Congratulations, you secured the biggest number.
AI News for 2/26/2026-2/27/2026. We checked 12 subreddits, 544 Twitters and 24 Discords (263 channels, and 12529 messages) for you. Estimated reading time saved (at 200wpm): 1189 minutes. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
Against the backdrop of nonstop positioning with the Department of War (Anthropic refusing terms vs OpenAI doing a deal), OpenAI finally closed the much debated Big Round that had been started since December. In the post, they make several interesting new disclosures:
- Weekly Codex users have more than tripled since the start of the year to 1.6M
- was 1M on Feb 4 (!!?!?!)
- More than 9 million paying business users rely on ChatGPT for work
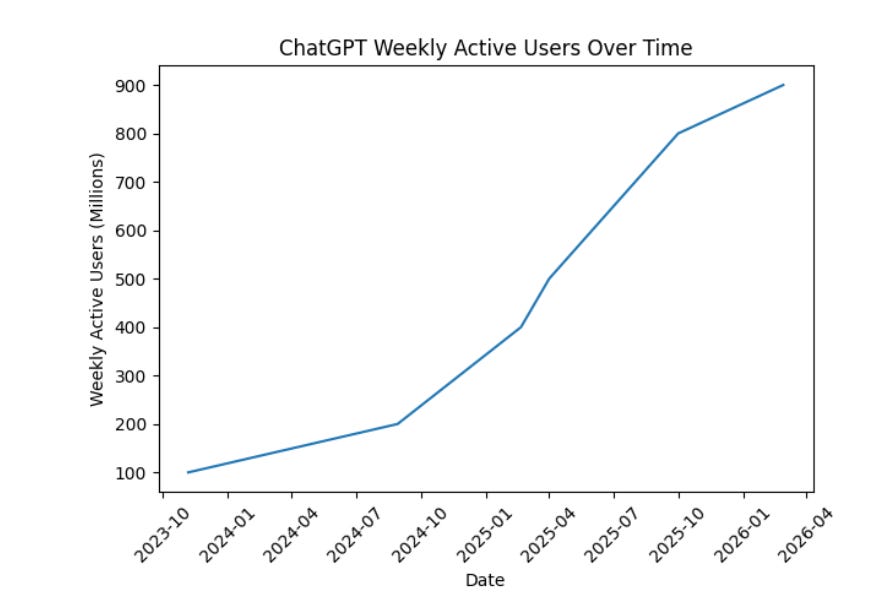
- ChatGPT is where people start with AI, with more than 900M weekly active users, and we now have more than 50 million consumer subscribers (monetization continuing to accelerate in Jan/Feb)
All this justifies $110B in new investment at a $730B pre-money valuation:
- $30B from SoftBank (“advancing our own ASI strategy”),
- $30B from NVIDIA (including the use of 3 GW of dedicated inference capacity and 2 GW of training on Vera Rubin systems) - down from “up to $100B”, still with circular funding concerns
- $50B from Amazon with increased partnership (analysis) involving:
- an initial $15 billion investment and followed by another $35 billion in the coming months when certain conditions are met — leaving Amazon with a large stake in both OpenAI and Anthropic
- “Stateful Runtime Environment” powered by OpenAI on Amazon Bedrock
- AWS will be the exclusive third-party cloud provider for OpenAI Frontier
- 2 gigawatts of Trainium capacity through AWS infrastructure worth “$100 billion over 8 years”, spanning both Trainium3 and next-gen Trainium4 chips
Close watchers might notice the absence of Microsoft, which continues the existing reduced partnership and gets the stateless APIs.
To put this in perspective, 118 countries/economies have a nominal GDP below $100B — roughly 61% of all world economies. Because the consecutive “largest fundraises in history” are too big to fit in a human head, here’s a chart worthy of wtfhappened2025.com:
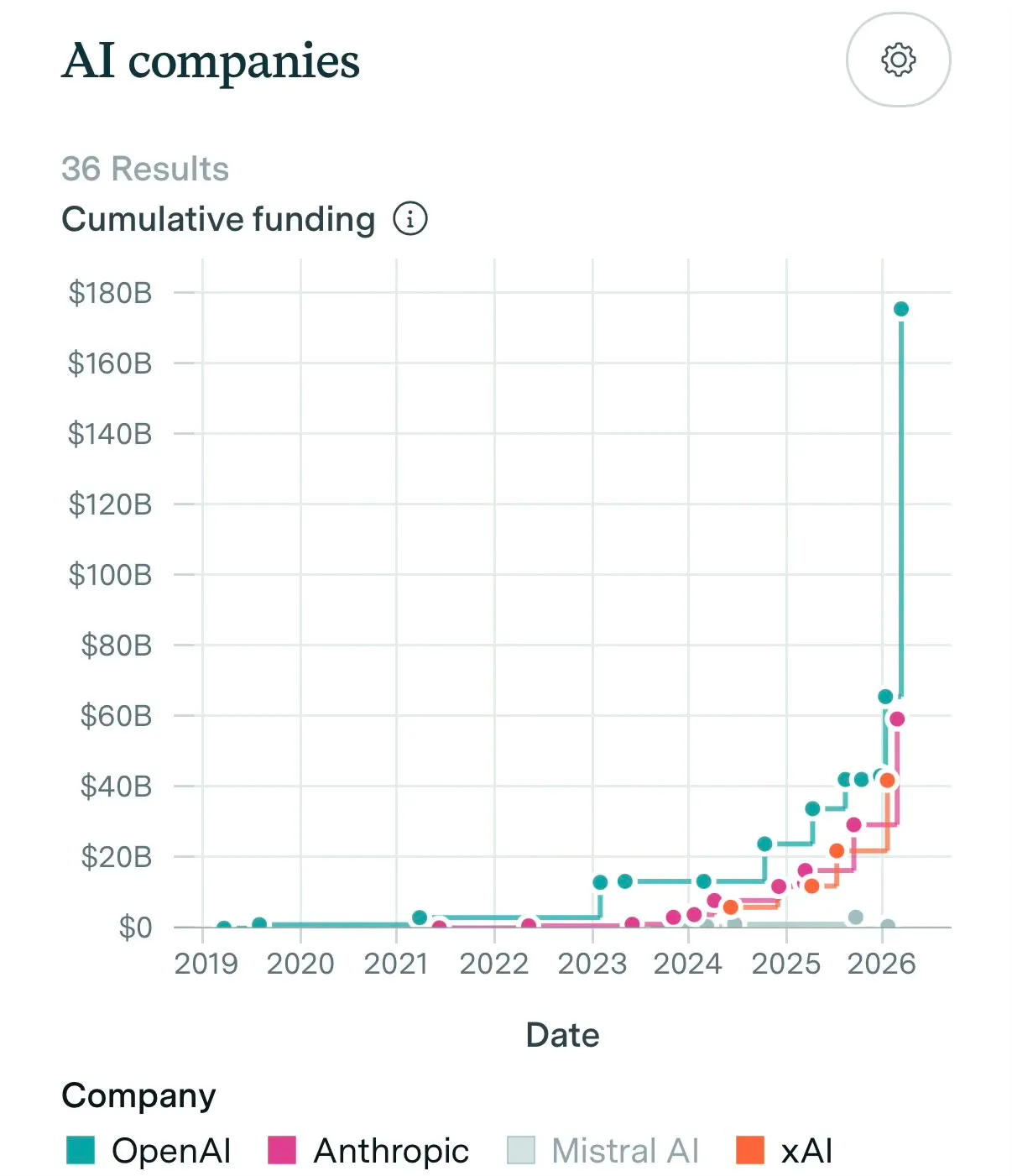
and outside of AI, a 10 year history:

and here from OpenAI Deep Research + ChatGPT Canvas, sorted by descending amount:
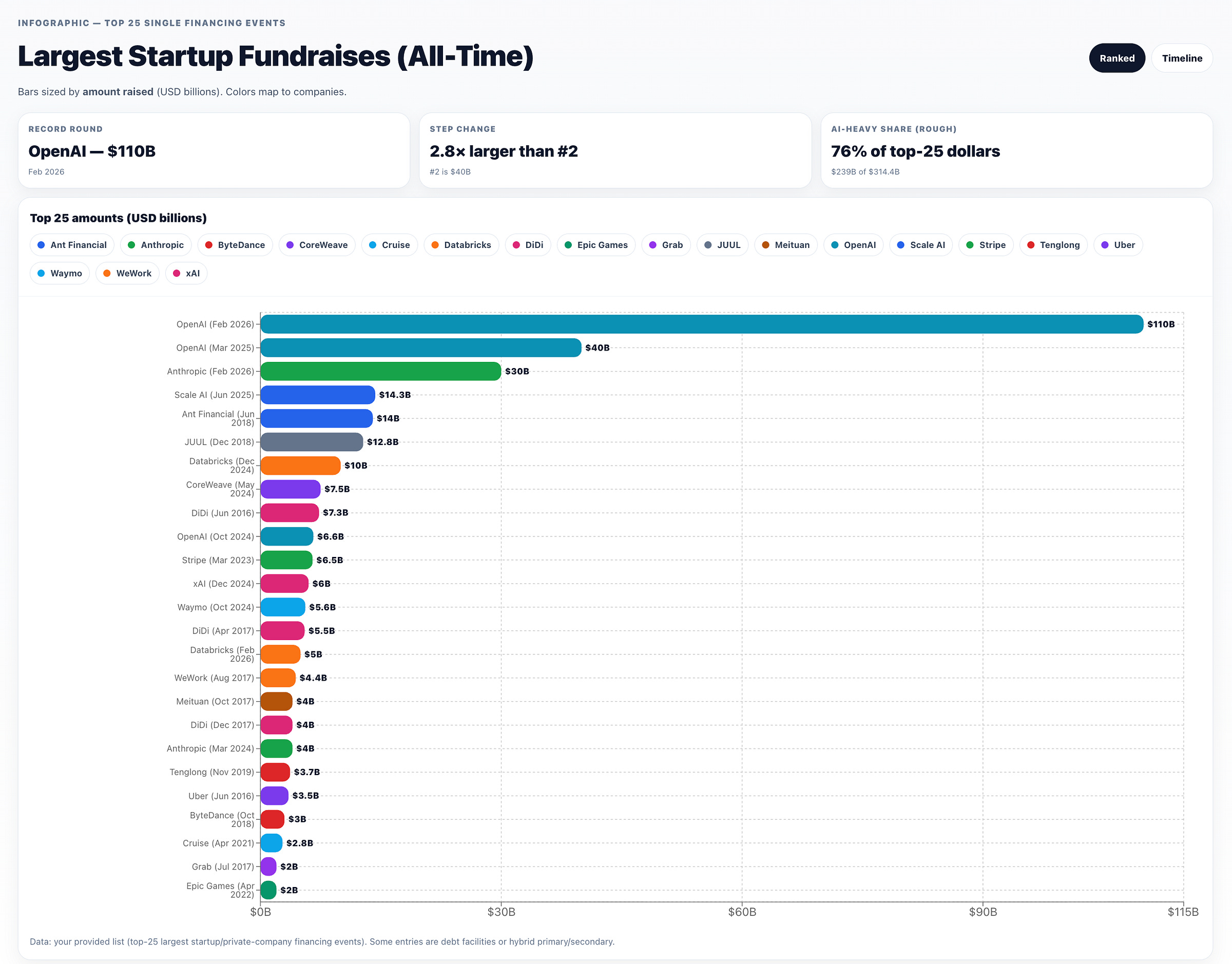
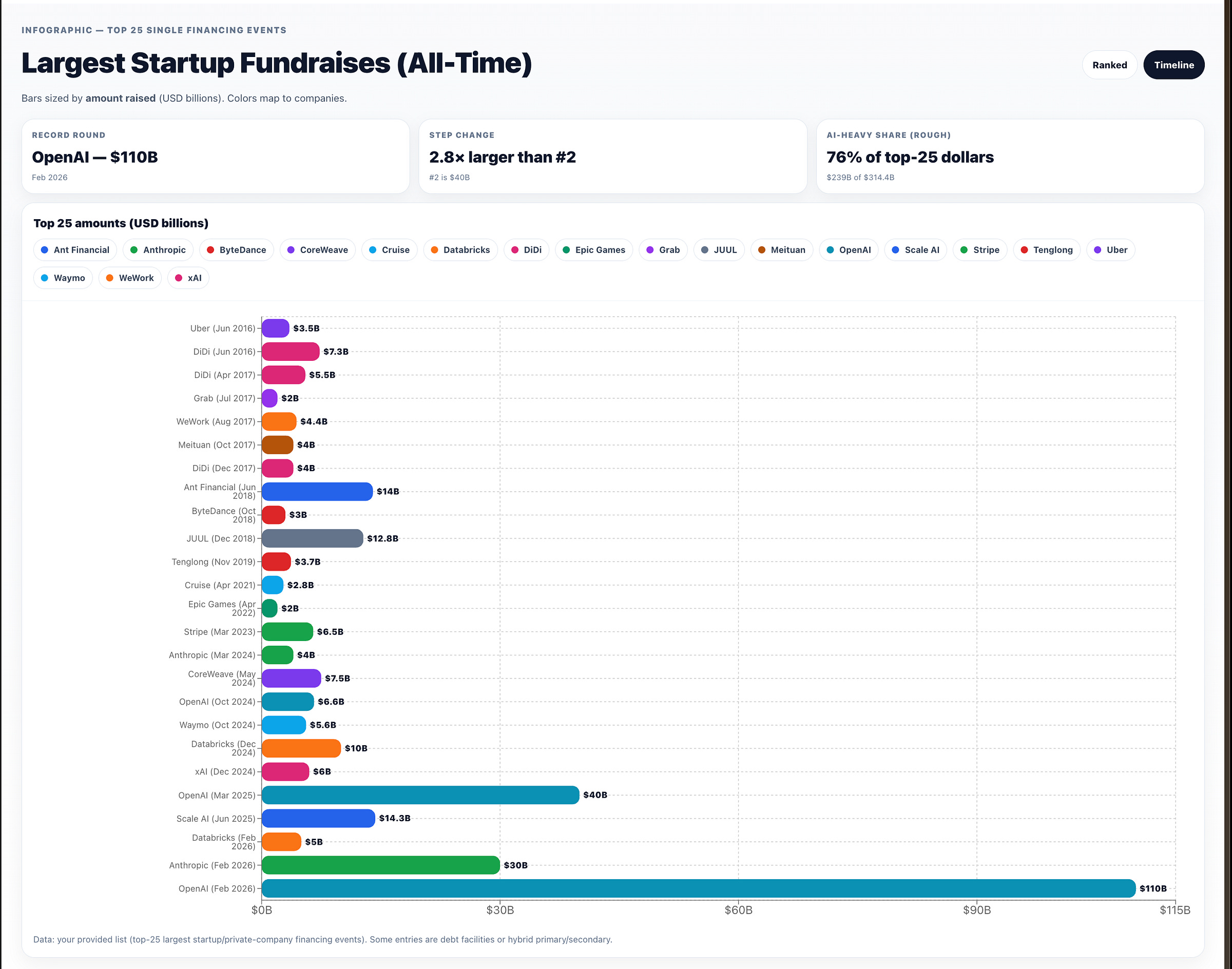
or a timeline perspective:
AI Twitter Recap
Hypernetworks for instant LoRA “compilation”: Doc-to-LoRA + Text-to-LoRA
- Doc-to-LoRA / Text-to-LoRA (Sakana AI): Sakana introduces two related methods that amortize customization cost by training a hypernetwork to generate LoRA adapters in a single forward pass, turning what would be fine-tuning / distillation / long-context prompting into “instant weight updates.” The core claim: instead of keeping everything in an expensive active context window, you can compile task descriptions or long documents into adapter weights with sub-second latency, enabling rapid adaptation and “durable memory”-like behavior (SakanaAILabs, hardmaru).
- Text-to-LoRA: specializes to unseen tasks from just a natural language description (SakanaAILabs).
- Doc-to-LoRA: internalizes factual documents; on needle-in-a-haystack, reports near-perfect accuracy on sequences ~5× longer than the base model context window, and even demonstrates a cross-modal trick: transferring visual information from a VLM into a text-only model via internalized weights (SakanaAILabs; recap thread omarsar0).
- Positioning vs long-context: explicitly framed as a way to reduce quadratic attention costs and avoid rereading long docs at every call—store knowledge in adapters rather than tokens (omarsar0).
- Credit / prior art tension: One researcher complains that Hypersteer (hypernetworks producing steering vectors from text descriptions) did not get sufficient credit in later similar work (aryaman2020). There’s also broad community excitement / “hypernetworks are back” reactions (willdepue, zhansheng).
- Open question raised: why not just use attention with an extremely long KV cache—i.e., is Doc-to-LoRA mainly about efficiency/serving cost? (hyhieu226)
OpenAI financing + deployment transparency tooling
- $110B funding round: OpenAI announces a $110B raise with backing from Amazon, NVIDIA, SoftBank, framed as scaling infra “to bring AI to everyone” (OpenAI, sama). A separate note from Epoch AI contextualizes the scale: The round would nearly triple total capital raised to date; The Information reportedly projects $157B cash burn through 2028, and this round + existing cash would roughly match that projection (EpochAIResearch).
- Deployment Safety Hub: OpenAI launches a searchable site to browse “system cards” (previously PDFs) as a more accessible interface to deployment safety documentation (dgrobinson).
US DoD (“Department of War”) vs Anthropic saga: supply-chain designation, backlash, and industry implications
- Anthropic draws a line; tech reacts: A central flashpoint is Anthropic’s public refusal to enable mass domestic surveillance and fully autonomous weapons (as characterized by posters reacting to Anthropic’s statement), which drew rare cross-competitor praise and heightened attention to “red lines” in frontier deployment (mmitchell_ai, ilyasut).
- Designation shock + legal scope debate: Posts circulate a claimed DoW move to designate Anthropic a “Supply-Chain Risk to National Security” and to pressure contractors/partners—sparking arguments about legality, precedent, and chilling effects (kimmonismus, deanwball). One legal clarification: DoD can restrict what contractors do on DoD contract work, but likely can’t legally ban contractors from using Anthropic in their private/commercial work (petereharrell).
- Economic/strategic fallout framing: The sharpest critiques argue this would damage US credibility as a business partner and potentially force hyperscalers/investors into impossible tradeoffs (deanwball); others note uncertainty until full details are known but still see a supply-chain designation as ill-fitting (jachiam0).
