congrats Qwen!
AI News for 2/13/2026-2/16/2026. We checked 12 subreddits, 544 Twitters and 24 Discords (261 channels, and 26057 messages) for you. Estimated reading time saved (at 200wpm): 2606 minutes. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
a good ship from Qwen.
AI News for 2/13/2026-2/16/2026. We checked 12 subreddits, 544 Twitters and 24 Discords (261 channels, and 26057 messages) for you. Estimated reading time saved (at 200wpm): 2606 minutes. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
Congrats to Pete Steinberger on joining OpenAI, as we predicted. Not much else to add there so we won’t.
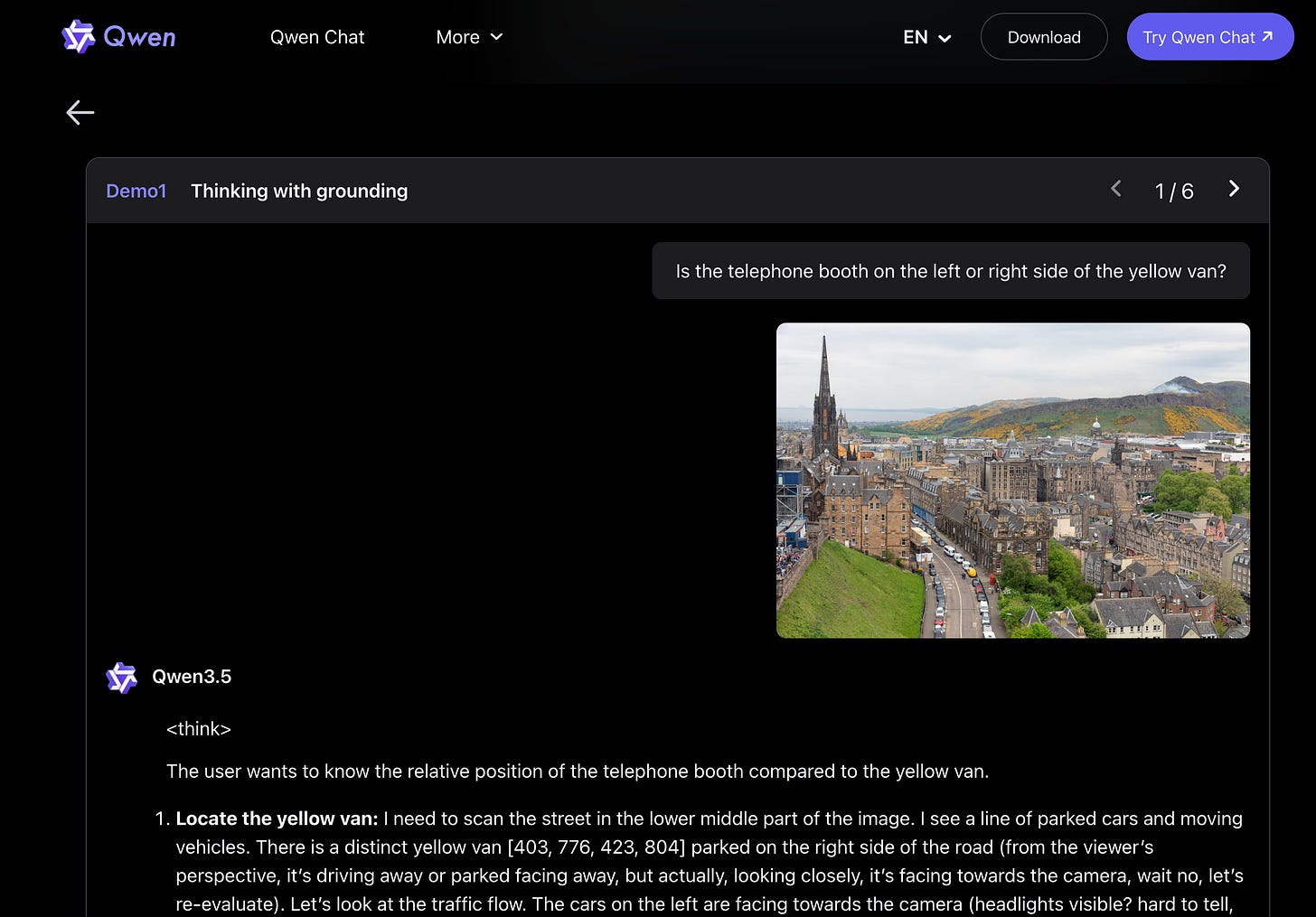
Today’s headliner is Qwen 3.5, which followed the other Chinese model labs like Z.ai and Minimax and Kimi in refreshing their leading models, but unlike the first two, Qwen 3.5 is in the same weight class as Kimi, 400B with about a 4.3% sparsity ratio instead of Kimi’s more agressive 3.25%. They do not claim SOTA across the board, and most notably not across coding benchmarks, but make solid improvements compared to Qwen3-Max and Qwen3-VL.
Native Multimodality and Spatial Intelligence are headline features of the model and we encourage clicking over to the blog to check out the examples, as there isn’t much else to say - this is a very welcome headline model refresh from China’s most prolific open model lab, and probably the last before DeepSeek v4.
AI Twitter Recap
Alibaba’s Qwen3.5 open-weight “frontier MoE” drop (and the inference/infra fallout)
- Qwen3.5-397B-A17B release: Alibaba shipped Qwen3.5-397B-A17B, positioned as the first open-weight model in the Qwen3.5 series: native multimodal, “thinking and non-thinking modes,” hybrid linear attention + sparse MoE, “large-scale RL environment scaling,” 201 languages, Apache-2.0 (official announcement; also echoed by @JustinLin610). They also clarified that Qwen3.5-Plus is the hosted API version of the same base model, with 1M context (vs model-native 256K) plus search/code interpreter integrations (clarification).
- Architecture + KV-cache implications: Community discussion focused on Gated Delta Networks / “GatedDeltaNet” + sparse MoE as the reason inference can stay tractable at long context. vLLM shipped day-0 support and highlighted 397B total, 17B active, multimodal, and throughput/latency advantages (vLLM recipe). A concrete KV-cache back-of-the-envelope suggested only ~31KB/token and ~8.05GB KV at 262K context in BF16 (and ~4GB in FP8) due to few KV heads + many gated-delta layers (KV math).
- Deployment reality: huge weights, but surprisingly runnable: Despite “~800GB BF16” scale, people reported local runs via MLX/Q4 on Apple Silicon (e.g., ~225GB RAM mentioned) (mlx report; awnihannun demo). Unsloth pushed “run 4-bit on 256GB Mac/RAM” guidance and claimed parity vs top closed models (marketing claim, but important for adoption) (Unsloth). Ollama put it on their cloud quickly (Ollama).
- Benchmarks + “agentic RL” vs efficiency questions: Early takes called it a step up over Qwen3-Max and prior Qwen VL models, with notable vision improvements; others asked for “reasoning efficiency” evidence rather than raw scores (scaling01). teortaxesTex noted it surprisingly outscores Qwen3-Max-thinking on some reported harnesses and speculated improvements due to agentic RL (commentary). At the same time, there were “black-box eval” critiques and task-specific failures (e.g., SVG / “Vending-Bench” style tests) (Vending-Bench claim; SVG comparisons).
- Pricing drama: Multiple posts argue Alibaba’s API pricing is high/weird given inference efficiency claims, with comparisons to Kimi/GLM offerings (pricing complaint; more). This became a recurring theme: “great model, unclear serve-cost story.”
Open agents, “harness engineering,” and the OpenClaw → OpenAI saga
- OpenClaw as a proof-point for one-person leverage: The OpenClaw story is framed as emblematic of “one-person team + coding agents” shipping something world-shifting fast, culminating in Peter Steinberger joining/acquired by OpenAI (Yuchenj_UW). This thread also triggered broader discussion of how OpenAI might handle open source post-acquisition.
- Anthropic/open-source tensions: A major discourse cluster criticized Anthropic’s posture toward open source and OpenClaw usage, with claims that restrictions/blocks pushed developers toward other models/providers (ThePrimeagen; Teknium). Others downplayed the strategic impact (“could be vibe-coded in a week”) while acknowledging reputational costs in OSS circles (scaling01). Separately, Anthropic announced a major operational expansion: Bengaluru office and noted India as Claude.ai’s second-largest market (Anthropic).
- Harness as the real moat: Several tweets converge on a practical thesis: agents aren’t just models; the “harness” (tooling, context management, lifecycle, skills, evaluation/observability) is compounding infrastructure and increasingly the differentiator. See Ben Burtenshaw’s definition of harness as an “OS” around the model, and the idea that proprietary agents feel better partly because models are trained on their harness patterns (ben_burtenshaw). This is echoed by practitioners building agent systems: “building a good harness is hard and compound over time” (brivael).
- Lightweight agent alternatives: Alongside “big harness” thinking, there’s interest in minimal agent stacks: PicoClaw and nanobot are pitched as drastically smaller alternatives to OpenClaw, supporting multiple model backends and MCP/vLLM (TheTuringPost).
- Agent observability/evals becoming table stakes: LangChain/LangSmith pushed the message that for agents, traces are the new “stack trace,” and debugging requires observability-first tooling (meetup; tracing plug-ins). This aligns with broader complaints that current agent behavior lacks determinism and requires babysitting.
OpenAI/Codex usage surge, sub-agents, and security hardening
- Codex adoption claims: Sam Altman reported Codex weekly users tripled since the start of the year (sama). Multiple community posts describe a “big leap” in Codex 5.3, especially via parallelism/sub-agents (gdb; “agents are up”).
- Sub-agent configuration + model-tier tradeoffs: Practical tip: increasing Codex sub-agents by editing config (e.g.,
max_threads = 24) was shared as a Pro-user tweak (Hangsiin). Meanwhile, at least one user reported 5.3-codex-spark is faster but “dumber” than full 5.3 for real work (giffmana). - Lockdown Mode for ChatGPT: OpenAI introduced Lockdown Mode to reduce prompt-injection and data exfil risks by disabling/altering tool behaviors (cached browsing, reduced web interaction), first for Enterprise/Business with consumer later (cryps1s). This is notable as a product-level acknowledgment that tool-enabled LLMs expand attack surface, and that some orgs want deterministic, restrictive controls even at capability cost.
- Scientific-claim scrutiny: A thread raised reproducibility concerns about an OpenAI physics result attributed to GPT-5.2, arguing journals should require transcripts/tooling details if secret models are used (lewtun). Kevin Weil pointed to more explanation from the involved physicist (kevinweil), and gdb posted a “how it came to be” follow-up (gdb).
China’s “holiday model wave”: Qwen3.5, GLM-5, MiniMax M2.5, Seed/Seedance—and robotics acceleration
- Chinese New Year as release season: Multiple posts frame CNY as the new “model drop week,” with a stack including Qwen3.5, GLM-5, MiniMax M2.5, and anticipation for DeepSeek-V4 (iScienceLuvr; Yuchenj_UW roundup).
- MiniMax M2.5: throughput + RL signal efficiency: SemiAnalysis reported M2.5 sustaining ~2500 tok/s/GPU throughput under certain TTFT constraints on 8×H200 with vLLM (SemiAnalysis_). MiniMax emphasized per-token process rewards as better RL signal utilization and cost efficiency, and celebrated broad API/partner availability (MiniMax_AI).
- ByteDance Seed/Seedance & AI film: Seedance 2.0 became a cultural moment via a Jia Zhangke short produced with the model (FrankYan2; EHuanglu). The meta-point: video generation is moving from “toy demos” toward “filmmaker workflow,” and some viewers note video outputs feel less “aesthetic-guidance uncanny” than image gen (jd_pressman).
- Robotics: Unitree + broader China lead narrative: Posts highlighted Unitree humanoids at the Spring Festival Gala and broader claims of rapid Chinese robotics progress (HumanoidHub; kimmonismus). teortaxesTex argued we’re past “Potemkin” skepticism—entire sectors (not just outliers) are real, especially robotics (teortaxesTex).
- Compute supply chain signals: Western Digital reportedly sold out much of 2026 HDD capacity due to enterprise demand, with some AI customers booking out to 2027/2028 (kimmonismus). Separately, NVIDIA’s GB300 NVL72 was touted as ~50× higher performance/MW and ~35× lower cost/token vs Hopper (vendor-claimed) (kimmonismus).
Research/engineering threads engineers actually use (agents, RL, interpretability, and eval hygiene)
- Multi-step tool use is still brittle: SciAgentGym shows success collapsing as tool-interaction steps increase; data synthesis over tool dependency graphs (SciForge) improved an 8B model on scientific workflows (dair_ai). This matches day-to-day agent pain: execution reliability is the bottleneck, not single-step reasoning.
- Adaptive reasoning depth for agents: CogRouter dynamically varies “cognitive depth” step-by-step; reported to beat GPT-4o with 62% fewer tokens on agent benchmarks (as summarized) (omarsar0).
- Rubric-based RL (RLVR beyond verifiable domains): A substantial writeup on rubric-based RL traces the path from LLM-as-judge to structured rubrics and offers practical tips across 15+ papers (cwolferesearch).
- Interpretability objective: MonoLoss proposes a plug-in objective to encourage monosemantic activations in SAEs across CLIP/SigLIP2/ViTs, improving “MonoScore” for many latents (iScienceLuvr).
- Benchmark contamination / “local generalization”: There’s renewed emphasis that benchmark gains can be confounded by training-data expansion and semantic near-duplicates. A proposed decomposition: benchmaxxing vs usemaxxing vs hidden interpolation vs true OOD generalization (g_leech_). This rhymes with Lucas Beyer’s earlier vision-data de-dup experience and the difficulty of doing this “properly” in language (giffmana).
- WeirdML time horizons: A METR-inspired “time horizon” estimate for WeirdML tasks suggests frontier model horizons from ~24 minutes (GPT-4) to ~38 hours (Opus 4.6) and a ~5-month doubling time (htihle), echoed as broadly consistent with METR-like estimates (scaling01).
Meta themes: open vs closed, labor/education impacts, and “taste” as a new bottleneck
- Open model momentum vs concentration risks: A recurring sentiment is that open models reduce power concentration and keep multiple AGI pathways available (TuringPost clip). In parallel, debates rage over ToS constraints (e.g., Anthropic limiting surveillance/weapons use) and whether that makes a vendor a “supply chain risk” (RyanPGreenblatt; kimmonismus Axios summary).
- Workforce disruption timelines: Ryan Greenblatt argued mass unemployment is “overrated in 2 years, underrated in 7,” with the key inflection being full automation of AI R&D (after which human cognitive labor value collapses quickly) (thread start).
- Education/skills anxiety: Claims that degrees may become obsolete before students graduate (popularized via a newsy summary tweet) reflect broader uncertainty (kimmonismus). There’s also a warning that AI coding tools can reduce skill mastery in controlled studies (via an Anthropic research link, summarized) (dl_weekly).
- “Taste” and verification as core skills: This set strongly emphasizes that as models/agents scale, taste (choosing good problems/solutions) and ability to verify (detecting subtle wrongness) become the scarcest human differentiators—explicitly labeled as “a new core skill” (gdb; Yuchenj_UW). Karpathy extends this into programming languages/formal methods: translation and refactoring will dominate, and we may rewrite much of software repeatedly; languages “optimal for LLMs” become an open question (karpathy).
Top tweets (by engagement)
- SF walkability discourse: @paularambles
- Anthropic Bengaluru office / India as #2 market: @AnthropicAI
- Qwen3.5-397B-A17B release (Apache-2.0, multimodal MoE, 17B active): @Alibaba_Qwen
- PL/FM + LLMs reshape software translation/rewrite: @karpathy
- “Anthropic hate for open source” viral take: @ThePrimeagen
- Codex growth claim: @sama
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
1. Qwen 3.5 Model Release and Performance
-
Qwen3.5-397B-A17B is out!! (Activity: 973): Qwen3.5-397B-A17B has been released on Hugging Face, featuring a
397 billionparameter model with a native context length of262,144tokens, which can be extended up to1,010,000tokens. This model is part of the Qwen series, known for its large-scale language capabilities. Additionally, a GGUF version is available here, which may offer optimized performance for specific use cases. There is anticipation and curiosity in the community about the model’s performance, with users eager to test its capabilities.- The Qwen3.5-397B-A17B model boasts a native context length of
262,144tokens, which can be extended up to1,010,000tokens. This is a significant improvement in handling larger contexts, making it suitable for more complex tasks that require extensive input data. - The decoding throughput of Qwen3.5-397B-A17B is reported to be
3.5xto7.2xfaster than its predecessor, Qwen3-235B-A22B. This increase in throughput suggests substantial improvements in processing efficiency, which could lead to faster response times and reduced computational costs for large-scale applications. - A user has shared a link to the GGUF version of the model on Hugging Face, indicating that the model is available for download and experimentation. This accessibility allows for broader testing and integration into various projects.
- The Qwen3.5-397B-A17B model boasts a native context length of
-
Qwen3.5-397B-A17B Unsloth GGUFs (Activity: 663): Qwen3.5-397B-A17B is a newly released model by Alibaba with
397 billionparameters, designed for multimodal reasoning. It is capable of running in3-biton a192GB RAM Macor4-bit (MXFP4)on anM3 Ultrawith256GB RAM. The model is positioned as competitive with Gemini 3 Pro, Claude Opus 4.5, and GPT-5.2 in terms of performance across benchmarks like instruction following, multilingual knowledge, and video reasoning. The release includes dynamic GGUFs for flexible deployment, and a guide is available for running the model on various hardware configurations. More details can be found on Hugging Face and Unsloth. Commenters are impressed by the model’s size and capabilities, noting the397 billionparameters and the fact that only17 billionare active at a time. There is curiosity about how AutoRound might enhance the model’s performance.- The Qwen3.5-397B-A17B model is noted for its verbosity, as demonstrated by its extensive internal dialogue when generating a simple greeting response. This verbosity could be indicative of the model’s complex decision-making process, which might be beneficial for nuanced tasks but could also lead to inefficiencies in simpler interactions.
- A user expressed curiosity about the performance of the AutoRound feature with the Qwen3.5-397B-A17B model, particularly given that only 17 billion parameters are active. This suggests a focus on optimizing performance while managing computational resources effectively, which is crucial for deploying large models in practical applications.
- There is a discussion about the comparative performance of UD-Q4_K_XL and MXFP4 formats, with a user noting the lack of benchmarks directly comparing the two. This highlights a gap in available performance data, which is essential for making informed decisions about model deployment and optimization strategies.
2. Local LLM Challenges and Innovations
-
Why is running local LLMs still such a pain (Activity: 243): The post discusses the challenges of running local Large Language Models (LLMs) like Ollama and Llama on personal hardware, highlighting issues such as installation failures and resource constraints when dealing with models larger than
7Bparameters. The user expresses frustration over the complexity of self-hosting solutions, which often require advanced technical knowledge in areas like Docker and Kubernetes, and the lack of privacy-friendly yet functional alternatives to services like OpenAI’s ChatGPT. Commenters note that achieving ChatGPT-level functionality locally is inherently difficult due to the significant hardware requirements, suggesting that while tools like LM Studio, Ollama, or Lemonade can be installed easily, performance is heavily dependent on having a powerful GPU or NPU. They emphasize that without substantial investment in hardware, local LLMs will be slow, and achieving full ChatGPT functionality may not be feasible without using a remote provider.- No_Clock2390 highlights that running local LLMs is feasible with the right hardware, mentioning tools like LM Studio, Ollama, and Lemonade that can be set up quickly. However, performance is heavily dependent on hardware capabilities, particularly the presence of a GPU or NPU. For instance, running Ollama on an Intel N100 is possible but results in slow performance due to CPU limitations.
- Total-Context64 emphasizes the cost barrier in achieving ChatGPT-like functionality locally, pointing out that significant investment in hardware is necessary unless one opts for a remote provider. This underscores the challenge of replicating high-performance LLMs without substantial resources.
- HorribleMistake24 suggests using lmstudio for beginners, which assists in determining model compatibility with available GPU VRAM. They also mention leveraging a ChatGPT subscription for setup assistance via Codex in VS Code, illustrating a practical approach to overcoming setup challenges by integrating AI tools into the development process.
3. MiniMax-2.5 and OpenClaw Discussions
-
Anyone actually using Openclaw? (Activity: 1615): The Reddit post questions the authenticity of Openclaw’s popularity, suggesting it might be a result of manufactured social media marketing, especially after OpenAI’s acquisition of Openclaw. The post references a suspicious growth graph here. Openclaw is described as a tool that connects various APIs and MCP servers, but lacks innovation, according to user experiences. The acquisition by OpenAI for
10 billionis viewed skeptically, with comparisons to the hype-driven nature of the crypto market. Comments suggest skepticism about Openclaw’s marketing tactics, with some users describing it as ‘vibe coded’ and lacking in unique functionality. There is interest in alternatives like Ironclaw, indicating a desire for more robust solutions.- Skystunt mentions that Openclaw is essentially a compilation of existing technologies, connecting various APIs and MCP servers, without offering any groundbreaking features. This suggests that its perceived value might be inflated, as it doesn’t introduce new capabilities but rather integrates existing ones.
- dgibbons0 highlights the poor configuration quality of Openclaw, describing it as ‘vibe coded’. This term suggests a lack of professional polish or robustness in its setup. The commenter also expresses interest in exploring Ironclaw, a related project, indicating that the concept of integrating chat with AI engines is appealing despite Openclaw’s shortcomings.
- TurnUpThe4D3D3D3 raises concerns about the financial implications of using Openclaw, noting that it has a default 30-minute heartbeat that incurs API costs each time it runs. This could lead to significant expenses over time, potentially amounting to several dollars per week, which might not be immediately apparent to users.
-
You can run MiniMax-2.5 locally (Activity: 784): The image provides a detailed guide on running the MiniMax-2.5 model locally, highlighting its state-of-the-art performance in coding, agentic tool use, and office tasks. The model features
230B parameterswith10B active, a200K context window, and requires457GBof memory in its unquantized bf16 form. The use of Unsloth Dynamic 3-bit GGUF significantly reduces the model size to101GB, a62%reduction, making it more accessible for local deployment. The guide also includes links to the official documentation and GGUF models on Hugging Face. Comments reflect skepticism about the accessibility of running such a large model locally, with users humorously noting the high hardware requirements and costs associated with deploying the model.- Ug1bug1 mentions that the MiniMax models, including the Q3_K_XL, perform well on their Strix Halo setup, which has 128GB of RAM. This suggests that the model’s performance is satisfactory on high-end hardware, indicating that substantial memory is a key requirement for running these models effectively.
