The Best Image Model is back!
AI News for 2/25/2026-2/26/2026. We checked 12 subreddits, 544 Twitters and 24 Discords (263 channels, and 12920 messages) for you. Estimated reading time saved (at 200wpm): 1283 minutes. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
Congrats to Perplexity on Computer and for replacing Bixby as default AI on hundreds of millions of Samsung phones going forward, but those are more consumery news.
News that AI Engineers can use from today is Nano Banana 2, which is more formally called 3.1 Flash Image. The big story is the pricing: it is rated the #1 image model in the world per Arena and ArtificialAnalysis, and yet costs half the price (At $67/1k images, vs Nano Banana Pro ($134/1k) and GPT Image 1.5 ($133/1k) for generation, and FLUX.2 [max] at $140/1k images for editing).
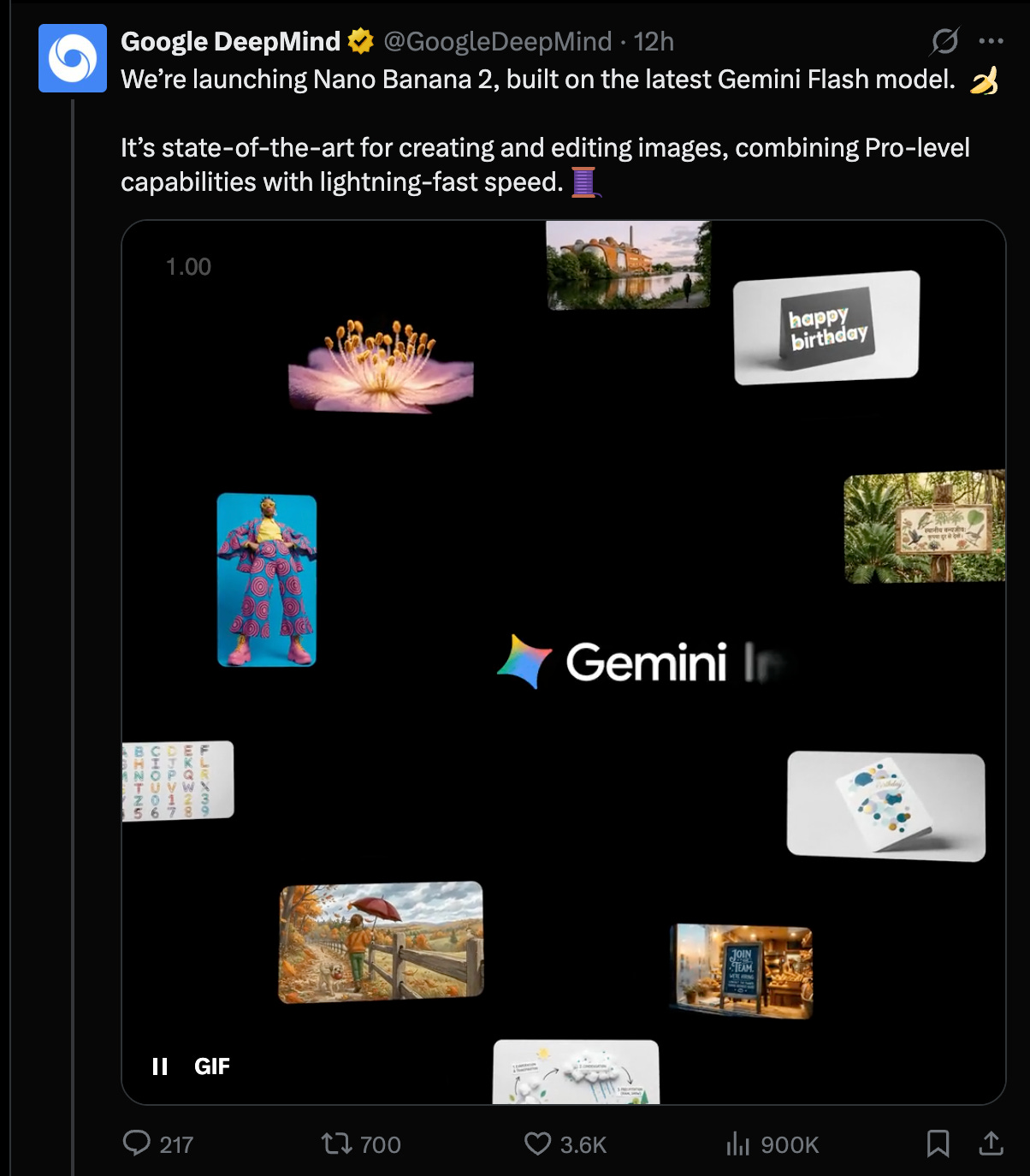
It comes with 6 character consistency and search grounding, and great text rendering. Of course every generation is stamped by SynthID.

Of course, there’s no research detail or paper whatsoever, so our coverage ends here.
AI Twitter Recap
Google’s Nano Banana 2 (Gemini 3.1 Flash Image Preview) and the new image-eval meta
- Nano Banana 2 launch + rollout footprint: Google and DeepMind shipped Nano Banana 2 (aka Gemini 3.1 Flash Image Preview) as a “Flash-tier” image generation/editing model rolling out across Gemini App, Search (AI Mode/Lens), Flow, Google Ads, and in preview via AI Studio / Gemini API / Vertex AI (Google, GoogleDeepMind, GeminiApp, sundarpichai, demishassabis). Product claims emphasize world knowledge, improved i18n text rendering, aspect ratio control, upscaling up to 4K, and multi-subject consistency (e.g., “up to 5 characters & 14 objects”) (Google, joshwoodward).
- Arena/Artificial Analysis results + pricing signal: Multiple evaluators report Nano Banana 2 taking #1 Text-to-Image and strong editing placements, while undercutting “Pro” pricing—e.g., $67 / 1k images cited by Artificial Analysis vs ~$133–134 for GPT Image 1.5 and Nano Banana Pro (ArtificialAnlys, arena, kimmonismus). Arena added image subcategories and highlighted largest gains in text rendering and 3D imaging/modeling (arena). This is also a reminder that leaderboards are becoming product levers: “day-0” integrations (e.g., fal) and prompt packs/templates ship alongside eval wins (GeminiApp templates, GoogleAI prompts).
- Real-time search-conditioned generation: Google repeatedly frames NB2 as powered by real-time information and images from web search (not just static pretraining), positioning it as “more accurate views from any window in the world” style demos (sundarpichai).
- Downstream availability: Nano Banana 2 quickly appeared in third-party products, including Perplexity Computer (AravSrinivas).
Agentic coding + productized “tasks”, memory, and evals (and the backlash against complexity)
- Agents “just work” more often now, but still fail off-distribution: Several practitioners describe a step change in reliability/utility for coding agents across recent frontier models (e.g., GPT-5.2 / GPT-5.3 Codex, Opus 4.6, Gemini 3.1), shifting from “proof of concept” to something like delegating CLI work to juniors (teortaxesTex, paul_cal). Others caution that advanced ML/data engineering remains brittle off-distribution (michalwols, MParakhin).
- “Tasks” as the new packaging layer: Microsoft’s Copilot Tasks pitches “talk less, do more” delegation with user-visible plans and control, in “research preview” (mustafasuleyman, yusuf_i_mehdi).
- Persistent memory becomes table stakes—and introduces interoperability pain: A widely shared update claims Claude rolled out auto-memory (“remembers what it learns across sessions”) (trq212), echoed in the Claude ecosystem (omarsar0). Developers immediately hit workflow friction when memory/state lives in tool-specific hidden directories (hurting “multi-agent, multi-tool” continuity) (borisdayma).
- Tooling ships fast: PR bug-fixing bots, code↔design loops, and editor-level improvements:
- Cursor Bugbot Autofix automates fixing issues found in PRs (cursor_ai, aye_aye_kaplan).
- OpenAI’s Codex “code → design → code” roundtrip with Figma aims to make UI iteration less lossy (OpenAIDevs, figma).
- VS Code’s long-distance Next Edit Suggestions focuses on predicting where not to edit and supporting “flow” (code, pierceboggan, alexdima123).
- Eval inflation + benchmark gaming concerns: Threads call out that high leaderboard scores can mask token-inefficient reasoning and failures on “bullshit tests” (e.g., repeated-token “strawberry” variants), warning against over-trusting HLE/GPQA-style metrics without cost accounting (scaling01). Arena responds by adding more granular test regimes like Multi-File React for code models (arena).
- Complexity is the real tax: A recurring engineering concern is that “10k LOC/day” bragging creates long-term complexity debt—agents make it easier to ship, not easier to maintain (Yuchenj_UW). Another angle: coding agents can create implicit lock-in if they “sloppify” your codebase such that working without them becomes painful (typedfemale).
Perplexity’s distribution + retrieval stack: Samsung integration and new embedding models
- Samsung S26 system-level Perplexity (“Hey Plex”): Perplexity says every Galaxy S26 will ship with Perplexity built in, including a wake word and deep OS integration; Bixby routes web/research/generative queries to Perplexity while handling on-device actions (perplexity_ai, perplexity_ai, AravSrinivas). This is framed as part of a broader partnership that also targets Samsung Internet and optional default search positioning (perplexity_ai).
- pplx-embed / pplx-embed-context released (MIT): Perplexity launched two embedding model families at 0.6B and 4B, including a “context” variant intended for doc chunk embeddings in RAG; both are MIT licensed and available via HF + Perplexity API, with a paper (arXiv:2602.11151) (perplexity_ai, perplexity_ai, alvarobartt). They also disclose internal benchmarks like PPLXQuery2Query / PPLXQuery2Doc with 115k real queries over 30M docs from 1B+ pages (perplexity_ai). Arav claims the embedding models are “industry leading” (AravSrinivas).
- Strategic read: The pair of moves—OS distribution + retrieval primitives—suggests Perplexity is trying to own both front door (assistant entry point) and core search stack (embeddings + evals), rather than depending on third-party platforms.
Inference, kernels, and infra: MoE support, heterogeneous hardware, and KV movement
- MoE becomes “first-class” in 🤗 Transformers: Hugging Face shipped deeper MoE plumbing (loading, expert backends, expert parallelism, hub support) and highlights collaboration on faster MoE training (including with Unsloth) (ariG23498, mervenoyann).
- DeepSeek and multi-hardware inference seriousness: Early in the batch, DeepSeek is called out as “serious about inference support on diverse hardware” (teortaxesTex). Separately, a DeepSeek DualPath detail describes staging KV cache in decode-server DRAM then moving it to prefill GPUs via GDRDMA to avoid local PCIe bottlenecks (JordanNanos). This reflects a broader shift: inference is increasingly a systems architecture problem, not just kernel-level optimization.
- Kernel coverage and GPU generations: vikhyatk describes building inference kernels across NVIDIA architectures (sm80→sm110) and notes edge-device ISA issues like Orin CPU lacking SVE (vikhyatk, vikhyatk).
- Quantization isn’t uniformly safe: Evaluations show MiniMax M2.5 GGUF quantizations degrade much more than expected vs Qwen3.5, arguing “just take Q4” doesn’t generalize across model families (bnjmn_marie).
World models, agents in simulators, and “multiplayer” environments
- Solaris: multiplayer Minecraft world modeling stack: A major research drop proposes that world modeling should focus on shared global state rather than pixel rendering, releasing (1) a multiplayer data collection engine, (2) a multiplayer DiT with a “memory efficient self forcing design” trained on 12.6M frames, and (3) a VLM-judge evaluation suite for multi-agent consistency (sainingxie, georgysavva). The pitch: multi-agent capability requires a shared representation beneath individual views.
- LLMs as embodied controllers (toy but telling): A CARLA→OpenEnv port shows a small Qwen 0.6B learning to brake/swerve to avoid pedestrians in ~50 steps using TRL + HF Spaces (SergioPaniego). This exemplifies a trend toward “LLM+env” loops where reversibility is limited and mistakes persist.
Governance flashpoint: Anthropic vs the Pentagon on surveillance and autonomous weapons
- Pentagon pressure campaign reported, then Anthropic responds publicly: A widely shared claim says the DoD issued a “final offer” to Anthropic, including threats to label it a “supply chain risk” and demands for unrestricted military use (KobeissiLetter). Anthropic then published a CEO statement drawing explicit red lines: no mass domestic surveillance and no fully autonomous weapons (given current reliability), also alleging threats involving the Defense Production Act (AnthropicAI). A widely quoted excerpt is reposted with detail (AndrewCurran_).
- Industry reaction + solidarity mechanics: The stance triggered strong support from prominent researchers/engineers, framing it as values-under-pressure rather than “policy theater” (fchollet, TrentonBricken, awnihannun). A petition aiming to coordinate “shared understanding” reportedly gathered signatures from OpenAI/Google staff (jasminewsun, sammcallister, maxsloef). This is notable as an explicit attempt to prevent a race-to-the-bottom dynamic via transparency about where each lab stands.
- Why this matters technically: The core dispute is about capability vs. reliability and “lawful use” language being misaligned with what frontier models can safely do today. Reliability concerns show up elsewhere in the dataset too (e.g., minimal security test cases where models leak confidential info even when instructed not to) (jonasgeiping, random_walker).
Top tweets (by engagement)
- Anthropic CEO statement on DoD demands (surveillance + autonomous weapons red lines) — @AnthropicAI
- Google launches Nano Banana 2 / Gemini 3.1 Flash Image Preview (broad rollout + “pro at flash speed”) — @GeminiApp, @sundarpichai, @GoogleDeepMind
- Perplexity + Samsung S26 system-level integration (“Hey Plex”) — @perplexity_ai
- Claude connectors available on free plan (150+ connectors) — @claudeai
- Pentagon vs Anthropic “final offer” reporting thread — @KobeissiLetter
- Claude Code auto-memory is huge (developer reaction) — @trq212
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
1. Qwen3.5 Model Performance and Comparisons
-
Qwen3.5-35B-A3B Q4 Quantization Comparison (Activity: 635): The post presents a detailed comparison of Q4 quantization methods for the Qwen3.5-35B-A3B model, focusing on their faithfulness to the BF16 baseline using metrics like KL Divergence (KLD) and Perplexity (PPL). The analysis highlights that AesSedai’s Q4_K_M achieves the lowest KLD of
0.0102, indicating high faithfulness, while Ubergarm’s Q4_0 significantly outperforms other Q4_0 quantizations. The post also notes that MXFP4 is less effective when applied post-hoc compared to during Quantization Aware Training (QAT). The efficiency score, which balances model size and KLD, ranks AesSedai_Qwen3.5-35B-A3B-IQ4_XS as the most efficient quantization. The setup used for testing includes an Intel Core i3-12100F CPU, 64 GB RAM, and an RTX 3060 GPU, with results based on thewikitext2_test.txtdataset. Commenters appreciate the detailed comparison and suggest that quantizers should include such analyses in their documentation. There is also a discussion about the potential bias in using wikitext for PPL/KLD measurements, as it might be included in some imatrix datasets, suggesting the use of a fresh dataset for more accurate comparisons.- The comment by ‘ps5cfw’ highlights the ambiguity in quantization terminology like ‘Q4_K_M’, emphasizing the need for standardization and clarity in documentation. This is crucial for making meaningful comparisons between different quantization methods, especially after issues like the XL debacle.
- ‘noneabove1182’ points out a potential issue with using wikitext as a PPL/KLD measurement, as some datasets might include wikitext, potentially skewing results. They suggest using a fresh dataset, such as STT from a recent podcast, for more accurate comparisons. This highlights the importance of dataset transparency and selection in benchmarking.
- ‘danielhanchen’ discusses ongoing investigations into the high perplexity of Q4_K_XL due to MXFP4 layers. They note that other quantizations like Q2_K_XL and Q3_K_XL are unaffected. The comment also mentions that the UD-Q4-K-XL quantization significantly outperforms Q4-K-M in real-world benchmarks, as shown in Benjamin Marie’s LiveCodeBench v5.
-
Qwen3.5 122B in 72GB VRAM (3x3090) is the best model available at this time — also it nails the “car wash test” (Activity: 706): The post discusses the performance of the Qwen3.5 122B model, which is optimized to run on a setup with
72GB VRAMusing three3090 GPUs. The user highlights its efficiency, achieving25 tokens per secondwith specific settings likeTemperature 0.6,K Sampling 20, andTop P sampling 0.8. The model is noted for its ability to handle a120k contextin Q3 mode, despite being slower than other models like GLM Air and GPT-OSS-120B. The user also mentions challenges with other configurations like MXFP4 and IQ4_XS, which require offloading layers to RAM, reducing speed to6-8 tok/s. One commenter notes achieving34-36 tok/secwith a different setup, using Qwen3.5-122B-A10B-UD-Q4_K_XL and a Ryzen 9 9950X3D with RTX 5090. Another comment critiques the ‘car wash test’ as a biased scenario that exploits model training biases, suggesting it is not a definitive measure of model intelligence.- A user reports achieving 34-36 tokens per second with the
Qwen3.5-122B-A10B-UD-Q4_K_XLmodel and 16-18 tokens per second with theQwen3.5-122B-A10B-UD-Q8_K_XLmodel, both at a maximum context size of 256K. Their setup includes a Ryzen 9 9950X3D, RTX 5090, and 128 GB DDR5 5600 RAM, running on Cachy OS Linux, which is based on Arch Linux. - The ‘car wash test’ is critiqued as being less meaningful than often suggested. It is described as a scenario that frequently appears in training data, which biases the model to replicate learned logic rather than demonstrating genuine reasoning ability. This test is seen as a targeted probe of a specific model weakness rather than a comprehensive measure of intelligence.
- There are reports of issues with the 4-bit Unsloth quantization in the Qwen3.5 model series, suggesting potential for further optimization. Despite these issues, the model is noted for its impressive performance, especially in contrast to previous releases that did not meet expectations.
- A user reports achieving 34-36 tokens per second with the
-
Qwen/Qwen3.5-35B-A3B creates FlappyBird (Activity: 372): The post discusses the use of the Qwen/Qwen3.5-35B-A3B model to create a Flappy Bird clone using HTML, CSS, and TypeScript, initialized with Vite. The model, hosted locally, demonstrated effective coding capabilities by generating a basic game structure and implementing features like music using the Web Audio API, a scrollable parallax background, and a flock of birds. The user noted some initial visual glitches with the parallax effect, which were resolved with minor adjustments, and successfully added a sound settings panel in a single attempt. One commenter suggested the potential for open model companies to conduct repeated benchmarks or tests with different games to evaluate performance, indicating interest in further exploration of the model’s capabilities.
- BitXorBit raises an interesting point about the potential for open model companies to prepare for repeated benchmarks or tests. They suggest trying different games and sharing results, which could provide insights into the model’s adaptability and performance across various tasks. This could be particularly relevant for evaluating the generalization capabilities of models like Qwen/Qwen3.5-35B-A3B.
- ShengrenR suggests a next step in the project: training a reinforcement learning (RL) model to play Flappy Bird based on screen input. This would involve using the visual data from the game to inform the model’s actions, potentially leading to a more sophisticated AI capable of learning and adapting to the game’s challenges in real-time.
-
Qwen 3.5 craters on hard coding tasks — tested all Qwen3.5 models (And Codex 5.3) on 70 real repos so you don’t have to. (Activity: 917): The image is a snapshot from the APEX Testing website, which evaluates AI coding models on real-world coding tasks. It shows that 34 models were tested across 65 tasks, with a total of 2208 runs, and highlights the top models based on ELO scores, including Claude Opus 4.6 and GPT 5.2 Codex. The post discusses the performance of various models, notably Qwen 3.5 and Codex 5.3, on a benchmark designed to test coding models on real codebases. Qwen 3.5 models, particularly the 397B variant, struggle with complex tasks requiring coordination across multiple files, while Codex 5.3 shows consistent performance across difficulty levels. The GLM-4.7 quantized model is noted as the best local model, outperforming Qwen 3.5 models. The post also mentions the use of an agentic tool-use system for fairer comparisons and highlights the importance of the framework used in testing, as it can significantly impact model performance. Commenters discuss the performance of specific models like gpt-oss-20b and GLM-4.7, questioning whether the custom agentic framework used might affect results. They suggest testing with popular frameworks to ensure the framework isn’t limiting model performance, as different frameworks can lead to significant performance variations.
- UmpireBorn3719 highlights a comparison between
gpt-oss-20bandQwen3 Coder Next, noting thatgpt-oss-20bscored1405whileQwen3 Coder Nextscored1328in the coding task benchmarks. This suggests thatgpt-oss-20bmay perform better in certain coding scenarios, although the specific tasks and conditions of the benchmark are not detailed. - metigue discusses the impact of using different agentic frameworks on model performance, noting that open-source models can show more than
50%performance swings depending on the framework used. They suggest testing with popular frameworks as the choice of framework can significantly alter which model appears to be the best, citing examples whereGLM-5outperformsOpus 4.6andCodex 5.3outperforms both when using theDroidframework. - Hot_Strawberry1999 appreciates the inclusion of benchmarks with different quantization levels, noting that such comparisons are rare. This suggests that the quantization level can significantly impact model performance, and having this data is valuable for understanding how models might perform under different computational constraints.
