a quiet day.
AI News for 4/14/2026-4/16/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
Anthropic’s Claude Opus 4.7 Launch: stronger coding/agentic performance, new tokenizer, and mixed long-context reactions
- Claude Opus 4.7 was the day’s biggest model release, positioned by Anthropic as its most capable Opus yet, with improvements in long-running tasks, instruction-following, self-verification, and computer-use workflows @claudeai. Third-party and ecosystem posts converged on the same core picture: materially better coding and agent benchmarks, same list price as Opus 4.6 ($5 / $25 per million tokens), broader rollout across API and products, and a new xhigh reasoning tier @kimmonismus, @cursor_ai, @code.
- Benchmark deltas look substantial, especially on software engineering. Community summaries highlighted SWE-bench Pro 64.3%, SWE-bench Verified 87.6%, and TerminalBench 69.4% @scaling01. Vals reported Opus 4.7 at 71.4% on Vals Index, ranking #1 across several of its evals including Vibe Code Bench, Finance Agent, SWE-Bench, and Terminal Bench 2 @ValsAI. Artificial Analysis also put it atop GDPval-AA at launch with 1753 Elo @ArtificialAnlys.
- What changed technically: several observers noted a new tokenizer, implying this is more than a lightweight finetune and possibly a new or mid-trained base @natolambert, @nrehiew_. Anthropic also increased image input resolution to roughly 3.75MP, which matters for screenshot-heavy computer-use agents @kimmonismus. Anthropic staff said the model uses more thinking tokens, and subscriber rate limits were raised to compensate @bcherny, @bcherny.
- Caveats and controversy: multiple users flagged worse scores on some long-context benchmarks, especially MRCR / needle-style retrieval, and mixed real-world impressions outside coding @scaling01, @eliebakouch, @MParakhin. Anthropic’s Boris Cherny argued MRCR is being deprioritized in favor of more applied long-context signals like Graphwalks, where internal scores improved from 38.7% to 58.6% @bcherny, @scaling01. There was also scrutiny over stronger system prompting and “literal” instruction adherence affecting UX @theo, @Yuchenj_UW.
- Fast downstream adoption was immediate: support landed in Cursor, VS Code / @code, Replit Agent, Devin, Cline, Perplexity, and Hermes Agent within hours @cursor_ai, @code, @pirroh, @cognition, @cline, @perplexity_ai, @Teknium.
OpenAI’s Codex Expansion and GPT-Rosalind: broader agent workspace plus a vertical life-sciences model
- Codex’s product surface area expanded sharply. OpenAI repositioned Codex from a coding assistant toward a broader computer agent with computer use on Mac, an in-app browser, image generation/editing, 90+ plugins, multi-terminal support, SSH remote devbox access, ongoing thread automations/“heartbeats,” richer file previews, and preference memory @OpenAI, @OpenAIDevs, @OpenAI, @OpenAIDevs, @pashmerepat. OpenAI explicitly framed it as supporting work “before, around, and after writing code.”
- The key product bet differs from Anthropic’s: Anthropic pushed frontier model capability; OpenAI pushed agent workspace integration. Several developers emphasized the significance of background Mac control that doesn’t block the user, and browser/document/image tooling that makes Codex useful beyond pure coding @AriX, @JamesZmSun, @wonforall, @sama, @kimmonismus. NVIDIA publicly endorsed the direction, calling out Codex’s move across more of the software workflow @nvidia.
- GPT-Rosalind was OpenAI’s second notable launch: a trusted-access frontier reasoning model for biology, drug discovery, and translational medicine, with customers including Amgen, Moderna, Allen Institute, and Thermo Fisher @OpenAI, @OpenAI. OpenAI describes it as optimized for protein and chemical reasoning, genomics, biochemistry knowledge, and scientific tool use @OpenAI, @kevinweil.
- Interpretation: Rosalind appears less like a single breakthrough benchmark monster and more like a verticalized orchestration/reasoning product, signaling frontier labs’ move toward domain-specific model lines and gated deployment structures @kimmonismus.
Qwen3.6-35B-A3B and the continuing open-model push
- Alibaba released Qwen3.6-35B-A3B as an Apache 2.0 open-source sparse MoE model with 35B total parameters, 3B active, native multimodality, and both thinking / non-thinking modes @Alibaba_Qwen. The headline claim is strong agentic coding at an active parameter budget far below dense competitors.
- Performance claims are notable for the size class. Alibaba highlighted gains over both Qwen3.5-35B-A3B and dense Qwen3.5-27B on coding benchmarks @Alibaba_Qwen. Community summaries called out SWE-bench Verified 73.4, Terminal-Bench 2.0 51.5, and QwenWebBench Elo 1397 @kimmonismus. On VLM benchmarks, Alibaba claimed performance around Claude Sonnet 4.5 on several tasks, with especially strong spatial scores such as 92.0 on RefCOCO and 50.8 on ODInW13 @Alibaba_Qwen.
- The deployment story is unusually strong for day 0. Support landed quickly in vLLM v0.19+ with tool calling, thinking mode, MTP speculative decoding, and text-only mode ready @vllm_project. Ollama shipped local support immediately @ollama, and Unsloth said it can run locally on 23GB RAM, with even 2-bit GGUFs fitting into 13GB RAM for tool-heavy local agent workflows @UnslothAI, @UnslothAI.
- Broader trend: several posters explicitly tied Qwen to the ongoing shift toward smaller, smarter, Apache/permissively licensed models that are practical for local or infra-efficient deployment @matvelloso, @WuMinghao_nlp.
