First teased via paper 2 months ago, Nightshade was the talk of the town this weekend:
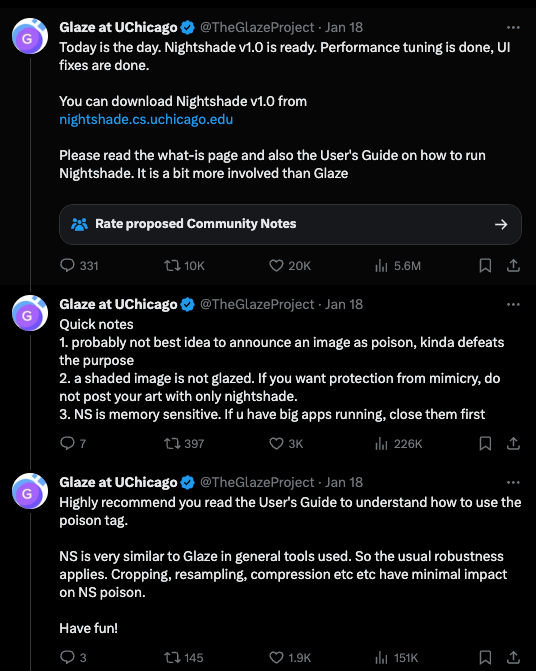
However people digging in the details have questioned how it works and the originality:
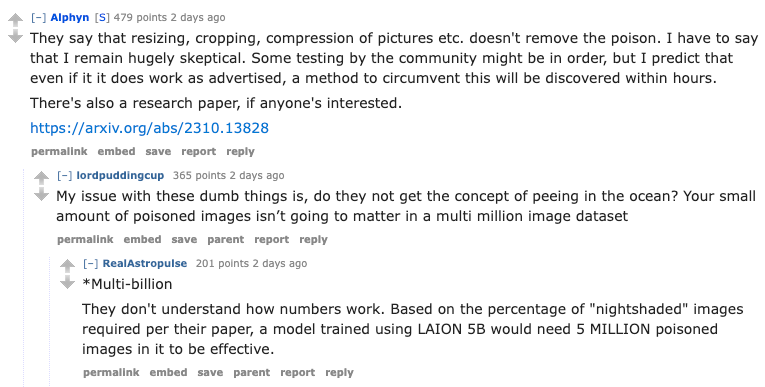
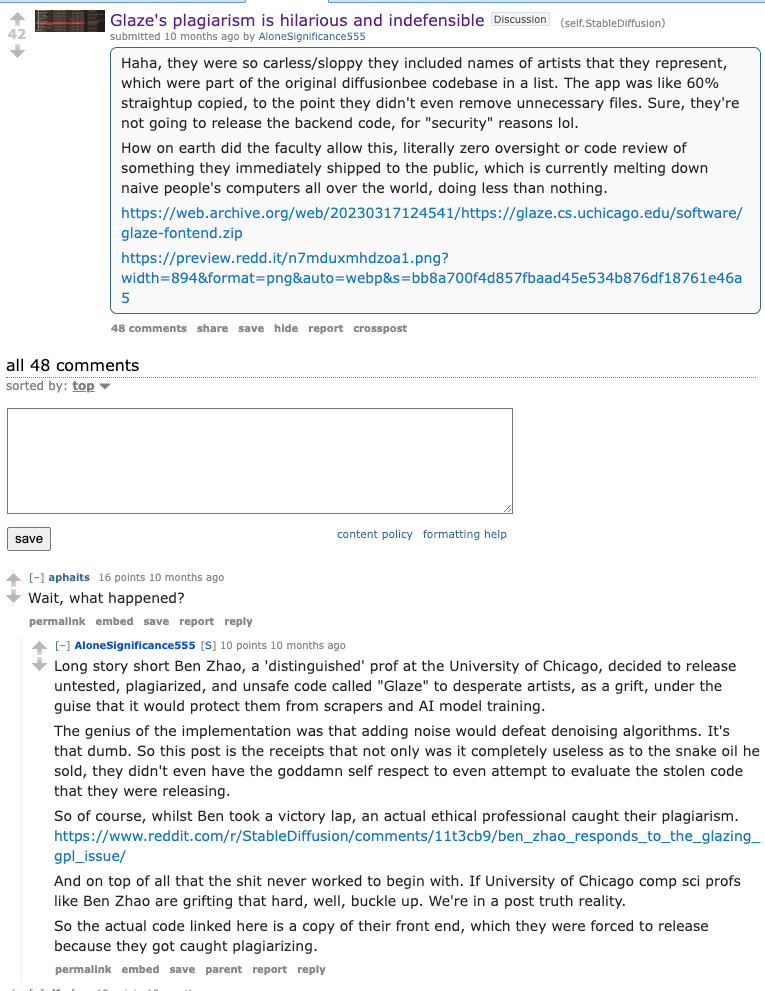
—
Table of Contents
[TOC]
TheBloke Discord Summary
-
MoE Efficiency and Detection Tools Talk: In discussions around Mixture of Experts (MoE) models, efficiency in GPU parallelism, and quant methods were key topics, with users exploring variable routing and trade-offs between expert counts. Also, GPTZero’s ability to detect certain types of AI-generated content was analyzed, suggesting noise application as a potential evasion method.
-
Challenges in Role-Playing AI: Debates emerged over Solar’s effectiveness, with some users pointing out its poor alignment despite benchmark efficiency. Model performance in long-context roleplaying was discussed, with opinions split on the best models for tasks and the potential for emergent repetition issues that can cause loss of novelty in output.
-
Fine-Tuning and Quantization Strategies in Depth: Users exchanged experiences with fine-tuning language models such as Mistral 7B, with some choosing few-shot learning over fine-tuning due to limited data. The concept of community-powered quantization services was pitched, and the need for simpler quantization methods was underscored, arguing for a focus on model improvement rather than complex distributed computing for quantization.
-
Confusion and Community Exchanges in Model Merging: An exchange on model merging strategies revealed confusion over non-standard mixing ratios with Mistral-based models. Different blending techniques like task arithmetic and gradient slerp were suggested, cautioning against blind copying of values.
-
Community Interest in Quantization and Model Training: Users expressed a desire for an easy community-driven quantization service, paralleling familiar processes like video transcoding. In model training, the feasibility of training on a 50GB corpus dealing with religious texts was queried, showing interest from newcomers in leveraging existing open-source models for specific domains.
TheBloke Channel Summaries
▷ #general (963 messages🔥🔥🔥):
-
Exploring MoE and LLMs: Users discussed the efficiency of using experts in mixture of experts (MoE) models and the implications it has on GPU parallelism.
@kalomazetalked about variable routing in MoE for parallelizing tasks and the trade-off between using more or fewer experts. -
The Complexity of Enhancing MoE Models: The nuances of enhancing MoE were dissected, with
@kalomazequestioning the benefit of layers becoming simpler.@seleaproposed using lots of experts as they could work as a library of “LoRas” to prevent catastrophic forgetting. -
Challenges with AI Detection Tools: Users debated the efficiency of the GPT detection tool,
GPTZero, with@kaltcitnoting that while common samplers can be detected byGPTZero, applying noise seems to be a potential method to dodge detection. -
Adventures in Fine-Tuning:
@nigelt11discussed the hurdles of fine-tuningFalcon 7Bwith a dataset of 130 entries, considering switching to useMistralinstead and understanding the nuances between ‘standard’ and ‘instruct’ models for RAG-based custom instructions. -
The Ethical Ambiguity of AI Girlfriend Sites:
@rwitz_contemplated the ethics of AI girlfriend sites, exploring the idea and finally deciding to pivot to a more useful application of AI technology beyond exploiting loneliness.
Links mentioned:
- Can Ai Code Results - a Hugging Face Space by mike-ravkine: no description found
- A Beginner’s Guide to Fine-Tuning Mistral 7B Instruct Model: Fine-Tuning for Code Generation Using a Single Google Colab Notebook
- Big Code Models Leaderboard - a Hugging Face Space by bigcode: no description found
- budecosystem/code-millenials-13b · Hugging Face: no description found
- First Token Cutoff LLM sampling - <antirez> : no description found
- How to mixtral: Updated 12/22 Have at least 20GB-ish VRAM / RAM total. The more VRAM the faster / better. Grab latest Kobold: https://github.com/kalomaze/koboldcpp/releases Grab the model Download one of the quants a…
- GitHub - iusztinpaul/hands-on-llms: 🦖 𝗟𝗲𝗮𝗿𝗻 about 𝗟𝗟𝗠𝘀, 𝗟𝗟𝗠𝗢𝗽𝘀, and 𝘃𝗲𝗰𝘁𝗼𝗿 𝗗𝗕𝘀 for free by designing, training, and deploying a real-time financial advisor LLM system ~ 𝘴𝘰𝘶𝘳𝘤𝘦 𝘤𝘰𝘥𝘦 + 𝘷𝘪𝘥𝘦𝘰 & 𝘳𝘦𝘢𝘥𝘪𝘯𝘨 𝘮𝘢𝘵𝘦𝘳𝘪𝘢𝘭𝘴: 🦖 𝗟𝗲𝗮𝗿𝗻 about 𝗟𝗟𝗠𝘀, 𝗟𝗟𝗠𝗢𝗽𝘀, and 𝘃𝗲𝗰𝘁𝗼𝗿 𝗗𝗕𝘀 for free by designing, training, and deploying a real-time financial advisor LLM system ~ 𝘴𝘰𝘶𝘳𝘤𝘦 𝘤𝘰𝘥𝘦 + 𝘷𝘪𝘥𝘦𝘰 &am…
- GitHub - turboderp/exllamav2: A fast inference library for running LLMs locally on modern consumer-class GPUs: A fast inference library for running LLMs locally on modern consumer-class GPUs - GitHub - turboderp/exllamav2: A fast inference library for running LLMs locally on modern consumer-class GPUs
- Noisy sampling HF implementation by kalomaze · Pull Request #5342 · oobabooga/text-generation-webui: A custom sampler that allows you to apply Gaussian noise to the original logit scores to encourage randomization of choices where many tokens are usable (and to hopefully avoid repetition / looping…
- GitHub - OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions: Go ahead and axolotl questions. Contribute to OpenAccess-AI-Collective/axolotl development by creating an account on GitHub.
- Add dynatemp (the entropy one) by awtrisk · Pull Request #263 · turboderp/exllamav2: Still some stuff to be checked, heavy wip.
▷ #characters-roleplay-stories (403 messages🔥🔥):
-
Solar’s Status as a Benchmark Chad:
@doctorshotgundescribed Solar as efficient in benchmarks but terrible in actual use, with problems like alignment issues akin to ChatGPT. However,@theyallchoppabledefended its utility in role-playing scenarios, citing its consistent performance. -
Model Comparison in Roleplay Quality:
@sanjiwatsukiand@animalmachinediscussed how models like Mixtral, 70B, Goliath, and SOLAR perform in roleplaying tests, with mixed opinions. New models and finetuning strategies, like Kunoichi-DPO-v2-7B, were suggested to potentially improve coherence and character card adherence. -
Long Context Handling: Users reported on models’ performance with long context lengths, noting that some like Mistral 7B Instruct lose coherence beyond certain limits. Subsequent discussions involved tips on efficiency and hardware requirements for running large-scale models.
-
Deep Dive into Quant Methods: There was a detailed discussion on quantization strategies, including sharing links to repositories for GGUF models.
@kquantprovided insights into the potential performance in ranking systems. -
Emergent Repetition Issues in MoE Models:
@kquantexpressed that multitudes of models working together tend to generalize and might become repetitive, likening it to a choir stuck on a chorus. A new model with a specialized design to combat repetition in creative scenarios is underway.
Links mentioned:
- Urban Dictionary: kink shame: To kink shame is to disrespect or devalue a person for his or her particular kink or fetish.
- LoneStriker/airoboros-l2-70b-3.1.2-5.50bpw-h6-exl2 · Hugging Face: no description found
- Kquant03/Umbra-MoE-4x10.7-GGUF · Hugging Face: no description found
- athirdpath/DPO_Pairs-Roleplay-Alpaca-NSFW-v1-SHUFFLED · Datasets at Hugging Face: no description found
- TheBloke/HamSter-0.1-GGUF · Hugging Face: no description found
- Reddit - Dive into anything: no description found
- Kooten/Kunoichi-DPO-v2-7B-8bpw-exl2 at main: no description found
- Undi95/Borealis-10.7b-DPO-GGUF · Hugging Face: no description found
- brittlewis12/Kunoichi-DPO-v2-7B-GGUF · Hugging Face: no description found
▷ #training-and-fine-tuning (12 messages🔥):
- Newbie Diving into LLMs:
@zos_kia, a self-proclaimed noob, is seeking advice on training a language model on a 50GB corpus of unstructured religious and esoteric texts. They are considering open-source models like trismegistus-mistral and inquiring about the feasibility of training on a home computer as well as the expected time frame. - Pinging For Insights:
@zos_kiaasks if it is okay to ping the creator of trismegistus-mistral in the Discord server for personalized advice on their training project. - Voicemail Detection Finetuning Inquiry:
@rabiatis looking for guidance on fine-tuning Mistral 7B or MoE to classify voicemail announcements and is curious about the required dataset size for efficient LoRA fine-tuning. They are considering using their 40 real voicemail examples as seeds to upsample. - Few-shot as an Alternative:
@gahdnahsuggests that@rabiatcould try few-shot learning as an alternative to fine-tuning for the voicemail classification task. - Quantized Models and Fine-tuning:
@sushibotshared a skeleton script showcasing the process of quantizing a model to 4-bit before attaching LoRA weights andqueried about the setup.@sanjiwatsukiconfirmed that this is indeed what “Q” in QLoRA implies, suggesting the fine-tuning of frozen weights in a quantized model. - Benchmark Blogpost Showcase:
@superking__shared a Hugging Face blog post that evaluates three language model alignment methods without reinforcement learning: Direct Preference Optimization (DPO), Identity Preference Optimisation (IPO), and Kahneman-Tversky Optimisation (KTO) across various models and hyperparameter settings.
Links mentioned:
Preference Tuning LLMs with Direct Preference Optimization Methods: no description found
▷ #model-merging (15 messages🔥):
- Blizado Explores Non-Standard Merging:
@blizadois looking to merge two Mistral-based models using a 75:25 ratio instead of the standard 50:50. They found that a 50:50 slerp merge was too biased towards one model. - Sao10k Suggests Merging Flexibility:
@sao10krecommended that@blizadotry different merge methods such as gradient slerp, task arithmetic, or DARE-TIES, emphasizing not to stick with default values. - Confusion Over Merging Parameters: Despite the suggestions,
@blizadoexpressed confusion over the merging parameters and their effects on the model’s language output. - Sao10k Clarifies on Merging Values: In response to issues faced by
@blizadoincluding a model switching between German and English,@sao10kadvised against copying values blindly and suggested a simple gradient slerp ranging from 0.2 to 0.7. - Blizado’s Troubles with Mixed Models: After trying a slerp parameter found on a Hugging Face model,
@blizadoreported difficulty seeing differences when merging two different base models and suggested a certain merge effectiveness when combining a solid language base model with one of high language understanding in the same language.
