an Advanced ICP from LinkedIn Data: A member is exploring how to extract detailed Ideal Customer Persona (ICP) information from LinkedIn content and shared their steps, such as analyzing CSVs and posts, to derive multiple persona attributes ("Demographics, Psychographics, Personality Color," etc.).
-
Prompt Engineering Advice for Hobbyist: In response to a member inquiring about prompt engineering for knowledge and code exploration, they received suggestions on using open variables and markdown to guide the AI’s behavior and improve responses. A brief example of how to set up a meta-prompt involving an expert system was provided ("meta-prompting expert system").
-
Strategies to Improve LLM Recall Debated: Discussing how to enhance Long-Lived Memory (LLM) recall, members brought up limitations of the context window in platforms like ChatGPT Plus and considered the use of separate computational environments for functions like counting. There was also a mention of combining GPT-4-vision with OCR for data extraction from documents ("gpt-4-vision and OCR").
-
Challenges with Data Retrieval from Long Texts: One participant aimed to extract all data fields from long-form documents with accuracy, pondering if OCR alone could be more effective than the current method. However, there was a consensus that overcoming retrieval limitations inherent to LLMs is a fundamental issue not overcome easily ("cannot mitigate this in the way you're imagining").
HuggingFace ▷ #general (153 messages🔥🔥):
- Seeking AI for Product Photography: Members inquired about AI that can manipulate images, such as showing a shirt worn by a kid in various poses while maintaining logo placement. No specific AI solutions were suggested within the conversation.
- Community-Driven Computer Vision Course Launched: A new community-built computer vision course is now available on GitHub, and the community is encouraged to contribute towards its improvement.
- Stable Diffusion Minecraft Skin Generator Spotlight: A member shared their success with their space getting featured as part of the "Spaces of the Week" using Stable Diffusion Finetuned on Minecraft Skin generation.
- Kaggle Notebooks' Storage and GPU Queries: Discussions revolved around Kaggle notebooks' features, such as enabling internet, using the provided storage, and choosing between P100 and T4 GPUs for better VRAM capacity.
- Parquet Converter Bot and Dataset Dtypes: A member expressed curiosity over how the parquet converter bot handles non-standard data types such as
list[string]in datasets, seeking clarification on whether it can correctly convert these for dataset previews on Hugging Face.
Links mentioned:
HuggingFace ▷ #today-im-learning (5 messages):
- Discover Med-Gemini's Potential: A video titled "Med-Gemini: A High-Level Overview" provides insight into Google's family of Multimodal GenAI models called Med-Gemini, built for the medical field. The goal of the video is to inform so as to keep the AI and medical communities alert, not anxious about GenAI, as explained in this YouTube overview.
- In Search of Clarity: User .rak0 is requesting help for rephrasing a pharma domain-related follow-up question (q2) by integrating all the details from an initial query (q1) but did not provide further details or context for the questions.
- Deployment Inquiry About HF Models on Ray: thepunisher7 inquired about assistance with deploying HuggingFace (HF) models on Ray, yet no follow-up discussion or resolution was provided.
Link mentioned: Med-Gemini: A High-Level Overview: A high-level overview on Med-Gemini, Google's "Family" (said in the voice of Vin Diesel) of Multimodal GenAI models for medicine. Med-Gemini has folks in the...
HuggingFace ▷ #cool-finds (5 messages):
-
Accelerating Diffusion Models with PyTorch 2: A tutorial on Hugging Face demonstrates how to reduce inference latency up to 3x for text-to-image diffusion models like Stable Diffusion XL (SDXL) without needing advanced techniques, by solely utilizing optimizations in PyTorch 2.
-
Physics-Informed Neural Networks Explored: ETH Zürich's lecture on Physics-Informed Neural Networks - Applications offers insights into integrating physical laws with deep learning, available as a YouTube video.
-
Collaborate on MPI-Codes: The MPI-Codes repository on GitHub invites contributions to the development of MPI codes, accessible at this GitHub link.
-
LangGraph Agents Meet RAG for Email Smarts: An article on Medium outlines how LangChain's LangGraph Agents have been enhanced with Retriever-Augmented Generation (RAG) for crafting intelligent emails.
Links mentioned:
HuggingFace ▷ #i-made-this (8 messages🔥):
-
A Dreamy Batch Update: The MoonDream2 batch processing space was highlighted, providing a link to easily access the upgraded model at Moondream2 Batch Processing.
-
Launching FluentlyXL V4: The FluentlyXL V4 model has been released, focusing on improvements in contrast, realism, and anatomy. It's available for use at Fluently Playground and the model page can be viewed here.
-
Typo Alert in Model Card: A keen observation was made about a typo in the title of the Fluently XL V4 model card, correcting it from Fluenlty to Fluently.
-
Incredible Local Results with FluentlyXL V4: Positive feedback was shared regarding the FluentlyXL V4, including successful image generations with correct coloring and anatomy when tested locally on an NVIDIA RTX 3070.
-
Translation Achievement for Portuguese Speakers: A call for review assistance was put out for the Portuguese translation of chapters 0 and 1 of the Hugging Face audio course, with the corresponding PR available at GitHub PR #182.
Links mentioned:
HuggingFace ▷ #computer-vision (6 messages):
-
Seeking CGI vs. Real Image Classifier: A member inquired about a classifier model that can distinguish between CGI/graphics and real photographs, to assist in cleaning a dataset. No specific solutions were provided in the messages given.
-
Positive Feedback for a Useful Tool: A member expressed enthusiasm, referring to a tool or information shared previously as "an awesome tool for sure."
