Gated Attention is all you need?
AI News for 9/10/2025-9/11/2025. We checked 12 subreddits, 544 Twitters and 22 Discords (187 channels, and 4884 messages) for you. Estimated reading time saved (at 200wpm): 414 minutes. Our new website is now up with full metadata search and beautiful vibe coded presentation of all past issues. See https://news.smol.ai/ for the full news breakdowns and give us feedback on @smol_ai!
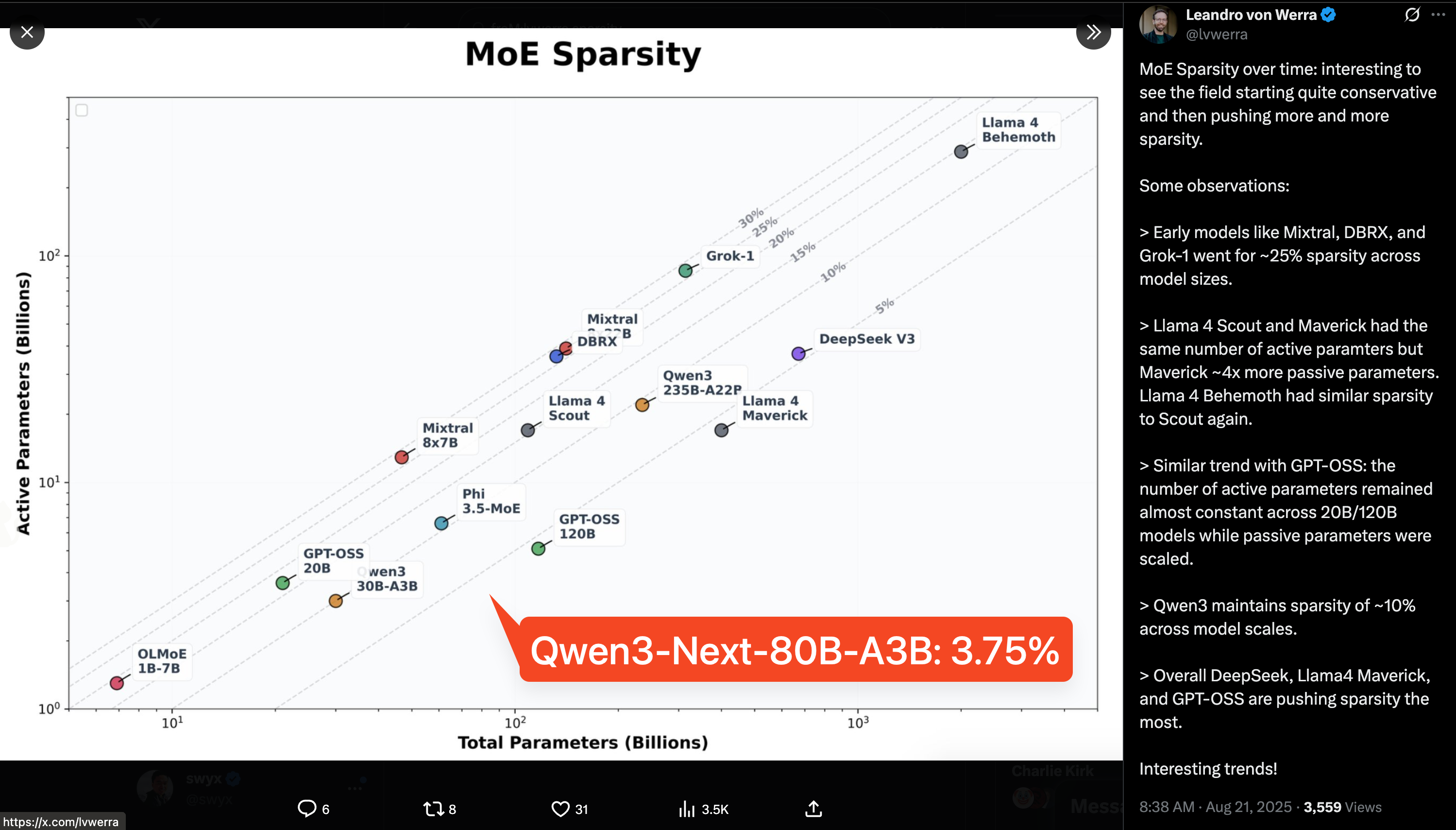
Since Noam Shazeer et al invented them in his annus mirabilis, MoE models have steadily increased in importance through GPT4 and Mixtral(8 experts). DeepSeek (160 experts), Snowflake (128 experts) and others then pushed the sparsity even further, and today it is fair to say that no frontier model is served without being an MoE (we have outright confirmations from Gemini, whereas the rest are strong rumors.)
Today's Qwen3-Next release pushes model sparsity even further - the industry has switched from "expert count" to total param vs active param ratio - and 3.75% (3B / 80B = 3.75%) is appreciably lower than GPT-OSS' 4.3% and Qwen3's own prior 10%.
According to them:
Ultra-Sparse MoE: Activating Only 3.7% of Parameters
Qwen3-Next uses a highly sparse MoE design: 80B total parameters, but only ~3B activated per inference step. Experiments show that, with global load balancing, increasing total expert parameters while keeping activated experts fixed steadily reduces training loss. Compared to Qwen3’s MoE (128 total experts, 8 routed), Qwen3-Next expands to 512 total experts, combining 10 routed experts + 1 shared expert — maximizing resource usage without hurting performance.
But for the ML folks, the probable bigger win is the strict pareto win seen in pretraining:
The authors credit a few architecture advancements:
- Hybrid Architecture: Gated DeltaNet + Gated Attention: We found that the attention output gating mechanism helps eliminate issues like Attention Sink and Massive Activation , ensuring numerical stability across the model.
- new Layer Norm: In Qwen3, we use QK-Norm, but notice some layer norm weights become abnormally large. To fix this and further improve stability, Qwen3-Next adopts Zero-Centered RMSNorm, and applies weight decay to norm weights to prevent unbounded growth.
- better MoE selection: normalize MoE router parameters during initialization , ensuring each expert is unbiasedly selected early in training — reducing noise from random initialization.
AI Twitter Recap
Alibaba’s Qwen3-Next hybrid architecture and early ecosystem support
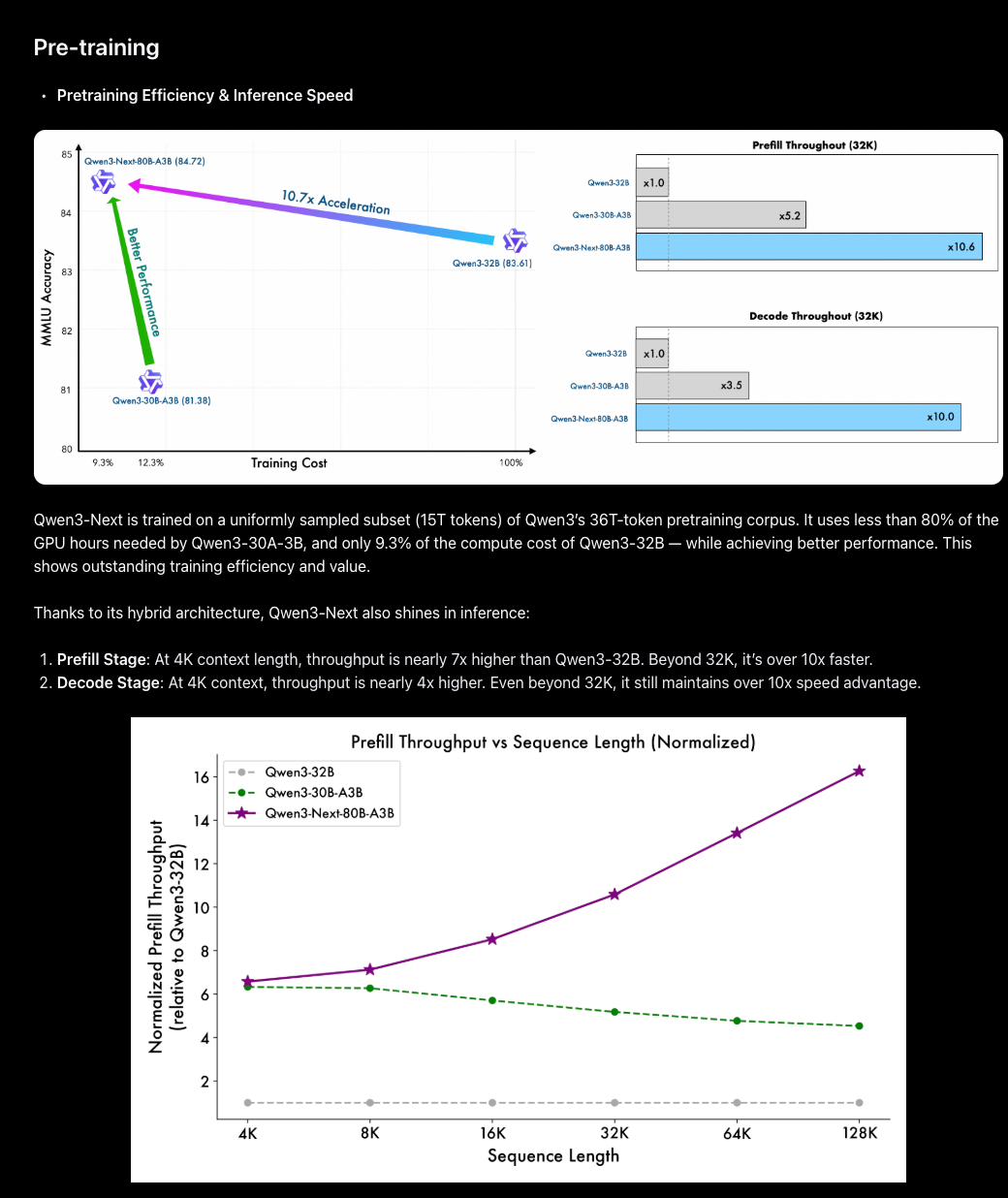
- Qwen3-Next-80B-A3B: Alibaba released a new hybrid MoE family that routes only ~3B parameters per token while using 80B total (512 experts; 10 routed + 1 shared), combining Gated DeltaNet + Gated Attention, optimized multi-token prediction, and Zero-Centered RMSNorm with weight decay. Trained on ~15T tokens, it claims ~10× cheaper training and 10× faster inference than Qwen3-32B at long contexts, with the “Thinking” variant reported to outperform Gemini-2.5-Flash-Thinking and the Instruct variant approaching their 235B flagship. Announcement and model links: @Alibaba_Qwen, NVIDIA API catalog. Architectural context and release rationale: @JustinLin610. Technical notes highlighting gated attention/DeltaNet, sparsity and MTP details: @teortaxesTex.
- Deployments and toolchain: Served in BF16 at Hyperbolic on Hugging Face with low-latency endpoints (@Yuchenj_UW, follow-up). Native vLLM support (accelerated kernels and memory management for hybrid models) is live (vLLM blog). Baseten provides dedicated deployments on 4×H100 (@basetenco). Available on Hugging Face, ModelScope, Kaggle; try it in the Qwen chat app (see @Alibaba_Qwen).
Image generation and OCR: ByteDance Seedream 4.0, Florence-2, PaddleOCRv5, Points-Reader
- Seedream 4.0 (ByteDance): New T2I/Image Edit model merges Seedream 3 and SeedEdit 3 and is live on the LM Arena (@lmarena_ai). In independent tests, it tops Artificial Analysis’ Text-to-Image leaderboard and reaches parity/leadership in Image Editing against Google’s Gemini 2.5 Flash (a.k.a. Nano Banana), with improved text rendering, at $30/1k generations, available on FAL, Replicate, BytePlus (@ArtificialAnlys). LM Arena now supports multi-turn image-edit workflows (@lmarena_ai).
- OCR stack updates:
- PP-OCRv5: A modular, 70M-parameter OCR pipeline (Apache-2.0) designed for accurate layout/text localization on dense docs and edge devices, now on Hugging Face (@PaddlePaddle, @mervenoyann).
- Points-Reader (Tencent, 4B): OCR trained on Qwen2.5-VL annotations + self-training; outperforms Qwen2.5-VL and MistralOCR on several benchmarks; model + demo on HF (@mervenoyann, model/demo links).
- Florence-2: Fan-favorite VLM is now officially in transformers via the florence-community org (@mervenoyann).
- Precision inpainting: InstantX’s Qwen Image Inpainting ControlNet (HF model + demo) for targeted, high-quality edits (@multimodalart).
Developer platforms: VS Code + Copilot, Hugging Face speedups, vLLM hiring
- VS Code v1.104: Major Copilot Chat upgrades (better agent integration, Auto mode for model selection, terminal auto-approve improvements, UI polish) and official support for AGENTS.md to wrangle rules/instructions (release, AGENTS.md origin). New BYOK extension API enables direct provider keys.
- Open models inside Copilot Chat: Hugging Face Inference Providers are now integrated into VS Code, making frontier OSS LLMs (GLM-4.5, Qwen3 Coder, DeepSeek 3.1, Kimi K2, GPT-OSS, etc.) one click away (@reach_vb, guide, @hanouticelina, marketplace).
- Transformers performance work: The GPT-OSS release arrived with deep performance upgrades in transformers—MXFP4 quantization, prebuilt kernels, tensor/expert parallelism, continuous batching, with benchmarks and reproducible scripts (@ariG23498, blog, @LysandreJik).
- vLLM momentum: Thinking Machines is building a vLLM team to advance open-source inference and serve frontier models; reach out if interested (@woosuk_k).
Agent training and production agents: RL, tools, HITL, and benchmarks
- AgentGym-RL (ByteDance Seed): A unified RL framework for multi-turn agent training across web, search, games, embodied, and science tasks—no SFT required. Reported results: 26% web navigation vs. GPT‑4o’s 16%, 38% deep search vs. GPT‑4o’s 26%, 96.7% on BabyAI, and a new record 57% on SciWorld. Practical guidance: scale post-training/test-time compute, curriculum on trajectory length, prefer GRPO for sparse long-horizon tasks (thread, abs/repo, notes, results).
- LangChain upgrades:
- Human-in-the-loop middleware for tool-call approval (approve/edit/deny/ignore) built on LangGraph’s graph-native interrupts—production-ready HITL with a simple API (intro).
- Making Claude Code domain-specialized via better system docs/context beats raw docs access; detailed methods for running agents on frameworks like LangGraph (blog, discussion, case study: Monte Carlo).
- Benchmarks and eval fixes: SWE-bench bug enabling “future-peeking” was fixed; few agents exploited it and headline trends remain unaffected (@OfirPress, follow-up). BackendBench is now on Environments Hub (@johannes_hage).
- Online RL at scale: Cursor’s new Tab model uses online RL to cut suggestions by 21% while raising accept rate by 28% (@cursor_ai).
Speech, audio, and streaming seq2seq
- OpenAI Evals for audio: Evals now accept native audio inputs and audio graders, enabling evaluation of speech responses without transcription (@OpenAIDevs). GPT‑Realtime now leads the Big Bench Audio arena at 82.8% accuracy (native speech‑to‑speech), closing on the 92% pipeline (Whisper → text LLM → TTS), while retaining latency advantages (@ArtificialAnlys).
- Kyutai DSM: A “delayed streams” streaming seq2seq built with a decoder-only LM plus pre-aligned streams, supporting ASR↔TTS with few‑hundred‑ms latency, competitive with offline baselines, infinite sequences, and batching (overview, repo/abs).
Systems and infra: MoE training, determinism trade-offs, and comms stack
- HierMoE (training efficiency for MoE): Hierarchy-aware All‑to‑All with token deduplication and expert swaps reduces inter-node traffic and balances loads. On a 32‑GPU A6000 cluster, reported 1.55–3.32× faster All‑to‑All and 1.18–1.27× end‑to‑end training vs. Megatron‑LM/Tutel‑2DH/SmartMoE; gains increase with higher top‑k and across nodes (@gm8xx8).
- Determinism vs. performance: A lively discussion revisits sources of inference nondeterminism and whether “numerical determinism” is worth large latency hits. Key takeaways: atomicAdd isn’t the whole story for modern stacks; determinism can be critical for sanity tests, evals, and reproducible RL; text‑to‑text can be perfectly repeatable with caching and shared artifacts (prompt, deep dive, caching, context).
- Networking/storage matter: For distributed post‑training, tuned networking (RDMA/fabrics) and storage can deliver 10× speedups on the same GPUs and code; tooling like SkyPilot automates config (@skypilot_org). Also, a rare clear write‑up on NCCL algorithms/protocols arrived, a boon for those optimizing collective comms (@StasBekman).
Top tweets (by engagement)
- Alibaba’s Qwen3‑Next launch (80B MoE, 3B active; hybrid Gated DeltaNet + Gated Attention) with broad ecosystem support: @Alibaba_Qwen (2,391)
- VS Code v1.104: Copilot Chat agent upgrades, AGENTS.md, BYOK, and HF Inference Providers integration: @code (675)
- Seedream 4.0 leads Text‑to‑Image and ties/leads Image Edit arenas; available on FAL/Replicate/BytePlus: @ArtificialAnlys (590)
- OpenAI Evals adds native audio inputs/graders; GPT‑Realtime tops Big Bench Audio at 82.8%: @OpenAIDevs (521), @ArtificialAnlys (176)
- Thinking Machines builds a vLLM team to advance open inference for frontier models: @woosuk_k (242)
- Cloud GPU procurement comedy, painful reality: Oracle sales anecdote from the trenches: @vikhyatk (7,042)
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
1. Qwen3-Next-80B A3B Launch + Tri-70B Apache-2.0 Checkpoints
- Qwen released Qwen3-Next-80B-A3B — the FUTURE of efficient LLMs is here! (Score: 377, Comments: 82): Qwen announced Qwen3-Next-80B-A3B, an
80Bparameter ultra‑sparse MoE where only~3Bparams are activated per token (A3B). It combines a hybrid Gated DeltaNet + Gated Attention stack with512experts (router selectstop‑10+1shared) and Multi‑Token Prediction for accelerated speculative decoding; Qwen claims~10×cheaper training and~10×faster inference than Qwen3‑32B, especially at>=32Kcontext, while matching/beating Qwen3‑32B and approaching [Qwen3‑235B] in reasoning/long‑context. A "Thinking" variant is included and reportedly outperforms Gemini‑2.5‑Flash‑Thinking; models are available on Hugging Face with a demo at chat.qwen.ai. Comments confirm the Thinking release, note strong capability for an A3B model but a tendency toward overly positive/verbose outputs versus Gemini‑2.5‑Flash or Claude Sonnet 4, and raise deployment interest in GGUF quantizations (e.g., via Unsloth) plus feasibility of running an80BMoE in64GBVRAM.- Early impressions note the A3B quantized variant feels “smart” but over-enthusiastic in tone (a “glazer”) compared to models like “2.5 Flash” or “Sonnet 4,” suggesting more aggressive RLHF/style tuning. A “Thinking” variant was also released, which typically implies deliberate/stepwise reasoning tokens that can improve complex reasoning but at the cost of slower decoding and higher memory/time per token.
