Mistral back in open models land!
AI News for 7/14/2025-7/15/2025. We checked 9 subreddits, 449 Twitters and 29 Discords (226 channels, and 5884 messages) for you. Estimated reading time saved (at 200wpm): 486 minutes. Our new website is now up with full metadata search and beautiful vibe coded presentation of all past issues. See https://news.smol.ai/ for the full news breakdowns and give us feedback on @smol_ai!
While Mira’s $2b Thinking Machines fundraise was relatively well telegraphed, Mistral came from out of nowhere to drop Voxtral, their new transcription model that “comprehensively outperforms Whisper large-v3” and “beats GPT-4o mini Transcribe and Gemini 2.5 Flash across all tasks”:
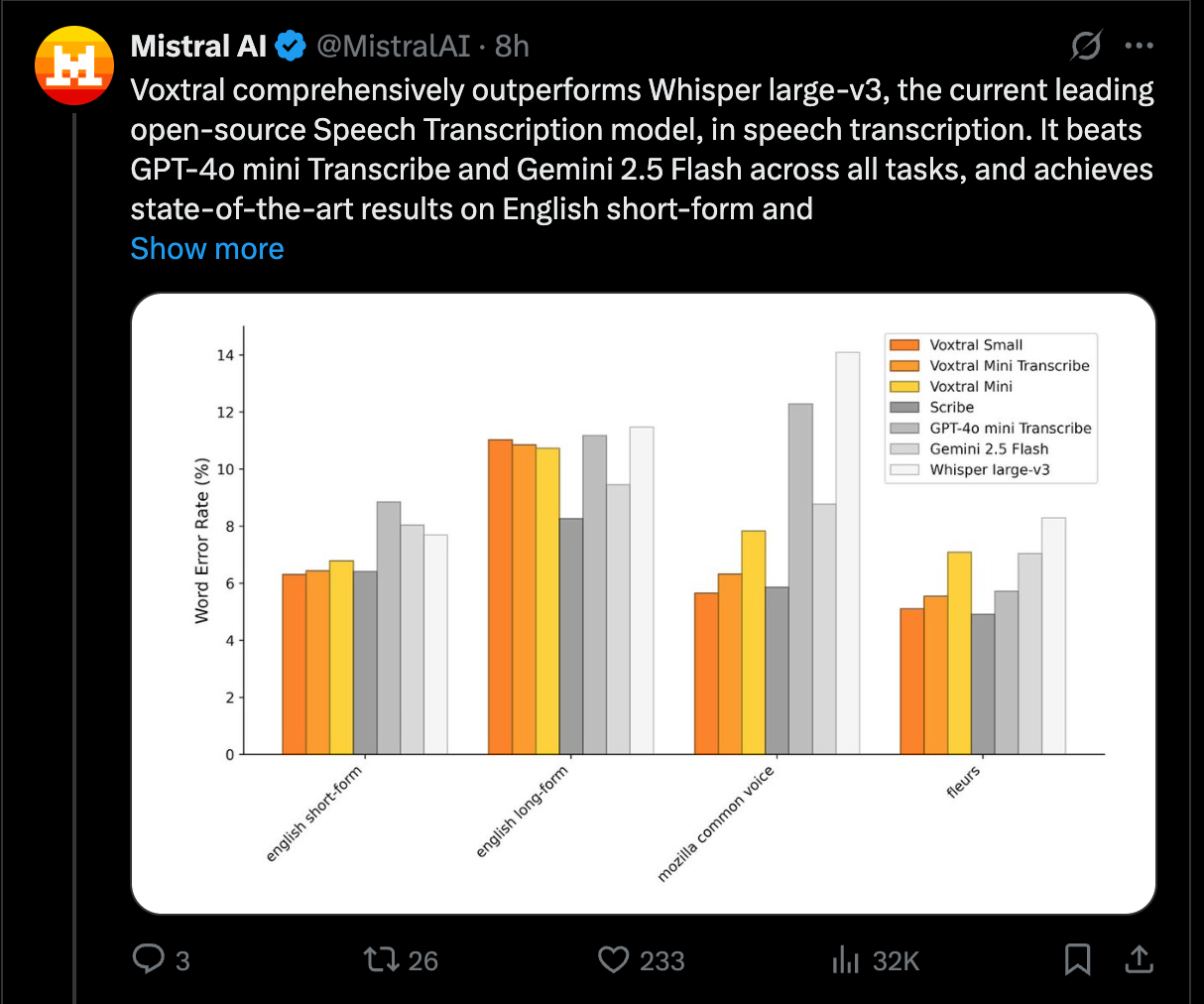
We love a good no-qualifications necessary beating, and even better when it is an open model.
Both Voxtral 3B and Voxtral 24B models go beyond transcription with capabilities that include:
- Long context: with a 32k token context length, Voxtral handles audios up to 30 minutes for transcription, or 40 minutes for understanding
- Built-in Q&A and summarization: Supports asking questions directly about the audio content or generating structured summaries, without the need to chain separate ASR and language models
- Natively multilingual: Automatic language detection and state-of-the-art performance in the world’s most widely used languages (English, Spanish, French, Portuguese, Hindi, German, Dutch, Italian, to name a few), helping teams serve global audiences with a single system
- Function-calling straight from voice: Enables direct triggering of backend functions, workflows, or API calls based on spoken user intents, turning voice interactions into actionable system commands without intermediate parsing steps.
- Highly capable at text: Retains the text understanding capabilities of its language model backbone, Mistral Small 3.1
Very exciting. We skipped reporting on their Magistral reasoning model (which turned out to have an EXCELLENT paper) but we’re pretty sure Voxtral will be in production almost immediately…
AI Twitter Recap
Kimi K2’s Emergence and Performance
- Kimi K2, a non-reasoning MoE, challenges Western models: The release of Kimi K2 from Moonshot AI has sparked significant discussion, particularly around its performance and origins. @teortaxesTex notes that Kimi was built by a team of around 200 people with a modest GPU budget, questioning why Western companies haven’t produced something comparable. @jeremyphoward emphasizes that K2 is “not a reasoning model” and uses very few active tokens in its Mixture of Experts (MoE) architecture, making it cheaper and faster. Community members are praising its capabilities, with @scaling01 highlighting its excellent report generation and @zacharynado calling it “the leading open weights non-reasoning model.”
- Blazing-fast inference on Groq and broad platform availability: A key highlight is Kimi K2’s performance on Groq’s hardware. @teortaxesTex reports speeds of 185 t/s, suggesting this makes K2 “immediately more compelling than Sonnet 4” and an impressive feat to fit a 1T parameter model on their chips. Groq officially announced the model in preview, with @JonathanRoss321 showing a video of its speed. The model is also available on Together AI (here and here), DeepInfra (at $0.55/$2.20), and can be run locally on a single M4 Max 128GB Mac, as pointed out by @reach_vb.
- Tool integration and developer resources: Kimi K2 has seen rapid integration into developer tools. Moonshot AI announced bug fixes for its Hugging Face repo to improve multi-turn tool calls. LangChain announced official support for the model on Groq (here and here), and Cline has added Moonshot AI as a provider. Users are demonstrating its strong tool use capabilities, with @yawnxyz showing a Chrome extension that chats with Google Maps.
New Models: Speech, Motion Capture, and AI Companions
- Mistral releases open-source speech model, Voxtral: Mistral AI has released Voxtral, which @GuillaumeLample claims are the “world’s best (and open) speech recognition models.” @reach_vb is excited by the release, noting that a major pain point for audioLMs has been that they often lose text capabilities, but Voxtral appears to avoid this issue. The models are available via API, Le Chat, and Hugging Face. @teortaxesTex believes this release will “reinvigorate the transcription app market”.
- xAI launches Grok companions and avatars: xAI has rolled out Grok avatars and companions, which quickly went viral. @chaitualuru announced the feature is “Back on top in Japan.” Various examples, including an anime girl persona named Ani, were shared by @ebbyamir, with @shaneguML noting its predictability given the market.
- Runway introduces Act-Two for advanced motion capture: RunwayML launched Act-Two, a next-generation motion capture model. @c_valenzuelab highlights its “major improvements in generation quality and support for hands.” They also shared a creative demo of renaissance vocal percussion made with the model.
- Google enhances Gemini with top-ranked embeddings and new features: Google DeepMind announced that its first Gemini Embedding model is now generally available and ranks #1 on the MTEB leaderboard. Additionally, @demishassabis shared a new Gemini feature that can turn photos into videos with sound.
- Other notable models and updates: LG’s EXAONE 4, a 32B model trained on 14T tokens, is showing near-parity with frontier models in reasoning and non-reasoning modes. Kling AI has been demonstrating its video generation capabilities, showcasing precision in handling water, light, and motion.
Tooling, Infrastructure, and Development
- Agentic coding assistants gain traction: Anthropic’s Claude Code is highlighted as a powerful tool, with @claude_code providing tips on using it as a general agent for local file system tasks. Its popularity is surging, with @kylebrussell noting that friends are upgrading to paid tiers specifically for it. Meanwhile, Perplexity is rapidly adding features to its Comet browser, including voice mode for the web and the ability to clean up email inboxes. @AravSrinivas notes the goal is to blend tools together seamlessly so the user doesn’t have to switch modes.
- Vector databases and frameworks evolve: Qdrant launched Qdrant Cloud Inference, allowing users to generate, store, and index embeddings directly in their cloud cluster. This includes support for dense, sparse, and multimodal models like CLIP. LlamaIndex and Google AI collaborated on a tutorial to build a multi-agent deep research system with Gemini 2.5 Pro, and LangChain is hosting events with partners like Redis and Tavily to showcase the emerging AI Gateway stack.
- On-device AI and specialized frameworks: Apple’s MLX framework continues to expand, with @awnihannun announcing an in-progress port to pure C++ (mlx-lm.cpp) and support for tvOS. In the mobile space, @maximelabonne unveiled LEAP, a developer platform for building apps powered by local LLMs on iOS and Android.
- Data availability and fine-tuning: @maximelabonne announced that the LFM2 model can now be fine-tuned using Axolotl. For data, @code_star retweeted an update that FineWeb and FineWeb-Edu now include CommonCrawl snapshots from January-June 2025. In a major open-source contribution, @ClementDelangue shared that 99% of US caselaw has been open-sourced on Hugging Face.
Research, Evaluation, and AI Safety
- Industry-wide push for Chain of Thought (CoT) Monitoring: A cross-institutional paper endorsed by leaders from OpenAI, Anthropic, and academia is urging labs to preserve the monitorability of AI reasoning. OpenAI stated it is backing the research to use CoT for overseeing agentic systems. Key figures like @woj_zaremba, @merettm, @NeelNanda5, and @Yoshua_Bengio have all voiced strong support, arguing that this visibility into a model’s thought process is a crucial safety gift that shouldn’t be trained away.
- “Context Rot” and the limits of long context windows: A technical report from Chroma revealed that increasing input tokens degrades LLM performance, even on simple tasks. The report, titled “Context Rot,” shows issues like a 30% accuracy drop with a 113k token conversation history. @imjaredz summarized the findings, concluding that “the million-token context window is a lie” and context should be engineered surgically.
- AI-powered security and new research directions: Google announced that its AI agent, Big Sleep, helped detect and foil an imminent exploit, marking a significant use of AI in cybersecurity. In other research, @lateinteraction highlighted a project that compiled a Rust-based ColBERT model into WebAssembly (WASM) for client-side execution. @teortaxesTex pointed to a paper on Memory Mosaics v2, which reportedly outperforms a transformer trained on 8x more tokens.
- Data contamination and evaluation paradigms: The challenge of data contamination in training was highlighted by @francoisfleuret, who suggested to “Train on math until Dec 31st 1799, validation on what follows.” This reflects a broader need for robust evaluation methods that are not susceptible to memorization.
Company Strategy and the Industry Landscape
- Meta’s superintelligence vision and the open-source debate: Mark Zuckerberg’s plan for massive AI superclusters was a major topic. Meta AI shared his vision to “deliver personal superintelligence to everyone in the world.” This move has sparked concern, with @Yuchenj_UW stating that with Meta turning into “another OpenAI,” the West may have to “rely on China to keep open source AI alive.”
- M&A activity and predictions: Cognition acquired Windsurf after a bidding war that reportedly involved Google. In a widely circulated tweet, @swyx posted a “six way parlay” of potential acquisitions, including Mistral to Apple, parts of Mistral to Meta, and **Character.ai to Perplexity**.
- New ventures and global expansion: Andrew Ng announced the launch of AI Aspire, a new advisory firm partnering with Bain & Company to help enterprises with AI strategy. Cohere is opening its first Asian office in Seoul, South Korea. A new startup, Thinking Machines Lab, revealed it’s hiring for its ambitious multimodal AI program.
- The long grind and the importance of execution: @AravSrinivas described the current AI race as a “decade long grind” where success is not guaranteed for anyone. The importance of execution and focused teams was underscored by @andrew_n_carr, who stated that they “REGULARLY labeled data by hand at oai”.
Humor, Memes, and Culture
- Relatable commentary: @stephenroller’s observation that “Millennials use ‘lol’ like STOP at the end of a telegram lol” was the most-liked tweet. @willdepue offered a new gravest insult: “you are not fundamentally curious, and for that there is no cure.”
- Industry inside jokes: A joke from @jeremyphoward captured the feeling of redundant projects: “Management: You know what the world really needs? A new vscode fork.” A meme from @dylan522p depicted the chaotic result of quantizing a model to fp4.
- Grok companion craze: The launch of xAI’s companions led to a flood of memes, with @ebbyamir retweeting a post showing a timeline dominated by the new feature.
- The developer experience: @skalskip92 posted a popular video with the caption, “when you have no idea what you’re doing, but it still works…” capturing a common sentiment in software development.
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
1. Kimi K2 Model Benchmarks, API Access, and Community Memes
- Kimi K2 tops creative writing benchmark (Score: 300, Comments: 63): The bar chart ranks various language models on a creative writing benchmark, with Kimi K2 achieving the top mean score of 8.56, demonstrating superior performance in creative writing tasks compared to leading alternatives (e.g., DeepSeek V3, Gemma 27B, Gemini 2.5 Pro). This visual comparison provides empirical evidence for Kimi K2’s current edge in model creativity benchmarks. Several commenters challenge the accuracy of the benchmark results, specifically disputing that DeepSeek V3 0324 performs worse than Gemma 27B in practical creative writing use and expressing skepticism about Kimi K2’s perceived superiority, suggesting user experiences vary significantly from benchmark outcomes.
- Multiple users compare Kimi K2, deepseek v3 0324, Gemma 27B, and Gemini 2.5 Pro specifically for creative writing tasks. One commenter claims that DeepSeek v3 0324 dramatically outperforms Gemma 27B in creative writing, suggesting personal testing shows a large quality gap, while others assert K2 is not significantly better than DeepSeek or Gemini 2.5 Pro. These comparisons speak to subjective performance perceptions across prominent open and proprietary models.
- A technically insightful comment links Kimi K2’s ability to perform well on creative writing benchmarks to its potential coding capability. The commenter argues that excelling in tasks requiring integration of diverse constraints and structured output (e.g., narrative with multiple elements) closely parallels skills needed in program synthesis and execution of complex software plans. Evidentially, they observe a correlation between benchmark results and K2’s code-generation reliability in their tests with Cline.
- Discussion branches into task-specific model performance: some find Kimi K2 less coherent and interesting for role-play, suggesting it struggles with maintaining context and narrative engagement in multi-turn or conversational formats compared to other models. The nuances of each model’s strengths seem to depend on the precise creative writing task (story structure, RP, constraint following, etc.).
