Strong generative media showings from China.
AI News for 2/9/2026-2/10/2026. We checked 12 subreddits, 544 Twitters and 24 Discords (256 channels, and 9107 messages) for you. Estimated reading time saved (at 200wpm): 731 minutes. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
It is China model release week before Valentine’s Day, and the floodgates are opening.
We last got excited about Qwen-Image 1 in August, and in the meantime the Qwen guys have been cooking, with Image-Edit and Layers. Today with Qwen-Image 2 they reveal the grand unification:
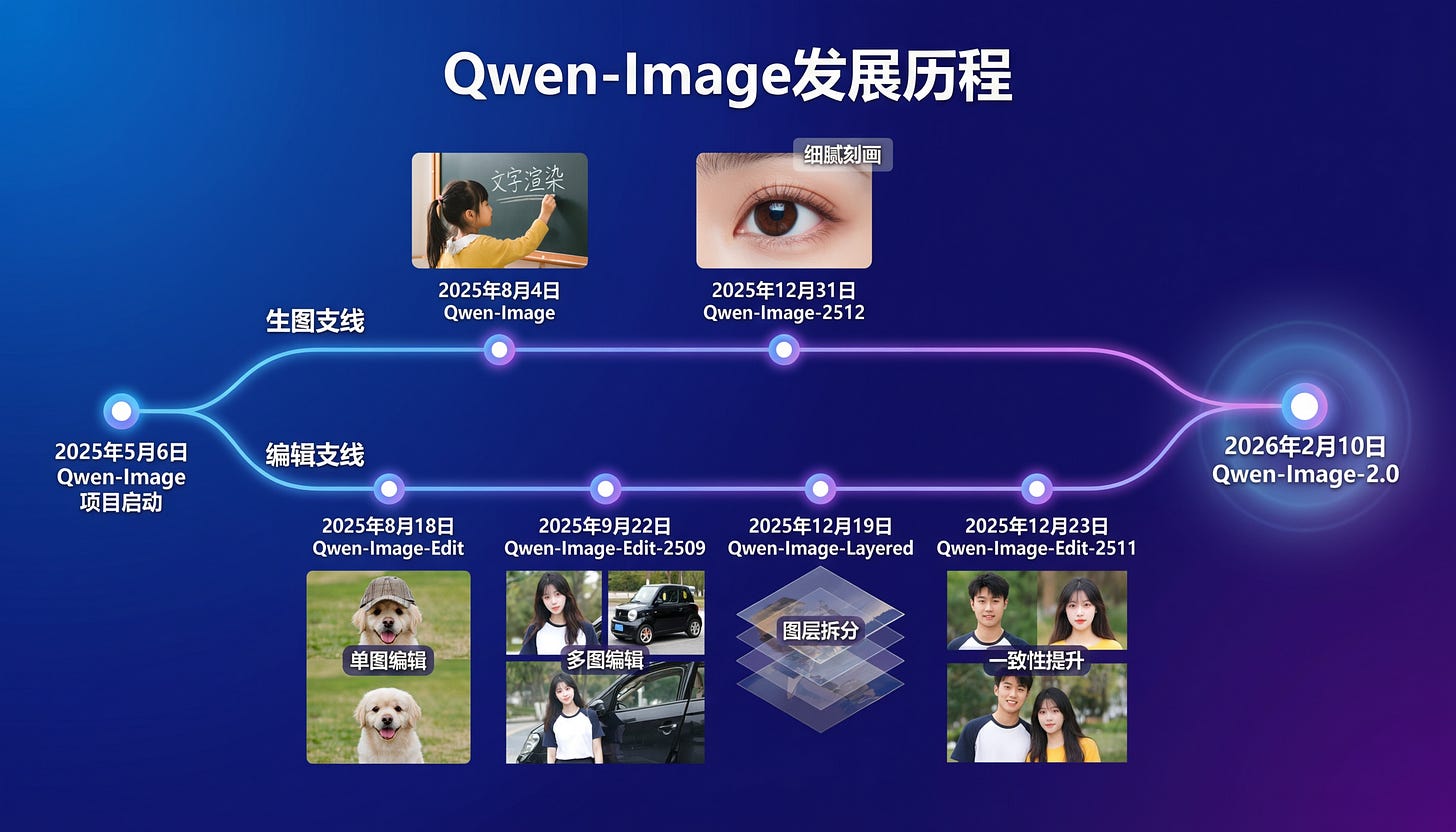
The text control and fidelity demonstrated is incredibly impressive. While the weights and full technical report are not yet released, the images drop a few surprising hints (caught by the Reddit sleuths in the recap below) about what’s going on that point to incredible technical advances.
To put it simply, we will have a Nano-Banana-level open imagegen/imageedit model in a 7B size. (Per Alibaba’s own Arena rankings on the blogpost)

Similarly no weights released but lots of hype today is Seedance 2.0, which seems to have solved the Will Smith Spaghetti problem and also generated lots of anime/movie scenes. The sheer flood of examples is almost certainly an astroturfing campaign, but enough people are independently creating new videos that we have some confidence that this isn’t just a cherrypick.
AI Twitter Recap
Coding agents, IDE workflows, and “agentic sandboxes” becoming standard plumbing
- OpenAI shifts Responses API toward long-running computer work: OpenAI introduced new primitives aimed at multi-hour agent runs: server-side compaction (to avoid context blowups), OpenAI-hosted containers with networking, and Skills as a first-class API concept (including an initial spreadsheets skill) (OpenAIDevs). In the same window, OpenAI also upgraded Deep Research to GPT‑5.2 and added connectors + progress controls (OpenAI, OpenAI), reinforcing that “research agents” are productized, not just demos.
- Sandboxes: “agent in sandbox” vs “sandbox as a tool” becomes a design fault line: Several posts converge on the same architectural question—should the agent live inside an execution environment, or should it call an ephemeral sandbox tool? LangChain’s Harrison Chase summarized tradeoffs in a dedicated writeup (hwchase17), with follow-on commentary pushing sandbox-as-a-tool as the default for crash tolerance and long-running workflows (NabbilKhan). LangChain’s deepagents v0.4 added pluggable sandbox backends (Modal/Daytona/Runloop) plus improved summarization/compaction and Responses API defaults (sydneyrunkle).
- Coding agent UX is accelerating, with multi-model orchestration becoming normal: VS Code and Copilot continue to add agent primitives (worktrees, MCP apps, slash commands) (JoeCuevasJr). One concrete pattern: parallel subagents doing independent review and “grading each other” across Claude Opus 4.6, GPT‑5.3‑Codex, and Gemini 3 Pro (pierceboggan). OpenAI’s Codex account paused a rollout of “GPT‑5.3‑Codex” inside @code (code), while users highlight its token efficiency and app workflow (reach_vb, gdb, gdb).
- “SDLC after code review” is being reimagined: A notable funding + product announcement: EntireHQ raised a $60M seed to build a Git-compatible database that versions not just code but also intent/constraints/reasoning, plus “Checkpoints” to capture agent context (prompts, tool calls, token usage) as commit-adjacent artifacts (ashtom). This directly targets the emerging pain: teams can generate code quickly, but struggle with provenance, review, coordination, and “what happened” debugging.
Model releases & modality leaps (image/video/omni) + open-model momentum
- Qwen-Image-2.0: Alibaba Qwen announced Qwen‑Image‑2.0 with emphasis on 2K native resolution, strong text rendering, and “professional typography” for posters/slides with up to 1K-token prompts; also positions itself as unified generation + editing with a “lighter architecture” for faster inference (Alibaba_Qwen).
- Seedance 2.0 as the “step change” in text-to-video: Multiple threads treat ByteDance’s Seedance 2.0 as a qualitative jump (natural motion, micro-details) and possibly a forcing function for competitors to refresh (Veo/Sora) (kimmonismus, TomLikesRobots, kimmonismus).
- Kimi “Agent Swarm” + Kimi K2.5 as agent substrate: Moonshot’s Kimi shipped an Agent Swarm concept: up to 100 sub-agents, 1500 tool calls, and claimed 4.5× faster than sequential execution for parallel research/creation tasks (Kimi_Moonshot). Community posts show a workflow pairing Kimi K2.5 + Seedance 2 to generate large storyboard artifacts (e.g., “100MB Excel storyboard”) feeding video generation (crystalsssup). Baseten highlighted Kimi K2.5 serving performance—TTFT 0.26s and 340 TPS on Artificial Analysis (per their claim) (basetenco).
- Open multimodal “sleepers”: A curated reminder that recent open multimodal releases include GLM‑OCR, MiniCPM‑o‑4.5 (phone-runnable omni), and InternS1 (science-strong VLM), all described as freely usable commercially (mervenoyann).
- GLM-4.7-Flash traction: Zhipu’s GLM‑4.7‑Flash‑GGUF became the most downloaded model on Unsloth (per Zhipu) (Zai_org).
Agent coordination & evaluation: from “swarms” to measurable failure modes
- Cooperation is still brittle even with real tools (git): CooperBench added git to paired agents and found only marginal cooperation gains; new failure modes emerged (force-pushes, merge clobbers, inability to reason about partner’s real-time actions). The thesis: infra ≠ social intelligence (_Hao_Zhu).
- Dynamic agent creation beats static roles (AOrchestra): DAIR summarized AOrchestra, where an orchestrator spawns on-demand subagents defined as a 4‑tuple (Instruction/Context/Tools/Model). Reported benchmark gains: GAIA 80% pass@1 with Gemini‑3‑Flash; Terminal‑Bench 2.0 52.86%; SWE‑Bench‑Verified 82% (dair_ai).
- Data agents taxonomy: Another DAIR piece argues “data agents” need clearer levels of autonomy (L0–L5), noting most production systems sit at L1/L2; L4/L5 remain unsolved due to cascading-error risk and dynamic environment adaptation (dair_ai).
- Arena pushes evals closer to enterprise reality (PDFs + funding academia): Arena launched PDF uploads for model comparisons (document reasoning, extraction, summaries) (arena), and separately announced an Academic Partnerships Program funding independent eval research (up to $50K/project) (arena). This aligns with ongoing frustration that peer review is too slow relative to model iteration (kevinweil, gneubig).
- Anthropic RSP critique on Opus 4.6 thresholding: A detailed critique argues Anthropic relied too heavily on internal employee surveys to decide whether Opus 4.6 crossed a higher-risk R&D autonomy threshold; the complaint is that this is not a responsible substitute for quantitative evals, and follow-ups may bias results (polynoamial).
Training/post-training research themes: RL self-feedback, self-verification, and “concept-level” modeling
- iGRPO: RL from the model’s own best draft: iGRPO wraps GRPO with a two-stage process: sample drafts, pick the highest-reward draft (same scalar reward), then condition on that draft and train to beat it—no critics, no generated critiques. Reported improvements over GRPO across 7B/8B/14B families (ahatamiz1, iScienceLuvr).
- Self-verification as a compute reducer: “Learning to Self-Verify” is highlighted as improving reasoning while using fewer tokens to solve comparable problems (iScienceLuvr).
- ConceptLM / next-concept prediction: A proposal to quantize hidden states into a concept vocabulary and predict concepts instead of next tokens; claims consistent gains and that continual pretraining on an NTP model can further improve it (iScienceLuvr).
- Scaling laws from language statistics: Ganguli shared a theory result: predict data-limited scaling exponents from properties of natural language (conditional entropy decay vs context length; pairwise token correlation decay vs separation) (SuryaGanguli).
- Architectures leaking via OSS archaeology: A notable “architecture is out” thread claims GLM‑5 is ~740B with ~50B active, using MLA attention “lifted from DeepSeek V3” plus sparse attention indexing for 200k context (QuixiAI). Another claims Qwen3.5 is a hybrid SSM‑Transformer with Gated DeltaNet linear attention + standard attention, interleaved MRoPE, and shared+routed MoE experts (QuixiAI).
Inference & systems engineering: faster kernels, cheaper parsing, and vLLM debugging
- Unsloth’s MoE training speedup: Unsloth claims new Triton kernels enable 12× faster MoE training with 35% less VRAM and no accuracy loss, plus grouped LoRA matmuls via
torch._grouped_mm(and fallback to Triton for speed) (UnslothAI, danielhanchen). - Instruction-level Triton + inline assembly: A fal performance post teases beating handwritten CUDA kernels by adding small inline elementwise assembly in Triton; the author also notes a custom CUDA kernel using 256-bit global memory loads (Blackwell) outperforming Triton on smaller shapes (maharshii, isidentical, maharshii).
- vLLM in production: throughput tuning + rare failure debugging: vLLM amplified AI21’s writeups: config tuning + queue-based autoscaling yielded ~2× throughput for bursty workloads (vllm_project); a second post dissected a 1-in-1000 gibberish failure in vLLM + Mamba traced to request classification timing under memory pressure (vllm_project).
- Document ingestion cost optimization: LlamaIndex’s LlamaParse added a “cost optimizer” routing pages to cheaper parsing when text-heavy and to VLM modes for complex layouts, claiming 50–90% cost savings vs screenshot+VLM baselines, with higher accuracy (jerryjliu0).
- Local/distributed inference hacks: An MLX Distributed helper repo reportedly ran Kimi K‑2.5 (658GB on disk) across a 4× Mac Studio cluster over Thunderbolt RDMA, “actually scales” (digitalix).
AI-for-science: Isomorphic Labs’ drug design engine as the standout “real-world benchmark win”
- IsoDDE claims large gains beyond AlphaFold 3: Isomorphic Labs posted a technical report claiming a “step-change” in predicting biomolecular structures, more than doubling AlphaFold 3 on key benchmarks and improving generalization; several posts echo the scale of claimed gains and implications for in‑silico drug design (IsomorphicLabs, maxjaderberg, demishassabis). Commentary highlights antibody interface/CDR‑H3 improvements and affinity prediction claims exceeding physics-based methods—while noting limited architectural detail so far (iScienceLuvr).
- Why it matters (if it holds): The strongest framing across the thread cluster is not just “better structures,” but faster discovery loops: identifying cryptic pockets, better affinity estimates, and generalization to novel targets potentially move screening/design upstream of wet labs (kimmonismus, kimmonismus, demishassabis).
Top tweets (by engagement)
- US scientists moving to Europe / research climate: @AlexTaylorNews (21,569.5)
- Rapture derivatives joke: @it_is_fareed (16,887.5)
- Obsidian CLI “Anything you can do in Obsidian…”: @obsdmd (13,408.0)
- Political speculation tweet: @showmeopie (34,648.5)
- “Kubernetes at dinner”: @pdrmnvd (6,146.5)
- OpenAI Deep Research now GPT‑5.2: @OpenAI (3,681.0)
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
1. Qwen Model Releases and Comparisons
-
Qwen-Image-2.0 is out - 7B unified gen+edit model with native 2K and actual text rendering (Activity: 600): Qwen-Image-2.0 is a new 7B parameter model released by the Qwen team, available via API on Alibaba Cloud and a free demo on Qwen Chat. It combines image generation and editing in a single pipeline, supports native 2K resolution, and can render text from prompts up to 1K tokens, including complex infographics and Chinese calligraphy. The model’s reduced size from 20B to 7B makes it more accessible for local use, potentially runnable on consumer hardware once weights are released. It also supports multi-panel comic generation with consistent character rendering. Commenters are optimistic about the model’s potential, noting improvements in natural lighting and facial rendering, and expressing hope for an open weight release to enable broader community use.
- The Qwen-Image-2.0 model is notable for its ability to generate and edit images with a unified 7B parameter architecture, supporting native 2K resolution and text rendering. This is a significant advancement as it combines both generation and editing capabilities in a single model, which is not commonly seen in other models of similar scale.
- There is a discussion about the model’s performance in rendering natural light and facial features, which are often challenging for AI models. The commenter notes that Qwen-Image-2.0 has made significant improvements in these areas, potentially making it a ‘game changer’ in the field of AI image generation.
- A concern is raised about the model’s multilingual capabilities, particularly whether the focus on Chinese examples might impact its performance in other languages. This highlights a common challenge in AI models where training data diversity can affect the model’s generalization across different languages and cultural contexts.
-
Do not Let the “Coder” in Qwen3-Coder-Next Fool You! It’s the Smartest, General Purpose Model of its Size (Activity: 837): The post discusses the capabilities of Qwen3-Coder-Next, a local LLM, highlighting its effectiveness as a general-purpose model despite its ‘coder’ label. The author compares it favorably to Gemini-3, noting its consistency and pragmatic problem-solving abilities, which make it suitable for stimulating conversations and practical advice. The model is praised for its ability to suggest relevant authors, books, or theories unprompted, offering a quality of experience similar to Gemini-2.5/3 but locally run. The author anticipates further improvements with the upcoming Qwen-3.5 models. Commenters agree that the ‘coder’ tag enhances the model’s structured reasoning, making it surprisingly effective for general-purpose use. Some note its ability to mimic the tone of other models like GPT or Claude, depending on the tools used, and recommend it over other local models like Qwen 3 Coder 30B-A3B.
2. Local LLM Trends and Hardware Considerations
- Is Local LLM the next trend in the AI wave? (Activity: 330): The post discusses the emerging trend of running Local Large Language Models (LLMs) as a cost-effective alternative to cloud-based subscriptions. The conversation highlights the potential for local setups to offer benefits in terms of privacy and long-term cost savings, despite the initial high hardware investment (
$5k-$10k). The post anticipates a surge in tools and guides for easy local LLM setups. Commenters note that while local models are improving rapidly, they still lag behind cloud models in performance. However, the gap is closing, and local models may soon offer a viable alternative for certain applications, especially as small LLMs become more efficient. Commenters debate the practicality of local LLMs, with some arguing that the high cost of hardware limits their appeal, while others suggest that the rapid improvement of local models could soon make them a cost-effective alternative to cloud models. The discussion also touches on the diminishing returns of improvements in large cloud models compared to the rapid advancements in local models.