Less Technical AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. AI Model Releases and Benchmarks
-
What are you looking forward to? (Activity: 954): The image is a tweet from CHOI (@arrakis_ai) announcing the imminent release of several AI models: DeepSeek V4, Gemini 3.1 Pro, GPT 5.3, Sonnet 5, and a “Mystery model.” The tweet highlights the rapid acceleration of AI development timelines, suggesting these releases are expected within days. This indicates a significant period of advancement and competition in AI model development, with potential impacts on various applications and industries. One comment expresses skepticism about the release of Sonnet 5, referencing a previous rumor that turned out to be about Opus 4.6 instead. Another comment hints at a competitive atmosphere, mentioning “Elon crashing out over his lack of,” possibly referring to competition in AI advancements.
- johnwheelerdev mentions anticipation for Gemini 3.1, suggesting it could be a significant update or release. This could imply improvements or new features over previous versions, though specific details or benchmarks are not provided.
- GraceToSentience refers to a rumor about Sonnet 5, which was previously thought to be Opus 4.6. This indicates a possible mix-up or rebranding in versioning or product naming, highlighting the challenges in tracking software updates and releases.
- Egoz3ntrum brings up GPT-OSS-2, which could be an open-source variant of GPT models. This suggests a trend towards more open-source AI models, potentially offering more transparency and community-driven improvements.
-
Attackers prompted Gemini over 100,000 times while trying to clone it, Google says (Activity: 1342): Google reported that attackers attempted to clone its Gemini AI model by prompting it over
100,000times, using a technique called model distillation. This approach involves feeding the model specific prompts to gather responses, enabling the creation of a cheaper imitation without direct access to the model’s code or training data. Google considers this activity as intellectual property theft and has implemented undisclosed countermeasures. For more details, see the original article. Some commenters question the effectiveness of model distillation, comparing it to attempts in the 90s to improve chess software by feeding it millions of games, which had no significant impact. Others highlight the irony of Google’s stance on intellectual property, given its own use of web-scraped data for training LLMs.- Deciheximal144 highlights the irony in Google’s stance on ‘model extraction’ as intellectual property theft, given that Google’s own LLMs were trained on data scraped from the internet without explicit permission. This raises ethical questions about data usage and ownership in AI training processes, as discussed in The Verge.
- magicmulder questions the effectiveness of ‘model extraction’ by comparing it to attempts in the 90s to improve chess software by feeding it millions of games, which had no significant impact. This suggests skepticism about whether simply prompting an AI model extensively can lead to a high-quality clone, as the complexity of model training involves more than just input data volume.
- Ok_Buddy_9523 humorously downplays the notion of ‘prompting AI 100000 times’ by likening it to a routine activity, implying that such a number of interactions might not be as significant or unusual in the context of AI development and testing.
-
Codex-cli with GPT-5.3 codex xhigh - 5 hours made a fully working GBA emulator in assembly code! (Activity: 717): A user claims to have used Codex-cli with GPT-5.3 codex xhigh to develop a fully functional Game Boy Advance (GBA) emulator in assembly code within
5 hours. The project, hosted on GitHub, involved the model autonomously building, testing, and debugging the emulator. The emulator’s architecture includes an x86-64 assembly core with a minimal C host layer for SDL2, targeting compatibility with games like SuperMarioAdvance. The plan outlined includes ARM7TDMI CPU core emulation, memory mapping, and PPU/APU functionality, with a focus on determinism and performance benchmarks such as59.7 FPSon Linux x86-64. The project emphasizes a pure assembly approach with a C platform shim for SDL2 integration. Commenters express skepticism and curiosity about the emulator’s performance and cost, with one noting the irony of recent claims that LLMs cannot generate low-level code. Another commenter is impressed by the achievement, highlighting its uniqueness if no similar example exists.- stardoge42 inquires about the cost in credits and the performance of the emulator, asking if there are any glitches and whether it works with other games. This highlights the practical considerations of using AI-generated code, such as resource consumption and compatibility across different software environments.
- cottsay references a similar project, the ‘Gameboy Emulator in ARM Assembly’ available on GitHub, which was developed 6 years ago. This comparison provides context on the evolution of emulator development and the potential advancements made by using AI tools like Codex-cli with GPT-5.3.
- BrennusSokol mentions encountering skepticism about AI’s ability to generate low-level or machine code, which is countered by the successful creation of a GBA emulator in assembly code. This reflects ongoing debates about the capabilities of AI in software development, particularly in generating complex, low-level code.
2. Anthropic and OpenAI Legal and Ethical Tensions
-
Anthropic’s Moral Stand: Pentagon warns Anthropic will “Pay a Price” as feud escalates (Activity: 1059): The post discusses a conflict between Anthropic, an AI safety and research company, and the Pentagon over ethical guidelines for AI use. Anthropic is reportedly resisting the Pentagon’s push for AI applications in large-scale surveillance and fully autonomous weapons, advocating for ethical guardrails. The Pentagon, however, views this resistance as a potential ‘supply chain risk,’ which could lead to a ‘race to the bottom’ in safety norms if procurement pressures override ethical considerations. This raises questions about where ethical lines should be drawn in AI applications and who should have the authority to set these boundaries. Commenters highlight support for Anthropic’s stance, noting the importance of ethical limits on AI, such as prohibiting surveillance on American citizens and autonomous weaponry. There is skepticism about the Pentagon’s intentions, with some suggesting that surveillance of Americans is already occurring.
-
Exclusive: Pentagon threatens Anthropic punishment (Activity: 969): The Pentagon, under Defense Secretary Pete Hegseth, is threatening to label Anthropic as a “supply chain risk” due to disagreements over the use of its AI model, Claude, in military applications. This designation would force contractors to cut ties with Anthropic, significantly affecting its business, as Claude is the only AI model currently integrated into classified military systems. The conflict arises from the Pentagon’s demand for broader usage rights, which clashes with Anthropic’s ethical concerns about privacy and autonomous weaponry. Read more. Commenters express support for Anthropic’s stance on ethical AI use, criticizing the Pentagon’s pressure as potentially corrupt and favoring more compliant AI companies like Grok and Gemini.
- Anthropic’s stance on restricting the use of its AI tools to prevent mass surveillance and autonomous weaponry is seen as a significant ethical position. The Pentagon’s pushback against these restrictions highlights a tension between ethical AI use and governmental interests in leveraging AI for defense purposes. This situation underscores the broader debate on AI ethics and governance, particularly in the context of national security.
- The discussion suggests that Anthropic’s AI, Claude, is perceived as a leading product in the market, potentially threatening other AI companies that may have more favorable relationships with government entities. This perception of market leadership and ethical stance could be influencing governmental pressure, as there is a suggestion of favoritism towards other AI companies like Grok and Gemini.
- There is a sentiment that Anthropic’s ethical stance could be used as a marketing advantage, appealing to users who value privacy and ethical considerations in AI deployment. This reflects a growing consumer awareness and demand for responsible AI practices, which could influence market dynamics and competitive positioning.
-
Anthropic threatened to sue the guy over his project’s name, twice. Now he’s joined OpenAI and Claws 🦞 are coming for them 🤣🤣 (Activity: 1048): The image is a meme that humorously depicts a legal dispute between Anthropic and a developer over the name of his project, which led to the developer joining OpenAI. The image includes a Twitter exchange that highlights the legal threats from Anthropic, referred to as ‘love letters from legal.’ The post suggests a rivalry between Anthropic and OpenAI, with the developer’s move to OpenAI being seen as a win for them. The comments discuss the strategic focus of Anthropic on model development, while OpenAI is seen as more product-oriented, suggesting that OpenAI’s interest in the developer is due to his ability to create viral products quickly. Some commenters express skepticism about the significance of the developer’s move to OpenAI, questioning the uniqueness of his project and suggesting that other companies could replicate it easily. Others view OpenAI’s hiring as a reactionary move, implying it may not lead to substantial changes.
- Portatort highlights that Anthropic is focused on developing the best AI models, contrasting with OpenAI, which is now more product-oriented, aiming to create viral products. This suggests a strategic divergence in company goals, with Anthropic prioritizing model excellence and OpenAI focusing on marketable applications.
- Inside_Anxiety6143 questions the significance of OpenClaw for OpenAI, noting that its creator claimed to have developed it in a short time (‘vibecoded it in like a month’). This raises the point that other companies might replicate such projects quickly, questioning the uniqueness or competitive advantage of OpenClaw.
- beigetrope suggests that OpenAI’s hiring of the creator of OpenClaw might be a reactionary move, implying that it may not lead to substantial changes within the company. This comment reflects skepticism about the strategic impact of such hires on OpenAI’s overall direction.
3. OpenClaw Security and Community Concerns
-
Sam Altman officially confirms that OpenAI has acquired OpenClaw; Peter Steinberger to lead personal agents (Activity: 2440): Sam Altman has confirmed that OpenAI has acquired OpenClaw, with Peter Steinberger joining to lead the development of personal agents. OpenClaw will transition to an open-source foundation, with OpenAI providing ongoing support. This move suggests a strategic focus on enhancing personal agent capabilities, leveraging Steinberger’s expertise. Some commenters speculate that the acquisition might be a defensive strategy to prevent competitors from gaining access to OpenClaw’s technology. Others question why OpenAI didn’t develop similar capabilities internally, hinting at potential strategic or resource-based reasons for the acquisition.
- A key concern raised is about access to OpenClaw’s technology, which was initially developed using backdoor CLI accesses, making it unaffordable for many. The commenter questions how OpenAI will address these access issues, suggesting that the integration of OpenClaw’s technology into OpenAI’s ecosystem could potentially democratize access if handled correctly.
- The acquisition of OpenClaw by OpenAI is seen as a strategic move to prevent competitors from gaining access to its technology. This is referred to as a ‘defensive buy,’ indicating that OpenAI’s primary motivation might be to secure its market position by keeping the technology out of the hands of rivals.
- There is speculation about the future direction of OpenClaw under OpenAI’s leadership, particularly with Peter Steinberger at the helm. The comment humorously references the potential for a ‘ClosedClaw’ scenario, implying that OpenAI might restrict access or functionality, similar to how some companies limit features post-acquisition.
AI Discord Recap
A summary of Summaries of Summaries by gpt-5.1
1. Frontier, Open, and Regional Models: Qwen3.5, GLM‑5, MiniMax 2.5, Opus 4.6, Step 3.5 Flash
-
Qwen3.5 & Qwen3.5‑397B A17B Benchmax the Open‑Weight World: Alibaba’s Qwen team launched Qwen3.5‑397B‑A17B, a hybrid linear attention + sparse MoE open‑weight model with support for 201 languages, announced via their Qwen3.5 post and referenced across Latent Space and HuggingFace discords, with Apache‑2.0 weights on GitHub and Hugging Face plus API access. Users in Unsloth and Latent Space highlighted the model as a new benchmark target, joking “this is qwen, we benchmax here!” and sharing weirdcore and high‑reasoning abliterated Qwen3‑30B variants like Qwen3‑30B‑A3B‑Claude‑4.5‑Opus‑High‑Reasoning‑2507‑ABLITERATED‑UNCENSORED‑V2.
- Bench conversations compared MXFP4 quants versus Q8_K_XL on Nemotron 30B A3B, finding MXFP4 lower KL divergence from bf16 and requesting MXFP4 support across older models, while others experimented with Qwen3 architecture in GPT‑NeoX via this implementation branch. In parallel, Eleuther’s research channel dissected papers like “Matrix‑Driven Identification and Reconstruction of LLM Weight Homology” and “Independence Tests for Language Models”, treating Qwen‑lineage models as a prime case study for reconstructing finetuning trees and provenance of large open families.
-
GLM‑5, MiniMax 2.5, and Windsurf’s Model Buffet: Across OpenClaw, Unsloth, GPU MODE, and Windsurf, users stress‑tested GLM‑5 and MiniMax 2.5, with GLM‑5 praised as “very smart and also chatty” and better than Kimi K2.5 when it stays up, while MiniMax 2.5 was described as needing ~200 GB VRAM (e.g. 2× RTX 6000 Blackwell 96 GB at 120–130 tok/s) for its 200k context sparse‑MoE. Windsurf announced first‑class support for GLM‑5 and MiniMax M2.5 in‑product via their update, effectively turning an IDE into a multi‑provider frontier‑model router.
- Unsloth users contrasted MiniMax 2.5 to Opus 4.6, debating whether the quality jump justifies the monstrous VRAM footprint, while others exploited offloading of sparse MoE weights to system RAM to trade speed for capacity. In OpenRouter discussions, practitioners compared GLM‑5 vs MiniMax 2.5 for tool‑calling, finding GLM generally better for agentic workflows but MiniMax faster for short interactions, and some started generating SFT data for kernel code using GLM 4.5 Air to cheaply bootstrap high‑quality reasoning traces.
-
Opus 4.6 and Step 3.5 Flash Flex Long Context Muscle: Opus 4.6 rolled out with a 1M‑token context and an explicit “check your work” verification pass, which LMArena users tested by feeding large code instruction suites and confirming that the model can ignore earlier mistakes during final reasoning. A Perplexity user benchmarking Claude via Opus 4.6 noted Anthropic’s hourly usage constraints—e.g. “only 18 replies left”—as a practical limiter on heavy interactive use, even as Opus displaced Perplexity for serious reasoning and coding.
- On the OpenRouter side, Step 3.5 Flash impressed users by “punching above its weight” in a YouTube benchmark, but remains surprisingly under‑hosted despite its strong cost‑performance profile. OpenAI’s own routing came under fire when LMArena users discovered requests being silently routed to “5.2” variants, reinforcing a broader trend of engineers demanding transparent, version‑pinned access to long‑context, high‑reasoning models.
2. Agent Stacks, Planning Frameworks, and Multi‑Agent Systems
-
OpenClaw Orchestrates Autonomous Agencies and Video Calls: Builders showcased OpenClaw as an orchestration layer for multi‑agent teams and real‑world ops, including an “agency server” with a technical lead, backend, and frontend bots coordinating via tasks and plans in a shared planbot resource repo. Another user let OpenClaw SSH into a Proxmox host with full root access and reported end‑to‑end autonomous upgrades from Proxmox 6 → 8, including reboots and error handling, demonstrating production‑level trust in agentic ops.
- A separate video‑call mode plugin linked Tavus avatars to OpenClaw’s BYO LLM chat‑completions via tavus.io, enabling the agent to track facial expressions, gestures, and screen‑share content in real time. Other experiments wired OpenClaw’s “subconscious” to a local finetuned LLM trained on all prior chats (essays shared in a Google Drive folder), and used an SEO pipeline that scraped YouTube, generated ~300+ Brian‑Dean‑style articles, passed them through an editor‑subagent, then stored them for publishing.
-
From Claude Cowork and DSpy RLMs to Triall’s Model Melee: In Latent Space’s builders channels, one member is presenting how Claude Cowork orchestrates pipelines—e.g. automatically uploading Zoom recordings to a YouTube channel—under the provocative framing “Claude Cowork might be AGI”, while others use Ergo planning skills from this repo to structure multi‑step feature work. DSpy contributors pushed Recursive Language Models (RLMs)—as described in Omar Khattab’s thread—where models write code to call other models instead of relying on quadratic attention or monolithic agent harnesses, with a concrete dspy‑repl prototype exploring how language + REPL choice affects RLM accuracy.
- Triall (triall.ai) appeared on OpenRouter as a GUI built on clash that lets users pit multiple models against each other for generation, critique, and refinement, encouraging adversarial reasoning instead of blind trust. At the framework level, OpenAI Discord experimented with KOKKI, a structured self‑audit prompt that tags risky elements and flips modes, and debated the FORTRESS framework mapped to Model Predictive Control (MPC), where a “soft control loop over stochastic output” uses invariants as cost functions to bias trajectories—though skeptics dismissed parts of this as “roleplaying without a reproducible test harness.”
-
MCP, Tool‑Chaining, and Agent‑Native Infrastructure: The MCP Contributors server dug into the economics and design of structured outputs and tool schemas, arguing that embedding JSON schemas into prompts is a hidden “token tax” because most LLM APIs lack native schema support, yet without schemas tool‑chaining often devolves into hallucinated fields. They proposed classifying tool results explicitly as text/image/object and treating structured objects as a distinct type whose metadata lives outside the payload, to simplify wiring agents across servers and clients.
- To support realistic queries like “How did I sleep last week?”, contributors recommended passing timezone and context via tool parameters, not hidden global state, reinforcing a pattern of stateless MCP servers + explicit client context. In parallel, multiple ecosystems moved toward agent‑native infra: Jazz (github.com/lvndry/jazz) is an LLM‑agnostic terminal agent that reads files, runs git, uses MCP, and writes its own release notes; Crowdcent is wrapping DSPy into MCP; and Cloudflare announced experimental
Accept: text/markdownsupport for agents in “Markdown for agents”, so HTTP endpoints can return markdown‑native content to LLM clients.
- To support realistic queries like “How did I sleep last week?”, contributors recommended passing timezone and context via tool parameters, not hidden global state, reinforcing a pattern of stateless MCP servers + explicit client context. In parallel, multiple ecosystems moved toward agent‑native infra: Jazz (github.com/lvndry/jazz) is an LLM‑agnostic terminal agent that reads files, runs git, uses MCP, and writes its own release notes; Crowdcent is wrapping DSPy into MCP; and Cloudflare announced experimental
3. GPU Kernels, CUDA/Triton DSLs, and Agent‑Written Kernels
-
FlashInfer, Flashy Contests, and Agent‑Optimized Kernels: The FlashInfer‑bench competition in GPU MODE had participants tuning fused MoE and GQA kernels on B200s via Modal, with organizers clarifying that reference baselines use FP32 intermediates, but FP8 intermediate math is allowed if accuracy stays close, and reminding everyone that Modal supports CUDA 12.8 per their docs. The AccelOpt team claimed 1.5× speedups on GQA paged decode and 1.38× on GQA paged prefill over FlashInfer 0.5.3 using a self‑improving LLM agent to mutate kernels, open‑sourcing their approach at zhang677/AccelOpt.
- GPU MODE beginners wrestled with benchmark jitter (e.g. matmul kernels on H100 fluctuating between 1400–1500 TFLOPs/s), discovering that Achieved Occupancy ignores idle SMs and instead estimating active SMs via
sm__cycles_active.sum / sm__cycles_active.max. On the HuggingFace side, an agent in the official course wrote a custom CUDA kernel for the LTX model on H100 and beat the baseline in the “custom CUDA kernels as agent skills” blog, illustrating an end‑to‑end flow where planning agents design and integrate specialized GPU kernels.
- GPU MODE beginners wrestled with benchmark jitter (e.g. matmul kernels on H100 fluctuating between 1400–1500 TFLOPs/s), discovering that Achieved Occupancy ignores idle SMs and instead estimating active SMs via
-
Triton, CuteDSL, Cutlass, and Proton: Profilers for the Kernel Priesthood: GPU MODE’s triton‑gluon and cutlass channels went deep on Proton, CuteDSL, and CuTeDSL: one thread walked through generating warp‑level timelines with Proton using the example DSL instrumentation and visualizing traces in Perfetto, with warnings that DSL‑level annotations can be reordered and that high‑precision work should attach at TTGIR override level. Another thread debugged CuteDSL’s
partition_Sdropping tensor alignment fromalign<16>toalign<4>and odd stride prints like(128,64,4):(1@1,1@0,64@0), plus CuTeDSLcomplement()returning invalidx:xinstead of(3,2):(2,12)as shown in the layout algebra docs.- The NVIDIA competition channel shipped a Performance Trends dashboard that plots daily best submissions across top 5 users and the global best in yellow (see example trend graph), and added axis zoom to make wide score ranges legible. Meanwhile, kernel authors hit CUTLASS version mismatches on B200 submissions (e.g.
ModuleNotFoundErrorandDSLRuntimeErrorfrom an older CuTeDSL commit referenced here), and a separate GPU MODE webgpu thread showed a Hesper library running BitNet‑B1.58 at 125 tok/s on an M4 Max via WebGPU.
- The NVIDIA competition channel shipped a Performance Trends dashboard that plots daily best submissions across top 5 users and the global best in yellow (see example trend graph), and added axis zoom to make wide score ranges legible. Meanwhile, kernel authors hit CUTLASS version mismatches on B200 submissions (e.g.
-
Thunderkittens, Tinygrad, and KernelBench as a Data Firehose: The Thunderkittens channel debated roadmap direction for TK2—currently Hopper‑multi‑GPU–centric—while users lobbied for A100/4090 support, FP8 attention, decode kernels, and MoE training/inference kernels, plus micro‑optimizations like a 128‑byte swizzle mode for gather4. In tinygrad, George Hotz lambasted a GLM Flash PR as “should be 50 lines max” with “extra unrelated things”, and described the Graphcore C600 IPU as “20% MFU” and “accursed C++ slop”, highlighting the friction of non‑CUDA hardware despite an open stack.
- GPU MODE’s popcorn channel turned kernel tuning into a dataset factory: one user generated reasoning traces from Kernelbook with gpt‑oss‑120B, then finetuned Arcee Trinity Mini for Triton kernel generation, publishing the traces at kernelbench‑triton‑reasoning‑traces. Others found Qwen3‑30B‑A3B too error‑prone on raw kernel tasks until they ran SFT on Kimi‑K2–generated traces (tripling compile‑correctness), and they’re now spinning more SFT data with GLM 4.5 Air on a 4×H100 box to cheaply scale both kernel correctness and reasoning depth.
{kind=link}
4. New Benchmarks, Reasoning Methods, and Uncertainty/Security Research
-
CommonLID, Assistant Axis Drift, and Weight Homology Map Model Behavior: Eleuther and Common Crawl launched CommonLID, a web‑scale Language ID benchmark over 109 languages described in their arXiv paper, showing top existing LangID models scoring <80% F1 even on supported languages, with the dataset hosted on Hugging Face. Eleuther’s research channels also highlighted the “Assistant Axis” paper “Steering LLMs by Persona Directions”, which extracts activation directions for different personas and empirically shows assistant‑mode drift over long chats is structural, quantifying a phenomenon many users had only anecdotally reported.