-
Requests for PyTorch Lightning Resources: A query was raised about pytorch lightning examples for evaluating and visualizing object detection model training.
-
Comprehensive PyTorch Lightning and 3LC Integration Examples Shared: A user shared a segmentation example using PyTorch Lightning and provided extensive details on various integrations and tutorials for different models such as SegFormer, Detectron, YOLOv5, and YOLOv8.
-
Course Directory Inquiry: A user asked about the existence of a #cv-study-group channel which is mentioned in the HuggingFace Community Computer Vision Course, but could not be found in the browse channel.
Links mentioned:
HuggingFace ▷ #NLP (3 messages):
- Curiosity About RARR Implementation: A member inquired if anyone has experimented with RARR (Retrofit Attribution using Research and Revision), which finds attributions for language model outputs and edits them to correct unsupported content.
- Discrepancies in Zero-Shot Classification Results: A user faced an issue with a zero-shot classification model where the results for labels "art" and "gun" were counterintuitive with probabilities of 0.47 and 0.53 respectively, differing from those on the model's HuggingFace API page. They provided a code snippet and mentioned using the model
"MoritzLaurer/deberta-v3-large-zeroshot-v2.0"for clarification.
Link mentioned: Paper page - RARR: Researching and Revising What Language Models Say, Using Language Models: no description found
HuggingFace ▷ #diffusion-discussions (1 messages):
sayakpaul: Might be a better question for A1111 forums.
LlamaIndex ▷ #blog (4 messages):
-
LlamaIndex.TS version 0.3 Launches: Version 0.3 of LlamaIndex.TS has been introduced, boasting new features such as Agent support for ReAct, Anthropic, and OpenAI, along with a generalized AgentRunner class. The update also includes standardized Web Streams and a more comprehensive type system, with compatibility for React 19, Deno, and Node 22 outlined in the release tweet.
-
RAG Tutorial Series on YouTube: A new tutorial by @nerdai covers the essentials of Retrieval-Augmented Generation (RAG), advancing to management of long-context RAG and its evaluation. The YouTube link provided may require an updated browser; users can watch the video here and access the accompanying GitHub notebook here.
-
Tutorial for Agentic RAG Support Bot Data Stack: A tutorial/notebook sequence authored by @tchutch94 and @seldo details the construction of a data stack for a RAG-based support bot, highlighting the importance of more than just the vector database. The teaser and full content can be found in their latest post.
-
RAG Application Accuracy Boost with Reranker Guide: Plaban Nayak provides a guide on post-processing retrieved nodes with a reranker to enhance a RAG application's accuracy. It features a local setup using Llama 3 from Meta, @qdrant_engine, LlamaIndex, and ms-marco-MiniLM-L-2-v2, as noted in the post found here.
Links mentioned:
LlamaIndex ▷ #general (112 messages🔥🔥):
-
Querying Without Uploading Documents: Users discussed the possibility of querying Llama Index without needing to re-upload and convert documents into nodes if embeddings and metadata already exist in MongoDB. The tutorial provided details how the
VectorStoreIndexcan be utilized with a MongoDB vector store to make use of the query engine, maintaining the data structure and avoiding redundant processing. -
Integrating External APIs with QueryPipeline: A user inquired about extending QueryPipeline to fetch live data from an external API in addition to serving data from an existing index. The discussion led to the suggestion of using an agent with tools to handle conditional real-time data fetching based on the query's content.
-
Exploring Parallel Requests in llamacpp: Concerns were raised regarding deadlocks when attempting to serve parallel queries in llamacpp’s Python environment. The current consensus is that llamacpp does not support continuous batching in a CPU server, leading to sequential request handling.
-
Content Moderation Blog Post: A new blog post on "Content Moderation using LlamaIndex" was shared, showing how to create AI-driven solutions for content moderation using Llama Index-powered Large Language Models (LLMs). The blog post offers a deep dive into applications for social media and gaming moderation along with a demonstration.
-
Using Trulens with MongoDB and LlamaIndex: There was a request for guidance on using the Trulens evaluation tool with MongoDB and LlamaIndex embeddings. It was suggested to follow this guide on Obsarvability in LlamaIndex and to consider alternatives like Arize Phoenix or Langfuse for advanced capabilities.
Links mentioned:
LlamaIndex ▷ #ai-discussion (6 messages):
-
Choosing the Right GPU for AI Tasks: Discussions focused on whether a gaming card like the RTX 4080 with 16 GB VRAM is adequate for running and fine-tuning smaller LLMs. It was noted that a higher VRAM is beneficial, with the RTX Turing 24 GB being a possible recommendation, though for private or sensitive data, local computation was preferred over cloud solutions like Google Colab.
-
Local vs. Cloud Computing Preferences: One member is considering a local PC for fine-tuning smaller language models due to privacy concerns with some data, as well as the potential general utility of a powerful computer funded by work resources.
-
Word Loom Specification Introduced: A user introduced Word Loom, an open specification designed for managing and exchanging language for AI, which separates code from natural language and supports composability and mechanical comparisons. Feedback was solicited for the Word Loom proposed update which aims to be friendly to globalization techniques.
Link mentioned: Word Loom proposed update: Word Loom proposed update. GitHub Gist: instantly share code, notes, and snippets.
Modular (Mojo 🔥) ▷ #general (8 messages🔥):
- Curiosity About Mojo's Package Management: A member inquired about how package managing works in Mojo with a positive emoji, suggesting interest in the process and mechanics of the bot's package management system.
- Mojo Bot Turns One: A member noted that tomorrow will be the 1-year anniversary of Mojo's launch, bringing attention to the milestone for the community.