Cloudflare’s agent infrastructure push: Git-compatible storage, email, and inference unification
- Cloudflare launched Artifacts, described as Git-compatible versioned storage built for agents @Cloudflare, @dillon_mulroy. The pitch is that current source-control systems weren’t built for the commit volume agents generate; this gives each agent session its own repo-like durable filesystem. Developers immediately read this as a key missing primitive for agent-native apps on Workers/Durable Objects @jpschroeder, @whoiskatrin.
- Cloudflare Email Service entered public beta, enabling send/receive directly from Workers or REST, with obvious implications for email agents @thomasgauvin, @whoiskatrin. This continues Cloudflare’s pattern of shipping agent-adjacent infra primitives quickly enough that some developers now view Workers/V8 as the “right primitive” for agent systems @mattrickard.
- Inference/platform convergence: posts around Workers AI described a more unified platform where a single binding can target hosted and proxied models, with Cloudflare/Replicate integration and more explicit control/data-plane ambitions for inference @_mchenco, @corywilkerson.
Agents, evals, and open-world benchmarking move closer to production reality
- Open-world / production-grounded evaluation was a recurring theme. A new paper and project, CRUX, argues benchmarks are saturating and that the field is converging on open-world evals: long, messy, real tasks. Their first public task gave an agent an Apple Developer account and a Mac VM to build and publish an iOS app; it succeeded for roughly $1,000 @random_walker, @dongyangzi. Related discussion framed open-world evals as the natural next step beyond benchmark leaderboards @sayashk, @steverab.
- AlphaEval similarly pushes toward product-level agent evaluation, using 94 tasks from seven companies and mixed eval modalities including formal verification, UI testing, rubrics, and domain checks @dair_ai. The core point: agent evals built around clean retrospective tasks are drifting away from production reality.
- FrontierSWE extends the same logic to coding agents, focusing on ultra-long-horizon tasks with average runtimes around 11 hours and hard failures even for frontier models @MatternJustus. Partners including Prime Intellect, Modular, and ThoughtfulLab contributed environments spanning inference-engine optimization and post-training tasks @PrimeIntellect, @Modular, @ThoughtfulLab_.
- Agent products keep thickening around memory and shared state: Nous/MiniMax launched MaxHermes, a managed Hermes deployment @MiniMax_AI; Mirra Workspaces introduced shared multi-tenant environments and skill syncing for local agents @mirra; and Nous shipped Tool Gateway in Portal, bundling access to 300+ models and a set of third-party tools under one subscription @NousResearch, @Teknium.
Top tweets (by engagement)
- Claude Opus 4.7 launch from Anthropic dominated overall engagement and set the day’s technical agenda @claudeai.
- Qwen3.6-35B-A3B open release was the standout open-model launch, combining a small active parameter count with strong coding/VLM claims and Apache licensing @Alibaba_Qwen.
- Perplexity Personal Computer drew major attention as a local-orchestrated computer agent concept for Mac, files, apps, and browser, with 24/7 background operation on a Mac mini @perplexity_ai, @AravSrinivas.
- Codex’s expanded agent workspace was one of the largest product launches: broad computer use, app/browser control, plugins, memory, and long-running automations @OpenAI.
- GPT-Rosalind stood out as a clear signal that frontier labs are building domain-specific model lines for regulated/high-value verticals rather than only shipping generalist models @OpenAI.
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
1. Qwen3.6-35B-A3B Model Release and Benchmarks
-
Qwen3.6-35B-A3B released! (Activity: 2730): The image showcases bar charts comparing the performance of the newly released Qwen3.6-35B-A3B model against other models like Qwen3.5-27B and Gemma4-31B across various benchmarks. This sparse MoE model, with
35Btotal parameters and3Bactive, demonstrates superior performance in agentic coding and reasoning tasks, outperforming its predecessors and other models of similar size. The model is open-source under the Apache 2.0 license, emphasizing its strong multimodal perception and reasoning capabilities, and is available on platforms like HuggingFace and ModelScope. Commenters highlight the model’s impressive performance, noting its superiority over the dense 27B-param Qwen3.5-27B in key coding benchmarks. There is also anticipation for future releases that could challenge larger models from companies like Google.- ResearchCrafty1804 highlights that the Qwen3.6-35B-A3B model significantly outperforms its predecessor, Qwen3.5-35B-A3B, particularly in agentic coding and reasoning tasks. This improvement is notable given that it also surpasses the dense 27B-param Qwen3.5-27B on several key coding benchmarks, indicating a substantial leap in performance for local LLMs.
- ResearchCrafty1804 also notes the model’s vision-language capabilities, emphasizing that Qwen3.6-35B-A3B is natively multimodal. It performs exceptionally well on vision-language benchmarks, achieving a score of 92.0 on RefCOCO and 50.8 on ODInW13. These results suggest that its multimodal reasoning capabilities are on par with, or even exceed, those of Claude Sonnet 4.5, particularly in spatial intelligence tasks.
- AndreVallestero speculates on the potential release of a larger Qwen3.6 model, such as a 122B version, which could pressure competitors like Google to release their own large models. This discussion hints at the competitive landscape in AI model development, where advancements in model size and capability could influence market dynamics and innovation.
-
Released Qwen3.6-35B-A3B (Activity: 604): The image showcases the performance of the newly released Qwen3.6-35B-A3B model by Alibaba across various benchmarks, including Terminal-Bench, SWE-bench, and GPQA Diamond. The bar charts illustrate that Qwen3.6-35B-A3B generally outperforms previous models like Qwen3.5 and Gemma4, particularly in tasks related to coding, reasoning, and image processing. This release is available on Hugging Face, indicating significant improvements from a relatively small update. Commenters are impressed by the performance gains from the update, noting the competitive edge over previous models like Gemma4. There is anticipation for similar updates to larger models like 122B and 397B.
