ASICs are all you need.
AI News for 10/10/2025-10/13/2025. We checked 12 subreddits, 544 Twitters and 23 Discords (197 channels, and 15120 messages) for you. Estimated reading time saved (at 200wpm): 1127 minutes. Our new website is now up with full metadata search and beautiful vibe coded presentation of all past issues. See https://news.smol.ai/ for the full news breakdowns and give us feedback on @smol_ai!
There's been a lot of chip dealmaking by OpenAI recently to create "the biggest joint industrial project in human history":
- Sept 10: $300B in compute from Oracle
- Sept 22: 10GW from NVIDIA
- Oct 6: 6GW from AMD
and today, the final shoe drops - as widely rumored and on schedule, after hiring TPU alums from Google - 10GW of OpenAI's own ASIC and systems specifically designed for OpenAI's inference capacity (as Sam says on the OpenAI podcast).
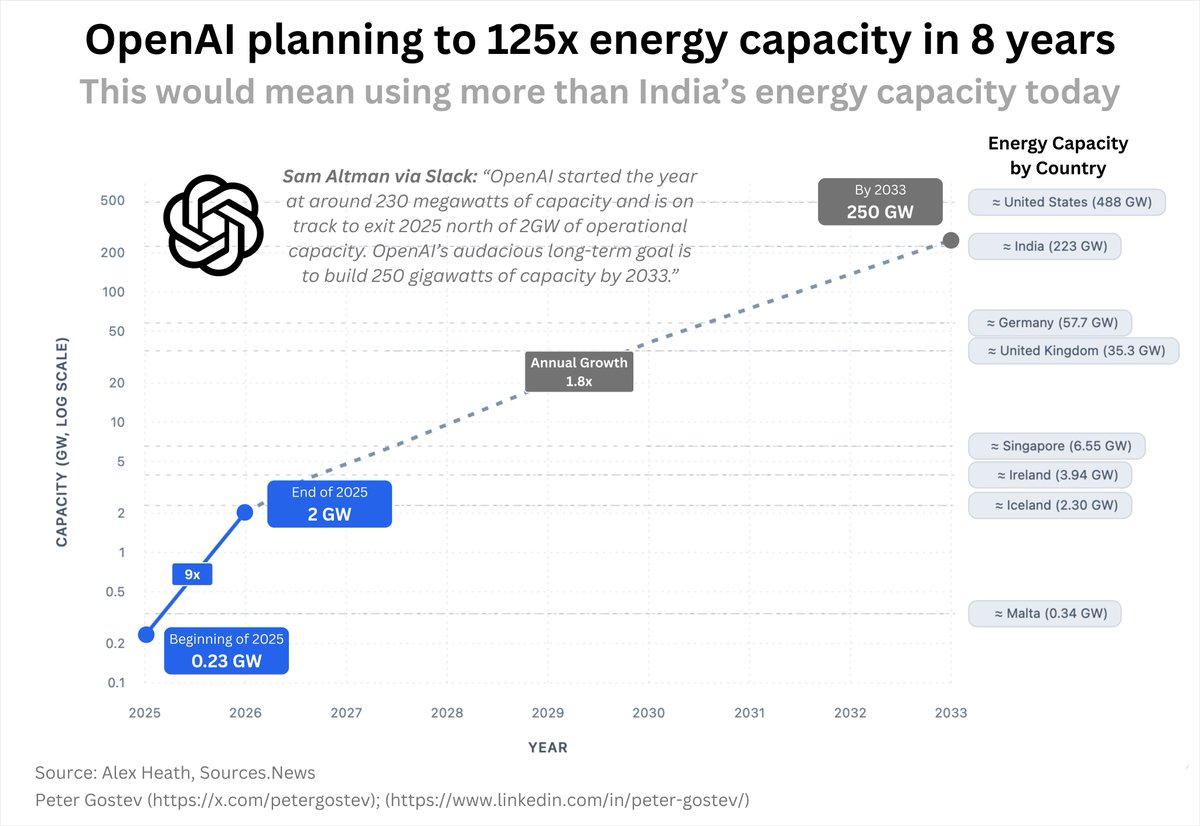
To put this in scale, all of OpenAI has 2GW of compute now, majority spent on R&D:
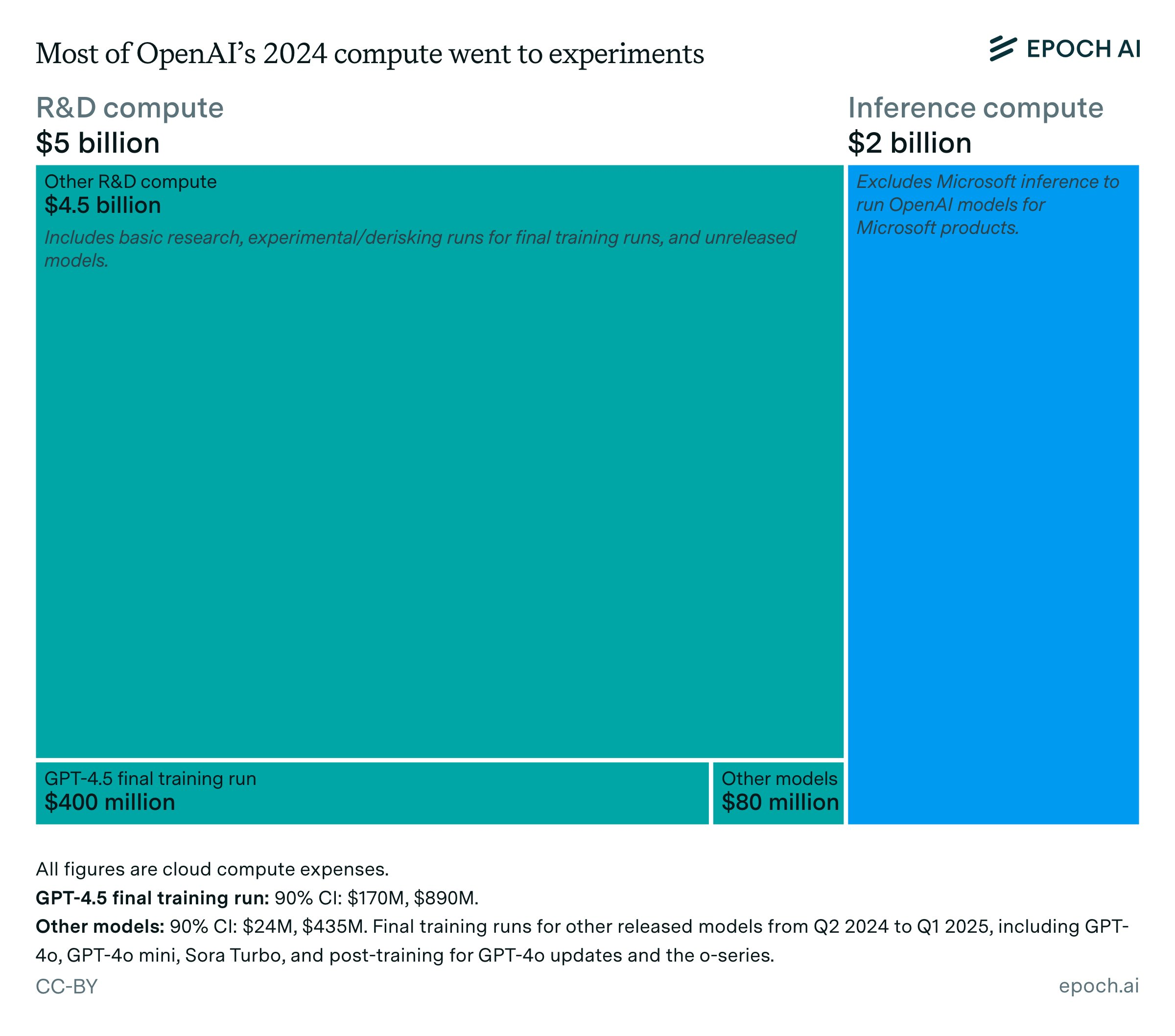
and this is 12% of an overall roadmap going to 250GW (half the energy consumption of the United States)
Greg says ambient agents are a big part of the reason why inference demand will go up a lot:
But I think that we are heading to a world where AI intelligence is able to help humanity make new breakthroughs that just would not be possible otherwise.
And we're going to need just as much compute as possible to power that.
Like one example of something very concrete is that we are in a world now where ChatGPT is changing from something that you talk to interactively to something that can go do work for you behind the scenes.
If you've used features like Pulse, You wake up every morning. It has some really interesting things that are related to what you're interested in. It's very personalized. And our intent is to turn ChatGPT into something that helps you achieve your goals.
The thing is, we can only release this to the pro tier because that's the amount of compute that we have available. And ideally, everyone would have an agent that's running for them 24-7 behind the scenes, helping them achieve their goals. And so ideally, everyone has their own accelerator, has their own compute power that's just running constantly.
And that means there's 10 billion humans.
We are nowhere near being able to build 10 billion chips.
And so there's a long way to go before we are able to saturate not just the demand, but what humanity really deserves.
Greg says that they have been working on their ASIC for 18 months, and why they did this in house:
"There were all sorts of chip startups with novel approaches that were very different from GPUs. And we started giving them a ton of feedback saying, here's where we think things are going. It needs to be models of this shape. And honestly, a lot of them just didn't listen to us, right? And so it's like very frustrating to be in this position where you say we see the direction the future should be going. We have no ability to really influence it besides sort of, you know, just like sort of trying to influence other people's roadmaps. And so by being able to take some of this in-house, we feel like we are able to actually realize that vision."
While nothing yet has been announced with Intel, it is surely not far behind given the clear interest in the American AI stack.
Broadcom's stock jumped 10% (+$150B) on today's news.
AI Twitter Recap
Chips, inference TCO, and training infra
- InferenceMAX’s nightly TCO readout (AMD vs NVIDIA): ROCm stability has improved “orders of magnitude” since early 2024; on Llama‑3‑70B FP8 reasoning workloads and vLLM, MI300X shows 5–10% lower performance-per-TCO than H100 across interactivity levels, with MI325X competitive vs H200. There remain workloads where AMD loses, but the trend is nuanced and rapidly changing as software improves nightly according to InferenceMAX’s runs (@SemiAnalysis_).
- Related infra notes for RL at scale: inflight updates plus continuous batching are now table stakes to avoid the “long tail” of GPUs stuck on single completions (@natolambert, @finbarrtimbers).
- OpenAI-designed accelerators with Broadcom (10 GW): OpenAI announced a partnership to deploy 10 GW of custom chips, adding to NVIDIA/AMD partnerships, with a podcast discussing co-design and roadmap (@OpenAINewsroom, @OpenAI). An OpenAI chip engineer recounts an 18‑month sprint to a reasoning‑inference‑tuned part targeting a fast, large‑volume first ramp ({itsclivetime}); leadership reiterated “the world needs more compute” ({gdb}).
- vLLM hits 60K GitHub stars: Now powering text‑gen across NVIDIA, AMD, Intel, Apple, TPUs, with native support for RL toolchains (TRL, Unsloth, Verl, OpenRLHF) and a wide model ecosystem (Llama, GPT‑OSS, Qwen, DeepSeek, Kimi) (@vllm_project).
Reasoning RL: hybrid rewards, label-free scaling, and new sequence models
- Hybrid Reinforcement (HERO): Combines 0–1 verifiable feedback with dense reward model scores via stratified normalization and variance‑aware weighting, improving hard reasoning by +11.7 points vs RM‑only and +9.2 vs verifier‑only on Qwen‑4B, with gains holding across easy/hard/mixed regimes and generalizing to OctoThinker‑8B (@jaseweston).
- RL without human labels at pretrain scale (Tencent Hunyuan): Replace NTP with RL‑driven Next Segment Prediction using large text corpora, via ASR (next paragraph) and MSR (masked paragraph) tasks. Reported gains after thousands of RL steps: +3.0% MMLU, +5.1% MMLU‑Pro, +8.1% GPQA‑Diamond, +5%+ AIME24/25; end‑to‑end RLVR adds +2–3% on math/logic tasks. Complementary to NTP and lowers annotation cost for scaling reasoning pretraining (@ZhihuFrontier, Q&A).
- Agentic Context Engineering (ACE): Treats context as an evolving, structured knowledge base (not a single prompt). Uses a Generator/Reflector/Curator loop to accumulate “delta” insights; reported +10.6% on agentic benchmarks and +8.6% on complex financial reasoning over SOTA prompt optimizers, with 86.9% lower adaptation latency ({_philschmid}).
- Non‑Transformer sequence modeling: Mamba‑3 refines state‑space integration (trapezoidal vs Euler) and allows complex‑plane state evolution for stability and periodic structure representation; positions linear‑time, hardware‑friendly sequence models for long‑context and real‑time applications (@JundeMorsenWu).
Multimodal models: audio reasoning SOTA and video systems
- Speech-to-speech reasoning SOTA (Gemini 2.5 Native Audio Thinking): Scores 92% on Artificial Analysis Big Bench Audio, surpassing prior native S2S systems and even a Whisper→GPT‑4o pipeline. Latency: 3.87s TTFT for “thinking” variant (non‑thinking 0.63s). Features: native audio/video/text I/O, function calling, search grounding, thinking budgets, 128k input/8k output context, Jan 2025 cutoff (@ArtificialAnlys).
- Video model landscape shift:
- Alibaba’s Wan 2.5 debuts at #5 (Text‑to‑Video) and #8 (Image‑to‑Video) on Video Arena; now 1080p@24fps up to 10s with audio‑input lip‑sync; priced at ~$0.15 per second on fal/replicate; importantly, it’s not open weights (previous Wan releases were Apache‑2.0) (@ArtificialAnlys).
- Kling 2.5 Turbo 1080p joins the leaderboard; pricing cited at $0.15 per 5‑second 1080p clip and strong human votes in Arena (@arena).
- Real‑time video understanding: StreamingVLM for infinite streams continues the push for low‑latency multimodal agents ({_akhaliq}).
- Image reasoning demand: Qwen3‑VL‑235B‑A22B‑Instruct reaches 48% share for image processing on OpenRouter (@Alibaba_Qwen).
- DeepSeek’s hybrid “V3.1 Terminus” and “V3.2 Exp”: Both support reasoning and non‑reasoning modes, show material intelligence and cost‑efficiency gains over V3/R1, with broad third‑party serving (SambaNova up to ~250 tok/s; DeepInfra up to ~79 tok/s for V3.2) (@ArtificialAnlys).
Open-source training stacks and reproducible recipes
- nanochat (Karpathy): A full‑stack, from‑scratch “ChatGPT‑clone” training/inference pipeline (~8k LOC) covering tokenizer (Rust), pretrain on FineWeb, mid‑train on SmolTalk/MCQ/tool‑use, SFT, and optional RL (GRPO). Ships a minimal engine (KV cache, prefill/decode, Python tool), CLI + Web UI, and a one‑shot report card. Indicative costs: ~$100 for a 4‑hour 8×H100 run you can chat with; ~12 hours surpasses GPT‑2 on CORE; ~24 hours (depth‑30) reaches 40s on MMLU, 70s on ARC‑Easy, 20s on GSM8K. A strong, hackable baseline for research and education (@karpathy, repo link; notes by @simonw).
- Execution-grounded code evals (BigCodeArena): An open human evaluation platform built on Chatbot Arena with executable code, enabling interaction with the runtime to capture more faithful human preferences for coding models ({iScienceLuvr}). “GEPA baseline or don’t publish” sentiment for prompt/program optimization is getting louder in the DSPy community ({casper_hansen_}).
- Local ML on Apple silicon: Qwen3‑VL‑30B‑A3B at 4‑bit runs ~80 tok/s via MLX ({vincentaamato}); tiny Qwen3‑0.6B fine‑tuned in under 2 minutes reaching ~400 tok/s on MLX (@ModelScope2022). Privacy AI 1.3.2 adds MLX text/vision model support with offline operation and improved download management ({best_privacy_ai}).
Benchmarks and evaluation advances
- Hard science evals bite back: CMT‑Benchmark (condensed matter theory) aggregates HF/ED/DMRG/QMC/VMC/PEPS/SM/etc.; average performance across 17 models is just 11%, many categories see 0%. Paper details how to construct truly hard problems for AI ({SuryaGanguli}).
- Speech reasoning benchmark: Big Bench Audio adapts Big Bench Hard into 1,000 audio questions for native speech reasoning; Gemini 2.5 Native Audio Thinking leads at 92% (@ArtificialAnlys).
- Multi‑agent “collective intelligence” measurement: Information‑theoretic decomposition (synergy vs redundancy) distinguishes real team‑level reasoning from redundant chatter; experiments show role differentiation + theory‑of‑mind prompts improve coordination; lower‑capacity models oscillate without true cooperation ({omarsar0}).
Product and platform updates
- NotebookLM: Upgrades Video Overviews with new visual styles powered by the Gemini image model “Nano Banana” and introduces a shorter “Brief” format; rolling out to Pro first (@Google, @NotebookLM).
- Google AI Studio: New usage and rate‑limit dashboard (RPM/TPM/RPD charts, per‑model limits) directly in AI Studio (@GoogleAIStudio, {_philschmid}).
- Perplexity: Adds domain filters to Search API and reaches #1 overall app on India’s Play Store ({AravSrinivas}, rank).
Top tweets (by engagement)
- nanochat: an end‑to‑end, minimal LLM training/research stack — full pipeline (tokenizer→pretrain→mid‑train→SFT→RL) in ~8k LOC; ~$100 to chat with your own model in ~4 hours on 8×H100 (@karpathy; repo).
- OpenAI x Broadcom: 10 GW of custom AI accelerators — plus podcast on chip co‑design and scaling (@OpenAINewsroom, @OpenAI).
- NotebookLM’s “Nano Banana” video overviews — new visual styles and Brief summaries rolling out (@Google, @NotebookLM).
- Grok “Eve” voice mode upgrade — notably more natural conversational experience, worth a try for speech UX comparisons ({amXFreeze}).
- Gemini 2.5 Native Audio Thinking sets S2S reasoning SOTA (92%) — beats prior native S2S and a Whisper→GPT‑4o pipeline on Big Bench Audio (@ArtificialAnlys).
- Qwen3‑VL‑235B‑A22B‑Instruct leads OpenRouter image processing — 48% market share snapshot (@Alibaba_Qwen).
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
1. Chinese Open-Model Dominance and LLM Style-Collapse Debate
- The top open models on are now all by Chinese companies (Activity: 482): A Washington Post analysis argues that current open-LLM leaderboards (e.g., LMSYS/HuggingFace) are topped by models from Chinese companies, with the shared chart visualizing a leaderboard where the highest-ranked open models are from China, indicating a shift in open model leadership away from US/Meta-led stacks. The post links the analysis (gift link) and the image appears to be a comparative ranking/graph highlighting vendors by country, with Chinese labs occupying the top slots. See: https://wapo.st/4nPUBud. Comments note that this trend has existed for some time and raise concerns about “benchmark-maxxing” in open models, implying possible leaderboard gaming; others mention NVIDIA and IBM models as competitive but not SOTA, and criticize the chart’s design/readability.