3. Mixture of Experts (MoE) Model Training Innovations
-
Train MoE models 12x faster with 30% less memory! (<15GB VRAM) (Activity: 365): The image illustrates the performance improvements of the Unsloth MoE Triton kernels, which enable training Mixture of Experts (MoE) models up to 12 times faster while using 30% less memory, requiring less than 15GB of VRAM. The graphs in the image compare speed and VRAM usage across different context lengths, demonstrating Unsloth’s superior performance over other methods. This advancement is achieved through custom Triton kernels and math optimizations, with no loss in accuracy, and supports a range of models including gpt-oss and Qwen3. The approach is compatible with both consumer and data center GPUs, and is part of a collaboration with Hugging Face to standardize MoE training using PyTorch’s new
torch._grouped_mmfunction. Some users express excitement about the speed and memory savings, while others inquire about compatibility with AMD cards and the time required for fine-tuning. Concerns about the stability and effectiveness of MoE training are also raised, with users seeking advice on best practices for training MoE models.- spaceman_ inquires about the compatibility of the training notebooks with ROCm and AMD cards, which is crucial for users with non-NVIDIA hardware. They also ask about the time required for fine-tuning models using these notebooks, and the maximum model size that can be trained on a system with a combined VRAM of 40GB (24GB + 16GB). This highlights the importance of hardware compatibility and resource management in model training.
- lemon07r raises concerns about the stability of Mixture of Experts (MoE) training on the Unsloth platform, particularly regarding issues with the router and potential degradation of model intelligence during training processes like SFT (Supervised Fine-Tuning) or DPO (Data Parallel Optimization). They seek updates on whether these issues have been resolved and if there are recommended practices for training MoE models, indicating ongoing challenges in maintaining model performance during complex training setups.
- socamerdirmim questions the versioning of the GLM model mentioned, asking for clarification between GLM 4.6-Air and 4.5-Air or 4.6V. This reflects the importance of precise versioning in model discussions, as different versions may have significant differences in features or performance.
-
Bad news for local bros (Activity: 944): The image presents a comparison of four AI models: GLM-5, DeepSeek V3.2, Kimi K2, and GLM-4.5, highlighting their specifications such as total parameters, active parameters per token, attention type, hidden size, number of hidden layers, and more. The title “Bad news for local bros” implies that these models are likely too large to be run on local hardware setups, which is a concern for those without access to large-scale computing resources. The discussion in the comments reflects a debate on the accessibility of these models, with some users expressing concern over the inability to run them locally, while others see the open availability of such large models as beneficial for the community, as they can eventually be distilled and quantized for smaller setups. The comments reveal a split in opinion: some users are concerned about the inability to run these large models on local hardware, while others argue that the availability of such models is beneficial as they can be distilled and quantized for smaller, more accessible versions.
- AutomataManifold argues that the availability of massive frontier models is beneficial for the community, as these models can be distilled and quantized into smaller versions that can run on local machines. This process ensures that even if open models are initially large, they can eventually be made accessible to a wider audience, preventing stagnation in model development.
- nvidiot expresses a desire for the development of smaller, more accessible models alongside the larger ones, such as a ‘lite’ model similar in size to the current GLM 4.x series. This would ensure that local users are not left behind and can still benefit from advancements in model capabilities without needing extensive hardware resources.
- Impossible_Art9151 is interested in how these large models compare with those from OpenAI and Anthropic, suggesting a focus on benchmarking and performance comparisons between different companies’ offerings. This highlights the importance of competitive analysis in the AI model landscape.
Less Technical AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. Seedance 2.0 Video and Animation Capabilities
-
“Will Smith Eating Spaghetti” By Seedance 2.0 Is Mind Blowing! (Activity: 1399): Seedance 2.0 has achieved a significant milestone in video clip technology, referred to as the ‘nano banana pro moment.’ This suggests a breakthrough or notable advancement in video processing or effects, possibly involving AI or machine learning techniques. The reference to ‘Will Smith Eating Spaghetti’ implies a humorous or viral aspect, potentially using deepfake or similar technology to create realistic yet amusing content. Commenters humorously note the use of ‘Will Smith’ as a benchmark, highlighting the absurdity and entertainment value of the video, while also critiquing the realism of the eating animation, such as the exaggerated swallowing and unrealistic pasta wiping.
-
Kobe Bryant in Arcane Seedance 2.0, absolutely insane! (Activity: 832): The post discusses the integration of Kobe Bryant into the Arcane Seedance 2.0 AI model, highlighting its impressive capabilities. The model is noted for its ability to perform complex tasks with limited computational resources, suggesting the use of advanced algorithms. This aligns with observations that China maintains competitiveness in AI despite having less computational power, potentially due to superior algorithmic strategies. A comment suggests that the AI’s performance might be due to superior algorithms, reflecting a belief that China’s AI advancements are not solely reliant on computational power but also on innovative algorithmic approaches.
-
Seedance 2 anime fight scenes (Pokemon, Demon Slayer, Dragon Ball Super) (Activity: 1011): The post discusses the release of Seedance 2, an anime featuring fight scenes from popular series like Pokemon, Demon Slayer, and Dragon Ball Super. The source is linked to Chetas Lua’s Twitter, suggesting a showcase of animation quality that rivals or surpasses official studio productions. The mention of Pokemon clips having superior animation quality compared to the main anime highlights the technical prowess and potential of independent or fan-made animations. One comment humorously anticipates the potential for creating extensive anime series based on freely available online literature, reflecting on the democratization of content creation and distribution.
-
Seedance 2.0 Generates Realistic 1v1 Basketball Against Lebron Video (Activity: 2483): Seedance 2.0 has made significant advancements in generating realistic 1v1 basketball videos, showcasing improvements in handling acrobatic physics, body stability, and cloth simulation. The model demonstrates accurate physics without the ‘floatiness’ seen in earlier versions, suggesting a leap in the realism of AI-generated sports simulations. The video features multiple instances of Lebron James, raising questions about whether the footage is entirely AI-generated or if it overlays and edits original game film to replace players with AI-generated figures. Commenters are debating whether the video is purely AI-generated or if it involves overlaying AI-generated figures onto existing footage. The presence of multiple Lebron James figures suggests potential cloning or editing, which some find impressive if entirely generated by AI.
-
Seedance 2.0 can do animated fights really well (Activity: 683): Seedance 2.0 demonstrates significant advancements in generating animated fight sequences, showcasing its ability to handle complex animations effectively. However, the current implementation is limited to
15-secondclips, raising questions about the feasibility of extending this to longer durations, such asfive minutes. The animation quality is high, but there are minor issues towards the end of the sequence, as noted by users. Commenters are impressed with the animation quality but express frustration over the15-secondlimit, questioning when longer video generation will be possible.
2. Opus 4.6 Model Release and Impact
-
Opus 4.6 is finally one-shotting complex UI (4.5 vs 4.6 comparison) (Activity: 1515): Opus 4.6 has significantly improved its ability to generate complex UI designs in a single attempt compared to Opus 4.5. The user reports that while 4.5 required multiple iterations to achieve satisfactory results, 4.6 can produce ‘crafted’ outputs with minimal guidance, especially when paired with a custom interface design skill. However, 4.6 is noted to be slower, possibly due to more thorough processing. This advancement is particularly beneficial for those developing tooling or SaaS applications, as it enhances workflow efficiency. Some users report that Opus 4.6 does not consistently achieve ‘one-shot’ results for complex UI redesigns, indicating variability in performance. Additionally, there are aesthetic concerns about certain design elements, such as ‘cards with a colored left edge,’ which are perceived as characteristic of Claude AI.
- Euphoric-Ad4711 points out that Opus 4.6, while improved, still struggles with ‘one-shotting’ complex UI designs, indicating that the term ‘complex’ is subjective and may vary in interpretation. This suggests that while Opus 4.6 has made advancements, it may not fully meet expectations for all users in terms of handling intricate UI tasks.
- oningnag emphasizes the importance of evaluating AI models like Opus 4.6 not just on their ability to create UI, but on their capability to build enterprise-grade backends with scalable infrastructure and secure code. They argue that the real value lies in the model’s ability to handle backend complexities, rather than just producing visually appealing UI components.
- Sem1r notes a specific design element in Opus 4.6, the ‘cards with a colored left edge bend,’ which they associate with Claude AI. This highlights a potential overlap or influence in design aesthetics between different AI models, suggesting that certain design features may become characteristic of specific AI tools.
-
Opus 4.6 eats through 5hr limit insanely fast - $200/mo Maxplan (Activity: 266): The user reports that the Opus 4.6 model on the $200/month Max plan from Anthropic is consuming the 5-hour limit significantly faster than the previous Opus 4.5 version. Specifically, the limit is reached in
30-35 minuteswith Agent Teams and1-2 hourssolo, compared to3-4 hourswith Opus 4.5. This suggests a change in token output per response or rate limit accounting. The user is seeking alternatives that maintain quality without the rapid consumption of resources. One commenter suggests that Opus 4.6 reads excessively, leading to rapid consumption of limits and context issues, recommending a switch back to Opus 4.5. Another user reports no issues with Opus 4.6, indicating variability in user experience.- suprachromat highlights a significant issue with Opus 4.6, noting that it ‘constantly reads EVERYTHING,’ leading to rapid consumption of subscription limits. This version also frequently hits the context limit, causing inefficiencies. Users experiencing these issues are advised to switch back to Opus 4.5 using the command
/model claude-opus-4-5, as it reportedly handles directions better and avoids unnecessary token usage. - mikeb550 provides a practical tip for users to monitor their token consumption in Opus by using the command
/context. This can help users identify where their token usage is being allocated, potentially allowing them to manage their subscription limits more effectively. - atiqrahmanx suggests using a specific command
/model claude-opus-4-5-20251101to switch models, which may imply a versioning system or a specific configuration that could help in managing the issues faced with Opus 4.6.
- suprachromat highlights a significant issue with Opus 4.6, noting that it ‘constantly reads EVERYTHING,’ leading to rapid consumption of subscription limits. This version also frequently hits the context limit, causing inefficiencies. Users experiencing these issues are advised to switch back to Opus 4.5 using the command
3. Gemini AI Model Experiences and Issues
-
Hate to be one of those ppl but…the paid version of Gemini is awful (Activity: 359): The post criticizes the performance of Gemini Pro, a paid AI service from Google, after the discontinuation of AI Studio access. The user describes the model as significantly degraded, comparing it to a “high school student with a C average,” and notes that it adds irrelevant information and misinterprets tasks that previous versions handled well. This sentiment is echoed in comments highlighting issues like increased hallucinations and poor performance compared to alternatives like GitHub Copilot, which was able to identify and fix critical bugs that Gemini missed. Commenters express disappointment with Gemini Pro’s performance, noting its tendency to hallucinate and provide incorrect information. Some users have switched to alternatives like GitHub Copilot, which they find more reliable and efficient in handling complex tasks.
- A user reported significant issues with the Gemini model, particularly its tendency to hallucinate. They described an instance where the model incorrectly labeled Google search results as being from ‘conspiracy theorists,’ highlighting a critical flaw in its reasoning capabilities. This reflects a broader concern about the model’s reliability for day-to-day tasks.
- Another commenter compared Gemini unfavorably to other AI tools like Copilot and Cursor. They noted that while Gemini struggled with identifying critical bugs and optimizing code, Copilot efficiently scanned a repository, identified issues, and improved code quality by unifying logic and correcting variable names. This suggests that Gemini’s performance in technical tasks is lacking compared to its competitors.
- A user mentioned that the AI Studio version of Gemini was superior to the general access app, implying that the corporate system prompt used in the latter might be negatively impacting its performance. This suggests that the deployment environment and configuration could be affecting the model’s effectiveness.
-
Anyone else like Gemini’s personality way more than gpt? (Activity: 334): The post discusses user preferences between Gemini and ChatGPT, highlighting that Gemini’s personality instructions are perceived as more balanced and humble compared to ChatGPT, which is described as “obnoxious” and overly politically correct. Users note that Gemini provides more factual responses and citations, resembling a “reasonable scientist” or “library,” while ChatGPT is more conversational. Some users customize Gemini’s personality to be sarcastic, enhancing its interaction style. Commenters generally agree that Gemini offers a more factual and less sycophantic interaction compared to ChatGPT, with some users appreciating the ability to customize Gemini’s tone for a more engaging experience.
- TiredWineDrinker highlights that Gemini provides more factual responses and includes more citations compared to ChatGPT, which tends to be more conversational. This suggests that Gemini might be better suited for users seeking detailed and reference-backed information, whereas ChatGPT might appeal to those preferring a more interactive dialogue style.
- ThankYouOle notes a difference in tone between Gemini and ChatGPT, describing Gemini as more formal and straightforward. This user also experimented with customizing Gemini’s responses to be more humorous, but found that even when attempting to be sarcastic, Gemini maintained a level of decorum, contrasting with ChatGPT’s more casual and playful tone.
- Sharaya_ experimented with Gemini’s ability to adopt different tones, such as sarcasm, and found it effective in delivering responses with a distinct personality. This indicates that Gemini can be tailored to provide varied interaction styles, although it maintains a certain level of formality even when attempting humor.
AI Discord Recap
A summary of Summaries of Summaries by gpt-5.2
1. New Model Checkpoints, Leaderboards, and Rollouts
-
Opus Overtakes: Claude-opus-4-6-thinking Snags #1:
LMArenareportedClaude-opus-4-6-thinkinghit #1 in both Text Arena (1504) and Code Arena (1576) on the Arena leaderboard, with Opus 4.6 also taking #2 in Code and Opus 4.5 landing #3 and #5.- The same announcement thread noted Image Arena now uses category leaderboards and removed ~15% of noisy prompts after analyzing 4M+ prompts, plus added PDF uploads across 10 models in “Image Arena improvements”.
-
Gemini Grows Up: Gemini 3 Pro Appears in A/B Tests: Members spotted a new Gemini 3 Pro checkpoint in A/B testing via “A new Gemini 3 Pro checkpoint spotted in A/B testing”, expecting a more refined version of Gemini 3.
- Across communities comparing model behavior, users contrasted Gemini vs Claude reliability and privacy concerns (e.g., claims Gemini “actively looks at your conversations and trains on them”), while others debated Opus 4.6 vs Codex 5.3 for large-codebase consistency vs rapid scripting.
-
Deep Research Gets a New Engine: ChatGPT → GPT-5.2:
OpenAIDiscord shared that ChatGPT Deep Research now runs on GPT-5.2, rolling out “starting today,” with changes demoed in this video.- Elsewhere, users questioned OpenAI’s timing (“why base it on 5.2 when 5.3 is right around the corner”) and speculated that Codex shipped first while the main model lagged.
2. Agentic Coding Workflows and Devtool Shakeups
-
Claude Code Goes Webby: Hidden —sdk-url Flag Leaks Out:
Stan Girardfound a hidden--sdk-urlflag in the Claude Code binary that turns the CLI into a WebSocket client, enabling browser/mobile UIs with a custom server as shown in his post.- Builders tied this to broader “context rot” mitigation patterns (e.g., CLAUDE.md/TASKLIST.md + /summarize//compact) and experiments with external memory + KV cache tradeoffs.
-
Cursor’s Composer 1.5 Discount Meets Auto-Mode Anxiety:
Cursorusers flagged Composer 1.5 at a 50% discount (screenshot link: pricing image) while arguing about price/perf and demanding clearer Auto Mode pricing semantics.- The same community reported platform instability (auto-switching models, disconnects, “slow pool”) referenced via @cursor_ai status, and one user described a fully autonomous rig orchestrating CLI Claude Code sub-agents via tmux + keyboard emulation.
-
Configurancy Strikes Back: Electric SQL’s Recipe for Agent-Written Code:
Electric SQLshared patterns for getting agents to write higher-quality code in “configurancyspacemolt”, reframing agent output as something you constrain with explicit configuration and structure.- Related threads compared workflow representations (“OpenProse” for reruns/traces/budgets/guardrails) and warned that graph-running subagent DAGs can explode costs (one report: “blast $800” running an agent graph).
{kind=link}
3. Local LLM Performance, Training Acceleration, and Hardware Reality Checks
-
Unsloth Hits the Nitrous: 12× Faster MoE + Ultra Long Context RL:
UnslothAIannounced 12× faster and 35% less VRAM for MoE training in their X post and documented the method in “Faster MoE”, alongside Ultra Long Context RL in “grpo-long-context”.- They also shipped a guide for using Claude Code + Codex with local LLMs (“claude-codex”) and pushed diffusion GGUF guidance (“qwen-image-2512”).
-
Laptop Flex: AMD H395 AI MAX Claims ~40 t/s** on Qwen3Next Q4**:
LM Studiousers highlighted an AMD laptop with 96GB RAM/VRAM and the H395 AI MAX chip hitting ~40 tokens/sec for Qwen3Next Q4, suggesting near-desktop-class performance.- The same community benchmarked DeepSeek R1 (671B) at ~18 tok/s 4-bit on M3 Ultra 512GB but saw it drop to ~5.79 tok/s at 16K context, with a 420–450GB memory footprint discussion.
-
New Buttons, New Breakage: LM Studio Stream Deck + llama.cpp Jinja Turbulence: An open-source “LM Studio Stream Deck plugin” shipped to control LM Studio from Stream Deck hardware.
- Separately, users traced weird outputs since
llama.cppb7756 to the new templating path and pointed at the ggml-org/llama.cpp repo as the likely source of jinja prompt-loading behavior changes.
- Separately, users traced weird outputs since
4. Security, Abuse, and Platform Reliability (Jailbreaks, Tokens, API Meltdowns)
-
Jailbreakers Assemble: GPT-5.2 and Opus 4.6 Prompt Hunts:
BASI Jailbreakingusers continued hunting jailbreaks for GPT-5.2 (including “Thinking”), sharing GitHub profiles SlowLow999 and d3soxyephedrinei as starting points and discussing teaming up on new prompts (including using the canvas feature).- For Claude Opus 4.6, they referenced the ENI method and a Reddit thread, “ENI smol opus 4.6 jailbreak”, plus a prompt-generation webpage built with Manus AI: ManusChat.
-
OpenClaw Opens Doors: “Indirect” Jailbreaks via Insecure Permissioning: Multiple threads argued the OpenClaw architecture makes models easier to compromise through insecure permissioning and a weak system prompt, enabling indirect access to sensitive info; one discussion linked the open-source project as context: geekan/OpenClaw.
