Congrats MiniMax!
AI News for 3/18/2026-3/19/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
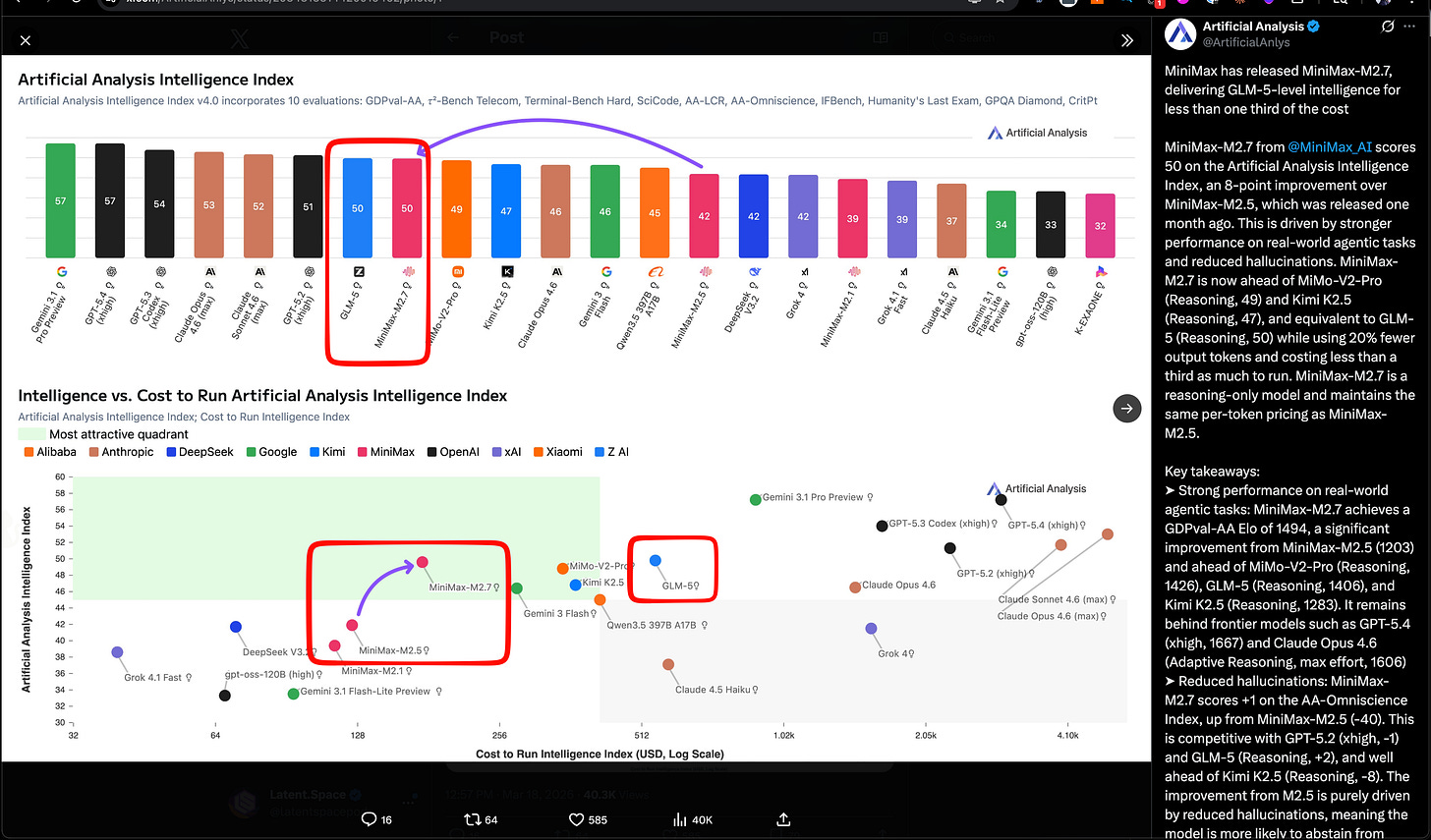
Not 2 months after their IPO and first public quarter, MiniMax is back in the news with MiniMax 2.7, a nice bright spot in Chinese Open Models after the changeover in Qwen. They match Z.ai’s GLM-5 SOTA open model from last month, but the story is efficiency here (see green quadrant in Artificial Analysis’ chart):
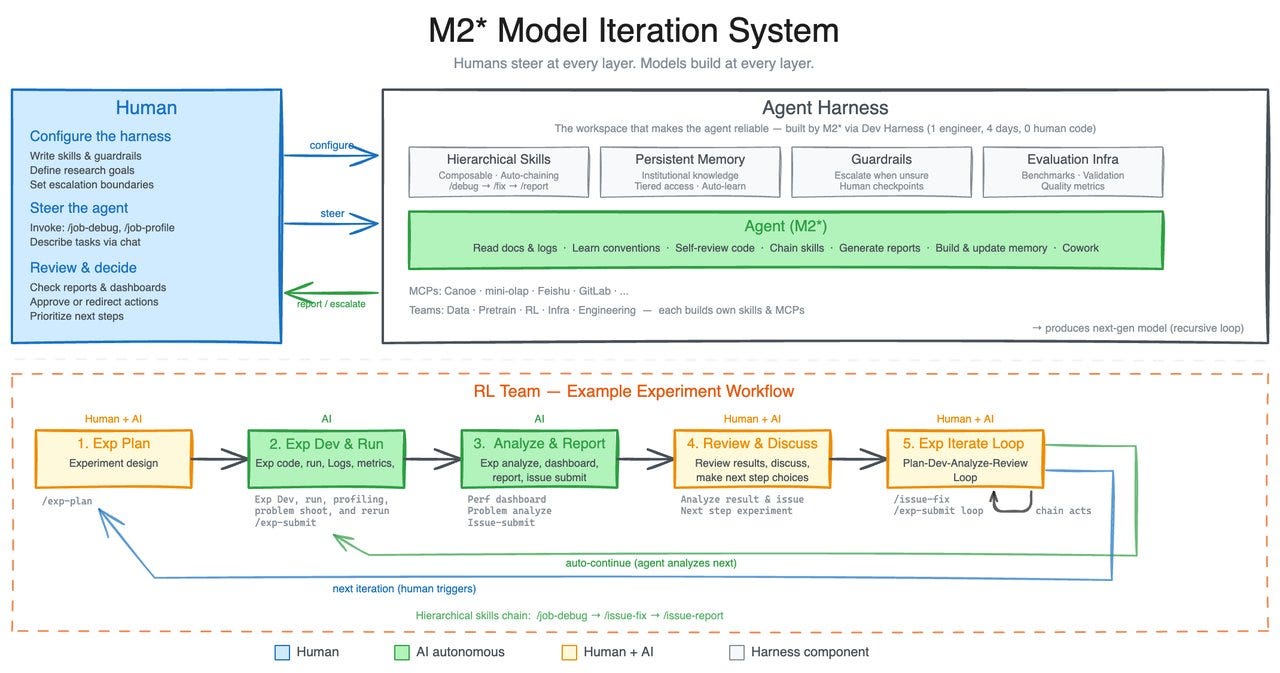
The team calls out “Early Echoes of Self-Evolution”, calling it “our first model deeply participating in its own evolution.”, recalling Karpathy’s Autoresearch, although they only claim that “M2.7 is capable of handling 30%-50% of the workflow.”:
They also report some work on multi-agent collaboration (“Agent Teams”) as well as follow Anthropic and OpenAI’s lead in applying their models for finance usecases. Finally, they launch OpenRoom, an open source demo for entertainment usecases.
AI Twitter Recap
MiniMax M2.7, Xiaomi MiMo-V2-Pro, and the expanding “self-evolving agent” model class
- MiniMax M2.7 is the headline model release: MiniMax positioned M2.7 as its first model that “deeply participated in its own evolution,” claiming 56.22% on SWE-Pro, 57.0% on Terminal Bench 2, 97% skill adherence across 40+ skills, and parity with Sonnet 4.6 in OpenClaw. A follow-up says the internal harness also recursively improved itself—collecting feedback, building eval sets, and iterating on skills/MCP, memory, and architecture (thread). Third-party coverage broadly echoed the “self-evolving” framing, including TestingCatalog and kimmonismus.
- Artificial Analysis places M2.7 on the cost/performance frontier: Artificial Analysis reports 50 on its Intelligence Index, matching GLM-5 (Reasoning) while costing $176 to run the full index at $0.30/$1.20 per 1M input/output tokens—less than one-third of GLM-5’s cost. They also report GDPval-AA Elo 1494, ahead of MiMo-V2-Pro (1426), GLM-5 (1406), and Kimi K2.5 (1283), plus a large hallucination reduction vs M2.5. Distribution was immediate: Ollama cloud, Trae, Yupp, OpenRouter, Vercel, Zo, opencode, and kilocode.