- Reflecting on Yearly Progress: Members celebrated Mojo's 1-year anniversary, highlighting the significant features added and improved within the year like traits, references, and lifetimes.
- Anticipation for Anniversary Release: After acknowledgment of the anniversary, another member raised anticipation by hinting at a possible big release "tmr" (tomorrow), expressing hope and curiosity about upcoming updates.
- A Release Dedicated to a Member: In response to the anticipation of a big release, a member humorously suggested that they did a release specifically for the inquiring member, adding a personal touch to the community engagement.
Modular (Mojo 🔥) ▷ #💬︱twitter (3 messages):
- Modular Tweets Shared: Members in the 💬︱twitter channel shared links to Modular's latest tweets. The content of the tweets was not discussed, but the links to the respective tweets are here, here, and here.
Modular (Mojo 🔥) ▷ #✍︱blog (2 messages):
-
Mojo🔥 24.3 Embraces Community Contributions: The latest major release of Mojo🔥 24.3 marks the first update since the Mojo🔥 standard library was open-sourced, boasting significant improvements thanks to the community's input. The announcement post extends special thanks to contributors for their pull requests, highlighting the platform’s enhancement and inclusivity.
-
MAX 24.3 Unveils Engine Extensibility: The new release of MAX 24.3 introduces the MAX Engine Extensibility API, designed for developers to seamlessly integrate and manage their AI pipelines. It underscores the cutting-edge capabilities of the MAX Engine in delivering low-latency, high-throughput inference, and the MAX Graph APIs facilitate the creation of bespoke inference models, enhancing MAX's programmability for various workloads.
Links mentioned:
Modular (Mojo 🔥) ▷ #announcements (1 messages):
-
MAX ⚡️ & Mojo🔥 24.3 Released: Version 24.3 of MAX and Mojo is now live, bringing community-driven enhancements to the standard library since its open-sourcing. Instructions for installation are provided, along with a launch blog expressing gratitude towards community contributors.
-
Celebrating Contributions: Special thanks are extended to the individual contributors for their pull requests to Mojo; detailed acknowledgment is shared with links to their respective GitHub profiles.
-
Diving Into MAX Extensibility: The latest MAX update introduces a preview of the new MAX Engine Extensibility API, described to improve AI pipeline programming and composition, detailed in a dedicated MAX extensibility blog.
-
Changelog Chronicles 32 Updates: The changelog lists 32 significant updates, fixes, and features, including a highlight of the rename of
AnyPointertoUnsafePointerin Mojo with several improvements. -
Mojo's Milestone Moment: Happiness is shared on the occasion of the first anniversary of Mojo's launch with the community that has contributed to its growth.
Links mentioned:
Modular (Mojo 🔥) ▷ #ai (1 messages):
- Defining Consciousness in AI: A member expressed the view that consciousness is both a philosophical and scientific concept that must be quantified before it can be simulated by AI. A suggested approach for AI research involves starting with simpler creatures, like worms, because their brains might be easier to map and code.
Modular (Mojo 🔥) ▷ #tech-news (2 messages):
-
CHERI Set to Transform Computer Security: The CHERI architecture promises to mitigate 70% of common vulnerability exploits, signaling a major shift in computer hardware security. Details on its impact were shared during a recent conference, suggesting daily usage may soon be a reality.
-
Rethinking Software Development with CHERI: The adoption of CHERI could lead to more efficient Unix-style software development by making processes orders of magnitude faster, as detailed in the Colocation Tutorial, sparking conversations about increasing software reuse across programming languages.
-
Unlocking Performance with Scalable Compartmentalization: They highlighted that CHERI's scalable compartmentalization could significantly lower performance costs in creating sandboxes, impacting diverse areas from web browsers to Wasm runtimes. The transformative potential was discussed in this YouTube video.
-
Hardware Simplification and Speed-Up on the Horizon: The discussion raised questions about whether CHERI might make traditional security methods like MMU-based memory protection redundant, thereby simplifying hardware and accelerating software.
-
Microkernels Poised for Renaissance with CHERI: Improvement in Inter-Process Communication (IPC) speed thanks to CHERI has led to speculation about a potential revolution in operating system development, where microkernels could become mainstream.
Links mentioned:
Modular (Mojo 🔥) ▷ #🔥mojo (60 messages🔥🔥):
- Mojo's "Rust but simpler" Ambition: The discussed goal for Mojo is to keep the "Rust but simpler" appeal, with the hope that lifetimes and mutability can be automatically inferred, ideally in all cases as they are in Hylo, offering a model without the need for annotations that Rust requires.
- Mojo's Compatibility with Ubuntu 24.04: Users report that Mojo installs and operates without issues on the newer Ubuntu 24.04, even though official documentation does not mention support beyond 20.04 and 22.04 versions.
- Pointers vs. References in Mojo: A user provided a code example exploring the use of pointers as a potentially more readable alternative to references in Mojo, while others discussed the associated risks and limitations, especially around memory allocation errors.
- Lifetimes Discussion and Future Development: Lifetimes and borrow checking are being assessed, with an emphasis on improving upon Rust's model. The specifics of aliasing restrictions and borrow checking semantics are still actively being developed and are not yet finalized.
- Atomic Operations in Mojo for Parallelization: The Mojo language supports atomic operations, with the in-discussion mention of the Atomic class in the standard library, which can be used for creating values with atomic operations.