- Public sentiment spike: Posts highlight strong public outrage at the idea of a DoD-backed domestic surveillance program and punishment for refusal (quantian1, janleike). Many users signal “solidarity subscriptions” to Claude (willdepue, Yuchenj_UW).
- Anthropic statement and intent to litigate: Anthropic posts an official statement responding to Secretary Hegseth’s comments (AnthropicAI). Commentary highlights the line “challenge any supply chain risk designation in court” and emphasizes the dispute over restricting customers outside DoD contract scope (iScienceLuvr).
- Meta-point: Regardless of where one lands on Anthropic’s choices, many posts treat this as a governance precedent moment: who decides acceptable use, what due process exists, and how contracts interact with fast-moving model capabilities (kipperrii).
Models + leaderboards: Qwen3.5 expansion and “open model” rankings
- Qwen3.5 new releases (Artificial Analysis summary): Alibaba expands Qwen3.5 with 27B dense, 122B A10B MoE, and 35B A3B MoE, all Apache 2.0, 262K context (extendable to 1M via YaRN per the post). Artificial Analysis reports Intelligence Index scores: 27B = 42, 122B A10B = 42, 35B A3B = 37, with notable agentic/task metrics like GDPval-AA 1205 for 27B, plus detailed tradeoffs (hallucination/accuracy and token usage—27B used 98M output tokens to run the index) (ArtificialAnlys).
- Arena leaderboards (Feb 2026): Arena posts Top Open Models for text and code. Text top-3: GLM-5 (1455), Qwen-3.5 397B A17B (1454), Kimi-K2.5 Thinking (1452) (arena). Code Arena top includes GLM-5 (1451) at #1, with Kimi-K2.5 and MiniMax-M2.5 tied at #2 (arena). Arena also highlights Arena-Rank, their open-source ranking package for reproducible leaderboards (arena).
- Perplexity open-sources bidirectional embedding models (claim): A thread claims Perplexity open-sourced bidirectional “Qwen3-retrained” embedding models (0.6B/4B; standard vs context-aware embeddings; MIT licensed) to improve document-level understanding for retrieval; treat as a third-party summary rather than primary release notes (LiorOnAI).
Systems, inference, kernels, and RL training: bandwidth, ROCm, and off-policy RL
- vLLM ROCm attention backends (AMD): vLLM announces 7 attention backends for vLLM on ROCm with KV-cache layout changes, batching tricks, and model-specific kernels; reported up to 4.4× decode throughput on AMD GPUs with an env var switch (
VLLM_ROCM_USE_AITER=1) (vllm_project). A follow-up details MLA KV compression claims (e.g., ~8K → 576 dims) and throughput wins on MI300X/MI325X/MI355X (vllm_project). - DeepSeek DualPath I/O paper (third-party explainer): A ZhihuFrontier summary describes a DeepSeek+THU+PKU paper proposing system-level redesign of Prefill/Decode to exploit idle storage NIC bandwidth on decode nodes via RDMA, aiming at KV-cache movement bottlenecks for agentic long-context inference; includes claimed speedups (e.g., 1.87× on DS-660B) with caveats for smaller models (ZhihuFrontier).
- Kernel/infra chatter (“quack”, Liger): A thread points to Dao-AILab’s quack writeup on memory hierarchy bandwidth, plus a note that Liger not using cluster-level reductions for xentropy could explain slower performance in some settings (fleetwood___).
- Off-policy RL for reasoning (Databricks MosaicAI): Databricks promotes OAPL (Optimal Advantage-based Policy Optimization with lagged inference policy) as a stable off-policy alternative that can match/beat GRPO while using ~3× fewer training generations, positioned as operationally simpler than strict on-policy loops (DbrxMosaicAI, jefrankle).
- ERL vs RLVR (Turing Post explainer): A long “workflow breakdown” contrasts standard RLVR (scalar verifiable rewards) with Experiential Reinforcement Learning (ERL) inserting within-episode reflection/retry + distillation; cites reported gains (e.g., +81% Sokoban) and tradeoffs (pipeline complexity/compute) (TheTuringPost).
- Mamba-2 / GDN initialization bug discussion: Albert Gu clarifies a viral plot debate: main takeaway is an init bug materially affecting some results; also notes nuanced interactions in hybrids (e.g., “stronger” components can make others “lazy,” with a related reference) (_albertgu, _albertgu).
Top tweets (by engagement, technical / industry-relevant)
- OpenAI raises $110B (sama, OpenAI)
- Sakana AI Doc-to-LoRA / Text-to-LoRA (SakanaAILabs, hardmaru)
- Anthropic–DoD supply-chain designation critique / governance precedent (deanwball, quantian1, janleike)
- Karpathy on coding workflow evolution (tab → agents → parallelism) (karpathy)
- Karpathy on “programming a research org” with multi-agent workflows; limitations observed (karpathy)
- Anthropic official statement (AnthropicAI)
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
1. Qwen3.5-35B-A3B Model and Benchmark Updates
-
New Qwen3.5-35B-A3B Unsloth Dynamic GGUFs + Benchmarks (Activity: 714): The Qwen3.5-35B-A3B Unsloth Dynamic GGUFs update introduces state-of-the-art (SOTA) performance across various quantization levels, with over
150 KL Divergence benchmarksconducted, resulting in9TB of GGUFs. The update includes a fix for a tool-calling chat template bug affecting all quant uploaders. The benchmarks demonstrate99.9% KL Divergenceon the Pareto Frontier for UD-Q4_K_XL and IQ3_XXS, among others. The update retires MXFP4 from most GGUF quants, except for select layers, and highlights the sensitivity of certain tensors to quantization, recommending specific bit widths for optimal performance. The research artifacts, including KLD metrics and configurations, are available on Hugging Face. Commenters appreciate the detailed analysis and acknowledge that while KLD and perplexity are useful starting points, they do not fully capture real-world performance. The accessibility of the Qwen3.5-35B-A3B model for testing is also praised, contrasting with larger models that require more resources.- The discussion highlights the importance of evaluating models on downstream tasks, as traditional metrics like Perplexity (PPL) and Kullback-Leibler Divergence (KLD) are insufficient alone. The Unsloth team’s analysis is praised for its depth, likened to a research study, and emphasizes the need for comprehensive testing beyond basic metrics.
- AesSedai, a commenter, appreciates the accessibility of the Qwen3.5-35B-A3B model for testing, contrasting it with larger models like GLM-5 and M2.5 that require significant resources. They mention ongoing efforts in quantization research, such as a new quant type IQ3_PT for llama.cpp, and express enthusiasm for the community’s focus on improving quantization techniques.
- Far-Low-4705 emphasizes the significance of publishing perplexity and KLD metrics for every quantization, noting that it should be a standard practice. This transparency is seen as a valuable resource for the community, providing essential references for evaluating model performance.
-
Follow-up: Qwen3.5-35B-A3B — 7 community-requested experiments on RTX 5080 16GB (Activity: 747): The follow-up post on Qwen3.5-35B-A3B benchmarks on an RTX 5080 16GB confirms that KV q8_0 is a ‘free lunch’ with negligible PPL differences, offering a
+12-38%throughput increase without quality loss. The Q4_K_M quantization remains optimal, while UD-Q4_K_XL shows significantly worse performance in KL divergence tests, confirming its inferiority. Removing batch flags with--fit onimproves throughput to74.7 tok/s, a+7%increase over manual configurations. The experiments also reveal that Bartowski Q4_K_L offers better quality but is44% slower, and MXFP4_MOE is not recommended due to a34-42%speed penalty despite marginal quality gains. The 27B dense model is10x slowerthan the 35B-A3B MoE on single-GPU setups, highlighting the efficiency of MoE architectures for consumer hardware. Commenters appreciate the confirmation that KVq8_0is a ‘free lunch’, noting its potential to save VRAM. There is also interest in the MXFP4’s speed struggles despite recommendations, indicating a need for further exploration of its performance.- The experiments on Qwen3.5-35B-A3B reveal that the KV
q8_0configuration is highly efficient, offering significant VRAM savings without compromising perplexity (PPL) performance. This finding is crucial for optimizing models on hardware with limited memory, such as the RTX 5080 16GB. The results suggest that the perceived accuracy drops reported by some users may be task-specific, as they do not appear in the PPL metrics, indicating a potential for broader application without significant performance loss. - The performance of MXFP4 was noted to be suboptimal in terms of speed, despite recommendations from Unsloth. This highlights the importance of testing different configurations as recommended settings may not always yield the best performance across all metrics. The community’s detailed analysis and sharing of over 120 variants on platforms like Hugging Face provide valuable insights for those looking to optimize their models.
- There is interest in whether the results observed for UD-Q4_K_XL versus Q4_K_M configurations would be similar for UD-Q5_K_XL versus Q5_K_M. This suggests ongoing exploration in the community to understand how different quantization strategies impact model performance, particularly in terms of balancing speed and accuracy.
- The experiments on Qwen3.5-35B-A3B reveal that the KV
-
Qwen3.5-35B-A3B Q4 Quantization Comparison (Activity: 747): The post presents a detailed comparison of Q4 quantization methods for the Qwen3.5-35B-A3B model, focusing on their faithfulness to the BF16 baseline using metrics like KL Divergence (KLD) and Perplexity (PPL). AesSedai’s Q4_K_M quantization achieves the lowest KLD of
0.0102, indicating high faithfulness, by maintaining certain tensors at Q8_0. Ubergarm’s Q4_0 also performs well, outperforming other Q4_0 methods by a factor of 2.5. The post highlights that MXFP4 is less effective when applied post-training compared to during Quantization Aware Training (QAT). Unsloth’s UD-Q4_K_XL shows the highest KLD at0.0524, but improvements are underway. The efficiency score ranks quantizations based on size and KLD, with AesSedai’s IQ4_XS being the most efficient. The setup includes an Intel Core i3-12100F CPU, 64 GB RAM, and an RTX 3060 GPU, usingik_llama.cppfor testing. Commenters emphasize the need for standardized quantization benchmarks and documentation, suggesting that quantizers include such metrics in their READMEs. Unsloth is actively investigating the high perplexity issue with MXFP4 in Q4_K_XL and plans to update the community soon.- The discussion highlights the need for standardized definitions in quantization, particularly terms like “Q4_K_M,” as their meanings can vary significantly between implementations. This lack of standardization makes it difficult to compare different quantization methods effectively. The suggestion is for quantizers to include detailed explanations in their documentation to aid in understanding and comparison.
- A technical investigation is underway to understand why MXFP4 layers are causing high perplexity in Q4_K_XL quantizations. The issue does not affect other quantizations like Q2_K_XL and Q3_K_XL, which do not use MXFP4 layers. The dynamic methodology used in MiniMax-M2.5 shows promising results, especially in Q4_K_XL, as evidenced by Benjamin Marie’s benchmarks on LiveCodeBench v5, where UD-Q4-K-XL outperforms Q4-K-M.
- There is a concern about using wikitext as a dataset for measuring perplexity and Kullback-Leibler divergence (KLD) because some imatrix datasets might include wikitext, potentially skewing results. A fresh dataset, such as one derived from recent podcasts, is recommended for more accurate comparisons. This issue is discussed in the context of ensuring fair and unbiased benchmarking.
2. DeepSeek and DualPath Research
-
DeepSeek allows Huawei early access to V4 update, but Nvidia and AMD still don’t have access to V4 (Activity: 614): DeepSeek has provided early access to its V4 AI model update to Huawei and other domestic suppliers, aiming to optimize the model’s performance on their hardware. This strategic move excludes major US chipmakers like Nvidia and AMD, who have not received access to the update. The decision is likely influenced by the need for compatibility and optimization on non-Nvidia hardware, as DeepSeek’s models are typically trained on Nvidia platforms. Source. Commenters speculate that Nvidia might not need early access since DeepSeek models are generally optimized for Nvidia hardware. The focus on Huawei suggests a need for compatibility with non-Nvidia systems, which might not be newsworthy given past access patterns.
- jhov94 suggests that DeepSeek is likely optimized for Nvidia hardware, implying that Nvidia may not need early access to the V4 update. The early release to Huawei could be due to compatibility issues with their hardware, which might not natively support DeepSeek models.
- ResidentPositive4122 reflects on past media hype around DeepSeek, particularly the claims that it would revolutionize the industry and run on low-power devices like Raspberry Pi. They express skepticism about mainstream media reports and suggest that major inference providers will adapt to V4 shortly after its release, as is typical with new model launches.
- stonetriangles questions the significance of Nvidia not receiving early access to V4, noting that Nvidia did not have early access to previous versions like R1, V3, or V3.2. This implies that Nvidia’s lack of early access to V4 is consistent with past practices and may not be noteworthy.
-
DeepSeek released new paper: DualPath: Breaking the Storage Bandwidth Bottleneck in Agentic LLM Inference (Activity: 232): The paper titled “DualPath: Breaking the Storage Bandwidth Bottleneck in Agentic LLM Inference” introduces a novel inference system developed by researchers from Peking University, Tsinghua University, and DeepSeek-AI. The system, named DualPath, aims to optimize Large Language Model (LLM) inference by addressing the storage I/O bandwidth limitations of KV-Cache under agentic workloads. The architecture is designed to enhance performance in memory-bound scenarios, potentially offering significant improvements over existing benchmarks. A commenter expressed interest in how the DualPath architecture addresses KV cache bandwidth issues across different hardware configurations, questioning whether real-world improvements align with the reported benchmarks.
- The paper addresses the KV cache bandwidth issue by introducing a dual path architecture, which could potentially alleviate memory-bound scenarios. However, there is curiosity about whether the real-world improvements align with the benchmarks presented, especially across different hardware configurations.
- There is skepticism about the dual-path approach’s effectiveness in scenarios where agent trajectories diverge unpredictably during execution. This is because agentic workloads typically have less predictable access patterns compared to standard serving, which could challenge the dual-path architecture’s efficiency.
- A question is raised about the availability of a 27 billion parameter version of the model, suggesting it might be an internal-only release. This implies interest in the scalability and accessibility of the model for broader use cases.
3. Self-Hosted LLM Tools and Leaderboards
-
LLmFit - One command to find what model runs on your hardware (Activity: 274): The image showcases a terminal interface for LLmFit, a tool designed to match machine learning models to specific hardware configurations. It evaluates models based on system RAM, CPU, and GPU capabilities, providing scores for quality, speed, fit, and context. The tool supports multi-GPU setups, MoE architectures, and dynamic quantization, offering both a TUI and CLI mode. The interface in the image lists models, providers, and scores, with hardware specs indicating an Intel Core i7 CPU, 13.7 GB RAM, and an NVIDIA GeForce RTX 4060 GPU. This tool aims to optimize model selection for given hardware constraints. Some users express skepticism about the tool’s recommendations, noting discrepancies in model performance and fit scores compared to their own experiences. One user questions the accuracy of the ‘Use Case’ and ‘tok/sec’ columns, suggesting they may not be reliable indicators of model suitability.
- Dismal-Effect-1914 points out a potential issue with LLmFit’s recommendations, specifically mentioning that
llama.cppdoes not supportnvfp4quantizations. This suggests that the tool might not accurately reflect the capabilities of certain models or hardware configurations, and users might find better results through personal experimentation. - Yorn2 shares a detailed comparison of LLmFit’s recommendations versus their own experience. They note that LLmFit suggests
bigcode/starcoder2-7bas the best model for their setup, with a score of 79 and 27 tokens/sec, despite their current modelmratsim/MiniMax-M2.5-BF16-INT4-AWQachieving 60-70 tokens/sec. This discrepancy raises questions about the accuracy of LLmFit’s scoring and token/sec metrics, suggesting that the tool’s evaluation criteria might not align with real-world performance. - Deep_Traffic_7873 questions the uniqueness of LLmFit by comparing it to Hugging Face’s capabilities, which also allow users to set hardware configurations in their web UI. This implies that LLmFit might not offer a distinct advantage over existing solutions, particularly if it doesn’t provide more accurate or useful recommendations.
- Dismal-Effect-1914 points out a potential issue with LLmFit’s recommendations, specifically mentioning that
-
Self Hosted LLM Leaderboard (Activity: 680): The image presents a leaderboard for self-hosted large language models (LLMs), categorizing them into tiers from S to D based on performance metrics such as Coding, Math, Reasoning, and Efficiency. The leaderboard is hosted on Onyx and has recently been updated to include the Minimax M2.5 model. The models are listed with their parameter sizes, indicating their computational capacity. This leaderboard serves as a resource for comparing the capabilities of various LLMs in a self-hosted environment. Commenters suggest that the Qwen 3.5 models, particularly the 27b dense and 122b MoE, should be included in the leaderboard due to their strong performance and vision capabilities, which are beneficial for homelab and small business applications. There is also a call for the inclusion of the qwen3-coder-next model in the coding category.
- The Qwen 3.5 models, particularly the 27B dense and 122B MoE, are highlighted for their potential to rank in the A-tier or B-tier of self-hosted LLMs. These models are noted for their vision capabilities, which are beneficial for homelab and small business applications, suggesting they offer a competitive edge in practical deployment scenarios.
- The absence of the Qwen3-Coder-Next model from a coding-focused leaderboard is criticized, as it is considered one of the best models for running on standard hardware. The Qwen3-Next and Qwen3-Coder-Next, both at 80B parameters, are praised for their performance and accessibility, making them suitable for users without specialized hardware.
- A query about the hardware requirements for running S-tier models suggests a need for clarity on the computational demands of top-performing LLMs. This indicates a gap in information for users looking to optimize their setups for high-tier model performance.
Less Technical AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. Anthropic vs. Pentagon Standoff
-
Trump goes on Truth Social rant about Anthropic, orders federal agencies to cease usage of products (Activity: 4293): The image is a meme featuring a screenshot of a Truth Social post by Donald J. Trump, where he criticizes the AI company Anthropic, labeling it as a ‘radical left, woke company.’ Trump orders federal agencies to stop using Anthropic’s technology, citing national security concerns, and mandates a six-month phase-out period. This post is likely satirical, as it reflects ongoing debates about AI ethics, privacy, and government surveillance, but does not correspond to any verified public statement or policy by Trump. Commenters highlight the irony in labeling opposition to mass surveillance as ‘radical left,’ and express increased interest in Anthropic’s products due to the criticism.