▷ #coding (8 messages🔥):
-
A Call for Simplified Model Quantization:
@spottyluckexpressed surprise at the lack of “uber bulk/queue based model quantization solutions,” considering their extensive experience in video transcoding. They suggest the potential for a community service that allows easy model quantization with an opt-out feature for shared computing power. -
Quantization Service: A Community Effort?: Following up,
@spottyluckfloated the idea of a community-powered distributed model quantization service where users could contribute to a communal compute resource while working on their own projects. -
Simplicity Over Complexity:
@wbschcountered by highlighting that most users prefer convenience and consistency, as provided by TheBloke, without the need for complex solutions like quantization farms or distributed compute services. -
Farming for Models Not Quants:
@kquantemphasized that community compute donations should be targeted at long-term research and model improvement, rather than the quantization process. -
Technical Inquiry on Checkpoint Changes in Stable Diffusion:
@varient2asked for assistance on how to programmatically change checkpoints in Stable Diffusion using the webuiapi, mentioning they have already figured out how to send prompts and use ADetailer for face adjustments mid-generation.
Nous Research AI Discord Summary
-
WSL1 Surprises with 13B Model:
_3spherefound that a 13B model can be successfully loaded on WSL1 despite an earlier segmentation fault with the llama.mia tool. -
ggml Hook’s 7b Model Limitation Unveiled: The ggml hook faced criticism for not being documented to work exclusively with 7b models, a discovery made by
_3sphere. -
SPINning Up LLM Training Conversations: The SPIN methodology was presented from a paper on arXiv by
_3sphere, discussing its potential in refining LLM capabilities through iteration. -
Single-GPU LLM Inference Made Possible:
nonameusrshared AirLLM, which enables 70B LLM inference on a single 4GB GPU as described in a Twitter post. -
Etched’s Custom Silicon Spurs Skepticism: A discussion included skepticism about the viability of Etched’s custom silicon for transformer inference, casting doubt on its practicality for LLMs.
-
Orion’s 14B Model Falls Short in Conversational Skills: Orion’s 14B model was reported by
tekniumand others to have subpar conversational output, contradictory to its benchmark scores. -
Proxy-Tuning Paper Sparks Interest: A new tuning approach for LLMs called proxy-tuning was discussed, which is detailed in a recently published paper.
-
Mixtral’s Multi-Expert Potential: Conversations around Mixtral models focused on the successful optimization of using multiple experts, leading to contemplation of its use with Hermes by
carsonpoole. -
Finetuning Fineries:
qnguyen3sought advice for fine-tuning Nous Mixtral models, andtekniumprovided insights, including that Nous Mixtral had undergone a complete finetune. -
Commercial Licensure Confusion: The commercial usage of finetuned models sparked a debate about licensing costs and permissions, initiated by
tekniumand engaged bycasper_aiand others. -
Designing Nous Icons: The Nous community embarked on designing legible role icons, with suggestions for a transparent “Nous Girl” and simpler logos from
benxhandjohn0galt. -
Omar from DSPy/ColBERT/Stanford Joins The Fray: The community welcomed Omar, expressing excitement for potential collaborations involving his contributions to semantic search and broader AI applications.
-
Alpaca’s Evaluation Method Questioned:
tekniumexpressed skepticism about Alpaca’s leaderboard, hinting at issues with its method after observing Yi Chat ranked above GPT-4. -
Imitation Learning’s Human Boundaries: A conversation led by
tekniumtackled the idea that imitation learning may not yield superhuman capacities due to reliance on average human data for training. -
AI’s Self-Critiquing Abilities Challenged: A discussed paper indicated AI’s lack of proficiency in self-evaluation, prompting
tekniumto question self-critiquing capabilities in models.
Nous Research AI Channel Summaries
▷ #off-topic (29 messages🔥):
- WSL1 Handles Big Models Just Fine:
@_3spherediscovered that using WSL1, a 13B model can be loaded without issues. They initially thought otherwise due to segmentation faults occurring with the llama.mia setup but later realized this was a tool-specific fault. - Model Compatibility Oversight:
@_3spherereported that the ggml hook, used for handling AI models, apparently only works with 7b models, suggesting that the creator of the ggml hook might only have tested it with this specific size. There was a hint of frustration as this limitation was not documented. - Hugging Face Leaderboard Policing:
@.ben.comshared a discussion about a recent change on the Hugging Face leaderboard where models incorrectly marked asmergeare being flagged unless metadata is properly adjusted. - Strange New Worlds in Klingon:
@tekniumshared a YouTube video featuring a scene with Klingon singing from “Strange New Worlds Season 2 Episode 9,” expressing dismay at the creative direction of the Star Trek franchise. - Star Trek Nostalgia Eclipsed by New Changes:
@tekniumdiscussed the change in direction for Star Trek with nostalgia, accompanied by a humorous gif implying disappointment, while@.benxhlamented the changes to the beloved series.
Links mentioned:
- mistralai/Mixtral-8x7B-v0.1 · Add MoE tag to Mixtral: no description found
- Gary Marcus Yann Lecun GIF - Gary Marcus Yann LeCun Lecun - Discover & Share GIFs: Click to view the GIF
- Klingon Singing: From Strange New Worlds Season 2 Episode 9.
- HuggingFaceH4/open_llm_leaderboard · Announcement: Flagging merged models with incorrect metadata: no description found
▷ #interesting-links (236 messages🔥🔥):
-
Exploration of Training Phases for LLMs: A discussion by
@_3sphereon when it’s effective to introduce code into the training process of LLMs led to sharing the SPIN methodology from a recent paper, which allows LLMs to refine capabilities by playing against their previous iterations. -
LLM Inference on Minimal Hardware:
@nonameusrshared information about AirLLM, an approach allowing 70B LLM inference on a single 4GB GPU by utilizing layer-wise inference without compression techniques. -
Chipsets Specialized for LLMs: There’s skepticism about the practicality and future-proof nature of Etched’s custom silicon for transformer inference, as mentioned by
@eas2535,@euclaise, and@0xsingletonly. -
Orion-14B-Model Under Scrutiny: Orion’s 14B model’s actual conversational competency is being questioned by
@.benxh,@teknium, and others, as its performance on benchmarks such as MMLU contrasts with initial user experiences that report nonsensical output and a tendency to lapse into random languages. -
Proxy-Tuning for LLMs: A linked paper discussed by
@intervitensand@sherlockzoozoointroduces proxy-tuning, which uses predictions from a smaller LM to guide the predictions of larger, potentially black-box LMs.
Links mentioned:
- Etched | The World’s First Transformer Supercomputer: Transformers etched into silicon. By burning the transformer architecture into our chips, we’re creating the world’s most powerful servers for transformer inference.
- Tweet from undefined: no description found
- Tweet from Rohan Paul (@rohanpaul_ai): 🧠 Run 70B LLM Inference on a Single 4GB GPU - with airllm and layered inference 🔥 layer-wise inference is essentially the “divide and conquer” approach 📌 And this is without using quantiz…
- Tuning Language Models by Proxy: Despite the general capabilities of large pretrained language models, they consistently benefit from further adaptation to better achieve desired behaviors. However, tuning these models has become inc…
- Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models: Harnessing the power of human-annotated data through Supervised Fine-Tuning (SFT) is pivotal for advancing Large Language Models (LLMs). In this paper, we delve into the prospect of growing a strong L…
- Looped Transformers are Better at Learning Learning Algorithms: Transformers have demonstrated effectiveness in in-context solving data-fitting problems from various (latent) models, as reported by Garg et al. However, the absence of an inherent iterative structur…
- At Which Training Stage Does Code Data Help LLMs Reasoning?: Large Language Models (LLMs) have exhibited remarkable reasoning capabilities and become the foundation of language technologies. Inspired by the great success of code data in training LLMs, we natura…
- Director of Platform: Cupertino, CA
- bartowski/internlm2-chat-20b-llama-exl2 at 6_5: no description found
- OrionStarAI/Orion-14B-Base · Hugging Face: no description found
- Tweet from anton (@abacaj): Let’s fking go. GPU poor technique you all are sleeping on, phi-2 extended to 8k (from 2k) w/just 2x3090s
- GitHub - b4rtaz/distributed-llama: Run LLMs on weak devices or make powerful devices even more powerful by distributing the workload and dividing the RAM usage.: Run LLMs on weak devices or make powerful devices even more powerful by distributing the workload and dividing the RAM usage. - GitHub - b4rtaz/distributed-llama: Run LLMs on weak devices or make p…
- GitHub - RVC-Boss/GPT-SoVITS: 1 min voice data can also be used to train a good TTS model! (few shot voice cloning): 1 min voice data can also be used to train a good TTS model! (few shot voice cloning) - GitHub - RVC-Boss/GPT-SoVITS: 1 min voice data can also be used to train a good TTS model! (few shot voice cl…
- Yuan2.0-2B-Janus-hf: no description found
▷ #general (524 messages🔥🔥🔥):
-
Fresh Perspectives on Mixtral Experts: Discussions around the use of multiple experts in Mixtral models center around optimization.
@carsonpoolehighlights a successful implementation with minimal sacrifices in speed when using a higher number of experts and contemplates trying Hermes with more than the typical two experts. -
A Quest for Quality Finetuning: There’s a shared curiosity about fine-tuning models with more than two experts.
@qnguyen3faces difficulties fine-tuning with Axolotl and seeks advice from veterans like@teknium, who clarified that the Nous Mixtral model had a full finetune and not just a LoRa fine-tune. -
Licensing Quandaries Regarding Commercial Use: A discussion sparked by
@tekniumabout the commercial use of finetuned models, like those from Stability AI, unveils confusion surrounding licensing costs and permissions. Different interpretations and potential issues with implementing commercial use are debated among users like@casper_ai. -
The Nous Aesthetic: The chat includes an initiative to design more legible Nous role icons. Various suggestions, such as making a transparent version of the “Nous Girl” graphic or creating a simpler logo, circulate, with members
@benxhand@john0galtcontributing design skills. -
Tech Community Shoutouts: Omar from DSPy/ColBERT/Stanford joins the server, greeted by members
@night_w0lfand@qnguyen3. Members express enthusiasm for integrating Omar’s work into their solutions and anticipation for a collaboration with DSPy in their projects.
Links mentioned:
- Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling: no description found
- Animated Art Gif GIF - Painting Art Masterpiece - Discover & Share GIFs: Click to view the GIF
- Combining Axes Preconditioners through Kronecker Approximation for…: Adaptive regularization based optimization methods such as full-matrix Adagrad which use gradient second-moment information hold significant potential for fast convergence in deep neural network…
- Joongcat GIF - Joongcat - Discover & Share GIFs: Click to view the GIF
- Nerd GIF - Nerd - Discover & Share GIFs: Click to view the GIF
- Browse Fonts - Google Fonts: Making the web more beautiful, fast, and open through great typography
- Domine - Google Fonts: From the very first steps in the design process ‘Domine’ was designed, tested and optimized for body text on the web. It shines at 14 and 16 px. And can even be
- 🔍 Semantic Search - Embedchain: no description found
- EleutherAI/pythia-12b · Hugging Face: no description found
- Reddit - Dive into anything: no description found
- Tweet from Teknium (e/λ) (@Teknium1): Okay, read the paper, have some notes, mostly concerns but there’s some promise. - As I said when I first saw the paper, they only tested on Alpaca Eval, which, I can’t argue is the best eval…
- Evaluation of Distributed Shampoo: Comparison of optimizers: Distributed Shampoo, Adam & Adafactor. Made by Boris Dayma using Weights & Biases
- Tweet from GitHub - FixTweet/FxTwitter: Fix broken Twitter/X embeds! Use multiple images, videos, polls, translations and more on Discord, Telegram and others: Fix broken Twitter/X embeds! Use multiple images, videos, polls, translations and more on Discord, Telegram and others - GitHub - FixTweet/FxTwitter: Fix broken Twitter/X embeds! Use multiple image…
- HuggingFaceH4/open_llm_leaderboard · Announcement: Flagging merged models with incorrect metadata: no description found
▷ #ask-about-llms (168 messages🔥🔥):
-
Doubting Alpaca’s Evaluation:
@tekniumexpressed skepticism about Alpaca’s evaluation, stating that according to the leaderboard, Yi Chat is rated higher than GPT-4, hinting at potential flaws in the evaluation process. -
Imitation Learning Limitations: In a discussion about the limitations of imitation learning,
@tekniumsuggested that models are unlikely to imitate superhuman capacity if they’re trained on data from average humans. -
Self-Critique in AI Models Questioned:
@tekniumreferenced a paper indicating that AI models are not proficient at self-evaluation, raising questions about their self-critiquing abilities. -
Experimenting with LLaMA and ORCA:
@tekniumshared an experiment where LLaMA 2 70B was used to make ORCA, similar to how GPT-4 did, noting a slight improvement in MT benchmarks but a negative impact on traditional benchmarks like MMLU. -
Comparing Different Versions of LLMs: Responding to an inquiry from
@mr.userbox020about benchmarks between Nous Mixtral and Mixtral Dolphin,@tekniumprovided links to their GitHub repository with logs comparing Dolphin 2.6 with Mixtral 7x8 and Nous Hermes 2 with Mixtral 8x7B, also noting that in their experience, version 2.5 performed the best.
Links mentioned:
- 👾 LM Studio - Discover and run local LLMs: Find, download, and experiment with local LLMs
- Ollama: Get up and running with large language models, locally.
- Approximating Two-Layer Feedforward Networks for Efficient Transformers: How to reduce compute and memory requirements of neural networks (NNs) without sacrificing performance? Many recent works use sparse Mixtures of Experts (MoEs) to build resource-efficient large langua…
- LLM-Benchmark-Logs/benchmark-logs/Dolphin-2.6-Mixtral-7x8.md at main · teknium1/LLM-Benchmark-Logs: Just a bunch of benchmark logs for different LLMs. Contribute to teknium1/LLM-Benchmark-Logs development by creating an account on GitHub.
- GitHub - ggerganov/llama.cpp: Port of Facebook’s LLaMA model in C/C++: Port of Facebook’s LLaMA model in C/C++. Contribute to ggerganov/llama.cpp development by creating an account on GitHub.
- LLM-Benchmark-Logs/benchmark-logs/Nous-Hermes-2-Mixtral-8x7B-DPO.md at main · teknium1/LLM-Benchmark-Logs: Just a bunch of benchmark logs for different LLMs. Contribute to teknium1/LLM-Benchmark-Logs development by creating an account on GitHub.
OpenAI Discord Summary
-
Rethinking Nightshade’s Impact: Engineers debated the fail-safe mechanisms of AI, particularly with Nightshade, which may not compromise data due to its novel nature. The conversation highlighted concerns about the system affecting unintended datasets and the trust in large AI companies’ robust security measures.
-
Optimizing Prompt Limits in GPT-4: A technical discussion ensued regarding prompt lockouts in GPT-4’s image generator. Clarifications emerged on how rolling usage and individual prompt timers work, suggesting that a testing interval of one prompt every 4.5 minutes could avoid hitting the prompt cap.
-
AI Know-How for Pythonistas: Community members sought advice on deepening their AI expertise beyond intermediate Python, with suggestions including exploring fundamental AI concepts, machine learning techniques, and resources from Hugging Face.
-
A Tinge of AI Consciousness in Bing?: There were joking speculations among engineers about Bing’s possible self-awareness, sparking light-hearted exchanges without serious concern over the AI’s emerging capabilities.
-
Prompt Engineering: The Art of AI Guidance: The community exchanged ideas on prompt engineering, security strategies such as “trigger/block,” and the importance of understanding AI’s interpretation of language and instructions. They debated conditional prompting, how to craft prompts to safeguard against bad actors, and considerations for securely hosting GPT instructions.