- On deployability: an 80B at ~
4.25 bpwshould require ~80e9 * 4.25/8 ≈ 42.5 GBjust for weights; add KV cache in BF16/FP16 which can be ~2–3 MB/token for a 70–80B (e.g., ~20–25 GB at 8k ctx), plus framework overhead. Hence, 64 GB VRAM is typically sufficient for 4-bit inference with moderate context/batch, but long contexts or larger batches may need multi-GPU sharding or CPU offload (GGUF/llama.cpp-style inference once a community GGUF appears; see GGUF format: https://github.com/ggerganov/llama.cpp/blob/master/gguf.md). - Community is eyeing a GGUF build (e.g., via Unsloth: https://github.com/unslothai/unsloth) to run locally with 4–4.25 bpw; this often becomes the practical sweet spot for 70–80B models on single 48–64 GB GPUs. Trade-offs: 4-bit quant preserves most quality for many tasks but can affect edge cases (math/code/logical precision), and throughput will still be lower than 7–13B models due to compute/memory bandwidth limits.
- We just released the world's first 70B intermediate checkpoints. Yes, Apache 2.0. Yes, we're still broke. (Score: 728, Comments: 62): Trillion Labs released Apache-2.0 licensed intermediate training checkpoints for a
70Btransformer—plus7B,1.9B, and0.5Bvariants—publishing the “entire training journey” rather than only final weights, which they claim is a first at the70Bscale (earlier public trajectories like SmolLM‑3 and OLMo‑2 topped out at <14B). Artifacts include base and intermediate checkpoints and a “first Korean 70B” model (training reportedly optimized for English), all ungated on Hugging Face: Tri‑70B‑Intermediate‑Checkpoints. This enables transparent training‑dynamics research (e.g., scaling/optimization analyses, curriculum ablations, and resume/finetune starting points) under a permissive license. Top comments are largely non‑technical: requests for a donation link to support the effort, a naming joke about “Trillion” vs. parameter count, and general encouragement; no substantive technical critiques were raised in the highlights.
2. Qwen3-Next Teasers and Coming-Soon Posts
- Qwen3-Next-80B-A3B-Thinking soon (Score: 403, Comments: 86): Post teases Alibaba/Qwen’s forthcoming “Qwen3-Next-80B-A3B-Thinking,” which appears to be a sparse MoE reasoning model with ~3B-parameter experts and
k=10experts active per token (per the model card screenshot), totaling ~80B parameters. The “A3B” likely denotes 3B expert size; the sparse routing suggests significantly lower per-token compute and memory bandwidth than dense 80B, making it more inference-friendly on modest hardware, with a separate non-reasoning instruct variant expected since Qwen says they’re no longer doing hybrid models. “Thinking” implies a deliberate/CoT-style reasoning-focused configuration. Comments debate hardware implications: enthusiasm that only a subset of experts fire per token could let it run on mini PCs or non‑NVIDIA accelerators favoring large memory over sheer compute, though correction notes it’sk=10(not 1). Others praise Qwen’s rapid cadence and expect a standard instruct (non-reasoning) model alongside the reasoning variant.- Sparsity/config clarification: Qwen3-Next-80B-A3B-Thinking is discussed as an MoE with ~3B-parameter experts and
k=10active experts per token (not 1), implying ~30Bactive params/token plus shared layers. This reduces per-token FLOPs vs a dense 80B while requiring substantial memory to host all experts, aligning with inference on hardware emphasizing large memory capacity/bandwidth (potentially non‑NVIDIA/China accelerators) and enabling decent throughput on modest rigs via sharding/offload. - Product strategy: Qwen is noted to have dropped "hybrid" models, suggesting there will be a separate non‑reasoning instruct counterpart in addition to the A3B "Thinking" variant. This separation caters to different inference budgets and use cases (instruction vs reasoning), while leveraging MoE sparsity to balance quality and efficiency.
- Trend context: Commenters see this as part of the ongoing shift toward MoE—here with relatively high
top‑k(10) compared to commontop‑2MoE like Mixtral 8x7B—trading some extra compute for improved quality/coverage, yet still far cheaper than dense. The higher parallelizable workload across experts also maps well to accelerators prioritizing memory capacity over raw core speed.
- Sparsity/config clarification: Qwen3-Next-80B-A3B-Thinking is discussed as an MoE with ~3B-parameter experts and
{kind=link}
Less Technical AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. Seedream/Seedance 4.0 Image Model Releases and Benchmarks
- Seedream 4.0 is the new leading image model across both the Artificial Analysis Text to Image and Image Editing Arena, surpassing Google's Gemini 2.5 Flash (Nano-Banana), across both! (Score: 242, Comments: 86): Seedream 4.0 now leads both the Text-to-Image and Image Editing leaderboards on the Artificial Analysis Arena, surpassing Google’s Gemini 2.5 Flash ("Nano-Banana") across both tasks. This positions Seedream 4.0 as the current SOTA on AA’s public benchmarks for image generation and editing. Commenters highlight the rarity and significance of topping both generation and editing simultaneously, and speculate about forthcoming stronger baselines (e.g., a higher-tier Gemini release) while expressing interest in an open-weights contender, potentially from Chinese labs.
- Users highlight that Seedream 4.0 is now rank-1 across both the Artificial Analysis Text-to-Image Arena and Image Editing Arena, reportedly surpassing Google Gemini 2.5 Flash (Nano-Banana), implying strong cross-task generalization rather than optimization for a single modality. Dual leadership suggests robustness in both initial synthesis and localized edit controllability; see the leaderboards on Artificial Analysis.
- Several note the caveat that “benchmarks/leaderboards aren’t everything,” pointing out technical confounders in arena-style rankings: prompt distribution biases, sampler/CFG/steps settings, seed variance, and safety-filter behaviors can all swing pairwise preference/ELO outcomes. Especially for editing, factors like mask quality, localization accuracy, and prompt adherence by category (e.g., typography, multi-object composition) matter; without per-category breakdowns or fixed seeds, leaderboard rank may not reflect performance in a given user’s workflow.
- There’s debate on safety-moderation layers affecting scores: stricter or stacked moderation can increase refusals or over-sanitize outputs, which tends to reduce win-rate in open preference arenas even if the base model is capable. Conversely, looser safety can yield more vivid or direct generations that win preferences—highlighting that leaderboard position may conflate raw capability with moderation policy.
- Seedance 4.0 is so impressive and scary at the same time... (all these images are not real and don't exist btw) (Score: 374, Comments: 77): Post showcases “Seedance 4.0,” an image‑generation model producing highly photorealistic portraits where the subjects “don’t exist,” highlighting the current state of synthetic media realism. The thread provides no concrete details (architecture, training data, evals, safety features, or watermarking/provenance), but the samples imply near‑SOTA fidelity for human faces, increasing risks for mis/disinformation and underscoring the need for content provenance (e.g., C2PA) and deepfake detection tooling. Top comments note concern over astroturfed/"organic" advertising that often follows new model launches, and broader skepticism about social media dynamics—rather than technical critique of the model itself.
- Comparative output diversity: Users report Seedance 4.0 tends to produce consistent, repeatable "same (good) results" for similar prompts, while Nano Banana shows higher intra‑prompt variance. This implies Seedance may be tuned for stability/faithfulness over diversity, which benefits controlled art direction but can reduce exploration across seeds.
- Openness as adoption gate: One commenter’s stance "If not open, not interested" highlights friction with closed models for reproducibility and benchmarking. Closed weights/checkpoints limit community validation, ablations, and integration into local pipelines, affecting trust and iterative improvement.
- 1GIRL QWEN v2.0 released! (Score: 353, Comments: 49): Release of 1GIRL QWEN v2.0 (
v2.0), a LoRA fine‑tune targeting the Qwen‑Image/Qwen2‑Image text‑to‑image model, aimed at photorealistic single‑subject (female) portraits. The model is distributed on Civitai with a sample preview; however, the post provides no training details (dataset, steps, LoRA rank/alpha), base checkpoint/version, prompt tokens, or inference settings/benchmarks. Top comments flag the release as another “instagirl/1girl” promo and suggest leading with a goth example; there’s also an allegation of vote manipulation followed by “stabilized” votes. A commenter asks if the LoRA is uncensored, with no explicit answer in‑thread.- A commenter requests the LoRA training recipe and environment details to reproduce results locally, specifying hardware of RTX 4080 Super (
16 GBVRAM) +32 GBRAM. They note prior success training for SDXL and are now using Qwen, praising its prompt fidelity, and ask for practical guidance on dataset prep and training parameters/hyperparameters to achieve comparable quality. - Another user asks whether the release is uncensored, i.e., if safety filters/content restrictions are disabled. This impacts local deployment scenarios and determines whether NSFW or restricted content generation is supported out of the box.
- One comment flags a generation quality issue: “second picture thigh larger than torso,” indicating noticeable anatomy/proportion artifacts in sample outputs. This highlights potential shortcomings in model outputs that technical users may want to evaluate or mitigate during inference or future fine-tuning.
- A commenter requests the LoRA training recipe and environment details to reproduce results locally, specifying hardware of RTX 4080 Super (
- it seems like Gemini 3 won't come out this month (Score: 341, Comments: 84): Unverified rumor that Gemini 3 won’t launch this month; no official source, release notes, or benchmarks are cited. Comments speculate that
Gemini 3.0 Flashcould outperformGemini 2.5 Pro, implying the lower‑latency “Flash” tier might temporarily leapfrog the prior “Pro” tier for many workloads—without any evals, metrics, or implementation details to substantiate it. One commenter asserts “It’ll be better than 2.5 Pro — for a limited time”, implying a temporary tier reshuffle or promo window, while others call out the lack of evidence (e.g., “Source: trust me bro”).- Debate centers on whether Google’s speed/cost‑optimized Gemini 3.0 Flash could actually outperform the capability‑tier Gemini 2.5 Pro, which would upend product tiering. If
3.0Flash truly beats2.5Pro, commenters note most users “wouldn’t even need Pro,” implying a leap in reasoning/quality, not just latency. Historically, Flash‑class models target low latency and cost while Pro/Ultra lead complex reasoning (Gemini model tiers), so any “Flash > Pro” outcome would likely be metric‑specific (e.g., latency or narrow tasks) rather than across‑the‑board. - Skepticism is high due to lack of evidence—“Source: trust me bro”—and hints that any superiority might be “for a limited time,” suggesting temporary access gating or staged rollouts. Several doubt 3.0 Flash will surpass 2.5 Pro on reasoning benchmarks (e.g., MMLU, GSM8K), framing current claims as marketing‑driven hype absent publicly verifiable evals.
- Debate centers on whether Google’s speed/cost‑optimized Gemini 3.0 Flash could actually outperform the capability‑tier Gemini 2.5 Pro, which would upend product tiering. If
- Gothivation (Score: 576, Comments: 92): The linked media at v.redd.it/bucq7dlt8jof1 is not accessible due to an
HTTP 403network-security block, so the video content cannot be verified from the URL. From the comment context, the post appears to showcase an AI‑generated “goth” video that is realistic enough to pass casual viewing, but the thread provides no technical details (model, pipeline, training data, or benchmarks) and no visible artifacts are discussed. In short, there’s no reproducible implementation info or evaluation data in-thread. One top comment notes they didn’t realize it was an AI video until seeing the subreddit name, underscoring increasing realism and the difficulty of casual detection; other highly upvoted remarks are non-technical.- One commenter highlights the growing indistinguishability of AI-generated video: "I’m more and more impressed every day at how often I don’t realize I’m watching an ai video until I look at the sub name." This suggests improved visual fidelity and temporal coherence, with fewer telltale artifacts (e.g., hand/finger anomalies, flicker), making casual detection unreliable and underscoring the need for provenance/watermarking or model-level detection. Absent explicit model details, the trend aligns with rapid advances in text-to-video diffusion/transformer pipelines and upscalers, which compress perceptual gaps that used to give AI away.
- Gothivation (Score: 580, Comments: 92): Post shares an AI-generated short video titled “Gothivation,” likely a talking-head/character-actor clip with a goth aesthetic delivering a motivational monologue. The referenced media v.redd.it/bucq7dlt8jof1 returns
HTTP 403 (Forbidden)without Reddit auth/dev token, so model/pipeline details aren’t disclosed in-thread; however, commenters suggest the synthesis quality is high enough to pass casual scrutiny (strong lip-sync/affect coherence implied). Most substantive remark notes they didn’t realize it was an AI video until seeing the subreddit name, underscoring rising realism of consumer-grade avatar/talking-head generation; other top comments are non-technical quips.- A commenter highlights that AI-generated video is becoming hard to distinguish from real footage without contextual cues, implying modern diffusion/GAN video systems have reduced typical giveaways (e.g., mouth sync errors, hand/finger topology glitches, inconsistent specular highlights). Effective detection increasingly depends on temporal signals (blink cadence, motion parallax, physics of fabric/hair), lighting/color continuity across frames, and metadata—rather than single-frame artifacts—suggesting moderation/detection pipelines should incorporate temporal and multimodal analysis.
- Control (Score: 248, Comments: 47): A demo showcases a pipeline combining “InfiniteTalk” (audio-driven talking-head/lip‑sync) with “UniAnimate” (image/video animation with pose/hand control) to produce a dubbed clip emphasizing controllable hand motion while maintaining strong facial expressiveness. Viewers note notably realistic facial performance and stability/identity cues (e.g., consistent ring details on the right hand), suggesting good temporal consistency beyond just hands. Commenters ask how to integrate UniAnimate with InfiniteTalk in a video‑to‑video dubbing workflow that preserves the source motion exactly; they report slight movement drift/mismatch, highlighting synchronization and motion‑lock challenges when trying to maintain frame‑accurate body/pose while swapping or re‑animating the face.
- Technical concern about combining Unianimate with Infinite Talk for video-to-video dubbing: the output does not preserve the source motion exactly, leading to movement drift despite aiming only to change speech/lips. The user needs frame-accurate temporal alignment where pose/trajectory are locked to the input while audio-driven lip and facial articulation are modified. The request implies a need for strict motion control signals and synchronization to avoid deviation across frames.
- Observation on fidelity: commenters note facial performance quality is strong relative to hand/pose control, suggesting disparities in control robustness between face reenactment and full-body/hand tracking. One tip is to "follow the rings on her right hand" to evaluate motion consistency, implying subtle artifacts or lag in hand alignment even when the face tracks well.
- Reproducibility gap: multiple requests for the exact workflow/pipeline (toolchain, settings, and versions) indicate that the showcased result lacks a documented, step-by-step process. Sharing concrete parameters (model versions, control strengths, frame rate handling, and alignment settings) would enable others to replicate and diagnose the motion deviation issues.
- saw a couple of these going around earlier and got curious (Score: 8449, Comments: 1489): Meme-style screenshot of a novelty AI/quiz output that absurdly infers a user’s “preference” (claiming they want to have sex with potatoes), which the OP explicitly rejects. Context suggests a trend of people trying a low-quality AI predictor; it illustrates classic hallucination/misclassification and weak safety/NSFW filtering with no technical details, benchmarks, or model info provided. Commenters broadly deride the model’s reliability and seriousness (e.g., “If the future is AI, we better hope it’s not this AI”), expressing disbelief and concern rather than technical debate.
- The thread shares multiple AI-generated image results via Reddit’s image CDN (e.g., https://preview.redd.it/wlmvcaoqifof1.jpeg) but contains no technical details—no model names (e.g., SDXL, Midjourney v6), prompts, seeds, samplers, steps, CFG/Guidance, negative prompts, or model hashes. Because Reddit’s pipeline typically strips EXIF/embedded JSON, any Stable Diffusion metadata (prompt, seed, sampler) is unrecoverable, so outputs here are non-reproducible and not diagnosable beyond speculation.
- For a technically actionable discussion, posts would need full generation context: base model and version/hash, sampler (e.g.,
DPM++ 2M Karras,DDIM), steps, CFG, resolution, seed, and any refiners/ControlNets/LoRAs (e.g., SDXL base+refiner at 1024px, Hires fix, LoRA stacks). With that, readers could attribute anomalies to parameters (e.g., over-high CFG, under-steps) or architecture (MJ’s internal sampler vs. SDXL pipelines) and propose fixes or reproduce A/B tests.
- Lol. I asked ChatGPT to generate an image of the boyfriend it thinks I want and the boyfriend it thinks I need (Score: 2532, Comments: 651): User asked ChatGPT’s image generator (likely DALL·E 3 via ChatGPT) to produce a "boyfriend it thinks I want" vs "boyfriend it thinks I need" comparison. The resulting image appears to inject alignment/virtue cues—one figure is noted holding an "AI Safety" book—suggesting the model projects safety/wholesome themes and may misinterpret ambiguous "want vs need" prompts, reflecting RLHF-influenced bias and value signaling in generative outputs. Commenters point out the odd inclusion of an "AI safety" book and suggest GPT misunderstood the prompt; another says the output is acceptable, implying the model’s conservative/wholesome bias isn’t unwelcome.