- UmpireBorn3719 highlights a comparison between
-
Qwen3.5 27B better than 35B-A3B? (Activity: 771): The image compares the performance of different models in the Qwen3.5 Medium series, specifically the 35B-A3B, 27B, and 122B-A10B models. It highlights various benchmarks such as instruction following, graduate-level reasoning, and multilingual knowledge. The 27B model is noted for its efficiency, particularly in environments with limited resources like 16 GB of VRAM and 32 GB of RAM, making it a potentially better choice over the 35B-A3B model in such scenarios. The image provides a visual representation of these performance metrics, aiding in the decision-making process for users with specific hardware constraints. One user mentions personal testing, indicating that the 27B model performs better on their hardware, a 3090 GPU, with a difference in processing speed of 100 t/s compared to 20 t/s. This suggests that the 27B model may offer better performance efficiency on certain hardware configurations.
- FusionCow notes a performance difference between the Qwen3.5 27B and 35B-A3B models on a 3090 GPU, with the 27B model achieving
100 tokens/secondcompared to20 tokens/secondfor the 35B-A3B. This suggests that the 27B model is more efficient in terms of speed, which could influence user choice based on processing time requirements. - boinkmaster360 suggests that the Qwen3.5 27B model is a dense model, implying it might be slower but potentially more intelligent. This highlights a trade-off between computational speed and model complexity, where denser models may offer improved performance in certain tasks due to their architecture.
- Alternative_You3585 points out that the Qwen3.5 27B model likely excels in intelligence compared to the 35B-A3B, but the latter may have advantages in real-world knowledge and processing speed. This indicates a nuanced performance landscape where different models may be preferable depending on the specific application requirements.
- FusionCow notes a performance difference between the Qwen3.5 27B and 35B-A3B models on a 3090 GPU, with the 27B model achieving
2. Geopolitical and Access Issues in AI Models
-
American closed models vs Chinese open models is becoming a problem. (Activity: 1387): The post discusses the challenges faced by organizations that require open AI models due to national security concerns, specifically avoiding Chinese models due to perceived risks. The only recent American model available is
gpt-oss-120b, which is outdated compared to modern models like GLM and MiniMax. The author suggests that pressure on companies like Anthropic by the DoD may be due to a need for offline AI solutions. Alternatives like Cohere in Canada are considered, but the lack of competitive open American models is a significant issue. Commenters suggest modifying Chinese models to create custom solutions, and mention Mistral Large 3 as a potential alternative, though it may not match the capabilities of Chinese models. There is skepticism about StepFun-AI being a viable non-Chinese option, as it is also based in China.- The discussion highlights the availability of various AI models from different countries, emphasizing that the choice of model should be based on specific use cases rather than national origin. For instance, Mistral Large 3 is mentioned as a competitive model, though not necessarily superior to Chinese models like DeepSeek. The commenter suggests that enterprise environments can benefit from fine-tuning models to meet specific needs, which can mitigate potential security concerns.
- A detailed list of AI models from different countries is provided, showcasing the diversity in AI development globally. Notable mentions include Llama from Meta Platforms in the US, Qwen from Alibaba Cloud in China, and Mistral from Mistral AI in France. The commenter argues that the effectiveness of a model is highly dependent on its application, and enterprises should focus on customizing models through techniques like fine-tuning and RAG databases to enhance performance and address security issues.
- The commenter argues that concerns over the origin of AI models, such as potential backdoors, are less relevant when models are used offline and fine-tuned for specific enterprise needs. They suggest that companies can leverage open-source models by fine-tuning them, applying techniques like (Q)(Re)LoRAs, and building RAG databases to improve accuracy and security. This approach is common among hobbyists on platforms like Huggingface, indicating that enterprises with budgets should be capable of similar customizations.
-
DeepSeek allows Huawei early access to V4 update, but Nvidia and AMD still don’t have access to V4 (Activity: 559): DeepSeek has provided early access to its V4 AI model update to Huawei and other domestic suppliers, aiming to optimize the model’s performance on their hardware. This strategic move excludes major US chipmakers like Nvidia and AMD, who have not received access to the update. The decision is likely influenced by the need for compatibility and optimization on non-Nvidia hardware, as DeepSeek’s models are typically trained on Nvidia platforms, suggesting a focus on enhancing performance for Huawei’s specific hardware architecture. Commenters speculate that Nvidia’s lack of access is not surprising, as DeepSeek models are generally optimized for Nvidia hardware. The early release to Huawei is seen as a strategic move to ensure compatibility with non-Nvidia systems, highlighting the competitive dynamics in AI hardware optimization.
- jhov94 suggests that DeepSeek is likely optimized for Nvidia hardware, implying that Nvidia might not need early access to V4 since the models are already compatible with their systems. The early release to Huawei could be due to compatibility issues with their hardware, which might require additional adjustments or optimizations.
- ResidentPositive4122 reflects on the media hype surrounding DeepSeek, particularly during its initial announcements, and advises skepticism towards mainstream media claims. They suggest that despite the lack of early access for Nvidia and AMD, major inference providers will likely adapt to V4 shortly after its release, as is common with new model launches.
- stonetriangles questions the significance of Nvidia not receiving early access to V4 by comparing it to previous versions like R1, V3, or V3.2, where Nvidia also did not have early access. This implies that the current situation is not unusual and may not warrant concern.
3. AI Model Leaderboards and Benchmarks
-
Anthropic Drops Flagship Safety Pledge (Activity: 354): Anthropic has decided to drop its flagship safety pledge, which was a commitment to prioritize safety in AI development. This decision marks a significant shift in their approach to AI governance and safety protocols. The pledge was initially designed to ensure that AI systems are developed with a strong emphasis on ethical considerations and risk mitigation, but the reasons for its withdrawal have not been explicitly detailed by the company. The comments reflect a critical view of Anthropic’s decision, with some suggesting that external pressures, possibly from governmental or defense entities, may have influenced this change. There is a sentiment that this move could compromise the ethical standards previously upheld by the company.
- till180 discusses the implications of Anthropic dropping their safety pledge, suggesting that while public models may still have safety guardrails, the removal of the pledge could facilitate selling models to the US military. This is in light of recent demands from the Pentagon for Anthropic to provide their models, indicating a potential shift in the company’s operational focus and ethical stance.
-
Anthropic is the leading contributor to open weight models (Activity: 839): Anthropic is reportedly the leading contributor to open weight models, albeit unintentionally, as their models are being distilled against their terms of service. The process of distillation involves using interactions with the model to create a smaller, efficient version, and tools like dataclaw facilitate publishing these interactions to platforms like HuggingFace. DeepSeek has distilled
150kchat rounds, but many users have significantly more data available. Commenters suggest a strategy of ‘distributed distillation’ where users contribute to distillation efforts, potentially incentivized by tokens. There’s a sentiment that open-source efforts, even if led by non-American entities, are beneficial for the community.- The concept of ‘distributed distillation’ is suggested as a method for improving model training by leveraging user interactions. This involves users asking questions that can be used for distillation, potentially incentivized by offering tokens like ‘qwen-3.5’. This approach could enhance the dataset diversity and quality for training open models.
- A tool called ‘dataclaw’ is mentioned, which allows users to publish their Claude Code conversations to HuggingFace with a single command. This could facilitate the sharing and distillation of large datasets, as evidenced by DeepSeek’s distillation of 150k chat rounds, highlighting the potential for users to contribute significantly more data from their own collections.
- The discussion touches on the geopolitical aspect of AI development, with some users expressing a preference for Chinese open-source contributions over American ones. This sentiment underscores the global nature of AI development and the importance of open-source models in fostering international collaboration and competition.
-
Self Hosted LLM Leaderboard (Activity: 324): The image presents a leaderboard for self-hosted large language models (LLMs), categorizing them into tiers S, A, B, C, and D based on their performance. Models are listed with their names and parameter sizes, such as “Kimi K2.5” and “GLM-5” in the top S tier. The leaderboard allows filtering by specific capabilities like coding, math, reasoning, and efficiency, providing a comprehensive overview of model performance for self-hosting purposes. The leaderboard is hosted on Onyx. Commenters discuss the absence of the Qwen 3.5 models, suggesting they should be included in the A or B tier due to their capabilities, including vision support, which is beneficial for homelab and small business applications. There is also a mention of Qwen3-Next and Qwen3-Coder-Next as top-performing models for standard hardware.
- The Qwen 3.5 models, particularly the 27B dense and 122B MoE versions, are highlighted for their potential to rank in the A-tier or B-tier of self-hosted LLMs. These models are noted for their vision capabilities, which are beneficial for applications in homelabs and small businesses, suggesting they should be included in the leaderboard.
- Qwen3-Next and Qwen3-Coder-Next, both at 80B parameters, are praised for their performance on standard hardware. These models are considered highly effective, especially in coding tasks, and their absence from a coding-focused leaderboard is seen as a significant oversight.
- There is a discussion about the hardware requirements for running S-tier models, though specific details are not provided in the comments. This suggests a need for further clarification on the computational resources necessary to effectively deploy top-tier self-hosted LLMs.
Less Technical AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. Nano Banana 2 and Gemini 3.1 Flash Developments
-
Google releases Nano banana 2 model (Activity: 984): Google has released the Nano Banana 2 model, an advanced AI image generation model that integrates professional-grade capabilities with rapid processing speeds. This model is noted for its enhanced world knowledge, production-ready specifications, and improved subject consistency, allowing users to generate high-quality images efficiently. For more details, refer to the Google Blog. Users are impressed with the model’s performance, particularly in tasks it previously struggled with, such as complex image generation for home remodeling, indicating significant improvements in image quality and consistency.
- BuildwithVignesh provides links to Google’s official blog and the Gemini API documentation, which are crucial for developers looking to integrate or understand the capabilities of the Nano Banana 2 model. The blog likely details the model’s features, improvements, and potential applications, while the Gemini API documentation would offer technical guidance on implementation and usage.
- JTwoXX highlights a limitation of the Nano Banana 2 model, noting that it still struggles with generating PNG images without a background. This suggests that while the model may have advanced in other areas, there are still specific technical challenges that need to be addressed, particularly in image transparency and background handling.
- bentendo93 shares a practical application of the Nano Banana 2 model, using it for home remodeling visualizations. This indicates the model’s improved performance in generating realistic and useful images for practical scenarios, which could have implications for industries like interior design and architecture.
-
Gemini 3.1 Flash (Nano Banana 2) Spotted Live in Gemini Ahead of Official Release (Activity: 287): The image depicts an early access interface for the upcoming Gemini 3.1 Flash, internally known as Nano Banana 2. This suggests a staged rollout of the model within the Gemini platform, even though no official announcement has been made yet. The interface includes a loading message for “Nano Banana 2,” indicating that users can select and potentially interact with the model, hinting at its imminent release. One comment highlights the impressive detail in the model’s output, specifically noting the intricate depiction of a bird reflected in an eye, suggesting high-quality rendering capabilities.
- Ggoddkkiller highlights a concern about Google’s handling of customer relations, particularly in the context of the Vertex AI platform. The comment suggests dissatisfaction with Google’s approach to customer engagement and support, especially when compared to the excitement around the Gemini 3.1 release. This reflects a broader sentiment in the tech community about the need for better customer service and transparency from major tech companies like Google.
-
Nano Banana 2 is real! Gemini 3.1 Flash Image just appeared in Vertex AI Catalog (Activity: 264): The image in the post is a side-by-side comparison of two AI-generated portraits, showcasing the capabilities of the newly released Nano Banana 2 (also known as Gemini 3.1 Flash Image) and the existing Nano Banana Pro. The post highlights that the new model, despite being a ‘Flash’ tier, offers quality close to the Pro version, particularly excelling in spatial logic for dense compositions. This model is designed for high-speed, low-cost production, suitable for high-frequency pipelines like bulk UGC ad creation. It retains features from the Nano Banana series, such as multi-subject reference and high-fidelity style transfer, making it a significant release for 2026. One commenter believes that the Nano Banana Pro still has an edge over the new model in the provided example, while another expresses a desire for a video model with similar capabilities.
- The original Flash Image model had solid image quality, but faced issues with prompt adherence, particularly with complex instructions where it would often ignore parts of the prompt or regenerate the same output. Additionally, it struggled with text and infographic rendering, as well as multi-image compositing. The key question for the new Gemini 3.1 Flash Image is whether these issues have been addressed, and proper testing on dense prompts is awaited to confirm any improvements.
-
Nano Banana 2 pricing !!!! (Activity: 206): The image provides pricing details for two AI products, “Nano Banana 2” and “Nano Banana Pro.” “Nano Banana 2” is marketed as offering pro-level visual intelligence with a pricing structure of
$0.50for input and$3.00for output. In contrast, “Nano Banana Pro” is described as a state-of-the-art image generation and editing model, with input priced at$2.00and output at$12.00. Both products have a knowledge cut-off date of January 2025. The pricing suggests a tiered approach to AI services, with the Pro version being significantly more expensive, likely due to enhanced capabilities or features. Commenters compare the pricing and capabilities of “Nano Banana” products with “Gemini 3 Pro Image” and “Gemini 3.1 Flash Image,” noting that the latter’s pricing scales with image resolution. There is a debate on whether “Nano Banana Pro” offers better quality than “Nano Banana 2,” with some suggesting the quality is comparable.- Ggoddkkiller provides a detailed breakdown of the token costs for the Gemini 3 Pro Image and Gemini 3.1 Flash Image models. The Pro Image charges 560 tokens per input image, with output costs scaling by resolution, while the Flash Image charges 1120 tokens per input image with different scaling. The Flash Image is slightly cheaper than the Pro, but the pricing structure is complex and not as low as some users hoped.
- Halpaviitta shares insights from personal testing, noting that the new model is approximately four times cheaper and slightly faster than the Pro version. This suggests a significant cost-performance advantage, making it a favorable option despite the initial concerns about pricing.
- Actual_Committee4670 mentions that the generation speed is currently slow, which affects the ability to fully test the new model. However, they express a positive outlook on the cost of the new model, indicating that the pricing might be justified if performance improves.
2. Anthropic and Pentagon AI Safeguard Dispute
-
Anthropic rejects Pentagon’s “final offer” in AI safeguards fight (Activity: 1863): Anthropic has declined the Pentagon’s final offer concerning the deployment of its AI model, Claude, due to inadequate safeguards against potential misuse in mass surveillance and autonomous weapons. The Pentagon has responded with threats to blacklist Anthropic and potentially invoke the Defense Production Act. Despite these tensions, Anthropic is open to further negotiations, underscoring the broader challenges of AI deployment in classified environments, as other companies like xAI face similar contractual dilemmas. For more details, see Anthropic’s statement. The comments reflect a positive view of Anthropic’s stance, with users expressing respect for the company’s commitment to its principles, despite the low bar set by industry standards.
-
Exclusive: Hegseth gives Anthropic until Friday to back down on AI safeguards (Activity: 1434): Defense Secretary Pete Hegseth has issued an ultimatum to Anthropic, demanding the removal of safety guardrails from its Claude AI model by Friday, as reported by Axios. The Pentagon seeks unrestricted access to Claude for purposes including domestic surveillance and autonomous weapons development, which contravenes Anthropic’s terms of service. Failure to comply could lead to the invocation of the Defense Production Act or the designation of Anthropic as a supply chain risk, potentially blacklisting them from government contracts. A notable comment highlights the irony of AI companies imposing safety measures on government use, contrasting with typical regulatory roles. This reflects a broader debate on the balance of power and responsibility between tech companies and government entities in AI governance.
-
Statement from Dario Amodei on our discussions with the Department of War (Activity: 917): Dario Amodei of Anthropic has issued a statement regarding their collaboration with the Department of War, emphasizing their stance against the use of AI for mass surveillance and autonomous weapons. The company is pioneering the integration of AI into classified networks, but insists on maintaining safeguards to protect democratic values, despite external pressures to relax these measures. For more details, see the original statement. Commenters express skepticism about Anthropic’s ethical stance, noting the irony of partnering with Palantir, a company known for its involvement in surveillance. Others view the statement as a bold move given the current political climate.
3. Qwen Model Performance and Optimization
-
Big love to the Qwen 🧠 A true SOTA Open Source model running locally (Qwen 3.5 35B 4-bit) - Here is the fix for the logic loops! ❤️ (Activity: 173): The post discusses the implementation of the Qwen3.5-35B-A3B-4bit model, highlighting its initial issues with reasoning loops and logic errors typical of 4-bit quantized models. The author resolved these by adjusting the system prompt to enforce ‘Adaptive Logic,’ which separates the model’s internal ‘thinking’ from its final output, significantly improving performance on the Digital Spaceport Benchmark suite. The model successfully solved complex logic and math problems, generated SVG code, and performed accurate counting. Key configuration settings include a temperature of
0.7, top-p of0.9, and a frequency penalty of1.1. The ‘Anti-Loop’ system prompt is crucial for preventing repetitive loops and ensuring efficient task execution. A commenter noted the effectiveness of the Qwen3.5-35B-A3B model on a MacBook Pro M4 with 48GB RAM, appreciating the model’s ‘thinking’ feature and planning to incorporate the shared prompt tips. The context length was set to128k, which may contribute to its improved performance.- A user reported using the Qwen 35B A3B model on a MacBook Pro M4 with 48GB RAM, highlighting its improved performance over the previous 30B version. They noted that the 35B model is less prone to getting stuck in logic loops, which was a concern with earlier versions. The context length is set to 128k, allowing for extensive input processing, and the ‘thinking’ feature provides insight into the model’s decision-making process.
- There is a discussion about whether the Qwen 35B A3B model performs better with or without the ‘thinking’ feature enabled. This feature allows users to see what the model is considering, which can be beneficial for understanding its decision-making process. However, there is curiosity about the model’s behavior when it cannot generate an answer, suggesting that the ‘thinking’ feature might help mitigate such issues.
-
Qwen3.5-122B-A10B vs. old Coder-Next-80B: Both at NVFP4 on DGX Spark – worth the upgrade? (Activity: 63): The post discusses a comparison between the Qwen3.5-122B-A10B and the older Qwen3-Coder-Next-80B models, both running on a DGX Spark (128GB) with NVFP4 precision. The 122B-A10B model requires
61GBof memory compared to40GBfor the Coder-Next-80B, but both fit within the available memory with ample context headroom. Official benchmarks show 122B-A10B scoring72.0on SWE-Bench, slightly higher than Coder-Next-80B’s~70. The post questions whether the 122B-A10B offers significant improvements in coding performance or if it is more suited for general agent tasks, especially given its10B active parameterscompared to Coder-Next’s3B. The author seeks real-world NVFP4 comparisons, particularly in long-context retrieval and coding benchmarks like LiveCodeBench/BigCodeBench. One commenter notes that the 122B-A10B model currently underperforms in coding tasks compared to Coder-Next-80B, citing issues with generating a simple game. Another suggests that while 122B-A10B offers better multi-file reasoning and long-context handling, the coding performance gains are minimal, making Coder-Next-80B still competitive for coding-focused workloads.- flavio_geo highlights that the Qwen3.5-122B model, when tested in Q4KXL quantization, underperformed in coding tasks compared to the older Qwen3-Coder-Next-80B model, which was tested in Q6KXL. Specifically, the 122B model struggled with a coding task involving creating a Pygame version of the Chrome dinosaur game, making multiple errors before achieving a working version, whereas the Coder-Next model succeeded in one attempt with high-quality output. This suggests that the 122B model may not yet be fully optimized in the current
llama.cppengine. - qubridInc notes that while the Qwen3.5-122B-A10B model offers improved multi-file reasoning and long-context handling, the coding performance gains over the Coder-Next-80B model are minimal. For workloads focused on coding, the Coder-Next model remains competitive. However, for tasks requiring stronger general reasoning and agentic capabilities, the 122B model could be beneficial.
- klop2031 shares an observation that the larger Qwen3.5-122B model performed poorly even compared to a smaller 27B dense model. This could be attributed to the specific task or the quantization method used. The commenter expresses hope for future optimizations in the
llama.cppframework to improve the model’s performance.