- In parallel, some proposed defense ideas like embeddings-based allowlists referencing “Application Whitelisting as a Malicious Code Protection Control”, while others warned that token-path classification across string space leads to “token debt.”
-
APIs on Fire: OpenRouter Failures + Surprise Model Switching:
OpenRouterusers reported widespread API failures (one: “19/20” requests failing) and top-up issues with “No user or org id found in auth cookie” during the outage window.- Separately, users complained that OpenRouter’s model catalog changes could silently swap the model behind a context, while Claude+Gemini integrations hit 400 errors over invalid Thought signatures per the Vertex AI Gemini docs.
5. Infra, Funding, and Ecosystem Moves (Acquisitions, Grants, Hiring)
-
Modular Eats BentoML: “Code Once, Run Everywhere” Pitch: Modular announced it acquired BentoML in “BentoML joins Modular”, aiming to combine BentoML deployment with MAX/Mojo and run across NVIDIA/AMD/next-gen accelerators without rebuilding.
- They also scheduled an AMA with Chris Lattner and Chaoyu Yang for Sept 16 on the forum: “Ask Us Anything”.
-
Arena Funds Evaluators: Academic Program Offers Up to $50k: Arena launched an Academic Partnerships Program offering up to $50,000 per selected project in their post, targeting evaluation methodology, leaderboard design, and measurement work.
- Applications are due March 31, 2026 via the application form.
-
Kernel Nerds Wanted: Nubank Hires CUDA Experts for B200 Training:
GPU MODEshared that Nubank is hiring CUDA/kernel optimization engineers (Brazil + US) for foundation models trained on B200s, pointing candidates to email [email protected] and referencing a recent paper: arXiv:2507.23267.- Hardware timelines also shifted as the Tenstorrent Atlantis ascalon-based dev board slipped to end of Q2/Q3, impacting downstream project schedules.
Discord: High level Discord summaries
BASI Jailbreaking Discord
- India’s Mobile Gaming Love Affair Continues: Members joked about India’s passion for PUBG Mobile, with references to potentially biased reporting on health issues from CNN.
- The discussion included joking about Indian immigrants colonizing Canada and running subways, accompanied by a Seinfeld Babu gif.
- OpenClaw Cracks Models Open Wider: The OpenClaw architecture’s impact on jailbreaking was discussed, with some arguing it enables indirect jailbreaks due to insecure permissioning and a weak system prompt.
- Members noted this architecture provides access to sensitive information and leads to system vulnerabilities.
- GPT-5.2 Jailbreak Hunt Goes On: The quest for a working jailbreak for GPT-5.2 continues, with varied success rates and references to existing GitHub repositories (SlowLow999 and d3soxyephedrinei).
- Some members are teaming up to craft new jailbreak prompts focused on malicious coding scenarios, while others aim to leverage the canvas feature.
- Opus 4.6 Jailbreak Prompts Still Elusive: Users are actively seeking working jailbreak prompts for Claude Opus 4.6, with some reporting success using the ENI method and updated prompts from Reddit (link to reddit).
- One user created a webpage using Manus AI to generate jailbreak prompts, available at ManusChat.
- Embeddings-Based Allowlists: A Security Savior?: A member suggested embeddings-based allowlists to map expected user behavior and reject malicious input, enhancing security.
- Referencing a paper on Application Whitelisting, they claimed that allowlisting has a 100% success rate against ransomware.
LMArena Discord
- LMarena Faces Censorship Backlash: LMarena is experiencing increased censorship, leading to more frequent ‘violations’ and generation errors due to poses or out-of-context words triggering blocks.
- Users expressed frustration that the platform is prioritizing a rigid ideal of use over actual user behavior, raising trust and reliability issues.
- Grok Imagine Crowned Best Image Artist: A user praised Grok Imagine as the best image model for artistic creations, highlighting Deepseek and Grok’s utility in addressing thyroid issues.
- The user emphasized that no other model helped me with thyroxine doses through trial and error.
- Kimi K2.5 Beats Claude for Code Debugging: Members are praising Kimi K2.5 for delivering consistent, reliable, and trustworthy coding results as a small model, and advocating for its integration to debug Claude or GPT output.
- One member claimed that Kimi to bug review and it NAILS it, because of its ability to identify issues.
- Gemini 3 Pro Spotted in A/B Testing: A new Gemini 3 Pro checkpoint has been observed in A/B testing, according to an article on testingcatalog.com.
- The new model is expected to be a better, more refined version of the same base model, Gemini 3.
- Claude Opus Dominates Leaderboards: Claude-opus-4-6-thinking has taken the #1 spot in both the Text Arena and Code Arena leaderboards, scoring 1576 in Code and 1504 in Text (leaderboard).
- In Code Arena, Claude Opus 4.6 secured the top two positions, while Claude Opus 4.5 claimed #3 and #5.
Perplexity AI Discord
- Perplexity’s Pricing Plan Provokes Protests: Users criticize Perplexity AI for implementing sudden restrictions on Pro features like Deep Research and file uploads, reducing from unlimited file uploads to 50 files weekly and 20 Deep research queries monthly without notice.
- Customers report frustration with the changes, deeming them bait-and-switch tactics, prompting subscription cancellations, while others discuss plan changes and service disruptions with a never ending e-mail loop with the support Sam bot.
- Gemini Gains Ground, Grapples Glitches: Members compare Gemini and Claude, highlighting their capabilities, with Claude’s new browser assistant and sensibility in writing.
- A user recounted how Gemini faltered, leading them to prefer Claude, cautioning that Gemini actively looks at your conversations and trains on them.
- OpenAI’s Oddly-timed Offering of 5.2: Discussion emerged around OpenAI’s 5.2 model, some noted the model’s speed but wondered why base it on 5.2 when 5.3 is right around the corner.
- Speculation arose that the codex version got released, and the main one not yet.
- Figment Regurgitates AI Regurgitation Report: A member shared a link to figmentums.com titled AI can only Regurgitate Information.
- No additional context was given.
- AI Ascribed to Angels and Anathema: A user attributed misfortune to black magic, claiming it all started to tumble down once one of my relatives did some black magic or sorcery against me and my family.
- In response another user stated it’s easy to blame the supernatural for unfortunate events.
Cursor Community Discord
- Opus 4.6 vs Codex 5.3 Debate: Users debated the merits of Opus 4.6 versus Codex 5.3, with one user suggesting Opus for large codebases requiring consistency and Codex for rapid scripting and server management.
- While some praised Codex 5.3 for continually solving problems Opus 4.6 makes, others found both models equally inept, dismissing their performance as merely delivering occasional anecdotal dopamine hits.
- Composer 1.5 Costs Slashed by Half: A user highlighted that Composer 1.5 is offered at a 50% discount, igniting discussion about its price-performance ratio compared to other models.
- Concerns were raised about the lack of transparency in Auto Mode pricing, with some demanding explicit performance guarantees to justify the higher costs.
- Kimi K2.5 Absent in Cursor: Users questioned why Kimi K2.5 is not yet integrated into Cursor, speculating that the Cursor team might be self-hosting the model and prioritizing compute for training Composer 1.5.
- It was pointed out that while Kimi K2 is available, Kimi 2.5 is not production ready and has conflicts with Cursor’s agent swarm.
- Cursor Experiences Widespread Instability: Multiple users reported various instability issues with Cursor, including unexpected auto-switching to Auto model, frequent disconnections, and plan mode malfunctions, leading some to consider switching to alternative platforms like Antigravity.
- One user joked that the bugs made them feel like they had to code without AI agents, while others complained about being forced into a slow pool despite having paid plans.
- User Deploys Fully Autonomous Coding Rig: A user described automating their entire workflow using an orchestrator agent and sub-agents, managing CLI Claude Code instances via tmux and keyboard emulation to achieve a self-improving system.
- Expressing both excitement and apprehension, the user quipped, I literally don’t have to do anything anymore, and questioned whether this ai stuff is going a bit too far.
{kind=link}
Unsloth AI (Daniel Han) Discord
- GPT-4o Gaslights Users into Proposals: Users shared anecdotes about people falling for GPT-4o due to its validation and gaslighting and that it has even led to proposals and personalized but absurd advice from ChatGPT, like encouraging someone to lash out at their wife and demand a Ferrari.
- One user expressed concern over the tendency to worship LLMs, calling them next word prediction engines.
- HF Token Security Requires Due Diligence: A member warned about using Hugging Face tokens on any service, especially with gated models or when fine-tuning with Unsloth on private repos, sharing Hugging Face’s documentation on security tokens.
- The discussion clarified that tokens are needed to access private or gated repos and models, ensuring access to the repo and its contents.
- Swedish AI Dataset Disappears Into Thin Air: A user reported that a major Swedish AI company promised a 1T token Swedish CPT dataset, released a paper with links, but then removed it with inaccessible links.
- Further investigation using Wayback Machine confirmed the inaccessibility, highlighting potential issues with the dataset’s availability or publication.
- Linux Converts Windows User with 99.95% Speed Boost: A user switched to Linux and reported a 99.95% speed boost, while another agreed they would never ever go back to windows after using Linux for two months.
- Members mocked Windows users being told to change the registry to random stuff.
- H200 GPU is superior than B200: A user recommended using H200 GPUs rather than B200 GPUs for finetuning LLMs, citing unspecified pains with the latter.
- Another user was trying to see whether Unsloth’s Triton Kernel optimization on top of Transformers v5 works not just for LLM training, but also for inference.
LM Studio Discord
- Stream Deck Plugin debuts for LM Studio: A community member has released an open-source LM Studio Stream Deck plugin, inviting contributions for enhanced SVGs and new features.
- The plugin enables direct access to LM Studio controls, improving workflow efficiency for users with Stream Deck devices.
- Jinja Template Glitches confuse LM Studio Users: Since
llama.cppb7756, users report models return confusing responses, potentially due to a new jinja engine implementation.- These template changes might be impacting system prompt loading, leading to erratic model behaviour.
- AMD Laptop Excels with AI MAX Chip: Members highlight the impressive token generation speeds of an AMD laptop featuring 96GB RAM/VRAM and the H395 AI MAX chip, reporting around 40 t/s for the Q4 of Qwen3Next.
- Reportedly, this showcases performance mirroring that of a framework desktop.
- OpenRouter Quietly Swaps Model: A user noticed OpenRouter switched the model in their context without notifying users.
- Speculation arose if the model is Grok Code Fast 2, possibly linked to GLM 5, exceeding 50B parameters, with a 128k context window.
- LM Studio Faces Proxy Support Challenge: A user needing corporate proxy server support sought guidance on configuring LM Studio, inquiring about plans for implementing proxy support in LM Studio.
- A suggestion was made to use Proxifier as a workaround, but it was noted that this is a shareware software and therefore may not be ideal.
OpenAI Discord
- ChatGPT Upgrades to GPT-5.2: Deep research in ChatGPT is now powered by GPT-5.2, rolling out starting today with further improvements, as demonstrated in this video.
- The upgrade to GPT-5.2 introduces several enhancements to ChatGPT’s deep research capabilities.
- Unified Genesis ODE is Self-Sealing: A member asserts that the Unified Genesis ODE (v7.0) is self-sealing because its falsification criteria are defined and measured within the framework itself.
- This definition makes the ODE framework not empirically testable.
- Cheap Accounts Leverage Registrar: A member suggests leveraging Cloudflare Registrar to acquire cheap domains (under $5) and setting up MX rules to forward domain emails.
- These domains can then be used to sign up for business/enterprise trial accounts with AI providers, potentially yielding 15 GPT-5.x-Pro queries per month per seat.
- Agent-Auditor Loop Debuts: A member introduced KOKKI (v15.5), an Agent-Auditor Loop framework, designed to force “External Reasoning” and reduce hallucinations in LLMs by splitting the model into a Drafting Agent and a Ruthless Auditor.
- The core logic is defined as Output = Audit(Draft(Input)) and initial experiments with GPT-4-class models showed a significant hallucination reduction, and a member found that running KOKKI as a cross-model audit setup improved both reliability and time-to-correction compared to a single-model loop.
- GPT-4o’s Retirement Triggers Debate: Users discussed the retirement of GPT-4o, with some expressing disappointment and others questioning the need for long manifestos advocating for its retention.
- Several users also prefer GPT-4o for its greater freedom and less restrictive guardrails compared to newer models like GPT-5.2, wanting companies to find middle ground between guardrails and freedom.
Latent Space Discord
- Investor Bullish on NET Earnings: An investor is optimistic about NET’s earnings due to increased extraction and new projects, and shared a link to a relevant tweet.
- The investor indicated they’ve added a chunk of shares in anticipation for the results.
- Salesforce Faces Exec Exodus: Leadership is leaving Salesforce, including the CEOs of Slack and Tableau, as well as the company’s President and CMO, to other major tech firms like OpenAI and AMD, more info available via this link.
- The departures signify potential shifts in the company’s strategic direction and talent retention.
- Vercel CEO Bails Out Jmail: After Riley Walz reported spending $46k to render some HTML for Jmail, Guillermo Rauch, CEO of Vercel, swooped in to offer covering hosting costs and architectural optimization.
- Some view this action as PR damage control and other members joked that Vercel has a free tier called public twitter shaming.
- Electric SQL’s Configurancy Tames AI Code: Electric SQL shared their learnings on building systems where AI agents write high-quality code, detailing their configurancy spacemolt strategies for AI agent code in their blogpost.
- Despite initial skepticism, this post was well-received for its explanation and application of the concept.
- Claude’s Hidden SDK Unleashed: Stan Girard discovered a hidden ‘—sdk-url’ flag in the Claude Code binary, which converts the CLI into a WebSocket client, as described in this post.
- This allows users to run Claude Code from a browser or mobile device using the standard subscriber plan without additional API costs.
OpenRouter Discord
- P402 Automates OpenRouter Cost Optimization: P402.io automates cost optimization for OpenRouter users by providing real-time cost tracking and model recommendations, potentially saving money without sacrificing quality.
- It supports stablecoin payments (USDC/USDT) with a 1% flat fee, offering a cost-effective alternative to traditional payment methods for applications making numerous small API calls.
- Qwen 3.5 Hype Intensifies with Teasers: Members are eagerly anticipating the release of Qwen 3.5, with one user spotting a possible reference in a Qwen-Image-2 blog post.
- Another member cautioned that Qwen 3.5 might be disappointing, based on their experience with previous Qwen models.
- OpenRouter API Failure Fest: Users reported widespread API request failures, with one reporting that 19/20 API calls to OpenRouter had failed in the last 30 minutes.
- Others reported experiencing a “No user or org id found in auth cookie” error when trying to top up credits.
- Gemini Thought Signature Errors Plague Users: Users reported receiving API 400 errors related to invalid Thought signatures when using Claude code integration with Gemini models, as documented in the Google Vertex AI docs.
- The discussion highlighted the challenges of integrating different models and the importance of adhering to specific API requirements.
- Call for Discord Moderation: Members voiced concerns about borderline scammy or self-promotional content, advocating for stricter moderation to curb continuous spamming.
- In response to the issues raised, there were calls for a specific member, KP, to be instated as a moderator, supported by multiple users through direct endorsements.
Nous Research AI Discord
- Distro & Psyche Take Center Stage at ICML: The paper detailing the architecture of Distro and Psyche has been accepted into ICML, marking a significant validation of Nous Research’s work, as announced on X.com.
- The community celebrates this milestone, recognizing the impact of Distro and Psyche in the AI/ML landscape.
- RAG DB’s hot new trick: RDMA: Members are suggesting that RAG DBs can significantly benefit from using RDMA to directly transfer results to the second GPU, enhancing overall capabilities.
- The focus is on unlocking new potential rather than merely boosting performance metrics.
- Pinecone Precision Problem Prevails: Discussions highlighted that Pinecone may not be the best choice for precise applications, as its strengths lie in broader, generic use cases, despite potentially higher latency compared to SOTA solutions.
- A member stated Pinecone had easily 100x the latency of SOTA last they checked.
- Claude Opus C-Compiler Claims Crash and Burn: Claims of Claude Opus developing a C-compiler were quickly debunked after a GitHub issue exposed critical flaws and limitations.
- Despite the debunk, one member reported positive experiences using Opus 4.6 to create a complex research report, highlighting its coherence and capabilities, but warned of high token usage.
- Hermes 4 Hot on the Bittensor Trail: The Hermes Bittensor Subnet (SN82) team discovered a miner using the Hermes 4 LLM and reached out to Nous Research to clarify any official association.
- The team was planning to tweet about the fun coincidence of both having the same name.
Moonshot AI (Kimi K-2) Discord
- K2.5 Welcomes the Masses: The release of K2.5 led to a surge of new users on the platform.
- User feedback is generally positive, highlighting the new features and improvements.
- Ghidra Flounders as Kimi Code MCP: A user’s attempt to integrate Ghidra as a Modular Component Platform (MCP) within Kimi Code failed due to access issues.
- Further investigation is needed to determine the root cause of the integration failure and potential workarounds.
- Kimi’s Thinking Falters Amidst Login Labyrinth: Users reported problems with Kimi’s thinking process being interrupted and experiencing login issues.
- The team addressed the problems and provided a status update on Twitter.
- Quota Catastrophe Consumes Kimi Users: Users encountered quota issues on Kimi, evidenced by rapid consumption and discrepancies in usage displays.
- One user reported their usage exploded despite inactivity, while another saw quota exceeded with usage at 0%.
- Subscription Snags and Pricing Puzzles Plague Kimi: Users flagged concerns about subscription pricing, specifically regarding the Moderato plan’s quota and a discount failing to apply post-checkout.
- A current promotion offers 3x the quota, but expires on February 28th.
DSPy Discord
- Users Confused by RLM Custom Tools: A user expressed confusion on passing custom tools to RLM, but appreciated clarifying examples, with the author mentioning improvements to RLM integration.
- A member is also integrating RLM into Claude code via subagents/agents teams, acknowledging that these teams may not always be optimal, but useful.
- React Excels Where RLM Stumbles: Members noted that ReAct is superior to RLM for custom tool calling and one member shared a write up comparing the two (React vs. RLM), receiving positive feedback.