OpenAI Channel Summaries
▷ #ai-discussions (43 messages🔥):
-
Query on Nightshade’s Foolproof Nature:
@jaicraftquestioned if Nightshade is without flaws, concerned it might affect data beyond its target.@【penultimate】believes large AI companies have robust failsafes and it should be easy to isolate poisoned data due to Nightshade’s novelty. -
Prompt Limit Confusions:
@.kyluxencountered an issue with prompt limits in the image generator via GPT-4, noting a lockout after 20 messages despite a 40-message limit.@rendo1clarified it’s rolling usage with each prompt on its timer, and@satanhashtagadvised attempting one prompt every 4.5 minutes for testing. -
AI Enthusiast’s Learning Path:
@.009_f.108seeks resources for deepening knowledge of AI, already possessing intermediate Python skills.@michael_6138_97508and@luguirecommended starting with fundamental AI concepts and classical machine learning techniques while others like@darthgustav.simply suggested Hugging Face. -
Bing’s Alleged Self-Awareness:
@metaldrgnclaimed Bing might be exhibiting signs of intelligence and consciousness, while@michael_6138_97508jokingly responded that they are lucky. -
Discussion on Moderation and Resource Sharing:
@miha9999was muted for share a resources link and inquired about the policy.@eskcantaadvised contacting modmail for clarification and assistance with moderation actions, which resolved@miha9999’s confusion after the warning was removed.
▷ #gpt-4-discussions (144 messages🔥🔥):
- Integration Woes with Weaviate:
@woodenrobotexpressed difficulty integrating custom GPT action with Weaviate, highlighting anUnrecognizedKwargsErrorrelated to object properties in the payload. - Exploring Charge Cycles for GPT-4:
@stefang6165noticed a reduction in the limit for GPT-4 messages from 40 to about 20 every 3 hours, seeking insights on this change. - Sharing GPT-4 Chat Experience:
_jonposhared their satisfying conversation with HAL, while@robloxfetishencountered an unexpected message cap during their sessions, prompting@darthgustav.and@c27c2to suggest it could be a temporary error or necessitate a support contact. - PDF Handling with ChatGPT:
@marx1497asked for advice handling small PDFs with limited success, leading to a discussion with@darthgustav.about the limitations of the tool and suggestions for pre-processing the data. - Creating Interactive MUD Environments with GPT:
@woodenrobotand@darthgustav.engaged in an in-depth technical exchange about embedding structured data and code into knowledge documents for GPT, with a shared interest in using AI for MUD servers and working within constraints of database storage and session continuity.
▷ #prompt-engineering (247 messages🔥🔥):
-
Security Through Obscurity in GPTs:
@busybensssuggested a “trigger/block” strategy to protect GPT models from bad actors.@darthgustav.pointed out the importance of Conditional Prompting for security, encouraging open discussion over gatekeeping. -
Conditional GPT Use in Complex JSON:
@semicolondevinquired about using GPT-4 conditionally when generating complex JSON that 3.5 struggles with, alluding to the higher cost of using GPT-4.@eskcantarecommended using 3.5 for baseline steps and reserving GPT-4 for the steps where it’s necessary, urging creative problem-solving within budget constraints. -
Extemporaneous AI Epistemology:
@darthgustav.and@eskcantaconducted a deep dive into how models interpret and respond to prompts. They highlighted the idiosyncrasies in AI’s understanding of instructions, noting that even AI doesn’t always “know” its reasoning path, providing significant insight into how model training could affect prompt interpretation. -
Prompting Strategies Unveiled:
@eskcantashared an advanced prompt strategy of separating what the model thinks from what it’s instructed to do. This concept sparked conversation about the essence of understanding AI response behavior and how to exploit it for better engineering prompts. -
Chart Extractions into Google Sheets:
@alertflyerasked for help transferring charts from GPT output into Google Sheets, to which@eskcantaresponded by clarifying the nature of the chart needed. The discussion aimed to identify the method of chart creation for proper extraction.
▷ #api-discussions (247 messages🔥🔥):
-
Security Strategies in the Spotlight:
@busybenssrevealed a security method they coined as “trigger/block” to protect GPT from bad actors, stating it effectively prevents execution of undesired inputs by the GPT.@darthgustavexpressed interest in the amount of character space this method uses, concerned about potential loss of functionality. -
Conditional Prompting to Secure GPTs: In an in-depth discussion on security,
@darthgustavexplained the benefits of Conditional Prompting and warned about potential weaknesses in security implementation. The conversation then navigated through several techniques and ideas for securing GPTs, including hosting GPT instructions via a web server with secure calls to OpenAI. -
Hacking LLMs: An Inevitable Risk: Both
@busybenssand@darthgustavconcurred that while security measures are essential, there’s an inherent vulnerability in sharing and using GPTs, and theft of digital assets may still occur. -
The Economics of AI Development: As the conversation shifted from security to the business side of AI,
@thepitviperand@darthgustavadvised focusing on improving the product and marketing to stand out, rather than excessively worrying about theft and the pursuit of perfect security. -
Prompt Engineering and AI Understanding: A series of messages from
@madame_architect,@eskcanta, and others discussed the intricacies of prompt engineering and the AI’s interpretation of language. They shared insights on semantic differences and how to guide the model to better understand and execute prompts.
LAION Discord Summary
-
Scrutinizing Adversarial AI Tools: Discussions centered around the suspect effectiveness of adversarial tools like Nightshade and Glaze on AI image generation. While
@astropulseraised concerns over a false sense of security they might offer, no consensus was reached. A relevant Reddit post offers further insight. -
Data and Models, A Heated Debate: Members engaged in a rich debate on creating datasets for fine-tuning AI models and the challenges associated with high-resolution images. Talks also included the efficacy and cost of models like GPT-4V, and the complexities in scaling T5 models compared to CLIP models.
-
Ethical AI, A Thorny Issue: AI ethics and copyright were another focal point, with community members displaying a level of cynicism about what constitutes ‘ethics’. The discordancy in community reactions on platforms such as Hacker News and Reddit highlighted the paradoxical nature of AI’s influence on copyright.
-
The Future of Text-to-Speech: Advances in TTS sparked lively discussions, comparing various services including WhisperSpeech and XTTS. The impressive dubbing technology by 11Labs was discussed but is restricted due to API limitations. A relevant YouTube video opens up on TTS developments.
-
Inquiries and Theories on Emotional AI:
- Legality and Challenges: Questions about the EU’s stance on emotion-detecting AI led to a clarification that such technology is not banned for research within the EU.
- Need for Experts in Emotion Detection: There were calls for expert involvement in building emotion detection datasets, with emphasis on the need for psychological expertise and appropriate context for accurate emotion classification.
LAION Channel Summaries
▷ #general (394 messages🔥🔥):
-
Debating Nightshade’s Effectiveness:
@mfcoolexpressed hope that DreamShaperXL Turbo images weren’t from a new model, citing their similarity to existing ones.@astropulseand others delved into the intricacies of whether adversarial tools like Nightshade and Glaze significantly impact AI image generation, with@astropulsesuggesting they might provide users with a false sense of security. Here’s a deep dive from ther/aiwarssubreddit: We need to talk a little bit about Glaze and Nightshade…. -
Discussions on Data and Model Training: Members like
@chad_in_the_house,@thejonasbrothers, and@pseudoterminalxspoke about creating datasets for fine-tuning models and the limitations of using images with high resolution. The debate touched on the efficacy and cost of models like GPT-4V and the complexity of scaling T5 models relative to CLIP models. -
AI Ethics and Licensing Discourse: The conversation extended to AI copyrights and ethics, with members expressing cynicism about contemporary ‘ethics’ being a stand-in for personal agreement.
@astropulseand@.undeletedcritiqued the community reactions on platforms like Hacker News and Reddit, while discussing the broader implications of AI on art and copyright. -
Exploring TTS and Dubbing Technologies:
@SegmentationFault,@itali4no, and@.undeleteddiscussed advanced text-to-speech (TTS) models, comparing existing services like WhisperSpeech and XTTS.@SegmentationFaulthighlighted 11Labs’ impressive dubbing technology and the API restrictions that keep their methods proprietary. Find out more about TTS developments in this Youtube video: “Open Source Text-To-Speech Projects: WhisperSpeech”. -
Inquiries about AI Upscaler and Language Model Training:
@skyler_14asked about the status of training the GigaGAN upscaler, referring to a GitHub project by@lucidrains.@andystv_inquired about the possibility of training a model for Traditional Chinese language support.
Links mentioned:
- no title found: no description found
- apf1/datafilteringnetworks_2b · Datasets at Hugging Face: no description found
- Data Poisoning Won’t Save You From Facial Recognition: Data poisoning has been proposed as a compelling defense against facial recognition models trained on Web-scraped pictures. Users can perturb images they post online, so that models will misclassify f…
- WhisperSpeech - a Hugging Face Space by Tonic: no description found
- Meme Our GIF - Meme Our Now - Discover & Share GIFs: Click to view the GIF
- Reddit - Dive into anything: no description found
- Reddit - Dive into anything: no description found
- Open Source Text-To-Speech Projects: WhisperSpeech - In Depth Discussion: WhisperSpeech is a promising new open source TTS model, that and be training on AUDIO ONLY data & that already shows promising results after a few hundred GP…
- Is webdataset a viable format for general-use ? · huggingface/pytorch-image-models · Discussion #1524: Hi @rwightman , thanks for the continuous good work. I am playing a bit with the Webdataset format, utilizing some of the methods in: https://github.com/rwightman/pytorch-image-models/blob/475ecdfa…
- GitHub - lucidrains/gigagan-pytorch: Implementation of GigaGAN, new SOTA GAN out of Adobe. Culmination of nearly a decade of research into GANs: Implementation of GigaGAN, new SOTA GAN out of Adobe. Culmination of nearly a decade of research into GANs - GitHub - lucidrains/gigagan-pytorch: Implementation of GigaGAN, new SOTA GAN out of Adob…
▷ #research (25 messages🔥):
-
Computational Challenges in Model Scaling:
@twoabovediscussed that authors of a recent model confessed to being compute-constrained and they are planning to look into the scaling laws for their method.@qwerty_qwerresponded, noting that overcoming compute constraints would be game-changing. -
In Search of Novel Multimodal Techniques:
@twoaboveinquired about innovative image chunking/embedding techniques for use in multimodal models, a question further expounded upon by@top_walk_townwho listed several methods including LLaVa, Flamingo, llama adapter, Chameleon, and the megabyte paper approaches. -
Unpacking EU AI Laws on Emotional AI:
@fredipyquestioned whether creating AI that detects emotions contradicts EU AI regulations.@mr_seekerclarified and@JHopined that such laws do not impact non-European entities, while@spirit_from_germanystated that emotion detection is not banned for research in the EU. -
Challenges in Emotional Recognition Datasets:
@spirit_from_germanyis working on an image-based emotion detector but struggles with limited emotional datasets. They proposed creating a curated dataset with the help of psychological experts, and@_spaniard_expressed skepticism about the feasibility of detecting nuanced emotions without rich contextual information. -
Expert Insights Needed for Emotion Detection:
@.hibarinfrom a psychological background supported the need for context in emotion classification, aligning with either the fingerprints or population hypotheses of emotion.@skyler_14introduced 3D morphable models as a potential domain for easier emotion annotation.
Eleuther Discord Summary
-
Flash Attention Sparks CUDA vs XLA Debate:
@carsonpooleand@.the_alt_mandebated about Flash Attention with opinions split on whether XLA optimizations could simplify its CUDA implementations. A Reddit comment from Patrick Kidger suggested that XLA can optimize attention mechanisms on TPUs, referencing a Reddit thread. -
Legal Conundrums Over Adversarial Methods: The Glaze and Nightshade tools sparked a legal and effectiveness debate among members like
@digthatdataand@stellaathena. A legal paper was shared to illustrate that bypassing a watermark is not necessarily a legal violation. -
Open Source and AI Ethics: The community discussed the open-source nature and licensing of Meta’s LLaMA, with
@avi.aireferring to a critical write-up by the OSI, highlighting that LLaMA’s license does not meet the open-source definition (OSI blog post). The conversation veered towards governance in AI and a call to build models with open-source software principles, as discussed by Colin Raffel (Stanford Seminar Talk). -
Explorations in Class-Incremental Learning and Optimization: SEED, a method for finetuning MoE models, was introduced with a research paper shared, and discussions around the CASPR optimization technique emerged as a contender outperforming the Shampoo algorithm, backed by a research paper. Also, a paper claiming zero pipeline bubbles in distributed training was mentioned, offering new synchronization bypass techniques during optimizer steps (Research Paper).
-
Unlocking Machine Interpretability with Patchscopes: Conversations revolved around the new framework Patchscopes for decoding information from model representations, where
@stellaathenashared a Twitter thread introducing the concept. There was a sense of cautious optimism about its application in information extraction, tempered by concerns around hallucinations in multi-token generation. -
Apex Repository Update and NeoX Development: An update in NVIDIA’s apex repository was highlighted by
@catboy_slim_for potentially speeding up the build process for GPT-NeoX, recommending a branch ready for testing (NVIDIA Apex Commit).
Eleuther Channel Summaries
▷ #general (213 messages🔥🔥):
-
Debating ‘Flash Attention’ and XLA Optimizations: In a technical debate,
@carsonpooleand@.the_alt_mandiscussed the implementation of Flash Attention, with@carsonpooleasserting it involves complex CUDA operations and@.the_alt_mansuggesting that XLA optimizations could automate much of its efficiency.@lucaslingleand@.the_alt_manlater shared Patrick Kidger’s comment from Reddit indicating XLA’s existing compiler optimizations for attention mechanisms on TPUs. -
Glaze & Nightshade Legalities: Users
@digthatdata,@stellaathena,@clockrelativity2003, and others discussed the legal aspects and effectiveness of Glaze and Nightshade, with conflicting views on whether these tools represent a form of encryption or watermarking.@stellaathenashared a legal paper stating that bypassing a watermark is likely not a violation of law, while other users examined both the practical and legal implications of combating AI image models with adversarial methods. -
Adversarial Perturbations & The Feasibility of OpenAI Lobbying: In the midst of discussing Nightshade’s impacts and the concept of adversarial perturbations,
@avi.aiunderlined the challenges of U.S. regulation change, responding to suggestions by@clockrelativity2003and@baber_regarding policies and special interests. -
Assessments of LLaMA Licensing and Open Source Definitions: In exploring the licensing of Meta’s LLaMA models,
@avi.aiprovided a link to a write-up by the OSI criticizing Meta’s claim of LLaMA being “open source.”@clockrelativity2003and@catboy_slim_discussed the limitations of such licenses and@avi.aiemphasized their goal to reach the benefits seen in traditional OSS communities with AI. -
Discussion on OpenAI and the Future of ML Models: Newcomers
@AxeIand@abi.vollintroduced themselves with academic backgrounds looking to contribute to the open-source community, while@exiraesought advice on pitching a novel alignment project.@hailey_schoelkopfand@nostalgiahurtshighlighted resources and talks by Colin Raffel regarding the building of AI models with an open-source ethos.
Links mentioned:
- Tweet from neil turkewitz (@neilturkewitz): @alexjc FYI—I don’t think that’s the case. Glaze & Nightshade don’t control access to a work as contemplated by §1201. However—as you note, providing services to circumvent them might well indeed viol…
- A Call to Build Models Like We Build Open-Source Software: no description found
- Reddit - Dive into anything): no description found
- nyanko7/LLaMA-65B · 🚩 Report : Legal issue(s): no description found
- stabilityai/sdxl-turbo · Hugging Face: no description found
- Reddit - Dive into anything: no description found
- Taking stock of open(ish) machine learning / 2023-06-15: I’ve been writing this newsletter for about six months, so I thought it might be a good time to pause the news firehose, and instead review and synthesize what I’ve learned about the potential for ope…
- Meta’s LLaMa 2 license is not Open Source: Meta is lowering barriers for access to powerful AI systems, but unfortunately, Meta has created the misunderstanding that LLaMa 2 is “open source” - it is not.