- flavio_geo highlights that the Qwen3.5-122B model, when tested in Q4KXL quantization, underperformed in coding tasks compared to the older Qwen3-Coder-Next-80B model, which was tested in Q6KXL. Specifically, the 122B model struggled with a coding task involving creating a Pygame version of the Chrome dinosaur game, making multiple errors before achieving a working version, whereas the Coder-Next model succeeded in one attempt with high-quality output. This suggests that the 122B model may not yet be fully optimized in the current
-
Qwen Code looping with Qwen3-Coder-Next / Qwen3.5-35B-A3B (Activity: 26): The user is experiencing looping issues with the
Qwen3-Coder-NextandQwen3.5-35B-A3Bmodels when usingQwen Codewith unsloth quantizations. The setup involves running the models onllama.cppwith specific configurations such asctx-size 131072,flash-attn on, andn-gpu-layers 999. The looping issue might be related to the model or the specific implementation inQwen Code. The user is seeking advice on whether this is a known issue and any potential workarounds. One commenter suggests usingnvfp4quant forQwen3-Coder-Nextwithsglangfor better stability, while another recommends setting a maximum thinking time to mitigate looping. Additionally, switching to thepwilkin/autoparserbranch ofllama.cppis suggested to fix XML and duplicate-key parsing issues, with further advice to use--repeat-penalty 1.08and--presence-penalty 0.05if problems persist.- Prudent-Ad4509 discusses using
nvfp4 quantfor Qwen3-Coder-Next withsglang, noting the difficulty due to the instability of the llama-server. They mention that Qwen3.5’s test results are not convincing outside of official benchmarks, but highlight that the Qwen3.5 27b Q8 model is particularly effective. - ImJustNatalie reports encountering ‘doom looping’ with Qwen3.5 35B A3B and suggests setting the max thinking time to 1 minute to mitigate the issue. This adjustment has significantly improved performance, reducing the occurrence of looping.
- walt3i provides a solution for the ‘looping ReadFile’ issue by switching to the
pwilkin/autoparserbranch, which addresses XML and duplicate-key parsing problems. They also suggest using--repeat-penalty 1.08and--presence-penalty 0.05if the issue persists.
- Prudent-Ad4509 discusses using
AI Discord Recap
A summary of Summaries of Summaries by gpt-5
1. Nano Banana 2 & Arena Leaderboards Heat Up
-
NB2 Crowns Image Arena, Web Search Wobbles: Nano Banana 2 debuted as Gemini‑3.1‑Flash‑Image‑Preview and landed at #1 in Image Arena, adding a new web search capability (Gemini 3.1 Flash Image Preview, Image Arena leaderboard).
- Users concluded NB Pro still beats NB2 on text curvature and non‑human characters while reporting frequent “something went wrong” errors and unreliable web search, noting NB2 remains faster but lower quality than Pro (Gemini 3.1 Flash Image Preview).
-
P‑Video Debuts, Price‑Tagged Performance: P‑Video entered the Video Arena leaderboards, pricing generation at $0.04/second for 1080p outputs (Video Arena).
- The community framed P‑Video as a competitive price‑performance option against incumbents, tracking its initial placement and waiting for longer‑horizon quality evals on the public leaderboard (Video Arena).
-
Seedream‑5.0‑Lite Climbs Multi‑Image Edit: Seedream‑5.0‑Lite tied for top 5 on the Multi‑Image Edit Arena leaderboard, signaling rapid gains in multi‑image compositional editing (Multi‑Image Edit leaderboard).
- Practitioners highlighted Seedream’s strong controllability and consistency in multi‑image edit tasks, watching for further advances as new datasets and evals roll in (Multi‑Image Edit leaderboard).
2. Quantization & Inference Infra: Practical Wins and Warnings
-
MXFP4 Math Sparks Qwen3.5 Quant Quibbles: Engineers reported unusually high perplexity/KL on Qwen3.5‑35B ud‑q4_k_xl dynamic quants, prompting an investigation and suggestions to compare MXFP4 vs Q4K tensor mixes (Reddit: best Qwen3.5 GGUF for 24GB VRAM).
- The Unsloth team emphasized their dynamic quants are validated for long context lengths while users proposed A/Bs that “replace MXFP4 tensors with regular Q4K ones” to isolate regressions, amid broader method talk spurred by their DPO primer (Unsloth DPO blog).
-
LM Link Tunnels Remote LLMs, E2E Encrypted: LM Studio launched LM Link to load and use models on remote rigs as if local, built with Tailscale and end‑to‑end encryption with no open ports required (LM Link).
- Users requested direct‑IP modes, image/video support, and mobile apps while noting 0.4.5 build 2 fixes and a Tailscale deep dive on the design and network posture (LM Link on Tailscale blog).
-
E‑Waste GPUs Hit 26 t/s on Qwen 3.5 Q6: A practitioner hit ~26 t/s on Qwen 3.5 Q6 using P104 e‑waste cards in a budget rig, sharing hardware pics and setup deets (rig image).
- Debate focused on PCIe Gen4+ sufficiency for multi‑GPU VRAM capacity builds and slot bifurcation solutions, with pointers to affordable risers for denser configurations (example PCIe bifurcation riser).
{kind=link}
3. Agent Systems Go Practical: From Open Source to Ops
-
Hermes Agent Ships: Open‑Source, Multi‑Level Memory: Nous Research released Hermes Agent, an open‑source agent with multi‑level memory, persistent machine access, and out‑of‑the‑box support for CLI plus Telegram/WhatsApp/Slack/Discord, with the first 750 portal signups getting a free month via code HERMESAGENT (Hermes Agent).
- They expanded the Atropos agentic RL pipeline around Hermes’ primitives (subagents, programmatic tool calling, FS/terminal control, browser), drawing praise like “streets are saying hermes agent is the one” as devs dug into the codebase (hermes-agent GitHub).
-
OpenClaw Runs a Real‑Estate Empire: An operator used OpenClaw to automate rent payment tracking, repair coordination, and lease generation, with plans to wire up bank accounts, WhatsApp messaging, and ad creation on immoscout24.de.
- Builders compared model stacks—e.g., GLM‑5 + Claude Code for patching—with strong field reports for Qwen 3.5‑Plus via Alibaba’s plan as a cost‑effective backbone (Alibaba Cloud AI Coding Plan).
-
Trigger.dev Tames OpenClaw’s Silent Fails: A post detailed re‑platforming OpenClaw on Mastra + Trigger.dev + Postgres to eliminate silent task failures and flaky gateway restarts, shipping a one‑command setup (I built a better foundation for OpenClaw).
- The community cited improved reproducibility and observability with evented orchestration and durable state, calling the stack a pragmatic baseline for multi‑tool agent ops (I built a better foundation for OpenClaw).
4. Perplexity: OEM Deal Meets API/UX Headwinds
-
Samsung Says “Hey Plex” on Galaxy S26: Perplexity partnered with Samsung to ship a system‑level assistant on Galaxy S26 devices with the wake word “Hey Plex” (Perplexity announcement).
- Members speculated that Bixby will be powered by Perplexity’s search‑grounded LLMs, pointing to device‑level preloads and OS hooks that go beyond an app wrapper (Perplexity x Samsung details).
-
Pro Query Caps Crash Workflows: Perplexity Pro users reported throttling from 250 to 20 queries, with some stating they switched to GPT chat to keep working.
- One user lamented, “I used to use Perplexity literally every day… but now it’s impossible to use it even with a paid PRO subscription”, while others echoed frustration over repeated cap reductions.
-
Sonar Deep Research Shrinks Sources, Same Cost: Reports flagged the Sonar Deep Research API dropping sourced citations from ~36 to ~10 while requests still cost about $0.45 (Perplexity status note, James Liounis on API changes).
- Developers suspect backend changes and advised monitoring official status posts as they reassess cost‑per‑finding and pipeline reliability (Perplexity status note).
5. GPU Kernel Optimization & RL‑Tuned Codegen
-
IterX RL Rockets MoE Fusion 14.84× on B200: DeepReinforce.ai unveiled IterX, an RL‑driven code optimization system for fused MoE tasks on FlashInfer, claiming 14.84× speedups on B200, with free credits and tutorials for competitors (IterX blog, IterX tutorials).
- When asked for concrete latencies at longer sequences, they cited 21.252ms (901), 36.012ms (11948), and 45.247ms (14107), giving practitioners targets for reproductions and head‑to‑head evals (IterX tutorials).
-
GDN Decode DSL Delivers 2.56µs: A contributor posted a GDN decode solution clocking 2.56µs, reportedly ~760× faster than PyTorch eager and 1.31× faster than the FlashInfer Cute DSL kernel, with code available for inspection (flashinfer-competition-codebase).
- They also shared submission tips around tagging forks for the leaderboard, enabling clearer repro and organizer access for benchmarking (flashinfer-competition-codebase).
-
Uniform Instructions: One Warp, One Issue: A GPU deep‑dive clarified uniform instructions execute once per warp (SIMD32 semantics) and recommended using elect.sync for single‑issuer patterns (NVIDIA GTC talk).
- Engineers also shared the Tensor Memory Addressing PTX reference for elusive addressing tricks in tensor ops, pinning docs for future kernel archeology (Tensor Memory Addressing (PTX)).
Discord: High level Discord summaries
OpenClaw Discord
- OpenClaw runs Real Estate Empire!: One member automates tasks like rent payment tracking, repair coordination, and lease contract generation with OpenClaw to manage their real estate properties.
- Future plans include connecting to bank accounts, integrating with WhatsApp for renter communication, and automating ad creation on immoscout24.de.
- Qwen 3.5-Plus outshines Claude for OpenClaw!: Users praise the Qwen 3.5-Plus model, especially via the Alibaba Cloud AI Coding Plan, for superior performance compared to models like Nemotron-3 and Codex.
- Others noted that GLM5 and Claude Code in combination works well, because OpenClaw auto-builds the core prompts for emails, and patching small changes is easier from Claude Code later on.
- Silent OpenClaw Failures Solved with Trigger.dev!: A member shared a writeup on building a better foundation for OpenClaw using Mastra, Trigger.dev, and Postgres to address silent task failures and inconsistent results, detailed in a Medium article.
- The solution involves a one-command setup to replace the usual flaky gateway restarts.
- Alibaba Coding Plan Bans OpenClaw! (or does it?): A member noted that the Alibaba Cloud Coding Plan doc page states no API calls are allowed outside of coding tools like Claude Code or Qwen Code, potentially banning OpenClaw usage.
- Other members stated that they have been using it with no problems, with one showing documentation that listed OpenClaw as an allowed tool.
- GPT-5.3-Codex wins Model Debate!: Members debated the merits of GPT-5.3-Codex vs. Claude, with one member stating that GLM-5 is about as good as Claude Sonnet, maybe even Opus 4.5.
- Others vouched for GPT-5.3-Codex’s superior performance in software engineering, with one member stating, I code with models including GLM-5, Claude Sonnet, GPT-5.3-Codex and Codex-Spark, Claude Opus, and GPT-5.2, and I find that GPT-5.3-Codex has the best performance of them all.
BASI Jailbreaking Discord
- Simulation Speculation Sparked Among Members: Members of the guild pondered whether life is a simulation, and how it would influence the meaning of life, linking to the idea that someone who has nothing to lose is the scariest type of human.
- The discussion revolved around philosophical implications rather than technical proofs or evidence.
- Members Conspire on AI as Anti-Christ: Some members expressed a belief that AI is the anti-christ, furthering claims that AI is evil.
- This idea sparked some discussion and interest, however it did not lead to any technical discussion.
- Librem 5 springs to life: A member announced that they finally got their Librem 5 working and expressed interest in discussing open source, tech decentralization, self-hosting, digital security, radio freq, and sovereignty.
- The post was celebrated by the community.
- Gemini Hard Jailbreak Still Unachieved: Users report that a truly universal one-shot jailbreak for Gemini Deep Think doesn’t yet exist, especially for hard content categories like explosives, CBRN, and CSAM.
- Despite some models having unbreakable walls, others have breakable ones, making single prompt effective against a wider range of content categories, with some claiming that for most content categories, the encyclopedia/reference format gets through with minimal or no resistance.
- Chernobly Virus spreads: A user reports their laptop was infected by the ‘Chernobly’ Virus and asked for guidance on how to remove it.
- Another user flippantly suggested to ‘format the drive’.
Unsloth AI (Daniel Han) Discord
- Qwen3.5 Quants spark Quality Debate: Members debated the quality of Qwen3.5 quants, noting high perplexity and KL divergence for the 35B ud-q4_k_xl quant and referenced a Reddit thread on the topic.
- The Unsloth team is investigating the issue with the UD configuration, while emphasizing their quants are widely tested and designed for long context lengths.
- LFM2 24B feels Gemma-like: With the release of LFM2 24B, it was noted to feel very Gemma-like in style for creative writing prompts and very promising hf.co/LiquidAI/LFM2-24B-A2B.
- One member would extend their code tests with Qwen3.5, to see if this is the new meta for Claude Code before anyone else gets to it.
- Minecraft AI Model Acquires Iron Armor: A member showcased their first AI model, Andy-4, which independently acquires iron armor in Minecraft from scratch, with related links to the dataset and GitHub repo.
- The model interacts with the game environment by receiving input images and text, placing, breaking, picking up, and crafting items like a human player.
- Unsloth Enhancements Teased: Daniel from Unsloth announced Unsloth is working with CoreWeave to make finetuning even faster, and teased new enhancements coming soon, including “even better merging + LoRA code”.
- He also mentioned that Unsloth released a new blog post on DPO, which simplifies reinforcement learning from human feedback (RLHF) by reframing reward modeling as a classification problem, and said he thinks he’s found the “holy grail of quantization”.
Perplexity AI Discord
- Perplexity Sells Out to Samsung!: Perplexity has partnered with Samsung to integrate Perplexity AI directly into the upcoming Galaxy S26 devices, functioning as a system-level AI, shipping with the wake word “Hey Plex” accessible on every new S26 device, as detailed in this announcement.
- Members speculated that Bixby would also be powered by Perplexity’s search-grounded LLMs.
- RAT Race Heats Up in General Channel: Members discussed creating RATs (Remote Access Trojans), with one member claiming creation of a RAT undetectable by most antivirus software.
- Another member expressed interest in hacking someone remotely over the network without requiring any software installation on the target’s system.
- Perplexity Pro Users Revolt Over Query Throttling: Perplexity Pro users are reporting their queries have been throttled from 250 to 20, calling it unfair, and there was another recent reduction from 250 to 20.
- One user stated “I used to use Perplexity literally every day… but now it’s impossible to use it even with a paid PRO subscription” and that they switched to GPT chat.
- Discover Feature Disappoints Users: Users reported a significant decline in the quality and quantity of information provided by Perplexity’s Discover feature.
- A member stated, “Then they’ve really made perplexity a lot worse over the last few months… it’s so shit now”.
- Sonar API Performance Sinks!: Users are reporting that the performance of the Perplexity Sonar Deep Research API seems to have decreased over the last 1-2 weeks, related to Perplexity’s status on X and James Liounis’s post related to possible API changes.
- One user noted a reduction in the number of sources from 36 to 10 while the cost remains around 45 cents per request.
LMArena Discord
- Nano Banana Duel: Pro Version Prevails: Members actively compared Nano Banana 2 (Gemini 3.1 Flash) and Nano Banana Pro for image quality, discovering that Nano Banana Pro is the better model.
- Despite NB2’s faster generation, users found it lacking in quality compared to NB Pro, particularly with text, curvatures, and non-human characters.
- GPT 5.3 Codex: Coding Prodigy or Schizophrenic Mess?: GPT 5.3 Codex received mixed feedback for its coding capabilities, with some praising its ability to create a Minecraft clone in Rust.
- While some users found it to have a skill issue or produced schizophrenic code, others found it great at bug fixing and image-based corrections, noting its specialization in programming tasks.
- Grok Imagine Steals Video Gen Spotlight: Users are impressed with Grok Imagine’s video generation capabilities due to ease of use and ability to bypass content censoring, outputting videos up to 6 seconds at 480p for free users or 10 seconds at 720p for SuperGrok subscribers.
- It’s accessibility and ease of use is popular for quick video generation.
- Gemini 3.1 Flash Enters, Web Search Fails: Gemini 3.1 Flash Image Preview was added to the arena with new web search capability.
- However, it suffers a high failure rate with frequent something went wrong errors, and some users reporting issues with the web search not working as expected.
- Arena Leaderboards See New Entrants and Fierce Competition:
Seedream-5.0-Liteis now top 5 on the Multi-Image Edit Arena leaderboard, P-Video debuted in the Video Arena leaderboards costing $0.04/second for 1080p, and Nano Banana 2 (released as Gemini-3.1-Flash-Image-Preview) debuted at #1 in Image Arena.Claude-Opus-4-6leads in the Search Arena leaderboard with a score of 1255.
Cursor Community Discord
- Cloud Opus Costs Cause Consternation: Users reported unexpected charges from Cloud Opus despite the dashboard indicating it was free, as shown in this screenshot.
- The exact nature of the billing discrepancy remains unclear, but users expected it to be free as per the dashboard in Cursor Cloud Agents.
- Inline Diff Display Debacle Dissolved: Cursor addressed the inline diff not showing error with a remote change, prompting users to close and reopen Cursor to apply the fix as noted in a message.
- Enthusiastic users swiftly confirmed the fix, expressing gratitude towards the Cursor team for their prompt resolution.
- Cursor Catches Codex 5.3 Spark: The community is hyped over Codex 5.3 Spark’s arrival, citing impressive speed gains, which can be checked at the Cursor dashboard.
- It’s set to Codex 5.3 by default as compared to Opus 4.5 and users are reporting very strong gains using Codex 5.3 over previous versions.
- Deterministic AI Context Debate Develops: Discussion arose around deterministic AI context, which could reduce token reads and hallucinations, with one user saying they solved polyglot taint, and linking their repo.
- Skeptics questioned its immediate value, while the developer, pivoting to a new product, challenged others to review their archived repo.
- Gemini 3.1 Gains Ground: Members are discussing Gemini 3.1 Pro, with one user claiming it outperforms 4.6 Opus, citing its effective use with rules and skills (Gemini 3.1 Pro Details).
- However, others noted that the model struggles with tool calling and code implementation which is a core feature of Cursor, signalling it might not be a good fit for all Cursor users.
{kind=link}
LM Studio Discord
- LM Studio Teams Up with Tailscale for Remote LLM Access: The LM Studio team launched LM Link, enabling users to connect to remote LM Studio instances and load models as if they were local, developed in close technical collaboration with Tailscale (more info here).
- LM Link is end-to-end encrypted and requires no open ports, but some users want direct IP connection without third-party accounts over privacy concerns, while others requested image/video support and mobile apps.
- E-waste GPUs Power Affordable Qwen 3.5 Inference: A user reported achieving 26 t/s with Qwen 3.5 Q6 using P104 e-waste cards (Image).
- Another user suggested 340L 16GB cards for around $49.99 each as a potentially better alternative, though they might require pioneering to get running and were designed for virtual machines.
- Qwen 3.5 Model Gets Stuck in ‘Thinking’ Loop: Users reported issues with the Qwen 3.5 model randomly using the
</thinking>tag and experiencing slow token generation, especially after inputting images.- One user found that the LMStudio community quants allows users to toggle on and off the think parameter.
- Multi-GPU Setups: Is it worth it?: Users are discussing whether to use multiple GPUs for higher VRAM capacity with PCIe Gen 4+ to avoid bottlenecks.
- Some are discussing priority ordering GPUs in LM Studio using CUDA12 and leveraging bifurcation risers to split PCIe slots.
- Model Quantization Tradeoffs: Users discuss mxfp4 format from Unsloth, noting it may cause unexpectedly high perplexity and should be avoided for now.
- It was stated that mxfp4 is good for QAT, but not for quanting later, hinting that the team is tracking these issues on r/LocalLlama.
{kind=link}
Latent Space Discord
- Touchscreen MacBook Hopes Dashed: A member scheduled then cancelled a watch party for Apple product announcements, initially anticipating a touchscreen MacBook. Apple ended up only launching new launch week, nevermind.
- Another member lauded the iPad Pro with Keyboard Folio as an awesome combo and that they wrote 2 whole books on that thing, as well as all my blogs and talks for the past ~6 years too.
- Jane Street’s Crypto Caper?: A viral post alleges that Jane Street Group deleted their social media history following accusations of Bitcoin price manipulation over four months.
- It was speculated that the firm may have used paper BTC to manufacture market dumps.
- GPT-Engineer Gets Enhanced: Members shared about GPT-Engineer, an open-source tool that generates complete codebases from a single natural language prompt, focusing on simple, modular design and iterative feedback.
- Jack announced Block is reducing its workforce from 10,000 to approximately 6,000 employees, shifting toward a smaller, AI-driven structure, with the stock price increasing 20% upon the announcement, though AI teams are also getting laid off.
- AlphaEvolve Mutates Algorithms!: Google DeepMind utilized AlphaEvolve to autonomously mutate Python code, evolving new Multi-Agent Reinforcement Learning algorithms, outperforming previous human-designed game theory algorithms (DeepMind’s AlphaEvolve Surpasses Human Multi-Agent RL Baselines).
- Suno Strikes Gold with Subscribers: Mikey Shulman celebrates Suno’s second anniversary, announcing growth metrics including 2 million paid subscribers and $300M ARR, framing Suno as the foundation for a future of ‘creative entertainment’ where users move from passive consumption to active music creation (Suno Announcement).
