Lumiere - text to video
Enter Lumiere from Google Research. Every part of this video is computer generated:
In particular I would draw your attention to their inpainting capabilities - watch the syrup pour on the cake and stay there:

This is a step above anything we’ve yet seen coming out of Pika and Runway. This seems to come from a Space-Time diffusion process:
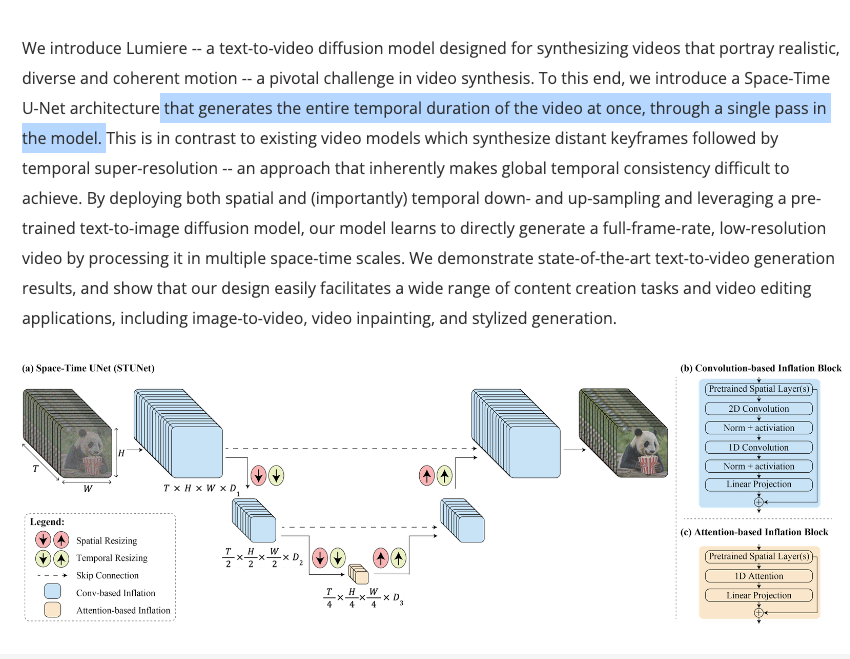
which we think Einstein would particularly enjoy.
Code Evals beyond HumanEval
In other news, Manveer of UseScholar.org is collating a comprehensive list of all evals, including some code ones we haven’t heard of:
- https://github.com/amazon-science/cceval
- https://infi-coder.github.io/inficoder-eval/
- https://evalplus.github.io/leaderboard.html
- https://leaderboard.tabbyml.com/
- https://huggingface.co/datasets/mbpp
- https://huggingface.co/datasets/nuprl/CanItEdit
—
Table of Contents
[TOC]
PART 1: High level Discord summaries
TheBloke Discord Summary
-
Reheating the Old Flamewar: A fiery debate erupted around AI and roleplay, spurred by
@frankenstein0424and@kalomaze, steering the conversation towards moderation and the lighter side of things with humor. -
The Rat Pack’s Digital Cards: Rat-themed character cards flooded
#general, enticing a range of reactions from@rogue_variant,@mrdragonfox, and@.justinobserver. -
Model Mayhem: Seeking API Assistance:
@priyanshuguptaiitgnavigated the labyrinth of running models like Mistral-7B through an API, aided by@itsme9316and@kalomaze, among others. Missing tokenizers and fine-tuning generated much buzz in the hive. -
Need for Speed: GPUs & Ai Model Rentals: The community dove deep into GPUs, discussing storage on platforms like runpod.io and pondering over NVIDIA’s A100 GPU end-of-life, alongside practical nuances of renting GPUs for AI processing.
-
Discussion of LLM Deployment and API Usage:
@frankenstein0424opened a dialogue seeking insights on deploying AI models for bot hosting, with responses pointing towards utilizingSillyTavernfor connecting LLM APIs such as together.ai and mistral.ai. -
Probing Mergekit’s Possibilities:
@222gateinvestigated the potential of mergekit to connect gguf models while also seeking wisdom on the daring endeavor of fusing vision and non-vision AI models. -
Frankenstein’s Model: Conversations center on LLava’s multimodal abilities and the aspiration of frankenmerging—
@seleaclarifies LLava’s working and discusses the challenges inherent in model cross-integration and training.
Nous Research AI Discord Summary
- Antique Data for Modern Testing: One user is testing models using Q&As from antique school books, questioning the reliability of models on current datasets.
- Learning Rates for LLMs Discussed: A consensus is suggesting to start with learning rates around 1e-5, referencing rates from previous architecture papers, and adjusting based on early epoch observations.
- RestGPT Earns Recognition: RestGPT is gaining attention as an example of LLMs controlling applications via RESTful APIs, showcasing the expanding capabilities of LLMs in real-world interfacing.
- Inference and Fine-Tuning Quirks: Various users have noted issues with inference methods, including sporadic
EOStoken inclusions, as well as OOM issues during LLM fine-tuning, with suggestions to sort data by decreasing length to troubleshoot. - Code-Related Evaluations for LLMs: Benchmarks like
HumanEval,MBPP, andDeepSeekare being used for LLM evaluations, along with a shared concern about the maintenance of the Hugging Face code and open PRs.
Mistral Discord Summary
-
Mistral Instructs on Autocomplete Design:
@i_am_domprovided clarification that Mistral Instruct is designed as an autocomplete system which would suggest omitting tags for plain text input. Sophia Yang’s association with Mistral garnered attention in the community, confirmed by her responsive emoji. -
Deployment & docker with vLLM: vLLM supports using a local model file with the
--modelflag, and for docker users, the HuggingFace cache directory is bind-mounted which eliminates the need to redownload the model on Docker rebuilds. -
Mixtral 8x7b Summarization Issues: Users reported unpredictable response cutoffs in summarization tasks with Mixtral 8x7b, despite stable VRAM, and changing prompt syntax was suggested as a partial fix. Meanwhile, JSON-formatted API responses remain a challenge and Mistral’s 7B models are now deployable through Amazon SageMaker JumpStart.
-
Finetuning Challenges and Recommendations: Attempting to finetune the Mixtral model appears costly and complex with mixed success, while ColbertV2 is recommended for training embeddings models. Both prompt optimization and fine-tuning were also discussed as methods to improve results.
-
Sharing Code for Debugging and Client Package Discussions:
@jakobdylancshared a link to their code on GitHub to debug an issue with the “openai” python package, which led to a discussion about the comparability of Mistral’s client library. The conversation included the possibility of transitioning to Mistral’s package for its lightness but raised concerns about compatibility with vision models. -
Philosophical and Math-Transformers Engagement: A user’s philosophical inquiry did not garner traction, while another suggested combining mathematical theory with transformer models and the A* algorithm to produce new mathematical concepts, which reflects the community’s creative and theoretical discussions.
Key links mentioned:
- Mistral 7B models on SageMaker
- Discord LLM Chatbot code snippet
- Mistra - Overview on GitHub
- OpenAI python package
LM Studio Discord Summary
- Ubuntu Users Overcome libclblast.so.1 Hurdle: Ubuntu 22.04 users faced a missing
libclblast.so.1error in LM Studio, which was tackled by creating symbolic links as a fix. - Apple Neural Engine Integration in LM Studio: Discussions in LM Studio probed the utilization of Apple’s Neural Engine via Metal API, and the “asitop” tool was suggested for monitoring.
- Mixing and Matching AI Models with LM Studio: An inquisitive approach to integrate the Retrieval-Augmented Generation (RAG) with LM Studio was met with suggestions pointing to third-party applications and setup help.
- Model Behavior and Performance Variance: LM Studio users grappled with model inconsistency issues, sharing tips like reducing “Randomness” or “Temperature” settings, and queried about model difference, such as between Dolphin versions 2.5 and 2.7, although the Discord link with specifics was not accessible in the provided content.
- CodeShell’s GPU Acceleration Conundrum: Users reported that GPU acceleration was greyed out for CodeShell in LM Studio, with a possible workaround involving renaming the model file to insert “llama,” but with uncertain results.
- Hardware Enthusiasts Wrestle with VRAM Display Errors: One user’s Nvidia 3090 displaying “0Bytes” of VRAM kicked off discussions on hardware specifications, budget-fitting setups for running models like Mixtral, and stability configurations for offloading workloads to GPU.
- Enticing Intel GPU Support on the Horizon?: A GitHub pull request hinted at upcoming support for Intel GPUs in llama.cpp, potentially boosting LM Studio’s hardware compatibility.
OpenAccess AI Collective (axolotl) Discord Summary
Logit Distillation’s Progress and Voice Synthesis Challenge: Discussions revealed progress in logit distillation using GPT-4 logits with success in backfilling strategies. However, adding custom tokens for voice synthesis to LLMs, as high as 8k, would require extensive pretraining, as shared by participants like @ex3ndr, @le_mess, and @stefangliga.
Jupyter SSL Woes and Self-Rewarding Language Models: SSL issues with Jupyter in the Latitude container surfaced without a solution, leading @dctanner to utilize SSH port forwarding. Interest in Self-Rewarding Language Models sparked discussion, with a PyTorch implementation shared by @caseus_.
DPO Dataset Loading Success, Strategy Struggles, and Local Dataset Queries: Members discussed overcoming DPO dataset loading issues using a PR, with @dangfutures using a micro batch size of 1 amidst out-of-memory errors. There was a collaborative effort to address prompt strategies and finetuning with llava models, indicating the Axolotl framework’s flexibility, referenced by @caseus_, @noobmaster29, and @gameveloster.
Insight into Optimal LoRA Hyperparameters and Dataset Overlap Confirmation: A shared Lightning AI article provided insights on effective LoRA hyperparameter usage, as @noobmaster29 and @c.gato discussed alpha, rank, and batch size variations. Dataset overlap concerns between dolphin and openorca datasets were confirmed, signaling data redundancy awareness.
YAML Configuration and Prompt Tokenization for RLHF: RLHF projects encountered a KeyError within YAML configurations, but a resolution via new type formats (chatml.argilla and chatml.intel) was found and shared by @alekseykorshuk. Configurations for local datasets and prompt tokenization strategy updates were also discussed, emphasizing the evolving nature of these components.
Cog Configurations for ML Containers: @dangfutures shared a Cog configuration guide detailing the use of CUDA “12.1”, Python “3.11”, and Python packages installations for machine learning containers, as per the Cog’s documentation. This practical snippet demonstrates active community guidance on infrastructure setup.
Eleuther Discord Summary
Byte-Level BPE Enables Multilingual LLM Responses: The Llama 2 model generates responses in multiple languages using byte-level BPE, which supports Hindi, Tamil, and Gujarati.
Mamba’s Scalability Questioned: Enthusiastic debate unfolded over Mamba’s potential to scale and replace Transformers, with a lack of evidence concerning its performance at larger scales provoking skepticism among technical users.
Google Steals the Show with Lumiere: Google Research’s space-time diffusion model for video generation, Lumiere, attracted attention, despite concerns over dataset size and data advantages.
First-of-its-kind Conference on Language Modeling: Excitement buzzed around the announcement of the inaugural Conference on Language Modeling at the University of Pennsylvania, promising to bring deep insights into language modeling research.
MoE Implementation Challenges and Parallelism: A developer shared a pull request to implement Mixture of Experts (MoE) in GPT-NeoX, voicing conundrums on validating MoE with single GPU limits and seeking insights into parallelism optimizations, while another pull request scrutinizes the potential of fused layernorm in performance enhancements.
LAION Discord Summary
-
Quick Model Training Estimates: A training time inquiry from
@astropulseregarding a tiny model of size 128x128 led@nodjato estimate a couple of days’ runtime on a dual 3090 rig, referencing Appendix E of an unspecified paper for further details. -
GPT-4 Caps Confusion: User
@helium__discussed reduced token caps for GPT-4 with others like@astropulseconfirming they have encountered similar constraints. -
Implications of Image Scale on Model Performance: According to
@thejonasbrothers, ImageNet models with resolutions under 256x256 tend to underperform, advocating for larger image resolutions despite increased training times. -
Safe Multimodal Dataset Discussions: A conversation led by
@irina_rishregarding the safety and integrity of datasets for multimodal model training saw participation and solution-seeking by@thejonasbrothers,@progamergov, and others. -
First Language Modeling Conference Promoted:
@itali4noinformed about the Conference on Language Modeling (CoLM) that is scheduled to happen at the University of Pennsylvania. A pertinent tweet provides more details about the event. -
Innovations in Reward Modeling: A paper shared by
@thejonasbrotherssuggests Weight Averaged Reward Models (WARM) as a solution for reward hacking in LLMs, find the details in the linked paper. -
Advancing Unsupervised Video Learning:
@vrus0188showcased a paper on VONet, an unsupervised video object learning framework outperforming contemporary techniques, with the corresponding code available on GitHub.
HuggingFace Discord Summary
-
HuggingFace Introduces New Perks and Releases: Community members are engaging with new activities and opportunities highlighted by HuggingFace, including a new channel for high-level contributors, the second chapter of the Making games with AI course, and a performance breakdown on how Gradio was optimized. Furthermore,
transformers v4.37features new models and a 4-bit serialization, while Transformers.js now supports running Meta’s SAM model in the browser. -
Enthusiasm and Challenges in Open-Sourcing and Machine Learning: Open-source contributions remain a vibrant part of the community’s spirit. Users report difficulties with ONNX model exports and seek starter guides for learning machine learning — being directed to a useful guide on Hugging Face. Another user is creating a privacy-conscious transcription tool for sensitive audio consultations, intending to use Hugging Face’s transformers and pyannote.audio 3.1, combining it with Go and protobuf definitions.
-
AI Innovation and Collaboration Showcase: The channel features a variety of AI projects and intellectual discussions, including InstantID for identity-preserving generation and Yann LeCun’s endorsement. Users also share information about Hedwig AI’s new video platform and inquire about AI background effects used in a YouTube video. Open-source contributions like QwenLM’s journey with Large Language Models are presented with related resources.
-
Creators Flaunt Their Latest AI Tools and Studies: Community members show off enhancements such as a faster
all-MiniLM-L6-v2, scripts for PCA in embedding comparisons, and projects for detecting fakes visually. An enhancement of the Open LLM Leaderboard with Cosmos Arena gets a nod, and tools like HF-Embed-Images for easy image dataset embedding, 3LC for ML training and data debugging, and Gabor Vecsei’s GitHub repositories are highlighted. -
Peering into the Diffuser-Discussions: Karras’s improvements in DPM++ generate anticipation among users, who also share reflections on diffusion scheduling and its origins, citing k-diffusion and a paper about diffusion-based generative models. One user is working on diagrams for diffusion models to gain a comprehensive understanding for potential reimplementation.
-
Exploring NLP and Diffusion Models: The NLP channel discusses the nuances of model parallel training, with a guide being shared to help transition from single GPU to multi-GPU training setups. Curiosity arises about multilingual models generating responses without direct language tokens, while slow inference issues with DeciLM-7B models prompt users to seek speed optimization solutions.
Perplexity AI Discord Summary
-
RPA AI Efficiency and Dark Mode Dominance: Discussions touched on the efficiency of RPA AI, while users lamented the lack of a light mode in labs, noting only dark mode availability. Frustrations also surfaced with Android microphone permission settings lacking adequate options.