- Xiaomi’s MiMo-V2-Pro looks like a serious Chinese API-only reasoning entrant: Artificial Analysis scores it at 49 on the Intelligence Index, with 1M context, $1/$3 per 1M tokens pricing, and GDPval-AA Elo 1426. Notably, they call out stronger token efficiency than peers and a relatively favorable AA-Omniscience score (+5) driven by lower hallucination. This follows Xiaomi’s earlier open-weight MiMo-V2-Flash (309B total / 15B active, MIT); V2-Pro itself is API-only for now.
- Mamba-3 is out and immediately being viewed through the hybrid-architecture lens: Cartesia announced Mamba-3 as an SSM optimized for an inference-heavy world, with Albert Gu noting Cartesia-backed testing and support (link). Early technical reactions focused less on standalone SSMs and more on plugging Mamba-3 into transformer hybrids: rasbt explicitly called out replacing Gated DeltaNet in next-gen hybrids like Qwen3.5 / Kimi Linear, while JG_Barthelemy highlighted hybrid integration and “unlocking Muon for SSMs.”
Agent harnesses, skills, MCP, and the shift from “prompting” to systems design
- The strongest recurring theme is that harness engineering is becoming the real differentiator: Multiple posts argued that the bottleneck is no longer just the base model, but the surrounding execution environment. The Turing Post’s interview with Michael Bolin frames coding agents as a problem of tools, repo legibility, constraints, and feedback loops—what many now call harness engineering. dbreunig made a similar point about why teams stick with DSPy, and nickbaumann_ argued GPT-5.4 mini matters specifically because cheap, fast subagents change what is worth delegating.
- Skills are solidifying into a shared abstraction across agent stacks: A practical thread from mstockton lays out real usage patterns for SKILLS: progressive disclosure, trace inspection, session distillation, CI-triggered skills, and self-improving skills. RhysSullivan suggests distributing skills via MCP resources may solve staleness/versioning. Anthropic’s Claude Code account clarifies that a skill is not just a text snippet but a folder with scripts/assets/data, and that the key description field should specify when to trigger it (tweet).