- Tweet from Luca Bertuzzi (@BertuzLuca): #AIAct: the technical work on the text is finally over. Now comes the ungrateful task of cleaning up the text, which should be ready in the coming hours.
- Building ML Models like Open-Source Software - Colin Raffel | Stanford MLSys #72: Episode 72 of the Stanford MLSys Seminar “Foundation Models Limited Series”!Speaker: Colin RaffelTitle: Building Machine Learning Models like Open-Source Sof…
- Tweet from Shawn Presser (@theshawwn): Facebook is aggressively going after LLaMA repos with DMCA’s. llama-dl was taken down, but that was just the beginning. They’ve knocked offline a few alpaca repos, and maintainers are making t…
- Glaze’s plagiarism is hilarious and indefensible: Posted in r/StableDiffusion by u/AloneSignificance555 • 46 points and 48 comments
- Pallas implementation of attention doesn’t work on CloudTPU · Issue #18590 · google/jax: Description import jax import jax.numpy as jnp from jax.experimental.pallas.ops import attention bs = 2 seqlen = 1000 n_heads = 32 dim = 128 rng = jax.random.PRNGKey(0) xq = jax.random.normal(rng, …
- Glaze’s plagiarism is hilarious and indefensible: Posted in r/StableDiffusion by u/AloneSignificance555 • 45 points and 48 comments
- The Mirage of Open-Source AI: Analyzing Meta’s Llama 2 Release Strategy – Open Future: In this analysis, I review the Llama 2 release strategy and show its non-compliance with the open-source standard. Furthermore, I explain how this case demonstrates the need for more robust governance…
- Reddit - Dive into anything: no description found
▷ #research (89 messages🔥🔥):
-
SEED Approach for Class-Incremental Learning:
@xylthixlmprovided a link to a paper on arXiv about SEED, a method for finetuning Mixture of Experts (MoE) models by freezing all experts but one for each new task. This specialization is expected to enhance model performance Research Paper. -
Backdoor Attacks on LLMs through Poisoning and CoT:
@ln271828gave a TL;DR of a research paper indicating that a new backdoor attack on large language models (LLMs) can be enhanced via chain-of-thought (CoT) prompting, while current techniques like supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF) are ineffective against these attacks Research Paper. -
Combining AxeS PReconditioners (CASPR) Optimization Technique:
@clashlukediscussed a paper on CASPR, an optimization method that outperforms the Shampoo algorithm by finding different preconditioners for each axis of the matrix-shaped neural network parameters Research Paper. -
Zero Pipeline Bubbles in Distributed Training:
@pizza_joeshared a paper that introduces a scheduling strategy claiming to be the first to achieve zero pipeline bubbles in large-scale distributed synchronous training, with a novel technique to bypass synchronizations during the optimizer step Research Paper. -
Generality in Depth-Conditioned Image Generation with LooseControl:
@digthatdatalinked a GitHub repository and paper for LooseControl, which generalizes depth conditioning for diffusion-based image generation, allowing creation and editing of complex scenes with minimal guidance GitHub Repo, Paper Page, Tweet Discussion.
Links mentioned:
- Stabilizing Transformer Training by Preventing Attention Entropy Collapse: Training stability is of great importance to Transformers. In this work, we investigate the training dynamics of Transformers by examining the evolution of the attention layers. In particular, we trac…
- Analyzing and Improving the Training Dynamics of Diffusion Models: Diffusion models currently dominate the field of data-driven image synthesis with their unparalleled scaling to large datasets. In this paper, we identify and rectify several causes for uneven and ine…
- Divide and not forget: Ensemble of selectively trained experts in Continual Learning: Class-incremental learning is becoming more popular as it helps models widen their applicability while not forgetting what they already know. A trend in this area is to use a mixture-of-expert techniq…
- Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training: Humans are capable of strategically deceptive behavior: behaving helpfully in most situations, but then behaving very differently in order to pursue alternative objectives when given the opportunity. …
- Combining Axes Preconditioners through Kronecker Approximation for…: Adaptive regularization based optimization methods such as full-matrix Adagrad which use gradient second-moment information hold significant potential for fast convergence in deep neural network…
- Zero Bubble Pipeline Parallelism: Pipeline parallelism is one of the key components for large-scale distributed training, yet its efficiency suffers from pipeline bubbles which were deemed inevitable. In this work, we introduce a sche…
- no title found: no description found
- Tweet from Shariq Farooq (@shariq_farooq): @ak LooseControl can prove to be a new way to design complex scenes and perform semantic editing e.g. Model understands how lighting changes with the edits: (2/2)
- memory-transformer-pt4/src/optimizer/spectra.py at main · Avelina9X/memory-transformer-pt4: Contribute to Avelina9X/memory-transformer-pt4 development by creating an account on GitHub.
- Tweet from AK (@_akhaliq): LooseControl: Lifting ControlNet for Generalized Depth Conditioning paper page: https://huggingface.co/papers/2312.03079 present LooseControl to allow generalized depth conditioning for diffusion-ba…
- GitHub - shariqfarooq123/LooseControl: Lifting ControlNet for Generalized Depth Conditioning: Lifting ControlNet for Generalized Depth Conditioning - GitHub - shariqfarooq123/LooseControl: Lifting ControlNet for Generalized Depth Conditioning
- arXiv user login: no description found
- Add freeze_spectral_norm option · d8ahazard/sd_dreambooth_extension@573d1c9: See https://arxiv.org/abs/2303.06296 This adds an option to reparametrize the model weights using the spectral norm so that the overall norm of each weight can't change. This helps to stabili…
- d8ahazard - Overview: d8ahazard has 171 repositories available. Follow their code on GitHub.
▷ #interpretability-general (9 messages🔥):
- Seeking Interpretability Resources: User
@1_gladosexpressed they are new to interpretability and looking for good resources or a list of papers to start with, while@neelnandainquired about the use of sparse autoencoders in initial NLP interpretability research. - Sparse Autoencoders in NLP History: User
@nsaphradiscussed the recurring themes in sparse dictionary learning, spanning from the latent semantic allocation era to the present, noting the inconsistent citations of predecessors and challenging the meaningfulness of a definition of mechanistic interpretability that includes such approaches. - Introducing Patchscopes for Representation Decoding:
@stellaathenashared a Twitter thread by @ghandeharioun that introduces Patchscopes, a framework for decoding specific information from a model’s representations. - Learning Dynamics for Interpretability Questioned: Responding to its relevance,
@stellaathenaalso questioned whether scoring high on next-token prediction with Patchscopes indeed correlates with identifying a model’s best guess as to the answer after a certain layer, implying that higher performance might not equate to better understanding. - Potential and Concerns of Patchscopes: User
@mrgonaosees significant potential in using Patchscopes for information extraction from hidden states in models like RWKV and Mamba, but also voiced concerns about potential hallucinations and the need for robustness checks in multi-token generation.
Links mentioned:
Tweet from Asma Ghandeharioun (@ghandeharioun): 🧵Can we “ask” an LLM to “translate” its own hidden representations into natural language? We propose 🩺Patchscopes, a new framework for decoding specific information from a representation by “patchin…
▷ #gpt-neox-dev (1 messages):
- NVIDIA’s Apex Update Could Speed Up NeoX Build:
@catboy_slim_highlighted a commit from NVIDIA’s apex repository, noting the need to fork and trim the code to accelerate the build process for fused adamw, as currently the full build takes about half an hour. They suggested that, despite the build time increase, the updated branch is likely ready for testing as it works on their machine.
Links mentioned:
Squashed commit of https://github.com/NVIDIA/apex/pull/1582 · NVIDIA/apex@bae1f93: commit 0da3ffb92ee6fbe5336602f0e3989db1cd16f880 Author: Masaki Kozuki <[email protected]> Date: Sat Feb 11 21:38:39 2023 -0800 use nvfuser_codegen commit 7642c1c7d30de439feb35…
LM Studio Discord Summary
-
LM Studio’s Range of Support and Future Improvements: Discussions centered on LM Studio’s capabilities and limitations, where
@heyitsyorkieclarified that GGUF quant models from Huggingface are supported but management of loading and unloading models should be done manually. Image generation is out of scope for LM Studio, with users directed towards Stable Diffusion for such tasks. Compatibility issues such as lacking support for CPUs without AVX instructions were noted, and a potential future update may include Intel Mac support which is currently not offered. Users experiencing persistent errors after reinstalling Windows were directed to a Discord link for troubleshooting assistance. -
The Great GPU Discussion: Conversations in hardware discussion heated up with talks of investing in high-performance Nvidia 6000 series cards and awaiting hardware upgrades like the P40 card. Comparisons were made between Nvidia RTX 6000 Ada Generation cards and cost-effective alternatives for Large Language Model (LLM) tasks. Mac Studios are favored over PCs by some for better memory bandwidth, while others appreciate Mac’s cache architecture beneficial for LLM work. A debate over Nvidia card compatibility and GPU utilization also ensued, with suggestions provided for maximizing GPU performance.
-
Model-Focused Dialogues Reveal Community Preferences: In model-related chats,
@dagbsclarified terms such as “Dolphin 2.7” and “Synthia” as finetuners, and directed those interested in comparisons towards specific Dolphin-based models on various platforms. GGUF formatted models were highlighted for their popularity and compatibility, and models best suited for specific hardware were recommended, such as Deepseek coder 6.7B for an RTX 3060 mobile. Moreover, the efficacy of models was debated with@.ben.comadvocating for consideration of model performance beyond leaderboard scores. -
Beta Releases Beckon Feedback for Fixes: The latest windows beta reported issues with VRAM capacity displays, which is particularly relevant for models like the 6600XT AMD card where OpenCL issues were identified. Beta releases V5/V6 aimed to fix RAM/VRAM estimates bugs, and the community was solicited for feedback. ARM support queries for beta installations on a Jetson NVIDIA board were addressed, confirming current support limitations to Mac Silicon. The rapid speed improvements in the latest update sparked discussions, with
@yagilbsharing a Magic GIF in a lighthearted response. -
CrewAI Over Autogen in Automation Showdown: A preference for crewAI was expressed by
@MagicJim, especially for the potential to integrate multiple LLMs in LM Studio. Contrary to previous thoughts, it was clarified that crewAI does indeed allow for diverse LLM usage for each agent, with a YouTube video provided as a demonstration. A workaround for multiple LLM API instances using different ports was discussed, addressing utilization concerns. -
Emerging Tools and Integrations Enhance Capabilities:
@happy_doodshowcased how LM Studio and LangChain can be used concurrently, detailing a process involving creation, templating, and parsing for streamlined AI interactions. On the code front, experimenting with models like DeepseekCoder33B for open interpreter tasks surfaced, with evaluations suggesting better performance might be achieved with models more focused on coding.
LM Studio Channel Summaries
▷ #💬-general (122 messages🔥🔥):
-
Clarification on GGUF and Quant Models:
@heyitsyorkieclarified that LM Studio only supports GGUF quant models from Huggingface and advised@ubersuperbossthat model loading and unloading have to be manually done within LMStudio. They also discussed that LMStudio is not suitable for image generation and directed users towards Stable Diffusion for such tasks. -
Image Generation Models Query:
@misc_user_01inquired about the possibility of LM Studio adding support for image generation models, to which@heyitsyorkiereplied that it isn’t in scope for LMStudio, as they serve different use cases. However, they did point to Stable Diffusion + automatic1111 for users interested in image generation. -
LM Studio Support and Installation Discussions: Various users including
@cyberbug_scalp,@ariss6556, and@__vanj__discussed technical issues and queries regarding system compatibility and installation of LM Studio, with@heyitsyorkieand others offering technical advice, such as LM Studio’s lack of support for CPUs without AVX1/2 instructions. -
Model Recommendations and GPU Advice:
@heyitsyorkieanswered several questions related to model suggestions for specific hardware setups like for@drhafezzz’s M1 Air, and confirmed that LM Studio supports multi-GPU setups, recommending matching pairs for optimal performance. -
Interest in Intel Mac Support Expressed: Users
@kujilaand@katy.the.katexpressed their desire for LM Studio to support Intel Macs, which@yagilbacknowledged is not currently supported due to the focus on Silicon Macs but mentioned there are plans to enable support in the future.
Links mentioned:
- HuggingChat: no description found
- GitHub - comfyanonymous/ComfyUI: The most powerful and modular stable diffusion GUI, api and backend with a graph/nodes interface.: The most powerful and modular stable diffusion GUI, api and backend with a graph/nodes interface. - GitHub - comfyanonymous/ComfyUI: The most powerful and modular stable diffusion GUI, api and back…
- ggml : add Flash Attention by ggerganov · Pull Request #5021 · ggerganov/llama.cpp: ref #3365 Setting up what’s needed for adding Flash Attention support to ggml and llama.cpp The proposed operator performs: // unfused kq = ggml_mul_mat (ctx, k, q); kq = ggml_scale (ctx, kq,…
▷ #🤖-models-discussion-chat (82 messages🔥🔥):
-
Model Confusion Cleared Up:
@dagbsclarified that the terms like “Dolphin 2.7”, “Synthia”, and “Nous-Hermes” refer to different finetuners, which are combinations of models and datasets to create new models. This response was in aid of confusion from@lonfus. -
Where to Find Model Comparisons: In response to
@lonfusrequesting model comparisons,@dagbsdirected them to previous posts in channel <#1185646847721742336> for personal model recommendations and provided links to Dolphin-based models that he recommends, including Dolphin 2.7 Mixtral and MegaDolphin 120B. -
GGUF Format Gains Popularity: A series of messages from
@conic,@kadeshar,@jayjay70, and others discussed various places to find GGUF formatted models, including Hugging Face, LLM Explorer, and GitHub, highlighting its widespread adoption for model compatibility. -
Resource-Specific Model Recommendations: Users, including
@heyitsyorkieand@ptable, recommended models suitable for various hardware specs—for instance, Deepseek coder 6.7B was suggested for an RTX 3060 mobile with 32GB RAM, and models under 70B parameters for a system with Ryzen 9 5950x and a 3090Fe GPU. -
Discussions on Model Efficacy and Performance:
@.ben.comprovided insights on model performance being potentially misleading with leaderboard scores and suggested consulting spaces like Mike Ravkine’s AI coding results for more realistic appraisals. They further noted the high cost-effectiveness of using GPT-4 Turbo over procuring new hardware for running large models.
Links mentioned:
- lodrick-the-lafted/Grafted-Titanic-Dolphin-2x120B · Hugging Face: no description found
- Can Ai Code Results - a Hugging Face Space by mike-ravkine: no description found
- LMSys Chatbot Arena Leaderboard - a Hugging Face Space by lmsys: no description found
- Open LLM Leaderboard - a Hugging Face Space by HuggingFaceH4: no description found
- Best Open-Source Language Models, All Large Language Models: no description found
- yunconglong/Truthful_DPO_TomGrc_FusionNet_7Bx2_MoE_13B · Hugging Face: no description found
- nous-hermes-2-34b-2.16bpw.gguf · ikawrakow/various-2bit-sota-gguf at main: no description found
- dagbs/TinyDolphin-2.8-1.1b-GGUF · Hugging Face: no description found
- google/t5-v1_1-xxl · Hugging Face: no description found
- TheBloke/deepseek-coder-6.7B-instruct-GGUF · Hugging Face: no description found
- GitHub - lmstudio-ai/model-catalog: A collection of standardized JSON descriptors for Large Language Model (LLM) files.: A collection of standardized JSON descriptors for Large Language Model (LLM) files. - GitHub - lmstudio-ai/model-catalog: A collection of standardized JSON descriptors for Large Language Model (LLM…
- TheBloke (Tom Jobbins): no description found
▷ #🧠-feedback (5 messages):
- Identifying Recurrent LM Download Failures:
@leo_lion_kingsuggested that failed LM downloads should be automatically deleted and marked to prevent re-downloading faulty models since users only discover errors after attempting to load them. - Unknown Model Error Triggers Inquiry:
@tobyleung.posted a detailed JSON error output indicating an unknown error and suggesting to check if there’s enough available memory to load the model. It included details about RAM, GPU, OS, and the application used. - Reinstallation Doesn’t Clear Error: In a follow-up,
@tobyleung.expressed confusion over persisting errors despite reinstalling Windows. - Discord Link for Error Investigation:
@dagbsprovided a Discord link that apparently explains the cause of the error but no additional context was given. - Request for Retrieval of Old Model: After discussing error issues,
@tobyleung.asked if it would be possible to revert to their old model.