-
Dream Bot Discontinued Creating Channel Confusion: Confirmations were made regarding channel closures, with notably the Dream bot being no longer available, leading to user confusion and a suggestion for more regular news summaries on channel updates.
-
GPT-4 vs. Gemini Pro Clarified: Users sought to distinguish between GPT-4 and Gemini Pro models within Perplexity AI’s pro version, receiving guidance on model selection settings, and prompting community managers to encourage community recognition of helpful contributions.
-
Feature Inquiry and Credit Support: Questions arose about a potential teams feature and issues with credit support, alongside speculation regarding future app support for Wear OS in light of a potential collaboration with Rabbit.
-
Extended API and VSCode Integration Hints: There were requests for information on increasing API rate limits for product integration, recommendations for the Continue.dev extension to integrate with VSCode, and light-hearted encouragement for Pro subscribers to donate credits to an imaginary “church of the God prompt”.
LlamaIndex Discord Summary
-
Hackathon Heats Up with LlamaIndex: IFTTT is hosting an in-person hackathon from February 2-4, featuring $13,500 in prizes, including $8,250 in cash, with the objective to build projects that solve real problems. The excitement is palpable and expertise is guaranteed with access to mentors. Hackathon announcement tweet.
-
Meet MemGPT for Memorable Chatbots: MemGPT is a new OSS project, highlighted by
@charlespacker, designed for creating chat experiences with enriched capabilities like long-term memory and self-editing, leveraging LlamaIndex technology for advanced AI chat solutions. It can be installed via pip, paving a path to a personalized AI experience. OSS project spotlight tweet. -
SQLite Meets Llama-Index:
@pveierlandasked about any existing sqlite-vss integrations for llama-index but no documentation or solutions could be identified during the discussions. -
Pandas Query Engine Pandemonium: Members discussed issues related to the PandasQueryEngine with open-source LLMs like Zephyr 7b, shedding light on the complexity of query pipelines in large language models. Documentation was shared but the pressing CSV file issue in RAG chatbot building remained largely unresolved.
-
Enhancing RAG Chatbots with Dynamic Knowledge:
@sl33p1420provided insights through their Medium article on how to augment RAG chatbots by integrating dynamic knowledge sources. The comprehensive guide walks readers through the nuances of model selection and server setup to chat engine construction for creating a robust LLM-powered RAG QA chatbot. Empowering Your Chatbot article.
OpenAI Discord Summary
-
AI Community Connections Fall Short: A user sought more LLM discord servers, but received no recommendations, highlighting a potential gap in community resource sharing.
-
AI Behavior Benchmark: The comparison of AI diversity to human complexity prompted discourse, underlining the notion that a variety of AI behaviors might emerge from distinct designs and environments.
-
Seeking the Best Tools: Queries for effective LLM evaluation & monitoring tools for a GPT-4-based chatbot were raised but went unanswered, indicating a demand for such resources.
-
Image AI Scrutiny: Questions about Dall.E’s image handling capabilities were asked, however, there was no conclusive discussion on the specifics or causes of the issues.
-
AGI Control Argument: Control over AGI dominated conversations with questions around who will maintain authority over such technology and considerations about its potential uses.
-
File Upload Constraints Clarity: Clarifications were made about limits for file uploads in Custom GPT (up to 20 files, 512MB each, and 2 million tokens for text files), while discussing strategies to bypass the restrictions, such as merging documents.
-
GPTs Marketplace Vanishing Act: An inquiry was made about missing CustomGPTs on GPTs Marketplace, which remained unresolved, signaling a possible need for transparency or technical support.
-
Word Processing with Grimoire GPT: The development of a word processor using Grimoire GPT within ten minutes was shared, showcasing the rapid implementation capabilities of GPT-based applications.
-
Custom GPT Network Troubles: Network errors following responses from a custom GPT were reported with no solutions presented, highlighting continuing technical concerns within the community.
-
Thread Intricacies in GPT: Confusion surfaced when a file from one GPT thread seemingly influenced another, suggesting possible file handling issues across threads, with the community awaiting confirmation on expected behavior.
-
Enhanced Context Management for AI: A concern regarding the handling of chat logs for extracting information was mentioned, specifically about the significant impact the size and format of logs can have on the AI’s performance in this area.
-
Refining AI Assistance via Prompts: Suggestions for prompt ideas suitable for organization or executive assistance roles were discussed, with emphasis on tailoring Custom GPT prompts to include user background info for enhanced performance.
-
Championing Clear Communication Goals: Advice on refining tasks within the description fields of a custom GPT was shared, with the recommendation to articulate clear objectives and desired outcomes, whether seeking AI or human collaboration.
-
Simplicity vs. Effectiveness in AI Command: A user advised focusing on clear goals over the ‘most effective’ language when guiding AI, suggesting a pragmatic approach to achieve desired outcomes.
DiscoResearch Discord Summary
-
Prompt Perplexity? Template Tinkering To The Rescue: Community collaboration identifies a discrepancy in templates between a local and demo instance of a model, suggesting f-strings and newline formatting for better compatibility with DiscoLM models. Guidance includes reference to DiscoLM German 7b v1 and community gratitude for support in navigating LLM intricacies.
-
Translation Evaluation and Predictive Musings: The implementation of Lilac for translation quality and Distilabel for filtering bad translations is discussed, though GPT-4 costs are mentioned as a concern. Llama-3 predictions emphasize a 5-trillion-token pretraining focused on multilingual capability, with a hat tip to advanced context chunking research, and a new German LM with a 1-trillion-token dataset announces its impending debut, hinting at significant compute demands.
-
Mistral Molds New Paths: A project similar to the Mistral embedding model is launched on GitHub utilizing Quora data, with discussions around hosting on Hugging Face or GitHub and whether to craft a BigGraph or Table Embedding model. Also, Voyage’s new code embedding model,
voyage-code-2, is spotlighted for its advancements in semantic code retrieval, detailed in their blog post. -
Axolotl Adoption Anecdotes: Troubleshooting for Axolotl includes advice on dataset integration using supported formats and referencing in the Axolotl config, managing GPU recognition in Docker with the NVIDIA Container Toolkit, and a hint to seek specialized help on the Axolotl Discord. A problematic newline issue with DiscoLM German model prompts a community chipset fix, amending the
config.jsonto resolve output glitches as discussed on Hugging Face.
Latent Space Discord Summary
-
Karpathy Sheds Light on Tech’s Human Impact: Andrej Karpathy’s new blog post discusses the difficulty those outside the tech industry face in adapting to rapid technological changes. Anxiety and discomfort are common emotional responses to the pace of innovation.
-
Perplexity’s Complex Progress Visualized: A tweet from
@madiatorshows the non-linear development trajectory of the AI model Perplexity over a span of three months. -
Scaling Down Model Size While Keeping Cognition Intact: Research on training smaller language models (LMs) reveals potential to maintain grammar and reasoning capabilities, as discussed in the TinyStories paper.
-
Discord Enlists AI for Smarter Notifications: Discord has begun using large language models (LLMs) for summarizing community messages to create notification titles, signaling a potential shift in privacy policy considerations.
-
Breakthrough in Image Generation by Stability AI: Stability AI has developed a diffusion model capable of generating megapixel-scale images outright, which could signal the end of traditional latent diffusion techniques.
-
Lucidrains Set to Tackle SPIN and Meta Paper:
@lucidrainsis preparing implementations of SPIN and a new Meta paper approach in separate projects, with self-rewarding-lm-pytorch being the repository to watch for progress updates.
LangChain AI Discord Summary
-
LangChainJS Experimental Foray:
@ilguappohas shared an in-development project on GitHub entitled LangChainJS Workers which controversially strays from best web API practices but explores a novel endpoint for emoji reactions in Discord messages. They are also tackling the steep learning curve of TypeScript and its integration into the current project. -
Teaming Up for RAG Systems: An interest in end-to-end Retrieval-Augmented Generation (RAG) solutions has been voiced by
@alvarojauna, seeking collaborations or precedents, while@allenpan_36670has sparked a clarifying discussion on GPT chat completion’s handling of message lists, with@lhc1921alluding to ChatML’s prompt structures as a method for handling such data. -
Initiating Intelligent PDF Dialogues:
@a404.ethbroadcasted the launch of a tutorial series with Part 1 available on YouTube, guiding users through the creation of Full Stack RAG systems enabling conversations with PDF documents leveraging PGVector, unstructured.io, and semantic chunker technologies. -
LLaMA Outshines Baklava in Artistic Judgement: In a comparison battle of AI models,
@dwb7737posted findings on a GitHub Gist showcasing LLaMA’s superior performance over Baklava in art analysis tasks. -
Engineers Beware of Mischievous Links: A cautionary note regarding a potential spam message posted by
@eleussin the langserve that included a sequence of bars, underscores, and a suspicious Discord invite link, implying the need for vigilance against such behaviors in technical communities.
LLM Perf Enthusiasts AI Discord Summary
- New Horizons for LLM Perf Guild:
@jeffreyw128kicked off 2024 with an energizing welcome and revealed intentions to expand the Discord guild through a new wave of select invitations and member referrals. - Eyeing the State-of-the-Art in Document Layout: Discourse in the guild highlighted the Vision Grid Transformer as a cutting-edge model for understanding document layouts, particularly excel at identifying charts within PDFs as shared by
@res6969, with the GitHub repository available here. - #share Your Knowledge: A new channel named #share emerged from community collaboration, ready to house mutual knowledge exchanges, as decided by
@degtrdgand@jeffreyw128. - Synergy Through LLM Activities:
@yikesawjeeztouched on the vibrancy of the LLM space, pointing out engaging happenings such as paper clubs, implementation sessions, and codejams which are quite the nexus for the LLM performance aficionados. - Infiltrate with Intelligence: In a light-hearted tone,
@yikesawjeezproposed that members expand their reach and influence by bringing their LLM performance expertise to outside events.
Skunkworks AI Discord Summary
Based on the provided messages, there isn’t sufficient context or substantial technical content relevant to an engineer audience to generate a summary. Both messages appear to be informal communications without any discernible technical discussion or key points.
YAIG (a16z Infra) Discord Summary
- Quest for Cloud Independence: @floriannoell asked about on-premise AI solutions that do not rely on major cloud providers like AWS, GCP, or Azure, mentioning watsonx.ai as a point of reference for desired capabilities.
- Tailoring AI to Fit the Mold: In the process of discussing on-premise solutions, @spillai suggested @floriannoell elucidate specific AI requirements such as pretraining, finetuning, or classification, to guide the search towards a more fitting on-premise AI system.
Alignment Lab AI Discord Summary
- Catch the Slim Orca Dataset on Hugging Face: Slim Orca dataset is now hosted on Hugging Face, boasting ~500k GPT-4 completions with enhanced quality through GPT-4 refinements. This dataset is noted for needing only 2/3 the computational power for performance comparable to larger data slices (Slim Orca).
- Training Made Efficient with Slim Orca Models: Two models, jackalope-7b and Mistral-7B-SlimOrca, demonstrate the high efficiency and performance of practice on the Slim Orca subset. This advancement was shared by
@222gatein the community chat, spotlighting the dataset’s reduced computational requirement without compromising output quality.
Datasette - LLM (@SimonW) Discord Summary
- Offline LLM Enhancement Unveiled: The
llm-gpt4allversion 0.3 has been released, featuring improvements including offline functionality for models and the ability to adjust model options such as-o max_tokens 3. The release also incorporates fixes from community contributors.
PART 2: Detailed by-Channel summaries and links
TheBloke ▷ #general (1398 messages🔥🔥🔥):
- AI and RP community unite: Users
@frankenstein0424and@kalomazeengage in a heated discussion about AI and roleplay, leading to calls for moderation and jokes about the situation. - Obsession with rats: The chat room
#generalhas been spammed with rat-related character cards, inciting mixed reactions from users such as@rogue_variant,@mrdragonfox, and@.justinobserver. - Mistral 7B and coding with AI: User
@priyanshuguptaiitgseeks help running models like Mistral-7B through an API and receives directions from@itsme9316,@kalomaze, and others. They discuss difficulties with the API, mentioning issues like missing tokenizers and fine-tuning options. - Exploring MoEs and Mergekit: A serious technical discussion unfolds between users
@kquant,@sanjiwatsuki, and@kalomaze, focusing on the nuances of fine-tuning Mixture of Experts (MoE) models, their performance, and their unique challenges. - GPU talk and renting for AI: The chat delves into the world of GPUs, discussing storage options on platforms like runpod.io, and the End-of-Life announcement for NVIDIA’s A100 GPU. They also touch on the practical aspects of using rented GPUs for large language models.
Links mentioned:
- No Way GIF - Stunned Wow Omg - Discover & Share GIFs: Click to view the GIF
- Tweet from Jon Durbin (@jon_durbin): Working on an RP-enhancing DPO dataset using cinematika data, meaning the responses are human-written (but still llm augmented). Let’s see if this works 🤞🏻
- Screenshot to HTML - a Hugging Face Space by HuggingFaceM4: no description found
- openaccess-ai-collective/mistral-7b-llava-1_5-pretrained-projector · Hugging Face: no description found
- Brain GIF - Brain - Discover & Share GIFs: Click to view the GIF
- TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF · Hugging Face: no description found
- All Your Base Are Belong To Us Cats GIF - All Your Base Are Belong To Us Cats Cat - Discover & Share GIFs: Click to view the GIF
- Create a Network Volume: no description found
- Prompt-Engineering for Open-Source LLMs: Turns out prompt-engineering is different for open-source LLMs! Actually, your prompts need to be engineered when switching across any LLM — even when OpenAI…
- Mad Men Conversing GIF - Mad Men Conversing Feel Bad For You - Discover & Share GIFs: Click to view the GIF
- What Do You Mean By That GIF - What Do You Mean By That - Discover & Share GIFs: Click to view the GIF
- DIE ANTWOORD - RATS RULE [Music Video]: Die Antwoord - Mount Ninji and Da Nice Time Kid - Rats Rule/ Featuring JACK BLACK !More of these comming soon, subscribe to dont miss out!Used videos:/ DIE A…
- Speaking with Angry Rats Baldur’s Gate 3: Speaking with Angry Rats Baldur’s Gate 3. You can see Baldur’s Gate III Speaking with Angry Rats Scene following this video guide. Baldur’s Gate III is a rol…
- yahma/alpaca-cleaned · Datasets at Hugging Face: no description found
- GitHub - openai/consistencydecoder: Consistency Distilled Diff VAE: Consistency Distilled Diff VAE. Contribute to openai/consistencydecoder development by creating an account on GitHub.
- Neil deGrasse Tyson Explains the Simulation Hypothesis: Neil deGrasse Tyson and comic co-host Chuck Nice are here (or are they?) to investigate if we’re living in a simulation. We explore the ever-advancing comput…
- GitHub - deep-floyd/IF: Contribute to deep-floyd/IF development by creating an account on GitHub.
- Samsung 870 QVO 8TB SSD Memory Storage | Samsung UK: Discover incredible storage with a Samsung SSD. Enjoy improved performance, easy management with Samsung Magician and awesome reliability.