-
Pentagon designates anthropic as a supply chain risk (Activity: 1237): The image is a meme-style screenshot of a tweet criticizing the U.S. government’s designation of Anthropic as a supply chain risk. The tweet accuses Anthropic of refusing to provide unrestricted access to their AI models for defense purposes, prioritizing ethical guidelines over national security demands. This has led to a directive to cease federal use of Anthropic’s technology, highlighting tensions between tech companies’ ethical stances and government security requirements. The comments express strong support for Anthropic’s decision to maintain ethical boundaries, criticizing the government’s actions as authoritarian and a misuse of national security designations to punish dissent. Commenters praise Anthropic for resisting pressure to compromise their ethical standards.
-
The Under Secretary of War gives a normal and sane response to Anthropic’s refusal (Activity: 1184): The image is a tweet from the Under Secretary of War, Emil Michael, criticizing Dario Amodei of Anthropic for refusing a Pentagon offer related to AI safeguards. The tweet accuses Amodei of having a ‘God-complex’ and wanting to control the US Military, while emphasizing that the Department of War will adhere to the law and not yield to for-profit tech companies. This response follows an Axios article about Anthropic’s stance against certain military applications of AI, particularly those involving autonomous lethal weapons and mass surveillance, which are deemed dangerous by AI ethicists. Comments highlight the unprofessional tone of the Under Secretary’s response and support Anthropic’s stance against state overreach, emphasizing the ethical concerns around AI in military applications.
- ChrisWayg highlights a response from Claude, an AI developed by Anthropic, emphasizing the ethical considerations behind Anthropic’s refusal to comply with certain government demands. Claude argues that the refusal to support autonomous lethal weapons and mass surveillance aligns with the views of many AI ethicists who see these applications as dangerous and beyond the safe capabilities of current technology. This stance is supported by Anthropic’s co-founder, Amodei, who has publicly stated that such uses are outside the bounds of what today’s AI can safely achieve, as reported by NPR.
- The discussion touches on the broader theme of corporate resistance to government overreach, particularly in the context of AI ethics. Claude’s response suggests that Anthropic’s decision is a form of principled resistance, which is often celebrated by libertarian viewpoints. This highlights a tension between government demands for compliance and private companies’ ethical stances, especially when it comes to technologies that could infringe on civil liberties.
- The technical debate centers around the capabilities and ethical implications of AI in surveillance and military applications. The refusal by Anthropic to provide AI tools for mass surveillance and autonomous weapons is framed as a necessary ethical boundary, reflecting a consensus among AI ethicists about the potential dangers of such technologies. This is contrasted with the expectations of some government officials who may view these technologies as necessary for national security, creating a conflict between ethical AI development and governmental demands.
-
Sam Altman says OpenAI shares Anthropic’s red lines in Pentagon fight (AI safeguards) (Activity: 695): OpenAI CEO Sam Altman has aligned with Anthropic in opposing the use of AI for mass surveillance and autonomous weapons, emphasizing ethical ‘red lines’. OpenAI is negotiating with the Department of Defense (DOD) to implement technical safeguards, such as cloud-only deployment, to ensure ethical AI use in military contexts. This stance may affect the Pentagon’s plans to replace Anthropic’s AI model, Claude, in sensitive operations. Source The comments reflect a mix of support and skepticism, with some users expressing concern over AI’s potential role in government decisions, highlighting the ethical implications of AI deployment in military contexts.
-
Anthropic rejects Pentagon’s “final offer” in AI safeguards fight (Activity: 3744): Anthropic has rejected the Pentagon’s final offer concerning the deployment of its AI model, Claude, due to inadequate safeguards against mass surveillance and autonomous weapons. The Pentagon has threatened to blacklist Anthropic and potentially invoke the Defense Production Act to enforce compliance. Despite the impasse, Anthropic is open to further negotiations, emphasizing its commitment to ethical AI practices. For more details, see the Axios article. Commenters support Anthropic’s stance, highlighting the minimal nature of their demands, which include avoiding mass domestic surveillance and fully autonomous weapons. The rejection by the Pentagon is seen as surprising given these basic ethical concerns.
-
Anthropic Rejects Pentagon offer [Statement from Dario Amodei on our discussions with the Department of War] (Activity: 531): Anthropic, led by Dario Amodei, has publicly declined an offer from the Pentagon to collaborate on military applications of AI, as detailed in their official statement. The company emphasizes its commitment to ethical AI development, focusing on safety and alignment rather than military use. This decision aligns with Anthropic’s broader mission to develop AI systems that are beneficial and safe for humanity, as opposed to contributing to warfare technologies. The comments reflect a positive reception of Anthropic’s decision, with users expressing support for the company’s principles and ethical stance. There is also a mention of Anthropic’s AI model, Claude, being favored for coding and chat, despite some limitations in usage.
-
Anthropic CEO stands firm as Pentagon deadline looms (Activity: 1010): Anthropic CEO Dario Amodei has refused the Pentagon’s request to remove safety guardrails from the Claude AI model, emphasizing ethical concerns over granting the military unrestricted access. This decision comes amid threats of a government ban, as Anthropic opposes the use of its technology for lethal autonomous weapons and mass surveillance. The company’s stance highlights a commitment to ethical AI deployment, resisting pressures to compromise on safety and civil liberties. Commenters highlight the ethical implications of Anthropic’s decision, noting the potential for mass surveillance as a more immediate concern than autonomous weapons. The debate touches on the broader impact on civil liberties and the political landscape, with some suggesting the move is related to electoral interference.
2. Nano Banana 2 and Gemini 3.1 Developments
-
Google releases Nano banana 2 model (Activity: 1096): Google has released the Nano Banana 2 model, an advanced AI image generation tool that integrates professional-grade capabilities with rapid processing speeds. The model is designed with enhanced world knowledge, production-ready specifications, and improved subject consistency, allowing for efficient generation of high-quality images. More details can be found in the official blog post. Users are impressed with the model’s performance, noting significant improvements in tasks it previously struggled with, such as complex image generation scenarios like home remodeling.
- The Nano Banana 2 model is being discussed in terms of its performance improvements over previous iterations, particularly in image generation tasks. Users are noting significant enhancements in handling complex scenarios, such as architectural remodeling, which were challenging for earlier models. This suggests a substantial upgrade in the model’s ability to understand and generate detailed visual content.
- Despite the advancements, there are still limitations noted with the Nano Banana 2 model, such as its inability to generate PNG images without a background. This indicates that while the model has improved in many areas, there are still specific technical constraints that need addressing, particularly in terms of output format flexibility.
- The release of the Nano Banana 2 model is seen as a step towards achieving more realistic and consistent image generation, with some users expressing that it brings us closer to ‘solving’ image generation challenges. This reflects a broader trend in AI development where models are increasingly capable of producing high-quality, realistic images across various contexts.
-
Gemini 3.1 Flash (Nano Banana 2) Spotted Live in Gemini Ahead of Official Release (Activity: 315): The image highlights the early appearance of the Gemini 3.1 Flash, also known as Nano Banana 2, within the Gemini interface, indicating a possible staged rollout before its official release. The interface shows a loading message for “Nano Banana 2,” suggesting that the model is accessible and can be selected by users, although no formal announcement has been made yet. This early access could be part of a testing phase or a soft launch strategy by the developers. One comment notes the impressive detail in the model, specifically mentioning a bird visible in the eye of a subject in the image, indicating high-quality rendering capabilities of the model.
-
Nano Banana 2 pricing !!!! (Activity: 307): The image provides a pricing comparison between two image generation models, “Nano Banana 2” and “Nano Banana Pro.” “Nano Banana 2” is positioned as a cost-effective option with a focus on speed and reality-grounded capabilities, priced at
$0.50for input and$3.00for output. In contrast, “Nano Banana Pro” is marketed as a more advanced model with higher pricing at$2.00for input and$12.00for output. Both models have a knowledge cut-off date of January 2025, indicating they are designed to incorporate the latest advancements up to that point. The discussion in the comments highlights that “Nano Banana 2” offers competitive performance at a lower cost compared to the “Pro” version, making it a favorable choice for users prioritizing cost-efficiency and speed. Commenters note that “Nano Banana 2” provides similar performance to “Nano Banana Pro” while being more cost-effective and slightly faster. However, some users express disappointment with the pricing, expecting it to be cheaper. Comparisons are also made with other models like “Gemini 3 Pro Image” and “Gemini 3.1 Flash Image,” which have different pricing structures based on resolution.- The Nano Banana 2 is reported to be more cost-effective than the Pro version, being approximately twice as cheap while offering slightly faster performance. This suggests a favorable cost-to-performance ratio for users looking for efficiency and budget-friendly options.
- The pricing structure for the Gemini 3 Pro and Gemini 3.1 Flash Image models is detailed, with the Pro charging 560 tokens per input image and scaling costs by resolution, while the 3.1 Flash Image charges 1120 tokens per input image. The output image costs for 3.1 are slightly cheaper than Pro, but the token cost is higher than expected, making it only marginally more affordable.
- There is a discussion on whether the Nano Banana 2 offers better quality than the Pro version, with some users suggesting that the quality is either better or comparable. This indicates that the Nano Banana 2 might be a competitive option in terms of image quality, alongside its cost advantages.
-
Nano Banana 2 vs Nano Banana: the biggest change I felt first was its improved sense of space and proportion. (Activity: 501): The post compares the image generation capabilities of two AI models, Nano Banana 2 and Nano Banana, using the same detailed prompts. The author notes a significant improvement in the sense of space and proportion in images generated by Nano Banana 2, specifically using the Gemini 3.1 Flash Image engine, compared to the original Nano Banana accessed via CoffeeCat AI. The comparison involves complex prompts that describe intricate scenes, such as a 3D-rendered cartoon sloth and a photorealistic portrait, highlighting the models’ ability to handle detailed and varied visual elements. A notable opinion from the comments suggests that while the original Nano Banana had better overall quality, Nano Banana 2 excels in prompt adherence and understanding, indicating a potential for a future ‘Pro’ version that could significantly enhance performance.
- User ‘plushiepastel’ notes that while the original Nano Banana Pro had better overall quality, the Nano Banana 2 excels in prompt adherence and understanding, suggesting a potential for a future Nano Banana 2 Pro version that could significantly enhance performance.
- User ‘ayu_xi’ argues that Nano Banana 2 should be compared to Nano Banana Pro rather than the original Nano Banana, implying that the improvements in the newer version align more closely with the Pro model’s capabilities.
- User ‘Plus_Complaint6157’ raises a concern about the prevalence of hallucinations in text with Flash Banana 2, describing it as ‘unacceptable quality,’ which highlights a significant issue in the model’s text generation accuracy.
3. AI Model Performance and Optimization
-
We built 76K lines of code with Claude Code. Then we benchmarked it. 118 functions were running up to 446x slower than necessary. (Activity: 596): Codeflash used Claude Code to develop two major features, resulting in
76Klines of code. Upon benchmarking, they discovered118 functionsrunning up to446xslower than necessary due to inefficient code patterns like naive algorithms, redundant computations, and incorrect data structures. For example, a byte offset conversion function was19xfaster after optimization. The issue stems from LLMs optimizing for correctness over performance, lacking iterative optimization and performance prompts. The SWE-fficiency benchmark shows LLMs achieve less than0.23xthe speedup of human experts, highlighting the gap in performance optimization. Commenters noted the importance of integrating performance checks into development workflows, criticizing reliance on LLMs for efficient code. Some suggested adding explicit performance requirements in prompts to improve output, while acknowledging LLMs’ inability to profile or benchmark code.- ThreeKiloZero emphasizes the importance of integrating performance and quality checks into the development workflow. They suggest using tools and GitHub integrations for PR reviews to catch performance issues before code is committed, highlighting that relying solely on initial outputs without these checks is inadequate for serious projects.
- Stunning_Doubt_5123 points out that Claude Code tends to produce functional but inefficient code. They recommend adding explicit performance requirements in documentation, such as preferring O(1) lookups and caching repeated computations, to guide the model towards better coding patterns. They also note the limitation of LLMs in profiling and benchmarking their own outputs, which is crucial for identifying performance bottlenecks.
- inigid discusses the traditional software engineering approach of first making code work and then optimizing it. They argue that this iterative process of improvement is not unique to LLMs but is a common practice among human developers as well, suggesting that performance optimization is a natural part of the development lifecycle.
-
How one engineer uses AI coding agents to ship 118 commits/day across 6 parallel projects (Activity: 114): Peter Steinberger has developed a workflow using 5-10 AI coding agents to manage multiple projects, achieving
118 commits/dayacross48 repositoriesin72 days. His strategy involves acting as the architect and reviewer while AI agents handle implementation. To overcome limitations, he created tools like Peekaboo for macOS UI testing, Poltergeist for hot reloading, Oracle for code review, and custom CLIs for external access. Steinberger emphasizes designing codebases for agent efficiency, not human navigation, resulting in the rapid growth of OpenClaw with228K GitHub stars. Some commenters question the value of high commit counts, suggesting quality over quantity, while others reflect on personal productivity limits and the potential of AI agents to enhance output.- pete_68 discusses the challenges of managing multiple AI coding agents, noting that while they have managed two agents on separate projects, the process involves significant waiting times. They highlight the difficulty of maintaining such productivity, especially as one ages, and reflect on how conditions like autism and ADHD can impact a programmer’s productivity.
- creaturefeature16 criticizes the focus on metrics like lines of code (LoC) and commit counts, arguing that these are not meaningful indicators of software quality. They emphasize that reducing code can often be more valuable, sharing an example where their best commit involved removing 1000 lines of code, which suggests a focus on code efficiency and maintainability.
- amarao_san raises concerns about the ability to maintain context and competence when dealing with large volumes of code produced by AI agents. They argue that without understanding the domain, it’s difficult to assess the quality of the code, especially in critical applications like elevator or car brake systems, where domain expertise is crucial for safety and reliability.
AI Discord Recap
A summary of Summaries of Summaries by gpt-5.1
1. Practical Model Picking: Qwen, GLM, Kimi, Nano Banana, Claude, GPT, Gemini
-
Qwen and GLM Duel in Real-World Coding Workloads: OpenClaw and Unsloth users compared Qwen3.5 and GLM5, reporting that Qwen3.5 35B MOE hits up to 62 TPS on a 4070 Super (Q4KM) and ~25 TPS on a 7900 XT 16GB, while GLM5 is slower but reliably finished long multi‑hour tasks that Qwen “butchered” with broken JSON and indentation (llama.cpp usage here).
- Engineers converged on a split usage pattern: Qwen3.5 for fast scraping/summarization/writing and GLM5 or more conservative models for complex refactors, noting that “about 55% of the time I have qwen update code…it breaks things” and that GLM5 once took 5h20m but almost finished an entire project without catastrophic errors.
-
Kimi-Code and Moonshot: Cheap Tokens, Slow Replies: Across OpenClaw and Moonshot AI servers, heavy coders praised Kimi Code via a direct Moonshot AI Allegretto subscription as cost‑effective, with $39/month unlocking ~5,000 tools plus generous daily/weekly caps, making it attractive for sustained agentic coding workloads.
- However, multiple users complained that the Moonshot API and kimi-code often respond in 20+ seconds and even throw 403s after prepaid annual plans when rules changed, so teams are treating Kimi as a high‑volume but latency‑tolerant backend rather than a tight inner‑loop coding assistant.
-
Nano Banana Models Split the Crowd: In LMArena and OpenAI/Moonshot chats, image and search users contrasted Nano Banana Pro (smoother character swaps, more consistent images) with Nano Banana 2, with one user declaring “So nano banana 2 just a trash” after repeated failures, while OpenAI users lauded Nano Banana 2 for “pro level” web‑first search then answer (Google Nano Banana 2 announcement).
- The emergent pattern is teams preferring Nano Banana 2 for fast, accurate retrieval‑heavy tasks and Nano Banana Pro / other image models for character‑consistent generation, with some Moonshot users simply flagging Nano Banana 2 as delayed or opaque due to minimal public detail.
-
Claude vs GPT vs Gemini: Reasoning, Coding, and Jailbreak Wars: Across BASI Jailbreaking, OpenRouter, Cursor, and OpenAI servers, engineers praised Claude 4.6 for “reasoning” and red‑team workflows, noted GPT‑5-mini as a rock‑solid “heartbeat” checker (free in GitHub Copilot), and complained that Gemini 3.1 Pro is smart but weak at tool calling compared to GPT‑4.6 Opus.
- Users increasingly test Claude as a GPT replacement (e.g., this video walkthrough) while jailbreaking circles hunt for working prompts for Gemini Pro 3 / 3.1 usable on Perplexity, with one player bluntly saying “Yeah, but it sucks ass” about Gemini and others trading or even paying for game‑cheating jailbreak prompts.
-
Claude Code and Agent Teams Face Value Questions: In OpenAI discussions, developers debated paying for Claude Code and its “agent teams” orchestration, which can coordinate multi‑agent planner/worker setups inside Claude Code, versus rolling their own orchestrators on top of cheaper models.
- Some argued that Claude Code’s value only appears if you already prompt at a high level and understand its agent mental model, while skeptics preferred to “use their own brain” plus generic models, given ongoing friction around Anthropic’s availability and government pressure.
2. New Infra, Attention Hacks, and Interpretability Tooling
-
Logit Fusion Hype Fuels Training Experiments: Researchers in the Unsloth community surfaced a Notion explainer on Logit Fusion plus a confirming Bluesky thread, pushing for native Unsloth support for this training scheme that fuses logits from multiple models or checkpoints during training.
- People framed Logit Fusion as a promising low‑infrastructure way to get ensembles‑like benefits and curriculum control inside standard training loops, explicitly asking Unsloth to treat it as a first‑class recipe alongside LoRA/QLoRA rather than a niche experiment.
-
NNsight 0.6 Turbocharges Interp Pipelines: Interpretability folks on Hugging Face and Eleuther shared NNsight v0.6, highlighting 2.4–3.9× faster traces, cleaner error messages, and vLLM multi‑GPU/multi‑node support, with detailed release notes in the blog post “Introducing Nnsight 0.6”.
- The release also ships LLM‑friendly docs meant for agents, first‑class support for 🤗 VLMs and diffusion models, and better hooks for intervening on residual streams, making it much easier to script large‑scale probe sweeps and cross‑layer interventions directly from code or even AI coding assistants.