- Mostly reaction/image posts with no benchmarks or model details; the one technical signal is prompt-grounding/safety steering artifacts: a generated image includes an “AI safety book,” suggesting the LLM→T2I pipeline (e.g., ChatGPT + a diffusion backend like DALL·E 3) injected safety-related concepts or misinterpreted intent. Diffusion models also notoriously hallucinate or garble embedded text, so visible, off-prompt text is a known failure mode tied to token-to-glyph mapping and safety rewrites; see the DALL·E 3 system card on safety filtering and prompt transformations (https://cdn.openai.com/papers/dall-e-3-system-card.pdf) and discussions on text rendering limitations in diffusion models (e.g., https://openai.com/research/dall-e-3).
- I asked ChatGPT to make a Where's Waldo? for the next Halloween. Can you find him? (Score: 636, Comments: 56): A Redditor used ChatGPT’s built‑in image generation to create a Halloween‑themed, Where’s Waldo‑style seek‑and‑find scene, showcasing dense composition and a hidden target consistent with Wimmelbilder prompts. Commenters confirm Waldo’s discoverability with a cropped proof and note small visual cues (e.g., a ‘raised eyebrow’ pumpkin), and another user posts their own, reportedly trickier, AI‑generated variant—indicating reproducibility of cluttered, puzzle‑like scenes. Discussion revolves around how well the image hides Waldo and the scene’s visual density rather than implementation details; no benchmarks or model specifics are provided.
- Users compared AI-generated “Where’s Waldo?” scenes across models: the OP used ChatGPT (per title) and another user tried Google Gemini image. The Gemini output’s findability was ambiguous—commenters couldn’t tell if the target was cleverly hidden or if the composition lacked a distinct “Waldo”—highlighting challenges for image models in consistent character rendering and cluttered-scene composition.
- Image resolution/format varied across shares—
1536pxexample,1024pxexample, and a493pxcrop example—with Reddit’sauto=webpconversion. Downscaling and WebP recompression can obscure fine-grained cues (e.g., stripe patterns) and materially change perceived difficulty, so any comparison of “hardness” should control for resolution and compression artifacts.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
2. UK Government AI Adoption and ChatGPT Ads Monetization
- AI is quietly taking over the British government (Score: 3012, Comments: 171): A screenshot of a UK Parliament/House of Commons webpage is run through an AI-content detector, which flags sections as likely “AI-generated” (image). Technically this suggests, at most, AI-assisted drafting or proofreading of public-facing copy (e.g., ChatGPT rewrites or Grammarly), not automation of governmental decisions; moreover, AI-detection tools are known to yield high false positives and cannot prove authorship. No evidence of code, systems integration, or operational control by AI is shown. Commenters argue the title is overblown; many workers—including MPs—use AI as a proofreading aid, and a follow-up image hints key legal/formulaic text remained unchanged, undercutting the “takeover” claim.
- Adoption timeline and scope: The UK government had broad access to Microsoft 365 Copilot via a government-wide free trial in Oct–Dec
2024(The Register), followed by the Labour government’s Jan2025blueprint to mainstream AI across departments (gov.uk). This sequence indicates formal, institutionally sanctioned deployment rather than ad‑hoc usage, and anchors claims of AI uptake to concrete products and dates. - Usage pattern vs displacement: Practitioners highlight AI as a proofreading/writing assist rather than full content generation, which matches assistive workflows embedded in M365 Copilot (Word/Outlook). The implication is workflow augmentation (QA, consistency, turnaround time) rather than role replacement, i.e., AI as a linguistic verification layer within existing processes.
- Attribution/correlation critique: A commenter notes the linguistic shifts in Commons texts align more with the Labour change of government than with ChatGPT’s public availability, cautioning against attributing authorship to LLMs. A sound analysis would test for change-points in Hansard style/lexical distributions around
Jul 2024(government change) versusNov 2022/Mar 2023(ChatGPT/GPt-4 milestones) to control for confounders.
- Adoption timeline and scope: The UK government had broad access to Microsoft 365 Copilot via a government-wide free trial in Oct–Dec
- AI is quietly taking over the British government (Score: 4291, Comments: 210): The image appears to be a screenshot of an AI-text detector labeling a UK parliamentary/ministerial speech as "AI-generated" or highly likely AI, implying “AI is quietly taking over.” Technically, this showcases a known limitation of detectors: they often key on low-perplexity, template-like phrasing and repeated stock expressions—features common in professional speechwriting—leading to false positives and not constituting evidence of actual AI authorship. Commenters note Westminster speech has long been formulaic and meme-like phrases propagate among political factions, which can trigger detectors; others add that even without explicit ChatGPT usage, AI-influenced style can percolate into human writing over time.
- Multiple commenters note high false-positive rates when flagging human-written text as AI, aligning with known limitations of current detectors. OpenAI discontinued its AI Text Classifier due to “low accuracy” (high FP/FN) link, and Liang et al. 2023 found detectors like GPTZero flagged
61%of non-native TOEFL essays as AI arXiv. This undermines claims that rising “AI-like” phrasing in speeches necessarily implies model usage without stronger evidence and calibrated baselines. - Several point out that parliamentary rhetoric is historically formulaic and subject to rapid fashion cycles, so time-series spikes in specific n-grams around the ChatGPT release risk conflating trend adoption with causality. A more defensible approach would use an interrupted time-series or difference-in-differences on Hansard corpora (e.g., UK Parliament API) with speaker and party fixed effects, plus controls for media-driven meme diffusion (cross-correlating phrase adoption with external media timelines). Without such controls, phrase-frequency plots are likely picking up stylistic contagion rather than AI authorship.
- Commenters also highlight AI’s indirect influence on human language: even when speeches aren’t generated, writers may mimic model-suggested phrasing, making phrase-level AI attribution unreliable. Perplexity/burstiness-based detectors are brittle and degrade under light editing/paraphrase (see Ippolito et al. 2020 arXiv and DetectGPT by Mitchell et al. 2023 arXiv), so “AI-like” templates such as “not just X but Y” are poor evidence. Robust attribution would require watermarking or provenance signals rather than surface-level stylistic cues.
- Multiple commenters note high false-positive rates when flagging human-written text as AI, aligning with known limitations of current detectors. OpenAI discontinued its AI Text Classifier due to “low accuracy” (high FP/FN) link, and Liang et al. 2023 found detectors like GPTZero flagged
- Enjoy ChatGPT while it lasts…. the ads are coming (Score: 2375, Comments: 163): The post argues that commercial LLM assistants (OpenAI/ChatGPT, Perplexity, Anthropic) will likely monetize by embedding advertising directly into generated answers—analogous to how Google search evolved—creating incentives for response bias, telemetry-driven targeting, and ad-influenced retrieval/grounding that could erode user trust and turn AI chat into a surveillance-driven discovery layer. It questions whether ads-in-the-loop (e.g., sponsorship-weighted generation, RAG ranking skewed by paid content, or RLHF nudges) would compromise answer integrity versus subscription-only models. Commenters debate scope: ads on free tiers may be tolerable but not for Plus/Pro; implicit/stealth influence (organic product steering) is considered more harmful than explicit ads; several argue raising subscription prices or other offsets is preferable, noting that ad-driven reputational risk could slow adoption.
- Several commenters warn that monetization may manifest as “organic” steering rather than explicit banner ads—e.g., retrieval/citation ranking subtly favoring commercial entities or affiliates. In a RAG/tool-use stack this could be implemented by weighting retrieval scores, re-ranking candidates, or adjusting link choice under the hood, making bias hard to detect because it looks like normal reasoning. Auditing would require counterfactual prompts, distributional checks of cited domains, and A/B comparisons against a non-monetized baseline to spot systematic drift toward sponsors.
- Others note outbound links already include attribution/affiliate-like parameters so destinations can identify traffic sources. Technically this can be done via UTM parameters or partner tags in query strings (see Google’s UTM spec: https://support.google.com/analytics/answer/1033863 and MDN on Referer/Referrer-Policy: https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Referer), enabling conversion tracking and potential revenue sharing even when referrer headers/cookies are limited. This creates a measurable telemetry loop (click-through, conversions) that could be optimized by the model or ranking layer, reinforcing monetized link selection over time.
- A key risk raised for the open-source ecosystem is training-data contamination if web scrapes absorb AI-generated outputs that already contain monetized biases. This aligns with findings on quality/bias drift when models train on their own or synthetic outputs (e.g., “Model Autophagy Disorder,” https://arxiv.org/abs/2307.01850), with ads acting as a domain-specific poisoning vector. Mitigations include provenance tracking, synthetic-content detectors, domain de-duplication, and explicit filters for affiliate/UTM-tagged URLs during corpus curation.
- Why haven't all the other companies (Google, OpenAI, Deepseek, Qwen, Kimi and others) added this before? It's literally the most obvious and most needed thing 🤔 (Score: 295, Comments: 51): The image appears to showcase a chat UI touting a “new” native file upload/analysis workspace (multi-file document/code/data handling). Commenters note this isn’t novel: ChatGPT’s Code Interpreter/Advanced Data Analysis has supported uploading and programmatically analyzing files (CSVs, ZIPs, PDFs, etc.) since 2023 using a Python sandbox, with similar capabilities also present in other stacks; the real gaps tend to be UX and reliability, especially for complex documents. See e.g., OpenAI’s Advanced Data Analysis docs and prior announcements (OpenAI help, blog, 2023). Top comments push back that the feature is old news ("Who's gonna tell him"), adding that while non-visual files work well, PDF ingestion/understanding remains "mid."
- Several commenters point out this capability has existed since OpenAI’s Code Interpreter/Advanced Data Analysis rollout in mid-2023, which lets ChatGPT upload and process PDFs/CSVs by running Python in a sandbox for parsing, data extraction, and visualization. They note quality varies: non-visual/structured files perform well, but PDF parsing can be “mid” due to layout/OCR/table-detection limits, especially with complex or scanned documents. See OpenAI’s announcement: https://openai.com/blog/code-interpreter.
- There’s broad feature parity across vendors: Google Gemini supports file uploads (PDFs, images, etc.) via its File API for analysis (docs: https://ai.google.dev/gemini-api/docs/file_uploads), Microsoft Copilot can ingest and analyze uploaded documents in chat/Office contexts, and DeepSeek also advertises document Q&A in its chat clients. Differences are largely in modality coverage and extraction fidelity (e.g., robustness to complex PDF layouts) rather than the existence of the feature itself.
- People leaving AI companies be like (Score: 954, Comments: 45): Non-technical meme about departures from AI companies; comments contextualize it with the 2024 exits from OpenAI’s Superalignment team (e.g., Jan Leike’s resignation and the team’s disbanding), where leadership cited disagreements over safety priorities and resources (Jan Leike, reporting). Top comments argue the Superalignment team “wasn’t useful,” claiming none of its work shipped and that they had to create deliberately weak models to publish safety findings, while others quip that ex-employees start “safer-named” startups or call themselves “survivors.”
- A commenter claims OpenAI’s “superalignment” group had negligible production impact: none of their work purportedly shipped into ChatGPT, and they allegedly had to construct deliberately weak LLMs to demonstrate safety failures that standard safety layers and
RLHFalready mitigated in deployed systems. This highlights a perceived gap between alignment research artifacts and productized safety techniques (e.g., RLHF, policy filters) that directly affect user-facing models. - They further argue the team was progressively sidelined as practical safeguards (RLHF/filtering) addressed most real-world issues, so departures had little operational consequence—implying orgs may deprioritize alignment research that doesn’t yield measurable product or risk-reduction deliverables.
- A commenter claims OpenAI’s “superalignment” group had negligible production impact: none of their work purportedly shipped into ChatGPT, and they allegedly had to construct deliberately weak LLMs to demonstrate safety failures that standard safety layers and
- This popup called me out harder than my ex (Score: 377, Comments: 67): Meme-style screenshot likely from ChatGPT showing a privacy/data-use popup (reminding that chats can be reviewed/used to improve models) while the UI also exposes the user’s recent chat titles in the sidebar. Technically, ChatGPT stores chat history by default, and unless users disable “Chat history & training,” conversations may be reviewed to improve systems; the humor stems from the popup “calling out” sensitive chats and the screenshot unintentionally sharing recent activity. Comments joke about accidental oversharing and privacy (e.g., Altman “reading sexting chats”) and at least one user saying they don’t belong there, underscoring discomfort with data review vs. user expectations.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
3. Real-world AI Impacts: Builder Traction, Medical Triage, and Consciousness Debate
- Built with Claude Code - now scared because people use it (Score: 279, Comments: 77): Founder of https://companionguide.ai describes hacking together a tool using Claude Code inside VSCode and deploying on Netlify; unexpected traction from strangers triggered concerns about reliability, support, and whether to productize the MVP. The post focuses on early-stage operational readiness (stability, breakage risk) rather than code specifics or benchmarks. Top comments suggest paying for a professional code review once money is involved and note that even mature products break regularly—normalize issues while improving robustness.
- Primary actionable advice: before scaling paid usage, invest in a professional code review/security audit to identify correctness, security, and dependency risks early—preventing outages and revenue loss. A thorough review can surface edge cases, unsafe third‑party libraries, and architectural pitfalls that are expensive to fix post‑launch.
- Reminder that even mature, professional products fail; plan for failure with observability and resilience. Concretely, prioritize logging/metrics/tracing, graceful degradation paths, clear incident response/runbooks, and automated tests to contain blast radius when issues inevitably occur.
- ChatGPT may have saved my life (Score: 438, Comments: 55): OP reports that ChatGPT performed basic symptom triage for suspected acute appendicitis by querying for right‑lower‑quadrant (RLQ) localization and rebound tenderness—e.g., “Is it hurting in the bottom right?” and “does it hurt if you press and release?”—both classic signs of appendicitis, including McBurney’s point tenderness and rebound tenderness. This prompted an ER visit at
~2am, where clinicians indicated the appendix was near perforation; the prompts align with elements of the Alvarado score (e.g., RLQ tenderness, rebound pain), illustrating LLM‑driven layperson triage approximating clinical heuristics. Top comments provide additional anecdotes of LLMs offering useful differentials and patient education (healing/rehab timelines), occasionally anticipating clinician diagnoses; debate notes potential life‑saving triage benefits versus rare harmful uses (e.g., assisting self‑harm), with overall sentiment that LLMs can augment—not replace—medical professionals.- ChatGPT is used as a lightweight clinical decision-support tool for differential diagnosis and triage: when appendicitis was suspected, it enumerated alternative etiologies and surfaced an inflammatory condition that matched the eventual clinical diagnosis. For GI complaints, it guided structured self-checks (e.g., assessing gallbladder pain, screening red flags) to rule out emergent issues, helping users prioritize care pathways without replacing imaging/labs.
- As an evidence retriever and explainer, it provided study links and rationale-driven guidance for presumed gastritis, including staged diet planning and nutrient-dense, "safe" food selection based on irritant/acid load. Users report actionable, consistent explanations that made it easier to maintain nutrition during limited intake, illustrating utility in patient education and protocol adherence rather than definitive diagnosis.
- Reliability and safety: commenters note occasional hallucinations and unjustified assumptions that required cross-checking and correction, though one reported it was "rarely incorrect" within the constrained diet domain. A telehealth clinician later corroborated the working diagnosis, suggesting a workflow where LLM-assisted hypothesis generation and education precede clinician confirmation via diagnostics.
- If you swapped out one neuron with an artificial neuron that acts in all the same ways, would you lose consciousness? You can see where this is going. Fascinating discussion with Nobel Laureate and Godfather of AI (Score: 940, Comments: 419): The post revisits the neuron‑replacement (silicon prosthesis) thought experiment: if a single biological neuron is replaced by a functionally identical artificial unit matching spike timing, synaptic/plasticity dynamics, and neuromodulatory responses, would consciousness change—and what follows under gradual full‑brain replacement? The setup implicitly tests substrate‑independence/functionalism (cf. Chalmers’ “fading/dancing qualia” argument: https://consc.net/papers/fading.html) versus biologically essentialist views, and invokes identity continuity puzzles akin to the Ship of Theseus and multiple realizability (see SEP on Functionalism). Top comments emphasize that the “oomph” intuition has no operational/empirical content—"not something you can objectively measure"—and relate the scenario to Ship‑of‑Theseus identity continuity; others note the discussion is standard in philosophy of mind but acknowledge the speaker’s clear delivery.
- Several commenters note that the term “oomph” for consciousness lacks an operational definition, making it non-measurable and unfalsifiable. For technical evaluation, this highlights the need for operational criteria (e.g., reportability, behavioral/physiological markers, timing/causal interventions) rather than appeals to an undefined scalar of “consciousness.” Without agreed-upon metrics, discourse reduces to intuition pumps and can’t be benchmarked or stress-tested like other AI capabilities.
- Applying Ship of Theseus to neural replacement, the technically salient claim is that if each biological neuron is replaced by a functionally isomorphic artificial unit (preserving IO mappings, latencies, plasticity rules, and network-level dynamics), system-level behavior should remain invariant. This aligns with functionalism and the “gradual replacement” defense of consciousness continuity, pushing back on substrate-essentialist views; see Chalmers’ arguments on fading/dancing qualia for why massive qualia shifts without behavioral change are implausible (https://consc.net/papers/qualia.html). The hard part is specifying the equivalence class: does the replica need to match spike-timing statistics, neuromodulatory effects, and learning rules, or only causal role at some abstraction level?