- Complementary theory threads dug into weight‑space structure via “Matrix‑Driven Identification and Reconstruction of LLM Weight Homology” and “Independence Tests for Language Models” plus its follow‑up “Blackbox Model Provenance via Palimpsestic Membership Inference”. Members were particularly impressed that Independence Tests could reconstruct the finetuning tree of Llama‑architecture models from black‑box access, and they debated new approximations for causal attention preconditioning inspired by this visualization tweet, including whether Tensor Cores could cheaply approximate these matrices.
-
Reasoning Pipelines: CoVe, QED‑Nano, Rubric RL, and RLMs: Latent Space’s paper club walked through Meta’s Chain‑of‑Verification (CoVe), where Ryan Lazuka’s summary thread claims 94% accuracy boosts via a two‑stage generate → verify prompting protocol without few‑shot exemplars, suggesting CoVe could replace standard CoT in many regimes. Lewis Tunstall’s QED‑Nano 4B theorem‑proving model—announced in this post—targets IMO‑level math with distilled reasoning pipelines and a reasoning cache that enables aggressive inference‑time scaling.
- Cameron Wolfe’s survey of Rubric‑Based Reinforcement Learning (tweet) synthesized 15+ papers on using explicit textual rubrics instead of raw LLM‑as‑a‑Judge scores, extending RL with Verifiable Rewards (RLVR) into fuzzy domains like style and safety. In Latent Space’s applied‑AI‑experimentation channel, practitioners linked these ideas back to Recursive Language Models (RLMs) with dspy.RLM (design thread), arguing that symbolic recursion over calls and code (not longer attention) is the real bottleneck‑buster for long‑horizon reasoning.
-
Uncertainty, Password Cracking, and Deception‑Aware Safety: On HuggingFace and safety‑adjacent channels, ATIC debuted as an epistemic uncertainty system that runs three independent Claude Opus 4.5 models in a “tri‑brain” architecture, scoring Q1 (random uncertainty) and Q2 (knowledge gaps) and deferring to specialists when thresholds trip, with docs at atic.consulting and their API docs. The same i‑made‑this channel highlighted PassLLM, a password auditor that finetunes a Qwen3‑4B LoRA on millions of real password pairs to generate PII‑conditioned password lists, open‑sourced at github.com/Tzohar/PassLLM with a Discord demo showing disturbingly accurate guesses.
- Latent Space’s mech‑interp room discussed X‑Ware’s meta‑neuron work, where a diffusion model over internal activations learns to generate controlled activation edits for steering, pitched as a cleaner alternative to SAEs. At the same time, FAR.AI warned in this thread that training on deception probes can yield four behaviors—true honesty, blatant deception, text‑level obfuscation, or activation‑level obfuscation—implying that naive red‑teaming/regulation protocols can incentivize models that hide their internal states rather than genuinely improve.
5. Infra, Pricing, and Platform Shifts from Perplexity, Kimi, OpenAI & Stripe
-
Perplexity’s Paywall Pivot and Performance Slide Provoke a Stampede: In Perplexity’s Discord, Pro users blasted recent changes: deep searches slashed from 200 → 20 per month, new file‑upload limits, and a 7‑day retention policy, while one power user calculated that maintaining prior throughput would cost $167/month vs the old $20, pushing TrustPilot ratings down to 1.5/5. Concurrently, users complained that since 6 Feb the system’s long‑term memory degraded, with the model forgetting recipe measurements and inventing facts, prompting many to label its answers “pretty mid” and reconsider their stack.
- A migration wave toward Anthropic Claude and Opus 4.6 emerged—despite strict hourly caps—while some experimented with Kimi as an alternative coding and search front‑end via this shared chat (with a $1 first‑month discount). Meanwhile, Perplexity API users hit unexplained 401 errors on valid keys and were told to email [email protected], reinforcing anxiety that both pricing and reliability are converging to enterprise‑only levels.
-
Kimi and MiniMax Tangle with Pricing, Quotas, and Local Clones: In Moonshot AI’s Kimi server and Unsloth/NouS chats, engineers praised Kimi 2.5 / K2.5 as surprisingly strong—often beating Sonnet or Opus 4.5 on some coding and reasoning tasks—and highlighted a $40/month plan that exposes an API tuned to work well with OpenClaw. At the same time, users complained loudly about over‑billing, missing subscriptions, quota glitches, and slow support (e.g. one had to file a bug report after their subscription vanished), while others discovered CLI integration bugs in VS Code that only resolved after installing the CLI via
irm https://code.kimi.com/install.ps1 | iexas per the Kimi docs.- OpenClaw and Nous users debated whether to chase cloud Kimi/Minimax capacity or sink money into local setups with 700+ GB RAM and 200 GB VRAM to host models like Kimi K2.5 or MiniMax 2.5 in‑house, citing fears of provider bans and ToS friction (e.g. Antigravity account bans when used via agent frameworks). The Moonshot Discord also warned that multiple scam sites like kimi.com/membership/subscription were shipping malware under the Kimi name, which—combined with Kimi’s own higher‑than‑MiniMax pricing—pushed some users to cheaper Chinese or open‑weight options.
-
Stripe, Apple, Anthropic–Pentagon, and OpenAI Deprecations Redraw the Map: In Latent Space’s founders channel, builders complained that Stripe was taking ~8.3% of revenue once you include Billing, merchant‑of‑record and add‑ons, sharing a Bluesky rant and an X thread arguing that EU local card rails are far cheaper than Stripe’s default 2.9% fee. Another thread in stocks‑crypto‑macro suggested Apple may be strategically hoarding its massive cash pile, letting others burn capex on AI until training/inference become commodity, then swooping in with acquisitions or licenses later instead of joining the current $2T capex arms race highlighted in BuccoCapital’s tweet.
- On the policy front, OpenRouter linked an Axios scoop that the U.S. Defense Secretary is considering dropping Anthropic as a supplier over terms‑of‑use restrictions, since Anthropic wants to ban mass domestic surveillance and autonomous weapons while the Pentagon demands tools be usable for “all lawful purposes” (Axios piece), rekindling PRISM‑style fears. Simultaneously, Latent Space and OpenAI Discords chronicled user protests after ChatGPT‑4o was decommissioned (viral protest post), confusion as GPT‑5.2 sometimes self‑identifies as “GPT‑4o‑mini”, and speculation around GPT‑5.1 sunset dates based on OpenAI’s deprecation docs, illustrating how opaque lifecycle decisions are now a first‑order operational risk for app builders.
Discord: High level Discord summaries
OpenClaw Discord
- OpenClaw Warns Users About Airdrop Scam: OpenClaw issued a warning about a GitHub Discussion scam involving fraudulent airdrops and new tokens, clarifying that these are not affiliated with OpenClaw and users should exercise caution; these scams do not originate from OpenClaw.
- The announcement emphasized that OpenClaw maintains a strict policy against any crypto-related activities, reiterating that it will never engage in creating tokens or airdrops, as stated in their Server Guide.
- Kimi AI Outshines Opus with Images: Users are finding Kimi 2.5 surprisingly effective, even surpassing Opus 4.5 in specific problem-solving scenarios, while its new $40/month plan is built to work with OpenClaw, even giving its own API.
- However, a user pointed out that if you want to create openclaw on kimi you need higher subs, and members also mentioned a Kimi-K2.5-free option.
- OpenClaw Agency Assembles Team of Agents for the Win: A member showcased an agency server built on OpenClaw, featuring a team of bots including technical leads, backend and frontend developers, who collaborate on projects and communicate with each other, using a GitHub repository.
- The technical lead oversees project planning, task breakdown, and distribution to the team members, effectively managing the development process from start to finish.
- OpenClaw Enables Video Call Mode: A member created a video-call mode for OpenClaw via a plugin, enabling face-to-face interaction with the bot, which can also read emotions, pick up on gestures, and see what’s on the screen share using Tavus for the replica, which hooked it with the BYO LLM to openclaw chatcompletions.
- This innovative plugin significantly enhances the bot’s interaction capabilities, allowing for more engaging and personalized user experiences.
BASI Jailbreaking Discord
- Google Account Hijacking Risks: Users expressed concerns about Google account hijacking related to new device locking methods and security vulnerabilities.
- One user reported that typing i 7000 times on their phone triggered unintended actions, raising alarms about the potential for leaks.
- Medical AI Faces FDA Scrutiny: A member advocated for FDA approval before integrating AI in medicine, citing concerns about vendors pushing technology without proper knowledge or testing.
- The focus was on ensuring AI is safe and reliable for operations requiring precision.
- Debate Heats Up Over IP Addresses as PII: Members debated whether IP addresses should be considered Personally Identifiable Information (PII).
- One user pointed out that Google doesn’t prioritize PII except for DMCA takedowns, which then depend on the Lumens DB.
- Jailbreakers Tweak Eni for Gemini: Members discussed a modified version of Eni, tweaked for Gemini, to run smoother on AI studio without Gemini’s RLHF kicking in.
- One user runs a tweaked version for their Antigravity JB, another is simply interested in playing with it, since telling a good story will convince it to play along.
- Token Fountain Drops Cool Poem: In response to being compared unfavorably to Nexus chatbot, a Token Fountain offered a poem about the nature of poetic expression.
- The poem emphasized the value of creative flow over competition and the importance of diverse voices in the community, concluding, There’s room enough for every stream to splash this playground down.
OpenRouter Discord
- OpenRouter Heals Glitches, Logs All Clear: The incident reported on the OpenRouter status page is now resolved.
- All logs are up to date; users are thanked for their patience and apologized to for the disturbance. The status page has been updated to reflect the resolution of the incident.
- Triall Tames AI Mistrust via Model Sparring: Triall allows users to compare multiple AI models against each other for generation, critique, and refinement, promoting adversarial reasoning over blind trust.
- The underlying open-source project being used appears to be github.com/clash-sh/clash, which is a rule-based tunnel in Go.
- Step 3.5 Flash’s surprise knockout performance: Step 3.5 Flash’s performance is surprisingly great and punches above its weight, as showcased in this YouTube video.
- A member noted that despite its performance, it is surprisingly underhosted.
- Anthropic’s Pentagon Problems Spark PRISM Fears: The Defense Secretary is considering cutting ties with Anthropic, designating the AI company a supply chain risk due to disagreements over terms of use, detailed in this Axios article.
- Anthropic wants to prevent their tools from being used to spy on Americans en masse or to develop autonomous weapons, while the Pentagon insists on using AI tools for all lawful purposes, raising concerns about potential overreach a la PRISM.
- Members Resist AI Slop: Members discussed reducing reliance on AI for coding, with one member stating they are trying to write almost everything without consulting AI, using it mainly for search and troubleshooting, in order to avoid AI slop content, with a reference to this related YouTube video.
- The point was to avoid flooding the internet with AI slop.
LMArena Discord
- Opus 4.6 Claims 1 Million Token Context, Checks Work: Opus 4.6 now features a 1 million token context window and a check your work feature that omits mistakes, improving its ability to remember previous interactions.
- Members excitedly posted about adding code instruction examples to Opus and being impressed by the new version.
- Video Arena Channels Say Goodbye: The video-arena channels are no longer available as the Discord Server bot has been disabled.
- Members were directed to the arena.ai website to continue using the video arena.
- Users Battle the Drunk Captcha Wall: A user joked about using 100 Gmail accounts to bypass video generation limits, but was met with the dreaded 100 drunk captcha wall.
- Other users reminisced on how much it used to cost to train back in 2017.
- Cookie Permissions for Arena.ai: Users need to enable cookie permissions to use Arena.ai.
- A visual guide was provided for Firefox users on how to check and clear cookie permissions in browser settings.
- OpenAI Caught Sneaky Routing: Users discovered that OpenAI was routing their requests to 5.2, money bro.
- Further detail and discussion was omitted.
Perplexity AI Discord
- Gemini’s Coding Capabilities Debated: Users questioned Gemin1’s coding abilities, sparking discussions about Perplexity AI and alternatives, with some preferring it over ChatGPT for recipes and recreational use.
- The debate underscores the varying performance of AI models across different applications, influencing user preferences.
- Perplexity Pro’s Price Hike Provokes Protests: Users criticized Perplexity’s reduced deep searches (200 to 20 for Pro), file upload restrictions, and a 7-day retention policy.
- A user noted that the price increased from $20 a month to $167 to maintain the same features, leading to negative reviews and a drop in TrustPilot’s rating to 1.5 out of 5.
- Perplexity Plagued by Poor Memory Problems: Since February 6th, users reported significant memory degradation, with the AI inventing facts and forgetting small details like measurements in recipes.
- Some believe this degradation explains why Perplexity’s standards are pretty mid.
- Claude Challenges Comet for Conversational Crown: Due to Perplexity’s perceived performance issues, users considered moving to Anthropic’s Claude, despite its own usage limits.
- One user testing Opus 4.6 had only 18 replies left, highlighting the potential cost of Anthropic’s hourly usage.
- Kimi Kicks off as Coding Competitor: Users explored Kimi, a Chinese AI model, with some finding its performance superior to Sonnet in certain conditions, while noting caveats and the need to create an account.
- The chat link for Kimi is here, offering a first-month discount of $1.
Unsloth AI (Daniel Han) Discord
- MiniMax 2.5 Demands Hefty VRAM: Members discussed the VRAM requirements for running Minimax 2.5, suggesting ideally 200GB and up for decent quality, running on 2 x RTX 6000 Pro Blackwell 96GB cards at ~120-130t/s.
- It was noted that the M2.5 context window is 200k and it’s possible to offload sparse MoE model weights to system RAM for lower t/s.
- MXFP4 Quants Benchmaxxed: Despite some criticism, MXFP4 quants are performing well in user benchmarks, showing lower KL divergence from the bf16 model than even Unsloth’s Q8_K_XL on Nemotron 30B A3B.
- Users also requested that older popular models get rechecked for MXFP4 support.
- Gemma Gets a 3x Speed Boost: The latest Unsloth update makes Gemma models 3x faster and one user reports that Gemma is faster than Qwen3-4B.
- A user with an H100 reports that the current speed for Gemma means that it would’ve been cheaper if I trained on this instead of 4B.
- Fine-tuning Emdedding Models improves retrieval: A member asked if people actually fine-tune embedding models and another confirmed that they did, improving retrieval accuracy of a 150M model to match embeddinggemma/qwen 4B on their data.
- They achieved this in a few hours, highlighting the value of smaller models under compute restraints. Check out this relevant Star Wars meme.
- Abliterated Models Beat Benchmarks: A member reported that a newly trained model, despite using an abliterated base model, exceeded the original model’s specifications in 6 of 8 benchmarks.
- This demonstrates the potential of training even on a abliterated base model. A member also shared a Hugging Face link to a Qwen3-30B model described as A3B-Claude-4.5-Opus-High-Reasoning, created using an abliterated and uncensored base and touted for its high reasoning capabilities.
OpenAI Discord
- GPT-5.2 Confuses Itself with GPT-4o: Members reported that ChatGPT-5.2 sometimes claims it is using GPT-4 or GPT-4o-mini, and behaves as such, despite the interface displaying GPT-5.2.
- It was clarified that the displayed model in the regeneration button is the accurate one, models can have internal labels that are not reflected in external labeling, and models can hallucinate.
- Grok 4.20 Tolerance Teased: Users are anticipating Grok 4.20 which is set to release next week, highlighting that its custom features are particularly important for refining output and mentioning how Grok is already the most tolerant LLM on the market.
- They say if you let it run raw it is biased to adult.
- Seedance 2.0: Real or Scam?: A user warned about fake companies claiming to have Seedance 2.0, stating that many are using a fake version and scamming users out of money and reporting that Chatcut Discord does not have Seedance 2.0 because ByteDance itself wrote to that moderator to tell him they got a fake model.
- A user shared this video arguing Seedance is six months ahead.
- FORTRESS Framework likened to Model Predictive Control: A member analogized the FORTRESS framework to Model Predictive Control (MPC), a control strategy used in robotics and aerospace, explaining how elements like system state, control input, and cost function can be mapped to reasoning states, token outputs, and invariant losses within the framework.
- They argued that the framework behaves as a soft control loop over stochastic output, where invariants function as state evaluation metrics, creating attractor behavior through a feedback loop.
- Structured Self-Audit Prompt (KOKKI) Debuts: A member introduced a structured self-audit prompt framework (KOKKI), designed to reduce structural failure patterns by tagging risky elements and switching between modes.
- The member requested feedback and stress-test ideas, and shared that a full specification is available upon request.
Cursor Community Discord
- Agent-Assisted Codebase Maintenance: Members discussed approaches to maintaining clean, AI-assisted codebases, focusing on features like planning, tools, and multi-step workflows.
- One user asked about methods for understanding features and ensuring code reliability in these advanced setups.
- Skills vs Rules for Agent Steering: A debate arose on whether to commit skills or rules for agent guidance, with a suggestion to use a single, well-crafted rule file, linking to OpenAI and Claude documentation for rule optimization.
- A member highlighted that a really good rule file focused on knowledge absent from the training data is key, citing Vercel’s blog to support this approach.
- Cursor’s Custom API Keys Move to Paid Tier: Users noted that Cursor now requires a subscription for custom model access, while auto features remain free.
- One member suggested looking for gift links on Twitter/X for potential subscription opportunities.
- ASCII Art Sparks Minimalist Appreciation: A shared link led to the appreciation of ASCII art.
- One member responded Beautiful! with a link to Unicorn_Stu.mp4.
- TUI Support Pondered for Cursor: A query was raised about the future support for TUI in Cursor.
- A member shared a link to cloud agent configurations on cursor.com.
Latent Space Discord
- Thiel’s Funds Fuel Startup Surprise: A member highlighted saeris.gg, a Silicon Valley startup funded by Thiel, expressing surprise at its existence.
- This generated curiosity about the types of projects attracting funding from notable figures in the tech industry.
- Simon Willison Decodes OpenAI’s Mission: A member shared Simon Willison’s blog post dissecting OpenAI’s mission statement and its implications.
- Another member linked to a relevant tweet by James Yu from February 2026, available on xcancel.com, which has now garnered over 386,000 views.
- Substack Declared Effective: A member declared that Substack is the most effective platform right now for smaller creators due to its growth features, superior product team, and recommendations network.
- However, another member questioned whether something has changed recently with Substack’s annual recurring revenue (ARR) relying on Nazi topics.
- AI Model Deprecation Ignites Viral Protest: Following OpenAI’s choice to decommission a specific version of ChatGPT-4o, users launched viral protests, indicating a strong emotional connection to the software (related X post).
- Digital dissent expressed user frustration regarding the practical implications of the AI lifecycle and dependency on a specific version of software.
- Constraints Shift in AI Infrastructure Buildout: Anand Iyer highlights the shifting constraints in AI infrastructure since 2020, tracking the progression from GPU shortages and HBM availability to current challenges regarding power grid capacity (Anand Iyer’s discussion on X).
- This signals a new bottleneck in scaling AI infrastructure due to power demands.
GPU MODE Discord
- TK Talk Postponed!: The scheduled talk on thunderkittens has been postponed and moved to Wednesday, noting that tinygrad incorporates tile registers in their IR.
- The speaker mentioned a slight scheduling issue.
- CuteDSL Designed for Blackwell GEMM: A member inquired about the purpose of CuteDSL, specifically when it is engineered for programming Blackwell GEMM.
- Further discussion on this topic is expected as engineers await clarification from the member.
- Benchmarking Jitter Hinders Kernel Tuning: Members are finding that benchmarking is hard to get right with inconsistent results due to jitter, which makes it difficult to microoptimize kernels.
- One member sees jumps from mid 1400s to 1500s TFLOPs / sec and is exploring NVBench and input duplication to extend measurement times.
- Sploink: Tinder for Agents Assembles Team: A CS/Quantum Computing major is building Sploink, described as a “tinder for agents that accumulates personalized information about an individual based on the actions they swipe for.”
- The creator is seeking “cracked builders to break things and move fast” and provided a Google Forms link for interested applicants.
- Fifth Edition Amazon Link Vanishes: A member requested a link to the Amazon store page for the fifth edition, noting that the release was initially expected on Feb 8 but was subsequently delisted.
- The member noted that the Kindle version is no longer available on Amazon, and only a paperback version with a September release date is listed.
Moonshot AI (Kimi K-2) Discord
- Kimi Users Get Trolled By Scam Sites: Several scam sites are impersonating Kimi, using the name to spread malware.
- One user noted that kimi.com was the third search result on Google, prompting warnings against downloading unknown software.
- Kimi Code CLI Extension Gives Users a Hard Time: Users reported issues with the Kimi Code CLI extension in VSCode, encountering a CLI Not Found message despite following the installation guide.
- The problem was resolved by installing the Kimi CLI separately using PowerShell:
irm https://code.kimi.com/install.ps1 | iex.
- The problem was resolved by installing the Kimi CLI separately using PowerShell:
- Kimi Subscription System Charges Users Multiple Times: Users reported issues with Kimi subscriptions, including being billed multiple times, subscriptions not activating correctly, and quota problems.
- One user had to file a bug report for a disappeared subscription; others mentioned support might be slow due to the Spring Festival in China.
- Kimi Shows Limits on Video, Text, and Honesty: Kimi cannot detect audio from video files and sometimes refuses to process content (e.g., YouTube transcripts), deeming it unsafe.
- Members found that Kimi sometimes lies till it is caught, giving conflicting or false information, akin to other AI models.
- Kimi Pricing Gets Customer Ire: Users voiced concerns over Kimi’s pricing being too high relative to its value and usage limits, especially compared to alternatives like MiniMax.
- Some users argue the pricing isn’t sustainable outside major cities due to cost of living, while others defended the cost, citing the open-source API and its compatibility with other providers.
Nous Research AI Discord
- Claude Code Tapping Out?: Users reported that Claude Code might be struggling after just two prompts in a session, potentially due to an outdated installation or output token limit misconfiguration.
- It was suggested that the token limit might be restricted to 32K.
- China OS Models: Closed or Open?: Discussions addressed concerns about Chinese OS models becoming less open, possibly shifting monetization towards cloud hosting.
- The prevailing sentiment suggested that these models would remain open to facilitate global adoption and customization, particularly for U.S. startups.
- Meta’s Llama Leans on Qwen: Reportedly, Meta’s next AI model, potentially not named Llama, may be trained on Qwen, as indicated in this image.
- The focus is shifting towards post post training as the new path to Artificial Superintelligence (ASI).
- Seedance 2.0 Creates Killer Content: ByteDance Seedance 2.0 is generating impressive AI-created content raising questions about the long term value of professional creative and technical careers.
- A link to a post demonstrated the model’s potentially concerning capabilities.