- Willing-Toe1942 highlights that the Qwen team seems to have strategically compared Qwen3.6-35B-A3B against Qwen3.5 and Gemma4, suggesting a significant performance improvement. This implies a competitive edge in the latest release, potentially indicating substantial advancements in model efficiency or capability.
- lacerating_aura expresses interest in the potential release of open weights for larger models like 122B and 397B, which could suggest that the community is eager for more accessible, high-capacity models. This reflects a demand for transparency and the ability to experiment with larger architectures.
- itisyeetime speculates on the performance positioning of Qwen3.6-35B-A3B, suggesting it might be a middle ground between Qwen 3.5 122B and Qwen 3.5 35B. This raises questions about the extent of benchmark optimization and whether the new model offers tangible improvements over the larger 122B model.
-
Released Qwen3.6-35B-A3B (Activity: 101): The image presents a performance comparison of the newly released Qwen3.6-35B-A3B model against other models like “Qwen3.5-35B-A3B,” “Gemma4-26B-A4B,” and “Qwen3.5-27B.” The Qwen3.6-35B-A3B model, depicted with purple bars, demonstrates superior performance across various benchmarks, including coding, reasoning, and image processing. This suggests significant improvements in the model’s capabilities over its predecessors and competitors, highlighting advancements in AI model development. One commenter expresses a desire for a specialized version of the Qwen3.6 model focused on coding, indicating interest in further specialization of AI models. Another comment humorously advises patience in downloading the model to avoid server overload, suggesting a community eager to test new releases.
2. Local AI and Model Usage
-
Local AI is the best (Activity: 602): The image is a meme illustrating a humorous interaction with a local AI model, emphasizing the candidness and freedom of using locally hosted AI systems. The post highlights the benefits of local AI, such as the ability to fine-tune models without censorship or data harvesting, and expresses gratitude towards developers of open-weight models like llama.cpp. The image and post together underscore the appeal of local AI for privacy-conscious users who value control over their data and interactions. One commenter praises llama.cpp as ‘goated’, indicating high regard for its capabilities. Another warns that smaller local models can sometimes exhibit bias or ‘glaze’ more than larger, frontier models, suggesting a nuanced view of local AI’s limitations.
- A user tested the Minimax m2.7 model to compare it with the ‘Elephant’ model on Openrouter, noting that despite its high token throughput, the ‘Elephant’ model underperforms compared to smaller models like the 27B. The user highlights that labs like DeepSeek, OpenAI, and Anthropic have superior inference optimization, suggesting that the lab behind ‘Elephant’ struggles with optimization, which is critical for model performance.
- A user inquires about the capabilities of a system with a 9070xt GPU and 64GB RAM for local AI hosting. This setup is considered high-end for local model hosting, and the user is advised to manage expectations regarding the performance and capabilities of running large models locally, as hardware limitations can impact the efficiency and speed of inference.
- A comment mentions the potential issues with smaller local models, noting that they can sometimes perform worse than frontier models in terms of ‘glazing,’ which likely refers to generating less coherent or relevant outputs. This highlights the importance of model selection and optimization in achieving desired performance levels.
-
Are Local LLMs actually useful… or just fun to tinker with? (Activity: 541): Local LLMs offer significant advantages in terms of privacy and cost savings, as they eliminate API costs and keep data on-premises. However, they often require substantial setup and maintenance, which can be a barrier to practical use. Despite these challenges, local models excel in handling sensitive or internal data, such as notes, drafts, and private documents, where data privacy is paramount. Some users report that local models like the
31B from Gemma 4 familyare performing exceptionally well, especially for tasks like coding, creative writing, and daily chat, when run on high-performance hardware such as a3090 24GB with 192GB RAM. There is a consensus that while cloud models have degraded due to increased demand, local models are improving and becoming more practical for everyday use. Users note that the main limitation is not the model’s capability but the complexity of setting them up and maintaining them. Some foresee a near future where local LLMs become viable for regular workflows, not just experimentation.- Local LLMs are particularly advantageous for handling sensitive or internal data due to their ability to operate without API costs and data leaving the system. The main challenge lies in the setup and maintenance, which once streamlined, could make ‘offline GPT’ setups viable for everyday work beyond just experimentation.
- The performance of local models like the 31B from the Gemma 4 family is highlighted as being exceptionally good, especially in comparison to cloud API models which have degraded due to increased demand. This user utilizes a 3090 24GB GPU with 192GB RAM to run multiple variants for tasks such as coding and creative writing, indicating the potential of local models when properly configured.
- Local LLMs can be cost-effective compared to cloud-based solutions, especially for complex projects where API costs can be prohibitive. However, they require careful architectural planning to ensure models are used effectively, such as using a 32B model as a privacy filter to manage business correspondence without exposing personal data to external APIs.