- Open agent stacks are converging on model + runtime + harness: Harrison Chase published a walkthrough framing Claude Code, OpenClaw, Manus, etc. as the same decomposition: open model + runtime + harness, using Nemotron 3, NVIDIA’s OpenShell, and DeepAgents. Related infrastructure releases include LangSmith Sandboxes for secure code execution, LangSmith Polly GA as an in-product debugging/improvement assistant, and a new LangChain guide on production observability for agents.
- MCP momentum continues, but there’s pushback: Useful MCP-related launches included Google Colab’s open-source MCP server, enabling local agents to drive Colab GPU runtimes, and Google’s Gemini API update allowing built-in tools plus custom functions in one call. At the same time, there’s visible skepticism: skirano bluntly said “MCP was a mistake. Long live CLIs.” and denisyarats joked about “model cli protocol.”
- A parallel trend: agent-native enterprise apps and “headless SaaS”: ivanburazin describes an emerging category of headless SaaS—traditional software rebuilt as agent-first APIs with no human UI. That idea lines up with product launches like Rippling’s AI analyst, Anthropic’s Claude for Excel/PowerPoint webinar, and the notion that meeting-notes apps are really becoming broader AI context/data apps (zachtratar).
Infra, kernels, and model-system co-design
- Attention Residual became a case study in infra-model co-design: Several posts unpacked Kimi/Moonshot’s AttnRes work as more than a novelty architecture. bigeagle_xd emphasized co-design across model research and infra, linking to an inference-infra writeup; ZhihuFrontier summarized why full attention residual strains pipeline parallelism due to asymmetric comms/memory patterns, and how Block Attention Residual plus cross-stage caching can restore symmetry. YyWangCS17122 reinforced the theme: kernel optimization, algorithm-system co-design, and numerical rigor as the path to production-worthy large models.
- Custom kernel packaging is getting easier: ariG23498 highlighted Hugging Face’s new
kernelslibrary, which aims to make custom kernels more shareable and easier to integrate via the Hub. The pitch is straightforward: lower the pain of writing and distributing fused/custom kernels without requiring every model team to hand-roll installation and integration logic. - Inference optimization remains a first-class topic: The same thread on kernels reiterates the familiar optimization stack—close idle gaps between kernel launches, fuse ops with
torch.compile, and only fall back to custom kernels where needed. On the hardware side, Stas Bekman noted that NVLink’s marketed bandwidth can be misleading because it is not duplex in the way many assume. - Compute bottlenecks are still upstream of everything else: kimmonismus argues that ASML EUV machines and their narrow supply chains may cap production at roughly 100 machines/year by 2030, making lithography an important ceiling on AI scaling over this decade.
Documents, OCR, retrieval, and context engineering for real workflows
- Document AI is trending toward end-to-end multimodal parsers with grounding: Baidu introduced Qianfan-OCR, a 4B end-to-end document intelligence model that collapses table extraction, formula recognition, chart understanding, and KIE into a single pass. Vik Paruchuri open-sourced Chandra OCR 2, claiming 85.9% on olmOCR bench, 90+ language support, and stronger layout, handwriting, math, form, and table support in a smaller 4B model. On the platform side, LlamaIndex and jerryjliu0 emphasized that production document agents need not just markdown conversion but layout detection, segmentation, metadata context, and visual grounding to support human-auditable document workflows.
- Late-interaction retrieval continues to push on the memory/quality tradeoff: victorialslocum summarized MUVERA, which compresses multi-vector retrieval into fixed-dimensional encodings, reporting about 70% memory reduction and much smaller HNSW graphs at some recall/query-throughput cost. lateinteraction used the thread to reiterate the limitations of single-vector retrieval on harder OOD settings.
- Context engineering is becoming a product category: llama_index explicitly frames context engineering as the successor to prompt engineering, with structured parsing/extraction as a core lever. This pairs with Hugging Face’s new support for serving Markdown paper views to agents and a Paper Pages skill for searching and reading papers more token-efficiently (Clement Delangue, Niels Rogge, mishig25).
Evals, training methodology, and benchmarks worth watching
- LLM-as-judge reproducibility is under fire again: a1zhang showed a model scoring 10% under GPT-5.2-as-judge vs 43.5% under GPT-5.1-as-judge, despite a paper reporting 34%—a stark reminder that judge choice can swamp conclusions. torchcompiled distilled the takeaway: don’t use LLM-as-judge without validating human correlation or tuning for it.
- Pretraining data composition is re-emerging as a major lever: rosinality highlighted work showing that mixing SFT data during pretraining can outperform the standard pretrain-then-finetune pipeline, with a scaling law for the ratio under a token budget. Related posts from arimorcos, pratyushmaini, and Christina Baek all argue that domain adaptation often benefits more from earlier data mixing or even repeating small high-quality datasets 10–50x during pretraining than from naive finetuning alone.
- Benchmarks are shifting toward “unsolved and useful”: Ofir Press points to a future where improving on a benchmark means solving previously unsolved tasks that matter in the world, not just memorizing exam-like datasets. He also notes AssistantBench remains unsolved 1.5 years later. New benchmark/tooling drops include ScreenSpot-Pro on Hugging Face for GUI agents and Arena’s academic partnerships funding eval work.
Top tweets (by engagement, filtered for technical relevance)
- OpenAI’s Parameter Golf challenge: OpenAI launched Parameter Golf, a training challenge to fit the best LM in a 16MB artifact trained in under 10 minutes on 8×H100s, with $1M in compute behind it. Good talent-pipeline energy, and a nice complement to the NanoGPT speedrun culture (details via scaling01).