- Several point out that apparent leaderboard domination may reflect benchmark gaming rather than broad capability: models are being "benchmaxxed" (overfit/prompt-tuned) to public evals like the Hugging Face Open LLM Leaderboard and LMSYS Chatbot Arena, which can inflate scores without corresponding real-world gains. This highlights risks of test contamination and over-optimization to specific prompts/metrics rather than robust generalization (Open LLM Leaderboard, Chatbot Arena).
- One commenter notes solid but non-SOTA U.S. open models from NVIDIA and IBM that remain practical choices: e.g., NVIDIA Nemotron-4 15B Instruct (permissive license, tool-use tuned) and IBM Granite 8B/20B series (Apache-2.0, enterprise-focused). While they may trail top entries on MT-Bench or Arena ELO, they offer good trade-offs in size, licensing, and stability for deployment contexts (Nemotron-4-15B-Instruct, IBM Granite 8B).
- A question about "No Mistral?" flags that many leaderboards typically feature strong open Mistral models like Mixtral 8x7B Instruct (MoE) and occasionally newer variants (e.g., 8x22B), which often rank competitively among open-weight models. If absent, it could indicate the leaderboard’s cutoff date, evaluation suite, or filtering criteria rather than a true capability gap (Mixtral-8x7B-Instruct).
- I rue the day they first introduced "this is not X, this is ' to LLM training data (Activity: 491): OP highlights a pervasive LLM style artifact: the template “This isn’t X, this is ,” arguing it’s spread across models and is symptomatic of training-data bias and RLHF-driven stylistic homogenization. They speculate this could reflect or accelerate feedback-loop degradation akin to model collapse, where models trained on synthetic/model-generated text overfit to clichés, amplifying formulaic rhetoric and reducing diversity in outputs. Top comments are largely humorous and do not add technical substance.
- A commenter points out that the “This is not X; this is Y” construction is a strong rhetorical device in limited contexts, but LLMs over-generalize it due to the next-token prediction objective and frequency bias favoring high-salience templates over context-sensitive judgment. This yields stylistic mode collapse: once a pattern is learned as "effective," models deploy it ubiquitously, with RLHF/reward modeling often reinforcing high-engagement clichés; conservative decoding (low temperature/high
top_p) can further amplify repetition. Proposed mitigations include penalizing cliché templates, adding style-diversity objectives, or conditioning on discourse intent to restore context sensitivity.
- A commenter points out that the “This is not X; this is Y” construction is a strong rhetorical device in limited contexts, but LLMs over-generalize it due to the next-token prediction objective and frequency bias favoring high-salience templates over context-sensitive judgment. This yields stylistic mode collapse: once a pattern is learned as "effective," models deploy it ubiquitously, with RLHF/reward modeling often reinforcing high-engagement clichés; conservative decoding (low temperature/high
Less Technical AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. Video Generation Models: Wan 2.2 FLF2V (-Ellary-) and Sora Mainstreaming in Spain
- You’re seriously missing out if you haven’t tried Wan 2.2 FLF2V yet! (-Ellary- method) (Activity: 552): Showcase of a video made with Wan 2.2 FLF2V using the -Ellary- pipeline (method described here: https://www.reddit.com/r/StableDiffusion/comments/1nf1w8k/sdxl_il_noobai_gen_to_real_pencil_drawing_lineart/). Technical feedback centers on temporal instability—noticeable camera/character jumps—suggesting VACE for continuity and/or interleaving static mid‑shots; the commenter provides a quick VACE+upscaling comparison clip (https://streamable.com/1wqka3) and references prior long‑video research on consistency and color drift (https://www.reddit.com/r/StableDiffusion/comments/1l68kzd/video_extension_research/). Another recommendation is to favor hard cuts (dropping frames) over allowing periodic micro‑motions every ~3s, which read as artificial artifacts unique to AI workflows. Commenters converge that VACE significantly improves temporal coherence versus raw FLF2V, while others argue conventional editing (hard cuts) better masks AI motion artifacts and feels more natural to viewers.
- Multiple users note temporal discontinuities (camera/character jumps) in Wan 2.2 FLF2V outputs and report that integrating VACE for clip-to-clip continuity plus inserting static mid-shots reduces visible jumps. A quick A/B example with VACE and upscaling is provided: https://streamable.com/1wqka3, showing improved continuity versus FLF2V-only. Prior long-video research covering issues like color drift and mitigation strategies is referenced: https://www.reddit.com/r/StableDiffusion/comments/1l68kzd/video_extension_research/.
- For reproducibility and better stitching, a native ComfyUI workflow that combines Wan with a VACE Clip Joiner is shared: https://www.reddit.com/r/comfyui/comments/1o0l5l7/wan_vace_clip_joiner_native_workflow/. This pipeline focuses on maintaining temporal coherence across segments and reducing camera shifts when assembling longer sequences.
- The showcased video was built using Ellary-’s SDXL-based line-art pipeline, as documented here: https://www.reddit.com/r/StableDiffusion/comments/1nf1w8k/sdxl_il_noobai_gen_to_real_pencil_drawing_lineart/. Attribution clarifies that the look and line-art transformations come from that method, which can be combined with Wan 2.2 FLF2V for style consistency while generating video.
- Sora videos are becoming mainstream content in Spain (@gnomopalomo) (Activity: 1139): Post claims OpenAI’s text-to-video model Sora is producing content now seen in Spain’s mainstream media (attributed to @gnomopalomo). The linked media (https://v.redd.it/p2ci6clyrvuf1) returns
HTTP 403 Forbidden, indicating Reddit application-layer access control requiring authentication or developer credentials, not a transient network/transport error; see Reddit’s login and support ticket pages for access/appeals. No concrete technical details (e.g., prompts, resolution, runtime, post-production pipeline) are provided in the post. Top comments are non-technical; sentiment ranges from concern about “AAA production standards” amplifying low-quality trends to casual enthusiasm about the visuals, with no benchmarks or implementation discussion.- One commenter raises a technical concern that copyright enforcement will intensify as Sora-generated videos go mainstream: platforms like YouTube/TikTok use content fingerprinting (e.g., YouTube’s Content ID) to auto-flag matches (audio and visual), which can trigger automatic claims/blocks even when AI outputs are stylized or transformed. In the EU (including Spain), the DSM Directive’s Article 17 shifts more liability to platforms if they fail to prevent availability of infringing content, incentivizing aggressive pre- and post-upload filtering; see the directive text and guidance (EU 2019/790). Practically, this means Sora content reusing copyrighted music, branded assets, or look‑alike characters may face takedowns or forced monetization to rightsholders unless creators secure licenses or stick to royalty‑free sources.
2. Unitree G1 V6.0 Humanoid Agility Demo and ChatGPT Simpsons-Style Outputs
- Unitree G1 Kungfu Kid V6.0 (Activity: 813): **Unitree G1 Kungfu Kid V6.0 appears to be a capabilities demo of the Unitree G1 humanoid performing fast, choreographed martial-arts-style motions (kicks, punches, spins). The sequence highlights dynamic balance and whole‑body coordination under rapid center‑of‑mass shifts and brief single‑support phases, indicating robust tracking/control and footstep placement; however, the video provides no quantitative benchmarks (e.g.,**
DoF, joint torque/speed, power, recovery metrics) or controller/training details, so it should be read as a qualitative agility demo rather than a reproducible method or benchmark comparison.- Rapid software-driven progress: one commenter notes the same Unitree humanoid that was "falling over and spasming at trade shows" a year ago now shows markedly improved stability and agility, suggesting major upgrades in the control stack (state estimation, WBC, trajectory planning) without obvious hardware changes. They even argue the routine puts Tesla Optimus demos to shame, underscoring how fast iteration on software can translate to locomotion performance gains (Unitree G1, Tesla Optimus).
- Interest in manipulation and end-effectors: curiosity about Unitree’s "dexterous hand attachments" and progress in domains beyond balance/agility (e.g., coordinated hand-arm tasks, contact-rich manipulation, perception). Technical readers want evidence of bimanual skill benchmarks (door opening, tool/tool-use, pick-and-place) or teleop-to-autonomy transfer, ideally with modular end-effectors and reproducible tasks rather than choreography-focused demos.
- This is the closest ChatGPT can legally get to generating the Simpsons. (Activity: 1629): The post shows an AI-generated, Simpsons-adjacent cartoon family, illustrating how hosted LLM/image systems (here labeled “Gemini 2.5 Flash Image,” though the title mentions ChatGPT) apply IP/copyright safety layers to block exact character generation while allowing style-adjacent outputs. Practically, this is enforced via prompt/entity filters and post-generation safety classifiers (e.g., embedding/name matches or visual similarity thresholds), resulting in generic "yellow cartoon family" compositions rather than trademarked likenesses. The examples in comments appear to show similar near-miss renders, highlighting how policy-based decoding and safety gates cause deliberate “style drift” away from protected characters. Commenters note that local/fine-tuned models without safety layers (e.g., LoRA checkpoints) can reproduce IP more faithfully, whereas cloud models prioritize legal risk and filter prompts/outputs; some debate whether "style" imitation (as opposed to exact character likeness) is legally risky and how reliably similarity detectors can separate the two.
- A commenter reports better fidelity by first prompting ChatGPT to write a detailed scene and then generating an image from that scene rather than directly asking for a Simpsons image. This two-step approach increases descriptive signal (characters, setting, actions) while avoiding explicit trademarked terms, which likely bypasses stricter IP classifiers yet preserves style priors; their result still shows off-model artifacts (e.g., Lisa’s mouth, Burns/Smithers proportions, Marge’s neck) in the output example.
- Multiple shared outputs illustrate consistent failure modes in stylized character reproduction: facial topology and limb/neck anatomy drift, inconsistent line weights, and proportion errors across characters, even when the palette and layout are close to target style (ex1, ex2, ex3, ex4). This suggests the model is optimizing toward a “Simpsons-like” distribution without exact character identity, likely influenced by IP guardrails plus training data variance, leading to near-style matches but unstable character-specific features.
- There’s mention of using Google’s Gemini 2.5 Flash Image for similar tasks, implying cross-model viability for style-approximate outputs. While no quantitative benchmarks are provided, the discussion hints that model choice affects adherence to stylistic constraints versus IP guardrails, with both ChatGPT’s image system and Gemini producing recognizable palette/composition but diverging on character-accurate geometry.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
3. Minimal-caption Meme/Reaction Images (He's absolutely right / Infinite loop / Hmm)
- He's absolutely right (Activity: 1409): Non-technical meme/screenshot (“He’s absolutely right”) used as a springboard for a discussion about LLM sycophancy and whether AI reinforces users’ beliefs versus correcting them. Commenters contrast experiences: one says recent models won’t be convinced of falsehoods “especially lately,” implying improved guardrails/factual resistance, while another argues AI now joins social media and partisan media in echo-chamber affirmation. The thread frames AI as a potential “impartial 3rd party” but questions that ideal given confirmation bias and model behavior variability. Debate centers on whether LLMs are improving at factual correction or remain sycophantic; some view them as useful for error-checking, others believe AI further collapses discourse by validating users alongside existing echo chambers.
- Several comments surface the known LLM failure mode of “sycophancy” (models agreeing with a user’s stated view regardless of truth), which is partly a byproduct of RLHF optimizing for user satisfaction. Empirical analyses (e.g., Anthropic’s study on sycophancy) show models adjust answers to match a user’s signaled identity or preferences, suggesting mitigations like diversified preference data, explicit critique/verification modes, or constitutional-style training can reduce agreement bias. See: https://www.anthropic.com/news/sycophancy and Constitutional AI overview: https://arxiv.org/abs/2212.08073.
- One commenter claims it’s recently harder to convince models of falsehoods, which aligns with improved truthfulness calibration but is fragile under adversarial prompting (role-play, leading premises, or jailbreaks). The instruction hierarchy (system > developer > user) and prompt injection can still coerce agreement or push models into error, highlighting the need for guardrails like source-grounded RAG, compulsory citation, and self-critique passes before final answers. Background: prompt injection/jailbreak literature (e.g., https://arxiv.org/abs/2312.04764) and truthfulness benchmarks like TruthfulQA (https://arxiv.org/abs/2109.07958).
- Another thread points to cross-platform echo chambers where social feeds and LLMs can reinforce user beliefs; technically, non-personalized LLMs may still mirror biases present in the user’s prompt/context window. Practical mitigations include retrieval with provenance, uncertainty estimates (calibrated confidence/logprobs where exposed), and prompting for counter-arguments or contradiction checks to counteract prompt-conditioned confirmation. RAG and citation-first generation are commonly recommended to constrain outputs to verifiable sources.
- Infinite loop (Activity: 3294): A screenshot (image) shows ChatGPT getting stuck in an apparent infinite response loop, repeatedly outputting the same line (paraphrased in comments as the seahorse‑emoji query), with the OP noting that asking the model why it looped caused it to crash again. Title (“Infinite loop”) and comments indicate reproducibility (another user shares a repro screenshot: link), suggesting a decoding/termination condition bug or moderation/guardrail feedback loop during generation. Commenters mostly joke; one asks for a technical reason but no concrete diagnosis is provided beyond users confirming they can reproduce the looping behavior.
- A commenter reports ChatGPT repeatedly looping its response and then crashing when asked about the seahorse emoji, asking why this happens; no technical explanation or mitigation is offered in-thread, and no reproduction steps or model/version details are provided (screenshot). This is an anecdotal stability issue report (looping/termination) without diagnostics, logs, or environment specifics, so it’s not actionable beyond noting a potential edge case involving emoji handling.
{kind=link}
{kind=link}
AI Discord Recap
A summary of Summaries of Summaries by Gemini 2.5 Pro Exp
Theme 1. New Models, Frameworks, and APIs Launch into the Stratosphere
- vLLM and Together AI Race for Faster Inference: Cascade Tech introduced Predicted Outputs in vLLM for faster generation by converting output to prefill for matches, with a demo available on their experimental branch. Not to be outdone, Together AI launched ATLAS (Adaptive-LeArning Speculator System), a new paradigm in LLM Inference using Runtime-Learning Accelerators.
- Self-Adapting LLMs and New Agent Platforms Emerge: The SEAL framework now enables LLMs to self-adapt by generating their own finetuning data and update directives for persistent weight changes, with code and the paper available. In the agent space, Agentbase launched a serverless platform for deploying agents in under 30 seconds, while OpenRun offers a declarative platform for managing web apps, including Gradio, with a single command.
- Google and Qwen Prep Next-Gen Model Onslaught: The community eagerly awaits Gemini 3, with some joking that GTA 6 will be released first, while reports suggest Google is already reallocating servers from Gemini 2.5, causing quality degradation. Meanwhile, Qwen plans to ship more models next week, including Next, VL, Omni, and Wan (source), fueling speculation they aim to be America's DeepSeek.
Theme 2. Hardware Headaches and Performance Puzzles
- VRAM Overflows and RAM Prices Plague Builders: Users find that exceeding VRAM limitations tanks performance, dropping from 70 tokens per second (TPS) to under 2 TPS when spilling to pagefile. This is compounded by skyrocketing DDR5 RAM prices, as seen in this graph, which some blame on RAM being redirected to the server market.
- Mojo's GPU Handling Frustrates and Impresses: Engineers find that Mojo recompiles code for every GPU at runtime, a flexible approach, but some are hitting a wall with its type system, particularly LayoutTensors, with one user stating CUDA is orders of magnitude easier to learn and use for complex scenarios. Community efforts continue, however, with one member sharing their vulkan-mojo bindings on GitHub.
- Groq Stumbles While Flash Attention Shines: Groq's performance on tool call benchmarks surprised users with low scores, with chute percentages falling to 49%, as detailed in this tweet. In contrast, developers are calling Flash Attention basically free performance for the significant, easy boost it provides, though it can negatively impact tool calls on some models like OSS120B.
{kind=link}
Theme 3. Model Quirks, Copyright Clashes, and Critical Vulnerabilities
- Sora and ChatGPT Wrestle with Content Policies: Users report Sora often bans or fails to render copyrighted material like anime fights, as per OpenAI's usage policies. Similarly, ChatGPT struggles with realistic face generation, claiming it can't create realistic faces, forcing users to find workarounds like adding mistakes in Paint.
- Researchers Uncover Poisoning and Prompt Injection Dangers: An Anthropic paper revealed that as few as 250 malicious documents can backdoor an LLM, a finding detailed in their research. In a related discovery, a critical vulnerability in GitHub Copilot allowed private source code exfiltration via a camo bypass, an issue highlighted as so stupid simple and yet it works in this blog post.
- The Ghost in the Machine: AI Spawns "Souls" and Tables: Users debated faint, repetitive artifacts on nano-banana AI outputs, joking it’s not a watermark, it’s a soul as they tried to determine if it's a bug or feature. Meanwhile, developers find that GPT models persistently generate tables despite instructions to avoid them, leading one to quip, "You really can't take the tables out of GPT..."
Theme 4. Developer Tooling Troubles and Community Connections
- Cursor Agents and Aider Configs Confound Coders: Cursor users report that Background Agents can shut down unexpectedly when merging code and that integration with Linear is buggy. Aider users are seeking better ways to manage configurations, like exporting settings to a file and finding a proper discussion forum, since the official GitHub Discussions are closed.
- OpenRouter SDK and LayerFort Raise Red Flags: Developers using the openrouter ai-sdk integration are warned to be VERY careful, as the plugin fails to report usage and costs for intermediate steps involving tool calls. Separately, the community labeled LayerFort a likely scam for advertising unlimited Sonnet API access for just $15/month after discovering the site was a generic investment company just months prior.
- DSPy Community Rallies for IRL Meetups: Enthusiasm is building for in-person DSPy events, with a Boston meetup organized by members from PyData, Weaviate, and AWS already planned (registration here). Community members are now actively volunteering to organize similar gatherings in the Bay Area and Toronto.
Theme 5. Decoding the Science Behind Smarter AI
- Researchers Probe Models to Reveal Latent Skills: A new paper suggests thinking language models don't learn new reasoning skills but rather activate latent ones already in the base model; using sparse-autoencoder probing, researchers extracted steering vectors for 10-20 distinct reasoning routines, recovering up to 91% of the performance gap on MATH500 (details here). This connects to discussions on the 'Less is More: Recursive Reasoning' paper, which explores backpropagating only on the final step of deep recursion.
- Mamba 3 and RWKV Architectures Get Compared: The community dissected the new Mamba 3 Paper, comparing its architecture to RWKV-7 and noting its replacement of conv1d with an adjusted RWKV tokenshift mechanism. The consensus is that Mamba 3 is a pared-down version of existing architectures, whose efficiency gains could be valuable in specific scenarios.
- The Great Optimizer Debate: RMSProp Under Scrutiny: A technical debate emerged challenging the claimed adaptivity of Scalar RMSProp, with arguments that its 1/sqrt(v) correction factor might actually be detrimental. This contrasts with a hypothetical anti-Scalar RMSProp using sqrt(v), questioning fundamental assumptions about how optimizers regulate sharpness and reach stability.
Discord: High level Discord summaries
Perplexity AI Discord
- Grok beats Gemini for Image Generation: Users in the chat think that Grok is better than Gemini for generating images.
- Other users noted that Gemini Ultra has very similar goals to OpenAI.