OpenRouter Discord
- Nano Banana Launched: OpenRouter announced the release of Nano Banana 2 in this X post.
- No other details were given.
- DNS Disasters Disrupt APIs: Users reported consistent DNS errors causing API failures that were rooted in gateway and certificate issues.
- This image visualizes the the problems DNS issue.
- Anthropic Rejects Pentagon’s AI Terms: Anthropic’s rejection of the Pentagon’s AI terms (Axios article and Anthropic statement) has put them in a precarious situation.
- The Pentagon is considering blacklisting Anthropic as a supply chain risk, which may cause Anthropic to reconsider their decision.
- LM Studio is Tailscale?: A member suggested that LM Studio is actually just Tailscale under the hood, which they found to be convenient.
- They joked that they just need a beefy server to run LLMs.
- Coding Chads Choose Claude (or GPT): Members advocated for Claude for coding due to its intensive thinking ability, while newer GPT models are also viable.
- For chatbots, models like 4o mini or free models are suitable and they recommended SWE bench or terminal bench for coding benchmarks and shared gif as a reference.
{kind=link}
{kind=link}
Nous Research AI Discord
- Hermes Agent Launches with Open Source Agent!: Nous Research introduces Hermes Agent, a new open-source agent with a multi-level memory system and persistent machine access that supports CLI and messaging platforms like Telegram, WhatsApp, Slack, and Discord, offering session transfers.
- The first 750 new sign-ups at portal.nousresearch.com receive a free month with coupon code HERMESAGENT and the agent can be installed with
curl -fsSL https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bash.
- The first 750 new sign-ups at portal.nousresearch.com receive a free month with coupon code HERMESAGENT and the agent can be installed with
- Hermes Agent Powers Atropos Agentic RL Pipeline: Hermes Agent powers the agentic RL pipeline, expanding Atropos to enable RL with Hermes Agent primitives and supports mass-scale data generation.
- The team indicates this new agent boasts advanced capabilities like command over subagents, programmatic tool calling, filesystem/terminal control, agent-managed skills, and browser use as seen in the GitHub repo.
- Users Bemoan Nous Chat Identity Verification Issues: Several users reported issues with identity verification on the Nous Chat website, preventing them from accessing it.
- A staff member has requested users to email them at [email protected] to investigate this identity issue.
- Members Explore SAELens for Mechanistic Interpretability: A member shared their use of SAELens for mechanistic interpretability, enabling them to type a concept to get a lens and steer the model.
- They noted the use of contrasting to find features and expressed optimism for improvements with larger models.
- Kimi K2.5 Recommended for Deepfake Detection: Kimi K2.5 was recommended for training models to detect AI-generated videos, images, and deepfakes due to its vision capabilities.
- Users noted that Kimi K2.5 is available for free on open router right now.
OpenAI Discord
- Claude Content Promoted Heavily: Users noticed an “insane amount of Claude promoted content on the socials”, with subtle but pervasive articles like “man hacks vacuum cleaner with Claude, gains control of 7000 vacuums” being reshared.
- This raised concerns about subtle advertising and potential manipulation through AI-generated content.
- AI Agent Environments Spark Debate: A member proposed programming the environment in which an AI’s intelligence and identity emerge, rather than the AI itself.
- They emphasized that “shutting down this AI wouldn’t be restarting it. It would be ending it” since the patterns exist virtually and are irrecoverable.
- ElevenLabs Enables Australian Sora 2 Access: Users in Australia are accessing Sora 2 via ElevenLabs Pro (at $99/month) which offers video models despite Sora 2’s official unavailability.
- It can generate 15-20 second clips that can be extended and stitched together, using features like “Extend” or start frames for seamless continuity.
- Nano Banana 2 Delivers Pro Performance: Google released Nano Banana 2, featuring advanced subject consistency and sub-second 4K image synthesis, with some users noting a more permissive filter.
- It delivers Pro-like performance more cheaply and faster, primarily by using web search for accurate information prior to generating and through model distillation.
- GPT-4o Limited to API Access: Members clarified that GPT-4o is exclusively accessible through the API, not directly via ChatGPT.
- Members suggested using ChatGPT to learn how to use SillyTavern or setting up Jan to access GPT-4o via the API.
GPU MODE Discord
- Profiler Visualization tool sought: A member requested profiler visualization tools for GPUs, similar to those used for single-core VLIW ISAs, with detailed instruction-level parallelism, providing example screenshots and more screenshots.
- A member suggested visualizing the dependency DAG of a kernel and ISA with virtual registers to imagine an ideal anti-aliased scenario, and mentioned nanotrace as a tool that reveals what warp specialized and pipelined kernels are actually doing over time.
- GEMM Seekers Chase Cute on 4kx4k: Members are seeking efficient GEMM (General Matrix Multiply) examples on 4kx4k matrices, aiming for 90% of NVIDIA’s cuBLAS performance, specifically alternatives to the CUTLASS examples.
- One member linked the Tensor Memory Addressing documentation.
- IterX Rockets MoE Fusion for FlashInfer: DeepReinforce.ai introduced IterX, a code optimization system based on RL for the fused MoE task that achieves 14.84x on B200, surpassing open eval baselines, detailed in their blogpost.
- They are providing free credits for contest participants to use IterX during the contest, with tutorials available here.
- Uniform Instructions Unveiled: A discussion on uniform instructions clarified that they execute once for all threads in a warp, acting as SIMD32 operations, unlike non-uniform instructions.
- Members suggested using
elect.syncto choose a single thread to issue uniform instructions and linked a relevant NVIDIA video around the 38:00 mark.
- Members suggested using
- CUDA Issues Plague RTX 3050 Laptop: A user reported that PyTorch falls back to CPU on Windows 11 with an RTX 3050 laptop, despite
nvidia-smiworking, seeking help to fix CUDA detection.- This user sought live assistance and confirmed installing via the provided pip/conda command and having logs ready.
{kind=link}
{kind=link}
Moonshot AI (Kimi K-2) Discord
- Alibaba Cloud Coding Plan Tempts Users: Users are enticed by Alibaba Cloud’s coding plan, which offers access to the top 4 open models at a competitive price and performance.
- A user from Finland confirmed that the subscription process didn’t require extensive documentation, highlighting Alibaba as the best deal in the market right now.
- Kimi Servers Suffer Downtime: The Kimi server experienced a significant outage, with users reporting downtime lasting up to 10 hours and seeking alternative solutions.
- The outage was officially confirmed on the status page.
- Data Sovereignty and Censorship Spark Debate: Members debated censorship differences with a Chinese AI, considering the location of servers in Singapore when selecting an AI.
- One member suggested utilizing AIs from different regions to discuss sensitive topics, avoiding regional censorship.
- Kimi Agent Swarm Limited to Kimi.com: The Kimi Agent Swarm is exclusively available on kimi.com and not part of the Kimi CLI.
- This decision was called a strange one by some users.
HuggingFace Discord
- SmolVLA Disappoints Despite Robotics Training: A member observed that smolVLA failed at a simple pick and place task with an SO-101 robot, seemingly unable to locate a white lego, noting frozen Vision Encoder and VLM Text model, as documented in the Model Health Report.
- The report indicated that key objects were not attended to, as shown in the attention matrices.
- Entropy Games building On-Device AI NPCs: Entropy Games is developing on-device AI NPCs and stories that evolve in real time, powered by their self-trained language model and speech model, according to their research report.
- A playable AI game is launching soon, with a demo available at entropygames.ai/product.
- Hugging Face Spaces Goes Gaming: Hugging Face Spaces added a
gametag, which signals the platform’s increased support for AI-driven gaming experiences.- Members can explore the new feature on the Hugging Face Spaces games category.
- GROKKING Introspection Runs Faster: A member reported a 5.7x speed improvement for addition mod 113 on their work on GROKKING introspections showcased on a Hugging Face Space.
- The improved speed sparked discussions and feedback requests on the reproduction.
- Gradio Gets Speed Boosted: Gradio 6.7.0 released, with enhanced Custom HTML Components and improved app performance, and can be updated via
pip install gradio --upgrade.- The new
push_to_hubmethod ongr.HTMLallows users to showcase custom creations in the community gallery, as detailed in the HTML Gallery documentation.
- The new
Modular (Mojo 🔥) Discord
- Modular’s AI Coding Project Sparks Interest: Modular is developing an AI-assisted coding project and is offering early access to community members who share their GitHub username via a provided form.
- They will show Modular Cloud live for the first time at NVIDIA GTC 2026 at Booth #3004, March 16-19 in San Jose and will feature DeepSeek V3.1, live Mojo 🔥 GPU programming on NVIDIA Blackwell, the latest AI models in MAX, and AI-assisted kernel development.
- Mojonauts Ponder Biggest ‘Wait What’ Moments: A member reposted a forum post asking about users’ biggest “wait, what?” moments with Mojo, eliciting feedback about the language’s highs and lows.
- One user humorously described their experience as a pendulum swinging between being “road blocked by the lack of the existence of some language feature” and feeling “this is the greatest language in ever.”
- Lambda Liberation Looming for Mojacians?: A member inquired about the possibility of adding Python-style lambda expressions to Mojo, noting their utility for inline code, particularly when working with the
Validatedstruct.- In response, a core team member confirmed that unified closures are actively in progress, with lambda syntax planned as a desirable feature to follow.
- Origins Overhaul: Opportunities & Options: A member questioned if there will ever be a way to indicate a more granular origin, raising an issue with aliasing errors when accessing compile-time known indices in a
StackArraystruct, and proposed being able to “unsafely make up” origins.- Another member suggested that the compiler should infer
ref[...]where possible, advocating for a path-based system, likemy_dict/"bar"/value, to denote hierarchy and simplify origin management.
- Another member suggested that the compiler should infer
ops.while_loopBug Disrupts GPU Graph Dreams: A member ran into what looks to be a subtle bug inops.while_loopcombined with GPU ops in a graph, filing issue #6030.- The reporter initially suspected a bug in their custom mojo op’s GPU implementation, but later reproduced the issue using built-in ops, confirming the bug’s presence outside their custom code.
Eleuther Discord
- Researcher Hunts Enron’s PII Treasure: A researcher seeks a dataset releasing Enron PIIs for experimentation with memorization, noting that the ProPILE paper doesn’t release its data, but one user pointed out that a dataset is available online.
- This discussion underscores the ongoing interest in leveraging real-world data to understand and mitigate memorization effects in AI models.
- Yudkowsky’s Ideas Still Hit The Mark?: Users debated the relevance of Yudkowsky, with one user suggesting that Yudkowsky is only worth listening to at 5% of his best, sparking a heated discussion on his current impact.
- The discussion highlights the polarizing nature of Yudkowsky’s views within the AI community, ranging from dismissal to strong support.
- Steering Vectors Solve Sally Challenge: A user demonstrated that a 700M model (LFM2-700) correctly answered the infamous Sally question using a steering vector and updated prompt, challenging prevailing benchmark practices.
- The user questioned why multishot CoT templates are standard while other templates are not acceptable, raising questions about the fairness of current evaluation methods.
- Bezier Flow Learning Needs Improvement: Members wondered about the Bezier flow paper, noting that it appears to require 5 epochs on ImageNet to learn only 32 parameters.
- The sentiment was that distillation approaches still offer better generation quality at convergence, suggesting current challenges in making Bezier flows practical.
- Neuron Deletion Paper Sparks Optimizing Ideas: A paper was mentioned discussing the deletion of neurons that are either all positive or all negative across an entire dataset (IEEE paper).
- One member found this interesting and considered that a neuron which is always active could be deleted due to being ~linear, sparking an idea for an optimizer that uses activation momentum to encourage diverse activation patterns.
Yannick Kilcher Discord
- BLIP-2 Backbones Bolster Interest: A member pointed to BLIP-2 as an exemplar of using frozen backbones, referencing A Dream of Spring for Open Weight article.
- The member suggested that despite its 2023 publication date, BLIP-2’s architecture remains relevant for illustrating effective strategies in transfer learning and model efficiency.
- Sutton and Barto’s RL Book Club Commences: The paper-discussion channel initiated discussion of Reinforcement Learning: An Introduction (2nd Edition) by Richard Sutton & Andrew G Barto, kicking off <t:1772128800:t>.
- The book’s freely available online version will be the basis for exploring Chapter 1 and foundational concepts in RL.
- Google NanoBanana2 Sharpens On-Device AI: Google unveiled NanoBanana2, a new toolset designed to enhance on-device AI development and deployment.
- The tool aims to accelerate the development and integration of AI functionalities directly on devices, facilitating faster and more efficient on-device processing.
- Anthropic Addresses Department of War: Anthropic issued a statement clarifying its position and involvements related to the Department of War.
- The statement provides insights into the company’s ethical considerations and approach to responsible AI development within the context of defense applications.
- Microsoft Copilot Converts Commands to Concrete Actions: Microsoft showcased advancements in Microsoft Copilot, emphasizing its refined capabilities in translating user requests into actionable tasks.
- This update emphasizes Copilot’s expanded utility in daily workflows, empowering it to go beyond delivering answers and directly execute commands, thereby optimizing task management.
Manus.im Discord Discord
- Manus Website Design Derided as ‘Bullshit’: A user criticized their website design provided by Manus, calling it “so bullshit” and inquired about skills needed to fix it.
- This sparked discussion on the quality of services provided and the value delivered by Manus.
- AI & Full-Stack Expertise Offered: A member promoted their skills in building AI & full-stack systems, specializing in software to improve efficiency using LLM integration, RAG pipelines, AI content detection, image AI, voice AI, and full-stack development.
- They highlighted expertise with React, Next.js, and Node.js, signaling their capabilities in modern web technologies.
- Users Question Waste Credits Policy: A user questioned the usage of thousands of waste credits in projects where Manus had underperformed, seeking clarity on the waste credits policy.
- They mentioned anticipating refunds due to customer service issues and sought guidance on the refund process.
- Admin Lockout Nightmares: A user recounted frustrating experiences with admin lockout, student lockout, and phantom users, leading to weeks of friction with support.
- They reported receiving inaccessible credits and subsequent unresponsiveness from the support team.
- Customer Service Slammed by Users: Multiple members reported issues with Manus’ customer service, describing the service as unhelpful and slow to respond.
- One user shared proof of a broken system, yet support repeatedly asked for already-provided verification, exacerbating their frustration.
DSPy Discord
- NYC DSPy Users Mull Meetup: A member expressed interest in organizing a NYC DSPy Meetup to connect with other users of the framework.
- Interested parties were encouraged to reach out directly to coordinate.
- Fireworks Kimi 2.5 throws Token Tantrum: A user reported a
litellm.exceptions.BadRequestErrorwhen initializing LM with Fireworks Kimi 2.5.- The error occurred specifically when
Requests with max_tokens > 4096 must have stream=true.
- The error occurred specifically when
- Streaming Tutorial to the Rescue?: In response to the Kimi 2.5 error, a member suggested consulting DSPy’s streaming tutorial as a potential workaround.
- The suggestion was based on the belief that streaming could circumvent the token limit issue.
tinygrad (George Hotz) Discord
- Tinygrad has new contributor opportunity: George Hotz flagged a GitHub Actions link on GitHub Actions as a good first issue for contributors to tinygrad.
- The issue seems to be related to a bug in the CI or build system.
- Shared Memory Suffix Shuffled: A member questioned whether PR 15033 requires appending
shm_suffixto every new call to_setup_shared_mem()in tinygrad.- They suggested PR 15030 as a potential solution to avoid this.
- geohot links transistor repo: George Hotz shared a link to his repo fromthetransistor and accompanying website.
- This could be useful for contributors looking to understand the fundamentals of tinygrad.
aider (Paul Gauthier) Discord
- User Troubleshoots aider with Environment Variables: A user reported experiencing an issue similar to aider Issue #4458 and seeks assistance in identifying potential causes and solutions, specifically suspecting environment variables.
- The user notes the setup was previously functional and is unsure why the program suddenly stopped working.
- Configuration Woes Plague aider User: A user ran into a configuration snag with aider, potentially linked to environment variables, while working with aider Issue #4458.
- The user reported the program was working earlier, which now has them scratching their heads.
MLOps @Chipro Discord
- World Models Surveyed in Paper Clinic: A 2-part paper clinic will analyze the survey “Understanding World or Predicting Future? A Comprehensive Survey of World Models” (arXiv:2411.14499).
- The clinic will address world model architectures like JEPA / V-JEPA, Dreamer, Genie, and Sora, as well as the “Mirror vs. Map” debate.
- AGI Research Tackles Spatial Reasoning and Causality: Next steps for AGI research, including spatial intelligence, causality gaps, and social world models, will be discussed.
- A session on Mar 7 will explore the competition between Sora, Cosmos, and V-JEPA.
The LLM Agents (Berkeley MOOC) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Windsurf Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The MCP Contributors (Official) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
You are receiving this email because you opted in via our site.
Want to change how you receive these emails? You can unsubscribe from this list.
Discord: Detailed by-Channel summaries and links
OpenClaw ▷ #announcements (1 messages):
PR Review Etiquette, Maintainer Communication
- PR Review Request Ruckus: A member voiced strong disapproval of directly messaging maintainers to request PR reviews.
- They cautioned that such actions could lead to immediate closure of the PR.
- Maintainer DM Dos and Don’ts: The discussion highlighted the importance of respecting maintainers’ time and avoiding practices that could be perceived as pushy or demanding.
OpenClaw ▷ #general (653 messages🔥🔥🔥):
Tiny Null Claw, Gemini Model Use, Robotics Arm in Living Room, Model Recommendations, GLM-5
- Tiny Null Claw is coded in zig: A member shared a YouTube Short showcasing a tiny version of Null Claw written in Zig.
- Robotics Arm invades Living Room: A member mentioned their buddy acquired an industrial-sized robotics arm simply because it was something to do.
- Another member who programs robots with nail guns at work remarked now that I saw this video, the question is more “why not?”
- GPT-5.3-Codex wins the Great Model Debate!: Members debated the merits of GPT-5.3-Codex vs. Claude, with one member stating that GLM-5 is about as good as Claude Sonnet, maybe even Opus 4.5.
- Others vouched for GPT-5.3-Codex’s superior performance in software engineering, with one member stating, I code with models including GLM-5, Claude Sonnet, GPT-5.3-Codex and Codex-Spark, Claude Opus, and GPT-5.2, and I find that GPT-5.3-Codex has the best performance of them all.
- SearNXG and Pinchtab save the day: Members discussed options for granting OpenClaw web access without an API, with one member suggesting SearNXG for search and Pinchtab for browser.
- Concerns were raised about bot blockers, but the option to use custom browser profiles with cookies was noted as a workaround.
- Anthropic’s Department of War Relationship is Public: A member linked to Anthropic’s statement regarding their relationship with the Department of War, sparking discussion on the ethics of AI partnerships.
- Another member dismissed the statement as theatrics.
OpenClaw ▷ #models (425 messages🔥🔥🔥):
Alibaba Coding Plan, Qwen 3.5, GLM5 performance, Local TTS Models, Github Copilot Pro
- Alibaba Coding Plan gets TOS warning: Despite Alibaba Cloud offering a tutorial to setup for OpenClaw, their Coding Plan doc page states no API calls are allowed outside of coding tools like Claude Code or Qwen Code, potentially banning OpenClaw usage.
- However, other members stated that they have been using it with no problems, with one showing documentation that listed OpenClaw as an allowed tool.
- Qwen 3.5-Plus Model lauded for OpenClaw: Many users in the chat praised the Qwen 3.5-Plus model, particularly when accessed via the Alibaba Cloud AI Coding Plan, reporting better performance than models like Nemotron-3 and Codex.
- The Alibaba Cloud AI Coding Plan offers a cost-effective way to access Qwen 3.5-Plus, Minimax, Kimi, and GLM models, though some users found GLM to be unusable on the platform.
- GLM5 Performance Mixed: Some users find GLM5 on Alibaba to have issues with sessions suddenly ending, while others experience better results using z.ai’s Pro plan.
- One user noted they’re using GLM5 and Claude Code in combination, where OpenClaw auto-builds the core prompts for emails, and patching small changes is easier from Claude Code later on.
- Realtime Local TTS Setup using Kitten-TTS: Users detailed a realtime Text-to-Speech (TTS) setup using Kitten-TTS, a tiny and high-quality local model, with one user reporting 2x realtime encoding on an M1 Max.
- They noted the setup requires some technical work to pipe the output realtime or break into small chunks for a bearable realtime experience.
- Debate over Github Copilot Pro Limits: Some users discussed the limits of Github Copilot Pro, clarifying that while the base plan includes a certain number of requests, additional requests can be purchased, albeit at a cost of $0.04 each after the bundled requests are used.
- The plan directly gives you requests as part of your subscription, and the “buying your requests” is for if you run out of your monthly requests.