Links mentioned:
Modular (Mojo 🔥) ▷ #community-blogs-vids (4 messages):
- Mojo Rising: A YouTube video titled "Mojo Lang - Tomorrow's High Performance Python? (with Chris Lattner)" discusses Mojo, a new language by the creator of Swift and LLVM that aims to leverage best practices from CPU/GPU-level programming. You can watch it here.
- Podcast Enthusiasm: A member expresses enthusiasm for the podcast featuring Chris Lattner and mentions promoting his programming language (PL) talks internally.
- Back-to-Back Lattner: Excitement was shared by another member who is pleased to see another podcast featuring Chris Lattner.
- Python's Power Unleashed: The MAX Platform and its potential to unleash Python's capabilities were discussed in another PyCon Lithuania video.
Links mentioned:
Modular (Mojo 🔥) ▷ #performance-and-benchmarks (2 messages):
- Multi-Core Processing Achieved: A member has optimized processing to handle 100M records in 3.8 seconds using multi-core methods. They asked if they should do a Pull Request (PR) to the main branch.
- Interest in Exploring atol Function: Another member expressed an intention to intensely review the
atolfunction, drawing upon their recent experiences from working on the atol-simd project.
Modular (Mojo 🔥) ▷ #nightly (2 messages):
- Inquiring About Missing Function Names: Several members noticed an absence of function names and inquired about whether this feature would be reinstated in the future. There is a shared interest in knowing if function names will return to the chatbot's configuration.
OpenInterpreter ▷ #general (61 messages🔥🔥):
- Eager Anticipation for OpenInterpreter App: A member inquired about the release timeline for the OpenInterpreter app.
- Discord Events Decoded for Newcomers: Members discussed the logistics of joining Discord events, clarifying that newcomers can join and listen without prior knowledge, and there's an option to participate in the chat.
- Windows Compatibility Queries for OS Mode: Conversations were focused on OS mode compatibility with Windows, discussing various issues encountered and solutions like adjusting commands for Windows or using the
--osflag with GPT-4 for better compatibility. - Multimodal Integration in OpenInterpreter: Discussions delved into integrating models with specialized capabilities, such as vision and OCR, using tools like Idefics2 from Hugging Face, within OpenInterpreter.
- Community Assistance and Collaborations: Members offered help with Git for uploading a translated README.md, and shared experiences with building browser AI agents, reflecting a spirit of cooperative learning and sharing of resources.
Links mentioned:
OpenInterpreter ▷ #O1 (12 messages🔥):
- Ollama Bot's Independent Streak: A member shared success in getting something to work on Ollama but noted issues with it not waiting for responses and acting independently instead.
- Troubleshooting Ngrok Domains: A user outlined steps to configure ngrok by creating a domain, editing a file called
tunnel.py, and modifying the command line to include the new domain name. The steps included a link to ngrok's domain setup at ngrok Cloud Edge Domains. - Echo's Volume Conundrum: One user inquired about adjusting the Echo's volume, while others confirmed the same issue and suggested that the manufacturing team is exploring alternatives.
- Speaker Search in Progress: In relation to the speaker issue for a device, a user noted that the electronics team is discussing options with vendors and this process, including validation and potential changes, may take weeks.
- Acceleration of Whisper RKNN: A user provided a link to a GitHub branch that offers a significant speed boost for anyone using a SBC with Rockchip RK3588. The branch allows for local Whisper RKNN processing that's reportedly 250% faster. The link to the GitHub page is here: GitHub - rbrisita/01 at rknn.
- Error Troubleshooting for Litellm: A user was confused by an error received when attempting to interact with what appears to be the Litellm library, running a specific command. Another user suggested adding
--api_key dummykeyas a potential solution and provided Discord server links for further assistance.
Links mentioned:
OpenInterpreter ▷ #ai-content (2 messages):
-
OSS AI Vtuber Starter Kit Launched: A new AI Vtuber starter kit has been released that requires just an OpenAI key, YouTube Key, and Google credentials.json for English TTS. Those interested can check it out on Twitter and access the repository on GitHub.
-
AI Vtuber Repo for Offline Use: Another AI Vtuber repository has been made available that runs entirely offline without the need for an API and boasts an uncensored experience. Further details and demonstration can be viewed in the YouTube video and the source code is up on GitHub.
Links mentioned:
Latent Space ▷ #ai-general-chat (33 messages🔥):
- AI Town World Editor Unleashed: Participants shared an innovative project, AI Town with a World Editor, where a developer deployed 300 AI agents in an environment reminiscent of Westworld, with functioning AI on a Macbook M1 Max 64G.
- OpenAI Site Redesign Feedback: A link to a tweet discussing OpenAI's website redesign was posted, pointing out performance issues such as lag and visual glitches on OpenAI's new platform.
- Insight into Claude's Development: An anecdote about Claude's development process was shared, describing how whiteboard brainstorming sessions were transcribed by Claude into documentation, covered in this backstory.
- Running LLMs on MacBooks Explored: Discussions around running large language models (LLMs) locally on MacBooks occurred, referencing tools like Llama3-8B-q8, and resources for operating LLMs across various devices and platforms.
- Semantic Chunking for Document Processing: Conversation focused on unique text chunking techniques, specifically semantic chunking, and various implementations of it were shared, including links to resources from LlamaIndex and LangChain's Semantic Chunker.
Links mentioned:
Latent Space ▷ #llm-paper-club-west (35 messages🔥):
- A Mamba Meeting via Zoom: Members arranged to meet on Zoom, sharing a direct link to the meeting.
- Getting Ready for Mamba Deep Dive: Anticipation built as members prepared to start the meeting, with a reference to a detailed Mamba Deep Dive document.