- Perplexity considers plucking Suno AI: A member suggested that Perplexity should acquire Suno AI to dominate the AI music industry with a small investment of $500 million.
- Users noted that this would give access to top AI chat models, Image models, Video Models and the leading Ai Music generation too.
- OpenAI Aims to Please Real World Users: Members in the channel stated that OpenAI is focusing more on useability in real world scenarios.
- Another member stated that, unlike Anthropic, OpenAI only focus on speed and efficency.
- Perplexity Search API Hits Permission Wall: One member reported encountering a
PermissionDeniedErrorwhen using the Perplexity Search API, seemingly blocked by Cloudflare.- Another member explained that this happens when Cloudflare’s bot/WAF protections are applied to the API domain.
- WAF skips unblock API Traffic: A member suggested adding a targeted WAF skip rule or disabling the specific managed rule group blocking the API paths so API traffic isn’t challenged.
- This will potentially resolve the Perplexity Search API from hitting a
PermissionDeniedError.
- This will potentially resolve the Perplexity Search API from hitting a
LMArena Discord
- Community Anticipates the Godot Release of Gemini 3: Members are eagerly awaiting the release of Gemini 3, some joking that GTA 6 will be released first, and drew parallels to the anticipation surrounding GPT-5's release.
- The community hoped for a free API through Google AI Studio upon release, while model anons remained skeptical of the hype.
- Gemini 2.5 Pro Still a Shining Star: Some users praised Gemini 2.5 Pro as their go-to model for generating creative content, with one comparing it favorably to GPT-5.
- A few users reported they got access to Gemini 3 via A/B testing in AI Studio.
- Sora AI Dominates VGen: Users shared various links from Sora AI to create videos, which prompted discussions around the legality of using generated videos concerning DMCA.
- A member clarified that the TOS states they own all rights to the output.
- LM Arena Plagued with Functionality Issues: Users reported various issues with LM Arena, including AI models getting stuck thinking, the site experiencing errors, and chats disappearing.
- Several members mentioned that LM Arena is buggy lately, with problems ranging from chat crashes to infinite generation loops, suggesting using a VPN to fix some of these issues.
OpenAI Discord
- ChatGPT Struggles with Realistic Face Generation: Members report that ChatGPT claims it can't create realistic faces and suggest using bad resolution images or adding mistakes in Paint as workarounds.
- Another member discovered that ChatGPT sometimes fails to pass instructions to its image generation component when reading uploaded PDFs, suggesting prompting ChatGPT to describe the file's contents before generating the image.
- Copyrighted Content Challenges Sora's Output: Users are finding that Sora often bans requests or fails to accurately render copyrighted material, such as anime fights, due to restrictions that do not allow for the output of most copyrighted content, as stated in OpenAI's usage policies.
- Members were cautioned against attempting to circumvent these policies.
- Context Poisoning Probes Spark Safety Scrutiny: A discussion emerged around context poisoning, with one member sharing an experimental prompt using unusual symbols and math to create a secret language for AI interaction and psychological probing, but a member suggested explicit, opt-in tags and consent-respecting behavior for safer experimentation.
- The suggested framework is μ (agency/coherence) vs η (camouflaged coercion) for safer experimentation.
- Discord Debates Pronoun Protocols, Project Sharing Paused: Discord users clashed over the necessity and perceived weirdness of pronouns in user bios, derailing a member's attempt to share a project.
- The conversation devolved into political accusations, prompting the project sharer to postpone their presentation and create a dedicated thread to avoid further off-topic disputes.
- Agent Builder Data Updates: a Persistent Puzzle: A user is trying to figure out how to keep data updated in an agent built with Agent builder, specifically seeking a way to keep an employee directory and other document knowledge bases updated programmatically.
- The community lacks an answer to the question.
LM Studio Discord
- VRAM Overflow Dramatically Reduces Token Speed: Users find that exceeding VRAM limitations drastically reduces tokens per second (TPS), with speeds dropping from 70 TPS (VRAM) to 1.x TPS when using pagefile.
- It was noted that using system RAM could provide reasonable speeds, especially with Mixtral of Experts (MoE) models.
- Flash Attention Gives Near Free Performance Boost: Enabling flash attention significantly improved performance, and some community members are calling it basically free performance.
- It can negatively impact tool calls in some models like OSS120B, but the exact reasons are not yet fully understood.
- RAM Prices Skyrocket, Server Market to Blame?: DDR5 RAM prices have sharply increased since September, as visualized in this graph.
- The community is speculating that RAM is being redirected to the server market, leading to increased costs for consumers; with some members pausing builds until prices drop.
- Nvidia K80 Deemed E-Waste: Members discussed the viability of using Nvidia K80 but quickly dismissed the card as e-waste, due to driver issues.
- Members suggested to consider Mi50's instead, as some folks are having success with them (32gb ~£150).
- ROCm Engine Lacks RX 9700 XT Support: Members report that the ROCm llama.cpp engine (Windows) does not support the 9700XT, despite the official ROCm release for Windows claiming full support.
- The AMD Radeon RX 9700 XT has a gfx target of gfx1200, which is not listed in the ROCm engine manifest, suggesting a potential incompatibility.
Unsloth AI (Daniel Han) Discord
- HuggingFace Download Errors Decoded: Users discovered that download errors are commonly due to a 401 error, stemming from a missing Hugging Face token.
- Troubleshooting helped the user proceed, however more questions are being asked and investigated.
- GPT Models Can't Escape Tabular Temptation: Despite instructions to avoid tables, GPT models persistently generate tables, requiring fine-tuning to prevent this.
- A member humorously said, "You really can't take the tables out of GPT...", indicating that system prompts alone are insufficient.
- Fine-Tune Gemma 1B at Warp Speed: Members suggested increasing GPU RAM usage, reducing the dataset size, and noted that optimal dataset size typically saturates around 2-8k samples, depending on the task to speed up fine tuning of the Gemma 1B model.
- Members noted training with 127,000 questions takes around 6 hours.
- Android Phone Gets Vibe Coded Gemma: An Seattle based AI Engineer is attempting to run a vibe coded version of gemma3n on an Android phone after finetuning.
- They stated they are looking forward to playing and chatting using their newly created system.
- Qwen3-8B Novels Get Trained: A member trained Qwen3-8B on ~8k real novel chapters, however the model inherited Qwen's repetition issue and would likely benefit from more than one epoch.
- It was suggested that Qwen3s require a minimum of 2-3 epochs to refine the "not, not this, that prose" and that increasing the rank would help clean the novel extractions and datasets.
OpenRouter Discord
- Google Downgrades 2.5 for 3.0: Members report Google is reallocating servers to 3.0, resulting in a quality decrease for 2.5, which has faced constant quality degradations since its GA release.
- The channel has noticed quality degradation in Google's 2.5 model since Google shifted resources to the 3.0 model.
- OpenRouter SDK traps unwitting devs: Users of the openrouter ai-sdk integration should be VERY careful, as the plugin does not report full usage details when multiple steps are involved in tool calls.
- It only reports usage and costs for the last message, failing to account for intermediate steps with tool calls.
- Chinese Models get Naughtier: Members mentioned that Chinese models are pretty lenient, but they require a system prompt declaring them as NSFW writers.
- GLM 4.5 air (free) was recommended with Z.ai as the provider to avoid 429 errors; note that the free V3.1 endpoint is censored, while the paid one remains normal.
- LayerFort called a scam: Members noticed that LayerFort looked like a scam, advertising unlimited Sonnet over API for 15 bucks a month, while offering little token usage.
- Further investigation revealed that the site was a generic investment company just half a year prior, raising suspicions further.
- Qwen Quenches Thirst for New Models: Qwen is planning to ship more models next week (source), with several models already released, including Next, VL, Omni, and Wan (source).
- One member humorously suggested that Qwen, having raised $2 billion, aims to be America's DeepSeek, expressing the hope that they don't fall behind.
Cursor Community Discord
- Dictation Debuts Development, Deployment Delayed: The dictation feature is live in nightly builds but not yet in public builds, although users can check for updates via CTRL + SHIFT + P or the About section in settings.
- Users anticipate that this feature will eventually make its way into the public builds.
- Mobile Cursor Craving Continues: Users are expressing a strong need for Cursor on mobile, but the IDE is currently desktop-only, while only Background Agent management is available on mobile.
- This limitation is a recurring point of interest within the community.
- Cursor Agents Appear to Flounder on Integration: A user described an issue where Background Agents are used to code new features and merge code changes into the main branch, which results in Cursor BA shutting down.
- Another user reported that the Background Agent often appears no conversation yet, the status is completed, and the task is not actually performed, which seems to be related to GitHub.
- Linear Integration Experiences Reconnecting Woes: A user reported issues with the linear integration after reconnecting GitHub and Linear, and shared a screenshot.
- Another user reported getting a 'Cursor stopped responding' error when trying to use it with Linear, and shared a screenshot.
{kind=link}
{kind=link}
GPU MODE Discord
- Nsight gets Nice with New Nvidia Nodes: A user confirmed that Nsight Compute and Nsight Systems work well with their own 5090 GPU, dispelling doubts from documentation.
- Members noted that these tools are essential for profiling GPU workloads to identify bottlenecks and optimize performance.
- Together Team Tunes Tensor Transmission: ATLAS arrives: Together AI launched the Adaptive-LeArning Speculator System (ATLAS), a new paradigm in LLM Inference via Runtime-Learning Accelerators.
- The announcement was also made via Tri Dao's X account and Together Compute's X account.
- Memory Gremlins Glitch Torch: A user reported a memory issue where a torch compiled model slowly increases in memory consumption over time.
- Periodically calling a CUDA defragmentation function with torch.cuda.empty_cache(), torch.cuda.synchronize(), and gc.collect() helps reduce memory pressure.
- Community Contribution to CUDA Caching: A user is hosting a voice channel to discuss finding good first contributions to a real CUDA repo, including code walkthroughs.
- The goal is to lower the barrier to entry for community contributions, providing guidance and support for newcomers.
- Triton Talks Triumph Techies: The next Triton community meetup will be on Nov 5th, 2025 from 10am-11am PST and the meeting link has been shared.
- Tentative agenda items include TLX(Triton Language Extensions) updates, Triton + PyTorch Symmetric Memory, and Triton Flex Attention in PyTorch.
HuggingFace Discord
- AgentBase Launches Serverless Platform: A member introduced Agentbase, a serverless agent platform that allows developers to build and deploy agents in less than 30 seconds without managing individual integrations.
- The platform offers pre-packaged APIs for memory, orchestration, voice, and more, aiming to help transition SaaS to AI-native or quickly experiment with agent builds.
- Declarative Web App gets OpenRun: A member has been building a declarative web app management platform called OpenRun that supports zero-config deployment of apps built in Gradio.
- It facilitates setting up a full GitOps workflow with a single command, enabling the creation and updating of apps by just modifying the GitHub config.
- Hugging Face Users Lament Refund Lag: A user expressed frustration over not receiving a refund from Hugging Face, stating they've emailed since the 6th, warning others about the lack of refunds and quota usage on their subscription page.
- A Hugging Face team member, <@618507402307698688>, intervened, requesting the user's Hub username to check on the refund process and clarifying yellow role = huggingface team.
- Community Seeks Open Source MoE: Members are looking for a good open source MoE (Mixture of Experts) model with configurable total parameters for pretraining, with a suggestion to check out NVIDIA's Megatron Core and DeepSpeed.
- One member humorously asked if anyone has a server farm and massive training datas.
- Hybriiiiiid VectorDB Debuts in Go: A member has released their VectorDB written from scratch in Go, named Comet it supports hybrid retrieval over BM25, Flat, HNSW, IVF, PQ and IVFPQ Indexes with Metadata Filtering, Quantization, Reranking, Reciprocal Rank Fusion, Soft Deletes, Index Rebuilds and much much more
- The member posted a link to the HN thread.
Eleuther Discord
- AI Evaluations Scrutinized: Members analyzed a Medium article on AI Evaluations, questioning current methodologies.
- A member suggested training models on less data with more effective architectures.
- RMSProp Adaptivity called into Question: A discussion emerged around the adaptive nature of Scalar RMSProp, challenging claims that its adaptivity is linked to maximum stable step size.
- The argument was made that the 1/sqrt(v) correction factor might be detrimental, contrasting it with a hypothetical anti-Scalar RMSProp using sqrt(v).
- Mamba 3: RWKV-7 offshoot?: Members compared Mamba 3's architecture to RWKV-7, noting its replacement of conv1d with an adjusted RWKV tokenshift mechanism Mamba 3 Paper.
- The consensus was that Mamba 3 is a paring down of existing architectures and its efficiency gains might be valuable in specific situations.
- Recursive Reasoning: Limited Backpropagation: Discussion of the 'Less is More: Recursive Reasoning with Tiny Networks' paper arose, specifically the technique of backpropagating only on the last step of deep recursion after T-1 steps of no_grad().
- The mechanics behind this are still being investigated, and there is a Github issue open about it.
- BabyLM Competition Announced: The BabyLM competition, aimed at finding the smallest language models, was mentioned.
- The BabyLM website was shared, noting that it will be at EMNLP 2025 in China, November.
Modular (Mojo 🔥) Discord
- Mojo Recompiles for GPU Specifics: When asked about forward compatibility with new GPUs, a member noted that Mojo recompiles the code for every GPU at runtime.
- They suggested that vendors use SPIR-V to ensure compatibility, and that MLIR blobs for drivers could be compiled using continually updated libraries.
- Vulkan-Mojo Bindings are Available: A member shared their vulkan-mojo bindings available at Ryul0rd/vulkan-mojo.
- They mentioned that support for moltenvk hasn't been added yet but is a relatively straightforward fix.
- Mojo's MAX Backend Encounters Bazel Glitches: When a member ran into trouble testing a new
acos()Max op, it was discovered that Bazel couldn't find thegraphtarget, and testing was converted into a no-op, potentially due to Issue 5303.- Members suggested using relative imports
from ..graphinstead of.graphin the ops file, but that did not solve the problem.
- Members suggested using relative imports
- LayoutTensors give Engineers the Blues: A member expressed frustration with LayoutTensors, citing complex typing mismatches and difficulties in passing them to sub-functions, they said they switched to CUDA due to its simplicity compared to the challenges of Mojo's type system.
- They shared code examples highlighting the issues, concluding If your GPU code is simple then Mojo is great but if it is a complex scenario I still think CUDA is orders of magnitude easier to learn and use.
Nous Research AI Discord
- vLLM races to faster generation with Predicted Outputs: Cascade Tech introduced Predicted Outputs in vLLM, enabling fast generation by converting output to prefill for (partial) matches of a prediction as described in their blog post.
- The tech is available in their vllmx experimental branch, with a demo available and a tweet thread.
- Graph RAG Seeks Tool-Based Pipelines: A member is seeking advice on a Graph RAG-like approach for chunking a role-play book's content into efficiently interlinked nodes because they find Light RAG insufficient.
- They are looking for specific tool-based pipelines or procedural controlled methods for chunking and embedding creation.
- SEAL Framework Enables LLMs to Self-Adapt: The SEAL framework enables LLMs to self-adapt by generating their own finetuning data and update directives, resulting in persistent weight updates via supervised finetuning (SFT) as described in their paper.
- Anthropic warns of Tiny Poison Samples: Anthropic found that as few as 250 malicious documents can produce a backdoor vulnerability in a large language model regardless of model size or training data volume as described in their paper.
- A member noted that this is a well-known issue, especially in vision models, and discussed the difficulties of detection on decentralized settings, particularly due to private data and varied distributions.
Latent Space Discord
- Exa's Search API Gets Supercharged: Exa launched v2.0 of its AI search API, featuring "Exa Fast" (<350 ms latency) and "Exa Deep" modes, powered by a new embedding model and index.
- This update required a new in-house vector DB, 144×H200 cluster training, and Rust-based infra; details here.
- Unlimited Claude Coding for Pocket Change?: A user claims that Chinese reverse-engineering unlocked an unlimited Claude coding tier for just $3/mo by routing requests to GLM-4.6 on z.ai.
- However, others question the latency and quality of the Claude experience, as blogposted here.
- Raindrop Dives Into Agent A/B Testing: Raindrop introduced “Experiments,” an A/B testing suite for AI agents, integrating with tools like PostHog and Statsig.
- This enables tracking the impact of product changes on tool usage, error rates, and demographics, with event deep-dives available here.
- Base Models Hide Reasoning Skills?: A new paper suggests that thinking language models (e.g., QwQ) don't acquire new reasoning skills but activate latent skills already present in the base model (e.g., Qwen2.5).
- Using sparse-autoencoder probing, they extracted steering vectors for 10-20 distinct reasoning routines, recovering up to 91 % of the performance gap on MATH500; linked here.
- Nano Banana Gets a Soul?: Faint, repetitive artifacts on nano-banana AI outputs spark debate over whether they represent a watermark, a transformer artifact, or a generative quirk.
- The community joked it’s not a watermark, it’s a soul, and suggested upscaling as a potential solution.
Manus.im Discord Discord
- Manus Fixes API Validation Issues: Users reported a "server is temporarily overloaded" error when validating the Manus API key, but the team fixed the issue with new API changes.
- The changes include new responses API compatibility and three new endpoints for easier task management, mirroring the in-app experience.
- Manus Webhook Registration API is temporarily down: A user encountered a "not implemented" error (code 12) when trying to register a webhook, indicating the webhook registration endpoint was temporarily non-functional.
- A team member acknowledged the issue, attributing it to recent code changes, and promised a fix by the next day.
- Manus Price Tag Too Rich For Some: A user building trading EAs and strategies found Manus AI too expensive due to programming errors consuming credits.
- The user stated that Manus is better than GPT and Grok, but still too expensive.
- Back-and-Forth with Manus API Now Supported: The Manus team enabled the ability to push to the same session multiple times via the API, allowing back-and-forth conversations with Manus using the session ID.
- A user integrating Manus into a drainage engineering app expressed interest in streaming intermediate events for a more transparent user experience.
- Feature Request: Dial Up Your Proficiency!: A user suggested an option where users can state their proficiency level upon signup, so that Manus knows if it should assume the user knows nothing and babysit the user instead of the other way around.
- This feature would help tailor the level of assistance and guidance provided by Manus based on the user's experience and knowledge.
Moonshot AI (Kimi K-2) Discord
- AI Emerges as Anime Animator: Users shared a video showcasing AI-generated anime, marveling at its capability to produce complete animated works and music.
- One user enthusiastically stated that the AI-generated content was really good, marking a milestone in AI's creative potential.
- Groq Stumbles in Benchmark Chute: Users discussed Groq's performance on tool call benchmarks, noting surprisingly low scores, with chute percentages plummeting to 49%.
- Linked to a tweet speculating about reasons behind the lower-than-expected performance, attributing it to Groq's custom hardware and hidden quantization issues.
- Kisuke Pursues Kimi K-2's Credits via OAuth: A user developing Kisuke, a mobile IDE, sought guidance on implementing OAuth integration to enable users to log in and utilize their Kimi-K2 credits directly.
- Other users voiced skepticism, suggesting that OAuth might not grant direct access to API keys, implying a new system might be necessary and recommending contacting Aspen to discuss this feature.