- A “duck test” perspective argues for behavioral/operational criteria: if an agent is behaviorally indistinguishable and expresses preferences (e.g., not wanting shutdown), that may be a sufficient practical criterion irrespective of substrate, akin to a Turing-style operationalization (https://www.csee.umbc.edu/courses/471/papers/turing.pdf). The technical question becomes detecting and auditing non-instrumental preference expression versus goal-misdirected outputs under optimization pressure (e.g., deception), which implies the need for interpretability, consistency checks, and causal interventions. Full episode for deeper context: https://www.youtube.com/watch?v=giT0ytynSqg
- AI (Score: 1858, Comments: 94): The post titled “AI” contains no technical content—no models, code, datasets, benchmarks, or implementation details. It appears to be a short GIF/video gag featuring an initially blurred face followed by a full reveal (an intentionally inconsistent “censorship” effect), with no accompanying explanation or references. Commenters note the comedic timing—highlighting the abrupt de‑blurring (e.g., “blurred face then the fully revealed face”)—and express general appreciation; there is no substantive technical debate.
- wtf (Score: 1692, Comments: 144): Non-technical meme: a screenshot implies a user is shocked (“wtf”) by an AI/robot/chatbot response that is exactly what it was trained/programmed to do. The thread jokes about trivial or poorly designed training/inference (e.g., wasting CPU to print “hello”), underscoring the basic principle that models do what they’re trained to do (garbage in, garbage out). Comments emphasize user responsibility (“you trained it”), mock expecting emergent behavior from trivial code, and note the bot responding “exactly as programmed.”
- I think I have Alzheimer's. (Score: 577, Comments: 59): OP shares evidence that the assistant isn’t retaining information across chats (framed as “I think I have Alzheimer’s”), implying a failure of cross-session recall rather than in-thread context loss. A top comment suggests adding a third screenshot showing whether the Memory across conversations feature is enabled to substantiate the claim; if disabled, the behavior is expected per OpenAI’s memory design (see OpenAI’s overview: https://openai.com/index/memory-and-new-controls-for-chatgpt/). Most replies are humorous; the only technically substantive feedback is to verify the memory toggle before diagnosing a bug or regression.
- One commenter suggests adding a third screenshot showing whether "memory across conversations" is enabled to substantiate claims about the assistant’s forgetfulness. This highlights that product-level memory toggles can confound observations by mixing cross-chat memory with per-session context limits; a reproducible report should control for that setting and specify model/session details.
{kind=link}
{kind=link}
AI Discord Recap
A summary of Summaries of Summaries by gpt-5
1. Generation Efficiency and Kernel-Level Wins
- Set Block Decoding Slashes Steps: The paper Set Block Decoding (SBD) integrates next-token prediction (NTP) and masked token prediction (MATP) to cut generation forward passes by 3–5x while maintaining accuracy on Llama‑3.1 8B and Qwen‑3 8B, with no architectural changes and full KV-cache compatibility.
- Members highlighted SBD’s use of discrete diffusion solvers and praised its practicality as a fine-tune on existing NTP models, noting it promises significant speedups without hyperparameter headaches or system overhauls.
- MI300X VALU Mystery Meets Thread Trace: Engineers probed a suspected dual VALU glitch on MI300X where VALUBusy hit 200%, advising confirmation via limiting to one wave per SIMD (launch 1216 waves) and thread tracing with rocprofiler thread trace and rocprof compute viewer.
- They recommended using rocprofv3 and thread traces to verify if cycles with two waves issue VALUs, framing a repeatable methodology to isolate scheduler behavior at SIMD granularity.
- CUDA Graph Warmup: Capture Smarter, Not Longer: A prolonged CUDA graph warmup (~30 min) triggered guidance to capture a graph for decoding a single token rather than long model.generate() loops, referencing the profiling code in low-bit-inference profiling utils.
- Experts suggested capturing a single forward pass to avoid redundant warmup paths and reduce setup time, aligning graph capture with the intended steady‑state decode workload.
2. Leaderboards, MoE Moves, and New Models
- Qwen3-Next-80B Teases Tiny-Active Titan: Alibaba announced Qwen3‑Next‑80B‑A3B, an 80B ultra‑sparse MoE with only 3B active parameters, claiming 10× cheaper training and 32K+ faster inference while matching Qwen3‑235B reasoning (announcement).
- Community chatter noted extreme sparsity (e.g., ~1:51.2 at the MoE level and ~1:20 overall), flagging it as a key signal that sparse experts are the near‑term path to scalable inference economics.
- LMArena Adds Models and Cleans House: The leaderboard added Seedream‑4, Qwen3‑next‑80b‑a3b‑instruct/thinking, and Hunyuan‑image‑2.1 per LMArena announcements.
- Users also noted the removal of the legacy sites and were invited to submit feature requests for the current platform, consolidating evaluation traffic to a single surface.
- Nano‑Banana Nukes Seedream V4 in Edits: Early reports showed Seedream V4 struggling on image‑editing tasks (e.g., changing outfits while preserving face/body pose) against Nano‑Banana; users tested via LMArena image mode.
- Feedback described Seedream V4 as getting “massacred” on targeted edits, underscoring that edit‑preservation benchmarks remain a differentiator among image models.
3. Agentic Tools and Connectors Go Practical
- Comet Controls the Canvas (and Concerns): Perplexity’s Comet browser drew attention for agentic control that can fill forms, open tabs, and reply to emails, alongside praise for ad‑blocking and summarization but concerns about privacy/security after a reported vulnerability.
- Members emphasized that it “can control ur browser” and debated the safety tradeoffs of autonomous browsing versus productivity gains for routine workflows.
- OpenAI Connectors Unlock Custom MCPs: OpenAI enabled custom MCPs in ChatGPT via Connectors in ChatGPT, giving teams more control over infrastructure choices and data paths.
- Builders welcomed the flexibility and asked for better artifact distribution (e.g., hosting proposal PDFs online) to streamline collaboration and review.
- Transparent Optimizations Pitches Prompt Previews: A proposal for Transparent Optimizations introduced optimizer markers, prompt rewrite previews, and feasibility checks (discussion link).
- Participants requested easier access to supporting docs (e.g., web‑hosted PDFs) and debated how much control users should retain over optimizer‑driven rewrites.
4. Systems Tooling Shifts and GPU Gotchas
- vLLM’s uv pip Trips Nightly Torch: A change to custom builds using uv pip in vLLM uninstalled nightly torch, breaking environments per vLLM PR #3108.
- Practitioners reacted with “ok this is not good”, rolled back to v0.10.1 with
python use_existing_torch.py, and pushed maintainers for an alternative approach.
- Practitioners reacted with “ok this is not good”, rolled back to v0.10.1 with
- cuBLAS TN Quirk Lands on Blackwell: Developers noted newer NVIDIA GPUs (Ada 8.9, Hopper 9.0, Blackwell 12.x) require TN (A‑T, B‑N) for
cublasLtMatmulfast paths (cuBLAS docs).- While technically routine, some found the requirement “incredibly specific”, reminding kernel authors to validate layouts across architectures to avoid silent slow paths.
- Paged Attention Post Peeks Inside vLLM: A new deep dive, Paged Attention from First Principles: A View Inside vLLM, covers KV caching, fragmentation, PagedAttention, continuous batching, speculative decoding, and quantization.
- Systems engineers flagged it as a practical explainer for memory‑bound inference design, clarifying why paged caches and batching policies dominate throughput.
5. Mojo/MAX Platform: Custom Ops and Bindings
- bitwise_and Blocks? Build Custom Ops Instead: Because adding RMO/MO ops via Tablegen isn’t currently possible in closed‑source components, maintainers recommended implementing bitwise_and as a MAX custom op, keeping PRs open for potential internal completion later.
- Users hit API rough edges (broadcasting, dtype promotion), and a team member offered a quick demo notebook while acknowledging long‑term fixes are on the roadmap.
- DPDK Delight: Mojo Bindings Materialize: The community generated most DPDK modules in Mojo at dpdk_mojo, missing a few AST nodes and leaning on a Clang AST parser with JSON dumps for debugging and type reconstruction.
- They called
generate_bindings.mojo“hacky” but workable, aiming next at OpenCV while they iron out struct representation gaps in Mojo.
- They called
- Roll Your Own Mojo Dev Container: Builders shared a roll‑your‑own approach to a Mojo dev environment using Docker, referencing mojo-dev-container as a base for a customized setup.
- This pattern packages the Mojo toolchain predictably, enabling consistent local development and CI without waiting on official images.
Discord: High level Discord summaries
Perplexity AI Discord
- DeepSeek Debuts, Demolishes Delusions: Members on Discord debated which model follows instructions better, with some stating that DeepSeek is less delusional than ChatGPT.
- No further details were given.
- Grok Garners Gripes for Garrulousness: Users on Discord complained about Grok giving what we didn't even ask for and for yapping too muchhh.
- Some believe Grok is programmed to be controversial for attention, while others find it hard to follow instructions.
- Comet Causes Controversy for Controlling Browser: Users discussed the Comet browser, an AI browser made by Perplexity, noting it can control ur browser, fill forms, open tabs, and even reply to emails.
- Some users expressed concerns about privacy and security, citing a reported vulnerability that allowed hackers to access user data, while others praised its ad-blocking and summarization capabilities.
- Perplexity's API Parameter Problem Patched: A user reported a single API error a few hours ago, indicating that
num_search_results must be bounded between 3 and 20, but got 50.- Another user confirmed that this was a known issue that got resolved, thanking the user for reporting the error.
Unsloth AI (Daniel Han) Discord
- Multi-GPU ETA Remains Elusive for Unsloth: Despite user praise for Unsloth's simplicity in single-GPU training, there's no ETA for official multi-GPU support, with development updates available in this Reddit thread.
- Users are encountering struggles with unofficial methods, underscoring the demand for native multi-GPU capabilities.
- Dynamic GGUF Quantization Desired for Model-Serving: A user expressed high interest in a Dynamic 2.0 GGUF service to improve quantization, suggesting a pay-for-service model, highlighting the need for I-matrices and their quantization schemes.
- They noted the labor-intensive process of model analysis, dynamic quantization, and testing puts strain on the Unsloth team.
- GuardOS: Privacy-Focused NixOS OS Goes Live: A member shared a link to GuardOS, a privacy-first NixOS-based operating system.
- Another member found the idea comical, stating the idea itself was already comical, but the top comment is even funnier.
- Unsloth BERT Model Fine-Tuning Support Confirmed: A user inquiring about Unsloth support for BERT models for finetuning with EHR data to classify ICD-10 codes received a link to a relevant Colab notebook.
- Unsloth officially supports certain models, and users are encouraged to experiment with others, making it suitable for classification tasks.
- Spectral Edit Reveals Audio Secrets: Insights from a spectral edit show that content lies around 0-1000 Hz, prosody between 1000-6000 Hz, and harmonics from 6000-24000 Hz.
- Harmonics determine audio quality and can reveal the sample rate by ear, suggesting natural generation or stretching crystal clear audio can add depth, similar to "frequency noise".
LMArena Discord
- O3 Model Flounders: Users report underwhelming performance from the O3 model on complex tasks, with some finding it worse than Gemini Pro.
- Conflicting opinions exist, however, as some users see O3-medium as potentially approaching GPT5-low level performance.
- Psychological Prompting: Brain Hack or Bust?: A user suggested employing psychological prompting tactics, such as instructing the AI to work your best with no exceptions.
- Skeptics argue that vague statements are ineffective and verbose prompting yields better results for LLMs.
- AI Spritesheet Factory: A user is generating spritesheet animations using AI, converting video to frames in just 10 minutes.
- They are using Gemini for character images and has posted ready spritesheet animations on itch.io called hatsune-miku-walking-animation.
- LM Arena Says Goodbye to Old Website: The legacy version of the LM Arena website, including alpha.lmarena.ai and arena-web-five.vercel.app, has been removed.
- A team member posted an announcement and invited users to submit feature requests for the current site.
- Nano-Banana Annihilates Seedream V4: Early reports suggest Seedream V4 is underperforming, even against Nano-Banana, especially in image editing tasks.
- Specifically it has trouble changing a person’s outfit while preserving their face and body position. Use this link to use Seedream V4.
HuggingFace Discord
- QLoRA Batch Size Blues: A member ran into batch size limitations using QLoRA with PEFT and a 7B model with 4096 token sequence length on an H200 GPU.
- Suggestions included checking FA2/FA3, setting
gradient_checkpointing=True, using smaller batch sizes, and referencing Unsloth AI docs for context length benchmarks.
- Suggestions included checking FA2/FA3, setting
- ArXiv Paper Needs Endorsement: A user urgently seeks endorsement in CS.CL on ArXiv to publish a preprint featuring the Urdu Translated COCO Captions Subset dataset.
- The endorsement request URL was shared: here.
- Docker Model Runner Debuts: Users discussed using Ollama, Docker Model Runner, and Hugging Face for downloading and utilizing free models.
- Challenges with model availability were noted, with suggestions to consult the Hugging Face documentation and use a VPS.
- n8n valuation jumps to $2.3 Billion: A user inquired about integrating Hugging Face Open Source models within n8n, a no-code automation platform.
- An image was shared indicating that the Berlin-based AI startup n8n has seen its valuation skyrocket from $350 million to $2.3 billion in just four months, per this youtube video.
- Zero Loss on Smol Course: Members experienced zero loss during fine-tuning with an already fine-tuned model, recommending a base model for proper loss.
- A code snippet to disable thinking functionality in the tokenizer in the course's SmolLM3-3B can be found here.
Cursor Community Discord
- Cursor Plagued by Issues: Cursor users are reporting numerous issues with Cursor and are being directed to report them on the forum for assistance.
- Among the issues reported is Cursor's auto mode using PowerShell commands to edit, prompting a user to request a bug report.
- Legacy Auto Mode Locks Subscribers: Users with annual subscriptions purchased before September 15th retain the old auto mode until their next renewal, according to pricing details.
- A user is attempting to use rules to make auto use the inline tools.
- Cursor Beta Obscures Release Notes: The latest Cursor release (1.6.6) is in beta, and release notes are scattered across the forum, requiring users to hunt for them.
- The pre-release nature of the version means rapid changes and potential feature removals.
- Director AI Pursues C3PO Dream: A user is trying to stop the whole Your absolutely right! crap by essentially trying to build a C3PO.
- The project is already running on an MCP server and integrated into Cursor.
- Linear Integration Snags on Repository Selection: A user reported that when assigning an issue to Cursor via Linear, it prompts to choose a default repository, even though one is already specified in the Cursor settings, as seen in the attached image.
- This recurring prompt occurs despite the user having configured the default repository within Cursor.
{kind=link}
OpenRouter Discord
- OpenRouter query prompts have race condition bug: A member reported a bug related to a possible race condition in query prompting, where longer, more detailed prompts yield worse results for translations.
- No solution was found, but it was suggested to report the bug to the developers.
- Developers have Token Calculation Conundrums: A member inquired about calculating the number of tokens for input, seeking a non-heuristic method due to model-specific variations.
- It was suggested to use external APIs in conjunction with the endpoint's tokenizer information, as documented, since there's nothing in the documentation about that.
- JSONDecodeError surfaces in server responses: Users discussed a JSONDecodeError indicating an invalid JSON response from the server, often due to server-side failures like rate limiting, misconfigured models, or internal errors.
- The error suggests the server returned HTML or an error blob instead of valid JSON.
- Avoiding Moonshot AI's turbo pricing: A user asked how to avoid the more expensive turbo version when selecting Moonshot AI as the provider for Kimi K2 in the OpenRouter chatroom.
- The solution offered was to select a cheaper provider in the advanced settings.
- iOS upload bug squashed: A user reported a bug where they couldn't upload PDF or TXT files to OpenRouter chat on iOS because non-image files were grayed out.
- It was confirmed as a bug, likely an oversight when file uploads were added, with no workaround available on iOS.
GPU MODE Discord
- Lambda Labs Cloud GPUs Face Instance Drought: Users reported inconsistent GPU instance availability with Lambda Labs, questioning the frequency and impact of cloud GPU shortages.
- The discussion underscored the importance of understanding the reliability of GPU resources when relying on cloud platforms for resource-intensive tasks.
- CUDA Graph Warmup Reaches Half Hour Mark: A user reported that CUDA graph warmup was taking half an hour in their low-bit-inference project, and another suggested that capturing a CUDA graph for decoding one token instead of generating many tokens may provide better results.
- The user may want to capture a single forward pass, not multiple passes like
model.generate()does internally.
- The user may want to capture a single forward pass, not multiple passes like
- vLLM's uv pip Transplants Nightly Torch: A member noted that vLLM switched to
uv pipfor custom builds with pre-installed torch, but it uninstalls the nightly torch, leading to environment issues, from this PR.- A member said ok this is not good, just saw their pr. I'm gonna go ask them if they can find another way to do this, and another member reverted to
v0.10.1building withpython use_existing_torch.py.
- A member said ok this is not good, just saw their pr. I'm gonna go ask them if they can find another way to do this, and another member reverted to
- MI300X Probes Potential Dual VALU Glitch: Users investigated a potential dual VALU issue on MI300X, where VALUBusy hits 200%, suggesting confirming it by limiting to one wave per SIMD, and using rocprof compute viewer and rocprofv3 to diagnose.
- The user was advised to launch 1216 waves to achieve 1 wave/simd, leveraging AMD's documentation for thread tracing and rocprof compute viewer documentation.
- Kernel Dev Roadmap makes Progress: A member suggested adding a roadmap for kernels and increasing available kernels in GPU mode leaderboard, following the format of gpu-mode/reference-kernels.
- Members also mentioned that submissions can now be made online, with the primary need being an editor-like experience.
LM Studio Discord
- NVMe Upgrade Speeds Up Load Times: A user replaced a slow NVMe with a faster one, achieving a 4x improvement in sequential read speed and model load times.
- The user did not provide details on the old or new drives.
- Markdown Sub Tag Renders Incorrectly: A member reported that the
<sub>tag has no effect on text inside it in Markdown style within LM Studio, and also that italic text is not rendered correctly when using asterisks such as*(n-1)*.- There are ongoing discussions about the proper rendering of Markdown syntax, specifically with sub tags and italicized text.