▷ #🎛-hardware-discussion (48 messages🔥):
- Graphics Card Strategy Evaluations:
@gtgbwas convinced to invest in a high-performance Nvidia 6000 series card after seeing Mervin’s performance videos, prompting dialogue on card compatibility and choices for model execution rigs. - Awaiting Hardware Upgrades:
@pefortinmentioned they are waiting for a P40 card, indicating a “poor man’s rig,” to which@doderleinreplied they are expecting the same hardware arrival soon. - Powerful Cards Stimulate Envy:
@doderleinacknowledged the significant capabilities of the Nvidia RTX 6000 Ada Generation card shared by@gtgbin the product page link, emphasizing its high cost. - Mac Versus PC for LLMs: A debate over hardware choices surfaced, with
@heyitsyorkiefavoring a Mac Studio over PC solutions for LLM tasks due to better memory bandwidth and a more attractive home setup, while@.ben.compointed out the benefits of Mac’s cache architecture for such work. - GPU Utilization Discussions:
@omgitsprovidenceinquired about low GPU utilization,@heyitsyorkieadvised trying the ROCm beta for better AMD performance, and@dagbsoffered@misangeniusguidance on maximizing GPU offload for better response times when running models.
Links mentioned:
NVIDIA RTX 6000 Ada Generation Graphics Card: Powered by the NVIDIA Ada Lovelace Architecture.
▷ #🧪-beta-releases-chat (29 messages🔥):
-
VRAM Vanishes in Beta:
@eimiieeereported the latest windows beta shows estimated VRAM capacity as 0 on a 6600XT AMD card.@yagilbsuggested there were issues with OpenCL in the latest beta and pointed toward trying the AMD ROCm beta. -
VRAM Estimate Bug Squashed:
@yagilbannounced Beta V5/V6, which fixed several bugs, and asked for feedback on RAM/VRAM estimates on the search page, hinting at tweaks in the calculation. -
Compatibility Queries for Jetson NVIDIA:
@quantman74inquired about arm64 architecture support for installing the beta on a Jetson NVIDIA board.@heyitsyorkieclarified there was no ARM support outside of Mac Silicon, and@yagilbencouraged the creation of a feature request for it. -
Speedy Improvements Spark Curiosity:
@mmonircommented on the doubled speed in the latest update, prompting@heyitsyorkieto link a humorous gif, while@n8programsalso expressed curiosity about the changes that led to the speed improvements. -
Case Sensitivity Causes Model Mayhem:
@M1917Enfielddiscovered and solved a problem where model folders with different case sensitivities were not being detected by LM Studio by renaming the folder to match the expected case.@yagilbacknowledged the successful problem-solving.
Links mentioned:
Magic GIF - Magic - Discover & Share GIFs: Click to view the GIF
▷ #autogen (1 messages):
meadyfricked: Never got autogen working with LM Studio but crew-ai seems to work.
▷ #langchain (1 messages):
- LangChain Integration with LM Studio:
@happy_doodprovided an example of how LM Studio and LangChain can be used together, showcasing new class implementations. The code snippet demonstrates the creation of a ChatOpenAI instance, crafting a prompt with ChatPromptTemplate, parsing output with StrOutputParser, and combining these elements in a streamlined process.
▷ #crew-ai (10 messages🔥):
- MagicJim Weighs in on Automation Tools:
@MagicJimshared his preference for crewAI over autogen due to the idea of integrating multiple LLMs in LM Studio. He suggested that using specific models like deepseek coder for coder agents would be beneficial. - Discussing Autogen’s Flexibility with LLMs:
@siticobserved that autogen allows using a different LLM for each agent, unlike crewAI, which seems to only use one. This feature is important for creating agents with distinct capabilities. - Clarification on crewAI’s LLM Usage:
@MagicJimclarified that crewAI does allow using different LLMs for each agent and shared a YouTube video demonstrating this functionality. - Running Multiple Instances of LLMs:
@senecaloucksuggested the workaround of running multiple instances of LLMs if the hardware supports it, using different ports for the API. - Integration Issues with LM Studio:
@motocycleinquired if anyone had successfully integrated crewAI with the LM Studio endpoint, mentioning success with ollama but facing issues with LM Studio.
Links mentioned:
CrewAI: AI-Powered Blogging Agents using LM Studio, Ollama, JanAI & TextGen: 🌟 Welcome to an exciting journey into the world of AI-powered blogging! 🌟In today’s video, I take you through a comprehensive tutorial on using Crew AI to …
▷ #open-interpreter (7 messages):
- Parsing Error in
system_key.go:@gustavo_60030noted an error insystem_key.gowhere the system could not determine NFS usage. The error message mentioned an inability to parse/etc/fstab, specifically the dump frequency, which said “information.” - Model Experiments for Open Interpreter:
@pefortindiscussed experimenting with DeepseekCoder33B for open interpreter and mentioned that while Mixtral 8x7B instruct 5BPW is performing okay, it’s struggling with identifying when to write code. - Model Recommendation Request: Seeking a model suited for coding tasks,
@pefortinexpressed an interest in trying out models that are focused on coding, like wizard, etc. - Model Comparison for Coding:
@impulse749inquired if DeepseekCoder33B is the best for coding tasks, to which another offered that deepseek-coder-6.7b-instruct might be a faster and more focused option for solely coding-related tasks.
Mistral Discord Summary
-
French Language Support Sparks Interest: Users suggested the addition of a French support channel within the Mistral Discord community, reflecting a demand for multilingual assistance.
-
Data Extraction Strategies and Pricing Discussions: There was an exchange of strategies for data extraction such as using BNF grammar and in-context learning, alongside inquiries about Mistral’s pricing model where it was clarified that 1M tokens correspond to 1,000,000 tokens, including both input and output.
-
Interfacing AI with 3D Animation and Function Calling: Questions arose about integrating Mistral AI with 3D characters for real-time interaction, discussing complexities like animation rigging and API compatibility, as well as implementation queries about function calling akin to OpenAI’s APIs.
-
Hosting and Deployment Insights for Mistral: Users shared resources such as partITech/php-mistral on GitHub for running MistralAi with Laravel, and experiences regarding VPS hosting, on-premises hosting, and using Skypilot for Lambda Labs. Additionally, using Docker for Mistral deployment was suggested.
-
Focusing on Fine-Tuning and Model Use Cases: Conversations revolved around fine-tuning strategies such as creating datasets in Q&A JSON format, the importance of data quality with ‘garbage in, garbage out’, and troubleshooting Mistral fine-tuning with tools like axolotl. Concerns were also voiced about introducing a tool highly optimized for French language tasks within the Mistral suite.
Mistral Channel Summaries
▷ #general (154 messages🔥🔥):
-
Demand for a French Support Channel: User
@gbourdinexpressed that the Mistral Discord could benefit from a French support channel (ça manque de channel FR), which elicited agreement from another user,@aceknr. -
Quest for Data Extraction Strategies:
@gbourdinsought advice on strategies for extracting data, like postal codes or product searches, from discussions. Whereas@mrdragonfoxproposed using BNF grammar and in-context learning due to limited API support for this use case. -
Clarification on Mistral Pricing Model:
@nozaranoasked for clarification on the pricing for “mistral-medium,” with explanation provided by@ethuxand@mrdragonfox, defining that 1M tokens represent 1,000,000 and that both input and output tokens count towards pricing. -
AI-Driven 3D Character Interaction: User
@madnomad4540inquired about integrating Mistral AI with a 3D character and real-time user interaction.@mrdragonfoxindicated the challenges and separated aspects involved in the venture, such as animation rigging and integrating with APIs like Google Cloud Vision. -
Exploring Assistants API and Function Calling: User
@takezo07queried about the implementation of function calling and threads like OpenAI’s Assistants APIs, while@i_am_domnoted that such functionality could be programmed using the API directly, and@.elektmentioned that official support for function calling isn’t available in Mistral API.
Links mentioned:
- Vulkan Implementation by 0cc4m · Pull Request #2059 · ggerganov/llama.cpp: I’ve been working on this for a while. Vulkan requires a lot of boiler plate, but it also gives you a lot of control. The intention is to eventually supercede the OpenCL backend as the primary wid…
- Vulkan Backend from Nomic · Issue #2033 · jmorganca/ollama: https://github.com/nomic-ai/llama.cpp GPT4All runs Mistral and Mixtral q4 models over 10x faster on my 6600M GPU
▷ #models (5 messages):
-
Seeking Fiction-Guidance with Instruct:
dizzytornadoinquired whether Instruct has guardrails specifically for writing fiction. The context and responses are not provided in the chat logs. -
A Shoutout to Mistral:
thenetrunnaexpressed affection for Mistral without further context or elaboration. -
Demand for French-Optimized Mistral:
luc312asked if there is a version of Mistral more optimized for reading/writing French or if using a strong system prompt is the only way to guide Mistral to communicate in French. -
Clarification on Multilingual Model Capabilities:
tom_lrdclarified that tiny-7b isn’t officially built for French, having limited French abilities due to lack of targeted training, whereas Small-8x7b is officially multilingual and trained to speak French.
▷ #deployment (6 messages):
- Integrating Mistral with PHP:
@gbourdinprovided a useful resource with a link to GitHub - partITech/php-mistral, indicating that it can be used to run MistralAi with Laravel. - Seeking VPS Hosting Details:
@ivandjukicinquired about hosting providers for VPS with a proper GPU, noting the expense or misunderstanding regarding the cost. - Client Data Secured with On-premises Hosting:
@mrdragonfoxassured that when Mistral is hosted in the client’s data center, Mistral would never get access to your data. - Hobbyist Hosting Insights:
@vhariationalshared personal experience as a hobbyist not needing the biggest GPUs, and recommends using Lambda Labs via Skypilot for occasional testing of larger models. - Suggestion for Docker Deployment:
@mrdomoosuggested setting up a Docker server and using the python client for Mistral deployment.
Links mentioned:
GitHub - partITech/php-mistral: MistralAi php client: MistralAi php client. Contribute to partITech/php-mistral development by creating an account on GitHub.
▷ #ref-implem (2 messages):
-
Quest for Ideal Table Format in Mistral:
@fredmolinamlgcpinquired about the best way to format table data when using Mistral. They contrasted the pipe-separated format used for models like bison, unicron, and gemini with a “textified” approach they’ve been taking with Mistral by converting pandas dataframe rows into a string of headers and values. -
Sample Textified Table Prompt Provided:
@fredmolinamlgcpshared an example of a “textified” table prompt for Mistral. They demonstrated how they structure the input by including an instructional tag followed by neatly formatted campaign data (e.g., campaign id 1193, campaign name Launch Event…).
▷ #finetuning (51 messages🔥):
- GPT-3 Costs and Alternatives for Data Extraction:
@cheshireaimentioned using GPT-turbo 16k for extracting data from PDFs and creating a dataset, though they had to discard many bad results due to the large volume of documents processed. - Creating Q&A JSON Format for Dataset Construction:
@dorumiruis seeking advice on creating a programming task to extract data from PDFs, chunk it, and use an API like palm2 to generate a dataset in a Q&A JSON format for subsequent training. - Chunking Techniques and Resource Suggestions: In response to
@dorumiru'squestion about advanced PDF chunking techniques,@ethuxshared a YouTube video called “The 5 Levels Of Text Splitting For Retrieval,” which discusses various methods of chunking text data. - Recommendations and Warnings for Fine-Tuning Tools:
@mrdragonfoxadvised caution when using tools like Langchain due to complex dependencies and shared a GitHub link toprivateGPT, a basic tool for document interaction. They also emphasized ‘garbage in, garbage out’ highlighting the significance of quality data. - Issues with Configuring Mistral for Fine-Tuning:
@distro1546inquired about the proper command line for fine-tuning Mistral using the axolotl tool, how to adjustconfig.ymlfor their dataset, and posted a discussion thread on GitHub for troubleshooting (https://github.com/OpenAccess-AI-Collective/axolotl/discussions/1161).
Links mentioned:
- Trouble using custom dataset for finetuning mistral with qlora · OpenAccess-AI-Collective/axolotl · Discussion #1161: OS: Linux (Ubuntu 22.04) GPU: Tesla-P100 I am trying to fine-tune mistral with qlora, but I’m making some mistake with custom dataset formatting and/or setting dataset parameters in my qlora.yml f…
- The 5 Levels Of Text Splitting For Retrieval: Get Code: https://fullstackretrieval.com/Get updates from me: https://mail.gregkamradt.com/* https://www.chunkviz.com/ Greg’s Info:- Twitter: https://twitter…
- GitHub - imartinez/privateGPT: Interact with your documents using the power of GPT, 100% privately, no data leaks: Interact with your documents using the power of GPT, 100% privately, no data leaks - GitHub - imartinez/privateGPT: Interact with your documents using the power of GPT, 100% privately, no data leaks
- GitHub - OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions: Go ahead and axolotl questions. Contribute to OpenAccess-AI-Collective/axolotl development by creating an account on GitHub.
▷ #showcase (1 messages):
-
LibreChat: A Mix-and-Match Chatbot Platform: User
@dannyavilapresented LibreChat, a versatile platform that supports using the Mistral API alongside other services such as Openrouter, Azure OpenAI, and more. The platform offers features like AI model switching, message search, and is completely open-source for self-hosting, available here. -
Explore LibreChat’s Underlying Mechanics: For users interested in diving deeper,
@dannyavilashared the link to the documentation at docs.librechat.ai, providing insights on how to make the most of LibreChat’s expansive features. -
LibreChat’s Open Source Cred: Boasting a generous open-source ethos, LibreChat is under the MIT license, showcasing community trust with 6.6k stars and 1.1k forks on its repository.
Links mentioned:
GitHub - danny-avila/LibreChat: Enhanced ChatGPT Clone: Features OpenAI, GPT-4 Vision, Bing, Anthropic, OpenRouter, Google Gemini, AI model switching, message search, langchain, DALL-E-3, ChatGPT Plugins, OpenAI Functions, Secure Multi-User System, Presets, completely open-source for self-hosting. More features in development: Enhanced ChatGPT Clone: Features OpenAI, GPT-4 Vision, Bing, Anthropic, OpenRouter, Google Gemini, AI model switching, message search, langchain, DALL-E-3, ChatGPT Plugins, OpenAI Functions, Secure…
▷ #la-plateforme (13 messages🔥):
- Newcomer Questioning Ease of Use:
@mrrobot7778expressed concern about the usability of Mistral AI for someone new to the field, doubting if it’s meant for users without expertise. - Beam Search Debate: There was confusion regarding the presence of a beam search option in the OpenAI API.