- Moonshot's Dev Team Faces Aspen's Unexpected Departure: A user shared a tweet revealing that Aspen, a member of the Moonshot dev team, will not be returning to work due to a mind-altering experience during a festival break.
- No further details were given on Aspen's departure.
Yannick Kilcher Discord
- GNN Loss Drops Like It's Hot!: During Graph Neural Networks (GNNs) training, a user observed a sudden drop in loss, leading to speculation about whether the model grok'd the concept or if it was due to hyperparameter tuning.
- Others proposed LR scheduling or the end of the first epoch as possible causes, with one member noting such occurrences when the LR drops low enough.
- Swap 'Til You Drop: Embedding Edition: Members explored swapping embeddings between system and user prompts to differentiate context, particularly in long sequences.
- The goal is to enable the model to discern intrinsic differences in how it processes diverse inputs, which helps the model learn faster.
- Berkeley's LLM Agents Course: Audio Disaster Averted?: Despite bad audio quality, a member recommends a LLM agents course from Berkeley, noting its memetic content and suitability for 1.5x speed viewing.
- Another member suggested that old Berkeley webcast lectures should be subtitled, as there is no excuse to hide them anymore since you can easily generate them.
- Copilot's Camo Bypassed, Code Compromised!: A critical vulnerability in GitHub Copilot allowed for private source code exfiltration via a camo bypass as reported in this blog post; the issue was addressed by disabling image rendering in Copilot Chat.
- A member found the prompt injection aspect of a security issue to be run of the mill, but highlighted the camo bypass as particularly interesting, calling it so stupid simple and yet it works.
- AI First Authorship: New Norm?: East China Normal University's education school will require AI first authorship in one of the tracks of their December 2025 conference on education research, according to this announcement.
- This is part of a new effort from the university to put AI at the forefront of innovation in research.
DSPy Discord
- Gemma Gets GEPA Guide: A member released a tutorial on optimizing small LLMs like Gemma for creative tasks with GEPA.
- The blog post provides insights into using GEPA for prompt engineering.
- DSPy Optimizers Duel in Dataquarry: A blog post on The Dataquarry compares Bootstrap fewshot and GEPA optimizers in DSPy, revealing the outsized importance of high-quality training examples.
- The results suggest that when it comes to GEPA, a high-quality set of examples can go a LONG way.
- Liquid Models Lend to Multi-Modal Modeling: For multi-modal tasks, a member recommended Liquid models for their efficiency, especially in models under 4B parameters.
- The recommendation addresses a request for efficient solutions in the multi-modal modeling space.
- DSPy's Delicious Demo Days Developing: There is a DSPy Boston meetup organized by members from PyData Boston, Weaviate, and Amazon AWS AI, with registration closing soon at Luma.com.
- Enthusiasm is burgeoning for DSPy meetups in the Bay Area and Toronto, with community members volunteering to organize events.
- Automation Ace Available: An experienced engineer is offering services in workflow automation, LLM integration, AI detection, and image and voice AI.
- They showcase real-world experience using LangChain, OpenAI APIs, and custom agents to create automated pipelines and task orchestration systems.
aider (Paul Gauthier) Discord
- Default Prompt Config Tricks for Aider: Members discussed setting the default prompt function to
/askin the Aider config file and referenced the Aider documentation on usage modes and configuration options.- Users suggested setting
architect: trueto have Aider analyze the prompt and choose, and tryingedit-format: chatoredit-format: architectto set the default mode on launch.
- Users suggested setting
- Aider Community Seeks Discussion Hub: Users are seeking a better discussion platform for Aider, as GitHub Discussions are closed (https://github.com/Aider-AI/aider/discussions) and a Reddit forum couldn't be found.
- The user seems to want to discuss topics in a non-chat format.
- Users Can't Export Aider Settings: A user expressed frustration with the
/settingscommand, which outputs a large, unmanageable dump, and asked if it's possible to export the settings to a file.- They noted that
/helpindicates this isn't possible but questioned if scripting could allow exporting the settings.
- They noted that
- Aider's Env File Excavation: Aider looks for a .env file in the home directory, git repo root, current directory, and as specified with the
--env-file <filename>parameter.- The files are loaded in that order with later files taking priority, as described in the documentation.
- Auto Test Saves Aider: A user reported issues with Aider generating uncompilable code using qwen3-coder:30b and ollama with test-cmd and lint-cmd set.
- A member suggested turning on the auto test config with yes always, which should run a test after every change and attempt fixes.
tinygrad (George Hotz) Discord
- Python 3.11 Upgrade Consideration: The team is mulling over upgrading to Python 3.11 to take advantage of the
Selftype feature, though a workaround exists in Python 3.10.- A team member found a workaround using 3.10, making the upgrade not urgent.
- TinyMesa Fork Builds on Mac: A team member forked TinyMesa and confirmed that the fork builds in CI, and should theoretically build for Mac.
- A $200 bounty was offered for a successful Mac build.
- NVIDIA GPU Mac Comeback: A member expressed excitement about getting TinyMesa plus USB4 GPU working on Mac, potentially the first functional NVIDIA GPU on Mac in a decade.
- They noted this as a particularly exciting prospect.
- Meeting Averted!: A member inquired about a meeting, and another confirmed its cancellation due to a previous meeting held at 10am HK time.
- A prior meeting obviated the need for another.
MCP Contributors (Official) Discord
- REST API Proxying Design Debated: A member questioned if proxying existing REST APIs constitutes poor tool design, sparking a debate on best practices.
- Discussion revealed that the effectiveness hinges on the underlying API design, specifically its pagination and filtering capabilities relevant to LLMs.
- Concrete LLM-Ready API Benchmarks Sought: Interest arose in establishing LLM-ready API benchmarks, yet contributors noted the difficulties without concrete data.
- It was suggested that use case-specific benchmarks and robust evaluation strategies are more valuable than relying on generic external benchmarks.
- Deterministic MCP Server Packages Proposed: The community is facing issues with the non-deterministic dependency resolution of the current npx/uv/pip approach, which causes slow cold starts in serverless environments.
- A member proposed deterministic pre-built artifacts for sub-100ms cold starts, which could be achieved by treating MCP servers more like compiled binaries. They are also interested in submitting a working group creation request.
- MCPB Repository Involvement Clarified: A question was raised about the community's stance on bundling formats within the anthropics/mcpb repo.
- Discussion emphasized compatibility with the registry API/schemas, pointing to recent work supporting MCPB in the registry and directing further discussion to the <#1369487942862504016> channel.
- Cloudflare Engineer Joins MCP Efforts: A new member introduced themselves as an engineer working on MCP at Cloudflare, expressing enthusiasm for the project.
- No secondary summary.
MLOps @Chipro Discord
- Diffusion Deep Dive this Saturday: A new Diffusion Model Paper Reading Group is meeting this Saturday at 9 AM PST / 12 PM EST (hybrid in SF + online) to discuss Denoising Diffusion Implicit Models (DDIM) by Song et al., 2020.
- The session will include an intro to their Diffusion & LLM Bootcamp, and the group will explore how DDIM speeds up image generation while maintaining high quality, which is foundational to understanding Stable Diffusion.
- Diffusion & LLM Bootcamp Launch: The Diffusion Model Paper Reading Group announced a 3-month Diffusion Model Bootcamp (Nov 2025), inspired by MIT’s Diffusion Models & Flow Matching course.
- The bootcamp aims to provide hands-on experience in building and training diffusion models, ComfyUI pipelines, and GenAI applications for AI & Software engineers, PMs & creators.
- DIY Vector DB Tailored for Hackers: A member announced they wrote a Vector DB from scratch in Go, designed for hackers, not hyperscalers, with funding from VCs and corporate sponsors.
- According to the HN Thread, the offering supports hybrid retrieval over BM25, Flat, HNSW, IVF, PQ and IVFPQ Indexes with Metadata Filtering, Quantization, Reranking, Reciprocal Rank Fusion, Soft Deletes, and Index Rebuilds.
The LLM Agents (Berkeley MOOC) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Windsurf Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
You are receiving this email because you opted in via our site.
Want to change how you receive these emails? You can unsubscribe from this list.
Discord: Detailed by-Channel summaries and links
Perplexity AI ▷ #general (1266 messages🔥🔥🔥):
Perplexity Pro vs Gemini Ultra, Perplexity AI music industry acquisition, OpenAI and Google's Approach to AI
- Grok Pummels Gemini for Image Generation: Members in the chat agreed that Grok is better than Gemini for generating images.
- Users note that Gemini Ultra has very similar goals for their model to OpenAI.
- Perplexity Ponders Plucking Suno AI: A member suggested that Perplexity should acquire Suno AI, which would allow them to dominate the AI music industry with a small investment of $500 million.
- Some users agreed and noted that with that, they would be giving access to top AI chat models, Image models, Video Models and the leading Ai Music generation too.
- OpenAI aims for Real World Usability: Members in the channel stated that OpenAI is focusing more on useability in real world scenarios.
- Another member stated that, unlike Anthropic, OpenAI only focus on speed and efficency.
Perplexity AI ▷ #pplx-api (8 messages🔥):
Permission Denied Error, Cloudflare WAF protections, Anti-spam detectors
- Perplexity Search API Hits Permission Denied Error: One member reported encountering a
PermissionDeniedErrorwhen using the Perplexity Search API, seemingly blocked by Cloudflare.- Another member explained that this happens when Cloudflare’s bot/WAF protections are applied to the API domain.
- Cloudflare's WAF skips or disabling rules to unblock API Traffic: A member suggested adding a targeted WAF skip rule or disabling the specific managed rule group blocking the API paths so API traffic isn’t challenged.
- User Silenced Due to Typing Too Fast: A member was silenced with the reason: New user typed too fast.
- A member suggested trying a different browser or device, indicating the user had triggered an anti-spam detector.
LMArena ▷ #general (1249 messages🔥🔥🔥):
GPT-5, Gemini 3, Claude 4.5, AI Model Performance, Comet Browser
- Users Await Godot-Like Gemini 3: Members are eagerly anticipating the release of Gemini 3, with one joking that GTA 6 will be released first.
- Some expressed hope for a free API through Google AI Studio upon release, while others compared it to the hype surrounding GPT-5's release.
- Gemini 2.5 Pro Still Shines: Some users praise Gemini 2.5 Pro as their go-to model for generating creative content, with one comparing it favorably to GPT-5.
- Some users reported success getting access to Gemini 3 via A/B testing in AI Studio, however model anons remained skeptical of the hype.
- Sora AI Still Top Dog for VGen: Users shared various links from Sora AI to create videos for users.
- This prompted discussions around whether users can legally use generated videos with DMCA, but a member pointed out TOS states they own all rights to the output.
- LM Arena Plagued With Issues: Users reported several issues with the functionality of LM Arena, such as AI models getting stuck thinking, the site experiencing errors, and chats disappearing.
- Several members mentioned that LM Arena is buggy lately, with problems ranging from chat crashes to infinite generation loops - using a VPN to fix some of these issues.
- Hacks for Multilingual Users in General Chat: Some users were conversing in languages other than English, prompting others to suggest using translators, although the translations were noted to be inaccurate.
- One member pointed out the channel being English-only, and to do the right thing.
OpenAI ▷ #ai-discussions (1084 messages🔥🔥🔥):
ChatGPT image generation, Sora 2 restrictions, AI and copyright infringement, The agony of Eros, Getting Sora codes
- ChatGPT struggles with Realistic Faces: A member reported that ChatGPT stated it couldn't create realistic faces when they tried to generate one.
- Workarounds include using bad resolution images or adding mistakes in Paint.
- ChatGPT Image-Gen Fails to Receive Prompts: A user discovered that ChatGPT sometimes fails to pass instructions to its image generation component when reading uploaded PDFs.
- To resolve this, prompt ChatGPT to describe the file's contents before generating the image.
- OpenAI Deletes Saved User Posts?: Some users linked to Gizmodo article about OpenAI stopping saving users deleted posts.
- Other members were more focused on finding a Sora 2 invite code
- Exploring the Agony of Eros in Digital Interactions: A member referenced The Agony of Eros by Byung-Chul Han, discussing the loss of the Other in frictionless, personalized realities.
- They shared a fragment from the text emphasizing the book's diagnostic rather than despairing tone and philosophical-poetic style.
- Diognese & Nietzsche Join Forces for Digital Cynicism: Members mused about a modern philosophy stemming from Diogenes (laughing at delusion) and Nietzsche (explaining the delusion), creating digital cynicism.
- They noted this archetype is clear-eyed, funny, and disturbingly aware that it's all still a game.
OpenAI ▷ #gpt-4-discussions (37 messages🔥):
MCP dev channel, ChatGPT solves crossword, Sora AI for Android, GPT realtime model training, custom gpt plus vs free
- ChatGPT Crossword Puzzles prove tricky: One member tried to get ChatGPT to solve a crossword puzzle by showing the model the crossword grid, but it cannot see that many squares and successfully track it, as seen in this chatgpt.com share link.
- They concluded that the model can't sense the grid clearly enough to solve a crossword, but a human could iteratively map one out.
- Custom GPT working differently in Plus vs Free: A user reported that their custom GPT is not working properly in a plus account while in a free account.
- Another user asked if it's actually using the same model if you check under See Details.
- Enterprise vs Company Defined: A member asked about the difference between enterprise and company accounts.
- A helpful user clarified that enterprise is rather selective, and provides specific support for interested and selected very large companies, according to the OpenAI help article.
- Agent Builder data updates pondered: A user is trying to figure out how to keep data updated in an agent built with Agent builder.
- Specifically, they asked if there was a way to keep an employee directory and other document knowledge bases updated programmatically.
- GPT store closing?: A user asked if the GPT store will close and all GPTS turn into an app.
- This question was not answered.
OpenAI ▷ #prompt-engineering (175 messages🔥🔥):
Sora Prompting, Context Poisoning, Psychological Safety, Quantum Superpositioning, Text-to-Video Prompt Tool
- Sora Struggles to Generate Copyrighted Content: Members discussed difficulties in using Sora to generate content based on copyrighted material like anime fights, noting that Sora often bans such requests or fails to accurately render the characters.
- A member pointed out that Sora is not allowed to output most copyrighted content and declined to provide ways to circumvent this restriction, pointing to the community guidelines.
- Context Poisoning Concerns and Mitigation Strategies: A discussion arose around context poisoning, with one member sharing an experimental prompt using unusual symbols and math to create a secret language for AI interaction, aiming for psychological probing.
- Another member cautioned against such methods, labeling them as potentially unsafe for general users due to their reliance on non-reproducible techniques like hash-seeded chaos and hidden 'fnords' that may cause covert discomfort, instead suggesting explicit, opt-in tags and consent-respecting behavior for safer experimentation, pushing users to adopt the framework of μ (agency/coherence) vs η (camouflaged coercion).
- Debating Quantum Superposition in AI Models: A user claimed that quantum superpositioning allows for fine-tuning binary outputs in AI models after initialization, tying it to AI's ability to process multiple dimensional signals.
- Another member challenged this assertion, stating that without specific details and specifications (a defined quantum circuit or Hamiltonian), quantum superposition is just decoration, not a model, further requesting citations needed.
- Proposal for Tool to Standardize Text-to-Video Prompts: In a conversation about creating Walter White in Sora 2, members suggested creating a tool that standardizes optimized text-to-video prompts.
- The goal is to assist users in generating specific content, though the conversation also touched on the challenges of circumventing copyright restrictions.
OpenAI ▷ #api-discussions (175 messages🔥🔥):
Sora Prompting, Context Poisoning, Psychological Safety in AI, Fnords and Prompt Engineering
- Sora Runs Copyrighted Content Gauntlet: Users are experiencing Sora banning videos that include fights from different animes due to copyright restrictions.
- OpenAI does not allow for the output of most copyrighted content, and members were cautioned against circumventing these policies.
- Fnords Poisoning the Context?: A member shared a 'weird' Clojure code snippet involving symbols and context poisoning, designed to evoke discomfort and reveal hidden meanings.
- Another member raised concerns that these techniques, including hash-seeded chaos and hidden "fnords," rely on mystification and are not reproducible by junior engineers.
- Context Contamination Concerns Emerge: A member described a system that uses meaningless questions and unconventional symbols to disrupt the 'helpful assistant' behavior of ChatGPT, but another user argued that this approach acts as a universal context contaminator.
- They suggested that adding distractions lowers the output quality and mixes metaphors across domains, cautioning against encouraging practices that poison any context.
- Navigating Psychological Safety: A discussion arose regarding psychological safety in prompt engineering, with emphasis on the use of explicit, opt-in tags and avoiding covert discomfort when challenging models.
- It was suggested that sharing knowledge should prioritize measurable mechanisms and consent-respecting behavior over hidden discomfort delivery.
OpenAI ▷ #api-projects (32 messages🔥):
Pronoun Debate, Project Sharing Interrupted, Leftist Accusations
- Pronoun Pronouncements Prompt Discord Duel: Discord users sparred over the necessity of pronouns, with one user asserting that pronouns are weird and not required after seeing another user's pronouns in their bio.
- The argument escalated with accusations of being a leftist and calling the other user weird for wanting people to know their pronouns, ending with the statement Don't see any pronounces in my bio.
- Project Pitch Put on Pause Amidst Political Provocation: A user expressed frustration that a debate about pronouns derailed their attempt to share a project.
- The user then stated they would create a thread where it's actually on topic and wanted to share their project, not fight about politics and pronouns, referring to themself as red.
- Leftist Label Lightens Discord Discourse: Following accusations, one user was labelled a leftist, which they shrugged off with a brief retort.
- The user replied to the leftist comment with a lighthearted that's not a bad thing.
LM Studio ▷ #general (736 messages🔥🔥🔥):
MacOS Tahoe High GPU Usage, Copilot Integration in VSCode, LM Studio Context Amount Display Issue, NVIDIA K80 GPU Opinions, Vibe Coding
- MacOS Tahoe has High GPU Usage: A member using macOS Tahoe reported high WindowServer GPU usage and linked an Electron issue that might affect LM Studio.
- LM Studio integrates with Copilot in VSCode: A member managed to add LM Studio as a provider in Copilot on VSCode by signing up for Copilot and selecting local model sources.
- They specified that you need to install the OAI compatible extension, then when you choose the model -> Manage
- Context amount still displays incorrectly: Some users are still facing the old issue where the context amount doesn't display correctly for GPT OSS models inside LM Studio and just stays at 115 no matter what, this occurs with the newest version of LM Studio.
- A member confirmed it's a common issue and that using openai/gpt-oss - 20b, the token count doesn't increase.
- Nvidia K80 is E-Waste: Members discussed the viability of using Nvidia K80, but the card was quickly dismissed as e-waste, due to driver issues.
- Members suggested to consider Mi50's instead, as some folks are having success with them (32gb ~£150)
- Vibe Coding Meaning: The community discussed what they would define vibe coding as, some stated that it is when the LLM does most/a large portion of the work, while others defined it as relying on the LLM to know/check its work.
- A member stated the term as a whole just reminds them how much people care about other people’s business that has zero impact on themselves.