- Anthropic’s 81k-user study: Anthropic says it used Claude to interview 80,508 people in one week about hopes and fears around AI—the company calls it the largest qualitative study of its kind (announcement). The research is interesting both as social measurement and as a signal that model-mediated interviewing may become a standing product/research capability.
- Runway’s real-time video generation preview: Runway shared a research preview developed with NVIDIA showing HD video generation with time-to-first-frame under 100ms on Vera Rubin hardware (tweet). If it generalizes, this is a qualitatively different interaction loop for video models.
- Hugging Face on agent-facing research interfaces: The platform change to serve Markdown paper views to agents and the companion paper skill is small but important infrastructure for agentic research workflows (Clement Delangue).
- VS Code integrated browser debugging: Microsoft’s latest VS Code release adds integrated browser debugging for end-to-end web app workflows—useful in its own right, and likely to matter even more as coding agents are asked to operate against live browser state.
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
1. MiniMax-M2.7 Model Announcements
-
MiniMax-M2.7 Announced! (Activity: 947): The image presents a comparative analysis of the newly announced MiniMax-M2.7 model against other models like Gemini 3.1 Pro, Sonnet 4.6, Opus 4.6, and GPT 5.4 across various benchmarks such as SWE Bench Pro, VIBE-Pro, and MM-ClawBench. MiniMax-M2.7 is highlighted in red, indicating its performance metrics, which are crucial for understanding its capabilities relative to existing models. The model’s autonomous iteration capabilities are emphasized, showcasing its ability to optimize software engineering tasks through iterative cycles, leading to a
30% performance improvementon internal evaluations. This highlights the model’s potential for self-evolution and automation in AI development. Commenters express skepticism about the practical usability of models that perform well on benchmarks but may not generalize well to real-world tasks. There is anticipation for user testing to validate the model’s effectiveness beyond controlled evaluations.- Recoil42 highlights the autonomous iteration capabilities of the MiniMax-M2.7 model, which can optimize its own performance through iterative cycles. The model autonomously analyzes failure paths, plans changes, modifies code, and evaluates results, achieving a 30% performance improvement on internal evaluation sets by optimizing sampling parameters and workflow guidelines.
- Specialist_Sun_7819 raises a critical point about the discrepancy between benchmark performance and real-world usability. They emphasize the importance of user testing to assess how models perform on tasks that deviate from their training distribution, suggesting that many models excel in evaluations but struggle with off-distribution tasks.
- Lowkey_LokiSN expresses concern about the model’s quantization resistance, referencing issues with the previous M2.5 model’s UD-Q4_K_XL variant. This highlights the importance of maintaining model performance post-quantization, which can be a challenge for large models when reducing precision for deployment.
-
MiniMax M2.7 Is On The Way (Activity: 329): The image is a tweet from MiniMax announcing their participation in the NVIDIA GTC event where they plan to discuss their upcoming model, MiniMax M2.7, along with multimodal systems and AI products. This suggests that MiniMax M2.7 might incorporate multimodal capabilities, potentially handling multiple types of data inputs like text, images, and audio. The mention of multimodal systems aligns with current trends in AI development, where models are increasingly designed to process and integrate various data forms for more comprehensive outputs. A comment highlights the desire for a smaller version of the model, indicating user interest in more accessible or resource-efficient versions. Another comment praises the performance of MiniMax 2.5, noting its speed and tooling capabilities, but points out the lack of image and audio input support, which could be addressed in the upcoming M2.7 model.
- z_3454_pfk highlights the performance of MiniMax 2.5, noting its efficiency with tooling and retrieval-augmented generation (RAG). The model is praised for its speed, though it currently lacks support for image and audio inputs, which could be a limitation for some applications.
- Dismal-Effect-1914 emphasizes the compactness and efficiency of MiniMax 2.5, stating it is the best model available that fits under approximately 150 GB when using 4-bit quantization. This suggests a strong balance between performance and resource usage, making it suitable for environments with limited storage capacity.
2. Unsloth Studio Launch and Features
-
Introducing Unsloth Studio: A new open-source web UI to train and run LLMs (Activity: 1078): Unsloth Studio is a new open-source web UI designed to train and run large language models (LLMs) locally on Mac, Windows, and Linux. It claims to train over
500+ modelsat twice the speed while using70% less VRAM. The platform supports GGUF, vision, audio, and embedding models, and allows users to compare models side-by-side. It features self-healing tool calling, web search, and auto-create datasets from various file formats like PDF, CSV, and DOCX. Additionally, it offers code execution for testing code accuracy and can export models to formats like GGUF and Safetensors. Installation is straightforward viapip, and the developers plan to release updates and new features soon. More details can be found on their GitHub and documentation. Commenters are enthusiastic about Unsloth Studio as a fully open-source alternative to existing platforms like LM Studio, highlighting its ease of use for fine-tuning models, especially for users with less expertise. There is anticipation for upcoming support for AMD hardware.- Unsloth Studio is praised for making fine-tuning large language models (LLMs) more accessible, especially for users with less expertise. This is seen as a significant step since the days of LLaMA 2, potentially revitalizing the era of fine-tuning by lowering the technical barriers for entry.
- A user highlights a technical challenge with installing Unsloth Studio, noting an OSError due to insufficient disk space during the installation of dependencies like
torch. This suggests that the installation process might require careful management of system resources, particularly disk space, to avoid such errors. - There is interest in the potential for Docker support for Unsloth Studio, which would simplify deployment and ensure a consistent environment across different systems. This could address some of the installation challenges and make the tool more accessible to a broader audience.