- Selective Copying Curiosity: A member questioned if selective copying in Mamba functions like a recall test, attempting to duplicate previously seen tokens.
- Mamba Finetuning Inquiry: The discussion touched upon how Mamba architectures might lead to overfitting during finetuning compared to transformers.
- State Space Model Discussions and Papers: State space models and their connection to complex systems being approximated by LTI systems were brought up, along with links to two relevant papers, one on induction heads and another on multi token analysis.
Links mentioned:
OpenAccess AI Collective (axolotl) ▷ #general (24 messages🔥):
-
Questioning Benchmark Relevance: A member questions the usefulness of complex prompting for benchmarks that do not test practical performance.
-
Instruct Tags and Masking Practices: The discussion revolves around whether to mask instruct tags during training to potentially improve ChatML performance. A custom ChatML format and the importance of unmasking what the model generates are topics of interest.
-
Announcement of Llama-3 8B Extension: A new Llama-3 8B Instruct Gradient with an extended context length is introduced, and uses RoPE theta adjustments for minimal training on longer contexts Llama-3 8B Gradient.
-
Debate on RoPE Theta and Context Length: Members debate the necessity and technical feasibility of a model with a 1M context length. Some discuss limitations, while others suggest it can be constrained during inference.
-
ChatML Training Trouble: A collaborator encounters an
AttributeError: GEMMAwhen training with ChatML. The issue is mitigated by removing the ChatML args, but the necessity of training with ChatML for the dataset is pointed out.
Links mentioned:
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (11 messages🔥):
- Call for Collaboration in Bug Triage: A member offered assistance with compute resources to those willing to help with triaging and troubleshooting bugs/issues, emphasizing the value such help offers to the project.
- Identifying Environmental Causes for Issues: There was a consensus that many reported issues may stem from users' local environments or machines and that these need someone to reproduce them to confirm.
- Multithreading Patch Proposed for Orpo Trainer: A patch was shared to address an issue where the Orpo trainer was only using one worker for preprocessing, with a member posting the pull request here.
- Clarification on TRL Trainer Preprocessing Step: Members discussed a fix related to the preprocessing step in the TRL trainer, noting that it also applies across various RL methods and trainers like DPOTrainerArgs and that the fix has been included in the same pull request.
- Python Version Set for Axolotl Development: A brief exchange determined that Python 3.10 is the minimum required version, allowing the use of
match..casein Axolotl's codebase.
Link mentioned: FIX: TRL trainer preprocessing step was running in one process by ali-mosavian · Pull Request #1583 · OpenAccess-AI-Collective/axolotl: Description We weren't passing dataset_num_proc to TRL training config, thus the initial data preprocessing steps in the TRL trainer was running in one process only. Motivation and Context Speeds ...
OpenAccess AI Collective (axolotl) ▷ #general-help (3 messages):
- Model Verbose, Could Use Token Training?: A member noted that while training llama 3 8b instruct for regular conversations, they observed that the model's outputs and sentence lengths are unusually long. They questioned whether certain tokens, such as the end of text and punctuation, need additional training.
- Seeking the Right Training Balance: The same individual pondered whether the verbosity issue could be resolved with increased data volume and additional epochs to optimize model performance.
- Batch Size and Epoch Curiosity: Another member inquired about the specifics of their training regimen, showing interest in the number of epochs and batch train size currently being used.
OpenAccess AI Collective (axolotl) ▷ #axolotl-help-bot (15 messages🔥):
-
Config Queries Get Clarified: A member asked for guidance on configuring a dataset structured with roles and messages for use with OpenAccess-AI-Collective/axolotl. A detailed configuration was provided using
UserDefinedDatasetConfigto match the dataset's structure. -
Adaptation Strategy for Datasets: To align with a provided configuration, members were advised to flatten the conversation structure of their datasets and adjust the formats prior to processing with the
sharegpttype. -
Describing Dataset Configuration: A user sought completion for a dataset configuration sequence specific to
sharegpttype andLlama2ChatConversation. The correct format of the dataset path, conversation type, human and model field, as well as input and output roles, were specified.
Links mentioned:
OpenAccess AI Collective (axolotl) ▷ #axolotl-phorm-bot (15 messages🔥):
-
DeepSpeed Stage 3 Quality Concerns Addressed: A member asked if DeepSpeed Stage 3 (ZeRO-3) degrades model quality. The consensus is that ZeRO-3 is designed to optimize memory usage for distributed training and does not inherently degrade model quality, as long as proper implementation and integration are ensured.
-
Combining Flash Attention with DeepSpeed for Finetuning: It is possible to use both Flash Attention and DeepSpeed Stage 3 for finetuning by first integrating Flash Attention into the model and configuring DeepSpeed with ZeRO-3 optimizations in the training script.
-
Accelerating Training with DeepSpeed Stage 3: DeepSpeed's ZeRO-3 can speed up training by enabling larger models to be trained on existing hardware, increasing batch sizes, and reducing the need for model parallelism through optimized memory usage.
Links mentioned:
LAION ▷ #general (27 messages🔥):
- Exploring AI in Education: A member expressed concerns about the impact of using AI assistants in education, hinting that it might condition children to rely on AI rather than learning how to learn independently.
- Revolutionizing Motion in Image-to-Video: A paper introducing Motion-I2V, a novel image-to-video generation framework, was shared, offering insight into a two-stage process with explicit motion modeling, optimized by diffusion-based motion field predictors and motion-augmented temporal attention. The paper can be found at Motion-I2V.