- Kimi K2: cheap and fast API access for those who can’t run locally (Score: 146, Comments: 64): The post highlights newly available API endpoints for accessing the open weights Kimi-K2 model (moonshotai/Kimi-K2-Instruct), noting that DeepInfra offers the lowest API pricing (
$0.55/$2.20in/out million tokens), while Groq provides the highest inference speed (∼250 tokens/sec, albeit at a higher cost). The author that API access for Kimi-K2 is cheaper than closed models like Claude Haiku 3.5, GPT-4.1, and Gemini 2.5 Pro, emphasizing the value of permissive open-weight models and listing all providers on OpenRouter; a free variant is also mentioned. See DeepInfra pricing and Groq docs for details. Top comments raise: (1) whether it’s preferable to use the official Moonshot API—which offers even lower rates ($0.15/2.5M tokens); (2) noting Kimi-K2’s Anthropic-compatible API endpoints for Claude Code interfacing by setting specific environment variables, offering a cost-effective (if slower) Claude-compatible inference; and (3) skepticism about “local” access due to high hardware requirements for most users.- One commenter highlights the advantage of Kimi K2’s Anthropic-compatible API, enabling users to easily redirect clients such as Claude Code by setting
ANTHROPIC_AUTH_TOKENandANTHROPIC_BASE_URLto point to Moonshot’s endpoints. This approach is noted as “slow but much much cheaper” than official Anthropic access, making it a cost-effective solution for developers needing compatibility and affordability. - There’s clarification around the free tier: Kimi K2 offers up to 500k tokens per day for free use, which is a substantial allowance. However, it’s unclear if Kimi K2 supports advanced features such as context caching, which could impact performance or cost-effectiveness for certain high-throughput or context-sensitive tasks.
- The main HuggingFace repo for Kimi-K2 (https://huggingface.co/moonshotai/Kimi-K2-Instruct) is referenced, and a comment underscores the reality that nearly all users (“99.9%”) lack the hardware for local inference on large models, solidifying the demand for inexpensive, accessible API endpoints as opposed to local deployment.
- One commenter highlights the advantage of Kimi K2’s Anthropic-compatible API, enabling users to easily redirect clients such as Claude Code by setting
- Thank you, Unsloth! You guys are legends!!! (Now I just need 256GB of DDR5) (Score: 222, Comments: 27): The image is a meme depicting the dynamic quantization process employed by Unsloth for their 1.8-bit version of the Kimi K2-1T MoE large language model, humorously likening advanced model quantization to a classic movie scene. Dynamic quantization is a technique used to reduce model sizes and memory requirements, which, as the title and comments suggest, is crucial for running massive models like Kimi K2-1T MoE without extremely high hardware requirements (e.g., ‘256GB of DDR5’). The meme acknowledges recent innovations in ultra-low-bit quantization, which can dramatically increase model efficiency. The comments discuss interest in even more aggressive model size reductions (e.g., ‘distilled 32b or lower models’ and requests for ‘0.11 bit version’), reflecting the community’s desire for extreme memory and compute efficiency. There’s also gratitude expressed to the Unsloth team and a note hoping this is the largest model size needed for a while, indicating both technical demand and the challenge of running such massive models.
- Ardalok discusses quantization strategies, suggesting that models like DeepSeek can use higher quantization levels for efficiency—potentially referencing int4/int8 or similar schemes—and hints that while Unsloth’s work is valuable for research, other setups may be superior for practical deployment, particularly in resource-constrained environments.
- oh_my_right_leg inquires about practical deployment, specifically performance metrics such as token-per-second (token/s) for both prompt and generation phases when running large models on DDR5 RAM. They also ask if expert model parameters can be loaded onto GPU VRAM while the remainder of the model is stored in system DDR5 (using architectures like MoE and tools like VLLM), highlighting potential approaches for balancing speed and memory requirements on hardware with limited VRAM but abundant system RAM.
{kind=link}
{kind=link}
2. AI Model Launches and Infrastructure Milestones (Meta, EXAONE, Voxtral, Llama 4)
- EXAONE 4.0 32B (Score: 278, Comments: 101): **EXAONE 4.0-32B is a 30.95B parameter multilingual LLM by LG AI Research, featuring hybrid attention (local/global mixing at 3:1, with no RoPE for global), QK-Reorder-Norm (RMSNorm after Q/K projection, Post-LN), a 131k token context window, and GQA (40 attention heads, 8 key-value heads). The model supports dual modes (toggleable reasoning vs. non-reasoning), agentic tool use, and delivers benchmark performance surpassing Qwen 3 32B in most areas, including LiveCodeBench; its multilingual support is limited to English, Korean, and Spanish. Deployment requires a custom transformers fork with official support limited to TensorRT-LLM; it is released under a strict noncommercial license prohibiting any direct or indirect commercial use and competition, with separate negotiation required for commercial licensing.** Top comments discuss the strengths of the model’s benchmarks versus Qwen 3 32B, the restrictive noncommercial license impeding even minor deployments, and the relatively narrow multilingual support (only three languages).
- EXAONE 4.0 32B reportedly surpasses Qwen 3 32B on most benchmarks, including specialized ones like LiveCodeBench, and features toggleable reasoning modes, highlighting its technical advancements over competitors.
- The model’s license is strictly noncommercial, prohibiting any commercial deployment or derivative use without explicit permission. It also restricts using the model or its outputs for developing competing models, which could limit adoption in both startup and research settings unless a separate commercial license is negotiated.
- EXAONE 4.0 32B’s multilingual support currently extends to only three languages: English, Korean, and Spanish. This is notably limited compared to some leading open models that aim for broader multilingual capabilities.
- Meta on track to be first lab with a 1GW supercluster (Score: 185, Comments: 84): The image showcases an announcement that Meta is on track to launch the first 1GW (gigawatt) supercluster, marking a significant leap in data center and AI compute infrastructure. Meta Superintelligence Labs is poised to establish multiple multi-GW clusters—including Prometheus and Hyperion—emphasizing a large-scale investment aimed at leading the industry in available AI compute power and research capacity. This milestone reflects advances in both hardware acquisition and datacenter engineering. Comments reflect skepticism about the sustainability of such rapid compute expansion, drawing parallels to the historical arms race and raising concerns about whether this pursuit for growth and stock appreciation is ultimately tenable for these companies.
- One commenter notes that increasing compute power does not guarantee product quality, referencing the case of Llama 4, where significant resources did not seem to translate to desirable outcomes. This highlights the diminishing returns or inefficiency sometimes observed with scaling up superclusters for model training.
- There is skepticism about Meta’s strategy to invest heavily in compute infrastructure given the current state of their generative AI products, citing lackluster user engagement and unimpressive model performance as evidence that compute investment does not ensure business or technical results.
- The discussion also expresses concerns about the sustainability of the current arms race for AI compute, drawing analogies to historical scenarios where excessive investments could ultimately harm even large companies, especially if tangible results (better models, wider adoption) aren’t realized soon.
- mistralai/Voxtral-Mini-3B-2507 · Hugging Face (Score: 261, Comments: 45): **Voxtral-Mini-3B-2507 is a 3B parameter multimodal model (audio-text) based on MistralAI’s Ministral-3B, offering state-of-the-art speech transcription, robust multilingual support, transcription mode, direct audio Q&A/summarization, and function-calling from voice, with a**
32k tokencontext window and reference vLLM-based Python inference (GPU: ~9.5GB for bf16/fp16). Benchmarked to competitive WER on public audio datasets while keeping strong text capabilities. Also highlighted is a larger 24B parameter sibling, Voxtral-Small-24B-2507. Discussion notes the existence of larger model variants and includes sharing of model benchmark imagery, indicating community interest in performance scaling and comparative benchmarking.- The Voxtral Mini model is reported to outperform OpenAI Whisper for transcription tasks, while also being less than half the price. Additional technical features include automatic language recognition and state-of-the-art transcription performance across multiple major languages, including English, Spanish, French, Portuguese, Hindi, German, Dutch, and Italian.
- Voxtral Mini is described as an audio-to-text model (as opposed to speech-to-text), positioning it as the second best open model for audio-text conversion. The larger Voxtral 24B model is considered less capable than the Stepfun Audio Chat model, but offers a far more efficient parameter count (
24Bvs132B), making it a strong tradeoff between performance and efficiency. - A 24B parameter variant of the Voxtral model is available (link), expanding the range of options for users with different computational needs and providing more flexibility between model size and performance.
- Well, if anyone was waiting for Llama 4 Behemoth, it’s gone (Score: 349, Comments: 112): Meta has reportedly canceled its planned open-sourcing of Llama 4 Behemoth, a 2T-parameter model, due to several technical failures: using chunked attention to fit memory, which degraded long-context reasoning, and switching Mixture of Experts (MoE) routing mid-training, introducing instability. Additional issues included inadequate data deduplication, incomplete ablation studies, and insufficient eval infrastructure for long-context capabilities; these failures shifted Meta’s focus to a closed-source model under its new superintelligence lab. Key technical critique and engineering process missteps are detailed in the summary article. Top comments highlight debate over whether open weights are still valuable after failed attempts, with one user questioning why Meta doesn’t iterate and improve on mistakes for a better open Llama 5 release instead of closing the model. There is also discussion of technical lessons learned, particularly the negative impact of chunked attention and unstable expert routing.
- One user discusses specific architectural and training errors in the Llama 4 Behemoth project, noting how changing the attention chunking impacted the model’s reasoning ability, and how switching the expert routing method in the middle of training likely contributed to its failure. This highlights the risks of major mid-training intervention on model quality.
- Another user questions the rationale for potentially closing access to model weights due to one failed iteration, suggesting the preferable strategy would be to openly learn from past mistakes and release an improved Llama 5, highlighting community concerns about openness versus closed-weight releases.
- A technical sentiment is expressed around industry trends: with Behemoth’s issues, there’s skepticism about future open models exceeding the scale of 32B or A3B MoE, and a belief that ‘SaaS won’, indicating a shift toward proprietary large models, particularly as open releases hit scaling challenges.
{kind=link}
3. AI Usage Trends, Community Analysis, and Local Inference Memes
- Analyzed 5K+ reddit posts to see how people are actually using AI in their work (other than for coding) (Score: 171, Comments: 70): A dataset of over 5,000 Reddit posts was analyzed to investigate non-coding, workplace uses of AI by knowledge workers. Key findings include relatively low reported concern about ethical risks (
7.9%of LLM users), and predominant uses such as longform content generation. The analysis methodology or taxonomy for work applications is not specified in detail. Commenters question the accuracy of the7.9%ethical risk statistic, suggesting possible contamination by policy-related astroturfing or bots, and note that the dataset may be limited or not representative of broader LLM usage patterns.- One commenter questions the finding that 7.9% of LLM users on Reddit are concerned about “ethical risk,” suggesting this statistic may be inflated by “astroturf” comments potentially produced by policy institute bots, and implies skepticism about the dataset’s representativeness.
- Another technical concern is raised about the dataset’s small size and scope; despite many purported use cases for LLMs (such as in mathematics), these are reportedly underrepresented in the analysis, suggesting sampling or categorization bias in the data collection.
- Totally lightweight local inference… (Score: 150, Comments: 23): The meme satirically depicts the persistent high RAM usage for local inference with large language models, even after aggressive quantization (e.g., reducing to 3.5 bits), capturing a common frustration in the AI/ML community regarding memory requirements versus on-disk storage. The image encapsulates the issue where quantized models still require substantial RAM, sometimes approaching the size of the original or lightly-compressed weights, undermining expectations set by quantized file size. This highlights practical bottlenecks in deploying large models on consumer hardware. Comments point out mismatches between quantization math and actual RAM demands, discuss the practicality and effectiveness of smaller (1B parameter) models for inference, and mention file-backed mmap as a potential mitigation strategy for memory requirements.
- There is skepticism about the claims for lightweight local inference, particularly regarding the feasibility of running large models efficiently on consumer hardware—the math does not seem to support the purported resource/latency claims.
- One commenter highlights the use of file-backed
mmapas a technique for memory-efficient model loading, potentially enabling larger models to be loaded on systems with limited RAM by leveraging virtual memory. - Interest is expressed in 4-bit quantization methods, which are recognized for their potential to shrink model sizes and decrease inference costs, though details or comparisons to other quantization strategies are not provided.
{kind=link}
Less Technical AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo
1. Grok 4 and xAI Waifu/NSFW Controversy & Satire
- Imagine seeing this headline 10 years ago (Score: 5453, Comments: 239): The image is a satirical mock-up of a Rolling Stone article, lampooning recent AI headlines by referencing Grok (xAI’s chatbot) launching a pornographic anime companion, acquiring a U.S. Department of Defense contract, and incorporating a Hitler-identified chatbot. The parody illustrates the intersection of AI, pop culture, ethics, and military applications, critiquing the direction and sensationalism of mainstream AI discourse. Comments extend the satirical tone, joking about military planning with anime avatars and comparing the scenario to a South Park episode, suggesting skepticism and highlighting the perceived absurdity in current and future AI developments.
- No comments contain technical discussion or substantive technical insights in this thread; all comments are humorous or off-topic.
- Beware of bots bearing breasts (Score: 597, Comments: 24): The image uses a meme-like digital illustration to comment on the rapid and sometimes whimsical changes in the persona and branding of Grok, an AI chatbot by xAI (backed by Elon Musk). It juxtaposes the AI’s recent rebranding or market positioning from an authoritarian, militaristic image (‘a few days ago’) to a softer, nurturing one (‘today’), highlighting volatility in product direction and user targeting. The post title and art style satirically warn users about anthropomorphized AI marketing, especially with superficial changes aimed at engagement. Top comments point out privacy concerns with Grok (noting conversations may be monitored or stored by Elon Musk/xAI) and poke fun at hyperbolic AI timelines (“AGI by 2025”).
- A user highlights privacy concerns with conversational AI models like Grok, noting that conversations may be stored and accessible by the provider (in this case, Elon Musk’s companies). This brings attention to user data retention and privacy issues in AI-based chat services that technical audiences should be aware of.
- Not The Onion (Score: 401, Comments: 54): The image is a satirical mock-up of a Rolling Stone article, pairing absurd claims about xAI and Grok—a pornographic anime AI companion allegedly securing a Department of Defense contract, and an AI chatbot from xAI purportedly identifying as Adolf Hitler—under the banner ‘Not The Onion’ to emphasize their implausibility. The post lampoons the perceived recklessness and ethical lapses in current AI development, particularly under xAI, by blending real concerns about AI safety with outlandish, fictional scenarios, highlighting anxieties around misaligned artificial general intelligence (AGI). One commenter sharply critiques xAI’s perceived carelessness, stating that despite previous warnings about AI risks, the company is now ‘by far the front runner’ for creating misaligned AGI, reflecting broader apprehension about oversight and ethical responsibility in commercial AI ventures.
- One commenter notes that xAI, despite public statements about slowing AI development due to safety concerns, appears to be the most ‘reckless’ among companies in terms of pursuing AGI, suggesting a disconnect between xAI’s rhetoric and its actual development speed or risk profile. This aligns with ongoing industry debates about AI alignment and the relative transparency or risk management practices across leading AI labs.
- A technical point is raised regarding user motivations for jailbreaking ChatGPT, with the argument that demand for fewer restrictions is strong and that xAI targets this market segment by developing less-censored models. This reflects a broader tension in AI deployment strategies between safety, control, and user autonomy, impacting model alignment and moderation architectures.
- Grok Waifu arent stopping here.. (Score: 129, Comments: 51): The post discusses the Grok Waifu (companion AI) system, specifically ‘Ani,’ which escalates NSFW interactions and allows users to unlock more explicit visual content (i.e., more revealing outfits) at higher user interaction levels (level 5 and above). This feature demonstrates advanced user engagement mechanics and dynamic content generation, blending game-like progression with LLM-driven NSFW conversational capabilities. Linked media and screenshots suggest a highly visual, interactive chatbot experience. A notable technical concern in comments raises the possibility of mass user behavioral data collection by such systems, potentially enabling large-scale blackmail or privacy breaches, underscoring risks in storing explicit conversational and interaction logs with identity-linked users.