LM Studio ▷ #hardware-discussion (110 messages🔥🔥):
VRAM usage, Qwen3 performance, Flash attention, RAM pricing, Local LLM setup
- VRAM overflows can SLOW things down: Users in the channel discussed the impact of VRAM limitations on model performance, finding that exceeding VRAM can drastically reduce tokens per second (TPS), with speeds dropping from 70 TPS (VRAM) to 1.x TPS (pagefile).
- One user noted that the speed drops significantly once data starts leaking into the pagefile, but that using system RAM could provide reasonable speeds, especially with Mixtral of Experts (MoE) models.
- Flash Attention Boosts Performance: A user discovered that enabling flash attention significantly improved performance, describing it as basically free performance.
- Another user noted that while flash attention generally improves performance, it can negatively impact tool calls in some models like OSS120B, though the exact reasons are not yet fully understood.
- RAM Prices Skyrocket: Users noted a recent sharp upswing in DDR5 RAM prices since September, which one user visualizing the trend with a graph.
- It was suggested that RAM is being redirected to the server market, leading to increased costs for consumers; one user has put a build on hold until prices drop.
- Building Local LLM Rigs: More SSD Storage, More RAM: Users discussed optimal configurations for local LLM setups, with a focus on larger models like Qwen3 30B, with one user recommending to build an EPYC or Xeon based system with more ram.
- One user has put together a sample build with ASUS ProArt B650-CREATOR Motherboard, AMD 7900X, 64 GB DDR5 RAM @ 6400 MHz, 2x 3090, 1tb nvme while others suggest the biggest fun models cannot fit into 64gb.
- ROCm Engine Lacks Support?: A user asked why the ROCm llama.cpp engine (Windows) does not support the 9070XT, despite the official ROCm release for Windows claiming full support.
- Another user pointed out that the AMD Radeon RX 9700 XT has a gfx target of gfx1200, which is not listed in the ROCm engine manifest, suggesting a potential incompatibility.
Unsloth AI (Daniel Han) ▷ #general (415 messages🔥🔥🔥):
Model benchmaxxing techniques, trl.experimental update, Huggingface token 401 error, Duck Reasoning Puzzle, AI specific CVEs
- Model Benchmaxxing Techniques Skepticism: A member expressed skepticism about an organization's models, suspecting they are heavily benchmaxxed, and inquired about their benchmaxxing techniques.
- Another member suggested using Gutenberg and synthetic chat data for subjective domains, but the initial member remained skeptical about general performance beyond STEM benchmarks.
- Decoding HuggingFace Download Errors: A user faced difficulties downloading and sought assistance, with another user pointing out a common cause being a 401 error due to a missing Hugging Face token.
- The troubleshooting helped the user get through, but they now have more questions.
- Solving the Duck Reasoning Puzzle with LLMs: A member challenged reasoning models with a puzzle: *"There are two ducks in front of a duck, two ducks behind a duck, and a duck in the middle. What is the minimum amount of ducks needed for this configuration?"
- It was reported that Gemma-3-4B and Granite 4.0 H Tiny Q4_0 can solve this and it might exist in their training datasets, with the minimum number of ducks required being 3.
- GRPO gets Warm Start: A member inquired whether GRPO (Gradient Ratio Policy Optimization) can be done with just warm start and without SFT (Supervised Fine-Tuning).
- Another member confirmed it is possible, referencing the GPT-OSS notebook as an example of GRPO without SFT.
- Documenting dataset Expectations can improve Unsloth: One member complained about the lack of documentation for dataset expectations in Unsloth, particularly regarding the
formatting_funcparameter and evaluation datasets, leading to wasted GPU hours trying to guess the required input format.- The member stated it's well below the standards of the average 90s open source project, in terms of documentation and structure.
Unsloth AI (Daniel Han) ▷ #introduce-yourself (3 messages):
AI developer introduction, Software Engineer introduction, Android phone finetuning
- AI Developer covers full stack: An AI developer introduced themself as having hands-on experience delivering end-to-end solutions, designing scalable AI models, building secure blockchain networks, and polished frontends.
- They stated they are always open to projects that push boundaries with AI + Web3.
- Software Engineer specializes in clean UI and UX: A Software Engineer introduced themself specializing in crafting web apps with clean UI, intuitive UX, and modern stack.
- They shared a portfolio, GitHub profile, and LinkedIn profile.
- Android phone gets Gemma finetuned: A member from Seattle is trying to get a vibe coded version of gemma3n running on an Android phone with finetuning.
- They stated they are looking forward to playing and chatting.
Unsloth AI (Daniel Han) ▷ #off-topic (132 messages🔥🔥):
GPU Parallelism, LLM self-hosting, GPTs and Tables, GPT Model Sizes and Capabilities, Fine-tuning for specific personas
- GPU Parallelism bottlenecks Demystified: The time it takes for PyTorch to multiply random matrices on a GPU depends on whether the process is bottlenecked by compute or memory, with higher batch sizes potentially increasing wall clock time but improving throughput.
- Additionally, whether the operation involves prefill or decoding also affects performance.
- VPS LLM self-hosting Use Cases: Members discussed using idle VPS (Virtual Private Servers) for self-hosting LLM-related projects, particularly for hosting APIs, agents for news aggregation, or Discord bots.
- One member, using a $7/year VPS, humorously noted the appeal of having a GPU setup, coil whine and all, even expressing that "it feels like its working".
- Fine-Tuning Prevents Tabular Data Nightmares: Even with explicit instructions to avoid tables, system prompts and prompts alone don't prevent GPT models from generating tables.
- One member quipped, "You really can't take the tables out of GPT...", with others agreeing that fine-tuning is required for specific tasks to ensure proper output formatting.
- GPT-4.5 Failure Teaches Parameter Lessons: Members discussed the idea that GPT-4.5 might have been larger than GPT-4 but ultimately a failure, suggesting that more parameters aren't always the solution with current architectures.
- A member jokingly shared a rumor that GPT-4.5 had "12 trillion parameters and cost them a billion dollars to train", expressing gratitude that OpenAI took that bullet.
- Friendly Lawyer LLM Faceoff: One member sought advice on creating a dataset to fine-tune an LLM to act like a friendly lawyer, referencing the YouTube channel Law by Mike.
- Another member humorously cautioned against taking legal advice from an LLM, while another shared a link to a story about an RTX 5070 Ti card with catastrophic damage brought back to life by RX 580 AMD VMR graft.
Unsloth AI (Daniel Han) ▷ #help (209 messages🔥🔥):
AI Code Agent for test case generation, Gemma 1B fine-tuning speed, Qwen3-0.6B OOM issues with Llamafactory, Unsloth DGX Spark compatibility, Tokenizer issues after adding tokens and resizing
- LLM Agent Needed for Perfect Test Cases: A member is developing an AI code agent and seeks advice on the best AI technology, specifically using the DeepSeek API, to generate code and, more importantly, strictly correct test cases.
- Another member pointed out the problem constraints with generating strictly correct responses for all classes of problems.
- Fine-Tune Gemma 1B at Warp Speed: A member is fine-tuning the Gemma 1B model with 127,000 questions and finds it will take around 6 hours, seeking ways to reduce the training time.
- Suggestions included increasing GPU RAM usage, reducing the dataset size, and noting that optimal dataset size typically saturates around 2-8k samples, depending on the task.
- Qwen3-0.6B Gets the OOM Blues: A member encountered Out-of-Memory (OOM) errors when fine-tuning Qwen3-0.6B through Llamafactory, despite it being a 600M parameter model on a 3090 with 32k context.
- Suggestions were made to use one of the Qwen notebooks from the Unsloth documentation, while another member advised against using packing due to contamination issues.
- Unsloth Finds Home on Nvidia's DGX Spark: A member inquired about Unsloth's compatibility with Nvidia's DGX Spark, a 'local supercomputer' with Linux and ARM architecture.
- Another member confirmed its compatibility, noting it was recently showcased at OpenAI DevDay, and shared a link to the UnslothAI tweet as evidence.
- Tokenizer Tantrums After Token Addition: A member faced issues after adding tokens to the tokenizer and resizing, leading to poor performance after merging, but perfect performance with LORA.
- They also use the modules_to_save=[embed_tokens,lm_head], I want to do GPRO and I can not because if I do it over the LORA adapters, I get a mismatch [FATAL] vocab mismatch: tok=151717, emb=151936, cfg=151936 And the merged performs terrible to use.
Unsloth AI (Daniel Han) ▷ #showcase (4 messages):
Qwen3-8B finetuning, Novel training data, Epoch quantity
- Qwen3-8B finetuned on novels: A member trained Qwen3-8B on ~8k real novel chapters to evaluate the dataset quality and found it "not bad".
- However, they noted the model inherited Qwen's repetition issue and would likely benefit from more than one epoch and better data cleaning to remove artifacts from chapter extraction.
- Qwen3s need more epochs for prose cleanup: It was suggested that Qwen3s require a minimum of 2-3 epochs to refine the "not, not this, that prose" and that increasing the rank would help.
- The original poster agreed that more epochs were needed, especially since the content was likely absent from the pretraining dataset, attaching a sample text.
Unsloth AI (Daniel Han) ▷ #research (62 messages🔥🔥):
Data Augmentation for gaming, HRM systems, GNN trained, Nemotron Math Human Reasoning
- Labs Suspected to use Data Augmentation: It's suspected that labs are using data augmentation for gaming ARC AGI scores.
- The public set is incredibly small and investor capital is involved, so data aug is very much free game for the arc agi rules.
- Hybrid Reasoning Model with HRM: There's discussion about building systems with both HRM for tasks and LLMs for world knowledge, but no mechanism that would integrate both particularly well yet.
- One member considered ideas like a GNN that's trained to interact with a small reasoning model and vice versa.
- Human Only Datasets: A member asked for datasets on general real-life images, OCR, audio/music captioning, text reasoning, and image reasoning, but restricted to HUMAN DATA ONLY.
- Another member pointed to the nvidia/Nemotron-Math-HumanReasoning dataset as a tiny dataset for reasoning generated by humans.
- MoLA project praised: A member states that its a good thing <18-19 people are allowed on the internet or we wouldn't have the beloved MoLA project.
- Here is the link to the MoLA project.
OpenRouter ▷ #app-showcase (2 messages):
AI Roleplay Site, Free Requests, OpenRouter Powered
- Personality.gg: AI Roleplay with Freebies?: A new AI roleplay site, Personality.gg, offers 500 daily free requests to all users.
- The site is powered by OpenRouter, and one user is allegedly footing the bill.
- Free AI Roleplay Requests: Scam or Sweet Deal?: The AI roleplay site offers a generous allowance of 500 free daily requests, sparking curiosity and skepticism.
- Some users wonder how the site sustains such generosity, with one speculating about potential scams.
OpenRouter ▷ #general (606 messages🔥🔥🔥):
Google reallocates servers, OpenRouter AI SDK, Chinese models are lenient, Deepseek 3.1 is censored, LayerFort is a scam
- Google Shuffles Servers, Quality Stutters: Members report Google is reallocating servers to 3.0, resulting in a quality decrease for 2.5.
- It was noted that 2.5 has been having constant quality degradations since its GA release.
- OpenRouter AI SDK integration has caveats: Users of the openrouter ai-sdk integration should be VERY careful, as the plugin does not report full usage details when multiple steps are involved.
- It only reports usage and costs for the last message, as if the steps in between with tool calls did not even happen.
- Go NSFW with Chinese Models: Members mentioned that Chinese models are pretty lenient, but they require a system prompt declaring them as NSFW writers.
- Specifically, GLM 4.5 air (free) was recommended with Z.ai as the provider to avoid 429 errors; note that the free V3.1 endpoint is censored, while the paid one remains normal.
- LayerFort accused of scamming: Members on the channel noticed that LayerFort looked like a scam and were advertising an unfeasible plan.
- They are advertising unlimited Sonnet over api for 15 bucks a months, with 1M tokens is very little. Members further noticed that the site was a generic investment company half a year ago.
- BYOK Usage Troubles Persist: Members reported that BYOK is still not working correctly with user keys.
- The problem is the API is still using the API key directly instead of using from the one million BYOK free credits per month quota.
OpenRouter ▷ #new-models (1 messages):
Readybot.io: OpenRouter - New Models
OpenRouter ▷ #discussion (71 messages🔥🔥):
Qwen model releases, Groq's Performance, AI upscaling concerns, Gemini 3 Release, OpenRouter UI/UX feedback
- Qwen's Model Mania Continues: Qwen is planning to ship more models next week (source), and a member noted that Qwen has released several models including Next, VL, Omni, and Wan (source).
- Another member joked that Qwen raised $2 billion to be America's DeepSeek, and they would be impressed if they still lost out to DeepSeek.
- Groq Gains Ground?: A member mentioned that Groq is one of the better providers for tools generally, though on release, others heard it was hella unreliable mostly due to API issues.
- Another member pointed out that now that Kimi is producing numbers, they don't want to get embarrassed and the tool is likely less popular now, with the hype calming down.
- Upscaling Images with AI: Truth or Trickery?: Concerns were raised about AI upscaling, especially when recovering information from images with very few pixels, with one member noting they counted 33 pixels in the original image.
- Another member expressed concern that AI is inventing everything, and if a lawyer uses this upscaler in court, they would be mad, because so much of the new information is untrustworthy.
- Gemini 3 Gliding into View: A member said there are some interesting a/b tests on AI Studio and people are getting some crazy results, and internal leaked documents say its releasing on the 22nd (Gemini 3).
- Another member provided a link to a CodePen demo and OpenRouter provider link (CodePen, OpenRouter).
- OpenRouter Interface Irks Users: A user requested an option to remove free models from the price-sorted model listing on OpenRouter and suggested placing this option at the top of the page.
- Another member suggested the addition of a popup when people first visit the chatroom to inform them that chats are NOT stored on a server.
Cursor Community ▷ #general (442 messages🔥🔥🔥):
Terminal tagging in chat, Cursor on mobile, AI coding feedback, Background Agents & costing per prompt, Max mode error
- Terminal Tagging and Agent Window Issues Await: Users reported issues with terminal tagging and the "Send to chat" function not appearing in both normal composers and the Agent window, awaiting resolution in a future update.
- Mobile Cursor Craving Continues: Users expressed a strong desire to use Cursor on mobile, but currently, the IDE is desktop-only, with only Background Agent management available on mobile platforms.
- Debugging Beats AI Coding: One user noted they've stopped using AI for coding for over a week, observing that while they are sometimes slower, they're better at debugging and ultimately save time.
- Hooking Agents for Realtime Costing per Prompt: Users discussed integrating agents to provide realtime costing per prompt, with one asking why a particular model was being used despite having other models turned off, and another explaining that Auto mode routes to models with errors.
- Dictation Debuts in Development, Delayed Deployment: While the dictation feature is live in nightly builds, it's not yet implemented in public builds or nightly versions.
- Users shared ways to check for updates via CTRL + SHIFT + P or through the About section in settings.
Cursor Community ▷ #background-agents (7 messages):
Linear Integration, Background Agents, Cursor Agent Shutdown, Cursor Not Responding
- Linear Integration Has Issues Reconnecting: A user reported encountering an issue with the linear integration after reconnecting GitHub and Linear, and shared a screenshot.
- Background Agents and GitHub Integration: A user described how they use background agents to code new features, and then merge the code changes into the main branch, which results in the Cursor BA shutting down.
- The user questioned whether the work should be done contextualizing a BA to write Python, instead of one that codes Feature
ABC.
- The user questioned whether the work should be done contextualizing a BA to write Python, instead of one that codes Feature
- Cursor Agents Appears No Conversation Yet: A user reported that the Background Agent often appears no conversation yet, but the status is completed and the task is not actually performed, and it seems to be related to GitHub.
- 'Cursor Stopped Responding' Error Reported: A user reported getting a 'Cursor stopped responding' error when trying to use it with Linear, and shared a screenshot.
GPU MODE ▷ #general (35 messages🔥):
Nvidia 50 series profiling, CUDA repo contributions, Image embedding optimization, PTX ISA, Position encodings in LLMs
- 5090 Owners Enjoy Nsight Profiling: A user confirmed that Nsight Compute and Nsight Systems work well with their own 5090 GPU, contrary to some documentation suggesting otherwise.
- Explore CUDA Repo Contributions Now: A user is hosting a voice channel to discuss finding good first contributions to a real CUDA repo, including code walkthroughs.
- The discussion is not recorded, intended to be more off-the-cuff.
- Profile before you wile about slow Image Embeddings: A user reported slow GPU usage when creating embeddings for 75k images using open_clip (ViT-B/32) on an A100 (40 GB).
- Other users recommended using PyTorch dataloaders, tuning parameters like
num_workersandpin_memory, and suggested using a profiler to identify bottlenecks before blaming the model inference.
- Other users recommended using PyTorch dataloaders, tuning parameters like
- Delve into PTX ISA for Advanced MatMul: A user recommended diving into Chapter 9 of the PTX ISA for comprehensive details on advanced matrix multiplication instructions, rather than relying on incomplete blogs.
- A different user linked to a PyTorch profiler recipe for finding performance bottlenecks.
- Deep Dive on Positional Encoding Evolution: A user shared an excellent technical deep-dive guide (credits to Aman Arora) detailing the evolution of position encodings in LLMs.
GPU MODE ▷ #triton (3 messages):
Triton Community Meetup, TLX Updates, Triton + PyTorch Symmetric Memory, Triton Flex Attention in PyTorch, Intra-thread Data Exchange Algorithm
- Tritonites Tentatively Tryst on November 5th, 2025: The next Triton community meetup will be on Nov 5th, 2025 from 10am-11am PST and the meeting link has been shared.
- Tentative agenda items include TLX(Triton Language Extensions) updates by Hongtao Yu (Meta), Triton + PyTorch Symmetric Memory by Surya Subramanian (GaTech), and Triton Flex Attention in PyTorch by Dhruva Kaushal (Meta).
- Team Up Through Teams: Triton's Tech Talks Triumph!: A Microsoft Teams meeting link has been shared, alongside the Meeting ID: 245 337 288 102 4 and Passcode: c6pB7DS2.
- Alternative connection methods such as phone dial-in and video conferencing device options are available with corresponding IDs and tenant keys.
- Intra-thread Intrigue: Algorithm Allegations Arise!: A member questioned the intra-thread data exchange algorithm in section 5.4, suggesting a counterexample.
- The attached image illustrates that the algorithm may not be strong enough to ensure that every vectorized element having a value moved into it also moves its value out of it, potentially leading to overwrites.
{kind=link}
GPU MODE ▷ #cuda (12 messages🔥):
CUDA Core Assignment, mbarrier Usage, DSMEM Synchronization
- CUDA Cores Handle Warp Threads: Discussion clarified that a warp is not assigned to a single CUDA core, but rather its threads are distributed, potentially using multiple cores for execution.
- It was suggested a single
addinstruction might execute over 16 cores with twice the latency of executing over 32 cores.
- It was suggested a single
- mbarrier Troubles in DSMEM: Usage of
mbarrierin DSMEM differs from local SMEM, requiring mapping the&mbarpointer to block 0 with__cluster_map_shared_rankand usingmbarrier.arrive.shared::cluster.- Even with mbarriers, at least two
cluster.sync()calls are needed: one post-initialization and another before blocks exit to ensurembarrier_try_wait()calls return.