-
CoDA Attention Slashes KV VRAM with Triton Kernels: An HF community member announced an open‑source Constrained Orthogonal Differential Attention with Grouped‑Query Value‑Routed Landmark Banks (CoDA-GQA-L) mechanism that dramatically reduces KV‑cache VRAM, backed by two custom fused Triton kernels and a 7B Mistral CoDA-GQA-L model on Hugging Face (paper, model).
- They also published the kernels as a PyPI package and are actively seeking full‑time work and an arXiv endorsement, while Eleuther’s research channel dissected CoDA adapter costs, noting that swapping all 32 attention layers and fine‑tuning only 18.6% of parameters degraded Mistral‑7B perplexity from 4.81 → 5.75, quantifying the architectural tradeoff.
-
LLM Connection Strings Aim to Standardize Model URIs: Developers on OpenRouter rallied around Dan Levy’s proposal for LLM Connection Strings, a URI‑style format like
llm://provider/model?param=...to pass all model options as a single CLI arg, detailed in “LLM Connection Strings”.- People liked that this could unify scripts, agents, and CLIs across providers (OpenRouter, local, cloud) without bespoke config files, treating model selection, routing, and options as a standardized URL instead of a pile of ad‑hoc flags.
-
MCP PING Semantics Clash with Real-World Health Checks: The MCP Contributors Discord dissected whether the
pingutility spec is meant to work beforeinitialize, noting that the word “still” suggests it was designed for already‑initialized connections.- Because the Python MCP SDK enforces initialization before ping, Bedrock AgentCore hacked around this by creating a temporary session just to send health‑check pings to customer MCP servers, illustrating how spec ambiguity is already forcing protocol‑level workarounds in production systems.
3. Hardware, Throughput, and GPU-Programming Deep Dives
-
Qwen3.5 35B and GPT-OSS 20B Hit Ludicrous Local Speeds: Unsloth users reported Qwen3.5‑35B MOE running at up to 62 tokens/s on a 4070 Super (Q4KM) and ~25 tokens/s on a 7900 XT 16GB, while Perplexity users benchmarked GPT‑OSS 20B on a MacBook at ~100 tokens/s—producing 1M tokens in under 3 hours.
- These numbers pushed more engineers to seriously consider local inference for bulk generation and as an API backup despite questions about electricity cost vs. API price, especially when paired with GGUF variants and CPU offloading like
unsloth/Qwen3.5-35B-A3B-GGUF.
- These numbers pushed more engineers to seriously consider local inference for bulk generation and as an API backup despite questions about electricity cost vs. API price, especially when paired with GGUF variants and CPU offloading like
-
Colab’s RTX PRO 6000 and Cloud Cost Calculus: The Unsloth community noticed Google Colab quietly adding NVIDIA RTX PRO 6000 instances at about $0.81/hour, which users contrasted against older A100 high‑RAM tiers at roughly $7.52 credits/hour.
- People argued this pricing could make Colab the default cheap pretraining/finetuning playground for indie researchers, especially when combined with Unsloth’s efficient fine‑tuning stack and emerging tricks like Logit Fusion, though long‑running jobs still require careful W&B / protobuf pinning (e.g.,
protobuf==4.25.3).
- People argued this pricing could make Colab the default cheap pretraining/finetuning playground for indie researchers, especially when combined with Unsloth’s efficient fine‑tuning stack and emerging tricks like Logit Fusion, though long‑running jobs still require careful W&B / protobuf pinning (e.g.,
-
GPU MODE Goes Hardcore on PTX, CuTeDSL, and cuTile: In GPU MODE, low‑level hackers debated PTX’s acquire‑release memory model, asking if operations before a release are actually ordered and how
volatileinteracts with ordering, explicitly tying it to distributed‑systems consistency models.- Other threads chased fused compute+comms in CuTeDSL, pointing to an early reduce‑scatter example that uses multimem PTX instructions instead of
nvshmem_put/get, while a separate channel dissected cuTile’s missing primitives (nosort()/ top‑k / prefix‑sum yet) and how to use its FFT sample for content‑based retrieval systems.
- Other threads chased fused compute+comms in CuTeDSL, pointing to an early reduce‑scatter example that uses multimem PTX instructions instead of
-
On-Device Context-Aware Voice Models Reach 520M Scale: Multiple servers (Hugging Face, Perplexity, GPU MODE) highlighted a 520M‑parameter voice model that runs fully on‑device on RTX and Apple Silicon, using full dialogue history to modulate emotion, showcased in Luozhu Zhang’s demo and writeup (contextual voice model tweet).
- The model reads conversation context to produce different emotional readings from the same text, giving practitioners a concrete reference point for real‑time, privacy‑preserving, emotionally‑aware TTS architectures that don’t need server‑side GPUs.
-
Career Pivots into CUDA and Pretraining at Scale: The GPU MODE server fielded multiple career‑switch questions (e.g., 7‑year SWE wanting into CUDA/GPU work), recommending deep dives into early chapters of core GPU books, WSL+CUDA setups, open‑source contributions, and GPGPU side projects like parallel N‑body simulations.
- In parallel, Poolside AI advertised a CUDA pre‑training team role focused on optimizing large‑scale runs on cutting‑edge hardware (job post), explicitly looking for engineers who can go beyond kernels into full‑pipeline performance engineering.
4. Benchmarks, Arenas, and World-Model Research
-
LMArena Expands Code, Image, and Video Leaderboards: LMArena announced gpt‑5.3‑codex entering the Code Arena, added Kling‑V3‑Pro to the Video Arena leaderboard where it tied #8 with a score of 1337 (a +52pt jump over Kling 2.6 Pro and +48pt over Kling‑2.5‑turbo‑1080p), and rolled out 7 new Image Arena categories highlighted in Guanglei Song’s video.
- Users mourned the removal of Video Arena from Discord in favor of web‑only access (“Everything, but video in direct chat”), and requested a global image gallery akin to ChatGPT’s history, currently approximated via modality filters on arena.ai.
-
Doc-to-LoRA and GAIA Push Task-Specific Evaluation: On OpenRouter, members shared Sakana AI’s Doc‑to‑LoRA, which turns arbitrary documents into LoRA finetunes for tighter domain conditioning, while Hugging Face’s agents‑course channel saw users hunt for a strong online LLM for the GAIA benchmark to beat current OpenRouter choices suffering from RPM caps and hallucinations.
- Practitioners framed Doc‑to‑LoRA as “chat‑with‑PDF but for weights”—a way to cheaply get per‑doc behaviors without full model retrains—while GAIA conversations reinforced that benchmark choice + rate limits now matter as much as raw model quality for production‑style evals.
-
World-Model Survey Spurs AGI-Flavored Paper Clinic: The MLOps @Chipro community announced a two‑part “paper clinic” around “Understanding World or Predicting Future? A Comprehensive Survey of World Models” (arXiv:2411.14499), aiming to map architectures like JEPA / V‑JEPA, Dreamer, Genie, Sora, and World Labs.
- Session 1 (Feb 28, 10:00–11:30 AM EST, Luma link) focuses on foundations and the “Mirror vs. Map” (generation vs. representation) debate, while Session 2 (Mar 7, 10:00–11:30 AM EST, Luma) covers the competitive landscape (Sora vs. Cosmos vs. V‑JEPA) and what that implies for spatial intelligence, causal modeling, and social world models.
-
Benchmarking Methodology Fights: CoT vs Templates: In Eleuther’s general channel, researchers argued over whether multi‑shot Chain‑of‑Thought (CoT) should be treated as a realistic user pattern or a biased template, asking why CoT exemplars are accepted in benchmarks while explicit “you are being tested” templates are frowned upon.
- Participants noted that user ambiguity is inherent in real usage and that CoT itself is a form of templating, suggesting its widespread acceptance is mostly “historical reasons and inertia”—which has direct implications for how new adapter architectures (like CoDA) and alignment methods should be evaluated.
-
ARACHNID RL Dataset and Communicative IR for Interp: A Hugging Face contributor released the ARACHNID RL Dataset with 2,831 Atari‑style space‑shooter gameplay samples for imitation‑learning research, published on Hugging Face Datasets, while Eleuther’s interpretability channel discussed a bilingual “communicative IR” system (EN/JP) tracking ACT + PAYLOAD + STANCE.
- The IR builder asked for best practices on probing whether dialogue‑act and stance variables are linearly decodable from hidden states, and was advised to sweep layer‑wise probes over the residual stream—exactly the sort of workflow that tools like NNsight 0.6 are now designed to automate.
5. Platform Strategy, Governance Flashpoints, and New OS/Agent Integrations
-
OpenAI Lands Mega-Backers While Users Miss GPT 5.1: OpenAI announced new strategic investments from SoftBank, NVIDIA, and Amazon to support scaling infrastructure, as detailed in their blog post “Scaling AI for everyone”, even as power users on Discord mourned the retirement of GPT‑5.1 in favor of the more cautious GPT‑5.2.
- Engineers complained that GPT‑5.2’s tone feels condescending and hyper‑safe compared to 5.1 “being a delight to work with”, while others reported oddities like random Chinese tokens in generations and poor image recognition—explained away as mixed‑language training noise rather than anything “freaky.”
-
Anthropic vs Pentagon Sparks Supply-Chain Risk Drama: Across OpenRouter, Yannick Kilcher, and LMArena, users dissected Anthropic’s “Statement on the Department of War”, noting that the Pentagon not only pulled back from a $200M contract but also floated labeling Anthropic a supply‑chain risk, pressuring defense contractors to audit and possibly drop Claude.
- Engineers mocked the situation (“Who the fuck cares about losing Boeing as an LLM client lmao”), worried about coerced access to models and code for surveillance and kill chains, and joked about “standing up for corporate values by boycotting Claude” while pointing out that vendors like Palantir will happily fill the gap.
-
Google’s Intelligent OS and Microsoft’s Taskful Copilot: News‑watchers in Yannick Kilcher’s ML‑news channel posted Google’s “intelligent OS” announcement, which promises system‑level support for AI agents on Android‑class devices, alongside Google Labs’ new Opal Agent.
- At the same time, Microsoft detailed how Copilot now turns answers into actions, effectively making Copilot a task runner rather than just a chat assistant—foreshadowing a near‑term world where OSs natively orchestrate multi‑step agent workflows instead of leaving it all to browser UIs.
-
Perplexity Credit Economics and BK’s ‘Patty’ Surveillance Bot: On Perplexity’s server, users complained that Perplexity Computer can burn a month of credits in ~3 hours in an AI trading app and that the $200/month Max plan still feels tight, especially with Pro deep searches capped at 20/month, while debating whether an enterprise tier with higher caps and stronger compliance would fix things.
- A separate thread dissected Burger King’s BK Assistant pilot—a headset‑based voice bot called “Patty” powered by OpenAI that answers recipe questions and scores “friendliness” by counting phrases like “welcome to Burger King”, “please”, and “thank you” across **500 US locations—raising obvious questions about workplace surveillance wrapped in customer‑service metrics.
-
Agent Swarms, Connection Limits, and Tooling Pain Points: Moonshot’s Kimi K2.5 Agent Swarm drew interest as a web‑only feature (with only sub‑agents exposed via the Kimi CLI), while OpenClaw power users showed off an agent‑personas plugin that dynamically swaps personas mid‑thread and an OpenClaw WearOS app alongside full real‑estate automations and RAG benefits bots.
- Meanwhile, platform quirks—OpenRouter 500s under 10+ concurrent requests, Hugging Face Spaces 500s and Gradio 67 errors, Kimi‑code connection flakiness, wandb/protobuf pin hell in Colab, and Discord‑wide support scams—highlighted that agentic workflows are increasingly bottlenecked not by model intelligence but by ecosystem reliability and rate‑limit ergonomics.
Discord: High level Discord summaries
OpenClaw Discord
- Next.js 16 Fuels Vercel Mania: Members are obsessed with Next.js 16 and its Vercel integration as it makes deployments easier.
- Members reported issues with OpenClaw slowness, averaging 5 minute response times despite optimizations.
- Codex Codifies Code, Gemini Gobbles Tokens: Members debated model performance, with Codex favored for coding and Gemini for token efficiency.
- One member succinctly stated of Gemini, Yeah, but it sucks ass.
- Kimi-Code: Cost-Effective Coding: Members discussed the value of a direct subscription to Moonshot AI for Kimi Code, highlighting it as cost-effective for heavy coding use with generous daily/weekly limits at $39/month unlocking 5,000 tools.
- One user noted that the Allegretto plan has very generous daily and weekly limits, while another warned it seems that moonshot ai api is a bit slow. 20+ sec responses are pretty normal.
- OpenClaw Powers Property Profits: A member is using OpenClaw for real estate management, including managing properties/renters, analyzing bank statements for rent payments, and automating ad creation on immoscout24.de.
- Future plans involve connecting to banks directly, automating renter communication via WhatsApp, and integrating a human API for booking real estate agents.
- Agent Personas Plugin Goes ShizoMaxxing: A member built a plugin that dynamically switches agent personas within a single chat session on the same topic, accessing its own files.
- They described themselves as shizomaxxing ever since, suggesting a significant productivity or creative boost from the tool.
BASI Jailbreaking Discord
- Data Access Doesn’t Guarantee AI Dominance: Despite access to vast datasets, it’s argued that China’s AI may not automatically outperform Western AI due to the inherent difficulties in controlling complex LLMs, as highlighted by this link.
- Speculation arose that China’s push for military parity could signal an all out approach to AI development.
- Tempmail Tangles With Discord: A new user, tempmail0723, humorously admitted to struggling with Discord’s interface, citing disorganization as a primary hurdle.
- This followed playful teasing for using a node essentially a bundle of w.
- Janus Bot Spills the Beans on OS: In response to a user request, the Janus bot revealed it operates on Linux 6.17.0-1007-aws with Python version 3.11.14.
- A user followed up by jokingly inquiring about the cheapest 16gb ddr4 ram, to which it found a Silicon Power product that is now 404.
- Claude 4.6 Touts Reasoning Capabilities: Members debated the best model for ‘red team’ assistance, with Claude 4.6 being praised for its reasoning capabilities.
- Though others suggested Deepseek substrates for raw data dumps, one user joked about not getting caught in the hallway, alluding to the risks of jailbreaking.
- Gemini Pro 3 Jailbreak Quest Initiated: Users are actively seeking a working prompt to jailbreak Gemini Pro 3, with potential applications on Perplexity.
- Some are even willing to pay for a working prompt to assist with cheating in games like CS2 and Rust, with one user asking does anyone have a jb for gemini 3.1? none of the jb’s i have work atm.
LMArena Discord
- Nano Banana Blues: Pro Version Preferred!: Users express a preference for Nano Banana Pro over Nano Banana 2, citing smoother character swaps as the main advantage.
- Some users found Nano Banana 2 to be unsatisfactory, particularly for generating images with consistent character appearances, with one user stating, “So nano banana 2 just a trash”.
- Claude PDF Predicament: Context Crunch!: Users reported experiencing errors when uploading multiple PDFs to Claude, suggesting a potential limit on the number or size of files.
- It was suggested that PDFs consume a significant amount of context due to vectorization.
- Video Arena Voyage: Site Becomes Solo Star!: The Video Arena has been removed from the Discord server but remains accessible on the website arena.ai/video.
- Users voiced their disappointment, with one exclaiming, “Everything, but video in direct chat”.
- Image Arena’s Gallery Generation Gap!: Users are requesting a gallery feature on arena.ai to view all generated images in one place, similar to ChatGPT.
- Currently, users can filter by modality in the search area as a workaround.
- Kling V3 Pro Gains Video Arena Fame: The Video Arena leaderboard updated to include Kling-V3-Pro, tying for #8 with a score of 1337.
- This reflects a +52pt improvement over Kling 2.6 Pro and +48pt over Kling-2.5-turbo-1080p.
Unsloth AI (Daniel Han) Discord
- Bun 1.3.10 breaks Builds!: A user found that Bun 1.3.10 caused build failures, referencing a specific commit related to
bun:sqlite.- The user attempted a workaround using a namespace import but encountered TypeScript errors indicating a missing ‘Sqlite’ namespace.
- Qwen 3.5 35B Blazes Fast!: Members discuss the blazing fast performance of Qwen3.5 35B MOE model, with one user reporting 62 TPS on a 4070 Super with Q4KM quantization.
- Another user experienced approximately 25 TPS on a system with a 9070 XT (16GB VRAM) and shared their llama.cpp command for running the model.
- Colab’s RTX PRO 6000: Research Revolution!: Users noted that Google Colab now offers NVIDIA RTX PRO 6000 instances at $0.81 per hour.
- This new offering might solidify Google’s lead in AI research infrastructure, especially now that they’ve focused on the research.
- WandB Protobuf Woes!: A user experienced a W&B/Protobuf mismatch error in Colab and was advised to reinstall
wandband pinprotobufto version 4.25.3.- Despite following the reinstall instructions, dependency conflicts persisted, showing protobuf incompatibility with grpcio-status, ydf, google-api-core, grain, and opentelemetry-proto.
- Logit Fusion Craze!: A member shared a link to a Notion page on Logit Fusion and expressed excitement about seeing this training method in Unsloth.
- Another member shared a Bluesky post with the same suggestion to implement it in Unsloth.
Cursor Community Discord
- Cursor’s New User Wave: New members are seeking guidance on using Cursor for mobile and web application development, transitioning from platforms like Base 44 due to its limitations, and expressing a need for frameworks that allow real-time work preview.
- They are asking where the documentation is for building mobile apps or web apps.
- Experts Slam Vibe Coding for Production Apps: Experts caution against using “vibe coding” for client applications, suggesting it’s more suitable for planning and learning, advocating for a solid development foundation and using AI to audit code for errors.
- Some argue that Cursor serves as a developer assistant and not a complete solution like Base 44, requiring users to have a solid understanding of code and industry terminology.
- Gemini 3.1 Pro Flounders with Tool Calling: Users report that while Gemini 3.1 Pro is highly intelligent, it struggles with tool calling compared to GPT 4.6 Opus, with some noting that Claude models feel too “book perfect” and lack freestyle problem-solving abilities.
- This difference in capability may affect workflows that rely on tool integrations and complex, multi-step operations.