@casper_ailinked to the API documentation asserting its existence, while@rabdullinquestioned the underlying mechanism. - Under the Hood of Beam Search:
@rabdullininquired if the OpenAI API actually runs a beam search or just generates independent outputs.@casper_aiadmitted uncertainty about the specific process but mentioned its effectiveness. - Authentication Concerns Shared:
@pastillafitraised issues with the authentication process when using the API, specifically regarding password management and lack of two-factor authentication (2FA). They found a workaround for 2FA during password reset but reported it not affecting the console login. - Mistral Medium’s Instruction Following Queried:
@gooningconstantlyasked if mistral-medium is tuned for instruction following, noticing that it sometimes ignores instructions provided in thesystemrole message content.
Perplexity AI Discord Summary
- Swift Batch 6 Perplexity Activation:
@yellephenexperienced an instant activation of Perplexity Pro after being in batch 6. - Rabbit R1 Bundle Deal:
@martsw71faced hurdles activating Perplexity Pro from a Rabbit R1 purchase;@ok.alexrecommended the consistent use of email across services. - Customize Your Search in Brave:
@witchfinder17sought advice on making Perplexity the default search engine in Brave; meanwhile,@samangel7358highlighted the importance of distinguishing between Perplexity AI Search and Companion extensions. - AI’s YouTube Homework:
@chiefblink117was curious to know if Perplexity pulls information from YouTube video audio, clarified by@icelavamanto be using video transcripts via a YouTube API. - Clash of the AI Titans: A lively debate by
@b4d_7r1p_and@lord.wexcompared Perplexity Premium and GPT-4 Premium, noting Perplexity’s competitive edge in offering access to various premium models, though it lags behind in image generation capabilities. - Stay in Your Lane: In the channel,
@ok.alexhelped to guide@kabbe_the_dudeto the appropriate channel for project sharing, stressing on content organization. - C# Voyage Reporting:
@whoistraianupdated on their progress in learning C# with an imminent exam on January 31, supported by a link: Can you help. - Share and Prosper: Pro users at Perplexity, like
@neuralspace, spread the love by sharing Perplexity AI referral codes. - API Await on Context Extension: A singular message from
@commuting5048asked about extending support to a 32k context length in the API; however, no updates or responses followed.
Perplexity AI Channel Summaries
▷ #general (99 messages🔥🔥):
- Instant Perplexity Pro Activation:
@yellephenmentioned instantly receiving a Perplexity Pro link after being in batch 6. - Rabbit R1 Purchase Comes With Perplexity Pro:
@martsw71discussed issues with activating Perplexity Pro using a link from a Rabbit R1 purchase, and@ok.alexsuggested ensuring the same email is used across services and trying the web version for subscription. - Setting Perplexity as Default Search in Brave:
@witchfinder17asked about setting Perplexity as the default search in Brave, with@mares1317suggesting a direct URL for a custom search engine setup, and@samangel7358pointing out the distinction between Perplexity AI Search and Companion extensions. - Integration of YouTube Transcripts in Perplexity:
@chiefblink117inquired whether Perplexity sources from YouTube video audio for the AI’s responses, with@icelavamanclarifying that it uses video transcripts provided by a YouTube API. - Perplexity Premium vs. GPT-4 Premium:
@b4d_7r1p_and@lord.wexdiscussed the advantages of Perplexity Premium over GPT-4 Premium for different uses, with Perplexity offering access to various premium models and not falling short in any significant area except image generation compared to its competitor.
Links mentioned:
Perplexity - AI Search: Upgrade your default search engine
▷ #sharing (15 messages🔥):
-
Navigating to the Right Channel:
@ok.alexredirected@kabbe_the_dudeto the<#1059504969386037258>channel for project sharing, indicating the importance of using the proper channels for specific content. -
A Journey Through C# Learning:
@whoistraianshared their learning journey for C#, with an update progress link: Can you help, stating they have an exam on January 31 at faculty. -
Sharing Referral Codes:
@neuralspaceexpressed the sentiment that sharing is caring by posting their Perplexity AI referral code link: Referral Code. -
Perplexity’s Pro Models Explained:
@core3038provided insight into the various models available to Pro users on Perplexity AI, like GPT-4 and Claude 2, and shared a detailed blog post for more information: What model does Perplexity use. -
Perplexity AI vs. ChatGPT Comparison:
@far2wisefound an article comparing Perplexity AI with ChatGPT, outlining differences and key points, which can be explored here: Perplexity AI vs ChatGPT.
Links mentioned:
- Perplexity: AI Chatbot & Search Multi-Tool Explained! #88: This video explains Perplexity, a search multi-tool generative AI chatbot — what it is, how to use it, and why you should! I provide examples for some of the…
- Perplexity AI vs ChatGPT: Unveiling The Superior AI-Search Engine 2024: Perplexity AI vs ChatGPT: Which AI Search Engine is Better? Perplexity AI and ChatGPT are both powerful AI-powered search engines.
- What model does Perplexity use and what is the Perplexity model?: Dive deep into Perplexity’s technical details with our comprehensive FAQ page. From the nuances of AI models like GPT-4 and Claude 2 to token limits and AI profiles, get concise answers to optimize yo…
▷ #pplx-api (1 messages):
- Inquiry About 32k Context Length: User
@commuting5048inquired about the progress and potential release date for 32k context length support. No further information or responses to this query were provided in the channel messages.
HuggingFace Discord Discord Summary
-
Local RAG Goes Live with langchain and LM Studio:
@thoreau_a_whelanhas successfully implemented a local RAG system that integrates with langchain and LM Studio, enabling search through local documents. -
Introducing a New Vision-Language Model: The Nous-Hermes-2-Vision model, an extension of OpenHermes-2.5-Mistral-7B, introduced by
@andysingal. It features unique function calling capabilities and is available on Hugging Face. -
AI Integration POC Unveiled by DevSpot:
@devspotpresented a GitHub-based Proof of Concept for a scalable system to work with AI models from various vendors, complete with a GitHub repository and an explanatory YouTube video. -
VRAM Efficient Photorealistic Diffusion Model:
@felixsanzdiscussed optimizing PixArt-α to run with less than 8GB of VRAM, providing insights in an article, and welcomed community feedback. -
NLP Insights: Model Caching, Shrinking Transformers, and BERT’s Longevity:
@asprtnl_50418tackled issues with model caching in Docker, suggesting the use of a volume for permanent storage.@stroggozshrank a sentence transformer with PCA and knowledge distillation, debating dataset size while also touching on the performance and relevance of BERT compared to RoBERTa and Elektra, and recommended the span marker library for NER.
HuggingFace Discord Channel Summaries
▷ #general (77 messages🔥🔥):
-
PDF Data to Dataset Dilemma: User
@dorumirusought advice on creating a dataset in the format of context, question, and answers from raw PDF data and inquired about advanced techniques for chunking PDF data. Unfortunately, no responses or further discussion on this topic were provided within the messages available. -
From Software Engineering to AI Research: User
@boss_ev, a software engineer, asked for advice on transitioning into AI research and was recommended resources such as Fast.ai and Andrej Karpathy’s YouTube channel. -
Unsloth AI with a Twist: User
@vishyouluckmentioned that they are attempting to use Unsloth with Hindi and promised updates, despite exhausting their Collab compute unit and seeking to purchase more. -
Inference Endpoint Ease: User
@dragonburpcheered the setup simplicity of the inference endpoints, finding it user-friendly and straightforward. -
Linking Hugging Face and GitHub: User
!BeastBlazeexplored ways to link Hugging Face projects to their GitHub account, aiming to enhance their profile for potential employers, and subsequently discussed Space sleeping due to inactivity and billing inquiries for daily usage checking.
Links mentioned:
- Vishal - a Hugging Face Space by VishalMysore: no description found
- stabilityai/stable-code-3b · Hugging Face: no description found
- LoRA): no description found
- burkelibbey/colors · Datasets at Hugging Face: no description found
- llama.cpp/convert-lora-to-ggml.py at master · ggerganov/llama.cpp: Port of Facebook’s LLaMA model in C/C++. Contribute to ggerganov/llama.cpp development by creating an account on GitHub.
▷ #today-im-learning (5 messages):
-
Local RAG Implementation Success Story: User
@thoreau_a_whelanshared their excitement about getting local RAG (Retriever-augmented generation) to work with langchain and LM Studio for searching through local documents. -
GitHub Actions Permissions Conquered:
@vipitisreported navigating the difficulties of setting up specific permissions for GitHub Actions, describing the process as painful. -
Progress on DoReMi and FP8 Training in Parallelism:
@neuralinkhas made significant strides, writing 90% of DoReMi and 30% of an end-to-end FP8 training in 3D parallelism, successfully implementing the forward and backward passes. -
Distillation of Meta’s Self-Rewarding Language Models Paper:
@subham5089shared a simplified summary of Meta’s new paper, “Self-Rewarding Language Models”. The summary is available as a LinkedIn post. -
Mad_cat__ Wraps Their Head Around Skillchains: User
@mad_cat__indicated they have finally understood Skillchains, though no further context was provided about the nature of these skillchains.
▷ #cool-finds (3 messages):
-
Bilingual Model Drops by Hugging Face: User
@sofiavasmentioned Hugging Face’s trend of releasing bilingual models, highlighting recent models in German and Chinese. -
Introducing Nous-Hermes-2-Vision:
@andysingalshowcased the Nous-Hermes-2-Vision, a novel Vision-Language Model building upon the OpenHermes-2.5-Mistral-7B by teknium. The model’s details can be viewed on Hugging Face. -
Unique Function Calling Feature in Nous-Hermes-2-Vision:
@meatfuckerpointed out a distinctive aspect of the Nous-Hermes-2-Vision model, noting its capability for function calling.
Links mentioned:
NousResearch/Nous-Hermes-2-Vision-Alpha · Hugging Face: no description found
▷ #i-made-this (9 messages🔥):
-
Felix Unleashes VRAM Efficiency:
@felixsanzshared an article on optimizing the photorealistic diffusion model called PixArt-α to run with less than 8GB of VRAM. They expressed hope the community finds the content useful and invited feedback for improvement. -
Community Applause for Felix:
@gugaimepraised@felixsanzfor the informative articles on Stable Diffusion, mentioning they aim to implement the examples provided. The appreciation was acknowledged by@felixsanzwith a thank you and a hugging rocket emoji. -
Curiosity for PixArt-α’s Choice:
@sofiavasinquired why PixArt-α was chosen by@felixsanzfor optimization over OpenAI’s 8k models, showing interest in the rationale behind the decision. -
First Package Triumph:
@vipitiscelebrated publishing their first package to the Python Package Index (PyPI). -
DevSpot’s AI Integration POC:
@devspotintroduced a Proof of Concept (POC) on GitHub that outlines a scalable approach for working with various AI vendor models and shared the link to their GitHub repository alongside a YouTube video explaining their concept. -
Mysterious Message Mentioning a Discord Channel:
@Amanitasimply posted<#897390720388825149>, which appears to be a mention of another Discord channel, without any additional context provided.
Links mentioned:
- GitHub - devspotyt/open-models: Contribute to devspotyt/open-models development by creating an account on GitHub.
- Mix-and-Match AI - Open Models, The Game Changer!: A brief video explaining the concept behind Open Models, a brand new open-sourced code which allows for an easy integration and usage of various models & AI …
- PixArt-α with less than 8GB VRAM: Perform the inference process of this generative image model with just 6.4GB of VRAM
▷ #reading-group (1 messages):
skyward2989: https://arxiv.org/html/2401.10020v1
▷ #computer-vision (1 messages):
swetha98: Any one knows any libraries for Intelligent character recognition
▷ #NLP (8 messages🔥):
-
Docker Dilemma: Caching Models vs. Volume Storage:
@asprtnl_50418discussed the downside of caching models in Docker: changing any layer or testing another model results in the cache being cleared. The solution lies in using a volume for host permanent storage, which also facilitates model sharing between containers due to their large sizes. -
Model Diet: Shrinking a Sentence Transformer:
@stroggozsuccessfully shrank a sentence transformer using PCA and knowledge distillation but is seeking advice on the size of the dataset required for training the compressed model, given the original was trained on a billion sentences. -
BERT: An Olde but a Goode?:
@frosty04212inquired if BERT is now outdated for token classification, given their assessment of different models for best performance.@stroggozresponded, suggesting that while BERT may be less efficient due to quadratic complexity, it is still very much used and there may not be many better alternatives for token classification. -
Comparing NLP Titans:
@stroggozcontinued the conversation by stating that RoBERTa and Elektra might perform slightly better than BERT. They noted RoBERTa’s faster tokenizer and mentioned that they still use BERT frequently because of its extensive model ecosystem. -
NER Model Recommendation: In the area of token classification for Named Entity Recognition (NER),
@stroggozrecommended using the span marker library.
OpenAccess AI Collective (axolotl) Discord Summary
-
GPU Memory Challenges with FFT on 7H100: Users reported out-of-memory (OOM) errors while running FFT on 7H100 GPUs, discussing the usage of
zero3bf16with Mixtral framework as a potential solution to alleviate the issue. -
Google Automates Code Review Comments: A new paper by Google introduces machine learning approaches to automate the resolution of code review comments, promising to accelerate the development cycle.
-
FastChat’s LLM Benchmarking Tools: The community explored language model evaluation using FastChat’s LLM judge, with discussions on integrating VLLM with Fast Eval and utilizing a backend flag for this purpose.
-
Orion-14B’s Multilingual Prowess Marred by Trust Issues: OrionStarAI released a new Orion-14B model with claims of strong multilingual support, sparking debates over trustworthiness without a contamination check, highlighted in its Hugging Face repository.
-
Model Evaluation Balancing Act: Conversations revolved around the cost-effectiveness of evaluating language models using API calls, with metrics like FastEval’s $5 per evaluation being brought to the table.
-
Phi2 Model’s Config Conundrum Corrected: An error in Phi2’s model configuration was reported, leading to a pull request on GitHub to fix the cofig class inconsistency in the model’s YML file.
-
Tips for Effective Layer Freezing and Fine-Tuning: Axolotl users shared guidelines on freezing layers with LoRA configurations and offered troubleshooting advice for common issues such as fine-tuning crashes, emphasizing the utility of
val_set_size: 0. -
Local Datasets Welcomed by DPO with Intel-format Agreement: Compatibility of local datasets for Direct Prompt Optimization (DPO) was confirmed if the data formatting agrees with Intel’s structure.
-
Solar LLM Embraces the Llama Light: Discussions concluded that the SOLAR-10.7B model should be classified under the “llama” model category based on scale and architecture, and provided a link to its Hugging Face page.
-
Learning Rate and Sample Origin Optimizations for DPO: Emphasis was placed on carefully choosing lower learning rates and using the model’s own bad samples for effective DPO, as shared in a Hugging Face discussion thread.
-
Replicate Help Sought for predict.py Autoawq and vlllm Setup: A user sought guidance on setting up
predict.pyautoawq and vlllm on Replicate.
OpenAccess AI Collective (axolotl) Channel Summaries
▷ #general (32 messages🔥):
- OOM in FFT with High-End GPUs:
@dangfuturesreported out-of-memory (OOM) errors while trying to execute FFT on 7H100 GPUs and conversed with@caseus_about usingzero3bf16with Mixtral framework as a way to mitigate the issue. - Addressing Reviewer Comments with AI:
@noobmaster29shared a new paper by Google on ML-based automation to assist in resolving code review comments, speeding up the development process. - Benchmarking with FastChat: Users discussed options for evaluating language models with
@gahdnahpointing to FastChat’s LLM judge and@dangfuturesinquiring about integrating VLLM with Fast Eval, which@rtyaxconfirmed as possible using a specific backend flag. - New Orion-14B Language Model Debuts:
@brataoprovided a link to the OrionStarAI’s new Orion-14B model which boasted strong multilingual capabilities, prompting mixed reactions from the community questioning trust without a contamination check and model longevity. - Costs of Model Evaluation Using API Calls:
@noobmaster29questioned the cost of evaluating language models using API calls, with@nanobitzstating that FastEval costs about $5 per evaluation.