- GitHub - oobabooga/text-generation-webui: A Gradio web UI for Large Language Models. Supports transformers, GPTQ, AWQ, EXL2, llama.cpp (GGUF), Llama models.: A Gradio web UI for Large Language Models. Supports transformers, GPTQ, AWQ, EXL2, llama.cpp (GGUF), Llama models. - GitHub - oobabooga/text-generation-webui: A Gradio web UI for Large Language Mod…
- Mac | Jan: Jan is a ChatGPT-alternative that runs on your own computer, with a local API server.
- Port of self extension to server by Maximilian-Winter · Pull Request #5104 · ggerganov/llama.cpp: Hi, I ported the code for self extension over to the server. I have tested it with a information retrieval, I inserted information out of context into a ~6500 tokens long text and it worked, at lea…
- Nature: Nature is the foremost international weekly scientific journal in the world and is the flagship journal for Nature Portfolio. It publishes the finest …
- Solving olympiad geometry without human demonstrations - Nature: A new neuro-symbolic theorem prover for Euclidean plane geometry trained from scratch on millions of synthesized theorems and proofs outperforms the previous best method and reaches the performance of…
- main : add Self-Extend support by ggerganov · Pull Request #4815 · ggerganov/llama.cpp: continuation of #4810 Adding support for context extension to main based on this work: https://arxiv.org/pdf/2401.01325.pdf Did some basic fact extraction tests with ~8k context and base LLaMA 7B v…
- YT Industries: Decoy MX CORE 3
TheBloke ▷ #characters-roleplay-stories (427 messages🔥🔥🔥):
-
Model Comparison and Usage Queries: Users discussed their experiences with various models like
Nous HermesandSanjiWatsuki/Lelantos-Maid-DPO-7Bfor specific roleplay tasks.@ks_cfoundKunoichi dpo v2to be the best for character interpretation. -
Frontend Features and Lorebooks:
@animalmachineshared insights on the value of a lorebook feature for roleplay chats and pointed to the relevant documentation on SillyTavern’s usage of World Info. -
Automating Data Collection for Model Training:
@frankenstein0424is scripting to automate the creation of training data for their bot from website messaging, planning to gather a dataset for a highly specialized task. -
Quantization and Model Performance:
@keyboardkingdiscussed the difficulty in getting grammatically correct output from sub 10gb models and voiced concerns about whether deeper quantization renders models like7Bsuboptimal. -
Deployment and API Choices for Bots:
@frankenstein0424sought advice for hosting and using models likeMixtral AIthrough external APIs, with suggestions including usingSillyTavernfrontend to connect to various LLM APIs such as together.ai and mistral.ai.
Links mentioned:
- Mistral AI | Open-weight models: Frontier AI in your hands
- World Info | docs.ST.app: World Info (also known as Lorebooks or Memory Books) enhances AI’s understanding of the details in your world.
- NeverSleep/Noromaid-13B-0.4-DPO-GGUF · Hugging Face: no description found
- LoneStriker/Noromaid-13B-0.4-DPO-3.0bpw-h6-exl2 · Hugging Face: no description found
- makeMoE: Implement a Sparse Mixture of Experts Language Model from Scratch: no description found
- Rentry.co - Markdown Paste Service: Markdown paste service with preview, custom urls and editing.
- Models - Hugging Face: no description found
- Another LLM Roleplay Rankings: (Feel free to send feedback to AliCat (.alicat) and Trappu (.trappu) on Discord) We love roleplay and LLMs and wanted to create a ranking. Both, because benchmarks aren’t really geared towards rolepla…
- TheBloke/CaPlatTessDolXaBoros-Yi-34B-200K-DARE-Ties-HighDensity-GGUF · Hugging Face: no description found
- text-generation-webui/modules/sampler_hijack.py at 837bd888e4cf239094d9b1cabcc342266fee11c0 · oobabooga/text-generation-webui: A Gradio web UI for Large Language Models. Supports transformers, GPTQ, AWQ, EXL2, llama.cpp (GGUF), Llama models. - oobabooga/text-generation-webui
- How to mixtral: Updated 12/22 Have at least 20GB-ish VRAM / RAM total. The more VRAM the faster / better. Grab latest Kobold: https://github.com/kalomaze/koboldcpp/releases Grab the model Download one of the quants a…
- text-generation-webui/modules/logits.py at main · oobabooga/text-generation-webui: A Gradio web UI for Large Language Models. Supports transformers, GPTQ, AWQ, EXL2, llama.cpp (GGUF), Llama models. - oobabooga/text-generation-webui
- The Sarah Test: (by #theyallchoppable on the Ooba and SillyTavern Discord servers) See also: https://rentry.org/thecelltest The Sarah Test is a simple prompt to test a model’s coherency, logical consistency, whatever…
- Intro: Intro Changelog Performing the cell test Checking logits Effect of samplers Model Results Summary Model Results Table Closing thoughts Future improvements Appendix A: Potential problem with the prompt…
TheBloke ▷ #training-and-fine-tuning (5 messages):
- Eager to Train Locally:
@superking__expressed enthusiasm about starting to experiment with training locally to save on compute costs before becoming proficient. - Credit for Implementation Queried: A user asked
@superking__if they were responsible for implementing a method for loading a single model, recalling their name from a pull request (PR). - Acknowledgement of Contribution:
@jondurbinconfirmed he implemented the 2-adapter method, clarifying the existing code for null reference was already present. - Seeking Solution for a Shared Issue:
@carlito.88inquired about a previous issue, wondering if a resolution had been found. - Query on LLMS and TensorRT Conversion:
@bycloudquestioned the community for experiences on training/finetuning large language models (LLMs) and converting them into TensorRT optimized models.
TheBloke ▷ #model-merging (2 messages):
- Inquiry on Merging gguf Models:
@222gateasked if anyone knows whether merging gguf’s is possible using mergekit, expressing interest in experimenting with it despite assumptions of infeasibility. - Fusion of Vision and Non-Vision Models:
@222gatequeried the community for any attempts or documentation on merging a vision model with a non-vision model, indicating a need for guidance on such cross-modality merges.
TheBloke ▷ #coding (13 messages🔥):
- Understanding LLava’s Composition:
@seleaexplained that LLava models incorporate CLIP for image recognition; tokens from CLIP are appended before a text prompt in a language model. There’s a necessity to train the model to interpret CLIP embeddings correctly. - Adding Multimodality is Complex: For
@lordofthegoonsenquiry on adding multimodality,@seleaindicated the challenge lies in training the text model to understand and utilize image embeddings efficiently. - Frankenmerging Models:
@lordofthegoonspondered about partially extracting layers from LLava to merge them with another model, while@seleaadmitted to not knowing much about frankenmerges but speculated on the possibility of adding CLIP understanding to another model. - Glitches in Frankenmerged Models:
@seleamentioned that even if a frankenmerge were successful, the resultant model would likely operate glitchily due to the inherent complexities of combining different systems. - Improving Model Training with LLava:
@seleaproposed the idea of using LLava to distill accurate image descriptions and retrain the text-processing part of models like Stable Diffusion which currently employs a “wacky machine code” for prompting. ,
Nous Research AI ▷ #off-topic (18 messages🔥):
- Charming Old School Data: User
@everyoneisgrossmentioned that they purchase antique school books to manually input Q&As for model testing, expressing some skepticism with models that perform too well on modern datasets. - Fine-Tuning AI Models:
@pradeep1148shared a YouTube video titled “Finetuning TinyLlama using Unsloth,” which includes sections on data preparation, training, inference, and model saving. - Turning “Machine Learning” into “Money Laundering”:
@euclaiseposted a funny tweet about a Chrome extension that replaces “machine learning” with “money laundering” and shared the GitHub link for the extension. - Cuda Kernels Allow Non-Power-of-Two Configurations:
@carsonpoolediscussed the advantages of writing kernels in CUDA over Triton, noting that configurations can be set to non-powers-of-two, sometimes yielding better performance. - Satirical Spin on AI Company Expectations:
@sumo43joked about the lofty expectations set by companies calling themselves AI companies, suggesting a play on words with “token companies” that merely generate tokens.
Links mentioned:
- Tweet from cts🌸 (@gf_256): twitter is more funny if you replace “machine learning” with “money laundering”. So i made a chrome extension that does this https://github.com/stong/ml-to-ml
- Finetuning TinyLlama using Unsloth: You will learn how to do data prep, how to train, how to run the model, & how to save it (eg for Llama.cpp).**[NOTE…
Nous Research AI ▷ #interesting-links (38 messages🔥):
- Prompt Lookup Revolution:
@leontellopromoted efficient prompt lookup for input-grounded tasks by sharing a mention of its significance, stating it’s a “free lunch” that should be utilized more. - Control Applications with LLMs:
@mikahdanghighlighted RestGPT, a project showcasing an LLM-based autonomous agent that can control real-world applications via RESTful APIs. - Function Calling as the Future:
@mikahdangand@tekniumheld a passionate agreement on the importance of function calling for reasoning and planning as integral to the future of LLMs integration with APIs. - Unraveling Non-determinism in GPT-4: A conversation led by
@burnytechlinked articles discussing GPT-4’s non-determinism due to Sparse MoE, with contributions from@stefangliga,@stellaathena, and@betadoggoon the challenges and implications. - Diffusion Model Considerations:
@mikahdangshared research on Contrastive Preference Learning and scalability of diffusion language models, sparking a debate about their underestimation in NLP. Different views were expressed by@_3sphere,@betadoggo, and@manojbhregarding the potential and challenges of merging autoregressive and diffusion models for various tasks.
Links mentioned:
- Are Diffusion Models Vision-And-Language Reasoners?: Text-conditioned image generation models have recently shown immense qualitative success using denoising diffusion processes. However, unlike discriminative vision-and-language models, it is a…
- Diffusion Language Models Can Perform Many Tasks with Scaling and…: The recent surge of generative AI has been fueled by the generative power of diffusion probabilistic models and the scalable capabilities of large language models. Despite their potential, it…
- Contrastive Preference Learning: Learning from Human Feedback…: Reinforcement Learning from Human Feedback (RLHF) has emerged as a popular paradigm for aligning models with human intent. Typically RLHF algorithms operate in two phases: first, use human…
- Tweet from Weyaxi (@Weyaxi): I published BagelHermes-2x34B, a Mixture of Experts model, combining @jon_durbin’s bagel 🥯 and @NousResearch’s Hermes2 📨 Hermes excels in math, while Bagel is superior in QA and science. So…
- GitHub - Yifan-Song793/RestGPT: An LLM-based autonomous agent controlling real-world applications via RESTful APIs: An LLM-based autonomous agent controlling real-world applications via RESTful APIs - GitHub - Yifan-Song793/RestGPT: An LLM-based autonomous agent controlling real-world applications via RESTful APIs
- Non-determinism in GPT-4 is caused by Sparse MoE: It’s well-known at this point that GPT-4/GPT-3.5-turbo is non-deterministic, even at temperature=0.0. This is an odd behavior if you’re used to dense decoder-only models, where temp=0 shou…
- Tweet from Maksym Andriushchenko 🇺🇦 (@maksym_andr): GPT-4 is inherently not reproducible, most likely due to batched inference with MoEs (h/t @patrickrchao for the ref!): https://152334h.github.io/blog/non-determinism-in-gpt-4/ interestingly, GPT-3.5 …
Nous Research AI ▷ #general (271 messages🔥🔥):
-
Batch Size Example Disclosed:
@leontelloshared an example of batched inference for machine learning models, providing a code snippet to illustrate how to run batched prompts using a model and tokenizer from thetransformerslibrary on a GPU. -
Helpful Tools for Chat Templating:
@osansevieromentioned a helpful resource for those working with chat templates, pinpointing potential usefulness for developers. -
Discussion on OpenAI’s Logit Distillation: “Is anyone doing logit (soft) distillation of GPT4?”
@dreamgenqueried, sparking a conversation on the availability of logits from OpenAI’s API and the feasibility and methods of distilling large language models. Users debated the value and strategies of distillation, noting it as a potentially unexplored area. -
RUGPULL Visualization App Development:
@n8programsis working on an application called RUGPULL, intended for exploring UMAP representations of corpora, with an ability to see the distance and relevance between chunks, all in an engaging, interactive graph format. -
Qwen 72B Base vs Llama 2 70B Base Discussed: The conversation turned towards comparing the Qwen 72B base and Llama 2 70B base models regarding their usability for fine-tuning. Some users like
@intervitensand@s3nh1123mentioned issues like VRAM consumption and the advantages of multilingual support, respectively; however, the consensus seemed elusive due to a lack of extensive experimentation with Qwen.
Links mentioned:
- Introducing Qwen: 4 months after our first release of Qwen-7B, which is the starting point of our opensource journey of large language models (LLM), we now provide an introduction to the Qwen series to give you a whole…
- Brain GIF - Brain - Discover & Share GIFs: Click to view the GIF
- Cat Explode GIF - Cat Explode Explosion - Discover & Share GIFs: Click to view the GIF
- Tweet from anton (@abacaj): I got some concrete numbers on phi-2 DPO. You can see clear jump in model capabilities first turn and second turn for MT-bench using DPO. More epochs does not really help overall, my model was overfit…
- GitHub - KillianLucas/aifs: Local semantic search. Stupidly simple.: Local semantic search. Stupidly simple. Contribute to KillianLucas/aifs development by creating an account on GitHub.
- HuggingFaceH4/open_llm_leaderboard · Discussions: no description found
- HuggingFaceH4/open_llm_leaderboard · Flagging models with incorrect tags: no description found
- 01-ai/Yi-34B · Hugging Face: no description found
- cognitivecomputations/dolphin · Datasets at Hugging Face: no description found
Nous Research AI ▷ #ask-about-llms (57 messages🔥🔥):
-
Finding the Optimal Learning Rate (LR): Users
@alyosha11and@bozoid.discussed finding the best LR for LLMs, suggesting to use evaluation datasets or benchmarks.@bozoid.mentioned that learning rates from previous architectures’ papers could yield decent results, while@tekniumadvised starting with a ballpark LR of around 1e-5 and adjust after observing results at 3 epochs. -
Inference Tricks for Mistral and Llama: User
@blackl1ghtquestioned about alternative inference methods formistraloverllama.cpp, and@.ben.comrecommendedexllamav2. In connection,@blackl1ghtreported an issue with theEOStoken being included in streaming responses, which@max_paperclipsconfirmed happens sporadically, depending on the model. -
OOM Issues and Sequence Length in Fine-tuning LLMs: User
@besiktasdescribed an out-of-memory (OOM) issue encountered when fine-tuning, even when previous forward/backward passes were successful.@yonta0098recommended checking if longer sequences are causing the issues and maybe sorting the data by decreasing length to trigger OOM early if that’s the case. -
Discussions on LLM Evaluation and Fine-tuning:
@rememberlennyinitiated a discussion on code-related evaluations for LLMs, and various users, including@manveerxyzand@besiktas, mentioned benchmarks such asHumanEval,MBPP, andDeepSeek.@besiktasalso raised concerns about the quality of some parts of the Hugging Face code and mentioned PRs that haven’t been addressed. -
Fine-tuning Challenges and Hugging Face Problems:
@besiktasprovided a link to a test implementation to diagnose fine-tuning memory leaks by gradually increasing the context length and described difficulties with the Hugging FaceFuyuProcessor. This sparked a discussion about the challenges of contributing to such large-scale collaborative projects.