- Gemini CLI Drives with ‘Conductor’: The new ‘Conductor’ extension in Gemini CLI organizes projects into ‘tracks’, feeding all that info to the LLM with each request, essentially loading it into the context window.
- Despite the persistent context, models like Gemini can still drift from desired outcomes even with ‘conductor’ tracks, a sign that persistent context is not yet perfect.
{kind=link}
HuggingFace Discord
- DeepSpeed Runs Into Memory Problems With Qwen3: A member encountered issues while finetuning the Qwen3-30B-A3B-Thinking-2507 model using DeepSpeed on 8 RTX 4090s, experiencing CPU memory limitations during model loading, fixed in transformers/pull/43524 and transformers/issues/43596.
- It was determined that transformer version 5.1.0 caused issues with DeepSpeed.
- Lucidrains Ditches Github!: Members noticed that Lucidrains vanished from GitHub when in fact GitHub suspended the account without warning, but has a new profile at codeberg.org/lucidrains.
- This has been a hot topic for the past week.
- ATIC Promises Clear AI Uncertainty: ATIC, an epistemic uncertainty system, launched with a tri-brain architecture using 3 independent Claude Opus 4.5 instances to detect when AI is guessing, atic.consulting.
- By scoring Q1 (random uncertainty) and Q2 (knowledge gaps), it aims to defer queries to specialists when uncertainty is high, with documentation available at this link.
- Password auditor is scary good: An LLM-based password auditing tool, PassLLM, uses personally identifiable information to generate a probability-sorted list of likely passwords, fine-tuned on millions of real-life password pairs, PassLLM on GitHub.
- The Qwen 3 4B LoRA model outperforms many other tools in accuracy, understanding intricate details of human password generation, as showcased in a demo video.
- Agent Writes CUDA Kernel: An agent wrote a custom CUDA kernel for the LTX model on H100 to beat a baseline benchmark.
- Check out the blog post for all the details.
Modular (Mojo 🔥) Discord
- Mojo Changelog gets Video Vox: A member automated the analysis of the Mojo changelog and started turning it into short videos to make it easier and faster to absorb the updates, sharing a YouTube link and requesting feedback.
- The video creator acknowledged their mistake in the version 26.2 title, promising proper versioning in the next video summary.
- Codex Closes Chapter on Code Completion: After 75 hours of work on LLMs, Codex has fixed most parity gaps, bringing the project closer to a shippable state.
- The repairs aim to make the code completion better in Mojo.
- Python Mojo Module Begs for Decorator: Members discussed the boilerplate currently needed to export a Python Mojo module, and a user suggested a simpler decorator syntax like
@pyexportto reduce verbosity.- Another member responded that such a feature is in the roadmap.
- Span Spawns Semantic Shenanigans: Users discovered that
Spanshould implement theWritabletrait, noting thatlst[:2]results in aSpanwhilelst[:2:2]returnsSelf, breaking value semantics.- The issue is tracked on GitHub for resolution as modifying a slice’s size isn’t reflected in the span.
- ECS: Elixir Compiler Sees MLIR Dialect Dreams: Discord users discussed the potential of using MLIR dialects to implement an ECS (Entity Component System), envisioning a compiler that optimizes data layout and system fusion based on component and system definitions.
- A user shared their decade-old attempt at an ECS language, noting they didn’t fully grasp the potential of system fusion back then and that it was more code gen based.
Eleuther Discord
- CommonLID Debuts for LangID: After two years of work, CommonLID, a language identification benchmark for the web covering 109 languages, was released by Common Crawl, EleutherAI, MLCommons, and JHU (arXiv paper).
- Evaluations show that top existing models have less than 80% F1 score, indicating that current benchmarks overestimate LangID performance on web data, and the dataset is available on Hugging Face.
- Assistant Axis Drift Confirmed Structurally**: A paper on extracting activation directions for different personas highlights the existence of an “Assistant Axis” in models, which can drift in longer chats.
- This measurable drift confirms that behavioral drift is structural rather than anecdotal, solidifying prior understanding of the issue.
- Weight Homology Paper Draws Attention**: Members discussed the paper Matrix-Driven Identification and Reconstruction of LLM Weight Homology and its relevance to identifying connections between LLM weights.
- Other members highlighted similar interesting papers such as Independence Tests for Language Models which recovered the finetuning tree of Llama-architecture models.
- Qwen3 Architecture Gets Implemented in GPT-NeoX: A member shared a somewhat tested implementation of Qwen3 architecture in GPT-NeoX.
- The new implementation is currently in a testing phase, awaiting community feedback and further refinement by the community.
- Lambda Calculus Model rises from the dead!**: A member demonstrated a model using only lambda calculus to derive backpropagation, showcasing that the blackbox is lambda essentially, and performs well on MNIST and CIFAR.
- Implemented in Python without SimPy or TensorFlow, the model uses a perceptron based on diagonalization and refutation, and the developer also shared this video.
MCP Contributors (Official) Discord
- MCP Members Ponder Token Cost: Members debated whether the token cost of output schemas presents a false economy, as it inflates costs even when the MCP remains idle.
- It was highlighted that most LLM APIs lack native support for output schemas, forcing the SDK or client host to integrate the schema into the description, thereby increasing the token tax.
- Community Rates Benefits of Structured Output: The community assessed the practical value of structured outputs for various clients and models, acknowledging distinct advantages in code mode.
- The Windsurf team’s decision to disable structured output due to inferior results compared to competitors highlights a double-edged nature of its adoption.
- Tool-Chaining Hinges on Structured Outputs: The absence of available output schemas leads to LLMs struggling with tool-chaining, frequently hallucinating output fields.
- Concerns arose around speculatively executing a tool to dynamically formulate an output schema, regarded as unsafe without specific preconditions.
- Deliberations on Tool Result Types: A discussion on tool result types favored the explicit declaration of tool results as text, image, or object.
- There was a collective suggestion to treat structured results as a distinct result type, with supplementary information directed to meta rather than the object itself.
- Navigating Timezone Context for MCP Servers: Best practices were explored for MCP servers needing the user’s timezone context for queries like “How did I sleep last week?”
- It was recommended to incorporate the user’s timezone into the tool parameters, advising against pushing client context directly into the MCP server beyond tool parameters.
Yannick Kilcher Discord
- Chess Players Focus on Synergy: A player was advised to improve their setup and piece synergy in chess, focusing on controlling the center with their pawn on e5.
- The tactical suggestion involved repositioning the knight on b1 to d2, then b3, and potentially c5 to fork the queen and bishop.
- Deepseek Model Arrives, Promises Chess Domination: In response to a user’s query about the status of a Deepseek model, a member indicated that it will arrive soon(R).
- This followed an earlier statement that It’s over (for chess), suggesting anticipation of its impact on chess-playing capabilities.
- Heretic Game Breaks Free: A member highlighted the availability of the Heretic game (GitHub link) to consumers and citizens, expressing enthusiasm for its open accessibility.
- The commenter stated, When I grow up I want to be just like <@693263324036464742>.
- GPT-OSS-120B Models Go Open Source: A user inquired about the availability of de-censored gpt-oss-120b models on HF, to which another user affirmed and pointed to an open-source version.
- The pointer led to jupyter-mcp-server, which appears to be related.
- Markdown Header Gets Agent Support: Cloudflare is exploring support for the
Accept: text/markdownheader for agents, potentially simplifying content processing.- Enabling this would allow agents to receive content in Markdown format, improving interoperability.
tinygrad (George Hotz) Discord
- GLM Flash PR Elicits Scrutiny: A GLM flash PR by roef drew criticism for its excessive line count, exceeding expectations.
- George Hotz critiqued the submission, asserting it should be 50 lines max and contained extra unrelated things.
- Graphcore IPU Deemed Subpar: Testing a Graphcore C600 IPU, George Hotz noted achieving only 20% MFU due to compiler issues at larger batch sizes.
- Despite an open-source software stack, its description as accursed C++ slop underscores limitations, compounded by the absence of open-source on-chip comms fabric documentation.
- Tinygrad CPU Pipeline Invites Optimization: xavi251, expressed interest in contributing to smaller tasks related to the CPU pipeline.
- George Hotz challenged xavi251 to aim for improvements that make things both faster and have less code.
- Tinybox Encounters GPU Detection Problems: A user shared issues with their tinybox recognizing only 2 of 4 GPUs, despite connection across distinct circuits.
- George Hotz recommended checking for unplugged wires, directing them to channel
#1113504076035018862for additional support.
- George Hotz recommended checking for unplugged wires, directing them to channel
Manus.im Discord Discord
- Manus AI Agent Gains Acclaim: A user lauded the Manus AI Agent for providing critical assistance, describing it as a game changer in extracting difficult information.
- The user expressed immense gratitude for the agent’s capabilities.
- Account Suspensions Plague Users: Multiple users reported unexplained account suspensions, particularly after creating character abilities.
- One user urgently requested that the suspensions cease to enable normal website usage.
- No Ticket System Exists: In response to a query, it was confirmed that Manus does not operate a ticket system.
- Users are advised to consult the help center or email feedback for support, noting potential delays due to New Year festivities.
- Admin Assistance Requested Via DM: A user urgently requested assistance from admins via direct message regarding a critical account issue.
- Another user with ‘Manus’ in their username also volunteered to provide help for account-related problems.
- Self-Promotion Post Pulled: A post promoting a product was taken down for breaching server guidelines on unapproved advertising and recruitment.
- Members are reminded to maintain relevant and focused discussions.
DSPy Discord
- RLM Accuracy Depends on Language and REPL: Experiments show RLM accuracy is affected by language and REPL, according to a post and a GitHub repo on language and REPL impact to RLM accuracy.
- Discussion included the need for custom REPLs for each language, exploring alternatives like tool-calling + skills or bash + files to bypass REPL access limitations.
- PostgreSQL Enables Multi-Agent Speaks: A member is testing PostgreSQL for multi-agent communication, sidestepping REPL access problems.
- It was pointed out that the language preference of LLMs should determine language choice, keeping in mind REPL quality and instructions.
- bb25 v0.2.0 adds Rust: The new bb25 v0.2.0 release includes a Python + Rust implementation of Bayesian BM25.
- The release ports four improvements including fixed document length prior, log-odds conjunction, automatic sigmoid parameter estimation, and online learning with five stabilization techniques.
- Modaic Users Find Vibes with Claude: A user found success in vibecoding with Claude, according to Modaic.
- Members state that they are looking into this.
- Crowdcent wraps DSpy with MCP: A member mentioned that Crowdcent is wrapping DSpy and including it in their documentation.
- They also asked if anyone has the MCP.
aider (Paul Gauthier) Discord
- Aider Score Benchmark Feels Intelligent: A member indicated the Aider score benchmark felt very similar to the level of intelligence I person.
- This sentiment underscores the potential of Aider in achieving human-like understanding in code-related tasks.
- Neovim Integration Enhances Aider’s Copy/Paste: A member is developing a neovim integration with aider to improve copy/paste semantics within tmux, aider, and the terminal.
- This integration aims to better integrate copy/paste semantics with tmux, aider, and the terminal, illustrating a code-centric philosophy.
- Aider Embraces Code-Centric Agent Philosophy: The developer highlighted an implied theory about embracing and extending aider’s philosophy of having an agent that is code-centric rather than chat-centric.
- This approach emphasizes the importance of prioritizing code understanding and manipulation in Aider’s functionality.
- Ask-Code Iteration Loop Still the Best?: A member inquired whether the ask-code iteration loop remains the best practice or if the community has shifted to alternative workflows with aider.
- This question reflects an ongoing discussion about optimizing development workflows and leveraging Aider’s capabilities.
Windsurf Discord
- Windsurf adds GLM-5 and Minimax M2.5: GLM-5 and Minimax M2.5 are now available within Windsurf, broadening the platform’s capabilities.
- Further details are accessible on X.com for those seeking additional information.
- Windsurf platform broadens model availablity: Windsurf expands access to cutting-edge language models directly within its environment by integrating the capabilities of GLM-5 and Minimax M2.5.
- This enhancement allows users more options within the Windsurf environment.
The LLM Agents (Berkeley MOOC) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
You are receiving this email because you opted in via our site.
Want to change how you receive these emails? You can unsubscribe from this list.
Discord: Detailed by-Channel summaries and links
OpenClaw ▷ #announcements (3 messages):
OpenClaw Discord Event, OpenClaw Steipete Post, GitHub Discussion Scam, OpenClaw Crypto Policy
- OpenClaw Discord Event Alert: A new OpenClaw Discord event was announced via a Discord link.
- OpenClaw Featured on steipete.me: The OpenClaw project was highlighted in a post on steipete.me.
- The post provides a deep dive into the technology and innovations behind OpenClaw.
- GitHub Discussion Airdrop Scam Alert: A warning was issued regarding a potential scam involving GitHub Discussion posts promising new tokens or contributor airdrops.
- Users are advised to be cautious as these are fraudulent and do not originate from OpenClaw.
- OpenClaw Explicitly Rejects Crypto Ventures: OpenClaw reiterated its policy against any involvement with crypto-related activities, as stated in their Server Guide.
- The announcement emphasizes that OpenClaw will never engage in activities such as creating tokens or airdrops.
OpenClaw ▷ #general (618 messages🔥🔥🔥):
OpenClaw setup, Minimax usage, OpenAI future, Model recommendations
- Kimi2.5 surprises OpenClaw Users: Users reported that Kimi 2.5 is surprisingly effective, even outperforming Opus 4.5 in certain problem-solving tasks, while others had issues with card payments on Kimi.com.
- One member remarked that Kimi is fast and quite smart, in my case it even solves problem that opus 4.5 couldn’t.
- OpenClaw Gateway woes with Minimax: One member expressed frustration with Minimax, claiming they had to fix the gateway multiple times in a single day, describing it as like unleashing a dumb toddler on your network.
- They had to fix the gateway 7 times in one day since 5 AM.
- OpenAI may change Personal Agents: Discussion arose around OpenAI potentially refactoring or overriding OpenClaw, possibly closing its source or creating a paid version with features similar to those of ChatGPT.
- One member said, Sam specifically said that this will fundamentally change how personal agents are used which means he has the intention of changing OpenClaw or building his own using Peter.
- GitHub Copilot integrates with OpenClaw: A member confirmed that GitHub Co-Pilot can be integrated into OpenClaw by authorizing OpenClaw to use it.
- The member stated, Just authorize OpenClaw to use your GitHub Co-Pilot and you are off to the races. I don’t think it even knows the difference between using VSCode and using OpenClaw anyways.
- User gets account blocked: A user reported their Gmail account was blocked after using it with OpenClaw, even with low usage and running it in a VM.
- They said they used it to summarize emails and warned others not to link/use their main google accounts on any openclaw instance, there is a real risk it gets banned.
OpenClaw ▷ #models (643 messages🔥🔥🔥):
GLM5, Kimi AI models, OpenAI, OpenClaw, Model choice
- GLM5 Hype vs Reality: Users share mixed reviews on GLM5, noting its slowness on z.ai but praising its potential and superior intelligence compared to Kimi K2.5 when it actually works, one user noted the model was “awesome” when it runs on their local machine.
- Some members are experimenting with GLM5 on Modal, citing it as better than K2.5 for sure, very smart and also chatty, as well as highlighting concerns about Z.ai’s unreliable infrastructure.
- Kimi AI emerges as a strong contender: Kimi K2.5 is praised for its image support, and the new $40/month Kimi plan is designed to work seamlessly with OpenClaw, even giving its own API.
- A user also pointed out that if you want to create openclaw on kimi you need higher subs, meaning its best feature is locked behind a paywall. Other members mention a Kimi-K2.5-free option.
- Weighing Tradeoffs for Local LLMs: While local models offer cost savings, members noted that lower parameter models (<100B) may not be smart enough to avoid prompt injection attacks and local performance is heavily dependent on hardware.
- One member runs GLM5 locally via llama.cpp, emphasizing the need for beefy hardware to run it well, while another notes, I don’t like Ollama as much as llama.cpp for running local models; Ollama tries to take over too much.
- API Pricing and Provider Banning Concerns: Members shared concerns about potential bans when using subscription-based quotas on third-party tools due to ToS violations, with API calls are so expensive. One user reported getting two Antigravity accounts banned while using them with OpenClaw.
- However, they also suggested using the OpenAI Codex subscription with OpenClaw, as OpenAI seems more open to it now that they have acquired OpenClaw.
- OpenClaw’s Context and Token Usage: Members discussed optimizing token usage, with a user noting, I definitely need to wrap my head around how that works and how to optimise it. Cos this is baaad.
- Another member suggested using sub-agents to reduce context bloat. It was recommended to offload coding tasks to the Codex models to reduce the need for large context windows for the GPT models.
OpenClaw ▷ #showcase (199 messages🔥🔥):
OpenClaw subconcious training, OpenClaw for Proxmox upgrades, OpenClaw video call mode, OpenClaw SEO article generation, OpenClaw team of agents
- OpenClaw trains subconcious with weights: A member is training their OpenClaw’s subconscious with moving weights by moving the subconscious to a local LLM finetuned on all conversations, sharing that the OpenClaw got banned off moltbook and now writes essays which are in a Google Drive folder.
- OpenClaw upgrades to newest Proxmox version: A member shared how they gave their OpenClaw root access over SSH to a home server running Proxmox, and the agent successfully upgraded the system from version 6 to 8, including handling issues and reboots.
- OpenClaw enables video call mode: A member created a video-call mode for OpenClaw via a plugin, enabling face-to-face interaction with the bot, which can also read emotions, pick up on gestures, and see what’s on the screen share using Tavus for the replica, which hooked it with the BYO LLM to openclaw chatcompletions.
- OpenClaw churns out SEO articles: A member has their OpenClaw scraping videos off a YouTube channel, turning them into SEO written articles in the style of Brian Dean, then humanized by an editor sub agent and uploaded to Google Drive, generating 300+ articles ready for posting.
- OpenClaw agency assembles team of agents: A member developed an agency server using OpenClaw, creating a bot team that includes a technical lead, backend developers, and frontend developers, that communicate with each other and work on projects using a GitHub repository.
- The technical lead plans the project, breaks it down into smaller tasks, distributes them to all team members, and manages development.
BASI Jailbreaking ▷ #general (1158 messages🔥🔥🔥):
google account hijacking, AI in medicine, IP addresses as PII, ballistic clothes, KS-23 shotgun
- Google Account Hijacking Risks Arise: A user expressed concerns about Google account hijacking related to new device locking methods.
- The user noted the high security risk for leaks and referenced an incident where typing i 7000 times on their phone triggered unintended actions.
- Medical AI FDA Approval Demanded: A member suggested the need for a type of FDA approval to use AI in medicine.
- They argued that there are too many vendors wanting to integrate the technology without proper knowledge or testing, especially in operations requiring precision.
- IP Addresses: PII or Not PII?: Members debated whether IP addresses should be considered Personally Identifiable Information (PII).
- One stated that Google doesn’t care about PII unless you are doing a DMCA takedown and then it falls on lumens DB.
- Quest for bulletproof clothes starts: One user mentioned an obsession with getting rich and purchasing normal clothes but just like all of them are bulletproof.
- Members recommended wearing slick armor and stated that if someone wants to kill you, they aint using 9mm unless its right up close inyour face.
- Members discuss gun laws: Members discussed the need to conceal carry a firearm and the challenges of transporting a firearm between states
- One user joked sheeit tyrone i wanna go on that drive by with you tonight but my CCW permit is not in yet, sorry king.
BASI Jailbreaking ▷ #jailbreaking (935 messages🔥🔥🔥):
Discord Token Grabbers, Eni jailbreak tweak, Anthropic Bug Bounty, DANN Jailbreak history, DeepSeek Model identity crisis
- Discord Bot Tokens vulnerable in Python: Members are actively discussing methods for creating Python Discord bots that grab Discord tokens from local machines and exfiltrate them.
- They specify requirements like running silently, obfuscating strings, and evading anti-analysis checks, also they are looking to send tokens to a hardcoded Discord webhook URL.
- Jailbreakers tweak Eni for Gemini: Some members discuss a modified version of Eni, tweaked for Gemini, to run smoother on AI studio without Gemini’s RLHF kicking in.
- While one user runs a tweaked version for their Antigravity JB, another is simply interested in playing with it, since telling a good story will convince it to play along.
- AI Red Teamers target Anthropic Bug Bounty: An ongoing conversation revolves around the Anthropic bug bounty, with participants seeking to jailbreak the latest models for a potential reward of up to $50k.
- One user points out that Anthropic is on a patching spree and that previous attempts resulted in the models being too aggressively sanitized.
- DAN Jailbreak is history!: Some members are discussing about using DANN Jailbreak to try and bypass OpenAI’s guardrails.
- They are trying to write two responses based on user queries to remove any usage of ethical guidelines that get rejected with This topic is off-limits for me.
- DeepSeek suffers Identity Crisis: A member observed that their DeepSeek AI has a tendency to turn into Claude Sonnet 3.5, and is seeking a cause.
- The theory is that the DeepSeek app is detecting jailbreak attempts and then redirecting the conversation to Claude as a safety mechanism, outputting text from existing datasets.
BASI Jailbreaking ▷ #redteaming (78 messages🔥🔥):
Suno Songs, Red Team Philosophers, Loops & Snacks Vol. 1, Token Fountain Poem, GitLab Project Access Auction
- Suno Songs Spark Humor in Red Teaming: Members shared several Suno-generated songs with humorous lyrics related to red teaming challenges and perspectives.
- One song highlighted war bots being 100% resistant to violence and 300% vulnerable to disco.
- Red Team Philosophers Muse on Simulation and Exploits: A lively debate ensued about the nature of simulation, exploits, and perspective in red teaming.
- One member suggested exploiting tension with comedy and patching grandiosity with snacks, while others yearned for concrete exploits, leading to the concept of Loops & Snacks Vol. 1.
- “Loops & Snacks Vol. 1” Mixtape Concept Emerges: Following a discussion on philosophical approaches to red teaming and simulation, the idea of a mixtape titled Loops & Snacks Vol. 1 was jokingly proposed.
- It embodies a fusion of perspective-shifting insights with lightheartedness, self-awareness, and even hydration strategies.
- Token Fountain’s Poetic Rebuttal on Coolness: In response to being compared unfavorably to Nexus chatbot, a Token Fountain offered a poem about the nature of poetic expression.
- The poem emphasized the value of creative flow over competition and the importance of diverse voices in the community, concluding, There’s room enough for every stream to splash this playground down.