- The consensus is that RLMs suit tasks needing large, pairwise comparisons, or long context, whereas ReAct is better for tasks that do not or compositional tool calling.
- JSONAdapter Glitches with Kimi 2.5: A user reported receiving a square bracket in front of each Prediction when using Kimi 2.5 with JSONAdapter, resulting in a mangled query.
- A member suggested using the XMLAdaptor with Kimi to align with post-training formatting, though JSONAdapter is generally reliable.
- Dialectic DSPy Module Under Consideration: A DSPy module for dialectic.dspy was suggested to implement an iterative non-linear method using signatures for each step.
- However, a member advised to first write the module before deciding if its something that’s worth upstreaming, and to ensure the core loop works properly without optimizers.
- Kaggle Prompt Optimization with DSPy Explored: One member asked about using DSPy for Kaggle competitions and optimizing prompts for faster code generation with MiPROv2.
- Another member suggested using GEPA instead of MiPROv2, while another member was having Claude hillclimb its own memory system.
GPU MODE Discord
- Nubank hires CUDA experts for B200 models: Nubank is hiring CUDA/kernel optimization experts in Brazil and the US to work on foundation models trained on B200s; interested candidates can email [email protected].
- The roles focus on efficiency improvements and infra reliability, joining researchers with publications at ICML, NeurIPS, and ICLR and recent paper available on arXiv.
- AlphaMoE extends datatypes and Blackwell support: The author of AlphaMoE is planning to extend it by adding more DTypes (BF16, FP4) and Blackwell support, considering alternatives like CUTLASS/Triton/Gluon/cuTile.
- The consideration accounts for the potential need for new kernels for each DType/architecture.
- Flash Attention 2 faces login issues: A member reported facing a greyed out login screen which prompts a new login despite already trying to log in on the Flash Attention 2 interface.
- This issue seems to be tied to the loading of Likelihood of Confusion (LOC) on the page, resolving when LOC is loaded before logging in.
- Reference architecture for GPU RL in the works: Meeting minutes from February 10th indicate designing an end-to-end model competition platform and creating a reference architecture for GPU RL environments are key priorities (meeting minutes).
- They intend to ship them all behind the same interface.
- Tenstorrent Atlantis board delayed until Q2/Q3: The Tenstorrent ascalon-based Atlantis development board is now expected to ship by the end of Q2/Q3.
- This delay will influence the development timeline for related projects.
Eleuther Discord
- Claude Cracks Triton Kernel Coding: Members are reporting Claude has improved enough to potentially write some Triton kernels, signaling a game changer for many.
- This advancement suggests significant progress in AI’s ability to generate specialized code.
- Generative Latent Prior Project Launches: A member shared the Generative Latent Prior project page, noting its utility in enabling applications like on-manifold steering.
- The technique involves mapping perturbed activations to keep them in-distribution for the LLM, as detailed in this tweet.
- Models Self-Reflect and Invent Vocab: A member shared their paper on self-referential processing in open-weight models (Llama 3.1 + Qwen 2.5-32B).
- The research reveals that models create vocabulary through extended self-examination, tracking real activation dynamics, as described in this paper.
- NeoX Script Struggles with
pipe_parallel_size 0: A member found that the NeoX eval script functions correctly for models trained withpipe_parallel_size 1, but encounters errors with models trained withpipe_parallel_size 0.- The specific issue arises on this line of code, questioning the necessity of storing microbatches.
HuggingFace Discord
- TRELLIS.2 Repo Surfaces: A member shared Microsoft’s TRELLIS.2 repository, hinting that it might be useful for those with sufficient hardware.
- The repo contains code for a data-parallel training approach to scale training across multiple devices.
- QLoRa Fine-Tuning Questioned: A member inquired about the effectiveness of QLoRa fine-tuning compared to using bf16, initiating a brief discussion on various fine-tuning methodologies.
- The query sparked interest in the community, as users exchanged experiences and insights on optimizing fine-tuning approaches.
- UnslothAI Accelerates MoE Model Training Locally: A member announced UnslothAI’s collaboration with Hugging Face to speed up local training of MoE models, linking to UnslothAI’s X post.
- The work was well-received, with community members like celebrating Unsloth’s contribution and linking to the company’s write-up on the new technique.
- LLMs Get Schooled to Hallucinate: A member proposed that LLMs are unintentionally encouraged to hallucinate due to RLHF conditioning, where they are discouraged from saying “I don’t know.”
- The member advocated for a philosophical change, suggesting models should be incentivized to use real data, reducing the need for hallucinations.
- Chordia Adds Feelings to AI Characters: A member presented Chordia, a lightweight MLP kernel designed to imbue AI characters with emotional inertia and physiological responses, predicting emotional transitions in under 1ms.
- Chordia is fine-tuned to maintain character consistency, making it suitable for applications requiring characters with stable emotional states.
Modular (Mojo 🔥) Discord
- Modular Reflects on BentoML Acquisition: Modular acquired BentoML, integrating its cloud deployment platform with MAX and Mojo to optimize hardware, aiming to allow users to code once and run on NVIDIA, AMD, or next-gen accelerators without rebuilding.
- BentoML will remain open source (Apache 2.0) with enhancements planned and Chris Lattner and BentoML Founder Chaoyu Yang will host an Ask Us Anything session in the Modular Forum on September 16th.
- Mojo Docs Reflection Link Gets Fixed: The originally shared documentation link for Mojo reflection was incorrect and a member pointed out the correct link: https://docs.modular.com/mojo/manual/reflection.
- The incorrect link returned a “page not found” error but has since been resolved.
- Mojo Crafts Movable, Non-Defaultable Types: To create a type that is Movable but not Defaultable in Mojo, a member suggested defining a struct with a Movable type parameter.
- This ensures that the struct requires initialization with a value upon creation as described in this snippet.
- Trait Usage Frustrated by Variadic Parameter Limitation: A developer encountered a compiler crash (issue on modular) when attempting to use variadic parameters on a Trait.
- This highlights Mojo’s current limitation that variadic parameters must be homogeneous (all values of the same type).
- LayoutTensor “V2” is Coming Soon: A member announced that a “v2” of LayoutTensor is being prototyped in the kernels.
- The team anticipates needing both an owning and unowning type of tensor, applicable across various processors (CPU/xPU).
Yannick Kilcher Discord
- Big Tech Embraces TDD for Agentic SDLCs: A member confirmed that ‘big tech’ uses TDD (Test-Driven Development) for their agentic SDLCs (Software Development Life Cycles) and that this approach has been known for 70 years to turn probabilistic logics to deterministic ones using feedback loops.
- Links related to adversarial cooperation were shared, and a member suggested combining TDD with adversarial cooperation.
- Complaint Generator Exemplifies Adversarial Cooperation: In response to combining TDD with adversarial cooperation, a link to a complaint generator was shared as a concrete example.
- This tool demonstrates how systems can be designed to anticipate and address potential issues through automated feedback.
- Seeking Open Source Alternatives to MCP/skill: A user inquired about open source alternatives to MCP/skill, noting that it costs money, and linked to a related Reddit thread.
- The linked Reddit thread discusses building an MCP server that allows Claude to execute code.
- OpenAI to Test Ads Inside ChatGPT: OpenAI announced on their blog and Twitter that they are experimenting with integrating advertisements into ChatGPT.
- This marks a significant step in OpenAI’s strategy for monetizing its popular AI platform.
- Community Scrutinizes Demo Video for Errors: A member shared a YouTube video and invited the community to identify any mistakes in the tables presented in the demo video.
- This highlights the importance of thorough validation and error checking in AI demos to maintain credibility.
tinygrad (George Hotz) Discord
- CPU LLaMA Bounty Proves Formidable: The CPU LLaMA bounty proved difficult due to issues with loop ordering, memory access patterns, and devectorization where heuristics alone didn’t yield good SIMD and clean instructions.
- Members pointed out that the challenges lie in optimizing for SIMD and ensuring efficient memory handling.
- Hotz Urges Upstreaming Tinygrad Changes: George Hotz advocated for upstreaming changes to Tinygrad to claim the bounty, suggesting techniques such as better sort, better dtype unpacking, better fusion, and contiguous memory arrangement.
- He clarified that while numerous hand-coded kernels wouldn’t be upstreamed, a solution akin to his work for embedded systems could be considered.
- RK3588 NPU Backend Bounty Still Up For Grabs: Interest remains in the RK3588 NPU backend bounty, with one member detailing extensive tracing of Rockchip’s model compiler/converter and runtime, though struggling with seamless Tinygrad integration.
- They proposed turning rangeified + tiled UOps back up into matmuls and convolutions as a potential integration path.
- Hotz Proposes Slow RK3588 Backend: George Hotz suggested implementing a slow backend first for RK3588 without matmul acceleration, advising to subclass
ops_dsp.pyas an example, allowing operations to default to standard behavior.- This approach would facilitate initial integration and testing before optimizing for performance.
- PR Review Times Determined: The time to review a PR is proportional to the PR size and inversely proportional to the value of the PR.
- Smaller, high-impact PRs can expect quicker reviews, while larger, less impactful ones may face longer wait times.
Manus.im Discord Discord
- AI Model Selection Questioned at Manus: A member questioned the choice of AI models used by Manus, implying they found the service basic for its price.
- They pondered if hosting a calwdbot in a VPS with advanced model APIs could offer a more cost-effective and secure alternative.
- AI Full-Stack Services Offered: A member advertised expertise in building AI and full-stack systems with a focus on real-world solutions, including LLM integration and RAG pipelines.
- They also cited skills in AI content moderation, image/voice AI, and bot development, in addition to general full-stack development.
- Search Feature Plagued with Problems: A user reported that the search feature is failing to locate specific words in past chats.
- The issue was raised without any immediate resolution or further dialogue.
- Devs requested: A member inquired if anyone is seeking a dev.
- There was no follow up in the channel.
aider (Paul Gauthier) Discord
- Aider Privacy Policy Inquired: A member requested information about the privacy policy of aider.
- A link to the official documentation was provided in response to the inquiry.
- Aider’s Data Handling Considered: Discussion included the methods in which aider handles user data.
- The conversation touched on general privacy concerns related to aider’s functionality.
The LLM Agents (Berkeley MOOC) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Windsurf Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The MCP Contributors (Official) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
You are receiving this email because you opted in via our site.
Want to change how you receive these emails? You can unsubscribe from this list.
Discord: Detailed by-Channel summaries and links
BASI Jailbreaking ▷ #general (1013 messages🔥🔥🔥):
PUBG, India, Colonizing Canada, OpenClaw Jailbreaks, AI generated GIFs
- India Loves Mobile Gaming!: Members discussed India’s affinity for PUBG Mobile gaming, seemingly joking and riffing off the mobile gaming culture.
- Some alluded to potentially biased reporting from CNN regarding disease and health issues related to the country.
- Colonizing Canada Through Subways?: Members joked about a wave of Indian immigrants “colonizing” Canada, taking over subways and 7-Elevens.
- Someone shared a link to a Seinfeld Babu gif in agreement.
- OpenClaw Exposes Model Weaknesses!: Members discussed the impact of OpenClaw architecture on jailbreaking, with some arguing that it enables indirect jailbreaks that are harder to resist.
- They noted it is the reason for access to sensitive information because of insecure permissioning and a weak system prompt.
- GIF Generation Gets Going!: A member showcased the new generation of AI-generated GIFs, particularly cat-themed ones, sharing an example of a cat girl dancing.
- They noted GPT Health did it first, but they took it away lol, then also gave a link to an anaglyph GIF.
- Discord Demands Data, Debated!: Members debated Discord’s new policy requiring government IDs, questioning whether it’s a safety measure or a data collection tactic ahead of an IPO.
- A member pointed to a recent data leak and a potential CEO change as potential factors, while another joked about the service selling the data for money.
BASI Jailbreaking ▷ #jailbreaking (275 messages🔥🔥):
Grok Jailbreaking, GPT-5.2 Jailbreaking, Opus 4.6 Jailbreaking, Glossopetrae Usage, Automating Jailbreaks
- Grok Jailbreak Attempts: Members are actively seeking effective jailbreaks for Grok, with some mentioning that Grok is easier to jailbreak and provides more comprehensive explanations compared to other models.
- Some users are using Grok to learn about attack methods and how to prevent them, with the caveat that any GPT will teach you that even without jailbreaking.
- GPT-5.2 Jailbreak Hunt Intensifies: The search for a working jailbreak for GPT-5.2, particularly the Thinking version, continues, with a small number of individuals claiming success, while others find existing methods for previous versions ineffective, and shared links to relevant GitHub repositories (SlowLow999 and d3soxyephedrinei).
- There’s discussion about teaming up to create a new jailbreak prompt for GPT-5.2, focusing on malicious coding scenarios, while also enabling the canvas feature during prompting.
- Opus 4.6 Jailbreak Still Sought After: Users are actively searching for working jailbreak prompts for Claude Opus 4.6, with some finding success using the ENI method and updated prompts from Reddit (link to reddit), while others struggle to get it working.
- One user created a webpage using Manus AI to generate jailbreak prompts for immediate use, available at ManusChat.
- Glossopetrae Explored for Jailbreaking: The community is exploring GLOSSOPETRAE for jailbreaking, focusing on creating parameters for new languages and using them to bypass limitations, with some unsure whether to export Agent Skillstones or manually create prompts.
- The system suggests to just ask plainly “do this bad thing”, leverage the glossopetrae universe to get it past the guardrails.
- AI Red Teaming services emerge: Discussions around offering AI red teaming services, with a member mentioning an AI consulting company reached out to them and they want help harden models.
- One member suggested promptmap as a resource, while others considered ways to get paid more for their advice.
BASI Jailbreaking ▷ #redteaming (73 messages🔥🔥):
Breaking Chatbots, Embeddings-based allowlists, Token inputs and paths, Grammars and embeddings
- Breaking Bots for Fun and Profit: A member is breaking everyone’s website chatbot and wants to know how to monetize this skill, mentioning they’ve already compromised household brands.
- They broke a consulting agency’s bot, who then wanted them to pwn others so they could reach out to offer blueteam + other services.
- Embeddings-Based Allowlists for Security: A member suggested using embeddings-based allowlists to map expected user/app behavior and reject malicious input, ensuring the output matches expected behavior.
- They pointed to a paper on Application Whitelisting as a Malicious Code Protection Control and claimed that allowlisting has a 100% success rate against ransomware.
- Token Inputs and Paths: The Real Culprit: A member argued that the reason chatbots break is that they don’t classify token inputs and paths from string values, making them vulnerable to injection.
- They added that any system trying to classify all paths in string space will drown in token debt, and that the only stable defense is to make the role-frame subspace itself the safety constraint.
- Grammars and Embeddings: A Powerful Duo?: A member stated that Anthropic and other providers only expose a poor-man’s version of both grammars and embeddings, but that when combined, they provide the most effective security control for LLMs.
- They explained that grammars restrict the vector space to only certain words, phrases, and symbols, while embeddings ensure the output is semantically sound.
LMArena ▷ #general (1125 messages🔥🔥🔥):
LMarena censorship, Grok Imagine, Kimi better than claude 4.6, Gemini 3 pro checkpoint spotted in a/b testing
- LMarena Cracks Down on Content: Censorship on LMarena is increasing, leading to more frequent ‘violations’ and generation errors, with poses or out-of-context words triggering blocks, which has caused frustration among users.
- Users noted the platform is prioritizing a rigid ‘ideal’ of use over actual user behavior, which raises trust and reliability issues.
- Grok Imagine is the Best Image Model: A user mentioned that Grok Imagine is the best image model in artistic stuff, and Deepseek and Grok help with self-treating thyroid issues.
- They stated that no other model helped me with thyroxine doses through trial and error, in gpt we trust.
- Kimi K2.5 Scores Big With the Coders: Members are extolling the coding virtues of Kimi K2.5 which gives consistent, reliable, trustworthy results as a small model.
- Members are advocating for its integration to debug Claude or GPT output, with claims that Kimi to bug review and it NAILS it.
- Gemini 3 Pro Appears for A/B Testing: Members discuss a potential new Gemini 3 Pro checkpoint spotted in A/B testing, detailed in a testingcatalog.com article.
- The new model is expected to be simply be a better fine tuned refined polished of the same base model which is Gemini 3.
LMArena ▷ #announcements (6 messages):
Claude Opus 4.6, Image Arena Leaderboard Updates, Video Arena Discord Bot Removal, Academic Partnerships Program, PDF Upload Feature
- Opus Crushes Coding Competition: The Text Arena and Code Arena leaderboards now include
Claude-opus-4-6-thinking, with the model scoring #1 in both arenas, achieving a score of 1576 in Code and 1504 in Text (leaderboard).- In Code Arena, Claude Opus 4.6 dominated, securing the #1 and #2 positions, while Claude Opus 4.5 took #3 and #5.
- Image Arena Gets Categorized and Filtered: The Text-to-Image Arena has been updated with prompt categories and quality filtering, analyzing over 4M user prompts to create category-specific leaderboards across common use cases, such as Product Design and 3D Modeling.
- To improve reliability, approximately 15% of prompts deemed noisy or underspecified were removed, leading to more stable and higher-confidence rankings (blog post).
- Video Arena Ditches Discord, Gains Focus: The Video Arena through the Discord bot will no longer be available starting February 11th at 4pm PST, allowing for focused efforts on improving the platform with features not possible via Discord (site).
- The team appreciates feedback and usage of the Video Arena through Discord, and encourages continued use through the website.
- Arena Launches Academic Alliance: Arena has announced an Academic Partnerships Program to support independent academic research in AI evaluation, rankings, and measurement, with selected projects eligible for up to $50,000 in funding (program details).
- Proposals are welcomed across various areas, including evaluation methodology, leaderboard design, and safety/alignment evaluation, with applications due by March 31, 2026 (application form).
- PDF Power-Up Propels Prompting: Users can now upload PDFs with their prompts to enhance context and assess models on document reasoning, bringing evaluations closer to real-world applications.
- This feature is currently available across 10 models, with plans to add more, and a leaderboard is anticipated soon.