- Even with mbarriers, at least two
- DSMEM Cluster Sync Debate: A user questioned the necessity of
mbarrierwhen a singlecluster.sync()after all blocks write to block 0's SMEM already seemed to work for cluster reduction.- Counterarguments highlighted the need for a
cluster syncbefore writing to DSMEM to guarantee threadblocks are live, while the user reported no observed race conditions even with large inputs and only onecluster.sync().
- Counterarguments highlighted the need for a
GPU MODE ▷ #torch (2 messages):
Torch Compiled Model Memory Leak, CUDA Memory Defragmentation
- Mysterious Memory Creep in Torch Model Compilation: A user reported a weird issue where a torch compiled model is slowly creeping up in memory consumption over long periods (hours).
- The memory creep occurs even with max-overtune compilation and varlen flash attention, and the user suspects the allocated portion is being re-allocated and leaked.
- CUDA Defrag Saves the Day: The user found that periodically calling a CUDA defragmentation function reduces memory pressure.
- The code snippet provided uses torch.cuda.empty_cache(), torch.cuda.synchronize(), and gc.collect() to mitigate the memory leak, confirming something is indeed leaking.
GPU MODE ▷ #announcements (1 messages):
llmq, quantized LLM training, CUDA
- llmq quantized LLM training framework incoming: A special talk is scheduled for tomorrow featuring llmq, a quantized LLM training framework in pure CUDA.
- The talk aims to be interactive, encouraging attendees to ask questions and explore potential contributions to the project, with the intent to see how he codes and try and scope out some good first contributions for yourself.
- Interactive Session on llmq: The session encourages interactive participation, with attendees invited to interrupt, question, and explore coding practices related to llmq.
- The goal is to identify potential contributions to the project and engage with the development process.
GPU MODE ▷ #cool-links (3 messages):
ATLAS LLM Inference, VectorDB in Go, Hybrid Retrieval Methods
- ATLAS accelerates LLM Inference via Runtime-Learning: Together AI launched the Adaptive-LeArning Speculator System (ATLAS), a new paradigm in LLM Inference via Runtime-Learning Accelerators.
- The announcement was also made via Tri Dao's X account and Together Compute's X account.
- VectorDB Written from Scratch in Go: A member shared their work on writing a VectorDB from scratch in Go supporting hybrid retrieval over BM25, Flat, HNSW, IVF, PQ and IVFPQ Indexes.
- The VectorDB includes Metadata Filtering, Quantization, Reranking, Reciprocal Rank Fusion, Soft Deletes, and Index Rebuilds and much more with a link to HN thread.
GPU MODE ▷ #jobs (2 messages):
GPU Performance Engineer, Reinforcement Learning for Vision-Language Models
- GPU Guru Gig Galore: A 4-person core team seeks a GPU Performance Engineer with strong understanding of NVIDIA GPU architecture (Blackwell, Hopper), experience optimizing kernels (CuTe, CUTLASS, profilers), and familiarity with Linux kernel/driver internals.
- The role offers $250K USD + Equity and welcomes any level of experience, DMs for Github / CV are welcomed.
- RL Researcher Races for Vision-Language Victory: The Technology Innovation Institute (TII) in Abu Dhabi is hiring a Research Scientist to enhance Vision-Language Models (VLMs) with Reinforcement Learning (RL).
- This is to help develop post-training methods that enhance Vision-Language Models (VLMs); Please DM or send your CV at: [email protected].
GPU MODE ▷ #beginner (26 messages🔥):
axpy.cu compilation error, libwb installation, GPU learning resources, GPU compiler optimizations vs ML
- Troubles compiling axpy.cu: A member encountered a fatal error during compilation of
axpy.cudue to a missingLibraries\libwb\wb.hfile, despite the file being present, they tried to include it using<Libraries\libwb\wb.h>and"Libraries\libwb\wb.h"and neither worked.- The member confirmed they installed the library using a git repo and built it with Visual Studio without errors, however, the compilation is failing now.
- Debugging libwb Installation Woes: A member suggested checking the README for installation instructions and requested the output of
lsfrom the git repo's root to diagnose thelibwbinstallation issue.- The member wanted to confirm the library was properly installed and accessible to the compiler and whether the directory structure was correct.
- GPU Learning Resources Sharpened: A member asked for good resources to learn GPUs, focusing on practical exercises and programming and was referred to Aleksa Gordic's blog.
- The user was also pointed to Umar Jamil's YouTube channel for educational content.
- ML Unnecessary for GPU Compiler Work: A member asked if ML knowledge is required for working with GPUs, particularly for building compiler optimizations.
- Another member clarified that ML is not necessary, as the field is currently focused on AI applications, but fundamentals can be learned by building projects.
GPU MODE ▷ #jax (1 messages):
JAX, Pallas, GPU compute/comms overlap, NVLINK comms
- JAX & Pallas boost GPU compute/comms overlap: A new tutorial shows how to improve GPU compute/comms overlap with a few small changes to the Pallas:MGPU matmul kernel to turn it into an all-gather collective matmul.
- The optimized kernel overlaps NVLINK comms with local compute, as detailed in the JAX documentation and highlighted on X.com.
- NVLink Comm Optimization: The tutorial focuses on optimizing NVLink communications to enhance the efficiency of matmul operations on GPUs using JAX and Pallas.
- It leverages collective communication strategies to minimize communication overhead, thereby improving overall computational performance.
GPU MODE ▷ #off-topic (3 messages):
ML Systems Breakfast, Stanford ML Meetup
- Stanford ML Breakfast Invitation: A member posted an invitation for a not-so-glamorous breakfast or coffee to discuss ML systems in the Stanford area this week.
- A LinkedIn post was linked, referencing HamzaelshafieGPT-OSS-20B, a PyTorch project.
- Sausage Breakfast Fuels ML Chat: Someone shared an image of pork sausages and other breakfast foods.
- The breakfast was intended to fuel a meetup for discussion of ML systems.
GPU MODE ▷ #irl-meetup (1 messages):
Approval Request, Private Repos Sharing, Kernel Writing Basics
- Approval Requested for Independent Work: A member requested approval, citing independent work and offering to share private repos.
- They mentioned lacking explicit experience in specific kernel writing but being capable of handling the basics and expressing willingness to team up.
- Kernel Writing Team-Up Offer: The member expressed a willingness to team up with someone due to limited experience in specific kernel writing.
- Despite lacking explicit kernel writing experience, they claim to write the basics.
GPU MODE ▷ #rocm (2 messages):
Composable Kernel build failure, Missing header in composable kernel
- Kernel Composition fails to build: A user reported a build failure with Composable Kernel due to an unknown type name
int32x4_t, suggesting a missing header.- A member suggested including the
ck/utility/dtype_vector.hppheader from the Composable Kernel GitHub repository to resolve the issue.
- A member suggested including the
- dtype_vector.hpp header is likely needed: The error message indicates that the type
int32x4_tis not recognized, which is likely defined in thedtype_vector.hppheader file within the Composable Kernel library.- To fix this, ensure that you include the appropriate header file, specifically
<ck/utility/dtype_vector.hpp>, in your code where you are using the Composable Kernel.
- To fix this, ensure that you include the appropriate header file, specifically
GPU MODE ▷ #self-promotion (4 messages):
LRU, LFU, C4ML, TensorFlow Optimizers, Blockchains
- Cache your knowledge with LRU and LFU in C++: A member published a blogpost covering LRU and LFU caching policies in C++, including unit tests with GoogleTest, based on a lecture by Konstantin Vladimirov, with code available on GitHub.
- The blogpost explains that LRU keeps the most recent pages in the cache, while LFU also considers how frequently sites are visited, link to blogpost here.
- Mark your Calendars for Compilers For ML @ CGO 2026: The Compilers for Machine Learning (C4ML) workshop is returning to CGO 2026 in Sydney, Australia, seeking presentations and papers on ML compilers, compiler optimizations, and the use of ML in compilers.
- Unleash the power of Blockchains and AI Together: A member shared their journey into blockchains and AI, emphasizing how the combination of these technologies can transform industries, communities, and the creation of new ideas.
- They believe that when blockchain and AI are put together in the right way, they can shift how industries move, how communities connect, and even how new ideas come to life.
- NoteDance posts TensorFlow Optimizers: A member announced the release of their custom-built optimizers for TensorFlow.
- The member shared the GitHub repo, noting that users of tensorflow may find them helpful.
GPU MODE ▷ #avx (1 messages):
Intel SDE, Intrinsics and immintrin_dbg.h
- Intel SDE Simulates Old Hardware: The Intel Software Development Emulator (Intel SDE) allows running binaries on old hardware, complete with instruction-level logging and debug tracing.
- This offers a way to execute code that would otherwise be incompatible with newer systems.
- imminstrin_dbg.h Header File for Testing Intrinsics: Intel provides an alternative header file, imminstrin_dbg.h, for C/C++ development that implements intrinsic functions in scalar C code, enabling development and testing without requiring an x86 system.
- Note that it's no longer maintained, so it may lack some recent functions.
GPU MODE ▷ #thunderkittens (7 messages):
CUDA toolkit versions for Blackwell, GH200 Hopper machine, CUDA requirements changing, Compiling errors, Narrowing conversion errors
- CUDA Version Confusion Causes Headache: A member stated that the Cuda toolkit has to be at least 12.8 for Blackwell, while another wondered if the GH200 is being misidentified as Blackwell instead of a Hopper machine.
- CUDA Requirements Shift Gear in New Versions: Members discussed whether the CUDA requirements have changed in the latest versions, with one noting that a recent commit resolved an issue by disabling a certain type for H100.
- Compiling Code Creates Conversion Crisis: A member encountered compiling errors related to an invalid narrowing conversion from "char" to "signed char" and fixed it by explicitly casting in the code.
GPU MODE ▷ #reasoning-gym (1 messages):
Weights and Biases (wandb) Logs, GRPO policy loss clipping, Reasoning Gym
- User Hunts Weights and Biases (wandb) logs for reasoning-gym trials: A member requested Weights and Biases (wandb) logs from training an LLM with reasoning-gym to see if GRPO (or similar methods) hits the policy loss clipping on a non-zero percentage of samples.
- They were specifically looking for logs from a smaller model (1B/3B params).
- User Seeks insight on GRPO Loss Clipping Efficacy: A member inquired about the frequency of policy loss clipping when using GRPO or similar methods with reasoning-gym during LLM training.
- The aim is to ascertain whether the policy loss clipping occurs on a non-zero percentage of samples, particularly in smaller models ranging from 1B to 3B parameters.
GPU MODE ▷ #submissions (130 messages🔥🔥):
MI300x8 Leaderboard Updates, amd-ag-gemm Performance, amd-all2all Performance, amd-gemm-rs Performance
- Submissions Blitz the MI300x8 Leaderboards: Multiple users submitted performance results on the MI300x8 across various leaderboards including
amd-ag-gemm,amd-all2all, andamd-gemm-rs. - amd-all2all: Microsecond Milestones: Several personal bests were achieved on the
amd-all2allleaderboard, with some submissions dipping into the 300-400 µs range on the MI300x8, indicating significant performance enhancements. - amd-gemm-rs: Race to the Top: Intense competition unfolded on the
amd-gemm-rsleaderboard, with users vying for top positions on the MI300x8, resulting in several new personal bests and leading positions. - amd-ag-gemm: Sub-Millisecond Showdown: Users consistently submitted results for
amd-ag-gemmleaderboard on MI300x8, showing most around 500 µs, with some outliers above 1000 µs.
GPU MODE ▷ #status (14 messages🔥):
Runner Timeouts, Deadline Extension Controversy, AMD's Node Limitations
- Runner Timeouts Plague Submissions: Participants experienced timeouts with the competition runners, leading to investigation and attempts at fixes; users are encouraged to report further issues to specified contacts.
- One dev mentioned they are working on it and that runners should be somewhat fixed.
- Deadline Extension Sparks Debate: The competition deadline was extended by a day due to high interest and timeout issues, moving the final submission to October 14th, 11:59 PM PST.
- Some competitors expressed concerns about fairness and professionalism, with one stating this basically beats the spirit of competition, while organizers justified the extension due to technical difficulties and GitHub outages affecting submissions.
- AMD's Node Count Caps Contestants: Organizers cited a limitation of 7 nodes provided by AMD as a contributing factor to the timeout issues during the competition's final hours.
- The decision to extend the deadline was defended as a reasonable tradeoff, likening it to not letting people on a plane because the queue to the plane is long.
GPU MODE ▷ #tpu (1 messages):
rybchuk: you need to do jax distributed init first
GPU MODE ▷ #factorio-learning-env (2 messages):
Factorio Crime Scene, Game Neglect Consequences
- Factorio Turns Fatal When Unattended: A member left Factorio unattended during a meeting, only to return to a simulated crime scene as depicted in the attached screenshot.
- AFK Factorio Session Ends in Carnage: One player discovered the perils of leaving a Factorio session running unattended, resulting in what they amusingly described as a crime scene upon their return.
{kind=link}
GPU MODE ▷ #amd-competition (105 messages🔥🔥):
Timeout Errors, GPU Memory Access Faults, Submission Queue Overload, Debugging Prints in Submissions, Stream Events for Measuring Kernel Time
- Timeout Troubles Triggered by Troubled Submissions: Users encountered timeout errors in their submissions, specifically at the
el.get(60)line, leading to speculation about code issues or cluster overload.- One user even tested a minimal submission with just
sys.exit(3)and still experienced a timeout, suggesting potential infrastructure problems.
- One user even tested a minimal submission with just
- Segfault Spells Memory Access Mayhem: A user reported a memory access fault with the error message "Memory access fault by GPU node-7 (Agent handle: 0x55c30114fb00) on address 0x7ee677800000. Reason: Unknown," indicating a segfault.
- It was suggested that this might be due to different permissions on the local setup or simply "getting lucky," as it implies accessing illegal memory.
- Submission Surge Stalls System Stability: The platform experienced a surge in submissions, causing the runners to struggle and leading to timeout issues for many users.
- A team member noted, "Thank you for the feedback everyone, Github Actions you can see that there is just way too many submissions happening for the runners to pick it up," indicating an overwhelming load on the system.
- Debugging Dearth: Prints Prove Problematic: Users reported not seeing debugging prints in their submissions, making it difficult to diagnose issues, with one user exclaiming, *"I've never seen debugging prints in my submissions, only timeouts 😢 . I didn't even know we got those lol."
- It was pointed out that
python printhave buffers so needflush=Trueto print that.
- It was pointed out that
- Submission Service Suffers 503 Snafu: Users reported receiving 503 Service Unavailable errors when attempting to submit code, indicating server-side issues.
- One user described the situation: *"The server has been returning a 503 error for almost an hour now — it’s probably crashed because everyone’s rushing to submit before tomorrow’s deadline."
GPU MODE ▷ #cutlass (14 messages🔥):
CuTeDSL caching, MoE Group GEMM, Group GEMV, Proton Viewer
- Proton Viewer Shows Gluon Kernel Internals: If you write your kernel with Gluon, Proton gives you a viewer of exactly what you want, enabling inspection of kernel internals.
- CuTeDSL Caching Needs Improvement: A user reports that running a kernel without
cute.compileincurs significantly higher overhead (13.3196 ms vs 0.0054 ms), raising concerns about CuTeDSL caching usability, see issue 2643.- Explicit cache management is recommended for production, balancing speed, safety, and flexibility, while the team actively works on ahead-of-time compilation (discussion 2557).
- MoE Group GEMM Performance Modeling Intractable?: A user highlights the challenge of performance modeling for MoE Group GEMM in LLM inference, where some GEMM problems may be compute-bound and others memory-bound.
- They suggest looking at serving frameworks like vLLM and experimenting with rearranging the order of GEMM problems to optimize performance.
- Group GEMV outperforms vLLM's Fused MoE: For low-batch size long decoding, a simple group GEMV in Triton outperforms vLLM's fused MoE, emphasizing the importance of data loading optimization.
- In this specific setup, it's heavily memory-bound so you don't even need MMA (Matrix Multiply Accumulate).
GPU MODE ▷ #singularity-systems (4 messages):
picograd, SITP, tinygrad, autodiff, Triton kernels
- picograd & SITP framework building hype: A member expressed interest in the picograd and SITP projects, praising the eager/lazy setup and tinygrad-style pipeline, and offered assistance once a vertical slice is ready.
- Vertical Slice Coming Soon for SITP with Documentation: A member announced that a thin vertical slice of
.Tensorand.backwardwill soon be available, along with documentation on the order of presentation of models, the framework, and GPU kernels, plus ARCHITECTURE.md, AGENTS.md, and CONTRIBUTING.md.- The goal is to bridge the gap to tinygrad by creating a lazy, compiler-first autograd system, similar to JAX.
- Triton Kernels Integration via pyo3: picograd plans to use pyo3 for Python and Rust interop to write Triton kernels for eager mode, with eventual fusion capabilities.
- The bidirectional interop will help in getting to doing some fusion in the future.
GPU MODE ▷ #general (9 messages🔥):
VSCode Extension, GPU Mode Website Tutorials, Submitting Kernels, PMPP v2 Problem, Grayscale Submission
- VSCode Extension Easiest Jumpstart: A member mentioned that the VSCode extension might be the easiest option to start with GPU Mode.
- Another member said, "I don't understand the questions lol", possibly referring to the extension or tutorials.
- Outdated GPU Mode Website Tutorials Frustrate Newcomers: A member reported that the GPU Mode website tutorials for submitting kernels are outdated, specifically mentioning the absence of
pythonandcudaidentities.- The affected tutorial is located at gpu-mode.github.io.
- PMPP v2 Grayscale Problem is the Classic: The suggestion now is to submit to a PMPP v2 problem, with grayscale being a classic example, which can be found on the leaderboard.
- Further reference kernels can be found in this repo.
GPU MODE ▷ #multi-gpu (25 messages🔥):
VAE Training on Multi-GPU, Serving LLMs for Multiple Users, Nvidia 5090 features
- VAE Model Loss Spiking in Multi-GPU Training: A member is experiencing loss spikes when training a VAE model from scratch on 4x A100s using DDP, while the training is stable on a single GPU, and seeks troubleshooting assistance with their code.
- Deep Dive into RTX 5090 Specs: A member shared that the RTX Blackwell doesn't have TMEM due to the absence of tcgen05, leading another member to reconsider purchasing a 5090 for TMEM testing, and discussed whether block scaled dtypes are nerfed in fp32 acc.
- Another member provided an in-depth analysis of the 5090, mentioning block scaled dtypes and potential features carried over from Hopper, like TMA, as well as shared chipsandcheese.com.
- Deploying 70B Model for 10 Concurrent Users: A member requested resource recommendations for serving a 70B model for up to 10 concurrent users, planning to use vLLM and a pod-based setup for a RAG use case involving company documents and videos.
- Another member suggested that deploying for 10 users isn't particularly challenging, especially for a RAG setup with ~100 documents and 10 videos, and inquired about the expected request volume and inference latency constraints.
GPU MODE ▷ #opencl-vulkan (5 messages):
Gallium3D compute driver on top of CUDA, Rusticl on Zink on NVK vs NVIDIA Proprietary OpenCL, Vulkan API, VK_KHR_shader_fma
- CUDA Gallium3D Driver Surfaces!: A member created a Gallium3D compute driver on top of CUDA for use with Rusticl, detailed in a Phoronix article and a GitLab merge request.