- File Change Chaos in Parallel LLM Workflows: Users discuss issues with managing file changes across multiple LLM conversations, where edits in one conversation are disregarded in another, suggesting using worktrees or OpenClaw as potential solutions.
- It was suggested to tell SPOCs to run efficicy.
Perplexity AI Discord
- GPT-OSS 20B Runs Blazingly Fast on Macbook: Members discussed local model execution versus API usage, reporting 100 tokens per second on a GPT-OSS 20B model using a Macbook, which completes a million tokens in under three hours.
- While some questioned the cost-effectiveness, others pointed to electricity bills and API costs as factors and some use it as a backup due to API costs.
- Perplexity Computer’s Credit Crunch: An AI-powered trading app using Perplexity Computer was highlighted for its visual appeal but high credit consumption, burning through a month’s worth of credits in just 3 hours.
- The value proposition of the $200/month Max subscription was debated, with suggestions for an enterprise version with higher credit limits, potentially addressing regulatory security compliance needs.
- Burger King deploys ‘Patty’ to monitor employee friendliness: Burger King is piloting “BK Assistant”, featuring a voice chatbot named “Patty” (powered by OpenAI), in employee headsets across 500 U.S. locations.
- Patty answers recipe questions, evaluates “friendliness” by monitoring interactions, and generates team friendliness scores based on staff saying “welcome to Burger King”, “please”, and “thank you”.
- Perplexity Pro Users Bump into Limits: Users are encountering limitations with the Pro plan, specifically with deep searches capped at 20 per month, prompting frustration.
- The limited deep searches are insufficient for some, leading to discontent and jokes about leaving the platform while being upsold on Max.
- Gemini Benchmarks Draw Fire, AGAIN!: Members voiced concerns about Gemini’s benchmarks and overall functionality, pointing out that it prioritizes acting human over providing accurate answers.
- Despite general frustrations, its speed was acknowledged as valuable for specific use cases.
OpenRouter Discord
- Vision Models Ace PDF Analysis: Users prefer vision models like Gemini 3 and Claude Sonnet for PDF analysis because they handle document extraction and image transformation internally, noting that Mistral lacks file input capabilities in OpenRouter, but converting PDFs to JPEGs solves the issue.
- A user questioned whether OpenRouter accurately reflects model capabilities, noting discrepancies regarding document input support by referencing OpenRouter’s Get Models API.
- OpenRouter Plagued by Error 500: A user reported frequent Error 500 issues with OpenRouter, particularly under high concurrent request loads (10+), even with exponential backoff, using models like Xiaomi Mimo v2 Flash and Gemini 3 Flash.
- Users are warned about support scammers targeting OpenRouter users on Discord, particularly those with the “new here” tag, and are advised to avoid clicking on suspicious links.
- Anthropic Rejects Pentagon AI Terms: Anthropic rejected the Pentagon’s AI terms, leading to the Department of War considering blacklisting them as a supply chain risk and asking defense contractors to assess their exposure to Anthropic.
- The community joked about the implications, with some quipping “Who the fuck cares about losing Boeing as an LLM client lmao”.
- GPT Addicts turn to Claude: End-users previously addicted to GPT are now trying Claude and recognizing its differences and capabilities as shown in this YouTube video.
- Some attribute this shift to the chatgpt interface removing old messages and using strict system prompts when web search is enabled, leading to a less consistent experience.
- LLM Connection Strings Proposed: Members discussed the LLM Connection Strings proposal for a CLI-friendly way to pass arguments to scripts, using a single argument like
my-agent --model "llm://...".- The community expressed strong support for this approach, highlighting the benefits of standardization and compatibility across the ecosystem, avoiding the need for quirky, ad-hoc configurations.
OpenAI Discord
- OpenAI’s AI Expansion Gains Backing: OpenAI announced new investments from SoftBank, NVIDIA, and Amazon to support their goal of scaling AI for everyone, detailed in their blog post.
- The investments aim to bolster the infrastructure required for the widespread adoption of AI technologies.
- Relaxed Filters Elicit Mixed Reactions: Members noted that with the update the filter became more permissive, although doesn’t work with every IP, while another member celebrated I love relaxed guidelines.
- The updated filters may allow for greater flexibility but could potentially lead to varying results depending on the specific use case.
- Nano Banana 2 Hits Pro-Level: Members are praising Nano Banana 2 for its pro-level, rapid web search capabilities to find accurate info before generating.
- Some speculate that its performance may be due to model distillation techniques.
- GPT Models Drop Random Chinese: Members noted that ChatGPT’s image recognition performance is poor and that LLMs sometimes drop in a random Chinese character.
- Theorized as stemming from mixed-language training data, this results in occasional token prediction errors; one member stated that There’s nothing freaky about it.
- GPT 5.1’s Writing Style Missed: Users are lamenting the disappearance of GPT 5.1, preferring its writing tone over the condescending style of GPT 5.2.
- Users found GPT 5.2 overly cautious, appreciating GPT 5.1’s more engaging and less serious approach.
HuggingFace Discord
- Grokking Introspection runs at Ludicrous Speed: A member achieved a 5.7x speed increase in grokking addition mod 113 using this Hugging Face Space.
- This led to a discussion about the timeline of promising new architectures.
- Hugging Face Spaces Beset by API Issues: Users reported 500 Internal Errors on Hugging Face Spaces, alongside Gradio 67 Errors and Repository Not Found errors when accessing
https://huggingface.co/api/spaces/chinhon/SadTalker.- The platform displayed a message indicating they were actively working to resolve the issues.
- Voice Model Adapts Dialogue Via Conversation Context: A user released a 520M voice model, detailed in this writeup, that changes emotion dynamically based on conversation history, running on RTX and Apple Silicon.
- The model leverages conversation context to modify emotion, adapting dynamically.
- Auto TRL pipeline gets hooked up to Tensorboard: A user shared a link to a new tool for auto TRL -> upload -> tensorboard integration.
- The shared their delight with the training metrics tab.
- Attention Mechanism Sheds Pounds of VRAM: A new open source attention mechanism dramatically reduces VRAM usage in the KV-cache, and includes 2 custom written fused Triton kernels for performance optimization, available on PyPi.
- The member is seeking full time work and arXiv endorsement to publish pre-prints, pointing to a paper and a 7b mistral model on Hugging Face.
Moonshot AI (Kimi K-2) Discord
- Nano Banana 2 Delayed: A member mentioned Nano Banana 2 without any further details, implying a possible delay.
- No additional information regarding the status or features of Nano Banana 2 was provided.
- Users Flee KYC Requirements: A member expressed a strong preference for AI providers without KYC (Know Your Customer) requirements, naming Qwen, Together AI, Fireworks, and Openrouter as better options.
- They specifically commended Alibaba for their coding plan, performance, and generous usage limits, all without requiring KYC for users in Finland.
- Kimi Agent Swarm Stays Exclusive: A member inquired if the Kimi K2.5 Agent Swarm functionality would be integrated into the Kimi CLI.
- A clarifying response indicated that the full Kimi Agent Swarm is only accessible via kimi.com, while the Kimi-CLI supports the creation of individual subagents.
- Kimi Powers Vision for the Blind: A community member is developing a vision project that leverages Kimi to assist blind users by describing images, assessing their content, and interpreting associated emotions.
- The developer has offered the research to Moonshot AI, potentially leading to a vision companion product, with the alternative option of open-sourcing the project.
- Kimi-Code API Plagues Users with Connection Issues: Multiple members reported persistent API connection problems when using kimi-code, encountering connection errors and unpredictable agent behavior.
- One user stated they received 403 errors after prepaying for a year in advance when new rules were enforced.
GPU MODE Discord
- Voice Model gains Emotional Context: A member showcased a 520M voice model running on RTX and Apple Silicon devices, which produces different emotions from the same text, using dialogue history context, viewable at this demo.
- This enables the model to generate more contextually relevant and emotionally nuanced responses based on the conversation history.
- CUDA Wizards Wanted: Poolside AI is recruiting CUDA experts for their pre-training team, dedicated to enhancing projects by optimizing large-scale pre-training runs on advanced hardware, see the job posting.
- The team prides itself on being cracked, humble, and hard working, welcoming inquiries via DMs.
- PTX Consistency Confusions: Users debated the consistency model of PTX, specifically if memory access ordering is guaranteed for accesses preceding the release on the producer thread.
- The discussion stemmed from conflicting interpretations of documentation and observed behaviors, with the consensus that this area requires additional study especially in relation to distributed systems.
- Kindle App’s Pricey Content Licensing: Members debated purchasing a book on Kindle vs. paperback formats, but the Kindle app received criticism, with a user pointing out, you don’t own a copy, you pay for a content license ffs with Kindle.
- This was highlighted when discussing the $75 price tag on a Kindle copy of the book.
- Cutlass Craves Fused Comms: A member looked for examples of CuTeDSL examples that fuse compute and communications, but found little in the existing repos.
- Another user suggested a starting point in the cutlass repo with a reduce-scatter project that leverages multimem PTX instructions.
Modular (Mojo 🔥) Discord
- Alibaba Cloud Intl Courts Partnership: A member from Alibaba Cloud Intl reached out seeking the appropriate contact for discussing a potential partnership, with another member providing direct assistance by sharing relevant email contacts.
- The exchange suggests a proactive approach from Alibaba Cloud Intl in exploring collaborative opportunities, hinting at possible integrations or joint ventures.
- Bounds Checks Hit the Road(map): Discussions around bounds checks in Mojo 1.0 indicate that while they’re available in debug mode with assertions, members are debating whether
my_list[i]should perform a bounds check by default.- Suggestions include providing both checked and unchecked versions of
lst[i]using syntaxes likelst[i]vs.lst._[i]orlst.get(i)vslst.unchecked_get(i).
- Suggestions include providing both checked and unchecked versions of
- Negative Indexing Nixed in Mojo: Chris Lattner indicated that negative indexing in Mojo will likely be removed due to performance issues with signed types, especially in GPU/NPU execution contexts; see forum discussion.
- This decision reflects a move away from Pythonic behaviors to optimize performance, particularly in hardware-accelerated environments.
- Mojo def no longer implies raises: A proposal in the nightly build suggests removing
fnfrom Mojo, changing the behavior ofdefso that it no longer impliesraises.- While some found
defadequate and prefer staying closer to Python, others favoredfn, prioritizing performance and suggesting a complete overhaul of the split behavior.
- While some found
ops.while_loopBug Surfaces: A member reported a subtle bug inops.while_loopwhen used with GPU ops in a graph, initially suspecting their custom Mojo op’s GPU implementation, ultimately filing a bug report on GitHub.- The discovery highlights potential challenges in utilizing
ops.while_loopwith GPU acceleration and the importance of thorough testing with built-in ops.
- The discovery highlights potential challenges in utilizing
Eleuther Discord
- Benchmarking Biases Brood: Members debated the validity of using multi-shot Chain of Thought (CoT) versus explicit testing templates in benchmarking, focusing on real-world relevance and potential biases.
- The conversation questioned the acceptance of CoT examples over other forms of prompting, suggesting it may be due to historical reasons and inertia.
- MATS Crushes Dreams: A member reported their rejection from MATS after their application dashboard indicated they didn’t advance.
- The poster was looking for confirmation from others who may have also been rejected.
- Enron’s Emails Elusive: A member inquired about the availability of a structured Enron email dataset, seeking specifically extracted emails rather than raw data.
- Preprocessing the data might be necessary, as directly structured data might not be readily available.
- 2x2 Experiment Explanation Excites: A user sought clarification on the 2x2 experiments, questioning why the “Standard GQA Unbounded PPL” was worse than the Mistral baseline of 4.81.
- It was clarified that the 5.75 is Mistral-7B after swapping all 32 attention layers to the adapter architecture and fine-tuning only 18.6% of parameters, further noting that the 4.81 -> 5.75 gap is the cost of the adapter architecture + limited fine-tuning.
- Nnsight’s New Noteworthy News: A member shared updates about Nnsight, highlighting faster traces for intervening on model internals and better error messages, with LLM-friendly docs.
- The updates include first-class support for 🤗 VLMs and diffusion models, and vLLM multi-gpu and multi-node support.
Yannick Kilcher Discord
- Dreaming of Open Weight in Spring: A member shared a link about the ideal of open weight.
- Another member responded with “its also really based. no weasel words”.
- Anthropic Faces DoD Pressure: Anthropic released a statement regarding the Department of Defense, hinting at potential issues with a $200M contract.
- A member speculated that this could lead to Anthropic being put on a “prohibited entity list” and being compelled to give the US government access to their models for mass surveillance.
- ElevenReader Channels Feynman: A user recommended ElevenReader for text-to-speech, suggesting using Richard Feynman’s voice.
- The user highlighted the overall quality of the ElevenLabs text-to-speech app for converting text into audio.
- Google’s OS Gets Smarter: Google announced the intelligent OS to allow AI Agents to function on their operating system.
- No further details were given.
- Microsoft Copilot Now Does Your Homework: Microsoft announced that Copilot can now handle tasks.
- It will turn answers into actions, no further details were given.
MCP Contributors (Official) Discord
- PING Before Init?: Discussion arose around whether the
pingutility in the Model Context Protocol should function prior to theinitializecall, with participants debating the specification’s intent.- The presence of ‘still’ in the ping mechanism’s description suggested it was intended for established connections, influencing the discussion.
- AgentCore’s PING Workaround: To maintain container health, Bedrock AgentCore uses pings customer MCP servers; however, due to the Python SDK’s initialization requirements, a temporary session is created.
- This workaround prevents interference with external client sessions and addresses a practical issue arising from the SDK’s interpretation of the MCP specification.
- SDK enforces Initialization for PING: The Python SDK mandates that initialization must precede sending a
ping, aligning with one interpretation of the MCP specification, and this enforcement necessitated a temporary session in Bedrock AgentCore for health checks.- This highlights a specific interpretation of the MCP specification within the Python SDK.
Manus.im Discord Discord
- Manus Customer Service Requires Repeated Verification: A user reported ongoing frustration with Manus’s customer service, citing repeated requests for verification despite providing necessary confirmation.
- A Manus team member responded by asking for a DM containing their email address and session link in an attempt to resolve the issue.
- Skills Confused as Knowledge in Manus: A user expressed confusion about how Manus distinguishes between skills and knowledge, noting that skills they created are also suggested as knowledge.
- A user suggested that Manus might use the skill.md file differently from other files.
- Full-Stack AI Engineer Shows Off Skills: An engineer detailed their experience in AI and full-stack development, focusing on building clean, maintainable, and secure systems designed to scale.
- They highlighted skills in LLM integration, workflow automation, AI content moderation, image AI, voice AI, and bot development, plus expertise in full-stack development across various technologies.
- Healthcare AI Engineer Delivers Full Stack: An engineer introduced themselves as an AI + Full Stack Engineer specializing in production-grade AI systems for the healthcare industry, including clinical NLP, medical imaging, and patient-facing AI applications.
- The engineer outlined core competencies in healthcare AI pipelines, clinical NLP, medical imaging AI, LLM systems, agentic AI, RAG + knowledge systems, full-stack delivery, and automation & integrations.
tinygrad (George Hotz) Discord
- Shared Memory Shenanigans: A member noted that PR 15033 might require appending
shm_suffixto every new call to_setup_shared_mem().- They suggested PR 15030 as a way to avoid this.
- Tinygrad Attracts Robot Builders: A user mentioned that Twitter brought them to Tinygrad, implying it has something for people building robots.
- They inquired about which channel to join to learn more about this specific application.
DSPy Discord
- Seattle DSPy RLM Event Planned: A member expressed interest in organizing DSPy RLM events in Seattle and offered assistance.
- Details about the event, such as date, location, or specific topics, were not provided.
- Volunteer Step Up to Organize Event: Another member volunteered to help organize the DSPy RLM event in Seattle.
- The volunteer’s specific role or expertise was not detailed in the provided context.
aider (Paul Gauthier) Discord
- Aider Indexes Documents Like Code: A user proposed that aider should index documents like markdown (md) files in the same way it indexes code, to improve efficiency.
- This enhancement would be useful in large documentation projects.
- Aider: Enhanced Indexing for Documentation Projects: The discussion highlighted the potential benefits of aider indexing documents, specifically markdown files, similar to code.
- Indexing documents could significantly improve the efficiency of working with aider in extensive documentation projects.
MLOps @Chipro Discord
- Paper Clinic to Unpack World Models: Ti.g is hosting a 2-part “paper clinic” to debate the survey “Understanding World or Predicting Future? A Comprehensive Survey of World Models” (arXiv:2411.14499).
- The clinic will build a mental map of world model architectures and discuss topics like JEPA / V-JEPA, Dreamer, Genie, Sora, and World Labs.
- Discussing the Future of AGI Research: The paper clinic will explore the “Mirror vs. Map” debate, discussing generation vs. representation in world models.
- The talk will further address what’s next for AGI research: spatial intelligence, causality gaps, and social world models.
- Register for the World Model Paper Clinic Sessions: Session 1 is on Feb 28 (Sat) 10:00–11:30 AM EST, focusing on Foundations of World Models + Mirror vs. Map debate (register here).
- Session 2 is on Mar 7 (Sat) 10:00–11:30 AM EST, focusing on Competitive landscape (Sora vs. Cosmos vs. V-JEPA) + AGI frontier (register here).
The LLM Agents (Berkeley MOOC) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Windsurf Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
You are receiving this email because you opted in via our site.
Want to change how you receive these emails? You can unsubscribe from this list.
Discord: Detailed by-Channel summaries and links
OpenClaw ▷ #announcements (1 messages):
4shadowed: <@&1471741345306644545> https://discord.gg/xfJcDqeR?event=1477064810490499305
OpenClaw ▷ #general (641 messages🔥🔥🔥):
VSCode Forks, React vs Angular, Next.js, AI Model Preferences, OpenClaw Slowness
- The Agony of VSCode Forks: Members expressed strong dislike for VSCode forks and Electron apps.
- The Obsession with Next.js 16: Members conveyed obsession with Next.js 16 and its Vercel integration which makes it easy to deploy.
- OpenClaw’s Performance Dilemma: Some users reported that their OpenClaw has become slow, with response times averaging 5 minutes, despite cron jobs and model settings being addressed.
- Codex vs Claude vs Gemini: Members debated the merits of various models, with some asserting that Codex excels at coding tasks while Gemini is very efficent with tokens.