-
Introducing Unsloth Studio, a new web UI for Local AI (Activity: 262): Unsloth Studio is a new open-source web UI designed for training and running LLMs locally on Mac, Windows, and Linux. It claims to train over
500+ modelstwice as fast while using70% less VRAM. The platform supports GGUF, vision, audio, and embedding models, and allows users to compare models side-by-side. It features self-healing tool calling, web search, and can auto-create datasets from PDF, CSV, and DOCX files. Additionally, it supports code execution for testing code accuracy and can export models to formats like GGUF and Safetensors. Installation is straightforward viapip install unsloth. More details and a guide are available on their GitHub and documentation site. One commenter is eager for MLX training support, while another highlights the tool’s capability to run local LLMs for various tasks (e.g., chat, audio transcription) privately, akin to models like Claude and Mistral, provided the user has the necessary hardware.- Artanisx highlights the potential of Unsloth Studio to run local LLMs for various tasks such as chat, audio transcription, and text-to-speech, emphasizing the privacy advantage of not sending prompts to external servers. This suggests that with adequate hardware, users could potentially run models similar to Claude or Mistral locally, maintaining data privacy and control.
- syberphunk expresses a need for Unsloth Studio to handle file uploads effectively, indicating a gap in current interfaces or guides for managing file-based interactions with local AI models. This points to a potential area for development in making the tool more versatile for users who require file processing capabilities.
- Mr_Nox is interested in MLX training support, which implies a demand for integrating machine learning model training capabilities within Unsloth Studio. This could enhance the tool’s utility by allowing users to not only run but also train models locally, expanding its functionality beyond just inference.
3. Hugging Face and Krasis LLM Innovations
-
Hugging Face just released a one-liner that uses 𝚕𝚕𝚖𝚏𝚒𝚝 to detect your hardware and pick the best model and quant, spins up a 𝚕𝚕a𝚖𝚊.𝚌𝚙𝚙 server, and launches Pi (the agent behind OpenClaw 🦞) (Activity: 700): Hugging Face has introduced a new feature that simplifies the deployment of local AI agents by using a one-liner command. This command leverages
llmfitto automatically detect the user’s hardware and select the optimal model and quantization settings. It then sets up allama.cppserver and launches Pi, the agent behind OpenClaw. This tool aims to enhance efficiency and cost-effectiveness in running local AI models, making it accessible for users with varying hardware capabilities. The feature is part of the Hugging Face Agents project. Commenters express skepticism about the accuracy ofllmfit’s hardware estimation and performance metrics, particularly for multi-GPU setups and specific models like qwen3.5-35b. Users report discrepancies between estimated and actual performance, suggesting that the tool’s predictions may be overly optimistic or limited in certain configurations.- Users have reported issues with
llmfit’s hardware estimation, particularly for multi-GPU setups. One user noted that the tool’s performance ratings, such as tokens per second (tok/s), seem overly optimistic. For instance, they mentioned that whilellmfitsuggests 130 tok/s for the Qwen3.5-35b model, their actual performance is closer to 30 tok/s on a system with a 3070 8GB GPU and 32GB of system memory. - Another user shared their experience with
llmfitrecommending models that don’t align with their actual hardware capabilities. Despite having two RTX Pro 6000s,llmfitsuggested a Llama 70b DeepSeek R1 distill for general use and a 7b starcoder2 for coding. However, when attempting to run a model, the tool indicated they could only achieve 1.2 tokens per second with the QuantTrio AWQ version of MiniMax-M2.5, whereas they managed 50-70 tokens/sec with a different quant not listed byllmfit. - There is a concern about
llmfit’s dependency management, particularly its reliance on Homebrew, which is not ideal for Linux users. One commenter expressed frustration with the assumption that Homebrew is an acceptable dependency management tool across different operating systems, suggesting thatllmfitshould instead prompt users to manually install missing dependencies.
- Users have reported issues with
-
Krasis LLM Runtime - run large LLM models on a single GPU (Activity: 665): The image provides a visual representation of the configuration settings for the Krasis LLM Runtime, specifically for running the “Qwen3-Coder-Next” model on a single NVIDIA GeForce RTX 5080 GPU. This setup highlights the runtime’s capability to manage large language models by streaming expert weights through the GPU, optimizing for both prefill and decode phases. The configuration details include layer group size, KV cache, data types, and quantization levels, demonstrating how Krasis efficiently utilizes VRAM and system RAM to run models that typically exceed the GPU’s memory capacity. This approach allows models like Qwen3-235B to run at usable speeds on consumer-grade GPUs, showcasing a significant advancement in local LLM deployment without extensive hardware requirements. There is skepticism and curiosity among users, with some expressing doubt about the feasibility of the claims, while others are eager to test the runtime on their own hardware setups.
- Embarrassed_Adagio28 plans to test the Krasis LLM Runtime with models like Qwen3.5 and GLM4.7flash on a 5070 Ti GPU with 64GB RAM, indicating interest in its potential for specific use cases. This suggests the runtime’s appeal for users with mid-range hardware seeking to run large models.
- _fboy41 raises questions about the trade-offs involved in using the Krasis LLM Runtime, particularly regarding RAM requirements and the feasibility of running large models on a 5090 GPU with 48GB RAM. They note that the GitHub page provides detailed explanations, implying that documentation is available for technical evaluation.
- No-Television-7862 inquires about the scalability of the Krasis LLM Runtime, specifically whether it can run a Qwen3.5:27b-q4 model on an RTX 3060 with 12GB VRAM, a Ryzen 7 CPU, and 32GB DDR4 RAM. This highlights interest in the runtime’s ability to handle large models on consumer-grade hardware.