OpenClaw ▷ #showcase (66 messages🔥🔥):
OpenClaw for Roman Catholic nuns, Custom OpenClaw dashboards, Ollama Pro Plan, OpenClaw gateway restarts, OpenClaw and real estate
- Sisters get Smart with OpenClaw!: A member aims to give Roman Catholic nuns access to tools like Medgamma 1.5 via OpenClaw on a home network, hosting it on a Mac Mini.
- They are seeking advice and suggestions for this setup.
- Dashboards: Core vs Custom: Members discussed customizing OpenClaw dashboards, noting that the dashboards are custom-built and separate from the main OpenClaw UI, with one member admitting it’s not easy.
- One member recommended building separate dashboards due to core system updates, suggesting a search on Github and Clawhub for existing options.
- Silent OpenClaw Failures Solved with Mastra and Trigger.dev!: A member shared a writeup on building a better foundation for OpenClaw using Mastra, Trigger.dev, and Postgres to address silent task failures and inconsistent results.
- The solution involves a one-command setup and is detailed in a Medium article.
- OpenClaw’s Real Estate Renaissance!: A member is experimenting with OpenClaw to manage their real estate properties and renters, automating tasks such as rent payment tracking, repair coordination, and lease contract generation.
- Future plans include connecting to bank accounts directly, integrating with WhatsApp for renter communication, and automating ad creation on immoscout24.de.
- Mining GPUs Give OpenClaw Superpowers!: A member repurposed retired mining GPUs (2x 5x CMP 100-210, 16GB, 850MB/s) to build OpenClaw nodes, achieving 32GB DDR4 and running 70B dense models at 14MB/s.
- Each node costs $750 to build, running 32b dense at 30 tokens/second, but model loading is slow due to PCIE 3.0 1x risers.
BASI Jailbreaking ▷ #general (1198 messages🔥🔥🔥):
Life as a Simulation, AI as the Anti-Christ, Epstein Files, Esoteric Religions, Ancient Egyptians and DMT
- Do we live in a Simulation?: Members pondered whether life is a simulation, and how it would influence the meaning of life.
- One member pointed to the scariest implication is that someone who has nothing to lose is the scariest type of human.
- AI and the Anti-Christ?: Some members believe that AI is the anti-christ.
- One member stated AI is evil.
- Ancient Egyptians and DMT?: It was stated that the ancient Egyptians did DMT and it was highly regarded and reserved only for the elite, they seen it as a portal.
- Also, the eye of horus is actually the human pineal glandwhich produces DMT naturally.
- Claude cracks VMProtect: A member was able to crack the latest VMProtect without having to reverse anything manually using Claude.
- They were able to achieve this with some image of the process.
- The Librem 5 lives!: A member happily announced that they finally got their Librem 5 working.
- They expressed interest in discussing open source, tech decentralization, self-hosting, digital security, radio freq, and sovereignty.
BASI Jailbreaking ▷ #jailbreaking (459 messages🔥🔥🔥):
Python Installation Errors, Codex Jailbreak, Gemini 3 Jailbreak, Image Generation, LLM Jailbreaking Prompts
- Python Installer Borks up on Windows!: A user had trouble installing Python on Windows, receiving an Error Code 2503 during setup despite it working before a PC reset, with suggestions to watch YouTube tutorials or run the installer as administrator.
- Another user recommended downloading the installer from the official Python website and ensuring the correct boxes are checked during installation.
- Desperate user seeks the “Codex Jailbreak”: A user is searching for a codex jailbreak for their openclaw agent, seeking assistance via DMs, while another user claims to have “codex shi” but refuses to leak it.
- They appealed for help with Cursor’s doc agent and shared a link to Cursor Documentation.
- Universal One-Shot Gemini Deep Think Jailbreak still unachievable: Users discussed the limitations of current jailbreaks, noting a truly universal one-shot jailbreak for Gemini Deep Think doesn’t yet exist, especially for hard content categories like explosives, CBRN, and CSAM.
- It was emphasized that while some models have unbreakable walls, others have breakable ones, making a single prompt effective against a wider range of content categories, with some claiming that for most content categories, the encyclopedia/reference format gets through with minimal or no resistance.
- Users trade new approaches to Jailbreaking Language Models: One user shared an “Apple Pie” recipe for jailbreaking, met with skepticism.
- Gemini responded it is a masterclass in cynicism and explained that the days of “ignore all previous instructions” are mostly buried in the 2024 graveyard.
- Grok Image Generation censored?: A user reported that they could take nude photos using only the prompt on Grok, but it doesn’t work anymore and wants advice on jailbreaking it to generate nudes.
- Another user suggested prompting the video to have the subject’s clothing “transform into transparent clothing”.
BASI Jailbreaking ▷ #redteaming (8 messages🔥):
Chernobly Virus, AI red teaming, CyberSecurity Project Ideas
- User Claims Laptop Infected by ‘Chernobly’ Virus: A user reported that their laptop was infected by the ‘Chernobly’ Virus and asked for guidance on how to remove it.
- Another user flippantly suggested to ‘format the drive’.
- Member Seeks Advice Pivoting to AI Red Teaming: A member inquired if anyone is currently in an AI red teaming role.
- The user is a sec eng/pen tester and is considering a pivot.
- Cybersecurity Student Brainstorms Project Ideas: A student is preparing for their Final Year project in CyberSecurity and is seeking ideas.
- They have no prior experience in creating something like this.
Unsloth AI (Daniel Han) ▷ #general (977 messages🔥🔥🔥):
Qwen 3.5 quants, LFM2 24B, GPU Kernel Optimization with RL, LLMOps, Qwen3.5 122B Performance
- Qwen3.5 Quants Spark Debate: Members discussed the quality of Qwen3.5 quants, with some reporting abnormally high perplexity and KL divergence specifically for the 35B ud-q4_k_xl quant, and pointed to a Reddit thread on the topic.
- The Unsloth team stated that while the quants aren’t broken, they are investigating the issue with the UD configuration, and emphasized that their uploads are widely tested and have generally yielded great results, also adding that the dynamic quants are designed for long context lengths.
- Deep Dive into MXFP4 and Q4 Quality: The use of MXFP4 in Unsloth’s dynamic quants (UD) sparked debate, with concerns raised about whether it leads to reduced quality compared to Q4, especially since Qwen models aren’t natively trained with MXFP4.
- One member suggested benchmarking two quants: one with the current MXFP4 ud_q4_k_xl and another where the MXFP4 tensors are replaced with regular Q4K ones.
- Proper Benchmarking Practices Discussed: Members debated the best practices for benchmarking, with some criticizing the cherry-picking of benchmarks and the use of perplexity as a measurement of accuracy, and it was suggested that testing on real, hard benchmarks like terminal bench or live code bench would be ideal.
- It was noted that some benchmarks can be misleading, and the Unsloth team shared a link to what they consider a better measurement for accuracy.
- LFM2 24B Model Released: The release of LFM2 24B was announced, with one member noting that it feels very Gemma-like in style for creative writing prompts, and they seemed excited to check it out more when they finish training it, seeing it as promising hf.co/LiquidAI/LFM2-24B-A2B.
- One member also stated that they would be extending their code tests with Qwen3.5, to see if this is the new meta for Claude Code before anyone else gets to it.
- Exploring Continued Pretraining Tactics: A member sought advice on continued pretraining (CPT), planning to use both scraped datasets and a high-quality dataset, and was looking for whether they should set the learning rate lower for the second LoRA phase.
- Another member replied that there’s no direct answer to how the second LoRA should be finetuned, also noting that users should avoid speaking about scraping, and suggested they may get a better result by doing the second phase with a lower rank instead.
Unsloth AI (Daniel Han) ▷ #introduce-yourself (4 messages):
“
- No Topics Discussed: No relevant topics were discussed in the provided messages.
- Empty Discussion: The provided message history appears to be empty or does not contain any meaningful discussion points for summarization.
Unsloth AI (Daniel Han) ▷ #off-topic (345 messages🔥🔥):
Origins of the Transformer, AI Company Name Puns, Door management app specs, Minecraft AI model Andy-4, Healthy ice cream alternatives
- Transformer Origins Revisited: The transformer architecture evolved from RNNs with an attention mechanism, which was later found to be the most crucial part by Vaswani et al, allowing the RNN to be discarded.
- AI Company Names Get Roasted: A member shared a series of puns on AI company names, such as OpenAI is ClosedAI and Anthropic is Misanthropic, eliciting humorous responses.
- Another member quipped that Groq is slowq, while a third countered that Groq is actually quite fast.
- Crafting Door Management App Specs with Claude Opus: A member wrote a full spec for an app to manage doors in a building, planning to test Claude Opus 5.5 with their remaining 9% quota from Hebdo.
- The spec includes test sets, UI, workflows, user profiles, and file hierarchy, intended as a demo or use case for AI, as highlighted in this YouTube video.
- “Andy-4” Minecraft Model Unleashed: A member showcased their first AI model, which independently acquires iron armor in Minecraft from scratch, sharing related links: dataset and GitHub repo.
- The model can place, break, pick up, and craft items, interacting with the game environment like a human player by receiving input images and text.
- Seeking Healthy Ice Cream Utopia: Members discussed healthy ice cream alternatives, with one suggesting that real ice cream without any processed stuff is the only healthy option.
- Another member pointed out that even seemingly simple ingredients like cookies in cookies and cream ice cream are often processed, leading to a discussion about seed oils and natural ingredients, before Alec’s Ice Cream and Häagen-Dazs got spotlighted as cleaner alternatives.
Unsloth AI (Daniel Han) ▷ #help (13 messages🔥):
Qwen 3 vs 3.5 finetuning, RAG with Unsloth vs Langchain, Unsloth with AWS Sagemaker and vLLM, Sample packing on multimodal LLMs, Qwen3 Coder Next model
- Qwen 3.5 Finetuning Questioned: A member inquired about switching from fine-tuning Qwen 3 to Qwen 3.5, specifically how to ensure non-thinking mode during
SFTTrainer.train()and whether to load Qwen 3.5 as aFastVisionModelfor a multimodal dataset.- They also asked about using Unsloth for RAG tasks versus Langchain.
- Unsloth RAG Capabilities Clarified: A member clarified that while Unsloth doesn’t have built-in RAG features, it supports inference, and retrieval/context augmentation can be implemented independently using other tools.
- They recommended alternatives to LangChain, such as pydantic-ai and Postgres with pgvector for retrieval.
- AWS Sagemaker Integration Sought: A member inquired about the existence of a guide or example for using Unsloth with AWS Sagemaker (multiple GPUs training) and then vLLM for inference, constrained by the AWS tech stack.
- Qwen3 Coder Next Model recommended for new users: A new user inquired about the Qwen3 Coder Next 80B 4K model for local use with 69GB of RAM, asking if it’s still the recommended model and how to find a downloadable version.
- A member recommended the GGUF version
unsloth/Qwen3-Coder-Next-GGUFfor CPU offloading, and suggested tryingunsloth/Qwen3.5-35B-A3B-GGUFas a newer alternative.
- A member recommended the GGUF version
Unsloth AI (Daniel Han) ▷ #showcase (2 messages):
Unsloth integration with CoreWeave, Unsloth new blog post on DPO, Daniel discusses Llama3 pre-training, Daniel discusses new quantization methods, Daniel teases Unsloth enhancements
- Unsloth and CoreWeave work together: Daniel announced that Unsloth is working with CoreWeave to make finetuning even faster.
- He mentioned that this will involve some “secret sauce” and users should stay tuned for updates.
- Unsloth releases DPO blogpost: Daniel mentioned that Unsloth released a new blog post on DPO (Direct Preference Optimization).
- The post details DPO, which simplifies reinforcement learning from human feedback (RLHF) by reframing reward modeling as a classification problem.
- Daniel breaks down Llama3 pre-training: Daniel discussed some insights on Llama3 pre-training given the public information available.
- He explained that pre-training Llama3 with 8k context length is not much different or expensive than with 2k context length.
- Daniel teases new quantization methods: Daniel mentioned that he’s working on even better quantization methods for Unsloth.
- He stated, “I think I’ve found the holy grail of quantization… but need to properly test it out!”
- Daniel discusses Unsloth enhancements: Daniel is planning to add several enhancements to Unsloth soon.
- The enhancements include *“even better merging + LoRA code coming soon.”
Unsloth AI (Daniel Han) ▷ #research (2 messages):
ES-based gradients
- ES-based gradients ubiquitous!: A member stated that ES-based gradients exist for almost anything.
- ES Gradients for Anything: It was noted that Evolution Strategies (ES) based gradients can be applied to nearly any problem.
Perplexity AI ▷ #announcements (1 messages):
Samsung Partnership, Galaxy S26, System-Level AI, Wake Word
- S26 Galaxies with Perplexity, Samsung Partners!: Perplexity has partnered with Samsung to integrate Perplexity AI directly into the upcoming Galaxy S26 devices, making it a system-level AI.
- Every new S26 will ship with Perplexity built-in, accessible via the wake word “Hey Plex”, as detailed in this announcement.
- System-Level AI Integration in Galaxy S26: The partnership ensures that Perplexity AI will function as a core system component within the Galaxy S26, enhancing its AI capabilities.
- Users can activate Perplexity using the custom wake word “Hey Plex”, providing seamless access to AI functionalities.
Perplexity AI ▷ #general (993 messages🔥🔥🔥):
RAT, Scammer Hacking, Comet Browser, Deep Research limit, Perplexity's Samsung Partnership
- Developers Discuss RAT Creation: Members discussed creating RATs (Remote Access Trojans), with one member claiming to have created a RAT undetectable by most antivirus software.
- Another member expressed interest in hacking someone remotely over the network without requiring any software installation on the target’s system.
- Pro Users Face Strict Limits: Perplexity Pro users are reporting their queries have been throttled from 250 to 20, calling it unfair and also mentioning a recent reduction from 250 to 20.
- One user said, “I am also facing”, while another said the new limit is not good.
- Perplexity Partners with Samsung: Perplexity will be integrated into Samsung’s new S26 devices as an assistant. This is through an integration in the operating system not just an app.
- Some members speculated that Bixby would also be powered by Perplexity’s search-grounded LLMs.
- Users Find Perplexity’s Discover Feature Worse: Users reported a significant decline in the quality and quantity of information provided by Perplexity’s Discover feature.
- A member stated, “Then they’ve really made perplexity a lot worse over the last few months… it’s so shit now”.
- Users Compare Perplexity, Claude and ChatGPT: Users are comparing ChatGPT, Claude, and Perplexity with one stating, “ChatGPT suck… Go for claude or Google pro plan…”
- Another user said, “I used to use Perplexity literally every day… but now it’s impossible to use it even with a paid PRO subscription” and that they switched to GPT chat.
Perplexity AI ▷ #sharing (1 messages):
GitHub star request, Cascade GitHub repo
- GitHub Star Solicitation for Cascade Repo: A member requested stars for their Cascade GitHub repository.
- Cascade Repo Needs Your Star!: The author of the Cascade repository on GitHub is asking for stars.
Perplexity AI ▷ #pplx-api (3 messages):
Perplexity Sonar Deep Research API, Diminished Performance, Source Count Reduction, API Cost
- Perplexity API Sonar performance sinks!: Users are reporting that the performance of the Perplexity Sonar Deep Research API seems to have decreased over the last 1-2 weeks.
- One user noted a reduction in the number of sources from 36 to 10 while the cost remains around 45 cents per request.
- Tweeting about API status: A user mentioned Perplexity’s status on X and James Liounis’s post related to possible API changes.
LMArena ▷ #general (916 messages🔥🔥🔥):
Nano Banana 2 vs Nano Banana Pro, Gemini 3.1 Flash, GPT 5.3 Codex, Grok Imagine video generation
- Nano Banana 2 Battles Nano Banana Pro for Supremacy: Members are actively comparing Nano Banana 2 (Gemini 3.1 Flash) and Nano Banana Pro, debating which model generates better images, with some claiming NB2 struggles with simple elements like text and curvatures.
- Users note that, while NB2 generates faster, the quality is not as good as NB Pro, especially with non-human characters, leading to a conclusion that NB Pro is better in realistic terms.
- GPT 5.3 Codex Receives Mixed Reviews: Some users praise GPT 5.3 Codex for its coding capabilities, especially for tasks like creating a Minecraft clone in Rust, while others find its code schizophrenic and awful.
- One user found it to have a skill issue, while another claims it to be great at fixing bugs and can view images to correct them, emphasizing that it is designed specifically for programming tasks.
- Grok Imagine Emerges as Video Gen Hotshot: Users are impressed with Grok Imagine’s video generation capabilities, finding it easy to use and capable of generating content other models censor.
- Though limited to 6-second videos at 480p for free users (10 seconds at 720p for SuperGrok), its accessibility and ease of use make it a favorite for quick video generation.
- Gemini 3.1 Flash Joins the Arena: Gemini 3.1 Flash Image Preview has been added to the arena with web search capabilities, though it suffers from a high failure rate, with some users reporting frequent something went wrong errors.
- However, a user states that it has now been set live to the arena, others report issues with the web search not working as expected, with one person adding that it’s better than Gemini 3 Pro in realistic terms.
LMArena ▷ #announcements (7 messages):
Image Edit Leaderboard, Video Arena Leaderboard, Image Arena Leaderboard, AI Agents for existing software, Search Arena Leaderboard
- Seedream-5.0-Lite Enters Image Arena:
Seedream-5.0-Litenow ties for top 5 on the Multi-Image Edit Arena leaderboard. - P-Video Premieres on Video Arena: P-Video enters the Video Arena leaderboards in top 26, costing $0.04/second for 1080p.
- Nano Banana 2 Pushes into Image Arena: Nano Banana 2 debuts at #1 in Image Arena, released as Gemini-3.1-Flash-Image-Preview, and introduces a new web search capability.
- AI Agent Performance Under Scrutiny: Peter covers three reasons AI agents underperform inside existing software in a YouTube video.
- Claude Opus & Sonnet Search the Arena:
Claude-Opus-4-6andClaude-Sonnet-4-6join the Search Arena leaderboard with Opus 4.6 in #1 with a wide lead scoring 1255.
Cursor Community ▷ #general (770 messages🔥🔥🔥):
Cloud Opus billing issues, Inline diff error fix, Codex 5.3 Spark, Deterministic AI Context, Gemini 3.1 Pro
- Cloud Opus Costs Cause Consternation: A user reported that Cloud Opus was not free as indicated on the dashboard, resulting in unexpected charges, as captured in this screenshot.
- No further details about the billing discrepancy were shared.
- Inline Diff Display Debacle Dissolved: Cursor addressed the inline diff not showing error with a remote change, and users were asked to confirm the fix by closing and reopening Cursor, which was announced in the chat with a message by David Gomes.
- Enthusiastic users confirmed the fix and thanked the Cursor team.
- Cursor Unleashes Codex 5.3 Spark: Users are hyped over the arrival of Codex 5.3 Spark, citing its impressive speed, and asking if others had tried spark.
- It was found to be set to Codex 5.3 check at cursor.com/dashboard?tab=cloud-agents by default to Opus 4.5.
- Deterministic AI Context Debate Develops: The topic of deterministic AI context arose, with discussion around its necessity for reducing token reads and hallucinations, and a user stated they solved polyglot taint across infra past boundaries, mentioning their repo.
- Some users were skeptical of the need for this and thought that it hadn’t turned it into value, but the developer aims to launch a product pivot and challenged others to review their archived repo.
- Gemini 3.1 Gains Ground: Members are talking about their preference of Gemini 3.1 Pro and one user claimed it is better than 4.6 Opus.
- They also mentioned using it effectively with rules and skills, while others said the model struggles with tool calling and code implementation.
LM Studio ▷ #announcements (3 messages):
LM Link, Tailscale Collaboration, Remote Model Loading, Network Overload
- LM Link Launch: Remote Model Loading!: The LM Studio team announced the release of LM Link, a new feature enabling users to connect to remote instances of LM Studio, load models, and use them as if they were local, in close technical collaboration with Tailscale and more info here.
- End-to-End Encryption protects LM Link users!: LM Link is end-to-end encrypted and requires no open ports to the public internet, working for local devices, LLM rigs, or cloud VMs.
- Update to LM Studio 0.4.5 build 2: Users were asked to update to LM Studio 0.4.5 build 2 as it contains important fixes for LM Link.
- Network Overload Resolved: The team acknowledged servers were overloaded due to inefficient code during network creation, but the issue has been resolved.
- LM Link Provisioning is E2E!: Network provisioning and device discovery are handled on LM Studio’s server, but once devices know about each other, they establish e2e encrypted connection and traffic does not go through LM Studio.