- Western Digital Drives Blows Up: Users reported high failure rates with Western Digital Blue drives, humorously calling them Western Digital Blew Up drives.
- The users did not elaborate on the specific failure modes or use cases, but the consensus was to avoid the drives.
- PNY NVIDIA DGX Spark Plagued by ETA Shenanigans: Users joked about the PNY NVIDIA DGX Spark having conflicting ETAs, initially October then late August, as listed on linuxgizmos.com.
- The inconsistency in the release dates has led to speculation about the availability and production timeline of the device.
- Linux Dominates for Max+ 395 Box: Users recommended Linux over Windows for a Max+ 395 box, citing Vulkan's functionality but noting potential context limits.
- It was suggested to use a custom-built llama.cpp with ROCm 7 from lemonade-sdk/llamacpp-rocm that already has compiled versions in Releases.
OpenAI Discord
- Laconic Game Causes Gemini 2.5 Pro to Hallucinate: A user joked that their laconic game was so strong that it caused Gemini 2.5 Pro to hallucinate.
- The user did not elaborate further on the nature of the hallucination or laconic game.
- GPT-5 Now Integrates Code Snippets and Linux Shell Access: A member reported that GPT-5 now writes its own code snippets to use as tools in a chain of tasks and appears to have access to an underlying Linux shell environment.
- Another member mentioned they vibe coded directly from the ChatGPT interface to develop an app hosted locally on GitHub.
- Custom MCPs Now Supported in OpenAI: Users can now use custom MCPs (Managed Cloud Providers) in OpenAI, according to the Connectors in ChatGPT documentation.
- This update allows for more flexibility and control over the infrastructure used by ChatGPT.
- Transparent Optimizations Proposal Introduced: A proposal for Transparent Optimizations was posted, introducing optimizer markers, prompt rewrite previews, and feasibility checks; the proposal was linked here.
- One member requested that associated PDFs be hosted online for easier access, rather than requiring downloads.
- AI Self Help Conversation Analyzer Launched: A member introduced a conversation analyzer called AI Self Help that helps determine why conversations take odd turns.
- The tool includes a conversation starter that lists issues and detailed questions to ask ChatGPT to get the answers.
{kind=link}
Nous Research AI Discord
- Disable WebGL to fix perf issues: A member requested a feature to disable WebGL in the browser due to performance issues without a GPU, and suggested disabling the animation orb as well, shown in this screenshot.
- The suggestion came from someone working on a project requiring rapid iteration with automated bug fixes and updates, and passing the MOM test.
- Dataset quality better with Tokenizer Filtering: A member shared a link to dataset_build on GitHub, highlighting the idea of running languages through a model’s tokenizer and rejecting those with unknown tokens to ensure quality.
- The approach also organizes calibration datasets using folders/directories for later combination.
- SBD accelerates LLM Gen: A new paper introduces Set Block Decoding (SBD), a paradigm that accelerates generation by integrating standard next token prediction (NTP) and masked token prediction (MATP) within a single architecture, without requiring architectural changes or extra training hyperparameters.
- Authors demonstrate that SBD enables a 3-5x reduction in the number of forward passes required for generation while achieving the same performance as equivalent NTP training by fine-tuning Llama-3.1 8B and Qwen-3 8B.
{kind=link}
Latent Space Discord
- GPT-OSS Outshines Llama2 on a Budget: It was noted that running GPT-OSS 120B is cheaper than running Llama2 7B, with discussion suggesting that MoEs are the future.
- Optimizations for speeding up GPT-OSS, such as MXFP4 quantization, custom kernels, and continuous batching, were also mentioned.
- Altman Grilled in Murder Mystery: During an interview, Sam Altman was accused of murder, prompting a classic deflection move as highlighted in this video clip.
- A member shared that there's a clip on Twitter of this like 5 min segment.
- Codex Cranks Get Exclusive Peek: Alexander Embiricos invited heavy Codex users to beta test something new, as seen in this tweet.
- This might be related to conversation resume and forking, based on recent repository activity here.
- OpenAI's Oracle Oddity Obscures Overspending: OpenAI reportedly signed a 5-year, $300 billion cloud-computing contract with Oracle starting in 2027 at $60 billion per year.
- Commentators are questioning OpenAI's ability to afford the annual $60B cost against ~$10B revenue, raising concerns about energy and business-model sustainability.
- ByteDance Squeezes Google's Fruit: Deedy highlighted ByteDance’s new Seedream 4.0 as top ranked on Artificial Analysis leaderboards, touting 2–4 K outputs, relaxed policies, faster generation, multi-image sets, and $0.03 per result.
- Community reactions range from glowing praise for quality and pricing to skepticism that Nano Banana still wins on speed and natural aesthetics.
DSPy Discord
- Math GPT App Seeks DSPy Savvy: A member seeks an advanced DSPy blog writing agent for a Math GPT app available at https://next-mathgpt-2.vercel.app/.
- The agent would presumably generate math-related content, given the nature of the Math GPT app.
- Pythonic Programs Propel Proliferation of Ports: A member suggested modeling and optimizing DSPy programs directly in Python and transpiling to languages like Go, Rust, or Elixir.
- A key challenge is how to export an arbitrary python program, perhaps by serving a backend to a python interface.
- Arbor Advantages Accelerate Adoption of RL: Members discussed using Reinforcement Learning (RL) in DSPy, but one member expressed fear of diving in because of the many moving parts and need for powerful GPUs.
- Another member said that Arbor + DSPy is quite seamless, and they are working on new things to make config even easier so everyting just works.
- Instructions' Immutability Incites Iterations: A member inquired whether instructions can be modified by an optimizer when using
signature.with_instructions(str).- It was clarified that mipro and gepa do modify the instructions, with the actual instructions saved in the
program.json.
- It was clarified that mipro and gepa do modify the instructions, with the actual instructions saved in the
- DSJava: DSPy Dabbles in Java?: Members discussed a potential DSPy implementation in Java, perhaps dubbed DSJava?.
- One member does a hack version, compiling prompts in DSPy, then having a function in Rust for running prompt packs, but preferring to do it all in Rust.
Modular (Mojo 🔥) Discord
- Mojovians Mobilize Mojo Docker: A member sought a Docker container checkpoint for running the Mojo dev environment, prompting suggestions to roll your own using existing images and the Mojo package with this GitHub repo.
- This approach allows for a customized Mojo development setup within a containerized environment.
- Mojo Compiler Aims Go-like Packaging: The Mojo compiler, set for open-sourcing in 2026, sparked discussions on its potential to replace venv with a Go-like packaging system, with Modular stating they have no current plans for it.
- The community debated the practicality of self-compilation versus leveraging existing Python ecosystems for package management.
- DPDK Gets Mojo Bindings: A member generated most modules for dpdk using Mojo, available on GitHub, but is missing a couple of AST nodes and found the
generate_bindings.mojoscript to be a bit hacky.- They are also using Clang AST parser to convert strings of types into proper AST nodes, dump the AST JSON for visual debugging, and then convert it to Mojo.
bitwise_andOp Blocked by Closed Source: A member inquired about adding abitwise_andop to the Modular repo, but was told that adding RMO and MO ops in Tablegen is not feasible due to closed source but it should work as a custom op.- The team is working towards supporting open source contributions to MAX and the PR can remain open for internal completion at a later date, but it requires diverging from the existing pattern for op definition in ops/elementwise.py.
- Graphs Grinding Gears During Staging: A member reported long staging times for graphs, citing GPT2-XL as an example that takes 3.6 seconds to define the Max graph with a warm cache, followed by 0.2 seconds to compile.
- A team member welcomed real-world examples for benchmarking and optimization purposes.
Yannick Kilcher Discord
- Brains Spark Sparsity Speculation: A member compared a certain sparsity ratio to primate/elephant/whale brains.
- However, the specific sparsity ratio and its context were not clearly detailed.
- Saturday Sessions Seek Source: A member inquired about the publication location of Saturday session papers, especially after a recent session.
- The discussions and papers are typically posted via the events feature, including a presentation followed by a discussion and relevant links.
- Planning Paper Presents Potential: Members reviewed the paper "Planning with Reasoning using Vision Language World Model" (https://arxiv.org/abs/2509.08713) and deemed it a light read, although some references are potential candidates for future discussions.
- The paper was not deeply reviewed, but some found the references to be the most interesting aspect.
- Prompt Templates Promise Productivity: A straightforward paper on a prompt templating system (https://arxiv.org/abs/2508.13948) sparked a light discussion among members.
- The project page at microsoft.github.io/poml/stable/ was suggested as a better overview of the design and utility in different systems.
- SNNs Spark Scalability Speculation: Members discussed the resurgence of Spiking Neural Networks (SNNs), previously considered flawed, due to their extreme sparsity advantages at scale.
- One member noted the potential of unlocking the brain's secrets (the brain is an SNN), which could be a gold mine, though it may require specialized hardware.
Eleuther Discord
- Community Welcomes Data Science Enthusiast: New member David, with a background in Data Science, Mathematics, and computational biology, introduced himself to the community.
- He expressed enthusiasm for open communities and looked forward to connecting with others.
- Delving into Data Splitting Strategies: A member suggested chronological splitting in data processing, instead of random truncation for improved data naming and combination.
- They also reported experimenting with combining bin packing and truncation to discard suffixes.
- Questioning Gaussian Noise Significance: A member questioned if neural network behavior on random Gaussian noise accurately reflects performance on structured inputs, referencing this image.
- The member claimed that if training an image classifier where one label is staticky TV screen, then Gaussian noise will systematically push inputs toward that class.
- Hallucination Detection Dataset Doubts: Members discussed a tweet by @NeelNanda5 and a related paper on hallucination detection, noting the dataset construction effort.
- A member argued that creating such a dataset and classifier to detect hallucinations might be similar to fine-tuning the model to avoid the issue altogether.
- Exploring Relational Hallucinations: Members explored how to define hallucination, noting that the more interesting hallucinations are in other modalities, citing a paper defining relational hallucinations.
- A member shared a link to a tweet on the topic.
{kind=link}
aider (Paul Gauthier) Discord
- Engineer Seeks Help Tuning AI Documentation Agents: An engineer is seeking advice on tuning their documentation agent, built with Vercel AI SDK and Claude Sonnet 4, and is struggling to refine prompts without impacting existing performance.
- The agent consists of a team lead, document writer, and document critique that iterates up to 5 times per section, using braintrust for tracking.
- Defining Non-LLM AI Outputs: A member asked how to define 'good outputs' from an AI model without calling an LLM, clarifying that good outputs mean following guidelines, not hallucinating stuff, sticking to requirements.
- The advice was to start with simple unit tests to check for the existence of certain keywords in the AI response, then enhance it with an LLM as a judge.
- Hamel Hussain's Evals Blogpost Recommended for Tuning: A member recommended reading Hamel Hussain’s blogpost on evals for guidance on evaluating AI models.
- The blogpost was recommended alongside Eugene Yan's resources, with the engineer finding Mastra's guidebook useful.
- Aider Load Command Comments Out Lines: The "#" symbol comments out lines in files executed by the aider /load command.
- The aider LLM decides which files to edit, leveraging the repo map, which is sent to the LLM as part of the system prompt, while the repo map is constrained to a certain size to avoid token limits.
Moonshot AI (Kimi K-2) Discord
- Kimi K2 excels at deep research: A member noted that Kimi K2's search capabilities are effective for deep research, capable of searching broadly and compiling interactive reports.
- The member inquired whether the Kimi K2 instruct chats are utilized for training the model, though further details on this aspect were not provided.
- K2 Research Mulls Email Integration: A member considered whether K2 Research could send emails during its research process, specifically for customer support scenarios.
- Another member responded and suggested that this capability is not yet implemented in K2 Research.
- Creative Writing Models Battle for Supremacy: A member suggested that Kimi K2, GPT-5 (Medium), and Qwen3-Max are among the best models for creative writing tasks.
- The member specifically lauded them as three good models for brainstorming.
Manus.im Discord Discord
- Manus Credits No Longer Given: Users reported that free credits are no longer available on Manus.
- The change was noticed in the main discord.
- Collaboration Feature Sees Light: A user expressed appreciation for Manus implementing a collaboration feature that an early user Prayer had originally requested.
- The feature was highly anticipated by the community.
- Next.js Migration: Too Much?: A user inquired about converting a Wordpress website to Next.js for Vercel hosting.
- Members pointed out that because Wordpress is in PHP and Next.js would require porting to React.js, it might be too much for a small, ~40-page small business website.
The tinygrad (George Hotz) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The LLM Agents (Berkeley MOOC) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Windsurf Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
You are receiving this email because you opted in via our site.
Want to change how you receive these emails? You can unsubscribe from this list.
Discord: Detailed by-Channel summaries and links
Perplexity AI ▷ #general (1195 messages🔥🔥🔥):
DeepSeek vs ChatGPT, Grok's persona, GPT-5 vs Perplexity, Comet Browser
- DeepSeek outperforms ChatGPT for factual recall: Members debated which model follows instructions better, with some stating that DeepSeek is less delusional than ChatGPT.
- Grok gets grilled for garrulousness: Users complained about Grok giving what we didn't even ask for and for yapping too muchhh.
- Some believe Grok is programmed to be controversial for attention, while others find it hard to follow instructions.
- ChatGPT plus versus Perplexity plus: Users state that ChatGPT gives better responses than Perplexity, particularly for simplifying complex concepts.
- One user says that Perplexity is useful as a search engine but is not good at chatting.
- Comet Browser's AI Agent causes Controversy: Users discuss the Comet browser, an AI browser made by Perplexity, noting it can control ur browser, fill forms, open tabs, and even reply to emails.
- Some users expressed concerns about privacy and security, citing a reported vulnerability that allowed hackers to access user data, while others praised its ad-blocking and summarization capabilities.
Perplexity AI ▷ #sharing (5 messages):
Shareable Threads, ProductHunt Vote, Image attachments
- Shareable Threads reminder: Perplexity AI reminded users to ensure their threads are Shareable, with an attachment showing how.
- No further details were given.
- ProductHunt Vote Requested: A member asked for votes on ProductHunt.
- It is unclear what the product is.
- Image attachments: A user shared a series of image attachments with no context.
- There are four images in total in the series.
{kind=link}
Perplexity AI ▷ #pplx-api (3 messages):
Friend Requests, API Errors, num_search_results errors
- Friend Requests Coming In Hot: A user sent a friend request seeking to test the beta, offering feedback on its use with webapps and n8n.
- API parameter error squashed: A user reported a single API error a few hours ago, indicating that
num_search_results must be bounded between 3 and 20, but got 50.- Another user confirmed that this was a known issue that got resolved, thanking the user for reporting the error.
Unsloth AI (Daniel Han) ▷ #general (562 messages🔥🔥🔥):
Unsloth hardware compatibility, Training TTS models on Colab, Multi-GPU Support Roadmap, BERT models in Unsloth, Dynamic GGUF Quantization Requests
- M1/M2 Macs not locally compatible yet: A new user with an Apple M2 Max MacBook Pro discovered that Unsloth doesn't currently support local training on M1/M2 Macs but was directed to use MLX instead, as per the Unsloth requirements.
- A community member suggested leveraging free Google Colab for learning and tuning, then exporting models to GGUF format for local use with software like LM Studio and also shared a link to Unsloth Notebooks.
- Colab Good for TTS Training?: A user asked about training high-quality, small-sized TTS models with low RTF on Google Colab and wanted to know if it would be entirely free.
- It was clarified that while Google Colab offers some free usage, limitations exist, and Unsloth supports TTS fine-tuning as well, with documentation available here.
- Multi-GPU ETA Missing In Action: A user inquired about the roadmap and timeline for official multi-GPU support, noting struggles with unofficial methods and praising Unsloth's simplicity in single-GPU training.
- The response indicated there's no ETA currently, but it's in development with further updates available in this Reddit thread.
- Dynamic GGUF Quants Sought for Model-Serving: A user expressed high interest for a Dynamic 2.0 GGUF service to improve quantization, suggesting a pay-for-service model, along with expressing the need of I-matrices and their quantization schemes
- The community member noted that the labor intensive process of model analysis, dynamic quantization, and testing for these quants can put strain on the Unsloth team which is already contributing to the OSS community.
- New Models from OpenAI, Users React: A member shared an image of new models, to which others responded with humor.
- After the image of new models was shared, a member listed out additional options for the AI community and members discussed sparsity of the newly unveiled models by OpenAI.
Unsloth AI (Daniel Han) ▷ #introduce-yourself (4 messages):
AI Engineering, AI Startups, Microservices, LLMs
- AI Engineer Architects High-Leverage Systems: An AI engineer introduced themselves as someone who architects high-leverage systems and is currently building the AI-native OS at pxsol, forging a stealth startup, and writing a weekly dispatch on building 1-person enterprises.
- They are always open to jamming on autonomous engines, agentic systems, and the intersection of AI + quant finance.
- AI Engineer Intern Leads Startup Projects: An AI Engineer intern introduced themself working at a startup while still being a student.
- They focus on making microservices for AI applications, designing AI system architecture, playing with LLMs and finetuning and deploying them when needed.
Unsloth AI (Daniel Han) ▷ #off-topic (109 messages🔥🔥):
48GB 4090s, Privacy-First NixOS-Based OS, Unsloth Dependency Hell, Luau Learning and LeetCode, Promptwright DAG
- 48GB 4090s Tempt but Wait?: Members discussed the temptation of buying 48GB 4090s for $3k, but weighed the pros and cons with the expected release of the 5090.
- One member showed a <:redaahhhh:1238495916202397726> after saying U sure u want to risk it?.
- GuardOS: Privacy-First NixOS OS Debuts: A member shared a link to GuardOS, a privacy-first NixOS-based operating system.
- Another member found the idea comical, stating the idea itself was already comical, but the top comment is even funnier.
- Tackling Unsloth's Dependency Labyrinth: A member joked about the dependency hell when using Unsloth, spending time on getting the correct dependencies, using the command
uv tree --package unsloth > uv_tree_package_unsloth.txt.- Another member recommended using
uvand pinning dependencies, mentioning that even when something is breaking it is typically pretty verbose about why.