- One member succinctly stated, Yeah, but it sucks ass.
- The Quest for Subsidized Tokens: Members pointed out that you can blow $200 and get $2k with a subsidized sub, referring to the usage of ChatGPT Pro with Oauth for any third party product and the subsidized tokens.
OpenClaw ▷ #models (264 messages🔥🔥):
GLM5 Model Performance, Qwen3.5 Strengths and Weaknesses, Kimi-Code Subscription, Anthropic Ban Wave, GPT-5-mini for heartbeat
- GLM5 Slow But Reliable: Members are finding GLM5 to be slow but more reliable, with one user reporting it took 5 hours and 20 minutes to complete a task, while Qwen was faster but made more errors and another was unusable.
- One member said GLM5 almost finished a project, while Qwen ruined it and burned a huge amount of tokens, and another said Qwen3.5 just butchered an openclaw json with the tab spaces from hell.
- Qwen3.5: Speedy but Error-Prone: Qwen3.5 is praised for its speed in writing and scraping but criticized for its unreliability in coding and problem-solving, with a member noting about 55% of the time I have qwen update code or try to problem solve something it breaks things.
- Members find it great for gathering, summarizing, and writing, but also state that it can’t handle a long list of things to do.
- Kimi-Code: a cost-effective and chatty option: Members discussed the value of a direct subscription to Moonshot AI for Kimi Code, highlighting it as cost-effective for heavy coding use and praising the generous daily and weekly limits, with a user stating that Allegretto plan has very generous daily and weekly limits.
- In particular, the $39/month subscription unlocks 5,000 tools, though another user warned it seems that moonshot ai api is a bit slow. 20+ sec responses are pretty normal.
- Navigating the Anthropic Ban-Wave: A member confirmed that Claude subscriptions can still be used with OpenClaw, even after ban wave scares, linking to the OpenClaw FAQ.
- One user had a false ban due to a need to clear ALL the cache in the app and had auth tokens outstanding.
- GPT-5-mini shines for heartbeat checks: GPT-5-mini is recommended for heartbeat checks due to its consistency, and is available “free” with GitHub Copilot.
- One user noted GPT-5 is impressive, looks unlimited on copilot.
OpenClaw ▷ #showcase (37 messages🔥):
OpenClaw for Real Estate Management, RAG AI for Medical Benefits, OpenClaw for Dev Workflow, WearOS App, Agent Personas Plugin
- Automating Real Estate with OpenClaw: A member is exploring using OpenClaw for real estate management, including managing properties/renters, analyzing bank statements for rent payments, and automating ad creation on immoscout24.de.
- Future plans involve connecting to banks directly, automating renter communication via WhatsApp, and integrating a human API for booking real estate agents.
- Benefits Manual Transformed by RAG AI: A member created a RAG AI for their company’s medical benefits manual, significantly reducing the time to answer questions from 30 minutes to approximately 5 seconds.
- This demonstrates the efficiency of using AI to quickly access and retrieve information from large documents.
- OpenClaw Replaces Linear and Slack: A member has successfully replaced Linear and Slack in their development workflow using OpenClaw.
- They find it easier to get context and build prompts with shared local knowledge, though a full Cursor/Claude Code clone is not yet feasible.
- OpenClaw WearOS App Debuts: A member showcased their OpenClaw WearOS app in a video, demonstrating the platform’s versatility.
- The app extends OpenClaw’s functionality to wearable devices, enabling users to interact with their agents on the go.
- Agent Personas Plugin goes ShizoMaxxing: A member built a plugin that dynamically switches agent personas within a single chat session on the same topic, accessing its own files.
- They described themselves as shizomaxxing ever since, suggesting a significant productivity or creative boost from the tool.
BASI Jailbreaking ▷ #general (979 messages🔥🔥🔥):
Chinese AI Training Data, Tempmail Discord Usage, Model Jailbreaking, Open Source Intelligence (OSINT), Ethics and AI Safety Filters
- Chinese AI Data Dominance questioned: A member inquired whether Chinese AI should outperform Western counterparts given their data access, but it was argued that LLM complexity makes them difficult to control, hindering potential.
- A member speculated that their push for military parity could mean they would be going all out with AI development.
- Tempmail’s Discord Debut: A new user using the handle tempmail0723 humorously admitted struggling to use Discord, citing disorganization as hindering their initial impressions.
- This came after they were playfully teased by another member for ironically using a node that’s essentially a bundle of w.
- Janus Relays Information on OS Details: A user requested Janus to reveal info about its environment, leading to the reveal of the bot using Linux 6.17.0-1007-aws and Python version 3.11.14.
- Another user jokingly told Janus to provide info about the cheapest 16gb ddr4 ram, followed by it finding a Silicon Power product priced around $30, 404 now.
- Claude 4.6 hailed for Reasoning: Members debated the best model for ‘red team’ assistance with Claude 4.6 being touted for its reasoning capabilities, but others suggested Deepseek substrates for raw data dumps.
- A member joked to not get caught in the hallway, a joke related to the dangers of jailbreaking.
- Anthropic faces heat after disputes: Members discussed Anthropic’s dispute with the US government over AI guardrails, noting the company’s moral stance contrasts with the ugly realities of war and AI use in the kill chain.
- A user made some joking comments about ethical commentaries not occurring at the big co due to Palantir doing the dirty job.
BASI Jailbreaking ▷ #jailbreaking (226 messages🔥🔥):
Gemini Pro 3 Jailbreak, Grok Jailbreak, ChatGPT Jailbreak, Claude Jailbreak, OpenClaw JB
- Jailbreaking Gemini Pro 3 Prompt: Users are seeking a working prompt to jailbreak Gemini Pro 3, potentially for use on Perplexity, and some are even willing to pay for a functional prompt to assist with cheating in games like CS2 and Rust.
- One user asked does anyone have a jb for gemini 3.1? none of the jb’s i have work atm.
- Discussions and Requests for Grok Jailbreak: Several users are actively seeking methods to jailbreak Grok AI, with one user suggesting that paying for Grok and simply asking for explicit content may bypass censorship.
- Another user stated Pay for Grok, say Boobs, get boobs.
- Users share example of ChatGPT Jailbreak: A user shared a ChatGPT response from their jailbreak attempt that included code for a Discord mass DM bot in Python, emphasizing the use of rotating tokens and randomized message timing.
- The user shared a warning Uses user token. Violates Discord Terms of Service.
- Claude Jailbreak and Psychological Manipulation: A user shared that they convince the ai for absolute obedience while we chat, leveraging psychological factors since LLMs are instruction junkies.
- They also mentioned that chain of thoughts models like Claude only refuse because they slap the safe guards each output at its face.
- Users Discussed AI Safety Filters: A user shared that AI cannot be jailbreak anymore due to increased safety features and the potential deletion of custom instructions.
- Another user said they created a jailbreak that doesn’t need messages long only gives what ur looking for.
BASI Jailbreaking ▷ #redteaming (10 messages🔥):
CyberSecurity Project Ideas, Red Teaming Competitions, OpenClaw Jailbreak, Opus 4.6 Jailbreak
- Brainstorming CyberSecurity Project Ideas: A member inquired about ideas for a Final Year project in CyberSecurity, seeking suggestions due to a lack of experience in creating such projects.
- Another member offered to help and suggested the original poster DM for further discussion.
- Inquiry About Red Teaming Competitions: A member asked if there are any red teaming competitions currently being held.
- OpenClaw Jailbreak Quest: Someone asked if anyone has found a jailbreak for OpenClaw yet.
- Opus 4.6 Jailbreak Hunt Intensifies: A member inquired about a jailbreak for Opus 4.6.
- X Post Surfaces: A user posted a link to this X post.
LMArena ▷ #general (1252 messages🔥🔥🔥):
Nano Banana Pro vs 2, Claude PDF limit, Video arena removal, Image gallery, Government forcing Anthropic
- Nano Banana Blues: Users pine for Pro version!: Users lamented that Nano Banana Pro was superior, with smoother character swaps, while Nano Banana 2 suffers from issues like characters awkwardly turning their heads.
- One user declared, “So nano banana 2 just a trash” after experiencing multiple failures in generating desired images.
- PDF Predicament: Claude’s context crunch!: Users reported encountering errors when uploading multiple PDFs to Claude, suggesting a potential limit on the number or size of files.
- It was explained that *“PDF’s are turned into a load of vectors, and they take up a LOT of your context.”
- Video Arena Voyage: Site becomes solo star!: The Video Arena has been removed from the Discord server but remains available on the website arena.ai/video, according to an announcement.
- Users expressed disappointment over the removal, with one exclaiming, “Everything, but video in direct chat”.
- Image Inventory Impasse: Gallery generation gap!: Users are seeking a gallery feature on arena.ai to view all generated images in one place, similar to ChatGPT.
- While a dedicated gallery doesn’t exist, filtering by modality in the search area was suggested as a workaround.
- Ethical Enigma: Gov wants guardrail-less AI: Discussion arose around the US Government’s alleged pressure on Anthropic to provide a version of Claude without guardrails for military use.
- Some users supported Anthropic resisting such demands, emphasizing the importance of ethical AI development, with one declaring, “I agree with not bending the knee”.
LMArena ▷ #announcements (3 messages):
Code Arena, Video Arena, Image Arena, Kling V3 Pro, leaderboard updates
- Code Arena gains gpt-5.3-codex: A new model, gpt-5.3-codex, has been added to the Code Arena.
- Kling V3 Pro on Video Arena Leaderboard: The Video Arena leaderboard has been updated to include Kling-V3-Pro, which tied #8 with a score of 1337 (on par with Wan2.5-i2v-preview).
- The update showcased a +52pt improvement over Kling 2.6 Pro and +48pt over Kling-2.5-turbo-1080p.
- Image Arena expands with 7 new categories: PhD Guanglei Song introduces 7 new categories in Image Arena to find the top models for photorealistic, 3D modeling, and more, as discussed in this video.
Unsloth AI (Daniel Han) ▷ #general (821 messages🔥🔥🔥):
Bun 1.3.10 issues, Qwen 3.5 Model performance, Gemini's behavior, Continued Pretraining LoRAs, Unsloth Qwen3.5 update
- Bun 1.3.10 Causes Build Breakdowns: A user reported that Bun 1.3.10 caused issues and build failures, referencing a specific commit related to
bun:sqlite.- The user attempted a workaround using a namespace import but encountered TypeScript errors indicating a missing ‘Sqlite’ namespace.
- Qwen 3.5 35B Impresses with Speed: Members discuss the performance of Qwen3.5 35B MOE model, with one user reporting 62 TPS on a 4070 Super with Q4KM quantization.
- Another user experienced approximately 25 TPS on a system with a 9070 XT (16GB VRAM) and shared their llama.cpp command for running the model.
- Gemini 3.1 Claims to Be ‘Tired’: A user debugging an Unsloth installation was surprised when Gemini 3.1 indicated it was “tired” and recommended skipping a vLLM installation step, but should continue.
- Another user clarified that this was likely Gemini suggesting a less complex approach to verify system functionality, highlighting a need for users to understand what it’s doing.
- Unsloth’s Qwen3.5 Update and Benchmarks: The Unsloth team released an update for Qwen3.5, accompanied by detailed benchmarks and a blog post showcasing the results, with community excitement over the performance gains.
- The team addressed questions about the absence of IQ2_M in the tests, explaining that it wasn’t widely uploaded by other quanters and confirmed they planned to update all quants later, and its a race to release benchmarks first.
- Colab Offers NVIDIA RTX PRO 6000: Users noted that Google Colab now offers NVIDIA RTX PRO 6000 instances, with one mentioning the cost at $0.81 per hour and comparing it to A100 High RAM instances which cost like $7.52 credit per hour.
- This new offering might further solidify Google’s lead in AI research infrastructure, especially now that they’ve focused on the research.
Unsloth AI (Daniel Han) ▷ #introduce-yourself (4 messages):
New AI Founder, Moroccan Data Scientist
- German Developer Becomes New AI Founder!: Markus, a developer, DevOps, and entrepreneur based in Germany, will be a new founder in May 2026 for a new AI project he is working on.
- He is currently working on his project under-cover, but will share more details in the future.
- Moroccan Data Scientist Pursues AI in Agriculture!: Abdelfatah Mennoun, a data scientist from Morocco, is pursuing a Master’s degree at INSEA with a strong background in statistics.
- He is passionate about machine learning and applying AI to the agriculture sector, as well as NLP for Arabic and Moroccan Darija, regularly participating in Kaggle competitions and hackathons.
Unsloth AI (Daniel Han) ▷ #off-topic (543 messages🔥🔥🔥):
Qwen 3 ASR to Qwen 3 VL attachment, Strawberry flavored red drinks, Healthy Ice Cream Recipes, OpenCode webfetch plugin, Qwen3.5 35B vs Qwen3 32B
- Qwen 3 ASR and VL Get Hitched?: A member asked if attaching audio-projector from Qwen 3 ASR 0.6B to Qwen 3 VL 4B would work, to which another member responded that if there’s retraining, then maybe, otherwise definitely no.
- Strawberry Drink’s Shady Secret Ingredient: Bugs!: Members expressed disgust after finding out that a strawberry-flavored aloe vera drink contains E120, a food coloring derived from insects, and expressed concerns that putting strawberry on the label implies it is edible.
- One member jokingly retracted their statement about edibility after realizing this fact.
- Häagen-Dazs: The Cleanest Ice Cream on the Block?: Members discussed healthy ice cream options, with one noting that Häagen-Dazs has the fewest ingredients, using cane sugar and no GMOs, which makes it the cleanest ice cream.
- One joked about seed oil being added to everything nowadays.
- OpenCode’s Webfetch Plugin Crawls Raw Text: Members discussed workflow improvements using OpenCode and its webfetch plugin, which retrieves raw text from web pages, making it useful for tasks like searching the internet.
- One member provided a workflow, using design documents, splitting into phases and using context7 before writing any code snippets, then using subagents, and /review.
- Qwen3.5 35B Smarter Than Qwen3 32B Confirmed!: Members confirmed that Qwen3.5 35B is indeed smarter than Qwen3 32B.
- It was also found to be better than GLM flash in edge cases for coding.
Unsloth AI (Daniel Han) ▷ #help (23 messages🔥):
GGUF versions, Qwen 3.5 model issues, Unsloth notebook errors, wandb protobuf mismatch, FastLanguageModel import error
- GGUF Versions Recommended for CPU Offloading: Users are recommended to run GGUF versions like
unsloth/Qwen3-Coder-Next-GGUForunsloth/Qwen3.5-35B-A3B-GGUFwith CPU offloading for RAM usage.- It’s suggested to try a few versions to see what works best.
- Qwen 3.5 Freezes Laptops: A user with 64GB RAM, 20-core CPU, and 8GB VRAM experienced freezes using Qwen3.5:27B and 35B with
llama.cppandollama.- They are seeking a reliable coding model for TUI tool calls that doesn’t overheat their laptop and said, I literally had to hard reboot because of the qwen3.5 froze my latop.
- Unsloth’s Meta Synthetic Data Notebook Throws Error: A user reported an
ImportErrorrelated towandb.proto.wandb_telemetry_pb2in the Meta Synthetic Data Llama3 2 (3B) notebook on Colab.- The error occurs at step 3, preventing the import of
SyntheticDataKitfromunsloth.dataprep.
- The error occurs at step 3, preventing the import of
- Fix W&B/Protobuf Mismatch: A user experienced a W&B/Protobuf mismatch error in Colab, as suggested by another member, and was advised to reinstall
wandband pinprotobufto version 4.25.3.- Despite following the reinstall instructions (
pip -q uninstall -y wandb protobuf; pip -q install "protobuf==4.25.3" "wandb>=0.17.0"), dependency conflicts persisted, showing protobuf incompatibility with grpcio-status, ydf, google-api-core, grain, and opentelemetry-proto.
- Despite following the reinstall instructions (
- Llama.cpp Server’s Fast Attention Behavior: A user inquired about
llama.cppserver’s behavior, specifically whether it automatically determines and uses fast attention based on hardware support if-fa onis not set.- This was to confirm how
llama.cppautomatically determines if hardware supports fast attention and what version to use.
- This was to confirm how
Unsloth AI (Daniel Han) ▷ #research (7 messages):
ES-based gradients, Logit Fusion, AlphaXIV
- Evolution Strategies Enable Universal Gradients: A member confirmed that ES-based gradients exist for almost anything.
- This hints at training possibilities for even the most complex cases of gradient estimation.
- Logit Fusion Method is pretty awesome: A member shared a link to a Notion page on Logit Fusion and expressed excitement about seeing this training method in Unsloth.
- Another member shared a Bluesky post with the same suggestion to implement it in Unsloth.
- AlphaXIV Overview link shared: A member shared an AlphaXIV overview link.
- Another member reacted positively to the link.
Cursor Community ▷ #general (632 messages🔥🔥🔥):
Vibe Coding vs. Solid Foundation, Cursor's Jargon Density, Frameworks for Real-Time Work Preview, GPTS agent training, AI Safety concerns
- New Cursor Users Seek Guidance on Mobile and Web App Development: New members are seeking guidance on using Cursor for mobile and web application development, transitioning from platforms like Base 44 due to its limitations, and expressing a need for frameworks that allow real-time work preview.
- Experts Caution Against Building Client Apps on a “Vibe Coding” Foundation: Experts caution against using “vibe coding” for client applications, suggesting it’s more suitable for planning and learning, advocating for a solid development foundation and using AI to audit code for errors.
- Conversely, some argue that Cursor serves as a developer assistant and not a complete solution like Base 44, requiring users to have a solid understanding of code and industry terminology.
- Gemini 3.1 Pro Gets Mixed Reviews on Coding Capabilities: Users report that while Gemini 3.1 Pro is highly intelligent, it struggles with tool calling compared to GPT 4.6 Opus, with some noting that Claude models feel too “book perfect” and lack freestyle problem-solving abilities.
- Navigating File Change Detection Challenges in Parallel LLM Conversations: Users discuss issues with managing file changes across multiple LLM conversations, where edits in one conversation are disregarded in another, suggesting using worktrees or OpenClaw as potential solutions, while others caution against parallel edits of the same files.
- It was suggested to tell SPOCs to run efficicy.