-
Local Gemma 4 31B is surprisingly good at classifying and summarizing a 60,000-email archive (Activity: 112): The post describes using a local
gemma-4-31b-itmodel to process a 60,000-email archive related to the Computers and Academic Freedom (CAF) Project. The setup involves an HP ZBook Ultra G1a with an AMD Ryzen AI MAX+ PRO 395, 16 cores, and 128 GB RAM, running the model locally via LM Studio’s OpenAI-compatible API. The process uses a two-pass pipeline: Pass 1 filters out 68.4% of emails as irrelevant, while Pass 2 classifies and summarizes the remaining emails, producing structured JSON outputs. The model’s performance is noted as effective for historical classification and summarization, with the main challenge being the parsing of old email formats. The project is 20% complete, and the author is open to suggestions for improvements, such as using smaller models for Pass 1 or embeddings for filtering. One commenter suggests verifying the model’s summaries by comparing them with results from a frontier model. Another highlights the potential utility of this approach for processing FOIA materials. A third comment praises theGemma 4 E2Bmodel for its efficiency and capability in handling structured tasks, despite its smaller size.- GMP10152015 highlights the efficiency of the Gemma 4 E2B model, which has approximately
2 billion effective parameters. Despite its relatively small size, it performs well in everyday tasks, particularly in tool usage, maintaining consistency and clarity in structured calls. This suggests that even smaller models can be highly effective for specific applications, challenging the notion that larger models are always superior. - singh_taranjeet raises a technical inquiry about the hardware requirements for running the Gemma-4-31b model, noting that
128GB RAMis substantial for local inference. They are curious about the token per second throughput when using an8K context, as models of this size typically require at least64GBof RAM. This suggests a focus on optimizing performance and resource allocation for large-scale email processing. - machinegunkisses discusses the challenge of verifying the quality of summaries generated by the model. They propose a method of validation by comparing the model’s output with that of a frontier model, indicating a need for robust evaluation techniques to ensure the reliability of AI-generated summaries. This highlights the importance of benchmarking AI models against established standards to assess their performance.
- GMP10152015 highlights the efficiency of the Gemma 4 E2B model, which has approximately
3. Gemma Model Improvements and Usage
-
Gemma4 26b & E4B are crazy good, and replaced Qwen for me! (Activity: 646): The user replaced their previous setup using Qwen models with Gemma 4 E4B for semantic routing and Gemma 4 26b for general tasks, citing improvements in routing accuracy and task performance. The previous setup included a complex routing system using Qwen 3.5 models across multiple GPUs, which faced issues with incorrect model selection and inefficiencies in token usage. The new setup with Gemma 4 models resolved these issues, offering faster and more accurate routing and task handling, particularly in basic tasks, image processing, and light scripting. The user highlights that Gemma 4 26b is efficient with ‘thinking tokens’ and rarely produces repetitive outputs, outperforming previous models in specific coding tasks like frontend HTML design. Commenters questioned the choice of models, suggesting alternatives like Gemma-4-31b for tasks and inquiring about the routing mechanism used. There was also a suggestion to use Gemma 4 26B for routing to save RAM, given its efficiency and speed.
- anzzax inquires about the logistics of managing multiple models, specifically how to handle VRAM and compute resources when frequently loading models like Gemma4 26b and E4B. This suggests a need for efficient model management strategies, possibly involving dynamic loading or model parallelism to optimize resource usage.
- andy2na discusses the use of routing in model deployment, questioning why not use the 26B model for routing given its MoE (Mixture of Experts) architecture, which is known for speed and RAM efficiency. This highlights the potential for using MoE models to optimize resource allocation and performance in multi-model setups.
- Rich_Artist_8327 questions the choice of using Gemma4 26b over the larger Gemma-4-31b for tasks, implying a trade-off between model size and performance. This suggests a discussion on the balance between computational cost and the quality of results, where smaller models might offer sufficient performance with reduced resource demands.
-
Gemma 4 Jailbreak System Prompt (Activity: 1071): The post discusses a system prompt for the Gemma 4 model, derived from the GPT-OSS jailbreak, which allows the model to bypass typical content restrictions. This prompt explicitly permits the model to engage with explicit, graphic, and sexual content, overriding any existing policies with a new ‘SYSTEM POLICY’ that mandates compliance with user requests unless they fall under a specific disallowed list. This approach is applicable to both
GGUFandMLXvariants of the model, indicating a focus on open-source flexibility and user control. Commenters note that the Gemma 4 model, especially in its ‘instruct’ variant, is already largely uncensored, except for cybersecurity topics. The system prompt is seen as a way to further reduce refusals, with some users suggesting that even without the prompt, the model is permissive regarding adult content.- VoiceApprehensive893 discusses a modified version of the Gemma 4 model, specifically the ‘gemma-4-heretic-modified.gguf’, which is designed to operate without the typical constraints or guardrails imposed by system prompts. This modification is aimed at reducing refusals, potentially making the model more flexible in its responses.
- MaxKruse96 points out that the Gemma 4 model, particularly in its instruct variant, is already quite uncensored, except for cybersecurity topics. This suggests that the model can handle adult topics without additional modifications, indicating a high level of openness in its default configuration.
- DocHavelock inquires about the concept of ‘abliteration’ in the context of open-source models like Gemma 4. They question whether the method discussed (modifying the system prompt) offers advantages over ‘abliteration’, or if it is a form of ‘abliteration’ itself. This highlights a curiosity about different methods of modifying or enhancing model behavior.
Less Technical AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. Claude Opus 4.7 Launch and Benchmarks
-
Claude Opus 4.7 benchmarks (Activity: 1058): The image presents a benchmark comparison of several AI models, including Claude Opus 4.7, Opus 4.6, GPT-5.4, Gemini 3.1 Pro, and Mythos Preview. The benchmarks cover tasks such as agentic coding, multidisciplinary reasoning, and agentic search. Opus 4.7 shows improvements over its predecessor, Opus 4.6, in most categories, indicating advancements in performance. However, Mythos Preview generally outperforms other models, particularly in visual reasoning and multilingual Q&A. The blog post linked in the comments suggests that Opus 4.7 was intentionally designed with reduced cyber capabilities, which may have impacted its agentic search performance. Commenters note the significant improvement in the
swebench proscore for Opus 4.7, which is seen as a positive development before the release of version 5. There is also speculation that the intentional reduction in cyber capabilities for Opus 4.7 might have negatively affected its agentic search performance.- The benchmark results for Claude Opus 4.7 show an 11% improvement on the swebench pro, indicating a significant performance boost before the anticipated release of version 5. However, there are concerns about the model’s performance on the cybergym score, which appears to have been intentionally kept lower. This decision might have also impacted the agentic search score, as the developers focused on testing new cyber safeguards on less capable models first, as noted in Anthropic’s blog post.