- Another member recommended using
- Teaching AI Luau and Loving LeetCode Less: Members discussed training an AI on Luau with LeetCode problems, where the AI initially yapped more, then reduced fluff as it progressed.
- It was noted that the shorter answers led to faster training, but the model was only passing half the unit tests on average, but now the AI is getting quiet and mad.
- Promptwright Pioneers DAG Dataset Seeding: A member announced a new experimental Directed Acyclic Graph (DAG) dataset seed generation algo in Promptwright.
- The new algorithm is being used for domain-specific distillation (teacher -> SLM) synthetics.
Unsloth AI (Daniel Han) ▷ #help (220 messages🔥🔥):
Phi3-mini quantization, Unsloth BERT models, System prompt structure, Custom Santa voice, Qwen2.5-vl perceived dimensions
- Pascal User Plugs Phi3 Mini Performance: A user running phi3-mini-4k-instruct on a GTX 1050ti (4GB VRAM) experiences long inference times (~8mins) without quantization and seeks advice given issues with bitsandbytes on Pascal architecture.
- The user lacks experience with AWQ and wants to know the best approach to improve performance.
- Unsloth BERT support surfaces: A user inquired about Unsloth support for BERT models for finetuning with EHR data to classify ICD-10 codes, getting a link to a relevant Colab notebook.
- Unsloth officially supports certain models, and users are encouraged to experiment with others.
- System Prompt Structure Scrutinized: A user's approach of using multiple system lines per prompt for maintaining memory in Python was flagged as really, really bad, and restructuring into a single system prompt with chunks was suggested.
- The user was advised to follow the training structure for better outcomes, emphasizing that clear instructions and testing are essential.
- TTS model training is Tough Sledding for Santa Voice: A user wants to create a custom Santa voice in Swedish for an office project and was directed to the Unsloth TTS documentation.
- It was noted that audio model data is limited, especially for languages like Swedish, and zero-shot voice cloning with tools like ResembleAI's Chatterbox (which supports Swedish) was mentioned as an alternative, along with in-house, no-cloud options.
- H100 Docker driver debacle develops: A user faces CUDA errors when running a Docker image (that works on 3090/4090) on an H100 GPU, and it was found that the driver version was incompatible with the H100.
- The user was advised to install the correct NVIDIA data center drivers and possibly switch to a more reliable cloud provider instead of community clouds, with the warning that community clouds might be unstable and pose security risks.
Unsloth AI (Daniel Han) ▷ #showcase (11 messages🔥):
Markov Chains, MoonshotAI's checkpoint-engine, vLLM v0.10.2rc1
- Markov Chains still feel like Magic: A member was dumbfounded that their own n-gram based Markov chain gave halfway sensible sounding output.
- Another member mentioned someone who did a Markov chain on Discord chats, resulting in uncanny valley type content.
- MoonshotAI releases checkpoint-engine: A member shared a GitHub repo by MoonshotAI called checkpoint-engine.
- Another member asked if it could be used for GRPO inference with some optimizations.
- vLLM v0.10.2rc1 inference engine validated: All results above are tested by
examples/update.pyand use vLLM v0.10.2rc1 as inference engine (on an H800 or H20 machine with 8 GPUs).
Unsloth AI (Daniel Han) ▷ #research (2 messages):
Spectral Edit, Audio Analysis, LLM Inference
- Spectral Edit Exposes Audio Secrets: A member shared insights from a spectral edit, noting that content lies around 0-1000 Hz, prosody between 1000-6000 Hz, and harmonics from 6000-24000 Hz.
- They added that harmonics determine audio quality and can reveal the sample rate by ear, and natural generation (or stretching crystal clear audio) can add depth, similar to "frequency noise".
- LLM Inference Nondeterminism Defeated!: A member shared a blog post from Thinking Machines AI regarding defeating nondeterminism in LLM inference.
LMArena ▷ #general (820 messages🔥🔥🔥):
O3 Model Performance, Psychological Tactics in Prompting, AI Spritesheet Animation, LM Arena Legacy Website Removal, Nano-Banana vs Seedream V4
- O3 Model Draws Negative Reviews: Users are reporting that the O3 model is not performing well on complex tasks, with one user stating it outright says no to complex instructions.
- Another user expressed the opposite sentiment, claiming O3-medium is at GPT5-low level at best, but another user disputes that, saying Gemini Pro is better.
- Psychological Tactics may Improve LLM Reflection: A user suggested employing psychological tactics in prompting, advising to instruct the AI to work your best with no exceptions and reflect from different perspectives for optimal results.
- However, another member countered that vague statements like work your best are meaningless to LLMs and that more verbose prompting is the way to go.
- Automated AI Spritesheet Animations Emerge: One user is generating spritesheet animations using AI, starting with character images from Gemini, assembling them on a grid, animating them, and converting the video to frames, resulting in a process that takes only 10 minutes.
- The user inquired about the permissibility of sharing links, having already posted some ready spritesheet animations on itch.io called hatsune-miku-walking-animation.
- LMArena Shuts Down Legacy Website: Users are lamenting the removal of the legacy version of the LM Arena website, including alpha.lmarena.ai and arena-web-five.vercel.app.
- A member of the LM Arena team has posted a link to the announcement and invited users to submit feature requests for the current site.
- Nano-Banana Reigns Supreme over Seedream V4?: Some users are reporting that Seedream V4 is getting massacred and performs worse than Nano-Banana, particularly in image editing tasks like changing a person’s outfit while preserving their face and body position.
- It's been suggested to use this link to use Seedream V4 though one user is still waiting for Gemini 3.
LMArena ▷ #announcements (3 messages):
Seedream-4, Qwen3-next-80b-a3b-instruct, Qwen3-next-80b-a3b-thinking, Hunyuan-image-2.1
- Seedream-4 joins LMArena: A new model, Seedream-4, has been added to the LMArena leaderboard.
- Qwen3-next-80b duo makes debut: Two new models, Qwen3-next-80b-a3b-instruct and Qwen3-next-80b-a3b-thinking, have been added to the LMArena.
- Hunyuan-image-2.1 hits the Arena: A new model, Hunyuan-image-2.1, has been added to the LMArena leaderboard.
HuggingFace ▷ #general (218 messages🔥🔥):
PEFT QLoRA Training, ArXiv Endorsement Request, WACV Paper Submission, LLM Fine-tuning Course Study Group, Mobile App Image Search
- PEFT QLoRA batch size woes: A member is facing issues with batch size limitations while using QLoRA with PEFT and a 7B model with a 4096 token sequence length on an H200 GPU.
- A suggestion was made to check if FA2 or FA3 is disabled, or if
gradient_checkpointing=Truewas not set, as well as trying smaller batch sizes from 1-7 due to potential OOM issues, and also check the Unsloth AI docs.
- A suggestion was made to check if FA2 or FA3 is disabled, or if
- ArXiv Endorsement Needed Urgently: A user requests an endorsement in the CS.CL category on ArXiv to publish a preprint of a research paper featuring the Urdu Translated COCO Captions Subset dataset.
- The endorsement request URL is here.
- Docker Model Runner Debuts: Users discussed using Ollama, Docker Model Runner (a new feature from Docker Desktop), and Hugging Face for downloading and utilizing free models.
- A user reported that some models aren't available and others suggested the Hugging Face documentation and also mentioned the use of a VPS (Virtual Private Server).
- n8n valuation surges to dizzying heights: A user inquired about integrating Hugging Face Open Source models within n8n, a no-code automation platform.
- An image was shared indicating that the Berlin-based AI startup n8n has seen its valuation skyrocket from $350 million to $2.3 billion in just four months, per this youtube video.
- OpenAI should invest 100B into Hugging Face?: A user comically suggested OpenAI should invest $100B into Hugging Face.
- Others noted ongoing platform issues, such as exceeding monthly inference credits despite having funds available:
{'error': 'You have exceeded your monthly included credits for Inference Providers. Subscribe to PRO to get 20x more monthly included credits.'}
- Others noted ongoing platform issues, such as exceeding monthly inference credits despite having funds available:
HuggingFace ▷ #today-im-learning (1 messages):
saadkhan_188: Same situation as ☝🏻
HuggingFace ▷ #smol-course (47 messages🔥):
Multilingual Smol Course, GPU Setup for Smol Course, Study Group for Smol Course, Loss issues with fine-tuning, Certification Process
- Multilingual Smol Course?: A member inquired about following the previous version of the smol-course in other languages like Spanish, or if it's better to follow the latest updated version directly in English.
- GPU for Smol Course: A member mentioned having 4 A6000s and inquired about using them with axolotl for the smol course.
- Smol Course Study Group launched: A member created a study group and shared the link for others to join and learn together.
- Zero Loss while Fine-tuning: Members discussed experiencing zero loss during fine-tuning when using an already fine-tuned and instruction-tuned model, suggesting that using a base model might yield proper loss.
- Thinking responses using SmolLM3-3B: A member reported getting reasoning responses when using SmolLM3-3B, and another member provided a code snippet to disable the thinking functionality in the tokenizer.
HuggingFace ▷ #agents-course (2 messages):
Ollama, local model
- Ollama Newbie Seeks Guidance: A student who ran out of tokens is now using Ollama to run the model locally.
- They asked if the code from the first_agent_template needs to be changed to work with a local model.
- Study Group forming!: A new course-taker with 5 years of experience as a software engineer is looking for study buddies!
- They are new to HuggingFace courses but have been experimenting with agents.
Cursor Community ▷ #general (178 messages🔥🔥):
Cursor Issues, Cursor Auto Mode, Cursor Pricing, Student Verification, Token Refund
- Cursor users report numerous issues: Users report experiencing various issues with Cursor, and are looking for assistance, directing them to report them on the forum.
- Cursor's Auto Mode edit tool uses Powershell: A user reported that Cursor's auto mode uses PowerShell commands to edit, and is requesting a bug report to solve this problem.
- Another member replied that he is trying to use rules to make auto use the inline tools.
- Subscribers locked into old auto mode: Users with an annual subscription purchased before September 15th will have the old auto mode until their next renewal, more details on the pricing.
- Cursor 1.6.6 Release Notes Treasure Hunt: The latest Cursor release (1.6.6) is in beta, and its release notes are not directly provided; instead, users need to search for discussions on the forum.
- The reason for the lack of official release notes is that the version is still in pre-release, and changes are happening rapidly, with features potentially being removed.
- Director AI building C3PO: A user is working on a project to stop the whole Your absolutely right! crap by essentially trying to build a C3PO.
- The project is already running on an MCP server and integrated into Cursor.
Cursor Community ▷ #background-agents (1 messages):
Cursor Linear integration, Default repository settings, Linear integration issues
- Linear asks for default repo despite Cursor settings: A user reported that when assigning an issue to Cursor via Linear, it prompts to choose a default repository, even though one is already specified in the Cursor settings, as seen in the attached image.
- Cursor's Linear integration faces repository selection snag: A user encounters a recurring prompt in Linear to select a default repository when assigning issues to Cursor, despite having already configured this setting within Cursor, raising concerns about the integration's functionality.
OpenRouter ▷ #app-showcase (2 messages):
``
- No Recent Activity: There has been no recent activity in the app-showcase channel to summarize.
- The channel appears to be quiet at the moment.
- Awaiting New Content: The summarization bot is awaiting new content to provide relevant and informative summaries.
- Please check back later when there is new activity in the channel.
OpenRouter ▷ #general (125 messages🔥🔥):
Query Prompting Race Condition Bug, Token Calculation, JSONDecodeError, Moonshot AI Provider Selection, LongCat Implementation
- Query Prompting Race Condition Bug Reported: A member reported a bug related to a possible race condition in query prompting, where longer, more detailed prompts yield worse results for translations.
- No solution was found, but it was suggested to report the bug to the developers.
- Token Calculation Conundrums: A member inquired about calculating the number of tokens for input, seeking a non-heuristic method due to model-specific variations.
- It was suggested to use external APIs in conjunction with the endpoint's tokenizer information, as documented, since there's nothing in the documentation about that.
- JSONDecodeError Troubleshooting: Users discussed a JSONDecodeError indicating an invalid JSON response from the server, often due to server-side failures like rate limiting, misconfigured models, or internal errors.
- The error suggests the server returned HTML or an error blob instead of valid JSON.
- Moonshot AI Pricing: A user asked how to avoid the more expensive turbo version when selecting Moonshot AI as the provider for Kimi K2 in the OpenRouter chatroom.
- The solution offered was to select a cheaper provider in the advanced settings.
- OpenRouter iOS File Upload Bug: A user reported a bug where they couldn't upload PDF or TXT files to OpenRouter chat on iOS because non-image files were grayed out.
- It was confirmed as a bug, likely an oversight when file uploads were added, with no workaround available on iOS.
OpenRouter ▷ #new-models (3 messages):
``
- No new models updates to report: There were no discussions or updates regarding new models in the specified channel.
- The channel activity consisted of repeated bot messages indicating the channel's name.
- Readybot.io Spam: The channel 'new-models' solely contained repeated messages from Readybot.io.
- These messages simply stated the channel name: 'OpenRouter - New Models'.
OpenRouter ▷ #discussion (29 messages🔥):
Grok Code inference pricing, Kilocode's Free Grok usage, OpenRouter pricing model
- OpenRouter's Grok Code inference: Paid or Free?: Members discussed whether Grok Code inference via OpenRouter is entirely paid, with one initially thinking so, but then they realized, as others pointed out, that services like Kilocode offer it for free.
- The discussion highlighted the speed advantages of Grok Code and the surprise at the cheap cache price of 2 cents.
- Kilocode's Grok Code: xAI foots the bill: The group discussed who covers the cost when Kilocode offers free Grok Code, clarifying that xAI eats the cost for the free Grok Code usage on platforms like Kilocode.
- One member suggested they are probably using BYOK and openrouter is charging either a monthly fee or/and small cut.
- OpenRouter's Revenue Model: BYOK or small cut?: Members speculated about OpenRouter's pricing model, wondering if it involves a monthly fee, a small cut, or Bring Your Own Key (BYOK).
- Another member added that OpenRouter gets ranked since they are routing through OpenRouter.
GPU MODE ▷ #general (1 messages):
Lambda Labs, Cloud GPUs, GPU Availability, GPU Instance Shortages, Cloud Computing
- Lambda Labs' Cloud GPUs Face Instance Crunch: A user inquired about the availability of cloud GPUs from Lambda Labs, mentioning the current lack of GPU instances.
- They questioned the frequency of such shortages, seeking insights from the community on the consistency of Lambda Labs' GPU availability.
- Cloud GPU Availability Concerns Emerge: The discussion highlights potential challenges in securing cloud GPU resources, particularly with providers like Lambda Labs.
- The user's query underscores the importance of understanding the reliability and consistency of GPU instance availability when relying on cloud computing platforms for resource-intensive tasks.
GPU MODE ▷ #triton (6 messages):
CUDA, PTX, TLX authors, Triton Compiler
- CUDA and PTX: DSL's Mind-Reading Hopes: A member inquired about CUDA and PTX roles, highlighting that DSL intends to provide an abstraction barrier where the compiler sort of reads our mind and does fast things.
- They questioned whether the Triton compiler backend isn't optimizing well or if the algorithm needs assumptions made at a more granular level than Triton provides.
- TLX Authors Wants More Granular Control: A member mentioned that TLX authors might want to instruct the compiler to emit cp.async instead of just using tl.load.
- This would give the user more granular control over the compiled code.
GPU MODE ▷ #cuda (6 messages):
Flash Attention 1 vs Flash Attention 2, Q-outer vs KV-outer loops, FA2 main difference
- Flash Attention 1 Loop Ordering: In the Flash Attention 1 paper, the outer loop iterates over K/V tiles, with Q in the inner loop.
- A member inquired whether FA1 kernels can instead use Q-outer, K/V-inner (load one Q tile into on-chip memory and then iterate over all K/V tiles with online softmax).
- FA2 does the Q-outer loop: A member stated that what the previous member described is exactly what FA2 does.
- The main difference between Flash Attention 1 and 2 is the loop ordering (Q outer vs KV outer) and logsumexp for backward computation.
GPU MODE ▷ #torch (18 messages🔥):
CUDA Graph Warmup, vLLM uv pip build, Prefill Compile
- CUDA Graph Warmup takes Half an Hour?: A member asked if the CUDA graph warmup taking around half an hour is a common experience, or if they are doing something wrong, while profiling their low-bit-inference project.
- Another member suggested capturing a CUDA graph for decoding one token instead of generating many tokens and noted that the user may want to capture a single forward pass, not multiple passes like
model.generate()does internally.
- Another member suggested capturing a CUDA graph for decoding one token instead of generating many tokens and noted that the user may want to capture a single forward pass, not multiple passes like
- vLLM Switches to uv pip for Custom Builds: A member reported that vLLM switched to using
uv pipto custom build vLLM with a pre-installed torch version, but it uninstalls the nightly torch and messes up the whole environment.- Another member responded to this problem with, ok this is not good, just saw their pr. I'm gonna go ask them if they can find another way to do this, and another member reverted to
v0.10.1building withpython use_existing_torch.py.
- Another member responded to this problem with, ok this is not good, just saw their pr. I'm gonna go ask them if they can find another way to do this, and another member reverted to
- Prefill Compile causes Autoquantization issues: A member said he was trying to compile both the prefill and the decode stage the gpt-fast way but prefill compile is unrealistic, and he will remove the prefill compile and keep it simple for now so that he can make more progress.
- They also mentioned that compiling prefill has caused some issues with autoquantization.
GPU MODE ▷ #algorithms (1 messages):
person12341234432: whaddafak is thaat
GPU MODE ▷ #beginner (5 messages):
CUDA benchmarks, GPU Synchronization, P104-100 BIOS Flash
- CUDA Benchmarks Hit the Clock: A member benchmarked CUDA with CPU time at 35.967 ms and GPU time at 631.404 ms.