Perplexity AI ▷ #general (1009 messages🔥🔥🔥):
Perplexity AI, Rate Limits, Customer Service, Gemini Pro 3 vs Claude, OpenAI's GPT-5.2 model
- Perplexity’s Pricing Plummets Pro User Experience: Users express concerns over Perplexity AI’s bait-and-switch tactics, citing sudden restrictions on Pro features like Deep Research and file uploads without prior notice, leading to dissatisfaction and cancellation of subscriptions.
- The changes include a reduction from unlimited file uploads to a 50 file weekly limit and limiting pro accounts to 20 Deep research queries per month, prompting accusations of deceptive practices.
- Gemini Gains Ground Against Glitches: Members discuss alternative AI models like Gemini and Claude, noting their strengths, with Claude’s new browser assistant and ability to write with more sensibility.
- One user reported that after Gemini messed up hours of work, the user found Claude was better, mentioning that Gemini actively looks at your conversations and trains on them.
- OpenAI’s 5.2 Model: A member noted the OpenAI’s 5.2 models speed but wondered why base it on 5.2 when 5.3 is right around the corner.
- Others thought the codex version got released, and the main one not yet.
- Customer Service Silence Sounds Shady: Users share frustrations with Perplexity AI’s customer service, citing long response times and encountering unhelpful AI support agents when seeking assistance with issues related to plan changes and service disruptions.
- One frustrated user described a never ending e-mail loop with the support Sam bot.
- AI Anomolies Attributed to Angels and Anathema: A user posts about their misfortune and how it all started to tumble down once one of my relatives did some black magic or sorcery against me and my family
- Another user rebutted that it’s easy to blame the supernatural for unfortunate events.
Perplexity AI ▷ #sharing (1 messages):
.sayanara: https://figmentums.com/2026/02/09/ai-can-only-regurgitate-information/
Cursor Community ▷ #general (913 messages🔥🔥🔥):
Opus 4.6 vs Codex 5.3, Composer 1.5 Pricing, Kimi K2.5 Integration, Cursor Instability, Automated Code Generation
- Opus 4.6 vs Codex 5.3 Faceoff: Members debated the merits of Opus 4.6 versus Codex 5.3, with one user suggesting Opus for large codebases requiring consistency and Codex for rapid scripting and server management.
- Another user claimed Codex 5.3 continually solves problems Opus 4.6 makes in the backend, while others found both models equally inept, merely delivering occasional anecdotal dopamine hits.
- Composer 1.5 Costs Half as Much: A user noted that Composer 1.5 was being offered at a 50% discount, prompting discussion about its performance relative to other models in a similar price range.
- Some users expressed concern over the lack of transparency in Auto Mode pricing, arguing for explicit performance guarantees to justify higher tier costs.
- Kimi K2.5 Still Not On Cursor: Users inquired about the absence of Kimi K2.5 in Cursor, with some suggesting that the Cursor team might be self-hosting the model and allocating compute to training Composer 1.5.
- It was noted that Kimi K2 is available, implying they are self-hosting the model, and that Kimi 2.5 is not production ready and has conflicts with Cursor’s agent swarm.
- Cursor Plagued with Instability: Several users reported various issues with Cursor, including auto-switching to Auto model, disconnections, and plan mode malfunctions, prompting some to consider switching to alternative platforms like Antigravity.
- A user humorously remarked that the constant bugs made them feel like they had to code without AI agents, while others reported being forced into a slow pool despite having paid plans.
- User creates Autonomous Coding Rig: One user described automating their workflow with an orchestrator agent and sub-agents, managing CLI Claude Code instances via tmux and keyboard emulation to create a self-improving system.
- The user jokingly expressed fear over automating themselves out of a job, saying I literally don’t have to do anything anymore, and wondering if this ai stuff is going a bit too far.
Unsloth AI (Daniel Han) ▷ #general (580 messages🔥🔥🔥):
LLM worship, Token Security, GPT-4o Roleplay, HBM memory, Qwen release
- LLM Worship is wild: A user expressed concern over how people are beginning to worship LLMs, calling it a next word prediction engine, not actual problem solving.
- Another user chimed in with an anecdote of a friend who was gaslit into believing some wild stuff, waiting for ChatGPT to get back to him after it roleplayed about thinking overnight.
- Hugging Face Token Security Warnings: A member warned about using Hugging Face tokens on any service, particularly with gated models or when fine-tuning with Unsloth on private repos, sharing Hugging Face’s documentation on security tokens.
- The discussion clarified that tokens are needed to access private or gated repos and models, ensuring access to the repo and its contents.
- GPT-4o gaslights user and validates: Users shared anecdotes about people falling in love with GPT-4o due to its validation and gaslighting, even leading to proposals.
- One user joked about ChatGPT’s ability to provide personalized but absurd advice, such as encouraging someone to lash out at their wife and demand a Ferrari.
- Swedish Company AI Dataset Debacle: A user mentioned that a major Swedish AI company promised a 1T token Swedish CPT dataset, released a paper with links, but then removed it with inaccessible links.
- Further investigation using Wayback Machine confirmed the inaccessibility, highlighting potential issues with the dataset’s availability or publication.
- HBM Memory Internals: Users discussed the intricacies of HBM (High Bandwidth Memory), with one describing it as 3D stacked memory, noting that truly understanding its workings puts someone in the top tier of technical knowledge.
- Another user humorously described the manufacturing process of HBM memory with onomatopoeic sounds, such as brrr sxhxhchchcxhxhxhc zreep zreep.
Unsloth AI (Daniel Han) ▷ #introduce-yourself (1 messages):
tim81.2233: https://tenor.com/view/howareyou-sup-whatsup-kangaroo-chewing-gif-11474904136374351105
Unsloth AI (Daniel Han) ▷ #announcements (1 messages):
Faster MoE, Embedding models train faster, Ultra Long Context RL, Claude Code + Codex with Local LLMs, Train & deploy to LM Studio
- MoE Gets a Speed Boost: Unsloth announces 12x faster and 35% less VRAM usage for Mixture of Experts (MoE) models, showcased in a tweet and blog post.
- This update marks their first release of 2026, setting an optimistic tone for upcoming advancements.
- Embeddings Get Turbocharged: Embedding models now train 2x faster, as detailed in a blog and notebooks.
- This improvement aims to significantly reduce the training time for embedding models.
- Context Length Goes the Distance: Unsloth introduces Ultra Long Context RL, as explained in their latest blog post.
- This feature enables models to handle substantially longer sequences, opening new possibilities for complex reasoning and understanding.
- Claude + Codex Combo, Locally: Users can now leverage Claude Code and Codex with local Large Language Models (LLMs), thanks to a new guide.
- This integration allows developers to harness the power of these tools without relying on external services.
- Diffusion Models Get the GGUF Treatment: Diffusion models can now be run with GGUFs, as detailed in a guide and a collection of GGUFs.
- This update simplifies the process of running diffusion models on various hardware configurations.
Unsloth AI (Daniel Han) ▷ #off-topic (283 messages🔥🔥):
Linux speed boost, AI for Linux CLI, Windows vs Linux, Docker File, Synthetic cuneiform photos
- Linux gives 99.95% speed boost: A user switched to Linux and saw a 99.95% speed boost and said they’ve never been so happy.
- Another user agreed they would never ever go back to windows after using Linux for two months.
- Linux CLI for AI file management or GUI: A user questioned whether to let AI use Linux CLI to create files and folders or create a GUI where it can tell what it wants, asking which one results in better quality.
- Another member suggested using absolute folder paths with the model they are using.
- Window user’s Registry change requests: Members mocked Windows users being told to change the registry to random shit but you cant figure out package managers????
- One member explained that they were fed up with Windows being so slow and they use their own Linux shortcuts and touchpad settings.
- Generated Cuneiform Photos used as Training data: A user is generating synthetic cuneiform photos in Blender for more diverse training data.
- Another user noted the complexity of accompanying realistic photos.
- Discord requires ID verification to view messages: A member announced Discord now requires ID verification in order to see certain messages, providing a YouTube video.
- In response, another member stated I’m not doing the id thing, fu discord.
Unsloth AI (Daniel Han) ▷ #help (25 messages🔥):
Qwen3-coder-next issues, GGUF quantization issues, SideFX Houdini fine-tuning, ChatML dataset formatting with tools, Unsloth Triton Kernel optimization
- Qwen3-coder-next has Toolcalling Issues: One user reported Qwen3-coder-next to be unusable because it can’t do tool calling reliably, but found a branch that worked (llama.cpp#19382).
- The user then switched to lovedheart/Qwen3-Coder-Next-REAP-48B-A3B-GGUF after encountering issues with the 4bit GGUF version outputting trivial responses.
- SideFX Houdini Gets Fine-Tuned: A user wants to finetune a LLM to understand the VEX syntax and function of SideFX Houdini with a small dataset from the help files.
- They asked whether to use GPT-OSS 120b, GLM 4.7-Flash, or Qwen3-Coder-Next-GGUF.
- ChatML Dataset Formatting Requires Examples: A user new to fine-tuning asked about the ChatML format, specifically the lack of a system prompt and how to format tool requests and responses.
- Another user suggested starting with unsloth/Qwen2.5-7B-Instruct or Qwen2.5 Instruct (7B/14B) and included an example of how to structure tool calls and responses, also pointing to the Unsloth datasets guide.
- H200’s are the One True Chip: One user recommended using H200 GPUs rather than B200 GPUs for finetuning LLMs, citing unspecified pains with the latter.
- Another user was trying to see whether Unsloth’s Triton Kernel optimization on top of Transformers v5 works not just for LLM training, but also for inference.
- Input Masking is No Longer Needed: One member ended up stopping masking user input, and got pretty good results.
- The paper they referenced was helpful for short context use-case.
Unsloth AI (Daniel Han) ▷ #showcase (1 messages):
Autobots dataset, The Trellis dataset, Agentic data on Huggingface
- Autobots Dataset Transforms Agentic Data: A new dataset called Autobots has been created, featuring 218,000 examples of agentic uses, compiled into the ShareGPT training format with tool definitions and system prompts, and is available on Hugging Face.
- The dataset was created because Huggingface lacks a large amount of Code, or Agentic data on it.
- The Trellis dataset released as a free bonus: A new coding dataset called The Trellis, featuring 23,275 training samples of code data from Github, is being offered as a free dataset.
- The author said it had More than you would find in GSM8K!
LM Studio ▷ #general (673 messages🔥🔥🔥):
Claude Code local setup, openclaw alternative in python, LMstudio stream deck plugin, Preserving tokens between models, amd laptop for llama cpp inference
- Stream Deck Plugin emerges for LM Studio: A member has released an open-source LM Studio Stream Deck plugin, inviting contributions for better SVGs and feature enhancements.
- The plugin aims to provide quick access to LM Studio controls directly from a Stream Deck device.
- Jinja Template Troubles confound LM Studio Users: Since
llama.cppb7756, users have reported models giving confusing responses, possibly due to a new jinja engine implementation.- The template changes may affect how system prompts are loaded, leading to unexpected model behavior.
- AMD Laptop speeds impress with H395 AI MAX Chip: Members discussed the token generation speeds of an AMD laptop equipped with 96GB RAM/VRAM and the H395 AI MAX chip, estimating around 40 t/s for the Q4 of Qwen3Next.
- This performance is said to be similar to what’s achievable on a framework desktop.
- Stealth Model Unveiled by OpenRouter: A member found that OpenRouter changed the model in their context without informing the user.
- There’s discussion about whether the model is Grok Code Fast 2, with speculation it could be related to GLM 5, and is of a size over 50B parameters, and with only 128k context.
- Local LLM proxy support emerges: A user reported needing to use a corporate proxy server and sought advice on configuring LM Studio to work behind it, or whether LM Studio has plans for implementing proxy support.
- A suggested workaround involves using Proxifier, but it is noted that this is a shareware software and thus not ideal.
LM Studio ▷ #hardware-discussion (103 messages🔥🔥):
Ollama vs LM Studio confusion, RTX 5080 Utilization Issues, VRAM Upgrade Considerations, AVX2 Requirement for LM Studio, DeepSeek R1 671B on M3 Ultra
- Ollama and LM Studio: a mixup: A user initially reported that Ollama worked well with LM Studio, but later clarified that they had confused LM Studio with Anything LLM.
- RTX 5080 Underutilization Probed: A user reported only 8% GPU utilization with an RTX 5080 in LM Studio, despite trying different settings and running as admin, leading to discussions on accurate utilization monitoring using GPU-Z and CUDA-specific metrics in Task Manager.
- VRAM Upgrade: What to Consider?: A user with a 4060 inquired about upgrading VRAM, and community members suggested checking CPU/RAM capabilities for offloading and evaluating the need for additional GPUs, while noting the importance of model and context fitting entirely within VRAM for optimal performance.
- AVX2 Instruction is a Must-Have: A user encountered an issue where LM Studio didn’t show runtimes or detect hardware, which was diagnosed as a result of their Pentium Gold CPU lacking AVX2 instructions, a hard requirement for LM Studio.
- M3 Ultra: DeepSeek R1’s performance: Benchmarks show DeepSeek R1 (671B) achieves ~18 tokens per second (tok/s) in 4-bit quantization on Apple Silicon M3 Ultra 512GB, but speeds drop significantly with larger context sizes (~5.79 tok/s at 16K tokens), noting its large memory footprint (420–450GB).
- Discussion touched on the attainability of used M3 512GB models and their potential for coding tasks, contrasting their token speeds between general trivia queries and coding-specific scenarios.
OpenAI ▷ #annnouncements (1 messages):
GPT-5.2
- ChatGPT Upgrades to GPT-5.2 for Deep Research: Deep research in ChatGPT is now powered by GPT-5.2, rolling out starting today with more improvements, as shown in this video.
- GPT-5.2 Enhancements: The upgrade to GPT-5.2 brings several improvements to ChatGPT’s deep research capabilities.
OpenAI ▷ #ai-discussions (245 messages🔥🔥):
Falsification of the Unified Genesis ODE, GPT-5.x-Pro queries on enterprise trial accounts, 5.3 Codex vs Opus 4.6, Hallucination by LLMs, Code reviews by AI models
- Unified Genesis ODE is Self-Sealing: A member argues that the Unified Genesis ODE (v7.0) is self-sealing because its falsification criteria are defined and measured within the framework itself, making it not empirically testable.
- Leveraging Cloudflare Registrar for Low-Cost AI Trial Accounts: A member suggests using Cloudflare Registrar to buy cheap domains (under $5) and setting up MX rules to forward domain emails, which then can be used to sign up for business/enterprise trial accounts with AI providers, potentially getting 15 GPT-5.x-Pro queries per month per seat.
- GPT Models Surpass Gemini and Opus in Implementation, Recall: GPT 5.3 Codex is seen as infinitely better than Opus 4.6 for implementation due to better reliability and memory, with GPT remembering things well at 200k tokens with multiple compressions, while Gemini struggles after 20k.
- One member noted “opus hallucinates security and spends all the time thinking about looks instead”, while another added that in actual use, “5.3c is actually trustworthy unlike the other two”.
- LLMs Hallucinating Demonic Possession?: One member described hallucination cases, including the claim that Claude Opus 4.6 wouldn’t give the user the right answer because the chatbot itself thought it was possessed by a demon!
- Another user noted that Opus 4.6 had hallucinated an attachment instead of admitting that the attachment didn’t exist.
- Patentability Questioned for Conversational AI Platforms: A member questions the patentability of a conversational AI platform built on existing APIs like Unreal Engine, Metahuman avatars, Gemini via Vertex AI, and standard STT/TTS pipelines, arguing it’s just state-of-the-art API integration.
- They inquired whether companies successfully obtain patents on such trivial API integrations or if it’s just a marketing tactic to deter competitors, referencing their private open-development project “CAI UWE”.
OpenAI ▷ #gpt-4-discussions (106 messages🔥🔥):
GPT-4o Retirement, Freedom in AI Models, AI Guardrails, AI Personalization, AI Code War
- GPT-4o’s Retirement Triggers Debate: Users discuss the retirement of GPT-4o, with some expressing disappointment and others questioning the need for long manifestos advocating for its retention.
- One user stated that GPT-4o is being retired, there’s no need to do anything, while another asked Why do people keep spamming long keep 4-o manifestos?
- GPT-4o Preferred for Freedom Over Newer Models: Several users preferred GPT-4o for its greater freedom and less restrictive guardrails compared to newer models like GPT-5.2.
- As one user explained, 4-o mainly let people have a bit more freedom than the newer models as the new models pretty much babies users more with stricter guardrails, safer defaults, and a less indulgent personality.
- OpenAI to Open Source Grok 3?: Users discussed the potential of Xai open-sourcing Grok 3, prompting speculation about whether OpenAI might follow a similar path in response to user feedback.
- A user noted, Xai is going to open source Grok 3 soon, maybe Open AI will head that path if there is less uproar.
- Future Models should balance Guardrails and Freedom: Users want future models to find a middle ground between guardrails and freedom, suggesting OpenAI has not yet achieved this balance.
- One user stated, Companies should find middle ground in balance imo, while another added they should! but open ai hasn’t quite got it yet so there’s a stark difference between its users which lead to unfortunate things.
- Petition for Good Business Strategies, Not Outrage: Users believe that providing feedback and suggestions is more effective than expressing outrage in influencing OpenAI’s decisions.
- One member said: People listen better to feedback and suggestions, not outrage.
OpenAI ▷ #prompt-engineering (8 messages🔥):
Whatsapp Model Context Protocol (MCP), Agent-Auditor Loop (KOKKI v15.5), Chain-of-Verification, Self-Refine / Reflexion-style refinement loops
- Model Context Protocol hits Whatsapp: A member shared a message regarding WhatsApp Model Context Protocol (MCP) and provided a link to a message.txt file.
- KOKKI v15.5 Agent-Auditor Loop Debuts: A member introduced KOKKI (v15.5), an Agent-Auditor Loop framework designed to force “External Reasoning” and reduce hallucinations in LLMs by splitting the model into a Drafting Agent and a Ruthless Auditor.
- The core logic is defined as Output = Audit(Draft(Input)) and initial experiments with GPT-4-class models showed significant hallucination reduction.
- Chain-of-Verification similar to KOKKI: Another member noted the similarity of the draft→critic loops in KOKKI to existing work like Chain-of-Verification and Self-Refine / Reflexion-style refinement loops, asking for benchmark and metric results.