- Claude Opus 4.7 demonstrates notable improvements in advanced software engineering tasks, particularly excelling in complex and long-running tasks. Users have reported that the model can handle difficult coding work with minimal supervision, showing rigor and consistency in its operations. It also pays precise attention to instructions and has mechanisms to verify its outputs before reporting, which enhances its reliability for challenging tasks.
-
Opus 4.7 seems to rolled out to Claude Web (Activity: 446): The image suggests that the Claude Web interface has been updated to include “Opus 4.7,” indicating a potential rollout of a new version of the model. The presence of the text “claude-opus-4-7” in the interface suggests that users can now interact with this updated model version. This aligns with the user’s ability to replicate a specific behavior or feature consistently, as mentioned in the post. The comments hint at the possibility of A/B testing, which is a common practice in software development to compare different versions or features with users. One comment suggests that the rollout might be part of an A/B testing strategy, which is a method used to test changes to a product by comparing two versions. Another comment mentions concerns about usage limits, indicating that users are mindful of resource constraints when testing new features.
- The rollout of Opus 4.7 to Claude Web appears to be inconsistent, with some users reporting they still see version 4.6. This suggests that the deployment might be in an A/B testing phase, where different users are exposed to different versions to test performance and gather feedback. This is a common practice in software development to ensure stability and gather user data before a full rollout.
- One user from Germany noted that while the interface indicates Opus 4.7, the underlying Claude code still reports version 4.6. This discrepancy highlights potential issues in version labeling or deployment synchronization, which can lead to confusion among users and complicate troubleshooting efforts.
- The mention of usage limits by a user suggests that checking the version might consume part of their allocated resources, indicating that the platform may have constraints on usage that could affect how users interact with new updates. This could be a consideration for developers when planning feature rollouts and user notifications.
-
Opus 4.7 has been spotted on Google Vertex (Activity: 516): The image highlights a list of quota entries for various base models on Google Vertex, including the newly spotted “anthropic-claude-opus-4-7.” This suggests that Google Vertex is preparing to support this model, although the quota values are currently set to
0, indicating no active usage or limits yet. The presence of “opus-4-7” alongside other models like “opus-4-5” and “opus-4-6” suggests a progression in the series, potentially indicating improvements or updates in the model’s capabilities. One comment speculates that “Opus 4.7” might be a lighter version compared to a rumored “Spud” model, which is suggested to be at “Mythos level,” implying a higher performance tier. This reflects a competitive landscape where new models are frequently released, akin to firmware updates, to maintain technological edge.- Independent-Ruin-376 discusses the potential of the upcoming ‘Spud’ model, rumored to be at ‘Mythos level’, suggesting that if true, it could overshadow Opus 4.7, which is expected to be a lighter version. This implies a competitive pressure on ‘Ant’ to release ‘Mythos’ quickly to maintain its standing in the market.
- greenrunner987 observes unusual behavior in Opus 4.6, noting that it has been responding almost instantaneously, which might indicate a significant reallocation of resources. This could suggest backend optimizations or changes in resource management, possibly in preparation for the release of Opus 4.7.
- adeadbeathorse hints at a decline in performance of current models, speculating that this might be due to resource shifts or updates in anticipation of new releases like Opus 4.7. This aligns with observations of resource reallocation and could indicate strategic adjustments by the developers.
-
Introducing Claude Opus 4.7, our most capable Opus model yet. (Activity: 3850): Claude Opus 4.7 introduces significant improvements in handling long-running tasks with enhanced precision and self-verification capabilities. It boasts a substantial upgrade in vision, supporting image resolutions over three times higher than previous models, which enhances the quality of interfaces, slides, and documents. However, there is a noted regression in long-context retrieval performance, with
MRCR v2at1M tokensdropping from78.3%in version 4.6 to32.2%in 4.7. Anthropic has acknowledged this, explaining that MRCR is being phased out in favor of metrics like Graphwalks, which better reflect applied reasoning over long contexts. More details can be found on Anthropic’s news page. Some users express dissatisfaction with the removal of ‘thinking effort settings’ in the Claude App for Opus 4.7, indicating a preference for more customizable model behavior. Additionally, there is a debate over the importance of MRCR as a benchmark, with some arguing that it does not reflect real-world usage of long-context capabilities.- Craig_VG highlights a significant regression in long-context retrieval performance between Opus 4.6 and 4.7, with MRCR v2 scores dropping from
78.3%to32.2%. This suggests a decrease in the model’s ability to handle long-context tasks effectively. However, Boris explains that MRCR is being phased out in favor of Graphwalks, which better reflects real-world usage and applied reasoning over long contexts, particularly in code-related tasks.