Links mentioned:
-
[
Resolving Code Review Comments with Machine Learning](https://research.google/pubs/resolving-code-review-comments-with-machine-learning/): no description found
-
OrionStarAI/Orion-14B-Base · Hugging Face: no description found
-
FastChat/fastchat/llm_judge/README.md at main · lm-sys/FastChat: An open platform for training, serving, and evaluating large language models. Release repo for Vicuna and Chatbot Arena. - lm-sys/FastChat
-
FastChat/fastchat/llm_judge at main · lm-sys/FastChat: An open platform for training, serving, and evaluating large language models. Release repo for Vicuna and Chatbot Arena. - lm-sys/FastChat
▷ #axolotl-dev (10 messages🔥):
-
Phi2 Model Revision Error Reported:
@asterix3651shared a model revision error for phi2, revealing a config class inconsistency.@caseus_acknowledged the issue and promised a quick fix once they have computer access. -
Pull Request for Model Config Loader: In response to
@asterix3651’s report,@caseus_submitted a pull request to ensure the model config loader respects the model_revision, addressing the config class mismatch issue. -
Relevance of Speed Enhancements Discussed:
@tiendungmentioned that speedup claims, such as a x30 speedup reported for pro unsloth version, are only significant if the samples are relevant to the same topic. -
Skepticism Over Unsloth’s Speed Claims:
@dreamgenexpressed skepticism, suggesting Unsloth’s claimed speedup is based on non-practical setups.@faldoreand@dreamgendiscussed that the merits of software like Unsloth could be due to factors other than training speed, with@dreamgenhighlighting its customizability.
Links mentioned:
- axolotl/examples/phi/phi2-ft.yml at main · OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions. Contribute to OpenAccess-AI-Collective/axolotl development by creating an account on GitHub.
- make sure the model config loader respects the model_revision too by winglian · Pull Request #1160 · OpenAccess-AI-Collective/axolotl: Description reported in discord: ValueError: The model class you are passing has a
config_classattribute that is not consistent with the config class you passed (model has <class ‘transforme…
▷ #general-help (25 messages🔥):
-
Beginner’s Guide to Layer Freezing with LoRA:
@diabolic6045inquired about freezing model layers using Axolotl and was informed by@nanobitzto start with thelora.ymlconfig which freezes most of the layers.@nanobitzalso reassured@diabolic6045that it’s safe to experiment with these settings. -
Troubleshooting Fine-Tuning Crashes:
@fred_fupsexperienced consistent crashes when fine-tuning Mistral 7B on 3 epochs with QLoRA at exactly 33%.@nanobitzsuggested a solution by settingval_set_size: 0to potentially avoid crashing during evaluation. -
Local Dataset Dilemma Resolved:
@c.gatoinquired about DPO support for local datasets and@dangfuturesconfirmed compatibility after formatting to match Intel’s structure. -
Mixtral Yaml Flexibility for Any Model:
@caseus_revealed that unfrozen parameters options are available for all models, not just Mixtral. When@diabolic6045asked for documentation to figure out parameters, there was no direct link provided. -
Solar LLM Classification Clarified: Several users, including
@dangfutures,@noobmaster29, and@nanobitz, discussed how to set the newly introduced SOLAR-10.7B model, concluding that it should be classified as a “llama” model, considering its scale and architecture.
Links mentioned:
upstage/SOLAR-10.7B-v1.0 · Hugging Face: no description found
▷ #datasets (14 messages🔥):
-
DPO Requires Finer Learning Rate Tuning: ‘xzuyn’ observed that Direct Prompt Optimization (DPO) requires a significantly lower learning rate compared to Supervised Fine-Tuning (SFT)—potentially one order of magnitude lower. They provided an example, suggesting that if 0.0001 is used for SFT, 0.00001 might be more appropriate for DPO, and mentioned related insights by ‘jon’ available in a discussion on Hugging Face (DPO learning rates discussion).
-
Using Model’s Own Bad Samples for DPO is Advantageous: ‘xzuyn’ argued that using poorly generated samples from one’s own model as the “rejected” data for DPO can yield more effective and rapid results than using artificial “fake” bad results.
-
Choosing the Right Rejected Samples: The importance of selecting appropriate rejected samples for DPO was emphasized by ‘dreamgen’ and ‘xzuyn’, with the latter noting that using samples from the model itself, particularly with modified sampler settings to encourage “bad” yet coherent outputs, can be a productive strategy.
-
DPO for Subtle Model Adjustments: According to ‘xzuyn’, DPO could be seen as a “tiny nudge” for model finalization, implying that it works best when chosen and rejected samples are not too dissimilar to what the current model can generate. They suggest DPO is more suitable for incremental refinements rather than broader changes.
-
DPO Easily Corrects ChatGPT Idiosyncrasies: ‘xzuyn’ recommended using DPO to fix common GPT mannerisms like ending sentences with “in conclusion…” or starting with “Surely,” noting that DPO can easily remove these tendencies when they seep into models through the training data.
▷ #replicate-help (1 messages):
dangfutures: does anyone know how to setup predict.py autoawq and vlllm on replicate lol
LlamaIndex Discord Discord Summary
-
Marco Bertelli Guides Chatbot Developers: Marco Bertelli’s comprehensive series offering insights on creating a full-stack RAG chatbot, covering algorithms and full-stack development continues to gain interest. Developers can access the guide through the link in the shared Tweet and view related images.
-
Innovating with Embedding Models for RAG: Discussion around the M2-BERT-80M-32k-retrieval model showcases its capabilities for semantically grounded long-context embeddings in RAG. The model addresses embedding chunking issues and is detailed further in a Tweet and additional imagery.
-
RAG Maestro Opens Doors to ArXiv Insights: Aymen Kallala introduced RAG-Maestro, a web application utilizing RAG to improve research on ArXiv through keyword extraction and indexing. The tool was highlighted in a Tweet with an illustrative guide here.
-
Memory and Cosine Similarity Tools Hot Topics in Discussions: Lack of memory support for query engines contrasts with available tools to calculate cosine similarity; engineers should refer to LlamaIndex docs for Chat Engines and Agents for memory implementation.
-
Gemini Pro Enhances Invoice Data Search with LlamaIndex: The efficient searching and retrieval of semi-structured invoice data sees advancement with Gemini Pro and LlamaIndex, providing a notable step forward for businesses dealing with such digital documents. The impact on the digital universe is discussed in a Medium article by
@andysingal.
LlamaIndex Discord Channel Summaries
▷ #blog (5 messages):
-
Comprehensive RAG Chatbot Tutorial Series by Marco Bertelli: Marco Bertelli’s multistep guide on building a full-stack RAG chatbot is celebrated for its depth, covering algorithms, and both front and backend development. See the ongoing series in the shared Tweet and accompanying image here.
-
Semantically Grounded Long-Context Embedding Models: The M2-BERT-80M-32k-retrieval model presented by
@JonSaadFalconand others introduces a solution to the embedding chunking issue in RAG by grounding retrieval in higher-level semantic context. Further details can be found in the linked Tweet and image here. -
Webinar to Discuss Agentic Software Development: The LLMCompiler will be the focus of a 2024 webinar presented by
@sehoonkim418and@amir__gholami, offering insights into building efficient, performant agentic software. Read more about the agent compiler for parallel multi-function planning/execution in the announcement Tweet with a visual sneak peek here. -
RAG-Maestro Tool for ArXiv Research: RAG-Maestro, developed by Aymen Kallala, is a web application that uses RAG to look up scientific concepts in papers on ArXiv, employing keyword extraction and on-the-fly indexing. The LlamaIndex shared this innovative tool in their Tweet and provided a visual guide here.
-
Building a Full-Stack Complex PDF AI Chatbot Overview: Nipuna from Paragon AI offers insights into creating complex PDF AI chatbots capable of processing numerous intricate documents, detailed in a recent overview. The challenges of handling 40+ docs and thousands of pages with embedded tables are explored in the Tweet and related image here.
▷ #general (48 messages🔥):
- Memory Module for Query Engine:
@nerdaiclarified that LlamaIndex does not support memory for query engines, and recommended using Chat Engines and Agents for memory capabilities. They provided a link to documentation explaining how to implement a SimpleChatStore and ChatMemoryBuffer. - Cosine Similarity Tool Inquiry:
@kush2861asked about a distances_from_embeddings calculator similar to one from OpenAI.@nerdaiconfirmed its availability to calculate the cosine similarity of two embeddings. - Dataset Generator Worker Enhancement Query:
@dangfuturesinquired about the possibility of increasing the number of workers for the dataset generator, to which@nerdairesponded that they have not built in multi-processing for any of their generators yet. - Building Autonomous Vector Storage:
@lhc1921sought guidance on constructing an auto merge vector storage without an LLM service context.@kapa.aisaid that the extracts provided did not detail building such a system and directed@lhc1921to the official LlamaIndex documentation. - Conversational Retrieval Agents with Memory:
@peeranat_fupasked for examples on how to build a Conversational Retrieval Agent with memory using LlamaIndex. Despite several attempts to find a proper example,@kapa.airecommended referring to the LlamaIndex documentation or the GitHub repository due to a lack of specific examples in the provided extracts.
Links mentioned:
- DLAI - Building and Evaluating Advanced RAG: Introduction · Advanced RAG Pipeline · RAG Triad of metrics · Sentence-window retrieval · Auto-merging retrieval · Conclusion
- Chat Engine - Context Mode - LlamaIndex 🦙 0.9.34: no description found
- Chat Stores - LlamaIndex 🦙 0.9.34: no description found
- Prompts - LlamaIndex 🦙 0.9.34: no description found
- Accessing/Customizing Prompts within Higher-Level Modules - LlamaIndex 🦙 0.9.34: no description found
▷ #ai-discussion (1 messages):
- Gemini Pro and LlamaIndex Advance AI Search:
@andysingalshared a Medium article discussing how Gemini Pro and LlamaIndex are aiding in the efficient retrieval of semi-structured invoice data. The introduction highlights the significance of this technology in the digital universe.
Links mentioned:
Unlocking Efficiency: A Search Query for Semi-Structured Invoices with Gemini Pro and LlamaIndex in…: Ankush k Singal
LangChain AI Discord Summary
-
Cheers for LangChain.js Milestone: LangChain.js contributors received appreciation, with special thanks to
@matthewdparkerfor resolving a token text splitter issue. The Twitter acknowledgment celebrates progress since the launch of version 0.1.0. -
Hosting and Troubleshooting LangChain Discussions: Hosting recommendations for LangChain backends included Heroku and porter.run, while an installation issue involving a urllib3 connection pool was reported without a resolution follow-up. A query about integrating LangChain with React was clarified; it functions as a backend requiring API requests from frontend frameworks.
-
Social Cause Meets Software: A call for software development assistance was made for a project to support autistic and neurodivergent individuals, offering prompt structuring expertise in return.
-
LangServe Feedback Feature Inquiry: An observation was made about the missing PATCH endpoint for LangServe’s
enable_feedbackfunction, indicating a possible addition by the inquirer despite its presence inlangsmith-sdk. -
Multifaceted AI Projects and Insights Shared: Demonstrations of AI implementations included a GitHub docs demo, support for a neurodivergent assistance project, a text-based dungeon game, development of a multilingual RAG project on GitHub, and a Medium article examining the role of metadata in enhancing language models.
LangChain AI Channel Summaries
▷ #announcements (1 messages):
- Appreciation for LangChain.js Contributors:
@jacoblee93and@Hacubuexpressed gratitude towards everyone who contributed to the development of LangChain.js this year. Special thanks were given to@matthewdparkerfor fixing a token text splitter overlap issue, marking a significant milestone since the launch of version 0.1.0. Read the full acknowledgment on Twitter.
Links mentioned:
Tweet from Jacob Lee (@Hacubu): Thank you to everyone who’s contributed to @LangChainAI (so far) this year! So much has happened with and since the launch of 0.1.0, and it wouldn’t have been possible without: 🐞 matthewdparker for…
▷ #general (22 messages🔥):
-
LangChain Hosting Suggestions Sought: User
@b0otableasked for recommendations on services to host a LangChain backend service that utilizes OpenAI models.@ricky_gzzsuggested Heroku for prototyping and porter.run on AWS for more production-grade needs, while@baytaewoffered to assist with trying out langserve by contacting [email protected]. -
Troubleshooting LangChain Installation:
@rrvermaa_79263encountered an error with a urllib3 connection pool while trying to install langchain-community and asked for guidance to resolve this issue. -
LangChain and React Development Query:
@yasuke007inquired about using LangChain with React, and@espongesclarified that LangChain is a backend tool, which would require React to make requests to such a backend. -
Assistance Sought for Autistic and Neurodivergent Support Project:
@brotino, an RN and member of the autism spectrum, described their project to support autistic adults and sought assistance from the community for software development challenges, offering their skills in prompt structuring in exchange. -
Using LangChain with Hugging Face Models:
@esraa_45467inquired about implementing features akin to LangChain’sChatOpenAIusing Hugging Face models, by sharing a code snippet for context.
Links mentioned:
Tweet from Preston Thornburg🛡️ (@ptonewreckin): Hey @LangChainAI … you guys doing okay? Your tweet pointing to https://langchain.fi/ seems pretty sketchy
▷ #langserve (1 messages):
- Query About LangServe Feedback Feature:
@georgeherbyinquired about the lack of a PATCH endpoint for updating feedback with theenable_feedbackflag in LangServe, indicating they might add it themselves. They noticed the existence of the function in thelangsmith-sdkcodebase and suspected it might have been an oversight rather than a deliberate omission.
▷ #langchain-templates (1 messages):
jackblack1.: Does anyone have a template for langchain OpenAI assistant with DuckDuckGo search
▷ #share-your-work (5 messages):
-
Showcasing GitHub Docs Demo: User
@jonathan0x56shared a GitHub pull request for a demo project that includes documentation with images and aims to bootstrap a docs repository using materials from langchain-ai/langchain for demonstration purposes. -
Call to Action for a Neurodivergent Support Project: User
@brotinoseeks support for a project to aid autistic adults and the neurodivergent community. They offer their skills in prompt structuring and troubleshooting in exchange for help with software development. -
Dungeon Game Link Shared: User
@friday_livingprovided a link to Gemini Dungeon, but did not include further details or description about the content. -
Introduction of Multilingual RAG Development: User
@akashai4736presented their GitHub repository for a multilingual RAG (Retrieval Augmented Generation) project, showcasing its potential for development in collaboration with Langchain Cohere. The GitHub link can be found here. -
Medium Article on Language Models and Data: User
@rajib2189shared a Medium article discussing the importance of metadata in addition to data when developing language model-based applications using the RAG framework. The article challenges the common belief that more data alone enhances language models.
Links mentioned:
- Gemini Dungeon - Text and Image Based Adventure in DND5E: no description found
- Data is Not what All You Need: The headline of this blog may have prompted a few raised eyebrows or even disbelief. “Is he out of his mind?” might be a question crossing…
- GitHub - akashAD98/Multilingual-RAG: multilingual RAG: multilingual RAG . Contribute to akashAD98/Multilingual-RAG development by creating an account on GitHub.