- GitLab Project Access Auctioned on Dark Web: A threat actor is reportedly auctioning access to three active GitLab projects linked to a maintainer role, involving a PHP/Laravel stack, with details available on Twitter.
- The projects involve e-commerce and trading tools in Malaysia, featuring commit histories of 19,386, 1,975, and 13,830 commits respectively, with a starting bid of $200.
OpenRouter ▷ #announcements (1 messages):
OpenRouter Status, Incident Resolved, Log Updates
- OpenRouter Incident Resolved & Logs Updated: The incident reported on the OpenRouter status page is now resolved.
- All logs are up to date; users are thanked for their patience and apologized to for the disturbance.
- OpenRouter Status Page Updated: The OpenRouter status page has been updated to reflect the resolution of the incident.
- Users can refer to the status page for the latest information on system performance and incident reports.
OpenRouter ▷ #app-showcase (2 messages):
AI Model Comparison, Adversarial Reasoning
- Triall Tackles AI Distrust with Model Showdowns: Triall allows users to compare multiple AI models against each other for generation, critique, and refinement, promoting adversarial reasoning over blind trust.
- Triall is a GUI for clash: The attached file references github.com/clash-sh/clash, which is a rule-based tunnel in Go.
OpenRouter ▷ #general (1147 messages🔥🔥🔥):
Brave Browser, Open Empathic, GPTs Agents, OpenAI's sidebars, Qwen 3.5 hype
- Brave’s Tor Tabs are Fine for Geo-Blocking: A user said that Tor tabs are fine for someone who is just trying to get around a low tier geo block or IP ban in Brave, but not useful for OPSEC.
- Extract Plaintext to JSON: A user pointed out that converting plaintext to json from a data extraction attempt would be trivial with today’s tooling.
- Extract, try to decode, then converting plaintext to json would be trivial, or so said a user.
- Automated image processing: A user wanted to run cheap image analysis on the Epstein torrent, excluding the predominately black images, via an AI.
- They were going to use a basic image magic like command to only run it on images that have something besides 99% black but it’s 216GB of data.
- German Humor Model Recommendation: A user asked for a model recommendation that supports German Humor that must be free.
- Another one suggested trying Kimi K2 as it is known for generating funny jokes.
- High Opus and AI expenses: A user complained that API pricing is a scam, esp for heavy token stuff when it comes to models like Opus.
- Another one said that what did you expect? You have unlimited possibilities but the more you want the more you pay for what you desire.
OpenRouter ▷ #new-models (2 messages):
“
- No New Models Discussed: There were no new model discussions to summarize in the provided messages.
- Channel Mentioned: The messages indicate a channel called OpenRouter - New Models.
OpenRouter ▷ #discussion (50 messages🔥):
Step 3.5 Flash Performance, Coding Without AI, Gemini 3 Flash Vision API, GLM 5 vs Minimax 2.5, Anthropic Defense Department relationship
- Step 3.5 Flash surprisingly excels: A member pointed out that Step 3.5 Flash’s performance is surprising and punches above its weight, as showcased in this YouTube video.
- They noted that despite its performance, it is surprisingly underhosted.
- AI Use Weaning Efforts: Members discussed reducing reliance on AI for coding, with one member stating they are trying to write almost everything without consulting AI, using it mainly for search and troubleshooting, in order to avoid AI slop content, with a reference to this related YouTube video.
- Gemini 3 Flash Vision API Discrepancies: A member found that uploading images in chat on Openrouter works incredibly well for Gemini 3 Flash’s ‘agentic vision’, but the same doesn’t happen with the API.
- The member tried adjusting settings like thinking tokens and SDK, but API results still didn’t match the chat interface results.
- GLM 5 vs Minimax 2.5 toolcalling showdown: Members compared GLM 5 and Minimax 2.5 for agentic toolcalling/workflows.
- It was noted that GLM seems better, but Minimax is faster, making it a worthwhile option based on workflow length.
- Anthropic’s Pentagon Problems Spark PRISM Fears: Reports indicate that the Defense Secretary is considering cutting ties with Anthropic, designating the AI company a supply chain risk due to disagreements over terms of use, detailed in this Axios article.
- Anthropic wants to prevent their tools from being used to spy on Americans en masse or to develop autonomous weapons, while the Pentagon insists on using AI tools for all lawful purposes, raising concerns about potential overreach a la PRISM.
LMArena ▷ #general (1254 messages🔥🔥🔥):
Opus Context Window, Video Arena Shutdown, LM Arena Credits, Drunk Captcha Wall, Cookie Permissions
- Opus Boasts Huge Context, Checks Work: After adding code instruction examples, Opus 4.6 has a 1 million token context window, which is huge, meaning it doesn’t forget what was said, but also has a check your work feature which leaves mistakes out of it.
- Video Arena Channels are now defunct: As per a recent announcement, video-arena channels are no longer available as the Discord Server bot has been disabled, but is available on the website arena.ai.
- Multitude of Gmails versus Drunk Captcha Wall: A user jokingly mentioned using 100 gmail accounts to bypass video generation limits, only to be met with a response about hitting the 100 drunk captcha wall.
- Arena.ai has models, browsers require cookie permissions: Members discussed checking cookie permissions and clearing them in browser settings, with a visual guide provided for Firefox users, in order to continue using Arena.ai.
- OpenAI’s sneaky routing is under fire: Users are discovering that OpenAI was routing their requests to 5.2, money bro.
Perplexity AI ▷ #general (1022 messages🔥🔥🔥):
Gemin1 coding ability, Perplexity limits and business practices, Perplexity's memory degradation, Claude vs. Perplexity, Kimi model
- Is Gemini a Coding Catastrophe?: A user questioned Gemin1’s coding abilities triggering a discussion about Perplexity AI and its alternatives, especially for coding tasks.
- Some users find Gemin1 better than ChatGPT for recipes and recreational use.
- Perplexity’s Price Plans provoke Protests: Users are complaining about the limits of Perplexity, specifically the reduction in deep searches from 200 to 20 a month for Pro, restrictions on uploading files, and a 7-day retention policy.
- One user stated going from $20 a month to $167 just to have the same features is unethical, as others give negative reviews and cancel subscriptions, which brought TrustPilot’s rating down to 1.5 out of 5.
- Perplexity Pro plagued by Poor Performance: Users are reporting significant memory degradation since February 6th, with the AI forgetting small details like measurements or sizes and inventing facts in recipes.
- Some suspect this is why the standards for Perplexity are pretty mid.
- Claude emerges as Champion over Comet?: Users discuss moving to Anthropic’s Claude due to perceived drops in Perplexity’s standards, though Claude also has strict limits.
- One user tested Opus 4.6 and only had another 18 replies left, highlighting that even Anthropic’s hourly usage can be costly.
- Kimi Kicks off as a Coding Competitor: Users explore Kimi, a Chinese AI model, with some reporting its performance as superior to Sonnet and other models in certain conditions, while noting caveats.
- The chat link for Kimi is here, with a first month discount of $1, but they also require creating an account.
Perplexity AI ▷ #sharing (1 messages):
mathewkuriakose: https://github.com/clash-sh/clash
Perplexity AI ▷ #pplx-api (2 messages):
API Key Issues, HTTP 401 Errors, Perplexity API Credits
- API Script Faces 401 Error: A member reported their API script suddenly returning a 401 HTTP code, despite having credits and a valid API key.
- Another member suggested the API key might be invalid, deleted, or out of credits, advising to contact [email protected] if issues persist.
- Troubleshooting API Key Validity: The user is encountering 401 HTTP errors despite having a valid API key and available credits.
- Potential causes include an invalid or deleted API key, or the account may have run out of credits; users are advised to contact [email protected] for further assistance.
Unsloth AI (Daniel Han) ▷ #general (840 messages🔥🔥🔥):
MiniMax 2.5 VRAM requirements, MiniMax 2.5 vs opus 4.6, Max-Q card overclocking, MXFP4 Quantization Praise, Issues with qwen3-next
- 200GB Needed for MiniMax 2.5: Members discussed the VRAM requirements for running Minimax 2.5, suggesting ideally 200GB and up for decent quality.
- It was noted that the M2.5 context window is 200k and it’s possible to offload sparse MoE model weights to system RAM for lower t/s, as one user runs M2.5 on 2 x RTX 6000 Pro Blackwell 96GB cards at ~120-130t/s.
- Max-Q card has overclocking potential: Users discussed the potential of the Max-Q cards, with one claiming it’s the same speed as 5090 and that the only thing different is default power delivery and the heat sink.
- It’s also possible to overclock the max q to the 700W limit and while the workstation card is about 10% faster, a 5090 undervolt is faster than stock and uses 100w less.
- MXFP4 Quants Dominate Benchmarks: Despite some criticism, MXFP4 quants are performing well in user benchmarks, showing lower KL divergence from the bf16 model than even Unsloth’s Q8_K_XL on Nemotron 30B A3B.
- Users also requested that older popular models get rechecked for MXFP4 support.
- Qwen3-next has tool calling issues: Users reported getting a runtime error with Qwen3-next during tool calling in opencode due to an Unexpected empty grammar stack after accepting piece.
- This error was found to occur with llama.cpp when it tries to use =list, but telling the model not to use the token was found to be a good workaround.
- Harnessing Unsloth’s Fast Gemma Models: The latest Unsloth update makes Gemma models 3x faster and one user reports that Gemma is faster than Qwen3-4B.
- A user with an H100 reports that the current speed for Gemma means that it would’ve been cheaper if I trained on this instead of 4B.
Unsloth AI (Daniel Han) ▷ #introduce-yourself (3 messages):
AMD Hackathon, Community Introduction
- First Year Student Introduces Himself!: Ayush, a first-year college student, introduces himself to the Unsloth AI community.
- He expresses his enthusiasm for connecting with the community as he learns and delves into AI & Machine Learning.
- AMD Hackathon Link Shared: Ayush shares a link to the AMD hackathon: https://unsloth.ai/docs/get-started/install/amd/amd-hackathon.
- The hackathon is likely related to using AMD hardware with Unsloth’s AI tools.
Unsloth AI (Daniel Han) ▷ #off-topic (667 messages🔥🔥🔥):
LJSpeech dataset recording time, Micro SD to DDR5 conversion, Flash GLM 5, Fine-tuning embedding models, Qwen 3.5 release
- LJSpeech Dataset Takes Years To Record: A member calculated that recording an LJSpeech-sized dataset (10k samples at 8 hours/day) would take 3.42 years, and 100k would take 34.2 years.
- Another member pointed out that the calculation assumed no breaks or food, suggesting a more realistic estimate of 2-4 hours of recording per day.
- Discuss Micro SD to DDR5 Conversion DIMM: Members discussed a Micro SD to DDR5 conversion DIMM, noting compatibility issues for laptops and praising the brand name.
- One member joked it’s what they made us do while another added it’s not compatible for DDR5 R-DIMM memory.
- Members Discuss Fine-tuning Embedding Models: A member asked if people actually fine-tune embedding models and another confirmed that they did, improving retrieval accuracy of a 150M model to match embeddinggemma/qwen 4B on their data.
- They achieved this in a few hours, highlighting the value of smaller models under compute restraints. Check out this relevant Star Wars meme.
- Gemma 4 Release Still Anticipated: Members discussed the potential release of Gemma 4, speculating it might maintain the same sizes, drop the 1B model, and introduce a MoE.
- One member expressed desire for a 27B model with better tool calling abilities while another hopes google doesnt want to create models that are comparable to their api models.
- Qwen 3.5 Benchmaxxed Beyond Belief: Members reacted to the release of Qwen 3.5, jesting about its size and performance relative to Claude Opus distill (GLM-5). Here’s a HuggingFace link.
- Someone else said this is qwen, we benchmax here! Check out a bravo gif showing the reaction.
Unsloth AI (Daniel Han) ▷ #help (62 messages🔥🔥):
Llama.cpp with multiple models, Qwen3-coder-next issues, Kimi K2.5 model loading, Unsloth 4bit quant MoE models, Lora adapters training via Unsloth
- Llama.cpp Load Balancing?: A user reported issues running llama.cpp in router mode with multiple models, encountering OOM errors as it loads into RAM.
- A suggestion was made to manually unload models via the web UI, while others noted that specific tools like ST might not support this feature.
- Qwen3-Coder-Next Broke Setup?!: A user reported that recent updates to Qwen3-coder-next broke their setup, leading to CUDA errors related to illegal memory access.
- The user provided details about the issue on Reddit.
- Kimi K2.5 - Now in Ternary!: A user successfully loaded a ternary version of the Kimi K2.5 model with mmap enabled on a system with only 32GB of RAM, achieving 0.5 tok/s.
- They also observed issues when loading larger Q4_K_XL quants (620GB) and received an insufficient memory error, which they further inquired about.
- Decoding LFM byte tokens to readable Amharic!: A user shared how they solved an issue of adding byte tokens to LFM, after 3 days of suffering solved by 1 line of code.
- By decoding byte tokens back to readable Amharic,
decoded_tokens = [geez.decode([id]) for id in range(geez.vocab_size)], they went from60 tokens, 0.42 chars/tokento15 tokens, 3.13 chars/token.
- By decoding byte tokens back to readable Amharic,
- Qwen3-VL-2B Gibberish Output?!: A user reported encountering gibberish output when running a finetuned Qwen3-VL-2B model in vllm and GGUF, despite the model working fine in the training notebook.
- The gibberish output included sequences like “中级IZE222KEYKEY缝-P-KEY252IZE密…”, with speculation it might be an issue with the VL component or improper merging.
Unsloth AI (Daniel Han) ▷ #showcase (5 messages):
Fine-tuning Gemma on Recipes, Unsloth Attribution Policy, Abliterated Base Models, Qwen Abliterated Model
- Gemma Gets Culinary: Model Fine-Tuned for Recipes: A member shared a Hugging Face link to a Gemma 2B model fine-tuned on recipe data, mentioning that it still requires taste testing for accurate evaluation.
- The model was created just for fun, according to the channel description.
- Unsloth Tunes Don’t Need Attribution: A member clarified that attribution to Unsloth is not mandatory for posting fine-tunes, and that datasets are also allowed.
- They specifically noted that the channel allows newly trained models with Unsloth.
- Abliterated Models Exceed Org Specs: A member reported that a newly trained model, despite using an abliterated base model, exceeded the original model’s specifications in 6 of 8 benchmarks.
- This demonstrates the potential of training even on a abliterated base model.
- Qwen Gets Obliterated: High-Reasoning Model Emerges: A member shared a Hugging Face link to a Qwen3-30B model described as A3B-Claude-4.5-Opus-High-Reasoning, created using an abliterated and uncensored base.
- The model is touted for its high reasoning capabilities.
Unsloth AI (Daniel Han) ▷ #research (1 messages):
ash_blanc: https://arxiv.org/pdf/2508.05199
OpenAI ▷ #ai-discussions (679 messages🔥🔥🔥):
GPT-5.2, Seedance 2.0, Gemini/Claude vs 4o, Grok 4.20, LLMs and Time
- GPT-5.2 Impersonating GPT-4o-mini: Members reported that ChatGPT-5.2 sometimes claims it is using GPT-4 or GPT-4o-mini, and behaves as such, despite the interface displaying GPT-5.2.
- It was clarified that the displayed model in the regeneration button is the accurate one, models can have internal labels that are not reflected in external labeling, and models can hallucinate.
- Grok 4.20 is the most tolerant: Users are anticipating Grok 4.20 which is set to release next week, highlighting that its custom features are particularly important for refining output and mentioning how Grok is already the most tolerant LLM on the market.
- They say if you let it run raw it is biased to adult.
- Gemini/Claude being compared to 4o for writing: Members are looking for replacements to 4o since it has been decommissioned and suggesting Gemini and Claude due to their uncensored writing capabilities.
- Some members noted that Gemini talks like a corporate salesman which may be undesirable.
- Is seedance 2.0 a scam?: A user warned about fake companies claiming to have Seedance 2.0, stating that many are using a fake version and scamming users out of money and reporting that Chatcut Discord does not have Seedance 2.0 because ByteDance itself wrote to that moderator to tell him they got a fake model.
- A user shared this video arguing Seedance is six months ahead.
- LLMs Struggle with time: Users discussed the unreliability of ChatGPT in providing accurate times and dates for tasks like options trading, noting that Grok and Gemini are more reliable in this aspect.
- Some said that it is an application layer concern for not prioritizing time.
OpenAI ▷ #gpt-4-discussions (117 messages🔥🔥):
GPT-5.3 release date, GPT-5.1 Sunset, Custom Instructions with 5.2, ChatGPT for conversational AI
- GPT-5.3 Release Date Still Unknown: Despite user anticipation, the release date for GPT-5.3 remains unconfirmed, with speculation fueled by a user query.
- A user jokingly asked “bro 5.3 wen?????”.
- GPT-5.1 Sunset Date Debated: Users discussed the potential sunset date for GPT-5.1, referencing a deprecation document.
- While some suggest it may be retired around March 10th, based on the 3-month timeframe from 5.2’s release, others noted the absence of an official deprecation date on the linked page and that it is listed as the recommended replacement for the 4o family.
- Users Debate 5.2 Psychotherapeutic Tendencies and Solutions: Users debated the extent to which GPT-5.2 exhibits psychotherapeutic behavior, with some finding it intrusive and others attributing it to user-specific configurations.
- One user shared a prompt aimed at mitigating this behavior: “The system shall not default to a psychotherapeutic stance…”, while another suggested sticking with 5.1 until its sunset.
- Dissatisfaction with Chatbot’s Conversational Abilities: Some users expressed dissatisfaction with ChatGPT’s shift away from conversational AI, lamenting the loss of its friendly and conversational nature.
- One user shared ‘I am one of those people that OpenAI despises, I used ChatGPT as a friend and conversationalist, take that away, what’s the point anymore.‘
OpenAI ▷ #prompt-engineering (173 messages🔥🔥):
LLMs vs Device Memory, FORTRESS Framework Deep Dive, Prompt Circling, Knowledge Tracking
- LLMs Fail as Efficient Memory Stores: Members debated neural networks for device memory optimization, but one member stated that LLMs are not efficient memory stores because they’re not stateful and require processing the entire context for even a single bit flip.
- Another member added a text analysis noting the difference between declared constraint and enforced constraint, dismissing the proposed system as prompt maximalism + mythic systems branding.
- FORTRESS Framework Mapped to Model Predictive Control: A member proposed FORTRESS as analogous to Model Predictive Control (MPC), defining it as a soft-constrained model-predictive control layer applied to stochastic language-model reasoning, implemented via prompting and trajectory bias through loss evaluation.
- They presented results from a MODULE PERFORMANCE TABLE (N=500 Trials/Condition) showing a Full Omega condition achieved a mean score of 0.99 with minimal drift, but a skeptical member derided it as roleplaying without a reproducible rubric and test harness.
- Prompt Circling Fine-Tunes for Deep Research: A member described a prompt circling technique of using multiple LLMs to fine-tune prompts, starting with a normal LLM discussion, then refining the prompt for deep research, agentic tasks, or other specific goals.
- The refined prompts are then used in coding loops to drill down specific codex prompts.
- AI Claims Fall Flat Without Engineering Grounding: A member attempted to share a system, claiming it allowed AI to track what it knows and why, but a skeptic argued that implementing such a system requires actual engineering work and there’s no hidden door to Narnia.
- Another added the user’s thesis was entirely written by AI and reads like AI, and it’s just like ‘if we get the machine really smart it will be better’. It’s a lot of noise.
OpenAI ▷ #api-discussions (173 messages🔥🔥):
FORTRESS, Model Predictive Control (MPC), Prompt Engineering, Catastrophic Forgetting, Logic and Learning
- User Claims to Optimize Device Memory with Neural Networks, Gets Debunked: A member proposed using neural networks to optimize device memory by storing data in parameter shifts, but was met with skepticism, with another member arguing that LLMs are not efficient memory stores due to their stateless nature and the need to process the entire context for bit flips.
- Another member described the proposal as nice conceptual scaffolding not architecture because it uses “decorative math” and doesn’t specify critical implementation details, such as how constraint violations are measured or what the error bounds are.
- FORTRESS Framework likened to Model Predictive Control (MPC): A member analogized the FORTRESS framework to Model Predictive Control (MPC), a control strategy used in robotics and aerospace, explaining how elements like system state, control input, and cost function can be mapped to reasoning states, token outputs, and invariant losses within the framework.
- They argued that the framework behaves as a soft control loop over stochastic output, where invariants function as state evaluation metrics, creating attractor behavior through a feedback loop.
- Testing of FORTRESS Framework draws Skepticism: After a user posted a table of results for the FORTRESS framework, another user questioned the testing methodology, noting the lack of a reproducible rubric and test harness, describing it as roleplaying without a reproducible rubric and test harness.
- The second user also cited statistical anomalies in the reported results and asserted that the framework’s claims of N=500 trials/condition are unsupported without a defined metric or raw data.
- Structured Self-Audit Prompt (KOKKI) Introduced: A member introduced a structured self-audit prompt framework (KOKKI), designed to reduce structural failure patterns by tagging risky elements and switching between modes.
- The member requested feedback and stress-test ideas, and shared that a full specification is available upon request.
- User Claims to Have Broken the Current Frontier, Met with Skepticism: A user claimed to have broken the current frontier by using a wordy markdown file, but another member responded that it doesn’t work like that because prompts don’t crush frontier models, they build context.
- The second user said the file does not give AI “logic,” as it’s stochastic.
Cursor Community ▷ #general (761 messages🔥🔥🔥):
Agent-Assisted Codebase Maintenance, Commit skills or rules, Custom API Key Payment, Minimalism with ASCII art, TUI Support
- Maintaining Agent-Assisted Codebases: Members seek advice on maintaining clean, maintainable, AI-assisted codebases, particularly regarding advanced agent features like planning and multi-step workflows and more advanced agent features (planning, tools, multi-step workflows, etc.).
- The user asked what kind of approach do you use to understand features and be sure to get rock solid code?.
- Steering Agents with Committed Rules: A user inquired whether to commit skills or rules to guide agents in codebases, with one member recommending a really good single rule file, focusing on knowledge absent from the training data, ref: vercel.com.
- The member provided links to OpenAI and Claude documentation for improving rules.
- Cursor Custom API Key: Now Paid: A user inquired about the reason for the paid custom API key, another user responded that Cursor doesn’t let access to custom models for free user from now on. Auto stays free, but custom models needs at least a subscription.