- LLaMA3 Performance and Hopes for Specialty Fine-tunes: Member appraises LLaMA3 for its effective performance even when 4bit quantized and expresses hope for specialized field-specific fine-tunes and another code release by Meta for LLaMA3.
- Exploring MagVit2 Implementation: A new member working on MagVit2 requested advice for improving their VQ-VAE model's reconstruction quality and pondered if additional loss functions might be necessary.
- Seeking Guidance on SoundStream Implementation: A member struggling with their first paper implementation on the SoundStream codec by Google sought clarification on omitted indices and values from the paper, with other members suggesting resources and possible meanings for the discussed variables.
Links mentioned:
LAION ▷ #research (12 messages🔥):
-
No ETA on Project Completion: It was stated that there is currently no estimated time of arrival (ETA) for a particular project.
-
Soon TM Becomes a Reality: A phrase "Soon TM" surfaced, playfully signaling that an event or release is expected shortly without a specific timeframe.
-
Inquiry About LAION Stockfish Dataset Configuration: A request was made for the configuration details of the LAION stockfish dataset to assess its potential use for training a chess bot, with an emphasis on the importance of the "skill" level of the dataset.
-
Kolmogorov-Arnold Networks Offer Alternative: A new research paper on arXiv introduces Kolmogorov-Arnold Networks (KANs), a potential alternative to Multi-Layer Perceptrons (MLPs) featuring learnable activation functions and spline parameterization, promising better accuracy and interpretability.
-
VisualFactChecker: A Training-Free Pipeline for Accurate Captions: Another arXiv paper presents the VisualFactChecker (VFC), which is a pipeline that produces high-fidelity and detailed captions for visual content through a proposal-verification-captioning process, significantly improving the quality of image and 3D object captioning.
Links mentioned:
AI Stack Devs (Yoko Li) ▷ #app-showcase (28 messages🔥):
- Crisp Diffusion Model Outputs: A member mentioned that the diffusion model outputs on Hexagen World are really crisp, implying high-quality AI-generated content.
- Nostalgia for AI-Driven Farmville: A participant suggested the idea of remaking old MySpace/Facebook style games like Farmville, using generative AI.
- Unique AI Town Setup Concept: .ghost001 expressed a desire to set up a 1950s themed AI town game where one AI character is a communist spy, to see if the town's AI inhabitants can uncover the spy.
- Hexagen World as a Gaming Platform: Conversation centered around Hexagen World as a potential platform for such AI-driven games, with jakekies suggesting it to .ghost001 who was looking for a place to execute their 1950s spy town idea.
- Hexagen World Discovery and Discord Invitation: The origin of the Hexagen World find was attributed to Twitter, and an invitation was extended by angry.penguin to their AI animation Discord server for those interested in learning more about AI animation.
Links mentioned:
AI Stack Devs (Yoko Li) ▷ #ai-town-discuss (3 messages):
- Chatbot Quirks Puzzling User: A member reported experiencing odd messages in ai-town, including empty texts and a string of numbers that interrupt the conversation flow. They are currently utilizing ollama and llama3 8b configurations.
- Tokenizer Troubles a Possible Culprit: In response to the mentioned chat issues, a member suggested that the problem might stem from the tokenizer, especially considering the numeric nature of the disruptive messages.
- ollama Mysteries: The same member who posited the tokenizer theory also mentioned a lack of familiarity with ollama, indicating a potential knowledge gap in diagnosing the issue further.
AI Stack Devs (Yoko Li) ▷ #ai-town-dev (7 messages):
- Switching to Linux Considered: A member expresses considering ditching Windows for Linux but wonders about the process and implications for gaming.
- Gaming on Linux Assurance: Another member provides valuable links showing that Stellaris has native support for Mac and Linux, implying that gaming wouldn't be a concern for the member considering the switch.
- Dual Boot as a Safe Bet: It's suggested to the member considering a switch to Linux to perhaps create a dual boot system for flexibility.
- Stellaris Runs Well on Mac: An experience with playing Stellaris on a MacBook Pro is shared, noting satisfactory performance except for slowdowns in the late game.
Link mentioned: WineHQ - Stellaris: no description found
LangChain AI ▷ #general (25 messages🔥):
- Peeking into Groq Access Protocols: Members discussed access to Groq's AI services, with one citing a direct signup link to Groq at Groq's console, thus clarifying there isn't a waitlist for access.
- Langchain Video Sparks RAG Indexing Queries: Inquiry into handling documents exceeding the 8k token context window for Llama3 within RAG sparked discussions, but concerns were raised about potential diminished abilities with larger context windows.
- Looping AI Conversations: One member sought advice for an issue with a human-AI interaction project where the AI consistently veered off script and looped its responses without clear cause, and was searching for strategies to maintain the intended conversational flow.
- Integration Woes with Text Embedding and Langchain: A user expressed difficulty integrating a jumpstart text embedding model with Langchain due to reliance on a Sagemaker endpoint instead of an API key.
- CSV Embedding Conundrum: A member sought advice on embedding a single CSV column and retrieving corresponding data from another upon request, questioning traditional methods and prompting suggestions on more sophisticated data retrieval approaches.
LangChain AI ▷ #langserve (1 messages):
- Confusion over Feedback Mechanism: A member expressed uncertainty regarding the feedback feature in LangServe, mentioning they've successfully submitted feedback but saw no changes in LangSmith. The note clarifies that a successful response does not ensure the feedback has been recorded; it may be silently rejected if deemed unauthenticated or invalid by the server.