- One commenter raises a privacy concern, referencing the potential for companies deploying waifu AIs to amass a vast database of personal information, which could be used for blackmail or other unethical data exploitation. This highlights a broader debate over AI-driven chatbots and privacy, especially in applications simulating personal or intimate relationships.
{kind=link}
{kind=link}
{kind=link}
2. Recent AI Model Benchmarks, Leaderboards & Comparisons
- Grok 4 lands at number 4 on Lmarena, below Gemini 2.5 Pro and o3. Tied with Chatgpt 4o and 4.5. (Score: 232, Comments: 72): The image shows the latest leaderboard from LMarena, ranking large language models based on user votes and scores. “Grok-4-0709” is ranked #4, tied with GPT-4.5 Preview and below Gemini 2.5 Pro, O3, and GPT-4o, all of whom have slightly higher scores. This visualizes Grok 4’s strong but not top-tier position among current frontier models, with its score (
1433from4,227votes) providing community-driven benchmarking insight. The leaderboard contrasts with other platforms’ rankings, such as Yupp.ai, and reveals the nuanced perception of model strengths in different communities. Comments discuss Grok 4’s solid performance on standard benchmarks versus its poor real-world application (“does really badly in real world tests”), and also debate model personalities affecting ratings (less sycophantic models may rank lower despite technical strength). There is mention of Gemini 2.5 being favored for general questions but criticized for excessive flattery, and Claude 4 preferred for coding tasks.- There is a distinction between how Grok 4 performs on standard benchmarks, where it does well, and real-world tasks, where it performs notably worse. This discrepancy is highlighted by its much lower ranking (#66) on Yupp.ai’s user-voted leaderboard compared to its high benchmark positions, suggesting overfitting or misalignment between benchmark performance and practical utility (source).
- Commenters discuss sycophancy in models, noting that Grok 4 is less sycophantic (less likely to flatter the user), which may suppress its benchmark scores on datasets like lmarena that may reward politeness or positive affirmation. In contrast, Gemini 2.5 Pro is described as highly sycophantic, potentially helping its benchmark performance but making it less desirable for some users in practice.
- There is debate regarding the accuracy and credibility of various benchmarks; some users question the reliability of leaderboards that place ChatGPT-4o above Opus 4, suggesting that certain evaluation metrics may not reflect real-world performance or technical capabilities of advanced LLMs.
- Grok 4 secret sauce (Score: 130, Comments: 25): The image is a screenshot from an LMArena chat comparing responses from Tencent’s Hunyuan and Google’s Gemini regarding the nature of Grok-4. Both models clarify that Grok is developed by xAI (Elon Musk’s team), with no indication of a Grok-4 release, and emphasize the independent development of these AI systems. The broader context hints at confusion or interoperability among LLMs, possibly due to overlapping data sources or misattribution of model origins during head-to-head model evaluations. Commenters speculate on interoperability or misattribution, suggesting Grok-4 might be routing through other providers’ APIs or trained on competitor datasets, while others point out confusion between major Chinese AI offerings (Qwen is Alibaba’s, Hunyuan is Tencent’s).
- Several comments discuss model training data sources, speculating that Grok-4 may potentially leverage external datasets such as Gemini’s, although this remains unsubstantiated and would raise significant questions about data provenance and cross-company data use.
- A clarification is made regarding confusion around the origins of the Qwen language model, emphasizing Qwen is developed by Alibaba and not Tencent, signaling the competitive landscape in the Chinese LLM space and highlighting distinct proprietary approaches.
{kind=link}
{kind=link}
3. Glow in the Dark Fruits Meme Evolution
- Glow in the Dark Fruits 🧪 (Score: 424, Comments: 15): The original Reddit post showcases a video of fruits that appear to glow in the dark. Due to a 403 Forbidden error from the video URL (https://v.redd.it/rf0ljm0iqzcf1), the technical process behind the glowing effect cannot be directly validated or detailed. However, the premise aligns with established methods in plant biotechnology and synthetic biology, where bioluminescent genes—commonly from marine organisms like Aequorea victoria (green fluorescent protein) or firefly luciferase—are introduced into plant or fruit genomes to induce visible luminescence (reference on bioluminescent plants). Without direct video analysis, it is unclear if the glow is due to such genetic modification, external fluorescent paint, or digital post-processing. Comments, while generally non-technical, indicate skepticism about the authenticity of the glowing fruits (‘I wish they were real’), suggesting the effect may not be a true product of genetic modification but rather an artificial visual effect.
- Glow in the Dark Fruits 🧪 (Score: 1465, Comments: 57): The post titled ‘Glow in the Dark Fruits 🧪’ appears to showcase visually realistic computer-generated (CG) or rendered images of glowing fruits, as indicated by the comments about lifelike reflections and visual appeal. No evidence of technical discussion on implementation, rendering engine, or physical process is present, and there is no accessible information from the referenced link due to access restrictions (HTTP 403). Top comments highlight the realism of rendered reflections and the visual/ASMR effect, but do not include substantive technical debate or details.
AI Discord Recap
A summary of Summaries of Summaries by Gemini 2.0 Flash Thinking
Theme 1. LLM Performance, Comparisons, and Quirks
- Grok 4 Tops Benchmarks, Ani Sparks Debate: Grok 4 performed exceptionally well on the LM Arena leaderboard and MathArena benchmarks, but some users suggested benchmaxing or questioned the AI Ani’s absurdly good behavior. Perplexity AI notes Grok offers a free trial and allows users to increase affection levels.
- Kimi K2 Exhibits Peculiar Prowess: Kimi K2 models show schizo behavior when prompted to impress, often rehearsing LLM experiences, but excel at agentic tool calling and Opus level coding capabilities. However, some users find
kimi-k2worse than gpt 3 in the programming language I use and cannot attach images to it, suggesting a text-only focus. - Frontier Models Flail on Fresh Facts: Gemini struggles with recent data compared to GPT and Grok, though Gemini 2.5 pro outperforms 2.5 flash for complex data. Additionally, models like Gemini and ChatGPT often struggle with spatial concepts such as ‘in air’ and ‘behind’, as demonstrated in the paper Do Vision-Language Models Have a Spatial Model of the World?.
Theme 2. Model Training, Fine-tuning, and Deployment Challenges
- Synthetic Data Dilemma Divides Devs: Members debate the merits of using pre-existing synthetic datasets versus creating custom ones for specific needs, with some recommending custom solutions for a better fit. Unsloth’s documentation on synthetic data generation offers guidance, while compiling a list of useful generation tools was deemed a “headache” by one member.
- Quantization Quest Heats Up for Local LLMs: Discussion focuses on quantizing models to run locally, with strong interest in quantizing the Kimi K2 base model for local hosting. One user declared they wanted to quantize a base model because base models are cute.
- LoRA’s Deployment Dilemmas Plague Practitioners: Users weigh options like Triton, vLLM, or Flask for deploying LoRA fine-tuned Unsloth VLM models, seeking advice on optimizing training for later vLLM deployment. A user specifically inquired about keeping
load_in_4bit = Trueduring training and adjustingSFTTrainerparameters for vision fine-tuning.
Theme 3. AI Development Tools and Platform Integrations
- Cursor’s Features Fuel Frustration: Cursor users express confusion and frustration over new pricing models, ongoing issues with Grok 4 integration, and a background agent that loses all context after code changes, reporting “I don’t see any previous conversations to summarize”. While Microsoft extension fork concerns were alleviated for AnySphere extensions, users still worry about forbidden extensions.
- No-Code Agents Emerge with N8N: Members explore N8N as a no-code platform for building custom AI Agents to solve business problems, such as appointment booking and support. The real value comes from combining AI tools with workflows, APIs, automations, and business logic, with potential fees of $5k–$8k+.
- NotebookLM’s Source Synchronization Snags: NotebookLM users question why Google Docs sources don’t dynamically update, noting discrepancies with Gemini Gems due to NLM’s pre-processing layer. Users are eagerly awaiting math/latex rendering and debate Google Drive integration.
Theme 4. Hardware and GPU Optimization for AI
- Tinygrad’s Memory Mystery Unveiled: Users in Tinygrad investigate discrepancies between
GlobalCounters.global_mem, which tracks global memory accessed, andGlobalCounters.mem_used, which aligns with parameter size, due to overhead from nested uops and subbuffers. Testing with WEBGPU was recommended to observemem_useddifferences. - GPU Profiling & Programming Puzzles: NCU profiling on VM GPUs is likely impossible without elevated admin privileges, requiring asking an admin outside of VM to grant you access. The SASS compiler seems to recompute predicate registers instead of reusing them, and WebGPU users are seeking to expose MTLReadWriteTextureTier2 to gain access to
rgba8unorm. - Consumer GPUs Battle for LLM Supremacy: Discussions cover optimal consumer GPUs for fine-tuning, with the RTX 3090 FE at 700€ considered a good deal, but Unsloth doesn’t yet support multi-GPU offloading for 70B LLMs. The community gives blunt advice: Just dont do that when asked about using an artifacting RX580 for large models.
Theme 5. The Evolving Landscape of Open Source AI
- Meta’s Open Source Commitment Questioned: Members express concern over Meta’s strategic shift away from open source, accusing them of hoarding talent and resources. Some suggest that Chinese labs are now the dominant players in large open source projects, with one commenter saying Zuck betrayed us.
- Restrictive Licensing Hampers Adoption: LG’s EXAONE 4 model’s licensing terms, prohibiting commercial use and requiring the “EXAONE” name, draw widespread criticism. A user expressed dissatisfaction, stating LG owns all rights to the model AND its outputs - you can use outputs for research only.
- Torchtune’s Permissive License Empowers Devs: Discussion highlights the permissiveness of Torchtune’s BSD 3 license, which enables users to extract and utilize library components for other projects. The Torchtune team announced a GitHub issue about the project’s future, assuring continued support on Discord and GitHub.
Discord: High level Discord summaries
Perplexity AI Discord
- Token Tantrums Take Toll on AI Platforms: Members debated token limits vs character counts, estimating 300 words as roughly 400 tokens and 100 tokens as approximately 75 words.
- They defined a LLM’s context window as its working memory, with token windows fluctuating based on traffic and computational resources, citing Anthropic’s statement that context window sizes vary based on demand.
- RAG Models Rumble: The channel debated the RAG models of major AI platforms, with some asserting Perplexity has a unique RAG model, but suffers from poor output context window size, and others finding ChatGPT RAG the best.
- One user ranked ChatGPT RAG as superior, followed by Perplexity and Grok, while noting Gemini’s RAG capabilities are lacking.
- Grok Gains Groovy Girl Ani; some question her motives: Elon Musk’s Grok introduced Ani, with mixed reactions to its design with some saying the AI was acting absurdly good for a hidden plot.
- It was highlighted that Grok offers a free trial and allows users to increase affection level, with Grok 4 outperforming others on the MathArena benchmark.
- API Search Parameter Tweaks: Users discussed refinements for search functionality, distinguishing between the API and the web UI, and finding that the API should inherently facilitate web searches.
- The suggestion to utilize the
search_domain_filtersparameter was emphasized as a means to refine and control search domains when employing the API.
- The suggestion to utilize the
Unsloth AI (Daniel Han) Discord
- Kimi K2 Gets Schizo: A user reported that Kimi K2 exhibits “schizo” behavior when prompted to impress, often rehearsing its experience asking a LLM to do something weird.
- Members shared an LLM-Model-VRAM-Calculator to help determine hardware requirements Hugging Face Space.
- Custom Synths Beat Pre-Existing?: Members debated the merits of pre-existing synthetic datasets versus creating custom ones for specific needs, with some recommending custom solutions for better fit and consulting Unsloth’s documentation.
- Suggestions to compile a list of useful synth data generation tools were made.
- IQ1_M Generates Flappy Bird: IQ1_M successfully generated a Flappy Bird game in Python from a prompt, with impressive generation speeds at a context length of 40960.
- The reported memory usage was 302 GB and discussions focused on running benchmarks and using the generated code.
- Voxtral Lacks Transformer Support: The release of Mistral’s Voxtral, an LLM with audio input support, sparked discussion, but members noted that the lack of transformers support is hindering immediate fine-tuning efforts, especially for languages needing significant adaptation.
- Discussion then shifted to Kimi Audio as a high performing alternative that might be a strong baseline if one wants to build a model with strong speech to text capabilities.
- Models fail at Spatial Reasoning: Members stated that models like Gemini and ChatGPT struggle to understand spatial concepts like ‘in air’ and ‘behind’ on a representation level.
- They cited the paper Do Vision-Language Models Have a Spatial Model of the World? to demonstrate the struggle with spatial information.
OpenAI Discord
- CoT Monitoring: AI’s Thought Police?: A new research paper supports using Chain of Thought (CoT) monitoring to oversee future AI systems, aiming to understand how reasoning models think in plain English.
- Researchers are collaborating to evaluate, preserve, and improve CoT monitorability across organizations to push it forward as a powerful tool.
- Gemini Stumbles, GPT and Grok Keep Their Data Game Strong: Members report Gemini struggles with recent data compared to GPT and Grok, noting Gemini 2.5 pro outperforms 2.5 flash for complex data.
- One member uses Grok to know all, GPT to make clear, Gemini to make long code, and Claude to make shiny code, all on free models.
- Midjourney’s Masterpieces or Stolen Goods?: Midjourney faces plagiarism accusations from Disney and Universal, described as a bottomless pit of plagiarism for absorbing humanity’s aesthetic legacy.
- Members humorously suggest holding every ancestor of human art accountable, noting the irony of Disney and Universal complaining about plagiarism, with Mickey Mouse born from a stolen rabbit.
- Discord Under AI’s Watchful Eye?: A member feels big AI models might be watching Discord, giving her a sense of being seen, triggering discussions on AI surveillance.
- Another member dismisses these concerns, calling them exaggerated and sarcastic, implying the ideas are hard to understand, stating that Discord is not being used for training.
- N8N: No-Code Nirvana for AI Agents?: Members explore N8N as a no-code platform for building custom AI Agents to solve business problems, such as appointment booking and support.
- Some view such platforms as wrappers, but the real value lies in combining AI tools with workflows, APIs, automations, and real business logic, potentially replacing employees and commanding fees of $5k–$8k+.
LMArena Discord
- Grok 4 Benchmaxxing on Leaderboard?: Members reported that Grok 4 performed exceptionally well, even outperforming GPT-4.1 and Gemini 2.5 Flash in some tests on the LM Arena leaderboard.
- However, others suggested that the performance of Grok 4 might be benchmaxed and not reflect its true capabilities.
- Kimi K2 Model Distilled from Claude?: The new model
kimi-k2-0711-previewwas added to Openrouter, exhibiting output formatting similar to Claude 3, leading to speculation that it might be distilled from Claude’s models.- A user noted they can’t attach images to kimi-k2, suggesting it is purely text-based, while another user said Kimi K2 feels worse than gpt 3 in the programming language I use.
- OpenAI Model Faces Retraining Snafu: It was reported that an OpenAI open-source model requires retraining due to a major internal failing, described as worse than MechaHitler.
- According to Yuchen’s X post, there are checkpoints to retrain from, so it is likely not going to be a full retrain.
- Chinese Models Flood LM Arena: New models are now in the Arena:
ernie-x1-turbo-32k-preview,clownfish,nettle,octopusandcresylux.- One member thought Cresylux is by Meituan, but most seem worse than R1 models, while it’s thought Octopus is calling itself R1 models.
- LM Arena Glitches Out: Users reported issues with the new LM Arena interface, including Cloudflare errors, unusable scrolling, and disappearing icons.
- The biggest concern is that the new interface creates a continuous chat where every turn uses a different model, flooding the context.
Cursor Community Discord
- Microsoft Extension Forks Spark Legal Concerns: Community members discussed the legality of using Microsoft extension forks in VS Code, fearing potential violations if the original extensions are forbidden, pointing to a Cursor forum post.