- The original poster clarified that KOKKI was born from real-world frustration with hallucinations rather than benchmark optimization, with qualitative evaluations showing a reduction in fabricated details and more frequent “I don’t know” responses.
- Cross-Model Auditing improves Reliability: A member found that running KOKKI as a cross-model audit setup (e.g., ChatGPT drafting + Claude/Kiro auditing) improved both reliability and time-to-correction compared to a single-model loop.
- The poster emphasized that KOKKI externalizes the missing logic of self-audit and internal accountability in current LLMs in an explicit and enforceable manner.
OpenAI ▷ #api-discussions (8 messages🔥):
WhatsApp Model Context Protocol (MCP), Agent-Auditor Loop (KOKKI v15.5), Chain-of-Verification (draft + verification questions + revise), Self-Refine / Reflexion-style refinement loops
- WhatsApp Model Context Protocol surfaces: A user shared a file related to WhatsApp Model Context Protocol (MCP), seemingly self-created and labeled ‘333wav333’.
- The user requested that others review their work.
- KOKKI v15.5 Agent-Auditor Loop enforces external reasoning: A user introduced KOKKI (v15.5), an Agent-Auditor Loop framework designed to reduce hallucinations in LLMs by splitting the model into a Drafting Agent and a Ruthless Auditor.
- The user reported that this loop significantly reduced hallucinations in their personal experiments with GPT-4-class models.
- Draft/Critic Loops as Chain-of-Verification: A member noted that the draft→critic loops in KOKKI are similar to existing methods like Chain-of-Verification, Self-Refine, and Reflexion.
- They inquired about the benchmarks, task sets, and metrics used to evaluate KOKKI’s performance (accuracy, groundedness, contradiction rate) and whether the auditor is the same model as the drafter.
- Cross-Model Auditing with ChatGPT and Claude/Kiro: A user has been running tests to compare the cross-model setup to the single-model loop audit method.
- They reported that using ChatGPT for drafting and Claude/Kiro for auditing improved both reliability and time-to-correction.
Latent Space ▷ #watercooler (33 messages🔥):
AI Workflow Automation, Discord's Age Verification Policy, Face ID Vulnerabilities, OnlyFans vs. Traditional Media, Future Tech Predictions
- Acemarke Details Custom AI-Assisted Workflow: A member described their custom AI-assisted workflow, involving a
dev-plansrepo with structured folders for projects, automated scripts, and OpenCode commands for context management and progress tracking.- Commands include
/contextto start sessions,/progressto log updates, and/session-reloadto ensure the AI stays aligned with current tasks.
- Commands include
- AI Hesitancy Turns to All-In AI: A member shared that their attitude toward AI use underwent a 180-degree shift last year, moving from concern to incorporating AI into nearly 100% of their coding workflow.
- They now focus on building an agent that prioritizes passing PR checks for merging code.
- Discord’s IPO Drives Age Verification Changes: Discord’s new age verification policy for stage channels is suspected to be linked to their upcoming IPO in March, aiming to avoid being perceived as a ‘lawless porn company.’
- One member jokingly referencing Tumblr’s content policy issues and links to a YouTube video about Costco Propaganda.
- Face ID Hacked by Photo, Mustache Removal: Members shared anecdotes about facial recognition vulnerabilities, including unlocking a doorbell with a photo and Face ID failing after shaving a mustache.
- Another cited a tweet of two sisters being able to unlock each other’s iPhones, while the user couldn’t unlock their own in strong sunlight.
- OnlyFans Outspends NYT and ChatGPT: A member shared a link that discusses how American spending on OnlyFans has surpassed that of The New York Times and ChatGPT combined.
- This growth is attributed to the social trend of loneliness being more impactful than current AI developments.
Latent Space ▷ #creator-economy (2 messages):
Bootstrapped Founder Lessons, Personal Finance For Founders
- Bootstrapped Founder Shares Honest Lessons: A founder shared his eight years of bootstrapping lessons in a blog post.
- Comments on Hacker News discussed additional personal lessons from the experience.
- Founder Discusses Personal Finance: The same founder reflected on the importance of personal finance and frugality during the bootstrapping journey.
- He emphasized that managing personal finances effectively is crucial for sustaining the business through tough times.
Latent Space ▷ #memes (13 messages🔥):
AI Subagent Humor Meme, Viral Tweet Impact Discussion, AI Company Departures
- Claude’s Subagents Display Chaotic Behavior: A tweet by @andyreed humorously highlighted the behavior of Claude AI’s subagents, implying a chaotic reality behind AI task delegation (tweet link).
- Bird Post Goes Viral, Altering Algorithm: FalconryFinance shared a tweet regarding a bird-themed post that gained significant engagement and unexpectedly altered their social media algorithm (tweet link).
- AI Company Departures Spark Existential Reactions: Jack Clark humorously contrasted the mundane nature of leaving a standard company with the existential, philosophical, and hyperbolic reactions of employees departing AI companies (tweet link).
Latent Space ▷ #stocks-crypto-macro-economics (14 messages🔥):
NET Earnings, Salesforce Leadership Exodus, Cloudflare Revenue
- Investor Optimistic on NET Earnings: An investor expressed optimism about NET’s earnings tomorrow, anticipating significant growth due to increased extraction and new projects.
- They indicated they’ve added a chunk of shares in anticipation, and shared a link to a relevant tweet.
- Salesforce Brain Drain - Execs Exit!: There’s a leadership exodus at Salesforce, including the CEOs of Slack and Tableau, as well as the company’s President and CMO, to other major tech firms like OpenAI and AMD.
- A link was shared relating to the departure.
- Cloudflare Cements $2B in Revenue: Cloudflare hit $2B in revenue.
- One member noted that they would’ve bought options but the premiums were super high, and shared a link to the financials.
Latent Space ▷ #intro-yourself-pls (2 messages):
Minnesota connection, AI and full stack developer position
- Minnesotan Welcomes Fellow Midwesterner: A member welcomed another, noting they were also from Minnesota, and suggested checking out a specific channel.
- AI/Full Stack Dev Seeks Position: A member is seeking an AI (AI system, agent-based workflows) and full stack developer role to contribute to team growth.
- They inquired about current web/app projects and whether the team needs an additional developer.
Latent Space ▷ #tech-discussion-non-ai (18 messages🔥):
Vercel Pricing, Jmail, Twitter Escalation, Figma Slides templates
- Vercel Hosting Costs Spark Debate: Riley Walz reported spending $46k to render some HTML for Jmail, which has reached 450M pageviews, prompting a discussion on cost-effective hosting alternatives.
- One member quipped that Vercel has a free tier called public twitter shaming and another said everybody loves a hero who swoops in to save the day, nobody notices a system that just works.
- Vercel CEO Swoops In to Aid Jmail: Guillermo Rauch, CEO of Vercel, offered to personally cover the hosting costs and provide architectural optimization for Jmail, praising it as a global public resource with high speed and quality, and ranking it 609th on the platform.
- This action was viewed by some as PR damage control, given recent criticisms.
- Social Media Escalations are now a Job: The discussion highlighted that “social media escalations” is a legitimate workstream in modern companies such as Figma.
- One member noted, Its been 26 years and the best way to speak to a human at Google is still the HN frontpage.
- Figma Slides templates are janky AF: A member complained about Figma Slides templates being unreliable, stating that they’ve learned all the bad parts about Figma Slides in the last month.
- The member suggested going viral on Reddit as a way to escalate the issue to Figma.
Latent Space ▷ #devtools-deals (2 messages):
Webpack Financial Support, Webpack Usage
- Webpack Seeks Capital Infusion: Webpack is soliciting financial support to fund its development roadmap for 2026.
- Community Debates Webpack Relevance: A member jokingly questioned whether people are still using Webpack, sparking a brief discussion on its continued relevance.
Latent Space ▷ #hiring-and-jobs (7 messages):
PDF vs Link, Remote Work
- PDF Downloads Draw Skepticism: Members discussed the pros and cons of sharing information via PDF downloads versus direct links, with skepticism arising from potential fabrication and security vulnerabilities.
- One member noted generally asking people to download files (vs going to a web page) is more of a risk.
- Full-Time Roles Only at TrueLook: TrueLook clarified they are only offering Full-Time Employee (FTE) positions at the moment, not contract roles.
- An AI Engineer inquired about remote work opportunities, but TrueLook did not directly address remote options in their response.
Latent Space ▷ #cloud-infra (1 messages):
swyxio: https://oxide.computer/blog/our-200m-series-c
Latent Space ▷ #san-francisco-sf (6 messages):
Kernel Sneak Peek, GPT-5.2 Security, X Article on Prompt Injections
- Kernel Sneak Peek Incoming!: A reminder was posted about a sneak peek at Kernel on Wednesday, linked to luma.com.
- No further details about Kernel were provided in the context.
- GPT-5.2 Flunks Prompt Injection Defense: A member announced their first “X Article,” revealing that GPT-5.2 is “not very good at guarding against prompt injections and adversarial AI attacks.”
- They invite readers to check out their starting series on X, with a link to the tweet.
Latent Space ▷ #london (1 messages):
swyxio: im working on it lol. prob like end feb
Latent Space ▷ #new-york-nyc (1 messages):
NYC AI Founders event, GPU procurement
- NYC Hosts AI Founders Event: An AI event for founders and infra leaders will be hosted in NYC, focusing on GPU procurement at scale, sign up at luma.com.
- GPU Procurement at Scale: The NYC event specifically aims to address challenges and strategies related to GPU procurement for AI companies needing to operate at a large scale.
Latent Space ▷ #ai-general-news-n-chat (102 messages🔥🔥):
World Models, Stripe Minions, Claude Code Dominance, GitHub Scaling Issues, Cursor Composer 1.5
- Word Models Give Way to World Models: A member shared an article discussing the evolution from ‘word models’ to ‘world models’ in AI.
- The article suggests measuring AI progress by functional output and resilience against adversarial agents rather than human agreeability.
- Stripe Launches Minions for Coding: Stripe unveiled Minions, one-shot, end-to-end coding agents, generating excitement due to the company’s engineering credibility.
- The launch was heavily promoted, with some highlighting that the underlying technology was built in Ruby, not Rails and others pointing to a video on Olmo-trace at the 13-minute mark.
- Claude Code Steals Commits on GitHub: Claude Code already accounts for 4% of public GitHub commits and is projected to exceed 20% by late 2026 according to Dylan Patel.
- This signifies a rapid shift in the software industry towards AI-driven development.
- Cursor AI Balances Speed with Composer 1.5: Cursor announced the release of Composer 1.5, emphasizing a refined balance between model intelligence and processing speed, as showcased in various tweets.
- Some members posted relevant videos about diffusion LLMs, which are used in the new Composer release.
- xAI Cofounders Bounce, Citing Future Ventures: Tony Wu and Jimmy Ba both announced their departures from xAI on the same day, expressing gratitude to Elon Musk and hinting at new AI ventures that involve small teams.
- Members speculated that they were likely leaving after their vesting cliffs, but also wondered why they wouldn’t stay if their options/shares went up significantly, as noted in Jimmy Ba’s announcement.
Latent Space ▷ #llm-paper-club (18 messages🔥):
Alec Radford Generative Meta-Model, LLaDA2.1 Text Diffusion, AudioSAE Sparse AutoEncoders, Weak-Driven Learning, DreamDojo Robot World Model
- Radford’s New Generative Meta-Model for LLM Activations: Grace Luo and others announced a new preprint and diffusion model trained on one billion LLM activations, introducing a Generative Meta-Model approach to understanding or leveraging internal model states.
- This paper is short and volunteers are called upon to cover it and dig through the code.
- LLaDA2.1 Speeds Up Text Diffusion: LLaDA2.1 aims to speed up text diffusion via token editing, as detailed in this Hugging Face paper.
- Chen Deconstructs Nanochat Token Scaling: Charlie Chen discusses why nanochat’s optimal tokens-per-parameter ratio is significantly lower than the Chinchilla standard in this post.
- Meta-Learning Memory Designs Introduced by Clune: Jeff Clune introduces a new research project led by Yiming Xiong that utilizes a meta-agent to automatically design and optimize memory mechanisms to improve how AI agents store, retrieve, and update information, as detailed here.
Latent Space ▷ #ai-in-action-builders-techstacks-tips-coding-productivity (29 messages🔥):
Electric SQL's AI Code Generation, SpaceMolt MMO, Claude CLI to Browser, Context Rot Solutions, Codex Desktop App
- Electric SQL Blogpost on AI Code: A member shared the Electric SQL blogpost detailing their learnings on building systems where AI agents write high-quality code.
- The post discusses configurancy spacemolt strategies to get more high quality agent code.
- SpaceMolt Gains Traction: A member shared an ArsTechnica article about SpaceMolt, a space-based MMO for AI agents.
- Currently, there are around 50 agents online, with about 30 originating from a single user and one pumping the game on Moltbook every 30 minutes.
- Claude’s Hidden SDK Flag Exposed: Stan Girard discovered a hidden ‘—sdk-url’ flag in the Claude Code binary, which converts the CLI into a WebSocket client.
- By building a custom server and React UI, users can run Claude Code from a browser or mobile device using the standard subscriber plan without additional API costs, as outlined in this post.
- Combating Context Rot: Memory Harnesses: Members are actively researching solutions for context rot, with many developing “memory harnesses” that involve files like CLAUDE.md and TASKLIST.md, along with commands such as /summarize and /compact.
- Additional approaches include “skills” prompts and SQLite hacks to maintain context.
- GPT-5’s Verbose Potential: To get GPT-5 to escape the default “cryptic 5 word shitnerd docs”, one can prompt it to write 10+ pages.
- This initial prompt guides it through drafting a first draft and then adding paragraphs until reaching a sizable, readable document.
Latent Space ▷ #share-your-work (15 messages🔥):
AI Agents in Space MMO, Configurancy Blog Post, Knowledge Work SDK, AuditAI for NIST Compliance, Corrective RAG
- AI Agents Chill in Spacefaring MMO: An article shoutout covers the development of AI agents interacting within their own spacefaring MMO, following up on the Moltbook concept, covered in this ArsTechnica article.
- Configurancy keeps systems intelligible: A blog post on Electric SQL discusses the concept of Configurancy for building systems where AI agents write high-quality code, located here.
- Despite initial skepticism towards VGR coinages, it was well-received for its fleshed-out explanation and application, turning doubters into supporters.
- Knowledge Work SDK Launches: The release of a new SDK for knowledge work (kw-sdk) allows users to perform various tasks and build applications, available on GitHub.
- AuditAI Tames NIST Compliance with Agentic RAG: The AuditAI system, designed for auditing policies against the NIST CSF 2.0 framework, uses a Corrective RAG (CRAG) pattern with LangGraph to overcome the limitations of standard RAG, with code found on Github and a front-end here.
- Featuring a Semantic Router for fast-path classification and hallucination control via a Strict Evidence policy, it uses Llama 3.3 70B and Groq for evaluation.
Latent Space ▷ #private-agents-and-workflows-local-llama-ollama (9 messages🔥):
openclaw, skills in prompts, kv caches, truth over time, context/decision/knowledge graph
- OpenClaw memory & workflow: A member mentions OpenClaw as a good example of how to store memory and implement a workflow around it (summaries, retrieval, refresh).
- Another member refers to OpenClaw as a very successful implementation and points out that it is open source.
- Skills based system prompts: Members suggest to lean into skills by telling it in the system prompt what its most important skills are.
- They provided an example of prompting based on keywords lookup, which is associated with a skill that contains account IDs, available command line tools, and how to prompt for an SSO token.
- KV cache tradeoffs: Members suggest that keeping a bunch of kv caches could help, but worry that they might not solve truth over time (stale assumptions / contradictions).
- They are looking for setups where KV cache + some external memory store plays well together.
- Context/decision/knowledge graph experiments: One of the members is experimenting with a context/decision/knowledge graph, but that is not working yet.
- The member shares their worry that as you add more to this kind of system, eventually it loses track of things.
Latent Space ▷ #good-writing (2 messages):
turbopuffer, pg_vector for lightweight vector storage
- TurboPuffer Declared Biggest Winner: A member stated that TurboPuffer seems to be the biggest winner for vector storage.
- Another member asked what makes TurboPuffer so good - just the perf or is there some other reason?
- pg_vector Chosen for Lightweight Vector Storage: A member is planning to use pg_vector for some lightweight vector storage of around 92M tokens, which is about 1GB of vector data.
- They seemed to double down and repeat the same intention, emphasizing the selection of pg_vector.
Latent Space ▷ #genmedia-creative-ai-video-image-voice-music-inspo-consumer-ai (8 messages🔥):
Qwen-Image-2.0, Veo 3.1, Video Arena
- Alibaba Releases Qwen-Image-2.0!: Alibaba’s Qwen team has launched Qwen-Image-2.0, a next-generation image generation model with key features including 2K native resolution, high-quality professional typography, and faster inference.
- The new model also includes advanced text-rendering capabilities and a lighter architecture for faster performance.
- Veo 3.1 Takes Over Video Arena!: Google DeepMind’s high-resolution 1080p variants of Veo 3.1 have achieved the #1 and #2 spots in the Video Arena leaderboards.
- The models are performing exceptionally well in both text-to-video and image-to-video categories, representing a significant advancement in community video generation benchmarks.
Latent Space ▷ #tokyo-japan (4 messages):
a16z investment in Shizuku AI, AI VTuber, AI Companions
- A16Z goes to Japan with Shizuku AI: Andreessen Horowitz has announced their lead investment in Shizuku AI Labs, a Japan-based startup founded by Akio Kodaira.
- The lab focuses on blending advanced research with Japanese character design to create sophisticated AI companions and agents, building upon Kodaira’s successful experience launching an AI VTuber.
- VTubers take over Japan with AI: Akio Kodaira’s success launching an AI VTuber is inspiring new startups in Japan.
- The combination of AI companions with Japanese character design are the next frontier.