LangChain AI ▷ #share-your-work (6 messages):
-
Introducing Word Loom: An open spec for managing language for AI, Word Loom, focuses on separation of code from natural language and composability. The updated spec aims to be friendly to mechanical comparisons and globalization techniques, with details available on GitHub.
-
LangChain v0.1.17 Upgrade Notice: One member has upgraded their project to LangChain v0.1.17 and OpenAI v1.25.0 and adjusted the code to match recent package updates, mentioning the challenges of outdated documentation. They have shared their deployment at this application link.
-
LLMs Benchmarked for Content Creation: A member is testing LLMs that excel in content creation tasks like scriptwriting and summarization, proposing to share a detailed report if there's community interest.
-
Deploying Langserve on GCP: Langserve has been deployed on Google Cloud Platform (GCP) using Cloud Run, allowing for scalability and the addition of backend REST codebase. The setup includes plans for py4j integration and micro-payments via cryptocurrency.
-
Pydantic for Defining GPT Tools: A tool has been created to use Pydantic for defining tools in GPT, with the aim to make tool writing more systematic. The repository is available on GitHub.
-
Article on Enhanced LangChain Agents: An article discusses how to enhance LangChain's LangGraph Agents with RAG for intelligent email drafting, potentially providing significant improvements to the agent's capabilities. The write-up can be found on Medium.
Links mentioned:
LangChain AI ▷ #tutorials (1 messages):
- Adaptive RAG Paper Showcases Dynamic Strategy Selection: tarikkaoutar highlighted a paper on Adaptive RAG, which dynamically selects the best strategy for Retrieval-Augmented Generation based on query complexity. They shared a YouTube video providing an overview of the paper.
Link mentioned: - YouTube: no description found
tinygrad (George Hotz) ▷ #general (20 messages🔥):
-
Inquiry Into Learning tinygrad: A member was interested in learning more about tinygrad after being intrigued by a podcast featuring Lex Fridman and inquired about resources for comparison with PyTorch, specifically regarding kernels. Another member suggested exploring the tinygrad GitHub repository documentation for more information.
-
Hardware Considerations for tinygrad Development: One member considered purchasing hardware for tinygrad development and debated between a dedicated setup with an AMD XT board or opting for a new Mac M3.
-
Troubleshooting tinygrad on M1 Mac: Sytandas encountered an AssertionError related to an invalid Metal library when running tinygrad on an M1 Mac, suggesting potential issues with conda python. Wozeparrot pointed towards a fix discussed in a specific Discord channel.
-
Potential tinygrad Conda Issue on macOS: It was revealed that system updates including brew and pip3 might correlate with the tinygrad conda issues experienced by Sytandas, while the aforementioned fix for conda python was confirmed to be under development for the past two months.
-
Bounty on tinygrad Conda Fix: A brief exchange confirmed that there is indeed a bounty for resolving the tinygrad issue with conda python, and some significant progress had been reported just two days prior to the inquiry.
tinygrad (George Hotz) ▷ #learn-tinygrad (13 messages🔥):
- CUDA Confusion: A member questioned whether CUDA=1 was used when running a script, hinting at a possible performance-related consideration.
- RedNode vs. OpNode Debate: A member was curious about the difference between RedNode and OpNode in the symbolic part of tinygrad, contemplating if it's just to adhere to PEMDAS or if it complicates the symbolic compiler logic.
- MNIST Accuracy Anomaly: An issue was raised regarding the MNIST example always yielding 100% accuracy; a member suspected a version-related problem with the installation sourced via pip.
- Resolution Through Compilation: The user resolved the accuracy reporting issue by installing tinygrad from the source instead of using pip, commending the simplicity of the compile process of tinygrad.
- The Importance of blobfile: The mention of blobfile in the LLaMA example code was questioned; it was clarified that blobfile is a dependency for the function load_tiktoken_bpe in tinygrad.
Link mentioned: tinygrad: You like pytorch? You like micrograd? You love tinygrad! <3
Mozilla AI ▷ #llamafile (33 messages🔥):
-
Matrix Multiplication Performance Riddle: A user puzzled over the discrepancy in np.matmul performance, highlighting they achieved 600 gflops on their system versus the 29 gflops mentioned in a blog post by Justine Tunney. In a reply, the concept of measuring flops is clarified with emphasis on different calculation methods.
-
File Renaming Results Vary across Llamafile Versions: An inconsistency was noted in output when running a file renaming example from a llamafile post, suggesting variation between different versions or executions with the output
een_baby_and_adult_monkey_together_in_the_image_with_the_baby_monkey_on.jpg. -
Choosing the Right Infrastructure for Llamafile: A user inquired about the most cost-effective way to experiment with llamafile, considering options like vast.ai or colab pro plus for their limited local machine capabilities.
-
GEMM Function Optimization Chase: A user sought advice on accelerating a generic matrix-matrix multiplication (GEMM) function in C++, trying to surpass 500 gflops (where numpy apparently reaches over 600 gflops). A series of code snippets were shared, and a suggestion was given to consider aligning data and experiment with different microtile sizes.
-
Concurrent Llamafiles and Resource Sharing: Its mentioned that multiple llamafiles can be run at the same time on different ports, but it's underscored that such processes compete for system resources as dictated by the operating system, emphasizing the lack of specialized interaction between concurrent instances.
Links mentioned:
Cohere ▷ #general (24 messages🔥):
-
Newcomers Greeted Warmly: Several members, including sssandra and co.elaine, welcomed new users to the server, indicating a friendly and supportive community environment.
-
Text Compression Using LLMs Session: A reminder was posted for a session on Text Compression using LLMs, which included a Google Meet link for live participation.