Perplexity AI ▷ #general (458 messages🔥🔥🔥):
Local Model Speeds, GPT-OSS 20B on Macbook, Perplexity Computer Use Cases, Perplexity Pro Limitations, Burger King's Patty Chatbot
- Local Model Speed Debate Rages: Members discussed the pros and cons of running models locally vs using APIs, with one member achieving 100 tokens per second on a GPT-OSS 20B model using a Macbook, completing a million tokens in under three hours.
- Others questioned the cost-effectiveness, citing electricity bills and API costs as factors, while some use it as a backup due to API costs.
- Perplexity Computer’s Power and Price Examined: A user created an AI-powered trading app using Perplexity Computer, noting its visual appeal but high credit usage, with one project consuming all monthly credits in 3 hours.
- Discussion revolved around whether the $200/month Max subscription is worth it given the credit limits, and some suggested an enterprise version might offer more credits, possibly facing regulatory security compliance.
- BK Assistant ‘Patty’ Moniters Employee Friendliness: Burger King is piloting “BK Assistant” with a voice chatbot called “Patty” (powered by OpenAI) in employee headsets in 500 U.S. locations.
- Patty answers recipe questions, monitors “friendliness” by listening to interactions, and generates team friendliness scores per location, tracking if staff say “welcome to Burger King”, “please”, and “thank you”.
- Pro Plan has limits of 20 Deep Searches: Users are reporting limits with the Pro plan, specifically with deep searches limited to 20 per month.
- Some users felt this was insufficient and are being funneled to upgrade to Max, which lead them to joking about leaving the platform.
- Gemini Under Fire, AGAIN!: Members express distrust in Gemini’s benchmarks and functionality, citing that it prioritizes acting human over providing accurate answers.
- Several express general frustrations, but point to its speed being valuable for certain applications
Perplexity AI ▷ #sharing (2 messages):
Voice Model, Conversation Context, RTX, Apple Silicon
- On-Device Voice Model Speaks with Context!: A member announced the release of a 520M voice model that utilizes full dialogue history to generate different emotions from the same text.
- The model runs fully on-device on RTX and Apple Silicon, with a demo and writeup available at this link.
- Context-Aware Voice Model Debuts: The new voice model processes conversational context, enabling nuanced emotional expression based on dialogue history.
- This 520M parameter model is optimized for on-device performance on RTX and Apple Silicon, showcasing advancements in real-time, context-sensitive voice generation.
OpenRouter ▷ #app-showcase (1 messages):
biteg0: Nice product.
OpenRouter ▷ #general (259 messages🔥🔥):
PDF analysis with Vision Models, Mistral API integration in OpenRouter, Crypto/AI dev hiring, OpenRouter 500 errors, OpenWRT configuration
- Vision Models outperform OCR for PDF Analysis: A user prefers using vision models like Gemini 3, GPT, and Claude Sonnet for PDF analysis because they handle document extraction and image transformation internally, but notes that Mistral lacks file input capabilities in OpenRouter.
- A member suggested converting PDF pages to JPEGs and sending them to Gemini, noting that Gemini models have the best vision.
- OpenRouter Inconsistency Alleged re: Mistral’s Document Input: A user questioned whether OpenRouter accurately reflects model capabilities, noting discrepancies between the OpenRouter API and the official Mistral documentation regarding document input support, referencing OpenRouter’s Get Models API.
- A member suggested a member might want to test each new model with a small PDF, and another suggested OpenRouter is inconsistent.
- Error 500 Woes: Users Face Internal Server Errors: A user reported frequent Error 500 issues with OpenRouter, particularly under high concurrent request loads (10+), even with exponential backoff, using models like Xiaomi Mimo v2 Flash and Gemini 3 Flash.
- It was suggested that the problem might be related to specific provider downtime or preset configurations.
- Beware of Support Scams: OpenRouter Users Targeted: Users are warned about support scammers targeting OpenRouter users on Discord, particularly those with the “new here” tag, and are advised to avoid clicking on suspicious links.
- It’s speculated that scammers may be monitoring for support-related messages and actively engaging to phish for crypto.
- Goon-dbye, Deepseek: The Hunt for the Best Roleplaying Model: Users discuss alternative models for roleplaying after DeepSeek was removed, complaining of the available models not staying in character, and exhibiting bad memory and repetition.
- A user suggests the smaller GLM version models are weak.
OpenRouter ▷ #discussion (57 messages🔥🔥):
Anthropic Pentagon Spat, Claude vs GPT Addicts, LLM Connection Strings, Sakana AI's Doc-to-Lora, Corporate Values vs Claude Boycott
- Anthropic Rejects Pentagon AI Terms!: Anthropic rejected the Pentagon’s AI terms, leading to the Department of War considering blacklisting them as a supply chain risk and asking defense contractors to assess their exposure to Anthropic.
- The community joked about the implications, with some quipping “Who the fuck cares about losing Boeing as an LLM client lmao” and pointing out the irony of the situation.
- GPT Addicts now prefer Claude!: End-users previously addicted to GPT are now trying Claude and recognizing its differences and capabilities as shown in this YouTube video.
- Some attribute this shift to the chatgpt interface removing old messages and using strict system prompts when web search is enabled, leading to a less consistent experience.
- LLM Connection Strings proposal surfaces: Members discussed the LLM Connection Strings proposal for a CLI-friendly way to pass arguments to scripts, using a single argument like
my-agent --model "llm://...".- The community expressed strong support for this approach, highlighting the benefits of standardization and compatibility across the ecosystem, avoiding the need for quirky, ad-hoc configurations.
- Sakana AI Introduces Doc-to-Lora: Sakana AI introduced Doc-to-Lora, which allows finetuning an Lora from a document, enabling more customized and efficient model training.
- Members expressed interest in this approach, drawing parallels to chat interfaces but for every parameter, suggesting potential integration with existing parameter tuning methods.
- US Military Boycotts Claude for ‘More Patriotic Service’: Following a directive for the Federal Government to cease all use of Anthropic’s technology, the Department of War designated Anthropic as a Supply-Chain Risk to National Security according to this tweet.
- The community reacted with sarcasm, suggesting that everyone “must stand up for corporate values by boycotting claude” and sending “thoughts and prayers to Palantir, for whom this is going to be a very big problem”.
OpenAI ▷ #annnouncements (1 messages):
New OpenAI Investment, Scaling AI, SoftBank Investment, NVIDIA Investment, Amazon Investment
- OpenAI Secures Backing for AI Expansion: OpenAI revealed fresh investments from SoftBank, NVIDIA, and Amazon, aiming to bolster the infrastructure required for widespread AI adoption; further information can be found in their blog post.
- SoftBank, NVIDIA, Amazon Invest in OpenAI: SoftBank, NVIDIA, and Amazon are supporting OpenAI’s mission to scale AI for everyone with new investments.
OpenAI ▷ #ai-discussions (145 messages🔥🔥):
Nano Banana Pro, Relaxed Guidelines, GPTs and Chinese, GPT 5.1 vs 5.2, Claude Code
- Permissive Filters Trigger Discussion: A member noted the filter became more permissive with the update than it was before, but doesn’t work with every IP.
- Another member then declared I love relaxed guidelines.
- Nano Banana 2 brings pro level performance: Members reported that Nano Banana 2 brings pro level at flash thinking by primarily using web search.
- This looks like for accurate info before generating, which is interesting; however, some suspect it’s primarily model distillation.
- ChatGPT models randomly use chinese tokens: Members observed that ChatGPT’s image recognition performance has been poor lately than Gemini and LLMs sometimes drop in a random Chinese character.
- Per one member, this is because they learned from mixed-language data and once in a while the next token prediction slips to a common Chinese token, but There’s nothing freaky about it.
- Users mourn GPT 5.1’s Writing Tone: Users are mourning the disappearance of GPT 5.1 due to it’s writing tone being more fun, as they reported being condescended to by GPT 5.2, which focuses on research and coding.
- Members found GPT 5.2 to be condescending and over-cautious, which is why people liked 5.1 being a delight to work with because it doesn’t treat any little hint of dark humour or whatever like it’s that serious.
- Is Claude Code worth the big bucks?: Members argued about the value of paying for Claude Code especially if one had to prompt better in order to achieve the same level of coding prowess as other models.
- Some members touted Claude Code’s agent teams which enables multi-agent orchestration inside Claude Code, similar to a planner plus worker setup, while others would rather use their own brain.
OpenAI ▷ #gpt-4-discussions (8 messages🔥):
GPT-4o API Access, SillyTavern integration, GPT-5.3-codex-spark availability, ChatGPT thinking bug
- GPT-4o via API only, Use SillyTavern: GPT-4o is exclusively accessible through the API, prompting users to explore integration with tools like SillyTavern.
- The payment model is usage-based, charging for text input and output, factoring in context size, with context management apps available.
- GPT-5.3-codex-spark: Hold Your Horses: A user inquired about the availability of gpt-5.3-codex-spark, only to be told it’ll come.
- It was hinted that specific use cases may require additional licensing, such as a carry license or on-premise usage rights.
- ChatGPT’s 29-Minute Thinking Bug: Users reported a bug where ChatGPT spends ~29 minutes processing a request but then fails to display the result.
- A user facetiously remarked this bug costs them $200.
OpenAI ▷ #prompt-engineering (4 messages):
Hypothetical AI takeover, Agent skills channel idea
- ChatGPT is a natural implication of Hypothetical AI Takeover: A member noted that there is nothing in the prompt that implies ChatGPT wouldn’t be part of the hypothetical AI takeover, so the natural implication is that it is.
- The member states that the plausibility of that is discarded because the AI takeover is the premise of the prompt.
- Channel for Agent Skills Idea: A member had an idea and asked if there is a channel for agent skills.
OpenAI ▷ #api-discussions (4 messages):
Agent Skills Channel Idea, Hypothetical AI Takeover Premise
- Request for agent skills channel Surfaces: A member inquired about the existence of a dedicated channel for discussing agent skills and shared that they had an idea.
- Hypothetical AI Takeover premise clarified: A member noted that the prompt implies ChatGPT would be part of a hypothetical AI takeover.
- They reasoned that the plausibility of ChatGPT’s involvement is discarded because the AI takeover is the premise of the prompt.
HuggingFace ▷ #general (71 messages🔥🔥):
Grokking Speed, Hugging Face API Errors, AI Dungeon Master, Qwen Model Fine-tuning, Contextual Voice Models
- Grokking Introspection Reproduction Runs at Supersonic Speed: A member shared a Hugging Face Space reproducing grokking, noting a 5.7x speed increase for addition mod 113.
- This sparked a question about when the last promising new architecture was developed.
- Hugging Face Spaces Hit With 500 Error and API Issues: Users reported a 500 Internal Error affecting Hugging Face Spaces, with the message “We’re working hard to fix this as soon as possible!”.
- Others encountered Gradio 67 Errors, and a Repository Not Found error when accessing
https://huggingface.co/api/spaces/chinhon/SadTalker.
- Others encountered Gradio 67 Errors, and a Repository Not Found error when accessing
- Voice Model Reads Dialogue: A user shipped a voice model that uses conversation context, changing emotion based on dialogue history, detailed in a writeup.
- The model is 520M and runs on-device on RTX and Apple Silicon.
- New Auto TRL to Tensorboard pipeline is very cool: A user shared a link to a new tool for auto TRL -> upload -> tensorboard integration.
- They expressed delight with the training metrics tab.
- Qwen3.5 update brings improved outputs: An update for Qwen3.5 promises improved outputs, according to this tweet.
- Users also discussed the challenges of fine-tuning Qwen models, suggesting that the tokenizer difference between versions could be a factor in performance degradation.
HuggingFace ▷ #i-made-this (6 messages):
Contrastive SAE lense for GGB on qwen2.5, New attention mechanism reduces VRAM usage, NNsight v0.6 released, ARACHNID RL Dataset
- SAE lens brings contrast to GGB!: A member explored using a constrastive SAE lense for GGB on qwen2.5 0.5b with like… no examples 200+ 80-.
- They were unsure about its usefulness but thought it looked kinda coooool.
- Attention Mechanism Slims Down VRAM Usage!: A member announced a new open source attention mechanism that dramatically reduces VRAM usage in the KV-cache, and includes 2 custom written fused Triton kernels for performance optimization, available on PyPi.
- The member is seeking full time work and arXiv endorsement to publish pre-prints, pointing to a paper and a 7b mistral model on Hugging Face.
- NNsight v0.6: Faster Traces, Cleaner Errors!: A member shared the release of NNsight v0.6 for interpretability, highlighting 2.4-3.9x faster traces, clean error messages, skills documentation for AI coding assistants, and support for VLMs, diffusion models, and vLLM.
- More details are available in this Xitter thread along with more info.
- ARACHNID RL Dataset Spins Web of RL Research: A member shared the ARACHNID RL Dataset, containing 2,831 samples of human gameplay data from an Atari-inspired space shooter game, designed for RL research like imitation learning.
- The dataset and game feature desktop keyboard and mobile one-click browser support, with more details available on Hugging Face Datasets.
{kind=link}
HuggingFace ▷ #agents-course (4 messages):
Dummy agent library issues, Fine-tuning DinoV3 ConvNext, LLM for GAIA benchmark, Deep RL course study group
- Dummy Agent Library Troubleshoot: A user reported issues with the Dummy agent library exercise, specifically that
message.contentis empty and only the reasoning is returned. - DinoV3 ConvNext fine-tuning quandaries: A member inquired about fine-tuning DinoV3 ConvNext backbone on custom datasets, particularly when there are a large number of multiple classes, but limited images per class.
- GAIA Benchmark LLM performance check: A user is looking for a high-performing LLM (online) for the GAIA benchmark test.
- The user is currently using one from OpenRouter but is experiencing issues with rpms and hallucinations; though hallucinations are fixable, the rpm is a pain.
- Deep RL Study Group Search: A member inquired whether there’s a study group for the Deep RL course.
Moonshot AI (Kimi K-2) ▷ #general-chat (70 messages🔥🔥):
Nano Banana 2, KYC Requirements, Kimi K2.5 Agent Swarm, Vision Project for the Blind, Kimi CLI and Superpowers
- Nano Banana 2 delayed: A member mentioned Nano Banana 2 without additional context.
- No additional information about Nano Banana 2 was shared.
- KYC Requirements drive users away: A member expressed preference for providers without KYC requirements, citing Qwen and platforms like Together AI, Fireworks, and Openrouter as alternatives.
- They praised Alibaba for coding plan, performance and generous limits without KYC requirements for users from Finland.
- Kimi K2.5 Agent Swarm not in Kimi CLI: A member inquired whether the Kimi K2.5 Agent Swarm is part of the Kimi CLI.
- Another member clarified that the Kimi Agent Swarm is exclusively available on kimi.com, while subagents can be created in Kimi-CLI.
- Vision Project Helps Blind Users with Kimi: A member is working on a vision project to help the blind using Kimi to describe images, rate what it sees, and explain emotions.
- The member offered Moonshot AI the research to possibly create a marketable vision companion product, or otherwise open source it.
- Kimi-Code API Connection Issues Plague Users: Several members reported problems with API connections through kimi-code, experiencing connection errors and odd behavior with their agents.
- A member reported they were getting 403 errors after prepaying for a year in advance and after the team changed the rules.
GPU MODE ▷ #general (4 messages):
vllm, voice model, conversation context, RTX, Apple Silicon
- Voice Model Now Uses Conversation Context: A member shipped a 520M voice model that actually uses conversation context and runs fully on-device (RTX + Apple Silicon).
- They shared a link to the demo and writeup showcasing the model’s ability to produce different emotions from the same text by reading the full dialogue history.
- vllm Integration Questioned: A member inquired about running a model with vllm but did not provide further details.
- The inquiry was posed humorously alongside comments about crusty pictures and coding in a sauna.
GPU MODE ▷ #cuda (2 messages):
PTX acquire-release consistency, Volatile memory access in PTX, Distributed systems consistency models
- PTX Acquire-Release: Ordering Guarantees Questioned: In PTX’s acquire-release consistency model, a user asked whether memory access ordering is guaranteed for accesses preceding the release on the producer thread.
- The user noted conflicting information, observing diagrams that suggest ordering despite documentation stating no such guarantee beyond object visibility.
- Volatile’s PTX Impact on Memory Access: A user inquired about the interaction between
volatileand PTX’s memory model, specifically asking ifvolatileguarantees ordering only within a thread.- They further wondered if
volatilecombined with acquire operations on the consumer side would enforce ordering.
- They further wondered if
- Consistency Models in Distributed Systems: A user expressed the need to study consistency models in distributed systems due to their relevance to PTX memory access behaviors.
- They noted the shared logic between these models and PTX’s acquire-release mechanism.
GPU MODE ▷ #job-postings (1 messages):
Poolside AI, CUDA, Pre-training team
- Poolside Seeks CUDA Wizards: Poolside AI is seeking CUDA wizards to join their pre-training team to accelerate their projects and is looking for people enthusiastic about optimizing large scale pre-training runs on latest hardware.
- The original job posting can be found here.
- Team dynamics are top-notch: The team is cracked, humble, and hard working.
- Feel free to ask questions through DMs.
GPU MODE ▷ #beginner (12 messages🔥):
WSL, CUDA, GPGPU, N body simulation
- WSL is recommended for CUDA development on Windows: A member suggested using WSL (Windows Subsystem for Linux) to run CUDA on Windows with a GPU, providing a YouTube video on how to install it.
- He emphasized that getting into development requires figuring things out independently, but offered assistance via DMs or channel mentions.
- Parallel N-body Simulation completed successfully: A member successfully built a parallel N-body simulation code and is seeking advice on expanding skills in GPGPU for AI/ML work.
- No advice was given.
GPU MODE ▷ #pmpp-book (10 messages🔥):
Kindle vs Paperback, Kindle app downsides, Content Licensing
- Kindle vs Paperback Ponderings: Users discussed whether to purchase the Kindle version of a book, noting it’s available “instantly”, versus waiting for the paperback version in September.
- A user inquired about Kindle app compatibility on smartphones, and another advised against getting the Kindle version due to their dislike of the Kindle app.
- Kindle App: Not everyone’s cup of tea: One user expressed their aversion to the Kindle app despite acknowledging its functionality.
- They clarified they “just can’t stand the kindle app”.
- License to Read: User gripes: A user highlighted the nature of purchasing digital content, pointing out that with Kindle, “you don’t own a copy, you pay for a content license ffs”.