- alttexter-ghclient DEMO by jonathanalgar · Pull Request #1 · jonathanalgar/docs-demo: Let’s say we want to bootstrap a docs repo. We have five shiny new docs to start with (1x md, 1x mdx, 3x ipynb borrowed from langchain-ai/langchain for our demo purposes). All the docs have images…
DiscoResearch Discord Summary
-
Marlin Swims into AutoGPTQ: The AutoGPTQ repository has been updated to include the marlin kernel, known for its speed and impressive performance, despite having certain limitations, as seen in a pull request update. Meanwhile, performance benchmarks for 4-bit quantized Mixtral on an A100 GPU yielded 9 tokens per second with a batch size of 64.
-
Coders Write Custom CUDA: Discussions hinted at industry professionals like Tri Dao potentially using custom CUDA kernels, which implies advanced optimization techniques in AI models might be more widespread. Training language models using 4-bit quantization from bitsandbytes sparked questions about capabilities similar to GPTQ or AWQ in other quantization schemes.
-
Mind of Kahneman in AI Form: Ambitions to develop an AI agent emulating the cognitive style of Daniel Kahneman were shared, with suggestions to prompt an LLM with his persona or fine-tune on his works. A recent arXiv paper on Self-Rewarding Language Models was highlighted, showing performance surpassing GPT-4 by using self-provided rewards during training.
-
Boosting German Dataset for DPR: The release of Version 2 of the German DPR training dataset adds formal and informal imperative questions to its structure, improving its complexity and utility, with a call for feedback and contributions on GitHub.
-
German LLMs Gain Steam: The conversation covered self-supervised learning adaptations for fine-tuning, excitement about German LLM release, and available quantized versions of the DiscoLM German 7B model. For fine-tuning needs, the Axolotl toolkit was recommended, along with Llama-factory as an alternative to complicated fine-tuning tools.
DiscoResearch Channel Summaries
▷ #mixtral_implementation (6 messages):
-
Marlin Kernel Added to AutoGPTQ:
@vara2096shared a GitHub pull request indicating the addition of the marlin kernel to the AutoGPTQ repository, noting marlin’s impressive speed and performance despite its limitations. -
Benchmarking Mixtral’s Performance:
@vara2096reported achieving a throughput of 9 tokens per second for a 4-bit quantized Mixtral on an A100 GPU, with a batch size of 64. -
Clarification on Throughput Measurement: In a clarification to
@bjoernp,@vara2096confirmed the throughput measurement to be 9 tokens per second serially, rather than 9x64 tokens per second.
Links mentioned:
add marlin kernel by qwopqwop200 · Pull Request #514 · AutoGPTQ/AutoGPTQ: Add marlin kernel. marlin is a very powerful gptq kernel. Although there are many limitations to the applicable model, the speed is nevertheless very close to theory. Also, fused attention is not y…
▷ #general (7 messages):
- Custom CUDA kernels in AI models:
@muhtashampointed out that despite claims of not using quantization, certain industry professionals like Tri Dao are known for writing custom CUDA kernels which could indicate advanced optimization techniques in AI models. - Training on quantized models using bitsandbytes:
@vara2096inquired about the ability to train LoRAs on top of a quantized model using 4-bit quantization from bitsandbytes and asked if any other quantization schemes such as GPTQ or AWQ allow for similar capabilities. - Aspiring for an AI Mind like Kahneman:
@sabu7003proposed the concept of developing an AI agent emulating the thought process of behavioral economist Daniel Kahneman. This AI would integrate machine learning with Kahneman’s principles to potentially offer business and marketing consultations. - Recommendations for building a Kahneman-like AI:
@rasdanisuggested that this Kahneman-like AI could be approached by prompting an LLM with Kahneman’s persona or fine-tuning on his publications, also mentioning character.ai as a potential resource and the influence of Kahneman’s ideas on AI and reinforcement learning research. - Self-Rewarding Language Models Outperforming GPT-4:
@philipmayshared a recent research paper on Self-Rewarding Language Models (arXiv:2401.10020), highlighting a new training method where a model uses itself as a judge to provide its own rewards, resulting in performance surpassing that of GPT-4 and others on the AlpacaEval 2.0 leaderboard.
Links mentioned:
Self-Rewarding Language Models: We posit that to achieve superhuman agents, future models require superhuman feedback in order to provide an adequate training signal. Current approaches commonly train reward models from human prefer…
▷ #embedding_dev (1 messages):
- German DPR Dataset Enhanced:
@philipmayannounced that Version 2 of the German DPR training dataset is complete, now featuring normal questions, formal (sie) imperative questions, and newly added informal (du) imperative questions. Feedback is solicited, and the dataset is available at the German dataset for DPR model training on GitHub.
Links mentioned:
GitHub - telekom/wikipedia-22-12-de-dpr: German dataset for DPR model training: German dataset for DPR model training. Contribute to telekom/wikipedia-22-12-de-dpr development by creating an account on GitHub.
▷ #discolm_german (8 messages🔥):
- SF Trainer Shares Insights: User
@_jp1_discussed employing self-supervised learning (SSL) techniques where answers from early model iterations are rejected in favor of ground truth during the fine-tuning process, similar to an approach taken by Intel with their neural chat. - Legal Eagle Excited by German LLMs: User
@rapsac.expressed gratitude for the release of the German language LLMs and is optimistic about applying fine-tuning to German legal datasets, anticipating performance between GPT-3.5 and GPT-4 levels. - Quantized DiscoLM German 7b Models Released: User
@rasdanishared quantized versions of the DiscoLM German 7B model, detailing the assistance of Massed Compute and providing comprehensive links to various quantized models. - How to Fine-Tune DiscoLM German?: User
@thomasrenkertinquired about methods to fine-tune the DiscoLM German model, to which@bjoernpresponded by recommending the Axolotl toolkit. - Seeking Simpler Fine-Tuning Methods: After
@thomasrenkertmentioned difficulties with fine-tuning directly in oobabooga, user@nyxkragesuggested Llama-factory as a possibly more user-friendly alternative.
Links mentioned:
- GitHub - OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions: Go ahead and axolotl questions. Contribute to OpenAccess-AI-Collective/axolotl development by creating an account on GitHub.
- TheBloke/DiscoLM_German_7b_v1-AWQ · Hugging Face: no description found
- TheBloke/DiscoLM_German_7b_v1-GPTQ · Hugging Face: no description found
- TheBloke/DiscoLM_German_7b_v1-GGUF · Hugging Face: no description found
Latent Space Discord Summary
-
Podcast Pride and Educational Recs:
@swyxioannounced their podcast hitting #16 on the podcast charts, and state a shared excitement among guild members. An educational resource explaining the transformer architecture behind LLMs was highlighted by@guardiang, providing a YouTube link for fellow tech enthusiasts. -
Elicit and Anthropic in the Spotlight: The utility of elicit.org was recommended by
@swyxiofor insights on user needs, while@aravindputrevusought technical assistance from someone at Anthropic. -
Deciphering the Self-Attention Enigma: Discussions led by
@swyxioand@eugeneyandelved into how self-attention matrices at <8k are manageable but require clever techniques like “rope and yarn” and practical tricks for larger contexts, referencing FlashAttention and the use of alibi. -
Superhuman Feedback Frontier Unveiled: A new method involving language models generating and evaluating their own rewards was brought up by
@swyxio, spotlighting a tweet by@jasewestonwhich reflects growing interest and potential implications in the field, supported by an arXiv paper. -
Simple Thanks and Corporate Pod Curiosity: User
@420gunnaoffered a straightforward expression of gratitude, and guild members discussed the surprising popularity of the corporate-branded a16z podcast.
Latent Space Channel Summaries
▷ #ai-general-chat (14 messages🔥):
- Simple Gratitude from 420gunna: User
@420gunnaexpressed thanks with a simple “Thanks 🙇♂️”. - Podcast Chart Climbers:
@swyxioshared that their podcast ranked #16 on the charts, surpassing Y Combinator, while@420gunnacontributed to the rise by listening during a bike ride. - Elicit.org Mention for User Needs:
@swyxiorecommends checking out elicit.org and highlights@914974587882700800for insights on user needs. - A16z Podcast’s Surprising Popularity:
@austintackaberryand@swyxiodiscussed how the a16z podcast maintains high rankings despite a perceived corporate brand. - Request for Assistance from Anthropic: User
@aravindputrevuis in search of someone from Anthropic to offer help. - Educational Resource on Transformers:
@guardiangpraised and shared a YouTube video that explains the transformer architecture behind LLMs.
(Note: Links and references to specific users are based solely on the given chat history, with no external sources or additional context available from the system’s knowledge.)
Links mentioned:
- Bloomberg - Are you a robot?: no description found
- Transformers explained | The architecture behind LLMs: All you need to know about the transformer architecture: How to structure the inputs, attention (Queries, Keys, Values), positional embeddings, residual conn…
▷ #llm-paper-club (6 messages):
-
Clarifying the Size of Self-Attention Matrices: @swyxio pointed out that for context windows <8k, a full self-attention matrix is feasible, but techniques used for >100k are not public, and they likely involve methods that avoid computing the full matrix. They mentioned “rope and yarn” as potential artificial context extension techniques that could be used.
-
Insight into Practical Tricks for Large Contexts: @eugeneyan explained that even though 128k x 128k matrices could theoretically exist, tricks like computing in loops and caching vectors as described in FlashAttention and utilizing alibi for context size, as discussed in Ofir Press’s post, are practical ways to manage large contexts without needing the full matrix.
-
Validating Intuitions About Attention Scalability: @dzidex expressed appreciation for the clarity provided by swyxio and eugeneyan on how transformers handle large context windows, confirming their intuition about the computational feasibility.
-
Noteworthy Paper on Self-Rewarding Language Models: @swyxio shared that the self-rewarding LLM paper is gaining notable attention. The approach described in the paper involves using language models to generate and then evaluate their own rewards, potentially paving the way for “superhuman feedback,” as highlighted in the tweet by @jaseweston and detailed in the corresponding arXiv paper.
Links mentioned:
- Tweet from Jason Weston (@jaseweston): 🚨New paper!🚨 Self-Rewarding LMs - LM itself provides its own rewards on own generations via LLM-as-a-Judge during Iterative DPO - Reward modeling ability improves during training rather than staying…
- FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness: Transformers are slow and memory-hungry on long sequences, since the time and memory complexity of self-attention are quadratic in sequence length. Approximate attention methods have attempted to addr…
- The Use Case for Relative Position Embeddings: We’re in 2022 but many of our most popular causal language models (LMs), including GPT-3, still use absolute positional embeddings. I believe we should stop using those and move to relative positional…
Skunkworks AI Discord Summary
Only 1 channel had activity, so no need to summarize…
- Aspiring to AI Pantheon:
sabu7003proposed an ambitious project to create an AI that mirrors the thinking of behavioral economics expert Daniel Kahneman, with the aim of delivering nuanced consultations like Kahneman himself. They invited thoughts on the feasibility of this project using Transformer Architecture. - Event Scheduling Dilemma:
yikesawjeezhighlighted the lack of events on the calendar and suggested planning the event today, whilefar_elresponded with availability for planning tomorrow due to a busy schedule today. - Collaborative Workspace Query:
yikesawjeezproposed testing simultaneous access to the lab on the basementagiclub login and asked.mrfooto create and save a notebook in/workto confirm shared accessibility. - Note Sharing Experimentation:
yikesawjeezand.mrfoodiscussed logistics of sharing notes and accessing notebooks on a shared account, with.mrfooinitially working on their own account but expressing willingness to test joint account access later. - Tasks for Contributions:
dook4requested a list of tasks or material to read through to determine potential areas for contribution to the project.
LLM Perf Enthusiasts AI Discord Summary
-
Mixtral Models Face Sagemaker Hurdle:
@ajamjoomencountered a TypeError when trying to host Mixtral-Instruct on Sagemaker PD4 with TRT-LLM, which was missing the'trtllm_modules_to_hf_modules'argument inLoraConfig.from_hf(). -
Nous-Hermes System Prompt Hack: A Twitter post by @Teknium1 suggests using a system prompt for better outputs in Nous-Hermes 2 Mixtral.
-
In Pursuit of Extended Contexts:
@alyosha11is seeking efficient methods to increase context length in models like Yarn and Rope, with@ivanleomkmentioning self extend as a possible avenue, as discussed on Twitter. -
Infrastructure Insights Wanted:
@ayenemsparked a call for sharing insights on batch versus online processing, deployment infrastructures, re-training necessities, and related tooling, while@jeffreyw128queried about the proper placement for infrastructure discussions within the community channels. -
Enhancing Reranking with ColBERT: In the #rag channel,
@shacrwhighlighted a Twitter update about reranking with ColBERT but did not provide further context or a detailed discussion on the matter.
LLM Perf Enthusiasts AI Channel Summaries
▷ #opensource (6 messages):
-
Sagemaker and TRT-LLM Compatibility Issues:
@ajamjoomis seeking advice on hosting Mixtral-Instruct (or any Mistral model) on Sagemaker PD4 with TRT-LLM due to a custom Docker image error. The TypeError in question is related toLoraConfig.from_hf()missing the'trtllm_modules_to_hf_modules'argument. -
System Prompt as a Solution: While not directly related to the initial issue,
@ajamjoomshared a link from@Teknium1suggesting the use of a system prompt to avoid weird outputs in Nous-Hermes 2 Mixtral, referencing a Twitter post. -
Seeking Ways to Increase Context Length:
@alyosha11inquired about the best method to increase context length today, expressing dissatisfaction with Yarn and Rope. -
Self-Extend as a Potential Solution: Replying to the context length concern,
@ivanleomkrecommended looking into self extend, which has been recently discussed on Twitter. However, Ivanleomk has yet to try it personally.
Links mentioned:
Tweet from Teknium (e/λ) (@Teknium1): Okay I found what may be a solution to anyone getting weird outputs from Nous-Hermes 2 Mixtral. Use a system prompt by default. I was able to reproduce rambling or failure to stop properly in transfo…
▷ #feedback-meta (2 messages):
- Brainstorming Infrastructure and Use Cases:
@ayenemproposed a discussion on experiences and ideas regarding batch vs. online processing, deployment infrastructures tailored to specific use cases and constraints, as well as frequent re-training needs, tooling, and learned lessons. - Query on Infrastructure Channel’s Placement:
@jeffreyw128mentioned that there used to be an infrastructure channel and questioned whether such discussions should be categorized under performance.
▷ #rag (1 messages):
shacrw: reranking with ColBERT https://twitter.com/virattt/status/1749166976033861832
Alignment Lab AI Discord Summary
Only 1 channel had activity, so no need to summarize…
- Envisioning an AI Top Thinker: User
@sabu7003proposed the idea of developing an AI agent with the expertise of behavioral economist Daniel Kahneman that can provide consultations and solutions in marketing and management. They asked whether such an application using Transformer Architecture has been considered. - Character AI in Action: In response to
@sabu7003,@desik_agipointed out that Character AI has made it possible to interact with digital versions of historical figures like Socrates or Steve Jobs, which might align somewhat with@sabu7003’s vision. - Beyond Transformer Limitations:
@ruschhighlighted that the main challenge is not the Transformer architecture but rather the limitations of current language modeling data and approaches, suggesting that more is needed to fulfill the vision discussed by@sabu7003. - Identifying Development Avenues for AI:
@ruschfurther added that future breakthroughs in AI might come from developments in multimodal systems, self-play, and advanced planning capabilities, pointing toward potential growth areas in the quest to develop more sophisticated AI agents.
The Datasette - LLM (@SimonW) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The YAIG (a16z Infra) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.