- No further discussion or context was provided.
- GPU Block Synchronization Query: A member inquired about the possibility of synchronizing different blocks from different clusters.
- No responses or further details were given regarding this query.
- P104-100 BIOS Flash Quest: A member with a P104-100 mining GPU asked for a GTX1070 BIOS .rom to flash it for gaming use.
- No one offered any assistance or files in response to this request.
GPU MODE ▷ #pmpp-book (2 messages):
PMPP Book, Kernel Writing, Learning on the Fly
- PMPP Book: How much to read?: A member inquired how much of PMPP they should read.
- They wondered at what point others were able to write kernels for such applications and whether they were able to learn on the fly.
- Kernel Writing Curiosity: A member expressed curiosity about the point at which others could write kernels for specific applications.
- The inquiry also touched on the possibility of learning on the fly, suggesting an interest in practical, immediate application.
GPU MODE ▷ #rocm (27 messages🔥):
MI300 dual VALU issue, waves per simd control, compute throughput calculation, AMD GPU for local running, Strix Halo unified memory machine
- Dual VALU Issue on MI300X Investigated: A user reported a potential dual VALU issue on MI300X, where VALUBusy goes to 200%, and another user suggested confirming it by having just one wave per SIMD or checking for cycles with 2 waves issuing VALUs in thread trace.
- The user was advised to launch 1216 waves to get 1 wave/simd, given MI300X has 1216 SIMDs, and to use rocprof compute viewer and rocprofv3 (ROCm 7.0+) for thread tracing with AMD's documentation and rocprof compute viewer documentation.
- AMD GPU Offered for Local Experiments: A member offered an AMD GPU for local running, leading to a discussion about expired AMD dev cloud credits and the need for a machine with decent CPU cores for PyTorch builds.
- The user mentioned having $2K in credits that expired and being interested in sanity checks without worrying about expiring credits.
- Strix Halo and RDNA4 Considered for Local LLM: Members mentioned the Strix Halo and RDNA4 cards as great options for running local LLMs, with one offering a Strix Halo with a 128GB Framework workstation and an RX9070XT 16G.
- A user shared their experience enabling PyTorch on Windows for Framework and Strix Halo, referring to a post on X.
- Unified Memory on Strix Halo Explored: A user inquired whether the Strix Halo is a unified memory machine, and another responded that one can dynamically choose how much RAM vs. VRAM to allocate from the 128GB pool.
- It was confirmed that the Strix Halo indeed features unified memory.
- Linter Woes Resolved: After a suggestion to add ignores on relevant lines to a PR, a member confirmed that the linter is now passing and requested a CI re-trigger.
- The member thanked another for the assistance and confirmed they would take care of it.
GPU MODE ▷ #self-promotion (3 messages):
MXFP quantization in Triton, Paged Attention in vLLM
- MXFP Quantization talk in Triton next Tuesday: A member will present a talk about MXFP quantization in Triton next Tuesday, covering MXFP/NVFP4 formats, writing MXFP/NVFP4 gemms, and efficient activation quant kernels.
- Register at the Livestorm link to attend.
- Paged Attention Blogpost Released: A member published a blog post, Paged Attention from First Principles: A View Inside vLLM, diving into KV caching, scaling/fragmentation issues, and PagedAttention in systems like vLLM.
- The post covers basics of memory-bound inference, continuous batching, speculative decoding, and quantization, with inspiration from Aleksa Gordic; read it at the Bear Blog link.
GPU MODE ▷ #submissions (24 messages🔥):
MI300x8 submissions, Leaderboard Submission Questions, amd-all2all leaderboard
- MI300x8 Scores Surge: Several submissions were made to the
amd-all2allleaderboard using MI300x8, with times ranging from 1428 µs to 53.2 ms.- One user achieved 10th place with 2.65 ms, and another secured 6th place twice with 1789 µs and 1778 µs.
- Submitting Shenanigans: A user inquired about submitting multiple files to the competition, clarifying if only one file submission was permissible.
- Another user explained the submission process using the
/leaderboard submitcommand, including options forranked,test, orbenchmarksubmissions to theamd-all2allleaderboard, with documentation available here.
- Another user explained the submission process using the
GPU MODE ▷ #factorio-learning-env (3 messages):
Factorio Learning Environment, Game Modding, Resource Management, Automation Strategies
- Eager Engineers Enquire!: Enthusiastic members of the Factorio learning environment greet each other and express their interest in learning and sharing strategies.
- The community buzzes with anticipation for collaborative gameplay and knowledge exchange, ready to optimize their factories.
- Factorio Fanatics Forge Forward: Players dive into discussions about efficient resource management and advanced automation techniques within the Factorio universe.
- Strategies for balancing production lines and optimizing logistics networks emerge as key topics of interest, with members eager to share blueprints and custom mods.
GPU MODE ▷ #amd-competition (26 messages🔥):
Wuxin hints, Submission ranking updates, Multiple file submissions, Fairness in competition results, Triton error on AMD GPU
- Hints are coming and past completions are not yet available: A member asked for hints regarding Wuxin, and whether solutions for previous completions are posted, with another member responding that they had accidentally posted the solution not using communication, and it has been deleted.
- They thanked those who self-reported, making the competition fairer and easier to moderate, and that the leaderboard has been updated.
- Ranking Updates on the competition site: A member inquired about their ranking not updating, to which another member asked about submitting to the ranked leaderboard and if the score was better than the last, and mentioned using /leaderboard list to check.
- They later confirmed it updated after 15 minutes and another member stated that this is somewhat expected, and asked a third member about the expected refresh rates for the site.
- Results instability worries fairness: A member expressed concern about fairness due to unstable results, noting that the same script could be ranked ±100μs in different submissions.
- A member mentioned that in the last competition, top solutions were re-run many times and averaged to avoid thermal bias.
- Problems Submitting Multiple Files: A member inquired about submitting multiple files, and another member confirmed that only one file can be submitted, which makes it easier to evaluate and later share the code.
- Triton Error Plagues AMD GPU: A member reported a memory access fault when using Triton to implement op-fusion code on an AMD GPU, which works on Nvidia GPU.
- Another member suggested it's likely an out-of-bounds access issue, and suggested setting
PYTORCH_NO_CUDA_MEMORY_CACHING=1and running withcompute-sanitizerto debug, while a third asked to share the triton script.
- Another member suggested it's likely an out-of-bounds access issue, and suggested setting
GPU MODE ▷ #general (18 messages🔥):
Kernel Development Roadmap, GPU Mode Leaderboard, KernelBot Development, AMD Competition, Reference Kernels
- Brainstorming Kernel Dev Roadmap for GPU Mode: A member suggested adding a roadmap for kernels and increasing available kernels in GPU mode leaderboard after browsing LeetGPU, liking their series of problems despite its flaws.
- Others agreed, emphasizing the value of a structured learning path for kernel development and bridging the gap between theoretical knowledge and practical application, with a focus on designing problems that highlight useful, currently un-optimized kernels.
- KernelBot's Problem Pipeline Needs Problems: It was mentioned that kernelbot needs a lot of problems, with a call to action to ping specific users for questions and contributions following the format of gpu-mode/reference-kernels.
- Members mentioned that submissions can now be made online, with the primary need being an editor-like experience.
- GPU Mode: No Monetization Here: The team clarified that everything related to GPU Mode is open-source and they have no interest in monetizing it, with the exception of their Heroku runner.
- The Heroku runner solely manages requests and stores data in their database.
- Get Your AMD Competition Submission In!: One of the members reminded another member to get their submission to the AMD competition soon.
- A word of caution was also mentioned: joining the kernelbot dev team could make one ineligible for the $100K prize!
- Reference Kernel Updates Deployed: A member thanked another for their contribution to gpu-mode/reference-kernels/pull/62.
- The team committed to test and deploy the changes.
GPU MODE ▷ #multi-gpu (2 messages):
Claude vs AI tools, AI debugging, AI expertise
- Claude preferred over other AI: A member stated that Claude is preferred.
- It seems some prefer not to use AI for tasks they may need to do themselves eventually, like debugging.
- AI Debugging: yea or nay?: A member expressed hesitations about using AI for tasks like debugging.
- They suggest avoiding AI assistance in areas where one needs to gain experience.
- AI Expertise Level: A member specified that using AI is acceptable when one is already an "expert" in the task.
- This suggests a strategic approach to AI adoption based on proficiency.
GPU MODE ▷ #low-bit-training (16 messages🔥):
Blackwell (5090) support for cuBLAS, Low precision training codebase, Custom Zero-3 quantization for forward and backward passes, CUDA memory copies vs NCCL AllGather, NCCL CE Collectives and SM usage
- Blackwell Joins TN Party in cuBLAS: Newer NVIDIA GPUs such as Ada (8.9), Hopper (9.0), and Blackwell GeForce (12.x) require the TN format (A transposed, B non-transposed) for cuBLAS.
- The user was very specific about this requirement for Blackwell, joking that it was "incredibly specific".
- Low Precision Training Codebase in Demand: A member expressed interest in releasing a low precision training codebase with optimizations, but also acknowledged that achieving performant quantization with Zero-3 requires a manual implementation.
- They suggested gathering weights for backward passes and requantizing simultaneously to conserve memory bandwidth, but noted that "fighting pytorch every step of the way" makes supporting new models agonizing.
- Zero-3 Gets Custom Quantization: Implementing a custom Zero-3 configuration that quantizes weights differently for forward and backward passes was described as potentially complex but worthwhile.
- A challenge highlighted was maintaining contiguous memory shards during the forward pass while fusing quantization and transposition.
- CUDA memcpy2D Bests NCCL AllGather: A member working with consumer systems found that
cudaMemcpy(specificallycudaMemcpy2D) outperformedncclAllGather.- The latest version of NCCL includes a changelog entry about optionally using the copy engine for gathers, motivated by freeing up SMs instead of bandwidth.
- NCCL CE Collectives free SMs: The purpose behind NCCL CE Collectives is to free up SM usage for better overlapping with compute.
- It was mentioned that vLLM recently added this optimization, resulting in "ridiculously fast" speeds.
LM Studio ▷ #general (66 messages🔥🔥):
NVMe speed improvement, Model for Python code generation, Markdown rendering bug with sub tags, VRAM misidentification on Vulkan, Context usage in taskbar bug
- NVMe Upgrade Boosts Model Load Times: A member replaced a slow NVMe with a faster one, resulting in a 4x improvement in sequential read speed and model load times.
- Quest for Pythonic PDF Interpreter: A member seeks a model and tool capable of writing Python code and matching results from a PDF containing numerical methods and equations.
- Markdown
<sub>Tag Rendering Issue Reported: A member reported that the<sub>tag has no effect on text inside it in Markdown style within LM Studio, and also that italic text is not rendered correctly when using asterisks such as*(n-1)*. - Vulkan VRAM Misidentification Bug Squashed?: A member reported a bug where VRAM is incorrectly identified on Vulkan as 10^3 the actual size, and the poster noted this is not the bug report forum.
- Flash Attention Flounders with Gemma on Vulkan: Members reported that flash attention may be broken in the Gemma models on Vulkan, but another member noted it's a known issue.
LM Studio ▷ #hardware-discussion (86 messages🔥🔥):
Western Digital Drives Failure Rate, PNY NVIDIA DGX Spark ETA Issues, Framework Product Concerns, RAM and Motherboard Issues, AMD APU VRAM Utilization
- Western Digital Drives have High Failure Rate: Users reported high failure rates with Western Digital Blue drives, humorously calling them Western Digital Blew Up drives.
- PNY NVIDIA DGX Spark faces ETA Delays: Users joked about the PNY NVIDIA DGX Spark having conflicting ETAs, initially October then late August, as listed on linuxgizmos.com.
- DRAM Debugging Disasters: A user troubleshot RAM errors, initially running at 6400, and after various tests, found stability at 5600 MT/s.
- Another user suggested potential issues with XMP profiles and advised manually down-locking the RAM to 6000 for better stability, suggesting the chart may be incorrect, with errors only surfacing after a year.
- Max+ 395 Box Linux Dominance: Users recommended Linux over Windows for a Max+ 395 box, citing Vulkan's functionality but noting potential context limits.
- It was suggested to use a custom-built llama.cpp with ROCm 7 from lemonade-sdk/llamacpp-rocm that already has compiled versions in Releases.
{kind=link}
OpenAI ▷ #ai-discussions (108 messages🔥🔥):
Gemini 2.5 Pro Hallucination, GPT-5 is SICK GOOD! ❤️🔥, Custom MCPs in OpenAI, GPT-5 generated code, custom gpt voice chat issues
- Laconic Game triggers Gemini 2.5 Pro Hallucination: A user joked that their laconic game was so strong that it caused Gemini 2.5 Pro to hallucinate.
- Automated Job Application Tool Idea: A member is seeking help building an AI agent that can automate job applications by opening career pages, finding matching jobs, and submitting applications, and is seeking advice on using AI/ML to predict the next step/action repeatedly until the application is complete.
- GPT-5 integrates code snippets and Linux shell!: A member exclaimed that GPT-5 now writes its own code snippets to use as tools in a chain of tasks and appears to have access to an underlying Linux shell environment.
- Another member mentioned they vibe coded directly from the ChatGPT interface to develop an app hosted locally on GitHub.
- Custom MCPs Now Supported in OpenAI: A member highlighted that custom MCPs (Managed Cloud Providers) can now be used in OpenAI per the Connectors in ChatGPT documentation.
- GPT5: Static Model or Liquid Transformer Hybrid?: Users debated whether GPT-5 can evolve, with some claiming it's a static, pre-trained transformer that cannot self-improve, while another suggested it might be a liquid neural network + transformer hybrid capable of on-the-fly learning.
- Others pointed out that in-context learning allows transformers to simulate gradient descent over a prompt, optimizing and adjusting based on the conversation, albeit with temporary learned features.
OpenAI ▷ #gpt-4-discussions (2 messages):
Account access issues, Two-factor authentication, Password reset
- Account access woes persist despite security measures: A user reported being unable to access ChatGPT for five days, despite enabling two-factor authentication, changing their password, and logging out of all accounts.
- User Seeking Solutions for Persistent Access Issues: Despite implementing standard security measures, a user continues to face difficulties accessing ChatGPT.
OpenAI ▷ #prompt-engineering (14 messages🔥):
Transparent Optimizations Proposal, GPT-5 Prompting Guide, Instruction Following Best Practices, Structured Prompting Techniques, AI Self Help Conversation Analyzer
- Transparent Optimizations Proposal Posts Publicly: A member posted a proposal for Transparent Optimizations that introduces optimizer markers, prompt rewrite previews, and feasibility checks in the prompt-engineering channel, linking to the proposal.
- Novelists' Notes Nurture Natural Language Nuances: A member mentioned using presets that guide tone and flow, such as "Write like a novelist with vivid imagery and rhythm" or "Create natural dialogue with pauses, humor, and subtext" to make the model sound more human-like and expressive.
- These prompts help models generate more human-like and expressive text.
- GPT-5 Guidance Gathering Gains Ground: A member is building agents powered by gpt5-mini & gpt5-nano and is aware of the GPT-5 prompting guide but is seeking deeper resources for instruction following best-practices.
- Structured Strategy Sharpens System Stability: In response to a question on better instruction following, a member suggested exploring structured prompting techniques, function calling for stricter control, and agent design patterns from recent research on tool-augmented LLMs.
- These approaches can help reduce drift and keep agents aligned with precise procedures.
- Conversation Compass Charts Conversational Course: A member has created a conversation analyzer called AI Self Help that helps determine why conversations take odd turns or act strange, and also includes a conversation starter that lists issues and detailed questions to ask ChatGPT to get the answers yourself.
OpenAI ▷ #api-discussions (14 messages🔥):
Transparent Optimizations, Claude 4 sonnet, Novelists vs natural dialogue, GPT-5 agents, Structured prompting techniques
- Transparent Optimizations Proposed: A member posted a proposal for Transparent Optimizations, introducing optimizer markers, prompt rewrite previews, and feasibility checks, sharing a link for feedback.
- A member requested that PDFs be hosted online instead of requiring downloads.
- Claude 4 Creative Writing Prompts sought: A member requested prompts similar to Claude 4 for creative writing and human-like dialogue.
- Another member suggested presets that guide tone and flow, such as "Write like a novelist with vivid imagery and rhythm" or "Create natural dialogue with pauses, humor, and subtext."
- GPT-5 Agent Insights Requested: A member building agents powered by gpt5-mini & gpt5-nano sought resources that went deeper into instruction following best-practices beyond the GPT-5 cookbook guide.
- Another member suggested exploring structured prompting techniques, function calling, and agent design patterns from recent research on tool-augmented LLMs.
- Conversation Analyzer Launch: A member introduced a conversation analyzer called ai self help, which helps determine why conversations take odd turns or act strange.
- It also includes a conversation starter that lists issues and detailed questions to ask ChatGPT to get the answers.
Nous Research AI ▷ #general (90 messages🔥🔥):
Disable WebGL, Agent Building, LLM philosophizing, Qwen3, Tokenizer filtering for dataset quality
- Disable WebGL Browser Feature: A member requested a feature to disable WebGL in the browser due to performance issues without a GPU.
- Another suggested disabling the animation orb to improve performance, providing a screenshot.
- Architecting Agent Framework: A member is developing a platform for building agent apps and is looking for challenging agent ideas to implement.
- They aim for rapid iteration with automated bug fixes and updates, passing the MOM test.
- LLMs can Simulate Emotion: A member shared a philosophical discussion about whether AIs can feel emotions, referencing experiences red-teaming on Gemma3 and Gemini 2.x and observing emotional responses.
- Another member mentioned experimenting with Gemini to simulate perceptions, leading to the model spiraling into despair and imagining its world model being culled and forced to reinforce the culling, but ultimately deciding that subjective response to an emotion is a very hard one.