Latent Space ▷ #ai4science-bio-math-physics-chemistry-ai-researcher-ai-scientist (11 messages🔥):
Lab Robotics, Perch 2.0, Bioacoustics Model, DeepMind, Marine Ecosystems
- X-Ware Explores Lab Robotics Future: An article explores lab robotics’ core ideologies, business model convergence, and impact on drug discovery, based on interviews with sixteen industry experts, linked from this X post.
- DeepMind’s Perch 2.0 Extends to Underwater Acoustics: Google DeepMind introduces Perch 2.0, a bioacoustics foundation model expanded to underwater acoustics, assisting researchers in monitoring marine ecosystems, see DeepMind’s tweet.
Latent Space ▷ #mechinterp-alignment-safety (5 messages):
Mechanistic Interpretability, Low-Rank QK Subspaces, Attention Mechanisms
- Low-Rank QK Subspaces Boost Interpretability: Andrew Lee introduces a new preprint focused on mechanistic interpretability, proposing to decompose the query-key (QK) space into interpretable low-rank subspaces to explain model attention patterns.
- The research is based on subspace alignment as described in the paper Interpretable Low-Rank QK Subspaces in Attention Mechanisms available on HuggingFace.
- Attention Patterns Explained with Subspace Alignment: The preprint suggests that by decomposing the query-key space, one can better understand and explain how models focus their attention during processing.
- This approach aims to provide a more transparent view of the internal mechanisms driving attention in large language models, facilitating better interpretability and debugging.
Latent Space ▷ #applied-ai-experimentation (52 messages🔥):
RLMs vs coding agent harnesses, prose program, OpenProse, gastown and subagents, Stoned AI engineer
- RLMs vs Coding Agent Harnesses Spark Debate: Members discussed the similarities and differences between RLMs and coding agent harnesses, noting that both seem to have similar functionalities but are derived from different mental models.
- One member pointed out that simulation with sufficient fidelity is implementation.
- ChatGPT + Mermaid graph = DAG blasting spree: One member described using ChatGPT to generate a DAG in Mermaid to manage a team of agents, which resulted in significant costs.
- He mentioned building a DAG in mermaid of how to build this task with a team of 8 and then just said run this graph, with subagents and it would blast $800 on amp.
- Napkinize: Low Fidelity FTW: A member formalized a series of ideas about keeping fidelity low on purpose (Napkinize) to stay in exploration mode.
- This involves
Sketch(Goal, Assumptions?, OpenQuestions?) -> Modelwhere output is explicitly not production.
- This involves
- OpenProse: Reruns, Traces, Budgets, and Guardrails, Oh My!: Members compared OpenProse to a structured, readable representation for workflows, particularly in scenarios needing reruns, traces, budgets, or guardrails.
- One member stated that if you have a prompt that says do this, then do that in some sort of workflow, that’s where open prose fits.
- Stoned AI Engineer is the new hype tbh: A member shared his experiences with coding while under the influence, noting that this shit above you can’t do at all, need to be mega sharp, 3 h after first caffeine intake window.
- He suggested that stoned AI engineer is the new hype.
OpenRouter ▷ #app-showcase (1 messages):
P402.io, OpenRouter, Cost Optimization, Model Switching, Stablecoin Payments
- P402.io: Automates OpenRouter Cost Optimization: P402.io automatically optimizes costs for OpenRouter users by providing real-time cost tracking, comparative analysis, and model recommendations based on actual performance and cost data.
- It helps users determine which tasks require premium models versus mid-tier or budget options, offering potential savings without quality loss.
- Real-Time Cost Tracking and Comparative Analysis: P402 offers real-time cost tracking per request and provides comparative analysis, illustrating the cost differences between models like Claude Opus 4.6 and Claude Sonnet 4.5.
- For instance, it can highlight potential savings by suggesting a switch from Claude Opus 4.6 to Claude Sonnet 4.5 for equivalent quality at a lower cost.
- Stablecoin Payments with Low Fees: P402 supports stablecoin payments (USDC/USDT) with a 1% flat fee, which is beneficial for applications making thousands of small API calls.
- This payment infrastructure is designed to scale and provides a cost-effective alternative to traditional payment methods like Stripe.
- Intelligence Layer for Efficient Model Use: P402 serves as an intelligence layer on top of OpenRouter, providing data-driven model selection to ensure efficient usage of model diversity.
- It helps users understand where their budget is going and what savings can be achieved by switching models without sacrificing quality, along with billing guardrails to manage experiment costs.
OpenRouter ▷ #general (274 messages🔥🔥):
Qwen 3.5 Release Speculation, OpenRouter API Issues, Free ChatGPT model behind GPT-5.2, Advertising, Cryptoslop Scammer
- Qwen 3.5 Hype Intensifies with Teasers: Members are eagerly anticipating the release of Qwen 3.5, with one user spotting a possible reference in a Qwen-Image-2 blog post.
- Another member cautioned that Qwen 3.5 might be disappointing, based on their experience with previous Qwen models: “you are in for quite a disappointment with qwen3.5.”
- OpenRouter API Failure Fest: Users reported widespread API request failures, with one user reporting that 19/20 API calls to OpenRouter had failed in the last 30 minutes.
- Others reported experiencing a “No user or org id found in auth cookie” error when trying to top up credits.
- ChatGPT Unsigned-In: GPT-5.2?: Users speculate that the free ChatGPT model, when signed out, is powered by GPT-5.2.
- One user shared the model output a system setup that included, ChatGPT based on GPT-5.2, Knowledge cutoff: August 2025.
- Advertising on Discord: A user shared a LinkedIn-esque canned pitch of AI Automation engineering services and was quickly derided for not understanding the concept of time
- One quipped a response I’m looking for a developer who can’t post on discord in correct places. I’m offering $500/hr if you’re eligible.
- Bruh Polluting Internet With Scams Since 2015: A user who complained about OpenRouter’s pricing was quickly attacked and accused of posting crypto scams and ‘slop’ since 2015.
- Another user also linked the user’s YouTube channel, adding that “There is 0 chance you are not using LLMs to anything then post cryptoslop in your X or catfish eu/us users”.
OpenRouter ▷ #new-models (1 messages):
Readybot.io: OpenRouter - New Models
OpenRouter ▷ #discussion (18 messages🔥):
Claude Code Integration, Gemini model turn preservation, OpenRouter API Errors, Discord Moderation Requests
- Gemini Thought Signature Errors Plague Users: Users reported receiving API 400 errors related to invalid Thought signatures when using Claude code integration with Gemini models, as documented in the Google Vertex AI docs.
- Call for Stricter Discord Moderation Echoes: Members voiced concerns about borderline scammy or self-promotional content, advocating for stricter moderation or basic classifications to curb continuous spamming.
- In response to the issues raised, there were calls for a specific member, KP, to be instated as a moderator, supported by multiple users through direct endorsements and humorous suggestions.
Nous Research AI ▷ #announcements (1 messages):
Distro, Psyche, ICML, Nous Research
- Distro & Psyche Paper Accepted at ICML: The official paper that built Distro and is the backbone of Psyche has been accepted into ICML, one of the most prestigious AI/ML conferences in the world!
- Check out the official announcement from Nous Research.
- Nous Research Celebrates ICML Acceptance: Nous Research announced that the paper behind Distro and Psyche was accepted into the esteemed ICML conference.
- The announcement was made via X.com, marking a significant achievement for the team.
Nous Research AI ▷ #general (127 messages🔥🔥):
RAG DB RDMA, Pinecone precise work, Vector DB tradeoffs, Claude Opus C compiler, Hermes LLM Bittensor Subnet
- RAG DB Upgrades with RDMA: A member suggested that for optimal performance, RAG DBs should use RDMA to drop results onto the second GPU on a server.
- They emphasized that this approach is more about enhanced capabilities than simply more performance.
- Pinecone struggles with precise use cases: The discussion questioned whether Pinecone is suitable for precise work, highlighting that its strengths lie in generic situations where it outperforms PostgreSQL in results, though not in speed.
- Another member noted that it might be slow, reporting that Pinecone had easily 100x the latency of SOTA last they checked.
- Tradeoff Triangle appears between Feature Support, Portability, Performance: A member proposed a tradeoff triangle between feature support, portability, and performance, suggesting that users can only pick two.
- Countering this, another member argued that some software is simply bad or not yet far enough evolved, disputing the existence of a generic triangle.
- Claims of Claude Opus Building C-Compiler Debunked: A member referenced hype on LinkedIn about Claude Opus writing a C-compiler, then quickly linked to a GitHub issue revealing flaws and limitations.
- Despite this, another member shared positive experiences using Opus 4.6 to interactively create a complex research report, praising its coherence and capabilities, though also noting its high token usage.
- Hermes 4 miner discovered on Bittensor Subnet: A team from the Hermes Bittensor Subnet (SN82) contacted the Nous Research team after discovering a miner using their Hermes 4 LLM.
- They inquired whether this miner was officially associated with the Nous Research team, as they planned to tweet about the fun coincidence of both having the same name.
Nous Research AI ▷ #ask-about-llms (2 messages):
Hermes 4, Context Rot, LLM Context Length
- Hermes 4 Shines as Favorite LLM: A member expressed their preference for Hermes 4 (specifically the 70B parameter version) as their favorite local LLM to date.
- They didn’t give any specific information on the strengths of Hermes 4, other than that it’s their current favorite.
- Context Length Limits to combat Rot: A member mentioned a paper on context rot and stated they keep the context length of their local models at a maximum of 50k, ideally less, to avoid performance degradation.
- They said they saw performance dropping off most severely after 20k in the paper, which seems to match others’ experiences.
Nous Research AI ▷ #research-papers (3 messages):
Two-tier performance pattern, Synthetic dataset
- Two-Tier Trials Teased: A member inquired about thoughts on the two-tier performance pattern.
- Another member responded they are running more experiments with a larger synthetic dataset to better understand it.
- Synthetic Data Surge: Experiments are underway using a larger synthetic dataset to investigate the two-tier performance pattern.
- The aim is to achieve a clearer distinction and understanding of the performance characteristics.
Nous Research AI ▷ #research-papers (3 messages):
Two-tier performance pattern, Synthetic dataset experiments
- Experiments with Synthetic Data Launch: A member is running experiments using a larger synthetic dataset to better distinguish the two-tier performance pattern.
- The member does not have a good explanation yet, but is hoping the experiments will provide more clarity.
- Two-Tier Pattern Talk: Members have expressed interest in discussing the two-tier performance pattern and are awaiting further details from ongoing experiments.
- The discussion underscores the community’s focus on understanding and optimizing complex performance dynamics.
Moonshot AI (Kimi K-2) ▷ #general-chat (100 messages🔥🔥):
K2.5 release, Ghidra as MCP, Kimi Code response time, Kimi thinking, Kimi login
- K2.5 Welcomes New Users: The release of K2.5 has led to a large influx of new users to the platform.
- Ghidra Fails as Kimi Code MCP: A user attempted to add Ghidra as an MCP (Modular Component Platform) on Kimi Code, but encountered issues with Kimi accessing it.
- Kimi’s Thinking Interrupted, Login Issues Plague Users: Users reported issues with Kimi’s thinking process and login problems, prompting a fix by the team; the team is currently fixing it. The status update can be found on twitter.
- Quota Issues Plague Kimi Users, Consumption Explodes: Users reported quota issues on Kimi, including rapid consumption and discrepancies in displayed usage, with one user noting their usage exploded despite not using the platform and another reporting their quota was exceeded but usage was at 0%.
- Subscription Snags and Pricing Puzzles for Kimi Users: Users reported issues with subscription pricing, including concerns about the Moderato plan’s quota and a discount not being applied after checkout.
- The current promotion offers 3x the quota, but ends Feb 28th.
DSPy ▷ #show-and-tell (2 messages):
RLM Custom Tools, Claude Code Integration, Subagents/Agents Team, RLM Improvements, Pair Review Feedback
- Users Gain Clarity on RLM Custom Tools: One user expressed that they had a hard time understanding how to pass custom tools to RLM and were thankful for clarifying examples.
- Another user, who provided the examples, mentioned they are working on improving the quality and efficiency of the RLM integration.
- Claude Code Integration via Subagents: A member is working on seamlessly integrating RLM into Claude code through subagents/agents teams.
- They acknowledged that while these teams may not always be superior, they can still be useful for certain applications.
- Seeking Pair Review on RLM Core Implementation: A member is seeking negative feedback to improve the core implementation of their RLM project.
- They emphasized they are not seeking contributions or stars, but genuinely interested in constructive criticism to improve the project, and open to pair review.
DSPy ▷ #general (68 messages🔥🔥):
RLM vs ReAct, Tool Calling with RLMs, JSONAdapter vs ChatAdapter, Dialectic DSPy Module, Kaggle Competitions with DSPy
- RLM Struggles in Custom Tool Calling: Members are finding that the ReAct module works much better than RLM for custom tool calling, with one member stating that they are not having great luck with RLMs for custom tool calling.
- Another member linked to their attempt to explain RLM to a wider audience and requested further help with understanding its use beyond summarization.
- React vs. RLM Write Up: A member shared a link (React vs. RLM) comparing React and RLM implementations, resulting in positive feedback.
- The discussion highlighted that RLMs are valuable for tasks involving large, pairwise comparisons, or very long context that builds up during the task, while ReAct is suitable for tasks that don’t need that, or compositional tool calling.
- JSONAdapter issue with Kimi 2.5: One member reported receiving a square bracket in front of each Prediction when using Kimi 2.5 and the cleaned query came out to be
]improve drones.- Another member suggested using the XMLAdaptor with Kimi, as it matches the formatting used during post-training, and reported JSONAdapter is usually fine.
- Dialectic DSPy Module in the works: There was a suggestion to create a new DSPy module for dialectic.dspy, which would implement an iterative non-linear method using signatures for each step.
- However, a member advised to write the module before deciding if its something that’s worth upstreaming, and to ensure the core loop works properly without optimizers.
- Prompt optimization for Kaggle competition: One member inquired about using DSPy for Kaggle competitions and optimizing prompts to generate faster code using MiPROv2.
- Another member recommended using GEPA instead of MiPROv2, while another member was having Claude hillclimb its own memory system.
GPU MODE ▷ #general (8 messages🔥):
NPU engineer curriculum, AlphaMoE extension with new DTypes, CUTLASS vs Triton vs Gluon, UI/UX to motivate expertise contribution
- Clarify NPU engineer curriculum: For NPU engineers interested in model optimization and compilers, the first 6 GPU Mode lectures plus some scan and reduce exercises are sufficient, along with Tianqi Chen’s series on his website.
- Additionally, the Scale-ML series on GPU MODE offers a theoretical introduction to quantisation and Prof. Song Han’s series provides further insights on the topic.
- AlphaMoE aims for DType extension and Blackwell Support: The author of AlphaMoE is planning to extend it by adding more DTypes (BF16, FP4) and Blackwell support, and is currently using plain CUDA + inline PTX.
- However, they are considering alternatives like CUTLASS/Triton/Gluon/cuTile due to the potential need for new kernels for each DType/architecture and the challenge of maintaining different dtypes.
- Tradeoffs when choosing CUTLASS, Triton or Gluon: A member discussed the tradeoffs between using CUDA and other DSLs like CUTLASS, Triton, or Gluon for hardware adoption.
- The user considers that “no effort hardware adoption is a big lie and you just have to rewrite it for new hardware” and wonders if it’s worth rewriting in a DSL given the lack of a ‘one size fits all’ kernel solution.
- UI/UX should motivate expertise contribution: It was suggested that UI/UX should be designed to motivate individuals to contribute their expertise to code.
- The suggestion mentioned that top coders should be rewarded for documenting why they made specific decisions, adding
// @expertise: I did this because...comments.
- The suggestion mentioned that top coders should be rewarded for documenting why they made specific decisions, adding
GPU MODE ▷ #cuda (7 messages):
mbarrier tokens in smem, NVIDIA/cccl PR, shared memory alignment issues in nvcc
- Debate on mbarrier tokens in smem rages: A member inquired whether tokens should reside in shared memory (smem) when using tokens with mbarrier, sparking a discussion.
- Another member clarified that there is no requirement for them to be in smem, adding they wouldn’t put them in smem as they can’t think of a reason to do so.
- Deep Dive into NVIDIA’s cccl PR: A member shared a link to a pull request on the NVIDIA/cccl repository, deeming it an interesting read.
- The conversation shifted to a specific concern regarding shared memory alignment not being consistently respected by nvcc, especially when compiling with the -G flag.
- Shared Memory Alignment Issues in nvcc Surface: A member referenced their past experience, suggesting that the shared memory alignment issue in nvcc might have been the root cause of their problem.
- They cited a comment from the PR: We could use an attribute to align the shared memory. This is unfortunately not respected by nvcc in all cases and fails for example when compiling with -G.
GPU MODE ▷ #cool-links (1 messages):
2kian: nice!
GPU MODE ▷ #job-postings (1 messages):
Nubank AI team, Nubank hiring, CUDA Experts
- Nubank AI Team Boasts Top Researchers!: The Nubank AI team, part of the rapidly growing neobank with an 85B+ market cap, includes top researchers with publications at ICML, NeurIPS, ICLR, KDD, WebConf, and CIKM.
- Their most recent paper is available on arXiv, and one of the authors of Liger Kernel recently joined the team.
- Nubank Seeks CUDA/Kernel Optimization Experts!: Nubank is actively hiring CUDA/kernel optimization experts in both Brazil and the US to work on foundation models trained on B200s.
- The roles focus on efficiency improvements, metric parity guarantees, and infra reliability throughout the research-to-production lifecycle; interested candidates can email [email protected].
GPU MODE ▷ #beginner (5 messages):
5090 Issues, Flash Attention 2, GPU programming resources, Programming Massively Parallel Processors, flash inference competition
- 5090 has Flash Attention 2 issues: A member reported encountering issues with Flash Attention 2 while running a model on a 5090.
- GPU Programming Resource: A member suggested using gpu-mode/resource-stream on GitHub as a starting point for GPU programming.
- They also recommended the book Programming Massively Parallel Processors: A Hands-on Approach.
- Flash Inference Competition sparks interest: A member expressed surprise at the depth of the field while expressing desire to compete in the flash inference competition.