-
API Implementation and Production Key Issue: One user expressed confusion about implementing the AI API into their QA chatbox, while another faced an issue where their registered production key still functioned as a trial key, which co.elaine addressed by asking about the error message encountered.
-
Guide to Using Preambles in Prompts: co.elaine helped a user on how to reference documents in chat prompts by directing them to the Cohere documentation on using the 'preamble' parameter and provided a summary of its function.
-
Building a Document Search System: A user sought advice on building a search system for retrieving documents based on natural queries, outlining potential strategies involving document embeddings, summaries, and key information extraction.
Link mentioned: Preambles: no description found
Cohere ▷ #collab-opps (1 messages):
- Stockholm LLM Enthusiasts Unite: A member expresses interest in meeting up in Stockholm to discuss Large Language Models (LLMs), mentioning the perceived small size of the community in this area. An invitation to grab lunch and chat further about the topic was extended.
Interconnects (Nathan Lambert) ▷ #ml-questions (10 messages🔥):
-
Ensemble Reward Models Gain Spotlight: Discussion revolved around the use of an ensemble of reward models during the Reinforcement Learning (RL) phase in AI alignment, as seen in DeepMind's Sparrow. It was noted that ensemble techniques, including the use of an "Adversarial Probing" reward model, might help avoid mode collapse—a potential consequence of overfitting—despite the presence of a KL penalty.
-
Llama 3's Dual Approach Causes Stir: A member asked why Llama 3 used both Proximal Policy Optimization (PPO) and Decentralized Proximal Policy Optimization (DPO), with speculation about whether this was due to uncertainty about the better technique, or a more complex reason. Another member suggested that the full technical report has not been released yet, hinting at confusion in the community and potential reasons related to data timescale constraints.
-
Bitnet's Practicality in Question: There is curiosity about whether the Bitnet approach to training large models will see larger-scale applications given successful small-scale reproductions. A member shared links to Bitnet implementations, including Bitnet-LLama-70M and a ternary update from Agora on GitHub.
-
Barriers to Bitnet Advancement Explored: Discussion addressed the lack of large model training with Bitnet, citing a GitHub rationale that Bitnet's inference is currently inefficient without specialized hardware supporting 2-bit mixed precision. It was mentioned that significant investment would be needed to create a chip to realize Bitnet's benefits and there are uncertainties regarding its scaling laws.
-
The Ongoing Challenge of Specialized Hardware for Bitnet: The conversation extended into the possibility of advancements in CUDA magic, like the recent fp6 kernel, or the development of a ternary chip to support Bitnet's practical application. Historical efforts by IBM were referenced, though it was noted there may not be continuity with those involved in the original work.
Links mentioned:
Interconnects (Nathan Lambert) ▷ #ml-drama (2 messages):
-
Mysterious Model Mayhem: A member shared a tweet questioning the origin of a model resembling one created by Neel Nanda and Ashwinee Panda, suggesting it might be undergoing collective pentesting. The discussion includes suspicions of a deliberate leak and the appearance of the model on platforms like 4chan and Reddit.
-
Sleuthing the Anomalous Anon's Model: The same individual quoted Teortaxes' tweet expressing skepticism about the nature of the model found and the legitimacy of treating it as the same as Neel and Ashwinee's creation, urging for model weights release or testing of the anonymous version.
Link mentioned: Tweet from Teortaxes▶️ (@teortaxesTex): ...actually, why the hell am I assuming it's not their model, disseminated for collective pentesting - miqu-like oddly specific quant leak to preclude improvements - sudden 4chan link, throwaway...
Interconnects (Nathan Lambert) ▷ #random (11 messages🔥):
-
Anthropic Launches Claude App: Anthropic has released their Claude app similar to OpenAI's application. No further reviews of its performance compared to OpenAI's offering were provided.
-
Symbols of Success: Members praised the branding and logo of Anthropic, potentially inferring positive user sentiment towards the company's visual appeal.
-
ML Collective Activity Update: A conversation confirmed that ML Collective meetings are still happening, but not on a weekly basis.
Interconnects (Nathan Lambert) ▷ #posts (2 messages):
- Recognition for Improved Performance: A member expressed enthusiastic approval, acknowledging that someone has significantly improved their performance after receiving critical feedback.
Alignment Lab AI ▷ #general-chat (1 messages):
manojbh: Hello
Datasette - LLM (@SimonW) ▷ #llm (1 messages):
- LLM as a Digital Housekeeper: A member inquired about the existence of a Language Model capable of identifying and deleting a multitude of 7B localmodels that are scattered across their hard drive by various apps and libraries.
DiscoResearch ▷ #discolm_german (1 messages):
-
Exploring the Middleway with Qdora: A user highlighted an alternative method with Qdora, presumably inspired by previous discussions on model expansion. It involves a post-pretraining method for Large Language Models (LLMs) that prevents catastrophic forgetting.
-
Block Expansion Results Discuss Skills Acquisition for LLMs: The conversation pointed towards research on block expansion for LLMs, such as transitioning from LLaMA to CodeLLaMA. This method aims to acquire new skills without losing previous capabilities, a significant advancement for models like LLaMA Pro-8.3B.
Link mentioned: LLaMA Pro: Progressive LLaMA with Block Expansion: Humans generally acquire new skills without compromising the old; however, the opposite holds for Large Language Models (LLMs), e.g., from LLaMA to CodeLLaMA. To this end, we propose a new post-pretra...
AI21 Labs (Jamba) ▷ #jamba (1 messages):
paulm24: Jamba-Instruct is out: https://twitter.com/AI21Labs/status/1786038528901542312