Links mentioned:
-
pretrain-mm/tests/test_model.py at 4159505915d5e15952957aa5607eadf9fc6c70cd · grahamannett/pretrain-mm: Contribute to grahamannett/pretrain-mm development by creating an account on GitHub.
-
nuprl/CanItEdit · Datasets at Hugging Face: no description found
-
mbpp · Datasets at Hugging Face: no description found
-
FuyuProcessor broken and causes infinite loop · Issue #27879 · huggingface/transformers: transformers/src/transformers/models/fuyu/processing_fuyu.py Line 618 in 75336c1 while (pair := find_delimiters_pair(tokens, TOKEN_BBOX_OPEN_STRING, TOKEN_BBOX_CLOSE_STRING)) != ( I am not sure exa…
-
GitHub - amazon-science/cceval: CrossCodeEval: A Diverse and Multilingual Benchmark for Cross-File Code Completion (NeurIPS 2023): CrossCodeEval: A Diverse and Multilingual Benchmark for Cross-File Code Completion (NeurIPS 2023) - GitHub - amazon-science/cceval: CrossCodeEval: A Diverse and Multilingual Benchmark for Cross-Fil…
-
InfiCoder-Eval: Systematically Evaluating Question-Answering for Code Large Language Models: no description found
-
EvalPlus Leaderboard: no description found
-
Coding LLMs Leaderboard: no description found
,
Mistral ▷ #general (225 messages🔥🔥):
- Mistral Instruct Autocomplete Clarification: User
@i_am_domhas clarified that Mistral Instruct is autocomplete by design and suggested skipping tags for plain text input, which will prompt the model to predict completion to the input. - Sophia Yang Confirmed as Mistral: User
@jarsalfirahelexpressed surprise at learning Sophia Yang, known from YouTube, is associated with Mistral. Sophia acknowledged with a thank you emoji. - Mistral Knowledge Base File Uploads: User
@vivacious_gull_97921inquired if Mistral supports uploading files to the knowledge base, to which@sophiamyangresponded that it’s not currently supported, suggesting the use of Mistral with other RAG tools. - Mistral 7B Foundation Models on Amazon SageMaker:
@sophiamyangshared a blog on SageMaker, announcing the availability of Mistral 7B models for deployment via Amazon SageMaker JumpStart. The post illustrates how to discover and deploy the model. - Moderation on Mistral Discord and Future Plans:
@sophiamyangconfirms that moderators are set up on the Mistral Discord after@ethuxsuggested the need for them due to scams. They welcomed recommendations for better moderation setups.
Links mentioned:
- Cat Berg Cat GIF - Cat Berg Cat Orange Cat - Discover & Share GIFs: Click to view the GIF
- Mistral 7B foundation models from Mistral AI are now available in Amazon SageMaker JumpStart | Amazon Web Services: Today, we are excited to announce that the Mistral 7B foundation models, developed by Mistral AI, are available for customers through Amazon SageMaker JumpStart to deploy with one click for running in…
- Open LLM Leaderboard - a Hugging Face Space by HuggingFaceH4: no description found
- GPT-4: We’ve created GPT-4, the latest milestone in OpenAI’s effort in scaling up deep learning. GPT-4 is a large multimodal model (accepting image and text inputs, emitting text outputs) that, while less ca…
Mistral ▷ #models (81 messages🔥🔥):
- Summarization Shenanigans with Mixtral 8x7b: User
@atom202300reported issues with Mixtral 8x7b and the Huggingface Text Generation Interface (TGI) wherein the model would unpredictably cut off responses during summarization tasks. Despite a stable VRAM, the problem persisted for specific examples, suggesting sensitivity to prompt structure. - Prompt Patterns Prompt Problems:
@sublimatorniqand@atom202300discussed the effect of altering prompt syntax on summarization performance, finding that changing from square brackets to parentheses reduced premature stopping, while@mrdragonfoxmentioned that Mixtral requires careful increment adjustments to prevent spamming. - Troubleshooting Model Stops with Seeds:
@sublimatorniqtheorized that the use of different seeds could induce variable stopping behaviors—with one seed causing early stops and another leading to extended responses. - Open-Weights and Finetuning Frustrations:
@wayne_denginquired about the availability of source code and finetuning possibilities for the Mixtral model.@mrdragonfoxstated that many have attempted finetuning without success due to high costs and the model’s complexity. - Mistral API JSON Response Request: User
@madmax____sought help with forcing the Mistral API to return responses in JSON format, but found theresponse_formatparameter ineffective.@akshay_1shared a link, possibly as a solution to the issue but the context of the link was not provided.
Links mentioned:
- Getting Started with pplx-api: no description found
- GitHub - huggingface/text-generation-inference: Large Language Model Text Generation Inference: Large Language Model Text Generation Inference. Contribute to huggingface/text-generation-inference development by creating an account on GitHub.
Mistral ▷ #deployment (21 messages🔥):
- Local Model Use in vLLM:
@shihard_85648asked for a way to use a local model file with vLLM, having downloaded the “raw” Mistral file, and@mrdragonfoxadvised to use the--modelflag followed by the full local path. This bypasses the need to download the model from HuggingFace, which is the usual process as explained by@vhariational. - vLLM Docker Image Clarification:
@vhariationalreferenced the vLLM documentation, indicating that the Huggingface cache directory is bind-mounted at runtime, meaning you wouldn’t need to redownload the model when rebuilding the Docker image. - Model Path Configuration Instructions:
@mrdragonfoxprovided a detailed link to the vLLM documentation, elaborating on the engine arguments including how to specify paths for both model and tokenizer. - Efficient Mistral MoE Setup Inquiries: User
@yoann_binquired about an economical setup for running Mistral MoE at 12token/s on hardware less than $3,000, leading to@mrdragonfoxsuggesting a 32GB M1 Mac or using two 3090 GPUs for higher performance. - Technical Specs and Performance Metrics: In the discussions about configurations,
@mrdragonfoxmentioned running mistral 8x7b on anA6000(a 48GB VRAM GPU) with ‘6bpw’ (bits per weight), achieving about 60 tokens/second withexllamav2.
Links mentioned:
Engine Arguments — vLLM: no description found
Mistral ▷ #finetuning (7 messages):
- Prompt Optimizations Proposed:
@akshay_1suggested optimizing the prompts as an easier solution for the issues encountered with the Retriever-Augmented Generator (RAG) application. - Embedding Model Training vs. Cost: Training an embedding model might not be cost-effective at a small scale, according to
@akshay_1. - ColbertV2 for Embedding Training: For those looking into training an embedding model,
@akshay_1recommended checking out ColbertV2. - Identifying RAG App Limitations:
@mrdragonfoxhighlighted that an embedding model might need training when dealing with unique terminologies as they might not cluster effectively with intended meanings.
Mistral ▷ #showcase (2 messages):
- Tips for Enhanced Function Calling:
@akshay_1recommends usingdspy,SGLang,outlines, andinstructorfor better function calling, stating it works really good. - Advocating for Fine-tuning: In a follow-up,
@akshay_1mentions that fine-tuning on a dataset will yield better results if one is not satisfied with the initial solutions suggested.
Mistral ▷ #la-plateforme (11 messages🔥):
- Code Sharing for Error Investigation:
@sophiamyangasked@jakobdylancto share their code because of an unfamiliar error. Jake provided a link to a specific part of their GitHub repository, describing the issue with the “openai” python package used in their Discord LLM Chatbot. - Package Compatibility Discussion:
@sophiamyangquestioned@jakobdylancabout the python client package being used, linking to Mistral’s client (Mistra - Overview), and expressed uncertainty about reproducing the error. Jakob confirmed the use of the OpenAI python package and contemplated switching to Mistral’s package for its lightweight nature despite potential issues with vision models. - Error Reproduction Troubles:
@jakobdylancadmits difficulty in reproducing the error but promises to report back to@sophiamyangif it occurs again. - Philosophical Query Lacks Response: User
@jrffvrrposed an existential question about the most beautiful person in the world and followed with a test message, seemingly checking functionality with no further discussion on the topic. - Intersection of Transformers and Mathematics:
@stefatorusproposed the idea of training transformer models on mathematics and using an A* algorithm to generate potentially fruitful mathematical ideas worthy of exploration.
Links mentioned:
-
Discord-LLM-Chatbot/llmcord.py at ec908799b21d88bb76f4bafd847f840ef213a689 · jakobdylanc/Discord-LLM-Chatbot: Multi-user chat | Choose your LLM | OpenAI API | Mistral API | LM Studio | GPT-4 Turbo with vision | Mixtral 8X7B | And more 🔥 - jakobdylanc/Discord-LLM-Chatbot
-
Mistra - Overview: Mistra has 29 repositories available. Follow their code on GitHub.
-
GitHub - openai/openai-python: The official Python library for the OpenAI API: The official Python library for the OpenAI API. Contribute to openai/openai-python development by creating an account on GitHub.
,
LM Studio ▷ #💬-general (172 messages🔥🔥):
-
Ubuntu Users Encounter libclblast.so.1 Error: Ubuntu 22.04 users, including
@d0mperand@josemanu72, were struggling with an error when opening LM Studio related to a missinglibclblast.so.1file. After much discussion, the creation of symbolic links resolved the issue. -
Performance Questions on Apple Silicon Neural Engine: LM Studio’s utilization of the Apple Silicon Neural Engine was a question posed by
@crd5, where@Aqualitekinghelped clarify that the neural engine might be used indirectly via Apple’s Metal API and suggested monitoring with “asitop” tool. -
Queries on AI Modeling and Setup: Various users, including
@golangorgohome,@cloakedman, and@christianazinn, exchanged info on the suitable hardware for LM Studio and alternative setups for different AI applications, such as image-to-text and local hosting of model implementations. -
LM Studio Model Compatibility and Troubleshooting: Users like
@bright_chipmunk_28966and@yagilbdiscussed issues with loading certain models in LM Studio, leading to advice on updating to newer versions and checking for compatibility on platforms like HuggingFace. -
Exploration of RAG with LM Studio:
@elevonsinquired about integrating RAG with LM Studio, and though there were no straightforward solutions within LM Studio itself,@heyitsyorkieand@thelefthandofurzaprovided guidance on third-party apps and setup assistance.
Links mentioned:
- LM Studio Beta Releases: no description found
- CLBlast/doc/installation.md at master · CNugteren/CLBlast: Tuned OpenCL BLAS. Contribute to CNugteren/CLBlast development by creating an account on GitHub.
- GitHub - HeliosPrimeOne/ragforge: Crafting RAG-powered Solutions for Secure, Local Conversations with Your Documents - V2 Web GUI 🌐 Product of PrimeLabs: Crafting RAG-powered Solutions for Secure, Local Conversations with Your Documents - V2 Web GUI 🌐 Product of PrimeLabs - GitHub - HeliosPrimeOne/ragforge: Crafting RAG-powered Solutions for Secure,…
- GitHub - john-rocky/CoreML-Models: Converted CoreML Model Zoo.: Converted CoreML Model Zoo. Contribute to john-rocky/CoreML-Models development by creating an account on GitHub.
- Core ML Tools — Guide to Core ML Tools: no description found
LM Studio ▷ #🤖-models-discussion-chat (15 messages🔥):
- Model Error Mystery: User
@alex_m.presented an issue with LM Studio where the model fails regardless of configuration, showing a JSON error with Exit code: 0.@gustavo_60030responded, suggesting checking a different Discord channel for possible solutions. - Channel Direction Confusion: After
@alex_m.was directed to one support channel,@heyitsyorkieintervened to recommend another as the appropriate place for discussing model errors. - AI’s Unpredictable Personality:
@cloakedmancommented on the unpredictability of AI models, remarking how the same model can provide different responses.@fabguysuggested that reducing the temperature setting can increase consistency in the AI’s responses. - AI Consistency Tips:
@cloakedmaninquired about what@fabguymeant by reducing temperature.@fabguyreplied, clarifying that setting “Randomness” or “Temperature” to zero can yield consistent answers given the same seed is used. - Dolphin Version Differences:
@cloakedmanasked for insights on the differences between Dolphin 2.5 and 2.7 AI versions. Although@fabguyprovided a Discord link for detailed comparison, the link was not accessible in the summary provided.
LM Studio ▷ #🧠-feedback (16 messages🔥):
- GPU Acceleration Greyed Out for CodeShell:
@czkokoreported that CodeShell was listed as not supported for GPU acceleration despite being supported in version 0.2.11.@yagilbconfirmed that the architecture is not currently considered supported by the LM Studio app. - Potential Workaround for GPU Support:
@yagilbsuggested a workaround by renaming the model file to include “llama” which might enable GPU acceleration, but@czkokofollowed up saying the workaround did not change the greyed-out GPU acceleration or RoPE. - Conservative App Behavior Regarding GPU Acceleration:
@yagilbpointed out that the app errs on the side of caution by graying out options for unsupported architectures, mentioning a previous discussion. - User Feedback on GPU Acceleration:
@heyitsyorkieconfirmed that the GPU acceleration remains grayed out even after trying the suggested workaround and commented that the current UI state, which indicates “not supported,” is clear enough. - Discussion Invitation:
@yagilbextended an invitation to continue the conversation about the GPU acceleration issue for CodeShell in a different thread, providing a Discord channel link for further discussion.
LM Studio ▷ #🎛-hardware-discussion (29 messages🔥):
- VRAM Woes Amidst Hardware Talk: User
@cheerful_panda_16252reported an issue with VRAM capacity showing as “0Bytes” despite owning a Nvidia 3090 with 24GB VRAM.@cloakedmanalso expressed concern that this might affect the recommended settings of the software. - Call for Hardware Specs:
@yagilbdirected users to provide their hardware specifications in order to address the VRAM capacity problem, guiding them to a specific Discord channel with a posted link. - Potential Boost for Intel GPU Users: A GitHub pull request shared by
@heyitsyorkiesuggests that Intel GPU users might soon see support in llama.cpp View Pull Request. However,@goldensun3dsshowed skepticism regarding the timeline of this update. - Exploring Budget Configurations for Mixtral:
@yoann_binquired about the cheapest hardware configuration capable of running Mixtral at 12t/s, mentioning the potential of an M1 Pro.@rugg0064contributed by clarifying the bandwidth differences between M2 Pro, M1, and high-end GPUs like the RTX 4090. - Hardware Compatibility Discussions and Recommendations:
@cloakedmanshared difficulties with system crashes when offloading to a GPU, and@bobzdaroffered troubleshooting tips including layer adjustments and prompt compression. The discussion evolved into@cloakedmanfinding a stable setting for their system.
Links mentioned:
- Part 1:Building and Optimizing a High-Performance Proxmox Cluster On a Budget.: In our guide for building a Proxmox cluster, we’ve primarily focused on utilizing second-hand components to cater to small producers or…
- Feature: Integrate with unified SYCL backend for Intel GPUs by abhilash1910 · Pull Request #2690 · ggerganov/llama.cpp: Motivation: Thanks for creating llama.cpp. There has been quite an effort to integrate OpenCL runtime for AVX instruction sets. However for running on Intel graphics cards , there needs to be addi…
LM Studio ▷ #🧪-beta-releases-chat (2 messages):
- Thumbs Up for WhiteRabbit 33B: User
@johntdaviesmentioned successful testing with the WhiteRabbit 33B model (Q8), giving positive feedback for its performance.