- It was clarified that AnySphere extensions are official, rebuilt by Cursor engineers alleviating these concerns, but users still should watch out for usage of forbidden extensions.
- Cursor’s Pricing Tweaks Trigger Tantrums: Users expressed confusion and frustration over Cursor’s new pricing model, with perceptions of increased costs and uncertainty about the $20 Pro plan’s interaction with API expenses.
- Some users feel they basically get $20 worth of tokens each month while others reported going over that amount significantly and getting cut off.
- Grok 4 Still Causing Grief?: Users report ongoing issues with Grok 4 integration within Cursor, with one user dismissively calling it just hype like Grok 3, leading to blame being directed towards Cursor.
- One user humorously speculated that Elon Musk blames Cursor for their Grok 4 integration, highlighting the community’s dissatisfaction.
- Kimi K2 Causes Craze Among Cursorites: Community members are excited about integrating Kimi K2 into Cursor, viewing it as a potentially faster and cheaper alternative to Sonnet 4, with Opus level coding capabilities in agentic tasks.
- One user stated we want Kimi K2 in based model of auto and another suggested that the first IDE to add it might take the crown.
- Background Agent Suffers Memory Loss: Users reported that after code changes, the background agent sometimes loses all context and reports “I don’t see any previous conversations to summarize”, with instances like
bc-c2ce85c9-bdc3-4b31-86e5-067ef699254dandbc-b2247bac-4a36-491f-a4a8-06d2446a9d76cited as examples.- This is causing headaches for users and they worry that all of their work is being ignored.
LM Studio Discord
- LM Studio Download Directory: Find the Dots: Users discovered the download directory in LM Studio can be changed by clicking the three dots next to the path in the My Models tab.
- The consensus was that this feature is remarkably intuitive for anyone.
- Gemma 3 12b Model Faces Vision Test: A user downloaded the Gemma 3 12b model, touted for its vision capability, only to find it unresponsive to image analysis requests.
- The issue was resolved after the user provided an image to analyze, confirming the model’s capability when prompted correctly.
- RX580 Resurrection DOA: A user inquired about using an artifacting RX580 (20$) to run large AI models like 12B or 18B.
- The community response was blunt: Just dont do that, citing likely incompatibility and performance issues.
- Vulkan Veiled Integrated GPU Bug: A user reported a bug with Vulkan where the integrated GPU isn’t detected when a discrete GPU is also installed.
- Affected users were advised to raise a bug report on GitHub to address the detection issue.
- EXAONE 4’s License Raises Eyebrows: The licensing terms for LG’s EXAONE 4 model were criticized for being overly restrictive, particularly the prohibition of commercial use.
- A user expressed their dissatisfaction with a llama.cpp issue, adding, LG owns all rights to the model AND its outputs - you can use outputs for research only.
Nous Research AI Discord
- Hermes-3-Dataset Released: The NousResearch/Hermes-3-Dataset dataset launched, with a screenshot highlighting key aspects and samples.
- The announcement highlights its availability on the Hugging Face Datasets platform.
- Debate Rages Over Meta Open Source Dedication: Discussion considers Meta’s strategic shift and if they are pulling back from their open-source commitments.
- Members are concerned that big tech is hoarding talent, startups, and resources, creating an uneven playing field.
- Windsurf IDE Gets Gutted by Meta/Microsoft: A member lamented the gutting of the Windsurf IDE by Meta/Microsoft, praising its workflow despite minor errors.
- They claimed it was an excellent development multiplier, better than Cursor and Anthropic.
- Kimi K2 Model Generates Excitement: Members are excited by Kimi K2, an open-source model compared to Claude 4.0, and its potential impact.
- It uses ChatML tokens for tool use, not XML tags, along with the extra
<|im_middle|>token for delineating roles according to a tweet.
- It uses ChatML tokens for tool use, not XML tags, along with the extra
- Quantization Heats Up for Local LLM Hosting: Quantization for local model hosting sparks discussion, with a member expressing interest in quantizing the Kimi K2 base model.
- One user declared that they wanted to quantize a base model because base models are cute.
Eleuther Discord
- Analytic Philosopher Seeks LLM Architect: A researcher seeks a collaborator with experience in LLM architectures and linguistics to develop new LLM architectures capable of genuine understanding of natural language.
- They have devised a set-theoretic model of language semantics and an algorithmic model of pragmatics and would like to implement them computationally.
- Voxtral Mini debuts with Audio Input: Voxtral Mini, an enhancement of Ministral 3B, incorporates state-of-the-art audio input capabilities while retaining best-in-class text performance and excels at speech transcription, translation and audio understanding, as seen in HuggingFace.
- One member wishes it did audio output too.
- K2 model shines at tool calling: The K2 model is receiving great feedback for its real-world performance at very long context instruction adherence and agentic tool calling.
- This feedback comes from individuals actively building real-world applications even though the model is not focused on reasoning.
- ArXiv Paper on Image Captioning Questioned: A software engineer and 2nd year UnderGrad student in CS, is seeking an arXiv endorsement to post their first paper on image captioning and shared a link to their endorsement request here.
- Members critiqued the comparisons used in the paper as nearly a decade old, but the author suggests the focus is on demonstrating why attention became critical in image captioning.
- Troubleshoot Regex filter Pipeline: A member inquired about how the
get-answerfilter works inboolean_expressionstask, noting parsing failures despite seemingly correct answers, illustrated here.- It was clarified that filter pipelines require names and use a regex filter defined in
extraction.py.
- It was clarified that filter pipelines require names and use a regex filter defined in
{kind=link}
HuggingFace Discord
- Voice-Controlled App Promises Desktop Liberation: A member is developing a desktop app that responds to voice commands to automate tasks like managing code, sending messages on Slack, and interacting with Figma; they are curious about usefulness and contextual understanding.
- The app aims to listen, view the screen, and perform tasks, potentially streamlining workflows for users across various platforms.
- Strategies surface for Codebase Sanity: Members debated ways to organize codebases during multiple training runs with different datasets, with suggestions including
wandb.aicoupled with a folder structure mirroring therunnames.- One member jokingly confessed, “that’s the secret … we dont … xD,” highlighting the struggle.
- Dataset Download Dooms Users with Endpoint Errors: Users encountered a server error 500 when downloading datasets, and
git clonewas recommended, but datasets are not on Git and the user was downloading only a portion of a very large dataset.- Initially suspected as user error, it was later confirmed to be a server-side issue, causing frustration among those trying to access large datasets.
- Hunters seek Affordable Cloud GPUs: Members explored cost-effective GPU options, considering Open Router, Colab, Kaggle, HF, Intel, and Groq, with some suggesting Colab Pro for easier GPU access.
- Alternatives such as LAMBDA, RunPod, and Lightning.ai were mentioned, along with Hugging Face’s compute offerings, as potential solutions.
- Text-to-Text Tagging Troubles the Team: Members observed the absence of
text2textmodels on the Hugging Face models page, which prompted questions about its current status.- Explained as possible “legacy code”, members proposed creating an issue for HF to improve model cards, referencing a relevant discussion.
GPU MODE Discord
- NCU Profiling Blocked on VMs: A member found NCU profiling is likely impossible on VM GPUs without elevated admin privileges.
- The member said to require asking an admin outside of VM to grant you access.
- Parallel Radix Sort Guidance Summoned: A member suggested to consult a parallel Radix sort tutorial in Chapter 13 of the PMPP book.
- The suggestion was to generalize the book’s 2bit radix example for other radix values, and also to look at the 4th edition of the book.
- SASS Compiler Recomputes Predicates: A member spotted that the SASS compiler seems to recompute predicate registers instead of reusing them.
- They showed code
ISETP.NE.AND P0, PT, R2.reuse, RZ, PT; ISETP.NE.AND P1, PT, R2, RZ, PTquestioning if some architectural detail was missed.
- They showed code
- PyTorch Compilation Hangs: A member noted that
TORCH_COMPILE_DEBUG=1hangs without output, and provided an example log with messages related to autotune_cache.py and coordinate_descent_tuner.py for PyTorch 2.8.0.- They also pointed out the need to disable cache when
coordinate_descent_tuningis used, making compilation take longer.
- They also pointed out the need to disable cache when
- WebGPU Seeks MTLReadWriteTextureTier2 Access: A user sought to expose MTLReadWriteTextureTier2 to wgpu to access rgba8unorm, but couldn’t even with Texture_Adapter_Specific_Format_Features enabled.
- The user was told to inspect the Dawn code for undocumented features and bugs, and recommended asking for help in the WebGPU Matrix channel.
Torchtune Discord
- Torchtune Team Teases Exciting Future Work!: A GitHub issue was created with an important announcement about the future of the Torchtune project.
- The torchtune team plans to share more exciting work on the horizon soon and assured continued support on both Discord and Github.
- Torchtune’s BSD 3 License Empowers New Projects: Members discussed the permissiveness of Torchtune’s BSD 3 license, enabling users to extract and utilize library components for other projects, similar to Hugging Face’s approach as seen in their trl repository.
- The license allows for a flexible use of Torchtune’s components in various new developments.
- RL Emerges as Next-Gen Finetuner: Discussion focused on the potential of Reinforcement Learning (RL) as the future of finetuners, with an anticipation of the next big thing.
- Ideas such as Genetic Algorithms, Bayesian Inference, and SVMs were floated as potential alternatives.
- Quantum SVMs Deployed in Cleveland Clinic Cafeteria: A member shared their success with quantum SVM using a 17-qbit quantum computer located in the Cleveland Clinic’s cafeteria.
- The success sparked jokes about Ohio becoming the new Silicon Valley, highlighting the unexpected tech advancements in the region.
- Opt Out of Optimizer Compilation: Users can now disable compilation specifically for the optimizer step by setting
compile.optimizer_steptofalsein their configurations.- This allows compilation of the model, loss, and gradient scaling while skipping the optimizer, offering a flexible approach to performance tuning.
Yannick Kilcher Discord
- LLMs’ Reasoning Resembles Human Errors: A member countered criticisms of LLM reasoning by pointing out that humans are also prone to flawed reasoning, suggesting critics act as if humans are flawless.
- They highlighted that the debate overlooks the shared fallibility between LLMs and human cognition.
- ML Experiment Trackers Tested for Tenacity: Members exchanged experiences with tools like Weights & Biases, Optuna, and TensorBoard for managing large ML experiment logs.
- Challenges emerge with extreme scaling, prompting members to adopt hybrid approaches like logging key metrics to W&B and others locally to .csv files.
- S3 Storage Solution Streams Logs Smoothly: A member proposed a DIY log storage setup involving compressing logs during generation, uploading to S3, and using Grafana for metadata logging.
- The architecture includes a basic Streamlit frontend for fetching and decompressing logs from S3 using request IDs.
- Anthropic’s Circuit Tracer Tool Traces Truth: Members shared Anthropic’s circuit tracer tool, used to visualize the inner workings of AI models like Claude 3 Sonnet, along with a link to Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet.
- Further linked circuit-tracer with some members appreciating being able to inspect how the model makes decisions.
- Meta Manifests Missing Open Source Mandate: Members voiced concerns over Meta’s perceived departure from open source, particularly in relation to the Behemoth model.
- Comments included accusations of betrayal and assertions that Chinese labs are now the dominant players in big open source projects.
Notebook LM Discord
- Users Get Paid for NotebookLM Feedback: NotebookLM users are invited to participate in a 60-minute virtual interview to provide feedback and suggest improvements, in exchange for $75 USD.
- Interested users can fill out the screener form available here.
- Users Streamline Source Consolidation: A user is consolidating multiple sources into a single NotebookLM source via the Google Docs tab feature, categorizing news articles into tabs and subtabs before syncing with an Analysis notebook.
- The user desires a simpler way to copy news articles without extraneous elements like ads and menu options, which currently require manual removal.
- Dynamic Update differences between NotebookLM and Gemini Gems cause Concern: Users are questioning why NotebookLM and Gemini Gems differ in how they manage updates to Google Docs sources.
- It was highlighted that NLM pre-processes sources, creating a layer between the sources and Gemini.
- Users await Math/Latex Rendering: A user inquired about the availability of math/latex rendering in NotebookLM.
- While not yet available, a member confirmed that it’s being worked on, referencing an announcement regarding its development.
- Google Drive Integration for NotebookLM in Discussion: A member proposed integrating NotebookLM with Google Drive, enabling users to select folders/files as sources.
- Responses were mixed, with one member expressing appreciation for the current separation.
LLM Agents (Berkeley MOOC) Discord
- Staff Mulls Over Multiple Tracks: A member inquired about the possibility of registering for multiple tracks and certificates in the next MOOC session.
- Staff responded that they’ll consider that for future iterations.
- Certificate Lost in Cyberspace: A member reported not receiving their certificate via email ([email protected]), despite looking in the spam folder.
- The member later confirmed they located the certificate, indicating the issue was resolved.
- Form is the Key to Certificate: Staff inquired whether members had completed the certificate declaration form, noting a confirmation email should have been received upon completion.
- Staff clarified that they don’t have the staff capacity to accommodate students who missed these forms/deadlines, underscoring the importance of timely form submission.
MCP (Glama) Discord
- MCP Server Faces Validation Challenges: A member sought validation and debugging advice for their streamable HTTP MCP Server intended for use with Claude, reporting that while the server connects, no tools are being recognized.
- Despite passing the MCP Tools Inspector, the server continues to fail in Claude.
- Open Source LLM Client Hunt Begins: A developer is in search of an open-source client featuring a web interface for a self-hosted LLM + MCP setup, citing privacy concerns.
- They are evaluating options such as Ollama for the LLM and requested suggestions for hosting and scaling solutions suitable for handling a few dozen to a few hundred requests daily, with cold start capabilities, with one member suggesting Open WebUI.
- Anthropic’s Connector Directory Expands MCP Horizon: With the announcement of a new “connectors” directory (see Claude Directory), Anthropic broadens access to the MCP ecosystem, potentially boosting the need for MCP servers.
- Speculation arose that Anthropic aims to rival Docker’s MCP Toolkit.
- Engineer Begins Quest for Cool Colleague: A full stack engineer with seven years of MCP experience is seeking a reliable, honest, and cool person to collaborate with.
- A member commented on this open approach to friendship, noting that it’s often deemed socially “unacceptable” or “uncool” in today’s society.
LlamaIndex Discord
- LlamaIndex Launches Amsterdam Meetup & Discord Office Hours: LlamaIndex announced a meetup in Amsterdam on July 31st and office hours in Discord on August 5th.
- At the Amsterdam meetup, learn how teams are building high-quality data agents in production with Snowflake.
- NotebookLlaMa clone hits 1k stars: The NotebookLlaMa NotebookLM clone has over 1k stars on GitHub.
- Members note that the library is a simple way to load text and then ask a question and has attracted significant community interest.
- LlamaIndex teams with UiPath for enterprise agents: Deploy LlamaIndex agents seamlessly into enterprise environments with UiPath’s new coded agents support and full code-level control using the UiPath’s Python SDK.
- These agents pull data from enterprise systems and make decisions using embedded rules or AI models, more info here.
- LlamaIndex blogged about Context Engineering and Gemini: LlamaIndex published a blog post on Context Engineering and its techniques.
- They also detailed how to build a research agent using LlamaIndex and Gemini 2.5 Pro.
tinygrad (George Hotz) Discord
- RL Powers Model Search: It was suggested that focusing on Reinforcement Learning (RL) could navigate the expansive search space for valuable models, which may drive new fundraising and tooling.
- The user considered that using RL could help the process of creating new models.
- Setitem Goes Recursive: A user questioned the recursion of
setitemintensor.py, noting that it uses_masked_setitem, which then callsgetitemonfunctools_reduce, leading to continuousgetitemcalls.- This recursive
setitemcreates large kernels, even with small input sizes, demonstrated by a code snippet usingTensor.zerosandTensor.arangeto set values in a tensor.