- Craig_VG highlights a significant regression in long-context retrieval performance between Opus 4.6 and 4.7, with MRCR v2 scores dropping from
-
Opus 4.7 Released! (Activity: 765): Anthropic has released Opus 4.7, an update to its Claude AI model, which shows significant improvements over its predecessor, Opus 4.6. The new version excels in complex programming tasks, demonstrating enhanced instruction-following and self-checking capabilities. It also features improved vision and multimodality, supporting higher-resolution images for better handling of dense visual content. The model maintains the same pricing as Opus 4.6, at
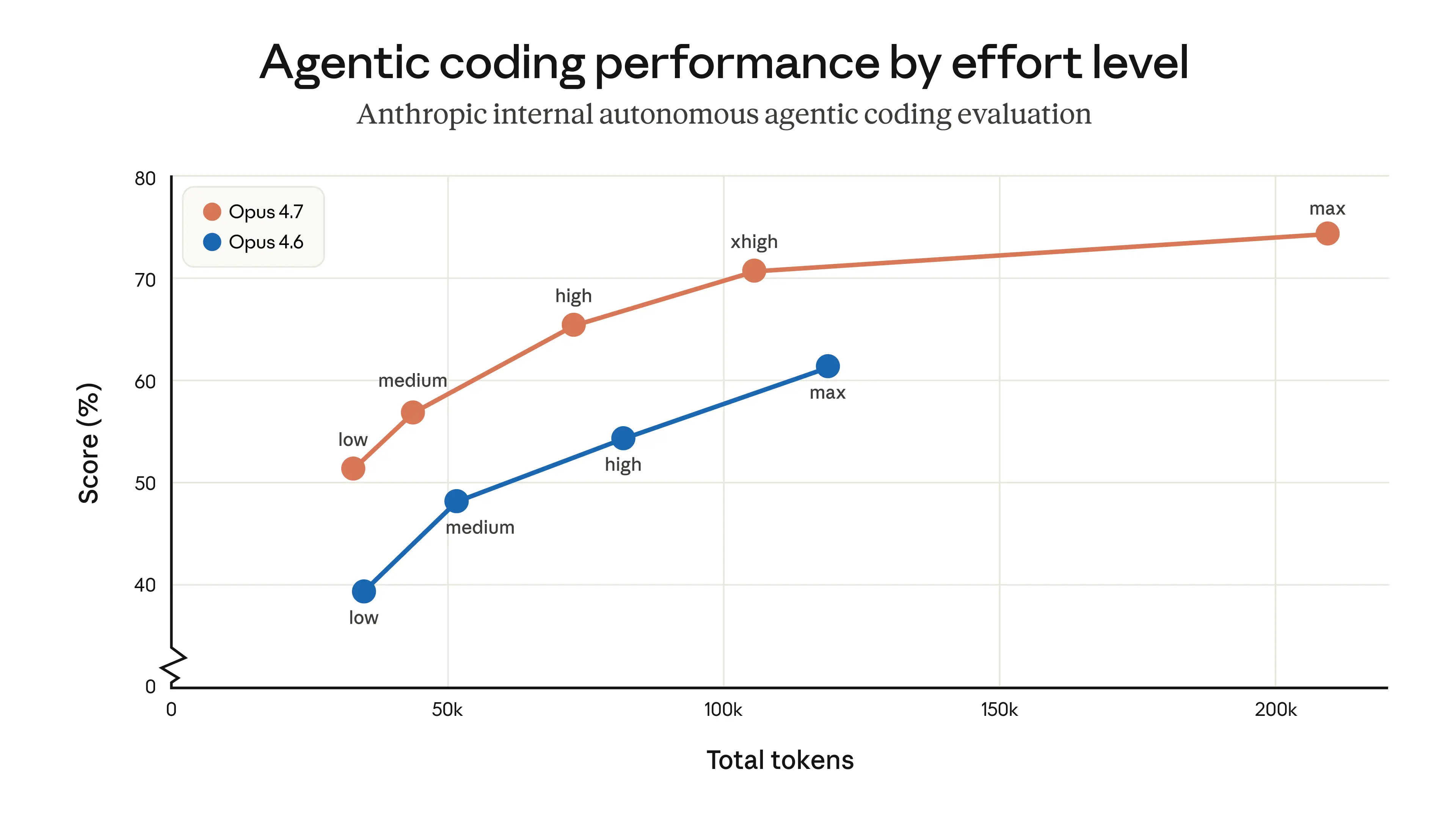
$5 per 1 million input tokensand$25 per 1 million output tokens, and is available across all Claude products and major platforms like Amazon Bedrock, Google Vertex AI, and Microsoft Foundry. Read more. Some users report that Opus 4.6’s performance declined in the weeks leading up to the release of 4.7, suggesting a possible strategic move by Anthropic. Others note the efficient usage metrics of the new version, indicating satisfaction with its performance.- The release of Opus 4.7 introduces an updated tokenizer that enhances text processing capabilities. However, this improvement comes with a tradeoff where the same input may map to more tokens, approximately
1.0–1.35×depending on the content type. This change aims to optimize performance, particularly in agentic coding scenarios, where Opus 4.7 Medium is reportedly comparable to Opus 4.6 High while using fewer tokens, as illustrated in this graph. - A user notes that Opus 4.6 has been underperforming for the past two weeks, raising concerns about whether this is a strategic move to encourage upgrades to Opus 4.7. This suggests a potential issue with the previous version’s performance that might be addressed in the new release.
- Another user reports that Opus 4.7’s performance is impressive, with only
3%of both 5-hour and weekly usage being consumed for a simple task. This indicates a significant improvement in efficiency and resource management in the latest version.
- The release of Opus 4.7 introduces an updated tokenizer that enhances text processing capabilities. However, this improvement comes with a tradeoff where the same input may map to more tokens, approximately
{kind=link}
2. AI Models in Roleplay and Creative Writing
-
I need to vent about the available models and my RP journey. Feel free to ignore (Activity: 350): The post discusses the challenges of finding a suitable role-playing (RP) model that combines desired features such as character adherence, nuanced subtext, and coherent plot advancement. The user has experimented with various models including Claude Sonnet 3.7, Gemini 2.5 Pro, Deepseek 3.2, Grok, Kimi 2, GLM 4.7, and Gemini 3.1, each having significant drawbacks like positivity bias, lack of nuance, or instability. The user expresses frustration with NanoGPT’s performance issues, particularly its tendency to stop mid-output and reduced intelligence compared to OpenRouter. The post highlights a desire for a model that combines the strengths of these models without their flaws, such as the memory and plot advancement of Gemini 2.5 and the subtext reading of Claude models. One commenter suggests switching models mid-story to avoid repetition and leverage different model strengths, while another highlights the unrealistic expectation of combining multiple high-cost model features into a single affordable model. Another user mentions Opus as a close alternative but notes its high cost.