LM Studio ▷ #autogen (1 messages):
senecalouck: Try it using 127.0.0.1 in the script.
LM Studio ▷ #langchain (1 messages):
gciri001: Is it possible to use Langchain and MySql with LLAMA 2 withouts openAI api?
LM Studio ▷ #crew-ai (4 messages):
- Model Loading Failure Frustration: User
@ferrolingaencountered an error with the message “unknown (magic, version) combination” when trying to load a model. The error report included system diagnostics indicating sufficient RAM and VRAM but a potential issue with the model file itself. - Incorrect File Format Diagnosis:
@draco9900quickly identified that@ferrolinga’s issue stemmed from using a model that is not in GGUF format—a necessary format for LM Studio. - Solution Suggestion: In response to the loading issue,
@heyitsyorkieadvised@ferrolingato use GGUF files specifically and recommended searching for “TheBloke - GGUF” in the Model Explorer for optimal results, as LM Studio requires GGUF model formats, not pytorch/ggml or .bin files. ,
OpenAccess AI Collective (axolotl) ▷ #general (50 messages🔥):
- Logit Distillation Chat:
@dreamgendiscusses logit distillation using GPT-4 logits and techniques like backfilling with open-source models and masking loss.@nruaifexpresses interest in the topic and considers further discussion. - Voice Synthesis Adaptation Inquiry:
@ex3ndrqueries about adding custom tokens for voice synthesis to LLMs and learns from@le_messand@stefangligathat adding a large number of tokens, like 8k, would necessitate extensive pretraining. - Challenges with QLoRA Finetuning: Several participants including
@stefangliga,@noobmaster29, and@c.gatodiscuss the limitations of QLoRA finetuning, especially with a significant number of new tokens, stressing that simple auxiliary networks won’t suffice and full embedding layer finetuning must be considered. - Model Finetuning Tips and Loss Evaluation:
@ex3ndrshares their experience with finetuning custom tokens, highlighting concerns with unusually high loss figures, while@noobmaster29and@c.gatoprovide insights on what loss metrics to aim for in different scenarios. - Using Special Tokens in Axolotl Finetuning: Guidance on how to configure special tokens for finetuning is shared by
@faldore, including code snippets for embeddinglm_headand specifyingeos_token. This was in response to@dreamgenpointing to@faldore’s success with a project like Dolphin on Hugging Face.
Links mentioned:
- Magic GIF - Magic - Discover & Share GIFs: Click to view the GIF
- axolotl/src/axolotl/utils/lora_embeddings.py at dc051b861d4d0f20c673ad55ac93b2a43fa56fc4 · OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions. Contribute to OpenAccess-AI-Collective/axolotl development by creating an account on GitHub.
- cognitivecomputations/dolphin-2.6-mixtral-8x7b at main: no description found
OpenAccess AI Collective (axolotl) ▷ #axolotl-dev (4 messages):
- Jupyter issues in Latitude container:
@dctannerraised a problem encountering SSL issues with Jupyter running in the Latitude container due to Cloudflare’s tunneling for port forwarding. No solution was provided yet. - SSH Port Forwarding as a Band-Aid:
@dctanneris currently using SSH port forwarding as a workaround for the Jupyter issue in the Latitude container. - Intriguing Idea: Self-Rewarding Language Models:
@dctannershares interest in incorporating the concept of Self-Rewarding Language Models into the axolotl framework. - Self-Rewarding Model Implementation:
@caseus_responds to the idea with a link to a PyTorch implementation on GitHub, lucidrains/self-rewarding-lm-pytorch, which is an implementation of the training framework proposed in Self-Rewarding Language Model from MetaAI.
Links mentioned:
GitHub - lucidrains/self-rewarding-lm-pytorch: Implementation of the training framework proposed in Self-Rewarding Language Model, from MetaAI: Implementation of the training framework proposed in Self-Rewarding Language Model, from MetaAI - GitHub - lucidrains/self-rewarding-lm-pytorch: Implementation of the training framework proposed in…
OpenAccess AI Collective (axolotl) ▷ #general-help (116 messages🔥🔥):
-
DPO Dataset Mysteries Unraveled:
@dangfuturesand@c.gatodiscussed issues with loading datasets for DPO, finding success with a prior pull request (PR #1137).@dangfuturesmentioned overcoming an out-of-memory error by using a micro batch size of 1. -
Struggling with Strategy?:
@c.gatohelped@dangfuturesnavigate prompt strategies for datasets, sharing code snippets and a GitHub file link. To fix a persistent error, they advised to implement a fix from the DPO fixes branch on GitHub. -
CI-CD Goodness or Local Frustration?:
@caseus_highlighted an automated ci-cd sanity check for remote datasets, which doesn’t cover local datasets. Meanwhile,@dangfuturesand@c.gatodiscovered that reverting to a previous commit allowed for using local datasets, despite initial errors. -
LoRA Hyperparameter Head-Scratchers:
@noobmaster29inquired about optimal settings for LoRA’s alpha and rank hyperparameters, prompting@c.gatoto share an article providing insights into their effective usage. Discussion included varying alpha and rank as well as batch size considerations during training. -
Branching out for LLAMA:
@gamevelosterand@noobmaster29explored finetuning with llava models, pointing to a specific branch of axolotl and considering whether existing configs could be adapted for this purpose. The conversation highlights the community’s collaborative effort in sharing knowledge and resources.
Links mentioned:
- axolotl/src/axolotl/prompt_strategies/dpo/chatml.py at main · OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions. Contribute to OpenAccess-AI-Collective/axolotl development by creating an account on GitHub.
- axolotl/tests/e2e/test_dpo.py at main · OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions. Contribute to OpenAccess-AI-Collective/axolotl development by creating an account on GitHub.
- GitHub - OpenAccess-AI-Collective/axolotl at llava: Go ahead and axolotl questions. Contribute to OpenAccess-AI-Collective/axolotl development by creating an account on GitHub.
- Finetuning LLMs with LoRA and QLoRA: Insights from Hundreds of Experiments - Lightning AI: LoRA is one of the most widely used, parameter-efficient finetuning techniques for training custom LLMs. From saving memory with QLoRA to selecting the optimal LoRA settings, this article provides pra…
- configs/pretrain-llava-mistral.yml · openaccess-ai-collective/mistral-7b-llava-1_5-pretrained-projector at main: no description found
- Feat: Add sharegpt multirole by NanoCode012 · Pull Request #1137 · OpenAccess-AI-Collective/axolotl: Description: Allow multiple roles for input and output. NOTE: Beta and hardcoded values for now! How to use: - type: sharegpt + type: sharegpt.load_multirole Only supports conversation: (chatml|zep…
- DangFutures/DPO_RAG · Datasets at Hugging Face: no description found
OpenAccess AI Collective (axolotl) ▷ #datasets (4 messages):
- Dolphin Data Doubts:
@noobmaster29inquired if there was any overlap between the dolphin dataset and the openorca dataset.@dangfuturesexpressed belief that there is sure to be overlap. - Overlap Confirmation: Upon hearing
@dangfutures’ belief,@noobmaster29sought clarification and confirmed understanding that the two datasets do indeed overlap.
Links mentioned:
cognitivecomputations/dolphin · Datasets at Hugging Face: no description found
OpenAccess AI Collective (axolotl) ▷ #rlhf (13 messages🔥):
-
Configuration Key Error for
argilla_apply_chatml:@alekseykorshukencountered aKeyError: 'prompt'when usingargilla_apply_chatmlin their YAML configuration for a project with Reinforcement Learning Hub (RLHF). They initially sought assistance with this configuration issue. -
Solution Identified in Unittests: Later,
@alekseykorshukresolved the issue by discovering newtypeformats (chatml.argillaandchatml.intel) within the unittests on the main branch, and confirmed that this solution worked for them, prompting them to share the update with the community. -
Clarification Sought on Branch Usage: After the solution was shared,
@dangfuturessought clarification on which branch@alekseykorshukused to find the successful newtypeformats.@alekseykorshukclarified they used the main branch. -
Config Doubt for Local Datasets:
@matanvetzlerinquired if the same configuration would apply to local datasets and requested to see the config setup.@alekseykorshukassumed local datasets should work similarly by just changing thetype. -
Prompt Tokenization Strategy Issue and Solution:
@pierrecolomboreported aValueError: unhandled prompt tokenization strategy: intel_apply_chatml, to which@c.gatoresponded advising to update tochatml.intelif using the latest commit due to breaking changes.@pierrecolomboacknowledged the solution with thanks.
OpenAccess AI Collective (axolotl) ▷ #replicate-help (1 messages):
- Cog Configuration Guide Shared:
@dangfuturesprovided a snippet defining a configuration for Cog, referencing documentation on their GitHub page. The configuration is set up for GPU usage with CUDA “12.1”, uses Python “3.11”, and includes installation of various Python packages likeaiohttp[speedups],megablocks,autoawq, and more via a custompip installcommand referencing multiple package URLs.
Links mentioned:
-
cog/docs/yaml.md at main · replicate/cog: Containers for machine learning. Contribute to replicate/cog development by creating an account on GitHub.
-
no title found: no description found
,
Eleuther ▷ #general (56 messages🔥🔥):
-
Byte-Level BPE’s Multilingual Abilities:
@synquidexplained that the Llama 2 model can generate responses in languages like Hindi, Tamil, and Gujarati using byte-level BPE (Byte Pair Encoding), which does include tokens for these languages. -
Seeking Code for Mistral 7b Fine-Tuning: User
@aslawlietrequested assistance for code to fine-tune Mistral 7b for token classification, but did not receive a direct response within the provided messages. -
Skepticism About Mamba Replacing Transformers: Users, including
@stellaathena,@stefangliga, and@mrgonao, expressed skepticism regarding Mamba scaling and replacing Transformers, noting the absence of evidence that it will maintain its performance at larger scales. Discussions centered on the engineering challenges and the need for more research to validate Mamba’s scalability. -
Finetuning as a Service Inquiry: User
@kh4dienreached out for recommendations on finetuning large language models, expressing a preference for full supervision tuning rather than methods like QLORA.@stellaathenasuggested that running finetuning personally on rented GPUs might be a simple out-of-the-box solution. -
Evaluating Impact of Fine-Tuning LLMs:
@everlasting_gomjabbarqueried the community about comprehensive studies highlighting the benefits of fine-tuning Large Language Models (LLMs), suggesting that the real-world justifications for the investment in fine-tuning are often unclear. No direct response catered to this query was provided in the discussion.
Links mentioned:
Self-Rewarding Language Models: We posit that to achieve superhuman agents, future models require superhuman feedback in order to provide an adequate training signal. Current approaches commonly train reward models from human prefer…
Eleuther ▷ #research (65 messages🔥🔥):
-
Exploring Cryptographic Hiding in LLMs:
@ai_waifushared a paper that introduces a cryptographic method to hide a secret payload in a Large Language Model’s response, requiring a key for extraction and remaining undetectable without it.@fern.bearquestioned the claim that the method doesn’t modify the response distribution, arguing that some distribution must change to convey information. -
Weight Averaged Reward Models (WARM) Introduced by Google DeepMind:
@jacquesthibshighlighted a paper that discusses WARM, a strategy to combat reward hacking in LLMs aligning with human preferences through RLHF, by averaging fine-tuned reward models in weight space, and shared an author’s thread for further insights. -
Google’s Realistic Video Generation Research:
@pizza_joelinked to a demonstration of Google Research’s space-time diffusion model for video generation, with accompanying paper.@thatspysaspyand@ad8ediscussed the significance, with@ad8enoting Google’s data advantage while@main.aicountered with information on dataset size in comparison to other models. -
Exploration of Model Constraints in Unsupervised Learning:
@rybchukasked about research regarding models learning the correct constraints to minimize loss in an unsupervised manner, with several users, including@fern.bear, discussing empirical risk minimization and the nature of constraints in learning. -
First Conference on Language Modeling Announced:
@stellaathenashared an announcement regarding the first Conference on Language Modeling, set to be held at the University of Pennsylvania. The conference will be a gathering for those interested in language modeling research and advancements.
Links mentioned:
- Tweet from Conference on Language Modeling (@COLM_conf): We are pleased to announce that the first Conference on Language Modeling will be held at the University of Pennsylvania in Philadelphia at the Zellerbach Theatre. Thanks so much to UPenn CS as we…
- Lumiere: A Space-Time Diffusion Model for Video Generation: We introduce Lumiere — a text-to-video diffusion model designed for synthesizing videos that portray realistic, diverse and coherent motion — a pivotal challenge in video synthesis. To this end, we …
- Meta-Prompting: Enhancing Language Models with Task-Agnostic Scaffolding: We introduce meta-prompting, an effective scaffolding technique designed to enhance the functionality of language models (LMs). This approach transforms a single LM into a multi-faceted conductor, ade…
- Active Inference as a Model of Agency: Is there a canonical way to think of agency beyond reward maximisation? In this paper, we show that any type of behaviour complying with physically sound assumptions about how macroscopic biological a…
- Excuse me, sir? Your language model is leaking (information): We introduce a cryptographic method to hide an arbitrary secret payload in the response of a Large Language Model (LLM). A secret key is required to extract the payload from the model’s response, …
- Lumiere - Google Research: Space-Time Text-to-Video diffusion model by Google Research.
- Tweet from AK (@_akhaliq): Google Deepmind presents WARM On the Benefits of Weight Averaged Reward Models paper page: https://huggingface.co/papers/2401.12187 Aligning large language models (LLMs) with human preferences thro…
- Tweet from Stella Biderman (@BlancheMinerva)): @Wetassprior @daphneipp In the Pythia paper we explore the effect of term frequency on fact learning over the course of training. If you squint at Fig. 4, it seems like there is weak evidence that the…
- Tweet from Alexandre Ramé (@ramealexandre): Introducing DeepMind’s Weight Averaged Reward Model (WARM) for alignment via RLHF! We merge multiple reward models into one that’s more reliable and robust. WARM efficiently captures the best …
- k-diffusion/k_diffusion/models/image_transformer_v2.py at master · crowsonkb/k-diffusion: Karras et al. (2022) diffusion models for PyTorch. Contribute to crowsonkb/k-diffusion development by creating an account on GitHub.
Eleuther ▷ #scaling-laws (3 messages):
- Scaling Doubts on relora:
@joey00072raised a concern that relora might not scale beyond 1 billion parameters based on hearsay from Twitter or Discord, although the original reLoRA paper does not make this claim. - reLoRA Paper’s Limits:
@joey00072mentioned that the reLoRA models were only tested up to a size of 350 million parameters, seeking further studies or feedback on scaling beyond this point.
Eleuther ▷ #interpretability-general (2 messages):
- Exploring Truth Representation Interventions: User
@80melondiscussed a technique involving intervening or negating a truth representation in language model outputs without using patching. They then observed changes in the language model’s output based on various completions. - Seeking Maximally Causal Truth Direction:
@80melonmentioned the goal of their experiment was to identify a truth direction that had a direct and significant impact on the language model’s various outputs.