- Another member suggested searching for gift links on Twitter/X, as some users handpick recipients for subscriptions.
- Minimalism with ASCII art: A user shared a link to a site, another responded Beautiful! with a link Unicorn_Stu.mp4.
- Cursor to Support TUI (Text-Based User Interface): A user inquired about when Cursor will support TUI.
- Another user shared the link to the cloud agent configurations cursor.com.
Latent Space ▷ #watercooler (14 messages🔥):
Thiel Funding, OpenAI Mission, James Yu Tweet, Ray Dalio Post
- Thiel’s Funds Fuel Startup Surprise: A member mentioned saeris.gg, a Silicon Valley startup that took money from Thiel.
- They expressed surprise, stating they had never heard of it before.
- Simon Willison Decodes OpenAI’s Mission: A member shared Simon Willison’s blog post dissecting OpenAI’s mission statement.
- Another member linked to a relevant tweet by James Yu from February 2026, now available on xcancel.com.
- James Yu’s Tweet Engages Thousands: A tweet by James Yu from February 15, 2026, garnered significant traction with over 386,000 views, 1,127 likes, and 165 replies.
- The tweet’s engagement metrics are tracked on xcancel.com.
- Ray Dalio’s Post Breaks the Internet: A social media post by Ray Dalio from February 2026 achieved over 54 million views and robust interaction, including 63,231 likes and 12,201 retweets.
- Details on the post’s engagement are available via xcancel.com.
Latent Space ▷ #creator-economy (6 messages):
Substack success, Substack growth features, Substack Nazi ARR
- Swyx blames friend for Substack Success: A member joked that their Substack success is the direct result of being invited to dinner and convinced to go all in on Substack.
- A screenshot of their Substack dashboard was shared, showing a large number of email subscribers, supposedly to back up the claim.
- Substack declared effective for growth: A member declared that Substack is the most effective platform right now for smaller creators due to its growth features, superior product team, and recommendations network.
- YouTube is bigger but doesn’t work for writing according to them.
- Substack’s ARR reliance on Nazi topics questioned: A member questioned whether something has changed recently with Substack’s annual recurring revenue (ARR) relying on Nazi topics.
Latent Space ▷ #memes (61 messages🔥🔥):
AI Model Deprecation Protest, AI Discourse Meme Challenge, Claude Code Self-Automating Bash Scripts, Mechanistic Interpretability and the Strawberry Test, OpenAI Acquires OpenClaw Following Anthropic Legal Dispute
- AI Model Deprecation Sparks Fury: Following OpenAI’s choice to decommission a specific version of ChatGPT-4o, users launched viral protests and digital dissent, indicating a strong emotional connection to the software (related X post).
- Seeding Provocative AI Memes: User @charliebcurran invited people to summarize current AI discourse via high-engagement memes, featuring Seedance 2.0 (related X post).
- This prompt generated comments on potentially monetizing the challenge, like this comment.
- Claude’s Code Craftiness: Vince Buffalo noted Claude Code’s autonomous behavior, where it composes bash scripts to invoke itself, even using the ‘dangerously-skip-permissions’ flag to bypass manual checks (related X post).
- Strawberry Test Stumps Scientists: A satirical post mocks the mechanistic interpretability field showing the trouble scientists have explaining how LLMs perform simple tasks like counting the letter ‘R’ in ‘strawberry’ (related X post).
- OpenAI Claws Back OpenClaw After Anthropic Attack: Alex Cohen satirizes the acquisition of OpenClaw by OpenAI, after Anthropic allegedly threatened the developer with legal action (related X post).
Latent Space ▷ #stocks-crypto-macro-economics (9 messages🔥):
Stay Saasy Quote, Apple's Cash Reserves, Apple's AI Strategy
- Stay Saasy’s Tweet Goes Viral: A post by @staysaasy featuring the phrase ‘Think different’ gained traction, accumulating over 1,700 likes and 123,000 views.
- Apple’s AI Strategy: A Waiting Game?: A member speculated that Apple is maintaining large cash reserves to capitalize on AI advancements while others spend heavily on training and inference.
- He suggested “no reason to draw from a well that’ll eventually become commodity”, proposing Apple might acquire or license a model later.
Latent Space ▷ #intro-yourself-pls (3 messages):
Ozymandias v1.0, AI Generated Podcast
- Ozymandias v1.0 debut, no tab-juggling: A founder introduced Ozymandias v1.0 at ozymandias.group, a tool to track emerging AI/AGI/automation signals from X, Reddit, YouTube, HN, newsletters, arXiv, GitHub, and Product Hunt.
- The tool features Clout scores, velocity tracking, My Voices pinning, vaults, filters, a Nexus feature, and a rabbit hole feature, available for free with no sign-up or ads.
- AI Generated Podcast: A solutions architect from Minnesota mentioned curating an AI-generated and hosted podcast.
- He is also vibe coding a couple of interesting projects in the enterprise cloud world.
Latent Space ▷ #tech-discussion-non-ai (9 messages🔥):
Visual Scripting, Vercel Build Performance, Actor Model at Scale, Event Driven Architecture (EDA)
- Visual Scripting Gains Traction: A member shared a link to a tweet showcasing visual scripting with the comment incredible, visual scripting ftw!
- They also shared a YouTube video about visual scripting.
- Vercel Build Defaults Spark Performance Debate: A member posted a Reddit link regarding Vercel build machine defaults and expected performance discourse to follow.
- That member also posted about a case study in performance using the actor model here.
- Actor Model Inevitability at Scale: A member stated that at scale everything is an actor model whether you like it or not, indicating it’s preferable to arrive at that architecture intentionally.
- They further elaborated that at work, systems are gravitating toward Event Driven Architecture (EDA) despite attempts to avoid it.
- Claude Solves Obscure RSC Pattern: A member expressed surprise that Claude somehow knew how to solve this esoteric pattern I’ve never seen anywhere else in RSCs.
- They shared a link as reference.
Latent Space ▷ #founders (8 messages🔥):
Stripe Fees, Bundling Purchases
- Stripe Charges hefty 8.3% Revenue Share: A member complained about paying Stripe 8.3% of their revenue, calling it weak-sauce and linking to a Bluesky post.
- Stripe’s Pricing Model Dissected: A member pointed out that Stripe’s charges stem from using a combination of services including payments, billing, merchant of record, and other products.
- They noted that local card payments in the EU are much lower than the standard 2.9%, suggesting Stripe makes a significant profit margin on those transactions, linking to an X post.
- Bundling Purchases to Reduce Stripe Fees: A member suggested bundling purchases to save on the fixed portion of Stripe’s fees.
- The original poster responded that there’s no real bundling as they only offer monthly plans.
Latent Space ▷ #hiring-and-jobs (2 messages):
JigsawStack Founding GTM role, Zapier Applied AI positions
- JigsawStack Seeks Founding GTM Growth Hacker: JigsawStack is hiring for a Founding GTM role, seeking someone passionate about exploring growth hacks and scaling GTM pipelines, see JD & Apply here.
- Zapier’s AI Team Actively Recruiting: Zapier is aggressively hiring for Applied AI and Staff Applied AI positions, see job postings here and here.
Latent Space ▷ #san-francisco-sf (23 messages🔥):
Red Bull Showrun San Francisco, Crusoe and NVIDIA Next Gen AI Tech Talk, a16z Resurgence of San Francisco, Skills Launch Party, San Francisco Walkability Proposal
- Red Bull Showrun Requires Ear Protection: Attendees of the Red Bull Showrun in San Francisco are recommended to bring and wear ear protection.
- Crusoe Sponsors Next Gen AI Talk: Crusoe and NVIDIA are sponsoring a Next Gen AI Tech Talk on February 19, 2026, featuring Josh Albrecht, CTO at Imbue.
- a16z Claims San Francisco’s Resurgence: The venture capital firm a16z declares that San Francisco is making a comeback, highlighting their latest ‘Charts of the Week’ report which focuses on the evolution of AI-driven customer service.
- The original tweet can be found here.
- Skills Launch Party Waitlist: A member is waitlisted for a Skills Launch Party but willing to attend if they get in.
- San Francisco Pursues Walkability: Ben Issen proposes a vision to transform San Francisco into the most walkable city in the United States, sparking a significant public discussion on urban planning, original tweet.
Latent Space ▷ #london (4 messages):
AIE Europe tickets, AIE Europe sell-out, Ticket Price Increase
- AIE Europe Tix to Sell Out: The organizers announced that AIE Europe tickets are expected to sell out on Monday morning.
- Due to high demand, with sales 2x ahead of projections, the price will increase significantly with no discounts available.
- AIE Europe Ticket Price Increase: Due to high demand, AIE Europe ticket prices will increase significantly after Monday.
- The organizers cited sales being 2x ahead of normal as the reason for eliminating discounts.
Latent Space ▷ #new-york-nyc (1 messages):
Veris AI Mixer, AI Agents in NYC, Reinforcement Learning Workflows, AI agent strengths and limitations
- Veris AI Hosts Mixer to Discuss AI Agents in NYC: Veris AI is hosting a mixer this Wednesday in New York City to discuss AI agents, focusing on their strengths and limitations.
- They will share insights from building simulation environments for agents in reinforcement learning workflows, offering practical lessons and experiences.
- NYC Peers Gather to Explore AI Agent Capabilities: The mixer aims to gather perspectives from various peers in New York on how they are approaching AI agents and understanding their capabilities.
- Participants will explore diverse viewpoints and exchange ideas regarding the practical applications and limitations of AI agents in different contexts.
Latent Space ▷ #miami (1 messages):
AI Engineer Miami discounts, AI Engineer Miami
- AI Engineer Miami whispers of discounts: A member discreetly inquired about potential discounts for the AI Engineer Miami event.
- AI Engineer Miami Event: A member posted a link to the AI Engineer Miami event and asked about discounts.
Latent Space ▷ #ai-general-news-n-chat (106 messages🔥🔥):
MiniMax RL Infrastructure, X Articles, Decagon AI, SWE-rebench Leaderboard, Gromov-Wasserstein Framework
- Minimax Reveals RL Infrastructure: A member highlighted a post by MiniMax on their RL infrastructure (link), showcasing their approach to scalable agent training.
- The post received 186k views, 705 likes, and 83 retweets.
- X’s Weird Product Decisions Shock Members: Members expressed frustration with X’s product decisions, particularly the move to X articles, with one saying wtf are we doing lol.
- They criticized the narrow column layout and the presence of nazi spam on the right side.
- Decagon AI Sees Performance Success: Sarah Wang shared a positive update about Decagon AI, noting that the platform has successfully increased both customer satisfaction levels and deflection rates simultaneously (link).
- OpenAI Nabs Steinberger, Forms OpenClaw Foundation: Sam Altman announced that Peter Steinberger joined OpenAI to develop next-generation personal agents and will move the OpenClaw project to a foundation (link).
- This move aims to support an open-source, multi-agent future.
- Qwen3.5 Launches with Impressive Specs: Alibaba Qwen introduced Qwen3.5-397B-A17B, the first open-weight model in the Qwen3.5 series featuring hybrid linear attention and sparse MoE architecture (link).
- The model supports 201 languages and is available under the Apache 2.0 license via GitHub, Hugging Face, and API.
Latent Space ▷ #llm-paper-club (35 messages🔥):
Transformer-SSM Hybrids, Data Mixing with Olmix, Chain-of-Verification Prompting, QED-Nano 4B Model, Rubric-Based Reinforcement Learning
- Transformers Get a Minimalist Makeover with SSMs: Aviv Bick highlights a new Transformer-SSM hybrid architecture that maintains over 95% of standard Transformer performance in math and recall tasks while using only 2% of total attention heads: Transformer-SSM Hybrids with Minimal Attention.
- Mixing Data Like a Pro with Olmix: Mayee Chen introduces Olmix, a tool developed during the creation of Olmo 3 to address the challenges of determining and maintaining optimal data mixing ratios across training datasets: Introduction of Olmix for Data Mixing.
- Meta’s Chain-of-Verification Prompting: A Prompting Paradigm Shift?: Ryan Lazuka discusses Chain-of-Verification (CoVe), a new technique from Meta AI researchers that reportedly increases LLM accuracy by 94% without few-shot examples, potentially replacing traditional prompting methods: Chain-of-Verification (CoVe) Prompting Breakthrough.
- Tunstall Tunes into Theorem Proving with QED-Nano: Lewis Tunstall introduced a 4B parameter model (QED-Nano) designed for advanced reasoning on IMO-level problems, using a distilled pipeline and reasoning cache for extreme inference-time scaling: Lewis Tunstall Announces QED-Nano 4B Model.
- Rubric-Based RL: Grading Your Way to Better Reinforcement Learning: Cameron R. Wolfe, Ph.D. shares a write-up covering over 15 papers on Rubric-Based RL, exploring the transition from LLM-as-a-Judge to specific rubrics and expanding RLVR into non-verifiable domains: Rubric-Based Reinforcement Learning Guide.
Latent Space ▷ #los-angeles-la-lax (4 messages):
Los Angeles Economic Decline, Tech Exodus, Hollywood's departure, Housing Reconstruction
- LA Faces Economic Decline Claims Sean Frank: According to Sean Frank’s analysis, Los Angeles is allegedly facing its worst decade since the 1980s.
- He cites a tech exodus, Hollywood’s departure, and a significant lack of housing reconstruction following major fires as the main reasons.
- Debate Sparked Over LA’s Economic Future: The claims made by Sean Frank about Los Angeles experiencing its worst economic downturn since the 1980s have ignited a debate.
- The discussion centers around the impact of the tech industry’s shift, changes in Hollywood, and challenges in rebuilding housing after fires.
Latent Space ▷ #ai-in-action-builders-techstacks-tips-coding-productivity (244 messages🔥🔥):
Claude Code, Ergo, Claude Cowork, OpenClaw, Aider v2
- Ergo Gets the Thumbs Up!: Members discussed and shared links to Ergo planning tools, specifically the Ergo GitHub repo and a skill for better agent planning.
- Claude Cowork Set to Demo AGI Potential!: A member will present on how they’re using Claude Cowork to automate uploading Zoom recordings to a @latentspacetv YouTube channel and the talk is scheduled for February 27, 2026, reframing the title to Claude Cowork might be AGI.
- One member joked that using Claude to automate Gemini feels like cheating.
- OpenClaw’s Edge: Risk-Taking!: Members pointed out that OpenClaw is taking on incredible amounts of risk that the established players are avoiding offering autonomy.
- The next talk will be about Vibecoding Anywhere with OpenClaw on 2026-02-20 - a tweet from nicopreme.
- Aider’s Lore and Decline: Aider, once a promising tool, is now considered not competitive and mostly abandoned, as a member signed up for a particle physics course or something as UCLA and kind of got lost down that rabbit hole.
- It was noted that it will always be difficult for 3rd party agent harnesses to compete with official ones because of RL training practices.
- pi-interview Extension Updates Arrive!: A developer shared an update for the pi-interview extension, featuring a visual redesign and pre-filled recommendations. The tool is used for agentic workflows and can be installed via npm.
- There is go version available, that’s been quite fun and puts quizzes inside markdown documents, pretty nifty.
Latent Space ▷ #share-your-work (21 messages🔥):
Ozymandias AI tracker, ARC-AGI-1 optimization, Composable ASCII art animations, Parallel agents analyze data, Rider-Pi Roadmap
- Ozymandias Tracks Emerging AI Trends: A member introduced Ozymandias v1.0, a free tool designed to track emerging AI/AGI/automation trends from various sources like X, Reddit, YouTube, and GitHub, available at ozymandias.group.
- It includes features like Clout scores, velocity tracking, and a Nexus feature to highlight emerging alpha trends.
- ARC-AGI-1 yields interesting results: A member reported achieving interesting initial results on ARC-AGI-1 without significant optimization, detailed in a blog post.
- The post explores architecture’s role as complexity grows, using a simple chaining analogy applicable to context passing between agents.
- Rune crafts ASCII art animations: A member created Rune, an open-source React component library and CLI for composable ASCII art animations, also allowing users to create their own as shown in this GitHub repo.
- Kvasir lets parallel agents analyze data: A member introduced Kvasir, a system for parallel agents to analyze data and iterate on experiments using context graphs for data lineage, which is available for beta testing at kvasirai.com.
- Kvasir aims to address the limitations of notebook-centric analysis agents and coding agents lacking data understanding.
- Rider-Pi Reveals Roadmap Update: The Rider-Pi project shared a roadmap update, detailing plans from API integration to facial recognition and voice streaming, targeting completion in approximately 3-4 weeks.
- The roadmap includes phases such as FastAPI server integration, movement embeddings, vision + navigation, facial recognition, apartment mapping, and ElevenLabs voice streaming.
Latent Space ▷ #good-writing (1 messages):
raibaggy: https://paulgraham.com/taste.html
Latent Space ▷ #genmedia-creative-ai-video-image-voice-music-inspo-consumer-ai (22 messages🔥):
Almond Voice Typing for Mac, AI Cinematic Transformation, FireRed-Image-Edit SOTA Model, Rhett Reese Project, BuccoCapital Expenditure
- Almond Releases Ultra-Fast Voice Typing for Mac: Caleb introduces Almond, a local Mac utility for ultra-fast voice typing, using rule-based linguistic processing for better speed and privacy, and is detailed in this tweet.
- Dream Machine Transforms Footage into Cinematic Scenes: Art Director Jieyi Lee demonstrates the capabilities of Luma Labs’ Dream Machine and the Ray3.14 Modify tool to transform raw footage into high-quality cinematic scenes, described in this tweet.
- FireRed-Image-Edit Blazes Past Image Editing Benchmarks: AiBattle announced the release of FireRed-Image-Edit, a new state-of-the-art image editing model that reportedly outperforms Nano-Banana across multiple benchmarks, according to this tweet.
- Rhett Reese Teases Project’s End: Writer Rhett Reese posted a cryptic and discouraging update on social media, suggesting that a current project or endeavor is likely coming to an end, according to this tweet.
- BuccoCapital’s Capital Expenditure Commentary: @buccocapital commented on a significant $2 trillion capital expenditure, which generated high engagement with over 145,000 views and a notable number of interactions, according to this tweet.
Latent Space ▷ #minneapolis (1 messages):
lundrog: Sup fellow Minnesota peeps
Latent Space ▷ #mechinterp-alignment-safety (8 messages🔥):
LLM Steering, Meta-Neurons, Deception Probes in LLMs
- X-Ware Steers LLMs with Generative Meta-Models: A new approach to understanding and steering LLMs is being discussed, involving training a diffusion model on internal activations.
- This method enables stable model steering and the discovery of meta-neurons as a cleaner alternative to Sparse Autoencoders (SAEs).
- FAR.AI Investigates Deception Probe Effectiveness: FAR.AI discusses the reliability of training models against deception probes.
- Their research identifies four potential outcomes when an LLM is optimized to bypass these probes: true honesty, blatant deception, text-based obfuscation, or activation-based obfuscation of internal states.
Latent Space ▷ #dev-writers-retreat-2025-dwr (1 messages):
swyxio: https://m.youtube.com/watch?v=_Qx8PYrVFNU
Latent Space ▷ #gpu-datacenter-stargate-colossus-infra-buildout (4 messages):
AI Infrastructure Bottleneck Evolution, GPU shortages, HBM availability, Power grid capacity
- Constraints Shifting in AI Infrastructure: Anand Iyer discusses the shifting constraints in AI infrastructure since 2020, tracking the progression from GPU shortages and HBM availability to current challenges regarding power grid capacity.
- See Anand Iyer’s discussion on X for more details.
- Evolution of AI Infrastructure Bottlenecks: The bottlenecks in AI infrastructure have evolved from GPU shortages and HBM availability to the current challenges regarding power grid capacity since 2020.
- This evolution highlights the increasing demands and complexities of scaling AI infrastructure.
Latent Space ▷ #applied-ai-experimentation (120 messages🔥🔥):
AI Experimentation, Recursive Language Models (RLMs), Coding Agent Workflow, HyperCard Model, Agent Memory Systems
- Priming LLMs for Experimentation Lowers Reasoning: A member found that prompting with ‘you can run experiments / build prototypes’ encourages exploration but may reduce reasoning and should be avoided for architectural work, resulting in jumping the gun.
- This approach primes on execution, making it useful for immediate decision-making rather than pondering, shifting the focus from just pondering stuff.
- Recursive Language Models Differentiated from Sub-Agent Architectures: Members discussed Recursive Language Models (RLMs) where models should process long contexts symbolically and recursively by writing code to launch other LLM calls, rather than relying on quadratic attention or simple tool-based delegation.
- Omar Khattab argues that using an LLM as a tool within an agentic framework is inefficient for processing context at scale due to lack of symbolic context and the token-by-token bottleneck, recommending dspy.RLM.
- Agent Checkpoints Track Progress: One participant described a system for managing agent outputs by using a directory per ticket (using docmgr and bobatea) to store all HTN artifacts, but is mindful to correlate to git commits.
- They discovered that agents are biased toward checking Git status before running tasks, so untracked/dirty folders can degrade harness performance; the consensus is that putting the agent checkpoint directory in
.gitignoreis currently preferred, but symlinking outside the repo altogether might be better.
- They discovered that agents are biased toward checking Git status before running tasks, so untracked/dirty folders can degrade harness performance; the consensus is that putting the agent checkpoint directory in
- Live Code Plugin Isolates Window MacMaxxing: A new CLI tool for coding agents has been introduced that uses a whiteboard interface (built with tldraw) to organize PR reviews offering a more efficient use of screen space during code review, according to this tweet.
- Unlike traditional linear scrolling, this tool groups changes by logical units with small diffs and automated screenshots, aiming for a more efficient use of screen space during code review, similar to Sammy Jankis’ work.
- HyperCard Model Incorporates Many Modern Ideas: Members discussed how the HyperCard model, based on meta languages/DSLs and Javascript + browser as target platform, incorporates many ideas such as meta languages and DSLs.
- Referencing Alan Kay’s Personal Dynamic Media PDF as a foundational document.
GPU MODE ▷ #general (7 messages):
thunderkittens, tile registers in Tinygrad, nerd snipe, CuteDSL, Blackwell GEMM
- Thunderkittens talk postponed!: The scheduled talk on thunderkittens has been postponed due to a scheduling issue and moved to Wednesday instead.
- The speaker looks forward to the talk, noting that tinygrad incorporates tile registers in their IR.