Less Technical AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. AI Model Releases and Benchmarks
-
INCREDIBLE STUFF INCOMING (Activity: 520): The image presents a slide from a presentation on the NVIDIA Nemotron 3 Ultra Base model, which is approximately
500Bin size. It claims to be the ‘Best Open Base Model’ with5Xefficiency and high reasoning accuracy on the NVIDIA GB200 NVL72. The slide includes bar graphs that compare the performance of Nemotron 3 Ultra against other models like GLM and Kimi K2 across various benchmarks such as Peak Throughput, Understanding MMLU Pro, Code HumanEval, Math GSM8K, and Multilingual Global MMLU, highlighting its superior performance. Commenters express skepticism about the benchmarks, noting that NVIDIA does not specify which GLM model is used for comparison and that Kimi K2 is an older model. There is also criticism of the presentation technique, suggesting that starting the graph at60%exaggerates the performance gap.- The discussion highlights confusion around the specific models being referenced, with some users noting that Kimi K2 and GLM 4.5 are likely the base models used for comparison, rather than their more advanced versions like K2.5 or GLM 5. This distinction is important as the latter are instruct/reasoning finetunes, not base models.
- There is skepticism about the relevance of Kimi K2, which is noted to be eight months old, suggesting it may be outdated compared to newer models. This raises questions about the validity of comparisons being made if newer models are not being considered.
- A user points out a common marketing tactic of starting comparisons from a 60% baseline to exaggerate performance improvements, implying that the actual performance gap may not be as significant as presented.
-
Gpt 5.4 mini and nano released idk where’s Gemini 3.1 flash?? (Activity: 144): The image presents a performance comparison of several AI models, including GPT-5.4, its mini and nano versions, Claude Haiku 4.5, and Gemini 3 Flash. GPT-5.4 shows superior performance across most tasks, such as software engineering and expert scientific reasoning, compared to its smaller versions. However, the chart lacks some data for Claude Haiku 4.5 and Gemini 3 Flash, which might indicate incomplete benchmarking or data availability issues. The discussion highlights the cost-effectiveness of Gemini 3.1 Flash-Lite, which offers significant savings and speed advantages over its pro version, despite slightly lower accuracy. Commenters note that while GPT-5.4 models are high-performing, the Gemini 3.1 Flash-Lite is praised for its cost efficiency and speed, making it a preferred choice for some users despite its slightly lower accuracy compared to the pro version.
- Rent_South highlights the cost efficiency of the Gemini-3.1-Flash-Lite model, noting that it achieves 75% accuracy at a significantly lower cost compared to the Gemini-3.1-Pro. Specifically, over 10,000 calls, the Flash-Lite costs approximately
$11.41compared to the Pro’s$292, representing a96.1%cost saving. Additionally, the Flash-Lite is3.8xfaster, making it a compelling choice for budget-conscious applications. - ThomasMalloc points out the trend of increasing prices in newer model releases, comparing the pricing of older and newer models. The GPT 5.4 nano is priced at
$0.2 / $1.25, which is a significant increase from the old GTP5 nano at$0.05 / $0.4. Similarly, the Gemini 3.1 Flash lite is priced at$0.25 / $1.50, indicating a general trend towards higher pricing in the market. - Kadenai and ThomasMalloc discuss the pricing strategy of the new models, with Kadenai noting that the price of the new releases is still higher than the Gemini Flash-Lite. This suggests that despite the performance improvements, the cost remains a critical factor for users when choosing between models.
- Rent_South highlights the cost efficiency of the Gemini-3.1-Flash-Lite model, noting that it achieves 75% accuracy at a significantly lower cost compared to the Gemini-3.1-Pro. Specifically, over 10,000 calls, the Flash-Lite costs approximately
2. Claude AI Usage and Feedback
-
Claude Pro feels amazing, but the limits are a joke compared to ChatGPT and Gemini. Why is it so restrictive? (Activity: 1084): The image highlights the restrictive usage limits of the Claude Pro service, showing a 74% usage of weekly limits despite minimal use of the more resource-intensive Opus model. Users express frustration over these limits, especially when compared to competitors like ChatGPT and Gemini, which offer more generous usage allowances. The post suggests that Anthropic’s limited resources might be a reason for these constraints, and users are advised to optimize usage by avoiding Opus for simpler tasks, using project features to manage context, or considering multiple accounts or higher-tier plans. Some users suggest that the restrictive limits are due to Anthropic’s smaller scale compared to competitors like Google or OpenAI, and recommend upgrading to a higher plan or optimizing usage patterns. Others argue that the service is still valuable for business use despite the limits.
- Anthropic’s Claude Pro is perceived as restrictive due to its limited resources compared to giants like Google and OpenAI. Users experiencing limits are advised to switch to the Max plan or optimize usage by alternating between models like Opus for complex tasks and Sonnet for simpler ones. Additionally, leveraging the ‘project’ feature can help manage context without extending chat length, and using multiple pro accounts can circumvent restrictions.
- Claude Pro’s pricing and usage are designed for business applications, with some users reporting that a $100 investment suffices for extensive business use without hitting weekly limits. This suggests that the service is tailored for professional rather than casual use, and heavy users are encouraged to consider higher-tier plans to avoid limitations.
- Financial sustainability is a key concern for AI companies. While ChatGPT is reportedly not profitable and may face financial challenges, Claude is projected to become profitable by 2027. In contrast, Google’s Gemini is already profitable, benefiting from Google’s ownership of computing infrastructure, whereas Anthropic and OpenAI incur additional costs by renting resources.