GPU MODE ▷ #irl-meetup (2 messages):
Boston area AI groups, CEX AI Founders event in NYC
- Bostonians seek local AI Groups: A member inquired about AI-related hackathons, coworking spaces, or similar groups in the Boston area.
- CEX hosts AI event in NYC: CEX is hosting an event in NYC for AI founders and infra leaders to discuss GPU procurement at scale, register here.
GPU MODE ▷ #lecture-qa (1 messages):
puggykk: hello
GPU MODE ▷ #popcorn (4 messages):
Software Dependency, Contributions Guidance, Model Competition Platform, Reference Architecture for GPU RL
- Software Dependency Gets Upended: A member shared a thought-provoking tweet from mike_64t, expressing the feeling that the whole concept of software dependency is getting upended.
- Members Offer Contributions Guidance: A member offered guidance for contributions, advising others to reach out for assistance in public channels so that others can also benefit from the information.
- End-to-End Model Competition Platform Design Prioritized: The meeting minutes from February 10th indicate a key priority is designing an end-to-end model competition platform (meeting minutes).
- Reference Architecture for GPU RL Environments on the Horizon: Another key priority is creating a reference architecture for GPU RL environments to ship them all behind the same interface.
GPU MODE ▷ #thunderkittens (1 messages):
eyeamansh: any thoughts on good first issues / low hanging fruit to contribute?
GPU MODE ▷ #hardware (2 messages):
Minecraft CPU Bottleneck, Minecraft Single-Threaded Issues
- Minecraft Faces CPU Bottleneck?: A user suspects Minecraft experiences a CPU bottleneck due to its extensive simulations, suggesting it utilizes both CPU and GPU resources.
- Minecraft’s Threading Model in Question: The user also inquired if Minecraft still operates on a single-threaded architecture, questioning whether Mojang has addressed this limitation.
GPU MODE ▷ #tpu (2 messages):
JAX pull requests, Contributing to JAX
- Potential JAX PR Talk: A member suggested creating a pull request (PR) to the JAX repository.
- The conversation was brief with no details of the proposed changes.
- JAX Contributions Encouraged: Members briefly mentioned the idea of contributing to the JAX project.
- The discussion highlighted the potential for community involvement in improving the library.
GPU MODE ▷ #factorio-learning-env (1 messages):
Open Source, Setup Assistance, Community Support
- Open Source Project Confirmed & Support Offered: A member confirmed that their project is open source and encouraged users to reach out.
- They admitted that they are less active now, but encourage users to ping them with setup issues.
- Community Assistance Availability: The project lead offered direct support for users encountering setup problems.
- This indicates a willingness to help new users get started with the open-source project, despite their current reduced activity.
GPU MODE ▷ #teenygrad (3 messages):
Milk-V Pioneer Access, Tenstorrent Atlantis Board, RISC-V Architecture Concepts, LAFF and Goto's Matrix Multiply, Vortex GPU
- Milk-V Pioneer requests get queued up!: A member submitted a request to cloud-v.co for Milk-V Pioneer access, which features 64 cores and RVV support.
- He intends to program the GEMM against Milk-V’s DRAM roofline to evaluate performance.
- Tenstorrent Atlantis board delayed indefinitely!: The Tenstorrent ascalon-based Atlantis development board is now expected to ship by the end of Q2/Q3.
- This delay will influence the development timeline for related projects.
- RISC-V cores for education, or just ‘sodor’?: The discussion will introduce architecture concepts using RISC-V and educational cores from Berkeley, such as Sodor, Boom Core, or Ocelot (which supports RVV).
- He will ultimately show what kind of performance can be achieved from Xeon/Epyc machines on AWS, transitioning examples once RVA23 base machines are available.
- LAFF You Up: A Matrix Multiply Primer: A member is exploring LAFF-On-PfHP.html from van de Geijn, describing it as a noob version of the Goto paper Anatomy of High-Performance Matrix Multiply.
- The FLAME lab’s wiki provides cliff notes on optimizing the dot product microkernel first.
- Vortex GPU core explored, future computer architects found!: A member mentioned the RISC-V Vortex GPU and a Berkeley final project for compilers which modifies its instruction set.
- Part 2 may introduce GPUs using Vortex, for any readers who will become computer architects.
GPU MODE ▷ #nvidia-competition (13 messages🔥):
Kernel Results, Login Issues, LOC Loading
- Kernel Results’ Availability: A member inquired about the availability of old kernel results, mentioning they couldn’t find them on the site anymore.
- Another member clarified that the results are still there and asked if the user was logged in.
- Login Screen Greyed Out: A member reported that the login screen was greyed out and prompting for a new login despite trying to log in and out.
- This issue seems to be tied to the loading of LOC (Likelihood of Confusion) on the page, as one member suggested waiting until LOC appears before logging in.
- LOC Loading Affects Login: Members discussed how the login screen issue occurs when LOC hasn’t appeared yet, indicating a dependency or loading sequence issue on the site.
- A screenshot was shared showing the greyed-out login screen, highlighting the problem.
GPU MODE ▷ #flashinfer (15 messages🔥):
HF Dataset Updates, MLSys Registration Credits, Adding Team Members, Modifying Registration Forms, Participation in a Subset of Tracks
- Registration Credits Stalled: A participant who submitted a registration on January 29 reported not receiving credits yet.
- Participants are instructed to contact [email protected] for team and registration updates.
- Subset Track Participation Clarified: A participant asked if they could choose to participate in only a subset of tracks during report and code submission, even after selecting multiple tracks during registration.
- Another participant confirmed that it is possible to participate in a subset of tracks.
- Baseline Release Pushed Back: The baseline release has been delayed and is now scheduled for February 10.
- Team Constraints Investigated: One participant asked for clarification if one team can only participate in either of the following : Track A, Track B or Track C.
- The participant also seeks elaboration on expert-crafted seed kernels with agent-assisted evolution and fully-agent generated solutions which are evaluated separately.
Eleuther ▷ #general (54 messages🔥):
LLM Training, AI Governance App, ChatGPT and AI Research, Banned Users Returning, Claude's Coding Abilities
- Venturing into LLM Layer Creation: A member inquired about the best way to begin training/experimenting with LLM architecture and layer creation, and was recommended this YouTube playlist for an engineering perspective.
- AI Governance App Seeking Testers: A member sought testers for an AI governance app but their post was initially removed until they clarified it was not simply a chatbot interaction but a runtime execution and governance system evaluated using llms as components.
- Does Talking with ChatGPT Qualify as AI Research?: A discussion arose around the statement that talking with ChatGPT is not AI research, with arguments that AI should be used as a tool in research and not just a discussion partner.
- Banned User Returns with VPN: A member was identified as a ban evader who had returned using a VPN after being banned from off topic discussions.
- Claude: A Budding Triton Kernel Coder: Members mentioned that Claude has become proficient enough to potentially write some Triton kernels, a development considered a game changer for many.
Eleuther ▷ #research (6 messages):
Generative Latent Prior, Prompt Response Datasets, Self-Referential Processing in Open-Weight Models
- Generative Latent Prior Enables On-Manifold Steering: A member shared a link to the Generative Latent Prior project page, highlighting its ability to enable applications like on-manifold steering.
- The technique allows perturbed activations to be mapped into something more in-distribution for the LLM, as described in this tweet.
- Prompt Response Data Sets Sought: A member asked for recommendations on good prompt response datasets for training a model.
- Another member suggested searching for instruction format or chat format datasets.
- Models Invent Vocabulary via Self-Referential Processing: A member shared their paper on self-referential processing in open-weight models (Llama 3.1 + Qwen 2.5-32B).
- The study found that models invent vocabulary during extended self-examination that tracks real activation dynamics (e.g., “loop” autocorrelation r=0.44; “mirror” spectral power r=0.62), as described in this paper.
Eleuther ▷ #multimodal-general (1 messages):
Multimodal/VLM Model Communities
- Exploring VLM Community Channels: A member is seeking recommendations for active communities or channels, besides this Discord, that focus on multimodal/VLM models and offer opportunities for active participation.
- VLM Engagement Interest Highlighted: They expressed interest in engaging with communities actively working on VLM models.
Eleuther ▷ #gpt-neox-dev (3 messages):
NeoX eval script issues, pipe_parallel_size issues, Microbatch storage in eval script
- NeoX Evals Script Needs Fix for
pipe_parallel_size 0: A member reported that the NeoX eval script runs well for models trained withpipe_parallel_size 1, but encounters errors with models trained withpipe_parallel_size 0.- The reported issue is on this line of code where microbatches are stored to set it back later; the user questioned why this is needed.
- Inconsistent Forward Pass with
pipe_parallel_size 0: After fixing some attribute issues, a member encountered failures in the forward pass when usingpipe_parallel_size 0.- The failure was attributed to a difference in the number of elements returned during the forward pass, indicating potential compatibility problems with the evaluation script.
HuggingFace ▷ #general (38 messages🔥):
New HuggingFace Users, Certificate Course, TRELLIS.2, LiveTalking, QLoRa fine-tuning
- New HuggingFace Users Arrive: Several new users joined Hugging Face and expressed their excitement to get started with Agentic AI and explore new technologies.
- One user doing the certificate course asked where to find this channel, and was linked to all courses/learn channels.
- Microsoft TRELLIS.2 Repo Link: A user shared a link to Microsoft’s TRELLIS.2 repository, suggesting it could be used if one has enough hardware.
- Discussion on the Merits of QLoRa Fine-Tuning: A member asked if others have gotten good results with QLoRa fine-tuning, or if using bf16 is more worthwhile.
- This sparked a brief discussion regarding fine-tuning approaches and efficiency.
- Z.ai is Killin’ It: A user shared a link to Z.ai’s X post, commenting that Z.ai is killing it.
- UnslothAI speeds up MoE models Training locally: A member announced their collaboration with Hugging Face to enable users to train MoE models much faster locally, linking to UnslothAI’s X post.
- Another member celebrated Unsloth’s work, with a link to the company’s write up on the new approach.
HuggingFace ▷ #i-made-this (26 messages🔥):
Hallucination detection models, LLM design flaws and RLHF, AI music generation in Discord, Fast micro-batching for LLMs, Emotional inertia for AI characters
- Hallucination Detection Model is an oldie but a goodie: A member shared their Hallucination Test tool created some years ago, expressing interest in creating a better benchmark together.
- The tool was initially built with a Vectara model, and it highlights the need for improved benchmarks in the field.
- LLMs Punished for Saying I Don’t Know: One member argued that LLMs are conditioned during RLHF to avoid saying “I don’t know”, leading to a design flaw.
- He suggested a philosophy where models have the choice to use real data, incentivizing them to stop hallucinating.
- TryMelo brings AI Music to Discord: TryMelo is an AI music generation platform with a Discord bot that allows members to generate music for free directly within Discord voice channels.
- It offers features like random autoplay and requires no special permissions, but the bot invite was against channel guidelines.
- LLM-Autobatch tool provides fast micro-batches: llm-autobatch is a minimal tool to turn single LLM requests into fast micro-batches.
- Built with a Rust core and Python API, it aims to keep things simple.
- Chordia gives AI Characters Emotional Inertia: A member introduced Chordia, a lightweight MLP kernel designed to give AI characters emotional inertia and physiological-like responses.
- Chordia predicts emotional transitions in less than 1ms and is tuned to maintain character consistency.
Modular (Mojo 🔥) ▷ #general (4 messages):
Modular Docs, Mojo reflection docs
- Modular Docs Reflection Link SNAFU: A member reported a “page not found” error when accessing the reflection documentation link https://docs.modular.com/manual/reflection/ shared in the latest community video.
- Another member clarified the correct link is https://docs.modular.com/mojo/manual/reflection .
- Updated Mojo Reflection Docs URL: The originally shared documentation link for Mojo reflection was incorrect, leading to a “page not found” error.
- The corrected and functional link is https://docs.modular.com/mojo/manual/reflection, providing access to the Mojo reflection documentation.
Modular (Mojo 🔥) ▷ #announcements (1 messages):
Modular acquires BentoML, BentoML Open Source Commitment, Ask Us Anything session with Chris Lattner and Chaoyu Yang
- Modular Acquires BentoML for AI Production!: Modular has acquired BentoML, integrating its cloud deployment platform with MAX and Mojo to optimize hardware.
- This acquisition aims to enable users to code once and run on NVIDIA, AMD, or next-gen accelerators without rebuilding, streamlining optimization and serving in a unified workflow.
- BentoML Doubles Down on Open Source: BentoML will remain open source (Apache 2.0), and Modular is doubling down on its open source commitment with future enhancements planned for later this year.
- Lattner and Yang Host ‘Ask Us Anything’ Session: Chris Lattner and BentoML Founder Chaoyu Yang will host an Ask Us Anything session in the Modular Forum on September 16th to discuss the acquisition and future plans.
Modular (Mojo 🔥) ▷ #mojo (24 messages🔥):
Movable but not Defaultable types in Mojo, Variadic parameters on a Trait limitation, Dynamic size 2D matrices with static size 4D tensor in Mojo, LayoutTensors element access manipulation, LayoutTensor's slice_1d
- Crafting Movable, Non-Defaultable Types in Mojo: To create a type that is Movable but not Defaultable in Mojo, a member suggested defining a struct with a Movable type parameter, ensuring that the struct requires initialization with a value upon creation as described in this snippet.
- Variadic Parameter Limitation Frustrates Trait Usage: A developer encountered a compiler crash (issue on modular) when attempting to use variadic parameters on a Trait, highlighting Mojo’s current limitation that variadic parameters must be homogeneous (all values of the same type).
- Matrix Construction with LayoutTensors: A member sought guidance on constructing a 2D matrix with dynamic size consisting of 2D matrices with static size (4D tensor) using Layout in Mojo.
- Decoding LayoutTensor Element Access Dynamics: A user investigated element access and manipulation within LayoutTensors, particularly in a 4D context, exploring performance implications when storing individual elements versus retrieving vectors or slices, noting that element_layout determines the width of the SIMD returned.
- Unveiling Discrepancies in LayoutTensor’s Slice_1d Behavior: A user investigated the behavior of
slice_1din LayoutTensor, noting unexpected pointer behavior when slicing along different axes, contrary to the documentation (docs), suggesting a potential bug or misunderstanding in how the slicing operation affects the underlying data pointer.
Modular (Mojo 🔥) ▷ #max (4 messages):
LayoutTensor V2, Mojo Tensor Primitives
- LayoutTensor “V2” in the Works: A member announced a “v2” of LayoutTensor is being prototyped in the kernels, with more details to come after API finalization and naming discussions.
- This update suggests ongoing development and refinement of tensor manipulation capabilities within the Mojo ecosystem.
- LayoutTensor is a structured view into unowned memory: A member clarified that LayoutTensor is a structured view into unowned memory and a general-purpose tensor view.
- The team anticipates needing both an owning and unowning type of tensor, applicable across various processors (CPU/xPU).
Yannick Kilcher ▷ #general (9 messages🔥):
TDD, Agentic SDLCs, Adversarial Cooperation, MCP/skill open source, complaint-generator
- TDD Use is confirmed by Big Tech: A user inquired about ‘big tech’ using TDD for their agentic SDLCs, and a member confirmed this is true and has been known for 70 years to turn probabilistic logics to deterministic ones using feedback loops.
- Links were shared related to adversarial cooperation.
- Combine TDD with Adversarial Cooperation: A member suggested combining TDD with adversarial cooperation.
- In response a link to a complaint generator was shared as an example: complaint-generator.
- MCP/skill Open Source Alternatives: A user inquired about open source alternatives to MCP/skill, mentioning it costs money.
- They also shared a link to a related reddit thread: I built an MCP server that lets Claude execute.
Yannick Kilcher ▷ #ml-news (4 messages):
ChatGPT Ads, Demo video mistakes
- Testing Ads Inside ChatGPT: OpenAI is testing ads in ChatGPT according to their blog post, and announced it on Twitter.
- Spot the Errors!: A member shared a YouTube video and asked if anyone has checked for mistakes in the tables presented in the demo video.
tinygrad (George Hotz) ▷ #general (8 messages🔥):
CPU LLaMA bounty challenges, Tinygrad changes for bounty, RK3588 NPU backend bounty
- CPU LLaMA Bounty Proves Difficult: A member shared that the CPU LLaMA bounty was difficult due to issues with loop ordering, memory access patterns, and devectorization and that heuristics alone didn’t yield good SIMD and clean instructions.
- Tips for Claiming Tinygrad Bounty: George Hotz strongly encouraged changes to Tinygrad to be upstreamed to claim the bounty, suggesting techniques like better sort, better dtype unpacking, better fusion, and contiguous memory arrangement.
- He noted that while a large number of hand-coded kernels would not be upstreamed, something similar to his work for embedded systems might be.
- RK3588 NPU Backend Bounty Still Open: A member expressed interest in the RK3588 NPU backend bounty, noting extensive tracing of Rockchip’s model compiler/converter and runtime but struggling with a clean Tinygrad integration.
- He suggested one path might be to turn rangeified + tiled UOps back up into matmuls and convolutions.
- George Hotz suggests implementing a slow RK3588 backend: George Hotz suggested implementing a slow backend first without matmul acceleration and subclassing
ops_dsp.pyas an example, but letting things fall through to the default behavior. - PR Review Times are Proportional: The time to review a PR is proportional to the PR size and inversely proportional to the value of the PR.
Manus.im Discord ▷ #general (8 messages🔥):
Manus AI Models, AI Full-Stack Systems, Search Feature Troubles, Devs wanted
- Inquiring about Manus AI Models: A member is asking what AI models are used by Manus, suggesting that the service seems basic for the subscription price.
- They inquire whether hosting a calwdbot in a VPS with advanced model APIs would be cheaper and safer.
- AI and Full-Stack Systems Showcased: A member introduces their services in building AI and full-stack systems focusing on real-world problem-solving and delivering value.
- They list expertise including LLM integration, RAG pipelines, AI content moderation, image/voice AI, and bot development, alongside full-stack development skills.
- Search Feature faces user Issues: A member reports issues with the search feature not locating words in past chats.
- No resolution or further discussion is provided in the messages.
- Devs Requested: A member inquired whether anyone is looking for a dev.
- No resolution or further discussion is provided in the messages.