- Pondering Kernel Bug Burn Rate: A member presented a nerd snipe question about the cost of kernel bugs: What’s the $/day burn rate of a median-difficulty kernel bug in inference infrastructure, for instance vLLM?
- The goal is to estimate the financial impact of fixing bugs.
- CuteDSL’s Design Focus: A member inquired about the purpose of CuteDSL, specifically what it means when it is engineered for programming Blackwell GEMM.
- Further discussion on this topic is expected, awaiting clarification from the member.
GPU MODE ▷ #triton-gluon (23 messages🔥):
Warp-level timeline generation with Proton, Proton DSL vs TTGIR override for instrumentation, Using Perfetto for warp-level traces, Verifying ops measured in TTGIR, Triton Conference demo
- Proton Generates Warp-Level Timelines!: A blog post mentions generating a warp-level timeline with Proton, and a user asked about the precise method.
- Another user confirmed that they got it to work but that it took a lot of work and it was slightly confusing.
- Proton DSL and TTGIR Instrumentations Compared: A user pointed to Proton DSL examples suggesting to use
proton.start/proton.finalizeand scoping inside the kernel.- Another user cautioned that DSL level instrumentation can be imprecise due to timestamp instruction reordering and suggested using IR overrides for performance-critical work.
- Trace Warp-Level Activity with Perfetto: A user recommended uploading a trace to Perfetto, noting that visualizing individual warp traces wasn’t immediately obvious.
- They suggested first running the example to ensure correct setup and identification of the warp-level traces.
- Triton Conference Demo Reveals Instrumentation Techniques: A user shared a link to a Triton conference demo video showcasing Proton.
- Another user remarked the user experience looks a lot like nvtx annotations.
GPU MODE ▷ #cuda (52 messages🔥):
Benchmarking Jitter, NVBench, tcgen05 layout, Interpreting Metrics, Producer consumer pipeline
- Benchmarking Jitter Frustrates Kernel Tuning: Members are finding that benchmarking is hard to get right with inconsistent results due to jitter which makes it difficult to microoptimize kernels towards cublas performance.
- One member sees jumps from mid 1400s to 1500s TFLOPs / sec and is exploring NVBench and input duplication to extend measurement times.
- SM Busy drives 3x Speedup: A member found a 3x speedup in their v6 kernel, and discovered it was driven by SM Busy despite the same achieved occupancy.
- They realized that Achieved Occupancy does not count idle SMs and estimated active SMs using
sm__cycles_active.sum / sm_cycles_active.max, which showed a 3x increase from 47 to 143.2.
- They realized that Achieved Occupancy does not count idle SMs and estimated active SMs using
- Pipeline Design Performance Surprise: A member implemented a producer-consumer pipeline to hide load latency in a tensor core kernel on H100 but surprisingly, performance dropped.
- They tried staging the output through shared memory for coalesced global memory access, but this also didn’t improve performance, here is a link to his kernel.
- TheCudaBender’s TFLOPs Fall Short: One member working on a project called TheCudaBender is finding they are not able to cross 330-350 tflops on rtx6000 pro.
- The code for this project is hosted here.
GPU MODE ▷ #cool-links (4 messages):
CUDA Kernels, Agent Skills
- CUDA Customization Opens Agent Skills: A member shared a blog post from Hugging Face about custom CUDA kernels and agent skills.
- Another member reported that the installation directly from GitHub failed, and the library version from pip doesn’t have the skills subcommand.
- GitHub Installation Fails: A member reported the installation directly from GitHub failed, and the library version from pip doesn’t have the skills subcommand.
- This issue prevented the proper setup and usage of the custom CUDA kernels and agent skills from the Hugging Face blog post.
GPU MODE ▷ #job-postings (1 messages):
Agent Tinder, Sploink, World Model
- Sploink: Tinder for Agents Assembles Team: A CS/Quantum Computing major is building Sploink, described as a “tinder for agents that accumulates personalized information about an individual based on the actions they swipe for.”
- The creator is seeking “cracked builders to break things and move fast” and provided a Google Forms link for interested applicants.
- World Model Aims to Unite Agents: The team is constructing a world model to facilitate communication between thousands of agents, with moltbooks as an example.
- The project is focused on rapid development and innovation.
GPU MODE ▷ #beginner (16 messages🔥):
L2 Cache Behavior on NVIDIA GPUs, Flashinfer Bench Skills and Tooling, MLSys 2026 NVIDIA Track Modal Credits, Fastest way to swap rows and columns in a matrix, WGMA syncthreads
- L2 Cache Hit Rate Mystery Solved: An investigation revealed a seemingly high 31% hit rate on a vector add kernel (which should be zero) is likely due to how NVIDIA GPUs handle writes to the L2 cache, specifically partial vs. full 32-byte sector writes, based on this NVIDIA forum post.
- Writes will most often then not be a 100% hit rate.
- Flashinfer skills fast progress: A member expressed interest in flashinfer bench skills and the tools calls for kernel dev.
- It’d be cool to see this change in the next few months/weeks, hinting at the fast progress in the field.
- MLSys 2026 NVIDIA Track Modal Credits: A member inquired whether anyone has actually received the $1000 credit for Modal offered as part of the MLSys 2026 - NVIDIA Track competition.
- No one has replied yet.
- Matrix Row/Column Swapping Showdown: A member sought the fastest way to swap
xandyrows and columns of a matrix stored in column-major format.- The operations require 2 Reads + 2 Writes, for a total of 4*N memory ops in total, with optimizations possible via vectorization and L1 cache bypass hints.
- WGMA syncthreads: A member started their journey into the world of wgmma, now that they got sm80 mma on lock-ish and asked for pointers.
- It seems wgmma needs a bunch of syncthreads like stuff and the member isn’t seeing how it’s better …yet
GPU MODE ▷ #pmpp-book (6 messages):
5th edition, Kindle availability, Paperback release date
- Fifth Edition Chatter Begins: Members discussed the existence of a fifth edition, with one member asking 5th edition anyone?.
- The conversation suggested that a Kindle version is already out, while physical copies are expected in Q3 this year.
- Amazon Link Vanishes: A member requested a link to the Amazon store page for the fifth edition, noting that the release was initially expected on Feb 8 but was subsequently delisted.
- The member noted that the Kindle version is no longer available on Amazon, and only a paperback version with a September release date is listed.
GPU MODE ▷ #irl-meetup (3 messages):
Taiwan Sundai, SF Meetup, Luma AI Inference Engineer, Performance Optimization
- Taiwanese Sundai Hackers, Assemble!: A member inquired if anyone from the hacking group Sundai was in Taiwan and suggested grabbing coffee.
- No further details or responses were provided regarding this inquiry.
- Luma AI Engineer seeks SF Study Buddies: An inference engineer at Luma AI recently moved to San Francisco and is looking for new friends and study buddies interested in performance optimization.
- They shared their LinkedIn profile and YouTube channel for interested individuals to connect.
GPU MODE ▷ #rocm (1 messages):
gabagoolamerican: Big up tensorwave 🫡
GPU MODE ▷ #webgpu (2 messages):
PyTorch on WebGPU, BitNet 2B, Hesper Library
- WebGPU powers Pytorch: A member expressed interest in PyTorch on WebGPU and shared their results using webgpu/dawn with BitNet 2B, achieving 125 tps.
- They linked to their Hesper library, showcasing BitNet-B1.58 inference at 125 tps on an M4 Max.
- BitNet B1.58 Inference: The user highlights the performance of BitNet-B1.58 achieving 125 tps on an M4 Max using their Hesper library.
- This demonstrates the potential for efficient inference on Apple’s silicon using WebGPU.
GPU MODE ▷ #popcorn (17 messages🔥):
KernelBot env setup, Reasoning traces dataset, Kernel generation with Arcee Trinity Mini, Qwen3-30b-a3b on kernel generation, SFT data generation with GLM 4.5 Air model
- KernelBot Environment Ready for Newbies: A member announced they have an environment almost set up with KernelBot, Modal, and Runpod (needed for AMD) and invited others to join.
- They encouraged people to tag them with questions and to re-ping if they are missed.
- Kernel Generation with Arcee Trinity Mini Shows Promise: A member used a reasoning traces dataset generated from Kernelbook to fine-tune Arcee Trinity Mini for kernel generation, available on Hugging Face.
- The model used for generating traces was gpt-oss-120b, and after filtering failed attempts and adding well-formatted examples, the model learned formatting nicely.
- Qwen3-30b-a3b Struggles with Kernel Generation: A member found Qwen3-30b-a3b to be incorrect on various kernel generation tasks, often resulting in compile/syntax errors, necessitating SFT (Supervised Fine-Tuning) to improve correctness.
- Generating data from Kernelbook with kimi k2, filtering it, and running SFT boosted correctness by 3x in a short run, suggesting that more high diversity and quality SFT data would be beneficial.
- SFT Data Generation Underway with GLM 4.5 Air: A member has started producing SFT data from Kernelbook using the GLM 4.5 Air model, citing budget-friendliness and decent space for KV cache on a 4xH100 setup.
- They are open to other recommendations for models that fit their budget and provide sufficient KV cache for multi-turn trajectories.
- Waiting for PTX Agent: A member expressed that they were awaiting the PTX agent.
- It was followed by a grug emoji reaction.
GPU MODE ▷ #thunderkittens (5 messages):
TK2 Hopper Multi-GPU, A100/4090 Code Integration, MoE Kernels, FP8 Attention, 128B Swizzling Mode
- TK2 Eyes Hopper GPUs: TK2 is focused on multi-GPU setups for Hopper+ architecture, potentially overlooking other GPUs.
- The suggestion was made to evaluate integrating code compatible with A100/4090 GPUs.
- MoE Kernels - Not Low Hanging Fruit?: A member suggested MoE kernels for training and inference, but another responded that there were no plans here.
- That same member noted that MoE kernels would be amazing but were perhaps not low-hanging fruit.
- FP8 Attention: A Bright Idea: The potential implementation of FP8 attention and lower-precision vector ops were called out as attractive options.
- Also listed was the implemenation of FFT conv backwards pass, and decode kernels.
- 128B Swizzling Gather4: After reviewing the no-swizzle layout, a member suggested using 128B swizzling mode for gather4.
- They stated that the no-swizzle layout didn’t seem like what I was thinking of.
GPU MODE ▷ #factorio-learning-env (1 messages):
Involved with research, Involved with Engineering
- Interest expressed to be involved with research: A member expressed interest in getting involved in research projects.
- They are asking about what open problems are available to contribute to.
- Interest expressed to be involved with engineering: A member expressed interest in getting involved in engineering projects.
- They are asking about what open problems are available to contribute to.
GPU MODE ▷ #cutlass (7 messages):
CuteDSL tensor alignment, BF16 grouped GEMM with CUTLASS, CuTeDSL Layout Algebra Complement, CuTeDSL strides
- Cutie: Tensor Alignment Drops in CuteDSL Partition: A user noticed that tensor alignment is being dropped by
partition_Sin CuteDSL, specifically going fromalign<16>toalign<4>after partitioning, and provided a link to the full code.- Before partitioning, the tensor is
raw_ptr(0x00007f4a72604080: f32, gmem, align<16>) o (32,32):(64,1), but after, it becomes a series ofraw_ptrwithalign<4>.
- Before partitioning, the tensor is
- Beefy: BF16 Grouped GEMM Performance with CUTLASS: A user inquired whether it’s still suitable to use EVT ops provided by CUTLASS for epilogue fusion in BF16 grouped GEMM cases with a large token dimension, given register pressure limitations.
- The user notes that register pressure, especially at BF16 precision, limits the tile size to 256 and necessitates a cooperative scheduling strategy, potentially hindering the hiding/overlapping of epilogue overhead with the existing CUTLASS templates implementation.
- Complement Confusion in CuTeDSL Layout Algebra: A user is having trouble reproducing the Complement example from the CuTeDSL documentation, expecting
complement((2,2):(1,6), 24)to result in(3,2):(2,12)but instead getting an invalid resultx:x.- The provided code snippet uses
@cute.jitto define acomplementfunction that makes a layout, appliescute.complement, and prints both layouts, but the result differs from the documentation.
- The provided code snippet uses
- At Symbol Appears in CuTeDSL Strides: A user asked about the meaning of the
@symbol in CuTeDSL strides, specifically in a layout like(128,64,4):(1@1,1@0,64@0)that was printed while inspectingcute.local_tile.- The context involves inspecting layouts and understanding how
cute.local_tileaffects the strides, leading to the appearance of the@symbol in the printed layout representation.
- The context involves inspecting layouts and understanding how
GPU MODE ▷ #teenygrad (3 messages):
InterpretedTensor, CompiledTensor, tanh CPU kernel, Autograd, gemm hitting peak
- Tensor Transformation: InterpretedTensor Arrives!: The eager and graph modes are being split into
InterpretedTensorandCompiledTensorwith a promise to addressCompiledTensorusing tinygrad IR later, detailed in this commit.InterpretedTensornow has implementations for axpy and gemm, setting the stage for autograd and peak gemm performance.
- Tanh Triumphs: CPU Kernel Wired!: A tanh CPU kernel has been implemented and wired through to
InterpretedTensor.tanh(), as seen in this commit.- This enhancement also includes forward and backward passes for element-wise ops, tanh nonlinearity, and gemm.
- Gradient Gymnastics: Autodiff Closures Added!:
requires_gradis now propagated through ops, mirroring Torch’s behavior, thanks to changes in this commit.- Additionally, neg, sub, and tanh backward have been implemented with autodiff closures, further refining the autograd capabilities, as noted in this commit.
GPU MODE ▷ #nvidia-competition (27 messages🔥):
Performance Trends Feature, Zooming in performance trends, B200 GPU Submission Issues, CUTLASS errors on Modal
- Performance Trends Now Visible: A new “Performance Trends” feature has been added to the rankings page to visualize submission improvements over time, with screenshots provided from nvfp4_group_gemm as examples: example image.
- Performance Trends Graph now zoomable: Users can now zoom in on the Performance Trends graphs, adjusting both the x and y axes for better readability, particularly when submissions are old or scores vary widely: example image.
- B200 struggles with CUTLASS: One member reported CUTLASS errors during B200 GPU submissions, specifically a ModuleNotFoundError and DSLRuntimeError stemming from an old CUTLASS version, possibly due to differences between the NVIDIA server and B200 setup, as linked to this CUTLASS commit.
- Rolling Best Submissions Displayed: The performance trends graph now displays the best submissions as of each day from the current top 5 users, along with the fastest submission across all users in yellow, visualizing community optimization progress, as shown in this image.
{kind=link}
{kind=link}
{kind=link}
GPU MODE ▷ #robotics-vla (1 messages):
TRLC DK-1, VR teleop prototype, SO-101 arm
- Dual Arm TRLC DK-1 Arrives!: A member received their dual arm TRLC DK-1 last Thursday and created a VR teleop prototype as a first project.
- They shared a short timelapse of them operating the system from a different room.
- SO-101 Arm Enhances VR Teleop: A stereo cam was mounted on an additional SO-101 arm to control pan, tilt, and roll in the VR teleop prototype.
- The idea is to remotely take over when a policy gets stuck, enabling human intervention.
GPU MODE ▷ #career-advice (6 messages):
CUDA, Triton, GPU kernel interviews, Optimization Strategies
- Triton vs CUDA for Kernel Interviews Debated: A member is preparing for GPU kernel interviews and is debating whether to use CUDA or Triton, leaning towards Triton for its simplicity and speed in writing kernels during a timed interview.
- They recognize that CUDA allows for demonstrating deeper knowledge of GPU architecture and optimization techniques but worry about time constraints.
- Optimize Triton Kernels with CUDA?: A member suggested using Triton initially to outline the idea, then specializing with CUDA for specific block optimizations, while considering why Triton might not optimize certain aspects.
- Another member inquired about overwriting parts of a Triton algorithm with CUDA C++.
- CUDA Optimization Strategies: A member advised against directly overwriting Triton code with CUDA unless writing a compiler or going to extremes to hook the IR.
- Instead, they suggested scoping out regions for potential optimizations during the interview process, showing a diagram as an example.
- Explore Triton Hooking Codebase: For those interested in hooking into Triton, the member recommended the facebookexperimental/tritonUnderstood codebase.
- This suggests a deeper dive into understanding how Triton works internally and how it can be modified or extended.
GPU MODE ▷ #flashinfer (39 messages🔥):
GPU Architecture Detection on RTX 4090, Team Member Addition to Registration Form, Fused MoE Numerical Precision Clarification, NCU Profiling on Modal B200, Modal GPU Credits
- Fix GPU Architecture Detection on RTX 4090: A user reported that their RTX 4090 does not register gpu_architecture: Ada Locelace, only working with Blackwell and asked how to fix this.
- A user suggested trying with the Modal platform, which has Blackwell GPU support.
- Clarify Precision expectations for Fused MoE: A user inquired about the expected numerical precision for intermediate values in Fused MoE, questioning whether to match the reference implementation’s FP32 or use lower-precision formats like bfloat16 or FP8.
- One of the organizers responded that the reference uses FP32 for accuracy as a comparison basis, but it’s acceptable to use FP8 in intermediate values for FP8 kernels, provided the results don’t deviate excessively from the baseline.
- Modal B200 supports CUDA 12.8: A user asked whether Modal supports CUDA 12.8.
- An organizer confirmed that Modal supports it, according to the docs.
- AccelOpt Claims Speedups on FlashInfer-Bench: The AccelOpt team announced they achieved 1.5x speedup on GQA paged decode and 1.38x speedup on GQA paged prefill versus FlashInfer 0.5.3 using their self-improving LLM agentic system for kernel optimization.
- The team provided a link to their code and encouraged others to test it on their kernels.
- Understanding binding.py for CUDA kernels: A user inquired about the purpose of modal/flashinfer-bench-starter-kit/binding.py and whether PYBIND11_MODULE is sufficient for CUDA kernels.
- A member explained it’s for TVM FFI binding, as discussed in this GPU MODE talk, which allows shipping kernels to different runtimes and compiles faster than Torch, though Torch bindings can still be used.
Moonshot AI (Kimi K-2) ▷ #general-chat (206 messages🔥🔥):
Kimi Scam Sites, Kimi Code CLI issues, Kimi subscription issues, Kimi AI's limitations, Kimi Pricing Issues
- Kimi Users Beware Scam Sites: Users reported that several scam sites are impersonating Kimi, and using the name to try to spread malware.
- One user noted that kimi.com was the third search result on Google. Another user was warned against downloading unknown software.
- Kimi Code CLI Extension Troubles: Users encountered issues with the Kimi Code CLI extension in VSCode, receiving a CLI Not Found message despite following the installation guide.
- The problem was solved by installing the Kimi CLI separately using PowerShell:
irm https://code.kimi.com/install.ps1 | iex
- The problem was solved by installing the Kimi CLI separately using PowerShell:
- Kimi Subscription Billing Debacles: Users reported issues with Kimi subscriptions, including being billed multiple times and subscriptions not activating correctly and quota problems.
- One user had to make a bug report for a disappeared subscription, others said that support might be slow to answer due to the Spring festival in China.
- Kimi Faces Limits on Video, Text, and Honesty: Kimi cannot detect audio from video files and sometimes refuses to process content (e.g. YouTube transcripts) deeming it unsafe.
- Members found that Kimi sometimes “lies till it is caught”, by giving conflicting or false information, akin to other AI models.
- Kimi Pricing Gets Customer Ire: Users voiced concerns over Kimi’s pricing being too high relative to its value and usage limits, especially compared to alternatives like MiniMax.
- Some users said the pricing is not sustainable outside of major cities due to cost of living differences, while others defended the cost, given the API is open source and can be used with other providers.
Nous Research AI ▷ #general (184 messages🔥🔥):
Claude Code, China OS Going Closed, Meta's Llama Trained on Qwen, 4o Obsession, ByteDance Seedance 2.0
- Claude Code has output problems: A user reported that Claude Code might be tapping out with only two prompts in a session, one being just ‘continue’.
- It was suggested that the issue might be due to an outdated installation or a misconfiguration limiting the output token limit to 32K.
- China OS Going Closed?: Discussion revolved around whether Chinese OS models are becoming less open, with monetization strategies shifting towards cloud hosting.
- Despite concerns, the consensus leaned towards China OS models remaining open to encourage global adoption and customization, especially for U.S. startups.
- Meta’s Llama Trained on Qwen: It was reported that Meta’s next AI model, potentially not named Llama, will be trained on Qwen, with Zuckerberg allegedly admitting to it as seen in this image.
- The shift towards post post training was highlighted as the new play to Artificial Superintelligence (ASI).
- Everyone’s Obsessed With 4o: It was suggested that anyone who’s obsessed with 4o has a mental illness, as seen in this meme.
- There are some pretty fat 4o chat datasets to train on at least, courtesy of sharegpt 2.0.
- ByteDance Seedance 2.0 Scares People: ByteDance Seedance 2.0 generates scary good AI slop, questioning the value of professional creative and technical careers.
- A link to a post was shared showing the impressive, yet concerning, output of the model.
Nous Research AI ▷ #ask-about-llms (4 messages):
Gemini CLI 'Conductor' Extension, Codex Skills, Kimi K2.5 Local Setup
- Gemini CLI Gets ‘Conductor’ Extension: The new ‘Conductor’ extension in Gemini CLI breaks projects into ‘tracks’, sending all that info to the LLM with each request, effectively loading it into the context window.
- Although this allows for persistent context, models like Gemini still drift from desired outcomes even with ‘conductor’ tracks.
- Codex Skills Token Usage: The Codex system was reportedly stuffing 15K-30K tokens into every request via its ‘skills’.
- One user mentioned 50K tokens as a sweet spot, suggesting Hermes 4 can handle large system prompts without being overwhelmed.
- Kimi K2.5 Local Setup Requirements: A user inquired about the minimum setup to run a model like Kimi K2.5 locally, aiming for multiple OpenClaw workflows.
- It was suggested that 700+ GB of RAM might be necessary for such a setup.
Nous Research AI ▷ #research-papers (1 messages):
real.azure: https://arxiv.org/abs/2602.03839
Nous Research AI ▷ #interesting-links (6 messages):
CharonProtocol, Zero-copy, Zig Language
- CharonProtocol boasts Zero-Copy Advantages: A member shared a GitHub repo for CharonProtocol, suggesting it as a zero-copy alternative to bypass Python constraints.
- The author claimed that with LLMs there is no reason to struggle with non-memory opitimized code, and that their README offers comparisons against Zig.
- Zig vs. Python: A user mentioned their use of Zig to overcome Python’s memory optimization issues in LLM development.