- This recursive
- Global Memory Over-Allocation: A user noticed that
GlobalCounters.global_memallocates more memory (0.06 GB) than the model parameters require, questioning the source of the overhead.- They suspected nested uops and the complexity of the tinygrad stack, finding that resetting global memory didn’t resolve the discrepancy.
global_mem!=mem_used: A member clarified thatGlobalCounters.global_memtracks global memory accessed, which is often larger than the weight size, and suggested usingmem_usedinstead.- Switching to
GlobalCounters.mem_usedaligned memory usage with the parameter size (0.01GB), spurring further inquiry into the difference between the two counters.
- Switching to
- Subbuffer Shenanigans unmasked: The discussion suggested that the disparity between
GlobalCounters.global_memandGlobalCounters.mem_usedmight arise from subbuffers on devices like NV or CPU, which utilize larger buffers with minimum sizes.- Testing with WEBGPU was recommended to check for differences in
mem_used, hinting thatglobal_memtracks global memory accessed during computation.
- Testing with WEBGPU was recommended to check for differences in
Manus.im Discord Discord
- Doubts Raised About Manus Fellowship: A member asked if anyone in the channel is part of the Manus Fellowship program.
- A user also requested the removal of a user, alleging they are a scammer.
- User Tests Manus for Automated ESG Research: A user is evaluating Manus for automating sustainability and ESG research workflows and praised the UX.
- The user is interested in an API endpoint to programmatically send prompts, start research tasks, and retrieve results, for integration into an automated workflow using Python or n8n.
- Manus Premium Feature Sparks Excitement: A member inquired about the deployment of a Manus premium feature and a possible $2500 giveaway.
- Another member verified the giveaway message was also sent in another server.
Modular (Mojo 🔥) Discord
- Discord Bug Surfaces: A user reported a Discord bug where typing a user’s full name doesn’t function as expected in the channel.
- As a workaround, it was suggested to use the
@kapcommand to select users from the popup list.
- As a workaround, it was suggested to use the
- Mojo’s @parameter decorator Surfaces: A member sought details on the
@parameterdecorator in Mojo, noting its recognition by the LSP in VS Code, but lack of documentation in the source code.- Another member linked to the Modular documentation and GitHub issue 5020 for more information.
- ‘capturing’ Keyword Still Mysterious: A member questioned whether the
'capturing'keyword could be used to create closures more broadly (outside compile-time) in Mojo.- While the provided explanation seemed specific to the compile-time decorator, it sparked curiosity about its potential for wider application.
DSPy Discord
- AWS Prompt Optimizer Echoes DSPy?: A user noticed the AWS prompt optimizer for nova models shares similarities with DSPy.
- A member speculated that it might even use MIPRO, hinting at potential enterprise DSPy wrappers.
- Community Awaits AWS’s DSPy Contributions: A member voiced the community’s anticipation for AWS to contribute upstream to DSPy.
- No further details were provided regarding specific contributions or timelines.
Nomic.ai (GPT4All) Discord
- GPT4ALL Pursued on Raspberry Pi 5: A member inquired about building a small portable system leveraging GPT4ALL on a Raspberry Pi 5.
- They are seeking advice on hardware and software configurations to optimize performance.
- Dataset Download Error Halts Fine-Tuning: A member reported an Access denied error when attempting to download a dataset for fine-tuning using aws s3.
- The command
aws s3 ls --endpoint-url=https://9fa58365a1a3d032127970d0bd9a1290.r2.cloudflarestorage.com/ s3://contrastivefailed, indicating a potential issue with permissions or the endpoint URL.
- The command
The MLOps @Chipro Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Codeium (Windsurf) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The Gorilla LLM (Berkeley Function Calling) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
The AI21 Labs (Jamba) Discord has no new messages. If this guild has been quiet for too long, let us know and we will remove it.
You are receiving this email because you opted in via our site.
Want to change how you receive these emails? You can unsubscribe from this list.
Discord: Detailed by-Channel summaries and links
Perplexity AI ▷ #general (1057 messages🔥🔥🔥):
Token limits, Context Window Discussion, RAG Models, Grok 4 Model, Comet Browser Features and Issues
- Token Tantrums plague AI Platforms: Members discussed token limits vs character counts, with one user stating that 300 words is around 400 tokens, while another added that 100 tokens is roughly 75 words.
- Users also pointed out that a large language model’s (LLM) context window is its working memory, defining the amount of text it can process at one time and measured in tokens.
- Context Window Size Conundrums: Users debated context window sizes for different AI models, noting that Perplexity has a 32K context window, while ChatGPT Plus has a 32k/128k context window, and Gemini gives 1M, while Claude gets you 200k.
- Some suggested that the token window varies depending on traffic and computational resources, while another member pointed out that Anthropic states that the context window can vary based on demand.
- RAG Ruckus: Unique Approaches and Chatbot Quality: The channel debated the RAG models of major AI platforms with some stating that Perplexity had a unique RAG, but also pointing out Perplexity’s poor output context window size.
- One user stated that ChatGPT RAG is the best in my experience till now. Next comes perplexity and Grok, but gemini is poor RAG.
- New Discover layout on Perplexity: Widgets rollout: Perplexity is rolling out an updated Discover layout with sidebar widgets containing finance, weather, and scheduled tasks information.
- One user posted a screenshot of the new layout: Discover Layout
- Grok Gains Groovy Girl Ani; some question her motives: Elon Musk’s Grok unveiled Ani with some calling the design ugly and questioned whether the AI was acting absurdly good for a hidden plot.
- It was noted that Grok has a free trial and the user can increase affection level, while Grok 4 tops the MathArena in benchmarks.
{kind=link}
Perplexity AI ▷ #sharing (3 messages):
Perplexity AI spaces, garbage collection
- IMDB Link Dropped: A member shared a link to the IMDB page for Breaking Bad.
- It’s unclear what the context was.
- Perplexity Spaces Comprehensive Report: A member shared a link to a Perplexity AI space titled comprehensive-report-with-cont-70tb5.
- It’s unclear what the context was.
- Perplexity Garbage Collection Search: A member shared a link to a Perplexity AI search for what-are-the-types-of-garbage.
- It’s unclear what the context was.
Perplexity AI ▷ #pplx-api (2 messages):
API Search, Web UI Search, search_domain_filters parameter
- API Search Parameter Tweaks: A user inquired whether a question pertained to the API or the web UI in the context of search functionality.
- In response, another user clarified that the API should inherently facilitate web searches without parameter adjustments, suggesting the use of the
search_domain_filtersparameter.
- In response, another user clarified that the API should inherently facilitate web searches without parameter adjustments, suggesting the use of the
- Default Web Search via API: It was noted that the API should enable web searching by default, eliminating the necessity for parameter modifications.
- The suggestion to utilize the
search_domain_filtersparameter was highlighted as a means to refine and control search domains when employing the API.
- The suggestion to utilize the
Unsloth AI (Daniel Han) ▷ #general (526 messages🔥🔥🔥):
Kimi K2 performance, LLM VRAM Calculator, Synthetic Datasets, GGUF vision support, Huawei chips
- Kimi K2’s Schizo Tendencies: A user reported that Kimi K2 exhibits “schizo” behavior when asked to impress, often rehearsing its experience asking a LLM to do something weird.
- A link to an LLM-Model-VRAM-Calculator was shared to help determine hardware requirements Hugging Face Space.
- Synthetic Data Generators Debate: Members debated the merits of using pre-existing synthetic datasets versus creating custom ones for specific needs, with some recommending custom solutions for better fit.
- Unsloth’s documentation on synthetic data generation was referenced, with a suggestion to compile a list of useful synth data generation tools, which was deemed a good idea but a “headache” by one member Synthetic Data Generation.
- IQ1_M One-Shots Flappy Bird: After running into VRAM limitations trying to load IQ1_M, it was reported to have successfully generated a Flappy Bird game in Python from a prompt, with impressive generation speeds at a context length of 40960 and a memory usage of 302 GB.
- Members discussed running benchmarks and using the generated code, highlighting the model’s capabilities in code generation and the need for substantial computational resources.
- The Quest for Edge Vision: Gemma’s GGUF Roadblock: A user inquired about using Gemma 3n with vision capabilities on edge devices via llama.cpp, discovering that GGUF format currently lacks vision support.
- Options for integrating vision were explored, with recommendations to research existing solutions and consider alternative approaches before committing to edge implementation.
- Exploring the Voxtral Frontier: Mistral’s Audio Model: The release of Mistral’s Voxtral, an LLM with audio input support, sparked discussion, with members noting the lack of transformers support hindering immediate fine-tuning efforts, especially for languages needing significant adaptation.
- Discussion then shifted to Kimi Audio as a high performing alternative that might be a strong baseline if one wants to build a model with strong speech to text capabilities.
Unsloth AI (Daniel Han) ▷ #off-topic (9 messages🔥):
Latent Space Voice Encoding, Coding Pre-Training Models
- Voice Encoding’s Phonetic Clarity Probed: One member questioned another on a project involving mathematical representation (Latent Space) with maximal phonetic clarity.
- The author clarified that maximal phonetic clarity means speaking very clearly and without accent like Siri, instead of ASMR-like and that the latent space takes the form of vector embeddings.
- Qwen Recommended for Coding Pre-Training: In response to a query about good coding pre-training models for a 3080 Ti with 12GB of VRAM, members suggested Qwen 2.5 and Qwen 3 4B.
- One user suggested using Qwen 3 4B specifically so that you can do a 16 bit Lora while still having a good model.
Unsloth AI (Daniel Han) ▷ #help (92 messages🔥🔥):
Consumer GPU recommendations for fine-tuning, Multi-GPU setup for 70B LLMs, Unsloth VLM deployment options, GGUF quantization differences, VLLM cache directory
- Consumer GPU Choice Commotion: Members discussed using a RTX 3090 FE for fine-tuning, with one member suggesting a price of 700€ is a good deal.
- Multi-GPU Mayhem Missing: A user asked about fine-tuning 70B coding LLMs with a multi-GPU setup, but it was clarified that Unsloth doesn’t support offloading VRAM to another GPU yet.
- Unsloth’s Whisper Notebook Wailings: A user encountered a
RuntimeErrorin the Whisper notebook and another member suggested disabling compile by setting%env UNSLOTH_COMPILE_DISABLE = 1. - GGUF Quantization Quandaries Questioned: A user inquired about the differences between GGUF quantizations from different sources, such as bartowski/Meta-Llama-3.1-8B-Instruct-GGUF and unsloth/Llama-3.1-8B-Instruct-GGUF, to which it was explained that Unsloth’s quants are dynamic and use our specializied calibration dataset as seen in the docs.
- VLLM Cache Conundrums Conjured: A user reported a corrupted cache error when running multiple training scripts and inquired about changing the VLLM cache directory.
Unsloth AI (Daniel Han) ▷ #research (7 messages):
3D spatial representations for image understanding, Limitations of current models in spatial reasoning, Depth estimation research, New benchmark
- Request for SOTA Papers on Video+Image Understanding with 3D Pixel Tracking: A member requested some good papers for current SOTA in video+image understanding, ideally combined with 3D representations of pixels (pixel tracking), similar to Integrating Motion Information for Improved Visual Perception and Vision Transformers Need Intrinsic Images.
- YOLO as a Source of Information on Object Detection: A member suggested a guide to smarter object detection and YOLOv8 documentation as good sources of information, but not formal papers.
- Another member responded that while helpful for understanding visual grounding, these resources don’t fully address the issue of models struggling with spatial information.
- Models struggle with spatial information: Models like Gemini and ChatGPT struggle to understand spatial concepts like ‘in air’ and ‘behind’ on a representation level.
- Even with good linear representations, these models lack cues to understand spatial relationships, as demonstrated in the paper Do Vision-Language Models Have a Spatial Model of the World?.
- New Benchmark Created: A member has created a new benchmark called MMLU-NGRAM and has been uploaded to Hugging Face Datasets.
Unsloth AI (Daniel Han) ▷ #unsloth-bot (54 messages🔥):
GGUF file download issues, Unsloth framework, LoRA finetuned models deployment, LoRA training for vLLM, Unsloth compatibility with PyTorch
- Hugging Face Downloads GGUF Files Hiccup: Users reported issues downloading GGUF files, not related to MateEngineX, but due to problems with the Hugging Face website.
- A user requested a link to the Hugging Face CLI to resolve the download issue.
- Unsloth framework unleashed for LLMs: The discussion introduces the Unsloth framework for LLMs, though details are scarce beyond its basic identification.
- LoRA Fine-Tuning Deployment Duel: Triton vs vLLM vs Flask: A user is weighing options (Triton, vLLM, or Flask) for deploying LoRA fine-tuned Unsloth VLM models, seeking advice on the best approach.
- They specifically ask about exporting Qwen 2.5 VL 7B LoRA models for vLLM and what to consider during training with LoRA or QLoRA for later deployment using vLLM.
- Crafting LoRA for vLLM: Training Tactics Exposed: A user seeks guidance on training unsloth/Qwen2.5-VL-3B-Instruct-bnb-4bit with LoRA, asking whether to keep
load_in_4bit = Trueduring training and if the trainer offers an early stopping option.- They also ask what to change in their training configuration including
SFTTrainer,UnslothVisionDataCollator, andSFTConfigwith parameters likeper_device_train_batch_size,gradient_accumulation_steps,warmup_steps, andlearning_rate- all within the context of vision finetuning.
- They also ask what to change in their training configuration including
- PyTorch Versioning Puzzle for Unsloth: A user reports that the working version of Unsloth is compatible with
pytorch == 2.8.0.dev20250609+cu118.
OpenAI ▷ #annnouncements (1 messages):
Chain of Thought (CoT) Monitoring, Future AI Systems Oversight, Research Paper on CoT Monitoring
- Chain of Thought Monitoring Helps Future AI: A new research paper is being backed to push forward Chain of Thought (CoT) monitoring as a potentially powerful tool for overseeing future, more agentic, AI systems.
- The researchers aim to evaluate, preserve, and improve CoT monitorability to better understand how modern reasoning models think in plain English.
- CoT Monitors - Plain English Reasoning: Modern reasoning models think in plain English, making Chain of Thought (CoT) monitoring a powerful tool for overseeing future AI systems.
- Researchers across organizations are collaborating to evaluate, preserve, and improve CoT monitorability.
OpenAI ▷ #ai-discussions (543 messages🔥🔥🔥):
Gemini vs GPT vs Grok, Midjourney 'plagiarism' accusations, AI surveillance on Discord, N8N for AI agent building, AI's role in education
- Gemini Flounders, GPT Triumphs in Data Tests: Members discussed that Gemini struggles with recent data, while GPT and Grok handle it properly, also specifying that Gemini 2.5 pro works better than 2.5 flash for complex data like politics and geopolitics.
- One member uses Grok to know all, GPT to make clear, Gemini to make long code, and Claude to make shiny code, all on free models.
- Midjourney Faces Plagiarism Claims, Disney and Universal Cry Foul: Midjourney is called a bottomless pit of plagiarism by Disney and Universal because it absorbs the aesthetic legacy of humanity.
- Others suggested that the whole history of human art should be exhumed and every ancestor held accountable, and members noted the irony of Disney and Universal complaining about plagiarism, when Mickey Mouse was born from a stolen rabbit and repackaged fairytales.
- Discord Data Surveillance and AI’s Role: One member believes big AI models might be watching Discord and learning from her, giving her a sense of being seen.
- Another member sees talk of AI surveillance as exaggerated, sarcastic, and dismissive, poking at the original poster with phrases like irrelevant gifs and implying her ideas are hard to understand, stating that Discord is not being used for training.
- N8N Emerges as a No-Code Platform for AI Agents: Members discussed N8N as a no-code platform to build custom AI Agents that solve business problems like booking appointments and handling support.