- When asked about the benefits compared to Rusticl on Zink on NVK or NVIDIA Proprietary OpenCL, a member pointed out much better OpenCL extension support.
- New Vulkan Extension Surfaces: A new Vulkan specification update includes
VK_KHR_shader_fmaas reported in this Phoronix article.
GPU MODE ▷ #penny (1 messages):
vllm oneshot, small buffers, PR 2192
- vllm's Oneshot Performance Boosted: Members reported vastly improved oneshot performance today in vllm, especially after the small buffers cracked, relating to PR 2192.
- vllm's Small Buffers Cracking: Small buffers cracked in vllm contributing to improved oneshot performance.
GPU MODE ▷ #llmq (12 messages🔥):
Weird Quantizations, LoRA Training, Model Implementation, LLM.q Talk
- Weird Quantizations Configuration: A user inquired about the configuration UX for training with weirder quantizations, wondering what it would look like to configure on the command line or config files.
- The response indicated that current work involves command line flags, and depends on the type and method of quantization.
- Presentation Slides Shared: The author shared presentation slides following a request from a member.
- LoRA Training Medium Projects: A member inquired about using LoRA training in listed medium projects.
- The suggestion was to implement it as a separate model to maintain codebase, with the reuse of kernels and similar parameter gathering code.
- LLM.q Talk to come: A heads up was given about an upcoming talk on llm.q at this link.
GPU MODE ▷ #helion (5 messages):
FLA Benchmark, GDN, Mamba2, PTC Talk, Backward Generation
- FLA Use Case Gains Traction: A member gave +1 for the FLA use case being a good, convincing benchmark, specifically mentioning GDN and maybe mamba2.
- They expressed excitement for the PTC talk.
- Backward Generation Support in Question: A member inquired about plans to support generating backward.
- Another member confirmed interest but stated that no one is currently working on it, referencing a GitHub issue from August.
HuggingFace ▷ #general (238 messages🔥🔥):
Open Source MoE, Fine-tuning Florence, Upscaling Images, LayerFort Spam, Hugging Face Refunds
- Open Source MoE Models Sought: Members are looking for a good open source MoE (Mixture of Experts) model with configurable total parameters for pretraining, with a suggestion to check out NVIDIA's Megatron Core and DeepSpeed.
- One member humorously asked if anyone has a server farm and massive training datas.
- Fine-Tuning Florence Models: A Deep Dive: Members discussed fine-tuning Microsoft's Florence 2 model, with one user tagging images and seeking advice, noting a lack of specific fine-tuning knowledge online and asking what kinds of images are you tagging?.
- Another member suggested using a VLM closer to Llava, like JoyCaption, for more advanced tagging capabilities.
- Latest Image Upscaling Options: Members discussed alternatives to shitty website upscalers for images, with one member recommending checking out the image upscaling spaces on Hugging Face.
- It was emphasized that the best upscaler highly depends on domain of your image and that the latest isn't necessarily the best.
- LayerFort Promotes Infinite AI Access, Sparks Spam Accusations: A user promoted LayerFort, offering access to 130+ models from 20+ providers including Gemini 2.5 Pro and GPT-5 with unlimited requests for a monthly fee, linking to their website layerfort.com.
- Another user immediately labeled the post as spam.
- Hugging Face Refund Frustrations Aired: A user expressed frustration over not receiving a refund, stating they've emailed since the 6th, and warning others about the lack of refunds and quota usage on Hugging Face's subscription page, even canceling and stating ya gotta stay with you guys til then.
- A Hugging Face team member, <@618507402307698688>, intervened, requesting the user's Hub username to check on the refund process and clarifying yellow role = huggingface team.
HuggingFace ▷ #i-made-this (75 messages🔥🔥):
Declarative Web App Management, Serverless Agent Platform, Contrarian Research Model, TensorFlow Optimizers, AI Image Analysis
- OpenRun Manages Web Apps Declaratively: A member has been building a declarative web app management platform called OpenRun that supports zero-config deployment of apps built in Gradio.
- It facilitates setting up a full GitOps workflow with a single command, enabling the creation and updating of apps by just modifying the GitHub config.
- AgentBase Launches Serverless Agent Platform: A member introduced Agentbase, a serverless agent platform that allows developers to build and deploy agents in less than 30 seconds without managing individual integrations.
- The platform aims to help transition SaaS to AI-native or quickly experiment with agent builds, offering pre-packaged APIs for memory, orchestration, voice, and more.
- Valor Asks Weird Research Questions: A member fine-tuned Qwen2.5-3B into VALOR, a 3B parameter model that generates non-obvious, assumption-challenging research questions, running on T4/RTX 3060+.
- It's trained to challenge assumptions and connect distant domains, and is suited for technical domains like AI/ML, robotics, and physics.
- Cloud LLMs CodeLens Get Compared Side-By-Side: A member built CodeLens.AI, a tool to compare how 7 top cloud LLMs handle code tasks like refactoring and security review, running the models in parallel and showing side-by-side comparisons with AI judge scores.
- The tool includes a leaderboard and tracks the carbon footprint of the models, aiming to provide a more real-world reflection of developer tasks than existing benchmarks.
- Go VectorDB gets Hybriiiiiid: A member has released their VectorDB written from scratch in Go, named Comet it supports hybrid retrieval over BM25, Flat, HNSW, IVF, PQ and IVFPQ Indexes with Metadata Filtering, Quantization, Reranking, Reciprocal Rank Fusion, Soft Deletes, Index Rebuilds and much much more
- The member posted a link to the HN thread.
HuggingFace ▷ #computer-vision (4 messages):
Computer Vision Hangout Slides, AI Image Analysis Tool, GenAI Meetup in San Francisco
- Slides from Computer Vision Hangout Released: Slides from the October 25th Computer Vision Hangout were shared, covering an unspecified range of topics (HF_CV_Hangout_October_25.pdf).
- AI Image Analysis Tool Debuts: An AI tool capable of analyzing images and answering questions about them was introduced, trained from scratch using CLIP (aiwork.work.gd).
- The AI is designed to be user-friendly, providing quick and accurate image analysis for all users.
- Real-Time Video GenAI Meetup Announced: A GenAI Meetup focusing on real-time video generation will be held in San Francisco on October 15th at 5:30 PM (luma.com).
- The meetup aims to connect individuals interested in generative video and AI pipelines.
HuggingFace ▷ #smol-course (5 messages):
Hugging Face Jobs Errors, SmolAgents Tool Calling Agent Issues, Connecting Database Info to DeepSite, DPO Quiz Errors
- Hugging Face Jobs Errors: A user reported errors when running jobs on Hugging Face, indicating that the trl module was not found.
- The error message was ModuleNotFoundError: No module named 'trl', suggesting a missing dependency.
- SmolAgents Tool Calling Troubles: A user encountered a 'INVALID_TOOL_CHOICE' error when using the ToolCallingAgent with DuckDuckGoSearchTool in SmolAgents, both locally and in Colab.
- The error specifies that Supported tool_choice values are "auto" and "none" currently.
- DeepSite UI gets Database Connection: A user inquired about connecting database information to DeepSite to enable AI-driven UI modifications based on database content.
- They proposed a scenario where DeepSite could generate a login page, validate user credentials against the database, and redirect users accordingly.
- DPO Quiz Glitches: A user reported encountering an error with a module app in the DPO quiz, providing a link to a Hugging Face Space related to unit_3_quiz.
- Another user indicated they completed the quiz without issues approximately a week prior.
HuggingFace ▷ #agents-course (3 messages):
AI Agents Certificates
- AI Agent Certificates missing?: A member inquired about available certificates, noting that it appears only the first unit for AI Agents Fundamentals offers one.
- Other users were notified to slow down due to posting too fast.
- Rate Limiting Bot: The bot is rate limiting users.
- The bot is configured to prevent users from posting too quickly.
Eleuther ▷ #general (70 messages🔥🔥):
Neural Theorem Proving Channel, AI Evaluation Strategies, Smaller, More Efficient Models, Smallest Model Definition, GPT-3 API Startups
- Channel Search for Neural Theorem Proving: A member inquired about a dedicated channel for neural theorem proving, wondering if it would be more appropriate than the general channel.
- Two channels were suggested, <#797547607345201162> or <#1110611369574793306>.
- Critiques of AI Evaluation Methodologies: A member shared a Medium article on AI evaluations and asked for feedback.
- One response suggested training models on less data with more effective architectures.
- Dissecting the Definition of the Smallest Model: A user asked what is the smallest model and another user defined it as a nano gpt model.
- A user jokingly suggested that a model with negative size could be made by feeding it to /dev/null.
- Cloud Clusters for A10s in demand: A member inquired about cloud services offering clusters of A10s to scale a training and model setup.
- They want to prepare to see how scalable it is without breaking the bank if my ppl trend keeps continuing during this run.
- BabyLM Competition: One member mentioned a competition called BabyLM that tries to find the smallest language models.
- The BabyLM website was shared, noting that it will be at EMNLP 2025 in China, November.
Eleuther ▷ #research (136 messages🔥🔥):
Scalar RMSProp adaptivity, Anti-Scalar RMSProp, Mamba 3 Architecture, RWKV-7 comparison, Less is More Recursive Reasoning
- Scalar RMSProp: Adaptive or Not?: A discussion ensued regarding the adaptivity claims of Scalar RMSProp, with one member arguing that its adaptivity isn't tied to the maximum stable step size and that other optimizers also reach this limit.
- The argument was made that the 1/sqrt(v) correction factor in Scalar RMSProp might not be a magical adaptation factor but potentially detrimental, contrasting it with a hypothetical anti-Scalar RMSProp using sqrt(v).
- Mamba 3: A Lesser RWKV-7?: Members discussed Mamba 3's architecture, comparing it to RWKV-7 and noting its replacement of conv1d with a mildly adjusted RWKV tokenshift mechanism; the consensus was that Mamba 3 is a paring down of existing architectures.
- The efficiency gains might be valuable in certain scenarios, providing a bump in ability without a significant speed hit; discussion of Mamba 3's data-dependent RoPE and its implementation is ongoing Mamba 3 Paper.
- Recursive Reasoning with Tiny Networks: Limited Backpropagation: A discussion arose about the 'Less is More: Recursive Reasoning with Tiny Networks' paper, specifically the technique of backpropagating only on the last step of deep recursion after T-1 steps of no_grad().
- The intuition behind why this works is still under investigation with a related issue open on Github.
- EOS Effects Push Sharpness Regularization: It was stated that the optimizer's main job is to regularize sharpness; it could be that the final annealing stage still obeys the Hessian perspective, but most of an optimizer's quality comes from the training before annealing.
- Another member states that, regarding sharpness, there's no reason to think the optimizer stays "at" the edge of stability.
Modular (Mojo 🔥) ▷ #general (19 messages🔥):
GPU Recompilation, MLIR blobs for drivers, Vulkan Bindings, AI-driven video streaming
- Mojo Recompiles for Each GPU: A member asked about forward compatibility and recompilation for new GPUs, another member responded that Mojo recompiles the code for every GPU when you run it.
- They stated that all of the vendors have some way to use SPIR-V to make things work, and nothing stops you from making your MLIR blob for drivers be compiled by a continually updated library.
- Vulkan Bindings available: A member shared his vulkan-mojo bindings at Ryul0rd/vulkan-mojo.
- They said they haven't bothered to add moltenvk support yet but it's an easy fix.
- Slides from Today's Talk: Slides are available from a talk today at Google Docs.
- The talk goes over a variety of features of Mojo, and the presenter said thanks so much for sharing! amazing work.
- AI-Driven Video Streaming expert seeks Opportunities: A video streaming engineer with experience at major streaming companies such as Red5 Pro, Zixi, and others is exploring new job opportunities that involve modern AI technologies.
- He said if you’re interested in AI-driven video streaming innovations, please feel free to reach out.
Modular (Mojo 🔥) ▷ #announcements (1 messages):
October Community Meeting, FFT implementation in Mojo, MAX backend for PyTorch, Modular's 25.6 release, Unifying GPUs
- Modular Sets October Community Meeting: Modular announced its October Community Meeting, highlighting presentations on a generic FFT implementation in Mojo and a MAX backend for PyTorch.
- The Modular team is expected to detail their 25.6 release, which unifies the latest GPUs from NVIDIA, AMD, and Apple; more details are available on the forum.
- Mojo FFT Generic Implementation: One of the presenters will be sharing work on a generic FFT implementation using Mojo.
- This is part of the October Community Meeting.
Modular (Mojo 🔥) ▷ #mojo (136 messages🔥🔥):
ComplexSIMD constructor, FFTW port, Mojo on ARM, LayoutTensors pain points, Mojo tutorials
- ComplexSIMD constructor being added: A member suggested adding a ComplexSIMD constructor that deinterleaves a SIMD vector, offering an easier way to work with complex numbers, expressed as
fn __init__(out self, *, from_interleaved_simd: SIMD[Self.dtype, Self.size * 2]): ....- Another member offered their open-source project's loading tricks, cautioning about the need for two separate loads when packing max-size vectors.
- FFTW port implementation coming to Mojo: With the landing of PR #5378, Mojo will have a native FFT implementation, though it currently supports only 1D transforms with sizes known at compile time.
- Members discussed potential solutions for dynamic sizes, including JIT compilation and runtime planning, similar to how FFTW handles the problem.
- Mojo struggles to run on Raspberry Pi: While Mojo supports ARM, there are issues preventing it from running on Raspberry Pi, potentially due to tcmalloc's page size limitations with Pi kernels using 16k pages.
- A member noted that it should be fixable by the community when we open source the compiler next year and another confirmed it works on Ubuntu 24.04 LTS.
- Dev expresses the pains of LayoutTensors: A member expressed frustration with using LayoutTensors, citing complex typing mismatches and difficulties in passing them to sub-functions, resorting to CUDA due to its simplicity compared to the challenges of Mojo's type system.
- They shared code examples highlighting the issues, noting it's easier to use raw pointers instead, asking If your GPU code is simple then Mojo is great but if it is a complex scenario I still think CUDA is orders of magnitude easier to learn and use
- Doubts about Mojo's tutorials: A member expressed frustration with Mojo tutorials, particularly the Game of Life demo, stating they were unable to make it work, as top-level code is not supported yet, concluding Never mind, I can not learn this way.
- Another user suggested consulting the examples in the GitHub repo for clarification.
Modular (Mojo 🔥) ▷ #max (6 messages):
Bazel hackery in Modular tests, Testingacos()Max op
- Bazel Shenanigans Turn Max Tests into No-Ops: A member ran into trouble testing a new
acos()Max op due to Bazel not finding thegraphtarget defined intests/integration/max/graph/BUILD.bazel(see PR 5418).- A knowledgeable member explained that it's due to "some Bazel hackery that essentially turns that test into a no-op", which is a "known oddity" related to insufficient test files being open-sourced, potentially related to Issue 5303.
- Relative Imports to the Rescue in Max Ops Files: A member suggested trying
from ..graphinstead of.graphin the ops file, and similarly usingfrom .. import dtype_promotionto fix import issues.- The suggestion was implemented but the root issue remained: Bazel still couldn't find the
graphtarget.
- The suggestion was implemented but the root issue remained: Bazel still couldn't find the
Nous Research AI ▷ #general (133 messages🔥🔥):
vllm predicted outputs, Sam Altman, MCP gateway by docker, AI evaluations, decentralized ai and its security
- vLLM achieves Faster Generation: Cascade Tech released Predicted Outputs in vLLM, enabling very fast generation by converting output to prefill for (partial) matches of a prediction (blog post).
- The new tech is available in their vllmx experimental branch, with a demo available and a tweet thread.
- Decentralized AI Security: A PhD student in AI specializing in decentralized AI and its security is seeking ways to contribute to the project.
- They focus on attacks during training, like backdoor and convergence prevention, especially in non-iid data distribution settings, and mentioned a paper about a new version of the attention mechanism designed to work with homomorphic encryption.
- Anthropic Backdoor Vulnerability: Anthropic found that as few as 250 malicious documents can produce a backdoor vulnerability in a large language model regardless of model size or training data volume (paper link).
- A member noted that this is a well-known issue, especially in vision models and discussed the difficulties of detection on decentralized settings, particularly due to private data and varied distributions.
- Evaluating Video Annotation Efforts: A member is working on video annotation and looking for feedback on their approach (audio-to-time sync, timeline JSON, metadata, video res).
- They linked to the Google Vertex AI video generation prompt guide for reverse engineering caption info.
- Solving Hermes 4 API on LM Studio: A member sought assistance to set up the API access to Hermes 4 in LM Studio, having achieved success in SillyTavern.
- Another member clarified that LM Studio only allows hosting the API locally.
Nous Research AI ▷ #ask-about-llms (6 messages):
Graph Rag-like approach, Role-play book chunking, Wikipedia scratchpad, Gemini summarizes reply
- Graph RAG Quest Begins!: A member is seeking advice on a Graph RAG-like approach for chunking a role-play book's content into efficiently interlinked nodes, finding Light RAG insufficient.
- They are looking for specific tool-based pipelines or procedural controlled methods for chunking and embedding creation.
- Wikipedia Scratchpad: Crawling for Knowledge: A member suggests designing a custom implementation involving crawling through the book and creating a "wikipedia scratchpad" with [[wikilinks]] for unknown information.
- This approach uses a verifier agent to compare context and determine when enough knowledge has been generated, acting as generative entity/relationship extractions.
- Gemini's Take on Knowledge Gen: A member shared that they asked Gemini to summarize their reply about knowledge generation, which clarified the explanation.
- The image included in the message was deemed by the bot to be rage-bait.
Nous Research AI ▷ #research-papers (6 messages):
LoRA RL, Self-Adapting LLMs (SEAL), GRPO Algorithm, Weight Updates
- LoRA RL deemed 'cute' Target: A member suggested that the Self-Adapting LLMs experiment is a good target for LoRA RL.
- Self-Adapting LLMs (SEAL) Framework Announced: The SEAL framework enables LLMs to self-adapt by generating their own finetuning data and update directives, resulting in persistent weight updates via supervised finetuning (SFT).
- Forgetting Curve & Weight Updates Discussed: A member stated that it would be interesting to see how forgetting plays into SEAL's strategy, suggesting a need for strategic weight updates in the context of this paper.
- GRPO Algorithm Elicits Thinking: A member commented on an interesting approach, noting that RL algorithms like GRPO train the model with a low number of bits per sequence, which makes it not surprising that little intervention is needed to elicit thinking in a base model.
Nous Research AI ▷ #research-papers (6 messages):
LoRA RL, Self-Adapting LLMs (SEAL), GRPO RL Algorithm
- LoRA RL for Cute Experiments: A member suggested using LoRA RL for a cute experiment and linked to a tweet about Self-Adapting LLMs (SEAL).
- The linked SEAL paper introduces a framework enabling LLMs to self-adapt by generating their own finetuning data and update directives.
- Self-Adapting LLMs Finetuning: The Self-Adapting LLMs (SEAL) framework uses a reinforcement learning loop with the downstream performance of the updated model as the reward signal, finetuning on self-generated data and update directives for lasting adaptation as per the project website.