Eleuther ▷ #gpt-neox-dev (3 messages):
-
Working Hard on MoE Implementation:
@xyzzyrzis contributing to the implementation of MoE (Mixture of Experts) with a pull request, seeking tips and feedback for deeper validation. Concerns aboutmpu.get_model_tensor_parallelism_world_size()and its relation to PipeModelDataParallelTopology and axonn 3D tensor parallelism were raised, with uncertainty about how to proceed with a single-GPU setup. -
Single-GPU Limits Parallelism Testing:
@xyzzyrzexpressed difficulty in testing parallelism enhancements due to only having access to a single-GPU node. They provided initial numbers showing a significant slowdown when increasing num-experts and referenced an existing MoE branch with overlapping work. -
Fused Layernorm Pull Request Scrutiny: They are also following the progress on another pull request regarding fused layernorm, found here, and noted there wasn’t much time difference detected which might suggest limited room for further improvements.
-
Interest in Improving Deepspeed Inference:
@xyzzyrzindicated willingness to work on Deepspeed Inference to potentially improve performance as discussed in Issue #845, pending availability of compute resources.
Links mentioned:
-
fused layernorm by yang · Pull Request #1105 · EleutherAI/gpt-neox: Add simple util for timings Add fused layernorm kernel from Megatron
-
Add MoE by yang · Pull Request #1129 · EleutherAI/gpt-neox: Closes #479
-
Build software better, together: GitHub is where people build software. More than 100 million people use GitHub to discover, fork, and contribute to over 420 million projects.
-
Investigate DeepSpeed Inference · Issue #845 · EleutherAI/gpt-neox: DeepSpeed wins most inference benchmarks I see. We should test their claims on neox models. EleutherAI spends a significant amount of compute running inference, so any improvement in inference perf…
,
LAION ▷ #general (124 messages🔥🔥):
-
Quick Training Time Inquiry:
@astropulsewas curious about the time required to train a tiny model in the 128x128 range.@nodjaresponded that it should take no more than a couple of days on a dual 3090 system, and suggested checking appendix E of a mentioned paper. -
GPT-4 Token Allocations Adjusted: User
@helium__raised a concern over reduced caps for GPT-4, with other users like@astropulseconfirming similar experiences. -
Cautionary Notes on Tiny ImageNet Models:
@thejonasbrotherspointed out that ImageNet models with resolutions below 256x256 did not perform well, and recommended better performance is seen at larger scales with significant training time. -
Discussion on Crafting Safe Multimodal Datasets:
@irina_rishinitiated a conversation about ensuring the safety of datasets utilized for multimodal model training, stressing the need for solutions guaranteeing data integrity. Challenges and potential solutions were discussed by various users, including@thejonasbrothers,@progamergov, and@.undeleted. -
Upcoming Conference on Language Modeling Announcement:
@itali4noshared the venue announcement for the first Conference on Language Modeling (CoLM), which will be held at the University of Pennsylvania, along with an invite to another user,@chad_in_the_house, who anticipates taking them to food trucks.
Links mentioned:
- Tweet from Conference on Language Modeling (@COLM_conf): We are pleased to announce that the first Conference on Language Modeling will be held at the University of Pennsylvania in Philadelphia at the Zellerbach Theatre. Thanks so much to UPenn CS as we…
- no title found: no description found
LAION ▷ #research (2 messages):
-
Combating LLM Reward Hacking with WARM: User
@thejonasbrothersshared a research paper addressing reward hacking in large language models (LLMs) through a method called Weight Averaged Reward Models (WARM). The paper proposes fine-tuning multiple reward models (RMs) and averaging them to improve robustness and reliability under distribution shifts and human preference inconsistencies. -
VONet Breaks Ground in Unsupervised Video Learning:
@vrus0188introduced a paper on VONet, an unsupervised video object learning framework using parallel U-Net attention and object-wise sequential VAE. The method outperforms existing techniques for decomposing video scenes across multiple datasets with its novel approach, and the code is accessible on GitHub.
Links mentioned:
-
WARM: On the Benefits of Weight Averaged Reward Models: Aligning large language models (LLMs) with human preferences through reinforcement learning (RLHF) can lead to reward hacking, where LLMs exploit failures in the reward model (RM) to achieve seemingly…
-
VONet: Unsupervised Video Object Learning With Parallel U-Net Attention and Object-wise Sequential VAE: Unsupervised video object learning seeks to decompose video scenes into structural object representations without any supervision from depth, optical flow, or segmentation. We present VONet, an innova…
,
HuggingFace ▷ #announcements (1 messages):
-
HuggingFace Levels Up!: Introducing a new channel
<#1197143964994773023>to showcase the highest-leveled community members. Activities such as posting, reacting, and creating repositories or papers on the Hub will earn members experience points. -
Making Games with AI - Chapter 2 Released: The second chapter of the Making games with AI course is now available. Interested parties can celebrate and learn more on Thomas Simonini’s Twitter post.
-
Gradio Performance Optimizations Revealed: The Gradio team shared insights into making Gradio faster by “…slowing it down!” after a lag issue was reported by
@oobabooga. The full story and technical breakdown can be followed on this HuggingFace post. -
Transformers.js Introduces Meta’s SAM Model in-browser: Version 2.14 of Transformers.js runs Meta’s SAM model completely within your browser. Users can experiment with this using npm and details on usage can be found in the linked HuggingFace post.
-
transformers v4.37 Packed with Innovations: The latest release of
transformers v4.37introduces several new models and features including Qwen2, Phi-2, SigLIP, and 4-bit serialization. More details can be found on GitHub.
Links mentioned:
- @abidlabs on Hugging Face: ”𝗛𝗼𝘄 𝘄𝗲 𝗺𝗮𝗱𝗲 𝗚𝗿𝗮𝗱𝗶𝗼 𝗳𝗮𝘀𝘁𝗲𝗿 𝗯𝘆… 𝘀𝗹𝗼𝘄𝗶𝗻𝗴 𝗶𝘁…”: no description found
- @Xenova on Hugging Face: “Last week, we released 🤗 Transformers.js v2.14, which added support for SAM…”: no description found
- Release v4.37 Qwen2, Phi-2, SigLIP, ViP-LLaVA, Fast2SpeechConformer, 4-bit serialization, Whisper longform generation · huggingface/transformers: Model releases Qwen2 Qwen2 is the new model series of large language models from the Qwen team. Previously, the Qwen series was released, including Qwen-72B, Qwen-1.8B, Qwen-VL, Qwen-Audio, etc. Qw…
- @philschmid on Hugging Face: “What’s the best way to fine-tune open LLMs in 2024? Look no further! 👀 I am…”: no description found
- @abidlabs on Hugging Face: “There’s a lot of interest in machine learning models that generate 3D objects…”: no description found
- GitHub - Vaibhavs10/open-tts-tracker: Contribute to Vaibhavs10/open-tts-tracker development by creating an account on GitHub.
- Tweet from Xenova (@xenovacom): Introducing the 🛝 Jinja Playground: Design LLM chat templates directly in your browser with instant feedback. Built with
@huggingface/jinja, a minimalistic JavaScript implementation of the Jinja … - @merve on Hugging Face: “Explaining the 👑 of zero-shot open-vocabulary object detection: OWLv2 🦉…”: no description found
- Fine-Tune W2V2-Bert for low-resource ASR with 🤗 Transformers: no description found
- PatchTSMixer in HuggingFace: no description found
- Preference Tuning LLMs with Direct Preference Optimization Methods: no description found
- Tweet from Niels Rogge (@NielsRogge): New @YouTube video in my ChatGPT at home series: fine-tuning Mistral-7B on a GPU rented on @runpod_io Involves chat templates, QLoRa, packing, Flash Attention 2, bfloat16… a lot of things to expla…
HuggingFace ▷ #general (49 messages🔥):
-
Morning Cheer for Open-Sourcing:
@osansevierokicks off the day ready for open-source contributions. Replies like@Cubie | Tomkeeps the spirit high with a resounding “Always 💪”. -
ONNX Export Woes:
@blahblah6407is facing issues exporting a fine-tuned model to ONNX, encountering an[ONNXRuntimeError]regardingTrilu(14)node implementation. -
Looking for Guidance in Machine Learning:
@𝐀𝐌𝐎𝐔𝐑inquires about starting points for learning machine learning. They receive assistance from_mad.haven_who shares a useful guide on Hugging Face to grasp the basics. -
AI Video Background Inquiry:
@omnirootsposts a YouTube video titled “THE FUTURE OF AI IS PURE IMAGINATION” and asks the community for information on the AI background effects used. -
Leveling Up on HuggingFace: Discussions by
@realmrfakenameand@lunarfluregarding the integration of Discord and Hub activities influence the level displayed by LevelBot, and potential future feature of displaying levels on user profiles is also considered.
Links mentioned:
- Dreamoving - a Hugging Face Space by jiayong: no description found
- THE FUTURE OF AI IS PURE IMAGINATION: Shrinking the lag time between what we imagine and what we create. The future of AI. #ai #jasonsilva #singularity #possibility #awe #tech
- GitHub - dreamoving/dreamoving-project: Official implementation of DreaMoving: Official implementation of DreaMoving. Contribute to dreamoving/dreamoving-project development by creating an account on GitHub.
HuggingFace ▷ #today-im-learning (6 messages):
-
Getting the Hang of It:
@not_lainmentioned that although a task may be challenging at first, it becomes easier with practice, implying a learning curve in their recent endeavors. -
Privacy-Conscious Transcription Tool Development:
@n278jmis building a tool that transcribes and summarizes audio recordings of consultations. The objective is to operate entirely locally to maintain the privacy of the data due to the sensitive nature of the consultations. -
Tool Specifications Unveiled:
@n278jmdetailed the tool’s workflow: “Meeting audio upload as input -> transcription with speaker diarization -> meeting summary as output”. They plan to use Hugging Face’s transformers for the audio transcription, pyannote.audio 3.1 for speaker diarization, and a DistilBERT model for summarization, all tied together with a simple HTML front end. -
Python as a Blast from the Past:
@n278jmexpressed some challenges with the Python language due to a long absence from using it, particularly when parsing lists and dictionaries to integrate diarization data with transcription results. -
Considering Protobuf for Pipeline Communications:
@n278jmis contemplating writing protobuf definitions to bridge pipelines and possibly use Go for processing the results of the transformers. This suggests they’re considering alternatives to Python for parts of their project workflow.
HuggingFace ▷ #cool-finds (9 messages🔥):
-
New Identity-Preserving AI Demo:
@osansevierohighlighted InstantID, a tool for identity-preserving generation within seconds, and shared a positive tweet from Yann LeCun that endorses the InstantID demo on Gradio Spaces. Try it here. -
Hedwig AI Video Intro on YouTube:
@forestwow7397shared a YouTube video introducing Hedwig AI, a platform aimed at transforming the utilization and understanding of video data through AI. -
Enigmatic AI Backgrounds:
@omnirootsrequested information on the AI-generated background effect used in a YouTube video by Jason Silva, sparking curiosity among other users. -
QwenLM Opensource Journey:
@osansevieroshared an update from QwenLM, presenting an overview of their opensource journey with Large Language Models, along with important links to their academically published paper, GitHub repository, and Hugging Face models. -
PhotoMaker Offers Efficient Personalized Generation:
@ggabe_2provided an arXiv paper link discussing PhotoMaker, a novel method for efficient and personalized text-to-image generation, promising in identity fidelity and text controllability. -
Fine-Tuning LLMs with VPGs:
@andysingalshared a study on fine-tuning multimodal large language models (MLLMs) to follow zero-shot demonstrative instructions, tackling issues related to current visual prompt generators (VPGs) biasing. The study introduces a new module called Visual Prompt Generator Complete (VPG-C) that improves the models’ understanding of such instructions. Read the study.
Links mentioned:
- Introducing Qwen: 4 months after our first release of Qwen-7B, which is the starting point of our opensource journey of large language models (LLM), we now provide an introduction to the Qwen series to give you a whole…
- PhotoMaker: Customizing Realistic Human Photos via Stacked ID Embedding: Recent advances in text-to-image generation have made remarkable progress in synthesizing realistic human photos conditioned on given text prompts. However, existing personalized generation methods ca…
- Fine-tuning Multimodal LLMs to Follow Zero-shot Demonstrative…: Recent advancements in Multimodal Large Language Models (MLLMs) have been utilizing Visual Prompt Generators (VPGs) to convert visual features into tokens that LLMs can recognize. This is achieved…
- THE FUTURE OF AI IS PURE IMAGINATION: Shrinking the lag time between what we imagine and what we create. The future of AI. #ai #jasonsilva #singularity #possibility #awe #tech
- Youtube Video Intro hedwigAI: Welcome to the world of seamless streaming with Hedwig AI, where we’re transforming the way video data is utilized and understood. In this video, we showcase…
- h94/IP-Adapter-FaceID at main: no description found
- Tweet from Omar Sanseviero (@osanseviero): InstantID: Identity-Preserving Generation in Seconds Try it at https://hf.co/spaces/InstantX/InstantID
- Tweet from Yann LeCun (@ylecun): Yay, I’m a Marvel superhero! Where’s my Iron Man suit? ↘️ Quoting Gradio (@Gradio) 🔥InstantID demo is now out on Spaces. Thanks @Haofan_Wang et al, for building a brilliant Gradio demo fo…
HuggingFace ▷ #i-made-this (14 messages🔥):
-
Quick Inference with “Tiny” Model:
@Cubieaffirmed the efficiency of an enhancement toall-MiniLM-L6-v2which maintains fast inference by only adding a Dense layer, potentially expediting comparisons of embeddings. -
PCA Script Adoption in sbert Library:
@stroggozmentioned the utilization of PCA for comparisons of embeddings and credited their script to the one in the sbert library. -
Visualizing Suspected Fakes: In response to
@lunarflu’s query about a heatmap’s purpose,@not_lainand@thenameless7741seemed to confirm its use in detecting potential fakes without providing additional context. -
Upgrade and Migration of Open LLM Leaderboard:
@thenameless7741notified about the migration of their project, Cosmos Arena, which includes various features such as model types, weight types, and licenses, and mentioned it contains a few regressions and bugs post-update.@osansevieroreacted positively, considering sharing it with their team. -
Zero-Effort Image Embedding with Hugging Face:
@tony_assiintroduced their GitHub project, HF-Embed-Images, which provides a one-line solution for generating embeddings for image datasets with the Hugging Face ecosystem. -
Debugging Machine Learning Training with 3LC:
@paulend76teased the upcoming public Beta for 3LC, an ML training and data debugger/editor, integrating with PyTorch and free for non-commercial purposes; they provided links to a YouTube video and blog post for more insights and invited feedback for their Beta. -
Exploring Gabor Vecsei’s GitHub Repos:
@ggabe_2shared a link to@gaborvecsei’s GitHub profile, encouraging others to explore the repositories, and highlighted a recent project on live transcription with Whisper.
Links mentioned:
- Cosmos Arena: no description found
- GitHub - TonyAssi/HF-Embed-Images: Generates image embeddings for 🤗 Datasets: Generates image embeddings for 🤗 Datasets. Contribute to TonyAssi/HF-Embed-Images development by creating an account on GitHub.