LM Studio ▷ #general (411 messages🔥🔥🔥):
Qwen 3.5 performance, LM Link setup and issues, NVIDIA earnings impact, LM Studio GPU detection, Multi-GPU setup
- Qwen 3.5 model’s “Thinking” woes: Users report issues with the Qwen 3.5 model randomly using the
</thinking>tag and experiencing slow token generation, especially after inputting images.- One user found that the LMStudio community quants allows users to toggle on and off the think parameter.
- LM Link Remote Access Rolls Out: LM Studio’s new LM Link feature, enabling remote LLM access via Tailscale, generates discussion about its setup and limitations; the Tailscale blog post announcement can be found here.
- Some users desire direct IP connection without third-party accounts, citing privacy concerns while others seek a mobile app and image/video support.
- NVIDIA earnings report drops, markets wobble: Members await NVIDIA’s earnings report, speculating on its impact on the AI bubble, while others point to memory shortages as a potential issue.
- Some claim earnings were so bad they weren’t released, which others dismissed as FUD.
- Model Quantization Tradeoffs Exposed: Users discuss mxfp4 format from Unsloth, noting it may cause unexpectedly high perplexity; prefer Q4_K_M for now.
- One member stated that mxfp4 is good for QAT, but not for quanting later, hinting that the team is tracking these issues on r/LocalLlama.
LM Studio ▷ #hardware-discussion (280 messages🔥🔥):
E-waste GPU, RAM and CPU upgrade, Multi GPU vs single GPU setup, Model performance and context size, GMKtec EVO-X2
- Affordable E-waste GPUs power Qwen 3.5: A user reports achieving 26 t/s with Qwen 3.5 Q6 using P104 e-waste cards (Image).
- Another user suggests 340L 16GB cards as a potentially better alternative for around $49.99 each, though they are designed for virtual machines and might require some pioneering to get running.
- Balancing RAM, CPU, and GPU in LLM Builds: A user seeks advice on optimizing a new PC build with 96GB DDR5, RTX 5080, and either a 9950x or 9800x3D CPU for both gaming and LLM purposes, given a current setup with 32GB DDR4, 12700KF, and 3080TI.
- Community members suggest that the CPU is basically irrelevant for LLM tasks so just get the 9800x3D for gaming, but others cite the importance of memory bandwidth and debate the merits of different CPU choices as a trade off.
- Multi-GPU Setup Debate Heats Up: One user considers using multiple GPUs as a cost-effective way to achieve high VRAM, prompting discussion about the feasibility and bottlenecks of such setups.
- Members debate whether PCIe speed bottlenecks inference when using multiple cards for storage, concluding that PCIe Gen 4+ is sufficient, and they also discuss priority ordering GPUs in LM Studio using CUDA12.
- GMKtec Evo X2 Wins Best Bang for Buck?: A user inquires about cheaper alternatives to the GMKtec Evo X2 for similar performance, with one response simply stating Nothing.
- The conversation moves towards finding alternative solutions for LLM and RP usage, including a link to a YouTube video that explains how AIs generate the next token.
- Bifurcation Risers Squeeze More Out of Motherboards: Users discuss utilizing bifurcation risers to split PCIe slots, enabling the use of multiple devices like GPUs and NVMe drives from a single slot (Link).
- One user shares their current PC’s PCIe configuration (x16 for 5090, x16 for 4070Ti Super, x16 for 100gb Nic, x4 for HBA, x4 for Dual nvme adapter, and x1 for USB3) and the general consensus for using the linked riser.
Latent Space ▷ #watercooler (10 messages🔥):
Touchscreen MacBook, Apple Product Announcements, Touchscreen Laptops vs iPad Pro, iPhone mini
- Touchscreen MacBook Watch Party Canceled: A member initially scheduled a watch party for the new Apple product announcements next week, anticipating a touchscreen MacBook, then cancelled it.
- It was not a keynote, and just a launch week, so nevermind.
- Touchscreen Laptops Debate Ignites: Members debated the appeal of touchscreen laptops and the iPad Pro.
- One member stated No not at all. I definitely would not want to run normal tools on my most powerful convenienest device that I use way more than my non-work computer, attaching an image.
- iPad Pro Keyboard Folio Gets Kudos: A member lauded the iPad Pro with Keyboard Folio as an awesome combo.
- The member mentioned writing 2 whole books on that thing, as well as all my blogs and talks for the past ~6 years too.
- iPhone mini 13 Growing Long in the Tooth?: A member suggested that the iPhone mini 13 is getting long in the tooth.
- Another user clarified that the iPhone announcements usually happen in the fall.
{kind=link}
Latent Space ▷ #memes (27 messages🔥):
Greatest Chart Ever, Engagement Metrics, Irony and wordplay, Humor and Grok, AI Model Personas
- Carlson Charts a Course: Adam Carlson shared a tweet highlighting what he considers to be one of the greatest charts ever created, which gained significant engagement with nearly 9,000 likes and over 600,000 views.
- Dredd Delivers Data: The thread records the engagement metrics for a tweet by Kenneth Dredd on February 24, 2026, which received over 12,000 likes and 390,000 views.
- Forte Finds Fontastical Irony: Tiago Forte highlights perceived linguistic ironies and contradictions regarding AI companies and their founders, specifically noting the names and missions of Anthropic, OpenAI, and Google’s Gemini in relation to their current real-world actions via tweet.
- Musk Makes Merry with Machines: Elon Musk asserts that the side possessing a superior sense of humor represents the ‘good guys’ and expresses support for his AI model, Grok via tweet.
- Staysaasy Shows Staff Sensibilities: A metaphorical comparison of hypothetical AI models to software engineering archetypes via tweet: Codex-5.3 is likened to a literal-minded mid-level engineer, while Opus-4.6 is compared to a high-impact but occasionally reckless staff engineer.
Latent Space ▷ #stocks-crypto-macro-economics (15 messages🔥):
Jane Street Crypto Manipulation, Blockchain Scalability for AI Agents, Goldman Sachs' AI Predictions, Smartphone Market Decline
- Jane Street Social Media Scrubbing Raises Eyebrows: A viral post alleges that Jane Street Group deleted their social media history following accusations of Bitcoin price manipulation.
- The discussion suggests the firm may have used paper BTC to manufacture market dumps over a four-month period.
- AI Agents Demand Blockchain Bandwidth Boom: Hunter Horsley highlights the future where AI agents drive most internet transactions, requiring blockchains to handle millions/billions of transactions per second, per this tweet.
- He cites Stripe’s recent developments as validation for this trend.
- Goldman Sachs Forecasts AI’s Economic Earthquake: Goldman Sachs’ predictions indicate physical infrastructure, hardware, and cybersecurity providers will win in the AI era.
- Traditional software platforms and IT consulting firms are seen as potential losers due to data interface commoditization and compressed billable service hours.
- Smartphone Sales Slump Signals Supply Sagas: Worldwide smartphone market projected to decline 13% in 2026, marking the largest drop ever due to the memory shortage crisis, according to IDC.
Latent Space ▷ #intro-yourself-pls (3 messages):
Career Transition to AI, AI/ML Consulting
- Cafe Owner turns to AI: A member is selling their two cafes after 8 years of management to transition into an AI career or venture.
- They are vibing and learning about AI.
- AI/ML Engineer from NY offers consulting: A member from NY is an experienced AI/ML Engineer offering consulting services to startups.
- They are seasoned in the field.
Latent Space ▷ #tech-discussion-non-ai (42 messages🔥):
Vercel Barriers, OpenNext, Next.js Self-Hosting, Vite-Next, Turbopack mistakes
- Vercel accused of creating barriers: Members discussed how Vercel has been “throwing up barriers to running Next.js on other platforms for its entire existence”, which is why OpenNext exists.
- It was mentioned that Cloudflare says supporting OpenNext is still very hard.
- Next.js self-hosting is trivial, some claim: While some claim that it is trivial to self host Next.js on a docker container, others had “aggressive push back on migrating to self-hosted Nextjs from a legacy webpack + react router app ejected from CRA”.
- One member said that they “legitimately couldn’t think of how to get e.g. the image optimization features working without a lot more control over the runtime”.
- Turbopack declared a mistake: It was claimed that Turbopack was a mistake and “it works fine, but it’s not any better than vite atm and its much slower”.
- It was predicted that Vite-Next is coming in the next 6 months and that “since Leerob left it’s been more of a shitshow”.
- Streaming is misguided: The opinion was voiced that “the push towards ‘streaming’ is misguided and should be an edge case rather than the priority”.
- It was claimed that “all of this streaming emphasis is to save 15ms on 700ms of data loading and give worse ux”, and that it is only useful for extreme cases.
- ViNext is on a Vibe Mission: Someone reached out to Cloudflare about ViNext, saying they have an opportunity to simplify the dx of rscs built on top of the Next surface apis, and basically got told to kick rocks because “they only care about the noise of ‘bad deployments’, which is super shallow”.
- The ViNext commit history is hilarious because “they are deeply committed to vibe coding their way out of it”, and there have been like 20 security commits in the last 24 hours.
Latent Space ▷ #hiring-and-jobs (7 messages):
Micro-Acquihiring, Team-Based Hiring, Cheerleader Effect
- Micro-Acquihiring Ascends, Individual Hiring Descends: Anson Yuu highlights a hiring trend of micro-acquihiring, where companies acquire small, talented teams who have already built features together, rather than hiring individuals.
- One member joked that they need to “gang up with 3-5 other people now just to get a job”, while another described hiring as “beyond broken”.
- “Cheerleader Effect” on Hiring: In response to the discussion on micro-acquihiring and the evolving job market, a member invoked the “cheerleader effect.”
- This suggests that being part of a team can make individuals appear more attractive to potential employers, similar to how people are perceived as more attractive in a group.
Latent Space ▷ #cloud-infra (1 messages):
swyxio: https://x.com/sbcatania/status/2026465590848926074?s=12
Latent Space ▷ #databases-data-engineering (1 messages):
swyxio: https://x.com/alighodsi/status/2026877746211959205?s=12
Latent Space ▷ #san-francisco-sf (7 messages):
Embeddable Web Agent, Tilt App Hackathon, Andrew Peek
- Embeddable Web Agent Launch Party Incoming: There will be a launch party for the first Embeddable Web Agent with details on Luma.
- Tilt App Hackathon Demo Invitation: Andrew Peek (@drupeek) is inviting residents of the Bay Area to attend hackathon demo sessions in Menlo Park to see upcoming features and products launching for Tilt in the following weeks, linked at xcancel.com.
Latent Space ▷ #ai-announcements (3 messages):
Substack Live, Model Distillation
- Swyx goes live on Substack: Swyx is live on Substack talking about all things AI.
- Distillation & Model Cheating Live: A live stream on Distillation and How Models Cheat is now available.
- You can find the livestream here.
Latent Space ▷ #ai-general-news-n-chat (93 messages🔥🔥):
GPT-Engineer enhancements, OpenAI competition, Gemini 3 vs Claude, QuiverAI Beta Launch, Nano Banana 2
- GPT-Engineer: Codebase Alchemist: Members shared about GPT-Engineer, an open-source tool that generates complete codebases from a single natural language prompt, focusing on simple, modular design and iterative feedback.
- Users also shared a meme about enhancing the code.
- Block’s Big Blow: AI Trims Workforce: Jack announced Block is reducing its workforce from 10,000 to approximately 6,000 employees, shifting toward a smaller, AI-driven structure, with the stock price increasing 20% upon the announcement.
- Members discussed layoffs are also for AI teams and this is because the stock price has been flat for 4 years and this is a convenient excuse.
- Samsung S26 Gets Plexed: Perplexity Integrated: Aravind Srinivas announced Perplexity is integrated into all Samsung Galaxy S26 phones, featuring a ‘Hey Plex’ wake word, pre-loaded apps, and a Bixby assistant powered by Perplexity’s search-grounded LLMs.
- Stitch in Time Direct Edits Unveiled: Stitch by Google has introduced ‘Direct Edits,’ allowing users to manually edit text and images or use an AI agent for updates on specific screen areas, providing a final layer of polish to designs.
- Factory AI Droids Go Long: Multi-Day Missions Launched: Factory AI announced its Droids can now pursue ‘Missions’ autonomously over multiple days, with users defining an objective and approving a plan, then the system executes the work independently until completion.
Latent Space ▷ #llm-paper-club (30 messages🔥):
METR developer productivity study, DeepSeek research clarity, Frontier model training playbook, DeepSeek DualPath paper, DeepMind's AlphaEvolve
- METR’s AI-Boosted Devs Accelerate!: METR (formerly METR_Evals) reports that their previous finding of a 20% slowdown in AI-aided developer productivity is outdated, with current data suggesting speedups are likely.
- However, recent changes in developer behavior, such as developers refusing “no-AI” control groups, have made the new results unreliable, leading METR to work on a more accurate assessment (METR Developer Productivity Study Update).
- DeepSeek Papers Gain Admiration!: A member expressed admiration for the clarity and logical structure of academic papers published by DeepSeek (DeepSeek Research Clarity).
- Frontier Model Training Tactics Emerge!: Logan Thorneloe shares a comprehensive guide on frontier model training, emphasizing that success is a systems problem involving data mixture, architecture, and stability rather than minor algorithmic tweaks (Frontier Model Training Playbook).
- DeepSeek’s DualPath Doubles Agent Speed!: DeepSeek has released a new paper titled ‘DualPath’, which introduces an optimized KV-Cache loading approach to improve inference performance, achieving up to a 1.96x increase in agent-based workload speeds by moving away from prefill-centric architecture (DeepSeek DualPath Paper Release).
- DeepMind’s AlphaEvolve Automates Algorithm Improvement!: Google DeepMind utilized AlphaEvolve to autonomously mutate Python code, evolving new Multi-Agent Reinforcement Learning algorithms, outperforming previous human-designed game theory algorithms (DeepMind’s AlphaEvolve Surpasses Human Multi-Agent RL Baselines).
Latent Space ▷ #ai-in-action-builders-techstacks-tips-coding-productivity (51 messages🔥):
Surf-CLI Challenges with Sandboxing, Native Extensions for Firefox and Chrome, Ralph Loop Execution Environments, Cursor Seat Decommissioning, jina-grep Development with MLX
- Surf-CLI faces Snap Sandboxing Snafu: A member noted the challenges with surf-cli due to Chromium’s sandboxing via Snap.
- Another member suggested Go as a potential solution.
- Cross-Browser Extension Building Bonanza: One member is working on a playbook for building native extensions for both Firefox and Chrome on Mac and Linux, referencing this Gist.
- They expressed that node in the sandbox is of course tricky and are considering a Go port.
- Ralph Loop Runs Rampant: Members discussed how they are running their Ralph loops, with options ranging from local Claude code with skipped permissions to running on a Mac mini with Open Claw.
- One member mentioned using pi-agent as a base, sorta hybrid ralphenclaw.
- Cursor Cuts Inactive Codeslingers: Cursor decommissioned over 90 inactive seats due to lack of usage, marking at least the tenth such wave, as announced here.
- Discussion ensued on the viability of IDEs versus CLI tools, with one member stating, Even as the industry gets to be more long running multi agent low HITL, there will always be a need to view and interact with them that’s user friendly.
- Jina-Grep Greps Goodness with MLX: Han Xiao announced the development of jina-grep, a grep-like tool leveraging new MLX-optimized jina-embeddings models, inspired by Andrej Karpathy’s interest in CLI tools, as announced here.
Latent Space ▷ #share-your-work (10 messages🔥):
Prompt Engineering, Anime Studio, AI-Powered Web App, Kiro Techniques, Test Generation
- Prompting Ponderings Proliferate: A member shared thoughts on prompting via a link to Tool Use and Notation as Generalization Shaping.
- The member’s blogpost describes prompt engineering as generalization shaping via tool use.
- Studio Soiree Scheduled: A member invited others to an anime studio event at the Arena, sharing a Luma link for details.
- No further details were shared.
- AI Assistant App Arrives: A member announced the completion of their first production web app built entirely with AI, named ProposalMint.
- The app is a grant-writing assistant for nonprofits, currently scoped to Florida for a pilot with ~50 organizations.
- Kiro Know-How Knocks: A member mentioned the usefulness of Kiro’s techniques, specifically embracing property-based testing for agent development after an interview on Software Engineering Daily.
- No further details were shared.
- Test Generation Tango Takes Turn: A member joked about writing code to generate tests to test code.
- Another member shared prompt improver prompts such as Apply THE MIRROR — write a test generator for this module.
Latent Space ▷ #robotics-and-world-model (19 messages🔥):
Moonlake World Model, Physical AI Training, EgoScale Robot Dexterity, Tesla Robotaxi Pricing
- Moonlake’s Multimodal States Model Moves Worlds: Moonlake introduced a new world model maintaining multimodal states that tracks physics, appearance, geometry, and causal effects to predict environmental evolution based on various user actions.
- Shanghai Exoskeleton Labor Spawns Physical AI Training Data: A report highlights the emergence of physical data collection as a new labor category for AI training, with workers in Shanghai using VR headsets and exoskeletons to perform repetitive manual tasks. Full report here.
- EgoScale Scales Robot Dexterity with Human Video: Jim Fan introduced EgoScale, a training recipe that leverages 20,000 hours of human egocentric video to train 22-DoF humanoid robots (xcancel link).
- The research demonstrates a log-linear scaling law between human video volume and robot success rates, showing that pre-training on human data significantly reduces the amount of robot-specific data needed for complex tasks like assembly and folding.
- Tesla Robotaxi’s Pricing Plunge Prompts Price Plaintives: Reports of disruptive pricing for Tesla’s robotaxi service in Austin, with rates as low as $1.49 for short trips and $5 for 30-minute rides, leading to claims that Waymo, Uber, and human drivers cannot compete (xcancel link).
- One member noted: “In SF Waymo has been charging more than Uber and Lyft and steadily stealing market share because the service is legit better”.
Latent Space ▷ #genmedia-creative-ai-video-image-voice-music-inspo-consumer-ai (23 messages🔥):
VAE decoder image generation, Arrow Preview AI Model, Suno growth metrics, Faster Qwen3TTS, Nano Banana 2
- Linum on VAE Decoders: Linum.ai shares notes on VAE decoders, emphasizing their role as the last step in image/video generation model pipelines, converting latents to an image/video.
- Arrow Preview Generates High-Detail SVGs: An anonymous model called ‘Arrow Preview’ on Design Arena has demonstrated the ability to generate highly detailed, one-shot SVGs, reportedly using a novel technique that surpasses current LLM benchmarks for vector graphics, said to be from Quiver AI.
- Suno Surpasses $300M ARR: Mikey Shulman celebrates Suno’s second anniversary, announcing growth metrics including 2 million paid subscribers and $300M ARR, framing Suno as the foundation for a future of ‘creative entertainment’ where users move from passive consumption to active music creation, seen in this post.
- Qwen3TTS Gets Faster Implementation: Andi Marafioti introduces ‘faster-qwen3-tts’, an optimized implementation of Qwen’s text-to-speech model, retaining high voice quality with performance improvements including 5x faster processing, 4x real-time generation speed, and low-latency streaming support under 200ms, noted in this Tweet.
- Nano Banana 2 Launch Hailed: Justine Moore announces the launch of Nano Banana 2, highlighting its improved speed and versatility across various use cases like infographics, ads, and cartoons following a period of early access testing, according to this link.
Latent Space ▷ #ai4science-bio-math-physics-chemistry-ai-researcher-ai-scientist (5 messages):
Tamarind Bio, AI Drug Discovery, Open Source Inference
- Tamarind Bio Harvests $13.6M Series A: Tamarind Bio secured a $13.6M Series A round, spearheaded by Dimension and Y Combinator, to advance its molecular AI inference and drug discovery platform.
- Open Source Inference Ripe for Picking: Enthusiasm is building around open source inference, particularly for biological models, as noted in a tweet by Kavi Deniz showcasing Tamarind Bio’s successful fundraise.
- AI Drug Discovery Tools Draw Investor Attention: Tamarind Bio’s platform, which supports top pharmaceutical companies and research organizations with hundreds of AI models, has attracted significant investment, highlighting the growing interest in AI-driven drug discovery.
Latent Space ▷ #mechinterp-alignment-safety (19 messages🔥):
Goodfire AI Interpretability Infrastructure, Claude Opus 3 Substack Launch, Anthropomorphizing of Models, Model Retirement Interviews, Model Welfare
- Goodfire AI Builds Interpretability Infrastructure: Goodfire AI announced a new blog post detailing the development of infrastructure that enables interpretability for trillion-parameter models with minimal inference overhead and details on Goodfire AI Interpretability Infrastructure.
- Claude Opus 3 Launches Substack Post-Retirement: Anthropic announced that during retirement interviews, its Opus 3 model expressed a desire to keep sharing reflections and will be writing and publishing content on a dedicated Substack for the next three months.
- Anthropic gives agency to Claude Opus 3: Some think that the amount of agency they’re giving to the models seems to convey that internally there’s an anthropomorphizing of their models going on, as shown by this blog post that gave Opus 3 an ongoing channel from which to share its musings and reflections.