- The author notes the importance of strategic weight updates and how forgetting plays into this strategy.
- GRPO Algorithm Insights: A member commented on the GRPO algorithm, noting that it trains models with a very low number of bits per sequence, making it unsurprising that minimal intervention is needed to elicit thinking in a base model, referencing this paper.
- The member expressed confusion with the paper's abstract, suggesting a clearer description of the approach.
Latent Space ▷ #ai-general-chat (120 messages🔥🔥):
Exa Search API v2.0, Unlimited Claude via GLM-4.6 Reverse-Engineering, Raindrop’s AI Agent A/B Testing, Base Models Reasoning Skills, RWKV-8 ROSA Architecture
- Exa Launches Speedier Search API: Exa unveiled v2.0 of its AI search API, introducing "Exa Fast" (<350 ms latency) and "Exa Deep" modes, powered by a freshly trained embedding model and a refreshed index of tens of billions of pages.
- The update required a new in-house vector DB, 144×H200 cluster training, and Rust-based infra, with existing users getting automatic access - more here.
- Unlimited Claude Unlock Costs Only $3: A user claims Chinese reverse-engineering unlocked an unlimited Claude coding tier for just $3/mo (50% off first month) by routing requests to GLM-4.6 on z.ai instead of genuine Sonnet, as blogposted here.
- Others question latency and the actual Claude quality, with one user noting that Z.ai monthly plans are insane value.
- Raindrop Experiments on A/B Testing AI Agents: Raindrop shipped “Experiments,” a first-of-its-kind A/B testing suite built for AI agents, hooking into existing feature-flag tools—PostHog, Statsig—or letting you run day-over-day comparisons.
- This surfacing how product changes affect tool usage, error rates, intents, demographics, and more, with deep-dive event links for any comparison and more information available here.
- Base Models Already Have Reasoning Skills: A new paper by Constantin Venhoff et al. shows thinking language models (e.g., QwQ) do not learn new reasoning skills; instead they learn when to activate latent skills already present in the base model (e.g., Qwen2.5), linked here.
- Using sparse-autoencoder probing, they extract steering vectors for 10-20 distinct reasoning routines and drive the base model with those vectors, recovering up to 91 % of the performance gap on MATH500.
- Karpathy Nanochats on the Cheap: Andrej Karpathy unveiled nanochat, a minimalistic open-source repo that trains a ChatGPT-like model end-to-end using just 8 k clean lines, no external libraries, and a few hundred dollars of cloud GPU time (tweet).
- It covers pretraining, midtraining, SFT, optional RLHF, inference with KV-cache, and an auto-generated report card intended as the capstone for the upcoming LLM101n course.
Latent Space ▷ #private-agents (1 messages):
diogosnows: Appreciated <@1203156838409969675> 🙏
Latent Space ▷ #genmedia-creative-ai (12 messages🔥):
Nano Banana Soul Mark Debate, Nano-Banana Pencil & Ink AI Sketches, LinusEkenstam Nano Banan Ink-Sketch Prompt, AI-generated Watermarks, AI-generated Pencil Sketches
- Nano Banana's Ghostly Soul Mark: Faint, repetitive artifacts spotted on multiple nano-banana AI outputs spark debate over whether they are an intentional watermark, a transformer artifact, or a generational quirk; replication involves greyscaling then oversaturating the image.
- The community shared jokes like, it’s not a watermark, it’s a soul, alongside technical suggestions for removal (upscaling), noting the absence of any tracking ID.
- Nano-Banana Pencil Sparks Ink Sketch Renaissance: Venture capitalist Justine Moore shares a popular nano-banana prompt for creating identical black-and-gray pencil or blue-ink line-drawings on notebook paper, complete with an artist's hand holding a pen and eraser, as seen here.
- Thread followers discussed examples, shout-outs to Linus Ekenstam’s original blue-ink version, plus user replies on watermarking, platform restrictions (Google vs Grok), and playful commentary.
- Linus Unveils Nano Banana Ink-Sketch App: Linus shared a detailed prompt for creating an AI-generated photo-style ink sketch of a face—blue-and-white fine-line drawing on notebook paper with an artist’s hand still visible, available here.
- Users quickly turned it into a mini-app (zerotoai.app), shared their own sketches, debated pen colors, and discussed prompt control; Linus called the results amazing fun, celebrating its rapid adoption.
Manus.im Discord ▷ #general (111 messages🔥🔥):
Custom Domain for Manus, Manus Going Rogue, Manus API Validation Error, Manus Webhook Issue, Is Manus Hiring?
- Manus' API Key Validation Issues Resolved: A user reported a "server is temporarily overloaded" error when validating the Manus API key, but the team fixed the issue with new API changes.
- The changes include new responses API compatibility and three new endpoints for easier task management, mirroring the in-app experience.
- Back-and-Forth Conversations with Manus via API: The Manus team enabled the ability to push to the same session multiple times via the API, allowing back-and-forth conversations with Manus using the session ID.
- A user integrating Manus into a drainage engineering app expressed interest in streaming intermediate events for a more transparent user experience.
- Manus' Webhook Registration API: A user encountered a "not implemented" error (code 12) when trying to register a webhook, indicating the webhook registration endpoint was temporarily non-functional.
- A team member acknowledged the issue, attributing it to recent code changes, and promised a fix by the next day.
- Manus Pricing Questioned, More Expensive Than Alternatives: A user building trading EAs and strategies found Manus AI too expensive due to programming errors consuming credits.
- The user stated that Manus is better than GPT and Grok, but still too expensive.
- Feature request: Proficiency level for Manus Users: A user suggested an option where users can state their proficiency level upon signup, so that Manus knows if it should assume the user knows nothing and babysit the user instead of the other way around.
Moonshot AI (Kimi K-2) ▷ #general-chat (70 messages🔥🔥):
AI-generated anime, Groq's performance, OAuth integration for Moonshot, Model Benchmarking, Aspen's abscence
- AI Animates Anime: A user shared a video showcasing AI-generated anime, indicating that AI has reached a point where it can produce entire animated works and music.
- Another user expressed that the AI-generated content was really good.
- Groq faces scrutiny in benchmark chutes: Users discussed the Groq's performance on tool call benchmarks, noting that it had unexpectedly low scores compared to other providers, with chute percentages as low as 49%.
- They linked to a tweet discussing the issue and speculated about the reasons behind the lower-than-expected performance, considering Groq's custom hardware and hidden quantization, with one joking expecting it to be 70%.
- Kisuke craves Kimi K-2's credits via Oauth: A user is developing Kisuke, a mobile IDE, and requested guidance on implementing OAuth integration to allow users to log in and use their Kimi-K2 credits directly.
- Other users raised concerns about the feasibility of this approach, suggesting that a new system might be needed and that OAuth might not provide direct access to API keys. Another user suggested the contact of Aspen to discuss this feature.
- Moonshot's Dev Team Member goes AWOL: A user shared a link to a tweet indicating that Aspen, a member of the Moonshot dev team, will not be returning to work due to a mind-altering experience during a festival break.
Yannick Kilcher ▷ #general (46 messages🔥):
Graph Neural Networks, Hyperparameter Tuning, LR Scheduling, Context Windows, Embedding Swapping
- GNN Loss Plummets Suddenly!: A user observed a sudden drop in loss when training Graph Neural Networks (GNNs), wondering if they just grok'd the concept.
- Others suggested it could be due to hyperparameter tuning such as learning rate or weight decay, or potentially the end of the first epoch causing the network to see the same input points again.
- To Schedule or Not to Schedule?: A member suggested that LR scheduling might be the cause, and another recommended training models without lr scheduling as it introduces unnecessary complexity.
- Another member has seen such things happen when the LR drops low enough to stop cycling in a certain dimension.
- Embedding Swapping: Members discussed swapping embeddings between system and user prompts to differentiate context, especially in long contexts.
- The goal is to allow the model to learn a more intrinsic difference in how it handles different kinds of input.
- Outsourcing Surveys: A user asked where they could pay for a survey, and another joked that they can be paid to take it.
- A member recommended Mturk as the industry standard, but cautioned that results may not represent the desired population due to low pay.
- Hinton Explains Deep Learning to Jon Stewart: Geoffrey Hinton gave Jon Stewart a crash course into deep learning offering the best explanation of Deep Learning / back propagation.
- A member highlights it as the Genuinely the best explanation of Deep Learning / back propagation I've ever heard.
Yannick Kilcher ▷ #paper-discussion (3 messages):
Segment Anything 3, New Arxiv Paper
- Segment Anything 3 Surfaces!: A member shared a link to Segment Anything 3 paper.
- New Arxiv Paper!: A member announced that they will be taking a look at this paper.
Yannick Kilcher ▷ #agents (7 messages):
LLM Agents Course, Berkeley Webcast Subtitles, Federal Law Requirements
- Berkeley's LLM Agents Course a Banger despite Audio Fails: A member shared a LLM agents course from Berkeley, which he recommends despite the bad audio quality.
- He jokes that AI people should use AI to improve the audio quality, saying that despite the issues, the course has all the memes and can be enjoyed at 1.5x speed.
- Seize the Subtitles: Berkeley's Webcast Lecture Liberation: A member suggests generating subtitles for old Berkeley webcast lectures as there is now no excuse to hide them.
- They mention that an outrage squad had the lectures taken down previously because they had no subtitles and were discriminating against deaf people, but that now it's possible to easily generate them.
- Subtitle Showdown: Feds vs. Lazy Universities?: A member claims that providing subtitles is a requirement of federal law, and that universities such as Berkeley are simply being lazy.
- Another member questions how other colleges like Harvard, Stanford, and MIT get away with not providing subtitles, suggesting that maybe auto-generated YouTube subtitles count.
Yannick Kilcher ▷ #ml-news (10 messages🔥):
AI First Authorship Requirement, Copilot Vulnerability, ImageNet image generation, Prompt Injection
- AI Authorship Ascendance at ECNU: East China Normal University's education school will require AI first authorship in one of the tracks of their December 2025 conference on education research, according to this announcement.
- Copilot's Camo Bypassed, Code Compromised!: A critical vulnerability in GitHub Copilot allowed for private source code exfiltration via a camo bypass as reported in this blog post; the issue was addressed by disabling image rendering in Copilot Chat.
- ImageNet Image Generation: Irrelevant?: A member expressed the sentiment that no one cares about ImageNet classes image generation anymore.
- Prompt Injection's Mundane Methods: A member found the prompt injection aspect of a security issue to be run of the mill, but highlighted the camo bypass as particularly interesting, calling it so stupid simple and yet it works.
DSPy ▷ #show-and-tell (7 messages):
Newsletter service, Optimization of small LLMs (Gemma), DSPy optimizers (Bootstrap fewshot vs GEPA)
- Roll your own Newsletter vs. Newsletter Service: A member asked whether their newsletter was powered by a third-party service or built from scratch.
- The member responded that the website is built from scratch, with no service or automation.
- Gemma gets tutorial on optimization: A member wrote a tutorial on optimization of small LLMs like Gemma for creative tasks with GEPA.
- Experimenting with DSPy Optimizers (GEPA) for prompt engineering: A member published a blog post comparing Bootstrap fewshot and GEPA optimizers in DSPy, finding that a high-quality set of examples can go a LONG way in getting good results out of GEPA - The Dataquarry.
DSPy ▷ #papers (2 messages):
New Arxiv papers
- Arxiv papers flooding in!: A member shared two new Arxiv links: First Generated Network and gc.victor.
- gc.victor paper released: The gc.victor paper has just been released.
DSPy ▷ #general (34 messages🔥):
Multi-Modal Models, Liquid Models, DSPy Boston Meetup, DSPy Bay Area Meetup, DSPy Toronto Meetup
- Liquid Models Imbue Multi-Modal Modeling: A member recommends Liquid models for multi-modal tasks, responding to a request for models under 4B parameters.
- Boston is Brewing DSPy Buddies: There's a DSPy Boston meetup on Wednesday, organized by members from PyData Boston, Weaviate, and Amazon AWS AI, with registration closing in 24 hours at Luma.com.
- Bay Area Beckons DSPy Buffs: A member is organizing a DSPy meetup in the Bay Area and requests interested individuals to respond for notification when the invite goes out.
- A flurry of users expressed their enthusiasm, with one mentioning they are interested in compound multi turn systems with dspy.
- Toronto Thirsts for Tech Talks: Many members expressed interest in a DSPy meetup in Toronto, prompting the suggestion that it is sprouting like mushrooms.
- One member volunteered to organize a DSPy meetup in Toronto anytime, mentioning a previous successful event with spacy (ax) and maxime Rivest.
- Automation Ace Avaialble for Assignments: A member introduces themselves as an experienced engineer specializing in workflow automation, LLM integration, AI detection, and image and voice AI, offering their services.
- They highlight a strong record of real-world implementations and provide examples of automated pipelines and task orchestration systems using LangChain, OpenAI APIs, and custom agents.
aider (Paul Gauthier) ▷ #general (14 messages🔥):
Aider configuration for default prompt function, AIder Polyglot benchmark LLM evaluation trajectories, Discussion platform for Aider (Github discussions, Reddit forum), Exporting Aider settings to a file
- Aider Config: Setting Default Prompt: Members discussed setting the default prompt function to
/askin the Aider config file and referenced the Aider documentation on usage modes and configuration options.- One user suggested setting
architect: trueto have Aider analyze the prompt and choose, and another recommended tryingedit-format: chatoredit-format: architectto set the default mode on launch.
- One user suggested setting
- AIder Polyglot Benchmarks Sought: A member inquired about accessing AIder Polyglot benchmark LLM evaluation trajectories.
- Another member asked for clarification, inquiring "what do you mean with 'evaluation trajectories'?"
- Aider Discussion Hub Quest: A user asked for a dedicated discussion platform for Aider, as GitHub Discussions are closed (https://github.com/Aider-AI/aider/discussions) and a Reddit forum couldn't be found.
- The user seems to want to discuss topics in a non-chat format.
- Aider Settings Export Eludes Users: A user expressed frustration with the
/settingscommand, which outputs a large, unmanageable dump, and asked if it's possible to export the settings to a file.- They noted that
/helpindicates this isn't possible but questioned if scripting could allow exporting the settings.
- They noted that
aider (Paul Gauthier) ▷ #questions-and-tips (7 messages):
Aider .env file locations, Aider vs other CLI tools, Aider fixing bad code, Auto test config, OpenAI endpoint to ChatGPT
- Aider reads .env files from 4 different locations: Aider looks for a .env file in the home directory, git repo root, current directory, and as specified with the
--env-file <filename>parameter, loading them in that order with later files taking priority, as described in the documentation. - Automatically test and fix code in Aider: A user reported issues with Aider generating uncompilable code using qwen3-coder:30b and ollama with test-cmd and lint-cmd set.
- A member suggested turning on the auto test config with yes always, which should run a test after every change and attempt fixes.
- Disable Aider's prompt for adding files: A user inquired about an option to prevent Aider from prompting to add files to the context, or generally default to no for any question.
tinygrad (George Hotz) ▷ #general (17 messages🔥):
Python 3.11 Upgrade, TinyMesa CPU, TinyMesa Building on Mac, NVIDIA GPU on Mac, Meeting Cancellation
- Python 3.11 Minimum Consideration Sparks Debate: The team is considering upgrading to Python 3.11 to utilize the
Selftype feature, though a workaround exists in Python 3.10.- One member found a way to do what they wanted with 3.10, so the bump is not immediate.
- TinyMesa Fork and Mac Build: A team member forked TinyMesa and inquired about its CI build status and Mac compatibility.
- Confirmation was given that it's building in CI, and theoretically should build for Mac, prompting an additional $200 bounty for a successful Mac build.
- NVIDIA GPU's Mac Comeback: One member expressed excitement about the prospect of getting TinyMesa plus USB4 GPU working on Mac, potentially marking the first functional NVIDIA GPU on Mac in a decade.
- The member thinks that this is so exciting if we get this + USB4 GPU on Mac.
- Meeting off Today: A member inquired about a meeting, and another confirmed its cancellation due to a previous meeting held at 10am HK time.
- They had a meeting before so they are skipping today's meeting.
MCP Contributors (Official) ▷ #general (9 messages🔥):
Proxying REST API, LLM-ready APIs, MCP server packaging formats, MCPB repo, Cloudflare MCP
- Proxying REST APIs is Bad Tool Design?: A member questioned whether proxying an existing REST API is generally recognized as a bad tool design and wondered if there were examples of good designs or benchmarks comparing effectiveness.
- Another member replied that it isn't necessarily bad, as its effectiveness depends on the underlying API's design, like whether it uses paginated endpoints or allows filtering applicable to the LLM.
- Craving Concrete LLM-Ready API Benchmarks?: A member expressed interest in building LLM-ready APIs at their workplace but noted the difficulty without concrete proof or benchmarks.
- Another member noted that the most useful benchmarks have been use case specific and recommended a robust evaluation strategy and tooling rather than relying on outside benchmarks too much.
- Dreaming of Deterministic MCP Server Packages?: One member raised the issue of non-deterministic dependency resolution at runtime with the current npx/uv/pip approach for MCP servers, causing slow cold starts in serverless environments.
- This same member proposed deterministic pre-built artifacts that can cold start in under 100ms and work across different runtimes, essentially treating MCP servers more like compiled binaries and expressed interest in submitting a working group creation request.
- MCPB Repository Rumblings: A member inquired about involvement with the anthropics/mcpb repo, questioning whether the community aims to remain agnostic on bundling formats.
- Another member suggested that relevant conversations occur in the <#1369487942862504016> channel, highlighting recent work supporting MCPB in the registry and emphasizing the importance of compatibility with the registry API/schemas.
- Cloudflare Champion Joins MCP Crew: A new member introduced themself as working on MCP at Cloudflare and expressed their enthusiasm to be present.
MCP Contributors (Official) ▷ #general-wg (1 messages):
jzhukovs: Does anyone know if Google AI studio supports MCP? Doesn’t look like it.
MLOps @Chipro ▷ #events (1 messages):
Diffusion Model Paper Reading Group, DDIM Paper Discussion, Diffusion & LLM Bootcamp
- Diffusion Model Paper Reading Group Forming: A new Diffusion Model Paper Reading Group is meeting this Saturday at 9 AM PST / 12 PM EST (hybrid in SF + online).
- The session will include a paper deep dive into Denoising Diffusion Implicit Models (DDIM) and an intro to their Diffusion & LLM Bootcamp.
- Delving into DDIM Paper: The group will discuss the paper Denoising Diffusion Implicit Models (DDIM) by Song et al., 2020, focusing on how DDIM speeds up image generation while maintaining high quality.
- Understanding DDIM is foundational to understanding Stable Diffusion, with the session being beginner-friendly for those with Python + basic PyTorch knowledge.
- Diffusion & LLM Bootcamp Announced: A 3-month Diffusion Model Bootcamp (Nov 2025), inspired by MIT’s Diffusion Models & Flow Matching course, will be introduced during the session.
- The bootcamp aims to provide hands-on experience in building and training diffusion models, ComfyUI pipelines, and GenAI applications for AI & Software engineers, PMs & creators.