- Imbalance in Balance: In this demo, we see how 3LC helps Data Scientists quickly and efficiently pinpoint and address issues in their model. By adding weight to underrepresented s…
- Introducing 3LC: With our innovative approach to data quality, 3LC paves the way for more accurate model training, without changing where your data lives.
- gaborvecsei - Overview: I push my boundaries as far as I can. Also I love chocolate. 😎 - gaborvecsei
- GitHub - gaborvecsei/whisper-live-transcription: Quick and dirty example for live transcription with Whisper: Quick and dirty example for live transcription with Whisper - GitHub - gaborvecsei/whisper-live-transcription: Quick and dirty example for live transcription with Whisper
HuggingFace ▷ #diffusion-discussions (5 messages):
- DPM++ Updates on the Horizon:
@keturnexpressed anticipation for improvements in the DPM++ with Karras after issues addressed in a recent PR, hoping to see these enhancements in the next release. - Inquiry into Diffusion Scheduling:
@vtabbott_brought up questions about HuggingFace’s diffusion implementation, specifically thescheduling_euler_distance.pyfile and its origins. - Karras’s Paper Sheds Light on Diffusion: In response,
@keturnexplained that the “euler” calculations follow the naming from k-diffusion, which implements concepts from Karras’s paper titled Elucidating the Design Space of Diffusion-Based Generative Models. They further clarified that the Euler scheduler is likely derived from the DDIM paper, and mentioned differences between “variance preserving” and “variance exploding” without certainty on their mathematical equivalence. - Diving Deep into Diffusion Models:
@vtabbott_mentioned working on diagrams for diffusion models to ensure a thorough understanding strong enough to reimplement the processes.
HuggingFace ▷ #NLP (4 messages):
- Model Parallel Training Explained:
@mr_nilqhighlighted that the current approach is inference-only and recommended using the Trainer with Accelerate for model parallel training. The user shared a helpful HuggingFace guide explaining when and how to transition from single GPU to multi-GPU training setups. - Llama 2’s Multilingual Mysteries:
@dhruvbhatnagar.0663inquired how Llama 2 model can generate responses in languages like Hindi, Tamil, or Gujarati without specific tokens in its vocabulary.@vipitisreplied with a suggestion to observe the token ids generated and to investigate further. - DeciLM-7B Slow Inference Troubles:
@kingpokiis experiencing slow inference times with Deci/DeciLM-7B on an Nvidia 3060, taking about 23 seconds for 50 tokens. The user tried quantizing the model but encountered issues and is seeking advice on improving inference speed without impacting their ability to finetune the model.
Links mentioned:
Efficient Training on Multiple GPUs: no description found
HuggingFace ▷ #diffusion-discussions (5 messages):
-
Anticipation for Improved DPM++:
@keturnis looking forward to enhancements in DPM++ as mentioned by Karras, hoping that the issues addressed in a recent PR will show significant improvement in the next release. -
Euler’s Place in HuggingFace Schedulers: In response to
@vtabbott_’s query about thescheduling_euler_distance.py,@keturnexplains that it aligns with the naming from k-diffusion, and eventually with Karras’s Elucidating the Design Space of Diffusion-Based Generative Models. They mention that Euler scheduler is related to the DDIM paper and there’s a variance distinction withdiffusers’sscheduling_ddimwhich might relate to being “variance preserving” or “variance exploding”. -
Digging Deep into Diffusion:
@vtabbott_expresses a keen interest in deeply understanding diffusion models to the extent of being able to reimplement them, demonstrating a commitment to crafting accurate explanatory diagrams. ,
Perplexity AI ▷ #general (57 messages🔥🔥):
- Discussions on Model Adjustments: Users discussed various topics including the efficiency of RPA AI (
@moyaoasis), light mode availability on labs (@hvciand@icelavamanresponding with only dark mode available), and frustration with using the microphone feature on Android where the app permissions lacked options for the mic (@.cryptobadger). - Channel Navigation Confusion: People admitted confusion over channels existing or being removed, particularly related to generating pictures and the Dream bot that is no more, with
@ok.alexconfirming a channel’s closure and@oscar_010expressing a need for news summaries on Perplexity. - Clarification on Model Usage:
@iprybilovychhad questions about discerning between GPT-4 and Gemini Pro models on Perplexity AI’s pro version, which were addressed by@icelavaman, explaining model selection settings, with follow-up engagement by community managers like@Dynoencouraging community recognition for helpful posts. - Feature Inquiries and Assistance: A user inquired about a potential teams option and support issues with credit (
@umyong), while another user@zwaetschgeraeuberspeculated about future app support for Wear OS, following a perceived collaboration with Rabbit. - API Enquiries and Extensions Discussed:
@generativeai_strategy_44986requested information about increasing the rate limit of the API for product integration,@dogemeat_recommended the Continue.dev extension for integration with vscode, and@speedturkeyhumorously encouraged Pro subscribers to donate credits to “the church of the God prompt”.
Links mentioned:
- Continue - CodeLlama, GPT-4, and more - Visual Studio Marketplace: Extension for Visual Studio Code - Open-source autopilot for software development - bring the power of ChatGPT to your IDE
- no title found: no description found
Perplexity AI ▷ #sharing (12 messages🔥):
-
Troubleshooting Application Errors:
@_marcos75reported issues accessing Perplexity shares due to an “Application error.” After receiving advice, they shared an example link that was causing trouble: BMW Humanoid Factory.@icelavamansuggested that it is likely a browser issue rather than a perplexity error. -
Perplexity as a Research Powerhouse:
@nicknalbachshared a positive review of using Perplexity, emphasizing its ability to quickly consolidate information from multiple sources, as demonstrated when searching for new phone and cell phone plans. -
Perplexity Praise and Recommendation:
@zenrobot.ethresponded to@nicknalbach’s feedback, endorsing the impressive speed and accuracy of Perplexity’s search capability. -
Workflow Enhancement through Perplexity:
@joe_hellermentioned discovering how Perplexity can complement workflow, sparking curiosity from@icelavamanwho asked for a public example.@ivibudhhumorously inferred the response might be AI-generated. -
Real-World Assistant for Mechanical Engineering:
@n_667testified to using Perplexity as an assistive tool for mechanical engineering courses and personal projects, noting time-saving benefits.
Perplexity AI ▷ #pplx-api (3 messages):
-
Confusion Over API Usage: User
@tpsk12345expressed difficulty in using the API and requested an update from Alex, with no additional context provided. -
Inquiry About Online Model Citations:
@donvitophtested thepplx-70b-onlinemodel via the API and raised a question about whether the online models return citation URLs. The exact usage was shown with a code snippet for calling thechat.completions.createfunction. ,
LlamaIndex ▷ #blog (2 messages):
-
Hackathon Excitement with Cash Prizes: IFTTT announces an in-person hackathon from February 2-4 with prizes totaling $13,500, including $8,250 in cash. The event encourages participants to build projects that solve real problems and offers expert feedback. Hackathon announcement tweet.
-
Introducing MemGPT for Advanced Chat Experiences: MemGPT, spotlighted by
@charlespacker, is an OSS project for creating chat experiences featuring long-term memory, self-editing memory, and infinite context windows, built with LlamaIndex. Installation is quick through pip, offering a personalized AI experience. OSS project spotlight tweet.
Links mentioned:
MemGPT: no description found
LlamaIndex ▷ #general (65 messages🔥🔥):
- SQLite-VSS Integration for Llama-Index:
@pveierlandinquired about any existing sqlite-vss integrations for llama-index but received no documented responses or solutions. - Pandas Query Engine Troubles:
@techexplorer0pointed out that there are issues when using the PandasQueryEngine with open-source LLMs like Zephyr 7b. A documentation link with an example for building a query pipeline with Pandas was shared but did not directly address working with CSV files in building a RAG chatbot. - Open Source LLMs with RAG:
@zaesarseeking how to implement a RAG with open-source LLMs like dolphin mistral in the Llama-Index course on deeplearning.ai received a suggestion from@emanuelferreirato use LlamaIndex’s base LLM module.@cheesyfishessuggested using olama for easy local setups and vLLM for production. - SubQuestionQueryEngine in Streamlit:
@matthews_38512mentioned using SubQuestionQueryEngine at Streamlit but no solution was present. Later a conversation between@kapa.ai, presumed to be the chatbot and@matthews_38512, offered detailed steps and links to LlamaIndex documentation for setting up a SubQuestionQueryEngine. - Implementing Chatbots with Memory Over CSV:
@techexplorer0sought to create a conversational chatbot with memory leveraging RAG over multiple CSV files using an open-source LLM for data aggregations and received guidance about structured workflows from@kapa.ai, including a link to the official LlamaIndex documentation. There was also a request on setting a Query Pipeline to use the maximum number of workers, where@kapa.aiprovided a potential solution involvingos.cpu_count().
Links mentioned:
- Query Pipeline over Pandas DataFrames - LlamaIndex 🦙 0.9.36: no description found
- Step-wise, Controllable Agents - LlamaIndex 🦙 0.9.36: no description found
- Customizing LLMs within LlamaIndex Abstractions - LlamaIndex 🦙 0.9.36: no description found
- OpenAI Agent with Query Engine Tools - LlamaIndex 🦙 0.9.36: no description found
- Query Pipeline - LlamaIndex 🦙 0.9.36: no description found
LlamaIndex ▷ #ai-discussion (1 messages):
- New Insights on Dynamic Knowledge for RAG Chatbots: User
@sl33p1420shared their latest Medium article about integrating dynamic sources in RAG chatbots. The article focuses on enhancing chatbots by harnessing advanced knowledge integration techniques. - Detailed RAG Chatbot Development Guide: The same user also highlighted their previous works that form a series, starting with An In-depth Journey, moving through model selection, server setup, and finally the chat engine construction.
Links mentioned:
Empowering Your Chatbot: Unveiling Dynamic Knowledge Sources with Advanced Integration: Explore the next frontier in chatbot development adding how dynamic knowledge sources are harnessed.
OpenAI ▷ #ai-discussions (7 messages):
- Looking for AI Community Spaces: User
stranger_54257asked for links to more LLM discord servers but did not receive any responses. - AI Diversity Mirrors Human Complexity:
@bambooshootsdiscussed how a broad spectrum of behaviors in superintelligent AI might emerge due to various designs, objectives, and learning environments, similar to the diversity seen in humanity. - Seeking LLM Evaluation and Monitoring Tools:
@coderindajungleasked for suggestions regarding LLM evaluation & monitoring tools for a chatbot application built on GPT-4, but no suggestions were given. - Concerns about Dall.E’s Image Handling:
@brnstquestioned why Dall.E struggles with recreating or editing images when provided with an example, but the conversation did not yield an answer. - Control Over AGI Dominates the AI Ethics Debate:
@catcapitolstated that with regard to artificial general intelligence (AGI), the main concern is about who controls it and their uses of the technology.
OpenAI ▷ #gpt-4-discussions (28 messages🔥):
- File Upload Facts Uncovered:
@solbusclarified for@mrbr2023that up to 20 files of up to 512MB each can be uploaded to a Custom GPT as knowledge, while text files are limited to 2 million tokens each. They discussed the potential strategy of combining documents into single files to bypass the 20-file limit, but also considered possible downsides like inefficiency in searching large files. - GPTs Marketplace Mystery:
@sstrader29inquired about missing CustomGPTs on the GPTs Marketplace, but no specific answer was provided in the summarized conversation. - Grimoire GPT for Word Processing:
@eligumpexcitedly shared their creation of a word processor using the Grimoire GPT in under ten minutes. - Custom GPT Network Error Enigma:
@valikamirequested advice regarding persistent network errors after their custom GPT provides responses, but no resolution was mentioned. - Intertwined GPT Threads:
@snowmkr_jkexpressed confusion when a file from one thread seemed to impact another, presenting a potential issue with file handling across separate threads, awaiting community confirmation on whether that should happen.
OpenAI ▷ #prompt-engineering (10 messages🔥):
-
Looking for Better Context Handling in Answers:
@ArianJwants to answer additional questions based on chat logs concerning career topics, but finds that directly inputting the logs and questions doesn’t yield good results.@darthgustav.inquires about the size of the logs and the number of questions asked simultaneously to diagnose the issue. -
Executive Assistant Prompt Suggestions:
@jdf.wwpasks for prompt ideas suited for organization or executive assistants.@darthgustav.responds by asking about their goal and suggests using his Custom GPT for Plus subscribers or guiding ChatGPT with a user’s background information. -
Custom GPT’s Descriptive Language:
@archipelagicis seeking advice on the most effective language to use for refining tasks within the description field of a custom GPT.@eskcantarecommends defining clear objectives and communicating those goals effectively, whether seeking help from the AI or human collaborators. -
Simplicity Over Effectiveness for AI Guidance: In response to concerns about refining prompts,
@eskcantaadvises focusing on deciding what one wants from the AI and finding ways to achieve that rather than worrying about the ‘most effective’ language.
OpenAI ▷ #api-discussions (10 messages🔥):
-
Prompt Engineering Enthusiasm:
darthgustav.supports the idea that a good prompt engineering plan works well every time, implying a consistent strategy for successful AI interactions. -
Improving Contextual Understanding:
@ArianJis facing issues with the AI not answering questions based on chat logs. The user seeks advice on handling chat logs for extracting additional information, but faces challenges with the AI understanding the context. -
Inquiry About Prompt Size for Chat Logs:
darthgustav.inquires about the size in bytes of the chat logs that@ArianJis using, which might influence the AI’s ability to process and answer the questions. -
Efficient Language for Custom GPT Configurations:
@archipelagicasks about the most effective language to use when refining descriptions for a custom GPT model.eskcantaresponds, emphasizing the importance of clarity in communicating goals, both to the AI and when seeking help. -
Solving for Desired AI Outcomes: Instead of focusing on the ‘most effective’ language,
eskcantaadvises to work towards clear outcomes with the AI, suggesting an approach of adapting to achieve specific goals rather than seeking a universally ‘best’ method. ,
DiscoResearch ▷ #mixtral_implementation (10 messages🔥):
-
Template Troubles for
theBloke Q6:@eric_73339revealed struggles with different outcomes between a local model and a demo version. They suspected the issue was with the prompt template format. -
Mixtral Template Clarification:
@sebastian.bodzashared the correct Mixtral chat template as per the Hugging Face tokenizer, highlighting discrepancies with the readme.md documentation. -
Better Formatting with f-strings:
@bjoernpsuggested using f-strings and adding newlines after each role to correct@eric_73339’s ChatML template for compatibility with DiscoLM models. -
Demo Site Model & Template Usage:
@bjoernppointed out that https://demo.discoresearch.org uses DiscoLM German 7b v1 and provided a link to avoid issues with chat templates. -
Gratitude for Community Support:
@eric_73339thanked the community for assistance with adapting to large language models (LLMs) and fixing template issues.