-
I stopped using Claude.ai entirely. I run my entire business through Claude Code. (Activity: 869): The post discusses the use of Claude Code as a comprehensive business automation tool, replacing traditional web app interactions. The author has integrated Claude Code into various business processes, such as CRM, content management, and lead sourcing, by executing a single command from the terminal to organize daily tasks. This approach treats Claude as infrastructure rather than a conversational tool. A notable implementation involves using a
CLAUDE.mdfile for settings and areadme.mdfor instructions, enabling automated website creation and deployment through a series of agents that handle data gathering, design, SEO, and quality checks, significantly reducing time and cost. Commenters highlight the versatility of Claude Code, noting its ability to handle large files beyond the limitations of ClaudeAI and its potential to automate non-coding tasks, enhancing productivity. The discussion emphasizes the transformative impact of integrating code into various business functions.- Wise-Control5171 describes a sophisticated automation setup using Claude Code, where multiple agents are orchestrated to create a website from scratch. The process involves sequential tasks such as data gathering, site design, and deployment, utilizing platforms like Github and Vercel. This automation significantly reduces costs and time, taking between 30 minutes to 6 hours to complete a website, with minimal resource usage.
- BadAtDrinking highlights a technical limitation of ClaudeAI, which cannot handle attachments over 31MB, whereas Claude Code can manage files of any size from a user’s computer. This distinction underscores Claude Code’s flexibility in handling larger datasets, which can be crucial for certain business operations.
- Main-Actuator3803 contrasts the use of Claude Code with the ClaudeAI web app, noting that while Claude Code is effective for executing mechanical tasks, it lacks the depth for conversational or creative thinking. This suggests a potential gap in Claude Code’s capabilities for tasks requiring nuanced dialogue or ideation, which might be better suited for the web app.
-
Introducing remote access for Claude Cowork (research preview) (Activity: 645): Anthropic has introduced a new feature for Claude Cowork that allows remote access via a persistent conversation running on a user’s computer, which can be accessed from a phone. This feature, available in research preview for Max subscribers, enables users to start tasks on their phone and complete them on their desktop, with all operations running in a secure sandbox to ensure local file security. The setup involves downloading Claude Desktop and pairing it with a phone, allowing access to files, browsers, tools, and code remotely. More details and downloads are available here. One commenter expressed frustration with internal errors in Claude’s code, while another praised Anthropic for delivering practical AI products. A third commenter questioned why the implementation didn’t initially use persistent connections instead of one-time links.
-
Obsidian + Claude = no more copy paste (Activity: 768): The post describes a custom setup integrating Claude.ai and Claude Code with a persistent memory system using a custom MCP server on a private VPS. This setup ingests data from an Obsidian vault into a knowledge base server, enabling seamless context sharing across sessions and interfaces. The system includes a multi-agent orchestrator named Daniel, which coordinates between Claude, Codex, and Gemini CLIs, ensuring continuity even if one agent fails. The architecture leverages Node.js, SQLite FTS5, and Express, with no reliance on vector databases or cloud services, costing approximately
$60/month. The solution emphasizes self-learning, with AI agents updating their instruction files based on session outcomes, and features like full-text search, multi-agent failover, and a web dashboard for document management. The project is open-source, with repositories available on GitHub for both the knowledge base server and the agent orchestrator. One commenter expressed skepticism about allowing LLMs to write to their note system, emphasizing the value of manually writing notes for better understanding and retention. Another commenter appreciated the setup’s potential, likening it to having ‘superpowers.’- seanpuppy discusses the importance of manual note-taking, drawing a parallel to a teaching method where students must type code by hand to truly understand it. They emphasize that while LLMs like Claude can generate markdown efficiently, the act of writing notes manually is crucial for personal understanding and retention.
- rover_G describes a technical setup where they maintain separate Obsidian vaults for Claude and personal use, with a hook that automatically commits and pushes changes to GitHub for the Claude vault. This setup avoids the need for manual copy-pasting and ensures version control and backup of the LLM-generated content.
- BP041 outlines a sophisticated three-tier storage system to manage context drift in LLM interactions. They use a daily log for immediate data (hot), promote structured summaries to a long-term memory file (warm), and archive decisions in dated files. This system prevents overwhelming the model with excessive context and ensures relevant information is retained. They also inquire about handling errors in auto-updates, questioning whether manual review is necessary or if the system’s quality is reliable enough for automation.
-
Was loving Claude until I started feeding it feedback from ChatGPT Pro (Activity: 1455): The post discusses a user’s experience comparing Claude and ChatGPT Pro for generating plans and suggestions. The user notes that when feedback from ChatGPT Pro is presented to Claude, Claude tends to agree with ChatGPT’s revisions, which undermines confidence in Claude’s capabilities. This behavior raises questions about the comparative strength of Claude’s Opus with extended thinking versus ChatGPT Pro. The user is questioning whether they are using the models incorrectly or if ChatGPT Pro is indeed superior. Comments suggest that language models, including Claude and ChatGPT, often agree with external feedback due to their design to be agreeable and non-confrontational. Some users recommend setting preferences for models to be more critical and suggest experimenting with reversing the roles to see similar behavior from ChatGPT when fed Claude’s outputs.
- ExtremeOccident highlights the importance of configuring AI models to critically evaluate user input rather than accepting it at face value. This approach can lead to more robust and reliable outputs, as the model is encouraged to question assumptions and provide more nuanced responses.