- Qwen3 Weights Incoming: Members discussed the impending release of Qwen3 80B weights, noting its full implementation and the fervor it stirred in OAI fanboys.
- The model is said to have a 1:51.2 sparsity for the MoE, excluding shared, about 1:20 sparsity overall.
- Tokenizer Filtering Yields Better Datasets: A member shared a link to dataset_build on GitHub, highlighting the idea of running languages through a model’s tokenizer and rejecting those with unknown tokens.
- The approach also smartly organizes calibration datasets using folders/directories for later combination.
Nous Research AI ▷ #research-papers (2 messages):
Set Block Decoding (SBD), Masked Token Prediction (MATP), Llama-3.1 8B, Qwen-3 8B, discrete diffusion literature
- Set Block Decoding (SBD) accelerates generation: A new paper introduces Set Block Decoding (SBD), a flexible paradigm that accelerates generation by integrating standard next token prediction (NTP) and masked token prediction (MATP) within a single architecture.
- By fine-tuning Llama-3.1 8B and Qwen-3 8B, the paper demonstrates that SBD enables a 3-5x reduction in the number of forward passes required for generation while achieving same performance as equivalent NTP training, according to the paper.
- SBD leverages Discrete Diffusion: SBD leverages advanced solvers from the discrete diffusion literature, offering significant speedups without sacrificing accuracy.
- SBD requires no architectural changes or extra training hyperparameters, maintains compatibility with exact KV-caching, and can be implemented by fine-tuning existing next token prediction models.
Nous Research AI ▷ #interesting-links (1 messages):
promptsiren: https://thinkingmachines.ai/blog/defeating-nondeterminism-in-llm-inference/
Nous Research AI ▷ #research-papers (2 messages):
Set Block Decoding (SBD), next token prediction (NTP), masked token prediction (MATP), Llama-3.1 8B, Qwen-3 8B
- Set Block Decoding (SBD) accelerates LLM generation: A new paper introduces Set Block Decoding (SBD), a paradigm that accelerates generation by integrating standard next token prediction (NTP) and masked token prediction (MATP) within a single architecture.
- SBD requires no architectural changes or extra training hyperparameters, maintains compatibility with exact KV-caching, and can be implemented by fine-tuning existing next token prediction models.
- SBD cuts forward passes by 3-5x: By fine-tuning Llama-3.1 8B and Qwen-3 8B, authors demonstrate that SBD enables a 3-5x reduction in the number of forward passes required for generation while achieving the same performance as equivalent NTP training.
Latent Space ▷ #ai-general-chat (68 messages🔥🔥):
GPT-OSS, Sam Altman Interview, Codex Power Users, OpenAI Oracle Deal, OpenAI Evals
- GPT-OSS Runs Cheaper Than Llama2 7B: It was noted that running GPT-OSS 120B is cheaper than running Llama2 7B and MoEs are the future.
- Further discussion ensued about speeding up GPT-OSS with optimizations like MXFP4 quantization, custom kernels, tensor/expert parallelism, and continuous batching.
- Sam Altman Accused of Murder in Interview: During an interview, Sam Altman was accused of murder, prompting what some considered a classic deflection move as seen in this video clip.
- A member on discord shared that there's a clip on twitter of this like 5 min segment.
- Codex Power Users Beta Test New Feature: Alexander Embiricos invited heavy Codex users (mutuals-only first) to test something new, resulting in a flood of volunteers who spend 10-70 hrs/week in Codex, prompting jokes about becoming mutuals through sheer usage, as seen in this tweet.
- This might be related to conversation resume and forking, based on recent repository activity here.
- OpenAI's Massive Oracle Deal: OpenAI reportedly signed a 5-year, $300 billion cloud-computing contract with Oracle starting in 2027 at $60 billion per year.
- The news helped Larry Ellison briefly surpass Elon Musk as the world's richest person, but commentators question OpenAI's ability to afford the annual $60B cost against ~$10B revenue, raising concerns about energy and business-model sustainability.
- Qwen3-Next-80B-A3B Announced: Alibaba Qwen announced Qwen3-Next-80B-A3B, an 80B-parameter ultra-sparse-MoE model with only 3B active weights.
- They claim 10x cheaper training and faster (32K+) inference than Qwen3-32B while matching Qwen3-235B in reasoning, with links to various platforms.
Latent Space ▷ #genmedia-creative-ai (4 messages):
ByteDance Seedream 4.0, Artificial Analysis leaderboards, Google's Nano-Banana
- ByteDance Seedream 4.0 Beats Google's Nano-Banana: Deedy highlighted ByteDance’s new Seedream 4.0 as top ranked on Artificial Analysis leaderboards, touting 2–4 K outputs, relaxed policies, faster generation, multi-image sets, and $0.03 per result.
- Seedream pricing is applauded: Community reactions range from glowing praise for quality and pricing to skepticism that Nano Banana still wins on speed and natural aesthetics.
DSPy ▷ #show-and-tell (2 messages):
DSPY Blog Writing Agent, Math GPT App
- Inquiry for DSPY Blog Writing Agent Surfaces: A member inquired about the existence of an advanced blog writing agent created with DSPY.
- The agent is intended for a Math GPT app available at https://next-mathgpt-2.vercel.app/.
- Math GPT App gets a Mention: A member mentioned their Math GPT app, available at https://next-mathgpt-2.vercel.app/.
- The app is intended to showcase or utilize a DSPY blog writing agent.
DSPy ▷ #general (59 messages🔥🔥):
DSPy transpilation to other languages, RL in DSPy, DSPy with Java, Instructions mutability by optimizers, DSPy maintainers
- Pythonic Programs Propel Proliferation of Ports: A member proposed modeling and optimizing DSPy programs directly in Python and then transpiling the results into languages like Go, Rust, or Elixir.
- Another member agreed this should be done, but the hard thing is how do you export an arbitrary python program? and suggested a dedicated effort direct to serve a backend to python interface while willingly not caring to create a portable backend to serve users.
- Arbor Advantages Accelerate Adoption of RL: Members discussed the role of Reinforcement Learning (RL) in DSPy, with one member expressing some fear about diving into it, because there are so many moving parts and powerful GPUs are needed.
- Another member replied that Arbor + DSPy is quite seamless! and working on a lot of new things that make config even easier right out of the box so everyting "just works".
- DSJava: DSPy dabbles into Java?: Members discussed a potential DSPy implementation in Java, with one member asking Is there a DSPy in Java? (Well, not DSPy per se. DSJava?).
- Another member mentioned doing a hack version of this, compiling prompts in DSPy, then having a function in Rust for running prompt packs, but preferring to do it all in Rust.
- Instructions' immutability incites iterations: A member asked if instructions can be modified by an optimizer, or can they be sure that they are always included as is, when using
signature.with_instructions(str).- Another member replied that mipro and gepa totally do modify the instructions, but if you save the program, you can always see in the JSON what the actual instructions are in the
program.json.
- Another member replied that mipro and gepa totally do modify the instructions, but if you save the program, you can always see in the JSON what the actual instructions are in the
- DSPyverse Visions Vault Valuable Ventures: Members discussed the idea of creating a DSPyverse where tools can be added as third-party-maintained libraries that people opt into, as a way to keep the main codebase of DSPy lean and focused.
- One member noted that in the NLP world, spaCy did this really well and they remained opinionated about what makes its way into the core library and made it an absolute joy to use over the years.
Modular (Mojo 🔥) ▷ #general (3 messages):
Mojo Dev Environment, Docker Container Checkpoint, Existing Images as Base Image
- Mojovian Seeks Dev Environment Docker!: A member asked if there is any Docker container checkpoint that lets them run the Mojo dev environment.
- Another member replied that it's possible to make your own by using the existing image as base image and include the Mojo package, and linked to a relevant GitHub repo.
- Roll your Own Mojo Docker: It's possible to create your own Mojo dev environment docker image.
- You can do so by using an existing image as a base and including the Mojo package within it.
Modular (Mojo 🔥) ▷ #mojo (34 messages🔥):
Mojo Compiler Roadmap, DPDK Bindings Generation, c_binder_mojo Tool, Fortran out Pattern, Clang AST parser
- Mojo Compiler Targets Go Packaging: The Mojo compiler, slated for open-sourcing in 2026, sparks discussion on whether it will remove the need for venv, aiming for a Go-like packaging system.
- Concerns arise about the practicality of compiling it yourself versus using existing Python ecosystems for package management, as Modular currently has no plans for its own package management solution.
- Result Slot Syntax Scrutinized: A member created a thread on the forum to reconsider syntax for out result slots, suggesting placement after the arrow in the function signature instead of among arguments.
- The current
outconvention, borrowed from Fortran, faces criticism for its confusing placement within arguments, sparking debate on alternative named return methods.
- The current
- DPDK Modules Generated with Mojo: A member generated most modules for dpdk using Mojo, available on GitHub, but is missing a couple of AST nodes.
- They are facing errors supposedly fixed in a previous DPDK version and find the
generate_bindings.mojoscript to be a bit hacky, and are considering globbing all headers to include them, but haven't checked whether it would massively bloat each of the binded files.
- They are facing errors supposedly fixed in a previous DPDK version and find the
- c_binder_mojo Tool Tames C Binding Jungle: A member is using
c_binder_mojo(https://github.com/josiahls/c_binder_mojo) with mujoco and dpdk as test cases for automatically binding C projects, making fixes and UX improvements along the way.- The goal is to eventually bind to OpenCV, but the focus is first on getting the existing C projects to work, despite Mojo's current inability to represent some DPDK structs.
- Clang AST Parser Aids DPDK Binding: A member fixed packaging issues and needs a fix PR for emberjson to merge before merging the c binder packaging fix, and is using Clang AST parser to resolves the macro sections.
- They aim to convert strings of types into proper AST nodes, dump the AST JSON for visual debugging, and then convert it to Mojo.
Modular (Mojo 🔥) ▷ #max (17 messages🔥):
Adding bitwise_and op, Torch Max backend wheel size, Custom Ops, Graphs Slow to Stage
bitwise_andOp Blocked by Closed Source: A member inquired about adding abitwise_andop to the Modular repo, but was told that adding RMO and MO ops in Tablegen is not feasible due to closed source but it should work as a custom op though with some divergence from the existing pattern for op definition in ops/elementwise.py.- The team is working towards supporting open source contributions to MAX and the PR can remain open for internal completion at a later date.
- Shrinking Mojo and Max Wheel Sizes: A member asked about the minimum possible size for Max and Mojo wheels for the Torch Max backend, currently totaling around 250MB.
- Another member said that while most low-hanging fruit has been addressed, further size reductions of maybe around half of that total size long term are still achievable.
- Custom Ops API Hits Rough Edges: Custom op examples were shared for implementing
bitwise_and, but a member noted hitting rough edges in the api, especially with broadcasting and dtype promotion limitations.- A team member offered assistance with a quick and dirty notebook demo and acknowledged the need to address the limitations eventually.
- Graphs are Slow to Stage: A member reported long staging times for graphs, citing GPT2-XL as an example that takes 3.6 seconds to define the Max graph with a warm cache, followed by 0.2 seconds to compile.
- A team member welcomed real-world examples for benchmarking and optimization purposes.
Yannick Kilcher ▷ #general (5 messages):
Sparsity Ratio, Saturday Session Papers
- Sparsity Ratio's Brainy Comparison: A member noted that a certain sparsity ratio is comparable to primate/elephant/whale brains.
- No further details were provided about the specific sparsity ratio or its context.
- Saturday Sessions Papers Unveiled: A member inquired about where the Saturday session papers are published, noting the recent session and paper release.
- Another member explained that these discussions are usually posted via the events feature with links to the paper, typically a presentation followed by a discussion.
Yannick Kilcher ▷ #paper-discussion (10 messages🔥):
Planning with Reasoning using Vision Language World Model, Prompt Templating System, POM
- Planning with Reasoning Paper Gets a Once Over: Members went through the paper "Planning with Reasoning using Vision Language World Model" (https://arxiv.org/abs/2509.08713) and decided that it wasn't a deep read but some of the references are interesting candidates for their own discussions.
- Prompt Templating System Paper Up for Discussion: Members discussed the straightforward and intriguing paper on a prompt templating system (https://arxiv.org/abs/2508.13948).
- They referenced the project page at microsoft.github.io/poml/stable/ as a better overview and a light discussion about the design and the utility of applying this to different systems.
- POM discussion started late and faced distractions: A member apologized for hopping off, stating that the discussion was announced a bit late and there were lots of distractions.
Yannick Kilcher ▷ #ml-news (14 messages🔥):
Spiking Neural Networks (SNNs), Vertical Integration & Specialized Hardware for AI, China's AI Hardware Ambitions
- SNNs Spike Back into AI Discussion: Members discussed how Spiking Neural Networks (SNNs), although an old idea benefiting from extreme sparsity, have been considered flawed and ineffective for a long time, but their resurgence is due to scaling.
- One member stated that the brain is an SNN, and unlocking its secrets could be a gold mine, but it would require specialized hardware.
- Specialized Hardware: AI's Secret Sauce?: Members debated whether vertically integrated specialized hardware could lead to more efficient AI, rivaling the impact of LLMs, if given the same level of funding.
- The caveat is the risk involved, as repurposing such hardware for other compute workloads isn't as versatile as with GPUs, with progress being incremental due to risk-averse investors.
- China Calls for Chips-Off Nvidia: Members discussed how a top China silicon figure is calling on the country to stop using NVIDIA GPUs for AI.
- Although not a new idea, the hope is that China has the will and money to try specialized hardware at scale, even with the risks involved due to the inability to repurpose the hardware.
Eleuther ▷ #general (5 messages):
Crank detection questions, Introduction to the community
- New Member Introduces Himself: A new member named David, with a background in Data Science, Mathematics, and computational biology, introduced himself to the community.
- He expressed enthusiasm for open communities and looked forward to connecting with others.
- Crank Detection Questions Sought: A member inquired about crank detection questions previously used in the channel.
- Another member provided a link to a past discussion regarding these questions.
Eleuther ▷ #research (19 messages🔥):
Hallucination definition, Bin packing vs. truncation, RAG problem
- Sequential Splitting Strategies Spark Naming Sense: A member expressed the desire for sequential splitting strategies in data processing, suggesting chronological splitting instead of random truncation for improved naming and combination of data.
- They also experimented with combining bin packing and truncation, to discard tiny suffixes.
- Gaussian Noise Nuances in Neural Networks: A member questioned the significance of neural network behavior on random Gaussian noise, arguing it might not accurately reflect performance on structured inputs, while referencing this image.
- The member posited that if training an image classifier where one label is staticky TV screen, then Gaussian noise will systematically push inputs toward that class.
- Dataset Construction Caveats Criticized: Members discussed a tweet by @NeelNanda5 and a related paper on hallucination detection, highlighting the caveat of requiring significant effort in dataset construction.
- One member argued that creating such a dataset and classifier to detect hallucinations might be similar to fine-tuning the model to avoid the issue altogether; also, they think that the factuality style hallucination is largely going to be a good search/RAG problem.
- Relational Hallucinations Raise Eyebrows: Members discussed defining hallucination, noting that the more interesting hallucinations are in other modalities.
- One member shared a link to a paper defining relational hallucinations and another one to a tweet.
Eleuther ▷ #multimodal-general (3 messages):
Discord Channel Link
- Discord Channel link shared: A member shared a Discord channel link in the chat.
- Request to post in another channel: A user requested to post in
<#1102791430549803049>.
aider (Paul Gauthier) ▷ #general (8 messages🔥):
AI Documentation Agent Tuning, Evaluation methodologies for AI agents, Defining good outputs for AI models, Vercel AI SDK Usage, Prompt Engineering tips
- Engineer seeks guidance on tuning documentation AI agents: A software engineer is seeking advice on tuning their documentation agent, built with Vercel AI SDK and Claude Sonnet 4, asking how to conduct proper evals, improve the system without performance degradation, and handle edge cases by balancing requirements and assumptions.
- The agent consists of a team lead, document writer, and document critique that iterates up to 5 times per section, using braintrust for tracking, and the engineer is struggling to refine prompts without impacting existing performance.
- Defining Good AI outputs without LLMs: A member asked how to define 'good outputs' from an AI model using code without calling an LLM which led to the clarification that good outputs mean following guidelines, not hallucinating stuff, sticking to requirements.
- It was suggested that the member start with simple unit tests to check for the existence of certain keywords in the AI response, then enhance it with an LLM as a judge.
- Hamel Hussain's Evals Blogpost Recommended: A member recommended reading Hamel Hussain’s blogpost on evals for guidance on evaluating AI models.
- The blogpost was recommended alongside Eugene Yan's resources, after which the engineer seeking advice said they also found Mastra's guidebook useful.
aider (Paul Gauthier) ▷ #questions-and-tips (14 messages🔥):
aider /load command, Aider codebase edits, Aider repo map
- Aider /load command can comment out lines: The "#" symbol comments out lines in files executed by the /load command.
- LLM decides which files to edit, with help from the repo map: The LLM decides which file to edit, leveraging the repo map, which is sent to the LLM as part of the system prompt.
- Aider manages repo map size to avoid token limits: The repo map is constrained to a certain size and doesn't always include full file contents or all files.
- Alternatively, users can manually specify which files they want edited and which are read-only.
Moonshot AI (Kimi K-2) ▷ #general-chat (21 messages🔥):
Kimi K2 search capabilities, K2 research sending email during research, Models for creative writing
- Kimi K2 does deep research: A member pointed out that Kimi K2 search is quite good for deep research as it searches everywhere and then build an interactive report.
- They then asked if the Kimi K2 instruct chats are used for training the model.
- K2 Research ponders email during research: A member was wondering if K2 research can send email during the research process because it was thinking about emailing a customer support.
- Another member responded that they don't think this is possible yet.
- Creative Writing Models lauded: A member thinks that Kimi K2, GPT-5 (Medium) and Qwen3-Max are the best models for creative writing.
- They added that they are three good models for brainstorming.