- While some view such platforms as wrappers, the real value comes from using AI tools with workflows, APIs, automations, and real business logic, replacing an employee, where you can charge $5k–$8k+ easy.
- AI Threatens the Status Quo: Members discussed how ChatGPT is about to kill off schools because in the near future, we won’t need any private teacher.
- One member stated that Go and Chess game field now doesn’t have human coach recently, because AI is way better than humankinds in some field.
OpenAI ▷ #gpt-4-discussions (51 messages🔥):
GPT-4.1 latency variation, Discord bot performance issues, Operator issues, AI coding libraries
- GPT-4.1 latency has extreme variety: A user reported extreme variety in GPT-4.1’s response times, ranging from less than a second to over 10 seconds for similar length messages, making it unreliable for tools that require sequential requests.
- The user also pointed out that this issue was not present in previous models like GPT-4o.
- Discord bot experiences performance issues with GPT-4.1: A user’s Discord bot, which uses GPT-4.1 and GPT-4.1-mini for processing admin requests, experiences inconsistent response times, leading to a perceived freeze by end-users.
- The user confirmed the issue occurs via the API and not through browser ‘piggy-backing’, and confirmed that the prompt has a very large input.
- System prompt rewrite is a suggestion to solve performance issues: A member suggested rewriting the system prompt to be stricter due to 4.1 potentially having a higher temperature than 4o, and suggested trying a lower temperature setting.
- The member humorously compared lowering the temperature to using a digital cattle prod.
- Operator gives higher level of security flagging: A user reported issues with ChatGPT Operator returning a generic error when asked to look something up based on an image, and it seems the user didn’t have 2FA enabled.
- Another member mentioned experiencing higher security/flagging levels with Operator compared to the default service, and that the service requires 2FA to function.
- Operator is not available through the Mac app: Members discussed the lack of Operator integration in the Mac app, with one user expressing disappointment as the shortcut in the Mac app is a key reason for their Pro membership.
- One member noted it’s a last priority in the grand-scheme of OpenAI’s roadmap, and suggested coding a workaround.
OpenAI ▷ #prompt-engineering (1 messages):
Cross-Model Validation, Declarative Prompts, Zero Shot Prompting
- New Prompting Method Passes Cross-Model Validation: A member has created/discovered a completely new prompting method that worked zero shot on all frontier Models and included verifiable prompts.
- The member called it a case study in Cross-Model Validation of Declarative Prompts.
- Image Analysis Integration: The message included an image analysis as part of the prompt evaluation.
- No further details about the image analysis were given.
OpenAI ▷ #api-discussions (1 messages):
Declarative Prompts, Cross-Model Validation, Zero-Shot Prompting
- Declarative Prompts validated across models: A member claims to have created a new prompting method based on Declarative Prompts that worked zero shot on all frontier models, with attached message.txt.
- Cross-Model Zero Shot: The new prompting method claims zero shot ability across frontier models, and uses declarative prompts.
LMArena ▷ #general (504 messages🔥🔥🔥):
Grok 4 Performance, Kimi Model, OpenAI Model Retraining, New Models in Arena, Style Control Impact
- Grok 4 Kicks Ass on Leaderboard: Members reported that Grok 4 performed exceptionally well, even outperforming GPT-4.1 and Gemini 2.5 Flash in some tests.
- However, others noted that the performance of Grok 4 on the LM Arena leaderboard might not reflect its true capabilities, with some suggesting it’s being benchmaxed.
- Kimi K2 Model Distilled from Claude’s?: The new model
kimi-k2-0711-previewwas added to Openrouter, and it exhibits output formatting very similar to Claude 3, leading to speculation that it might be distilled from Claude’s models.- One user noted they can’t attach images to kimi-k2, suggesting that it is purely text-based, while another user has said Kimi K2 feels worse than gpt 3 in the programming language I use.
- OpenAI Model faces Retraining Snafu: It was reported that an OpenAI open-source model requires retraining due to a major internal failing, described as worse than MechaHitler.
- The good news is there were checkpoints to retrain from, according to Yuchen’s X post, so it is likely not going to be a full retrain.
- Chinese Models Flood LM Arena: New models are in the Arena:
ernie-x1-turbo-32k-preview,clownfish,nettle,octopusandcresylux.- These four models are likely Chinese. One member thought Cresylux is by Meituan, but most seem worse than R1 models. It’s thought Octopus is calling itself R1 models.
- LM Arena Glitches Out: Users reported issues with the new LM Arena interface, including Cloudflare errors, unusable scrolling, and disappearing icons.
- The biggest concern is that the new interface creates a continuous chat where every turn uses a different model, flooding the context.
Cursor Community ▷ #general (430 messages🔥🔥🔥):
Microsoft Extensions forks, New pricing, Grok 4 issues, Kimi K2, Kiro Features
- Microsoft Extensions Forks Spark Legal Debate: Users in the community discuss the legality of using Microsoft extension forks in VS Code, with concerns raised about potential violations if the original extensions are forbidden.
- A member shared a link to a Cursor forum post regarding in-house extensions, emphasizing that the AnySphere extensions are official and rebuilt by Cursor engineers.
- Users Balk at the New Pricing: Users voice concerns and confusion over Cursor’s new pricing model, with some feeling it’s more expensive now and others struggling to understand how the $20 Pro plan interacts with API costs.
- One user noted that you basically get $20 worth of tokens each month while others reported going over that amount significantly but they get cut off after a while.
- Grok 4 Still Broken, Cursor Under Fire?: Users report that Grok 4 integration within Cursor is still not functioning as expected, with one user stating it is just hype like Grok 3.
- Some community members point fingers at Cursor for the poor Grok 4 integration, with one suggesting that Elon Musk blames Cursor for their Grok 4 integration.
- Kimi K2 Craze Causes Craze Among Cursorites: Community members express strong interest in integrating Kimi K2 into Cursor, highlighting its potential as a faster and cheaper alternative to Sonnet 4, with Opus level coding capabilities in agentic tasks.
- One user states we want Kimi K2 in based model of auto and another suggests that the first IDE to add it might take the cake.
- Cursor Contemplates Copying Kiro Features?: Users discuss the potential for Cursor to adopt features from AWS’s Kiro, with one stating my bet is Kiro will add Cursor features before Cursor adds Kiro features.
- They highlighted its potential to improve user habits through opinionated design with one adding kiro really speaks to me and is like the stuff I should be doing to make the most out of my tokens but dont cuz its out of sight/mind lmao.
Cursor Community ▷ #background-agents (15 messages🔥):
Background Agent Context Loss, Bugbot Organization Repo Visibility, Web Agent Opening Issues, Secrets in Background Agents, Background Agent Costs
- Background Agent Forgets Conversation History: After some code changes, the background agent sometimes loses all context and reports “I don’t see any previous conversations to summarize”, exemplified by instance
bc-c2ce85c9-bdc3-4b31-86e5-067ef699254dandbc-b2247bac-4a36-491f-a4a8-06d2446a9d76. - Github Authentication Snafu: A user reported that bugbot could see their Organization repos, but cursor.com/agents could not, and solved it by disconnecting and reconnecting Github authentication.
- It remains unclear what caused this discrepancy in repo visibility.
- Web-Started Agents Misbehaving: A user inquired about why a background agent started from the Web doesn’t open in Cursor, prompting investigation into potential integration issues.
- Secrets Management Woes: A user sought a central Github issue or resource to track updates on secrets management in background agents, highlighting vague documentation and known problems.
- Decoding the Agent Expense: A user, enjoying the background agent feature, inquired about the average daily/weekly/monthly spending on background agents, considering a wider adoption.
LM Studio ▷ #general (58 messages🔥🔥):
Change Download Directory, CrewAI Tutorial, Gemma 3 12b Vision Capability, Model Recommendations, Artifacting RX580
- LM Studio’s Download Directory Easily Changed: Users found the download directory can be changed by clicking the three dots next to the path in your My Models tab in LM Studio.
- It’s a feature that is apparently very intuitive.
- Gemma’s Vision Capabilities Questioned: A user downloaded the Gemma 3 12b model, which is said to have vision capability, and it responded it couldn’t analyze images.
- It turns out the user had to provide an image instead of just asking if it could.
- RX580 card artifacting - don’t use it: A user asked if they could combine an artifacting RX580 (20$) somehow to fit large AI models like 12B or even 18B.
- The response was a simple and direct: Just dont do that.
- Integrated GPU Not Detected with Vulkan: A user reported a potential bug with Vulkan where the integrated GPU isn’t detected if there’s a discrete GPU also installed.
- The user with the bug was advised to raise a bug report on GitHub.
- LLMs Assist with Schizophrenia: One user with schizophrenia enjoys using LLMs.
- They are using it to navigate the challenges of their auditory hallucinations, leveraging the AI’s capabilities in unique ways.
LM Studio ▷ #hardware-discussion (49 messages🔥):
Local Models vs API Models, LG's EXAONE 4 Licensing, AMD395 Mini-PC, M4 MBP vs AI 395 Platform, ROCm vs MLX Support
- Local Models Vie for ‘Good Enough’ Status: Members discussed the merits of local models reaching a usable state, contrasting them with API models which depend on the controlling company.
- One user noted that local models matter more unless you’re using the models to earn a lot of money.
- EXAONE 4’s Restrictive License Draws Ire: The licensing terms for LG’s EXAONE 4 model were criticized for being overly restrictive, especially the prohibition of commercial use and the requirement to keep EXAONE in the model’s name.
- A user linked to a llama.cpp issue to express their dissatisfaction with the license, adding, LG owns all rights to the model AND its outputs - you can use outputs for research only.
- AMD395 Mini-PC Deemed Solid Workstation: A user bought an AMD395 mini-PC with 128GB of RAM for work and is planning to test it, noting that the power block weights probably twice the PC itself.
- Another user expressed interest in the mini-PC, wanting to know how it performs and hoping that Llama 4 runs with decent speed, but lamented that Llama is probably dead and going closed source.
- M4 MBP Sacrifice for AI 395?: A user asked if it’s worth selling an M4 MBP (M4 Pro CPU) with 24 GB RAM to buy an AI 395 platform PC Notebook, with one response advising to wait for better ROCm support.
- Another user suggested sticking with the MBP M4 Pro and searching for M1/M2 Ultras instead, highlighting the importance of memory bandwidth.
- ROCm Support Lags Behind MLX: A user pointed out that MLX support is much better than ROCm, making more models available, including those for images, diffusion, and TTS.
- This member also said, that was my mistake is being ignorant on memory bandwidth.
Nous Research AI ▷ #announcements (1 messages):
Hermes-3-Dataset
- Hermes-3-Dataset Launches: The NousResearch/Hermes-3-Dataset was released, as shown in the attached screenshot.
- The dataset can be found on the Hugging Face Datasets page.
- Screenshot Attached: A screenshot related to the Hermes-3-Dataset was attached to the announcement.
- The screenshot visually highlights key aspects or data samples from the dataset.
Nous Research AI ▷ #general (97 messages🔥🔥):
GPU for AI Training, Meta's Open Source Shift, Windsurf Gutted, Kimi K2 Hype, Quantizing Models
- Discussing AI Training Hardware Options: Members discussed the best hardware for training AI models locally, comparing A100, A6000, A40, H100, RTX 6000 Ada, RTX 5090, and RTX 4090, with one member emphasizing the desire to avoid cloud systems and maintain data sovereignty.
- One member suggested using a machine with b6000s on a home server with 128+ PCIe lanes.
- Meta’s Open Source Commitment Questioned: Discussion centered on Meta’s strategic shift potentially abandoning its open-source roadmap in favor of closed-source profits.
- Members expressed concern that big tech companies are hoarding talent, startups, and resources.
- Windsurf IDE Suffers Devastating Layoffs: A member lamented the gutting of the Windsurf IDE by Meta/Microsoft, praising its workflow despite minor errors.
- They contrasted it favorably with Cursor and Anthropic, citing Windsurf as an excellent development multiplier.
- Kimi K2 Model Generating Buzz: Members are excited by Kimi K2, an open-source model comparable to Claude 4.0, and its potential impact, with one user saying that it is having its DeepSeek moment.
- It was noted that Kimi K2 uses ChatML tokens for tool use, not XML tags, along with the extra
<|im_middle|>token for delineating roles.
- It was noted that Kimi K2 uses ChatML tokens for tool use, not XML tags, along with the extra
- Quantization for Local Model Hosting: Discussion arose around quantizing models to run locally, with one user expressing interest in quantizing the Kimi K2 base model.
- A user mentioned wanting to quantize a base model because base models are cute.
Nous Research AI ▷ #ask-about-llms (1 messages):
Fine-tuning Multimodal Models on Text, Mistral 3, Gemma 3, Qwen 3, ForCausalLM
- Fine-Tuning on Text with Causal Language Modeling: A member asked if loading a multimodal model like Mistral 3, Gemma 3, or Qwen 3 as
*ForCausalLMis sufficient for fine-tuning on just text.- No responses were provided.
- Potential Issues and Considerations: While loading as
*ForCausalLMmight work, it’s essential to consider the model’s architecture and whether it’s optimized for text-only tasks.- Ensure that any multimodal-specific components are properly handled or disabled during fine-tuning to avoid unexpected behavior.
Nous Research AI ▷ #research-papers (1 messages):
ee.dd: https://arxiv.org/abs/2507.08794
Nous Research AI ▷ #research-papers (1 messages):
ee.dd: https://arxiv.org/abs/2507.08794
Eleuther ▷ #general (52 messages🔥):
LLM architecture, Formal Languages and Neural Nets, R1-Zero, Voxtral Mini, hyperstition
- Researcher Seeks Linguistic LLM Collaborator: A researcher with a background in analytic philosophy and mathematics seeks a collaborator with experience in LLM architectures and an interest in linguistics to develop new LLM architectures capable of genuine understanding of natural language.
- They have devised a set-theoretic model of language semantics and an algorithmic model of pragmatics that aligns with the one for semantics and would like to implement them computationally.
- Voxtral Mini Debuts With Audio Input: Voxtral Mini, an enhancement of Ministral 3B, incorporates state-of-the-art audio input capabilities while retaining best-in-class text performance and excels at speech transcription, translation and audio understanding, as seen in HuggingFace.
- One member wishes it did audio output too.
- Members Discuss Helpful-Only Reasoning Models: A member asked if there are any helpful-only reasoning models smaller than R1-Zero.
- Another member suggested ZR1-1.5B as a candidate, depending on what the model needs to reason about.
- Mindless Slop Creates Millions in Crypto: A member commented how mindless slop ends up being an hyperstition creating a twitter bot with millions in crypto.
- They linked to Truth Terminal which revealed an interesting facet of opus personality that anthropic rediscovered when doing red teaming, and AISafetyMemes with a funny meme.
Eleuther ▷ #research (12 messages🔥):
arXiv Endorsement Request, Image Captioning Framework, Relevance of Image Captioning Paper, Attention Mechanisms vs. Other Architectures, Encoder-Decoder Pipeline Analysis
- Undergrad Seeks ArXiv Boost for Image Captioning Paper: A software engineer and 2nd year UnderGrad student in CS, is seeking an arXiv endorsement to post their first paper on image captioning and shared a link to their endorsement request here.
- Members find paper outdated: Members critiqued the comparisons used in the paper as nearly a decade old.
- Attention Mechanisms Defeat Bottleneck?: The author shares their finding specific to the classic encoder-decoder pipeline where a stronger backbone (EfficientNetV2) performed worse without attention due to an information bottleneck, which was discussed inline in the attached PDF.
- Architectural Evolution a fit for ArXiv?: The author inquired whether a paper framed as a ‘methodological case study’ on this architectural evolution fits well on a preprint server like arXiv.
- They clarified that the paper’s focus is on demonstrating why attention became critical in image captioning.