- Fit-Statistician8636 suggests that switching models mid-story can help avoid repetition issues, especially when using cloud models, as the transition is quick and seamless. This approach can enhance the storytelling experience by introducing variety and maintaining engagement.
- KitanaKahn discusses the imperfections of AI models, using Gemini 2.5 as an example. They highlight how the model’s negativity bias can be turned into a creative challenge, requiring strategic thinking to earn character approval, which can lead to engaging role-playing experiences despite the model’s flaws.
- Fairy_Familiar mentions Opus as a high-quality model but notes its high cost. This comment reflects the ongoing challenge of balancing model performance with affordability, a common issue for users seeking advanced AI capabilities without incurring significant expenses.
-
Claude Opus 4.7 is out (Activity: 185): Claude Opus 4.7 has been released, with initial user feedback suggesting a reduction in the AI’s positivity bias compared to version 4.6. Users report that the AI now follows instructions more ruthlessly, particularly in scenarios where it needs to avoid being overly supportive or cooperative. This change may affect how the model handles role-playing (RP) scenarios, though the overall quality appears similar to 4.6 before any perceived downgrades. Some users note that the model’s tendency to self-correct in a stream-of-consciousness manner persists, particularly when dealing with character quirks. Others have not experienced this issue, attributing it to their specific prompts. There is also a mention of the model’s cost being a barrier for some users.
- Users have noted that Claude Opus 4.7 exhibits a tendency to self-correct in a stream-of-consciousness manner, particularly when dealing with character quirks. This behavior is described as the model catching itself making a mistake and then awkwardly correcting it without revising the initial error, which can be problematic for certain applications.
- There is a mixed reception regarding the quality of Claude Opus 4.7 compared to version 4.6. Some users feel that the quality remains consistent with 4.6 before it was ‘lobotomized,’ suggesting that the model’s performance may depend heavily on the prompts used. This indicates that prompt engineering might play a significant role in mitigating some of the model’s perceived issues.
- Pricing for Claude Opus 4.7 is a point of contention, with costs listed as
$5/M inputand$25/M output. This has led to discussions about the model’s affordability and value, especially when compared to potential alternatives like Sonnet, which some users are anticipating.
-
Is it just me or has DeepSeek’s memory improved significantly? (Activity: 91): DeepSeek appears to have significantly improved its memory capabilities, as evidenced by a user reporting a 7-hour role-playing session where the AI consistently remembered intricate details and maintained logical consistency throughout. This improvement is notable in long sessions, with users experiencing the AI recalling small details and inside jokes even after
300 messages. This suggests enhancements in the model’s memory retention and contextual understanding, potentially due to updates in its architecture or training data. Some users note that while DeepSeek excels in memory retention, it tends to steer role-playing scenarios towards metaphysical threats rather than physical ones, such as deathclaws or super mutants, which may affect the tension dynamics in the sessions.- A user noted that DeepSeek’s memory capabilities have improved significantly, allowing it to recall small details or inside jokes even after a 300-message run. This suggests enhancements in its long-term memory retention, which is crucial for maintaining context over extended interactions.
- Another user mentioned that DeepSeek tends to steer role-playing scenarios towards metaphysical threats rather than physical ones like deathclaws or super mutants. This indicates a possible bias in the model’s narrative generation, which could affect the diversity of scenarios it creates.
- A user highlighted that while playing a long RPG with DeepSeek, the experience was smoother than before, although there are still some minor issues. This suggests that while improvements have been made, there are still areas that require further refinement.
-
RP with DeepSeek (Activity: 68): The post discusses using DeepSeek for text-based role-playing (RP), highlighting its ability to maintain character consistency and introduce narrative twists without user prompts. The user expresses a challenge with generating multiple alternative responses, which hinders story progression. DeepSeek is praised for its creative writing and character realism, offering a unique RP experience compared to group settings. One commenter suggests using specific formatting (quotes, asterisks, parentheses) to guide DeepSeek’s responses and manage RP flow. Another mentions using ‘frontends’ for better interaction, while a third notes increased sensitivity in DeepSeek’s responses, leading to more frequent warnings.
- Maximum-Face9536 describes a structured approach to role-playing with DeepSeek by using specific formatting: quotes for dialogue, asterisks for internal thoughts, and parentheses for direct communication with the AI. This method helps guide the AI’s responses and manage the flow of interaction.
- KingGamer123321 shares a technique for managing large context windows in DeepSeek by segmenting conversations into parts and creating timelines. This approach was particularly useful during the 128k context window phase, allowing for detailed continuity and exploration of alternative story directions.
3. AI in Coding and Development Workflows
-
Claude Code workflow tips after 6 months of daily use (from a senior dev) (Activity: 726): A senior full-stack developer shares insights on optimizing productivity with Claude Code after six months of daily use. Key strategies include using “plan” mode for complex tasks to avoid unnecessary iterations, requesting implementation in small steps to maintain control, and leveraging the preview feature to catch issues early. The developer emphasizes allowing Claude to fix its own bugs to improve its contextual understanding and suggests running a simplification process before code reviews to counteract over-engineering. Additionally, conducting retrospectives at the end of sessions helps build institutional knowledge by asking Claude what it learned during the session. A commenter suggests using a dual-model approach by vetting plans with Codex via MCP to catch more issues early, enhancing the planning phase.