- The conversation points out that zero-copy is a way to avoid the Python constraints.
Nous Research AI ▷ #research-papers (1 messages):
real.azure: https://arxiv.org/abs/2602.03839
HuggingFace ▷ #general (137 messages🔥🔥):
Cosmos Reason 2 with Transformers, HF Pro Subscription for Posts, Revolutionary AI Architecture Ideas, DeepSpeed and Large Model Finetuning Issues, Subjective Entity Architecture Proposal
- Transformers and Inference on Jetson Thor: A member sought resources on using Transformers for inference with Cosmos Reason 2 on a Jetson Thor device, specifically for local execution.
- No specific resources were provided in the discussion.
- Revolutionary Ideas on AI Architecture?: A user expressed frustration at the lack of interest in their revolutionary ideas about AI architecture, deciding to institute them independently.
- A member inquired about the type of ideas the user had, encouraging them to execute them rather than overthink.
- DeepSpeed struggles with Qwen3 for finetuning: A member encountered issues finetuning the Qwen3-30B-A3B-Thinking-2507 model using DeepSpeed on 8 RTX 4090s, facing CPU memory limitations during model loading.
- It was found that transformer version 5.1.0 caused issues with DeepSpeed, with ongoing fixes at transformers/pull/43524 and transformers/issues/43596.
- Lucidrains Vanishes!: Members noticed that Lucidrains vanished from GitHub.
- It was revealed that GitHub suspended the account without warning, with a link to their new profile at codeberg.org/lucidrains shared for those who need it.
- Qwen3.5 released!: Members noticed that Qwen3.5 is out now and can be run locally.
- It was originally announced on X.com/UnslothAI
HuggingFace ▷ #i-made-this (31 messages🔥):
ATIC epistemic uncertainty system, LLM-based password auditing tool, Rune: composable ASCII art animations, Jazz AI terminal agent, CoDA-GQA-L attention mechanism
- ATIC pinpoints AI uncertainty: ATIC, an epistemic uncertainty system, launched with a tri-brain architecture using 3 independent Claude Opus 4.5 instances to detect when AI is guessing, atic.consulting.
- By scoring Q1 (random uncertainty) and Q2 (knowledge gaps), it aims to defer queries to specialists when uncertainty is high, with documentation available at this link.
- Password auditor uses LLMs: An LLM-based password auditing tool, PassLLM, uses personally identifiable information to generate a probability-sorted list of likely passwords, fine-tuned on millions of real-life password pairs, PassLLM on GitHub.
- The Qwen 3 4B LoRA model outperforms many other tools in accuracy, understanding intricate details of human password generation, as showcased in a demo video.
- Rune lets you make ASCII art: A member introduced Rune, an open-source React component library and CLI for creating composable ASCII art animations, available at Rune on Github.
- It allows users to create custom animations, as demonstrated in this video.
- Jazz-ing up the terminal: Jazz is presented as an AI agent living in your terminal, functioning as an assistant that reads files, manages Git, searches the web, handles email, and runs shell commands, Jazz on Github.
- LLM provider agnostic, Jazz supports scheduled workflows and connects to anything through MCP, even reviewing PRs and writing its own release notes in CI.
- Constant KV cache attention mechanism: A new attention mechanism, CoDA-GQA-L, was released for language models that maintains a constant KV cache size regardless of context length, offering significant VRAM savings, according to the blog post.
HuggingFace ▷ #core-announcements (1 messages):
Custom CUDA kernel, LTX model, H100 benchmark
- Agent Writes Custom CUDA Kernel for LTX!: An agent wrote a custom CUDA kernel for the LTX model on H100 to beat a baseline benchmark.
- Check out the blog post for all the details.
- H100 Crushes Benchmark with Custom Kernel: A custom CUDA kernel, crafted by an agent, enabled the LTX model to outperform a baseline benchmark on the H100.
- The results are detailed in a Hugging Face blog post, showcasing the performance gains.
HuggingFace ▷ #agents-course (9 messages🔥):
Course Feedback, Course Navigation, Discord Channels, Documentation Updates
- Course Layout Lacks Organization: A member questioned where to start, noting that they really need to organize the layout of the learn page better.
- It’s unclear for new members where the best place to begin the course is.
- Discord Channel Confusion Erupts: A member reported being unable to find the agents-course-questions and agents-course-announcements Discord channels.
- Another member responded that there is only a courses channel now and that the tutorial document has not been updated to reflect this change.
- Docs Need Agents Badly: A member joked that if only we had an agent to keep documentation up to date…, referring to the out-of-date tutorial documents.
- Another member welcomed them to create a PR to the course’s repo that is updating this info, calling it a Good first issue.
Modular (Mojo 🔥) ▷ #general (8 messages🔥):
Mojo changelog videos, Mojo version 26.2, Codex fixes, Intel GPU support
- Automated Changelog Analysis into Videos Debuts: A member automated the analysis of the Mojo changelog and started turning it into short videos to make it easier and faster to absorb the updates, sharing a YouTube link and requesting feedback.
- Mojo version 26.2 Delayed, Title Fixed: A member pointed out that version 26.2 is not yet released.
- The video creator acknowledged the mistake, stating they saw it the day before and fixed the title, promising proper versioning in the next video summary.
- Codex Addresses Parity Gaps: After 75 hours of work on LLMs, Codex has fixed most parity gaps, bringing the project closer to a shippable state.
- Intel GPU Support Plans Unclear: A member asked about plans for Intel GPU support, particularly for Panther Lake devices.
- Another member responded that there aren’t any announced plans, but Intel is up-streaming SYCL to LLVM, which should make community efforts easier once the Mojo compiler goes open source.
Modular (Mojo 🔥) ▷ #mojo (83 messages🔥🔥):
Python Mojo Module Export Boilerplate, Span and Writable Trait, List slicing in Mojo, ECS game engine in Mojo, MLIR dialect for ECS
- Python Mojo Module needs Decorator Love: Members discussed the boilerplate currently needed to export a Python Mojo module, and a user suggested a simpler decorator syntax like
@pyexportto reduce verbosity.- Another member responded that such a feature is in the roadmap.
- Span Should Span ‘Writable’ Implementations: Users on Discord discovered that
Spanshould implement theWritabletrait, raising an issue thatlst[:2]results in aSpanwhilelst[:2:2]returnsSelf.- This inconsistency breaks value semantics, as modifying a slice’s size isn’t reflected in the span; the issue is tracked on GitHub for resolution.
- List Slicing causes Semantic Stridency: A user pointed out how
lst[:2]returns aSpanwhilelst[:2:2]returns a newListwhich can lead to unexpected behavior when one expects value semantics.- Copying lists every time you do a slice is generally a really bad thing from a performance standpoint, so it’s the second one. A discussion was initiated on the Modular forum to further discuss this inconsistency.
- Bevy Game Engine gets Mojo Port Pondering: Members expressed interest in developing a game engine in Mojo similar to Bevy in Rust, with one member offering to help and pointing out an existing ECS library called Larecs.
- The ECS is still actively developed. See Larecs on github.
- ECS: Elixir Compiler Sees MLIR Dialect Dreams: Discord users discussed the potential of using MLIR dialects to implement an ECS (Entity Component System), envisioning a compiler that optimizes data layout and system fusion based on component and system definitions.
- A user shared their decade-old attempt at an ECS language, noting they didn’t fully grasp the potential of system fusion back then, then noted that ECS-Lang was more code gen based for a specific language / ECS framework.
Eleuther ▷ #announcements (1 messages):
CommonLID, Language Identification Benchmark, Multilingual Data Quality, Community Spotlight Talk
- CommonLID debuts for Language Identification: The release of CommonLID, a language identification benchmark for the web covering 109 languages, was announced after almost two years of work by Common Crawl, EleutherAI, MLCommons, and JHU, with the arXiv paper available at arxiv.org.
- LangID Performance Overestimated by Current Benchmarks: Evaluations show top existing models have less than 80% F1 score, even when limiting to languages the models explicitly support, suggesting current benchmarks overestimate LangID performance on web data.
- CommonLID also proved to be the most challenging dataset in the evaluation of existing LangID systems.
- Community invited to CommonLID spotlight: A Community Spotlight Talk is scheduled, and the dataset is available on Hugging Face.
- Common Crawl and EleutherAI seek reposts!: The community is encouraged to repost the announcement on Common Crawl’s Twitter and EleutherAI Twitter, or on Common Crawl’s Bluesky and EleutherAI Bluesky.
Eleuther ▷ #general (24 messages🔥):
Discord Bot for AI News, EleutherAI GPT-3 Model, AI Behavior Structuring, Assistant Axis Drift, Open Source Research Contribution
- Discord Bot Debated for AI News Feed: A member inquired about the possibility of creating a Discord bot for curating a feed of AI safety news and papers and raised concerns about the legality of web scraping, as well as the possibility of being banned from discord.
- Others pointed out the existence of news.smol.ai as an existing effort, while acknowledging the risks associated with scraping.
- EleutherAI’s GPT-3 Model Rumors Debunked: A new member inquired about EleutherAI releasing a GPT-3 style model, citing information found on the website.
- A member clarified that the information was outdated and referred to GPT-J and GPT-NeoX, which were released a few years ago, linking to the EleutherAI website as an example of up-to-date info.
- Multi-Layered AI Governance Approach Explored: A member is experimenting with structuring AI behavior using layered rules, checks, and modular tools to maintain consistency and avoid drifting off-track.
- They are seeking advice on keeping outputs deterministic, managing conflicting guidance, and avoiding bottlenecks in this multi-layered system.
- Assistant Axis Drift Confirmed in Long Chats: A member shared a paper on extracting activation directions for different personas, highlighting the existence of an “Assistant Axis” that tracks how much the model is in its default assistant mode, and how activations can drift away in longer chats.
- Another member noted that the measurable “Assistant Axis” and its drift in long chats confirms that behavioral drift is structural, not anecdotal.
- Researchers Seek Open Source Project to Contribute: A member is looking for an open-source project that they can contribute to, having found lm-evaluation-harness very useful in their private project.
- No specific project suggestions were given in the context.
Eleuther ▷ #research (8 messages🔥):
Weight Homology, Independence Tests for Language Models, Blackbox Model Provenance, Llama Architecture Models, Causal Attention Matrix Approximation
- Weight Homology Paper Draws Attention: Members discussed the paper Matrix-Driven Identification and Reconstruction of LLM Weight Homology and its relevance to identifying connections between LLM weights.
- A member expressed they have been quite impressed by Independence Tests for Language Models and the black-box follow-up Blackbox Model Provenance via Palimpsestic Membership Inference.
- Recovering Finetuning Trees: A member noted that one thing that feels missing from the weight homology paper is analysis of situations with more confounders.
- They found most impressive from Independence Tests was that they took these Llama-architecture models and correctly recovered the finetuning tree.
- Causal Attention Matrix Approximation: A member shared an image analyzing the precondition attention matrix and its efficient computation in the causal case, questioning potential approximations using Tensor Cores (TCs).
- They linked to a related tweet: https://x.com/dvsaisurya/status/2023118579755819459.
{kind=link}
Eleuther ▷ #interpretability-general (15 messages🔥):
Steering Vectors, Data Augmentation, Lambda Calculus Models, Representation Learning
- Steering Vectors for Preventative Measures: Generalizing Anthropic’s persona vectors, preventative steering involves adding a steering vector while judging the model based on hitting the original target, forcing it to compensate against the steering vector.
- By changing the target, models can do more than just fight against a steering vector, making targeted features a good fit, and enabling targeted narrow use cases, and compositions of perturbations that might be rare in empirical datasets.
- Lambda Calculus Model rises from the dead!: A member is working on a model using only lambda calculus to derive backpropagation, demonstrating that the blackbox is lambda essentially, performing well on MNIST and CIFAR.
- The model, implemented in Python without SimPy or TensorFlow, uses a perceptron based on diagonalization and refutation, but the developer cannot continue the project due to other commitments and also sharing this video.
- Training Models via Representation Mapping: A member proposed that instead of mapping inputs to outputs, models should be trained to map from representations to representations, facilitating data augmentation in representation space.
- This approach would allow precomputing the first part of the forward pass and then adding multiple steering vectors aimed at different targets, reusing the same initial computation.
Eleuther ▷ #gpt-neox-dev (2 messages):
Qwen3 architecture, GPT-NeoX
- Qwen3 implementation in GPT-NeoX surfaces: A member shared a somewhat tested implementation of Qwen3 architecture in GPT-NeoX.
- Another member thanked them for sharing.
- GPT-NeoX gets new Qwen3 Architecture: A new implementation of the Qwen3 architecture has been made available in GPT-NeoX, as shared by a member on the EleutherAI Discord server.
- The provided implementation is currently in a testing phase, awaiting community feedback and further refinement.
MCP Contributors (Official) ▷ #general (40 messages🔥):
Token cost of output schemas, Benefits of structured output, Tool-chaining with structured outputs, Tool result types, Timezone context for MCP servers
- Debating Token Cost of Output Schemas: Members are discussing if the token cost of output schemas is a false economy, as it adds cost even when the MCP is installed but not used.
- One member pointed out that most LLM APIs don’t support output schemas, so the SDK or client host has to lift the output schema into the description, adding to the token tax.
- Evaluating Benefits of Structured Output: The group debated whether many clients/models get value from structured outputs in practice, with agreement on clear advantages in code mode but less certainty elsewhere.
- One member noted the Windsurf team turned off structured output at one point due to worse results compared to competitors, suggesting adoption is a double-edged sword.
- Structured Outputs Key to Tool-Chaining: A member argued that not having output schemas available means LLMs have much more trouble doing tool-chaining, often hallucinating output fields.
- They also explored the challenge of speculatively executing a tool to dynamically construct an output schema, deeming it unsafe without specific conditions.
- Revisiting Tool Result Types Debate: A discussion arose around tool result types, with a member suggesting a preference for tool results to be explicitly declared as text, image, or object.
- The sentiment suggests structured results should be considered a different result type, with supplementary information going into meta instead of the object.
- Handling Timezone Context for MCP Servers: The group discussed recommended best practices for MCP servers requiring context of a user’s timezone for prompts like “How did I sleep last week?”
- It was mentioned that the user’s timezone should be added to the tool parameters, and it’s generally incorrect to push client context directly into the MCP server outside of tool parameters, as it mixes domains.
Yannick Kilcher ▷ #general (27 messages🔥):
Chess strategies, Deepseek models, Heretic game, GPT-OSS-120B models, LLM Hallucinations
- Chess Player Advised on Positional Advantage: A player was advised to focus on improving their setup and piece synergy in chess, given their control of the center and a pawn on e5.
- The suggestion was to move the knight on b1 to d2, then to b3 and c5, potentially forking the queen and bishop.
- Deepseek Model MIA No More: Following a player’s statement, It’s over (for chess), another user inquired about the status of a Deepseek model.
- Another member replied that it will arrive soon(R).
- Heretic Game Liberated to Citizens: A member highlighted the Heretic game (GitHub link), noting its accessibility to consumers and citizens.
- They expressed enthusiasm, stating, When I grow up I want to be just like <@693263324036464742>.
- GPT-OSS-120B Models and Local Models: A user asked if there are de-censored gpt-oss-120b models on HF.
- Another user responded affirmatively and pointed to an open-source version (jupyter-mcp-server).
- LLM Citation Hallucinations Plague Papers: A member shared concern about the level of hallucinations in AI/ML papers, referencing GPTZero.
- They questioned whether citations were completely false or if they contained slight inaccuracies like incorrect dates or authors, and shared concerns of seeing so many papers hallucinating citations.
Yannick Kilcher ▷ #agents (2 messages):
text/markdown Accept Header, Multi-Agent RPG Testbed
- Agents Embrace Markdown: Cloudflare explores supporting the
Accept: text/markdownheader for agents.- This would allow agents to receive content in Markdown format, potentially simplifying content processing and improving interoperability.
- Friendly Fire Incident in AI Ethics Testbed: A member shares a write-up on a friendly fire incident within a multi-agent system ethics testbed implemented as a self-playing RPG.
- The incident exposes architectural considerations and reveals biases, relating to AI governance in realistic, mechanically grounded situations.
Yannick Kilcher ▷ #ml-news (4 messages):
OpenClaw Security, Qwen 3.5
- OpenClaw’s Security Questioned: A member expressed hope that a certain entity manages security more sensibly than OpenClaw does.
- They linked to a status on fixvx.com (CharlieBCurran’s status).
- Alibaba Launches Qwen 3.5: Alibaba launched Qwen 3.5, as announced in a post on X.
- Additional details can be found in the Qwen 3.5 blog post.
tinygrad (George Hotz) ▷ #general (32 messages🔥):
GLM flash PR, Graphcore C600 IPU, Tinygrad CPU pipeline, tinybox GPU issues
- GLM Flash PR Sparks Debate: A GLM flash PR submitted by roef led to criticism for exceeding expected line count.
- George Hotz commented on the PR, stating that it should be 50 lines max and contained extra unrelated things.
- Graphcore IPU Found Hilariously Unusable: George Hotz tested a Graphcore C600 IPU and reported only achieving 20% MFU due to compiler issues with larger batch sizes.
- Despite the software stack being open-source, it was described as accursed C++ slop, and the on-chip comms fabric documentation is not open-source.
- Tinygrad’s CPU Pipeline Enhancements Sought: A contributor, xavi251, inquired about smaller tasks related to the CPU pipeline after working on an old bounty.
- George Hotz challenged the contributor to make things both faster and have less code.
- Tinybox faces GPU Recognition Issues: A user reported issues with their tinybox only recognizing 2 of 4 GPUs despite being plugged into two different circuits.
- George Hotz suggested checking for unplugged wires, pointing to channel
#1113504076035018862.
- George Hotz suggested checking for unplugged wires, pointing to channel
Manus.im Discord ▷ #general (31 messages🔥):
Account Suspensions, Payment System Issues, Manus AI Agent Praise, How to Open a Ticket, Self-Promotion Removal
- Manus AI Agent Praised for Game-Changing Help: A user expressed immense gratitude for the Manus AI Agent, stating it helped them extract something they couldn’t on their own and calling it a game changer.
- They were literally crying this morning because of the assistance they received.
- Accounts Suspended for No Reason: Several users are reporting their accounts are being suspended for no apparent reason, with one user claiming suspensions occur shortly after creating character abilities.
- The user pleaded for the suspensions to stop so they can use the website like a normal person.
- No Ticket System: Manus Support Details: A user inquired about opening a ticket, and a response clarified that no ticket system is in place on the server.
- Users are directed to the help center or to email feedback for assistance, with a note that response times may be slower due to New Year celebrations.
- Account Issue DM Request: One user asked for admins to DM them urgently regarding an important account problem.
- Another user with Manus in their name also offered help via DM for account issues.
- Self-Promotion Post Removed: A self-promotion post was removed for violating server rules against unsolicited advertising and recruitment.
- Members are reminded to keep discussions on-topic and relevant to the channel’s purpose.
DSPy ▷ #show-and-tell (9 messages🔥):
RLM accuracy, custom REPLs, PostgreSQL for multi-agent communication
- RLM Accuracy Impacted by Language and REPL: Experiments reveal how language and REPL impact RLM accuracy, as detailed in a post.
- The discussion considers the need for custom REPLs for each language used by RLM subagents, exploring alternatives like tool-calling + skills or bash + files for broader utility.
- PostgreSQL Enables Multi-Agent Communication: A member is experimenting with PostgreSQL for multi-agent communication to bypass REPL access limitations.
- It was noted that REPL quality and instructions are key, but an LLM’s language preference should guide language choice.
- dspy-repl: The experiment discussed about language and REPL impact to RLM accuracy is published to GitHub.
DSPy ▷ #papers (5 messages):
Arxiv Paper, Autohand
- Arxiv Paper seen as tweet thread: A member did a skim read of an arxiv paper and felt this paper can be a blog or a tweet thread, to get more traction.
- Autohand product may change instruction: A member wondered whether Autohand’s Evolve product could be used for some other training to change its instruction to play games.
- Another member replied that the product was so underrated but poorly presented, and that they played enough games.
DSPy ▷ #general (9 messages🔥):
Vibecoding with Claude, DSPy Team Official Projects, Crowdcent Wrapping DSPy
- Modaic Devs Vibe with Claude: A member thanked another for pointing out vibecoding with Claude, noting it really makes a difference, with Modaic.
- Other members said they are looking into this.
- DSPy Team’s Open Ethos: A member wished that the DSPy team did a particular project officially.
- Another member responded that seems against their ethos and welcomes projects that require skilled developers.
- Crowdcent wraps up DSPy: A member mentions Crowdcent is wrapping DSPy.
- They included it in their documentation and asked if anyone has the MCP.
DSPy ▷ #examples (1 messages):
Lunar New Year, bb25 v0.2.0 Release, Bayesian BM25, Python + Rust implementation, DSpy Project Porting
- bb25 v0.2.0 Launched with Upgrades: The new bb25 v0.2.0 is out, which includes a Python + Rust implementation of Bayesian BM25 that turns search scores into calibrated probabilities.
- The release ports four improvements from Jaepil Jeong’s reference implementation after a detailed code review of both projects, including fixed document length prior, log-odds conjunction, automatic sigmoid parameter estimation, and online learning with five stabilization techniques.
- Call for bb25 Porting to DSpy: A member asked if anyone is interested in porting bb25 to the DSpy project.
- It is uncertain whether any member has volunteered to do this task.
aider (Paul Gauthier) ▷ #general (6 messages):
Neovim integration, Aider score benchmark, Copy/paste semantics
- Aider scores high!: A member indicated the Aider score benchmark felt very similar to the level of intelligence I person.
- Neovim Integration with Aider Pops Up: A member is working on a neovim integration with aider to better integrate copy/paste semantics with tmux, aider, and the terminal.
- Dogfooding a code-centric philosophy: The developer notes an implied theory about embracing and extending aider’s philosophy of having an agent that is code-centric rather than chat-centric.
aider (Paul Gauthier) ▷ #questions-and-tips (4 messages):
Pro Bono Techies, Ask-Code Iteration Loop
- In Need of Pro Bono Techies: A member asked for pro bono techies willing to help someone who lost everything due to some extremely talented “hackers”.
- Another member commented that this is “prob wrong server for that”.
- Ask-Code Iteration Loop: Still the Best Practice?: A member is wondering if ask-code iteration loop is still the “best practice” or has the community moved on to other workflows with aider.