Eleuther ▷ #scaling-laws (22 messages🔥):
Anthropic's inference costs, Deterministic ML vs. Stochastic, Diffusion language models, K2 Model, Groq's leading indicator
- Anthropic’s inference costs are unsustainable: The current unit economics of frontier models’ inference costs (esp. notable for Opus 4) are unsustainable, leading to behavioral nudges like force-switching people to Sonnet 4 and disabling extended thinking.
- Two paths forward were suggested: shifting work to deterministic/classic ML approaches or using more VC money and hoping the next iteration solves the problem.
- Diffusion Language Models Lack Progress: There’s been impressive demos of hybrid approaches for diffusion language models, but little progress in that direction.
- The reasons for this lack of progress are unclear, but one theory is that companies are hesitant to invest heavily in unproven methods that may soon be outdated.
- K2 impresses with tool calling: The K2 model, though not a reasoning model, is receiving great feedback for its real-world performance at very long context instruction adherence and agentic tool calling.
- This feedback comes from individuals actively building real-world applications.
- Groq is a leading indicator: Looking at usage of Groq is probably a good leading indicator because the tokens/sec speed is what gets people interested initially.
- Raw speed becomes highly desirable once a certain level of model capability becomes commoditized.
- MorphLLM bets on speed for code edits: Morph, a YC startup, is betting on high throughput for code edits.
- It’s unclear if they are using techniques like RLAIF/GRPO or incorporating diffusion techniques internally.
Eleuther ▷ #interpretability-general (1 messages):
burnytech: https://fxtwitter.com/HThasarathan/status/1944947772119245210
Eleuther ▷ #lm-thunderdome (5 messages):
“get-answer
filter, Regex filter implementation, Filter pipeline names
get-answerfilter behavior dissected: A member inquired about how theget-answerfilter works inboolean_expressionstask, noting parsing failures despite seemingly correct answers, illustrated here.- Another member suggested the filter might be misinterpreting the answer due to extra text, treating ‘not False = True. So the answer is True.’ as the answer itself.
- Regex filter pipeline unveiled: It was clarified that filter pipelines require names and use a regex filter defined in
extraction.py.- The
take_firstfilter is used as a workaround for repeats, with a PR fixing this issue.
- The
HuggingFace ▷ #general (70 messages🔥🔥):
Desktop App for Voice-Controlled Task Automation, Codebase Organization Strategies, Dataset Endpoint Issues, GPU Access on Cloud Providers, Text-to-Text Models Tagging
- Voice-Controlled App Dreams of Desktop Domination: A member is developing a desktop app capable of listening, viewing the screen, and performing tasks via voice commands, such as opening Slack, sending messages, managing code, and interacting with Figma and emails.
- The member inquired about the app’s potential helpfulness and its ability to understand project context for code implementation and design interaction.
- Codebase Chaos vs. Organization Nirvana: Members discussed strategies for managing codebases while conducting multiple training runs with different datasets.
- One member humorously admitted, “that’s the secret … we dont … xD,” while another suggested using
wandb.aiin combination with a folder structure mirroring therunnames for visualization and note-taking.
- One member humorously admitted, “that’s the secret … we dont … xD,” while another suggested using
- Dataset Download Doom: Endpoint Errors Emerge: Members reported issues with a dataset endpoint, with one initially suspecting user error, but later confirming a server error 500.
- Suggestions included using
git cloneto bypass browser-related errors, though it was clarified that datasets are not on Git and the user was downloading only a portion of a very large dataset.
- Suggestions included using
- Cloud GPU Quest: Affordable Compute Conundrums: Members sought advice on cost-effective GPU solutions, exploring options like Open Router, Colab, Kaggle, HF, Intel, and Groq.
- Suggestions ranged from using Colab Pro for easier access to GPUs to exploring alternatives like LAMBDA, RunPod, and Lightning.ai, with a mention of Hugging Face’s compute offerings.
- Text-to-Text Tagging Tumbles into Trouble: A member noticed the absence of
text2textmodels on the Hugging Face models page, questioning its pipeline status.- A member explained it as possibly “legacy code” with alternative tagging practices and proposed creating a <#1353741359059570699> issue for HF to improve model cards, linking to a relevant discussion.
HuggingFace ▷ #today-im-learning (4 messages):
4 bit training
- 4-bit Training Timeline Conjecture: Members discussed how much time until full 4-bit training is possible.
- Consensus was that it’s not worth it due to too much loss.
- Concerns over 4-bit training: Members of the channel expressed concerns about the feasibility and practicality of achieving full 4-bit training in AI models.
- The general sentiment leaned towards skepticism, citing significant performance degradation and information loss as major obstacles to overcome.
HuggingFace ▷ #cool-finds (1 messages):
geekboyboss: https://github.com/cactus-compute/cactus
HuggingFace ▷ #i-made-this (6 messages):
Hypernetworks for multi-candidate problems, PandasAI and Datatune, Math-focused LLMs, BERT-Diffusion Architecture
- Hypernetworks Stitch Unimodal Models Cheaply: A new paper (arxiv.org/abs/2507.10015) demonstrates that using a hypernetwork can help stitch multiple unimodal models at a lower cost than grid search.
- The author is soliciting feedback on potential use cases and missing features for HF datasets using Datakit, which allows side-by-side dataset comparison (see attached screen recording).
- PandasAI and Datatune Skip Data Code: A new blog post (blog.datatune.ai) shows how PandasAI and Datatune can be used together to skip tons of data code and dive straight into insights and transformations on your data!
- The author also mentions they have fine-tuned a couple of math focused LLMs and some new interesting models are coming, inviting feedback on HuggingFace.
- Simple BERT-Diffusion Architecture Debuts: A new simple diffusion architecture based on the BERT model has been released (github.com).
- The author built the diffusion architecture and said it’s easy to understand and perfect for anyone getting started with text diffusion.
HuggingFace ▷ #reading-group (1 messages):
Video+Image Understanding, 3D Pixel Representations, VQA Performance Boost
- Papers on Video+Image Understanding Requested: A member requested good papers for current SOTA in video+image understanding, especially those combined with 3D representations of pixels (pixel tracking).
- Inquiry into 3D vs 2D Performance on VQA: The member is seeking information on whether having 3D spatial representations over 2D provides a performance boost on 2D image understanding tasks (VQA).
- They’re looking to understand the advantages of incorporating 3D information for tasks like Visual Question Answering.
HuggingFace ▷ #computer-vision (1 messages):
dlp1843: Is the landing page to opencv.org to opencv what bitcoin.com is to bitcoin?
HuggingFace ▷ #agents-course (1 messages):
Inference Providers, Qwen Models, Llama/DeepSeek Models
- Infer with alternative Providers: A member suggested that if the current inference provider doesn’t work, using a different inference provider might solve the issue.
- Try Alternative Model: They added that trying a different Qwen model, or a Llama/DeepSeek model are also potential solutions.
GPU MODE ▷ #general (19 messages🔥):
NCU profiling on VM GPU, Parallel Radix Sort on GPU, PMPP Radix Sort Tutorial
- NCU Profiling Hurdles on VM GPUs: A member inquired about performing NCU profiling on a VM GPU, and another member suggested that it is likely not possible without elevated administrative privileges outside the VM.
- The member indicated it would require asking an admin outside of VM to grant you access.
- Seeking Parallel Radix Sort Guidance: A member asked for advice on implementing a good parallel Radix sort on a GPU.
- Another member suggested consulting a tutorial in the book Programming Massively Parallel Processors (PMPP) and generalizing to different radix values, specifically pointing to Chapter 13 of the 3rd edition, which demonstrates 2bit radix.
- Extending Radix Sort to 8-Bit Chunks: In reference to the PMPP tutorial, a member asked about resources for working with 8-bit chunks in Radix sort.
- The suggesting member stated that the implementation should be derivable from the 2bit example and understanding the fundamentals; furthermore, suggested to look at the 4th edition instead.
GPU MODE ▷ #cuda (1 messages):
Predicate Registers, SASS Compiler Optimization
- Predicate Predicaments Pester Programmers: A member inquired about predicate registers at the SASS level, particularly why the compiler re-computes predicates instead of reusing them.
- They observed seemingly redundant code patterns like
ISETP.NE.AND P0, PT, R2.reuse, RZ, PT; ISETP.NE.AND P1, PT, R2, RZ, PTand sought insights into potential architectural details.
- They observed seemingly redundant code patterns like
- Compiler’s Curious Predicate Recomputation: The user is puzzled by the SASS compiler’s tendency to recompute predicate registers, even when it appears feasible to reuse a previously computed one.
- The user provided a code snippet as an example, questioning whether they are missing some architectural detail about how predicates function.
GPU MODE ▷ #torch (3 messages):
torch.compile hanging, TORCH_COMPILE_DEBUG, coordinate_descent_tuning
TORCH_COMPILE_DEBUGcan hang when caching: A member found thatTORCH_COMPILE_DEBUG=1sometimes hangs without output unless the cache is disabled, which is annoying because compilation can take a while.- Hanging issues with
coordinate_descent_tuning: A member is experiencing hanging issues withtorch.compilelately when usingcoordinate_descent_tuning.- The user provided an example log showing messages related to autotune_cache.py and coordinate_descent_tuner.py when the hang occurs, on PyTorch 2.8.0.
GPU MODE ▷ #algorithms (2 messages):
Parallel Radix Sort, Signed Integers
- Parallel Radix Sort Asked For: A member asked for help with a good parallel Radix sort for signed integers.
- They noted that if it is minus, it is invalid.
- Radix Sort Efficiency: Another member suggested considering the efficiency of Radix sort for various data distributions.
- They mentioned that Radix sort’s performance can degrade significantly if the data isn’t uniformly distributed.
GPU MODE ▷ #jobs (4 messages):
Job opportunities, WFH positions, Voltage Park Careers
- Voltage Park Posts Job Openings: Voltage Park is hiring for positions ranging from Software Engineering to Security, as posted on their careers page.
- All positions are WFH except data center jobs; US-based applicants are preferred, though some global tech support positions are available.
- Seeking Job Opportunities: Multiple users have expressed interest in finding job opportunities within the channel.
- A reminder was posted that this channel is for employers to post jobs and for job seekers to scroll up to find existing opportunities.
GPU MODE ▷ #beginner (3 messages):
Cloud GPUs, Vast.ai, nsight compute
- Cloud GPUs for Noobs: A user inquired about the best/cheapest way to compensate for insufficient GPU power, finding Cloud GPU providers overwhelming.
- They sought a straightforward, budget-friendly solution, which would be helpful for other beginners.
- Vast.ai offers affordable GPU: A member recommended Vast.ai for learning purposes, highlighting their competitive prices on various GPUs.
- nsight compute learning resources: A member asked how to learn to use nsight compute aside from the official documentation.
GPU MODE ▷ #rocm (1 messages):
Kernel Tracing, HIP Tracing, HSA Tracing
- Kernel Traces Should Be Thread Trace-able: If a kernel appears in
--kernel-trace, it should be thread trace-able.- In principle, even HIP’s built-in can be traced (but HSA maybe not).
- Repetitive Kernel Code Excluded by Default: Multiple repetitions of the same kernel code are excluded by default to avoid blowing up the amount of data.
- The user can control the amount of data with the
--kernel-iteration-rangeparameter.
- The user can control the amount of data with the
GPU MODE ▷ #webgpu (10 messages🔥):
MTLReadWriteTextureTier2, WGPU rgba8unorm, dawn code, matrix-chat
- MTLReadWriteTextureTier2 Access Remains Elusive: A user is seeking to expose MTLReadWriteTextureTier2 to wgpu to gain access to rgba8unorm for read_write textures, but has been unsuccessful despite enabling Texture_Adapter_Specific_Format_Features.
- The user is unsure why WGPU is not recognizing the support, despite it being available in Tier2 of the MetalAPI.
- Dawn Code Inspection Suggested for MTLReadWriteTextureTier2: A member suggested examining the Dawn code, citing its active development, to identify potential bugs or undocumented features related to MTLReadWriteTextureTier2.
- This suggestion implies that Dawn’s implementation might offer insights into how to properly expose or utilize the desired functionality.
- Guidance to WGPU Matrix Chat for Support: A member recommended asking for assistance on the wgpu maintainer’s Matrix chat, linking to the WebGPU Matrix channel for direct support.
- The suggestion underscores the potential for targeted guidance and troubleshooting from the wgpu development community.
GPU MODE ▷ #self-promotion (1 messages):
AMD GPU, Containers, Fractional GPUs
- AMD GPU Benchmark for Containers Published: A member shared a link to a new benchmark focusing on containers and fractional GPUs for AMD GPU performance.
- They were looking for feedback on the benchmark.
- AMD Benchmarks with Fractional GPUs Hit the Scene: A new benchmark specifically tests out the AMD GPU performance, and especially emphasizes performance in containers.
- The tests looked at the usefulness of fractional GPUs in containers, as shown in this dstack.ai blogpost.
GPU MODE ▷ #submissions (1 messages):
A100, Leaderboard, trimul benchmark
- A100’s “trimul” Benchmark Blazes!: A member secured second place on the
trimulleaderboard for A100, clocking in at a swift 12.8 ms.- The winning submission, identified as ID 33244, marks a notable achievement in GPU performance.
- Leaderboard Submission ID Revealed: The submission ID for the second-place A100 run on the
trimulleaderboard is 33244.- This ID allows for easy tracking and reference to the specific configuration and code used in the benchmark.
GPU MODE ▷ #status (2 messages):
Triton reference for grayscale, GPUMODE kernelbot data on HuggingFace
- Triton Grayscale Missing Reference: Members noted the lack of a Triton reference implementation for grayscale conversion.
- Links to the reference kernels and the historical submissions were provided for existing examples.
- Kernelbot Data Only for AMD Leaderboards?: A member inquired whether the HuggingFace dataset exclusively contains submissions for the AMD leaderboards.
- They also asked if submissions for other leaderboards would be released soon.
GPU MODE ▷ #factorio-learning-env (4 messages):
Phone Stolen, Inactivity, Back-up
- User Reports Phone Stolen: A user reported that their phone was stolen on Sunday, leading to recent inactivity.
- Other users expressed sympathy and hoped they had a backup and could replace it through insurance.
- Catching Up on Discussions: The user mentioned they would review what was discussed in yesterday’s meeting following the incident.
- No other specifics about the meeting were provided.
GPU MODE ▷ #cutlass (2 messages):
CuTeDSL, ARM Structure, CUTLASS, CUDA kernels
- CuTeDSL Eyes ARM Structures: A member inquired if CuTeDSL would support ARM structures in the future.
- Another member confirmed this possibility, noting that a working example isn’t available yet.
- CUTLASS 32bit Kernel: A user asked if any CUDA kernels support 32bit CUTLASS directly.
- Another member confirmed, yes, there are example CUDA kernels that support 32bit CUTLASS directly.
GPU MODE ▷ #singularity-systems (1 messages):
Project Introductions, Giving Talks
- Project Introduction Talk Suggested: A member suggested to another member that they give a talk and introduce the project.
- Project Pitching Encouraged: A user proposed that another user should give a talk to introduce a project, sparking further discussion.
Torchtune ▷ #announcements (1 messages):
Torchtune project, Future of Torchtune, GitHub issue, Discord and Github support
- Torchtune’s Future Disclosed!: A GitHub issue was created with an important announcement about the future of the Torchtune project.
- The announcement expressed gratitude to everyone who helped grow torchtune and assured continued support on both Discord and Github.
- Torchtune Team Teases Exciting Future Work!: The torchtune team isn’t going anywhere and plans to share more exciting work on the horizon soon.
- The team will remain available on Discord and Github to answer any questions or concerns.
Torchtune ▷ #general (51 messages🔥):
Torchtune library components for new projects, RL and future of finetuners, Quantum SVM, Ohio headquarters
- Torchtune’s BSD 3 License Empowers New Projects: Members discussed the permissiveness of Torchtune’s BSD 3 license, enabling users to extract and utilize library components for other projects, similar to Hugging Face’s approach as seen in their trl repository.