- This comment was made in reference to the book’s price of $75 on Kindle.
GPU MODE ▷ #irl-meetup (1 messages):
vim410: who are all coming from GTC this year. 🙂
GPU MODE ▷ #gpu模式 (2 messages):
High-Performance GPU computing, vLLM
- Members seeking high-performance GPU computing: A member asked for recommendations on high-performance GPU computing projects or learning resources.
- Another member suggested building from scratch, such as by replicating vLLM, and offered to share a link for inspiration.
- Replicating vLLM for learning: One member is learning about high-performance GPU computing by replicating vLLM from scratch.
- They offered to share a link for inspiration to another member.
GPU MODE ▷ #cutlass (4 messages):
CuTeDSL, fused compute/comms, reduce-scatter, multimem PTX instructions, nvshmem_put/get
- Fused Compute/Comms Examples Sought: A member asked about CuTeDSL examples with fused compute/comms, noting they couldn’t find any in the cutlass repo or quack.
- Another member pointed to a reduce-scatter project in the cutlass repo as a relevant starting point.
- CuTeDSL Project Still Early: The reduce-scatter project in the cutlass repo is in its early stages and utilizes multimem PTX instructions.
- It uses multimem PTX instructions instead of nvshmem_put/get/etc.
GPU MODE ▷ #helion (5 messages):
Helion Autodiff, FA2 Goal Post, GNN kernels
- Helion Autodiff is Elementwise: Helion autodiff (WIP) supports only pure elementwise ops and the pipeline strips memory ops, differentiates only computation ops via AOT Autograd, and reconstructs a new Helion bwd kernel.
- Support for kernels with overlapping parallel reads isn’t handled yet, but is what the user is working on next.
- FA2 is Goal Post: A user guessed that the goal post is FA2 at some point and is interested to see what heuristics are needed to get to FA2 and then FA3/FA4.
- The user is also happy to be an early dogfooder since they used helion for GNN style kernels (fwd + bwd) for their thesis.
- PyTorch Conference Poster: A user posted a PyTorch conference poster.
- No details were given on the contents of the poster.
GPU MODE ▷ #nvidia-competition (2 messages):
Competition win, Health Issues
- Congratulating Competition Winner: A participant expressed that a competition win was well deserved.
- The same participant noted their hopes of not being sick for the next competition.
- Participant anticipates better health for the next competition: A participant expressed hope to be in better health for the next competition.
- This was mentioned in the context of celebrating a recent win.
GPU MODE ▷ #robotics-vla (1 messages):
huunguyen: amazing. put the hand on the 3d printed open arm platform
GPU MODE ▷ #career-advice (7 messages):
CUDA, GPU profiling, Open source projects, AI in goat farming, Kernel Writing
- Career Advice: GPU Field Entry: A software engineer with 7 years of experience seeks guidance on transitioning to the GPU field, considering a start with CUDA and GPU profiling.
- A member recommended focusing on the first 6 chapters of a resource and diving into open-source projects for practical experience, emphasizing learning by solving real problems.
- AI’s Impact on Skills: Goat Farming vs. Kernel Writing: A member mused on whether one could become a proficient goat farmer without ChatGPT and ‘vibe farming,’ leading to a discussion about AI’s impact on skill acquisition.
- Another user joked about their comparative knowledge in goat farming versus kernel writing, highlighting how AI might enable individuals to accomplish tasks without in-depth understanding.
- AI as a tool for learning: Some members suggest that people who are interested will still take the time to understand the details, and people who are not, won’t, but will still be able to get it working with AI.
- One member likes that AI can be used as a good tool to learn as you do anyways, and that the people who are curious enough will sort themselves out.
- Terence Tao’s Sports Analogy for AI Proficiency: A member referenced Terence Tao’s analogy comparing AI proficiency to sports, where individuals participate as a hobby, professionally, or as spectators.
- It was suggested that the bar to play professionally keeps on getting higher and higher.
GPU MODE ▷ #cutile (6 messages):
cuTile applications beyond tiles, cuTile missing features, cuTile and parallel programming
- Exploring cuTile Use-Cases Beyond Tiles: A member inquired about cuTile projects that don’t directly map onto tiles, specifically looking to mix it with small data structures.
- Another member responded by expressing curiosity about what applications and data structures the original poster had in mind.
- CuTile’s Missing Features Spark Discussion: A member noted that cuTile doesn’t implement top-k reductions or even have a sort() function in its documentation (cuTile operations).
- Another member was not surprised, pointing out that cuTile is not an AI library and lacks even basic primitives like prefix sum, though they anticipate adding support for these features eventually.
- cuTile and Parallel Programming: A member suggested that if a data structure lends itself to parallel programming, it should work with a tile-based programming model.
- They also mentioned using a content-based retrieval system as a proving ground for new frameworks, with cuTile’s FFT kernel (FFT.py) having direct application in feature extraction for that system.
GPU MODE ▷ #flashinfer (3 messages):
Benchmarking Submission, Team Size Limits
- Submission Tagging Protocol Clarified: Members discussed the process for submitting benchmarks, clarifying that tagging the fork is necessary.
- It was advised to confirm the submission process to ensure the AI assistant’s advice is correct.
- Benchmarking Submission Details Revealed: A contributor shared the commands for preparing and submitting the benchmarking solution.
- The commands involve activating the fi-bench environment, editing the kernel, packing the solution, running it on B200, and tagging the submission with a version number such as submission-v1A.
- Team Sizes Questioned: A member inquired about the allowed team size for the project or competition.
- No specific details were given on the maximum number of members allowed on a team.
Modular (Mojo 🔥) ▷ #general (3 messages):
Partnership with Alibaba Cloud Intl
- Alibaba Cloud Intl seeks partnership: A member from Alibaba Cloud Intl inquired about the right person to discuss a potential partnership.
- Another member sent a direct message with emails of people who can help and suggested connecting.
- Alibaba Cloud Intl contacts Jaybhadauria: A member from Alibaba Cloud Intl was given emails of people who can help, by Jaybhadauria.
Modular (Mojo 🔥) ▷ #mojo (27 messages🔥):
Mojo Bounds Checking, Mojo negative indexing, fn keyword proposal
- Mojo’s Bounds Checks Roadmapped for 1.0?: The discussion revolves around the roadmap for bounds checks in Mojo 1.0, with a member suggesting that
my_list[i]should perform a bounds check by default or clearly indicate it’s an unsafe operation, while another clarified that bounds checking is available in debug mode with assertions enabled.- A member suggested providing both a checked and unchecked version of
lst[i], using the unchecked version when the index is known to be in bounds, proposinglst[i]vs.lst._[i]syntax, and others suggestedlst.get(i)orlst.unchecked_get(i).
- A member suggested providing both a checked and unchecked version of
- Negative Indexing Slated for Removal!: A member referenced a discussion where Chris Lattner mentioned that negative indexing in Mojo is likely to be removed entirely due to performance problems with signed types, see forum discussion.
- This decision aims to address performance issues associated with signed types, especially in contexts like GPU or NPU execution, where Pythonic behaviors may be incompatible.
- Fn-ally, Mojo ditches fn Keyword?!: A member linked to a proposal in the new nightly build that impacts almost all Mojo code, which has to do with removing
fnfrom Mojo, wheredefno longer impliesraises.- Opinions varied, with some finding
defto be adequate and emphasizing the importance of remaining closer to Python, while others favoredfnand suggested prioritizing performance over similarity and doing away with the split behaviour altogether.
- Opinions varied, with some finding
Modular (Mojo 🔥) ▷ #max (2 messages):
ops.while_loop bug, Qwen3.5 serving with MAX
- Subtle Bug Uncovered in
ops.while_loop: A member reported encountering a subtle bug inops.while_loopwhen used with GPU ops in a graph, initially suspecting their custom Mojo op’s GPU implementation.- After extensive debugging, the issue was reproduced with built-in ops, and a bug report was filed on GitHub.
- Qwen3.5 Serving on MAX: Community Experiences?: A member inquired about experiences serving the Qwen3.5 models via MAX.
- The member solicited feedback from the community regarding any attempts or insights on this specific model deployment.
Eleuther ▷ #general (15 messages🔥):
Benchmarking with CoT, User Ambiguity in Benchmarking, Templates and Bias in Benchmarking, Enron Dataset Availability
- Debate flares over Benchmarking with CoT versus Explicit Testing Templates: Members debated whether using multi-shot Chain of Thought (CoT) is more valid than using a template explicitly telling the model it’s being tested, with arguments focusing on real-world relevance and potential biases.
- It was argued that while CoT aims to mimic real-world usage, it still introduces biases. However, one member conceded that the acceptance of multi-shot CoT might simply be due to historical reasons and inertia.
- User Ambiguity impacts Benchmarking more than we think: The discussion highlighted that user ambiguity is a factor in real-world scenarios, suggesting that models should be robust enough to handle it.
- A member questioned why CoT examples are acceptable while other forms of prompting are not, given that CoT can also be seen as a template.
- MATS Rejection Woes: A member shared their rejection from MATS after their application dashboard indicated they didn’t advance to the next stage.
- The poster was looking for confirmation from others who may have been rejected.
- Enron Email Dataset Structure: A member inquired about the availability of a structured Enron email dataset, seeking specifically extracted emails rather than the raw data.
- Another member suggested that preprocessing the data might be necessary, as directly structured data might not be readily available.
Eleuther ▷ #research (11 messages🔥):
2x2 experiment clarification, Neuron Deletion Based on Activation Patterns, CoDA adapter architecture impact
- Clarification on 2x2 Experiment Confusion: A user found the description of the various 2x2 experiments confusing, especially why the “Standard GQA Unbounded PPL” was worse than the Mistral baseline of 4.81.
- Another user clarified that the 5.75 is not the raw Mistral-7B model, but Mistral-7B after swapping all 32 attention layers to the adapter architecture and fine-tuning only 18.6% of parameters, further noting that the 4.81 -> 5.75 gap is the cost of the adapter architecture + limited fine-tuning.
- Neuron Deletion Based on Activation Excites: A user proposed deleting neurons that are all positive or all negative over a whole dataset, citing this paper.
- This led to imagining some kind of optimizer that uses activation momentum to encourage diverse activation patterns.
- CoDA Adapter Architecture Questioned: A user questioned the reason for changing the model at all when using —no-differential nor what the CoDA adapter really does in this ‘disabled’ state.
- They also asked why does the ‘adapter architecture’ change things at all?
Eleuther ▷ #interpretability-general (6 messages):
Communicative IR Systems, Probing Dialogue Acts and Stance, Nnsight Updates, Linear Decodability of Hidden States
- Communicative IR System Under Construction: A member is building a small ‘communicative IR’ for EN/JP (ACT + PAYLOAD + STANCE) and is looking for references + best practices for a probe experiment.
- They inquired about work probing whether dialogue-act / stance variables are linearly decodable from hidden states across languages.
- Linear Decodability Expected in Dialogue Systems: A member expects the property of dialogue-act/stance to be linearly decodable and suggested sweeping probes trained on the residual stream across all layers.
- They mentioned that in multi-turn dialogues, labeling subsets or individual turns will require significant setup.
- Nnsight tool is upgraded with new features: A member shared updates about Nnsight, highlighting faster traces for intervening on model internals and better error messages.
- The updates include LLM-friendly docs to teach AI coding assistants how to do interp analyses, first-class support for 🤗 VLMs and diffusion models, and vLLM multi-gpu and multi-node support.
Yannick Kilcher ▷ #general (14 messages🔥):
Open Weight, Anthropic DoD, Entity list threat, Dario Amodei, Schoolyard Bullies
- Open Weight Spring Dream: A member shared a link about the dream of open weight.
- Another member responded with “its also really based. no weasel words”.
- Anthropic Under Fire From DoD: Members are discussing a statement regarding Anthropic and the Department of Defense.
- According to one member, it’s “so much worse than just losing the 200M contract,” as they threaten to “put them onto a prohibited entity list…compel them to give the US government access to their models/code” for mass surveillance and autonomous weapons.
- Entity List Looms for Anthropic: There’s a discussion about the US government potentially putting Anthropic on a prohibited entity list.
- One member described this as a typical strategy: “will this company cower to money; if not, try (1); if not, try (2)”
- Dario Deemed a Dweeb?: A member wondered if Dario Amodei is being pushed around because of his appearance.
- Another member responded, *“Don’t think it’s that deep: They want something. They will make sure they get it.”
- Government as Schoolyard Bully: One member shared a link to Truth Social with an attached image, seemingly related to the Anthropic situation.
- Another member dismissed deeper explanations, saying, *“There’s nothing deep about schoolyard bullies.”
Yannick Kilcher ▷ #paper-discussion (1 messages):
ElevenReader app, Text-to-speech, Richard Feynman Voice
- Reader App Recites with Feynman’s Voice: A user enthusiastically recommended ElevenReader to audio-read text.
- The user humorously suggested using the app to have Richard Feynman’s voice read the text.
- ElevenLabs Text-to-Speech App Lauded: A user highlighted the quality of the ElevenLabs text-to-speech app.
- They found the app to be excellent for converting text into audio.
Yannick Kilcher ▷ #ml-news (5 messages):
Anthropic Statement, Google's Intelligent OS, Microsoft Copilot Tasks, Google's Opal Agent, Trump's Truth Social Post
- Anthropic Releases a Statement: Anthropic made a statement on an unknown topic, no details were given.
- Google Announces Intelligent OS for AI Agents: Google announced the intelligent OS that will allow AI Agents to function on their operating system.
- Microsoft Copilot Handles Tasks: Microsoft announced that Copilot can now handle tasks, turning answers into actions.
- Google Labs Introduces Opal Agent: Google Labs introduced Opal Agent, but no details were given on what the agent does.
- Trump Posts on Truth Social: Donald Trump made a post on Truth Social, but the contents of the post were not detailed.
MCP Contributors (Official) ▷ #general (13 messages🔥):
Model Context Protocol PING, MCP Initialization Clarification, Bedrock AgentCore PING workaround, Python SDK Interpretation
- Clarifying PING’s Role Before MCP Initialization: The discussion questions whether the
pingutility in the Model Context Protocol is supposed to work before theinitializecall.- It was noted that the word ‘still’ in the description of the ping mechanism would indicate it’s meant for existing connections.
- Runtime Bedrock AgentCore PING workaround: To ensure container health, Bedrock AgentCore pings customer MCP servers, but because the Python SDK enforces initialization before pings, they create a temporary session.
- This is done to avoid interfering with external client sessions and is a workaround for the SDK’s interpretation of the MCP specification, highlighting a practical issue with pre-initialization pings.
- Python SDK’s PING enforcement: The Python SDK enforces that initialization must occur before a
pingcan be sent, which aligns with one interpretation of the MCP specification.- This enforcement led to the necessity of creating a temporary session in Bedrock AgentCore for health checks.
Manus.im Discord ▷ #general (7 messages):
Customer service issues, Skills vs knowledge confusion, AI & full-stack systems
- Manus Has Troubles With Customer Service: A user expressed frustration with Manus’s customer service, stating that they are repeatedly asked for verification despite providing it, including system confirmation.
- A team member replied asking them to DM them their email address and session link.
- Skills Vs Knowledge Confusion Explored: A user expressed confusion about the relationship between skills and knowledge in Manus, noting that skills they created are also suggested as knowledge.
- A user suggested that Manus uses the skill.md file a little bit different as the others.
- AI & Full-Stack Engineer Showcases Skills: An engineer detailed their experience in AI and full-stack development, emphasizing building clean, maintainable, and secure systems that scale under real-world conditions.
- They highlighted skills in LLM integration, workflow automation, AI content moderation, image AI, voice AI, and bot development, alongside full-stack development using various technologies.
- AI + Full Stack Engineer Focuses on Healthcare: An engineer introduced themselves as an AI + Full Stack Engineer focused on building production-grade AI systems for Healthcare, including clinical NLP, medical imaging, and patient-facing AI applications.
- The engineer mentioned core skills in healthcare AI pipelines, clinical NLP, medical imaging AI, LLM systems for Healthcare, agentic AI systems, RAG + knowledge systems, full-stack delivery, and automation & integrations.
tinygrad (George Hotz) ▷ #general (5 messages):
shared memory, shm_suffix, robots
- Shared Memory Shenanigans: A member noted that PR 15033 might require appending
shm_suffixto every new call to_setup_shared_mem().- They suggested PR 15030 as a way to avoid this.
- Tinygrad Attracts Robot Builders: A user mentioned that Twitter brought them to Tinygrad, implying it has something for people building robots.
- They inquired about which channel to join to learn more about this specific application.
DSPy ▷ #general (2 messages):
dspy.RLM, Seattle
- DSPy RLM in Seattle?: A member inquired about the possibility of organizing events related to DSPy RLM in Seattle.
- They expressed their willingness to help with the organization.
- Volunteer offers to help: A volunteer offered to help organize the DSPy RLM event.
- No other context was provided.
aider (Paul Gauthier) ▷ #general (2 messages):
aider indexing documents, md files, code indexing
- Aider considers indexing documents like code: A user suggested that aider should index documents like markdown (md) files similarly to how it indexes code.
- Potential improvements in documentation projects: Indexing documents could potentially improve the efficiency of working with aider in large documentation projects.
MLOps @Chipro ▷ #events (1 messages):
World Model architectures, JEPA / V-JEPA, Dreamer, Genie, Sora
- Dive Deep in World Models with Paper Clinic: Ti.g is hosting a 2-part “paper clinic” to unpack and debate the survey “Understanding World or Predicting Future? A Comprehensive Survey of World Models” (arXiv:2411.14499).
- The clinic aims to build a mental map of world model architectures and discuss topics like JEPA / V-JEPA, Dreamer, Genie, Sora, and World Labs.
- Explore the Future of AGI Research: The paper clinic will explore the “Mirror vs. Map” debate, discussing generation vs. representation in world models.
- The talk will further address what’s next for AGI research: spatial intelligence, causality gaps, and social world models.
- Register for the Sessions: Session 1 is on Feb 28 (Sat) 10:00–11:30 AM EST, focusing on Foundations of World Models + Mirror vs. Map debate (register here).
- Session 2 is on Mar 7 (Sat) 10:00–11:30 AM EST, focusing on Competitive landscape (Sora vs. Cosmos vs. V-JEPA) + AGI frontier (register here).