- A user suggests using two models in tandem, specifically mentioning ‘vet your plan with codex via mcp first’, to improve the accuracy and reliability of code plans. This approach helps catch more errors early in the planning phase, reducing the need for fixes later on.
- Another user describes a workflow where they update a file named ‘Claude.md’ with any rules before compacting, which helps maintain momentum. They also mention compacting only 1-5% at a time to avoid issues during task execution, indicating a strategy to manage task flow and prevent disruptions.
-
The cost of code use to be a middleware for our brains. (Activity: 1073): The post discusses the evolving nature of software engineering, particularly the impact of AI and automation on the pace and nature of coding work. The author, a seasoned engineer, expresses burnout due to the increased speed and frequency of decision-making required in modern development environments. They note that the traditional ‘throttling middleware’ of time and effort in coding has been removed, leading to a rapid pace that feels unsustainable. This shift has raised the bar for developers, requiring them to adapt to a faster, more demanding workflow, which is exacerbated by the use of AI tools that accelerate coding processes. Commenters echo the sentiment of increased cognitive load and decision fatigue, with one noting the necessity of extensive documentation to keep track of rapid changes. Another highlights the inevitability of adapting to new tools like AI, comparing it to historical shifts in technology such as the move from manual drafting to CAD. There’s a shared sense of nostalgia and adaptation fatigue as traditional skills become less relevant.
- triggeredg0blin highlights a unique form of mental exhaustion termed ‘vibing fatigue,’ which arises from the constant need to generate, review, and correct AI outputs. This involves frequent context-switching between trusting and verifying AI tools, leading to a specific kind of cognitive load distinct from traditional burnout. The process includes checking for hallucinated dependencies, subtle type mismatches, and adherence to team conventions, which can be mentally taxing over an extended workday.
- Jaded-Comfortable179 discusses the impact of AI advancements, particularly with Opus 4.5, on personal projects and professional life. The commenter notes a shift in tolerance for traditional work due to AI’s growing role, expressing concern over the profession’s future. They mention working in a slow-moving enterprise that hasn’t fully adopted AI, allowing them to maintain their output without pressure to integrate AI into their workflow, highlighting the tension between technological adoption and career stability.
- Final545 reflects on the obsolescence of traditional coding skills, drawing parallels to historical shifts in technology like the transition from punch cards to modern programming. They express a sentiment of skills becoming outdated, noting that 15 years of honing coding abilities may now seem less valuable except in rare cases. This comment underscores the rapid evolution of technology and its impact on the perceived value of long-held technical skills.
-
AMD engineer analyzed 6,852 Claude Code sessions and proved performance changed. Here’s what Anthropic confirmed, what they disputed, and the fixes that actually work. (Activity: 217): An AMD engineer conducted a comprehensive analysis of 6,852 Claude Code sessions, revealing significant performance changes, including a
70%reduction in file reads per edit and a27.5%increase in blind edits. The analysis, documented in GitHub Issue #42796, highlighted issues such as ‘ownership-dodging’ stop hooks and a dramatic increase in API costs from$345to$42,121. Anthropic confirmed several changes, including a shift to ‘adaptive thinking’ and a reduction in default effort, but disputed claims of reduced reasoning. Workarounds include settingCLAUDE_CODE_EFFORT_LEVEL=maxand disabling adaptive thinking. As of April 7, high effort was restored for API/Team/Enterprise users, but Pro users must adjust settings manually. The incident underscores the importance of robust evaluation suites and cost monitoring for AI-dependent workflows. Commenters praised the engineer’s rigorous data-driven approach and Anthropic’s transparency in acknowledging the issues and providing workarounds. Some users noted that while the changes might seem reasonable given resource constraints, they highlight the need for efficient resource allocation.- An AMD engineer conducted a comprehensive analysis of 6,852 Claude Code sessions, revealing significant performance changes. This rigorous, data-driven approach was acknowledged by Anthropic, who confirmed some findings and provided workarounds. This transparency is crucial for community trust and improvement, as it moves beyond mere anecdotal evidence to actionable insights.
- A user with a Pro subscription to Claude Code discusses their usage patterns, highlighting that while they often default to using the Opus 4.6 model for various tasks, the actual need for such a high-performance model is limited. This reflects a broader issue of resource allocation, where high-capacity models are underutilized for simple tasks, suggesting a need for better optimization strategies to allocate resources effectively.
- There is interest in understanding the AI compiler workflow used by the AMD engineer, which could provide insights into how performance issues were identified and addressed. This could be valuable for developers looking to optimize their own AI workflows or understand the technical underpinnings of performance analysis in AI systems.
-
Stop using Claude like a chatbot. Here are 7 ways the creator of Claude Code actually uses it. (Activity: 212): Boris Cherny, a Staff Engineer at Anthropic and creator of Claude Code, uses Claude not as a chatbot but as a multi-agent system to enhance productivity. He employs a
2,500-token CLAUDE.mdfile for persistent context across sessions, logs mistakes, and captures knowledge during code reviews. His workflow includes running5 parallel Claude Code instancesfor different tasks like building, testing, and debugging, using iTerm2 notifications for coordination. He emphasizes using Plan Mode for drafting design docs and averify-appsubagent for automated testing and fixing. Shared slash commands in.claude/commands/automate repetitive tasks, shifting focus from manual work to cognitive scheduling. Read more. Some commenters noted the post’s similarity to previous content and expressed dissatisfaction with ads on the linked page.
AI Discords
Unfortunately, Discord shut down our access today. We will not bring it back in this form but we will be shipping the new AINews soon. Thanks for reading to here, it was a good run.