Links mentioned:
- DiscoResearch/DiscoLM_German_7b_v1 · Hugging Face: no description found
- Templates for Chat Models: no description found
- DiscoLM German 7b Demo: no description found
DiscoResearch ▷ #general (11 messages🔥):
-
Evaluating Translation Quality:
@bjoernpdiscussed the challenges in evaluating translations and recommended using Lilac for manual checks. They mentioned trying to create a method to filter out bad translations using Distilabel, but recognized its potential cost with GPT-4. -
DiscoLM German Poised to Shine:
@_jp1_expressed interest in comparing the DiscoLM German performance to other models, acknowledging the availability of the English messages for this purpose. -
Predictions for Llama-3 Unveiled:
@bjoernpshared detailed predictions for the upcoming Llama-3 release, which included extensive pretraining on 5 trillion tokens, a focus on multilingualism and code, and advanced context chunking as illuminated by a recent paper. -
Delve into Data Multiple Epochs: In response to
@maxidlsuggesting more than one epoch for training,@rasdaniquestioned if this has been attempted post-Datablations paper, with@bjoernpreplying it’s currently not seen as necessary. -
German LM On the Horizon:
@maxidlrevealed an upcoming German LM with about 1 trillion tokens in the dataset and discussed the implications for compute resources, hoping for simplifications after establishing a solid first checkpoint. They linked a Twitter post regarding their approach.
Links mentioned:
In-Context Pretraining: Language Modeling Beyond Document Boundaries: Large language models (LMs) are currently trained to predict tokens given document prefixes, enabling them to directly perform long-form generation and prompting-style tasks which can be reduced to do…
DiscoResearch ▷ #embedding_dev (4 messages):
-
Embarking on a Mistral-like Journey:
@sebastian.bodzaannounced the creation of a dataset similar to the Mistral embedding model and shared their project on GitHub: Embedding Training. The aim is to first generate diverse Topics leveraging Quora topics data. -
Size Matters for Hosting:
@sebastian.bodzamentioned the plan to host the generated data on Hugging Face or GitHub, depending on the dataset’s size. -
To BGE or GTE? That Is the Question:
@sebastian.bodzaspeculated on potentially training a BigGraph Embedding (BGE) or Graph ‘n’ Table Embedding (GTE) model. -
Voyage to Enhanced Code Retrieval:
@sebastian.bodzabrought to attention Voyage’s new code embedding model,voyage-code-2, which has shown a significant improvement in semantic code retrieval tasks. The model’s details are shared in a Voyage AI blog post.
Links mentioned:
- voyage-code-2: Elevate Your Code Retrieval: TL;DR – We are thrilled to introduce voyage-code-2, our latest embedding model specifically tailored for semantic retrieval of codes and related text data from both natural language and code querie…
- GitHub - SebastianBodza/Embedding_Training: Contribute to SebastianBodza/Embedding_Training development by creating an account on GitHub.
DiscoResearch ▷ #discolm_german (19 messages🔥):
- Axolotl Usage Inquiry:
@thomasrenkertwas trying to use Axolotl and managed to get it running in Docker but struggled with how to include a personal dataset.@rasdaniprovided assistance, suggesting to convert the dataset into a supported format and referencing it in the configuration. - Navigating Axolotl GPU Quirks:
@thomasrenkertfaced an issue where Axolotl did not recognize GPUs from within the Docker container, to which@devnull0recommended setting up GPU access as per the NVIDIA Container Toolkit guide and installing necessary CUDA libraries, possibly using Conda. - Referral to Axolotl Discord for Support: As questions about Axolotl debugging arose,
@bjoernpreferred users to the Axolotl Discord for more specialized assistance. - DiscoLM German Model Newline Issue:
@thewindmomreported an issue when runningdiscolm_german_7b_v1.Q4_K_M.ggufwith Ollama where the output consisted of endless newlines, a problem shared among users according to a Hugging Face discussion thread. - Fix for DiscoLM Newline Glitch:
@_jp1_noted a fix for the aforementioned newline issue in the DiscoLM_German model’sconfig.json, changing"eos_token_id": 2to32000(commit details). They called for community members to test if the issue was resolved with this update.
Links mentioned:
-
Installing the NVIDIA Container Toolkit — NVIDIA Container Toolkit 1.14.4 documentation: no description found
-
Join the OpenAccess AI Collective Discord Server!: Check out the OpenAccess AI Collective community on Discord - hang out with 1546 other members and enjoy free voice and text chat.
-
DiscoResearch/DiscoLM_German_7b_v1 · Endless Spaces: no description found
-
Fix wrong EOS token in config.json · DiscoResearch/DiscoLM_German_7b_v1 at 560f972: no description found
-
GitHub - OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions): Go ahead and axolotl questions. Contribute to OpenAccess-AI-Collective/axolotl development by creating an account on GitHub.
-
GitHub - OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions.): Go ahead and axolotl questions. Contribute to OpenAccess-AI-Collective/axolotl development by creating an account on GitHub.
,
Latent Space ▷ #ai-general-chat (28 messages🔥):
- Karpathy’s Perspective on Technology Change:
@swyxioshared a new blog post by Andrej Karpathy highlighting the challenges faced by those outside the tech industry in adapting to change. They cited personal examples to emphasize the anxiety and fear that technological change can induce in people. - Perplexity’s Non-Linear Progress:
@swyxiolinked to a tweet from@madiatorvisualizing the non-linear three-month journey of development for the AI model Perplexity. - Exploring Grammar and Reasoning in Smaller Models:
@nuvic_discussed a paper on training smaller LMs with hopes of retaining their grammar and reasoning capabilities, pointing to the possibility that coherent language might be achievable without massive parameter counts (TinyStories paper). - Discord Applies AI to Create Notification Titles:
@.onacomputercommented on Discord’s new approach of using LLMs to summarize and generate notification titles based on community messages, which@vcarland@youngphlofound surprising considering past privacy policies. - Stability’s New Diffusion Model Unveiled:
@swyxioannounced a notable diffusion model development by Stability AI that generates megapixel scale images directly, bypassing latent diffusion processes, and also shared an AI news summary service.
Links mentioned:
- @clem on Hugging Face: “Re-posting @karpathy’s blogpost here because it’s down on…”: no description found
- TinyStories: How Small Can Language Models Be and Still Speak Coherent English?: Language models (LMs) are powerful tools for natural language processing, but they often struggle to produce coherent and fluent text when they are small. Models with around 125M parameters such as GP…
- JSONalyze Query Engine - LlamaIndex 🦙 0.9.36: no description found
- Tweet from Mahesh Sathiamoorthy (@madiator): In case you thought Perplexity’s journey was straightforward and linear.
- Torvalds Speaks: Impact of Artificial Intelligence on Programming: 🚀 Torvalds delves into the transformative influence of Artificial Intelligence on the world of coding.🚀 Key Topics:* Evolution of programming languages in …
- [AINews] RIP Latent Diffusion, Hello Hourglass Diffusion: AI Discords for 1/22/2024. We checked 19 guilds, 291 channels, and 4368 messages for you. Estimated reading time saved (at 200wpm): 436 minutes. Katherine…
Latent Space ▷ #llm-paper-club (5 messages):
- SPIN Implementation on the Horizon: User
@swyxioannounced that@lucidrainsis planning to implement SPIN, sharing a link to the GitHub repository self-rewarding-lm-pytorch. - Clarification on SPIN and Meta Paper Implementation:
@ivanleomkinitially thought the implementation was for the new Meta paper, but@swyxioclarified that@lucidrainswill implement both SPIN and Meta’s approach separately. - Check the ReadMe for More Info: For further details,
@swyxiodirected users to the bottom of the repository’s readme file.
Links mentioned:
GitHub - lucidrains/self-rewarding-lm-pytorch: Implementation of the training framework proposed in Self-Rewarding Language Model, from MetaAI: Implementation of the training framework proposed in Self-Rewarding Language Model, from MetaAI - GitHub - lucidrains/self-rewarding-lm-pytorch: Implementation of the training framework proposed in…
,
LangChain AI ▷ #general (16 messages🔥):
- LangChainJS Workers Project Peek:
@ilguapposhared their work-in-progress project, despite hesitations due to it being standard and not reflecting best web API practices. It includes a fun endpoint for emoji reactions in Discord messages. - Typescript: The Learning Curve:
@ilguappois learning TypeScript, which is currently implemented in their project from a template, and@lolis0518acknowledges the difficulty of the language but is willing to give it a try. - Seeking End-to-End RAG Solutions:
@alvarojaunainquired about projects related to end-to-end Retrieval-Augmented Generation (RAG) systems, looking for potential collaborations or examples. - GPT Chat Completion Clarifications:
@allenpan_36670questioned the dynamics of how the GPT chat completion endpoint processes a list of messages, which@lhc1921addressed by referring to ChatML’s prompt template that handles such lists. - Chat With Your PDFs Tutorial:
@a404.ethannounced a tutorial covering the creation of a full stack RAG using PGVector, unstructured.io, and the semantic chunker, aiming to enable chatting with PDF documents through OpenAI. The first part of the tutorial is available on YouTube.
Links mentioned:
- Chat With Your PDFs: An End to End LangChain Tutorial For Building A Custom RAG with OpenAI. Part 1: A common use case for developing AI chat bots is ingesting PDF documents and allowing users to ask questions, inspect the documents, and learn from them. In …
- GitHub - anaxios/langchainjs-workers: Contribute to anaxios/langchainjs-workers development by creating an account on GitHub.
LangChain AI ▷ #langserve (2 messages):
-
Mischievous Link Spam: User
@eleussposted a message with a long sequence of bars and underscores, followed by what appears to be a Discord invitediscord.gg/pudgysand tagged@everyone, which resembles spam behavior or an attempt to playfully clutter the chat. -
Insight on Feedback Mechanism:
@georgeherbyexplained the process for handling feedback, mentioning that users can provide written comments as follow-up to any feedback given, positive or negative. This feedback gets added to the same record for consistency.
LangChain AI ▷ #share-your-work (1 messages):
- LLaMA Outperforms Baklava in Art Analysis:
@dwb7737shared a TLDR that LLaVA seems to be more effective at analyzing and classifying artwork than Baklava. They provided a GitHub Gist for more details on the comparison.
Links mentioned:
Ollama models - Image Summarization: Ollama models - Image Summarization. GitHub Gist: instantly share code, notes, and snippets.
LangChain AI ▷ #tutorials (2 messages):
-
CrewAI gets Obsidian Note-Taking Power:
business24.aishared a YouTube tutorial titled “Use crewAI and add a custom tool to store notes in Obsidian.” The tutorial demonstrates how to create a custom tool for crewAI that enables users to add search results as a note in Obsidian using OpenAI’s ChatGPT 4 and ChatGPT 3. -
Launching Tutorial Series for Building RAG with PDFs:
a404.ethposted the first video of a three-part tutorial series, titled “Chat With Your PDFs: An End to End LangChain Tutorial For Building A Custom RAG with OpenAI. Part 1”. The tutorial guides viewers through developing AI chatbots capable of interacting with PDF documents, using tools like PGVector, unstructured.io, and the semantic chunker.
Links mentioned:
-
Chat With Your PDFs: An End to End LangChain Tutorial For Building A Custom RAG with OpenAI. Part 1: A common use case for developing AI chat bots is ingesting PDF documents and allowing users to ask questions, inspect the documents, and learn from them. In …
-
Use crewAI and add a custom tool to store notes in Obsidian: In this Tutorial, we create a custom tool for crewAI to add search results as a note in Obsidian. We use it with OpenAI ChatGPT 4 and ChatGPT 3 and Multiple …
,
LLM Perf Enthusiasts AI ▷ #announcements (1 messages):
- Ringing in 2024 with Quality LLM Talk:
@jeffreyw128welcomed everyone to 2024 and praised the Discord as a hub for top-tier LLM discussions. He announced his plans to inject fresh energy into the group with a new round of hand-selected invites and encouraged current members to send referrals.
LLM Perf Enthusiasts AI ▷ #offtopic (2 messages):
- Document Layout SOTA Unveiled: User
@res6969inquired about the state-of-the-art in document layout understanding, particularly for identifying bounding boxes around charts in PDF reports. They later updated with the Vision Grid Transformer as a potential solution, linking to its GitHub repository here.
Links mentioned:
GitHub - AlibabaResearch/AdvancedLiterateMachinery: A collection of original, innovative ideas and algorithms towards Advanced Literate Machinery. This project is maintained by the OCR Team in the Language Technology Lab, Alibaba DAMO Academy.: A collection of original, innovative ideas and algorithms towards Advanced Literate Machinery. This project is maintained by the OCR Team in the Language Technology Lab, Alibaba DAMO Academy. - Git…
LLM Perf Enthusiasts AI ▷ #feedback-meta (6 messages):
- New Channel Creation:
@jeffreyw128announced the creation of a new channel, initially without a specific name. - Channel Naming Brainstorm:
@degtrdgsuggested the name #share for the newly created channel. - Channel Renamed to #share: Following
@degtrdg’s suggestion,@jeffreyw128agreed and renamed the channel to #share. - Discussing LLM Perf-Related Activities:
@yikesawjeezmentioned ongoing activities such as Swyx’s paper club, Skunkworks paper implementation sessions, and weekly codejams/challenges that are potentially relevant to the LLM Perf community. - LLM Perf Infiltration Idea:
@yikesawjeezhumorously proposed the idea of LLM Perf community members joining other events to bring their expertise on training, architecture, tuning, and performance. ,
Skunkworks AI ▷ #general (1 messages):
far_el: good lad
Skunkworks AI ▷ #off-topic (1 messages):
pradeep1148: https://www.youtube.com/watch?v=n3gkZ_IRwCI ,
YAIG (a16z Infra) ▷ #ai-ml (2 messages):
- In Search of On-Premise AI Solutions: User
@floriannoellinquired about on-premise AI solutions that work independently of major cloud providers like AWS, GCP, or Azure, specifically mentioning watsonx.ai as a reference for what they’re looking for. - Custom Needs for AI Solutions: In response,
@spillaiprompted@floriannoellto clarify the intended use case for the AI technology, suggesting that identifying specific needs such as pretraining, finetuning, inference, or classification could lead to a more targeted on-premise solution. ,
Alignment Lab AI ▷ #open-orca-community-chat (1 messages):
- Slim Orca Dataset Now Available on HF:
@222gateinformed that the Slim Orca dataset is accessible on Hugging Face and provided instructions for finetuning using this dataset. The dataset boasts ~500k GPT-4 completions, and Slim Orca has been refined using GPT-4 to remove inaccuracies, requiring 2/3 the compute for similar performance to larger data slices. - Efficient High-Performance Training with Slim Orca: The Open Orca team has curated a subset to enable efficient training, which has been corroborated by demo models such as jackalope-7b and Mistral-7B-SlimOrca, showcasing the dataset’s effectiveness.
Links mentioned:
Open-Orca/SlimOrca · Datasets at Hugging Face: no description found
,
Datasette - LLM (@SimonW) ▷ #llm (1 messages):
llm-gpt4allRelease 0.3 Goes Live:@simonwannounced the new release ofllm-gpt4allversion 0.3 which includes a fix by<@461550757901107221>and several other improvements. The update notably allows access to model options like-o max_tokens 3and enables models to work without an internet connection.
Links mentioned:
Release 0.3 · simonw/llm-gpt4all: Now provides access to model options such as -o max_tokens 3. Thanks, Mauve Signweaver. #3 Models now work without an internet connection. Thanks, Cameron Yick. #10 Documentation now includes the l…