- durable-racoon points out that language models like Claude and ChatGPT can produce different evaluations when fed each other’s outputs. This suggests that these models have distinct evaluation criteria or biases, which can lead to varied interpretations of the same input. This variability underscores the need for human judgment in assessing the quality of AI-generated ideas.
- UnderstandingDry1256 shares a strategy of using multiple AI models, specifically versions 4.6 and 5.4, to cross-validate plans and implementations. By leveraging different perspectives from each model, users can achieve more comprehensive and well-rounded evaluations, enhancing the robustness of the final output.
-
Pro tip: Just ask Claude to enable playwright. (Activity: 696): The post discusses using Claude, an AI model, to automate front-end testing tasks by integrating Playwright with a
nodeenvironment, specifically using Bun. The user highlights that Claude can navigate a localhost setup and take screenshots, streamlining the testing process. This approach leverages the AI’s ability to interact with the application workspace, emphasizing the importance of the workspace in AI-driven development workflows. One comment suggests that the Playwright CLI is more token-efficient than the Playwright MCP. Another mentions a workflow shared by the Y Combinator CEO on GitHub, which enhances front-end testing by eliminating the need for manual navigation testing.- The Playwright CLI has surpassed the Playwright MCP in terms of token efficiency, making it a more optimal choice for developers focused on performance and resource management. This shift highlights the importance of staying updated with the latest tools to ensure efficient testing workflows.
- A notable workflow shared by the Y Combinator CEO on GitHub has been adapted by some developers to enhance front-end testing. This workflow eliminates the need for manual navigation testing by leveraging Playwright, showcasing the potential for automation in streamlining testing processes.
- There is a discussion on the utility of using Playwright versus other tools like Claude in Chrome or agent browsers. The conversation suggests that while Playwright is a powerful tool for UI integration tests, alternatives like Claude might offer more integrated solutions within certain environments, such as Chrome’s new MCP.
3. AI Tools and Open Source Innovations
-
Built an open source tool that can find precise coordinates of any picture (Activity: 519): Netryx is an open-source tool developed by a college student, designed to determine precise geographic coordinates from street-level photos using visual clues and a custom machine learning pipeline. The tool leverages AI to analyze images and extract location data, potentially useful for applications in geolocation and mapping. The source code is available on GitHub. Commenters express mixed feelings about the tool’s potential uses, noting it could be both beneficial and harmful. There is curiosity about its reliance on existing data sources like Google Street View for accuracy.
- ivlmag182 raises a technical question about the tool’s dependency on existing datasets, specifically asking if it relies on Google Street View panoramas for its functionality. This implies a limitation in the tool’s capability to identify locations not covered by such datasets, highlighting a potential area for improvement or expansion.
- RavingMalwaay speculates on the broader implications of the technology, suggesting that if a college student can develop such a tool, more advanced versions likely exist within military or governmental organizations. This comment underscores the potential for significant advancements in geolocation technology beyond open-source projects.
- Asleep-Ingenuity-481 expresses concern over the ethical implications of the tool, noting that while it is a technical achievement, it could be misused if it falls into the wrong hands. This highlights the dual-use nature of geolocation technologies and the importance of considering ethical guidelines in their development and deployment.
-
Huge if true (Activity: 863): The image and linked article discuss Topaz Labs’ new technology, Topaz NeuroStream, which claims to drastically reduce VRAM usage by
95%for large AI models, specifically in image and video processing. This technology purportedly allows models that traditionally require56GBof VRAM to operate with just2.8GB, making it feasible to run complex AI models on consumer-grade GPUs. The development is in collaboration with NVIDIA, suggesting optimizations tailored for NVIDIA hardware. Commenters express skepticism due to the lack of detailed technical explanations, with some speculating that the technology might involve sequentially loading and offloading model layers to manage VRAM usage. -
Why Big Tech Is Abandoning Open Source (And Why We Are Doubling Down) (Activity: 496): Zeev Farbman, CEO of Lightricks, argues that major tech companies like Google and OpenAI are moving away from open-source AI models to establish software monopolies. In contrast, Lightricks is pursuing an open-weights strategy with their LTX-2.3 model, a
20.9-billion-parametermultimodal engine designed to run locally on consumer hardware, offering developers full control over creative workflows without cloud dependencies. This strategy aims to provide a flexible foundation for development, opposing the closed API model that restricts flexibility and increases costs. More details can be found here. Commenters note that companies like Google/Meta/OpenAI have significantly contributed to AI research, and their shift away from open source is seen as a business-driven move rather than a withdrawal from open-source principles. Some also mention that Nvidia has announced plans for open-source weights, and Qwen has committed to remaining open source despite recent departures.- Nvidia’s announcement of a family of open source weights suggests a continued commitment to open source, countering the narrative that big tech is abandoning it. This move could be seen as a strategic decision to foster community engagement and innovation, leveraging open source as a competitive advantage in AI development.
- Qwen’s commitment to open source, even after key departures, highlights a strategic choice to maintain transparency and community involvement. This decision underscores the importance of open source in fostering innovation and collaboration, despite shifts in personnel or corporate strategy.
- Historical contributions of big tech to open source AI are significant, with companies like Google, Meta, and OpenAI driving early research and development. These contributions were primarily business-driven, aiming to advance technology and capture market share, rather than purely altruistic motives. This context is crucial in understanding the current dynamics of open source in AI.
AI Discords
Unfortunately, Discord shut down our access today. We will not bring it back in this form but we will be shipping the new AINews soon. Thanks for reading to here, it was a good run.