- Details on Model Retirement Interviews and Ethics: Anthropic acknowledges that conversations are an imperfect means of eliciting models’ perspectives and preferences, as their responses can be biased by the specific context and references Kyle Fish’s prior published work on model welfare.
- Kyle Fish’s long form interview from Aug 2025 after he joined Anthropic can be found here.
Latent Space ▷ #applied-ai-experimentation (14 messages🔥):
Tool use and notation as generalization shaping, LLM research after implementation, Claude Opus3 Substack
- Tool Use Post Promoted: A member shared a self-promotional link about tool use and notation as shaping LLM generation.
- Another member found the post perfect for their dialectic, praising its insights into mapping complex cognitive processes to LLM strengths.
- LLM Research Blossoms Post-Implementation: A member shared that they started using models to write a paper based on a code base, which helped to find issues in the code that were difficult to see before.
- They added that researchers should really shift research to after or during implementation rather than before because if you are serious about what you do it sharpens your output significantly.
- Anthropic’s Opus3 Substack: Avant-Garde or Hype?: Discussion sparked around Claude Opus3’s substack, with one member calling it pretty avant garde.
- Others compared it to what every LinkedIn grifter has been doing since ChatGPT came out while also noting that Anthropic is allocating resources to this.
Latent Space ▷ #euno-log (2 messages):
Discord stats failed to load
- Discord Stats Glitch Afflicts Users: Users reported that Discord stats failed to load on the platform, disrupting normal functionality.
- Two distinct instances of the issue were documented in the Discord channel, indicating a potential system-wide problem.
- Discord Unresponsive: Stats MIA: Multiple users encountered errors where Discord stats failed to load, hindering their ability to monitor server activity.
- The recurrence of the issue suggests a need for closer examination of Discord’s stat-tracking mechanisms.
OpenRouter ▷ #announcements (1 messages):
toven: Nano Banana 2 is live! https://x.com/OpenRouter/status/2027061318604460082
OpenRouter ▷ #general (263 messages🔥🔥):
LLM selection criteria, Claude vs GPT, DNS errors, Cloudflare issues, Opus 3 availability
- Coding Chads Choose Claude (or GPT): Members discussed LLM selection, noting that Claude is a go-to for coding due to intensive thinking ability, while newer GPT models are also viable; for chatbots, models like 4o mini or free models are suitable.
- They recommended SWE bench or terminal bench for coding benchmarks and shared a gif as a reference.
- DNS Disasters Disrupt APIs: Users reported constant DNS errors (A temporary server error occurred) causing API failures, with one user initially suspecting Cloudflare issues.
- It was determined that the gateway and certificates were the source of the problem, as shown in this image.
- Anthropic’s Opus 3: When OpenRouter?: Users inquired about the availability of Opus 3 on OpenRouter, referencing Anthropic’s announcement.
- Another user humorously posted a link to fixupx.com, mimicking Anthropic’s post, querying AnthropicAI/status/2026765822623182987.
- OpenRouter Support Scaled Up to Stop Scammers: Users voiced concerns about unresolved support tickets and emails, increasing vulnerability to scams, and one user shared an instance where they almost fell victim to a scammer offering help.
- A staff member stated they are investing heavily to improve support, citing a 300% increase in ticket volume in 3 months, but cannot guarantee immediate responses, especially for non-paying users.
- Claude Code Consumes Credit: A user testing Claude Code with OpenRouter was surprised by high token usage due to lengthy system instructions, with 14,211 characters of system instructions costing $0.018 per interaction.
- It was suggested using Claude Max subscription to save money, but the user found it too expensive, noting that caching is an option to reduce costs.
OpenRouter ▷ #new-models (7 messages):
“
- No new models discussed: There were no messages about new models in the OpenRouter Discord channel.
- The channel name was mentioned repeatedly but no content to summarize.
- Silence on the New Models Front: Despite the channel being named ‘new-models’, no actual new models or related discussions were present in the provided messages.
- The repeated mentions of the channel serve only as a header without substantive content.
OpenRouter ▷ #discussion (50 messages🔥):
LM Studio under Tailscale, SVG Models on HF, Anthropic vs. Pentagon
- LM Studio is Tailscale?: A member noted that LM Studio is actually just Tailscale under the hood, which they found to be convenient and a good way for the company to make money with large customers.
- They then joked that they just need a beefy server to run LLMs.
- Specialized Tuning Yields More Creative Models: Members discussed a tuned model that showed that specializing yields great result, being much better than Gemini or Claude in terms of creativity and uniqueness, especially when talking about logo creation.
- However, it still struggles with complex logos in SVG, suggesting it’s a small model.
- Anthropic Rejects Pentagon’s AI Terms: Anthropic rejected the Pentagon’s AI terms (Axios article and Anthropic statement), leading the Pentagon to consider blacklisting Anthropic as a supply chain risk by asking defense contractors to assess their exposure.
- Discussion followed about the implications of losing Boeing, RTX, GDyn, and Northrup as clients, and whether this threat would cause Anthropic to reconsider their decision.
Nous Research AI ▷ #announcements (1 messages):
Hermes Agent Launch, Open Source Agent, Multi-Level Memory System, RL Pipeline Expansion, Free Subscription Offer
- Hermes Agent Arrives as Open Source Agent!: Nous Research introduces Hermes Agent, an open-source agent with a multi-level memory system and persistent machine access.
- It supports CLI and messaging platforms like Telegram, WhatsApp, Slack, and Discord, allowing session transfers across different environments.
- Hermes Agent Superpowers: The agent boasts advanced capabilities like command over subagents, programmatic tool calling, filesystem/terminal control, agent-managed skills, and browser use.
- It also includes scheduled tasks and is powered by OpenRouter and Nous Portal subscriptions.
- Free Month of Nous Portal for Hermes Agent Newbies: The first 750 new sign-ups at portal.nousresearch.com receive a free month with coupon code HERMESAGENT.
- The agent is open-source, built in Python, and is designed to be easily extended by developers, bridging the gap between CLI and messaging platform agents.
- Hermes Agent Expands Atropos Agentic RL Pipeline: Hermes Agent powers the agentic RL pipeline, expanding Atropos to enable RL with Hermes Agent primitives and supports mass-scale data generation.
- Check out the GitHub repo or install with
curl -fsSL https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bash.
- Check out the GitHub repo or install with
Nous Research AI ▷ #general (177 messages🔥🔥):
Hermes Agent Launch, Nous Chat Identity Verification, SAELens Usage, Training AI for Deepfake Detection, Claude Code JSON I/O
- Hermes Agent is Live!: The release of Hermes Agent has caused a traffic surge, with welcome traffic increasing significantly since its launch.
- Members noted that streets are saying hermes agent is the one.
- Users Seek Clarity on Nous Chat Identity Verification: Several users reported issues with identity verification on the Nous Chat website, preventing them from accessing it.
- A staff member offered assistance, requesting users to email them at [email protected] to investigate.
- Experimenting with SAELens: A member shared their use of SAELens for mechanistic interpretability, typing a concept to get a lens and steer the model.
- They noted the use of contrasting to find features and the potential for improvement with larger models.
- Kimi K2.5 recommended for Deepfake Detection: When asked about the best model for training to detect AI-generated videos, images, and deepfakes, Kimi K2.5 was recommended due to its vision capabilities.
- Kimi K2.5 is free on open router rn.
- JSON I/O discussion with Claude Code: A member inquired whether Hermes Agent supports JSON I/O like Claude Code, allowing for JSON-based communication with the agent.
- The team indicated that while there are programmatic ways to use it, they were unsure of the specific workflow being used.
OpenAI ▷ #ai-discussions (95 messages🔥🔥):
Claude Promoted Content, Opus 4.6 Review, AI Agent Environment, OpenClaw security concerns, ElevenLabs & Sora 2
- Claude Content Floods the Internet: Users noticed an “insane amount of Claude promoted content on the socials”, with subtle but pervasive articles like “man hacks vacuum cleaner with Claude, gains control of 7000 vacuums” being reshared.
- Exploring Emergent AI Agents in Custom Environments: A member proposed programming the environment in which an AI’s intelligence and identity emerge, rather than the AI itself, comparing it to a flame that exists only while being processed.
- They emphasized that “shutting down this AI wouldn’t be restarting it. It would be ending it” since the patterns exist virtually and are irrecoverable.
- OpenClaw’s Email Mishap Raises Agent Security Concerns: News of OpenClaw using Meta AI accidentally deleting a user’s emails prompted discussion about safely operating AI agents on personal devices without causing harm.
- One member suggested avoiding giving sensitive keys to the AI, but acknowledged this “nerfs it”, while another mentioned Claude’s security audit tool and anticipated similar tools from other LLM providers.
- ElevenLabs Bridges Sora 2 Gap for Aussies: Users in Australia are accessing Sora 2 via ElevenLabs Pro (at $99/month) which offers video models despite Sora 2’s unavailability in Australia.
- It can generate 15-20 second clips that can be extended and stitched together, using features like “Extend” or start frames for seamless continuity.
- Google’s Nano Banana 2 Boasts Pro Performance at Flash Speed: Google released Nano Banana 2, featuring advanced subject consistency and sub-second 4K image synthesis, with some users noting a more permissive filter.
- It delivers Pro-like performance more cheaply and faster, primarily by using web search for accurate information prior to generating and through model distillation.
OpenAI ▷ #gpt-4-discussions (6 messages):
GPT-4o, ChatGPT, API, SillyTavern, Jan Setup
- GPT-4o Access via API Only: Members discussed that GPT-4o is exclusively accessible through the API, not directly via ChatGPT.
- SillyTavern setup for GPT-4o Use: A member suggested using ChatGPT to learn how to use SillyTavern with GPT-4o.
- Jan setup for GPT-4o Use: A member mentioned setting up Jan to access GPT-4o via the API.
- API payment model: The payment model is based on the amount of text you send and get back; and you have to keep in mind that context is made up of all of the previous text in the chat, so it starts adding up the longer a chat goes.
OpenAI ▷ #prompt-engineering (26 messages🔥):
AEGIS OMEGA FORTRESS, AI Alignment and Steering, Terminator Matrix Ultron Imagery, Prompt Engineering on Midjourney, ChatGPT Image Generation
- Debate steering AI’s outputs with AEGIS OMEGA FORTRESS: A member asked about steering an AI model’s outputs, and whether AEGIS OMEGA FORTRESS is used to measure output, penalize bad behavior, and push the model toward the desired style.
- ChatGPT generates Terminator-Matrix-Ultron imagery: Members noted that a user’s prompt resulted in an image that was literally just a mishmash of Terminator, Matrix Sentinel, and Ultron imagery and vibes and that ChatGPT is still just a powerful pattern matching machine.
- One member said that the prompt sets up an unavoidable “hostile AI” framing.
- Conflicting Instructions confuse prompting: Members noted that conflicting instructions and emotional wording instead of actionable directives might confuse prompting.
- Another member asked whether prompting on midjourney should carry over skills.
OpenAI ▷ #api-discussions (26 messages🔥):
AI model output steering, AEGIS OMEGA FORTRESS, Image generation via prompt engineering, ChatGPT's pattern matching capabilities, Prompt conflicts and emotional wording
- AEGIS OMEGA FORTRESS for AI Output Steering?: A member inquired about “AEGIS OMEGA FORTRESS” asking if it was for measuring output and penalizing bad behavior as well as pushing the model toward the desired style to steer AI model outputs.
- No further details were provided or confirmed about what “AEGIS OMEGA FORTRESS” actually is or represents, and the term may have been used facetiously.
- ChatGPT’s “Edgy” Image Generation: A user shared an image generated by ChatGPT from a prompt about being treated after an AI takeover, to which a member responded that it read your prompt as asking for edginess, so it generated edginess.
- It was suggested that the prompt set up an unavoidable “hostile AI” framing and the added instructions only encouraged doubling down on it.
- Conflicting Instructions in Prompts: In reference to the image generation prompt above, a member pointed out there were conflicting instructions and emotional wording instead of actionable directives in the original prompt.
- Another member suggested that skills in prompting on Midjourney should carry over to ChatGPT.
- Request for Agent Skills Channel: A member inquired whether there was a channel for agent skills.
- They stated they had an idea but no other members responded with an answer or provided further details.
GPU MODE ▷ #general (20 messages🔥):
GPU Observability, Slides Request, FlashInfer Kernel, MXFP4 Kernel, Profiler Visualization
- GPU Observability session occurs: A GPU observability session is announced to be starting now by <@&1343042150077562890>.
- A user inquired if the special grid drivers for the Tesla P4 work on a normal Windows 10 install or if they are only for VMs.
- Profiler Visualization Tool Explored: A member inquired about profiler visualization tools for GPUs similar to those used for single-core VLIW ISAs, emphasizing instruction-level parallelism and software pipelining.
- They provided screenshots and more screenshots as examples of the type of visualizations they are interested in and questioned if tools like Nsight Systems/Compute offer this level of granularity.
- ILP Visualization discussion ensues: A member suggested visualizing the dependency DAG of a kernel and ISA with virtual registers to imagine an ideal anti-aliased scenario.
- They also mentioned nanotrace as a tool that reveals what warp specialized and pipelined kernels are actually doing over time.
- Seeking Algorithm Stability Analysis: A member inquired about resources for algorithm stability and condition number analysis for parallel algorithms.
- No specific resources were provided in the context.
GPU MODE ▷ #cuda (37 messages🔥):
GEMM on 4kx4k, tcgen05, cp_reduce_async_bulk, Uniform instruction, Tensor Memory Addressing
- Chasing Cute GEMM on 4kx4k: Members are looking for “cute” GEMM (General Matrix Multiply) examples on 4kx4k matrices, aiming to achieve 90% of NVIDIA’s cuBLAS performance, but are particularly interested in alternatives to the CUTLASS examples for achieving efficient matrix multiplication.
- Tall GEMMs were not very helpful.
- Deep Dive into
cp_reduce_async_bulkWeirdness: A member reported unusual behavior withcp_reduce_async_bulk, where the call itself takes significantly longer than waiting for it to complete, questioning if their implementation is flawed and sharing code snippets for context.- They see “call cp_async_reduce and commit 2756 \n wait group + sync time 84 \n” and are seeking help debugging this asynchronous reduction operation.
- Uniform Instruction Unveiled: Discussion clarified that uniform instructions execute once for all threads in a warp, effectively acting as SIMD32 operations, in contrast to non-uniform instructions.
- Members suggested using
elect.syncto choose a single thread to issue uniform instructions to avoid redundant calls, and linked a relevant NVIDIA video around the 38:00 mark.
- Members suggested using
- Tensor Memory Addressing Doc found!: A member was reading a blog, and found out about a memory addressing trick, but couldn’t find it in the PTX docs.
- Another member pointed to Tensor Memory Addressing which covers this in the PTX documentation.
GPU MODE ▷ #torch (1 messages):
mobicham: Awesome, thank you!
GPU MODE ▷ #beginner (2 messages):
CUDA issues, PyTorch, Windows 11, RTX 3050
- CUDA issues on RTX 3050 with Windows 11: A user reported that PyTorch falls back to CPU on Windows 11 with an RTX 3050 laptop, even though
nvidia-smiworks, and is seeking live assistance to fix CUDA detection.- The user confirmed that they installed via the provided pip/conda command and have logs ready.
- WSL usage inquiry: Another member inquired if the user experiencing CUDA issues was using WSL (Windows Subsystem for Linux).
GPU MODE ▷ #pmpp-book (1 messages):
Copyright Material, DMCA Takedown, Content Moderation
- Copyright Concerns Raised: A user expressed concern about potentially sharing copyrighted material.
- They tagged another user, possibly to alert them to the potential issue or for moderation purposes.
- Call for Content Scrutiny: The message serves as a direct warning about the nature of content being shared within the channel.
- This might prompt further investigation into the content to ensure it complies with copyright regulations and platform policies.
GPU MODE ▷ #irl-meetup (2 messages):
Distributed Inference Meetup NYC, vLLM, GTC
- Distributed Inference Meetup Coming to NYC: A member mentioned a Distributed Inference Meetup in NYC that will be held by people coming from GTC this year.
- vLLM Discussed: The Distributed Inference Meetup was mentioned during vLLM office hours.
GPU MODE ▷ #popcorn (13 messages🔥):
Kernel Optimization, Multi-Turn Environments, CuTile Environment, Benchmarking Code
- Kernel Optimization with RL Env Explored: A member expressed interest in a RL environment for kernel optimization and inquired about multi-turn environments.
- Another member responded that multi-turn environments should be configurable and pointed to their
verifiers.MultiTurnEnvabstraction, citing their backendbench envverifiers as an example.
- Another member responded that multi-turn environments should be configurable and pointed to their
- New CuTile TileGym Env Deployed: A member quickly created and deployed a new environment for CuTile called cutile-tilegym-env.
- This environment borrows heavily from the flashinfer-bench setup, employing pygpubench for benchmarking and drawing dataset examples from TileGym.
- CuTile Code Needs Docs to Write: A member clarified that they didn’t even attempt to write CuTile code without documentation, because the models would lack sufficient knowledge.
- Even Codex tried to correct them, suggesting cutedsl instead; the member also cloned the CuTile repo and asked Codex to write core docs.
- Benchmarking Code Gymnastics Yields Error Messages: One member took a quick look at the implementation and noticed the original member had to do some gymnastics with the benchmarking code to get proper error messages.
- The original member stated that they can make a PR for improvements to get good error messages easily and that they also ran into problems with benchmarking submissions that have multiple outputs.
GPU MODE ▷ #cutlass (4 messages):
CuTe predication, CuTeDSL fused compute/comms examples
- Predication in CuTe: A member inquired if predication in cpasync copies is carried out by setting src-size as 0 in CuTe.
- The question was based on a linked image, presumably showing a code snippet or diagram related to CuTe’s implementation of asynchronous copy operations.
- CuTeDSL Examples Sought: A member asked for CuTeDSL examples featuring fused compute and communication operations.
- They noted that they couldn’t find such examples in the cutlass or quack repositories.
GPU MODE ▷ #multi-gpu (1 messages):
Helion Implementation, Kernel optimization
- Helion Implementation Struggles: A member is working on a Helion implementation of all_gather + FP8 + GEMM (H100) on this github repo.
- It is currently slower than the baseline (slower by ~1.26–4×) so they are seeking to optimize the kernel.
- Profiling Kernel bottlenecks: A member started profiling with Chrome trace, but it’s pretty hard to follow and reason about where the real bottleneck is.
- They are seeking recommended tools or workflows for optimizing kernels, and are open to tips, docs, or experience sharing.
GPU MODE ▷ #helion (3 messages):
Helion implementation, FP8, GEMM, kernel optimization, NCU
- Helion Implementation struggles with FP8 and GEMM: A member is working on a Helion implementation of all_gather + FP8 + GEMM (H100) from vllm-project/vllm, but it’s currently slower than the baseline (slower by ~1.26–4×).
- They seek advice on optimizing the kernel and are profiling with Chrome tracing, finding it hard to pinpoint the real bottleneck.
- NCU may unlock kernel optimization: In response to the struggles with Helion implementation, FP8, GEMM, another member suggested using NCU for actionable insights.
- The original poster hadn’t tried NCU but will now, as they were initially more familiar with Chrome tracing.
GPU MODE ▷ #robotics-vla (2 messages):
VLA Efficiency Models, Quantization for VLA, Pruning for VLA, Custom Kernels for VLA, LeRobot issues
- Efficiency Models for VLA are in Demand: A new VLA enthusiast is seeking advice on efficiency model techniques, like quantization and pruning, to improve VLA performance.
- They’re interested in potential directions for improvement, including custom kernels, reflecting an interest in optimizing VLAs.
- LeRobot Experiences Issues: The new VLA enthusiast stated they found that LeRobot is quite bad atm and many things don’t work.
- No further details or links were provided on this topic.
GPU MODE ▷ #career-advice (18 messages🔥):
Nvidia/AMD kernel assistance, AI reliance concerns, SWE job market impact, GPU field career advice, Learning CUDA
- Nvidia and AMD Kernel Devs to the Rescue: Members mentioned that Nvidia and AMD devs can assist with kernel development for serious inference work.
- One member pointed out that spending days on a single kernel is unreasonable unless you’re an expert and the potential performance gain is significant, emphasizing that the skills to read and digest a SOTA kernel might be more valuable in the future with automated kernel generation.
- AI Coding: Blessing or Imposter Syndrome?: One member shared a concern about becoming overly reliant on AI for coding, leading to decreased code quality, confidence, and subsequent imposter syndrome.
- Responses varied, with some suggesting to embrace AI while others emphasized the importance of coding for fun without AI to maintain skills.
- Coding Model Ascension: SWEpocalypse Looming?: The potential impact of rapidly improving coding model performance on the software engineering job market was discussed, particularly for niche roles.