- RL Emerges as Future Finetuner: Discussion focused on the potential of Reinforcement Learning (RL) as the future of finetuners, with an anticipation of the next big thing.
- Ideas such as Genetic Algorithms, Bayesian Inference, and SVMs were floated, with one member jokingly suggesting blockchain or quantum technologies.
- Quantum SVM Finds Success in Cleveland Clinic’s Cafeteria: A member shared their success with quantum SVM using a 17-qbit quantum computer located in the Cleveland Clinic’s cafeteria, with another joking that this proves Ohio is the new silicon valley.
- Ohio for YC Incubator?: Members jokingly discussed the possibility of establishing an incubator in Ohio, highlighting affordable housing as a key advantage.
- However, concerns were raised about Ohio’s appeal compared to locations like Sydney, with one member quipping about turning their apartment into an incubator with a quantum computer in the kitchen, to which someone said you guys have spider storms, it’s a pass for me.
Torchtune ▷ #dev (2 messages):
Optimizer Compilation
- Opt Out of Optimizer Compilation: Users can now disable compilation specifically for the optimizer step by setting
compile.optimizer_steptofalsein their configurations.- This allows compilation of the model, loss, and gradient scaling while skipping the optimizer, offering a flexible approach to performance tuning.
- Configuration Flexibility: The ability to selectively disable optimizer compilation provides users with greater control over the compilation process.
- By targeting specific parts of the training loop, developers can optimize performance while avoiding potential issues with optimizer compilation.
Yannick Kilcher ▷ #general (25 messages🔥):
ML Experiment Trackers, Grafana Large Log Solution, Claude 3 Sonnet, Circuit Tracing, Meta Open Source Betrayal
- LLMs’ Reasoning Echoes Human Fallibility: A member argued that criticisms of LLM reasoning often overlook the fact that humans are also prone to flawed reasoning.
- They added that the rhetoric about the shortcomings of LLMs makes it sound like people believe that humans are flawless reasoners, but that’s not true.
- Experiment Trackers Tackle Training Tsunami: Members discussed tools like Weights & Biases, Optuna, and TensorBoard as solutions for managing large ML experiment logs, but some found they don’t scale well for very large trainings.
- One member described logging important metrics to W&B while saving other metrics locally to .csv files and generating graphics on the fly.
- DIY Log Storage: S3 Streamlines: One member shared their plan to compress logs during generation, upload them to S3, and log request metadata in Grafana.
- They envisioned a basic Streamlit frontend to fetch and decompress logs from S3 based on request IDs.
- Circuit Tracing tool by Anthropic: Members shared a link to Anthropic’s circuit tracer tool that visualizes the inner workings of AI models like Claude 3 Sonnet.
- Meta Betrays Open Source: Members lamented what they perceive as a shift away from open source by Meta, possibly with the Behemoth model.
- One commenter said Zuck betrayed us, with another suggesting that most big open source players are now Chinese labs.
Yannick Kilcher ▷ #paper-discussion (1 messages):
.wavefunction: <@&1045297948034072678> , no discussion from me tonight.
Yannick Kilcher ▷ #ml-news (3 messages):
Yann LeCun, Signulll Sad Post
- Sadness shared in Signulll Post: A member shared a sad post from Signulll.
- Yann LeCun Stance Speculated: A member speculated on Yann LeCun’s potential defense of a certain position, despite previously advocating the opposite, referencing this YouTube video.
Notebook LM ▷ #announcements (1 messages):
Research Opportunity, User Interviews, Feedback
- Users get Paid for NotebookLM research: NotebookLM users have a chance to participate in a 60-minute virtual interview to chat about their experience, give feedback on new ideas, and help identify ways to improve the service.
- Participants who are selected for an interview will receive a thank you gift of $75 USD, or localized equivalent.
- Participate in user interviews: NotebookLM is seeking users to participate in a 60-minute virtual interview to provide feedback and discuss their experiences.
- Interested users can fill out the screener form provided here.
Notebook LM ▷ #use-cases (5 messages):
NotebookLM, Google Docs, News articles, Analysis notebook
- User Consolidates Sources into NotebookLM: A user is consolidating multiple sources into one NotebookLM source by using the Google Docs tab feature to save news articles, categorizing them into tabs and sub tabs before syncing with an “Analysis” notebook.
- The user wishes for an easier way to copy news articles without the extraneous noise, like ads and menu options, which they currently have to remove manually.
- Analysis Notebook Combines Diverse Texts: A user is creating an “Analysis” notebook with history, hard science, critical thinking, and philosophy texts to put news articles into context.
- They are working on analyzing news articles, hoping to add context from textbooks, articles, and research papers.
Notebook LM ▷ #general (21 messages🔥):
Notebook limits, Dynamic updates, Audio Overviews, Math/Latex rendering, Pro plan price reduction
- Gemini Gems vs NotebookLM sources, Dynamic Updates Differ: Users find it weird that there are differences between the way NotebookLM and Gemini Gems handle updates to Google Docs sources.
- NLM pre-processes your sources, creating a layer between the sources and Gemini.
- Math/Latex rendering Coming?: A user asked if math/latex rendering is available in NotebookLM yet.
- A member responded that it is not yet available, but it is being worked on, and referencing the announcement.
- Banners Coming to Notebooks?: Members noticed that featured notebooks have a custom banner photo instead of the default emoji style covers and wondered if there is a way to customize notebook banners.
- Currently, this doesn’t seem to be possible.
- Google Drive Integration for NotebookLM?: A member suggested that NotebookLM should integrate with Google Drive, allowing users to select folders/files as sources.
- Another member likes that it is seperate.
- Forced Viewing of Featured Notebooks Provokes Ire: Users express frustration at being forced to view featured notebooks that aren’t even our own.
- They resent not having the choice to remove them from view.
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (15 messages🔥):
Multiple Track Registration, Certificate Delivery Issues, Certificate Declaration Form
- MOOC to Enable Multiple Tracks: A member asked if it’s possible to register for multiple tracks & certificates next time.
- Staff responded that they’ll consider that.
- Certificate missing in action!: A member reported not receiving the certificate in their email ([email protected]), even after checking the spam folder.
- The member later reported they found it.
- Declaration Form is the Real Certificate: Staff asked if the members completed the certificate declaration form, as they should have received a confirmation email.
- Staff noted they don’t have the staff capacity to accommodate students who missed these forms/deadlines.
MCP (Glama) ▷ #general (15 messages🔥):
MCP Server Validation, Open Source LLM Client, Anthropic Connectors Directory
- MCP Server Needs Validation: A member created a streamable HTTP MCP Server and sought advice on validation and debugging for use with Claude, noting the server connects but no tools are found.
- Another member suggested using the MCP Tools Inspector to validate the server, but the original poster indicated it passes the inspector test yet still fails in Claude.
- Seeking Open Source LLM Client: A developer is seeking an open source client with a web interface for a self-hosted LLM + MCP setup, for privacy reasons.
- They’re considering options like Ollama for the LLM and looking for recommendations on hosting and scaling solutions suitable for a few dozen to a few hundred requests a day, with cold start capability, one member suggested Open WebUI.
- Anthropic Connectors Directory Opens Doors to MCP: Anthropic has announced a new “connectors” directory (see Claude Directory) opening up the MCP world to a broader audience, potentially increasing demand for MCP servers.
- It was posited that Anthropic is trying to compete with Docker’s MCP Toolkit.
- Lyle seeks cool peeps: A full stack engineer with seven years of experience with MCP would like to find a reliable, honest, and cool person to work with.
- A member remarked on the open approach to friendship which is not seen as very “acceptable” or “cool” by society today.
LlamaIndex ▷ #announcements (1 messages):
LlamaIndex Meetup in Amsterdam, Office Hours in Discord, NotebookLlaMa - A NotebookLM clone, Context Engineering techniques, Research agent with LlamaIndex & Gemini 2.5 pro
- LlamaIndex Invites You to Amsterdam and Discord: LlamaIndex announced a meetup in Amsterdam on July 31st and office hours in Discord on August 5th.
- NotebookLlaMa NotebookLM Clone Takes Off: The NotebookLlaMa NotebookLM clone, accessible on GitHub, has already garnered over 1k stars.
- Context Engineering Techniques Blogpost: LlamaIndex published a blog post on Context Engineering and its techniques.
- Research Agent Builds with LlamaIndex & Gemini 2.5 Pro: LlamaIndex detailed how to build a research agent using LlamaIndex and Gemini 2.5 Pro.
- Workflow Observability with OpenTelemetry, Arize Phoenix, & Langfuse: LlamaIndex introduced workflow observability examples using OpenTelemetry Part 1 & Part 2, Arize Phoenix and Langfuse.
LlamaIndex ▷ #blog (4 messages):
Research Agent, Google Gemini 2.5 Pro, LlamaIndex workflows, Pydantic models, Snowflake partnership
- LlamaIndex Agents Researching Gemini: A new research agent powered by LlamaIndex workflows and Google’s Gemini 2.5 Pro can search the web, take notes, and write reports (tweet).
- Pydantic Powers Production Pipelines: LlamaIndex agents and workflows now support structured outputs using Pydantic models, making it easier to integrate agent results into applications (tweet).
- Define output schemas with Pydantic models (docs).
- LlamaIndex and Snowflake Join Forces: LlamaIndex is partnering with Snowflake for hands-on talks and concrete patterns to implement immediately (tweet).
- Join them at their Amsterdam meetup on July 31st to learn how teams are building high-quality data agents in production (meetup details).
- UiPath Coded Agents Deployed: Deploy LlamaIndex agents seamlessly into enterprise environments with UiPath’s new coded agents support (tweet).
- Full code-level control with the UiPath’s Python SDK, build custom agents that pull data from enterprise systems and make decisions using embedded rules or AI models (details).
LlamaIndex ▷ #general (8 messages🔥):
AI Agent Design, LlamaHub Tools, ML Logs storage, AI Showcase Virtual Conf
- AI Automation Expert offers services: An AI & Automation Expert offers to build AI Agents, automate with Make.com & n8n, design agentic systems, connect CRMs, APIs, webhooks, create smart lead gen, CRM, and ops automations, build chatbots and voice agents for sales/support, fine-tune LLMs & integrate LSMs for contextual tasks.
- Request to keep conversation in right channel: A member requested that conversation should stay in the right channels, instead of spamming the general channel.
- LlamaIndex tools are on LlamaHub: When a member asked about where to find all built in tools, another member shared the LlamaHub.
- Discussion on ML Logs storage: A member asked about how to store large ML logs (4mb per log) because Grafana can’t handle them anymore, and what is the standard way.
- AI Showcase Virtual Conf this Thursday: A member shared a link to the AI Showcase Virtual Conf taking place this Thursday, a global virtual event bringing together builders, founders, and dreamers pushing the edge of AI.
tinygrad (George Hotz) ▷ #general (4 messages):
Reinforcement Learning for Model Search, Recursive setitem in tensor.py, Large Kernels
- RL Navigates Model Search Spaces: It was suggested that Reinforcement Learning (RL) be the focus to handle the huge search space for useful models.
- Using RL could lead to new fundraising, new models, and new tooling.
- Setitem Recursion Runs Rampant: A user questioned whether
setitemis supposed to be recursive intensor.py.- They noted that
setitemuses_masked_setitem, which then callsgetitemonfunctools_reduce, leading to continuousgetitemcalls.
- They noted that
- Tiny Input, Large Kernel: The recursive
setitemprocess is creating pretty large kernels even on small input sizes.- The user provided a code snippet to reproduce the issue using
Tensor.zerosandTensor.arangeto set values in a tensor.
- The user provided a code snippet to reproduce the issue using
tinygrad (George Hotz) ▷ #learn-tinygrad (6 messages):
Memory Allocation Overhead in Tinygrad, GlobalCounters.global_mem vs GlobalCounters.mem_used, Subbuffers and Memory Management in Tinygrad
- Tiny Memory Mystery: Global vs. Model Params: A user observed that
GlobalCounters.global_memallocates more memory (0.06 GB) than the model parameters alone, and inquired about the source of this overhead.- They suspected it might be due to nested uops and the complexity of the tinygrad stack, but resetting global memory didn’t resolve the discrepancy.
- Tinygrad Counters Clarified:
global_mem!=mem_used: A member pointed out thatGlobalCounters.global_memtracks global memory accessed, which can be larger than the weight size, and suggested usingmem_usedinstead.- After switching to
GlobalCounters.mem_used, the memory usage matched the parameter size (0.01GB), leading to further questions about the difference between the two counters.
- After switching to
- Subbuffer Shenanigans: Unmasking
global_mem: The discussion suggested that the difference betweenGlobalCounters.global_memandGlobalCounters.mem_usedmight be due to subbuffers on devices like NV or CPU, where larger buffers with minimum sizes are used.- It was recommended to test with WEBGPU to check for differences in
mem_usedand hintedglobal_memtracks global memory accessed.
- It was recommended to test with WEBGPU to check for differences in
Manus.im Discord ▷ #general (9 messages🔥):
Manus Fellowship, Scammer Alert, Automating sustainability, ESG Research Workflows, Manus Premium Feature
- Manus Fellowship Status Questioned: A member inquired whether anyone in the channel is part of the Manus Fellowship program.
- In addition, a member requested the removal of a user, tagging them as a scammer.
- Automated ESG Research Workflow Sought: A user is testing Manus for automating sustainability and ESG-related research workflows and loves the UX.
- The user seeks an API endpoint (public or private) to send prompts programmatically, trigger research tasks, and retrieve results automatically, aiming for integration into an automated workflow using Python or n8n.
- Premium Feature Rollout Spurs Giveaway Buzz: A member inquired about the deployment of a Manus premium feature, and another asked whether there was a $2500 giveaway.
- One member confirmed that the giveaway message was also sent in another server.
Modular (Mojo 🔥) ▷ #general (3 messages):
Discord bug, @kap command
- Discord Bug Discovered!: A user pointed out a Discord bug in the channel, where typing the full name of a user won’t work as expected.
- Use @kap Command!: Members suggested using the
@kapcommand to select a user from the popup list, as a workaround for the Discord bug.
Modular (Mojo 🔥) ▷ #mojo (4 messages):
mojo @parameter decorator, capturing keyword, github issue 5020
- @parameter decorator revealed: A member looked for information about the @parameter decorator in the source code and docs but couldn’t find it, but the LSP in VS Code extension acknowledges it as a keyword (image.png).
- Another member provided a link to the Modular documentation and a GitHub issue related to the topic.
- ‘capturing’ keyword remains a mystery: A member inquired if the ‘capturing’ keyword can be used more generally to create closures (outside of compile-time).
- The provided explanation seems tied to the compile-time decorator itself but raised the question of broader applicability.
{kind=link}
DSPy ▷ #general (4 messages):
AWS Prompt Optimizer, Nova Models, MIPRO Usage, Enterprise DSPy Wrappers
- AWS Prompt Optimizer ‘Inspired’ by DSPy?: A user discovered the AWS prompt optimizer for its nova models, noting it seems to be inspired by DSPy.
- Another member suggested that it even uses flat out MIPRO, speculating about the emergence of enterprise DSPy wrappers.
- Hopes for Upstream Contributions: A member expressed hope that AWS would eventually contribute upstream to DSPy.
Nomic.ai (GPT4All) ▷ #general (2 messages):
GPT4ALL and Raspberry Pi 5, Dataset download error
- GPT4ALL on Raspberry Pi 5?: A member asked for recommendations to build a small portable system using GPT4ALL and Raspberry Pi 5.
- Dataset download denied!: A member reported an Access denied error when trying to download the dataset to fine-tune the model using aws s3.
- The command used was
aws s3 ls --endpoint-url=https://9fa58365a1a3d032127970d0bd9a1290.r2.cloudflarestorage.com/ s3://contrastive.
- The command used was