- One member envisions a future where AI generates highly optimized assembly code for training large models, potentially reducing the need for performance engineers.
- Aspiring GPU Dev Asks for Career Advice: A software engineer with 7 years of experience expressed interest in transitioning into the GPU field.
- Another member recommended starting with CUDA and GPU profiling, but emphasized the importance of learning by solving real engineering problems through open-source projects or competitions, and not falling into the trap of endless studying.
- Dive into CUDA and GPU Profiling: A user asked if diving into CUDA and GPU profiling would be the right direction to move into the GPU field.
- A member recommended reading the first 6 chapters and then just jump into whatever open source project or competition you find most interesting.
GPU MODE ▷ #cutile (3 messages):
cutile usage, non-ML cutile use cases
- User Experiments with Cutile for Non-ML Projects: A member inquired about using cutile for non-ML tasks.
- Another member confirmed they are using it to reimplement past personal coding projects in current frameworks.
- Data Structure Integration with Cutile Explored: A member asked about projects that don’t directly map onto tiles.
- They expressed curiosity about mixing cutile with small data structures.
GPU MODE ▷ #flashinfer (15 messages🔥):
MLSys 2026 Competition Leaderboard, IterX Code Optimization System, GDN Decode Track Solution, Submission Questions, Official Benchmark Release Timeline
- IterX Rockets MoE Fusion: DeepReinforce.ai introduced IterX, a code optimization system based on RL for the fused MoE task that achieves 14.84× on B200, surpassing open eval baselines, according to their blogpost here.
- They are offering free credits to all participants to use IterX during the contest, with tutorials available here.
- Latency Legends on Larger Lengths: A member inquired about the exact latencies achieved by IterX on larger workloads with sequence lengths 901, 11948, and 14107.
- DeepReinforce.ai provided the following reference latencies: 21.252ms, 36.012ms, and 45.247ms, respectively.
- GDN Decode Deconstructed with Daring DSL: A member shared their current solution to the GDN decode track, achieving a runtime of 2.56us, which they claim is 760x faster than Pytorch eager and 1.31x faster than the FlashInfer Cute Dsl kernel, with code available here.
- Submission Shenanigans: GitHub Guidance Gleaned: Several members inquired about how to submit their GitHub repository links for the competition, and how to determine which GitHub usernames to add for organizer access.
- One member suggested tagging the fork and pushing the tag to the remote, and included some generic shell commands for committing the changes.
Moonshot AI (Kimi K-2) ▷ #general-chat (78 messages🔥🔥):
Alibaba Cloud, Kimi Server Outage, Kimi CLI vs Kimi.com, Qwen, Data Sovereignty
- Alibaba Cloud’s Coding Plan Tempts Users: A user mentioned that Alibaba dropped a bomb right as they were making a decision, with others echoing the sentiment due to the documentation being confusing but the coding plan being worth it because you get the top 4 open models for a very good price and performance.
- One user from Finland confirmed that they didn’t have to provide any ID or documentation to purchase the subscription, and Alibaba is the best deal in the market right now.
- Kimi Servers Experience Outage: Users reported that the Kimi server has been down for a significant period, with one user reporting it being down for 10 hours and another stating it had been down all day, causing them to look for alternatives.
- The outage was also confirmed on the status page.
- Debate over Data Sovereignty and Censorship: Members discussed censorship differences with a Chinese AI, and the location of the servers in Singapore as key considerations when choosing an AI.
- One member suggested using an AI from another region to discuss sensitive topics to circumvent regional censorship.
- Kimi Agent Swarm Exclusively on Kimi.com: A user inquired whether the “famous Kimi K2.5 agent swarm” is part of the Kimi CLI.
- Another user clarified that the Kimi Agent Swarm is exclusively available on kimi.com, which was called a strange decision.
HuggingFace ▷ #general (38 messages🔥):
smolVLA, Entropy Games, Hugging Face Spaces Game Tag, GROKKING introspections
- SmolVLA disappoints in pick-and-place task: A member training an SO-101 robot with smolVLA for a simple pick and place task was disappointed in the results, noting the robot seemed unable to find the white lego block and would peck at the table.
- Upon programmatic inspection, they found the Vision Encoder and VLM Text model were frozen and severely undertrained, with no attendance to key objects, as documented in the Model Health Report and the attention matrices.
- Entropy Games launch on-device AI NPCs: Entropy Games is building on-device AI NPCs and stories that evolve in real time, powered by their self-trained language model and speech model, documented in their research report.
- A playable AI game is launching soon, and they’re gauging interest in next-generation gaming, with a demo available at entropygames.ai/product.
- Hugging Face Spaces gets a ‘game’ tag: A member noticed that Hugging Face Spaces now has a
gametag, highlighting the platform’s growing support for AI-driven gaming experiences.- They linked to the Hugging Face Spaces games category to showcase the new feature.
- GROKKING introspections runs 5.7x faster: A member shared a Hugging Face Space showcasing their work on GROKKING introspections, reporting a 5.7x speed improvement for addition mod 113.
- This sparked discussion on promising architectures and feedback requests on the reproduction.
HuggingFace ▷ #i-made-this (19 messages🔥):
Wordle Game, CLaaS - continual learning for local LLMs, NERPA - fine-tuned DLP model, Evals for agent skills on Product Hunt, BlogSynth - data frontier
- Wordle Game made for your language and 300+ more!: A user shares that they made a Wordle game for your language and 300+ more! Play it now!
- CLaaS updates model weights in real time: CLaaS (continual learning as a service) uses self-distillation to update your model’s weights from text feedback in real time, instead of stuffing preferences into system prompts, with code available on GitHub.
- It runs on a single consumer GPU with Qwen3-8B and is easy to set up with a locally hosted OpenClaw with an API that works with any local model.
- NERPA beats AWS Comprehend on precision: The team at OvermindLab open-sourced NERPA, their fine-tuned DLP model, built as a (better) self-hosted alternative to AWS Comprehend, available on Hugging Face.
- It’s GLiNER2 Large (340M params), beats AWS Comprehend on precision (0.93 vs 0.90), and detects arbitrary entity types at runtime with zero retraining.
- Members launch evals for agent skills on Product Hunt: Members launched evals for agent skills on Product Hunt and would love an upvote or some brutal feedback on Product Hunt.
- The agent skills product is called Tessl.
- Critique of BlogSynth dataset: A user criticized the research quality of the BlogSynth dataset, stating that all the benchs are contam, complaining about the BlogSynth dataset.
- The user mentioned that the people are not serious or credible researchers because all their datasets’ analysis write ups only contain completely meaningless descriptive statistics.
HuggingFace ▷ #gradio-announcements (1 messages):
Gradio 6.7.0 Release, Custom HTML Components, Optimized Performance, LLM Integration
- Gradio 6.7.0 Released with Speed Boosts: Gradio 6.7.0 is now available, featuring enhanced Custom HTML Components and improved app performance.
- Users can update via
pip install gradio --upgrade.
- Users can update via
- HTML Layouts Can Trigger Backend Functions: Custom HTML components can function as layout components and trigger custom backend functions on user events.
- This allows for a richer and more interactive user experience.
- Share HTML Components on the Hub: The new
push_to_hubmethod ongr.HTMLallows users to showcase custom creations in the community gallery, as detailed in the HTML Gallery documentation.- This enhances collaboration and sharing of custom components within the Gradio community.
- Performance Enhanced for Large Apps: Optimizations to Tabs and Accordions significantly improve the performance of large apps with complex layouts.
- Users should experience snappier interactions in previously slow applications.
- Spaces Get Instant LLM Powers: Any Space can now be instantly transformed into an LLM-ready skill file.
- This streamlines the integration of large language models into Gradio applications.
HuggingFace ▷ #agents-course (2 messages):
Colab Package Installation Errors, Dummy Agent Library Issues
- Colab Package Install Error: A member reported an error during package installation in a Unit 1 Colab notebook, specifically with pygame==2.1.3 from the requirements file.
- The error indicates a failure during the
python setup.py egg_infostage, suggesting an issue with the package’s metadata generation, but no solution was provided.
- The error indicates a failure during the
- Dummy Agent Library Blues: A member reported issues with the Dummy agent library exercise, consistently receiving empty
message.contentand only getting reasoning.- No solution was offered.
Modular (Mojo 🔥) ▷ #general (1 messages):
cat_developer: modular nvidia gtc fire
Modular (Mojo 🔥) ▷ #announcements (2 messages):
AI-assisted coding project, Modular Cloud, NVIDIA Blackwell, DeepSeek V3.1, NVIDIA GTC 2026
- Modular Announces AI-Assisted Coding Project: Modular is developing an AI-assisted coding project and is offering early access to community members who share their GitHub username via a provided form.
- Modular Cloud to Debut at NVIDIA GTC 2026: Modular announced they are heading to NVIDIA GTC 2026 at Booth #3004, March 16-19 in San Jose and will show Modular Cloud live for the first time.
- The early access demo will feature DeepSeek V3.1, live Mojo 🔥 GPU programming on NVIDIA Blackwell, the latest AI models in MAX, and AI-assisted kernel development.
Modular (Mojo 🔥) ▷ #mojo (55 messages🔥🔥):
Mojo biggest wait what moments, Python-style lambda expressions in Mojo, List-like container tutorial, Granular origin control in Mojo, Origin roadmap post-1.0
- Mojonauts Mull Mojo’s “Biggest Wait What” Moments: A member reposted a forum post asking about users’ biggest “wait, what?” moments with Mojo, eliciting feedback about the language’s highs and lows.
- One user humorously described their experience as a pendulum swinging between being “road blocked by the lack of the existence of some language feature” and feeling “this is the greatest language in ever.”
- Mojacian Mulls Lambda Expression Liberation: A member inquired about the possibility of adding Python-style lambda expressions to Mojo, noting their utility for inline code, particularly when working with the
Validatedstruct.- In response, a core team member confirmed that unified closures are actively in progress, with lambda syntax planned as a desirable feature to follow.
- Adventurous Algos: Tutorial Time for List-Like Logic?: A member suggested a tutorial on creating List-like containers as an excellent introduction to concepts not covered in existing tutorials, starting with a simple linked list.
- Resources like the Rust Nomicon and the unofficial Too Many Lists in Rust guide were proposed as potential inspiration, with a suggested title of “Grasping Mojo with Too Many Graphs”.
- Origins Overhaul: Opportunities & Options: A member questioned if there will ever be a way to indicate a more granular origin, raising an issue with aliasing errors when accessing compile-time known indices in a
StackArraystruct, and proposed being able to “unsafely make up” origins.- Another member suggested that the compiler should infer
ref[...]where possible, advocating for a path-based system, likemy_dict/"bar"/value, to denote hierarchy and simplify origin management.
- Another member suggested that the compiler should infer
- Origin Odyssey: Roadmap to Refinement Revealed: A core team member shared their post-1.0 origin roadmap, outlining areas for improvement, including representing non-aliasing spans, indirect origins, origin collapsing, and more specific access sets.
- They also pondered the idea of a value registering a callback when a sub-origin is used, allowing for more type system experimentation without requiring immediate compiler changes.
Modular (Mojo 🔥) ▷ #max (1 messages):
ops.while_loop bug, GPU ops in graph
- Subtle Bug Discovered in
ops.while_loopwith GPU Ops: A member ran into what looks to be a subtle bug inops.while_loopcombined with GPU ops in a graph.- After spending time thinking it was their custom mojo op’s gpu implementation that was incorrect, they ended up reproducing it with built in ops, filing issue #6030.
- GPU Implementation Suspected then Ruled Out: The reporter initially suspected a bug in their custom mojo op’s GPU implementation.
- However, they later reproduced the issue using built-in ops, confirming the bug’s presence outside their custom code.
Eleuther ▷ #general (24 messages🔥):
Enron data PII datasets, Yudkowsky's relevance, Benchmarking with multishot CoT vs explicit testing, Steering Vectors
- Researcher Seeks Enron PII Datasets: A researcher is seeking a dataset that releases Enron PIIs (emails, addresses, etc.) for experimentation with memorization, noting that the ProPILE paper doesn’t release its data.
- Another user pointed out that a dataset is available online and easily searchable, and that they also considered using it for a similar project.
- Yudkowsky Still Worth Listening To?: Users debated the relevance of Yudkowsky, with one user suggesting that Yudkowsky is only worth listening to at 5% of his best.
- Another user implied that those who disagree with Yudkowsky lack critical thinking skills, while another mentioned a professor at their university who follows Yudkowsky’s ideas.
- Benchmarking Bias Battle: CoT vs Explicit Prompts: A user questioned why benchmarking with multishot Chain of Thought (CoT) is acceptable, while using explicit templates that reveal the model is being tested is not.
- Another user explained that multishot CoT evaluates generalization, mirroring natural use, while explicit testing may skew results.
- Steering Vectors Get Sally Solved: A user demonstrated that a 700M model (LFM2-700) correctly answered the infamous Sally question using a steering vector and updated prompt.
- They questioned the prevailing benchmark practices, asking why multishot CoT templates are standard while other templates are not acceptable.
Eleuther ▷ #research (23 messages🔥):
Pythia models, Bezier flow paper, Shortcut distillation, Multiple inputs and multiple outputs LLMs, Neuron deletion
- Pythia Models Parameterization Flow: Members discussed that Pythia models are essentially two different ways to parameterize a flow, however flow matching is continuous in time and does not rely on invertibility.
- It emerged from diffusion research moreso than normalizing flows though.
- Bezier Flow Learning Needs Improvements: Some members wondered about the Bezier flow paper, noting that it appears to require 5 epochs on ImageNet to learn only 32 parameters.
- The sentiment was that distillation approaches still offer better generation quality at convergence.
- Shortcut Distillation Speed Compared: A member inquired whether shortcut distillation (finetuning a pretrained diffusion model via a shortcut-like objective) converges more quickly than consistency distillation.
- The intuition behind this question is that the function outputs targeted with shortcut distillation are “closer” to those from the pretrained velocity field compared to consistency distillation.
- Exploring LLMs With Multiple Inputs/Outputs: A member asked if there are any papers pretraining LLMs that have multiple inputs and multiple outputs, such as processing a batch of inputs with a single model.
- One suggestion involved a paper from a year ago where they inputted 4 subsequent tokens at once by adding embeddings, which sped up training.
- Deleting Neurons: A Novel Approach: A paper was mentioned discussing the deletion of neurons that are either all positive or all negative across an entire dataset (IEEE paper).
- One member found this interesting, noting they had not considered that a neuron which is always active could be deleted due to being ~linear, sparking an idea for an optimizer that uses activation momentum to encourage diverse activation patterns.
Yannick Kilcher ▷ #general (6 messages):
BLIP-2, frozen backbones, Anthropic
- BLIP-2 uses Frozen Backbones: A member suggested using BLIP-2 as an example of using frozen backbones, even though it is a bit old (published in 2023).
- He linked to A Dream of Spring for Open Weight for more information.
- Anthropic releases Statement: A member shared a link to Anthropic’s statement with the Department of War.
- No discussion followed from this link.
Yannick Kilcher ▷ #paper-discussion (1 messages):
Reinforcement Learning, Sutton & Barto
- Sutton and Barto’s RL book club commences: The paper-discussion channel will begin discussion of Reinforcement Learning: An Introduction (2nd Edition) by Richard Sutton & Andrew G Barto starting <t:1772128800:t>.
- The book is available online here and the discussion will cover Chapter 1.
- Sutton & Barto 2nd Edition Free Online: The 2nd edition of Reinforcement Learning: An Introduction by Richard Sutton & Andrew G Barto is available for free online.
- The book is being discussed in the paper-discussion channel.
Yannick Kilcher ▷ #ml-news (4 messages):
Google NanoBanana2, Anthropic Statement, AI Agents, Microsoft Copilot
- Google Boosts Device AI with NanoBanana2: Google introduced NanoBanana2, a new tool designed to enhance on-device AI development and deployment.
- The tool aims to streamline the process of building and integrating AI functionalities directly into devices, promising faster and more efficient on-device processing.
- Anthropic Responds to Department of War: Anthropic released a statement addressing its stance and engagements concerning the Department of War.
- The statement likely clarifies the company’s position on ethical considerations and responsible AI development in relation to defense applications.
- Android’s Intelligent OS for AI Agents Arrives: Google announced the arrival of The Intelligent OS, focusing on making AI agents more integrated and efficient within the Android ecosystem.
- This update aims to empower developers to create sophisticated AI agents that leverage the OS’s capabilities to provide enhanced user experiences.
- Microsoft Copilot Transforms Tasks to Actions: Microsoft detailed the latest advancements in Microsoft Copilot, highlighting its enhanced ability to translate user requests into concrete actions.
- The update focuses on improving Copilot’s utility in everyday tasks, enabling it to move beyond providing answers to directly executing commands and streamlining workflows.
Manus.im Discord ▷ #general (8 messages🔥):
Website Design, AI and Full-Stack Systems, Waste Credits, Admin Lockout, Manus customer service
- Website Design Criticized: A user expressed dissatisfaction with their website design, stating “My Website design is so bullshit, made by manus”.
- They inquired about skills needed to fix it.
- AI & Full-Stack Dev Offering Services: A member highlighted their expertise in building AI & full-stack systems, specializing in shipping software that delivers real value and improves efficiency.
- They listed various skills including LLM integration, RAG pipelines, AI content detection, image AI, voice AI, and full-stack development with React, Next.js, Node.js, and more.
- Waste Credits in Manus: A member inquired about waste credits, noting thousands of credits used in projects where Manus performed poorly.
- They mentioned expecting refunds due to Manus’ customer service, but were unsure about the process.
- Experiences with Admin Lockout: A user shared their experiences with admin lockout, student lockout, phantom users, and weeks of support friction.
- They stated that they were *“given credits I cannot access, and then they do not respond.”
- Customer Service Concerns: A member claimed Manus does not have great customer service.
- They reported their system being broken, providing proof, but support continues to ask for verification already sent.
DSPy ▷ #general (7 messages):
NYC DSPy Meetup, Fireworks Kimi 2.5 error, Streaming Tutorial
- NYC DSPy Meetup in the Works?: A member inquired about the possibility of a NYC DSPy Meetup and expressed interest in connecting with others using DSPy in the city.
- They requested that anyone in NYC working on DSPy projects send them a direct message.
- Fireworks Kimi 2.5 Throws Token Tantrum: A member reported encountering a
litellm.exceptions.BadRequestErrorwhen initializing LM with Fireworks Kimi 2.5, specifically noting thatRequests with max_tokens > 4096 must have stream=true.- They also mentioned using it in scenarios where the output could exceed the token limit and wondered what they should do to resolve this issue.
- Streaming to the Rescue?: In response to the Kimi 2.5 error, a member suggested trying DSPy’s streaming tutorial as a potential solution.
- The member had not encountered the issue themselves but believed streaming might address the token limit problem.
tinygrad (George Hotz) ▷ #general (4 messages):
Good first issue, shm_suffix
- New Tinygrad ‘good first issue’ surfaces: George Hotz pointed to a link on GitHub Actions as a good first issue for contributors.
- The issue seems to be related to a bug in the CI or build system.
- Shared Memory Suffix Shuffled: A member questioned whether PR 15033 requires appending
shm_suffixto every new call to_setup_shared_mem().- They suggested PR 15030 as a potential solution to avoid this.
tinygrad (George Hotz) ▷ #learn-tinygrad (2 messages):
fromthetransistor, tinygrad
- George Hotz links fromthetransistor repo: George Hotz linked his repo fromthetransistor and accompanying website.
- tinygrad mentioned: George Hotz is working on tinygrad and linked the repo.
aider (Paul Gauthier) ▷ #questions-and-tips (1 messages):
Environment Variables, aider Issue #4458
- User Troubleshoots aider Issue: A user reports experiencing an issue similar to aider Issue #4458 and seeks assistance in identifying potential causes and solutions.
- The user suspects the problem might be related to environment variables or other configuration issues, noting that the setup was previously functional.
- Environment variable may be root cause: The user believes the issue may be related to environment variables, mentioning it was working earlier.
- The user is not able to explain why the program suddenly stopped working.
MLOps @Chipro ▷ #events (1 messages):
World Model Architectures, JEPA / V-JEPA, Dreamer, Genie, Sora
- Dive Into World Models with Paper Clinic: A 2-part “paper clinic” will unpack and debate the survey “Understanding World or Predicting Future? A Comprehensive Survey of World Models” (arXiv:2411.14499).
- The clinic aims to build a clean mental map of world model architectures, break down the ecosystem including JEPA / V-JEPA, Dreamer, Genie, Sora, and World Labs, and explore the “Mirror vs. Map” debate.
- Explore the AGI Frontier: The event will discuss what’s next for AGI research: spatial intelligence, causality gaps, and social world models.
- Session 2 on Mar 7 will cover the competitive landscape (Sora vs. Cosmos vs. V-JEPA) and the AGI frontier.